
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91 values | source stringclasses 1 value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
Deploy PostgreSQL into IBM Cloud private
This story describes how to deploy PostgreSQL, an open source object-relational database system, into IBM Cloud private, IBM’s new Kubernetes based private cloud, by using helm charts and persistent volumes.
- The first step is to install IBM Cloud private . The detailed instructions to do so can be found here. Once you have installed IBM Cloud private, the next steps are as follows:
- Create a persistent volume or set up dynamic provisioning
- Install PostgreSQL 9.6.4 Helm Chart
- Start using PostgreSQL!
Create a persistent volume
- Create a persistent volume and a persistent volume claim. This can be done using the IBM Cloud private App Centre UI as show below.
- On the upper left dropdown menu, click on Platform and select storage.
a) To create a persistent volume, click on Create persistent volume and then fill in the required details as shown below.
Enter the details on the following dialog box and click on create.
The persistent volume is now created.
b) Create a persitent volume claim as follows:
Click on the Persistent Volume claim tab and the click on Create PersistenVolumeClaim.
Enter the details in the following dialog box and click on create.
Note: It is required that the Access mode and size be the same for the persistent volume and the persistent volume claim.
The persistent volume claim is now created and bound to the persistent volume as seen below.
- Dynamic provisioning allows storage volumes to be created on-demand. You can use storage classes to provision these volumes. To setup dynamic provisioning environment, follow the instructions detailed here.With Dynamic Provisioning, no persistent volume or claim is required beforehand.
- Using the App Centre UI, you can setup dynamic provisioning during the installation of the chart by setting the “persistence.useDynamicProvisioning” field to true.
Install PostgreSQL 9.6.4 Helm chart
- The next step is to install PostgreSQL. There are two ways to install PostgreSQL:
- 1. Using IBM Cloud private’s UI to deploy the chart.
- Open IBM Cloud private 2.1 , log in and you will see the dashboard. From the upper left dropdown menu scroll to the bottom of the dropdown options and select, “Catalog”.
Select the ibm-postgres-dev chart and click on the chart.
Click on Configure to configure the chart
Enter the release name and select the checkbox to accept the license terms after reading them.
By default, the chart will create a user ‘postgres’ and generate a random password, but you can also specify your own values here:
Once you are ready and have reviewed the chart and all the advanced settings, click on Install.
Now your chart is deployed!
You can check the status of your deployment by clicking on Helm releases on the above dialog.
Clicking on your deployment will lead you to the page where you can check if your deployment is now in the running state.
2. From the command line by using Helm commands.
- For the second option to use the command line to deploy the chart, you can directly access the Helm charts at:.
- The chart that deploys PostgreSQL creates the default user ‘postgres’ for you with a database called postgres.
Once installed, PostgreSQL can be used in the following manner:
- To get your deployment name, run
kubectl get pods
2. Use this deployment name for the next steps.
3. Get the user password using the following command:
PGPASSWORD=$(kubectl get secret --namespace default <deployment name> -o jsonpath="{.data.password}" | base64 --decode; echo)
4. To connect to your database, you can run the following command to start a simple client (using the environment variable from above):
kubectl run <deployment name>-client --rm --tty -i --image postgres \ --env "PGPASSWORD=$PGPASSWORD" \ --command -- psql -U postgres \
-h <deployment name> postgres
5. The following example shows the above commands in action:
6. To connect to your database directly from outside the K8s cluster:
a) If using the default setting for Nodeport:
PGHOST=$(kubectl get nodes --namespace default -o jsonpath='{.items[0].status.addresses[0].address}')
PGPORT=$(kubectl get svc --namespace default <deployment name> -o jsonpath='{.spec.ports[0].nodePort}')
b) For cluster IP,
PGHOST=127.0.0.1
PGPORT=5432
- Execute the following commands to route the connection:
export POD_NAME=$(kubectl get pods --namespace default -l "app=<deployment name>" -o jsonpath="{.items[0].metadata.name}")
kubectl port-forward $POD_NAME 5432:5432
Conclusion
Using this story you can deploy and run PostgreSQL into IBM Cloud private.Thank you! Comments and questions are welcome.
Originally published at developer.ibm.com. | https://medium.com/@robinabhatia3691/deploy-postgresql-into-ibm-cloud-private-597492c999 | CC-MAIN-2018-09 | refinedweb | 755 | 57.06 |
Let's start by implementing our own class instance of a predefined interface within the System namespace. The motivational context is the following: We need to sort an ArrayList of strings in ascending order by the length of the string. OK. That sounds simple enough. So how are we going to do that? If we look at the public methods of ArrayList, we see that it provides an overloaded pair of Sort() member functions:
System.Collections.ArrayList Sort: Overloaded. Sorts the elements in the ArrayList, or a portion of it.
Let's look at the documentation for the two different methods and see which one, if either, fits the bill. Here's the one with an empty parameter list:
public virtual void Sort() ...
No credit card required | https://www.safaribooksonline.com/library/view/c-primer-a/0201729555/0201729555_ch04lev1sec1.html | CC-MAIN-2018-09 | refinedweb | 127 | 67.55 |
Posting to the Twitter APIApr 05, 2009 Python Tweet
Just to provide a little bit of context, I'm working on a project that will be similar to secrettweet. Users will be able to post anonymous messages. Those messages will be reviewed manually through the Django admin, and once they're approved, they'll be posted to a Twitter account through their API.
I'd like to be able to trigger the Twitter post via the admin - in other words, when a message is marked 'approved', saving the record kicks off a process that does the post and updates the message record to include the post date, posted=True, and the new status id. But I'm not sure how to do that, so instead I wrote a script that will probably run on a cron (I'll run it manually until I work out any bugs and figure out what kind of traffic I can expect).
I tried a couple of different methods for posting to the API before I settled on the final script. I could have done it with just one line, using os.system() to execute the curl call suggested in the Twitter API docs:
import os os.system('curl --user "twitter_username:twitter_password" -d status="' + message + '"')
But I needed access to the status id in the response, and I couldn't figure out how to get to it this way. So I moved on to subprocess():
import subprocess, Popen mypost = Popen('curl --user "twitter_username:twitter_password" -d status="' + message + '" \ ""', stdout=subprocess.PIPE, shell=True) return_value = mypost.communicate()[0]
Using subprocess(), I got a return_value as an XMl string, kind of a pain to parse but at least I was a step closer. Just as a note, I didn't try the JSON format, so I'm not sure what kind of response it returns - that might have been easier to parse but I may never know now. I decided to keep moving.
I did try using urllib/urllib2.Request and encoding the username/passwd into the url, but kept getting 403's. I realize now that I probably just needed to add basic authentication to the request headers, but it was late and I was tired:
url = '' % (username,password)
There are a few good libraries out there - python-twitter, in particular, is the one that kept coming up in searches. Python-twitter is a complete interface that covers all parts of the Twitter API. I'd recommend using it if you're buiding a project that needs to be able to post and get feeds in various formats. But I only need to post, and I didn't see the sense in installing that much code for my simple needs. Besides, I liked the challenge of writing my own.
In the end, I wound up deconstructing python-twitter, boiling it down to almost nothing and adding a few changes of my own. The method I finally settled on uses urllib/urllib2 and a few other common modules for encoding and parsing:
(Full disclosure: After a clue from the lovely and talented Zach Voase, I've wittled it down even further and changed the code here to reflect said wittling.)
request = urllib2.Request('') request.headers['Authorization'] = 'Basic %s' % ( base64.b64encode(twitter_username + ':' + twitter_password),) request.data = urllib.urlencode({'status': message}) response = urllib2.urlopen(request) # The Response
I'm sure I could probably tweek this a little more - I'm not happy until I've refactored down to the absolute fewest lines of code possible. But for now, this'll do. Here's the complete script, including the db connections I'm setting up to grab unposted records and update them with their new status ids on a successful post:
#!/usr/bin/python import MySQLdb as Database import base64, urllib, urllib2(twitter_username + ':' + twitter() | http://www.mechanicalgirl.com/post/posting-twitter-api/ | CC-MAIN-2020-50 | refinedweb | 632 | 60.35 |
Published:04/04/2016 Last Updated:04/04/2016
I have been learning Python by dribs and drabs since my days with the Health & Life Sciences group. I started out using the default installation on the Linux systems on which I had access. This was usually Python 2.6 (Py2). Now, with the Intel Distribution for Python coming out soon (just went to beta release a few days before I wrote this), I decided to make the plunge and step up to Python 3 (Py3).
One of the codes I was playing with involved finding the area of a triangle. If you remember any trigonometry (or have just done a quick web search), you recall that the area of a triangle is half the product of the base length times the height of the triangle (from the base). The specific details of the problem I was addressing required use of isosceles triangles, so I chose the base of the isosceles triangle to be the base of the area computation, rather than one of the legs of the isosceles. In that way, I could form a right triangle with one side being half the base length and the hypotenuse as the leg of the isosceles triangle. Further, since all side lengths had to be integral, I decided to compute the height of the overall triangle by use of the Pythagorean Theorem. Thus, I wrote the following function to test the relationship of the three sides of a potential right triangle:
>>> def pythagorean_triple(c, a, b): ... return (c*c == (a*a + b*b))
Because I would have two sides of a right triangle I wanted to compute the third side with a variation of the above formula. I take the square of the hypotenuse, subtract the square of the other given side (half the base of the isosceles triangle), and then compute the square root of that difference. In fact, I want to take the truncated integral version of that square root. This last bit is due to the fact that I’m trying to see if the area of the isosceles triangle is integral. If the third side is any fractional value, I know that I don’t have a Pythagorean Triple and, therefore, the isosceles triangle doesn’t have an integral area. (In the general case this isn’t necessarily true since the multiplication of the integral base length could give an integral value. However, due to the special relationship of the isosceles side lengths that I haven’t gone into, I knew that this would never happen.)
>>> e = 126500416/2 >>> e 63250208 >>> d = int(math.sqrt(126500417*126500417 - e*e)) >>> d 109552575 >>> pythagorean_triple(126500417, e, d) True
This is exactly what I expected. When I ran the same thing in Py3, I got this:
>>> e = 126500416/2 >>> e 63250208.0 >>> d = int(math.sqrt(126500417*126500417 - e*e)) >>> d 109552575 >>> pythagorean_triple(126500417, e, d) False
I was running the above interactively, so before I got to the test for Pythagorean Triple, I was puzzled with the output of the value from ‘e’ [line 3]. I just shrugged my shoulders since I knew I was dividing an even value (126500416) by 2. While the printed result was an obvious floating point value, the actual value was arithmetically equivalent to the integral value. My jaw dropped when I saw the final line of output that was contrary to the Py2 output and contrary to what I knew about the triangle I was describing.
My first thought was that I might have discovered some weird corner case in the Python interpreter or runtime. I immediately realized that it was more likely something that I’d done wrong. Nothing wrong with the code between the two runs. (I’d actually cut-and-pasted from one Python session to the other.) I next started asking around about this specific case to folks that were much more knowledgeable in Python programming than I am.
The answer came back quickly. The division operator in Py3 has changed from the definition used in Py2. Specifically, the single slash operator will compute the floating value regardless of the operands, i.e., “true division”. In Py2, if the operands were both integral the quotient would be the integral portion of the result (floor or truncated division). To get a quotient that was a floating point value required that one of the operands be a float. (This tracks with how at least one other programming language I am fluent in and had obviously colored my expectations about arithmetic operations in other languages.)
Using the double slash operator in Py3 will give me the integral quotient that I’m expecting, and, since I’m interested in integer slide lengths, it is what I should be using anyway. All of this should have been obvious to me when the output value of ‘e’ was a float. This episode does remind me to try to know all about the tools I’m using before I get bit by some unexpected behavior from an application. I likely do not need to delve into all the dusty corner cases that could potentially arise, but something as obvious as this change between Python versions (and that has been well-documented online) should not have caught me unaware. I should read a little further in my Python 3 text before I go off halfcocked | https://software.intel.com/content/www/us/en/develop/blogs/i-was-just-dipping-in-a-toe-and-got-bit-by-python.html | CC-MAIN-2020-40 | refinedweb | 897 | 67.18 |
HTTPWebRequest Body Formatting
HTTPWebRequest Body Formatting - API docs were sloppily done. Actual parameter names were "recipients" and "text " - code worked fine after this change. URL encoding in the
making a httpwebrequest Post, including a request body - making a httpwebrequest Post, including a request body. Windows and .. If it is a format exception, i have corrected it : string requestBody
HttpWebRequest.GetResponse Method (System.Net) - The HttpWebRequest has an entity body but the GetResponse() method is called the stream to a higher level stream reader with the required encoding format.
Retrieving HTTP content in .NET with WebRequest/WebResponse - NET WebRequest and WebResponse classes. is important in Web request applications and getting the data into the proper format for posting
HttpWebRequest and GZip Http Responses - NET framework - WebClient or HttpWebRequest - you'll find that Gzip is not natively supported. Accepting Raw Request Body Content in ASP. .. from HTML pages. in response I get HTML and Javascript in JSON format.
WebClient, HttpWebRequest or HttpClient to perform HTTP requests - HttpWebRequest and WebClient are available in all . The result body of a web request can sometimes be more useful as a string. .. to a view engine, or return the error in a format that the program can handle or display.
Solved: Receive 400 "Bad request" when attempting to Post - The json is formatted like this: using (var client = new WebClient()) This is the error message I receive from Postman: "The request body
How to Create JSON body text in HTTP Request - How to send body using POST method of HTTP Request activity optionally adding a method to it that will return the object properly formatted.
How To Make REST API Requests in PowerShell - We'll show Powershell's Invoke-WebRequest making a REST API "+ 15558675309"; From = $number; Body = "Hello from PowerShell" We append the .json extension to the URL to get the response back in JSON format.
Making HTTP Requests - The URL of an API Gateway API request has the following format: . API actions require you to include JSON-formatted data in the body of the
web api get post data from request
How to get POST data in WebAPI? - public async Task Post() { dynamic obj = await Request. But turns out, in WebAPI, the data from a POST comes back at you as a stream.
Getting raw Request (POST) data from Request in Web Api controller - Here you skip using the built in web api object mapper and do the mapping yourself. Below is just how to get the raw post data. This is simple
Using HTTP Methods (GET, POST, PUT, etc.) in Web API - NET Web API for a major project we're working on, and part of HTTP methods represent those requested actions. For example, some commonly-used HTTP methods will retrieve data from a server, submit data to a server for
Get Request Post body from web api method - I am trying to get the raw http request (headers and body or just body by itself will be ok) within a web api method, I have this code : byte[]
Accepting Raw Request Body Content in ASP.NET Core API - Unfortunately the process to get at raw request data is rather indirect, with no NET Core Web API project and changed the default ValuesController to this You can accept a string parameter and post JSON data from the
Accepting Raw Request Body Content with ASP.NET Web API - I mentioned hints, and Web API allows you to use parameter [HttpPost] public string PostJsonString([FromBody] string text) { return text; } It requires that the data is formatted in JSON or XML.
Parameter Binding in Web API - HTTP POST request is used to create new resource. It can include request data into HTTP request body and also in query string. As you can see above, Post() action method includes primitive type parameters id and name. So, by default, Web API will get values from the query string.
Implement POST Method in Web API - Create Web API for CRUD operation - Part 3: Implement Post Method we created necessary infrastructure for the Web API and also implemented GET methods. The HTTP POST request is used to create a new record in the data source in
Sending HTML Form Data in ASP.NET Web API: Form-urlencoded - This article shows how to post form-urlencoded data to a Web API controller with ASP. HTML forms use either GET or POST to send data to the server. If the form uses POST, the form data is placed in the request body.
How To Post Data To WebAPI Using jQuery - In this article, you will learn, how to post the data to WebAPI, using jQuery. Created, student);; } else {; result = Request.
httpwebrequest body json
How to post JSON to a server using C#? - The way I do it and is working is: var httpWebRequest = (HttpWebRequest) WebRequest.Create(""); httpWebRequest.ContentType = "application/ json"
C# JSON Post using HttpWebRequest - Here is a precise and accurate example of a POST request and reading the response(though without serializing the JSON data). Only mistake I
How to pass JSON data using httpwebrequest post method. - Hi,. I want to pass JSON data using httpwebrequest POST method. JSON class: public class CreatePerson { public string name { get; set; }
HTTP POST Request with C# – Tutorials, tips&tricks, snippets.. - I work a lot with JSON, so here I'll show how to send a JSON string. Here we go! var httpWebRequest = (HttpWebRequest)WebRequest.
Send post Http request with Content Type application Json on C# - Send post Http request with Content Type application Json on C# ToString();; HttpWebRequest httpWReq = (HttpWebRequest) WebRequest.
[Solved] How to pass json body in ajax post request in c# (for API - try { var httpWebRequest = (HttpWebRequest)WebRequest. ContentType = " application/json"; using (var streamWriter = new
How to post JSON data to API using C# - Json package from NuGet packages. How do I post JSON data to API using C #? public string Post(Uri url, string value); {; var request = HttpWebRequest.
send json data using http request post method - i need to send json data using HttpWebRequest with Post method in c#,the details are as follows Example request "template": { "name": "Quote
REST Api Code samples - HttpWebRequest request = (HttpWebRequest)WebRequest.Create(URL); request.Method = "POST"; request.ContentType = "application/json"; request. Accept
REST - application/json: PC*MILER will render the response in JSON format following + resource + queryString); HttpWebRequest req = WebRequest. #TextArea1 { width: 693px; height: 167px; } </style> </head> <body> <div>
c# read post data from http request
How to Get the HTTP Post data in C# - This code reads the raw input stream from the HTTP request. Use this if the data isn't available in Request.Form or other model bindings or if
Get the Body on HTTP POST in C# - This is the output of the HTTP POST: Thanks! most of the post data is send in key value here you are having data, and your key might be SGEmail. .com/ questions/716024/c-sharp-xml-in-http-post-request-message-body.
How to get the body of a HTTP Request using C# · GitHub - How to get the body of a HTTP Request using C#. GitHub Gist: instantly share code, notes, and snippets.
Accepting Raw Request Body Content in ASP.NET Core API - Unfortunately the process to get at raw request data is rather indirect, POST HTTP/1.1
How to: Send data by using the WebRequest class - This procedure is commonly used to post data to a Web page. If you need to set or read protocol-specific properties, you must cast your that permits data to be sent with a request, such as the HTTP POST method: C# Copy.
Create HTTP GET and POST Request with C# - Learn How to make HTTP requests using c# along with get and post get or post ) on a web resource and process the received data from the
[ASP.net C#] How do I receive form data which was posted in - Refer - Read Post Data submitted to ASP. NameValueCollection nvc = Request.Form . Request["firstname"]; or string firstname = Request.
c# - Sending GET/POST requests in .NET - In fact both those method get a response and read it and deal with the . The hardest part of managing HTTP requests is that there are a million
HTTP Get and Post request in C#.net - This article shows you how to post a Form data to a different URL from ASP. " Method" which is Method of our form, default is Post but you can also use Get Url =;; myremotepost. void Page_Load(object sender, EventArgs e){; if (Request.
Posting Form Data from ASP.NET Page to Another URL - In this tutorial I will show you how to make an http get and http post request using c#.net. If | http://www.brokencontrollers.com/article/10692240.shtml | CC-MAIN-2019-39 | refinedweb | 1,448 | 62.27 |
# VVVVVV??? VVVVVV!!! :)
If you're reading this text, you've either thought that something was wrong with the headline or you've seen the name of a familiar computer game. VVVVVV is an indie platformer game that has stolen the hearts of many players by its pleasant external simplicity and no less pleasant internal complexity. A few days ago, VVVVVV turned 10 years, and the author of the game — Terry Cavanagh — celebrated this holiday by publishing its source code. What mind-boggling things is it hiding? Read the answer in this article.

Introduction
------------
Oh, VVVVVV… I remember coming across it shortly after the release and being a big fan of pixel retro games, I was so excited to install it on my computer. I remember my first impressions: «Is that all? Just running around the square rooms?» I thought after a few minutes of playing. I didn't know what was waiting for me at the time. As soon as I got out of the starting location, I found myself in a small but confusing and florid two-dimensional world full of unusual landscapes and pixel artifacts unknown to me.
I got carried away by the game. Eventually, I completely beat the game despite some challenges, like high complexity with skillfully applied game control, for instance — the main character can't jump, but is able to invert the direction of the gravity vector on himself. I have no idea how many times my character died then, but I'm sure the number of deaths is measured in the tens of hundreds. After all, every game has its own unique zest :)
Anyway, let's go back to the source code, posted [in honor of the game's anniversary](http://distractionware.com/blog/2020/01/vvvvvv-is-now-open-source/).
At the moment, I'm a developer of the PVS-Studio, which is a static code analyzer for C, C++, C#, and Java. In addition to directly developing, we are also engaged in our product promotion. For us, one of the best ways to do this is to write articles about checking open source projects. Our readers get engaging articles on programming topics, and we get the opportunity to demonstrate the capabilities of PVS-Studio. So when I heard about the opening of the VVVVVV source code, I just couldn't get past it.
In this article, we'll look at some interesting errors found by the PVS-Studio analyzer in the VVVVVV code, and take a detailed look at these errors. Point the gravity vector down and make yourself comfortable — we're just about to start!
Overview of Analyzer Warnings
-----------------------------
### Warning 1
[V512](https://www.viva64.com/en/w/v512/) A call of the 'sprintf' function will lead to overflow of the buffer 'fileSearch'. FileSystemUtils.cpp 307
```
#define MAX_PATH 260
....
void PLATFORM_migrateSaveData(char *output)
{
char oldLocation[MAX_PATH];
char newLocation[MAX_PATH];
char oldDirectory[MAX_PATH];
char fileSearch[MAX_PATH];
....
/* Same place, different layout. */
strcpy(oldDirectory, output);
sprintf(fileSearch, "%s\\*.vvvvvv", oldDirectory);
....
}
```
As you can see, the strings *fileSearch* and *oldDirectory* are of the same size: 260 characters. After writing the contents of the *oldDirectory* string in the format string (the third *sprintf* argument), it will look like:
```
*contents\_oldDirectory\\*.vvvvvv*
```
This line is 9 characters longer than the original value of *oldDirectory*. It is this sequence of characters that will be written in *fileSearch*. What happens if the length of the *oldDirectory* string is more than 251? The resulting string will be longer than *fileSearch* could contain, which will lead to violating the array bounds. What data in RAM can be damaged and what result it will lead to is a matter of rhetorical question :)
### Warning 2
[V519](https://www.viva64.com/en/w/v519/) The 'background' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 1367, 1373. Map.cpp 1373
```
void mapclass::loadlevel(....)
{
....
case 4: //The Warpzone
tmap = warplevel.loadlevel(rx, ry, game, obj);
fillcontent(tmap);
roomname = warplevel.roomname;
tileset = 1;
background = 3; // <=
dwgfx.rcol = warplevel.rcol;
dwgfx.backgrounddrawn = false;
warpx = warplevel.warpx;
warpy = warplevel.warpy;
background = 5; // <=
if (warpy) background = 4;
if (warpx) background = 3;
if (warpx && warpy) background = 5;
break;
....
}
```
The same variable is assigned a value twice in a row. However, this variable isn't used anywhere between assignments. Which is weird… This sequence may not violate the logic of the program, but such assignments themselves indicate some confusion when writing code. Whether this is a mistake in fact — only the author will be able to say for sure. Although there are more vivid examples of this error in the code:
```
void Game::loadquick(....)
{
....
else if (pKey == "frames")
{
frames = atoi(pText);
frames = 0;
}
....
}
```
In this case, it's clear that an error is hiding somewhere either in logic or in redundant assignment. Perhaps, the second line was written temporarily for debugging, and then was just left forgotten. In total, PVS-Studio issued 8 warnings about such cases.
### Warning 3
[V808](https://www.viva64.com/en/w/v808/) 'pKey' object of 'basic\_string' type was created but was not utilized. editor.cpp 1866
```
void editorclass::load(std::string &_path)
{
....
std::string pKey(pElem->Value());
....
if (pKey == "edEntities")
{
int i = 0;
for (TiXmlElement *edEntityEl = pElem->FirstChildElement();
edEntityEl;
edEntityEl = edEntityEl->NextSiblingElement())
{
std::string pKey(edEntityEl->Value()); // <=
//const char* pText = edEntityEl->GetText() ;
if (edEntityEl->GetText() != NULL)
{
edentity[i].scriptname = std::string(edEntityEl->GetText());
}
edEntityEl->QueryIntAttribute("x", &edentity[i].x);
edEntityEl->QueryIntAttribute("y", &edentity[i].y);
edEntityEl->QueryIntAttribute("t", &edentity[i].t);
edEntityEl->QueryIntAttribute("p1", &edentity[i].p1);
edEntityEl->QueryIntAttribute("p2", &edentity[i].p2);
edEntityEl->QueryIntAttribute("p3", &edentity[i].p3);
edEntityEl->QueryIntAttribute("p4", &edentity[i].p4);
edEntityEl->QueryIntAttribute("p5", &edentity[i].p5);
edEntityEl->QueryIntAttribute("p6", &edentity[i].p6);
i++;
}
EditorData::GetInstance().numedentities = i;
}
....
}
```
This code is very strange. The analyzer warns about the created but not used variable *pKey*, but in reality, the problem was more interesting. I intentionally highlighted the line triggered the warning with an arrow, as this function contains more than one string definition with the name *pKey*. That's right, another such variable is declared inside the *for* loop. It overlaps the one that's declared outside of the loop.
Thus, if you refer to the value of the *pKey* string outside the *for* loop, you'll get the value equal to *pElem->Value()*, but when doing the same inside the loop, you'll get the value equal to *edEntityEl->Value()*. Overlapping names is a rather rough error, which might be very difficult to find on your own during code review.
### Warning 4
[V805](https://www.viva64.com/en/w/v805/) Decreased performance. It is inefficient to identify an empty string by using 'strlen(str) > 0' construct. A more efficient way is to check: str[0] != '\0'. physfs.c 1604
```
static char *prefDir = NULL;
....
const char *PHYSFS_getPrefDir(const char *org, const char *app)
{
....
assert(strlen(prefDir) > 0);
...
return prefDir;
} /* PHYSFS_getPrefDir */
```
The analyzer found a fragment for potential micro-optimization. It uses the *strlen* function to check if the string is empty. This function traverses all string elements and checks each of them for a null-terminator ('\0'). If we get a long string, its each character will be compared with a null-terminator.
But we just need to check that the string is empty! All you need to do is to find out if the first string character is a terminal null. Therefore, to optimize this check inside the assert, it's worth writing:
```
str[0] != '\0'
```
That's the recommendation the analyzer gives us. Sure, the call of the strlen function is in condition of the *assert* macro, therefore it will only be executed in the debugging version, where the speed isn't that important. In the release version, the call of the function and the code will execute fast. Despite this, I wanted to demonstrate what our analyzer can suggest in terms of micro-optimizations.
### Warning 5
To demonstrate the essence of another error, I have to cite two code fragments here: the *entclass* class declaration and its constructor. Let's start with the declaration:
```
class entclass
{
public:
entclass();
void clear();
bool outside();
public:
//Fundamentals
bool active, invis;
int type, size, tile, rule;
int state, statedelay;
int behave, animate;
float para;
int life, colour;
//Position and velocity
int oldxp, oldyp;
float ax, ay, vx, vy;
int cx, cy, w, h;
float newxp, newyp;
bool isplatform;
int x1, y1, x2, y2;
//Collision Rules
int onentity;
bool harmful;
int onwall, onxwall, onywall;
//Platforming specific
bool jumping;
bool gravity;
int onground, onroof;
int jumpframe;
//Animation
int framedelay, drawframe, walkingframe, dir, actionframe;
int yp; int xp;
};
```
This class constructor looks as follows:
```
entclass::entclass()
{
clear();
}
void entclass::clear()
{
// Set all values to a default,
// required for creating a new entity
active = false;
invis = false;
type = 0;
size = 0;
tile = 0;
rule = 0;
state = 0;
statedelay = 0;
life = 0;
colour = 0;
para = 0;
behave = 0;
animate = 0;
xp = 0;
yp = 0;
ax = 0;
ay = 0;
vx = 0;
vy = 0;
w = 16;
h = 16;
cx = 0;
cy = 0;
newxp = 0;
newyp = 0;
x1 = 0;
y1 = 0;
x2 = 320;
y2 = 240;
jumping = false;
gravity = false;
onground = 0;
onroof = 0;
jumpframe = 0;
onentity = 0;
harmful = false;
onwall = 0;
onxwall = 0;
onywall = 0;
isplatform = false;
framedelay = 0;
drawframe = 0;
walkingframe = 0;
dir = 0;
actionframe = 0;
}
```
Quite many fields, wouldn't you say? It's no wonder, PVS-Studio issued a warning for a bug, hiding here:
[V730](https://www.viva64.com/en/w/v730/) It is possible that not all members of a class are initialized inside the constructor. Consider inspecting: oldxp, oldyp. Ent.cpp 3
As you can see, two class fields initializations got lost in such a long list. As a result, their values remained undefined, so they can be incorrectly read and used somewhere else in the program. It is very difficult to detect such a mistake just by reviewing.

### Warning 6
Look at this code:
```
void mapclass::loadlevel(....)
{
....
std::vector tmap;
....
tmap = otherlevel.loadlevel(rx, ry, game, obj);
fillcontent(tmap);
.... // The tmap vector gets changed again many times.
}
```
PVS-Studio warning: [V688](https://www.viva64.com/en/w/v688/) The 'tmap' local variable possesses the same name as one of the class members, which can result in a confusion. Map.cpp 1192
Indeed, looking inside the *mapclass* class, you can find the same vector with the same name there:
```
class mapclass
{
public:
....
std::vector roomdeaths;
std::vector roomdeathsfinal;
std::vector areamap;
std::vector contents;
std::vector explored;
std::vector vmult;
std::vector tmap; // <=
....
};
```
Unfortunately, same name vector declaration inside the function makes the vector declared in the class invisible. In turns out that the *tmap* vector gets changed only inside of the *loadlevel* function. The vector declared in the class remains the same!
Interestingly, PVS-Studio has found 20 of such code fragments! For the most part, they relate to temporary variables that have been declared «for convenience» as class members. The game author (and its only developer) wrote about himself that he used to have this bad habit. You can read about it in the post — the link is given at the beginning of the article.
He also noted that such names led to harmful bugs that were difficult to detect. Well, such errors may be really destructive, but catching them becomes less difficult if you use static analysis :)
### Warning 7
[V601](https://www.viva64.com/en/w/v601/) The integer type is implicitly cast to the char type. Game.cpp 4997
```
void Game::loadquick(....)
{
....
else if (pKey == "totalflips")
{
totalflips = atoi(pText);
}
else if (pKey == "hardestroom")
{
hardestroom = atoi(pText); // <=
}
else if (pKey == "hardestroomdeaths")
{
hardestroomdeaths = atoi(pText);
}
....
}
```
To understand what's going on, let's take a look at the variables' definitions from the given part of code:
```
//Some stats:
int totalflips;
std::string hardestroom;
int hardestroomdeaths;
```
*totalflips* and *hardestroomdeaths* variables are integer, so it's perfectly normal to assign them the result of the *atoi* function. But what happens if you assign an integer value to *std::string*? Such assignment turns out to be valid from the language perspective. As a result, an unclear value will be written in the *hardestroom* variable!
### Warning 8
[V1004](https://www.viva64.com/en/w/v1004/) The 'pElem' pointer was used unsafely after it was verified against nullptr. Check lines: 1739, 1744. editor.cpp 1744
```
void editorclass::load(std::string &_path)
{
....
TiXmlHandle hDoc(&doc);
TiXmlElement *pElem;
TiXmlHandle hRoot(0);
version = 0;
{
pElem = hDoc.FirstChildElement().Element();
// should always have a valid root
// but handle gracefully if it does
if (!pElem)
{
printf("No valid root! Corrupt level file?\n");
}
pElem->QueryIntAttribute("version", &version); // <=
// save this for later
hRoot = TiXmlHandle(pElem);
}
....
}
```
The analyzer warns that the *pElem* pointer is unsafely used right after its checking for *nullptr*. To make sure the analyzer is right, let's check out the definition of the *Element()* function which returns the value which, in turns, initializes the *pElem* poiter:
```
/** @deprecated use ToElement.
Return the handle as a TiXmlElement. This may return null.
*/
TiXmlElement *Element() const
{
return ToElement();
}
```
As we can see from the comment, this function might return *null*.
Now imagine that it really happened. What will happen in this case? The fact is that this situation won't be handled in any way. Yes, there will be a message that something went wrong, but the incorrect pointer will be dereferenced just one line below. Such dereferencing will result in either the program crash or undefined behavior. This is a pretty serious mistake.
### Warning 9
This code fragment triggered four PVS-Studio analyzer warnings:
* [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always true: x >= 0. editor.cpp 1137
* [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always true: y >= 0. editor.cpp 1137
* [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always true: x < 40. editor.cpp 1137
* [V560](https://www.viva64.com/en/w/v560/) A part of conditional expression is always true: y < 30. editor.cpp 1137
```
int editorclass::at( int x, int y )
{
if(x<0) return at(0,y);
if(y<0) return at(x,0);
if(x>=40) return at(39,y);
if(y>=30) return at(x,29);
if(x>=0 && y>=0 && x<40 && y<30)
{
return contents[x+(levx*40)+vmult[y+(levy*30)]];
}
return 0;
}
```
All warnings relate to the last *if* statement. The problem is that all four checks, performed in it, will always return *true*. I wouldn't say it's a serious mistake, but it's quite funny. The author decided to take this function seriously and just in case checked each variable again :)
He could have removed this check, as the execution flow won't get to the expression "*return 0;*" anyway. It won't change the program logic, but will help to get rid of redundant checks and dead code.
### Warning 10
In his article on the game's anniversary, Terry ironically noted that one of the elements that controlled the game's logic was the huge switch from the *Game::updatestate()* function, responsible for a large number of different states of the game at the same time. And it was quite expected that I would find the following warning:
[V2008](https://www.viva64.com/en/w/v2008/) Cyclomatic complexity: 548. Consider refactoring the 'Game::updatestate' function. Game.cpp 612
Yes, you got it right: PVS-Studio gave the function the following complexity rating — 548. Five hundred and forty-eight!!! This is how the «neat code» looks like. And this is despite the fact that, except for the switch statement there is almost nothing else in the function. In the switch itself, I counted more than 300 case-expressions.
You know, in our company we have a small competition for the longest article. I'd love to bring the entire function code (3,450 lines) here, but such a win would be unfair, so I'll just limit myself to the [link](https://github.com/TerryCavanagh/VVVVVV/blob/f7c0321b715ceed8e87eba2ca507ad2dc28a428d/desktop_version/src/Game.cpp#L622) to the giant switch. I recommend that you follow the link and see its length for yourself! For the matter of that, in addition to *Game::updatestate()*, PVS-Studio has also found 44 functions with inflated cyclomatic complexity, 10 of which had a complexity number of more than 200.

Conclusion
----------
I think the above errors are enough for this article. Yes, there were a lot of errors in the project, but it's a kind of a feature. By opening his code, Terry Cavanagh showed that you don't have to be a perfect programmer to write a great game. Now, 10 years later, Terry recalls those times with irony. It's important to learn from your mistakes, and practice is the best way to do it. And if your practice can give rise to a game like VVVVVV, it's just magnificent! Well… It's high time to play it one more time :)
These weren't all errors found in the game code. If you want to see for yourself what else can be found — I suggest that you [download and try PVS-Studio](https://www.viva64.com/en/pvs-studio-download/)! Also, don't forget that we [provide](https://www.viva64.com/en/b/0614/) open source projects with free licenses. | https://habr.com/ru/post/484388/ | null | null | 2,925 | 57.27 |
Revision history for App-Genpass 2.34 04.08.14 * GH #3: When provided some empty types, it would loop forever. 2.33 20.11.12 * Reinstate configuration reading which was removed with the move to Moo. * RT #81287: Update docs to reflect Mouse no longer used. (Props to zaxon) 2.32 01.07.12 * RT #77652: Depend directly on MooX::Types::MooseLike. (nice catch, Brad Bowman!) 2.31 26.06.12 * number was accidentally a Bool instead of Int. (nice catch, Jonathan Swartz! *COUGH*USETHECHI*COUGH*) 2.30 26.03.12 - Move from Mouse to Moo - MUCH FASTER! 2.20 27.11.11 - Add minlength and maxlength (Neil Bowers). - Correct warning (Neil Bowers). 2.10 08.08.11 - Removing the need for "special" boolean flag. Using 'noreadable' or readable => 0 will negate special. Readable will exclude special characters. (Tim Heaney - oylenshpeegul) 2.04 06.08.11 - Clarify the distribution contains an application as well. (Neil Bowers). - POD fix. (Tim Heaney) 2.03 03.08.11 (this release, as the previous, are due to Neil Bowers, so thanks!) - Using readable with special now throws an exception. Added in docs. - Typo in POD. 2.02 03.08.11 - RT #69980: clarify the usage of default number of passwords in generate() method. (reported by Neil Bowers, thanks!) 2.01 10.03.11 - Fix tests by requiring namespace::clean at least 0.2 2.00 17.02.11 ** Major change ** - Moving to Mouse instead of Moose. Should work much faster for users without causing problems. (since it's a big change, I'm noting this as a very major release) 1.01 18.07.10 - Fixed small test bug, must return from default coderef - Explaining how much "speeds" noverify adds (0.1 secs for 500 passwords of 500 char length) 1.00 17.07.10 [API Change] - renamed "repeat" (-r) to "number" (-n) - renamed -e to -r. [Docs] - Document default configuration files 0.11 16.07.10 - Correctly implement optional default configuration file - Add optional homefolder configuration file - Moving to Dist::Zilla... it's awesome! 0.10 07.06.10 - Minimum requirement of MooseX::Getopt => 0.12 0.09 31.05.10 - Auto-read default configuration file (/etc/genpass.yaml) 0.08 30.05.10 - Added description for genpass app Now --help works 0.07 30.05.10 - Added MX::* to Build.PL - Added single char options (-l, -v, etc.) 0.06 29.05.10 - Finally adding genpass CLI !! - POD fix C<> vs. <code></code> 0.05 01.01.09 - added documentation for all attributes - first stable finished release 0.04 01.01.09 - replaced die with Carp's croak - added test for wantarray options - adding documentation for wantarray options 0.03 14.12.09 - fixed small bug in password repetition - adding test that statistically catches it 0.02 11.12.09 - removing special chars, refactored nicely - added verification process - more tests - rewrote some tests - fixed bug that appeared in original genpass, where unreadable chars would be inserted into the chars array twice - removed BUILD - adding test for number of types wanted with a die 0.01 10.12.09 First version, released on an unsuspecting world. | https://metacpan.org/changes/distribution/App-Genpass | CC-MAIN-2015-18 | refinedweb | 524 | 70.29 |
).
@d
@omz, sorry another question about colliding betas so to speak. I seen yesterday we got a new thing (well for me it was new, a renew on the 2.x beta for 7 days , instead of an update in TestFlight). Great idea btw. Not sure if that's a new thing apple opened up to you or if it's been there all the time.
But if at anytime the 2.x beta is expired or not, if I delete it and install the App Store version will it just take the place of the beta leaving all my files intact?
Just want to make sure what will happen
@Phuket2 If you delete the app (tap and hold, then tap the delete icon) then your files will be deleted. If you install the App Store version over the beta, the data will probably stay in place, I don't think there were any major changes to Pythonista's data structure in the beta.
@dgelessus , ok thanks for that. I would have done it the wrong way and lost my data 😱 I should know better, but it appears I don't. Thanks again, makes sense
- Webmaster4o
Hey, this topic just hit 20k views!
Seem to me the split-screen toggle is broken in the beta.
I had a full screen console and I could swipe left and right between it and the editor, then I pushed the split screen button and now swiping left/right transitions between either the editor with the file browser on the left or the editor with the (narrow) console on the right. Problem is, the split screen button seems to have disappeared now and I can't for the life of me figure out how to get the full screen console back.
Just went and checked in version 2 and the toggle remains after switching to split-screen. In the beta it disappears and only the help button remains at the top left of the console pane.
see
from objc_util import ObjCClass ObjCClass('NSUserDefaults').standardUserDefaults().setBool_forKey_(False, 'DockedAccessoriesPanel')
then restart the app
Any idea when the next beta will be, or better yet a release?
- Webmaster4o
New beta literally fixes all the worst bugs, I'm so happy :D
- Improved console prompt: the text input area now expands automatically for multi-line statements
- Improved auto-indentation (also works when splitting a line now)
And also it also has most of my most-wanted editor features!
- Some improvements for external keyboard users 😍
- Experimental Today widget for running scripts in notification center
- Code completions can now be suggested based on fuzzy-matching
Thanks a lot, @omz, this is great work 👍 | https://forum.omz-software.com/topic/2747/python-3-x-progress-update/320 | CC-MAIN-2021-39 | refinedweb | 443 | 67.99 |
How to convert webpage into PDF by using Python
I was finding solution to print webpage into local file PDF, using Python. one of the good solution is to use Qt, found here,.
It didn't work at the beginning as I had problem with the installation of PyQt4 because it gave error messages such as 'ImportError: No module named PyQt4.QtCore', and 'ImportError: No module named PyQt4.QtCore'.
It was because PyQt4's not installed properly. I used to have the libraries located at C:\Python27\Lib however it's not for PyQt4.
In fact, it simply needs to download from (mind the correct Python version you are using), and install it to C:\Python27 (my case). That's it.
Now the scripts runs fine so I want to share it. for more options in using Qprinter, please refer to.
thanks to below posts, and I am able to add on the webpage link address to be printed and present time on the PDF generated, no matter how many pages it has.
Add text to Existing PDF using Python
To share the script as below:
import time from pyPdf import PdfFileWriter, PdfFileReader import StringIO from reportlab.pdfgen import canvas from reportlab.lib.pagesizes import letter from xhtml2pdf import pisa import sys from PyQt4.QtCore import * from PyQt4.QtGui import * from PyQt4.QtWebKit import * url = '' tem_pdf = "c:\\tem_pdf.pdf" final_file = "c:\\younameit.pdf" app = QApplication(sys.argv) web = QWebView() #Read the URL given web.load(QUrl(url)) printer = QPrinter() #setting format printer.setPageSize(QPrinter.A4) printer.setOrientation(QPrinter.Landscape) printer.setOutputFormat(QPrinter.PdfFormat) #export file as c:\tem_pdf.pdf printer.setOutputFileName(tem_pdf) def convertIt(): web.print_(printer) QApplication.exit() QObject.connect(web, SIGNAL("loadFinished(bool)"), convertIt) app.exec_() sys.exit # Below is to add on the weblink as text and present date&time on PDF generated outputPDF = PdfFileWriter() packet = StringIO.StringIO() # create a new PDF with Reportlab can = canvas.Canvas(packet, pagesize=letter) can.setFont("Helvetica", 9) # Writting the new line oknow = time.strftime("%a, %d %b %Y %H:%M") can.drawString(5, 2, url) can.drawString(605, 2, oknow) can.save() #move to the beginning of the StringIO buffer packet.seek(0) new_pdf = PdfFileReader(packet) # read your existing PDF existing_pdf = PdfFileReader(file(tem_pdf, "rb")) pages = existing_pdf.getNumPages() output = PdfFileWriter() # add the "watermark" (which is the new pdf) on the existing page for x in range(0,pages): page = existing_pdf.getPage(x) page.mergePage(new_pdf.getPage(0)) output.addPage(page) # finally, write "output" to a real file outputStream = file(final_file, "wb") output.write(outputStream) outputStream.close() print final_file, 'is ready.'
★ Back to homepage or read more recommendations:★ Back to homepage or read more recommendations:
From: stackoverflow.com/q/23359083 | https://python-decompiler.com/article/2014-04/how-to-convert-webpage-into-pdf-by-using-python | CC-MAIN-2019-26 | refinedweb | 449 | 52.76 |
At Datadog, we're really into metrics. We love them, we store them, but we also generate them. To do that, you need to juggle with integers that are incremented, also known as counters.
While having an integer that changes its value sounds dull, it might not be without some surprises in certain circumstances. Let's dive in.
The Straightforward Implementation
class SingleThreadCounter(object): def __init__(self): self.value = 0 def increment(self): self.value += 1
Pretty easy, right?
Well, not so fast, buddy. As the class name implies, this works fine with a single-threaded application. Let's take a look at the instructions in the
increment method:
>>> import dis >>> dis.dis("self.value += 1") 1 0 LOAD_NAME 0 (self) 2 DUP_TOP 4 LOAD_ATTR 1 (value) 6 LOAD_CONST 0 (1) 8 INPLACE_ADD 10 ROT_TWO 12 STORE_ATTR 1 (value) 14 LOAD_CONST 1 (None) 16 RETURN_VALUE
The
self.value +=1 line of code generates 8 different operations for Python. Operations that could be interrupted at any time in their flow to switch to a different thread that could also increment the counter.
Indeed, the
+= operation is not atomic: one needs to do a
LOAD_ATTR to read the current value of the counter, then an
INPLACE_ADD to add 1, to finally
STORE_ATTR to store the final result in the
value attribute.
If another thread executes the same code at the same time, you could end up with adding 1 to an old value:
Thread-1 reads the value as 23 Thread-1 adds 1 to 23 and get 24 Thread-2 reads the value as 23 Thread-1 stores 24 in value Thread-2 adds 1 to 23 Thread-2 stores 24 in value
Boom. Your
Counter class is not thread-safe. 😭
The Thread-Safe Implementation
To make this thread-safe, a lock is necessary. We need a lock each time we want to increment the value, so we are sure the increments are done serially.
import threading class FastReadCounter(object): def __init__(self): self.value = 0 self._lock = threading.Lock() def increment(self): with self._lock: self.value += 1
This implementation is thread-safe. There is no way for multiple threads to increment the value at the same time, so there's no way that an increment is lost.
The only downside of this counter implementation is that you need to lock the counter each time you need to increment. There might be much contention around this lock if you have many threads updating the counter.
On the other hand, if it's barely updated and often read, this is an excellent implementation of a thread-safe counter.
A Fast Write Implementation
There's a way to implement a thread-safe counter in Python that does not need to be locked on write. It's a trick that should only work on CPython because of the Global Interpreter Lock.
While everybody is unhappy with it, this time, the GIL is going to help us. When a C function is executed and does not do any I/O, it cannot be interrupted by any other thread. It turns out there's a counter-like class implemented in Python: itertools.count.
We can use this
count class as our advantage by avoiding the need to use a lock when incrementing the counter.
If you read the documentation for
itertools.count, you'll notice that there's no way to read the current value of the counter. This is tricky, and this is where we'll need to use a lock to bypass this limitation. Here's the code:
import itertools import threading class FastWriteCounter(object): def __init__(self): self._number_of_read = 0 self._counter = itertools.count() self._read_lock = threading.Lock() def increment(self): next(self._counter) def value(self): with self._read_lock: value = next(self._counter) - self._number_of_read self._number_of_read += 1 return value
The
increment code is quite simple in this case: the counter is just incremented without any lock. The GIL protects concurrent access to the internal data structure in C, so there's no need for us to lock anything.
On the other hand, Python does not provide any way to read the value of an
itertools.count object. We need to use a small trick to get the current value. The
value method increments the counter and then gets the value while subtracting the number of times the counter has been read (and therefore incremented for nothing).
This counter is, therefore, lock-free for writing, but not for reading. The opposite of our previous implementation
Measuring Performance
After writing all of this code, I wanted to make sure how the different implementations impacted speed. Using the timeit module and my fancy laptop, I've measured the performance of reading and writing to this counter.
I'm glad that the performance measurements in practice match the theory 😅. Both
SingleThreadCounter and
FastReadCounter have the same performance for reading. Since they use a simple variable read, it makes absolute sense.
The same goes for
SingleThreadCounter and
FastWriteCounter, which have the same performance for incrementing the counter. Again they're using the same kind of lock-free code to add 1 to an integer, making the code fast.
Conclusion
It's pretty obvious, but if you're using a single-threaded application and do not have to care about concurrent access, you should stick to using a simple incremented integer.
For fun, I've published a Python package named fastcounter that provides those classes. The sources are available on GitHub. Enjoy! | https://julien.danjou.info/atomic-lock-free-counters-in-python/ | CC-MAIN-2020-40 | refinedweb | 916 | 64.91 |
Driving the WS2811 at 800 kHz with an 8 MHz AVR
From Just in Time
This page describes how to drive a WS2811 from an 8Mhz or 9.6Mhz AVR like an Atmel ATmega88, ATtiny2313 or ATtiny13 without added components such as an external oscillator. With only 30 instructions for the driver loop (110 bytes for the complete function), the driver code presented here is likely to be the shortest code that delivers the exact timing (i.e. exactly 10 clock cycles for 1 byte, exactly 60 clock cycles for 6 bytes, etc.). With even less code a "sparse driver" for 9.6Mhz MCUs can drive long led strings with only a few bytes of buffer in RAM.
Of course, if you're creating a hardware project that controls more than 1 LED, you're going to have to demonstrate it with a Knight Rider LED sequence (which, I just learned, is actually called a Larson scanner)... The sources for all the demonstrations in these videos can be found on github.
Contents
Download source code
The library is header-only. Using it is a matter of downloading the source code and including it in your AVR code. Example source code can be found here. The code comes as an avr-eclipse project consisting for a large part of C++ demonstration code and the main driver function in assembly, in files ws2811_8.h and ws2811_96.h (for the 9.6Mhz version).
I don't recommend trying to understand the assembly code by reading these sources. How the code functions is described below. Usage information is in the next section. The rest of this page describes the 8Mhz version. The 9.6Mhz code was added later, but is created in the same way.
New: If you'd like to see the assembly code in action, take a look at the online AVR emulator!
Usage
You'll need the C++ compiler for this to work (turning ws2811.h into "pure C" is left as an exercise to the reader). I am told that this works just as good for an Arduino, but I haven't tested this myself. Remember that this code was written and optimized for 8Mhz and 9.6Mhz, it would run too fast on an 16Mhz Arduino. From the sources, you'll need files ws2811.h, ws2811_8.h, ws2811_96.h and rgb.h, though you only include "ws2811.h". A simple example of how to use this code:
#include <avr/io.h> // for _BV() #define WS2811_PORT PORTD// ** your port here ** #include "ws2811.h" // this will auto-select the 8Mhz or 9.6Mhz version using ws2811::rgb; namespace { const int output_pin = 3; rgb buffer[] = { rgb(255,255,255), rgb(0,0,255)}; } int main() { // don't forget to configure your output pin, // the library doesn't do that for you. // in this example DDRD, because we're using PORTD. DDRD = _BV( output_pin); // send the RGB-values in buffer via pin 3 // you can control up to 8 led strips from one AVR with this code, as long as they // are connected to pins of the same port. Just // provide the pin number that you want to send the values to here. send( buffer, output_pin); // alternatively, if you don't statically know the size of the buffer // or you have a pointer-to-rgb instead of an array-of-rgb. send( buffer, sizeof buffer/ sizeof buffer[0], output_pin); for(;;); }
History
WS2811 LED controllers are hot. Projects using WS2811 (or WS2812, WS2812B or NeoPixel) LED strips have been featured on HackaDay several times in the last few months. One feature showed how an AVR clocked at 16Mhz could send data at the required high rates. Inspired by this, I ordered an LED strip and 16Mhz oscillators from ebay. The LED strip arrived quickly, only the oscillators took weeks to arrive, which gave me plenty of time to think about the possibility of driving these led strips from an 8Mhz atmega88 without an external oscillator. With only 10 clock ticks per bit, this was going to be a challenge.
Normally I'd go straight to the datasheet and start working from there, but in this particular case the datasheets are not so very informative. Luckily, the HackaDay links provide some excellent discussions. This one by Alan Burlison is especially helpful. That article not only explains in great detail why a library like FastSPI isn't guaranteed to work, but it comes with working code for a 16Mhz AVR that appears rock solid in its timing.
Small problem: I didn't have any 16Mhz crystals on stock, so I ordered a few, on ebay again and sat back for the 25 day shipping time to pass. 25 Days is a long time. The led strip had arrived and was sitting on my desk. 25 Days is a really long time. Maybe it could work off an AVR on its internal 8Mhz oscillator? It would be a lot of work. But 25 days is a very, very, long time.
So, that is how I got to sit down and write my 8Mhz version of a WS2811@800Khz bit banger. The challenge is of course that I have 10 clock cycles for every bit, no more no less, and 80 cycles for every byte, no more no less. I wanted the timing to be as rock-steady as Alan's, give-or-take the imprecise nature of the AVR internal oscillator. The part about it being steady was important to me. People have argued that the code can be made a lot easier if you're willing to have a few extra clock cycles in between bytes or triplets and that such code works for them. I agree that such code is a lot easier to create or read. It's trivial, in fact. However, the WS2811's datasheets are ambiguous at best with regards to the maximum allowed delay between bytes (or bits) and anyway, I liked the challenge of trying to have zero clock ticks delay between bytes or triplets.
The challenge
For a full description of the required protocol to communicate with a WS2811, please refer to either Alans page or the datasheet. In summary, the microcontroller should send a serial signal containing 3 bytes for every LED in the chain, in GRB-order. The bits of this signal are encoded in a special way. See the figure below.
This image shows a sequence of a "0" followed by a "1". Every bit starts with a rising flank. For zeros, the signal drops back to low "quickly" while for ones the signal stays high and drops nearer the end of the bit. I've chosen the following timing, in line with Alans observations and recommendations:
- Zero: 250ns up, 1000ns down
- One: 1000ns up, 250ns down
Giving a total duration of 1250ns for every bit, or 10μs per byte. These timings do not fall in the ranges permitted by the data sheet, but Alan describes clearly why that should not be a problem. 1250ns means 10 clock ticks per bit. That is not a lot. A typical, naive implementation would need to do the following things at every bit:
- determine whether the next bit is a 1 or a 0
- decrease a bit counter and determine if the end of a byte has been reached, if at the end:
- determine if we're at the end of the total sequence
- load a new byte in the data register
- decrement the byte counter
- reset the bit counter
- jump back to the first step
Oh yes, and that is of course in addition to actually switching the output levels.
All of that does not fit into a single 10-clock time frame. Luckily, it doesn't have to. My first version of this driver partially unrolled the bit loop into a 2-bit loop. This allowed all those actions described above to fit within the loop, but it also required 4 versions of the loop (one for every 2-bit combination). The code would jump from one version of the loop to the other as appropriate.
When writing code for the 9.6 Mhz version and the version for sparse LED strings (strings where most LEDs were off), I figured out a way where I could basically have one small loop for each bit but where the code for the last two bits would be unrolled, giving enough time to fetch the next byte and reset the bit counter. This resulted in the much smaller driver code that I have now.
Defining the puzzle
Inventing a notation
Juggling with many states, jumping from one piece of code to the other without introducing phase errors turns out to be interesting. I spent a couple of lonely lunch breaks and several pages in my little (paper!) notebook before I even figured out how to describe the problem. When a notation became clear, however, the going was easy enough and this exercise turned into one of the nicer kinds of pastimes.
The image above shows the full code for the driver in a spreadsheet with pseudo assembly code in the yellow blocks. To the left of each yellow block is a graphic representing the wave form being generated. Tilt your head to the right to see the more conventional waveform graphic. The blue blocks show where the signal could be high or low, depending on the current bit value being sent. Each horizontal row in the yellow blocks represents a clock tick, not necessarily an instruction word. To the left of each waveform graphic there are numbers from 00 to 19 that represent the "phase" at the corresponding clock tick. Phases 00-09 are those of the first 7 bits, phases 10-19 are those of the last bit.
What makes this notation so convenient is the fact that I can now easily determine the waveform phase at each point in the code and can also check whether a jump lands in the correct phase. Each jump at phase n (0 <= n < 09) should land at a label which is placed at phase n + 2 (modulo 10), because jumps take 2 clock cycles. Put differently: each jump should be to a label that is two lines down from the jump location (or 8 or 18 lines up).
The drawn waveforms make it easy to verify that when I jump from the middle of a wave, the code lands in a place where that same wave form is continued. It also shows clearly where the 'up' and 'down' statements that do the actual signal levels need to go.
Wherever there is a "^^^" in the table, it means that the previous instruction takes 2 clock cycles, so that particular clock cycle still belongs to the previous instruction.
How the code works
In summary, the code works as follows: The start of a bit waveform occurs at label s00. At this point the value of the bit to be sent is assumed to be in the carry flag. The line is pulled high and if the current bit (carry flag) is a zero bit, it is pulled low two clock cycles later. Then a bit counter is decreased and if we're not in the second-to-last bit, we continue the second half of the waveform by jumping to label cont06, which is above s00. From cont06 the code just waits a while, then brings the line down (which has no effect if the line was already brought down) and shifts the next bit from the data byte into the carry flag. From here the code falls back into label s00, ready to transmit the next bit.
If we were in the second-to-last bit, the code continues downward after label skip03. We need to free up the data register for the next byte, so we quickly test the last bit of the current byte and then branch into one of two essentially equivalent pieces of code. The code on the left hand side generates a "1"-waveform, while the code on the right generates a "0" for the last bit of the byte. In between the OUT-instructions we find some free cycles to reset the bit counter (to 7), to load the next byte and to decrease the 16-bit byte counter. If indeed there is a next byte to send, we jump up to either label cont07 or cont09 where the rest of the bit waveform is generated before we continue with the bits of the next byte.
Combining the code
The latest version of the code is pretty small (32 instructions/64 bytes), but earlier versions were bigger, requiring jumps over longer address distances. This posed a problem, because a jump from the end of the code right to the beginning would be too long for the branch instructions of the AVR.
Note how all conditional jumps are in the form of branch instructions ("BRCC", "BREQ", etc). There is one important limit to these relative branches, they can only jump to a range of [PC - 63, PC + 64] (with PC the address of the jump instruction)! Any instruction more than 64 instructions away from the branch cannot be reached.
At first I tried to piece the code together manually in a spreadsheet that would calculate the maximum jump distance for me. After a few failed attempts I gave up and decided that computers are better at this. In the end, I just wrote a dedicated program in C++ that uses some common sense heuristics to shuffle the blocks of code around until it finds a sequence in which all jumps are within range.
After this, it became a matter of just pasting the code blocks into one sequence and changing some of the pseudo instructions into real instructions.
Summary
The main point of this text is not that I can show 4 (four!) Larson scanners in one led strip. Actually there are two different points I am trying to make:
First of all, it is possible to control WS2811 led strips from an AVR without external 16 Mhz oscillator with clock-tick-exact timing and I want to tell the world.
Secondly, during this exercise I discovered that this kind of extremely time-critical code can be solved with a number or techniques:
- unrolling loops. That is not a new technique, but in this case it not only saves on the number of test-and-jump-to-the-starts (the normal reason to unrol a loop), but also decreases the number of other tests and allows me to sweep a few precious left-over clock cycles into contiguous blocks.
- Write a conditional jump in such a way that the jump is made in case there is not much left to do, saving a precious clock cycle for the busy case. Ignore the reflex to jump in "exceptional cases", trying to minimize the total number of times a jump is made.
- when code is "phase critical", abandon the idea of a list-of-instructions and organize the code in "phase aligned" side-by-side blocks, where a jump is most often a jump "to the right" or "left".
- Use software to optimize code layout in memory. I am not aware of any assembler that will automatically do this when jump labels are out of reach, but I know I have wished for it more than once.
{{#set: |Article has average rating={{#averagerating:}} }} {{#showcommentform:}}
{{#ask: Belongs to article::Driving the WS2811 at 800 kHz with an 8 MHz AVRModification date::+
| ?Has comment person | ?Has comment date | ?Has comment text | ?Has comment rating | ?Belongs to comment | ?Comment was deleted#true,false | ?Has comment editor | ?Modification date | ?Has attached article | format=template | template=CommentResult | sort=Has comment date | order=asc | link=none | limit=100
}} | http://rurandom.org/justintime/index.php?title=Driving_the_WS2811_at_800_kHz_with_an_8_MHz_AVR | CC-MAIN-2019-43 | refinedweb | 2,633 | 69.62 |
You can build the source in two ways: using make files or using Ant. The source code ships with both. For those of you who are familiar and comfortable with make files, you are welcome to use them to build the source. I personally find this approach to be very frustrating. If you select this approach, follow the build instructions for your platform as detailed here.
I recommend the Ant approach, which is both Java-centric and cross-platform. Follow these steps to build with Ant:
For a basic build, I recommend the following targets:
ant dist-docs
ant dist-jdk
ant dist-docs
ant dist-jdk
This will build the JavaDocs for the SDK (mozilla\directory\java-sdk\dist\doc), as well as a JAR file containing the basic LDAP access classes (mozilla\directory\java-sdk\dist\packages).
Building the LDAP Filters (Reg Exp with Jakarta-ORO)
The filter classes enhance the basic SDK by supporting regular expression filtering of LDAP entries in a lookup/search procedure. The filter classes written for the SDK rely upon an external regular expression engine developed by Daniel Savarese and distributed by ORO, Inc. Savarese founded ORO and donated the source code to the Apache Jakarta project in June 2000. At the time that the SDK classes were written, ORO still owned the software, thus the package namespaces begin with “com.oroinc”. Once Apache received the software, it changed the packaging to match its naming conventions (org.apache.oro).
In order to successfully compile the filter classes, you must change all references to the old ORO packaging to reference the new names. Fortunately, the API has remained untouched in every other way (class names, method signatures, etc.), so the necessary changes are relatively minor.
The compilation steps are as follows:
Now that you have built the SDK (either in part or in whole), you are ready to try it out.
Testing the Interface
The first step is to include the JAR file(s) in your system classpath. This could be as simple as including ldapjdk.jar, ldapjdk.jar and jakarta-oro-2.0.8.jar, or all of the Netscape Directory SDK jars in your classpath. The simple test in this article requires you to place only the ldapjdk.jar file in your classpath.
With your classpath set up, you are prepared to write a test program. The following are the five essential steps for performing an LDAP operation on a server:
LDAPConnection
LDAPv2
LDAPv3
connect()
authenticate()
disconnect()
finally{}
To see a complete example, download the accompanying source code for this article.
Please enable Javascript in your browser, before you post the comment! Now Javascript is disabled.
Your name/nickname
Your email
WebSite
Subject
(Maximum characters: 1200). You have 1200 characters left. | http://www.devx.com/Java/Article/22299/0/page/2 | CC-MAIN-2014-52 | refinedweb | 459 | 64.41 |
NAME
swapon, swapoff -- control devices for interleaved paging/swapping
LIBRARY
Standard C Library (libc, -lc)
SYNOPSIS
#include <unistd.h> int swapon(const char *special); int swapoff(const char *special);
DESCRIPTION
The swapon() system call makes the block device special available to the system for allocation for paging and swapping. The names of potentially available devices are known to the system and defined at system configuration time. The size of the swap area on special is calculated at the time the device is first made available for swapping. The swapoff() system call disables paging and swapping on the given device. All associated swap metadata are deallocated, and the device is made available for other purposes.
RETURN VALUES
If an error has occurred, a value of -1 is returned and errno is set to indicate the error.
ERRORS
Both swapon() and swapoff() can fail if: [ENOTDIR] A component of the path prefix is not a directory. [ENAMETOOLONG] A component of a pathname exceeded 255 characters, or an entire path name exceeded 1023 characters. [ENOENT] The named device does not exist. [EACCES] Search permission is denied for a component of the path prefix. [ELOOP] Too many symbolic links were encountered in translating the pathname. [EPERM] The caller is not the super-user. [EFAULT] The special argument points outside the process's allocated address space. Additionally, swapon() can fail for the following reasons: [EINVAL] The system has reached the boot-time limit on the number of swap devices, vm.nswapdev. [ENOTBLK] The special argument is not a block device. [EBUSY] The device specified by special has already been made available for swapping [ENXIO] The major device number of special is out of range (this indicates no device driver exists for the associated hardware). [EIO] An I/O error occurred while opening the swap device. Lastly, swapoff() can fail if: [EINVAL] The system is not currently swapping to special. [ENOMEM] Not enough virtual memory is available to safely disable paging and swapping to the given device.
SEE ALSO
config(8), swapon(8), sysctl(8)
HISTORY
The swapon() system call appeared in 4.0BSD. The swapoff() system call appeared in FreeBSD 5.0. | http://manpages.ubuntu.com/manpages/precise/en/man2/swapoff.2freebsd.html | CC-MAIN-2014-10 | refinedweb | 357 | 55.64 |
See my new blog at .jeffreypalermo.com
When it pulls my code files into the Code directory, my casing is lost. MyObjectException.cs becomes myobjectexception.cs. I've already logged a bug with Microsoft, so hopefully this will get fixed. The code inside is good, but the filename is converted to all lowercase.
Otherwise the project convert wizard works well. I took my VS.NET 2003 project, and I opened the project file in VS 2005. The convert wizard was automatically launched, and it succeeded. It removed every CodeBehind and Inherits attributes from my @Page directives, and it converted all my code-behind files to code-beside (converted them from stand-alone classes to partial classes that merge with the aspx file upon compilation). It pulled all my class files into the Code directory, and it preserved all my namespaces.
The issue I'm wrestling with now is how to declare variables of type MyUsercontrol. All my usercontrols were converted to code-beside with partial classes, and my code can't see the user controls (build error). There is code in the Code directory that is referencing a Usercontrol type (to dynamically load later on), and I'm guessing that the code in the Code directory is compile first (and it can't find the user control which will be compiled later). I'm not sure if this is a bug or if I just haven't figured out the *new* way | http://codebetter.com/blogs/jeffrey.palermo/archive/2004/08/17/22328.aspx | crawl-002 | refinedweb | 242 | 64.61 |
I am a beginner to using mock in python and trying to use.
Please tell me the basic calls to get me working in below scenario. I am using pythons Requests module.
In my views.py, I have a function that makes variety of requests.get() calls with different response each time
def myview(request):
res1 = requests.get('aurl')
res2 = request.get('burl')
res3 = request.get('curl')
//Mock the requests module
//when mockedRequests.get('aurl') is called then return 'a response'
//when mockedRequests.get('burl') is called then return 'b response'
//when mockedRequests.get('curl') is called then return 'c response'
Here is what worked for me:
import mock @mock.patch('requests.get', mock.Mock(side_effect = lambda k:{'aurl': 'a response', 'burl' : 'b response'}.get(k, 'unhandled request %s'%k))) | https://codedump.io/share/OI36I79wOF11/1/python-mock-requests-and-the-response | CC-MAIN-2017-09 | refinedweb | 130 | 63.76 |
Around 6 years ago I was introduced to a programming technique that really blew my mind. John, My boss at the time and the tech director at inXile, had written it as part of the code base for the commercial version of a game called Line Rider and I believe he said he first heard about the technique from a friend at Sony.
Since seeing it at inXile, I’ve seen the same technique or variations on it at several places including Monolith and Blizzard, and have had the opportunity to use it on quite a few occasions myself.
What is this technique? I’m not sure if it has an actual name but I refer to it as “Macro Lists” and it’s a good tool towards achieving the DRY principle (don’t repeat yourself –’t_repeat_yourself)
Macro lists are often useful when you find yourself copy / pasting code just to change a couple things, and have multiple places you need to update whenever you need to add a new entry into the mix.
For example, let’s say that you have a class to store how much of each resource that a player has and lets say you start out with two resources – gold and wood.
To implement this, you might write some code like this:
enum EResource { eResourceGold, eResourceWood, }; class CResourceHolder { public: CResourceHolder() { m_resources[eResourceGold] = 100.0f; m_resources[eResourceWood] = 0.0f; } float GetGold() const { return m_resources[eResourceGold ]; } void SetGold(float amount) { m_resources[eResourceGold ] = amount; } float GetWood() const { return m_resources[eResourceWood]; } void SetWood(float amount) { m_resources[eResourceWood] = amount; } private: float m_resources[2]; };
That seems pretty reasonable right?
Now let’s say that you (or someone else who doesn’t know the code) wants to add another resource type. What do you need to do to add a new resource?
- Add a new enum value to the enum
- Initialize the new value in the array to zero
- Make a Get and Set function for the resource
- Increase the array size of m_resources to hold the new value
If #1 or #3 are forgotten, it will probably be really obvious and it’ll be fixed right away. If #2 or #4 are missed though, you are going to have some bugs that might potentially be very hard to track down because they won’t happen all the time, and they may only happen in release, or only when doing some very specific steps that don’t seem to have anything to do with the resource code.
Kind of a pain right? As the code gets more mature and more features are added, there will likely be other places that need to be updated too that will easily be forgotten. Also, when this sort of stuff comes up, people tend to copy/paste existing patterns and then change what needs to be changed – which can be really dangerous if people forget to change some of the values which need to be changed.
Luckily macro lists can help out here to ensure that it’s IMPOSSIBLE for you, or anyone else, to forget the steps of what to change. Macro lists make it impossible to forget because they do the work for you!
Check out this code to see what I mean. It took me a little bit to wrap my head around how this technique worked when I first saw it, so don’t get discouraged if you have trouble wrapping your head around it as well.
#define RESOURCE_LIST \ RESOURCE_ENTRY(Gold, 100.0) \ RESOURCE_ENTRY(Wood, 0) // make the enum #define RESOURCE_ENTRY(resource, startingValue) \ eResource#resource, enum EResource { eResourceUnknown = -1, RESOURCE_LIST eResourceCount, eResourcefirst = 0 }; #undef RESOURCE_ENTRY class CResourceHolder { public: CResourceHolder() { // initialize to starting values #define RESOURCE_ENTRY(resource, startingValue) \ m_resources[eResource#resource] = startingValue; RESOURCE_LIST #undef RESOURCE_ENTRY } // make a Get and Set for each resource #define RESOURCE_ENTRY(resource, startingValue) \ float Get#resource() const \ {return m_resources[eResource#resource];} \ void Set#resource(float amount) \ {m_resources[eResource#resource] = amount;} \ RESOURCE_LIST #undef RESOURCE_ENTRY private: // ensure that our array is always the right size float m_resources[eResourceCount]; };
In the above code, the steps mentioned before happen automatically. When you want to add a resource, all you have to do is add an entry to the RESOURCE_LIST and it does the rest for you. You can’t forget any of the steps, and as people add new features, they can work with the macro list to make sure people in the future can add resources without having to worry about the details.
Include File Variation
If you used the above technique a lot in your code base, you could imagine that someone might name their macros the same things you named yours which could lead to a naming conflict.
Keeping the “global macro namespace” as clean as possible is a good practice to follow and there’s a variation of the macro list technique that doesn’t pollute the global macro namespace like the above.
Basically, you put your macro list in a header file, and then include that header file every place you would normally put a RESOURCE_LIST.
Here’s the same example broken up that way. First is ResourceList.h:
/////////////////////////////////// // RESOURCE_ENTRY(ResourceName, StartingValue) // // ResourceName - the name of the resource // StartingValue - what to start the resource at // RESOURCE_ENTRY(Gold, 100.0) RESOURCE_ENTRY(Wood, 0) ///////////////////////////////////
And now here is CResourceHolder.h:
/////////////////////////////////// // make the enum #define RESOURCE_ENTRY(resource, startingValue) \ eResource#resource, enum EResource { eResourceUnknown = -1, #include "ResourceList.h" eResourceCount, eResourcefirst = 0 }; #undef RESOURCE_ENTRY class CResourceHolder { public: CResourceHolder() { // initialize to starting values #define RESOURCE_ENTRY(resource, startingValue) \ m_resources[eResource#resource] = startingValue; #include "ResourceList.h" #undef RESOURCE_ENTRY } // make a Get and Set for each resource #define RESOURCE_ENTRY(resource, startingValue) \ float Get#resource() const \ {return m_resources[eResource#resource];} \ void Set#resource(float amount) \ {m_resources[eResource#resource] = amount;} #include "ResourceList.h" #undef RESOURCE_ENTRY private: // ensure that our array is always the right size float m_resources[eResourceCount]; };
The Downside of Macro Lists
So, while doing the above makes code a lot easier to maintain and less error prone, it comes at a cost.
Most notably is it can be really difficult to figure out what code the macros will expand to, and it can be difficult to alter the functionality of the macros. A way to lessen this problem is that you can tell most compilers to make a file that shows what your code looks like after the preprocessor is done with it. It can still be difficult even with this feature, but it does help a lot.
When you have compiler errors due to macros, because perhaps you forgot a parameter, or it’s the wrong type, the compiler errors can be pretty difficult to understand sometimes.
Another problem with macros is that I don’t know of any debuggers that will let you step through macro code, so in a lot of ways it’s a black box while you are debugging, which sucks if that code malfunctions. If you keep your functionality simple, straightfoward and format it cleanly, you ought not to hit many of these problems though.
Instead of using macro lists, some people prefer to put their data into something like an xml or json data file, and then as a custom build step, use XSLT or the like to convert that data into some code, just like the C++ preprocessor would. The benefit here is that you can see the resulting code and step through it while debugging, but of course the downside is it can be more difficult for someone else to get set up to be able to compile your code.
To Be Continued…
Macro lists are great, but what if you want your lists to have sublists? For instance, what if you wanted to define network messages for your game in a format like this, and have it automatically expand into full fledged classes to be able to ensure that message parsing and data serialization was always done in a consistent way to minimize bugs and maximize efficiency (less code to write and less testing to do)?
As you might have noticed, macro lists can take parameters to help them be flexible (like, the starting value of the resources… you could add more parameters if you wanted to), but, a macro list can’t contain another macro list. At least not how the above implementations work.
I’m going to show you how to tackle this problem in the next post, so stay tuned! (: | http://blog.demofox.org/2013/05/03/macro-lists-for-the-win/ | CC-MAIN-2017-22 | refinedweb | 1,396 | 51.92 |
Figure 1-1 is a Unified Modeling Language (UML) diagram of the classes and interrelationships in the Media Mania object model. A Movie instance represents a particular movie. Each actor who has played a role in at least one movie is represented by an instance of Actor. The Role class represents the specific roles an actor has played in a movie and thus represents a relationship between Movie and Actor that includes an attribute (the name of the role). Each movie has one or more roles. An actor may have played a role in more than one movie or may have played multiple roles in a single movie.
We will place these persistent classes and the application programs used to manage their instances in the Java com.mediamania.prototype package.
We will make the Movie, Actor, and Role classes persistent, so their instances can be stored in a datastore. First we will examine the complete source code for each of these classes. An import statement is included for each class, so it is clear which package contains each class used in the example.
Example 1-1 provides the source code for the Movie class. JDO is defined in the javax.jdo package. Notice that the class does not require you to import any JDO-specific classes. Java references and collections defined in the java.util package are used to represent the relationships between our classes, which is the standard practice used by most Java applications.
The fields of the Movie class use standard Java types such as String, Date, and int. You can declare fields to be private; it is not necessary to define a public get and set method for each field. The Movie class includes some methods to get and set the private fields in the class, though those methods are used by other parts of the application and are not required by JDO. You can use encapsulation, providing only the methods that support the abstraction being modeled. The class also has static fields; these are not stored in the datastore.
The genres field is a String that contains the genres of the movie (action, romance, mystery, etc.). A Set interface is used to reference a set of Role instances, representing the movie's cast. The addRole( ) method adds elements to the cast collection, and getCast( ) returns an unmodifiable Set containing the elements of the cast collection. These methods are not a JDO requirement, but they are implemented as convenience methods for the application. The parseReleaseDate( ) and formatReleaseDate( ) methods are used to standardize the format of the movie's release date. To keep the code simple, a null is returned if the parseReleaseDate( ) parameter is in the wrong format.
package com.mediamania.prototype; import java.util.Set; import java.util.HashSet; import java.util.Collections; import java.util.Date; import java.util.Calendar; import java.text.SimpleDateFormat; import java.text.ParsePosition; public class Movie { private static SimpleDateFormat yearFmt = new SimpleDateFormat("yyyy"); public static final String[] MPAAratings = { "G", "PG", "PG-13", "R", "NC-17", "NR" }; private String title; private Date releaseDate; private int runningTime; private String rating; private String webSite; private String genres; private Set cast; // element type: Role private Movie( ) { } public Movie(String title, Date release, int duration, String rating, String genres) { this.title = title; releaseDate = release; runningTime = duration; this.rating = rating; this.genres = genres; cast = new HashSet( ); } public String getTitle( ) { return title; } public Date getReleaseDate( ) { return releaseDate; } public String getRating( ) { return rating; } public int getRunningTime( ) { return runningTime; } public void setWebSite(String site) { webSite = site; } public String getWebSite( ) { return webSite; } public String getGenres( ) { return genres; } public void addRole(Role role) { cast.add(role); } public Set getCast( ) { return Collections.unmodifiableSet(cast); } public static Date parseReleaseDate(String val) { Date date = null; try { date = yearFmt.parse(val); } catch (java.text.ParseException exc) { } return date; } public String formatReleaseDate( ) { return yearFmt.format(releaseDate); } }
JDO imposes one requirement to make a class persistent: a no-arg constructor. If you do not define any constructors in your class, the compiler generates a no-arg constructor. However, this constructor is not generated if you define any constructors with arguments; in this case, you need to provide a no-arg constructor. You can declare it to be private if you do not want your application code to use it. Some JDO implementations can generate one for you, but this is an implementation-specific, nonportable feature.
Example 1-2 provides the source for the Actor class. For our purposes, all actors have a unique name that identifies them. It can be a stage name that is distinct and different from the given name. Therefore, we represent the actor's name by a single String. Each actor has played one or more roles, and the roles member models the Actor's side of the relationship between Actor and Role. The comment on line [1] is used merely for documentation; it does not serve any functional purpose in JDO. The addRole( ) and removeRole( ) methods in lines [2] and [3] are provided so that the application can maintain the relationship from an Actor instance and its associated Role instances.
package com.mediamania.prototype; import java.util.Set; import java.util.HashSet; import java.util.Collections; public class Actor { private String name; private Set roles; // element type: Role [1] private Actor( ) { } public Actor(String name) { this.name = name; roles = new HashSet( ); } public String getName( ) { return name; } public void addRole(Role role) { [2] roles.add(role); } public void removeRole(Role role) { [3] roles.remove(role); } public Set getRoles( ) { return Collections.unmodifiableSet(roles); } }
Finally, Example 1-3 provides the source for the Role class. This class models the relationship between a Movie and Actor and includes the specific name of the role played by the actor in the movie. The Role constructor initializes the references to Movie and Actor, and it also updates the other ends of its relationship by calling addRole( ), which we defined in the Movie and Actor classes.
package com.mediamania.prototype; public class Role { private String name; private Actor actor; private Movie movie; private Role( ) { } public Role(String name, Actor actor, Movie movie) { this.name = name; this.actor = actor; this.movie = movie; actor.addRole(this); movie.addRole(this); } public String getName( ) { return name; } public Actor getActor( ) { return actor; } public Movie getMovie( ) { return movie; } }
We have now examined the complete source code for each class that will have instances in the datastore. These classes did not need to import and use any JDO-specific types. Furthermore, except for providing a no-arg constructor, no data or methods needed to be defined to make these classes persistent. The software used to access and modify fields and define and manage relationships among instances corresponds to the standard practice used in most Java applications.
It is necessary to identify which classes should be persistent and specify any persistence-related information that is not expressible in Java. JDO uses a metadata file in XML format to specify this information.
You can define metadata on a class or package basis, in one or more XML files. The name of the metadata file for a single class is the name of the class, followed by a .jdo suffix. So, a metadata file for the Movie class would be named Movie.jdo and placed in the same directory as the Movie.class file. A metadata file for a Java package is contained in a file named package.jdo. A metadata file for a Java package can contain metadata for multiple classes and multiple subpackages. Example 1-4 provides the metadata for the Media Mania object model. The metadata is specified for the package and contained in a file named com/mediamania/prototype/package.jdo.
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE jdo PUBLIC [1] "-//Sun Microsystems, Inc.//DTD Java Data Objects Metadata 1.0//EN" ""> <jdo> <package name="com.mediamania.prototype" > [2] <class name="Movie" > [3] <field name="cast" > [4] <collection [5] </field> </class> <class name="Role" /> [6] <class name="Actor" > <field name="roles" > <collection element- </field> </class> </package> </jdo>
The jdo_1_0.dtd file specified on line [1] provides a description of the XML elements that can be used in a JDO metadata file. This document type definition (DTD) is standardized in JDO and should be provided with a JDO implementation. It is also available for download at. You can also alter the DOCTYPE to refer to a local copy in your filesystem.
The metadata file can contain persistence information for one or more packages that have persistent classes. Each package is defined with a package element, which includes the name of the Java package. Line [2] provides a package element for our com.mediamania.prototype package. Within the package element are nested class elements that identify a persistent class of the package (e.g., line [3] has the class element for the Movie class). The file can contain multiple package elements listed serially; they are not nested.
If information must be specified for a particular field of a class, a field element is nested within the class element, as shown on line [4]. For example, you could declare the element type for each collection in the model. This is not required, but it can result in a more efficient mapping. The Movie class has a collection named cast, and the Actor class has a collection named roles; both contain Role references. Line [5] specifies the element type for cast. In many cases, a default value for an attribute is assumed in the metadata that provides the most commonly needed value.
All of the fields that can be persistent are made persistent by default. Static and final fields cannot be made persistent. A field declared in Java to be transient is not persistent by default, but such a field can be declared as persistent in the metadata file. Chapter 4 describes this capability.
Chapter 4, Chapter 10, Chapter 12, and Chapter 13 cover other characteristics you can specify for classes and fields. For a simple class like Role, which does not have any collections, you can just list the class in the metadata as shown on line [6], if no other metadata attributes are necessary. | http://etutorials.org/Programming/Java+data+objects/Chapter+1.+An+Initial+Tour/1.1+Defining+a+Persistent+Object+Model/ | CC-MAIN-2016-44 | refinedweb | 1,688 | 56.55 |
A few posts ago, a thoughtful commenter said they'd like to understand "why React is so compelling for you". I tried to outline some of those reasons in that post (because Redux goes against so much of what I find beautiful in React). But I didn't really explain how core React can be so elegant. Nor did I properly highlight how so many current-day practices are slowly eroding that elegance.
(That prior post was titled The Splintering Effects of Redux and can be found here:)
"Locus of Control" vs. "Separation of Concerns"
When nearly all of our enterprise applications were delivered by server-side processing, MVC ruled the day. MVC was a useful pattern because it kept us from blindly shoving ALL THE THINGS!!! into a single class/page/module/function. It made us more vigilant about separating data (Model) from display (View) from logic (Controller).
If there's any "problem" with this pattern, it's that it started to get... "fuzzy" as our apps got pushed mostly, or entirely, into the UI layer. There are still devs who try to adhere to the idea that all data calls should be separated from all display which should be separated from all logic. But that paradigm doesn't provide as much value in a Single Page Application.
The current generation of "rich" internet applications makes these distinctions challenging (if not outright erroneous). Does that sound like heresy to you? If so, consider that the more real-time processing capability which gets pushed-to/built-in the browser, the more the browser effectively becomes a true console.
Have you ever built a true console app?? (It's OK if you haven't. But it's useful to this topic if you have.) Although it may feel archaic today, if you ever built, say, a small Visual Basic app designed to run directly in the operating system, you might start to feel what I'm getting at.
In a console app, you typically have a variety of components that you can position somewhere on the screen. Most of those components come with a set of common features:
Attributes that control the component. Usually, these attributes define the component's initial appearance/behavior.
An internal store that holds ongoing information about the component. This could include: the component's position, current display features, information about related components, etc.
Pre-existing or programmer-defined actions. These events are frequently triggered by a user's interaction with that component.
An interface for this component to "talk" to other components, or to interact with other data stores.
Some components are standalone. But many are container components, capable of housing one-or-more child components.
Notice that there's nothing in this component model that even attempts to satisfy an MVC pattern. Under a rigorous MVC approach, the component's own internal memory would be handled somewhere else - in the Model. Any of the logic that is triggered through its actions would be handled somewhere else - in the Controller. Even any tweaks to the component's display features would be handled somewhere else - in the View.
So is a console-application component somehow "bad" programming? After all, here we have one "thing" - a component - that has logic, and data, and display all wrapped up in one bundle. So that's gotta be a problem... right??
Umm... no.
You see, the console component that we're talking about here can reasonably handle logic and data and display, all wrapped up into the same "thing", because we only give that component power over those things that should naturally be in its locus of control.
In other words, the console component can (and should) handle the data (the Model) that belongs in that component. It can (and should) handle the display (the View) of that component. It can (and should) handle the logic (the Controller) to process the actions that are triggered from that component.
A Different Kind of Console
With every new browser update, they come ever closer to being true consoles. And if you're a React developer, a lot of this verbiage probably sounds very familiar to you.
React has components. Those components (can) have their own internal state. Every component has a
render() function to handle its own display (which can return
null if there is no display to be rendered). And they can have any number of associated functions, which handle the logic associated with their own actions.
This can all be demonstrated with the most basic of examples:
import React from 'react'; export default class Counter extends React.Component { state = {counter:0}; decrement = () => { this.saveCounter(this.state.counter - 1); this.setState(prevState => {counter:prevState.counter - 1}); }; increment = () => { this.saveCounter(this.state.counter + 1); this.setState(prevState => {counter:prevState.counter + 1}); }; render = () => { return ( <> <div>Counter = {this.state.counter}</div> <button onClick={this.increment}>Increment</button><br/> <button onClick={this.decrement}>Decrement</button><br/> <button onClick={this.reset}>Reset</button><br/> </> ); }; reset = () => { this.saveCounter(0); this.setState({counter:0}); ); saveCounter = (counter = 0) => { fetch(`{counter}`); }; }
In this scenario, I'm thinking of the entire
<Counter> component as, essentially, a "thing". A "logical unit", if you will. So even though there's a lot going on with this little example, it's all part of one logical unit.
The
<Counter> component has its own memory (state). But that actually makes sense, because the only memory it's responsible for is related directly to this logical unit.
It has its own layout (rendering). But that makes perfect sense, because it's only rendering the items that are directly related to itself.
It has actions - and the logic needed to process those actions. But again, that makes perfect sense, because those actions are all directly related to itself.
And finally, we even have the initial phases of a data layer, as witnessed in the
fetch() inside
saveCounter(). But that makes a lot of sense here, because the data it's saving is specifically related to itself.
In other words, even though this one component does rendering, internal data, external data, and logic tied to actions, that all makes sense. Because all of that stuff falls under this component's locus of control.
I'm not gonna lie. I see a certain beauty in this. If I want to know what's going on with a particular component, I look right inside the component's code. I know... radical concept, huh? And it's not like I'm just making this stuff up on my own. When you look all over React's core docs, they give many examples that are very similar to this.
But code like this is becoming increasingly rare "in the wild". The beauty of this model is disintegrating - because React is eating itself.
This Is Why We Can't Have Nice Things
Outside of blogs and tutorial sites, you rarely see much code like above in "real" applications. And I don't mean just because the above example is small/simple. I mean, because React devs have been demonizing many of the simple concepts illustrated in this example. They keep picking at this basic framework until the result is hardly recognizable.
Separation of Concerns
MVC may not be "a thing" much anymore, but it still hangs heavy in many minds. I've received feedback, from other professional React devs, that an example like the one above violates separation of concerns. Of course, for all the reasons that I outlined above, I think that's flat-out ridiculous. But nevertheless, many React devs seem to have some kind of fear about putting too much "logic" in any of their components.
The last place I worked, they literally created two components for every one. The first component held the
render(). The second one held all of the functions that were used in that component. They called this sibling component the dispatcher. Then they bound all the functions from the dispatcher to the first component. And they somehow thought this was a brilliant way to foster separation of concerns. I thought it was abject idiocy.
The more you do to fling these functions into far-off files/directories, the more obtuse you make your app. And the more difficult you make your troubleshooting.
The way we build applications today is like building a car and deciding that the engine should be in Chicago, the wheels and driveshaft should be in Atlanta, the gas tank should be in Seattle, and the cabin should be in Dallas. And then we congratulate ourselves because we have separation of concerns.
The problems arise because we all have nightmares of apps that we had to maintain in the distant past. Horrific "vehicles" that included an engine, a coal-burning power plant, a Victrola record player, a toaster oven, and three broken down analog televisions - all crammed side-by-side in a single file/class/function/component. And we've been so traumatized by that experience, that now we try to build new cars with every different part flung out to far-off places. But we rarely stop to think, "Wait a minute. What are the parts that still belong together, in one place, very near each other?"
Obsession With "Purity"
React/JavaScript devs these days are obsessed with the notion of purity. Pure components. Pure functions. Pure dogma. These devs will gladly chug a pint of bleach - as long as you assure them that it's absolutely pure bleach.
Look, I get it. As much as you can, it's useful to break down your app into as many "pure" components/functions as possible. That purity leads to easier testing and fewer bugs. And the example above is definitely not "pure".
But you can't build anything bigger than a blog demo without eventually having to create some "impure" components/functions. Your app will need to have some kinda state, and external memory, and side-effects. It'll need to talk to some kinda data store. And there's no way to do those things without violating the Holy Scripture of Purity.
The State-Management Nightmare
One way that devs strive for more "purity" is by chunking some big, heavy, state-management apparatus into their app and then allowing it to handle all that nasty, dirty, impure state/data management stuff. So they'll take a component like the one above, and when they're done with it, it will basically be left with nothing but the
render() function. Then they'll strain an oblique trying to pat themselves on the back because the refactored component is so "pure". But that's not purity. That's obscurity.
Sure, we could handle most of this oh-so-evil logic in reducers and actions and subscribers and all sorts of other state-management constructs. Then, when we open the code file for this component, we'd be all self-satisfied with its "purity". But... the component wouldn't make any sense.
With state-management thrown into the gears, you'd open this file and have a hard time figuring out how the counter is set. Or where it's set. You'd have to trace that logic through directories/files that "live" nowhere near this one. And somehow, React devs think that's... a good thing???
Klasses R Stoopid
Sooo many React devs nowadays wake up every morning and sacrifice a fatted calf and their first-born child on the Altar of Functions. They're brainwashed by the React Illuminati that any code with a
class keyword in it is somehow Evil & Stooopid. And any code that consists of only functions is Holy & Righteous.
They can rarely articulate any empirical reason why these demonic classes are actually so... "bad". They just furl their brow, dig their nose, and mutter something about how "Classes are da sux. And yer stooopid."
It's not that I don't have empathy for the
class haters. It's a big word. It's too confusing for all but the most advanced of programmers. It's got that "OOP-shtank" all over it. You can't be expected to put up with code that actually has a
class keyword in it! That's just not fair!! You're perfectly within your rights to curl up into the fetal position any time you so-much-as look upon that scary, nasty, horrible
class keyword.
This is not some diatribe against functions. Functions are beautiful. Functions are great. But in the example above, everything shown there is part of a single logical unit. We could create a single
counter.js file that has all of the functions defined on this page, outside a class, but that would only obfuscate the original intent of this single component.
What many in the class-hating, function-worshipping crowd seem to miss is that, in this context, the
class is a logical namespace for all of the data/display/logic that should be tied to the
<Counter> component. Yes... you could break that up into a series of loosely-connected functions - but that serves no logical purpose, other than to appease the Function God.
(If you want to get my full breakdown regarding the abject silliness of your
class hatred, check out this post:)
Anything Outside of a Hook is Stoopid
I won't go into this point in toooo much detail, cuz it's kinda an extension of the previous point about classes-vs-functions. But nowadays, even if you LOVE functions. And even if you publicly DENOUNCE classes. That's... not good enough for the elitists. If you haven't spent your nights/weekends/holidays figuring out how every dang snippet of code can be refactored into a Hook, then you're just a script kiddie posing as a "real" programmer.
The Hooks crowd feels downright cultish to me. There are already sooo many examples I've seen - on the interwebs, or in person - where someone takes a class-based component that's supposedly bad/wrong/evil, then they refactor it into a Hook that has just as many LoC - maybe more, and they feel all self-satisfied, like they've done something special and they deserve a cookie. And a smiley face. And a bowl of ice cream, with extra sprinkles on top.
Loss of Focus
In the "default" React framework, there's a real beauty in
setState().
setState() is only designed to work on the component where it's called. In other words,
setState() is specifically confined to that component's locus of control. Of course, you can pass a state variable down to the descendants. You can even pass a function that will allow the descendants to invoke a change on that state variable. But the actual work of updating that state variable is only ever done inside the component where it resides.
This is critical, because state-management tools throw this concept out the window. And once you throw that concept out the window, you start implementing a whole bunch of clunky constructs (like reducers and actions) in an attempt to shove that genie back in the bottle.
But you don't have to jump through all of those hoops if you keep state where it "belongs" - inside whatever component naturally should control it. This allows you to keep all of the updates for those state variables in one, logical place.
All of the obfuscating overhead of tools like Redux comes about because they're trying to recapture the control of state updates that already existed in React's default model.
Conclusion
Despite what this might read like, the fact is that I don't much care if you're using Redux (or other state-management tools) on your projects. I don't care if you want to split all of these functions off into their own far-flung directories. I don't care if you think I'm an idiot because I (continue to) commit the sin of using the evil
class keyword.
But so many of these fads that have swept through the React community (and they are fads) have the very tangible effect of degrading what was, originally, a very beautiful framework. It's only a matter of time before someone comes up with a Hooks replacement, and then they'll be telling you that you're an idiot for using those old, washed-up constructs. (Even though they won't be able to give you any empirical reason to backup their contentions.)
So much of what made React amazing in the first place has now become rare in "real" React applications. The React Illuminati have spent so much time trying to craft fixes/replacements for original React features (that were never broken to begin with), that now we have React apps/components that are harder to troubleshoot than spaghettified jQuery apps.
You can rarely ever just open the code for a component and see what it's doing. The elitists have flung all of the logic into the dark corners of the application.
I'm not saying that every React component must/should look like the one above. But the farther we stray from that model, the more we undercut many of the things that made React great in the first place.
Discussion (46)
Thank you! The ironic thing is that now I'm doing almost all of my development in Hooks. But not because I "saw the light". It was basically a practical decision based on the teams/projects in which I'm currently working. I've already written a few articles that explain some of the benefits (and problems) that I've found with Hooks. I'll probably be doing a few more where I outline some of the stuff that I genuinely enjoy about them. But overall, I doubt that anyone can really convince me that classes are "bad" or "wrong". At worst, they're just "different" from functions/Hooks.
Man.. the speed in which you generate these posts is epic.
"Production quality" React code bases in the wild indeed tend to become a convoluted mess.
Do you have any experience with other modern frontend frameworks (specifically Svelte comes to my mind)?
Svelte has poor typescript which leads to an even bigger convoluted mess (tried it in a side project, not going back until it gets first class ts support)
Well.. I used this on a side project and it worked fine (svelte, sapper and typescript).
Typescript is a whole other discussion but in general it does not reduce the convolution of a codebase (if anything it adds complexity and in return you get its advantages)
I tried that monorepo relatively recently and it totally broke vscode, errors appeared in random places, my code wasnt compiling and more... Maybe it was a bug they fixed right after, but it's definitly a bad first impression...
On typescript: I think it prevents you from doing some stupid stuff which would convolute your codebase
Too bad you had that experience. It worked for me in vscode just fine (maybe I needed to install a plugin or two). If your thing is on GitHub maybe I can have a look.
I am curious, how can typescript prevent you from convolution your codebase (I am not anti typescript or anything)?
Typescript:
Noe that I think about it, it doesn't prevent u from writing messy code that much, but I guess its something? Idk
I'm not anti-TS either. But I've always maintained that dynamic typing is a feature. Not a bug. Static typing is good. It's powerful. But it's not the end-all/be-all. And there are some times when dynamic typing can actually be very useful.
Can you give a moment where dynamic typing is useful? Not saying ur wrong, just cannot think of any myself
The most common example (IMHO) is on return types. Now, don't get me wrong: I think you can take this concept wayyyy too far. And I'm not saying this should be done all the time - or even most of the time. But it's not terribly uncommon in JS to have
getName()return a string if there is just one name, or an array of strings, if there are multiple names.
I know that, in TS, we have union types. Those can help us consume functions that return multiple types. In a "true" statically-typed language, that's not an option. Like, in Java, you can't designate a method as returning a string or an array (although you can accomplish something similar by using generics - which are handled much better in C#).
I often use dynamic typing as a type of semaphore to indicate different stages in a variable's "life cycle". For example, I have a frontend app that has to call to an API to get all of its data. The data sits originally in
statevalues like this:
Obviously, the API calls will run asynchronously. And with React's render cycle, it can be tricky to assure that we're not calling the same endpoint for data that we've already received. So in any code that would invoke an API call, there is a check that looks like this:
I don't want to set the initial
statevalues to empty objects, because it's at least possible that the API will return an empty object. So then there would be no quick-and-easy way to simply look at the
statevariables and know whether they've received the API data load.
I could just set the original
statevalues to
null. Or I could set additional variables like
hasRolesApiBeenCalledand
hasRolesApiResponseBeenReceived, but that starts to become a headache. And seeing the
falsevalue in my code is a clear visual indicator (to me) that we're checking to see whether anything's been received from the API at all. Because the simple value of
falsewould never be a valid, standalone value received from my API.
Heres an example solving the first issue with getName:
For the semaphore example I dont really get the problem, cant you do somsthing like:
I typed those on my phone so idk if I didn't make any typos or stuff, but the logic is there.
Maybe I understood the problems you enumerated wrong, if that's the case than sorry I guess:)
I only used f#, so idk too much about c#, what features do c# generics have you'd like to see in ts?
The original question was in regards to where dynamic typing could be "useful" - not required. So from that perspective, there's really nothing to solve in my examples. I'm just explaining to you where dynamic typing can be useful - to me.
Every programming problem can be "solved" with static typing. There is no scenario where we can say, "Well, this particular problem simply can't be solved unless we switch to dynamic typing." (Conversely, every programming problem can also be "solved" with dynamic typing as well.)
What I see in your examples is what I often experience from devs who are firmly ensconced in static typing. They look at every approach that involves dynamic typing and they say, "Why couldn't we do it with static typing this way??" And of course, the answer is always that you could certainly do it that way. And there's certainly nothing wrong with approaching programming tasks through a static-typing lens - just as there's nothing wrong with doing them through dynamic typing.
My only "issue" is that the static-typing crowd tends to look at dynamically-typed languages as though they have a bug or a flaw that they're constantly trying to fix. But dynamic typing isn't a bug in a language. It's a feature.
Now... you may not like that feature. You may prefer to work in languages that don't have that feature. And that's fine. We all have our preferences and our own way of grokking code. But the plain simple truth is that JS is, and has always been, a dynamically-typed language. And there's nothing necessarily "wrong" about that.
If you feel that a particular project is best addressed using TypeScript, then that's cool. I'd probably agree with you. If TypeScript is your go-to tool-of-choice on nearly any project, I wouldn't necessarily agree with you - but I get it. But if you're thinking that JS's dynamic typing is an inherent flaw that needs to be completely washed out of the language, then I'd say you're working in the wrong language. Because dynamic typing wasn't some bug in the language's source code that needs to be "fixed".
Fair enough, I now get what you are trying to say:)
A nice approach is the one taken by f# - being statically typed but being able to infer almost everything, but sadly js has a bunch of wild parts which you cannot really infer the result of
I've been looking at Svelte - a lot! It has some great promise - although I gotta admit that the whole dependence upon templates kinda makes me wary. I can't see a templating architecture anymore without thinking of Handlebars - which makes me throw up a little bit in my mouth.
But aside from that, it looks really cool. The only downside to some of these other tools is that it's one thing to read up on them, or play around with them. But to actually do a lot of serious coding with them, it'd all have to be in my free time - because my "day jobs" are typically consumed with the established paradigms - like React, or Angular, or (yes, even) jQuery.
I wholeheartedly agree with the sentiment you express around "you don't know how good a tool is (and don't actually understand it) until you do serious coding with it".
Templates are an interesting topic. They have some advantages especially around predictability (which also helps the compiler afaik). In other frameworks that used templating I often felt limited by it (especially when the template was in a different file than the JS code).
In Svelte I haven't felt that so far. If that moment comes I will probably start resenting it as well :)
Actually, having the ability to use stuff like #await, custom-actions and variables from the store right in your template feels really expressive and empowering to me.
TBH, I didn't really understood what actions are about (and didn't make use of them) until I watched this talk:
Anyhow, I am yet to see a huge application built in Svelte and React does put food on the table, but so many of the design decisions and tradeoffs Svelte makes strike me as fundamentally better than React's.
In the context of this post, the Svelte solution for 'store' comes to mind. Would be interesting to directly compare and contrast it with React context and Rudux :)
Agree on all fronts. Even though I've been coding since I was (literally) in junior-high, I've actually been a late adopter on many new languages/technologies. I hate the experience of falling in love with a language/framework, only to see it fall into obscurity. The last time I did this, I was a fairly-early adopter on Flex. And we know where that ended up...
So I guess you can say that I'm kinda "lurking" on Svelte. I'm genuinely excited about it. But I'm not gonna be that guy converting my HUGE personal project over to it unless I start to feel that it has some serious "legs".
I agree. On the other hand, if everyone is sitting on the fence until a thing is mainstream, who exactly has the power to make anything mainstream? Are we waiting for the entry-level programmers of the world to pick the next thing because it is the easiest to use without knowing much? Are we waiting for facebook or google to tell us it's okay?
To me, this is part of the conundrum of being a modern dev (and especially, a modern JavaScript dev). The beauty is that the language (and the massive universe of associated packages) is evolving at a breakneck pace. The downside to that evolution is that you can burn a lot of valuable time and effort trying to build something in a soon-to-be-dead fork of the evolution, merely because you placed your bet on the wrong technology.
I don't have a "proper" answer for this. But I was intrigued recently by a comment that I read from Ben Halpern on this platform:
"Inelegant software which has a huge following and a big ecosystem is often better than objectively cleaner, better software."
I wanna hate him for stating this (plainly obvious fact). On many levels, he's absolutely right. But it still sucks when you're convinced that you've found some package/solution/language/whatever that you swear is superior - but it just never gains a following.
I keep agreeing with you. My question is: what is our (senior devs who have been around for awhile and could contribute code to any one of these frameworks) role in making something that we think is better mainstream?
A different way to phrase it: how does this process of evolution select for the winning frameworks and tools?
Some of this comes down to deeply personal choices about where/how you work and what's important to you as a dev. I'll freely admit that, for much of my professional life, I've been working for whomever could drop the most coin into my bank account. There's nothing wrong with that. But it does tend to leave you working for larger corporations. Big corporations so rarely spawn "green fields" work - it's all tied to big legacy projects. And those legacy codebases are rarely ever rewritten (nor should they be). So it's highly impractical to suggest switching-to/introducing any new tool/library/technology.
I really think that being on the "evolutionary edge" of technology requires a bit of a conscious choice on the part of the dev. So many (well-paying) jobs amount to "Add a new feature/module to this Big Hairy Legacy Codebase". So if you want to be in a place where you can actually have a role in making something mainstream, you'd have to consciously filter for that while you're making a job choice. Of course, many devs - even some very experienced and talented devs - don't feel like they can afford to weed out Big Corporate X that wants to throw money at them to crank out new Visual Basic modules...
I see your point. My thinking is: even if I could make my team to select technology X, I don't think it will make that much impact. No one outside of my immediate vicinity gives a $#!t about what I think and probably they shouldn't. I didn't earn it.
I just wonder, if it is not people like us that make these things popular who is it then?
It is also indirectly related to another comment I wrote about dev culture:
Ah, I didn't know js files aren't compiled. I thought it processes them so that it can do its treeshaking magic and all.
On the one hand your points make a lot of sense to me and I can relate. On the other hand I wonder whether we (devs) became too spoiled for our own good. We seem to prioritise DX over UX and expect to be hand held (by our free tools and the communities that back them) every step of the way
You can't really have "much impact" on the broader adoption of any given technology. For the most part, that's a good thing, because our individual tech obsessions are never quite as clear-cut and obvious as we'd like to think.
You can rarely do much to individually shape opinion, because programming is the tactical expression of a vast marketplace of ideas. Once any marketplace gets large enough, it's nearly impossible for any one person to really drive the market.
It'd be like if you woke up this morning with a revelation that Microsoft will be the hottest, most profitable stock for the next 10 years. You can throw all of your money into the stock. And if your intuition is correct, you'll eventually make a lot of money. But your bulk purchase of MS stock will have only an infinitesimal effect on the price. You can praise the stock to all your friends, but again, that's not gonna have any material impact on the stock, good-or-bad. In the end, "the market" as a whole will drive the long-term direction of the stock.
The only possible exception to this in tech is if you can (or even want to) find a way to become one of the tech's "thought leaders". If Dan Abramov wakes up tomorrow morning and decides that React is a stooopid name, and we should all be calling it "ButtJS" (pronounced "butt-joos"), then by golly, that's what most React fanboys are gonna start calling it. They'll even write deep think pieces about why ButtJS is such a better name. And they'll cover you in snark and scorn if you still insist on calling it "React".
😂 you killed me.
You are right.
I still feel there is some "missing link" here... but maybe this feeling is wrong.
Wow. That's really an epic post. I really like the way we used to do things in React, but today is frustrating the amount of "bullshit" you have to do to create a "pure React app", that's sucks.
Thanks Adam to write something honest and realistic about React ecosystem.
Thank you for the feedback! As you can tell from some of the other comments, some people are definitely not in agreement... But I'm fully aware that some people truly like all the ways that React has changed/evolved over time. I still truly love React - but I'm not always a fan(boy) of every new way that the current code morphs.
You're welcome Adam. I see how this post generated rants. That was the biggest reason why I left Twitter and stoped to following some "ReactJS rockstars" (it was too bullshit to me). Sometimes I get myself thinking when development became a religion and not a technical working, dogmatism took place over pragmatism, people do things because they "believe" is better, and because their "shepherds" said it was better, not because are really better.
Keep up the good work.
I very much agree with a lot of these points. Redux solves a problem by creating a new one, which leads to another level of abstraction, which in return creates a problem that needs yet another layer of abstraction. There is even a reduce reducers library. Reminds me of joelonsoftware.com/2001/04/21/dont...
But, MVC is dead...? Guess what this very platform is running on ;)
Haha, I hadn't seen that post before, but I love it. "Architecture Astronauts". I'm gonna be using that one. And to think that he wrote that nearly 20 years ago...
I would never say that MVC is dead. But 10-12 years ago, it was definitely a full-blown fad. It was one of those catch phrases that devs just spewed to make them sound more knowledgeable.
Good post! I largely agree with you, though I may myself be part of the anti-class/pro-hook cults in some capacity.
I really dislike the class keyword in JavaScript. It makes something messy (prototype inheritance) look neat but doesn't actually fix any of the messiness. It misleads devs into thinking it's well defined.
The namespace job you describe I generally use files or even directories for - a typical complex component of mine might have a couple files containing comonents, one or two files with hooks, and an index file that brings it all together. It typically contains zero class keywords, excepting any test assuring compatibility with class components.
Functions, meanwhile. JS is a function programming language with some other stuff attached. I've treated it like that for fifteen years now, and it's been extremely compliant for that time. Function purity is a useful concept, especially for certain modes of reasoning, but I will agree it's overvalued. React hooks are quite honestly a massive godsend here, and I will not be moved on that subject.
But apart from these opinions of mine, I feel you speak truth and I agree.
Not trying to argue, but I'm legitimately curious. Can you outline any scenarios where this theoretical "problem" actually leads to tangible problems? Like, have you ever seen a bug that would have been avoided if the developer hadn't "thought it was well defined"?
Every time I hear a JS dev rail against classes, it always seems (to my ear) to be tied almost entirely to theory with almost no basis in tangible effects. Specifically, it also sounds (to me) like, "This is the way that I think about the language. And anything that allows others to conceptualize it in another way is bad."
Many of the NPM packages we use have some very "messy" stuff under the hood. But when we use that NPM package, it's typically pretty simple for us to call a single function or drop a single component into our
render()and suddenly we don't have to think about all the "messy" stuff. But I've never heard an anti-class person follow up their objection by saying that we should banish NPM.
Even in the scope of a single application: I figure out how to do
<SomeComplexMessyThing>. Once I've solved that riddle, I package it into a function or component that can be used by anyone else working in the app. They just drop
<SomeComplexMessyThing>into their new code and... it works.
In theory, it'd be great if everyone understood all of the underlying "stuff" that was happening with the components/functions/packages/libraries that they were importing. But that's just not realistic.
And finally: This is... "good"?
But this is... "bad"???
Again, I'm not trying to argue about anything. I'm just legitimately curious (and confused). After reading thousands of words about the "evil"
classkeyword on the internet, and hearing similar sentiments from other devs in-person, I'm still waiting to hear an empirical answer, from anyone, that explains why
classis somehow "wrong".
Actual bugs? Not on my own watch, no. But I have seen juniors with some extremely wrong ideas about how classes work in JS, which hampered them. The
classkeyword is syntactic sugar, as you know - by itself not a bad thing. However, it obscures things - and it makes people think in ways that cause them problems when easier solutions are available.
Your second example isn't bad - but for proper equivalence the first one would have to look like this:
Then you can new either one and get an instance.
Now what happens when Fred the Junior goes
const bar = new foo(); bar.sayHello = () => console.log('Begone'); bar.sayHello();? Probably what he expected. But then Andy the Junior goes
delete bar.sayHello();because he needs that to not be present, and... Well, that didn't go to plan.
Consider this instead:
A simple factory function, same outcome as your top example except you can get more of them. Results are a lot easier to reason about, what you see is what you get, there's no secret machinery in the engine.
I'm just not aware of any advantage of classes in JS that makes them, their pitfalls, and the wrong ideas they spawn, worth it.
Meanwhile, my last two years were spent building exactly the kinds of abstractions you speak of, and as I mentioned, no classes in there. None needed.
One of the biggest drawbacks to localizing state in a class is lack of composability. With hooks you can easily share data across components, which becomes incredibly valuable when it involves async requests or state that needs to be accessed between multiple components.
I almost always have the
constructorin my own apps because there's almost always a few other things happening there, so I've gotten too-much in the habit of starting with the
constructor"by default". But you're right. It's doing nothing here. So I've removed it.
I just re-jiggered it so that
saveCounter()is called first, as a side-effect of the existing
state.countervalue.
I agree with Michi on this one. Removing the
prevStatemodifier removes the explicit indication that we're updating the current state in relation to previous state. And it's "hardly readable" without a space after the colon?? Meh. Poe-tay-toe / poe-tah-toe. Now we're getting into tabs-vs-spaces territory...
I sincerely appreciate the feedback.
been running in my had for a while how to describe the mess happens in react today.
excellent paper, thanks for writing it :)
I don't think that last example makes it more readable. Not everything needs to be destructured. prevState is very explicit and that's a good thing imo
React is beast urz a sucks man.
hahahahah sad
I wish I could give this more hearts.
hahahahah good! | https://dev.to/bytebodger/react-is-eating-itself-fga | CC-MAIN-2021-17 | refinedweb | 6,952 | 63.59 |
The class Timer is a timer class for measuring user process time. A timer t of type Timer is an object with a state. It is either running or it is stopped. The state occures while the timer is running it counts as the first interval.
#include <CGAL/Timer.h>
The timer class is based in the C function std::clock() on PC systems and the C function getrusage() on standard POSIX systems. The counter for the std::clock() based solution might wrap around (overflow) after only about 36 minutes. This won't happen on POSIX systems. The system calls to these timers might fail, in which case a warning message will be issued through the Cgal error handler and the functions return with the error codes indicated above. The precision method computes the precision dynamically at runtime at its first invocation. | http://www.cgal.org/Manual/3.5/doc_html/cgal_manual/Miscellany_ref/Class_Timer.html#Cross_link_anchor_1927 | crawl-003 | refinedweb | 142 | 72.97 |
.
The design mode of InfoPath is well documented in InfoPath's online Help system. The focus of this chapter has been to expose the technical details of InfoPath solutions, particularly where existing documentation is lacking, such as how InfoPath interprets view stylesheets to establish node bindings. For that reason, this section provides only a cursory overview of InfoPath design mode and happily refers you to the online Help system for a more in-depth investigation.
That said, there are a number of reasons InfoPath in design mode may be useful to you:
As a tool for learning how valid solutions can be created
As a form design tool for developers or IT workers who aren't as XML-savvy
As an expedient way to create forms, given an existing XML schema, instance document, or web service
As an expedient way to configure other aspects of a solution besides the default view, e.g., secondary views, submission behavior, web services integration, etc. (see "Developing Solutions that Play Nice with Design Mode" later in this chapter).
As a solution packaging and deployment tool that supports automatic update notifications
As an IDE for InfoPath scripting, with the help of Microsoft Script Editor
InfoPath design mode provides a WYSIWYG environment for creating forms meant to be run by InfoPath in editing mode. It has sophisticated support for the creation of HTML layout tables and lets you drag and drop different kinds of form controls onto the form view canvas. You can begin creating a form in one of three ways:
From scratch.
From a "data source," which can be an XSD schema, an XML instance document, a WSDL-defined web service, or a Microsoft Access or SQL Server database.
By customizing one of the sample forms that come bundled with InfoPath.
If we had decided to create our event form example from within design mode, rather than by hand, we would only need an example instance document, or better yet, a schema, to get started. Since we already have the schema (Example 10-10), let's take a quick look at what this would involve. Figure 10-10 shows a newly created form in design mode, not unlike the one we created by hand.
To create a new form starting with an XML schema, select File Design a Form... New from Data Source. From within the Data Source Setup Wizard, choose "XML Schema or XML data file," click Next, and finally click Browse to find the XML schema file.
InfoPath design mode utilizes as much information as possible from the schema to aid you in creating your form. In fact, just by dragging and dropping from the Data Source task pane, shown on the right side of the window in Figure 10-10, we can create a functional form in just a few seconds.
The Data Source task pane provides an Explorer-like view of the underlying XML schema for the form you are designing. Some icons signify groups, and others fields, in InfoPath's terminology. A field is an attribute or an element that can contain only text, or rich text in the case of XHTML content. A group is an element that can contain element children, i.e., other groups or fields. In XSD terms, fields (except for rich text fields) have simple content and groups have complex content. When you drag an element or attribute onto the canvas, InfoPath automatically creates an appropriate section (for a group) or form control (for a field). When more than one choice is equally appropriate, it immediately prompts you to choose which control or section type you want.
In our example in Figure 10-10, the "Location" text box is selected. As a result, the corresponding location field to which it is bound is automatically highlighted in the Data Source task pane. Note also that the optional section in which the text box occurs is also bound to the location field. As you navigate through the form in design mode, you will see where the binding for each control is in the data source tree.
When you want to have more control (no pun intended) over exactly what kinds of form controls or sections should appear in your form, you can switch to the Controls task pane, shown in Figure 10-11.
When you drag a control or section onto the canvas from the Controls task pane, you are immediately prompted to choose what group or field in the data source to bind that control or section to. In the example shown in Figure 10-11, the location field is chosen as the binding for the optional section being dragged onto the canvas. The resulting XSLT view stylesheet created by InfoPath will include the "Click here to add" link for the location field when it is absent, and will display the optional section itself when the location element is present. However, this is an example of a structural binding, rather than a text binding, which means that, as such, the end user will not be able to edit the content of the location field, but will only be able to add or remove it. To provide editing support, we additionally need to create a text binding. We can do this either by dragging a Text Box control onto the canvas, inside the optional section, and then selecting the location field when prompted for a binding, or we can start from the Data Source task pane instead and simply drag the location field into the optional section we created for it. A corresponding Text Box control will automatically be created. Either way, we end up with the location field having two bindings, a text binding and a structural binding, just as was the case with the event form example we created by hand.
Another thing to note about Figure 10-10 is that the entire form appears exactly as InfoPath in design mode created it, as a result merely of dragging-and-dropping fields, groups, sections, or controls onto the canvas. No additional edits were made. Thus, it not only makes reasonable choices about what controls or section types to use, but it also automatically tries to make the field names friendlier, so "location" becomes "Location," "start-time" becomes "Start Time," etc.
We can relate some of these controls back to some terminology introduced earlier in the chapter under "The XSLT Stylesheet," for the event form solution created by hand. Specifically, the Text Box and Rich Text Box controls result in the creation of text bindings, and the various kinds of sections (optional, repeating, choice, etc.) result in the creation of structural bindings and corresponding editing control declarations (xsf:xmlToEdit elements) in the form definition file. Other kinds of bindings, such as those employed by the checkbox and radio button controls, can best be explored by perusing the sample forms that come bundled with the InfoPath application.
When creating a new blank form rather than starting from a schema or instance document, InfoPath automatically creates a schema for you as form controls are added to the design. To disable this default behavior, uncheck the "Automatically create data source" checkbox in the Controls task pane. Table 10-2 shows the controls and the XSD declarations they create in the schema for the fields to which they are bound. These mappings reveal not only how this handy feature works, but, perhaps more importantly, it gives you some clues about how to design your own schemas and forms. Specifically, it shows which controls make sense to bind to which data types.
Control(s)
Data Source Type
XSD Element Declaration
Text Box, List Box, Drop-Down List Box, Option Button
Element field (string)
xsd:string-typed element
Rich Text Box
Element field (XHTML)
Complex-typed element with XHTML content.
Date Picker
Element field (date)
xsd:date-typed element
Check Box
Element field (boolean)
xsd:boolean-typed element
Picture, Ink Picture
Element field (base64binary)
xsd:base64binary-typed element
All of the controls that bind to automatically created element fields can also bind to attribute fields, with one exception. The Rich Text Box control binds to an element field that can contain XHTML elements. Since attributes cannot contain elements, Rich Text Box controls cannot bind to attribute fields. The Button, Hyperlink, and Expression Box controls can never have bindings. The Expression Box control is essentially a way for you to create an xsl:value-of instruction from within design mode. You specify the XPath expression whose value you want displayed. If necessary, editing will be explicitly disabled in the resulting stylesheet, through use of the xd:disableEditing annotation, because Expression Box controls are meant primarily to display derived information, such as a sum of numbers. They are not used to establish editing bindings.
The Layout task pane provides a set of table-based layout templates to choose from and a set of table operations for manipulating them. The Views task pane allows you to manage multiple views in your form template, each of which corresponds to an instance of the xsf:view element in the form definition file.
Once you have finished designing your form, you have the option of publishing it through the InfoPath interface. Click on "Publish Form..." in the Design Tasks task pane, and a wizard will guide you through the process. You have a choice between three publication targets: shared folder, SharePoint form library, or web server. Publication to a web server requires that WebDAV be enabled on the server. All of the form's files will be packaged into an .xsn file and saved at the location that you specify.
Once you've selected your publishing target and location, you'll be prompted to provide a user-accessible location (URL or network path) for your solution. This dialog is shown in Figure 10-12. The value of this field is used to populate the publishUrl attribute of the xsf:xDocumentClass element, i.e., the root element of the form definition file. It identifies the central location from which all users will initially retrieve the form and receive form updates. InfoPath uses the value of the publishUrl attribute in two ways:
InfoPath assigns this value to the href pseudo-attribute of the mso-infoPathSolution PI when InfoPath saves a filled-out form
InfoPath checks this value to verify that the form template has not moved from its original published location.
You will want to modify this field only if the user-accessible URL or path is different from the URL or path where you originally put the file. Changing the value will be necessary, for example, if you need to publish the file to a web server using a network drive but require your users to download the file via an HTTP URL.
There are a number of alternative approaches to developing InfoPath solutions. How much work should you do by hand?[3] And how much work should you do in design mode? Table 10-3 lists possible alternative solution development strategies.
[3] When I say "by hand," I really mean any way other than using InfoPath in design mode. One of the key advantages of the underlying XML syntax of solutions is not only that you can modify things manually, but you can also use XML tools to generate, modify, or otherwise process solutions.
Development strategy
Level of risk
1. Never use design mode.
Safe
2. Always use design mode.
3. Build a solution in design mode, but customize and maintain it by hand, never going back to design mode.
4. Build a solution in design mode, customize a portion of it by hand, and maintain it both ways.
Daring
5. Build a solution entirely by hand and later open it in design mode.
Crazy?
Options 1, 2, and 3 are safe because they never burden InfoPath design mode with having to read in a form template that it didn't itself create. Options 4 and 5 share the risk that InfoPath will have trouble opening your solution, because your dirty little fingers have been touching it. And if InfoPath opens your solution without complaining, you run the risk that parts of your solution will get overwritten. The primary problem is that, while the InfoPath XML editor will accept virtually any XSLT stylesheet you throw at it, the InfoPath form designer is much more finicky.
From within design mode, changing a view that you have created by hand is always a risky proposition. While this section describes a mechanism by which you can preserve manual changes, a number of things could still go wrong. Always back up your form template files before opening them in design mode.
For example, the form designer requires the xd:binding and xd:xctname attributes to be explicitly present on all controls in the view stylesheet. Otherwise, it will not correctly identify all bindings or form controls, even though the editor has no problem identifying them. There are a number of other limitations that design mode imposes. For example, it chokes on common XSLT constructs such as xsl:call-template, but not without first displaying an error message specifying exactly what is not supported. Again, this is a limitation of design mode, not the InfoPath XML editor. If you build or modify a solution by hand, you can feel free to use any XSLT instruction you wish.
Does this effectively mean that, once you skirt design mode with a manual modification, there's no going back? Well, it would, if it wasn't for another InfoPath feature called the preserve code block. This is a mechanism by which you can mark portions of an XSLT view stylesheet as untouchable regions, for your eyes only. Note that you won't be able to use the form designer to edit or customize the controls declared therein, and that's the whole point. This is done by wrapping your manual customizations in a template rule annotated with mode="xd:preserve". The template rules in the xd:preserve mode and the xsl:apply-templates instructions that invoke them will remain untouched. Note that all template rules and named templates that you invoke from within a preserved code block will also need to be preserved, using mode="xd:preserve". Otherwise, design mode will discard them, resulting in an invalid stylesheet, in the case of missing named templates. For named templates, you will also have to add an arbitrary match attribute, so that it will still be legal XSLT after you add a mode attribute. To ensure that your named-template-cum-template-rule doesn't match any nodes, you can use a pattern that is guaranteed to match nothing, such as @*/*.
Example 10-20 shows our first example stylesheet (Example 10-3) with the entire view protected by the xd:preserve mode.
<xsl:stylesheet <xsl:template <html> <head> <title>Announcement</title> </head> <body> <xsl:apply-templates </body> </html> </xsl:template> <xsl:template <h1> <xsl:value-of </h1> <p> <xsl:value-of </p> </xsl:template> </xsl:stylesheet>
Figure 10-13 shows the result of opening the corresponding form template in design mode. We only see a red box that says "Preserve Code Block." This alerts us that custom stylesheet code is being skipped over. We can commence to drag and drop other controls onto the form canvas, add text before or after the block, or create layout tables around the block, moving it around as necessary.
Example 10-21 shows the XSLT stylesheet as output by the form designer after making a small change (adding some text to the bottom of the form). We see that it's much more verbose, including all of its CSS and namespace declaration boilerplate. However, our template rule in the xd:preserve mode is indeed preserved unaltered, and our solution will continue to work as expected in InfoPath's editing mode.
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet <xsl:output <xsl:template <html> <head> <style tableEditor="TableStyleRulesID">TABLE.xdLayout TD { BORDER-RIGHT: medium none; BORDER-TOP: medium none; BORDER-LEFT: medium none; BORDER-BOTTOM: medium none } TABLE { BEHAVIOR: url (#default#urn::tables/NDTable) } TABLE.msoUcTable TD { BORDER-RIGHT: 1pt solid; BORDER-TOP: 1pt solid; BORDER-LEFT: 1pt solid; BORDER- BOTTOM: 1pt solid } </style> <title>Announcement</title> <meta http-</meta> <style controlStyle="controlStyle">BODY{margin- left:21px;color:windowtext;background-color:window;layout-grid:none;} .xdListItem {display:inline-block;width:100%;vertical-align:text-top;} .xdListBox,.xdComboBox{margin:1px;} .xdInlinePicture{margin:1px; BEHAVIOR: url(#default#urn::xdPicture) } .xdLinkedPicture{margin:1px; BEHAVIOR: url(#default#urn::xdPicture) url(#default#urn::controls/Binder) } .xdSection{border:1pt solid #FFFFFF;margin:6px 0px 6px 0px;padding:1px 1px 1px 5px;} .xdRepeatingSection{border:1pt solid #FFFFFF;margin:6px 0px 6px 0px;padding:1px 1px 1px 5px;} .xdBehavior_Formatting {BEHAVIOR: url(#default#urn::controls/Binder) url(#default#Formatting);} .xdBehavior_FormattingNoBUI{BEHAVIOR: url(#default#CalPopup) url(#default#urn::controls/Binder) url(#default#Formatting);} .xdExpressionBox{margin: 1px;padding:1px;word-wrap: break-word;text-overflow: ellipsis;overflow- x:hidden;}.xdBehavior_GhostedText,.xdBehavior_GhostedTextNoBUI{BEHAVIOR: url(#default#urn::controls/Binder) url(#default#TextField) url(#default#GhostedText);} .xdBehavior_GTFormatting{BEHAVIOR: url(#default#urn::controls/Binder) url(#default#Formatting) url(#default#GhostedText);} .xdBehavior_GTFormattingNoBUI{BEHAVIOR: url(#default#CalPopup) url(#default#urn::controls/Binder) url(#default#Formatting) url(#default#GhostedText);} .xdBehavior_Boolean{BEHAVIOR: url(#default#urn::controls/Binder) url(#default#BooleanHelper);} .xdBehavior_Select{BEHAVIOR: url(#default#urn::controls/Binder) url(#default#SelectHelper);} .xdRepeatingTable{BORDER-TOP-STYLE: none; BORDER- RIGHT-STYLE: none; BORDER-LEFT-STYLE: none; BORDER-BOTTOM-STYLE: none; BORDER- COLLAPSE: collapse; WORD-WRAP: break-word;}.xdTextBox{display:inline-block;white- space:nowrap;text-overflow:ellipsis;;padding:1px;margin:1px;border: 1pt solid #dcdcdc;color:windowtext;background-color:window;overflow:hidden;text-align:left;} .xdRichTextBox{display:inline-block;;padding:1px;margin:1px;border: 1pt solid #dcdcdc;color:windowtext;background-color:window;overflow-x:hidden;word- wrap:break-word;text-overflow:ellipsis;text-align:left;font-weight:normal;font- style:normal;text-decoration:none;vertical-align:baseline;} .xdDTPicker{;display:inline;margin:1px;margin-bottom: 2px;border: 1pt solid #dcdcdc;color:windowtext;background-color:window;overflow:hidden;} .xdDTText{height:100%;width:100%;margin- right:22px;overflow:hidden;padding:0px;white-space:nowrap;} .xdDTButton{margin-left:-21px;height:18px;width:20px;behavior: url(#default#DTPicker);} .xdRepeatingTable TD {VERTICAL-ALIGN: top;}</style> </head> <body> <div> <xsl:apply-templates </div> <div> </div> <div>This is some text I just typed in.</div> </body> </html> </xsl:template> <xsl:template <h1> <xsl:value-of</xsl:value-of> </h1> <p> <xsl:value-of</xsl:value-of> </p> </xsl:template> </xsl:stylesheet>
One thing to note about the use of mode="xd:preserve" for a solution's default view is that InfoPath will not overwrite your stylesheet (and hence won't add any of the boilerplate shown above), as long as you do both of the following:
Annotate all template rules in the stylesheet with mode="xd:preserve" (except for a root template rule that initially applies templates) until InfoPath opens it without complaining
Do not make any changes to the default view from within design mode
You may be asking yourself, "then why should I bother opening the solution in design mode at all if I'm not going to make any changes to the default view?" The answer is that there are plenty of other things about a solution that you may want to configure or change from within design mode besides the default view, e.g., submission behavior, secondary views, scripting, custom validation, custom error messages, secondary data sources, and solution packaging and publication. In fact, I recommend avoiding option 5 in Table 10-3, unless you employ this precise strategy. Unless you particularly want to learn how InfoPath design mode generates XSLT stylesheets and you have some patience for experimentation, you should avoid making changes within design mode to XSLT views that you created outside of design mode.
Among the use cases for employing both design mode and hand-editing is the need to develop multiple views for a single solution. For example, you may already have an XSLT stylesheet that displays your document type in a particular way, e.g., on a web site, but you still haven't developed a form for gathering instances of that document type. You can use InfoPath design mode to rapidly develop the form as your default view, and you can then manually edit the form definition file (manifest.xsf) to add your existing stylesheet as an alternate view for your users to see, like a preview of how the document will look when published. Unlike a default view stylesheet, a secondary view stylesheet doesn't need to be annotated with mode="xd:preserve" unless you specifically open that view from within design mode. If you never switch to that view in design mode, you won't have to worry about the form designer choking on it, and it will survive in your solution unaltered.
InfoPath's "preserve code block" feature is thus useful for both options 4 and 5 in Table 10-3. With option 4, you can isolate only the part of the stylesheet that you need to customize outside of design mode. With option 5, the safest approach, again, is to wrap your entire stylesheet (all but the root template rule) in a "preserve code block." Just to be sure that it's clear what it means to "wrap the entire stylesheet in a preserve code block." Example 10-22 shows an example of this technique.
<xsl:stylesheet <xsl:template <xsl:apply-templates </xsl:template> <xsl:template <html> <!-- ... --> <xsl:apply-templates <!-- (All xsl:apply-templates instructions use <!-- ... --> </xsl:template> <!-- ... --> <!-- (All template rules use mode="xd:preserve") --> </xsl:stylesheet> | https://flylib.com/books/en/2.633.1.89/1/ | CC-MAIN-2019-43 | refinedweb | 3,601 | 51.28 |
Hello eveyone
I’m working with selectors and tags and I need to load the next page while keeping the tag.
<li class="cmp-pressreleaselist__page_next"> <a data- ${'Next' @ i18n} </a> </li>
The issue is that is aem the namespaces where the tag is located is separated by column “:”, example “paris:louvre” but the href doesn’t accept columns “:”
example dref="content/core/adobe/home.2022.info:events.1.html
Does anyone know how can I make it work ?
Solved! Go to Solution.
Views
Replies
Total Likes
You have to encode the colon in order to use it in href attribute. Use encoded value %3A instead of colon and it will work as expected.
exampleto use href="content/core/adobe/home.2022.info%3Aevents.1.html
Hi,
Can you try with
@ context='uri'
I suggest using Sling Model if there is a business logic included for URI or string manipulation. | https://experienceleaguecommunities.adobe.com/t5/adobe-experience-manager/href-link-with-column-value/m-p/448055 | CC-MAIN-2022-27 | refinedweb | 149 | 55.64 |
I am brand new to Visual C++ programming. I started reading a book and the tutorials available here, and started playing with come code.
I've created a Button on a GUI in a dialog based project. Separatly I've written a console application that does something. Now, I took that code and pasted it in the event description of that Button.
The original code uses a header file I've made. I've included it in the .cpp sourse for the GUI, but the compiler says that there is no such file or directory.
Here's are some sections of the code to see where I put stuff:
Code:
// Initial GUI.cpp : Defines the class behaviors for the application.
//
#include "stdafx.h"
#include "Initial GUI.h"
#include "Initial GUIDlg.h"
#include <BAFParse.h>
#ifdef _DEBUG
#define new DEBUG_NEW
#undef THIS_FILE
static char THIS_FILE[] = __FILE__;
#endif
/////////////////////////////////////////////////////////////////////////////
// CInitialGUIApp
BEGIN_MESSAGE_MAP(CInitialGUIApp, CWinApp)
//{{AFX_MSG_MAP(CInitialGUIApp
Code:
void CInitialGUIDlg::OnOpenFile()
{
FILE *inp;
int SpaceLeftU, NameLengthU, SpaceLeftP;
char **Units, **Params;
................................ | http://cboard.cprogramming.com/cplusplus-programming/66645-adding-functionality-controls-gui-printable-thread.html | CC-MAIN-2016-30 | refinedweb | 165 | 68.87 |
Initialize
This package provides a common interface for initialization annotations on top level methods, classes, and libraries. The interface looks like this:
abstract class Initializer<T> { dynamic initialize(T target); }
The
initialize method will be called once for each annotation. The type
T is
determined by what was annotated. For libraries it will be the Symbol
representing that library, for a class it will be the Type representing that
class, and for a top level method it will be the Function object representing
that method.
If a future is returned from the initialize method, it will wait until the future completes before running the next initializer.
Usage
@initMethod
There is one initializer which comes with this package,
@initMethod. Annotate
any top level function with this and it will be invoked automatically. For
example, the program below will print
hello:
import 'package:initialize/initialize.dart'; @initMethod printHello() => print('hello'); main() => run();
Running the initializers
In order to run all the initializers, you need to import
package:initialize/initialize.dart and invoke the
run method. This should
typically be the first thing to happen in your main. That method returns a Future,
so you should put the remainder of your program inside the chained then call.
import 'package:initialize/initialize.dart'; main() { run().then((_) { print('hello world!'); }); }
Transformer
During development a mirror based system is used to find and run the initializers, but for deployment there is a transformer which can replace that with a static list of initializers to be ran.
This your own initializer
Lets look at a slightly simplified version of the
@initMethod class:
class InitMethod implements Initializer<Function> { const InitMethod(); @override initialize(Function method) => method(); }
You would now be able to add
@InitMethod() in front of any function and it
will be automatically invoked when the user calls
run().
For classes which are stateless, you can usually just have a single const instance, and that is how the actual InitMethod implementation works. Simply add something like the following:
const initMethod = const InitMethod();
Now when people use the annotation, it just looks like
@initMethod without any
parenthesis, and its a bit more efficient since there is a single instance. You
can also make your class private to force users into using the static instance.. | https://www.dartdocs.org/documentation/initialize/0.5.1/index.html | CC-MAIN-2017-47 | refinedweb | 376 | 52.29 |
/\
/__\
Given an arbitrary picture, how do we convert this to ASCII art? The technique is dead simple - convert the image to gray scale and replace each pixel in the image with a character representing the brightness value. For example, a * character is darker than a ! character.
The following Haskell program does just that. It uses the PGM package to load an image (so it's already converted to gray scale). All it does it map the pixel to a character using a function and amap and then do some jiggery pokery to turn it into an image.
import Graphics.Pgm
import Text.Parsec.Error
import Data.Array.Base
brightness = " .`-_':,;^=+/\"|)\\<>)iv%xclrs{*}I?!][1taeo7zjLu" ++
"nT#JCwfy325Fp6mqSghVd4EgXPGZbYkOA&8U$@KHDBWNMR0Q";
loadImage :: String -> IO (UArray (Int,Int) Int)
loadImage path = do
r <- pgmsFromFile path
case r of
Left e -> error "Failed to parse file"
Right i -> return (head i)
brightnessToChar :: Int -> Int -> Char
brightnessToChar m b = brightness !!
(round ((fromIntegral b) / (fromIntegral m) * (fromIntegral ((length brightness) - 1))))
imageToAscii :: UArray (Int,Int) Int -> UArray (Int,Int) Char
imageToAscii image = amap (brightnessToChar 255) image
convertImage :: String -> String -> IO ()
convertImage image out = do
img <- loadImage image
let ((_,_),(h,w)) = bounds img
let x = imageToAscii img
writeFile out (unlines [ [ x ! (i,j) | i <- [0..w] ] | j <- [0..h] ])
return ()
Interesting learning exercises for me were the nested list comprehension to go through the array and the use of
Eitherto represent a choice of return values. This seems to be used when you want to return more data than simply "it failed" (which you'd use
Maybe).
Because I can't quite work out how to get a tiny font, it's easier to post a screen shot of some ASCII art (kind of defeats the purpose, I know!). Below is the Ubuntu logo rendered (badly!) as ASCII art.
| http://www.fatvat.co.uk/2009/09/generating-ascii-art.html | CC-MAIN-2020-16 | refinedweb | 303 | 63.29 |
Section 3.2
Algorithm Development
Programming is difficult (like many activities that are useful and worthwhile -- and like most of those activities, it can also be rewarding and a lot of fun). When you write a program, you have to tell the computer every small detail of what to do. And you have to get everything exactly right, since the computer will blindly follow your program exactly as written. How, then, do people write any but the most simple programs? It's not a big mystery, actually. It's a matter of learning to think in the right way.
A program is an expression of an idea. A programmer starts with a general idea of a task for the computer to perform. Presumably, the programmer has some idea of how to perform the task by hand, at least in general outline. The problem is to flesh out that outline into a complete, unambiguous, step-by-step procedure for carrying out the task. Such a procedure is called an "algorithm." (Technically, an algorithm is an unambiguous, step-by-step procedure that terminates after a finite number of steps; we don't want to count procedures that go on forever.) An algorithm is not the same as a program. A program is written in some particular programming language. An algorithm is more like the idea behind the program, but it's the idea of the steps the program will take to perform its task, not just the idea of the task itself. The steps of the algorithm don't have to be filled in in complete detail, as long as the steps are unambiguous and it's clear that carrying out the steps will accomplish the assigned task. An algorithm can be expressed in any language, including English. Of course, an algorithm can only be expressed as a program if all the details have been filled in.
So, where do algorithms come from? Usually, they have to be developed, often with a lot of thought and hard work. Skill at algorithm development is something that comes with practice, but there are techniques and guidelines that can help. I'll talk here about some techniques and guidelines that are relevant to "programming in the small," and I will return to the subject several times in later chapters.
3.2.1 Pseudocode and Stepwise Refinement
When programming in the small, you have a few basics to work with: variables, assignment statements, and input/output routines. You might also have some subroutines, objects, or other building blocks that have already been written by you or someone else. (Input/output routines fall into this class.) You can build sequences of these basic instructions, and you can also combine them into more complex control structures such as while loops and if statements.
Suppose you have a task in mind that you want the computer to perform. One way to proceed is to write a description of the task, and take that description as an outline of the algorithm you want to develop. Then you can refine and elaborate that description, gradually adding steps and detail, until you have a complete algorithm that can be translated directly into programming language. This method is called stepwise refinement, and it is a type of top-down design. As you proceed through the stages of stepwise refinement, you can write out descriptions of your algorithm in pseudocode -- informal instructions that imitate the structure of programming languages without the complete detail and perfect syntax of actual program code.
As an example, let's see how one might develop the program from the previous section, which computes the value of an investment over five years. The task that you want the program to perform is: "Compute and display the value of an investment for each of the next five years, where the initial investment and interest rate are to be specified by the user." You might then write -- or at least think -- that this can be expanded as:
Get the user's input Compute the value of the investment after 1 year Display the value Compute the value after 2 years Display the value Compute the value after 3 years Display the value Compute the value after 4 years Display the value Compute the value after 5 years Display the value
This is correct, but rather repetitive. And seeing that repetition, you might notice an opportunity to use a loop. A loop would take less typing. More important, it would be more general: Essentially the same loop will work no matter how many years you want to process. So, you might rewrite the above sequence of steps as:
Get the user's input while there are more years to process: Compute the value after the next year Display the value
Following this algorithm would certainly solve the problem, but for a computer, we'll have to be more explicit about how to "Get the user's input," how to "Compute the value after the next year," and what it means to say "there are more years to process." We can expand the step, "Get the user's input" into
Ask the user for the initial investment Read the user's response Ask the user for the interest rate Read the user's response
To fill in the details of the step "Compute the value after the next year," you have to know how to do the computation yourself. (Maybe you need to ask your boss or professor for clarification?) Let's say you know that the value is computed by adding some interest to the previous value. Then we can refine the while loop to:
while there are more years to process: Compute the interest Add the interest to the value Display the value
As for testing whether there are more years to process, the only way that we can do that is by counting the years ourselves. This displays a very common pattern, and you should expect to use something similar in a lot of programs: We have to start with zero years, add one each time we process a year, and stop when we reach the desired number of years. So the while loop becomes:
years = 0 while years < 5: years = years + 1 Compute the interest Add the interest to the value Display the value
We still have to know how to compute the interest. Let's say that the interest is to be computed by multiplying the interest rate by the current value of the investment. Putting this together with the part of the algorithm that gets the user's inputs, we have the complete algorithm:
Ask the user for the initial investment Read the user's response Ask the user for the interest rate Read the user's response years = 0 while years < 5: years = years + 1 Compute interest = value * interest rate Add the interest to the value Display the value
Finally, we are at the point where we can translate pretty directly into proper programming-language syntax. We still have to choose names for the variables, decide exactly what we want to say to the user, and so forth. Having done this, we could express our algorithm in Java as:
double principal, rate, interest; // declare the variables int years; System.out.print("Type initial investment: "); principal = TextIO.getlnDouble(); System.out.print("Type interest rate: "); rate = TextIO.getlnDouble(); years = 0; while (years < 5) { years = years + 1; interest = principal * rate; principal = principal + interest; System.out.println(principal); }
This still needs to be wrapped inside a complete program, it still needs to be commented, and it really needs to print out more information in a nicer format for the user. But it's essentially the same program as the one in the previous section. (Note that the pseudocode algorithm uses indentation to show which statements are inside the loop. In Java, indentation is completely ignored by the computer, so you need a pair of braces to tell the computer which statements are in the loop. If you leave out the braces, the only statement inside the loop would be "years = years + 1;". The other statements would only be executed once, after the loop ends. The nasty thing is that the computer won't notice this error for you, like it would if you left out the parentheses around "(years < 5)". The parentheses are required by the syntax of the while statement. The braces are only required semantically. The computer can recognize syntax errors but not semantic errors.)
One thing you should have noticed here is that my original specification of the problem -- "Compute and display the value of an investment for each of the next five years" -- was far from being complete. Before you start writing a program, you should make sure you have a complete specification of exactly what the program is supposed to do. In particular, you need to know what information the program is going to input and output and what computation it is going to perform. Here is what a reasonably complete specification of the problem might look like in this example:
"Write a program that will compute and display the value of an investment for each of the next five years. Each year, interest is added to the value. The interest is computed by multiplying the current value by a fixed interest rate. Assume that the initial value and the rate of interest are to be input by the user when the program is run."
3.2.2 The 3N+1 Problem
Let's do another example, working this time with a program that you haven't already seen. The assignment here is an abstract mathematical problem that is one of my favorite programming exercises. This time, we'll start with a more complete specification of the task to be performed:
"Given a positive integer, N, define the '3N+1' sequence starting from N as follows: If N is an even number, then divide N by two; but if N is odd, then multiply N by 3 and add 1. Continue to generate numbers in this way until N becomes equal to 1. For example, starting from N = 3, which is odd, we multiply by 3 and add 1, giving N = 3*3+1 = 10. Then, since N is even, we divide by 2, giving N = 10/2 = 5. We continue in this way, stopping when we reach 1, giving the complete sequence: 3, 10, 5, 16, 8, 4, 2, 1.
"Write a program that will read a positive integer from the user and will print out the 3N+1 sequence starting from that integer. The program should also count and print out the number of terms in the sequence."
A general outline of the algorithm for the program we want is:
Get a positive integer N from the user; Compute, print, and count each number in the sequence; Output the number of terms;
The bulk of the program is in the second step. We'll need a loop, since we want to keep computing numbers until we get 1. To put this in terms appropriate for a while loop, we want to continue as long as the number is not 1. So, we can expand our pseudocode algorithm to:
Get a positive integer N from the user; while N is not 1: Compute N = next term; Output N; Count this term; Output the number of terms;
In order to compute the next term, the computer must take different actions depending on whether N is even or odd. We need an if statement to decide between the two cases:
Get a positive integer N from the user; while N is not 1: if N is even: Compute N = N/2; else Compute N = 3 * N + 1; Output N; Count this term; Output the number of terms;
We are almost there. The one problem that remains is counting. Counting means that you start with zero, and every time you have something to count, you add one. We need a variable to do the counting. (Again, this is a common pattern that you should expect to see over and over.) With the counter added, we get:
Get a positive integer N from the user; Let counter = 0; while N is not 1: if N is even: Compute N = N/2; else Compute N = 3 * N + 1; Output N; Add 1 to counter; Output the counter;
We still have to worry about the very first step. How can we get a positive integer from the user? If we just read in a number, it's possible that the user might type in a negative number or zero. If you follow what happens when the value of N is negative or zero, you'll see that the program will go on forever, since the value of N will never become equal to 1. This is bad. In this case, the problem is probably no big deal, but in general you should try to write programs that are foolproof. One way to fix this is to keep reading in numbers until the user types in a positive number:
Ask user to input a positive number; Let N be the user's response; while N is not positive: Print an error message; Read another value for N; Let counter = 0; while N is not 1: if N is even: Compute N = N/2; else Compute N = 3 * N + 1; Output N; Add 1 to counter; Output the counter;
The first while loop will end only when N is a positive number, as required. (A common beginning programmer's error is to use an if statement instead of a while statement here: "If N is not positive, ask the user to input another value." The problem arises if the second number input by the user is also non-positive. The if statement is only executed once, so the second input number is never tested. With the while loop, after the second number is input, the computer jumps back to the beginning of the loop and tests whether the second number is positive. If not, it asks the user for a third number, and it will continue asking for numbers until the user enters an acceptable input.)
Here is a Java program implementing this algorithm. It uses the operators <= to mean "is less than or equal to" and != to mean "is not equal to." To test whether N is even, it uses "N % 2 == 0". All the operators used here were discussed in Section 2.5.
/** * This program prints out a 3N+1 sequence starting from a positive * integer specified by the user. It also counts the number of * terms in the sequence, and prints out that number. */ public class ThreeN1 { public static void main(String[] args) { int N; // for computing terms in the sequence int counter; // for counting the terms TextIO.put("Starting point for sequence: "); N = TextIO.getlnInt(); while (N <= 0) { TextIO.put("The starting point must be positive. Please try again: "); N = TextIO.getlnInt(); } // At this point, we know that N > 0 counter = 0; while (N != 1) { if (N % 2 == 0) N = N / 2; else N = 3 * N + 1; TextIO.putln(N); counter = counter + 1; } TextIO.putln(); TextIO.put("There were "); TextIO.put(counter); TextIO.putln(" terms in the sequence."); } // end of main() } // end of class ThreeN1
As usual, you can try this out in an applet that simulates the program. Try different starting values for N, including some negative values:
Two final notes on this program: First, you might have noticed that the first term of the sequence -- the value of N input by the user -- is not printed or counted by this program. Is this an error? It's hard to say. Was the specification of the program careful enough to decide? This is the type of thing that might send you back to the boss/professor for clarification. The problem (if it is one!) can be fixed easily enough. Just replace the line "counter = 0" before the while loop with the two lines:
TextIO.putln(N); // print out initial term counter = 1; // and count it
Second, there is the question of why this problem is at all interesting. Well, it's interesting to mathematicians and computer scientists because of a simple question about the problem that they haven't been able to answer: Will the process of computing the 3N+1 sequence finish after a finite number of steps for all possible starting values of N? Although individual sequences are easy to compute, no one has been able to answer the general question. To put this another way, no one knows whether the process of computing 3N+1 sequences can properly be called an algorithm, since an algorithm is required to terminate after a finite number of steps! (This discussion assumes that the value of N can take on arbitrarily large integer values, which is not true for a variable of type int in a Java program.)
3.2.3 Coding, Testing, Debugging
It would be nice if, having developed an algorithm for your program, you could relax, press a button, and get a perfectly working program. Unfortunately, the process of turning an algorithm into Java source code doesn't always go smoothly. And when you do get to the stage of a working program, it's often only working in the sense that it does something. Unfortunately not what you want it to do.
After program design comes coding: translating the design into a program written in Java or some other language. Usually, no matter how careful you are, a few syntax errors will creep in from somewhere, and the Java compiler will reject your program with some kind of error message. Unfortunately, while a compiler will always detect syntax errors, it's not very good about telling you exactly what's wrong. Sometimes, it's not even good about telling you where the real error is. A spelling error or missing "{" on line 45 might cause the compiler to choke on line 105. You can avoid lots of errors by making sure that you really understand the syntax rules of the language and by following some basic programming guidelines. For example, I never type a "{" without typing the matching "}". Then I go back and fill in the statements between the braces. A missing or extra brace can be one of the hardest errors to find in a large program. Always, always indent your program nicely. If you change the program, change the indentation to match. It's worth the trouble. Use a consistent naming scheme, so you don't have to struggle to remember whether you called that variable interestrate or interestRate. In general, when the compiler gives multiple error messages, don't try to fix the second error message from the compiler until you've fixed the first one. Once the compiler hits an error in your program, it can get confused, and the rest of the error messages might just be guesses. Maybe the best advice is: Take the time to understand the error before you try to fix it. Programming is not an experimental science.
When your program compiles without error, you are still not done. You have to test the program to make sure it works correctly. Remember that the goal is not to get the right output for the two sample inputs that the professor gave in class. The goal is a program that will work correctly for all reasonable inputs. Ideally, when faced with an unreasonable input, it will respond by gently chiding the user rather than by crashing. Test your program on a wide variety of inputs. Try to find a set of inputs that will test the full range of functionality that you've coded into your program. As you begin writing larger programs, write them in stages and test each stage along the way. You might even have to write some extra code to do the testing -- for example to call a subroutine that you've just written. You don't want to be faced, if you can avoid it, with 500 newly written lines of code that have an error in there somewhere.
The point of testing is to find bugs -- semantic errors that show up as incorrect behavior rather than as compilation errors. And the sad fact is that you will probably find them. Again, you can minimize bugs by careful design and careful coding, but no one has found a way to avoid them altogether. Once you've detected a bug, it's time for debugging. You have to track down the cause of the bug in the program's source code and eliminate it. Debugging is a skill that, like other aspects of programming, requires practice to master. So don't be afraid of bugs. Learn from them. One essential debugging skill is the ability to read source code -- the ability to put aside preconceptions about what you think it does and to follow it the way the computer does -- mechanically, step-by-step -- to see what it really does. This is hard. I can still remember the time I spent hours looking for a bug only to find that a line of code that I had looked at ten times had a "1" where it should have had an "i", or the time when I wrote a subroutine named WindowClosing which would have done exactly what I wanted except that the computer was looking for windowClosing (with a lower case "w"). Sometimes it can help to have someone who doesn't share your preconceptions look at your code.
Often, it's a problem just to find the part of the program that contains the error. Most programming environments come with a debugger, which is a program that can help you find bugs. Typically, your program can be run under the control of the debugger. The debugger allows you to set "breakpoints" in your program. A breakpoint is a point in the program where the debugger will pause the program so you can look at the values of the program's variables. The idea is to track down exactly when things start to go wrong during the program's execution. The debugger will also let you execute your program one line at a time, so that you can watch what happens in detail once you know the general area in the program where the bug is lurking.
I will confess that I only rarely use debuggers myself. A more traditional approach to debugging is to insert debugging statements into your program. These are output statements that print out information about the state of the program. Typically, a debugging statement would say something like
System.out.println("At start of while loop, N = "+ N);
You need to be able to tell from the output where in your program the output is coming from, and you want to know the value of important variables. Sometimes, you will find that the computer isn't even getting to a part of the program that you think it should be executing. Remember that the goal is to find the first point in the program where the state is not what you expect it to be. That's where the bug is.
And finally, remember the golden rule of debugging: If you are absolutely sure that everything in your program is right, and if it still doesn't work, then one of the things that you are absolutely sure of is wrong. | http://math.hws.edu/javanotes/c3/s2.html | crawl-001 | refinedweb | 3,923 | 67.89 |
stories
A new Flutter package for implementing instagram like stories.
Getting Started
Including package in project
to include just add it to the dependency like in the above picture
Using the widget in your project
Include these two dependencies at the beginnin of the file say "main.dart"
import 'package:stories/models/story.dart'; import 'package:stories/stories.dart'; body: StoriesWidget( "", "Sourav Mandal", "time", getStories(), ),
StoriesWidget{ arg1 : url of the profile pic of the user or brand arg2 : name of the user or brand arg3 : time of the status arg4 : list of stories that are instance of a class "Story" present in the package }
Below is an example method to generate dummy stories
List<Story> getStories() { List<Story> stories = new List(); for (int i = 0; i < 10; i++) { stories.add( new Story( "", "Caption", ), ); } return stories; } | https://pub.dev/documentation/stories/latest/ | CC-MAIN-2021-25 | refinedweb | 135 | 50.46 |
Triangle in C++
Determine if a triangle is equilateral, isosceles, or scalene.
Triangle
Determine.
Note
For a shape to be a triangle at all, all sides have to be of length > 0, and the sum of the lengths of any two sides must be greater than or equal to the length of the third side. See Triangle Inequality.
Dig Deeper
The case where the sum of the lengths of two sides equals that of the third is known as a degenerate triangle - it has zero area and looks like a single line. Feel free to add your own code/tests to check for degenerate triangles.
Getting Started
Make sure you have read the C++ page on exercism.io. This covers the basic information on setting up the development environment expected by the exercises.
Passing the Tests
Get the first test compiling, linking and passing by following the three rules of test-driven development. Create just enough structure by declaring namespaces, functions, classes, etc., to satisfy any compiler errors and get the test to fail. Then write just enough code to get the test to pass. Once you've done that, uncomment the next test by moving the following line past the next test.
This may result in compile errors as new constructs may be invoked that you haven't yet declared or defined. Again, fix the compile errors minimally to get a failing test, then change the code minimally to pass the test, refactor your implementation for readability and expressiveness and then go on to the next test.
Try to use standard C++11 facilities in preference to writing your own low-level algorithms or facilities by hand. CppReference is a wiki reference to the C++ language and standard library. If you are new to C++, but have programmed in C, beware of C traps and pitfalls.
Source
The Ruby Koans triangle project, parts 1 & 2
Submitting Incomplete Solutions
It's possible to submit an incomplete solution so you can see how others have completed the exercise. | http://exercism.io/exercises/cpp/triangle/readme | CC-MAIN-2018-09 | refinedweb | 337 | 61.36 |
The objective of this post is to explain how to configure the ESP8266 to work as an access point. Additionally, we will also set a webserver to work on top of it.
Introduction
The objective of this post is to explain how to configure the ESP8266 to work as an access point. Additionally, we will also set a webserver to work on top of it. Most of the coding is based on the example provided in the ESP8266 Arduino IDE libraries, which I encourage you to try.
With this method, another device can connect to the ESP8266 and exchange data with it, without the need for a external WiFi network.
The code
First of all, we will need to include ESP8266WiFi.h library, which will provide all the functionality needed to set the access point, in the WiFi extern variable. You can check the implementation of the functionalities here.
Additionally, we will also include the ESP8266WebServer.h library, in order to be able to set our webserver. This will be a very simple demonstration but you can read more about setting a HTTP webserver on the ESP8266 in this previous post.
#include <ESP8266WiFi.h> #include <ESP8266WebServer.h>
Since we are going to set an access point, we need to specify its SSID (network name) and password. We are going to do it in two global variables, so we can easily change the values.
const char *ssid = "MyESP8266AP"; const char *password = "testpassword";
Next, we declare a global object variable from the ESP8266WebServer class, so we will be able to access it in our functions. This class will provide the methods needed to set the HTTP server.
As argument for the constructor of this class, we will pass the port where the server will be listening to. Since 80 is the default port for HTTP, we will use this value, so we will not need to specify it in the URL when accessing to our ESP8266 server using a browser.
ESP8266WebServer server(80);
Next, we start our setup function by opening a serial connection, to output some messages to the Arduino IDE serial monitor.
After that, we call the softAP method on the WiFi extern variable, passing as input both the SSID and password variables defined early.
Serial.begin(115200); WiFi.softAP(ssid, password);
Since we need to know the IP of the server in order to contact it, we will now get it using the softAPIP method on the WiFi object. Just as an example, we will also get the server MAC address with the softAPmacAddress method.
Serial.println(); Serial.print("Server IP address: "); Serial.println(WiFi.softAPIP()); Serial.print("Server MAC address: "); Serial.println(WiFi.softAPmacAddress());
Finally, we are going to configure the HTTP server. So, we call the on method on our previously declared server global object and specify as first argument a URL and as second argument a handling function that will be executed when a HTTP request is made to that URL. We will define the handling function later.
Finally, to start our server, we call the begin method on the server object, still in the setup function.
server.on("/", handleRoot); server.begin();
To handle the actual incoming of HTTP requests, we need to call the handleClient method on the server object, on the main loop function.
void loop() { server.handleClient(); }
To finish the code, we will specify a handling function, which will just return a simple “Hello World” message, as response to a HTTP request. To do so, we call the send method on our server object, passing as input the HTTP response code, the content type of the response and the actual response.
Important: WordPress inserts a line break automatically after and before the HTML tags on the code. Please remove them and make sure all the arguments of the send method are on the same line, to avoid an error while compiling.
void handleRoot() { server.send(200, "text/html", " <h1>Hello from ESP8266 AP!</h1> "); }
The full source code can be seen bellow.
#include <ESP8266WiFi.h> #include <ESP8266WebServer.h> const char *ssid = "MyESP8266AP"; const char *password = "testpassword"; ESP8266WebServer server(80); void handleRoot() { server.send(200, "text/html", " <h1>Hello from ESP8266 AP!</h1> "); } void setup() { Serial.begin(115200); WiFi.softAP(ssid, password); Serial.println(); Serial.print("Server IP address: "); Serial.println(WiFi.softAPIP()); Serial.print("Server MAC address: "); Serial.println(WiFi.softAPmacAddress()); server.on("/", handleRoot); server.begin(); Serial.println("Server listening"); } void loop() { server.handleClient(); }
Testing the code
To test the code, just upload it to the ESP8266 and open the Arduino IDE serial monitor. You should get an output similar to figure 1, where both the IP and the MAC address of the server are printed.
Figure 1 – Output of the program on the Arduino IDE serial console.
After that, if you check the available networks on your computer or smartphone, you should see the “MyESP8266AP” network, as shown in figure 2 (Windows 8 menu). Connect to it using the password we defined in the code.
Figure 2 – ESP8266 Access Point as an available network.
Finally, open a web browser and connect to the IP that was printed on the serial console. To do so, type the following on the search bar (I’m using the IP of my device, if yours is different please change it):
You should get an output similar to figure 3, which shows the message we defined on the code.
Figure 3 – Hello World response from the ESP8266 server.
Related Posts
Technical details
- ESP8266 libraries: v2.3.0 | https://techtutorialsx.com/2017/04/25/esp8266-setting-an-access-point/ | CC-MAIN-2017-26 | refinedweb | 920 | 64.91 |
Hide Forgot
From Bugzilla Helper:
User-Agent: Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.2.1) Gecko/20030120
Description of problem:
redhat-config-user throws an exeption in mainwindow, refresh_user with no other
explanation. useradd, userdel etc all work properly.
Version-Release number of selected component (if applicable):
How reproducible:
Always
Steps to Reproduce:
1.redhat-config-users
2.
3.
Actual Results: messagebox with "the user database cannot be read. Program will
exit now.
Expected Results: If there is somthing wrong with /etc/passwd /etc/group this
gives no information of what to do. /etc/passwd, /etc/group, /etc/shadow all
exist and are readable and command line user utilities all work.
Additional info:
Problem seems have something to do with associating names with gids
Have you modified any of these files by hand? This error is usually caused by
people deleting a user from /etc/passwd but not from /etc/shadow. In this case,
the files are out of sync and this breaks libuser, which is the backend that
redhat-config-users uses.
As far as I remember users have only to added and taken away with useradd,
userdel. Both the /etc/passwd file and /etc/shadow file have the same number of
entries.
It is failing in the try block with the call to userEnt.get.
def refresh_users(self):
self.user_dict = {}
self.gid_dict = {}
# pull up information about users and store the objects in
# a dictionary keyed by user name
i = 0
for user in self.get_user_list(self.get_filter_data()):
i = i + 1
if i >= self.service_interval:
service_pending_events()
i = 0
userName = user.get(libuser.USERNAME)[0]
userEnt = self.ADMIN.lookupUserByName(userName)
self.user_dict[user] = userEnt
# try to get a name to associate with the user's primary gid,
# and attempt to minimize lookups by caching answers
try:
gidNumber = userEnt.get(libuser.GIDNUMBER)[0]
except:
messageDialog.show_message_dialog(_("The user database cannot be
read. Program will exit now."))
os._exit(0)
Try adding a print statement to /usr/share/redhat-config-users/mainWindow.py
file to show us which user name it's tripping up on.
In the refresh_users() function, add:
'print userName' after the 'userName = user.get(libuser.USERNAME)[0]
That should print out the user name of each user as it's processed. What is the
last user name that it prints out?
I found a rogue user is /etc/shadow- . The problem on this machine is resolved
but the problem of poor error notification with no user direction remains. The
average user is not going to know what is wrong so he will call you. You can do
better.
The problem is that the database can be broken in any number of ways. There's
no way for redhat-config-users to know what the problem might be. All it knows
is that the call to libuser fails. Creating this error message was in response
to bug #73375, so the behavior has improved.
The majority of these bugs is caused by people who try to delete a user manually
by deleting them from /etc/passwd. They forget to delete the user in
/etc/shadow, so the two files get out of sync. I would argue that the "average
user", as you say, will not run into this problem because they don't modify
those files by hand.
But there's no way for me to give the user a set of steps to take because
there's no way to know in what way the files are corrupted. Maybe there are
mismatched entries in the files. Maybe there are invalid (non-ASCII) characters
in the files. Maybe something else. There's no way for redhat-config-users to
know.
I think the current error message at least gives the user some indication that
something is wrong with the user and group database. At any rate, I cannot
change the behavior at this point since we are past string freeze. Resolving as
'notabug' since this is the expected behavior. | https://partner-bugzilla.redhat.com/show_bug.cgi?id=84053 | CC-MAIN-2020-10 | refinedweb | 664 | 67.55 |
Does any one know how to have different swift control access for different targets. Basically I have an iOS framework in swift with two targets A and B. I wanted a class say "Hello" as public in target A and internal in target B. One of the way to have this define a Swift flag and have something like this.
#if FLAG
public class Hello {
#else
class Hello {
#endif
Unfortunately, this isn't something you can do in Swift. In Objective-C you could do tricks like this and the compiler would ignore anything that wasn't valid inside the macros that weren't excluded. This is not the case for Swift. The entire file must be valid, including parts that are being ignored because of the
#if's | https://codedump.io/share/uWBaroJAxQ73/1/swift-control-access-per-targets | CC-MAIN-2017-13 | refinedweb | 129 | 72.66 |
I was able to setup namespaces correctly using the step by step guide on microsoft's site (). However when I try to replicate those folders, the Replicate Folder Wizard errors out with "Security cannot be set on the replicated folder. the network location cannot be reached."
7 Replies
Sorry here is the correct link:
http:/
Hopefully, you've solved your problem by now. But for those that find this thread while looking for an answer, here's what caused the problem for me and how I worked around it:
When creating the DFS namespace, by default the wizard creates a folder C:\DFSRoots\namespace_name. I was trying to create my target folders in this folder, since that seemed a nice way to keep things together. However, DFS uses this folder to create shortcut\folders, and if you have a folder with the same name, DFS freaks out and you'll get the error described above.
What I did to work around this is to create another folder: C:\DFSTargets, and created my target folders here. Then DFS is free to create what it needs in C:\DFSRoots\namespace_name. | https://community.spiceworks.com/topic/153179-dfsr-error-when-creating-replication-group | CC-MAIN-2019-09 | refinedweb | 188 | 59.84 |
# Fast and effective work in command line
There are a lot of command line tips and trics in the internet. Most of them discribe the trivials like "learn the hotkeys" or "`sudo !!` will run previous command with sudo". Instead of that, I will tell you what to do when you have already learned the hotkeys and know about `sudo !!`.
### The terminal should start instantly
How much time you spend to launch a terminal? And another one? For a long time I've used Ctrl+Alt+T shortcut to launch a terminal and I thought it is fast. When I've migrated from Openbox to i3, I began to launch a terminal via Win+Enter, that binding worked out of the box. You know what? Now I don't think that Ctrl+Alt+T is fast enough.
Of course, the thing is not a millisecond speedup, but that you open a terminal at the level of reflexes, completely oblivious to that.
So, if you often use a terminal, but grab a mouse for launching it, try to configure a handy hotkey. I'm sure, you will like it.
### Zsh instead of Bash
This is a holywar topic, I know. You should install Zsh for at least three features: advanced autocompletition, typo correction and multiple pathname completition: when a single Tab converts `/u/s/d` into `/usr/share/doc`. Arch Linux has already migrated to Zsh in it's installation CD. I hope Zsh will once become a default shell in Ubuntu. That will be a historical moment.
Starting to use Zsh is not difficult at all. Just install it via package manager and find a pretty config. I recommend to take config used in Arch Linux:
```
$ wget -O ~/.zshrc https://git.grml.org/f/grml-etc-core/etc/zsh/zshrc
```
The only thing left is to change your default shell and relogin.
```
$ chsh -s $(which zsh)
```
Thats all, just keep working like nothing happened.
### How the shell prompt should look like
Shell prompt is a small piece of text shown in the terminal at the beginning of your command line. It should be configured for your kind of work. You can perceive it as a dashbord of a vehicle. Please, put some useful information there, let it help you navigate! Make it handy especially if you see it every day!
Shell prompt should be colored. Do not agree? Try to count how many commands were executed in this terminal:
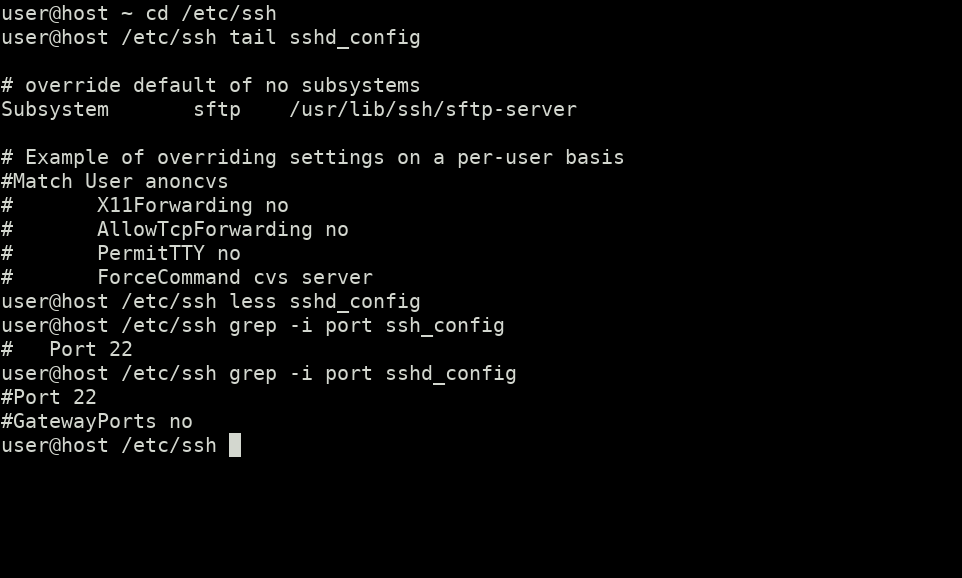
And now with color:
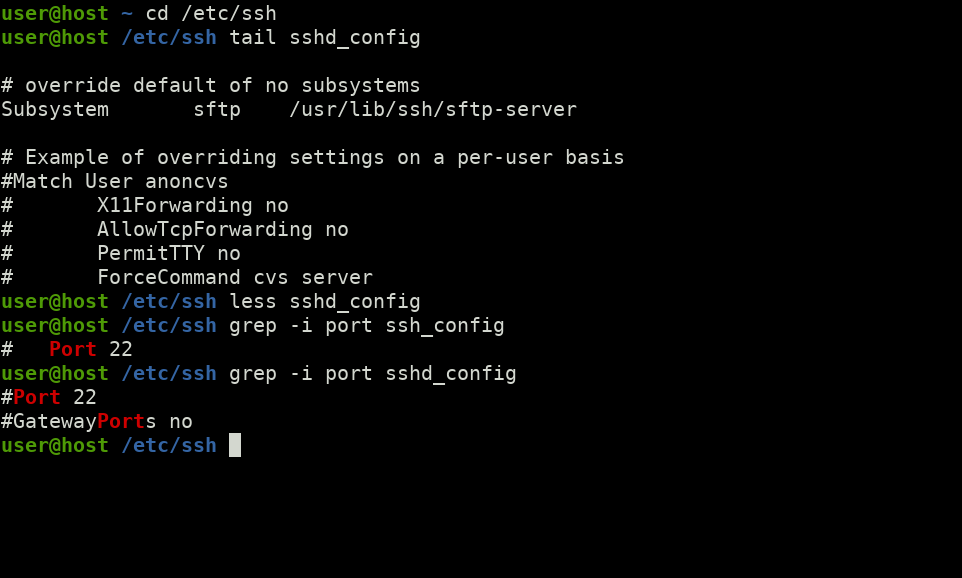
Shell prompt should display a current working directory of a shell. If current working directory is not displayed, you have to keep it in mind and periodically check it with `pwd` command. Please don't do that. Keep in mind some really important things and don't waste your time for `pwd` command.
If you sometimes switch to root account, you need a "current user" indication. The particular user name is often not important, but it's status (regular or root) is. The solution is to use color: red shell prompt for root and green for regular user. And you will never take over root shell as regular.
If you connect to servers using ssh, you need to distinguish your local and remote shells. For that purpose your shell prompt should contain a hostname, or even better — indicate an ssh connection.
Shell prompt can show the exit code of the last command. Remember that zero exit code means a command exited successfully, non-zero — command exited unsuccessfully. You can obtain last command's exit code via `echo $?`, but typing all that is a damn long thing. Let the shell show you unsuccessfull exit instead.
If you work with Git repos, it will be useful to see the repository status in shell prompt: current branch and the state of working directory. You will save some time on `git status` and `git branch` commands and won't commit to a wrong branch. Yes, the calculation of status may take significant time in fat repositories, but for me the pros outweight the cons.
Some people add clock to the shell prompt or even the name of a virtual terminal (tty), or some arbitrary squiggles. That's all superfluous. It's better to keep much room for commands.
Thats how my shell prompt looks like in different conditions:
You can see on the screenshot that the terminal titlebar does the similar job. It's also a piece of a dashboard and it's also should be configured.
So, how all this stuff should be implemented in `.zshrc`? The `PROMPT` variable sets the left prompt and `RPROMPT` sets the right prompt. The `EUID` variable defines the status of a user (regular or root) and `SSH_CLIENT` or `SSH2_CLIENT` presence indicates ssh connection. So we can have a template:
```
if [[ -n "$SSH_CLIENT" || -n "$SSH2_CLIENT" ]]; then
if [[ $EUID == 0 ]]; then
PROMPT=...
else
PROMPT=...
fi
else # not SSH
if [[ $EUID == 0 ]]; then
PROMPT=...
else
PROMPT=...
fi
fi
```
I don't show the copy-paste-ready code since the exact implementation is a matter of taste. If you don't want to bother and the screenshot above is ok for you, than take my cofig from [the Github](https://github.com/laurvas/dotfiles/blob/master/zsh/prompt.zsh).
Summary:
* Colored shell prompt is a must have.
* The required minimum is a current working directory.
* Root shell should be clearly visible.
* The name of a user don't care a payload if you use only one account.
* The hostname is useful if you connect to servers via ssh, it's not mandatory if don't.
* It's useful to see unsuccessful exit code of a last command.
* Git repo status saves time on `git status` and `git branch` commands and brings foolproof.
### Heavily use the command history
The most part of commands in your life you enter more than once, so it would be cool to pull them out from the history instead of typing again. All modern shells save a command history and provide several ways of searching through that history.
Perhaps you are already able to dig the history using Ctrl+R keybinding. Unfortunately it has two disadvantages:
1. The command line should be empty to begin the search, i.e. in case "one began to type a command — remembered about the search" you have to clean out your typing first, then press Ctrl+R and repeat your input. That takes too long.
2. Forward search don't work by defaul since Ctrl+S stops the terminal.
The most fast and convenient type of search works this way:
1. You begin to type a command,
2. you remember about the search,
3. you press a hotkey and the shell offers you commands from history that started the same way.
For example you want to sync a local directory with a remote one using Rsync and you already did it two hours earlier. You type `rsync`, press a hotkey one or two times and the desired command is ready to be launched. You don't need to turn on the search mode first, the shell prompt don't change to `(reverse-i-search)':`, and nothing jumps anywhere. You're just scrolling through history the same way you press the arrows ↑↓ to scroll through previously entered commands but with additional filtering. That's damn cool and saves a lot of time.
This kind of search don't work by default in Bash and Zsh, so you have to enable it manually. I have chosen PgUp for searching forward and PgDown for searching backward. It's far to reach them, but I've alredy made a habit. Maybe later I will switch to something closer like Ctrl+P and Ctrl+N.
For Bash you need to add a couple of strings to `/etc/inputrc` of `~/.inputrc`:
```
"\e[5~": history-search-backward
"\e[6~": history-search-forward
```
If you have taken a foreign complete `.zshrc`, it's highly probable that PgUp and PgDown already do the job. If not, then add to `~/.zshrc`:
```
bindkey "^[[5~" history-beginning-search-backward # pg up
bindkey "^[[6~" history-beginning-search-forward # pg down
```
Fish and Ipython shells already have such a search binded to arrows ↑↓. I think that many users migrated to Fish just for the arrows behavior. Of course, it is possible to bind the arrows this way in both Bash and Zsh if you wish. Use this in `/etc/inputrc` of `~/.inputrc`:
```
"\e[A":history-search-backward
"\e[B":history-search-forward
```
And this for in `~/.zshrc`:
```
autoload -U up-line-or-beginning-search
autoload -U down-line-or-beginning-search
zle -N up-line-or-beginning-search
zle -N down-line-or-beginning-search
bindkey "^[[A" up-line-or-beginning-search
bindkey "^[[B" down-line-or-beginning-search
```
It's curious that over time I began to write commands bearing in mind that later I will pull them out from history. Let me show you some techniques.
**Join the commands** that always follow each other:
```
# ip link set eth1 up && dhclient eth1
# mkdir /tmp/t && mount /dev/sdb1 /tmp/t
```
**Absolute paths instead of relative** let you run a command from any directory:
`vim ~/.ssh/config` instead of `vim .ssh/config`, `systemd-nspawn /home/chroot/stretch` instead of `systemd-nspawn stretch` and so on.
**Wildcard usage** makes your commands more universal. I usually use it in conjunction with `chmod` and `chown`.
```
# chown root:root /var/www/*.sq && chmod 644 /var/www/*.sq
```
### Keyboard shortcuts
Here is the required minimum.
Alt+. — substitutes the last argument of the previous command. It's also may be accessed with `!$`.
Ctrl+A, Ctrl+E — jumps to the beginning and the end of the line respectively.
Ctrl+U, Ctrl+Y — cut and paste. It's handy when you type a complex command and notice that you need to execute another one first. Hmm, where to save the current input? Right here.
Ctrl+W — kills one word before the cursor. It clears out the line when being pressed and hold. By default the input is saved to the clipboard (used for Ctrl+Y).
Ctrl+K — cuts the part of the line after the cursor, adding it to the clipboard. Ctrl+A Ctrl+K quickly clears out the line.
PgUp, PgDown, Ctrl+R — history search.
Ctrl+L clears terminal.
### Keyboard responsiveness
I want to show you a small setup that allows you to scroll, navigate and erase faster. What do we do when we want to erase something big? We press and hold Backspace and watch it runs back wiping characters. What is going on exactly? After Backspace is pressed, one character disappears, then goes a small delay, then autorepeat is triggered: Backspace erases characters one by one, like you hit it repeatedly.
I recommend you to adjust the delay and autorepeat frequency for the speed of your fingers. The delay is required when you want to erase only one character — it gives you the time to release a key. Too big delay makes you wait for an autorepeat. Not enough for you to be annoyed, but enough to slow down the transfer of your thoughts from the head to the computer. The bigger the autorepeat frequency is, the faster the text is being erased and the more difficult is to stop this process. The goal is to find an optimum value.
So, the magic command is:
```
$ xset r rate 190 20
```
190 — delay duration in milliseconds,
20 — frequency in repeats per second.
I recommend to start from these values and increase the delay bit by bit until false positives, then return a little. If the delay is too small, you won't be able to use the keyboard. To fix this an X-server or complete computer should be restarted. So, please be carefull.
In order to save parameters you need to add this command somewhere in X autostart.
### Process exit indication
I often have to start some long-running processes: a fat backup, big data transfer, archive packing/extracting, package building an so on. Usually I start such a process, switch to another task and gaze occasionally if my long-runnig process has exited. Sometimes I dive too deep into work and forget about it. The solution is to add process exit notification that will take me out of trance.
There are many tools for that purpose: notify-send, dzen2, beep, aplay, wall. All of them are good somehow, but don't work with ssh connection. That's why I use terminal beep:
```
$ long-running-command; echo $'\a'
```
ASCII encoding has 0x7 character, named [bell](https://en.wikipedia.org/wiki/Bell_character). It is used to beep the PC speaker. PC-speaker is not a modern thing, not every computer has it and it's not heared in headphones. That's why some terminals use a so called visual bell. I use urxvt, and it performs visual bell by raising urgency flag. What is it? It's a thing used when a window want to tell you it is urgent.
You can check how your terminal reacts on bell character right now:
```
$ sleep 3; echo $'\a'
```
Three seconds are given for you to switch to another window, it may be required.
Unfortunately, not every terminal can display visual bell by raising urgency flag. I've checked the most popular.
| Terminal emulator | visual bell as urgency flag |
| --- | --- |
| konsole | may be enabled in preferences |
| urxvt | yes |
| xfce4-terminal | may be enabled in preferences |
| xterm | no |
| cool-retro-term | no |
| lxterminal | no |
| gnome-terminal | no |
It's too long to type `echo $'\a'`, so I've made a `wake` alias.
### Aliases
By default commands `cp`, `scp` and `rm` work non-recursively and that sucks! It's a damn bad legacy! Well, it may be fixed using aliases. But first let's look when non-recursive behavior can be useful.
```
$ mkdir foodir
$ cp * foodir
```
Only files will be copied into `foodir`, but not directories. The same situation goes with `rm`:
```
$ rm *
```
will delete only files and symlinks, but keep directories. But how often do you need this feature? I like to think that `cp` and `rm` always work recursively.
Ok, but what about security? Maybe non-recursive behavior protects your files? There is one case when you have a symlink to the directory and you want to remove that symlink, but keep the directory. If a slash is appended (intentionally or occasionaly) to the directory name and the recursive mode is switched on via `-r`, the directory will become empty! EMPTY!
```
$ ln -s foodir dir_link
$ rm -r dir_link/
```
Without `-r` arg it will abuse and don't remove anything. So, recursive `rm` increases the risk of loosing data a little.
I turned on the recursive mode for `cp`, `scp` и `rm`, and also added `-p` for `mkdir` to create nested directories easily.
```
alias cp='cp -r'
alias scp='scp -r'
alias rm='rm -r'
alias mkdir='mkdir -p'
```
For two years I've never regretted about these aliases and never lost data. There is also a downside: it's possible to copy/remove less data, than it was needed and not get sight of it when working on the system without aliases. So, please be careful. I know what I do and always run `rm` with caution.
The most popular are `ls` aliases and you probably already use them:
```
alias ls='ls -F --color=auto'
alias la='ls -A'
alias ll='ls -lh'
alias lla='ll -A'
```
Also a colored grep is much more pretty than colorless:
```
alias grep='grep --colour=auto'
```
Aliases don't work in scripts, don't forget that fact! You have to explicitly specify all arguments.
### Touch typing
It's obvious, but I remind you: touch typing helps to type faster. It will be hard in the beginning, but you'll overcome the limits over time.
The best time to learn touch typing is vacation, when nobody bothers you. Please don't hurry when learning! Your goal is *to memorize* where each character is located, not so much with your mind, but with your fingers. It's better to type slow, but without mistakes rather than fast with mistakes. Remember that masters have good results not by fast fingers but not doing mistakes.
Don't forget to take a break. Your brain and fingers need to take a rest. When mistakes begin to appear, that means you need to take a break.
### That is all for today
I hope these tips will really help you. Good luck! | https://habr.com/ru/post/481940/ | null | null | 2,772 | 74.69 |
We’ve updated the Publisher’s Guide () with how IE7 detects if a file is a feed. If you publish feeds, make sure that your site’s feed is detected and readable in IE7.
If a user browses to a feed though the feed discovery button on the CommandBar, IE7 assumes it is a feed and applies the feed reading view.
When a user clicks on a link to a feed, IE7 uses the MIME Content-Type information to determine if it is a feed. Here is a list of recommended MIME Content-Types:
RSS 2.0 (.91 and .92): use text/xml (recommended) or application/rss+xml
Atom 1.0: use application/atom+xml
RSS 1.0: use application/xml or text/xml
For generic Content-Types (ex: “text/xml” and “application/xml”) IE7 reads the file and looks for specific strings to determine if it is a feed. For details, please read the Publisher’s Guide.
Let us know if there are any issues with our implementation. For sites that follow the guidelines but are not properly detected in IE7 Beta 2 Preview, please post the site on our wiki.
– Jane
So, in essence, it will no longer be possible to apply a xslt stylesheet to an RSS feed. That ‘s not so important, but I had a bunch of ideas for OPML, so I’d be sad if you used the same type of "forced control" on it in the future.
Could it be possible to default to use a stylesheet if it is present, and go to feed reading view only if it is a RSS feed AND no stylesheet is present?
Thanks
Why should an RSS 1.0 feed not use application/rdf+xml? That would seem perfectly reasonable considering that the RSS in RSS 1.0 stands for "RDF Site Summary".
Do you have any particular reason for recommending text/xml over application/xml? I know that the MS XML stack refuses to admit that RFC 3023 exists, and I really don’t care, but because there are other implementations that do care, and will treat what would otherwise be well-formed XML as not-well-formed if served as text/xml without a charset param on the content-type header, it seems like needlessly bad advice.
Phil:
For RSS 2.0, we’re basically following Dave’s recommendation () and common practice (e.g.).
I understand the rationale for recommending application/xml, but perhaps this is something that the RSS Advisory Board should take up?
I’ll post to the rss-public list.
– Sean
James:
We avoided application/rdf+xml because we wanted to avoid interfering with any registered mime-handlers for RDF content.
For background:
text/xml and application/xml are traditionally handled by the browser (and are already considered "ambiguous" by the browser, so scanning the content to figure out how to handle it is not a fundamental change in functionality).
application/rss+xml and application/atom+xml are specific enough that we considered it acceptable (as an RSS reader) to handle those directly.
application/rdf+xml is neither traditionally handled by the browser, nor specific to the RSS 1.0 usage. As such, we don’t want to change how that mime-type is handled without a specific need.
It appears, however, that there are few, if any, RSS 1.0 feeds that use application/rdf+xml, so its not a problem. If that changes, we will consider moving application/rdf+xml to "ambiguous". Ambiguous handling means that we assume that the mime-type means multiple things (we do this today for text/plain and application/octet-stream, for example). So we would then handle it ourselves first, scan it to figure out if it’s an RSS 1.0 feed, and hand it off to a registered mime handler only if we decide its not an RSS 1.0 feed.
On the whole, however, I’d prefer to keep the status quo and use application/xml or text/xml for RSS 1.0, because its far simpler for us (given that we have to do scanning of those mime-types for RSS 2.0 feeds anyway).
This link in the story "feed discovery button" does not work when going thru Bloglines, and I thought it was just an anti-FF link lol.
Thanks for this information, I’ll implement it for BDN as well (newsfeed site listed in my URL). Can you tell me why no one appears to be supporting OPML instead of putting a whole bunch of <link entries in your header section? A link to one opml file seems a lot cleaner and easier to maintain (particularly with the way ASP.NET controls work today) than having to put a link entry in for EACH rss file you have.
I ask the same question as Matt Terenzio – will it no longer be possible to apply XSLT to an XML-feed and have it showed in sthe way specified?
I myself would prefer if IE 7 choosed to view the site with the specified XSLT-stylesheet and show in one way or another for the user that it’s a feed and give them the option to do whatever you want them to be able to do with it.
Why would I prefer this? Well IE 7 is above all a webbrowser and therefore should emphasize the webrendering of XML-files. I want to be able to use a styled XML-file as my webpage and I want to be able to know that people will be shown that site and not only my texts from within that site. To not show them that is to work against an evolvement into a semantic web…
I didn’t notice until Ben borrowed the same heuristic for Firefox, but why when you are sniffing for RSS 1.0 do you check for both "<rdf:RDF" *and* the RDF namespace URI? I would guess that the set of things with one and not the other is empty, or at the very least vanishingly small compared to the unchecked set of thing with the string "<feed" but without an Atom namespace URI. | https://blogs.msdn.microsoft.com/rssteam/2006/03/30/publishers-guide-update-with-mime-detection/ | CC-MAIN-2016-30 | refinedweb | 1,030 | 69.52 |
sage-python, import matplotlib: no module named _tkagg
EDIT 2: Below is the description of a problem and a subsequent edit, where I thought I had the solution. In fact, what I did was move the problem from one place to another... I am no longer receiving the error No module named _tkagg and I am getting a plot window, but after opening a tk window I get a stack trace that reads:
Exception in Tkinter callback Traceback (most recent call last): File "/opt/sage/local/lib/python2.6/lib-tk/Tkinter.py", line 1410, in __call__ return self.func(*args) File "/opt/sage/local/lib/python2.6/site- packages/matplotlib/backends/backend_tkagg.py", line 245, in resize self.show() File "/opt/sage/local/lib/python2.6/site- packages/matplotlib/backends/backend_tkagg.py", line 249, in draw tkagg.blit(self._tkphoto, self.renderer._renderer, colormode=2) File "/opt/sage/local/lib/python2.6/site-packages/matplotlib/backends/tkagg.py", line 18, in blit _tkagg.tkinit(id(tk), 0) AttributeError: 'module' object has no attribute 'tkinit'
along with no actual plot on the tk window. This issue remains unresolved.
I am using Sage's python and trying to import matplotlib.pyplot in order to generate some visual output (to the screen for now, to a file at some point). I understand the backend I should use is TkAgg for this, and I have that set in my matplotlibrc file.
When running a short script pleasePlot.py:
# pleasePlot.py import matplotlib.pyplot as plt def main(): x = [0,1,2,3,4,5] y = [1,6,4,4,2,7] plt.plot(x,y) plt.show() main()
as
bash$ python pleasePlot.py
I am greeted with absolutely no output. When examining this closer, by running a sage-python (python2.6.4.p10) shell I get the following:
>>>import matplotlib.pyplot Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/opt/sage/local/lib/python2.6/site-packages/matplotlib/pyplot.py", line 95, in <module> new_figure_manager, draw_if_interactive, show = pylab_setup() File "/opt/sage/local/lib/python2.6/site- packages/matplotlib/backends/__init__.py", line 25, in pylab_setup globals(),locals(),[backend_name]) File "/opt/sage/local/lib/python2.6/site- packages/matplotlib/backends/backend_tkagg.py", line 11, in <module> import matplotlib.backends.tkagg as tkagg File "/opt/sage/local/lib/python2.6/site-packages/matplotlib/backends/tkagg.py", line 1, in <module> import _tkagg ImportError: No module named _tkagg
I have tried
sage -f python-2.6.4.p10 sage -f matplotlib-1.0.1
but this does not magically fix the problem. As well, Google seems to not be much help. What do you think?
EDIT 1: FIXED! I am able to get a plot window from either the sage-python prompt -or- by running this 'program' from the bash shell. What I did was to track down the _tkagg call (by reading the stack trace more carefully) coming from the file
/opt/sage/local/lib/python2.6/site-packages/matplotlib/backends/tkagg.py
the file starts out as:
import _tkagg yada yada yada
so I went searching around ... (more) | https://ask.sagemath.org/question/8197/sage-python-import-matplotlib-no-module-named-_tkagg/?answer=12582 | CC-MAIN-2019-13 | refinedweb | 518 | 52.46 |
LG TV controller
Hi!
I just got my TV controller working and would like to share this to you.
Behind.
I bought this one: RS232 To TTL Converter Module
• Connect the radio like always.
• Connect the VCC on RS232 to 5v, ground to ground, RX to D6 and TX to D7
With this code I can controll the power and volume on the TV. I can also see if the TV is on or off.
#include <MySensor.h> #include <SPI.h> #include <SoftwareSerial.h> MySensor gw; MyMessage msg(1, V_LIGHT); MyMessage msg2(2, V_PERCENTAGE); //Software Serial for RS232 to TTL board, define output pins SoftwareSerial mySerial(6, 7); // RX, TX String tvPower = "00"; //Power 00=off 01=on int tvVolume = 0; //Volume const String tvid = "01"; //The ID you set in your TV unsigned long previousMillis = 0; // last time update int messageToSend = 0; void setup() { // Initialize library and add callback for incoming messages gw.begin(incomingMessage, AUTO, true); // Send the sketch version information to the gateway and Controller gw.sendSketchInfo("LG TV RS232", "1.1"); gw.present(1, S_LIGHT); gw.present(2, S_DIMMER); //Software Serial for RS232 to TTL board, begin mySerial.begin(9600); } void loop() { // Alway process incoming messages whenever possible gw.process(); if (mySerial.available() > 0) { String incommingString; // read the incoming byte: //incomingByte = mySerial.read(); // say what you got: incommingString = mySerial.readStringUntil('\n'); Serial.print("I received: "); Serial.println(incommingString); parseSerialString(incommingString); } //Check if TV is on unsigned long currentMillis = millis(); if(currentMillis - previousMillis > 30000) { previousMillis = currentMillis; if(messageToSend>0) messageToSend=0; if(messageToSend==0){ sendMessage("ka", "FF"); //Set status to FF if you want to see the current power status. messageToSend++; }else if(messageToSend==1){ sendMessage("kf", "FF"); //Set status to FF if you want to see the current volume. messageToSend++; } } } void incomingMessage(const MyMessage &message) { if (message.sensor==1) { if(message.getBool()){ setPower("01"); }else{ setPower("00"); } // Store state in eeprom gw.saveState(message.sensor, message.getBool()); // Write some debug info Serial.print("Incoming change for sensor:"); Serial.print(message.sensor); Serial.print(", New status: "); Serial.println(message.getBool()); } else if (message.sensor == 2) { Serial.println( "V_PERCENTAGE command received..." ); int dimvalue= atoi( message.data ); if ((dimvalue<0)||(dimvalue>100)) { Serial.println( "V_DIMMER data invalid (should be 0..100)" ); return; }else{ Serial.print("V_PERCENTAGE value: "); Serial.println(dimvalue); } gw.saveState(message.sensor, dimvalue); dimvalue = round(dimvalue*2/10); Serial.print("New value: "); Serial.println(dimvalue); setVolume(dimvalue); } } //Send message to tv void sendMessage(String tvcommand, String tvstatus){ mySerial.println(tvcommand + " " + tvid + " " + tvstatus); } //Turn TV on or off void setPower(String tvstatus){ sendMessage("ka", tvstatus); } //Set TV volume void setVolume(int volume){ String strVolume; if(volume<0) volume=0; if(volume>64) volume=64; strVolume = String(volume, HEX); if(strVolume.length()==1){ strVolume = "0" + strVolume; } sendMessage("kf", strVolume); } //Parse incomming serial string void parseSerialString(String serialString){ String tvcommand; String tvstatus; tvcommand = serialString.substring(0,1); tvstatus = serialString.substring(7,9); if(tvcommand=="a"){ tvPower = tvstatus; gw.send(msg.set(tvPower.toInt())); Serial.println("Power is: " + tvPower); } if(tvcommand=="f"){ tvVolume = tvstatus.toInt(); gw.send(msg.set(tvVolume)); Serial.println("Volume is: " + tvstatus); } }
Any feedback on the code is welcome! This is my first project for MySensors and I have a lot to learn!
Very cool, thanks for sharing!
Nice!
Make sure to add your project to OpenHardware.io and tag it with "MySensors" and "Contest2016"
Nice!
Make sure to add your project to OpenHardware.io and tag it with "MySensors" and "Contest2016"
Thanks, I will do that!
- sundberg84 Hardware Contributor last edited by
Nice! I will check my Samsung if I can do that!
Great job.
@sundberg84 said:
Nice! I will check my Samsung if I can do that!
Great job.
Thanks!
In my "research" I found out that some Samsung TV's and other manufactors have a serial port that can be controlled like this.
- scalz Hardware Contributor last edited by
very cool idea..
Thanks!.
- sundberg84 Hardware Contributor last edited by sundberg84
Sooo... after some waiting i recieved my RS232 to TTL... but soon found out that my Samsung does not use the RS232... but a 3.5mm stereo as a service port... seems like its the same protocoll so it should be able to do everything from changing channel to volyme, source and other cool stuff...
Build Plans:
A great weekend project...
I will be back!
@sundberg84 Sounds like it would work! Looking forward too see the result!
- sundberg84 Hardware Contributor last edited by sundberg84
Im not having any luck with this project. I have made my Arduno->RS232 to TTL -> 3.5 plug and it seems to work when im testing. Connecting it to my Samsung does nothing. TV does not seem like its able to send any status... What i have read its possible to send command in hex to do different thing but at this point im pausing this project... I need a new TV as well so i might solve it with bying a LG
- Sparkman Hero Member last edited by
@sundberg84 I'm not sure if any of the current LG TV's have an RS232 port anymore. Most new ones (at least the "smart" ones) are now running WebOS and can in theory be controlled through it over IP. I have two LG TV's, one is a 2010 and it has a serial port, but my 2012 Smart TV does not.
Cheers
Al
@sundberg84 That´s too bad! I thought it would work with the 3.5 mm plug.
It would be funny to see the salespersons reaction when you are in the store and asks after a TV with a RS232 port!.
Why not have the Arduino keep polling the TV to see if it's on, and then only when it is on, then send some signal to your controller (Domotics) that the TV just came on. Then Domotics could do whatever (turn on/off other lights, etc...)? Power (battery) is not a concern on this node, as it's powered by USB.
.
Perhaps further debugging and/or careful programming and error trapping between Arduino and TV could alleviate some of those problems? And/or, once TV is set to on, have Arduino check less frequently?
I still would prefer the former solution over the latter, to make it more nice, faster response, and higher WAF as well as "show off to friends" factor. I mean, let's get our priorities straight, that is at least partly why we do this, right?
- Jeroen van Pelt last edited by
It seems the link to the RS232 to TTL converter went stale. I am ordering this one instead:
I am going to have to try this. I have a 60 inch Sharp Aquos TV that has a 9 pin serial port. I have ordered one of these: RS232 TTL converter It is a china version, but I couldn't beat it at $0.73 with free shipping. The other nice thing is that in the manual for my TV on page 51 it shows the complete serial protocol and command set. If I can in some way combine this with the IR sender and receiver project to control my cable box too, this would be a well rounded solution.
So I received my serial converter the other day and did some testing. I connected the converter to one of my FTDI adapters and to the TV. I found out how to send the commands to the TV. The TV will respond with OK if the command was successful or ERR if it wasn't. The one thing I can't get from the TV is feedback such as power on and other commands. It would be nice to be able to tell when it is turned on and off manually, but I will work with what I have.
@dbemowsk Nice to see that you got it working! Behinde my tv there is a USB port that is powered only when the TV is on. Maybe its the same on your tv and that way you could check if the TV is on it not.
@Smurphen, that is a good point.I could wire the 5 volts from that to an input on the nano and check for a state change on that. I have seen USB cables that are basically a short usb extension with another pigtail coming off to pull power for a device. Can't remember what it was from though. If I could find one of those, I could keep the functional use of the USB port (if needed) while still pulling power for this.
My next step is to write the sketch needed to do the control from MySensors. Part of my problem in this is that I am currently running Domoticz which I am seeing doesn't work well with this. Some of the functions I may have a hard time implementing. I am looking at possibly getting a Vera controller soon though which may be more flexible in this regard.
Just out of curiosity, which parts is hard to implement in domoticz?
I guess I was just thinking about things like setting volume level and channel number. With my Sharp Aquos TV I have to send 2 parts, the command and the parameter. An example would be for volume, on the node side I need to send the command "VOLM" and a number from 0 to 60. I would need 2 parts in Domoticz. Somthing to tell it to use the volume command, and something else to send it the level (the 0 to 60).
I was thinking of somehow controlling it with my Amazon Echo which I was reading up on and seems a bit tedious to integrate. I would like to be able to say things like, "Alexa, change the channel to 43", or "Alexa, set volume level to 20".
Some of what I am planning with this node is not only control of my TV, but also IR control of my cable box. This is going to make my node more complex. I don't think it is going to be that hard to do some of the basic stuff in Domoticz, like power on/off and channel up/down, but like for volume, there is no volume up/down command. And for changing the channel, I do that on the cable box. I don't use the internal tuner on the TV. Some of this I would program the node to handle, like when a channel change is sent, do that with the IR to the cable box, whereas a power command would control both the TV and cable box.
These are some of the things that I think are going to be a bit difficult with Domoticz.
Just an idea, use a dimmer in domoticz for the volume, when you receive a value from the controller, then send VOLM and the value.. There is no need for the controller to know how to set the volume (the VOLM command)
For IR commands, that's probably another story, Haven't looked that much into it (yet).. Right now I have a logitech harmony elite, integrated with domoticz, so that I (from domoticz) can turn on different scenes.. But I can not send an individual command to the tv, or the?? | https://forum.mysensors.org/topic/2965/lg-tv-controller | CC-MAIN-2018-47 | refinedweb | 1,881 | 66.13 |
JSP EL expressions in
EL (Expression Language) Objective: To make JSP easier to write.
Expression language inspired by ECMAScript and the XPath expression language, which provides simplified expressions in the JSP in the method. It is a simple language, based on the available namespace (PageContext attributes), nested properties and on the set of operators (arithmetic type, relational and logic-based) access to operator, mapping to the Java class static methods can be spread function and a set of implicit objects.
EL provides a JSP scripting elements to use run-time expressions outside the function. Scripting element refers to the page file can be used to embed Java code in JSP elements. They are often used for objects that affect the operation and implementation of the content generated by the calculation. JSP 2.0 EL expression will be added as a scripting element.
Second, JSP EL Introduction
1 grammar
$ (Expression)
2, [] and. Operator
EL provide "." And "[]" two operators to access the data.
When you want to access the property name contains special characters, such as. Or? Such as letters or numbers are not symbols, they have to use "[]." For example:
$ (User.My-Name) should be replaced by $ (user ["My-Name"])
If you want to when the dynamic value, you can use "[]" to do, and "." Values can not be dynamic. For example:
$ (SessionScope.user [data]) is a variable in the data
3, the variable
EL access the variable data is simple, for example: $ (username). It means that out of a range variable named username.
Because we did not specify which of a range of username, so it will sequence from the Page, Request, Session, Application range search.
If the way to find the username, the direct return, not to look down, but if all of the range are found, would return null.
Properties range in the name of the EL
Page PageScope
Request RequestScope
Session SessionScope
Application ApplicationScope
Second, JSP EL expression in the effective
Effective expression can contain text, operator, variable (object reference) and the function call. We will learn these effective expressions of each:
1, text
JSP expression language defines expressions used in the following text:
2 operators
JSP expression language provides the following operators, most of which are commonly used in Java operators:
3, implicit object
JSP expression language defines a set of implicit objects, many objects and expressions in the JSP scriplet available:
In addition, several implicit objects available, allowing easy access to the following objects:
In addition to these two types of implicit objects in addition to the scope of some object allows access to a variety of variables, such as the Web context, session, request, page:
Third, with particular emphasis on:
1, note that when the expression is referenced by name one of these objects, return the corresponding object rather than the corresponding property. For example: if an existing pageContext attribute containing some other value, $ (pageContext) also return PageContext object.
2, note that <% @ page isELIgnored = "true"%> that are disabled for EL language, TRUE is prohibited. FALSE said they were not prohibited. JSP2.0 EL is enabled in the default language.
4, an example
1, for example,
<% = Request.getParameter ("username")%> is equivalent to $ (param.username)
2, for example, but the following sentence to be completed EL language is empty, if a username is not displayed null, but does not display the value.
<% = User.getAddr ()%> equivalent to $ (user.addr).
3, for example:
<% = Request.getAttribute ("userlist")%> is equivalent to $ (requestScope.userlist)
4, for example, Principle 3 above cases.
$ (SessionScope.userlist) 1
$ (SessionScope.userlist) 2
$ (ApplicationScope.userlist) 3
$ (PageScope.userlist) 4
$ (Uselist) meaning: the implementation of the order of 4123.
"." Back to just a string, no real built-in objects, can not call the object.
4, for example,
<% = User.getAddr ()%> is equivalent to $ (user.addr)
The first sentence of the previous user, as a variable.
The second sentence, user, must be in a certain range of properties.
Related Posts of JSP EL expressions in ")
js page Jump implementation of a number of ways
The first is: <script language="javascript" type="text/javascript"> window.location. alert
EJB ant script to deploy template works
<? xml <! - Property variables -> <! - The ...
RoR explained
ROR is Ruby on Rails. Ruby is a well-known has been very good dynamic language It's dynamic language. Simple and easy. Dynamic languages are interpreted, but the performance may make a discount, but not absolute, because the application is complex, th ... | http://www.codeweblog.com/jsp-el-expressions-in/ | CC-MAIN-2015-14 | refinedweb | 731 | 56.55 |
Objects that use colormaps by default linearly map the colors in the colormap from data values vmin to vmax. For example:
pcm = ax.pcolormesh(x, y, Z, vmin=-1., vmax=1., cmap='RdBu_r')
will map the data in Z linearly from -1 to +1, so Z=0 will give a color at the center of the colormap RdBu_r (white in this case).
Matplotlib does this mapping in two steps, with a normalization from
[0,1] occurring first, and then mapping onto the indices in the
colormap. Normalizations are classes defined in the
matplotlib.colors() module. The default, linear normalization is
matplotlib.colors.Normalize().
Artists that map data to color pass the arguments vmin and vmax to
construct a
matplotlib.colors.Normalize() instance, then call it:
In [1]: import matplotlib as mpl In [2]: norm = mpl.colors.Normalize(vmin=-1.,vmax=1.) In [3]: norm(0.) Out[3]: 0.5
However, there are sometimes cases where it is useful to map data to colormaps in a non-linear fashion.
One of the most common transformations is to plot data by taking
its logarithm (to the base-10). This transformation is useful to
display changes across disparate scales. Using
colors.LogNorm()
normalizes the data via \(log_{10}\). In the example below,
there are two bumps, one much smaller than the other. Using
colors.LogNorm(), the shape and location of each bump can clearly
be seen:
import numpy as np import matplotlib.pyplot as plt import matplotlib.colors as colors import matplotlib.cbook as cbook N = 100 X, Y = np.mgrid[-3:3:complex(0, N), -2:2:complex(0, N)] # A low hump with a spike coming out of the top right.(2, 1) pcm = ax[0].pcolor(X, Y, Z, norm=colors.LogNorm(vmin=Z.min(), vmax=Z.max()), cmap='PuBu_r') fig.colorbar(pcm, ax=ax[0], extend='max') pcm = ax[1].pcolor(X, Y, Z, cmap='PuBu_r') fig.colorbar(pcm, ax=ax[1], extend='max') plt.show()
Similarly, it sometimes happens that there is data that is positive
and negative, but we would still like a logarithmic scaling applied to
both. In this case, the negative numbers are also scaled
logarithmically, and mapped to smaller numbers; e.g., if
vmin=-vmax,
then they the negative numbers are mapped from 0 to 0.5 and the
positive from 0.5 to 1.
Since the logarithm of values close to zero tends toward infinity, a small range around zero needs to be mapped linearly. The parameter linthresh allows the user to specify the size of this range (-linthresh, linthresh). The size of this range in the colormap is set by linscale. When linscale == 1.0 (the default), the space used for the positive and negative halves of the linear range will be equal to one decade in the logarithmic range.
N = 100 X, Y = np.mgrid[-3:3:complex(0, N), -2:2:complex(0, N)] Z1 = np.exp(-X**2 - Y**2) Z2 = np.exp(-(X - 1)**2 - (Y - 1)**2) Z = (Z1 - Z2) * 2 fig, ax = plt.subplots(2, 1) pcm = ax[0].pcolormesh(X, Y, Z, norm=colors.SymLogNorm(linthresh=0.03, linscale=0.03, vmin=-1.0, vmax=1.0), cmap='RdBu_r') fig.colorbar(pcm, ax=ax[0], extend='both') pcm = ax[1].pcolormesh(X, Y, Z, cmap='RdBu_r', vmin=-np.max(Z)) fig.colorbar(pcm, ax=ax[1], extend='both') plt.show()
Sometimes it is useful to remap the colors onto a power-law
relationship (i.e. \(y=x^{\gamma}\), where \(\gamma\) is the
power). For this we use the
colors.PowerNorm(). It takes as an
argument gamma (gamma == 1.0 will just yield the default linear
normalization):
Note
There should probably be a good reason for plotting the data using this type of transformation. Technical viewers are used to linear and logarithmic axes and data transformations. Power laws are less common, and viewers should explicitly be made aware that they have been used.
N = 100 X, Y = np.mgrid[0:3:complex(0, N), 0:2:complex(0, N)] Z1 = (1 + np.sin(Y * 10.)) * X**(2.) fig, ax = plt.subplots(2, 1) pcm = ax[0].pcolormesh(X, Y, Z1, norm=colors.PowerNorm(gamma=0.5), cmap='PuBu_r') fig.colorbar(pcm, ax=ax[0], extend='max') pcm = ax[1].pcolormesh(X, Y, Z1, cmap='PuBu_r') fig.colorbar(pcm, ax=ax[1], extend='max') plt.show()
Another normaization that comes with Matplotlib is
colors.BoundaryNorm(). In addition to vmin and vmax, this
takes as arguments boundaries between which data is to be mapped. The
colors are then linearly distributed between these "bounds". For
instance:
In [4]: import matplotlib.colors as colors In [5]: bounds = np.array([-0.25, -0.125, 0, 0.5, 1]) In [6]: norm = colors.BoundaryNorm(boundaries=bounds, ncolors=4) In [7]: print(norm([-0.2,-0.15,-0.02, 0.3, 0.8, 0.99])) [0 0 1 2 3 3]
Note unlike the other norms, this norm returns values from 0 to ncolors-1.
N = 100 X, Y = np.mgrid[-3:3:complex(0, N), -2:2:complex(0, N)] Z1 = np.exp(-X**2 - Y**2) Z2 = np.exp(-(X - 1)**2 - (Y - 1)**2) Z = (Z1 - Z2) * 2 fig, ax = plt.subplots(3, 1, figsize=(8, 8)) ax = ax.flatten() # even bounds gives a contour-like effect bounds = np.linspace(-1, 1, 10) norm = colors.BoundaryNorm(boundaries=bounds, ncolors=256) pcm = ax[0].pcolormesh(X, Y, Z, norm=norm, cmap='RdBu_r') fig.colorbar(pcm, ax=ax[0], extend='both', orientation='vertical') # uneven bounds changes the colormapping: bounds = np.array([-0.25, -0.125, 0, 0.5, 1]) norm = colors.BoundaryNorm(boundaries=bounds, ncolors=256) pcm = ax[1].pcolormesh(X, Y, Z, norm=norm, cmap='RdBu_r') fig.colorbar(pcm, ax=ax[1], extend='both', orientation='vertical') pcm = ax[2].pcolormesh(X, Y, Z, cmap='RdBu_r', vmin=-np.max(Z)) fig.colorbar(pcm, ax=ax[2], extend='both', orientation='vertical') plt.show()
Sometimes we want to have a different colormap on either side of a conceptual center point, and we want those two colormaps to have different linear scales. An example is a topographic map where the land and ocean have a center at zero, but land typically has a greater elevation range than the water has depth range, and they are often represented by a different colormap.
filename = cbook.get_sample_data('topobathy.npz', asfileobj=False) with np.load(filename) as dem: topo = dem['topo'] longitude = dem['longitude'] latitude = dem['latitude'] fig, ax = plt.subplots() # make a colormap that has land and ocean clearly delineated and of the # same length (256 + 256) colors_undersea = plt.cm.terrain(np.linspace(0, 0.17, 256)) colors_land = plt.cm.terrain(np.linspace(0.25, 1, 256)) all_colors = np.vstack((colors_undersea, colors_land)) terrain_map = colors.LinearSegmentedColormap.from_list('terrain_map', all_colors) # make the norm: Note the center is offset so that the land has more # dynamic range: divnorm = colors.DivergingNorm(vmin=-500., vcenter=0, vmax=4000) pcm = ax.pcolormesh(longitude, latitude, topo, rasterized=True, norm=divnorm, cmap=terrain_map,) # Simple geographic plot, set aspect ratio beecause distance between lines of # longitude depends on latitude. ax.set_aspect(1 / np.cos(np.deg2rad(49))) fig.colorbar(pcm, shrink=0.6) plt.show()
The
DivergingNorm described above makes a useful example for
defining your own norm.
class MidpointNormalize(colors.Normalize): def __init__(self, vmin=None, vmax=None, vcenter=None, clip=False): self.vcenter = vcenter colors.Normalize.__init__(self, vmin, vmax, clip) def __call__(self, value, clip=None): # I'm ignoring masked values and all kinds of edge cases to make a # simple example... x, y = [self.vmin, self.vcenter, self.vmax], [0, 0.5, 1] return np.ma.masked_array(np.interp(value, x, y)) fig, ax = plt.subplots() midnorm = MidpointNormalize(vmin=-500., vcenter=0, vmax=4000) pcm = ax.pcolormesh(longitude, latitude, topo, rasterized=True, norm=midnorm, cmap=terrain_map) ax.set_aspect(1 / np.cos(np.deg2rad(49))) fig.colorbar(pcm, shrink=0.6, extend='both') plt.show()
Total running time of the script: ( 0 minutes 1.021 seconds)
Keywords: matplotlib code example, codex, python plot, pyplot Gallery generated by Sphinx-Gallery | https://matplotlib.org/3.1.0/tutorials/colors/colormapnorms.html | CC-MAIN-2022-33 | refinedweb | 1,345 | 54.08 |
11 May 2012 15:32 [Source: ICIS news]
?xml:namespace>
The production facilities were shut down after the blaze on 23 April damaged an electricity supply unit.
Togliattikauchuk’s butadiene and methyl tertiary-butyl ether (MTBE) units were restarted on May 1, while its co-polymer styrene-butadiene rubber (SBR) unit resumed production on May 2, the company said.
It added that its isoprene and isoprene rubber units restarted on May 8-9.
The company’s isobutylene, isobutene and butyl rubber facilities were shut down for regular maintenance before the fire, and these units are due to restart from May 15, it said.Togliattikauchuk, based in Samara region, Central Russia and. | http://www.icis.com/Articles/2012/05/11/9559106/russias-togliattikauchuk-restarts-production-facilities-after-fire.html | CC-MAIN-2013-20 | refinedweb | 111 | 62.68 |
FileDialog QML Type
Dialog component for choosing files from a local filesystem. More...
Properties
- defaultSuffix : string
- fileUrl : url
- fileUrls : list<url>
- folder : url
- modality : Qt::WindowModality
- nameFilters : list<string>
- selectExisting : bool
- selectFolder : bool
- selectMultiple : bool
- selectedNameFilter : string
- shortcuts : Object
- sidebarVisible : bool
- title : string
- visible : bool
Methods
Detailed Description
FileDialog provides a basic file chooser: it allows the user to select existing files and/or directories, or create new filenames. The dialog is initially invisible. You need to set the properties as desired first, then set visible to true or call open().
Here is a minimal example to open a file dialog and exit after the user chooses a file:
import QtQuick 2.2 import QtQuick.Dialogs 1.0 FileDialog { id: fileDialog title: "Please choose a file" folder: shortcuts.home onAccepted: { console.log("You chose: " + fileDialog.fileUrls) Qt.quit() } onRejected: { console.log("Canceled") Qt.quit() } Component.onCompleted: visible = true }
A FileDialog window is automatically transient for its parent window. So whether you declare the dialog inside an Item or inside a Window, the dialog will appear centered over the window containing the item, or over the Window that you declared.. DefaultFileD.
The QML implementation has a sidebar containing shortcuts to common platform-specific locations, and user-modifiable favorites. It uses application-specific settings to store the user's favorites, as well as other user-modifiable state, such as whether or not the sidebar is shown, the positions of the splitters, and the dialog size. The settings are stored in a section called
QQControlsFileDialog of the application-specific QSettings. For example when testing an application with the qml tool, the
QQControlsFileDialog section will be created in the
Qml Runtime settings file (or registry entry). If an application is started via a custom C++ main() function, it is recommended to set the name, organization and domain in order to control the location of the application's settings. If you use Settings objects in other parts of an application, they will be stored in other sections of the same file.
QFileDialog stores its settings globally instead of per-application. Platform-native file dialogs may or may not store settings in various platform-dependent ways.
Property Documentation
This property holds the suffix added to the filename if no other suffix was specified.
This property specifies a string that will be added to the filename if it has no suffix already. The suffix is typically used to indicate the file type (e.g. "txt" indicates a text file).
If the first character is a dot ('.'), it is removed.
This QML property was introduced in Qt 5.10.
The list of file paths which were selected by the user.
The path to the currently selected folder. Setting this property before invoking open() will cause the file browser to be initially positioned on the specified folder.
The value of this property is also updated after the dialog is closed.
By default, the url is empty.
Note: On iOS, if you set folder to shortcuts.pictures, a native image picker dialog will be used for accessing the user's photo album. The URL returned can be set as source for Image. This feature was added in Qt 5.5. to actually load or save the chosen file.
A list of strings to be used as file name filters. Each string can be a space-separated list of filters; filters may include the ? and * wildcards. The list of filters can also be enclosed in parentheses and a textual description of the filter can be provided.
For example:
FileDialog { nameFilters: [ "Image files (*.jpg *.png)", "All files (*)" ] }
Note: Directories are not excluded by filters.
See also selectedNameFilter.
Whether only existing files or directories can be selected.
By default, this property is true. This property must be set to the desired value before opening the dialog. Setting this property to false implies that the dialog is for naming a file to which to save something, or naming a folder to be created; therefore selectMultiple must be false.
Whether the selected item should be a folder.
By default, this property is false. This property must be set to the desired value before opening the dialog. Setting this property to true implies that selectMultiple must be false and selectExisting must be true.
Whether more than one filename can be selected.
By default, this property is false. This property must be set to the desired value before opening the dialog. Setting this property to true implies that selectExisting must be true.
Which of the nameFilters is currently selected.
This property can be set before the dialog is visible, to set the default name filter, and can also be set while the dialog is visible to set the current name filter. It is also updated when the user selects a different filter.
A map of some useful paths from QStandardPaths to their URLs. Each path is verified to exist on the user's computer before being added to this list, at the time when the FileDialog is created.
For example,
shortcuts.home will provide the URL of the user's home directory.
This QML property was introduced in Qt 5.5.
The title of the dialog window.
Method Documentation
Closes. | http://doc.qt.io/qt-5/qml-qtquick-dialogs-filedialog.html | CC-MAIN-2018-22 | refinedweb | 863 | 50.12 |
Boy, it's my lucky day today :-)
antonio.lopez@ptbsl.com wrote:
> Hello all
>
> We are a small group of programmers trying to develop sort of Model
> Driven Architecture.
> With this porpouse we've developed a brand new rdf api and the hole
> platform (models included) are RDF instead of MOF.
> We agree 100% with this article
> ()
I do too ;-)
> We think jackrabbit its the perfect tool to mantain the desing
> information (RDF models) and we think it would be very
> valuable to have some RDF facilities, for instance:
>
> * Make searches with *sparQL* or even our modifed api *perVERSA*
> (base on vesa).
>
> * RDF import/export funtionality would be very usefull, not just
> XML sintax but N3 or even TRIX .
>
> If you consider interesting this features we could help.
I planned to talk to David about RDF support in JackRabbit in
switzerland in two weeks (we'll be speaking at the same conference), but
now that the cat is out of the bag, I'll throw in my 2 cents.
JSR170 deals very well with namespaced content and therefore is able to
digest and consume all RDF/XML that you can throw at it.
Writing an RDF import/export facility is therefore not more difficult
than hooking up an RDF parser (Sesame Rio would be my choice) and decide
how to encode the RDF into the JCR node space.
No changes are required to the spec, even if, I have to say, if I had to
start over I would add the ability to "type" the relationships between
nested nodes, but it's too late for this round and we can work around that.
As for querying, once the RDF is normalized into a JCR environment,
XPath can be used to query that RDF model, but it's going to be suboptimal.
Implementing a SparQL query interface would be very interesting to have,
but what it's unclear to me, is how the non-RDF part of the JCR tree
(well, graph really) will look like from a SparQL point of view.
I mean, if I have a document like
<a about="...">
<b>blah</b>
</a>
and I consider this to be XML, the JCR encoding will be something like
node[a]^element
+- property[about]^attribute='...'
+- node[b]^element
+-property[text()]^string='blah'
if I consider the above to be RDF, the JCR encoding will be something like
node[resource]^uri='...'
+- property[type]^uri='#a'
+- property[#b]^string='blah'
note how the same exact document yields such different JCR nodes and
properties.
But the real question is: given an XML document and an RDF/XML document,
what does it mean to query both with the same query language? using
xpath on RDF/XML feels weird but the same thing can be said for using
Sparql on top of an XML tree.
At the end of the day, adding RDF support to a JCR repository is clearly
doable, but I'm not sure it makes all that much sense.
--
Stefano. | http://mail-archives.apache.org/mod_mbox/jackrabbit-dev/200502.mbox/%3C4207ACD5.2020800@apache.org%3E | CC-MAIN-2013-48 | refinedweb | 498 | 63.73 |
(This is an older SID, its original PDF can be found here)
Martin Odersky
October 1, 2009
Arrays have turned out to be one of the trickiest concepts to get right in Scala. This has mostly to do with very hard constraints that clash with what’s desirable. On the one hand, we want to use arrays for interoperation with Java, which means that they need to have the same representation as in Java. This low-level representation is also useful to get high performance out of arrays. But on the other hand, arrays in Java are severely limited.
First, there’s actually not a single array type representation in Java but
nine different ones: One representation for arrays of reference type and
another eight for arrays of each of the primitive types
byte,
char,
short,
int,
long,
float,
double, and
boolean. There is no common
type for these different representations which is more specific than just
java.lang.Object, even though there are some reflective methods to deal with
arrays of arbitrary type in
java.lang.reflect.Array. Second, there’s no way
to create an array of a generic type; only monomorphic array creations are
allowed. Third, the only operations supported by arrays are indexing, updates,
and get length.
Contrast this with what we would like to have in Scala: Arrays should slot
into the collections hierarchy, supporting the hundred or so methods that are
defined on sequences. And they should certainly be generic, so that one can
create an
Array[T] where
T is a type variable.
How to combine these desirables with the representation restrictions imposed
by Java interoperability and performance? There’s no easy answer, and I
believe we got it wrong the first time when we designed Scala. The Scala
language up to 2.7.x “magically” wrapped and unwrapped arrays when required in
a process called boxing and unboxing, similarly to what is done to treat
primitive numeric types as objects. “Magically” means: the compiler generated
code to do so based on the static types of expressions. Additional magic made
generic array creation work. An expression like
new Array[T] where
T is a type
parameter was converted to
new BoxedAnyArray[T].
BoxedAnyArray was a special
wrapper class which changed its representation depending on the type of the
concrete Java array to which it was cast. This scheme worked well enough for
most programs but the implementation “leaked” for certain combinations of type
tests and type casts, as well as for observing uninitialized arrays. It also
could lead to unexpectedly low performance. Some of the problems have been
described by David MacIver [1] and Matt Malone [2].
Boxed arrays were also unsound when combined with covariant collections. In summary, the old array implementation technique was problematic because it was a leaky abstraction that was complicated enough so that it would be very tedious to specify where the leaks were to be expected.
The obvious way to reduce the amount of magic needed for arrays is to have two representations: One which corresponds closely to a Java array and another which forms an integral part of Scala’s collection hierarchy. Implicit conversions can be used to transparently convert between the two representations. This is the gist of the array refactoring proposal of David MacIver (with contributions by Stepan Koltsov) [3]. The main problem with this proposal, as I see it, is that it would force programmers to choose the kind of array to work with. The choice would not be clear-cut: The Java- like arrays would be fast and interoperable whereas the Scala native arrays would support a much nicer set of operations on them. With a choice like this, one would expect different components and libraries to make different decisions, which would result in incompatibilities and brittle, complex code. MacIver and Koltsov introduce some compiler magic to alleviate this. They propose to automatically split a method taking an array as an argument into two overloaded versions: one taking a Java array and one taking a generic Scala array. I believe this would solve some of the more egregious plumbing issues, but it would simply hide the problem a bit better, not solve it.
A similar idea—- but with a slightly different slant—- is to “dress up” native
arrays with an implicit conversion that integrates them into Scala’s
collection hierarchy. This is similar to what’s been done with the
String to
RichString conversion in pre-2.8 Scala. The difference to the MacIver/Koltsov
proposal is that one would not normally refer to Scala native arrays in user
code, just as one rarely referred to RichString in Scala. One would only rely
on the implicit conversion to add the necessary methods and traits to Java
arrays. Unfortunately, the String/RichString experience has shown that this is
also problematic. In par- ticular, in pre 2.8 versions of Scala, one had the
non-intuitive property that
"abc".reverse.reverse == "abc" //, yet "abc" != "abc".reverse.reverse //!
The problem here was that the
reverse method was inherited from class
Seq
where it was defined to return another
Seq. Since strings are not sequences,
the only feasible type reverse could return when called on a
String was
RichString. But then the equals method on
Strings which is inherited from
Java would not recognize that a
String could be equal to a
RichString.
The new scheme of Scala 2.8 solves the problems with both arrays and strings.
It makes critical use of the new 2.8 collections framework which accompanies
collection traits such as
Seq with implementation traits that abstract over
the representation of the collection. For instance, in addition to trait
Seq
there is now a trait
trait SeqLike[+Elem, +Repr] { ... }
That trait is parameterized with a representation type
Repr. No assumptions
need to be made about this representation type; in particular it not required
to be a subtype of
Seq. Methods such as
reverse in trait
SeqLike will
return values of the representation type
Repr rather than
Seq. The
Seq
trait then inherits all its essential operations from
SeqLike, instantiating
the
Repr parameter to
Seq.
trait Seq[+Elem] extends ... with SeqLike[Elem, Seq[Elem]] { ... }
A similar split into base trait and implementation trait applies to most other
kinds of collections, including
Traversable,
Iterable, and
Vector.
We can integrate arrays into this collection framework using two implicit
conversions. The first conversion will map an
Array[T] to an object of type
ArrayOps, which is a subtype of type
VectorLike[T, Array[T]]. Using this
conversion, all sequence operations are available for arrays at the natural
types. In particular, methods will yield arrays instead of
ArrayOps values as
their results. Because the results of these implicit conversions are so short-
lived, modern VM’s can eliminate them altogether using escape analysis, so we
expect the calling overhead for these added methods to be essentially zero.
So far so good. But what if we need to convert an array to a real
Seq, not
just call a
Seq method on it? For this there is another implicit conversion,
which takes an array and converts it into a
WrappedArray.
WrappedArrays
are mutable
Vectors that implement all vector operations in terms of a given
Java array. The difference between a
WrappedArray and an
ArrayOps object
is apparent in the type of methods like
reverse: Invoked on a
WrappedArray, reverse returns again a
WrappedArray, but invoked on an
ArrayOps object, it returns an
Array. The conversion from
Array to
WrappedArray is invertible. A dual implicit conversion goes from
WrappedArray to
Array.
WrappedArray and
ArrayOps both inherit from an
implementation trait
ArrayLike. This is to avoid duplication of code between
ArrayOps and
WrappedArray; all operations are factored out into the common
ArrayLike trait.
So now that we have two implicit conversions from
Array to
ArrayLike
values, how does one choose between them and how does one avoid ambiguities?
The trick is to make use of a generalization of overloading and implicit
resolution in Scala 2.8. Previously, the most specific overloaded method or
implicit conversion would be chosen based solely on the method’s argument
types. There was an additional clause which said that the most specific method
could not be defined in a proper superclass of any of the other alternatives.
This scheme has been replaced in Scala 2.8 by the following, more liberal one:
When comparing two different applicable alternatives of an overloaded method
or of an implicit, each method gets one point for having more specific
arguments, and another point for being defined in a proper subclass. An
alternative “wins” over another if it gets a greater number of points in these
two comparisons. This means in particular that if alternatives have identical
argument types, the one which is defined in a subclass wins.
Applied to arrays, this means that we can prioritize the conversion from
Array to
ArrayOps over the conversion from
Array to
WrappedArray by
placing the former in the standard
Predef object and by placing the latter
in a class
LowPriorityImplicits, which is inherited from
Predef. This way,
calling a sequence method will always invoke the conversion to
ArrayOps. The
conversion to
WrappedArray will only be invoked when an array needs to be
converted to a sequence.
Essentially the same technique is applied to strings. There are two implicit
conversions: The first, which goes from
String to
StringOps, adds useful
methods to class
String. The second, which goes from
String to
WrappedString, converts strings to sequences.
That’s almost everything. The only remaining question is how to implement
generic array creation. Unlike Java, Scala allows an instance creation
new Array[T] where
T is a type parameter. How can this be implemented, given
the fact that there does not exist a uniform array representation in Java? The
only way to do this is to require additional runtime information which
describes the type
T. Scala 2.8 has a new mechanism for this, which is
called a
Manifest. An object of type
Manifest[T] provides complete
information about the type
T. Manifest values are typically passed in implicit
parameters; and the compiler knows how to construct them for statically
known types
T. There exists also a weaker form named
ClassManifest which can
be constructed from knowing just the top-level class of a type, without
necessarily knowing all its argument types. It is this type of runtime
information that’s required for array creation.
Here’s an example. Consider the method
tabulate which forms an array from
the results of applying a given function
f on a range of numbers from 0
until a given length. Up to Scala 2.7,
tabulate could be written as follows:
def tabulate[T](len: Int, f: Int => T) = { val xs = new Array[T](len) for (i <- 0 until len) xs(i) = f(i) xs }
In Scala 2.8 this is no longer possible, because runtime information is
necessary to create the right representation of
Array[T]. One needs to
provide this information by passing a
ClassManifest[T] into the method as an
implicit parameter:
def tabulate[T](len: Int, f: Int => T)(implicit m: ClassManifest[T]) = { val xs = new Array[T](len) for (i <- 0 until len) xs(i) = f(i) xs }
When calling
tabulate on a type such as
Int, or
String, or
List[T],
the Scala compiler can create a class manifest to pass as implicit argument to
tabulate. When calling
tabulate on another type parameter, one needs to
propagate the requirement of a class manifest using another implicit parameter
or context bound. For instance:
def tabTen[T: ClassManifest](f: Int => T) = tabulate(10, f)
The move away form boxing and to class manifests is bound to break some
existing code that generated generic arrays as in the first version of
tabulate above. Usually, the necessary changes simply involve adding a
context bound to some type parameter.
GenericArray
For the case where generic array creation is needed but adding manifests is
not feasible, Scala 2.8 offers an alternative version of arrays in the
GenericArray class. This class is defined in package
scala.collection.mutable along the following lines.
class GenericArray[T](length: Int) extends Vector[T] { val array: Array[AnyRef] = new Array[AnyRef](length) ... // all vector operations defined in terms of ‘array’ }
Unlike normal arrays,
GenericArrays can be created without a class manifest
because they have a uniform representation: all their elements are stored in
an
Array[AnyRef], which corresponds to an
Object[] array in Java. The
addition of
GenericArray to the Scala collection library does demand a
choice from the programmer—- should one pick a normal array or a generic
array? This choice is easily answered, however: Whenever a class manifest for
the element type can easily be produced, it’s better to pick a normal array,
because it tends to be faster, is more compact, and has better
interoperability with Java. Only when producing a class manifest is infeasible
one should revert to a
GenericArray. The only place where
GenericArray is
used in Scala’s current collection framework is in the
sortWith method of
class
Seq. A call
xs.sortWith(f) converts its receiver
xs first to a
GenericArray, passes the resulting array to a Java sorting method defined in
java.util.Arrays, and converts the sorted array back to the same type of
Seq as
xs. Since the conversion to an array is a mere implementation
detail of
sortWith, we felt that it was unreasonable to demand a class
manifest for the element type of the sequence. Hence the choice of a
GenericArray.
In summary, the new Scala collection framework resolves some long-standing problems with arrays and with strings. It removes a considerable amount of compiler magic and avoids several pitfalls which existed in the previous implementation. It relies on three new features of the Scala language that should be generally useful in the construction of libraries and frameworks: First, the generalization of overloading and implicit resolution allows one to prioritize some implicits over others. Second, manifests provide type information at run-time that was lost through erasure. Third, context bounds are a convenient shorthand for certain forms of implicit arguments. These three language features will be described in more detail in separate notes.
Contents | http://docs.scala-lang.org/sips/completed/scala-2-8-arrays.html | CC-MAIN-2016-44 | refinedweb | 2,375 | 52.9 |
I have a devise user model, and part of the information I ask of them is their 5 digit zip code. If their zip code is 08601, then, when they go to edit their user settings, they see their zip code as 8601, without the 0 in front. Is there a way to format the zip code that devise displays in the account settings (something like "%05d")? Here is what I have in that field so far:
<div class="form-group">
<%= f.label :zip_code %><br />
<%= f.text_field :zip_code, class: "form-control", autofocus: true %>
</div>
Problem might be in your database column data type
Since you are using ZIP code in your form I think you have used zip_code column in database as integer that's why you are getting this. Change data type of column to string and then try saving your data.
If you want to keep data type integer
If you do so you need to change your zip_code to string everytime you use it and add 00 before zip_code. This is not a good approach of programming and may be the problem later.
But You can do this in model
def self.zip_code_string @zip = self.zip_code.to_s "00"+@zip end
And to display or use
@user.zip_code_string
will work | https://codedump.io/share/0fhmWBzl2RIi/1/display-5-digit-zip-in-devise | CC-MAIN-2017-09 | refinedweb | 212 | 81.12 |
Testing a Peltier cooler with a 100W solar panel using two BME280 sensors, an ESP8266, a DS18B20 temperature sensor and Google Charts
I’ve had an interest in thermoelectric cooling with Peltier devices for years. When electricity is supplied to these devices, one side gets hot and the other gets cold. I’ve created this experiment to see how effective a 100W solar panel powering a Peltier cooler is in cooling air to make a mini air conditioner. The efficiency of a Peltier is much lower than other methods of cooling such as the refrigerant-based modern air conditioning units.
For my testing I used two sensors to take measurements of air temperature and humidity before and after the air has passed through the fins of a heat sink connected to the Peltier. A third temperature sensor measures the temperature of this heat sink. The speed the air travels through the heat sink is controlled by a fan.
Sensor readings and fan speed control are managed by an ESP8266 microcontroller. This also sends the sensor readings to a web server to be displayed in a web-browser.
To replicate this experiment you will need the following items…
100w Solar Panel
Step Down Module
Peltier Module
ESP8266 Module
DS18B20 Sensor
BME280 Sensors
Motor Controller
PC Case Fan
… and some sort of plastic Tupperware style box.
This project uses the ESP8266 to control the speed of the PC fan based on the temperature of the Peltier. You can see more details on this method here Temperature Controlled Fan. In this experiment I wanted to prevent the heat sink dropping below 0 degrees because at ~0 C it takes energy to turn water on the heat sink into ice without actually changing the temperature.
For more information about using two BME280 sensors you can see this project Two BME280 Sensors Over SPI
Before starting to assemble the items I connected the solar panel to the step down module and set the output to 12 volts. The motor controller in this experiment outputs 5 volts when 12v is supplied to the input. I used this to power the ESP8266 via the 5v rail. I also checked this as below.
Checking Step Down Voltage
Checking Motor Controller Output 5 Volts
First Test
To make sure everything was working before assembling I wired everything together on the bench and pushed the DS18B20 temperature sensor into the fins of the Peltier heat sink
Wired up on the Bench
I used Google’s free charting software to create live charts from the values coming from sensors. Below you can see the temperature of the Peltier dropping and the speed of the fan increasing when I switch on the power from the solar panel. The animation is about 5x speed.
Fan Speed Temperature Readings
Assembly
I used a plastic food container because I wanted to use something transparent so all the parts of the project were all visible. The first image shows the project mostly assembled with a few wires not connected and the Peltier cooler not in place. The PC case fan sucks air out of the plastic container.
Part Assembled Top View
This image shows the project with the Peltier cooler in place and all the wires connected.
Top View Assembled
This image shows the insides of the project. The first BME280 is reading the ambient temperature and humidity. The second BME280 on the right is reading the temperature and humidity after the air has been sucked through the fins of the Peltier heat sink. The DS18B20 is reading the temperature of the heat sink.
Inside the Project
Results
I knew that one 100W solar panel combined with the inefficiency of a Peltier cooler was not going to produce a lot of cold air but I was a little disappointed with the results. Below are two charts. The first one shows the Peltier temperature and the fan speed after the power is connected. The second shows the two readings from the two BME280s. On this experiment the temperature difference is only about 5C with the fan running at only 60% so not much cool air!
Fan Speed and Peltier Temperature Readings
BME280 Readings (5x Speed)
I took a reading of the amps being used by the Peltier device and it was 3.4A. It’s sold as a 6A device so I tried a few other things such as connecting the Peltier alone to the solar panel and also using batteries for the Peltier but the amps were still below 4A so maybe it’s just a 4A device.
I also tried another test of disconnecting the PC fan so there was no airflow over the heatsink to see how this affected the temperature.
Note that in the graph below the fan speed shown is the fan speed the code is requesting from the motor controller. The fan is disconnected so is at 0%
Arduino Sketch
The code is a combination of the code from the two BME280 sensors over SPI project and the fan control with temperature sensor project.
The Sketch starts by including all the necessary libraries, assigning pins on the ESP8266 and setting up some variables. The main function void loop() has two parts. The first takes a reading of the Peltier heat sink temperature and adjusts the case fan speed based on the this. The second part runs every two seconds and calls the function connectToWebAndSendData which collects information from the various sensors and sends this to the web server along with the current fan speed.
On the web server this data is converted into a JSON formatted text file by this PHP script –
A line from this JSON text file looks something like this:
{"peltier":{"peltier_temp":2.00,"fan_speed":20},"sensor_temp":{"air_temp":30.08,"processed_temp":24.63},"sensor_humidity":{"air_humidity":51.88,"processed_humidity":49.62}}
This line is used by Google Charts code in an HTML page to create the dynamically updating graphs. Code here –
The Arduino code looks like this:
#include <ESP8266WiFi.h> #include <ESP8266HTTPClient.h> #include <Wire.h> #include <SPI.h> #include <Adafruit_Sensor.h> #include <Adafruit_BME280.h> #include <OneWire.h> #include <DallasTemperature.h> // assign the ESP8266 pins to Arduino pins #define D1 5 #define D2 4 #define D3 0 #define D4 2 #define D5 14 // assign the SPI bus to pins #define BME_SCK D1 #define BME_MISO D5 #define BME_MOSI D2 #define BME1_CS D3 #define BME2_CS D4 #define SEALEVELPRESSURE_HPA (1013.25) #define D7 13 // fan PWM #define D8 15 // fan on #define ONE_WIRE_BUS 12 // Peltier thermometer sensor int fanPinPwm = 13; int fanPinOn = 15; int dutyCycle = 0; // Setup a oneWire instance to communicate with OneWire device OneWire oneWire(ONE_WIRE_BUS); // Pass our oneWire reference to Dallas Temperature. DallasTemperature sensors(&oneWire); Adafruit_BME280 bme1(BME1_CS, BME_MOSI, BME_MISO, BME_SCK); // software SPI Adafruit_BME280 bme2(BME2_CS, BME_MOSI, BME_MISO, BME_SCK); // software SPI long previousMillis = 0; // store last time sensor data uploaded long interval = 2000; // interval at which to send data const char *ssid = "YOUR WIFI SSD"; const char *password = "your wifi password"; String actionUrl = ""; void setup() { Serial.begin(115200); delay(10); // Explicitly set the ESP8266 to be a WiFi-client WiFi.mode(WIFI_STA); WiFi.begin(ssid, password); // peltier temp sensor sensors.begin(); pinMode(fanPinPwm, OUTPUT); // sets the pin as output: pinMode(fanPinOn, OUTPUT); // sets the pin as output: analogWriteRange(100); // to have a range 1 - 100 for the fan analogWriteFreq(10000); // PWM // BME temp and humidity sensors bool status; status = bme1.begin(); if (!status) { Serial.println("Could not find a valid BME280 sensor 1 , check wiring!"); } status = bme2.begin(); if (!status) { Serial.println("Could not find a valid BME280 sensor 2 , check wiring!"); } } void loop() { // This part controls the fan speed based on the temperature of the Peltier float peltierTemp = readPeltierTemp(); // Request sensor value peltierTemp = constrain(peltierTemp, 0, 30); // constrain the peltier temp reading between 0 and 30 int fanSpeedPercent = map(peltierTemp, 0, 30, 100, 10); // invert the fan speed and make a percent controlFanSpeed (fanSpeedPercent); // Update fan speed // Only send data to server every 2 seconds unsigned long currentMillis = millis(); if (currentMillis - previousMillis > interval) { previousMillis = currentMillis; connectToWebAndSendData(fanSpeedPercent); } } // sends data from three sensors and fan speed void connectToWebAndSendData (int fanSpeedPercent) { if (WiFi.status() == WL_CONNECTED) { //Check WiFi connection status HTTPClient http; String actionUrlWithQueryString = actionUrl; actionUrlWithQueryString.concat(getPeltierTempAsQueryString()); //add the peltier temp actionUrlWithQueryString.concat(getBMEValuesAsQueryString()); // add the BME data actionUrlWithQueryString.concat("&fan_speed="); // add the fan speed actionUrlWithQueryString.concat(fanSpeedPercent); Serial.println(actionUrlWithQueryString); http.begin(actionUrlWithQueryString); //Specify destination for HTTP request int httpCode = http.GET(); if (httpCode > 0) { // file found at server if (httpCode == HTTP_CODE_OK) { String payload = http.getString(); Serial.println(payload); } http.end(); } } } float readPeltierTemp () { sensors.requestTemperatures(); // Send the command to get temperatures Serial.print("Temperature: "); Serial.println(sensors.getTempCByIndex(0)); return sensors.getTempCByIndex(0); } String getPeltierTempAsQueryString() { String queryString = "?peltier_temp="; queryString.concat(readPeltierTemp ()); Serial.println(queryString); return queryString; } String getBMEValuesAsQueryString() { String queryString = "&air_temp="; queryString.concat(bme1.readTemperature()); queryString.concat("&air_humidity="); queryString.concat(bme1.readHumidity()); queryString.concat("&processed_temp="); queryString.concat(bme2.readTemperature()); queryString.concat("&processed_humidity="); queryString.concat(bme2.readHumidity()); Serial.println(queryString); return queryString; } void controlFanSpeed (int fanSpeedPercent) { Serial.print("Fan Speed: "); Serial.print(fanSpeedPercent); Serial.println("%"); digitalWrite(fanPinOn, HIGH); // set the motor controller pin on analogWrite(fanPinPwm, fanSpeedPercent); // set the fan speed via PWM }
Conclusion
The low power of a single solar panel and poor cooling efficiency of the Peltier were never going to make an effective air conditioner. In the future I may run another experiment for drying and heating air. I’ve also since discovered that the Peltiers work much better when they aren’t driven hard. This video explains it –
Buy Me A Coffee
If you found something useful above please say thanks by buying me a coffee here...
4 Replies to “Solar Peltier Mini Air Conditioner Experiment”
Shouldn’t you be dumping the heat from the hot side of the peltier somewhere?
The hot side is outside the box with the two fans attached to it.
Very interesting data!
I suspected peltier cells are not optimal for air conditioning, but what about a portable cooler for a six-pack of beer cans?
Yep.. probably just enough to cool drinks cans with some good insulation. | https://robotzero.one/solar-peltier-aircon-investigation/ | CC-MAIN-2022-33 | refinedweb | 1,677 | 52.49 |
Good catch!
I'll apply the patch (if somebody doesn't beat me to it).
----- Original Message -----
From: "Glenn Olander" <glenn@greenoak.com>
To: "Tomcat Developers List" <tomcat-dev@jakarta.apache.org>
Sent: Monday, December 30, 2002 8:05 AM
Subject: Re: Duplicate session IDs?
> fyi, the version he checked in contains a bug. It should append jvmRoute
> within
> the loop. It should look like this:
>
> String sessionId = generateSessionId();
> String jvmRoute = getJvmRoute();
> // @todo Move appending of jvmRoute generateSessionId()???
> if (jvmRoute != null) {
> sessionId += '.' + jvmRoute;
> }
> synchronized (sessions) {
> while (sessions.get(sessionId) != null){ // Guarantee
> uniqueness
> sessionId = generateSessionId();
> if (jvmRoute != null) {
> sessionId += '.' + jvmRoute;
> }
> }
> }
> session.setId(sessionId);
>
> return (session);
>
> Remy Maucherat wrote:
>
> >Glenn Olander wrote:
> >
> >
> > I can also report that I've seen this happen when the system is
> > under load. We had a
> > user log in and gain access to another user's session. I'm sure
> > you can understand that
> > makes it a very serious bug for security-sensitive applications,
> > perhaps even deserving
> > some kind of security alert announcement.
> >
> > Tim's patch is robust and seems like a good candidate for
> > inclusion in the source
> > at the earliest opportunity since it ensures that no duplicate
> > session id's will be
> > commisioned (and ManagerBase already uses SecureRandom).
> >
> > Bill enabled the (ugly but very safe) code for getting rid of
> > duplicates. That will be in 4.1.x, at least for> | http://mail-archives.apache.org/mod_mbox/tomcat-dev/200212.mbox/%3C009401c2b03a$5beb8a70$ec66a8c0@bbarkerxp%3E | CC-MAIN-2013-48 | refinedweb | 226 | 50.02 |
The visualization is an important part of any data analysis. This helps us present the data in pictorial or graphical format. Data visualization helps in
- Grasp information quickly
- Understand emerging trends
- Understand relationships and pattern
- Communicate stories to the audience
I’m a PhD student in the Department of Civil Engineering at IIT Guwahati. I work in the transportation domain, thus I’m fortunate that I get to work with lots of data. In the data analysis part of the task, I have to often perform exploratory analysis. When comes to visualization my all-time favourite is ggplot2 library (R’s plotting library: R is a statistical programming language) which is one of the popular plotting tools. Recently, I also started implementing the same using python due to recent advancements in this language the top of the Matplotlib library and also combined to the data structures from pandas. The Seaborn blog series will be comprised of the following five parts:
Part-1. Different types of plots using seaborn
Part-2. Facet, Pair and Joint plots using seaborn
Part-3. Seaborn’s style guide and colour pallets
Part-4. Seaborn plot modifications (legend, tick, and axis labels etc.)
Part-5. Plot saving and miscellaneous
Aim of the article
The aim of the current article is to get familiar ourself with different types of plots. We will explore various types of plots and also tweak them a little bit to suit our need using Seaborn and Matplotlib library. I have aggregated different plots into the following categories.
- Distribution plots
- Categorical plots
- Regression Plot
- Time Series Plots
- Matrix plots
Importing libraries
The first step of any analysis is to install and load the relevant libraries.
import numpy as np # Array manipulation import pandas as pd # Data Manipulation import matplotlib.pyplot as plt # Plotting import seaborn as sns # Statistical plotting
About dataset
The first step of any analysis is to load the dataset. Here, we are loading the dataset from Seaborn package using load_dataset( ) function. We can check the first 5 observations using the head( ) function.
tips = sns.load_dataset("tips") tips.head()
Lets’ explore the shape of the dataset. The dataset contains 244 observations and 7 variables.
tips.shape
(244, 7)
Defining, and
poster. The
notebook style is the default. Here we are going to set it to paper and scale the font element to 2.
sns.set_style('white') sns.set_context("paper", font_scale = 2)
1. Distribution Plots
All type of distribution plot can be plotted using displot( ) function. To change the plot type you just need to supply the kind = ` ` argument which supports histogram (hist), Kernel Density Estimate (KDE: kde) and Empirical Cumulative Distribution Function (ECDF: ecdf).
1.1 Histogram
We can plot a histogram using the displot( ) function by supplying kind = “hist”. We can also supply the bins argument as per our requirement. I have set the aspect ratio to 1.5 to make the plot a little bit wider.
sns.displot(data=tips, x="total_bill", kind="hist", bins = 50, aspect = 1.5)
1.2 Histogram + KDE
We can plot a histogram + KDE (overlaid) using the displot( ) function by supplying kind = “hist” and kde = True.
sns.displot(data=tips, x="total_bill", kind="hist", kde = True, bins = 50, aspect=1.5)
1.3 Gaussian Kernel Density Estimation (KDE) Plot
We can plot a KDE using the displot( ) function by supplying kind = “kde”.
sns.displot(data=tips, x="total_bill", kind="kde", aspect=1.5)
1.4 ECDF plot
We can plot an ECDF using the displot( ) function by supplying kind = “ecdf”.
sns.displot(data=tips, x="total_bill", kind="ecdf", aspect=1.5)
2. Categorical Plot Types
2.1 Plots that shows every observation
First, we will start with plots which are very helpful in displaying individual observations. These plots are very useful when we have a small dataset.
2.1.1 Stripplot
A strip plot could be a good alternative to box or violin plot when we want to display all observations but this work fine when we have a small dataset.
Let’s see how the tips are distributed over different days.
It comes handy if you have a figure (fig) and axis (ax) object. You could get it by using plt.subplots( ) function obtained from Matplotlib library. Here we fixed the figure size to 10 x 6. We supplied day on the x-axis and tip on the y-axis. You can add little bit randomness using jitter = True so that you could see the observations if they are overlapping. Here, I have added a point size of 8.
To make the plot visually aesthetic, I have removed the top and right spines using: sns.despine(right = True).
You can observe that people tips a big chunk during the weekend (especially Saturdays).
fig, ax = plt.subplots(figsize=(10, 6)) sns.stripplot(x = "day", y = "tip", data = tips, jitter = True, ax = ax, s = 8) sns.despine(right = True) plt.show()
2.1.2 Swarmplot
The swarm plot is also known as a bee swarm plot. It is similar to a strip plot, but the points are adjusted along the categorical axis so that they don’t overlap. It provides a better representation of the distribution of values, but not very scalable for a large number of observations.
fig, ax = plt.subplots(figsize=(10, 6)) sns.swarmplot(x = "day", y = "tip", data = tips, ax = ax, s = 8) sns.despine(right = True) plt.show()
2.2 Plots based on abstract representation
Plots with abstract information include boxplot, violin plot, and boxen (letter value plot)
2.2.1 (a) Boxplot
A box and whisker plot (box plot) displays the five-number summary of a set of data. The five-number summary is the minimum, first quartile (Q1), median, third quartile (Q3), and maximum. A vertical line goes through the box at the median. The whiskers go from each quartile to the minimum or maximum.
Let’s observe the median tips for each day by gender. Here, we have supplied the sex variable into hue so that it will plot the box separate for male and female with distinct filled colours.
Note: One thing to note that you can see the legend title is small than the labels. We will fix it in the next plot.
fig, ax = plt.subplots(figsize=(10, 6)) sns.boxplot(x = "day", y = "tip", data = tips, ax = ax, hue = "sex") sns.despine(right = True) plt.show()
To fix the legend title and to change the legend labels, we could access the legend internals using ax.get_legend_handles_labels() and can save the outputs into handles and labels. To modify the legend we use ax.legend( ), where we supply the handles object and provide new labels string in a list. Additionally, we could increase the font and title font size.
fig, ax = plt.subplots(figsize=(10, 6)) sns.boxplot(x = "day", y = "tip", data = tips, ax = ax, hue = "sex") handles, labels = ax.get_legend_handles_labels() ax.legend(handles, ["Men", "Woman"], title='Gender', fontsize=16, title_fontsize=20) sns.despine(right = True) plt.show()
2.2.1 (b) Boxplot + Stripplot
Sometimes we need to display how the data points are distributed. We can achieve this by overlapping a stripplot on a boxplot.
fig, ax = plt.subplots(figsize=(10, 6)) sns.stripplot(x = "day", y = "tip", hue = "sex", data = tips, ax = ax, dodge=True, s = 8, marker="D", palette="Set2", alpha = 0.7) sns.boxplot(x = "day", y = "tip", data = tips, ax = ax, hue = "sex") handles, labels = ax.get_legend_handles_labels() ax.legend(handles, ["Men", "Woman"], title='Gender', fontsize=16, title_fontsize=20) sns.despine(right = True) plt.show()
2.2.2 Violin Plot
A violin plot plays a similar role as a box and whisker plot. Unlike a box plot, in the violin plot, it features a kernel density estimation of the underlying distribution across several levels. Here, we have plotted day on the x-axis and tips on the y-axis with hue corresponding to sex using a violin plot.
fig, ax = plt.subplots(figsize=(10, 6)) sns.violinplot(x = "day", y = "tip", data = tips, ax = ax, hue = "sex") handles, labels = ax.get_legend_handles_labels() ax.legend(title='Gender', fontsize=16, title_fontsize=20) sns.despine(right = True) plt.show()
2.2.3 Boxenplot (Letter-value plot)
The Boxenplot is also known as the letter-value plot is introduced by Heike Hofmann, Karen Kafadar and Hadley Wickham.
Article Title: “Letter-value plots: Boxplots for large data”
The letter-value plot covers the following sort comings of box-plot:
(1) it conveys more detailed information in the tails using letter values, but only to the depths where the letter values are reliable estimates of their corresponding quantiles and (2) outliers are labelled as those observations beyond the most extreme letter value.
Read more on that in the article that introduced the plot [Hofmann et al., (2011)]: link
fig, ax = plt.subplots(figsize=(10, 6)) sns.boxenplot(x = "day", y = "tip", data = tips, ax = ax, hue = "sex", palette="pastel") handles, labels = ax.get_legend_handles_labels() ax.legend(title='Gender', fontsize=16, title_fontsize=20) sns.despine(right = True) plt.show()
2.3 Plots with Statistical Estimates
2.3.1 Count Plot
seaborn.countplot() method is used to illustrate the counts of observations in each categorical bin using bars.
Let’s visualize how many are smoker and non-smoker across two gender groups in the tips dataset.
fig, ax = plt.subplots(figsize=(10, 6)) sns.countplot(x = "sex", data = tips, ax = ax, hue = "smoker", palette="Set1") handles, labels = ax.get_legend_handles_labels() ax.legend(handles, ["Yes", "No"], title='Smoker', fontsize=16, title_fontsize=20) sns.despine(right = True) plt.show()
2.3.2 Point plot
Point plots can be more useful than bar plots when one need to compare between different levels of one or more categorical variables. It is particularly helpful when one needs to understand how the levels of one categorical variable changes across levels of a second categorical variable. The lines that join each point from the same
hue level allows interactions to be judged by differences in slope. The point plot shows only the mean (or other estimator) value. Here, I have added an error bars cap width of 0.1.
fig, ax = plt.subplots(figsize=(10, 6)) sns.pointplot(x = "day", y = "total_bill", data = tips, ax = ax, hue = "sex", capsize = .1, palette="Set1", dodge = 0.2) handles, labels = ax.get_legend_handles_labels() ax.legend(handles, ["Men", "Women"], title='Gender', fontsize=16, title_fontsize=20) sns.despine(right = True) plt.show()
2.3.3 Barplot
A bar plot represents an estimate of central tendency for a numeric variable with the height of each rectangle and provides some indication of the uncertainty around that estimate using error bars. The bar plot shows only the mean (or other estimator) value.
fig, ax = plt.subplots(figsize=(10, 6)) sns.barplot(x = "day", y = "tip", data = tips, ax = ax, hue = "sex", palette="pastel") handles, labels = ax.get_legend_handles_labels() ax.legend(title='Gender', fontsize=16, title_fontsize=20) sns.despine(right = True) plt.show()
You can also change the estimator to other estimators to represent the bar hight. Here, in the below plot I have included the np.sum as an estimator so that the bar height will represent the sum in each category. To exclude the error bar I have included the ci = None argument.
fig, ax = plt.subplots(figsize=(10, 6)) sns.barplot(x = "day", y = "tip", data = tips, ax = ax, hue = "sex", palette="pastel", estimator = np.sum, ci = None) handles, labels = ax.get_legend_handles_labels() ax.legend(title='Gender', fontsize=16, title_fontsize=20) sns.despine(right = True) plt.show()
3. Regression Plots
Regression plots are very helpful for illustrating the relationship between two variables. This can be plotted by combining a relational scatterplot and fitting a trend line on that.
3.1 Relational Plot
3.1.1 Scatter Plot
Scatter plot is useful for illustrating the relationship between two continuous variables. To plot a scatterplot we could use the scatterplot( ) function from Seaborn library.
fig, ax = plt.subplots(figsize=(10, 6)) sns.scatterplot(x = "total_bill", y = "tip", data = tips, ax = ax, hue = "sex", s = 50) sns.despine(right = True) plt.show()
3.2 Regression Plot using regplot( )
A regression plot can be generated using either regplot( ) or lmplot( ). The regplot() performs a simple linear regression model fit while lmplot() combines regplot() and FacetGrid. Inaddition, lmplot( ) offers more customization than the regplot( ).
3.2.1 (a) Linear Regression plot
Here, we want to explore the relationship between the total bill paid and tip. We can plot this by supplying the total bill to x-axis and tip to the y-axis. Here, I have used a diamond marker (“D”) to present the point shape and coloured the points to blue. The trend line (regression line) shows a positive relationship between the total bill and tips.
fig, ax = plt.subplots(figsize=(10, 6)) sns.regplot(x='total_bill', y="tip", data=tips, marker='D', color='blue') sns.despine(right = True) plt.show() plt.clf()
3.2.1 (b) Adding the Regression Equation
In some case, especially for publication, or presentation, you may want to include the regression equation inside the plot. The regplot( ) or lmplot( ) does not offer this functionality yet. But externally we can compute the regression slope and intercept and supply to the plot object. Here, I have used the scipy package to estimate the regression slope and intercept and added to the plot using line_kws argument.
from scipy import stats fig, ax = plt.subplots(figsize=(10, 6)) # get coeffs of linear fit slope, intercept, r_value, p_value, std_err = stats.linregress(tips['total_bill'], tips['tip']) sns.regplot(x='total_bill', y="tip", data=tips, marker='D', color='blue', line_kws={'label':"tip = {0:.2f} + {1:.2f} * total_bill".format(intercept, slope)}) sns.despine(right = True) # Add legend ax.legend(fontsize=16) plt.show() plt.clf()
3.2.2 residplot
The residplot helps you visualize the regression residuals which also provide the validity of one of the regression’s core assumptions. The residuals should not be either systematically high or low. In the OLS context, random errors are assumed to produce residuals that are normally distributed. Therefore, the residuals should fall in a symmetrical pattern and have a constant spread throughout the range.
fig, ax = plt.subplots(figsize=(10, 6)) sns.residplot(x = 'total_bill', y="tip", data=tips, color='blue') sns.despine(right = True) plt.show() plt.clf()
3.2.3 Non-Linear Regression Plot
In the above examples, we showed a relationship that is linear. There might be situations when the relationship between variables is non-linear. Here, to illustrate this example, we will be using the auto-mpg dataset from UCI repository.
auto = pd.read_csv("auto-mpg.csv") auto.head()
Here, if we plot the relationship between weight (weight of the vehicle) and mpg (miles per gallons), we can observe the relationship is non-linear. In such cases, a non-linear fit could be much appropriate. So to plot the non-linear relationship you can increase the order argument value from 1 (default) to 2 or more.
Here, we first plotted a scatterplot, then overlayed a linear regression line and over that a regression line of order 2. You could see that the regression line of order 2 provides a better fit to the non-linear trend.
fig, ax = plt.subplots(figsize=(12, 8)) # Generate a scatter plot of 'weight' and 'mpg' using skyblue circles sns.scatterplot(auto['weight'], auto['mpg'], label='data points', s = 50, color='skyblue', marker='o', ax = ax) # Plot a blue linear regression line of order 1 between 'weight' and 'mpg' sns.regplot(x='weight', y='mpg', data=auto, scatter=None, color='blue', label='order 1') # Plot a red regression line of order 2 between 'weight' and 'mpg' sns.regplot(x='weight', y='mpg', data=auto, scatter=None, order=2, color='red', label='order 2', ax = ax) sns.despine(right = True) # Add a legend and display the plot plt.legend(loc='upper right') plt.show()
3.3 Rgeression Plot using lmplot( )
lmplot provides more flexibility in generating regression plots. You can supply a categorical variable in hue argument to plot trend line based on the categories. Here, we provided sex into hue argument so that it plots two separate regression line based on the gender category. I also changed the default colour using palette argument.
# Create a regression plot with categorical variable sns.lmplot(x='total_bill', y="tip", data=tips, hue='sex', markers=["o", "x"], palette=dict(Male="blue", Female="red"), size=7, legend=None) plt.legend(title='Gender', loc='upper left', labels=['Male', 'Female'], title_fontsize = 20) sns.despine(right = True) plt.show() plt.clf()
3.4 Logistic Regression Plot
Let’s plot a binary logistic regression plot. For this, we need a discrete binary variable. Let’s assume that tip amount> 3 dollars is a big tip (1) and tip amount≤ 3 is a small tip (0). We can use numpy libraries np.where( ) function to create a new binary column “big_tip”. Now we can fit a binary logistic regression using lmplot( ) by supplying the logistic = True argument.
tips["big_tip"] = np.where(tips.tip > 3, 1, 0) ax = sns.lmplot(x="total_bill", y="big_tip", data=tips, logistic=True, n_boot=500, y_jitter=.03, aspect = 1.2)
4. Time Series Plots
Though seaborn package can be used to plot time series data. Though I prefer Matplotlib for time series plotting as it is very convenient to use. One could directly supply date as index column into plots.
Here, we are going to use the sales dataset, which contains sales date, sales value, ads budget and GDP.
sales_data = pd.read_csv("Sales_dataset.csv", parse_dates=True, index_col = 0) sales_data.head()
One of the best ways of plotting time series is to make a convenient function. Here I have created a function that takes axes, x, y, color, xlabel and ylabel arguments.
Step1: we use ax.plot( ) to generate a line plot and also supply a line color
Step2: we set the xlabel and ylabel using ax.set( )
Step3: setting the y-tick parameter color
# Define a function called timeseries_plot def timeseries_plot(axes, x, y, color, xlabel, ylabel): # Plot the inputs x, y in the provided color axes.plot(x, y, color=color) # Set the x-axis label axes.set_xlabel(xlabel) # Set the y-axis label axes.set_ylabel(ylabel, color=color) # Set the colors tick params for y-axis axes.tick_params('y', colors=color)
Let’s plot the sales values based on dates
# Define style sns.set_style('white') sns.set_context("paper", font_scale = 2) # setting figure and axis objects fig, ax = plt.subplots(figsize = (12, 8)) # Plotting sales values timeseries_plot(ax, sales_data.index, sales_data["Sales"], "blue", "Time (years)", "Sales") sns.despine(right = True) plt.show()
We can plot two variables together with a common x-axis. Here, I have plotted sales and GDP using a common x-axis [by setting ax.twinx( ) ] and left y-axes used for presenting sales and right y-axis used for presenting GDP.
# Defining style sns.set_style('white') sns.set_context("paper", font_scale = 2) # Create figure and axes object and set the figure size fig, ax = plt.subplots(figsize = (12, 8)) # Add first time series based on Sales timeseries_plot(ax, sales_data.index, sales_data["Sales"], "blue", "Time (years)", "Sales") # Create a twin Axes that share the x ax2 = ax.twinx() # Add second time series based on GDP timeseries_plot(ax2, sales_data.index, sales_data["GDP"], "red", "Time (years)", "GDP") plt.show()
5. Heat Maps
Sometimes we need to plot rectangular data as a colour-encoded matrix to visualize patterns in a dataset. Heat maps come as a handy tool in such circumstances. But Seaborn’s heatmap only takes data in matrix form. So, first, you need to prepare a matrix that you want to supply in a heatmap. Panda’s crosstab( ) function is one of the best tools for this job.
Let’s see mean tips given by male and female over different days. Here, in the crosstab, I’m using a mean aggregate function for calculating mean tips over different days given by male and female.
crosstab1 = pd.crosstab(index=tips['day'], columns=tips['sex'], values=tips['tip'], aggfunc='mean') crosstab1
In addition to highlighting the values with colour using the heatmap( ) function, we could add a text annotation and colour bar by supplying annot = True and cbar = True. Here, I have opted for a “Reds” colour palette with 8 discrete colour mapping. For convenience, I have rotated the x-tick labels to 90 degrees.
You can observe that the highest average tip was given by females on Sunday.
fig, ax = plt.subplots(figsize=(10, 6)) sns.heatmap(crosstab1, annot = True, cbar = True, cmap = sns.color_palette("Reds", 8), linewidths=0.3, ax = ax) # Rotate tick marks for visibility plt.yticks(rotation=0) plt.xticks(rotation=90) #Show the plot plt.show()
Matplotlib and Seaborn are really awesome plotting libraries. I would like to thank all the contributors of Matplotlib and Seasborn library.
I hope you learned something new!
Featured image by Tumisu from Pixabay
3 thoughts on “Generate Publication-Ready Plots Using Seaborn Library (Part-1)”
Nitin Joshi
Nice Information…
Diego A
Hi!
Where you can download the Sales_dataset.csv dataset, I appreciate the information.
Rahul Raoniar
Hi Diego! I have updated the data source in the article. I hope it helps. | https://onezero.blog/generate-publication-ready-plots-using-seaborn-library-part-1/ | CC-MAIN-2021-31 | refinedweb | 3,519 | 60.21 |
...one of the most highly
regarded and expertly designed C++ library projects in the
world. — Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
The header file 'boost/algorithm/cxx11/one_of.hpp' contains four variants
of a single algorithm,
one_of.
The algorithm tests the elements of a sequence and returns true if exactly
one of the elements in the sequence has a particular property.
The routine
one_of takes
a sequence and a predicate. It will return true if the predicate returns
true for one element in the sequence.
The routine
one_of_equal
takes a sequence and a value. It will return true if one element in the sequence
compares equal to the passed in value.
Both routines come in two forms; the first one takes two iterators to define the range. The second form takes a single range parameter, and uses Boost.Range to traverse it.
The function
one_of returns
true if the predicate returns true for one item in the sequence. There are
two versions; one takes two iterators, and the other takes a range.
namespace boost { namespace algorithm { template<typename InputIterator, typename Predicate> bool one_of ( InputIterator first, InputIterator last, Predicate p ); template<typename Range, typename Predicate> bool one_of ( const Range &r, Predicate p ); }}
The function
one_of_equal
is similar to
one_of, but
instead of taking a predicate to test the elements of the sequence, it takes
a value to compare against.
namespace boost { namespace algorithm { template<typename InputIterator, typename V> bool one_of_equal ( InputIterator first, InputIterator last, V const &val ); template<typename Range, typename V> bool one_of_equal ( const Range &r, V const &val ); }}
Given the container
c containing
{ 0, 1,
2, 3, 14, 15 },
then
bool isOdd ( int i ) { return i % 2 == 1; } bool lessThan10 ( int i ) { return i < 10; } using boost::algorithm; one_of ( c, isOdd ) --> false one_of ( c.begin (), c.end (), lessThan10 ) --> false one_of ( c.begin () + 3, c.end (), lessThan10 ) --> true one_of ( c.end (), c.end (), isOdd ) --> false // empty range one_of_equal ( c, 3 ) --> true one_of_equal ( c.begin (), c.begin () + 3, 3 ) --> false one_of_equal ( c.begin (), c.begin (), 99 ) --> false // empty range
one_of and
one_of_equal work on all iterators except
output iterators.
All of the variants of
one_of
and
one_of_equal run in
O(N) (linear) time; that is, they compare against each
element in the list once. If more than one of the elements in the sequence
satisfy the condition, then algorithm will return false immediately, without
examining the remaining members of the sequence.
All of the variants of
one_of
and
one_of_equal take their
parameters by value or const reference, and do not depend upon any global
state. Therefore, all the routines in this file provide the strong exception
guarantee.
one_ofand
one_of_equalboth return false for empty ranges, no matter what is passed to test against.
one_of_equal one element in the sequence, the expression
*iter == valevaluates to true (where
iteris an iterator to each element in the sequence) | http://www.boost.org/doc/libs/1_63_0/libs/algorithm/doc/html/the_boost_algorithm_library/CXX11/one_of.html | CC-MAIN-2017-09 | refinedweb | 475 | 54.42 |
Linked by Thom Holwerda on Mon 6th Oct 2008 10:37 UTC, submitted by John Mills
Thread beginning with comment 332704
To view parent comment, click here.
To read all comments associated with this story, please click here.
To view parent comment, click here.
To read all comments associated with this story, please click here.
Member since:
2005-07-06
If you read the very limited documentation on the ECMA web site regarding governance of these issues, you will actually find that it is worse than that. ADO.Net and ASP.Net are merely namespaces no matter what anyone says, and it's not where the meat is. Without the reasonable and non-discriminatory terms that ECMA membership requires you might well require an explicit license from Microsoft to use .Net ECMA standards, and those RAND terms are simply not guaranteed to be in place forever. That's the situation, and it governs .Net technology such as the CLR and Common Language specification.
There was much bluster from Miguel and a few others on a mailing list a while ago that there was a letter from Microsoft and HP guaranteeing RAND terms to be irrevocable. No such letter has ever materialised, and until that happens questions remain. | http://www.osnews.com/thread?332704 | CC-MAIN-2018-26 | refinedweb | 207 | 64.41 |
I need some help,Here is the problem, I work for a company that lays ceramic floor tile and I need a program that estimates the number of boxes of tile for a job. A job is estimated by taking the dimensions of each room in feet and inches, and converting these dimensions into multiple of the tile size(round up any partial multiple) before multipylying to get the number of tiles for the room. A box contains 20 tiles, so the total number needed should be divided by 20 and round up to get the number of boxes. the tiles are assumed to be square. The program should initially prompt the user for the size of the tiles in inches, and the number of rooms to be input. It should then input the dimensions for each room, and output the tiles needed for that room. After the last room is input, the program also should output the total number of tiles needed, the number of boxes needed, and how many extra tiles will be left over.
Gives all the numbers the book asks ]for although I didn’t use any functions. It also needs a way to check for invalid inputs like 13 for inches and number of rooms < 0. I’ll keep working on it. Didn’t you get some code from that programming website? Send me what you got, maybe it’ll give me some ideas.
// #include "stdafx.h" #include <iostream> using namespace std; int main() { int tileSize; int numOfRooms; int roomWidIn; int roomWidFt; int roomLenIn; int roomLenFt; int lenTot; int widTot; int tilesPerRm = 0; int totalTiles = 0; int numOfBoxes = 0; int a; cout << "Enter number of rooms: "; cin >> numOfRooms; cout << "Enter size of tile in inches: "; cin >> tileSize; while (numOfRooms > 0) { cout << "Enter room width (feet and inches, separated by a space): "; cin >> roomWidFt >> roomWidIn; cout << "Enter room length (feet and inches, separted by a space): "; cin >> roomLenFt >> roomLenIn; widTot = ((roomWidFt*12+roomWidIn)/tileSize); if (((roomWidFt*12+roomWidIn)%tileSize) != 0) ++widTot; lenTot = ((roomLenFt*12+roomLenIn)/tileSize); if (((roomLenFt*12+roomLenIn)%tileSize) != 0) ++lenTot; cout << "Room requires " << (widTot * lenTot) << " tiles." << endl; totalTiles = totalTiles + (widTot * lenTot); numOfRooms = numOfRooms - 1; } cout << "Total Tiles required is " << totalTiles << "." << endl; numOfBoxes = totalTiles/20; if ((totalTiles%20) != 0) ++numOfBoxes; cout << "Number of boxes needed is " << numOfBoxes << "." << endl; cout << "There will be " << (numOfBoxes*20) - totalTiles << " extra tiles." << endl; cin >> a; return 0; } | https://www.daniweb.com/programming/software-development/threads/60654/looking-for-a-way-to-check-for-invalid-inputs-and-or-are-functions-easier | CC-MAIN-2017-09 | refinedweb | 398 | 60.85 |
I previously wrote an article on how to get a record from Airtable by a unique field value such as an email or username. I'm going to expand on that using a practical example, a user database. If you are building apps using Airtable as the backend, this can come in handy. Let's look at an example user database base I have created.
Just want the code?
Get the full working demo on Github. If you want to follow along, download the starter files folder and rename it to whatever you would like and run yarn to install the dependencies.
The starter files will already have the bare bones of the app such as the login and register pages along with the routes for displaying these pages. This article will focus on building out the user controller for creating a user and handling the login.
Creating a user
When the user submits their information on the registration page, it will send a post request to the /user/add route. This has been specified in registration form's action attribute. Let's first create a route in our index.js file for this post request.
// index.js router.post("/user/add", userController.addUser);
When a user posts a request to this route it will call the addUser function in userController.js. Let's create this function.
// userController.js exports.addUser = (req, res, next) => { const { fullname, email, username } = req.body; table.create( { email, username, display_name: fullname }, function(err, record) { if (err) { console.error(err); return; } req.body.id = record.getId(); // store password } ); };
We are using Airtable's create method to create the record. Notice I did not include the password field because we need an additional step to hash the password before saving it to the database. We will get to that later on.
Add a constraint to the email and username fields
We have a small problem with adding users. Right now as it stands, we can add another user using email addresses and usernames that already exist in the database. Airtable currently does not have a feature to set constraints on fields. Lucky for us we can do it from our code through the API.
To do this we are going to create a helper function that will return true or false depending on if the user exists or not.
// userController.js const findUser = async (email, username) => { let recordExists = false; const options = { filterByFormula: `OR(email = '${email}', username = '${username}')` }; const users = await data.getAirtableRecords(table, options); users.filter(user => { if (user.get("email") === email || user.get("username") === username) { return (recordExists = true); } return (recordExists = false); }); return recordExists; };
Then we need to call this function from our addUser function and only if it returns true we create the user, if not we render the login page with a message. The addUser function now becomes.
// userController.js exports.addUser = async (); next(); } ); };
Storing the user's password
We are successfully creating a user record but we are not storing the user's password. We could store the plain text password entered but obviously that's not good. I'm going to use the bcrypt package to hash the user's plain text password and store that hashed password in the Airtable base.
First we need to install the bcrypt npm package and require it in our userController.js file. This has already been done for you if you are using the starter files.
We then create a function to create a hashed password and store it in the newly created user record. Since the user record is already create we need to update the user record to add the password. We will use Airtable's update method for that.
// userController.js exports.storePassword = (req, res) => { const { password, id } = req.body; bcrypt.hash(password, 10, function(err, hash) { if (err) { console.error(err); return; } table.update( id, { password: hash }, function(err) { if (err) { console.error(err); return; } res.render("login", { message: "Your account has been created!" }); } ); }); };
We then need to modify our addUser function to call this function immediately after the record is created so that we can have access the user's email and password. To do this will modify the route to call the storePassword function after addUser and call next() when the record is created in the addUser function to call the next function in our route chain, the storePassword function.
// index.js router.post("/user/add", userController.addUser, userController.storePassword);
// userController.js exports.addUser = (); // The user has been successfully create, let's encrypt and store their password next(); } ); };
Logging the user in
Now let's create the flow for logging the user in. The login form sends a post request to this route /user/auth.
// index.js router.post("/user/auth", userController.authenticate);
We will create a function, called authenticate, to find the user by email or username and compare the passwords to decide whether to log in the user.
// userController.js exports.authenticate = (req, res) => { const { username, password } = req.body; const options = { filterByFormula: `OR(email = '${username}', username = '${username}')` }; data .getAirtableRecords(table, options) .then(users => { users.forEach(function(user) { bcrypt.compare(password, user.get("password"), function(err, response) { if (response) { // Passwords match, response = true res.render("profile", { user: user.fields }); } else { // Passwords don't match console.log(err); } }); }); }) .catch(err => { console.log(Error(err)); }); };
This completes part 1. You can get the full working code on Github.
In part 2, we will implement a simple session to persist the user data when they are logged in. Keep an eye out for part 2 👀.
Discussion (0) | https://dev.to/cjwd/creating-a-user-database-with-airtable-part-1-44ij | CC-MAIN-2021-25 | refinedweb | 925 | 65.93 |
Important Reminders............................... 3InternalRevenueService Tax Guide Important Dates ........................................ 4
Chapter
7. Basis of Assets................................... 35
Introduction You are in the business of farming if you culti- vate, operate, or manage a farm for profit, ei- ther as owner or tenant. A farm includes stock, dairy, poultry, fish, fruit, and truck farms. It also includes plantations, ranches, ranges, and orchards. This publication explains how the federal tax laws apply to farming. Use this publication as a guide to figure your taxes and complete your farm tax return. If you need more informa- tion on a subject, get the specific IRS tax publi- cation covering that subject. We refer to manyof these free publications throughout this pub- Nonqualified section 179 property. The list Work opportunity credit. This credit re-lication. See chapter 21 for information on or- of property you cannot treat as section 179 places the jobs credit, which expired Januarydering these publications. property includes additional items. See chap- 1, 1995. The work opportunity credit applies to The explanations and examples in this ter 8. 35% of the qualified first-year wages you paypublication reflect the Internal Revenue Ser- to certain individuals who begin working forvice’s interpretation of tax laws enacted by Business property located in federal disas- you from October 1, 1996, through SeptemberCongress, Treasury regulations, and court de- ter area. Any business or income-producing 30, 1997. See Form 5884.cisions. However, the information given does property you acquire to replace destroyed Research credit. This credit expired Julynot cover every situation and is not intended to business or income-producing property that 1, 1995. However, the credit is extended forreplace the law or change its meaning. This was located in a federal disaster area is qualified expenses paid or incurred from Julypublication covers subjects on which a court treated as property similar or related in service 1, 1996, through May 31, 1997. You cannotmay have made a decision more favorable to or use to the destroyed property. See chapter take the credit for any expenses from July 1,taxpayers than the interpretation of the Ser- 13. 1995, through June 30, 1996. See Form 6765.vice. Until these differing interpretations are Orphan drug credit. This credit expiredresolved by higher court decisions or in some Tax rates and maximum net earnings for January 1, 1995. However, the credit is ex-other way, this publication will continue to pre- self-employment taxes. For 1996, the maxi- tended for qualified expenses paid or incurredsent the interpretation of the Service. mum amount of net earnings from self-em- from July 1, 1996, through May 31, 1997. You ployment subject to the social security part cannot carry back any part of an unused busi-Comments and recommendations. In com- (12.4%) of the self-employment tax is ness credit attributable to the orphan drugpiling this Farmer’s Tax Guide, we have $62,700. There is no maximum limit on the credit to a year ending before July 1, 1996.adopted a number of suggestions that readers amount subject to the Medicare part (2.9%). See Form 6765.sent to us. We welcome your suggestions for For 1997, the maximum amount subject tofuture editions. the social security tax (12.4%) will be pub- Individual taxpayer identification number lished in Publications 533 and 553. There is no (ITIN). If you are a nonresident or resident Please send your comments and rec- maximum limit on the amount subject to the alien who does not have and is not eligible for ommendations to us at the following Medicare part (2.9%). a social security number (SSN), the IRS will is- address: See chapter 15. sue an ITIN you can use in place of an SSN. Internal Revenue Service File Form W–7 with the IRS. It usually takes Wage limits for social security and Medi- about 30 days to get the ITIN. Enter the ITIN Technical Publications Branch T:FP:P care taxes. The maximum amount of 1997 wherever your SSN is requested on a tax re- 1111 Constitution Avenue N.W. wages subject to the social security tax will be turn. If you must include another person’s SSN published in Circular A. There is no wage base on your return and that person does not have Washington, DC 20224 limit for the amount subject to Medicare tax. and is not eligible for an SSN, enter that per- See chapter 16. son’s ITIN. We respond to many letters by telephone.It would be helpful if you include your area Federal unemployment (FUTA) tax. For An ITIN is for tax use only. It does notcode and daytime phone number with your re- 1997, the gross FUTA tax rate remains 6.2% entitle you to social security benefitsturn address. and the federal wage base remains $7,000. or change your employment or immi- Alien farm workers. Wages paid to an gration status under U.S. law. See Form W–7.Farm tax classes. Many state Cooperative alien who is admitted to the United States, per-Extension Services conduct farm tax work- forms contract farm labor for you, and then re-shops in conjunction with the IRS. Please con- turns to his or her own country when the con- tract is completed, are exempt from thetact your county extension office for moreinformation. federal unemployment (FUTA) tax. This ex- Important Changes emption, which expired after 1994, has been made permanent as of January 1, 1995. If you for 1997 paid FUTA tax on these alien workers in 1995, The following items highlight a number ofImportant Changes you can file an amended Form 940, Employ- er’s Annual Federal Unemployment (FUTA) administrative and tax law changes for 1997. Increased section 179 deduction. Beginningfor 1996 Tax Return, for a refund. You must use the in 1997, the total cost of deductible section 1995 form. Amounts paid in 1996 can be ad- 179 property increases to $18,000. It contin- The following items highlight a number of justed on the 1996 Form 940. See the form in- ues to increase annually until 2003. See chap-administrative and tax law changes for 1996. structions. Also see chapter 16 for information ter 8.Standard mileage rate. The standard mile- on the FUTA tax.age rate for the cost of operating your car, van, Voluntary withholding. Beginning in 1997,pickup, or panel truck in 1996 is 31 cents per Credit for diesel-powered vehicle re- you can request income tax withholding at amile for all business miles. See chapter 5. pealed. You cannot claim the credit for a die- rate of 7%, 15%, 28%, or 31% from the fol- sel-powered vehicle purchased after August lowing payments:Form 8645 obsolete. Form 8645, Soil and 20, 1996. See chapter 18.Water Conservation Certification, has been 1) Commodity Credit Corporation (CCC)obsoleted. You are no longer required to at- loans included in income. Higher earned income credit. The maximumtach Form 8645 to Form 1040 when you de- earned income credit has been increased to 2) Certain disaster relief payments receivedduct conservation expenses. See chapter 6. $3,556 for 1996. To claim the credit, you must under the Agricultural Act of 1949 or title II have earned income (including net earnings of the Disaster Assistance Act of 1988.Limits on depreciation of business cars. from self-employment) and modified adjusted 3) Unemployment compensation.The total section 179 deduction and deprecia- gross income of less than $28,495 and meettion you can take on a car you use in your busi- certain other requirements. For more informa- 4) Certain other government payments.ness and first place in service in 1996 is tion, including what counts as earned income,$3,060. Your depreciation cannot exceed see Publication 596, Earned Income Credit. You can request withholding from the$4,900 for the second year of recovery, payer on Form W4–V, Voluntary Withholding$2,950 for the third year, and $1,775 for each Tax credits. The following credits have been Request. It will be available in January 1997.later tax year. See chapter 8. changed or extended. See chapter 21 for information on ordering the
Page 2form. See chapter 4 for information on CCC 1040. The IRS is working to decrease the time Form W–4 for 1997. You should make newloans and disaster relief payments. it takes to respond to your correspondence. If Forms W–4 available to your employees and you write, the IRS will usually reply within ap- encourage them to check their income taxElectronic deposit of taxes. If your total de- proximately 30 days. withholding for 1997. Those employees whoposits of social security, Medicare, and with- owed a large amount of tax or received a largeheld income taxes were more than $50,000 Tele-Tax. The IRS has a telephone service refund for 1996 may need to file a new Formduring 1995, you must begin making electronic called Tele-Tax. This service provides re- W–4. See chapter 16.deposits for all depository tax liabilities that corded tax information on approximately 140occur after June 30, 1997. See Publication topics such as filing requirements, employ- Earned income credit. You, as an employer,51(Circular A). ment taxes, taxpayer identification numbers, must notify employees who worked for you and tax credits. Recorded tax information is and from whom you did not withhold incomeSIMPLE retirement plan. Beginning in 1997, available 24 hours a day, 7 days a week, to tax about the earned income credit. See chap-you may be able to set up a savings incentive taxpayers using push-button telephones, and ter 16.match plan for employees (SIMPLE). You can during regular working hours to those usingset up a SIMPLE plan if you have 100 or fewer dial telephones. The topics covered and tele- Children employed by parents. Wages youemployees and meet other requirements. See phone numbers for your area are listed in the pay to your children age 18 and older for ser-Publication 560, Retirement Plans for the Self- Form 1040 instructions. vices in your trade or business are subject toEmployed. social security taxes. See chapter 16. Unresolved tax problems. IRS has a Prob-Self-employed health insurance deduction. lem Resolution Program for taxpayers who Change of address. If you change your homeThe deduction for health insurance costs of have been unable to resolve their problems or business address, you should use Formself-employed individuals is increased to 40% with the IRS. If you have a tax problem you 8822, Change of Address, to notify IRS. Befor tax years beginning in 1997. The deduction have been unable to resolve through normal sure to include your suite, room, or other unitwill increase to 45% for tax years beginning in channels, write to your local IRS District Direc- number. Send the form to the Internal Reve-1998 through 2002, then rise gradually to 80% tor or call your local IRS office and ask for nue Service Center for your old address.in 2006. See chapter 5. Problem Resolution assistance. Although the Problem Resolution Office Form 1099–MISC. If you make total paymentsMedical savings accounts. For tax years be- cannot change the tax law or technical deci- of $600 or more during the year to anotherginning after 1996, a self-employed individual sions, it can frequently clear up misunder- person, other than an employee or a corpora-may be able to take a deduction for contribu- standings that resulted from previous con- tion, in the course of your farm business, youtions made to medical savings accounts tacts. For more information, see Publication must file information returns to report these(MSAs) to help cover medical expenses for 1546, How to Use the Problem Resolution payments. See chapter 2.the self-employed individual and his or her em- Program of the IRS.ployees. See Publication 553, Highlights of Taxpayers who have access to TTY/TDD Farmers and crew leaders must withhold1996 Tax Changes. equipment can call 1–800–829–4059 to ask income tax. Farmers and crew leaders must for help from Problem Resolution. withhold federal income tax from farm workersLong-term care insurance. A qualified long- who are subject to social security and Medi-term care insurance contract issued after Overdue tax bill. If you receive a bill for over- care taxes. See chapter 16.1996 will generally be treated as an accident due taxes, do not ignore the tax bill. If you oweand health insurance contract. See Publica- the tax shown on the bill, you should make ar- Social security tests for hand-harvest la-tion 553. rangements to pay it. If you believe it is incor- borers. If you pay hand-harvest laborers less rect, contact the IRS immediately to suspend than $150 in annual cash wages, the wages action until the mistake is corrected. See Pub- are not subject to social security and Medicare lication 594, Understanding the Collection taxes, even if you pay $2,500 or more to allImportant Reminders Process, for more information. your farm workers. The hand-harvest laborer The following reminders are included to must meet certain tests. See chapter 16.help you file your tax return. Payment voucher for Form 1040. To helpDirect deposit of refund. If you are due a re- process tax payments more accurately and ef- Penalties. There are various penalties youfund on your 1996 tax return, you can have it ficiently, the IRS is sending Form 1040–V, should be aware of when preparing your re-deposited directly into your bank account. See Payment Voucher, to most Form 1040 filers turn. You may be subject to a penalty if you:your income tax package for details. this year. 1) Do not file your return by the due date. If you have a balance due on Form 1040, This penalty is 5% for each month or partClub dues. Generally, you are not allowed any send the voucher with your payment. Follow of a month that your return is late, up todeduction for dues you pay or incur for mem- the instructions that come with the voucher. 25%.bership in any club organized for business, There is no penalty for not using the paymentpleasure, recreation, or other social purpose. voucher, but the IRS strongly encourages you 2) Do not pay your tax on time. This penaltyHowever, you may be able to deduct dues you to use it. is 1/ 2 of 1% of your unpaid taxes for eachpay to a chamber of commerce or professional month, or part of a month after the datesociety. See chapter 5. Payment voucher for Forms 940 and 940– the tax is due, up to 25%. EZ. If you are required to make a payment of 3) Substantially understate your tax. ThisDepreciation of general asset account. You federal unemployment tax with Form 940 or penalty is 20% of the underpayment.can elect to place assets subject to MACRS in 940–EZ, use the payment voucher at the bot- 4) File a frivolous tax return. This penalty isone or more general asset accounts. After you tom of the form. For more information, see the $500.have established the account, figure deprecia- form instructions.tion on the entire account by using the applica- 5) Fail to supply your social security number.ble depreciation method, recovery period, and Publication on employer identification This penalty is $50 for each occurrence.convention for the assets in the account. See numbers (EIN). Publication 1635, Under-chapter 8. standing Your EIN, provides general informa- Tax shelter penalties. Tax shelters, their tion on employer identification numbers. Top- organizers, their sellers, or their investors mayWritten tax questions. You can send written ics include how to apply for an EIN and how to be subject to penalties for such actions as:tax questions to your IRS District Director. If complete Form SS–4. See chapter 21 for infor- 1) Failure to furnish tax shelter registrationyou do not have the address, call 1–800–829– mation on getting the publication. number. The penalty for the seller of the
Page 3 tax shelter is $100; the penalty for the in- The U.S. Census Bureau also uses this infor- taxes are not listed here, but are explained in vestor in the tax shelter is $250. mation for its economic census. See the list of detail in Publication 509, Tax Calendars for 2) Failure to register a tax shelter. The pen- Principal Agricultural Activities Codes on page 1997. alty for the organizer of the tax shelter is 2 of Schedule F. Fiscal year taxpayers. Generally, the due the greater of 1% of the amount invested dates listed apply to all taxpayers, whether in the tax shelter, or $500. Rounding off dollars. You can round off they use a calendar year or a fiscal year. How- cents to the nearest whole dollar on your re- ever, fiscal year taxpayers should refer to Pub- 3) Not keeping lists of investors in poten- turn and schedules. To do so, drop amounts lication 509 for certain exceptions that apply tially abusive tax shelters. The penalty for under 50 cents and increase amounts from 50 to them. the tax shelter is $50 for each person re- to 99 cents to the next dollar. For example, quired to be on the list, up to a maximum $1.49 becomes $1 and $2.50 becomes $3. of $100,000. If you do round off, do so for all amounts. However, if you have to add two or more 1997—Calendar Year Fraud penalty. The fraud penalty for un- amounts to figure the total to enter on a line,derpayment of taxes is 75% of the part of the include cents when adding the amounts and During Januaryunderpayment due to fraud. round off only the total. Criminal penalties. You may be subject to Employers. Give your agricultural employeescriminal prosecution (brought to trial) for ac- their copies of Form W–2 for 1996 as soon Alternative ways of filing. IRS offers several as possible. The due date for giving Formtions such as: alternatives to make filing your tax return eas- W–2 to your employees is January 31, 1) Tax evasion. ier. They are more convenient and accurate 1997. Copy A of Form W–2 must be filed by 2) Willful failure to file a return, supply infor- and will help us process your return faster. February 28, 1997. mation, or pay any tax due. TeleFile. Most taxpayers who filed a 1995 Form 1040EZ will receive a special TeleFile January 15 3) Fraud and false statements. tax package that allows them to file their 1996 tax returns by phone. TeleFile is easy, fast, Farmers. You can elect to pay your 1996 esti- 4) Preparing and filing a fraudulent return. free, and available 24 hours a day. mated income tax using Form 1040–ES. On-line filing. You can file your tax return You have until April 15 to file your 1996 electronically using a computer and IRS-ac- federal income tax return (Form 1040). IfReminders— cepted software. This software is available at you do not pay your estimated tax by thisBefore you file your tax return, be sure to: retail stores and from on-line filing companies. date, you must file your 1996 return and Use address label. Transfer the address Using the software, you can file your return pay any tax due by March 3, 1997.label from the tax return package you receivedin the mail to your tax return, and make any electronically, for a fee, through the softwarenecessary corrections. company or an on-line filing company. January 31 Claim payments made. Be sure to in- 1040PC format. You can print your return Farm employers. File Form 943 to report so-clude on the appropriate lines of your tax re- in 1040PC format with most tax software pack- cial security and Medicare taxes and with-turn any estimated tax payments and federal ages. The 1040PC is shorter than the regular held income tax for 1996. Deposit any un-tax deposit payments you made during the tax tax return. There is less paper for your records deposited tax. If the total is less than $500year. Also, you must file a return to claim a re- and it is processed faster when you mail it to and not a shortfall (see Deposit Rules andfund of any payments you made, even if no tax the IRS. its discussion of Safe harbors under Em-is due. Electronic filing. Many paid tax return ployer’s Tax Calendar in Publication 509), Attach all forms in order. Attach all preparers can file your return electronically af- you can pay it with the return. If you haveforms and schedules in sequence number or- ter they prepare it. If you prepare your own tax deposited the tax you owe for the year inder. The sequence number is just below the return, you generally must go through a tax re- full and on time, you have until February 10year in the upper right corner of the schedule turn preparer or other company that provides, to file the return. (Do not report wages foror form. Attach all other statements or attach- for a fee, IRS-accepted electronic filing nonagricultural services on Form 943.)ments last, but in the same order as the forms services. All farm businesses. Give annual informationor schedules they relate to. Do not attach The free IRS Volunteer Income Tax Assis- statements to recipients of certain pay-these other statements to the related form or tance (VITA) and Tax Counseling for the Eld- ments you made during 1996. You can useschedule. erly (TCE) programs may also be able to help the appropriate version of Form 1099 or Complete Schedule SE. Fill out Schedule you file your return electronically. See your in- other information return. See chapter 2.SE (Form 1040) if you had net earnings from come tax package for information on these Federal unemployment (FUTA) tax. Fileself-employment of $400 or more. programs. Form 940 (or 940–EZ) for 1996. If your un- Use correct lines. List income, deduc- You may be able to file your state tax return deposited tax is $100 or less, you can ei-tions, credits, and tax items on the correct electronically with your federal return if you ther pay it with your return or deposit it. If itlines. use one of the methods listed earlier. is more than $100, you must deposit it. See Sign and date return. Make sure the tax More information. Call Tele-Tax and lis- chapter 16. However, if you have depos-return is signed and dated. ten to topic 252 for more information. Check ited the tax you owe for the year in full and Submit payment. Enclose a check for your income tax package for information about on time, you have until February 10 to fileany tax you owe. Write your social security Tele-Tax. the return.number on the check. Also include the tele-phone number and area code where you can February 10be reached during the day. If you receive aForm 1040–V, Payment Voucher, follow the in- Important Dates Farm employers. File Form 943 to report so-structions for completing and sending in the You should take the action indicated on or cial security, Medicare, and withheld in-voucher. before the dates listed. Saturdays, Sundays, come tax for 1996. This due date applies and legal holidays have been taken into ac- only if you had deposited the tax for theBusiness codes for farmers. You must enter count, but local banking holidays have not. A year in full and on time. If not, you shouldon line B of Schedule F (Form 1040) a code statewide legal holiday delays a due date only have filed the return by January 31.that identifies your principal business. It is im- if the IRS office where you are required to file Federal unemployment (FUTA) tax. Fileportant to use the correct code, since this in- is located in that state. Form 940 (or 940–EZ) for 1996. This dueformation will identify market segments of the Due dates for deposits of withheld income date applies only if you had deposited thepublic for IRS Taxpayer Education programs. taxes, social security taxes, and Medicare tax for the year in full and on time. If not,
Page 4 you should have filed the return by January tax return unless you record them when they 31. occur. 1. Prepare your tax returns. You need goodFebruary 28All farm businesses. File information returns Importance of records to prepare your tax return. These records must document the income, ex- (Form 1099) for certain payments made Good Records penses, and credits you report. Generally, these are the same records you use to monitor during 1996 to a taxpayer other than a cor- poration. See chapter 2. There are differ- your farming business and prepare your finan- ent forms for different types of payments. cial statements. Use a separate Form 1096 to summarize and transmit the form for each type of Introduction Support items reported on tax returns. You payment. must keep your business records available at all times for inspection by the IRS. If the IRSAll employers. File Form W–3, Transmittal of A farmer, like other taxpayers, must keep examines any of your tax returns, you may be Wages and Tax Statements, along with records to prepare an accurate income tax re- asked to explain the items reported. A com- Copy A of all the Forms W–2 you issued for turn and determine the correct amount of tax. plete set of records will speed up the 1996. See chapter 2. This chapter explains why you must keep examination. records, what kinds of records you must keep,March 3 and how long you must keep them for federal
● Deductions taken for depreciation Deductions taken for casualty losses, such turn runs out. 2. The period of limitations is the period of as fires or storms● How you used the asset time in which you can amend your return to claim a credit or refund, or the IRS can assess Filing● When and how you disposed of the asset additional tax. The period of time in which you can amend your return to claim a credit or re- Requirements and●
● The selling price The expenses of sale fund is generally the later of: Return Forms 1) 3 years after the date your return is due or filed, or Examples of records that may show this in-formation include: 2) 2 years after the date the tax is paid.● Purchase invoices Returns filed before the due date are treated Important Reminders● Real estate closing statements as filed on the due date. Form 1099–MISC. If you make total payments● Canceled checks The IRS has 3 years from the date you file of $600 or more during the year to another your return to assess any additional tax. If you person, other than an employee or a corpora- file a fraudulent return or no return at all, the tion, in the course of your farming business,Financial account statements as proof of IRS has a longer period of time to assess addi- you must file Form 1099–MISC to report thesepayment. If you do not have a canceled tional tax. payments.check, you may be able to prove payment with Keep copies of your filed tax returns.certain financial account statements prepared They help in preparing future tax re- Estimated tax. When you figure your esti-by financial institutions. These include ac- turns and making computations if you mated tax for 1997, you must include any al-count statements prepared for the financial in- later file an amended return. ternative minimum tax you expect to owe. Seestitution by a third party. The following is a list chapter 14 and Publication 505, Tax Withhold-of acceptable account statements. ing and Estimated Tax. 1) An account statement showing a check Employment taxes. If you have employees, clearing is accepted as proof if it shows you must keep all employment tax records for the: at least 4 years after the date the tax becomes a) Check number, due or is paid, whichever is later. Introduction If you are a citizen or resident of the United b) Amount, Assets. Keep records relating to property until States, single or married, and your gross in- c) Payee’s name, and the period of limitations expires for the year in come for the tax year is at least the amount which you dispose of the property in a taxable d) Date the check amount was posted to shown later in the applicable category, you disposition. You must keep these records to the account by the financial institution. must file a 1996 federal income tax return, figure any depreciation, amortization, or deple- even if no tax is due. This also applies to minor 2) An account statement showing an elec- tion deduction, and to figure your basis for children. If you do not meet the gross income tronic funds transfer is accepted as proof computing gain or loss when you sell or other- requirement, you may still need to file a tax re- if it shows the: wise dispose of the property. turn if you have self-employment income, are a) Amount transferred, Generally, if you received property in a entitled to a complete refund of tax withheld, nontaxable exchange, your basis in that prop- b) Payee’s name, and or are entitled to a refund of the earned in- erty is the same as the basis of the property c) Date the transfer was posted to the ac- come credit. Gross income is explained later. you gave up, increased by money you paid. count by the financial institution. You must keep the records on the old prop- 3) An account statement showing a credit erty, as well as on the new property, until the Topics card charge (an increase to the cardhold- period of limitations expires for the year in This chapter discusses: er’s loan balance) is accepted as proof if it which you dispose of the new property in a tax- ● Filing requirements shows the: able disposition. ● Identification number a) Amount charged, Records for nontax purposes. When your ● Estimated tax b) Payee’s name, and records are no longer needed for tax pur- ● Main tax forms used by farmers c) Date charged (transaction date). poses, do not discard them until you check to see if you have to keep them longer for other ● Partnership return These account statements must be highly purposes. For example, your insurance com- ● Corporation returnlegible and readable. pany or creditors may require you to keep them longer than the IRS does. ● S corporation return Proof of payment of an amount alone does not establish that you are enti- tled to a tax deduction. You should Useful Itemsalso keep other documents, such as credit You may want to see:card sales slips and invoices. Publication □ 505 Tax Withholding and Estimated Tax □ 541 PartnershipsHow Long To Keep □ 542 CorporationsRecordsYou must keep your records as long as they Form (and Instructions)may be needed for the administration of any This chapter discusses various forms youprovision of the Internal Revenue Code. Gen- may have to file with the IRS. We have noterally, this means you must keep records that listed them separately here.
When you must pay estimated tax and file your 19) Unemployment compensation. return depends on whether you qualify as a 20) Other income reported on line 21, FormSelf-employed. If you are self-employed, you farmer. To qualify as a farmer, you must re- 1040, not reported with any of the itemsmust file an income tax return if you had net ceive at least two-thirds of your total gross in- listed above.earnings of $400 or more from self-employ- come from farming in the current or prior year.ment, even though you may not be otherwise Gross income is not the same as total in- There are brief descriptions of forms andrequired to file a return. See chapter 15. come shown on line 22 of Form 1040. schedules used by farmers later.
Nonqualified Farmer Due Dates for 1997 If you did not qualify as a farmer in 1996 be- cause less than two-thirds of your total gross income was from farming and you do not ex- pect to qualify in 1997, you will not qualify for the special estimated tax payment and return due dates. In this case, you must generally make quarterly estimated tax payments on April 15, June 16, and September 15, 1997, and on January 15, 1998. You must file your return by April 15, 1998. For more information on estimated taxes, see Publication 505.
● Cancellation of debt and Produce Usual business practice. The number of ani- ● When you sell produce or livestock (including mals you would have sold had you followed Income from other sources poultry) you raise for sale on your farm, the en- your usual business practice in the absence of tire amount you receive is ordinary income. drought will be determined by all the facts andUseful Items This includes money and the fair market value circumstances. If you have not yet establishedYou may want to see: of any property or services you receive. a usual business practice, the usual business practices of similarly situated farmers in your Publication Where to report. Table 4–1 shows where to general region will be relied on. □ 525 Taxable and Nontaxable Income report the sale of produce and livestock on your tax return. Drought sales in successive years. If you □ 550 Investment Income and Expenses make this election in successive years, the fol- Schedule F. When you sell produce or lowing special rules prevent your first election □ 908 Bankruptcy Tax Guide livestock bought for resale, your profit or loss from adversely affecting your second election: is the difference between your basis in the □ 925 Passive Activity and At-Risk Rules item and any money plus the fair market value 1) Do not include the amount deferred from of any property you receive for it. Report these one year to the next as received from the amounts on Schedule F for the year you re- sale or exchange of livestock in the later Form (and Instructions) ceive payment. year when figuring the amount to be post- □ Sch E (Form 1040) Supplemental poned. See Amount to be postponed, Form 4797. Sales of livestock held for Income and Loss later, which describes the computation. draft, breeding, dairy, or sporting purposes □ Sch F (Form 1040) Profit or Loss From may result in ordinary or capital gains or 2) To determine your normal business prac- Farming losses, depending on the circumstances. In ei- tice for the later year, exclude any earlier ther case, you should always report these year for which you made this election. □ 982 Reduction of Tax Attributes Due to sales on Form 4797 instead of Schedule F. Discharge of Indebtedness Animals you do not hold primarily for sale are □ considered business assets of your farm. See Connection with drought area. The live- 1099–G Certain Government Payments stock does not have to be raised in a drought chapter 10. □ 1099–PATR Taxable Distributions area nor does the sale have to take place in a Received From Cooperatives drought area to qualify for this postponement. Sale by agent. If your agent sells your pro- However, the sale must occur solely because □ 4797 Sales of Business Property duce or livestock, you must include the net of drought conditions that affected the water, proceeds from the sale in gross income for the grazing, or other requirements of the livestock □ 4835 Farm Rental Income and year the agent receives payment. This applies so that the sale became necessary. Expenses even if you arrange for the agent to pay you in See chapter 21 for information about get- a later year. See Constructive receipt in chap- Classes of livestock. You must make theting these publications and forms. ter 3. election separately for each generic class of
Reduction of basis of depreciable prop- For the definition of a related person, see 1) Depreciable property.erty. You can choose to apply any portion of Related persons under At-Risk Amounts in 2) Land you use in your farming business.the excluded canceled debt to reduce the ba- Publication 925.sis of your depreciable property before reduc- 3) Other qualified property.ing other tax benefits. The amount you apply Limit. If your canceled debt is qualified farmcannot exceed the total adjusted bases of all debt, you cannot exclude from income moredepreciable property you held at the beginning than the sum of your adjusted tax benefits and Form 982of the tax year following the tax year of your the total adjusted bases of your qualified prop- erty, defined later. If the discharged debt is Use Form 982 to show the amounts excludeddebt cancellation. more than this limit, you must include the ex- from income and the reduction of tax benefits Depreciable property. Depreciable prop- cess in gross income. in the order listed on the form.erty, for this purpose, means any property sub-ject to depreciation, but only if a reduction ofbasis will reduce the depreciation or amortiza- Adjusted tax benefits. Adjusted tax benefits When to file. You must file Form 982 with yourtion otherwise allowable for the period imme- means the sum of the following: income tax return for the tax year in which thediately following the basis reduction. cancellation of debt occurred. If you do not file 1) Any net operating loss (NOL) for the year When to make basis reductions. The re- this form with your original return, you must file of the discharge and any NOL carryoversduction in basis is made to the property you it with an amended return or claim for credit or to that year.hold at the beginning of the tax year following refund if the cancellation occurred in bank- 2) Any general business credit carryover to ruptcy or insolvency or involved qualified farmthe tax year of the debt cancellation. Recapture of basis reductions. If the ba- or from the year of discharge, multiplied debt or qualified real property business debt. by 3. If you do not make the elections on yoursis of property is reduced under these provi-sions and later sold or otherwise disposed of 3) Any minimum tax credit available at the original return, you must establish reasonableat a gain, the part of the gain due to this basis beginning of the tax year following the tax cause with IRS before you can make them onreduction is taxable as ordinary income under year of the debt cancellation, multiplied an amended return or claim for credit. Thethe depreciation recapture provisions. Any by 3. elections may be revoked only with IRSproperty that is not section 1245 or section 4) Any net capital loss for the year of the dis- consent.1250 property is treated as section 1245 prop- charge and any capital loss carryovers toerty. For section 1250 property, determine the that year. More information. For information on debtstraight-line depreciation adjustments as cancellation, other than qualified farm debt,though there were no basis reduction for debt 5) Any passive activity loss and credit carry- see Publication 908.cancellation. Sections 1245 and 1250 prop- overs available from the tax year of theerty and the recapture of gain as ordinary in- debt cancellation. The credit carryover iscome are explained in chapter 11. multiplied by 3. 6) Any foreign and possession tax credit car- Income FromQualified Farm Debt ryovers to or from the year of the dis-You can exclude from income the cancellation charge, multiplied by 3. Other Sourcesor discharge of qualified farm debt by a quali- This section discusses other types of incomefied person. Your debt is qualified farm debt if: You multiply the credits by 3 to make them you may receive. comparable with the deduction benefits. 1) You incurred it directly in operating a farming business, and Example. You have a $200 general busi- Barter income. If you do work for someone ness credit carryover in the year of debt can- 2) At least 50% of your total gross receipts and are paid in products, property, or in work cellation. You apply $300 of the cancellation for the 3 tax years preceding the year of done for you, you must report as income the as follows: debt cancellation were from your farming fair market value of what you receive. The business. 1) Multiply the credit by 3 for a result of same rule applies if you trade farm products To see if you meet this requirement, di- $600. for other farm products, property, or someone vide your total gross receipts from farming 2) Subtract the $300 canceled debt from else’s labor. This is called barter income. For for the 3-year period by your total gross $600. example, if you help a neighbor build a barn
The first part of the discussion on depreciation for investment. Property held for sale. You can never depre-gives you basic information on what property If you use part of your home for business, ciate property held primarily for sale to cus-can and cannot be depreciated, when to begin you may be able to take a depreciation deduc- tomers in the ordinary course of business.and end depreciation, and how to claim tion for this use.depreciation. Equipment used to build capital improve- Intangible Property ments. You cannot deduct depreciation onWhat Can Be Intangible property is generally any property equipment you are using to build your own that has value but that you cannot be see or capital improvements. You must add depreci-Depreciated touch. It includes items, such as copyrights, ation on equipment used during the period ofYou can depreciate property only if it meets all patents, franchises, trademarks, and trade construction to the basis of your improve-of the following basic requirements: names. ments. See Uniform Capitalization Rules in 1) The property must be used in business or chapter 7. held for the production of income (for ex- Computer software. Computer software in- ample, to earn rent or royalty income), cludes all programs used to cause a computer Rented property. Generally, a person who to perform a desired function. Computer uses depreciable property in a trade or busi- 2) The property must have a determinable software also includes any data base or similar ness or holds it for producing income is enti- useful life longer than one year, and item that is in the public domain and is inciden- tled to the depreciation deduction for the prop- 3) The property must be something that tal to the operation of qualifying software. erty. This is usually the owner of the property. wears out, decays, gets used up, be- Software purchased before August 11, For rented property, this is usually the lessor. comes obsolete, or loses value from natu- 1993. If you purchased software before Au- An owner or lessor is the person who gener- ral causes. gust 11, 1993 (before July 26, 1991, if ally bears the burden of exhaustion of capital
4) Any computer and related peripheral For automobiles placed in service duringDispositions and Conversions equipment unless it is used only at a reg- 1996, the depreciation deduction, includingWhen you transfer ownership of property in a ular business establishment and owned the section 179 deduction, cannot be moregeneral asset account or you permanently or leased by the person operating the than $3,060 for 1996 (the first tax year of thewithdraw it from use in your trade or business establishment. recovery period). For 1997 and 1998 (second
Transfers between spouses. No gain or loss You can use Table 10–1 to figurePartially nontaxable exchange. If you ex- your gain or loss from a foreclosure is recognized (included in income) on a trans-change your property for like-kind property or repossession. fer of property from an individual to (or in trustand also receive money or unlike property in for the benefit of) a spouse, or a formerthe exchange, you have a partially nontaxable Amount realized on a nonrecourse spouse if incident to divorce. This rule doesexchange. You are taxed on the gain you real- debt. If the borrower is not personally liable not apply if the transferee spouse is a nonresi-ize, but only to the extent of the money and the for repaying the debt (nonrecourse debt) se- dent alien. Nor does this rule apply to a trans-fair market value of the unlike property re- cured by the transferred property, the amount fer in trust to the extent the adjusted basis ofceived. A loss is not deductible. realized by the borrower includes the full the property is less than the amount of the lia- Example 1. You trade farm land that cost bilities assumed and the liabilities on the amount of the debt canceled by the transfer.you $30,000 for $10,000 cash and other land property. The full amount of the canceled debt is in-to be used in farming with a fair market value cluded even if the property’s fair market value For more information, see Property Settle-of $50,000. You have a gain of $30,000, but is less than the canceled debt. ments in Publication 504.only $10,000, the cash received, is taxable. If, Example. In 1991, Ann paid $200,000 forinstead of money, you received a tractor with a farm land. She paid $15,000 down and bor-fair market value of $10,000, your taxable gain Exchanges of multiple properties. Under rowed the remaining $185,000 from a bank.is still limited to $10,000, the value of the the like-kind exchange rules, you must gener- Ann is not personally liable on the loan (nonre-tractor. ally make a property-by-property comparison course debt), but pledges the land as security. to figure your recognized gain and the basis of In 1996, the bank foreclosed on the loan be- Example 2. Assume in Example 1 that the the property you receive in the exchange. cause Ann stopped making payments. Whenfair market value of the land you received was However, for exchanges of multiple proper- the bank foreclosed on the loan, the balanceonly $15,000. Your $5,000 loss is not ties, you do not make a property-by-property due was $180,000 and the fair market value ofdeductible. comparison if you: the land was $170,000. The amount Ann real- Unlike property given up. If you tradeproperty for like-kind property and also give up 1) Transfer and receive properties in two or ized on the foreclosure is $180,000, the debtunlike property in the exchange, you have a more exchange groups, or canceled by the foreclosure. She figures hertaxable gain or deductible loss only on the un- gain or loss by comparing the amount realizedlike property you give up. This gain or loss is 2) Transfer or receive more than one prop- ($180,000) with her adjusted basis ($200,000).the difference between the fair market value erty within a single exchange group. She has a $20,000 deductible loss.and the adjusted basis of the unlike property. Amount realized on a recourse debt. If the borrower is personally liable for the debt For more information, see Multiple Prop-Like-kind exchanges between related par- (recourse debt), the amount realized on the erty Exchanges in chapter 1 of Publication foreclosure or repossession does not includeties. Special rules apply to like-kind ex- 544.changes made between related parties. the amount of the canceled debt that is in-These rules affect both direct and indirect ex- come to the borrower from cancellation ofchanges. Under these rules, if either party dis- Deferred exchanges. A deferred exchange is debt. However, if the fair market value of theposes of the property within 2 years after the one in which you transfer property you use in transferred property is less than the canceledexchange, then the exchange is disqualified business or hold for investment and, at a later debt, the amount realized by the borrower in-from nonrecognition treatment. The gain or time, you receive like-kind property you will cludes the canceled debt up to the fair marketloss on the original exchange must be recog- use in business or hold for investment. The value of the property. The borrower is treatednized as of the date of that later disposition. property you receive is replacement prop- as receiving ordinary income from the can-The 2-year holding period begins on the date erty. The transaction must be an exchange celed debt for that part of the debt not in-of the last transfer of property that was part of (that is, property for property) rather than a cluded in the amount realized. See Cancella-the like-kind exchange. transfer of property for money that is used to tion of debt, later. Related parties. Under these rules, a re- purchase replacement property. Example. Assume the same facts as in thelated party generally includes: a member of For more information, see Deferred Ex- example above except that Ann is personallyyour family (spouse, brother, sister, parent, changes in chapter 1 of Publication 544. liable for the loan (recourse debt). In this case, | https://www.scribd.com/document/545298/US-Internal-Revenue-Service-p225-1996 | CC-MAIN-2019-43 | refinedweb | 8,206 | 64 |
[Date Prev][Date Next][Thread Prev][Thread Next][Date index][Thread index]
Re: st: Understanding the difference between gen and egen
I would add that the confusion stems from the fact that the -egen- functions occupy a separate namespace from the functions available to expressions in general (not just to -gen-). All seasoned Stata users know this, though we may not have thought of it that particular way. But Stata is full of many different types of entities having separate namespaces (variables, labels, scalars & matrices, command names, functions, egen functions); we just learn to read every identifier in the context of its namespace.
This is not to say that it isn't confusing; it's just that it needs to be emphasized to beginners as an important part of understanding Stata, and once you get it, it's fairly easy.
To add to the confusion, not only do -egen- functions occupy a separate name space, but their names can begin with a digit. You can create an egen function 3abc, so that you would code...
egen a = 3abc(y)
It could even be just a number!:
egen a = 3(y)
Of course, this is not a good idea, but the syntax allows it.
Another oddity: "sum", the built-in cumulative sum function, can appear in any expression -- such as the argument to some egen functions. Thus, you can write,
egen a = sum(sum(y))
The first "sum" is an egen function; the second "sum" is the built-in cumulative sum function.
All this might add to the confusion, but once you understand it, then it all becomes easy.
--David
At 12:41 PM 6/13/2006, Richard Campbell.
[...]
*
* For searches and help try:
*
*
* | http://www.stata.com/statalist/archive/2006-06/msg00530.html | CC-MAIN-2014-49 | refinedweb | 283 | 67.59 |
You are using a MAC, and you need to make sure that when you get a message, you properly validate the MAC.
If you're using an ever-increasing nonce (which we strongly recommend), check to make sure that the nonce associated with the message is indeed larger than the last one. Then, of course, recalculate the MAC and check against the transmitted MAC.
The following is an example of validating a MAC using the OMAC1 implementation in Recipe 6.11, along with AES-128. We nonce the MAC by using a 16-byte nonce as the first block of input, as discussed in Recipe 6.12. Note that we expect you to be MAC'ing the ciphertext, as discussed in Recipe 6.18.
#include <stdlib.h> #include <string.h> /* last_nonce must be a pointer to a NULL on first invocation. */ int spc_omac1_validate(unsigned char *ct, size_t ctlen, unsigned char sent_nonce[16], unsigned char *sent_tag, unsigned char *k, unsigned char **last_nonce) { int i; SPC_OMAC_CTX c; unsigned char calc_tag[16]; /* Maximum tag size for OMAC. */ spc_omac1_init(&c, k, 16); if (*last_nonce) { for (i = 0; i < 16; i++) if (sent_nonce[i] > (*last_nonce)[i]) goto nonce_okay; return 0; /* Nonce is equal to or less than last nonce. */ } nonce_okay: spc_omac_update(&c, sent_nonce, 16); spc_omac_update(&c, ct, ctlen); spc_omac_final(&c, calc_tag); for (i = 0; i < 16; i++) if (calc_tag[i] != sent_tag[i]) return 0; if (sent_nonce) { if (!*last_nonce) *last_nonce = (unsigned char *)malloc(16); if (!*last_nonce) abort(); /* Consider an exception instead. */ memcpy(*last_nonce, sent_nonce, 16); } return 1; }
This code requires you to pass in a char ** to track the last nonce that was received. You're expected to allocate your own char *, set it to NULL, and pass in the address of that char *. The validate function will update that memory with the last valid nonce it saw, so that it can check the new nonce against the last nonce to make sure it got bigger. The function will return 1 if the MAC validates; otherwise, it will return 0.
Recipe 6.11, Recipe 6.12, Recipe 6.18 | http://etutorials.org/Programming/secure+programming/Chapter+6.+Hashes+and+Message+Authentication/6.21+Securely+Authenticating+a+MAC+Thwarting+Capture+Replay+Attacks/ | CC-MAIN-2017-22 | refinedweb | 343 | 73.17 |
- Java program to count words in a sentence using split method.
To count the number of words in a sentence, we first take a sentence as input from user and store it in a String object. Words in a sentence are separated by space character(" "), hence we can use space as a delimiter to split given sentence into words. To split a string to multiple words separated by spaces, we will call split() method.
public String[] split(String regex);
split() method returns an array of Strings, after splitting string based of given regex(delimiters). To fine the count of words in sentence, we will find the length of String array returned by split method.
Java program to find the count of words in a sentence
package com.tcc.java.programs; import java.util.Scanner; /** * Java Program to Count Words in Sentence */ public class WordCount { public static void main(String args[]) { String str; Scanner scanner = new Scanner(System.in); System.out.println("Enter a Sentence"); str = scanner.nextLine(); // Printing number of words in given sentence System.out.println("Number of Words = " + str.split(" ").length); } }Output
Enter a Sentence I Love Java Programming Number of Words = 4
Recommended Posts | https://www.techcrashcourse.com/2017/09/java-program-to-count-words-in-sentence.html | CC-MAIN-2020-05 | refinedweb | 197 | 65.93 |
window matching improvement?
Is there a way to set an option so that that Docky always uses the Window class to match applications when there is no launcher?
If I launch several different java applications, even using the technique of agent.jar to change the window class it does not work - because these applications do not have an associated launcher in /usr/share/
Seems there should be a checkbox 'match windows using class for unknown applications'.
or is there something else I am doing wrong ???
A side-note is that Docky appears to use a random icon from one of the java windows as the dock icon. When I right-click the dock icon, it does list all of the 'java' windows.
Question information
- Language:
- English Edit question
- Status:
- Solved
- For:
- Docky Edit question
- Assignee:
- No assignee Edit question
- Solved by:
- Robert Dyer
- Solved:
- 2011-07-25
- Last query:
- 2011-07-25
- Last reply:
- 2011-07-25
Sorry Robert, but that is exactly what I reported against. The link you referred to shows changing the .desktop launcher for a particular application. If you re-read my question, you'll see that my applications do not have an associated launcher...
When there is no launcher, Docky should default to matching using the Window class I think.
And the reason I posted that link is because that is all the support Docky has. If that page can't help you, nothing can.
You can make launchers for your apps you know, you don't have to rely only on ones provided by them.
I'm sorry but that is not really the case. Often the 'process' is started without any reference to the 'launcher' system.
For example, many IDE's like Eclipse and IntelliJ have their own external launching frameworks, and the end result is simply a process.
For this to work, Docky needs to group 'processes/windows' using the Window class when a launcher does not exist/not used.
I have also evaluated 'AVN' in comparison to Docky, and this works fine there - but I prefer the simplicity and UI of Docky, so I was hoping this might be fixed.
Seems strange that you need to create 'launchers' for the grouping functionality to work, when Docky has access to alternative information when this is not available.
Docky *always* uses the launchers to match windows. IF it can't find any appropriate launchers, then it simply groups them all by the WM_CLASS. In the case of Java, almost every Java app has the same WM_CLASS (this is the default for AWT based apps, I am unsure about SWT based). Thus, all Java apps which have no launcher will wind up grouping together. Just add a launcher, change the WM_CLASS (there are ways to do this, I recommend nagging the app's developer) and you're all set.
Eclipse matches fine for me out of the box, fyi. So your Eclipse install must be broken.
I'm sorry, but I don't think you're reading my question/problem correctly.
Docky DOES NOT use the WM_CLASS when there is no launcher. It groups all of the applications under the same 'icon'. I am using the agent.jar with my launched applications, and I've used xprop to determine that the WM_CLASS is indeed changed, yet Docky groups the IntelliJ (which has a WM_CLASS of java_lang_Thread), with my application windows (which have a WM_CLASS of OnRamp).
Eclipse seems to work works fine on my system with Docky - it is any application 'launched by eclipse' using run configurations...
For example, run the following in Eclipse using different agent.jar entries - they will all be grouped under the same icon...
package freewayplugin;
import javax.swing.JFrame;
import javax.swing.JLabel;
public class Test {
/**
* @param args
*/
public static void main(String[] args) {
JFrame hello = new JFrame();
hello.
hello.pack();
hello.
}
}
Please stop re-opening this. You have all the available information.
Fine. I will AVN where the product works and the support is not handling by an ignorant a$&.
First of all, it is AWN. You might want to learn the name if you plan to download it.
Second, I am not ignorant. I am simply pointing out what Docky is capable of and how to configure those capabilities. If those capabilities are not within scope of your specific problem, then we can not help you because Docky does not (currently) support the feature you require.
Third, I more or less brush this problem off as starting with Docky 3 our window matching will be done by the BAMF library (the same library doing window matching for the Unity launcher) and thus this problem is either a) fixed in BAMF and thus will be fixed in Docky 3 *or* not fixed in BAMF and thus a problem for BAMF (and not us).
Fourth, if you want to call me names then please stop using our product. I won't support users that are overly rude, so you are on your own now.
I only responded in kind. Maybe if you would have started with the last response (limitation of Docky not others) instead of trying to explain to me incorrectly that I was doing something wrong, it might have been a shorter conversation.
Boy I hope you don't do this for a living, but I wouldn't be surprised given the state of the industry. Good luck to you.
If you work on your reading comprehension skills you might have an easier time in the future.
I don't get paid to do this, but when I come across users like you I really wish I did because it is hardly worth wasting my free time to deal with derogatory users such as yourself.
http://
wiki.go- docky.com/ index.php? title=How_ to_Customize_ Window_ Matching | https://answers.launchpad.net/docky/+question/165940 | CC-MAIN-2017-43 | refinedweb | 970 | 71.85 |
On Sat, Feb 20, 2010 at 5:53 PM, Steven D'Aprano <steve at remove-this-cybersource.com.au> wrote: > On Sat, 20 Feb 2010 17:34:15 -0800, Jonathan Gardner wrote: >> In terms of "global", you should only really use "global" when you are >> need to assign to a lexically scoped variable that is shared among other >> functions. For instance: >> >> def foo(): >> i = 0 >> def inc(): global i; i+=1 >> def dec(): global i; i-=1 >> def get(): return i >> return (inc, dec, get) > > That doesn't do what you think it does: > > >>>> def foo(): > ... i = 0 > ... def inc(): global i; i+=1 > ... def dec(): global i; i-=1 > ... def get(): return i > ... return (inc, dec, get) > ... >>>> inc = foo()[0] >>>> inc() > Traceback (most recent call last): > File "<stdin>", line 1, in <module> > File "<stdin>", line 3, in inc > NameError: global name 'i' is not defined > > > The problem is that i is not global. Inside the inc and dec functions, > you need to declare i nonlocal, not global, and that only works in Python > 3 or better. > Oops. :-( -- Jonathan Gardner jgardner at jonathangardner.net | https://mail.python.org/pipermail/python-list/2010-February/568859.html | CC-MAIN-2018-26 | refinedweb | 184 | 79.7 |
Eclipse BIRT Report Object Model (ROM)
IncludedLibrary Structure
Report design can include a number of libraries, library is a reusable component with a number of predefined elements or resources. Included library structure is used to supply a link to the library file and a namespace that is unique to each included libraries.
Elements from the library is referenced using the library namespace. For example, report includes a library, file name is "/library1.rptlibrary"; namespace is "lib1". Report design references a table(t1) from the library using "lib1.t1"
File name of the library.
File name of the library that is included, it can either in absolute or relative path.
Namespace of the library.
Namespace is unique to each included library, elements or resources(image, dataset or datasource) inside a library is referenced using the namespace prefix. | http://www.eclipse.org/birt/ref/rom/structs/IncludedLibrary.html | CC-MAIN-2013-48 | refinedweb | 136 | 58.08 |
Provided by: manpages-dev_5.05-1_all
NAME
ioctl_tty - ioctls for terminals and serial lines
SYNOPSIS
#include <termios.h> int ioctl(int fd, int cmd, ...);
DESCRIPTION different calling process, give up this controlling terminal. If the process was session leader, then send SIGHUP and SIGCONT to the foreground; otherwise, place zero in *argp. TIOCNXCL void Disable exclusive mode. Line discipline TIOCGETD int *argp Get the line discipline of the terminal. TIOCSETD const int *argp Set the line discipline of the terminal.otermin following bits are used by the above).zero, and clear it otherwise. If the CLOCAL flag for a line is off, the hardware carrier detect (DCD) signal is significant, and an open(2) of the corresponding terminal set"); else puts("TIOCM_DTR is not set"); close(fd); }
SEE ALSO
ldattach(1), ioctl(2), ioctl_console(2), termios(3), pty(7)
COLOPHON
This page is part of release 5.05 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at. | http://manpages.ubuntu.com/manpages/focal/man2/ioctl_tty.2.html | CC-MAIN-2020-45 | refinedweb | 174 | 59.19 |
Closure Interpreter ===================
Disclaimer: Just for fun, as an self-educational experiment. Not fit for any purpose whatsoever. Inspired by Chapter 6 of LiSP, which in turn was based upon the paper "Using closures for code generation".
This is a JavaScript metacircular "fast interpreter" which removes some of the interpretive overhead by doing a direct translation of the tree of AST nodes into a tree of closures. That is, the following (SpiderMonkey- / Esprima-style) AST snippet
{ type: "BinaryExpression" operator: "+" left: { type: "Identifier", name: "a" } right: { type: "Identifier", name: "b" } }
gets converted to something like
function() { return (function() { return stack[0]; })() + (function() { return stack[1]; })(); }
This means that we do not need to decode the AST at runtime. Additionally, where a simpler interpreter would implement variable lookup by checking a series of hash tables, we speed things up by converting the hash lookups into array references.
Compared to a full compiler, we still incur a lot of overhead due to the cost of function calls. Perhaps more importantly, since we do not linearize the AST, we are still forced to use exceptions for break/continue/return. JS engines do major deoptimization when encountering exceptions, so this is not great. Overall, it makes for an approximate 65x slowdown on SunSpider.
On the upside, this "compilation" process is fairly straightforward, and the resulting code still looks very much like a plain old eval-apply interpreter.
"Tricky" language bits that have been implemented:
varand
functiondeclarations
eval(but without strict mode) | https://www.npmjs.com/package/closure-interpreter | CC-MAIN-2015-35 | refinedweb | 245 | 51.38 |
Passcode module!
I made a super simple to use module to lock your scripts by face-id or fingerprint!
You can Find it at ! Let me know what you think!
@ClackHack, can you help me a bit with your code?
If I run the passcode script, it crashes Pythonista (with a non-helpful ObjC exception for the line where
lock()is called).
If I run the code in the Readme, nothing happens (as
lockis never called, I think).
If I run the script, no crash, asks Touch ID
@mikael I've to say that my first run crashed but when I've restarted Pythonista, no more crash
I think it is because your iPad does not have FaceID?
@mikael As it runs ok on my iPad TouchId, I hope @ClackHack follows this topic and will try the topic you linked if he needs FaceId.
@cvp, I would not be surprised if Pythonista is simply not set up for Face ID:
”In any project that uses biometrics, include the NSFaceIDUsageDescription key in your app’s Info.plist.”
@cvp, I would not be surprised if Pythonista is simply not set up for Face ID:
Yes, I think that is the problem. I've considered adding a
NSFaceIDUsageDescription, but I wasn't sure if Apple might have an issue with it because Pythonista doesn't really use FaceID if you don't access it via ObjC (same is true for some other things I've put in the Info.plist though, so I might still just do it in the next update).
@mikael Hey Mikael, this module should work. It runs without crash on my iphone 11 face-id, and it works with touch-id on my iPad. Have you tried to restart the app? I will look more into this issue.
@mikael I find it convenient to use it in the code shortcuts. I named it Scriptlock and the code should read:
import passcode,importlib,sys importlib.reload(passcode) passcode.lock() if not passcode.auth_completed: sys.exit()
@ClackHack, which version of iOS and Pythonista are you running on the iPhone?
@ClackHack, also, is there some magic in importing
passcodetwice?
@mikael
I am running on the latest IOS and Pythonista, so pythonista 3.3 and IOS 13.3.1
However it worked on the last Pythonista update, and on past IOS 13 versions. I believe, but cannot say with 100% certainty that it worked on IOS 11 & 12.
I used to have issues with it saying that the passcode module was not imported, so I saw online that importlib.reload would fix that. It is completely vestigial I believe, but I like to err on the side of caution! | https://forum.omz-software.com/topic/6214/passcode-module/2 | CC-MAIN-2021-17 | refinedweb | 446 | 81.63 |
;
using System.Collections.Generic;
class C
{
string ss = "aa";
public IEnumerable<int> GetIter ()
{
yield return 1;
yield return 2; // Set a breakpoint here
yield return 3;
}
public static void Main()
{
foreach (var item in new C ().GetIter ()) {
}
}
}
Then go to watch window and add `ss'. Error Unknown identifier: ss
if you add Console.WriteLine (ss); to the top of GetIter(), it works.
This suggests to me that it's a runtime or compiler issue.
I would guess that mcs isn't emitting a "this" reference on the closure class. It should always do that for debug code, even if it isn't used.
Good point Michael. Although I don't think it's worth always adding `this' reference, because it can significantly alter generated code and you will still have to handle cases which don't follow this assumption.
VS prints "An object reference is required for the non-static field, method, or property 'C.ss'" when the `this' proxy is not available. We could probably show better error message but I'd go with an error message instead of adding `this' everywhere (it's quite tricky for anonymous methods).
the error message is fixed in git master
IIRC csc always generates the "this" reference for debug code, but I could be wrong.
Yes but only for iterators not for other kinds of lifted blocks like anonymous methods or async blocks
MD now prints the message even if the name does not exist at all
fixed | https://xamarin.github.io/bugzilla-archives/45/4527/bug.html | CC-MAIN-2019-47 | refinedweb | 246 | 71.55 |
Python provides different methods for file and directory name manipulation. The basename() method is one of the most popular methods which is used to return the basename of the specified path. The basename means the name of the specified file or directory. The file name or directory name is extracted from the complete path and the base name is returned.
Full Name = Path + Basename
Before learning and examining the basename() method of Python let’s examine what is base name and how differs it from the file or directory name. The full name consists of the path and file/directory basename. The basename specifies the name path of the complete path. In the following example “/home/ismail/” is the path and the “file.txt” is basename.
/home/ismail/file.txt
Find Basename of File
The basename() method is provided by the os module. The complete path for the basename() method is os.path.basename(). So first we import the os module in order use the basename() method.
import os.path basename = os.path.basename("/home/ismail/file.txt") print(basename)
Find Basename of Directory/Folder
A directory or folder complete path also contains a base name. The directory or folder name is the base name in the complete path. For the “/home/ismail/Downloads” the basename is “Downloads”.
import os.path basename = os.path.basename("/home/ismail/Downloads") print(basename) | https://pythontect.com/python-os-path-basename-method-tutorial/ | CC-MAIN-2022-21 | refinedweb | 230 | 59.4 |
[Solved]ScrollView and Flickable don't respect Image.PreserveAspectFit
- stereomatching
@
import QtQuick 2.1
import QtQuick.Controls 1.0
Rectangle {
id: root
width: 1200
height: 600
Row{ Rectangle{ height:root.height width: root.width / 3 color: "black" z: 1 } Flickable{ height:root.height width: root.width / 3 contentHeight: image.height contentWidth: image.width Image{ id: image source: "" fillMode: Image.PreserveAspectFit smooth: true } } ScrollView{ height:root.height width: root.width / 3 Image{ source: "" fillMode: Image.PreserveAspectFit smooth: true } } }
}
@
What I want to do is, change the fillMode of the image dynamically, when the image is too large
I want them become filckable or scrollable, but neither Flickable nor ScrollView respect Image.PreserveAspectFit, how could I make them respect the fillMode of the Image?
- chrisadams
Hi,
I don't really know how ScrollView works, but your Flickable has its contentWidth and contentHeight bound to the width/height of the image, so the fillMode of the Image probably won't have any effect, I guess. (Although, it's early and my brain hasn't switched on yet, so maybe I'm misunderstanding something).
Cheers,
Chris.
chris is right. I don't understand what you are trying to achieve by setting the PreserveAspectFit mode. The image is never stretched to an incorrect aspect ratio so the flag will do nothing unless you constrain either the width or the height but that is pointless when you have a scrollable view.
If you are trying to implicitly center the image when it is not being scrolled, you could try something like this though:
@
ScrollView {
id: scrollview
height:root.height
width: root.width
Item {
id: container
width: Math.max(img.implicitWidth, root.width - 20)
height: Math.max(img.implicitHeight, root.height - 20)
Image{
id: img
anchors.centerIn: parent
source: ""
smooth: true
}
}
}
}
@
- stereomatching
Thanks to both of you and sorry that I haven't mentioned my intentions clearly.
when the image is too large,I want to handle the view with two ways
1: when the fillMode is Pad, I could use the
scrollView or flickable to view the whole image
2: when the fillMode is PreserveAspectFit, the image will
shrink to appropriate size
Since it is impossible to do it with Flickable or ScrollView, I would find
another solutions, like
create a new component, with two Images, when the fillMode is
PreserveAspectFit, I show the Image with ScrollView or Flickable;
change it back to normal Image when it is other fillMode | https://forum.qt.io/topic/29103/solved-scrollview-and-flickable-don-t-respect-image-preserveaspectfit | CC-MAIN-2018-13 | refinedweb | 404 | 66.33 |
Scenario: Download Script
You are working as ETL Developer / SSIS Developer for Car Insurance company. They receive text files in their source folder. You need to create an SSIS Package that should convert these text files into Excel Files. The Excel File Name should be the same as Text file and Sheet Name should also be same as file name.
Here are couple of samples files I am using for test
Log File Information : In case your SSIS Package fail. Log file will be created in the same folder where your Excel File will be created.The name of log file will be same like your source file that Package was processing.
Solution:
We care going to use Script Task in SSIS Package to convert Text/CSV/Tab delimited files to Excel Files. We are going to create variable Files
FileDelimiter : Provide the delimiter such as comma (,), Pipe( | ) Whatever your files are using.
FileExtension : Provide the extension of files you would like to convert such .txt, .csv
SourceFolderPath : Source folder path where text files exists
Create Variables in SSIS Package to use in Script Task to Convert Text Files to Excel Files
Step 2: Add Script Task to SSIS Package and Map Variables
Bring Script Task to Control Flow Pane and open it by double clicking. Add the SSIS Package variables to it so we can use inside.
Add variables to Script Task in SSIS Package to use for converting CSV files to Excel Files
Step 3: Add Script to Script task Editor in SSIS Package to Convert Text Files to Excel Files
Click Edit Button and it will open Script Task Editor.
Under #region Namespaces, I have added below code
using System.IO; using System.Data.OleDb;
Under public void Main() {
I have added below code. CreateTableStatement = ""; string ColumnList = ""; //Reading file names one by one string SourceDirectory = SourceFolderPath; string[] fileEntries = Directory.GetFiles(SourceDirectory,"*"+FileExtension); foreach (string fileName in fileEntries) { // do something with fileName / + "\\" + filenameonly + ";" + "Extended Properties=\"Excel 12.0 Xml;HDR=YES;\""; OleDbConnection Excel_OLE_Con = new OleDbConnection(); OleDbCommand Excel_OLE_Cmd = new OleDbCommand(); //drop Excel file if exists File.Delete(DestinationFolderPath + "\\" + filenameonly + ".xlsx");.Now.ToString("yyyyMMddHHmmss")+".log")) { sw.WriteLine(exception.ToString()); Dts.TaskResult = (int)ScriptResults.Failure; } }
Step 4: Save Script and Run your SSIS Package to Convert Text Files to Excel Files
Save the script in Script Task Editor and execute your SSIS Package. It should read each of the file from Source Folder and create new excel file in Destination Folder. The package do not delete the files from Source Folder. You can add that script to Script Task or use File system task to do that.
As I had two text files, It created two excel files for me. One for each Text file.
How to convert CSV files to Excel Files in SSIS Package by using Script Task- C# scripting language | http://www.techbrothersit.com/2016/03/how-to-convert-csvtext-files-to-excel.html | CC-MAIN-2018-17 | refinedweb | 472 | 62.48 |
mbrtowc—
#include <wchar.h>size_t
mbrtowc(wchar_t * restrict wc, const char * restrict s, size_t n, mbstate_t * restrict mbs);
mbrtowc() function examines at most n bytes of the multibyte character byte string pointed to by s, converts those bytes to a wide character, and stores the wide character in the wchar_t object pointed to by wc if wc is not
NULLand s points to a valid character. Conversion happens in accordance with the conversion state described by the mbstate_t object pointed to by mbs. The mbstate_t object must be initialized to zero before the application's first call to
mbrtowc(). If the previous call to
mbrtowc() did not return (size_t)-1, the mbstate_t object can safely be reused without reinitialization. The behaviour of
mbrtowc() is affected by the
LC_CTYPEcategory of the current locale. If the locale is changed without reinitialization of the mbstate_t object pointed to by mbs, the behaviour of
mbrtowc() is undefined. Unlike mbtowc(3),
mbrtowc() will accept an incomplete byte sequence pointed to by s which does not form a complete character but is potentially part of a valid character. In this case,
mbrtowc() consumes all such bytes. The conversion state saved in the mbstate_t object pointed to by mbs will be used to restart the suspended conversion during the next call to
mbrtowc(). In state-dependent encodings, s may point to a special sequence of bytes called a “shift sequence”. Shift sequences switch between character code sets available within an encoding scheme. One encoding scheme using shift sequences is ISO/IEC 2022-JP, which can switch e.g. from ASCII (which uses one byte per character) to JIS X 0208 (which uses two bytes per character). Shift sequence bytes correspond to no individual wide character, so
mbrtowc() treats them as if they were part of the subsequent multibyte character. Therefore they do contribute to the number of bytes in the multibyte character. Special cases in interpretation of arguments are as follows:
mbrtowc() ignores wc and n, and behaves equivalent to
mbrtowc(NULL, "", 1, mbs);
mbrtowc() uses its own internal state object to keep the conversion state, instead of an mbstate_t object pointed to by mbs. This internal conversion state is initialized once at program startup. It is not safe to call
mbrtowc() again with a
NULLmbs argument if
mbrtowc() returned (size_t)-1 because at this point the internal conversion state is undefined. Calling any other functions in libc never changes the internal conversion state object of
mbrtowc().
NULL, a NUL wide character has been stored in the wchar_t object pointed to by wc.
NULL, the corresponding wide character has been stored in the wchar_t object pointed to by wc.
mbrtowc() sets errno to EILSEQ. The conversion state object pointed to by mbs is left in an undefined state and must be reinitialized before being used again. Because applications using
mbrtowc() are shielded from the specifics of the multibyte character encoding scheme, it is impossible to repair byte sequences containing encoding errors. Such byte sequences must be treated as invalid and potentially malicious input. Applications must stop processing the byte string pointed to by s and either discard any wide characters already converted, or cope with truncated input.
mbrtowc() again with s pointing to one or more subsequent bytes of the multibyte character and mbs pointing to the conversion state object used during conversion of the incomplete byte sequence.
mbrtowc() function may cause an error in the following cases:
EILSEQ]
EINVAL]
mbrtowc() function conforms to ISO/IEC 9899/AMD1:1995 (“ISO C90, Amendment 1”). The restrict qualifier is added at ISO/IEC 9899:1999 (“ISO C99”).
mbrtowc() is not suitable for programs that care about internals of the character encoding scheme used by the byte string pointed to by s. It is possible that
mbrtowc() fails because of locale configuration errors. An “invalid” character sequence may simply be encoded in a different encoding than that of the current locale. The special cases for s == NULL and mbs == NULL do not make any sense. Instead of passing
NULLfor mbs, mbtowc(3) can be used. Earlier versions of this man page implied that calling
mbrtowc() with a
NULLs argument would always set mbs to the initial conversion state. But this is true only if the previous call to
mbrtowc() using mbs did not return (size_t)-1 or (size_t)-2. It is recommended to zero the mbstate_t object instead. | https://man.openbsd.org/mbrtowc.3 | CC-MAIN-2018-26 | refinedweb | 728 | 61.06 |
Simple Java question with comments needed
Pro 5.rar - FILES NEEDED HERE
Write a program in Java and run it in BlueJ according to the following specifications:
- excellent
There are 2 failre students with average grade 56.5
Requirements and restrictions
- Use the Student.java and Students.java classes from the course website to represent and process student records and modify them accordingly:
- The encapsulation principle must be strictly enforced.
- The main method in class Students should only read the text file, and print student records (student names, grade and grade type) and statistics (number of students and averages).No other kinds of computations should be included in the main method (e.g. checking student grade intervals and student type, counting students, totaling grades).
- All counting, totaling, computing averagas, checking grade intervals, and assigning grade types to students should be implemented in class Student. Hints: use static variables in class Student and add methods to compute and return (or print) averages. Modify the toString() method to return the grade type too.
- When you write your program
- use proper names for the variables suggesting their purpose.
- format your code accordingly using indentation and spacing.
- use multiple line comment in the beginning of the code and write your name, e-mail address, class, and section.
- for each line of code add a short comment to explain its | https://www.studypool.com/discuss/308441/simple-java-question-with-comments-needed | CC-MAIN-2016-44 | refinedweb | 225 | 56.76 |
Wednesday, November 10, 2004
Dream Last Night
After inexplicably returning home, I had to explain how I had lost not only the car, but a backpack and a book which it contained. Each of these losses seemed more significant than the last.
Friday, October 15, 2004
Telnet and IMAP4 incompatible!
You...
Friday, October 8, 2004
In Theory, My Ass
Thursday, September 30, 2004
#politics
Sunday, August 29, 2004
How I Spent My Summer Vacation
My?
Friday, August 20, 2004
Things I didn't know Python could do
>>> class x:
... y = 0
...
>>> for x.y in range(5):
... print x.y,
...
0 1 2 3 4
>>>
>>> x = [None]
>>> for x[0] in range(5):
... print x,
...
[0] [1] [2] [3] [4]
>>>
Monday, August 2, 2004
Python Developers Considered Harmful
I.
Monday, July 5, 2004
Python implementation of Smalltalk's "become:".
Saturday, June 12, 2004
Beautiful day, twelve mile bikeride (n/t)
Tuesday, June 1, 2004
Cat vomit and subsequent things
Conversation touching degrees of separation, Jen's background, past trips
and the like. The cats join in, with their plaintive mewls at the swaying
of the SUV. Light traffic, good time.
Nearly there, a gagging sound. Splash. Viscous lapping noises from the
rear now accompanying each small-town twist of the road. Splash, splash.
Stopping to see if Emma is alright. As much as any animal standing in a
pool of its own vomit can be, she is. We drive the last ten minutes to our
destination, set free the two prisoners, one of whom carries with her the
stench, but both of whom seem fine at last.
Night fall. Turkey burgers. Sleep.
In the hallway, slow drips from the ceiling. It is a gray day. Sheets
fall from the morning sky but, on the highway, from twelve foot puddles,
rise up again onto the windshield, to be shoved down by two madly flailing
wipers. Jen and I in borrowed raincoats.
Home Depot, identical to the others, only the faces have been changed.
CAT5 comes in pink, makes a festive belt, and is inexpensive when bought to
fit a waist instead of a corridor. The drapes are cut, we leave the store
behind. Traffic makes up for lost time, drags us to near a standstill. We
hit an old, independent book store. Shelves stuffed with fifty, eighty,
hundred year old books. _Gray's Anatomy_, complete with notes from a
previous owner. Piles of Daniel Steele near the back. I buy _Heart of
Darkness_ for a dollar. Unsated, on to a nationwide chain, with floors and
floors of the shiniest new publications. Near the registers, two rivers
spill from the ceiling. Coconut ice cream on the way home.
Once home, back out again to the grocery. Hectic pace as two cooks seek
out the items of two confusingly overlapping lists. I push the cart.
Home again. Later, on the dock, swaying in the wash of large boats, a
thick fog settling over the yard, maybe over the town, county, state.
Soft, permeable, yet simultaneously impenetrable. The dock and house are
cut off, separated from the world. Crabs climb onto the dock and splash
back into the water.
Curry and rice. A movie. Sleep.
The sun is out. The sky is bluer than the water, cloudless. Kayaks out
into the ocean, through the headwind, to an island. We walk around,
barefoot in the sand. Gulls feast on overturned crabs, armored legs
flailing in protest. We dig holes in the wet sand and quickly fill them in
to cover the animals we find. We paddle back.
Leftover curry. Reading in the sun. Salad, falafel, lemon turkey.
Scrabble, I lose badly. Sleep.
Sunday is even windier than Saturday. Whitecaps out in the channel. A
banana for breakfast, then in to catch a bus, cash or traveler's checks,
please, back to Boston. I forget _Heart of Darkness_ in the pocket of my
raincoat, read Gibson instead.
Monday, March 22, 2004
Two days of PyCon sprinting!
Friday, March 5, 2004
Twisted "chat server" in one expression
(lambda r,p,b: (r.listenTCP(6665,(type('F',(p.Factory,object),{'protocol':(type('P',(b.LineReceiver,object),{'connectionMade':lambda s:s.factory.c.append(s),'lineReceived':lambda s,m:(s.factory.m(m),None)[1]})),'c':[],'m':lambda s,m:[c.sendLine(m)for c in s.c]}))()),r.run()))(*(lambda p,i:(i(p,'reactor'),i(p,'protocol'),i('twisted.protocols.','basic')))('twisted.internet.',lambda a,b:__import__(a+b,None,None,b)))
Wednesday, March 3, 2004
Good Night
exarkun@boson:~$ telnet localhost 56197
Trying ::1...
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
telnet.ShellFactory
Twisted 1.2.0
username: admin
>>> import os
>>> os
<module 'os' from '/usr/lib/python2.3/os.pyc'>
>>> os.getpid()
22749
>>> os
<module 'os' from '/usr/lib/python2.2/os.pyc'>
>>> os.getpid()
22762
>>> Connection closed by foreign host.
Interpretation is left as an exercise for the reader. Suffice it to say that all the dirty hacks in the server melted away tonight, and the transition from supporting only listening ports to supporting connected protocol instances was almost effortless. The interpreter version change was a last minute afterthought that I was happily surprised to see actually work.
Sunday, February 29, 2004
Generating Python functions from a template
def ;)
Friday, February 20, 2004
Evil returns
import gc, sys, struct, opcode, inspect
class NotGiven:
pass
def notGiven(param):
caller = sys._getframe(1)
for potentialFunction in gc.get_referrers(caller.f_code):
if getattr(potentialFunction, 'func_code', None) == caller.f_code:
break
elif getattr(getattr(potentialFunction, 'im_func', None), 'func_code', None) == caller.f_code:
potentialFunction = caller.im_func
break
else:
raise Exception("You're insane.")
argspec = inspect.getargspec(potentialFunction)
bytes = caller.f_code.co_code
lasti = caller.f_lasti
varStart = bytes.rindex(chr(opcode.opmap['LOAD_FAST']), 0, lasti)
(varIndex,) = struct.unpack('H', bytes[varStart+1:lasti])
value = argspec[3][varIndex]
return value is param
def foo(x = NotGiven(), y = NotGiven(), z = NotGiven()):
print 'x given?', not notGiven(x)
print 'y given?', not notGiven(y)
print 'z given?', not notGiven(z)
if __name__ == '__main__':
for args in ('', 'x', 'y', 'z', 'xy', 'xz', 'yz', 'xyz'):
print 'Passing', ' '.join(args) or 'nothing'
foo(**dict.fromkeys(args))
Thanks to teratorn for bringing NOT_GIVEN to my attention. :)
Saturday, February 7, 2004
Triple Headed X.
Saturday, January 31, 2004
Today I installed the Hurd.
Friday, January 30, 2004
Unions.
Monday, January 26, 2004
Two lessons learned.
| https://as.ynchrono.us/2004/ | CC-MAIN-2021-04 | refinedweb | 1,058 | 69.28 |
( (*). int inherits from object, so it meets the constraint. All struct types inherit from at least two reference types, and some of them inherit from many more. (Enum types inherit from System.Enum, many struct types implement interface types, and so derived type has a member M as well. (**).
————
(*) or be identical to T, or possibly to inherit from a type related to T by some variant conversion.
(**).
… or Bravo<IComparable, int>
"Accessibility domain" is a nice way of referring to it.
Memory layout is an implementation detail. But whether a type is a reference type or a value type is not. And I think it's quite confusing that value type inherits a reference type.
(I'm not saying this was a bad decision, just that it can be confusing.)
>>Derived type which inherits from a base type implicitly has all inheritable members of the base type.
That is what Cardelli and Wegner stated as:
"{a1:t 1, .. ,an:tn, .. ,am:tm } ≤ {a 1:u1, ..,an:un }
iff ti ≤ ui for i ∈ 1..n.
i.e., a record type A is a subtype of another record type B if A has all the attributes (fields) of B, and possibly
more, and the types of the common attributes are respectively in the subtype relation."
"Is the compiler wrong? Of course not."
This made me smile.
(sorry if this double posts, it looks like the first one got eaten)
I am confused by the "constructors are not inheritable" statement. I always think of them as being inherited in the sense that the base class's constructor must be satisfied by derived classes. For example:
public class Foo { public Foo(int i){} }
public class Bar : Foo{
public Bar(int i) : base(i){} // ok
public Bar(): base(0){ } // ok
public Bar(){} // illegal since base c-tor isn't satisfied
}
Foo's constructor definitely is not inherited in the same sense as a method, but I still think of it as being inherited. Most likely, this is just an example of my mental model being out of sync with reality.
(sorry if this double posts, it looks like the first one got eaten)
I completely agree with "implements" being a better term for talking about interfaces in relation to classes then is "inherits". I use "implements when talking about classes (here goes) implementing a certain interface.
@Chris B: Take a look at it the other way around:
public class Foo
{
public Foo() { }
public Foo(int value) { }
}
public class Bar : Foo
{
public Bar() : base() { }
}
You can't call new Bar(1) as it does define a constructor that matches that signature. It didn't inherit any constructor.
@Johnathan,
Sure, I have to explicitly define the constructor for Bar(int) if I need one, but I do have access to the Foo(int) constructor from Bar. It is natural that no Foo constructor can initialize a new instance of Bar (not all Foos are Bars), but all Bar constructors must be capable of initializing Foos (all Bars are Foos). Therefore, all Foo constructors must accessible from any Bar constructor. I guess I am having trouble differentiating the inheritance of a protected method from the inheritance of a constructor.
For example:
public class Foo {
protected Foo(int i) { }
protected void M() { }
}
public class Bar : Foo{
public Bar(int i) : base(i) { }
public Bar(): this(0) { }
public void M2(){ base.M(); }
}
Are both M and Foo(int) not implicitly defined on Bar in this case?
Glad you mentioned the sync block… value types don't conform to the public interface of System.Object (they can't be used with the `lock` statement) so they aren't really subtypes of System.Object.
Unless and until they get boxed, anyway.
I seem to recall that one of your earlier posts mentioned that none of "inherits", "implements", "derives from", and "satisfies a where constraint" include LSP-substitutability. When you redefine terms, almost anything is possible, and even the sort of reasoning this blog post is based on breaks down.
Except that lock isn't part of Object's public interface. There is no method or other accessible member of Object that relates to the lock statement in C#. Rather, lock is syntactic sugar for calling Monitor.Enter and Monitor.Exit wrapped into a try/finally block. Technically, you could call Monitor.Enter and pass in a value type, but it's not very useful, which I assume is why C# doesn't allow you to use it in the lock statement.
Java is OK – inner class D has two x members: inaccessible inherited from B and accessible in outer class. 🙂
Forgive me if this is a double post. I don't know if my first post got eaten, just like Chris B's and Jonathan van de Veen's, or if it's just awaiting moderation, but I see no indication that it was successfully submitted.
———-
>> A derived type which inherits from a base type implicitly has all inheritable members of the base type. That's it!
Well, no, not exactly. I'd say it's more accurate (and more important) to say that a derived type that inherits from a base can be implicitly used as a base type. Inheriting the base's members is kind of a side effect of that.
Basically, you've described composition ("has-a" relationships), not inheritance ("is-a" relationships). A derived type must maintain its base's composition, but only so that it will still be usable as its base.
A car, for instance, has wheels, doors, and an engine. All cars have these traits (for the sake of discussion, we'll ignore Jeeps on the beach, "yard-cars" in the South, and Doc Brown's Delorean in 2015). A sports car, therefore, has wheels, doors, and an engine, as do luxury cars and family sedans. They each share these traits, because they all share the same is-a relationship with the base class "car". Someone who needs to use a car doesn't need specific instructions to use a sports car, a luxury car, or a family sedan, they only need to know how to use a car, and any of these types of cars will work for them.
When stressing the "is-a" relationship of inheritance, then it does indeed make it surprising that "where T : class" is combined with "where U : T" (read ":" as "is a"), that it doesn't follow that "where U : class" is implicit. The fact that it doesn't is the result of two decisions (and I'm not necessarily criticizing the decisions themselves) that are confusing to newbies:
* Value types nominally derive from reference types. Value types *aren't* (not is-a) reference types, not the way a family sedan *is a* car, but they can be implicitly *converted* to reference types.
* In a generic constraint, "class" actually means "reference type", and an interface is a reference type. Except that an interface is less like a type and more like a contract that can be, as you said, implemented by either a reference type or a value type. You could say that interfaces provide more of a "does-a" relationship than an "is-a" relationship. But we don't have a separate concept in C# for implementing a "does-a" relationship, other than pretending it's the same as inheriting an "is-a" relationship. So we treat interfaces like types instead of contracts, and, using the same implicit conversion as above, treat an interface type as a reference type, even if it's implemented by a value type. | https://blogs.msdn.microsoft.com/ericlippert/2011/09/19/inheritance-and-representation/ | CC-MAIN-2017-09 | refinedweb | 1,262 | 61.67 |
Instructions how-to use Zabbix as your Controller with MQTT, part 2 (Auto-Discovery of Sensors)
Part 2. First have a look at part 1.
Here's an additional script created in Python to implement Auto-Discovery and automatic creation of sensors and nodes in Zabbix. It's using the Zabbix-API to check and create hostgroup, hosts and items automatically, if they're new and presented to the Controller (after power-on of the node sensors). The script runs on my RPI, where my Mosquitto and Zabbix is installed too.
Script description.
The script connects to the mosquitto broker and listens to the MQTT traffic from the MySensors network.
- First it checks if the Zabbix-hostgroup exists, named "MySensors". If not it's created automatically.
- When a new sensor-node is presented via MQTT a Zabbix-host is created automatically, added to the hostgroup, and the host is named with the Topics prefix + Node-ID.
- When a new Child sensor is presented a Zabbix-Item is created, added to the host, and given the name of the Presentation Topic. The key of the Zabbix-Item is set to the value of Child-Id. The Item-name can later be modified to anything of your preference.
Run the script in the background together with the script described in part 1. The first script passes the data to Zabbix. And this script handles the automatic creation of the sensors.
Script:
import paho.mqtt.client as mqtt import time from pyzabbix import ZabbixMetric, ZabbixSender from zabbix.api import ZabbixAPI # Create ZabbixAPI class instance zapi = ZabbixAPI(url='', user='Admin', password='zabbix') # Moquitto Topic Prefix topic_sub = "domoticz/in/MyMQTT/" # Name of Zabbix hostgroup hostGroup = 'MySensors' # Create hostgroup, if missing result = zapi.do_request('hostgroup.get', {'filter': {'name': [hostGroup]}}) if [name['name'] for name in result['result']] == []: zapi.hostgroup.create(name=hostGroup) result = zapi.do_request('hostgroup.get', {'filter': {'name': [hostGroup]}}) print(time.strftime("%c")+" Hostgroup created: "+hostGroup+" : "+str(result)) # log hostgroup creation # Get hostgroup-id groupId = [name['groupid'] for name in result['result']] # Mosquitto: the callback for when the client receives a CONNACK response from the server. def on_connect(client, userdata, flags, rc): print("Connected with result code "+str(rc)) # Mosquitto: subscribing in on_connect() means that if we lose the connection and # reconnect then subscriptions will be renewed. client.subscribe(topic_sub+"+/+/+/+/+") # Mosquitto: the callback for when a PUBLISH message is received from the server. def on_message(client, userdata, msg): msg.topic = msg.topic.replace("/", ".") myNode = msg.topic[:msg.topic.find(".", len(topic_sub)+1)] myItem = msg.topic[len(myNode)+1:] mySplit = myItem.split('.') # Check if host (node) exist, or create new host. # 255 = child, 0 = presentation, 17 = S_ARDUINO_NODE if myItem == '255.0.0.17': result = zapi.do_request('host.get', {'filter':{'host':[myNode]}}) if [host['host'] for host in result['result']] == []: # new node sensor, create host result = zapi.do_request('host.create', {'host': myNode, 'interfaces': [{'type': 1, 'main': 1, 'useip': 1, 'ip': '127.0.0 .1', 'dns': '', 'port': '10050'}], 'groups': [{'groupid': groupId[0]}]}) print(time.strftime("%c")+" Host created: "+myNode+" : "+str(result)) # log host creation # create item I_BATTERY_LEVEL result = zapi.do_request('host.get', {'filter':{'host':[myNode]}}) hostId = [item['hostid'] for item in result['result']] result = zapi.do_request('item.create', {'hostid': hostId[0], 'value_type': '0','type': '2', 'name': 'I_BATTERY_LEVEL', ' key_': '255.3.0.0'}) print(time.strftime("%c")+" Item created: I_BATTERY_LEVEL : "+str(result)) # log item creation if mySplit[1] == '0': # command = presentation if mySplit[0] != '255': # child = 255, don't create item result = zapi.do_request('item.get', {'host': myNode, 'filter': {'key_':[mySplit[0]]}}) if [host['key_'] for host in result['result']] == []: # new child, create item result = zapi.do_request('host.get', {'filter':{'host':[myNode]}}) hostId = [item['hostid'] for item in result['result']] result = zapi.do_request('item.create', {'hostid': hostId[0], 'value_type': '0','type': '2', 'name': myItem, 'key_': mySplit[0]}) print(time.strftime("%c")+" Item created: "+myItem+" : "+str(result)) # log item creation # Mosquitto: client start-up. client = mqtt.Client() client.on_connect = on_connect client.on_message = on_message client.connect("localhost", 1883, 60) # Mosquitto: blocking call that processes network traffic, dispatches callbacks and # handles reconnecting. client.loop_forever()
Run the script e.g. in the background as a daemon and printouts sent to a log file "zabbix_cnfg.log
python -u mqtt_zabbix_api.py > zabbix_cnfg.log 2>&1 &
I'm quite new with Python scripting, so it's possible the code isn't that elegant. But it works fine for me. :simple_smile:
And it's fun!? | https://forum.mysensors.org/topic/5890/instructions-how-to-use-zabbix-as-your-controller-with-mqtt-part-2-auto-discovery-of-sensors/1 | CC-MAIN-2019-04 | refinedweb | 728 | 51.44 |
I asked on Twitter today what Linux things they would like to know more about. I thought the replies were really cool so here’s a list (many of them could be discussed on any Unixy OS, some of them are Linux-specific)
- tcp/ip & networking stuff
- what is a port/socket?
- seccomp
- systemd
- IPC (interprocess communication, pipes)
- permissions, setuid, sticky bits, how does chown work
- how the shell uses fork & exec
- how can I make my computer a router?
- process groups, session leaders, shell job control
- memory allocation, how do heaps work, what does malloc do?
- ttys, how do terminals work
- process scheduling
- drivers
- what’s the difference between Linux and Unix
- the kernel
- modern X servers
- how does X11 work?
- Linux’s zero-copy API (sendfile, splice, tee)
- what is dmesg even doing
- how kernel modules work
- embedded stuff: realtime, GPIO, etc
- btrfs
- QEMU/KVM
- shell redirection
- HAL
- chroot
- filesystems & inodes
- what is RSS, how do I know how much memory my process is using
- iptables
- what is a network interface exactly?
- what is syslog and how does it work?
- how are logs usually organized?
- virtual memory
- BPF
- bootloader, initrd, kernel parameters
- the
ipcommand
- what are all the files that are not file files (/dev, stdin, /proc, /sys)
- dbus
- sed and awk
- namespaces, cgroups, docker, SELinux, AppArmor
- debuggers
- what’s the difference between threads and processes?
- if unix is text-based, how do desktop environments like GNOME fit in?
- how does the “man” system work.
- kpatch, kgraph, kexec
- more about the stack. Are C vars really stack slots? How tf do setjmp and longjmp work?
- package management
- mounts and vfs
this is great for so many reasons!
- I need to draw 11 more drawings about Linux this month and these are such great ideas
- there are many things I don’t know on this list and it’s a cool reminder of how much interesting stuff there still is to learn! A few of these I barely even know what they are (dbus, SELinux) or only have a pretty sketchy notion (seccomp, how X11 works, many more)
- it’s also a cool reminder of how far I’ve come – I at least know where to start with most of the things on this list, even if I definitely could not explain a lot of them in detail without looking some stuff up.
Also I sometimes want to remind people that you too could write interesting blog posts / drawings on the internet – for instance “what is dmesg even doing” is an interesting topic, and totally possible to learn about! (I just read dmesg on Wikipedia and now I know more!) | https://jvns.ca/blog/2016/11/21/things-to-learn-about-linux/ | CC-MAIN-2019-09 | refinedweb | 441 | 65.56 |
The.
Over the months, we developed integration testing on top of our unit testing to validate that our storage drivers are able to deal with real world databases. That is not really different from generic integration testing.
Integration testing is about plugging all the pieces of your software all together and running. In what I call "database integration testing", the pieces will be both your software and the database system that you are going to rely on.
The only difference here is that one of the module is not coming from the application itself but is an external project. The type of database that you use (RDBMS, NoSQL…) does not matter. Taking a step back, what I will describe here could also apply to a lot of other different software modules, even something that would not be a database sytem at all.
Writing tests for integration
Presumably, your Python application has unit tests. In order to test against a database back-end, you need to write a few specific classes of tests that will use the database subsystem for real. For example:
import unittest import os import sqlalchemy class TestDB(unittest.TestCase): def setUp(self): url = os.getenv("DB_TEST_URL") if not url: self.skipTest("No database URL set") self.engine = sqlalchemy.create_engine(url)
This code will try to fetch the database URL to use from an environment variable, and then will rely on SQLAlchemy to create a database connection.
import unittest import os import sqlalchemy import myapp class TestDB(unittest.TestCase): def setUp(self): url = os.getenv("DB_TEST_URL") if not url: self.skipTest("No database URL set") self.engine = sqlalchemy.create_engine(url) def test_foobar(self): self.assertTrue(myapp.store_integer(self.engine, 42))
You can then add as many tests as you want using the connection stored in
self.engine. If no test database URL is, the tests will be skipped; however that decision is up to you. You may want to have these tests always run and fail if they can't be run.
In the
setUp() method, you may also need to do more work, like create a database and delete a database.
import unittest import os import sqlalchemy class TestDB(unittest.TestCase): def setUp(self): url = os.getenv("DB_TEST_URL") if not url: self.skipTest("No database URL set") self.engine = sqlalchemy.create_engine(url) self.connection = self.engine.connect() self.connection.execute("CREATE DATABASE testdb") def tearDown(self): self.connection.execute("DROP DATABASE testdb")
This will make sure that the database you need is clean and ready to be used to testing.
Launching modules, a.k.a. databases
The main problem we encountered when building integration testing with databases, is to find a way to start them. Most users are used to start them system-wide with some sort of init script, but when running sandboxed tests, that is not really a good option. Browsing the documentation of each storage allowed us to find a way to start them in foreground and control them "interactively" via a shell script.
The following is a script that you can use to run Python tests using nose and is heavily inspired by the one we wrote for Ceilometer.
#!/bin/bash set -e clean_exit() { local/dev/null 2>&1 then echo "Could not find $1 command" 1>&2 exit 1 fi } wait_for_line () { while read line do echo "$line" | grep -q "$1" && break done < "$2" # Read the fifo for ever otherwise process would block cat "$2" >/dev/null & } check_for_cmd postgres trap "clean_exit" EXIT # Start PostgreSQL process for tests PGSQL_DATA=`mktemp -d /tmp/PGSQL-XXXXX` PGSQL_PATH=`pg_config --bindir` ${PGSQL_PATH}/initdb ${PGSQL_DATA} mkfifo ${PGSQL_DATA}/out ${PGSQL_PATH}/postgres -F -k ${PGSQL_DATA} -D ${PGSQL_DATA} &> ${PGSQL_DATA}/out & # Wait for PostgreSQL to start listening to connections wait_for_line "database system is ready to accept connections" ${PGSQL_DATA}/out export DB_TEST_URL="postgresql:///?host=${PGSQL_DATA}&dbname=template1" # Run the tests nosetests
If you use tox to automatize your test run, you can use this scripts (I call it
run-test.sh) in your
tox.ini file.
[testenv] commands = {toxinidir}/run-tests.sh {posargs}
Most databases are able to be run in some sort of standalone mode where you can connect to them using a either a Unix domain socket, or a fixed port. Here are the snippet used in Ceilometer to run with MongoDB and MySQL:
# Start MongoDB process for tests MONGO_DATA=$(mktemp -d /tmp/MONGODB-XXXXX) MONGO_PORT=29000 mkfifo ${MONGO_DATA}/out mongod --maxConns 32 --nojournal --noprealloc --smallfiles --quiet --noauth --port ${MONGO_PORT} --dbpath "${MONGO_DATA}" --bind_ip localhost &>${MONGO_DATA}/out & # Wait for Mongo to start listening to connections wait_for_line "waiting for connections on port ${MONGO_PORT}" ${MONGO_DATA}/out export>IMAGE_3<<
# Start MySQL process for tests MYSQL_DATA=$(mktemp -d /tmp/MYSQL-XXXXX) mkfifo ${MYSQL_DATA}/out mysqld --datadir=${MYSQL_DATA} --pid-file=${MYSQL_DATA}/mysql.pid --socket=${MYSQL_DATA}/mysql.socket --skip-networking --skip-grant-tables &> ${MYSQL_DATA}/out & # Wait for MySQL to start listening to connections wait_for_line "mysqld: ready for connections." ${MYSQL_DATA}/out export DB_TEST_URL="mysql://root@localhost/testdb?unix_socket=${MYSQL_DATA}/mysql.socket&charset=utf8"
The mechanism is always the same. We create a fifo with
mkfifo, and then run the database daemon with the output redirected to that fifo. We then read from it until we find a line stating the the database is ready to be used. At that point, we can continue and start running the tests. You have to read continuously from the fifo, otherwise the process writing to it will block. We redirect the output to
/dev/null, but you could also redirect it to a different log file, or not at all.
Note: Evgeni Golov pointed it exists a pg_virtualenv for PostgreSQL and my_virtualenv for MySQL that does the same kind of thing, but with more bells and whistles.
One step further: using parallelism and scenarios
The described approach is quite simple, as it only support one database type. When using an abstraction layer, such as SQLAlchemy, it would be a good idea to run all these tests against different RDBMS, such as MySQL and PostgreSQL for example.
The snippet above allows to run both RDBMS in parallel, but the classic approach of unit tests does not allow that. Using one scenario for each database backend would be a great idea. To that end, you can use the testscenarios library.
import unittest import os import sqlalchemy import testscenarios load_tests = testscenarios.load_tests_apply_scenarios class TestDB(unittest.TestCase): scenarios = [ ('mysql', dict(database_connection=os.getenv("MYSQL_TEST_URL")), ('postgresql', dict(database_connection=os.getenv("PGSQL_TEST_URL")), ] def setUp(self): if not self.database_connection: self.skipTest("No database URL set") self.engine = sqlalchemy.create_engine(self.database_connection) self.connection = self.engine.connect() self.connection.execute("CREATE DATABASE testdb") def tearDown(self): self.connection.execute("DROP DATABASE testdb")
$ python -m subunit.run test_scenario | subunit2pyunit test_scenario.TestDB.test_foobar(mysql) test_scenario.TestDB.test_foobar(mysql) ... ok test_scenario.TestDB.test_foobar(postgresql) test_scenario.TestDB.test_foobar(postgresql) ... ok --------------------------------------------------------- Ran 2 tests in 0.061s OK
To speed up tests run, you could also run the test in parallel. It can be intesting as you'll be able to spread the workload among a lot of different CPUs. However, note that it can require a different database for each test or a locking mechanism to be in place. It's likely that your tests won't be able to work altogether at the same time on only one database.
(Both usage of scenarios and parallelism in testing will be covered in The Hacker's Guide to Python,
in case you wonder.) | https://julien.danjou.info/db-integration-testing-strategies-python/ | CC-MAIN-2018-39 | refinedweb | 1,227 | 55.84 |
Scala 2.8 Beta 1 Released
- |
-
-
-
-
-
-
-
Read later
My Reading List
The creators of the Scala programming language have just released the long-awaited first beta of Scala 2.8.
It includes a huge number of bug fixes with respect to 2.7.7, and many new features. This beta is the foundation for the release of the upcoming final version of 2.8.0, expected in a few months.
The small increase in the version number (from 2.7.7) does not properly reflect how many changes the language has undergone. Unfortunately, Scala 2.8 is not binary compatible with the 2.7 branch.
Some examples of new features are (see the release announcement for a comprehensive listing):
Redesigned Collection Library
Scala's collection library has been completely redesigned. It is now not only easier to implement new collections, users will also notice the benefits (while being mostly backwards compatible), as Daniel Sobral remarked on the Scala-User mailinglist:
Scala 2.7 doesn't have the necessary power to make a "map" that returns a "Map" from a "Map". Being able to do things like that is the main reason for the new collection library in Scala 2.8."
More on the new collections can be found in this entry on the Scala website.
Named and Default Arguments
Scala 2.8 also offers new language features, like the new named and default arguments. Named arguments look like assignments to the names of the called method's formal parameters:
def resize(width: Int = 800, height: Int = 600) = { ... } resize(width = 120, height = 42)
Named and default arguments work hand in hand; one can pick a certain parameter by its name and use defaults for the others:
resize(height = 42)
These novelties are also used in another new feature: case classes have a copy method whose parameters default to the current values. Using named arguments, one can selectively change values for the copied instance, as shown on the Scala website.
Improved Interactive Interpreter
Scala's interactive interpreter has become a lot more powerful with support for tab-completion on packages, classes, and members. The feature uses reflection, and works not only for Scala code but just as well with Java. A blog post by Arjan Blokzijl explores more of the new features.
Improved Eclipse Plug-in
A new version of the Scala Eclipse plug-in will be released along with Scala 2.8. Integration with the JDT has been greatly improved; a new build manager makes compilation much faster and more reliable. A presentation by Miles Sabin (PDF), the main developer of the Scala plug-in, has further details about the work that has happened last year.
InfoQ also talked to Miles to learn more about the current status and the future of the IDE. The IDE comes with support for the new version of Scala, but does it also support Scala 2.7?
The IDE is currently intrinsically linked to the compiler ... it's the latter that drives all of the IDEs semantically sensitive features. It will be possible to loosen the dependency a little to support multiple versions for releases beyond 2.8, but unfortunately not for earlier versions. For now I recommend that people create separate Eclipse instances for work on the 2.7 vs. 2.8 streams.
A recent meeting report mentioned that the Scala IDE will get its own release schedule, what is the intention behind that?
With the 2.8 stream, the IDE is on a much more solid footing that it has been previously. It should be possible to move forward more quickly now, and we need to option of releasing more frequently than the main Scala toolchain.
What are your plans for the future of the IDE?
My goal is for the Scala tooling to be at least on a par with the tooling for Java. There's a way to go on that, but we can get there.
With the 2.8 final release I hope to launch a dedicated web presence for the IDE which will be the primary source for releases on the new cycle, will collect the existing but somewhat scattered documentation and resources for the IDE, and be a central organizing point for users and contributors.
Of course, the Eclipse IDE is not the only one with support for 2.8; NetBeans and IntelliJ are on their way too.
Scala Days 2010
On April 15-16, Scala enthusiasts will meet at Scala's birthplace, the EPFL in Lausanne, Switzerland, for the first Scala Days, "to exchange ideas and form business relations, as well to discover the latest practical and theoretical development concerning the Scala language".
Get the Scala 2.8 Beta, and make sure to report bugs and problems so they can be fixed for the final release, which should be ready
Hurray
by
challe wdll
Re: Hurray
by
Simon Pearce
(I mean, one missing apostrophe, two random commas, one misspelled word ... not bad in one sentence of 18 word).
Re: Hurray
by
Matt Russell
Muphry's law. | https://www.infoq.com/news/2010/01/scala-beta1 | CC-MAIN-2016-36 | refinedweb | 839 | 63.09 |
SKOS Reference Last Call Working Draft TODO List
Editorial Tasks
Add RDFa metadata?
WG Reviews
In the following, the original review text and comments are given, interleaved with responses. Those comments which I consider to have been addressed are rendered in strikethrough text.
Review from Guus Schreiber
This document is in good shape. I have no objections to publishing, provide the comments below are taken into account. Most comments are editorial.
GENERAL EDITING
Please change "foo/bar" examples.
Section 1.4 changed to dogs/cats. SKB
Section 1.6.1 changed to Person/hasParent/hasMother. SKB
Examples using foo/bar changed to love/adoration. SKB
"Integrity constraints/conditions": use one of these forms consistently
Changed in 9.6.2. SKB
"data" variably used as singular or plural, e.g. "SKOS data are" but also "some given data conforms to "
Usage changed consistently to plural. SKB
SYNOPSIS
"documented with various types of note" note => notes
I believe this is ok as it stands, with the plural form of types. SKB
STATUS
The 2nd "feature at risk" is unclear. We have to state the options and how the current choice might change (e.g. adding property-chaining axioms).
Done. SKB
SEC. 1
Consider to add a note about the overall design rationale behind SKOS, roughly covering the following issues: - wide coverage of KOSs required - therefore danger of SKOS schema overcommitment - WG rationale: if in doubt, don't include a formal constraint (least commitment strategy), but suggest usage convention or specialization instead => see Primer
The following has been added before Section 1.6 (How to Read this Document).2: suggest to change section title to "SKOS Overview"
Done. SKB
1.3
" ...I.e. SKOS is itself an OWL Full ontology." delete this part of the sentence as it is more or less a repetition of the earlier part.
Removed. SKB.
I suggest to delete this paragraph. I think the issue is made clear enough in the rest of the text (also in 1.4), and this paragraph might be perceived as too opinionated.
Removed. SKB
1.4
Should we label this section explicitly as "Informative"?
Left as is. SKB
1.5
These statements are not integrity conditions. I.e. the graph below is perfectly consistent with the SKOS data model, despite the fact that <A> and <B> have not been explicitly declared as instances of skos:Concept.
I find this unclear, in particular the "despite" part. I would reverse the argument: OWL Full does not require that <A> and <B> are explicitly defined as concepts, so the model is consistent. You could also argue that it is till an integrity constraint, as it disallows, for example, <A> to be a concept scheme. This is the only point in my review where I would appreciate some discussion.
The section has been rewritten. SKB 1.7
"an RDF graph" => "a RDF graph"
I believe that "an RDF Graph" is the correct usage. Adopting the wisdom of the crowd, Google gives 36,000 hits for "an RDF graph" and 785 for "a rdf graph". SKB
SEC. 2:
I suggest to make the table ordering more logical:
skos:Concept skos:ConceptScheme skos:inScheme skos:hasTopConcept skos:topConceptInScheme skos:altLabel skos:hiddenLabel skos:prefLabel skos:note skos:notation skos:changeNote skos:definition skos:editorialNote skos:example skos:historyNote skos:scopeNote skos:semanticRelation skos:broaderTransitive skos:broader skos:narrowerTransitive skos:narrower skos:related skos:Collection skos:OrderedCollection skos:member skos:memberList skos:mappingRelation skos:closeMatch skos:exactMatch skos:broadMatch skos:narrowMatch skos:relatedMatch
The table is ordered according to document section. We suggest to leave it as is. SKB
SEC. 4
Example 5:
<MyConcept> skos:topConceptInScheme <MyScheme> .
This statement could have been derived from the inverse semantics. Either remove or explicate in the text.
Triple removed. SKB
I find the name "skos:topConceptInScheme" too contrived. I prefer the natural inverse of "skos:hasTopConcept", namely "skos:topConceptOf". This is probably also eaier to understand and remember.
Changed to skos:topConceptOf. SKB
4.6.3 named RDF graphs
Explain (or refer to Primer) the issue of schema containment and potential use of SPARQL + named graphs
This section has been removed following discussion during the 19-08-08 telecon. SKB
SEC. 5
5.6.2
For an application that needs to identify labels using URIs, consider using the SKOS eXtension for Labels defined in Appendix A.
Instead of this single sentence I suggest to make a separate note about XL (e.g. "5.6.3 Defining label relations"), explicating in a few sentences why this is needed, just to point readers in the right direction.
New section added. SKB
5.6.4
This note feels a bit redundant as the point about language tags is already made at the end of 5.4
The note does provide illustrative examples, so I would suggest it remain. SKB
SEC. 7
"7" => "seven"
Done. SKB
Example 25: I suggest to refrain from using the construct "rdf:value" as it is so rarely used. If you really need it, you have to add an explanatory note + RDF ref.
Dealt with in the primer. See:. SKB
SEC. 8
S26: skos:related is disjoint with the property skos:broaderTransitive.
Is skos:related also disjoint with skos:narrowerTransitive?
Yes, due to the fact that skos:related is symmetrical. Added explanatory note. SKB
8.6.4.
Explain briefly rationale why skos:related is not transitive.
Dealt with in the primer. See:. SKB
8.6.6
"(e.g. simple query expansion algorithms)": delete "simple"
Done. SKB
8.6.10
First par: ".. distinct in nature, and that therefore a ..." => ".. distinct in nature. Therefore a ..."
Done. SKB
SEC 9
9.6
Suggest to explain briefly the use of "( .. )" notation in Turtle.
Done (in 9.5). SKB
SEC 10
S46: should skos:exactMatch not also be disjoint with skos:narrowMatch?
Symmetry of exactMatch will ensure this. Added explanatory note. SKB
10.6.7:
"link to individuals" to => two
Done. SKB
Generally speaking, using owl:sameAs in this way will lead to inappropriate inferences, which may sometimes (but not always) be detectable by checking consistency with the SKOS data model.
Obscure sentence. The point was already made above, suggest to delete this sentence.
Done. SKB
APPENDIX
"A property xl:labelRelation is defined. " => "The SKOS data model also defines the property xl:labelRelation."
Done. SKB
A1
I suggest to use "skos-xl:" in the examples instead of "xl". In this document it is not ambiguous, but in actual usage it might lead to reduced clarity. People will use the reference as a model.
Is this allowed? A hyphen in a namespace name? I have replaced with skosxl. SKB
A2.1
"an RDF plain literal": an => a
See above comment. SKB
A2.2
Shouldn't there be a definition c.q. semantic condition to define the cardinality of precisely 1 for xl:literalForm? BTW this would make the FuctionalProperty definition superfluous.
Condition S52 has been changed to reflect this. SKB
A2.4.1
"As stated above ...": this has actually not been stated yet, see previous comment.
See above response. SKB
Second, the function is not surjective. In other words, there may be no instances of xl:Label with a literal form corresponding to a given plain literal.
I cannot parse this sentence (in particular the last part); please reformulate.
Reworded as: In other words, for a given plain literal <code>l</code>, there may <strong>not</strong> be an instance of <code>skosxl:Label</code> with <code>l</code> as a literal form. SKB
Reworded a bit more, to avoid possible misreading as a normative statement, as: In other words, for a given plain literal <code>l</code>, there might not be any instances of <code>skosxl:Label</code> with literal form <code>l</code>. AJM
A3.4.2
"Note the two integrity conditions on the SKOS labeling properties defined in Section 5." => "In Section 5 two integrity conditions were defined on the basic SKOS labeling properties."
Done. SKB
Review from Margherita Sini
Abstract: OK
Status of This Document: OK
Changes: OK
1.1. Background and Motivation:
In the background and motivation, i would suggest to add a sentence that mention that today no real unified or standardized way for representing thesaurus exists: there are ISO standards to structure thesauri (with specific well defined relationships), but no technical way of representing those... Some are just in word files, some printed in hard copies, some in any custom defined ms access forms... So This is one other reason why we need SKOS (if not alreaqdy covered by last 2 paragraphs).
Amended as: "..." AJM
1.2. What is SKOS?
I would suggest to change <<<Using SKOS, a knowledge organization system can be expressed as data.>>> with "... as formalized data." or "... as computer-processable data."
Inserted "...machine readable data...". SKB
In the sentence <<<SKOS concepts can be assigned one or more notations, which are lexical codes used to uniquely identify the concept within the scope of a given concept scheme (also known as classification codes).>>> ... can we mention something that identify that these "codes" (even if i would prefer to call them differently... such as "specific alphanumeric or numeric values, or symbols") are or may be different from codes used to create/generate the URI? why do we need to "uniquely identify the concept within the scope of a given concept scheme"... is the URI not enough?
Amended as: "SKOS concepts can be assigned one or more <strong>notations</strong>,ues." AJM).
This is a new requirement and we don't think this can be addressed in the current draft. AJM
1.3. SKOS, RDF and OWL:
I think there is an editorial mistake here: <<<by the logical characteristics of and interdependencies between those classes and properties>>>. Is it a mistake "of and"?
by the logical characteristics of, and interdependencies between, those classes and properties. SKB
Suggestion: instead of saying <<<<using the "concepts" of the thesaurus as a starting point for creating classes, properties and individuals >>>> I would say "using the "elements" of the thesaurus as a starting point for creating classes, properties and individuals " or "using the "main descriptors" of the thesaurus as a starting point for creating classes and individuals, the non-descriptors for labels and relationships for properties ".
This paragraph has been removed in response to a comment from Guus. AJM
In the sentence <<.>>> maybe you can even add an example in which sometimes in a thesaurus we may have non-descriptors with refer to a maybe more generic descriptor... The 2 are related by the USE/UsedFor relationships but may not necessarily synonyms... so sometimes USE/UsedFor can be converted into an alternative label for a concept, sometimes they can be converted in actually 2 different concepts.
This paragraph has been removed in response to a comment from Guus. AJM
In the next paragraph: <<<Taking this approach, the "concepts" of a thesaurus or classification scheme are modeled as individuals in the SKOS data model>>> this means that skos:Concept is in OWL an individual?
No. skos:Concept is an owl:Class. The particular instances of skos:Concept, e.g. ex:Cat or ex:Dog are individuals (with rdf:type skos:Concept). SKB
In last example, you are basically saying that representing a thesaurus in SKOS+OWL i may have some thesaurus elements ("concepts") as owl:class and some others as skos:concepts???
The example illustrates that owl:Classes and skos:Concepts may be mixed arbitrarily. There is nothing in the SKOS Recommendation to prevent this.
Last sentence <<<need to appreciate the distinction>>> means that users do need to do the distinction or it is not mandatory to make the distinction (between skos:Concept and owl:Class)?
Ideally, users should be aware of the distinction, as different inferences may arise, depending on whether skos:Concepts or owl:Classes are defined. If applications are to respect the underlying semantics of the languages (OWL and RDF), then they would need to make the distinction. It may be that we can make this clearer. SKB
1.4. Consistency and Integrity: OK
1.5. Inference, Dependency and the Open-World Assumption
Sentence <<<and for the possibility of then using thesauri>>> should maybe be "and for the possibility of using thesauri" (editorial mistake)?
"then" removed. SKB
1.6. How to Read this Document
I am not a native english speaker so some of my comments may be not appropriate... E.g. sentence <<<Integrity Conditions — if there are any integrity conditions, those are given next.>>> is "next" here to be interpreted as "in this section"?
The integrity conditions are given in the appropriate context. The word "next" is unnecessary here and possibly confusing, so it has been removed. SKB
1.7. Conformance: OK
Section: 2.
My comment about the URI would be that i suggest to keep alive and resolvable the old URI for legacy system, but the new URi should be also published so that new systems may show the new changes. It will be up to the user to decide if they want to move to the new uri or not.
No response needed. AJM
3.3. Class & Property Definitions
<<<skos:Concept is an instance of owl:Class>>>. Means that skos:Concept its an Individual in OWL? I was actually thinking that skos:Concept is an owl:Class...
You are right in your thinking. skos:Concept is an owl:Class. This is exactly what the text says. Recall that owl:Class is a "meta-class", in that instances of owl:Class are classes. SKB
3.5.1. SKOS Concepts, OWL Classes and OWL Properties You say <<<This specification does not make any statement about the formal relationship between the class of SKOS concepts and the class of OWL classes>>> But in section 3.3. Class & Property Definitions you just said "skos:Concept is an instance of owl:Class"... so how could you not make statement about their relationship if you say one is an instance of the other.... It is not a contracdition?
The statement here is intended to highlight the fact that there is no expectation or requirement for a particular skos:Concept to be interpreted as an owl:Class or to have an associated owl:Class. This has been made clearer through the following text Other than the assertion that <code>skos:Concept</code> is an instance of <code>owl:Class</code>, this specification does <strong>not</strong> make any additional statement about the formal relationship between the class of SKOS concepts and the class of OWL classes. SKB
Other than the assertion that <code>skos:Concept</code> is an instance of <code>owl:Class</code>, this specification does <strong>not</strong> make any additional statement about the formal relationship between the class of SKOS concepts and the class of OWL classes. SKB
From the examples and the text i understood that you do not want to specify if skos:Concept is a class or an individual or any other element (e.g. ObjectProperty)... But then why have you said that <<<skos:Concept is an instance of owl:Class>>>?
See above. AJM.
Personally I can see that from a KOS we may have skos:Concept as owl:Class (e.g. "cows" its a class). Or we may have instances (e.g. "Batissa violacea", its a specific species of a mollusc).
skos:Concept is the class of SKOS concepts, thus is defined as an instance of owl:Class. Sections 1.2 and 1.3 are intended to explain this. SKB
4.2. Vocabulary
Why the <<skos:topConceptInScheme>> has been introduced? the "skos:hasTopConcept" is enough to be able to represent in any system the top level elements of a scheme... Do we really have to use <<skos:topConceptInScheme>>? If i generate my skos file this new statement will make my file bigger without introducing really a new information. In fact I can infere this from the "skos:hasTopConcept"...
skos:topConceptInScheme was introduced in order to address ISSUE 83 and to allow the statement of the relationship between skos:inScheme and skos:hasTopConcept (without resorting to the use of an anonymous property which is known to be problematic). There is no need to assert skos:topConceptInScheme for any concept that is the subject of a skos:hasTopConcept assertion. The fact that the two properties are inverses will allow such an inference to be made. SKB....
This is, in principle, already possible using SKOS XL, because an instance of xl:Label can have a skos:inScheme property. However a discussion of design patterns such as this is beyond the scope of the SKOS Reference, and probably needs further exploration within the community of practice. AJM
And what about the URI of the skos:Concept? will it be the one from one scheme (e.g. <skos:Concept rdf:) or from the other scheme (e.g. <skos:Concept rdf:)?)-- for working with multiple concept schemes in SKOS, and these need further investigation. Many of these design patterns remain to be explored or well documented, therefore we feel a discussion of these issues is beyond the scope of the SKOS Reference (but would make a great subject for a follow-up note). AJM
4.6.4. Top Concepts and Semantic Relations
How the example is consistent? as we are probably sure that skos:hasTopConcept will be used for top concept which do not have any BT... should we instead enforce this to be correct in SKOS? i mean enforce that a top Concept cannot have BT....
The example is intended to highlight precisely the fact that the constraint that you mention (top concept cannot have BT) is not explicitly represented in the SKOS data model and thus there is no inconsistency in the example. SKB
We felt it was adequate to handle this situation by a usage convention, which applications can check if they need to, rather than add a formal constraint in the data model. AJM
5. Lexical Labels
I am still convinced that in future version of SKOS we do not need "A resource has no more than one value of skos:prefLabel per language." anymore.... because one day all indexing will be done using URIs... so we do not need distinction between preferred and non preferred... we may represent a concept with simply more labels per language.... E.g. which one is preferred between "canotto"@IT and "gommone"@IT ? why we should prefer an acronym to a full form or viceversa? why we force people to disambiguate into a term for real synonyms such as "Argentina (fish)" and "Argentina" ?
This issue is out of scope for the current draft. AJM
6.5.3. Unique Notations in Concept Schemes
<<<By convention, no two concepts in the same concept scheme are given the same notation. If they were, it would not be possible to use the notation to uniquely refer to a concept (i.e. the notation would become ambiguous).>>> I think that what should be really unique is the URI. This sentence is ok as it only "By convention" notation unique.
No action. SKB
6.5.4. Notations and Preferred Labels
Section 7: ok
Section: 8.1. Preamble
What about the proposal to change skos:broader into skos:hasBroader (same for narrower)? makes much more clear the use of the rt...
The WG formally resolved ISSUE-82 by adding editorial changes to the documents highlighting the intended interpretation of broader and narrower. Hence the SKOS Reference now contains passages such as ." AJM
8.4. Integrity Conditions
<<<skos:related is disjoint with the property skos:broaderTransitive.>>> Why it is not specified skos:related is disjoint with the property skos:narrowerTransitive?
The assertion is not needed due to the fact that skos:related is symmetrical. Added an explanatory noteSKB
I remember that skos:broader and skos:broaderTransitive were of very difficult comprehension by some users especially for the hierarchical relationships between them (myself I was thinking as should be skos:broaderTransitive subclass of skos:broader instead of the opposite). In order to make this more comprehensible, would it be possible to add an examples such as "skos:broaderTransitive" may be the "ancestor" relationship. This is transitive. A chidren relationships may be the "father" and also "adoptive father". "adoptive father" is not transitive... This is a good examples explaining the same situation as in SKOS. (maybe help?)
We feel this is out of scope for the SKOS Reference, but may be appropriate in the SKOS Primer. AJM
8.6.7. Reflexivity of skos:broader
Example 39 (consistent): are we really sure we do not want to set skos:broader as anti-simmetric? in most of the cases when we use skos:broader one concept is more generic than the other... so skos:broader is actually used as non simmetric... do we have use cases for which should be not like this?
Note that reflexivity and symmetry are two different qualities. Section 8.6.7 is about the reflexivity of skos:broader, and does not discuss symmetry. The WG formally resolved ISSUE-69 such that skos:broader should be not normatively irreflexive, to leave open the exploration of various design patterns for working with SKOS and OWL in combination. AJM
Section: 9. ok
Section: 10.
yes i wish actually to chain skos:exactMatch... it may be useful.
Is this an explicit request for property chain axioms relating to the mapping properties? No action taken. SKB
The WG formally resolved ISSUE-75 such that no property chain axioms shall be stated in the SKOS data model involving skos:exactMatch, because this is an area for further research. This does not prevent applications asserting their own property chain axioms and drawing their own conclusions. AJM
Appendix A ok
Appendix B and C ok
Another general comment would be: would not be better to have more meaningful examples instead of "foo" and "bar" ?
Examples changed. SKB
Meeting Minutes
Relevant meeting minutes: -- resolved ISSUE 72, 73, 75, 86 -- resolved ISSUE 83
Implementation: Scheme Containment Properties (ISSUE-83)
ISSUE 83 was resolved at as per text at
- TODO change data model in section 4
- TODO change prose in section 4 (add a new note?)
Implementation: Addition of Wording on URI Dereference Behaviour (ISSUE-86)
ISSUE 86 was resolved at
- Appendix on URI Dereference Behaviour
- Sean TODO
Text drafted: ]".
- Added appendix to working copy. 08/07/08
Implementation: Updates to Mapping Properties Section (ISSUES 72, 73, 75)
ISSUES 72, 73 and 75 were resolved at
- . Text describing resolution of ISSUES 72, 73 and 75
- ??? TODO
- Definition of closeMatch
- Justification of inclusion of closeMatch
- Update to RDF schema.
- . List of changes since last WD
- ??? TODO
Editorial: Identify Features at Risk
- . Identification of features AT RISK
- Sean TODO
- Initial list added. 08/07/08
Editorial: References Section
- TODO do the references section
- TODO link up all citations properly
Editorial: RDFa?
- TODO sprinkle some RDFA
SKOS Reference 2nd Working Draft TODO List
Set up master.html document under W3C CVS, including folding in post-edits from first WD
- Alistair --done
. Remove redundant appendices
- Alistair --done
Draft new section on notations
- Alistair --done
Redraft section on mapping properties
- Alistair --done
Draft new appendix on XL, and remove current section on label relations
- Guus TODO draft some wording and examples ???
Alistair incorporate content into draft & finish --done
Update section on semantic relations, including notes on irreflexivity, and wording to explain directionality of broader/narrower
- Sean --done
- Notes on irreflexivity added to Section 8.6.7. 27/05/08
- Sentence added in Section 8.1 27/05/08
Update sections referencing owl:imports
- Sean --done
- Propose removal of text from Section 4.6.2 from "In the example below, owl:imports..".
- Text stripped out of Section 4.6.2 27/05/08
Update namespace
- Alistair --done
Update vocabulary and quick access
- Alistair TODO
Review editors' comments in draft, remove/update as appropriate
- Alistair --done
Redraft formal schema (SKOS)
- Sean --done
Draft schema set up at [ SKOS RDF Schema] using Recipe 3.
Draft new formal schema (XL)
- Sean --done
Draft schema set up at [ SKOS XL RDF Schema] using Recipe 3.
Run checks on formal schemas
- Alistair --done
Remove summary tables, then regenerate from schemas
- Alistair --done
- Create timestamped editors' draft
- Alistair TODO
Fix headings in timestamped editors' draft and number tables, examples etc.
- Alistair TODO
- Compile a list of changes since last WD
- Alistair TODO
- Notify WG and request review
- Alistair TODO
Email to editors of primer on any guidance for extending SKOS (was rules of thumb)
- Sean --done
- Mailed Antoine, Ed. 15/05/08 SKB
Response from Antoine 21/05/08. See [ SkosPrimer20080221].
- Sean --done
- Mailed Ralph with proposal to provide short overview including generated table. 15/05/08 SKB.
Namespace to be. 19/05/08 SKB.
- SKOS/OWL Patterns
- Remove Appendix.
- Additional WG Note?
Terminology: Patterns may not be quite right.
Wiki page: [ SKOSandOWL]
Other Actions
- Namespaces setup for dereferencing (recipe 3)
- See K, L, T above re. formal schema.
- TODO Review section 1.2 "what is SKOS?" for section numbers and content
- TODO note on unique preflabels in schemes
- --done examples consistent, not consistent, entailment, non-entailment | http://www.w3.org/2006/07/SWD/wiki/SKOS/Reference/Planning.html | CC-MAIN-2014-42 | refinedweb | 4,161 | 56.86 |
Hello everyone!! I really need some help! I am trying in implement a tic tac toe game made of different classes in which the board can be expandable. I have most of it figured it out but after I ask the first player for their move it ends the game and says that player 1 won the game. I want my check Winner function in my gameboard class to check for 4 in a row no matter the size of thew board. This is my code: /* The main class first asks the user to set the parameters of the board and creates a board to the exact size the user wants. The board has to be at least 3 by 3 or larger. Next the user is prompted to enter in their first move. The first spot is represented by 0 and continues to go as large as the board. It then places the player's move and then asks player 2 for the same information. After both players make their moves it checks for a winner or a draw. If they both return false users are able to enter a new move until someone wins or the game ends in a draw. */ import javax.swing.JOptionPane; public class TicTacToeGame { static int X = 0; static char PLAYER1 = 'X', PLAYER2 = 'O', EMPTY = '?'; public static void main(String[] args) { String input; input = JOptionPane.showInputDialog("Enter an value for the height and width of the board?"); X = Integer.parseInt(input); char[][] board = new char[X][X]; GameBoard.clearBoard(board); do { Player.makeMove(board, PLAYER1); GameBoard.drawBoard(board); if (GameBoard.checkDraw(board, X) || GameBoard.checkWinner() || GameBoard.checkWinner()) break; Player.makeMove(board, PLAYER2); GameBoard.drawBoard(board); } while (!GameBoard.checkDraw(board, X) && !GameBoard.checkWinner() && !GameBoard.checkWinner()); if (GameBoard.checkWinner() == true) { JOptionPane.showMessageDialog(null, "Player 1 was won the game!"); } else if (GameBoard.checkWinner() == true) { JOptionPane.showMessageDialog(null, "Player 2 was won the game!"); } if (GameBoard.checkDraw(board, X) == true) { JOptionPane.showMessageDialog(null,"Game has ended in a TIE! Please play again."); } } } public class GameBoard { static char PLAYER1 = 'X', PLAYER2 = 'O', EMPTY = '?'; enum State{Blank, X, O}; public static void drawBoard(char board[][]) { // Reads in user input and displays board with players moves // The board continues to store each move and replaces an empty space // with the players X or O for (int i = 0; i < board.length; i++) { for (int j = 0; j < board.length; j++) System.out.print(" " + board[i][j] + " "); // prints out each space and places a space between each space to make the board easier to read System.out.print("\n"); } System.out.print("\n"); } public static void clearBoard(char board[][]) { // Asks user for input on what the height and width of the board with be // and then creates an EMPTY board for (int i = 0; i < board.length; i++) { for (int j = 0; j < board.length; j++) { board[i][j] = EMPTY; //places a ? mark in each empty spot } } } public static boolean checkWinner() { int n = 4; State[][] board = new State[n][n]; int moveCount = 0; int x = 0, y = 0; State s = null; if(board[x][y] == State.Blank){ board[x][y] = s; } moveCount++; //check end conditions //check col for(int i = 0; i < n; i++){ if(board[x][i] != s) return false; if(i == n-1){ return true; } } //check row for(int i = 0; i < n; i++){ if(board[i][y] != s) return false; if(i == n-1){ return true; } } //check diag if(x == y){ //we're on a diagonal for(int i = 0; i < n; i++){ if(board[i][i] != s) return false; if(i == n-1){ return true; } } } //check anti diag (thanks rampion) for(int i = 0;i<n;i++){ if(board[i][(n-1)-i] != s) return false; if(i == n-1){ return true; } } return false; } public static boolean checkDraw(char board[][], int X) { // First counts up how many moves have been made and then compare // the count to height * width to see if there is any space left. int count = 0; for (int i = 0; i < board.length; i++) { for (int j = 0; j < board.length; j++) { if (board[i][j] == PLAYER1 || board[i][j] == PLAYER2) count++; } } if (count == X * X) return true; else return false; } } import javax.swing.JOptionPane; public class Player { public static void makeMove(char board[][], char player) { //Is called by the main class and is used to find out where the user would like to place their game piece int x = 0, y = 0; String input; input = JOptionPane.showInputDialog("Enter an X value"); x = Integer.parseInt(input); // user input on what row they would like input = JOptionPane.showInputDialog("Enter an Y value"); y = Integer.parseInt(input); //user input on what column they would like board[x][y] = player; //sets the board to the correct location } }
0 | https://www.daniweb.com/programming/software-development/threads/438905/tic-tac-toe-java-error | CC-MAIN-2017-34 | refinedweb | 792 | 75.2 |
On Tue, 27 Oct 2009 12:17:30 +0100, Fabio wrote: > >> +%if 0%{?fedora} >= 12 > >> +Requires: libvirt-client > >> +%else > >> +Requires: libvirt > >> +%endif > >> + > > > > What is this explicit dependency on a package name supposed to achieve? > > > There is the automatic arch-specific dependency on the libvirt SONAME > > already, and it is tons better than a non-arch-specific and version-less > > dependency on a package name. > >. It's good practise to add a comment to the .spec file that explains this explicit dependency. >. Really? What policy is that? Programs in bin paths are covered by the primary metadata. Such a dependency would be more accurate. | https://www.redhat.com/archives/fedora-devel-list/2009-October/msg01238.html | CC-MAIN-2014-10 | refinedweb | 103 | 59.5 |
Problem: I want to execute a command and write to its standard input. Or: I want to execute a command and read from its standard output.
Solution: Create a pipe with popen()
Syntax:
FILE *popen ( char *command, char *type);
Here we are using the easy way with popen(). It forks off a process, executes the shell and runs the program specified by the parameter char *command. Then a pipe is created between your process and the one just created by popen(). The parameter char *type makes the pipe either a write or a read pipe. And just like a stream opened with fopen() you use scanf() and printf() to get your data through the pipe.
Note that with popen() you have the functionality of the shell at your disposal, like file expansion characters (wildcards) but also redirection.
popen("ls /home","r"); /* read the current directory into your process */ popen("sort > ./output","w"); /* sort some output generated by your process and write it to the file output */
This example writes lines to the wc (word count) utility.
#include <stdio.h> #define MAXSTRS 5 main() { int cntr; FILE* fp_pipe; /* filepointer for the pipe */ char* psz_pipe_input[MAXSTRS] = /* some strings to use as input */ {"one", "two", "three", "four", "five"}; /* Create one way pipe line with call to popen() */ /* The UNIX utility "wc -w" is a WordCounter... */ fp_pipe = popen("wc -w", "w"); if ( fp_pipe == NULL ) { printf("popen error!"); exit(1); } /* This loop throws those strings in the pipe to wc*/ for(cntr=0; cntr<MAXSTRS; cntr++) { fprintf(pipe_fp, strings[cntr]); fputc(' ', pipe_fp); } if (pclose(pipe_fp)==-1) { printf("pclose error!"); exit(1); } return(0); }
To read the output of a program, use something like the following snippet:
FILE *ls = popen("/bin/ls -l /","r"); char str[300]; int ret=0; memset((void *)str,0,sizeof(str));
if(ls != NULL) { fflush(ls); ret+=fread((void *)&str[ret],sizeof(char),sizeof(str),ls);
printf("%s\n",str);
pclose(ls); } | https://www.vankuik.nl/Piping_with_popen | CC-MAIN-2021-04 | refinedweb | 321 | 69.41 |
Introduction
In this tutorial, we will introduce NumPy which is a very important library when we use Python for Machine Learning.
Table of Contents:
- Description and the first use of Numpy library
- Defining special arrays with Numpy
- Defining arrays with special methods
- Special functions of the Numpy arrays
- Mathematical operations with Numpy arrays
- Summary
We start by importing the Numpy library and defining an array with Numpy. Secondly, we define special arrays with Numpy and learn to define arrays with special functions. We mention some functions which are used very often when we work with Numpy arrays. After that, we refer to some mathematical functions used with Numpy arrays. Finally, we summarize the tutorial in the last section.
Description and the first use of Numpy library
NumPy is a library for the Python programming language. It supports fast computation for large multidimensional arrays and offers a wide collection of high-level mathematical functions to work on them. It is essential for Data science and used very often in Machine and Deep learning projects.
We first import the Numpy library with its very often used abbreviation “np” in the following line.
import numpy as np
Then we define a Numpy array: This is a one-dimensional array containing elements 1, 2, 3, 4, 5. We can see our array with the embedded “print” function in Python.
first_array=np.array([1,2,3,4,5]) print(first_array)
—————————————–
[1 2 3 4 5]
We define another array. This one is a 3×3, 2-dimensional array(matrix) that contains numbers from 1 to 9.
second_array=np.array([[1,2,3],[4,5,6],[7,8,9]]) print(second_array)
—————————————–
[[1 2 3] [4 5 6] [7 8 9]]
We can access specified elements of the Numpy arrays with indexes given in square brackets. The first element of the array has the index 0. For example, the element in the 3rd index of the “first_array” is printed below.
print(first_array[3])
—————————————–
4
To reach the element in the second row and the second column of the “second_array” could be printed with the following line. We give [1, 1] indexes here because the first row and the first column have the index 0.
print(second_array[1,1])
—————————————–
5
Defining special arrays with Numpy
In this section, we mention the zeros, ones, and eye functions in Numpy.
We can call the “zeros” function to define an array including 0 for all elements. For example, we can define a one-dimensional 5 element zeros array with the line below.
zeros_array=np.zeros(5) print(zeros_array)
—————————————–
[0. 0. 0. 0. 0.]
Similarly, we can define a two-dimensional 2×2 zeros array with the following line.
zeros_matrix=np.zeros((2,2)) print(zeros_matrix)
—————————————–
[[0. 0.] [0. 0.]]
One’s function is similar to the zeros function. In the following line, we define a 3×3 array containing all elements 1.
ones_matrix=np.ones((3,3)) print(ones_matrix)
—————————————–
[[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]]
Eye function creates an identity matrix (unit matrix) which involves 1’s in the diagonal and 0’s in other elements. We define a 3×3 unit matrix in the line below.
unit_matrix=np.eye(3) print(unit_matrix)
—————————————–
[[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]]
Defining arrays with special methods
In this section, we mention arange, linspace, and random functions in Numpy.
We can create an array including the numbers in a range with the “arange” function. We give the lower bound and upper bound of the range for the two-parameter passing versions of the function. We define an array with the numbers between 0 and 10 in the following code line.
range_array=np.arange(0,10) print(range_array)
—————————————–
[0 1 2 3 4 5 6 7 8 9]
In the three-parameter passing version, we give the step size from one element to the next. We define an array between 0 and 15 with step size 3 below.
step_array=np.arange(0,15,3) print(step_array)
—————————————-
[ 0 3 6 9 12]
We define a linear spaced array with the “linspace” function. We give 3 parameters to this function: The first one is the lower bound of the array and the second is the upper bound. The third parameter is how many elements we want for the output array when we divide the range with equal intervals. For example, we define a 5-element linear spaced array between 0 and 100 in the following code line.
linear_array=np.linspace(0,100,5) print(linear_array)
—————————————-
[ 0. 25. 50. 75. 100.]
“Random” is a special module in the Numpy library and has many different functions inside. First, we will show the “rand” function. We create a random array with the parameter which determines the number of elements. The array contains floating-point numbers between 0 and 1. In the following code, a 5 element array is created.
random_float=np.random.rand(5) print(random_float)
—————————————-
[0.20279302 0.59716957 0.94310218 0.03177052 0.88601822]
We can generate a Gaussian distributed(standard normal distribution) random array with the “random” function. For example, we can see the output of this function for a 5-element array in the following code.
random_gaussian=np.random.randn(5) print(random_gaussian)
—————————————-
[ 1.07442191 1.10276759 1.1536396 1.56249421 -0.14813009]
We can generate a random integer number between the parameters we give with the “randint” function. In the sample use, we generate a random number between 0 and 100 in the code line below.
random_number=np.random.randint(0,100) print(random_number)
—————————————-
25
We can pass the third parameter to generate a random array with the number of elements determined with this parameter. For example, we create a 5 element random array between 0 and 100 in the following line.
random_array=np.random.randint(0,100,5) print(random_array)
—————————————-
[64 32 62 27 30]
Special functions of the Numpy arrays
In this section, we will explain “sum”, “min”, “max”, “argmin”, “argmax”, “std”, “var” functions and the slicing operation of the Numpy arrays. These functions could be used with any type of Numpy arrays. First of all, we will create a random numpy array with 5 integer numbers between 0 and 100 as we mention in the previous section. We will use this array to show the special functions.
random_array=np.random.randint(0,100,5) print(random_array)
—————————————-
[64 32 62 27 30]
We calculate the sum of the elements in the array with the “sum” function in the following code line.
print(random_array.sum())
—————————————-
215
We can get the smallest element of the array with the “min” function.
print(random_array.min())
—————————————-
27
We can access the biggest element of the array with the “max” function in the line below.
print(random_array.max())
—————————————-
64
We can access the index of the smallest element with the “argmin” function.
print(random_array.argmin())
—————————————-
3
Similarly, we can get the index of the biggest element with the “argmax” function.
print(random_array.argmax())
—————————————-
0
We can calculate the standard deviation of the Numpy array with the “std” function.
print(random_array.std())
—————————————-
16.419500601419035
“var” function calculates the variance of the array.
print(random_array.var())
—————————————-
269.6
We can get a determined part of the array with a slicing operation. For example, we can take the first 3 elements of the random array in the following line.
print(random_array[:3])
—————————————-
[64 32 62]
We can take the elements between indexes 1 and 3 in the code line below.
print(random_array[1:3])
—————————————-
[32 62]
We can also take the elements after the third index with the slicing operation given in the below code.
print(random_array[3:])
—————————————-
[27 30]
Mathematical operations with Numpy arrays
In this section, we will show addition, subtraction, multiplication, division, and some other mathematical functions with the Numpy arrays. First of all, we will create two Numpy arrays to show the functions.
array_1 = np.array([1,2,3,4,5]) array_2 = np.array([6,7,8,9,10])
The addition operation of the two arrays is shown in the following line.
print(array_1 + array_2)
—————————————
[ 7 9 11 13 15]
Subtraction of the array_1 from array_2 is shown in the line below.
print(array_2 - array_1)
—————————————
[5 5 5 5 5]
Multiplication of the two arrays could be calculated like the below.
print(array_1 * array_2)
—————————————
[ 6 14 24 36 50]
We can divide the array_2 to array_1 like the following.
print(array_2 / array_1)
—————————————
[6. 3.5 2.66666667 2.25 2. ]
We can calculate the element-wise exponentiation with two stars.
print(array_1 ** array_2)
—————————————
[ 1 128 6561 262144 9765625]
Summary
Numpy is an essential library in Python for Machine Learning. In this tutorial, we explain some base functions of this library. We give information about creating Numpy arrays and special functions/operations with them. | https://pdf.co/blog/numpy-in-python | CC-MAIN-2021-17 | refinedweb | 1,461 | 55.44 |
Redux Saga Test PlanRedux Saga Test Plan
Test Redux Saga with an easy plan.Test Redux Saga with an easy plan..
Table of ContentsTable of Contents
- Integration Testing
- Unit Testing
- Extending inspect options
- Install
DocumentationDocumentation
Integration TestingIntegration Testing
Requires global
Promise to be available
One downside to unit testing sagas is that it couples your test to your
implementation. Simple reordering of yielded effects in your saga could break
your tests even if the functionality stays the same. If you're not concerned
with the order or exact effects your saga yields, then you can take an
integrative approach, testing the behavior of your saga when run by Redux Saga.
Then, you can simply test that a particular effect was yielded during the saga
run. For this, use the
expectSaga test function.
Simple ExampleSimple Example
Import the
expectSaga function and pass in your saga function as an argument.
Any additional arguments to
expectSaga will become arguments to the saga
function. The return value is a chainable API with assertions for the different
effect creators available in Redux Saga.
In the example below, we test that the
userSaga successfully
puts a
RECEIVE_USER action with the
fakeUser as the payload. We call
expectSaga
with the
userSaga and supply an
api object as an argument to
userSaga. We
assert the expected
put effect via the
put assertion method. Then, we call
the
dispatch method with a
REQUEST_USER action that contains the user id
payload. The
dispatch method will supply actions to
take effects. Finally,
we start the test by calling the
run method which returns a
Promise. Tests
with
expectSaga will always run asynchronously, so the returned
Promise
resolves when the saga finishes or when
expectSaga forces a timeout. If you're
using a test runner like Jest, you can return the
Promise inside your Jest
test so Jest knows when the test is complete.
import { call, put, take } from 'redux-saga/effects'; import { expectSaga } from 'redux-saga-test-plan'; function* userSaga(api) { const action = yield take('REQUEST_USER'); const user = yield call(api.fetchUser, action.payload); yield put({ type: 'RECEIVE_USER', payload: user }); } it('just works!', () => { const api = { fetchUser: id => ({ id, name: 'Tucker' }), }; return expectSaga(userSaga, api) // Assert that the `put` will eventually happen. .put({ type: 'RECEIVE_USER', payload: { id: 42, name: 'Tucker' }, }) // Dispatch any actions that the saga will `take`. .dispatch({ type: 'REQUEST_USER', payload: 42 }) // Start the test. Returns a Promise. .run(); });
Mocking with ProvidersMocking with Providers
expectSaga runs your saga with Redux Saga, so it will try to resolve effects
just like Redux Saga would in your application. This is great for integration
testing, but sometimes it can be laborious to bootstrap your entire application
for tests or mock things like server APIs. In those cases, you can use
providers which are perfect for mocking values directly with
expectSaga.
Providers are similar to middleware that allow you to intercept effects before
they reach Redux Saga. You can choose to return a mock value instead of allowing
Redux Saga to handle the effect, or you can pass on the effect to other
providers or eventually Redux Saga.
expectSaga has two flavors of providers, static providers and dynamic
providers. Static providers are easier to compose and reuse, but dynamic
providers give you more flexibility with non-deterministic effects. Here is one
example below using static providers. There are more examples of providers in
the
docs.
import { call, put, take } from 'redux-saga/effects'; import { expectSaga } from 'redux-saga-test-plan'; import * as matchers from 'redux-saga-test-plan/matchers'; import { throwError } from 'redux-saga-test-plan/providers'; import api from 'my-api'; function* userSaga(api) { try { const action = yield take('REQUEST_USER'); const user = yield call(api.fetchUser, action.payload); const pet = yield call(api.fetchPet, user.petId); yield put({ type: 'RECEIVE_USER', payload: { user, pet }, }); } catch (e) { yield put({ type: 'FAIL_USER', error: e }); } } it('fetches the user', () => { const fakeUser = { name: 'Jeremy', petId: 20 }; const fakeDog = { name: 'Tucker' }; return expectSaga(userSaga, api) .provide([ [call(api.fetchUser, 42), fakeUser], [matchers.call.fn(api.fetchPet), fakeDog], ]) .put({ type: 'RECEIVE_USER', payload: { user: fakeUser, pet: fakeDog }, }) .dispatch({ type: 'REQUEST_USER', payload: 42 }) .run(); }); it('handles errors', () => { const error = new Error('error'); return expectSaga(userSaga, api) .provide([ [matchers.call.fn(api.fetchUser), throwError(error)] ]) .put({ type: 'FAIL_USER', error }) .dispatch({ type: 'REQUEST_USER', payload: 42 }) .run(); });
Notice we pass in an array of tuple pairs (or array pairs) that contain a
matcher and a fake value. You can use the effect creators from Redux Saga or
matchers from the
redux-saga-test-plan/matchers module to match effects. The
bonus of using Redux Saga Test Plan's matchers is that they offer special
partial matchers like
call.fn which matches by the function without worrying
about the specific
args contained in the actual
call effect. Notice in the
second test that we can also simulate errors with the
throwError function from
the
redux-saga-test-plan/providers module. This is perfect for simulating
server problems.
Example with ReducerExample with Reducer
One good use case for integration testing is testing your reducer too. You can
hook up your reducer to your test by calling the
withReducer method with your
reducer function.
import { put } from 'redux-saga/effects'; import { expectSaga } from 'redux-saga-test-plan'; const initialDog = { name: 'Tucker', age: 11, }; function reducer(state = initialDog, action) { if (action.type === 'HAVE_BIRTHDAY') { return { ...state, age: state.age + 1, }; } return state; } function* saga() { yield put({ type: 'HAVE_BIRTHDAY' }); } it('handles reducers and store state', () => { return expectSaga(saga) .withReducer(reducer) .hasFinalState({ name: 'Tucker', age: 12, // <-- age changes in store state }) .run(); });
Unit TestingUnit Testing
If you want to ensure that your saga yields specific types of effects in a
particular order, then you can use the
testSaga function. Here's a simple
example:
import { testSaga } from 'redux-saga-test-plan'; function identity(value) { return value; } function* mainSaga(x, y) { const action = yield take('HELLO'); yield put({ type: 'ADD', payload: x + y }); yield call(identity, action); } const action = { type: 'TEST' }; it('works with unit tests', () => { testSaga(mainSaga, 40, 2) // advance saga with `next()` .next() // assert that the saga yields `take` with `'HELLO'` as type .take('HELLO') // pass back in a value to a saga after it yields .next(action) // assert that the saga yields `put` with the expected action .put({ type: 'ADD', payload: 42 }) .next() // assert that the saga yields a `call` to `identity` with // the `action` argument .call(identity, action) .next() // assert that the saga is finished .isDone(); });
Extending inspect optionsExtending inspect options
To see large effect objects while Expected & Actual result comparison you'll need to extend inspect options. Example:
import util from 'util'; import testSaga from 'redux-saga-test-plan'; import { testableSaga } from '../sagas'; describe('Some sagas to test', () => { util.inspect.defaultOptions.depth = null; it('testableSaga', () => { testSaga(testableSaga) .next() .put({ /* large object here */ }) .next() .isDone(); }); });
InstallInstall
yarn add redux-saga-test-plan --dev
npm install --save-dev redux-saga-test-plan | https://www.npmjs.com/package/redux-saga-test-plan | CC-MAIN-2021-43 | refinedweb | 1,141 | 56.25 |
The Penguin Machine
The Penguin Machine is a remake of The Incredible Machine, written by Sierra a few years ago on Atari ST and Amiga. A level editor is included in the package.
Sébastien Migniot
(smigniot)
Changes
Links
Releases
The Penguin Machine 1.0 — 7 Oct, 2005
Pygame.org account Comments
Zoran Popovic 2012-04-15 15:32:06
twimc, thing runs on Python 2.7 (fedora 16) with additional modifications (beside those by David O' Shea), concerning errors like "TypeError: integer argument expected, got float" and "TypeError: range() integer end argument expected, got float." - I had to add min and max functions in surfutils.c (e.g. static double min(double x, double y) {return (x < y ? x : y);} static double max(double x, double y) {return (x > y ? x : y);}), and corrected Objects.py:
line 45:
pilsource.resize((math.trunc(pilsource.size[0]/coeff), math.trunc(pilsource.size[1]/coeff))).save(filename)
lines 367 and 393:
for i in range(math.trunc(step)+1):
...
Mind I wasn't coding for ages, and I have played just one level ... a great game, wish I could do more for it .. | https://www.pygame.org/project/139 | CC-MAIN-2022-33 | refinedweb | 191 | 59.9 |
+ Post New Thread
I am getting the following error in the JS compilated GWT java code:
In Dispatcher class the following error: Cannot read property...
Draggable method onMouseMove has comment
// elem.getClassName throwing GWT exception when dragged widget is over // SVG / VML
I use...
Internet Explorer 8
Windows 7 (64 bit)
GXT 3.0.2
GWT 2.4
I have posted this issue before, and now getting it under different scenario.
If I...
If you run the underlying test case you can see that the style "z-index: 1000;" is not added to the div.
Test case:
public class GXTTest...
public void onModuleLoad() {
final DateField df = new DateField();
TextButton tb = new TextButton("Test");
...
Version(s) of Ext GWT
Ext GWT 3.0.1
Browser versions and OS
Chrome 21.0.1180.89 - Dev Mode
Chrome 21.0.1180.89
Linux 3.2.0-29-generic...
Hello!
I'm using RC2.
I have a BorderLayout with 3 Regions:
North
Center
East
I wanted to have the East-Region collapsible and floatable....
If you ran this example in IE and change value of combo box it show Info on right hand side...
Hi,
I was experimenting the same thing reported here:...
Hi,
Stetchmax doesn't seem to work for an HBoxLayoutContainer... your examples page has an extra long button for the vboxlayoutcontainer, but...
GXT 3.0.2
GWT 2.4
Internet Explorer 8
Windows 7 : 64bit
If I create a VerticalLayoutContainer and then put HorizontalLayoutContainer children...
GWT 3.0.2
GXT 2.4
Internet Explorer 8
Windows 7 : 64bit
I have a VBoxLayoutContainer as a child widget of a FieldLabel (within a FieldSet) also...
This has taking a while to reproduce, since it seems a variety of things must be in alignment. Under this scenario if you resize the browser window...
A GWTTestCase with this code will pass using GXT 3.0.0 but fails in 3.0.1 and 3.0.2b. DomQuery.select doesn't seem to work anymore with class name...
Dear All;
Cell grid is have a column resize bug. Colum resizeable but inline widget dont resize (exclude Progress bar);
Internet Explorer 8
Windows 7, 64 bit
GXT 3.0.2 Shapshot (9/19/2012)
If I throw a GWT Label (or HTML) widget into the field label, alignment...
GWT provides GWTMockUtilities which will disarm/restore calls to GWT.create so GWT can be tested using standard mocking frameworks such as EasyMock. ...
A text field with a validator shows in case of error after validation an error mark behind the field and reduce the length of the textfield.
...
Sencha is used by over two million developers. Join the community, wherever you’d like that community to be
or Join Us | http://www.sencha.com/forum/forumdisplay.php?84-Sencha-GXT-Bugs/page28&order=desc | CC-MAIN-2014-41 | refinedweb | 452 | 68.67 |
Google Signs a Friendship Pact with Euro Publishers
Google needs friends in Europe. It may have finally found some.
Tomorrow, Google and eight legacy European newspaper publishers — the Guardian, the Financial Times, Die Zeit, FAZ, El Pais, Les Echos, La Stampa, and NRC Media — will announce an agreement to collaborate on product development, innovation, training, and research to “help support a sustainable news ecosystem and promote innovation in digital journalism.” Google has included a €150m innovation fund.
First, a few disclosures: I advise the Guardian. I was part of a meeting with the publishers and Google last January, when this was worked out. I have given my (free) advice to Google on this deal and its relations with news publishers, especially in Europe, underscoring what I have said publicly. I am rooting for this to succeed.
So what is success? Let me start with what it’s not. Success is not Google paying €150m in blackmail to publishers as it did in France; I’d rather see such funds go to true investment in innovative news startups or to news companies’ bottom lines via mutually beneficial new business models. Success is not training a bunch of journalists in the digital skills they should have or doing more research into exactly how screwed old media is — and I say that as someone who trains journalists and performs research. Success is not going to be measured by a slight deceleration in the velocity of attacks from EU politicians and publishers against Google and Silicon Valley or a few more europennies for legacy publishers selling old-fashioned, volume-based advertising.
No, success in my view will come when:
- Google headquarters pays attention to news as a vital component of the information that Google helps organize, and when Google devotes its own core product development talent to news not as a standalone brand but where appropriate as an integral element of Google’s own services and businesses, from search to mobile. At Google, if it’s not about product, it doesn’t matter. So, Google: Is this about product?
- Google establishes new best practices — models for Facebook, Twitter, Amazon, et al to follow — in creating products that bring news publishers what they really need: not more anonymous traffic, but more information — more data — about their users and their content. The training I want to see from Google would educate not just journalists but also commercial staff in how to use that data to build and improve their services and their businesses, because that is Google’s real expertise. Google is a personal services company; so should news companies be.
- Google helps news startups as much as it helps news oldsters and it helps news organizations around the world as much as it does the squeaky, rusty wheels of Europe. As long as this initiative is devoted just to Europe, it will look like a response to the badgering Google has received at the hands of Germany’s Axel Springer, Burda, et al. This initiative needs to be about news and an informed society the world over.
- Publishers understand that Google is neither their assassin nor their savior but now a necessary partner in distribution, advertising, data, and technology. The same goes for the other, demonized American technology giants. We will know this initiative is working when media companies negotiate with Silicon Valley not on the basis of poor-mouthed whining or political blackmail but out of mutual benefit.
I think all that is possible and more. Last December, as the process that led to this agreement was heating up, I wrote a post here asking what Google could do for news and then another asking what news could do for Google and one more in the same vein about Facebook. Thus what I was saying in private was what I had shared publicly. Those posts contain my wishlists:
- asking the Valley’s best brains to help reimagine news as a valued service;
- building containers that let news travel to users where they are, with business models attached;
- bringing news organizations more data so they can provide greater relevance and value in return (with privacy done right);
- reinventing advertising around value over volume;
- investing in real innovation.
I also ask the news industries’ best brains to help Google, Facebook, and Twitter — which, like it or not, are our new news trucks — to discover, promote, and thus support quality news instead of just bringing more eyeballs to the 4,000th rewrite of the same damned story about the same fucking dress.
I must take my hat off to Springer and Burda. Their political shenanigans led to the antitrust decision against Google, the European Parliament vote against Google, the German link law and Spanish link tax, and much political chest-thumping against Google. They backed Google into a corner and forced Google to make nice. This agreement — albeit with publishers other than Springer and Burda — and new attitude are the result. So congratulations to Germany’s publishers. But now I hope they realize it is time to move on. Protectionism will not save their businesses. Innovation will. Collaboration will.
Facebook realizes that Germany’s publishers could come after it next. To its credit, Facebook has invited publishers in and listened to their needs and responded with new products that help both news companies and news users. Chris Cox, Facebook’s head of product, has said that news matters to Facebook; there, news is about product. Various news companies are working with Facebook on new means to distribute their content to users inside the service.
At this month’s International Journalism Festival in Perugia, Italy, Facebook’s Andy Mitchell gave a keynote that highlighted all this but still stirred controversy. George Brock, of the other City University, and Jay Rosen of NYU each castigated Mitchell for not grappling with the big questions that are raised when Facebook becomes a — perhaps the — key distributor of news. What is Facebook’s responsibility to be open about the distribution decisions it makes? How does Facebook’s policing of community standards conflict with freedom of speech and of the press? Are Facebook, Twitter, and Google more than mere distributors or newsstands? Are they indeed becoming news editors? This is a vital discussion well worth having. It is not a discussion about these companies’ obligations to news organizations. It is a discussion about their obligation to society.
There was a time when Google cared about news; that’s when it made Google News. Then there appeared to be a time when Google didn’t so much care about it. But now Google and Facebook, Twitter, and Amazon, too, have no alternative but to care about news, whether by force from European publishers and politicians or by choice.
Now technologists and journalists need to come together to use technology to reimagine what news can be, to investigate new ways to sustain journalism, to recalibrate how we measure our success (moving from mass-media metrics of reach and frequency to service metrics of impact and value), and to reaffirm the obligation these powerful institutions have to serve and protect the interests of the public.
This is the moment when that can happen. That is why I welcome Google’s Digital News Initiative with this starter kit of news companies. I encourage Google, Facebook, Twitter, Amazon, and news enterprises to meet at eye level and grapple with these issues and opportunities.
At first, the work of this group will be tactical as they — to quote the Google press release — begin “dialogue focusing on ads, video, apps, data insights, paid-for journalism, and Google News.” Anyone — old company or new — can apply for a share of Google’s €150m innovation fund. But no one should expect some magic app to result to salve and solve news’ woes, though we should expect to see real products and progress.
As I see it, the real importance of this announcement is that it opens the door to collaboration around big questions and big opportunities. I greatly respect the eight publishers represented here and Google but I hope this conversation will soon include many more news and technology companies. This is a good start. | https://medium.com/whither-news/google-signs-a-friendship-pact-with-euro-publishers-c6113cf0e058 | CC-MAIN-2017-17 | refinedweb | 1,363 | 58.42 |
Content count41
Donations0.00 CAD
Joined
Last visited
Days Won1
Everything posted by riviera
help qLib Plugin Installation?
riviera replied to Funk_Wagnalls's topic in General Houdini QuestionsHey man -- I think these very same instructions are described in the README file for qLib. Btw, please don't use the version 0.2.5, it's _very_ old -- use the "dev branch" thing. cheers
- seems like delta mush is all the rage these days --
- That's a cool idea... Although I was aware of the "reference geometry" input of the Edit SOP, I always felt that there should be something similar, but more general-purpose, in terms of "surface space" editing. So, having this in qLib scratches more than one itch, so to speak. (I couldn't have guessed that it could be done using a simple Edit SOP, though ) What you can find right now in qLib: - there's a gallery item ("Point Wrangle: delta mush utility"), which is a PointWrangle SOP preset, containing the necessary math for converting to/from "surface space" (or whatever you'd like to call it) - gallery items for smoothing/relaxing geometry (a pointcloud- and a topology-based one), and there's a Smooth Points qL SOP that wraps it all up in a single node - a "Displace by Delta qL SOP", implementing delta mush as a single node Having a single-node delta mush is fast (all is packed inside a single VEX block), but we're also planning to have a capture/deform pair implemented (to allow for more in-between trickery), as this is pose-based deformation territory, where many interesting things can happen. --- Yes, the actual math behind delta mush is pretty easy. It is not the math, but the effort it took that matters, though -- the time they took experimenting and (production-) testing, and concluding "hey, this works!" This is what we all got from it, not just the deformer math.
Water inside of air field
riviera replied to ssh's topic in Finished WorkHi -- I got really curious and ran my first very simple tests: (vimeo is still processing them but hopefully they'll work ) One probably couldn't get simpler than I did: every random 4th (or 2nd) emitted particle is "air" instead of water (so I'm basically emitting a water/air mixture). Even with this simpleton setup, the results look much nicer. (Fliptank tests also looked promising. I'm planning to do a cgi re-creation of Prometheus' title sequence waterfall scene for some time now, and this technique seems like a must-have for that...)
Houdini UI Python Library
riviera replied to Stalkerx777's topic in ScriptingVery nice! Cheers! (Also, the function you use, hou.ui.createDialog() doesn't seem to be documented anywhere in the 13.0 docs, so your code is extra useful...)
L-system Local Variable (g vs t)
riviera replied to kidsreturnjj's topic in EffectsThere is a subtle but important difference. There are probably better L-system experts than me, but hopefully I won't spread misinformation here... First thing to know is that (at least this is what I concluded) for each letter in the generated L-system string, Houdini seems to store the number of iteration when the letter is added to the final string. So Houdini knows when each letter was generated. Now, the difference between g and t is that one refers to this stored iteration value, the other refers to the current iteration value (I don't recall which is which, though). I ran into this when I wanted to build a tree, where for the first few iterations only the trunk was created -- with letters in it that started to grow branches after a given generation count (so instead of growing a tree with shorter branches at the top, I wanted equal-length ones, hopefully I'm making some sense here...). In other words, I wrote a rule to expand the branch letters after the L-system ran for say 10 iterations (that allowed only the trunk to grow.) It could be done using one of the letters (g/t) but not the other. Don't remember which but it takes only 2 tries to find out. L-systems can be mind-bending, and there are some features that not even documented or just hinted in the docs. (I really wouldn't like to spread stupidity, though, so please anyone correct me if I'm wrong. This was quite some time ago.) cheers, imre
- You're welcome, no big deal. In the meantime I took a look at this OnCreated.py -- here's my take on it, a minimalistic version, just by node type. I found that although on SOP level one is better careful about coloring, it can be quite the opposite on the OBJ level (probably because there's much less node types to choose from). Right now I find very helpful to color objects, lights and cameras differently. (This might change, though ) cheers OnCreated_py.zip
Alternative to Fuse SOP?
riviera replied to Skybar's topic in General Houdini QuestionsI recently tried to do a fuse on a 60mil points point cloud to get rid of duplicates, and after running on one thread for ~15 mins it started to eat up all 64gigs (!) memory of my work machine. So it can be risky with heavy geometry. Perhaps the process could be speeded up by a VEX-pointcloud preprocessing that finds duplicate points and group them. The run the Fuse SOP only on that group.
- As an opportunity for another shameless plug, qLib comes with galleries that are basically regular Houdini nodes with some similarly customized interfaces. This is a regular Null SOP that provides information about its input geometry (also has auto-naming buttons). You can link those bounding box parameters on the Null to initial boundaries of a pyro sim to have a really fitting initial container, for example. ...or you can just go really nuts and roll an "align geometry" operator from a single Transform SOP: Very useful. (Although not strictly color-coding, but at least it's user interface-related )
- I know I'm going to lose lots of $$$-s, but I'll tell it for free You can add buttons as spare parameters (Edit Parameter Interface...), then use a one-liner callback script (python) like: hou.pwd().setName("DISPLAY"); hou.pwd().setColor(hou.Color((0,.4,1))); hou.pwd().setDisplayFlag(True); [/CODE] or [CODE] hou.pwd().setName("RENDER"); hou.pwd().setColor(hou.Color((.4,.2,.6))); hou.pwd().setRenderFlag(True); [/CODE] or [CODE] hou.pwd().setColor(hou.Color((.8,.8,.8))); hou.pwd().setName("OUT"); hou.pwd().setRenderFlag(True); hou.pwd().setDisplayFlag(True); [/CODE] This is for DISPLAY, RENDER and OUT, accordingly. Once you added all buttons of your liking, you save the parameters as defaults ("Save as Permanent Defaults"). I have quite a few operators where I added some extra interface for convenience (for example my Object Merge SOP has a button which auto-names the SOP based on the name of the geometry that is merged). cheers
How to follow particles on motion curve?
riviera replied to Greenfish's topic in General Houdini Questions cheers
- ...and now for something not entirely different... This is how my Null SOP's default preset looks like: These buttons are one-liner python scripts which rename and colorize the Null accordingly. So I never type "OUT", I just click. ) I color "display" nodes to blue (same as display flag color); OUTs (render outputs) are purple (same as render flag color), animated ones are yellow, "waypoints" (important network points marking end of a section) are red, and that's about it. ("export points", e.g. where I fetch data from to other networks are green) I'll check out this OnCreated.py script, I didn't know this functionality existed. I wish it was documented... A word of warning: don't go too crazy with colors, or else you end up with networks that drive you crazy because they look like rainbows, and you lose what you thought you'd gain. This is an actual production network (hence a few dead ends ), IMHO this is the amount of coloring that provides relevant information without polluting everything with colored candy )
zoom/track viewport without adjusting camera parms
riviera replied to substep's topic in General Houdini QuestionsIn Maya there are camera parameters (which affect the viewport only) that allows you to pan and zoom on the view if it were a 2d image (and it won't affect your camera render frustrum). The tool you're talking about adjusts these parameters based on the user's mouse inputs in the viewport. The closest you can get to this in Houdini by adjusting the Screen Window X/Y and Size parameters (and reset them before you render, as they do change the camera frustrum AFAIK). But I don't think there's an interactive tool for that so you have to tweak these in the camera parameter panel. Such a tool would be very useful sometimes, though. (Another thing I'd like to have is a "dolly-zoom" camera tool. 3dsmax has it and I wrote one for myself back in my Maya days, but I don't know how to do it in Houdini.)
BulletSOP 2.0.9
riviera replied to MilanSuk's topic in BulletDo you accept bug reports from people who buy the source? Some kind of maintenance plan perhaps, even? :DDD (just kidding) Anyhow, sounds like a great thing!
- I can even provide some explanations on the various aspects of particle retiming if anyone's interested. (Although hopefully everything's explained in the qLib example scene -- look for the "Timeblend qL" one)
- I know I'm spreading the shameless advertising of our asset library qLib all over the place, but it happens that we worked at the issue of particle retiming to quite some extent. I'm at work right now where we have limited facebook access, so I can only post the github address: -- but if you check our our page on facebook (especially the "photos" section), you'll find screenshots with related explanations about how to retime particles using qLib tools (there are various example files in the distribution, too). (For instance, check this video: . This is an animated boolean, 20 frames long, slowed down with a 10x factor or so. It's an actual example scene that covers various ways of proper sub-frame emission, death, subframe-accurate age attributes and attribute mapping.)cheers )
$CEX, $CEY, $CEZ no longer working properly?
riviera replied to TheAdmira1's topic in General Houdini QuestionsWe also reported this and sesis answer was that it doesn't work because of some internal evaluation inconsistency, so they're removing it (!), and we should use the centroid() function instead. While our first reaction was righteous outrage (kidding :-D) we realized we always had evaluation problems with these variables, especially when used in digital assets. so we switched to centroid() since then. A hint: $GCX Y Z variables still work, so use that when not in the mood for much typing. Just don't tell the sesi guys :-D
How to create temporary colors similar to SoftTransform?
riviera replied to magneto's topic in General Houdini QuestionsJust an idea--if you add color attribute to a guide geometry, the guide geom will be drawn using those colors (instead of the default guide color). So, you might achieve similar results by creating colored particles for all your geometry points, and use that geometry as a guide. (I hope I'm making sense here...) Not the exact same result, but might be close. (I'm talking about the guide geometry within a SOP asset, of course )
- True enough-- those webs were generated using a spiderweb asset which would fit very nicely on Orbolt. Jokes aside, the issue here is that it relies heavily on qLib assets, so I'm not sure how to proceed here. (Believe it or not but when Orbolt came out, we had a lengthy discussion on how to fit qLib into the Orbolt "way of things". Should we _move_ to orbolt? [no] Should we upload to orbolt? [yes] We have almost a hundred separate asset files, should we upload them one-by-one or should we collapse all our assets to a single .otl file? [neither] etc etc.) Needless to say, that discussion has _not_ reached its conclusions yet. I'm not sure if it's allowed to upload assets to Orbolt that rely on other assets (that are freely available but not necessarily included). So we're not really sure on how to proceed -- although we would like the idea of uploading finished high-level assets to the store ("we" meaning everyone involved in qLib, me being the one who happened to build the web asset). Imre ps.: Btw, there's actually a spiderweb example scene in the qLib distro (not the same as the asset, though, but using a different approach).
- As Mate said, at a certain point we agreed on not supporting anything pre-H12 any more (since this library is basically a "byproduct" of our working with Houdini, and at that point we all were using H12). This also allowed us to take advantage of new features like namespacing and to clean up some "H11-isms". However since it's under version control it's entirely possible to get a local clone from github, and go back in the commit history to a point where the assets are not yet namespaced, and build and use that version. Although it won't be the latest stuff, it'll still give you considerable advantages over an out-of-the-box H11. We started moving to namespaces between v0.0.28 and v0.0.29, so if you revert to somewhere there, you'll still be fine under H11, too. (Or just grab 0.0.28 from the downloads section.) Imre ps.: There's a note explaining qLib namespacing here, if interested:
per-particle radius scale for flip fluid simulation?
riviera replied to riviera's topic in EffectsThat's great, I wasn't aware that it does this. However I'd prefer a solution where I create this manually (as I don't want the point count to be changed, and reseed does that). My fluid surface wouldn't do much movement anyway (it would be a calm water surface with some depth).
sprite rendering artefacts
riviera replied to nomad's topic in General Houdini QuestionsThis is an excellent idea! (I'll try to remember this next time I have to do "semi-sprites" )
HOT variants ("Drew vs Christian" :))
riviera replied to riviera's topic in Houdini Ocean ToolkitBtw, in H11 the mineigvec attribute was of type vector, but in H12 it seems to be a scalar (I suppose this might be a minor bug or typo when porting to the new geo architecture?). Just sayin' (I'll try to fix this in my repo and push it back...) | https://forums.odforce.net/profile/56-riviera/?do=content&change_section=1 | CC-MAIN-2019-47 | refinedweb | 2,508 | 60.24 |
Python SDK - Overview¶
What it does¶
The Python API for Aldebaran robots allows you to:
- use all of the C++ API from a remote machine, or
- create Python modules that can run remotely or on the robot.
Using Python is one of the easiest ways to program with Aldebaran robots.
Mastering key concepts¶
Please make sure to have read the Key concepts first.
The basic approach is:
- Import ALProxy
- Create an ALProxy to the module you want to use
- Call a method
This can be seen in the following example, which is explored in detail in the tutorial: Using the API - Making NAO speak.
from naoqi import ALProxy tts = ALProxy("ALTextToSpeech", "<IP of your robot>", 9559) tts.say("Hello, world!")
Or in Japanese:
# -*- encoding: UTF-8 -*- from naoqi import ALProxy tts = ALProxy("ALTextToSpeech", "<IP of your robot>", 9559) tts.setLanguage("Japanese") tts.say("こんにちは")
Installation¶
Please read: Python SDK - Installation Guide.
Samples and tutorials¶
A progressing series of tutorials is available in: Python SDK - Tutorials.
See also: Python SDK - Examples. | http://doc.aldebaran.com/2-4/dev/python/intro_python.html | CC-MAIN-2019-13 | refinedweb | 170 | 61.77 |
Why should you use visual studio code ?
Visual Studio Code is a free source-code editor made by Microsoft for Windows, Linux and macOS. Features include support for debugging, syntax highlighting, intelligent code completion, snippets, code refactoring, and embedded Git.
It currently supports hundreds of programming languages and file formats. Several common languages come supported by default (JavaScript, HTML, CSS, etc), and others gain support by adding integrated extensions. If you find a language that isn't supported by an existing extension, the open nature of the extensions system means you can build one.
In this blog post you will learn how to set up visual studio code on your local environment for C and C++, this can get tricky but if you follow step by step you can set it up easily.
Step 1: Download Visual studio code.
Type vscode on your browser and click on the first link of the page, or just click here.
Now download the installer according to your operating system.
Step 2: Install vscode
This step is easy, accept the agreement and click next.
Check the following options as shown in above image and click next and install.
Step 3: Download extensions for visual studio code.
Once you have installed visual studio code, now its time to install some extensions. Click on the button where red arrow is pointing in above image.
Now click on C/C++ extension from Microsoft as shown in the below image. If you don't see the extension search C/C++ and you will find it.
Install the extension.
Now we have to install another extension called Code Runner.
Now we have successfully installed code editor but we need a compiler to compile and output our code, for that we will be installing MinGW.
Step 4: Download MinGW
Type mingw on google and choose following first link as shown in the image below or Click Here.
Now click download.
Step 5: Install MinGW
Open the installer, you should see something like the below image. Click on install and choose your directory where the software should be installed and click continue.
After installing, click on continue and right click on every checkbox and choose mark for installation.
After checking all checkboxes you should see something like image below.
Now click Installation on top left corner and then choose Apply Changes. You should see something like shown in the image below.
And then click on Apply.
Once you complete the installation, you should see something like the image below.
Click close and close the installer.
Step 6: Copy Bin Path
Now open 'This PC' and open 'local Disk C' you should see mingw file and click on bin folder.
Now you have to copy the folder destination which is above the page as shown below.
Now right click and copy or just press 'Ctrl + C' on your keyboard.
Step 7: Environment Variables
Open 'Control Panel' from your start menu and click on System. If you don't find system on your control panel just type 'system' on the search bar which you can find in top right corner of the control panel.
Click on Advanced system setting on right side you should see system properties as shown in the image below.
Now click on Environment Variables you should see something as shown in the image below.
Now click on the path in system variable and click on edit as shown in the image below.
Now click on new and paste the bin path that we have copied in the previous step and then click Ok.
Now click ok till there are no pop ups left.
Step 8: Let's check if MinGW has been successfully installed or not.
Click on search button near the bottom left of windows and search for command prompt.
g++ --version
And if you see something like the image above, voila! we did it.
🛑 🛑 If you get some error don't worry just reinstall mingw as shown in the step 4 and step 5 and it should solve the problem.🛑🛑
Step 8: Let's write our first program in C++
Hurray! we have successfully set up vscode for C and C++ now lets test it by writing our first program in vscode.
Open vscode.
Click on 'File' in upper left section and choose 'Open Folder'.
Lets make a new folder in dekstop and select the folder.
Now click on the document symbol in the side bar. If you dont see a sidebar just press Ctrl + B on keyboard.
Now make a file with a extension of .cpp as shown in the image below
Now lets type our first code. You can copy and paste the code that I have provided below.
#include<iostream> using namespace std; int main() { cout<<"hello world"; }
Step 9: Run the code.
Right click and click on run or press keyboard shortcut 'Ctrl+Alt+N'.
And there you go you have written your first program in C++, I hope this tutorial was helpful if you are facing any problem while installing let me know in the comment section or email me at blog.webdrip.in.
Get more insights like this on my blog,.
Top comments (6)
Just one thing I'd add to this, after I installed mingw, I was trying to run my c file but it didn't work because my vs code needed a restart, so if vs code was already open before installing mingw, just give vs code a restart and everything should work.
thank you...i set up my vs code following this guide...
I'm glad, you found it helpful.
it's really helpful. its worth reading
Glad you find it helpful!
Thank you!
when I run my code, I see this error:
'g++' is not recognized as an internal or external command,
operable program or batch file.
What am I supposed to do? | https://practicaldev-herokuapp-com.global.ssl.fastly.net/narottam04/step-by-step-guide-how-to-set-up-visual-studio-code-for-c-and-c-programming-2021-1f0i | CC-MAIN-2022-40 | refinedweb | 977 | 73.68 |
In this snippet, we are going to create a python method to reverse the order of a number. This is one of the questions on Codewars. If you enter -123 into the method you will get -321. If you enter 1000 into the method you will get 1. Below is the entire solution.
def reverse_number(n): num_list = list(str(n)) num_list.reverse() if "-" in num_list: num_list.pop(len(num_list)-1) num_list.insert(0, "-") return int("".join(num_list))
If you do follow my website you know that I always write simple python code and post them here, but starting from the next article, I will stop posting python code for a while and start to talk about my python journey and the cool software which is related to python. I hope you will appreciate this new style of writing and thus will make learning python for everyone a lot more fun than just staring at the boring and sometimes long python snippet.
Like, share or follow me on Twitter.
If you have any solution for this problem do comment below. | https://www.cebuscripts.com/2019/04/17/codingdirectional-reverse-a-number-with-python/ | CC-MAIN-2019-18 | refinedweb | 179 | 82.75 |
This is the third part in a five-part series on compiling and concatenating ES6 code using Gulp and Babel. If you haven't started from the beginning, I recommend doing so.
Otherwise, welcome back!
At this point, you have built a single JavaScript bundle consisting of third-party libraries and self-authored components. In Part 3, we're going to add a JS configuration file that will enable us to build multiple bundles with unique dependencies and self-authored components.
This part is unique among the five in that it requires a bit of background to get started. To understand how this is going to work, you should know a bit about building dynamic tasks with Gulp 4. And in this particular approach, we're using a JavaScript configuration file to drive those dynamic tasks. I wrote an article that follows this approach, and I recommend at least skimming through that before continuing.
Step 1: Add JS Config
Create a new file at
src/config.js that will serve as your main JS configuration. (As stated in other parts, you're welcome to put this file wherever you'd like, you'll just have to update the code appropriately to reflect your changes.)
src/config.js
module.exports = [ { name: 'main', deps: [ '~jquery/dist/jquery.min', 'vendor/my-lib' ], files: [ 'components/foo', 'components/bar' ] }, { name: 'lodash', deps: [ '~lodash/lodash' ] } ]
This configuration is unique even to the introductory article – here's what's going on:
- Each item in the exported array is an object.
- Each object must have a
nameproperty and either a
depsor a
filesproperty.
nameis the resulting filename of the bundle (sans the
.jsextension).
depsis an array of third-party dependencies (files we don't want to process with Babel).
filesare self-authored files that will be compiled with Babel.
.jsextension is assumed throughout and never used.
- The tilde (
~) is a shorthand for looking into the
node_modulesdirectory. Otherwise, all paths are considered relative to the
srcdirectory.
Step 2: Manually Add Dependency
Because I want to show you how it can work if you add a third-party dependency that isn't available as an NPM package, let's create a dummy dependency at
src/vendor/my-lib.js:
src/vendor/my-lib.js
class MyLib { constructor() { console.log('MyLib'); } }
Step 3: Update Gulpfile
We have some big adjustments to make to the Gulpfile. Here we're still taking a similar approach to Part 2 in having the build run in series with functions
jsDeps(),
jsBuild(),
jsConcat(). The difference is that within each function we are reading the configuration file (
src/config.js) and building dynamic anonymous tasks for each item within the configuration array. The bulk of this is explained in the introductory article on dynamic Gulp 4 tasks, but there are some comments in the code to help.
gulpfile.js
// Import "parallel" function, along with the others we've // been using. const { parallel, series, src, dest } = require('gulp'); const babel = require('gulp-babel'); const concat = require('gulp-concat'); const plumber = require('gulp-plumber'); // Import the config array as `jsConfig`. const jsConfig = require('./src/config'); // Use variables to reference project directories. const srcDir = './src'; const tmpDir = './tmp'; const destDir = './dist'; function jsDeps(done) { // Loop through the JS config array and create a Gulp task for // each object. const tasks = jsConfig.map((config) => { return (done) => { // Create an array of files from the `deps` property. const deps = (config.deps || []).map(f => { // If the filename begins with ~ it is assumed the file is // relative to node_modules. The filename must also be // appended with .js. if (f[0] == '~') { return `./node_modules/${f.slice(1, f.length)}.js` } else { return `${srcDir}/${f}.js` } }); // If we don't exit in the case that there is no deps property // we will hit an error and Gulp will abandon other tasks, so // we need to gracefully fail if the config option is missing. if (deps.length == 0) { done(); return; } // Build the temporary file based on the config name property, // i.e. [name].deps.js. return src(deps) .pipe(concat(`${config.name}.deps.js`)) .pipe(dest(tmpDir)); } }); // Run all dynamic tasks in parallel and exit from the main task // after all (anonymous) subtasks have completed. return parallel(...tasks, (parallelDone) => { parallelDone(); done(); })(); } /** * jsBuild() is identical to jsDeps() with a few exceptions: * * 1. It looks at the `files` property (not the `deps` property). * 2. It processes the concatenated bundle with Babel. * 3. It does not support the tilde importer because we assume * all self-authored files are within the source directory. * 4. Temp files are named [name].build.js. */(dest(tmpDir)) } }) return parallel(...tasks, (parallelDone) => { parallelDone(); done(); })(); } // jsConcat() takes the two temporary files from each config // object ([name].deps.js and [name].build.js) and combines // then into a single bundle. function jsConcat(done) { const tasks = jsConfig.map((config) => { return (done) => { const files = [ `${tmpDir}/${config.name}.deps.js`, `${tmpDir}/${config.name}.build.js` ]; // The allowEmpty option means the task won't fail if // one of the temp files does not exist. return src(files, { allowEmpty: true }) .pipe(plumber()) .pipe(concat(`${config.name}.js`)) .pipe(dest(destDir)) } }) return parallel(...tasks, (parallelDone) => { parallelDone(); done(); })(); } exports.default = series( parallel(jsDeps, jsBuild), jsConcat );
Now you're ready to run the build again:
$ npm run build
Upon successful build, notice:
- The
.jsextensions were automatically added to the bundles.
- MyLib (
src/lib/my-lib.js) did not get compiled by Babel, but was simply added to the bundle.
dist/lodash.jsis not the minified version. While you wouldn't keep this for production, this is just an example to show that the
depsfiles are not processed with Babel but taken directly as they are.
That's it for Part 3! Now you can have multiple JS bundles without messing with the Gulpfile whenever you need to add a new dependency or create a separate bundle. In the next part you will learn how we can minify our bundle and clean up the temporary files.
Or, if you don't want to go right to the next step, you can jump around throughout the series: | https://cobwwweb.com/compile-es6-code-gulp-babel-part-3 | CC-MAIN-2019-22 | refinedweb | 1,007 | 58.48 |
This is my java assignment for school and I have done most of the work. But I still have some other features I have problems with adding. This is a guessing game where to program requests a number from the user between 1-1000.
It will tell the user if the user's guess was too high or too low. And when the user entered the correct guess the program will add the result to the high score list and ask the user if he wants to play again. The high score list consists of name, nr of guesses and how long time it took for the user to guess the correct number.
The following features are:
1. I want it to say "Stupid Guess" if you guess a number greater than 1000 or less than 0 and the program shouldn't count it as a guess.
2. I want it to say "Stupid Guess" if you guess a non-numeric value 0 and the program shouldn't count it as a guess.
3. The user should be able to input 'quit' and the program should stop.
Could you please give me some hints? :)
package game; import java.util.*; public class Game { public void start() { Scanner in = new Scanner(System.in); Random generator = new Random(); String ch; int numberOfGuesses; String name; int[] guesses = new int[1000]; String names[] = new String[1000]; double times[] = new double[1000]; int counter = 0; double start; double end; int num = 0; String n = ""; do { if(counter > 0) { int i, j; for(i = 0;i < counter; i++) for(j = 0; j <counter-1; j++) { if(guesses[j] > guesses[j+1]) { int temp = guesses[j]; guesses[j] = guesses[j+1]; guesses[j+1] = temp; ///////////////////// String tempName = names[j]; names[j] = names[j+1]; names[j+1] = tempName; } if(guesses[j] == guesses[j+1] && times[j] > times[j+1]) { int temp = guesses[j]; guesses[j] = guesses[j+1]; guesses[j+1] = temp; ///////////////////// String tempName = names[j]; names[j] = names[j+1]; names[j+1] = tempName; ///////////////////// double time = times[j]; times[j] = times[j+1]; times[j+1] = time; } } System.out.println("Current highscore list: "); System.out.println("Name Guesses"); for(i=0; i < counter; i++) { System.out.print(names[i]+" "); System.out.println(guesses[i]); System.out.println("Time: "+times[i] / 1000); } } int randomIndex = generator.nextInt( 1001); numberOfGuesses = 0; int target = randomIndex + 1; start = System.currentTimeMillis(); do { System.out.print("Please enter your guess(1-1000): "); n = in.next(); if(isIntNumber(n)) num = Integer.parseInt(n); } while(!isIntNumber(n)); while(target != num) { if(target < num) System.out.println("Too high"); else if(target > num) System.out.println("Too low"); numberOfGuesses++; System.out.println("Please enter your guess"); num = in.nextInt(); } numberOfGuesses++; System.out.println("Right ... the number was "+target); end = System.currentTimeMillis(); System.out.print("Please enter you name: "); name = in.next(); guesses[counter] = numberOfGuesses; names[counter] = name; times[counter] = end-start; System.out.print("Do you wish to play again ? (yes/no)"); ch = in.next(); counter++; } while(ch.equalsIgnoreCase("yes")); } public boolean isIntNumber(String num){ try{ Integer.parseInt(num); } catch(NumberFormatException nfe) { return false; } return true; } public static void main(String[] args) { Game game=new Game(); game.start(); } } | https://www.daniweb.com/programming/software-development/threads/316367/what-to-do | CC-MAIN-2017-09 | refinedweb | 531 | 59.5 |
Functional .NET - Laziness Becomes You
In the previous post, I talked about some of the basic ideas you can learn from Functional Programming and apply to your code right now. The first topic that was tackled was extensibility through the use of closures. Today, I’ll cover laziness in your APIs, how it can help, and what pitfalls might arise.
Laziness Explained
One of the hallmark features of the Haskell programming language is lazy evaluation. This gives us the ability to delay the computation of a given function, structure, etc, until it is absolutely needed. Sounds very agile in a way of the last responsible moment, actually. Why is it useful? By delaying the computation, we can gain performance increases by avoiding the calculations ahead of time. With this, we can create infinite data structures, as well as control structures such as if/then/else statements. Let’s take two Haskell examples of infinite structures, the first being an infinite list of 1 to whatever, and the next of all, yes, I know, the trite Fibonacci sequence. Opening up the GHCi, we can type along:
Prelude> take 3 l
[1,2,3]
Prelude> let fibs = 0 : 1 : zipWith (+) fibs (tail fibs)
Prelude> :t fibs -- All Fibonacci numbers
fibs :: [Integer]
Prelude> take 5 fibs
[0,1,1,2,3]
I find when explaining some of these topics, that Haskell as a language works best. The Fibonacci sequence is calculated with a cons of 0 and then a cons of 1 to the zipWith of addition of the Fibonacci sequence and the tail of the Fibonacci sequence. This takes the initial cons and then takes the previous (the tail) and the current and adds them together in an even/odd fashion. But the important thing to note is that even though the list goes on forever, evaluating this didn’t cause my system to crash.
Just as well, we could rewrite the following in F# pretty much the same as above with a few changes. The sequence comprehensions do not understand infinite sequences, so we can use other means as well. And since F# is an eagerly evaluated language, we’ll have to use a thunk to express the laziness. We’ll get into what that is a little later below:
> let l = Seq.init_infinite id;;
val l : seq<int>
> Seq.take 3 l;;
val it : seq<int> = seq [0; 1; 2]
// Fibonacci with map2
> #r "FSharp.PowerPack.dll";;
> let rec fibs : LazyList<int> =
- LazyList.consf 0
- (fun () -> (LazyList.cons 1
- (LazyList.map2 (+) fibs (LazyList.tl fibs))));;
val fibs : LazyList<int>
> Seq.take 3 fibs;;
val it : seq<int> = seq [0; 1; 1]
But another use could be the control statements of if/then/else as a simple example. Imagine if you will that you were implementing this as a function instead of as a language feature. The last thing you’d want to do is eagerly evaluate the else statement before its needed, else it could cause some unwanted side effects or even possibly crash.
There are some really good articles on the Haskell Wiki on how laziness works and the performance metrics that you can check out as well. As much as I love talking about Haskell, let’s move onto .NET and talk a little about where it can fit there as well.
How Lazy Is .NET Anyways?
So, the question becomes, just how lazy can .NET be? Well, there are several pieces to cover, including iterators, delayed evaluation through functions and lazy values, of which the latter will be covered in a later post.
Iterators
With the advent of iterators in C# 2.0 and the ability to yield values on an as needed basis through the use of continuations. For example, we could rewrite the fibs sequence using a C# 2.0 iterator such as this:
static IEnumerable<ulong> Fibonacci
{
get
{
ulong i = 1;
ulong j = 1;
while (true)
{
yield return i;
var temp = i;
i = j;
j = j + temp;
}
}
}
With this, we’re able to calculate every number as we want them and nothing beforehand. If you step through the code, you’ll see how it operates. But, moving on, we can also use this to express API calls that are right now, thoroughly eager. Take for example, the Directory.GetFiles method which takes a path and some options, and returns a string array of the file names. The problem with that is that you could be traversing a directory of thousands of images or documents, and is there a need at that point to evaluate all of them, when you may only want the top 5?
In a previous post, “Functional .NET – Fighting Friction in the BCL”, I did exactly that to implement the Directory.GetFiles in a lazy evaluated manner. The underlying Kernel32 implementations in Windows use an iterator pattern of FindFIrstFile and FindNextFile of which we can easily take advantage. Let’s once again look at the example:
public static IEnumerable<string> GetFiles(
string directory,
SearchOption option)
{))
yield return file;
}
}
}
else
{
var filePath = Path.Combine(directory, findData.cFileName);
yield return filePath;
}
} while (NativeMethods.FindNextFile(findHandle, findData));
}
}
}
Now, through the power of LINQ, we are able to pick and choose what type of file we want and how many we want at the same time. Such examples might be:
var fiveFiles = GetFiles(@"C:\Work").Take(5);
var results = from file in GetFiles(@"C:\Tools", SearchOption.AllDirectories)
where (File.GetAttributes(file) & FileAttributes.Hidden) != 0
select new FileInfo(file);
Well, that’s all very good and interesting. But what about another idea of delaying evaluation with functions?
Thunking About It
Another way of delaying the execution of a given statement is by wrapping it in a function. This is called a thunk, which is a function which takes no arguments and delays the computation of the function return value. The function returned forces the thunk then to obtain the actual value. The reason for doing so is once again as above to not compute until absolutely needed. Such scenarios for this could be the initialization of a container or some other potentially expensive operation.
static Func<double> Average(IEnumerable<int> items)
{
return () => items.Average();
}
This in itself is interesting in that we get a function back at which point we are free to evaluate it when it’s absolutely needed. We can also write a version of the
Is anybody using this in practice though? The answer is yes!
The Common Service Locator library on CodePlex has a very good example of using this in practice. For example, when we want to register the StructureMap container, here is the following code used:
var container = new Container(x =>
x.ForRequestedType<ICustomerRepository>()
.TheDefaultIsConcreteType<CustomerRepository>());
ServiceLocator.SetLocatorProvider(
() => new StructureMapServiceLocator(container));
If we look at the actual implementation in the source code, we find we set our thunk in the SetLocatorProvider and then only force the eval once you call the Current property as follows with the comments being my own:
public static class ServiceLocator
{
// The thunk
// Should be just Func<IServiceLocator> instead
private static ServiceLocatorProvider currentProvider;
// Force the eval
public static IServiceLocator Current
{
get { return currentProvider(); }
}
public static void SetLocatorProvider(ServiceLocatorProvider newProvider)
{
currentProvider = newProvider;
}
}
Pretty straight forward, and yet a powerful concept.
Side Effects and Laziness
Laziness in your APIs can be a good thing. But with this good thing, there are downfalls that some beginners can make. I noted back in September of last year some of these pitfalls in my post “Side Effects and Functional Programming”. In this post, I covered a couple of cases including:
- Order of Side Effects with Laziness
- Exception Management
- Resource Management
- Closure scope
These are important to keep in mind as we’re mixing paradigms because laziness and side effects don’t mix. Alas, many do say that Haskell has been harder for them to pick up in part due to the lazy evaluation.
Conclusion
With just these two examples of iterators and thunks, we have some ideas on how we can apply laziness to our codebase, with some careful consideration of side effects of course. There are yet many other cases to cover in this area, but I think for now this is a good starting point. Other areas yet to explore with how to improve your code with functional constructs yet to come is around the use of expressions and functions to rid yourselves of the evil “magic strings”. | http://weblogs.asp.net/podwysocki/functional-net-laziness-becomes-you | CC-MAIN-2016-07 | refinedweb | 1,399 | 61.97 |
An App Walkthrough Screen is a slider screen which allows the user to learn everything about the features of a mobile app when they open the application for the first time. We can implement this feature in a React Native application in multiple ways. In this React Native tutorial, we describe how we implemented the Walkthrough Screens in all of our React Native Templates so that you can speed up your app development by reusing our open source code.
In this tutorial, we will make use of react-native-app-intro-slider package to implement the app walkthrough screens. react-native-app-intro-slider is a simple and configurable app introduction slider written for React Native projects. It helps developers implement an easy-to-use, yet very configurable app introduction slider/swiper based on FlatList. Therefore, we are using this package to implement our walkthrough screens.
Firstly, let’s look at the following steps that we need to perform to build this app:
- Installing react-native-app-intro-slider npm package
- Importing the package into the JavaScript code
- Creating a state for handling the visible status
- Creating two simple functions for handling the slide visible state
- Deciding whether to show the walkthrough screens or main app
- Adding mock data for the feed package
- Building the stylesheet for a better design & UX
Now, let’s implement these steps to get our final product, which will look and behave exactly like in the animation below:
1. Install react-native-app-intro-slider package
In this step, we need to install the react-native-app-intro-slider in our project. To do this, you can execute the following code on your NPM or command prompt:
Using NPM or command prompt :
npm install react-native-app-intro-slider --save
As a result, you can see all the modules it downloads into our project in the above screenshot. These packages are stored in node_modules directory of our project, which you are already familiar with, if you’ve ever done React Native before.
2. Import the Package to App.js
In this step, you need to import our newly installed react-native-app-intro-slider package to our App.js file. Here, we import the package as AppIntroSlider as shown in the code snippet below:
import AppIntroSlider from 'react-native-app-intro-slider';
Therefore, the package react-native-app-intro-slider will be imported to your App.js file. Now, you can use its various modules and methods.
3. Handle Walkthrough Visibility Status with State
In this step, we need to create a state to handle the walkthrough visibility status, by checking whether it is visible or not in the app interface. Thus, we create a variable named show_Main_App to store the Boolean value for our state handler. You can do this using the following React Native code snippet:
constructor(props) { super(props); this.state = { show_Main_App: false }; }
4. Toggling the Visibility State with Two Functions
Creating a state is not enough, we need a mechanism to toggle the visibility status of the walkthrough screens as well. Thus, in order to handle the state values we need to create two simple functions. These handler functions are shown in the code snippet below:
on_Done_all_slides = () => { this.setState({ show_Main_App: true }); }; on_Skip_slides = () => { this.setState({ show_Main_App: true }); };
As a result, the above two functions on_Done_all_slides() and on_Skip_slides = () will enable the program to handle the state show_Main_App and set it as true.
5. Displaying the Walkthrough Screens and the Main App
In this step, we initialize a simple condition to make our walkthrough visible in the app’s user interface. In order to achieve this, we need to make use of the render() function which will return a template <View> to the main app interface if the condition of our state show_Main_App is true, otherwise, it will return AppIntroSlider module to our app interface to display the actual walkthrough screens. You can make use of following code snippet for this operation:
render() { if (this.state.show_Main_App) { return ( <View style={styles.MainContainer}> <Text style={{ textAlign: 'center', fontSize: 20, color: '#000' }}> This is your main App screen After App Walkthrough. <Text> ); } else { return ( <AppIntroSlider slides={slides} onDone={this.on_Done_all_slides} showSkipButton={true} onSkip={this.on_Skip_slides} /> ); } }
As a result, using the above code you can set up a condition to decide whether to show the walkthrough screen or the main app. Most importantly, make sure that you configure your project with the exact same configurations shown in the above code snippet.
6. Adding Mock Data to the React Native Walkthrough Screens
In this step, we will add some mock data to our React Native Walkthrough Screens, that are built on top of AppIntroSlider package. We are using the following dataset with a slides list that contains key, title, text, image, etc. You can use your own dataset but keep in mind that every key should be a unique value. Here’s a React Native example on how to achieve this:
const slides = [ { key: 'k1', title: 'Ecommerce Leader', text: 'Best ecommerce in the world', image: { uri: '', }, titleStyle: styles.title, textStyle: styles.text, imageStyle: styles.image, backgroundColor: '#F7BB64', }, { key: 'k2', title: 'fast delivery', text: 'get your order insantly fast', image: { uri: '', }, titleStyle: styles.title, textStyle: styles.text, imageStyle: styles.image, backgroundColor: '#F4B1BA', }, { key: 'k3', title: 'many store ', text: 'Multiple store location', image: { uri: '', }, titleStyle: styles.title, textStyle: styles.text, imageStyle: styles.image, backgroundColor: '#4093D2', }, { key: 'k4', title: '24 hours suport', text: ' Get Support 24 Hours with Real Human', image: { uri: '', }, titleStyle: styles.title, textStyle: styles.text, imageStyle: styles.image, backgroundColor: '#644EE2', } ];
The meaning of each keyword in the above code snippet is explained below:
- key: The key should be unique for each slide.
- title: It represents the title of the slide.
- text: It represents the description text of the swipe page.
- image: You need to pass the image path of the slide here.
- titleStyle: You will use this to call the title style.
- textStyle : You will use this to style the description text.
- imageStyles: You will use this to call the image style.
- backgroundColor : Using this, you will define background color in HEX color code format.
7. Styling the UI & UX Components
Finally, in this step, we need to add some styles to our walkthrough screens, to customize the app design of the new user flow. Let’s go ahead and add the following CSS stylesheet to your app:
const styles = StyleSheet.create({ MainContainer: { flex: 1, paddingTop: 20, alignItems: 'center', justifyContent: 'center', padding: 20 }, title: { fontSize: 26, color: '#fff', fontWeight: 'bold', textAlign: 'center', marginTop: 20, }, text: { color: '#fff', fontSize: 20, }, image: { width: 200, height: 200, resizeMode: 'contain' } });
Note: You can use any CSS styling to your application. It will not affect the overall functioning of the application.
Run the React Native project you’ve just finished, and you should see the completed creation of a Walkthrough Flow in React Native.
Summary
We can use a number of ways to build a walkthrough flow app in React-Native but using a 3rd party npm package is comparatively simple and quick. Following these seven steps will help you configure your walkthrough app in react-native using react-native-app-intro-slider package.
You can also find and study lots of other configurations using this package. So, let your imagination and knowledge flow. Finally, by following the steps mentioned in this tutorial, you will be able to create a simple app walkthrough to guide new users through your new application in React-Native.
If you want to build an advanced Walkthrough App template with an unlimited number of walkthrough steps, extensible code and modularized colors, strings, and images, check out a free walkthrough React Native template from Instamobile.io.. | https://www.instamobile.io/react-native-tutorials/walkthrough-screens-react-native-app/ | CC-MAIN-2021-31 | refinedweb | 1,277 | 53.41 |
The code for this walkthrough is available here. This blog has also been posted on Medium.
React is a JavaScript library for building user interfaces. That’s it. It’s a way to use JavaScript to define UI elements based on user-defined properties and internal state.
It has a clean, functional style. You can create simple components that compose very well into larger components, which you can then use to compose pages and entire applications. This simple composability is one of the main reasons I enjoy working with it.
But, it is not an application framework. It doesn’t pretend to be. This can be useful when all you want is some quick UI. But, as the application grows, you will need to depend on outside libraries for things like state-management, routing, and forms.
In this article, I cover how a React application can and should handle user input with Formik. Learn how to handle form input, from basic form input using simple state through to advanced form components using Formik.
Note: I will be assuming some familiarity with React in general, including lifecycle hooks and props/state. If you need a refresher, checkout this great article here and the official React docs.
A Simple Search
React applications can start simply – maybe you want to list that long list of todos you created the last time you did a coding tutorial, a list of movies from a demo application, or maybe all the Steam games you bought on sale but haven’t played yet. In the latter case, you could end up with way too many to deal with, so you need to be able to search for them.
Here’s a simple component that will let us find our long-lost games.
import React, { Component } from 'react' export default class SimpleForm extends Component { state = { searchTerm: '', } handleSubmit = event => { event.preventDefault() // prevent form post this.props.onSearch(this.state.searchTerm) } handleSearch = event => { const searchTerm = event.target.value this.setState((prevState, props) => ({ searchTerm, })) } render = () => ( <div> <form onSubmit={this.handleSubmit}> <input type="text" placeholder="Search games" value={this.state.searchTerm} onChange={this.handleSearch} /> <input type="submit" value="Submit" /> </form> </div> ) }
Not too bad.. React
makes you allows you to control the data flow explicitly in your application. This is great in that the data-flow is unidirectional, which helps cut down on side effects in large applications. It does what we want in this case.
A Small Addition
The Steam Autumn Sale is coming up soon, and I want to make sure I can add some games to my collection. Let’s add a small form so we can accomplish this.
import React, { Component } from 'react' import TextInput from './TextInput' //re-usable TextInput! export default class AddGameForm extends Component { state = { title: '', releaseYear: '', genre: '', price: '', } handleChange = event => { const { name, value } = event.target this.setState((prevState, props) => ({ [name]: value, })) } handleSubmit = event => { event.preventDefault() // prevent form post // handle add here } render() { const { title, releaseYear, genre, price } = this.state return ( <div className="addGameForm"> <form onSubmit={this.handleSubmit}> <TextInput id="title" name="title" type="text" label="Title " placeholder="Game title" value={title} onChange={this.handleChange} /> <TextInput id="releaseYear" name="releaseYear" type="text" label="Release year " placeholder="1993" value={releaseYear} onChange={this.handleChange} /> <TextInput id="genre" name="genre" type="text" label="Genre " placeholder="Action/Arcade/Shooter" value={genre} onChange={this.handleChange} /> <TextInput id="price" name="price" type="text" label="Price " placeholder="13.37" value={price} onChange={this.handleChange} /> <div> <input className="btn" type="submit" value="Add Game" /> </div> </form> </div> ) } }
Here we can see multiple custom
TextInput controls in their natural habitat. We can continue to grow the number of inputs if necessary, and we’ve added a nice ES6 feature to assign to the appropriate part of our
state.
this.setState((prevState, props) => ({ const { name, value } = event.target // destructure properties [name]: value, // ES6 computed property key }))
But wait… What about different types of inputs? Checkboxes? Dropdowns? What about validating each of those form inputs? What about only validating after the user has left a field to promote good UX? What about asynchronous validation? What about disabling inputs and changes while asynchronous submission is occurring? How do we handle nested form values? How about checking for changes and dirty fields?
As you can see, there are many concerns when developing a user experience for forms. These are the types of things that separate a frustrating experience from a quality one. We could definitely handle all these cases with some work, and over time, it would be great to abstract out many of the concerns above and develop a library that we could use to address these issues. Luckily for us, Formik already has.
Formik
As a basic example, let’s look at what Formik gives us. You can use it as a higher-order component or a render callback (also applicable as a child function). This allows for greater flexibility in the props and state, as well as enhanced composability. There is also no need to track the state of the form elements explicitly. You can allow your form to handle itself, which is one of the key elements of React and a component-based architecture.
Here is a basic version of the Add Game form using Formik (with a render callback).
import React, { Component } from 'react' import TextInput from './TextInputFormik' import { Formik, Form, Field } from 'formik' import Yup from 'yup' import isEmpty from 'lodash/isEmpty' export default class AddGameForm extends Component { render() { return ( <div className="addGameForm"> <Formik validationSchema={Yup.object().shape({ title: Yup.string() .min(3, 'Title must be at least 3 characters long.') .required('Title is required.'), })} initialValues={{ title: 'asdf', releaseYear: '', genre: '', price: '12', }} onSubmit={(values, actions) => { // this could also easily use props or other // local state to alter the behavior if needed // this.props.sendValuesToServer(values) setTimeout(() => { alert(JSON.stringify(values, null, 2)) actions.setSubmitting(false) }, 1000) }} render={({ values, touched, errors, dirty, isSubmitting }) => ( <Form> <Field type="text" name="title" label="Title" component={TextInput} /> <Field type="text" name="releaseYear" label="Release Year" component={TextInput} /> <Field type="text" name="genre" label="Genre" component={TextInput} /> <Field type="text" name="price" label="Price" component={TextInput} /> <button type="submit" className="btn btn-default" disabled={isSubmitting || !isEmpty(errors) || !dirty} > Add Game </button> </Form> )} /> </div> ) } }
The Formik component gives us access to numerous props that we can use to get the behavior we want. Any of these can be extracted to their own contents or adjusted based on internal state or props passed down to it. Let’s break down some key features that Formik provides.
Validation
Formik leans on Yup for validation. This provides a simple, yet powerful, way to validate an object schema for your form controls.
validationSchema={Yup.object().shape({ title: Yup.string() .min(3, 'Title must be at least 3 characters long.') .required('Title is required.'), })}
The
validationSchema prop takes a
Yup schema or a function that returns one. There are many types of validators, such as for objects, strings, numbers, dates, etc. You can also create your own. The validators can be chained to allow precise constraints for acceptable values.
You also do not need to use Yup – you can write your own validation functions with plain JavaScript by providing a
validation prop instead of a
validationSchema.
validate={values => { let errors = {} if (!values.price) { errors.price = 'Required' } else if (values.price > 60) { errors.price = 'Costs too much, wait for the sale!' } return errors }}
The
errors object simply has a matching key for each value in the form values object.
Form Layout
Formik provides
Form and
Field components as well, which are merely helping components to take care of basic
<form> and
< input > tags. These follow established conventions which are outlined more in the documentation. In these cases we’re passing a custom
TextInput component that allows us to control how the labels, inputs, and error messages are laid out. Below is a basic example.
import React from 'react' import classnames from 'classnames' const InputFeedback = ({ children }) => ( <span className="text-danger">{children}</span> ) const Label = ({ error, children, ...props }) => { return <label {...props}>{children}</label> } const TextInput = ({ field: { name, ...field }, // { name, value, onChange, onBlur } form: { touched, errors }, // also values, setXXXX, handleXXXX, dirty, isValid, status, etc. className, label, ...props }) => { const error = errors[name] const touch = touched[name] const classes = classnames( 'form-group', { 'animated shake error': !!error, }, className ) return ( <div className={classes}> <Label htmlFor={name} error={error}> {label} </Label> <input id={name} className="form-control" type="text" {...field} {...props} /> {touch && error && <InputFeedback>{error}</InputFeedback>} </div> ) } export default TextInput
We create a
div that holds our label, input, and error output. Here we’re using stateless functional components for our elements. This keeps our templates simple without the need to hook into the React lifecycle or keep track of internal state. This is a great pattern to use because it means that they are truly just JavaScript functions that transform data into markup. With a little work, this would make a great addition to anyone’s component library!
More great examples can be found on codesandbox.
Form State and Submission
If you have developed line-of-business applications like I have, you know that form state and submission handling is sometimes annoying and prone to repetition. Formik handles this by creating a convention that allows us to easily handle submitting the form, setting state, and tracking whether the form is dirty.
onSubmit={(values, actions) => { // this could also easily use props or other // local state to alter the behavior if needed // this.props.sendValuesToServer(values) setTimeout(() => { alert(JSON.stringify(values, null, 2)) actions.setSubmitting(false) }, 1000) }}
Here we’re just faking a server delay and then
alerting the values. We also have
actions that Formik provides to make our UX dynamic and more pleasant for the user. We can disable the submit button while the form is submitting, dirty, or otherwise not in a state that we want, as shown below.
No more explicit state handling for disabling inputs, and no more saving copies of objects to check on dirty state! Huzzah!
Conclusion
React has come a long way – it has a thriving community of developers and many great libraries to choose from. I think Formik is one of them. It takes a lot of the pain and tedium out of developing forms by giving you concise conventions and solid patterns to follow.
If you haven’t used React or Formik in the past, I encourage you to give it a try. It has been a joy to work with, so far, with a development cycle that is top-notch and a true lack of ceremony around creating reusable, composable components. This dynamic nature (after all, it is just JavaScript) grants great power and flexibility.
If you want to learn more about React or Formik, check out the source code for these samples here, our “Now Playing” reference application, or contact Keyhole for access to our React training course! | https://keyholesoftware.com/2017/10/23/the-joy-of-forms-with-react-and-formik/ | CC-MAIN-2021-43 | refinedweb | 1,805 | 57.57 |
A widget that renders an XHTML template. More...
#include <Wt/WTemplate.h>
A widget that renders an XHTML template.
The XHTML template may contain references to variables which replaced by strings are widgets.
Since the template text may be supplied by a WString, you can conveniently store the string in a message resource bundle, and make it localized by using WString::tr().
Placeholders (for variables and functions) are delimited by:
${...}. To use a literal
"${", use
"$${". Place holder names can contain '_', '-', '.' and alfanumeric characters.
Usage example:
There are currently three syntactic constructs defined: variable place holders, functions and conditional blocks.
${var} defines a placeholder for the variable "var", and gets replaced with whatever is bound to that variable:
Optionally, additional arguments can be specified using the following syntax:
${var arg1="A value" arg2='A second value'}
The arguments can thus be simple strings or quoted strings (single or double quoted). These arguments are applied to a resolved widget in applyArguments() and currently supports only style classes.
You can bind widgets and values to variables using bindWidget(), bindString() or bindInt() or by reimplementing the resolveString() and resolveWidget() methods.
<!-- ... -->) around variables that are bound to widgets will result in bad behaviour since the template parser is ignorant about these comments and the corresponding widgets will believe that they are rendered but aren't actually.
${fun:arg} defines a placeholder for applying a function "fun" to an argument "arg".
Optionally, additional arguments can be specified as with a variable placeholder.
Functions are resolved by resolveFunction(), and the default implementation considers functions bound with addFunction(). There are currently three functions that are generally useful:
For example, the following template uses the "tr" function to translate the age-label using the "age-label" internationalized key.
${<cond>} starts a conditional block with a condition name "cond", and must be closed by a balanced
${</cond>}.
For example:
Conditions are set using setCondition().
The template can return a bound widget using resolve(), which already tries to cast the widget to the proper type.
This widget does not provide styling, and can be styled using inline or external CSS as appropriate.
A function type.
Creates a template widget with given template.
The
templateText must be proper XHTML, and this is checked unless the XHTML is resolved from a message resource bundle. This behavior is similar to a WText when configured with the Wt::TextFormat::XHTML textformat.
Binds a function.
Functions are useful to automatically resolve placeholders.
The syntax for a function 'fun' applied to a single argument 'bla' is:
${fun:bla}
There are three predefined functions, which can be bound using:
Applies arguments to a resolved widget.
Currently only a
class argument is handled, which adds one or more style classes to the widget
w, using WWidget::addStyleClass().
Binds an empty string to a variable.
If a widget was bound to the variable, it is deleted first.
Binds an integer value to a variable.
Creates a new widget with the given arguments, and binds it, returning a raw pointer.
This is implemented as:
This is a useful shorthand for creating and binding a widget in one go.
Binds a string value to a variable.
Each occurrence of the variable within the template will be substituted by its value.
textFormat, the
valueis validated according as for a WText. The default (TextFormat::XHTML) filters "active" content, to avoid XSS-based security risks.
Binds a widget to a variable.
The corresponding variable reference within the template will be replaced with the widget (rendered as XHTML). Since a single widget may be instantiated only once in a template, the variable
varName may occur at most once in the template, and the
widget must not yet be bound to another variable.
The widget is reparented to the WTemplate, so that it is deleted when the WTemplate is deleted.
If a widget was already bound to the variable, it is deleted first. If previously a string or other value was bound to the variable, it is removed.
You may also pass a
nullptr
widget, which will resolve to an empty string.
Binds a widget to a variable, returning a raw pointer.
This is implemented as:
Erases all variable bindings.
Removes all strings and deletes all widgets that were previously bound using bindString() and bindWidget().
This also resets all conditions set using setCondition(), but does not remove functions added with addFunction()
Returns a condition value. internal path encoding is done on the template text.
Utility method to safely format an XHTML string.
The string is formatted according to the indicated
textFormat. It is recommended to use this method when specializing resolveString() to avoid security risks.
Utility method to safely format an XHTML string.
The string is formatted according to the indicated
textFormat. It is recommended to use this method when specializing resolveString() to avoid security risks.
Renders the errors during renderring.
Handles a variable that could not be resolved.
This method is called from resolveString() for variables that could not be resolved.
The default implementation implementation writes "??" + varName + "??" to the result stream.
The result stream expects a UTF-8 encoded string value.
result, without unsafe active contents. The format() methods may be used for this purpose.
Returns whether internal paths are enabled.
Refresh the widget.
The refresh method is invoked when the locale is changed using WApplication::setLocale() or when the user hit the refresh button.
The widget must actualize its contents in response.
Reimplemented from Wt::WWebWidget.
Unbinds a widget by variable name.
This removes a previously bound widget and unbinds the corresponding variable, effectively undoing the effect of bindWidget().
If this template does not contain a widget for the given
varName,
nullptr is returned.
Unbinds a widget by widget pointer.
This removes a previously bound widget and unbinds the corresponding variable, effectively undoing the effect of bindWidget().
If this template does not contain the given widget,
nullptr is returned.
Reimplemented from Wt::WWidget.
Renders the template into the given result stream.
The default implementation will call renderTemplateText() with the templateText().
Renders a template into the given result stream.
The default implementation will parse the template, and resolve variables by calling resolveString().
You may want to reimplement this method to manage resources that are needed to load content on-demand (e.g. database objects), or support a custom template language.
Return: true if rendered successfully.
Notifies the template that it has changed and must be rerendered.
If you update a WTemplate with e.g bindWidget or setCondition, or change the template text, the template will automatically be rerendered.
However, if you create a subclass of WTemplate and override resolveString or resolveWidget, you will have to notify the WTemplate if it has changed with a call to reset().
Returns a widget for a variable name.
This is a convience method, which calls resolveWidget() and dynamic casts the result to type
T. You may use this method to fetch widgets that have previously been bound using bindWidget().
If the cast fails, a null pointer is returned.
Resolves a function call.
This resolves a function with name
name, and one or more arguments
args, and writes the result into the stream
result. The method returns whether a function was matched and applied.
The default implementation considers functions that were bound using addFunction().
Resolves the string value for a variable name.
This is the main method used to resolve variables in the template text, during rendering.
The default implementation considers first whether a string was bound using bindString(). If so, that string is returned. If not, it will attempt to resolve a widget with that variable name using resolveWidget(), and render it as XHTML. If that fails too, handleUnresolvedVariable() is called, passing the initial arguments.
You may want to reimplement this method to provide on-demand loading of strings for your template.
The result stream expects a UTF-8 encoded string value.
result, without unsafe active contents. The format() methods may be used for this purpose.
Resolves a widget for a variable name.
The default implementation returns a widget that was bound using bindWidget().
You may want to reimplement this method to create widgets on-demand. All widgets that are returned by this method are reparented to the WTemplate, so they will be deleted when the template is destroyed, but they are not deleted by clear() (unless bind was called on them as in the example below).
This method is typically used for delayed binding of widgets. Usage example:
Sets a condition.
This enables or disables the inclusion of a conditional block.
The default value of all conditions is
false.
Configures when internal path encoding is done.
By default, the internal path encoding (if enabled) is done on the template text before placeholders are being resolved. In some rare situations, you may want to postpone the internal path encoding until after placeholders have been resolved, e.g. if a placeholder was used to provide the string for an anchor href.
The default value is
true
Enables internal path anchors in the XHTML template.
Anchors to internal paths are represented differently depending on the session implementation (plain HTML, Ajax or HTML5 history). By enabling this option, anchors which reference an internal path (by referring a URL of the form
href="#/..."), are re-encoded to link to the internal path.
The default value is
false.
Sets the template text.
The
text must be proper XHTML, and this is checked unless the XHTML is resolved from a message resource bundle or TextFormat is Wt::TextFormat::UnsafeXHTML. This behavior is similar to a WText when configured with the Wt::TextFormat::XHTML textformat.
Changing the template text does not clear() bound widgets or values.
Sets how the varName should be reflected on bound widgets.
To easily identify a widget in the browser, it may be convenient to reflect the varName, either through the object name (recommended) or the widget's ID.
The default value is TemplateWidgetIdMode::None which does not reflect the varName on the bound widget.
Returns the template.
Returns how the varName is reflected on a bound widget. | https://webtoolkit.eu/wt/doc/reference/html/classWt_1_1WTemplate.html | CC-MAIN-2021-31 | refinedweb | 1,666 | 58.79 |
Question about Java program to memorize a sequence of colors
The files must be called <YourNameProg7.java>.
Ensure.
As always, you are required to write elegant code. In particular, you should avoid hard coding the color values in the interior of your program. You should declare those values one time in an array at the top of the program.
Note:
? Your program should contain a class named YourNameProg7.
? Use a simple FlowLayout layout manager scheme.
? Use an inner class for the listener.
As always:
? Limit your use of class variables and instance variables - use them only if appropriate.
? Use appropriate modifiers for your methods. The modifiers we've discussed are private, public, static, and final.
? Use helping methods if appropriate.
? Mimic the sample session precisely. In particular, note the dialog box's text, the window's title, and the window's text..
Extra Credit.
Sample session:
After closing the dialog box, here's the main window:
After clicking the hint button:
After typing the first color:
After pressing enter and clicking the hint button:
After entering all five colors correctly:
Solution Preview
Please find below the java code. I have compiled and tested it in NetBeans. I have added the Hint button so you would be able to get extra credits. The logic is simple. attemptNumber variable keeps track of the attempt number. There is an event listener on the text field that checks the color entered. Good luck!
HERE IS THE SAME CODE BUT WHICH EXTENDS JFRAME. I HAVE MOVED JFRAME SETTINGS INTO ITS CONSTRUCTOR (YourNameProg7) SO THE MAIN() IS NOW VERY SIMPLE.
You can also test the program using javac.exe compiler as follows:
To compile:
javac.exe -g YourNameProg7.java
Then run:
java YourNameProg7
Source Code:
import javax.swing.*;
import java.awt.*;
import java.awt.event.*;
public class YourNameProg7 extends JFrame {
JLabel colLabel=new JLabel("Enter Color Number 1: ");
JTextField colText=new JTextField(10);
JButton butHint=new JButton("Hint");
int attemptNumber = 1;
...
Solution Summary
A java program in a single java file<YourNameProg7.java>. When launched you will see a question "How good is your memory? try to memorize following color sequence". Then the form will appear where the user can enter his guess. If the user correctly enters all the colors, the program prints a "Congratulations" message. | https://brainmass.com/computer-science/memory-management/question-about-java-program-to-memorize-a-sequence-of-colors-285176 | CC-MAIN-2017-39 | refinedweb | 381 | 59.7 |
Editor's note: Part 2 in this series of excerpts from ASP.NET in a Nutshell focuses on ASP.NET custom server controls.
For the reasons cited earlier in the chapter, user controls are not always the ideal choice for reuse. They tend to be very good for quickly reusing existing user interface elements and code, but are not especially useful for developing reusable building blocks for multiple web applications. This is where custom server controls come in.
A custom server control is, in its essence, a class that derives from either the Control or
WebControl class of the System.Web.UI namespace, or from one of the classes that derive from these controls. Custom server controls can be used in your ASP.NET Web Forms pages in very much the same way you use the built-in server controls that come with ASP.NET. There are two primary categories of custom server controls:
When designing a new custom server control, you need to consider some issues to decide which type of control to create:
Controlclass and override the Render method to create your custom output.
Note that by default, custom server controls expose all public members of the class from which they are derived. This exposure is important to consider when designing a control for use by other developers if you want to limit the customizations they can make. For instance, you might not want developers to change the font size of your control. In such a case, you should avoid deriving from a control that exposes that property.
Perhaps the best way to understand the process of creating a rendered custom server control is to see one. Example 6-4 shows a class written in Visual Basic .NET that implements a custom navigation control with the same functionality as the Nav.ascx user control discussed earlier in this chapter. Unlike the user control, which has the linked pages and images hardcoded into the control itself, the custom control in Example 6-4 gets this information from an XML file.
Example 6-4: NavBar.vb
Imports Microsoft.VisualBasic Imports System Imports System.Data Imports System.Drawing Imports System.IO Imports System.Text Imports System.Web Imports System.Web.UI Imports System.Web.UI.WebControls Namespace aspnetian Public Class NavBar Inherits Panel Private NavDS As DataSet Private _showDividers As Boolean = True Public Property ShowDividers( ) As Boolean Get Return _showDividers End Get Set _showDividers = value End Set End Property Sub NavBar_Load(sender As Object, e As EventArgs) Handles MyBase.Load LoadData( ) End Sub Protected Overrides Sub Render(Writer As HtmlTextWriter) Dim NavDR As DataRow Dim RowNum As Integer = 1 Dim SB As StringBuilder MyBase.RenderBeginTag(Writer) MyBase.RenderContents(Writer) Writer.Write("<hr width='80%'>" & vbCrLf) For Each NavDR In NavDS.Tables(0).Rows SB = new StringBuilder( )(vbCrLf) SB.Append(vbTab) SB.Append(vbTab) SB.Append("<img border='0' align='absMiddle' alt='") SB.Append(NavDR("text")) SB.Append("' src='") SB.Append(NavDR("imageUrl")) SB.Append("' id='") SB.Append("img") SB.Append(RowNum.ToString( )) SB.Append("' name='") SB.Append("img") SB.Append(RowNum.ToString( )) SB.Append("'></a>")(NavDR("text")) SB.Append("</a>") SB.Append(vbCrLf) If _showDividers = True Then SB.Append("<hr width='80%'>") Else SB.Append("<br/><br/>") End If SB.Append(vbCrLf) Writer.Write(SB.ToString( )) RowNum += 1 Next MyBase.RenderEndTag(Writer) End Sub Protected Sub LoadData( ) NavDS = New DataSet( ) Try NavDS.ReadXml(Page.Server.MapPath("NavBar.xml")) Catch fnfEx As FileNotFoundException CreateBlankFile( ) Dim Html As String Html = "<br>No NavBar.xml file was found, so one was " & _ "created for you. Follow the directions in the file " & _ "to populate the required fields and, if desired, " & _ "the optional fields." Me.Controls.Add(New LiteralControl(Html)) End Try End Sub Public Sub CreateBlankFile( ) 'Code to create a blank XML file with the fields used by ' the control. This code is included as a part of the file ' NavBar.vb, included with the sample files for the book. End Sub End Class End Namespace
The real meat of the NavBar control begins with the class declaration, which uses the
Inherits keyword to declare that the control derives from the Panel control. This gives the control the ability to show a background color, to be hidden or shown as a unit, and to display the contents of its begin and end tags as part of the control..
Example 6-7: Blog.cs
using System; using System.Data; using System.Drawing; using System.IO; using System.Web; using System.Web.UI; using System.Web.UI.HtmlControls; using System.Web.UI.WebControls; namespace aspnetian { public class Blog:Panel, INamingContainer { protected DataSet BlogDS; protected TextBox TitleTB; protected TextBox BlogText; private string _addRedirect; private string _email; private string _mode = "display"; public string AddRedirect { get { return this._addRedirect; } set { this._addRedirect = value; } } public string Email { get { return this._email; } set { this._email = value; } } public string Mode { get { return this._mode; } set { this._mode = value; } } protected override void OnInit(EventArgs e) { LoadData( ); base.OnInit(e); } protected override void CreateChildControls( ) { if (this._mode.ToLower( ) != ; } protected void CreateBlankFile( ) { // code to create new file...omitted to conserve space } } // closing bracket for class declaration } // closing bracket for namespace declaration
Displaying the blog entries is only half the battle. While it would certainly be possible to edit the XML file directly in order to add a new blog entry, it makes much more sense to make this a feature of the control. This is what the NewBlog method does. In the NewBlog method, we instantiate Label and TextBox controls for data entry and a Button control to submit the new blog entry. When the Button is clicked, the Submit_Click event handler method is called when the control is re-created on the server. The Submit_Click event handler, in turn, calls the AddBlog method to insert a new row into the BlogDS dataset and then writes the contents of the dataset back to the underlying XML file. Before using the control, of course, we'll need to compile it and place it in the application's bin directory. The following snippet can be used to compile the control:
csc /t:library /out:bin\blog.dll /r:system.dll,system.data.dll, system.xml.dll,system.web.dll blog.cs
Example 6-8 shows the ASP.NET code necessary to instantiate the Blog control programmatically. Note the use of the PlaceHolder control to precisely locate the Blog control output. For this code to work correctly, the compiled assembly containing the Blog control must reside in the application's bin subdirectory.Figure 6-2 shows the output of the control when used in the client page shown in Example 6-8.
Example 6-8: BlogClient.aspx
<%@ Page Sub Page_Load( ) Dim Blog1 As New Blog( ) PH.Controls.Add(Blog1) End Sub </script> </head> <body> <form runat="server"> <table border="1" width="100%" cellpadding="20" cellspacing="0"> <tr> <td align="center" width="150"> <img src="aspnetian.jpg"/> </td> <td align="center"> <h1>Blog Display Page<h1> </td> </tr> <tr> <td width="150" valign="top"> <aspnetian:NavBar <strong>Navigation Bar</strong> <br/> </aspnetian:NavBar> </td> <td> <asp:placeholder </td> </tr> </table> </form> </body> </html>
Example 6-9 shows the code necessary to instantiate the control declaratively. The example uses the TagPrefix
aspnetian2 because both the NavBar control and the Blog control use the same namespace, but are compiled into separate assemblies (which means that using the same TagPrefix for both would result in an error).
Example 6-9: BlogAdd.aspx
<%@ Page Sub Page_Load( ) 'Uncomment the line below to explicitly create a blank ' XML file, then comment the line out again to run the control 'NB1.CreateBlankFile( ) End Sub </script> </head> <body> <form runat="server"> <table border="1" width="100%" cellpadding="20" cellspacing="0"> <tr> <td align="center" width="150"> <img src="aspnetian.jpg"/> </td> <td align="center"> <h1>Blog Add Page<h1> </td> </tr> <tr> <td width="150" valign="top"> <aspnetian:NavBar <strong>Navigation Bar</strong> <br/> </aspnetian:NavBar> </td> <td> <aspnetian2:Blog </td> </tr> </table> </form> </body> </html>
As you can see, whether the control is used programmatically or declaratively, the amount of code necessary to provide simple blogging functionality is made trivial by the use of a custom server control. Note that you can also have the same page use the Blog control in either Display or Add mode, depending on the user's actions, as explained in the following section.
In the next installment, learn more custom server controls, including added design-time support and more..
Return to the .NET DevCenter. | http://www.onjava.com/lpt/a/2436 | CC-MAIN-2014-35 | refinedweb | 1,415 | 58.08 |
Creating a custom widget for Netlify CMS
JavaScript Room
・3 min read
Hi, devs!
Today I would like to share a few things I've found recently working with Netlify CMS. This CMS has a set of built-in fields, that you can use in your schema. Those fields are called "widgets" in the Netlify CMS ecosystem. Each widget describes the specific entry data type. For example, there are widgets
Date,
Text,
Boolean, etc. You can find all available widgets in the official docs.
Most of the time, you probably will be fine with these built-in widgets. But it's also nice to look forward and think in advance, what if someday I need more functionality than the original widgets provide? Luckily, authors of Netlify CMS thought of this also and made it possible to create and register a custom widget. Moreover, you even can find a few articles that show and explain how to do that. But, all of them weren't clear enough for me, they are hiding quite important details of the implementation. So I had to read all of the articles to make it work. So the goal of this post is putting all of the important things together.
If you are not interested in further reading and want to see the actual code, you can directly go to the demo on codesandbox or github repo
Let's write some code
A custom widget consists of two different React.js components: "control" and "preview". The first one is taking input from a user and the second one is responsible for how the user input data will be rendered in the preview area. As far as I understood, the preview component is optional and if you don't have it the data will be rendered in the preview anyway, but you have no control over the styling in this case.
So, let's start with writing these two React.js components.
I made the "control" component based on
CKEditor, which is a rich text editor (similar to built-in
Markdown widget).
// Control component - src/components/customWidget/CustomWidgetControl.js import React, { PureComponent } from 'react'; import CKEditor from '@ckeditor/ckeditor5-react'; import ClassicEditor from '@ckeditor/ckeditor5-build-classic'; export class CustomWidgetControl extends PureComponent { onChange = (event, editor) => { const data = editor.getData(); this.props.onChange(data); } render() { return ( <CKEditor editor={ ClassicEditor } onChange={this.onChange} /> ); } }
The important things about the control component:
- It CAN NOT be a functional component (React.FC). If you make it FC it will not save data for some reason, so be aware of it.
- You need to update the stored data manually. For this, the control component has a prop
onChangethat receives the new value as a parameter. We need to call this prop on every change.
// Preview component - src/components/customWidget/CustomWidgetPreview.js import React from 'react'; export const CustomWidgetPreview = (props) => { return ( <div dangerouslySetInnerHTML={{ __html: props.value}} /> ); }
What we need to know here is just that we get the value from the component's props. In this case, we get the HTML string and render it as a raw HTML.
Register the widget
So, we have created components for our custom widget. Now we need to introduce this widget to Netlify CMS, make it visible for it. Talking by Netlify CMS' terminology, we have to register our widget.
// src/cms/cms.js import CMS from 'netlify-cms-app'; import { CustomWidgetControl, CustomWidgetPreview } from '../components/customWidget'; CMS.registerWidget('mywidget', CustomWidgetControl, CustomWidgetPreview);
registerWidget() method accepts three arguments: widget name, control component and preview component. The last one is optional as I mentioned above.
Make sure that the JavaScript file with this code is injected into the CMS pages. In this particular case, it's done by
gatsby-plugin-netlify-cms plugin, but it very depends on how you use Netlify CMS.
Add the field to your schema
// static/admin/config.yml ... fields: - {label: "Title", name: "title", widget: "string"} - {label: "My Custom Widget", name: "mywidgetname", widget: "mywidget"}
Recap
- Control component can not be a function
- Call
onChangeprop in control component to update the value
- Use
valueprop in the preview component to access the input data
I hope, this article will help you and save your time on research. Please let me know in comments if something stays unclear to you.
Source code / Demo
room-js
/
netlify-cms-custom-widget
Small demo to show how to create a custom widget for Netlify CMS
Tell me about a time you messed up
So I brought down the site for a little while this morning. Now I'm interested ...
| https://practicaldev-herokuapp-com.global.ssl.fastly.net/room_js/create-a-custom-widget-for-netlify-cms-4gl9 | CC-MAIN-2020-05 | refinedweb | 757 | 55.64 |
In the last post, we had set up a repository and installed the Flask library. Now, let's set up our first route.
Routes
In a web application, routing is the process of using URLs to drive the user interface (UI) shown on the browser. That is, when you are navigating within the website, notice that the URL at the top of the browser window keeps changing.
These URL "routes" are mapped to code in a web framework by implementing routing.
The most basic route is
/.
Entrypoint
Create a file and name it
app.py. This will be the entry point of all our Flask routes.
app.py
from flask import Flask app = Flask(__name__)
Here, we have initialised our
app by assigning it an instance of
Flask.
The
/ route
Add the
hello_world function to
app.py.
app.py
from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello, World!'
Notice we have added the
route decorator to the function, specifying which route the function should work for.
Running the route
To test the brand new route, simply:
flask run
You should see the following in the terminal window.
* Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on (Press CTRL+C to quit)
Click on the link (or copy-paste it to a browser) to view your application.
There you have it, your first route!
Tips
- If you are running this on a different machine on your local network (e.g. on a virtual machine or similar) and can't access the application on that machine, simply add the
-hparameter to
flask runto specify the host.
flask run -h 0.0.0.0
And then navigate to
{{ip.of.virtual.machine}}:5000.
- Similarly, if port
5000of your development machine is being used by another application, you can specify a different port with
-p.
flask run -h 0.0.0.0 -p 7000
Click here to go the next post where we look at adding an input form to the page and submitting its data to the server. | http://python.instructive.club/?flask_2 | CC-MAIN-2022-05 | refinedweb | 358 | 75.3 |
Users want to know that any confidential information they provide to a website will be protected. That’s why modern web applications need to have SSL if they want to be trusted. This, however, can be quite challenging to set up for an ingress controller of an application running on Google Kubernetes Engine (GKE). The biggest challenge for me was a lack of documentation or guidelines featuring an end-to-end implementation of cert-manager and the nginx ingress controller. In this article, I’ll show you step-by-step how I went about it by walking you through setting-up your GKE hosted web application with ingress and SSL.
Generally, you can think of an SSL certificate as a kind of public key used in encrypting data that is transmitted between a browser and a web server: when connecting to a website that claims to be secure, the browser will request a certificate from the server. If it trusts the certificate, it will send a digitally signed acknowledgement - which manifests as a green padlock in the address bar!
The project I worked on was a small e-commerce platform running where customers were expected to provide personal information to make online payments. We needed a compatible solution that users could trust to request, renew and apply SSL certificates.
In the case of our application, the browser requests are first handled by the ingress controller, from which the browser will request a certificate. Therefore, the ingress controller needs to know about the certificate, as well as how and where to find it in the cluster. The solution also would ideally be cost-effective, widely trusted, hassle-free to administer, and compatible with our application running in a Kubernetes pod on GKE.
Figuring out what to do: Our SSL solution
After a quick Google search, I happened across the Let’s Encrypt project, which provides digital certificates to people enabling SSL and TLS on their websites - and it turned out to be ideal for a number of reasons. It was:
- Highly reliable,
- Widely trusted, and
- Free.
I also discovered that cert-manager, a native Kubernetes certificate management controller, is able to manage the whole process of requesting and renewing certificates, and storing them in your cluster somewhere. In other words, it unburdens you from having to manually update them. It can also help with issuing certificates from a variety of sources: Should you choose to change your certificate provider, you would only need to make a change to one kubernetes object, and the other pieces remain the same.
Getting started
While every effort has been made to make this writing clear and simple, a basic understanding of docker and kubernetes will go a long way to helping you make sense of what we are doing. With that in mind, then, we can start going through what I did to add SSL to my web application.
There are also a few things that you’ll need to have, that will not be covered here:
- A Google Kubernetes Engine (GKE) cluster: You can find instructions on how to create your own here. Also install Helm and Tiller, instructions here. This is the main environment where your application will be deployed to.
- A domain name: This is so that your application is accessible over the internet using a human friendly address.
Lastly, here are some of the important concepts worth understanding before we start:
- Helm Chart: This is helpful to understand because we will use helm charts to install cert-manager and nginx-ingress-controller.
- Ingress Controller: An ingress controller is a kind of load balancer, and the entry point of external traffic into our kubernetes cluster. In this example we will use the nginx ingress controller.
- Issuer and Cluster Issuer: These kubernetes object are important parts in requesting SSL certificates from Let’s encrypt and storing them in our cluster.
Step 1: Setting up a service with an nginx ingress controller
For the purpose of this article, we will launch a simple nginx container with no special configuration, and all it will show is this:
In this instance, nginx is a web server responsible for serving the HTML page we have showing “Hello” and the docker whale. To launch this pod in your cluster, run:
kubectl run hello-docker-b --image=docker.io/lsizani/hello --port=80 --labels='app=hello-docker-b'
This will create a deployment called
hello-docker, which will specify launching an nginx image from the google container registry and open port 80 on the image.
We are not yet able to access our new service from the internet, so our next step will be to make it available.
Let’s install our nginx ingress controller using helm:
helm install stable/nginx-ingress --name nginx-ingress-controller --set rbac.create=true
This will create the following resources:
RESOURCES: ==> v1/ServiceAccount NAME AGE nginx-ingress-controller 2s ==> v1beta1/ClusterRole nginx-ingress-controller 2s ==> v1beta1/ClusterRoleBinding nginx-ingress-controller 2s ==> v1beta1/RoleBinding nginx-ingress-controller 2s ==> v1beta1/Deployment nginx-ingress-controller-controller 2s nginx-ingress-controller-default-backend 2s ==> v1/Pod(related) NAME READY STATUS RESTARTS AGE nginx-ingress-controller-controller-f6dbd6cb9-2xknm 0/1 ContainerCreating 0 2s nginx-ingress-controller-default-backend-5dbd6c6575-ddtnp 0/1 ContainerCreating 0 2s ==> v1/ConfigMap NAME AGE nginx-ingress-controller-controller 2s ==> v1beta1/Role nginx-ingress-controller 2s ==> v1/Service nginx-ingress-controller-controller 2s nginx-ingress-controller-default-backend 2s
Also, it will tell you that this is what it has done. The beauty of installing our ingress controller using helm is that helm will do most of the work for us.
Next, we create a backend-service for our new pod. This backend service will be a resource of type ClusterIP - a service that allows the ingress controller to route traffic to the pods which match its label. Let’s see the spec:
**apiVersion**: v1 **kind**: Service **metadata**: **labels**: **app**: hello-docker **name**: hello-docker-svc **namespace**: default **spec**: **ports**: - **port**: 80 **protocol**: TCP **targetPort**: 80 **selector**: **app**: hello-docker **sessionAffinity**: None **type**: ClusterIP **status**: **loadBalancer**: {}
To create this resource in our cluster, we write our spec in a .yaml file and run (you can name the file anything):
kubectl create -f cluster-ip.yaml
This service will be assigned an IP address that is accessible within the cluster (hence: cluster IP), and it will be listed on port 80. It will then pass along any traffic directed to its IP on port 80 to its underlying pods, also on port 80. In case it is unclear, had the pods been listening on port 3000, then
targetPort would be 3000 and the service would send traffic to port 3000 of the pod.
The next piece of the puzzle is to set up an ingress resource. This is what will get us external access to the service. Here is a spec for our ingress resource:
**apiVersion**: extensions/v1beta1 **kind**: Ingress **metadata**: **name**: hello-docker **annotations**: **kubernetes.io/ingress.class**: nginx **nginx.ingress.kubernetes.io/ssl-redirect**: "false" **spec**: **rules**: - **http**: **paths**: - **path**: / **backend**: **serviceName**: hello-docker **servicePort**: 80
To create this resource in our cluster, we write our spec in a .yaml file and run:
kubectl create -f ingress.yaml
Before we continue, here’s a quick recap of what we have done so far:
- First, we created a deployment called hello-docker which launched a single pod with a hello-docker label.
- Then, we created a ClusterIP (service) that gives internal access to pods with the hello-docker IP.
- Finally, we created an Ingress resource that exposes the service to the internet, allowing us to view the application from a browser.
Still on track? Awesome! Now, to see our running app, we find the external IP from our ingress-controller. In order to do this, run:
kubectl get services
It essentially lists all the services running under the default namespace. This is my output:
The IP we’re interested in is EXTERNAL-IP of the nginx-ingress-controller-controller. When I click on that address, it shows me my page with “Hello!” and the docker whale. If everything is working correctly, you should see the same thing.
Step 2: Install cert-manager
Cert-manager will be responsible for requesting an SSL certificate on your behalf and also renewing it as necessary. Official documentation can be found here.
Before we get into installing cert-manager, you will need to assign a domain name to that external IP. Working this out depends on a number of things that I cannot discuss here right now, so hopefully you know how your configure your DNS!
We will once again use helm to install:
helm install --name cert-manager --namespace kube-system stable/cert-manager
If you were successful in installing nginx-ingress-controller using helm, then you will most likely be able to install cert manager without any issues.
Cert-manager needs to be able to manage your DNS entries to add/update SSL certificates as needed. To give it the correct access, we create an IAM policy for it, with role DNS Administrator. We then get access keys for the IAM service account and store them as kubernetes secrets. The script below does this:
#!/usr/bin/env bash ROBOT=clouddns DNS=your-project-id gcloud iam service-accounts create ${ROBOT} \ --display-name=${ROBOT} \ --project=${DNS} gcloud iam service-accounts keys create ./${ROBOT}.key.json \ --iam-account=clouddns@${DNS}.iam.gserviceaccount.com \ --project=${DNS} gcloud projects add-iam-policy-binding ${DNS} \ --member=serviceAccount:${ROBOT}@${DNS}.iam.gserviceaccount.com \ --role=roles/dns.admin kubectl create secret generic clouddns \ --from-file=./clouddns.key.json \ --namespace=kube-system
You can save the script to a file and run:
sh create-sa.sh
When this completes successfully, we can begin with getting SSL certificates for your app!
Step 3: Creating a certificate issuer
We will need to do certificate issuing twice: the first time is to get a test certificate in order to ensure that we have all our pieces working correctly. This will be evident when a certificate is successfully applied. The second, then, is to associate the certificate from your issuer with the domain name that you have configured for your app.
With the first certificate issuing, the test certificate comes from a staging environment on Let’s Encrypt. Considering that the staging environment has less restrictions on access compared to the production environment, it is a good place to first iron-out any kinks in your setup. We begin by creating a resource of type ClusterIssuer:
apiVersion: certmanager.k8s.io/v1alpha1 kind: ClusterIssuer metadata: name: letsencrypt-staging namespace: default spec: acme: server: email: your-email-address@gmail.com privateKeySecretRef: name: letsencrypt-staging dns01: providers: - name: clouddns clouddns: serviceAccountSecretRef: name: clouddns key: clouddns.key.json project: your-project-id
To create the issuer in your cluster, you run:
kubectl create -f cluster-issuer.yaml
To check that nothing went wrong, you can run:
kubectl describe clusterissuer letsencrypt-staging
You want to lookout for Status block, which shows the status of a request to ACME to obtain an account for SSL registration. Mine comes back with:
The next part is to associate the certificate from your issuer with the domain name that you have configured for your app. I set my app to use
app.hello-docker.tk, so that will be the domain for which I request a certificate. This is the spec for the certificate resource (remember to replace my domain name with your own):
apiVersion: certmanager.k8s.io/v1alpha1 kind: Certificate metadata: name: hello-docker-stg namespace: default spec: secretName: hello-docker issuerRef: name: letsencrypt-staging kind: ClusterIssuer commonName: app.hello-docker.tk dnsNames: - app.hello-docker.tk acme: config: - dns01: provider: clouddns domains: - app.hello-docker.tk
To create a certificate in your cluster, run:
kubectl create -f ssl-cert-stg.yaml
It takes about two minutes to complete the certificate request, but to check on its progress you can run:
kubectl describe certificate hello-docker-stg
When mine completed successfully, this was the output on the events section:
Now that we know that our setup works, we will create another issuer to get us a production certificate. The spec is very similar to the one we already have:
apiVersion: certmanager.k8s.io/v1alpha1 kind: ClusterIssuer metadata: name: letsencrypt-production namespace: default spec: acme: server: email: your-email@gmail.com privateKeySecretRef: name: letsencrypt-production dns01: providers: - name: clouddns clouddns: serviceAccountSecretRef: name: clouddns key: clouddns.key.json project: your-project-id
To create this issuer in your cluster, run:
kubectl create -f cluster-issuer-prod.yaml
If that completes successfully, add a certificate resource:
apiVersion: certmanager.k8s.io/v1alpha1 kind: Certificate metadata: name: hello-docker-prod namespace: default spec: secretName: hello-docker-prod issuerRef: name: letsencrypt-production kind: ClusterIssuer commonName: app.hello-docker.tk dnsNames: - app.hello-docker.tk acme: config: - dns01: provider: clouddns domains: - app.hello-docker.tk
Then, create the certificate in your cluster:
kubectl create -f ssl-cert-prod.yaml
You can then look at its status periodically with:
kubectl describe certificate hello-docker-prod
Once you have been issued a certificate, you need to inform your ingress controller that you have a certificate it can use. First, export the ingress controller deployment:
kubectl get deployment nginx-ingress-controller-controller -o yaml
This will output the deployment in .yaml format. We then want to add a line in the deployment, at the
args stanza. This is what the
args stanza should look like after editing:
- args: - /nginx-ingress-controller - --default-backend-service=default/nginx-ingress-controller-default-backend - --election-id=ingress-controller-leader - --ingress-class=nginx - --configmap=default/nginx-ingress-controller-controller - --default-ssl-certificate=default/hello-docker-prod
The line we added is:
- --default-ssl-certificate=default/hello-docker-prod
When you’re done editing, save the file and run:
kubectl apply -f ingress-deployment.yaml
If this completes without any errors, you should see it recreating the ingress-controller pod. To check on this, run:
kubectl get pods
You should see the ingress controller pod within a few seconds or a few minutes, depending on how long ago you ran apply.
And now, with all of that done, when you visit your domain on a browser it will have a valid SSL certificate! This is what I see:
Summary and final comments
We started out by deploying a docker image to our kubernetes cluster. Then, to make this application visible and accessible from outside the cluster, we gave it a ClusterIP and an Ingress. We were able to add and configure the ingress the way we did because we also installed an ingress controller to our cluster.
This nginx-ingress-controller can be used to expose other services that we may be interested in adding to our cluster, like having a customer-facing frontend and a backend API and even a separate admin frontend. However, they would most likely be available under the same root domain. Setting up additional sub-domains would only require creating more certificate resources.
For anyone interested in taking this a step further, something that might be cool to look at is adding a wildcard certificate. In essence, this would allow you to have one SSL certificate that applies to all of the services under your ingress controller. If you do tackle that, I’d love to hear what you have to say about the process, and what you found particularly valuable or interesting!
Lunga Sizani is a Software engineer at 2U Inc. He has just over five years experience working as a software developer with a variety of technologies. One of his favourite pastimes, which incidentally happens to also be his day job, is to solve problems he is isn’t officially “qualified” to be solving - because how else does one learn? | https://www.offerzen.com/blog/how-i-added-letsencrypt-ssl-to-a-google-kubernetes-engine-application | CC-MAIN-2019-43 | refinedweb | 2,635 | 51.38 |
Add validation to an ASP.NET Core MVC app
In this section:
- Validation logic is added to the
Moviemodel.
- You ensure that the validation rules are enforced any time a user creates or edits a movie.
Keeping things DRY
One of the design tenets of MVC is DRY ("Don't Repeat Yourself"). ASP.NET Core MVC encourages you to specify functionality or behavior only once, and then have it be reflected everywhere in an app. This reduces the amount of code you need to write and makes the code you do write less error prone, easier to test, and easier to maintain.
The validation support provided by MVC and Entity Framework Core Code First is a good example of the DRY principle in action. You can declaratively specify validation rules in one place (in the model class) and the rules are enforced everywhere in the app.
Add validation rules to the movie model
Open the Movie.cs file. The DataAnnotations namespace provides a set of built-in validation attributes that are applied declaratively to a class or property. DataAnnotations also contains formatting attributes like
DataType that help with formatting and don't provide any validation.
Update the
Movie class to take advantage of the built-in
Required,
StringLength,
RegularExpression, and
Range validation attributes.
public class Movie { public int Id { get; set; } [StringLength(60, MinimumLength = 3)] [Required] public string Title { get; set; } [Display(Name = "Release Date")] [DataType(DataType.Date)] public DateTime ReleaseDate { get; set; } [Range(1, 100)] [DataType(DataType.Currency)] [Column(TypeName = "decimal(18, 2)")] public decimal Price { get; set; } [RegularExpression(@"^[A-Z]+[a-zA-Z""'\s-]*$")] [Required] [StringLength(30)] public string Genre { get; set; } [RegularExpression(@"^[A-Z]+[a-zA-Z0-9""'\s-]*$")] [StringLength(5)] [Required] public string Rating { get; set; } }
The validation attributes specify behavior that you want to enforce on the model properties they're applied to:
The
Requiredand
MinimumLengthattributes indicate that a property must have a value; but nothing prevents a user from entering white space to satisfy this validation.
The
RegularExpressionattribute is used to limit what characters can be input. In the preceding code, "Genre":
- Must only use letters.
- The first letter is required to be uppercase. White space, numbers, and special characters are not allowed.
The
RegularExpression"Rating":
- Requires that the first character be an uppercase letter.
- Allows special characters and numbers in subsequent spaces. "PG-13" is valid for a rating, but fails for a "Genre".
The
Rangeattribute constrains a value to within a specified range.
The
StringLengthattribute lets you set the maximum length of a string property, and optionally its minimum length.
Value types (such as
decimal,
int,
float,
DateTime) are inherently required and don't need the
[Required]attribute.
Having validation rules automatically enforced by ASP.NET Core helps make your app more robust. It also ensures that you can't forget to validate something and inadvertently let bad data into the database.
Validation Error UI
Run the app and navigate to the Movies controller.
Tap the Create New link to add a new movie. Fill out the form with some invalid values. As soon as jQuery client side validation detects the error, it displays an error message.
Note
You may not be able to enter decimal commas in decimal fields. To support jQuery validation for non-English locales that use a comma (",") for a decimal point, and non US-English date formats, you must take steps to globalize your app. This GitHub issue 4076 for instructions on adding decimal comma.
Notice how the form has automatically rendered an appropriate validation error message in each field containing an invalid value. The errors are enforced both client-side (using JavaScript and jQuery) and server-side (in case a user has JavaScript disabled).
A significant benefit is that you didn't need to change a single line of code in the
MoviesController class or in the Create.cshtml view in order to enable this validation UI. The controller and views you created earlier in this tutorial automatically picked up the validation rules that you specified by using validation attributes on the properties of the
Movie model class. Test validation using the
Edit action method, and the same validation is applied.
The form data isn't sent to the server until there are no client side validation errors. You can verify this by putting a break point in the
HTTP Post method, by using the Fiddler tool , or the F12 Developer tools.
How validation works
You might wonder how the validation UI was generated without any updates to the code in the controller or views. The following code shows the two
Create methods.
// GET: Movies/Create public IActionResult Create() { return View(); } // POST: Movies/Create [HttpPost] [ValidateAntiForgeryToken] public async Task<IActionResult> Create( [Bind("ID,Title,ReleaseDate,Genre,Price, Rating")] Movie movie) { if (ModelState.IsValid) { _context.Add(movie); await _context.SaveChangesAsync(); return RedirectToAction("Index"); } return View(movie); }
The first (HTTP GET)
Create action method displays the initial Create form. The second (
[HttpPost]) version handles the form post. The second
Create method (The
[HttpPost] version) calls
ModelState.IsValid to check whether the movie has any validation errors. Calling this method evaluates any validation attributes that have been applied to the object. If the object has validation errors, the
Create method re-displays the form. If there are no errors, the method saves the new movie in the database. In our movie example, the form isn't posted to the server when there are validation errors detected on the client side; the second
Create method is never called when there are client side validation errors. If you disable JavaScript in your browser, client validation is disabled and you can test the HTTP POST
Create method
ModelState.IsValid detecting any validation errors.
You can set a break point in the
[HttpPost] Create method and verify the method is never called, client side validation won't submit the form data when validation errors are detected. If you disable JavaScript in your browser, then submit the form with errors, the break point will be hit. You still get full validation without JavaScript.
The following image shows how to disable JavaScript in the FireFox browser.
The following image shows how to disable JavaScript in the Chrome browser.
After you disable JavaScript, post invalid data and step through the debugger.
The portion of the Create.cshtml view template is shown in the following markup:
<h4>Movie</h4> <hr /> <div class="row"> <div class="col-md-4"> <form asp- <div asp-</div> <div class="form-group"> <label asp-</label> <input asp- <span asp-</span> </div> @*Markup removed for brevity.*@
The preceding markup is used by the action methods to display the initial form and to redisplay it in the event of an error.
The Input Tag Helper uses the DataAnnotations attributes and produces HTML attributes needed for jQuery Validation on the client side. The Validation Tag Helper displays validation errors. See Validation for more information.
What's really nice about this approach is that neither the controller nor the
Create view template knows anything about the actual validation rules being enforced or about the specific error messages displayed. The validation rules and the error strings are specified only in the
Movie class. These same validation rules are automatically applied to the
Edit view and any other views templates you might create that edit your model.
When you need to change validation logic, you can do so in exactly one place by adding validation attributes to the model (in this example, the
Movie class). You won't have to worry about different parts of the application being inconsistent with how the rules are enforced — all validation logic will be defined in one place and used everywhere. This keeps the code very clean, and makes it easy to maintain and evolve. And it means that you'll be fully honoring the DRY principle.
Using DataType Attributes
Open the Movie.cs file and examine the
Movie class. The
System.ComponentModel.DataAnnotations namespace provides formatting attributes in addition to the built-in set of validation attributes. We've already applied a
DataType enumeration value to the release date and to the price fields. The following code shows the
ReleaseDate and
Price properties with the appropriate
DataType attribute.
[Display(Name = "Release Date")] [DataType(DataType.Date)] public DateTime ReleaseDate { get; set; } [Range(1, 100)] [DataType(DataType.Currency)] public decimal Price { get; set; }
The
DataType attributes only provide hints for the view engine to format the data (and supplies elements/attributes such as
<a> for URL's and
<a href="mailto:EmailAddress.com"> for email. You can use the
RegularExpression attribute to validate the format of the data. The
DataType attribute is used to specify a data type that's more specific than the database intrinsic type, they're not validation attributes. In this case we only want to keep track of the date, not emit HTML 5
data- (pronounced data dash) attributes that HTML 5 browsers can understand. The
DataType attributes do not provide any validation.
DataType.Date doesn't specify the format of the date that ReleaseDate { get; set; }
The
ApplyFormatInEditMode setting specifies that the formatting should also be applied when the value is displayed in a text box for editing. (You might not want that for some fields — for example, for currency values, you probably don't want the currency symbol in the text box for editing.)
You can use the
DisplayFormat attribute by itself, but it's generally a good idea to use the
DataType attribute.attribute can enable MVC to choose the right field template to render the data (the
DisplayFormatif used by itself uses the string template).
Note
jQuery validation doesn; } [StringLength(60, MinimumLength = 3)] public string Title { get; set; } [Display(Name = "Release Date"), DataType(DataType.Date)] public DateTime ReleaseDate { get; set; } [RegularExpression(@"^[A-Z]+[a-zA-Z""'\s-]*$"), Required, StringLength(30)] public string Genre { get; set; } [Range(1, 100), DataType(DataType.Currency)] [Column(TypeName = "decimal(18, 2)")] public decimal Price { get; set; } [RegularExpression(@"^[A-Z]+[a-zA-Z0-9""'\s-]*$"), StringLength(5)] public string Rating { get; set; } }
In the next part of the series, we review the app and make some improvements to the automatically generated
Details and
Delete methods.
Additional resources
Feedback
Send feedback about: | https://docs.microsoft.com/en-us/aspnet/core/tutorials/first-mvc-app/validation?view=aspnetcore-2.2 | CC-MAIN-2019-26 | refinedweb | 1,700 | 55.03 |
Hey guys, new to the forum here.
EDIT: Alright guys, sorry about this whole edit, i'm doing more research and tests on this. The code basically is designed to center my text. Now I want to be able to insert double variables into this equation. I've tested the sprintf function outside of my program using %.0f and this works good, i can print the double variables. Now when I use it in my program I get a "buffer = 0, its too small error". How can i get around this?
Thanks guys! I'm new to C++, just started 2 weeks agoThanks guys! I'm new to C++, just started 2 weeks agoCode:void center (char* w) { int l, c; char length [80]; //sets a character array to 80 l = sprintf_s(length,"%s", w); //calculates length of string l = ((80-l)/2); //calculates amount of spaces on the left side printf("\n"); for (c = 0; c < l; c++) //inserts spaces before the string printf(" "); printf("%s",w); //inserts the string, then creates a new line } int main () { double a, b, c; char text [80]; sprintf_s(text,"Equation #%d\n\n",count); center(text); center("Enter coefficient of x^2: "); scanf_s("%d", &a); center("Enter coefficient of x^1: "); scanf_s("%d", &b); center("Enter coefficient of x^0: "); scanf_s("%d", &c); sprintf_s(text,"Equation #%d\n\n",count); center(text); sprintf_s(text, "Is F ( x ) = %d x ^ 2 + %d x ^ 1 + %d x ^ 0 the correct equation? Y/N? ", a, b, c); center(text); cin >> reply; cin.get (); return (0) } | http://cboard.cprogramming.com/cplusplus-programming/130058-sprintf-output-error.html | CC-MAIN-2015-35 | refinedweb | 260 | 69.52 |
A set of SVG icons for CRUD applications (hand-picked among thousands at Material Design Icons) packaged as a React component with light & dark themes and tooltip.
React-CRUD-Icons comes in Light and Dark theme.
... and 6 sizes: Tiny, Small, Medium, Large, Big, and Huge.
The package can be installed via npm:
npm install react-crud-icons --save
You will need to install React and PropTypes separately since those dependencies aren't included in the package.
Below is a simple example of how to use the component in a React view. You will also need to include the CSS file from this package (or provide your own). The example below shows how to include the CSS from this package if your build system supports requiring CSS files (Webpack is one that does).
import React from "react";
import Icon from "react-crud-icons";
import "../node_modules/react-crud-icons/dist/react-crud-icons.css";
class Example extends React.Component {
render() {
return (
<Icon
name = "edit"
tooltip = "Edit"
theme = "light"
size = "medium"
onClick = { doSomething }
/>
);
}
}
The component renders an inline SVG.
To package the code, I followed the steps from the blog post Building a React component as an NPM module by Manoj Singh Negi.
This article, along with any associated source code and files, is licensed under The MIT License | https://www.codeproject.com/Articles/5286750/React-Icon-Set-for-CRUD-Applications?PageFlow=FixedWidth | CC-MAIN-2021-04 | refinedweb | 217 | 62.98 |
I have a program, which is running on two processors, one of which does not have floating point support. So, I need to perform floating point calculations using fixed point in that processor. For that purpose, I will be using a floating point emulation library.
I need to first extract the signs, mantissas and exponents of floating point numbers on the processor which do support floating point. So, my question is how can I get the sign, mantissa and exponent of a single precision floating point number.
Following the format from this figure,
That is what I've done so far, but except sign, neither mantissa and exponent are correct. I think, I'm missing something.
void getSME( int& s, int& m, int& e, float number )
{
unsigned int* ptr = (unsigned int*)&number;
s = *ptr >> 31;
e = *ptr & 0x7f800000;
e >>= 23;
m = *ptr & 0x007fffff;
}
I think it is better to use unions to do the casts, it is clearer.
#include <stdio.h> typedef union { float f; struct { unsigned int mantisa : 23; unsigned int exponent : 8; unsigned int sign : 1; } parts; } double_cast; int main() { double_cast d1; d1.f = 0.15625; printf("sign = %x\n",d1.parts.sign); printf("exponent = %x\n",d1.parts.exponent); printf("mantisa = %x\n",d1.parts.mantisa); return 0; }
Example based on | https://codedump.io/share/H1RB47HNVVHl/1/how-to-get-the-sign-mantissa-and-exponent-of-a-floating-point-number | CC-MAIN-2016-50 | refinedweb | 214 | 64.91 |
Let us assume that we want to animate a nature of function which is exponentially decaying like y = a(b)^x where b = growth factor and a = initial value.
An exponentially decay function would look like this,
However, for now, we want to animate and plot the exponentially decaying tan function.
First import the libraries,
import numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation
Define the axes,
fig, a = plt.subplots()
Plotting a blank figure with axes,
xdata, ydata = [], [] line, = ax.plot(xdata, ydata)
Set the limit of the grids,
ax.set_xlim(0, 10) ax.set_ylim(-3.0, 3.0) ax.grid()
Define the function to generate the data which will be used in place of number of frames,
def frame_generator(i=0): while i < 50: i += 0.1 yield x, np.tan(2*np.pi*x) * np.exp(-x/5.)
Define function to plot the animation,
def animate(data): x, y = data xdata.append(x) ydata.append(y) xmin, xmax = ax.get_xlim() if x >= xmax: ax.set_xlim(xmin, 2*xmax) ax.figure.canvas.draw() line.set_data(xdata, ydata) return line
Activate the animation,
ani = FuncAnimation(fig, animate, frame_gen, blit=True, interval=2, repeat=False)
Plot the graph,
plt.show() | https://www.tutorialspoint.com/how-to-plot-exponentially-decaying-function-using-funcanimation-in-matplotlib | CC-MAIN-2021-10 | refinedweb | 205 | 52.15 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.