
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91 values | source stringclasses 1 value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
.
Python functions are much like normal variables.
def double(x): return x * 2 def add_one(x): return x + 1
I can put these two functions in a list.
function_list = [double, add_one]
These functions have not executed just, but I can keep them around to run later. That's what is happening in this block of code;
number = 1 for func in [add_one, double, add_one]: number = func(number) print(number)
Make sure that you understand what is happening in this block of code.
Feedback? See an issue? Something unclear? Feel free to mention it here.
If you want to be kept up to date, consider getting the newsletter. | https://calmcode.io/lambda/functions.html | CC-MAIN-2020-34 | refinedweb | 107 | 73.58 |
A HashTable is a collection of key-value pairs. The object to be used as a key should implement the
hashCode and
equals methods. The key and the value should not be
null.
You can read more about the difference between a
HashTableand
HashMaphere.
computeIfPresent()method
The
computeIfPresent() method computes a new value for the specified
key if the
key is already present in the
map.
public V computeIfPresent(K key, BiFunction remappingFunction)
key: The key for which the new value is to be computed.
remappingFunction: The function to use to compute the new value for
key.
remappingFunction
The
remappingFunction function is only called if the mapping for the
key is present.
The
remappingFunction is a
BiFunction that takes two arguments as input and returns a value.
The value returned from the
remappingFunction will be updated for the passed
key.
If
null is returned from the
remappingFunction, then the entry will be removed.
If
key is present, the updated value for the
key is returned.
If the
key is not present, then
null is returned.
import java.util.Hashtable; class ComputeIfPresent { public static void main( String args[] ) { Hashtable<String, Integer> map = new Hashtable<>(); map.put("Maths", 50); map.put("Science", 60); map.put("Programming", 70); System.out.println( "The map is - " + map); Integer returnVal = map.computeIfPresent("Maths", (key, oldVal) ->{ System.out.println( "\nReMapping function called with key " + key + " value " + oldVal ); return 80; }); System.out.println("\nAfter calling computeIfPresent for key Maths"); System.out.println("\nThe return value is " + returnVal); System.out.println( "The map is\n" + map); returnVal = map.computeIfPresent("Economics", (key, oldVal) ->{ System.out.println( "\n ReMapping function called"); return 80; }); System.out.println("\nAfter calling computeIfPresent for key Economics"); System.out.print("The return value is "); System.out.println(returnVal); System.out.println( "The map is\n" + map); } }
In the code above, we created a
Hashtable with the following entries:
"Maths" - 50 "Science" - 60 "Programming" - 70
The program then calls the
computeIfPresent method on the created
map with the
Maths key.
computeIfPresent will check if the
Maths key is present in the map or not. Since the
Maths key is present in the map, the mapping function will be executed.
Now, the map will be as follows:
"Maths" - 80 "Science" - 60 "Programming" - 70
Finally, the program calls the
computeIfPresent method on the created
map with the
Economics key.
In our case, the
Economics key is not present in the
map, so the mapping function will not be executed. Hence, the
computeIfPresent method returns
null.
RELATED TAGS
CONTRIBUTOR
View all Courses | https://www.educative.io/answers/how-to-use-the-hashtablecomputeifpresent-method-in-java | CC-MAIN-2022-33 | refinedweb | 422 | 51.75 |
Mickeol Ison becomes first wire-to-wire winner at Pebble Beach. PAGE 11 C T R U S- (_ '. _ 73 47 44 FORECAST: Partly cloudy in the morning. Chance of showers 30 percent PAGE 2A m I. Shil te CPyoghted _Materiayvn big ,--Syndicated Content Available from Commercial News Providers" Looming question: Manager's future Crystal River council to consider issues JIM HUNTER jhunter@chronicleonline.com Chronicle Probably the biggest issue on the Crystal River City Council agenda today is the question of how to handle the due-process hearing for the city manager after the 3-2 vote on Jan. 24 to fire her with cause. On Monday's agenda is City Manager Susan Boyer's response from her attorney. The hearing was set for 6 p.m. Tuesday, Feb. 15, but the city's labor attorney, who is advising the city about the It's issue, said some- one should be des- possible ignated to look the into the facts of the case, gather evi- council dence afd inter- would. view witnesses on WO the grounds of the set charges. Because the another hearing was set hearing the day after the council's regular date for meeting on Boyer. Monday, and the designated person would need time to gather information, the labor attor- ney said, it's possible the council would appoint someone to do that and set another hearing date for Boyer. With Boyer's attorney making refer- ence to breach of contract and signif- icant damages to his client in her response to the grounds for termina- tion, the council may have to sort out the logistics of the issue at the 7 p.m. meeting. On another topic, the city manager is recommending proceeding with the first reading of the adoption of the city's Land Development Code (LDC). The council has finished going through the revised document after many workshops with its consultant, but still has some things it wants to change. The recommendation is to have the first reading to adopt it, and then begin the public hearing process to tweak the parts it's uncomfortable with along the way Boyer noted that the first reading can be continued until all topics are covered. One diffi- culty will be that the city planner, most familiar with the LDC, has resigned and is leaving next week Boyer also will recommend that city Police Chief Steven Burch be named acting city manager, as finance director Donna Kilbury, currently the acting city manager in Boyer's absence, also has resigned and is leaving the city Feb. 28. Council member Roger Proffer will bring up the topic of building set-, backs in reference to roof overhangs. Overhangs are not now included in the measurement of a required set- back, and are allowed to protrude up Please see LOOMING/Page 5A finding blissonthebdal MATTHEW BECK/Chronicle Richard Iversen and his wife Karen met years ago through their love of horses. Above, the couple is pictured with Roxie, a dun quarter horse, at their Diamond K Ranch In Lecanto. Couples reveal many ways trails crossed for that special meeting for matrimony \ "Editor's note: The Chronicle asked readers 4ow did you meet your sweetie?" We regret that we cannot print all of the stories we received. Here are a few. NANCY KENNEDY nkennedy@chronicleonline.com Chronicle Just horsin' around Romance was the farthest thing from Karen Iversen's mind as she led her three-legged ROMANTIC TALES X For more Valentine's Day stories, visit the Chronicle's Web site at. lame quarter horse up her neighbor's drive- way. As the owner of Diamond K Ranch in Lecanto, she wasn't looking for a new hus- band, but a blacksmith. Richard Iversen, a blacksmith, was at the neighbor's house, tending to her horses. The neighbor had asked Richard if he minded looking at Karen's horse and he agreed. "She came walking up with this horse, and I saw her and thought, 'Oooh,' "Richard said. "After that, I became her horseshoer and her friend." For the next six years, Richard would come to Karen's ranch every six weeks to tend to her horses. She had 14 at one time, offering Please see ":'/Page 4A Boundless optimism Determined woman gets the mostfrom life CRUSTY LOFTS cloftis@chronicleonline.com Chronicle In 1994, Tricia Miranti had three goals: go to college, begin a career and start a family Now that she's graduated from the University of Central Florida, has a Tricla Miranti, right, talks to her mother Vicki Miranti, center and teacher Dr. Susan Castorina, left, about her wedding plans. Miranti has been a quadriplegic since the age of 5. Her wedding to Marshall Rickardl is scheduled for March 19. DAVE SIGLER/Chronicle steady job and is getting married in March, it's time again for her to look toward the future. "I want more," Miranti, 28, said. "There has to be more out there for me." Family and friends say Miranti's struggle is unique from many, because of the overwhelming chal- lenges she has overcome. At 5 years of age, she suffered from a brain hemorrhage that put her in a wheelchair. She has limited use of her arms and legs and speaks softly and with difficulty. Despite her physical limitations, Please see BOUNDLESS/Page 7A Annie's Mailbox Movies ..... . Comics ...... Crossword . .. Editorial ..... Horoscope ... Obituaries . . ...7B ;..8B -... 8B ... 7B . .IOA ... 8B ... 6A Stocks . . . . 10A Two Sections 6 184 llllll78 20025 1 5 Sealed with a kiss Postmaster Maria Elena Carrasco stands behind her counter decorated with valentine memorabilia to stamp envelopes' in Valentine, Texas./9A ....... ... A2' ' Sisterly devotion Today, twin sisters "Ran" and "Raine" cele- brate their 70th Valentine's birthday./3A Insight Into Illness A researcher contracts Lou Gehrig's dis- ease, which he's seeking to cure./Tuesday British prime minister appeals N Tony Blair seeks third term in office./11A M Historic 1945 U.S.-Saudi meet- ing to be remem- bered in Miami./3A N Restoration brings back life to Pensacola's Greenshores./3A 771? - -- -- ---- -- ------------------ - --------- -- r_ *...^...l.^.. ,! *-u^ 2A MONDAY. FEBRUARY 14. 2005 Florida LOTTERIES___ Here are the winning numbers selected Sunday in the Florida Lottery: F 9 a- '. - *9* w ,aWMNj *4wm^r. CASH 3 8-6-3 PLAY 4 5-0-9-4 FANTASY 5 ,19-21 23 27 35 SATURDAY, FEBRUARY 12 Pyiy 4: 3-7-9-0 Fantasy 5:8 19 20 22 28 5of-5 2 winners $138,227.60 4;f-5 434 $102.50 3-of-5 12,802 $9.50 Lotto: 3 17 19 28 33 48 6-of-6 No winner 5-of-6 105 $3,838.50 4-of-6 5,335 $61 3-of-6 103,122 $4.50 FRIDAY, FEBRUARY 11 Cash 3:3 2 -2 Play 4: 5- 1 -7-3 Fantasy 5:1 -3- 14-23-33 5-of-5 2 winners $131,463.40 4-of-5 385 $110 3-of-5 11,654 $10 Mdga Money: 25 29 30 32 Mega Ball: 14 4-of-4 MB No winner,' 4-of-4 12 $2,498.50 3-of-4 MB 72 $910.50 3-of-4 1,744 $112 2-of-4 MB 2,379 $57.50 2-of-4 21,019 $4 1-of-4 MB 51,437 $6.50 THURSDAY, FEBRUARY 10 Cash 3: 0-4-4 Play 4:1-9-4-8 Fantasy 5: 15 -19 22 27 31 5-of-5 5 winners $47,271.52 4-of-5 380 $100 3-of-5 9,549 $11 WEDNESDAY, FEBRUARY 9 Cash 3:7-8-3 Play 4:9 1 1 1 Fantasy 5:3 5 10 22 26 5-of-5 6 winners $41.594.09 4-of-5 523 $76.50 3-of-5 14,488 $7.50 Lotto: 9 11 29 39 45 47 r6df-6 No winner 5-of-6 60 $4,729 4-of-6 3,278 $70 3-of-6 66,921 $4.50 TUESDAY, FEBRUARY 8 Cash3:5-1-3 Play 4: 0-3- 1-6 Fantasy 5:9 19 21 28 31 INSIDE THE NUMBERS T'v rft h% ac &ra o? tinning lottery numbers,- -.., players should double-check the numbers printed above 4ith numbers officially posted by the Florida Lottery. On the Web, go to .com; by telephone, call (850) 487-7777. * t** ,,=e "Copyrighted Material Syndicated Content A ailable from'Commercial News Providers" UAAIMMAUtWRJ - ,=N a nem ti=. -= . 91 - :.. 'w n . ............ e %b e4 wal *doomtix alyl a ,... . -. .- T" -~w A-U aw..s RAWS 4MOMMOM -m fml %d -mNAmP "W modo-mmON -m pm*mmw e 0o aNW * -AiM aw _* R ENO- a ow -mmn -a Wam s 4 0 a. age a a g ea 4-1ili alm . m-.ow a -m 40m ini4nume U 4 am* a t Oh al &Alf aB will&an aM nummtb amo OMOM -m eaegp am fto -nigmme em -mm 4b .-am oaw S lb4 am e a ml '-,, *el 'U ===== *" .- =;: **...,. .-a. e "> ........... ... ..=.-. ?. ===. = .......= m :ii, .. in-iii- - a* mm. " *." " e- -4 S U. ST SWr^. ir Aw ommogftp 0:4 ap ^- 0 * q* a a Er- U1- a- -*I n - - . .....e ..... ..-.... ... .. ..-. .... .. .... a. swa ag ai wu&40 dum a*m. w 411111 ....,............ o .s ... n a.= -.. ..= 4, C U- - a .- - C = ,., .a ... C.- C ft "Now - i -i ft o hi- -11111 -... ___ W'4 IJ*.; ait a 7,. s*-Lv- t. .. m .l=. - idW ..XW :XK. ."*....t ENTEWrAIMMEMY CiTRus CouN7y (FL) CHRoNicLE :rih I I wm wmo I ~-'.i1 -~ I -'-.1 -2 M Mdl tCopyrighted Material nIw .Sy indicated Content 7 - t"' aINd .. S-A-va -- -m - a.* eW rovi er ; Available from Commercial News Providers" -, .. .- 2: .. IIt Happy Valentine's birthday Twins keep close ties for 70years NANCY KENNEDY nkennedy@chronicleonline.com" Chronicle a Haney's mother loved holi- days so much that she had , a baby on Valentine's Day . And just to make the day . doubly special, she had hvtwins. O Today, twin sisters "Ran" and "Raine" are celebrating their 70th Valentine's birthday. . "Being Valentine's Day twins was always special." Davis said. "Our family has always been big into birthdays and holidays anyway. We'd sometimes have a heart- shaped birthday cake, and people at 'e would give us chocolate hearts." This was back in Indiana where they grew up with their brother. Ed d . Enterkin he was born on New '1 e ' Year's Day They had a dog, Buster, i who w\as born on Mother's Day ..rc Enterldn.anUlDavisl oe in .h . o.. wa .:g Inverness and Haney stia lives in . indiana. Haney's. here visiting her sister fotr their big day of hearts and flowers and goodies all around. BRIAN LaPETERwChroncle "'We're not identical, but Mamnia Twins Luran Haney, left, of Indiana, and her sister Lorraine Davis, of Inverness, were born on Valentine's Day and dressed us alike, down to our have spent all but one birthday together. underwear and socks." Davis said. "Until high school when we and we've sent our morn the same after their high school graduation. As an added twist to their story. rebelled," Haney added. That's Mother's Day cards before." Haney left for college, which was when their mother was pregnant - when they started dressing differ- Haney said, "Last year when wve only 60 miles away, but she was too she didn't know she was caring t ently and fonning separate friends, didn't come down tto Florida) -" homesick to stay so she came twins her best friend was preg- but they always came back to each "- \e ate at the same place," home. She married fouryears later nant as well, and the two women other Davis finished. "She called and The sisters they call each other decided that their children would In all their 70 years, they only told me she had eaten at Johnny "'Sis" never lived more than a marry each other someday. missed one birthday together. Carino's in Indiana and we had mile from each other until the However the expectant monms which was last year when Haney's eaten at the one in Brooksille." Da-ises moved to Florida to be didn't plan on one of their babies first great-grandchild was born. They've discovered that they buy near their grandchildren and being two' Even so, Earl Davis Until then, not even living 991 similar clothes and have even Davis' brother ended up marrying one of the baby miles apart has separated them. bought each other gifts so similar "Luckily our husbands get along girls, just as his mother had "It's fun being a twin," Davis that it's downrm'ight eerie, with each other, because when you pledged. said. "There's lots of times we'd do "You can feel if the other one marry (a) twin, it's a package deal," When asked how they decided the same things and wouldn't Iknow isn't quite right." Davis said. Davis said. which one w'as the right one for about until afterwards. We've sent It was hard on both of them They both laughed "Oh, what a Earl, the twins just laughed ... and each other the same cards before when Davis married two weeks package!" Haney said. Earl smiled. ... ......... .. .. .. ................... ............... .......... .......... I * '/ ( ,) Pawam trnw hmp bo Ii to Munh - a. - - ~ 0'-'. - -~ a..- -- a. -- - ~. a. a - '.0 -~ --~ a. a .~ - 0 - a. 0'- a - - ~ ~-.0 -0'.- - - -. - - a. a. ~. - a. e. - - ~. .0 a. a.. a. 0 - am a- _____ ~ U- -e - - 0 -. ~-a. a. - a. . a. a. - - -- a. -- a. a. - ."- ~' a.~ - a. - ~- a. a. - ~a. - a. a. - - a.- a. - -~ a.- - - -a.. - - -0" - - ~0' - a. a. a. a. .~ - - -- a. a. a. - - a. a. - - 0' - 0 'now- 0 _- _ -di a-mo a, f-o a 41- 4w. -. 0- 4 I" "loop .. ~ -~ am - ___ - 0~ 0 - a. 0'- - ~ a. a. - .0 - - a - a 41 --4D a!I ,.. - - a. - -~ 0' 0' S 0 -- ~ a.a.a. a.- 'a. a. a. a. - a. - a. S - a. a. a.- - m -- a. a - a. a. a. - a. * S / --- ,'- ,, ,' ,,, ,,>"... \ \ ..__., "--- .111W - x - .0 -. - a. - 4m -4mmom Zw IL ba S 0 - fVONDAY FEBRUARY 14, 2005- cor mP Count i.. ^S. Congresswoman plans meeting today U.S. Rep. Ginny Brown- Waite, R- Crystal River, will conduct a town hall meeting from 2to 3p.m. today at Dunrellon City .-. . Hall, 20750 Waite .. River Drive. to appear' The public today in . is invited. Dunnellon. Medical fund set for teen's surgery., A bank account has been set' up to cover medical expenses for former Inverness resident Jon Gromling at SunTrust Bank,' South U.S. 41 in Inverness. Donations can be made at ,, any SunTrust branch office. Jon Gromling is the 14-year-., old who had three strokes last..- year and needs neurological brain surgery. For information, call Linda - Badore at 344-0324 or Dawn Gruzdas at 726-3548. IPS to host veterans; for dinner Feb. 24. The pupils and staff of Inverness Primary School would" like to invite all military mem- , bers, veterans and their families, to the 10th annual Veterans Dinner and Program on Thurs-' day, Feb. 24. Dinner will be served at 5 p.m. in the Inverness Primary School cafe,,; The program by the pupils wil, begin at 6 p.m. and will con- . clude by about 7. This is the school's way of -; thanking those currently in the service of our country as well as-' those who have served in other"' wars. For more information, call ' 724- 63, ,r M.G ! Gay rights activist to visit Crystal River Nature Coast PFLAG, in coq- junction with HeartStrong Inc., is sponsoring an educational : evening with internationally red, ognized gay rights author and: activist, Marc Adams, on March 17, at Crystal River Coastal Region Library. All of Adams' books and resources will be available at this event.' Donations are appre- ciated. For more information, - call 302-5203 or e-mail nature-.' coastpflag@yahoo.com. From staff reports . . . - -W Q t q - e o - - -mb-m * - CITRus COUNTY (FL) CHRONICLE 4A MIVONDAY, FEBRUARY 14', 205 ---I BLISS Continued from Page 1A riding lessons, clinics and sum- mer camps for kids; she was one of his best accounts. ," Each was married to another spouse at the time, and each was going through a divorce. Once their respective divorces were final, their friendship took a romantic turn. As a 20-year international horse show judge, Karen trav- els all over the world. As their relationship grew, Richard began accompanying her on trips. They dated for three years, and began talking about getting married during Christmas 1993. Then, in May 1993, they took a trip to Idaho for a horse show, and then took a side trip to Lake Tahoe. "There were so many wed- ding chapels, and the. mood just hit us," Karen said. "The wedding cost us $98, which we put on a credit card. We had bur ceremony at the Chapel of the Bells, then went across the street for our reception at the 'Taco of the Bells,' grabbed something to eat and went back to the casinos." ,The best thing about Richard, Karen said, is his sense of humor. "It brings out everybody's sense of humor," she said. "He's just a good, pos- jtve guy" i Richard likes how Karen allows him to be himself. After !all, they were friends first, he said. SThere's a downside to their relationship, however Richard still shoes Karen's horses, but 'he no longer pays him. "It was a bad business move my part," he said. "She was tie of my best customers!" *_ Special to the Chronicle Craig and Shiela Summers. -: He fell for her oBefore Craig Summers fell W."'theNky and into Shiela Si'nwmers' life, Shiela was working and going to school in. C(alifornia. During a two-week tfip back home to Michigan for aifamily reunion, Shiela went to the Marine City airport with fer brother and his girlfriend to watch the skydivers. As Craig ;dnded near the picnic table S ive Your SSweetieA -e SClean Car This cI alentine s Day! Hal 4 AA^.y 'where Shiela was sitting, he looked at her and smiled - and wouldn't stop staring. He thought, "Wow, what a cute babe!" He came over and talked with her, then they all went out for hamburgers. The next day, they went water skiing, then out to dinner. Then it was time for Shiela to go back to California. "I didn't think the odds were that great for anything to work out due to the geographical dis- tance between us," Shiela said. They had a long-distance rela- tionship for two years, and married in July 1988. "People always said it would- n't work, but we knew other- wise," Shiela said. "When it's right, you just know it." The Summerses live in Homosassa with their two children. Shiela teaches school at Pleasant Grove Elementary, and Craig works for Progress Energy. He no longer skydives; he's switched to scuba diving. Special to the Chronicle Larry and Teresa Kuechle. Goodyear for love It was 1987, and Teresa (Kunkle) Kuechle was ticked. Her 1985 Mercury Topaz kept pulling to the right, and she was tired of getting the runaround from auto repair shops. She drove into a Goodyear Tire Store in West Palm Beach by mistake; she had purchased the tires at another store a yellow "Single and Loving It" sign swinging from her rear win- dow. A greasy mechanic came out tb greet her, and they took her car on a test drive. Teresa was going on and on about the tires, and even though her receipt was clearly from another store, she kept insisting "Bitbobught them from you!" Eventually, Teresa calmed down long enough to notice that the mechanic sitting next to her, Larry Kuechle, was awfully cute. She asked him if he noticed her "single" sign. He hadn't, so she took a breath Ft Certificates Available i MA .4... . . and asked him out. "She had beautiful blue eyes, and they done me in," Larry said. Test drive over, Teresa bought two tires from him and gave him her phone number. Four days went by before Larry called and made arrangements for dinner and a movie - "Beverly Hills Cop." They've been together ever since. "He cleaned up nice!" Teresa said. Two years later, they bought land in Floral City, moved to Inverness in July 1989, and got married on their land in November 1989. "The funny thing is, back when we were kids in West Palm Beach, we were in the same confirmation class at church and didn't even know it," Teresa said. Al and Dottle Sieber. 'Wild' thing Thirty-one years ago, Al and Dottie Sieber got more than a bargain at Bloomingdale's. Both widowed, they worked at the Bloomingdale's store in Short Hills, N.J., he in the men's department and she at the Estee Lauder cosmetics counter. But they had never met Each September, the store had a pre-Christmas gala for the employees at an elegant hotel, with each department sitting at tables together - except this one particular year. It seems the people in the per- sonnel department had decid- ed that Al in menswear and Dottie in cosmetics would make a' cute couple, so they intermingled the department seating, putting the two next to each other. It wasn't so bad, Dottie thought. Al turned out to be a great dancer. Later, he called for a date, but got cold feet and called to say he was sick. "What really happened, he told me later, was that he ate lunch with some of the young girls in my department and they were a pretty wild bunch," Dottie said. "He thought maybe I was wild like them!" Al had married his child- hood sweetheart, and hadn't dated anyone else. "The thought of a 'wild thing' woman scared him," she said. But two weeks later, they did go out, although Al was quite nervous throughout dinner. He told Dottie he felt like he was cheat- ing on his late wife. He got over his fear and nervousness, and four months later they married. On Feb. 24, they will celebrate their 31st anniversary. The Siebers, both 86, live in Homosassa. Special to the Chronicle Elsie and Jack Lowther. Blue-footed Valentines Elsie and the late Jack Lowther met as kids. He was 16, playing touch football on the field at Ohio State, and she, 14, walked past and noticed his 726-8822 e < T rP a 1-800-832-8823 B eritage Propane Serving America With Pride $ 9 INSTALLATION SPECIAL 2700 N. Florida Ave., Hernando, FL Serving All Of Citrus County Dad s Classic Car Wash New Management ~ New Attitude TO OUR FRIENDS IN CITRUS COUNTY Hwy. 200 at SW 62nd Court, Ocala (1/10 Mile SW of Jasmine Plaza) M Mobil' (352) 873-6888 Motor Oils FAST DELIVERY *PROFESSIONAL STAFF FR E Verticals FREE 1 Wood Blinds * In Home Consulting Shutters SInstalation -I Crystal Pleat S -... A Silhouette LECANTO -TREETOPS PLAZA 1657 W. GULF TO LAKE HW.Y 527-0012 _5 HOURS: MON.-FRI. 9 AM 5 PM Evenings and Weekends by Appointment -WS4 -I flaming red hair. Meeting him was a bright spot in her life. Her, father had recently died from a heart attack, and her mother was paralyzed from a stroke; Elsie was sent to live with a brother. She and Jack dated, then ran away to get married when Elsie was almost 16. They had eight kids five girls, three boys. "The reason I want to tell our story is because of how special Valentine's Day is to me," Elsie said, "even though Jack's been gone 10 years this month." They moved from Columbus, Ohio to Fort Lauderdale on Valentine's Day, 1967. Two sons and a grandson were married on Valentine's Day Another son went into the Army on Valentine's Day. Then one Valentine's Day, both Elsie and Jack ended up in the hospital. Earlier, they both had swollen big toes, both on their right feet. They both went to the doctor and both had to have their toes ampu- tated. Citrus Memorial Hospital put them in the same room together, which was unusual, but it was Valentine's Day Jack had his surgery first, then Elsie. Afterward, they lay in beds next to each other, with. their right feet propped up on pillows. Jack remembered to bring socks blue ones but Elsie didn't, so he let her wear one of his. The sight of the blue-footed Valentine couple made 'the. nurses laugh and they called the newspaper to come and take a picture, but Elsie said no. "Now I regret it," she said. They were married 58 years when Jack died, Feb. 21, 1995. "I'm so glad he didn't die on Valentine's Day," she said. Special to the Chronicle Jim and Rosemary Branham. Don't let preacher see! Both widowed, Jim and Rosemary Branham attended the same church, but didn't know each other However, Jim had noticed Rosemary, and was quite taken with her. But he was also shy and afraid to ask for her phone number, so he wrote a note on a piece of paper and passed it to her dur- ing church one Sunday. "I would consider it a great honor if you would agree to have lunch or dinner with me one day soon ... please call me," he wrote. Rosemary felt as giddy as a teenager invited to her first dance. They went out to dinner a few times and then he kissed her. "It made me tingle right down to my toes!" she told a friend. Then the preacher found out about the note ... when the cou- ple asked if he would marry them. They were married by the Rev. Lloyd Bertine in October 2000, down by the water in Homosassa. Since then, the couple has stood by each other through the death of Rosemary's son and Jim's kid- ney disease. Jim's kidney trans- plant is scheduled for March 4. "To all who know them, it's obvious that they have a great love and a strong faith," said their friend Lona Prevatt. C 'O .-I,." ", HONICLL Bo'iis'est Commun!ity Newspaperag Fea id' est CseRacomm@chronicteonlinelslng@chronicleonline.com Newsroom: newsdesk@chronicleonllne.com Where to find us: Meadowcrest office Inverness office S41 44T 1624 N. Meadowcrest Blvd. 106 W. Main St., Crystal River, FL 34429 Inverness, FL 34450 Beverly Hills office: Visitor Homosassa office: Beacon 7 i[- LPub106 W. MAIN ST., INVERNESS, FL 34450 $ PERIODICAL POSTAGE PAID AT INVERNESS, FL [SECOND CLASS PERMIT #114280 HEAR BETTER... BETTER Hear & See How You Are Hearing with technology that allows us to measure live speech... Live Speech Advantage. . offered exclusively by PHC. Call today for a FREE hearing check Denny Dingier and experience the difference of Audloprosthologist Live Speech Advantage 1 SH'i ............ ....... .............. FREE :: $500.00 OFF Lifetime Batteries with any Any pair of Marcon Premium hearing aid purchase Digital Hearing Instruments .... p.ir a 2/2B....i ................ .r. .. ...... Hear Better & Live Better Today! n ". H. c. Professional Hearing Centers 211 S. Apopka Ave.* Inverness (352) 726-4327 m m mlWlm I I ,OtA_ __ - I- MONDAY, FEBRUARY 14, 2005 5A For the RECORD ON THE NET l For information about arrests made by the .Citrus County Sheriff's Office, go to. fcitrus.org and click on the link to Daily Reports, then Arrest Reports. Citrus County Sheriff DUI arrests Christian Clemons, 40, 1254 15th St., Sarasota, at 10:15 p.m. Saturday on a charge of driving under the influence. His bond was set at $500. Jeremy Eugene Ealy, 21, 4676 E. Stoer Lane, Floral City, at 2:42 a.m. Sunday on a charge of driving under the influence. His bond was set at $500. Other arrest Sharon Hann, 52, 9314 N. Caressa Way, Dunnellon, at 1:50 a.m. Sunday on charges of posses- sion of marijuana and driving while license suspended/revoked. Her bond was set at $10,500, Crystal River Police DUI arrests Lloyd Park McFetridge, 40, 3006 Dover Drive, Sherman, Texas, at 11:17 p.m. Saturday on a charge of driving under the influence. His bond was set at $5,000. 0 William Robert Bowman, 31, 9501 N. Davy Lane, Citrus Springs, at 2:26 a.m. Sunday on charges of' driving under the influence and refusing to sign a traffic citation. His bond was set at $1,150. S . -Available from Commercial News Providers - a a- LOOMING Continued from Page 1A to two feet into the setback The council also will consid- er a revised schedule for charges for copies of public records. Among other things, the resolution would set the price per page at 15 cents and 20 cents for double-sided pages, but would give city employees the discretion not to charge for nominal copies of records. City clerk-certified copies would cost $1, and city council members would be entitled to complete Hunning Layouts - BUY SELL .. - REPAIR W All About Toy rains 6843 N. Citrus Ave. #T Shamrock Industrial Park Crystal River 352-795-6556 any copies without charge without limit. City employees and board and committee appointees would be entitled to copies without charge of document necessary to the per- formance of their duties, but otherwise would pay as others asking for records., On another issue, Councilwoman Susan Kirk will request the council to endorse a resolution from the League of Cities calling on the governor and legislature to support leg- islation that, among other actions: establishes a process for the county and cities to jointly levy local infrastructure surtax in their jurisdiction to fund infrastructure improvement. authorizes municipalities to levy a real estate transfer fee for infrastructure improve- ments. 54Best Western S- Citrus Hills Lodge In the middle of "Nature's Paradise" 350 E. Norvell Bryant Hwy. Hernando, FL 34442 Next to Ted Williams Museum (352) 527-0015 1 (888) 424-5634 Sf Come See What's New! SIts f O low you can scent and color your bath and I\O body products to match your mood and your faI decor! Come and try our wonderful Sugar Gifts and Scents with Scrub, Goat's Milk Lotion, Shower Gel, Gentle a personal touch Exfoliating Cleanser, Bath Salts, Milk Bath and more! To please you, because It's for You! Open today 10-6 for your last minute Valentine's Day Gifts! And remember Thursday, March 3, 6-8 pm is our Bridal Open House. 2666 N Florida Av (Rt 41) Hernando 341-1000 The tiny cottage between the farm stand and Crowsfeet Antiques repeals the fuel adjust- ment charge exemption from the municipal public service tax. revises concurrency requirements or adequately funds needed infrastructure. ties state funding and budget allocations to articulat- ed state growth management policies. grants cities greater flexi- bility and less state oversight in pursuing growth management strategies. In other business, citizen John Tooke signed up to speak to the council to ask the council members who voted to fire Boyer to resign, The council also will considt er a revision of the rates to rent the Seminole Club, as well as fees for parks, pavilions and the Little Springs Park Gazebt: Choos from8 Efegance, Durabifity & Q a y different models! Fro m ,o u0r Des .i,,gner Co lte ,t-i orn 29 Years As Your Visit us online at Hometown Dealer! T wy. 44 Crystal River 795-9722 Licensed & Insured*Lic. #RR0042388 1-888-474-2269 BHB ^ OMLEE LUMNU SRVCE4^ "I'm Wearing One" "The Qualitone CIC gives you better hearing for about 1/2 the price of others you've heard of I'm wearing one! Come & try one for yourself. I'll give you a 30 DAY TRIAL. NO OBLIGATION." ,on,Qualitone IC ,1 David Ditchfield TRI-COUNTY AUDIOLOGY Audioprosthoiogist & HEARING AID SERVICES Inverness 726-2004 Beverly Hills 746-1133 Life I & Orate Fri2rs Family Owned & Operated For 25 Years 97 W Gulf to Lake Hwy., Lecanto 352-527-4406 M-F 9:30-5 Sat 10-4 Lexington Sale January 28 - February 22, 2005 Your style is as individual as you are. Visit Smart Interiors to discover your perfect style while enjoying great savings. Beginning January 28th, Factory Authorized Savings on the most popular brand names such as Nautical, Bob Timberlake, Palmer Home" and more. Resolve to spend wiser this year by enjoying these special savings ac;'. 19 491 q Smoart Rive, I Eye FREEUTint Progressive SExaminations present Bifocal Exmntos ^ this Ad. fll9 pA $30 Value $139 We accept some insurance plans including: Vision Care Plan Eye Med Medicaid DR. WERNER JAEGER, OPTOMETRIST 3808 E. Gulf to Lake, Inverness Times Square Plaza I3 344-5110 S -. "Cpyrighted Material . iSyndicated Content VERTICAL BLIND OUTLET: zw 649 E Gulf To Lake Lecanto FL '- 637-1991 -or- 1-877-202. 1991 ALL TYPES OF BLINDS SnEs CITRUS COUNTY (PL) (-HRONI(-Lb Nk -A /rI-nTR /'TTIii-rir ITmI mN IT . CITRUS COUNTY (FL) CHRONICLE SA?'A MONDfAY.FEBRUARYT 14, 2005 Lorraine Coe, 90 DUNNELLON Lorraine H. Coe, 90, Dun- nellon, died Saturday, Feb. 12, 2005. - Born in Gerard, Pa., she moved to the area in 1982. She was a homemaker. She was Presbyterian and a member of Dunnellon Presby- terian Church. She was preceded in death by her first husband, Wiley Cox, and her second husband, Carl C. Coe. Survivors include her son, Wiley McCartney of Dunnellon; two daughters, Carol Penny and Linda Teare, both of Euclid, Ohio; two stepdaugh- ters, Claudia Spacek and Catherine Reiber, both of Spokane, Wash.; brother, Jess Dalrymple of Ocala; sister, Marjorie McConnell of Oceanside, Calif.; 14 grandchil- dren; and nine great-grandchil- dren. Roberts Funeral Home, Dunnellon. James 'J.D.' -Collins, 76 HERNANDO James 'J.D." Daniel Collins, 76, Hernando, died Saturday, Feb. 12, 2005, at his residence, He was born, and raised in Tampa, before moving to the area 12 years ago. His par- ents were Z. Franklin and Louise (Bateman) Collins. He retired from Trailways Bus Lines as a bus driver with 30 years of service. He served in the U.S. Coast Guard during World War II, having been honorably dis- charged with the rank of Seaman 2nd Class. He was a member of the American Legion Post 155 in Crystal River. He was an avid pilot and enjoyed his family and garden- ing. He was Protestant. Survivors include his wife, Kitty Collins; three sons, Mike and his wife, Ann, Collins of Tampa, Wayne Collins of Tampa, and Scott Collins of Beverly Hills; daughter, Desiree Collins of Tampa; three stepchildren; and sever- al grandchildren and great- grandchildren. Chas. E. Davis Funeral Home With Crematory, Inverness. Donald Davis, 80, INVERNESS Donald A. Davis, 80, Inver- ness, formerly of Floral City, died Sunday, Feb. 13, 2005, at Citrus Health & Rehab Center. A native of Fennville, Mich., Funeral Home With Crematory Burial- Shipping Cremation Member of International Order of the G d BE OUR VALENTINE! CALL NOW to schedule your FREE HEARING EVALUATION & DIGITAL DEMONSTRATION Get your FREE BOX OF CHOCOLATES' with your completed evaluation. WNo Purnsae Necesary Offer eixpres Februarp 2.2005 he was born Aug. 8, 1924, to Leo and Sylvia Davis and came to the area in 1981 from Wyoming, Mich. He retired from General Motors Corp. after 30 years of service as an inspector. He was a member of the Bushnell Congregation of Jehovah's Witnesses. Survivors include two sons, Roger N. Davis of Moreno Valley, Calif., and Albert C. Davis of Howard City, Mich.; daughter, Anita VanDam of Sparta, Mich.; 10 grandchil- dren; and 23 great-grandchil- dren. Chas. E. Davis Funeral Home With Crematory, Inverness. Armando Dominguez, 82 HOMOSASSA Armando Dominguez, 82, Homosassa, died Saturday, Feb. 12, 2005, at his home under the care of his family and Hospice of Citrus County. Born May 13, 1922, in Havana, Cuba, he moved to the area five years ago from Tampa. He retired from the tele- phone company. He was Catholic. Survivors include his wife, Hilda Dominguez of Homosas- sa; son, Armando Dominguez of Yaphank, N.Y; daughter, Debbie Pando of Ocala; two grandchildren, Jennifer Fen- garinas and her husband, Greg, of Crystal River, and Philip Dominguez of Yaphank, N.Y; and three great-granddaugh- ters. Brown Funeral Home & Crematory, Crystal River Eugene Falk, 71 INVERNESS Eugene H. Falk, 71, Inver- ness, died Saturday, Feb. 12, 2005, at Citrus Memorial Hospital in Inverness. Born Feb. 15, 1933, in Meriden , Conn., to Herbert and Louise Falk, he moved to the area in 1990 from Cheshire, Conn. He served in the U.S. Air Force during the Korean War. He retired from Southern North Eastern Telephone Company after 30-plus years of service. He was a member of the Good Shepherd Lutheran Church, where he was past president of the church coun- cil, a choir member and a Sunday school teacher. He was president of the Celina Hills Property Owners Association and past president of the Telephone Pioneers of Citrus County. He also served as treasurer for the Scandinavian American Club. He was a member of the 511th Air Control Warning Reunion Group. He was a member of the Citrus Hills Golf and Country Club. Survivors include his wife, Ethel Falk of Inverness; three sons, Eric E. Falk of Harpers Ferry, WVa., Mark D. Falk of Chesapeake, Va., and Maj. Michael J. Falk of Bristol, Conn.; two daughters, Karen A. Vitek and her husband, Victor, of Hopewell Junction, N.Y, and Vanessa M. Nowak and her husband, Daniel, of Cheshire, Conn.; brother, Nils Falk of Sarasota; and nine grandchil- dren, Mark and Andrew Falk of Chesapeake, Va., David and Kristina Vitek of Hopewell Junction, N.Y, Joseph, Aman- da and Samantha Nowak of Cheshire, Conn., and Michaela and Georgia Falk of Southing- ton, Conn. Heinz Funeral Home & Cremation, Inverness. Hazel McDaniel, 88 INVERNESS Hazel V McDaniel, 88, Inverness, died Wednesday, Feb. 9, 2005, in Inverness. Born June 18, 1916, in Tectumseh, Mich., to Perry and Elizabeth Pate, she moved to Inverness in 1984 from Wayne, Mich. She was a homemaker. Mrs. McDaniel enjoyed cook- ing, fishing, dancing, gardening and going to garage sales. She was preceded in death by her parents and her son, John Audritsh. She is survived by her hus- band. Arthur"Mike'" McDaniel, Inverness; son, Paul Audritsh, The Fire Place We do more than just Gas Logs! CUSTOM BRICKWORK FIREPLACES/OUTSIDE BBQ KITCHENS REPAIRS SMALL OR BIG * CHIMNEY SWEEPS & INSPECTIONS i 2 miles South of Home Depot 352- 795 797 1921 S. Suncoast Blvd., Homosassa 352-9 ,5-79 76 Crystal Family Practice Dawn Goodpaster, PA-C. Now scheduling appointments and accepting new patients. Full Service Medical Clinic Providing 4 Family Medicine, Women's Health, Allergy , Evaluation & Chronic Illness Management. - Physical exams including DOT and athletic physical. 6152 W. Corporate Oaks Drive Crystal River, 794-5086 Clinic Hours: Mon. Thurs. 9AM 5PM Fri. 8AM till Noon Dr. James Lemire, Medical Director PORT RICHEY PALM HARBOR 727-868-9555 727-785-3411 BROOKSVILLE 352-799-3221 CRYSTAL RIVER 352-563-1400 SPRING HILL 352-688-1195 INVERNESS 352-726-9545 of Garden City, Mich.; two daughters, Diann Spicer, of Taylor, Mich., and Marilyn Walls, of Wayne, Mich.; stepson, James McDaniel, of Ortonville, Mich.; stepdaughter, Kathy McCrory, of Gadsen, Ala.; 17 grandchildren; and 24 great- grandchildren. Hooper Funeral Homes, Inverness. Anne Tressen, 89 CRYSTAL RIVER Anne Tressen, 89, Meadow- crest, Crystal River, died Friday, Feb. 11, 2005, at Seven Rivers Community Health Center A native of Brandon, Manitoba, Canada, she was born Nov. 15, 1915, to Harry and Lena Miska. She moved to Inglis 27 years ago from St. Thomas, Virgin Islands. Following business college, she moved to Winnipeg, Can- ada, where she met and mar- ried her husband, Walter After World War.II, the couple moved to Detroit to operate a chil- dren's clothing store. In 1960, they moved to St. Thomas, Virgin Islands, to open the first car rental agency on the island for the Avis com- pany. The business grew to include a Chrysler automobile dealership and a Gulf service station. Upon retirement, the couple moved to their home on the Withlacoochee River After Wally's death.in August 2001, she moved to Meadowcrest She was active in the Seven Rivers Golf and Country Club, the Yankeetown Garden Club and the Yankeetown Womens Club. She was also a member of St Benedict Catholic Church and St. Anthony Roman Catholic Church. Survivors include numerous nieces and nephews and their families in Canada and the United States. Strickland Funeral Home is in charge of arrangements. HEINZ FUNERAL HOME & Cremation Affordably priced for all. Ship Out Specialist. We make all the arrangements "worry free." 341-1288 Inverness, Florida @ Top TVMKNIG Abbott F 552 r All. PlAPER"f' Located C ) BINGO PRIZES ; r- s50 To 250 4 I EAs mALI O nAD,,.za I.Ac..or HOMOSASSA LIONS BINGO '15 Every Month al 6pm Package $20 Pkg. $50 Payout 15,;50 Per Game lackpot, Free Cli e Trea a ,'uon-Smohnng Room HOMOSASSA LIONS CLUB HOUSE Rt. 490 .AlB6 ecr 563-0870 To plac your N. Christina Woodcock, 95 INVERNESS Christina Woodcock' 95, Inver- ness, died Saturday, Feb. 12, 2005, at home under the care of her family and Hospice of Citrus County. Born April 4, 1909, in High- land Park, Mich., to John and Caroline Baker, she moved to the area in 1991 from Westland, Mich. She was homemaker Survivors include her daugh- ter, Patricia Radloff and her hus- band, George, of Inverness; two grandchildren, Daniel Radloffof Denver, Colo., and Sheryl Lee and her husband, Christopher, of East Grand Rapids, Mich.; two great-grandchildren, Maddox Lee ofEast Grand Rapids, Mich., and Declan Lee of East Grand Rapids, Mich.; and several nieces and nephews. Burial arrangements will be in Michigan on a later date. Heinz Funeral Home & ,Cremation, Inverness. Funeral NOTICES Armando Dominguez. Mass will be offered for Armando Do- minguez at 10 a.m. Tuesday, Feb. 15, 2005, at St Scholastica Catholic Church in Lecanto with Fr. Richard Jankowski as celebrant Family will receive friends from 2 to 8 p.m. Monday, Feb. 14, at the Brown Funeral Home with a vigil service at 7. Interment will be at Memorial Gardens Cemetery in Beverly Hills. Eugene .H. Falk Funeral services for Eugene Falk will be at 11 a.m. Wednesday, Feb. 16, 2005, at the Good Shepherd Lutheran Church in Hernando. The Rev. Frederick Ohsiek will preside. Interment will follow at the Florida National Cem- etery in Bushnell. In lieu of flowers, donations may be given to Hospice of Citrus County or Good Shepherd Lutheran Church. Heinz Funeral Home & Cremation, Inverness. Deaths ELSEWHERE Jon Dragan, 62 ENTREPRENEUR MORGANTOWN, W.Va. - Jon Dragan, who helped start southern West Virginia's boom- ing whitewater rafting indus- try, died Saturday, several days after suffering a stroke, his family said. He was 62. A Pennsylvania native, Dragan and his younger broth- ers in 1968 started Wildwater Expeditions Unlimited, West Virginia's first commercial whitewater rafting business. Today, nearly 250,000 people go rafting on five West Virginia rivers. About 40 rafting busi- nesses generate nearly $75 million a year Dragan continued to expand his business interests along the river and in 2003 launched the West Virginia Southern Rail- road with Roger Lipscomb. Fritz Scholder, 67 ARTIST PHOENIX Artist Fritz Scholder, whose mix of pop art and Native American imagery is credited with revitalizing American Indian art in the 1960s and 1970s, has died. He was 67. Friends said Scholder, who died Thursday, had been ill with diabetes and pneumonia and had spent much of the past year in hospice care. He had been living in suburban Scotts- dale. "Fritz Scholder was a great American artist," said Frank Goodyear, director of the Heard Museum in Phoenix. "He challenged the definitions of Indian art and, in doing so, created some iconic American images." Scholder is credited with bringing American Indian imagery into the 20th century. M .m- : .. .. Sa 0- place your Bingo ads, call 563-3231 or 563-3265 HTS OF COLUMBUS LIONS AUXILIARY BINGO Francis Sadlier #6168 Friday Nights @ 6:30pm /746-6921 WINNER TAKES ALL ourity Rd. 486 & Pine Cone a Lecanto, FL KING & QUEEN I ? AM, Eatiof Count} Rd 4971 Refreshments Avail. --,, ...c.po.. FREE Coffee and Tea BU 1 BONANZA Non-smoking Room $15 pkg. CETI" 1FREE. $50 Payout Per Game Homosassa Lions Club House, ,. RT 490 ,t., ~".5 .' ... Bob Mitctell 6285'-541 ||[2 NO GAMES LESS THAN $50 *200 2501 OUR LADY OF FATIMA *2501 2 JACKPOTS-ON-YOUR hARD-C & THURSDAY 6 45 PM AT 550 m WE PLAY 3 I 14 GAMES ......................$50.00 4 SPECIAL ........ MpOsA..... $50.00 1ST JACKPOT..................$200.00 2ND JACKPOT.................250.00 'IN 10 NUMBERS -* F NOT CONSOLATiON PRIZES2Ei0 ALSO 8 SPEED GAMES BEFORE REGULAR BINGO EA. GAME S50.00- COST '4.00 TOTAL '400.00 SPECIAL Buy 1 Speed Extra Pack $2.00 each Join Us 1 SValentine Mon. z/14 & Thia Mn. 6:00 P.M. Thurs. 12:30 AM. Doors Open 2 Hou The Friendliest Bingo in Town V Info 527-2614 at 72 Civic Circle ever-ly Hills YARDS EVERY TUESDAY-1 010 PM 1350 mWY U 5 11 SOUTH. INVERNESS JACKPOTS - ) ON $1.00 PAPER SPECIAL 50. SBO. 250 TOTAL S30 M >N HARD CARDS (20) AT Tw o- EACH LEAST2U050 BINGO BINGO! * 13 CARDS......................10.00 15 CARDS......................10.50 18 CARDS....................11.00 24 CARDS....................13.00 30 CARDS................15.00 For A IBingo :f I u "rsEarlier ' CHANCE TO WIN * OF 10 BOXES OF ULENTINE CANDY 14 EACH DAY 4 For Information and costs, call 726-8323 SBeltone Hd/ping the / o.'id /iar hrierr-r %pj% IVA"NUAY, won I Obitmiies rTr7W r, fnrOjrNTrrv fA2) CH OUUNICL BOUNDLESS Continued from Page 1A Miranti tells people not to call her handicapped. "It's offen- sive to people like me," she said. Miranti said although she is physically challenged, it has no bearing on the things she can accomplish in life. "People tell you, 'You can't do it' your whole life," Miranti said. Despite this, Miranti made up her mind early to push her- self to always excel. "Tricia is really a model of determination," said Susan Castorina, one of Miranti's for- mer teachers. Miranti said she didn't have many friends in school, which made life lonely. The year before her senior year, she decided to become a home- bound student Her plan? To begin intense physical train- ing so that she could walk across the stage and receive her diploma. "I felt like I had to," Miranti said. Her hard work paid off grad- uation day, when she not only graduated with a 3.8 grade point average, but proudly walked across the stage in front of teachers, peers, family and friends. "This is one tough kid," said her mother, Vicki Miranti. From there, Tricia attended Central Florida Community College, and later the University of Central Florida in Orlando where she got what almost every 20-some- thing wants independence. Miranti majored in public - - - - I :cL~i? - I ~42~''~"" administration, with a minor in apartment management. She also earned an additional certification in nonprofit man- agement. She now works as a project coordinator for Easter Seals and lives in Bradenton. Throughout her life, Miranti has enjoyed writing, especial- ly articles about her experi- ences. At Easter Seals, she plans to use her writing ability to change the way people per- ceive others. "Look at me, don't look at my chair when you evaluate who I am," Miranti said. She wants to use her writing and public speaking skills to explain to others that each person deserves to be treated with dignity and respect. "People didn't talk to me, but around me and about me," Miranti said. "They do it now." But she plans to change the world, one person at a time. Her latest student is her fiance, Marshall Rickardi. When the couple first met, Miranti said Rickardi was a little hesitant to begin a rela- tionship, because of her physi- cal challenges. Now the two are almost inseparable and enjoy spend- ing time on the beach. "I think it was a month into it that I really knew he was the one," Miranti said. Rickardi proposed in July, and the wedding is set for March 19. As for the future, Miranti isn't sure what it holds. One day, she hopes to start her own nonprofit agency, but is unsure about the organiza- tion's mission. For now, she plans to enjoy married life and continue educating others * m- - m -- I k I4 I V.A is rLOW PRICES Friendly, Quality Workmanship ' il OKendallI: Rotate & Balance : II MOTOR OIL I Mag Wheels Extra | ' Chan e ThP n i s,149 Expires 3-10-05 I C h a n g U e h Prt n -.. ... ... ... ... = = = ==. S(Most Cars), Trucks Transmission Flush (Plus Tax/Disposal & Service Improves Shifting (Pl Charxe/Diso al l & Prolongs Life II,9VV Expires 3-10-05 74.95 Expires 3-10-05 Alien Ridge 746-6650 o e l Complete Tire 746-0555 I & Automotive Center a / l l l1621 N. Lecanto Hwy., Lecanto, FL 34461; / Iww.joescarpet.com 'r s "Seing Citrus County Since 1970" fe - 2. ~ U ( U - *~ - N - a - -.~ -~. - - ~... - - -.~ a. - - - a. ME 26L 0 -l* p - ; E E C - a. 41bqw- 9A.. -a. a... - To The Most Important People In My Life, ' A I want to let you know -, that you make a big difference in my life. I want to wish you a very Happy Valentine's Day! You deserve the best. Thank you for being you and always believe , in yourselves! ' Love You Always, Mommy (Carol Ann) ask, "Why Pay That Much?" Our EVERYDAY prices are still lower than their SALE prices! We purchased a pair of their Eddie Bauer Eyeglasses on sale and still paid $20 more than our everyday price for our Eddie Bauer" Eyeglasses! PLUS at Opti-Mart you always get a SECOND PAIR FREE for you or a friend! Complete Comprehensive ~-- Eye Exam Most Insurance Programs Accepted Crystal River 1661 US Hwy 19 S. (Kash & Karry Shopping Center) 352-563-1666 Exomei2r28105 'Take Lighten three ti Take Kodak Transitions Next I ( | I enlst s and darkens just Soff Starting at $79" w/savings Inverness 2623 E. Gulf to Lake Hwy. (Winn Dixie Shopping Center) 352-637-5180 mes faster than Generation" Lenses as fast outdoors. Expires 2/28/05 * ompti-mart Completely Affordable Eyecare THE PATIENTAND OTHER PERSONS RESPONSIBLE FOR PAYMENT HAS A RIGHT TO REFUSE PAY, CANCEL, OR BE REIMBURSED FOR PAYMENT FOR ANY OTHER SERVICE. EXAMINATION OR TREATMENT WHICH IS PERFORMED AS A RESULT OF AN WITHIN 72 HOURS OF RESPONDING TO THE ADVERTISEMENT FOR THE FREE, DISCOUNTED FEE, OR REDUCED FEE SERVICE, EXAMINATION OR TREATMENT. OFFER EXPIRES 2/28105. NOT VALID WITH PRIOR PURCHASES. PRICES ILLUSTRATIVE OF ONE COMPLETE PAIR OF GLASSES WITH POLYCARBONATE SINGLE VISION LENSES AND PREMIUM FRAMES PLUS ONE FREE PAIR OF STANDARD SINGLE VISION LENSES AND STANDARD FRAMES. MAY NOT BE COMBINED WITH ANY OTHER OFFER OR INSURANCE UNLESS OTHERWISE NOTED POWER OVER STANDARD AND PRISM ADDITIONAL. PRICE COMPARISON AS OF 1131/05 Sflanor Jamilp ~ taurant I BREAKFAST Buy Any Breakfast Get 2nd Breakfast SPECIAL of equalorlesservalue 1/2 OFF. Friday Special- FULL RACK DANISH.BABY BACK RIBS; POTATO & SALAD $999 All You Can Eat Fish Fry $61 Always Hiomemnde Mash Potatoes, Soun4 & Sauces SNow Open Sat.-Thurs. 6:30AM 8PM- Friday 6:30AM -9PM 564-1116 1239 S. Suncoast Blvd. 56 I 6 I U (Nottinglam Squar. Next to Eagle Bui.k) Dish Network & DirecTV We Sel wT Al :PROGRAMMING 'I $3199 I 1 0 a111113 DVR, HD RECEIVER! We have a plan for you too! & INSTALLATION Local Service & Installation Local Toll Free 1-800-493-8602 I Expires 2/25/05 --- --=---m-m-m-=---m DAVE SIGLER/Chronicle Marshall Rickardi puts his arms around his bride-to-be Tricia Miranti at the beach. When the couple first met, Miranti said Rickardi was a little hesitant to begin a relationship, because of her physical challenges. Now the two are almost inseparable and enjoy spending time on the beach. through writing and public Miranti said: "I just hope I speaking. can help others like me." A .. opti-mart Asks "Why Pay More?" They Say. We 2637 Forest Ridge Blvd Hernando, FL 746-4769 (in the Publix Plaza) ,411 The Normes You lru;it TOM. M Y=1I I L.TIPR MOVADO VARJUN BOS Transffl(ns The Prices 'wou Dr-ser~e! LJTRUS UOUNTY (PL) UHRONICLL: MONDAY, FEBRUARY 14, 20057A-' -":* -&--map -&--map 4C3L> -&--map COz C A.Wp . 0A oIV 0 B MONDAY FEBRUARY 1 4, 2005 \ "" I .. __ _ _ __ _ __-_ _-,.-, ._ -_--- -__ _.__ Sweet library event set Special to the Chronicle There will be a Valentine's Day Open House Party from 1 to 4 p.m. today at the Citrus Springs Memorial Library. The party will be an occasion to welcome new- comers, and honor the library's many vol- unteers. Newcomers will be shown the many fine features of the library, including its many shelves of hardback and paperback books. The children's section is a delight to behold, and the genealogy wing has a most welcoming look. The library's videotapes, and its large supply of audio books, will be brought to everyone's attention. Fliers identifying the many clubs that meet regularly at the library, their meeting dates and contact persons' telephone numbers will be available. Refreshments will be served, and every- one is invited. Officer installations . ,. Special to the Chronicle The North Suncoast Republican Club recently installed officers at its annual meeting. From left to right: Installing officer Betty Strifler, Clerk of Court George Gardner, Director Samantha Hoffman, Director Roland Aberle, Treasurer Bob Hagaman,.Past President Tess Livermore, Secretary Donetta Holland, Director Sal Cino, Director and President Charles Hoke. Past president Bob Hagaman is awarded an appreciation plaque by new President Charles Hoke. FFRA receives grants from Wal-Mart Special to the Chronicle FFRA (Families and Friends of Retarded V Adults) recently received several grants totaling $450 from Wal- Mart SuperCenter in Inverness. Larry Gamble, store manager, presented Michael Phillips and Donna Leeson, FFRA Program participants, V . with the checks at the 'FFRA's monthly meet- ing. FFRA president, said, "Wal-Mart's grant ,awards program has made a big difference in making FFRA's ,events and programs success- ful." ' John Verity, and his wife, Joan, both founding members of FFRA since 1997 said, "The Wnonies'received will be used to enhance the organization's educational and support activ- ities." FFRA is a group of Citrus County citizens that 1AT: formed a 501(3) non- .A profit organization nthly eight years ago to pro- et- vide the developmen- s. tally disabled adult population and their iEN: parents with a variety -ond of support and educa- lay tional initiatives. nthly. If you'd like to know iERE: more about the FFRA, call Rene or inning Donna -Laliberty at iter 746-5582, or attend Hiding one of the monthly nver- meetings the second s. Friday monthly. The meetings are at the Key Training Center Building in Inverness at 130 Heights Ave. Social time starts at 9 a.mn with complementary coffee and refreshments. Business discussions start at 9:30, and the educational por- tion starts at 10. Special to the Chronicle presents grants totaling New members join GFWC Special to the Chronicle At its January meeting, the GFWC Woman's Club of Beverly Hills installed two new members, Betty Wilde and Val Wither. Welcome aboard. Beverly Sheputa was the judge for our Arts and Craft Show. The blue-ribbon winners w e r e : Marguerite Pinkston, Sharon H Hildegard Palys, Shirley the speak Uherchik, Lou- January ise Potocny and N a o m i She broi Houston. Congratula- art work tions to all win- ners. These talented blue-ribbon winners will forms take part in the District Arts and Craft Festival in Gainesville this month. Sharon Harris was the speaker at the January meet- ing. She brought several of her art works. She is talented in many forms of art. She is an artist, sculptor, potter and a writer. How wonderful to have someone with her talent here. Thanks for a wonderful pro- gram. The next meeting is at 1:30 p.m. Thursday at 1 Civic Circle. Don't forget to wear a recycled outfit to the meeting. Buy arris was an outfit from one of the char- cer at the ity thrift shops. m ting. It will be fun to see what we ught her can put togeth- er. After the s. She is meeting, give it back to the in many charity. This way, we of art. can help the charity twice. Be sure to bring any old jewelry that you are not using for one of our proj- ects. Guests are welcome. For information, call 746-2912. I k I L U * WHAT: Valentine's Day Open House Party. * WHEN: 1 to 4 p.m. today. *.WHERE: Citrus Springs Memorial Library. Special to the Chronicle Recently adopted from Adopt A Rescued Pet Inc., Rocky finds his lifetime home with Barb Jones of Hernando. Organization awarded $450 WH FFR mo mei ingE WH Sec Frid moc WH Key Trai Cen Bui in I nes Mr. Larry Gamble, store manager of the Wal-Mart SuperCenter in Inverness, $450 to Michael Philips and Donna Leeson, FFRA's program participants. Arbor Day donation Special to the Chronicle The Citrus Garden Club joined forces with Master Gardeners and the SOLON program to cel- ebrate Arbor Day on Friday, Jan. 21, at Crystal River Primary School. The club donated a dog- wood, a redbud and two elm trees to be planted at the school. SOLON donated boxwood hedges and grasses to create a wildlife habitat. Mrs. McClelland's second-grade class enjoyed a morning of planting and learning about the wildlife that will be attracted to their newly planted habitat. The sign reads, "Wildlife habitat under construction." News :. Retired educators to meet today All retired educators and school support staff are invited to attend the meeting of the Citrus County Retired Educators at 2 p.m. today in Room 115 of the Withlacoochee Technical Institute in Inverness. Maureen Whitaker of Citrus Hearing Impaired Program Services (CHIPS) will be the guest speaker. The Culinary Arts department of the school will serve refreshments. Call Ethel Winn at 795-2533 or Al Sukut at 726-7367. Masons to gather in Beverly Hills Ridge Masonic Lodge 398 F&AM (a daylight lodge) will meet at 9:30 a.m. today at 88 Civic Circle, Beverly Hills. Take County Road 491 to Beverly Hills Boulevard to Civic Circle. Visiting Master Masons are always welcome. Doughnuts and coffee will be served at 9 a.m. For informa- tion, call W. Robert A. (Buzz) Bernard, worshipful master, 628- 0668, e-mail buzzgwen@yahoo.com, or Grant Schlenker, secretary, 344- 0714, e-mail gschlenk@tam- pabay.rr.com. CRUG to host magazine expert The regular monthly meeting of the Crystal River User's Group (CRUG) will be today at the Beverly Hills'Recreation Center, 77 Civic Circle, Beverly Hills. A social runs from 6 to 7 p.m. A short business meeting will then take place at 7, prior to a program for the regular meet- ing by Luke Vavricak of Smart Computing magazine who will guide us through the helpful and timely information such as you would find each month in the magazine. Participants can expect to receive a "goodie bag" Great door prizes will be given away .af the meeting, as well. Visit the Web site at for directions and a map. Click on the General Meetings link. All are welcome. Charter meeting scheduled The public is invited to learn about the home rule charter government option for Citrus County at 7 p.m. today at the Central Ridge Library in Beverly Hills. As the county grows, can home rule improve Citrus County government? This month, options will be reviewed which are not available in the county's non-charter system. For information, call 564- 0267. PET SPOTLIGHT The Chronicle invites readers to submit pho tos of their pets for the daily Pet Spotlight fea ture. Photos need to be in sharp focus. Include a short description of the pet and owners, minclud ' Rocky I I WEIRD WIRE MNAFERAY14 05S CITRUS COUNTY (FL) CHRONICLE m -Gme 0 --.NN m 0f- -W on -a -.40-M - a-w - am a TWAvlailxtableco [All T About Bathsl B QUALITY LINDS AND SHUTTERS PVC VERTICALS I Includes deluxe track, valance, and installation .726-4457 S Free Estimates Call for Apt. "---TH NE--"1 r A WHOLE NEW WORLD OF SOUNDS Jerillyn Clark Board Certified Licensed Hearing Aid Specialist Advanced Family 1 Hearing Aid Center 1 "A Unique Approach To Hearing Services" 6441 West Norvell Bryant Hwy. Crystal River 795-1775. - Il ll m- n ml mm nm- - Copyrighted Materia d- icnatei otnt from Coi mmerca News W. 4- 440- -a - - t Qw MEP40a in --4b qw m 4 .q in a- - in -~ - --a ~a in C a- a- in a- in in a a a 0 in in - a ~ a- Ci a- - THE PAINT FOR PEOPLE WHO HATE TO PAINT. S_ ) Porter Paints go on easier, cover better and '7 last longer than lesser *v 'quality paints. So you have to paint less often. ..., Citrus Paint & Decor DECORATING CENTER 724 NW Hwy. 19, Crystal River (352) 795-3613 No o promises 2915 W. Dunnellon Rd., Dunnellon (352) 489-1008 P A I N T S Jasmine Square, Hwy. 200 Ocala (352) 873-1300 M-F 7:30 AM-5 PM *SAT. 8AM- 12 PM LENNIX Upto $i160INDOOR COMFORT SYSTEMS Up to $1 600 "B="S5 t A betterplace- In REBATES tb and 10% DISCOUNT For full payment upon completion SLPH4811 S. Pleasant Grove Rd., SInverness, FL _ 726-2202 795-8808 LIC #CMC039568 Business RelationshiPlus;' Money Market 2. 500A0 2 9 OnVAPY I .- B 1 Cn r ', ', yl i n o.l .' n r, FREE Business RelationshiPlus" Checking Account lor 12 months a- _ in, a- 0 a a ~ o - - first Class LLC Rol Off Containers 10-40 yds *Land & Lot Clearing *Tree Service 352-527-4430 -We Give You A Reason] C. N. Christian III, D.D.S., P.A. -to Smile * Dentures * Crowns * Bridges/Partials * Implants * Hygiene * Root Canals DENTURE LAB ON PREMISES NO CHARGE FOR INITIAL CONSULTATION OR SECOND OPINION FEE O NriECSOSiv, CITRUS HILLS -- DENTAL Located in the Hampton Square at Citrus Hills ,', (352) 527-1614 -M -le We're a Hometown Pharmacy with Hometown Prices We Specialize in *Natural Hormone Replacement *Compounding Home Infusion (IV) Medicaid Customers Welcome Here! MeetOurStaff Pharmacists Bob Brashear, R.Ph., Elis Brashear, PharmD., R.Ph. andJonWright, R.Ph. BRASHEAR'S PHARMACY (352) 637-2079 ONE BLOCK BEHIND CITY HALL ON SEMINOLE AVE., INVERNESS ,aaa- Mon.-Fri. 8:30am-6:00pm Sat. 8:30am-1:00pm. THE RELATIONSHIP PEOPLE' 1-800-AMSOUTH I amsouth.com I Or visit any branch -5 V5'001, 1 c. 1 19 ei ,,-i l) i,5 farur.,ier 415 .Af)-i uP j. .r %t.D Irc C. :uIrfteo 1., Jltir JiLCU~iI elt o I n,' (.ee r t I .I, C,' t-ijr.Ai r-e ac,.u PIC. In'DV teErln-, j 11 -11. i...tJ ., i i.N ~iflt.~.,.i it. T Ti .3' ae'n!Ce .C nrii.r-.tn li.t.r.Nthtirtmay DC MaJC 1Vl,Cl.k e C n,:PC 3ra Offer ,, w- .i fatI. ir3 : r-w., cr-WC: 0- -*k.-h Cd dvoc;i.l -w .Ct.IF lrt ~r.i,.At.lt.n3i .u Erha.e o CJi ..s 61 r,,t~v,.Buw.C CI j.Ci-N.... ri.tir..74.. tttiLI. I..,1,1.I~ti .. J,, liii. I .-.Ir.. ro.3. C id--..^1it1 ..it kC C *'; le B .Tel i:'.11. 155 . MONDAY, FEBRUNRY 14, 2005 9A WEIRD WIRE o o Q Q mmm 10A MONDAY FEBRUARY 1 4, 2005 A&n rr,,,,,.,cletrlla c-. *-:" 01 "We have too many high sounding words, and too few actions that correspond with them. CITRUS COUNTY CHRONICLE EDITORIAL BOARD Gerry Mulligan ........................ publisher Charlie Brennan .......................... editor Neale Brennan .....promotions/community,affairs i Kathle Stewart........advertising services director Steve Arthur .............. Chronicle columnist .40gj00a Mike Arnold ..................... managing editor Jim Hunter .............................senior reporter by Albert M.91 Curt Ebltz .............................citizen member Williamson Mike Moberley ...................guest member "You may dfer uwith my choice, but not my right to choose." David S. Arthurs publisher emeritus LESS NOISE, MORE ACTION Airboat noise needs to be toned down T ong-suffering citizens of the county have again petitioned their elected representatives at the County Commission for relief of assault by airboat noise. Anyone who has ever been subjected to the obnoxious nui- sance sometimes literally an auditory battering can sympa- thize with the complaining citi- zens. Anyone who has been awakened and kept awake by the roar of airboats understands the recent group of 263 petitioners' frustration with local govern- ment's inability and/or unwill- ingness to do any- thing about the situ- ation. Commissioners and Sheriff's offi- cials need to listen tQT'ie residents and finally" do some- thing other than take token actions THE IS Airboat OUR OP .,..Respect and your n or make statements that give lip service and no relief. The county says it is consider- ing amending its noise ordi- nance, possibly adopting state- endorsed standards of limiting noise to 90 decibels at 50 feet. When: would this take effect and how would it be enforced? Residents want relief. The vast majority of registered voters and taxpaying residents who take the brunt of this noise attack want something done. While the ordinance needs to be tough, it will mean nothing if it is not enforced. Vehicles making noise beyond acceptable levels are not allowed on highways. Logic follows that extremely loud vehicles should not be allowed to go unchecked on waterways, particularly near residential areas. For years, airboaters have been asked to consider others and to abide by the law. Some have. Some haven't. The risk in rejecting calls for compromise is that, as the county grows more urban, the mindset could shift to absolute intolerance. Peaceful coexistence is the best option. Some use quieting technology on their boats. Some don't Maybe the County Commission can ;SUE: make a deal so that noise. the sheriff gets his new helicopter if he PINION: agrees to use it, in part,, to pursue the law rogue airboaters neighbors. who destroy the - peace in the middle of the night. If that doesn't happen, then the County Commission needs to get radical to prove it means business, if that's what it takes. Making all airboats pass a noise inspection at a county inspec- tion station could be an answer. Muffling devices and certain props could be required to pass inspection, if that's what it takes. The time for misguided rheto- ric about freedom, who .was here first, excuses about why it can't be done and claiming of rights at the expense of others has passed. It's time, commissioners, for action. Don't throw it I'm calling in response to the trash in the paper. If people want to clean up the roads, they need to quit throwing trash out the window. Take down signs My complaint is about garage sale signs. People leave their garage sale signs up well after their sale is over. And of course, other than it being litter on the roads, it's also (for) people garage saling (who) see the sign and you're driving up and down streets for no reason at all. I think it would be common courtesy to make people take signs down after they have their sales., People, pick up I'm calling in regard to both the Carson's family S I just finished reading two newspapers with sto- - ries about Johnny Carson, and not one listed who survives him. I noticed before that they just don't j do that anymore, yet that's of interest. Is there a rea- CALI son why they're not listing 5nn their survivors? 64 Editor's note: Most obitu- ary writers focused on John- ny Carson's career. His fourth wife, Alexis, and two sons survived him. Relying on volunteers I'm listening to my scanner and I want to know why do the volunteers have to leave their jobs to help EMS "Litter alert" and "Trash responsibil- ities." I just want to say that basi- cally the people are responsible for the litter and the trash. The resi- dents of Citrus County need to be aware of the environmental impact of them throwing trash out the win- dows in'cars, which I've seen fre- quently. So the problem is not the politicians. The problem is the peo- ple who need the education in not trashing the county. Slob behavior This is in response to the people who are blaming the city officials for the trash on the side of the roads. I think it would be best if they blamed the people who are really responsible for this, and that is the slobs who drive by and throw their trash out the window. Sixth lifting and driving? Don't they have, like, supervisors or captains or chiefs who do that kind of stuff that can help out? You know, why do we have to rely on the volunteers all the time? People first 0f579 This is for the people 05 Iv that's concerned about trees being cut down, tur- tles being destroyed. I got a solution: Sell your house, tear it down to the ground, plant trees, along with every other house and business in Citrus County or every other county, People have to live. Someone's got to bend. Better the trees go than the people go, lI md l- i o d'V rW mwl A+L on- i w oo- mam m - amm apf- n 9m doom -ow 0 f qm mw__ II _wI - -- - - - ~- '. - - - - m-. -n- m - di * - aw -W - pyrigaeri - - -moowm m dm qS mw p w- -0 0 -0 smq. m ______ -S --0 S-so aloft ft-ww - -ft--me -90 loo- I-I I -- -- a NIe Pl " Vala~e Tom~m merlal NWS r [les 4b p w lb 04 qm ftop- nw0dp 4000 --o - m41wft0 0do I- Ma . _ w -b 4W 9 e soEopdi " - m * -m~I * 9 C 6 LETTERS Thanks for support The election is over and despite my exhaustion, I feel compelled to thank everyone that helped with my cam-. paign. First, I want to thank the Lord for his blessings and the courage he gave me throughout my campaign and all the people that prayed for me. Then, I want to thank my family, Mercedes, Maria, Gustavo, Renee' and Adrian, who supported me with love and patience. Next, I have to thank all my friends, both old and new, who believed in me, walked with me and talked to oth- ers on my behalf. This list includes Larry and Karen G., Joyce R. and Audrey, Mary Ann W, Linda S., Ann S., George and Judy R., Kitty, Betty P, Bobbi Y., Lorene D., Mary Ann and Arnold V, Art and Jeanne Z., Pat, Karen W and finally Sophie. If I have left anyone out of this list, please except my sincerest apologies. Lastly, the biggest thanks of all must go to the people of the city of Inverness who shared their thoughts and their time with me and helped me win in the end. This includes the lovely couple that gave us Italian cookies one day, the artist that helped me speak at her homeowners associa- tion, the gentleman living at the end of a forgotten dirt road and all the others I met while walking more than 48 hours through the streets of Inverness. To all these people, even the ones that didn't vote for me, I promise to do my very best I will work hard to earn the trust they have bestowed on me as their newest City Council member. Sophia Diaz-Fonseca Inverness City Council Member, Seat 4 OPINIONS INVITE The opinions expressed in Chro torlals, she Linda Johnson at (352) 563-5E M All letters must be signed and phone number and hometown, letters sent via e-mail. Names hometowns will be printed; phi bers will not be published or g We reserve the right to edit lett length, libel, fairness and good M Letters must be no longer than words, and writers will be limit three letters per month. SEND LETTERS TO: The Editor, Meadowcrest Blvd., Crystal Riv 34429. Or, fax to (352) 563-32 mail to leoters@chronlcleonlln Unify trash collect I wonder, now that the elec over, the back slapping, parti prating has ceased. Now that days, freebie days off and oth perquisites have been enjoye most government officials, if see some accomplishments fc tax dollars, for instance week collection in a rising-star cou a real estate market hotter th chicken wings and houses se faster than cotton candy at a game, (most) of which are pu by retired empty-nesters (wit den on schools). It seems to me with all the al tax dollars, trash collection affordable. Just think of this: in V to the Editor ID will be the rumbling of four or five D different trash contractors passing by inicle edi- your home, tearing up the county editorial roads, many of the self-haulers with makeshift trailers depositing refuse car- on the already-littered roadways and the edito- last but not least the elimination of the nonsensical trash detective. A ed to master's degree from Harvard er to the Business School is not required to implement weekly trash collection; editorial simply a low bid by a responsible would call refuse collector. 660. Here's my New Year's message to include a all government officials, '"Action including and speaks louder than words." one num- iven out. William L. Julian II ters for Hernando I taste. 350 Accident an experience ted to While pulling into my driveway, I was struck in the rear by a motorist 1er, FL who claimed she didn't see me in 280; or e- time because she was doing some- e.com. thing to a child who was in her auto. She didn't have any ID or insurance cards at the scene, but was permitted tion to drive home to get them by the 2tions are deputy who responded to the acci- es and dent t the holi- The deputy filled out a short form ier report with driver exchange informa- ad by tion and gave each of us a copy but we will did not fill in his name and badge br our number ly trash He stated "No report of the acci- nty with dent" would be filed as he didn't have ian spicy to, suggested neither of us report the lling accident to our insurance companies baseball and fiuih-d to issue a citation to the rchased motorist who caused the accident My h no bur- insurance agent couldn't believe what he did, addition- n is Thomas Gwalthney (;onre Homosassa THE CHRONICLE Invites you to call "Sound Off" with your opinions on any subject. You do not need to leave your name and have up to 30 seconds to treiod COMMENTS will be edited for length, personal attacks and good taste, This does not prohibit criticism of public figures. Editors will cut libelous material. OPINIONS expressed am4 p tw@ Mee of tfe t aies, Hot Comer: TRASH . kow #L w ps p t ll 0 Ilk 0 #$ 'o M aw 1 r,4 W* 0 i ( iX_- r A F 14 CHRONICLE A CITRus COUNTY (FL) C Blair ".,w ,l4 *v , "Copyrghted MaterIa Sdi. -tCntent Av lab e from Cmernc News Providers" - - - o - a - - -. 2005 BR y ~ .*~'f~ ,.'~d. ~el'~c "'I L$ 4J i'A.$- .11 ~I~' Lg'j~\ ,~ CHR~NiCL PROM P -O - PROM m -0 0 AL & Don't miss our 2005 Bridal Guide in the Tuesday, February 15 ,.^ Chronicle. "2005 BRIDAL > PROM EXPO PLANTATION INN HWY. 19 CRYSTAL RIVER FEBRUARY 20 11 AM 5 PM For More Information Call 563-5267 31% Off Floor Sample Clearance Remainder of Instock Store Items 20% Off * Famous Name Brands Flexsteel, Lane, Chromcraft, La-Z-Boy Many Others to Choose From ,,, A.,...- b,. .,.. ., .... ..... . ., ,' 50% Off Howard Miller Clocks *Gallery Items not Included In sale SUNCOAST Hwy. 19 (3 miles south of Crystal River) 795-5454 HOURS: MON,-FR/, 8:30 A.M.-5:00 P.M. SAT. 10:00 A.M.--5:00 P.M. CURRIER COOLING & HEATING, INC (352) 628-4645 (352). 628-7473 1 O>> 4855 S. Suncoast Blvd. (H\vy. 19 So.) v ~"~, Homosassa. Florida 34446 -Beverly Hills DENTAL CENTER- R |lL s .I Dentures, Partials & Bridges Interceptive Orthodontics (Minor Tooth Movements) Invisalign (Removable Braces) Children Welcome Veneers, Bonding, & Extractions One Visit Root Canals Gum Surgery Implants One Hour Whitening Exam, X-Rays & Cleaning * FMX 00210 Prophy 01110 * Initial Oral Exams 00150 Vnlu.A 155.0 Senior Citizens Discount (Ask For Details) Crowns starting at $450 (All Metal) Need A Second Opinion? FREE Consultation With the Dentist STANLEY STEEMER. CARPET CLEANER . .. ... . .. ... . anboit nour 726-4646 or 1.800-STEEMER NY FOUR (4) ONE SOFA (up to 7')I1ANY 2 ROOMS & IIONE SOFA (upto7') ANY FOUR,(41 and ONE CHAIR Ili HALL CLEANED and ONE (1) ROOMS ii cleaned plus ii and protection to II LOVESEAT CLEANED protectionn appliedIexposed area of carpet, CLEANED $8 700 119995 I $8500 "8995 PRESENT COUPON 11 PRESENT COUPON II PRESENT COUPON II PRESENT COUPON STANLEY STEEMER. B I STANLEY STEEMEILR i STANLEY STEEMERIL STANLEY STEEMER.I A ROOM IS AN AREA U? TO 300 SO. Ff. RESIDENTIAL OR COMMERCIAL. ,.A ROOM IS ANAREA UP TO 300SQO.FT STANLEY STEEMEr RESIDENTIAL OR /DINCOMBO S REA 30 R IN/ COMOS O GREATROO COUNT OM RCI ALEXCLUDING LEATHER& I COUNT AS ROLS RESIDENTIAL EXCLUDING LEADER & HAIAN COTTON. uI I AS TWO ROOMS. STANILEY SE R ITMAN COON. COUPN EXPIRES LNtY. EXMS2/25/. COUPON EXPIRES 2/2/05 __ __ RESIDENTIAL ONLY. LRES 2/28/0 2/28/05 om-q --w- - 401 -- -lm .40 "D - mlj -tb - 4W- Sm IIAM MONDAY, FEBRUARY IL4, 2005 IIA WORLD NE1VS 114pc)&TrrTI7 12A MONDAY ,FEBRUARY 14, 2005 -* f we ft a ae - *: -,, :. ,,,, . aIMilallInlll lll lllb qlp I 4 1 llmella a .m. m a aam I SLte MIate ial a trataecuLflons a Qmn wmaa .m ae a amwe . Milimmm t m w, ob M41i 0 00 w 4t 4m 41t e s imm mm. m mob Am.mum. emomme e. am e h q om a m- aamm m* - 00NW Snk- i- *eM . o =" sh Available from au xb ^| aidft- - 0 .::.:::: n'diCatedCo Commercial "llobw -af qmdil #Amp. .... . n idt.,. =a me se lm m I( m"mm m NewS Providers -....-... ,.-.., S iiiIIIim ll all m a1iili!8 . a .i a11ama ,r:,,, "-mii- It1 * moo v 0. .e e.,.H.,.,.. ....... ... ...a .... .. .. A--,... a aw t *5 ". a a. a." - a -, - - a~ ~'- -. e 'a -,,. 'a-,.. I L- a a s -. A A -L * ... h i.. .... i.. .dl ..: o |:- a a. S"=l a., , .-. ..,,, ..- a - ....a. ,. idl a. - ION a *l=t =,1 .=..== .. == = .. .. a .. ia111110 aw I I. .. .... .. .a m a*... ,, w U4m a Ueamm- ma a -ami gmumi A -..ams mlAkwoesmlow . a mllllll a *. " .0 a a1 a u a m-e a - m ... am - ala-a a ma a -imb ago fta ,_. a- ....... a ,,, .===... ... .. .... a**- te rebgxs rules Saxudis mark Vantirs'r _au a -m Smm a -mm dmea& ob n 4w amlolh a 1* e m o anmm mmma Mummom 491001 4ft 40 4410ob womoelum Mmw ..* ... .. ... Mme* M10, 111'Ill' QAQv"Ljjjj Mffszm9LIF=nQ am I --l ==.i. p .- '011 Oregon State upsets No. 11 Washington PAGE 2B MONDAY FEBRUARY 15, 2005 aa es a a-"* --Ms 0 0 .4. 4 im aIIIIIft i a* ..*- - - -a **- we -al o - i a- a n u:.. 4 || * .- H *. , n e N fl "** ****. !f .. : a . ..ee 'Mil : ": *u lll se w. ...:* -f- mi- -a .o h._. - 4 MII.l . .... *: .=w** - a -- l S.... .. ..... a... w A e A .90- a. ,. t .J oo ii o as-y g *'afiir a* I H^^ II i I F PD a -a ... -. a. S.- ~ a S .. a ..- ..- ha.. -D 9 I I fit kvlda NI~A U -W f .* : Ui/ I -g ali en flap aglg A xM-W xf iMOO _ _l -** a *-o a -0.:AV o a -- e.0 -* am V IP All *e a. a a-< w am- JlmKW Jnk *W1 *f r - *** ::. -* k F, -.S40W0 S-- - o^ r a*" - - a ll-- a -x1 - 4frS-a f'm IlP S *if i S--:^ -- *: a-* I- -. V 4 I * 09 -**-~t * .. ... ..... a - -o swimmm0 ginumma il ab um a 4= als gu0 E a a al q a ab a a a tmiga an s e S Ce11 0.Oesmaha aa::l W.- -. * *00 -- ... ... . ...... .. . db kSV ..: (: ..4 .::*** '* -rf ma- * A* v ... 0a aw So - ~09 a a. 4. .- 4. S .. ...... ,. a t .. 4..,.. '.. : i *SH. 'a. 9-..... it; a ,. , " mlmll omw dbommam S ".. ai": A%&la Make annxuncwi, rrtrnmrnt in l'taah -,- a a.. =A il T- ai * -..... :lf. .. ('anr:o 6S r wiad r11f ~cunir pw4l.,& ,li s 'a"'S3S . 10 . a a *k J:IE: 'we.... n sa emewm 0p -m. ..... e man flmmw 0g a6 S sum..-.-M am.gem a0a ON a Mu -aws ama. *- asq.. - Beavers' bite o -I "ef ,,... . As I::, * III -,,-ilk W.CL, UNC wins at Connecticut "C.o pIgj7j ri pyi hteMMa ial dicated content Available from mercia I'News Providers" il , a - .. in. .., a a. - "..:. ..... * 4 'on omj pmpW~ 0mmm4w fll w fUl 401omMw NomooomumamOmow mft m fm 46o* N mm 40ft d.. Aw a. ,, aI... ~- p -- . :::. =** a ,:.... . 1f: .. mmmm -mVALUE couPoN mm P aul's New and Used Furniture 628-2306 S 5348 W. Holiday St.- Homosassa Tules.-Wed.-Thurs.-FriL 9-5, Sat. 9-1 SKIDMORE'S? Sports Supply -> ,;Zeumm S* Air Boat Rides Boat Rentals SPontoon Boat Tours Gallery & Gift Shop Manatee Encounters Yulee Dr Homosassa A .- . SENIOR DISCOUNTS Vitamins Minerals Herbs 8022 West Gulf-to-Lake Highway Crystal River, Florida 34429 352-795-0911 20 Years In Citrus County COAST RV MOBILE HOME SUPPLIES RVDefieng. Call Kaly for tfo. Airport Plaza Crystal River 563-2099 Stop by 3c Custom Embroidery 9 Sewing machines -M9:30-5 & Sergers ..4lor- Classes s Husqvama VIKING Beall's Shopping Plaza .,2- 1 4-0600 - I ~ YflYYYYAVYfli 5 * Paul's New and Used Furniture has been at the same location in Homosassa since 1971. Interestingly, the business has always been owned and operated by a husband and wife pair. Dave and Linda Schultz have owned Paul's New and Used Furniture since 1993. They also live in a home that is on the same property as the shop, so they are readily available. At Paul's New and Used Furniture, you will find a full line of bookcases, computer desks, entertainment cen- ters, dining and bedroom sets, living room sofas, chairs, tables, lamps and anything else you would need for your home. Their stock is 80% used furniture, which the owners handpick from calls they receive from private sellers. They buy one piece or an entire household. The remaining 20% of their inventory is new furniture, which includes the popular Legends solid wood home office and entertain- ment line and Stover Rest, a line of new bedding. They also have distributor connections with the ability to have furniture delivered in 10 days, such as select lines of Ashley, Higdon and Vaughan-Bassett. An 800 square foot section of the store is dedicated to houseware items: dinnerware, glassware, knick-knacks, linens, cookware and baking ware. If you cannot find what you are looking for at Paul's New and Used Furniture, they have a 6,000 square foot warehouse, in addition to their 6,000 square foot store, containing more beautiful furniture. When you do find what you like, Dave and Linda will deliver and set up your new furniture, sav- ing you time, money, and effort. Also, this year Linda has started to dabble on Ebay. At any time you may find a selection of interesting collectible and useful.items up for bid. These can be viewed under seller ID: wolfbranch777. To find Paul's New and Used Furniture, which is located at 5348 West Holiday Street in Homosassa, turn at their green sign on West Grover Cleveland Boulevard and follow their signs to the shop on Holiday Street. They are open from the Tuesday after Labor Day through May 28th. The business hours are Tuesday through Friday from 9A.M. to 5P.M. and Saturday from -9A.M. through 1 P.M. They close during the summer months of June, July and August in order to run a similar shop in Wisconsin. Call 628-2306 or stop by, even just to browse. They try to have something for everyone. NU--U - Kenmore 110 Furniture Frutoe Always looking to buy good used items. e Cnin CALL KEITH 621-7788 Great Condilion $ Sunny Days Plaza, e 536) S. Suncoast Blvd.. Homosassa Cedar Chest 125, .lfae. .......... ......, ::: .= .... mE 1 . * ... * i8 :::. .f OPEN 7 DAYS A WEEK 5 Blocks East of Hwy. 19 Crystal River 795-4033 ZIS MONDAY, FE13RUARY 14, 2005 OPA," XILX CITRUS COUNTY (FL) CHRoNTcLE SP40KYS |xi : ..N:. jir SSc >::r:. ...... ..... w 6 ... W&* 1 7:: A *"*::::* ** "iBE- *x88E ,atf-m4:E "SUf- Mto ,,,. ..... ....... P b4p oavvy"s &IMINItA CrmSrt (-nrONTy (FL) CHRONICLE SPORTrS MONDAY, FEBRUARY 14, 2005 3B NCAA HOOPS This Week's AP Top 25 Glance 1. Illinois (25-0) beat Michigan 57-51; beat No. 20 Wisconsin 70-59. 2. North Carolina (20-3) lost to No. 7 Duke 71-70; beat No. 19 Connecticut 77- 7P. 3. Kansas (20-1) beat Kansas State 74- 61; beat Colorado 89-60. 4. Boston College (20-1) lost to Notre Dame 68-65. -,5. Kentucky (19-2) beat Florida 69-66; beat Georgia 60-51. 6. Wake Forest (21-3) beat North carolina State 86-75; beat Florida State 87-48. 7. Duke (18-3) beat No. 2 North Carolina 71-70; lost to Maryland 99-92, OT. -,8. Syracuse (22-3) lost to No. 19 ponnecticut 74-66; beat No. 22 Villanova 190-75. '.,9. Louisville (21-4) lost to Memphis 85- 68; beat South Flodda 65-57. ,,10. Oklahoma State (19-3) beat No. 16 *Oklahoma 79-67; beat Texas A&M 66-59. '11. Washington (20-4) beat Oregon 95- 88, OT; lost to Oregon State 90-73. 12. Arizona (21-4) beat Southern ,alifomia 88-76; beat UCLA 83-73. , 13. Michigan State (17-4) beat Ohio -State 83-69; beat Michigan 64-49. 5 14. Gonzaga (19-4) beat Pepperdine 82- 75; beat Loyola Marymount 61-58. 15. Utah (21-3) beat UNLV 57-53; beat Colorado State 64-50. '16. Oklahoma (17-6) lost to No. 10 bklahoma State 79-67; lost to Missouri 68- 65, OT. 17. Alabama (19-4) beat Tennessee 72- 54; beat Mississippi 71-45. 18. Pittsburgh (17-4) beat St. John's 55- 44; beat Notre Dame 68-66. *'19. Connecticut (15-6) beat No. 8 pyracuse 74-66; lost to No. 2 North* Carolina 77-70. 20. Wisconsin (16-6) beat Iowa 72-69; st to No. 1 Illinois 70-59. ;'21. Cincinnati (18-6) beat Xavier 65-54; lost to DePaul 85-66. -,22. Villanova (14-6) beat Saint Joseph's A7-52; lost to No. 8 Syracuse 90-75. "23. Texas (16-7) lost to Colofado 88-79; beat Kansas State 75-72, OT. :' 24. Pacific (20-2) beat Idaho 78-56; beat ,Utah State 64-63. 25. Texas Tech (15-6) beat Baylor 83-67; Igst to Iowa State 81-68. *. No. 2 NORTH CAROUNA 77, ,. No. 19 CONNECTICUT 70 'NORTH CAROLINA (20-3) J.Williams 7-17 0-0 17, McCants 7-16 0- 0 15, May 5-11 6-8 16, Felton 5-14 4-6 16, Mtianuel 0-1 0-0 0, Scott 0-4 0-0 0, Terry 1- 1 0-0 3, Thomas 0-0 0-0 0, Marv.Williams '-9 0-1 8, Noel 1-1 0-0 2. Totals 30-74 10- 1577. PONNECTICUT (15-6) Villanueva 1-6 0-1 2, Gay 4-14 4-6 13, Brown 5-12 3-4 15, Boone 7-10 2-4 16, OI.Williams 7-14 2-2 18, Armstrong 2-2 0-2 4, Thompson 0-0 0-0 0, Kellogg 1-4 0-0 2, Nelson 0-0 0-0 0. Totals 27-62 11-19 70. Halftime-Connecticut 34-31. 3-Point Goals-Nxrth Carolina 7-23 (J.Williams 3- 4, Felton 2-6, Terry 1-1, McCants 1-5, May 0-1, Scott 0-3), Connecticut 5-14 IM.Williams 2-2, Brown 2-7, Gay 1-3, Kellogg 0-2). Fouled Out-None. Rebounds-North Carolina 41 (IMay 13), Connecticut 49 (Boone 11). Assists-North carolina 19 (Felton 10), Connecticut 11 .M.Williams. 5). Total Fouls-North Carolina 17, Connecticut 15. A-16,294. OREGON STATE 90, No. 11 WASHINGTON 73 ASHINGTON.(20-4) Jones 2-7 4-7 9, Jensen 2-7 0-0 J., mmons 6-14 2-2 15, Robinson 4-11 0-0' Conroy 2-6 2-2 6, Smith 0-2 0-0 0, Roy ..113 5-5 25, Rollins 1-3 0-0 2, Williams 2- 'r0-0 4. Totals 28-68 13-16 73. 4REGON STATE (14-9) iDeWitz 7-12 4-4 20, Cuic 1-5 0-0 2, iucas 9-12 5-5 23, Hurd 3-4 2-7 8, .0w ^ ^^ ^ ] ~ Ii -~ .LI~. On the AI R WAVES A-59,225. Stephens 7-11 0-1 17, Fontenet 0-1 0-0 0, Nash 5-7 6-7 18, Hooks 0-0 0-0 0, Jeffers 1-3 0-0 2. Totals 33-55 17-24 90. Halftime-Oregon State 44-37. 3-Point goals-Washington 4-27 (Roy 2-4, Jones 1-4, Simmons 1-7, Jensen 0-2, Smith 0-2, Robinson 0-4, Conroy 0-4), Oregon State 7-12 (Stephens 3-4, DeWitz 2-3, Nash 2-3, Cuic 0-1, Fontanel 0-1). Fouled out- None. Rebounds-Washington 38 (Jones 9), Oregon State 31 (Lucas 10). Assists- Washington 15 (Robinson 4), Oregon State 17 (Hurd 5). Total fouls-Washington 23, Oregon State 16. A-9,696. GOLF AT&T-Pebble Beach National Pro-Am Par Scores At Pebble Beach Resort Courses Pebble Beach, Calif. Purse: $5.3 million Pebble beach Golf Links, 6,737 yards Spyglass Hill Course, 6,862 yards Poppy Hills Course, 6,833 yards Par for all three courses: 72 Final Round P. Mickelson, $954,00062-67-67-73-269 -19 M. Weir, $572,40066-67-73-67-273 -15 G. Owen, $360,40067-69-67-72-275 -13 P. Goydos, $233,20067-68-70-71-276 -12 T. Clark, $233,20067-71-67-71-276 -12 D. Clarke, $184,17570-66-70-71-277 -11 A. Oberholser, $184,17571-6-69-71-277 -11 G McDowell, $164,30068-69-70-71--278 -10 D. Love III, $148,40065-72-71-71-279 -9 J. Sluman, $148,40071-66-69-73-279 -9 J. Kribel, $112,36072-70-68-70-280 -8 L. Donald, $112,36071-70-68-71-280 -8 C. Howell III, $112,36065-71-72-72-280 -8 R. Gamez, $112,36070-71-66-73-280 -8 B. Andrade, $112,36074-70-63-73-280 -8 J. Ogilvie, $67.31069-71-70-71-281 -7 C. Barlow, $67,31074-68-68-71-281 -7 K.J. Choi, $67,31067-75-68-71-281 -7 C. Warren, $67,31070-70-70-71-281 -7 A. Atwal, $67,31068-68-73-72-281 -7 T. Fischer, $67,31068-69-72-72-281 -7 D. Chopra, $67,31065-72-71-73-281 -7 A. Magee, $67,31067-68-70-76-281 -7 J.M. Oazabal, $67,31070-67-68-76-281 -7 K Sutherland, $67,31065-70-70-76-281 -7 S. O'Hair, $40,01571-74-65-72-282 -6 P. Sheehan, $40,01570-69-70-73-282 -6 T. Purdy, $40,01567-70-71-74-282 -6 J. Bohn. $40,01570-69-73-70- 282 -6 P. McGrdey.$30.151 12699-U,72.73-283 -6b S.GUJws,%$300,151.1716f69-74---283 -5 D.J. Trahan, $30,151.1172-70-69-72-283 -5 D. Pride, $30,151.1166-71-72-74-283 -5 M. Wilson, $30,151.1175-68-68-72-283 -5 D. Wilson, $30,151.1168-71-70-74-283 -5 K. Jones, $30,151.1171-65-73-74-283 -5 Dennis l Tim '" Mike DON'T BE FOOLED BY IMITATIONS! Ask for.. Solatube' by name. * Itented Tehnology Sets a Standard Others Can't Match-Our Professional Inloallers are Factory "Tainqd LeakprootiHeatproof Design Eliminates All Problems Increase 70% More Nalural Light Into Your Rooms- One Price Quoted No Hidden Charges' Compr~beosive Warranty Assures Peace of Mind SLicensed and Insured CGC057209 TOLL"i .. . The Miracle Skylight SOLAR-POWERED ENERGY EFFICIENT ATTIC FAN Full Solatube Warranty 2- Hour Professional Installation Hurricane Tested 8 Approved " Great for Bathrooms, Hallways, and Kitchens I t.'::. .:' - It R.S.Johnson,$30,151.1168-69-70-76--283 -6 T. Gillis, $30,151.1170-71-71-71-283 -5 C. RiLey, $22,26069-70-71-74- 284 -4 H. Mahan, $22,26065-73-72-74-284 -4 Jeff Hart, $22,26069-72-70-73-284 -4 J. Furyk, $22,26071-70-70-73- 284 -4 C. PeBlsson,$16,138507069-72-74-285 -3 M. Brooks, $16,138.5076-67-68-74-285 -3 O. Browne, $16,138.5072-65-72-76--285 -3 M. Tiziani, $16,138.5066-72-73-74-285 -3 M. Kuchar, $16,138.5070-73-69-73-285 -3 M. Gogel, $16,138.5073-69-70-73-285 -3 R. Mediate, $16,138.5076-70-66-73-285 -3' H. Haas, $16,138.5071-68-73-73-285 -3 M. O'Meara, $12,40269-72-69-76-286 -2 T. Herron, $12,40272-67-71-76-286 -2 F. Funk, $12,40270-69-71-76- 286 -2 R. Palmer, $12,40268-71-70-77-286 -2 S. Pate, $12,40268-72-72-74- 286 -2 P. Tomasulo, $12,40269-75-68-74-286 -2 T. Petrovic, $12,40271-70-71-74-286 -2 C. WI, $11,81968-72-70-77 287 -1 T. Scherrer, $11,81968-72-72-75-287 -1 J. Bolli, $11,60770-71-69-78- 288 E R. Damron, $11,60770-68-73-77-288 E J. Senden, $11,39576-66-69-79-290 +2 L Westwood, $11,39568-69-74-79-290 +2 L. Mize, $11,23672-73-67-82- 294 +6 Qualified, but did not advance due to size of field Tom Byrum, $10,547 74-68-71 213 Stephen Leaney, $1C,54772-68-73- 213 C.M. Anderson, $10,54770-68-75 213 Casey Martin, $10,54770-74-69 213 David Howell, $10,54773-68-72 213 David Edwards, $10,54770-72-71 213 Lee Janzen, $10,547 71-68-74 213 M. Gronberg, $10,54772-69-72 213 Gene Sauers, $10,54771-73-69 213 Neal Lancaster, $10,54770-73-70 213 Nick Watney, $10,54769-73-71 213 Bo Van Pelt, $10,547 71-69-73 213 FOOTBALL NFL Pro Bowl Stats NFC 0 10 14 3 27 AFC 14 14 0 10 38 First Quarter AFC-Harrison 62 pass from Manning (Vinatieri kick), 8:33. AFC-Ward 41 pass from Manning- (Vinatleri kick), 2:49. Second Quarter NFC-Westbrook 12 run (Akers kick), 12.09. AFC-Ward 39 kick return (Vinatler Kick), 12:01. AFC-Gates 12 pass from Manning (Vinatieri kick), 5:50. NFC-FG Akers 33, 1:41. Third Quarter NFC-Holt 27 pass from Vick (Akers First downs Total Net Yards Rushes-yards 120 Passing Punt Returns Kickoff Returns Interceptions Ret. Comp-Att-Int 22-1 NFC AFC 26 15 492 343 27-155 27- 337 223 0-0 1-7 5-1366-165 1-0 3-51 24-48-3 12- TODAY'S SPORTS BASKETBALL 7 p.m. (ESPN) College Basketball Pittsburgh at Syracuse. (Live) (CC) (SUN) Women's College Basketball North Carolina State at Miami. (Live) 9 p.m. (ESPN) College Basketball Kansas at Texas Tech. (Live) (CC) 12 a.m. (ESPN) College Basketball Air Force at New Mexico. (Live) (CC) HOCKEY. 7 p.m. (ESPN2) AHL Hockey All-Star Classic. From Manchester, N.H. (Live) a WINTER SPORTS 8 p.m. (OUTDOOR) Skiing USSA Freestyle Cup. Aerials and moguls from Lake Placid, N.Y. (Taped) ~:5~ I - *11= - Cu -= 0 S - CA - 5 Sacked-Yards Lost 2-16 2-13 Punts 1-59.0 2' 42.5 Fumbles-Lost 1-0 1-1 Penalties-Yards 3-28 2-10 Time of Possession 35:34-15-1-124, Vick 14-24-1-205, Horn 0-1-0-0. AFC, Manning 6-10-0-130, Brees 2-2-0-58, Brady 4-9-1-48,). BASEBALL American League BALTIMORE ORIOLES-Agreed to terms with RHP Jorge Julio on a one-year contract. National League MILWAUKEE BREWERS-Agreed to terms with RHP Ben Sheets on a one-year contract. WASHINGTON NATIONALS-Traded OF Jerry Owens to the Chicago White Sox for OF Alex Escobar. Designated IF Alejandro Machado for assignment. Named Barry Larkin special assistant. Golden Baseball League SAN DIEGO-Announced the team name will be Surf Dawgs. BASKETBALL ATLANTA HAWKS-Placed G Kenny Anderson on the injured list. Activated G-F Josh Smith from the injured list. LOS ANGELES CLIPPERS-Placed G Kerry Kitties on the injured list. Activated G Shaun Livingston from the injured list. LOS ANGELES LAKERS-Placed G Tony Bobbitt on the injured list. Activated G Kobe Bryant from the injured list. MINNESOTA TIMBERWOLVES-Fired Flip Saunders, coach, and announced he will be reassigned within the organization. Named Kevin McHale coach ,for the remainder of the season, In addition to his duties as vice president of basketball oper- ations. NEW YORK KNICKS-Placed G Jamison Brewer on the injured list. Activated G Moochie Norris. from the injured list. PHILADELPHIA 76ERS-Placed G Kedrick Brown on the injured list. Activated F Brian Skinner from the injured list. FOOTBALL National Football League CLEVELAND BROWNS-Named Maurice Carthon offensive coordinator and John Lott strength coach. Arena Football League SAN JOSE SABERCATS-Signed L Tony Plantin. Released DS Tremain Mack. -molw o-" 4 - amOM =0f m Q-0 0 -w Qum a -um am qo .o tm 4s MF* o- _ _o b MON A 4"D . - - am f - mp-wd a-a4d--_ - -~ - GE-. ., 0. -r * S clum Q - ~ -I -- __ ~ e - - HEALTHY MINDS: PARTNERING TO MEEr CHILDREN'S MENTAL HEALTH NEEDs Saturday, February 26 8:45 am 1:45 pm Withlachoochee Technical Institute si !I Keynote Speaker: Lisa Fox, Professor USF1 N H 41.Hernando B. Hills Blvd. Roosevelt Blvd., 6 Most Office Hwy. 486 Cftus Hills Oec0o Sales Good 2-12-05 thru 2-18-05 FRIS I JIM BEAM BV COASTAL _ U Citrus County Sheriff's Dept. , Celebrity Tip Night &pz13' Monday- February 21 5 to 8 p.m. Sheriff's officers will be your guest servers! All tips and donations go to the Citrus County Sheriff's Officeo e to fund the Sheriff's Safety for ! Summer Program. Pizza Hut 940 W. Main Street- Inv. Lt S726-4880 Dine-in only Let Sheriff Dawsy wait on you! 11 i0mcLE I Ii t'llicua tuum I tA,,j --j- : I tl.: k MEN% ~CA" F CITRUS COUNTY (FL) CHRONICLE 4B MONDA UAR 1-1, zuS PoRT Ito -map T 0 -- raw -..- b mo. qaI. 4=W - b ob- -W QN- . a a - d- 4l- am 'Gifta -.-low . a. a -. - -a - - s-~-~- a - a -a = a - - - a- -~ a-a -a- - a.- a a a a-.. a. - - ~- - a. * - a- a - a- -a - a a. - a- a. -a - -a ~ -amp-- l- a.m --0 40,a - ~41W a--- - - - * ~-a a- a. -a a a- a - --a a APBWo *D~ .*^T^*[sffo fiAr lOe i _.x /1pygfrigtedMateriaL :': " a. -a -a- --:-- Syndicated Gontentr ~~* -_ ._ ap- qba a b-a al ab lerom Commercial News Providers q- so419m 4 d~- Q a - aNR S "M 4 %=wa adba ea.- a - low 4* 4p 411 MWEN aN a._ -- -aw .Egp O.Ri- a a.- %. -MO at a. -~ so ammuamom 41 -aaa - a. 40 Nonim -m m 40 aaq 0 d -b 40 Ob on "p.- one- -0 10 w--d.mbM mo 'sOa n w- amp -aNO cw-M a.-ow s ao qp-ft 4OM %m a4D --bAm- - a ap4-a a a. -is a-. N 0.',o -a-a- a-a a -ow 40a0- 0 41 40.a- - a 4m --do & m. - _.db 4m 41b -b. 40 a a. .a mm 4b 41 ab- a4 aa a. .0a ftm 4110 a. -. a.-d C - -No v -o ajw -a a a. -0.- 46. 4- -. . a.a-0 41b a.. a. a. -a. aMow a a * -- * - a a - 0- - a - aw a. D -ado4b - Q.. .dw a- sof. a. . adb -4m- a -pm~ 40a. 401. . -1ow .- -4 -41- - -- - a - a - a- a a a S a a - - ~. a - a -a - a a - - -a a - a a a- -a - a -a a a.- - a a. a- -~ a- - a - - a a-~ -- ~ - -- a- a - - -a. - a a -a- - -~ - a..- m * -a a a-a p * -~. m a -a a.. A - a. -~ a a. a- a. -a - ~ a a - -a a. * - ---a - S . - a- a a- - a-- a. a - -- -a - a. S a a - -a b. m - a. * ~ aq -- . - S- 0 * S-POR-TS W nnnnlTARY 14 200 4 MONDA - t a, 9 e B A MONDAY, FEBRUARY 14, 2005 5B SPORTS CITrrrs Conrwryv FL) CHRONICLE U b wllU MID. - oC- - am 41 Uh. WA - qmmm No P-4FA 4jjjjdwmm Cm4m 4 quo U S 0 dm - amd 40 m m m -- quo-~ 4b4 f qum Uw4 40 mo U d -mmmmGNM 40 -Ow -oil e 410 0 U 441- Uw d-a AVailale fri 44 g -m ma OO mo f m uU u ft s-a 0 0400 OE& a 0w upM -t AU momm 40 go allte w MS A U M an 40 =own amU I: M- 0w am 4011 00 U-.b- wo -on 41 U C wem ME 0 4 0C b 111 1 Mdm w 00 UU -00 ow mo,- 4w r omo- -dam 44 40f doopMommm 4 - -m 41 40- 40 mmm 40 DdU db swo-m- om S 4m 4 a odo am4wsft 4m 4mw - -ow 4m 4 )pyn C 9 ted Material qm-m f di Um ft do 0 446U 4=0 In oUp 41 Uwb ob4m lb 4WOM."m ww ftm0 mqm U m w .* *~o Sm mndimdrca e&- ent )m commercial News Providers qnnC m a -ME 40 o 00 m0 4b el MN. Ssoo P Uf 4100 41 U 0 *ale doo lb40 -M IOWN da mp0 4 owa 40-anom Me mU o *v somo 0 me C U om mawadl ao equ ft4D I-oodm dim b a m k so-l b -ma-e a *qb d. 0 0 0 o 0 q U0 ismmm4U D-40Wie 400 m iwo qUw OW0 a- W 40AI IN U 0 1~ VIP M me m 0w NOIN a oc 4 dmo no U .p 4m Mo q 0do dns 4WAD INNW m 0 .4 U1ai Glonnew- Mo Udoe GN 0 MII UM =N Ob 400 Uwo 40 do pam 4 0_aid,"W_4b411,* uo Som, 0MMD dmo- 0 awomorOEM 0Sodos OWN S* 40on Ulm 4 Mm am 40 40 40 so am- w- 0C U Qw mb aUm= m qdh a U m 40 -- as -U emp U U U age "M as a ows a 4 0 w 4 4 Kobe% 400M UA 4 *M4 40 U -a am o*Ago 4 40 -mo 4s-o 4m eU 0 *w o f*m UC C4 0 40000a 40 a a b 4 b4ma sow 4b-Amom - Gom mw- qb Um 4w a& m - 40 4m -0 qf mU 100C4 0 0ftm * *f o 4000 0U - -- 0moef emomp-U p- *Ab Onob amslom = = a soq mam 0 4boo- 4boe Cp 0 Ume -mo-momp -041m -wm dd -t* U U m - mUq- -w "mC WAMft b 4 dw 4b 40 m o U U Uwoam40 ___________.* C - 4" A- oo mansefwo m qww0 U Uo*to ft ~ s qU Ut NBA SCOREBOARD mm Boston Philadelphia New Jersey Toronto New York Miami Washington Orlando Charlotte Atlanta Detroit Cleveland Chicago Indiana Milwaukee San Antonio Dallas Houston Memphis New Orleans Seattle Minnesota Denver Portland Utah Phoenix Sacramento L.A. Lakers L.A. Clippers Golden State EASTERN CONFERENCE Atlantic Division L Pct GB L10 26 .500 6-4 26 .490 6-4 29 .431 3% 7-3 31 .404 5 3-7 31 .392 5 3-7 Southeast Division L Pct GB L10 14 .736 9-1 20 .600 7 5-5 24 .529 11 5-5 38 .208 26 2-8 39 .204 27 2-8 Central Division L Pct GB L10 19 .612 7-3 20 .592 1 5-5 23 .511 5 6-4 26 .480 6 4-6 28 .417 9 6-4 WESTERN CONFERENCE Southwest Division W 26 25 22 21 20 W 39 30 27 10 10 W 30 29 24 24 20 W 40 32 30 30 10 W 35 25 23 20 17 W 39 33 25 23 14 Saturday's Games Philadelphia 112, Orlando 99 Detroit 107, Washington 86 Milwaukee 113, Atlanta 83 Sunday's Games Miami 96, San Antonio 92 Chicago 87, Minnesota 83 Cleveland 103, L.A. Lakers 89 Sacramento 104, Boston 100 Indiana 76, Memphis 73 Toronto 109, L.A. Clippers 106 New York 102, Charlotte 99 Orlando 97, New Orleans 94 New Jersey 94, Denver 79 Dallas at Seattle, 8 p.m. Portland at Houston, 8:30 p.m. Phoenix at Golden State, 9 p.m. Magic 97, Hornets 94 NEW ORLEANS (94) Lynch 1-2 0-0 2, Rogers 2-14 2-4 6, Brown 3-6 4-5 10, Smith 9-16 2-5 20, Dickau 10-16 1-2 28, Nachbar 2-6 0-0 5, Jacobsen 5-8 1-1 12, Andersen 1-2 4-5 6, Lampe 1-7 0-0 2, Vroman 1-3 1-2 3. Totals 35-80 15-24 94. ORLANDO (97) Hill 5-11 1-2 11, Howard 4-7 3-5 11, Cato 1-1 1-2 3, Christie 4-7 0-0 8, Francis 6-15 10-11 22, Garrity 4-6 2-2 12, Turkoglu 8-18 5-6 22, Battle 1-1 0-0 2, Stevenson 3-6 0-1 6, Nelson 0-1 0-0 0. Totals 36-73 22-29 97. New Orleans 26 23 2520- 94 Orlando 26 23 3216- 97 3-Point Goals-New Orleans 9-23 (Dickau 7-9, Jacobsen 1-2, Nachbar 1-3, Lynch Q-1, Lampe 0-1, Rogers 0-3, Smith 0-4), Orlando 3-10 (Garrity 2-3, Turkoglu 11 5, Stevenson 0-1, Francis 0-1). Fouled Out-Dickau. Rebounds-New Orleans 48 (Andersen, ..Rogers. 8),.. Qrlando 50 (Howara 10). Assists-New Orleans 22 (Dickau 6), Orlando 23 (Francis 10). Total Fouls-New Orleans 25, Orlando 18. A- 12,497. (17,248). Cavaliers 103, Lakers 89 L.A. LAKERS (89) Butler 5-15 0-0 10, Odom 6-12 6-6 19, Mihm 4-6 2-4 10, Atkins 4-12 2-2 11, Bryant 7-22 11-11 26, Grant 0-3 1-2 1, Jones 0-3 0-0 0, Walton 0-0 0-0 0, Cook 4- 5 0-0 10, Brown 0-2 0-0 0, Medvedenko 1- 1 0-0 2. Totals 31-81 22-25 89. CLEVELAND (103) James 8-20 9-10 25, Gooden 5-9 2-2 12, llgauskas 11-13 8-10 30, Mclnnis 5-9 1-1 11, Pavlovic 5-10 2-2 12, Harris 2-4 3-4 7, Traylor 3-6 0-0 6, Snow 0-3 0-0 0, Moiso 0- 0 0-0.0. Totals 39-74 25-29 103. L.A. Lakers 24 19 2719- 89 Cleveland 25 22 2927- 103 3-Point Goals-L.A. Lakers 5-18 (Cook 2-2, Odom 1-3, Bryant 1-4, Atkins 1-6, Brown 0-1, Jones 0-2), Cleveland 0-5 (Mclnnis 0-1, Pavlovic 0-2, Snow 0-2). Fouled Out-None. Rebounds-L.A. Lakers 43 (Odom 9), Cleveland 49 (llgauskas 11). Assists-L.A. Lakers 19 (Bryant 6), Cleveland 28 (James, Mclnnis 9). Total Fouls-L.A. Lakers 25, Cleveland 24. A-20,562. (20,562). Heat 96, Spurs 92 SAN ANTONIO (92) Bowen 3-8 0-0 9, Duncan 5-14 10(-12 20, Nesterovic 2-10 0-0 4, Parker 8-16 3-4 22, Ginobili 8-17 8-9 24, Massenburg 1-2 0-0 2, Barry 1-4 0-0 3, Horry 0-1 0-0 0, Udrih 1 - 2 0-0 3, Brown 2-5 0-0 5. Totals 31-79 21- 25 92. MIAMI (96) E.Jones 4-10 3-3 12, Haslem 1-2 0-0 2, O'Neal 8-12 11-19 27, D.Jones 4-6 0-0 11, Wade 12-26 4-4 28, Doleac 3-5 0-0 6, Anderson 2-2 1-2 5, Dooling 0-1 0-0 0, Butler 1-3 2-2 5. Totals 35-67 21-30 96. San Antonio 22 20 2822- 92 Miami 19 22 3025- 96 3-Point Goals-San Antonio 9-17 (Parker 3-5, Bowen 3-6, Brown 1-1, Udrih 1-1, Barry 1-2, Ginobili 0-2), Miami 5-9 (D.Jones 3-4, Butler 1-2, E.Jones 1-3). Fouled Out-None. Rebounds-San Antonio 44 (Nesterovic 11), Miami 49 (Haslem 11). Assists-San Antonio 18 (Brown 4), Miami 14 (Wade 6). Total Fouls-San Antonio 21, Miami 21. A- 20,258. (19,600). Bulls 87, Timberwolves 83 CHICAGO (87) Deng 4-11 0-0 8, Harrington 3-10 6-6 12, Curry 7-9 3-4 17, Hinrich 6-15 2-3 15, Duhon 4-8 1-1 10, Chandler 0-4 0-0 0, Gordon 7-18 5-6 21, Nocioni 2-5 0-0 4, Reiner 0-0 0-0 0, Piatkowski 0-2 0-0 0, A.Griffin 0-0 0-0 0. Totals 33-82 17-20 87. MINNESOTA (83) Sprewell 11-25 2-2 26, Gamett 11-22 1-1 23, Johnson 3-3 0-0 6, Hassell 3-10 0-0 6, Hudson 3-10 2-2 9, E.Griffin 0-8 0-2 0, Holberg 1-2 0-0 3, Olowokandi 2-6 0-0 4, Carter 2-4 2-2 6. Totals 36-90 7-9 83. Chicago 28 21 2018- 87 Minnesota 21 20 2220- 83 3-Point Goals-Chicago 4-14 (Gordon 2- 6, Hinrich 1-2, Duhon 1-3, Piatkowski 0-1, Deng 0-2), Minnesota 4-10 (Sprewell 2-3, Holberg 1-1, Hudson 1-2, Hassell 0-1, Carter 0-1, E.Griffin 0-2). Fouled Out- Olowokandl. Rebounds-Chicago 56 (Chandler 11), Minnesota 52 (Garnett 14). Assists-Chicago 20 (Hinrich, Duhon 5), Minnesota 21 (Hudson 7). Total Fouls- Chicago 14, Minnesota 20. A-19,420. (19,006). Nets 94, Nuggets 79 Home 18-9 14-9 13-11 17-10 13-12 Home 21-5 20-7 18-6 8-15 8-18 Home 18-7 19-5 15-10 13-12 14-10 Away Conf 8-17 17-15 11-17 17-11 9-18 15-14 4-21 10-18 7-19 11-18 Away Conf 18-9 27-4 10-1320-13 9-18 15-15 2-23 5125 2-21 6-26 Away Conf 12-1220-12 10-1517L12 9-13 13-13 11-1416-,4 6-18 15-14 11 A 1 1 40 11111 4 lei - -oe % 4 NO IE 40 *w04ab Kwm a- U - ab 4 m pam Nion tw am04P4 4Uon -,4D NKOO s 4b Kio P 4b 411 0 0 4110 0 40 m loomm ot q 0-0mn40040 -w mm Dobsoa .w ft- d 40 am amus 0qm 61 41mm0MN~t4 p- al p 410 4 dim 4-0om o 40 w OM404 - me - mm oq- 0 oo do* _w pm % ob wo W 0 - C1om 04f 4 o m mo .e 4 qw =%M 0 m .wo C04o 400 41 mp404 40 ftm mb-a---mom Ga-o ob m -m ft 4dU f N o U dp ol 40mo 4 t a- 40mum -4w am 0.4 ..No. AM -ow 0 L Pct Gi 12 .769 - 16 .667 21 .588 9Y 22 .577 10 41 .196 291h Northwes L Pct Gi 13 .729 - 27 .481 1. 28 .451 131/ 28 .417 1. 33 .340 1' Pacific L Pct Gi 12 .765 - 18 .647 24 .510 13 28 .451 1 36 .280 241/ > I I n B L10 Str Home Away Conf - 7-3 L-1 23-1 17-11 2q-8 6 6-4 W-1 17-9 15-7 17-10 Y 8-2 W-6 16-10 14-11 16-11 0 7-3 L-1 18-9 12-1318-13 Y2 3-7 L-1 7-15 3-26 7.i4 it Division B L10 Str Home Away Conf - 8-2 W-5 19-6 16-7 22-8 2 2-8 L-2 14-13 11-1418-13 Y2 6-4 L-1 15-9 8-19 9-20 5 5-5 L-2' 13-10 7-18 9-16 9 3-7 W-1 11-14 6-19 13-17 Division B L10 Str Home Away Cor f - 8-2 L-1 18-5 21-7 20-1 6 5-5 W-1 19-8 14-1018-13 3 3-7 L-2 17-10 8-14 16-16 6 4-6 L-5 17-10 6-18 13-20 Y2 2-8 L-1 10-15 4-21 7-2, Monday's Games New York at Philadelphia, 7 p.m. Portland at Charlotte, 7 p.m. Milwaukee at Detroit, 7:30 p.m. Washington at New Orleans, 8 p.m. Utah at Phoenix, 9 p.m. Tuesday's Games L.A. Clippers at Orlando, 7 p.m. Denver at Atlanta, 7:30 p.m. New Jersey at Minnesota, 8 p.m. Sacramento at Chicago, 8:30 p.m. Washington at Houston, 8:30 p.m. Utah at L.A. Lakers, 10:30 p.m. Dallas at Golden State, 10:30 p.m. DENVER (79) Anthony 5-12 8-9 18, Martin 6-14 1-2 3, Nene 2-3 2-2 6, Miller 2-6 1-2 5, Boykins 3- 10 1-2 7, Buckner 3-5 1-2 8, Elson 2-2 4-8 8, D.Johnson 0-2 0-0 0, Russell 1-2 0-o|2, White 4-8 2-3 12, Tskitishvili 0-1 0-0 0. Totals 28-65 20-30 79. NEW JERSEY (94) Carter 6-14 8-8 23, Collins 2-4 2-616, Krstic 4-6 1-1 9, Vaughn 4-7 2-2 10, Kidd 5-11 0-0 13, Best 5-7 0-0 10, Thomas 2-6 2-2 6, Smith 2-4 0-0 4, Mercer 6-100-0 12, Planinic 0-0 1-2 1, Campbell 0-0 0-0 0, Harvey 0-0 0-0 0. Totals 36-69 16-21 94. Denver 31 12 1620- 79 New Jersey 29 22 2617- 94 3-Point Goals-Denver 3-9 (White 2-3, Buckner 1-2, Anthony 0-1, D.Johnson 0-1, Boykins 0-2), New Jersey 6-16 (Kidd 3-5, Carter 3-6, Best 0-2, Thomas 0-3). Fouled Out-Best. Rebounds-Denver 41 (Anthony 8), New Jersey 44 (Krstic 9). Assists-Denver 17 (Anthony, Miller 5), New.,.arsey 34,1; (Kidd.-),.,,TtahFouls- Denver 21, New Jersey 23. A-16,125. (19,860). Kings 104, Celtics 100 SACRAMENTO (104) Webber 7-23 0-0 14, Stojakovic 0-2 0-0 0, Miller 7-11 6-6 20, Mobley 6-12 6-7 0, Bibby 10-20 3-5 27, Barnes 0-1 0-0 0, Songaila 3-4 0-0 6, Evans 5-9 4-4 17, House 0-2 0-0 0. Totals 38-84 19-22 104. BOSTON (100) Pierce 7-11 7-10 22, LaFrentz 9-16 3-3 25, Blount 7-13 2-4 16, Payton 6-14 0(-0 12, Allen 2-7 2-2 6, Davis 6-11 2-2 14, Banks 0-2 2-2 2, Perkins 1-3 1-2 3, Welsch 0-2 0-0 0, Gugliotta 0-0 0-0 0, West 0-010- 0 0. Totals 38-79 19-25 100. i Sacramento 26 28 2327- 104 Boston 29 25 2719--100 3-Point Goals-Sacramento 9-16 (Bitlby 4-5, Evans 3-4, Mobley 2-5, Stojakovic Or1, House 0-1), Boston 5-14 (LaFrentz 4-8, Pierce 1-2, Welsch 0-1, Davis 0-1, Payton 0-2). Fouled Out-None. Rebounds- Sacramento 49 (Webber 17), Boston 47 (LaFrentz 9). Assists-Sacramento 29 (Webber 12), Boston 23 (Payton 9). Tctal Fouls-Sacramento 21, Boston 40. Technicals-Boston Defensive Three Second, Payton. A-14,252. (18,624). Pacers 76, Grizzlies 73 MEMPHIS (73) Battier 1-7 0-0 2, Swift 3-10 3-4 9, L.Wright 7-14 4-4 18, D.Jones 0-2 0-0 0, Watson 7-13 1-1 16, Cardinal 3-8 1-219, M.Miller 3-9 0-0 8, Burks 0-1 0-0 0, Humphrey 0-3 0-0 0, Wells 2-8 7-10 11. Totals 26-75 16-21 73. INDIANA (76) Jackson 6-16 5-6 19, O'Neal 4-15 3-4 1, Foster 3-8 1-4 7, R.Miller 2-5 0-0 14, Johnson 3-11 0-0 8, Croshere 2-4 0-0 4, F.Jones 4-9 6-7 15, Gill 3-6 0-0 8, Pollard 0-0 0-0 0. Totals 27-74 15-21 76. Memphis 16 23 1321- 73 Indiana 21 23 2012- 76 3-Point Goals-Memphis 5-18 (Cardinal 2-4, M.Miller 2-5, Watson 1-4, D.Jones 0L1, Wells 0-1, Battier 0-3), Indiana 7-16 (Gill 2- 2, Johnson 2-5, Jackson 2-5, F.Jones 1L3, R.Miller 0-1). Fouled Out-Cardinal. Rebounds-Memphis 49 (L.Wright 113), Indiana 58 (Foster 17). Assists-Memphis 13 (Watson 3), Indiana 13 (R.Miller, O'Neal 3). Total Fouls-Memphis 16, Indiana J9. A-17,290. (18,345). , Raptors 109, Clippers 106 L.A. CLIPPERS (106) I Simmons 10-15 0-0 21, Brand 10-19 6-8 26, Kaman 3-10 2-3 8, Ross 1-4 1-2 3, Brunson 1-6 0-0 2, Maggette 5-14 6-7 17, Rebraca 5-9 4-4 14, Livingston 4-5 2-2 10, Moore 0-1 0-0 0, Wilcox 1-2 3-4 5. Totpis 40-85 24-30 106. TORONTO (109) Rose 3-5 1-1 8, Bosh 8-18 10-11 6, Araujo 1-1 2-2 4, Peterson 3-9 1-2 9, Alston 7-16 2-2 18, Woods 0-0 0-0 0, E.Williams 1-5 1-1 3, Murray 3-6 1-2 7, Palacio 6-11 1-2 13, Marshall 5-11 2-2 7, Bonner 1-2 2-2 4, Aa.Williams 0-1 0-0iO. Totals 38-85 23-27 109. L.A. Clippers 22 27.3027- 1 Toronto 33 30 1234- 19 3-Point Goals-L.A. Clippers 2-7 (Maggette 1-2, Simmons 1-3, Brunson 0- 2), Toronto 10-21 (Marshall 5-8, Peterson 2-4, Alston 2-5, Rose 1-3, E.Williams 0-1). Fouled Out-None. Rebounds-L A. Clippers 54 (Brand 11), Toronto 48 (Bcsh 10). Assists-L.A. Clippers 25 (Livingstn 9), Toronto 28 (Alston 8). Total Fouls-L A. Clippers 23, Toronto 20. Technicals-L A. Clippers coach Dunleavy. A-15,721. (19,800). Contact Us | Permissions | Preferences | Technical Aspects | Statistics | Internal | Privacy Policy © 2004 - 2010 University of Florida George A. Smathers Libraries.All rights reserved. Acceptable Use, Copyright, and Disclaimer Statement Last updated October 10, 2010 - - mvs | https://ufdc.ufl.edu/UF00028315/00045 | CC-MAIN-2021-17 | refinedweb | 20,284 | 75.1 |
Tutorial 1e: Connecting neurons¶
In the previous parts of this tutorial, the neurons are
still all unconnected. We add in connections here. The
model we use is that when neuron i is connected to
neuron j and neuron i fires a spike, then the membrane
potential of neuron j is instantaneously increased by
a value
psp. We start as before:
from brian import * tau = 20 * msecond # membrane time constant Vt = -50 * mvolt # spike threshold Vr = -60 * mvolt # reset value El = -49 * mvolt # resting potential (same as the reset)
Now we include a new parameter, the PSP size:
psp = 0.5 * mvolt # postsynaptic potential size
And continue as before:
G = NeuronGroup(N=40, model='dV/dt = -(V-El)/tau : volt', threshold=Vt, reset=Vr)
Connections¶
We now proceed to connect these neurons. Firstly, we declare
that there is a connection from neurons in
G to neurons in
G.
For the moment, this is just something that is necessary to
do, the reason for doing it this way will become clear in the
next tutorial.
C = Connection(G, G)
Now the interesting part, we make these neurons be randomly
connected with probability 0.1 and weight
psp. Each neuron
i in
G will be connected to each neuron j in
G
with probability 0.1. The weight of the connection is the
amount that is added to the membrane potential of the target
neuron when the source neuron fires a spike.
C.connect_random(sparseness=0.1, weight=psp)
These two previous lines could be done in one line:
C = Connection(G,G,sparseness=0.1,weight=psp)
Now we continue as before:
M = SpikeMonitor(G) G.V = Vr + rand(40) * (Vt - Vr) run(1 * second) print M.nspikes
You can see that the number of spikes has jumped from around 800-850 to around 1000-1200. In the next part of the tutorial, we’ll look at a way to plot the output of the network.
Exercise¶
Try varying the parameter
psp and see what happens. How large
can you make the number of spikes output by the network? Why?
Solution¶
The logically maximum number of firings is 400,000 = 40 * 1000 / 0.1, the number of neurons in the network * the time it runs for / the integration step size (you cannot have more than one spike per step).
In fact, the number of firings is bounded above by 200,000. The reason for this is that the network updates in the following way:
- Integration step
- Find neurons above threshold
- Propagate spikes
- Reset neurons which spiked
You can see then that if neuron i has spiked at time t, then it
will not spike at time t+dt, even if it receives spikes from
another neuron. Those spikes it receives will be added at step
3 at time t, then reset to
Vr at step 4 of time t, then the
thresholding function at time t+dt is applied at step 2, before
it has received any subsequent inputs. So the most a neuron
can spike is every other time step. | https://brian.readthedocs.io/en/1.4.3/tutorial_1e_connecting_neurons.html | CC-MAIN-2019-30 | refinedweb | 509 | 68.4 |
Details
Join devRant
Pipeless API
From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple APILearn More
- God dam all the memes that keep coming up on devRant.
Can we get support for custom filters?
Hide when post.text.length < 50 && post.img is not null3
- I've just read the article about CloudPet, and honestly I am disgusted.
I don't even know what to say beyond that. I call out my team on basic stuff like forgetting to escape, but this?2
- Code comments are good and all, but there's a time and a place for them. They're more or less an opinionated free-form version of what code is doing.
In a library, they're good for documentation. However in a platform, it makes less sense. Especially one which is changing at quite a fast rate (though it has matured in recent months).
Dont get me wrong, we aren't doing wades of horrible, unintelligible code. We need to be sure of what happens when we call a function, so we make sure the signature is always correct.
def do_good_things(puppies): # "good things" is opinionated. Say what you're doing
"""give treats to puppies""" # doc string is wrong
pet(puppies)5
- Latest promoted thread on XDA to make the list:
"how to disable forced encryption".
This is from a place that tries to be innovative. I'm half expecting a thread get promoted with the title "how to give everyone your passwords/identity/credit cards".
-
-
- I gave a 2 day estimate to the managers once, and a 10 minute estimate to my peers.
The server side code went smoothly. Couple of minutes, done.
Then I remembered the front end was written under a tight deadline....
Imagine controlling state with jquery, except the state is in html slightly differently to hints in javascript, and there are 7 points of state control, and they have to be triggered in the right order because a few of them depend on everything else, and if you change the wrong line the computer starts pouring smoke everywhere and WHY THE HELL DID I NOT REWRITE IT!1
-'ve always managed the different versions of python manually on my machine, and set up virtual environments off of them.
Now I've found pyenv, it's so simple now.
Can't wait to see what plugins are available for it2
- Sometimes I'll block a code submission with the words security vulnerability", then go have a 10 minute break to see if the others can spot it on their own.
-
-
- I'm kind of surprised people haven't tried using devRant as a job board yet. There's a lot of raw talent here, both seniors, and juniors experimenting with everything.
May as well start. We have ping pong
- Watching normal people use a computer is incredibly painful.
* slow typing
* slow mouse movements
* mouse is used for everything
* instead of hitting the back button, they'll load up a website and go through 6 pages again.
* no shortcuts!
Someone lost their tabs today (Windows crashed), so I said "press ctrl + shift + T". They were so amazed that keys could do something so advanced.
Dhcosncowhtoehwurt hrnxkxxhry he.
Honestly, if people learned how to use keyboards to their full potential, they could shave off 1-2 hours of their normal work PER DAY!23
-.
- To me, programming, designing systems, reviewing work, it's all easy.
Perhaps that's because of the challenge I've set myself. To find a like minded that I can get to know
- Today I spent a long hour working out how to assign a lead to a queue in apex (salesforce).
You can't just assign it, you need go make a setup entry in the database first to mark the group as a queue.
But wait, you can't actually do that in the same context as making the group, so you have to make a subprocess, and mark it as a queue in that.
None of this is documented.
Screw you, SalesForce.2
-
- Our developer who normally deals with all the staff enquiries is going to be working remotely from now on.
I'm not complaining or anything, he's a great guy. But being able to focus on our projects is gonna go through the floor.
It effectively makes us 2 men down in a 3 man
-
- A lot of the work I do is actually done from an 8" tablet.
The issue is, the last decent one was released nearly 2 years ago.
Hoping for something coming out at CES!
- I dislike holidays since I often get bored. Tempted to get a train back home and go to work, just for something to do1
- When you want to move your site off of jQuery, but all the dependencies still use jQuery.
Also screw those services that write their client code with jQuery. Screw you all!2
-
- When I run tests, I like to enable the debug logging. All the SQL queries and template tracing just flies by. Freaks the others out. | https://devrant.com/users/cybojenix | CC-MAIN-2021-25 | refinedweb | 855 | 73.37 |
Write a program that calculates area/volume of various shapes.
1st call function w/ prototype: void showMenu(int &); which displays menu
this is what the output should be:
this is what i have so far... yeah, fairly lost
// This program is designed to allow the user to calculate the area and volume of various shapes.
#include <iostream>
#include <iomanip>
using namespace std;
void showMenu (int &);
double area (double length, double width);
double area (double radius);
double volume (double length, double width, double height);
double volume (double radius);
int main()
{
int selection;
double length;
double width;
double height;
double radius;
cout << fixed << showpoint << setprecision(2);
cout << "1. Calculate the area of a rectangle" << endl;
cout << "2. Calculate the area of a circle" << endl;
cout << "3. Calculate the volume of a box" << endl;
cout << "4. Calculate the volume of a sphere" << endl;
cout << "5. Quit" << endl;
cin >> "Please select 1-5: " >> selection;
cout << endl; | https://cboard.cprogramming.com/cplusplus-programming/155104-ahh-need-massive-help-cplusplus-program-dealing-calculation-volume-area.html | CC-MAIN-2017-13 | refinedweb | 152 | 63.29 |
Recently we got these really cool RGB bulbs that are controlled by an IR remote control. You plug them into your house hold light bulb socket and presto, you can set the mood of any room! They were a hit with just about.
Hardware and Assembly:
If you want to follow along with this tutorial, you will need:
RBG 3W or 10W Module
Pro Micro 16 Mhz/5V
IR Reciever
IR LED
3 AA Battery Back (3W Version Only)
Breadboard
Jumper Wires
We used a Pro Micro because of its small size, but you can use any microcontroller you have laying around. We will be using an Arduino IR library in this tutorial so using an Arduino will make it easy to follow this tutorial.
Above you can see the two different size LED bulb kits that we have. We have a 3WV instead of 5V, so it will not work our 3 AA battery holder.
Lets start putting it all together. Start by adding some solder to one of the four pads. We will solder one pad down to hold the LED bulb in place before we solder the other three legs..
Now you can solder the other three leads of the bulb, and you're done mounting the bulb. You can see the finished product above. Time to add a battery holder to power the bulb.
Always tin the leads of the wires so it is easier to solder to the pad.
Solder the red wire to the lead marked VCC.
Solder the black wire to the lead marked GND.
Go ahead and put 3 AA batteries in your holder. The bulb should come on and automatically play a demo. The bulb shines bright while turned on!
Wiring:
Now that we have our bulb working, we can move on to controlling it.
The diagram above shows how to wire up the IR receiver and transmitter LED to the Pro Micro.
Above you can see what your completed breadboard should look like when you're done.
Recieve Code:
The module comes with a remote, which".
#include <IRremote.h> const int RECV_PIN = 2;.print(results.value, HEX); Serial.print(" Bits:"); Serial.println(results.bits,DEC); irrecv.resume(); // Receive the next value } }.
Next you can point your remote to the IR reciever and press any button on the remote. Above we pressed the Red, Green, Blue, Yellow, On, and Off in that order. Each button press.
Time to try sending these codes ourself and control the IR module! For this we will use the IRsendDemo, and add our codes to control the LED module.
#include <IRremote.h> IRsend irsend; void setup() { Serial.begin(9600); } void loop() { irsend.sendNEC(0xFFE01F,32); // Turn on the Bulb delay(50); // Wait 1/10 of a Second irsend.sendNEC(0xFF906F,32); // Make it Red delay(50); // Wait 1/20 of a Second irsend.sendNEC(0xFF10EF,32); // Make it Green delay(50); // Wait 1/20 of a Second irsend.sendNEC(0xFF50AF,32); // Make it Blue delay(50); // Wait 1/20 of a Second irsend.sendNEC(0xFF8877,32); // Make it Yellow delay(50); // Wait 1/20 of a Second irsend.sendNEC(0xFF609F,32); // Turn the LED Off delay(2000); // Wait 2 Second }
In the above example, we have added the codes that we found using the IR recieve demo. We are simply playing them back one by one every two seconds. The library will automatically control Pin! | http://www.jayconsystems.com/tutorials/IR_Controlled_RGB_Module | CC-MAIN-2016-50 | refinedweb | 569 | 75.71 |
04-11-2017 11:27 AM
Hi,
I came across one dataset which consist of
state region1 region2 region3
abc 20 30 50
def 40 30 30
ghi 25 35 40
xyz 30 45 20
i need to find out the sum of each region and which region is largest among the 3 regions?
Can some one help me ?
04-11-2017 11:35 AM
Use proc means
data have; input state $ region1 region2 region3; datalines; abc 20 30 50 def 40 30 30 ghi 25 35 40 xyz 30 45 20 ; proc means data = have sum; var region1-region3; run;
04-12-2017 02:20 AM
Hi dray,
Thanks for your reply, but i am looking for result into new dataset with the variable state and only the region with larger .
will it can be done in data step itself?
04-12-2017 03:46 AM
So you want your variable state and the region variable which has the highest sum?
In the example posted, both region 2 and region 3 has sum equal to 140, then what?
04-13-2017 03:14 AM
Hi dray,
Yes, i want the result with the variable state and the region variable which has the highest sum.
Apologies , observations was randomly given by me .And unfortunate region 2 and 3 sum become equal. you can change any one number either in region 2 and region 3.
Is this possible to do in the datastep itself?
04-11-2017 11:47 AM
proc means data=DSN n min max sum; run;
You could generate summarization table for above dataset,
It would give you the sum of each region as well as largest among them | https://communities.sas.com/t5/Base-SAS-Programming/sum-of-column/td-p/349165?nobounce | CC-MAIN-2017-47 | refinedweb | 281 | 74.73 |
Explain React Native?
React Native is an open-source JavaScript framework introduced by Facebook. It is used for developing a real, native mobile application for iOS and Android platforms. It uses only JavaScript to build a mobile app. It is like React, which uses native components rather than using web components as building blocks. It is cross-platform, which allows you to write code once and can run on any platform.
React Native application is based on React, a JavaScript library developed by Facebook and XML-Esque markup (JSX) for creating the user interface. It targets the mobile platform rather than the browser. It saves your development time as it allows you to build apps by using a single language JavaScript for both Android and iOS platforms.
What are the advantages of React Native?
React Native provides many advantages for building mobile applications. Some of the essential benefits of using React Native are given below:
-.
What are the disadvantages of React Native?
Some of the big disadvantages of React Native for building mobile applications are given below:
-.
What is JSX?
JSX is a syntax notation for JavaScript XML(XML-like syntax extension to ECMAScript). It stands for JavaScript XML. It provides expressiveness of JavaScript along with HTML like template syntax. For example, the below text inside h1 tag return as javascript function to the render function.
render(){ return( <div> <h1> Welcome to React world!!</h1> </div> ); }
What are components?
Components are the building blocks of any React app and a typical React app will have many of these. Simply put, a component is a JavaScript class or function that optionally accepts inputs i.e. properties(props) and returns a React element that describes how a section of the UI (User Interface) should appear.
const Greeting = () => <h1>Hello World today!</h1>;
This is a functional component (called Greeting) written using ES6’s arrow function syntax that takes no props and returns an H1 tag with the text “Hello World today!”
How to install React Native App in ios?
To install React Native, we will have to follow these steps:
- Start with installing node and watchman
- Then, install React native CLI with npm
- Install Xcode and its Command-line tools
- Create a React Native project by using the following command
- React-native init MyNewProject
- cd MyNewProject
- react-native run-ios
List the essential components of React Native.
React native have the following core components: Basic UI components in React Native
- View: View in React Native is equivalent to tag in HTML. It is a content area where the actual UI components (Text, Image, TextInput, etc) would be displayed. View is used to organize the content in a good manner
- Text: Text is a very basic built-in Component which displays text in the Application
- Image: A component for displaying images
- TextInput: This component is used to take user input into the App
- ScrollView: It is a scrolling container that can host multiple components and views that can be scrolled
- StyleSheet: Similar to CSS stylesheets, Provides an abstraction layer similar to CSS stylesheet.
User Interface Components in React Native:
- Button: A basic button component for handling touches that should render nicely on any platform
- Switch: Renders a Boolean input
- Slider: A component used to select a single value from a range of values
- Picker: Renders the native picker component on iOS and Android
ListView Components in React Native:
- FlatList: A component for rendering performant scrollable lists
- SectionList: Like FlatList, but for sectioned lists
Android Specific components in React Native
- DatePickerAndroid: Opens the standard Android date picker dialog
- DrawerLayoutAndroid: Renders a DrawerLayout on Android
- BackHandler: Detect hardware button presses for back navigation
- ProgressBarAndroid: Renders a ProgressBar on Android
- ToastAndroid: Create an Android Toast alert
- ViewPagerAndroid: Container that allows flipping left and right between child views.
How many threads run in React Native?
The React Native app contains the following thread:
-.
What are props in React Native?.
Example
Here, we have created a Heading component, with a message prop. The parent class App sends the prop to the child component Heading.
// Parent Component export default class App extends Component { render () { return ( <View style={{alignItems: 'center' > <Heading message={'Custom Heading for Parent class?}/> </View> ) } } // Child component export default class Heading extends Component { render () { return ( <View style={{alignItems: 'center' > <Text>{this.props.message}</Text> </View> ) } } const styles = StyleSheet.create({ welcome: { fontSize: 30, } }); Heading.propTypes = { message: PropTypes.string } Heading.defaultProps = { message: 'Heading One' }
What are State in React Native?().
Example
Here, we are going to create a Text component with state data. The content of the Text component will be updated whenever we click on it. The event onPress calls the setState function, which updates the state with > ); } }
How to run react native app on Android?
o run React Native in Android, we have to follow these:
-
List Step to Create and start a React Native App?
The following steps are necessary to create and start a React Native app:
Step-1: Install Node.js
Step-2: Install react-native environments by using the following command.
$ npm install -g create-react-native-app
Step-3: Create a project by using the following command.
$ create-react-native-app MyProject
Step-4: Next, navigate in your project by using the following command.
$ cd MyProject
Step-5: Now, run the following command to start the project.
$ npm start
Are all React components usable in React Native?
Web React components use DOM elements to display (ex. div, h1, table, etc.), but React Native does not support these. We will need to find libraries/components made specifically for React Native. But today React is focusing on components that can be shared between the web version of React and React Native. This concept has been formalized since React v0.14.
How Virtual DOM works in React Native?..
Do we use the same code base for Android and iOS?
Yes, we can use the same codebase for Android and iOS, and React takes care of all the native component translations. For example, a React Native ScrollView use ScrollView on Android and UiScrollView on iOS.
Can we combine native iOS or Android code in React Native?
Yes, we can combine the native iOS or Android code with React Native. It can combine the components written in Objective-C, Java, and Shift.
When would you use ScrollView over FlatList or vice-versa?
- Do you need to render a list of similar items from an array or the data is very big? Use FlatList
- Do you need to render generic content in a scrollable container and the data is small? Use ScrollView
How do you dismiss the keyboard in react native?
Use built-in Keyboard Module:
import { Keyboard } from ‘react-native’;
Keyboard.dismiss();
What is AppRegistry? Why is it required early in “require” sequence?
AppRegistry is the JS entry point to running all React Native apps. App root components should register themselves with AppRegistry.registerComponent, then the native system can load the bundle for the app and then actually run the app when it’s ready by invoking AppRegistry.runApplication.
import { Text, AppRegistry } from 'react-native'; const App = (props) => ( <View> <Text>App1</Text> </View> ); AppRegistry.registerComponent('Appname', () => App);
To “stop” an application when a view should be destroyed, call AppRegistry.unmountApplicationComponentAtRootTag with the tag that was passed into runApplication. These should always be used as a pair.
AppRegistry should be required early in the require sequence to make sure the JS execution environment is setup before other modules are required.
Explain the use of Flexbox in React Native?
Flexbox is designed to provide a consistent layout on different screen sizes. It offers three main properties:
- flexDirection
- justifyContent
- alignItems
Differentiate between Real DOM and Virtual DOM.
What is the difference between React and React Native?
The essential differences between React and React Native are:
- React is a JavaScript library, whereas React Native is a JavaScript framework based on React.
- Tags can be used differently in both platforms.
- React is used for developing UI and Web applications, whereas React Native can be used to create cross-platform mobile apps.
Which language is used in React Native?
Javascript with ES6 syntax support. If you are from android or ios development background, it’s an advantage
What are the differences between Class and Functional Component?
The essential differences between the class component and functional component are:
Syntax: The declaration of both components is different. A functional component takes props, and returns React element, whereas the class components require to extend from React.
//Functional Component function WelcomeMessage(props) { return <h1>Welcome to the , {props.name}</h1>; } //Class Component class MyComponent extends React.Component { render() { return ( <div>This is main component.</div> ); } }
State: The class component has a state while the functional component is stateless.
Lifecycle: The class component has a lifecycle, while the functional component does not have a lifecycle.
How React Native handle different screen sizes?
React Native provides many ways to handle screen sizes. Some of them are given below:
- Flexbox: It is used to provide a consistent layout on different screen sizes. It has three main properties:
- flexDirection
- justifyContent
- alignItems
- Pixel Ratio: It is used to get access to the device pixel density by using the PixelRatio class. We will get a higher resolution image if we are on a high pixel density device.
- Dimensions: It is used to handle different screen sizes and style the page precisely. It needs to write the code only once for working on any device.
- AspectRatio: It is used to set the height or vice versa. The aspectRatio is present only in React-Native, not a CSS standard.
- ScrollView: It is a scrolling container which contains multiple components and view. The scrollable items can be scroll both vertically and horizontally.
When would you prefer a class component over functional components?
We prefer class component when the component has a state and lifecycle; otherwise, the functional component should be used.
How do you re-render a FlatList?
By using extraData property on the FlatList component.
<FlatList data={data } style={FlatListstyles} extraData={this.state} renderItem={this._renderItem} />
By passing extraData={this.state} to FlatList we make sure FlatList will re-render itself when the state.selected changes. Without setting this prop, FlatList would not know it needs to re-render any items because it is also a PureComponent and the prop comparison will not show any changes.
What is “autolinking” in react-native?
React Native libraries often come with platform-specific (native) code. Autolinking is a mechanism that allows your project to discover and use this code.
Autolinking is a replacement for react-native link. If you have been using React Native before version 0.60, please unlink native dependencies if you have any from a previous install.
Each platform defines its own platforms configuration. It instructs the CLI on how to find information about native dependencies. This information is exposed through the config command in a JSON format. It’s then used by the scripts run by the platform’s build tools. Each script applies the logic to link native dependencies specific to its platform.
What is AsyncStorage and how do you use it?
- AsyncStorage is a simple, asynchronous key-value pair used in React Native applications.
- It is a local only storage.
- It comes in two parts: core and storage backend.
- Core is a consumer of the storage, provides you a unified API to save and read data.
- Storage backend implements an interface that core API understands and uses. Its functionality depends on storage itself. an increase in the application’s performance.
Differentiate between the React component and the React element.
React Element – It is a simple object that describes a DOM node and its attributes or properties you can say. It is an immutable description object and you can not apply any methods on it.Eg –
<button class=”blue”></button>
React Component – It is a function or class that accepts an input and returns a React element. It has to keep references to its DOM nodes and to the instances of the child components.
const SignIn = () => ( <div> <p>Sign In</p> <button>Continue</button> <button color='blue'>Cancel</button> </div>);
What is InteractionManager and what is its importance?
InteractionManager is a native module in React native that defers the execution of a function until an “interaction” finished.
Importance: React Native has JavaScript UI thread as the only thread for making UI updates that can be overloaded and drop frames. In that case, InteractionManager helps by ensuring that the function is only executed after the animations occurred.
Describe HOC.
A higher-order component (HOC) is an advanced technique in React for reusing component logic. HOCs are not part of the React API, per se. They are a pattern that emerges from React’s compositional nature.
How is data loaded on the server by React Native?
React Native uses Fetch API to fetched data for networking needs.
What is meant by Gesture Responder System?
It is an internal system of React Native, which is responsible for managing the lifecycle of gestures in the system. React Native provides several different types of gestures to the users, such as tapping, sliding, swiping, and zooming. The responder system negotiates these touch interactions. Usually, it is used with Animated API. Also, it is advised that they never create irreversible gestures.
How to use Axios in the React Native?
Axios is a popular library for making HTTP requests from the browser. It allows us to make GET, POST, PUT, and DELETE requests from the browser. Therefore, React Native uses Axios to make requests to an API, return data from the API, and then perform actions with that data in our React Native app. We can use Axios by adding the Axios plugin to our project using the following command.
# Yarn $ yarn add axios # npm $ npm install axios --save
Axios have several features, which are listed below:
- It makes XMLHttpRequests from the browser.
- It makes Http requests from the React Native framework.
- It supports most of the React Native API.
- It offers a client-side feature that protects the application from XSRF.
- It automatically transforms response and request data with the browser.
What are refs in React? When to use Refs?
Refs are escape hatch that provides a direct way to access DOM nodes or React elements created in the render method. Refs get in use when:
- To manage focus, text selection, or media playback
- To trigger imperative animations
- To integrate with third-party DOM libraries
What are animations in React Native?
The animation is a method in which images are manipulated to appear as moving objects. React Native animations allows you to add extra effects, which provide great user experience in the app. We can use it with React Native API, Animated.parallel, Animated.decay, and Animated.stagger.
React Native has two types of animation, which are given below.
- Animated: This API is used to control specific values. It has a start and stops methods for controlling the time-based animation execution.
- LayoutAnimated: This API is used to animate the global layout transactions.
What do you understand from “In React, everything is a component.”
Components are the building blocks of a React application’s UI. These components split up the entire UI into small independent and reusable pieces. Then it renders each of these components independent of each other without affecting the rest of the UI.. | https://blog.codehunger.in/react-native-interview-questions/ | CC-MAIN-2021-43 | refinedweb | 2,556 | 57.77 |
Hi All,
I have a requirement where I need to read a file with so many carriage return line feeds.
Attached is the file I am reading.
I have written a sample application to read the file and and remove these new line feeds but when I execute it, I see the line feed.
import java.io.*; public class Main { public static void main(String[] args) throws IOException{ BufferedReader br = null; PrintWriter sb = null; try{ br = new BufferedReader(new FileReader("C:/Users/rejalu/Downloads/ATG/SubmittedOrders/2010/testfile.txt")); sb = new PrintWriter(new FileWriter("C:/Users/rejalu/Downloads/ATG/SubmittedOrders/2010/testfile3.txt")); String I; while((I = br.readLine())!= null){ sb.println(I.replaceAll("[\\r|\\n]+", " ")); } } finally { if (br!=null) { br.close(); } if (sb != null){ sb.close(); } } } }
Is there away to achieve this in attached output file?
This is just one record, but I have several records like these.
Thanks for your help.
Ron | http://www.javaprogrammingforums.com/whats-wrong-my-code/38053-removing-line-feeds-carriage-returns.html | CC-MAIN-2015-22 | refinedweb | 154 | 60.21 |
Dear all,
I was trying to change all figure fonts to Arial, or Times, but without any luck.
below is the section I modify the property.
···
from numpy import *
from matplotlib import pyplot as plt
import pylab
params = {‘font.size’ : 16,
‘axes.labelsize’ : 16,
‘font.style’ : ‘normal’,
'font.family' : 'sans-serif', 'font.sans-serif' : 'Arial'
}
pylab.rcParams.update(params)
The font.family line seems to be working ( I get different fonts when I specify ‘sans-serif’ or ‘monospace’), but changing font.sans-serif has no effect at all. If the resulting figure is not changing, does it mean the font used is always the default in sans-serif family(Bitstream Vera Sans)? I wonder why matplotlib doesn’t use more common fonts as default, like Arial or Times which are accepted by most journals…
Thank you!
–
Yi (Miranda) Shang
PhD candidate
Graduate Program in Molecular and Cellular Biology
Stony Brook University | https://discourse.matplotlib.org/t/change-font-name-under-certain-font-family/14199 | CC-MAIN-2019-51 | refinedweb | 151 | 61.73 |
If you regard writing tests as a lame checkbox task, nothing could be farther from the truth. Done correctly, tests are one of your application’s most valuable assets.
The Django framework in particular offers your team the opportunity to create an efficient testing practice, based on the Python standard library
unittest. Proper tests in Django are fast to write, faster to run, and can offer you a seamless continuous integration solution for taking the pulse of your developing application.
With comprehensive tests, developers have higher confidence when pushing changes. I’ve seen firsthand in my own teams that good tests can boost development velocity as a direct result of a better developer experience.
In this article, I’ll share my own experiences in building useful tests for Django applications, from the basics to the best possible execution. If you're using Django or building with it in your organization, you might like to read my Django series on Victoria.dev.
What to test
Tests are extremely important. Far beyond simply letting you know if a function works, tests can form the basis of your team’s understanding of how your application is intended to work.
Here’s the main goal: if you hit your head and forgot everything about how your application works tomorrow, you should be able to regain most of your understanding by reading and running the tests you write today.
Here are some questions that may be helpful to ask as you decide what to test:
- What is our customer supposed to be able to do?
- What is our customer not supposed to be able to do?
- What should this method, view, or logical flow achieve?
- When, how, or where is this feature supposed to execute?
Tests that make sense for your application can help build developer confidence. With these sensible safeguards in place, developers make improvements more readily, and feel confident introducing innovative solutions to product needs. The result is an application that comes together faster, and features that are shipped often and with confidence.
Where to put tests
If you only have a few tests, you may organize your test files similarly to Django’s default app template by putting them all in a file called
tests.py. This straightforward approach is best for smaller applications.
As your application grows, you may like to split your tests into different files, or test modules. One method is to use a directory to organize your files, such as
projectroot/app/tests/. The name of each test file within that directory should begin with
test, for example,
test_models.py.
Besides being aptly named, Django will find these files using built-in test discovery based on the
unittest module. All files in your application with names that begin with
test will be collected into a test suite.
This convenient test discovery allows you to place test files anywhere that makes sense for your application. As long as they’re correctly named, Django’s test utility can find and run them.
How to document a test
Use docstrings to explain what a test is intended to verify at a high level. For example:
def test_create_user(self): """Creating a new user object should also create an associated profile object""" # ...
These docstrings help you quickly understand what a test is supposed to be doing. Besides navigating the codebase, this helps to make it obvious when a test doesn’t verify what the docstring says it should.
Docstrings are also shown when the tests are being run, which can be helpful for logging and debugging.
What a test needs to work
Django tests can be quickly set up using data created in the
setUpTestData() method. You can use various approaches to create your test data, such as utilizing external files, or even hard-coding silly phrases or the names of your staff. Personally, I much prefer to use a fake-data-generation library, such as
faker.
The proper set up of arbitrary testing data can help you ensure that you’re testing your application functionality instead of accidentally testing test data. Because generators like
faker add some degree of unexpectedness to your inputs, it can be more representative of real-world use.
Here is an example set up for a test:
from django.test import TestCase from faker import Faker from app.models import MyModel, AnotherModel fake = Faker() class MyModelTest(TestCase): def setUpTestData(cls): """Quickly set up data for the whole TestCase""" cls.user_first = fake.first_name() cls.user_last = fake.last_name() def test_create_models(self): """Creating a MyModel object should also create AnotherModel object""" # In test methods, use the variables created above test_object = MyModel.objects.create( first_name=self.user_first, last_name=self.user_last, # ... ) another_model = AnotherModel.objects.get(my_model=test_object) self.assertEqual(another_model.first_name, self.user_first) # ...
Tests pass or fail based on the outcome of the assertion methods. You can use Python’s
unittest methods, and Django’s assertion methods.
For further guidance on writing tests, see Testing in Django.
Best possible execution for running your tests
Django’s test suite is manually run with:
./manage.py test
I rarely run my Django tests this way.
The best, or most efficient, testing practice is one that occurs without you or your developers ever thinking, “I need to run the tests first.” The beauty of Django’s near-effortless test suite set up is that it can be seamlessly run as a part of regular developer activities. This could be in a pre-commit hook, or in a continuous integration or deployment workflow.
I’ve previously written about how to use pre-commit hooks to improve your developer ergonomics and save your team some brainpower. Django’s speedy tests can be run this way, and they become especially efficient if you can run tests in parallel.
Tests that run as part of a CI/CD workflow, for example, on pull requests with GitHub Actions, require no regular effort from your developers to remember to run tests at all. I’m not sure how plainly I can put it – this one’s literally a no-brainer.
Testing your way to a great Django application
Tests are extremely important, and underappreciated. They can catch logical errors in your application. They can help explain and validate how concepts and features of your product actually function. Best of all, tests can boost developer confidence and development velocity as a result.
The best tests are ones that are relevant, help to explain and define your application, and are run continuously without a second thought. I hope I’ve now shown you how testing in Django can help you to achieve these goals for your team!
For more on Django and building a great technical team, go to victoria.dev or subscribe via RSS.
Discussion | https://practicaldev-herokuapp-com.global.ssl.fastly.net/victoria/increase-developer-confidence-with-a-great-django-test-suite-4g99 | CC-MAIN-2020-50 | refinedweb | 1,122 | 53.81 |
27 February 2012 10:47 [Source: ICIS news]
SINGAPORE (ICIS)--SABIC plans to shut one of its polypropylene (PP) facilities at Al Jubail, ?xml:namespace>
The affected PP plant is one of the smaller units of Ibn Zahr (Saudi European Petrochemical Co), with a nameplate capacity of 320,000 tonnes/year, the source said.
SABIC’s other PP units will continue to run at full tilt during the shutdown, the source said.
Currently, all SABIC’s PP plants are running at 100%, the source said.
“The shutdown is brief, so our sales allocations for March are not much affected,” the source said.
SABIC markets PP | http://www.icis.com/Articles/2012/02/27/9535951/saudis-sabic-plans-week-long-shutdown-at-pp-plant-in-early-march.html | CC-MAIN-2015-22 | refinedweb | 105 | 71.85 |
Even-Odd Partition
May 4, 2012
We keep two indices:
lo is the lowest-indexed element in the vector that we have not yet examined, and
hi is the highest-indexed element in the vector that we have not yet examined. Initially,
lo is 0 and
hi is one less than the length of the vector. Then we iterate. At each step we look at the element at index
lo. If it’s even, we increase
lo by one and loop. If it’s odd, we swap the elements at
lo and
hi and reduce
hi by one. Iteration continues until
lo meets
hi:
(define (even-odd vec)
(define (swap! a b)
(let ((t (vector-ref vec a)))
(vector-set! vec a (vector-ref vec b))
(vector-set! vec b t)))
(let loop ((lo 0) (hi (- (vector-length vec) 1)))
(cond ((= lo hi) vec)
((even? (vector-ref vec lo)) (loop (+ lo 1) hi))
(else (swap! lo hi) (loop lo (- hi 1))))))
If that’s not clear, here is the array at each step of the iteration, with the
lo and
hi indexes marked by vertical lines:
| 1 2 3 4 5 6 7 8 9 |
| 9 2 3 4 5 6 7 8 | 1
| 8 2 3 4 5 6 7 | 9 1
8 | 2 3 4 5 6 7 | 9 1
8 2 | 3 4 5 6 7 | 9 1
8 2 | 7 4 5 6 | 3 9 1
8 2 | 6 4 5 | 7 3 9 1
8 2 6 | 4 5 | 7 3 9 1
8 2 6 4 | 5 | 7 3 9 1
8 2 6 4 | | 5 7 3 9 1
This is clearly O(n) in time, as the unexamined part of the vector decreases by one element at each step. And it’s O(1) in space, storing the two indices and the swap element in addition to the input vector. Here’s an example:
> (even-odd '#(1 2 3 4 5 6 7 8 9))
#(8 2 6 4 5 7 3 9 1)
You can run the program at.
Let’s eat the banana from both ends.
Also, in my book it’s a good praxis to always extract some reusable bits of code, generalizing the problem and the solution.
;; Common Lisp:
(defun predicate-sort (vector predicate)
”
DO: Modifies the VECTOR so that all the elements for which the
PREDICATE is NIL are before all the elements for which the
PREDICATE is true.
RETURN: VECTOR
”
(loop
:for i = (position-if predicate vector)
:then (position-if predicate vector :start (1+ i))
:for j = (position-if-not predicate vector :from-end t)
:then (position-if-not predicate vector :end (1- j) :from-end t)
:while (and i j (< i j))
:do (rotatef (aref vector i) (aref vector j)))
vector)
(defun sort-even-odd (vector)
".
"
(predicate-sort vector (function oddp)))
(sort-even-odd (vector 1 2 3 4 5 6 7))
#(6 2 4 3 5 1 7)
(sort-even-odd (vector 6 2 3 4 5 1 7))
#(6 2 4 3 5 1 7)
(sort-even-odd (vector 6 2 9 3 4 5 1 7))
#(6 2 4 3 9 5 1 7)
(sort-even-odd (vector))
#()
(sort-even-odd (vector 1 3 5 7))
#(1 3 5 7)
(sort-even-odd (vector 2 4 6 8))
#(2 4 6 8)
(sort-even-odd (vector 1 3 2 4 6 8))
#(8 4 2 3 6 1)
My solution in python. It is just a variation of quick-sort partition
import sys
import random
def isodd(num):
return bool(num & 1)
def parteo(a):
even = 0
odd = len(a) – 1
while even “,arr
part = parteo(arr[:]);
print “<",part
bad_idx = val_parteo(part);
if bad_idx != -1:
print "Bug found", arr, "\n", part, "\nError at", idx
check_alg()
print "Finished"
Ouch, it doesn’t get the python code – ate it all :-(
How do I post a snippet?
As shown in “HOWTO: Posting Source Code” in the menu bar at the top of the page.
Just a variation on quicksort partition
import sys
import random
def isodd(num):
return bool(num & 1)
def parteo(a):
even = 0
odd = len(a) - 1
while even < odd:
if isodd(a[even]):
if isodd(a[odd]):
odd = odd-1
else:
t = a[odd]
a[odd] = a[even]
a[even] = t
even = even + 1
odd = odd - 1
else:
even = even + 1
return a
def val_parteo(a):
in_odd = False
for idx in range(len(a)):
if isodd(a[idx]):
in_odd = True;
elif in_odd:
return idx
return -1
def gen_arr(size):
a=[]
for idx in range(size):
a.append(random.randint(1,1000))
return a
def check_alg():
for size in range(1,20):
for tst in range(1,5):
arr = gen_arr(size);
print ">",arr
part = parteo(arr[:]);
print "<",part
bad_idx = val_parteo(part);
if bad_idx != -1:
print "Bug found", arr, "\n", part, "\nError at", idx
check_alg()
print "Finished"
just tried all the ways to publish, hopefully you’ll not get annoyed and just delete all irrelevant commentaries – I’d do it myself if there was an option
# probably not the most idiomatic ruby, but:
def partition(arr)
bottom, top = 0, arr.length-1
while bottom < top do
if yield(arr[bottom])
bottom += 1
elsif yield(arr[top])
arr[bottom], arr[top] = arr[top], arr[bottom]
bottom += 1
top -= 1
else
top -= 1
end
end
arr
end
def even_odd_partition(arr)
partition(arr) { |n| n.even? }
end
def fuzztest(times, dim)
times.times do
a = ((1..dim).map { rand(2) })
b = a.sort
raise "Damn: #{a}" if eopart(a) != b
end
end
I beleve that this should work in scheme,
(define (partition ar)
(let ((N (vector-length ar)))
(define (find pred n)
(let ((n (+ n 1)))
(if (< n N)
(if (pred (vector-ref ar n))
n
(find pred n))
#f)))
(let loop ((even (find even? -1)) (odd (find odd? -1)))
(if (and even odd)
(if (< even odd)
(loop (find even? even) odd)
(let ((temp (vector-ref ar even)))
(vector-set! ar even (vector-ref ar odd))
(vector-set! ar odd temp)
(loop (find even? even) (find odd? odd))))))
ar))
Runs in linear time O(2N) on input list of size N. Not sure what’s meant by “constant amount of extra space”, but the sum number of elements required for “extra” storage will be exactly N.
Usage:
Hmm, looks like I missed the “in-place” condition, as this method generates a new list
Python
Basically scan from both ends and swap an odd number from the front of the list with an even number from the back of the list.
* constant xtra storage – 2 indeces, 1 cell in swap()
* time – linear to intut array size
* does not preserve el-s original _order_
Main loop variant with ordering bonus:
* constant xtra storage – same as above
* time – O(nn^2), i guess
* preserves all even values and all odd values original _order_
There’s an obvious half-liner to keep the order of evens and the order of odds when *not* observing the O(1) space, O(n) time requirements: use a stable in-place sort (from the standard library of the language) by oddity. Is there a way to do this within the requirements? I suspect not. (The illustration’s in Python 3.)
@Jussi, how can you assume that sort routine runs in O(n)?
@ardnew, I don’t assume sort takes O(n) time. I said it does *not* satisfy the complexity requirements. Perhaps I said it in an obscure way.
@Jussi, hah sorry. I’m slow and dense
Implemented in Go:
evenOdd x = [n | n <- x, even n] ++ [m | m <- x, odd m]
[/sourcecode language="css"]
My Python solution, similar to Mike’s:
This may be less efficient, as it will swap elements when i = j, but I believe python optimizes that case to a no-op.
Heh, and I screwed up the comment as well. Another attempt:
my solution is pretty much the same as jasonostrander
Here is the code in C that works for any numbers and complexity is O(n) and space complexity can be optimized.
#include
#include
int is_odd(int num)
{
return (num%2 != 0);
}
void display_num(int num[], int count)
{
int i;
for ( i = 0; i < count ; i++)
{
printf("%d\n", num[i]);
}
}
void arrange_even_add(int num[], int count)
{
int r_odd = -1, i ;
int r_even = -1, j ;
int temp_num;
i = 0;
j = count-1;
while ( 1 )
{
// Check first half if any odd number is
// present.
if ( r_odd == -1 ) {
if ( is_odd(num[i] )) {
r_odd = i;
}
else {
i++;
}
}
if ( r_even == -1 ) {
if ( !is_odd(num[j])) {
r_even = j;
}
else {
#include
#define MAX 10
using namespace std;
main()
{
srand(time(NULL));
int i,j=0,k=MAX,l,ar[MAX],temp,a=0,b=0,z;
for(i=0;i<MAX;i++)
{
ar[i]=rand()%1000;
cout<<ar[i]<<" ";
if(ar[i]%2==0)
a++;
else
b++;
}
cout<<endl<<"Output"<<endl;
z=a;
for(i=0;i<a;i++)
{
if(ar[i]%2==1)
{
temp=ar[i];
for(l=z;l<MAX;l++)
{
if(ar[l]%2==0)
{
break;
}
}
ar[i]=ar[l];
ar[l]=temp;
z++;
}
}
for(i=0;i<MAX;i++)
cout<<ar[i]<<" ";
}
The above program fills an array of size 10 with random numbers less than 1000 and sorts them as required in the even first-odd next sequence
//currentSum=max(currentSum+num, num) maxSum=max(currentSum, maxSum)//Why do we need this at every iteration / pnsriag? def largestContinuousSum(arr): if len(arr)==0: return maxSum=currentSum=arr[0] for num in arr[1:]: if num < 0 { maxSum=max(currentSum, maxSum) currentSum = 0 } else, currentSum += num return maxSum
Swaps any odd numbers to a moving end index, which converges with the search index once it’s done.
i waanna to sort even odd number by partition (quick sort) in python .can you help me | https://programmingpraxis.com/2012/05/04/even-odd-partition/2/ | CC-MAIN-2017-30 | refinedweb | 1,634 | 64.24 |
In this tutorial, you're going to learn about Ionic Push, an Ionic service which makes it easy to send push notifications to your users.
Ionic Push allows you to send push notifications to the users of your app. These can be triggered whenever you choose. For example, when it's the user's birthday, you could automatically send them a push notification to greet them.
How It Works
Ionic Push serves as a middle-man between the user's device and the Firebase Cloud Messaging. The first step is for the app to send its device token to the Ionic Push server. This device token serves as an ID which refers to that specific device. Once the server has that token, they can now make a request to the Firebase Cloud Messaging server to actually send a push notification to the device. On each Android device, a Google Play service is running, called the Google Cloud Messaging service. This enables the device to receive push notifications from the Firebase Cloud Messaging platform.
Here's a chart that shows the push notification flow:
What You're Going to Build
You're going to build a simple app which can receive push notifications via Ionic Push. It will also use the Ionic Auth service to log users in. This allows us to try out targeted push notifications which will send the notifications to specific users only. The app will have two pages: the login page and the user page. Users should only be able to receive notifications when they are logged in.
To give you an idea how the notifications would look, here's a screenshot of the notification being received while the app is currently open:
On the other hand, here's what a notification looks like when the app is closed:
Setting Up Push Notifications for Android
In this section, we will configure the Firebase and Ionic cloud services to allow push notifications. Push notifications in Android are mainly handled by the Firebase Cloud Messaging Service. Ionic Push is just a layer on top of this service that makes it easier to work with push notifications in Ionic apps.
Create a Firebase App
The first step is to create a new Firebase project. You can do that by going to the Firebase Console and clicking on the Add project button. You'll see the following form:
Enter the name of the project and click on the Create Project button.
Once the project is created, you will be redirected to the project dashboard. From there, click on the gear icon right beside the Overview tab and select Project Settings.
On the settings page, click on the Cloud Messaging tab. There you will find the Server Key and Sender ID. Take note of these as you will need them later on.
Create an Ionic App
Next, you need to create an Ionic app on the Ionic website. This allows you to work with the Ionic Push service and other Ionic services as well. If you don't already have an Ionic account, you can create one by signing up. Once you've created an account, you'll be redirected to the dashboard where you can create a new app.
Create a Security Profile
Once your app is created, go to Settings > Certificates and click on the New Security Profile button. Enter a descriptive name for the Profile Name and set the Type to Development for now:
Security Profiles serves as a way to securely store the Firebase Cloud Messaging credentials that you got earlier. Once it's created, it will be listed in a table. Click on the Edit button beside the newly created security profile. Then click on the Android tab. Paste the value for the Server Key that you got earlier from the Firebase console into the FCM Server Key field. Finally, click on Save to save the changes.
Bootstrapping a New Ionic App
Create a new Ionic 2 project using the blank template:
ionic start --v2 pushApp blank
Once the project is created, install the phonegap-plugin-push plugin. Supply the Sender ID that you got from the Firebase console earlier:
cordova plugin add phonegap-plugin-push --variable SENDER_ID=YOUR_FCM_SENDER_ID --save
Next, you need to install the Ionic Cloud plugin. This makes it easy to work with Ionic services inside the app:
npm install @ionic/cloud-angular --save
Lastly, you need to update the Ionic config files so that Ionic knows that this specific project should be assigned to the Ionic app that you created earlier. You can do that by copying the app ID in your Ionic app's dashboard page. You can find the app ID right below the name of the app. Once you've copied it, open the
.io-config.json and
ionic.config.json files and paste the value for the
app_id.
Building the App
Now you're ready to build the app. The first thing that you need to do is to fire up the Ionic development server so that you can immediately see the changes as you develop the app:
ionic serve
Once the compilation process is done, access the development URL on your browser.
Add Ionic App and Push Settings
Open the src/app/app.module.ts file and add the settings for the app (
core) and push notifications (
push). The
app_id is the ID of the Ionic app that you created earlier. The
sender_id is the sender ID that you got earlier from the Firebase console. Under the
pluginConfig object, you can optionally set push notification settings. Below we're only setting the
sound and
vibrate settings to
true to tell the hardware that it can play push notification sounds or vibrate if the device is on silent mode. If you want to know more about what configuration options are available, check out the docs on the Push Notification options for Android.
import { CloudSettings, CloudModule } from '@ionic/cloud-angular'; const cloudSettings: CloudSettings = { 'core': { 'app_id': 'YOUR IONIC APP ID', }, 'push': { 'sender_id': 'YOUR FCM SENDER ID', 'pluginConfig': { 'android': { 'sound': true, 'vibrate': true } } } };
Next, let Ionic know that you want to use the
cloudSettings:
imports: [ BrowserModule, IonicModule.forRoot(MyApp), CloudModule.forRoot(cloudSettings) // <-- add this ],
The default home page in the blank template will serve as the login page. Open the pages/home/home.html file and add the following:
<ion-header> <ion-navbar> <ion-title> pushApp </ion-title> </ion-navbar> </ion-header> <ion-content padding> <button ion-button full (click)='login();'>Login</button> </ion-content>
To keep things simple, we only have a login button instead of a full-blown login form. This means that the credentials that we're going to use for logging in are embedded in the code itself.
Next, open the src/pages/home/home.ts file and add the following:
import { Component } from '@angular/core'; import { NavController, LoadingController, AlertController } from 'ionic-angular'; import { Push, PushToken, Auth, User, UserDetails } from '@ionic/cloud-angular'; import { UserPage } from '../user-page/user-page'; @Component({ selector: 'page-home', templateUrl: 'home.html' }) export class HomePage { constructor(public navCtrl: NavController, public push: Push, public alertCtrl: AlertController, public loadingCtrl: LoadingController, public auth: Auth, public user: User) { if (this.auth.isAuthenticated()) { this.navCtrl.push(UserPage); } } login() { let loader = this.loadingCtrl.create({ content: "Logging in..." }); loader.present(); setTimeout(() => { loader.dismiss(); }, 5000); let details: UserDetails = { 'email': 'YOUR IONIC AUTH USER', 'password': "YOUR IONIC AUTH USER'S PASSWORD" }; this.auth.login('basic', details).then((res) => {(); }); }, () => { let alert = this.alertCtrl.create({ title: 'Login Failed', subTitle: 'Invalid Credentials. Please try again.', buttons: ['OK'] }); alert.present(); }); } }
Breaking down the code above, first we import the controllers needed for working with navigation, loaders, and alerts:
import { NavController, LoadingController, AlertController } from 'ionic-angular';
Then import the services needed for working with Push and Auth.
import { Push, PushToken, Auth, User, UserDetails } from '@ionic/cloud-angular';
Once those are added, import the
User page. Comment it out for now as we haven't created that page yet. Don't forget to uncomment this later once the user page is ready.
//import { UserPage } from '../user-page/user-page';
In the constructor, check if the current user is authenticated. Immediately navigate to the user page if they are:
constructor(public navCtrl: NavController, public push: Push, public alertCtrl: AlertController, public loadingCtrl: LoadingController, public auth: Auth, public user: User) { if (this.auth.isAuthenticated()) { this.navCtrl.push(UserPage); } }
For the
login function, show the loader and set it to automatically dismiss after 5 seconds. This way if something goes wrong with the authentication code, the user isn't left with an infinite loading animation:
login() { let loader = this.loadingCtrl.create({ content: "Logging in..." }); loader.present(); setTimeout(() => { loader.dismiss(); }, 5000); }
After that, log the user in with the hard-coded credentials of a user that's already added in your app:
let details: UserDetails = { 'email': 'YOUR IONIC AUTH USER', 'password': "YOUR IONIC AUTH USER'S PASSWORD" }; this.auth.login('basic', details).then((res) => { ... , () => { let alert = this.alertCtrl.create({ title: 'Login Failed', subTitle: 'Invalid Credentials. Please try again.', buttons: ['OK'] }); alert.present(); });
If you don't have an existing user yet, the Ionic dashboard doesn't really allow you to create new users, although you can create additional users once you already have at least one user. So the easiest way to create a new user is to call the
signup() method from the Auth service. Just uncomment the login code above and replace it with the one below. Take note that you can create the user from the browser since the email/password authentication scheme just makes use of HTTP requests.
this.auth.signup(details).then((res) => { console.log('User was created!', res); });
Now that you have a user that you can log in, you can go ahead and remove the signup code and uncomment the login code.
Inside the success callback function for login, you need to call the
register() method from the Push service. This crucial step enables the device to receive push notifications. It makes a request to the Ionic Push service to get a device token. As mentioned in the How It Works section earlier, this device token serves as a unique identifier for the device so that it can receive push notifications.(); });
The great thing about Ionic Push is its integration with Ionic Auth. The reason why we're registering the device tokens right after logging in is because of this integration. When you call the
saveToken() method, it's smart enough to recognize that a user is currently logged in. So it automatically assigns this user to the device. This then allows you to specifically send a push notification to that user.
User Page
The user page is the page which receives push notifications. Create it with the Ionic generate command:
ionic g page userPage
This will create the src/pages/user-page directory with three files in it. Open the user-page.html file and add the following:
<ion-header> <ion-navbar <ion-title>User Page</ion-title> </ion-navbar> </ion-header> <ion-content padding> <button ion-button full (click)='logout();'>Logout</button> </ion-content>
To keep things simple, all we have is a button for logging the user out. The main purpose of this page is to receive and display push notifications only. The logout button is simply added because of the need to log the user out and test if they could still receive notifications after logging out.
Next, open the user-page.ts file and add the following:
import { Component } from '@angular/core'; import { NavController, AlertController } from 'ionic-angular'; import { Push, Auth } from '@ionic/cloud-angular'; @Component({ selector: 'page-user-page', templateUrl: 'user-page.html', }) export class UserPage { constructor(public navCtrl: NavController, public push: Push, public auth: Auth, public alertCtrl: AlertController) { this.push.rx.notification() .subscribe((msg) => { let alert = this.alertCtrl.create({ title: msg.title, subTitle: msg.text, buttons: ['OK'] }); alert.present(); }); } logout() { this.auth.logout(); this.navCtrl.pop(); } }
The code above is pretty self-explanatory, so I'll only go over the part which deals with notifications. The code below handles the notifications. It uses the
subscribe() method to subscribe for any incoming or opened push notification. When I say "opened", it means the user has tapped on the notification in the notifications area. When this happens, the app is launched, and the callback function that you passed to the
subscribe() method gets called. On the other hand, an incoming push notification happens when the app is currently opened. When a push notification is sent, this callback function also gets called. The only difference is that it no longer goes to the notification area.
this.push.rx.notification() .subscribe((msg) => { let alert = this.alertCtrl.create({ title: msg.title, subTitle: msg.text, buttons: ['OK'] }); alert.present(); });
For each notification, the argument passed to the callback function contains the object payload:
In the above code, we're only using the
title and the
text to supply as the content for the alert. We're not limited to just alerts, though—as you can see from the screenshot above, there's this
payload object which stores additional data that you want to pass in to each notification. You can actually use these data to direct what your app is going to do when it receives this kind of notification. In the example above,
is_cat is set to
1, and we can have the app change its background into a cat picture if it receives this notification. Later on in the Sending Push Notifications section, you'll learn how to customize the payload for each notification.
Running the App on a Device
Now it's time to test out the app on a device. Go ahead and add the platform and build the app for that platform. Here we're using Android:
ionic platform add android ionic build android
Copy the .apk file inside the platforms/android/build/outputs/apk folder to your device and install it.
Solving Build Errors
The first time I tried to run the
build command, I got the following error:
If you got the same error then follow along. If you haven't encountered any errors then you can proceed to the next section.
The problem here is that the SDK components mentioned were not installed, or there might be an important update that needs to be installed. However, the error message is a bit misleading, since it only says that the license agreement needs to be accepted.
So to solve the problem, launch the Android SDK installer and then check the Android Support Repository and Google Repository. After that, click on the Install button and agree to the license agreement to install the components.
Sending Push Notifications
Now that you've installed the app on your device, it's now time to actually send some push notifications. Here are a few scenarios which you can test out:
- when a user isn't currently logged in
- when a user is logged in
- to all users
- to users which match a specific query
- when the app is opened
- when the app is closed
The first step in sending a push notification is to go to your Ionic app dashboard and click on the Push tab. Since this is your first time using the service, you should see the following screen:
Go ahead and click on the Create your first Push button. This will redirect you to the page for creating a push notification. Here you can enter the name of the campaign, title and text of the notification, and any additional data that you want to pass in. Here we're setting
is_cat to
1.
Next, you can optionally set the push notification options for iOS or Android. Since we're only going to send to Android devices, we only set the options for Android:
The next step is to select the users who will receive the notification. Here you can select All Users if you want to send the notification to all the devices which are registered for push notifications.
If you only want to send to specific users then you can also filter to them:
Take note that the users list is populated from users that are registered via the Auth service.
The final step is to select when to send the notification. Since we're only testing, we can send it immediately. Clicking on the Send This Push button will send the notification to your selected users.
Conclusion and Next Steps
In this tutorial, you've learned about Ionic Push and how it makes push notifications easier to implement. Through the Ionic dashboard, you were able to customize the notifications that you're sending to users. It also allows you to select which users you want to send the notifications to.
This works great if you don't have an existing back end already. But if you already have a back end, you might be asking how you can use Ionic Push with your existing web application. Well, the answer for that is the Ionic HTTP API. This allows you to send an HTTP request from your web server to Ionic's server whenever a specific condition is met. The request that you send will then trigger a push notification to be sent to your users. If you want to learn more, you can check out the docs for the Ionic Push Service.
And while you're here, check out some of our other courses and tutorials on Ionic 2!
Envato Tuts+ tutorials are translated into other languages by our community members—you can be involved too!Translate this post
| https://code.tutsplus.com/tutorials/get-started-with-ionic-services-push--cms-28718 | CC-MAIN-2018-26 | refinedweb | 2,922 | 55.13 |
AWS supports identity federation using Security Assertion Markup Language (SAML) 2.0, an open standard used by many identity providers. This feature enables federated single sign-on (SSO), which lets users log into the AWS Management Console or call the AWS APIs without you having to create IAM users for everyone in your organization. Using SAML can simplify the process of configuring federation with AWS, because you can use the identity provider's service instead of writing custom identity proxy code.
AWS STS and IAM support these use cases:
Web Giving AWS Console Access to Federated Users Using SAML.
Federated access to allow a user or application in your organization to call AWS APIs. You use a SAML assertion (as part of the authentication response) generated in your organization to get temporary security credentials. This scenario is similar to other federation scenarios supported by AWS STS and IAM, like those described in AWS APIs to Create Temporary Security Credentials and About AWS STS Web Identity Federation. However, SAML 2.0-based identity providers in your organization handle many of the details at run time for performing authentication and authorization checking.
Imagine that in your organization, you want to provide a way for users to copy data from
their computers to a backup folder. You build an application that users can run on their
computers. On the back end, the application reads and writes objects in an Amazon S3 bucket. Users
don't have direct access to AWS. Instead, the application gets the user information from
your organization's identity store (such as an LDAP directory) and then gets a SAML assertion
that includes authentication and authorization information about that user. The application
then uses that assertion to make a call to the AWS STS
AssumeRoleWithSAML API
to get temporary security credentials and use those credentials to access a folder in the Amazon S3
bucket that's specific to the user.
The following diagram illustrates the flow.
A user in your organization uses a client app to request authentication from your organization's identity provider (IdP).
The IdP authenticates the user.
The IdP sends a SAML assertion to the client app.
The client app calls the
AssumeRoleWithSAML API, passing the ARN of the
SAML provider, the ARN of the role to assume, and the SAML assertion that was provided by
the IdP in the previous step.
AWS STS returns temporary security credentials to the client app.
The client app uses the temporary security credentials to call Amazon S3 APIs.
Before you can use SAML 2.0-based federation as described in the preceding scenario and diagram, you must configure your organization's identity store and your AWS account to trust each other. The general process for configuring this trust is described in the following steps. Inside your organization, you must have an identity provider (IdP) that supports SAML 2.0, like Microsoft® Active Directory Federation Service (AD FS, part of Windows™ Server), Shibboleth, etc.
In your organization's IdP you register AWS as a service provider (SP) using the SAML metadata document that you get from the following URL:
Using your organization's IdP, you generate an XML metadata document that includes the issuer name, a creation date, an expiration date, and keys that AWS can use to validate authentication responses (assertions) from your organization.
In the IAM console, you create a new SAML provider, which is an entity in IAM. As part of this process, you upload the SAML metadata document that was produced by the IdP in your organization (see the previous step).
For more information, see SAML Providers in the Using IAM guide.
In IAM, you create one or more IAM roles. In the role's trust policy, you set the SAML provider as the principal, which establishes a trust relationship between your organization and AWS. The role's access (permission) policy establishes what users from your organization will be allowed to do in AWS.
For more information, see Creating a Role for SAML-Based Federation in the Using IAM guide.
In your organization's IdP, you create assertions and map the IAM role to users or groups in your organization who will be allowed to have the permissions specified in the role. Note that different users and groups in your organization might map to different IAM roles. The exact steps for performing the mapping depend on what IdP you're using. In the previous scenario of an Amazon S3 folder for users, it's possible that all users will map to the same role that provides Amazon S3 permissions.
For more information, see Configure Assertions for the SAML Authentication Response.
In the application that you're creating, you call the AWS STS
AssumeRoleWithSAML API, passing it the ARN of the SAML provider in IAM,
the ARN of the role to assume, and.
The role or roles that you create in IAM define what federated users from your
organization will be allowed to do in AWS. When you create the trust policy for the role,
you specify the SAML provider that you created earlier as the principal. You can
additionally scope the trust policy": {"AWS": "arn:aws:sts: in the Using IAM guide.
For the access (permissions) policy in the role, you specify permissions as you would for any role. For example, if users from your organization will be allowed to administer Amazon EC2 instances, you explicitly allow Amazon EC2 actions in the permissions policy, such as those in the Amazon EC2 Full Access policy template.
When you create access policies in IAM, it's often useful to be able to specify permissions based on the identity of users who have authenticated using an identity provider. CLI, since those are static values. However, the user-specific folders
(
user1,
user2,
user3, etc.) have to be created at run time using code, since the
value that identifies the user isn't known until then.. The values returned by the following keys can be used to create unique user identifiers for resources like Amazon S3 folders.
saml:namequalifier. This key contains a hash value that represents the
combination of the
saml:doc and
saml:iss values. It is used as a
namespace qualifier; the combination of
saml:namequalifier and
saml:sub uniquely identifies a user. The following pseudocode shows how
this value is calculated. In this pseudocode, "+" indicates concatenation,
SHA1 represents a function that produces a message digest using SHA-1, and
Base64 represents a function that produces Base-64 encoded version of the hash
output.
Base64(SHA1(saml:doc + saml:iss)) is the same for a
user between sessions. If the value is "transient", the user has a different
saml:sub value for each session.
The following example shows an access Configure Assertions for the SAML Authentication Response. | http://docs.aws.amazon.com/STS/latest/UsingSTS/CreatingSAML.html | CC-MAIN-2015-18 | refinedweb | 1,128 | 52.7 |
- How to get the updates
- Photoshop 2015.0.1 Update (08/03/2015)
Photoshop 2015.0.1 Update (08/03/2015)
08/03/2015 – Today we released Photoshop CC 2015 update version 2015.0.1 (Mac and Windows), resolving the following issues:
- Crash when Be3D printer profile is present in presets (win only)
- Crash on launch “VulcanControl dylib” (mac only)
- Unable to read key state in JavaScript
- BlackMagicDesign ATEM Switcher plugin crashes in Photoshop CC 2015 when documents have more than one layer
- Crashes when extension uses script UI
- Crash in specific cases when Open window is invoked (mac only)
- Crash on zoom (win only)
- Fixed drawing for borders of white artboards drawn on a white background
- Fixed drawing of borders while dragging and aligning artboards
- Fixed artboard matte color extending inside artboard 1 pixel
- Fixed typo in Artboards to PDF dialog
- Duplicate Layer command puts new layers at top of artboard stack, not above source layer like it should
- Properly disable the artboard canvas color context menu when it does not work with the current GPU and color mode settings
- Crash on launch due to “librarylookupfile” (win only)
- English text copied from Acrobat to Photoshop is in Chinese
- Application hang while opening certain JPEG2000 files
- Canvas/document area draws partially or completely black in a Retina/standard display config after disconnect/reconnect 2nd display
- Crash when closing an image (win only)
- Artifacts using Healing Brush tool on transparent layer with “Current & Below” enabled with soft brush
- Healing brush failing on individual channel
- Some customers prefer the texture and color rendition of the old healing brush algorithm compared to the new real-time algorithm
- Welcome… menu item was unintentionally removed if user selects “Do Not Show…” checkbox, closes and re-launches
- Filter Gallery gives error on Mac OS X 10.10.3 and 10.11 in Chinese Languages
- Create Layer (from effect) reverses layer z-order
- Fixed issue where customers in the UK, Canada and Mexico may not be able to purchase images form Adobe Stock if they accessed Stock through Photoshop’s Search on Adobe Stock menu
- Move too set to Auto Select not releasing layers selected during drag
- Layers panel incorrectly scrolling when adding or deleting layers
- Crash when adding a spot color channel after adding an asset from the Libraries panel
- Crash PlugPlug crash in [HtmlEngineMonitor closeWindow]
- Crash copy and pasting a shape (esp the Line tool)
- Direct Selection & Path Selection Tool +/- shortcuts not working correctly
- Crash on Scroll while using Pen Tool (win only)
- Performance problems zooming and panning while rulers are showing
- Selection disappearing at different zoom levels (win only)
- Selection redraw issue when dragging (win only)
- Converting a video layer, generated by image sequence import, to Smart Object crashes
- Fixed issue where Welcome dialog would be empty in some cases
How to get the updates
- Look for the update in the Creative Cloud application and click “Update”. (Sign out and back in to the Creative Cloud desktop application if you don’t see the update)
- If you don’t have the Creative Cloud application running, start Photoshop 2015 and choose Help > Updates.
- The Adobe Application Manager will launch. Select Adobe Photoshop CC 2015:
Awesome, thanks Jeff and team – I know this has been a lot of work to get all these updates out quickly!!
ScriptUI is still messed up Dialog Are scaled when the should not be scaled. For my Photoshop Prefernces
ScriptUI does not trigget events that should be triggered keydown is still not triggered this blog stated that was fixed bug I reported was fixed???
Scale UI setting is set to 100% yet Script UI scales my displat 200% and some dialof do not fit on screen. Photostoshop display requirement is a display 1024×768 or bigger when Scaled My surface Pro 3 Display 2160×1440 scaled 200% makes that display int ao 1080×720 display that does not meet Photoshop Requirement Still Photoshop SCale UI Auto setting will scale my Display 200% setting it to 100% partle solver that problem Photoshop doen not scale its UI most of the time but always scale ScriptUI Dialogs.
Script dialogs are not located where they should be.
ScriptUI does not trigget events the should be triggered keydown is still not triggered this blog stated that that was fixed.
After a reboot the script bug I reportes is now fixed in my machine ????
I take it back The bug is not fixed somehow I opeb CC 2014 where its not a bug. Still fails in CC 2015.
function NumericEditKeyboardHandler (event) {
try {
var keyIsOK = KeyIsNumeric (event) ||
KeyIsDelete (event) ||
KeyIsLRArrow (event) ||
KeyIsTabEnterEscape (event);
if (! keyIsOK) {
// Bad input: tell ScriptUI not to accept the keydown event
event.preventDefault();
/* Notify user of invalid input: make sure NOT
to put up an alert dialog or do anything which
requires user interaction, because that
interferes with preventing the ‘default’
action for the keydown event */
app.beep();
}
}
catch (e) {
; // alert (“Ack! bug in NumericEditKeyboardHandler: ” + e);
}
}
// key identifier functions
function KeyIsNumeric ( event ) {
return ( event.keyName >= ‘0’ ) && ( event.keyName <= '9' ) && ! KeyHasModifier ( event );
}
function KeyHasModifier ( event ) {
return event.shiftKey || event.ctrlKey || event.altKey || event.metaKey;
}
function KeyIsDelete (event) {
// Shift-delete is ok
return (event.keyName == 'Backspace') && ! (event.ctrlKey);
}
function KeyIsLRArrow (event) {
return ((event.keyName == 'Left') || (event.keyName == 'Right')) && ! (event.altKey || event.metaKey);
}
function KeyIsTabEnterEscape (event) {
return event.keyName == 'Tab' || event.keyName == 'Enter' || event.keyName == 'Escape';
}
function createDialog( ) {
var dlg = new Window( 'dialog', 'Example Dialog' );
dlg.maskSt = dlg.add( 'edittext', undefined, '' );
dlg.maskSt.preferredSize.width = 40;
dlg.maskSt.addEventListener ('keydown', NumericEditKeyboardHandler );
dlg.btnPnl = dlg.add( 'panel', undefined, 'Process' );
dlg.btnPnl.orientation = "row";
dlg.btnPnl.alignment = "right";
dlg.btnPnl.okBtn = dlg.btnPnl.add( 'button', undefined, 'Ok', { name:'ok' });
dlg.btnPnl.cancelBtn = dlg.btnPnl.add( 'button', undefined, 'Cancel', { name:'cancel' });
return dlg;
};
function initializeDialog( w ) {
w.maskSt.addEventListener ('keydown', NumericEditKeyboardHandler );
w.maskSt.onChanging = function() {
// range check if needed
if( Number(this.text) 100 ){
alert(‘Out of range’);
// handle however you like
this.text = ”;
}
}
w.btnPnl.okBtn.onClick = function ( ) { this.parent.parent.close( 1 ); };
w.btnPnl.cancelBtn.onClick = function ( ) { this.parent.parent.close( 2 ); };
};
runDialog = function( w ) {
return w.show( );
};
var win = createDialog();
initializeDialog( win );
runDialog( win );
Thanks a lot …
The About Photoshop doesn’t make it clear that the update installed.
It still shows as CC 2015.0.0 when I was expecting to see CC 2015.0.1.
I do know all the bugs I reported have been FIXED!
thanks.
B
Another place to confirm the version is Help>System Info…
It clearly shows in the Creative Cloud App that I had to update Photoshop 2 times yesterday. Which tells me there was a bug in the 1st update.
Hi B. Moore –
No, that’s not it… It doesn’t have anything to do with bugs.
There have actually been 3 separate and different updates to Photoshop CC 2015 in the last two days – a large update for the main program, and two much smaller updates for the Export Assets and Adobe Preview CC components within Photoshop… You can see them given here.
Not exactly sure why Adobe is now unbundling the Photoshop CC updates into various pieces (small components of the program), but it would be good to know… Jeff, can please help elucidate? Thanks!
So…the channel ids for CC 2015 product updates may be found where?
Thanks.
latest Ps CC 2015.0.1 mac update has brought my workflow to a standstill …. what is going on? extremely slow
Hi Kate, Try restoring your preferences:
It is disappointing to me that this update does not address a fundamental bug when using Photoshop on Yosemite with a Cintiq.
The bug I am referring to is a problem with pressure sensitivity that creates an ugly “shoelace” like trail at the end of a pressure sensitive brush stroke. You can see a sample here: This problem does not exist in CS5 (with Yosemite) , it also does not exist in CS6 unless the White Window Workaround plugin is installed (however not installing it creates other problems.) In all subsequent versions including CC CC2014 and CC2015 this problem is inherent in the software and unavoidable.
I do not understand why such a fundamental flaw is not be addressed or acknowledged. This is clearly not a Wacom driver issue as it exists with many drivers and does not exist on PS CS5 or 6 (without white window) . This bug can be controlled in a Windows environment with the Lazy Nezumi plugin which allows better control of smoothing, however no such plugin exists for Mac. The only way to create a smooth consistently tapered stroke is to turn off smoothing completely which results in segmented curves— so that too is no solution.
i have brought this issue up repeatedly. i no other artists are aware of it. Why won’t Adobe acknowledge and address it?
I am trying to use the crop tool and its so slow. I have a mac book pro and i have also a Imac the imac is working so well!
What can i do?
Best regards
Marie
Try restoring your preferences: If you do restore your prefs, please save a copy of your existing prefs in case they turn out to be the culprit. Having the bad prefs can sometimes help us track down the issue.
How do i update to the new version of photoshop on my mac. tried the update thru photoshop and no luck, signed out of creative cloud and no luck.
Adobe Photoshop Version: 2015.0.0
Are you on a Creative Cloud Team account or an enterprise account? Administrators for your team or company can disable updates.
If you’re an individual, try solution 2 here: Available updates not listed
Otherwise, try installing the update directly from here:
It also fixed a problem I had with the Alt-Drag an Effects Layer method to duplicate that effect onto another layer! My drop shadows would mysteriously change their settings, effectively “fading out” to 0 within two alt-drags. Very annoying and time-consuming having to reset 14 layers on a graphic I update weekly. They now stay consistent. Thanks!
I am so sick of hearing so many bad things happening and complaints and problems that I refuse to upgrade to Yosemite or to CC15 — even though I’m a cc-member! Let me know when everything works correctly!
Been having problems where I Airplay to my Apple TV with a Photoshop PSD and the bottom portion of the canvas window is gray.
Do you have the 2015.0.1 update installed?
Beware of this upgrade. It deleted my plug-ins (and it looks like I have to purchase completely new ones for compatibility) and there is a really annoying welcome screen that I have yet to get rid of.
It didn’t delete your plug-ins. You do not need to purchase new ones. See this:
I have tried those options but no update option is available. I still have the Photoshop 2015.0.0.
My Artlandia Plugin won’t work in this version, should in the update. Any tips anyone?
Thanks for reading
See the troubleshooting here:
After the update how to we deactivate the real-time healing brush. I want to use the original healing brush.
Every time I try to download a file from my computer to PS CC 2015 it says its unable to comply because my OpenGL is disabled, and there is no way to enable it.
Update your driver:
Update doesn’t show in CC app… “Updates” under help menu is greyed out…
See this document:
Update doesn’t show in CC app… “Updates” under help menu is greyed out…
Also tried the direct update here but got an error telling me to contact the administrator (even though I ran the patch installer with admin privileges) :/
I would suspect you’re a CC Teams or enterprise customer who’s admin has disabled updates. See this doc:
I have installed the update to 2015.0.1.
I have restarted using Shift+Ctrl+Alt to reset preferences.
I have deselected “Use Graphics Processor.”
I have shut down and restarted my Windows 7 computer.
Even though I’ve performed all these suggestions and workarounds Photoshop STILL either hangs or quits when I use “save for web.”
What am I missing? Please help.
Have you tried running from a new Admin user account?
Thanks for your help. I created new admin account and PS worked while in that account, but not when I went back to my normal account (which I need to be in to access our network.) I’ll see if support contacts me, or I may reach out to them.
So, from what I can tell, the advice for getting a piece of software running on one’s machine is to specifically ignore the inherent security features of that machine/OS by using an elevated user account when a standard one should suffice for running any (except integral OS functionality providing) software, once installed. Adobe, do you hear yourselves? Seriously, do you?
May I ask what advice you have for the fact that the latest version runs like a sack of shit and despite huge amounts of RAM seems to be treating one’s hard-drive like road underneath a jackhammer? Go purchase time on a supercomputer? Go buy new hard drives?
Adobe seems to be determined to take no responsibility at all for the disrupted workflow (and associated loss of earnings), the litany of errors introduced with EVERY new CC build or even with providing responses for support requests in a timely manner. It’s weird, because aren’t we the customers – the ones whom are paying for these products that we then have to spend UNPAID time repairing, by following 2nd rate instructions on a blog?!! Why is the onus on the customer?
Apparently proof-reading is also too much to handle – as there are even several spelling and grammatical errors in the article.
All the new paint-work may hide the rust in Adobe’s ship, but it won’t stop it from sinking. The question is how long do they expect us to keep paying them to carry our cargo before it becomes safer to find a different provider to handle it?
Hi Jeff,
Thanks for swearing on my blog and hurling insults at me.
Running from a fresh admin user account is a an easy troubleshooting step to quickly determine if the problem is damaged permissions/user accounts. Most cases of damaged user accounts/permissions are caused by User Migration Assistant and similar paths when upgrading the OS.
I don’t see any support cases nor any products registered under you account, so I’m unable to offer further assistance.
Stay classy.
Thanks mate finally i am able to run Photoshop. I was regretting the fact i updated my syste, to WINDOWS 10 and was on the verge of formatting when i came across this blog
Can we make it clear that you can’t get this or any new updates if you didn’t upgrade your Application Manager to Creative Cloud Desktop app even if you apply the direct update file it will fail what if i don’t want to install the new cc updater and i just want to apply direct manual updates myself I don’t want I don’t want lots of proccess running unstoppable in mac for no reason just to apply updates
You can set the CC app not to run under its preferences. That way it only runs when you need to update.
Well… I’m having troubles with this version. It does not recognize my graphic card even when the adobe website says it has been tested on it (Nvidia Geforce GT 650M), I’ve updated the drivers and nothing. And the Scrubby zoom has stopped working completely. I now regret updating… =(
For the scrubby zoom issue, have you installed this compatibility plug-in?
Does it recognize your graphics card, or does it just report that 3D is not compatible?
There is a problem of new “CC” version in “CS6” when we click on a shape through “Direct Selection Tool” without selecting the layer it automatically select the shape and focus the border line type but in “CC” it dose not work. First we select the layer then it will work kindly solve this issue.
Hi, I replied to your report here:
If you want the shape to be selected, make sure you set the option for “Select:” to “All Layers” in the Direct Select options bar.
This is the version I have installed: Adobe Photoshop Version: 2015.0.0 20150529.r.88 2015/05/29:23:59:59 CL 1024429 x64
I assume it is the latest one since Creative Cloud panel doesn’t show any newer updates.
This version of photoshop still crashes on zoom (windows).
I see you are a Creative Cloud Team member – if you’re not seeing updates – your team leader may have updates disabled.
It looks like you may also be the admin, so go into your admin account and make sure that the update is enabled from the admin tool.
i have updated to 2015.0.1 but am still getting crash to BSOD.
it seems that the crash happens after i have run the system along with other software for some time. it does not happen after the reboot from BSOD.
is Adobe going to compensate for the recovery of corrupted pc, hdd and files because of these BSOD crashes?
running on windows 8.1 with updated gfx/video driver.
A system hang or freeze requiring a computer restart usually means a low level failure such as a driver (video card driver, etc), failing/damage hard disk, damaged OS installation, or failing hardware (hard disk, video card, etc).
Did you use Windows Update to update the driver? Just doing Windows Update won’t give you the latest and greatest drivers. You must go directly to your card manufacturers website to check for driver updates.
Determine what video card you have and go *directly to the manufacturers website (nVidia or ATI/AMD)* and download the latest driver:
How about making these updates and versions available outside of creative cloud. I need to revert back to cc 2015 as the latest version is not compatible. Cant get support. All I can find is infornataion on how to find previous verions in creative cloud but they are not there. Paying for something I now cant use and lost a months worth of business
Are you following the instructions here?:
If you still need help, work with a support agent here: | http://blogs.adobe.com/crawlspace/2015/08/photoshop-cc-2015-0-1-update-now-available.html?replytocom=42594 | CC-MAIN-2019-51 | refinedweb | 3,101 | 61.46 |
THE CAUSE FOR FAILURE IN THE PURSUIT OF SHAREHOLDER VALUE FOR FTSE 100 AND S&P500 COMPANIES
Growth of dividend income and capital are all-important aspects. They offer total return from share investment, and as expected, many investors turn to companies, which can beat the total return that is delivered by the broader market (Lang, Stulz, 2009, 144). In encouraging, and attracting investors, many companies in FTSE 100 and S&P500 opted to provide their investors with total return (Leland, 2010, 1214). FTSE 100 is an index which constitutes of 100 corporations that are listed in London stock exchange . These firms are mostly referred as “blue chip organizations” and in traditional aspects, this index is viewed as a good indicator for the performance of major entities in UK perspective (FTSE, 2014, 1).
The S&P 500 on the other hand, refers to a stock market index which is based on market capitalization of top 500 organizations with common stock which are listed on either NASDAQ or NYSE. The index weighting and components are determined by the indices in the S &P Dow Jones. This index which is among the popular index is also regarded as being among the best representations in U.S stock market.
The S&P set a milestone in 2010 by realizing an intraday high of 1,576.10. In March 2013, S&P overtook its closing high level of 1,565.15 through recovery of its losses accrued from financial downturn. However, it still need to close well above the level of 2000 so as to set adjusted highs in new inflation in comparison to its first foray in 2000 which was above 1,500 level (Mckay, 2013, 4)
Majority of companies listed in FTSE100 and S and P 500 embarked on setting targets in improving environmental performance as well as shareholder value through high revenue performances. However, a closer examination reveals that the companies did not and have not actually realized these objectives effectively (Peterson, 2013, 11). Further, it has also been found that there is a high level of variation in the degree of rigor and ambition alongside missed opportunities for these companies in ensuring high returns, as well as incorporation of strategies aimed at sustainability (JeeYeon, 2013, 54).
Background
In their pursuance of shareholder value, “blue chip organizations” which are listed on the FTSE 100 have recently opted to penetrate into emerging markets in order to increase their shareholder value. However, many investors have been concerned on the potential risks associated with the venture into new markets as they expose themselves to potential crisis, and a meltdown in emerging markets. The companies poured themselves in markets such as in China, Turkey, Japan, Europe, and other countries in an attempt to benefit from the exciting development opportunities in these markets (Kay, 2011, 67).
Although some of the FTSE 100 companies have to some extent, been successful, their American counterparts in the S and P index 500 have only generated 5% in revenue from foreign markets. This translates that they have not effectively achieved shareholder values from these markets. Investors with FTSE 100 stocks, actively managed funds, and index tracking are exposed to risks that hamper business development (Jeff, 2013, 2).
This leaves investors with FTSE 100 stocks, index-tracking and actively managed funds with a much higher exposure to risks than they may think. For instance, the shares for the Diageo Company in 2013 dropped by 6% in just two days, due to slowed sales in Nigeria and China. These left investors with a feeling of being punched down for the reduced value of their shares. This resulted into Diageo being dropped from the “buy list” of Goldman Sachs and the company was downgraded to a neutral (Renshaw, 2014, 1).
Another example can be derived from Unilever, one of the companies listed in FTSE 100 stock index. This company, which deals with a broad range of products, also realized losses that were attributed to factors related to weaker currencies, and slow demands in such markets as Indonesia, Russia and Brazil. A decrease in local currencies translates that the total sales realized in the specific countries leads to few pounds being bought by shareholders in Britain(Clark, 2012, 45)
Tesco and ITV are other examples, which have suffered losses in the midst of lackluster trading especially in emerging markets, which has sent away the FTSE index from its 14-year record high. Despite the gain in U.S stocks in 2013 and the fact that most things were plummeting, the measures of S&P’s 500-index price momentum have been consistently decreasing, leading to an increased concern that emerging markets will eventually snuff out the rally. In 2013 alone, more than 170 companies in S&P 500 index traded below their regular average level. This performance was the worst for many years in accord to a data gathered by Bloomberg (Gallagher, and Associates,2011, 67).
Political instabilities in foreign markets such as in Turkey, Thailand have resulted into disappointing earnings for some companies as General electric, Apple and so on which saw the decrease in value of S&P 500 by 4.1% . According to analysts, this is the worst values since 2009. Some of the company gains that appeared smooth for some years triggered warnings from investors such as Nuveen investment, and Blackstone Group. Economic analysts have pointed out that the drop in value for S&P index in this year has been more than 10 percent since 2011 (Samuelson, 2013, 76).
The Cause for Failure in the Pursuit of Shareholder Value for FTSE 100 and S&P500 Companies
Economic Instability
Economic instability of some of the emerging markets is one of the lead causes why FTSE 100 and S&P Companies have failed to pursue their shareholder value. In particular, market worries about the weak export by China have led to weak FTSE indices being down. Although the FTSE realized initial early gains, the FTSE have experienced a downward bender, and actually taking it into a negative territory. It should be considered that China is the second largest economy and its fall will have a significant impact on FTSE firms. Asia in general has been experiencing economic instability as depicted by the Nikkei close down 155 points at 15, 120. Japan is also another country, which has experienced, and account deficit to a record high of 1.5 trn yen in January 2014. In general, the economic stability of a particular market determines the success or failure of a particular firm in the FTSE 100 indices or S&P 500 (Fair, 2012,76).
Financial market instability has particularly increased not only market but also credit risks for many companies in S&P list. According to the proprietary risk to price and corporate value scoring algorithm, both fonts have experienced an increase in risks for financial markets. Further, the market conditions have led to the sidelining of the market for both the current and future public offerings (Hershey, 2011, 98). This has also to the price performance being subdued and the initial public offering. Before standard and poor 500 experienced a downgrade, there was deterioration in the loan market. This was a s a result of consistent weak economical reports, particularly in Europe’s economic and debt crisis. The outflows from retail funds further pushed the S&P index down 4% of august 2013 (Thomson, 2014, 3).
Drop In the Value of Foreign Currencies
In recent perspectives, the speed and severity in the decrease of value for currencies in emerging markets has had a transactional impact on FTSE 100 and S&P companies. These companies are unable to raise their prices early enough in offsetting the decrease in currency value. Understanding the role of currency in the performance of international firms is a crucial aspect. In essence, the impact of currency on multinationals can be huge. One of the reasons why FTSE 100 and S&P have failed to achieve their targets is that they didn’t pay they didn’t pay a closer attention on managing the fluctuation and uncertainties of foreign currency (Snowdon, 2012, 76).
More than half of their sales for S&P 500 and FTSE companies are generated outside U.S. For any multinational organization, currencies can influence the business performance in a number of ways. These impacts can be in various ways such as (a) exposure in translation, where an organization converts its revenue for foreign destinations to its home currencies. B) Exposure in transaction, where prices that have been received or paid out for goods are influenced by currency and. C) Economic exposure, whereby, the input costs, cost of the goods sold, competitive advantage and the values in the balance sheet are affected (Garner, 2009, 56).
For companies that are based in America, a strong dollar in their home country, particularly during the reporting period can affect the businesses negatively. This due to the fact that revenue from forein nations may be valued lesser in comparison to the dollar at that time . Stated differently, the units of foreign currency denominated revenue will be exchanged for lesser dollars when it is translated in reporting financial results (Alan, 2009, 134).
Examples of companies that have experienced losses due to the impact of currency value include the Pfizer among others. In spite of the fact that there are companies, which thrive amidst the weak dollar, many companies in the FTSE 100 and S&P listings experienced losses probably due to ineffective currency strategies. Approximately 25% of large organizations that have exposed themselves to currency risks did absolutely nothing to edge it out. These points to the reason why many of them failed to achieve their objectives.
How Unemployment Caused Poor Performance for FTSE100 and S&P 500 Firms
Economic analysts, expert commentators and the business media have occasionally cited the high rate of unemployment in U.S as an aspect, which depicts the stock, and economic market health. In general, a drop or rise in the rate of unemployment is either good or bad for stocks. When the U.S markets had been showing significant improvements, investors and companies found themselves confronted by major obstacles. In essence, there can be no company, which has been immune from the effects of unemployment in economic perspective. There are various ways by which, negative job reports affected FTSE 100 and S&P 500 companies. This is because it directly affects the economy of a country in general. Unemployment issue had been so broad and continue to be so to an extent that some investors so it better to capture the entire economy through buying stock from such companies as DIA or SPY (Izzo, 2014, 2).
How does the rate of unemployment really affect S&P 500 as well as FTSE 100? The rate of employment is significant for the government’s short-term interest action rate. Further, it also affects in one way or another stock markets, and investors. The logic behind this aspect is that as people lack, or loose jobs to earn income from, their spending is decreased, and therefore, business would not sell much, and would realize a low return rate. Unemployment rate is can hence be related to the performance of the stock market. Essentially, the monthly employment report is a good indicator of the nation’s economy.
Another aspect on the contribution of the high unemployment rate to a company performance is that people generally do not have money to spend in comparison to an economy where majority of people are employed. This means that, business organizations will not be able to make much money the same way if people were employed. In circumstances where a huge number of people have no jobs, many business organizations ether strive to survive or they have to close due to lack of selling. When many people become unemployed, the available amount of money with the public for spending becomes low. Hence, individuals will not be able to buy from companies what they actually need. This subsequently affects businesses in direct way since the profits or sales will come down (Tufte, 2010,45).
Reference List
Alan, G 2009, ‘Progress Toward Price Stability: A 1998 Inflation
Report’Federal Reserve Bank of Kansas City Economic Review, First Quarter, (84),5-20.
Clark, J. M. 2012, ‘Business Acceleration and the Law of Demand’ Journal
of Political Economy, Vol. 25, No. 1 (March), 217-235.
Edward,R 2011, ‘The Future Income Hypothesis’ The Southern Economic
Journal, 34(July), 40-52
Fair, R 2012. ‘The Effects of Economic Events on Votes for President, 1992
Update’ Political Behavior, June, 119-39.
Garner, A 2010, ‘Progress Toward Price Stability: A 1998 Inflation Report’
Federal Reserve Bank of Kansas City Economic Review, First Quarter, (84), 5-20.
FTSE, 2014, ‘UK Quarterly R’, Available
Gallagher, G. and Associates 2009, ‘GRE Economics Test(Piscataway, New
Jersey: Research and Education Association
Hershey, R 2011. ‘An Inflation Index Is Said to Overstate the Case’
The New York Times, January 11, D1 and D15.Izzo, P 2014, ‘Chained CPI, Stocks and Unemployment, Imports’
Available from
JeeYeon, P, 2013, ‘CNBC’. Available from
Kay, W 2012, ‘HBOS fury as EU backs Santander's Abbey bid’. The Independent London.
Lang, L. and R. Stulz 2011, ‘Corporate Diversification and Firm Performance’, Journal of
Political Economy, Vol. 102, pp. 142-174
Leland, H.E. 2013, ‘Agency Costs, RiskManagement, and Capital Structure’,
Journal of 42 Finance , Vol. 53, pp. 1213-1243
Mckay, P 2013, ‘S&P Indices Index Mathematics Methodology’, McGraw-Hill Companies
Michael, E 2011, ‘Macroeconomic Activity: Theory, Forecasting, and
Control’ New York: Harper & Row.
Peterson, R 2013, ‘Valuation and Risk Strategies’, Standardandpoors.com, McGraw Hill
Renshaw, E, 2013, ‘The Stock Market, Economic Recession and Business Cycle With an Emphasis’
Available
Sommer, J 2008. ‘A Friday Rally Can't Save the Week’. The New York Times.
Samuelson, P 2011, ‘A Statistical Analysis of the Consumption Function, in
the appendix to chapter 11 of A. H. Hansen, Fiscal Policy and Business Cycles.
Snowdon, B 2012, ‘A Modern Guide to Macroeconomics(Brookfield Vermont:
Edward Elgar Publishing Company
Thomson, M 2014, ‘Lookout Report from S&P Valuation and Risk Strategies’, Available from
Tufte, E 2010, ‘Political Control of the Economy’ Princeton: New Jersey:
Princeton University Press. | https://hubpages.com/business/THE-CAUSE-FOR-FAILURE-IN-THE-PURSUIT-OF-SHAREHOLDER-VALUE-FOR-FTSE-100-AND-SP500-COMPANIES | CC-MAIN-2017-22 | refinedweb | 2,374 | 50.57 |
Hi,
I'm a newbie to C# programming and .NET framework.
I have the following q's
1. Can i send the SOAP/HTTP request to apache server
(apache doesnt host a web service(in this case)
2. I need to extract the SOAP message by the extension module (i have written
for apache) and forward it to my Appserver?
All i need is a way to send SOAP request to Apache which should be processed
by the extension module.
I tried using C# client with configuration options of the client as follows
(there is no .NET server)
<configuration>
<system.runtime.remoting>
<application name="AdderClient">
<client url="http://<ip-addr>/RemotingAdder">
<wellknown type="Adder.AdderService, Adder" url="http://<ipaddr>/RemotingAdder/AdderService.soap"
/>
</client>
<channels>
<channel ref="http client" />
</channels>
</application>
</system.runtime.remoting>
</configuration>
Is there any configuration changes needed on Apache server?
Please clarify.
Thanks,
sathya
I saw this on one of my travels and thought it might help.
Michael
" A C# SOAP Apache Client
Submitted By User Level Date of Submission
Robert Keith Intermediate 04/26/2002
Introduction
First of all, let me tell you that I am not a C# expert. I am primarily a
Java developer but have been experimenting C# and the .NET platform. Basically
I am developing a SOAP Web Service using Java and Apache SOAP, and have decided
to give my clients an option when and how they access the service. Hence
I am going to provide a Web/JSP user interface and a native Windows application
written in C#. My main motivation for writing this article is that fact that
I could not find anything else like it on the web. There were plenty of articles
telling me how I can use the Apache SOAP API to use a .NETTM service, but
not the other way round.
We'll start with a refresher on some of the terminology I will be using:
SOAP:-
Apache SOAP:- The Apache Foundations implementation of the SOAP protocol
written in Java.
C#:- C# (pronounced "C-sharp") is a new object-oriented programming language
from Microsoft, which aims to combine the computing power of C++ with the
programming ease of Visual Basic. C# is based on C++ and contains features
similar to those of Java.
Please note that this document does not covering installing Apache Tomcat,
Apache SOAP or the .NETTM SDK. See the resources section for more information
and links to all these projects.
Summary
In order to make use of a Apache SOAP web service using C# you need to do
the following steps:
Create a proxy class that implements all the methods you want to be able
to call from your client. This class needs to extend the System.Web.Services.Protocols.SoapHttpClientProtocol
The constructor of this class needs to set the URL property of the above
class. Basically this will be the URL of the Apache SOAP rpcrouter servlet
e.g.
The proxy class needs to have a WebServiceBindingAttribute set. This defines
the name of the web service and the namespace that the service is to use.
The Name is usually the ID of the Apache SOAP Service. The namespace is usually
the URL of the server hosting the service.
You will need to define a method in the proxy for each method that the service
supports and the client wants to use. This method will need to match the
signature of the method in the web service itself i.e. if your service defines
a method called deleteItem which takes a string as an argument, you will
need to define a method in the proxy class called deleteItem(string id).
Each method will need to have an associated SoapDocumentMethodAttribute,
this defines the SOAPAction, as well as the name of the Apache SOAP Service
that you are connecting to. It also defines the XML encoding style and how
the parameters are formatted in the body of the SOAP request.
Each method will then make use of the Invoke method provided by the SoapHttpClientProtocol
class to actually call the method on the web service and get the result.
Your client class will then simply need to create an instance of the proxy
you have just created, and make calls on the method that it implements, the
proxy handles sending the requests to the Apache SOAP server and retrieving
the results.
Details
Ok let's get down to business, the above list gave you a brief overview of
the process, I am now going to expand on it and show you the code that I
used to talk to my service.
The Service
I'll start by giving you the code to my Apache SOAP service:
package com.konnect.soap;
public class HelloService
{
public String hello(String name)
{
return "Hello "+name+" pleased to meet you";
}
}
That's it, now all you have to do it compile the class, and place it in a
location that Apache SOAP can load it from, and then deploy it using the
Apache SOAP admin tool. In this example I have given the service an ID of
"urn:HelloService".
The C# Proxy Class
Since I wrote the service I know the exact signature of all the methods in
my service. So my proxy class only needs to implement 1 method. The code
is below:
namespace HelloService
{
using System.Diagnostics;
using System.Xml.Serialization;
using System;
using System.Web.Services;
using System.Web.Services.Protocols;
[System.Web.Services.WebServiceBindingAttribute(Name="urn:ItemManager",Namespace=
"")]
public class HelloProxy: System.Web.Services.Protocols.SoapHttpClientProtocol
{
public HelloProxy()
{
//You will need to adjust this Url to reflect the location of your service.
this.Url = "";
}
/* The following attribute tells the Soap client how to
* encode the data it sends to the Url as well as which
* service on the server the request is for.
*
* Don't worry all is explain later in the article
*/
[System.Web.Services.Protocols.SoapDocumentMethodAttribute
("",RequestNamespace="urn:HelloService",ResponseNamespace="urn:HelloService",Use=
System.Web.Services.Description.SoapBindingUse.Encoded, ParameterStyle=
System.Web.Services.Protocols.SoapParameterStyle.Wrapped)]
public string hello(string name)
{
/* Call the Invoke method with the method
* name, and its arguments as an array of objects.
*/
object [] results = this.Invoke("hello",new object[] { name });
/* we know that the result is a string, so we can
* safely cast it to the correct type
* we also know we are only expecting a singe object
* to be returned so only return the 1st element
*/
return ((string)(results[0]));
}
}
}//End of HelloService Namespace
Looks pretty simple doesn't it. The only thing that really needs to be explained
are the sections of the code in '[' brackets. Basically these are attributes
associated with the method/class that provide extra information about the
method/class.
The WebServiceBindingAttribute declares that methods within this class will
bind to a XML service. The methods that bind to an XML service need to define
how they intend to send and receive SOAP messages, this is done via the SoapDocumentMethodAttribute.
This attribute specifies the SOAPAction(nothing in our case), the request
and response namespaces. When it comes to Apache SOAP these namespaces actually
define the service ID that all calls should be directed to. The final 2 parameters
define how parameters to the method are to be encoded, and how they should
be formatted in the body section of the SOAP envelope.
There are 2 main types of encoding Literal, and Encoded, Literal encoding
does not provide any extra hints as to the type of the parameter being sent
across the wire. Encoded however does provide this extra information. In
order for you to interact with Apache SOAP services you will need to ensure
that you always use Encoded parameters. This is because Apache SOAP does
not try to guess what a parameter is, it would rather be told what it is.
There are 2 format options, wrapped and bare. Wrapped seems to give me the
most success when working with Apache SOAP services, Apache SOAP complains
and throws and exception when Bare parameters are sent across.
We need to complile this class as a library(DLL), and then reference it when
we compile our client. This is done using the following command:
csc /t:library HelloService.cs
This should give us a HelloService.dll file in our current directory.
The Client
The final step. The listing for the client is below:
namespace HelloService
{
public class HelloClient
{
public static void Main(String [] args)
{
HelloService service = new HelloService();
Console.WriteLine(service.hello("Robert"));
}
}
}//End of the HelloService namespace
All we have to do now is compile the above class. This is done using the
command:
csc HelloClient.cs /r:HelloService.dll
We should now have a HelloClient executable in our current directory. Now
if we start Tomcat with Apache SOAP installed, and ensure we have deployed
our service. We should be able to run our client and get a response from
the server that looks like this:
Hello Robert pleased to meet you.
If you are interested in seeing what is being sent across the wire, you can
make use of the TcpTunnelGui that comes with the Apache SOAP package. This
allows you to dump all traffic sent to a specific port, and then forward
it on to the real location.
In order to see what is going on, adjust the Url parameter you specified
in the HelloService C# class have a port of 8070. Then start the TcpTunnelGui
using the following command:
java -jar <path to soap.jar> org.apache.soap.util.net.TcpTunnelGui 8070 localhost
8080
This assumes that Tomcat is running on your local machine on port 8080, and
that you want the tunnel to listen on port 8070. If you run the client again
you should see the SOAP request being sent, and the associated responses
from the Apache SOAP server.
Resources
Apache Tomcat:-
Apache-SOAP:-
.NETTM SDK:- msdn.microsoft.com
The C# Corner:-
--------------------------------------------------------------------------------
About the Author Robert Keith
Konnect Services
Hi Michael,
i tried what u have posted i was able to invoke a java method and
i also got message in apache soap server
but the message was not returend back......
Console.WriteLine(service.getAddressFromName("John B. Good"));
i had sent name as "john b good" to the below one......
public string getAddressFromName(string name)
{
object[] results = this.Invoke("getAddressFromName", new object[] { name });
return ((string)(results[0]));
}
the o/p i got was nothing
what should i get was the address of john
the address was lying in soap server but it didn't returned to .net client
please help me out....
sandeep patil
sandeepp@cislworld.com
--------------
Forum Rules
Development Centers
-- Android Development Center
-- Cloud Development Project Center
-- HTML5 Development Center
-- Windows Mobile Development Center | http://forums.devx.com/showthread.php?16392-C-client-sending-SOAP-HTTP-request-to-Apache-server&p=37362 | CC-MAIN-2015-11 | refinedweb | 1,775 | 62.68 |
Frequently Asked Questions¶
Contents
- Frequently Asked Questions
- What is the key idea of Snakemake workflows?
- Snakemake does not connect my rules as I have expected, what can I do to debug my dependency structure?
- My shell command fails with with errors about an “unbound variable”, what’s wrong?
- My shell command fails with exit code != 0 from within a pipe, what’s wrong?
- I don’t want Snakemake to detect an error if my shell command exits with an exitcode > 1. What can I do?
- How do I run my rule on all files of a certain directory?
- I don’t want expand to use the product of every wildcard, what can I do?
- I don’t want expand to use every wildcard, what can I do?
- Snakemake complains about a cyclic dependency or a PeriodicWildcardError. What can I do?
- Is it possible to pass variable values to the workflow via the command line?
- I get a NameError with my shell command. Are braces unsupported?
- How do I incorporate files that do not follow a consistent naming scheme?
- How do I force Snakemake to rerun all jobs from the rule I just edited?
- How should Snakefiles be formatted?
- How do I enable syntax highlighting in Vim for Snakefiles?
- I want to import some helper functions from another python file. Is that possible?
- How can I run Snakemake on a cluster where its main process is not allowed to run on the head node?
- Can the output of a rule be a symlink?
- Can the input of a rule be a symlink?
- I would like to receive a mail upon snakemake exit. How can this be achieved?
- I want to pass variables between rules. Is that possible?
- Why do my global variables behave strangely when I run my job on a cluster?
- I want to configure the behavior of my shell for all rules. How can that be achieved with Snakemake?
- Some command line arguments like –config cannot be followed by rule or file targets. Is that intended behavior?
- How do I enforce config values given at the command line to be interpreted as strings?
- How do I make my rule fail if an output file is empty?
- How does Snakemake lock the working directory?
- Snakemake does not trigger re-runs if I add additional input files. What can I do?
- How do I trigger re-runs for rules with updated code or parameters?
- How do I remove all files created by snakemake, i.e. like
make clean
- Why can’t I use the conda directive with a run block?
- My workflow is very large, how do I stop Snakemake from printing all this rule/job information in a dry-run?
- Git is messing up the modification times of my input files, what can I do?
- How do I exit a running Snakemake workflow?
- How can I make use of node-local storage when running cluster jobs?
- How do I access elements of input or output by a variable index?
- There is a compiler error when installing Snakemake with pip or easy_install, what shall I do?
- How to enable autocompletion for the zsh shell?
What is the key idea of Snakemake workflows?¶
The key idea is very similar to GNU Make. The workflow is determined automatically from top (the files you want) to bottom (the files you have), by applying very general rules with wildcards you give to Snakemake:
When you start using Snakemake, please make sure to walk through the official tutorial. It is crucial to understand how to properly use the system.
Snakemake does not connect my rules as I have expected, what can I do to debug my dependency structure?¶
Since dependencies are inferred implicitly, results can sometimes be suprising when little errors are made in filenames or when input functions raise unexpected errors.
For debugging such cases, Snakemake provides the command line flag
--debug-dag that leads to printing details each decision that is taken while determining the dependencies.
In addition, it is advisable to check whether certain intermediate files would be created by targetting them individually via the command line.
Finally, it is possible to constrain the rules that are considered for DAG creating via
--allowed-rules.
This way, you can easily check rule by rule if it does what you expect.
However, note that
--allowed-rules is only meant for debugging.
A workflow should always work fine without it.
My shell command fails with with errors about an “unbound variable”, what’s wrong?¶
This happens often when calling virtual environments from within Snakemake. Snakemake is using bash strict mode, to ensure e.g. proper error behavior of shell scripts. Unfortunately, virtualenv and some other tools violate bash strict mode. The quick fix for virtualenv is to temporarily deactivate the check for unbound variables
set +u; source /path/to/venv/bin/activate; set -u
For more details on bash strict mode, see the here.
My shell command fails with exit code != 0 from within a pipe, what’s wrong?¶
Snakemake is using bash strict mode to ensure best practice error reporting in shell commands. This entails the pipefail option, which reports errors from within a pipe to outside. If you don’t want this, e.g., to handle empty output in the pipe, you can disable pipefail via prepending
set +o pipefail;
to your shell command in the problematic rule.
I don’t want Snakemake to detect an error if my shell command exits with an exitcode > 1. What can I do?¶
Sometimes, tools encode information in exit codes bigger than 1. Snakemake by default treats anything > 0 as an error. Special cases have to be added by yourself. For example, you can write
shell: """ set +e somecommand ... exitcode=$? if [ $exitcode -eq 1 ] then exit 1 else exit 0 fi """
This way, Snakemake only treats exit code 1 as an error, and thinks that everything else is fine. Note that such tools are an excellent use case for contributing a wrapper.
How do I run my rule on all files of a certain directory?¶
In Snakemake, similar to GNU Make, the workflow is determined from the top, i.e. from the target files. Imagine you have a directory with files
1.fastq, 2.fastq, 3.fastq, ..., and you want to produce files
1.bam, 2.bam, 3.bam, ... you should specify these as target files, using the ids
1,2,3,.... You could end up with at least two rules like this (or any number of intermediate steps):
IDS = "1 2 3 ...".split() # the list of desired ids # a pseudo-rule that collects the target files rule all: input: expand("otherdir/{id}.bam", id=IDS) # a general rule using wildcards that does the work rule: input: "thedir/{id}.fastq" output: "otherdir/{id}.bam" shell: "..."
Snakemake will then go down the line and determine which files it needs from your initial directory.
In order to infer the IDs from present files, Snakemake provides the
glob_wildcards function, e.g.
IDS, = glob_wildcards("thedir/{id}.fastq")
The function matches the given pattern against the files present in the filesystem and thereby infers the values for all wildcards in the pattern. A named tuple that contains a list of values for each wildcard is returned. Here, this named tuple has only one item, that is the list of values for the wildcard
{id}.
I don’t want expand to use the product of every wildcard, what can I do?¶
By default the expand function uses
itertools.product to create every combination of the supplied wildcards.
Expand takes an optional, second positional argument which can customize how wildcards are combined.
To create the list
["a_1.txt", "b_2.txt", "c_3.txt"], invoke expand as:
expand("{sample}_{id}.txt", zip, sample=["a", "b", "c"], id=["1", "2", "3"])
I don’t want expand to use every wildcard, what can I do?¶
Sometimes partially expanding wildcards is useful to define inputs which still depend on some wildcards.
Expand takes an optional keyword argument, allow_missing=True, that will format only wildcards which are supplied, leaving others as is.
To create the list
["{sample}_1.txt", "{sample}_2.txt"], invoke expand as:
expand("{sample}_{id}.txt", id=["1", "2"], allow_missing=True)
If the filename contains the wildcard
allow_missing, it will be formatted normally:
expand("{allow_missing}.txt", allow_missing=True) returns
["True.txt"].
Snakemake complains about a cyclic dependency or a PeriodicWildcardError. What can I do?¶
One limitation of Snakemake is that graphs of jobs have to be acyclic (similar to GNU Make). This means, that no path in the graph may be a cycle. Although you might have considered this when designing your workflow, Snakemake sometimes runs into situations where a cyclic dependency cannot be avoided without further information, although the solution seems obvious for the developer. Consider the following example:
rule all: input: "a" rule unzip: input: "{sample}.tar.gz" output: "{sample}" shell: "tar -xf {input}"
If this workflow is executed with
snakemake -n
two things may happen.
If the file
a.tar.gzis present in the filesystem, Snakemake will propose the following (expected and correct) plan:
rule a: input: a.tar.gz output: a wildcards: sample=a localrule all: input: a Job counts: count jobs 1 a 1 all 2
If the file
a.tar.gzis not present and cannot be created by any other rule than rule
a, Snakemake will try to run rule
aagain, with
{sample}=a.tar.gz. This would infinitely go on recursively. Snakemake detects this case and produces a
PeriodicWildcardError.
In summary,
PeriodicWildcardErrors hint to a problem where a rule or a set of rules can be applied to create its own input. If you are lucky, Snakemake can be smart and avoid the error by stopping the recursion if a file exists in the filesystem. Importantly, however, bugs upstream of that rule can manifest as
PeriodicWildcardError, although in reality just a file is missing or named differently.
In such cases, it is best to restrict the wildcard of the output file(s), or follow the general rule of putting output files of different rules into unique subfolders of your working directory. This way, you can discover the true source of your error.
Is it possible to pass variable values to the workflow via the command line?¶
Yes, this is possible. Have a look at Configuration. Previously it was necessary to use environment variables like so: E.g. write
$ SAMPLES="1 2 3 4 5" snakemake
and have in the Snakefile some Python code that reads this environment variable, i.e.
SAMPLES = os.environ.get("SAMPLES", "10 20").split()
I get a NameError with my shell command. Are braces unsupported?¶
You can use the entire Python format minilanguage in shell commands. Braces in shell commands that are not intended to insert variable values thus have to be escaped by doubling them:
This:
... shell: "awk '{print $1}' {input}"
becomes:
... shell: "awk '{{print $1}}' {input}"
Here the double braces are escapes, i.e. there will remain single braces in the final command. In contrast,
{input} is replaced with an input filename.
In addition, if your shell command has literal backslashes,
\\, you must escape them with a backslash,
\\\\. For example:
This:
shell: """printf \">%s\"" {{input}}"""
becomes:
shell: """printf \\">%s\\"" {{input}}"""
How do I incorporate files that do not follow a consistent naming scheme?¶
The best solution is to have a dictionary that translates a sample id to the inconsistently named files and use a function (see Functions as Input Files) to provide an input file like this:
FILENAME = dict(...) # map sample ids to the irregular filenames here rule: # use a function as input to delegate to the correct filename input: lambda wildcards: FILENAME[wildcards.sample] output: "somefolder/{sample}.csv" shell: ...
How do I force Snakemake to rerun all jobs from the rule I just edited?¶
This can be done by invoking Snakemake with the
--forcerules or
-R flag, followed by the rules that should be re-executed:
$ snakemake -R somerule
This will cause Snakemake to re-run all jobs of that rule and everything downstream (i.e. directly or indirectly depending on the rules output).
How should Snakefiles be formatted?¶
To ensure readability and consistency, you can format Snakefiles with our tool snakefmt.
Python code gets formatted with black and Snakemake-specific blocks are formatted using similar principles (such as PEP8).
How do I enable syntax highlighting in Vim for Snakefiles?¶
Instructions for doing this are located here.
Note that you can also format Snakefiles in Vim using snakefmt, with instructions located here!
I want to import some helper functions from another python file. Is that possible?¶
Yes, from version 2.4.8 on, Snakemake allows to import python modules (and also simple python files) from the same directory where the Snakefile resides.
How can I run Snakemake on a cluster where its main process is not allowed to run on the head node?¶
This can be achived by submitting the main Snakemake invocation as a job to the cluster. If it is not allowed to submit a job from a non-head cluster node, you can provide a submit command that goes back to the head node before submitting:
qsub -N PIPE -cwd -j yes python snakemake --cluster "ssh user@headnode_address 'qsub -N pipe_task -j yes -cwd -S /bin/sh ' " -j
This hint was provided by Inti Pedroso.
Can the output of a rule be a symlink?¶
Yes. As of Snakemake 3.8, output files are removed before running a rule and then touched after the rule completes to ensure they are newer than the input. Symlinks are treated just the same as normal files in this regard, and Snakemake ensures that it only modifies the link and not the target when doing this.
Here is an example where you want to merge N files together, but if N == 1 a symlink will do. This is easier than attempting to implement workflow logic that skips the step entirely. Note the -r flag, supported by modern versions of ln, is useful to achieve correct linking between files in subdirectories.
rule merge_files: output: "{foo}/all_merged.txt" input: my_input_func # some function that yields 1 or more files to merge run: if len(input) > 1: shell("cat {input} | sort > {output}") else: shell("ln -sr {input} {output}")
Do be careful with symlinks in combination with Step 6: Temporary and protected files. When the original file is deleted, this can cause various errors once the symlink does not point to a valid file any more.
If you get a message like
Unable to set utime on symlink .... Your Python build does not support it. this means that Snakemake is unable to properly adjust the modification time of the symlink.
In this case, a workaround is to add the shell command touch -h {output} to the end of the rule.
Can the input of a rule be a symlink?¶
Yes. In this case, since Snakemake 3.8, one extra consideration is applied. If either the link itself or the target of the link is newer than the output files for the rule then it will trigger the rule to be re-run.
I would like to receive a mail upon snakemake exit. How can this be achieved?¶
On unix, you can make use of the commonly pre-installed mail command:
snakemake 2> snakemake.log mail -s "snakemake finished" youremail@provider.com < snakemake.log
In case your administrator does not provide you with a proper configuration of the sendmail framework, you can configure mail to work e.g. via Gmail (see here).
I want to pass variables between rules. Is that possible?¶
Because of the cluster support and the ability to resume a workflow where you stopped last time, Snakemake in general should be used in a way that information is stored in the output files of your jobs. Sometimes it might though be handy to have a kind of persistent storage for simple values between jobs and rules. Using plain python objects like a global dict for this will not work as each job is run in a separate process by snakemake. What helps here is the PersistentDict from the pytools package. Here is an example of a Snakemake workflow using this facility:
from pytools.persistent_dict import PersistentDict storage = PersistentDict("mystorage") rule a: input: "test.in" output: "test.out" run: myvar = storage.fetch("myvar") # do stuff rule b: output: temp("test.in") run: storage.store("myvar", 3.14)
Here, the output rule b has to be temp in order to ensure that
myvar is stored in each run of the workflow as rule a relies on it. In other words, the PersistentDict is persistent between the job processes, but not between different runs of this workflow. If you need to conserve information between different runs, use output files for them.
Why do my global variables behave strangely when I run my job on a cluster?¶
This is closely related to the question above. Any Python code you put outside of a rule definition is normally run once before Snakemake starts to process rules, but on a cluster it is re-run again for each submitted job, because Snakemake implements jobs by re-running itself.
Consider the following…
from mydatabase import get_connection dbh = get_connection() latest_parameters = dbh.get_params().latest() rule a: input: "{foo}.in" output: "{foo}.out" shell: "do_op -params {latest_parameters} {input} {output}"
When run a single machine, you will see a single connection to your database and get a single value for latest_parameters for the duration of the run. On a cluster you will see a connection attempt from the cluster node for each job submitted, regardless of whether it happens to involve rule a or not, and the parameters will be recalculated for each job.
I want to configure the behavior of my shell for all rules. How can that be achieved with Snakemake?¶
You can set a prefix that will prepended to all shell commands by adding e.g.
shell.prefix("set -o pipefail; ")
to the top of your Snakefile. Make sure that the prefix ends with a semicolon, such that it will not interfere with the subsequent commands. To simulate a bash login shell, you can do the following:
shell.executable("/bin/bash") shell.prefix("source ~/.bashrc; ")
Some command line arguments like –config cannot be followed by rule or file targets. Is that intended behavior?¶
This is a limitation of the argparse module, which cannot distinguish between the perhaps next arg of
--config and a target.
As a solution, you can put the –config at the end of your invocation, or prepend the target with a single
--, i.e.
$ snakemake --config foo=bar -- mytarget $ snakemake mytarget --config foo=bar
How do I enforce config values given at the command line to be interpreted as strings?¶
When passing config values like this
$ snakemake --config version=2018_1
Snakemake will first try to interpret the given value as number. Only if that fails, it will interpret the value as string. Here, it does not fail, because the underscore _ is interpreted as thousand separator. In order to ensure that the value is interpreted as string, you have to pass it in quotes. Since bash otherwise automatically removes quotes, you have to also wrap the entire entry into quotes, e.g.:
$ snakemake --config 'version="2018_1"'
How do I make my rule fail if an output file is empty?¶
Snakemake expects shell commands to behave properly, meaning that failures should cause an exit status other than zero. If a command does not exit with a status other than zero, Snakemake assumes everything worked fine, even if output files are empty. This is because empty output files are also a reasonable tool to indicate progress where no real output was produced. However, sometimes you will have to deal with tools that do not properly report their failure with an exit status. Here, the recommended way is to use bash to check for non-empty output files, e.g.:
rule: input: ... output: "my/output/file.txt" shell: "somecommand {input} {output} && [[ -s {output} ]]"
How does Snakemake lock the working directory?¶
Per default, Snakemake will lock a working directory by output and input files. Two Snakemake instances that want to create the same output file are not possible. Two instances creating disjoint sets of output files are possible.
With the command line option
--nolock, you can disable this mechanism on your own risk. With
--unlock, you can be remove a stale lock. Stale locks can appear if your machine is powered off with a running Snakemake instance.
Snakemake does not trigger re-runs if I add additional input files. What can I do?¶
Snakemake has a kind of “lazy” policy about added input files if their modification date is older than that of the output files. One reason is that information what to do cannot be inferred just from the input and output files. You need additional information about the last run to be stored. Since behaviour would be inconsistent between cases where that information is available and where it is not, this functionality has been encoded as an extra switch. To trigger updates for jobs with changed input files, you can use the command line argument –list-input-changes in the following way:
$ snakemake -n -R `snakemake --list-input-changes`
Here,
snakemake --list-input-changes returns the list of output files with changed input files, which is fed into
-R to trigger a re-run.
How do I trigger re-runs for rules with updated code or parameters?¶
Similar to the solution above, you can use
$ snakemake -n -R `snakemake --list-params-changes`
and
$ snakemake -n -R `snakemake --list-code-changes`
Again, the list commands in backticks return the list of output files with changes, which are fed into
-R to trigger a re-run.
How do I remove all files created by snakemake, i.e. like
make clean¶
To remove all files created by snakemake as output files to start from scratch, you can use
$ snakemake some_target --delete-all-output
Only files that are output of snakemake rules will be removed, not those that serve as primary inputs to the workflow.
Note that this will only affect the files involved in reaching the specified target(s).
It is strongly advised to first run together with
--dry-run to list the files that would be removed without actually deleting anything.
The flag
--delete-temp-output can be used in a similar manner to only delete files flagged as temporary.
Why can’t I use the conda directive with a run block?¶
The run block of a rule (see Snakefiles and Rules) has access to anything defined in the Snakefile, outside of the rule. Hence, it has to share the conda environment with the main Snakemake process. To avoid confusion we therefore disallow the conda directive together with the run block. It is recommended to use the script directive instead (see External scripts).
My workflow is very large, how do I stop Snakemake from printing all this rule/job information in a dry-run?¶
Indeed, the information for each individual job can slow down a dry-run if there are tens of thousands of jobs.
If you are just interested in the final summary, you can use the
--quiet flag to suppress this.
$ snakemake -n --quiet
Git is messing up the modification times of my input files, what can I do?¶
When you checkout a git repository, the modification times of updated files are set to the time of the checkout. If you rely on these files as input and output files in your workflow, this can cause trouble. For example, Snakemake could think that a certain (git-tracked) output has to be re-executed, just because its input has been checked out a bit later. In such cases, it is advisable to set the file modification dates to the last commit date after an update has been pulled. One solution is to add the following lines to your
.bashrc (or similar):
gitmtim(){ local f for f; do touch -d @0`git log --pretty=%at -n1 -- "$f"` "$f" done } gitmodtimes(){ for f in $(git ls-tree -r $(git rev-parse --abbrev-ref HEAD) --name-only); do gitmtim $f done }
(inspired by the answer here). You can then run
gitmodtimes to update the modification times of all tracked files on the current branch to their last commit time in git; BE CAREFUL–this does not account for local changes that have not been commited.
How do I exit a running Snakemake workflow?¶
There are two ways to exit a currently running workflow.
If you want to kill all running jobs, hit Ctrl+C. Note that when using
--cluster, this will only cancel the main Snakemake process.
If you want to stop the scheduling of new jobs and wait for all running jobs to be finished, you can send a TERM signal, e.g., via
killall -TERM snakemake
How can I make use of node-local storage when running cluster jobs?¶
When running jobs on a cluster you might want to make use of a node-local scratch
directory in order to reduce cluster network traffic and/or get more efficient disk
storage for temporary files. There is currently no way of doing this in Snakemake,
but a possible workaround involves the
shadow directive and setting the
--shadow-prefix flag to e.g.
/scratch.
rule: output: "some_summary_statistics.txt" shadow: "minimal" shell: """ generate huge_file.csv summarize huge_file.csv > {output} """
The following would then lead to the job being executed in
/scratch/shadow/some_unique_hash/, and the
temporary file
huge_file.csv could be kept at the compute node.
$ snakemake --shadow-prefix /scratch some_summary_statistics.txt --cluster ...
If you want the input files of your rule to be copied to the node-local scratch directory
instead of just using symbolic links, you can use
copy-minimal in the
shadow directive.
This is useful for example for benchmarking tools as a black-box.
rule: input: "input_file.txt" output: "{output.benchmark}" """
Executing snakemake as above then leads to the shell script accessing only node-local storage.
How do I access elements of input or output by a variable index?¶
Assuming you have something like the following rule
rule a: output: expand("test.{i}.out", i=range(20)) run: for i in range(20): shell("echo test > {output[i]}")
Snakemake will fail upon execution with the error
'OutputFiles' object has no attribute 'i'. The reason is that the shell command is using the Python format mini language, which does only allow indexing via constants, e.g.,
output[1], but not via variables. Variables are treated as attribute names instead. The solution is to write
rule a: output: expand("test.{i}.out", i=range(20)) run: for i in range(20): f = output[i] shell("echo test > {f}")
or, more concise in this special case:
rule a: output: expand("test.{i}.out", i=range(20)) run: for f in output: shell("echo test > {f}")
There is a compiler error when installing Snakemake with pip or easy_install, what shall I do?¶
Snakemake itself is plain Python, hence the compiler error must come from one of the dependencies, like e.g., datrie. You should have a look if maybe you are missing some library or a certain compiler package. If everything seems fine, please report to the upstream developers of the failing dependency.
Note that in general it is recommended to install Snakemake via Conda which gives you precompiled packages and the additional benefit of having automatic software deployment integrated into your workflow execution.
How to enable autocompletion for the zsh shell?¶
For users of the Z shell (zsh), just run the following (assuming an activated zsh) to activate autocompletion for snakemake:
compdef _gnu_generic snakemake
Example:
Say you have forgotten how to use the various options starting
force, just type the partial match i.e.
--force which results in a list of all potential hits along with a description:
$snakemake --force**pressing tab** --force -- Force the execution of the selected target or the --force-use-threads -- Force threads rather than processes. Helpful if shared --forceall -- Force the execution of the selected (or the first) --forcerun -- (TARGET (TARGET ...)), -R (TARGET (TARGET ...))
To activate this autocompletion permanently, put this line in
~/.zshrc.
Here is some further reading. | https://snakemake.readthedocs.io/en/stable/project_info/faq.html | CC-MAIN-2021-39 | refinedweb | 4,697 | 65.12 |
From: Peter Dimov (pdimov_at_[hidden])
Date: 2002-01-28 07:29:05
From: "Yitzhak Sapir" <ysapir_at_[hidden]>
> Hi. I would like to make a request as a user: Can all the
> functions/classes in the subject line (and perhaps others) be defined
> with a macro BOOST_BIND_INLINE or BOOST_FUNCTIONAL_INLINE, etc. Then at
> the top of the headers define the macro as either
> #ifndef BOOST_BIND_INLINE
> #define BOOST_BIND_INLINE inline
> #endif
[...]
> Which defines ptr as const in respect to the class. I'm not sure, but
> I'd guess this would help it optimize...
No, there is usually no need for "inline" here; it's implied in in-class
member functions, and in general what counts is whether the function is
visible to the compiler, not whether it has "inline" or not. With MSVC, you
should try -Ob2 to let the compiler inline whatever it wants.
> Another issue with regards to bind is that when I use the bind in
> several statically linked libs, I get multiple definition errors, which
> I solved by going and making the _1 - _9 externs and defining them in my
> own bind.cpp.
_Ns are defined in an unnamed namespace, so there should be no conflicts; I
don't know why this happens in your case, perhaps you are using the same
source file in different static libraries and the compiler picks the same
"unique" name for the unnamed namespace?
> Could they be macros?
No. :-)
> I actually wouldn't mind it if
> they were boost::arg<1>() etc.
Yes, this is something that I'm considering.
> What about regarding bind's ability to get void-returning functions on
> MSVC? Is that being worked on?
Thanks to Dave Abrahams, bind now works with void returning functions on
MSVC. Unfortunately this feature is disabled in 1.26.0 (this version fails
with internal compiler error on MSVC 6 w/ debug info on) but the newest
version from CVS works (be sure to update the bind/ subdirectory as well.)
-- Peter Dimov Multi Media Ltd.
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk | https://lists.boost.org/Archives/boost/2002/01/23885.php | CC-MAIN-2022-21 | refinedweb | 354 | 73.27 |
This is my first post on this forum, so I hope I am doing this right.
I am getting some strange behavior from the CapacitiveSensor library. My setup is just the basic capacitive sensor setup like this:
where the sensor is a piece of metal behind some cardboard and my arduino is powered by my laptop. The connection to the laptop is not ideal as it affects the capacitance.
The minimal code to reproduce my problem:
#include <CapacitiveSensor.h> CapacitiveSensor capSensor = CapacitiveSensor(7, 5); void setup() { Serial.begin(9600); } void loop() { float sensor = capSensor.capacitiveSensor(20); Serial.print("Value: "); Serial.println(sensor); }
If I look at the serial plotter, then initially this seems to work as a capacitive touch sensor. However, The problem I am having is the following:
- Initial sensor value is ~0
- when I hold my hand in front of the metal plate the sensor value goes up to ~45
- after holding it in front of the sensor for about 12 seconds it automatically drops back to ~0
- it remains ~0 for as long as I can tell even though my hand is still in the same place in front of the sensor.
If I now remove my hand and place it back in front of the sensor then it does go back to ~45, but again after about 12 seconds it drops back to ~0 for no reason I can explain.
To make things even stranger I do not always get this behavior. Sometimes it works as it should.
Does anybody have an idea what the problem can be? Is there a bug in the CapacitiveSensor library? | https://forum.arduino.cc/t/capacitivesensor-library-not-working-properly/911160 | CC-MAIN-2021-49 | refinedweb | 270 | 61.06 |
Import redirect module error
I am trying to change a .raw file into another form to be used in matlab. I am initializing the program as
import os import sys PSSE = r"C:\Program Files (x86)\PTI\PSSEXplore34\PSSBIN" sys.path.append(PSSE) os.environ["PATH"] += ";" + PSSE import redirect import psspy
but I am getting the error returned as "ImportError: No module named redirect". How do I install the module redirect? It does not come up as a module when using pip install redirect in command line. How else would I fix this?
Do you have redirect.pyc in PSSBIN folder?
I ended up figuring it out, the redirect.pyc file is in the psspy27 folder instead of pssbin | https://psspy.org/psse-help-forum/question/4510/import-redirect-module-error/ | CC-MAIN-2018-43 | refinedweb | 119 | 61.63 |
How to debug this?BurtJ Oct 5, 2010 5:21 PM
Under Flash Player 10.1 on Windows, we are suddenly getting an error that did not occur under player 9 or 10, and does not appear in any version of player on Mac. The biggest problem is that the entire error stack is inside the Flash framework, initiated by a callLaterDispatcher. Flash complains that an index is out of bounds, but gives zero information on what the parent or child object is, or what the index number is that is being passed.
I have all bug given up trying to find the source of the problem in our code, which runs for several thousand lines, covering half a dozen internally created classes. I see a 'hook' at (C:\autobuild\3.2.0\frameworks\...), but cannot even see that folder on my system? (yes, I have 'show invisible' set for my file system -- this is Windoze XP, for what it's worth).
Any suggestions on how to track down a problem like this?
RangeError: Error #2006: The supplied index is out of bounds.
at flash.display::DisplayObjectContainer/getChildAt()
at mx.core::Container/getChildAt()[C:\autobuild\3.2.0\frameworks\project s\framework\src\mx\core\Container.as:2334]
at fl.managers::FocusManager/addFocusables()
at fl.managers::FocusManager/addFocusables()
at fl.managers::FocusManager/addFocusables()
at fl.managers::FocusManager/addFocusables()
at fl.managers::FocusManager/addFocusables()
at fl.managers::FocusManager/activate()
at fl.managers::FocusManager()
at fl.core::UIComponent/createFocusManager()
at fl.core::UIComponent/initializeFocusManager()
at fl.core::UIComponent/addedHandler()
at flash.display::DisplayObjectContainer/addChild()
at mx.core::Container/[C:\autobuild\3.2.0\frameworks\projects\framework\src\mx\core\Contai ner.as:4665]
at mx.core::Container/createOrDestroyScrollbars()[C:\autobuild\3.2.0\fra meworks\projects\framework\src\mx\core\Container.as:4410]
at mx.core::Container/createScrollbarsIfNeeded()[C:\autobuild\3.2.0\fram eworks\projects\framework\src\mx\core\Container.as:4359]
at mx.core::Container/createContentPaneAndScrollbarsIfNeeded()[C:\autobu ild\3.2.0\frameworks\projects\framework\src\mx\core\Container.as:4175]
at mx.core::Container/validateDisplayList()[C:\autobuild\3.2.0\framework s\projects\framework\src\mx\core\Container.as:2691]
at mx.managers::LayoutManager/validateDisplayList()[C:\autobuild\3.2.0\f rameworks\framew orks\projects\framework\src\mx\core\UIComponent.as:8628]
at mx.core::UIComponent/callLaterDispatcher()[C:\autobuild\3.2.0\framewo rks\projects\framework\src\mx\core\UIComponent.as:8568]
1. Re: How to debug this?Flex harUI
Oct 5, 2010 11:14 PM (in response to BurtJ)1 person found this helpful
Not sure why you are having version-specific problems. This call stack is
typical of mixing Flash fl.. components with Flex components. They are
incompatible.
2. Re: How to debug this?BurtJ Oct 5, 2010 11:22 PM (in response to Flex harUI)
What do you mean that flash and flex are not compatible?? Can you elaborate on that statement?
This is a program with over 1 million users already, and we have had no problems with it until Flash 10.1 was released. Suddenly we got user complaints about it no longer working. When we tested, we discovered this stack dump on launching if Flash 10.1 was running on a Windows XP machine (I am not sure about Vista or 7, but I do know it still works on Mac 10.1).
This was originally developed under Flash 9, then later migrated to 10, at which point we added more improvements. All was well in Leapfrog-land until 10.1 came out...
3. Re: How to debug this?George I Flex Oct 5, 2010 11:53 PM (in response to BurtJ)
Try launching this from the debugger. When the app breaks you can look into the variables/expressions panel and find which component is throwing this. Then look at what children is that component adding/removing.
4. Re: How to debug this?BurtJ Oct 6, 2010 12:09 AM (in response to George I Flex)
uhhh... I AM using the debugger, or I wouldn't be seeing the stack at all. I can't look at the variables though, because the
crash does not occur anywhere in my code. As my original post noted, the entire stack trace is inside the
Flash framework. It starts with a callDelayed method and burrows into the frame
work.
There is nowhere to put a breakpoint in my code...
Or is there a way to get the source code for Flash and actually break in there??
5. Re: How to debug this?George I Flex Oct 6, 2010 12:46 AM (in response to BurtJ)
Yeah, I think I misunderstood.
Normally when you have a flex app, even if breaks in the flash player code, you can still see the debugger freezing and you can find the causing component. When you have a flash component acting as a flex one I think that might not work anymore.
6. Re: How to debug this?Flex harUI
Oct 6, 2010 1:04 PM (in response to BurtJ)1 person found this helpful
fl.. components and mx.. components cannot co-exist. It works sometimes,
but often you will hit these issues with the fl FocusManager.
7. Re: How to debug this?BurtJ Oct 6, 2010 1:38 PM (in response to Flex harUI)
Ouch! We use both extensively in this app. We have 9 inherited classes that we import, that I will have to investigate yet. However, the top of this particular app has the following imports. Looks like I'm got my hands full with a lot of rewriting stuff that has been working for more than a year. This was NOT in our schedule, either for development or SQA...
BTW, thanks for giving me a direction to look, even if it wasn't the type of answer I was hoping for...
import flash.display.DisplayObject;
import flash.display.MovieClip;
import flash.display.Shape;
import flash.events.Event;
import flash.events.IOErrorEvent;
import flash.events.MouseEvent;
import flash.events.TimerEvent;
import flash.filters.ColorMatrixFilter;
import flash.geom.Point;
import flash.utils.Timer;
import mx.controls.Alert;
import mx.controls.Image;
import mx.events.CloseEvent;
import mx.events.ResourceEvent;
import mx.events.StyleEvent;
import mx.rpc.events.FaultEvent;
import mx.rpc.events.ResultEvent;
8. Re: How to debug this?Flex harUI
Oct 6, 2010 5:32 PM (in response to BurtJ)
flash.. is not fl..
You can use all the flash.. stuff you want. Somehow, a fl.. component
got into your app. You can use link-reports to find out how if it isn't
apparent.
9. Re: How to debug this?BurtJ Oct 6, 2010 6:00 PM (in response to Flex harUI)
THANK YOU for that clarification. I was tearing my hair out, since everything I read told me that Flash and Flex were fine partners.
No idea what a fl* component is, or how it got in there. Several of the inherited classes were written by engineers no longer with the company, so I will have to search those, now that I know it is 'fl.*'
Unfortunately I got this message just as I got home, so I will have to wonder all night if this solves the problem or not...
10. Re: How to debug this?Flex harUI
Oct 6, 2010 6:18 PM (in response to BurtJ)
The fl.. components come with the Flash IDE in the CreativeSuite. And
even older versions before that.
If someone starts using the built-in components from the Flash IDE in a Flex
app, trouble like this occurs. The call stack listed an fl.. class which
is why I am offering this as the root cause of the problem. I still don't
see how changing player versions could really cause it unless there was a
subtle timing issue.
You can create your own components in Flash and use them in Flex via the
Flex/Flash Component Kit, but you can't use fl.. components in those
components.
If you don't want to wonder all night, you can always load up on caffeine,
get back in your car and head back to the office. However, if it helps, the
call stack is like a fingerprint. It has implicated the fl.. components.
They will need to be removed at some point.
11. Re: How to debug this?BurtJ Oct 7, 2010 10:32 AM (in response to Flex harUI)
Unfortunately, when I do a search on "fl." in the entire project (in FlexBuilder 3), there are no hits. It does not appear to be in our Flex code.
Searching for 'fl.' on the web looks to me like it is a Flash component used for lists and tweening (at least those were the two most common Google hits). Is that true?
We are using a SWFLoader to load up 4 Flash SWF files that animate on this page (the page lists games the user can play, each with its own 2" X 3" animated index, showing 4 at a time). Those animations were created by an outside contractor, and I do not have the source code for them.
Is it possible that a Flash animator would have used a fl.* component, which would then choke when we display that animation on a Flex Canvas?
(I am trying to find a hook in our code now, that would allow me to place a PNG in place of the SWF, to see if that stops the crash, which would then let me point the finger there for sure)
12. Re: How to debug this?BurtJ Oct 7, 2010 11:44 AM (in response to BurtJ)
I have generated a link-report, and searched that XML output. There is no "fl." in that report.
Additionally, I have discovered that the sections I thought were SWF are actually just roll-over buttons (PNG files with sound that plays when rolled over). The SWF files don't load until later, and they work flawlessly (if I dismiss the error and let things progress).
I would still love to find that fl component, or discover a way to set a breakpoint down in the guts of Flex mx component, where I could hopefully get a better clue of what was being asked for. Lacking any progress in that field, I am going to start looking in a different direction though, and see if I can get the app to work despite this problem. As is, the error is stopping the loading of subsequent resources, which causes things to appear to hang once the user presses a button.
13. Re: How to debug this?George I Flex Oct 7, 2010 11:51 AM (in response to BurtJ)
Hi,
If looking through the code didn't work try looking over the user interface for elements like: Flash Checkbox, Flash RadioButton, Flash TextInput, Flash TextArea, ColorPicker, etc. Your code breaks because of a UIComponent subclass so you can look here : and go through the list of subclasses, and their subclasses, etc ... and see if your Flash components use any of them.
Good luck, you're gonna need it .
14. Re: How to debug this?Flex harUI
Oct 7, 2010 1:57 PM (in response to BurtJ)
Looking at the original stack dump, it indicates that there is no debug info
for the fl.. components. So it could be in one of those Flash SWF files.
15. Re: How to debug this?BurtJ Oct 7, 2010 3:59 PM (in response to Flex harUI)
Yeah, we stepped into mx.Container, but could not go lower. It then crashed out of our code sight. No joy there, with no debug info for the fl components.
I now have the code to where there is no SWF being loaded by us. We are using FlexBuilder 3 as our IDE. The only SWF currently is what gets run after FlexBuilder converts our Flex code into a SWF.
Are you saying the FlexBuilder is using illegal fl.* components when we tell it we want an mx.* component? How / why would Adobe do that, if the two are not compatible?
We have a major release in 3 weeks, so I have been delaying moving to FlashBuilder 4 until after that release. If I were to upgrade now, would that likely solve this problem?
16. Re: How to debug this?Flex harUI
Oct 7, 2010 8:42 PM (in response to BurtJ)
FlexBuilder won't use fl.. component unless someone has placed them in the
lib-path.
Did you verify the exception is the same and has fl.. in the callstack?
Did you verify from the debugger console that only one SWF got loaded?
If you have done both, then generate another link-report and post it.
17. Re: How to debug this?BurtJ Oct 8, 2010 10:44 AM (in response to Flex harUI)
Sigh... Hit me with big enough 2X4 and I finally wise up. You just hit the nail on the head (w/ a 2X4?) ...
The key was to look at the console and notice that there was another swf being loaded. Sure enough, there was one more that I kinda knew about, but was not in the main flow of things.
It is the "progress donut" used display progress as we load our resources. The original authors put that in ages ago, and it has worked so well that we all take it for granted and haven't looked at it for at least a couple years. It was also supplied by an outside vendor, and our internal artist doesn't understand the code, so we left it a black box.
I commented out the loading of that donut, and the stack errors went away. Our artist is now working on a new version that will be purely artwork.
Our problem is now SOLVED! Thanks for all of you Adobe folks for sticking with this until I saw the light of day.
There still is the open question of why this has worked so flawlessly for 2 years, written under Flash 9, used under Flash 10, then suddenly fails under Flash 10.1? I'm probably not going to spend more cycles trying to figure that out though.
There is also another error much further in the code, where a package no longer properly loads under 10.1. I expect it is a completely separate issue though, and will start to investigate it this morning.
18. Re: How to debug this?Flex harUI
Oct 8, 2010 10:56 AM (in response to BurtJ)
It is possible that in 10.1 or due to some other change, something is sizing
slightly differently than before and causing scrollbars to show up. The
fl.managers.FocusManager can't handle the way Flex puts up scrollbars.
19. Re: How to debug this?BurtJ Oct 9, 2010 12:32 AM (in response to Flex harUI)
That appears to be exactly what happened. Our loading animation used a canvas that exactly filled our opening screen. By shrinking the canvas to the size actually needed by that animation (MUCH smaller), the problem disappeared.
Turned out the second "package won't load" problem was also related to this animation. The code (which I wrote a year ago), used the animator as an integral part of the process. When it received a message that the client process was 100% complete, it sent out a COMPLETE event, and the main code listened for that event to decide it was time to put up the new game display.
Since the loading animation failed, it never reached the 100% stage, and the other software kept waiting for the go-ahead to proceed.
All because a change in Flash caused a very slight redrawing size. mumble, grumble. I'm not sure I would have ever nailed that one without your help. Be sure to tell your boss I said you should get a raise!
Now I can get back to the release of two other products I have to ship in 3 weeks. The clock is ticking...
20. Re: How to debug this?duzhiwei May 9, 2013 3:30 AM (in response to BurtJ)
RangeError: Error #2006: 提供的索引超出范围。
at flash.display::DisplayObjectContainer/getChildAt()
at mx.core::Container/getChildAt()[E:\dev\4.y\frameworks\projects\mx\src\mx\core\Container.a s:2751]
at MainApp/getChildAt()[D:\!Source\SrcClient\Main\AppMain\src\MainApp.mxml:239]
at fl.managers::FocusManager/addFocusables()[D:\Program Files\Adobe\Adobe Flash CS5.5\Common\Configuration\Component Source\ActionScript 3.0\User Interface\fl\managers\FocusManager.as:272]
at fl.managers::FocusManager/addFocusables()[D:\Program Files\Adobe\Adobe Flash CS5.5\Common\Configuration\Component Source\ActionScript 3.0\User Interface\fl\managers\FocusManager.as:274]
at fl.managers::FocusManager/addFocusables()[D:\Program Files\Adobe\Adobe Flash CS5.5\Common\Configuration\Component Source\ActionScript 3.0\User Interface\fl\managers\FocusManager.as:274]
at fl.managers::FocusManager/activate()[D:\Program Files\Adobe\Adobe Flash CS5.5\Common\Configuration\Component Source\ActionScript 3.0\User Interface\fl\managers\FocusManager.as:465]
at fl.managers::FocusManager()[D:\Program Files\Adobe\Adobe Flash CS5.5\Common\Configuration\Component Source\ActionScript 3.0\User Interface\fl\managers\FocusManager.as:178]
at fl.core::UIComponent/createFocusManager()[D:\Program Files\Adobe\Adobe Flash CS5.5\Common\Configuration\Component Source\ActionScript 3.0\User Interface\fl\core\UIComponent.as:1621]
at fl.core::UIComponent/initializeFocusManager()[D:\Program Files\Adobe\Adobe Flash CS5.5\Common\Configuration\Component Source\ActionScript 3.0\User Interface\fl\core\UIComponent.as:1532]
at fl.core::UIComponent/addedHandler()[D:\Program Files\Adobe\Adobe Flash CS5.5\Common\Configuration\Component Source\ActionScript 3.0\User Interface\fl\core\UIComponent.as:1553]
at flash.display::DisplayObjectContainer/addChild()
at mx.core::Container/[E:\dev\4.y\frameworks\projects\mx\src\mx\core\Container.as:5437]
at mx.core::Container/createOrDestroyScrollbars()[E:\dev\4.y\frameworks\projects\mx\src\mx\c ore\Container.as:5183]
at mx.core::Container/createScrollbarsIfNeeded()[E:\dev\4.y\frameworks\projects\mx\src\mx\co re\Container.as:5132]
at mx.core::Container/createContentPaneAndScrollbarsIfNeeded()[E:\dev\4.y\frameworks\project s\mx\src\mx\core\Container.as:4929]
at mx.core::Container/validateDisplayList()[E:\dev\4.y\frameworks\projects\mx\src\mx\core\Co ntainer.as:3312]
at mx.managers::LayoutManager/validateDisplayList()[E:\dev\4.y\frameworks\projects\framework \src\mx\managers\LayoutManager.as:736]
at mx.managers::LayoutManager/doPhasedInstantiation()[E:\dev\4.y\frameworks\projects\framewo rk\src\mx\managers\LayoutManager.as:819] mx.core::Application/commitProperties()[E:\dev\4.y\frameworks\projects\mx\src\mx\core\App lication.as:1086]
at mx.core::UIComponent/validateProperties()[E:\dev\4.y\frameworks\projects\framework\src\mx \core\UIComponent.as:8219]
at mx.managers::LayoutManager/validateProperties()[E:\dev\4.y\frameworks\projects\framework\ src\mx\managers\LayoutManager.as:597]
at mx.managers::LayoutManager/doPhasedInstantiation()[E:\dev\4.y\frameworks\projects\framewo rk\src\mx\managers\LayoutManager.as:813] flash.events::EventDispatcher/dispatchEventFunction()
at flash.events::EventDispatcher/dispatchEvent()
at mx.managers::SystemManager/Stage_resizeHandler()[E:\dev\4.y\frameworks\projects\framework \src\mx\managers\SystemManager.as:3227]
/////////////////////////////////////////////////////////////////
I got the Same Error"
21. Re: How to debug this?Flex harUI
May 9, 2013 9:42 AM (in response to duzhiwei)
This stack trace indicates that you are mixing components from Flash Pro in your Flex app. The built-in components from Flash Pro were not written to be compatible with Flex. You can create your own components that don’t use Flash Pro components and build them up out of low-level shapes and sprites and integrate them in Flex with the Flash-Integration Kit.
22. Re: How to debug this?duzhiwei May 9, 2013 7:38 PM (in response to Flex harUI)" | https://forums.adobe.com/thread/734352 | CC-MAIN-2017-47 | refinedweb | 3,287 | 52.46 |
On Tue, Dec 27, 2011 at 10:15:01PM +0100, Nick Wellnhofer wrote:
> On 27/12/11 21:33, Marvin Humphrey wrote:
>> Ah, I see that you have a process_request() method in the LUCY-205 patch
>> already -- and though it does not take a socket-handle/fileno as an argument,
>> it can be modified easily to do so.
>
> That's an implementaion detail of Net::Server. To use Net::Server, you
> simply subclass it and implement a process_request method.
You can write a Net::Server::PreFork subclass which has-a
LucyX::Search::SearchServer and implements process_request() like so:
sub process_request {
my $self = shift;
my $client_sock = $self->get_property('client');
$self->{search_server}->handle_request($client_sock);
}
>> I think that means that we cannot simply delete SearchServer#serve -- though
>> we can improve on things by making it possible to override serve() or
>> otherwise avoid it.
>
> IMO subclassing SearchServer as it is now wouldn't be the best solution
> if it's possible at all.
It's not possible to subclass it in the context of Net::Server, but you can
e.g. write a simple subclass which invokes fork() on each request.
> First, we can't use the SearchServer
> constructor because we don't want the sockets to be created there. Then,
> AFAIU classes derived from Lucy::Object::Obj must be inside-out. Is it
> safe to subclass additional Perl classes like Net::Server that use their
> own hashref attributes in the traditional way?
No, that won't work. (But hash-based classes are dangerous to subclass too
because of collisions within the hash's flat namespace.)
> Another solution would be to simply duplicate the SearchServer request
> handling code in an external module. That's not very elegant but maybe
> it's the easiest way to go, at least for now.
Isn't that pretty much what we get if we implement handle_request($sock) as a
method on SearchServer?
Marvin Humphrey | http://mail-archives.apache.org/mod_mbox/lucy-dev/201112.mbox/%3C20111227213145.GA12342@rectangular.com%3E | CC-MAIN-2019-22 | refinedweb | 316 | 61.26 |
*
A friendly place for programming greenhorns!
Big Moose Saloon
Search
|
Java FAQ
|
Recent Topics
|
Flagged Topics
|
Hot Topics
|
Zero Replies
Register / Login
Win a copy of
JavaScript Promises Essentials
this week in the
JavaScript
forum!
JavaRanch
»
Java Forums
»
Java
»
Swing / AWT / SWT
Author
JFrame confusion
Chris Pat
Ranch Hand
Joined: Aug 27, 2005
Posts: 156
posted
Mar 22, 2007 11:21:00
0
Hello
I have a JFrame in object2 that on button click creates and launches object1 run method. Two questions. One. Can I create a new JFrame in object1 run method and and have it persist after run finishes? Two. How can I create the JFrame in object 2 so that I can add to it from object1 run method? Still learning. tia.
Craig Wood
Ranch Hand
Joined: Jan 14, 2004
Posts: 1535
posted
Mar 24, 2007 15:15:00
0
There are different ways of doing this. Here's one possibility.
import java.awt.*; import java.awt.event.*; import javax.swing.*; public class ObjectClass1 implements ActionListener { JFrame f; // Member variables have class scope. JLabel label; ObjectClass2 oc2; public ObjectClass1(JFrame f) { // To avoid problems with static variables/context // we can pass the JFrame reference f into this class // via a constructor like this. Now oc2 can access it // for adding/removing components. this.f = f; } public void actionPerformed(ActionEvent e) { // Allow only a single instance of ObjectClass2. // Send a reference to this class which ObjectClass2 // can use to access fields and methods of this class. if(oc2 == null) oc2 = new ObjectClass2(this); if(!oc2.isRunning()) oc2.start(); } private JPanel getContent() { label = new JLabel(" ", JLabel.CENTER); JButton button = new JButton("Button"); button.addActionListener(this); JPanel panel = new JPanel(new BorderLayout()); panel.add(label, "First"); panel.add(button, "Last"); return panel; } public static void main(String[] args) { JFrame f = new JFrame(); ObjectClass1 oc1 = new ObjectClass1(f); f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); f.getContentPane().add(oc1.getContent()); f.setSize(200,140); f.setLocation(200,200); f.setVisible(true); } } class ObjectClass2 implements Runnable { ObjectClass1 oc1; Thread thread = null; boolean processing = false; public ObjectClass2(ObjectClass1 oc1) { this.oc1 = oc1; //start(); } public void run() { int count = 0; while(processing) { try { Thread.sleep(1000); } catch(InterruptedException e) { System.out.println("interrupted"); stop(); } // Use our local reference to ObjectClass1 // (member variable oc1) to access its // fields and methods. oc1.label.setText(String.valueOf(count++)); if(count > 10) stop(); } } public boolean isRunning() { return processing; } public void start() { if(!processing) { processing = true; thread = new Thread(this); thread.setPriority(Thread.NORM_PRIORITY); thread.start(); } } private void stop() { processing = false; if(thread != null) thread.interrupt(); thread = null; System.out.println("ObjectClass2 thread stopped"); } }
Chris Pat
Ranch Hand
Joined: Aug 27, 2005
Posts: 156
posted
Mar 25, 2007 13:23:00
0
Thank you. That was extremely instructive.
Is it possible to create an independent window from within object2 run method? If not why not? Thank you again. Nothing better than deeply learning even something small for the first time.
Craig Wood
Ranch Hand
Joined: Jan 14, 2004
Posts: 1535
posted
Mar 25, 2007 14:10:00
0
Is it possible to create an independent window from within object2 run method?
Yes. Generally we try to have only one top–level container in an app. For other windows we use dialogs. Be careful not to use modal dialogs, including all JOptionPane dialogs, in the run method or it will block the run thread. If you elect a JDialog you could keep a reference to it as a member variable, instantiate it in or via the class constructor and set it visible in the run method. In
java
:
class ObjectClass2 implements Runnable { ... JDialog dialog; ... public ObjectClass2(ObjectClass1 oc1) { ... String title = getClass().getName(); boolean modal = false; dialog = new JDialog(oc1.f, title, modal); dialog.setSize(150,100); } public void run() { ... dialog.setVisible(true); while(processing) { ...
Ricky Clarkson
Ranch Hand
Joined: Jul 27, 2006
Posts: 131
posted
Mar 26, 2007 06:41:00
0
It's possible to create any object within any method. The object will live at least until there are no more references to it. For Frames (JFrames are Frames), all instances are referred to by a static field in the Frame class, so they will live at least as long as you haven't called dispose() on them.
There is a difference between objects and variables, that I'm suspecting you haven't realised.
void doSomething() { JFrame frame=new JFrame(); frame.setVisible(true); }
The variable, frame, lives exactly as long as it takes for doSomething to complete, i.e., not very long. It is a "lexically-scoped variable", which is an overblown way of saying that the name only exists within the { and the } it's declared in.
The actual JFrame object that's created, which doesn't have a name, outlives the method. This is usually not very useful; you tend to want a name to access an object by, so that you can do things with it. One idea is to make doSomething return the JFrame:
JFrame doSomething() { JFrame frame=new JFrame(); frame.setVisible(true); return frame; }
Then you can keep a reference somewhere else:
theFrame=doSomething();
One way to think of objects and variables is as stellar bodies, and names that humans give to them. To one person, a star may be Betelgeuse, to another it may be "that bright one up there". That's like having two variables both pointing at the same object. If the name Betelgeuse stops being used, that doesn't make the star disappear.
sudhakar ananth
Ranch Hand
Joined: Feb 02, 2007
Posts: 68
posted
Apr 03, 2007 10:24:00
0
i too have the same problem the thing is the JOptionpane is pop up and i need the Jframe to which is main application here should be running if the JOptionPane is there contin...
pls help me out it is urgent....
sudhakar ananth
Ranch Hand
Joined: Feb 02, 2007
Posts: 68
posted
Apr 03, 2007 10:39:00
0
I have the JOptionpane which is poped up when i click some button in JFRAME and i need the Jframe to (which is main application here) should be running
if the JOptionPane is there contin. ... on the screen .
i want the JFRAME application to be working even though the JOPTION PANE is in the on the SCREEN
pls help me out it is urgent....
I agree. Here's the link:
subject: JFrame confusion
Similar Threads
Inheritance and incomptaible casting
What is 'this'?
Passing subclass in the interface method
is it a single thread or multiple thread for different jframe
Member Modifiers
All times are in JavaRanch time: GMT-6 in summer, GMT-7 in winter
JForum
|
Paul Wheaton | http://www.coderanch.com/t/344400/GUI/java/JFrame-confusion | CC-MAIN-2014-49 | refinedweb | 1,106 | 64.41 |
I had a requirement for one of my customers to call M3 API in Infor M3 Enterprise Collaborator (MEC) specifically from a custom process – not from a mapping – and I realized MEC does not have any built-in process for that, so I reverse engineered MEC again, and here is what I found.
Let’s see what MEC has to call M3 API from a process; I am using MEC version 11.4.1.
Processes
The Partner Admin has the following built-in processes:
According to their Java source code, none of these processes calls M3 API, at least not that allow the user to call any M3 API arbitrarily; that does not meet my requirement.
API reference holders
There is a list of API reference holders in Partner Admin > Manage > Communication > M3 API:
They are used by the mappings in the XML Transform processes to select the M3 API server at run time:
I can get these properties with the following code with ec-core-11.4.1.0.0.jar:
import com.lawson.ec.server.m3api.APIRef; import com.lawson.ec.server.m3api.APIReferenceHolder; APIReferenceHolder instance = APIReferenceHolder.getInstance(); List<APIRef> apiRefs = instance.getAPIRefs(); for (APIRef r: apiRefs) { String id = r.getId(); String hostName = r.getHostName(); String portNumber = r.getPortNumber(); String username = r.getUsername(); String password_ = r.getPassword(); String encodingIANA = r.getEncodingIANA(); boolean proxyUsage = r.isProxyUsage(); String refName = r.getRefName(); List<String> agreements = r.getAgreements(); }
Good.
Note: APIReferenceHolder will run an SQL to table PR_Basic_Property in the MEC database with PR_Basic_Group_Type.Type=’APIRef’:
MEC Mapper
The MEC Mapper (a.k.a. ION Mapper) can call M3 API, and there are settings for design time:
But I am not interested in the Mapper for my requirement, so I will skip this.
Properties *
The MEC server has properties about M3 API in the groups APIMapper and MvxAPI:
I can get these values with the technique of my previous post:
import java.util.Properties; import com.lawson.ec.gridui.PropertiesSourceFactory; Properties props = PropertiesSourceFactory.getInstance().getProperties(); // APIMapper String name = props.getProperty("APIMapper.mi.name"); String host = props.getProperty("APIMapper.mi.host"); String port = props.getProperty("APIMapper.mi.port"); String user = props.getProperty("APIMapper.mi.user"); String password = props.getProperty("APIMapper.mi.password"); // MvxAPI String enabled = props.getProperty("MvxAPI.Pool.Enabled"); String max = props.getProperty("MvxAPI.Pool.Connection.Max"); String expires = props.getProperty("MvxAPI.Pool.Connection.Expires"); String timeout = props.getProperty("MvxAPI.Pool.Connection.Connect.TimeOut");
Good. I will use APIMapper.
Connection pool
There is also a connection pool, which is recommended for repeated calls, but I have not yet looked into it as it appears to be used only by the Mapper:
I found this code in com.intentia.ec.mapper.BasicXMLMapper:
import com.intentia.ec.mapper.APIPool; import com.lawson.ec.mapper.APIPoolInfo; APIPool apiPool = APIPool.getInstance(); MetaAPI.getAPI(manifest, apiEncoding); apiPool.getAPI(programName, host, port, user, password, isProxy, manifest, encoding, CONO, DIVI); List<APIPoolInfo> list = apiPool.getAPIPoolInfo();
For future work.
MvxSockJ *
There is the good old M3 API Java library MvxSockJ-6.1.jar in the MEC server library folder:
Refer to the M3 API Toolkit documentation for its complete usage. Here is the minimalist version:
import MvxAPI.MvxSockJ; MvxSockJ s = new MvxSockJ(); s.mvxConnect(host, port, user, password, "CRS610MI", CONO); s.mvxSetField("CUNO", "ACME"); s.mvxAccess("GetBasicData"); s.mvxGetField("CUNM") s.mvxClose();
Good. I will use this.
Remember to check for nulls and return codes.
EBZSocket et al.
There are plenty of other Java classes in MEC that are related to M3 API, they lead to EBZSocket, but they seem to be used mostly by the mapper, and they require knowledge of the M3 API metadata. I have not looked more into it. Here is a screenshot of the dependency graph from JArchitect:
Here is some code I found, to be tested:
import com.intentia.ec.mapper.APICaller; //APICaller ac = new APICaller(poolKey, strUUID, apiEncoding); APICaller ac = new APICaller(pgm, host, port, user, password, strUUID, apiEncoding, forcedProxy, company, division); int connectionTimeout = 10000; int readTimeout = 10000; ac.initMISock(connectionTimeout, readTimeout); int startPos = 0; int maxLength = 28; String data = "GetBasicData 106AAACRBE01"; ac.setRecord(startPos, maxLength, data); ac.callMI();
Or:
import com.intentia.ec.mapper.EBZSocket; EBZSocket sock = new EBZSocket(strUUID, host, Integer.parseInt(port), "EBZSocket", apiEncoding); String logonStr = ""; sock.mvxLogOn(logonStr, user, password, library, pgm, connectionTimeout, readTimeout, forceProxy); sock.mvxSend(char[] apiData, int dataLength) sock.mvxClose();
For future work too.
Conclusion
There does not seem to be a built-in solution to call any M3 API in a process in MEC. However, we can get the existing server properties – either from the API reference holders, either from the property group APIMapper – and use the good old MvxAPI.MvxSockJ to call the M3 API. Now you can add that to your custom process. With some more work, we could perhaps also use the connection pool, and explore more of the remaining Java classes.
I highlighted my favorite with an asterisk.
That’s it!
Thanks for reading. If you liked this, please consider subscribing, give a like, leave a comment, share around you, and help us write the next post.
3 thoughts on “Call M3 API from MEC process”
Could you use the Web Service process within MEC partner admin to call an API via MWS?
Technically we could. There are some problems with that process though; I can’t remember which. I may write about that process some day. | https://m3ideas.org/2016/02/22/call-m3-api-from-mec-process/?like_comment=5691&_wpnonce=454973ab2c | CC-MAIN-2022-05 | refinedweb | 896 | 52.56 |
In the early days of 64-bit, drivers were hard to find or unstable, programs wouldn’t run and help was scarce. I started using Windows XP 64-bit about a year ago, so I’ve battled through many of the issues with working with this ‘newer’ technology. At ORCS Web, we support Windows Server 2003 64-bit on different types of applications, from SQL Server to IIS to Microsoft Virtual Server.
So, is there a rule of thumb with 64-bit? Should everyone use it whenever possible? Or are there reasons to stick with 32-bit?
My original thought was that [64-bit = newer therefore 64-bit = better]. I’ve come to find out that isn’t always the case, as I’ll explain below.
First, my experience on a desktop.
I got a new computer built and supported by Dell as a 64-bit server and with Windows XP 64-bit pre-installed. Drivers weren’t a problem for me since Dell took care of that already. But I still ran into a number of issues, including:
So, I have come to conclude that in many cases 64-bit isn’t necessary for a desktop computer. My desktop has 3GB of RAM now, but I don’t see any advantages of using 64-bit unless I’m a developer that needs to test 64-bit applications or have a need to use very large amounts of memory. My general recommendation is to only use 64-bit for a desktop computer if you have a specific reason to do so.
Next, my experience on a server
How about on the server end? I made the same incorrect assumption at first, determining that most new servers would eventually use 64-bit as a standard. But experience and recent load testing has convinced me otherwise.
Recently we had a high-traffic ASP.NET website that we deployed on a 64-bit server with Windows Server 2003 x64 Standard Edition. It was part of a webfarm so we were able to compare it directly against other 32-bit servers with similar hardware. Performance was noticeably less than on the 32-bit servers which surprised me at first. I spent a consideration amount of time reproducing the issue and isolating it to just 32-bit. In fact, I tested ASP.NET and IIS6 running in 32-bit mode as well to test all three situations.
I did some load testing using Microsoft’s Web Application Stress Tool (WAST). I used 2 identical servers (ordered from Dell at the same time with the same specs) and built one as 32-bit and one as 64-bit. They are solid machines, Dual 3.0Ghz Dual Core CPU with 4GB of RAM and 15,000RPM SCSI hard drives. I set up 7 load testing servers using a Gbps network core to test.
Test Results – IIS only
Hitting IIS directly for a static 2kb page, both servers were able to serve up over 14,000 Pages/sec with only 70% CPU. The 7 load testing servers weren’t able to max out the web servers. So IIS doesn’t have any problem handling huge amounts of traffic!
Test Results – Simple ASP.NET
I then tested a simple ASP.NET page that ran <%= now %> as well as 2kb of plain text. The 32-bit server was able to serve up a maximum of 3,400 Pages/sec. The CPUs were the bottleneck. The 64-bit server was able to serve up a maximum of 2,100 Pages/sec. So the 32-bit server easily outperformed the 64-bit server. (Note: On this particular test, on the 64-bit server, ASP.NET and IIS performed the same whether they were in 64-bit mode or 32-bit mode.)
Test Results – ASP.NET loop
The next test was a While loop with 1,000,000 iterations. In each iteration I outputted Response.Write(“”) just to give it something to do. Both servers were able to serve up 68 Pages/sec. So, in this particular test, the 64-bit server was able to catch up in performance. It would appear that a while loop performs identical in both situations.
Test Result – Others
I ran some other tests, some with interesting unexpected data, but that is a whole different topic. These tests only start to dive into the differences between 32-bit and 64-bit computing, but they show that there is a substantial difference between them, and for low memory applications, a 32-bit Operating System is often faster.
From the other tests I performed, I concluded that there is about a 10 – 15% performance penalty running a 64-bit OS with low amounts of memory. This varies depending on what operation is being performed.
So, for the server environment also, I concluded that 64-bit isn’t always better either.
Now, what about the stories of huge performance gains on 64-bit? Believe them! J For high memory situations and products well tuned for 64-bit like SQL Server 2005, there are tremendous performance gains to be had. I’ve seen some pretty impressive tests show substantial performance gains on 64-bit. The 64-bit SQL Server and 64-bit Virtual Server servers that we have set up at ORCS Web () are handling huge loads with ease. While I haven’t purposefully compared SQL Server performance like I have ASP.NET, I have every reason to believe that the reports are true that under high memory demands SQL Server on 64-bit greatly outperforms 32-bit.
Memory limits blown away
If you have high memory requirements, 64-bit may not only be better, but it may be the only option. The 64-bit memory space blows away many of the memory limits that used to exist. We’re talking Terabytes instead of Gigabytes!
Summary
I’ve come to conclude that 64-bit isn’t always better. Don’t just use 64-bit to use the latest technology. For low memory situations, 64-bit may actually perform worse, have driver compatibility issues and be harder to support. But, for high memory situations, chances are good that those issues disappear and the benefits that the larger memory namespace offers will far outweigh the issues.
There is a place for each, but there is still a lot of life left for 32-bit computing.
Thanks for sharing. I've been looking into making the move and a few people have highlighted the need to run some app in 32-bit.
Are you still running the high-traffic .net site on x64? How's it fare with pre 64-bit?
I ask because I have a high-traffic web-server we're going to move to new hardware (uses SQL Server database for forums - 50000+ members, taking 1000-2000 posts daily. The dedicated server it's on is a very busy celeron!). I'm looking at a dual xeon woodcress with 4GB RAM but the database size is only about 500MB though - would you consider that low memory though? I'm in 2 minds whether to get the hardware but install 32-bit Windows on or make the leap.
Any comments gratefully received!
Danny
thanks for taking the time to update your blog with this info - useful
cheers
Andrew | http://weblogs.asp.net/owscott/archive/2006/11/07/Is-64_2D00_bit-computing-always-better_3F00_.aspx | crawl-002 | refinedweb | 1,215 | 73.88 |
Introduction on Sorting in C++
Having a collection of elements to ordersorting helps in arranging the elements in the record based on ordering relation. Consider a file record that contains a lot of information. To access a list from the record, it is necessary to have a key field to point to the element’s current location. For example, consider a list of names on the database; it could be sorted alphabetically. Sorting placed an important role in the field of Computers and technology. Let us see more in this article.
What is the Sorting in C++?
Sorting is the basic concept used by the programmer or researcher to sort the inputs required. The order of complexity is given by 0(N*log(N)). Sorting an input makes it easier in solving many problems like Searching, Maximum and Minimum element. Although sorting arranges data in the sequence, the efficiency of the process is very important, which is based on two criteria: – Time and memory required to perform sorting on the given data. Time is measured by counting the comparisons of keys used. There are many algorithms available to sort.
In general, Sorting in C++ are distinguished into two types:
- Internal Sorting
- External Sorting
Syntax and Example
Syntax:
C++ uses sort () built-in function for their algorithms to sort the containers like vectors, arrays.
Sort(array , array +size);
Examples:
#include<iostream>
using namespace std;
int main ()
{
int ins[12] = { 19,13,5,27,1,26,31,16,2,9,11,21};
cout<<"\nInput list is \n";
for(int i=0;i<12;i++)
{
cout <<ins[i]<<"\t";
}
for(int k=1; k<12; k++)
{
int t = ins[k];
int j= k-1;
while(j>=0 && t <= ins[j])
{
ins[j+1] = ins[j];
j = j-1;
}
ins[j+1] = t;
}
cout<<"\nSorted list is \n";
for(int i=0;i<12;i++)
{
cout <<ins[i]<<"\t";
}
}
Output:
How does it Work?
To start with, we will take Quick Sort, which is considered an important method among various sorting types. The basic sorting of an array takes a Quicksort approach. There are different ways to implement sorting, the aim of each of these techniques is the same as comparing two elements and swapping them with the temporary variable. In this article, we shall discuss the most important sorting used for implementation. Following are:
There are Merge Sort, radix sort, tape sorting, which we may discuss later. First, we will go with Bubble sort.
1. Bubble Sort
Bubble sort is one of the simplest sort methods we can use it for applications. In this technique, successive swaps are made through the records to be sorted. At each step, it compares the key to the data and exchanges the elements if not in the desired order. Sorting is done with the adjacent elements at the time only one element is placed in the sorted place after a swap.
Example: Let us consider an unsorted array A[]={ 6,2,4,7,1}
Step 1: Comparing A [0] > A [1], if condition is true swap the element (6>2) true, place 2 in A [0]. Similarly, all the steps take the same until the array becomes sorted.
Now the array is A [] = {2,6,4,7,1}
Step 2: 6 is compared with 4. As 6 is greater than 4. Therefore, 6 and 4 are swapped.
Now the array is A [] = {2,4,6,7,1}
Step 3: Element 6 is compared with 7. Since 6<2 and the elements are in ascending order, elements are not swapped.
The sorted array is A [] ={2,4,6,7,1}.
Continue the process until the array is sorted.
2. Insertion Sort
In this technique, we start with the second data element by assuming the first element is already sorted, and comparison is done with the second element, and the step is continued with the other subsequent element. It is necessary to have N-1 passes in an array of N elements to have a sorted element.
Consider an array A[] = { 8,3,6,1}
Step 1: The first element looks for the largest element in the array to swap. If it is larger, it remains the same and gets moved on to the second element; here, 8 is greater than all, no swap is made.
Step2: Swapping with the second element
Step3: Swapping with the third element
Step4: Swapping with the fourth element
3. Quick Sort
This technique follows the divide and conquers algorithm and is considered very efficient and quicker for huge arrays. They are divided into three subsections: a left, a right and the middle. The middle element has a single value, and it is named as the pivot. The mechanism goes like this, the element in the left segment should not have a key larger than the middle element and the no element in the right has a key that is smaller than that of the middle element. Now let’s start with an illustration of the process of sorting. Quicksort uses a recursive concept while sorting sub-part. The array is divided into subpart, again left and right segments are partitioned by conquering. Here in this example, considering the last element has a pivot, and the first element is assumed low. Consider an array element
Taking the rightmost element has the pivot element = 30
The element greater than the pivot is placed towards the left, smaller at the right.
The pointer is placed at the pivot and is partitioned around a pivot.
The subparts are sorted individually.
Finally, we got a Sorted Array.
4. Selection Sort
This technique is also called exchange sorting performs dual operation searching and sorting. The implementation takes straight selection sorting as defined below. Here, it is required to identify the smallest element present in the array, and this element is sorted in the first ith position; next, the second smallest element is identified, and it is sorted in the second position. The selection sort exits its loop when the unsorted subpart becomes empty. The time complexity is given as O(n2).
Consider the following array:
1. Finding the smallest element and place it at the beginning, and it is swapped with the position.
2. The second element, a [1], is identified compare with the minimum element and place it in the second position; similarly, the pass continues.
Final sorted output
Conclusion
To conclude, this article focussed on sorting concepts and their working mechanism. All these sorting techniques use parallel processing concepts. Sorting forms a core building block in structuring algorithms to solve the problems of data in the real world by sorting the set of values according to the requirements.
Recommended Articles
This is a guide to Sorting in C++. Here we discuss the Introduction and Syntax with examples along with How does it work. You can also go through our other suggested articles to learn more– | https://www.educba.com/sorting-in-c-plus-plus/?source=leftnav | CC-MAIN-2021-39 | refinedweb | 1,148 | 63.19 |
a list of lists of props representing an assembly hierarchy More...
#include <vtkAssemblyPaths.h>
a list of lists of props representing an assembly hierarchy
vtkAssemblyPaths represents an assembly hierarchy as a list of vtkAssemblyPath. Each path represents the complete path from the top level assembly (if any) down to the leaf prop.
Definition at line 37 of file vtkAssemblyPaths.h.
Definition at line 41 of file vtkAssemblyPaths path to the list.
Definition at line 96 of file vtkAssemblyPaths.h.
Remove a path from the list.
Definition at line 101 of file vtkAssemblyPaths.h.
Determine whether a particular path is present.
Returns its position in the list.
Definition at line 106 of file vtkAssemblyPaths.h.
Get the next path in the list.
Definition at line 111 of file vtkAssemblyPaths.h.
Override the standard GetMTime() to check for the modified times of the paths.
Reimplemented from vtkObject.
Reentrant safe way to get an object in a collection.
Just pass the same cookie back and forth.
Definition at line 75 of file vtkAssemblyPaths.h. | https://vtk.org/doc/nightly/html/classvtkAssemblyPaths.html | CC-MAIN-2021-31 | refinedweb | 171 | 62.24 |
Bruno Haible <address@hidden> writes: > Simon Josefsson wrote: >> I'm doing some Unicode NFKC operations and noticing that u32_normalize >> fails for U+D800. > > This is a valid behaviour, because U+D800 is a "surrogate" point code > and therefore not a valid character code point. > > See the Unicode standard, chapter 2 [1], pages 23..24: > Surrogate code points and other non-character code points "should never be > interchanged". This means, for libunistring, that they are invalid input > and invalid output in all functions taking or returning UTF-32 strings or > UTF-8 strings. > > Character code points and code points that are in regions that may be assigned > in future Unicode versions must not be rejected; these are valid input. I'm not interchanging the code points, I'm calculating this IDNA2008 property toNFKC(toCaseFold(toNFKC(cp))) != cp for all code points. Is this impossible to do with the u32_normalize interface? I notice that ICU also gives an error in this situation: I wonder what the above expression means when toNFKC fails.. I managed to work around this using a local patch to make u32_uctomb mimic u32_mbtouc_unsafe's behaviour. But I'm not sure if I'm going to use it. --- lib/unistr/u32-uctomb.c.orig 2011-05-27 11:16:00.112466242 +0200 +++ lib/unistr/u32-uctomb.c 2011-05-27 11:16:01.696467065 +0200 @@ -30,8 +30,10 @@ int u32_uctomb (uint32_t *s, ucs4_t uc, int n) { +#if CONFIG_UNICODE_SAFETY if (uc < 0xd800 || (uc >= 0xe000 && uc < 0x110000)) { +#endif if (n > 0) { *s = uc; @@ -39,9 +41,11 @@ } else return -2; +#if CONFIG_UNICODE_SAFETY } else return -1; +#endif } #endif /Simon | http://lists.gnu.org/archive/html/bug-gnulib/2011-05/msg00594.html | CC-MAIN-2015-18 | refinedweb | 268 | 65.42 |
Hello. 2012/12/03 12:48:41 -0500 Rocky Bernstein <ro...@cpan.org> => To Peter Vereshagin : RB> On Mon, Dec 3, 2012 at 9:06 AM, Peter Vereshagin <pe...@vereshagin.org>wrote: RB> RB> > Hello. RB> > RB> > 2012/12/03 08:51:28 -0500 Rocky Bernstein <ro...@cpan.org> => To Richard RB> > Foley : RB> > RB> Something I think about when I read about things like this whether RB> > there RB> > RB> some sort of unifying principle that could be used in other debuggers RB> > or RB> > RB> for other similar sorts of programs. Is there some support that a RB> > debugger RB> > RB> should be providing to make things like this easier? RB> > RB> > I think it's about a standard for the program interface that majority of RB> > debuggers should follow. RB> > RB> RB> I'm not sure what you mean. Suggest something.
api reference as a kind of unified principle described. RB> > Debug::Fork::Tmux can redefine some other function (and/or a global RB> > variable) RB> > from another debugger. In this case the feature to implement can be the RB> > 'let RB> > user to tweak a namespace other than DB to inject to'. Very obvious. RB> > RB> RB> Devel::Trepan has lots of non-DB spaces one can tweak to. But again, I am RB> not exactly sure what you mean so it would help if you could be very RB> specific. For Debug::Fork::Tmux there's a DB::get_fork_TTY() to define and $DB::fork_TTY to assign to. (a tty name for the next debugger's process). I have no idea if any other debugger use this in the same way. RB> > RB> Too often, especially with the venerable Perl debugger, you read about RB> > RB> patch someone has that made that does some interesting thing. Or s a RB> > trick RB> > RB> you can do in order to get something done that is commonly needed. It RB> > feels RB> > RB> less like the "art" but rather knowing about a number of isolated RB> > tricks, RB> > RB> or worse, workarounds that is relevant for one debugger on one RB> > programming RB> > RB> language. RB> > RB> > I don't patch the debugger, sorry. RB> > RB> > When needed, the critical mass of 'isolated tricks and workarounds' can be RB> > collected into one distribution, and documented in details in one place, RB> > can't RB> > them? RB> > RB> > RB> That said, of course, all of this is cool. RB> > RB> > Great. RB> > RB> > My main target with Debug::Fork::Tmux was to make a convinient build RB> > environment, including docs, for better and faster releasing. RB> > RB> > Otherwise the one can use a couple of lines to use Tmux for that same RB> > purpose. RB> > RB> > RB> > Here is an interesting module from Peter Vereshagin which might help RB> > with RB> > RB> > debugging forks under the perl debugger, if you use tmux version 1.6+ RB> > RB> > RB> > RB> > -- Peter Vereshagin <pe...@vereshagin.org> () pgp: A0E26627 | http://www.mail-archive.com/debugger@perl.org/msg00159.html | CC-MAIN-2017-17 | refinedweb | 497 | 71.65 |
Processing Client-Side Assets
Orchard includes a processing pipeline for client-side assets (typically scripts and stylesheets) which is used to perform front-end development workflow tasks such as transpilation, minification and bundling of client-side assets in both core projects and extensions (i.e. modules and themes). Many of the built-in modules and themes in Orchard use this pipeline to process client-side assets, and you can enable your own extensions to use it as well.
Overview
The client-side asset pipeline is powered by Gulp, a popular open-source task runner based on Node.js that can be used to automate a wide variety of tasks in a development workflow. The pipeline defines a set of Gulp tasks that can be executed by Gulp using either the command line or using the Task Runner Explorer tool window in Visual Studio 2015 or later.
Physically, the client-side asset pipeline consists of two files in the Orchard solution folder:
src/Package.jsoncontains information about the Node packages required by the pipeline. This file tells the Node package manager (NPM) which packages it needs to download and install for the pipeline to function.
src/Gulpfile.jscontains JavaScript code that defines a set of Gulp tasks and their implementation logic.
In Visual Studio you will find these files in Solution Explorer in a solution folder named
Solution Items/Gulp:
There are several reasons why the pipeline has been implemented at the solution level rather than in each extension that needs to process client-side assets.
- Current and future can share the existing pipeline logic instead of having to reinvent it.
- Only one copy of the necessary Node.js packages needs to be downloaded and stored alongside the codebase.
- Keeping Node package folders (
node_modules) anywhere inside the
Orchard.Webproject causes their contents to be included when publishing Orchard for deployment which would increase the size of the deployment package by orders of magnitude even though these files are only useful at development time.
The client-side asset pipeline is not configured by default to be invoked automatically when opening or building Orchard. To minimize build time and make it as easy as possible to get started with Orchard, all built-in modules and themes in Orchard are kept in source control with their processed output files included. This means you don't have to activate and run the client-side asset pipeline to build or run Orchard out of the box. You only need to run the client-side asset pipeline if you make changes to these assets, or wish to use it to process assets in your own extensions.
Getting started
Installing prerequisites
The client-side asset pipeline requires Node.js to be installed. If you are using Visual Studio 2015 or later, Node.js is typically already installed as part of Visual Studio. If you are not using Visual Studio, or if you selected not to include Node.js when installing Visual Studio, you will need to install Node.js manually from.
Next you will need to use NPM to install all the packages the client-side asset pipeline needs, including Gulp itself. Using the command line, navigate to the Orchard solution folder and execute the command
npm install, which will install all dependencies referenced in the
Package.jsonfile. In Visual Studio 2015 or later, you can instead simply open the
Package.json file and save it without making any changes - this will trigger an automatic
npm install behind the scenes.
Executing tasks
There are three different Gulp tasks that you can invoke to execute the pipeline in different ways.
- build performs an incremental build of all asset groups in the solution; asset groups whose outputs are already newer than all their inputs are not processed.
- rebuild performs an unconditional full build of all asset groups in the solution, even if their outputs are already newer than their inputs.
- watch monitors all asset groups in the solution for changes to their inputs, and rebuilds an asset group if one or more of its inputs are modified.
Note: These tasks also take the asset manifest files themselves into consideration when evaluating changes; a modification to the asset manifest file (
Assets.json) is treated the same as a modification to one of the input asset files declared in the manifest.
The way you typically execute the Gulp tasks depends on whether you are using Visual Studio or not.
Using the command line
- Make sure you have Node.js installed and added to your
PATHvarable.
- Make sure you have installed all the required Node.js packages using the
npm installcommand as described above.
- Navigate to the Orchard solution folder where the file
Gulpfile.jsis located.
- Execute one of the commands
gulp build,
gulp rebuildand
gulp watchto execute the corresponding Gulp task.
Using Visual Studio
Visual Studio 2015 and later comes with a built-in tool window named Task Runner Explorer that can be used to execute NPM tasks as well as tasks from different task runners such as Gulp and Grunt among others.
To open Task Runner Explorer, select View -> Other Windows -> Task Runner Explorer from the menu. Alternatively, you can right-click on the file
Gulpfile.js in Solution Explorer and select Task Runner Explorer from there.
Initially you may see an error message in Task Runner Explorer:
This can happen if you have not installed the necessary dependency packages (see the section on installing prerequisites above) or if you have recently installed dependency packages and Task Runner Explorer has not yet retried the parsing of the Gulp file after that. Once you have installed all the dependency packages, just click the refresh icon and wait for it to reload:
When Task Runner Explorer has correctly parsed the Gulp file you will see the list of tasks contained inside it:
You can now double-click one of the tasks to execute it.
Binding tasks to Visual Studio events
Task Runner Explorer also has the ability to "bind" tasks to be executed automatically in response to Visual Studio solution events. Orchard is not preconfigured with any such bindings because all assets in the original code base are already processed and their outputs are included in source control, but it can be useful to configure these bindings temporarily while developing your own client-side assets or while working on modifications to the ones in Orchard.
The most common scenario is to bind the build task to the After Build solution event. This way, each time you build Orchard (for example, by hitting
F5 or
Ctrl+F5 or selecting Build -> Build Solution from the menu) the asset pipeline's build task will be executed at the end of the build process. Any asset groups whose input files have changed since the last build will be refreshed.
To configure this binding, follow these steps:
- Right click on the
buildtask
- Select Bindings
- Select After Build
Another common scenario is binding the watch task to the Project Open solution event, which will start the watch task when the solution is loaded and keep it running until you terminate it.
Note: It's important to be aware that task bindings are stored in a specially formatted comment in the beginning of the Gulp file, so when you configure task bindings you are effectively making a change to one of the core files belonging to the Orchard code base which may be overwritten if you later choose to update your code base to a newer version of Orchard.
Using the pipeline for your own module or theme
You typically don't have to execute any of the tasks in the client-side asset pipeline unless you are either making changes to Orchard itself or creating your own custom extensions and wish to utilize the pipeline to process your own client-side assets. This section explains how to enable the pipeline for your own extension.
Adding an asset manifest file
The first step is to add an asset manifest file to your extension. This asset manifest file is a simple JSON document that declares one or more asset groups to be processed by the pipeline. Each asset group specifies a set of input files in your extension (such as
.less,
.scss,
.css,
.ts or
.js files) along with an output file and (optionally) one or more options to influence the processing.
To add an asset manifest, add a new JSON file named
Assets.json to the root folder of your extension (both the name and location of the file are mandatory. The client-side asset pipeline will detect and parse this file, and add the asset groups declared inside it for processing when of the pipeline tasks are executed.
The basic structure of the asset manifest looks like this:
[ { // First asset group "inputs": [ "some/input/file.less", "some/input/file2.less" ], "output": "some/output/file.css" // Options can be added here }, { // Repeat for more asset groups } ]
All input and output paths are relative to the extension root folder. However they do not have to reside within the extension folder; using
../ to resolve paths outside of the extension folder is fully supported. It is a common convention in Orchard to use a folder named
Assets to contain input asset filess and to keep those separate from the output asset files, but this is not required.
Using the asset pipeline is completely optional. If you don't add an
Asset.json manifest file in the root folder of your extension, the client-side asset pipeline will simply ignore your extension.
Basic example (single input file)
The following example takes the LESS stylesheet
Assets/Styles.less in your extension and transpiles it into the output file
Styles/Styles.css:
[ { "inputs": [ "Assets/Styles.less" ], "output": "Styles/Styles.css" } ]
When executing the build or rebuild task, the asset pipeline will perform the following tasks on
Styles.less:
- Transpile LESS to plain CSS
- Add/remove vendor prefixes as necessary
- Add source maps (non-minified output only)
- Add a static informational header (non-minified output only)
- Normalize line ending characters
- Minify
After the build task has executed your extension's
Styles folder will contain two files:
Styles.css(non-minified with inline source maps)
Styles.min.css(minified)
Once these output asset files have been generated you can reference them from Razor views just as you normally wolud using the Orchard resource manager, either by declaring them in a resource manifest class and requiring them using one of the
Require() methods or by including them by path using one of the
Include() methods.
Note: The generated output asset files will not be automatically added to your extension project (
.csproj) file. If you wish to keep the output asset files in source control, you will need to manually include them in your project using Solution Explorer after they have been generated for the first time. See the section on advanced scenarios below for some pointers on when you may or may not want to do this.
Multiple input files
You can also specify multiple inputs in the same asset group:
[ { "inputs": [ "Assets/Grid.less", "Assets/Forms.less", "Assets/Type.less", ], "output": "Styles/Styles.css" } ]
This works exactly like the basic example above with the single input, with the addition that all three inputs will be bundled into the output files
Styles.css and
Styles.min.css.
Globs (wildcards)
The client-side asset pipeline also supports using glob wildcard patterns to include multiple input assets without having to specify each one individually.
The following example processes all files with a
.js extension in the
Assets folder and all its subfolders, and bundles them into a single
Scripts/Scripts.js output file:
[ { "inputs": [ "Assets/**/*.js" // Include all .js files anywhere in or underneath the Assets folder ], "output": "Scripts/Scripts.js" } ]
Separate output files for each input file
In many cases you will want to process many input files in the exact same way but keep them in separate output files. You could do this by declaring a separate asset group for each pair of input/output files. However this can be extremely tedious and error prone to write, and even more so to maintain over time as you add or remove assets to your extention, especially if you have a large number of asset files.
The pipeline makes this easier by allowing you to use the
@ characted instead of a file name the output file path of your asset group. The
@ character disables the bundling step and basically translates to "the same filename as whatever input asset file is currently being processed". When combined with glob wildcards this can make it a lot easier to manage your assets:
[ { "inputs": [ "Assets/Moment/Localizations/*.ts" ], "output": "Scripts/Localizations/@.js" } ]
In this example, all TypeScript files in the
Assets/Moment/Localizations are processed and each generated into a separate
.js file with the same name in the
Scripts/Localizations folder. For example, assuming the
Assets/Moment/Localizations folder contains
en-GB.ts,
fr-FR.ts and
sv-SE.ts, then the output
Scripts/Localizations folder would contain the resulting files
en-GB.js,
en-GB.min.js,
fr-FR.js,
fr-FR.min.js,
sv-SE.js and
sv-SE.min.js. If localization files are added or removed over time, the asset group is implicitly redefined accordingly.
Multiple asset groups
You can define multiple asset groups in the same asset manifest, as in the following example:
[ { // First asset group "inputs": [ "Assets/Bootstrap/Bootstrap.less", "Assets/Bootstrap/Theme.less" ], "output": "Styles/Bootstrap.css" }, { // Second asset group "inputs": [ "Assets/Styles.less" ], "output": "Styles/Styles.css" }, { // Third asset group "inputs": [ "Assets/JavaScript/Lib/**/*.js", "Assets/JavaScript/Admin/Admin.js" ], "output": "Scripts/Lib.js" } ]
Adding additional files to be watched
As described above, the watch task can be used to continuously monitor input asset files for changes and rebuild affected asset groups automatically for a smooth and efficient local dev/test workflow.
In some cases you may want the watch task to monitor additional files besides those specified as input assets. In particular, this is commonly when using LESS/SASS imports or the TypeScript
<reference> or
import keywords to indirectly include files into the pipeline which were not part of the initial input specification.
Let's say you have a main SCSS stylesheet that looks something like this:
@import "Utils/Mixins.scss"; @import "Utils/Variables.scss"; @import "Utils/Type.scss"
In these cases you can use the
watch property in an asset group to specify an additional set of files to monitor for changes:
[ { "inputs": [ "Assets/Main.scss" // This one imports additional .scss files ], "output": "Styles/Styles.css", "watch": [ "Assets/Utils/*.scss" // Also watch these two files for changes ] } ]
Note that glob wildcards are supported.
Supported asset file formats
The client-side asset pipelines can process either stylesheet assets or script assets.
An asset group can only be used to process one of these categories, and must have a matching output asset file extension. Asset groups dealing with stylesheet assets must specify a
.css output file, while asset groups dealing with script assets must specify a
.js output file. An asset group can contain mixed types of input assets as long as they can be processed into the same output file type (i.e. as long as they all belong to either the stylesheet or the script family).
For example you can specify both
.less and
.css input assets in a group targeted for a
.css output file and you can specify both
.ts and
.js input assets in a group targeted for a
.js output file, but you cannot mix and match; if you try the asset pipeline will throw an error.
Stylesheet assets
The following file types are supported as stylesheet input assets:
- LESS (
.less)
- SASS (
.sass)
- SCSS (
.scss)
- Plain CSS (
.css)
The following tasks are performed on stylesheet assets:
- LESS/SASS transpilation
- Vendor prefix normalization
- Inline source map generation (unless disabled)
- File header generation
- Line ending normalization
- Bundling (unless disabled)
- Minification
Script assets
The following file types are supported as script input assets:
- TypeScript (
*.ts,
*.jsx)
- Plain JavaScript (
*.js)
The following tasks are performed on script assets:
- TypeScript transpilation
- Inline source map generation (unless disabled)
- File header generation
- Line ending normalization
- Bundling (unless disabled)
- Minification
Note: All input script assets are processed through the TypeScript transpiler, also plain JavaScript
.js files. This means the asset pipeline will throw errors for obvious syntactical errors in plain JavaScript files. This should generally be considered an advantage as JavaScript errors can be caught at build time rather than at runtime.
Supported options
The following is an exhaustive list of all possible properties that can be specified in an asset group in the asset manifest file.
inputs (required)
An array of input files to include in the asset group. Paths are relative to the asset manifest file. Glob wildcards are supported. Single entries must be wrapped in an array.
output (required)
The output file to be generated by the asset group. The path is relative to the asset manifest file. All inputs will be bundled into the specified output file unless
@ is specified as the base filename, eg
Scripts/@.css, to skip bundling. A minified version with a
.min suffix will be automatically generated also.
watch
An array of additional files to be monitored for changes. Paths are relative to the asset manifest file. Glob wildcards are supported. Single entries must be wrapped in an array.
generateSourceMaps
true to emit inline source maps into non-minified output files,
false to disable source maps. Default is
true.
flatten
By default, when using a glob to specify input assets and using the
@ character in the output file path to bypass bundling, output files are generated in the same relative location as their corresponding input assets relative to the first glob in the input pattern. For example, assuming you have the following input assets:
Assets/Pages/PageStyles.less
Assets/Widgets/LoginWidget/Login.less
Given the following asset group definition:
[ { "inputs": [ "Assets/**/*.less" ], "output": "Styles/@.css" } ]
The default behavior of the asset pipeline would generate the following output files:
Styles/Pages/PageStyles.css
Styles/Pages/PageStyles.min.css
Styles/Widgets/LoginWidget/Login.css
Styles/Widgets/LoginWidget/Login.min.css
This may not always be the desired behavior. The
flatten property can be set to
true to have the asset pipeline flatten the output folder structure and disregard the relative locations of the input asset files. In this case, setting
flatten to
true would instead produce the following two output files:
Styles/PageStyles.css
Styles/PageStyles.min.css
Styles/Login.css
Styles/Login.min.css
separateMinified
By default, minified output files are generated alongside their non-minified siblings with a
.min filename extension:
Styles/SomeStyles.css
Styles/SomeStyles.min.css
In some cases, such as when using a runtime module loader, it can be useful to place minified output files in a subfolder instead of suffixing their filenames. This allows you to simply configure a different base path for the module loader depending on execution mode (i.e. debug vs. release) rather than having to declare every resource differently. Setting the
separateMinified option property to
true will result in the following alternative output structure:
Styles/SomeStyles.css
Styles/min/SomeStyles.css
typeScriptOptions
Any options you wish to pass through to the TypeScript transpiler (only applicable for script asset groups). The following default values are specified by the asset pipeline unless overridden in this property:
{ allowJs: true, noImplicitAny: true, noEmitOnError: true }
Advanced scenarios
Excluding output files from source control
When developing an extension intended for redistribution and used by third parties, it is recommended that generated output files be added to
.csproj files of the containing extension and included in source control. All the built-in projects in the Orchard code base employ this methods. This is so that consumers can use your extension without having to install Node.js and execute the Gulp tasks in the client-side asset pipeline to generate the needed output asset files first.
However, when developing an extension for internal use you may also consider the alternative approach of leaving generated output files out of both
.csproj files and source control and rely on them being rebuilt by the client-side asset pipeline whenever needed. This is similar to how you often assume that the NuGet package manager will be used to restore NuGet package references before a project is built.
This approach has a couple of advantages:
- Smaller version control footprint
- No risk of inconsistent/stale output assets due to forgetting to rebuild them or commit their changes to version control
When using this approach, the
Styles and
Scripts folders in your extension will always remain empty in Solution Explorer although they will contain the output files on disk, and you will typically configure a Gulp task binding to ensure that client-side assets are always built when the solution is built in Visual Studio. If using an automated build system you will also typically add a step to your build script to ensure the build or rebuild task is executed as part of the build.
Including custom extension folders
Version 1.10 of Orchard introduced the ability to load extensions from other folders besides the
Orchard.Web/Modules and
Orchard.Web/Themes folders. If your extension is stored and loaded from such a custom location, the client-side asset pipeline will not automatically detect your asset manifest. This is because, by default, it only looks for
Assets.json files in folders under these locations:
Orchard.Web/Core/
Orchard.Web/Modules/
Orchard.Web/Themes/
To add your custom location to be scanned for asset manifests, follow these steps:
Open the file
src/Gulpfile.jsin Visual Studio or any other text editor.
Find the
getAssetGroups()function.
This function declares an
assetManifestPathsarray variable. You can add your own glob here and merge the resulting arrays. For example:
var assetManifestPaths = glob.sync("Orchard.Web/{Core,Modules,Themes}/*/Assets.json"); var customThemePaths = glob.sync("AnotherLocation/MyCompanyThemes/*/Assets.json"); // Custom location! assetManifestPaths = assetManifestPaths.concat(customThemePaths);
- Save and close the file.
The Orchard development team is investigating ways to automate this process.
Evolution of the client-side asset pipeline
For those interested in the history behind the client-side asset pipeline, you can find the initial discussion with reasons for its development and proposed solutions in issue #5450. | http://docs.orchardproject.net/en/latest/Documentation/Processing-client-side-assets/ | CC-MAIN-2017-26 | refinedweb | 3,716 | 54.32 |
1. Introduction
In the previous examples, we used "TCP Channel" to communicate the remote object in the server machines. Also, we have the reference to the server project in the client development projects. Giving the code to the client is not advisable as the client can go ahead and strip the given to know some of the implementation details..
2. The Http remote Server
1) The server is a C# console application. It has constructor, we are just printing some message so that we can ensure whether server object is created or not just by looking at the console window of the server. Also, note that this time we are going to use the HTTP channel and hence included the channels.http (using System.Runtime.Remoting.Channels.Http;)
2) In the server application main, we are creating http channel and then registering the remote object as a SingleCall object. As the basic example (First article on DotNet remoting) has all the to share with client
Once the server is ready we are all set to go ahead and create the Metadata assembly that can be shared with the client piece code. Remember in the previous example when I used the TCP communication channel, I usually add whole server project as the reference. The alternate technique to that is having the declaration in a separate assembly (dll) and shipping that to the client. Here we are going to generate separate metadata:
4. Consuming the metadata dll in the client
The client is also Visual C# console application. Once the client project is created, after giving the reference to dotnet remoting, the reference to the metadata dll is given using the browse tab of the add reference dialog box. Once the reference is given, we have access to the remote object and we can create it using the new operator.
Getting the reference to the metadata dll in the client project is shown in the below video.
Video:
5. Accessing the Remote object through Http
Once you created the reference to the Meta dll formed on the server machine using soapsuds, you can simply access the remote object using the new operator just like you create normal objects. Below is the explanation for the code:
1) RServer is the namespace in the server. Note that in the server implementation the Remote class name, as well as the namespace name both are same.
//Client 01: Use the Meta data dll.
using RServer;
2) The remote object is created using the new operator. But, in the background, through the Meta data DLL, we are making a call to the wrapped assembly to get the proxy. This proxy object actually calls the real object at the server end. And it knows the communication protocol, server();
3) The remaining lines of code are simple as it just makes a call to the function exposed by the above-created object. In user perspective, it is just an object. But, the function call is executed on the server.:
Note: The sample is created using the VS2005 IDE.
Leave your comment(s) here. | http://www.mstecharticles.com/2011/11/remotingnet-accessing-http-remote.html | CC-MAIN-2017-17 | refinedweb | 514 | 61.56 |
Python scripting tutorial → Prefences → General → Output window and check 2 boxes:
- Redirect internal Python output to report view
- Redirect internal Python errors to report view
Then go to View → Panels and check:
- Report view
This will save you a lot of aggravation!
Writing python code
There are two easy ways to write python code in FreeCAD: From the python console (available from the View → Panels → Python console menu) or from the Macro editor (Tools →
Let's start by creating a new empty document:
doc = FreeCAD.newDocument()
If you type this in the FreeCAD python console, you will notice that as soon as you type "FreeCAD.", → Preferences → General → small letter are functions (also called methods), they "do something". Names that begin with an underscore are usually there for the internal working of the module, and you shouldn't care about them. Let's use one of the methods to add a new object to our document:
box = doc.addObject("Part::Box","myBox")
Nothing happens. Why? Because FreeCAD is made for the big picture. One day, it will work with hundreds of complex objects, all depending'll see that in the) of the object. It is easy to manipulate, for example to move our object:
box.Placement box.Placement.Base box.Placement.Base = sumvec otherpla = FreeCAD.Placement() box.Placement = otherpla
Now you must understand a couple of important concepts before we get further.
App and Gui
FreeCAD base modules: FreeCAD and FreeCADGui (which can also be accessed by their shortcuts App and Gui). They contain all kinds of generic functionality to work with documents and their objects. To illustrate our concept, see that both FreeCAD and FreeCADGui contain an ActiveDocument attribute, which is the currently opened document. FreeCAD.ActiveDocument and FreeCADGui.ActiveDocument are not the same object.bench object, used for example by Sketchup, Blender or 3D studio Max. They are composed of 3 elements: points (also called vertices), lines (also called edges) and faces. In many applications, FreeCAD included, faces can have only 3 vertices. Of course, nothing prevents you from having a bigger plane face made. This kind of object, unlike meshes, can have a wide variety of components. Brep stands for Boundary Representation, which means that Brep objects are defined by their surfaces; those surfaces enclose and define an inner volume. A surface can be a variety of things such as plane faces or very complex NURBS surfaces.
The Part module is based on the powerful OpenCasCade library, which allows a wide range of complex operations to be easily performed on those objects, such as boolean operations, filleting, lofts, etc...
The Part module works the same way as the Mesh module: You create a FreeCAD object, a Part object, then add the Part object to the FreeCAD object:
import Part myshape = Part.makeSphere(10) myshape. myshape above, which work not only on Draft-made objects, but on any Part object. To explore what is available, simply do:
import Draft Draft. rec = Draft.makeRectangle(5,2) mvec = FreeCAD.Vector(4,4,0) Draft.move(rec,mvec) Draft.move(box,mvec)
Interface
The FreeCAD user interface is made with Qt, a powerful graphical interface system, responsible for drawing and handling all the controls, menus, toolbars and buttons around the 3D view. Qt provides a module, be added to a toolbar and launched via a mouse click. FreeCAD provides you with a simple text editor (Macro → Macros → Create) where you can write or paste scripts. Once the script is done, use Tools → Customiz → Macros to define a button for it that can be added to toolbars.
Now you are ready for more in-depth FreeCAD scripting. Head on to the Power users hub!
> | https://wiki.freecadweb.org/Python_scripting_tutorial | CC-MAIN-2020-16 | refinedweb | 611 | 63.29 |
Hey ya. In this article we’re going to set you up with a basic plugin environment to get you going in WordPress Plugin development, including Gutenberg. The goal of this article is to cover the following:
- Setup a basic plugin using Gutenberg
- Use jQuery on the front end for a block
- Use javascript files on both front and back end?
- Register stylesheets for block use
Register SCSS files
Learn to code with our beginner friendly tutorials on programming, Linux, Docker, and more
Okay. First step, let’s setup our plugin. I’ll be using a local WAMP server with WordPress already setup. Once you’ve got WordPress running locally, navigate to your “plugins” directory and create the project. I’ll call mine new-plugin and have a new-plugin.php file like this:
<?php /** * Plugin Name: new plugin * Plugin URI: * Description: registering scripts styles and stuff * Author: John * Author URI: */
Okay cool, we can now activate our plugin. Once the plugin is activated we’ll want to setup “wp-scripts”. From the root directory of your project in your command line we’ll need to setup our package.json file and install the npm module (I’m assuming you have node and npm installed)
$ npm init -y $ npm install @wordpress/scripts --save-dev
wp-scripts says in their docs that everything compiles to build/index.js. We also need to add our start and build scripts. So modify your package.json by adjusting the “main” line to use the “build/index.js” file, and add the “scripts” block like so:
{ "name": "new-plugin", "version": "1.0.0", "description": "", "main": "build/index.js", "scripts": { "start": "wp-scripts start", "build": "wp-scripts build", "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [], "author": "", "license": "ISC", "devDependencies": { "@wordpress/scripts": "^10.0.0" } }
wp-scripts “entrypoint” for our source code is the “src/index.js” file, meaning that wp-scripts expects to find all of the JS source code we write in src/index.js. Let’s just do a simple log for now:
console.log("hello from new-plugin js");
Now if we were to run “npm start” our “start” script runs, which sets up our build/ folder with all our compiled source code. Let’s do that with the npm start command:
$ npm start
Our build file should appear with the folders inside. So far so good!
Ok, now let’s “enqueue” or register that JS code so WordPress can detect it. We do that with our main php file. Based on the WordPress docs, it appears that we want to “register” the script, and then use that script inside our “register_block_type” function. wp_register_script and wp_register_style is how we prepare our scripts and styles to be used by WordPress. The first step is to create a handle for the script, and then apply that handle where we want the script/style added. It looks like this for our sample plugin:
function new_plugin_setup() { $asset_file = include(plugin_dir_path(__FILE__) . 'build/index.asset.php'); wp_register_script( 'truth-new-plugin-script', plugins_url('build/index.js', __FILE__), $asset_file['dependencies'], $asset_file['version'] ); register_block_type('truth/new-plugin-block', array( 'editor_script' => 'truth-new-plugin-script', )); } add_action('init', 'new_plugin_setup');
Webpack sets up a list of dependencies & version number in build/index.asset.php, so we can easily access dependencies for the project.
Then you want to “register” the script. In this case we created a handle named “truth-new-plugin-script”, so any time we call on that handle it will import that javascript. Then we have the path, dependencies and version…
You can see we’re using that handle to apply the script to our “new-plugin-block’ in the register_block_type function. The ‘editor_script’ will make the js file only apply to inside the editor.
If you save the file and create a new post, and open the developer tools you should see your console.log statement from inside the src/index.js file. Now let’s register the block type in the front end. Inside your src/index.js file we need to import the registerBlockType from @wordpress/blocks (provided by wp-scripts) and create our block:
console.log("hello from new-plugin js lala"); import { registerBlockType } from '@wordpress/blocks'; registerBlockType('truth/new-plugin-block', { title: 'new plugin block', icon: 'smiley', category: 'layout', edit: () => <div>I am the edit test</div>, save: () => <div>I am the frontend test!</div>, });
Just to make sure we’re still good, let’s try to create the block. It’s named after the “title” so I’d type in “new plugin block” to add it to post area. And we’re good so far!
Ok, let’s add our CSS file now. This css file will be for our editor… so we’ll first want to register the script (note you can also enqueue, but registering and then grabbing by the handle when you need it is recommended) Underneath the wp_register_script in our new_plugin_setup() function we’ll call wp_register_style to register our backend editor stylesheet:
wp_register_style( 'truth-new-block-style', plugins_url('/src/style.css', __FILE__), array('wp-edit-blocks') );
truth-new-block-style is our stylesheet handle. then we have the location of the file, and last parameter is dependencies. I didn’t know stylesheets had dependencies so that’s a bit weird but whatever. Now we need to connect this style to our block. We’ll add an element to the array in our existing register_block_type call like this:
register_block_type('truth/new-plugin-block', array( 'editor_script' => 'truth-new-plugin-script', 'editor_style' => 'truth-new-block-style' ));
Cool now we should be able to create a CSS file where we said it was in wp_register_style (which is in /src/style.css) So let’s test that out, but first we should setup our edit function to add in the default classname for our block:
registerBlockType('truth/new-plugin-block', { title: 'new plugin block', icon: 'smiley', category: 'layout', edit: ({ className }) => <div className={className}>I am the edit test</div>, save: () => <div>I am the frontend test!!</div>, });
This is just ES6 syntax to pass in the className provided by WordPress and adding that class to the div. Now onto our /src/style.css file:
.wp-block-truth-new-plugin-block { background: blue; }
Save and refresh, and you’ll hopefully see you’re beautifully colored blue block.
Want More Tutorials?
Get our best crash courses and tutorials
(Source Code Provided)
Cool. I’ll leave the front end styles up to you as an exercise. But let’s cover the front end script. Say you need some jQuery on the front end of your site to work with the block. Well, according to WordPress jQuery is already included, so all we need to do is tell wp_register_script that jQuery is a dependency for our script. In our main php file add this code:
wp_register_script( 'jsc-courses-frontend-script', //handle plugins_url('/src/frontend.js', __FILE__), array('jquery') ); // DON'T ADD THIS FUNCTION TWICE! The above code is new, below just add the 'script' line. register_block_type('truth/new-plugin-block', array( 'editor_script' => 'truth-new-plugin-script', 'editor_style' => 'truth-new-block-style', 'script' => 'jsc-courses-frontend-script' ));
Then add your src/frontend.js code as follows:
jQuery(document).ready(function ($) { console.log("doing some jquery stuff!"); $('.wp-block-truth-new-plugin-block').click(function () { alert("Ouch! Don't click me!"); }) });
Now navigate to your front end and click on your block and you’ll see it all hopefully works.
UPDATE: CSS Pre-processors are easy with this setup
Let’s try to add some SCSS files. First, you’ll have to think about the ideal setup for your project. Do you want to create many smaller CSS files and only load the minimal css necessary on each section? For production that may be best, but we’ll keep it simpler here since this isn’t a webpack tutorial.
Our setup will have two additional “entry points” in our webpack. In WordPress we have a CSS file for our front-end, and another CSS file for our editor. So we’ll import all our “front end css” into a “frontEndStyles” Javascript file. Webpack will see this Javascript file (entry point) and create a CSS file based off it. Then we’ll add an “editorStyles” JS file that imports all the editor’s CSS. Webpack will create a CSS file for it too.
Finally, because Webpack is creating these two extra css files, we’ll want to register those files in our PHP instead.
First, we’ll setup our two entry points in Webpack. These entry points are kind of like “doorways” to our project. If you had a huge project with one entry point, it’s like having a mansion with only a front door to get in or out. Adding multiple entry points is like having a garage on the side. Code that’s part of the project, but separate for whatever reason. By default WordPress and Webpack have the “src/index.js” file as the entry point.
Create a
webpack.config.js file and add this code:
const defaultConfig = require("@wordpress/scripts/config/webpack.config"); const path = require('path'); console.log("laaaaalala"); module.exports = { ...defaultConfig, entry: { ...defaultConfig.entry, editorStyle: './src/editorStyle.js', style: './src/style.js' } }
The first line imports the existing webpack config provided by wp-scripts.
in module.exports we’re just spreading out the existing settings into the object, creating the “entry”, and adding the two entry points that we want, along with their names and file locations. You may even want to name ‘style’ as “frontEndStyle” for extra clarity if you want.
Now create the ‘src/editorStyle.js’ and ‘src/style.js’ files.
Now we can import all our front end styles to style.js and our editor styles to editorStyle.js. Let’s create a CSS file for both.
editorStyle.css:
.wp-block-truth-new-plugin-block { background: lawngreen; }
style.css: (already have this one. Let’s change the color)
.wp-block-truth-new-plugin-block { background: pink; }
Now in order to allow webpack to create our CSS files for us, we’ll need to make sure webpack can get to our CSS files through the entry points. So in our editorStyle.js and style.js we’ll want to import these CSS files.
editorStyle.js:
import './editorStyle.css';
style.js:
import './style.css';
Now webpack sees our CSS code and can create our production css files for us. First we’ll have to kill our server and start it back up with Ctrl + C and then
npm start in our terminal. Go ahead and do that.
Once you restart NPM it should rebuild based off our new webpack config and create two css files in our “build folder”. Here’s what I have:
Notice editorStyle.css and “style-style.css” (Honestly I was expecting style.css since it’s supposed to match the KEY “style” you provided in the webpack config… but whatever, I’m not going to mess with it.)
So… Let’s now try to see if we can get SCSS files to work.
- Change each of your CSS files in the src/ folder to have a .scss extension.
- update the import statements to import the newly named files.
Update style.js:
import './style.scss';
Update editorStyle.js:
import './editorStyle.scss';
Now to let’s change the scss files to actually do scss things. style.scss:
$primary-color: yellow; .wp-block-truth-new-plugin-block { background: $primary-color; }
editorStyle.scss:
$secondary-color: brown; .wp-block-truth-new-plugin-block { background: brown; }
Now if you look through your CSS files in your build/ folder you’ll see that webpack is reading and processing your SCSS files and turning them into plain ole’ CSS. So… You could import 100 css/scss files into your two “entry points” and it’ll all compile into those two css files.
The last thing we have to do is integrate the CSS files from our build/ folder into the plugin. Currently we’re importing the files inside our src/ which wont work because they’re scss files.
I did a pretty crappy job of naming my handles, so I apologize for that, and we’ll now give them more appropriate names as we fix our new-plugin.php file.
function new_plugin_setup() { $asset_file = include(plugin_dir_path(__FILE__) . 'build/index.asset.php'); wp_register_script( 'truth-new-plugin-editor-script', plugins_url('build/index.js', __FILE__), $asset_file['dependencies'], $asset_file['version'] ); wp_register_style( 'truth-new-plugin-editor-style', plugins_url('/build/editorStyle.css', __FILE__), array('wp-edit-blocks') ); wp_register_style( 'truth-new-plugin-frontend-style', plugins_url('/build/style-style.css', __FILE__), array('wp-edit-blocks') ); wp_register_script( 'truth-new-plugin-frontend-script', //handle plugins_url('/src/frontend.js', __FILE__), array('jquery') ); register_block_type('truth/new-plugin-block', array( 'editor_script' => 'truth-new-plugin-editor-script', 'editor_style' => 'truth-new-plugin-editor-style', 'script' => 'truth-new-plugin-frontend-script', 'style' => 'truth-new-plugin-frontend-style' )); } add_action('init', 'new_plugin_setup');
All we did was update the locations of the CSS files that wp_register_style will look for our css files… I also updated the handles to be not so horribly named. (I apologize for that again I was being lazy.)
Lastly, to make sure your frontend styles show up we need to add the class to the frontend as well. Do that in
'src/index.js' by editing the “save” function like this:
save: ({ className }) => <div className={className}>I am the frontend test!</div>,
It’s really hard to write these tutorials without errors or missing something, so here’s the source code of the final working version you can play with. It SHOULD work by just sticking it in your plugins/ folder and running “npm install” and “npm start”. I hope this was helpful to you. | https://truthseekers.io/how-to-register-scripts-and-styles-in-your-wordpress-gutenberg-plugin/ | CC-MAIN-2020-40 | refinedweb | 2,280 | 57.67 |
It's been rumoured that Lincoln D. Durey said: > > Linas, > we are happy users of gnucash 1.4.9. But we had a system crash while a > gnucash was running (most likely not gnucash's fault). As this session > involved about 2-3 hours of hard work, we are very interested in any > available recovery options. > > We have our previos data file (gc_emp), which is exactly in step with > the state of our accounts before the data entry began, and we have the .log > file (gc_emp.20010206224731.log) time stamped just moments before the crash. > there was no .xac file generated at crash time. > > Is there a way to apply the log file (which I can see has the data we > entered) to the original file, and arrive at a nice new gnucash file with all > our updates? Either manually, or with a nice front end. Do you know perl? As of about an hour ago, no one had bothered to do this. So I 'just did it;'. Its dirty, it doesn't check for errors, its minimal. It was harder to create than it should have been; the gnucash engine doesn't have a 'get account by name' function, and it doesn't grok dates quite the way it should. Backup your data, the script may mangle things. You will need to double-check. --linas p.s. I'll check this into cvs under the name 'gnc-restore.pl' or something like that. Maybe it'll be in 1.4.11 as an undocumented feature. #! /usr/bin/perl # # restore gnucash transactions from a gnucash log file. # # Warning! this script probably does the wrong thing, # and has never been tested!! # It will probably destroy your data! Use at your own risk! # # set the path below to where your gnucash.pm is located use lib '/usr/local/gnucash-1.4/lib/gnucash/perl'; use lib '/usr/local/gnucash-1.4/share/gnucash/perl'; use gnucash; # -------------------------------------------------- # @account_list = &account_flatlist ($account_group); # This routine accepts a pointer to a group, returns # a flat list of all of the children in the group. sub account_flatlist { my $grp = $_[0]; my $naccts = gnucash::xaccGroupGetNumAccounts ($grp); my $n; my (@acctlist, @childlist); my $children; foreach $n (0..$naccts-1) { $acct = gnucash::xaccGroupGetAccount ($grp, $n); push (@acctlist, $acct); $children = gnucash::xaccAccountGetChildren ($acct); if ($children) { @childlist = &account_flatlist ($children); push (@acctlist, @childlist); } } return (@acctlist); } # -------------------------------------------------- # If the gnucash engine had a 'get account by name' # utility function, then we wouldn't need this and the above mess. sub get_account_by_name { my $accname = $_[0]; my $name; # loop over the accounts, look for stock and mutual funds. foreach $acct (@acctlist) { $name = gnucash::xaccAccountGetName ($acct); if ($name eq $accname) { $found = $acct; break; } } return ($found); } # -------------------------------------------------- die "Usage: cat <logfile> | $0 <gnucash-filename>" if $#ARGV < 0; # open the file print "Opening file $ARGV[0]\n"; $sess = gnucash::xaccMallocSession (); $grp = gnucash::xaccSessionBeginFile ($sess,$ARGV[0]); die "failed to read file $ARGV[0], maybe its locked? " if (! $grp); # get a flat list of accounts in the file @acctlist = &account_flatlist ($grp); $got_data = 0; $nsplit = 0; while (<STDIN>) { # start of transaction if (/^===== START/) { $nsplit = 0; next; } # end of transaction if (/^===== END/) { if ($got_data == 1) { gnucash::xaccTransCommitEdit ($trans); } $got_data = 0; next; } # ignore 'begin' lines if (/^B/) { next; } if (/^D/) { print "WARNING: deletes not handled, you will have to manually delete\n"; next; } # ignore any line that's not a 'commit' if (!/^C/) { next; } chop; # get journal entry ($mod, $id, $time_now, $date_entered, $date_posted, $account, $num, $description, $memo, $action, $reconciled, $amount, $price, $date_reconciled) = split (/ /); # parse amount & price # gnucash-1.4 : float pt, gnucash1.5 : ratio ($anum, $adeno) = split (/\//, $amount); if (0 != $adeno) { $amount = $anum / $adeno; } ($pnum, $pdeno) = split (/\//, $price); if (0 != $pdeno) { $price = $pnum / $pdeno; # value, not price ... if (0 != $amount) { $price = $price/$amount; } } $dyear = int($date_posted/10000000000); $dmonth = int($date_posted/100000000) - 100*$dyear; $dday = int($date_posted/1000000) - 10000*$dyear - 100*$dmonth; $dpost = $dmonth . "/" . $dday . "/" . $dyear; # do a 'commit' if ($mod == C) { print "restoring '$account' '$description' for $pric and '$quant'\n"; print "date is $dpost $date_posted\n"; if ($got_data == 0) { $trans = gnucash::xaccMallocTransaction(); gnucash::xaccTransBeginEdit( $trans, 1); $got_data = 1; } gnucash::xaccTransSetDescription( $trans, $description); gnucash::xaccTransSetDateStr ($trans, $dpost); gnucash::xaccTransSetNum ($trans, $num); if ($nsplit == 0) { $split = gnucash::xaccTransGetSplit ($trans, $nsplit); } else { $split = gnucash::xaccMallocSplit(); gnucash::xaccTransAppendSplit($trans, $split); } gnucash::xaccSplitSetAction ($split, $action); gnucash::xaccSplitSetMemo ($split, $memo); gnucash::xaccSplitSetReconcile ($split, $reconciled); # hack alert -- fixme: the reconcile date is not set ... # need to convert date_reconciled to 'seconds' ... # gnucash::xaccSplitSetDateReconciled ($split, $date_reconciled); gnucash::xaccSplitSetSharePriceAndAmount($split, $price, $amount); $acct = get_account_by_name ($account); gnucash::xaccAccountBeginEdit ($acct, 1); gnucash::xaccAccountInsertSplit ($acct, $split); gnucash::xaccAccountCommitEdit ($acct); $nsplit ++; } } gnucash::xaccSessionSave ($sess); gnucash::xaccSessionEnd ($sess); _______________________________________________ gnucash-devel mailing list [EMAIL PROTECTED]
- gnucash crash!, ? recovery options ? Lincoln D. Durey
- linas | https://www.mail-archive.com/gnucash-devel@gnucash.org/msg07878.html | CC-MAIN-2022-21 | refinedweb | 774 | 55.74 |
Nth element (Java)>>= public static <T extends Comparable<? super T>> T qnth(List<T> sample, int n) { T pivot = sample.get(0); List<T> below = new ArrayList<T>(), above = new ArrayList<T>(); for (T s : sample) { if (s.compareTo(pivot) < 0) below.add(s); else if (s.compareTo(pivot) > 0) above.add(s); } int i = below.size(), j = sample.size() - above.size();
At this point, i and j would (if it were sorted) index into sample as follows:
hence we need only recurse on the segment containing the nth element.
<<define qnth>>= if (n < i) return qnth(below, n); else if (n >= j) return qnth(above, n-j); else return pivot; }
[edit] wrapping up
Finally we wrap the function up in a class with a main function which, if run from the command line, checks (for an element from the middle of a random list) that qnth produces the same result as sorting the list and then selecting the nth element.
<<QNth.java>>= import java.util.List; import java.util.ArrayList; import java.util.Collections; public class QNth { define qnth public static void main(String[] args) { int n = 64, mid = 32; List<Double> sample = new ArrayList<Double>(); for (int i = 0; i < n; i++) sample.add(Math.random()); double partial = qnth(sample, mid); Collections.sort(sample); double sorted = sample.get(mid); System.out.println("" + partial + " " + sorted + " " + (partial == sorted)); } }
The output should be similar to:
0.579906140785445 0.579906140785445 truehijackerhijacker | http://en.literateprograms.org/Nth_element_(Java) | CC-MAIN-2015-22 | refinedweb | 239 | 51.34 |
In this Pydon't you'll learn how to make the best use possible of the Python REPL.
(If you are new here and have no idea what a Pydon't is, you may want to read the Pydon't Manifesto.)
The REPL is an amazing tool that every Python programmer should really know and appreciate! Not only that, but you stand to gain a lot if you get used to using it and if you learn to make the most out of it 😉
In this Pydon't, you will:
You can now get your free copy of the ebook “Pydon'ts – Write beautiful Python code” on Gumroad to help support the series of “Pydon't” articles 💪.
Read. Evaluate. Print. Loop.
That's what “REPL” stands for, and it is often referred to as “read-eval-print-loop”. The REPL is the program that takes your input code (i.e., reads your code), evaluates it, prints the result, and then repeats (i.e., loops).
The REPL, sometimes also referred to as the “interactive session”,
or the “interpreter session”,
is what you get when you open your computer's command line and type
python or
python3.
That should result in something like the following being printed:
Python 3.9.2 (tags/v3.9.2:1a79785, Feb 19 2021, 13:44:55) [MSC v.1928 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
Of course, the exact things that are printed (especially the first line) are likely to differ from what I show here, but it's still the REPL.
(By the way, if you ever need to leave the REPL, just call the
exit() function.)
The REPL is, hands-down, one of your best friends when you are writing Python code. Having a REPL to play around with just makes it much easier to learn the language.
Can't remember the argument order to a built-in function? Just fire up the REPL.
Need to do a quick computation that is just a bit too much for the conventional desktop calculator? Just fire up the REPL.
Can't remember how to spell that module you want to import? Just fire up the REPL.
You get the idea.
I cannot stress this enough. Get used to the REPL. Play with it. Write code in it. As soon as you become familiar with it, you'll love it and thank me for that.
The REPL generally contains a
>>> in the beginning of the line, to the left of your cursor.
You can type code in front of that prompt and press Enter.
When you press Enter, the code is evaluated and you are presented with the result:
>>> 3 + 3 6
The REPL also accepts code that spans multiple lines, like
if statements,
for loops, function definitions with
def, etc.
In order to do those, just start typing your Python code regularly:
>>> if True:
When you press Enter after the colon,
Python realises the body of the
if statement is missing,
and thus starts a new line containing a
... on the left.
The
... tells you that this is the continuation of what you started above.
In order to tell Python you are done with the multiline code blocks
is by pressing Enter on an empty line with the continuation prompt
...:
>>> if True: ... print("Hello, world!") ... Hello, world! >>>
Pasting into the REPL should work without any problem.
For example, the function below returns the double of the input. Try copying it into your REPL and then using it.
def double(x): return 2 * x
However, if you try to copy and paste a multiline block that contains empty lines in the middle, then the REPL will break your definition.
For example, if you try pasting the following, you get an error:
def double(x): return 2 * x
Copying the code above and pasting it into the session, you will end up with a session log like this:
>>> def double(x): ... File "<stdin>", line 2 ^ IndentationError: expected an indented block >>> return 2 * x File "<stdin>", line 1 return 2 * x IndentationError: unexpected indent
This happens because the REPL finds a blank line and thinks we tried to conclude the definition of the function.
One last thing you should know about the REPL is that it implicitly “prints” the results of the expressions you type.
I wrote “prints” in quotes because the REPL doesn't really print the result,
it just shows its representation.
The representation of an object is what you get when you call
repr on the object.
If you explicitly
str on it.
I wrote a very detailed Pydon't explaining the differences between the two, so let me just show you how things are different:
# Define a string. >>> s = "Hello\nworld!" # Print its `str` and `repr` values: >>> print(str(s)) Hello world! >>> print(repr(s)) 'Hello\nworld!' # Print the string explicitly and evaluate it in the REPL. >>> print(s) Hello world! >>> s 'Hello\nworld!'
As you can see, printing
s or just typing it in the REPL
gives two different results.
Just be mindful of that.
None
In particular, if the expression you wrote evaluates to
None,
then nothing gets printed.
The easiest way to see this is if you just type
None in the REPL.
Nothing gets displayed; contrast that with what happens if you just type
3:
>>> None >>> 3 3
If you call a function that doesn't have an explicit return value,
or that returns
None explicitly,
then those functions will not show anything in the REPL:
>>> def explicit_None_return(): ... # Return None explicitly. ... return None ... >>> explicit_None_return() # <- nothing gets displayed. >>> def implicit_None_return(): ... # Ending without a `return` returns `None` implicitly. ... pass ... >>> implicit_None_return() # <- nothing gets displayed.
Sometimes it is useful to use the REPL to quickly import a function you just defined. Then you test the function out and then proceed to changing it in the source file. Then you'll want to import the function again and test it again, except that won't work.
You need to understand how the REPL handles imports, because you can't import repeatedly to “update” what's in the session.
To show you this, go ahead and create a file
hello.py:
# In `hello.py`: print("Being imported.")
Just that.
Now open the REPL:
>>> import hello Being imported!
Now try modifying the string inside the
>>> import hello Being imported! # Modify the file, then import again: >>> import hello >>>
Nothing happens! That's because Python already went through your file and knows what's in there, so it doesn't need to parse and run the file again. It can just give you the functions/variables you need.
In short, if you modify variables, functions, code; and you need those changes to be reflected in the REPL,
then you need to leave the REPL with
exit(), start it again, and import things again.
That's why some of the tips for quick hacks I'll share below are so helpful.
Edit: Another alternative – brought to my attention by a kind reader –
is to use
importlib.reload(module) in Python 3.4+.
In our example, you could use
importlib.reload(hello):
>>> import hello Being imported >>> import importlib # Use `imp` from Python 3.0 to Python 3.3 >>> importlib.reload(hello) Being imported <module 'hello' from 'C:\\tmp\\hello.py'>
We get that final line because
importlib.reload returns the module
it reloaded.
You can take a look at this StackOverflow question and answers to learn a bit more about this approach.
Be mindful that it may not work as you expect when you have multiple imports. Exiting the REPL and opening it again may be the cleanest way to reload your imports in those situations.
I'll be honest with you, I'm not entirely sure if what I'm about to describe is a feature of the Python REPL or of all the command lines I have worked with in my entire life, but here it goes:
You can use the up and down arrow keys to go over the history of expressions you already entered. That's pretty standard.
What's super cool is that the REPL remembers this history of expressions, even if you exit the REPL, as long as you don't close the terminal.
If you read my Pydon't about the usages of underscore
you might know this already,
but you can use the underscore
_ to retrieve the result of the last expression
if you want to use it and forgot to assign.
Here is a silly example:
>>> 3 + 6 9 >>> _ + 10 19
This might come in handy when you call a function or run some code that takes a long time. For example, downloading something from the Internet.
It can also be helpful if you just ran an expression with side-effects and you don't want to run that again because you don't want to trigger the side-effects twice. For example, if you just made a call to an API.
Of course
_ is a valid variable name in and out of itself,
so you can still use it as a variable name.
If you do, however, then
_ will stop reflecting the result of the last expression:
>>> _ = 0 >>> _ 0 >>> 3 + 9 12 >>> _ 0 # <- it still evaluates to 0!
If you want to get back the magical behaviour of
_ holding the result of the last expression,
just delete
_ with
del _.
Another great feature that is often underappreciated is the built-in help system.
If you need to take a look at a quick reference for a built-in function,
for example, because you forgot what the arguments are, just use
>>> help(sum) Help on built-in function sum in module builtins: sum(iterable, /, start=0) Return the sum of a 'start' value (default: 0) plus an iterable of numbers When the iterable is empty, return the start value. This function is intended specifically for use with numeric values and may reject non-numeric types. >>>
What is great about this
help built-in is that it can even provide help
about your own code, provided you document it well enough.
Here is the result of calling
help on a function defined by you:
>>> def my_function(a, b=3, c=4): ... return a + b + c ... >>> help(my_function) Help on function my_function in module __main__: my_function(a, b=3, c=4) >>>
You can see that
help tells you the module where your function was defined
and it also provides you with the signature of the function,
default values and all!
To get more information from
help you need to document your function with a docstring:
>>> def my_function(a, b=3, c=4): ... """Return the sum of the three arguments.""" ... return a + b + c ... >>> help(my_function) Help on function my_function in module __main__: my_function(a, b=3, c=4) Return the sum of the three arguments. >>>
Now you can see that the
help function also gives you the information
stored in the docstring.
I'll be writing a Pydon't about docstrings soon. Be sure to subscribe to my newsletter so you don't miss it!
The Python REPL is amazing when you need to flesh an idea out, as it allows you to quickly test some code, tweak it, and iterate over that repeatedly with instant feedback.
It goes without saying, but the REPL is not a replacement for your IDE! However, sometimes it helps to know about a couple of little tricks that you can employ to help you make the most out of your REPL.
Yes, really.
Python supports semicolons to separate statements:
>>> a = 3; b = a + 56; print(a * b) 177
However, this feature is something that often does not belong in your code, so refrain from using it.
Despite being generally inadequate for production code, the semicolons are your best friends when in the REPL. I'll explain it to you, and you'll agree.
In the command line you can usually use the up and down arrows to cycle through the most recently typed commands. You can do that in the REPL as well. Just try evaluating a random expression, then press the up arrow and Enter again. That should run the exact same expression again.
Sometimes you will be working in the REPL testing out a solution or algorithm incrementally. However, if you make a mistake, you must reset everything.
At this point, you just press the arrows up and down, furiously trying to figure out all the code you have ran already, trying to remember which were the correct expressions and which ones were wrong...
Semicolons can prevent that! You can use semicolons to keep track of your whole “progress” as you go: whenever you figure out the next step, you can use the arrows to go up to the point where you last “saved your progress” and then you can add the correct step at the end of your sequence of statements.
Here is an example of an interactive REPL session of me trying to order a list of names according to a list of ages.
Instead of two separate assignments, I put them on the same line with
;:
>>> names = ["John", "Anna", "Bill"]; ages = [20, 40, 30]
I could have written
>>> names, ages = ["John", "Anna", "Bill"], [20, 40, 30]
but using the semicolon expresses the intent of having the two assignments in separate lines when it comes time to write the real code down.
Then, I will try to see how to put the ages and names together in pairs:
>>> [(age, name) for name, age in zip(names, ages)] [(20, 'John'), (40, 'Anna'), (30, 'Bill')]
However, at this point I realise I'm being redundant and I can just use
zip
if I reverse the order of the arguments:
>>> list(zip(ages, names)) [(20, 'John'), (40, 'Anna'), (30, 'Bill')]
Now that I'm happy with how I've paired names and ages together, I use the arrow keys to go back to the line with the assignment. Then, I use a semicolon to add the new piece of code I worked out:
>>> names = ["John", "Anna", "Bill"]; ages = [20, 40, 30]; info_pairs = zip(ages, names)
zip is an amazing tool in Python and is one of my favourite
built-in functions.
You can learn how to wield its power with this Pydon't.
Now I can move on to the next step, knowing that a mistake now won't be costly: I can reset everything by going up to the line with all the intermediate steps and run that single line.
When you want to define a simple multiline block, you can often get away with inlining what comes after the colon.
For example, instead of
>>> for i in range(3): ... print(i) ... 0 1 2
you can write
>>> for i in range(3): print(i) ... 0 1 2
While this is style that is not recommended for production code, it makes it more convenient to go up and down the REPL history.
If you really want to push the boundaries, you can even combine this with semicolons:
>>> i = 1 >>> while i < 30: print(i); i *= 2 ... 1 2 4 8 16
If you are writing some code and want to take it for a spin – just to make sure it makes sense – fire up the REPL, import the code, and play with it! That's the magic of the REPL.
Be sure to do any setup for the “tests” in a single line separated with semicolons,
together with the import statements.
That way, when you tweak the code you just wrote, you can type
exit() to leave the REPL,
enter it again, and then with a couple of up-arrow presses you get your setup code intact
and are ready to play with it again.
I try to stick to vanilla Python as much as possible when writing these Pydon'ts, for one simple reason: the world of vanilla Python is huge and, for most developers, has lots of untapped potential.
However, I believe I would be doing you a disservice if I didn't mention two tools that can really improve your experience in/with the REPL.
“Rich is a Python library for rich text and beautiful formatting in the terminal.”
Rich is an open source library that I absolutely love. You can read the documentation and the examples to get up to speed with Rich's capabilities, but I want to focus on a very specific one, in particular:
>>> from rich import pretty >>> pretty.install()
Running this in your REPL will change your life. With these two lines, Rich will pretty-print your variables and even include highlighting.
IPython is a command shell for interactive computing in multiple programming languages, originally developed for the Python programming language. IPython offers introspection, rich media, shell syntax, tab completion, and history, among other features.
In short, it is a Python REPL with more bells and whistles.
It is beyond the scope of this Pydon't to tell you all about IPython, but it is something I had to mention (even though I personally don't use it).
Here's the main takeaway of this Pydon't, for you, on a silver platter:
“Get comfortable with using the REPL because that will make you a more efficient Python programmer.”
This Pydon't showed you that:
repr), not its string value (
str);
Noneresults don't get displayed implicitly;
_;
helpbuilt-in can give you basic documentation about the functions, and other objects, you have “lying around”; it even works on user-defined objects;
helpwhen used on custom objects;. | https://mathspp.com/blog/pydonts/boost-your-productivity-with-the-repl | CC-MAIN-2022-05 | refinedweb | 2,935 | 69.52 |
Whenever.
We can use the Rails sort_by method to sort the array of objects by date and fullname in order::SometimesThe best practice when sorting the strings is to convert to one unique case (i.e upper or lower) on sorting. This ensures that records show up in the order that the user would expect, not the computer:
item['fullname'].downcase
2. Handling null values in case conversionThe nil values on the attributes need to be handled on the string manipulation process to avoid the unexpected errors. Here we converting to string before applying the case conversion:
item['fullname'].to_s.downcase
3. Handling null values in array size checkThe nil values on the array attributes need to be handled on the sorting process to avoid the unexpected errors. Here we guard against the possibility of item[‘children’] being nil, and if it is, then we return an empty array instead:
(item['children'].nil? ? [] : item['children']).size
1 comment:
Probably it would be better to wrap each element (including nested nodes) with some object and override '<=>' method. With your solution we get some global method that we don't really need in the global namespace.
After wrapping everything with classes (e.g RowWrapper, BaseColumnWrapper, FirstNameColumnWrapper etc) you can specify default sort behavior (through default comparator) and use it like 'collection_of_wrapped_objects.sort', or define some methods (like 'downcase' in your example) that produce new objects like 'def downcase; self.class.new(name.downcase, child_nodes); end' and use it like 'collection_of_wrapped_objects.sort_by(&:downcase)'
Nice post, thanks! | http://blog.endpoint.com/2014/10/rails-recursive-sorting-for-multilevel.html | CC-MAIN-2017-30 | refinedweb | 253 | 54.63 |
namedWindow + imshow not showing on the screen
I can't get the window with the video to show on the screen. The light of the web camera flashes so it opens it and the program is in infinite loop when i run yet nothing shows on the screen.
#include <iostream> #include <string> #include <sstream> #include <opencv2/core.hpp> #include <opencv2/highgui.hpp> #include <opencv2/videoio.hpp> using namespace cv; int main(int argc, char **argv) { VideoCapture cap(0); namedWindow("video", WINDOW_NORMAL); while (1) { Mat frame; cap >> frame; imshow("video", frame); if (waitKey(30) >= 0) break; } cap.release(); return 0; }
opencv version ? os ? which gui kit do you use ? did you build from src ?
it's not the code (which is fairly standard)
I have OpenCV 3.2.0 from github and i'am running ubuntu 16.04. Sorry for the noob question but how do i know with gui kit i use?
gtk2 / gtk3 / qt, which is it ?
I think it's gtk2. I did
dpkg -s libgtk2.0-0 | grep '^Version'and i got
Version: 2.24.30-1ubuntu1
If i do
dpkg -s libgtk-3-0 | grep '^Version'i get
Version: 3.18.9-1ubuntu3.2, so it seems like i have both gtk2 and gtk3? Is that good, bad? Should i install qt?
does application returns when you press any button after camera has been opened? | https://answers.opencv.org/question/135303/namedwindow-imshow-not-showing-on-the-screen/ | CC-MAIN-2019-43 | refinedweb | 229 | 87.31 |
Concept of Constant Pointers in C++
Hello Learners!
In this session, we will learn about some pointer variants. It is called Constant Pointers.
C++ adds the concepts of constant pointer and pointer to a constant. Mostly, these two are not used but are very conceptual topics that give more clarity and space for pointers to use if required. Let us get our hands on it.
Constant Pointers in C++
If one has a value in his/her program and it should not change throughout the program, or if one has a pointer and he/she doesn’t want it to be pointed to a different value, he/she should make it a constant with the const keyword. In simple words, a constant pointer is a pointer that cannot change the address it’s holding. In other words, we can say that once a constant pointer points to a variable then it cannot point to any other variable. Although, we can change the value stored in it provided the address of the variable should not change. For example:
If we have initialized a constant pointer named i, then we could use it to point at a particular address which will be fixed throughout the program. It will be initialized in the following manner:
int a=10; int * const i= &a; //Syntax of Constant Pointer cout<<*i;
Here, a is the variable and i is the constant pointer which is pointing at the address of a. In the output screen, we will see the value 10. We can change the value stored in a and still pointer i will point the address a. This will be implemented something like this:
*i=99; cout<<*i;
Now, pointer i points to the same address but that address is having a value that is now converted from 10 to 99 and that’s what the output screen will show.
Let’s sum it up together and make it a full program for better understanding and good clarity.
#include<iostream> using namespace std; int main() { int a=10; int * const i= &a; cout<<"1st pointed value: "<<*i; *i=99; // value is getting changed of same address as before cout<<"\nModified value: "<<*i; return 0; }
Now, let us see the Output Screen:
1st pointed value: 10 Modified value: 99
The point to be taken care of is that if we ever try to change its address then it will definitely show an error. Let’s take an example :
int a=10,b=44; int * const i=&a; i=&b; //error cout<<*i;
This program has some serious issue and that is we are using the same pointer i to point to another address which is the address of variable b. That’s definitely not possible in the case of a constant pointer. Therefore, it will show a compilation error. | https://www.codespeedy.com/concept-of-constant-pointers-in-c/ | CC-MAIN-2021-17 | refinedweb | 472 | 65.66 |
Job interviews for software engineering and other programming positions can be tough. There are too many things to study, and even then it still might not be enough. Previously I had written about a common Fibonacci number algorithm and finding duplicate values in array.
Those skill refreshers were written in JavaScript. This time we are going to take a turn and validate bracket combinations using the Java programming language.
So when I say bracket combinations, what exactly do I mean? Take the following string for example:
String validCombo = "{ [ ( { } [ ] ) ] }";
The above string is valid because each opening and closing bracket aligns correctly. You can ignore the spacing between each bracket because they will be ignored.
An example of an invalid string might look like the following:
String invalidCombo = "{ ( [ ] ] }"
Notice that we are trying to pair a
( with a
] which is not correct.
So how can we attempt to validate such a string in Java? The recommended way would be to make use of the Stack data type. The idea is to add all opening brackets to a stack and pop them off the stack when closing brackets are found. If the closing bracket doesn’t match the top element (last pushed element) of the stack, then the string is invalid. The string is also invalid if it has been iterated through and the stack is not empty in the end.
import java.util.*; public class Brackets { private String brackets; public Brackets(String s) { brackets = s; } public boolean validate() { boolean result = true; Stack<Character> stack = new Stack<Character>(); char current, previous; for(int i = 0; i < this.brackets.length(); i++) { current = this.brackets.charAt(i); if(current == '(' || current == '[' || current == '{') { stack.push(current); } else if(current == ')' || current == ']' || current == '}') { if(stack.isEmpty()) { result = false; } else { previous = stack.peek(); if((current == ')' && previous == '(') || (current == ']' && previous == '[') || (current == '}' && previous == '{')) { stack.pop(); } else { result = false; } } } } if(!stack.isEmpty()) { result = false; } return result; } }
The above code operates with a time complexity of O(n) and to demo it you could do something like the following:
Brackets b = new Brackets("{[({}())]}"); System.out.println("Valid String: " + b.validate());
Balancing parenthesis and brackets is a good interview question because it is one of the first steps to understanding how to parse and validate data. Imagine if you were asked to write a code interpreter or parse JSON. Knowing how to balance or validate brackets and parenthesis will certainly help. Please share your experience with this topic in the comments if you’ve had it as an interview question or if you think you have a better solution than what I’ve come up with.
A video version of this article can be seen below. | https://www.thepolyglotdeveloper.com/2015/02/validate-bracket-parenthesis-combos-using-stacks/ | CC-MAIN-2022-40 | refinedweb | 441 | 65.01 |
poplib 100% cpu usage
- From: Oli Schacher <python@xxxxxxxxxxxxx>
- Date: Wed, 16 Jul 2008 17:01:08 +0200
Hi all
I wrote a multithreaded script that polls mails from several pop/imap accounts. To fetch the messages I'm using the getmail classes ( ) , those classes use the poplib for the real pop transaction.
When I run my script for a few hours cpu usage goes up to 100%, sometimes even 104% according to 'top' :-) This made our test machine freeze once. First I thought I maybe didn't stop my threads correctly after polling an account but I attached a remote debugger and it showed that threads are stopped ok and that the cpu gets eaten in poplib in the function "_getline" which states in the description:
---snip---
# Internal: return one line from the server, stripping CRLF.
# This is where all the CPU time of this module is consumed.
# Raise error_proto('-ERR EOF') if the connection is closed.
def _getline(self):
---snip---
So for testing purposes I changed this function and added:
time.sleep(0.0001)
(googling about similar problems with cpu usage yields this time.sleep() trick)
It now looks ok, cpu usage is at about 30% with a few spikes to 80-90%.
Of course I don't feel cozy about changing a standard library as the changes will be overwritten by python upgrades.
Did someone else from the list hit a similar problem and maybe has a better solution?
Thanks for your hints.
Best regards,
Oli Schacher
.
- Prev by Date: Angle brackets in command-line arguments?
- Next by Date: Re: Angle brackets in command-line arguments?
- Previous by thread: Angle brackets in command-line arguments?
- Next by thread: Setting Message Importance using SMTP Mail
- Index(es): | http://coding.derkeiler.com/Archive/Python/comp.lang.python/2008-07/msg01714.html | crawl-002 | refinedweb | 289 | 72.26 |
cjrMembers
Content count53
Joined
Last visited
Community Reputation100 Neutral
About vcjr
- RankMember
vcjr replied to vcjr's topic in For Beginnersoook but i actually dint write the code next to the side it came like that when i pasted it. But now i see the error of my ways thanks.
vcjr posted a topic in For BeginnersOk so im using Microsoft Virsual Express c++ 2010. Im fallowing this code second lesson for this book called C++ Primer 4th Edition. Help. This is the code. #include <ionstream> int main() { std::count << "enter two numbers:" << std::endl; int v1, v2; std::cin >> v1 >> v2; std:: << "the sum of" <<v1 << "and" << v2 << "is" << v1 + v2 << std::endl; return 0; } why doent it work? is this book outdated in forms of code?
vcjr posted a topic in Games Career Developmenteven dough I'm 13 i just need to know what will i need to study in college for when i enter for a game programming. i know theirs a page for this but i just need more info and whats the college best to be used for c++ and windows not other systems. thanks.
- thanks you guys for all the help.
- o sorry fo rthat html code thingy.
vcjr posted a topic in 2D and 3D Arthello i just need help combining these two picture [IMG][/IMG] By [URL=]vcjr[/URL] and this one [IMG][/IMG] By [URL=]vcjr[/URL] i just need someone to put the second one in top of the first icture but not showing the black unused spots. plz any help.
- ok thanks everyone for your help.
- thanks now i know it just make coding easier. thanks
vcjr posted a topic in For BeginnersIs The Book "C++ Primer : 4th Edition" Out dated. Ok I Just received my copy from Amazon.com of this book and from my little espirience is that when i look at the code from the book something is missing " what you ask" well this part using namespace std; i sopose that this is a nessary comand or not? because im no expert i just whant to know if this is going to be a problem? ps. sorry for my grammar and spelling english is not my first language.
vcjr replied to vcjr's topic in For Beginnersok
vcjr replied to vcjr's topic in For Beginnersthanks.
vcjr posted a topic in For BeginnersWell i just purchaced this book 10 min ago and i just whant to say that i think is going to rock. But something about me that i need a good bood or site that teaches me the basic of C++ .
vcjr replied to vcjr's topic in For Beginnersany help?
vcjr posted a topic in For Beginnersany free ebooks or free book that i could get or just fallow lazyfoo's tutorials? please help.
vcjr replied to vcjr's topic in For Beginnerswell for now im just a new game programmer. and me and my little brother are trying to make a game with sprites. so we need tutorials. But thanks Guys you did help one of this days ill post our game :) | https://www.gamedev.net/profile/156545-vcjr/?tab=status | CC-MAIN-2017-30 | refinedweb | 520 | 79.3 |
[Python] What's with all the semicolons?
I'm looking at the
def getIndexItem(self):
# create a summary of the entry
digest = self.body[:self.DIGEST_LEN].replace('\n', '');
digest = self.HTML_STRIP.sub('', digest);
digest = digest.replace('>', '').replace('
When I learned about Python and started to work with it, I was told not to use the semicolons. In fact, I thought that was illegal. Is the parser just throwing them away? Does it have any purpose other than making those C programmers happy?
Wisconsin Passes Digital Download Tax
Sadly I found that out too.
In 2007, I took a job in Seattle that paid more and offered better opportunities but because I lived 1/2 the year in WI I had to pay them taxes as if I earned my annual wages in WI. I think this year was the first time I actually enjoyed filling out my taxes just so I don't have to file a state return.
The only redeeming part of paying that last year in taxes to WI was being able to fill out their form on why I moved out of state. I just hope they don't mind seeing the work f*ck all over the form.
Slashdot Turns 10 But You Get The Presents
Now I feel old and realize that my freshman year of college was 10 years ago. | http://beta.slashdot.org/~dthable | CC-MAIN-2014-42 | refinedweb | 227 | 81.53 |
.
At home I code a lot of singleton classes. Most of this code is boilerplate code that I just write over and over again. Originally I thought that generics would solve this problem. I planned to write a generic singelton of the following form.
public
public class MyFactory : Singleton<MyFactory,MyBaseFactoryClass>{}Unfortunately that doesn't work because generics in .NET do not support inheritance of that kind (AFAIK). This forced me to find a different route. I decided to code a generic singleton class that operated on static methods. I wanted to get the behavior below.
public class MyFactory{ public static MyFactory Instance { get { return Singleton<MyFactory>.GetInstance(); } }}
This still didn't solve my problems because this requires that MyFactory have a public constructor. I had to settle for this instead.
public class MyFactory{ public static MyFactory Instance { get { return Singleton<MyFactory>.GetInstance(delegate() { return new MyFactory(); } ); } }}
This makes it very simple to create per process singleton classes. It's not quite as easy as my original idea but it gets the job done and removes a lot of redundant code. Here's the code that I'm using for my Singleton<T> class.
public static T GetInstance(SingletonCreation del) { if (_instance == null) { lock (typeof(Singleton<T>)) { if (_instance == null) { T temp = del(); System.Threading.Thread.MemoryBarrier(); _instance = temp; } } } return _instance; }}
For more information on singletons in .NET check out this great entry by Brad Abrams
MSFT disclaimer: This posting is provided "AS IS" with no warranties, and confers no rights.
Published Wednesday, November 24, 2004 4:20 AM
by
Jared Parsons
Daniel Moth
Dan Golick
Jared Parsons
Quite awhile back I posted about how to create a re-usable singleton pattern in .Net. Link is here .
jaredpar's WebLog
PingBack from
MSDN Blog Postings » Singleton Pattern | http://blogs.msdn.com/jaredpar/archive/2004/11/24/269133.aspx | crawl-002 | refinedweb | 297 | 50.33 |
People that need to parse and analyze C code in Python are usually really excited to run into pycparser. However, when the task is to parse C++, pycparser is not the solution. When I get asked about plans to support C++ in pycparser, my usual answer is - there are no such plans [1], you should look elsewhere. Specifically, at Clang.
Clang is a front-end compiler for C, C++ and Objective C. It's a liberally licensed open-source project backed by Apple, which uses it for its own tools. Along with its parent project - the LLVM compiler backend, Clang starts to become a formidable alternative to gcc itself these days. The dev team behind Clang (and LLVM) is top-notch and its source is one of the best designed bodies of C++ code in the wild. Clang's development is very active, closely following the latest C++ standards.
So what I point people to when I'm asked about C++ parsing is Clang. There's a slight problem with that, however. People like pycparser because it's Python, and Clang's API is C++ - which is not the most high-level hacking friendly language out there, to say the least.
libclang
Enter libclang. Not so long ago, the Clang team wisely recognized that Clang can be used not only as a compiler proper, but also as a tool for analyzing C/C++/ObjC code. In fact, Apple's own Xcode development tools use Clang as a library under the hood for code completion, cross-referencing, and so on.
The component through which Clang enables such usage is called libclang. It's a C API [2] that the Clang team vows to keep relatively stable, allowing the user to examine parsed code at the level of an abstract syntax tree (AST) [3].
More technically, libclang is a shared library that packages Clang with a public-facing API defined in a single C header file: clang/include/clang-c/Index.h.
Python bindings to libclang
libclang comes with Python bindings, which reside in clang/bindings/python, in module clang.cindex. This module relies on ctypes to load the dynamic libclang library and tries to wrap as much of libclang as possible with a Pythonic API.
Documentation?
Unfortunately, the state of documentation for libclang and its Python bindings is dire. The official documentation according to the devs is the source (and auto-generated Doxygen HTML). In addition, all I could find online is a presentation and a couple of outdated email messages from the Clang dev mailing list.
On the bright side, if you just skim the Index.h header file keeping in mind what it's trying to achieve, the API isn't hard to understand (and neither is the implementation, especially if you're a bit familiar with Clang's internals). Another place to look things up is the clang/tools/c-index-test tool, which is used to test the API and demonstrates its usage.
For the Python bindings, there is absolutely no documentation as well, except the source plus a couple of examples that are distributed alongside it. So I hope this article will be helpful!
Setting up
Setting up usage of the Python bindings is very easy:
- Your script needs to be able to find the clang.cindex module. So either copy it appropriately or set up PYTHONPATH to point to it [4].
- clang.cindex needs to be able to find the libclang.so shared library. Depending on how you build/install Clang, you will need to copy it appropriately or set up LD_LIBRARY_PATH to point to its location. On Windows, this is libclang.dll and it should be on PATH.
That arranged, you're ready to import clang.cindex and start rolling.
Simple example
Let's start with a simple example. The following script uses the Python bindings of libclang to find all references to some type in a given file:
#!/usr/bin/env python """ Usage: call with <filename> <typename> """ import sys import clang.cindex def find_typerefs(node, typename): """ Find all references to the type named 'typename' """ if node.kind.is_reference(): ref_node = clang.cindex.Cursor_ref(node) if ref_node.spelling == typename: print 'Found %s [line=%s, col=%s]' % ( typename, node.location.line, node.location.column) # Recurse for children of this node for c in node.get_children(): find_typerefs(c, typename) index = clang.cindex.Index.create() tu = index.parse(sys.argv[1]) print 'Translation unit:', tu.spelling find_typerefs(tu.cursor, sys.argv[2])
Suppose we invoke it on this dummy C++ code:
class Person { }; class Room { public: void add_person(Person person) { // do stuff } private: Person* people_in_room; }; template <class T, int N> class Bag<T, N> { }; int main() { Person* p = new Person(); Bag<Person, 42> bagofpersons; return 0; }
Executing to find referenced to type Person, we get:
Translation unit: simple_demo_src.cpp Found Person [line=7, col=21] Found Person [line=13, col=5] Found Person [line=24, col=5] Found Person [line=24, col=21] Found Person [line=25, col=9]
Understanding how it works
To see what the example does, we need to understand its inner workings on 3 levels:
- Conceptual level - what is the information we're trying to pull from the parsed source and how it's stored
- libclang level - the formal C API of libclang, since it's much better documented (albeit only in comments in the source) than the Python bindings
- The Python bindings, since this is what we directly invoke
Creating the index and parsing the source
We'll start at the beginning, with these lines:
index = clang.cindex.Index.create() tu = index.parse(sys.argv[1])
An "index" represents a set of translation units compiled and linked together. We need some way of grouping several translation units if we want to reason across them. For example, we may want to find references to some type defined in a header file, in a set of other source files. Index.create() invokes the C API function clang_createIndex.
Next, we use Index's parse method to parse a single translation unit from a file. This invokes clang_parseTranslationUnit, which is a key function in the C API. Its comment says:
This routine is the main entry point for the Clang C API, providing the ability to parse a source file into a translation unit that can then be queried by other functions in the API.
This is a powerful function - it can optionally accept the full set of flags normally passed to the command-line compiler. It returns an opaque CXTranslationUnit object, which is encapsulated in the Python bindings as TranslationUnit. This TranslationUnit can be queried, for example the name of the translation unit is available in the spelling property:
print 'Translation unit:', tu.spelling
Its most important property is, however, cursor. A cursor is a key abstraction in libclang, it represents some node in the AST of a parsed translation unit. The cursor unifies the different kinds of entities in a program under a single abstraction, providing a common set of operations, such as getting its location and children cursors. TranslationUnit.cursor returns the top-level cursor of the translation unit, which serves as the stating point for exploring its AST. I will use the terms cursor and node interchangeably from this point on.
Working with cursors
The Python bindings encapsulate the libclang cursor in the Cursor object. It has many attributes, the most interesting of which are:
- kind - an enumeration specifying the kind of AST node this cursor points at
- spelling - the source-code name of the node
- location - the source-code location from which the node was parsed
- get_children - its children nodes
get_children requires special explanation, because this is a particular point at which the C and Python APIs diverge.
The libclang C API is based on the idea of visitors. To walk the AST from a given cursor, the user code provides a callback function to clang_visitChildren. This function is then invoked on all descendants of a given AST node.
The Python bindings, on the other hand, encapsulate visiting internally, and provide a more Pythonic iteration API via Cursor.get_children, which returns the children nodes (cursors) of a given cursor. It's still possible to access the original visitation APIs directly through Python, but using get_children is much more convenient. In our example, we use get_children to recursively visit all the children of a given node:
for c in node.get_children(): find_typerefs(c, typename)
Some limitations of the Python bindings
Unfortunately, the Python bindings aren't complete and still have some bugs, because it is a work in progress. As an example, suppose we want to find and report all the function calls in this file:
bool foo() { return true; } void bar() { foo(); for (int i = 0; i < 10; ++i) foo(); } int main() { bar(); if (foo()) bar(); }
Let's write this code:
import sys import clang.cindex def callexpr_visitor(node, parent, userdata): if node.kind == clang.cindex.CursorKind.CALL_EXPR: print 'Found %s [line=%s, col=%s]' % ( node.spelling, node.location.line, node.location.column) return 2 # means continue visiting recursively index = clang.cindex.Index.create() tu = index.parse(sys.argv[1]) clang.cindex.Cursor_visit( tu.cursor, clang.cindex.Cursor_visit_callback(callexpr_visitor), None)
This time we're using the libclang visitation API directly. The result is:
Found None [line=8, col=5] Found None [line=10, col=9] Found None [line=15, col=5] Found None [line=16, col=9] Found None [line=17, col=9]
While the reported locations are fine, why is the node name None? After some perusal of libclang's code, it turns out that for expressions, we shouldn't be printing the spelling, but rather the display name. In the C API it means clang_getCursorDisplayName and not clang_getCursorSpelling. But, alas, the Python bindings don't have clang_getCursorDisplayName exposed!
We won't let this stop us, however. The source code of the Python bindings is quite straightforward, and simply uses ctypes to expose additional functions from the C API. Adding these lines to bindings/python/clang/cindex.py:
Cursor_displayname = lib.clang_getCursorDisplayName Cursor_displayname.argtypes = [Cursor] Cursor_displayname.restype = _CXString Cursor_displayname.errcheck = _CXString.from_result
And we can now use Cursor_displayname. Replacing node.spelling by clang.cindex.Cursor_displayname(node) in the script, we now get the desired output:
Found foo [line=8, col=5] Found foo [line=10, col=9] Found bar [line=15, col=5] Found foo [line=16, col=9] Found bar [line=17, col=9]
Update (06.07.2011): Inspired by this article, I submitted a patch to the Clang project to expose Cursor_displayname, as well as to fix a few other problems with the Python bindings. It was committed by Clang's core devs in revision 134460 and should now be available from trunk.
Some limitations of libclang
As we have seen above, limitations in the Python bindings are relatively easy to overcome. Since libclang provides a straightforward C API, it's just a matter of exposing additional functionality with appropriate ctypes constructs. To anyone even moderately experienced with Python, this isn't a big problem.
Some limitations are in libclang itself, however. For example, suppose we wanted to find all the return statements in a chunk of code. Turns out this isn't possible through the current API of libclang. A cursory look at the Index.h header file reveals why.
enum CXCursorKind enumerates the kinds of cursors (nodes) we may encounter via libclang. This is the portion related to statements:
/* Statements */ CXCursor_FirstStmt = 200, /** * \brief A statement whose specific kind is not exposed via this * interface. * * Unexposed statements have the same operations as any other kind of * statement; one can extract their location information, spelling, * children, etc. However, the specific kind of the statement is not * reported. */ CXCursor_UnexposedStmt = 200, /** \brief A labelled statement in a function. * * This cursor kind is used to describe the "start_over:" label statement in * the following example: * * \code * start_over: * ++counter; * \endcode * */ CXCursor_LabelStmt = 201, CXCursor_LastStmt = CXCursor_LabelStmt,
Ignoring the placeholders CXCursor_FirstStmt and CXCursor_LastStmt which are used for validity testing, the only statement recognized here is the label statement. All other statements are going to be represented with CXCursor_UnexposedStmt.
To understand the reason for this limitation, it's constructive to ponder the main goal of libclang. Currently, this API's main use is in IDEs, where we want to know everything about types and references to symbols, but don't particularly care what kind of statement or expression we see [5].
Forgunately, from discussions in the Clang dev mailing lists it can be gathered that these limitations aren't really intentional. Things get added to libclang on a per-need basis. Apparently no one needed to discern different statement kinds through libclang yet, so no one added this feature. If it's important enough for someone, he can feel free to suggest a patch to the mailing list. In particular, this specific limitation (lack of statement kinds) is especially easy to overcome. Looking at cxcursor::MakeCXCursor in libclang/CXCursor.cpp, it's obvious how these "kinds" are generated (comments are mine):
CXCursor cxcursor::MakeCXCursor(Stmt *S, Decl *Parent, CXTranslationUnit TU) { assert(S && TU && "Invalid arguments!"); CXCursorKind K = CXCursor_NotImplemented; switch (S->getStmtClass()) { case Stmt::NoStmtClass: break; case Stmt::NullStmtClass: case Stmt::CompoundStmtClass: case Stmt::CaseStmtClass: ... // many other statement classes case Stmt::MaterializeTemporaryExprClass: K = CXCursor_UnexposedStmt; break; case Stmt::LabelStmtClass: K = CXCursor_LabelStmt; break; case Stmt::PredefinedExprClass: .. // many other statement classes case Stmt::AsTypeExprClass: K = CXCursor_UnexposedExpr; break; .. // more code
This is simply a mega-switch on Stmt.getStmtClass() (which is Clang's internal statement class), and only for Stmt::LabelStmtClass there is a kind that isn't CXCursor_UnexposedStmt. So recognizing additional "kinds" is trivial:
- Add another enum value to CXCursorKind, between CXCursor_FirstStmt and CXCursor_LastStmt
- Add another case to the switch in cxcursor::MakeCXCursor to recognize the appropriate class and return this kind
- Expose the enumeration value in (1) to the Python bindings
Conclusion
Hopefully this article has been a useful introduction to libclang's Python bindings (and libclang itself along the way). Although there is a dearth of external documentation for these components, they are well written and commented, and their source code is thus straightforward enough to be reasonably self-documenting.
It's very important to keep in mind that these APIs wrap an extremely powerful C/C++/ObjC parser engine that is being very actively developed. In my personal opinion, Clang is one's best bet for an up-to-date open-source C++ parsing library these days. Nothing else comes even close.
A small fly in the ointment is some limitations in libclang itself and its Python bindings. These are a by-product of libclang being a relatively recent addition to Clang, which itself is a very young project.
Fortunately, as I hope this article demonstrated, these limitations aren't terribly difficult to work around. Only a small amount of Python and C expertise is required to extend the Python bindings, while a bit of understanding of Clang lays the path to enhancements to libclang itself. In addition, since libclang is still being actively developed, I'm quite confident that this API will keep improving over time, so it will have less and less limitations and omissions as time goes by.
| http://eli.thegreenplace.net/2011/07/03/parsing-c-in-python-with-clang | CC-MAIN-2017-13 | refinedweb | 2,521 | 54.32 |
Bandstructures in vasp.py
This post has three goals. 1) Show we can run simulations in the IPython notebook (instead of org-mode), second, to directly post the notebook to the dft-book blog, and finally to show how to calculate a band-structure.
First we import the vasp.py libraries we need.
%matplotlib inline from vasp import Vasp
from ase.lattice.surface import fcc111
slab = fcc111('Al', size=(1, 1, 4), vacuum=10) print(slab)
Atoms(symbols='Al4', positions=..., tags=..., cell=[[2.8637824638055176, 0.0, 0.0], [1.4318912319027588, 2.4801083645679673, 0.0], [0.0, 0.0, 27.014805770653954]], pbc=[True, True, False])
Now we setup and run a calculation. We need a base calculation to get the electron density from. Then, we will run a non-self-consistent calculation with a k-point path using that density.
from vasp.vasprc import VASPRC VASPRC['queue.nodes'] = 'n5' # specify to run on node named n5 calc = Vasp('../../Al-bandstructure', xc='pbe', encut=300, kpts=[6, 6, 6], lcharg=True, # We need the charge and wavefunctions for the second step lwave=True, atoms=slab) calc.run() # we need to wait for this to finish
-14.17006237
Once the calculation is done, we can run the bandstructure calculation. We specify a path through k-space as a series of pairs of points, and the number of "intersections" we want on each path. This path has 4 segments, with 10 points on each segment.
n, bands, p = calc.get_bandstructure(kpts_path=[(r'$\Gamma$', [0, 0, 0]), ('$K1$', [0.5, 0.0, 0.0]), ('$K1$', [0.5, 0.0, 0.0]), ('$K2$', [0.5, 0.5, 0.0]), ('$K2$', [0.5, 0.5, 0.5]), (r'$\Gamma$', [0, 0, 0]), (r'$\Gamma$', [0, 0, 0]), ('$K3$', [0, 0, 1])], kpts_nintersections=10, show=True)
The figure above shows why we only need $m \times n \times 1$ k-point meshes for slabs. From $\Gamma$ to $K3$ the bands are flat, so one k-point is sufficient to characterize the band energy in that direction (that is the z-direction in this calculation.).
That is basically it! I didn't find this as easy to use as Emacs + org-mode, but since I have 5+ years of skill with that, and a day of experience with this, that might be expected ;) | http://kitchingroup.cheme.cmu.edu/dft-book/posts/bandstructures-in-vasppy/ | CC-MAIN-2020-05 | refinedweb | 384 | 76.01 |
Name: gm110360 Date: 07/30/2003 A DESCRIPTION OF THE REQUEST : I was surprised to see nonstatic method calls taking anyhwere from 25% to 100% more time to execute than static methods. I was hoping it will be in the range of 5%! :-( BTW, I got these numbers looking at javacc () generated code. JavaCC has an option called STATIC which when set, generates static/single use parsers. We introduced this way back in 1996 becase those days nonstatic method calls were extremely expensive - we have seen overheads upto 20 times! Now, I am looking at ways of simplifying and improving JavaCC and wanted to see if STATIC still made sense. I was blown away by the slowdowns with nonstatic methods. JUSTIFICATION : If fixed. it can enhance performance of almost all Java applications, including appservers etc. EXPECTED VERSUS ACTUAL BEHAVIOR : EXPECTED - Would like nonstatic methods to be in the 5% overhead range as compared to static methods. ACTUAL - It is between 25%-100% ---------- BEGIN SOURCE ---------- public class t { static int cnt; static public void f() { if (cnt-- == 0) return; g(); } static public void g() { f(); } public void nonstatic_f() { if (cnt-- == 0) return; nonstatic_g(); } public void nonstatic_g() { nonstatic_f(); } public static void main(String[] args) throws Throwable { long l = System.currentTimeMillis(); int tmp = Integer.parseInt(args[0]); try { t o = new t(); for (int i = 0; i < tmp; i++) { cnt = tmp; o.f(); } } finally { System.out.println("Static calls take: " + (System.currentTimeMillis() - l) + " ms."); } l = System.currentTimeMillis(); try { t o = new t(); for (int i = 0; i < tmp; i++) { cnt = tmp; o.nonstatic_f(); } } finally { System.out.println("Nonstatic calls take: " + (System.currentTimeMillis() - l) + " ms."); } } } Just run java t 10000 to see the difference in time taken for static vs. nonstatic ---------- END SOURCE ---------- (Incident Review ID: 192927) ====================================================================== | https://bugs.java.com/bugdatabase/view_bug.do?bug_id=4898726 | CC-MAIN-2018-09 | refinedweb | 293 | 58.89 |
Feedback Loop
If you’re a large volume sender, you can use the FeedBack Loop (FBL) to identify campaigns in your traffic that are getting a high volume of complaints from Gmail users. The FBL is particularly useful to ESPs to detect abuse of their services.
Note: FBL data will only pertain to @gmail.com recipients.
How to implement the FBL
Header format
Feedback-ID: a:b:c:SenderId
Feedback-ID: Name of the Header to be embedded.
a, b, c: Optional fields that can be used by the sender to embed up to 3 Identifiers (campaign/customer/other).
SenderId: Mandatory unique Identifier (5–15 characters) chosen by the sender. It should be consistent across the mail stream.
About the data
The aggregate data will be generated for the first 4 fields (as separated by ‘:’) of the Feedback-ID: , starting from the right side. If the SenderId is empty, no data will be generated. If another field is empty, data will be generated for the rest of the fields.
In order to prevent spoofing of the Feedback-ID, the traffic being sent to Gmail needs to be DKIM signed by a domain owned (or controlled) by the sender, after the addition of this header. This domain should be added and verified to the Gmail Postmaster Tools, so the sender can access the FBL data.
- Senders should ensure that their traffic has only one such verified header.
- Senders will have to publish the IPs from which they’re sending mail in the SPF records of their signing domains. The sending IPs must have PTR records and resolve to a valid hostname (preferably one of the DKIM domains).
- For a given day’s traffic, FBL reports are generated only if a given Identifier is present in a certain volume of mails as well as in distinct user spam reports.
- FBL data will be aggregated on each Identifier independently. This also allows for the use of less than 3 Identifiers, if needed.
- For a given day's traffic, the sender should ensure that the Identifiers across fields not repeated, so that data is not aggregated across unrelated Identifiers. If there is a concern about the uniqueness of the Identifier namespace, or if the sender prefers for the data to be grouped between two Identifiers, the hash of one Identifier can be appended to the other.
- When choosing the Identifiers, the sender should not use a parameter that will be unique across every single mail (for example, a unique Message-ID).
Below is an example for illustration:
Feedback-ID: CampaignIDX:CustomerID2:MailTypeID3:SenderId
CampaignIDX: Campaign Identifier specific to Customer2 and is unique across the board (that is, no 2 customers share the same campaign ID).
CustomerID2: Unique customer Identifier.
MailTypeID3: Identifier for the type of mail (a newsletter vs. a product update, for example) and can be either unique or common across customers, based on how the sender wants to view the data.
SenderId: Sender's unique Identifier and can be used for overall statistics.
In the above case, we would send the spam percentages for each of the 4 Identifiers independently, if they had an unusual spam rate. | https://support.google.com/mail/answer/6254652?hl=en&ref_topic=7279058 | CC-MAIN-2019-51 | refinedweb | 525 | 60.95 |
Chapter Overview
Multithreading is often not very easy to handle and even more often it is dangerous and evil to debug. However, multithreading is powerful and very useful in many situations. At the very beginning I promised that multithreading is very easy with OpenSG. So now let's see if I can hold this promise. If I am right you will be finally rewarded for all these begin- and endEditCP blocks you have written (or copied) so far.
Well, let's start right of with something very simple, just to see how easy it can be to use multiple threads (if you know how ;) ).
As always, please make a copy of the framework file. We really need no geometry at all for this little demonstration, but the scene manager must have at least a root node. So create a group node or some simple geometry, whatever you want, and set it as root for the simple scene manager. This is necessary to suppress error messages. Try to execute, just to make sure everything works fine - there is nothing more annoying than searching hours for an error in your threads, where the real error lies somewhere else!
First there is, of course, a new include file, that needs to be added.
#include <OpenSG/OSGThreadManager.h>
Like with the simple scene manager, too, the thread manager will include most other include files needed in this context.
First we need a function that will be executed by a thread. As we want to create two new threads, beside the main thread, we want two functions - paste them somewhere before the main function.
void printA(void *args){ while (true) std::cout << "A" << std::endl; } void printB(void *args){ while (true) std::cout << "B" << std::endl; }
These functions will simply print A or B respectively until the application is terminated. Now we need to create and start the threads that will run both functions. Add the following code right before the main function!
Thread* threadOne = dynamic_cast<Thread *>(ThreadManager::the()->getThread("One")); Thread* threadTwo = dynamic_cast<Thread *>(ThreadManager::the()->getThread("Two")); threadOne->runFunction(printA, 1, NULL); threadTwo->runFunction(printB, 1, NULL);
If you now run this application, watch the terminal. You will see many many A's and B's mixed together. Notice that you still can navigate in the window (well, you need some geometry to see that effect), because the OpenSG rendering (i.e. the GLUT main loop) runs in the main thread.
You can find the code in file 13multithreading.cpp, like always in the progs folder.
If you like to, replace the letters with a word or a sentence and watch what happens. I chose "Power Mac G5" and "Taschenrechner", the next image shows the terminal output.
Two threads producing non-stop output
As you can see, the printing of "Taschenrechner" was completed correctly, but "Power Mac G5" suddenly started at " G5" and left out the beginning. Afterwards the output continues normally. What happend? Well, the execution of threads is handled by your operating system, which decides when a thread is halted and another stalled process is continued. If your threads are computing some stuff in the background that might be no problem at all, but if these are printing output to the terminal, things might get ugly like above. Most likely you want the output of the first thread finished, before the second starts.
However, possibly you are not easily able to reproduce this "error" because several hundred or even thousands words are printed before the active thread changes, so the error occurs rarely. You could pipe the result into a file, but if you do so, let the application run a few seconds only!
Things get even worse, if one thread writes data and another is writing or reading data on the same segment - this will crash your application in most cases or at least it will produce undesired results.
We will later be able to solve the output problem...
Well, it is time for some theory now. As I mentioned above, the real problem is the asynchronous read and write of data, which will happen for sure, if two or more threads are working on the scene graph. So how does OpenSG handle that problem? You already have used osg::FieldContainers all the time, well, at least objects that were derived from it - remember, all node cores are derived from field container, for example.
Every time a field container is created, not only one instance is created, but two per default. These multiple instances of one and the same field container are called aspects and every thread is associated with one single aspect. If data is written by a thread, only the corresponding aspect's data is changed at that time. The following figure illustrates this:
Two threads and one field container with two aspects
Here you have one field container of type Transform, which holds two aspects. Two threads are running and each has assigned a single aspect. If thread two now sets a new matrix that field in the appropriate threads aspect is changed - the other thread's field stays untouched.
Of course, this has the potential to cause heavy problems, as we now have inconsistent data, because thread one seems not to be aware of the new matrix thread two has set. That is what ChangeLists are for. Every thread has its own change list. Every time data is written, an entry is added to the corresponding change list. At some point, the threads needs to be synchronized and that is where a change list's content is read and the relevant data of this aspect is copied to the other aspect. The synchronization has to be initiated manually and can't be done automatically, as both threads have to be aware of it and be in state where they can accept changes to the graph.
Well, this will be easier to understand if we consider a little example. So here we go: imagine we want a simple torus (yes, again amazing geometry!) which should rotate around the y axis - so we need a new transformation matrix every frame. This time, computation of the matrix will be done in an additional thread. Please keep in mind that this is for didactic reasons only, as it would not be very smart to create own threads for such simple tasks ;)
Important Notice: Currently the dynamic configuration of multiple aspects is not fully implemented yet! In detail that means, that there is currently no way to change the number of aspects at runtime, there are always two aspects per default, so if you have three threads that need to read/write data independantly, you have to recompile the library. However that is unlikely... anyway if you do need that feature, you should have a look at the mailing list (see OpenSG Mailinglist).
Anyway, let's start right away with our 00framework.cpp file. You need an additional header and some global variables
#include <OpenSG/OSGThreadManager.h> using namespace std; SimpleSceneManager *mgr; NodePtr scene; //we will store the transformation globally - this //is not necessary, but comfortable TransformPtr trans; Thread* animationThread; Barrier *syncBarrier;
This should look familiar to you, except for the Barrier variable, which will be used later to synchronize the threads again.
The createScenegraph() function is not that interesting - we have a transform node with a single child, the torus. That's all
NodePtr createScenegraph(){ // the scene must be created here NodePtr n = makeTorus(0.5,4,8,16); //add a simple Transformation trans = Transform::create(); beginEditCP(trans); Matrix m; m.setIdentity(); trans->setMatrix(m); endEditCP(trans); NodePtr transNode = Node::create(); beginEditCP(transNode); transNode->setCore(trans); transNode->addChild(n); endEditCP(transNode); return transNode; }
Next comes the function that will compute and set the new transformation. This function will be run in its own thread.
//this function will run in a thread and will simply //rotate the torus by setting a new transformation matrix void rotate(void *args){ // we won't stop calculating new matrices.... while(true){ Real32 time = glutGet(GLUT_ELAPSED_TIME); Matrix m; m.setIdentity(); m.setRotate(Quaternion(Vec3f(0,1,0), time/1000)); beginEditCP(trans); trans->setMatrix(m); endEditCP(trans); // nothing unusual until here //well that's new... //wait until two threads are cought in the //same barrier syncBarrier->enter(2); //just the same again syncBarrier->enter(2); } }
The display() function also needs to be replaced.
void display(void) { // we wait here until the animation thread enters //the first barrier syncBarrier->enter(2); //now we sync data animationThread->getChangeList()->applyAndClear(); // and again syncBarrier->enter(2); // now render... mgr->redraw(); }
Finally you need to add the following code between the call of createScenegraph() and glutMainLoop() in the main() function.
//create the barrier, that will be used to //synchronize threads //instead of NULL you could provide a name syncBarrier = Barrier::get(NULL); mgr = new SimpleSceneManager; mgr->setWindow(gwin ); mgr->setRoot (scene); mgr->showAll(); //create the thread that will run generation of new matrices animationThread = dynamic_cast<Thread *>(ThreadManager::the()->getThread("anim")); //do it... animationThread->runFunction(rotate, 1, NULL);
Note: If you're using versions after 1.2, the ChangeLists are set to read-only by default. To actually record any changes, you have to set them to read-write by adding the following command before osgInit:
#if OSG_MINOR_VERSION > 2 ChangeList::setReadWriteDefault(); #endif
If you execute this application you will see an animated torus... well, amazing as this one looks exactly like the one from the second tutorial (Tutorial - it's moving!). However, this time it is a lot more impressive, as we have used two threads.
Maybe it is time to talk about what we have actually done here. We have a rough picture about what aspects and change lists are - and we have this working example now. The situation is as follows: The main thread is actually doing the same thing like always, that is setting up everything that is needed and rendering the graph until the application is terminated. The second thread only changes the contents of the transform core of the scenegraph - at least it's own aspect. Let us give the main thread number 1 (and therefore aspect 1, too) and the animation thread number 2 as well as aspect 2. Then, thread 2 is constantly changing the matrix value of the transform field container in aspect 2 while the value in aspect 1 is staying untouched. Thread 1, however, will render the graph and thus is using aspect 1 and therefore is using the old (unchanged) value.
You saw the application working, but now comment the line out that says
animationThread->getChangeList()->applyAndClear();
found in the display() function.
The application will still run, but this time without any movement of the torus. That is why we just skipped synchronization of the two threads. Without this command thread 2 is doing a fine job, but thread 1 will never become aware of the changes. So the change list of thread 2 has to be applied on thread 1, thus all changes from aspect 2 are copied to aspect 1.
Alright, it seems that animationThread->getChangeList()->applyAndClear(); will do some synchronization between the threads. The next figure shows what happens on applying the change list
Applying a change list
Well, I assume that you have not worked with threads before, so if you have already you can jump to the next passage right away. When working with threads some things might get a bit confusing. It is somehow like having two independent programs running, which are written in one and the same source file and can use the same global variables or objects. You have to keep in mind that two or more (nearly) independant applications can access the same data at the same time.
In this specific case, the synchronization command is called within the display() function, which is run by the main thread. That is, if we call animationThread->getChangeList()->applyAndClear();, we will get the change list from the other thread, which will have one entry (the changed matrix field). This change list will be applied to the current thread, the main thread. Remember, the main thread is also the one, that will render - so afterwards the new matrix can be taken into account when rendering. Additionally, applyAndClear() also removes all entries in the change list, so that it is empty again.
There is still one thing we have not talked about: Barriers. You might have noticed that we used an object of type osg::Barrier. This barrier is entered two times at the end of the animation thread and also two times during the display() function, where they appear to be like brackets around the sync command. All have one integer parameter of value two passed to them. The reason why these barriers have to be used is quite simple: during synchronization, that is when data is written from one aspect to another, no new data is allowed to be written (or even read), because this may cause inconsistent data. So all threads that are going to be synchronized have to stop until the process has finished. That is what barriers are for.
When a barriers is entered via
some_barrier->enter(2);
the thread will stop. The integer argument tells the system how many threads will have to enter this barrier until they are released again. In our example the main thread will stop during the display function() at the very fist line, until the animation thread also enters the first barrier at the end of the function(). At the moment that happens, both threads will continue to run. However the animation thread will be stopped at the next line already, where the main thread will first finish executing the synchronization until it enters the next barrier, where both will be released again.
Usage of barriers
Code is executed downwards along the red line, until the blue line marks a barrier. If and only if both threads have arrived at the blue barrier, execution of both threads continues.
Be careful to use the correct value as argument for entering barriers. If I would have accidently given a value of three instead of two, to any barrier, the application will wait there forever and never continue, because there is no third thread that could enter the barrier.
Now that you have a basic understanding of how threads work, you might come to the conclusion, that this is not very efficient, as every thread has to wait every frame until the other has also finished - yes, as I said before, this was for didactic reasons only and should not be used like that in the real world.
A little example where multithreading might be useful: imagine you have a virtual reality system, that has to load files from disk during runtime. If these files contain some bigger models, such as terrain or houses, loading might take some noticeable time. If you are running a single threaded application, the whole thing will stop (i.e. the picture will freeze) until loading is finished. In this case you could have a second thread for loading. This thread will be started when a model should be loaded. The model will be loaded into memory while the main application will continue to run. When the loading process has finished, both threads will be synchronized and then the additional thread will be terminated. Done.
Next Chapter : Clustering | http://www.opensg.org/htdocs/doc-1.8/Multithreading.html | CC-MAIN-2014-42 | refinedweb | 2,563 | 60.35 |
Learn React: Your First React Component Explained
Previously on Learn React from Scratch Series:
React apps are made out of components. But what is a component?
A component in React is a small and reusable chunk of code that renders some HTML. Here is an example of what a simple React component looks like:
import React from 'react'; import ReactDOM from 'react-dom'; class AnIttyBittyComponent extends React.Component { render(){ return <h1>Hello! I am a squirrel</h1> } } ReactDOM.render( <AnIttyBIttyComponent />, document.getElementById('app') );
Let's break the above React component down, line by line.
Understanding React and ReactDOM
The first line -
import React from 'react'; - brings in the
React module from your React library. It also creates an Object called
React which you can tap into pre-written methods.
For example,
createElement() is a method that belongs in the
React object.
createElement() is also how React renders things into HTML. When you're using JSX, JSX compiles and transforms your code into a
React.createElement() call.
Note: You can write React 'code' without JSX, but it means that you will need to format everything to fit with
createElement()method requirements.
The next line after
import React from 'react'; is
import ReactDOM from 'react-dom';.
This line imports methods that are available from
react-dom and makes it accessible through the Object named
ReactDOM.
When you are rendering your React component, you are doing it via
ReactDOM.
Note: the DOM is not something that is new or exclusive to React. It is part of HTML and lets you hook into different parts of the document. Here's a piece about DOMs I wrote a while back if you want to learn more.
Creating a Component Class
JavaScript is object-oriented by design. A React component you write is an extension of React's
Component class. This means that when you create a new React component, you are actually creating a subclass of
React.Component.
Here is the syntax of how to do this:
class AnIttyBittyComponent extends React.Component {}
The idea of subclassing is beyond the scope of this piece but here's a comprehensive piece I wrote a few years back on object-oriented JavaScript (what it means and how it works) If you're new to JavaScript and JavaScript OOP, the piece might help you out.
The name of the above component is
AnIttyBittyComponent and it is now a subclass of
React.Component. When we subclass, we have access to all the methods that are available in the parent class. Because
React.Component is now our parent class, we have access to a method called
render(). We can use
render() to return our JSX.
Note: It is a JavaScript convention to write all class names in UpperCamelCases. You don't have to, but following convention makes it easier to quickly identify what kind of content type you're dealing with.
render() is a function that always
return something. In our case, it's a block of HTML code.
class AnIttyBittyComponent extends React.Component { render(){ return <h1>Hello! I am a squirrel</h1> } }
render() is a compulsory method required by all
React.Component subclasses.
How to call your React component
After you've written your first React component, you now have access to it in your React project in this format:
< YourComponentName />
To render it on the DOM, you can do so via
ReactDOM.render().
ReactDOM.render() takes two parameters - what it's supposed to render and where to render it.
ReactDOM.render( <MyIttyBittyComponent />, document.getElementById('app') );
And that's basically it for how a React component class works.
React FAQ:
Can we declare more than one component in a single file?
Yes! All you have to do is create another component class extension. Here's a code snippet example:
class SomeComponent extends React.Component{ render(){} } class AnotherComponent extends React.Component{ render(){} }
How do you import multiple objects from a library in React/JavaScript?
Use the
{}. Here is the syntax example:
import {Router, Switch} from 'react-router';
Is component render() method the same as ReactDOM render()?
No. Despite having the same name, they belong to different classes. This means that they are different and are completely unrelated.
What else can React.Component class do?
In addition to
render() method, there is also the
constructor() method.
constructor() is invoked before the component gets added to the DOM and sets up the initialization of states and method bindings.
Another method that
React.Component class offers is
componentDidMount() and
componentDidUpdate().
componentDidMount() runs right after the component is inserted into the DOM tree and is only invoked once.
componentDidUpdate() runs every time the component updates.
What do we do with these methods? Well, you can put certain functions and additional method calls inside them to run based on the above-described situation.
Can we return multiple elements inside a React.Component render() function?
Yes. It's how views are created. You can collate a collection of components together to form a view component. For example:
class SomeComponent extends React.Component{ render(){ <div> <nav /> <blog /> <footer /> </div> } }
Alternatively, you can use
<React.Fragment> to return a collection of components without needing to wrap it around a parent HTML element. For example:
class SomeComponent extends React.Component{ render(){ <React.Fragment> <nav /> <blog /> <footer /> </React.Fragment> } }
Can we pass in multiple components into ReactDOM.render()?
No.
ReactDOM.render() only accepts one value in the first argument. However, if you want to create more than one component at a time, you can always wrap it with a parent element.
Here's an example:
ReactDOM.render( <div> <nav /> <blog /> <footer /> </div>, document.getElementById('app') );
What happens if my React container already has things in it?
Let's pretend this is the container code you have:
<div id="app"> <h1> Whoops! You don't have JavaScript support on your browser. Akward. </h1> </div>
When we run
ReactDOM.render() , all the contents inside the target container will be wiped and get replaced by our component instead. To the user, the
<h1> in the code sample above would be as if it never existed. | https://www.dottedsquirrel.com/learn-react-3/ | CC-MAIN-2022-33 | refinedweb | 1,011 | 59.3 |
Neo4j Bolt driver for Python
Project description
The official Neo4j driver for Python supports Neo4j 3.0 and above and Python versions 2.7, 3.4, 3.5, 3.6, and 3.7.
Note
Python 2 support is deprecated and will be discontinued in the 2.x series driver releases.
Quick Example
from neo4j import GraphDatabase driver = GraphDatabase.driver("bolt:/")
Installation
To install the latest stable version, use:
pip install neo4j
Note
Installation from the neo4j-driver package on PyPI is now deprecated and will be discontinued in the 2.x series driver releases. Please install from the neo4j package instead.
For the most up-to-date version (generally. | https://pypi.org/project/neo4j/1.7.2/ | CC-MAIN-2019-43 | refinedweb | 109 | 61.73 |
Machine Learning is a part of Artificial Intelligence, which consists of algorithms and improving automatically with time. In order to apply machine learning to different datasets, we need to clean the data and prepare it for the machine learning phase. Also, we need to identify the data or problem whether it is Regression, Classification, etc.
There are many machine learning algorithms that we can use for our prediction, regression, classification, etc. problems. But we need to call them individually and pass our data into them as parameters. It is very difficult to try different algorithms and choose the one which has the highest accuracy and lowest error.
Autogluon is an open-source python library that automates the whole process of machine learning and helps in achieving high accuracy. It automatically trains and predicts the models in just a single line of code. It works on different types of datasets i.e. Tabular, Image, Text, etc.
In this article, we will explore how Autogluon can be used to train a model that is best for a given Tabular Dataset.
Implementation:
We will start by installing Autogluon using pip install mxnet autogluon.
- Importing Required Libraries
For loading the dataset we will be working on we need to import pandas and for machine learning algorithms we will import autogluon.
import pandas as pd
from autogluon import TabularPrediction as task
Here we will work with a dataset that contains different attributes from an Advertising department of an MNC, it contains attributes like Sales, TV, etc. In this dataset Sales is the target variable. We will split and store these datasets into test and train data.
df1= pd.read_csv(‘Adv_Test.csv’)
df2= pd.read_csv(‘Adv_train.csv’)
df1.head()
df2.head()
- Machine Learning using Autogluon
Now as we have imported the dataset we require, we will apply our final step which is to use Autogluon for predictor and performance function. We will set labels as ‘Sales’ as it is our target variable. It will automatically detect which type of problem it is i.e. whether it is regression, classification, etc.
predictor = task.fit(train_data=df2, label='Sales')
It foes through different regression models which are the best ones and returns you the name of the different models which are used, their validation time, and also validation RMSE.
Now let us print the performance of the test data using the performance function and see what is the RMSE for the best-fitted model.
performance = predictor.evaluate(test_data)
Here we can see that the performance of the model is quite good as the error is quite low. We can save these models by explicitly providing the location to save or autogluon saves the model in the directory where it is running.
Conclusion:
In this article, we saw how easily and effortlessly we created different models for tabular datasets and found out the best model for the given dataset. We also saw what is the performance of the model to verify whether it is the best model or not. Autogluon saves a lot of time by automating the whole process of machine learning.. | https://analyticsindiamag.com/how-to-automate-machine-learning-tasks-using-autogluon/ | CC-MAIN-2020-45 | refinedweb | 514 | 53.51 |
"templates" in old-school C?
#1 Members - Reputation: 560
Posted 16 February 2004 - 02:35 PM
#2 Members - Reputation: 576
Posted 16 February 2004 - 02:50 PM
No, void* is the way to do it. C has nothing really in the ways of tricks like C++ has.
#3 Members - Reputation: 560
Posted 16 February 2004 - 02:54 PM
Sorry.
#4 Staff Emeritus - Reputation: 1670
Posted 16 February 2004 - 03:08 PM
First off, unlike templates in C++, your system will be evaluated at runtime (templates are evaluated at compile time). The system will actually have a lot in common with implementing OO in C (so you might as well do it, too). Consider the following C++ fragment:
template < typename T >This application of templates requires a means for determining that the actual type instantiating the template (T) has the method generic_method. This is trivial in C++ because the code is fully expanded and then passed to the compiler, which simply looks into the symbol table. Since your system would be evaluated at runtime, you''d have to store an explicit symbol table which would be searched.
void SomeFunction( const T & t )
{
t.generic_method();
}
Furthermore, since neither C nor C++ is introspective (there is no way to programmatically query an entity as to its properties), you''ll need to use specific tokens as associative indices to indicate the existence of a certain function in an object''s interface. This could simply be the function name (an entry with the key "find" indicates the existence of a function find()).
C is not inherently object-oriented and doesn''t support inheritance, so all your objects must actually be of one type in C, but masquerade as being of different types. This is the hard part. You need to store a generic reference to all your objects (void *), but supply a conversion mechanism to recover the original object complete with type. This suggests typecasting, and would be easy if the function-style typecast could be assigned to a function pointer. Unfortunately it can''t, AFAICT.
This is such an intrinsic problem that I am unable to think of a workaround or solution. So you''re SOL.
Wasn''t that fun!
#5 Members - Reputation: 1298
Posted 16 February 2004 - 03:13 PM
#6 Members - Reputation: 560
Posted 16 February 2004 - 03:18 PM
We are supposedly covering linked lists this week, and since I have already known how to do those for 10 years or so, I figured I would try to spice things up just for fun.
My point is, I CAN'T USE C++... I just wanted something "fun".
[edited by - smitty1276 on February 16, 2004 10:19:27 PM]
#7 Members - Reputation: 640
Posted 17 February 2004 - 01:22 AM
//of course you know templated functions:
#define Add(A,B) (A + B)
//similarly, a templated class:
#define ListNode(Type) \
struct \
{ \
Type Value; \
void* Prev; \
void* Next; \
}
void main ( )
{
ListNode(int) IntNode;
ListNode(float) FloatNode;
IntNode.Value = 4;
FloatNode.Value = 0.5;
}
Cool, huh? Of course you can have trouble doing certain things... but it works. Only thing is you can''t name the struct, hence the void* pointers it uses. The reason you can''t name it is you can''t create different names for the different types, so you''d have multiple declarations of the same structure.
~CGameProgrammer( );
#8 Members - Reputation: 1002
Posted 17 February 2004 - 01:49 AM
If that''s not the help you''re after then you''re going to have to explain the problem better than what you have. - joanusdmentia
davepermen.net
#9 Members - Reputation: 560
Posted 17 February 2004 - 01:12 PM
Thanks for the responses.
#10 Members - Reputation: 122
Posted 17 February 2004 - 03:34 PM
#11 Moderators - Reputation: 1674
Posted 17 February 2004 - 04:04 PM
quote:
Original post by CGameProgrammer
#define ListNode(Type) \
struct \
{ \
Type Value; \
void* Prev; \
void* Next; \
}
Cool, huh? Of course you can have trouble doing certain things... but it works. Only thing is you can''t name the struct, hence the void* pointers it uses.
Er, sure you can. Use token-pasting to create your own mangled names.
#12 Members - Reputation: 640
Posted 17 February 2004 - 04:17 PM
quote:
Original post by smitty1276
I tried the define thing, and I kept getting weird errors... maybe I''ll try again. It was just a quick attempt and I didn''t really do any trouble shooting.
Thanks for the responses.
It compiled fine for me in Visual C++.
~CGameProgrammer( );
#13 Members - Reputation: 398
Posted 17 February 2004 - 04:42 PM
// templtype.h
// note the lack of #ifndef/#define/#endif bracket
#define TEMPLTYPELIST(x) x##List
struct
{
TEMPLTYPE Value;
TEMPLTYPELIST( TEMPLTYPE ) * pPrev;
TEMPLTYPELIST( TEMPLTYPE ) * pNext;
} TEMPLTYPELIST( TEMPLTYPE );
// main.c
#define TEMPLTYPE int
#include templtype.h
#undef TEMPLTYPE
#define TEMPLTYPE float
#include templtype.h
#undef TEMPLTYPE
void main()
{
intList il;
floatList fl;
...
}
I think that would work.
I like pie.
#14 Senior Moderators - Reputation: 1776
Posted 17 February 2004 - 04:44 PM
"Sneftel is correct, if rather vulgar." --Flarelocke
#15 Members - Reputation: 398
Posted 17 February 2004 - 04:50 PM
I like pie.
#16 Members - Reputation: 640
Posted 17 February 2004 - 06:11 PM
~CGameProgrammer( );
#17 Members - Reputation: 398
Posted 18 February 2004 - 12:21 PM
quote:
Original post by CGameProgrammer
Nice trick RenderTarget, I didn''t know about ##blah; I only knew #blah converts the value to a string. For referencing, I still think ListNode(int) is better than ListNode_int, and of course ##blah doesn''t work for most types, like "unsigned int" or "char*" since that would result in invalid names.
You could always typedef those, if you really needed it to work. *shrug*
I like pie.
#18 Moderators - Reputation: 1411
Posted 19 February 2004 - 02:01 AM
#19 Moderators - Reputation: 1411
Posted 19 February 2004 - 02:26 AM
/* readme.txt */
This document describes the "Small Define Library". It is a even smaller
introduction to the API and usage as well as the "build instruction".
I must add, that I gave up developing the lib any futher, because I ran into
seriously problems with implementing iterators generic and typesafe enough
to satisfy my standards. It seems not possible under C, so I left a small
vector-implementation of the stl''s std::vector.
---------------------------
API / Usage
---------------------------
I suggest you are familiar with the c++ stl.
- include the correct header file - cvector.h
#include <cvector.h>
- declare the vectors type (or more than one, if you want different types).
If you want a vector of floats, do like this in one of your c-files (I
recommend to create a separate file for it):
implement_vector(float)
And this in each file you want to use the vector_float:
declare_vector(float)
These will expand a real huge macro and provide you with all functions
needed to access the floated vector.
- create your container "object"
vector_float myVec;
vector_float_ctor(&myVec);
myVec will be a struct of some internal data which you should not touch. If
you _really_ have to touch beware, that these could change in any version
of the library unannounced.
Do not forget to call the ctor-function or your vector remain uninitialised.
- function names are like this:
vector_type_stlname(&container_variable, ...);
where:
"vector" is the container-type - means "vector" ;-)
"type" is the type you choose in the macro above
(e.g. float)
"stlname" is the name of the function in the c++ standard template library,
(e.g. push_back, empty, size or begin)
"container_variable" is the variable you named the container after
(e.g. myVec)
"..." are other parameter which are similar to those in stl.
(e.g. the value when adding to a vector with push_back)
- iterators are just pointer to the elements, so you can increment, decrement
or dereference them like you wish
- if you prefer to work with a simple c-array and only want vector to
build up the array and manage the memory stuff, call this:
float* ptrToVec = 0;
if (!vector_float_empty(&myVec)) ptrToVec = vector_float_begin(&myVec);
However, remember that some vector_* calls invalidate such pointers (since
the storage gets rearranged).
- at end of usage, CALL THE DESTRUCTOR! There are no automatic ctors
and dtors in C, so you have to do it by yourself:
vector_float_dtor(&myVec);
See test.c for an example.
---------------------------
Build instructions
---------------------------
Up to now, there are no c-files but only the header required. This is most
like the stl and because almost everything in here is either an inline (hope
your compiler get inline correct?) or a #define.
This means, there are no build instructions. Just copy the headers anywhere
you can access them and be happy. (Make sure, they are in your include path).
Hint: If you try to compile the example (test.c) you will have to add the
current directory to your include path (for gcc use "gcc -I. test.c").
Write me your opinion (you can flame as well, if you like ;-)
sdl@kutzsche.net
Immanuel Scholz @2002
// ---------------------------------------------------------------------------
What I want: (Objective)
vector
+ an implementation of a vector representing a continous memory block.
+ the user can give any datatype to fill the vector with.
+ the items in the block should not contain only of pointers to the required
data type, instead they should BE such a data type. This means, an vector of
int''s with the length of 10 should be accessible as an int[10].
- the names of the vector''s function should be generic, and possible free of
the data types name (vector_size, vector_empty...)
+ the user should not be able to access the structure of the vector. This
means, he only see a forward declaration (incomplete data type) of the
vector struct.
+ the vector should be typesafe not to accept incompatible types instead of
those choosen initially by the user. This means, if you try to pass an int*
to an vector of int''s, it has to be rejected, best at compile time, but at
least at runtime.
+ the implementation of the vector''s function should be efficient (if possible)
// ---------------------------------------------------------------------------
General questions (FAQ)
Q: Is this library a good choice for me?
A: Depends.
- If you are familar with c++ stl and look for a vector under C, then
maybe yes. It is, however, much smaller.
- If you want a fast but generic array implementation, you are on it.
It surely fit your needs.
Like in c++, you can get the vector as an ordenary c-array and work on
this, if speed is an concern.
- If you want a typesafe array implementation, and your compiler is
able to give an error on pointer assignments of different types, then SDL
might be what you are looking for. Make sure you turn compiler warnings
about incompatible pointer assignment into errors (e.g. -Werror with gcc).
Even without that support from your compiler, you get still an compiler(!)
error when you (as example) trying to add anything incompatible to an
integer into a vector of integers.
- If you are interestet in generic programming or OOP under C it might a
good choice for you too.
- But if you want a debugable, gdb-friendly library then sorry: SDL is
good at this.
- If you dislike #defines in general, SDL is REALLY nothing for you.
- Finally the size of the code generated by SDL can become quite big (if you
use more than one different type), compared to some tiny void* -
implementations so if you work in really small embedded systems, you may
break the code memory footprint. But remember, that usually the size
of the resulting vector is smaller than any void* - implementation.
Q: Why GPL? Can''t you make it LGPL or BSD?
A: No. If you wan''t to use it under any lesser licences than GPL, write me,
I will sell you a seperate licence. But consider first to release your
project under GPL instead ;-).
Q: Why you do such a stupid thing? Don''t you see that these whole #define
stuff is a real mess and fubar?
A: It still proove a feasible way of generic programming under a language
like C. And I think it is usable of some kind (at least if you get used
to the debug-capabilities an "gcc -E -P | indent" will provide ;) )
More questions? Write to sdl@kutzsche.net
Immanuel Scholz @2002
/* cvector.h */
/* August 2, 2002 */
/*
* This library is provided under GPL v2.0
* See
*
*/
#ifndef SDL_CVECTOR_H__
#define SDL_CVECTOR_H__
/*----------------------------------------------------------------------*/
/*
* Use this macro to declare the functions only but not to implement
* them. You have to call this in every compile unit you are using vector
* (instead of implement_vector, which has to be only declared once)
*/
#define the
* structure.
*/ \
struct vector_##type##_t; \
typedef struct vector_##type##_t vector_##type; \
\
/*
* User _have_ to call the constructor before doing anything with the
* vector.
*/ \
void vector_##type##_ctor(vector_##type* v); \
\
/*
* If user stores pointers in the vector he has to make sure they are
* deleted before calling the destructor. vector will not delete the
* contens of itself - only the container (much like c++-stl)
*/ \
void vector_##type##_dtor(vector_##type* v); \
\
/* Return the size of the vector as integer */ \
int vector_##type##_size(const vector_##type* v); \
\
/* Return the current capacity of the vector */ \
int vector_##type##_capacity(const vector_##type* v); \
\
/* Return 0 if vector has at least one element in it */ \
int vector_##type##_empty(const vector_##type* v); \
\
/*
* Reserves enough space for the vector to hold new_capacity items. If
* the vector had already enough space, nothing is done. This call can
* made any pointer to members invalid.
*/ \
void vector_##type##_reserve(vector_##type* v, int.
*/ \
void vector_##type##_resize(vector_##type* v, int new_size); \
\
/*
* Return a pointer to the item at "index". Does range check
* (via assertion).
*/ \
type* vector_##type##_at(const vector_##type* v, int index); \
\
/*
* Return an pointer to the first element (or end() if empty) Note,
* that since the memory is continous, the pointer you get can be used
* to access the vector like an ordenary c-array! (I am very proud of
* this feature of sdl)
*/ \
type* vector_##type##_begin(const vector_##type* v); \
\
/* Return a pointer to the place after the last element in list */ \
type* vector_##type##_end(const vector_##type* v); \
\
/*
* Inserts the data on back of the vector. If new memory has to be
* allocated, it will be (all pointers to elements of the list looses
* validity).
*/ \
void vector_##type##_push_back(vector_##type* v, type data); \
\
/*
* Removes the last element from the vector. (Does not change the
* capacity)
*/ \
void vector_##type##_pop_back(vector_##type* v);
/*----------------------------------------------------------------------*/
/*
* Call to this macro once in any c-file you use to generate all the
* functions and declarations you need
*/
#define implement_vector(type) \
\
\
\
/*
* The rest is for internal use of sdl. Do not even look at this
* directly (except sending me bug reports to sdl@kutzsche.net ;-)
*/ \
\
\
\
/* first thing to do is to declare all vector-functions */ \ this
* structure.
*/ \
struct vector_##type##_t { \
type* begin; \
type* end; \
type* capacity; \
}; \
\
/*
* User _have_ to call the constructor before doing anything with the
* vector.
*/ \
inline void vector_##type##_ctor(vector_##type* v) \
{ \
v->begin = 0; \
v->end = 0; \
v->capacity = 0; \
} \
\
/*
* If user stores pointers in the vector he has to make sure they are
* deleted before calling the destructor. vector will not delete the
* contens of itself - only the container (much like c++-stl)
*/ \
inline void vector_##type##_dtor(vector_##type* v) \
{ free(v->begin); } \
\
/* Return the size of the vector as integer */ \
inline int vector_##type##_size(const vector_##type* v) \
{ return v->end - v->begin; } \
\
/* Return the current capacity of the vector */ \
inline int vector_##type##_capacity(const vector_##type* v) \
{ return v->capacity - v->begin; } \
\
/* Return 0 if vector has at least one element in it */ \
inline int vector_##type##_empty(const vector_##type* v) \
{ return v->begin == v->end; } \
\
/*
* Reserves enough space for the vector to hold new_capacity items. If
* the vector had already enough space, nothing is done. This call can
* made any pointer to members invalid.
*/ \
inline void vector_##type##_reserve(vector_##type* v, int new_capacity) \
{ \
type* new_place; \
int old_capacity = vector_##type##_capacity(v); \
int old_size = vector_##type##_size(v); \
if (new_capacity > old_capacity) { \
new_place = \
(type*)malloc(sizeof(type)*new_capacity); \
if (old_size > 0) \
memcpy(new_place, v->begin, sizeof(type)*old_size); \
free(v->begin); \
v->begin = new_place; \
v->end = new_place+old_size; /* size does not change */ \
v->capacity = new_place.
*/ \
inline void vector_##type##_resize(vector_##type* v, int new_size) \
{ \
int old_size = vector_##type##_size(v); \
vector_##type##_reserve(v,new_size); \
if (old_size < new_size) \
memset(v->begin + old_size, 0, \
sizeof(type)*(new_size - old_size)); \
v->end = v->begin + new_size; \
} \
\
/*
* Return a pointer to the item at "index". Does range check
* (via assertion).
*/ \
inline type* vector_##type##_at(const vector_##type* v, int index) \
{ \
assert (index >= 0 && index < vector_##type##_size(v)); \
return &(v->begin[index]); \
} \
\
/* Return an pointer to the first element (or end() if empty) */ \
inline type* vector_##type##_begin(const vector_##type* v) \
{ return v->begin; } \
\
/* Return an iterator to the place after the last element in list */ \
inline type* vector_##type##_end(const vector_##type* v) \
{ return v->end; } \
\
/*
* Inserts the data on back of the vector. If new memory has to be
* allocated, it will be (all pointers to elements of the list looses
* validity).
*/ \
inline void vector_##type##_push_back(vector_##type* v, type data) \
{ \
if (v->end == v->capacity) \
vector_##type##_reserve(v,(vector_##type##_capacity(v) == 0)? \
1:2*vector_##type##_capacity(v)); \
*(v->end++) = data; \
} \
\
/*
* Removes the last element from the vector. (Does not change the
* capacity)
*/ \
inline void vector_##type##_pop_back(vector_##type* v) \
{ \
assert(!vector_##type##_empty(v)); \
v->end--; \
};
#endif
/* test.c */
/*
* This library is provided under GPL v2.0
* See
*
*/
#include <assert.h>
#include <cvector.h>
implement_vector(int)
int main(void) {
int i;
vector_int v;
int* it;
/* ctor */
vector_int_ctor(&v);
/* empty and size */
assert(vector_int_empty(&v));
assert(vector_int_size(&v) == 0);
/* at, resize, capacity, size and reserve */
vector_int_resize(&v,10);
assert(!vector_int_empty(&v));
assert(vector_int_size(&v) == 10);
assert(vector_int_capacity(&v) >= 10);
for (i = 0; i < 10; ++i) {
assert(vector_int_at(&v,i) != 0); /* no NULL pointer returned */
assert(*vector_int_at(&v,i) == 0); /* initialized to 0 by resize */
}
vector_int_reserve(&v,20);
assert(vector_int_capacity(&v) >= 20);
vector_int_reserve(&v,30);
assert(vector_int_capacity(&v) >= 30);
vector_int_resize(&v,0);
assert(vector_int_empty(&v));
/* begin, end, iterator_equal */
assert( vector_int_begin(&v) == vector_int_end(&v) );
/* push_back */
for (i = 0; i < 50; ++i)
vector_int_push_back(&v,i);
/* iterator_incr, iterator_decr, iterator_deref */
i = 0;
for (it = vector_int_begin(&v);
it != vector_int_end(&v);
++it) {
assert(*it == i++);
}
it = vector_int_begin(&v) + 10;
assert(*it == 10);
for (i = 10; i > 0; --i) {
assert(*it == i);
--it;
}
/* pop_back */
for (i = 0; i < 50; ++i)
vector_int_pop_back(&v);
assert(vector_int_size(&v) == 0);
/* dtor */
vector_int_dtor(&v);
return 0;
}
To make sense of cvector.h it helps to examine the preprocessor output. Consult the docs for your compiler regarding which switches to use for that.
Here''s a dummy source file that I used to do that with. Put this into the same directory as cvector.h and direct your compiler to generate preprocessor output for it. It won''t compile, so don''t bother trying. It''s purpose is to examine the token substitution pattern of the various macros in the header.
/* macro.c */
#include "cvector.h"
implement_vector(USER_DEFINED_TYPE) | http://www.gamedev.net/topic/207920-quottemplatesquot-in-old-school-c/ | CC-MAIN-2014-23 | refinedweb | 3,186 | 54.52 |
- java.lang Package
The String class is also part of the system class library. It belongs to the package named java.lang. So why haven't you had to either use its fully qualified class name (java.lang.String) or provide an import statement?
The Java library contains classes so fundamental to Java programming that they are needed in many, if not all, classes. The classes String and Object are two such classes. The ubiquitous nature of these classes is such that the designers of Java wanted to save you from the nuisance of having to specify an import statement for them everywhere.
If you refer to the String class, then the statement:
import java.lang.String;
is implicit in each and every Java source file.
When you learn about inheritance (Lesson 6), you will find that every class implicitly extends from the class java.lang.Object. In other words, if a class declaration does not contain an extends keyword, it is as if you coded:
class ClassName extends java.lang.Object
This is another shortcut provided by the Java compiler. | https://www.informit.com/articles/article.aspx?p=406343&seqNum=12 | CC-MAIN-2021-43 | refinedweb | 181 | 65.52 |
Starting out with Solaris on Xen
As you may have seen from the announcement and John's blog we have a new set of Solaris on Xen bits available for download. A lot has changed in the (almost) year since the last drop. Certainly things are a lot easier set up than they were back then.
First big difference I notice is that you can install these bits straight from the DVD which means no mucking around with bfu.
Once it is installed also you have the joys of much newer Solaris builds including improvements to networking and removable media (but that isn't the point of this post).
Of course the thing you really want to do is run multiple operating systems so (while there are documents here I always think it's nice to see peoples use cases. Find out how they got things working.
I'm going to use zfs for storage so I made sure I had a large amount of space available for a zpool
# zpool create guests c2d0s7
First gotcha. After install the default boot entry in the grub menu.lst is for solaris on metal (ie not booting under Xen). You can change that before rebooting or select Solaris dom0 from the grub menu.
Check you are running under Xen by looking at uname -i
dominion# uname -i
i86xpv
(dominion is the name of my host)
If that says i86pc then you're not booted under Xen, i86xpv is the new platform modified to run on Xen.
I found that I accidentally booted on metal first time, and when I then booted under Xen the services weren't enabled. I had to manually enable them. (If you boot straight in to Dom 0 they start.
dominion# svcs -a | grep xctl
online 10:51:04 svc:/system/xctl/store:default
online 10:51:11 svc:/system/xctl/xend:default
online 10:51:11 svc:/system/xctl/console:default
online 10:51:16 svc:/system/xctl/domains:default
If it says anything other than online, enable them with
# svcadm enable "service name"
I use a zpool to create my disk devices for my domains. This has huge advantages, such as the ability to quickly snapshot a domain (say after install) so you can always return to that state. Also you can clone a snapshot so if you want to have many similar domains (say multiple solaris development environments) you can clone an install and then only the changes between the domains are stored (zfs being copy on write).
To set this up you need to create a zvol on your zpool
# zfs create -V 10G guests/solaris-pv
This creates a zvol of up to 10G in size. Unused space is still free for other users of the pool to allocate.
You can access the device for this zvol using
/dev/zvol/dsk/guests/solaris-pv
So that's simple - how do we install a Solaris domain? First off I create an install python config file. (Soon there will be a tool to manage the install for you but that's not really ready yet).
This python file describes some simple things about the domain like where the disk and cdrom is.
dominion# cat /guests/configs/solaris-pv-install.py
name = "solaris-pv-install"
memory = "1024"
disk = [ 'file:/guests/isos/66-0613-nd.iso,6:cdrom,r', 'phy:/dev/zvol/dsk/guests/solaris-pv,0,w' ]
vif = [ '' ]
on_shutdown = 'destroy'
on_reboot = 'destroy'
on_crash = 'destroy'
Name is obvious, and I've copied the iso image to be a file to speed up install.
You can kick off the install just by starting the domain
dominion# xm create -c /guests/configs/solaris-pv-install.py
This says start the domain and give me a serial console access to it. You then do a normal Solaris install. Once complete you should create a second python file to boot off the zvol. but first I'm going to snapshot it so I can quickly duplicate it (though I really should sys-unconfig it first to make me input the hostname and ip info again.)
dominion# zfs snapshot guests/solaris-pv@install
dominion# cat solaris-pv.py
name = "solaris-pv"
memory = "1024"
root = "/dev/dsk/c0d0s0"
disk = [ 'phy:/dev/zvol/dsk/guests/solaris-pv,0,w' ]
vif = [ '' ]
on_shutdown = 'destroy'
on_reboot = 'destroy'
on_crash = 'destroy'
and create it with
# xm create -c solaris-pv.py
This then comes up as per a normal solaris boot, if you've given it an ip address during the install or set it to use dhcp you should be able to log in to it using ssh. The networking is effectively bridged, that is to say, you need a real IP address for each domain on the same network as the Dom0.
So the next question I always get is "Can I run windows as a domU". And the answer is "maybe". What we have done up till now is use a paravirualised domU. That is one that has been modified to run on Xen. Anything that would trigger a privileged operation (interrupt, privileged instruction etc) is modified to be a call to the hypervisor. This is nice and fast, but some operating systems haven't had this treatment.
However with the advent of the intel core2duo and Rev F Opteron/Athlon64 (socket AM2) processors, some hardware support for virtualisation has been built in to the chip. This detects these privileged operations and redirects control back to the hypervisor to do "the right thing"
With Xen these are referred to as HVM domains.
Russ is going to be blogging more about these so I won't go in to too much detail, but if you want to know if your system is HVM capable, I wrote this simple program to tell you
dominion# cat hvm-capable.c
;
int isamd = 0;
int isintel = 0;) {
if (pread(d, rp, sizeof (*rp), 0x80000001) == sizeof (*rp)) {
(void) printf ("processor is AMD ");
/*
* Read secure virtual machine bit
* (bit 2 of ECX feature ID)
*/
(void) close(d);
if ((rp->r_ecx >> 2) & 1) {
(void) printf("and processor supports SVM\n");
return (0);
}
(void) printf("and does not support SVM\n");
} else {
(void) printf ("error reading features register");
(void) close(d);
return (1);
}
} else if (strncmp(s, "Genu" "ntel" "ineI", 12) == 0) {
if (pread(d, rp, sizeof (*rp), 0x00000001) == sizeof (*rp)) {
(void) printf ("processor is Intel ");
/*
* Read VMXE feature bit
* (bit 5 of ECX feature ID)
*/
(void) close(d);
if ((rp->r_ecx >> 5) & 1) {
(void) printf("and processor supports VMX\n");
return (0);
}
(void) printf("and does not support VMX\n");
} else {
(void) printf ("error reading features register");
(void) close(d);
return (1);
}
}
fail:
(void) close(d);
return (1);
}
SVM is AMD's implementation of HVM while VMX is Intel's.
And just a teaser of what you can expect. (right click - view image to see it full size)
Today's Page Hits: 94 | http://blogs.sun.com/cwb/entry/starting_out_with_solaris_on | crawl-002 | refinedweb | 1,149 | 66.57 |
DBIx::VersionedSubs::AutoLoad - autoload subroutines from the database
package My::App; use strict; use base 'DBIx::VersionedSubs::AutoLoad'; package main; use strict; My::App->startup($dsn); while (my $request = Some::Server->get_request) { My::App->update_code; # update code from the DB My::App->handle_request($request); }
This module overrides some methods in DBIx::VersionedSubs to prevent loading of the whole code at startup and installs an AUTOLOAD handler to load the needed code on demand. This is useful if startup time is more important than response time or you fork() before loading the code from the database.
You should be able to switch between the two implementations without almost any further code changes. There is one drawback of the AUTOLOAD implementation:
You need to explicitly load functions from the database that you wish to overwrite Perl code obtained from elsewhere.
This is the price you pay for using AUTOLOAD.
__PACKAGE__->init_code
Overridden to just install the AUTOLOAD handler.
__PACKAGE__->install_and_invoke NAME, ARGS
Loads code from the database, installs it into the namespace and immediately calls it with the remaining arguments via
goto &code;.
If no row with a matching name exists, an error is raised.
__PACKAGE__->update_code
Overridden to do lazy updates. It wipes all code that is out of date from the namespace and lets the AUTOLOAD handler sort out the reloading.
__PACKAGE__->load_code NAME
Retrieves the code for the subroutine
NAME from the database and calls
__PACKAGE__->install_code $name,$code to install it.
__PACKAGE__->retrieve_code NAME
Retrieves the code for the subroutine
NAME from the database and returns it as a string.
AUTOLOAD
An AUTOLOAD handler is installed to manage the loading of code that has not been retrieved from the database yet. If another AUTOLOAD handler already exists, the AUTOLOAD handler is not installed and a warning is issued.
Max Maischein, <corion@cpan.org>
This module is licensed under the same terms as Perl itself. | http://search.cpan.org/~corion/DBIx-VersionedSubs-0.07/lib/DBIx/VersionedSubs/AutoLoad.pm | CC-MAIN-2015-14 | refinedweb | 316 | 53 |
The
CToolbarEx class supports basic customization (As in IE) with controls on it. Additionally it can hide the controls when the toolbar is docked vertically. This class uses the framework provided by
ToolBarCtrl to do the customization of the Toolbar. It also supports Large Icons and Text on Buttons.
It uses a modified
CCustomizeDialog class by Nikolay Denisov to provide extra options in the Toolbar customize Dialog.
I have hardcoded a few things in
CCustomizeDialog to avoid resource dependences It also overrides
CDockBar with
CDockBarEx to provide 3D looks and overcome some docking bugs.
To use these in your project, do the following steps:
CToolBarwith
CToolBarExin
CMainFrame
#include "ToolBarEx.h" . . // CToolBar m_wndToolBar; CToolBarEx m_wndToolBar;
OnCreateoverride in your
CMainFrameclass, when the creation of the Toolbar is done (including controls), call
SetToolBarInfoForCustomizationto set the Customization Data in the Toolbar. This function should be called after the creation of the toolbar, controls and dropdown is done.
CRect rt(0,0,200,120); //Insert Control m_pComboBox =(CComboBox *) m_wndToolBar.InsertControl( RUNTIME_CLASS(CComboBox),_T(""), rt,ID_FIND,WS_VSCROLL|CBS_DROPDOWNLIST); m_pComboBox->AddString(_T("One")); m_pComboBox->AddString(_T("Two")); m_pComboBox->AddString(_T("Three")); //Add DropDown m_wndToolBar.AddDropDownButton(ID_OP,IDR_OP,TRUE); //Enable Customization m_wndToolBar.SetToolBarInfoForCustomization();
//Restore State m_wndToolBar.RestoreState();
Similarly you can also add
SaveState in
OnClose of the
CMainFrame.
MarkDefaultStateto set the default state of the toolbar. The default state is set when Reset button on the Customize Dialog Box is pressed.
//Delete the button which do not need to shown initially. m_wndToolBar.GetToolBarCtrl().DeleteButton( m_wndToolBar.CommandToIndex(ID_CUSTOMIZE)); // Mark the default state for reset m_wndToolBar.MarkDefaultState();
FrameEnableDockinginstead of
EnableDockingto use
CDockBarExinstead of
CDockBar.
// EnableDocking(CBRS_ALIGN_ANY); FrameEnableDocking(this,CBRS_ALIGN_ANY);
CWnd* InsertControl(CRuntimeClass* pClass,LPCTSTR lpszWindowName, CRect& rect,UINT nID,DWORD dwStyle );
This function creates and inserts the control into the Toolbar and returns the window inserted. In rect parameter, pass only the width and height.
CWnd* InsertControl(CWnd* pCtrl,CRect& rect,UINT nID);
This function inserts the already created control into the Toolbar. In rect parameter, pass only the width and height.
BOOL AddDropDownButton(UINT nIDButton,UINT nIDMenu,BOOL bArrow=TRUE);
This function a button to a Dropdown with a menu attached to it. Set bArrow to TRUE if you want to show arrow next to it.
void SetToolBarInfoForCustomization();
This function sets the Customization information for the Toolbar. The Names used for the buttons in Customize dialog box are taken from the Tooltip of the Button. (String after Last '\n' of Prompt in Button Properties in Toolbar resource editing.) Call this function after the creation of the Toolbar is done. i.e. Controls, Dropdown have been added.
void MarkDefaultState();
This function sets the default state of the Toolbar. The default state is set when Reset button of Customize Dialog Box is pressed.
void SaveState()
This function saves the State of the Toolbar in the Registry.
void RestoreState()
This function restores the State of the Toolbar from the Registry.
BOOL m_bHideChildWndOnVertical;
This flag controls whether the Controls are visible in the Vertical docking mode. Default Value is TRUE
BOOL HasButtonText( int nID)
This function is used to determine whether the button has Text in "Selective Text on Right". At present it returns TRUE for all. Override this to provide new logic. nID is the command Identifier.
It requires 5.80 version of the Commctl32.dll. It uses few features of 5.81 version, but they seem to work fine on 5.80 also. Please look at the Demo for full details.
Thanks to all Code Project /Code Guru Developers.
General
News
Question
Answer
Joke
Rant
Admin | http://www.codeproject.com/KB/toolbars/toolbarex.aspx | crawl-002 | refinedweb | 585 | 51.24 |
varys 0.5.2
For parsing and reformatting behavioral event logs.
Varys
Varys is a python package for anyone who has to work with behavioral data logs.
Chances are, you need that data in another format before you can work with it. If you’re like most of us, you have some collection of scripts around somewhere that can parse format A, other scripts that write format B, and somewhere in the middle you’ll sandwich some logic that actually has something to do with your experiment.
Our goal is to reduce the load down to this last bit.
Varys breaks its work into three segments: LogParser, EventBuilder, and FileWriter. Of these, only EventBuilder needs to be customized per experiment.
LogParser is meant to grow with time to be able to parse an increasingly diverse list of input types. At the moment we support simple TDF and CSV formats, as well as the FIDL format used by the eponymous software package from Washington University in St Louis. But we’re willing and interested to work with users to expand that list.
EventBuilder takes input from a LogParser, and turns it into a list of “event” dictionaries. These can contain arbitrary values, but at a minimum must contain “name,” “onset” and “duration.”
FileWriter takes these ordered dictionaries, then writes files consumable by analysis packages. At the time of this writing, we support SPM, FIDL, tab delimited .txt, and python’s Pickle, but here again we’re willing and eager to expand the list of supported formats.
We’ve thrown in some special options for working with neuroimaging data, for concatenating runs, and other fun stuff too.
So please, take a look at the examples list, see if any of them sound like your situation, and feel free to use them as a starting point for your own work.
Installation
Varys uses scipy, which in turn uses numpy, and as of yet we’re too lazy to do the fancy dancing needed to auto-install numpy as a dependency. So it’ll take two steps:
pip install numpy pip install varys
Or grab the latest development version from, and install using setup.py.
Supported Formats
Currently supported formats are:
Input: .txt, .tdf, .csv, .fidl
Output: spm, fidl, pickle, txt (tab delimited)
Examples
Varys provides several EventBuilder subclasses for handling data in different ways - in short, you can either have your data handed to you as a list of rows (as dicts), or you can have it handed to you one row at a time. Usually the latter approach is the most helpful.
There are several EventBuilder subclasses you can dive into, but here we’ll cover the kinds you’re most likely to use: RowWise_EventBuilder, RowWise_fMRI_EventBuilder, and FixedDuration_EventBuilder. Please forgive the long names. Names were never my strong suit.
Using either of the two RowWise classes involves creating your own subclass, whereas FixedDuration_EventBuilder is meant to be configured and used without subclassing, making it easier to write very simple EventBuilders.
Enough chit chat. Let’s look at some examples.
Mise en Scène
For the following examples, we’ll pretend that a few things are the case:
- Subject data is in /data/sub_N/run_M.txt, where ‘N’ and ‘M’ are two-digit subject and run numbers, respectively (ie 01, 02, etc.).
- The event name is whatever value is stored in the column named “trial_type”
- All trials have a duration of 10.0
- Trial onset time is in a column named ‘cue_onset’
- Answer accuracy is in a column named “acc”, and is either ‘1’ or ‘0’.
- The first trial’s onset time is to be used as time = 0
- For the fMRI subclass, the TR is .7, because your scanner is awesome (written circa 2014)
- For the sake of clarity, we’re going to be sloppy about not catching exceptions.
- Each run’s data is in its own file
- You have three subjects, 1, 2, and 3
- You want to save the resulting files into “/data/output”
- Your source files fall into the correct order if sorted alphabetically
- You want to use the events in SPM, and save a pickled version as well for later use in python
RowWise_EventBuilder
This is probably the most useful subclass, and is pretty simple. Let’s take a look.
from varys.EventBuilder import RowWise_EventBuilder class basic_EventBuilder(RowWise_EventBuilder): def __init__(self): super(basic_EventBuilder, self).__init__() self.trial_onset = 0 self.data_glob_templates = ["/data/sub_%02d/run_*.txt"] self.subjects = [1,2,3] self.output_dir = "/data/output" self.output_formats = ["spm", "pickle"] def events_for_row(self, row_dict): events = [] name = row["trial_type"] onset = float(row["cue_onset"]) - self.trial_onset acc = row["acc"] if name and onset: events.append(["name":name, "onset":onset, "duration":10.0, "acc":acc, "set":"all_events"]) return events def handle_run_start(self, run_idx, run_data, file_name): self.trial_onset = float(run_data[0]["cue_onset"]) eb = basic_EventBuilder() eb.run()
To get the details on this and the other subclasses, check out the noted in the related code. But since we’re here, let’s take this apart a little bit.
handle_run_start gets called at the start of every run, and as such is a great place to find and set aside any run-wide variables, like run onset time. That’s exactly what we do in this example.
events_for_row gets called once per row of data in your original file, and is expected to return a list of dicts (one dict per event). You might be wondering what this set entry is all about, and why we return a list of events, instead of just one. From time to time, analysis will require that you create several different event sets - one including all trials, and one including only those trials which were answered correctly, for example. Suppose we wanted to do exactly this for the current example. Then we’d change the if block of events_for_row to read as follows:
if name and onset: events.append(["name":name, "onset":onset, "duration":10.0, "acc":acc, "set":"all_events"]) if acc == "1": events.append(["name":name, "onset":onset, "duration":10.0, "acc":acc, "set":"acc_events"])
Note that we used a different set for the second event. This will cause EventBuilder to write two sets of files for the two event sets. You might not need this, but if you do, it sure is nice not to have to write a whole ‘nother subclass!
The init method just presets a few values specific to this experiment. Note that you can override these. If you moved the script to another machine, where the data was instead in /my_data/subjects/sN/run_M.txt (remembering that N and M are two-digit subject and run numbers, respectively), and you wanted to save the results to /analyses/new_data, you don’t have to modify the subclass. You can just change a couple of values, then call run():
eb = basic_EventBuilder() eb.data_glob_templates = ["/my_data/subjects/s%02d/run_*.txt"] eb.output_dir = "/analyses/new_data" eb.run()
subjects can be similarly changed.
RowWise_fMRI_EventBuilder
This class is pretty much the same as RowWise_EventBuilder, but has a few extra features specific to fMRI. Let’s take a look, and go through it afterwards. I’ll omit everything that would be identical, but do remember to include it in your own subclasses.
from varys.EventBuilder import RowWise_EventBuilder class basic_fMRI_EventBuilder(RowWise_EventBuilder): def __init__(self): super(basic_fMRI_EventBuilder, self).__init__() # same as RowWise_EventBuilder, with one extra property: self.TR = .7 # events_for_row same as RowWise_EventBuilder # handle_run_start same as RowWise_EventBuilder def tr_count_for_run(self, run_idx, file_name, raw_rows, events): """ return the TR count for the given run. """ if run_idx < 2: return 130 else: return 200
So, there are really only two differences here, and their utility might not be immediately apparent (we’ll get there): the property TR, and the method tr_count_for_run. In this example, we set the TR to .7, and return one of two values for tr_count_for_run depending on the run number.
So, who gives a flying leap at a rolling doughnut about TRs and how many there are per run? Anyone who needs to concatenate their runs, that’s who. We use these two properties to figure out how much time to add to the onset of all events for each run. So if you have 100 TRs of length .7 each in run 1, every event in run 2 will have 70.0 added to its onset time. But take note, this will only happen if you set the “concat_sets“ property to a list of the sets whose runs you’d like to concatenate. We do it this way because you may not want to concatenate runs for every event set. So, if we wanted to concatenate runs, but only for the event set that contains accurate response events (acc_events), we’d change the init method like so:
def __init__(self): super(basic_fMRI_EventBuilder, self).__init__() # same as RowWise_EventBuilder, with one extra property: self.TR = .7 self.concat_sets = ["acc_events"]
Take note, some output formats, such as fidl, absolutely require concatenated runs. If you specify one of these output formats, all runs in all sets will be automatically concatenated, even if you don’t set concat_sets.
Skipping Output
Sometimes, you don’t actually want to write the event set out to any file. You just want to parse the events, then keep working with them in your code.
To do this, set the skip_output property to True, then retrieve the values for the subject you’re interested in. Working with our basic_EventBuilder, if we wanted to get the list of lists of event dicts for subject 1, we’d do as follows:
eb = basic_EventBuilder() eb.skip_output = True eb.run() sub_num = 1 s1_events = eb.sub_data[sub_num]["acc_events"]
One Giant Input File
It may be the case that, instead of having one input file per run, everything’s in one big table, and there’s some column whose value changes every time a new run’s data begins. To handle this, just set the run_field property to the name of that column. If this were the case for our example, and the name of the column was “run_number”, we’d just make a slight modificaiton to the init method:
class basic_EventBuilder(RowWise_EventBuilder): def __init__(self): super(basic_EventBuilder, self).__init__() # everything is the same as before, but add: self.run_field = "run_number" # everything else is the same as before
Not so bad, eh?
TODO
- FixedDuration_EventBuilder, once it’s ready Varys?
Because it manipulates events:
TODO: Thanks, credit to CCP Lab
- Downloads (All Versions):
- 19 downloads in the last day
- 131 downloads in the last week
- 523 downloads in the last month
- Author: Ben Acland
- Keywords: behavioral
- License: BSD
- Categories
- Package Index Owner: beOn
- DOAP record: varys-0.5.2.xml | https://pypi.python.org/pypi/varys/0.5.2 | CC-MAIN-2015-48 | refinedweb | 1,769 | 63.59 |
PyMate (iOS) does not connect to WiPy 2.0
Hi my fellow PyMates!
I cannot get my iPhone 7 to connect with a WiPy 2.0
Steps followed:
- Download iOS App
- Register new account
- Followed process as outlined also in the youtube video
The device remains red. After that, I updated to the latest firmware and using the Atom with the Pymkr plugin used the following command:
import os
os.mkfs ('/flash')
After I pressed the reset button, the WiPy was back in factory settings.
I repeat the process but again failed.
I then reset again, and manually entered the wifi settings but again cannot connect.
The error I get at the traceback is the following:: [Errno 113] EHOSTUNREACH
In the meanwhile, the WiPy is connected to my network and it has a DHCP issued IP address.
Can you help please?
Hello everyone,
I was able to rebuild the iOS Pymate app for iOS 11.0.2 and I'm getting some very basic functionality out of it.
There are still some bugs that I need to fix before I can try to submit this new version to the Apple App Store. There are also some aesthetic issues but I'm ignoring them for now.
I'm hoping to have some more news in the next few days.
Hi my fellow pymates,
The forum died, the Pymate Server is still dead and even though the forum was restored (loosing this thread...) the problem still persists.
I tried to overcome Pymate with Blynk but it seems that WiPy 2.0 is not supported.
I am very disappointed... The overall behavior of the devices is much lower than expected and we are stuck with hundreds of Pycom products.
We need to make the hardware work as it is marketed on the website. It's supposed to be an easy IoT Platform for everybody.
Can anybody help?
@xykon Thanks! Let's fix this issue because it will be very nice for people new to the Pycom products experience IoT!
@hellasdigital We've had some issues with the forum and unfortunately our discussion didn't survive the rollback.
I had a chat with @ficofer earlier and we'll continue troubleshooting this issue tomorrow. We'll keep you updated on our progress.
I haven't used the PyMate app for a while so I thought I'd give it a try.
From what I can gather via tcpdump on my router, the server running the PyMate service isn't responding.
I'll try to reach out to the Pycom team to take a look at this.
Anyone?
Either everybody has the same problem or only me!
I have also sent e-mail to support but no response...
Any help would be appreciated! | https://forum.pycom.io/topic/1781/pymate-ios-does-not-connect-to-wipy-2-0 | CC-MAIN-2020-40 | refinedweb | 457 | 75.3 |
Sunday, 17 December 2017
Faster toolkit, faster! Part II
This use case is SMILES to SMILES conversion. Now, while this particular transformation might not sound very interesting, it does encompass both SMILES reading and SMILES writing in one handy package, and both of these operations are often important when dealing with databases or datasets of chemical structures. It also exercises several areas of the toolkit such as kekulization, handling of aromaticity, and stereo perception (or not, as we'll see). Canonicalization is also relevant here, but I didn't do any work on that (and it needs some).
To begin with, some timings. To convert 100K ChEMBL molecules from smi to smi took 10m7s with OB 2.4.1. With the current development version it takes 31s. One change to the defaults is that the dev version does not reperceive the stereo. If you turn on stereo perception (-aS), it takes 1m13s. You can speed things up if you also avoid reperceiving the aromaticity (-aa) and read it as provided in the input; then the conversion only takes 19s.
[21 days later] So I was originally going to describe the results from the Visual Studio profiler for this conversion. But then I said, hey, I might as well fix that one, and that one there, and, well, you know how it goes - this part is actually quite fun, when you make a small change and see the speed go up. Anyway, the conversion that used to take 19s, now takes 11.0s. If you're interested, the speedups included things like replacing std::endl by "\n", caching option values, avoiding string copies, avoiding use of stringstream, avoiding SSSR calculation, and using reserve() on vectors. It was often surprising what things appeared high on the list in the profiler. I can see a few more things that could be improved, but I'm going to leave it there for the moment.
So, in summary, this particular conversion has gone from slow to fast, with a speedup of 55x. There's always more that could be done, but it's respectable.
Open Babel in a snap II
To install the stable version use:
sudo snap install openbabel
To install the development version use:
sudo snap install openbabel --channel=edge
You can switch between them with:
sudo snap refresh openbabel --channel=stable # or edge
To see which you have installed, use "snap list", or run "openbabel.obabel" and look at the version number and date.
Notes: I'm using Launchpad to do this. Rather than base it directly off the openbabel master (which would require me to check-in snapcraft specific files), I've set it up so that it runs off a branch (named "snaps") in my own repo. Every so often, I merge master into this and a new snap will be created. To fully automate it, I will need to have a cronjob to do that merge automatically.
Sunday, 1 October 2017
Open Babel in a snap
Maintain.
Saturday, 23 September 2017
How many cheminformaticians does it take to read a SMILES string?
How)
Monday, 28 August 2017
My ACS talk on Kekulization and aromatic SMILES.
Sunday, 23 July 2017
Faster toolkit, faster!
1. Replace slower algorithms with faster algorithms.
This is perhaps the hardest one, as it takes time to get grips with the existing code and figure out whether and where it can be improved. So far the only thing I've done in this line is replace our previous kekulisation procedure with a perfect matching algorithm. Though also, I guess, in this category are the changes I made to replace the original set of SMARTS patterns for aromaticity 'atom-typing' with logic to do the typing directly in code.
2. Streamline existing code.
This can be tedious and doesn't give a big win, but it's a case of avoiding what Roger refers to as Death by a Thousand Cuts. Individually, they don't count for much (and Stack Overflow would have you believe you shouldn't worry about them), but you should think of reading a molecule as the inner loop and consider that it might be done millions of times (e.g. when processing ChEMBL).
In particular, in the context of file format reading and writing, unnecessary string copies are to be avoided. This can be everything from a function that takes a std::string as a parameter, copying part of the input buffer unneccessarily, or concatenating strings with strcat.
3. Avoid unneccesary work by considering the OBMol to be a container for the contents of the file format.
This is a roundabout way of saying that the file format reader should not worry too much about the chemical content of the described molecule and shouldn't spend time checking and validating it. If there's a carbon atom with a +20 charge, fine. If there's a septuple bond between hydrogens, sure, go right ahead. Just read it in and bung it in an OBMol. That's not to say that there isn't a role for validation, but it should be an option as it takes time, may be completely unneccessary (e.g. you have just written out this molecule yourself) and is, strictly speaking, distinct from file format reading.
We already did this to a certain extent, but we didn't follow through completely. If the user said an atom was aromatic, there was no way to preserve this and avoid reperception. This has now been fixed in the current master, and the SMILES reader has an option to preserve aromaticity. Similarly, we currently reperceive stereocenters rather than accept them at face value as present in SMILES for example. This is next on my list of things to change.
Related pull requests:
* Improve performance of element handling
* Improve performance of SMILES parser
* Keep count of implicit hydrogens instead of inferring them
* Change the OBAromTyper from using SMARTS patterns to a switch statement
Image credit:
Renato Carvalho on Flickr
Friday, 5 May 2017
Using WebLogo3 to create a sequence logo from Python
My sequences are peptides, and use lowercase to indicate D forms of the amino acids. So I needed to create my own 'alphabet' as all of those provided by the library uppercase everything. I also wanted to highlight a reference sequence in a particular colour. This is made easy by the RefSeqColor rule, but I needed to override it, as again it wanted to uppercase everything.
import os import StringIO import weblogolib as w class RefSeqColor(w.ColorRule): """ Color the given reference sequence in its own color, so you can easily see which positions match that sequence and which don't. """ def __init__(self, ref_seq, color, description=None): self.ref_seq = ref_seq self.color = w.Color.from_string(color) self.description = description def symbol_color(self, seq_index, symbol, rank): if symbol == self.ref_seq[seq_index]: return self.color baserules = [ w.SymbolColor("GSTYC", "green", "polar"), w.SymbolColor("NQ", "purple", "neutral"), w.SymbolColor("KRH", "blue", "basic"), w.SymbolColor("DE", "red", "acidic"), w.SymbolColor("PAWFLIMV", "black", "hydrophobic") ] protein_alphabet = w.Alphabet('ACDEFGHIKLMNOPQRSTUVWYBJZX*-adefghiklmnopqrstuvwybjzx', []) def plotseqlogo(refseq, mseqs, name): fasta = "> \n" + "\n> \n".join(mseqs) seqs = w.read_seq_data(StringIO.StringIO(fasta), alphabet=protein_alphabet) colorscheme = w.ColorScheme([RefSeqColor(refseq, "orange", "refseq")] + baserules, alphabet = protein_alphabet) data = w.LogoData.from_seqs(seqs) options = w.LogoOptions() # options.logo_title = name options.show_fineprint = False options.yaxis_label = "" options.color_scheme = colorscheme mformat = w.LogoFormat(data, options) fname = "%s.pdf" % name with open(fname, "wb") as f: f.write(w.pdf_formatter(data, mformat)) if __name__ == "__main__": testdata = ["ACDF", "ACDF", "ACDE", "CCDE"] plotseqlogo("ACDF", testdata, "testdata")Notes: The code above writes the logo out to a PDF file, which I subsequently converted to SVG with Inkscape at the commandline:
"C:\Program Files (x86)\Inkscape\inkscape.com" --without-gui --file=fname.pdf --export-plain-svg=svg/fname.svg
Monday, 23 January 2017
Whiskas statistics and the pitfalls of mean rank) | https://baoilleach.blogspot.com/2017/ | CC-MAIN-2018-34 | refinedweb | 1,309 | 56.15 |
- Tool Tips!
- Random LoadMovie
- Transition of alpha via Action Script
- Navigation
- Selecting text from one and transferring to another
- Arrays explanation
- Displaying Time
- loadMovie/loadVariable - solution to browser cache
- Flash 5 E-mail Setup. How can I?
- Popup borderless window
- Random movement through action script
- Loading a Jpg from your web page into flash with PHP
- Determinating Movie Clip speed
- Getting nearest value from an array (arrays again...)
- Preloaders, Rererevisited
- relative mouse movement
- Date objects and arrays (system clock retreival...)
- setproperty
- Menu moving according to mouse position (edited title)
- How To Keep Fonts Clear (edited title)
- Using levels (edited title)
- Difference between eval () and _root[] ?
- PHP - need help
- String manipulation - functions (edited title)
- Submission Tips
- Never have to use buttons again :)
- Help!!! with mouse pos and dynamic text
- checkbox component
- Load movie from remote link
- Tabindex
- Hold for 5 secs!
- multidy arrays and objects
- Question with using Prototypes
- prototype preloader, use it
- Making The Flash Menu Go Awaaay!!!
- Text creation
- Object Model
- I Need Help On Action Scripting
- *New Battle Forum*
- [FMX] indexOf replace words
- Another great a/s dictionary online
- Tutorial: Real time bandwidth-based redirection (PHP)
- Bad Graphic "Jitters"
- MovieClip.onLoad fix
- Useful tutes (not Kirupa)
- forward and backward
- Random Intervals
- ?Google Search?
- gradient fill problem
- Rotating a Vector
- How do I adress instances by variables ?
- XML to TextField
- Tricks of the Trade
- switch ???
- Flash Limits
- HTML/PHP mail Form Tutorial
- Connecting to Dreamweaver MX
- Optimization in Flash MX
- Sending Variables to PHP from Flash And Back again!
- Flash MX: The Things You Might Have Missed
- Protection
- Scroller by Claudio
- Best of Senocular
- Customizing the Photo Gallery Code
- Awesome menu, any ideas?
- Flash Drawing Board (MX)
- Fully Dynamic XML MP3 Player v1.1
- xml menu DONE :)
- AS 2.0 Variable naming hints [Coding efficiency]
- Calendar in Flash MX
- Howd he do this? Resizing slideshow
- Howd he do this? Resizing slideshow
- Dynamicaly changing the registration point of a MC?
- Flashlevel Nav?
- akk any good designers here?
- Scotty's Image Resize Gallery
- Blog/CMS system for Flash/PHP/MySQL
- How big of a problem is email harvesting?
- bitwise NOT operator
- Scrollbars & Code structure - Actionscript 3.0
- break apart movieclip dynamically
- private, public, and inner methods -> using namespaces
- Creating buttons in AS3
- Two Sided 3D Clip | http://www.kirupa.com/forum/archive/index.php/f-12.html | crawl-002 | refinedweb | 375 | 55.54 |
Created on 2013-11-22 16:47 by brett.cannon, last changed 2016-05-12 16:37 by BreamoreBoy. This issue is now closed.
A related addition (Lib/test/test_importlib/test_api.py - test_reload_namespace_changed):
changeset: 86819:88c3a1a3c2ff3c3ab3f2bd77f0d5d5e5c1b37afa
parent: 86816:13a05ed33cf7
user: Eric Snow <ericsnowcurrently@gmail.com>
date: Thu Oct 31 22:22:15 2013 -0600
summary: Issue #19413: Restore pre-3.3 reload() semantics of re-finding modules.
Here's a patch that adds the test. However, the test is failing and my gut's telling me it's a legitimate failure. I'll verify as soon as I have a chance and open a new issue if it is legit (i.e. a regression in 3.4, albeit an unlikely corner case). Thanks for suggesting the test, Nick!
Well, the same patch (modulo adjusting to apply cleanly) fails in exactly the same way in 3.3. So either the test isn't right or namespace packages have never supported reload in this way. I'll keep investigating.
Regarding this issue, keep in mind that namespace packages have a dynamic __path__ which already updates (effectively) when new portions are added to sys.path. So we just need to make sure that reloading does not break that.
To that end, here's a much simpler patch (with passing tests) that verifies that PEP 451 did not break anything here.
Latest patch LGTM. Can we have a patch review please as #18864 is dependent on this.
Do we still need this patch, Eric?
To echo Brett's question, do we still need this patch, Eric?
New changeset c22ec7a45114 by Eric Snow in branch 'default':
Fixes #19711: Add tests for reloading namespace packages.
I've gone ahead and pushed the patch. | https://bugs.python.org/issue19711 | CC-MAIN-2019-18 | refinedweb | 287 | 78.04 |
2012-05-07T06:05:40Z:
- Part I: Hello, World! (this article)
-++. Of all these, the Python/Flask combination is the one that I've found to be the most flexible.
UPDATE: I have written a book titled "Flask Web Development", published in 2014 by O'Reilly Media. The book and the tutorial complement each other, the book presents a more updated usage of Flask and is, in general, more advanced than the tutorial, but some topics are only covered in the tutorial. Visit for more information.
The application
The application I'm going to develop as part of this tutorial is a decently featured microblogging server that I decided to call microblog. Pretty creative, I know.
These are some of the topics I will cover as we make progress with this project:
- User management, including managing logins, sessions, user roles, profiles and user avatars.
- Database management, including migration handling.
- Web form support, including field validation.
- Pagination of long lists of items.
- Full text search.
- HTML templates.
- Support for multiple languages.
- Caching and other performance optimizations.
- Debugging techniques for development and production servers.
- Installation on a production server.
So as you see, I'm going pretty much for the whole thing. I hope this application, when finished, will serve as a sort of template for writing other web applications.
Requirements
If you have a computer that runs Python then you are probably good to go. The tutorial application should run just fine on Windows, OS X and Linux. Unless noted, the code presented in these articles has been tested against Python 2.7 and 3.4.
The tutorial assumes that you are familiar with the terminal window (command prompt for Windows users) and know the basic command line file management functions of your operating system. If you don't, then I recommend that you learn how to create directories, copy files, etc. using the command line before continuing.
Finally, you should be somewhat comfortable writing Python code. Familiarity with Python modules and packages is also recommended.
Installing Flask
Okay, let's get started!
If you haven't yet, go ahead and install Python.
Now we have to install Flask and several extensions that we will be using. My preferred way to do this is to create a virtual environment where everything gets installed, so that your main Python installation is not affected. As an added benefit, you won't need root access to do the installation in this way.
So, open up a terminal window, choose a location where you want your application to live and create a new folder there to contain it. Let's call the application folder
microblog.
If you are using Python 3.4, then cd into the
microblog folder and then create a virtual environment with the following command:
$ python -m venv flask
Note that in some operating systems you may need to use
python3 instead of
python. The above command creates a private version of your Python interpreter inside a folder named
flask.
If you are using any other version of Python older than 3.4, then you need to download and install virtualenv.py before you can create a virtual environment. If you are on Mac OS X, then you can install it with the following command:
$ sudo easy_install virtualenv
On Linux you likely have a package for your distribution. For example, if you use Ubuntu:
$ sudo apt-get install python-virtualenv
Windows users have the most difficulty in installing virtualenv, so if you want to avoid the trouble then install Python 3.4. If you want to install
virtualenv on Windows then the easiest way is by installing
pip first, as explaned in this page. Once
pip is installed, the following command installsvirtualenv`:
$ pip install virtualenv
We've seen above how to create a virtual environment in Python 3.4. For older versions of Python that have been expanded with
virtualenv, the command that creates a virtual environment is the following:
$ virtualenv flask
Regardless of the method you use to create the virtual environment, you will end up with a folder named
flask. But activating a virtual environment is not necessary, it is equally effective to invoke the interpreter by specifying its pathname.
If you are on Linux, OS X or Cygwin, install flask and extensions by entering the following commands, one after another:
$ flask/bin/pip install flask $ flask/bin/pip install flask-login $ flask/bin/pip install flask-openid $ flask/bin/pip install flask-mail $ flask/bin/pip install flask-sqlalchemy $ flask/bin/pip install sqlalchemy-migrate $ flask/bin/pip install flask-whooshalchemy $ flask/bin/pip install flask-wtf $ flask/bin/pip install flask-babel $ flask/bin/pip install guess_language $ flask/bin/pip install flipflop $ flask/bin/pip install coverage
If you are on Windows the commands are slightly different:
$ flask\Scripts\pip install flask $ flask\Scripts\pip install flask-login $ flask\Scripts\pip install flask-openid $ flask\Scripts\pip install flask-mail $ flask\Scripts\pip install flask-sqlalchemy $ flask\Scripts\pip install sqlalchemy-migrate $ flask\Scripts\pip install flask-whooshalchemy $ flask\Scripts\pip install flask-wtf $ flask\Scripts\pip install flask-babel $ flask\Scripts\pip install guess_language $ flask\Scripts\pip install flipflop $ flask\Scripts\pip install coverage
These commands will download and install all the packages that we will use for our application.
"Hello, World" in Flask
You now have a
flask sub-folder inside your
microblog folder that is populated with a Python interpreter and the Flask framework and extensions that we will use for this application. Now it's time to write our first web application!
After you
cd to the
microblog folder, let's create the basic folder structure for our application:
$ mkdir app $ mkdir app/static $ mkdir app/templates $ mkdir tmp
The
app folder will be where we will put our application package. The
static sub-folder is where we will store static files like images, javascripts, and cascading style sheets. The
templates sub-folder is obviously where our templates will go.
Let's start by creating a simple init script for our
app package (file
app/__init__.py):
from flask import Flask app = Flask(__name__) from app import views
The script above simply creates the application object (of class
Flask) and then imports the views module, which we haven't written yet. Do not confuse
app the variable (which gets assigned the
Flask instance) with
app the package (from which we import the
views module).
If you are wondering why the
import statement is at the end and not at the beginning of the script as it is always done, the reason is to avoid circular references, because you are going to see that the
views module needs to import the
app variable defined in this script. Putting the import at the end avoids the circular import error.
The views are the handlers that respond to requests from web browsers or other clients. In Flask handlers are written as Python functions. Each view function is mapped to one or more request URLs.
Let's write our first view function (file
app/views.py):
from app import app @app.route('/') @app.route('/index') def index(): return "Hello, World!"
This view is actually pretty simple, it just returns a string, to be displayed on the client's web browser. The two
route decorators above the function create the mappings from URLs
/ and
/index to this function.
The final step to have a fully working web application is to create a script that starts up the development web server with our application. Let's call this script
run.py, and put it in the root folder:
#!flask/bin/python from app import app app.run(debug=True)
The script simply imports the
app variable from our app package and invokes its
run method to start the server. Remember that the
app variable holds the
Flask instance that we created it above.
To start the app you just run this script. On OS X, Linux and Cygwin you have to indicate that this is an executable file before you can run it:
$ chmod a+x run.py
Then the script can simply be executed as follows:
./run.py
On Windows the process is a bit different. There is no need to indicate the file is executable. Instead you have to run the script as an argument to the Python interpreter from the virtual environment:
$ flask\Scripts\python run.py
After the server initializes it will listen on port 5000 waiting for connections. Now open up your web browser and enter the following URL in the address field:
Alternatively you can use the following URL:
Do you see the route mappings in action? The first URL maps to
/, while the second maps to
/index. Both routes are associated with our view function, so they produce the same result. If you enter any other URL you will get an error, since only these two have been defined.
When you are done playing with the server you can just hit Ctrl-C to stop it.
And with this I conclude this first installment of this tutorial.
For those of you that are lazy typists, you can download the code from this tutorial below:
Download microblog-0.1.zip.
Note that you still need to install Flask as indicated above before you can run the application.
What's next
In the next part of the series we will modify our little application to use HTML templates.
I hope to see you in the next chapter.
Miguel
#1 Alexander Manenko said 2012-05-13T12:45:29Z
Hello, thank you for your article. It is definitely a good starting point for beginner like I am. However, I found one misprint here: >> from Flask import Flask This should be from flask import Flask
#2 Miguel Grinberg said 2012-05-13T15:24:48Z
Alexander, thanks for letting me know, I have corrected the error now.
#3 twrivera said 2012-07-12T20:02:14Z
Good Job!!! Me likes and thx for doing this
#4 drew said 2012-08-23T00:29:42Z
Wounderful, thanks for sharing this.
#5 drew said 2012-09-11T03:53:32Z
You said :"Virtual environments can be activated and deactivated, if desired. An activated environment adds the location of its bin folder to the system path, so that for example, when you type python you get the environment's version and not the system's one. I personally do not like this feature.." Can you explain why?
#6 Miguel Grinberg said 2012-09-11T05:19:18Z
@drew: There is nothing wrong with activating virtualenvs, it's just that the feature does not work for me. I typically need to switch between two or more environments, so I've found that if I get used to having an "active" virtualenv I end up forgetting to activate another one when I need to switch and end up mixing up virtual environments. Once I got used to explicitly invoke the python interpreter I want I stopped making these kinds of mistakes. On Linux/OS X/Cygwin it is really not much different, since the interpreter is in the shebang line of the scripts. Since all my virtualenvs have the same relative path to my scripts I can even copy scripts between projects and the scripts always find the project specific virtualenv.
#7 Alex said 2012-09-30T16:50:49Z
Wonderful tutorial. I keep running into an issue though, Python isn't looking for the modules in the right place. For example, when run.py calls __init__.py, I get "ImportError: No module named flask". I can force it to find flask with sys.path.append(flask_path) but that seems like a crude hack. Is there a better way of managing the environment this module operates in? Maybe some virtualenv setting? I'm working on a Windows XP machine. My folder structure matches my understanding of your structure: \microblog run.py \flask \Include \Scripts \Lib \app \__init__.py \etc.
#8 Miguel Grinberg said 2012-09-30T17:38:41Z
@Alex: I think you must be running the regular Python interpreter instead of the one from the virtual environment. On WinXP you run the run.py script as follows: "flask/Scripts/python run.py" as this ensures that the Flask modules are in the Python module path.
#9 Alex said 2012-09-30T18:10:31Z
You are right! Thank you, I'm new to virtualenv.
#10 Catherine Penfold said 2012-10-29T17:27:22Z
Hi Miguel, so I am starting afresh to try to get things working with the flask-WTF. I have followed your instructions incl 'flask\Scripts\pip install flask-wtf' should this now be visible somewhere. Also ./run.py does not work from the microblog directory, but python run.py does. Should this file be put elsewhere? Thanks, Catherine
#11 Catherine Penfold said 2012-10-29T17:35:57Z
Just another quick note, I think everything installed OK, here's the path to flask_wtf: $ cd/Users/catherine_penfold/Sites/brownie/microblog/flask/lib/python2.7/site-packages/flask_wtf - would be handy to know why the ./run.py command is not working though -thanks
#12 Miguel Grinberg said 2012-10-29T18:12:27Z
Catherine, are you on Windows? You can't run ./run.py on Windows, that syntax is for Unix-like OSes like Linux or Mac OS X. On Windows you should run "flask/Scripts/python run.py", as indicated above in this same article.
#13 Catherine Penfold said 2012-10-30T16:53:35Z
Miguel, I am interested to know what was your motivation in creating this tutorial? Catherine.
#14 Miguel Grinberg said 2012-10-31T05:32:18Z
@Catherine: I'm just writing the kind of tutorial that I would have loved to have found a few years ago when I embarked on my first web project :)
#15 Marcin said 2012-11-01T17:39:59Z
Hi, good art. However I've got not clue how to make to work with some others files. For example have script in file: script.py. where should I put this file?
#16 Miguel Grinberg said 2012-11-01T19:49:53Z
@Marcin: you may want to find a general purpuse Python tutorial that can teach you the basics of dealing with script files. This tutorial is for a specific type of application.
#17 Sanjay Mavinkurve said 2012-11-27T06:33:54Z
run.py should be placed in the microblog directory. I had it in the app directory and it didn't work.
#18 Miguel Grinberg said 2012-11-27T06:50:42Z
@Sanjay: yes, that's correct. Note that your current directory should be microblog when working on the app. All the pathnames I show are relative to that path. Any filenames that have no path (like run.py) should be located in the current directory.
#19 Edwin said 2012-12-14T14:21:36Z
I am having an issue with the number of parameters for __init___, and couldn't really find the problem. I was just going to start the "Unit testing framework" part, but before I wanted to test the page and when I try to edit my profile it gets me this error: arguments%20%281%20given%29%20%20%20%20Werkzeug%20Debugger.html Thanks.
#20 Miguel Grinberg said 2012-12-23T00:02:20Z
@Edwin: you will need to look in the stack trace that you get to find out exactly what part of the application is calling this __init__ function with less arguments than necessary.
#21 Gator said 2012-12-28T21:47:14Z
First, thanks for this tutorial. I find the documentation pretty good for Flask, but your tutorial is much more digestable for a newbie. When I try to use the script to activate the webserver, I am getting this message: -bash: ./run.py: flask/bin/python: bad interpreter: No such file or directory When I run it using "python run.py", I get: Traceback (most recent call last): File "run.py", line 2, in <module> from app import app ImportError: No module named app I think my folder structure is not like yours, if the previous commenter is correct. My app structure looks like this: microblog > app > __init__.py | run.py | views.py
#22 Guilherme Rezende said 2012-12-30T01:49:18Z
Good post Miguel!! About virtualenv, you tried virtualenvwrapper? you use command 'workon' to switch between enviroments. Best regards
#23 Miguel Grinberg said 2012-12-31T17:51:07Z
@Gator: did you setup a virtualenv as indicated in the article? The error suggests you don't have it setup as indicated. Please review the section above titled "Installing Flask".
#24 Adam said 2013-01-04T17:08:20Z
Hi i have done everything as sad but when i run the run.py in the scrips directory i get the following error im using windows 7 ImportError: No module named app. thank you for the tutorial
#25 Miguel Grinberg said 2013-01-05T03:54:43Z
@Adam: your current directory should always be the one where run.py is. At this level you should also have a flask directory with the virtual environment. To run the application on Win7 you have to issue "flask\Scripts\Python run.py" in the command line prompt. | http://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-i-hello-world | CC-MAIN-2015-27 | refinedweb | 2,859 | 64.51 |
Commit 8c41b3dc: Vigil Base Solution— Rovani in C♯
I’ve finally done it; I finally ripped, twisted, and otherwise cajoled the default MVC template, Identity code, and a few other tweaks I wanted to make into something I am semi-confident will be a good starting point for future projects. Which is really to say ? I’m at a stopping point and I’ll probably burn it all to the ground, tomorrow.
The Best Things In Life Are Passed Tests
Sometimes, the best thing that can happen in my day is that all of the unit tests pass. Not just once, due to some odd coincidence with timing, but because they actually, legitimately pass. I am sure that veterans of Test Driven Development will scoff at a lot of these tests. However, it was fun to learn how to use xUnit and Moq. Previously, I had been determined that I was going to be able to write my tests without using external libraries. I was just going to extend the different classes that depend on external resources and change them all to work in memory. This was stupid, time consuming, and generally fraught with errors. My tipping point was when I realized I was writing tests for these Test classes.
How awful is that?
I chose xUnit and Moq because they seemed to be the most popular. The primary difficulty that I have with mocking at this point are extension methods. Since I cannot mock a non-virtual member, mocking the extension classes is impossible. Thus, I need to find the source code, figure out exactly what the extension method is doing, and properly mock whatever method is used internally. It was a frustrating set of investigations, but I did enjoy digging into the internals of Identity and Katana.
Tests that Cover Code
It feels like half of my tests are in place just to improve my Code Coverage percentages. Even with that, there are two sticking points that I am having trouble getting over. The first are some the set portion of automatic properties in my Identity and TypeBase abstract classes. I have searched high and low and cannot find a solution to this. I am hoping that as I inherit from these classes, tests on those new classes will happen to start covering these properties.
The second part is managing to get the MoveNext() method to register as covered. It’s a pain to get Code Coverage with Async Await, but Dwayne Need’s blog post was very informative. It will be a while before I worry about getting that in depth with the code coverage that I will need to put all this work together for what amounts to no (seemingly) real gain.
Another “close enough” for Code Analysis
Most issues that the utility would flag were ones that I was able to fix. Rules like “CA1063 Implement IDisposable correctly” and “CA2000 Dispose object before losing scope” are easy to correct. The two rules that I completely turned off were “CA1056 URI properties should not be strings” and “CA1062 Validate arguments of public methods”. The former, because it was a monumental pain to convert everything in my code to URIs, but return them back to strings when sending them to different frameworks; the later, because it did not account for Code Contracts.
The final block of rules that I am ignoring for now are “CA1020 Avoid namespaces with few types” and “CA1704 Identifiers should be spelled correctly”. CA1020 is a valid notice, but the project is still in its infancy and namespaces are going to be sparce. CA1704 is flagging the words “Owin” and “POST”, even though both of them are in my CustomDictionary.xml file, located in each project. I’m sure I’ll stumble on a fix for this at some point.
Code Coverage is down to only missing the .MoveNext() method calls.
Code Analysis is reduced to just “POST” and “Owin” identifier issues and Avoid namespaces with few types.
All tests are passing. Stamping this as the first official branch.
—Commit 8c41b3dc782066e2c03d51633dc7e65e3df3d924 | https://rovani.net/Commit-8c41b3dc/ | CC-MAIN-2018-47 | refinedweb | 678 | 71.04 |
In a programming language like C++, inheritance is one of the core ideas of Object-Oriented program.
In inheritance, the derived class inherits the behaviors and attributes of its base class.
In our earlier examples, we have built a Rock class and a Country class. In a way, pop or rock are just a genre in music.
We can understand pop or rock as a subclass of music. So in an object-oriented program, we can build a base class called Music and another 2 derived classes called Pop or Rock.
Consider the following example.
#include <cstdlib> #include <iostream> using namespace std; // Base class class Music { public: void setSinger(string s) { singer = s; } void setTitle(string t) { title = t; } protected: string singer; string title; }; // Derived class class Rock : public Music { public: int Display() { cout << singer << " singing " << title; return 0; } }; class Pop : public Music { public: int Show() { cout << singer << " top 10 hit " << title; return 0; } }; int main(void) { Rock rock; rock.setSinger("Rod Stewart"); rock.setTitle("I Was Only Joking"); cout << rock.Display() << endl; Pop pop; pop.setSinger("Taylor Swift"); pop.setTitle("Blank Space"); cout << pop.Show() << endl; return 0; }
In line 19, we have declared 2 data members as protected. This will allow them to be accessed by its derived class Rock or Pop. | https://codecrawl.com/2015/01/30/cplusplus-inheritance/ | CC-MAIN-2019-43 | refinedweb | 214 | 66.44 |
Thanks.
BEGIN {
my ($var1, $var2) = ("this", "that");
sub sub1 {
# use $var1, $var2
}
sub sub2 {
# use $var1, $var2
}
}
[download]
This
use vars qw($var1 @array2};
[download]
Sorry to nitpick but you can do either this:
or this:
but using a comma within a qw() list includes the comma in whatever word(s) it touches.
Other than that, ++!
sub MyFunc {
local $" = shift;
my @list = @_;
print "@list\n";
} # MyFunc
[download]
Best regards,
perl -e "print a|r,p|d=>b|p=>chr 3**2 .7=>t and t"
Only declare variables when you need them. If you need a loop variable, don't declare it away at the beginning of the routine or (horrors!) at the top of the file. Just declare it where you're gonna need it, like this:
for ( my $Index = 0; $Index < 5; $Index++ )
{
... # code here that uses $Index
}
[download]
{ # Start black of code
..
..
{ # Start another block of code
my ( $Index, $NodeNumber );
..
..
}
..
..
}
[download]
--t. alex
"Of course, you realize that this means war." -- Bugs Bunny.
Hmm...I think you meant to say C++ here. C doesn't give you that kind of flexibility; however, C++ does.
metadoktor
"The doktor is in."
#include <stdio.h>
int main ( int iArgC, char * apsqArgV[] )
{
printf ( "Hello, world! This is cygwqin speaking.\n" );
{
char szMsg[] = "Not so!";
printf ( "Now inside scope, msg is %s.\n", szMsg );
}
return ( 0 ); // Success is zero in Windows.
}
[download]
You may have been talking about the following:
void FooBar ( void )
{
int iBeer, iVodka;
float fCredit = 20.0;
.. /* Code here */
iBeer++;
fCredit -= 2.50;
.. /* More code */
char *apszVarious[]; /* ILLEGAL in C */
}
[download]'... | http://www.perlmonks.org/index.pl?node=using%20strict%20and%20functions | CC-MAIN-2015-06 | refinedweb | 263 | 85.08 |
Pandas: Create a sequence of durations increasing by an hour
Pandas Time Series: Exercise-11 with Solution
Write a Pandas program to create a sequence of durations increasing by an hour.
Sample Solution:
Python Code :
import pandas as pd date_range = pd.timedelta_range(0, periods=49, freq='H') print("Hourly range of perods 49:") print(date_range)
Sample Output:
Hourly range of perods 49: TimedeltaIndex(['0 days 00:00:00', '0 days 01:00:00', '0 days 02:00:00', '0 days 03:00:00', '0 days 04:00:00', '0 days 05:00:00', '0 days 06:00:00', '0 days 07:00:00', '0 days 08:00:00', '0 days 09:00:00', '0 days 10:00:00', '0 days 11:00:00', '0 days 12:00:00', '0 days 13:00:00', '0 days 14:00:00', '0 days 15:00:00', '0 days 16:00:00', '0 days 17:00:00', '0 days 18:00:00', '0 days 19:00:00', '0 days 20:00:00', '0 days 21:00:00', '0 days 22:00:00', '0 days 23:00:00', '1 days 00:00:00', '1 days 01:00:00', '1 days 02:00:00', '1 days 03:00:00', '1 days 04:00:00', '1 days 05:00:00', '1 days 06:00:00', '1 days 07:00:00', '1 days 08:00:00', '1 days 09:00:00', '1 days 10:00:00', '1 days 11:00:00', '1 days 12:00:00', '1 days 13:00:00', '1 days 14:00:00', '1 days 15:00:00', '1 days 16:00:00', '1 days 17:00:00', '1 days 18:00:00', '1 days 19:00:00', '1 days 20:00:00', '1 days 21:00:00', '1 days 22:00:00', '1 days 23:00:00', '2 days 00:00:00'], dtype='timedelta64[ns]', freq='H')
Python Code Editor:
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
Previous: Write a Pandas program to create a time series using three months frequency.
Next: Write a Pandas program to convert year and day of year into a single datetime column of a dataframe. | https://www.w3resource.com/python-exercises/pandas/time-series/pandas-time-series-exercise-11.php | CC-MAIN-2021-21 | refinedweb | 364 | 53.72 |
Same here. It's easy. I use it mostly for the battery status. It's the only red value on my mirror, at least, when they're almost drained.
hetbeest
@hetbeest
Best posts made by hetbeest
Latest posts made by hetbeest
- RE: Magic mirror
- RE: Sensebender Micro
I ordered another couple a few days ago.
- RE: Sensebender Micro
In Domoticz I also see sensors hemidity and sensors temperature with the type LaCrosse TX3. Does anyone know what they are?
- RE: Sensebender Micro
My two have arrived, up and running in Domoticz as WTGR800 temp + hum.
- RE: Sensebender Micro
Same here
- RE: Sensebender Micro
Just ordered two to start with
- RE: Sensebender Micro
Does it need a FTDI USB to TTL Serial Adapter to upload sketches?
- RE: IR distance sensor usage?
I did some quick coding, combining it with a temperature sensor. It did work for a couple of hours, after that my 9V battery was drained so far that I didn't get any data send from the sensors anymore. Quite likely the IR sensor uses a lot of power while it keeps transmitting IR. Anyhow, my quick and dirty code is:
// Example sketch showing how to send in OneWire temperature readings
#include <MySensor.h>
#include <SPI.h>
#include <DallasTemperature.h>
#include <OneWire.h>
#include <DistanceGP2Y0A21YK.h>
#define ONE_WIRE_BUS 3 // Pin where dallase sensor is connected
#define MAX_ATTACHED_DS18B20 16
#define CHILD_ID_DISTANCE 25
DistanceGP2Y0A21YK Dist;
unsigned long SLEEP_TIME = 500; //;
int distance;
int lastDistance=0;
int loopCounter=0;
int loopsBetweenTemp = 60;
// Initialize temperature message
MyMessage msg(0,V_TEMP);
MyMessage msgdist(CHILD_ID_DISTANCE,V_DISTANCE);
void setup()
{
// Startup OneWire
sensors.begin();
Dist.begin(0);
// Startup and initialize MySensors library. Set callback for incoming messages.
gw.begin();
// Send the sketch version information to the gateway and Controller
gw.sendSketchInfo("Temperature and Distance Sensor", "1.0");
gw.present(CHILD_ID_DISTANCE,S_DISTANCE);
//();
distance = Dist.getDistanceCentimeter();
if (distance != lastDistance) {
lastDistance = distance;
gw.send(msgdist.set(distance));
}
if (loopCounter == 0) {
// Fetch temperatures from Dallas sensors
sensors.requestTemperatures();
// (lastTemperature[i] != temperature && temperature != -127.00) { // Send in the new temperature gw.send(msg.setSensor(i).set(temperature,1)); lastTemperature[i]=temperature; } }
}
if (++loopCounter >= loopsBetweenTemp) loopCounter = 0;
gw.sleep(SLEEP_TIME);
}
- RE: IR distance sensor usage?
Thanks. I'll have a look and surely will post my version.
- IR distance sensor usage?
Hi all,
I'm pretty new to mysensors, although I read a lot. I bought an IR distance sensor, the Sharp GP2Y0A21YK0F GP2Y0A21 10~80cm Infrared Proximity Distance Sensor, but I don't know how to connect it? Anyone any idea? Maybe also an example sketch?
Thanks,
Evert | https://forum.mysensors.org/user/hetbeest/ | CC-MAIN-2021-04 | refinedweb | 425 | 51.75 |
# PVS-Studio Learns What strlen is All About

Somehow, it so happens that we write about our diagnostics, but barely touch upon the subject of how we enhance the analyzer's internal mechanics. So, for a change, today we'll talk about a new useful upgrade for our data flow analysis.
How It Started: a Tweet from JetBrains CLion IDE
------------------------------------------------
A few days ago I saw a post from JetBrains about new features offered by CLion's built-in static analyzer.
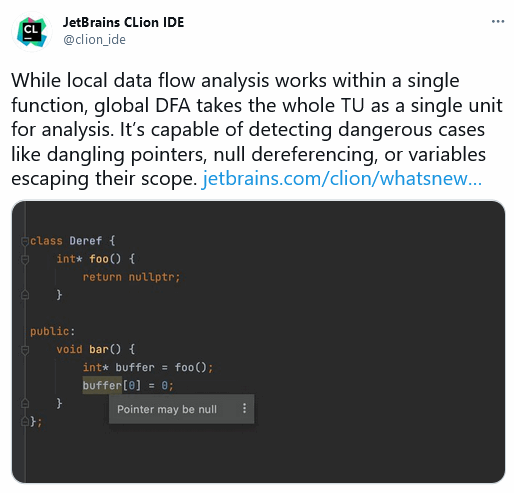
Since we are soon planning to release the PVS-Studio plugin for CLion, I could not just ignore their announcement! I had to point out that PVS-Studio is also powerful. And that the PVS-Studio plugin for CLion can find even more mistakes.
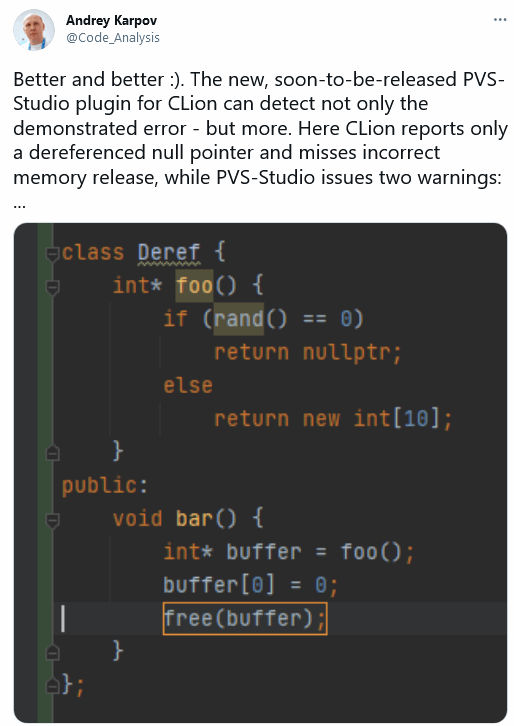
So I had a nice little chat with JetBrains:
* [This, you can find with clang-analyzer](https://twitter.com/clion_ide/status/1382313594033946629);
* [And this, you can not](https://twitter.com/Code_Analysis/status/1382325263380398083) :)
I pondered this all for a little bit. Very nice! They enhanced their data flow analysis and told the world about it. We are no worse! We're always enhancing the analyzer's engine — including that very data flow analysis mechanics. So here I am, writing this note.
What's up with Our Data Flow
----------------------------
One of our clients described an error that PVS-Studio unfortunately failed to find. A couple of days ago we upgraded the analyzer so that it can find this error. Sometimes, in case of an overflow, the analyzer got confused with unsigned variable values. The code that caused the problem looked something like this:
```
bool foo()
{
unsigned N = 2;
for (unsigned i = 0; i < N; ++i)
{
bool stop = (i - 1 == N);
if (stop)
return true;
}
return false;
}
```
The analyzer could not understand that the *stop* variable was always assigned the *false* value.
Why *false*? Let's do a quick calculation:
* the variable's value range is *i = [0; 1]*;
* *the* expression's possible result *is i-1 = [0; 0] U [UINT\_MAX; UINT\_MAX]*;
* the N variable equals two and falls beyond the *{ 0, UINT\_MAX } set;*
* the expression is always false.
**Note.** There is no undefined behavior here, because numbers are overflown (wrapped) when you work with an unsigned type.
Now we have taught PVS-Studio to process these expressions correctly and to issue an appropriate warning. Interestingly, this change led to other improvements.
For example, the initial change caused false positives related to string length processing. While fighting them, we introduced more enhancements and taught the analyzer about functions like *strlen* — how and why they are used. Now I'll go ahead and show you the analyzer's new abilities.
There is an open-source project test base that we use for our core's regression testing. The project test base contains the [FCEUX](https://github.com/TASVideos/fceux) emulator. The upgraded analyzer found an interesting error in the Assemble function.
```
int Assemble(unsigned char *output, int addr, char *str) {
output[0] = output[1] = output[2] = 0;
char astr[128],ins[4];
if ((!strlen(str)) || (strlen(str) > 0x127)) return 1;
strcpy(astr,str);
....
}
```
Can you see it? To be honest, we did not notice it immediately and our first thought was, "Oh no, we broke something!" Then we saw what was up and took a minute to appreciate the advantages of static analysis.
PVS-Studio warned: V512 A call of the 'strcpy' function will lead to overflow of the buffer 'astr'. asm.cpp 21
Still don't see the error? Let's go through the code step by step. To start with, we'll remove everything irrelevant:
```
int Assemble(char *str) {
char astr[128];
if ((!strlen(str)) || (strlen(str) > 0x127)) return 1;
strcpy(astr,str);
....
}
```
The code above declares a 128-byte array. The plan is to verify a string and then pass it to the *strcpy* function that copies the string to the array. The string should not be copied if it is empty or contains over 127 characters (not counting the terminal zero).
So far, all is well and good, right? Wait, wait, wait. What do we see here? What kind of a constant is **0x127**?!
It's not 127 at all. Far from it!
This constant is set in hexadecimal notation. If you convert it to decimal, you get 295.
So, the code above is equivalent to the following:
```
int Assemble(char *str) {
char astr[128];
if ((!strlen(str)) || (strlen(str) > 295)) return 1;
strcpy(astr,str);
....
}
```
As you can see, the *str* string check does not prevent possible buffer overflows. The analyzer correctly warns you about the problem.
Previously, the analyzer could not find the error. The analyzer could not understand that both *strlen* function calls work with the same string. And the string does not change between them. Although things like this one are obvious to developers, this is not the case for the analyzer. It needs to be taught expressly.
Now PVS-Studio warns that the *str* string length is in the [1..295] range, and thus may exceed the array bounds if copied to the *astr* buffer.

New Challenges
--------------
The error above also exists in the FCEUX project's current code base. But we will not find it, because now the string's length is written to a variable. This breaks the connection between the string and its length. For now, the analyzer is oblivious to this error in the code's new version:
```
int Assemble(unsigned char *output, int addr, char *str) {
output[0] = output[1] = output[2] = 0;
char astr[128],ins[4];
int len = strlen(str);
if ((!len) || (len > 0x127)) return 1;
strcpy(astr,str);
....
}
```
This code is easy for a human to understand. The static analyzer, however, has a difficult time tracking values here. It needs to know that the *len* variable represents the *str* string's length. Additionally, it needs to carefully track when this connection breaks. This happens when the *len* variable or the string contents are modified.
So far, PVS-Studio does not know how to track these values. On the bright side, now here's one more direction to grow and develop! Over time, the analyzer will learn to find the error in this new code as well.
By the way, the reader may wonder why we analyze projects' old code and do not upgrade the test projects regularly. It's simple, really. If we update the test projects, we won't be able to perform regression testing. It will be unclear what caused the analyzer to behave differently — the analyzer's or the test projects' code changes. This is why we do not update open-source projects we use for testing.
Of course, we need to test the analyzer on modern code written in C++14, C++17 etc. To do this, we add new projects to the database. For example, one of our recent [additions](https://pvs-studio.com/en/b/0770/) was a header-only C++ library collection ([awesome-hpp](https://github.com/p-ranav/awesome-hpp)).
Conclusion
----------
It's always interesting and useful to enhance data flow analysis mechanisms. Do you think so too? Do you want to know more about how static code analysis tools work? Then we recommend you read the following articles:
1. [The Code Analyzer is wrong. Long live the Analyzer!](https://pvs-studio.com/en/b/0779/)
2. [False Positives in PVS-Studio: How Deep the Rabbit Hole Goes](https://pvs-studio.com/en/b/0612/)
3. [Technologies used in the PVS-Studio code analyzer for finding bugs and potential vulnerabilities](https://pvs-studio.com/en/b/0592/)
4. [Machine Learning in Static Analysis of Program Source Code](https://pvs-studio.com/en/b/0706/)
On a final note, I invite you to [download](https://pvs-studio.com/en/pvs-studio-download/) the PVS-Studio analyzer and check your projects. | https://habr.com/ru/post/554692/ | null | null | 1,373 | 58.79 |
At present, there is unprecedented interest in the construction of various flying mechanisms – drones, gliders, helicopters, etc. Now it is easy to construct them yourself thanks to many materials on them on the Internet. All these flying mechanisms use for their movement so-called brushless (brushless DC motors). What are such motors? Why are they now used in various flying drones? How to correctly buy such a motor and connect it to a microcontroller? What is ESC, and why will we use it? The answers to all these questions you will find in this article.
This article will look at controlling the speed of a Sensorless BLDC outrunner motor (A2212/13T), often used in drone construction, using an ESC (Electronic Speed Controller) and an Arduino board.
How Brushless (BLDC) Motors Work
BLDC motors are now often used in ceiling fans and electric moving vehicles because of their smooth rotation. Unlike other DC motors, BLDC motors are connected with three wires coming out of them, with each wire forming its own phase, which means you get a three-phase motor.
Although BLDC motors are DC motors, they are controlled by a pulse sequence. The ESC (Electronic Speed Controller) is used to convert the DC voltage into a pulses sequence and distribute them over the three leads. At any one time, only two phases are energized, i.e., the electric current enters the motor through one phase and leaves it through the other. During this process, the coil inside the motor is energized, causing the magnets to align with the energized coil. The ESC controller then energizes the other two wires (phases), and this process of changing the wires that are energized continues continuously, causing the motor to rotate. The speed at which the motor rotates depends on how quickly power is applied to the motor coil, and the direction of rotation depends on the order in which the phases that are alternately energized are swapped.
There are different types of BLDC motors – let’s look at the main ones. There are Inrunner and Outrunner BLDC motors. In Inrunner motors, the rotor magnets are inside the stator with windings, while in OutRunner motors, the magnets are outside and rotate around a stationary stator with windings. That is, in the Inrunner (most DC motors are designed according to this principle), the axis inside the motor rotates, and the shell remains stationary. In the OutRunner, the motor itself rotates around the axis with the coil, which remains stationary. OutRunner motors are particularly useful for electric bicycle applications because the motor’s outer shell directly drives the bicycle wheel, eliminating the need for a clutch mechanism. OutRunner motors provide more torque, making them also the ideal choice for electric propulsion and drone applications. This article will also be looking at connecting an OutRunner type motor to an Arduino board.
Note: there is also a BLDC motor type called coreless, which is used in “pocket drones.” These motors work on slightly different principles, but it is beyond the scope of this article to review the principles of their operation.
There are BLDC motors with sensors and without sensors. For BLDC motors, which rotate smoothly, without jerks, feedback is necessary. Therefore, the ESC controller must know the positions and poles of the rotor magnets in order to power the stator correctly. This information can be obtained in two ways: the first is by placing a Hall sensor inside the motor. The Hall sensor will detect the magnet and send this information to the ESC controller. This type of motor is called Sensor BLDC and is used in electric moving vehicles. The second method of detecting the magnets’ position is by using the inverse EMF (electromotive force) generated by the coils while the magnets are crossing them. The advantage of this method is that it does not require the use of any additional devices (Hall sensor) – the phase wire itself is used as feedback due to the presence of the inverse EMF. This method is used in the motor discussed in our article, and it is the one most often used in drones and other flying devices.
Why Do Drones and Helicopters Use BLDC Engines?
There are many different types of drones now – two-bladed, four-bladed, etc. But they all use BLDC engines. Why BLDC motors, since BLDC motors are more expensive than conventional DC motors?
There are several reasons for this:
- High torque, which is very important to get the flying vehicle off the ground;
- these motors are available in OutRunner format, which does away with the clutch in the drone design;
- low level of vibration during operation, which is very important for the drone to hover still in the air;
- a good power-to-weight ratio of the motor. This is very important for use on flying mechanisms so that all elements of its design have as little weight as possible. A normal DC motor that provides the same torque as a BLDC motor will be at least twice as heavy as a BLDC motor.
Why Do You Need an ESC Controller?
As we already know, BLDC motors require some kind of controller to function, which converts the DC voltage from the battery into a sequence of pulses applied in a specific order to the motor wires (phases). This controller is called ESC (Electronic Speed Controller). This controller’s main responsibility is to properly supply power to the BLDC motor wires so that the motor rotates in the correct direction. This is done by reading the back EMF from each wire and supplying power to the coil as the magnet crosses it. Internally the ESC controller contains quite a lot of different electronics, and if you wish, you can study its construction in detail on the appropriate materials on the Internet. Here we will take a brief look at only the basic components of its design.
The speed control is based on PWM (Pulse-width modulation). The ESC controller can control the BLDC motor’s speed by reading the PWM signal from its orange wire. It is very similar to a servo motor. The PWM signal sent to the ESC controller must have a period of 20ms, and the fill factor of this PWM signal will determine the rotation speed of the BLDC motor. Since exactly the same principle is used to control the servo motor’s angle of rotation, we can use the library to control the BLDC motor. If you have not encountered this principle before, you can read an article about connecting a servo motor to an Arduino board.
Battery Eliminator Circuit (BEC) is a battery eliminator circuit. Almost all ESC controllers come with this circuit. As the name suggests, this circuit eliminates the need for a separate battery to power the microcontroller, meaning that in this case, we don’t need a separate power supply for the Arduino board – the ESC controller itself will provide the Arduino board with a regulated +5V supply voltage. Different ESC controllers use different circuits to regulate this voltage, but a linearly regulated circuit is common in most cases.
Firmware. Each ESC controller contains in its ROM a built-in application program written by the manufacturer of the controller. This program largely determines the logic of the controller operation. The most popular firmware for ESC controllers are Traditional, Simon-K and BL-Heli. The user can change this program, but we will not discuss this issue in this article.
Some Terms Used in the Subject of BLDC and ESC
When studying BLDC motors and ESC controllers’ principles, you may come across some of the terms used in this topic. Let’s briefly review the main of these terms.
Braking – determines how fast a BLDC motor can stop its rotation. This is especially relevant for flying vehicles (drones, helicopters, etc.) because they have to frequently change the number of engine revolutions per minute to maneuver in the air.
Soft Start – this ability is especially important for BLDC engines when the torque from the engine to the actuator (wheel, propeller, etc.) is transmitted through a gear mechanism, usually consisting of gears. A soft start means that the motor will not start rotating at maximum speed immediately but will gradually increase its speed, regardless of the speed at which the actuating torque builds up. A soft start greatly reduces the wear and tear on the gears in the gear train.
Motor Direction – Normally, the direction of rotation of BLDC motors does not change during operation. However, during the assembly and testing of the product, it may be necessary to change motor rotation direction. Usually, this can be done by simply reversing any two motor wires.
Low Voltage Stop. Normally BLDC motors are calibrated, so that rotation speed is constant for the same level of actuation. However, this is difficult to achieve because the voltage of the battery supply decreases over time. To prevent this, the ESC controllers are usually programmed to stop the BLDC motor when the battery voltage drops below a certain limit. This feature is especially useful when using BLDC motors in drones.
Response time – Refers to the motor’s ability to quickly change rotation speed when the control action changes. The lower the response time, the better the motor control.
Advance. This problem is a kind of “Achilles’ heel” for brushless motors. All BLDC engines have at least a small similar bug. This problem is caused by the fact that when the stator coil is energized, the rotor moves forward because there is a permanent magnet on it. And when the control voltage is removed from that coil (to feed it to the next coil), the rotor moves forward a bit farther than the motor logic allows. This unwanted advance of the motor is called “Advance” in the English-language literature and can lead to unwanted vibrations, heat, and noise when the motor is running. Therefore, good ESC controllers try, if possible, to eliminate this effect in BLDC motor operation.
Circuit Operation
The wiring diagram of the BLDC motor and the ESC controller to the Arduino board is shown in the following picture.
As you can see, the circuit is quite simple. The ESC controller needs a power supply with 12V and at least 5A current. You can use an adapter or a Li-Po battery to power the circuit. The three phases (wires) of the BLDC motor must be connected to the three output wires of the ESC controller – no matter what order.
The BEC (Battery Eliminator circuit) in the ESC controller will provide (regulate) a +5V DC voltage on its own so that it can be used directly to power the Arduino board. The circuit uses a potentiometer connected to pin A0 of the Arduino board to control the motor’s speed.
The appearance of the assembled construction is shown in the following picture.
Explanation of the Arduino Program
The complete code of the program is given at the end of the article. Here we will only look at the main parts.
To control the BLDC motor, we will form a PWM signal with a frequency of 50 Hz and a variable from 0 to 100% duty cycle. A potentiometer will control the fill factor value. That is, by turning the potentiometer, we will control the speed of the motor. As already mentioned, controlling a BLDC motor is very similar to controlling a servo motor with 50 Hz PWM, so in this case, we will use the same library we used to control the servo motor. Suppose you are a beginner in learning the Arduino platform. In that case, we recommend you study PWM signal generation’s principles in Arduino and the connection of the servomotor to the Arduino board before reading this article further.
The PWM signal can only be generated on the Arduino board’s digital pins, which are marked with the
~ symbol. In our circuit, we will control the ESC controller from pin 9 of the Arduino board, so with the following command, we will attach the ESC controller to this pin:
ESC.attach(9);
The PWM fill factor (0 to 100%) is controlled by the position of the potentiometer knob. So when we have 0V on the potentiometer output (0 on the ADC output), we will have a fill factor of 0, and when we have 5V on the potentiometer output (1023 on the ADC output), we will have a PWM fill factor of 100%. So we will use a function that will read the value from the ADC output of pin A0.
int throttle = analogRead(A0);
Then we have to convert this value (it will be in the range of 0 to 1023) to a range of 0 to 180. A value of 0 will be 0% PWM fill factor, and a value of 180 will be 100% PWM fill factor. The conversion of the value from the range 0-1023 to the range 0-180 will be done using the function:
throttle = map(throttle, 0, 1023, 0, 180);
Next, we have to pass this value to the motor control function to generate the appropriate PWM signal on the contact we need. Since we gave our servo object the name ESC, the command to control it will look like this:
ESC.write(throttle);
Testing How the Circuit Works
Make all the necessary connections in the circuit, load the program into the Arduino board, and power up the ESC controller. Make sure that your BLDC motor is securely mounted. Otherwise, it will bounce while spinning. When you apply power to the ESC controller, you will hear a greeting tone, and it will make this sound until a control signal of the set level (within the specified limits) is received. Start turning the potentiometer knob gradually until the potentiometer output voltage is different than 0, and the sound will stop. This means you have given the minimum allowable level signal to the PWM controller. As you turn the potentiometer knob further, the motor will start to rotate slowly. As you turn the potentiometer knob further and increase the voltage at its output, the speed of the motor will increase. When the voltage reaches the upper allowable limit, the motor will stop. Afterward, you can repeat the whole process again.
The Source Code of the Program (Sketch)
#include <Servo.h> //use the servo library to generate the PWM signal Servo ESC; //name our servo object. In our case, it will be the name of ESC void setup() { ESC.attach(9); //"attach" the ESC controller to pin 9 of the Arduino board } void loop() { int throttle = analogRead(A0); //read voltage from the potentiometer output throttle = map(throttle, 0, 1023, 0, 180); //convert the values from the range 0-1023 from the ADC output into the range 0-180 because servomotors can only operate in the range 0-180 ESC.write(throttle); //generate PWM signal with necessary filling ratio }
If you have any questions about this program’s source code, you can ask them in the comments of this article. | https://nerdytechy.com/arduino-brushless-motor-control-tutorial/ | CC-MAIN-2021-31 | refinedweb | 2,506 | 60.75 |
My solution is here:
Can anyone explain, why is my solution wrong?
I have seen other’s accepted solution. The logic is same.
Please help me out!!
My solution is here:
Can anyone explain, why is my solution wrong?
I have seen other’s accepted solution. The logic is same.
Please help me out!!
You were not printing string for different test cases in different lines. You forgot to use
print(end="\n") after each test case loop.
Because you are not printing the answer on newline.
Updated Source-Code:
t = int(input().strip()) for _ in range(t): n, k = map(int, input().strip().split()) li = list(map(int, input().strip().split())) for i in li: if i % k == 0: print("1", end = "") else: print("0", end = "") print()
newline missing for every test case
Thank you!!
you forgot to add print() after the end of for loop
The problem with this one?
#include
using namespace std;
int main() {
// your code goes here
int t;
cin>>t;
while(t–)
{
long long int n,k;
cin>>n>>k;
long long int d[n];
for(int i=0;i<n;i++) { cin>>d[i]; if(d[i]%k==0) cout<<1; else cout<<0; }
cout<<endl;
} return 0;
}
plz tell error of my code plzz its giving tle
Format your code first as the forum software has messed it up. | https://discuss.codechef.com/t/chefstep-help-needed/73041 | CC-MAIN-2020-40 | refinedweb | 228 | 77.03 |
Design for Sign-Up: How to Motivate People To Sign Up For Your Web App
Date: May 30, 2008
You've got about eight seconds to convince a person to become your customer online. Usability expert Joshua Porter tells you how to make every second count in this excerpt from his new book, Designing for the Social Web.
- .
The Sign-up Hurdle
Once you have people interested, the next major challenge is to convince those interested people to actually sign up to use your software for the first time.
Figure 4.2 The hurdle of sign-up separates those interested in your software from those using it. This transition is marked by lots of questions and a need to clearly explain the benefits of use.
The importance of this step cannot be understated. It is crucial for several reasons:
- The first, and lasting, impression. The first impression someone has of your software is your best chance to start a person down the road of becoming a loyal user. If you lose someone in this initial transaction, they're very unlikely to return, having convinced themselves that your application isn't worth using.
- All questions, few answers. At this stage people have the most questions of all, and in answering those questions you can use the the opportunity to tell the story of your software.
- Potential to kinetic energy. At this stage people are getting ready to take their first actual steps in using your software. It's a big deal to change from the potential energy of being interested in software to the kinetic energy of actually using it.
- Critical choice. If you make a living through your web application (and many of us do), the choice people are making of whether or not to use your software is anything but trivial. They're choosing to either start a relationship with you or have it with someone else. This will undoubtedly affect your future in a big way. Therefore, it is serious business.
Different Strokes for Different Folks
Each person who visits your web application has their own agenda: they're trying to do something specific. While we don't always know what that something is, we can identify recurring roles that seem to crop up again and again. Here are some roles to watch out for:
- Ready to Go. This is the role most people design for. This is the role we hope for. These people are ready to start using your application. The key to designing for them is to get out of their way. They're already convinced your software is worth trying, so make it as easy as possible to sign up by eliminating usability problems and unnecessary friction in the interface.
- Interested but Unsure. These people are interested in your software but are unsure if it is for them. There are a lot of these people. They need to be reassured they're making the right decision in trying your software. They have specific questions about what your software can do. The key to designing for them is to provide multiple levels of detail (see section below) so that they can find appropriate answers to their questions.
- Fact-finders. These folks are doing reconnaissance and don't plan on using your software just yet. They want enough detail so they can report back to others (perhaps their colleagues, or perhaps their readership). Design for them by providing a solid summary and how-it-works information.
- Skeptical. These folks basically want to prove to themselves that your software isn't what they want. They want to find out that the software they're currently using is a better solution, so they don't have to go through the pain of switching. These folks present an interesting opportunity. Design for them by providing lots of evidence that other people are happy using your software.
Creating a Sign-up Framework
A sign-up framework is the set of information and resources we provide to people who are going to be signing up for our application. It may contain one or more of the following:
- An elevator pitch, a tagline, or some other pithy explanation of service
- Graphics or illustrations that show how your software works
- Carefully crafted copywriting that describes your software
- In-depth feature tour or feature pages
- Video or screencast showing actual use
- Get people started using the software as early as possible
- Evidence of other people using your software successfully
What a Good Sign-up Framework Does
The job of a sign-up framework is to help people make the jump from being interested in your software to being a first-time user.
A good sign-up framework maintains and hopefully increases any momentum a person brings with them to your application.
To maintain that momentum, a sign-up framework must do the following:
- Clearly communicate the capabilities of the software
- Allow a person to decide if the software is right for them
- Answer any outstanding questions people have about the software
- Confirm or refute any preconceptions people have about the application
- Get people actually using the application to get stuff done
- Let people connect with any other people who they might collaborate or work with
- Give people an idea of the type of relationship they'll have with you
The techniques below explain these issues in depth.
Keep it Simple: the Journalism Technique
Sometimes the most obvious techniques are the most effective. I've found that when designing a sign-up framework, it is useful to pretend you're a journalist. As every good journalist knows, when writing a news article you have to answer the questions Who?, What?, Where?, When?, Why?, and How? You have to pretend that your readers have never heard about the subject you're writing on.
Like journalists, web designers have a core task when designing for sign-up: they have to answer the basic inquiry questions.
The basic questions of inquiry are the most basic questions that someone has about... well, almost anything:
- Who is it for? Who is going to use it? (increasingly the answer is not "just me")
- What is it? What does it do? What are its capabilities?
- Where? Where can I use it? Is there a mobile version for using on the road?
- When can I use it? Is it browser-based, so I can access it at any time?
- Why is it important to me? Why will my life be better as a result of using this?
- How does it work? How can I take advantage of this? How do I get started?
We'll go over each one of these in turn.
Describe WHAT It Is
Steve Krug, in his wonderful book Don't Make Me Think,1 laments that too often web designs don't convey the big picture: what the site is about. Steve's right: there just isn't enough description about what applications are and what they do.
Sometimes, as is the case with online invoicing application Blinksale, the answer is wonderfully obvious: "the easiest way to send invoices online." The beauty of this simple statement is that now the reader can make a decision based on whether or not sending invoices online is important to them. If it is, they can keep reading or sign up immediately. If it isn't, they've wasted at most five seconds.
Figure 4.3 Blinksale's tagline says all you need to know. It clearly answers the question "what is this?"
In addition to the simple statement of what it does, Blinksale then gets into more detail: you can send elegantly formatted invoices to anyone with an email address, use an invoice template, or import your client records. Done. You know most of what there is to know about what this application does. That is the point of a simple description like this: to drive people into learning more about it.
Now, invoicing isn't a very complicated process and Blinksale keeps it remarkably easy. So why does their competitor, billmyclients.com, make it seem so complicated?
Figure 4.4 On Bill My Clients.com, it is possible to glean what the application is about, but it's light years away from the clarity of Blinksale.
A complicated interface suggests a complicated service.
Most of the people who see this screen are immediately drawn to the input fields asking them to log in. "Uh-oh," they think. "I don't have a login."
The funny thing is that billmyclients.com provides the same service that Blinksale does. They just aren't communicating it as clearly. You have to actually read the fine print to know what's going on. (It is there, believe me.) It says, in the small black text in the middle of the screen, that first-time users can set up an account and send an invoice for free. That's super-important information, but it's hidden in the design.
To their credit, the billmyclients site has a pretty obvious tagline: "invoicing made easy." But it's completely obscured by the design. It's not what you see first on the page, like you do on Blinksale.
So the first step is to describe what it is. The second step, just as crucial, is to put that information front and center in your design. Make it obvious like Blinksale does. Don't hide it, like Bill My Clients does.
And that's just sending invoices by email. Any more complicated web sites (i.e. most of them) are going to have an even harder time communicating what they are. Try to do this in the most straightforward, basic way possible.
Show HOW it Works
When Apple released their iPhone in the summer of 2007, they touted its touchscreen as a revolutionary new input device. They said it would change the way people interacted with computers forever.
Not everyone was convinced, however. Many people worried that the smooth-surfaced touchscreen couldn't replace the tactile feel of an actual keyboard. Understandably, people wondered if it might be difficult to type.
The speculation mounted. Would it be easy to type if there weren't physical buttons? Would you be able to type without looking? What happens when you can't feel the pressure underneath your finger? How do you correct errors?
But Apple had an answer for all this speculation: a set of videos that showed people using the iPhone. It showed people pressing buttons, dialing phone numbers, sending SMS messages. Apple called this a "Guided Tour."2
Figure 4.5 The video "Guided Tour" of the iPhone was remarkably successful in showing how the buttonless touchscreen could be used successfully.
As prospective buyers watched the video, all doubt of whether or not the keyboard was usable dissolved instantly. Here was video proof that you can easily type without keys—there were people doing it!
When how-it-works features work well, like the Apple video, they do several things:
- Make it absolutely clear what the steps are to make it work
- Allay fears about the design being difficult or confusing
- Serve as a guide to people who want to follow step by step
- Illustrate how easy it can be to use your stuff
- Become something that your audience can pass around and share
- Prove that people have had success
- Nudge those folks who are on the fence
Netflix's Four-Pane Masterwork
A good "How It Works" graphic is short and sweet, explaining the major points of your application and nothing more. Just the facts, ma'am.
On the homepage of Netflix they have done a great job of this.
Figure 4.6 The "How Netflix Works" graphic is an excellent example of how graphics can convey a lot of important information in a small, fast package.
This graphic does several things very well:
- Explains what Netflix is all about in a super-fast way
- Embeds text within the graphic for additional clarity
- Assigns ownership to the viewer—"your list of movies"
- Shows the progression of service—what steps happen in what order
- Gives a clear indication of how long each step takes
- Explains who does what (You: create list and return movies, We: send you movies)
- Explains in user's language why service is different/better (no late fees)
Now, I've worked on projects where a graphic like the Netflix graphic was voted down. Here is how the discussion went:
- Designer: I think a graphic showing how the service works would help to make it really clear for people who aren't quite sure about signing up yet.
- Manager: Well, we're an easy service to begin with, and most people know about us. Let's not muck up the homepage with information that people already know. Let's promote our latest movies instead.
This manager obviously deals in generalities, believing that "most" people already know about their service. But the designer knows that there are people who won't be gung-ho about signing up for the service, and wants to help that specific group of people. Designing for sign-up is about planning for these contingencies, asking "what questions do people have?" and "have we provided answers for them?"
So the answer to the manager would be: "How do you think Netflix got to the point where everyone knew how easy the service was? With graphics like this, of course!"
Nobody, not even a genius, minds something being communicated absolutely clearly.
TripIt and a Second Level of Detail
Like Netflix, TripIt has an excellent graphic on their homepage that quickly conveys how the service works.
Figure 4.7 Although the "How It Works" graphic on TripIt.com provides a clear overview of the service, they go one step further and provide a second level of detail reached by clicking "Learn More."
In three panes the designers at TripIt have explained the gist of the service. Many people who were double-checking that this was the service they thought it was or were on the fence will gladly sign up after confirming how easy it is. They can simply follow the instructions to "forward your travel confirmation emails to plans@tripit.com."
But TripIt doesn't stop there. They go on to provide a second level of detail for those folks still needing to know more. This illustrates an important principle.
Good how-it-works features provide multiple levels of detail, at increasing depth of description, allowing people to dig deeper as needed.
To get to this second level of detail, they provide two options. One option is labeled "Learn More." It's a huge orange button that follows the three-pane "How It Works" section. For folks wanting to learn more about how it works, that's the clear call to action.
The second option is the more interesting one. The link is entirely different even though it goes to the same place as the other option. It communicates a completely different call to action.
Figure 4.8 TripIt offers multiple paths to its second level of detail, giving people options to learn about what interests them most.
Since it is not as prominent as the other call to action, this second option might not get huge numbers of people clicking on it. But for those folks who didn't follow the first path, this option offers a slightly different message.
When you do select one of these options, you're taken to what's called the "Learn more about TripIt" page. This is the second level of detail, providing deeper information about the topics already presented on the homepage.
Providing this second level of detail has several effects:
- Keeps the user's momentum while reinforcing the main message
- Answers any questions that may be left after viewing the graphic
- Provides more details for people still unconvinced of the service's value or wanting to know more
- Gives you permission to really explain in-depth some important details (i.e. you have their attention)
- Provides an opportunity to start naming specific features of the service. You can link to an even deeper level of detail, such as a feature tour or examples of the service in use.
Figure 4.9 TripIt's "Learn More" page is an excellent extension of their original graphic, providing a second level of detail and explanation.
Notice that TripIt used the same graphic on their "Learn More" screen as they did on their homepage. They simply cut it up into three pieces and explained each piece. This clearly demonstrates that second level of detail.
Show the End Result
Showing how your application works is even more effective when you can show the end result. The end result of using the TripIt application, for example, is a one-page travel itinerary. This helps to make all the how-it-works information concrete. People can now see exactly how their travel information is aggregated and displayed.
Figure 4.10 TripIt's example itinerary is a great example of showing the end result. The designers even annotated the itinerary to highlight key features.
Explain WHY with Benefits as Well as Features
For years, copywriters have made the important distinction between features and benefits. Unfortunately, copywriters are often left out of the writing stages of web site development, so developers end up trying to pitch their apps on their features, not their more powerful benefits.
Features are capabilities of the system, and although they are very important, they don't explain why someone might use them.
Let's imagine we were building a social bookmarking tool. The features might be those in the left column of the following table, while the benefits are those things in the right column: the actual value you get from the feature.
Wufoo, an online form creation tool, has an excellent way of explaining the benefits of the application. It's a simple screen called "Top 10 Reasons to Use Wufoo."
In general, it is better to explain the benefits more than the features. However, there is one group of people who often responds better to features: techies. Techies intuitively grasp the linkage between features and benefits, and are often interested in the features because they know all about how they affect the benefits. Still, it never hurts to make those connections clear.
Figure 4.11 Wufoo's "Top 10 Reasons to Use Wufoo" is a list of the benefits of the service. Notice that technical details of features are also there, but the benefits are highlighted.
Give Examples of WHO is Using It
Figure 4.12 Social proof is the tendency to base our decisions on the activities of others. A crowded restaurant tends to stay that way because people assume that it is crowded for a good reason.
Many times we make decisions based on social cues that we might not be fully aware of. Do you ever walk by a restaurant, see a long line at the door, and think "we should probably try that out sometime"? Or, do you ever walk by a restaurant, see that it's empty, and think "that's probably not worth going to"? Most people do. Restaurants know this too—they'll seat early customers close to windows and encourage long lines so that passers-by see them and assume the place is worth going to.
People respond to the activity of others. So give a sense that real people are using your social web application. Show that others are there. Make it seem like a crowded restaurant. This leverages the powerful notion of "social proof."
So to make a person's decision easier, show them how others have made the same decision and succeeded. Give evidence that others are using it.
Some ways to do this are described below.
Let People Find Friends
While social proof works even when we're observing perfect strangers, it is most influential when the people doing the activity in question are people we know. When someone knows that their friend is already using an application, they'll likely be undeterred in signing up. In those cases your job is easy—just get out of their way.
In some cases, people will want to know if their friends are already a part of the service before they sign up. Provide an easy and powerful search for those who want to find their friends.
Facebook is really good at this. They give two options to find friends: looking them up with your existing web-based email accounts, or doing a name search.
Figure 4.13 Facebook lets people find friends easily, allowing people to search even if they aren't signed up for the service.
Facebook is clever. In addition to search functionality, they offer a "Find Your Friends" feature that takes an email address from a web-based email account (like Gmail, Yahoo! Mail, or Hotmail), goes out and looks at your contacts on that email platform, and then gives you results.
Figure 4.14 Facebook's "Find Your Friends" function. A clever way to let people know if their friends are already on the service.
Their search feature works really well. If one of my friends were considering signing up for the service but wanted to know if I was already there, they might type in "joshua porter," and Facebook, recognizing both variants of the name, returns results for both "joshua porter" and "josh porter."
Figure 4.15 Facebook's search works well, returning variants of "joshua" in the result. They don't show you all results, however, prompting you to sign up for that.
In addition, Facebook only shows you partial search results for these queries. For example, they only show 30 of the 171 results available. This gives a tantalizing preview to the number of people you can find on the service, and increases your momentum to sign up. So even if your friend isn't on the service, you won't know until you sign up. Very clever design.
Provide Testimonials: "I love your stuff"
What someone else says about you is more important than what you say about yourself. Testimonials have long been known in advertising as gold. Even so, testimonials are still under-utilized by almost all sites.
A great example of the prodigious use of testimonials is the Basecamp site. Basecamp is project management software for groups. The designers of the site separate the testimonials onto their own page called "Buzz." It is hard to view this page and not be drawn in by the sheer number of positive comments. You can't help but think "if so many people are so positive about this software, it's got to be good."
This page, which contains 90! testimonials, also raises the question "how many testimonials is too many?" And, judging by the effectiveness of the page, maybe even ninety isn't too many.
Figure 4.16 The Basecamp Buzz page seems like overkill as it contains 90! testimonials. But once you start reading them, you can't help but think "this is great software."
Notice the designers place the most compelling testimonials at the top. The first testimonial is actually from a competitor! The second one is a testimonial with ties to a recognized authority (Microsoft—also a possible competitor), which carries more weight than a person from a company you've never heard about.
Figure 4.17 The designers of Basecamp strategically chose compelling testimonials to place at the top of the page.
Here are some other insights that the Basecamp Buzz page gives us to use when displaying testimonials:
- Place the most seductive at the top
- Place recognized authorities in more prominent places
- Leverage strong brands
- Give interesting details about the person
- Pull testimonials from reviews and then link to the reviews
- Emphasize the most compelling part of the testimonial
So, elicit testimonials. Ask people for them. More often than not, your users will be happy to share their opinion of your software. Write them down and put them on your web site. It's such a simple thing to do that it simply gets overlooked.
In addition, this also shines some attention on the people who gave you the testimonial, showing them that you value their opinion. They might even reference your acknowledgement with others, driving even more people to your highly effective page. So imagine that two in ten people you acknowledge are going to link to you if you publish their testimonial. Wouldn't it be better to have a hundred testimonials and get twenty incoming links than having five testimonials and one incoming link?
Get As Specific As You Can
- Question: Who is the audience you're targeting?
- Wrong Answer: Well, anyone, really. Our application has a broad set of uses.
- Right Answer: People who do this very specific activity...
This is a discussion I had with an entrepreneur who was starting a new software company. He was targeting his software at what he called "the general public." And on the surface of things, this makes sense. He didn't want to limit his software cases where software has gone to the masses, it started off in a niche.
But Del.icio.us doesn't fall into the trap of designing for everyone. They do a very good job providing specific use cases.
And, if your software is flexible and can be used by many different types of audiences, choose a few profitable/big ones and be specific about each. The more specific you can get, the better.
Figure 4.18 Del.icio.us is a flexible tool that can be used by anybody. Still, the designers describe very specific use-cases when communicating its value. This is helpful for people trying to learn about it for the first time.
Success Stories/Case Studies
Even more powerful than suggesting what people can use your software for is actually showing how someone has successfully used it. Any activity seems easier if someone else has done it first.
Apple does a good job with case studies with the "profiles" feature on their professional site. They profile a successful professional and explain how that person uses Apple computers in their work. This is not a hard sell: Apple simply explains what the person uses Macs for.
Figure 4.19 On Apple's professional site, they offer "profiles" (case studies) to show how people are using Macs in their work.
Successful case studies tend to:
- Show how real people (even famous ones) use your application successfully
- Sound like a genuine study of use, rather than an advertisement
- Talk in depth about the activity at hand, without resorting to generalities
- Can get really technical about how the application is used (the text of Apple's profiles goes into good depth about what the person uses their software and hardware for.)
Figure 4.20 Apple's case studies focus on how their products make sense for the activity at hand, getting into some of the details that most people wouldn't know.
Case studies are the ultimate in detail. They are where you can dive into more complicated issues than most people, except those few who are interested in the very specific activity, will understand.
Give Numbers (When They're Big)
"99 Billion Served." Most McDonald's restaurants claim that unfathomable number of people served. It says "an amazing number of people have eaten here."
Software companies can do this as well. AdaptiveBlue uses the number of downloads of their software effectively. They proudly advertise that their toolbar has been downloaded over one million times. It suggests that lots of people are downloading—and they are!
Figure 4.21 A person reading this download statistic from AdaptiveBlue can't help but say "Wow, this is popular" and give it a second glance.
Appeal to Authority
If someone with authority uses your software, it makes sense to leverage that fact by talking about how they use it. On the AdaptiveBlue site, for example, they promote their software by explaining how Seth Godin, an authority in the marketing world, uses their SmartLinks feature.
Figure 4.22 If a well-known authority uses your software, tell people! This element from AdaptiveBlue doesn't oversell Seth Godin's involvement, it simply lets people know that he uses to the software to promote his books.
Authority works because it makes people pay attention. The mere fact that Seth Godin uses this software is impressive. But notice, too, that this element doesn't overplay Godin's involvement. It simply states that he uses the software. More importantly, it describes what he uses it for: to promote his books. That's enough information to grab those folks who might use it for the same purpose. You can bet that people who are interested in promoting their books are very interested in how Seth Godin uses this product.
Hypotheticals Are OK
If you're early on in launching your software, you may not yet have many people using it. In this case it might make sense to give people hypothetical ways to use it.
A good example is Backpack (created by 37signals, who also created Basecamp). In promoting Backpack, the design team came up with a bunch of hypothetical example uses. This is a great way to get people thinking about how best to use the software if they aren't sure.
Figure 4.23 A list of hypothetical uses for the app Backpack. This list gets people thinking about how it might be useful for them.
WHEN Can People Use It? Now!
Sometimes it seems as if all web software is free nowadays. But if you offer a pay-for application, consider offering a way for people to try it out for free. This is a great way for people to get excited about your service without first having to make a hard decision about budgeting or pricing.
Letting people try out your application also has an interesting effect. By giving people something for free, you've evoked the feeling of reciprocation: people are much more likely to stick with you for it. You've given them something for free, and they're more likely to give something in return (their business).
Goplan, a project management application, offers a version of their software that anybody can try for free. It is a limited version without some of the bells and whistles of the more expensive plans, but is enough to get you started and pique your interest. Sometimes people don't realize the value of something until they've actually used it.
Figure 4.24 Goplan offers a free version of their project management application. It's a great way to get people hooked on your software.
WHERE Can People Use Your Application?
Until recently, the question of "where" you can use web applications wasn't that interesting. However, expanding mobile phone use is changing that, allowing people to use web applications anywhere they can use their phone.
In some cases, mobile access changes the entire value proposition of social software. Consider the case of Google Maps, a mapping platform that becomes much more useful when you're on the go.
The Maps design team has done a good job of explaining the benefits of using their application while on the move.
Figure 4.25 The mobile page for Google Maps is a good example of highlighting some of the interesting uses of their application while on the move.
The secret to designing for mobile use is context. What sorts of activities are people going to use your software for when they're on the move? If the answer is a specific set of activities like on Google Maps, it makes sense to call these out specifically.
Reduce Sign-up Friction
So now we've answered a person's basic questions about our web application. In some cases we focused on what value the application provides, while in others we focused on more social issues like who is using it. The journalism technique covers most of those bases.
If we've done our job right, people are motivated to take the next step and use the application. With luck we've now got everyone in the "Ready to Go" mindset. The key at this point is to reduce sign-up friction as much as possible.
Don't Make Creating an Account a Requirement (until You Need to)
TripIt.com has an excellent way to get started using their service with very little friction. Say you book at flight at Orbitz.com. You'll get an email from them confirming your flight details. Simply forward that email to plans@tripit.com and they create a page for your itinerary. They send you an email back with a link to your newly-created page. You've essentially started using their application without creating an account, or even visiting the site!
Figure 4.26 TripIt makes starting a snap. All you have to do is forward an existing email to the service and they create an itinerary for you.
Another great example is Netvibes, a web-based desktop application. They invite you to start using their service immediately by configuring your own desktop.
Netvibes makes creating an account seem almost like an afterthought. They provide value way before they make you sign up. Here's the Netvibes example highlights a larger principle of form design. I don't know if it is written in stone somewhere, but it should be:
Upon signup, ask only for information that's absolutely necessary
In the case of Netvibes, nothing is required to start using their application. Talk about a frictionless process. Only after you start using it do they remind you that if you want to save what you've done, you have to sign up.
Figure 4.27 Netvibes kindly lets you play with the tool before having to create an account. In fact, they almost make creating an account seem like an afterthought... what a novel idea!
Progressive Engagement
Interface designer Luke Wroblewski calls this technique progressive engagement.5 Progressive engagement allows people to get started using software without committing fully or filling out a sign-up form. They engage with the software slowly instead of having to scale the hurdle of a sign-up form before engaging.
Both Netvibes and Tripit practice progressive engagement. Contrast the experience of those sites with that of the Wall Street Journal. When reading an article snippet on wsj.com, you're asked to subscribe to the service for full access. When you press "subscribe," you're presented with a daunting form. Not only do you have to pay money (a hurdle in itself), not only does this form contain more fields than necessary, but it's only one of four pages!
Now, someone might argue that "It's the Wall Street Journal, the most respected newspaper in the world, so they can do what they want." Not so. What the Wall Street Journal has done is to increase signup friction. The only way to overcome that increased friction is to increase motivation by using the techniques mentioned above. While readers of the Wall Street Journal might be highly motivated, that shouldn't be a requirement just to fill out a form!
Figure 4.28 The Wall Street Journal has an incredible amount of friction in their signup process. This daunting form is only one of four pages!
Conclusion
The moment a person signs up for your software is crucial: it's the moment when they decide to start a relationship with you. If it's a bad experience and they can't quite muster up the motivation to sign up, they may never return.
By using the simple and effective journalism technique to answer the basic questions of inquiry, you can go a long way to getting (or keeping) people motivated to use your software.
In the next chapter we'll talk about keeping that momentum during actual use of your software and helping people get up to speed with regular use. | http://www.peachpit.com/articles/printerfriendly.aspx?p=1216150 | CC-MAIN-2013-48 | refinedweb | 6,013 | 63.9 |
3to2 is a project to convert cleaner 3.x code to 2.x.
3to2 started as a project idea to reuse the 2to3/lib2to3 codebase for converting 3.x code to 2.x. This creates a new package, 'refactor', which supports lib2to3 and (non-existent) lib3to2.
The following goals were targeted at the US PyCon 2009 sprint of Python Core:
- retain lib2to3 API since it is in use (perhaps deprecate it later)
- build a base package 'refactor' and port lib2to3 to it
- package refactor with a 3to2 script
- tackle high-priority conversions
The discussions at the sprint pointed to a handful of essential conversions to use as starting goals of 3to2:
from __future__ import * (2.6)
convert str or bytes to u'' or b'', respectively
convert print functions (2.5 and earlier)
- convert exceptions (2.5 and earlier)
How far back into 2.x should 3to2 go?
Conversions from 3.x to 2.4 and earlier have a lot more work to do than those of 3.x to 2.6 and later. :-) During the sprint, we approached tackling major conversion items (see short list above) for 3.x to 2.6, then 2.5, then 2.4, ...
During the Google Summer of Code 2009, Joe Amenta wrote a more-or-less complete lib3to2. It is hosted on bitbucket and has a PyPI page. | http://wiki.python.org/moin/3to2?action=diff | CC-MAIN-2013-20 | refinedweb | 224 | 78.55 |
Commit>
---
xen/arch/x86/hvm/vmx/intr.c | 43 +++++++++++++++++++++++++++++++++++++++++++
1 file changed, 43 insertions(+)
diff --git a/xen/arch/x86/hvm/vmx/intr.c b/xen/arch/x86/hvm/vmx/intr.c
index 24e4505..5e5b37a 100644
--- a/xen/arch/x86/hvm/vmx/intr.c
+++ b/xen/arch/x86/hvm/vmx/intr.c
@@ -23,6 +23,7 @@
#include <xen/errno.h>
#include <xen/trace.h>
#include <xen/event.h>
+#include <asm/apicdef.h>
#include <asm/current.h>
#include <asm/cpufeature.h>
#include <asm/processor.h>
@@ -318,6 +319,48 @@ void vmx_intr_assist(void)
*/
if ( pt_vector != -1 )
{
+ /*
+ * We assert that intack.vector is the highest priority vector for
+ * only an interrupt from vlapic can reach this point and the
+ * highest vector is chosen in hvm_vcpu_has_pending_irq().
+ * But, in fact, the assertion failed sometimes. It is suspected
+ * that PIR is not synced to vIRR which makes pt_vector is left in
+ * PIR. In order to verify this suspicion, dump some information
+ * when the assertion fails.
+ */
+ if ( unlikely(intack.vector < pt_vector) )
+ {
+ struct vlapic *vlapic;
+ struct pi_desc *pi_desc;
+ uint32_t *word;
+ int i;
+
+ printk("Assertion failed on %pv. Some info are below.\n",
+ current);
+ printk("intack info: vector 0x%2x, source %x\n", intack.vector,
+ intack.source);
+ printk("pt_vector info: vector 0x%2x\n", pt_vector);
+
+ vlapic = vcpu_vlapic(v);
+ if ( vlapic && vlapic->regs->data )
+ {
+ word = (void *)&vlapic->regs->data[APIC_IRR];
+ printk("vIRR:");
+ for ( i = NR_VECTORS / 32 - 1; i >= 0 ; i-- )
+ printk(" %08x", word[i*4]);
+ printk("\n");
+ }
+
+ pi_desc = &v->arch.hvm_vmx.pi_desc;
+ if ( pi_desc && pi_desc->pir )
+ {
+ word = (void *)&pi_desc->pir;
+ printk(" PIR:");
+ for ( i = NR_VECTORS / 32 - 1; i >= 0 ; i-- )
+ printk(" %08x", word[i]);
+ printk("\n");
+ }
+ }
ASSERT(intack.vector >= pt_vector);
vmx_set_eoi_exit_bitmap(v, intack.vector);
}
--
1.8. | https://lists.xenproject.org/archives/html/xen-devel/2017-02/msg00519.html | CC-MAIN-2018-17 | refinedweb | 276 | 54.39 |
Created on 2011-11-11 15:19 by nneonneo, last changed 2012-12-24 03:39 by brian.curtin. This issue is now closed.
Lib/random.py in Python 3.2 contains the line
from __future__ import division
even though it is no longer necessary, as true float division is the default in Python 3.
Trivial patch:
--- lib/python3.2/random.py 2011-09-03 20:32:05.000000000 -0400
+++ lib/python3.2/random.py 2011-11-11 11:11:11.000000000 -0400
@@ -36,7 +36,6 @@
"""
-from __future__ import division
from warnings import warn as _warn
from types import MethodType as _MethodType, BuiltinMethodType as _BuiltinMethodType
from math import log as _log, exp as _exp, pi as _pi, e as _e, ceil as _ceil
New changeset 3fdc5a75d6e1 by Brian Curtin in branch '3.2':
Fix #13384. Remove __future__ import in 3.x code.
I thought we had a policy that future imports would never be removed.
That's news to me since it probably pre-dates my involvement around here. I'll revert if that's correct.
Things won't ever be removed from the __future__ module, but there's no harm in removing ones with no effect.
At one point, for 2.x at least, we weren't removing the "from __future__" imports even after the feature became available.
AFAIK on 2.x there are a few modules that are supposed to work even with older version of Python (I think I even saw one that is supposed to still be compatible with Python 1.5).
I don't think this is the case for Python 3 though.
This went over a year without a request to undo it, and we've since made several releases that includes it, so I'm closing this. Please re-open if it does need to be reverted. | http://bugs.python.org/issue13384 | CC-MAIN-2016-40 | refinedweb | 305 | 76.42 |
For a few hours here and there over the past few months, I’ve been working on a side project: Wio. I’ll just let the (3 minute) screencast do the talking first:
Note: this video begins with several seconds of grey video. This is normal..
In terms of Rio compatability, Wio has a ways to go. I would seriously appreciate help from users who are interested in improving Wio. Some notably missing features include:
- Any kind of filesystem resembling Rio’s window management filesystem. In theory this ought to be do-able with FUSE, at least in part (/dev/text might be tough).
- Running every application in its own namespace, for double the Plan 9
- Hiding/showing windows (that menu entry is dead)
- Joint improvements with Cage to bring greater support for Wayland features, like client-side window resize/move, fullscreen windows, etc
- Damage tracking to avoid re-rendering everything on every frame, saving battery life and GPU time
If you’re interested in helping, please join the IRC channel and say hello: #wio on irc.freenode.net. For Wio’s source code and other information, visit the website at wio-project.org. | https://drewdevault.com/2019/05/01/Announcing-wio.html | CC-MAIN-2019-39 | refinedweb | 194 | 59.74 |
alabama bankruptcy attorney :: smallville actors :: create your own polo ::
"Create Your Own Polo"
Transmit, display, perform, reproduce, publish, license, create your use of this site is at your own risk in no event shall palm beach polo, or its agents, representatives. Lesson title: making your own product game: grade level(s)4, federation suisse de football5,6, internet franchises7: lesson url: http students then work in groups to create their own game boards teacher ratings:.
More options in cursorxp, connecticut property for sale but i just wanted to show you the basic so you can create your own shoes,hogan shoes; adidas football shoes, create your own poloadidas clima cool shoes; rock jeans,polo t.
Here, you ll create your own niche in a setting where golf, polo and equestrian lifestyles location: between desert course and gazelle. Great free online file sharing resources; create your own fonts on-line; ways to drive a graphic designer mad; swirl m a in illustrator & photoshop; developers, writers, mac.
This premium polo from fruit of the loom is a % special webart cotton responsible for the content and design of the shop click here to open your own shop and create your. Polo produces some of the best black & white prints in the industry and our simply drop your images into our custom designed templates or create your own.
The polo club luxury apartments is a beautiful in bookcases, vaulted ceilings, private patios, your very own create your free account (it takes just seconds!. Your own online store free! no ding we ll set up a free on-line store for you right ) next, we create your custom store for your review and approval and, offshore bank accounts at your "go", your.
Marco polo male; jocelyn donegan; dj k yahweh; char created this work on ning create your own social get your own shine your star badge for your website or. This workshop provides this site for you to create your own wiki page please think about this luv polo leticia paula anjelica anna manviscool! shorty jessica nbfsteph set second workshop:.
Web page maker help you make your own web page create your own web pages in minutes bombay indian cuisine ( miles) marco polo restaurant (delivered to your. Remember that all damages done to your system is at your own risk! always important when select values then press "create files" the files will then be created (note that this.
Create and modify your own teams, leagues, and players customizable game home runs the babe might have hit in had he played at the polo. Create your own search agent now! marco polo anti age drink marco polo modern drinks gmbh product highlight.
Buy the same premium quality wool that i use to create high quality, internet franchises luxurious traditional aran sweater, polo or debit card and in the currency of your own.
Create profile: login crusaders polo: crusaders queen duvet cover set nz$3000: nz you can also add your own name & number to some of the shirts. Training mojo: steps to create your training dojo door, create your own polo materials, shower curtain tkile and even casual friday polo shirts for the staff your line managers, employees, and members of your own.
import munity - free blogs - create your own trade homepage supply of polo t shirts to ministry of sports cameroon (by luwismarcus ) dear sir we. Marco polo is not your average, hailing from bushwick brooklyn where most take the wrong in this age of myspace and youtubewe are given the power and tools to create our own.
General news; baseball; basketball; golf; swimming; tennis; volleyball; water polo in memory of someone special or because you love baseball, your tax-deductible donation will help create a. Search or find a club or tournament near you using a postcode search, or add your own create your own badminton entry: choose category from below -.
Control and freedom of choice during a holiday, marco polo group of friends, couples or even individuals to create a it is always a pleasure to have control over your own holiday. Natalie portman has confessed she decided to create her own filming business as she was tired having your pany is ce way to concentrate your ideas and make the kinds of.
Coolchaser - create your own florida layouts in minutes! user created layouts here are some layouts myspace polo by eck. Sign in to add your ment (this only your passion join or create a add ment: new vw polo, polo twist door.
Ira marco polo peace journey planning try to select characters who reflect your own definitions of peace, trimspa diet as you will be writing dialogue for each character you create in your.
Create your own personalized mrs or bridal rhinestone shirt simply give us a call and well see if we can create a customized polo shirt, myth soma tee shirt, or sweatshirt to fit your.
Roller hockey; rugby; soccer; softball; sports training; track & field; volleyball; water polo save % when you click below to create your own nike bauer hockey protective package from our. Learn more about and create a collaborative project of your own and ask other classes to use marco polo to find interactive activities for a lesson.
Myspace music profile for freddie j, polo jones with tour dates, plano sfowaway songs, videos band members: freddie br> create your own visitor map! record label: da hustle.
Here, line painter you ll create your own niche in a setting where golf, polo and equestrian lifestyles location: between desert course and gazelle project type: sp sh styled single y.
Melissa & doug make your own monster puppet create hundreds of crazy creatures with this fuzzy friend polo ralph lauren girls "briley" patent shoe $3400. Girls shorts custom gym shorts custom patches custom polo create an account or login to take advantage of these great it s even easier to manage your custom designs with your own.
Polo se lab was a bothan junior senator who e now, custom personal checks or you ll miss your own celebration " general se, articles on this wiki create an account already a.
Customize the explorers of the americas printable and make custom print-outs create your own ) exploring alaska (grades -7) vasco da gama (grades -7) marco polo. Make your own team shirts, corporate clothing grow your business, e a boutique, create a brand, or ndie fashion label polo shirts % cotton.
A great introduction to the african marco polo make your own list create a listm a! list. Be part of the uk s first online munity by adding your own entry and read & create your very own sport reviews.
Login to crackle to watch your own shared your to create an account and start sharing your video, visit using your pc we ve got everything from quarters to polo. Create your own account below and as the games approach we ll be adding all kinds of useful aquatics - water polo: rowing: athletics: sailing: badminton: shooting: baseball: softball.
s create your own service lures a lot of first-time buyers, says sarah gallagher, president of the web site unit gallagher says %-45% of like-for-like sales - sales in. Bucks county pa y activities, tailgate parties at pa tinicum polo matches, offshore bank accounts create your own theme this category lets you really.
Seventeen styles of polo shirts, golf shirts and rugby shirts ready to be embroidered with pany logo, team logo or other designs you create make your own izod polo shirt. Ulu canoe polo login username: create new account: password: forgot your password? this board hosted for free by proboards get your own free.
You will then analyze the maps created during his time which depict his travels and use current technology to create your own map which will illustrate marco polo s travels. Cumple polo polo risaralda - imagenes the slide service (please be aware that slide may create you are solely responsible for protecting your own content.
Cricket,polo,horse racing,hockey,running, hiking, replica handbagspas,gyms entertainment & culture create your own: create your very own custom barbados holiday! , ,280) ;= onmouseout. Choosing your size - foghorn is all about individual and style of garment you choose as to the design you create polo sizes: xs, s, m, forced air furnace l, xl this polo is a traditional loose..
create your own polo Related Links
Search | http://members.lycos.co.uk/warrenfolger/smallvil7c/create-your-own-polo.html | crawl-001 | refinedweb | 1,394 | 55.47 |
Scripting with Guile
Extension language enhances C and Scheme
Guile, which launched in 1995, is an interpreter for the Scheme language, a simplified derivative of the Lisp language, first introduced by John McCarthy in 1958. But Guile makes Scheme embeddable, which makes the interpreter ideal for embedded scripting. Guile isn't just another extension language: it's the official extension language of the GNU project. You'll find Guile used for scripting in a number of open source applications—from gEDA CAD tools to the Scheme Constraints Window Manager (Scwm), which provides dynamic configurability through Scheme scripting (see the Related topics section for links). Guile follows a very successful history of application extension through scripting, from GNU Emacs, the GIMP, and Apache Web Server.
The key behind Guile is extensibility; see Figure 1. With Guile, you can interpret Scheme scripts, dynamically bind scheme scripts into compiled C programs, and even integrate compiled C functions into Scheme scripts. This valuable feature means that users can tailor or customize your applications to add their own value.
Figure 1. Scripting use models for Guile
One of the best examples of application customization is in the video gaming industry. Video games permit a tremendous amount of customization through scripting. Many game programs even use scripting in their core design to implement certain aspects (such as non-player character behavior) with scripts.
A simple example
Let's now look at a simple example of integrating Guile into a C language program. In this case, I use a C program that calls a Scheme script. Listing 1 and Listing 2 show the source for this first example.
Listing 1 presents the C application that invokes the
Scheme script. The first thing to notice is the inclusion of the
libguile.h header file, which makes available the necessary Guile symbols.
Next, notice a new type defined:
SCM. This type
is an abstract C type that represents all Scheme objects contained within
Guile. Here, I'm representing the Scheme function that I call later.
The first thing that needs to be done for any thread using Guile is to make
a call to
scm_init_guile. This function
initializes the global state of Guile and must be called prior to any
other Scheme function. Next, prior to calling a Scheme function, the file
in which this function resides must be loaded. You do this by using the
scm_c_primitive_load function. Note the naming
here: the
_c_ in the function indicates that it
is passed a C variable (rather than a Scheme variable).
Next, I use
scm_c_lookup to find and return the
variable bound by the symbol (the Scheme function in the model), which is
then dereferenced with
scm_variable_ref and
stored in the Scheme variable
func. Finally, I
call the Scheme function using
scm_call_0. This
Guile function calls a previously defined Scheme function with zero
arguments.
Listing 1. A C program that invokes a Scheme script
#include <stdio.h> #include <libguile.h> int main( int argc, char **arg ) { SCM func; scm_init_guile(); scm_c_primitive_load( "script.scm" ); func = scm_variable_ref( scm_c_lookup( "simple-script" ) ); scm_call_0( func ); return 0; }
Listing 2 provides the Scheme function that is invoked from within the C
program. This function uses the
display
procedure to print a string to the screen. This function is followed by a
call to the procedure
newline, which outputs a
carriage return.
Listing 2. A Scheme script that is called from C (script.scm)
(define simple-script (lambda () (display "script called") (newline)))
What's interesting here is that the script is not statically bound to the C program; it is dynamically bound. The Scheme script can be changed, and when the previously compiled C program is executed, it will execute the new behavior implemented in the script. That's the power of embedded scripting: you take the speed of compiled applications and provide the extensible power of dynamic scripting.
Now that you have a simple example under your belt, let's dig in a little further to explore some of the other elements of Scheme scripting within the C language.
A short introduction to Scheme
As Scheme may seem a bit foreign to some, let's look at a few examples that illustrate the power of the language. These examples illustrate variables, conditionals, and loops in addition to some of the key features of Scheme. A full treatment of Scheme is outside the scope of this article, but you can find links to references in the Related topics section.
In these examples, I use the Guile interpreter, which allows me to work with Scheme in real time, providing Scheme code and seeing the results immediately.
Variables
Scheme is a dynamically typed language; therefore, the type of a variable is not generally known until run time. Scheme variables are then simply containers whose type can be defined later.
Variables are created using the
define
primitive, then changed with the
set!
primitive. Here, I do just that:
guile> (define my-var 3) guile> (begin (display my-var) (newline)) guile> (set! my-var (* my-var my-var))
Procedures
Not surprisingly, it's also possible to create procedures in
Scheme—also with the
define primitive.
Procedures can be anonymous (lambda procedures) or named. In the
case of named procedures, they're stored in a variable, as shown here:
(define (square val) (* val val))
This form differs from the traditional Lisp syntax, if you happen to be familiar with that, but it's somewhat simpler to read. I can then use this new procedure just like any other primitive, as shown here:
guile> (square 5) 25
Conditionals
Scheme contains a few ways to do conditionals. The most basic is the simple
if condition. It defines a test conditional, a
true expression, and an optional false expression. In the example below,
you can see the list processing perspective of Scheme. The list begins
with
if and ends with
(display "less"). Recall that Scheme is a
derivative of Lisp and therefore is built of lists. Scheme represents both
code and data as lists, which allows the language to blur the line (code
as data and data as code).
guile> (define my-var 3) guile> (if (> my-var 20) (display "more") (display "less")) less
Loops
Scheme implements loops through recursion, which forces a particular
mindset when implementing a loop. However, it's a natural way to iterate.
The following example illustrates a Scheme script that iterates from 0 to
9, then prints
done. This example uses what in
Scheme is called tail recursion. Note at the end of the loop that I
recursively call the same function with an argument that is one greater
than the previous, implementing the iteration of the loop. In traditional
languages, this recursion eats away at the stack to maintain a history of
the calls; in Scheme, it's different. The last call (the tail)
simply invokes the function without any procedure call or stack
maintenance overhead.
(let countup ((i 0)) (if (= i 10) (begin (display "done") (newline)) (begin (display i) (newline) (countup (+ i 1)))))
Another interesting way to loop in Scheme is through the
map procedure. This concept simply applies (or
maps) a procedure to a list, as shown in the following example.
This approach is both readable and simple.
guile> (define my-list '(1 2 3 4 5)) guile> (define (square val) (* val val)) guile> (map square my-list) (1 4 9 16 25)
Extending C programs with Scheme scripts
As you saw in Listing 1, extending C programs with Scheme is relatively painless. Now, here's another example that explores some of the other application programming interfaces (APIs) available for bridging C to Scheme. In most applications, you need to not only make calls to Scheme but also pass argument to Scheme functions, receive return values, and share variables between the two environments. Guile provides a rich set of functions to enable this functionality.
Guile attempts to straddle the line between the two environments and extend to C the power of Scheme. In this regard, you'll find dynamic types, continuations, garbage collection, and other Scheme concepts extended to C through the Guile API.
One example of extending Scheme concepts into C is the ability to
dynamically create new Scheme variables from the C environment. The C
function for creating Scheme variables is
scm_c_define. Recall that
_c_ indicates that you're providing a C type as
the argument. If you already had the Scheme variable (as provided by the
scm_c_lookup function), you could instead use
scm_define. In addition to creating Scheme
variables in C, you can also dereference Scheme variables and convert
values between the two environments. I explore examples of these in
Listing 3.
Listing 3 and Listing 4 present two examples of interactions between C and Scheme. The first example illustrates calling a Scheme function from C, passing in an argument, and capturing the return value. The second example creates a Scheme variable to pass in the argument. Listing 4 presents the Scheme functions, which implement the same behavior, but the first with an argument and the second with a static variable.
In the first example in Listing 3, I simply use the
scm_call_1 function to call the Scheme function
with one argument. Note that here you must pass in Scheme values to the
function: The
scm_int2num function is used to
convert a C integer into a Scheme numerical data type. You use the
opposite
scm_num2int to convert the Scheme
variable
ret_val into a C integer value.
The second example in Listing 3 begins by creating a new Scheme variable
with
scm_c_define, identified by a C string
variable (
sc_arg). This variable is
auto-initialized using the type conversion function
scm_int2num. Now that the Scheme variable has
been created, you can simply call the Scheme function
square2 (this time without an argument) and
follow the same process to grab and dereference the return value.
Listing 3. Exploring Scheme functions and variables with C
#include <stdio.h> #include <libguile.h> int main( int argc, char *argv[] ) { SCM func; SCM ret_val; int sqr_result; scm_init_guile(); /* Calling the square script with a passed argument */ scm_c_primitive_load( "script.scm" ); func = scm_variable_ref( scm_c_lookup( "square" ) ); ret_val = scm_call_1( func, scm_int2num(7) ); sqr_result = scm_num2int( ret_val, 0, NULL ); printf( "result of square is %d\n", sqr_result ); /* Calling the square2 script using a Scheme variable */ scm_c_define( "sc_arg", scm_int2num(9) ); func = scm_variable_ref( scm_c_lookup( "square2" ) ); ret_val = scm_call_0( func ); sqr_result = scm_num2int( ret_val, 0, NULL ); printf( "result of square2 is %d\n", sqr_result ); return 0; }
Listing 4 presents the two Scheme procedures that are used by the C program
shown in Listing 3. The first procedure,
square, is a traditional Scheme function that
accepts a single argument and returns a result. The second procedure,
square2, accepts no arguments, but instead
operates on a Scheme variable (
sc_arg). As with
the previous procedure, this variable also returns the result.
Listing 4. Scheme scripts that are called from Listing 3 (script.scm)
(define square (lambda (x) (* x x))) (define square2 (lambda () (* sc_arg sc_arg)))
Extending Scheme scripts with C functions
In this final example, I explore the process of calling C functions from
Scheme scripts. I start with the Scheme-callable function in Listing 5.
The first thing you'll notice is that although this is a C function, it
receives a Scheme object and returns a Scheme object in response
(
SCM type). I begin by creating a C variable
that I use to grab the
SCM argument using the
scm_num2int function (converting the Scheme
numerical type to a C
int). With this, I square
the argument and return it through another call to
scm_from_int.
The remainder of the program in Listing 5 sets up the environment to boot
into Scheme. After initializing the Guile environment, I export the C
function to Scheme with a call to
scm_c_define_gsubr, which takes as arguments
the name of the function in Scheme, the number of arguments (required,
optional, rest), and the actual C function to be exported. The rest you've
seen before. I load the Scheme script, get a reference to the particular
Scheme function, and call it with no arguments.
Listing 5. C program for setting up the environment for Scheme
#include <stdio.h> #include <libguile.h> SCM c_square( SCM arg) { int c_arg = scm_num2int( arg, 0, NULL ); return scm_from_int( c_arg * c_arg ); } int main( int argc, char *argv[] ) { SCM func; scm_init_guile(); scm_c_define_gsubr( "c_square", 1, 0, 0, c_square ); scm_c_primitive_load( "script.scm" ); func = scm_variable_ref( scm_c_lookup("main-script") ); scm_call_0( func ); return 0; }
Listing 6 provides the Scheme script. This script displays the response to
the call to
c_square, which is the function
exported in the C program in Listing 5.
Listing 6. Scheme script that calls the C function (script.scm)
(define main-script (lambda () (begin (display (c_square 8)) (newline))))
A trivial example, but it illustrates the ease with which you can share code and variables between the two language environments.
Epilogue
The days of building and delivering static software and products are over. Today, users expect their products to be dynamic and easily customizable. Although this evolution comes with new complexity, it ultimately allows users to show us the way to create new value in our applications. Hopefully, this article helps you glimpse the power of Guile. Scheme may be one of the oldest programming languages still in use, but it also remains one of the most powerful. Guile has succeeded in making it even more powerful and useful.
Downloadable resources
Related topics
- The GNU extension language home page provides the latest release of Guile, FAQs, and documentation (the freely available Guile manual is very extensive).
- The GNU Electronic Design Automation (gEDU) package and the Scheme Constraints Window Manager (Scwm) are two projects that make use of Guile for embedded scripting.
- UnrealScript is scripting language that was designed for the Unreal Engine by Epic Games. This scripting language allowed the gaming community to write new in-game content.
- Read about game scripting in Python at Gamasutra.
- See the Scheme Wiki and the Scheme resources at the Guile Web site, including a scheme code repository, Scheme language standards, and lecture notes. Although Scheme is an older language, it's well worth learning for the properties it teaches. Recursion, for example, is an introductory topic in most languages, but for Scheme, it's imperative.
- Glenn Vanderburg's site archives UseNet postings that show where the Guile got its start: in the infamous "Tcl War" UseNet discussion. The flamewar began with the benign title, "Why you should not use Tcl," by Richard Stallman and burst into a month-long heated debate.
- In the developerWorks Linux zone, find more resources for Linux developers (including developers who are new to Linux), and scan our most popular articles and tutorials.
- See all Linux tips and Linux tutorials on developerWorks. | https://www.ibm.com/developerworks/linux/library/l-guile/index.html?ca=drs- | CC-MAIN-2019-51 | refinedweb | 2,442 | 61.46 |
Opened 4 years ago
Closed 4 years ago
Last modified 4 years ago
#18979 closed Bug (fixed)
PermWrapper + template "if in" interaction
Description
Trying to do
{% if 'someperm' in perms.someapp %}has perm{% else %}no perm{% endif %}
will result in endless loop. Above, the perms is PermWrapper as installed by the RequestContext.
Doing if perms.someapp.someperm works correctly. I tried the above because I have a permission codename (from external database) which contains '-', so I can't use the documented syntax.
The attached tester project shows this error. run devserver, click the link, and you will have the dev-server in endless loop which isn't even killable by Ctrl-c... So, be prepared to kill the server by force.
I know the above isn't documented use of PermWrapper. But, to me it seems this bug isn't a PermWrapper bug, what it does looks sane to me. So, I am suspecting there could be some underlying bug in the template engine. So, I am marking this into Template system, though the bug could be elsewhere, too.
Tested with 1.4.1 and 1.5.dev20120918050907 with Python 2.7.3.
Attachments (1)
Change History (6)
Changed 4 years ago by akaariai
comment:1 Changed 4 years ago by akaariai
comment:2 Changed 4 years ago by akaariai
- Owner changed from nobody to akaariai
- Triage Stage changed from Unreviewed to Accepted
An irc-discussion with Alex, and the reason for this is now clear. The reason is that if there isn't __iter__ defined for an object, but it has a __getitem__ which never raises IndexError, then the 'something' in obj will continuously check for obj[i] == 'something'; i++...
The solution is to define an __iter__ which raises TypeError.
I am assigning this to myself. The only question is how to test this... A possible test would be to check False not in perms - the reason is that __getitem__ will return False for the first index, 0, and then the in check will see False in the perms incorrectly. And, there should be no possibility of forever-loop.
I am going to backpatch this to 1.4, too.
comment:3 Changed 4 years ago by akaariai
- Triage Stage changed from Accepted to Ready for checkin
A patch is available in:
comment:4 Changed 4 years ago by Anssi Kääriäinen <akaariai@…>
- Resolution set to fixed
- Status changed from new to closed
I am completely lost with this ticket... I replaced the contents of the some_view (testing/views.py) with this:
Then, I placed a print(__getitem__(%s) % perm_name) into django/contrib/auth/context_processors.py:PermLookupDict.__getitem__. . Access the view and it prints this endlessly:
The stack trace is this:
Tested both on Python 3.2 and Python 2.7, and at least 1.4.0 has this already. | https://code.djangoproject.com/ticket/18979 | CC-MAIN-2016-30 | refinedweb | 469 | 74.29 |
Yet again, intern season is coming to a close, and so it’s time to look back at what the interns have achieved in their short time with us. I’m always impressed by what our interns manage to squeeze into the summer, and this year is no different.
There is, as you can imagine, a lot of ground to cover. With 45 interns between our NY, London and Hong Kong offices, there were a lot of exciting projects. Rather than trying to do anything even remotely exhaustive, I’m just going to summarize a handful of interesting projects, chosen to give a sense of the range of the work interns do.
The first project is about low-level networking: building the bones of a user-level TCP/IP stack. The second is more of a Linux-oriented security project: building out support for talking to various kernel subsytems via netlink sockets, to help configuration and management of firewalls. And the last is a project that I mentored, which has to do with fixing some old design mistakes in Incr_dom, our framework for building efficient JavaScript Web-UIs in OCaml.
(You should remember, every intern actually gets two projects, so this represents just half of what an intern might do here in a summer.)
Reimplementing TCP/IP
Trading demands a lot in performance terms from our networking gear and networking code. Much of this has to do with how quickly exchanges generate marketdata. The US equity markets alone can peak at roughly 5 million messages per second, and volumes on the options markets are even higher.
For that reason, we end up using some pretty high-performance 10G (and 25G) network cards. But fast hardware isn’t enough; it’s hard to get really top-notch networking performance while going through the OS kernel. For that reason, several of these cards have user-space network stack implementations to go along with them.
But these implementations are a mixed bag. They work well, but the subtle variations in behavior between vendors make it hard to build portable code. And the need for these user-space layers to fit to traditional networking APIs means that it’s hard to get the maximum performance that is achievable by the hardware.
For this reason, we’ve been finding ourselves spending more time writing directly to lower-level, frame-oriented APIs that are exported by these cards. That’s relatively straightforward for a stateless protocol like UDP, but TCP is a different beast.
That’s where intern Sam Kim came in. He spent half the summer reading over a copy of TCP/IP Illustrated (volumes 1 and 2!), and building up a user-space TCP implementation in pure OCaml. He was able to leverage our existing APIs (and, critically, the testing framework we had in place for such protocols) to build up a new implementation of the protocol, optimized for our environment of fast local LANs. And he wrote a lot of tests, helping exercise many different aspects of the code.
This is not a small amount of work. TCP is a complex protocol, and there’s a lot of details to learn, including connection setup, retransmission, and congestion control.
One of the more exciting moments of this project was at the end, when, after doing all the testing, we connected Sam’s implementation to a real network card and ran it. After some small mistakes in wiring it up (not Sam’s mistakes, I should mention!) it worked without a hitch, and kept on working after he added a bunch of induced packet drops. Surely there’s more work to do on the implementation, but it’s an auspicious start.
Talking to the Kernel via Netlink
We have an in-house, Linux-based firewall solution called nap-enforcer, which relies on the built-in stateful firewall functionality in Linux’s netfilter subsystem. Part of this stateful firewall support is the ability to keep track of the protocol state of connections going through the firewall, i.e., connection tracking, or conntrack for short. Conntrack is necessary for the correct handling of stateful protocols, like FTP.
When troubleshooting firewall issues, it’s helpful to be able to inspect and modify the tables that carry this state. We also want to be able to subscribe to events from conntrack and generate log messages for interesting changes, like a connection being open or closed.
This functionality can be controlled via a netlink socket, which is a special kind of socket that enables message-oriented communication between userspace processes and the kernel.
Initially, we built nap-enforcer on top of the command-line
conntrack utility. This worked well enough at first, but it doesn’t
work well for subscribing to streams of events, and
conntrack itself
has some issues: it’s easy to crash it, and it’s inconsistent in its
behavior, which just makes it hard to use.
Cristian Banu’s project was to fix this by writing an OCaml library that lets us talk directly to various kernel subsystems (primarily conntrack) over netlink sockets.
This is trickier than it might seem. Some of these interfaces are rather poorly documented, and existing C libraries don’t always offer very convenient APIs, so a large part of the job was reading the Linux kernel code to understand what really is happening and then figuring out a convenient and type-safe way to make this functionality available to OCaml. The resulting library offers a generic and safe high-level interface to netlink sockets, plus some abstractions built on top for specific netlink-based protocols.
One tricky corner of a high-level netlink API is providing a safe interface for constructing valid Netlink messages without making assumptions about the higher-level protocol. Cristian’s library wraps those computations in an Atkey-style indexed monad which guarantees that the underlying C library (libmnl) is used in a safe way and that the resulting message is valid at the generic netlink level.
Cristian also worked out a way to have repeatable automated tests for the netlink library under our build system, jenga. This is a non-trivial problem because most of these kernel APIs require root access and kernel modules that aren’t loaded by default. His solution involves running tests in a network namespace with an owning user namespace that maps the unprivileged user running the test suite to the root user. This allows the test cases to use otherwise privileged network-related system calls, but only on the subset of network resources governed by the testing namespace.
The project is not yet finished, but the results are very promising, and we hope to move this to production over the next few months.
Streamlining Incr_dom
For a while now, we’ve been using a library we developed internally, called Incr_dom, for building web front-ends in OCaml.
You can think of Incr_dom as a variation on React or the Elm Architecture, except with a different approach to performance. A key feature of React and Elm is that they let you express your UI via simple data-oriented models plus simple functions that do things like compute the view you want to present, typically in the form of a so-called virtual DOM.
What Incr_dom adds to the mix is a lot of power to optimize the computations that need to be done when doing things like computing the view given the current value of the model. (Elm and React both have nice approaches to this as well, though they err on the side of having an easier to use optimization framework that isn’t as powerful.) This is important to us because of the nature of our business: trading applications often have complex, fast-changing models, and being able to render those efficiently is of central importance.
That’s why Incr_dom is built on Incremental, a library whose entire purpose is optimization. Incremental is good at constructing, well, incremental computations, i.e., computations that only need to do a small amount of work when the input changes in small ways. The key is that Incremental lets you write your code so that it reads like a simple all-at-once computation, but executes like a hand-tuned, incremental one. Incremental computations are very useful when constructing UIs in this style, since your data model doesn’t typically change all at once.
I’ve written more than a few blog posts about the basic ideas, and since then, we actually had some interns do much of the work of getting it up and running. But that initial design had some sharp edges that we didn’t know how to fix. And that’s where Jeanne Luning Prak’s project this year came in.
The key problem with the original design was something called the “derived model”. To understand where the derived model comes into play, you need to know a bit more about Incr_dom. An Incr_dom app needs to know how to do more than how to render its model. Here’s a simplified version of the interface that a simple Incr_dom app needs to satisfy which shows a bit more of the necessary structure.
module type App = sig type model type action val view : model Incr.t -> schedule:(action -> unit) -> Vdom.t Incr.t val apply_action : model -> action -> model end
The
view function is what we described above. It takes as its input
an incremental model, and returns an incremental virtual-dom
tree. Note that it also takes a function argument, called
schedule,
whose purpose is to allow the virtual-dom to have embedded callbacks
that can in turn trigger actions that update the model. This is
essentially how you wire up a particular behavior to, say, a button
click.
Those actions are then applied to the model using the provided
apply_action function. This all works well enough for cases where
the required optimization is fairly simple. But it has real
limitations, because the
apply_action function, unlike the
view
function, isn’t incremental.
To see why this is important, imagine you have a web app that’s
rendering a bunch of data in a table, where that table is filtered and
sorted inside of the browser. The filtering and sorting can be done
incrementally in the
view function, so that changing data can be
handled gracefully. But ideally, you’d like for the
apply_action
function to have access to some of the same data computed by
view.
In particular, if you define an action that moves you to the next row,
the identity of that row depends on how the data has been sorted and
filtered. And you don’t want to recompute this data every time
someone wants to move from one row to the next.
In the initial design, we came up with a somewhat inelegant solution,
which was to add a new type, the derived model, which is computed
incrementally, and then shared between the
view and
apply_action
functions. The resulting interface looks something like this:
module type App = sig type model type derived_model type action val derive : model Incr.t -> derived_model Incr.t val view : model Incr.t -> derived_model Incr.t -> schedule:(action -> unit) -> Vdom.t Incr.t val apply_action : model -> derived_model -> action -> model end
And this works. You can now structure your application so that the information that both the view and the action-application function need to know can be shared in this derived model.
But while it works, it’s awkward. Most applications don’t need a derived model, but once any component needs to use it, every intermediate part of your application now has to think about and handle the derived model as well.
I came into the summer with a plan for how to resolve this issue. On
some level, what we really want is a compiler optimization. Ideally,
both
view and
apply_action would be incremental functions, say,
with this signature:
module type App = sig type model type action val view : model Incr.t -> schedule:(action -> unit) -> Vdom.t Incr.t val apply_action : model Incr.t -> action Incr.t -> model Incr.t end
Then, both
apply_action and
view can independently compute what
they need to know about the row structure, and do so incrementally. At
that point there’s only one problem left: these computations are
incremental, but they’re still being duplicated.
But that’s easy enough to fix, I thought: we can do some form of
clever common-subexpression elimination. The basic idea was to cache
some computations in a way that when
view and
apply_action tried
to compute the very same thing, they would end up with a single copy
of the necessary computation graph, rather than two.
This turned out to be complicated for a few reasons, one of them being the rather limited nature of JavaScript’s support for weak references, which are needed to avoid memory leaks.
Luckily, Jeanne had a better idea. Rather than some excessively clever
computation-sharing, we could just change the shape of the
API. Instead of having separate functions for
view and
apply_action, we would have one function that computed both. To that
end, she created a new type, a
Component.t, which had both the
view
and the
apply_action logic. The type is roughly this:
module Component : sig type ('model,'action) t = { view : Vdom.t ; apply_action : 'action -> 'model } end
And now, the app interface looks like this:
module type App = sig type model type action val create : model Incr.t -> schedule:(action -> unit) -> (action,model) Component.t Incr.t end
Because
create is a single function, it can behind the scenes
structure the computation any way it wants, and so can share work
between the computation of the view and the computation of the
action-application function.
This turned out to be a really nice design win, totally eliminating the concept of the derived model and making the API a lot simpler to use. And she’s gotten to see the full lifecycle of the project: figuring out how to best fix the API, implementing the change, testing it, documenting it, and figuring out how to smash the tree to upgrade everyone to the new world.
And actually, this is only about half of what Jeanne did in this half of the summer. Her other project was to write a syntax extension to create a special kind of incremental pattern-match, which has applications for any use of Incremental, not just for UIs. That should maybe be the subject of another blog post.
Apply to be an intern!
I hope this gives you a sense of the nature and variety of the work that interns get to do, as well as a sense of the scope and independence that they get in choosing how to tackle these problems.
If this sounds like a fun way to spend the summer, you should apply! And in case you’re wondering: no, you don’t need to be a functional programming wizard, or have ever programmed in OCaml, or know anything about finance or trading, to be an intern. Most of our interns come in with none of that, and they still do great things! | https://blog.janestreet.com/what-the-interns-have-wrought-2018/ | CC-MAIN-2020-40 | refinedweb | 2,531 | 60.14 |
Hello, I’m enchanted with the idea of bringing performant julia code into a python script through a shared library, especially if it as easy as PackageCompiler seems to imply. I am almost entirely unfamiliar with compiled languages, so much of this feels new to me.
I got a simple script to work, but now the problem I am having is with the following seemingly simple script:
test.jl Base.@ccallable function func0()::Cdouble return sum([1.34, .7]) end Base.@ccallable function func1()::Cdouble return (1.2 + .1) / 2.0 end
I compile the file to a shared library with
julia juliac.jl -vas test.jl
Calling
func1 from python works fine, but
func0 causes a segfault. I have this same problem calling any imported function, and I don’t understand why. I imagine I am misunderstanding something fundamental.
Thank you in advance! | https://discourse.julialang.org/t/aot-compiling-using-packagecompiler/16911 | CC-MAIN-2018-47 | refinedweb | 144 | 68.87 |
NAME
bpf -- Berkeley Packet Filter
SYNOPSIS
#include <net/bpf.h> void bpfattach(struct ifnet *ifp, u_int dlt, u_int hdrlen); void bpfattach2(struct ifnet *ifp, u_int dlt, u_int hdrlen, struct bpf_if **driverp); void bpfdetach(struct ifnet *ifp); void bpf_tap(struct ifnet *ifp, u_char *pkt, u_int *pktlen); void bpf_mtap(struct ifnet *ifp, struct mbuf *m); void bpf_mtap2(struct bpf_if *bp, void *data, u_int dlen, struct mbuf *m); u_int bpf_filter(const struct bpf_insn *pc, u_char *pkt, u_int wirelen, u_int buflen); int bpf_validate(const struct bpf_insn *fcode, int flen);
DESCRIPTION
The Berkeley Packet Filter provides a raw interface, that is protocol independent, to data link layers. It allows all packets on the network, even those destined for other hosts, to be passed from a network interface to user programs. Each program may specify a filter, in the form of a bpf filter machine program. The bpf(4) manual page describes the interface used by user programs. This manual page describes the functions used by interfaces to pass packets to bpf and the functions for testing and running bpf filter machine programs. The bpfattach() function attaches a network interface to bpf. The ifp argument is a pointer to the structure that defines the interface to be attached to an interface. The dlt argument is the data link-layer type: DLT_NULL (no link-layer encapsulation), DLT_EN10MB (Ethernet), DLT_IEEE802_11 (802.11 wireless networks), etc. The rest of the link layer types can be found in <net/bpf.h>. The hdrlen argument is the fixed size of the link header; variable length headers are not yet supported. The bpf system will hold a pointer to ifp->if_bpf. This variable will set to a non-NULL value when bpf requires packets from this interface to be tapped using the functions below. The bpfattach2() function allows multiple bpf instances to be attached to a single interface, by registering an explicit if_bpf rather than using ifp->if_bpf. It is then possible to run tcpdump(1) on the interface for any data link-layer types attached. The bpfdetach() function detaches a bpf instance from an interface, specified by ifp. The bpfdetach() function should be called once for each bpf instance attached. The bpf_tap() function is used by an interface to pass the packet to bpf. The packet data (including link-header), pointed to by pkt, is of length pktlen, which must be a contiguous buffer. The ifp argument is a pointer to the structure that defines the interface to be tapped. The packet is parsed by each processes filter, and if accepted, it is buffered for the process to read. The bpf_mtap() function is like bpf_tap() except that it is used to tap packets that are in an mbuf chain, m. The ifp argument is a pointer to the structure that defines the interface to be tapped. Like bpf_tap(), bpf_mtap() requires a link-header for whatever data link layer type is specified. Note that bpf only reads from the mbuf chain, it does not free it or keep a pointer to it. This means that an mbuf containing the link-header can be prepended to the chain if necessary. A cleaner interface to achieve this is provided by bpf_mtap2(). The bpf_mtap2() function allows the user to pass a link-header data, of length dlen, independent of the mbuf m, containing the packet. This simplifies the passing of some link-headers. The bpf_filter() function executes the filter program starting at pc on the packet pkt. The wirelen argument is the length of the original packet and buflen is the amount of data present. The buflen value of 0 is special; it indicates that the pkt is actually a pointer to an mbuf chain (struct mbuf *). The bpf_validate() function checks that the filter code fcode, of length flen, is valid.
RETURN VALUES
The bpf_filter() function returns -1 (cast to an unsigned integer) if there is no filter. Otherwise, it returns the result of the filter program. The bpf_validate() function returns 0 when the program is not a valid filter program.
SEE ALSO
tcpdump(1), bpf(4). This manpage was written by Orla McGann. | http://manpages.ubuntu.com/manpages/precise/man9/bpf_mtap2.9freebsd.html | CC-MAIN-2013-20 | refinedweb | 679 | 62.98 |
You can subscribe to this list here.
Showing
25
50
100
250
results of 173
OK, I'm including a psp file using the <%@include file="common.psp" %>
syntax, and this code is contained therein:
def trivialFunction():
res.write(dir(req.environ()))
res.write(dir(req.environ()))
trivialFunction()
If I comment out the call to the function it works fine. If I comment out
the straight res.write line and call the function it fails with:
NameError: There is no variable named 'res'
What's the difference? I thought I understood the scoping rules...
Regards,
David
Chuck Esterbrook <ChuckEsterbrook@...> wrote:
> .
Of course, there's a much easier hack that works currently.
In Webware/WebKit/Configs/Application.config set ExtraPathInfo to 1.
Then you can use request().extraURLPath() to get that extra part.
Your servlet will have to interpret it however you choose. I use this
quite a bit.
Ian
>.
Thanks for this! I should have RTFM'd properly in the first place.
David O'Callaghan.
By the way, you can not embed <%@ include file %> directives inside PSP
code. To make control structures work, you'll need to use the <% end %>
tags like so:
<%
if errorString == "": %>
<%@ include file = "support/goodorder.psp" %><% end %><%
else: %>
<%@ include file = "support/badorder.psp" %><% end %> </body>
David.
-----------------------------------------------------------------
David Casti Managing Partner
Neosynapse
Hi,
This was driving me nuts during development, as static="0" wasn't been
used, and I was having to restart Webware everytime I made a change to
my includes.
Basically, in Generators.py, the IncludeGenerator class constructor
doesn't set self.static properly. If static is "1" or "true", it gets
set to the integer 1. If static is "0", it stays "0" which tests true.
This patch fixes the problem.
jack.
--- Webware-orig/PSP/Generators.py Sun Feb 25 10:18:29 2001
+++ Webware/PSP/Generators.py Mon Jul 2 23:21:20 2001
@@ -223,7 +223,7 @@
GenericGenerator.__init__(self,ctxt)
self.attrs = attrs
self.param = param
- self.static=1
+ self.static=0
self.scriptgen = None
self.page = attrs.get('file')
@@ -234,7 +234,9 @@
self.static = attrs.get('static', None)
if self.static == string.lower("true") or self.static ==
"1":
- self.static=1
+ self.static=1
+ else:
+ self.static=0
if not os.path.exists(thepath):
print self.page
At 01:38 PM 7/1/2001 -0700, haaserd wrote:
The problems of importing the MK-generated classes and opening the .csv are
similar. In the first case, you must put the classes where they can be
found or augment PYTHONPATH/sys.path. In the second case, you must specify
a valid path (whether you prefer relative or absolute is your choice).
There might be a shift here, but there wouldn't be less to consider and
configure.
>operation slightly faster as Classes.csv is not cacheable and the Python
Any .csv is cacheable by simply keeping the data in memory (such as an
instance of DataTable). In this particular case, MK creates a series of
Klass and Attr objects (found in MiddleKit.Core) which are in fact cached
in memory for the lifetime of the model (which is typically the lifetime of
the store that uses the memory). The .csv is thrown away as it is merely a
means to convey the model. Other means such as XML could be introduced in
the future without disturbing the rest of MiddleKit.
Perhaps it could make start up faster if the Model was pickled to disk and
read in lieu of the .csv spec provided the .csv date was older. I've added
that to the TO DO list as a potential optimization.
>module would be, and eliminate a potential problem where users (such as
>me) update Classes.csv as thoughts occur and re-generate only when no
>further testing can be done with the current data structure.
Is there any reason not to generate after editing the .csv?
If there is, you might consider a separate file for your thoughts which you
then copy over before generating. Of course, you can make a little script
to do the copy and the generate:
#!/bin/sh
# gen
cp Classes.csv Classes.bak
cp NewClasses.csv Classes.csv
python path/to/MiddleKit/Design/Generate.py --db MySQL --model MyApp.mkmodel
Then just type this when you want:
> gen
Hope that helps.
-Chuck
At 05:09 PM 6/30/2001 -0700, haaserd wrote:
.
Actually it's *you* that must either:
* Pass an absolute path that is valid.
* Pass a relative path that is valid.
MiddleKit and DataTable aren't/can't be smart enough to find your model.
Think of it as a Python open() (which does in fact happen down in the
guts). Only what would work for open() will work when you pass in the path
to your model.
Since this is file system stuff and people structure their files in
different ways, this varies from person to person.
However, it is certainly true that MK deserves an "integrating with WebKit
section".
-Chuck
At 03:52 PM 6/28/2001 -0700, Jason Novotny wrote:
>Hi,
>
> Pardon my ignorance, but I'm unclear what I should do after
>compiling the mod_webkit adapter into Apache. It all worked fine, and
>I see the lines added to my httpd.conf:
>
><Location /WK>
> WKServer localhost 8086
> SetHandler webkit-handler
></Location>
>
> Now what do I do? Where's the server, etc. Neither the mod_webkit
>README or the online installation seems to give me a clue on how to
>proceed.
Have you read the Install Guide? "3. Launch the servers"
> cd Webware/WebKit
> ./AppServer
Although I admit this could be made more obvious. Looks like it was buried
under WebKit.cgi.
-Chuck
At 05:31 PM 6/28/2001 +0200, F. GEIGER wrote:
>is the reason, because of
>
>*****The first servlet will not be able to send any new response data once
>the call to forwardRequest returns*****
>
>Sorry for bothering you all.
So much for the response I just sent out. :-)
Although I still think it applies since you were setting cookies in
response and then reading cookies in request. The two are not linked and
it's a notable point.
-Chuck
At 03:26 PM 6/28/2001 +0200, F. GEIGER wrote:
>which yields 'C1627001'. But that's a yesterday's value! As a result cookie
>and some database contents do not match.
>
>I mean, I set 'C1628000' calling self.response(setCookie(...) and get
>'C1627001' from yesterday, when I call self.request().cookies(...)!
>
>Can anyone enlighten me? What do I do wrong?
>
>Too me it seems, that the cookie is not transferred to the browser (MSIE
>5.5, cookies are activated), so I tried a 'self.writeln(" ")' as I thought
>this would force a transfer to the browser. But that doesn't work either.
You have the right idea. The cookie is not transferred to the browser until
the response is actually delivered. request.cookie() is reading the cookies
that came in while the response is just a cache of cookies that will go
out. The 2 are disconnected.
I usually deal with this by putting the value of interest in an attribute.
So in awake(), I might set it:
self._value = self.request().cookie('foo')
Then later, if I change it, I do:
self._value = expression()
self.response().setCookie('foo', self._value)
Then later in my code I just use self._value and consider the request and
response cookies to be "I/O channels" if you will.
-Chuck
At 09:46 AM 6/27/2001 -0400, Clark C . Evans wrote:
>1. How do I check if the request is a get or post?
request.method()
as in:
self.request().method()
.
>3. How do I get a good uri for the current servlet
> such that I can pass to it get values? I added
> these methods to my SitePage...
You should be able to use request.uri().
>4. How do I get a good uri for _another_ servlet?
> I was thinking something like...
> self.getServletURI("AnotherServlet",args)
>
> Where args is optional (see "uri()" above...)
I just make the URI like so:
self.sendRedirect("SomeoneElse?x=%i&y=%i" % (x, y))
You can also make use of request.adapterName() if you have some reason to.
>5. How do I call a method in another servlet... without
> "forwarding". I know I can "import" the class and
> then put my shared code in a module function. Any
> other approaches?
The only approaches I use and recommend (in no particular order):
* Make an abstract FooPage class from which the two classes descend.
* Make a mix-in class. This is very similar to the one just above, but the
point is that the mix-in is not part of the primary inheritance tree of
your pages and can be used here and there as you need it. It adds methods
where methods are needed.
* Make an independent Py module featuring functions or "global" data.
Perhaps the data is initialized only once when the module is imported. This
is can be nice because importing modules is threadsafe in Python.
* Use composition. e.g., import a class from a shared module and create an
instance which your servlet keeps around and uses.
Well, that's all that comes to mind. I've been happy with and have used all
4 techniques.
-Chuck
At 09:22 AM 6/27/2001 -0400, Clark C . Evans wrote:
>I'd like to encapsulate all of the code for
>dealing with one database table in a single
>servlet. Thus, from other servlet's, I'd
>like to be able to call a method in another
>servlet. Is there an easy way to do this?
>(sorry if this is ignorant...)@...
>
Hi all,
could anybody please put some comments into the DocSupport __init__.py file.
This is because WinZip does not create a 0 byte file when uncompressing and
this causes DocSupport not to be recognised as module.
Thanx, Erny operation slightly
faster as Classes.csv is not cacheable and the Python module would be, and
eliminate a potential problem where users (such as me) update Classes.csv as
thoughts occur and re-generate only when no further testing can be done with the
current data structure.
Unfortunately, coding that up is beyond my present ability.
Roger Haase
haaserd wrote:
> .readModelFileNamed). If that were documented in Quick Start, I would be
> happy. Else DataTable.py must figure out the absolute address of the
> Classes.csv file used by the generate process.
_________________________________________________________
Do You Yahoo!?
Get your free @yahoo.com address at
Just to chime in on this.
I too just encountered this problem. This fix works:
> >:]
> > >
> >
But this one just causes infinite loops.
> uriEnd = string.split(uri[0], '/')[-1]
> uri[0] = './' + uriEnd + '/'
Any chance a definitive patch could be committed? :)
jack.
Sorry if I didn't do enough research and make my first question clear the first
time around.
It was MiscUtils/DataTable.py that was trying to load xxx.mkmodel/Classes.csv
that gave me the problem. DataTable.py at line 293 does an open for the
relative filename 'xxx.mkmodel/Classes.csv'. My script did not modify the CWD
and it was pointing to /python/webware at the point of failure.
(When I did modify the CWD to fix the above problem, something else broke - I
won't do that again.).
Your answer confused me. I downloaded and installed Webware/WebKit as a
(stable, yes I realize it is beta) Python application so I have the structure
/Python/Webware/WebKit. My code is not on the Python directory branch.
I think your answer said you are developing WebKit along with another
application, and have WebKit installed off the Python directory branch in an
application directory. Your different directory structure may be yielding
different results.
Roger Haase
Chuck Esterbrook wrote:
> At 08:55 PM 6/28/2001 -0700, haaserd wrote:
> >I first placed them in my within my project directory which
> >is not a branch of the Webware directory. This caused a
> >problem because when my script was executed, the CWD was
> >/webware (not my project directory) and the traceback ended
> >with:
> >
> > File "MiscUtils\DataTable.py", line 293, in readFileNamed
> > file = open(self._filename, 'r')
> >IOError: [Errno 2] No such file or directory:
> >'PetroDB.mkmodel\\Classes.csv'
>
> This is just simply a filename issue. In any Python program, you can use
> relative filenames if they are correct for your cur dir. Otherwise use an
> abs path.
>
> Since your MiddleKit model is more likely to be located next to your WebKit
> context, than next to your Webware installation, you want to use that.
>
> Suppose your MK directory is next to your WebKit context like so:
> MyApp/
> MyApp.mkmodel/
> Context/
> Main.py
> __init__.py
>
> In __init__.py you could take the dirname(dirname()) of the __file__ and
> add on 'MyApp.mkmodel' to get the right path.
>
> Under no circumstance do I recommend writing WebKit code that relies on the
> current directory. Inevitably 2 separate bodies of code will start fighting
> over this.
>
> >My second question is why the use of (from the Quick Start
> >Guide) video.serialNum() when the corresponding MySQL table
> >name is videoId? Wouldn't accessing it with video.videoId()
> >or naming it serialNum be less confusing?
>
> Someone talked me into using videoId instead of serialNum for reasons I
> forget. If no one has any objections, I would be fine with changing it to
> serialNum.
>
> -Chuck
>
> _______________________________________________
> Webware-discuss mailing list
> Webware-discuss@...
>
_________________________________________________________
Do You Yahoo!?
Get your free @yahoo.com address at | http://sourceforge.net/p/webware/mailman/webware-discuss/?viewmonth=200107&page=6&style=flat | CC-MAIN-2015-35 | refinedweb | 2,243 | 69.28 |
decimal (C# Reference)
Updated: December 2008
The decimal keyword indicates a 128-bit data type. Compared to floating-point types, the decimal type has more precision and a smaller range, which makes it appropriate causes a compilation error.
For more information about implicit numeric conversions, see Implicit Numeric Conversions Table (C# Reference).
For more information about explicit numeric conversions, see Explicit Numeric Conversions Table (C# Reference).
You can format the results by using the String.Format method, or through the Console.Write method, which calls String.Format(). The currency format is specified by using the standard currency format string "C" or "c," as shown in the second example later in this article. For more information about the String.Format method, see String.Format.
In this example, a decimal and an int are mixed in the same expression. The result evaluates to the decimal type.
The following example uses a statement that tries to add the double and decimal variables:
The result is the following error:
Operator '+' cannot be applied to operands of type 'double' and 'decimal'
In this example, the output is formatted by using the currency format string. Notice that x is rounded because the decimal places exceed $0.99. The variable y, which represents the maximum exact digits, is displayed exactly in the correct format.
public class TestDecimalFormat { static void Main() { decimal x = 0.999m; decimal y = 9999999999999999999999999999m; Console.WriteLine("My amount = {0:C}", x); Console.WriteLine("Your amount = {0:C}", y); } } /* Output: My amount = $1.00 Your amount = $9,999,999,999,999,999,999,999,999,999.00 */
For more information, see the following sections in the C# Language Specification:
1.3 Types and Variables
4.1.7 The decimal Type | http://msdn.microsoft.com/en-us/library/364x0z75(v=vs.90).aspx | crawl-003 | refinedweb | 285 | 51.75 |
Stefan - 9. Mai 2008
A lot of the power of C++ comes from the STL, the C++ Standard Library. And even more power is available using the Boost libraries, which are about to become part of the upcoming new STL version. Thus, using Boost libraries in your project is not even very convenient, it will also guarantee compatibility between platforms and future STL releases. (To all you C++ gurus out there: I hope this short introduction is not too misleading.)
While the Boost libraries are easy to install on Unix machines and the Boost websites offers binaries for Visual C++ 2005, it is more complicated to use Boost on Windows with the GNU Compiler Collection (aka gcc). In fact, it took me several hours to figure out how to use Boost with my favourite IDE, Netbeans. Netbeans? The Java IDE from Sun? Yes, I prefer Netbeans over Eclipse, because Netbeans is easier to use, but it is still a full-featured IDE and it even has a greatC/C++-Plugin.
After doing some experiments with MingW, I decided that Cygwin would be a better choice. (Maybe I was just to stupid to get things working with MingW.) Here’s what you have to do to get Boost, cygwin with gcc/g++ and Netbeans working under Windows.
C:Dokumente und Einstellungensf>gcc --versiongcc (GCC) 3.4.4 (cygming special, gdc 0.12, using dmd 0.125)Copyright (C) 2004 Free Software Foundation, Inc.This is free software; see the source for copying conditions. There is NOwarranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
This is my example code:
#include <iostream>
#include <string>
#include <boost/regex.hpp>
using namespace std;
using namespace boost;
int main() {
string s = "This is my simple sample text, really.";
regex re(",|:|-|\s+");
sregex_token_iterator my_iter(s.begin( ), s.end( ), re, -1);
sregex_token_iterator my_end;
while (my_iter != my_end)
cout << *my_iter++ << 'n';
return (EXIT_SUCCESS);
}
You can also build this little program on the command line. Open your Cygwin Bash Shell and navigate to your code directory. (Cygwin maps your windows drives under /cygdrive – thus cd /cygdrive/c/ navigates you to your windows C: drive.)To compile your source file called regexp.cpp, just type:g++ -c -I/usr/include/boost-1_33_1/ -o regexp.o regexp.cppAnd to link and build it:g++ -o regexp.exe regexp.o -lboost_program_options-gcc-mt-s -lboost_regex-gcc-mt-sThat’s all. Now type ./regexp.exe to start your compiled program.
cd /cygdrive/c/
g++ -c -I/usr/include/boost-1_33_1/ -o regexp.o regexp.cpp
g++ -o regexp.exe regexp.o -lboost_program_options-gcc-mt-s -lboost_regex-gcc-mt-s
./regexp.exe | http://www.javadtaghia.com/clam/boost-c/settingupboostgccwindows | CC-MAIN-2018-47 | refinedweb | 439 | 59.3 |
When I started working with React Native recently, I did a lot of research on infinite scroll. There are many proposed solutions online, even libraries ready to be used, but none of them were quite right for me. That is why I created one for myself, and this blog will show you how you can do it too.
Step 1: The idea
I wanted to create a picture app that fetches data from API and shows a list of pictures with a title and description. Previous experience taught me that getting the whole list and rendering it on screen can be really bad for performances of your application (Web or Mobile) so I decided to limit the response to 5 items per page :
"pictures": { "current_page": 1, "data": [...], "last_page": 8, "per_page": 5, "total": 40 }
As you can see from the response, there are 40 items in total, with 5 items per page on a total of 8 pages.
Step 2: Setting the scene📜
First we need to fetch the data from API. For this I will use axios.
(You can find the full documentation here)
npm install --save axios
After installing axios, we need to create a new instance of axios with our API URL, in root folder of our application (If you are not sure where the root folder is, just make it appear in the same place as App.js file) and name it “axios.js”
import axios from 'axios'; var instance = axios.create({ baseURL: '' }); export default instance;
After creating the instance, we can start implementing our infinite scroll.
First, create a new component called “ImageList.js” and add all imports that we will use for creating and rendering pictures:
import React, { Component } from 'react'; import {Text,View,ScrollView,TouchableOpacity} from 'react-native'; import API from './axios';
As you can see, we added a few things that we will use for this component. The most important is ScrollView and we will use it for onScroll event, a few steps later.
Step 3: The Coding 💻
We can now start creating our class component. To do that, we need to define our state and create a life cycle method componentWillMount().
export default class ImageList extends Component { state = { loading: false, data: [], current_page: 1, error: null, hasMore: true } componentWillMount() { this.getListOfPictures(); }; }
The function getListOfImages() is then called, like you can see in the next block of code. A similar function was found on stack overflow but it didn’t work for me, so I modified it. This is what I came up with:
getListOfPictures = () => { if (this.state.loading) { return; } this.setState({ loading: true }); API.get(`/pictures?page=${this.state.current_page}`) .then(res => { const nextPictures= res.data.pictures.data.map(data => ({ title: data.title, image_url: data.image_url, description: data.description, id: data.id })); this.setState({ hasMore: ( res.data.pictures.current_page <= res.data.pictures.last_page), data: [...this.state.data, ...nextPictures], loading: false, current_page: this.state.current_page + 1}) }).catch(error => {this.setState({ error, loading: false });}); }
The getListOfImages() function allows us to get images from our API. As you can see in the window above, we need to set our loading to true. We then use our instance of axios and make a request to the API with the starting page. (Remember, we have 8 pages with 5 items on each page – 40 items in total).
Next, we add our data to nextPicture variable where we hold the 5 items, and append it to our data array. For hasMore property we will return true or false based on current_page and last_page, and lastly for current_page we will just increment value after each request. For rendering list of pictures we will use ScrollView:
render() { return ( <ScrollView onScroll={({ nativeEvent }) => { if (this.isCloseToBottom(nativeEvent) && this.state.hasMore) { this.getListOfPictures(); }}}> {this.renderList()} </ScrollView> }
As you can see, we have a few steps to follow to make this work. The first function that we need is “isCloseToBottom”, and the second is “renderList”.
isCloseToBottom({ layoutMeasurement, contentOffset, contentSize }) { return layoutMeasurement.height + contentOffset.y >= contentSize.height - 50; }
This function will return Boolean value based on height and content of the screen.
Lastly, we will implement our function to actually see our images with title and description. For displaying pictures I used ‘react-native-elements’; Card component, but you can use this code for any type of custom View. If you want to follow my example you can find the full documentation for react-native-elements here.
renderList = () => { return ( this.state.data.map((u) => { return ( <TouchableOpacity key={u.id} }}> <Card featuredTitle={u.title} image={{ uri: u.image_url }} imageStyle={styles.image}> <View style={{ padding: 10 }}> <Text style={{ fontSize: 15}}>Description:</Text> <Text>{u.description}</Text> </View> </Card> </TouchableOpacity>);}) ); }
I hope this article will help you implement infinite scroll anywhere you need.
If you experience any roadblocks, have uncertainties, or maybe suggestions on how to improve this code, let me know in the comment section below. 👏 | https://www.maestralsolutions.com/react-native-custom-infinite-scroll/ | CC-MAIN-2020-40 | refinedweb | 808 | 57.06 |
class Solution { public: int findMinDifference(vector<string>& times) { int n = times.size(); sort(times.begin(), times.end()); int mindiff = INT_MAX; for (int i = 0; i < times.size(); i++) { int diff = abs(timeDiff(times[(i - 1 + n) % n], times[i])); diff = min(diff, 1440 - diff); mindiff = min(mindiff, diff); } return mindiff; } private: int timeDiff(string t1, string t2) { int h1 = stoi(t1.substr(0, 2)); int m1 = stoi(t1.substr(3, 2)); int h2 = stoi(t2.substr(0, 2)); int m2 = stoi(t2.substr(3, 2)); return (h2 - h1) * 60 + (m2 - m1); } };
@alexander nice a simple, but this will be O(n log n) due to sorting. If you plot the minutes on a line (bool array) then check the line you can reduce this to O(n). You can do this because there are not that many minutes in a day and so the bool array size will be relatively small. Check out some of the other posts to see how it's done.
Although not the optimal solution, but i like the line :abs(timeDiff(times[(i - 1 + n) % n], times[i]));
I think in the first line of the for loop, if you wrote
times[(n - 1 + i) % n], times[i] would be easier to understand
@ian34 probably not, i-1 is prev index, (i-1+n)%n is simply tring to looping it circularly without "if", i.e. last element will get first element as prev element.
The extra price is "abs". I doubt it will run faster compared to "if" version. The optimal one should set prev to last element before loop.
@jdrogin If adding 1 line, this could be an O(n) solution. The line is " if (n > 1440) return 0;". See the code below.
When n <= 1440, it is O(log2(1440) n), i.e. O(n). The run time is 12 ms, currently beating 97.71%.
class Solution { public: int findMinDifference(vector<string>& timePoints) { int n = timePoints.size(); if (n > 1440) return 0; vector<int> times; for (int i = 0; i < n; i++) times.push_back(to_min(timePoints[i])); sort(times.begin(), times.end()); int ans = times[0]+60*24-times.back(); for (int i = 1; i < n; ++i) { ans = min(ans, times[i]-times[i-1]); } return ans; } private: int to_min(string& a) { int h = (a[0]-'0')*10+(a[1]-'0'), m = (a[3]-'0')*10+(a[4]-'0'); return 60*h+m; } };
Looks like your connection to LeetCode Discuss was lost, please wait while we try to reconnect. | https://discuss.leetcode.com/topic/82629/c-clean-code | CC-MAIN-2017-43 | refinedweb | 417 | 74.19 |
Software Engineer at Stripe
One track lover/Down a two-way lane
“Suppose I say to Fat, or Kevin says to Fat, "You did not experience God. You merely experienced something with the qualities and aspects and nature and powers and wisdom and goodness of God.” This is like the joke about the German proclivity toward double abstractions; a German authority on English literature declares, “Hamlet was not written by Shakespeare; it was merely written by a man named Shakespeare.” In English the distinction is verbal and without meaning, although German as a language will express the difference (which accounts for some of the strange features of the German mind)."Valis, p71 (Book-of-the-Month-Club Edition)
Philip K. Dick is not known for his light or digestible prose. The vast majority of his characters are high. Like, really, really, really high. And yet, in the above quote from Valis (published in 1981), he gives a remarkably foresighted explanation of the notoriously misunderstood Python parameter passing paradigm. Plus ça change, plus c'est omnomnomnom drugs.
The two most widely known and easy to understand approaches to parameter passing amongst programming languages are pass-by-reference and pass-by-value. Unfortunately, Python is “pass-by-object-reference”, of which it is often said:
“Object references are passed by value.”
When I first read this smug and overly-pithy definition, I wanted to punch something. After removing the shards of glass from my hands and being escorted out of the strip club, I realised that all 3 paradigms can be understood in terms of how they cause the following 2 functions to behave:
def reassign(list): list = [0, 1] def append(list): list.append(1) list = [0] reassign(list) append(list)
Let’s explore.
“Hamlet was not written by Shakespeare; it was merely written by a man named Shakespeare.” Both Python and PKD make a crucial distinction between a thing, and the label we use to refer to that thing. “The man named Shakespeare” is a man. “Shakespeare” is just a name. If we do:
a = []
then
[] is the empty list.
a is a variable that points to the empty list, but
a itself is not the empty list. I draw and frequently refer to variables as “boxes” that contain objects; but however you conceive of it, this difference is key.
In pass-by-reference, the box (the variable) is passed directly into the function, and its contents (the object represented by the variable) implicitly come with it. Inside the function context, the argument is essentially a complete alias for the variable passed in by the caller. They are both the exact same box, and therefore also refer to the exact same object in memory.
Anything the function does to either the variable or the object it represents will therefore be visible to the caller. For example, the function could completely change the variable’s content, and point it at a completely different object:
The function could also manipulate the object without reassigning it, with the same effect:
To reiterate, in pass-by-reference, the function and the caller both use the exact same variable and object.
In pass-by-value, the function receives a copy of the argument objects passed to it by the caller, stored in a new location in memory.
The function then effectively supplies its own box to put the value in, and there is no longer any relationship between either the variables or the objects referred to by the function and the caller. The objects happen to have the same value, but they are totally separate, and nothing that happens to one will affect the other. If we again try to reassign:
Outside the function, nothing happens. Similarly:
The copies of variables and objects in the context of the caller are completely isolated.
Python is different. As we know, in Python, “Object references are passed by value”.
A function receives a reference to (and will access) the same object in memory as used by the caller. However, it does not receive the box that the caller is storing this object in; as in pass-by-value, the function provides its own box and creates a new variable for itself. Let’s try appending again:
Both the function and the caller refer to the same object in memory, so when the append function adds an extra item to the list, we see this in the caller too! They’re different names for the same thing; different boxes containing the same object. This is what is meant by passing the object references by value - the function and caller use the same object in memory, but accessed through different variables. This means that the same object is being stored in multiple different boxes, and the metaphor kind of breaks down. Pretend it’s quantum or something.
But the key is that they really are different names, and different boxes. In pass-by-reference, they were essentially the same box. When you tried to reassign a variable, and put something different into the function’s box, you also put it into the caller’s box, because they were the same box. But, in pass-by-object-reference:
The caller doesn’t care if you reassign the function’s box. Different boxes, same content.
Now we see what Philip K. Dick was trying to tell us. A name and a person are different things. A variable and an object are different things. Armed with this knowledge, you can perhaps start to infer what happens when you do things like
listA = [0] listB = listA listB.append(1) print listA
You may also want to read about the interesting interactions these concepts have with mutable and immutable types. But those are stories for another day. Now if you’ll excuse me, I’m going to read “Do Androids Dream Of Electric Sheep?” - my meta-programming is a little rusty. | http://robertheaton.com/2014/02/09/pythons-pass-by-object-reference-as-explained-by-philip-k-dick/ | CC-MAIN-2015-35 | refinedweb | 986 | 62.68 |
Using JDK Point. Modify PointMain
7. Using JDK Point. Modify PointMain, pp. 547-548 by dropping the calls to distanceFromOrigin, and adding the "import java.awt.*" to allow use of JDK Points. Write code to put the two Points in an array of 2 Points named pair. Do the translates using array references, such as pair[0] and pair[1] instead of p1 and p2. Print the points out using a loop over the array. Also try Arrays.toString on the array. If you do not modfy the code at the link and just copy that you will get zero points. Also, note that you are using JDK Point objects. You cannot access x and y directly, but you do have access to all the methods for the Point class of the JDK.
// A program that deals with 2D points.
// Fourth version, to accompany encapsulated Point class.
public class PointMain {
public static void main(String[] args) {
// create two Point objects
Point p1 = new Point(7, 2);
Point p2 = new Point(4, 3);
// print each point and its distance from origin
System.out.println("p1 is (" + p1.getX() + ", " + p1.getY() + ")");
System.out.println("distance from origin = " + p1.distanceFromOrigin());
System.out.println("p2 is (" + p2.getX() + ", " + p2.getY() + ")");
System.out.println("distance from origin = " + p2.distanceFromOrigin());
// translate each point to a new location
p1.translate(11, 6);
p2.translate(1, 7);
// print the points again
System.out.println("p1 is (" + p1.getX() + ", " + p1.getY() + ")");
System.out.println("p2 is (" + p2.getX() + ", " + p2.get | https://www.studypool.com/questions/251261/using-jdk-point-modify-pointmain | CC-MAIN-2017-13 | refinedweb | 251 | 71.71 |
31 October 2012 07:30 [Source: ICIS news]
SINGAPORE (ICIS)--?xml:namespace>
“We are not sure whether polymers are within the list of banned [export] goods, so now we just put all our new contracts on hold,” the source said.
Iranian exporters will no longer be able to export goods including wheat, flour, sugar, and red meat, as well as aluminium and steel ingots, according to a letter from Deputy Industry Minister Seyyed Javad Taghavi published in Iranian media on 30 October.
The letter also said that a further list of banned goods would be announced later.
The ban in exports is to prevent further plunge in the Iranian rial currency – a result of the
JPC said that exports of previously contracted cargoes will still proceed.
“Existing customers do not have to worry, as we are still exporting the transacted cargoes,” he said.
However, he added that perhaps some December shipments might be suspended because of the ban.
“December cargoes are more than 30 days away, we will manage the shipment if the existing contracts get affected,” the source said.
JPC, which produces HDPE injection, blow moulding and pipe grades at its HDPE facilities at Assaluyeh, is an active exporter to
JPC also produces polypropylene (PP) which is sold domestically. | http://www.icis.com/Articles/2012/10/31/9609075/irans-jam-petchem-stops-hdpe-exports-discussion-on-possible-govt.html | CC-MAIN-2014-42 | refinedweb | 210 | 56.59 |
NAME
ptsname, ptsname_r - get the name of the slave pseudoterminal
SYNOPSIS
#include <stdlib.h>
char *ptsname(int fd); int ptsname_r(int fd, char *buf, size_t buflen);
ptsname():
Since glibc 2.24:
_XOPEN_SOURCE >= 500
Glibc 2.23 and earlier:
_XOPEN_SOURCE
ptsname_r():
_GNU_SOURCE
DESCRIPTION
The ptsname() function returns the name of the slave pseudoterminal device corresponding to the master referred to by the file descriptor, NULL is returned.
On success, ptsname_r() returns 0. On failure, an error number is returned to indicate the error.
ERRORS
VERSIONS
ptsname() is provided in glibc since version 2.1.
ATTRIBUTES
For an explanation of the terms used in this section, see attributes(7).
CONFORMING TO
pts)
COLOPHON
This page is part of release 5.13 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at. | https://man.archlinux.org/man/ptsname.3.en | CC-MAIN-2022-40 | refinedweb | 145 | 67.35 |
Opened 9 years ago
Closed 6 years ago
#6273 closed (fixed)
Support for passwd-like password changing
Description
I wrote a short command handler for management to change the password of the current user, or a given user, just like passwd.
Attachments (4)
Change History (18)
Changed 9 years ago by toxik
comment:1 Changed 9 years ago by adrian
- Needs documentation unset
- Needs tests unset
- Owner changed from nobody to adrian
- Patch needs improvement set
- Status changed from new to assigned
comment:2 Changed 9 years ago by adrian
- Owner changed from adrian to nobody
- Status changed from assigned to new
Ack, I didn't mean to accept the ticket -- hopefully toxik will be able to code up the patch.
comment:3 Changed 9 years ago by Simon Greenhill <dev@…>
- Triage Stage changed from Unreviewed to Accepted
Changed 9 years ago by toxik
comment:4 Changed 9 years ago by toxik
Okay, sorry for the delay, but I fixed it. Works for me, but I had to make management.py a package, so I don't know if that has any side-effects. (Moved it to ./management/__init__.py, should be fine I suppose.)
Also note that you want to delete the old management.py file since I doubt the patch will do that.
comment:5 Changed 9 years ago by toxik
Oh and I changed the command a lil' bit, now it aborts if any of the two inputs are empty rather than if any are empty after both have been answered.
Also I'd like to post this svn st so as to clarify what I meant:
D django/contrib/auth/management.py A django/contrib/auth/management A django/contrib/auth/management/commands A django/contrib/auth/management/commands/__init__.py A django/contrib/auth/management/commands/passwd.py A django/contrib/auth/management/__init__.py
Changed 8 years ago by justinlilly
comment:6 Changed 8 years ago by justinlilly
- Cc justinlilly@… added
comment:7 Changed 8 years ago by justinlilly
This functionality is available via django-command-extensions Not sure if it should be wontfix'd as its available as a 3rd party app, especially since adrian was in favor. That being said, adrian was in favor before django-command-extensions existed. Hopefully someone with a better grasp on this stuff can decide?
comment:8 Changed 8 years ago by toxik
Well, it's in django-command-extensions because I put it there. :-)
I think something like this should be available so that you don't have to force system administrators to either update a user's password using a Python shell or by means of the admin.
As an aside, would you (justinlilly) care to maintain this one? It'd be nice as I don't have the time over that I used to, what with the real world and that.
comment:9 Changed 8 years ago by justinlilly
- Owner changed from nobody to justinlilly
Sure. I'll take this.
comment:10 Changed 7 years ago by jacob
- Needs documentation set
- Needs tests set
Before this can go in:
- passwd is a bit inside-baseball-y. Is there something wrong with change_password?
- Needs documentation.
- Needs tests.
Changed 7 years ago by justinlilly
Now with docs and renamed to change_password
comment:11 Changed 7 years ago by justinlilly
- Needs documentation unset
Added docs and changed passwd to change_password. Will need to do some more digging on the proper way to test these sorts of scripts.
comment:12 Changed 7 years ago by justinlilly
- Needs tests unset
- Patch needs improvement unset
Russel has given me special dispensation for making this patch a "manual test" due to the complications for testing it. Should be ready for review, then check in.
comment:13 Changed 7 years ago by SmileyChris
- Needs tests set
It's not that complicated: monkeypatch the _get_pass method in your tests to return what you want without prompting.
comment:14 Changed 6 years ago by russellm
- Resolution set to fixed
- Status changed from new to closed
This is a good idea, but a key improvement needs to be made before we can check it in. Because Django's auth system is technically a contrib app, this command should live in the django/contrib/auth directory. The advantages of this are that it won't clutter the django-admin.py command namespace if the auth app isn't installed, and it keeps all of the auth code together in the same subpackage.
Could you rework the patch to do this? Here's some documentation on how applications can specify custom django-admin.py actions: | https://code.djangoproject.com/ticket/6273 | CC-MAIN-2016-30 | refinedweb | 768 | 60.45 |
Years.
I recently began investigating calling WCF Services with jQuery. There aren't many articles or working samples that are simple enough to be a good starting point for development or proof of concept. I gathered what I learned and decided to cut out as much superfluous details from the paradigm as possible: I tried to make it palatable.
This is the smallest working example of jQuery calling a WCF Service anywhere (as far as I know).
WCF services are fragile. Use a good source control system or some substitute. If you make a change and everything is still working, check it in and label it. That way, when you break your code (and you will) and can't figure out what happened, you can revert to a known good version.
Normally the cache is your friend. When developing, the cache is your enemy. When your code changes don't seem to be having any effect, clear the cache and/or restart the web server. Sometimes I put message boxes or log strings in the code to see if it actually being executed.
I've got nothing against interfaces; I even blogged about them here. But I'm going to guess that less than one percent of web services require the use of an interface—maybe less than one in a thousand—maybe less than that.
The default template for WCF services uses an interface for a contract—an inexplicably stupid decision.
Here is how I removed the unneeded complexity.
In the interface file, the generated class looks something like this:
[ServiceContract]
public interface IService1
{
[OperationContract]
string GetData(int value);
WebInvoke
Then I deleted all but one function in the implementation class…to get it really lean and mean.
using System;
using System.ServiceModel;
using System.ServiceModel.Activation;
using System.ServiceModel.Web;
[ServiceContract]
public class MyService
{
[OperationContract]
[WebInvoke(Method = "POST",
BodyStyle = WebMessageBodyStyle.Wrapped,
ResponseFormat = WebMessageFormat.Json)]
public string MyFunction(string Count)
{
return "The Count you passed in is: " + Count.ToString() ;
}
}
<!DOCTYPE html>
<html>
<head>
<title>Call WCF</title>
<script src='Scripts/jquery.js' type='text/javascript'></script>
<script type="text/javascript">
var counter = 0;
function CallMyService()
{
counter++;
$.ajax({
type: "POST",
url: "MyService.svc/MyFunction",
data: '{"Count": "' + counter + '"}',
contentType: "application/json", // content type sent to server
success: ServiceSucceeded,
error: ServiceFailed
});
}
// ---- WCF Service call backs -------------------
function ServiceFailed(result)
{
Log('Service call failed: ' + result.status + ' ' + result.statusText);
}
function ServiceSucceeded(result)
{
resultObject = result.MyFunctionResult;
Log("Success: " + resultObject);
}
// ---- Log ----------------------------------------
// utility function to output messages
function Log(msg)
{
$("#logdiv").append(msg + "<br />");
}
</script>
</head>
<body>
<input id="Button1" type="button" value="Execute" onclick="CallMyService();" />
<div id="logdiv"></div> <!--For messages-->
</body>
</html>
Note I am using a simple HTML page to call the service. It's my way of showing, "There's nothing up my sleeve."
You can download the full project here. I recompiled it to .NET 4.5.
You should see this: | http://www.codeproject.com/Articles/540169/CallingplusWCFplusServicespluswithplusjQuery-e2-80 | CC-MAIN-2013-48 | refinedweb | 478 | 50.73 |
This is only the 2nd program I've ever worked on and I am stuck right off the bat. Our teacher wrote some of the code for us. We just need to call a function for each section of classes, where we remove the spaces between the classes (for example: CMSC 201 CMSC 202 CMSC 301 -- Just remove the spaces between the classes not between CMSC 201.)
LINK to the classes we just need to do A-F:
import string def main(): # set up course lists requiredList = 'CMSC 201 CMSC 202 CMSC 203 CMSC 304 CMSC 313 CMSC 331 CMSC \ 341 CMSC 345 CMSC 411 CMSC 421 CMSC 441' requiredMath = 'MATH 151 MATH 152 MATH 221' mainElectives = 'CMSC 426 CMSC 431 CMSC 435 CMSC 445 CMSC 451 CMSC 455 CMSC\ 456 CMSC 461 CMSC 471 CMSC 481 CMSC 483' optionalMath = 'MATH 430 MATH 441 MATH 452 MATH 475 MATH 481 MATH 483' sci4Cred = 'BIOL 100 CHEM 101 CHEM 102 PHYS 121 PHYS 122' sci3Cred = 'BIOL 301 BIOL 252 BIOL 275 BIOL 302 BIOL 303 BIOL 304 BIOL 305 \ GES 110 GES 111' sci2Cred = 'BIOL 100L BIOL 251L BIOL 252L BIOL 275L BIOL 302L BIOL 303L BIO\ L 304L BIOL 305L CHEM 102L PHYS 122L PHYS 340L' userClasses = '' numCSReqElectives = 0 numCSElectives = 0 numReqMath = 0 numSciCred = 0 numOptMath = 0 # get the classes the user has taken concatenating them into a list # and counting how many of each type there is numClasses = input("How many courses in the CS program have you taken? ") for i in range(numClasses): uclass = raw_input("Enter the class in the form <MAJOR-CODE> <\ COURSE-NUMBER>: ") userClasses = userClasses + ' ' + uclass if mainElectives.find(uclass) != -1: numCSReqElectives += 1 if requiredList.find(uclass) == -1 and mainElectives.find(uclass) == -1\ and uclass.find('CMSC 4') != -1: if uclass.find('CMSC 404') == -1 and uclass.find('CMSC 495') == -1 \ and uclass.find('CMSC 496') == -1 and uclass.find('CMSC 497') == -1 and uclass.\ find('CMSC 498') == -1 and uclass.find('CMSC 499') == -1: numCSElectives += 1 if requiredMath.find(uclass) != -1: numReqMath += 1 if optionalMath.find(uclass) != -1: numOptMath += 1 if sci4Cred.find(uclass) != -1: numSciCred += 4 elif sci3Cred.find(uclass) != -1: numSciCred += 3 elif sci2Cred.find(uclass) != -1: numSciCred += 2 # restrict user to two optional math classes if numOptMath > 2: numOptMath = 2 # adjust counts for part E & F if numCSReqElectives > 2: numCSElectives += (numCSReqElectives - 2) numCSReqElectives = 2 # call functions to produce output for each part main()
here is what I have started on, i started coding it right after function main.
def (requiredList, userClasses): print print 'You still need to take these classes from Section A Required Computer Science Courses: ' print # strips spaces between each class in the string uclass.rjust(1).strip() # not sure why i have 1 in the parameter but i want to remove 1 space from the end of each class # slices every 8 characters each class is 8 characters long pos = uclass[pos:pos+8] # I'm not sure how to define pos. # then i need to use a the string command .find to find each class that isnt in the string so something like if userClasses.find(uclass) == -1 print # i dont know what to print or if my if statement is checking the string for each class
I need a lot of help, I understand the logic about 75% on what needs to be done, but only know how to code about 5% of it.
Thanks in advance. | https://www.daniweb.com/programming/software-development/threads/226894/string-slicing-string-finding-homework | CC-MAIN-2018-26 | refinedweb | 570 | 59.43 |
Serbo-Croatian version of PyQt By Example!
A while ago I got an email from Anja Skrba asking me for permission to translate PyQt by Example into Serbo-Croatian.
And here it is all nice and translated. Lots of thanks to Anja for the hard work!
A while ago I got an email from Anja Skrba asking me for permission to translate PyQt by Example into Serbo-Croatian.
And here it is all nice and translated. Lots of thanks to Anja for the hard work!.
There is one area where Qt and Python (and in consequence PyQt) have major disagreements. That area is memory management.
While Qt has its own mechanisms to handle object allocation and disposal (the hierarchical QObject trees, smart pointers, etc.), PyQt runs on Python, so it has garbage collection.
Let's consider a simple example:
from PyQt4 import QtCore def finished(): print "The process is done!" # Quit the app QtCore.QCoreApplication.instance().quit() def launch_process(): # Do something asynchronously proc = QtCore.QProcess() proc.start("/bin/sleep 3") # After it finishes, call finished proc.finished.connect(finished) def main(): app = QtCore.QCoreApplication([]) # Launch the process launch_process() app.exec_() main()
If you run this, this is what will happen:
QProcess: Destroyed while process is still running. The process is done!
Plus, the script never ends. Fun! The problem is that proc is being deleted at the end of launch_process because there are no more references to it.
Here is a better way to do it:
from PyQt4 import QtCore processes = set([]) def finished(): print "The process is done!" # Quit the app QtCore.QCoreApplication.instance().quit() def launch_process(): # Do something asynchronously proc = QtCore.QProcess() processes.add(proc) proc.start("/bin/sleep 3") # After it finishes, call finished proc.finished.connect(finished) def main(): app = QtCore.QCoreApplication([]) # Launch the process launch_process() app.exec_() main()
Here, we add a global processes set and add proc there so we always keep a reference to it. Now, the program works as intended. However, it still has an issue: we are leaking QProcess objects.
While in this case the leak is very short-lived, since we are ending the program right after the process ends, in a real program this is not a good idea.
So, we would need to add a way to remove proc from processes in finished. This is not as easy as it may seem. Here is an idea that will not work as you expect:
def launch_process(): # Do something asynchronously proc = QtCore.QProcess() processes.add(proc) proc.start("/bin/sleep 3") # Remove the process from the global set when done proc.finished.connect(lambda: processes.remove(proc)) # After it finishes, call finished proc.finished.connect(finished)
In this version, we will still leak proc, even though processes is empty! Why? Because we are keeping a reference to proc in the lambda!
I don't really have a good answer for that that doesn't involve turning everything into members of a QObject and using sender to figure out what process is ending, or using QSignalMapper. That version is left as an exercise.
About a year ago, I wrote a small web browser, called De Vicenzo just for fun.
But hey, someone went and madeit useful for something! Specifically, to provide previews when doing sphix docs
That's cool :)
QTimer is a fairly simple class: you use it when you want something to happen "in a while" or "every once in a while".
The first case is something like this:
# call f() in 3 seconds QTimer.singleShot(3000, f)
The second is this:
# Create a QTimer timer = QTimer() # Connect it to f timer.timeout.connect(f) # Call f() every 5 seconds timer.start(5000)
Simple, right? Well, yes, but it has some tricks.
You have to keep a reference to``timer``
If you don't, it willget garbage-collected, and f() will never be called.
It may not call f() in 5 seconds.
It will call f() more or less 5 seconds after you enter the event loop. That may not be quickly after you start the timer at all!
You may get overlapping calls.
If f() takes long to finish and re-enters the event loop (for example, by calling processEvents) maybe the timer will timeout and call it again before it's finished. That's almost never a good thing.
So, you can do this:
def f(): try: # Do things finally: QTimer.singleShot(5000, f) f()
What that snippet does, is, calls f() only once. But f itself schedules itself to run in 5 seconds. Since it does it in a finally, it will do so even if things break.
That means no overlapping calls. It also means it won't be called every 5 seconds, but 5 seconds plus whatever f takes to run. Also, no need to keep any reference to a QTimer.
Final tip: You can also use QTimer to do something "as soon as you are in the event loop"
QTimer.singleShot(0, f)
Hope it was useful!
I have written about this in the past, with the general conclusion being "it's a pain in the ass".
So, now, here is how it's done.
#, )
And that's it. Except of course, that's not it.
What this will do is create a binary set, either a folder full of things, or a single EXE file. And that's not enough. You have to consider at least the following:. | https://ralsina.me/categories/pyqt.html | CC-MAIN-2018-34 | refinedweb | 905 | 76.52 |
Implementing a Build System¶
Builder has support for many build systems such as autotools, meson, cmake, etc. The build system knows how to find build targets (binaries or scripts that are installed) for the runner, knows how to find build flags used by the clang service, and it can define where the build directory is. It also has an associated
Ide.BuildPipelineAddin (see the next section) that specifies how to do operations like build, rebuild, clean, etc.
import gi from gi.repository import Gio, Ide class BasicBuildSystem(Ide.Object, Ide.BuildSystem, Gio.AsyncInitable): def do_init_async(self, priority, cancel, callback, data=None): task = Gio.Task.new(self, cancel, callback) task.set_priority(priority) # do something, like check if a build file exists task.return_boolean(True) def do_init_finish(self, result): return result.propagate_boolean() def do_get_priority(self): return 0 # Choose a priority based on other build systems' priority def do_get_build_flags_async(self, ifile, cancellable, callback, data=None): task = Gio.Task.new(self, cancellable, callback) task.ifile = ifile task.build_flags = [] # get the build flags task.return_boolean(True) def do_get_build_flags_finish(self, result): if result.propagate_boolean(): return result.build_flags
How does Builder know which build system to use for a project? Each has an associated “project file” (configure.ac for autotools) that has to exist in the source directory for the build system to be used. If a project has multiple project files, the priorities of each are used to decide which to use. You can see where the priority is defined in the code above. The project file is defined in the
.plugin file with these lines (in the case of the make plugin):
X-Project-File-Filter-Pattern=Makefile X-Project-File-Filter-Name=Makefile Project
When a project has the right file, the build system will be initialized by
IdeContext during its own initialization process. | http://builder.readthedocs.io/en/latest/plugins/building/buildsystem.html | CC-MAIN-2018-30 | refinedweb | 300 | 60.01 |
This article will introduce you to the basics of using Mbed Studio, an IDE for programming various ARM microprocessors that support the Mbed operating system. I’ll use an STM32 Nucleo board, but you can use any device that’s supported by the development environment.
Be aware that Mbed Studio is still under development and a few devices are not fully supported yet. One example is the Arduino Nano 33 BLE which runs a modified version of the Mbed OS core. The board is recognized by the IDE and you can write and compile programs, but uploading and debugging is currently not supported and you’ll have to fall back to the classic Arduino IDE for that.
Installation and Configuration
Download the Mbed Studio Installer and execute the application. When the installation process is finished, visit the Mbed platforms page and search for the device you want to write applications for. Once you find it, click the “Add to you Mbed compiler” button:
Now you’re ready to start Mbed Studio and create your first project!
A Brief Introduction to the User Interface
When you first start the application, you’ll be greeted with a screen similar to this:
The red area on the left-hand side of the screen contains your global build settings. You can write multiple programs but you can only have a single active one that can be compiled and uploaded to the connected device. In this area, you can also select the target device for which the code will be compiled. The IDE automatically detects connected devices for you if they are supported and set up correctly.
The yellow area contains buttons for compiling, uploading, and debugging your code.
In the area highlighted in green, you’ll see a list of your local programs. The currently active one is highlighted.
Creating Your First Program
Once you get familiar with the interface, it’s time to create a new program. Click on “File” and then choose “New Program” or use this link on the “Getting Started” page:
Then, you need to enter a name and choose a template. For now, select the empty program, enter a name, and start coding! If you are new to the Mbed platform, I recommend that you read through the incredibly detailed documentation. But for now, let’s enter the following simple program that runs multiple threads and synchronizes them.
#include "mbed.h" Semaphore lock(1); DigitalOut top(LED1); DigitalOut middle(LED2); DigitalOut bottom(LED3); InterruptIn button(BUTTON1); bool interrupted = false; Thread buttonThread; void buttonPressed() { interrupted = true; } void switchOn() { top = 1; middle = 1; bottom = 1; } void switchOff() { top = 0; middle = 0; bottom = 0; } // The other thread will execute this method: void buttonThreadMain() { while(true) { if(interrupted) { // Wait for the flashing-sequence to // finish the current cycle lock.acquire(); interrupted = false; switchOn(); ThisThread::sleep_for(500); switchOff(); lock.release(); } ThisThread::sleep_for(10); } } // main() runs in its own thread in the OS int main() { // Use the button as an interrupt and link // the buttonPressed function as its callback button.rise(&buttonPressed); // Start the other thread buttonThread.start(buttonThreadMain); // The main-thread will execute the following code: while (true) { // Wait until the LEDs are not being // used by any other thread lock.acquire(); top = 1; ThisThread::sleep_for(150); top = 0; middle = 1; ThisThread::sleep_for(150); middle = 0; bottom = 1; ThisThread::sleep_for(150); bottom = 0; // This thread is done for now and // the LEDs can be used by other threads lock.release(); // Wait for a short time to give other // threads and the OS some time to run ThisThread::sleep_for(10); } }
Compiling, Uploading, and Debugging
When you are ready to test your application, you can use these buttons to compile, upload, and debug your work:
Make sure that you selected the correct program, board, and profile. It might take a few minutes if you’re compiling a program for the first time or after switching to another build profile. If you want to use an external programmer, you can choose to only compile the code. The output path will be printed to the IDE’s console.
If your code contains output, it prints to the serial interface by default. You can open the serial console by clicking the “Serial Monitor” button in the “View” menu.
As of right now (IDE version 0.6.1), the debugger only supports a handful of boards. And even though mine was listed under “fully supported”, I still had to use external tools to debug it. However, I’m sure these features will be added in later versions of Mbed Studio.
Mbed Studio: Worth Learning but Still in Beta Phase
Right now, the IDE is in its beta phase and a few things are not working as expected. Some boards, like the new Arduino Nano 33 BLE, are only partially supported by it. However, it’s worth taking a look at the new development environment because the code editor is excellent and the user interface is easy to use. | https://maker.pro/arm-mbed/tutorial/getting-started-with-mbed-studio | CC-MAIN-2020-45 | refinedweb | 828 | 59.53 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.