
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91
values | source stringclasses 1
value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
Hi Michael, Am Mittwoch, den 18.04.2012, 19:21 +0300 schrieb Michael Snoyman: > I'm quite a novice at rewrite rules; can anyone recommend an approach > to get my rule to fire first? I’m not an expert of rewrite rules either, but from some experimentation and reading -dverbose-core2core (which is not a very nice present... | http://www.haskell.org/pipermail/haskell-cafe/2012-April/100793.html | CC-MAIN-2014-10 | refinedweb | 334 | 64.81 |
From: Jeremy Siek (jsiek_at_[hidden])
Date: 2001-09-03 15:01:23
On Mon, 3 Sep 2001 williamkempf_at_[hidden] wrote:
willia> --- In boost_at_y..., Jeremy Siek <jsiek_at_c...> wrote:
willia> >
willia> > in condition.html:
willia> >
willia> > Template parameter "Pr" should be replaced with "Predicate"
willia> > and linked ... | https://lists.boost.org/Archives/boost/2001/09/16911.php | CC-MAIN-2019-22 | refinedweb | 424 | 77.33 |
What i gotta do:
Write a program that inputs a tele phone #as astring in the form (555)555-5555. The program should use function strok() to extract the area code as a token , the first three digits of the phone # as a token and the last four as a token. the seven digits of the phone should be concatenated into one stri... | http://cboard.cprogramming.com/c-programming/67025-strtok-phone-number-printable-thread.html | CC-MAIN-2016-18 | refinedweb | 220 | 73.81 |
I’ve been hard at work finishing the Controller chapter for San Gria and wanted to come up with fun and practical encoders example.
Our main example app for hubbub is a twitter clone, and as I was working on the UI, and I was thinking “I wonder if we could add a TinyUrl facility? Actually, how about a TinyUrlCodec? Cou... | http://blogs.bytecode.com.au/glen/2008/12/06/a-cute-tinyurl-codec.html | CC-MAIN-2016-44 | refinedweb | 288 | 63.19 |
/* * __ #if __GNUC__ > 2 || (__GNUC__ == 2 && __GNUC_MINOR__ >= 95) /* * The syntax of the asm() is different in the older compilers like the 2.7 * compiler in MacOS X Server so this is not turned on for that compiler. */ static inline int strcmp( const char *in_s1, const char *in_s2) { int result, temp; register const... | http://opensource.apple.com/source/cctools/cctools-667.6.0/dyld/inline_strcmp.h | CC-MAIN-2016-30 | refinedweb | 206 | 65.05 |
Greetings,
We're having some trouble with a custom i.MX6Q board (based on sabreSD reference). It appears that our DDR3 is close to timing margins. I'd like to slow the DDR3 clock rate down to 396MHz. I tried plugging that value into the DDR3 programming spreadsheet and replacing the values in flash_header.S with the up... | https://community.nxp.com/t5/i-MX-Processors/Slowing-DDR3-clock-for-i-MX6Q/m-p/282524/highlight/true | CC-MAIN-2021-25 | refinedweb | 4,100 | 59.74 |
DFS-N: Client failback should be enabled on the following namespace
Published: April 27, 2010
Updated: June 30, 2010.
Client computers could experience slower response times if they fail over to a remote folder target and do not fail back to the local folder target when it comes back online.
Use DFS Management to enabl... | https://technet.microsoft.com/en-us/library/ff633410(v=ws.10).aspx | CC-MAIN-2017-22 | refinedweb | 197 | 58.01 |
14 December 2011 13:44 [Source: ICIS news]
DUBAI (ICIS)--Saudi Arabia-based Petro Rabigh plans to switch one of its linear low density polyethylene (LLDPE) plants at Rabigh to easy-processing polyethylene (EPPE) production in 2013, a company source said on Wednesday.
The Sumitomo Chemical and Saudi Aramco joint venture... | http://www.icis.com/Articles/2011/12/14/9516595/gpca-11-petro-rabigh-to-switch-lldpe-unit-to-eppe-in-2013.html | CC-MAIN-2014-52 | refinedweb | 149 | 51.58 |
csKeyValuePair Class Reference
A Key Value pair. More...
#include <cstool/keyval.h>
Query whether this pair is an "editor-only" pair.
They're marked as such in world files and are normally not kept in memory.
Implements iKeyValuePair.
Definition at line 75 of file keyval.h.
Get the key string of the pair.
Implements iK... | http://www.crystalspace3d.org/docs/online/new0/classcsKeyValuePair.html | CC-MAIN-2016-44 | refinedweb | 162 | 61.73 |
Ignoring once an unknown signature is worst than put as trusted any signature that comes by ?
Shouldn't this signature be in archlinux-keyring ?
Search Criteria
Package Details: liquidwar6 0.6.3902-1
Dependencies (9)
- curl (curl-http2-git, curl-git, curl-ssh)
- glu
- gtk2 (gtk2-patched-gdkwin-nullcheck, gtk2-patched-f... | https://aur.archlinux.org/packages/liquidwar6/?comments=all | CC-MAIN-2018-17 | refinedweb | 248 | 62.34 |
07 May 2009 21:19 [Source: ICIS news]
SAO PAULO (ICIS news)--?xml:namespace>
“The project is part of a $200m investment plan that aims to boost output capacity of acrylates, methacrylates, sulphates and styrene monomers produced by Unigel,” said Unigel strategic planning director Fabio Terzian on the sidelines of the B... | http://www.icis.com/Articles/2009/05/07/9214395/unigel-to-double-brazils-output-capacity-in-2009.html | CC-MAIN-2014-52 | refinedweb | 154 | 55.58 |
High Accuracy Remote Data Logging Using Mulitmeter/Arduino/pfodApp
Introduction: High Accuracy Remote Data Logging Using Mulitmeter/Arduino/pfodApp
Updated 26th April 2017
Revised circuit and board for use with 4000ZC USB meters.
No Android coding required
This instructable shows you how access a wide range of high acc... | http://www.instructables.com/id/High-Accuracy-Remote-Data-Logging-Using-Mulitmeter/ | CC-MAIN-2017-43 | refinedweb | 3,009 | 56.25 |
I would like to modify the Pythonid plugin to create a new module type, "Python Module" analogous to "Java Module." I want the user to be able do the following:
File | New Module -> The "Add Module" dialog appears. I want "Python Module" to appear as a choice. How do I get my module type to show up in this list?
The us... | https://intellij-support.jetbrains.com/hc/en-us/community/posts/207042445-Create-a-non-Java-project | CC-MAIN-2019-18 | refinedweb | 647 | 63.29 |
Currently our application cannot retain its state if refreshed. One neat way to get around this problem is to store the application state to localStorage and then restore it when we run the application again.
If you were working against a back-end, this wouldn't be a problem. Even then having a temporary cache in
local... | https://survivejs.com/react/implementing-kanban/implementing-persistency/ | CC-MAIN-2020-40 | refinedweb | 1,383 | 59.8 |
For example, if you have an array [20, 6, 7, 8, 50] and if I pass value 21 it should return [6,7,8] this sub array. Note: the sum of number should be in sequence.
[20, 6, 7, 8, 50] 21 - [6, 7, 8] 13 - [6, 7] 50 - [] - because it is not in sequence
I tried but not working
function sumoftwonumer(arr, s) { let hashtable =... | https://cmsdk.com/node-js/sum-of-n-number-inside-array-is-x-number-and-create-subset-of-result.html | CC-MAIN-2019-22 | refinedweb | 814 | 75.71 |
One of the quickest wins for improving the speed of a Django app is to fix the "oops didn't mean to" inefficient database reads that slipped into a codebase unnoticed over the years. Indeed, as the codebase matures and the team members change, and code gather dust old inefficient ORM queries can be overlooked. Simple O... | https://practicaldev-herokuapp-com.global.ssl.fastly.net/djangodoctor/spotting-inefficient-database-reads-in-django-5a9l | CC-MAIN-2021-04 | refinedweb | 514 | 59.3 |
Details
- Type:
Bug
- Status: Resolved
- Priority:
Blocker
- Resolution: Fixed
- Affects Version/s: 1.1
-
- Component/s: Replication
- Labels:None
- Skill Level:Dont Know
Description.
Issue Links
- relates to
COUCHDB-477 Add database uuid's
- Open
Activity
- All
- Work Log
- History
- Activity
- Transitions
I'd rather ... | https://issues.apache.org/jira/browse/COUCHDB-1259?focusedCommentId=13089973&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel | CC-MAIN-2015-40 | refinedweb | 3,765 | 63.59 |
How does one generate an output signal?
I've been playing with the demo code for our new ind.io but can't get it to raise any pins to HIGH. I'm assuming that the CH1, CH2... labels correspond to pins 0, 1... I've stripped the code down to the bare minimum writing HIGH and LOW to all the available pins. But I don't see ... | https://industruino.com/forum/help-1/question/how-does-one-generate-an-output-signal-219 | CC-MAIN-2019-39 | refinedweb | 246 | 57.16 |
12 November 2009 11:05 [Source: ICIS news]
MOSCOW (ICIS news)--Voronezhsintezkauchuk’s (Voronezh Rubber Co) synthetic rubber production fell in the January-September period due to adverse market conditions in the first half of 2009, the Russian company said in a statement released on Thursday.
In the first nine months ... | http://www.icis.com/Articles/2009/11/12/9262976/voronezhsintezkauchuks-9-month-synthetic-rubber-output.html | CC-MAIN-2014-49 | refinedweb | 123 | 55.24 |
Fedora Finder finds Fedoras. It provides a CLI and Python module that find and providing identifying information about Fedora images and release trees. Try it out:
fedfind images --release 26 fedfind images --release 27 --milestone Beta fedfind images --release 27 --milestone Beta --compose 1 --respin 1 fedfind images ... | https://pagure.io/fedora-qa/fedfind | CC-MAIN-2020-40 | refinedweb | 4,151 | 60.55 |
Feature #8977
String#frozen that takes advantage of the deduping
Description
During memory profiling I noticed that a large amount of string duplication is generated from non pre-determined strings.
Take this report for example (generated using the memory_profiler gem that works against head)
">=" x 4953
/Users/sam/.rb... | https://bugs.ruby-lang.org/issues/8977 | CC-MAIN-2016-40 | refinedweb | 2,467 | 66.23 |
RSS Viewer Applet: Ready to Rumble (6/6) - exploring XML
RSS Viewer Applet: Ready to Rumble
Helper Functions, Future Plans and Current DistributionFinally some typographic routines for converting pixel coordinates to and from channel item positions, and calculating line height, string widths and positions. When strings... | http://www.webreference.com/xml/column9/6.html | CC-MAIN-2013-48 | refinedweb | 651 | 57.47 |
This is a very rough post to collect some thoughts about trying to write .NET libraries that work inside of the Unity Editor and in UWP projects for Mixed Reality. Apply a large pinch of salt, it’s still a “work in progress” at this point so I’ll add to it/update it as I progress but I wanted somewhere to write things ... | https://mtaulty.com/2017/12/20/baby-steps-in-writing-libraries-for-uwp-and-the-unity-editor/ | CC-MAIN-2022-05 | refinedweb | 746 | 72.8 |
Subject: [boost] [Config] Multiple versions of Boost
From: Sohail Somani (sohail_at_[hidden])
Date: 2008-09-12 19:41:22
Recently, I had the pleasure of integrating a statically linked library
that used a version of Boost different from the one I was using. All
relevant compiler flags matched. Only the Boost version was... | https://lists.boost.org/Archives/boost/2008/09/142271.php | CC-MAIN-2021-39 | refinedweb | 346 | 69.18 |
Asked by:
How to create chart on a MSWord doc?
Question
Hi every body.
I've generated a word reporting class, and need to create some chart on it.
I searched the forum and figured out that it should be like below:
oDoc.Range.InlineShapes.AddChart(XLChartType....
The best overload for InlineShapes.Add gets two arguments... | https://social.msdn.microsoft.com/Forums/en-US/1931c7e7-8f3c-4a08-b64d-e49c60070751/how-to-create-chart-on-a-msword-doc?forum=worddev | CC-MAIN-2020-50 | refinedweb | 433 | 60.11 |
CLion starts 2017.3 EAP
Hi everyone,
We are glad to say that the Early Access Program for CLion 2017.3 is now open. The release is scheduled for the end of this year, and there are so many things planned!
For now, please feel free to download the build and check the new features and enhancements that are already includ... | https://blog.jetbrains.com/clion/2017/09/clion-starts-2017-3-eap/ | CC-MAIN-2022-21 | refinedweb | 1,057 | 59.74 |
I.
Atelier
How can I get a terminal connection to Caché server from Atelier?
Is it possible?
Atelier version 1.1.386
When I click on the Tools menu I see grayed out ("disabled") 'Add-Ins' and 'Templates' items.
Hi,
Working with Atelier a valid COS sentence like this:
if $e(chunk,1,1)="""{ }
Throws Missing closing quota... | https://community.intersystems.com/tags/atelier?filter=answered&sort=comments | CC-MAIN-2019-39 | refinedweb | 710 | 69.31 |
Find k numbers with most occurrences in the given Python array
In this tutorial, we shall find k numbers with most occurrences in the given Python array. The inputs shall be the length of the array, its elements, and a positive integer k. We should find k numbers that occur the highest number of times in the given arra... | https://www.codespeedy.com/find-k-numbers-with-most-occurrences-in-the-given-python-array/ | CC-MAIN-2021-10 | refinedweb | 624 | 55.51 |
1 Aug 02:14 2004
Re: [dnsop] Re: getaddrinfo/TTL and resolver application-interface
Jun-ichiro itojun Hagino <itojun <at> itojun.org>
2004-08-01 00:14:19 GMT
2004-08-01 00:14:19 GMT
> On the other hand, introducing an new ai_ttl field at the end of struct > addrinfo can be done without any effect on binaries (since the... | http://blog.gmane.org/gmane.ietf.dnsext/month=20040801 | CC-MAIN-2015-35 | refinedweb | 198 | 57.61 |
Please confirm that you want to add Yii2 Application Development Solutions–Volume 2 to your Wishlist.
Yii is an optimal, high-performance PHP framework for developing Web 2.0 applications. It provides fast, secure, and professional features to create robust projects; however, this rapid development requires the ability... | https://www.udemy.com/yii2-application-development-solutionsvolume-2/ | CC-MAIN-2017-39 | refinedweb | 1,917 | 53.71 |
13 July 2012 19:42 [Source: ICIS news]
HOUSTON (ICIS)--Petrobras will increase its diesel price by 6%, effective on 16 July, the Brazilian energy major said on Friday.
The increase is part of Petrobras’ policy to align ?xml:namespace>
Petrobras said the price to which the adjustment applies does not include Brazilian f... | http://www.icis.com/Articles/2012/07/13/9578307/brazils-petrobras-to-hike-diesel-prices-by-6.html | CC-MAIN-2015-22 | refinedweb | 117 | 60.85 |
My problems with my first example
I want to write a desktop calculator using Qt. I designed the first step of the form this way:
I added only one
signal & slotusing Designer. The
Calc.h,
Calc.ppand
main.cppare as follows respectively:
#ifndef CALC_H #define CALC_H #include <QDialog> namespace Ui { class Calc; } class C... | https://forum.qt.io/topic/72139/my-problems-with-my-first-example | CC-MAIN-2018-39 | refinedweb | 571 | 56.15 |
This is your resource to discuss support topics with your peers, and learn from each other.
04-23-2010 06:31 AM
I've seen it mentioned a few times and I'd REALLY need to know this.
How can I place my resources in a different, updateable cod? (I need to read some text-only configuration files that control the applicatio... | https://supportforums.blackberry.com/t5/Java-Development/How-can-I-place-resources-in-a-separate-cod/m-p/490262 | CC-MAIN-2017-04 | refinedweb | 614 | 67.25 |
The PC parallel port can be damaged quite easily if you make incorrect connections. If the parallel port is integrated to the motherboard, repairing a damaged parallel port may be expensive, and in many cases, it is cheaper to replace the whole motherboard than to repair that port. Your safest bet is to buy an inexpens... | http://www.codeproject.com/Articles/16715/Controlling-Floppy-Drive-Stepper-Motor-via-Paralle?msg=2768573 | CC-MAIN-2015-06 | refinedweb | 1,569 | 64.1 |
- Author:
- vaughnkoch
- Posted:
- October 7, 2010
- Language:
- Python
- Version:
- 1.2
- testing request client testcase
- Score:
- 2 (after 2 ratings)
This is an update to Simon Willison's snippet, along with one of the comments in that snippet.
This class lets you create a Request object that's gone through all the... | https://djangosnippets.org/snippets/2231/ | CC-MAIN-2016-36 | refinedweb | 223 | 52.6 |
.
Google Book Search API turns out to be the library that I found quite appealing. Yes, unfortunately again, I found there lacks a simple walk-through tutorial that can direct me step-by-step. That motivated me to write a blog tutorial for this!
To get started, follow below steps:
- Create a C# project, either a consol... | https://xinyustudio.wordpress.com/2014/12/18/google-book-search-in-c-a-step-by-step-walk-through-tutorial/ | CC-MAIN-2019-30 | refinedweb | 1,178 | 57.37 |
class for the reordering buffer that keeps the data from lower layer, i.e. TcpL4Protocol, sent to the application More...
#include <tcp-rx-buffer.h>
class for the reordering buffer that keeps the data from lower layer, i.e. TcpL4Protocol, sent to the application
Definition at line 40 of file tcp-rx-buffer.h.
Insert a p... | https://coe.northeastern.edu/research/krclab/crens3-doc/classns3_1_1_tcp_rx_buffer.html | CC-MAIN-2022-05 | refinedweb | 170 | 50.53 |
I have an environment where user's desktop and documents were redirected to a network share with offline files syncing to their desktops. Offline availability was also enabled for other network shares. Last week users came in and some had no files on their desktop when they logged in. The files were there on the server... | https://community.spiceworks.com/topic/2205115-trouble-with-offline-files | CC-MAIN-2022-05 | refinedweb | 527 | 80.62 |
Like every person, I have a burning desire to know who’s in my house when I’m not. A few months ago, I decided that I had had enough of the uncertainty of my extradomicilial activities, and that I needed to do something about it. I realized that I had two options. The first option would be to hire someone to be in my h... | https://www.stavros.io/posts/arduino-texting-motion-sensor/ | CC-MAIN-2020-29 | refinedweb | 765 | 69.41 |
Hi Team,
I have been trying to store our data to an extended path of an s3 connection present in dataiku.
Say the connection that was created takes us to: bucket_1 and my project name is dummy_1_project
Hence, whenever we create a recipe to store the file through dataiku folder creation in S3, by default, it stores int... | https://community.dataiku.com/t5/Setup-Configuration/Dataiku-to-store-file-into-custom-s3-folder/td-p/18197 | CC-MAIN-2021-49 | refinedweb | 511 | 74.19 |
Here I present version 1 . version 2 of the TINS windows binary packageAll 19 entries in a single convenient download.
Please let me know if something doesn't work (game crashes, dll not present, ...). I expect I will need to fix things, so keep an eye on this thread for updates.
I'll open the tins site for voting soon... | https://www.allegro.cc/forums/thread/590922/664310 | CC-MAIN-2022-40 | refinedweb | 816 | 77.43 |
by Emmanuel Proulx and Lucian Agapie
01/31/2005
WebLogic Workshop 8.1 offers a world of possibilities to those who know how to extend it. This article gives a real-world example of how to extend Workshop by adding a menu item, a toolbar button, and a frame. It is the first in a series examining Workshop controls and ex... | http://www.oracle.com/technetwork/articles/entarch/wlwseries-extensions-089994.html | CC-MAIN-2016-30 | refinedweb | 3,344 | 52.05 |
How to instantly destroy a conversation?Israel Fonseca Mar 23, 2009 9:53 PM
Is there any way to instantly destroy the actual (long-running or not) conversation? I mean, something like: Conversation.instance().immediateEnd().
Thks, Israel
This content has been marked as final. Show 2 replies
1. Re: How to instantly dest... | https://developer.jboss.org/thread/186915 | CC-MAIN-2018-17 | refinedweb | 365 | 50.43 |
For a class X and a QSet< X* >, how is it possible to make sure that the QSet doesn't contain duplicate elements?
The unique property in each object of type X is a QString that can be fetched using getName().
I've implemented the qHash(X*) function, the operator==(), operator<() and operator>(), but the QSet still acce... | http://m.dlxedu.com/m/askdetail/3/b42a5b8a7b6128dab07a5626b501b980.html | CC-MAIN-2018-22 | refinedweb | 571 | 65.32 |
the main purpose of this application is to ask the user for head or tail and the output the numbers of guesses + the percentage of correct. Im having trouble with finding the percentage of correct. please help me fix this problem
public class FlipCoin { public static void main(String[] args) { Scanner in = new Scanner(... | https://www.daniweb.com/programming/software-development/threads/397876/finding-the-percentage | CC-MAIN-2021-04 | refinedweb | 164 | 53.07 |
Công Nghệ Thông Tin
Quản trị mạng
Tải bản đầy đủ
5 Certificates and CRLs 215
5 Certificates and CRLs 215
Tải bản đầy đủ
216
Demystifying the IPsec Puzzle
currency of a certificate. OCSP provides more up-to-the-minute information, but that protocol has its own complications for IKE, because an IKE
negotiation can time o... | https://toc.123doc.org/document/968242-5-certificates-and-crls-215.htm | CC-MAIN-2017-43 | refinedweb | 3,292 | 51.18 |
Agenda
See also: IRC log
<trackbot> Date: 05 July 2011
<scribe> SCRIBE: gpilz
RESOLUTION: Agenda agreed
RESOLUTION: minutes approved
Issue-13016:
<trackbot> Sorry... adding notes to ISSUE-13016 failed, please let sysreq know about it
Gil: looks like a typo
Bob: issue accepted
Doug: it's already been fixed
Bob: any obje... | http://www.w3.org/2002/ws/ra/11/07/2011-07-05.html | CC-MAIN-2019-51 | refinedweb | 928 | 76.56 |
On Tue, Nov 17, 2015 at 5:00 PM, Ganesh Ajjanagadde <gajjanag at mit.edu> wrote: > On Sun, Nov 15, 2015 at 11:59 AM, Ganesh Ajjanagadde <gajjanag at mit.edu> wrote: >> On Sun, Nov 15, 2015 at 11:34 AM, Michael Niedermayer >> <michael at niedermayer.cc> wrote: >>> On Sun, Nov 15, 2015 at 11:01:58AM -0500, Ganesh Ajjanag... | https://ffmpeg.org/pipermail/ffmpeg-devel/2015-November/183433.html | CC-MAIN-2019-43 | refinedweb | 625 | 62.38 |
Feedback
Getting Started
Discussions
Site operation discussions
Recent Posts
(new topic)
Departments
Courses
Research Papers
Design Docs
Quotations
Genealogical Diagrams
Archives
Not strictly PLT-related, but Neil Brown has contributed an amazing series of articles to Linux Weekly News:
For this series we try to look f... | http://lambda-the-ultimate.org/node/4156 | CC-MAIN-2019-51 | refinedweb | 1,094 | 61.87 |
None
0 Points
Jun 18, 2007 10:23 PM|ruiray@hotmail.com|LINK
I have a Web Application Project in VS2005, the project builds successfully. Then I use the VS2005 Web Deployment Project to build it, I got the following error which is absurd since I'm not missing the System.Web dll assembly reference.
Error The type or name... | https://forums.asp.net/t/1123538.aspx?The+are+you+missing+an+assembly+reference+error | CC-MAIN-2021-31 | refinedweb | 249 | 74.69 |
Setup your iOS project environment with a Shellscript
Setup an iOS project environment
Nowadays an iOS project is more than only a *.xcodeproj file with some self-written Objective-C or Swift files. We have a lot of direct and indirect external dependencies in our projects and each new developer on the project or the b... | https://iosexample.com/setup-your-ios-project-environment-with-a-shellscript/ | CC-MAIN-2019-13 | refinedweb | 3,182 | 53.41 |
pthread_detach - detach a thread
#include <pthread.h>
int pthread_detach(pthread_t thread);
The pthread_detach() function shall indicate to the implementation that storage for the thread thread can be reclaimed when that thread terminates. If thread has not terminated, pthread_detach() shall not cause it to terminate.
... | http://pubs.opengroup.org/onlinepubs/9699919799.2008edition/functions/pthread_detach.html | CC-MAIN-2019-22 | refinedweb | 200 | 54.93 |
Perform a simple HTTP GET and parse the response as a DOM object:
def http = new HTTPBuilder('') def html = http.get( path : '/search', query : [q:'Groovy'] ) assert html instanceof GPathResult assert html.HEAD.size() == 1 assert html.BODY.size() == 1
In the above example, we are making a request, and automatically par... | http://groovy.codehaus.org/modules/http-builder/examples.html | CC-MAIN-2014-41 | refinedweb | 646 | 51.14 |
Is there any way to transfer files between computers using Python 3.6?
I want to transfer txt files between computers wihs are not on the same network.
1 answer
- answered 2018-01-13 18:11 Simon
Yes you can and if you know
socketyou could do it or use other libraries instead.
You would need to create a script that work... | http://quabr.com/48242507/is-there-any-way-to-transfer-files-between-computers-using-python-3-6 | CC-MAIN-2018-39 | refinedweb | 1,414 | 50.73 |
You can access the members of the IStorable interface as if they were members of the Document class:
Document doc = new Document("Test Document"); doc.status = -1; doc.Read( );
You can also create an instance of the interface by casting the document to the interface type, and then use that interface to access the metho... | http://etutorials.org/Programming/Programming+C.Sharp/Part+I+The+C+Language/Chapter+8.+Interfaces/8.2+Accessing+Interface+Methods/ | crawl-001 | refinedweb | 1,192 | 56.45 |
Caching Data Using URL Query Params in JavaScript
May 20th, 2022
What You Will Learn in This Tutorial
How to temporarily store data in a URLs query params and retrieve it and parse it for use in your UI. install one package,
query-string:
Terminal
cd app && npm i query-string
This package will help us to parse and set ... | https://cheatcode.co/tutorials/caching-data-using-url-query-params-in-javascript | CC-MAIN-2022-27 | refinedweb | 3,709 | 64.61 |
1 /* Soot - a J*va Optimization Framework2 * Copyright (C) 2005 package soot.tagkit;27 import soot.*;28 29 30 /** 31 * Represents the int annotation element32 * each annotation can have several elements 33 * for Java 1.5.34 */35 36 public class AnnotationDoubleElem extends AnnotationElem37 {38 39 double value;40 41 pub... | http://kickjava.com/src/soot/tagkit/AnnotationDoubleElem.java.htm | CC-MAIN-2018-26 | refinedweb | 106 | 50.23 |
This design is intended to address the following issues:
KNOX-179@jira: Simple way to introduce new provider/servlet filters into the chains
The basic issues is that the development and delivery of code is currently required to add a new provider into Knox.
This results in a barrier to entry for integrating new provide... | https://cwiki.apache.org/confluence/display/KNOX/KNOX-179%3A+Simple+way+to+introduce+new+Provider | CC-MAIN-2019-26 | refinedweb | 654 | 54.93 |
I have broken out boilerplate setup code such as secrets and storage rights into importable scripts. My code works fine in Databricks v6.x, but not on a Databricks v7.x cluster. In v7.x my code is falsely detected as databricks-connect usage, even if I run it in a notebook in the Databricks web GUI. Traceback in screen... | https://forums.databricks.com/questions/45383/databricks-7-databricks-connect-detection-false-po.html | CC-MAIN-2020-45 | refinedweb | 231 | 56.05 |
Brief items
Stable updates: 3.13.8, 3.10.35, and 3.4.85 were released on March 31. 3.12.16 and 3.2.56 were released on April 2.
Christ, even *I* find our configuration process tedious. I can only imagine how many casual users we scare away.
We thought this was a great idea, and have been experimenting with a new Facebo... | https://lwn.net/Articles/592321/ | CC-MAIN-2018-05 | refinedweb | 6,443 | 69.31 |
We develop a website for a microcontroller
With the advent of various kinds of smart sockets, light bulbs and other similar devices into our lives, the need for websites on microcontrollers has become undeniable. And thanks to the lwIP project (and its younger brother uIP), you won’t surprise anyone with such functiona... | https://prog.world/we-develop-a-website-for-a-microcontroller/ | CC-MAIN-2021-49 | refinedweb | 2,397 | 66.03 |
On Thu, 5 Feb 2004, [ISO-8859-1] Frédéric L. W. Meunier wrote: > BTW, to not write another e-mail. > > Thomas or anyone. How do I set --enable-vertrace in > makefile.bcb ? I tried adding -DLY_TRACELINE __LINE__ but it > complained. It would have to be expressed differently. The configure script is actually making a tex... | http://lists.gnu.org/archive/html/lynx-dev/2004-02/msg00104.html | CC-MAIN-2013-48 | refinedweb | 111 | 70.8 |
Lesson 21: Change Andee Bluetooth Device Name
Written by Jonathan Sim
You can find this lesson and more in the Arduino IDE (File -> Examples -> Andee). If you are unable to find them, you will need to install the Andee Library for Arduino IDE.
You'll only need to run this code once to change the Annikken Andee's Blueto... | http://resources.annikken.com/index.php?title=Lesson_21:_Change_Andee_Bluetooth_Device_Name | CC-MAIN-2017-09 | refinedweb | 167 | 61.06 |
9327/aws-multichain-network-couldn-connect-to-the-seed-node-error
I am new to multichain. I am using 2 instances on AWS EC2. I have created a blockchain using one instance..
>multichaind secondChain -daemon
MultiChain Core Daemon build 1.0 alpha 27 protocol 10007
MultiChain server starting
Looking for genesis block...
... | https://www.edureka.co/community/9327/aws-multichain-network-couldn-connect-to-the-seed-node-error?show=9328 | CC-MAIN-2019-47 | refinedweb | 265 | 62.24 |
I never really was much for pointers and strings...so I don't really see why a declaration like
char *s = "This is a string";
...works...when something like
int *x = 5;
...does not. It has something to do with a pointer to a character being synonymous with an array of characters or something, right? But....a pointer is... | http://cboard.cprogramming.com/cplusplus-programming/64818-pointers-characters-char-%2As.html | CC-MAIN-2015-14 | refinedweb | 175 | 78.35 |
I'm still learning C and I understand that to get rid of most implicit declaration warnings, you add the prototype header at the beginning. But I'm confused as to what you do when you have outside methods being used in your code.
This is my code when I'm using the outside methods
#include <stdio.h>
#include <string.h>
... | http://www.dlxedu.com/askdetail/3/1059d7e31c6a3b909a0f11f4ab8f13b8.html | CC-MAIN-2018-39 | refinedweb | 515 | 57.06 |
db_command
Creates an OLE DB command.
Parameters
- db_command
- A command string containing the text of an OLE DB command. There are two ways to specify the command.
The first way, appropriate for simpler commands, is to specify the command string as the value for the db_command argument:
The second way, appropriate fo... | http://msdn.microsoft.com/en-US/library/5dcd01t8(v=vs.71).aspx | CC-MAIN-2013-48 | refinedweb | 1,175 | 54.83 |
Opened 10 years ago
Closed 10 years ago
#3239 closed enhancement (invalid)
clear session method
Description
For some types of applications it's necessary/desirable to clear session variables at specific events (e.g. server start, user login). It would be convenient to have the following (untested) method available in S... | https://code.djangoproject.com/ticket/3239 | CC-MAIN-2017-04 | refinedweb | 185 | 54.02 |
Arab -Israeli conflict 1945-1979 Crisis in the Middle East
Day one • Roots of the conflict 1900-1945
Geography • Modern day Israel and Palestine • Located on the Eastern side of the Mediterranean Sea • Approximately 10,000 square miles
Origins of the Conflict • Jews claim land back to 2000 BCE (Canaan) • For hundreds o... | https://www.slideserve.com/norman-white/arab-israeli-conflict-1945-1979 | CC-MAIN-2020-34 | refinedweb | 2,236 | 52.9 |
Better JS Logger for Debugging
As web developers we really like putting
console.log all over the place when debugging our applications, although the Chrome dev tools come with an actual debugger that can be started by simply writing
debugger in your code. This gets messy rather fast, especially if you simply log the ob... | http://cmichel.io/better-js-logger-for-debugging/ | CC-MAIN-2017-47 | refinedweb | 719 | 59.19 |
Whenever I open the scala project, the cpu consumption always goes up over 100%. Not in the loading time or indexing time, but while I am doing nothing. only open JAVA projects are normal. Is it Scala plugin issue?
Whenever I open the scala project, the cpu consumption always goes up over 100%. Not in the loading time ... | https://intellij-support.jetbrains.com/hc/en-us/community/posts/205998929-Scala-project-occupies-more-than-100-CPU-time | CC-MAIN-2019-26 | refinedweb | 1,111 | 68.97 |
- Type:
Bug
- Status: Resolved (View Workflow)
- Priority:
Major
- Resolution: Fixed
- Component/s: subversion-plugin
- Labels:None
- Environment:sles 11, Jenkins 1.470, subversion server is CollabNet Subversion Edge 1.3.1
- Similar Issues:
Using the "Emulate clean checkout by first deleting unversioned/ignored files, ... | https://issues.jenkins-ci.org/browse/JENKINS-14551?focusedCommentId=169317&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel | CC-MAIN-2020-16 | refinedweb | 2,118 | 60.92 |
0
Hi - I'm having a problem converting a couple of things that work fine spelled out in function main, but not when I try to define them as functions. One is a process of filling in a one-dimensional array. I'd like to just be able to say "here's the array; fill it in with fillArray()", but can't find the right syntax.... | https://www.daniweb.com/programming/software-development/threads/238129/array-functions | CC-MAIN-2016-50 | refinedweb | 351 | 64.27 |
Travelers Companies Inc (Symbol: TRV). So this week we highlight one interesting put contract, and one interesting call contract, from the January 2018 expiration for TRV. The put contract our YieldBoost algorithm identified as particularly interesting, is at the $110 strike, which has a bid at the time of this writin... | http://www.nasdaq.com/article/one-put-one-call-option-to-know-about-for-travelers-companies-cm763010 | CC-MAIN-2017-13 | refinedweb | 261 | 64 |
!ATTLIST div activerev CDATA #IMPLIED>
<!ATTLIST div nodeid CDATA #IMPLIED>
<!ATTLIST a command CDATA #IMPLIED>
If I have the following code:
static class SceneData
{
static int width=100;
static int score;
static GameObject soundManager;
}
Can I use this to keep score that's available in all my scenes? If so then do I... | http://answers.unity3d.com/questions/323195/how-can-i-have-a-static-class-i-can-access-from-an.html | CC-MAIN-2014-49 | refinedweb | 1,116 | 70.43 |
No project description provided
Project description
Rex: an open-source domestic robot
This repository represent an experiment made using pyBullet and OpenAI Gym. It's a very work in progress project.
This project is mostly inspired by the incredible works done by Boston Dynamics.
The goal is to train a 3D printed legg... | https://pypi.org/project/rex-gym/0.1.5/ | CC-MAIN-2021-04 | refinedweb | 742 | 56.25 |
Created on 2015-08-14 02:55 by Andre Merzky, last changed 2015-09-12 23:36 by Andre Merzky.
- create a class which is a subclass of multiprocessing.Process ('A')
- in its __init__ create new thread ('B') and share a queue with it
- in A's run() method, run 'C=subprocess.Popen(args="/bin/false")'
- push 'C' though the q... | https://bugs.python.org/issue24862 | CC-MAIN-2021-21 | refinedweb | 945 | 70.02 |
Saturday, April 01, 2017
my elasticsearch dies a lot recently, when I heard Algolia has free plan (you'll need to put their logo on your site), I decided to give it a try.
hacker news readers will know, algolia is the search engine they're using.
algolia supports large number of languages and frameworks, no clojure tho... | https://jchk.net/blog/2017-04 | CC-MAIN-2021-21 | refinedweb | 2,313 | 55.27 |
A reader asked me last week
I have always used Server.CreateObject in ASP scripts and WScript.CreateObject in WSH scripts, because I was unable to find any *convincing* information on the subject and therefore assumed that they were there to be used, and were in some way beneficial… but perhaps they’re not?!
What exact... | https://blogs.msdn.microsoft.com/ericlippert/2004/06/01/whats-the-difference-between-wscript-createobject-server-createobject-and-createobject/ | CC-MAIN-2016-36 | refinedweb | 2,338 | 63.49 |
Last Updated on August 28, 2020
Real.
Kick-start your project with my new book Data Preparation for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Note: The examples in this post assume that you have Python 3 with Pandas, NumPy and Scikit-Learn i... | https://machinelearningmastery.com/handle-missing-data-python/ | CC-MAIN-2021-04 | refinedweb | 5,856 | 75.3 |
The esusers realm is the default Shield realm. The esusers realm enables the registration of users, passwords for
those users, and associates those users with roles. The
esusers command-line tool assists with the registration and
administration of users.
Like all other realms, the
esusers realm is configured under the
... | https://www.elastic.co/guide/en/shield/shield-1.3/esusers.html | CC-MAIN-2019-35 | refinedweb | 131 | 57.37 |
Table of Contents
IRule
Locationheader
@EnableZuulProxyvs.
@EnableZuulServer
@EnableZuulServerFilters
@EnableZuulProxyFilters
@Primary
autoCommitOffsetto
falseand Relying on Manual Acking
republishToDlq=false
republishToDlq=true
@SpanNameAnnotation
toString()method
toString()method
TracingFilter
WebClient
HttpClientBui... | https://cloud.spring.io/spring-cloud-static/Finchley.RELEASE/single/spring-cloud.html | CC-MAIN-2018-34 | refinedweb | 3,036 | 50.43 |
In this section of the C++ tutorial, let’s discuss the concept of loops in C++. Loops in C++ programming are used when a sequence of statements is to be executed repeatedly.
Loops in C++
There are times when you want the same thing to happen numerous times. For example, if you want to print a table of 2, how would you ... | https://www.codeatglance.com/loops-in-cpp/ | CC-MAIN-2020-40 | refinedweb | 271 | 76.96 |
What short.
A YouTube commenter said, “Too bad the talk ends just before the more interesting part where there’s actual logic in the item method. Was curious how you would pull these apart.” So in this video, let’s continue the demo from where it left off.
There will be more videos playing around with this code, from t... | https://qualitycoding.org/refactoring-mvvm-part2/ | CC-MAIN-2022-27 | refinedweb | 1,782 | 75.5 |
# Virtual function calls in constructors and destructors (C++)
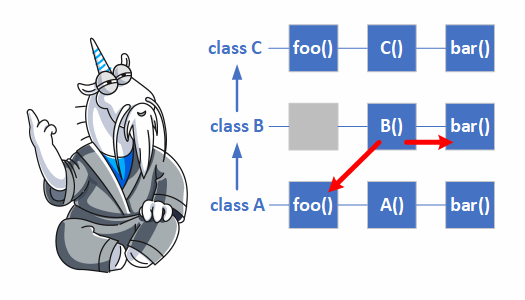
In different programming languages, the behavior of virtual functions differs when it comes to con... | https://habr.com/ru/post/591747/ | null | null | 1,689 | 50.73 |
If I have a random assortment of points in space, is there a way for me to copy and paste (or array) an object to all selected points using a chosen base point of the object?
Thanks in advance!
If I have a random assortment of points in space, is there a way for me to copy and paste (or array) an object to all selected... | https://discourse.mcneel.com/t/paste-or-array-object-to-multiple-points-in-space/114017 | CC-MAIN-2021-04 | refinedweb | 351 | 75.4 |
I caused a stupid accident in a single-disk ZFS pool, seemingly in the same way as the person in this mailing list thread, i. e., I seem to have overwritten important metadata. Can this be restored from the actual payload, or is there a way to retrieve the payload without the metadata?
Here's what I did, exactly:
- had... | https://serverfault.com/questions/118099/how-can-i-recover-overwritten-labels-pointer-blocks-and-ueberblocks-in-a-zfs-po/118209 | CC-MAIN-2020-10 | refinedweb | 174 | 59.67 |
. Note that all operations on Option values are currently using the database’s null propagation semantics which may differ from Scala’s Option semantics. In particular, None === None evaluates to false. This behaviour may change in a future major release of Slick..)
Joins are used to combine two different tables or que... | http://slick.lightbend.com/doc/1.0.1/lifted-embedding.html | CC-MAIN-2018-17 | refinedweb | 1,462 | 58.08 |
China 15.6 inch notebook laptop with Intel Z8350 CPU support Win 10 os
US $132.5-155.5 / Piece
1 Piece (Min. Order)
Shenzhen GST Communication Co., Ltd.
94.4%
import used computers wholesale used computers and laptops
US $120-450 / Set
5 Sets (Min. Order)
Shenzhen Riguan Photoelectric Co., Ltd.
96.5%
Delux Smart Voice ... | https://www.alibaba.com/showroom/used-laptops-no-os.html | CC-MAIN-2018-34 | refinedweb | 198 | 69.68 |
Tue 24 Jun 2014
PyDev and Python profiler UI Crowdfunding Project
Posted by Mike under Advocacy, Cross-Platform, Python
Last year there was an Indiegogo crowdfunding campaign in support of PyDev, the Python IDE plugin for Eclipse. It was put on by the primary developer of PyDev, Fabio Zadrozny. As a part of that campai... | http://www.blog.pythonlibrary.org/2014/06/24/pydev-and-python-profiler-ui-crowdfunding-project/ | CC-MAIN-2014-35 | refinedweb | 284 | 65.83 |
What is lambda expressions?
In essence, a lambda expression is an anonymous function, which can be used in a context where a regular named function could be used, but where the function in question exists for a single purpose and thus should not be given a name (to avoid using up the namespace). They are most often use... | https://www.daniweb.com/programming/software-development/threads/474397/lambda-expressions | CC-MAIN-2018-13 | refinedweb | 261 | 51.55 |
On 04/03/03 19:04:20 -0800 Craig R. McClanahan wrote:
> If you are willing to ensure that all your Actions use the same forward
> name, you don't have to do anything at all to accomplish this goal. When
> you call ActionMapping.findForward(), Struts checks the local forward
> declarations first, and then the globals. S... | http://mail-archives.apache.org/mod_mbox/struts-user/200304.mbox/%3c14840000.1049462152@saturn%3e | crawl-003 | refinedweb | 241 | 66.13 |
End a scroll view begun with a call to BeginScrollView.
See Also: GUILayout.BeginScrollView
// The variable to control where the scrollview 'looks' into its child elements. var scrollPosition : Vector2; // The string to display inside the scrollview. 2 buttons below add & clear this string. var longString = "This is a... | http://docs.unity3d.com/ScriptReference/GUILayout.EndScrollView.html | CC-MAIN-2015-11 | refinedweb | 102 | 50.94 |
Folks, I am trying to use utf-8 Tamil in a Rails application. When I edited Tamil unicode contents in a text box and checked the output. The text got distorted when it is showing it back. Any help appreciated -- -- Nandri, Dalit Amala தமிழ௠இணையம௠Telford, UK
on 2006-12-29 00:56
on 2006-12-29 01:22
... | https://www.ruby-forum.com/topic/92431 | CC-MAIN-2018-13 | refinedweb | 486 | 52.15 |
23 November 2010 16:24 [Source: ICIS news]
TORONTO (ICIS)--?xml:namespace>
K+S's agreed bid for Potash One on 22 November came amid some doubt over foreign investment in Canada after the government this month blocked BHP Billiton’s $39bn hostile bid for PotashCorp – only the second time since 1985 that a foreign takeov... | http://www.icis.com/Articles/2010/11/23/9413229/canada-not-likely-to-oppose-k-s-bid-for-potash-one-analysts.html | CC-MAIN-2013-20 | refinedweb | 336 | 61.7 |
@wimd Could you share how you done that?
I also want to check if gate is alive (backup-batterypowered node - if mains or gateway died, send me a message).
I also use domoticz.
nekitoss
@nekitoss
Best posts made by nekitoss
Latest posts made by nekitoss
- RE: Own action on heatbeat request
@wimd Could you share how you ... | https://forum.mysensors.org/user/nekitoss | CC-MAIN-2020-24 | refinedweb | 2,564 | 53.31 |
0
im stuck on a question from the book, java in 2 semesters chapter 7.
2a) write a program that asks the user to input a string, followed by a single character, and then tests whether the string starts with that character.
public class StringTest { public static void main(String[] args) { String s; char c; //input stri... | https://www.daniweb.com/programming/software-development/threads/397794/comparing-a-string-and-a-character-problem | CC-MAIN-2016-44 | refinedweb | 158 | 77.43 |
by David Tucker
The embedded local database included with Adobe AIR gives AIR developers a great deal of power. Now you can develop extensive relational data models that exist solely on the user's hard drive. As you develop powerful applications with Adobe AIR, you may be interested in using Object Relational Mapping (... | http://www.adobe.com/inspire-archive/october2009/articles/article7/ | CC-MAIN-2015-35 | refinedweb | 1,819 | 54.73 |
The author selected the Free and Open Source Fund to receive a donation as part of the Write for DOnations program..
As part of this tutorial, you’ll use the Bootstrap toolkit to style your application so it is more visually appealing. Bootstrap will help you incorporate responsive web pages in your web application so ... | https://www.digitalocean.com/community/tutorials/how-to-make-a-web-application-using-flask-in-python-3?comment=91408 | CC-MAIN-2022-27 | refinedweb | 7,450 | 64 |
#include <wx/richtext/richtextsymboldlg.h>
wxSymbolPickerDialog presents the user with a choice of fonts and a grid of available characters.
This modal dialog provides the application with a selected symbol and optional font selection.
Although this dialog is contained in the rich text library, the dialog is generic an... | https://docs.wxwidgets.org/3.0/classwx_symbol_picker_dialog.html | CC-MAIN-2018-51 | refinedweb | 356 | 55.44 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.