
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91 values | source stringclasses 1 value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
NAME
read
readlink() places the contents of the symbolic link pathname in the buffer buf, which has size bufsiz. readlink() does not append a null byte to buf. It will (silently) truncate the contents (to a length of bufsiz characters), in case the buffer is too small to hold all of the contents.
readlinkat()
The readlinkat() system call operates in exactly the same way as readlink(), except for the differences described here. been obtained using open(2) with the O_PATH and O_NOFOLLOW flags).
See openat(2) for an explanation of the need for readlinkat().
RETURN VALUE
On success, these calls return the number of bytes placed in buf. (If the returned value equals bufsiz, then truncation may have occurred.) On error, -1 is returned and errno is set to indicate the error.
ERRORS
ENAMETOOLONG
A pathname, or a component of a pathname, was too long.
ENOTDIR
A component of the path prefix is not a directory.
The following additional errors can occur for readlinkat():
ENOTDIR
pathname is relative and dirfd is a file descriptor referring to a file other than a directory.
VERSIONS
readlinkat() was added to Linux in kernel 2.6.16; library support was added to glibc in version 2.4.
CONFORMING TO
readlink(): 4.4BSD (readlink() first appeared in 4.2BSD), POSIX.1-2001, POSIX.1-2008.
readlinkat(): POSIX.1-2008.
NOTES.
Glibc
notes
On older kernels where readlinkat() is unavailable, the glibc wrapper function falls back to the use of readlink(). When pathname is a relative pathname, glibc constructs a pathname based on the symbolic link in /proc/self/fd that corresponds to the dirfd argument.
EXAMPLE
The following program allocates the buffer needed by readlink() dynamically from the information provided by lstat(2), falling back to a buffer of size PATH_MAX in cases where lstat(2) reports a size of zero.
#include <sys/types.h> #include <sys/stat.h> #include <limits.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char *argv[]) { struct stat sb; char .06 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at. | https://man.cx/readlink(2) | CC-MAIN-2020-29 | refinedweb | 363 | 67.35 |
Dataframe makes data processing easy and fast. Well! in most of the scenarios, We have to play with the dataframe columns name. If you are also struggling and looking for How to get pandas column name? You are in the correct place. Here you will get a python program to display the column names.
Get Pandas Column Name from pandas dataframe-
There are so many ways to get column names from dataframe pandas. Each has its own advantages and disadvantages that depends on the situation. In order to understand them Lets first create a dummy dataframe. We will see how with live coding examples.
import pandas as pd employee = { 'Name':['Ram', ' Sohan', 'Bob', 'Alica', 'Vanket'], 'Marks' :['27', '33', '26', '32', '54'], 'Earning':['100000', '500001', '300000', '170000', '100000000'], 'Location':['India', 'Pakistan', 'China', 'UK', 'America'], 'Rating':['4', '5', '1', '3', '1'] } dataframe = pd.DataFrame(employee)
output-
Ways to get pandas column names from dataframe
1. Get Pandas columns names using keys() Method-
The below code will return the column name list. Here is the complete syntax.
list(dataframe .keys())
Output
Here typecasting is necessary as keys() function return index objects. In order to convert this object to the list, We need to add it as an argument for the list() method.
2. Get Pandas column name using columns attribute-
To fetch columns in pandas you can also use Dot operator. After that, you have to Typecast the results into the list with columns attribute. Like below
list(dataframe.columns)
Here dataframe.columns return index type object, hence need to be typecasted into the list object.
3. Retrieve Pandas Column name using sorted() –
One of the easiest ways to get the column name is using the sorted() function. Below is the example for python to find the list of column names-
sorted(dataframe)
4. Get Pandas column name By iteration –
This is not the most recommended way to get the pandas column from the dataframe but It is the most familiar one. Using this technique you can easily print the python pandas columns header.
for columne_name in dataframe.columns: print(columne_name)
I hope you must like this article. Keep reading and stay motivated.
Thanks
Data Science Learner Team
Join our list
Subscribe to our mailing list and get interesting stuff and updates to your email inbox. | https://www.datasciencelearner.com/how-to-get-pandas-column-name/ | CC-MAIN-2021-39 | refinedweb | 383 | 75 |
import "github.com/tendermint/tendermint/libs/pubsub/query"
Package query provides a parser for a custom query format:
abci.invoice.number=22 AND abci.invoice.owner=Ivan
See query.peg for the grammar, which is a. More:
It has a support for numbers (integer and floating point), dates and times.
nolint
empty.go query.go query.peg.go
const ( // DateLayout defines a layout for all dates (`DATE date`) DateLayout = "2006-01-02" // TimeLayout defines a layout for all times (`TIME time`) TimeLayout = time.RFC3339 )
Condition represents a single condition within a query and consists of tag (e.g. "tx.gas"), operator (e.g. "=") and operand (e.g. "7").
Empty query matches any set of tags.
Matches always returns true.
Operator is an operator that defines some kind of relation between tag and operand (equality, etc.).
const ( // "<=" OpLessEqual Operator = iota // ">=" OpGreaterEqual // "<" OpLess // ">" OpGreater // "=" OpEqual // "CONTAINS"; used to check if a string contains a certain sub string. OpContains )
Query holds the query string and the query parser.
MustParse turns the given string into a query or panics; for tests or others cases where you know the string is valid.
New parses the given string and returns a query or error if the string is invalid.
Conditions returns a list of conditions.
Matches returns true if the query matches against any event in the given set of events, false otherwise. For each event, a match exists if the query is matched against *any* value in a slice of values.
For example, query "name=John" matches events = {"name": ["John", "Eric"]}. More examples could be found in parser_test.go and query_test.go.
String returns the original string.
func (p *QueryParser) Init()
func (p *QueryParser) Parse(rule ...int) error
func (p *QueryParser) PrintSyntaxTree()
func (p *QueryParser) Reset()
Package query imports 7 packages (graph) and is imported by 18 packages. Updated 2019-06-27. Refresh now. Tools for package owners. | https://godoc.org/github.com/tendermint/tendermint/libs/pubsub/query | CC-MAIN-2019-39 | refinedweb | 313 | 60.41 |
In one of my previous articles talking about how I thought svelte was revolutionary in what it does, someone brought up the library RiotJS, so I decided to give it a try. In this article I will be going on the key differences I noticed, in terms of syntax, component structure, and some functionality differences that stood out to me when using it.
Maturity
One thing I noticed straight from the beginning is Riot felt a lot more mature and full featured, while they are similar in terms of a lot of things, such as trying to drive the "zero dependency" package scheme, and mainly only having developer dependencies, Riot definitely seemed to have a lot more functionality and power compared to Svelte.
An example of this is documentation, Riot's documentation was honestly really helpful and a joy to read, everything I needed to know was there and with examples. While svelte's documentation is nice, Riot's was a lot better to me in a lot of cases, and that's one thing I loved about trying it.
Component Structure
In terms of how you structure and layout components, Svelte and Riot are very similar, but there is one key difference I noticed in terms of how you lay out components in each library/framework, when it comes to making components in Svelte components don't necessarily have a "root" element compared to how they are in Riot, as an example, a basic component in Svelte looks like this
<script></script> <style></style> <example-component></example-component>
Now you might say here
example-component is the root of the component, which in a sense it is, but notice how the parts of the structure aren't nested under a single DOM element or psuedo-element, now let's take a look at how Riot handles a component
<example-component> <script></script> <style></style> <!-- your html for the component here as well --> </example-component>
This is one thing I didn't really like about Riot personally, due to everything being nested under a (pseudo-)element of sorts, everything is smashed together in a way, while as with Svelte components, the structure of the component is split up due to them not being forced into a nest.
Now this could be something that isn't enforced completely in Riot, but when I tried to do a element Svelte style where the sections of the component are split up the Riot component builder seemed to not like it.
Functionality
Once again the functionality of the two libraries are very similar, but Riot uses a bit of a different model for things like reactivity and data structure. While Svelte components automatically update when a variable in the
<script> portion of the component, or a prop is updated it, Riot is a bit different in this case. Riot instead uses a state system, similar to other libraries such as react.
Let's take a look at a example comparison to how each library handles reactivity and state. Starting off with Svelte, the state management here is in a sense automatic, as Svelte handles the "state" of the component simply by the variables within it.
<script> let clicks = 0; function addClicks() { clicks += 1; } </script> <button onClick={addClicks}>Clicked {clicks} times</button>
Meanwhile in Riot, you have to manually create and update the state in a component for the component to update and re-render.
<clicker> <script> export default { state: { clicks: 0 }, addClick() { this.update({ clicks: this.state.clicks + 1 }); } }; </script> <button onclick={addClick}>Clicked {state.clicks} times</button> </clicker>
While this can be nice, it does add a bit of complexity to using the library, and to noobies who don't really understand state really well this can make the library a tiny bit more difficult to use in my experience.
Another thing I noticed is how Riot handles importing components. While in svelte you simply just
import the component and use it in your html, in Riot you have to in a sense "register" it with the component you want to use it in, for example
<app> <script> import Clicker from "./components/clicker.riot"; export default { components: { Clicker }, }; </script> <Clicker /> </app>
While in svelte using components is as simply as importing and using it
<script> import Clicker from "./components/clicker.svelte"; </script> <Clicker />
Setting things up
In terms of setting up a bare-bones project with each library it was pretty simple with both, just running command(s) to initialize them, however I personally didn't really like the default template for Riot, so I ended up making my own
Final Words
I like both libraries! While Svelte is still very infantile compared to how many years Riot has been in development, it's a lot simpler in terms of using it. I can see myself using both libraries for projects, mainly using Riot for bigger projects that require a more robust component structure and Svelte for smaller, maybe personal projects. In the end both libraries do what they do well, and I can definitely see Riot and Svelte competing in the future possibly, but for now Riot is definitely more mature, and definitely more fully functional in terms of features.
Discussion (8)
The sad thing about all these frameworks is that none of them really works well in an environment that's not completely centered around node.
What I really want is something like svelte but as a single executable, either written in JS with the option of a single-executable bundle or just written in C entirely, that actually integrates in a make/tup workflow and actually compiles my files at more than 1 LOC/h.
From what I've seen so far, svelte, with its lack of dependencies, seems like the only option where such a thing would be possible without a complete rewrite of the whole concept though.
Have you tried github.com/plentico/plenti? We use Go + V8 to compile components, so you don't need NodeJS/NPM on your computer.
That sounds like a pretty cool concept! I will definitely check that out :D
You won't get far in web development nowadays without node anyways.
I mean, for the longest time, you couldn't get far with anything without gnu software, yet they still split their tools very nicely. And wouldn't you know, there's
clangnow and it works perfectly well with
make. Try combining node and deno though.
Would you kindly explain what do you mean by " none of them really works well in an environment that's not completely centered around node" ? It is front-end, node is back-end, so ...??
have you ever tried integrating any of these "modern" web technologies with tup?
That's a net idea but i have no idea how you'd go about making it. | https://dev.to/hanna/riotjs-vs-svelte-35h4?utm_source=cloudweekly.news | CC-MAIN-2021-39 | refinedweb | 1,138 | 51.92 |
putgrent man page
putgrent — write a group database entry to a file
Synopsis
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <grp.h>
int putgrent(const struct group *grp, FILE *stream);
Description
The putgrent() function is the counterpart for fgetgrent(3). The function writes the content of the provided struct group into the stream. The list of group members must be NULL-terminated or NULL-initialized.
The struct group is defined as follows:
struct group { char *gr_name; /* group name */ char *gr_passwd; /* group password */ gid_t gr_gid; /* group ID */ char **gr_mem; /* group members */ };
Return Value
The function returns zero on success, and a nonzero value on error.
Attributes
For an explanation of the terms used in this section, see attributes(7).
Conforming to
This function is a GNU extension.
See Also
fgetgrent(3), getgrent(3), group(5)
Colophon
This page is part of release 4.11 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at.
Referenced By
fgetgrent(3), getgrent(3), getgrent_r(3). | https://www.mankier.com/3/putgrent | CC-MAIN-2017-26 | refinedweb | 176 | 65.12 |
On Feb 26, 10:20 am, "Diez B. Roggisch" <de... at nospam.web.de> wrote: > Am 26.02.10 17:08, schrieb Diez B. Roggisch: > > > > > > > Am 26.02.10 16:57, schrieb darnzen: > >> On Feb 26, 9:41 am, "Diez B. Roggisch"<de... at nospam.web.de> wrote: > >>> Am 26.02.10 16:32, schrieb darnzen: > > >>>> On Feb 26, 3:15 am, "Diez B. Roggisch"<de... at nospam.web.de> wrote: > >>>>> Am 26.02.10 06:07, schrieb darnzen: > > >>>>>> Having :( > > >>>>> Can you show how you pass the staticmethod to the C-function? Is > >>>>> the DLL > >>>>> utilized by ctypes? > > >>>>> I don't see any reason you couldn't use a bound method, which would > >>>>> give > >>>>> you your self, instead relying on global state. > > >>>>> Diez > > >>>> __main__.K<< *facepalm* should of tried that! > > >>>> Yeah I'm using ctypes. The DLL callback set ups are as follows. The > >>>> local callback is in the App namespace (in this case, some callbacks > >>>> are in different modules as noted in OP), but still no access to self: > > >>>> #Function wrapper > >>>> A.expCallback = WINFUNCTYPE(None, c_int, c_int, \ > >>>> POINTER(Data_s))(A.Callback) > > >>>> #DLL call to register the local callback function > >>>> DLLSetCallback(self.hID, A.SubID, EVENTID, A.expCallback) > > >>>> class A: > >>>> #Local callback function > >>>> @staticmethod > >>>> def Callback(hID, SubID, Data): > >>>> print 'I DON'T KNOW WHO I AM OR WHERE I CAME FROM!!' > >>>> print 'BUT WITH hID, and SubID, I CAN FIGURE IT OUT' > >>>> print 'IF I STORE A REFERENCE TO MYSELF IN A DICT' > >>>> print 'USING KEY GENERATED FROM hID, SubID' > >>>> pass > > >>>> I'm not sure why they need to be static callbacks, but the DLL doc's > >>>> say "when using object based languages, such as c++, callback > >>>> functions must be declared as static functions and not instance > >>>> methods", and I couldn't get it to work without setting it up that > >>>> way. I could probably have them all be "classless" functions, but with > >>>> 100's of these, my namespace would be polluted up the wazoo, and I'd > >>>> still have the problem that they wouldn't have access to instance > >>>> methods / properties. > > >>> The above code can't work with self, because you use > > >>> A.expCallback > > >>> which at best can of course be a classmethod. > > >>> You need to instead invoke DLLSetCallback with a bound method, like this > > >>> a = A() > >>> DLLSetCallback(self.hID, A.SubID, EVENTID, a.expCallback) > > >>> Also, the DLL-docs seem to refer to *C* or *C++*, where the concept of > >>> static functions is differently. If ctypes manages to get *some* > >>> callback passed, I'm 100% positive that it can pass *any* callable you > >>> like, including bound methods. > > >>> Diez > > >> Thinking about it some more, I believe I understand why it has to be > >> staticfunction. To use an bound method would require the wrapper to > >> include a reference to the instance as follows: > > >> A.expCallback = WINFUNCTYPE(None, POINTER(A), c_int, c_int, \ > >> POINTER(Data_s))(a.Callback) > > >> Since a = A(); a.foo() is really A.foo(self). The problem here is that > >> A is not a ctypes object and I can't change what arguments the DLL > >> uses in the callback in any case. Rewording my thoughts: a bound > >> method callback would require 'self' to be the first argument. I can > >> not make the DLL include 'self' as it doesn't know anything about the > >> objects in my program. Since I can't pass 'self', it has to be a > >> staticmethod. > > > No, that's not true. A bound method implictly knows about it self, and > > it's a callable. > > > What I guess is that you did the same mistake I did when I created that > > example - namely, not keeping a refernce to the bound method around. > > Ctypes will then garbage-collect the callback, which of course leads to > > all kinds of troubles. > > > Try this: > > > a = A() > > # keep this around > > bound_m = a.expCallback > > DLLSetCallback(self.hID, A.SubID, EVENTID, a.expCallback) > > AAAAHHRG, same error again. > > Of course, use > > DLLSetCallback(self.hID, A.SubID, EVENTID, bound_m) > > because the bound method changes with each time you create it. > > Sorry for the confusion. > > Diez Well, I got around this mess by putting all those static callbacks into a separate module in a new class. I set them up to call a bound method of that class which passes the arguments to the appropriate bound methods of other class instances. I just have to keep a little dict of the bound method callbacks when I register them with the class. I also found a simple trick for sharing globals between modules. Pretty simple, create an empty module, say shared.py, with only the pass statement in it. Then dynamically add properties to it such as shared.app = App(). Import shared into the modules that need access to app and done! Thanks for the help on this. Always learning! | https://mail.python.org/pipermail/python-list/2010-February/569657.html | CC-MAIN-2016-40 | refinedweb | 791 | 75.2 |
Hel.
Get Helios
There are two main ways to get Helios-related projects. The first — and recommended — way is to just grab a package relevant to you. The other way is via the Helios software repository at Eclipse.org.
Figure 1. Helios packages
Packages
Go to the Eclipse Helios Packages site, which contains 12 pre-bundled versions of Helios projects specific to your needs.
Helios repository
To get Helios using a software repository, download the Eclipse V3.6 SDK. Then you can launch Eclipse and access the software-update mechanism via Help > Install New Software (see Figure 2). Enter the proper Helios repository information, if it isn't already available. Once you are connected, you should see the list of available projects that are part of the Helios release. It's as simple as that. Once you're connected, you can simply choose what features to install into your Eclipse.
Figure 2. Browsing the Helios repository
Eclipse Marketplace
It's important to mention that the Eclipse Marketplace was launched as part of the Eclipse Helios release. It offers the Eclipse community a convenient portal that helps folks find open source and commercial Eclipse-related offerings. If you downloaded Helios via a package, you'll have access to the Eclipse Marketplace client via Help > Marketplace Client that allows you to easily browse the marketplace offerings and install them into Eclipse (see Figure 3).
Figure 3. Browsing the Eclipse Marketplace
The projects
Table 1. Helios projects
Project showcase
Linux tools
"The Eclipse Linux Tools project is pleased to be a part of the Helios simultaneous release," said Andrew Overholt, project lead. "Our project aims to provide tools for Linux® C/C++ developers, building on top of the rich Eclipse toolset, including the Platform, the CDT, BIRT, and GEF. We provide Eclipse plug-ins to integrate with native development tools, such as the GNU Autotools, LTTng, Valgrind, GCov, OProfile, RPM, GProf, and SystemTap. Our main goal is to provide a full-featured C and C++ IDE for Linux developers."
Overholt also said, "Helios includes our 0.6 release, which features improvements to many of our components. Our LTTng integration features a new histogram view to help with visualizing trace files and our GProf plug-ins now allow for easy viewing with BIRT-driven charts. Speaking only of 0.6 does not do justice to the work that has gone into our previous releases that have never been a part of the Eclipse simultaneous release:
- GNU Autotools integration with the CDT allowing for the many existing projects that use the GNU Autotools to build from within Eclipse
- a C/C++ call graph utility that is driven by SystemTap and visualized with Zest from GEF
- an RPM .spec editor with rpmlint integration
- display of GProf profiling data
- GCov code coverage display and annotation
- a framework for integrating native profiling tools with the CDT
- simple launching and visualization of Valgrind memory usage analysis tools for CDT projects
- single-click profiling with OProfile and integration with the CDT
- ChangeLog management tools which integrate with various version control providers
- plugins bridging the CDT's hover help functionality with various open source API documentation formats; called libhover
"On top of that, a lot of bug fixing has also gone into our 0.6 release."
And Overholt said, "The Linux Tools project also aims to increase the amount of Eclipse technology available in Linux distributions. We are working towards this goal by providing a build harness of the Eclipse SDK that is easy to consume for Linux distributions and already have a number of distribution consumers."
Figure 4. Linux Tools in action
Xtext
"Xtext is a language development framework that allows to easily develop your own domain-specific or full-fledged programming languages and corresponding Eclipse-based IDE support," said Sven Efftinge, Xtext committer. "Based on a grammar language and a set of modern APIs, one can describe the syntax and semantics of the language. Xtext provides a rich-featured and highly configurable IDE, including validation, code completion, an outline, formatting, syntax coloring, code-generation stubs, etc. In the Helios release, Xtext graduated to Version 1.0. It now features namespace-based scoping, builder infrastructure, validation and linking based on dirty state, quick fixes, linking to Java elements, enhanced serialization support, and much more. This makes Xtext amenable not only for domain-specific languages but also for full-fledged programming languages."
Figure 5. Xtext in action
Rich Ajax Platform (RAP)
RAP makes it easier to single-source desktop and web applications with Eclipse RCP and RAP.
RAP committer Benjamin Muskalla said, "The Rich Ajax Platform has grown into a mature platform for server-side OSGi development of rich Internet applications. As part of the Helios release, it not only offers many new state-of-the-art features like drag and drop, a GraphicsContext and rich theming capabilities but in addition tight integration with other Eclipse projects like EMF and Riena. Using RAP for single-sourcing existing RCP applications enjoys enormous popularity withtin the Eclipse community."
Figure 6. An example RAP application
Sequoyah
"Sequoyah was chartered in December 2009 to provide a project for mobile tools developers, regardless of which language or mobile platforms they use," said Eric Cloninger, project lead. "Our committers come from Motorola, Nokia, and Wind River. Sequoyah also has strong participation from RIM and the Symbian Foundation.
"We began the project by moving several narrowly focused subprojects from DSDP and took responsibility for the Pulsar package. For Helios, we've added new components and we will graduate as a mature project with this release. The future of Sequoyah is promising as we have several new proposals under way for supporting web applications and Android native development."
Figure 7. Sequoyah in action
PHP Development Tools (PDT)
Project lead Roy Ganor said, "Summarizing a great year for both the Eclipse and PHP communities, the Eclipse."
C/C++ Development Tools (CDT)
"The CDT project is offering improved debug support for the Helios release," said Doug Schaefer, CDT project lead. "First off, the DSF/GDB debug interface reached sufficient parity with existing CDI/GDB interface to warrant switch in default launch configuration type. Furthermore, a new Eclipse C/C++ Debugger (EDC) is introduced as optional component that provides direct debugger interface to OS APIs for Windows and Linux. On top of that, we introduced the new Codan static analysis framework as optional component to provide semantic error reports ahead of compile time. Also, support for C++0x is progressing well as matching support provided by gcc 4.3+."
Figure 8. C/C++ Development Tools (CDT)
Mylyn
Mik Kersten, project lead, said, "Since last year's Galileo release, Mylyn's APIs, features and integrations have grown substantially. Popular features such as Mylyn's Connector Discovery are now reusable. We've created scheduled presentation that will help the growing number of Mylyn users that manage very large task lists. C/C++ developers now get one-click multitasking and workspace focusing out of the box, with support for CDT. But what's most exciting is how much the Mylyn ecosystem has grown during the Helios release. As of June, the majority of leading Agile and ALM tools provide Mylyn connectors, helping an increasingly large portion of the developer community get the productivity benefits of the task-focused interface."
Friend of Helios and Eclipse
There are many people that use Eclipse out there, from developers to just users who sometimes want to give back to the Eclipse community in some fashion. The Friends of Eclipse program allows you to contribute back to the Eclipse community. To celebrate the upcoming Helios simultaneous release, The Eclipse Foundation wants to recruit 360 new Friends of Eclipse. For a $35 contribution, you can become a Friend of Eclipse and get early access to the Helios release, direct from the download server at the Eclipse Foundation. Your contribution will also help support the Eclipse community in a variety of ways:
- Providing more bandwith for users and developers
- Purchasing additional servers to host Eclipse projects
- Sending students to Eclipse conferences
- Sponsoring Eclipse community events
Figure 9. Become a friend of Helios and Eclipse
Helios review contest
The Eclipse Foundation wants to hear what you think of the Eclipse Helios projects being shipped as part of Helios. The Eclipse Foundation is hosting a review contest so if you write a review about Helios you'll be entered to win some prizes. All qualified reviews get a Helios T-shirt. Since Eclipse is a global community, feel free to write or record your review in any language that you're comfortable with.
Conclusion
The goal of this article was to take you through the Helios simultaneous release and showcase some of the projects that are part of the release. I gave you a tour of the Helios projects with some information from Eclipse project leaders.
So what are you waiting for? Go grab Eclipse Helios and give it a try.
Resources
Learn
- Watch the Helios In Action virtual conference for more information about Helios projects.
- Attend a free developerWorks Live! briefing to get up to speed quickly on IBM products and tools as well as IT industry trends.
-.
- As someone interested in development with Eclipse, you might want to check out a trial of IBM's Rational Application Developer Standard Edition, a commercial development tool built on Eclipse technology.
- | http://www.ibm.com/developerworks/opensource/library/os-eclipse-helios/index.html | CC-MAIN-2016-44 | refinedweb | 1,556 | 50.06 |
By Lee Underwood
In a previous article,
we quickly touched on the requirements for proper XHTML coding, especially in
relation to HTML 4.01. In this article, we'll take a closer look at what some
of those requirements are in relation to the
head portion of the
Web page. This is the portion of the document that the user agent (i.e., browser)
will read first. It's important that it doesn't stumble here. Remember, our
goal is to develop standards-based Web pages (here, I make the assumption that
the reader has a working knowledge of HTML).
Let's start at the top of a valid XHTML document and work our way down. For this part of the discussion, I'll be referring to the code below.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "">
<html xmlns="" xml:
<head>
<title>Document Title Goes Here</title>
<meta http-
<link rel="stylesheet" type="text/css" media="screen" href="/style/core-style.css" />
</head>
The first line shown above is the XML
declaration. This line defines the version of XML you're using as well as
the character coding. It's recommend by the World Wide Consortium (W3C) but
is not required. If you're not using XML, it's not necessary. In fact, it can
cause problems with some of the older browsers. Most of them will choke if they
encounter a page that begins with this encoding. If you don't include the XML
declaration, you'll need to include the meta tag below (also shown above, after
the
title tag). Do not include both.
If the XML declaration is used, it must be the first line on the page. If the content meta tag is used, it must be placed within the head of the document.
The content meta tag is divided into two parts. The first part (
content="text/html)
tells the browser the mime type. Mime is short for "Multipurpose
Internet Mail Extensions".
It was originally used in formatting e-mail but is now also used by Web browsers
to declare the type of content being served to the browser. The W3C actually
recommends using
application/xhtml+xml
as the mime type for an XHTML document. However, there are problems with using
it. An example is Internet Explorer (up to version 6 for both Windows and Mac),
which doesn't recognize it, nor do many other browsers. Using
text/html
should make your page acceptable to IE and is "allowable" by the W3C. The second
half of the meta statement (
charset=UTF-8) identifies the character
set used by the browser.
Note that the meta tag ends with a "
/>". This is because, in
XHTML, all tags must be closed, except for the DOCTYPE statement. The
meta tag is an empty element tag. This means the tag itself is
the content or a place holder for the content. Empty element tags include
<img /> and
<br />. Since the tag has no additional
content, it doesn't have an end tag and must be closed within itself. If you
leave a space before the slash, older browsers won't get confused.
If the XML declaration isn't used, the first line in the document must be the Document Type Definition (DTD), or DOCTYPE. This statement is used to "set out the rules and regulations for using HTML in a succinct and definitive manner" (W3C). Failure to use a full DTD could send your visitor's browser into 'quirks' mode, causing it to behave like a version 4 browser (interestingly, a large number of Web pages do not use the doctype statement; many of them are Web development sites). There are three doctypes available for XHTML: strict, transitional, and frameset. Be careful as these declarations are case-sensitive.
The strict DTD is used for documents containing only clean, pure structural mark-up. In these documents, all the mark-up associated with the layout comes from Cascading Style Sheets (CSS).
The transitional DTD is used when your visitors may have older browsers which can't understand CSS too well. You can use many of HTML's presentational features with this DTD.
Finally, use the frameset DTD when you want to use HTML to partition the browser window into two or more frames.
The DTD files referenced above are plain text files. You can enter the URL and download them. There is nothing earth-shattering in the files but you'll be able to see what the browser is reading.
The next line in our document is the XML namespace. This statement identifies the primary namespace used throughout the document. An XML namespace "is a collection of names, identified by a URI reference, which are used in XML documents as element types and attribute names" (W3C). The
html tag is included at the beginning, effectively combining the two tags. In addition, the language attribute is also included, in both XML (
xml:lang="en") and HTML (
lang="en") terms.
The rest of the header shown is basic HTML code. The
head tag
opens the header and must be closed before the body tag. The
title
tag follows the opening header tag. Next, the meta tags and the link to the
style sheet, if necessary, are included. Be sure to close the meta and style
sheet link tags with "
/>". Remember, in XHTML, all tags and attributes
must be lower case and all tags, except the DOCTYPE, must be closed.
The article "XHTML 1.0: Where XML and HTML meet" provides a further, in-depth study of transitioning to XHTML.
Created: July 27, 2004
Revised: July 27, 2004
URL: | http://www.webreference.com/authoring/xhtml/coding/ | crawl-002 | refinedweb | 944 | 74.08 |
OP Forum Moderator / Recognized Developer
Thanks Meter: 499
Join Date:Joined: Aug 2010Donate to Me
- Navigating to Project->Store->Create Store Package within Visual Studio 2013 (if you're looking for a store-ready appx, then this is your option to take)
- Using the Command Line tools
This thread will focus on how to use the command line tools rather than use the Visual Studio.
First thing's first, we have two core applications that we're going to use in order to handle package management and deployment:
- makeappx.exe - C:\Program Files (x86)\Windows Kits\8.1\bin\x86
- AppDeployCmd.exe - C:\Program Files (x86)\Microsoft SDKs\Windows Phone\v8.1\Tools\AppDeploy
makeappx.exe:
This does as the filename suggests, make appx files.
The easiest way to build an appx file out of the contents of your Debug/Release directory is to run the following command:
makeappx pack /v /d c:\pathtodirectory /p c:\pathtoappx.appx /l
the /v argument enables verbose output, the /d argument is your directory, the /p argument is your output package and the /l argument disables validation checks on manifest data and resource files.
If you are indeed building the appx manually from your Debug/Resource directory, please make sure to include any .dlls and .winmds that you may be referencing in separate projects that aren't in the main output directory.
AppDeployCmd.exe:
This is the command line version of the Windows Phone 8.1 Application Deployment program.
The easiest way to deploy an appx to your phone is to run the following command:
AppDeployCmd /install c:\pathtoappx.appx /targetdevice:de /leaveoptimized
The /install argument provides the path to the appx file you wish to deploy, the /targetdevice argument is the device that you wish to deploy to and the /leaveoptimized argument is an optional parameter to leave the optimized version of the appx package on the filesystem instead of deleting it.
Analyzing the contents of an appx package:
The Appx file is different from a Xap file in that it is ZIP64 compressed instead of using the common ZIP compression. As of now, it isn't possible to deploy a ZIP compressed appx or modify a ZIP64 compressed appx file.
Taking a look a generated appx package, you'll see contents similar to the following:
- Assets - Assets directory
- App.exe - Main exe
- resources.pri - compiled resources
- App.xbf - Binary XAML file for the App namespace (similar to App.xaml for Silverlight)
- MainPage.xbf - Binary XAML file fro the Main Page (similar to MainPage.xaml for Silverlight)
- [Content_Types].xml - XML file containing the content type of every file in the package
- App.xr.xml - XML file containing the root XAML types of the app
- AppxBlockMap.xml - XML file containing a crypto hash for each block of data stored in the package
- AppxManifest.xml - XML file containing the main manifest (similar to WMAppManifest.xml in Silverlight)
When you deploy the appx to your device while using the /leaveoptimized flag, you'll notice a new appx file in the format of nameofappx_Optimized.appx.
This specific appx package is generated every time you sideload an app to your phone and is the version that your phone receives. The deployer runs MDILXapCompile on every file in the package to precompile any managed assemblies into native code.
If you open up the optimized appx file, you'll notice that we have two new files:
- MDILXapCompileLog.txt - The output log of MDILXapCompile
- MDILFileList.xml - XML file that contains the assemblies that were successfully converted to native code.
Things to be wary of with Windows Phone 8.1 appx packages and the Store:
I've posted this on twitter earlier this week, but for pure Windows Phone 8.1 applications, it is possible to retrieve their contents from the Store by using the Download and install manually link. The appx files on the Store ARE NOT ENCRYPTED. From my understanding, it has to do with keeping compatibility between Windows 8.1 and Windows Phone 8.1. I'm curious to know when they decide to encrypt the files.
What's this have to do with the topic at hand? Everything. It is also possible to repackage an appx file from the Store.
Before I get into the how-to and the caveats, I'll explain how I even discovered the appx files were unencrypted.
I happened to be researching a particular capability I've been seeing in some files in a ROM dump from one of the newer Lumias and happened to paste it in to Bing. I was shocked to see direct links to the appx packages and noticed some familiar file names in the description of the link (AppxManifest.xml and MDILFileList.xml were the two that caught my eye). The even bigger kicker was the fact that these appx files are indeed searchable, but only from Bing (and DuckDuckGo which happens to use Bing). I decided to make more specific search queries to see if this was legit or if I happened to be losing my mind. It turns out that I wasn't.
"site:windowsphone.com/en-us AppxManifest.xml" happens to be the holy grail and will return any indexed Windows Phone 8.1 apps. The scary part is that you can still download apps that aren't published anymore and side load them. Here's an example Windows Phone 8.1 app that I happened to download (and also happens to be a Microsoft app)..
The link is self-explanatory. It's the Microsoft Remote Desktop Preview app. Now for the fun part.
Repackaging an app for development and testing purpose:
Before I begin this, I'm going to put a disclaimer out there, that this is just information to be used for dev purposes and as a way of trying to understand more of the packing process. I am by no means condoning any piracy so do NOT ask any questions or make any statements that involve searching for apps that you can't find, etc. I'm hoping Microsoft fixes this hole soon.
In the contents of the downloaded appx file, you'll notice we have even more files:
- AppxSignature.p7x - Signature for app.
- AppxMetadata - folder containing the CodeIntegrity security catalog file
To repackage and deploy an app to your device, the following must be done:
- Extract the contents of the appx into a blank folder
- Remove MDILFileList.xml, AppxSignature.p7x, and the AppManifest folder
- Run the makeappx command above to repackage
- Run the AppDeployCmd command above to deploy the app to your device
Common issues with redeployment:
- If it's an update to a System app (Calendar, Podcast), you won't be able to install it because it can't uninstall the app from your phone
- If it is a Microsoft or OEM app, you're most likely going to be unable to deploy it due to restricted capabilities. Some appx packages will include a WindowsPhoneReservedAppInfo.xml file that will contain the extra capabilities. You're free to remove them, but don't count on it actually working
- If the appx package contains an external DLL reference that isn't from your project (Live SDK dll for instance), you will receive an error deploying with a message stating that the assembly can't be optimized because it is an invalid assembly.
I've tried two workarounds in order to actually allow the deployment:
- Remove the strong name key
- and replace the dll with a version downloaded from the repository.
I tried this on an app, but the app will still crash when it tries to call functions that use the external dll
"Oh crap! I'm worried about people stealing my code, what do I do?
- Use Silverlight if you're doing a Windows Phone 8.1 app. Those are still encrypted from the store (Until someone installs the app with an interop-unlocked phone)
- Use WinRT C++ instead of C#. Yeah, that's the most difficult and crappy way to go, but it will make it a little harder (not impossible) for someone to jack your code
Again, I'm hoping that MS addresses this, but for now it is a nice way to analyze changes done in apps like the Calendar and Files app.
Happy testing folks
Last edited by snickler; 7th July 2014 at 06:35 AM. Reason: Failed bold tags | http://forum.xda-developers.com/windows-phone-8/development/wp8-1-creating-deploying-appx-packages-t2807743 | CC-MAIN-2014-42 | refinedweb | 1,394 | 62.17 |
Voucher alternatives and similar libraries
Based on the "Authentication" category
Simplicity6.4 0.0 L5 Voucher VS SimplicityA simple way to implement Facebook and Google login in your iOS and OS X apps.
SpotifyLogin4.8 0.0 Voucher VS SpotifyLoginAuthenticate with the Spotify API.
ReCaptcha4.1 3.7 Voucher VS ReCaptcha[In]visible ReCaptcha for iOS.
InstagramLogin2.0 0.0 Voucher VS InstagramLoginSimple way to authenticate Instagram accounts.
LinkedInSignIn1.1 1.1 Voucher VS LinkedInSignInSimple view controller to log in and retrieve an access token from LinkedIn.
Koosa1.0 0.0 Voucher VS KoosaDeclarative Swift framework for Attributed Role-based Access Control management
Cely0.8 0.3 L4 Voucher VS CelyA Plug-n-Play login framework written in swift.
* Code Quality Rankings and insights are calculated and provided by Lumnify.
They vary from L1 to L5 with "L5" being the highest. Visit our partner's website for more details.
Do you think we are missing an alternative of Voucher or a related project?
Popular Comparisons
README
Voucher
The new Apple TV is amazing but the keyboard input leaves a lot to be desired. Instead of making your users type credentials into their TV, you can use Voucher to let them easily sign into the TV app using your iOS app.
How Does It Work?
Voucher uses Bonjour, which is a technology to discover other devices on your network, and what they can do. When active, Voucher on tvOS starts looking in your local network and over AWDL (Apple Wireless Direct Link) for any Voucher Server, on iOS.
Once it finds a Voucher Server, it asks it for authentication. Here's the demo app:
The demo iOS app can then show a notification to the user (you can show whatever UI you want, or even no UI):
If the user accepts, then the iOS app can send some authentication data back to the tvOS app (in this case, an auth token string)
Installation
Voucher is available through Carthage and CocoaPods. You can also manually install it, if that's your jam.
Carthage
github "rsattar/Voucher"
CocoaPods
pod 'Voucher'
Manual
- Clone the repo to your computer
- Copy only the source files in
Vouchersubfolder over to your project
Using Voucher
In your tvOS app, when the user wants to authenticate, you should create a
VoucherClient instance and start it:
tvOS (Requesting Auth)
When the user triggers a "Login" button, your app should display some UI instructing them to open their iOS App to finish logging in, and then start the voucher client, like below:
import Voucher func startVoucherClient() { let uniqueId = "SomethingUnique"; self.voucher = VoucherClient(uniqueSharedId: uniqueId) self.voucher.startSearchingWithCompletion { [unowned self] authData, displayName, error in // (authData is of type NSData) if authData != nil { // User granted permission on iOS app! self.authenticationSucceeded(authData!, from: displayName) } else { self.authenticationFailed() } } }
iOS (Providing Auth)
If your iOS app has auth credentials, it should start a Voucher Server, so it can answer any requests for a login. I'd recommend starting the server when (and if) the user is logged in.
import Voucher func startVoucherServer() { let uniqueId = "SomethingUnique" self.server = VoucherServer(uniqueSharedId: uniqueId) self.server.startAdvertisingWithRequestHandler { (displayName, responseHandler) -> Void in let alertController = UIAlertController(title: "Allow Auth?", message: "Allow \"\(displayName)\" access to your login?", preferredStyle: .Alert) alertController.addAction(UIAlertAction(title: "Not Now", style: .Cancel, handler: { action in responseHandler(nil, nil) })) alertController.addAction(UIAlertAction(title: "Allow", style: .Default, handler: { action in let authData = "THIS IS AN AUTH TOKEN".dataUsingEncoding(NSUTF8StringEncoding)! responseHandler(authData, nil) })) self.presentViewController(alertController, animated: true, completion: nil) } }
Recommendations
Use tokens, not passwords
While you can send whatever data you like back to tvOS, you should you pass back an OAuth token, or better yet, generate some kind of a single-use token on your server and send that. Cluster, for example, uses single-use tokens to do auto-login from web to iOS app. Check out this Medium post that shows how I do it! The same model can apply for iOS to tvOS logins.
Voucher can't be the only login option
In your login screen, you must still show the manual entry UI according to the App Store Submission Guidelines (Section 2.27). Add messaging that, in addition to the on screen form, the user can simply open the iOS app to login.
Todo / Things I'd Love Your Help With!
Encryption? Currently Voucher does not encrypt any data between the server and the client, so I suppose if someone wanted your credentials (See Recommendations section above), they could have a packet sniffer on your local network and access your credentials.
Make Voucher Server work on
OS X, and even
tvOS! Would probably just need new framework targets, and additional test apps.
Further Reading
Check out Benny Wong's post on why Apple TV sign in sucks. He also has a demo tvOS Authing project, which you should check out!
Requirements
- iOS 7.0 and above
- tvOS 9.0
- Xcode 8
License
Voucher is available using an MIT license. See the LICENSE file for more info.
I'd Love to Know If You're Using Voucher!
Post to this Github "issue" I made to help us track who's using Voucher :+1:
*Note that all licence references and agreements mentioned in the Voucher README section above are relevant to that project's source code only. | https://swift.libhunt.com/voucher-alternatives | CC-MAIN-2020-24 | refinedweb | 880 | 56.05 |
ARRL
WORKED ALL STATES
& 5BWAS AWARD
Todd LeMense, KKØDX
ARRL WAS AWARDS MANAGER
Heartland DX Association
The WAS award rules are also available in
Adobe Acrobat format
.
1.The WAS (Worked All States) Award is available to all amateurs worldwide who submit proof with written confirmation of having contacted each of the 50 states of the United States of America. The WAS Awards program includes 9 different and separately numbered awards as listed below. In addition, endorsement stickers are available as listed below.
2.Two-way communications must be established on amateur bands with each state. Specialty awards and endorsements must be two-way (2X) on that band and/or mode. There is no minimum signal report required. Any or all bands may be used for general WAS. The District of Columbia may be counted for Maryland.
3).
4.Contacts may be made over any period of years. Contacts must be confirmed in writing, preferably in the form of QSL cards. Written confirmations must be submitted (no photocopies). Confirmations must show your call and indicate that two-way communications was established. Applications for specialty Awards or endorsements must submit confirmations that clearly confirm two-way contact on the specialty mode/band. Contacts made with Alaska must be dated January 3, 1959 or later and with Hawaii dated August 21, 1959, or after.
5.Specialty Awards (numbered separately) are available for OSCAR Satellite, SSTV, RTTY, 144 MHz, 432 MHz, 222 MHz, 50 MHz and 160 meters. Endorsement stickers for the basic mixed mode/band award and any of the specialty awards are available for SSB, CW, Novice, QRP, Packet, EME and any single band except 30 meters. The Novice endorsement is available for the applicant who has worked all states as a Novice licensee. QRP is defined as 10 watts input (or 5 watts output) of the applicant only and is affirmed by signature of the applicant on the application.
6.Contacts made through "repeater" devices or any other power relay method cannot be used for WAS confirmation. A separate WAS is available for Satellite contacts. All stations contacted must be "land stations." Contact with ships, anchored or otherwise, and aircraft, cannot be counted.
7.A US applicant must be an ARRL member to participate in the WAS program. DX stations are exempt from this requirement.
8.HQ reserves the right to spot call for inspection of cards (at ARRL expense) of applications verified by an HF Awards Manager. The purpose of this is not to call into question the integrity of any individual, but rather to ensure the overall integrity of the program. More difficult attained specialty awards (such as 222 MHz WAS for example) are more likely to be so called. Failure of the applicant to respond to such spot check will result in non-issuance of the WAS certificate.
9.Disqualification. False statements on this application or submission of forged or altered cards may result in disqualification. ARRL does not attempt to determine who has altered a submitted card; therefore do not submit any marked over cards. The decision of the ARRL Awards Committee in such cases is final.
5 Band WAS Rules
1. The 5BWAS certificate and plaque (see below #4) will be issued for having submitted confirmations with each of the 50 United States for contacts dated January 1, 1970, or after, on five amateur bands (10, 18 and 24 MHz excluded). Phone and CW segments of a band do not count as separate bands.
2. WAS Rules (MSD-264) that do not conflict with these 5BWAS rules also apply to the 5BWAS Award.
3. There are no specialty 5 Band awards or endorsements.
4. A handsome 9 X 12 personalized walnut plaque is available for a fee of $30 US (check or money order) plus shipping ($8 in USA).
5. The fee for the 5 Band WAS certificate is $10, which includes a lapel pin.
Application Procedure (Please follow carefully)
Confirmations (QSLs) and application form, WAS(
MSD-217
) or 5BWAS(
MSD-264
), may be submitted to KKØDX, ARRL HF Awards Manager. If you can have your applications so verified locally, you need not submit your cards to HQ via the mails.
Be sure that when cards are presented for verification to sort them alphabetically by state, as listed on the back of the application form.
All QSL cards sent to KKØDX must be accompanied by sufficient postage for their safe return (registered mail is recommended because it is traceable). Fifty (50) QSL cards typically weigh approximately 6 ounces.
Include a #10 (@4" x 9") SASE to: ARRL WAS Program, 225 Main Street, Newington, CT 06111
All applications sent to KKØDX must include the appropriate fee(s) with checks should be made out to ARRL:
$5 for each WAS certificate (the fee includes any endorsements on the same application)
$3 per endorsement application (if applying for multiple endorsements on the same application, the fee remains $3) Example: 10 Meters, SSB and Novice
Todd LeMense, KKØDX
3603 South 89th Street
Omaha, NE 68124-3931
kk0dx@arrl.net
(402)397-7465
Applications and Record Forms
The Worked All States application form is available as both
HTML
and
Adobe Acrobat files.
The 5 Band Worked All States application form is available as
Microsoft Word document
or
Adobe Acrobat files
.
The Worked All States record sheet is avalable as
HTML
or as an
Adobe Acrobat file.
The 5-Band WAS record sheet is available as either a
Microsoft Word document
or an
Adobe PDF file.
Adobe Acrobat
is required to view Adobe PDF files.
This page last updated on March 4, 2001
Todd LeMense, KKØDX | http://www.qsl.net/kk0dx/was/was.html | CC-MAIN-2014-42 | refinedweb | 935 | 61.87 |
Content-type: text/html
tis_key_create - Generates a unique thread-specific data key.
Standard C Library (libc.so, libc.a)
#include <tis.h>
int tis_key_create(
pthread_key_t *key,
void (*destructor)(void *));
None
Address of a variable that receives the key value. This value is used in calls to tis_getspecific(3) and tis_setspecific(3) to get and set the value associated with this key. Address of a routine that is called to destroy the context value when a thread terminates with a non-NULL value for the key. Note that this argument is used only when threads are present.
This routine generates a unique thread-specific data key. The key argument points to an opaque object used to locate data.
This routine generates and returns a new key value. The key reserves a cell. Each call to this routine creates a new cell that is unique within an application invocation. Keys must be generated from initialization code that is guaranteed to be called only once within each process. (See the tis_once(3) description for more information.)
Your program can associate an optional destructor function with each key. At thread exit, if a key has a non-NULL destructor function pointer, and the thread has a non-NULL value associated with that key, the function pointed to is called with the current associated value as its sole argument. The order in which data destructors are called at thread termination is undefined.
When threads are present, keys and any corresponding data are thread specific; they enable the context to be maintained on a per-thread basis. For more information about the use of tis_key_create(3) in a threaded environment, refer to the pthread_key_create(3) description.
DECthreads imposes a maximum number of thread-specific data keys, equal to the symbolic constant PTHREAD_KEYS_MAX.
If an error condition occurs, this routine returns an integer value indicating the type of error. Possible return values are as follows: Successful completion. The system lacked the necessary resources to create another thread-specific data key, or the limit on the total number of keys per process (PTHREAD_KEYS_MAX) has been exceeded. Insufficient memory exists to create the key. Invalid argument.
None
Functions: tis_getspecific(3), tis_key_delete(3), tis_once(3), tis_setspecific(3)
Manuals: Guide to DECthreads and Programmer's Guide
delim off | http://backdrift.org/man/tru64/man3/tis_key_create.3.html | CC-MAIN-2017-04 | refinedweb | 377 | 57.16 |
wctob - wide-character to single-byte conversion
#include <stdio.h> #include <wchar.h> int wctob(wint_t c);
The wctob() function determines whether c corresponds to a member of the extended character set whose character representation is a single byte when in the initial shift state.
The behaviour of this function is affected by the LC_CTYPE category of the current locale.
The wctob() function returns EOF if c does not correspond to a character with length one in the initial shift state. Otherwise, it returns the single-byte representation of that character.
No errors are defined.
None.
None.
None.
btowc(), <wchar.h>.
Derived from the ISO/IEC 9899:1990/Amendment 1:1995 (E). | http://pubs.opengroup.org/onlinepubs/007908775/xsh/wctob.html | CC-MAIN-2016-50 | refinedweb | 112 | 50.23 |
16 January 2013 14:44 [Source: ICIS news]
LONDON (ICIS)--?xml:namespace>
In its official economic outlook report for 2013 – Jahreswirtschaftsbericht 2013 – the government said that growth slowed in 2012 and the economy was in a weak phase over the winter months, mainly because of the eurozone sovereign debt and confidence crisis, as well as slow global economic growth.
However, the weakness would only be temporary and over the course of 2013 growth should accelerate again, mainly supported by German domestic demand, the government said.
Export growth is expected to slow to 2.8% in 2013, from 4.1% in 2012 and 7.8% in 2011. Gross wages are expected to increase by 2.6% in 2013, the same rate as in 2012, but down from 3.4% in 2011.
“
The government’s reduced GDP forecast for 2013 compares with 0.7% GDP growth in 2012, 3.0% in 2011 and 4.2% in 2010. For 2014, the government forecasts 1.6% GDP growth.
In related news, the country’ federal statistics office indicated earlier this week that
The full government report is available, in German, on the economics ministry’s website. | http://www.icis.com/Articles/2013/01/16/9632430/germany-slashes-2013-gdp-forecast-to-0.4.html | CC-MAIN-2014-35 | refinedweb | 191 | 69.38 |
How to: Measure PLINQ Query Performance
This example shows how use the Stopwatch class to measure the time it takes for a PLINQ query to execute.
Example
This example uses an empty
foreach loop (
For Each in Visual Basic) to measure the time it takes for the query to execute. In real-world code, the loop typically contains additional processing steps that add to the total query execution time. Notice that the stopwatch is not started until just before the loop, because that is when the query execution begins. If you require more fine-grained measurement, you can use the
ElapsedTicks property instead of
ElapsedMilliseconds.
using System; using System.Diagnostics; using System.Linq; class Example { static void Main() { var source = Enumerable.Range(0, 3000000); var queryToMeasure = from num in source.AsParallel() where num % 3 == 0 select Math.Sqrt(num); Console.WriteLine("Measuring..."); // The query does not run until it is enumerated. // Therefore, start the timer here. Stopwatch sw = Stopwatch.StartNew(); // For pure query cost, enumerate and do nothing else. foreach (var n in queryToMeasure) { } sw.Stop(); long elapsed = sw.ElapsedMilliseconds; // or sw.ElapsedTicks Console.WriteLine("Total query time: {0} ms", elapsed); Console.WriteLine("Press any key to exit."); Console.ReadKey(); } }
Module Example Sub Main() Dim source = Enumerable.Range(0, 3000000) ' Define parallel and non-parallel queries. Dim queryToMeasure = From num In source.AsParallel() Where num Mod 3 = 0 Select Math.Sqrt(num) Console.WriteLine("Measuring...") ' The query does not run until it is enumerated. ' Therefore, start the timer here. Dim sw = System.Diagnostics.Stopwatch.StartNew() ' For pure query cost, enumerate and do nothing else. For Each n As Double In queryToMeasure Next sw.Stop() Dim elapsed As Long = sw.ElapsedMilliseconds ' or sw.ElapsedTicks Console.WriteLine("Total query time: {0} ms.", elapsed) Console.WriteLine("Press any key to exit.") Console.ReadKey() End Sub End Module
The total execution time is a useful metric when you are experimenting with query implementations, but it does not always tell the whole story. To get a deeper and richer view of the interaction of the query threads with one another and with other running processes, use the Concurrency Visualizer. For more information, see Concurrency Visualizer.
See also
Feedback
Send feedback about: | https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/how-to-measure-plinq-query-performance | CC-MAIN-2019-26 | refinedweb | 366 | 53.78 |
#include <hallo.h> * Jay Berkenbilt [Mon, May 24 2004, 10:51:25PM]: > > > The Debian XML/SGML group has libxercesicu25 that depends on ICU > > so please coordinate with them before you do any upload. I'd > > suggest that the Mono group and the Debian XML/SGML group should > > be co-maintainers on the package (feel free to remove me or leave > > me as you see fit). > > I believe there is already a newer version of ICU in experimental, but > it is not the latest upstream version. There's probably something in Exactly. And it still has an RC bug. > the archives of the debian-xml-sgml-pkgs list about this since I > raised the question when packaging xerces24 and xerces25. > > I'm effectively maintaining the xerces packages right now as a member > of the Debian XML/SGML group. If you'd like me to try building and > testing the xerces packages with a version of the icu packages that > you're preparing to upload, I'd be happy to do that if you let me know > where I can get them from. Fine! I rebuilt xerces25 localy and it did build and link as expected, however I did no serios testing with it. You can find my packages on deb ./ Please test them troughout and report results. However, since my package are not going remove the old libicu* packages, I will upload it anyways. Regards, Eduard. -- Die Götter handhaben uns Menschen gleichsam wie Wurfgeschosse. -- Titus Maccius Plautus (Die Gefangenen) | https://lists.debian.org/debian-devel/2004/05/msg01554.html | CC-MAIN-2018-26 | refinedweb | 248 | 71.55 |
go to bug id or search bugs for
New/Additional Comment:
Description:
------------
These two functions, also in libuuid, would be useful.
----
NAME
uuid_parse - convert an input UUID string into binary representation
SYNOPSIS
#include <uuid/uuid.h>
int uuid_parse( char *in, uuid_t uu);
DESCRIPTION?).
----
NAME
uuid_unparse - convert an UUID from binary representation to a string
SYNOPSIS
#include <uuid/uuid.h>
void uuid_unparse(uuid_t uu, char *out);
void uuid_unparse_upper(uuid_t uu, char *out);
void uuid_unparse_lower(uuid_t uu, char *out);
DESCRIPTION
The uuid_unparse function converts the supplied UUID uu from the binary representation into a 36-byte
string (plus tailing ?\0?) of the form 1b4e28ba-2fa1-11d2-883f-b9a76 and stores this value in the char-
acter.. | https://bugs.php.net/bug.php?id=57052&edit=1 | CC-MAIN-2021-25 | refinedweb | 114 | 54.42 |
These program prints various different patterns of numbers and stars. These codes illustrate how to create various patterns using c programming. Most of these c programs involve usage of nested loops and space. A pattern of numbers, star or characters is a way of arranging these in some logical manner or they may form a sequence. Some of these patterns are triangles which have special importance in mathematics. Some patterns are symmetrical while other are not. Please see the complete page and look at comments for many different patterns.
* *** ***** ******* *********
We have shown five rows above, in the program you will be asked to enter the numbers of rows you want to print in the pyramid of stars.
#include <stdio.h> int main() { int row, c, n, temp; printf("Enter the number of rows in pyramid of stars you wish to see "); scanf("%d",&n); temp = n; for ( row = 1 ; row <= n ; row++ ) { for ( c = 1 ; c < temp ; c++ ) printf(" "); temp--; for ( c = 1 ; c <= 2*row - 1 ; c++ ) printf("*"); printf("\n"); } return 0; }
Download Stars pyramid program.
Output of program:
For more patterns or shapes on numbers and characters see comments below and also see codes on following pages:
Floyd triangle
Pascal triangle
Consider the pattern
*
**
***
****
*****
to print above pattern see the code below:
#include <stdio.h> int main() { int n, c, k; printf("Enter number of rows\n"); scanf("%d",&n); for ( c = 1 ; c <= n ; c++ ) { for( k = 1 ; k <= c ; k++ ) printf("*"); printf("\n"); } return 0; }
Using these examples you are in a better position to create your desired pattern for yourself. Creating a pattern involves how to use nested loops properly, some pattern may involve alphabets or other special characters. Key aspect is knowing how the characters in pattern changes.
Pattern:
* *A* *A*A* *A*A*A*
C pattern program of stars and alphabets:
#include<stdio.h> main() { int n, c, k, space, count = 1; printf("Enter number of rows\n"); scanf("%d",&n); space = n; for ( c = 1 ; c <= n ; c++) { for( k = 1 ; k < space ; k++) printf(" "); for ( k = 1 ; k <= c ; k++) { printf("*"); if ( c > 1 && count < c) { printf("A"); count++; } } printf("\n"); space--; count = 1; } return 0; }
Pattern:
1 232 34543 4567654 567898765
C program:
#include<stdio.h> main() { int n, c, d, num = 1, space; scanf("%d",&n); space = n - 1; for ( d = 1 ; d <= n ; d++ ) { num = d; for ( c = 1 ; c <= space ; c++ ) printf(" "); space--; for ( c = 1 ; c <= d ; c++ ) { printf("%d", num); num++; } num--; num--; for ( c = 1 ; c < d ; c++) { printf("%d", num); num--; } printf("\n"); } return 0; } | http://www.programmingsimplified.com/c-program-print-stars-pyramid | CC-MAIN-2014-15 | refinedweb | 432 | 71.38 |
my objective is to multiply any 2 numbers(int). The numbers can be extremely large (i.e. run into hundreds of digits) and are provided as strings. The expected output is a string which represents the product of the two numbers. "output shuld be a integer." here is what i coded.
Code :
public class LargeMultiply { static String test1a = "268435456"; static String test1b = "524288"; static String testcaseA = test1a; static String testcaseB = test1b; public static void main(String args[]){ LargeMultiply inst = new LargeMultiply(); String v = inst.multiply(testcaseA,testcaseB); System.out.println(v); } public String multiply(String num1, String num2){ Long a=Long.parseLong(num1); Long b=Long.parseLong(num2); return String.valueOf(a*b); } }
and here are outputs
if inputs are 268435456 524288 these then output is 140737488355328 the above code perform well in this case.
if inputs are 26843545623423 52428824234 then expected output is 1407375535307804420432982 this but it gives a -ve value due to max limit reached for "long" but if i use "double' then answer is in scientfic form and that is not needed i want output in integer form.
Is any way to display double in normal form(not with decimal point)?? | http://www.javaprogrammingforums.com/%20java-theory-questions/14443-how-can-i-do-printingthethread.html | CC-MAIN-2016-26 | refinedweb | 194 | 66.33 |
Hi everyone, I'm relatively new at C++ - knowning most of the basic rules and various structures of a C++ program - but I'm having a hard time developing a code - without the use of an arry (haven't learned it yet) - that determines the lowest number and drops it when calculating the average of a set of numbers. Here's the question:
"Write a program that calculates the average of a group of test scores, where the lowest score in the group is dropped. It should use the following functions:
void getScore() - should ask the user for a test score, store it in a reference parameter variable, and validate it. This function should be called by main once for each of the five scores to be entered.
void calcAverage() should calculate and display the average of the four highest scors. This function should be called just once by main, and should be passed the the five scores.
int findLowest() should find and return the lowest of the five scores passed to it. It should be called by calcAverage, who uses the function to determine which of the five scores to drop.
* Do not accept test scores lower than 0 or higher than 100."
This is what I have so far:.Code://#4: Lowest Score Drop #include <iostream> using namespace std; //Function Prototypes void getScore(int); void calcAverage(); int findLowest(); int main() { int testScore, sum = 0, count; double testAverage; char restartProgram; cout <<"This program will calculate the average of five test scores, where the" << endl; cout <<"lowest score in the group is dropped." << endl; do{ for(count = 1; count <= 5; count++) { cout <<"Please enter the score for test " << count <<"." << endl; cin >> testScore; if(testScore < 0 || testScore > 100) // Checks to see if input is valid: //0 <= testScore <= 100 { cout << testScore << " is invalid. Please enter a score that is greater" << endl; cout <<"than or equal to 0 or less than or equal to 100." << endl; break; // breaks out of if statement } else { sum += testScore; } getScore(sum); } cout <<"Do you wish to restart the program?(y/n)" << endl; cin >> restartProgram; }while(restartProgram == 'y' || restartProgram == 'Y'); //Continue rest of program later... system("pause"); //used for Dev C++ return 0; } | http://cboard.cprogramming.com/cplusplus-programming/98096-lowest-score-drop-cplusplus.html | CC-MAIN-2013-20 | refinedweb | 365 | 75.95 |
beagle: omap3: usb is dead
Bug Description
SRU Justification:
Impact: usb hud is dead on omap3 boards (beagles)
Fix: see the attached patches.
Testcase: boot the board with an unpatched kernel and see there's no nic, mouse, keyb, etcetc; try again with a patched kernel and check again nic, mouse, keyb, etcetc
===
This bug is actually a twofold problem:
1) config for our omap kernel had a problem
enabling USB_[EHCI|
/home/ppisati/
/home/ppisati/
drivers/
1289:
#ifdef CONFIG_
#include "ehci-omap.c"
#define PLATFORM_DRIVER ehci_hcd_
#endif
1394:
#ifdef CONFIG_
#include "ehci-platform.c"
#define PLATFORM_DRIVER ehci_platform_
#endif
and later in ehci_init():
#ifdef PLATFORM_DRIVER
retval = platform_
if (retval < 0)
goto clean0;
#endif
2) upstream broke ehci implementation since 3.5 (and it's still broken ATM)
Since the 3.5 tree, usb ehci for omap3 has been plagued with problems up to the point that it was disabled upstream:
[flag@newluxor linux-2.6]$ git show 06b4ba5
commit 06b4ba529528fbf
Author: Kevin Hilman <email address hidden>
Date: Fri Jul 6 11:20:28 2012 -0700
ARM: OMAP2+: omap2plus_
The EHCI driver is not stable enough to be enabled by default. In v3.5,
it has at least the following problems:
- warning dump during bootup
- hang during suspend
- prevents CORE powerdomain from entering retention during idle (even
when no USB devices connected.)
This demonstrates that this driver has not been thoroughly tested and
therfore should not be enabled in the default defconfig.
In addition, the problems above cause new PM regressions which need be
addressed before this driver should be enabled in the default
defconfig.
Signed-off-by: Kevin Hilman <email address hidden>
Signed-off-by: Tony Lindgren <email address hidden>
and lately this situation has spiraled down to the point where enabling it at boot triggers an oops and a subsequent dead usb hub:
vanilla 3.5 omap2plus_defconfig + ehci:
...
[ 4.200103] omap_wdt: OMAP Watchdog Timer Rev 0x31: initial timeout 60 sec
[ 4.208526] twl4030_wdt twl4030_wdt: Failed to register misc device
[ 4.215240] twl4030_wdt: probe of twl4030_wdt failed with error -16
[ 4.225860] omap_hsmmc omap_hsmmc.0: Failed to get debounce clk
[ 4.262084] hub 1-0:1.0: state 7 ports 3 chg 0004 evt 0000
[ 4.267913] hub 1-0:1.0: port 2, status 0501, change 0000, 480 Mb/s
[ 4.332305] platform ehci-omap.0: port 2 reset complete, port enabled
[ 4.339050] platform ehci-omap.0: GetStatus port:2 status 001005 0 ACK POWER sig=se0 PE CONNECT
[ 4.410400] Unable to handle kernel NULL pointer dereference at virtual address 00000000
[ 4.418884] pgd = c0004000
[ 4.421722] [00000000] *pgd=00000000
[ 4.425476] Internal error: Oops: 5 [#1] SMP ARM
[ 4.430297] Modules linked in:
[ 4.433471] CPU: 0 Not tainted (3.5.0 #16)
[ 4.438110] PC is at hub_port_
[ 4.442749] LR is at hub_port_
[ 4.447296] pc : [<c030b2bc>] lr : [<c030b0f4>] psr: 60000013
[ 4.447296] sp : df905eb8 ip : c05a9eb4 fp : 00000000
[ 4.459259] r10: 00000000 r9 : df306400 r8 : 00000032
[ 4.464691] r7 : df30ac00 r6 : 00000002 r5 : 00000000 r4 : df2a7400
[ 4.471496] r3 : 00000000 r2 : c059e324 r1 : c059e348 r0 : df2a7468
[ 4.478302] Flags: nZCv IRQs on FIQs on Mode SVC_32 ISA ARM Segment kernel
[ 4.485900] Control: 10c5387d Table: 80004019 DAC: 00000017
[ 4.491912] Process khubd (pid: 236, stack limit = 0xdf9042f8)
[ 4.497985] Stack: (0xdf905eb8 to 0xdf906000)
[ 4.502532] 5ea0: 00000002 df306400
[ 4.511047] 5ec0: 00000002 00000000 00000004 c008a078 00000001 00000002 00000003 df300400
[ 4.519561] 5ee0: 00000000 c044acb0 00000001 df2a7400 df30ac00 df300400 df300418 df306400
[ 4.528106] 5f00: 00000002 00000000 00000002 c030eb30 00000501 00000000 c059f090 c0656600
[ 4.536621] 5f20: 107e9dd6 00000000 df306408 df30a820 df30ac9c df30a800 00000004 df306401
[ 4.545135] 5f40: df306470 df30ac00 df306468 df30ac00 df30a820 df300400 00000009 c0065144
[ 4.553680] 5f60: 00000000 df904000 00000000 df88c100 c005cff4 df905f74 df905f74 00000000
[ 4.562194] 5f80: 00000501 c008a078 df82ff20 df82fef8 00000000 c030e4c0 00000013 00000000
[ 4.570709] 5fa0: 00000000 00000000 00000000 c005c8f8 00000000 00000000 00000000 00000000
[ 4.579254] 5fc0: 00000000 dead4ead ffffffff ffffffff c0700330 00000000 00000000 c0561550
[ 4.587768] 5fe0: df905fe0 df905fe0 df82fef8 c005c874 c0014154 c0014154 00000000 00000000
[ 4.596313] [<c030b2bc>] (hub_port_
[ 4.605468] [<c030eb30>] (hub_thread+
[ 4.613922] [<c005c8f8>] (kthread+0x84/0x90) from [<c0014154>] (kernel_
[ 4.622619] Code: e59f2690 e5933080 e2840068 e59f1688 (e593e000)
[ 4.629089] ---[ end trace 6fcdeaed28ce1f31 ]---
[ 4.790161] usbcore: registered new interface driver usbhid
...
ATM there's no activity upstream to resolve this bug in a sound way but a patch was posted to linux-omap that resolves it:
http://<email address hidden>
While it's not upstream, the patch touches only omap3 clock code so it's safe for all the other flavours and it's the only
option we have right now.
The aforementioned patch coupled with disabling the generic ehci/ohci driver implementation fix the usb bus on omap3.
and here are the patched (ehcifixA) and unpatched kernel to test out:
http://
and
http://
The attachment "Clock fix for omap3 (point 2 of 10615. | https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1061599 | CC-MAIN-2021-10 | refinedweb | 806 | 85.28 |
Every programmer has them lying around, you know what I'm talking about, those little utility functions that help with string conversions. Especially in website development, where everything is treated as plain text, I can't go without some easy functions to help me with the parsing of DateTimes, Booleans, Integers, and GUIDs, amongst others.
When I recently came across an article about TypeConverters, I immediately saw this opportunity to come up with a single Extension Method (with some overloads) that plugs right into the String class.
String
bool b = "true".ConvertTo<bool>();
DateTime d1 = " 01:23:45 ".ConvertTo<DateTime>();
Point p = "100,25".ConvertTo<Point>();
//convert, but use specific culture.
//in this case the comma is used as a decimal seperator
Double d = "1.234,567".ConvertTo<double>("NL")
//provide a default value, if conversion fails
Guid g = "i'm not a guid".ConvertTo<Guid>(Guid.Empty);
Although the Microsoft .NET Framework has plenty of conversion methods, for some reason, I always had difficulty when it came to 'proper' string handling. Localized date times that weren't understood, numbers that could only be parsed if I removed the separators, etc., and yet more methods to work with Enumerator values.
When I started experimenting with the TypeConverter, it seemed just too good to be true. But as always, I soon came back to earth when "it" wasn't too impressed with my localized numbers, e.g., -1.234,56. Anyway, I've managed to resolve this in what seems like a nice clean Extension Method that integrates into the String class.
TypeConverter
All the hard work is done by TypeConverters, which according to the MSDN documentation, provides a unified way of converting types of values to other types, as well as for accessing standard values and subproperties. I was particularly interested in the conversion from string to its strong typed counterpart, which can easily be achieved as explained by Scott.
TypeConverter converter = TypeDescriptor.GetConverter(typeof(double))
converter.ConvertFromString(null, null, text);
All that was left to do was wrapping this inside a generic function and adding two sets of overloads, which basically allow you to interpret the string and convert it to its defined type. But, if the format of the String can not be understood by the TypeConverter, it will raise an Exception.
Exception
//this will through an exception
//because the text can not be converted to the specified type
int x = "abcd".ConvertTo<int>();
//even this one will fail due to the localization that is set
//to dutch where comma's are used as decimal separators
int y = "1,234.56".ConvertTo<int>("NL");
The other set of methods allows you to specify a default value which will be used if the TypeConverter fails, in which case the Exception will be suppressed.
//use default value if TypeConverter will fail
DateTime a = "i'm not a date".ConvertTo<DateTime>(DateTime.Today);
//or with localization support
Double b = "1a".ConvertTo<Double>(CultureInfo.InstalledUICulture, -1);
Do take a look at the ugly part which resolves the "Numbers issue", by by-passing the BaseNumberConverter. It's not elegant or pretty, but it is contained and does the job. You might even want to swap out other TypeConverters, for example, the BooleanConverter in order to be able to handle strings like Yes, No, On, Off, etc.
BaseNumberConverter
BooleanConverter
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
If GetType(T).Equals(GetType(Integer)) Then
If value.StartsWith("&") Then
styles = NumberStyles.HexNumber
value = value.TrimStart("&Hh".ToCharArray)
Return Integer.Parse(value, styles, format)
ElseIf value.StartsWith("0x") Then
styles = NumberStyles.HexNumber
value = value.Substring(2)
Return Integer.Parse(value, styles, format)
Else
Return Integer.Parse(value, styles Xor NumberStyles.AllowDecimalPoint, format)
End If
End If
int, double, bool, etc.
Convert.ChangeType()
string test = "123,45";
double d = (double)Convert.ChangeType(test, typeof(double), new System.Globalization.CultureInfo("nl-BE"));
System.Diagnostics.Debug.WriteLine(d.ToString());
Enums
Type type = typeof(T);
if (type.IsEnum)
{
return (T)Enum.Parse(type, value, true);
}
else
{
return (T)Convert.ChangeType(value, type);
}
HandleThousandsSeparatorIssue
double d = (double)Convert.ChangeType("1,000.1", typeof(double))
DateTime d = StringHelper.ConvertTo<DateTime>("januari 1, 2001");
General News Suggestion Question Bug Answer Joke Praise Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages. | https://www.codeproject.com/Articles/127315/String-conversions-made-easy | CC-MAIN-2019-09 | refinedweb | 732 | 50.12 |
:
This is a Recommendation-Track document. RDF-compatible model-theoretic semantics of OWL 2, called "OWL 2 Full". The semantics given here is the OWL 2 semantic extension of RDFS [RDF Semantics]. Therefore, the semantic meaning given to an RDF graph by OWL 2 Full includes the meaning given to the graph by RDFS. Beyond that, OWL 2 Full gives additional meaning to all the language features of OWL 2, by following the design principles that have been applied to the semantics of RDF.
OWL 2 Full accepts every well-formed RDF graph [RDF] as a syntactically valid OWL 2 Full ontology, and gives a precise semantic meaning to it. The semantic meaning is determined by the set of OWL 2 Full semantic conditions, which include and extend all the semantic conditions for RDF and RDFS specified in [RDF Semantics].]. The OWL 2 Full semantic conditions specify exactly which triple sets are assigned a specific meaning, and what this meaning is.
OWL 2 Full interpretations are defined on the OWL 2 Full universe. The OWL 2 Full universe is identified with the RDFS universe, and comprises the set of all individuals. It is further divided into "parts", namely the classes, the properties, and the datatype values. Thus, the members of these parts are also individuals. Every class has a set of individuals associated with it, the so called "class extension", which is distinguished from the class itself. Analog, every property is associated with a "property extension", which consists of pairs of individuals. The classes subsume the datatypes, and the properties subsume the data properties, the annotation properties, and the ontology properties. Individuals may play different roles at the same time in an OWL 2 Full ontology. One individual can, for example, be both a class and a property, or both a data property and an annotation property.
In OWL 2 Full ontologies, usually no care is needed to ensure that URI references are actually in the appropriate part of the OWL universe. These "localizing" assumptions will typically follow from applying the OWL 2 Full semantic conditions.
A strong relationship holds between OWL 2 Full and the Direct Semantics of OWL 2 [OWL 2 Direct Semantics]. OWL 2 Full is, in a certain sense, able to reflect all logical conclusions of the Direct Semantics, when applied to an OWL 2 DL ontology [OWL 2 Structural Specification] in RDF graph form. The precise relationship is stated by the OWL 2 correspondence theorem.
The content of this document is not meant to be self-contained, but builds on top of the RDF Semantics document [RDF Semantics] by only adding the OWL 2 specific aspects of the semantics. Hence, the complete definition of OWL 2 Full is actually given by the combination of these two documents.
The italicized keywords MUST, MUST NOT, SHOULD, SHOULD NOT, and MAY specify certain aspects of the normative behavior of OWL 2 tools, and are interpreted as specified in RFC 2119 [RFC 2119].
The OWL 2 Full vocabulary is a set of URI references in the OWL namespace, owl:, which is given by the URI reference
Table 2.1 lists the OWL 2 Full vocabulary, which extends the RDF and RDFS vocabulary as specified by Sections 3.1 and 4.1 of [RDF Semantics]. Excluded are those URI references from the OWL namespace, which are mentioned in one of the other tables in this section.
Note: The use of the URI reference owl:DataRange has been deprecated as of OWL 2. The URI reference rdfs:Datatype SHOULD be used instead.
Table 2.2 lists the set of datatypes of OWL 2 Full. rdf:XMLLiteral is described in Section 3.1 of [RDF Semantics]. rdf:text is described in [RDF:TEXT]. All other datatypes are described in Section 4 of [OWL 2 Structural Specification].
Feature At Risk #1: owl:rational support
Note: This feature is "at risk" and may be removed from this specification based on feedback. Please send feedback to public-owl-comments@w3.org.
The owl:rational datatype might be removed from OWL 2 if implementation experience reveals problems with supporting this datatype.
Feature At Risk #2: owl:dateTime name.
Please send feedback to public-owl-comments@w3.org.
Table 2.3 lists the set of datatype facets of OWL 2 Full. Section 4 of [OWL 2 Structural Specification] describes the meaning of each facet, to which datatypes it can be applied, and which values it can take for a given datatype. The facet rdf:langPattern is further described in [RDF:TEXT].
Every well-formed RDF graph [RDF] is a syntactically valid OWL 2 Full ontology. If a OWL 2 Full ontology imports other OWL 2 Full ontologies, then the whole imports closure of that ontology has to be taken into account.
Definition 3.1 (Import Closure): Let K be a collection of RDF graphs. K is imports closed iff for every triple in any element of K of the form x owl:imports u then K contains a graph that is referred to by u. The imports closure of a collection of RDF graphs is the smallest imports closed collection of RDF graphs containing the graphs.
A OWL 2 Full ontology MAY contain an ontology header, if the ontology's author wants to explicitly signal that an RDF graph is intended as a OWL 2 Full ontology. Such an ontology header MAY additionally contain information about the ontology's version. The OWL 2 Mapping to RDF [OWL 2 RDF Mapping] provides details about the syntax of ontology headers.
OWL 2 Full provides a vocabulary interpretation and vocabulary entailment (see Section 2.1 of [RDF Semantics]) for the RDF and RDFS vocabularies, and the OWL 2 Full vocabulary.
From the RDF Semantics [RDF Semantics], let V be a set of URI references and literals containing the RDF and RDFS vocabulary, and let D be a datatype map according to Section 5.1 of [RDF Semantics]. A D-interpretation I of V is a tuple
I = 〈 IR, IP, IEXT, IS, IL, LV 〉.
IR is the domain of discourse or universe, i.e., a nonempty set that contains the denotations of URI references and literals in V. IP is a subset of IR, the properties of I. LV is a subset of IR that covers at least the value spaces of all datatypes in D. IEXT is used to associate properties with their property extension, and is a mapping from IP to P(IR × IR), where P is the powerset. IS is a mapping from URI references in V to their denotations in IR. IL is a mapping from typed literals in V to their denotations in IR, which maps all well-typed literals to instances of LV (Section 5.1 of [RDF Semantics] explains why the range of IL is actually IR instead of LV).
As detailed in [RDF Semantics], a D-interpretation has to meet additional semantic conditions, which constrain the set of RDF graphs that are true under this interpretation. An RDF graph G is said to be satisfied by a D-interpretation I, if I(G) = true.
The following definition specifies what a OWL 2 Full datatype map is. First, Table 4.1 defines sets that relate datatypes with their facets, and with the values a facet is allowed to take in combination with a certain datatype.
Definition 4.1 (OWL 2 Full Datatype Map): Let D be a datatype map as defined in Section 5.1 of [RDF Semantics]. D is a OWL 2 Full datatype map, if it contains at least all datatypes listed in Table 2.2, and if it defines the sets listed in Table 4.1 for each contained datatype.
The next definition specifies what a OWL 2 Full interpretation is.
Definition 4.2 (OWL 2 Full Interpretation): Let D be a OWL 2 Full datatype map, and let V be a vocabulary that includes the RDF and RDFS vocabularies, and the OWL 2 Full vocabulary together with all the datatype and facet names listed in Section 2. An OWL 2 Full interpretation, I = 〈 IR, IP, IEXT, IS, IL, LV 〉, of V with respect to D, is a D-interpretation of V that satisfies all the extra semantic conditions given in Section 5.
Table 4.2 defines the "parts" of the OWL 2 Full universe in terms of the mapping IEXT of an OWL 2 Full interpretation and by referring to the RDF, RDFS and OWL 2 Full vocabularies.
Further, the mapping ICEXT from IC to P(IR) that associates classes with their class extension, is defined as
ICEXT(c) = { x ∈ IR | 〈x,c〉 ∈ IEXT(I(rdf:type)) }
for c ∈ IC.
The following definitions specify what a consistent OWL 2 Full ontology is, and what it means that an OWL 2 Full ontology entails another OWL 2 Full Ontology.
Definition 4.3 (OWL 2 Full Consistency): Let K be a collection of RDF graphs, and let D be a OWL 2 Full datatype map. K is OWL 2 Full consistent with respect to D iff there is some OWL 2 Full interpretation with respect to D (of some vocabulary that includes the RDF and RDFS vocabularies, and the OWL 2 Full vocabulary together with all the datatype and facet names listed in Section 2) that satisfies all the RDF graphs in K.
Definition 4.4 (OWL 2 Full Entailment): Let K and Q be collections of RDF graphs, and let D be a OWL 2 Full datatype map. K OWL 2 Full entails Q with respect to D iff every OWL 2 Full interpretation with respect to D (of any vocabulary V that includes the RDF and RDFS vocabularies, and the OWL 2 Full vocabulary together with all the datatype and facet names listed in Section 2) that satisfies all the RDF graphs in K also satisfies all the RDF graphs in Q.
This section defines the semantic conditions of OWL 2 Full. The semantic conditions presented here are only those for the specific features of OWL 2. The complete set of semantic conditions for OWL 2 Full is the combination of the semantic conditions presented here and the semantic conditions given for Simple Entailment, RDF, RDFS and D-Entailment in [RDF Semantics].
Table 5.1 specifies semantic conditions for the different parts of the OWL 2 Full universe, as defined in Section 4. Table 5.2 and Table 5.3 list semantic conditions for the classes and the properties of the OWL 2 Full vocabulary. The remaining tables in this section specify the OWL 2 Full semantic conditions for the different language features of OWL 2.
Most semantic conditions are "iff" conditions, which completely specify the semantics of the respective language feature. For some language features, however, there are only "if-then" conditions in order to avoid certain semantic paradoxes and other problems with the semantics. Several language features with "iff" conditions, namely Sub Property Chains in Table 5.9, N-ary Axioms in Table 5.11, and Negative Property Assertions in Table 5.15, have a multi-triple representation in RDF, where the different triples share a common "root node" x. In order to treat this specific syntactic aspect technically, the "iff" conditions of these language features have been split into two "if-then" conditions, and the right-to-left "if" condition contains an additional premise of the form "∃x ∈ IR", which has the single purpose to provide the needed "root node" x.
Conventions used in this section:
Several conventions are used when presenting logic expressions in the below tables.
Having a comma between two assertions in a semantic condition, as in
c ∈ IC , p ∈ IP
means a logical "and".
If no scope is explicitly given for a variable x, as in "∀x:…" or in "{x|…}", then x is unconstrained, which means that x ∈ IR.
An expression of the form "l sequence of u1,…, un ∈ S" means that l represents a list of n elements, all of them being instances of the class S. Precisely, u1 ∈ S,… , un ∈ S, and there exist x1 ∈ IR,…, xn ∈ IR, such that
I(l) ∈ ICEXT(I(rdf:List)),
I(l) = I(x1),
〈x1,u1〉 ∈ IEXT(I(rdf:first)), 〈x1,x2〉 ∈ IEXT(I(rdf:rest)),
…,
〈xn,un〉 ∈ IEXT(I(rdf:first)), 〈xn,I(rdf:nil)〉 ∈ IEXT(I(rdf:rest)).
The following names for certain sets are used as convenient abbreviations throughout this and the following sections:
The semantic conditions in the following tables sometimes do not explicitly list typing statements in their consequent that one would normally expect. For example, the semantic condition for owl:allValuesFrom restrictions in Table 5.6 does not list the statement x ∈ ICEXT(I(owl:Restriction)) on its right hand side. Consequents are generally not mentioned, if they can already be deduced by means of the semantic conditions given in Table 5.2 and Table 5.3, occasionally in connection with Table 5.1. In the example above, the omitted consequent can be obtained from the third column of the entry for owl:allValuesFrom in Table 5.3, which determines that IEXT(I(owl:allValuesFrom)) ⊆ ICEXT(I(owl:Restriction)) × IC.
Table 5.1 lists the semantic conditions for the parts of the OWL 2 Full universe, as defined by Table 4.2 in Section 4. The semantic conditions say how the parts are related to other parts, and they further specify the semantics for the instances of some of the parts.
Table 5.2 lists the semantic conditions for the classes of the OWL 2 Full vocabulary, and certain classes from RDF and RDFS. It tells the sort of class, and specifies the part of the OWL 2 Full universe the extension of each class belongs to. As a specific note: For owl:NamedIndividual that there is no way in OWL 2 Full to restrict the set of individuals to only those being named by a URI, hence the extension of this class has been specified to equal the whole domain.
Not included in this table are the datatypes of OWL 2 Full, as given in Table 2.2. For a datatype URI U, the following semantic conditions hold: I(U) ∈ IDC, and ICEXT(I(U)) ⊆ LV.
Table 5.3 lists the semantic conditions for the properties of the OWL 2 Full vocabulary and certain properties from RDFS. It tells the sort of property, and specifies the domain and range for each property. As specific notes: owl:topObjectProperty relates every two individuals in the universe to each other. Likewise, owl:topDataProperty relates every individual to every datavalue. owl:bottomObjectProperty and owl:bottomDataProperty do not relate any individuals to each other at all. The ranges of the properties owl:deprecated and owl:hasSelf are not restricted to be boolean values, so it is possible for these properties to have objects of arbitrary type.
Not included in this table are the datatype facets of OWL 2 Full, as given in Table 2.3. For a facet URI U, the following semantic conditions hold: I(U) ∈ IP, and IEXT(I(U)) ⊆ IR × LV.
Table 5.4 lists the semantic conditions for boolean class expressions, including complements, intersections, and unions of classes. An intersection or union of a collection of datatypes is itself a datatype. While a complement of a class is created w.r.t. to the whole domain, a datatype complement is created for a datatype w.r.t. the set of data values only, and results itself in a datatype.
Table 5.5 lists the semantic conditions for enumerations, i.e. classes that consist of an explicitly given finite set of instances. In particular, an enumeration entirely consisting of datatype values is a datatype.
Table 5.6 lists the semantic conditions for property restrictions, including value restrictions, cardinality restrictions, and self restrictions. There are also semantic conditions for value restrictions dealing with n-ary datatypes. Note that the semantic condition for self restrictions does not entail the right hand side of a owl:hasSelf assertion to be a boolean value, so it is possible to have right hand sides of arbitrary type.
However, it has been proposed that there is no need to introduce such an additional sort of extension.
Table 5.7 lists the semantic conditions for datatype restrictions, which are specified for a datatype, and for a set of facets and facet values. Note that if no facet is applied to a given datatype, then the resulting datatype will be equivalent to the original datatype. Note further that the semantic conditions are specified in a way that applying a facet to a datatype, for which it is not defined, will lead to an unsatisfiable ontology. Likewise, adding an inapplicable facet value to a certain combination of a datatype a facet will lead to an unsatisfiable ontology. As a consequence, a datatype restriction with one or more specified facets will lead to an unsatisfiable ontology if applied to a datatype for which no facets are defined (usually a set of facets only exists for datatypes contained in the datatype map).
Table 5.8 extends the semantic conditions for the RDFS vocabulary. The original semantics for the language features regarded here are specified in [RDF Semantics], and they only provide for "if-then" semantic conditions, while OWL 2 Full specifies stronger "iff" semantic conditions. Note that only the additional semantic conditions are given here and that the other conditions on the RDF and RDFS vocabularies are retained.
Table 5.9 lists the semantic conditions for sub property chains. The semantics have been specified in a way to allow a sub property chain axiom to be satisfiable without requiring the existence of a property that represents the property chain. In particular, the property on the left hand side of the sub property assertion does not necessarily represent the property chain.
Table 5.10 lists the semantic conditions for equal and different individuals, equivalent and disjoint classes, and equivalent and disjoint properties. Also treated here are disjoint union axioms.
Table 5.11 lists the semantic conditions for n-ary axioms on different individuals, disjoint classes, and disjoint properties. Note that there are two alternative ways to specify owl:AllDifferent axioms, both of them having the same model-theoretic meaning.
Table 5.12 lists the semantic conditions for inverse property axioms.
Table 5.13 lists the semantic conditions for property characteristics, i.e. functionality and inverse functionality, reflexivity and irreflexivity, symmetry and asymmetry, and transitivity of properties.
Table 5.14 lists the semantic conditions for Keys. Keys are an alternative to inverse functional properties (see Table 5.13). They provide for compound keys, and they allow to specify the class of individuals for which a property plays the role of a key feature.
Table 5.15 lists the semantic conditions for negative property assertions. They allow to state that an individual u does not stand in a relationship p with another individual w. The second form based on owl:targetValue is more specific than the first form based on owl:targetIndividual in that it is restricted to the case of negative data property assertions. Note that the second form will coerce the target individual of a negative property assertion into a data value, due to the range defined for the property owl:targetValue in Table 5.3.
This section is concerned with a strong relationship that holds between OWL 2 Full and the Direct Semantics of OWL 2 [OWL 2 Direct Semantics].
One design goal of OWL 2 has been that OWL 2 Full should reflect every logical consequence of the Direct Semantics of OWL 2 [OWL 2 Direct Semantics], as long as this consequence and all its premises can be represented as valid OWL 2 DL ontologies in RDF graph form. However, a fundamental semantic difference exists between the Direct Semantics and OWL 2 Full, which complicates a comparison of their semantic expressiveness. The Direct Semantics treats classes as sets, i.e. subsets of the universe. Classes in OWL 2 Full, however, are individuals in the universe, which have such a set associated to them as their class extension. Hence, under OWL 2 Full, all classes are instances of the universe, but this cannot generally be assumed under the Direct Semantics. An analog distinction holds for properties.
An effect of this difference is that certain logical conclusions of OWL 2 DL do not become "visible" under OWL 2 Full, although they are reflected by OWL 2 Full at a set theoretical level. For example, consider the following two RDF graphs G1 and G2 (RDF graphs are presented here in the style used in [OWL 2 RDF Mapping]):
G1 := {
ex:C rdf:type owl:Class .
ex:D rdf:type owl:Class .
ex:C rdfs:subClassOf ex:D .
}
G2 := {
ex:C rdf:type owl:Class .
ex:D rdf:type owl:Class .
_:x owl:intersectionOf (SEQ ex:C ex:D) .
_:x rdfs:subClassOf ex:D .
}
Both graphs are OWL 2 DL ontologies in RDF graph form, and G1 entails G2 under the Direct Semantics. However, under OWL 2 Full this entailment does not hold. Actually, OWL 2 Full interprets G1 in a way such that the set theoretical relationship
ICEXT(I(ex:C)) ∩ ICEXT(I(ex:D)) ⊆ ICEXT(I(ex:D))
can be concluded. But since OWL 2 Full distinguishes between classes as individuals and their class extensions being the actual sets, G2 is not entailed, unless there exists some additional "helper" individual w, having the set S, defined by
S := ICEXT(w) = ICEXT(I(ex:C)) ∩ ICEXT(I(ex:D))
as its class extension. Whether such a helper individual exists or not has no effect on the answer to the question, whether the basic logical conclusion at the set theoretical level holds or not. The individual is, however, required to represent this conclusion as the RDF graph G2.
The following subsection introduces a set of "comprehension principles", which have the purpose to provide the missing "helper" individuals.
This section lists the set of comprehension principles of OWL 2 Full. These comprehension principles are not part of the set of semantic conditions given in Section 5, and therefore do not need to be met by a OWL 2 Full interpretation as defined in Section 4. They are, however, needed for the OWL 2 correspondence theorem (see Section 6.3) to hold, since the correspondence theorem compares OWL 2 Full and the Direct Semantics solely based on entailments.
Table 6.1 lists the comprehension principles for sequences, i.e. RDF lists build from any finite combination of individuals.
Table 6.2 lists the comprehension principles for boolean class expressions, including complements, intersections, and unions of classes.
Table 6.3 lists the comprehension principles for enumerations, i.e. classes that consist of an explicitly given finite set of instances.
Table 6.4 lists the comprehension principles for property restrictions, including value restrictions, cardinality restrictions, and self restrictions. There are also comprehension principles for value restrictions dealing with n-ary datatypes.
Table 6.5 lists the comprehension principles for datatype restrictions, which are specified for a datatype, and for a set of facets and facet values.
This section presents the OWL 2 correspondence theorem.
Theorem 6.1 (Correspondence Theorem): Let D be a OWL 2 Full datatype map, and let K and Q be collections of valid OWL 2 DL ontologies in RDF graph form that are imports closed, and without annotations occurring in Q. Let F(K) and F(Q) be the collections of OWL 2 DL ontologies in Functional Syntax that result from applying the reverse RDF mapping [OWL 2 RDF Mapping] to K and Q, respectively. If F(K) entails F(Q) with respect to the OWL 2 Direct Semantics [OWL 2 Direct Semantics] and with respect to D, then K entails Q with respect to OWL 2 Full extended by the comprehension principles, and with respect to D.
A sketch of a proof for this theorem is given in Appendix B.
The RDF Semantics document [RDF Semantics] defines so called "axiomatic triples" for the RDF and RDFS vocabularies. Examples of axiomatic triples are:
rdf:type rdf:type rdf:Property ,
rdf:type rdfs:domain rdfs:Resource ,
rdf:type rdfs:range rdfs:Class .
Axiomatic triples are used to give certain basic semantic meaning to all the URIs in the RDF and RDFS vocabularies. This semantic meaning is meant to be "axiomatic", in the sense that it holds for every ontology of the regarded language, including the empty ontology.
Typically, as shown by the examples above, axiomatic triples are used in the RDF Semantics to specify the part of the universe that the denotation of a vocabulary URI belongs to. In the case of properties of the regarded vocabulary, also the domains and the ranges are specified. These kinds of axiomatic triples can be equivalently restated in the form of semantic conditions that have neither premises nor bound variables. Using the names of the different parts of the universe, defined by Table 4.2, the example axiomatic triples above can be restated as:
I(rdf:type) ∈ IP ,
IEXT(I(rdf:type)) ⊆ IR × IC .
Unlike the RDF Semantics, OWL 2 Full does not provide an explicit list of axiomatic triples. It might not be possible to give a definition of OWL 2 Full that captures all intended "axiomatic aspects" of the language in the form of sets of RDF triples, just as it is not possible to define the whole semantics of OWL 2 Full in the form of a set of RDF entailment rules. However, Section 5 contains sets of semantic conditions that are "axiomatic" in the sense described above. Most of these semantic conditions actually have a form similar to those semantic conditions, which resulted from equivalently restating the example axiomatic triples above.
The semantic conditions given in Table 5.2 for "Classes" can be regarded as a set of OWL 2 Full axiomatic triples for classes: IC of all classes, or some subset of IC. Hence, in a corresponding RDF triple the URI C will typically be one of "rdfs:Class" or "owl:Class" (S=IC in both cases), or "rdfs:Datatype" (S=IDC).
For example, the semantic condition for the URI "owl:FunctionalProperty", given by
I(owl:FunctionalProperty) ∈ IC
has the corresponding RDF triple
owl:FunctionalProperty rdf:type rdfs:Class .
Further, for each URI U in the first column, if the third column contains an entry "ICEXT(I(U)) ⊆ S" (or "ICEXT(I(U)) = S") for some set S, then this entry corresponds to some RDF triple of the form "U rdfs:subClassOf C" (or "U owl:equivalentClass C"), where C is the URI of some class with ICEXT(I(C)) = S.
For example, the semantic condition
ICEXT(I(owl:FunctionalProperty)) ⊆ IP
has the corresponding RDF triple
owl:FunctionalProperty rdfs:subClassOf rdf:Property .
Additionally, the conditions on the sets given in Table 5.1 have to be taken into account. In particular, if an entry of the first column states "S1 ⊆ S2" for some sets S1 and S2, then this corresponds to some RDF triple C1 owl:subClassOf C2, where C1 and C2 are the URIs of some classes with ICEXT(I(C1)) = S1 and ICEXT(I(C2)) = S2, respectively, according to Table 5.2.
Note that some of the RDF triples received in this way already follow from the RDFS semantics [RDF Semantics].
The semantic conditions given in Table 5.3 for "Properties" can be regarded as a set of OWL 2 Full axiomatic triples for properties: IP of all properties, or some subset of IP. Hence, in a corresponding RDF triple the URI C will typically be one of "rdf:Property" or "owl:ObjectProperty" (S=IP in both cases), "owl:DatatypeProperty" (S=IODP), "owl:AnnotationProperty" (S=IOAP), or "owl:OntologyProperty" (S=IOXP).
For example, the semantic condition for the URI "owl:disjointWith", given by
I(owl:disjointWith) ∈ IP
has the corresponding RDF triple
owl:disjointWith rdf:type rdf:Property .
Further, for each URI U in the first column, if the third column contains an entry "IEXT(I(U)) ⊆ S1 × S2" for some sets S1 and S2, then this entry corresponds to some RDF triples of the forms "U rdfs:domain C1" and "U rdfs:range C2", where C1 and C2 are the URIs of some classes with ICEXT(I(C1)) = S1 and ICEXT(I(C2)) = S2, respectively.
For example, the semantic condition
IEXT(I(owl:disjointWith)) ⊆ IC × IC
has the corresponding RDF triples
owl:disjointWith rdfs:domain rdfs:Class ,
owl:disjointWith rdfs:range rdfs:Class .
Exceptions are the semantic conditions "IEXT(I(owl:topObjectProperty)) = IR × IR" and "IEXT(I(owl:topDataProperty)) = IR × LV", for which there are no corresponding domain and range triples.
These axiomatic triples are "simple" in the following sense: For every set S mentioned in the second and the third column of Table 5.2 for "Classes", there exists a URI C of some class in the vocabularies for RDF and RDFS, or those given in Section 2, for which S = ICEXT(I(C)). For every set S mentioned in the second column of Table 5.3 for "Properties", and as the left or right hand side of a Cartesian product in the third column of the table, there exists a URI C of some class in the vocabularies for RDF and RDFS or those given in Section 2, for which S = ICEXT(I(C)).
This section lists significant changes since the First Public Working Draft.
This section lists significant differences between OWL 2 Full and the original version of OWL Full, as defined in Section 5 of [OWL Semantics and Abstract Syntax]. Jie Bao (RPI), Peter F. Patel-Schneider (Bell Labs Research, Alcatel-Lucent) and Zhe Wu (Oracle Corporation). | http://www.w3.org/TR/2008/WD-owl2-rdf-based-semantics-20081202/ | CC-MAIN-2016-30 | refinedweb | 4,933 | 52.19 |
Hi everyone,
I';ve asked a question similar to this recently, but it just got me wondering... How can you control the duration of Color.Lerp in seconds?
Take this code for example:
var startColor : Color;
var endColor : Color;
function Update() {
renderer.material.color = Color.Lerp(startColor, endColor, Time.time);
}
How could modify this so I can explicitely control the duration of the transition in SECONDS?
Thanks in advance. :)
Not sure why you're asking since you already saw my answer in your other question:
Answer by aldonaletto
·
Oct 07, 2012 at 11:28 AM
The Lerp examples in the docs are terribly bad: using Time.time as the control variable limits things to the first second your game is playing! Ok, you could simply use Time.time/duration instead of just Time.time (duration in seconds), but this would not allow a new sequence without restarting the game.
That's a simple example that allows duration control and sequence restarting:
var startColor : Color;
var endColor : Color;
var duration: float = 5; // duration in seconds
private var t: float = 0; // lerp control variable
function Update() {
renderer.material.color = Color.Lerp(startColor, endColor, t);
if (t < 1){ // while t below the end limit...
// increment it at the desired rate every update:
t += Time.deltaTime/duration;
}
}
You can restart the Lerp sequence at any time just assigning 0 to t. A more elaborated version could do it when you press space, for instance:
var startColor : Color;
var endColor : Color;
var duration: float = 5; // duration in seconds
private var t: float = 0; // lerp control variable
function Update() {
if (Input.GetKeyDown("space")){
t = 0;
}
renderer.material.color = Color.Lerp(startColor, endColor, t);
if (t < 1){ // while t below the end limit...
// increment it at the desired rate every update:
t += Time.deltaTime/duration;
}
}
That doesn't seem to work, it does the same as the code I was using before... Duration is supposed to be in seconds, but when I enter five (or any other number) into the variable box, the Lerp still goes just as fast. :( What am I doing wrong?
Are you trying the last script? $$anonymous$$odifying duration in the Inspector and pressing space should Lerp from startColor to endColor in the duration specified. Create a new blank script, paste the code above and attach it to the object - but make sure the old version isn't also attached to it!
This will also work, just set the size of your array in the inspector, then set the colors.
using UnityEngine;
using System.Collections;
public class LerpColor : $$anonymous$$onoBehaviour
{
public Color[] c;
Color color;
float t = 0;
float i = 0.025f;
bool change = false;
void Awake()
{
color = c[0];
}
void Update()
{
renderer.material.color = Color.Lerp(c[0], c[1], t);
if(!change)
t+=i;
else
t-=i;
if(t>=1)
change = true;
if(t<=0)
change = false;
}
}
@aldonaletto It works for me, but the transition between the two colors is kinda in a gradient way, so I put the duration to 1, it switch color with gradient but it two fast, I want the colors changes without any gradient effect and kinda like a quick reverse but with adjustable duration. Any suggestion.
Still relevant after seven years.
Answer by Shadowphax
·
Jul 24, 2014 at 08:19 AM
Hi there.
I've not personally used the Color.lerp but I presume it works the same as any lerping function since the 3rd parameter is in the range 0 - 1.
I would recommend using Coroutines for this type of thing. Here is an example:
float duration = 5; // This will be your time in seconds.
float smoothness = 0.02f; // This will determine the smoothness of the lerp. Smaller values are smoother. Really it's the time between updates.
Color currentColor = Color.white; // This is the state of the color in the current interpolation.
void Start()
{
StartCoroutine("LerpColor");
}
IEnumerator LerpColor()
{
float progress = 0; //This float will serve as the 3rd parameter of the lerp function.
float increment = smoothness/duration; //The amount of change to apply.
while(progress < 1)
{
currentColor = Color.Lerp(Color.red, Color.blue, progress);
progress += increment;
yield return new WaitForSeconds(smoothness);
}
}
I haven't tested the code but I think it's good enough to demonstrate. If you don't know coroutines I would strongly recommend learning about them. It's very useful for animating things between 2 points. Not just colors but anything. It sure as hell beats keeping track of time variables in update loops.
Almost right ;)
Never seen it done like this, very interesting.
Smoothness/duration should be the other way around, wait for should be increment.
Shadowphax's code was correct the way he wrote it, atleast for me.
Answer by Fattie
·
Oct 10, 2018 at 02:33 PM
It's remarkably easy to cycle through all the colors of the rainbow:
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class ColorCycle : MonoBehaviour {
// put this script on your camera
// it's great for a Canvas for your UI
private Camera cam;
private float cycleSeconds = 100f; // set to say 0.5f to test
void Awake() {
cam = GetComponent<Camera>();
}
void Update() {
cam.backgroundColor = Color.HSVToRGB(
Mathf.Repeat(Time.time / cycleSeconds, 1f),
0.3f, // set to a pleasing value. 0f to 1f
0.7f // set to a pleasing value. 0f to 1f
);
}
}
That's it.
For an object ... with proper offset from the editor starting color look, etc.
using UnityEngine;
public class ObjectColorCycle : MonoBehaviour
{
public Renderer colorMe;
void Update()
{
Colorz();
}
float origHue = 0.5f;
float origSat = 0.5f;
float origVal = 0.5f;
void Start()
{
Color c = colorMe.material.color;
Color.RGBToHSV(c, out origHue, out origSat, out origVal);
}
private float cycleSeconds = 100f; // as you wish
void Colorz()
{
float h = Mathf.Repeat(origHue + Time.timeSinceLevelLoad / cycleSeconds, 1f);
colorMe.material.color = Color.HSVToRGB(h, origSat, origVal);
}
}
That's easy fortunately..
Color lerp once?
2
Answers
Time.deltaTime making color lerp appear fast, but won't reach 1
1
Answer
make an event occur after so many seconds?
1
Answer
Mathf.Lerp happens instantly
2
Answers
Smooth gradient between colours?
1
Answer
EnterpriseSocial Q&A | https://answers.unity.com/questions/328891/controlling-duration-of-colorlerp-in-seconds.html?childToView=1561431#answer-1561431 | CC-MAIN-2022-05 | refinedweb | 1,012 | 59.8 |
Armed with just these principles, you could implement your own rudimentary (and working) EAs. You may already have implemented something like this before. However, as they say, the devil's in the details. It's important to understand how the implementation details affect your EA.
Commonly, fitness is just a function of the individual's gene data structure.
However, the fitness measure need not be a true function in the mathematical sense. It might be probablistic, or it might depend also on other members of the population. It also often involves a model or simulation of the problem, executed with the individuals of the population.
The exit criteria sets the target for the fitness measure, but also usually includes an upper limit on the number of iterations, in case the evolution gets "stuck." A typical exit criteria might be: "stop when some individual achieves a fitness of 100, or when we have iterated 10,000 times." We'll talk more about evolution getting "stuck" later. Sticking with the biology jargon, each iteration of the loop is called a generation.
Selection and replacement grant breeding rights and cause extinction within the population, respectively. They are independent of the representation scheme, and should only rely on your choice of fitness measure. Usually a small fraction of the population are chosen for breeding or replacement each generation. For simplicity, often the same number of individuals are chosen for breeding and replacement, although this is not required (causing the population to change in size). Here are a few of the most common selection and replacement methods:
Recombination (or breeding) is the process of using existing pairs of "parent" genes to produce new "offspring" genes. The details of this operation depend on your representation scheme, but by far the most common recombination operation is called crossover. Crossover can be used with string and array representations. It involves making copies of the parents and then swapping a chunk between the copies. Here's a visual example on two string genes:
parent 1: "aaaaaaaaaaaaaa" (these are only copies -- the parents a
+re
parent 2: "AAAAAAAAAAAAAA" not modified in this operation)
cut here: ^ ^ (these two points chosen at random)
and then swap sections..
result 1: "aaaaaaAAAAAAaa"
result 2: "AAAAAAaaaaaaAA"
[download]
Mutation is a random process which slightly modifies the gene of an individual. With string genes, a mutation usually consists of changing a fixed number of characters, or changing each character with a very low probability (e.g, a 5% chance of changing each character). Other interesting mutations include lengthening, shortening, or modifying the gene, each with a respective probability.
use strict;
use List::Util qw/shuffle sum/;
my $str_length = 20;
my $pop_size = 50;
my @population = sort { fitness($a) <=> fitness($b) }
map { rand_string() } 1 .. $pop_size;
my $generations;
while ( $generations++ < 1000 and fitness($population[-1]) != $str_len
+gth ) {
my @parents = shuffle @population[-10 .. -1];
my @children;
push @children, crossover( splice(@parents, 0, 2) )
while @parents;
@population[0 .. 4] = map { mutate($_) } @children;
@population = sort { fitness($a) <=> fitness($b) } @population;
printf "Average fitness after %d generations is: %g\n",
$generations, (sum map { fitness($_) } @population)/@populatio
+n;
}
#####
sub fitness {
return $_[0] =~ tr/1/1/;
}
sub crossover {
my ($s1, $s2) = @_;
my ($start, $end) = sort {$a <=> $b} map { int rand length $s1 } 1
+ .. 2;
(substr($s1, $start, $end - $start), substr($s2, $start, $end - $s
+tart)) =
(substr($s2, $start, $end - $start), substr($s1, $start, $end -
+$start));
return ($s1, $s2);
}
sub mutate {
my $s = shift;
for (0 .. length($s) - 1) {
substr($s, $_, 1) = 1 - substr($s, $_, 1) if rand() < 0.2;
}
return $s;
}
sub rand_string {
join "" => map { rand() > 0.5 ? 0 : 1 } 1 .. $str_length;
}
[download]
On one hand, hill-climbing casues EA populations is to slowly cluster near the tops of these hills as they try to achieve maximum fitness. When most of the population's members are very close to one another (very few mutations or crossovers apart), their genes are very similar, they have much genetic material in common, and we say the population is not diverse. Hill-climbing is desired (we do want to maximize fitness after all), but only in moderation. If it happens too fast, it's easy for the whole population may become "stuck" on a small number of fitness hills that are not the highest in the solution space. Mathematically speaking, these are local optima.
On the other hand, when the population is diverse and spread out in the landscape, you may combine two "distant" parents to get a child somewhere in the middle, maybe on a new fitness hill. This allows for more fitness hills to be discovered, reducing the chance of getting stuck on a local optima.
(You may have noticed that in the ONE-MAX example, there are none of these. There's only one fitness hill, with the string of all 1s at the top. Its fitness landscape is a 20-dimensional hypercube. Mutation moves along one or more edges of the cube, and crossover moves to any vertex along the subcube induced by the parents. Non-trivial problems generally have fitness landscapes that are too complex to characterize.)
Here is how diversity is affected in general by the different operations:
In solving difficult problems with EAs, finding a good representation scheme with good recombination and mutation operations can often be the hardest piece of the puzzle. There is no magic advice for choosing the "right" representation, and in addition to adhering to these guidelines, the choice must be feasible to implement.
I think you'll enjoy working with evolutionary algorithms, as they're a bit of a departure from classical computation/analysis methods. Hopefully this guide will give you the background needed to have a lot of fun tinkering with EAs. Be creative and inventive, and happy evolving!
blokhead
Update: fixed moved evoweb link (thanks atcroft). | https://www.perlmonks.org/index.pl/?node_id=298877 | CC-MAIN-2020-05 | refinedweb | 967 | 53.51 |
Introduction
Regular Expressions provide a standard and powerful way of pattern matching for text data. The .NET Framework exposes its regular expression engine via System.Text.RegularExpressions Namespace. The Regex class is the primary way for developers to perform pattern matching, search and replace, and splitting operations on a string. Many beginners avoid using regular expressions because of the apparently difficult syntax. However, if your application calls for heavy pattern matching then learning and using regular expressions over ordinary string manipulation functions is strongly recommended. This article is intended to give beginners a quick overview of .NET Framework's offerings for pattern matching using regular expressions.
Note:
This article will not teach you how to write regular expressions. It focuses primarily on using classes from System.Text.RegularExpressions namespace. It is assumed that you are already familiar with regular expression syntax and are able to write basic regular expressions.
Basic Terminology
Before you go any further let's quickly glance over the basic terminology used in the context of regular expressions.Before you go any further let's quickly glance over the basic terminology used in the context of regular expressions.
- Capture : When you perform pattern matching using a regular expression result of a single sub-expression match is called as a Capture. The Capture and CaptureCollection classes represent a single capture and a collection of captures respectively.
- Group : A regular expression often consists of one or more Groups. A group is represented by rounded brackets within a regular expression (the whole regular expression itself is considered as a group). There can be zero or more captures for a single group. The Group and GroupCollection classes represent a single group and a collection of groups respectively.
- Match : A result obtained after a single match of a regular expression is termed as a Match. A match contains one or more groups. The Match and MatchCollection classes represent a single match and a collection of matches respectively.
Thus the relation between the regular expression related objects is:
Regex class--> MatchCollection--> Match objects--> GroupCollection--> Group objects--> CaptureCollection--> Capture objects
The Regex Class
The Regex class along with few more support classes represents the regular expression engine of .NET Framework. The Regex class allows you to perform pattern matching, search and replace, and splitting on the source strings. You can use the Regex class in two ways, viz. calling static methods of Regex class or by instantiating Regex class and then calling instance methods. The difference between these two approaches will be clear in the section related to performance. The following table lists some of the important methods of the Regex class along with the purpose of each:
In the following sections you are going to use many of the methods mentioned above.
Pattern Matching Using Regex Class
In this section you will use the pattern matching abilities of the Regex class. Begin by creating a new Console Application and import System.Text.RegularExpressions namespace at the top.
using System.Text.RegularExpressions;
Using IsMatch() Method
In this example you will check whether a string is a valid URL. Key-in the following code in the Main() method.
static void Main(string[] args) { string source = args[0]; string pattern = @"http(s)?://([w-]+.)+[w-]+(/[w- ./?%&=]*)?"; bool success = Regex.IsMatch(source, pattern); if (success) { Console.WriteLine("Entered string is a valid URL!"); } else { Console.WriteLine("Entered string is not a valid URL!"); } Console.ReadLine(); }
The Main() method receives the string to be tested as a command line argument. The pattern string variable holds the regular expression for verifying URLs. The code then calls the IsMatch() static method on the Regex class and passes the source and pattern strings to it. Depending on the returned boolean value a message is displayed to the user.
You could have achieved the same result by creating an instance of Regex class and then calling IsMatch() method on it, as shown below:
Regex ex = new Regex(pattern); success = ex.IsMatch(source);
Using Match() Method
In order to see how Match() method can be used, modify the Main() method as shown below:
static void Main(string[] args) { string source = args[0]; string pattern = @"http(s)?://([w-]+.)+[w-]+(/[w- ./?%&=]*)?"; Match match = Regex.Match(source, pattern);!"); } Console.ReadLine(); }
The code shown above makes use of the Match() method to perform pattern matching. As mentioned earlier the Match() method returns an instance of Match class that represents the first occurrence of the pattern. The Success property of the Match object tells you whether the pattern matching was successful or not. A for loop then iterates through the Groups collection (GroupCollection object). With each iteration, the group searched for and its status is outputted. Further, the Captures collection of each group is also iterated and with each iteration the captured value and its index in the string is outputted. The following figure shows a sample run of the above application.
Figure 1: A sample run of the application
Observe the above figure carefully. Our pattern contains 4 groups (three in rounded brackets of the regular expression and the whole expression) so Count property of the Groups collection returns 4. The first group (the whole expression) has value. The second group has value of s (from https). The third group has two captures - www. and codeguru. Finally, the last group has value of / (the / at the end of the URL).
Using Matches() Method
Matches() method is similar to Match() method but returns a collection of Match objects (MatchCollection). You can then iterate through all of the Match instances and see various group and capture values. The following code illustrates how this is done:
MatchCollection matches = Regex.Matches(source, pattern); foreach (Match match in matches) { Console.WriteLine("Match Value = {0}",match.Value); Console.WriteLine("============");!"); } }
The following figure shows a sample run of the above code:
Figure 2: Matches() method returns two Match objects
Notice how Matches() method has returned two Match objects (one for and other for).
Search and Replace Using Regex Class
The Regex class not only allows you to perform pattern matching but also allows you to search and replace strings. Consider, for example, that you are developing a discussion forum in ASP.NET. For the sake of reducing SPAM and promotional content you want to scan forum posts made by new members for URLs and then replace the URLs with ****. Something like this can easily be done with the search and replace abilities of the Regex class. Let's see how.
static void Main(string[] args) { string source = args[0]; string pattern = @"http(s)?://([w-]+.)+[w-]+(/[w- ./?%&=]*)?"; string result = Regex.Replace(source,pattern,"[*** URLs not allowed ***]"); Console.WriteLine(result); Console.ReadLine(); }
In the code fragment shown above the regular expression is intended to scan URLs from the input string. You then call the Replace() method of the Regex class. The first parameter of the Replace() method is the string in which you wish to perform the replacement. The second parameter indicates the replacement string. The Replace() method returns the resultant string after performing the replacement. If you run the above code you should see something like this in the console window:
Figure 3: The Replace() method of the Regex class
Notice how the URL has been replaced with the text you specify.
Splitting Strings Using Regex
Regex class also allows you to split an input string based on a regular expression. Say, for example, you wish to split a date in DD/MM/YYYY format at / so as to retrieve individual day, month and year values. The Split() method of the Regex class allows you to do just that. The following example shows how:
string strFruits = "Apple,Mango,Banana"; string[] fruits = Regex.Split(strFruits, ","); foreach(string s in fruits) { Console.WriteLine(s); }
In the above code the Split() method takes the source string and a regular expression for searching the delimiter (, in the above example). It then splits the string and returns an array of strings consisting of individual elements. A sample run of the above code is shown below:
Figure 4: Splitting Strings Using Regex
Regex Options
Most of the methods discussed above are overloaded to take a parameter of type RegexOptions enumeration. As the name suggests, the RegexOptions enumeration is used to indicate certain configuration options to the regular expression engine during the pattern matching process. The following table lists some of the important options of RegexOptions enumeration:
Just to illustrate how RegexOptions enumeration can be used write the following code in the Main() method and observe the difference due to RegexOptions value.
bool success1 = Regex.IsMatch(source, "hello"); Console.WriteLine("String found? {0}",success1); bool success2 = Regex.IsMatch(source, "hello", RegexOptions.IgnoreCase); Console.WriteLine("String found? {0}", success2);
As you can see, the second call to the IsMatch() method makes use of RegexOptions enumeration and specifies the case should be ignored during pattern matching. If you observe the output of the above code (see below) you will find that IsMatch() method without any RegexOptions returns false whereas with RexexOptions.IgnoreCase returns true.
Figure 5: IsMatch() method without RegexOptions returns false; with RegexOptions.IgnoreCase returns true
Note:
You can combine multiple RegexOptions values like this :
bool success2 = Regex.IsMatch(source, "hello", RegexOptions.IgnoreCase | RegexOptions.Compiled);
Performance Considerations
As mentioned earlier, the Regex class provides static as well as instance methods for pattern matching. The static methods accept the source string and the pattern as the parameters whereas the instance methods accept source string (since pattern is specified while creating the instance itself). The following code fragment makes it clear:
//Using static method bool success = Regex.IsMatch(source, pattern); //Using instance method Regex ex = new Regex(pattern); success = ex.IsMatch(source);
When you use static methods, the regular expression engine caches the regular expressions so that if the same regular expression is used multiple times the performance will be faster. On the other hand, if you use instance methods, the regular expression engine cannot cache the patterns because Regex instances are immutable (i.e. you cannot change them later). Naturally, even if you use the same pattern multiple times there is no way to boost the performance as in the previous case.
You should also be aware of the impact of RegexOptions.Compiled on the performance. While calling any of the Regex methods, if you use the RegexOptions.Compiled option then the regular expression is converted to MSIL code and not to regular expression internal instructions. Though this improves performance it also means that the regular expressions are also loaded as a part of the assembly making it heavy and may increase the startup time. So, you should carefully evaluate the use of RegexOptions.Compiled option.
Summary
Regular expressions provide a standard and powerful way of pattern matching. The Regex class represents .NET Framework's regular expression engine. The methods of Regex class are exposed as static as well as instance methods. These methods allow you to perform search, replace and splitting operations on input strings. Behavior of the regular expression engine can be configured with the help of RegExOptions enumeration. | http://mobile.codeguru.com/csharp/article.php/c19073/Working-with-Regular-Expressions-in-NET.htm | CC-MAIN-2017-26 | refinedweb | 1,836 | 56.35 |
Java Stream flatMap() is a very useful function to flatten the Stream after applying the given function to all the elements of the stream.
Table of Contents
Java Stream flatMap
Let’s look at the syntax of Stream flatMap() function.
<R> Stream<R> flatMap(Function<T, Stream<R>> mapper);
In simple words, flatMap() is used when we have a stream of collections and we want to flatten it rather than using
map() function and getting the nested Stream.
Let’s look at an example to better understand this scenario. Suppose we have few List of Strings:
List<String> l1 = Arrays.asList("a","b"); List<String> l2 = Arrays.asList("c","d");
Now we want to merge these lists and get a new list of Strings and change the letters to uppercase. Since we have multiple lists, we will have to first merge them to a single list and then apply map() function. Something like below code:
List<String> l = new ArrayList<>(); l.addAll(l1); l.addAll(l2); List<String> letters = l.stream() .map(String::toUpperCase) .collect(Collectors.toList());
Obviously this is a lot of rework and we have to manually merge the lists to get a single list of elements and then apply map() function. This is where
flatMap() is very useful. Let’s see how we can use flatMap() to perform the same operation.
List<String> betterLetters = Stream.of(l1, l2) .flatMap(List::stream) .map(String::toUpperCase) .collect(Collectors.toList());
Now it’s clear that we used flatMap() function to flatten the Stream of Lists to Stream of elements.
Java Stream flatMap() Real Life Example
Let’s look into a real life example where flatMap() function will be really helpful. Suppose we have a
State class that contains list of cities. Now we have a list of States and we want to get the list of all the cities. Here flatMap() will be very helpful as we won’t have to write nested for loops and iterate over the lists manually. Below is a complete example to show this scenario.
package com.journaldev.streams; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class JavaStreamFlatMapAggregateExample { public static void main(String[] args) { State karnataka = new State(); karnataka.addCity("Bangalore"); karnataka.addCity("Mysore"); State punjab = new State(); punjab.addCity("Chandigarh"); punjab.addCity("Ludhiana"); List<State> allStates = Arrays.asList(karnataka, punjab); //Java Stream flatMap way List<String> allCities = allStates.stream().flatMap(e -> e.getCities().stream()).collect(Collectors.toList()); System.out.println(allCities); //legacy way allCities = new ArrayList<String>(); for(State state : allStates) { for(String city : state.getCities()) allCities.add(city); } System.out.println(allCities); } } class State { private List<String> cities = new ArrayList<>(); public void addCity(String city) { cities.add(city); } public List<String> getCities() { return this.cities; } }
It’s very clear that flatMap() is very useful when we have to work with List of lists.
This example only collect all cities in a List.
How do you flatten and collect all States and its Cities in a Single List ? | https://www.journaldev.com/20775/java-stream-flatmap | CC-MAIN-2021-25 | refinedweb | 505 | 59.09 |
In this Pandas groupby tutorial, we are going to learn how to organize Pandas dataframes by groups. More specifically, we are going to learn how to group by one and multiple columns.
Furthermore, we are going to learn how to calculate some basics summary statistics (e.g., mean, median), convert Pandas groupby to dataframe, calculate the percentage of observations in each group, and many more useful things.
- More about working with Pandas: Pandas Dataframe Tutorial
First of all we are going to import pandas as pd, and read a CSV file, using the read_csv method, to a dataframe. In the example below, we use index_col=0 because the first row in the dataset is the index column.
import pandas as pd data_url = '' df = pd.read_csv(data_url, index_col=0) df.head()
We used Pandas head to see the first 5 rows of our dataframe. In the image above we can see that we have, at least, three variables that we can group our data by. That is, we can group our data by “rank”, “discipline”, and “sex”.
Of course, we could also group it by yrs.since.phd or yrs.service but it may be a lot of groups. As previously mentioned we are going to use Pandas groupby to group a dataframe based on one, two, three, or more columns.
Data can be loaded from other file formats as well (e.g., Excel, HTML, JSON):
- Pandas Excel Tutorial: How to Read and Write Excel Files
- Explorative Data Analysis with Pandas, SciPy, and Seaborn includes a short introduction to Pandas read_html
What is Groupby in Pandas?
In this section, we briefly answer the question of what is groupby in Pandas? Pandas groupby() method is what we use to split the data into groups based on the criteria we specify. That is, if we need to group our data by, for instance, gender we can type
df.groupby('gender') given that our dataframe is called df and that the column is called gender. Now, in this post we are going to learn more examples on how to use groupby in Pandas.
Python Pandas Groupby Example
Now we are going to learn how to use Pandas groupby. In this tutorial, we are starting with the simplest example; grouping by one column. Specifically, in the Pandas groupby example below we are going to group by the column “rank”.
There are many different methods that we can use on the objects we get when using the groupby method (and Pandas dataframe objects). All available methods on a Python object can be found using this code:
import IPython # Grouping by one factor df_rank = df.groupby('rank') # Getting all methods from the groupby object: meth = [method_name for method_name in dir(df_rank) if callable(getattr(df_rank, method_name)) & ~method_name.startswith('_')] # Printing the result print(IPython.utils.text.columnize(meth))
Note, that in the code example above we also import IPython to print the list in columns. In the following examples we are going to use some of these methods.
How to Display Pandas groupby Objects
In this subsection, we are going to learn how to print a Pandas groupby object. First, we can print out the groups by using the groups method to get a dictionary of groups:
df_rank.groups
We can also use the groupby method get_group to filter the grouped data. In the next code example, we are going to select the Assistant Professor group (i.e., “AsstProf”).
# Get group df_rank.get_group('AsstProf').head()
If we want to print some parts of the groupby object we can use the head method:
df_rank.head()
In the YouTube video below, we are going to through all the groupby in Pandas examples from above.
Pandas Groupby Count
In this section we are going to continue, warking with the groupby method in Pandas. More specifically, we are going to learn how to count how many occurrences there are in each group. That is. if we want to find out how big each group is (e.g., how many observations in each group), we can use .size() to count the number of rows in each group:
df_rank.size() # Output: # # rank # AssocProf 64 # AsstProf 67 # Prof 266 # dtype: int64
Additionally, we can also use the count method to count by group(s) and get the entire dataframe. If we don’t have any missing values the number should be the same for each column and group. Thus, by using Pandas to group the data, like in the example here, we can explore the dataset and see if there are any missing values in any column.
df_rank.count()
That was how to use Pandas size to count the number of rows in each group. We will return to this, later, when we are grouping by multiple columns. In some cases, we may want to find out the number of unique values in each group. This can be done using the groupby method nunique:
df_rank.nunique()
As can be seen in the last column (salary) there are 63 Associate Professors, 53 Assistant Professors, and 261 Professors in the dataset.
In this example, we have a complete dataset and we can see that some have the same salary (e.g., there are 261 unique values in the column salary for Professors). If we have missing values in the dataframe we would get a different result. In the next example we are using Pandas mask method together with NumPy’s random.random to insert missing values (i.e., np.NaN) in 10% of the dataframe:
df_null = df.mask(np.random.random(df.shape) < .1) df_null.isnull().sum().reset_index(name='N Missing Values')
Note, we used the reset_index method above to get the multi-level indexed grouped dataframe to become a single indexed. In the particular example, above, we used the parameter name to name the count column (“N Missing Values”). This parameter, however, can only be used on Pandas series objects and not dataframe objects.
That said, let’s return to the example; if we run the same code as above (counting unique values by group) we can see that it will not count missing values:
df_null.groupby('rank').nunique()
That is, we don’t get the same numbers in the two tables because of the missing values. In the following examples, we are going to work with Pandas groupby to calculate the mean, median, and standard deviation by one group.
Pandas Groupby Mean
If we want to calculate the mean salary grouped by one column (rank, in this case) it’s simple. We just use Pandas mean method on the grouped dataframe:
df_rank['salary'].mean().reset_index()
Having a column named salary may not be useful. For instance, if someone else is going to see the table they may not know that it’s the mean salary for each group. Luckily, we can add the rename method to the above code to rename the columns of the grouped data:
df_rank['salary'].mean().reset_index().rename( columns={'rank':'Rank','salary' : 'Mean Salary'})
Note, sometimes we may want to rename columns by just removing special characters or whitespaces, for instance. In a more recent post, we learn how to rename columns in Pandas dataframes using regular expressions or by the superb Python package Pyjanitor: the easiest data cleaning method using Python & Pandas.
Median Score of a Group Using the groupby Method in Pandas
Now lets group by discipline of the academic and find the median salary in the next example.
df.groupby('rank')['salary'].median().reset_index().rename( columns={'rank':'Rank','salary' : 'MedianSalary'})
Aggregate Data by Group using the groupby method
Most of the time we want to have our summary statistics on the same table. We can calculate the mean and median salary, by groups, using the agg method. In the next Pandas groupby example, we are also adding the minimum and maximum salary by group (rank):
df_rank['salary'].agg(['mean', 'median', 'std', 'min', 'max']).reset_index()
A very neat thing with Pandas agg method is that we can write custom functions and pass them along. Let’s say that we wanted, instead of having one column for min salary and one column for max salary, to have a column with the salary range:
def salary_range(df): mini = df.min() maxi = df.max() rang = '%s - %s' % (mini, maxi) return rang df_descriptive = df_rank['salary'].agg(['mean', 'median', 'std', salary_range]).reset_index()
Here, however, the output will have the name of the methods/functions used. That is, we will have a column named ‘salary_range’ and we are going to rename this column:
# Renaming Pandas Dataframe Columns df_descriptive.rename(columns={'rank':'Rank', 'mean':'Mean', 'median':'Median', 'std':'Standard Deviation', 'salary_range':'Range'})
Furthermore, it’s possible to use methods from other Python packages such as SciPy and NumPy. For instance, if we wanted to calculate the harmonic and geometric mean we can use SciPy:
from scipy.stats.mstats import gmean, hmean df_descriptive = df_rank['salary'].agg(['mean', 'median', hmean, gmean]).reset_index() df_descriptive
More about doing descriptive statistics using Python:
- Descriptive Statistics using Python and Pandas
- How to do Descriptive Statistics in Python using Numpy
Pandas Groupby Multiple Columns
In this section, we are going to continue with an example in which we are grouping by many columns. In the first Pandas groupby example, we are going to group by two columns and then we will continue with grouping by two columns, ‘discipline’ and ‘rank’. To use Pandas groupby with multiple columns we add a list containing the column names. In the example below we also count the number of observations in each group:
df_grp = df.groupby(['rank', 'discipline']) df_grp.size().reset_index(name='count')
Again, we can use the get_group method to select groups. However, in this case, we have to input a tuple and select two groups:
# Get two groups df_grp.get_group(('AssocProf', 'A')).head()
Pandas Groupby Count Multiple Groups
In the next groupby example, we are going to calculate the number of observations in three groups (i.e., “n”). We have to start by grouping by “rank”, “discipline” and “sex” using groupby. As with the previous example (groupby one column), we use the method size to calculate the n and reset_index, with the parameter name=”n”, to get the series to a dataframe:
df_3grps = df.groupby(['rank', 'discipline', 'sex']) df_n_per_group = df_3grps.size().reset_index(name='n')
Pandas groupby percentage
Now we can continue and calculate the percentage of men and women in each rank and discipline. In this, and the next, example we are going to use the apply method together with the lambda function.
perc = df.groupby(['rank', 'discipline', 'sex'])['salary'].size() # Give the percentage on the level of Rank: percbyrank = perc.groupby(level=0).apply(lambda x: 100 * x / float(x.sum())) print(percbyrank) print('Total percentage in group AssocProf. ', percbyrank.reset_index().query('rank == "AssocProf"')['salary'].sum())
Note, in the last line of code above we calculated the total of % for the group AssocProf and it’s 100, which is good. We are going to continue by calculating the percentage of men and women in each group (i.e., rank and discipline). In the next groupby example, we first summarize the total n (n=397). We can, for instance, see that there are more male professors regardless of discipline.
n = perc.reset_index()['salary'].sum() totalperc = perc.groupby(level=0).apply(lambda x:100*x/n).reset_index(name='% of total n') totalperc.reset_index()
df_rn = df.groupby(['rank', 'discipline']).mean()
Furthermore, if we use the index method we can see that it is MultiIndex:
df_rn.index
It’s easy to convert the Pandas groupby to dataframe; we have actually already done it. In this example, however, we are going to calculate the mean values per the three groups. Furthermore, we are going to add a suffix to each column and use reset_index to get a dataframe.
df_rn = df_rn.add_suffix('_Mean').reset_index() type(df_rn) # Output: pandas.core.frame.DataFrame
Using groupby agg with Multiple Groups
In this last section we are going use agg, again, but this time we are going to use it together with multiple groups. We are not going into detail on how to use mean, median, and other methods to get summary statistics, however. This is because it’s basically the same as for grouping by n groups and it’s better to get all the summary statistics in one table.
That is, we are going to calculate mean, median, and standard deviation using the agg method. In this groupby example we are also adding the summary statistics (i.e., “mean”, “median”, and “std”) to each column. Otherwise, we will get a multi-level indexed result like the image below:
If we use Pandas columns and the method ravel together with list comprehension we can add the suffixes to our column name and get another table. Note, in the example code below we only print the first 6 columns. In fact, with many columns, it may be better to keep the result multi-level indexed.
df_stats = df.groupby(['rank', 'discipline', 'sex']).agg(['mean', 'median', 'std']) df_stats.columns = ["_".join(x) for x in df_stats.columns.ravel()] df_stats.iloc[:,0:6].reset_index()
In the code chunk above, we used df.iloc in the last line. What we did was to take the first six columns, using iloc. After that, we reset the index and thus got eight columns, in total (see image below). If you need to learn more about slicing Pandas dataframes see the post in which you will learn how to use iloc and loc for indexing and slicing Pandas Dataframes.
Note, if we wanted an output as the first image we just remove the second line above (“df_stats.columns = …”). Additionally, as previously mentioned, we can also use custom functions, NumPy and SciPy methods when working with groupby agg. Just scroll back up and look at those examples, for grouping by one column, and apply them to the data grouped by multiple columns. More information about the different methods and objects used here can be found in the Pandas documentation.
Saving the Grouped Dataframe
In the last section, of this Pandas groupby tutorial, we are going to learn how to write the grouped data to CSV and Excel files. We are going to work with Pandas to_csv and to_excel, to save the groupby object as CSV and Excel file, respectively. Note, we also need to use the reset_index method, before writing the dataframe.
Now, before saving the groupby object we start by importing a data file from CSV. Here, we use the same example as above. That is, we load the salaries data, group the data by rank, discipline, and sex. When this is done, we calculate the percentage by rank (i.e., by group).
import pandas as pd data_url = '' df = pd.read_csv(data_url, index_col=0) perc = df.groupby(['rank', 'discipline', 'sex'])['salary'].size() percbyrank = perc.groupby(level=0).apply(lambda x: 100 * x / float(x.sum())
Saving Groupby as CSV
In this subsection, we are going to save the Pandas groupby object as a CSV file. Note, first we reset the index and we use the argument index and set it to False as we don’t want a column with the indexes in the resulting CSV file.
df.reset_index() df.to_csv('percentage_rank_per_disciplin.csv', index=False)
Saving Groupby as an Excel File
In this subsection, we are using the to_excel method to save the Pandas groupby object as a .xlsx file. Other than that, it’s the same as the example above where we used to_csv.
df.reset_index() df.to_excel('percentage_rank_per_disciplin.xlsx', index=False)
If you want a Jupyter notebook of the code used in this Pandas groupby tutorial, click here.
Conclusion:
In this Pandas groupby tutorial, we have learned how to use this method to:
- group one or many columns
- count observations using Pandas groupby count and size
- calculate simple summary statistics using:
- groupby mean, median, std
- groupby agg (aggregate)
- agg with our own function
- Calculate the percentage of observations in different groups
| https://www.marsja.se/python-pandas-groupby-tutorial-examples/?utm_source=rss&utm_medium=rss&utm_campaign=python-pandas-groupby-tutorial-examples | CC-MAIN-2020-24 | refinedweb | 2,653 | 64 |
See: Description
This is the latest version of the AWS WAF API, released in November, 2019. The names of the entities that you use to access this API, like endpoints and namespaces, all have the versioning information added, like "V2" or "v2", to distinguish from the prior version. We recommend migrating your resources to this version, because it has a number of significant improvements.
If you used AWS WAF prior to this release, you can't use this AWS WAFV2 API to access any AWS WAF resources that you created before. You can access your old rules, web ACLs, and other AWS WAF resources only through the AWS WAF Classic APIs. The AWS WAF Classic APIs have retained the prior names, endpoints, and namespaces.
For information, including how to migrate your AWS WAF resources to this version, see the AWS WAF Developer Guide.
AWS WAF is a web application firewall that lets you monitor the HTTP and HTTPS requests that are forwarded to Amazon CloudFront, an Amazon API Gateway REST API, an Application Load Balancer, or an AWS AppSync GraphQL API. AWS WAF also lets you control access to your content. Based on conditions that you specify, such as the IP addresses that requests originate from or the values of query strings, the API Gateway REST API, CloudFront distribution, the Application Load Balancer, or the AWS AppSync GraphQL API responds to requests either with the requested content or with an HTTP 403 status code (Forbidden). You also can configure CloudFront to return a custom error page when a request is blocked.
This API guide is for developers who need detailed information about AWS WAF API actions, data types, and errors. For detailed information about AWS WAF features and an overview of how to use AWS WAF, see the AWS WAF Developer Guide.
You can make calls using the endpoints listed in AWS Service Endpoints for AWS WAF.
For regional applications, you can use any of the endpoints in the list. A regional application can be an Application Load Balancer (ALB), an API Gateway REST API, or an AppSync GraphQL API.
For AWS CloudFront applications, you must use the API endpoint listed for US East (N. Virginia): us-east-1.
Alternatively, you can use one of the AWS SDKs to access an API that's tailored to the programming language or platform that you're using. For more information, see AWS SDKs.
We currently provide two versions of the AWS WAF API: this API and the prior versions, the classic AWS WAF APIs. This new API provides the same functionality as the older versions, with the following major improvements:
You use one API for both global and regional applications. Where you need to distinguish the scope, you specify a
Scope parameter and set it to
CLOUDFRONT or
REGIONAL.
You can define a Web ACL or rule group with a single call, and update it with a single call. You define all rule specifications in JSON format, and pass them to your rule group or Web ACL calls.
The limits AWS WAF places on the use of rules more closely reflects the cost of running each type of rule. Rule groups include capacity settings, so you know the maximum cost of a rule group when you use it. | https://docs.aws.amazon.com/AWSJavaSDK/latest/javadoc/com/amazonaws/services/wafv2/package-summary.html | CC-MAIN-2021-17 | refinedweb | 546 | 67.28 |
----------------------------------------------------------- This is an automatically generated e-mail. To reply, visit: -----------------------------------------------------------
Advertising
Patch looks great! Reviews applied: [42688] Passed command: export OS=ubuntu:14.04;export CONFIGURATION="--verbose";export COMPILER=gcc; ./support/docker_build.sh - Mesos ReviewBot On Jan. 23, 2016, 8:04 p.m., Neil Conway wrote: > > ----------------------------------------------------------- > This is an automatically generated e-mail. To reply, visit: > > ----------------------------------------------------------- > > (Updated Jan. 23, 2016, 8:04 p.m.) > > > Review request for mesos and Michael Park. > > > Bugs: MESOS-4445 > > > > Repository: mesos > > > Description > ------- > > The previous implementation was buggy in two scenarios: (1) the label sets > contained different #s of duplicate elements (2) the "left" label set > contained > duplicates and the "right" label set contained a value that didn't appear in > the > "left" set. > > > Diffs > ----- > > src/Makefile.am 19bf3a7c2e43ca04ed6e6d506e052de5537f7c2f > src/common/type_utils.cpp 76f48f6a1f5467db032ded8acd296d03353b4172 > src/tests/labels_tests.cpp PRE-CREATION > > Diff: > > > Testing > ------- > > make check > > REVIEW NOTES: > > * This is a WIP. > * Rather than implement a correct equality algorithm myself, I decided to > just use `std::unordered_multiset`. Computing equality correctly is a bit > involved. > * This requires a hash implementation for `Label`. I supplied this in new > function object in the `mesos` namespace, but we could also supply a > specialization of `std::hash<Label>`. Not sure which is better. > * The same bug occurs in other equality operators for repeated fields > (`CommandInfo.uris`, `Environment`, `DockerInfo`, etc.). I suppose we should > probably fix these as well? Note that the bugs in the old approach are a lot > less likely to occur when the struct has a lot of fields. > > > Thanks, > > Neil Conway > > | https://www.mail-archive.com/reviews@mesos.apache.org/msg21416.html | CC-MAIN-2016-44 | refinedweb | 251 | 53.68 |
Logging, Monitoring, and Troubleshooting Guide
An In-Depth Guide to OpenStack Logging, Monitoring, and Troubleshooting
Abstract
Chapter 1. About This Guide
Red Hat is currently reviewing the information and procedures provided in this guide for this release.
This document is based on the Red Hat OpenStack Platform 11 document, available at.
If you require assistance for the current Red Hat OpenStack Platform release, please contact Red Hat support.
This document provides an overview of the logging and monitoring capabilities that are available in a Red Hat OpenStack Platform environment, and how to troubleshoot possible issues.
Chapter 5, Troubleshooting.
Since the release of Red Hat OpenStack Platform 12, most of the services are containerized. The only exceptions are neutron and cinder. The new log path for these services is /var/log/containers./containers/httpd/default_error.log, which stores errors reported by other web services running on the same host.
2.1.5. Data Processing (sahara) Log Files
2.1.6. Database as a Service (trove) Log Files
2.1.7. Identity Service (keystone) Log Files
2.1.8. Image Service (glance) Log Files
2.1.9. Networking (neutron) Log Files
2.1.10. Object Storage (swift) Log Files
OpenStack Object Storage sends logs to the system logging facility only.
By default, all Object Storage log files to /var/log/containers
2.1.11. Orchestration (heat) Log Files
2.1.13. Telemetry (ceilometer) Log Files
2.1.14. Log Files for Supporting Services
The following services are used by the core OpenStack components and have their own log directories and files..
2.3. Remote Logging Installation and Configuration
All OpenStack services generate and update log files. These log files record actions, errors, warnings, and other events. In a distributed environment like OpenStack, collecting these logs in a central location simplifies debugging and administration.
For more information about centralized logging, see the Monitoring Tools Configuration guide.
Chapter 3. Configuring the Time Series Database (Gnocchi) for Telemetry
Time series database (Gnocchi) is a multi-tenant, metrics and resource database. It is designed to store metrics at a very large scale while providing access to metrics and resources information to operators and users.
3.1. Understanding the Time Series Database
This section defines the commonly used terms for the Time series database (Gnocchi)features.
- Aggregation method
- A function used to aggregate multiple measures into an aggregate. For example, the
minaggregation method aggregates the values of different measures to the minimum value of all the measures in the time range.
- Aggregate
- A data point tuple generated from several measures according to the archive policy. An aggregate is composed of a time stamp and a value.
- Archive policy
- An aggregate storage policy attached to a metric. An archive policy determines how long aggregates are kept in a metric and how aggregates are aggregated (the aggregation method).
- Granularity
- The time between two aggregates in an aggregated time series of a metric.
- Measure
- An incoming data point tuple sent to the Time series database by the API. A measure is composed of a time stamp and a value.
- Metric
- An entity storing aggregates identified by an UUID. A metric can be attached to a resource using a name. How a metric stores its aggregates is defined by the archive policy that the metric is associated to.
- Resource
- An entity representing anything in your infrastructure that you associate a metric with. A resource is identified by a unique ID and can contain attributes.
- Time series
- A list of aggregates ordered by time.
- Timespan
- The time period for which a metric keeps its aggregates. It is used in the context of archive policy.
3.2. Metrics
The Time series database (Gnocchi) stores metrics from Telemetry that designate anything that can be measured, for example, the CPU usage of a server, the temperature of a room or the number of bytes sent by a network interface.
A metric has the following properties:
- UUID to identify the metric
- Metric name
- Archive policy used to store and aggregate the measures
The Time series database stores the following metrics by default, as defined in the
etc/ceilometer/polling.yaml file:
[root@controller-0 ~]# docker exec -ti ceilometer_agent_central cat /etc/ceilometer/polling.yaml --- sources: - name: some_pollsters interval: 300 meters: - cpu - memory.usage - network.incoming.bytes - network.incoming.packets - network.outgoing.bytes - network.outgoing.packets - disk.read.bytes - disk.read.requests - disk.write.bytes - disk
The
polling.yaml file also specifies the default polling interval of 300 seconds (5 minutes).
3.3. Time Series Database Components
Currently, Gnocchi uses the Identity service for authentication and Redis for incoming measure storage. To store the aggregated measures, Gnocchi relies on either Swift or Ceph (Object Storage). Gnocchi also leverages MySQL to store the index of resources and metrics.
The Time series database provides the
statsd deamon (
gnocchi-statsd) that is compatible with the
statsd protocol and can listen to the metrics sent over the network. In order to enable
statsd support in Gnocchi, you need to configure the
[statsd] option in the configuration file. The resource ID parameter is used as the main generic resource where all the metrics are attached, a user and project ID that are associated with the resource and metrics, and an archive policy name that is used to create the metrics.
All the metrics are created dynamically as the metrics are sent to
gnocchi-statsd, and attached with the provided name to the resource ID you configured.
3.4. Running the Time Series Database
Run the Time series database by running the HTTP server and metric daemon:
# gnocchi-api # gnocchi-metricd
3.5. Running As A WSGI Application
You.
The Gnocchi API tier runs using WSGI. This means it can be run using Apache
httpd and
mod_wsgi, or another HTTP daemon such as
uwsgi. You should configure the number of processes and threads according to the number of CPUs you have, usually around
1.5 × number of CPUs. If one server is not enough, you can spawn any number of new API servers to scale Gnocchi out, even on different machines.
3.6.
metricd Workers
By default, the
gnocchi-metricd daemon spans all your CPU power in order to maximize CPU utilization when computing metric aggregation. You can use the
gnocchi status command to query the HTTP API and get the cluster status for metric processing. This command displays the number of metrics to process, known as the processing backlog for the
gnocchi-metricd. As long as this backlog is not continuously increasing, that means that
gnocchi-metricd is able to cope with the amount of metric that are being sent. If the number of measure to process is continuously increasing, you need to (maybe temporarily) increase the number of the
gnocchi-metricd daemons. You can run any number of metricd daemons on any number of servers.
For director-based deployments, you can adjust certain metric processing parameters in your environment file:
MetricProcessingDelay- Adjusts the delay period between iterations of metric processing.
GnocchiMetricdWorkers- Configure the number of
metricdworkers.
3.7. Monitoring the Time Series Database
The
/v1/status endpoint of the HTTP API returns various information, such as the number of measures to process (measures backlog), which you can easily monitor. Making sure that the HTTP server and the
gnocchi-metricd daemon are running and are not writing anything alarming in their logs is a sign of good health of the overall system.
3.8. Backing up and Restoring the Time Series Database
In order to be able to recover from an unfortunate event, you need to backup both the index and the storage. That means creating a database dump (PostgreSQL or MySQL) and doing snapshots or copies of your data storage (Ceph, Swift or your file system). The procedure to restore is: restore your index and storage backups, re-install Gnocchi if necessary, and restart it.
Chapter 4. Capacity Metering using the Telemetry Service
The Openstack Telemetry service provides usage metrics that can be leveraged for billing, charge-back, and show-back purposes. Such metrics data can also be used by third-party applications to plan for capacity on the cluster and can also be leveraged for auto-scaling virtual instances using Openstack Heat. For more information, see Auto Scaling for Instances.
The combination of ceilometer and gnocchi can be used for monitoring and alarms. This is supported on small-size clusters and with known limitations. For real-time monitoring, Red Hat Openstack Platform ships with agents that provide metrics data, and can be consumed by separate monitoring infrastructure and applications. For more information, see Monitoring Tools Configuration.
4.1. View Measures
To list all the measures for a particular resource:
# gnocchi measures show --resource-id UUID METER_NAME
To list only measures for a particular resource, within a range of timestamps:
# gnocchi measures show --aggregation mean --start START_TIME --end STOP_TIME --resource-id UUID METER_NAME
Where START_TIME and END_TIME are in the form iso-dateThh:mm:ss.
4.2. Create New Measures
You can use measures to send data to the Telemetry service, and they do not need to correspond to a previously-defined meter. For example:
# gnocchi measures add -m 2015-01-12T17:56:23@42 --resource-id UUID METER_NAME
4.3. Example: View Cloud Usage Measures
This example shows the average memory usage of all instances for each project.
gnocchi measures aggregation --resource-type instance --groupby project_id -m memory
4.4. Example: View L3 Cache Usage
If your Intel hardware and libvirt version supports Cache Monitoring Technology (CMT), you can use the
cpu_l3_cache meter to monitor the amount of L3 cache used by an instance.
Monitoring the L3 cache requires the following:
cmtin the
LibvirtEnabledPerfEventsparameter.
cpu_l3_cachein the
gnocchi_resources.yamlfile.
cpu_l3_cachein the Ceilometer
polling.yamlfile.
Enable L3 Cache Monitoring
To enable L3 cache monitoring:
Create a YAML file for telemetry (for example,
ceilometer-environment.yaml) and add
cmtto the
LibvirtEnabledPerfEventsparameter.
parameter_defaults: LibvirtEnabledPerfEvents: cmt
Launch the overcloud with this YAML file.
#!/bin/bash openstack overcloud deploy \ --templates \ <additional templates> \ is enabled for Telemetry polling.
# docker exec -ti ceilometer_agent_compute cat /etc/ceilometer/polling.yaml | grep cpu_l3_cache
If
cpu_l3_cache
This docker change will not persist over a reboot.
After you have launched a guest instance on this compute node, you can use the
gnocchi measures show command to monitor the CMT metrics.
(overcloud) [stack@undercloud-0 ~]$ gnocchi.5. View Existing Alarms
To list the existing Telemetry alarms, use the
aodh command. For example:
# aodh (an instance, image, or volume, among others). For example:
# gnocchi resource show 5e3fcbe2-7aab-475d-b42c-a440aa42e5ad
4.6. Create an Alarm
You can use
aodh to create an alarm that activates when a threshold value is reached. In this example, the alarm activates and adds a log entry when the average CPU utilization for an individual instance exceeds 80%. A query is used to isolate the specific instance’s id (
94619081-abf5-4f1f-81c7-9cedaa872403) for monitoring purposes:
# aodh%:
# aodh alarm update --name cpu_usage_high --threshold 75
4.7. Disable or Delete an Alarm
To disable an alarm:
# aodh alarm update --name cpu_usage_high --enabled=false
To delete an alarm:
# aodh alarm delete --name cpu_usage_high
4.8. Example: Monitor the disk activity of instances
The following example demonstrates how to use an Aodh alarm to monitor the cumulative disk activity for all the instances contained within a particular project.
1. Review the existing projects, and select the appropriate UUID of the project you need to monitor. This example uses the
admin tenant:
$ | +----------------------------------+----------+
2. Use the project’s UUID to create an alarm that analyses the
sum() of all read requests generated by the instances in the
admin tenant (the query can be further restrained with the
--query parameter).
# aodh | +---------------------------+-----------------------------------------------------------+
4.9. Example: Monitor CPU usage
If you want to monitor an instance’s performance, you would start by examining the gnocchi database to identify which metrics you can monitor, such as memory or CPU usage. For example, run
gnocchi resource show against an instance to identify which metrics can be monitored:
Query the available metrics for a particular instance UUID:
$ gnocchivalue lists the components you can monitor using Aodh alarms, for example
cpu_util.
To monitor CPU usage, you will need the
cpu_utilmetric. To see more information on this metric:
$ gnocchi metric show --resourcevalues.
Use Aodh to create a monitoring task that queries
cpu_util. This task will trigger events based on the settings you specify. For example, to raise a log entry when an instance’s CPU spikes over 80% for an extended duration:
aodhoperator defines that the alarm will trigger if the CPU usage is greater than (or equal to) 80%.
granularity- Metrics have an archive policy associated with them; the policy can have various granularities (for example, 5 minutes aggregation for 1 hour + 1 hour aggregation over a month). The
granularityvalue must match the duration described in the archive policy.
evaluation-periods- Number of
granularityperiods that need to pass before the alarm will trigger. For example, setting this value to
2will mean that the CPU usage will need to be over 80% for two polling periods before the alarm will trigger.
[u’log://']- This value will log events to your Aodh log file.Note
You can define different actions to run when an alarm is triggered (
alarm_actions), and when it returns to a normal state (
ok_actions), such as a webhook URL.
To check if your alarm has been triggered, query the alarm’s history:
aodh | +----------------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+
4.10. Manage Resource Types
Telemetry resource types that were previously hardcoded can now be managed by the gnocchi client. You can use the gnocchi client to create, view, and delete resource types, and you can use the gnocchi API to update or delete attributes.
1. Create a new resource-type:
$ gnocchi resource-type create testResource01 -a bla:string:True:min_length=123 +----------------+------------------------------------------------------------+ | Field | Value | +----------------+------------------------------------------------------------+ | attributes/bla | max_length=255, min_length=123, required=True, type=string | | name | testResource01 | | state | active | +----------------+------------------------------------------------------------+
2. Review the configuration of the resource-type:
$ gnocchi resource-type show testResource01 +----------------+------------------------------------------------------------+ | Field | Value | +----------------+------------------------------------------------------------+ | attributes/bla | max_length=255, min_length=123, required=True, type=string | | name | testResource01 | | state | active | +----------------+------------------------------------------------------------+
3. Delete the resource-type:
$ gnocchi resource-type delete testResource01
You cannot delete a resource type if a resource is using it.
Chapter 5. Troubleshooting
This chapter contains logging and support information to assist with troubleshooting your Red Hat OpenStack Platform deployment.
5.1. Support
If client commands fail or you run into other issues, contact Red Hat Technical Support with a description of what happened, the full console output, all log files referenced in the console output, and an
sosreport from the node that is (or might be) in trouble. For example, if you encounter a problem on the compute level, run
sosreport on the Nova node, or if it is a networking issue, run the utility on the Neutron node. For general deployment issues, it is best to run
sosreport on the cloud controller.
For information about the
sosreport command (
sos package), refer to What is a sosreport and how to create one in Red Hat Enterprise Linux 4.6 and later.
Check also the
/var/log/messages file for any hints.
5.2. Troubleshoot Identity Client (keystone) Connectivity Problems
When the Identity client (
keystone) is unable to contact the Identity service it returns an error:
Unable to communicate with identity service: [Errno 113] No route to host. (HTTP 400)
To debug the issue check for these common causes:
- Identity service is down
Identity Service now runs within httpd.service. On the system hosting the Identity service, check the service status:
# systemctl status httpd.service
If the service is not active then log in as the root user and start it.
# systemctl start httpd.service
- Firewall is not configured properly
- The firewall might not be configured to allow TCP traffic on ports
5000and
35357. If so, see Managing the Overcloud Firewall in the Advanced Overcloud Customization guide for instructions on checking your firewall settings and defining custom rules.
- Service Endpoints not defined correctly
On the system hosting the Identity service check that the endpoints are defined correctly.
Obtain the administration token:
# grep admin_token /etc/keystone/keystone.conf admin_token = 91f0866234a64fc299db8f26f8729488
Determine the correct administration endpoint for the Identity service:
Replace IP with the IP address or host name of the system hosting the Identity service. Replace VERSION with the API version (
v2.0, or
v3) that is in use.
Unset any pre-defined Identity service related environment variables:
# unset OS_USERNAME OS_TENANT_NAME OS_PASSWORD OS_AUTH_URL
Use the administration token and endpoint to authenticate with the Identity service. Confirm that the Identity service endpoint is correct. For example:
# openstack endpoint list --os-token=91f0556234a64fc299db8f26f8729488 --os-url= --os-identity-api-version 3
Verify that the listed
publicurl,
internalurl, and
adminurlfor the Identity service are correct. In particular ensure that the IP addresses and port numbers listed within each endpoint are correct and reachable over the network.
If these values are incorrect, add the correct endpoint and remove any incorrect endpoints using the
endpoint deleteaction of the
openstackcommand. For example:
# openstack endpoint delete 2d32fa6feecc49aab5de538bdf7aa018 --os-token=91f0866234a64fc299db8f26f8729488 --os-url= --os-identity-api-version 3
Replace TOKEN and ENDPOINT with the values identified previously. Replace ID with the identity of the endpoint to remove as listed by the
endpoint-listaction.
5.3. Troubleshoot OpenStack Networking Issues
This section discusses the different commands you can use and procedures you can follow to troubleshoot the OpenStack Networking service issues.
- Debugging Networking Device
- Use the
ip acommand to display all the physical and virtual devices.
- Use the
ovs-vsctl showcommand to display the interfaces and bridges in a virtual switch.
- Use the
ovs-dpctl showcommand to show datapaths on the switch.
- Tracking Networking Packets
Use the
tcpdumpcommand to see where packets are not getting through.
# tcpdump -n -i INTERFACE -e -w FILENAME
Replace INTERFACE with the name of the network interface to see where the packets are not getting through. The interface name can be the name of the bridge or host Ethernet device.
The
-eflag ensures that the link-level header is dumped (in which the
vlantag will appear).
The
-wflag is optional. You can use it only if you want to write the output to a file. If not, the output is written to the standard output (
stdout).
For more information about
tcpdump, refer to its manual page by running
man tcpdump.
- Debugging Network Namespaces
- Use the
ip netns listcommand to list all known network namespaces.
Use the
ip netns execcommand to show routing tables inside specific namespaces.
# ip netns exec NAMESPACE_ID bash # route -n
Start the
ip netns execcommand in a bash shell so that subsequent commands can be invoked without the
ip netns execcommand.
5.4. Troubleshoot Networks and Routes Tab Display Issues in the Dashboard
The Networks and Routers tabs only appear in the dashboard when the environment is configured to use OpenStack Networking. In particular note that by default the PackStack utility currently deploys Nova Networking and as such in environments deployed in this manner the tab will not be visible.
If OpenStack Networking is deployed in the environment but the tabs still do not appear ensure that the service endpoints are defined correctly in the Identity service, that the firewall is allowing access to the endpoints, and that the services are running.
5.5. Troubleshoot Instance Launching Errors in the Dashboard
When using the dashboard to launch instances if the operation fails, a generic
ERROR message is displayed. Determining the actual cause of the failure requires the use of the command line tools.
Use the
nova list command to locate the unique identifier of the instance. Then use this identifier as an argument to the
nova show command. One of the items returned will be the error condition. The most common value is
NoValidHost.
This error indicates that no valid host was found with enough available resources to host the instance. To work around this issue, consider choosing a smaller instance size or increasing the overcommit allowances for your environment.
To host a given instance, the compute node must have not only available CPU and RAM resources but also enough disk space for the ephemeral storage associated with the instance.
5.6. Troubleshoot Keystone v3 Dashboard Authentication
django_openstack_auth is a pluggable Django authentication back end, that works with Django’s contrib.auth framework, to authenticate a user against the OpenStack Identity service API. Django_openstack_auth uses the token object to encapsulate user and Keystone related information. The dashboard uses the token object to rebuild the Django user object.
The token object currently stores:
- Keystone token
- User information
- Scope
- Roles
- Service catalog
The dashboard uses Django’s sessions framework for handling user session data. The following is a list of numerous session back ends available, which are controlled through the SESSION_ENGINE setting in your local_settings.py file:
- Local Memory Cache
- Memcached
- Database
- Cached Database
- Cookies
In some cases, particularly when a signed cookie session back end is used and, when having many or all services enabled all at once, the size of cookies can reach its limit and the dashboard can fail to log in. One of the reasons for the growth of cookie size is the service catalog. As more services are registered, the bigger the size of the service catalog would be.
In such scenarios, to improve the session token management, include the following configuration settings for logging in to the dashboard, especially when using Keystone v3 authentication.
In /usr/share/openstack-dashboard/openstack_dashboard/settings.py add the following configuration:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'horizondb', 'USER': 'User Name', 'PASSWORD': 'Password', 'HOST': 'localhost', } }
In the same file, change SESSION_ENGINE to:
SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db'
Connect to the database service using the mysql command, replacing USER with the user name by which to connect. The USER must be a root user (or at least as a user with the correct permission: create db).
# mysql -u USER -p
Create the Horizon database.
mysql > create database horizondb;
Exit the mysql client.
mysql > exit
Change to the openstack_dashboard directory and sync the database using:
# cd /usr/share/openstack-dashboard/openstack_dashboard $ ./manage.py syncdb
You do not need to create a superuser, so answer 'n' to the question.
Restart Apache http server. For Red Hat Enterprise Linux:
#service httpd restart
=== OpenStack Dashboard - Red Hat Access Tab
The Red Hat Access tab, which is part of the OpenStack dashboard, allows you to search for and read articles or solutions from the Red Hat Customer Portal, view logs from your instances and diagnose them, and work with your customer support cases.
Figure 5.1. Red Hat Access Tab.
You must be logged in to the Red Hat Customer Portal in the browser in order to be able to use the functions provided by the Red Hat Access tab.
If you are not logged in, you can do so now:
- Click Log In.
- Enter your Red Hat login.
- Enter your Red Hat password.
- Click Sign in.
This is how the form looks:
Figure 5.2. Logging in to the Red Hat Customer Portal.
If you do not log in now, you will be prompted for your Red Hat login and password when you use one of the functions that require authentication.
5.6.1. Search
You can search for articles and solutions from Red Hat Customer Portal by entering one or more search keywords. The titles of the relevant articles and solutions will then be displayed. Click on a title to view the given article or solution:
Figure 5.3. Example of Search Results on the Red Hat Access Tab.
5.6.2. Logs
Here you can read logs from your OpenStack instances:
Figure 5.4. Instance Logs on the Red Hat Access Tab.
Find the instance of your choice in the table. If you have many instances, you can filter them by name, status, image ID, or flavor ID. Click View Log in the Actions column for the instance to check.
When an instance log is displayed, you can click Red Hat Diagnose to get recommendations regarding its contents:
Figure 5.5. Instance Logs on the Red Hat Access Tab.
If none of the recommendations are useful or a genuine problem has been logged, click Open a New Support Case to report the problem to Red Hat Support.
5.6.3. Support
The last option in the Red Hat Access Tab allows you to search for your support cases at the Red Hat Customer Portal:
Figure 5.6. Search for Support Cases.
You can also open a new support case by clicking the appropriate button and filling out the form on the following page:
Figure 5.7. Open a New Support Case.
| https://access.redhat.com/documentation/en-us/red_hat_openstack_platform/12/html-single/logging_monitoring_and_troubleshooting_guide/index | CC-MAIN-2019-47 | refinedweb | 4,089 | 54.32 |
It's a pointer to an array of characters.
It's a pointer to an array of characters.
Rust aims to be a C/C++ replacement, but it has a long way to go. There are a lot of legacy systems written in C/C++ that would cost too much time and money to be rewritten in Rust.
C/C++ are safe...
Hah. I remember some grumblings about a help troll.
What happened to him?
Salem is right about prototyping functions, OP:
#include <stdio.h>
void my_function(char*);
int main()
Is a .cvs file what the pharmacy uses to print the really, really long receipts? ;)
I didn't notice this thread was about C++ book recommendations. I read it as regular C.
Regardless, the C book I talked about is C Programming: A Modern Approach - Second Edition.
For C++, I'd...
Moden C by King is a great book. I've been going through it since the beginning of the year, and I've learned a lot. There are plenty of exercises and examples available. You can skip most of the...
Please format your code next time.
Surely there must be a way to load the questions from another file, yes?
Is the code legit? If so, where did you get access to a bank management system's codebase?
No problem! I think OP said he or she won't know how many players will be in the final ahead of time. So, he or she will need to calculate that.
If you're addressing this to me, I know how many because I counted the number of rows, each a player, from the input file.
Definitely simpler! I guess my newbie tendencies got the best of me and went a little overboard.
This was an interesting challenge. I spent the morning implementing my own solution. This program can take in a different number of players from a seperate file. I set the initial value for...
Do you have examples of the data file? I'd love to do this on my own and see if I can find a solution.
Can you please elaborate a little on this?
This is just an example, but the real text I'm using contains colons. Here is an example:
"BOB: I love the weather, but there is a problem: I hate going outdoors."
Spent some time last reworking the code with some suggestions.
I decided to just split on the space and check each token to see if it matches with the all words.
Seems like this works exactly...
My regex was not wrong. As laserlight pointed out, strtok doesn't take regular expressions, and that was why I didn't get the expected output.
I already provided code. Run my example.
Yeah, after doing more research after posting it, the only thing I've found was the pcre library, but that doesn't do the intended split. If you have a third-party library I don't know about, I'm all...
I'm trying to split this string:
"SPEAKER: Hello there, my friend. SPEAKER2: How are you, friend?"
into an array.
I know to use the strtok function from the strings header file, but I'm...
Exactly! One day you might not think of anything. Then, while you're working, you'll think, "Man, I wish I could just do this with one command," and boom, there's your idea.
An Introduction to C and GUI Programming might be what you're looking for.
Hi, Scatman.
I am in the same boat as you. I now understand the basics of C and hoping to improve my skills.
One thing that helped me to better understand the language is writing small programs... | https://cboard.cprogramming.com/search.php?s=5ff905218ef28d1b6fa975ca577be492&searchid=2056116 | CC-MAIN-2019-47 | refinedweb | 621 | 85.69 |
As you make the transition to .NET, you will probably find yourself using COM objects within .NET more than .NET objects within a COM project.
For the first lesson this hour, you will create a simple COM object using ATL and use the object within a managed C++ application. The first step is to create the ATL project and implement the COM object. Create a new project by selecting New, Project from the File menu. Select Visual C++ Projects from the list of project types and select the ATL Project template in the list of project templates. Give your project the name ATLCOMServer and click OK to create the project. Accept the default project settings by clicking Finish in the ATL Project Wizard.
The COM object you will be creating is the beginning of a simple system information object. It contains one interface that, in turn, contains one method and one property. Click Project, Add Class on the main menu. In the Add Class dialog that's displayed, select the ATL Simple Object template, as shown in Figure 21.2, and close the dialog by clicking Open.
In the ATL Simple Object Wizard, enter the name SimpleSysInfo in the Short Name field, as shown in Figure 21.3. Accept all the default options for this object by clicking Finish.
As mentioned earlier, your object will contain a single method. This method will be used to retrieve the current name of the machine the object is being run on by returning the results of the GetComputerName WIN32 API function. To add a method to an interface, expand the ATLCOMServer project in the Class View tree. Next, expand the Interfaces item. You should see the ISimpleSysInfo interface listed, as shown in Figure 21.4. Right-click this interface and select Add, Add Method in the context menu.
When the Add Method Wizard is displayed, give your method the name GetComputerName. Because interface functions return an HRESULT and you also need to return the computer name back to the caller, you have to create an out parameter. In the Parameter Type combo box, select the BSTR* parameter type. This will enable the Out and Retval check box under the Parameter Attributes heading. Check the Out and Retval check box. By doing this, you are creating a parameter that is going to be used to return a result back to the caller. In other words, the caller will pass you a buffer that you, in turn, will fill with the name of the computer. Give your parameter the name sComputerName and click the Add button to add the parameter to the parameter list, as shown in Figure 21.5. Click Finish to create the new interface method.
After you click Finish to create the method, the IDE will open the SimpleSysInfo.cpp file for you (if it isn't already open) and automatically scroll down to your new method. This method, as already mentioned, will use the GetComputerName function contained within the WIN32 API. However, because we are working within COM, you cannot simply pass the BSTR variable to the GetComputerName function because it expects a pointer to a regular character string. However, because you are using ATL, you can take advantage of the string-conversion macros it contains. Before you can use any of the ATL string-conversion macros, you must first insert the USES_CONVERSION macro, as shown in Listing 21.1, at the beginning of your function block. This macro is responsible for the variables and function calls necessary to perform the appropriate conversions.
1: STDMETHODIMP CSimpleSysInfo::GetComputerName(BSTR* sComputerName) 2: { 3: USES_CONVERSION; 4: 5: if( !sComputerName ) 6: return E_POINTER; 7: 8: DWORD dwSize = MAX_COMPUTERNAME_LENGTH + 1; 9: TCHAR sTemp[ MAX_COMPUTERNAME_LENGTH + 1 ]; 10: 11: if( !::GetComputerName( sTemp, &dwSize ) ) 12: return E_FAIL; 13: 14: *(sComputerName) = T2BSTR( sTemp ); 15: 16: return S_OK; 17: }
Following the USES_CONVERSION macro, line 5 of Listing 21.1 checks to make sure the caller-supplied buffer is valid and, if not, returns an HRESULT failure code. Next, declare the necessary local variables and call the GetComputerName function. Notice that because your interface method has the same name as the GetComputerName API call, you will need to preface the function call with the scope resolution operator (::). Finally, using the ATL string-conversion macro, which converts a native character string into a BSTR, assign the result to the caller-supplied buffer and return, as shown on line 14 of Listing 21.1. Although you currently have no way of testing the functionality of your object yet, it would be a good idea to compile your project before continuing.
Now you are going to add a property to the object. This property will actually perform the same functionality as the method you just added. Note that you would normally not have a property and function that perform the same tasks, but this is for illustration purposes only. Right-click the ISimpleSysInfo interface in Class View like you did earlier, but this time select Add, Add Property. In the Add Property Wizard, select the BSTR property type and give your property the name ComputerName, as shown in Figure 21.6. Click Finish to close the dialog.
As it did when you added a new method, the IDE will open the SimpleSysInfo.cpp file and scroll to the functions you just created. A property can contain a get function and a put function. Also, because you accepted the defaults when you created the property, the wizard has generated both functions for you. All that is left to do is implement these functions. The get_ComputerName function has the exact same signature (other than the name of the function, of course) as the interface function you added earlier. Because they both serve the same purpose to return the computer name you can simply copy the implementation for the GetComputerName function and place it within the get_ComputerName function. However, because the parameter name is different, you will have to change the code accordingly, as shown in Listing 21.2.
The put_ComputerName function is used to change the computer name. Because this is just a lesson and you're not creating a real shipping COM object, you might not want to implement this function. Listing 21.2 returns E_NOTIMPL, which is an HRESULT failure code signifying that the function is not implemented.
1: STDMETHODIMP CSimpleSysInfo::get_ComputerName(BSTR* pVal) 2: { 3: USES_CONVERSION; 4: 5: if( !pVal ) 6: return E_POINTER; 7: 8: DWORD dwSize = MAX_COMPUTERNAME_LENGTH + 1; 9: TCHAR sTemp[ MAX_COMPUTERNAME_LENGTH + 1 ]; 10: 11: if( !::GetComputerName( sTemp, &dwSize ) ) 12: return E_FAIL; 13: 14: *(pVal) = T2BSTR( sTemp ); 15: 16: return S_OK; 17: } 18: 19: STDMETHODIMP CSimpleSysInfo::put_ComputerName(BSTR newVal) 20: { 21: // not implemented 22: 23: return E_NOTIMPL; 24: }
Now that you have a working COM object, you can now learn how to use it within a managed application. Before you create the managed C++ application, however, you must change some of the build properties of the COM object to enable COM Interop. As mentioned at the beginning of this hour, COM Interop is accomplished by creating wrappers around the object you want to interoperate with. In this case, you will be creating a runtime callable wrapper (RCW) by running a utility provided by Visual Studio .NET on the type library that's generated whenever your COM DLL is built. This utility is called TlbImp.exe. Don't let the name confuse you, though. Although it sounds like it imports a type library, it doesn't. Rather, it creates a separate DLL, which is an assembly that runs within the common language runtime (CLR). This assembly contains the RCW that your .NET client will access. The RCW then performs the necessary marshaling and calls the COM object acting on the .NET client's behalf.
You can set up the TlbImp.exe tool to run each time you build your project so that you don't have to manually run it each time. In Class View, right-click the ATLCOMServer project and select Properties from the context menu. In the ATLCOMServer Property Pages dialog that's displayed, select Build Events, Post-Build Events from the list on the left side of the dialog. Select All Configurations from the Configuration drop-down box, as shown in Figure 21.7, because you want to build the .NET assembly in both Debug and Release modes. By doing this, you are specifying a tool you want to run after your project has been built.
In the Command Line field, you should already see a tool being run the regsvr32 tool. This tool is responsible for registering your COM object in the Registry. Click in the Command Line field and then click the button with the ellipsis (…) displayed at the end of the field. This will bring up the Command Line dialog, which allows you to specify more than one command. Add a carriage return after the regsvr32 command to begin a new command. Enter TlbImp.exe and the parameters shown in Figure 21.8. The first command-line argument specifies the DLL from which you want to extract type information. The second command-line argument is optional but recommended. It tells the tool to create a new DLL rather than overwrite the existing one. The macros within the dollar signs can be found by clicking the Macros button, selecting the appropriate macro, and then clicking the Insert button. For this project, use the same DLL name with the letters ASM at the end to make a distinction between the two files. Click OK to close the Command Line dialog.
In order to avoid any path issues with your COM object DLL while you run your .NET application, click the Linker item on the left side of the Configuration dialog. Change the Output File field on the right to ../bin/ATLCOMServer.DLL. When you create your .NET application, the executable for the project will be placed in the same location. You can now close the Property Pages dialog and build your COM object project. You shouldn't have any compilation errors, but because you have no way of testing the object, you cannot check for logical errors yet.
Now you can create the managed .NET application that will use the COM object you just created. Select New, Project from the main menu. Select Visual C++ Project from the list of project types and select the Managed C++ Application project template. Make sure the Add to Solution radio button is selected. Then, give your new project the name ManagedClient and click OK to create the project.
The TlbImp.exe tool created an assembly that can be used within managed applications. Because this is the case, you don't need to do anything else to set up the communication between your .NET client and the COM object. It behaves just like all the other assemblies and classes contained within those assemblies. Therefore, in the ManagedClient.cpp file, import the ATLCOMServerASM.dll file with the #using keyword, as shown in Listing 21.3. The assembly that was created also creates a default namespace that contains the interfaces and their associated coclasses. By default, this namespace is the same name as the DLL without the file extension. Therefore, add the appropriate namespace declaration, as shown on line 9 of Listing 21.3
1: #include "stdafx.h" 2: 3: #using <mscorlib.dll> 4: #using <..\bin\ATLCOMServerASM.dll> 5: 6: #include <tchar.h> 7: 8: using namespace System; 9: using namespace ATLCOMServerASM; 10: 11: void ComputerNameTest() 12: { 13: // create interop class 14: CSimpleSysInfoClass *SysInfo = new CSimpleSysInfoClass; 15: 16: // get machine name 17: String *sComputerName = SysInfo->GetComputerNameA();18: 18: 19: Console::WriteLine( "Computer Name as method: {0}", sComputerName ); 20: 21: // access ComputerName property 22: Console::WriteLine( "Computer Name as property: {0}", 23: SysInfo->ComputerName ); 24: 25: // attempt to set the computer name 26: try 27: { 28: SysInfo->ComputerName = S"vcsmarkhsch3"; 29: } 30: catch( Exception* e) 31: { 32: Console::WriteLine( "Setting computer name returned: \ 33: {0}\r\n", e->Message ); 34: } 35: } 36: 37: // This is the entry point for this application 38: int _tmain(void) 39: { 40: ComputerNameTest(); 41: 42: return 0; 43: }
Before we get into the implementation details, it's important to discuss what differences exist between the original COM object and the RCW assembly just created. When an assembly is created from a type library, the tool has to take into account the fundamental design differences between the two technologies. First of all, objects within the .NET Framework do not automatically contain an interface for IUnknown or IDispatch as they do for COM objects. Because they do not exist and there are no equivalent interfaces, the TlbImp tool simply removes those interfaces. Because IUnknown is used for object lifetime, it is not needed because object lifetime is contained and controlled by the common language runtime. For each coclass contained within a COM server, an equivalent class is created within the .NET assembly that is generated, and Class is appended to the coclass name.
In order to avoid the casting of interface pointers as you work with the new managed class and also to keep in line with the design of the .NET Framework, the RCW .NET assembly will flatten all interface members within a coclass. In other words, if a coclass implements several interfaces, the resulting .NET assembly will gather all the interface methods and properties for each implemented interface and place these within the managed class without using interfaces. Of course, one problem that is immediately apparent involves method and property name collisions. If one interface contains a method named A and another interface contains a method also named A, these two methods will collide when they are flattened within the managed class. To overcome this obstacle, the TlbImp tool will change the name of any colliding members by prefixing these members with the interface that implements them, followed by an underscore and the data member's original name. Therefore, in the example just mentioned, the first method will remain the same, A, whereas the next, colliding function will be renamed InterfaceName_A. Because the COM object you created does not implement more than one custom interface, no name collisions will occur. However, it is important to know the differences between the types within the COM object and the resulting RCW .NET assembly that is created.
Using the objects within the created RCW assembly is similar to using any other .NET Framework object. In the ManagedClient.cpp file, create a function named ComputerNameTest. It does not need to accept any parameters and can return void. To instantiate the class that represents the COM object, use the standard method of instantiating .NET objects with the C++ keyword new. This can be seen on line 14 of Listing 21.3, in which an object named CSimpleSysInfoClass is created. After creating the object, you can call its various methods and parameters, just as you would with any other .NET object. If you recall, when you created the COM object, you created an interface method named GetComputerName that accepts a BSTR as its parameter. However, because you are working within the CLR, there is no such data type as BSTR. Instead, use the equivalent data type, which is the System::String data type contained within the .NET Framework. The RCW will perform the necessary conversions from a String object to a BSTR, and vice versa.
Following the call to GetComputerName, print out the ComputerName property. Because you are not assigning the property to a value, the get_ComputerName interface method will be invoked. Although you did not implement the setter function for the ComputerName property, call it anyway. You can see, starting on line 28 of Listing 21.3, that the code to set the ComputerName property is wrapped within a try-catch exception block. The .NET Framework does not use HRESULT as COM does. Instead, the RCW will convert any HRESULT errors it receives by throwing exceptions instead. If you are returning E_NOTIMPL within the setter function of your ComputerName property, the exception message you receive reads, "Not implemented." If there is no equivalent exception within the .NET Framework's COM Interop namespace that can be mapped from an HRESULT, as is the case with a custom HRESULT, then a generic exception is thrown instead.
To finish your project, add the function call to ComputerNameTest within your _tmain function. Also, just as you did with the project properties of your COM object, change the Output File path to ../bin/ManagedClient.exe. Once you compile and run your application, your output should look similar to Figure 21.9. | https://flylib.com/books/en/3.121.1.175/1/ | CC-MAIN-2019-39 | refinedweb | 2,759 | 55.84 |
On Tue, 2016-06-21 at 21:38 +0200, Cyril Brulebois wrote: > Hi, > > Juerg Haefliger <juerg.haefliger@hpe.com> (2016-06-10): > > Package: kernel-wedge > > Version: 2.94 > > Severity: normal > > Tags: patch > > > > Module inclusion with wildcards should honor the KW_CHECK_NONFATAL > > env variable and not error out if it's set and a wildcard > > directory is not found. > > > > This is in line with how missing non-optional modules are treated > > when KW_CHECK_NONFATAL is set. > > > > diff --git a/commands/preprocess b/commands/preprocess > > index 045903b..1a54632 100755 > > --- a/commands/preprocess > > +++ b/commands/preprocess > > @@ -35,7 +35,7 @@ sub expandwildcards { > > if (! -d "$moddir/$subdir") { > > if (-d "$moddir/kernel/$subdir") { > > $subdir = "kernel/$subdir"; > > - } elsif ($checkdir) { > > + } elsif ($checkdir && !length($ENV{KW_CHECK_NONFATAL})) > > { > > die "pattern $pattern refers to nonexistent > > subdirectory"; > > } else { > > return (); > > Thanks for the report+patch. > > Ben, since you've been pushing most code to kernel-wedge recently, do you concur? I agree that this error shouldn't be fatal in case that variable is set, but there should still be a warning. Additionally, the variable test should exists() as well as length() to avoid a Perl warning when the variable is not defined at all. (find- dups gets away with this because the embedded Perl script does not enable warnings.) | https://lists.debian.org/debian-boot/2016/06/msg00194.html | CC-MAIN-2019-18 | refinedweb | 205 | 56.96 |
How to Create a Single Windows Executable from a Python and PyGame Project (Summary)
Here’s how you use PyInstaller and PyGame to create a single-file executable from a project that has a
data directory that contains resources like images, fonts, and music.
- Get PyInstaller.
- On Windows, you might also need pywin32 (and possibly MinGW if you don’t have Visual Studio).
- On Mac OS X, you will need XCode’s command line tools. To install the Command Line tools, first install XCode from the App Store, then go to Preferences – Downloads and there is an option to download them there.
- Modify your code so that whenever you refer to your
datadirectory, you wrap it using the following function:
def resource_path(relative): if hasattr(sys, "_MEIPASS"): return os.path.join(sys._MEIPASS, relative) return os.path.join(relative)
An example of usage would be
filename = 'freesansbold.ttf' myfontfile = resource_path(os.path.join(data_dir, filename)
This is mostly for convenience – it allows you to access your resources while developing, but then it’ll add the right prefix when it’s in the deployment environment.
- Specify exactly where your fonts are (and include them in the data directory). In other words, don’t use
font = Font(None, 26). Instead, use something like
font = Font(resource_path(os.path.join('data', 'freesansbold.ttf')), 14).
- Generate the
.specfile.
- Windows: (You want a single EXE file with your data in it, hence
--onefile).
python pyinstaller.py --onefile your_main_file.py
- Mac OS X: (You want an App bundle with windowed output, hence
--windowed).
python pyinstaller.py --windowed your_main_file.py
- Modify the
.specfile so that you add your
datadirectory (note that these paths are relative paths to your main directory.
- Windows: Modify the section where it says
exe EXE = (pyz,and add on the next line:
Tree('data', prefix='data'),
- Mac OS X: Modify the section where it says
app = BUNDLE(coll,and add on the next line:
Tree('data', prefix='data'),
- Rebuild your package.
python pyinstaller.py your_main_file.spec
- Look for your
.exeor your
.appbundle in the
distdirectory.
Phew! That took me a long time – the better part of a few hours to figure out. This post on the PyInstaller list really helped.
So why was I trying to package a Python executable file anyway? Read on…
Ludum Dare 26: 48-hour Game Design Compo
This weekend, I decided to participate in a 48-hour game design “competition”. Ludum Dare is a compo that asks you to create a video game from scratch in a 48-hour time period – you have to write your code and create all of your assets in that time period.
This means no reusing graphics, pictures, music, or sound from other projects, for example. You’re also not supposed to reuse code either. I decided to participate on the Thursday the day before. Most people use the previous weekend as a “warmup weekend” to test their tools, get some practice, and so forth. (My entry is located here, by the way).
I’ll do a more detailed compo writeup later, but I just want to concentrate on one thing that kept me up for hours after the competition: getting a Windows executable created from a Python project that uses PyGame and a data directory.
Python, Distribution, and You
I rather enjoy Python as a programming language. The syntax is reasonably concise, the language does a lot of things for you, and it’s well-laid out. There’s also a lot of good support in the form of third-party libraries. I’ve been using Python for various things for the past few years (usually small scripts for data extraction and analysis in research).
One thing I had never thought about before was distributing a Python project as an executable package, and while it was on my mind throughout the entire compo, I didn’t actually learn the process of creating the package until the last hour of the comp before submission. After you submit your primary platform, Ludum Dare allows you around 48 hours to compile for Windows, since the majority of reviewers use Windows.
The ideal submission is a single binary file (an .exe file for Windows) that doesn’t have to extract a lot of data, so that it’s easy for people to download and run your game.
PyInstaller vs. Py2exe vs. Py2app
I went on a wild goose chase trying to find out how to make a single executable file out of a Python project that would include all of my data assets. I first tried py2exe and py2app. py2app mostly worked all right, but py2exe was a pretty big mess.
The end story is that PyInstaller is newer and shinier than py2exe, and that you need to secret sauce code that someone out there on the Internet found before I did. PyInstaller basically runs EXE files by extracting the assets into a temporary data file that has a path _MEIPASS in it ((technical details here). Be sure that you check that every file is loaded in through that wrapper. The Tree() TOC syntax was also confusing, but basically, it’s the relative path of your data files and it will automatically load all of the files in that directory. Make sure it exists in the EXE portion (Windows) or the APP portion (Mac).. PyInstaller is pretty smart about rebuilding, and you save a lot of time.
I think in the long run, if you compare py2exe, py2app, and PyInstaller, PyInstaller is the program worth learning. It did have a pretty sharp curve for me – it didn’t help that I was trying to do this late at night after a challenging weekend!
If you do wish to use py2app to build your Mac OS X application bundle, then do keep in mind that you need to have a
import pygame._view because of some kind of obscure issue.
Anyway, that’s all there is to this post for now.
Appendix
Here’s the setup.py I used for py2app.
from setuptools import setup APP = ['painterscat.py'] DATA_FILES = ['data'] OPTIONS = { "argv_emulation": False, "compressed" : True, "optimize":2, # "iconfile":'data/game.icns', } setup( app=APP, data_files=DATA_FILES, options={'py2app': OPTIONS}, ) | https://irwinkwan.com/2013/04/ | CC-MAIN-2018-22 | refinedweb | 1,032 | 63.39 |
Learn to create a cluster enabled for Cloud Run for Anthos on Google Cloud and then deploy a prebuilt sample container to that cluster.
If you have a demo account, you can instead follow this quickstart on Qwikl.
- To ensure you have the latest version of the Cloud SDK, either install or update the Cloud SDK:
- Install and initialize the Cloud SDK.
- If you've already installed the Cloud SDK, update the installed components:
gcloud components update
Setting up the command-line environment and enabling the required APIs
Complete the following steps to set up your command-line environment for Cloud Run for Anthos and enable the required APIs:
Configure the
gcloudcommand-line tool to use the ID of your Cloud project by default:
gcloud config set project PROJECT-ID
Replace PROJECT-ID with your project's ID.
Set the zone where you want the new cluster to be deployed. You can use any zone where GKE is supported. For example:
gcloud config set compute/zone ZONE
Replace ZONE with your desired zone.
Run the
gcloud servicescommand to enable the following APIs in your Cloud project:
- Google Kubernetes Engine API: Create GKE clusters.
- Cloud Build API: Build containers.
- Container Registry API: Publish containers to Container Registry.
gcloud services enable container.googleapis.com containerregistry.googleapis.com cloudbuild.googleapis.com
This might take several seconds to complete. When the APIs have been enabled, the command line displays a message similar to the following:
Operation "operations/..." finished successfully.
Creating a GKE cluster with Cloud Run for Anthos enabled
Complete the following steps to create a cluster and enable it for Cloud Run for Anthos:
Create a new cluster using the command:
gcloud container clusters create CLUSTER_NAME \ --addons=HttpLoadBalancing,CloudRun \ --machine-type=e2-standard-4 \ --num-nodes=4 \ --enable-stackdriver-kubernetes
Replace CLUSTER_NAME with the name you want for your cluster.
Wait for the cluster creation to complete. During the creation process, you should see messages similar to the following:
Creating cluster my-cluster...done. Created [ \ projects/my-project/zones/us-central1-b/clusters/my-cluster].
where
my-projectis the ID of your Cloud project and
my-clusteris the cluster that you just created.
Set the
gclouddefaults for your Cloud Run for Anthos resources to the name of your new cluster and its location. You set these defaults to avoid specifying these values each time that you use the
gcloudcommand-line tool.
gcloud config set run/platform gke gcloud config set run/cluster CLUSTER_NAME gcloud config set run/cluster_location ZONE
Replace CLUSTER_NAME and ZONE with the same values that you used to create your new cluster.
Deploying a sample container
Use the Google Cloud Console to deploy a sample container and create a service in your cluster:
In the Cloud Console, go to the Cloud Run for Anthos page.
Open the Create service form by clicking Create service.
In the available clusters dropdown menu, select the cluster you just created.
Leave
defaultentered as the name of the namespace.
Enter a service name, such as
hello.
Click Next.
Select Deploy one revision from an existing container image, then select
hellofrom the demo containers drop-down.
Click Next.
Select External under Connectivity, so that you can invoke the service.
Click Create to deploy the image, cURL is used to demonstrate how to access your service and verify that it's working:
In the Cloud Console, go to the Cloud Run for Anthos page.
Click the name of your new Cloud Run for Anthos service to go to its Service details page.
Click info, located to the right of the service's URL.
Click Invoke in Cloud Shell to run the generated cURL command for your service in Cloud Shell.
The cURL request returns the source code of the sample container that your service is running. Now you've verified that your service is handling requests!
Clean up
You can either disable Cloud Run for Anthos, or you can delete the cluster and the Cloud Run for Anthos service to avoid incurring costs for running these resources.
Disabling Cloud Run for Anthos
To disable Cloud Run for Anthos and keep your cluster:
In the Cloud Console, go to the Google Kubernetes Engine page.
Go to Google Kubernetes Engine
Click the cluster where you want to disable Cloud Run for Anthos.
Click Edit.
Scroll down to Anthos Features and from the Cloud Run for Anthos on Google Cloud dropdown, select Disable.
Click Save.
Deleting Cloud Run for Anthos
To permanently delete your GKE cluster, including the Cloud Run for Anthos service and all its resources:
In the Cloud Console, go to the Google Kubernetes Engine page.
Go to Google Kubernetes Engine
Select the cluster you want to delete.
Click Delete, the click Delete again on the pop up.
What's next
To learn how to build a container from code source, push to Container Registry, and then deploy, see:
For an architectural overview of Cloud Run for Anthos that covers the changes from installing Cloud Run for Anthos on Google Cloud as an add-on to your Google Kubernetes Engine cluster, see: | https://cloud.google.com/anthos/run/docs/quickstarts/prebuilt-deploy-gke?hl=hu | CC-MAIN-2021-31 | refinedweb | 844 | 60.24 |
In Previous Chapter we have seen that to perform any Action, we need to compare the value taken from Excel sheet with the value of each method in Action Keyword class. Till the time there are just a few methods, this technique would work fine. But think of a scenario where a new action is adding almost daily in framework. It will be a tedious task to first add a new method in 'ActionKeyword' class then add that method in to compare the statement of 'DriverEngine' test. Think of the size of the list of IF/ELSE loop after a few releases.
Use of Java Reflection Class
Java gives the ability to overcome this problem with the help of Refection Classes. Reflection is a very useful approach to deal with the Java class at runtime as it can be used to load the Java class, call its methods or analysis the class at runtime. If in case you are not familiar with Java much, I would suggest you to simply copy-paste the code and start using it. Else it is better to Google 'Java Reflection Classes' and read about it. Just keep in mind the actual need of it, that we are using it to create a class at runtime and to analyze the Action Keyword class at runtime.
Let me again tell you the need for it in other words, so that the reason can be understood. As of now in the framework, whenever there is an addition of any new method in Action Keyword class, it is required to put that newly created method in the if/else loop of the main Driver Script. Just to avoid that situation it is required to use Java Reflection class, so that when a new method is added, this reflection class will load all the methods of Action Keyword class at run time.(); } }
Note: There is no change in the Action Keyword class, it is the same as in the last chapter.
Driver Script Class:
package executionEngine; import java.lang.reflect.Method; import config.ActionKeywords; import utility.ExcelUtils; public class DriverScript { //This is a class object, declared as 'public static' //So that it can be used outside the scope of main[] method public static ActionKeywords actionKeywords; public static String sActionKeyword; //This is reflection class object, declared as 'public static' //So that it can be used outside the scope of main[] method public static Method method[]; //Here we are instantiating a new object of class 'ActionKeywords' public DriverScript() throws NoSuchMethodException, SecurityException{ actionKeywords = new ActionKeywords(); //This will load all the methods of the class 'ActionKeywords' in it. //It will be like array of method, use the break point here and do the watch method = actionKeywords.getClass().getMethods(); } public static void main(String[] args) throws Exception { //Declaring the path of the Excel file with the name of the Excel file String sPath = "D://Tools QA Projects//trunk//Hybrid Keyword Driven//src//dataEngine//DataEngine.xlsx"; //Here we are passing the Excel path and SheetName to connect with the Excel file //This method was created in the last chapter of 'Set up Data Engine' ExcelUtils.setExcelFile(sPath, "Test Steps"); //Hard coded values are used for Excel row & columns for now //In later chapters we will use these hard coded value much efficiently //This is the loop for reading the values of the column 3 (Action Keyword) row by row //It means this loop will execute all the steps mentioned for the test case in Test Steps sheet for (int iRow = 1;iRow <= 9;iRow++){ //This to get the value of column Action Keyword from the excel sActionKeyword = ExcelUtils.getCellData(iRow, 3); //A new separate method is created with the name 'execute_Actions' //You will find this method below of the this test //So this statement is doing nothing but calling that piece of code to execute execute_Actions(); } } //This method contains the code to perform some action //As it is completely different set of logic, which revolves around the action only, //It makes sense to keep it separate from the main driver script //This is to execute test step (Action) private static void execute_Actions() throws Exception { //This is a loop which will run for the number of actions in the Action Keyword class //method variable contain all the method and method.length returns the total number of methods for(int i = 0;i < method.length;i++){ //This is now comparing the method name with the ActionKeyword value got from excel if(method[i].getName().equals(sActionKeyword)){ //In case of match found, it will execute the matched method method[i].invoke(actionKeywords); //Once any method is executed, this break statement will take the flow outside of for loop break; } } } }
The above code is now much more clear and simple. If there is any addition of method in Action Keyword class, driver script will not have any effect of it. It will automatically consider the newly created method. | https://www.toolsqa.com/selenium-webdriver/keyword-driven-framework/java-reflection-class/ | CC-MAIN-2022-21 | refinedweb | 819 | 52.53 |
See the object type "Asteroid" which is a sprite with a texture from the free bundle. You can select the instance above the top-left corner of the layout in "Layout view".
"Asteroid" wraps like the ship does (Wrap behavior), it moves "automaticly" (Bullet behavior) and it rotates on itself (Rotate behavior).
In the "Asteroid"'s properties, the "Set angle" property is set to "No". This way, the bullet behavior will still make the asteroid move along the screen, but the rotate behavior will define the angle at which the texture will be displayed, giving the "illusion" the asteroid is rotating on itself while following a straight trajectory.
Then any time the asteroid will leave the play-field, the wrap behavior will automatically make it appear on the other side of the screen.
The idea there is that when an "Asteroid" is being shot, it will "break" into two smaller asteroids.
"Asteroid" has an instance variable that keeps a "size ratio", to check if, when the asteroid gets shot, it should break into smaller parts or simply disappear.
The instance variable is therefore called "Size" and is a number variable (that I'll be able to use in the "sizing formula").
The default value is 1.
+ Breaking down the code
In "esGame" the group "AsteroidHandling" (event 16) contains the code for this game mechanic.
Everything happens on a collision between an "Asteroid" and a "Bullet"
The first action taken is to destroy the "Bullet" to prevent this event to be executed again next tick, to prevent the "Bullet" to hit another "Asteroid".
Event 18 is empty (it has no condition) so will be executed every tick.
As it is a sub event to the event 17, it will only execute if the event 17 executes.
And the event 17 being a triggered condition (in the "Events run top to bottom" section of the article) this sub event will only run for one tick each time.
This allows to create local variables and store values in those.
Using a local variable here allows to make sure that those values are reset each tick and can't be modified/used from outside of the current event.
So once a collision is detected the first step is to keep the UID of the "Asteroid" in a local variable. (event 18)
This will allow to pick this asteroid again at the end of the process to destroy it.
This is in anticipation of the fact that we might spawn two new "Asteroid" instances and that C2 always picks the latest spawned object.
The current angle of motion of the bullet behavior of this "Asteroid" instance is also kept in a local variable.
It will be used later when spawning new asteroids as trajectory basis from which the newly instances will diverge.
Event 19 is a sub event to event 17 and is "paired" with event 23.
This event is a test on the current picked instance (the "Asteroid" instance that has collided with a "Bullet") to see if its "Size"'s value is less than 2.5.
If it is, this means that we will split the asteroid into two smaller ones.
System: Set CurrentSize to Asteroid.Size + 0.5
This action stores the current "Size" (instance variable) value and adds 0.5 to it.
This is for the splitting of asteroids which is explained a few lines below.
System: Add 1 to Score
Adds 1 to the global variable "Score", the player just scored 1 point because he hit a "split-able" "Asteroid" with one of his "Bullet".
The splitting into two new instances happens event 20 which is a "Repeat 2 times" sub event.
It will only execute if it's parent event is executed (event 19, so when Asteroid.Size < 2.5) and will repeat the bunch of actions two times.
System: Create Asteroid at Asteroid.X, Asteroid.Y on layer 0
Edit: In the original capx and screenshots, the action was a "Asteroid: Spawn Asteroid", but stable release r103.2 (or earlier) broke it, so I have had to switch the action there to keep the game working as intended. The capx has been updated too.
The system creates a new "Asteroid" at the position of the currently picked "Asteroid" instance.
The first time the event runs, the picked instance is the instance that was in collision with "Bullet", the second time it is this newly spawned instance.
And actually, from this action, this is also the picked instance.
All the following actions will apply to this newly spawned instance and only this one.
Asteroid: Set Bullet angle of motion to int((CurrentAOM + random(125))%180) degrees
This action contains a bit of maths and a bit of system expressions. (the expressions each have a definition, be sure to check the manual out whenever you're wondering about them)
Let's break it down:
int()
Is a system expression that allows to make sure that the content between the parenthesis will be an integer.
CurrentAOM
Is a local variable we set earlier that contains the Bullet angle of motion of the parent "Asteroid" instance.
random(125)
Is another system expression that will return (generate) a random number.
In this case it will generate a number between 0 and 124 (included) to add to the parent's angle of motion, and make sure the child's trajectory is different from its parent's.
The value 125 was achieved arbitrary and through trials and errors/tweaking. It seemed to achieve the effect I was visualising, so it's good enough for me.
()%180
Is the mathematical "modulo" (or "modulus" ?) that makes sure the result between the parenthesis can't be greater than 180.
The modulo is necessary here because the bullet angle of motion can be expressed in the range of -180 to 180.
Asteroid: Set size (width, height) to ( 96 / CurrentSize , 96 / CurrentSize )
Affects the width and height properties of the Sprite object type and sets the current size of the texture/object to 96 (an arbitrary start value) divided by the value of the local variable CurrentSize which is the "Size" (instance variable) value of the parent instance + 0.5.
Dividing a value by a greater value returns a diminished result. So the newly spawned "Asteroid" is CurentSize smaller than its parent.
Asteroid: Set "Size" (instance variable) value to CurrentSize
Sets the current instance's "Size" value to the value of the local variable CurrentSize.
As on each split the "Size" value is incremented, the "Asteroid"'s size gets smaller, and it allows for the event19/event23 pairing/logic.
Asteroid: Set Rotate speed to random(20,180) degrees per second
As earlier, the random() system expression returns a float number here (because there is no int() in the formula) between 20 and 179 (included).
It sets the rotation speed (on itself, Rotate behavior) for the current "Asteroid" instance, allowing for a bit of visual diversity on screen (not all asteroids rotates at the same speed).
Asteroid: Set Bullet speed to random(AsteroidMaxSpeed - 10,AsteroidMaxSpeed)
Notice "AsteroidMaxSpeed" is a global variable I've set up while tweaking to get the nicest global speed for the Asteroids in my opinion.
The speed is randomized but kept in a close range so the Asteroids will generally move at the same speed (modulated by 10 pixels per seconds).
As one of the aim here is to produce a full project in less than 100 events, if you were to need space for one more event, you could put solid values (40,50) in this action and delete the global variable.
I kept it in here to show this as a tip for when you are tweaking. It is faster to edit only this one value and hit "Preview".
Also sometime, if the value is to be used across several spots of the event sheet/project, it is a viable solution to keep the value in a single spot and refer to it through its variable name in the sheets.
The two last actions are here for a visual final touch.
Asteroid: Set angle to Asteroid.Bullet.AngleOfMotion degrees
Asteroid: Move forward random(5,15) pixels
The newly spawned "Asteroid" is moved away by a few pixels from its parent.
For it to work, for this one tick, the angle of the Sprite is set to its Bullet angle of motion.
Then the "Asteroid" is "forwarded" by a random amount of pixels (at least 5, at max 14).
This is it for the split.
System: Pick all Asteroid
And so now, we need to "reset the picking" thanks to the system condition "Pick all".
At this point of the code, the instance picked is the second "Asteroid" child instance we spawned. That's why there's the need to "Pick all (instances" here.
Picking all "Asteroids" tells C2 that we want to select another instance among all of the "Asteroid" instances available.
System: CurrentUID not = 0
CurrentUID being a local variable, each tick its value is reset to 0.
It is unlikely that an "Asteroid" instance has the UID 0 (this UID is reserved to the very first object that was created in the project, and it wasn't an "Asteroid").
This check is not really useful, but it prevent execution if an incorrect UID (the local variable default value: 0) is stored. It's only a check, it's not worth much, and it could prevent deleting the wrong instance.
Asteroid: Pick instance with UID CurrentUID
Finally this common condition picks the parent "Asteroid" instance by its UID, which we had kept at the beginning of this process in the local variable CurrentUID. (the blank event 18)
The action "Asteroid: destroy" will apply to this instance, and this instance only.
I won't talk about the sub event 22 for now, it is part of the Audio system explained later in this tutorial.
Event 23 is a "Else" condition that will occur when event 19 (a test to see if the size of the "Asteroid" in collision is less than 2.5) is not executed (because its condition is not true, the "Asteroid"'s size is 3).
If this event executes, it means that the "Asteroid" instance in collision with a "Bullet" "Size" instance variable value is equal to 3.
In the game logic, and because that's the value I arbitrary chose via tweaking, it means it is the last piece, it won't split, just be destroyed.
It also adds 10 points to the player's score.
As earlier, the sub event 24 is for the audio and discarded in the discussion for now.
This closes the "AsteroidHandling" group
Remember the game point list in the first pages of the tutorial ?
Asteroid clone - base Mechanism
..° Ship moving like in the original Asteroid game (gravity 0-like type of physics, the ship rotates on itself, it can go forward, brake, momentum is present, wraps from one side of the screen to the other; it also can shoot at asteroids), controlled by the player.
..° Asteroids are moving rocks on a straight trajectory, warping on the sides of the screen like the player's ship, each asteroid hit by a bullet splits into two smaller asteroids, or if it is already the "smallest" allowed, is destroyed. Splitting an asteroid score 1 point, destroying an asteroid scores 10.
..° If the ship collides with an asteroid, the ship loses health up to 0 where it is game over. The asteroid is just destroyed, no score added.
The last point is handled in the group "PlayerHandling" (event 12)
Event 13 the "Player" collides with an "Asteroid".
Player: Substract int(35/ Asteroid.Size) from Health
This action does reduce the "Health" instance variable value according to the "Asteroid"'s "Size" value.
If the "Player" collides with a big "Asteroid" ("Size" = 1) it will lose 35 health points. (35/1 = 35)
If the "Player" collides with a small "Asteroid" ("Size" = 3) it will lose around 11 health points. (35/3 = 11.66...)
The "Health" is then displayed by the "LifeBar", but this matter will be discussed later in the tutorial.
Asteroid: Destroy
The "Asteroid" is simply destroyed.
Event 15, the "Player"'s "Health" is equal or less than 0.
This is game over.
For now, all you need to know about it is that it sets all the values required in the game logic, and goes to the "Score" layout.
More on this later.
With this group "PlayerHandling" you can see that the last basic mechanic of game-play is implemented.
This closes the presentation of the base mechanism elements, the game element the players can interact with.
I have looked over the asteroid handling group, and it seems like all of my events are in the correct spot. The issue I am having is that the smaller asteroids will not be destroyed, but instead will continue to break apart until they're infinitely small. If anyone can help me with this issue that would be highly appreciated, thank you. | https://www.construct.net/en/tutorials/asteroid-clone-less-events-212/asteroids-4 | CC-MAIN-2021-17 | refinedweb | 2,170 | 69.01 |
We’ve already seen in previous scraping articles how we can identify parts on a web page and scrape them into a dataframe. We would strongly recommend taking a look through our introductory piece on scraping before pressing forward here.
Another previous article stored player images for match/scouting reports, pre-match presentations, etc. This time, we will be looking to collate the heights, appearances and weights of each Premier League player from the official site. Let’s get our modules imported and run through our process:
from lxml import html import requests import pandas as pd import numpy as np import re
Take a look at a player page from the Premier League site. There is loads of information here, but we are interested in collecting the apps, height and weight data.
We could do this manually for each player of each team, but hopefully we can also scrape through a list of each player in each team, and a list of each team in the league to automate the process entirely. Subsequently, our plan for the code is going to be something like this:
- Scrape the clubs page and make a list of each team page
- Scrape each team’s page for players and make a list of each player
- Scrape each player page and take their height, weight and apps number
- Save this into a table for later analysis
Read the Clubs page and list each team
Our intro article goes through this in much more depth, so take a look there if any of the code below is confusing.
In short, we need to download the html of the page and identify the links pointing towards the teams. We then save this into a list that we can use later.
Take a look through the code and try to follow along. A reminder that more detail is here if you need it!
#Take site and structure html page = requests.get('') tree = html.fromstring(page.content)
#Using the page's CSS classes, extract all links pointing to a team linkLocation = tree.cssselect('.indexItem') #Create an empty list for us to send each team's link to teamLinks = [] #For each link... for i in range(0,20): #...Find the page the link is going to... temp = linkLocation[i].attrib['href'] #...Add the link to the website domain... temp = "" + temp #...Change the link text so that it points to the squad list, not the page overview... temp = temp.replace("overview", "squad") #...Add the finished link to our teamLinks list... teamLinks.append(temp)
Read through each team’s list of players and create a link for each one
Our process here is very similar to the first step, now we are just looking to create a longer list of each player, not each team.
The main difference is that we will create two links, as the data that we need is across both the player overview page, and the player stats page.
Once again, if anything here is confusing, check out the intro to scraping piece! You might also want to check out the for loop page as we have a nested for loop in this part of the code!
#Create empty lists for player links playerLink1 = [] playerLink2 = [] #For each team link page... for i in range(len(teamLinks)): #...Download the team page and process the html code... squadPage = requests.get(teamLinks[i]) squadTree = html.fromstring(squadPage.content) #...Extract the player links... playerLocation = squadTree.cssselect('.playerOverviewCard') #...For each player link within the team page... for i in range(len(playerLocation)): #...Save the link, complete with domain... playerLink1.append("" + playerLocation[i].attrib['href']) #...For the second link, change the page from player overview to stats playerLink2.append(playerLink1[i].replace("overview", "stats"))
Scrape each player’s page for their age, apps, height and weight data
If you have been able to follow along with the previous steps, you’ll be absolutely fine here too. The steps are very similar again, just this time we are looking to store data, not links.
We will start this step by defining empty lists for the datapoints we intend to capture. Afterwards, we’ll work through each player link to save the player’s details. We will also add a little line of code to add in some blank data if the site is missing any details – this should allow us to run without any errors. After collecting each player’s data, we will simply add it to the lists.
Let’s collect the data into lists, before we put it into a dataframe and save it as a spreadsheet:
#Create lists for each variable Name = [] Team = [] Age = [] Apps = [] HeightCM = [] WeightKG = [] #Populate lists with each player #For each player... for i in range(len(playerLink1)): #...download and process the two pages collected earlier... playerPage1 = requests.get(playerLink1[i]) playerTree1 = html.fromstring(playerPage1.content) playerPage2 = requests.get(playerLink2[i]) playerTree2 = html.fromstring(playerPage2.content) #...find the relevant datapoint for each player, starting with name... tempName = str(playerTree1.cssselect('div.name')[0].text_content()) #...and team, but if there isn't a team, return "BLANK"... try: tempTeam = str(playerTree1.cssselect('.table:nth-child(1) .long')[0].text_content()) except IndexError: tempTeam = str("BLANK") #...and age, but if this isn't there, leave a blank 'no number' number... try: tempAge = int(playerTree1.cssselect('.pdcol2 li:nth-child(1) .info')[0].text_content()) except IndexError: tempAge = float('NaN') #...and appearances. This is a bit of a mess on the page, so tidy it first... try: tempApps = playerTree2.cssselect('.statappearances')[0].text_content() tempApps = int(re.search(r'\d+', tempApps).group()) except IndexError: tempApps = float('NaN') #...and height. Needs tidying again... try: tempHeight = playerTree1.cssselect('.pdcol3 li:nth-child(1) .info')[0].text_content() tempHeight = int(re.search(r'\d+', tempHeight).group()) except IndexError: tempHeight = float('NaN') #...and weight. Same with tidying and returning blanks if it isn't there try: tempWeight = playerTree1.cssselect('.pdcol3 li+ li .info')[0].text_content() tempWeight = int(re.search(r'\d+', tempWeight).group()) except IndexError: tempWeight = float('NaN') #Now that we have a player's full details - add them all to the lists Name.append(tempName) Team.append(tempTeam) Age.append(tempAge) Apps.append(tempApps) HeightCM.append(tempHeight) WeightKG.append(tempWeight)
Saving our lists to a dataframe
You’ll have noticed that if the data wasn’t available, we add a blank item to the list instead. This is really important as it keeps all of our lists at the same length and means that player data is all in the same row.
We can now add this to a dataframe, made ridiculously easy through the pandas module. Let’s create it and check out our data:
#Create data frame from lists df = pd.DataFrame( {'Name':Name, 'Team':Team, 'Age':Age, 'Apps':Apps, 'HeightCM':HeightCM, 'WeightKG':WeightKG}) #Show me the top 3 rows: df.head()
#Show me Karius' height: df[df['Name']=="Loris Karius"]["HeightCM"]
272 189.0 Name: HeightCM, dtype: float64
Everything seems to check out, so you’re now free to use this data in Python for analysis or visualisation, or you may want to export it for use elsewhere, with the ‘.to_csv’ function:
df.to_csv("EPLData.csv")
One slight caveat with this dataset is that it includes players on loan – you may want to exclude them. Check out the data analysis course out to learn about cleaning your datasets.
Summary
In this article, we’ve covered a lot of fundamental Python tasks through scraping, including for loops, lists and data frames – in addition to increasingly complex ideas like processing html and css classes. If you’ve followed along, great work! But there’s no reason not to go back over these topics to make sure you’ve got a decent understanding of them.
Next up, you might want to take a look at visualising some of the age data to check out team profiles! | https://fcpython.com/scraping/scraping-premier-league-football-data-python | CC-MAIN-2018-51 | refinedweb | 1,307 | 65.22 |
Search the Community
Showing results for tags 'transform'.
Found 18 results
Rotation of arcade physics body
Doug posted a topic in Phaser 3Hi.
create ground mesh from a plane
yokewang posted a topic in Questions & AnswersHi, I want to create a ground mesh from a plane. let plane = new Plane(-0.4, -0.2, -0.6, 0.1); //normal and offset let planeMesh = Mesh.CreateGround("planeMesh", 100, 100, 2, scene); //to make the planeMesh to fit the plane, transformation should be added to the mesh planeMesh.rotation = ... planeMesh.positon = ... someone can help me out? Thanks.
Wobbly pick-up effect
daintycode posted a topic in Pixi.jsDisclaimer: I know this sounds nooby af, but I don't even know how it's called what I want and I do not search for a solution, I search for ideas.(: Maybe you guys played Hearthstone, or any other card game. When you pick up cards from your hand, they do some wobbly fx (<- I'd appreciate to get to know how to call this shit.) because the card has some elastic physics to it. My first idea to do this would be using pixi-projection with some easing to it. But then the question is what to apply with easing to let it look right and not completely fucked up?^^ I guess the scaling should to have some easing to it and the 4 corners need to "spread out" with different speeds? The next thing I thought about where displacement maps. But tbh, I have no idea how this black magic works and how to apply it doing some animated stuff. Please don't be like "oh you rookie..." - I know I am. Please don't be like "heres code: ..." - I want to know what I'm doing pls. Please be like "this is an interesting resource: <link to interesting resource>". Love.👾
solved Unity transform.forward, up and right
MackeyK24 posted a topic in Questions & AnswersIn unity they have transform.forward, right and up. The docs for unity say the forward is : 'The blue axis of the transform in world space.' using UnityEngine; using System.Collections; public class ExampleClass : MonoBehaviour { public float thrust; public Rigidbody rb; void Start() { rb = GetComponent<Rigidbody>(); } void Update() { rb.AddForce(transform.forward * thrust); } } How would I do this in Babylon.... Yo @Deltakosh or ANYBODY How do we get the forward vector in Babylon... Would this work: /** The blue axis of the transform in world space. */ public static GetForwardVector(mesh:AbstractMesh, force?:boolean):BABYLON.Vector3 { var matrix:BABYLON.Matrix = mesh.computeWorldMatrix(force); return BABYLON.Vector3.TransformCoordinates(BABYLON.Vector3.Forward(), matrix); } /** The red axis of the transform in world space. */ public static GetRightVector(mesh:AbstractMesh, force?:boolean):BABYLON.Vector3 { var matrix:BABYLON.Matrix = mesh.computeWorldMatrix(force); return BABYLON.Vector3.TransformCoordinates(BABYLON.Vector3.Right(), matrix); } /** The green axis of the transform in world space. */ public static GetUpVector(mesh:AbstractMesh, force?:boolean):BABYLON.Vector3 { var matrix:BABYLON.Matrix = mesh.computeWorldMatrix(force); return BABYLON.Vector3.TransformCoordinates(BABYLON.Vector3.Up(), matrix); } Also I saw some c++ code for getting forward vector using the quaternion, could I use this in babylon or SHOULD I even try use in Babylon ... Is there something already in Babylon for this:)); } Or am I way off
solved Empty Mesh/Node Object for Parenting?
MaverickGeek posted a topic in Questions & AnswersHow to create Empty Mesh/Node for Parenting? The Empty Node must have Position, & other Transform data!?
Update Vertex Data to reflect transform
Pryme8 posted a topic in Questions & AnswersSo if I have a ground plane, and am looking to manipulate the vertex data but need the values to be updated to their correct position after a rotation and transform that I applied. Is the playground showing the creation and manipulation of the mesh. Basically what I need to happen now is when I grab the VertexData the points will have the rotation and transformation applied. I have a good idea of how to do it manually with some vector manipulation but would like to just "bake" this information then grab it instead of doing a multiple steps.
Phaser world to screen (local to global)
alphard posted a topic in Phaser 2Good day to all! I have a question on Phaser's world-to-screen transformations, and I've googled almost nothing on it Is there a way to transform a sprite's world coordinates into the screen space (and visa versa)? It is a very useful feature and I can't beleave nobody still interested in it! I found poor documented Sprite.worldTransform.tx, Sprite.worldTransform.ty,but I'm not sure these fields always work properly (to be honest, I am sure they don't). Thank you!
Multiple renderers. One for webgl transforms, other for regular use. Full explanation
khalim posted a topic in Pixi.jsHi. Im fairly new on Pixi and im trying to do something with multiple renderers. I know i could add multiple canvas instead, however i need a dedicated webgl renderer to manipulate the transform and try to do some trapezoid forms. I also need both renderers to works on the same canvas to avoid creating multiple layers on the document.body. My approach was: 1. Have a main renderer and a main stage. 2. Have a sideRenderer that will be affected by different transforms (using gl.uniformMatrix4fv to change the shape of the whole renderer and achieve different shapes) and a sideStage that will hold any content (in this example, a simple sprite). 3. make the sideRenderer render to a RenderTexture, which will be the source of a Sprite, which will be added on the main stage. So in theory, anything that the side renderer renders to the RenderTexture should appear on the sprite on the main stage. If somehow i modify side renderer, the transformed output should be shown on the RenderTexture, if that makes any sense. I tried this with this example, and it doesnt works. If i append the sideRenderer.view to the document.body, it renders as expected, but its not what i want, as i need it to be part of a more complex logic. At some point this makes me realize that i cannot mix renderers like this ( maybe the sideRender is still working on the back while the mainRender is trying to render an incomplete RenderTexture ? ), cannot make one renderer render something for another renderer (sideRenderer to mainRenderer or viceversa), so i would like to know if there is any workaround or any way to override this behavior? Thanks for the help var renderer = null; var sideRenderer = null; var stage = null; var sideStage = null; var WIDTH = 1000; var HEIGHT = 500; var rt = new PIXI.RenderTexture( 1000, 500 ); var spriteRt = new PIXI.Sprite( rt ); init(); function init() { var rendererOptions = { backgroundColor: 0xffffff, transparent: true } // Create the renderer renderer = PIXI.autoDetectRenderer( WIDTH, HEIGHT, rendererOptions ); sideRenderer = PIXI.autoDetectRenderer( WIDTH, HEIGHT, rendererOptions ); // Add the canvas to the HTML document document.body.appendChild( renderer.view ); // Create a container object called the `stage` stage = new PIXI.Container(); sideStage = new PIXI.Container(); stage.addChild( spriteRt ); var loader = PIXI.loader; loader.add( 'texture', './media/crate.png' ); loader.once( 'complete', onLoadedAsset ); loader.load(); } function onLoadedAsset() { var texture = PIXI.Texture.fromFrame( './media/crate.png' ); var sprite = new PIXI.Sprite( texture ); sideStage.addChild( sprite ); update(); } function update() { sideRenderer.render( sideStage, rt ); renderer.render( stage ); requestAnimationFrame( update ); }
getBounds not world coordinates?
jwdevel posted a topic in Phaser 2:
Change children transform
trsh posted a topic in Pixi.jsWhen transform is added to parent, it's also added to children right? In some case I don't want this - I want to control my self, how children reacts when parent transform is changed. Can I do that? Any advice?
How to do various transforms
mwpowellhtx posted a topic in Questions & AnswersHello, As a frame of reference, in Helix Toolkit for WPF (C#, .NET), I am calculating and rendering some coordinates to model a football Goal Post, or pylons at the end zone corners if you prefer. I want to start with a single set of coordinates, and apply a transform that basically mirrors those coordinates on either end of the field, end zone, or what have you. This is extremely easy to apply using the WPF view XAML. Let's say I have the points for the post; 180 feet from either end of center field (Z axis): // assuming "world" coordinates originate at center field, measured in feet // that's 50 yards plus 10 for the end zone; post height is 6 feet. var points = [new BABYLON.Vector3(0, 0, 180), new BABYLON.Vector3(0, 6, 180)]; After that, I would CreateTube, let's say, to actually model the object. But for right now I just want to mirror about the Z axis. The modeling bits are beyond the scope of this question, unless they aren't. My transformation vector would be something like this, I think, but I could be wrong: new BABYLON.Vector3(0, 0, -1). Similar case for the uprights; 18.5 feet wide about the X axis: var points = [new BABYLON.Vector3(9.25, 10, 180), new BABYLON.Vector3(9.25, 40, 180)]; My transformation vector would be something like new BABYLON.Vector3(-1, 0, 0). Are there utilities in BABYLON that can facilitate such a transformation? Might do a similar thing for additive transformations, as contrasted with multiplicative, in this case. Thank you... Regards, Michael Powell
how to use transform in displayobject
vaibhavsilar posted a topic in Pixi.jsHello, I want to use setTransform method of canvas in pixijs. Is there any interface in pixijs to apply this concept. I have tried implementing like this: displayObj.localTransform = [1, 1, 1, 1, 0, 0]; but its not working. Please suggest. Thanks vbh
Unsupported animation in 3dsmax Babylon export?
kevzettler posted a topic in Questions & AnswersI.
position.set() doesn't work as expected
JeReT posted a topic in Pixi.jsHi, I am using Phaser with TypeScript and encountered some strange behavior: If I create some shape objects and change the position of one of them, the new position is applied to it (relative to the initial position) and to all other objects as well. I want to change the position of only one object, not all. How can I achieve that? here is some code for testing: class Main { game: Phaser.Game; graphics: Phaser.Graphics; constructor() { this.game = new Phaser.Game(800, 600, Phaser.AUTO, 'content', { create: this.create }); } create() { this.graphics = this.game.add.graphics(0, 0); this.graphics.lineStyle(5, 0xffffff); var circle1 = this.graphics.drawCircle(0.5 * this.game.width, 0.5 * this.game.height, 400); var circle2 = this.graphics.drawCircle(0.5 * this.game.width, 0.5 * this.game.height, 200); // this line shifts both circles. But why? circle1.position.set(100, 100); } }window.onload = () =>{ var game = new Main();};PS: it seems like the radius parameter of the drawCircle() method expects the diameter instead of the radius... | http://www.html5gamedevs.com/tags/transform/ | CC-MAIN-2018-51 | refinedweb | 1,814 | 59.19 |
Modify or examine a thread's signal-blocked mask
#include <signal.h> int pthread_sigmask( int how, const sigset_t* set, sigset_t* oset );
This argument is ignored if set is NULL.
You can use various combinations of set and oset to query or change (or both) the signal-blocked mask for a signal.
libc
Use the -l c option to qcc to link against this library. This library is usually included automatically.
The pthread_sigmask() function is used to examine or change (or both) the calling thread's signal mask. If set is non-NULL, the thread's signal mask is set to set. If oset is non-NULL, the thread's old signal mask is returned in oset.
You can't block the SIGKILL and SIGSTOP signals. | http://www.qnx.com/developers/docs/6.6.0_anm11_wf10/com.qnx.doc.neutrino.lib_ref/topic/p/pthread_sigmask.html | CC-MAIN-2018-09 | refinedweb | 125 | 75.4 |
Hi there, I'm new to wicket and got a problem, I searched google and the mailing list for 2 days now but can't find what I'm searching for, here is an reduced example of what I'm trying to do. This is very simplified and not the domain I'm working in, this is just used for ease. I'm using wicket:6:16:0. The Example in short: I have a person with multiple addresses. For the person there is a form with a textfield for the name. Under that textfield is an ajax link to add a panel containing an form for an address. The background-model is a class person with a name string and a list of addresses and an address class with a street/city string. My problem now is how i can dynamically add addresses to that person.
Models: ===Person.java=== ... private String name; private List<Address> addresses; //getter/setter ... ===/Person.java=== ===Address.java=== ... private String street; private String city; ... //getter/setter .... ===/Address.java=== ===AddressPanel.java=== ... public Address(String id, IModel<Address> model) { super(id, model); SetDefaultModel(model); Form<?> form = new Form<Void>("form"); TextField<String> street = new TextField<String>("street"); form.add(street); TextField<String> city = new TextField<String>("city"); form.add(city); add(city); } ===/AddressPanel.java=== ===AddressPanel.html=== <htmlstuff...> <wicket:panel> <form wicket: <input type="text" wicket: <input type="text" wicket: </form> </wicket:panel> </htmlstuff...> ===/AddressPanel.html=== ===PersonPage.html=== <htmlstuff...> <form wicket: <input type="text" wicket: <div wicket: <a href="#" wicket:add address</a> </form> </htmlstuff...> ===/PersonPage.html=== ===PersonPage.java=== public class PersonPage extends WebPage { Person person; public PersonPage() { person = new Person(); setDefaultModel(new CompoundPropertyModel<Person>(person); Form<?> form = new Form<Void>("form"); TextField<String> name = new TextField<String>("name"); form.add(name); add(form); //And here the troube begins, do I use an ListView? If so for AddressPanel I think, but which model do I give to it? AjaxSubmitLink addLink = new AjaxSubmitLink("addAddress", form) { @Override protected void onSubmit(AjaxRequestTarget target, Form<?> form) { // Do I now create a new Address or AddressPanel? If I create an AddressPanel which Model do I use? How is the Address appended to the addresses list in Person? } } } } many thanks in advance Gunnar | https://www.mail-archive.com/users@wicket.apache.org/msg84536.html | CC-MAIN-2020-24 | refinedweb | 369 | 50.53 |
Opened 9 years ago
Closed 9 years ago
Last modified 9 years ago
#9769 closed (invalid)
ManyToManyField Widget: saving object does not work
Description
In our application, we are unable to save a ManyToManyField, using the standard webform widgit. MultipleSelectChecbox also does not work. The scalar_properties, remain an empty list when objects are added through the webform. All other fields are properly saved.
When examining the request.POST object, I se that a numeric value is returned. However request.POST includes only ONE numeric value, when it SHOULD have returned several. The number returned, is always equal to the numbering of the last selected element in the list. (The last element in the list is named 1, the second last is named 2 an so on.) There seems to be no way of extracting all objects that are actually selected out from the returned number.
Example code (simplification of our aplication):
in models.py, we have somthing like:
... class Calculation(models.Model): ... scalar_properties = fields.ManyToManyField("ScalarProperty") ... class ScalarProperty(models.Model) ...
in views.py we have:
def edit(request, ...): instance = ... # The original object, before editing if request.POST.method == "GET": # Create form: .... elif request.POST.method == "POST": # Save object from form: calc = forms.CalculationForm(request.POST, instance=instance).save(commit=False) ... calc.save() # Redirect: ... ...
Change History (2)
comment:1 Changed 9 years ago by
comment:2 Changed 9 years ago by
Milestone post-1.0 deleted
Because you are using commit=False you need to use save_m2m() as documented. | https://code.djangoproject.com/ticket/9769 | CC-MAIN-2018-22 | refinedweb | 248 | 50.63 |
#include <qwidget.h> (although it is also possible to create top-level widgets without such decoration if suitable widget flags are used). In Qt, QMainWindow and the various subclasses of QDialog are the most common top-level windows.
A widget without a parent widget is always a top-level widget.
Non-top-level widgets are child widgets. These are child windows in their parent widgets. You cannot usually distinguish a child widget from its parent visually. Most other widgets in Qt are useful only as child widgets. (It is possible to make, say, a button into a top-level widget,Box and QTabDialog, etc.
Definition at line 60 of file qwidget.h. | http://qt-x11-free.sourcearchive.com/documentation/3.3.4/classQWidget.html | CC-MAIN-2018-22 | refinedweb | 112 | 51.44 |
We are happy to announce we’ve published a new major release of ReSharper Ultimate bundle: please say welcome to ReSharper Ultimate 2017.3.
Apart from 300+ fixed issues, ReSharper 2017.3 includes both long-awaited and unexpected features that will hopefully help you in your day-by-day routine:
- Visual Studio debugger extensions, such as searchable DataTips, values displayed right in the text editor, navigation to breakpoints, and creating breakpoints from the Find Results tool window.
- Performance guide for fine-tuning both ReSharper and Visual Studio settings to improve the overall IDE responsiveness in one place.
- Major updates to code formatting engine: support for aligning code in columns and other new code styles, as well as a way to disable or enable formatting for selected blocks of code with comments, or for files with EditorConfig.
- Improved Extract Method refactoring to support creating a local function and returning a value tuple instead of out parameter.
- Links to external resources in to-do items.
- New C# typing assists.
- Find Usages/Call Tracking presentation update.
- Enhanced Preview pane in tool windows.
- Support for tuples and
<inheritdoc/>in VB.NET.
- Ctrl+Shift+Click action to show the result of ReSharper Go to Declaration in Visual Studio Peek preview overlay which now works in Visual Studio 2015 and 2017 in addition to 2013.
- TypeScript support improvements, such as better performance when using type guards, auto-completion for imported paths, and tracking changes in npm modules.
- New code generation action to create deconstructor from selected fields/properties for C# 7.
Other ReSharper Ultimate tools have been updated as well:
- ReSharper C++ 2017.3 brings the same debugger features as the mainline ReSharper, improves language understanding including the C++17 and C++14 specification, integrates Clang-tidy, adds more code inspections, context actions, and formatting options, and supports Catch2 in its unit test runner.
- dotTrace 2017.3 provides async/await and Tasks support in Timeline profiling mode, adds forecasting performance to Timeline Viewer, and introduces viewing backtraces in methods and subsystems.
- dotCover 2017.3 supports Continuous Testing for .NET Core tests, improves ‘Show Covering Tests’ popup, introduces new document coverage summary indicator in ReSharper marker bar, and brings C# 7 local functions support.
- dotPeek 2017.3 introduces “Tools | Show PDB Content…” menu action, and adds “Open from NuGet Packages Cache” dialog to Assembly Explorer tab.
- dotMemory 2017.3 improves object search and receives a solid set of bug fixes.
Learn more about new features and download ReSharper Ultimate 2017.3.
It seems like some extensions are lacking in extension manager, and since they are only available via manager, I’d like to know what happened to extensions, like Heap allocation viewer?
The values displayed in the debuger are awesome, but are often cut off from the screen.
I think it’s maybe because I have the scrollbar minimap on?
It would be nice to have it wrap to the next line if it’s too long
Oops, meant to comment that on the top level.
But Mad Hatter, they probably didn’t update their extension yet, they need to do that for every version.
You can see here: the latest updated extensions.
@Mad, in the Extension Manager, you see only extensions compatible with installed ReSharper version. Authors have to repack their extensions using the latest SDK to add R# 2017.3 compatibility. Usually, it takes some time after a release.
We have Resharper Ultimate at work. I read dotCover(and the other dots) are included but it looks like those are on trial run for me. Looks like I’m not understanding something?
@Thanh, please contact ReSharper Support Team here | “Submit a request” and specify your license ID there to find you in our database.
Posting my accidental comment again:
The values displayed in the debuger are awesome, but are often cut off from the screen.
I think it’s maybe because I have the scrollbar minimap on?
It would be nice to have it wrap to the next line if it’s too long
@John, I’ve filed a new request on YouTrack, feel free to follow and upvote it.
The debugger extension is awesome! I love seeing the values displayed right in the editor… especially handy when debugging entity framework!
Selecting the closing namespace bracket “}” and overwriting it by typing that same bracket “}” again (in order to force document reformatting) inserts two new brackets.
This only happens when no blank line after the “}” and selecting from left to right. Or every time when selecting from right to left.
See example video:
@Uwe Please, try disabling “Surround typing” feature here ReSharper | Options | Environment | Editor | Editor Behavior | Brace and Parentheses | Surround selection on typing a brace or parentheses. A request for reference.
Thanks, Alexander.
Your workaround works for me!
Resharper C++ seems to create a lot of .TMP files after this update around source. Is this intentional? Could this be disabled?
It could be related to clang-tidy integration, but the files needed to run clang-tidy should be created in the system directory for temporary files and cleanup up afterwards. Please create an issue in YouTrack and tell us more about what files get created and where.
Is there any plans to create a new different color for code identifier syntax highlighting? Bright pink and blue hurts my eye.
Thanks.
@Penley Do you know that you might change any colours in Tools | Options | Environment | Fonts&Colors | ReSharper {some name} identifiers items? | https://blog.jetbrains.com/dotnet/2017/12/19/meet-resharper-ultimate-2017-3/ | CC-MAIN-2018-43 | refinedweb | 906 | 55.44 |
Maximize ROI with Cubewise
RO. Optimization matters.
Even before getting interested in Artificial Intelligence (AI), I have always enjoyed puzzles. French mathematical games (see trophy below left) for 30+ years. Moreover I managed to solve 50+ IBM Ponder This challenges.
In 2019, I met some IBM business partners in Vienna to explain the value of decision optimization.
IBM Planning Analytics / TM1 automates planning, budgeting, and forecasting.
IBM ILOG CPLEX Optimization Studio :
Rapid development and deployment of decision optimization models using mathematical and constraint programming.
Cubewise, enjoyed my presentation and even took some pictures during my presentation.
Later on, at their own customer events, it was my turn to take some pictures of them pitching CPLEX on top of PA.
I was very happy with that but that was only the beginning.
In 2020, they made me very happy. They asked me a puzzle (Not solve a puzzle this time, but write the challenge that will make other people crazy, not me!)
And not only for fun : the winner would get a real prize : a trip!
CUBE+WISE=MORE
Use each number between 0 and 9 only once, to replace the letters in the sentence.
The sum must be correct, you must use each number EXACTLY once. With the correct sum, there are many solutions. But which solution has the highest value for the letters R, O and I?
Target: Maximize the value of ROI. There is only 1 correct largest value for ROI. What number (like 123) corresponds to the letters ROI?
One can solve this challenge with a pencil but it takes some time.
Let me take the opportunity to explain how easy it is to solve this puzzle with IBM CPLEX.
Within IBM CPLEX you may rely on OPL and write
using CP;
...
dvar int CUBE;
dvar int WISE;
dvar int MORE;
dvar int ROI;
maximize ROI;
subject to {
CUBE+WISE==MORE;
ROI==100*R+10*O+I;
CUBE == 1000*C+100*U+10*B+1*E;
WISE == 1000*W+100*I+10*S+1*E;
MORE == 1000*M+100*O+10*R+1*E;
// all letters are different
allDifferent(append(C,U,B,E,W,I,S,M,O,R));
}
Which is very easy to read and gives the solution in less than 1 second.
You may do the same with Python.
CUBE=1000*C+100*U+10*B+E
WISE=1000*W+100*I+10*S+E
MORE=1000*M+100*O+10*R+E
ROI=100*R+10*O+I#constraints
mdl.add(CUBE+WISE==MORE)
mdl.add(mdl.all_diff(C,U,B,E,W,I,S,M,O,R))#objective
mdl.maximize(ROI)#solve
msol=mdl.solve()
You may also use a more generic model:
string maxobjective="ROI";
string equation="CUBE+WISE==MORE";
that will build the OPL model and solve this.
I used Constraint Programming solver within CPLEX. But Mathematical Programming works too both in OPL and Python.
Enumeration in OPL, Python or Javascript work fine too for this tiny challenge. For real business problems that could take years or even much more time. This approach cannot scale.
Thanks again Cubewise and congrats Cansu Agrali for winning this contest.
Let me quote Cubewise as why complete enumeration is not enough in real life:
Decision Optimization
“Considering we have a solid plan in place and we have an accurate vision of the future, there is only one thing left to do: execute it ! The reality is that we need to execute this plan in an environment that is full of constraints, conflicting targets, and thousands of options to consider. Decision Optimization focuses on what route is best to follow within the constraints we have, given the targets we set in a specific priority.
Today, CPLEX is the best performing solution to tackle these mathematical algorithm challenges. As a bonus, it integrates perfectly with TM1.”
No Optimization within AI is as bad as using only your reptile brain instead of your primate brain. Not wise when you want to get our of a maze.
| https://alexfleischer-84755.medium.com/maximize-roi-with-cubewise-e05140b12f7f?readmore=1&source=user_profile---------0---------------------------- | CC-MAIN-2021-49 | refinedweb | 669 | 65.32 |
Hey, I got this program where I have to write simple functions to calculate the time and cost for a roadtrip. I keep on getting errors on the travelTime() and travelcost() functions. The errors are error C2063: 'travelTime' : not a function and error C2063: 'travelcost' : not a function. Here is my code and any help would be appreciated.
Code:#include <stdio.h> #define MINUTES 60; /*function prototype*/ int roundUp(float); float travelTime(int, int, int); float travelcost(int, int, float, float); /*Main Function*/ int main() { /*declaire variables*/ int miles, carGasMileage, gasTankSize = 15, averageSpeed, restTime; float pricePerGall = 1.40, travelTime, travelcost, fillupTimes, mealCost; /*Get miles variable*/ printf("How many miles are you going to travel?: "); scanf("%d", &miles); /*Get car gas mileage*/ printf("\nWhat is the gas mileage that your car gets?: "); scanf("%d", &carGasMileage); /*Get average speed*/ printf("\nWhat is the average spped that you want to travel in mph units?: "); scanf("%d", averageSpeed); /*Get rest time--NOTE I had to eliminate the Brother rest time for this program-There had to be only one rest time*/ printf("\nHow many minutes do you plan on resting?: "); scanf("%d", &restTime); /*Get meal cost*/ printf("\nHow much will you spend on meals?: "); scanf("%f", &mealCost); /*clear screen*/ system("cls"); /*calculate the time*/ travelTime(miles, averageSpeed, restTime); /*calculate the cost*/ travelcost(miles, carGasMileage, pricePerGall); /*calculate the times that they will need to fill-up*/ fillupTimes = (miles / carGasMileage) / (gasTankSize * 7/8); roundUp(fillupTimes); /*display RoadTrip Results*/ printf("So, you're taking a trip to the Beach?\n"); printf("Are you interested in how long it is going to take?\n"); printf("It will take %5.0f minutes\n\n", travelTime); printf("Dude, Do you want to know how much it is going to cost?\n"); printf("It will cost $%4.2f\n\n", travelcost); printf("You are going to have to fill up %3.2f times on your way there.\n\n", fillupTimes); return 0; } int roundUp() { float a1, a2; int b1; b1 = a1; a2 = a1 - b1; if (a2 > 0.) b1++; return (b1); } float travelTime() { int miles, averageSpeed, restTime; float time; if (miles > 0){ time = (miles / averageSpeed) * MINUTES + restTime; } else printf("You didn't go anywhere!"); return (time); } float travelcost() { int miles, carGasMileage; float pricePerGall = 1.40, cost, mealCost; if (miles > 0){ cost = (miles / carGasMileage) * pricePerGall + mealCost; } else printf("You didn't go anywhere!"); return (cost); } | http://cboard.cprogramming.com/c-programming/37071-getting-not-function-error.html | CC-MAIN-2014-41 | refinedweb | 392 | 63.29 |
For the past two days, I have been showing you how to create your own Android apps. On day one, I showed you how to download and install the Java Development Kit (JDK), Eclipse, and the Android SDK. I even showed you how to create an Android virtual device and how to configure it to mimic your own actual device. On day two, I showed you how to configure Eclipse to work with the Android SDK and the Android virtual device (AVD) you created on day one. Today, I will be showing you how to make your application do something by adding IDs to objects in your layout and how to access those objects in code. As described in yesterday’s article, I am creating an Android application that allows me to test that my servers are online and accessible using a simple UDP client which will talk to my servers where I have a UDP server listening. Also mentioned in that article, I promised I would show you what my layout looks like. So, that is where we will begin today’s article which will be the third article of a multi-article series where I will teach you how to build your own Android apps, how to deploy your apps to physical devices such as cellphones and tablets, how to get your apps listed on Google Play, and even how to make money with your apps by including ads in them. So, let’s begin.
Since my app is extremely simple with only one function, I didn’t need to worry too much about the look of it. Instead, I kept it very basic and only included the pieces I need to make my app useful. As you can see below, I have included fields for adding the IP address of the server I want to test along with the port number my UDP server is listening on. I have also included a text box that allows me to enter a message to send to my UDP server as well as a text box for receiving a reply from the server. There is also one single button that will allow me to send my outgoing UDP message to my server. You will also notice that I have intentionally left a little bit of a gap at the top of my layout. That empty space is where I plan on placing my ads which we will get to on day 5 of this series.
Whenever you are working with objects that the user needs to interact with, it is advised to create meaningful IDs that easily identify each object. In my case, I have four text fields and one button. So, I had to create meaningful IDs that I can use later on in my Java code. To setup your IDs, click each field one at a time and modify the auto-generated ID on the Properties panel. For example, when I click on the text box that contains the IP address for the server I want to test, I can go to the Properties panel and change the ID to something like “@+id/txt_dest_ip”.
Even though you can click on any object that accepts text and add the text directly to the object via the Properties panel, Google’s best practices advises that you setup string variables. Not only does this help for when you want to reuse the same text in other locations. But, it also helps for when / if you decide to implement localization. By using string variables throughout your app, you can easily swap text in your app from one language to another. Since I’m only planning on supporting English at this time, I won’t go into how to setup your app for localization. I’ll save that for another article. However, I will still use string variables as opposed to adding labels and text directly to the Properties panel.
One way you can add string variables is by selecting an object on your form such as a label or an edit box and clicking the button next to the Text field in the Properties panel. This will bring up a dialog window that will allow you to pick from currently existing variables. If you need some text that isn’t already in the list, you can click the “New String…” button which will open another dialog window which will assist you with creating new strings. Personally, I don’t like messing with all of that. Instead, I know that all of my string variables are stored in the “strings.xml” file located under the res/values folder. When you first create your new Android application using the new Android Application Wizard, Eclipse will add a couple of string variables for you. To create new variables, you can simply copy one of the existing variables, paste it on a new line, change its name, and change its text. You can also just type out the entire line by hand if you prefer.
Even though the name implies one thing, the strings.xml file can also be used for more than just storing text for labels and such. For example, in my example below, I threw in a couple of <color> tags as well to demonstrate how to create colors which can also be swapped out just like your string variables. You can also store other variables in the strings.xml file such as dimensions, images, items, and arrays. To see what all is possible, type “<” (without the quotes) and press and hold the Ctrl key and press the spacebar. This will display an auto-complete window which will show you the different types of things you can store in the strings.xml file and reuse throughout your application.
Once you have defined your strings (and other variables) in the strings.xml file, swap back over to your layout. When there, you can assign your newly created variables to each item on your activity by clicking each item one at a time and selecting the corresponding field on the Properties panel. For example, since I created a new string called “default_dest_ip” and gave it a value of “127.0.0.1”, I want to assign this variable to my txt_dest_ip edit box I created earlier by clicking the “…” button next to the Text field on my Properties panel and selecting default_dest_ip from the list. Again, since I’ve been doing this for a while, it’s easier for me just to go straight to the layout XML and do everything there. Besides, just like in the strings.xml file, you can leverage Eclipse’s auto-complete feature inside your activity XML file by pressing and holding the Ctrl key and pressing the spacebar anywhere in your XML file. Depending on where you are at in the XML file, you will see options that relate to the area of the XML you are editing.
After you are finished laying out your activity the way you want it and have assigned IDs to all of the fields that the user will be interacting with, it is now time to write some code. The first thing we are going to code for will be our menu. When you created your project using the Android Application Wizard, a new menu was auto generated for you under the res/menu folder. By default, it has a menu item for settings. Since my application will not have a settings page, I have decided to change the only menu item in my res/menu/activity_main.xml file to be my exit button instead. So, just like before, I created a new string in my strings.xml file which I named “menu_exit” and gave it a value of “Exit”. Inside my res/menu/activity_main.xml file, I changed the only item in there to have an ID of “@+id/menu_exit” and a title of “@string/menu_exit”. Don’t worry if you misspell any of your variable names at any point in your application. Eclipse will notify you with little red error tags which you can mouseover to reveal the problem. Here is what my res/menu/activity_main.xml file looks like:
Next, expand all of the folders under the “src” folder until you see the activity Java file that got created after the new Android Application Wizard finished. When you double-click that file, you will see that a little bit of code has already been generated for you. However, just like everything else, it is up to you to do something with it. Since we are currently working on our menu, I will need to point out the “onCreateOptionsMenu”. If you decided to rename your res/menu/activity_main.xml file at any point, you will also need to change the first line of the onCreateOptionsMenu method to reflect that name change. For example, I typically get res/layout/activity_main.xml confused with res/menu/activity_main.xml. So, to keep from continuously opening the wrong file for editing, I will sometimes rename res/menu/activity_main.xml to something like res/menu/activity_main_menu.xml. Then, I will change the first line of the onCreateOptionsMenu to be “getMenuInflater().inflate(R.menu.activity_main_menu, menu);“. For now I will stick with the default name so that I don’t have to change this too.
Every time your application gets launched, the onCreateOptionsMenu will be triggered which will create your menu. Each activity in your app can have its own menu. Now that you have a menu being created when you launch your app, you will need to tell Android what to do when a user clicks one of your menu items. To do that, you will need to override a function called “onMenuItemSelected”. Inside that method, you will need to add a switch/case statement that checks the ID of the item being clicked and act accordingly. Since my menu only consists of one item, Exit, I will only have one case. That is also where I will call the built-in “finish()” method which will tell Android to close my application and free up the resources that it was using. Here are what my onCreateOptionsMenu and onMenuItemSelected methods look like:
After I have my Exit menu working, all I have left to do is to add the rest of the code that makes my UDP tester work. Since the remainder of the code is UDP specific, I’m not going to walk you through all of it. However, I have provided all of my code below in case you would like to create a UDP client of your own. That’s all for today. Tomorrow I will show you how to test your application using the Android emulator and the AVD you setup on day one.
package com.prodigy.mobile.android.udptester; import java.net.DatagramPacket; import java.net.DatagramSocket; import java.net.InetAddress; import android.app.Activity; import android.os.Bundle; import android.view.Menu; import android.view.MenuItem; import android.view.View; import android.widget.Button; import android.widget.EditText; public class MainActivity extends Activity { private Thread clientThread; private EditText txtOutMessage; private EditText txtOutIp; private EditText txtOutPort; private EditText txtInMessage; private Button btnSend; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); txtOutMessage = (EditText)findViewById(R.id.txt_out_msg); txtOutIp = (EditText)findViewById(R.id.txt_dest_ip); txtOutPort = (EditText)findViewById(R.id.txt_dest_port); txtInMessage = (EditText)findViewById(R.id.txt_recv_msg); btnSend = (Button)findViewById(R.id.btn_send); btnSend.setOnClickListener(new View.OnClickListener() { public void onClick(View v) { clientThread = new Thread(new Client()); clientThread.start(); } }); } @Override public boolean onCreateOptionsMenu(Menu menu) { getMenuInflater().inflate(R.menu.activity_main, menu); return true; } @Override public boolean onMenuItemSelected(int featureId, MenuItem item) { switch (item.getItemId()) { case R.id.menu_exit: if (clientThread != null && clientThread.isAlive()) { clientThread.interrupt(); } finish(); return false; default: return super.onMenuItemSelected(featureId, item); } } class Client implements Runnable { public Client() { } @Override public void run() { try { String outMessage = txtOutMessage.getText().toString(); String outIp = txtOutIp.getText().toString(); int outPort = Integer.parseInt(txtOutPort.getText().toString()); InetAddress serverAddr = InetAddress.getByName(outIp); DatagramSocket socket = new DatagramSocket(); byte[] buf = outMessage.getBytes(); DatagramPacket packet = new DatagramPacket(buf, buf.length, serverAddr, outPort); socket.send(packet); byte[] receiveData = new byte[1024]; DatagramPacket receivePacket = new DatagramPacket(receiveData, receiveData.length); socket.receive(receivePacket); final String recvMsg = new String(receivePacket.getData()).trim(); runOnUiThread(new Runnable() { @Override public void run() { txtInMessage.setText(recvMsg); } }); } catch(Exception e) { e.printStackTrace(); } } } }
PayPal will open in a new tab. | http://www.prodigyproductionsllc.com/articles/programming/create-your-own-android-apps-for-fun-or-profit-part-3/ | CC-MAIN-2015-40 | refinedweb | 2,073 | 64.41 |
Your browser does not seem to support JavaScript. As a result, your viewing experience will be diminished, and you have been placed in read-only mode.
Please download a browser that supports JavaScript, or enable it if it's disabled (i.e. NoScript).
Hi there
I'm setting up the dimensions of a dialog in Python, but the result is not correct as you can see on the image below.
Is this way the right way to do this or there is a better one?
import c4d
from c4d import gui
class OptionsDialog(gui.GeDialog):
def CreateLayout(self):
self.SetTitle('Dummy Dialog 700x200px')
self.AddMultiLineEditText(1000, c4d.BFH_SCALEFIT, inith=50, initw=500, style=c4d.DR_MULTILINE_READONLY)
self.SetString(1000, "Hello World!")
if self.GroupBegin(1001, c4d.BFH_CENTER, 2, 1):
self.AddDlgGroup(c4d.DLG_CANCEL|c4d.DLG_OK)
self.GroupEnd()
self.ok = False
return True
def Command(self, id, msg):
if id==c4d.DLG_CANCEL:
self.Close()
return False
elif id==c4d.DLG_OK:
self.ok = True
self.Close()
return True
def main():
dlg = OptionsDialog()
dlg.Open(c4d.DLG_TYPE_MODAL, xpos=-2, ypos=-2, defaultw=700, defaulth=200)
if __name__=='__main__':
main()
hello,
i can see that one, thanks, I added it to the bug entry.
Cheers,
Manuel
Hello,
For your next threads, please help us keeping things organised and clean. I know it's not your priority but it really simplify our work here.
I've added the tags and marked this thread as a question so when you considered it as solved, please change the state
About your question : I can confirm that.
It's working perfectly with a plugin. (even with a DLG_TYPE_MOD.
After diving into the code, strange enough, I've seen that adding a pluginid as a parameter to the open function does make it work as expected.
So you can retrieve a pluginID on this forum (top bar) and add it to your Open command
pluginid
open
Open
Now i can asked the devs why it need that.
Hey Manuel, how are you?
I'm sorry for the mess!
Could you please provide an example on how this PluginID should be used so we have the function working as expected?
I am still learning and I appreciate any help.
Thanks for your time!
Cheers
Hi Manuel
I think I did it correctly and now I have R21 rendering the dialog exactly like R19 and R20 is doing.
But I'm struggling to understand why the dialog is being created with slightly smaller dimension than the specified.
Why is this happening?)
@m_magalhaes said in Gui Dialog in Python not respecting the dimensions:
you never specified it was working as expected in R19/R20.
you never specified it was working as expected in R19/R20.
My fault in not being clear enough, I should have been more specific.
The problem was implicit, where on the image attached we see "Dialog 700x200px" (defaultw=700, defaulth=200), but with different numbers in red.
By deduction we can read something as not correct. But again, my fault in not being clear enough, sorry about that.
defaultw=700, defaulth=200
So, just to confirm, the issue is about the dimension in pixels not matching what was expected from the code.
I was expecting a dialog with 700x200 pixels, and was getting 686x193 in R19/20 and 333x146 in R21.
After your workaround, R21 is working better, but still not matching the 700x200 pixels.
Thank you again for your time!
Cheers
Ok now i got it. But there's not pictures attached to your post.
Are you using Windows or OSX ?
I've used the "Upload Image" button, don't know why the image is not visible for you.
I'm using Windows 10.
I hope you are able to see this one:
Cheers. | https://plugincafe.maxon.net/topic/11910/gui-dialog-in-python-not-respecting-the-dimensions | CC-MAIN-2021-25 | refinedweb | 626 | 67.76 |
]
posix_fallocate — pre-allocate storage for a range in a file
Standard C Library (libc, -lc)
#include <fcntl.h>
int
posix_fallocate(int fd, off_t offset, off_t len);.
If successful, posix_fallocate() returns zero. It returns -1 on failure,
and sets errno to indicate the error..
creat(2), ftruncate(2), open(2), unlink(2)
The posix_fallocate() system call conforms to IEEE Std 1003.1-2004
(“POSIX.1”).
The posix_fallocate() function appeared in FreeBSD 9.0.
posix_fallocate() and this manual page were initially written by Matthew
Fleming ⟨mdf@FreeBSD.org⟩.
All copyrights belong to their respective owners. Other content (c) 2014-2018, GNU.WIKI. Please report site errors to webmaster@gnu.wiki.Page load time: 0.091 seconds. Last modified: November 04 2018 12:49:43. | http://gnu.wiki/man2/posix_fallocate.2freebsd.php | CC-MAIN-2020-24 | refinedweb | 122 | 54.49 |
Hi!
This is my first day developing for the Nokia 6700 Classic!
I've got my Java installed, Netbeans Mobile, and finally the S40 SDK from Nokia. I've been able to compile and publish the GameBuilder1 demo to my phone. It's great.
I saw a 3D cube demo along with the GameBuilder demo, so I tried compiling it, sadly it failed telling me the following don't exist:
import java.nio.*;
import javax.microedition.khronos.egl.*;
import javax.microedition.khronos.opengles.*;
After about 40 minutes of surfing the internet looking for a nice JSR239.JAR file to download and add to my compile path - all I've seen is the bloody documents... documents, documents... and more documents.
Not a single set of classes anywhere! =(
Can somebody PLEASE point me towards a download for the above imports?
Please!? | http://www.khronos.org/message_boards/showthread.php/6278-Help!-S40-development?p=20366&mode=linear | CC-MAIN-2014-35 | refinedweb | 139 | 65.73 |
In ASP.NET MVC, handling errors in your controller actions or controller action results can be done using Exception filters. So I applied the HandleError actionfilter on top of my controller. When this exception filter handles an exception, it creates an instance of the HandleErrorInfo class and sets the Model property of the ViewDataDictionary instance when rendering the Error view.
1: [HandleError]
2: public class HomeController : Controller
3: {
4: public void Index()
5: {
6: throw new Exception("Test");
7: }
8: }
However no exception was catched after applying this filter. After some research I noticed that that this filter doesn’t catch exceptions in debug builds when custom errors are not enabled. The filter simply checks the value of HttpContext.IsCustomErrorEnabled to determine whether to handle the exception.
So open up your web.config and change the CustomErrors mode to On.
1: <system.web>
2: <customErrors mode="On">
3: </customErrors>
1 comment:
This is awesome!! really helpful for me. Thanks for sharing with us. Following links also helped me to complete my task. | http://bartwullems.blogspot.com/2010/01/exception-handling-in-aspnet-mvc-2.html | CC-MAIN-2017-47 | refinedweb | 172 | 58.58 |
shan_rish@yahoo.com writes:
> I built a pice of software
> in one server(HP-UX) with Purify installed and it was successful. I
> tried to build the same software in another server which is meant to be
> the replica of the previous server, and the build failed.
In that case, either the build environment on the second server is
different, or the second server is not an exact replica.
> Error: cannot find purify.h
What part of that error don't you understand?
> We have installed purify in the server. The Makefile specifies the
> PURIFYHOME as /opt/pure/purify.
Is that were purify is installed on the second server?
> There is another variable, in the Makefile, called -DNO_PURIFY which is
> used with CXXFLAGS and CFLAGS. The line is as follows
The CXXFLAGS is indeed a (make) variable. The '-DNO_PURIFY' is *not*
a variable; it's a *value*.
> I dont understand the variable -DNO_PURIFY, as i cant find the value of
> it.
It doesn't have a value, it *is* a value.
The meaning of that value is probably to not use purify.
However, since your build failed, your code doesn't use that
setting correctly. What you probably want to do is:
grep -l '#include .*purify\.h' *.cpp
Then examine all files that grep above gives you, and make sure
that all instances of '#include "purify.h"' are conditional:
#ifndef NO_PURIFY
# include "purify.h"
#endif
Alternatively, install purify on the second server, or at least copy
its purify.h header into the same place as it is on the first one.
Cheers,
--
In order to understand recursion you must first understand recursion.
Remove /-nsp/ for email. | http://fixunix.com/hp-ux/144180-hp-ux-makefile-doubt.html | CC-MAIN-2014-52 | refinedweb | 276 | 67.86 |
Hello guys.
Hope you people are doing well.
Got a task as below:
" required to write a material order recording program which applies struct and file IO features. When the program started, it should list the information about all the materials available (from “pricelist.txt”) and allow user to choose the material that he/she wants to order. Next, the program will prompt the user to enter the weight (kg) that he/she wants to order. Finally, the program will ask the user if the order is confirmed. If it is confirmed, the program will record/append the order to the text file name “order.txt "
Together with question , a txt file name “pricelist.txt” is provided which comprises the data of a list of materials. The data includes, material name, grade, and price per kg in usd.
The suggested algorithm for this program is as below, note that you can chose to or to not follow the algorithm provided but must fulfil the items listed in marking scheme.
1. Program started.
2. Create a global struct for the material with appropriate data members.
3. Create an array of the material struct to store all the data from the text file.
3.1 Load all the data from the “pricelist.txt” into the array created in step 2.
4. List and display the materials loaded into the array in step 2.1.
5. Prompt the user to choose the material by enter the index number.
5.1 Record the option entered by the user.
6. Prompt the user to enter the weight in kg for the order.
6.1 Record the weight.
7. Based on the option and weight recorded in step 4&5, calculate and prompt the user if the order is confirmed.
7.1 If it is confirmed, then append the order to the file “order.txt”.
7.2 Else inform the user the data has not been recorded.
8. Prompt if the user would like to continue order.
8.1 If yes, restart step 4.
8.2 Else, end the program.
9. Program end.
So the program is above,
i tried solving it as below
But i am not sure how will it calculate the rate with the weight.
using namespace std;
int main()
{
string filename= "pricelist.txt"; string descrip; string grade; double price; ifstream inFile; inFile.open(filename.c_str()); if (inFile.fail()) { cout <<"\n The file was not sucessfully opened. \n Please check that the file currently exists."; exit(1); } inFile >> descrip >> grade >> price; while (inFile.good()) { cout << descrip << ' ' << grade << ' ' << price << endl; inFile >> descrip >> grade >> price; } inFile.close(); }
struct Global
{
string Material_name;
char grade;
double price_per_kg;
};
Global first;
first.Material_name="Cobalt"; first.grade= "A"; first.price_per_kg = 6.5; Global second={"Cobalt",B,4.5}; Global third={"Nickel",A,2.68}; Global fourth={"Nickel",B,1.78}; Global fifth={"Tin",A,5.12}; Global six={"Tin",B,2.98}; Global seven={"Zinc",A,0.88}; Global eight={"Zinc",B,0.49}; display(first); display(second); display(third); display(fourth); display(fifth; display(six); display(seven); display(eight); int num double weight cout<<"Enter an index number to choose a material "<<endl; cin>>num cout<<"Enter the desired weight in kg for the order"<<endl; cin>>weight Price=global[num]*weight cout<<"You have selected <<global[i] ; /n to continue Press Y or N to exit return 0;
}
{
ofstream out2File;
out2File.open("order.txt",ios::app);
cout<<"Writing to file"<<endl; out2File<<"Material Name "; out2File<<"Weight"<<endl; out2File<<"Price "; out2File<<"6.7"; out2File.close(); cout<<"finished writing, file close"<<endl; system("PAUSE"); return 0;
}
It looks like you're new here. If you want to get involved, click one of these buttons!
hey iam using netbean so how could it be? | https://programmersheaven.com/discussion/437966/programming-c-structure | CC-MAIN-2018-30 | refinedweb | 623 | 68.77 |
Can you recommend me free povray model sites?
I know that there are list at povray.org site.
I need to have complex and sophisticated object
or some large inside modeling of architectures...
Thanks.
I need to have complex and sophisticated object
or some large inside modeling of architectures...
Thanks.
1. POVRAY newbie question: Model remains black?
Hi there,
this is some kind of newbie question, but can somebody
eventually enlighten me (or my object), please:
a model imported via SLP2POV from Pro/E remains black.
Background is visible, object, too. Object consists of a union of
triangles (a lot of those, though). Simple objects show up...
..so what am I doing wrong here? (See script below)
Any help greatly appreciated.
TIA
Walther.
#include "colors.inc"
#include "testobject.inc"
background { color rgb <0.4, 0.8, 0.2> }
camera {
location <1500.0, -3000.0, 200.0>
look_at <1500.0, -1000.0, -100.0>
object {TEST
scale 0.6
translate <500, 3, 1>}
light_source {<1, 1, 1> White }
3. povray: how to model a field of stars
4. Explosion algorithms ?
5. povray site
7. Convert povray model to .stl-format?
9. Free POVRAY Castle model
10. human model in povray?
11. ANN: New hosted site on Povray.co.uk
12. Another Povray site to review
13. POVRay (or other) model of human brain? | http://www.verycomputer.com/275_0db8ba0012dd5814_1.htm | CC-MAIN-2021-17 | refinedweb | 222 | 71.61 |
®
Simulations Featuring
Petrofac
Webinar Q&A
This document summarizes the responses to questions posed before and during the webinar. Additional
questions should be directed to AspenTech Support.
Questions Submitted Prior to the Event:
Q: Please show the fundamental equations used to compute the overall coefficient.
A: The equations used by Aspen Plate Fin Exchanger are documented on the Aspen HTFS Research
Network. You will need to subscribe in order to view our Design Handbook and Research Reports.
____________________________________________________________________________________
Q: Can Aspen EDR be used with Aspen HYSYS Dynamics?
A: Currently, Aspen EDR can only be used in steady-state simulation.
____________________________________________________________________________________
Q: Is there anything about modeling "core in kettle" in this webinar? Can you model “core in
kettle” type exchangers using Aspen EDR?
A: Yes, you can model core in kettle with Aspen Plate Fin Exchanger. Select plate-fin kettle as the
Exchanger type in the Application Options, Figure 1. Then, specify the Kettle geometry on the plate-fin
Kettles form, Figure 2.
Figure 1: Select plate-fin kettle
Figure 2: Specify the kettle geometry
___________________________________________________________________________________
Q: Is it possible for Aspen EDR to calculate a plate-fin heat exchanger operating as a reflux
condenser?
A: We do not currently have this capability in our plate-fin program. It is available in a Shell & Tube heat
exchanger.
____________________________________________________________________________________
Questions Submitted During the Webinar:
Q: What is EDR?
A: EDR is an acronym for Exchanger Design & Rating and is AspenTech’s software family for designing
Shell & Tube, Air Cooled, Plate, Plate Fin, and Fired Heater equipment.
____________________________________________________________________________________
Q: Is Aspen EDR is separate tool or an Aspen HYSYS module?
A: Aspen EDR is a separate suite of products from Aspen HYSYS. Aspen EDR can be used as a stand-
alone for heat exchanger fabricators, or it can be utilized in conjunction with Aspen HYSYS or Aspen Plus
to simulate exchanger performance in the context of the flow sheet.
____________________________________________________________________________________
Q: What is the difference between MUSE and EDR Plate Fin? Is one better to use in certain
applications?
A: Plate-fin was released in 2009 and was designed to replace MUSE. It has a more advanced
integration structure to handle different geometries of plate-fin exchangers more readily than MUSE
could. We also greatly improved the integration with Aspen HYSYS.
____________________________________________________________________________________
Q: What versions of Aspen Plus and Aspen HYSYS can incorporate Aspen EDR designs?
A: The integration has been possible for many years; however, V7.3 and higher shows that the
integration is much easier to use. Notably, in V8.0 the full Aspen EDR console was accessible from the
simulators for multiple types of heat exchangers.
Q: If we have an existing plate-fin exchanger configuration, can we change the rating method from
end point or weighted to EDR Plate Fin and run the model as usual to achieve the same results as
going into the Aspen EDR environment?
A: No, changing the model type to Aspen EDR will not run the Aspen EDR sizing optimization
automatically. Once you change the model type to EDR Plate Fin in Aspen HYSYS, you will need to
import the Aspen EDR file to specify the rigorous design. Once the file has been imported into Aspen
HYSYS, the Aspen EDR model will run in simulation mode in the flowsheet, which means that the design
will be fixed but the process conditions will be set by the Aspen EDR model.
____________________________________________________________________________________
Q: At the design stage of a new exchanger, we input the fouling factor. In debottlenecking, do we
need to perform "fouling factor adjustment" to match actual exchanger performance, then perform
the debottleneck?
A: Typically, many clients would do this. In this case study, Petrofac tried to match the information from
the client in the original case and then use the same fouling factors.
____________________________________________________________________________________
Q: Can you change Aspen EDR to select the smallest exchanger dimensionally or the lightest
exchanger?
A: Two different demonstrations were done during this webinar—one on Rigorous Shell & Tube sizing
from within Aspen HYSYS and the other for designing a plate-fin exchanger and importing the model into
Aspen HYSYS. The Shell & Tube design can be calculated to find the minimum area or the minimum cost
(typically what customers use). The plate-fin exchanger is good for quickly and accurately finding the
configuration of a multi-stream exchanger. This also designs on the basis of minimizing the area of the
exchanger. The weights are calculated as a result of the design found.
___________________________________________________________________________________
Q: Some plate-fin manufacturers have Fin Codes with geometric information of fin size, height,
thickness, pitch, etc. Does Aspen HYSYS have a database with those Fins Codes? What about
Aspen EDR?
A: Aspen EDR finds the best geometry of fins to meet the process requirements. It looks at fin height and
fin frequency, as well as fin type and whether it’s plain, perforated, or serrated fins—then finds the best
optimum. Our correlations are generally accepted in the industry and our single-phase, boiling, and
condensing coefficients for these fin types are widely accepted. You can introduce fabricators coefficients
into the system if you’d like to use those correlations, but ours are typically used as the baseline.
____________________________________________________________________________________
Q: How important was the hydraulic model for the design within Aspen EDR?
A: The hydraulic model helped with the line drop, as well as the equipment drops.
____________________________________________________________________________________
Q: Could you use a better solvent to reduce to the minimum of the Mercaptan in the sweetening
unit and respect the sales gas spec?
A: In this specific case, the licensor had to be contacted and the client was reluctant to make any
changes to the licensor processes. Also, this was an existing plant; therefore to make changes or suggest
new systems was very difficult. For additional information, please contact AspenTech Support.
Q: How do you properly design the layer patterns for a plate-fin? Does Aspen EDR do it by itself?
A: You can directly specify layer patterns in Aspen Plate Fin Exchanger and look at interlayer effects.
Many of the leading fabricators use our tool that way. When you’re designing and simulating the
exchanger, for most purposes, the stream simulation used is more than adequate. If you want to get into
the details of the design and ensure that the design will not be subject to high thermal stresses for
example, then you can impose the layer pattern—but this is not an output of the first-shot design. This
tends to be a detail that a plate-fin exchanger fabricator will specify to minimize the risk of damaging
thermal stresses. It will have some impact on overall thermal performance, but usually this isn’t too
significant.
____________________________________________________________________________________
Q: Is AspenTech currently working with vendors to have some standard products available as
selectable models, similar to what has been done with plate frame models within Aspen EDR?
A: Plate-fin exchangers are typically custom designed for each process application. Our design
optimization suggests the appropriate geometry for each set of process conditions.
____________________________________________________________________________________
Q: Which fouling factors are used for all 3 streams on PFHX?
A: In this design example, we didn’t specify any fouling resistance. Typically, fouling resistances in Plate-
fin heat exchangers are very low because they are made for clean stream applications. If you want to
specify fouling resistances for each stream, you can enter values on the Process Data form in the
program input as shown below in Figure 3.
Figure 3: Enter values on the Process Data form
Q: Lauren ran the case after updating the geometry in Aspen EDR. What was that case for?
A: In the recording, Lauren performs a demo of this and shows the value behind it. In Aspen Plate Fin
Exchanger, if you go to the Application Options, you can see the drop down menu for Calculation Mode.
The first option is Design which takes the inlet and outlet stream conditions and finds the appropriate
exchanger area and geometry needed to achieve the desired heat transfer. When you update the file
geometry, it takes the exchanger design found in Design mode and it makes it fixed—meaning you have
the inlet stream conditions and the plate-fin geometry. Then, in Simulation mode it calculates the outlet
stream conditions which gives you more accurate outlet conditions than your Aspen HYSYS flowsheet,
because you’re using a rigorous model rather than a simple model.
____________________________________________________________________________________
Q: What are the recommended UA values for PFHX?
A: This value is highly dependent on process conditions and will very in each case.
___________________________________________________________________________________
Q: Inside LNG exchangers in Aspen HYSYS, there is the possibility to simulate Wound Coil
exchangers. Does Aspen EDR have this capability?
A: There is a wound coil model in Aspen HYSYS, but it is not fully rigorous.
____________________________________________________________________________________
Q: What is the approach temp min/max for PFHX?
A: Plate-fin exchangers can take advantage of very small temperature differences—sometimes as low as
1 degree Kelvin. The maximum temperature approach is determined by thermal stress limitations of the
equipment and with large temperature differences, another exchanger type might be more suitable.
____________________________________________________________________________________
Q: Do the costs in Aspen EDR come from Aspen Capital Cost Estimator (ACCE)?
A: The costs developed by Aspen EDR can be fine-tuned to increase estimate accuracy and ultimately be
consistent with ACCE outputs, including major cost drivers such as material costs. Typically, the costs
output by Aspen EDR are used as relative costs to compare one heat exchanger design to another. Later
on, you may do rigorous costing for the entire project using one of the products from the Aspen Economic
Evaluation suite, which includes stand-alone tools such as Aspen In Plant Cost Estimator or Activated
Economics which is a feature in Aspen Plus and Aspen HYSYS.
____________________________________________________________________________________
Q: What is the Area Ratio and its significance?
A: When you look at the sales gas exchanger, it stated that the area ratio was less than one—meaning
that the area was inadequate to give you the outlet temperatures. In other words, the outlet temperature
couldn’t be achieved with the existing configuration.
____________________________________________________________________________________
Q: Regarding hydraulics, how do you account for the equipment inlet/outlet nozzle elevation
differences in Aspen HYSYS?
A: In Aspen Plate Fin Exchanger and all of the other Aspen EDR programs, you can specify that
gravitational pressure drop be taken into account. This can be very important in two phase applications,
particularly if the exchanger is operating in thermosiphon mode. All of the Aspen EDR programs can
factor in gravitational pressure drops and you can specify the elevations where necessary. See Figure 4.
Figure 4: Take pressure changes into account
__________________________________________________________________________________
Q: Does operation warning allow integration between Aspen EDR and simulation mode?
A: Yes, operation warnings will be active when the Aspen EDR model is run in simulation mode. You can
view them by opening the EDR Browser from the EDR Plate Fin tab.
Figure 5: Operate the EDR Browser
____________________________________________________________________________________
Q: In a first analysis, constant UA need not be assumed, if flow rates increase because of
increased heat transfer coefficients for sensible heat steams, can these increase at the 0.6 power
of flow and translate into a higher U?
A: Yes, if you can separate “U” and “A”, you can allow “U” to vary with process changes. You have to be
careful about apportioning changes to the specific hot or cold streams. For single-phase exchanger
applications, this may be adequate for limited changes in process flow rates. In any 2-phase
applications—such as the exchangers in the gas process models we discussed during the Webinar on
October 8
th
—this approach will not work. In addition, for processes where we are using a lot of
compressor power in a self-refrigerated process, exchanger pressure drop is very important. For both of
these reasons, rigorous exchanger modeling is extremely valuable. | https://www.scribd.com/document/244383697/11-4477-Petrofac-Webinar | CC-MAIN-2018-51 | refinedweb | 1,987 | 53.61 |
Question
22) A. John & Son Canada Corp has the following capital structure.
Security
1)6.0% Bond---30million
2)5.5% Straight bond ----10 million
3)7.5% Preferred stock ----10 million
4)Common stock -----50 million
Total $100 million
The 6% bond is a callable bond and yield to call (YTC) of this bond is 6.75%. The straight bond which has a coupon rate of 5.5% has a yield of 6.45%. The preference share of John & Son is currently trading at $95. The common stock of John & Son Canada Corp has a beta of 1.25. The T-bill rate is 2% and the return on TSX composite index is 9%. The corporate tax rate is 35%.
i) Compute the cost of capital after tax for each sources of financing (capital)? [6 marks]
ii) What is its WACC?
iii) If John & Son Canada Corp is evaluating an investment proposal that provide internal rate of return (IRR) of 12%, should the company go with the proposal assuming that the WACC ramains constant.
Top Answer
The cost of debt is the effective interest rate a company pays on its debts. It's the cost of debt, such as bonds and loans,... View the full answer | https://www.coursehero.com/tutors-problems/Finance/19990068-22-A-John-Son-Canada-Corp-has-the-following-capital-structure-Sec/ | CC-MAIN-2020-05 | refinedweb | 207 | 76.82 |
Introducing Data Annotations Extensions box.
A Quick Word About Data Annotations Extensions
The Data Annotations Extensions project can be found at, and currently provides 11 additional validation attributes (ex: Email, EqualTo, Min/Max) on top of Data Annotations’ original 4. You can find a current list of the validation attributes on the afore mentioned website.
The core library provides server-side validation attributes that can be used in any .NET 4.0 project (no MVC dependency). There is also an easily pluggable client-side validation library which can be used in ASP.NET MVC 3 projects using unobtrusive jquery validation (only MVC3 included javascript files are required).
On to the Preview
Let’s say you had the following “Customer” domain model (or view model, depending on your project structure) in an MVC 3 project:
public class Customer
{
public string Email { get; set; }
public int Age { get; set; }
public string ProfilePictureLocation { get; set; }
}
When it comes time to create/edit this Customer, you will probably have a CustomerController and a simple form that just uses one of the Html.EditorFor() methods that the ASP.NET MVC tooling generates for you (or you can write yourself). It should look something like this:
With no validation, the customer can enter nonsense for an email address, and then can even report their age as a negative number! With the built-in Data Annotations validation, I could do a bit better by adding a Range to the age, adding a RegularExpression for email (yuck!), and adding some required attributes. However, I’d still be able to report my age as 10.75 years old, and my profile picture could still be any string. Let’s use Data Annotations along with this project, Data Annotations Extensions, and see what we can get:
public class Customer
{
[Required]
public string Email { get; set; }
[Integer]
[Min(1, ErrorMessage="Unless you are benjamin button you are lying.")]
[Required]
public int Age { get; set; }
[FileExtensions("png|jpg|jpeg|gif")]
public string ProfilePictureLocation { get; set; }
}
Now let’s try to put in some invalid values and see what happens:
That is very nice validation, all done on the client side (will also be validated on the server). Also, the Customer class validation attributes are very easy to read and understand.
Another bonus: Since Data Annotations Extensions can integrate with MVC 3’s unobtrusive validation, no additional scripts are required!
Now that we’ve seen our target, let’s take a look at how to get there within a new MVC 3 project.
Adding Data Annotations Extensions To Your Project
First we will File->New Project and create an ASP.NET MVC 3 project. I am going to use Razor for these examples, but any view engine can be used in practice.
Now go into the NuGet Extension Manager (right click on references and select add Library Package Reference) and search for “DataAnnotationsExtensions.” You should see the following two packages:
The first package is for server-side validation scenarios, but since we are using MVC 3 and would like comprehensive sever and client validation support, click on the DataAnnotationsExtensions.MVC3 project and then click Install. This will install the Data Annotations Extensions server and client validation DLLs along with David Ebbo’s web activator (which enables the validation attributes to be registered with MVC 3).
Now that Data Annotations Extensions is installed you have all you need to start doing advanced model validation. If you are already using Data Annotations in your project, just making use of the additional validation attributes will provide client and server validation automatically. However, assuming you are starting with a blank project I’ll walk you through setting up a controller and model to test with.
Creating Your Model
In the Models folder, create a new User.cs file with a User class that you can use as a model. To start with, I’ll use the following class:
public class User
{
public string Email { get; set; }
public string Password { get; set; }
public string PasswordConfirm { get; set; }
public string HomePage { get; set; }
public int Age { get; set; }
}
Next, create a simple controller with at least a Create method, and then a matching Create view (note, you can do all of this via the MVC built-in tooling). Your files will look something like this:
UserController.cs:
public class UserController : Controller
{
public ActionResult Create()
{
return View(new User());
}
[HttpPost]
public ActionResult Create(User user)
{
if (!ModelState.IsValid)
{
return View(user);
}
return Content("User valid!");
}
}
Create.cshtml:
@model NuGetValidationTester.Models.User
@{
ViewBag.Title = "Create";
}
<h2>Create</h2>
<script src="@Url.Content("~/Scripts/jquery.validate.min.js")" type="text/javascript"></script>
<script src="@Url.Content("~/Scripts/jquery.validate.unobtrusive.min.js")" type="text/javascript"></script>
@using (Html.BeginForm()) {
@Html.ValidationSummary(true)
<fieldset>
<legend>User</legend>
@Html.EditorForModel()
<p>
<input type="submit" value="Create" />
</p>
</fieldset>
}
In the Create.cshtml view, note that we are referencing jquery validation and jquery unobtrusive (jquery is referenced in the layout page). These MVC 3 included scripts are the only ones you need to enjoy both the basic Data Annotations validation as well as the validation additions available in Data Annotations Extensions. These references are added by default when you use the MVC 3 “Add View” dialog on a modification template type.
Now when we go to /User/Create we should see a form for editing a User
Since we haven’t yet added any validation attributes, this form is valid as shown (including no password, email and an age of 0). With the built-in Data Annotations attributes we can make some of the fields required, and we could use a range validator of maybe 1 to 110 on Age (of course we don’t want to leave out supercentenarians) but let’s go further and validate our input comprehensively using Data Annotations Extensions. The new and improved User.cs model class.
{
[Required]
public string Email { get; set; }
[Required]
public string Password { get; set; }
[Required]
[EqualTo("Password")]
public string PasswordConfirm { get; set; }
[Url]
public string HomePage { get; set; }
[Integer]
[Min(1)]
public int Age { get; set; }
}
Now let’s re-run our form and try to use some invalid values:
All of the validation errors you see above occurred on the client, without ever even hitting submit. The validation is also checked on the server, which is a good practice since client validation is easily bypassed.
That’s all you need to do to start a new project and include Data Annotations Extensions, and of course you can integrate it into an existing project just as easily.
Nitpickers Corner
ASP.NET MVC 3 futures defines four new data annotations attributes which this project has as well: CreditCard, Email, Url and EqualTo. Unfortunately referencing MVC 3 futures necessitates taking an dependency on MVC 3 in your model layer, which may be unadvisable in a multi-tiered project. Data Annotations Extensions keeps the server and client side libraries separate so using the project’s validation attributes don’t require you to take any additional dependencies in your model layer which still allowing for the rich client validation experience if you are using MVC 3.
Custom Error Message and Globalization: Since the Data Annotations Extensions are build on top of Data Annotations, you have the ability to define your own static error messages and even to use resource files for very customizable error messages.
Available Validators: Please see the project site at for an up-to-date list of the new validators included in this project. As of this post, the following validators are available:
- CreditCard
- Date
- Digits
- EqualTo
- FileExtensions
- Integer
- Max
- Min
- Numeric
- Url
Conclusion
Hopefully I’ve illustrated how easy it is to add server and client validation to your MVC 3 projects, and how to easily you can extend the available validation options to meet real world needs.
The Data Annotations Extensions project is fully open source under the BSD license. Any feedback would be greatly appreciated. More information than you require, along with links to the source code, is available at.
Enjoy! | http://weblogs.asp.net/srkirkland/introducing-data-annotations-extensions | CC-MAIN-2015-22 | refinedweb | 1,338 | 51.07 |
Table of Contents
Plots in 2D
Plots using MatLab syntax
Plot is a simplest canvas to show data and functions. It is less Java oriented, but more oriented towards MatLab syntax (which does not assume operation with objects and dynamical access of methods).
from jhplot import * j=Plot() j.plot([-1,2,3], [0.5, 0.2, 0.3]) j.show() j.export("a.pdf") # save as PDF file # j.export("a.eps") # save as EPS (PostScript) format # j.export("a.svg") # save as SVG file
Here we created X-Y plot and saved as PDF image. You can also use the “savefig()” method, which is equivalent to the export method.
Interactive 2D canvaces
Below we discuss more complicated plot canvases which can be used to display data in 2D. Such canvaces usually have the names starting with the capital “H”. Typically, you can build a plot to show 2D data as this:
from jhplot * c1 = HPlot("Canvas",600,400,2,1) # canvas size 600x400, 2 plot regions c1.visible(100,200) # make it visible and position at 100 , 200 pixels on the screen c1.setAutoRange() # autorange for X c1.draw(object1) # draw object1 (H1D,F1D,P HPlot documentation. It should be noted the HPlot canvas can be replaced by any other canvas described above.
Several plotting regions
These canvases can be used to show several pads (plot regions) with plotted objects. Specify the number of divisions in X and Y in the constructors. The navigate to a specific plot region using the method “cd()”. Here is example of how to create 2×2 pads on a single canvas:
1: from jhplot import * 2: 3: c1 = HPlot("Canvas",500,400,2,2) 4: c1.visible() 5: c1. setRangeAll(0,10,0,10) 6: h1 = P1D("Simple") 7: 8: c1.cd(1,1); 9: h1.add(5,6); c1.draw(h1) 10: 11: c1.cd(1,2); 12: h1.add(4,3); c1.draw(h1) 13: 14: c1.cd(2,1); 15: h1.add(3,3); c1.draw(h1) 16: 17: c1.cd(2,2); 18: h1.add(2,1); c1.draw(h1) 19: c1.export ("example.pdf")
This works for HPlot, HPlotJa, HPlot3D and many other pads.
Here we use the same X and Y ranges. One can use “setAutoRange()” (after each “cd()”) method to set autorange for each pad. Also, try “setRange(xmin,xmax,ymin,ymax)” to set fixed ranges for each pads. it shows 4 pads with data points.
The plots are fully customizable, i.e. one can change any attribute (axis, label, ticks, ticks label). Read the section plot_styles about how to change various attributes and make different presentation styles.
Exporting to images
When functions, data_structures, histograms or diagrams are shown, one can create an image using the menu [File]-[Export]. One can also save image in a file using the method “export” to a variety of vector graphics formats as well as bitmap image formats.
In the example below, we save an instance of the HPlot class to a PDF file:
>>> c1.export('image.pdf')
we export drawings on the canvas HPlot (c1 represents its instance) into a PDF file. One can also export it into PNG, JPEG, EPS, PS etc. formats using the appropriate extension for the output file name.
As example, simply append the statement “c1.export('image.ps')” at the end of code snippets shown in sections functions, data_structures, histograms or diagrams, and your image will be saved to a PostScript file “image.ps”.
Images can be generated in a background (without a pop-up frame with the canvas). For this, use the method “c1.visible(0)”, where “0” means Java false.
Axis labels
Can be set using setNameX(“label”) and setNameY(“label”). These are global methods which should be applied to the HPlot canvas. However, every plotting object have their own methods, such as “setLabelX(“label”)” and setLabelY(“label”)”. If the labels are set to the object, the plot will display the object labels rather than those set using setNameX() and setNameY().
Ticks and subticks
One can redefine ticks using several methods of the HPlot
setRange(0,10,0,10) # set range for X and Y setNumberOfTics(1) # redefine ticks setNumberOfTics(0,2) # set 2 ticks on X setNumberOfTics(1,5) # set 5 ticks on Y setSubTicNumber(0,2) # set 2 subticks on X setSubTicNumber(1,4) # set 4 subticks on Y
The simple example illustrates this:
1: from jhplot import * 2: 3: c1 = HPlot("Canvas") 4: c1.visible() 5: c1.setRange(0,10,0,10) 6: c1.setNumberOfTics(1) 7: c1.setNumberOfTics(0,2) 8: c1.setNumberOfTics(1,5) 9: c1.setSubTicNumber(0,2) 10: c1.setSubTicNumber(1,4) 11: 12: h1 = P1D("Simple1") 13: xpos=5 14: ypos=7 15: h1.add(xpos,ypos) 16: c1.draw(h1) 17: 18: lab=HLabel("Point", xpos, ypos, "USER") 19: c1.add(lab) 20: c1.update() 21: c1.export ("example.pdf")
We labeled a point and generated a PDF files with the figure as shown in this figure:
Showing shapes and objects
You can show data and functions together with different 2D objects. Here is a simple example that shows a histogram, a data set in X-Y and 3 ellipses:
Look at the Section Drawing shapes.
Post editing
HPlotJa can be used to edit figures. For example, one can make inserts if one creates 2 plotting pads and then one can edit the pads using the “mouse-click” fashion. For example, run this script:
1: from java.awt import Color 2: from java.util import Random 3: from jhplot import * 4: 5: c1 = HPlotJa("Canvas",600,400,2,1) 6: c1.visible(1) 7: c1.showEditor(1) 8: 9: c1.cd(1,1) 10: c1.setAutoRange() 11: c1.setShowStatBox(0) 12: p1 = P1D("data points") 13: rand = Random() 14: for i in range(500): 15: p1.add(rand.nextGaussian(),rand.nextGaussian()) 16: c1.draw(p1) 17: 18: c1.cd(2,1) 19: c1.setAutoRange() 20: c1.setShowStatBox(0) 21: h2 = H1D("Histogram",15, -2.0, 2.0) 22: h2.setFill(1) 23: h2.setFillColor(Color.blue) 24: h2.setColor(Color.blue) 25: for i in range(10000): 26: h2.fill(1+rand.nextGaussian()) 27: c1.draw(h2)
Then edit the figure (increase the size of one pad, and then drag the other one):
Similarly, one can achieve the same using the method “setPad()” where you can specify the location and the sizes of the plot regions The script below creates 2 plotting pads. The second pad is located inside the first one. Then you can plot data as usual, navigating to certain pads using the “cd(i,j)” method.
from jhplot import * c1 = HPlotJa("Canvas",600,400,2,1) c1.visible(1) # change pad positions and sizes c1.setPad(1,1,0.1, 0.1, 0.8,0.8) c1.setPad(2,1,0.5, 0.14, 0.3,0.3)
Interactive plotting
HPlotJas canvas represents a way to prepare all objects for plotting, fitting and rebinning of data. Look at the Sect. Interactive Fit where this canvas is discussed in the context of plotting, rebinning and fitting.
Polar coordinates
For the polar coordinates, use the HChart canvas. A small code below shows ho to show a dataset filled from the X-Y array P1D
Example with 2D plot regions
In the example below, we create 4 plot regions (2 by 2) and plot functions and a histogram. Then we export the plot to EPS file for inclusion to a LaTeX document
1: from java.awt import Color,Font 2: from java.util import Random 3: from jhplot import * 4: 5: c1 = HPlot3D("Canvas",600,700,2,2) 6: c1.visible(1) 7: 8: c1.setGTitle("HPlot3D canvas tests") 9: r=Random() 10: 11: h1=H2D("My 2D Test1",30,-4.5, 4.5, 30, -4.0, 4.0) 12: f1=F2D("cos(x*y)*(x*x-y*y)", -2.0, 2.0, -2.0, 2.0) 13: f2=F2D("sin(4*x*y)", -2.0, 2.0, -2.0, 2.0) 14: f3=F2D("x^3-3*x-3*y^2", -2.0, 2.0, -2.0, 2.0) 15: 16: for i in range(1000): 17: h1.fill(r.nextGaussian(),r.nextGaussian()) 18: 19: c1.cd(1,1) 20: c1.draw(h1) 21: c1.setScaling(8) 22: c1.setRotationAngle(10) 23: c1.update() 24: 25: c1.cd(2,1) 26: c1.draw(f1) 27: c1.setScaling(8) 28: c1.setRotationAngle(30) 29: c1.update() 30: 31: c1.cd(1,2) 32: c1.draw(f2) 33: c1.setScaling(8) 34: c1.setRotationAngle(40) 35: c1.update() 36: 37: c1.cd(2,2) 38: c1.draw(f3) 39: c1.setAxesFontColor(Color.blue) 40: c1.setColorMode(4) 41: c1.setScaling(8) 42: c1.setElevationAngle(30) 43: c1.setRotationAngle(35) 44: c1.update() 45: 46: c1.export("figure.eps") # export to EPS format
The output of this script is shown below:
Use setAutoRange() if you want X-Y-Z ranges taken from the function definitions. Otherwise, use “setRange()” to fix ranges.
Here is another example showing 2D plots with data:
1: from jhplot import * 2: from java.util import Random 3: from java.awt import Color 4: 5: c1 = HPlot3D("Canvas",600,600) 6: c1.setGTitle("Galaxy") 7: c1.setNameX("X") 8: c1.setNameY("Y") 9: c1.visible(1) 10: c1.setElevationAngle(30) 11: c1.setBoxColor(Color.gray) 12: c1.setAxesFontColor(Color.gray) 13: c1.setBoxed(0) 14: c1.setRange(-10,10,-10,10,-10,10) 15: 16: p1=P2D("Galaxy") 17: p1.setSymbolSize(1) 18: p1.setSymbolColor(Color.blue) 19: rand = Random() 20: for i in range(10000): 21: x=3*rand.nextGaussian() 22: y=3*rand.nextGaussian() 23: z=0.4*rand.nextGaussian() 24: p1.add(x,y,z) 25: p2=P2D("Core") 26: p2.setSymbolSize(1) 27: p2.setSymbolColor(Color.yellow) 28: for i in range(5000): 29: x=0.9*rand.nextGaussian() 30: y=0.9*rand.nextGaussian() 31: z=0.8*rand.nextGaussian() 32: p2.add(x,y,z) 33: c1.draw(p1) 34: c1.draw(p2)
The output is shown below:
Embedding in JFrame
It is possible to embed SCaVis canvases in Java
java.swing.JFrame, so you can build an application with custom buttons.
Here is an example:
Density plots
You can also make density plots in which color represent density (or values). Look at this rather comprehensive example which shows how to plot F2D functions or 2D histograms (H2D) using several pads:
1: # Canvas2D example. Showing 2D function and labels in HPlot3D 2: 3: from jhplot import * 4: from java.awt import * 5: 6: f1=F2D("x^2+sin(x)*y^2",-2,2,-2,2); 7: c1=HPlot2D("Canvas",600,700) 8: c1.visible() 9: 10: 11: c1.setName("2D function"); 12: c1.setNameX("X variable") 13: c1.setNameY("Y variable") 14: 15: c1.setStyle(2) 16: c1.draw(f1) 17: 18: lab1=HLabel("ω test",0.7,0.55, "NDC") 19: lab1.setColor(Color.white) 20: c1.add(lab1,0.1) 21: 22: lab2=HLabel("β test",0.5,-0.8, "USER") 23: c1.add(lab2,0.1) 24: 25: # reduce font size for X 26: axis=c1.getAxis(0); 27: axis.setLabelHeightP(0.03) 28: 29: c1.update()
Other charts
SCaVis can be used to plot many other types of charts, such as Candlestick chart. Read Section about Financial charts.
— Sergei Chekanov 2010/03/07 17:38 | http://www.jwork.org/scavis/wikidoc/doku.php?id=man:visual:plots2d | CC-MAIN-2014-10 | refinedweb | 1,904 | 63.36 |
Python Certification Training for Data Scienc ...
- 48k Enrolled Learners
- Weekend/Weekday
- Live Class
In my previous blog, you have learned about Arrays in Python and its various fundamentals like functions, lists vs arrays along with its creation. But, those were just the basics and with Python Certification being the most sought-after skill in the programming domain today, there’s obviously so much more to learn. In this python numpy tutorial, you will understand each aspect of Numpy in the following sequence:
NumPy is a Python package which stands for ‘Numerical Python’. It is the core library for scientific computing, which contains a powerful n-dimensional array object, provide tools for integrating C, C++ etc. It is also useful in linear algebra, random number capability etc. NumPy array can also be used as an efficient multi-dimensional container for generic data. Now, let me tell you what exactly is a python numpy array.
NumPy Array: Numpy array is a powerful N-dimensional array object which is in the form of rows and columns. We can initialize numpy arrays from nested Python lists and access it elements. In order to perform these numpy operations, the next question which will come in your mind is:
To install Python NumPy, go to your command prompt and type “pip install numpy”. Once the installation is completed, go to your IDE (For example: PyCharm) and simply import it by typing: “import numpy as np”
Moving ahead in python numpy tutorial, let us understand what exactly is a multi-dimensional numPy array.
Here, I have different elements that are stored in their respective memory locations. It is said to be two dimensional because it has rows as well as columns. In the above image, we have 3 columns and 4 rows available.
Let us see how it is implemented in PyCharm:
import numpy as np a=np.array([1,2,3]) print(a)
Output – [1 2 3]
a=np.array([(1,2,3),(4,5,6)]) print(a)
O/P – [[ 1 2 3]
[4 5 6]]
Many of you must be wondering that why do we use python numpy if we already have python list? So, let us understand with some examples in this python numpy tutorial.
We use python numpy array instead of a list because of the below three reasons:
The very first reason to choose python numpy array is that it occupies less memory as compared to list. Then, it is pretty fast in terms of execution and at the same time it is very convenient to work with numpy. So these are the major advantages that python numpy array has over list. Don’t worry, I am going to prove the above points one by one practically in PyCharm. Consider the below example:
import numpy as np import time import sys S= range(1000) print(sys.getsizeof(5)*len(S)) D= np.arange(1000) print(D.size*D.itemsize)
O/P – 14000
4000
The above output shows that the memory allocated by list (denoted by S) is 14000 whereas the memory allocated by the numpy array is just 4000. From this, you can conclude that there is a major difference between the two and this makes python numpy array as the preferred choice over list.
Next, let’s talk how python numpy array is faster and more convenient when compared to list.
import time import sys SIZE = 1000000)
O/P – 380.9998035430908
49.99995231628418
In the above code, we have defined two lists and two numpy arrays. Then, we have compared the time taken in order to find the sum of lists and sum of numpy arrays both. If you see the output of the above program, there is a significant change in the two values. List took 380ms whereas the numpy array took almost 49ms. Hence, numpy array is faster than list. Now, if you noticed we had run a ‘for’ loop for a list which returns the concatenation of both the lists whereas for numpy arrays, we have just added the two array by simply printing A1+A2. That’s why working with numpy is much easier and convenient when compared to the lists.
Therefore, the above examples proves the point as to why you should go for python numpy array rather than a list!
Moving forward in python numpy tutorial, let’s focus on some of its operations.
You may go through this recording of Python NumPy tutorial where our instructor has explained the topics in a detailed manner with examples that will help you to understand this concept better.
import numpy as np a = np.array([(1,2,3),(4,5,6)]) print(a.ndim)
Output – 2
Since the output is 2, it is a two-dimensional array (multi dimension).
import numpy as np a = np.array([(1,2,3)]) print(a.itemsize)
Output – 4
So every element occupies 4 byte in the above numpy array.
import numpy as np a = np.array([(1,2,3)]) print(a.dtype)
Output – int32
As you can see, the data type of the array is integer 32 bits. Similarly, you can find the size and shape of the array using ‘size’ and ‘shape’ function respectively.
import numpy as np a = np.array([(1,2,3,4,5,6)]) print(a.size) print(a.shape)
Output – 6 (1,6)
Next, let us move forward and see what are the other operations that you can perform with python numpy module. We can also perform reshape as well as slicing operation using python numpy operation. But, what exactly is reshape and slicing? So let me explain this one by one in this python numpy tutorial.
reshape:
Reshape is when you change the number of rows and columns which gives a new view to an object. Now, let us take an example to reshape the below array:
data-src=As you can see in the above image, we have 3 columns and 2 rows which has converted into 2 columns and 3 rows. Let me show you practically how it’s done.
import numpy as np a = np.array([(8,9,10),(11,12,13)]) print(a) a=a.reshape(3,2) print(a)
Output – [[ 8 9 10] [11 12 13]] [[ 8 9] [10 11] [12 13]]
slicing:
As you can see the ‘reshape’ function has showed its magic. Now, let’s take another operation i.e Slicing. Slicing is basically extracting particular set of elements from an array. This slicing operation is pretty much similar to the one which is there in the list as well. Consider the following example:
data-src=
Before getting into the above example, let’s see a simple one. We have an array and we need a particular element (say 3) out of a given array. Let’s consider the below example: we need the 2nd element from the zeroth and first index of the array. Let’s see how you can perform this operation:
import numpy as np a=np.array([(1,2,3,4),(3,4,5,6)]) print(a[0:,2])
Output – [3 5]
Here colon represents all the rows, including zero. Now to get the 2nd element, we’ll call index 2 from both of the rows which gives us the value 3 and 5 respectively.
Next, just to remove the confusion, let’s say we have one more row and we don’t want to get its 2nd element printed just as the image above. What we can do in such case?
Consider the below code:
import numpy as np a=np.array([(8,9),(10,11),(12,13)]) print(a[0:2,1])
Output – [9 11]
As you can see in the above code, only 9 and 11 gets printed. Now when I have written 0:2, this does not include the second index of the third row of an array. Therefore, only 9 and 11 gets printed else you will get all the elements i.e [9 11 13].
linspace
This is another operation in python numpy which returns evenly spaced numbers over a specified interval. Consider the below example:
import numpy as np a=np.linspace(1,3,10) print(a)
Output – [ 1. 1.22222222 1.44444444 1.66666667 1.88888889 2.11111111 2.33333333 2.55555556 2.77777778 3. ]
As you can see in the result, it has printed 10 values between 1 to 3.
max/ min
Next, we have some more operations in numpy such as to find the minimum, maximum as well the sum of the numpy array. Let’s go ahead in python numpy tutorial and execute it practically.
import numpy as np a= np.array([1,2,3]) print(a.min()) print(a.max()) print(a.sum())
Output – 1 3 6
You must be finding these pretty basic, but with the help of this knowledge you can perform a lot bigger tasks as well. Now, lets understand the concept of axis in python numpy.
data-src=
As you can see in the figure, we have a numpy array 2*3. Here the rows are called as axis 1 and the columns are called as axis 0. Now you must be wondering what is the use of these axis?
Suppose you want to calculate the sum of all the columns, then you can make use of axis. Let me show you practically, how you can implement axis in your PyCharm:
a= np.array([(1,2,3),(3,4,5)]) print(a.sum(axis=0))
Output – [4 6 8]
Therefore, the sum of all the columns are added where 1+3=4, 2+4=6 and 3+5=8. Similarly, if you replace the axis by 1, then it will print [6 12] where all the rows get added.
Square Root & Standard Deviation
There are various mathematical functions that can be performed using python numpy. You can find the square root, standard deviation of the array. So, let’s implement these operations:
import numpy as np a=np.array([(1,2,3),(3,4,5,)]) print(np.sqrt(a)) print(np.std(a))
Output – [[ 1. 1.41421356 1.73205081]
[ 1.73205081 2. 2.23606798]]
1.29099444874
As you can see the output above, the square root of all the elements are printed. Also, the standard deviation is printed for the above array i.e how much each element varies from the mean value of the python numpy array.
Addition Operation
You can perform more operations on numpy array i.e addition, subtraction,multiplication and division of the two matrices. Let me go ahead in python numpy tutorial, and show it to you practically:
import numpy as np x= np.array([(1,2,3),(3,4,5)]) y= np.array([(1,2,3),(3,4,5)]) print(x+y)
Output – [[ 2 4 6] [ 6 8 10]]
This is extremely simple! Right? Similarly, we can perform other operations such as subtraction, multiplication and division. Consider the below example:
import numpy as np x= np.array([(1,2,3),(3,4,5)]) y= np.array([(1,2,3),(3,4,5)]) print(x-y) print(x*y) print(x/y)
Output – [[0 0 0] [0 0 0]]
[[ 1 4 9] [ 9 16 25]]
[[ 1. 1. 1.] [ 1. 1. 1.]]
Vertical & Horizontal Stacking
Next, if you want to concatenate two arrays and not just add them, you can perform it using two ways – vertical stacking and horizontal stacking. Let me show it one by one in this python numpy tutorial.
import numpy as np x= np.array([(1,2,3),(3,4,5)]) y= np.array([(1,2,3),(3,4,5)]) print(np.vstack((x,y))) print(np.hstack((x,y)))
Output – [[1 2 3] [3 4 5] [1 2 3] [3 4 5]]
[[1 2 3 1 2 3] [3 4 5 3 4 5]]
ravel
There is one more operation where you can convert one numpy array into a single column i.e ravel. Let me show how it is implemented practically:
import numpy as np x= np.array([(1,2,3),(3,4,5)]) print(x.ravel())
Output – [ 1 2 3 3 4 5]
Let’s move forward in python numpy tutorial, and look at some of its special functions.
There are various special functions available in numpy such as sine, cosine, tan, log etc. First, let’s begin with sine function where we will learn to plot its graph. For that, we need to import a module called matplotlib. To understand the basics and practical implementations of this module, you can refer Matplotlib Tutorial. Moving ahead with python numpy tutorial, let’s see how these graphs are plotted.
import numpy as np import matplotlib.pyplot as plt x= np.arange(0,3*np.pi,0.1) y=np.sin(x) plt.plot(x,y) plt.show()
Output –
data-src=
Similarly, you can plot a graph for any trigonometric function such as cos, tan etc. Let me show you one more example where you can plot a graph of another function, let’s say tan.
import numpy as np import matplotlib.pyplot as plt x= np.arange(0,3*np.pi,0.1) y=np.tan(x) plt.plot(x,y) plt.show()
Output –
data-src=
Moving forward with python numpy tutorial, let’s see some other special functionality in numpy array such as exponential and logarithmic function. Now in exponential, the e value is somewhere equal to 2.7 and in log, it is actually log base 10. When we talk about natural log i.e log base e, it is referred as Ln. So let’s see how it is implemented practically:
a= np.array([1,2,3]) print(np.exp(a))
Output – [ 2.71828183 7.3890561 20.08553692]
As you can see the above output, the exponential values are printed i.e e raise to the power 1 is e, which gives the result as 2.718… Similarly, e raise to the power of 2 gives the value somewhere near 7.38 and so on. Next, in order to calculate log, let’s see how you can implement it:
import numpy as np import matplotlib.pyplot as plt a= np.array([1,2,3]) print(np.log(a))
Output – [ 0. 0.69314718 1.09861229]
Here, we have calculated natural log which gives the value as displayed above. Now, if we want log base 10 instead of Ln or natural log, you can follow the below code:
import numpy as np import matplotlib.pyplot as plt a= np.array([1,2,3]) print(np.log10(a))
Output – [ 0. 0.30103 0.47712125]
By this, we come to the end of this python numpy tutorial. We have covered all the basics of python numpy, so you can start practicing now. The more you practice, the more you will learn.
Got a question for us? Please mention it in the comments section of this “Python Numpy Tutorial ” and we will get back to you as soon as possible.
To get in-depth knowledge on Python along with its various applications, you can enroll for live Python online training with 24/7 support and lifetime access. | https://www.edureka.co/blog/python-numpy-tutorial/ | CC-MAIN-2019-39 | refinedweb | 2,517 | 73.37 |
In this tutorial, you will learn how to find the duplicate records in a table.
Duplicate records in a table :
You can check for duplicate records of table. You can group record by any of fields of table. GROUP BY clause groups record over the field and Having clause refine records in SELECT statement. Having clause is used with the GROUP BY clause.
You can check this by writing following SQL query -
sql = "SELECT name as name_count from employee GROUP BY name HAVING ( COUNT(name) >1 )"
Example :
In this tutorial we are checking of duplicate record and listing name of such employees. Count function returns the count of the number of rows.
JDBCDuplicateRecords.java
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class JDBCDuplicateRecords { public static void main(String[] args) { System.out.println("Finding the duplicate records in a table.."); as name_count from employee GROUP BY name HAVING ( COUNT(name) > 1 )"; rs = statement.executeQuery(sql); System.out.println("Employee Name having duplicate names : "); while (rs.next()) { String name = rs.getString("name_count"); System.out.println(name); } conn.close(); } catch (Exception e) { e.printStackTrace(); } } }
Output :
Finding the duplicate records in a table.. Employee Name having duplicate names : Linda Roxi
Advertisements
Posted on: October | http://www.roseindia.net/tutorial/java/core/DuplicateRecord.html | CC-MAIN-2016-30 | refinedweb | 210 | 53.27 |
saying about COVID over these last two years. In this post we will:
- Download News Headlines from 2020 and 2021
- Extract Headlines About COVID with AI
- Setup requests to extract COVID headlines
- Load and transform raw archived headline data from the NY Times
- Extraction of COVID headlines using AI
- Use AI to Get COVID Headlines Sentiments
- Setup asynchronous polarity value extraction
- Load up AI extracted COVID headlines to send to the API
- Asynchronously send requests to get sentiment values for headlines
- Plot COVID Headline Sentiments for 2020 and 2021 – see Sentiment Graphs Here
- A table of the number of COVID headlines per month
- Graphing sentiment polarity values for each headline
- Graphing monthly, yearly, and total sentiment values
- Avoiding an asynchronous looping RuntimeError
- The graph of average sentiment values of COVID per month since 2020
- Create a Word Cloud of COVID Headlines for 2020 and 2021 – see Word Clouds Here
- Moving the parse function to a common file
- Code to create a word cloud
- Loading the file and creating word clouds of COVID headlines
- Use NLP to Find the Most Common Phrases in COVID Headlines So Far
- Moving the base API endpoint and headers to a common file
- Setting up requests to get most common phrases
- Creating the requests to get most common phrases for each month
- Calling the most common phrases API
- The most common phrases in each month of COVID headlines
- Summary of using AI to analyze COVID headlines over time
To follow along all you need is to get two free API keys, one from the NY Times, and one from The Text API, and install the
requests,
aiohttp, and
wordcloud libraries. To install the libraries, you can simple run the following code in your terminal or command line:
pip install requests wordcloud aiohttp
Download News Headlines from 2020 and 2021
The first thing we need to do is download our news headlines. This is why we need the NY Times API. We’re going to use the NY Times to download their archived headlines from 2020 to 2021. We won’t go through all the code to do that in this section, but you can follow the guide on How to Download Archived News Headlines to get all the headlines. You’ll need to download each month from 2020 to 2021 to follow this tutorial. If you want, you can also get the headlines for December 2019 when COVID initially broke out.
Extract Headlines about COVID with AI
After we have the downloaded news headlines we want to extract the ones that contain “COVID” in their title. We’re going to use The Text API to do this. The first thing we’ll need to do is set up our API requests and our map of month to month number as we did when we downloaded the headlines. Then we need to load and transform the JSON data into usable headline data. Finally, we’ll send our API requests and get all of the headlines from January 2020, through December 2021 that contain COVID in their headlines.
Setup Requests for COVID Headline Extraction with AI
Since we’re using a Web API to handle our extraction, the first thing we’ll need to do is set up sending API requests. We’ll start by importing the
requests and
json library. Then we’ll import the API key we got from The Text API earlier as well as the URL endpoint, “”. We need to set up the actual headers and the keyword endpoint URL. The headers will tell the server that we’re sending JSON content and pass the API key. Finally, we’ll set up a month dictionary so we can map month numbers to their names. This is for loading the JSON requests.
import requests import json from config import thetextapikey, text_url headers = { "Content-Type": "application/json", "apikey": thetextapikey } keyword_url = text_url+"sentences_with_keywords" month_dict = { 1: "January", 2: "February", 3: "March", 4: "April", 5: "May", 6: "June", 7: "July", 8: "August", 9: "September", 10: "October", 11: "November", 12: "December" }
Load and Transform Raw Data into Headlines and Text
Now that we’ve set up our requests, let’s load up our headlines. We’ll create a simple
load_headlines file with two parameters,
year, and
month. First, we’ll open up the file and headlines. Replace
<path to folder> with the path to your folder. From here, we’re going to create an empty string and empty list so we can loop through each entry and append the main and print headlines that go with each entry.
In our loop, we’ll have to check the
print_headline for each entry because sometimes it is empty. We will then check the last character of the print headline and turn it into a period if it’s punctuation. We’ll also check the last character of the main headline and get rid of it if it’s punctuation. We do this because we’re going to get all the sentences that contain the word COVID with our AI keyword extractor.
If the print headline exists, we’ll concatenate the main headline, a comma, and then the print headline and a space (for readability and separability) with the existing headlines text. If the print headline doesn’t exist, we’ll just concatenate the main headline. Else, if the length of the headlines text is greater than 3000, we’ll append the lowercase version to the headlines list and clear the string.
It doesn’t have to be 3000, choose this number based on your internet speed, the faster your internet, the higher number of characters you can send. We use these separate headlines to ensure the connection doesn’t timeout. At the end of the function, return the list of headlines strings.
# load headlines from a month # lowercase all of them # search for covid def load_headlines(year, month): filename = f"<path to folder>\\{year}\\{month_dict[month]}.json" with open(filename, "r") as f: entries = json.load(f) hls = "" hls_to_send = [] # organize entries for entry in entries: # check if there are two headlines if entry['headline']["print_headline"]: if entry['headline']["print_headline"][-1] == "!" or entry['headline']["print_headline"][-1] == "?" or entry['headline']["print_headline"][-1] == ".": hl2 = entry['headline']["print_headline"] else: hl2 = entry['headline']["print_headline"] + "." # append both headlines if entry['headline']["main"][-1] == "!" or entry['headline']["main"][-1] == "?" or entry['headline']["main"][-1] == ".": hl = entry['headline']["main"][:-1] else: hl = entry['headline']["main"] hls += hl + ", " + hl2 + " " elif entry['headline']['main']: if entry['headline']["main"][-1] == "!" or entry['headline']["main"][-1] == "?" or entry['headline']["main"][-1] == ".": hl = entry['headline']["main"] else: hl = entry['headline']["main"] + "." hls += hl + " " # if hls is over 3000, send for kws if len(hls) > 3000: hls_to_send.append(hls[:-1].lower()) hls = "" return(hls_to_send)
Extraction of COVID from Headlines using an NLP API
Now that we have the sets of headlines to send to the keyword extraction API, let’s send them off. We’ll create a function that takes two parameters, the year and month. The first thing the function does is call the
load_headlines function we created earlier to load the headlines. Then we’ll create an empty list of headlines to hold the COVID headlines.
Next, we’ll loop through each set of headlines and create a body that contains the headlines as text and the list of keywords we want to extract. In this case, just “covid”. Then, we’ll send a POST request to the keyword extraction endpoint. When we get the response back, we’ll load it into a dictionary using the JSON library. After it’s loaded, we’ll add the list corresponding to “covid” to the COVID headlines list. You can see what an example response looks like on the documentation page.
Finally, after we’ve sent all the sets of headlines off and gotten the responses back, we’ll open up a text file. We’ll loop through every entry in the COVID headlines list and write it to the text file along with a new line character. You can also send these requests asynchronously like we’ll do in the section below. I leave that implementation as an exercise for the reader.
def execute(year, month): hls = load_headlines(year, month) covid_headlines = [] for hlset in hls: body = { "text": hlset, "keywords": ["covid"] } response = requests.post(keyword_url, headers=headers, json=body) _dict = json.loads(response.text) covid_headlines += _dict["covid"] with open(f"covid_headlines/{year}_{month}.txt", "w") as f: for entry in covid_headlines: f.write(entry + '\n')
Use AI to Get COVID Headline Sentiments
Now that we’ve extracted the headlines about COVID using an AI Keyword Extractor via The Text API, we’ll get the sentiments of each headline. We’re going to do this by sending requests asynchronously for optimized speed.
Set Up Asynchronous Polarity Requests
As usual, the first thing we’re going to do is set up our program by importing the libraries we need. We’ll be using the
json,
asyncio, and
aiohttp modules as well as The Text API API key. After our imports, we’ll create headers which will tell the server that we’re sending JSON data and pass it the API key. Then we’ll declare the URL that we’re sending our requests to, the text polarity API endpoint. Next, we’ll make two
async/
await functions that will handle the asynchronous calls and pool them.
The first of the
async/
await functions we’ll create will be the gather function. This function will take two parameters (although, you could also do this with one), one for the number of tasks, and the number of tasks. The asterisk in front of the tasks parameter just indicates a variable number. The first thing we’ll do in this function is create a
Semaphore to handle the tasks. We’ll create an internal function that will use the created
Semaphore object to asynchronously await a task. That’s basically it, at the end we’ll return all the
gathered tasks.
The other function we’ll make will be a function to send an asynchronous POST request. This function will take four parameters, the URL or API endpoint, the connection session, the headers, and the body. All we’ll do is asynchronously wait for a POST call to the provided API endpoint with the headers and body using the passed in session object to complete. Then we’ll return the JSON version of that object.
import json import asyncio import aiohttp from config import thetextapikey headers = { "Content-Type": "application/json", "apikey": thetextapikey } text_url = "" polarities_url = text_url + "text_polarity" # configure async requests # configure gathering of requests async def gather_with_concurrency(n, *tasks): semaphore = asyncio.Semaphore(n) async def sem_task(task): async with semaphore: return await task return await asyncio.gather(*(sem_task(task) for task in tasks)) # create async post function async def post_async(url, session, headers, body): async with session.post(url, headers=headers, json=body) as response: text = await response.text() return json.loads(text)
Load Up AI Extracted COVID Related Headlines
Now that we’ve set up our asynchronous API calls, let’s retrieve the actual headlines. Earlier, we saved the headlines in text files. The first thing we’re going to do in this section is create a
parse function that will take two parameters, a year and a month. We’ll start off the function by opening up the file and reading it into an “entries” variable. Finally, we’ll just return the entries variable.
def parse(year, month): with open(f"covid_headlines/{year}_{month}.txt", "r") as f: entries = f.read() return entries
Asynchronously Send Requests to Extract Sentiment Values
With the headlines loaded and the asynchronous support functions set up, we’re reading to create the function to extract sentiment values from the COVID headlines. This function will take two parameters, the year and the month. The first thing we’ll do is load up the entries using the
parse function created above. Then we’ll split each headline into its own entry in a list. Next, we’ll establish a connector object and a connection session.
Now, we’ll create the request bodies that go along with the headlines. We’ll create a request for each headline. We’ll also need an empty list to hold all the polarities as we get them. If we need to send more than 10 requests, we’ll have to split those requests up. This is so we don’t overwhelm the server with too many concurrent requests.
Once we have the requests properly set up, the only thing left to do is get the responses from the server. If there were more than 10 requests that were needed, we’ll await the responses and then add them to the empty polarities list, otherwise we’ll just set the list values to the responses. After asynchronously sending all the requests and awaiting all the responses, we’ll close the session to prevent any memory leakage. Finally, we’ll return the now filled up list of polarities.
# get the polarities asynchronously async def get_hl_polarities(year, month): entries = parse(year, month) all_hl = entries.split("\n") conn = aiohttp.TCPConnector(limit=None, ttl_dns_cache=300) session = aiohttp.ClientSession(connector=conn) bodies = [{ "text": hl } for hl in all_hl] # can't run too many requests concurrently, run 10 at a time polarities = [] # break down the bodies into sets of 10 if len(bodies) > 10: bodies_split = [] count = 0 split = [] for body in bodies: if len(body["text"]) > 1: split.append(body) count += 1 if count > 9: bodies_split.append(split) count = 0 split = [] # make sure that the last few are tacked on if len(split) > 0: bodies_split.append(split) count = 0 split = [] for splits in bodies_split: polarities_split = await gather_with_concurrency(len(bodies), *[post_async(polarities_url, session, headers, body) for body in splits]) polarities += [polarity['text polarity'] for polarity in polarities_split] else: polarities = await gather_with_concurrency(len(bodies), *[post_async(polarities_url, session, headers, body) for body in bodies]) polarities = [polarity['text polarity'] for polarity in polarities] await session.close() return polarities
Plot COVID Headline Sentiments for 2020 and 2021
Now that we have created functions that will get us the sentiment values for the COVID headlines from 2020 to 2021, it’s time to plot them. Plotting the sentiments over time will give us an idea of how the media has portrayed COVID over time. Whether they have been optimistic or pessimistic about the outcome, some idea of what’s going on at large, and whether or not the general sentiment is good. See all the graphs here
Number of COVID Headlines Over Time
First let’s take a look at the number of COVID headlines over time.
Here’s the number of COVID headlines over time in graph format:
Graph Sentiment Polarity Values for Each Article
Now we’ve got everything set up, let’s plot the polarity values for each article. We’ll create a function which takes two parameters, the year and month. In our function, the first thing we’re going to do is run the asynchronous function to get the headline polarities for the year and month passed in. Note that this code is in the same file as the code in the section about using AI to get the sentiment of COVID headlines above.
Once we have the polarities back, we’ll plot it on a scatter plot using
matplotlib. We’ll set up the title and labels so the plot looks good too. Then, we’ll save the plot and clear it. Finally, we’ll print out that we’re done plotting the month and year and return the list of polarity values we got back from the asynchronous API call.
# graph polarities by article def polarities_graphs(year, month): polarities = asyncio.run(get_hl_polarities(year, month)) plt.scatter(range(len(polarities)), polarities) plt.title(f"Polarity of COVID Article Headlines in {month_dict[month]}, {year}") plt.xlabel("Article Number") plt.ylabel("Polarity Score") plt.savefig(f"polarity_graphs/{year}_{month}_polarity.png") plt.clf() print(f"{month} {year} done") return polarities
Graph Monthly, Yearly, and Total Sentiment Polarity Values
We don’t just want to graph the polarity values for each article though, we also want to graph the sentiment values from each month and year. We’ll create a function that takes no parameters but gets the polarity values for each month in both years. Note that for some odd reason, there were exactly 0 mentions of COVID in the NYTimes headlines from January to March of 2020. Why? I don’t know, maybe there were mentions of “coronavirus” instead, but that’s out of the scope of this post and I’ll leave that as an exercise to you, the reader, to figure out.
This function will loop through both 2020 and 2021 as well as each of the first 12 numbers, we’ll have to add 1 to the month number because Python is 0 indexed. Once we loop through the years, we can plot the average polarity for each month. Once we’ve plotted both years, we will plot all the months on the same graph to get a full look at the COVID pandemic. Make sure to clear the figure between each plot for clarity.
# graph polarities by month def polarities_month_graphs(): total_polarities_over_time = [] for year in [2020, 2021]: month_polarities = [] for month in range(12): # skip over the first three months if year == 2020 and month < 3: month_polarities.append(0) continue polarities = polarities_graphs(year, month+1) month_polarities.append(sum(polarities)/len(polarities)) total_polarities_over_time += month_polarities plt.plot(range(len(month_polarities)), month_polarities) plt.title(f"Polarity of COVID Article Headlines in {year}") plt.xlabel("Month") plt.ylabel("Polarity Score") plt.savefig(f"polarity_graphs/{year}_polarity.png") plt.clf() # get total graph for both years plt.plot(range(len(month_polarities)), month_polarities) plt.title(f"Polarity of COVID Article Headlines so far") plt.xlabel("Months since March 2020") plt.ylabel("Polarity Score") plt.savefig(f"polarity_graphs/total_polarity.png") plt.clf()
Avoiding RuntimeError: Event Loop is closed
If you run the above code, you’re going to get a
RuntimeError: Event loop is closed after running the
asyncio loop. There is a fix to this though. This isn’t an actual error with the program, this is an error with the loop shutdown. You can fix this with the code below. For a full explanation of what the error is and what the code does, read this article on the RuntimeError: Event loop is closed Fix.
"""""
Total Graph of average COVID Sentiment in NY Times Headlines from 2020 to 2021
Here’s the graph of the average COVID sentiment in NY Times Headlines from 2020 to 2021. Keep in mind that there were 0 headlines about COVID from January to March though, that’s why they’re at 0.
Create a Word Cloud of COVID Headlines for 2020 and 2021
Another way we can get insights into text is through word clouds. We don’t need AI to build word clouds, but we will use the AI extracted COVID headlines to build them. In this section we’re going to build word clouds for each month of COVID headlines since 2020. See all the word clouds here.
Moving the Parse Function to a Common File
One of the first things we’ll do is move the
parse function we created earlier to a common file. We’re moving this to a common file because it’s being used by multiple modules and it’s best practice to not repeat code. We should now have a
common.py file in the same folder as our polarity grapher file and word cloud creator file.
def parse(year, month): with open(f"covid_headlines/{year}_{month}.txt", "r") as f: entries = f.read() return entries
Code to Create a Word Cloud, Modified for COVID
We’ll use almost the same code we used to create a word cloud for the AI extracted COVID headlines as we did for creating a word cloud out of Tweets. We’re going to make a slight modification here though. We’re going to add “covid” to the set of stop words. We already know that each of the headlines contains COVID so it doesn’t add any insight for us to see in a word cloud.
from wordcloud import WordCloud, STOPWORDS import matplotlib.pyplot as plt import numpy as np from PIL import Image # wordcloud function def word_cloud(text, filename): stopwords = set(STOPWORDS) stopwords.add("covid")')
Load the File and Actually Create the Word Cloud from COVID Headlines
Now that we’ve created a word cloud function, let’s create the actual word cloud creation file. Notice that we’re importing the word cloud function here. I opted to create a second file for creating the COVID word clouds specifically, but you can also create these in the same file. This is just to follow orchestration pattern practices. In this file we’ll create a function that takes a year and a month, parses the COVID headlines from that month, and creates a word cloud with the text. Then we’ll loop through both 2020 and 2021 and each month that contains COVID headlines and create word clouds for each month.
from common import parse from word_cloud import word_cloud def make_word_cloud(year, month): text = parse(year, month) word_cloud(text, f"wordclouds/{year}_{month}.png") for year in [2020, 2021]: for month in range(12): if year == 2020 and month < 3: continue make_word_cloud(year, month+1)
Use NLP to Find Most Common Phrases in COVID Headlines
Finally, as an additional insight to how COVID has been portrayed in the media over time, let’s also get the most common phrases used in headlines about COVID over time. Like extracting the headlines and getting their polarity, we’ll also be using AI to do this. We’ll use the
most_common_phrases endpoint of The Text API to do this.
Moving the Base API Endpoint and Headers to the Common File
The first thing we’ll do in this section is modify the
common.py file we created and moved
parse to earlier. This time we’ll also move the base URL and headers to the common file. We’ll be using the same base API URL and headers as we did for getting the sentiment values and extracting the keywords.
from config import thetextapikey text_url = "" headers = { "Content-Type": "application/json", "apikey": thetextapikey }
Setup the Requests to Get Most Common Phrases using AI
The first thing we’ll do in this file is our imports (as always). We’ll be importing the
json and
requests libraries to send requests and parse them. We’ll also need the headers, base API URL, and parse function. Why are we using
requests instead of asynchronous calls? We could use asynchronous calls here, but it’s not necessary. You can opt to use them for practice if you’d like. Finally, we’ll also set up the
most_common_phrases API endpoint.
import json import requests from common import headers, text_url, parse mcps_url = text_url + "most_common_phrases"
Creating a Monthly Request Function with an NLP API
Now that we’ve set up our requests for the most common phrases, let’s make a function that will get the most common phrases for a specific month. This function will take two parameters, a year and a month. The first thing we’ll do is create a body to send to the API. Then we’ll call the API by sending a POST request to the most common phrases endpoint. When we get our response back, we’ll load it into a JSON dictionary and extract out the list of most common phrases. Finally, we’ll write the most common phrases to an appropriate file.
# get the mcps asynchronously def get_hl_mcps(year, month): body = { "text": parse(year, month) } response = requests.post(mcps_url, headers=headers, json=body) _dict = json.loads(response.text) mcps = _dict["most common phrases"] with open(f"mcps/{year}_{month}_values.txt", "w") as f: f.write("\n".join(mcps))
Call the API to Get the Most Common Phrases for Each Month
Now that we’ve written the function will extract the most common phrases from each set of monthly COVID headlines, we can just call it. We’ll loop through both years, 2020 and 2021, and all the months after March of 2020. For each loop, we’ll call the function we created above, and we will end up with a set of text files that contains the 3 most common phrases in headlines each month.
for year in [2020, 2021]: for month in range(12): if year == 2020 and month < 3: continue get_hl_mcps(year, month+1)
Most Common Phrases in COVID Headlines for Each Month since 2020
These are the 3 most common phrases in COVID headlines that we got using AI. Each phrase is equivalent to a noun phrase.
Summary of How to Use AI to Analyze COVID Headlines Since March 2020
In this post we learned how we can leverage AI to get insights into COVID headlines. First we learned how to use AI to extract headlines about COVID from the NY Times archived headlines. Then, we used AI to get sentiment values from those headlines and plot them. Next, we created word clouds from COVID headlines. Finally, we got the most common phrases from each set of monthly COVID headlines. “Using AI to Analyze COVID Headlines Over Time” | https://pythonalgos.com/using-ai-to-analyze-covid-headlines-over-time/ | CC-MAIN-2022-27 | refinedweb | 4,224 | 61.67 |
What you will learn in this section
You’ll learn about how to define various function and resuse them in your program.
Introduction
In our previous chapter, we seen how to write a block of code(function) and call in a program. How about defining a various function and calling them in a program. Yes, you can do this. Therefore, you can define module in a simple one line - module is a file containing Python definitions and statements.
There are various methods of writing modules, but the simplest way is to
- Create a file with a .py extension that contains functions and variables.
- Write the modules in the native language in which the Python interpreter itself was written.
Post writing a module, you can import it in another program to make use of its functionality. This is how we can use the Python standard library as well.
Start with basic modules
Let's write a most basic modules and import it. Create a file "ex11.py" and write below program:
import sys print('The command line arguments are:') for i in sys.argv: print(i) print('\n\nThe PYTHONPATH is', sys.path, '\n')
Then open your terminal and import "ex11.py" (without quote)
$ python ex11.py The command line arguments are: ex11.py ('\n\nThe PYTHONPATH is', ['/home/nescode/project/bitbucketsunil/hdpython', ''], '\n')
Let's explain what we did above: We import the sys module using import statement. Now you would be surprised what is sys module? The sys module contains functionality related to the python interpreter and its environment i.e. the system. When python executes the import sys statement, it looks for the sys module.and print the path.
from.. import statement
Let's say, you want to directly
import the argv variable into your program, then you can use the
from sys import argv statement. Let's create a new file named "ex12.py" and type this program.
from math import sqrt print("Square root of 16 is", sqrt(16))
Run you program and see the results it display
$ python ex12.py ('Square root of 16 is', 4.0)
A module's
__name__
Every module has a name and statements in.
Let's create another file named "ex13.py" and write this code
if __name__ == '__main__': print('This program is being run by itself') else: print('I am being imported from another module')
Now, run this code in terminal
$ python ex13.py This program is being run by itself
Every Python module has its
__name__ defined. If this is
__main__, that implies that the module is being run standalone by the user and we can take appropriate actions.
Practice drills and recommendation
Do this experiment before moving to next chapter.
- Read modules chapter from official python documentation
- Make mistake knowingly and analyse the errors.
- Do Googling with a keywords like - Python modules, Import a module, Import local path through python module.
- Write comment for every single line of code. | https://tutorial.hellodjango.com/python_modules.html | CC-MAIN-2018-47 | refinedweb | 492 | 67.04 |
10 May 2012 09:23 [Source: ICIS news]
SINGAPORE (ICIS)--?xml:namespace>
When the company brings the chlor-alkali plant on-stream, it will become the largest chlor-alkali producer in the province, an industry source said.
There are currently only two chlor-alkali manufacturers in
The chlor-alkali plant is the first phase of Anhui Hwasu’s chlor-alkali project at the site, according to the source.
The first phase also includes a 460,000 tonne/year polyvinyl chloride (PVC) plant and a 700,000 tonne/year calcium carbide plant at the same site, both of which are scheduled to be brought on-stream in August, added the source who did not provide the exact start-up dates.
According to the source, the producer plans to build capacities of 1m tonne/year of PVC, 1.4m tonne/year of calcium carbide, 760,000 dmt/year of chlor-alkali and 2.5m tonne/year of carbide slag-based cement under its chlor-alkali project.
The source did not provide further details | http://www.icis.com/Articles/2012/05/10/9558117/chinas-anhui-hwasu-to-start-up-chlor-alkali-facility-in.html | CC-MAIN-2014-42 | refinedweb | 171 | 53.1 |
Python's new type hinting feature allows us to type hint that a function returns
None
def some_func() -> None:
pass
Any function without annotations should be treated as having the most general type possible
def loop_forever():
while True:
print('This function never returns because it loops forever')
def always_explode():
raise Exception('This function never returns because it always raises')
-> None
There is no answer to this question, yet. Here are a couple of reasons:
When a function doesn't return, there is no return value (not even
None) that a type could be assigned to. So you are not actually trying to annotate a type; you are trying to annotate the absence of a type.
The type hinting PEP has only just been adopted in the standard, as of Python version 3.5. In addition, the PEP only advises on what type annotations should look like, while being intentionally vague on how to use them. So there is no standard telling us how to do anything in particular, beyond the examples.
The PEP has a section Acceptable type hints stating the following:.)
So it tries to discourage you from doing overly creative things, like throwing an exception inside a return type hint in order to signal that a function never returns.
Regarding exceptions, the PEP states the following:
No syntax for listing explicitly raised exceptions is proposed. Currently the only known use case for this feature is documentational, in which case the recommendation is to put this information in a docstring.
There is a recommendation on type comments, in which you have more freedom, but even that section doesn't discuss how to document the absence of a type.
There is one thing you could try in a slightly different situation, when you want to hint that a parameter or a return value of some "normal" function should be a callable that never returns. The syntax is
Callable[[ArgTypes...] ReturnType], so you could just omit the return type, as in
Callable[[ArgTypes...]]. However, this doesn't conform to the recommended syntax, so strictly speaking it isn't an acceptable type hint. Type checkers will likely choke on it.
Conclusion: you are ahead of your time. This may be disappointing, but there is an advantage for you, too: you can still influence how non-returning functions should be annotated. Maybe this will be an excuse for you to get involved in the standardisation process. :-)
I have two suggestions.
Allow omitting the return type in a
Callable hint and allow the type of anything to be forward hinted. This would result in the following syntax:
always_explode: Callable[[]] def always_explode(): raise Exception('This function never returns because it always raises')
Introduce a bottom type like in Haskell:
def always_explode() -> ⊥: raise Exception('This function never returns because it always raises')
These two suggestions could be combined. | https://codedump.io/share/YXrb2wqtDsZ7/1/type-hint-that-a-function-never-returns | CC-MAIN-2017-51 | refinedweb | 472 | 58.72 |
RAND48(3) Library Functions Manual RAND48(3)
NAME
drand48, erand48, lrand48, nrand48, mrand48, jrand48, srand48, seed48,
lcong48 -- pseudo-random number generators and initialization routines
LIBRARY
Standard C Library (libc, -lc)
SYNOPSIS
#include <<stdlib.h>>
double
drand48(void);
double
erand48(unsigned short xseed[3]);
long
lrand48(void);
long
nrand48(unsigned short xseed[3]);
long
mrand48(void);
long
jrand48(unsigned short xseed[3]);
void
srand48(long seed);
unsigned short *
seed48(unsigned short xseed[3]);
void
lcong48(unsigned short p[7]);
DESCRIPTION.
seed48() also initializes the internal buffer r(n) of drand48(),
lrand48(), and. seed48() returns
a pointer to an array of 3 shorts which contains the old seed. This
array is statically allocated, thus).
SEE ALSO
rand(3), random(3)
AUTHORS
Martin Birgmeier
NetBSD 6.1.5 October 8, 1993 NetBSD 6.1.5 | http://modman.unixdev.net/?sektion=3&page=jrand48&manpath=NetBSD-6.1.5 | CC-MAIN-2017-30 | refinedweb | 132 | 55.95 |
How (Form 1040) to determine what businesses the deceased had an ownership in. Check the business’ tax returns and/or any formal partnership agreement for special provisions or stipulations before deciding what to do with it.
You need to know how the business is set up before it can be properly valued and administered. Businesses may be set up in the following ways:
Sole proprietorship: A sole proprietorship is an unincorporated organization that is accounted for entirely on Schedule C of the decedent’s tax Form 1040. The company may be organized as a Limited Liability Company (LLC). It may even have its own Employer Identification Number.
If the decedent’s business is reported on Schedule C of tax Form 1040, you’re dealing with a sole proprietorship or an LLC where the decedent owned the entire business. Value this business as such.
Partnership: If the decedent held a partial interest in a business, it may have been formed as a partnership. Locate the decedent’s tax returns and look for the partnership entry on Schedule E to verify this.
If the deceased had a partnership interest, get a copy of the most recent partnership tax return (Form 1065). This tells you what percentage of the partnership the decedent owned and how the decedent held title in that property. A formal partnership agreement may include a provision for the surviving partner(s) to buy out the decedent’s interest and a formula for the buyout price. Or a separate buy-sell agreement could exist.
In the case of a sale, try to obtain the best price possible. This price sets the value for estate tax purposes if it reflects the fair market value of the partnership interest. The partnership may dissolve upon a partner’s death unless the agreement contains a provision to the contrary.
Subchapter S corporation: In these businesses only the shareholders pay income taxes on profits instead of paying tax first at the corporate level and then again when the profits are paid out as dividends. Your decedent’s most recent income tax returns should tell you whether he or she was an S corporation shareholder. You can also review the corporation’s income tax return (Form 1120S).
Be careful when dealing with S corporation shares which can only be transferred to an individual or to a qualifying trust. Selling or transferring shares to a nonqualified shareholder can cause the corporation to lose its S status.
Subchapter S corporation shares require valuation by an expert unless a buy-sell agreement is in place that fixes the formula or purchase price of the decedent’s stock by the remaining stockholders on his or her death. For the estate’s purposes, that price or formula is fair market value.
Closely held C corporation: If the decedent owned stock in a non-publicly traded company that’s not an S corporation, you’re dealing with a closely (or privately) held C corporation. With a C corporation, there are no income tax concerns about who may inherit the stock.
The corporation may have a buy-sell agreement that sets the price at which the other stockholders may buy the C corporation stock. This agreement sets the stock’s value for estate tax purposes, if the IRS considers the price fair market value. | http://www.dummies.com/how-to/content/how-to-list-and-value-a-decedents-small-businesses.navId-323702.html | CC-MAIN-2015-40 | refinedweb | 551 | 52.19 |
07-31-2019 07:51 AM
Hello everyone!
We're developing a project on ZYNQ-7000. In FPGA has been created some registers, and mapped in memory. We use it for tunning fpga alogorithms. We've been working for a long time and now unexpectedly ran into a problem when enabled optimizing switches in gcc compiler. It turned out that the data in the registers are not written correctly. I managed to fix the problem in a simple assembly example. So, the problem occurs unly when I store 1 or 2 bytes. In 4 bytes storing everething is ok in my test, but I'm not sure will problem not appear again. Unfortunately, our fpga developer has quited, and we can't tune fpga code fine. I'm a software developer, and I can work with this register by 4 bytes only. Can anybody answer, will writes correct in this case, or we must to dig deeper in AXI?
BOOST_AUTO_TEST_CASE(bus_error_asm) { using namespace m5; using namespace m5::registry; static const size_t registry_memory_address = 0x4000000; static const size_t registry_memory_size = 4000000; util::physical_memory registry_mem_{registry_memory_address, registry_memory_size}; fpga_registry_driver registry_{registry_mem_.get().addr, false}; asm volatile( "movw r3, 0x5678 \n\t" // Set in r3 value 0x5678 "strh r3, [%[mem1_ptr], #0] \n\t" // Store from r3 value to mem1_ptr "movw r3, 0x4321 \n\t" // Set in r3 value 0x4321 "strh r3, [%[mem2_ptr], #0] \n\t" // Store from r3 value to mem2_ptr "movw r3, 0 \n\t" // Set in r3 value 0 "strh r3, [%[mem1_ptr], #2] \n\t" // Store from r3 value to mem1_ptr "strh r3, [%[mem2_ptr], #2] \n\t" // Store from r3 value to mem2_ptr // Here, in mem1_ptr is 0x4321, not 0x5678 : : [mem1_ptr] "r" (®istry_.dsp_board()->board[0].low_amp), [mem2_ptr] "r" (®istry_.dsp_ctrl_common()->stable_period_diff) : "r3", "memory" ); BOOST_CHECK_EQUAL(registry_.dsp_board()->board[0].low_amp, 0x5678); BOOST_CHECK_EQUAL(registry_.dsp_ctrl_common()->stable_period_diff, 0x4321); }
07-31-2019 08:25 AM
Are the failing writes unaligned writes?
Dan
07-31-2019 08:38 AM
Not only. Aligned writes fails too, if after that I do an analigned write in the same word.
movw r3 #value1 strh r3 [%[aligned_ptr1]] <--- aligned write, but in *aligned_ptr1 will be value2 instead of value1 movw r3 #value2 strh r3 [%[aligned_ptr2]] movw r3 #0 strh r3 [%[aligned_ptr1] #2] <--- analigned write
I have to check single analigned writes.
07-31-2019 08:43 AM
Not quite my question.
The examples you show above are where a half word directly maps to the 32-bits on a bus. An unaligned half-word write would be to an offset of 3 from the word boundary, not 0, 1, or even to since all of these fit within a single bus "beat".
Dan
07-31-2019 08:59 AM
One other thing to look for ... in many common AXI-lite implementations, to include all of those generated from the VIvado demonstration code I've examined, there's a write-after-write bug which will drop the second write. Could that be what's going on here?
Feel free to check out this article for more details.
Dan
01-27-2020 11:46 AM
I'm running into the same problem. Unaligned writes using strh to M_AXI_HPM0_LPD (32 bits wide) on a Zynq UltraScale+ MPSoC trigger a processor fault (Cortex-R5 #0, baremetal).
This is happening inside memcpy() in a SDK 2018.2 installation:
0013a5d2: beq.n +16 ; addr=0x0013a5e6: memcpy + 0x0000009a 0013a5d4: lsls r2, r2, #31 0013a5d6: itt ne 0013a5d8: ldrbne.w r3, [r1], #+1 0013a5dc: strbne.w r3, [r0], #+1 0013a5e0: bcc.n +2 ; addr=0x0013a5e6: memcpy + 0x0000009a 0013a5e2: ldrh r3, [r1, #0] 0013a5e4: strh r3, [r0, #0] ; <- r0 contains 0x98000075, this triggers a jump to DataAbortHandler in the vector table
.section .vectors, "a" _vector_table: ldr pc,=_boot ldr pc,=Undefined ldr pc,=SVCHandler ldr pc,=PrefetchAbortHandler ldr pc,=DataAbortHandler NOP /* Placeholder for address exception vector*/ ldr pc,=IRQHandler ldr pc,=FIQHandler
The call was memcpy(0x98000000, &valid_data, 119);
Stacey
01-27-2020 01:03 PM
01-30-2020 06:53 AM
Of course! There's no such thing as an unaligned byte-wise operation. That's because all single byte transactions are automatically aligned, since there's no way to create an unaligned byte transaction.
Halfwords can be unaligned if one part of the word falls on one bus word, and the other part falls on another bus word. For example, with a 32-bit bus, if you try to write to byte 3 and 4. Byte 3 will be issued in the first write beat, and byte 4 in the second write beat. The problem only gets worse with full word writes.
Dan
01-30-2020 09:24 AM
Indeed. My followup was directed to anyone trying to work around this bug with the SDK 2018.2 memcpy to an external AXI bus on an Ultrascale+ Zynq part.
Stacey | https://forums.xilinx.com/t5/Processor-System-Design-and-AXI/Writing-bytes-on-AXI-error/m-p/1069895 | CC-MAIN-2021-31 | refinedweb | 799 | 72.76 |
It's like being \.'ed, only with less penguins.
He's also got an update to his LayoutAnimation series with a pretty cool new technique - I'll have to consider updating my codebase around his idea.
Not to sound too much like a fanboy, but Avalon just plain rocks. I’ve spent the last fifteen years simultaneously cursing (“I hate you!”) and coercing (“…but I’ll love you if you work!”) GDI and User into doing my evil bidding, and I’ve finally found a replacement that I actually want to use. Lord knows there’s been no dearth of presentation layers in the interim, but none of them caught my eye; either they didn’t have the full functionality I wanted, or they just plain felt heavy. Avalon, though, really fits the bill (ok, yes, it’s heavy, but for whatever reason it doesn’t feel that way). Especially now while I’m still learning about it, there are lots of ‘ah, suh-weet’ moments as I find that the pain of programming has been reduced.
Aaaaand then there’s Drag and Drop.
For whatever reason - perhaps there are other more important things to focus on shipping, or perhaps the old way was “good enough” – Avalon’s Drag & Drop implementation is simply a very thin wrapper around the same OLE drag & drop that I’ve been scratching my head over for years. You can see this for yourself by using the excellent Reflector .Net class browser and looking at the System.Windows.DragDrop implementation.
On the plus side this means that, unlike with the rest of Avalon (aside from the indispensible O’Reilly book), there is an absolute glut of information available discussing how to do Drag & Drop.
On the down side though, this means that it’s still challenging to do anything other than the most basic Drag&Drop implementation. Inter-app support, custom cursors, multi-drop-target scenarios, and custom drag windows require a little more effort than the rest of Avalon implies should be necessary.
Given some of the visual cues I’ll be adding to the DragDropTilePanel, the inter-app support (e.g., between two different instances of your app) provides the biggest challenge, as it means that we have to fully decouple our DragSource and DropTarget implementations. For many developers, such as those working on prototype, beta, or constrained-scenario apps, disallowing inter-app drag & drop is an acceptable limitation; that said, we really should write it correctly so that the drag source and drop target don’t share implementation.
That said; I’m going to wuss out for the next couple of posts and describe a simple Drag&Drop implementation that ignores inter-app support and clean factoring of drag source and drop target. Hopefully Dan and Ben won’t read this and give me grief about taking the easy way out…
Here’s the minimum code necessary to add Drag & Drop support to the TilePanel base class. On the plus side, this is very little code! Also, notice that even though we’re not doing anything related to animation here, all of the child objects smoothly animate to their new positions after a drop – all thanks to the animation code that Dan originally implemented.
public class DragDropTilePanel : TilePanel
{
protected override void OnInitialized(EventArgs e)
{
// Add mouse event handlers to each of our child objects
foreach (FrameworkElement child in Children)
{
child.MouseLeftButtonDown += new MouseButtonEventHandler(child_MouseLeftButtonDown);
child.MouseMove += new MouseEventHandler(child_MouseMove);
}
base.OnInitialized(e);
}
The code above sets up the mouse event handlers that inform us when the user interacts with one of the TilePanel’s child objects.
void child_MouseLeftButtonDown(object sender, MouseButtonEventArgs eventArgs)
// User pressed the mouse button on one of our draggable children. Don't start dragging
// just yet, but do track where the mouse was when the button was pressed.
FrameworkElement childElement = (FrameworkElement)sender;
_mouseDownLocationRelativeToChild = eventArgs.GetPosition(childElement);
We don’t start dragging until the user’s moved a sufficient distance from where they pressed the mouse button, so don’t start the drag in the MouseDown handler…
void child_MouseMove(object sender, MouseEventArgs eventArgs)
if (eventArgs.LeftButton == MouseButtonState.Pressed)
{
FrameworkElement draggedChildElement = (FrameworkElement)sender;
// The Mousebutton is pressed, but we haven't started dragging yet; check
// to see if we should. Only do so if we've moved far enough away from
// the initial mouse-down location.
Point currentMouseLocationRelativeToChild = eventArgs.GetPosition(draggedChildElement);
if (!PointIsOutsideDragThreshold(currentMouseLocationRelativeToChild))
{
// We're not ready to start dragging quite yet 'cause the user hasn't
// moved the mouse far enough.
return;
}
// Fade out the dragged item to give visual feedback that it's being moved.
draggedChildElement.Opacity = 0.5f;
// Create the DataObject that will contain the dragged child. This won’t work
// When dropped on another app (since it won’t be able to deref the DraggedObject)
DataObject dataObject = new DataObject();
dataObject.SetData("DraggedObject", draggedChildElement);
// Do the actual drop.
DragDrop.DoDragDrop(this, dataObject, DragDropEffects.Copy | DragDropEffects.Move);
// Restore the object's opacity.
draggedChildElement.Opacity = 1.0f;
The code above belongs to the ‘drag source’ – the object which instantiates the drag event. It first checks to ensure that the user has moved the mouse far enough to trigger the Drag; once that’s happened, it sets up the Drag by wrapping the dragged child element and adding it to the dataObject (which you can think of as a varargs passed to the Drag event handlers). Note that, to support inter-app drag&drop, we’d need to ensure that all data we store in dataObject is serializable (or, I suppose, we could use Remoting, but that’s more of a black box to me right now). If we try to pass an object like a FrameworkElement, then the OnDrop handler, which could well be called in another app, would fail as it tried to get that data from the DataObject.
Finally, it calls DoDragDrop. This function call is synchronous – it doesn’t return until the drag event is completed.
protected override void OnDrop(DragEventArgs dragArgs)
FrameworkElement childElement = (FrameworkElement)dragArgs.Data.GetData("DraggedObject");
// Get the current mouse position, and add half-an-object-width to it so that
// the drop position is more natural when an object is dropped onto another object.
// (drop onto the left half of an object, it'll insert before that one; drop onto
// the right half of an object, it'll insert after it).
Point currentMousePosition = dragArgs.GetPosition(this);
Point halfOffsetMousePosition = new Point(currentMousePosition.X + ChildSize / 2, currentMousePosition.Y);
// Move the object to the drop point. Set the childElement's DataContext
// to the object's new index in the list (caculated from the mouse position)
Children.Remove(childElement);
int dropIndex = GetChildIndexFromPosition(halfOffsetMousePosition);
Children.Insert(dropIndex, childElement);
childElement.DataContext = dropIndex;
The OnDrop code above belongs to the “drop target” – the object on which the dragged object was dropped. As described above, for our purposes here we’re assuming that OnDrop is in the same object (and same object instance) as the DoDragDrop call.
internal bool PointIsOutsideDragThreshold(Point currentMouseLocationRelativeToChild)
// Use the SystemParameter's drag distances and create a rectangle centered
// around the mousedown position - check to see if the current mouse position
// is outside that rectangle; if so, start a'draggin.
double horizontalDragThreshold = SystemParameters.MinimumHorizontalDragDistance;
double verticalDragThreshold = SystemParameters.MinimumVerticalDragDistance;
Rect dragThresholdRect = new Rect(_mouseDownLocationRelativeToChild.X - horizontalDragThreshold,
_mouseDownLocationRelativeToChild.Y - verticalDragThreshold,
horizontalDragThreshold * 2,
verticalDragThreshold * 2);
return !dragThresholdRect.Contains(currentMouseLocationRelativeToChild);
Point _mouseDownLocationRelativeToChild;
}
The function (and Point variable) above are used to determine if the mouse has moved outside the drag threshold.
There are a few other minor tweaks to round out our Drag support. First, we add the GetChildIndexFromPosition support function to TilePanel. This could have gone in DragDropTilePanel, but it could find other uses in TilePanel as well. Here’s that code.
protected int GetChildIndexFromPosition(Point position)
int row = (int)(position.Y / _oldChildSize);
int column = Math.Min(_oldChildrenPerRow, (int)(position.X / _oldChildSize));
int index = row * _oldChildrenPerRow + column;
return Math.Min(index, Children.Count);
The ‘Math.Min’s are there to deal with cases where the user drops after the end of a row.
And then finally, we need to tweak the xaml slightly to support our new DragDropTilePanel:
<?Mapping XmlNamespace="MyApp" ClrNamespace="BasicDragDrop" ?>
<Window x:Class="BasicDragDrop.Window1"
xmlns=""
xmlns:x=""
xmlns:
<Grid>
<RowDefinition Height="24"/>
<RowDefinition Height="*"/>
<Slider MinWidth="200" Minimum="50" Maximum="300"
SmallChange="40" Name="_slider" Grid.
<!-- Note: it's important to have a background in the TilePanel,
otherwise the OnDragOver call won't get to it! Not sure why... -->
<myapp:DragDropTilePanel
<Border Background="Red" Margin="4" />
<Border Background="Green" Margin="4" />
<Border Background="Blue" Margin="4" />
</myapp:DragDropTilePanel>
</Grid>
</Window>
Most of the changes are in converting from a StackPanel to a Grid so that the TilePanel completely fills the remaining window space. We also specify “AllowDrop” here to tell Avalon that we’re a valid drop target (otherwise we wouldn’t get drop events). Also, note that for whatever reason, we need to specify a background to our tilePanel, otherwise our OnDragOver doesn’t get called (we don’t have OnDragOver in the DragDropTilePanel implementation above, but we will soon enough, and this will prob’ly catch us, so we’ll add it now).
[Edit: Yeah, I realized I should be using a DockPanel instead of a Grid. I'll rewrite it...]
And that’s it. All in all, not a lot of code to add basic drag and drop support that works with any child object type! Of course, I’m really punting on some key issues (especially that inter-app bit). We’ll clean that up soon enough.
Updated project file attached (built against the Dec CTP. Compile against other versions at your own risk).
Next up: Custom drag windows.
Every Sunday, my wife and I head down to Starbucks with the Sunday paper and a red felt-tip pen, and tackle the New York Times crossword puzzle (or, if we’re particularly sleep-deprived because of our baby boy, the Seattle Times crossword – yes, I feel guilty every time we “wimp out”). Each time I open the paper, I’m hoping to see something different in the puzzle; mysterious circles in the squares, an odd-shaped puzzle, and so on. The best puzzle yet was the one that had tiny comic panels as clues; I don’t remember what they ended up meaning, but I do remember being excited about it.
When I see this – something different – I love it because it means we’re in for an Aha moment. Why are those circles there? What do those comics mean? The reason why I like the NYT Sunday puzzle so much is even if they don’t have some visual trick to them, discovering the common theme almost always elicits an “ah, cool.” It’s like humor in a way – the funniest stuff is that which ‘tricks’ you; looking at something for a long time and then seeing something that wasn’t there a moment ago (and yet, was there) triggers something pleasurable in the brain.
Yes, I’m going somewhere with this. Be patient…
Programming is just like crossword puzzles. It’s a mental exercise that lets you set attainable, quantifiable goals for yourself, and receive pleasure when you achieve those goals. And the Aha moment is the greatest part of it. It doesn’t matter if you’re working through a new algorithm or tracking down bugs and memory leaks. When you “get it”, you inevitably smile or let out a sigh of relief. Aha. It gives you that little mental-adrenaline boost that keeps you coding, even if it’s well past midnight.
Dan Crevier wrote a couple of blog entries (part 1, part 2) last October that talk about how to create a smoothly animating layout panel akin to what we’ve got in Project Max. Basically, when the window is resized, his TilePanel class smoothly animates its childrens’ movement so that they layout in a grid pattern (it’s hard to describe – you can download Max to see what I’m talking about).
The blog entries are very well written, but as I looked over the code, I kept wondering how it could work if the user resized the window while objects were currently smoothly re-laying themselves out. Offhand, it seemed like it’d require some pretty hairy tracking, but he didn’t seem to have any variables for that purpose.
It took about five minutes of thinking about the code before I got my ‘Aha’ moment; he’s found a way to let Avalon worry about all of the animation. All he’s doing is tracking where the child object should be, and he’s letting Avalon worry about (a) where the child object currently is, and (b) how to get from there to where it should be. This is done through the RenderTransform, which deals with the hairy tracking itself.
This was a twin Aha moment – not only did I suddenly understand how his code worked, but the sheer simplicity of it provided another twinge of coooool. He was able to offload the gross/fragile stuff to Avalon and just focus on where the child objects should be.
Why mention this? Because that particular Aha moment, like so many others, made me wonder what new doors my new found knowledge had opened. How hard, for example, would it be to add drag/drop to his TilePanel, and get a smoothly animating TilePanel that supported child reordering? And that question provided the impetus for me to create this blog.
So; finally, some code.
The first block of posts here will focus on adding Drag/Drop. I’ll be deriving a DragDropTilePanel from Dan’s TilePanel, with an admittedly fairly arbitrary goal of keeping the changes to the base TilePanel to a minimum.
The first (and pretty much only) change necessary in the base TilePanel class is a conceptual change. Because his TilePanel doesn’t support adding or removing children, the ArrangeOverride method is able to just worry about “Ignoring animation, where should the child object be right now?” He does this by using the child’s index in the list and calculating it’s grid (row/column) position.
Now though, those indices can change when children are added or removed, and this requires the TilePanel to now track two things:
(1) Where should the child object be right now, and
(2) Where should the child object have been the last time we moved it around?
By tracking both of these variables, we can smoothly animate adding/removing child objects, and notice that we still aren’t worrying about “Where is the child object right now” – Avalon continues to do that through the child's RenderTransform.
So how does the code change? The answer is very minimally. Here is Dan’s original ArrangeOverride, with changes marked in bold:
protected override Size ArrangeOverride(Size finalSize)
{
// Calculate how many children fit on each row
int childrenPerRow = Math.Max(1, (int)Math.Floor(finalSize.Width / this.ChildSize));
for (int i = 0; i < this.Children.Count; i++)
FrameworkElement child = this.Children[i] as FrameworkElement;
// Figure out where the child goes
Point newOffset = CalcChildOffset(i, childrenPerRow, this.ChildSize);
if (_oldChildrenPerRow != -1)
// Figure out where the child is now
// If the child's index has changed, it's because something has been added or
// removed. We need to use the child's old index to determine its old offset.
// The index is stored (for simplicity) in the child's DataContext.
Point oldOffset = CalcChildOffset((int)child.DataContext, _oldChildrenPerRow, _oldChildSize);
if (child.RenderTransform != null)
oldOffset = child.RenderTransform.Transform));
// Store the child's new index in the list. This'll normally
// be the same, unless an item has been added or removed from the list.
child.DataContext = i;
// Position the child and set its size
child.Arrange(new Rect(newOffset, new Size(this.ChildSize, this.ChildSize)));
_oldChildrenPerRow = childrenPerRow;
_oldChildSize = this.ChildSize;
return finalSize;
}
Ignoring comments, we only changed a few lines of code and we’ve now got the ability to smoothly add and remove child objects. This works by tracking the child object’s previous index (stored for convenience in child.DataContext), which gives us where the child should have been, and the child object’s current index (which is obtained simply by enumerating the children), which gives us where the child should currently be. Again, Avalon uses the child's RenderTransform to handle where the child currently is. After we’re done setting the child’s position, we store the child’s new index back in child.DataContext.
Storing the “previous index” in DataContext isn’t a very real-world thing to do – normally the children are objects which use DataContext for their own purposes. I’m using it here because I want to minimize changes to the base TilePanel code - plus, it’s kind of cool to see that this all works with basic Avalon elements, not just custom “drag-enabled” objects. Heck, try replacing one of the <Border>s with:
<TextBox Text="Test" />
And it’ll smoothly relayout just like any other child. Pretty cool!
In order to test this, we can easily add the ability to remove a child object by clicking on it. Add the following to the TilePanel class…
protected override void OnInitialized(EventArgs e)
// If the user clicks on a child object, we want to remove it.
foreach (FrameworkElement child in Children)
child.MouseLeftButtonDown += new MouseButtonEventHandler(ChildPressed);
void ChildPressed(object sender, MouseButtonEventArgs eventArgs)
Children.Remove((UIElement)sender);
…and you can now click on child objects to remove them . Try changing the animation time (the “500” in MakeAnimation) to 2000 or so, and try mixing removing child objects and resizing the border – it all works.
(Note that, in what may be a bug in Avalon, you won’t get subsequent mouse down events if you click the mouse button on an object that Avalon has moved “under” the cursor – you’ll need to move the mouse to get the event).
Alright, the babble/code ratio was dangerously off-kilter in this post – that shouldn’t be the norm moving forward. Next up, dragging and dropping!
I’ve attached a link to the project file. Note that this works with the Dec CTP. YMMV with other versions.
</Jeff>
Greetings, program! My wife can't stand to hear me babble on about programming, so I'm going leverage the internets (and maybe even the interwebs) to talk about code. You may not be able to stand it either, but then, you can't make me sleep on the couch, so tough!
I've been working for Microsoft for a while now. When I say "a while", I mean: long enough that I can't even find an english web page that refers to the first product I worked on. Yes, you crazy kids and your C language and your OOPses. In my day, code started on column seven, and by God not one space more!
I've worked on a bunch of other stuff too, some pretty cool, some very cool. I'm currently working on UI for Project Max along with some other wise guys whose blogs you may already be reading. I'm neck-deep in Avalon (AKA WinFX for you n00bs) goodness, so I expect most of my posts will focus on that.
Finally, a request: if you read something here and think, "wait, there's a better way..." or "what is this guy smokin'?!?" then by all means post a comment and correct-away! | http://blogs.msdn.com/jeffsim/ | crawl-002 | refinedweb | 3,239 | 54.73 |
This MPI program is written in C. When I enter 2 as the number of processors, the output is as follows:
P:0 Got data from processor 1 P:0 Got 100 elements P:0 value[5]=5.000000
But when I enter 3 or more processors, the program outputs
P:0 Got data from processor 1 P:0 Got 100 elements P:0 value[5]=5.000000
And then it stalls, and nothing else gets printed. I have to exit the program with [ctrl]+[c]. I do not know why the program stalls. I'd appreciate some hints or good direction.
Here is the code:
#include <stdio.h> #include <stdlib.h> #include <mpi.h> /* Run with two processes */ int main(int argc, char *argv[]) { int rank, i, count; float data[100],value[200]; MPI_Status status; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank); if(rank==1) { for(i=0;i<100;++i) data[i]=i; MPI_Send(data,100,MPI_FLOAT,0,55,MPI_COMM_WORLD); } else { MPI_Recv(value,200,MPI_FLOAT,MPI_ANY_SOURCE,55,MPI_COMM_WORLD,&status); printf("P:%d Got data from processor %d \n",rank, status.MPI_SOURCE); MPI_Get_count(&status,MPI_FLOAT,&count); printf("P:%d Got %d elements \n",rank,count); printf("P:%d value[5]=%f \n",rank,value[5]); } MPI_Finalize(); }
Because you are sending the data only to the process with
rank == 0 with the process with
rank == 1. That is why it works fine with 2 processes (0 and 1). With more processes, the processes with rank 2,3,4,5.... will enter the
else block and wait for non-sent data. That is why they halt the execution (waiting for data that will be never sent). You should make the process with rank 1 send the data to all other processes, with a single for loop encapsulating the send operation and give the for loop iterator as the destination rank in the
MPI_Send call. | https://www.codesd.com/item/why-does-this-mpi-program-no-longer-produce-information-with-more-than-2-processors.html | CC-MAIN-2020-45 | refinedweb | 312 | 65.42 |
Before someone hits me with a "Use Boost" - know that I want to know how to do this myself. :) And I've had a few beers. Here it is:
So, I seem to get the data I want, but then there's what looks like a seg fault. Big old Glibc error.So, I seem to get the data I want, but then there's what looks like a seg fault. Big old Glibc error.Code:
// Serializing a vector -
// Why I shouldn't read Reddit while watching youtube CompSci videos
#include <iostream>
#include <fstream>
#include <vector>
using namespace std;
struct vec3d
{
vec3d() {};
vec3d(double x, double y, double z) {this->x = x; this->y = y; this->z = z;}
virtual ~vec3d() {}
double x;
double y;
double z;
};
typedef vector<vec3d> PointList;
int main()
{
cout << "Structure" << endl;
cout << "---------" << endl;
PointList Points;
vec3d P1(1.99, 5.0, 9.0); Points.push_back(P1);
vec3d P2(2.0, 6.0, 10.555); Points.push_back(P2);
vec3d P3(3.0, 7.55, 11.0); Points.push_back(P3);
vec3d P4(4.5, 8.0, 12.0); Points.push_back(P4);
// Searializing struct to point.dat
ofstream os("points.dat", ios::binary);
if(!os.is_open()) {
cout << "Error opening points.dat for write" << endl;
return 1;
}
//int magicnumber = sizeof(Points);
os.write((char*)&Points, sizeof(Points));
os.close();
PointList NewPoints;
int file_sz;
// Reading from it
ifstream is("points.dat", ios::binary);
if(!is.is_open()) {
cout << "Error opening points.dat for read" << endl;
return 1;
}
is.seekg(0, ios::end);
file_sz = is.tellg();
is.seekg(0, ios::beg);
//is.read((char*)&NewPoints, magicnumber);
NewPoints.resize(file_sz);
is.read((char*)&NewPoints, file_sz);
// Display
cout << "Output:" << endl;
PointList::const_iterator it;
for(it = NewPoints.begin(); it != NewPoints.end(); ++it)
{
cout << it->x << " " << it->y << " " << it->z << endl;
}
return 0;
}
Sounds like a cool error.Sounds like a cool error.Code:
*** glibc detected *** /storage/Projects/Recent/File Input and Output/bin/Debug/File Input and Output: corrupted double-linked list: 0x0000000000866110 ***
Now, I would think the size of the file would suffice as the size of the NewPoints vector. But there's padding and other stuff going on, I'm sure. If someone has time, show mercy - waxing educational is welcome.
Writing and reading a vector to a binary file should not be that hard, and it probably isn't - but c++ is an expert's language... and I'm not there yet.
Side note: I picked up Scott Meyers Effective C++, I love it. Very approachable style, not nearly as dry as Koenig & Moo.
Edit: I know that's a c-style ungreppable cast, and I hate it too. But the C++ static_cast wouldn't even compile. I'm so ashamed, so very
ashamed.
Edit 2: Reading Salem's recommended link
[36] Serialization and Unserialization Updated! , C++ FAQnow... =) | https://cboard.cprogramming.com/cplusplus-programming/143556-serializing-vector-printable-thread.html | CC-MAIN-2017-34 | refinedweb | 465 | 69.79 |
Opened 6 years ago
Closed 6 years ago
#10940 closed (invalid)
Omission in tutorial, part 4: generic views
Description
When refactoring the poll app for generic views, no mention is made of the need to change one of the parameters passed into the vote() view from poll_id to object_id.
Original:
def vote(request, poll_id):
...snip...
Should be:
def vote(request, object_id):
...etc...
Change History (1)
comment:1 Changed 6 years ago by timo
- Needs documentation unset
- Needs tests unset
- Patch needs improvement unset
- Resolution set to invalid
- Status changed from new to closed
Note: See TracTickets for help on using tickets.
This is not necessary since vote is not a generic view. Notice that the URLconf keeps the poll_id variable:
(r'^(?P<poll_id>\d+)/vote/$', 'mysite.polls.views.vote') | https://code.djangoproject.com/ticket/10940 | CC-MAIN-2015-11 | refinedweb | 129 | 59.84 |
tmp open a corresponding FILE stream. The tmpfile64() function is a 64-bit version of tmpfile(). The file is automatically removed when it's closed or when the program terminates. The file is opened in update mode (as in fopen() 's w+ mode).
If the process is killed between file creation and unlinking, a permanent file may be left behind.
When a stream is opened in update mode, both reading and writing may be performed. However, writing may not be followed by reading without an intervening call to the fflush() function, or to a file-positioning function ( fseek() , fsetpos() , rewind() ). Similarly, reading may not be followed by writing without an intervening call to a file-positioning function, unless the read resulted in end-of-file.
Errors:
- EACCES
- The calling process doesn't have permission to create the temporary file.
- EMFILE
- The calling process already has already used OPEN_MAX file descriptors.
- ENFILE
- The system already has the maximum number of files open.
- EROFS
- The filesystem for the temporary file is read-only.
Examples:
#include <stdio.h> #include <stdlib.h> static FILE *TempFile; int main( void ) { TempFile = tmpfile(); … fclose( TempFile ); /* The temporary file will be removed when we exit. */ return EXIT_SUCCESS; }
Classification:
tmpfile() is ANSI, POSIX 1003.1; tmpfile64() is Large-file support
Last modified: 2013-12-23 | http://developer.blackberry.com/native/reference/core/com.qnx.doc.neutrino.lib_ref/topic/t/tmpfile.html | CC-MAIN-2014-15 | refinedweb | 216 | 59.4 |
Sorry for how sloppy the code was, I have fixed it up some.
Sorry for how sloppy the code was, I have fixed it up some.
Hello,
I am having problem with the program below. I can get the nextJButton to work but the previousJButton won't. previousJButton is supposed to make the page number go down, but it won't...
That solved the problem. I don't really know much about formatter myself, but I think your right about it being the problem. Thanks for the help
This is the shortened program, below it is the test program which I keep in another java file. I will comment at the problem section.
import java.util.Vector;
import java.awt.*;
import...
Hello, I am trying to clear a jlabel so I can put the current page number up. Instead it writes each number right after another and the jlabel won't clear. I am using setText("") Here is the... | http://www.javaprogrammingforums.com/search.php?s=5d859e83865a70261e6c129c7bae13df&searchid=783954 | CC-MAIN-2014-10 | refinedweb | 159 | 76.52 |
Want to see the full-length video right now for free?
On this week's episode, Chris takes us through everything we need to work with PDFs in our Rails apps: the easiest way to generate them, how to properly serve them as responses in our controllers, and even how to test them.
There are many ways to generate PDFs in Ruby and Rails, but we're going to focus on two: Prawn and PDFKit. Prawn gives you more control over output but has a steeper learning curve, while PDFKit lets you use what you already know (HTML) to generate PDFs from standard Rails view and style code.
The first tool that we'll look at is known as Prawn. It is a Ruby gem that
provides a powerful DSL for generating PDFs. To see a simple example,
install the
prawn gem and then run the following bit of Ruby:
require "prawn" Prawn::Document.generate("prawn_example.pdf") do text "Hello world!" stroke_circle [20, 20], 10 end
You should now have a new file called
prawn_example.pdf, with a bit of text
at the top and a circle at the bottom. Yay!
To see examples of just about anything you could ever want to do, check out Prawn by example, the official manual (which, of course, is generated by Prawn).
Prawn is very powerful, and if you need extremely precise control over PDF output, it's a good choice. The downside, however, is that you have to wrap your head around its rendering model, and learn its DSL for laying out documents.
As it turns out, however, we already know a pretty good language for laying out documents -- HTML. Wouldn't it be nice if we could write HTML and have it rendered as PDF?
Enter wkhtmltopdf (WebKit HTML to PDF), an engine that will take HTML and CSS, render it using WebKit, and output it as a PDF with surprisingly high quality and consistency.
wkhtmltopdf is a command-line tool, but there are several Ruby gems that wrap
it up for us. The one we'll focus on is PDFKit. To see a simple example,
install wkhtmltopdf on your machine, install the
pdfkit gem, and then run
the following bit of Ruby:
require "pdfkit" kit = PDFKit.new(<<-HTML) <p>Hello world!</p> HTML kit.to_file("pdfkit_example.pdf")
You should now have a new file called
pdfkit_simple_example.pdf with a bit of
text at the top. Yay!
What's awesome about pdfkit is that we can write the HTML and CSS that we know and love to build more complicated PDFs:
require "pdfkit" kit = PDFKit.new(<<-HTML) <style> * { color: red; } td { border: 1px solid #555; margin: 0; } tr:nth-child(2n) { background: #ccc; } </style> <p>Hello world!</p> <table> <tr> <td>Hello</td> <td>World</td> <td>-</td> <td>Data</td> </tr> <tr> <td>Hello</td> <td>-</td> <td>World</td> <td>Data</td> </tr> <tr> <td>-</td> <td>Hello</td> <td>World</td> <td>Data</td> </tr> </table> HTML kit.to_file("pdfkit_complicated_example.pdf")
You should now have a new file called
pdfkit_complicated_example.pdf with a
CSS-styled table of data. Yay!
We have basically all of HTML and CSS available, so we could make this look as nice as we want. PDFKit gives us a great balance between control and ease of use.
Now, let's take a look at how to actually use this in the context of a Rails app. You can follow along with the video in the associated Invoicer example application.
To start, we'll quickly review the foundation of this app based on its models and relationships. You can check this out in the Add initial models Product, Invoice, & LineItem commit, or check out the code locally with:
$ git checkout -b foundations 3eda9c631
If you take a look at
db/schema.rb, you'll see that we have three main models
that we're going to be working with:
Invoice,
Product, and
LineItem..
In the next commit we introduce a class to wrap up our PDF generation logic, as well as a layout, stylesheet, and view for our PDF. You can see all the changes in the Add Download class to handle PDF rendering commit, or check them out locally with:
$ git checkout a260c81
In addition, we also add both the PDFKit gem, and the render_anywhere gem.
PDFKit is explained above, but render_anywhere is new here. Its job is to allow
us to render our PDF template from our
Download object.
require "render_anywhere" class Download include RenderAnywhere def initialize(invoice) @invoice = invoice end def to_pdf kit = PDFKit.new(as_html) kit.to_file("tmp/invoice.pdf") end def filename "Invoice #{invoice.number}.pdf" end private attr_reader :invoice def as_html render template: "invoices/pdf", layout: "invoice_pdf", locals: { invoice: invoice } end end
The view, layout, and stylesheet are very familiar; in fact, they are simply copies of the existing views used to render the invoice show page. The one interesting bit is the inlining of the stylesheet into the HTML page. This is not necessary, but it simplifies the PDF generation as wkhtmltopdf now does not need to fetch any external resources to render the PDF.
<style> <%= Rails.application.assets.find_asset("invoice.pdf").to_s %> </style>
Our next commit introduces the needed code to render the PDF via a Rails controller. You can see all the changes in the Add DownloadsController for sending PDFs commit, or check it out locally with:
$ git checkout 63bcdb0
The changes are thankfully very simple. We first add a "Download" link to the
invoice page. Two interesting aspects here are the use of the
format: "pdf"
option in the path helper, and the addition of
target: "_blank" which is an
HTML option that will cause the link to open in a new tab.
We add a singular nested resource to our routes for the
download action,
nested within our invoice. Often these sorts of routes will be added as
additional member actions within a controller, for instance adding a
download action to the
InvoicesController, but in the spirit of REST, we
want to break this out and declare that a
Download is a distinct resource,
and not overload the
InvoicesController.
Lastly, we add the
DownloadsController which has the single
show action
which only responds with PDF via the
respond_to block. We use Rails'
send_file method to actually send the PDF, passing the needed options to
provide a filename and specify how to download.
class DownloadsController < ApplicationController def show respond_to do |format| format.pdf { send_invoice_pdf } end end private def invoice Invoice.find(params[:invoice_id]) end def download Download.new(invoice) end def send_invoice_pdf send_file download.to_pdf, download_attributes end def download_attributes { filename: download.filename, type: "application/pdf", disposition: "inline" } end end
Our next commit adds a bit of support code to allow for more rapid iteration while working in development mode. In production, we only want to use our PDF view to generate the PDF, but in development we'll be able to iterate and tweak our design and layout of the PDF much more quickly if we can render it as a normal HTML view.
You can see all of the changes in the Render PDF sample as HTML in dev mode commit, or check it out locally with:
$ git checkout 31a4233
We enable this by adding a development environment specific format handler in
the
DownloadsController to render the HTML view. In addition, we expose the
render attributes in our
Download objects so both the PDF generation and the
development-only HTML rendering will use the same rendering settings and data.
def show respond_to do |format| format.pdf { send_invoice_pdf } + + if Rails.env.development? + format.html { render_sample_html } + end end end
Our next commit adds a feature spec for our download code that allows us to make a number of assertions about the download file, and the contents therein. You can see all of the changes in the Add feature spec with PDF related assertions commit, or check them out locally with:
$ git checkout c4e5ace
To start, we'll add the pdf-reader gem which allows us to read in the PDF and make assertions about the content of the document. We end up with only the text content, so we're not able to make the same level of detailed assertions we can with say Capybara's page DSL, but it is certainly better than not testing at all.
In addition, we can wrap up the
headers of the response generated by our app
to allow us make a number of assertions about the download file itself.
describe "User downalods PDF" do scenario "for an invoice with normal data" do product = create(:product, item_number: 'abc-123') invoice = create(:invoice) line_item = create(:line_item, product: product, invoice: invoice) visit invoice_path(invoice) click_link "Download PDF" expect(content_type).to eq("application/pdf") expect(content_disposition).to include("inline") expect(download_filename).to include(invoice.number) expect(pdf_body).to have_content(product.description) end # ... end
Lastly, we have a commit that adds support for running this PDF generating app on Heroku. Since we rely on an external command, namely wkhtmltopdf, we need it to be present on our server in order for the app to run. Thankfully, we can add a single gem which provides a Heroku friendly version of wkhtmltopdf, and with that we're set.
# Gemfile group :staging, :production do gem "wkhtmltopdf-heroku" end | https://thoughtbot.com/upcase/videos/generating-pdfs-with-rails | CC-MAIN-2020-40 | refinedweb | 1,551 | 60.24 |
Metadata plugin for use in the OMERO CLI.
Project description
OMERO metadata plugin
Plugin for use in the OMERO CLI. Provides tools for bulk management of annotations on objects in OMERO.
Requirements
- OMERO 5.6.0 or newer
- Python 3.6 or newer
Installing from PyPI
This section assumes that an OMERO.py is already installed.
Install the command-line tool using pip:
$ pip install -U omero-metadata
Note the original version of this code is still available as deprecated code in version 5.4.x of OMERO.py. When using the CLI metadata plugin, the OMERO_DEV_PLUGINS environment variable should not be set to prevent conflicts when importing the Python module.
Usage
The plugin is called from the command-line using the omero command:
$ omero metadata <subcommand>
Help for each command can be shown using the -h flag. Objects can be specified as arguments in the format Class:ID, such as Project:123.
Bulk-annotations are HDF-based tables with the NSBULKANNOTATION namespace, sometimes referred to as OMERO.tables.
Available subcommands are:
- allanns: Provide a list of all annotations linked to the given object
- bulkanns: Provide a list of the NSBULKANNOTATION tables linked to the given object
- mapanns: Provide a list of all MapAnnotations linked to the given object
- measures: Provide a list of the NSMEASUREMENT tables linked to the given object
- original: Print the original metadata in ini format
- pixelsize: Set physical pixel size
- populate: Add metadata (bulk-annotations) to an object (see below)
- rois: Manage ROIs
- summary: Provide a general summary of available metadata
- testtables: Tests whether tables can be created and initialized
populate
This command creates an OMERO.table (bulk annotation) from a CSV file and links the table as a File Annotation to a parent container such as Screen, Plate, Project or Dataset. It also attempts to convert Image or Well names from the CSV into Image or Well IDs in the OMERO.table.
The CSV file must be provided as local file with --file path/to/file.csv.
If you wish to ensure that number columns are created for numerical data, this will allow you to make numerical queries on the table. Column Types are:
- d: DoubleColumn, for floating point numbers
- l: LongColumn, for integer numbers
- s: StringColumn, for text
- b: BoolColumn, for true/false
- plate, well, image, dataset, roi to specify objects
These can be specified in the first row of a CSV with a # header tag (see examples below). The # header row is optional. Default column type is String.
NB: Column names should not contain spaces if you want to be able to query by these columns.
Examples:
To add a table to a Project, the CSV file needs to specify Dataset Name and Image Name:
$ omero metadata populate Project:1 path/to/project.csv
project.csv:
# header s,s,d,l,s Image Name,Dataset Name,ROI_Area,Channel_Index,Channel_Name img-01.png,dataset01,0.0469,1,DAPI img-02.png,dataset01,0.142,2,GFP img-03.png,dataset01,0.093,3,TRITC img-04.png,dataset01,0.429,4,Cy5
This will create an OMERO.table linked to the Project like this:
If the target is a Dataset instead of a Project, the Dataset Name column is not needed.
To add a table to a Screen, the CSV file needs to specify Plate name and Well. If a # header is specified, column types must be well and plate.
screen.csv:
# header well,plate,s,d,l,d Well,Plate,Drug,Concentration,Cell_Count,Percent_Mitotic A1,plate01,DMSO,10.1,10,25.4 A2,plate01,DMSO,0.1,1000,2.54 A3,plate01,DMSO,5.5,550,4 B1,plate01,DrugX,12.3,50,44.43
This will create an OMERO.table linked to the Screen, with the Well Name and Plate Name columns added and the Well and Plate columns used for IDs:
If the target is a Plate instead of a Screen, the Plate column is not needed.
Developer install
This plugin can be installed from the source code with:
$ cd omero-metadata $ pip install .
License
This project, similar to many Open Microscopy Environment (OME) projects, is licensed under the terms of the GNU General Public License (GPL) v2 or later.
2018-2020, The Open Microscopy Environment
Project details
Release history Release notifications
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/omero-metadata/0.5.0/ | CC-MAIN-2020-10 | refinedweb | 733 | 53.31 |
This tutorial is regarding controlling servo motor with ESP32 over a web server using Arduino IDE. You will discover how to control Servo motor with ESP32 and you will also ready to make a simple web server with a slider to control the position of servo motor in both positions. Web server consists of a slider with a position from 0-180. With this slider, a user can control the shaft position. We use the Arduino IDE to program ESP32 dev kit module.
Video demonstration
Prerequisites For This Tutorial
To follow the concepts of this tutorial, you should have a background knowledge required to grasp concepts.
- First, you should know have an introduction of ESP32 boards, we are using ESP32 dev kit in this tutorial, so can read: Introduction to ESP32 development board
- You should also have an idea of GPIO pins of ESP32, you read this: How to use GPIO pins of ESP32 devkit
- As mentioned ahead, we are using Arduino IDE to program ESP32, you can read about how to install ESP32 in Arduino IDE and How to program ESP32.
Components Required
We will be using these components for this tutorial:
- ESP32 DOIT DEVKIT Development board
- Few jumper wires
- Servo motor ( you can use any sort of servo motor within the current limit of ESP32)
Interfacing Servo Motor With ESP32
In this section, We will review about basics of servo motor, types of servo motors, pinout and connection layout of servo motor interfacing with ESP32. In order to understand, interfacing circuit, you first need to understand its working. Let’s start with the basics.
Servo motor is controlled by giving a series of pulses to control pin. Almost all servo’s used for hobbyist projects works on the 50Hz frequency or the time period of control signal should be 20ms. Control signal width defines the position of a shaft that how much it will rotate. Pulse width and position of shaft are directly proportional to each other. They can rotate from 0 to 180 degree depending on pulse width. you can go through following tutorial to know more about PWM and its related terms:
Picture shown below provides more details about it.
You don’t need to worry about working and how to generate this control signal. Because we will use Servo library for ESP32 to provide a control signal. In next section, We will show you how to add Servo library for ESP32.
Pinout
Servo motor consists of three pins:
- Power pin is of red color.
- Ground pin is of brown color.
- Control signal usually has an orange, yellow and white color.
Before connecting it with ESP32, we need to make sure how much current is required to operate. For example, different power servo motors are available in market. When you are using small power servo motor like S0009, you can directly connect it with an ESP32 board. Because its current requirement is less than 10ms. We will use S0009 in this tutorial as shown above. You can also connect SG90, SG92R series directly with board. But if you want to use high power servo motor with ESP32, you need to use motor driver IC like UNL2003 between these two. Also if you want to use multiple Servos with ESP32, you still have to use current driver IC.
Connection diagram
Very simple connection layout is given here.
Above schematic use ESP32 DOIT DEVKIT 30 pin version. But if you are using 36 pin version or any other ESP32 board, you should check its pinout and find GPIO pin 13.
Now, You just make a connection according to this layout on a breadboard. To connect a single servo with ESP32, we will connect according to these connections:
- Connect Ground Pin of servo with Ground pin of ESP32
- Power pin >> Vin Pin
- Control Signal pin >> GPIO 13 of ESP32
you can use any pin of ESP32 as PWM pin because we need to provide PWM signal to control signal pin of servo. In this tutorial, we are using GPIO pin 13 as PWM pin as shown in layout. But you can also use any pin for control signal. But you need to specify the GPIO pin number inside the code which we will discuss in programming section of this guide.
Install Servo Library for ESP32
As mentioned in the last two sections, servo’s are controlled through a series of pulses with variable pulse width. But instead of creating its own code that how to create a series of pulses with variable pulse width, we can use ESP32 servo library. Follow these steps to download and install the library.
- Follow this link to get ESP32 Servo library for Arduino IDE.
- After downloading, you will get a .zip file.
- Use any software to Unzip this downloaded folder.
- You will get a folder with name ESP32-Arduino-Servo-Library-Master.
- Change the name of folder from
ESP32-Arduino-Servo-Library-Masterto ESP32_Arduino_Servo_Library.
- Copy this folder to Arduino library folder. You can find the Arduino library folder inside the Arduino installation folder.
- Now open your Arduino IDE, library for servo will be there. Now you can use it with ESP32.
Remember, you might have already installed library for servo motor in your Arduino IDE. But that library will not work with your ESP32, because that is for other boards like Arduino Uno, Arduino mega and stm32. Now we can use this library to control position of servo from a web server.
Example code
Upload this code to Arduino IDE, this code rotates the servo for 180 degrees in clockwise direction and for 180 degrees in back direction. Shaft will move from initial position till 180 degrees and then come back to the same position.
#include <Servo.h> static const int servoPin = 13; // defines pin number for PWM Servo servo1; // Create object for servo motor void setup() { Serial.begin(115200); servo1.attach(servoPin); // start the library }); } }
Controlling servo with POT example
This sketch controls the position of servo with the help potentiometer. GPIO32 is used as an analog pin. Voltage across POT is mapped to pulse width position which controls the shaft position. you can read of ADC of ESP32 in this article.
#include <Servo.h> static const int servoPin = 13; static const int potentiometerPin = 32; Servo servo1; void setup() { Serial.begin(115200); servo1.attach(servoPin); } void loop() { int servoPosition = map(analogRead(potentiometerPin), 0, 4096, 0, 180); servo1.write(servoPosition); Serial.println(servoPosition); delay(20); }
Now, We will show you an example of controlling servo motor from web server and after that, we will explain working of code and how to make a web server with esp32.
Creating Servo Web server with ESP32
After making the connection diagram and installing library, copy this code to Arduino IDE and upload it to ESP32 DOIT DEVKIT.
/********* Microcontrollerslab.com you can get more projects about ESP32 Microcontrollers lab *********/ #include <WiFi.h> #include <Servo.h> Servo ObjServo; // Make object of Servo motor from Servo library // Objects are made for every servo motor,we want to control through this library static const int ServoGPIO = 13; // define the GPIO pin with which servo is connected // Variables to store network name and password const char*</script>"); // Web Page client.println("</head><body><h1>ESP32 with Servo</h1>"); client.println("<p>Position: <span id=\"servoPos\"></span></p>"); client.println("<input type=\"range\" min=\"0\" max=\"180\" class=\"slider\" id=\"servoSlider\" onchange=\"servo(this.value)\" value=\""+valueString+"\"/>"); client.println("<script>var slider = document.getElementById(\"servoSlider\");"); client.println("var servoP = document.getElementById(\"servoPos\"); servoP.innerHTML = slider.value;"); client.println("slider.oninput = function() { slider.value = this.value; servoP.innerHTML = this.value; }"); client.println("$.ajaxSetup({timeout:1000}); function servo(pos) { "); client.println("$.get(\"/?value=\" + pos + \"&\"); {Connection: close};}</script>"); client.println("</body></html>"); //GET /?value=180& HTTP/1.1 if(header.indexOf("GET /?value=")>=0) { positon1 = header.indexOf('='); positon2 = header.indexOf('&'); valueString = header.substring(positon1+1, positon2); //Rotate the servo ObjServo.write(valueString.toInt()); Serial.println(valueString); } header = ""; client.stop(); Serial.println("Client disconnected."); Serial.println(""); } }
- Before you upload code, you need to change network credentials and change them with your WiFI name and password.
- After uploading this code to ESP32 board, open your serial monitor and note down the IP address as shown in picture below:
- Copy this IP address and open it with any web browser. you will see this web page in your browser. you will see a slider with position control.
- You can control the position of servo’s shaft with the help of this slider.
- You can move the slide in left or right position to rotate motor position in clockwise and ant-clockwise direction.
Code working
Now we will see how the code works and how to create a web server. you can check this ( create esp32 web server in Arduino ) tutorial for more information on creating a web server with ESP32. Main working of code is given below:
- It will create a web page with a slider. Any web client can connect to this web page through an IP address we get in the last section.
- The slider can control the position of shaft between 0 and 180 degrees. A web client can move the slider in left or right position to control shaft position.
- Web client once opens the web page, they do not need to update the page, again and again, to update position of slider because we use AJAX javascript file to refresh the web page automatically when a user updates the position of slider.
- Web page sends HTTP requests to ESP32 to update position of a servo motor.
These lines add libraries of the WiFi driver and servo motor.
#include <WiFi.h> // add library of WiFi for ESP32 #include <Servo.h> // add library of Servo for ESP32
This line makes an object of Servo motor from the Servo library. Objects are made for every servo motor if we want to control multiple servos through this single servo library. We can create upto 12 objects.
Servo ObjServo; // create object with name ObjServo
This line defines the name of GPIO pin to which we have connected servo motor.
static const int ServoGPIO = 13; // Pin number to which control signal pin is connected
These variables store network name and password for connecting ESP32 with WiFi network
const char* ssid = "PTCL-BB"; // Enter your network name const char* password = "5387c614"; //Enter your network password WiFiServer server(80);// Set the server port nunber to deafualt 80
This variable header stores the HTTP requests data received from a web client.
String header;
These variables store previous and update values of servo position and slider position.
String valueString = String(0); int positon1 = 0; int positon2 = 0;
First line defines the baud rate of serial communication and second line attack the GPIO pin with object of servo motor which we created earlier.
Serial.begin(115200); //define serial communication with baud rate of 115200 ObjServo.attach(ServoGPIO); // it will attach the ObjServo to ServoGPIO pin which is 13
This part of the code is used for connecting ESP32 to WiFi router. ESP32 connects to WiFi router and displays the IP address on serial monitor.. }
Before explaining code inside the loop function, we will explain HTML part of this code which we have used inside the main function. This HTML part of code is used to create slider and web page layout.
Creating a Web page
Following code is used for HTML page. This web page is responsible for making a range slider and updating web page automatically. If you are just a beginner with HTML and CSS, you can visit this website to learn the basics of HTML and CSS.
<!DOCTYPE html> <html> <head> <meta name="viewport" content="width=device-width, initial-scale=1"> <link rel="icon" href="data:,"> <style> body { text-align: center; font-family: "Trebuchet MS", Arial; margin-left:auto; margin-right:auto; } .slider { width: 300px; } </style> <script src=""></sc ript> </head> <body> <h1>ESP32 with Servo</h1> <p>Position: <span id="servoPos"></span></p> <input type="range" min="0" max="180" class="slider" id="servoSlider" onchange="servo(this.value)"/> <script>}; } </script> </body> </html>
Creating a range slider
To create a range slider in HTML, we use <input> and </input> tags. This line create a range slider with <input> and </input> tags.
<input type="range" min="0" max="180" class="slider" id="servoSlider" onchange="servo(this.value)"/>
- The type defines the type of slider because we want to create a range slider, therefore used “range” and define the minimum value of 0 and a maximum value of 180.
- One change feature calls a javascript function which is explained below.
This is a javascript code which is used to update web page automatically and send HTTP request having values of the slider position. We write javascript functions between <script> </script> tags. This code updates the web page with slider position value.}; }
These lines get the values of slider position from HTTP request data which is stored in header string. ObjServo.write() function rotate the servo motor according to received value of slider position.
if(header.indexOf("GET /?value=")>=0) { positon1 = header.indexOf('='); positon2 = header.indexOf('&'); valueString = header.substring(positon1+1, positon2); ObjServo.write(valueString.toInt()); Serial.println(valueString); }
In summary, In this tutorial you learned:
- you learned about serv motor.
- we explained how to connect servo motor with ESP32
- How to control servo motor with potentiometer
- How to control servo motor from a web page using a Slider.
I hope you liked this tutorial, if you enjoyed this tutorial, you surely like to read our past editorials. | https://microcontrollerslab.com/esp32-servo-motor-web-server-arduino/ | CC-MAIN-2020-05 | refinedweb | 2,254 | 55.34 |
Solved, setting up environment MAILMAN_CONFIG_FILE fixed that point
Le 2013-12-02 15:15, nicolas a écrit :
Hello,
I'm wondering why the wonderful hyperkitty archiver is not archiving some standard messages..
I tested message injection and it work, problem may not come from archiver itself...
in a mailman shell, i'm trying :
(py27)mailman@mail:~$ mailman shell Welcome to the GNU Mailman shell
from mailman.config import config for archiver in config.archivers:
... print archiver.name ... mail-archive prototype hyperkitty mhonarc
And that's nice, that reflects my conf, well..
But, adding a constructor to archive runner in order to verify in daemon mode (mailman start)
class ArchiveRunner(Runner): """The archive runner.""" def __init__(self, slice=None, numslices=1): super(ArchiveRunner, self).__init__(slice, numslices) debug_log.info('start archive trace') for archiver in config.archivers: debug_log.info("loaded archiver : %s" % archiver.name)
debug output gives :
Dec 02 14:21:02 2013 (23189) start archive trace Dec 02 14:21:02 2013 (23189) loaded archiver : prototype Dec 02 14:21:02 2013 (23189) loaded archiver : mail-archive Dec 02 14:21:02 2013 (23189) loaded archiver : mhonarc
and that explains why messages are archived with scripting but not while using smtp.
I'm using latest lp:mailman (slightly patched lp:~nkarageuzian/mailman/hyperkitty_compliance )
How could we explain this behavior ?
Regards
On Dec 02, 2013, at 03:42 PM, nicolas wrote:
Solved, setting up environment MAILMAN_CONFIG_FILE fixed that point
That will work, although it should *also* work to pass
-C <path> to
mailman start. A custom configuration file should get passed down to all the
subprocess runners.
-Barry
mailman-developers@python.org | https://mail.python.org/archives/list/mailman-developers@python.org/thread/HIYQZOO5JA3YEE4OVDKFKKAT7GMEVIJZ/ | CC-MAIN-2022-33 | refinedweb | 271 | 54.93 |
Important: Please read the Qt Code of Conduct -
qmake and linking against Android zlib
Hi,
What a statement I have to put in qmake to link against
/system/libs/libz.sofor any Android target?
All compiles fine,
#include <zlib.h>works out of the box without any additional
INCLUDEPATH
but linking fails.
All Android docs say zlib is part of Android NDK.
- SGaist Lifetime Qt Champion last edited by
Hi,
AFAIK
LIBS += -lz
should be enough if zlib is Androïd standard library.
Not that easy,
LIBS += -lzdoesn't work - still the same linking error.
I found that library in the location:
toolchains/llvm/prebuilt/linux-x86_64/sysroot/usr/lib/aarch64-linux-android/30/
of the NDK
or actually, inside many locations with different numbers and architectures.
Probably some
-Lsomewherehas to prelude
-lz
I found the solution:
My project was already linked with
zliband probably all Qt Android projects are,
so the statement
LIBS += -lzis not necessary at all.
I was trying to compile
miniziplibrary (part of zlib project) but Android doesn't support
fopen64.
The solution was to add
USE_FILE32APIto definitions to say
minizipnot to use that.
Adding to my qmake:
DEFINES += USE_FILE32APIsolved linking errors. | https://forum.qt.io/topic/127368/qmake-and-linking-against-android-zlib | CC-MAIN-2021-25 | refinedweb | 195 | 64.91 |
The BingScraper is python3 package having function to extract the text and images content on search engine `bing.com`.
Project description
- 
- # Bing Scraper
The bingscraper is python3 package which extracts the text and images content on search engine bing.com.
It helps the user in a way that he/she will be getting only meaningful results and images for their search query. It does not download the ad content and hence saving data for the user.
The script working in background requests for a search term and creates directory (if not made previously) in the root directory of the script where all the content of the related particular search is stored. This script will be downloading the hypertext and hyperlink to that text and saving it to a .txt file within the directory made by itself. This directory saves the text content as well as the images downloaded using the script.
## Requirements 1. Modules:
- requests: For requesting content through two HTTPS Methods: GET and POST. Used GET Method.
- BeautifulSoup: For creating JSON like dictionary using HTML Parser. Package uses bs4.
- os: For checking and making directories.
- PIL.Image: Pillow Module. For extracting image content.
- io.ByteIO: For saving the extracted image using the PIL.Image.
- Internet Connection: Continuous high speed internet connection is required for the proper function of the python package as it continuously creates the copy of the images into the local machine.
- Python: Version 3.6.4 or above. This package is written in python 3.6.4
## How to use
Install the above modules. Successful import of bingscraper depends only after the above imports.
Sample code in python:
import bingscraper as bs
search = str(input())
bs.scrape(search).text() #For Text Scraping.
bs.scrape(search).image() #For Image Scraping.
scrape() takes a string argument and the .text() or .image() does the scraping work.
Project details
Release history Release notifications
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/bingscraper/ | CC-MAIN-2019-04 | refinedweb | 337 | 60.41 |
Python comes with several built-in data types. These are the foundational building blocks of the whole language. They have been optimised and perfected over many years. In this comprehensive tutorial, we will explore one of the most important: the dictionary (or dict for short).
For your convenience, I’ve created a comprehensive 8000-word eBook which you can download directly as a high-resolution PDF (opens in a new window).
Unless stated otherwise I will be using Python 3.8 throughout. Dictionary functionality has changed over the last few Python versions. If you are using a version other than 3.8, you will probably get different results.
To check what version of Python you are running, enter the following in a terminal window (mine returns 3.8).
$ python --version Python 3.8.0
Here’s a minimal example that shows how to use a dictionary in an interactive Python shell. Feel free to play around!
Exercise: Add 2 apples and 3 oranges to your basket of fruits! How many fruits are in your basket?
Python Dictionary Video Tutorial
Don’t want to read the article? No problem, watch me going over the article:
Here’s the link to the Python freelancer course in case you want to start being your own boss with Python.
Python Dictionary – Why Is It So Useful?
When I first found out about dictionaries, I wasn’t sure if they were going to be very useful. They seemed a bit clunky and I felt like lists would be much more useful. But boy was I wrong!
In real life, a dictionary is a book full of words in alphabetical order. Beside each word is a definition. If it has many meanings, there are many definitions. Each word appears exactly once.
- A book of words in alphabetical order.
- Each word has an associated definition
- If a word has many meanings, it has many definitions
- As time changes, more meanings can be added to a word.
- The spelling of a word never changes.
- Each word appears exactly once.
- Some words have the same definition.
If we abstract this idea, we can view a dictionary as a mapping from a word to its definition. Making this more abstract, a dictionary is a mapping from something we know (a word) to something we don’t (its definition).
We apply this mapping all the time in real life: In our phone, we map our friends’ names to their phone numbers.
In our minds, we map a person’s name to their face.
We map words to their meaning.
This ‘mapping’ is really easy for humans to understand and makes life much more efficient. We do it all the time without even realising. Thus it makes sense for Python to include this as a foundational data type.
Python Dictionary Structure
A traditional dictionary maps words to definitions. Python dictionaries can contain any data type, so we say they map keys to values. Each is called a key-value pair.
The key ‘unlocks’ the value. A key should be easy to remember and not change over time. The value can be more complicated and may change over time.
We will now express the same list as above using Python dictionary terminology.
- Python dictionary is a collection of objects (keys and values)
- Each key has an associated value
- A key can have many values
- As time changes, more values can be added to a key (values are mutable)
- A key cannot change (keys are immutable)
- Each key appears exactly once
- Keys can have the same value
Note: we can order dictionaries if we want but it is not necessary to do so. We’ll explain all these concepts in more detail throughout the article. But before we do anything, we need to know how to create a dictionary!
Python Create Dictionary
There are two ways to create a dictionary in Python:
- Curly braces
{ }
- The
dict()constructor
Curly Braces { }
my_dict = {key1: value1, key2: value2, key3: value3, key4: value4, key5: value5}
We write the key, immediately followed by a colon. Then a single space, the value and finally a comma. After the last pair, replace the comma with a closing curly brace.
You can write all pairs on the same line. I put each on a separate line to aid readability.
Let’s say you have 5 friends and want to record which country they are from. You would write it like so (names and countries start with the same letter to make them easy to remember!).
names_and_countries = {'Adam': 'Argentina', 'Beth': 'Bulgaria', 'Charlie': 'Colombia', 'Dani': 'Denmark', 'Ethan': 'Estonia'}
The dict() Constructor
Option 1 – fastest to type
my_dict = dict(key1=value1, key2=value2, key3=value3, key4=value4, key5=value5)
So names_and_countries becomes
names_and_countries = dict(Adam='Argentina', Beth='Bulgaria', Charlie='Colombia', Dani='Denmark', Ethan='Estonia')
Each pair is like a keyword argument in a function. Keys are automatically converted to strings but values must be typed as strings.
Option 2 – slowest to type, best used with zip()
my_dict = dict([(key1, value1), (key2, value2), (key3, value3), (key4, value4), (key5, value5)])
names_and_countries becomes
names_and_countries = dict([('Adam', 'Argentina'), ('Beth', 'Bulgaria'), ('Charlie', 'Colombia'), ('Dani', 'Denmark'), ('Ethan', 'Estonia')])
Like with curly braces, we must explicitly type strings as strings. If you forget the quotes, Python interprets it as a function.
Option 2 with zip() – Python list to dict
If you have two lists and want to make a dictionary from them, do this
names = ['Adam', 'Beth', 'Charlie', 'Dani', 'Ethan'] countries = ['Argentina', 'Bulgaria', 'Colombia', 'Denmark', 'Estonia'] # Keys are names, values are countries names_and_countries = dict(zip(names, countries)) >>> names_and_countries {'Adam': 'Argentina', 'Beth': 'Bulgaria', 'Charlie': 'Colombia', 'Dani': 'Denmark', 'Ethan': 'Estonia'}
If you have more than two lists, do this
names = ['Adam', 'Beth', 'Charlie', 'Dani', 'Ethan'] countries = ['Argentina', 'Bulgaria', 'Colombia', 'Denmark', 'Estonia'] ages = [11, 24, 37, 75, 99] # Zip all values together values = zip(countries, ages) # Keys are names, values are the tuple (countries, ages) people_info = dict(zip(names, values)) >>> people_info {'Adam': ('Argentina', 11), 'Beth': ('Bulgaria', 24), 'Charlie': ('Colombia', 37), 'Dani': ('Denmark', 75), 'Ethan': ('Estonia', 99)}
This is the first time we’ve seen a dictionary containing more than just strings! We’ll soon find out what can and cannot be a key or value. But first, let’s see how to access our data.
Accessing Key-Value Pairs
There are 2 ways to access the data in our dictionaries:
- Bracket notation [ ]
- The get() method
Bracket Notation [ ]
# Get value for the key 'Adam' >>> names_and_countries['Adam'] 'Argentina' # Get value for the key 'Charlie' >>> names_and_countries['Charlie'] 'Colombia' # KeyError if you search for a key not in the dictionary >>> names_and_countries['Zoe'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'Zoe'
Type the key into the square brackets to get the corresponding value. If you enter a key not in the dictionary, Python raises a
KeyError.
This looks like list indexing but it is completely different! For instance, you cannot access values by their relative position or by slicing.
# Not the first element of the dictionary >>> names_and_countries[0] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 0 # Not the last element >>> names_and_countries[-1] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: -1 # You cannot slice >>> names_and_countries['Adam':'Dani'] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'slice'
Python expects everything between the brackets to be a key. So for the first two examples, we have a
KeyError because neither 0 nor -1 are keys in the dictionary. But is possible to use 0 or -1 as a key, as we will see soon.
Note: As of Python 3.7, the order elements are added is preserved. Yet you cannot use this order to access elements. It is more for iteration and visual purposes as we will see later.
If we try to slice our dictionary, Python raises a
TypeError. We explain why in the Hashing section.
Let’s look at the second method for accessing the data stored in our dictionary.
Python Dictionary get() Method
# Get value for the key 'Adam' >>> names_and_countries.get('Adam') 'Argentina' # Returns None if key not in the dictionary >>> names_and_countries.get('Zoe') # Second argument returned if key not in dictionary >>> names_and_countries.get('Zoe', 'Name not in dictionary') 'Name not in dictionary' # Returns value if key in dictionary >>> names_and_countries.get('Charlie', 'Name not in dictionary') 'Colombia'
The
get() method takes two arguments:
- The key you wish to search for
- (optional) Value to return if the key is not in the dictionary (default is None).
It works like bracket notation. But it will never raise a
KeyError. Instead, it returns either None or the object you input as the second argument.
This is hugely beneficial if you are iterating over a dictionary. If you use bracket notation and encounter an error, the whole iteration will stop. If you use get(), no error will be raised and the iteration will complete.
We will see how to iterate over dictionaries soon. But there is no point in doing that if we don’t even know what our dictionary can contain! Let’s learn about what can and can’t be a key-value pair.
Python Dict Keys
In real dictionaries, the spelling of words doesn’t change. It would make it quite difficult to use one if they did. The same applies to Python dictionaries. Keys cannot change. But they can be more than just strings. In fact, keys can be any immutable data type: string, int, float, bool or tuple.
>>> string_dict = {'hi': 'hello'} >>> int_dict = {1: 'hello'} >>> float_dict = {1.0: 'hello'} >>> bool_dict = {True: 'hello', False: 'goodbye'} >>> tuple_dict = {(1, 2): 'hello'} # Tuples must only contain immutable types >>> bad_tuple_dict = {(1, [2, 3]): 'hello'} Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list'
This is the second time we’ve seen
"TypeError: unhashable type: 'list'". So what does ‘unhashable’ mean?
What is Hashing in Python?
In the background, a Python dictionary is a data structure known as a hash table. It contains keys and hash values (numbers of fixed length). You apply
hash() to a key to return its hash value. If we call
hash() on the same key many times, the result will not change.
# Python 3.8 (different versions may give different results) >>> hash('hello world!') 1357213595066920515 # Same result as above >>> hash('hello world!') 1357213595066920515 # If we change the object, we change the hash value >>> hash('goodbye world!') -7802652278768862152
When we create a key-value pair, Python creates a hash-value pair in the background
# We write >>> {'hello world!': 1} # Python executes in the background >>> {hash('hello world!'): 1} # This is equivalent to >>> {1357213595066920515: 1}
Python uses this hash value when we look up a key-value pair. By design, the hash function can only be applied to immutable data types. If keys could change, Python would have to create a new hash table from scratch every time you change them. This would cause huge inefficiencies and many bugs.
Instead, once a table is created, the hash value cannot change. Python knows which values are in the table and doesn’t need to calculate them again. This makes dictionary lookup and membership operations instantaneous and of O(1).
In Python, the concept of hashing only comes up when discussing dictionaries. Whereas, mutable vs immutable data types come up everywhere. Thus we say that you can only use immutable data types as keys, rather than saying ‘hashable’ data types.
Finally, what happens if you use the hash value of an object as another key in the same dictionary? Does Python get confused?
>>> does_this_work = {'hello': 1, hash('hello'): 2} >>> does_this_work['hello'] 1 >>> does_this_work[hash('hello')] 2
It works! The reasons why are beyond the scope of this article. The full implementation of the algorithm and the reasons why it works are described here. All you really need to know is that Python always picks the correct value… even if you try to confuse it!
Python Dictionary Values
There are restrictions on dictionary keys but values have none. Literally anything can be a value. As long as your key is an immutable data type, your key-value pairs can be any combination of types you want. You have complete control!
>>> crazy_dict = {11.0: ('foo', 'bar'), 'baz': {1: 'a', 2: 'b'}, (42, 55): {10, 20, 30}, True: False} # Value of the float 11.0 is a tuple >>> crazy_dict[11.0] ('foo', 'bar') # Value of the string 'baz' is a dictionary >>> crazy_dict.get('baz') {1: 'a', 2: 'b'} # Value of the tuple (42, 55) is a set >>> crazy_dict[(42, 55)] {10, 20, 30} # Value of the Bool True is the Bool False >>> crazy_dict.get(True) False
Note: you must use braces notation to type a dictionary out like this. If you try to use the
dict() constructor, you will get SyntaxErrors (unless you use the verbose method and type out a list of tuples… but why would you do that?).
If you need to refresh your basic knowledge of Python sets, I recommend reading the ultimate guide to Python sets on the Finxter blog.
Python Nested Dictionaries
When web scraping, it is very common to work with dictionaries inside dictionaries (nested dictionaries). To access values on deeper levels, you simply chain methods together. Any order of bracket notation and
get() is possible.
# Returns a dict >>> crazy_dict.get('baz') {1: 'a', 2: 'b'} # Chain another method to access the values of this dict >>> crazy_dict.get('baz').get(1) 'a' >>> crazy_dict.get('baz')[2] 'b'
We now know how to create a dictionary and what data types are allowed where. But what if you’ve already created a dictionary and want to add more values to it?
Python Add To Dictionary
>>> names_and_countries {'Adam': 'Argentina', 'Beth': 'Bulgaria', 'Charlie': 'Colombia', 'Dani': 'Denmark', 'Ethan': 'Estonia'} # Add key-value pair 'Zoe': 'Zimbabwe' >>> names_and_countries['Zoe'] = 'Zimbabwe' # Add key-value pair 'Fred': 'France' >>> names_and_countries['Fred'] = 'France' # Print updated dict >>> names_and_countries {'Adam': 'Argentina', 'Beth': 'Bulgaria', 'Charlie': 'Colombia', 'Dani': 'Denmark', 'Ethan': 'Estonia', 'Zoe': 'Zimbabwe', # Zoe first 'Fred': 'France'} # Fred afterwards
Our dictionary reflects the order we added the pairs by first showing Zoe and then Fred.
To add a new key-value pair, we simply assume that key already exists and try to access it via bracket notation
>>> my_dict['new_key']
Then (before pressing return) use the assignment operator ‘=’ and provide a value.
>>> my_dict['new_key'] = 'new_value'
You cannot assign new key-value pairs via the
get() method because it’s a function call.
>>> names_and_countries.get('Holly') = 'Hungary' File "<stdin>", line 1 SyntaxError: cannot assign to function call
To delete a key-value pair use the
del statement. To change the value of an existing key, use the same bracket notation as above.
# Delete the Zoe entry >>> del names_and_countries['Zoe'] # Change Ethan's value >>> names_and_countries['Ethan'] = 'DIFFERENT_COUNTRY' >>> names_and_countries {'Adam': 'Argentina', 'Beth': 'Bulgaria', 'Charlie': 'Colombia', 'Dani': 'Denmark', 'Ethan': 'DIFFERENT_COUNTRY', # Ethan has changed 'Fred': 'France'} # We no longer have Zoe
As with other mutable data types, be careful when using the
del statement in a loop. It modifies the dictionary in place and can lead to unintended consequences. Best practice is to create a copy of the dictionary and to change the copy. Or you can use, my personal favorite, dictionary comprehensions (which we will cover later)—a powerful feature similar to the popular list comprehension feature in Python.
Python Dict Copy Method
>>> my_dict = {'a': 1, 'b': 2} # Create a shallow copy >>> shallow_copy = my_dict.copy() # Create a deep copy >>> import copy >>> deep_copy = copy.deepcopy(my_dict)
To create a shallow copy of a dictionary use the
copy() method. To create a deep copy use the
deepcopy() method from the built-in copy module. We won’t discuss the distinction between the copy methods in this article for brevity.
Checking Dictionary Membership
Let’s say we have a dictionary with 100k key-value pairs. We cannot print it to the screen and visually check which key-value pairs it contains.
Thankfully, the following syntax is the same for dictionaries as it is for other objects such as lists and sets. We use the
in keyword.
# Name obviously not in our dict >>> 'INCORRECT_NAME' in names_and_countries False # We know this is in our dict >>> 'Adam' in names_and_countries True # Adam's value is in the dict... right? >>> names_and_countries['Adam'] 'Argentina' >>> 'Argentina' in names_and_countries False
We expect INCORRECT_NAME not to be in our dict and Adam to be in it. But why does ‘Argentina’ return False? We’ve just seen that it’s the value of Adam?!
Remember at the start of the article that I said dictionaries are maps? They map from something we know (the key) to something we don’t (the value). So when we ask if something is in our dictionary, we are asking if it is a key. We’re not asking if it’s a value.
Which is more natural when thinking of a real-life dictionary:
- Is the word ‘facetious’ in this dictionary?
- Is the word meaning ‘lacking serious intent; concerned with something nonessential, amusing or frivolous’ in this dictionary?
Clearly the first one is the winner and this is the default behavior for Python.
>>> 'something' in my_dict
We are checking if ‘something’ is a key in my_dict.
But fear not, if you want to check whether a specific value is in a dictionary, that is possible! We simply have to use some methods.
Python Dictionary Methods – Keys, Values and Items
There are 3 methods to look at. All can be used to check membership or for iterating over specific parts of a dictionary. Each returns an iterable.
- .keys() – iterate over the dictionary’s keys
- .values() – iterate over the dictionary’s values
- .items() – iterate over both the dictionary’s keys and values
Note: we’ve changed Ethan’s country back to Estonia for readability.
>>> names_and_countries.keys() dict_keys(['Adam', 'Beth', 'Charlie', 'Dani', 'Ethan', 'Fred']) >>> names_and_countries.values() dict_values(['Argentina', 'Bulgaria', 'Colombia', 'Denmark', 'Estonia', 'France']) >>> names_and_countries.items() dict_items([('Adam', 'Argentina'), ('Beth', 'Bulgaria'), ('Charlie', 'Colombia'), ('Dani', 'Denmark'), ('Ethan', 'Estonia'), ('Fred', 'France')])
We can now check membership in keys and values:
# Check membership in dict's keys >>> 'Adam' in names_and_countries True >>> 'Adam' in names_and_countries.keys() True # Check membership in the dict's values >>> 'Argentina' in names_and_countries.values() True # Check membership in either keys or values??? >>> 'Denmark' in names_and_countries.items() False
You cannot check in the keys and values at the same time. This is because
items() returns an iterable of tuples. As
'Denmark' is not a tuple, it will return False.
>>> for thing in names_and_countries.items(): print(thing) ('Adam', 'Argentina') ('Beth', 'Bulgaria') ('Charlie', 'Colombia') ('Dani', 'Denmark') ('Ethan', 'Estonia') # True because it's a tuple containing a key-value pair >>> ('Dani', 'Denmark') in names_and_countries.items() True
Python Loop Through Dictionary – An Overview
To iterate over any part of the dictionary we can use a for loop
>>> for name in names_and_countries.keys(): print(name) Adam Beth Charlie Dani Ethan Fred >>> for country in names_and_countries.values(): print(f'{country} is wonderful!') Argentina is wonderful! Bulgaria is wonderful! Colombia is wonderful! Denmark is wonderful! Estonia is wonderful! France is wonderful! >>> for name, country in names_and_countries.items(): print(f'{name} is from {country}.') Adam is from Argentina. Beth is from Bulgaria. Charlie is from Colombia. Dani is from Denmark. Ethan is from Estonia. Fred is from France.
It’s best practice to use descriptive names for the objects you iterate over. Code is meant to be read and understood by humans! Thus we chose ‘name’ and ‘country’ rather than ‘key’ and ‘value’.
# Best practice >>> for descriptive_key, descriptive_value in my_dict.items(): # do something # Bad practice (but you will see it 'in the wild'!) >>> for key, value in my_dict.items(): # do something
If your key-value pairs don’t follow a specific pattern, it’s ok to use ‘key’ and ‘value’ as your iterable variables, or even ‘k’ and ‘v’.
# Iterating over the dict is the same as dict.keys() >>> for thing in names_and_countries: print(thing) Adam Beth Charlie Dani Ethan Fred
A Note On Reusability
# Works with general Python types >>> for key in object: # do something # Works only with dictionaries >>> for key in object.keys(): # do something
Do not specify keys() if your code needs to work with other objects like lists and sets. Use the keys() method if your code is only meant for dictionaries. This prevents future users inputting incorrect objects.
Python dict has_key
The method has_key() is exclusive to Python 2. It returns True if the key is in the dictionary and False if not.
Python 3 removed this functionality in favour of the following syntax:
>>> if key in d: # do something
This keeps dictionary syntax in line with that of other data types such as sets and lists. This aids readability and reusability.
Pretty Printing Dictionaries Using pprint()'}
It does not change the dictionary at all. It’s just much more readable now.
Python Dictionaries and JSON Files
We need to encode and decode all this data.
A common filetype you will interact with is a JSON file. It stands for Javascript Object Notation. They are used to structure and send data in web applications.
They work almost exactly the same way as dictionaries and you can easily turn one into the other very easily.
Python Dict to JSON
>>> import json >>> my_dict = dict(a=1, b=2, c=3, d=4) >>> with open('my_json.json', 'w') as f: json.dump(my_dict, f)
The above code takes
my_dict and writes it to the file
my_json.json in the current directory.
You can get more complex than this by setting character encodings and spaces. For more detail, we direct the reader to the docs.
Python JSON to Dict
We have the file
my_json.json in our current working directory.
>>> import json >>> with open('my_json.json', 'r') as f: new_dict = json.load(f) >>> new_dict {'a': 1, 'b': 2, 'c': 3, 'd': 4}
Note: the key-value pairs in JSON are always converted to strings when encoded in Python. It is easy to change any object into a string and it leads to fewer errors when encoding and decoding files. But it means that sometimes the file you load and the file you started with are not identical.
Python Dictionary Methods
Here’s a quick overview:
- dict.clear() – remove all key-value pairs from a dict
- dict.update() – merge two dictionaries together
- dict.pop() – remove a key and return its value
- dict.popitem() – remove a random key-value pair and return it as a tuple
We’ll use letters A and B for our dictionaries as they are easier to read than descriptive names. Plus we have kept the examples simple to aid understanding.
dict.clear() – remove all key-value pairs from a dict
>>> A = dict(a=1, b=2) >>> A.clear() >>> A {}
Calling this on a dict removes all key-value pairs in place. The dict is now empty.
dict.update() – merge two dictionaries together
>>> A = dict(a=1, b=2) >>> B = dict(c=3, d=4) >>> A.update(B) >>> A {'a': 1, 'b': 2, 'c': 3, 'd': 4} >>> B {'c': 3, 'd': 4}
We have just updated A. Thus all the key-value pairs from B have been added to A. B has not changed.
If A and B some keys, B’s value will replace A’s. This is because A is updated by B and so takes all of B’s values (not the other way around).
>>> A = dict(a=1, b=2) >>> B = dict(b=100) >>> A.update(B) # A now contains B's values >>> A {'a': 1, 'b': 100} # B is unchanged >>> B {'b': 100}
You can also pass a sequence of tuples or keyword arguments to update(), like you would with the dict() constructor.
>>> A = dict(a=1, b=2) # Sequence of tuples >>> B = [('c', 3), ('d', 4)] >>> A.update(B) >>> A {'a': 1, 'b': 2, 'c': 3, 'd': 4} >>> A = dict(a=1, b=2) # Pass key-value pairs as keyword arguments >>> A.update(c=3, d=4) >>> A {'a': 1, 'b': 2, 'c': 3, 'd': 4}
dict.pop() – remove a key and return its value
>>> A = dict(a=1, b=2) >>> A.pop('a') 1 >>> A {'b': 2}
If you try call dict.pop() with a key that is not in the dictionary, Python raises a KeyError.
>>> A.pop('non_existent_key') Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'non_existent_key'
Like the get() method, you can specify an optional second argument. This is returned if the key is not in the dictionary and so avoids KeyErrors.
>>> A.pop('non_existent_key', 'not here') 'not here'
dict.popitem() – remove a random key-value pair and return it as a tuple
>>> A = dict(a=1, b=2, c=3) # Your results will probably differ >>> A.popitem() ('c', 3) >>> A {'a': 1, 'b': 2} >>> A.popitem() ('b', 2) >>> A {'a': 1}
If the dictionary is empty, Python raises a KeyError.
>>> A = dict() >>> A.popitem() Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'popitem(): dictionary is empty'
Python Loop Through Dictionary – In Detail
There are several common situations you will encounter when iterating over dictionaries. Python has developed several methods to help you work more efficiently.
But before we head any further, please remember the following:
NEVER EVER use bracket notation when iterating over a dictionary. If there are any errors, the whole iteration will break and you will not be happy.
The standard Python notation for incrementing numbers or appending to lists is
# Counting my_num = 0 for thing in other_thing: my_num += 1 # Appending to lists my_list = [] for thing in other_thing: my_list.append(thing)
This follows the standard pattern:
- Initialise ’empty’ object
- Begin for loop
- Add things to that object
When iterating over a dictionary, our values can be numbers or list-like. Thus we can add or we can append to values. It would be great if our code followed the above pattern. But…
>>> my_dict = {} >>> for thing in other_thing: my_dict['numerical_key'] += 1 Traceback (most recent call last): File "<stdin>", line 2, in <module> KeyError: 'numerical_key' >>> for thing in other_thing: my_dict['list_key'].append(thing) Traceback (most recent call last): File "<stdin>", line 2, in <module> KeyError: 'list_key'
Unfortunately, both raise a KeyError. Python tells us the key do not exist and so we cannot increment its value. Thus we must first create a key-value pair before we do anything with it.
We’ll now show 4 ways to solve this problem:
- Manually initialise a key if it does not exist
- The get() method
- The setdefault() method
- The defaultdict()
We’ll explain this through some examples, so let’s go to the setup.
Three friends – Adam, Bella and Cara, have gone out for a meal on Adam’s birthday. They have stored their starter, main and drinks orders in one list. The price of each item is in another list. We will use this data to construct different dictionaries.
people = ['Adam', 'Bella', 'Cara', 'Adam', 'Bella', 'Cara', 'Adam', 'Bella', 'Cara',] food = ['soup', 'bruschetta', 'calamari', # starter 'burger', 'calzone', 'pizza', # main 'coca-cola', 'fanta', 'water'] # drink # Cost of each item in £ prices = [3.20, 4.50, 3.89, 12.50, 15.00, 13.15, 3.10, 2.95, 1.86] # Zip data together to allow iteration # We only need info about the person and the price meal_data = zip(people, prices)
Our three friends are very strict with their money. They want to pay exactly the amount they ordered. So we will create a dictionary containing the total cost for each person. This is a numerical incrementation problem.
Manually Initialize a Key
# Initialise empty dict total = {} # Iterate using descriptive object names for (person, price) in meal_data: # Create new key and set value to 0 if key doesn't yet exist if person not in total: total[person] = 0 # Increment the value by the price of each item purchased. total[person] += price >>> total {'Adam': 18.8, 'Bella': 22.45, 'Cara': 18.9}
We write an if statement which checks if the key is already in the dictionary. If it isn’t, we set the value to 0. If it is, Python does not execute the if statement. We then increment using the expected syntax.
This works well but requires quite a few lines of code. Surely we can do better?
Python Dict get() Method When Iterating
# Reinitialise meal_data as we have already iterated over it meal_data = zip(people, prices) total = {} for (person, price) in meal_data: # get method returns 0 the first time we call it # and returns the current value subsequent times total[person] = total.get(person, 0) + price >>> total {'Adam': 18.8, 'Bella': 22.45, 'Cara': 18.9}
We’ve got it down to one line!
We pass get() a second value which is returned if the key is not in the dictionary. In this case, we choose 0 like the above example. The first time we call get() it returns 0. We have just initialised a key-value pair! In the same line, we add on ‘price’. The next time we call get(), it returns the current value and we can add on ‘price’ again.
This method does not work for appending. You need some extra lines of code. We will look at the setdefault() method instead.
Python Dict setdefault() Method
The syntax of this method makes it an excellent choice for modifying a key’s value via the
append() method.
First we will show why it’s not a great choice to use if you are incrementing with numbers.
meal_data = zip(people, prices) total = {} for (person, price) in meal_data: # Set the initial value of person to 0 total.setdefault(person, 0) # Increment by price total[person] += price 0 0 0 3.2 4.5 3.89 15.7 19.5 17.04 >>> total {'Adam': 18.8, 'Bella': 22.45, 'Cara': 18.9}
It works but requires more lines of code than get() and prints lots of numbers to the screen. Why is this?
The setdefault() method takes two arguments:
- The key you wish to set a default value for
- What you want the default value to be
So setdefault(person, 0) sets the default value of person to be 0.
It always returns one of two things:
- The current value of the key
- If the key does not exist, it returns the default value provided
This is why the numbers are printed to the screen. They are the values of ‘person’ at each iteration.
Clearly this is not the most convenient method for our current problem. If we do 100k iterations, we don’t want 100k numbers printed to the screen.
So we recommend using the get() method for numerical calculations.
Let’s see it in action with lists and sets. In this dictionary, each person’s name is a key. Each value is a list containing the price of each item they ordered (starter, main, dessert).
meal_data = zip(people, prices) individual_bill = {} for (person, price) in meal_data: # Set default to empty list and append in one line! individual_bill.setdefault(person, []).append(price) >>> individual_bill {'Adam': [3.2, 12.5, 3.1], 'Bella': [4.5, 15.0, 2.95], 'Cara': [3.89, 13.15, 1.86]}
Now we see the true power of setdefault()! Like the get method in our numerical example, we initialise a default value and modify it in one line!
Note: setdefault() calculates the default value every time it is called. This may be an issue if your default value is expensive to compute. Get() only calculates the default value if the key does not exist. Thus get() is a better choice if your default value is expensive. Since most default values are ‘zeros’ such as 0, [ ] and { }, this is not an issue for most cases.
We’ve seen three solutions to the problem now. We’ve got the code down to 1 line. But the syntax for each has been different to what we want. Now let’s see something that solves the problem exactly as we’d expect: introducing defaultdict!
Python defaultdict()
Let’s solve our numerical incrementation problem:
# Import from collections module from collections import defaultdict meal_data = zip(people, prices) # Initialise with int to do numerical incrementation total = defaultdict(int) # Increment exactly as we want to! for (person, price) in meal_data: total[person] += price >>> total defaultdict(<class 'int'>, {'Adam': 18.8, 'Bella': 22.45, 'Cara': 18.9})
Success!! But what about our list problem?
from collections import defaultdict meal_data = zip(people, prices) # Initialise with list to let us append individual_bill = defaultdict(list) for (person, price) in meal_data: individual_bill[person].append(price) >>> individual_bill defaultdict(<class 'list'>, {'Adam': [3.2, 12.5, 3.1], 'Bella': [4.5, 15.0, 2.95], 'Cara': [3.89, 13.15, 1.86]})
The defaultdict is part of the built-in collections module. So before we use it, we must first import it.
Defaultdict is the same as a normal Python dictionary except:
- It takes a callable data type as an argument
- When it meets a key for the first time, the default value is set as the ‘zero’ for that data type. For int it is 0, for list it’s an empty list [ ] etc..
Thus you will never get a KeyError! Plus and initialising default values is taken care of automatically!
We have now solved the problem using the same syntax for lists and numbers!
Now let’s go over some special cases for defaultdict.
Python defaultdict() Special Cases
Above we said it’s not possible to get a KeyError when using defaultdict. This is only true if you correctly initialise your dict.
# Initialise without an argument >>> bad_dict = defaultdict() >>> bad_dict['key'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'key' # Initialise with None >>> another_bad_dict = defaultdict(None) >>> another_bad_dict['another_key'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'another_key'
Let’s say you initialise defaultdict without any arguments. Then Python raises a KeyError if you call a key not in the dictionary. This is the same as initialising with None and defeats the whole purpose of defaultdict.
The issue is that None is not callable. Yet you can get defaultdict to return None by using a lambda function:
>>> none_dict = defaultdict(lambda: None) >>> none_dict['key'] >>>
Note that you cannot increment or append to None. Make sure you choose your default value to match the problem you are solving!
Whilst we’re here, let’s take a look at some more dictionaries in the collections module.
OrderedDict
Earlier we said that dictionaries preserve their order from Python 3.7 onwards. So why do we need something called OrderedDict?
As the name suggests, OrderedDict preserves the order elements are added. But two OrderedDicts are the same if and only if their elements are in the same order. This is not the case with normal dicts.
>>> from collections import OrderedDict # Normal dicts preserve order but don't use it for comparison >>> normal1 = dict(a=1, b=2) >>> normal2 = dict(b=2, a=1) >>> normal1 == normal2 True # OrderedDicts preserve order and use it for comparison >>> ordered1 = OrderedDict(a=1, b=2) >>> ordered2 = OrderedDict(b=2, a=1) >>> ordered1 == ordered2 False
Other than that, OrderedDict has all the same properties as a regular dictionary. If your elements must be in a particular order, then use OrderedDict!
Counter()
Let’s say we want to count how many times each word appears in a piece of text (a common thing to do in NLP). We’ll use The Zen of Python for our example. If you don’t know what it is, run
>>> import this
I’ve stored it in the list zen_words where each element is a single word.
We can manually count each word using defaultdict. But printing it out with the most frequent words occurring first is a bit tricky.
>>> from collections import defaultdict >>> word_count = defaultdict(int) >>> for word in zen_words: word_count[word] += 1 # Define function to return the second value of a tuple >>> def select_second(tup): return tup[1] # Reverse=True - we want the most common first # word_count.items() - we want keys and values # sorted() returns a list, so wrap in dict() to return a dict >>> dict(sorted(word_count.items(), reverse=True, key=select_second)) {'is': 10, 'better': 8, 'than': 8, 'to': 5, ...}
As counting is quite a common process, the Counter() dict subclass was created. It is complex enough that we could write a whole article about it.
For brevity, we will include the most basic use cases and let the reader peruse the docs themselves.
>>> from collections import Counter >>> word_count = Counter(zen_words) >>> word_count Counter({'is': 10, 'better': 8, 'than': 8, 'to': 5, ...})
You can pass any iterable or dictionary to Counter(). It returns a dictionary in descending order of counts
>>> letters = Counter(['a', 'b', 'c', 'c', 'c', 'c', 'd', 'd', 'a']) >>> letters Counter({'c': 4, 'a': 2, 'd': 2, 'b': 1}) # Count of a missing key is 0 >>> letters['z'] 0
Reversed()
In Python 3.8 they introduced the
reversed() function for dictionaries! It returns an iterator. It iterates over the dictionary in the opposite order to how the key-value pairs were added. If the key-value pairs have no order, reversed() will not give them any further ordering. If you want to sort the keys alphabetically for example, use
sorted().
# Python 3.8 # Reverses the order key-value pairs were added to the dict >>> ordered_dict = dict(a=1, b=2, c=3) >>> for key, value in reversed(ordered_dict.items()): print(key, value) c 3 b 2 a 1 # Does not insert order where there is none. >>> unordered_dict = dict(c=3, a=1, b=2) >>> for key, value in reversed(unordered_dict.items()): print(key, value) b 2 a 1 c 3 # Order unordered_dict alphabetically using sorted() >>> dict(sorted(unordered_dict.items())) {'a': 1, 'b': 2, 'c': 3}
Since it’s an iterator, remember to use the keys(), values() and items() methods to select the elements you want. If you don’t specify anything, you’ll iterate over the keys.
Dictionary Comprehensions
A wonderful feature of dictionaries, and Python in general, is the comprehension. This lets you create dictionaries in a clean, easy to understand and Pythonic manner. You must use curly braces {} to do so (not dict()).
We’ve already seen that if you have two lists, you can create a dictionary from them using dict(zip()).
names = ['Adam', 'Beth', 'Charlie', 'Dani', 'Ethan'] countries = ['Argentina', 'Bulgaria', 'Colombia', 'Denmark', 'Estonia'] dict_zip = dict(zip(names, countries)) >>> dict_zip {'Adam': 'Argentina', 'Beth': 'Bulgaria', 'Charlie': 'Colombia', 'Dani': 'Denmark', 'Ethan': 'Estonia'}
We can also do this using a for loop
>>> new_dict = {} >>> for name, country in zip(names, countries): new_dict[name] = country >>> new_dict {'Adam': 'Argentina', 'Beth': 'Bulgaria', 'Charlie': 'Colombia', 'Dani': 'Denmark', 'Ethan': 'Estonia'}
We initialize our dict and iterator variables with descriptive names. To iterate over both lists at the same time we zip them together. Finally, we add key-value pairs as desired. This takes 3 lines.
Using a comprehension turns this into one line.
dict_comp = {name: country for name, country in zip(names, countries)} >>> dict_comp {'Adam': 'Argentina', 'Beth': 'Bulgaria', 'Charlie': 'Colombia', 'Dani': 'Denmark', 'Ethan': 'Estonia'}
They are a bit like for loops in reverse. First, we state what we want our key-value pairs to be. Then we use the same for loop as we did above. Finally, we wrap everything in curly braces.
Note that every comprehension can be written as a for loop. If you ever get results you don’t expect, try it as a for loop to see what is happening.
Here’s a common mistake
dict_comp_bad = {name: country for name in names for country in countries} >>> dict_comp_bad {'Adam': 'Estonia', 'Beth': 'Estonia', 'Charlie': 'Estonia', 'Dani': 'Estonia', 'Ethan': 'Estonia'}
What’s going on? Let’s write it as a for loop to see. First, we’ll write it out to make sure we are getting the same, undesired, result.
bad_dict = {} for name in names: for country in countries: bad_dict[name] = country >>> bad_dict {'Adam': 'Estonia', 'Beth': 'Estonia', 'Charlie': 'Estonia', 'Dani': 'Estonia', 'Ethan': 'Estonia'}
Now we’ll use the bug-finder’s best friend: the print statement!
# Don't initialise dict to just check for loop logic for name in names: for country in countries: print(name, country) Adam Argentina Adam Bulgaria Adam Colombia Adam Denmark Adam Estonia Beth Argentina Beth Bulgaria Beth Colombia ... Ethan Colombia Ethan Denmark Ethan Estonia
Here we remove the dictionary to check what is actually happening in the loop. Now we see the problem! The issue is we have nested for loops. The loop says: for each name pair it with every country. Since dictionary keys can only appear, the value gets overwritten on each iteration. So each key’s value is the final one that appears in the loop – ‘Estonia’.
The solution is to remove the nested for loops and use zip() instead.
Python Nested Dictionaries with Dictionary Comprehensions
nums = [0, 1, 2, 3, 4, 5] dict_nums = {n: {'even': n % 2 == 0, 'square': n**2, 'cube': n**3, 'square_root': n**0.5} for n in nums} # Pretty print for ease of reading >>> pprint(dict_nums) {0: {'cube': 0, 'even': True, 'square': 0, 'square_root': 0.0}, 1: {'cube': 1, 'even': False, 'square': 1, 'square_root': 1.0}, 2: {'cube': 8, 'even': True, 'square': 4, 'square_root': 1.4142135623730951}, 3: {'cube': 27, 'even': False, 'square': 9, 'square_root': 1.7320508075688772}, 4: {'cube': 64, 'even': True, 'square': 16, 'square_root': 2.0}, 5: {'cube': 125, 'even': False, 'square': 25, 'square_root': 2.23606797749979}}
This is where comprehensions become powerful. We define a dictionary within a dictionary to create lots of information in a few lines of code. The syntax is exactly the same as above but our value is more complex than the first example.
Remember that our key value pairs must be unique and so we cannot create a dictionary like the following
>>> nums = [0, 1, 2, 3, 4, 5] >>> wrong_dict = {'number': num, 'square': num ** 2 for num in nums} File "<stdin>", line 1 wrong_dict = {'number': num, 'square': num ** 2 for num in nums} ^ SyntaxError: invalid syntax
We can only define one pattern for key-value pairs in a comprehension. But if you could define more, it wouldn’t be very helpful. We would overwrite our key-value pairs on each iteration as keys must be unique.
If-Elif-Else Statements
nums = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # Just the even numbers even_squares = {n: n ** 2 for n in nums if n % 2 == 0} # Just the odd numbers odd_squares = {n: n ** 2 for n in nums if n % 2 == 1} >>> even_dict {0: 0, 2: 4, 4: 16, 6: 36, 8: 64, 10: 100} >>> odd_dict {1: 1, 3: 9, 5: 25, 7: 49, 9: 81}
We can apply if conditions after the for statement. This affects all the values you are iterating over.
You can also apply them to your key and value definitions. We’ll now create different key-value pairs based on whether a number is odd or even.
# Use parenthesis to aid readability different_vals = {n: ('even' if n % 2 == 0 else 'odd') for n in range(5)} >>> different_vals {0: 'even', 1: 'odd', 2: 'even', 3: 'odd', 4: 'even'}
We can get really complex and use if/else statements in both the key-value definitions and after the for loop!
# Change each key using an f-string {(f'{n}_cubed' if n % 2 == 1 else f'{n}_squared'): # Cube odd numbers, square even numbers (n ** 3 if n % 2 == 1 else n ** 2) # The numbers 0-10 inclusive for n in range(11) # If they are not multiples of 3 if n % 3 != 0} {'1_cubed': 1, '2_squared': 4, '4_squared': 16, '5_cubed': 125, '7_cubed': 343, '8_squared': 64, '10_squared': 100}
It is relatively simple to do this using comprehensions. Trying to do so with a for loop or dict() constructor would be much harder.
Merging Two Dictionaries
Let’s say we have two dictionaries A and B. We want to create a dictionary, C, that contains all the key-value pairs of A and B. How do we do this?
>>> A = dict(a=1, b=2) >>> B = dict(c=3, d=4) # Update method does not create a new dictionary >>> C = A.update(B) >>> C >>> type(C) <class 'NoneType'> >>> A {'a': 1, 'b': 2, 'c': 3, 'd': 4}
Using merge doesn’t work. It modifies A in place and so doesn’t return anything.
Before Python 3.5, you had to write a function to do this. In Python 3.5 they introduced this wonderful bit of syntax.
# Python >= 3.5 >>> A = dict(a=1, b=2) >>> B = dict(c=3, d=4) >>> C = {**A, **B} >>> C {'a': 1, 'b': 2, 'c': 3, 'd': 4}
We use ** before each dictionary to ‘unpack’ all the key-value pairs.
The syntax is very simple: a comma-separated list of dictionaries wrapped in curly braces. You can do this for an arbitrary number of dictionaries.
A = dict(a=1, b=2) B = dict(c=3, d=4) C = dict(e=5, f=6) D = dict(g=7, h=8) >>> all_the_dicts = {**A, **B, **C, **D} >>> all_the_dicts {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8}
Finally, what happens if the dicts share key-value pairs?
>>> A = dict(a=1, b=2) >>> B = dict(a=999) >>> B_second = {**A, **B} >>> A_second = {**B, **A} # Value of 'a' taken from B >>> B_second {'a': 999, 'b': 2} # Value of 'a' taken from A >>> A_second {'a': 1, 'b': 2}
As is always the case with Python dictionaries, a key’s value is dictated by its last assignment. The dict B_second first takes A’s values then take’s B’s. Thus any shared keys between A and B will be overwritten with B’s values. The opposite is true for A_second.
Note: if a key’s value is overridden, the position of that key in the dict does not change.
>>> D = dict(g=7, h=8) >>> A = dict(a=1, g=999) >>> {**D, **A} # 'g' is still in the first position despite being overridden with A's value {'g': 999, 'h': 8, 'a': 1}
Conclusion
You now know almost everything you’ll ever need to know to use Python Dictionaries. Well done! Please bookmark this page and refer to it as often as you need!
If you have any questions post them in the comments and we’ll get back to you as quickly as possible.
If you love Python and want to become a freelancer, there is no better course out there than this one:
I bought it myself and it is why you are reading these words today.
About the Author!
References
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
Where to Go From Here?
Congratulations! You’ve successfully mastered dictionaries in Python! Now, let’s dive into Python sets.
> | https://blog.finxter.com/python-dictionary/ | CC-MAIN-2021-43 | refinedweb | 7,733 | 64.91 |
Introduction to MonoTouch.Dialog
- PDF for offline use:
-
- Related Articles:
-
- Related SDKs:
-
The MonoTouch.Dialog (MT.D) toolkit is an indispensable framework for rapid application UI development in Xamarin.iOS. MT.D makes it fast and easy to define complex application UI using a declarative approach, rather than the tedium of navigation controllers, tables, etc. Additionally, MT.D has a flexible set of APIs that provide developers with a complete control or hands off approach, as well as additional features such as pull-to-refresh, background image loading, search support, and dynamic UI generation via JSON data. This guide introduces the different ways to work with MT.D and then dives deep into advanced usage.
Overview
MonoTouch.Dialog, referred to as MT.D for short, is a rapid UI development toolkit that allows developers to build out application screens and navigation using information, rather than the tedium of creating view controllers, tables, etc. As such, it provides a significant simplification of UI development and code reduction. For example, consider the following screenshot:
This entire screen was defined with the following code:
public enum Category { Travel, Lodging, Books } public class Expense { [Section("Expense Entry")] [Entry("Enter expense name")] public string Name; [Section("Expense Details")] [Caption("Description")] [Entry] public string Details; [Checkbox] public bool IsApproved = true; [Caption("Category")] public Category ExpenseCategory; }
When working with tables in iOS, there’s often a ton of repetitious code. For example, every time a table is needed, a data source is needed to populate that table. In an application that has two table-based screens that are connected via a navigation controller, each screen shares a lot of the same code.
MT.D simplifies that by encapsulating all of that code into a generic API for table creation. It then provides an abstraction on top of that API that allows for a declarative object binding syntax that makes it even easier. As such, there are two APIs available in MT.D:
- Low-level Elements API – The Elements API is based on creating a hierarchal. The example above illustrated the use of the Reflection API. This API doesn’t provide the fine-grained control that the elements API does, but it reduces complexity even further by automatically building out the element hierarchy based on class attributes.
MT.D comes packed with a large set of built in UI elements for screen creation, but it also recognizes the need for customized elements and advanced screen layouts. As such, extensibility is a first-class featured baked into the API. Developers can extend the existing elements or create new ones and then integrate seamlessly.
Additionally, MT.D has a number of common iOS UX features built in such as "pull-to-refresh” support, asychronous image loading, and search support.
This article will take a comprehensive look at working with MT.D, including:
- MT.D Components – This will focus on understanding the classes that make up MT.D to enable getting up to speed quickly.
- Elements Reference – A comprehensive list of the built-in elements of MT.D.
Advanced Usage – This covers advanced features such as pull-to-refresh, search, background image loading, using LINQ to build out element hierarchies, and creating custom elements, cells, and controllers for use with MT.D.
Understanding the Pieces of MT.D
Even when using the Reflection API, MT.D creates an Element hierarchy under the hood, just as if it were created via the Elements API directly. Also, the JSON support mentioned in the previous section creates Elements as well. For this reason, it’s important to have a basic understanding of the constituent pieces of MT.D.
MT.D builds screens using the following four parts:
- DialogViewController
- RootElement
- Section
Element
DialogViewController
A DialogViewController, or DVC for short, inherits from
UITableViewController and therefore represents a screen with a
table. DVCs can be pushed onto a navigation controller just like a regular
UITableViewController.
RootElement
A RootElement is the top-level container for the items that go into a DVC. It contains Sections, which can then contain Elements. RootElements are not rendered; instead they’re simply containers for what actually gets rendered. A RootElement is assigned to a DVC, and then the DVC renders its children.
Section
A section is a group of cells in a table. As with a normal table section, it can optionally have a header and footer that can either be text, or even custom views, as in the following screenshot:
Element
An Element represents an actual cell in the table. MT.D comes packed with a wide variety of Elements that represent different data types or different inputs. For example, the following screenshots illustrate a few of the available elements:
More on Sections and RootElements
Let’s now discuss RootElements and Sections in greater detail.
RootElements
At least one RootElement is required to start the MonoTouch.Dialog process.
If a RootElement is initialized with a section/element value then this value is used to locate a child Element that will provide a summary of the configuration, which is rendered on the right side of the display. For example, the screenshot below shows a table on the left with a cell containing the title of the detail screen on the right, "Dessert”, along with the value of the selected desert.
Root elements can also be used inside Sections to trigger loading a new nested configuration page, as shown above. When used in this mode the caption provided is used while rendered inside a section and is also used as the Title for the subpage. For example:
var root = new RootElement ("Meals") { new Section ("Dinner"){ new RootElement ("Dessert", new RadioGroup ("dessert", 2)) { new Section () { new RadioElement ("Ice Cream", "dessert"), new RadioElement ("Milkshake", "dessert"), new RadioElement ("Chocolate Cake", "dessert") } } } }
In the above example, when the user taps on "Dessert", MonoTouch.Dialog will create a new page and navigate to it with the root being "Dessert" and having a radio group with three values.
In this particular sample, the radio group will select "Chocolate Cake" in the "Dessert" section because we passed the value "2" to the RadioGroup. This means pick the 3rd item on the list (zero-index).
Calling the Add method or using the C# 4 initializer syntax adds sections. The Insert methods are provided to insert sections with an animation.
If you create the RootElement with a Group instance (instead of a RadioGroup) the summary value of the RootElement when displayed in a Section will be the cumulative count of all the BooleanElements and CheckboxElements that have the same key as the Group.Key value.
Sections
Sections are used to group elements in the screen and they are the only valid direct children of the RootElement. Sections can contain any of the standard elements, including new RootElements.
RootElements embedded in a section are used to navigate to a new deeper level.
Sections can have headers and footers either as strings, or as UIViews. Typically you will just use the strings, but to create custom UIs you can use any UIView as the header or the footer. You can either use a string to create them like this:
var section = new Section ("Header", "Footer")
To use views, just pass the views to the constructor:
var header = new UIImageView (Image.FromFile ("sample.png")); var section = new Section (header)
Getting Notified
Handling NSAction
MT.D surfaces an
NSAction as a delegate for handling callbacks.
For example, say you want to handle a touch event for a table cell created by
MT.D. When creating an element with MT.D, simply supply a callback function, as
shown below:
new Section () { new StringElement ("Demo Callback", delegate { Console.WriteLine ("Handled"); }) }
Retrieving Element Value
Combined with the
Element.Value property, the callback can
retrieve the value set in other elements. For example, consider the following
code:
var element = new EntryElement (task.Name, "Enter task description", task.Description); var taskElement = new RootElement (task.Name){ new Section () { element }, new Section () { new DateElement ("Due Date", task.DueDate) }, new Section ("Demo Retrieving Element Value") { new StringElement ("Output Task Description", delegate { Console.WriteLine (element.Value); }) } };
This code creates a UI as shown below. For a complete walkthrough of this example, see the Elements API Walkthrough tutorial.
When the user presses the bottom table cell, the code in the anonymous
function executes, writing the value from the
element instance to
the Application Output pad in Xamarin Studio.
Built-In Elements
MT.D comes with a number of built-in table cell items known as Elements. These elements are used to display a variety of different types in table cells such as strings, floats, dates and even images, to name just a few. Each element takes care of displaying the data type appropriately. For example, a boolean element will display a switch to toggle its value. Likewise, a float element will display a slider to change the float value.
There are even more complex elements to support richer data types such as images and html. For example, an html element, which will open a UIWebView to load a web page when selected, displays a caption in the table cell.
Working with Element Values
Elements that are used to capture user input expose a public
Value property that holds the current value of the element at any
time. It is automatically updated as the user uses the application.
This is the behavior for all of the Elements that are part of MonoTouch.Dialog, but it is not required for user-created elements.
String Element
A
StringElement shows a caption on the left side of a table cell
and the string value on the right side of the cell.
To use a
StringElement as a button, provide a delegate.
new StringElement ( "Click me", () => { new UIAlertView("Tapped", "String Element Tapped" , null, "ok", null).Show(); })
Styled String Element
A
StyledStringElement allows strings to be presented using
either built-in table cell styles or with custom formatting.
The
StyledStringElement class derives from
StringElement, but lets developers customize a handful of
properties like the Font, text color, background cell color, line breaking mode,
number of lines to display, and whether an accessory should be displayed.
Multiline Element
Entry Element
The
EntryElement, as the name implies, is used to get user
input. It supports either regular strings or passwords, where characters are
hidden.
It is initialized with three values:
- The caption for the entry that will be shown to the user.
- Placeholder text (this is the greyed-out text that provides a hint to the user).
- The value of the text.
The placeholder and value can be null. However, the caption is required.
At any point, accessing its Value property can retrieve the value of the
EntryElement.
Additionally the
KeyboardType property can be set at creation
time to the keyboard type style desired for the data entry. This can be used to
configure the keyboard using the values of
UIKeyboardType as listed
below:
- Numeric
- Phone
- Url
Boolean Element
Checkbox Element
Radio Element
A
RadioElement requires a
RadioGroup to be
specified in the
RootElement.
mtRoot = new RootElement ("Demos", new RadioGroup("MyGroup", 0))
RootElements are also used to coordinate radio elements. The
RadioElement members can span multiple Sections (for example to
implement something similar to the ring tone selector and separate custom ring
tones from system ringtones). The summary view will show the radio element that
is currently selected. To use this, create the
RootElement with the
group constructor, like this:
var root = new RootElement ("Meals", new RadioGroup ("myGroup", 0))
The name of the group in
RadioGroup is used to show the selected
value in the containing page (if any) and the value, which is zero in this case,
is the index of the first selected item.
Badge Element
Float Element
Activity Element
Date Element
When the cell corresponding to the DateElement is selected, a date picker is presented as shown below:
Time Element
When the cell corresponding to the TimeElement is selected, a time picker is presented as shown below:
DateTime Element
When the cell corresponding to the DateTimeElement is selected, a datetime picker is presented as shown below:
HTML Element
The
HTMLElement displays the value of its
Caption
property in the table cell. Whe selected, the
Url assigned to the
element is loaded in a
UIWebView control as shown below:
Message Element
Load More Element
Use this element to allow users to load more items in your list. You can
customize the normal and loading captions, as well as the font and text color.
The
UIActivity indicator starts animating, and the loading caption
is displayed when a user taps the cell, and then the
NSAction
passed into the constructor is executed. Once your code in the
NSAction is finished, the
UIActivity indicator stops
animating and the normal caption is displayed again.
UIView Element
Additionally, any custom
UIView can be displayed using the
UIViewElement.
Owner-Drawn Element
This element must be subclassed as it is an abstract class. You should
override the
Height(RectangleF bounds) method in which you should
return the height of the element, as well as
Draw(RectangleF bounds, CGContext context, UIView view) in which you should do all your
customized drawing within the given bounds, using the context and view
parameters. This element does the heavy lifting of subclassing a
UIView, and placing it in the cell to be returned, leaving you only
needing to implement two simple overrides. You can see a better sample
implementation in the sample app in the
DemoOwnerDrawnElement.cs
file.
Here's a very simple example of implementing the class:
public class SampleOwnerDrawnElement : OwnerDrawnElement { public SampleOwnerDrawnElement (string text) : base(UITableViewCellStyle.Default, "sampleOwnerDrawnElement") { this.Text = text; } public string Text { get;set; } public override void Draw (RectangleF bounds, CGContext context, UIView view) { UIColor.White.SetFill(); context.FillRect(bounds); UIColor.Black.SetColor(); view.DrawString(this.Text, new RectangleF(10, 15, bounds.Width - 20, bounds.Height - 30), UIFont.BoldSystemFontOfSize(14.0f), UILineBreakMode.TailTruncation); } public override float Height (RectangleF bounds) { return 44.0f; } }
JSON Element
The
JsonElement is a subclass of
RootElement that
extends a
RootElement to be able to load the contents of nested
child from a local or remote url.
The
JsonElement is a
RootElement that can be
instantiated in two forms. One version creates a
RootElement that
will load the contents on demand. These are created by using the
JsonElement constructors that take an extra argument at the end,
the url to load the contents from:
var je = new JsonElement ("Dynamic Data", "");
The other form creates the data from a local file or an existing
System.Json.JsonObject that you have already parsed:
var je = JsonElement.FromFile ("json.sample"); using (var reader = File.OpenRead ("json.sample")) return JsonElement.FromJson (JsonObject.Load (reader) as JsonObject, arg);
For more information on using JSON with MT.D, see the JSON Element Walkthrough tutorial.
Other Features
Pull-to-Refresh Support
Pull-to- Refresh is a visual effect originally found in the Tweetie2 app, which became a popular effect among many applications.
To add automatic pull-to-refresh support to your dialogs, you only need to do
two things: hook up an event handler to be notified when the user pulls the data
and notify the
DialogViewController when the data has been loaded
to go back to its default state.
Hooking up a notification is simple; just connect to the
RefreshRequested event on the
DialogViewController,
like this:
dvc.RefreshRequested += OnUserRequestedRefresh;
Then on your method
OnUserRequestedRefresh, you would queue some
data loading, request some data from the net, or spin a thread to compute the
data. Once the data has been loaded, you must notify the
DialogViewController that the new data is in, and to restore the
view to its default state, you do this by calling
ReloadComplete:
dvc.ReloadComplete ();
Search Support
To support searching, set the
EnableSearch property on your
DialogViewController. You can also set the
SearchPlaceholder property to use as the watermark text in the
search bar.
Searching will change the contents of the view as the user types. It searches
the visible fields and shows those to the user. The
DialogViewController exposes three methods to programmatically
initiate, terminate or trigger a new filter operation on the results. These
methods are listed below:
StartSearch
FinishSearch
PerformFilter
The system is extensible, so you can alter this behavior if you want.
Background Image Loading
MonoTouch.Dialog incorporates the TweetStation application’s image loader. This image loader can be used to load images in the background, supports caching and can notify your code when the image has been loaded.
It will also limit the number of outgoing network connections.
The image loader is implemented in the
ImageLoader class, all
you need to do is call the
DefaultRequestImage method, you will
need to provide the Uri for the image you want to load, as well as an instance
of the
IImageUpdated interface which will be invoked when the image
has been loaded.
For example the following code loads an image from a Url into a
BadgeElement:
string uriString = " image url"; var rootElement = new RootElement("Image Loader") { new Section(){ new BadgeElement( ImageLoader.DefaultRequestImage( new Uri(uriString), this), "Xamarin") } };
The ImageLoader class exposes a Purge method that you can call when you want to release all of the images that are currently cached in memory. The current code has a cache for 50 images. If you want to use a different cache size (for instance, if you are expecting the images to be too large that 50 images would be too much), you can just create instances of ImageLoader and pass the number of images you want to keep in the cache.
Using LINQ to Create Element Hierarchy
Via the clever usage of LINQ and C#’s initialization syntax, LINQ can be
used to create an element hierarchy. For example, the following code creates a
screen from some string arrays and handles cell selection via an anonymous
function that is passed into each
StringElement:
var rootElement = new RootElement ("LINQ root element") { from x in new string [] { "one", "two", "three" } select new Section (x) { from y in "Hello:World".Split (':') select (Element) new StringElement (y, delegate { Debug.WriteLine("cell tapped"); }) } };
This could easily be combined with an XML data store or data from a database to create complex applications nearly entirely from data.
Extending MT.D
Creating Custom Elements
You can create your own element by inheriting from either an existing Element or by deriving from the root class Element.
To create your own Element, you will want to override the following methods:
// To release any heavy resources that you might have void Dispose (bool disposing); // To retrieve the UITableViewCell for your element // you would need to prepare the cell to be reused, in the // same way that UITableView expects reusable cells to work UITableViewCell GetCell (UITableView tv) // To retrieve a "summary" that can be used with // a root element to render a summary one level up. string Summary () // To detect when the user has tapped on the cell void Selected (DialogViewController dvc, UITableView tableView, NSIndexPath path) // If you support search, to probe if the cell matches the user input bool Matches (string text)
If your element can have a variable size, you need to implement the
IElementSizing interface, which contains one method:
// Returns the height for the cell at indexPath.Section, indexPath.Row float GetHeight (UITableView tableView, NSIndexPath indexPath);
If you are planning on implementing your
GetCell method by
calling
base.GetCell(tv) and customizing the returned cell, you
need to also override the
CellKey property to return a key that
will be unique to your Element, like this:
static NSString MyKey = new NSString ("MyKey"); protected override NSString CellKey { get { return MyKey; } }
This works for most elements, but not for the
StringElement and
StyledStringElement as those use their own set of keys for various
rendering scenarios. You would have to replicate the code in those classes.
DialogViewControllers (DVCs)
Both the Reflection and the Elements API use the same
DialogViewController. Sometimes you will want to customize the look
of the view or you might want to use some features of the
UITableViewController that go beyond the basic creation of UIs.
The
DialogViewController is merely a subclass of the
UITableViewController and you can customize it in the same way that
you would customize a
UITableViewController.
For example, if you wanted to change the list style to be either
Grouped or
Plain, you could set this value by changing
the property when you create the controller, like this:
var myController = new DialogViewController (root, true){ Style = UITableViewStyle.Grouped; }
For more advanced customizations of the
DialogViewController,
such as setting its background, you would subclass it and override the proper
methods, as shown in the example below:
class SpiffyDialogViewController : DialogViewController { UIImage image; public SpiffyDialogViewController (RootElement root, bool pushing, UIImage image) : base (root, pushing) { this.image = image; } public override LoadView () { base.LoadView (); var color = UIColor.FromPatternImage(image); TableView.BackgroundColor = UIColor.Clear; ParentViewController.View.BackgroundColor = color; } }
Another customization point is the following virtual methods in the
DialogViewController:
public override Source CreateSizingSource (bool unevenRows)
This method should return a subclass of
DialogViewController.Source for cases where your cells are evenly
sized, or a subclass of
DialogViewController.SizingSource if your
cells are uneven.
You can use this override to capture any of the
UITableViewSource methods. For example, TweetStation uses this to track when the user has scrolled to the
top and update accordingly the number of unread tweets.
Validation
Elements do not provide validation themselves as the models that are well suited for web pages and desktop applications do not map directly to the iPhone interaction model.
If you want to do data validation, you should do this when the user triggers
an action with the data entered. For example a Done or Next button on the top toolbar, or some
StringElement used as a button to go to the next stage.
This is where you would perform basic input validation, and perhaps more complicated validation like checking for the validity of a user/password combination with a server.
How you notify the user of an error is application specific. You could pop up
a
UIAlertView or show a hint.
Summary
This article covered a lot of information about MonoTouch.Dialog. It discussed the fundamentals of the how MT.D works and covered the various components that comprise MT.D. It also showed the wide array of elements and table customizations supported by MT.D and discussed how MT.D can be extended with custom elements. Additionally it explained the JSON support in MT.D that allows creating elements dynamically from JSON. | http://developer.xamarin.com/guides/ios/user_interface/monotouch.dialog/ | CC-MAIN-2015-27 | refinedweb | 3,735 | 52.29 |
Recall that Views in Xamarin.Android and Themes in Xamarin.iOS are analogous components that let you customize a Screenlet’s look and feel. You can use the Views and Themes provided by Liferay Screens, or write your own. Writing your own lets you tailor a Screenlet’s UI to your exact specifications. This tutorial shows you how to do this.
You can create Views and Themes from scratch, or use an existing one as a foundation. Views and Themes include a View class for implementing the Screenlet UI’s behavior, a Screenlet class for notifying listeners/delegates and invoking Interactors, and an AXML or XIB file for defining the UI.
There are also different types of Views and Themes. These are discussed in the tutorials on creating Views and Themes in native code. You should read those tutorials before creating Views in Xamarin.Android or Themes in Xamarin.iOS.
First, you’ll determine where to create your View or Theme.
Determining the Location of Your View or Theme
If you plan to reuse or redistribute your View or Theme, create it in a new Xamarin project as a multiplatform library for code sharing. Otherwise, create it in your app’s project.
Creating a Xamarin.Android View
Creating Views for Xamarin.Android is very similar to doing so in native code. You can create the following View types:
Themed View: Creating a Themed View in Xamarin.Android is identical to doing so in native code. In Xamarin.Android, however, only the Default View Set is available to extend.
Child View: Creating a Child View in Xamarin.Android is identical to doing so in native code.
Extended View: Creating an Extended View in Xamarin.Android differs from doing so in native code. The next section shows you how.
Extended View
To create an Extended View in Xamarin.Android, follow the steps for creating an Extended View in native code, but make sure your custom View class in the second step is the appropriate C# class. For example, here’s the View class from the native code tutorial, converted to C#:
using System; using Android.Content; using Android.Util; using Com.Liferay.Mobile.Screens.Viewsets.Defaultviews.Auth.Login; namespace ShowcaseAndroid.CustomViews { public class LoginCheckPasswordView : LoginView { public LoginCheckPasswordView(Context context) : base(context) { } public LoginCheckPasswordView(Context context, IAttributeSet attributes) : base(context, attributes) {} public LoginCheckPasswordView(Context context, IAttributeSet attributes, int defaultStyle) : base(context, attributes, defaultStyle) {} public override void OnClick(Android.Views.View view) { // compute password strength if (PasswordIsStrong) { base.OnClick(view); } else { // Present user message } } } }
Awesome! Now you know how to create Extended Views in Xamarin.Android.
Creating a Xamarin.iOS Theme
Creating Themes for Xamarin.iOS is very similar to doing so in native code. You can create the following Theme types in Xamarin.iOS:
- Child Theme: presents the same UI components as its parent Theme, but lets you change their appearance and position.
- Extended Theme: inherits its parent Theme’s functionality and appearance, but lets you add to and modify both.
First, you’ll learn how to create a Child Theme in Xamarin.iOS.
Child Theme
Child Themes leverage a parent Theme’s behavior and UI components, letting you modify the appearance and position of those components. Note that you can’t add or remove components, and the parent Theme must be a Full Theme. The Child Theme presents visual changes with its own XIB file and inherits the parent’s View class.
Follow these steps to create a Child Theme in Xamarin.iOS: content from the parent Theme’s XIB file as a foundation for your new XIB file. In your new XIB, you can change the UI components’ visual properties (e.g., their position and size). You mustn’t change, however, the XIB file’s custom class, outlet connection, or
restorationIdentifier. These must match those of the parent XIB file.
In the View Controller, set the Screenlet’s
ThemeNameproperty to the Theme’s name. For example, this sets Login Screenlet’s
ThemeNameproperty to the
demoTheme from the first step:
this.loginScreenlet.ThemeName = "demo";
This causes Liferay Screens to look for the file
LoginView_demoin all apps’ bundles. If that file doesn’t exist, Screens uses the Default Theme instead (
LoginView_default).
You can see an example of
LoginView_demo in
the Showcase-iOS demo app.
Fantastic! Next, you’ll learn how to create an Extended Theme.
Extended Theme
An Extended Theme inherits another Theme’s UI components and behavior, but lets you add to or alter both. For example, you can extend the parent Theme’s View class to change the parent Theme’s behavior. You can also create a new XIB file that contains new or modified UI components. An Extended Theme’s parent must be a Full Theme.
Follow these steps to create an Extended Theme: the parent Theme’s XIB file as a template. Make your Theme’s UI changes by editing your XIB file in Visual Studio’s iOS Designer or Xcode’s Interface Builder.
Create a new View class that extends the parent Theme’s View class. You should name this class after the XIB file you just created. You can add to or override functionality of the parent Theme’s View class. Here’s an example that extends the View class of Login Screenlet’s default Theme (
LoginView_default). Note that it changes the login button’s background color and disables the progress presenter:
using LiferayScreens; using System; namespace ShowcaseiOS { public partial class LoginView_demo : LoginView_default { public LoginView_demo (IntPtr handle) : base (handle) { } public override void OnCreated() { // You can change the login button color from code this.LoginButton.BackgroundColor = UIKit.UIColor.DarkGray; } // If you don't want a progress presenter, create an empty one public override IProgressPresenter CreateProgressPresenter() { return new NoneProgressPresenter(); } } }
Set your new View class as the custom class for your Theme’s XIB file:
Figure 1: Set new View class in XIB Theme file.
Well done! Now you know how to create an Extended Theme.
Related Topics
Creating Android Views (native code)
Creating iOS Themes (native code)
Preparing Xamarin Projects for Liferay Screens
Using Screenlets in Xamarin Apps
Using Views in Xamarin.Android
Using Themes in Xamarin.iOS
Liferay Screens for Xamarin Troubleshooting and FAQs | https://help.liferay.com/hc/en-us/articles/360018160731-Creating-Xamarin-Views-and-Themes- | CC-MAIN-2022-27 | refinedweb | 1,026 | 58.58 |
In my understanding, we all agreed that most parts of a good module system can be done in Lua itself. But such system can become quite complex and even may use non-standard facilities (e.g. use of timestamps to re-load modules that have been modified since they were loaded; or hierarchical namespaces mapped to directories hierarchies, as in Python). Therefore, it would be a good idea to provide it outside the main distribution, through libraries and conventions. Another thing we agreed is that the standard libraries should come packaged inside tables, like all other libraries. However, (at least) two problems remain. The first one is bootstraping. If the module system depends on a library, how we are going to load that library? One solution is to put a simple system inside Lua (such as the current "require") and then use it to activate a more powerful system (that can re-define "require"). Roughly, that translates to "local _t = m", and then any access to b (or c) is translated to "_t.b" (or _t.c). Instead of a list of names, we can also use a single "*", which means a default for all non-declared globals. There are many uses for such declarations. First, something like global (nil) * disables access to any non-declared variable ("forces variable declarations"). Something like global ({}) * puts any non-declared variable in a new (private) table. Something like Public = {} global ({}) * global (Public) a,b,c puts all new names into a private table, but a,b and c, that go to the public table. (This builds something similar to my proposal for modules, but you do not have to prefix all names with "Public." or "Private.".) A little more complex example is global (metatable({}, {index=globals()})) * That puts all new names in a private table, but inherits all global names. -- Roberto | http://lua-users.org/lists/lua-l/2002-02/msg00363.html | CC-MAIN-2016-50 | refinedweb | 308 | 63.29 |
From: dan marsden (danmarsden_at_[hidden])
Date: 2005-11-29 14:20:12
--- John Maddock <john_at_[hidden]> wrote:
> There are still lots of issue with the comparison
> operators:
>
> The first error occurs in the < comparison, which
> ends up calling operator >
> in sequence_less.hpp:
>
> namespace sequence_less_detail {
> template <typename T,typename I1, typename I2>
> bool call(T const& self,I1 const& a, I2 const& b) {
> return *a < *b
> || !(*b > *a)
> && T::call(fusion::next(a), fusion::next(b));
> }
> }
>
> The thing is that's not a "less than" relation to
> begin with!
Yes, embarrasing typo, now corrected. It passed the
previous comparison tests. I extended the tests quite
a bit, defect failed tests before being fixed, passes
after fix.
> It's called from sequence_less::call which
> constructs a comparison object of
> type equal_to, which looks rather suspicious to me!
No problem here. The equal_to usage is to compare
iterators over the sequences being compared, to
established the loop termination point.
> I'm attaching the error messages below, but I think
> you're going to have to
> work with the test cases I sent you, *and* devise
> some runtime tests to
> ensure that these operators actually do what they're
> supposed to.
As mentioned above, I've extended the runtime tests to
avoid this sort of typo creeping through again. I also
copied the files that you sent to Joel into boost/tr1
and libs/tr1/test. I then ran all the tests with bjam
-sTOOLS=gcc. Amongst the mass of messages, it seemed
that tuple_test compiled, with some warnings about
unused variables. I believe this is a compile time
test, so this constitutes success? I hope this is how
the tests were supposed to be run, if not just give me
some pointers.
> Thanks for persuing this,
>
> John.
No problem, sorry about the dodgy first attempt.
Cheers
Dan
___________________________________________________________
WIN ONE OF THREE YAHOO! VESPAS - Enter now! -
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk | https://lists.boost.org/Archives/boost/2005/11/97336.php | CC-MAIN-2020-40 | refinedweb | 335 | 67.15 |
# JSONPath in PostgreSQL: committing patches and selecting apartments

*This article was [written](https://habr.com/ru/company/postgrespro/blog/448612/) in Russian in 2019 after the PostgreSQL 12 feature freeze, and it is still up-to-date. Unfortunately other patches of the SQL/JSON will not get even into version 13.*
> Many thanks to Elena Indrupskaya for the translation.
>
>
JSONPath
--------
All that relates to JSON(B) is relevant and of high demand in the world and in Russia, and it is one of the key development areas in Postgres Professional. The jsonb type, as well as functions and operators to manipulate JSON/JSONB, appeared as early as in PostgreSQL 9.4. They were developed by the team lead by Oleg Bartunov.
The SQL/2016 standard provides for JSON usage: the standard mentions JSONPath — a set of functionalities to address data inside JSON; JSONTABLE — capabilities for conversion of JSON to usual database tables; a large family of functions and operators. Although JSON has long been supported in Postgres, in 2017 Oleg Bartunov with his colleagues started their work to support the standard. Of all described in the standard, only one patch, but a critical one, got into version 12; it is JSONPath, which we will, therefore, describe here.
At elder times people used to store JSON in text fields. In 9.3 a special data type for JSON was added, but related functionality was rather poor, and queries with this type were slow because of time spent on parsing the text representation of JSON. So, a lot of users who hesitated to start using Postgres had to choose NoSQL databases instead. Performance of Postgres increased in 9.4, when, thanks to O. Bartunov, A. Korotkov and T. Sigaev, a binary variant of JSON appeared in Postgres — the type jsonb.
Since it is not necessary to parse jsonb each time, it is much faster to use this type. Of functions and operators that appeared at the same time as jsonb, some only work with the new, binary, type; for example: an important containment operator **@>**, which checks whether an element or array is contained in JSONB:
```
SELECT '[1, 2, 3]'::jsonb @> '[1, 3]'::jsonb;
```
returns TRUE since the right-side array is contained in the array on the left. But
```
SELECT '[1, 2, [1, 3]]'::jsonb @> '[1, 3]'::jsonb;
```
returns FALSE because of a different nesting level, which must be specified explicitly. For the jsonb type, an existence operator **?** (question mark) is introduced, which checks whether a string is an object key or an array element at the top level of the JSONB value, as well as two similar operators (for details refer [here](https://postgrespro.ru/docs/postgresql/9.4/datatype-json)). They are supported by GIN indexes with two GIN operator classes. The**->** (arrow) operator allows «moving» across JSONB; it returns the value by a key or by an array index in the case of an array. There are [a few more](https://postgrespro.ru/docs/postgresql/9.4/functions-json) operators for movement. However, it is not possible to define filters with a functionality similar to WHERE. It was a breakthrough: thanks to jsonb, the popularity of Postgres as an RDBMS with NoSQL features began to grow.
In 2014 A. Korotkov, O. Bartunov and T. Sigaev developed the jsquery extension, eventually included in Postgres Pro Standard 9.5 (and higher Standard and Enterprise versions). It adds extremely broad capabilities to work with json(b). This extension defines a query language to retrieve data from json(b), along with indexes to accelerate execution of the queries. This functionality was in demand with users, who were not ready to wait for the standard and for inclusion of the new functions in a «vanilla» version. The fact that the development was sponsored by Wargaming.net proves the practical value of the extension. A special type, jsquery, is implemented in the extension.
Queries in this language are compact and look similar to the following:
```
SELECT '{"apt":[{"no": 1, "rooms":2}, {"no": 2, "rooms":3}, {"no": 3, "rooms":2}]}'::jsonb @@ 'apt.#.rooms=3'::jsquery;
```
The query asks whether there are three-room apartments in the house. We have to explicitly specify the type jsquery since the @@ operator is also available in the jsonb type now. The specification of jsquery is [here](https://github.com/postgrespro/jsquery), and a presentation with numerous examples is [here](http://www.sai.msu.su/~megera/postgres/talks/pgconfeu-2014-jsquery.pdf).
So, everything needed to work with JSON has already been available in Postgres, and then the SQL:2016 standard appeared. The semantics turned out to be not so different from ours in the jsquery extension. It may be that the authors of the standard were looking at jsquery from time to time while inventing JSONPath. Our team had to re-implement what we already had a bit differently and of course, to implement plenty of new as well.
More than a year ago, at the March commitfest, the fruits of our programmer efforts were proposed to the community as 3 big patches that support the [SQL:2016](https://en.wikipedia.org/wiki/SQL:2016) standard:
SQL/JSON: JSONPath;
SQL/JSON: functions;
SQL/JSON: JSON\_TABLE.
But to develop a patch is only half the journey, it is also uneasy to promote patches, especially if they are big and involve multiple modules. A lot of review-update iterations are required, and quite a few resources (man-hours) need to be invested in promotion of the patch. The chief architect of Postgres Professional Alexander Korotkov himself undertook this task (thanks to the committer status he has now) and got the JSONPath patch committed, and this is the main patch in this series. The second and third patches have the Needs Review status now. JSONPath, on which the efforts were focused, enables manipulating the JSON(B) structure and is flexible enough to extract its elements. Of 15 items specified in the standard, 14 are implemented, which is greater than in Oracle, MySQL and MS SQL.
The notation in JSONPath differs from Postgres operators for manipulating JSON and from the notation of JSQuery. The hierarchy is denoted by dots:
$.a.b.c (in the notation of Postgres 11 we would have it as 'a'->'b'->'c');
$ is the current context of the element — the expression with $ actually specifies the json(b) area to process and, in particular, to be used in a filter, the remaining part is unavailable for manipulation in this case;
@ is the current context in the filter expression — all paths available in the expression with $ are went through;
[\*] is an array;
\* is a wildcard relevant to the expression with $ or @, it replaces any value on a path within one level of the hierarchy (between two dots in the dot notation);
\*\* is a wildcard relevant to the expression with $ or @, it replaces any value on a path regardless of the hierarchy — it is very convenient to use if we are unaware of the nesting level of the elements;
the "?" operator enables specifying a filter similar to WHERE:
$.a.b.c? (@.x > 10);
$.a.b.c.x.type(), as well as size(), double(), ceiling(), floor(), abs(), datetime(), keyvalue() are methods.
A query with the jsonb\_path\_query function (functions will be discussed further) may look as follows:
```
SELECT jsonb_path_query_array('[1,2,3,4,5]', '$[*] ? (@ > 3)');
jsonb_path_query_array
------------------------
[4, 5]
(1 row)
```
Although a special patch with functions has not been committed, the JSONPath patch already contains key functions to manipulate JSON(B):
```
jsonb_path_exists('{"a": 1}', '$.a') returns true (is called by the "?" operator)
jsonb_path_exists('{"a": 1}', '$.b') returns false
jsonb_path_match('{"a": 1}', '$.a == 1') returns true (called by the "@>" operator)
jsonb_path_match('{"a": 1}', '$.a >= 2') returns false
jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') returns 3, 4, 5
jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') returns 0 rows
jsonb_path_query_array('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') returns [3, 4, 5]
jsonb_path_query_array('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') returns []
jsonb_path_query_first('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') returns 3
jsonb_path_query_first('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') returns NULL
```
Note that the equality in JSONPath expressions is a single "=" vs. double in jsquery: "==".
For more elegant illustrations, we will generate JSONB in a one-column table `house`:
```
CREATE TABLE house(js jsonb);
INSERT INTO house VALUES
('{
"address": {
"city":"Moscow",
"street": "Ulyanova, 7A"
},
"lift": false,
"floor": [
{
"level": 1,
"apt": [
{"no": 1, "area": 40, "rooms": 1},
{"no": 2, "area": 80, "rooms": 3},
{"no": 3, "area": 50, "rooms": 2}
]
},
{
"level": 2,
"apt": [
{"no": 4, "area": 100, "rooms": 3},
{"no": 5, "area": 60, "rooms": 2}
]
}
]
}');
```
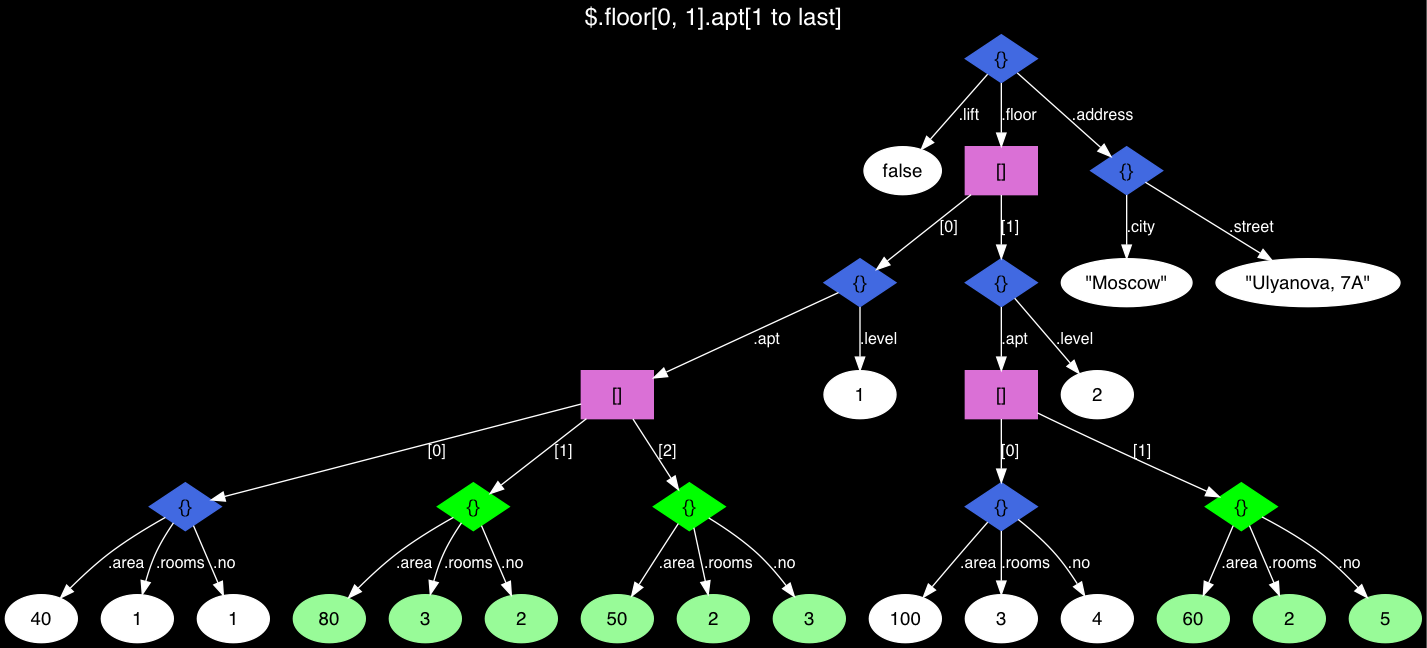
*Fig. 1 The JSON tree with apartment leaves visualized.*
This JSON looks weird, doesn’t it? It has a confusing hierarchy, but it's a real-life example, and in real life, you often have to deal with what there is and not with what there must be. Armed with the capabilities of the new version, let's find apartments on the 1-st and 2-nd floors, but not the first on the list of apartments of the floor (which are colored in green in the tree):
```
SELECT jsonb_path_query_array(js, '$.floor[0, 1].apt[1 to last]')
FROM house;
---------------------
[{"no": 2, "area": 80, "rooms": 3}, {"no": 3, "area": 50, "rooms": 2}, {"no": 5, "area": 60, "rooms": 2}]
```
In PostgreSQL 11 we will have to ask like this:
```
SELECT jsonb_agg(apt) FROM (
SELECT apt->generate_series(1, jsonb_array_length(apt) - 1) FROM (
SELECT js->'floor'->unnest(array[0, 1])->'apt' FROM house
) apts(apt)
) apts(apt);
```
Asking a very simple question now: are there any strings that contain the value of «Moscow» (anywhere)? It is really simple:
```
SELECT jsonb_path_exists(js, '$.** ? (@ == "Moscow")') FROM house;
```
In version 11, we would have to create a huge script:
```
WITH RECURSIVE t(value) AS (
SELECT * FROM house UNION ALL (
SELECT COALESCE(kv.value, e.value) AS value
FROM t
LEFT JOIN LATERAL jsonb_each (
CASE WHEN jsonb_typeof(t.value) = 'object' THEN t.value
ELSE NULL END
) kv ON true
LEFT JOIN LATERAL jsonb_array_elements (
CASE WHEN jsonb_typeof(t.value) = 'array' THEN t.value
ELSE NULL END
) e ON true
WHERE kv.value IS NOT NULL OR e.value IS NOT NULL
)
) SELECT EXISTS (SELECT 1 FROM t WHERE value = '"Moscow"');
```
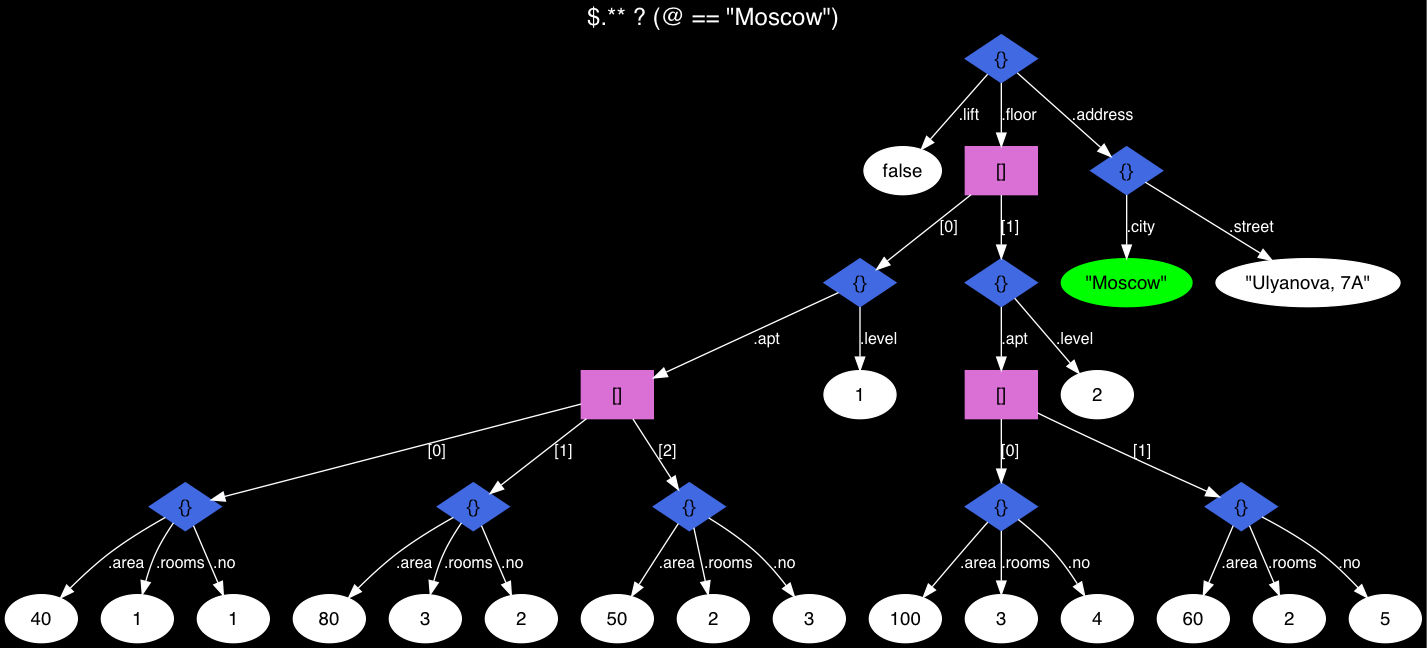
*Fig. 2 The JSON tree — Moscow found!*
Now searching for an apartment on any floor with the area from 40 to 90 square meters:
```
SELECT jsonb_path_query(js, '$.floor[*].apt[*] ? (@.area > 40 && @.area < 90)') FROM house;
jsonb_path_query
-----------------------------------
{"no": 2, "area": 80, "rooms": 3}
{"no": 3, "area": 50, "rooms": 2}
{"no": 5, "area": 60, "rooms": 2}
(3 rows)
```
Using our JSON to find apartments with the numbers larger than 3-rd:
```
SELECT jsonb_path_query(js, '$.floor.apt.no ? (@>3)') FROM house;
jsonb_path_query
------------------
4
5
(2 rows)
```
And this is how jsonb\_path\_query\_first works:
```
SELECT jsonb_path_query_first(js, '$.floor.apt.no ? (@>3)') FROM house;
jsonb_path_query_first
------------------------
4
(1 row)
```
It turns out that only the first value that meets the filtering condition is selected.
A Boolean operator JSONPath for JSONB — @@ — is called a match operator. It computes a JSONPath predicate by calling the jsonb\_path\_match\_opr function.
Another Boolean operator — @? — is the existence check, it answers the question whether a JSONPath expression will return SQL/JSON objects and calls the jsonb\_path\_exists\_opr function:
```
checking '[1,2,3]' @@ '$[*] == 3' returns true;
and '[1,2,3]' @? '$[*] @? (@ == 3)' also returns true
```
We can get the same result using different operators:
```
js @? '$.a' is equivalent to js @@ 'exists($.a)'
js @@ '$.a == 1' is equivalent to js @? '$ ? ($.a == 1)'
```
JSONPath Boolean operators are attractive because they are supported and accelerated by GIN indexes. jsonb\_ops and jsonb\_path\_ops are the appropriate operator classes. In the example below we turn off SEQSCAN since we manipulate a small table (for large tables the optimizer will choose Bitmap index on its own):
```
SET ENABLE_SEQSCAN TO OFF;
CREATE INDEX ON house USING gin (js);
EXPLAIN (COSTS OFF) SELECT * FROM house
WHERE js @? '$.floor[*].apt[*] ? (@.rooms == 3)';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on house
Recheck Cond: (js @? '$."floor"[*]."apt"[*]?(@."rooms" == 3)'::jsonpath)
-> Bitmap Index Scan on house_js_idx
Index Cond: (js @? '$."floor"[*]."apt"[*]?(@."rooms" == 3)'::jsonpath)
(4 rows)
```
All functions like jsonb\_path\_xxx() have the same signature:
```
jsonb_path_xxx(
js jsonb,
jsp jsonpath,
vars jsonb DEFAULT '{}',
silent boolean DEFAULT false
)
```
vars — is an argument of JSONB type to pass variables into a JSONPath expression:
```
SELECT jsonb_path_query_array('[1,2,3,4,5]', '$[*] ? (@ > $x)',
vars => '{"x": 2}');
jsonb_path_query_array
------------------------
[3, 4, 5]
```
It is tricky to go without `vars` when doing a join where one of the tables contains a field of type `jsonb`. Say, we are developing an application that searches apartments in that very house for employees, who recorded their requirements for a minimal area in a questionnaire:
```
CREATE TABLE demands(name text, position text, demand int);
INSERT INTO demands VALUES ('Gabe','boss', 85), ('Fabe','junior hacker', 45);
SELECT jsonb_path_query(js, '$.floor[*].apt[*] ? (@.area >= $min)', vars => jsonb_build_object('min', demands.demand)) FROM house, demands WHERE name = 'Fabe';
-[ RECORD 1 ]----+-----------------------------------
jsonb_path_query | {"no": 2, "area": 80, "rooms": 3}
-[ RECORD 2 ]----+-----------------------------------
jsonb_path_query | {"no": 3, "area": 50, "rooms": 2}
-[ RECORD 3 ]----+-----------------------------------
jsonb_path_query | {"no": 4, "area": 100, "rooms": 3}
-[ RECORD 4 ]----+-----------------------------------
jsonb_path_query | {"no": 5, "area": 60, "rooms": 2}
```
Lucky Fabe can select among four apartments. But as soon as we change one letter in the query from «F» to «G», there will be no choice! Only one apartment will be suitable.
One more keyword yet to mention: silent — is a flag to suppress error handling, which becomes the programmer's responsibility.
```
SELECT jsonb_path_query('[]', 'strict $.a');
ERROR: SQL/JSON member not found
DETAIL: jsonpath member accessor can only be applied to an object
```
An error occurred. But this way it won't occur:
```
SELECT jsonb_path_query('[]', 'strict $.a', silent => true);
jsonb_path_query
------------------
(0 rows)
```
By the way, mind the errors! According to the standard, numeric errors do not generate error messages, so it's the programmer's responsibility to handle them:
```
SELECT jsonb_path_query('[1,0,2]', '$[*] ? (1/ @ >= 1)');
jsonb_path_query
------------------
1
(1 row)
```
When computing the expression, array values are went through, which include zero, but division by zero does not generate an error.
Functions will operate differently depending on the mode selected: Strict or Lax (chosen by default). Assume that we are searching for a key using the Lax mode in a JSON that does not contain that key:
```
SELECT jsonb '{"a":1}' @? 'lax $.b ? (@ > 1)';
?column?
----------
f
(1 row)
```
Now using the Strict mode:
```
SELECT jsonb '{"a":1}' @? 'strict $.b ? (@ > 1)';
?column?
----------
(null)
(1 row)
```
That is, where we got FALSE in a the «lax» mode, in the «strict» mode we got NULL.
In the Lax mode, an array with a complex hierarchy [1,2,[3,4,5]] always unfolds to [1,2,3,4,5]:
```
SELECT jsonb '[1,2,[3,4,5]]' @? 'lax $[*] ? (@ == 5)';
?column?
----------
t
(1 row)
```
In the Strict mode, number «5» won't be found since it is at the bottom level of the hierarchy. To find it, we will have to change the query by replacing "@" with "@[\*]":
```
SELECT jsonb '[1,2,[3,4,5]]' @? 'strict $[*] ? (@[*] == 5)';
?column?
----------
t
(1 row)
```
В PostgreSQL 12, JSONPath is a data type. The standard says nothing of a need for the new type; this is a matter of implementation. With the new type, we gain full-featured work with `jsonpath` by means of operators and accelerating indexes that are already available for JSONB. Otherwise, we would have to integrate JSONPath at the level of executor and optimizer codes.
You can read about SQL/JSON syntax [here](https://www.postgresql.org/docs/devel/functions-json.html), for example.
Some examples in this article are taken from Oleg Bartunov's [presentation](https://www.highload.ru/spb/2019/abstracts/4871) at [Saint Highload++](https://www.highload.ru/spb/2019) in St. Petersburg on April 9, 2019.
Oleg Bartunov's blog touches upon [SQL/JSON standard-2016 conformance](https://obartunov.livejournal.com/200076.html) for PostgreSQL, Oracle, SQL Server and MySQL.
Here you can find a [presentation](http://www.sai.msu.su/~megera/postgres/talks/sqljson-china-2018.pdf) on SQL/JSON.
And here is the [introduction](https://github.com/obartunov/sqljsondoc/blob/master/README.jsonpath.md) to SQL/JSON. | https://habr.com/ru/post/500440/ | null | null | 2,727 | 54.63 |
PyCharm 4.5.4 has been uploaded and is now available from the download page.
It also will be available soon as a patch update from within the IDE (from PyCharm 4.5.x only).
The Release notes lists all fixes for this update.
As a recap, this minor bug update delivers the following fixes and improvements:
- a fix for debugging external packages while using remote interpreters (PY-11462).
- a number of fixes for the deployment subsystem.
- a major fix for the Django manage.py tool (PY-16434).
- a few fixes and improvements for the integrated Python debugger.
- a fix for running IPython Notebooks with Anaconda (PY-15938).
- a fix in order to support the local terminal for recently released Windows 10 (IDEA-143300).
- a number of improvements for python code insight, especially a fix for autocompletion when __init__.py contains __all__ (PY-14454).
- a fix of PyCharm hang in case of long console output (PY-14560)
- performance improvement for global inspections (IDEA-136646)
- a fix for viewing images with the debugger’s evaluate window (IDEA-144036)
- a bunch of improvements in underlying IntelliJ Platform and much more.
Download PyСharm 4.5.4 for your platform from our website and please report any problem you found in the Issue Tracker.
If you would like to discuss your experiences with PyCharm, we look forward to your feedback in comments to this post and on twitter.
Develop with Pleasure!
-PyCharm team
Any chance to fix to allow upload using patches, not re-downloading the whole ide?
It would be really helpful to those who package PyCharm if you could include a reference to which build number corresponds to release versions. During EAP its not difficult to find, simply clicking the release notes is all you have to do. However, on point releases the build number is no where to be found until PyCharm is installed :-/
Anyway, thanks for another great release!
Oops..nevermind. Sorry for the noise!
Is it just me, or did the editor font weight get heavier with the 4.5.4 update?
Just compared to WebStorm on the same Mac, both using Menlo 12/1.0, and the PyCharm editor seems more bold overall. (And the difference between bold and non-bold seems to be much less prominent in PyCharm now.)
Was this intentional?
No, there was no intention to modify fonts in this update. Could you please submit a support request here ? Please attach screenshots, list the versions you’re using, your platform, etc.
Just following up for anyone else who sees this: the Mac build of PyCharm with the bundled JDK customized by JetBrains (only) does render the editor font thinner/lighter weight in 4.5.4 than in the previous release, at least on some displays.
And JetBrains support was able to point me to a solution: Help > Find Action > type “Registry” > disable the force.default.lcd.rendering option, and the editor text renders like it did before. (Thanks to Anna from the PyCharm team.)
Anyone else had problems with inspections? On some files, especially if I create a new file from another file, the inspections just don’t trigger properly. False positives are reported (like clearly some variable being defined but PyCharm says it is not) and clear errors are not highlighted. Other files typically work the same.
PyCharm 4.5.3 works fine when I open the same project in that.
Oh and invalidating caches and restarting doesn’t help.
Hi,
i recently installed pucharm 4.5.4.
when am creating project the “project type ” drop down is not available.
i already hanving python 2.7.10.
and django 1.8.5 in as virtual env.
i cant configure the django server too…deployment option not available “Tools”
import error in “Manage.py”
can u please help me?
Please try File | Invalidate Caches and Restart. Otherwise, please file a bug describing your problem here: | https://blog.jetbrains.com/pycharm/2015/09/announcing-the-pycharm-4-5-4-release-update/ | CC-MAIN-2017-30 | refinedweb | 650 | 67.65 |
]
Sr Karthiga(33)
Kumaresh Rajalingam(12)
Abdul Rasheed Feroz Khan(5)
Monil Dubey(4)
Salman Faris(3)
Ravi Shankar(2)
Akkiraju Ivaturi(2)
Tamilan S(2)
Swatismita Biswal(1)
Munish A(1)
Abubackkar Shithik(1)
Manoj Kulkarni(1)
Ayush Rathi(1)
Vipul Jain(1)
Morgan Franklin(1)
Janshair Khan(1)
Tushar Dikshit(1)
Manikandan Murugesan(1)
Prasad Kambhammettu(1)
Logesh M(1)
Muhammed Fasil (1)
Delpin Susai Raj(1)
Waqas Sarwar(1)
Manpreet Singh(1)
Krishna Reddy(1)
Prashant Sharma(1)
Tejas Trivedi(1)
Priyaranjan K S(1)
Saillesh Pawar(1)
Shubham Sharma(1)
Menaka Priyadharshini B(1)
Suthahar J(1)
Nitin Pandit(1)
Ibrahim Ersoy(1)
Carmelo La Monica(1)
Yusuf Karatoprak(1)
Sumantro Mukherjee(1)
Prashant Bansal(1)
Jayesh Vyas(1)
Pritam Zope(1)
Aritro Mukherjee(1)
Afzaal Ahmad Zeeshan(1)
Mohit Patil(1)
Pooja Baraskar(1)
Venkatesan Jayakantham(1)
Resources
No resource found.
How To Control An LED Using Keypad
Sep 21, 2017.
In this article we are going to see how to add an additional key pad library. We will see how to control an LED using keypad by assigning a password character to it.
Gallery Android App Using Android Studio
Sep 19, 2017.
In this article, I will show you how to create an Android App using Android studio. Gallery is either in a building or on the internet, where photographs are on display..
Overview Of Ansible Automation
Aug 28, 2017.
You may have searched the Internet and still not understand what Ansible is and what it is used for, or how it can benefit your organization and fit into your DevOps workflow. Then you are in the right place!.
Getting Started With Microsoft Flow
Jul 25, 2017.
Microsoft Flow is a product to help us set up an automated Workflows between your favourite apps and services to synchronize files, get notifications, collect data, and more by the internet..
Creating Internet Connectivity Load Balancer Using Azure Portal
Jul 11, 2017.
Azure provides a variety of networking capabilities that can be used together or separately. But In this Article we will see about the one of the key capabilities (i.e Internet Connectivity).
Enabling Multi-Process Support In Firefox 54 For Faster Browsing
Jul 07, 2017.
In this article we will see how to enable a new feature of Mozilla Firefox ,called Multiprocess, on your computer.
Getting LED Lights ON/OFF In Arduino When Light Intensity Changes
Jul 05, 2017.
This article is for developers interested in the Internet of Things.
How To Switch ON/OFF LED Using ARDUINO UNO And C# Form Applications
Jun 26, 2017.
This article is for beginners interested in the Internet of Things.
Check Internet Connectivity In Xamarin iOS
May 26, 2017.
In this article, you will learn how to check internet connectivity in Xamarin iOS, using Xamarin Studio.
SharePoint 2016 Central Admin - Application Management - Configure Service Application Associations
May 09, 2017.
SharePoint 2016 Central Admin - Application Management - Configure Service Application Associations.
How To View Service Application Associations In SharePoint 2013 Central Administration
Jan 28, 2017.
In this article, you will learn how to view Service Application Associations in SharePoint 2013 Central Administration.
Explaining API Management To A Layman
Jan 16, 2017.
In this article, you will learn about API Management in a layman's style.
An Overview Of API World
Jan 15, 2017.
In this article, you will learn about API World.
Python Scripting On GPIO In Raspberry Pi
Nov 16, 2016.
In this article, you will learn Python Scripting on GPIO in Raspberry Pi.
Claims Based Authentication
Nov 14, 2016.
In this article, you will learn about claims based authentication.
How To Synchronize Windows 10 Time With The Internet Time Server
Nov 11, 2016.
In this article, you’ll learn about how to synchronize Windows 10 time with the Internet Time Server.
The Raspberry Pi And Arduino Board
Nov 10, 2016.
In this article, you will learn about Raspberry Pi and Arduino Board.
Internet Of Things (IoT) Sensors And Connectivity
Oct 08, 2016.
In this article, you will learn about IoT sensors and connectivity.
Setup Internet Information Services (IIS) Web Server In Azure
Sep 24, 2016.
In this article, you will learn how to setup Internet Information Services (IIS) Web Server in Azure.
Resolving The A5-Security Misconfiguration
Sep 19, 2016.
In this article, you will learn how to resolve the A5-security misconfiguration.
How To Change The Location Of Download Folder In Internet Explorer
Sep 06, 2016.
In this article, you will learn, how to change the location of download folder in Internet Explorer.
Attributes Of Induction Motor By Cloud Computing
Aug 25, 2016.
In this article you, will learn, how to turn Induction Motor on or off by Cloud Computing, using Internet of Things.
Register Identity Provider For New OAuth Application
Aug 23, 2016.
In this article, you will learn how to register identity provider for new OAuth application.
Delhi Chapter Meet June 19, 2016: Official Recap
Jun 20, 2016.
The C# Corner Delhi Chapter organized its monthly event, Delhi Chapter Meet at C# Corner, Noida on June 19, 2016.".
Connect Liquid Sensor With Arduino Mega 2560
Jun 13, 2016.
In this article you will learn how to connect Liquid Sensor with Arduino Mega 2560.
Serial Class Per Universal Windows Platform - Part One
Jun 12, 2016.
In this article, we will discuss the use of Serial Communication class, included in Windows.Devices namespace. At the hardware level, we will make use of Raspberry Pi2 board, Arduino Uno, etc.
Control Fan With Temperature Sensor Using Arduino Mega 2560
Jun 11, 2016.
In this article you will learn how to control fan with temperature sensor using Arduino Mega 2560.
Kickstart Raspberry Pi With Python
Jun 06, 2016.
In this article, you will learn how to start Raspberry Pi with Python.
Controlling Fan With IR Remote Using Arduino Mega 2560
Jun 06, 2016.
In this article you will learn about how to control Fan with IR Remote using Arduino Mega 2560.
Controlling The Servo Motor By Using Bluetooth Module
Jun 04, 2016.
In this article I will explain about controlling the Servo Motor using Bluetooth Module
Node.js In IoT Part-One
Jun 04, 2016.
In this article, you will learn about a very short introduction for Node.js in IoT projects.
Check Atmosphere Pressure Using Arduino Mega 2560
May 25, 2016.
In this article I will explain about checking the Atmosphere Pressure using Arduino Mega 2560.
Checking Temperature And Humidity Using Arduino Mega 2560
May 25, 2016.
In this article I will explain about checking the Temperature and Humidity using Arduino Mega 2560.
Working With Touch Sensor Using Arduino Mega
May 23, 2016.
In this article I will explain how to work with Touch Sensor using Arduino Mega.
Measuring The Capacitor Range With Arduino Mega 2560
May 21, 2016.
In this article I will explain about measuring the Capacitor Range with Arduino Mega 2560.
Web Server Blink Using Arduino Uno WiFi
May 21, 2016.
In this article you will learn how to realize a simple web server, using an Arduino UNO WiFi, to command the switch ON/OFF.
Working With Force Sensor Using Arduino Mega 2560
May 19, 2016.
In this article, I have explained about working with Force Sensor using Arduino Mega 2560.
Create A Simple Calculator With Ardunio Mega 2560
May 17, 2016.
In this article you will learn how to create a simple Calculator With Ardunio Mega 2560.
Smart Lighting Solution With Fedora 22 And Arduino
May 14, 2016.
In this article you will learn about a smart lighting solution with Fedora 22 and Arduino.
Ultrasonic Range Detector With Arduino Using The SR04 Ultrasonic Sensor
May 10, 2016.
In this article you will learn about Ultrasonic Range Detector with Arduino using the SR04 Ultrasonic Sensor.
Test Battery Life With Arduino Mega 2560
May 07, 2016.
In this article I have explained about testing the life of a Battery in Arduino Mega 2560.
Connecting Simple DC Motor In Arduino Mega 2560
May 05, 2016.
In this article I have explained about connecting simple DC Motor in the Arduino Mega 2560
Home Automation Using Arduino Uno
May 05, 2016.
In this article you will learn how to make your home automated using Arduino Uno.
Measure Water Level And Purity In A Tank With Arduino Mega 2560
May 04, 2016.
In this article I have explained how to measure water level and purity in a Tank with Arduino Mega 2560
Measuring Voice Speed With Arduino Mega 2560
May 03, 2016.
In this article I have explained about measuring Voice Speed with Arduino Mega 2560.
Display RGB Light With Arduino Mega 2560
May 02, 2016.
In this article you will learn how to display RGB Light With Arduino Mega 2560.
Tour On Pi From Device To First Program
May 02, 2016.
In this article you will see a tour on Pi from device to first program.
SharePoint 2013: How to Add Workflow Associations To A List Using Workflow Subscription Service
May 01, 2016.
In this article you will learn how to Add Workflow Associations to a List using Workflow Subscription Service in SharePoint 2013.
Measuring Dust Concentration - IoT
Apr 30, 2016.
In this article you will learn how to measure Dust Concentration in Internet of IoT.
Measuring Air Quality With IoT
Apr 29, 2016.
In this article you will learn how to measure Air Quality with IoT.
HelloWorld App In Raspberry Pi
Apr 26, 2016.
In this article we learn how to configure Windows 10 PC for Raspberry Pi and Run a HelloWorld Program In Raspberry Pi.
Introduction And Design Simulation Of Raspberry PI
Apr 26, 2016.
In this article we will learn about what Raspberry Pi is, components of Raspberry Pi devices, GPIO Pin Configurations, where to buy, operating System supported and preparing for work with Raspberry Pi.
Gas Leakage Detection In Home With IoT
Apr 25, 2016.
In this article you will learn about monitoring Gas Leakage Detection in Home with Internet of Things..
Introduction To Internet of Things (IOT)
Apr 22, 2016.
In this article you will learn about an introduction to Internet of Things (IOT)
Hello World With Intel Galileo
Apr 22, 2016.
In this article you will learn about Hello World with Intel Galileo.
Automatic Watering System To Plants By Using Arduino Mega 2560
Apr 22, 2016.
In this article I will explain about the Automatic Watering System to Plants using Arduino Mega 2560.
Experiment On IoT: Simple LED Blink Example
Apr 21, 2016.
This article helps you to work with a simple experiment of connecting LED lights with Raspberry Pi device (device only with Windows 10 IoT Core OS).
Plug In Your Raspberry PI And Configure For Usage
Apr 21, 2016.
This article briefs you about how to plug in your Raspberry Pi device.
Controlling Light & Fan Using Arduino Mega 2560
Apr 20, 2016.
In this article you will learn how to control Light/Fan.
Creating Advanced Notepad In C#
Apr 18, 2016.
In this article, we will create a notepad with features like Multi Tabbed Documents, Document Selector, File Association, Opening/Saving Multiple Files, Line Numbers, Running External Programs, Viewing files in Browser, Full Screen Mode etc.
Simple Earthquake Sensor Detection And Vibration Mode By Arduino Mega 2560
Mar 27, 2016.
In this article I will explain about Earthquake Sensor Detection and Vibration mode with Arduino Mega 2560.
Control The Arduino Board With Windows 10 PC or Mobile
Mar 25, 2016.
In this article, I'll show you how to control the Arduino board with the Windows 10 PC or Mobile using Windows Virtual Shield for Arduino.
Getting Started With ESP-12E NodeMcu V3 Module Using ArduinoIDE
Mar 11, 2016.
A step-by-step guide about setting up the ESP module and executing the "Blinking-LED" code in ArduinoIDE.
Building Custom Email Client In WPF Using C#
Mar 05, 2016.
In this blog, I explain the methods used to build applications that can receive and send email messages on the internet to clients.
Fingerprint Lock Using Arduino Mega 2560
Feb 27, 2016.
In this article I will explain about Fingerprint Lock using Arduino Mega 2560.
Understanding IoT Analytics And Its Future Growth Prospects
Feb 24, 2016.
In this article you will learn about understanding IOT analytics and its future growth prospects.
DHT11 Sensor With Arduino To Find Humidity And Temperature
Feb 24, 2016.
In this article you will learn how to find the temperature and humidity using the DHT11 sensor.
Playing Audio With Intel Edison
Feb 23, 2016.
In this article, I am going to show you how we can play an audio file with Edison by connecting it to Bluetooth speakers.
Pulse Checking Sensor Using Arduino Mega 2560
Feb 22, 2016.
In this article I will explain about Pulse Checking Sensor using Arduino Mega 2560.
Network And Internet Options In Windows 10
Feb 21, 2016.
In this article you will learn about network and internet options in Windows 10.
Controlling Fan/LED Using Arduino Uno
Feb 19, 2016.
In this article I will explain about controlling Fan/LED using Arduino Uno.
Controlling LED Using Arduino Mega 2560
Feb 18, 2016.
In this article I will explain how to control LED using Arduino Mega 2560.
Identifying Water Leaks Using Arduino Mega
Feb 17, 2016.
In this article I have explained about identifying water leaks using Arduino Mega.
Movement Detector Using The PIR Sensor
Feb 16, 2016.
In this article you will learn how to make a movement detector using the PIR Sensor.
LDR Using Arduino Mega 2560
Feb 15, 2016.
In this article I will explain about the Light Dependent Resistor using Arduino Mega 2560. It measures the light level.
Automatic Plant Watering System Using Arduino
Feb 15, 2016.
In this aticle we will learn how to create an automatic plant watering system using Android mobile
Liquid Crystal Display With Arduino Mega 2560
Feb 14, 2016.
In this article I will explain about Liquid Crystal Display with Arduino Mega 2560.
LPG Sensor Using Arduino Uno
Feb 14, 2016.
In this article you will learn how to find LPG gas leakages detected using the LPG Gas Sensor.
Blinking LED In Arduino Mega 2560
Feb 14, 2016.
In this article I have going to explain how to blink an LED In Arduino Mega 2560.
Using Relay In Intel Galileo
Feb 13, 2016.
In this article I will show you how to use the relay switch in Intel Galileo for ON and OFF lights.
The Working of Sound Sensor With Arduino Mega 2560
Feb 13, 2016.
In this article I have explained the working of sound sensor with Arduino Mega 2560.
Heart Beat Pulse Checking Through Arduino Mega
Feb 12, 2016.
In this article I will explain about heart beat pulse checking through Arduino Mega.
Controlling LED Using IR Remote In Arduino Mega
Feb 12, 2016.
In this article you will learn how to control LED using IR Remote in Arduino Mega.
Gas Detector Using Arduino
Feb 12, 2016.
In this article I will explain how to detect gas using Arduino Mega.
Turn LED ON/ OFF In Bluetooth Using Android Apps In Arduino Mega 2560
Feb 11, 2016.
In this article I will explain how to turn LED ON/OFF in Bluetooth using Android apps in Arduino Mega 2560.
Smart Traffic Light System Using Arduino
Feb 11, 2016.
In this article you will make a smart traffic light system using Arduino.
Identify Waterflow Detection Using Arduino Uno
Feb 10, 2016.
Here we are using the YF-S201 water flow sensor to identify whether the water flow has crossed the minimum level or not; these processes are controlled in the Arduino Micro Controller Kit
Finding Soil Moisture In Plants Using Arduino
Feb 10, 2016.
In this article I will explain about finding soil moisture in plants using Arduino.
About Internet-Association
NA
File APIs for .NET
Aspose are the market leader of .NET APIs for file business formats – natively work with DOCX, XLSX, PPT, PDF, MSG, MPP, images formats and many more! | http://www.c-sharpcorner.com/tags/Internet-Association | CC-MAIN-2017-51 | refinedweb | 2,655 | 65.62 |
diff --git a/ev++.h b/ev++.h
index 82b65b9..0f51bd5 100644
--- a/ev++.h
+++ b/ev++.h
@@ -1,7 +1,7 @@
#ifndef EVPP_H__
#define EVPP_H__
-/* work in progress, don't use unless you know what you are doing */
+#include "ev.h"
namespace ev {
@@ -44,8 +44,6 @@ namespace ev {
}
};
- #include "ev.h"
-
enum {
UNDEF = EV_UNDEF,
NONE = EV_NONE,
@@ -219,12 +217,15 @@ namespace ev {
#endif
EV_BEGIN_WATCHER (idle, idle)
+ void set () { }
EV_END_WATCHER (idle, idle)
EV_BEGIN_WATCHER (prepare, prepare)
+ void set () { }
EV_END_WATCHER (prepare, prepare)
EV_BEGIN_WATCHER (check, check)
+ void set () { }
EV_END_WATCHER (check, check)
EV_BEGIN_WATCHER (sig, signal)
@@ -259,8 +260,34 @@ namespace ev {
}
EV_END_WATCHER (child, child)
+ #if EV_MULTIPLICITY
+
+ EV_BEGIN_WATCHER (embed, embed)
+ void set (struct ev_loop *loop)
+ {
+ int active = is_active ();
+ if (active) stop ();
+ ev_embed_set (static_cast
Unlike
+periodic watcher to trigger in 10 seconds (by specifiying e.g.
ev_now ()
++ 10.) and then reset your system clock to the last year, then it will
take a year to trigger the event (unlike an
ev_timer, which would trigger
roughly 10 seconds later and of course not if you reset your system time
again).
Top
TBD.+.
Example: Define a class with an IO and idle watcher, start one of them in +the constructor.+
class myclass + { + ev_io io; void io_cb (ev::io &w, int revents); + ev_idle idle void idle_cb (ev::idle &w, int revents); + + myclass (); + } + + myclass::myclass (int fd) + : io (this, &myclass::io_cb), + idle (this, &myclass::idle_cb) + { + io.start (fd, ev::READ); + } + +
Topdiff --git a/ev.pod b/ev.pod index 0bb2074..5440be5 100644 --- a/ev.pod +++ b/ev.pod @@ -858,7 +858,7 @@ Periodic watchers are also timers of a kind, but they are very versatile Unlike C | https://git.lighttpd.net/mirrors/libev/commit/669bbc0040296b8966486b6e3f73c23eab498f7d.diff | CC-MAIN-2021-25 | refinedweb | 268 | 70.53 |
Your browser does not seem to support JavaScript. As a result, your viewing experience will be diminished, and you have been placed in read-only mode.
Please download a browser that supports JavaScript, or enable it if it's disabled (i.e. NoScript).
On 11/09/2016 at 23:28, xxxxxxxx wrote:
hello ,
when I want to disable an object , do something with it , then re-enable it with the same script , the result I get is the same if the first (disable ) wasn't there , so I have to make another script to complete the first script job .
another example , is when I set the target of pose morph = obj , then make the target = none (to clear the field , if it is not the correct way , please let me know ) in one code , the result is the same if I removed the part of the target = obj , so I have to make separate script , and every thing works fine .
what I want to know , is there an order of operations in the python code ? or it is just from top to bottom , I tried to arrange my code , so the part I want to compile first is in the beginning and the other part in the end , but this seems to not work , so is there is a workaround to this problem without having to do many scripts ?
if it is necessary I can provide the code I am working with ,
On 12/09/2016 at 08:21, xxxxxxxx wrote:
Hi,
I have to admit, I'm not sure I understand your questions.
After reading it multiple times, it could be you are missing a EventAdd() somewhere, but really this is just a wild guess.
Maybe a bit of code could help clear things up. But please also provide us with the usual details: Where are you using Python (Script Manager, Python Generator, a plugin)? If a plugin, what type and in which function?
On 12/09/2016 at 10:12, xxxxxxxx wrote:
hi , thanks for reply .
I put EventAdd() in the end of the script ,
I use the script in the script manager .
this is a simple script , no scene files needed , just paste it in the script manager.
import c4d
def main() :
#this is just scen preparation
obj = c4d.BaseObject(c4d.Ocube)
morph =c4d.BaseObject(c4d.Osphere)
doc.InsertObject(obj)
doc.InsertObject(morph)
obj[c4d.ID_BASELIST_NAME]="object"
obj[c4d.PRIM_CUBE_SUBX]=2
obj[c4d.PRIM_CUBE_SUBY]=2
obj[c4d.PRIM_CUBE_SUBZ]=2
morph[c4d.ID_BASELIST_NAME]="morph"
morph[c4d.PRIM_SPHERE_TYPE]=2
morph[c4d.PRIM_SPHERE_SUB]=6
doc.SetActiveObject(morph)
c4d.CallCommand(12236) #make editable
doc.SetActiveObject(obj)
c4d.CallCommand(12236) #make editable
pmTag =c4d.BaseTag(c4d.Tposemorph)
obj.InsertTag(pmTag)
pmTag[c4d.ID_CA_POSE_POINTS]=True
pmTag.AddMorph()
pmTag.UpdateMorphs()
mo = pmTag.AddMorph()
pmTag.UpdateMorphs()
count=pmTag.GetMorphCount()
pmTag.SetActiveMorphIndex(count-1)
#this is the problem
pmTag[c4d.ID_CA_POSE_TARGET]=morph
pmTag[c4d.ID_CA_POSE_TARGET]=None #problem line
c4d.EventAdd()
if __name__=='__main__':
main()
as you can see if you run the script you will see the cube will still have a cube shape , but if you
comment the "problem line " , the cube will have a sphere shape, then with another script just make the target = None , the target will be empty , but the cube will still have the sphere shape in the morph , which is what I want .
this is not the only situation I have this problem , but it is just an example , is it possible to make it in one script without the need to split it into another script ?
On 12/09/2016 at 10:51, xxxxxxxx wrote:
The "make editable" command doesnt re-evaluate the object. Using
SendModelingCommand() would do this, or use DrawViews() or I
think ExecutePasses() works as well before the make editable command.
On 12/09/2016 at 10:56, xxxxxxxx wrote:
Originally posted by xxxxxxxx
The "make editable" command doesnt re-evaluate the object. Using
SendModelingCommand() would do this, or use DrawViews() or I
think ExecutePasses() works as well before the make editable command.
Originally posted by xxxxxxxx
thanks for the tip , but I don't work with make editable command , it is just to create a simple scene to show the problem , because I didn't want to upload a scene file.
On 13/09/2016 at 00:50, xxxxxxxx wrote:
the following two lines:
pmTag[c4d.ID_CA_POSE_TARGET]=morph
pmTag[c4d.ID_CA_POSE_TARGET]=None #problem line
do basically nothing (as you already found out). The parameter is set to one value (morph) and directly afterwards to another value (None). Very simplified like writing one value into a BaseContainer and directly afterwards overwriting it with another value.
Instead you need to give Cinema 4D the chance (or rather command it to) evaluate the scene graph and execute all expressions (in this case the PoseMorph).
Like so:
pmTag[c4d.ID_CA_POSE_TARGET]=morph
doc.ExecutePasses(None, False, True, False, c4d.BUILDFLAGS_0)
pmTag[c4d.ID_CA_POSE_TARGET]=None #problem line
Note: The parameters passed to ExecutePasses() may vary depending on the given scenario.
On 13/09/2016 at 03:16, xxxxxxxx wrote:
thank you very much Andreas ,
this solved my problem , did not know there is such commands to tell c4d , evaluate the scene graph , I will have to read the documentation , thanks again for the help | https://plugincafe.maxon.net/topic/9706/13049_order-of-operations | CC-MAIN-2021-21 | refinedweb | 873 | 59.53 |
Collen Simango2,353 Points
how to store a returned value of a function in a new variable
def square(number): return number *number print(square(2)) result=repeat_square(2) print(result)
1 Answer
Tabatha Trahan16,542 Points
The code challenges are pretty picky, so first off I would suggest getting rid of the 2 print statements, and then take a closer look at your result variable that is to hold the value of the result of calling the square function. Make sure you use the correct function name (what you used to define the function) when you call the function. If you defined the function name as square, use the name square when calling the function- repeat_square is not defined in the code above. I hope this helps. | https://teamtreehouse.com/community/how-to-store-a-returned-value-of-a-function-in-a-new-variable | CC-MAIN-2019-26 | refinedweb | 128 | 66.41 |
Tell us what’s happening:
.
I believe that the by_three function is not reading correctly.
Here are the instruction related to the exercise:
…
First, def a function called cube that takes an argument called number. Don’t forget the parentheses and the colon!
Make that function return the cube of that number (i.e. that number multiplied by itself and multiplied by itself once again).
Define a second function called by_three that takes an argument called number.
if that number is divisible by 3, by_three should call cube(number) and return its result. Otherwise, by_three should return False.
Don’t forget that if and else statements need a : at the end of that line!
…
the link for the exercise is here: click here
Your code so far
def cube(number): return number * number * number print cube(3) def by_three(number): if number % 3 == 0: return cube(number) else: return False print by_three(3)
Your browser information:
Your Browser User Agent is:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36.
Link to the challenge: | https://forum.freecodecamp.org/t/can-you-help-me-write-the-syntax-inside-a-python-function-given-the-completed-exercise-i-have-somewhat-mastered/192877 | CC-MAIN-2018-30 | refinedweb | 188 | 68.67 |
A run is a sequence of adjacent repeated values. Write a program that generates a sequence of 20 random die tosses in an array and that prints the die values, marking the runs by including them in parentheses, like this:
1 2 (5 5) 3 1 2 4 3 (2 2 2 2) 3 6 (5 5) 6 3 1
Use the following pseudocode:
Set a boolean variable inRun to false.
For each valid index i in the array
If inRun
If values[i] is different from the preceding value
Print ).
inRun = false
If not inRun
If values[i] is the same as the following value
Print (.
inRun = true
Print values[i]
If inRun, print ).
Along with this the reason that I'm doing this with a Scanner for the size of the array is because the teacher assigned an additional assignment to make it work with ArrayLists, and using the Scanner was part of that.
Before the code I should mention once I get it working I will probably change it up so that the different operations are in their own methods.
Here's the code that I've done so far:
package diceroller; import java.util.Scanner; import java.util.Random; public class DiceRoller { public static void main(String[] args) { Scanner in = new Scanner(System.in); Random randomRoll= new Random(); System.out.print("Please enter size:"); int size = in.nextInt(); int [] diceRolls = new int [size]; for (int i= 0; i <= size ; i++) { diceRolls[i] = randomRoll.nextInt(6); } boolean inRun = false; for (int i = 0; i <= size; i++) { if ( inRun == true ) { if (diceRolls[i] != diceRolls[i-1]) { System.out.print(")"); inRun = false; } } if (inRun == false) { if(diceRolls[i] == diceRolls[i+1]) { System.out.print("("); inRun = true; } } System.out.print(i); } if(inRun) { System.out.print(")"); } } }
I don't really understand two things.
1) Every time I try to run it I don't get random numbers for my elements, it just counts up from 0.
2) It may be because my elements in the array are not being randomized correctly, but the runs are not being processed and marked with the () correctly. | http://www.dreamincode.net/forums/topic/300373-help-with-a-dice-roller-and-runs/ | CC-MAIN-2017-09 | refinedweb | 353 | 64 |
Protecting Black Women Includes Protecting Brittney Griner
Brittney Griner has probably played the best basketball of her career this season. Still, that hasn’t stopped the parade of idiots from harassing her in ways that are very misogynistic, homophobic and racist.
What boggles my mind is the stream of endless attacks coming from Black men who purport to “protect Black women,” but lean into attacking this particular Black woman who doesn’t meet their unrealistic standards of femininity. This is the type of hypocritical bullshit seen daily on social media and in the press.
Brittney doesn’t owe you anything and the jokes about her as a woman aren’t just jokes. They are hurtful, they are cruel and wreak of small “d” energy. If her height is what intimidates you, then you have short man energy, too. As a Black woman who writes, I deal with racism and misogynistic attacks because my work triggered some man, so I feel her struggle in my soul.
It has never really been about her femininity. It’s about you, your insecurities and a toxic masculinity that is rooted in white supremacy. Black women don’t have time to deal with your issues when we are too busy trying to save a world that often excludes us and shows no deference towards our pain.
Unsettling to me, too, is that many Black men have fallen down this rabbit hole of disrespect toward Brittney— especially when they have Black mothers, daughters, wives, sisters and others in their lives. When the world looks down on Black men, it is Black women who lift you up. But, many behave as if their support of us is something that is an option based upon what we give for men to gaze at in return (like wanting the WNBA to change their uniforms so that you can gawk at their bodies instead of watching them play the game).
Most don’t even realize that Black Lives Matter was founded by three Black queer women who were trying to save the lives of all Black people, but it was co-opted by Black men. Meanwhile there are Black women, including Black trans women, who are also being murdered out here in these streets.
Basketball is not just a man’s sport and the majority of the women in the league are Black women. The league as a whole did more to support the Black Lives Matter movement than any other sports league. They continue this work in their advocacy for women’s rights.
Brittney, herself, has been one of the more vocal players on many of these issues. She has used her platform wisely and opened up parts of her private life to the world, not for the purpose of expanding her celebrity, but to help. Some have used this openness as an avenue through which they antagonize and ridicule her, thinking that her celebrity is enough to protect her. It is not. If anything, it makes her more vulnerable to attacks on her femininity, her skills as a baller, her appearance and her life as whole.
When celebrities and professional athletes invite us into parts of their lives, it doesn’t mean that we are entitled to all of it. I say this because I know there’s the crowd that will chime in and use her previous marriage as an example when trying to prove a point. Look, none of us were there, we don’t know everything and, truthfully, I always thought it was an invasion of privacy that was used for the entertainment of heterosexuals. As a writer, I felt it was such an intrusion that I refused to write about it (actually, I was given the choice of writing it or being fired, so I quit).
All people deserve respect. To use Brittney, who admittedly takes pride in caring for herself as a Black woman, as the vessel for unloading your personal shortcomings is trite. The constant demands that she prove she is a woman are weird, grotesque and hinge on being predatory. Those demands cause me to worry for her safety because you are demanding she proves to your satisfaction (via nude photographs or inspection) something that is biologically true. Please tell me how that is not weird? You have no right to her body, it is hers.
There is not just sexism in this, there is also gendered racism at play.
Black women already have to contend with being considered lesser women than our white counterparts. Denying Black women the right to be authentically ourselves in our own bodies is an extension of this. Black women’s bodies were subjected to indignity and scrutiny on the auction block. So why are you doing the very thing that was done to us in slavery by demanding Brittney show you her body to prove her womanhood? The generational trauma of this exists on its own, in each of us as Black women— we don’t need you out here creating further doubt and discomfort for us when it comes to our bodies.
This is a societal issue as a whole when it comes to the treatment of Black women. However, it is also our problem as Black people. If you want to protect Black women, start here. Stop harassing Brittany Griner. Let this “proud, out Black woman” live her best life. When people chime in to harass her, step in and defend her, protect her. Let the world know that when it comes to the lives of Black women, hers matters, too. | https://aishakstaggers.medium.com/protecting-black-women-includes-protecting-brittney-griner-4f75d7a6b9de | CC-MAIN-2022-40 | refinedweb | 928 | 68.7 |
Overview
Atlassian SourceTree is a free Git and Mercurial client for Windows.
Atlassian SourceTree is a free Git and Mercurial client for Mac.
IMPORTANT: READ ME
In version 0.1.4, we are introducing two major changes:
- Tasks now have a
createddatetime field. This was added to make sure
--replayfailedreplayed tasks in the appropriate order
- Introduced South migrations.
IF YOU HAVE ALREADY INSTALLED
django-ztask - you can "fake" the first migration, and then run the second migration:
./manage.py migrate django_ztask --fake 0001 ./manage.py migrate django_ztask
If you are not using South in your Django project, it is strongly recommended you do. If you are not, you will have to add the "created" field to your database manually.
Installing
Download and install 0MQ version 2.1.3 or better from
Install pyzmq and django-ztask using PIP:
pip install pyzmq pip install -e git+git@github.com:dmgctrl/django-ztask.git#egg=django_ztask
Add
django_ztask to your
INSTALLED_APPS setting in
settings.py
INSTALLED_APPS = ( ..., 'django_ztask', )
Then run
syncdb
python manage.py syncdb
Running the server
Run django-ztask using the manage.py command:
python manage.py ztaskd
Command-line arguments
The
ztaskd command takes a series of command-line arguments:
--noreload
By default,
ztaskd will use the built-in Django reloader
to reload the server whenever a change is made to a python file. Passing
in
--noreload will prevent it from listening for changed files.
(Good to use in production.)
--replayfailed
If a command has failed more times than allowed in the
ZTASKD_RETRY_COUNT (see below for more), the task is
logged as failed. Passing in
--replayfailed will cause all
failed tasks to be re-run.
Settings
There are several settings that you can put in your
settings.py file in
your Django project. These are the settings and their defaults
ZTASKD_URL = 'tcp://127.0.0.1:5555'
By default,
ztaskd will run over TCP, listening on 127.0.0.1 port 5555.
ZTASKD_ALWAYS_EAGER = False
If set to
True, all
.async and
.after tasks will be run in-process and
not sent to the
ztaskd process. Good for task debugging.
ZTASKD_DISABLED = False
If set, all tasks will be logged, but not executed. This setting is often
used during testing runs. If you set
ZTASKD_DISABLED before running
python manage.py test, tasks will be logged, but not executed.
ZTASKD_RETRY_COUNT = 5
The number of times a task should be reattempted before it is considered failed.
ZTASKD_RETRY_AFTER = 5
The number, in seconds, to wait in-between task retries.
ZTASKD_ON_LOAD = ()
This is a list of callables - either classes or functions - that are called when the server first
starts. This is implemented to support several possible Django setup scenarios when launching
ztask - for an example, see the section below called Implementing with Johnny Cache.
Running in production
A recommended way to run in production would be to put something similar to
the following in to your
rc.local file. This example has been tested on
Ubuntu 10.04 and Ubuntu 10.10:
#!/bin/bash -e pushd /var/www/path/to/site sudo -u www-data python manage.py ztaskd --noreload -f /var/log/ztaskd.log & popd
Making functions in to tasks
Decorators and function extensions make tasks able to run.
Unlike some solutions, tasks can be in any file anywhere.
When the file is imported,
ztaskd will register the task for running.
Important note: all functions and their arguments must be able to be pickled.
(Read more about pickling here)
It is a recommended best practice that instead of passing a Django model object to a task, you intead pass along the model's ID or primary key, and re-get the object in the task function.
The Task Decorator
from django_ztask.decorators import task
The
@task() decorator will turn any normal function in to a
django_ztask task if called using one of the function extensions.
Function extensions
Any function can be called in one of three ways:
func(*args, *kwargs)
Calling a function normally will bypass the decorator and call the function directly
func.async(*args, **kwargs)
Calling a function with
.async will cause the function task to be called asyncronously
on the ztaskd server. For backwards compatability,
.delay will do the same thing as
.async, but is deprecated.
func.after(seconds, *args, **kwargs)
This will cause the task to be sent to the
ztaskd server, which will wait
seconds
seconds to execute.
Example
from django_ztask.decorators import task @task() def print_this(what_to_print): print what_to_print if __name__ == '__main__': # Call the function directly print_this('Hello world!') # Call the function asynchronously print_this.async('This will print to the ztaskd log') # Call the function asynchronously # after a 5 second delay print_this.after(5, 'This will print to the ztaskd log')
Implementing with Johnny Cache
Because Johnny Cache monkey-patches all the Django query compilers,
any changes to models in django-ztask that aren't properly patched won't reflect on your site until the cache
is cleared. Since django-ztask doesn't concern itself with Middleware, you must put Johnny Cache's query cache
middleware in as a callable in the
ZTASKD_ON_LOAD setting.
ZTASKD_ON_LOAD = ( 'johnny.middleware.QueryCacheMiddleware', ... )
If you wanted to do this and other things, you could write your own function, and pass that in to
ZTASKD_ON_LOAD, as in this example:
myutilities.py
def ztaskd_startup_stuff(): ''' Stuff to run every time the ztaskd server is started or reloaded ''' from johnny import middleware middleware.QueryCacheMiddleware() ... # Other setup stuff
settings.py
ZTASKD_ON_LOAD = ( 'myutilities.ztaskd_startup_stuff', ... )
TODOs and BUGS
See: | https://bitbucket.org/lcrees/django-ztask | CC-MAIN-2015-35 | refinedweb | 908 | 67.15 |
Learn how easy it is to sync an existing GitHub or Google Code repo to a SourceForge project! See Demo
You can subscribe to this list here.
Showing
5
results of 5
Gus Mueller wrote:
> >.
That's because the app as you compile it is merely a wrapper that starts
a new process. (Read the main .m file for details and look for execve.
For the _reasons_ of this, check the list archives...)
I _think_ what could work is building a minimal C extension that
contains the class and import that. While that's definitely more work
than adding a .m file to your project, it can probably be streamlined
with a template. I haven't heard of anyone who actually _did_ this, but
I don't see why it wouldn't work. Would be nice to find out, though...
Just
bbum@... (bbum@...) wrote:
>.
thanks,
-gus
--
"Christmas means carnage!" -- Ferdinand, the duck]...
b.bum
I searched the archives for "nswindow", so apologies if this has
already been answered already...
I created a new Cocoa-Python Application, compiled it and it worked
fine, I then wanted to see if I could make the window a custom one (for
some silly ideas I've got).. so I created a custom class called
PydgetWindow that extended NSWindow, and made the Window instance in the
MainMenu.nib file a custom class of the same type (PydgetWindow).
However, when I try and run it, I get the following message:
"Unknown Window class PydgetWindow in Interface Builder file,
creating generic Window instead"
This technique works out fine for a regular objc project, is this
something that is possible with pyobjc ?
thanks,
-gus
--
"Christmas means carnage!" -- Ferdinand, the duck
I am not entirely clear about what exactly is being discussed here...
this message was forwarded to me by Bill.
I will make the point (which Bill already undoubtedly knows) that in
Cocoa the types declared for arguments and return values in the API are
more about what the caller can do with the return value or what the
method will do with the argument rather than what the return value
really will be or what the argument must be.
For example, NSView's -subviews method is declared to return an
NSArray. Forever it has actually returned an NSMutableArray: the one
it uses to manage its subviews. The fact that it declares the return
value is NSArray means that the caller is not allowed to change it, not
that it CANNOT be changed. In reverse, NSWindow's -setTitle: takes an
NSString. That does not mean I cannot pass it an NSMutableString, it
means that under no circumstances will the window alter the string,
even if it is mutable.
Mike
Begin forwarded message:
> From: bbum@...
> Date: Tue Feb 4, 2003 1:37:00 PM US/Pacific
> To: pyobjc-dev@..., mferris@...
> Subject: Re: [Pyobjc-dev] NSString & mutability
>
> On Tuesday, Feb 4, 2003, at 15:56 US/Eastern, Just van Rossum wrote:
>> I'm totally willing to accept a surprise like that. I don't even see
>> the
>> problem when using such an API from Python: you call
>> fooObject.setMyNameIs_() with a Python string, you call myNameIs() and
>> get a Python string. Same string, different id. No problem in Python.
>
> I'm not willing to accept a surprise like that because it will greatly
> reduce the value of PyObjC in quite a number of situations. This is
> not idle speculation. I have made the same mistake in the past
> [creating a bridge that was dependent on internal implementation of
> underlying frameworks] and it rendered the bridge [Tcl <-> ObjC, in
> this case] nearly useless until it was fixed -- it broke-- or
> sometimes didn't break-- depending on what order the user did things
> simply because some random bit of code somewhere chose to return
> *this* private subclass vs. *that* private subclass as some internal
> optimization hack that was *not* apparent, no relevant to, the
> advertised API.
>
> The fundamental problem is that partial conversion relies on the
> internal implementation to stay the same over time. The current
> behavior does not; it remains consistent. Partial conversion
> behavior that is dependent upon the internal implementation of 'third
> party' [Apple is a third party, in this case] frameworks will lead to
> behavior that changes over time and through factors outside of our
> control.
>
> More below....
>
>> Can you please give an example of an _actual_ problem? I'll have a go
>> myself:
>
> Off the top of my head, no-- I can't remember a specific example. But
> that is mostly because I have been relying on the APIs as advertised
> by the classes and not their internal implementations for long enough
> that I haven't had this problem in a while. It *does* come up on the
> mailing lists on occasion, but searching for "nsmutablestring nsstring
> return" yields an awful lot of noise hits.
>
>> Let's assume the API does the reverse: it takes an immutable string,
>> yet
>> returns its internal mutable copy, although myNameIs is declared to
>> return an NSString. Now there _is_ a surprise: instead of a 100%
>> equivalent string we get an NSMutableString instance. Ok, a surprise,
>> but is it so bad? If the object internally uses a mutable string, it's
>> likely that this is clear from the nature of the object (eg. it's some
>> sort of editor for the string). So I still think such a surprise will
>> be
>> rare.
>
> I agree that the situations where this arise will be rare. But, when
> they do arise, the results are the absolute worst kinds of bugs in the
> world to fix. It breaks on customer A's computer, but not customer
> B's -- but they are [supposedly] identical. Oh, wait a minute,
> Customer B upgraded to version 1.234b of the some random plugin while
> customer A is still using 1.233.
>
> Another exmaple: What if Mike [who I included in this because he may
> have some useful input-- sorry, Mike :-] changes the implementation of
> TextExtras and throws an NSMutableString into some random object
> collection that ends up on the other side of the bridge at some point?
> The Python developer is screwed if there code breaks.
>
> What happens when Apple ships the 10.2.5 update and they change some
> random bit of internal implementation such that a method that used to
> return (NSMutableString*) now *always* returns (NSString*)? Assuming
> the PyObjC developer can figure out what is going on, are they now
> supposed to write OS X version specific code at the x.x.1 level?
>
> Now-- what about the developers that will be using PyObjC with
> multiple thousands of lines of code embedded in random frameworks
> across some large scale system? For them, the choice of using PyObjC
> now comes with the cost of having to ensure that every method that
> *may* return an NSMutableString* when it is declared with an NSString*
> return value is identified and compensated for. This is not a
> contrived example-- I and a number of people I have been in contact
> with since PyObjC became a visible project again-- have used PyObjC in
> this context in the past and are planning on doing so in the future
> [some already are]. This would be a deal killer for them.
>
> Bottom line: PyObjC -- just like the AppleScript in an AS Studio
> project or a good chunk of the ObjC in a pure ObjC Cocoa app -- is the
> glue that holds together all of the random objects in a fashion that
> solves whatever problem the developer is trying to address. The
> developer does not have full and complete control over those objects--
> heck, there may be entire chunks of implementation present that their
> code has no awareness of whatsoever [TextExtras]. For such a system
> to work, the objects must be glued together as advertised by the APIs.
> To do otherwise will render a system that is fragile. Worse, it
> will create a system whose fragility is dependent upon unreasonable
> expectations.
>
> It is reasonable to expect-- and history indicates it is true-- that
> the behavior of the NSCell API will remain consistent going forward.
> It is unreasonable to expect that the internal implementation will
> remain consistent over time, yet that is exactly what a partial
> conversion solution expects.
>
> b.bum
> | http://sourceforge.net/p/pyobjc/mailman/pyobjc-dev/?viewmonth=200302&viewday=11 | CC-MAIN-2015-18 | refinedweb | 1,371 | 61.36 |
I have a blocking, non-async code like this:
def f():
def inner():
while True:
yield read()
return inner()
async def f():
async def inner():
while True:
yield await coroutine_read()
return inner()
yield
async def
async
inner()
await
As noted above, you can't use
yield inside
async funcs. If you want to create coroutine-generator you have to do it manually, using
__aiter__ and
__anext__ magic methods:
import asyncio # `coroutine_read()` generates some data: i = 0 async def coroutine_read(): global i i += 1 await asyncio.sleep(i) return i # `f()` is asynchronous iterator. # Since we don't raise `StopAsyncIteration` # it works "like" `while True`, until we manually break. class f: async def __aiter__(self): return self async def __anext__(self): return await coroutine_read() # Use f() as asynchronous iterator with `async for`: async def main(): async for i in f(): print(i) if i >= 3: break if __name__ == "__main__": loop = asyncio.get_event_loop() loop.run_until_complete(main())
Output:
1 2 3 [Finished in 6.2s]
You may also like to see other post, where
StopAsyncIteration uses.
Upd:
Starting with Python 3.6 we have asynchronous generators and able to use
yield directly inside coroutines. | https://codedump.io/share/UUWKJrdCACfP/1/lazy-iterators-generators-with-asyncio | CC-MAIN-2017-43 | refinedweb | 191 | 59.94 |
WatcherWatcher
The file system watcher that strives for perfection, with no native dependencies and optional rename detection support.
FeaturesFeatures
- Reliable: This library aims to handle all issues that may possibly arise when dealing with the file system, including some the most popular alternatives don't handle, like EMFILE errors.
- Rename detection: This library can optionally detect when files and directories are renamed, which allows you to provide a better experience to your users in some cases.
- Performant: Native recursive watching is used when available (macOS and Windows), and it's efficiently manually performed otherwise.
- No native dependencies: Native dependencies can be painful to work with, this library uses 0 of them.
- No bloat: Many alternative watchers ship with potentially useless and expensive features, like support for globbing, this library aims to be much leaner while still exposing the right abstractions that allow you to use globbing if you want to.
- TypeScript-ready: This library is written in TypeScript, so types aren't an afterthought but come with the library.
ComparisonComparison
You are probably currently using one of the following alternatives for file system watching, here's how they compare against Watcher:
fs.watch: Node's built-in
fs.watchfunction is essentially garbage and you never want to use it directly.
- Cons:
- Recursive watching is not supported under Linux, so if you need to support Linux at all you are out of luck already.
- Even if you only need to support macOS or Windows, where native recursive watching is provided, the events provided by
fs.watchare completely useless as they tell you nothing about what actually happened in the file system, so you'll have to poll the file system on your own anyway.
- There are many things that
fs.watchdoesn't take care of, for example watching non-existent paths is just not supported and EMFILE errors are not handled.
chokidar: this is the most popular file system watcher available, while it may be good enough in some cases it's not perfect.
- Cons:
- It requires a native dependency for efficient recursive watching under macOS, and native dependencies can be a pain to work with.
- It doesn't watch recursively efficiently under Windows, Watcher on the other hand is built upon Node's native recursive watching capabilities for Windows.
- It can't detect renames.
- If you don't need features like globbing then chokidar will bloat your app bundles unnecessarely.
- EMFILE errors are not handled properly, so if you are watching enough files chokidar will eventually just give up on them.
- It's not very actively maintened, Watcher on the other hand strives for having 0 bugs, if you can find some we'll fix them ASAP.
- Pros:
- It supports handling symlinks.
- It has some built-in support for handling temporary files written to disk while perfoming an atomic write, although ignoring them in Watcher is pretty trivial too, you can ignore them via the
ignoreoption.
- It can more reliably watch network attached paths, although that will lead to performance issues when watching ~lots of files.
- It's more battle tested, although Watcher has a more comprehensive test suite and is used in production too (for example in Notable, which was using
chokidarbefore).
node-watch: in some ways this library is similar to Watcher, but much less mature.
- Cons:
- No initial events can be emitted when starting watching.
- Only the "update" or "remove" events are emitted, which tell you nothing about whether each event refers to a file or a directory, or whether a file got added or modified.
- "add" and "unlink" events are not provided in some cases, like for files inside an added/deleted folder.
- Watching non-existent paths is not supported.
- It can't detect renames.
nsfw: this is a lesser known but pretty good watcher, although it comes with some major drawbacks.
- Cons:
- It's based on native dependencies, which can be a pain to work with, especially considering that prebuild binaries are not provided so you have to build them yourself.
- It's not very customizable, so for example instructing the watcher to ignore some paths is not possible.
- Everything being native makes it more difficult to contribute a PR or a test to it.
- It's not very actively maintained.
- Pros:
- It adds next to 0 overhead to the rest of your app, as the watching is performed in a separate process and events are emitted in batches.
- "
perfection": if there was a "perfect" file system watcher, it would compare like this against Watcher (i.e. this is pretty much what's currently missing in Watcher):
- Pros:
- It would support symlinks, Watcher doesn't handle them just yet.
- It would watch all parent directories of the watched roots, for unlink detection when those parents get unlinked, Watcher currently also watches only up-to 1 level parents, which is more than what most other watchers do though.
- It would provide some simple and efficient APIs for adding and removing paths to watch from/to a watcher instance, Watcher currently only has some internal APIs that could be used for that but they are not production-ready yet, although closing a watcher and making a new one with the updated paths to watch works well enough in most cases.
- It would add next to 0 overhead to the rest of your app, currenly Watcher adds some overhead to your app, but if that's significant for your use cases we would consider that to be a bug. You could potentially already spawn a separate process and do the file system watching there yourself too.
- Potentially there are some more edge cases that should be handled too, if you know about them or can find any bug in Watcher just open an issue and we'll fix it ASAP.
InstallInstall
npm install --save watcher
OptionsOptions
The following options are provided, you can use them to customize watching to your needs:
debounce: amount of milliseconds to debounce event emission for.
- by default this is set to
300.
- the higher this is the more duplicate events will be ignored automatically.
depth: maximum depth to watch files at.
- by default this is set to
20.
- this is useful for avoiding watching directories that are absurdly deep, that would probably waste resources.
ignore: optional function that if returns
truefor a path it will cause that path and all its descendants to not be watched at all.
- by default this is not set, so all paths are watched.
- setting an
ignorefunction can be very important for performance, you should probably ignore folders like
.gitand temporary files like those used when writing atomically to disk.
- if you need globbing you'll just have to match the path passed to
ignoreagainst a glob with a globbing library of your choosing.
ignoreInitial: whether events for the initial scan should be ignored or not.
- by default this is set to
false, so initial events are emitted.
native: whether to use the native recursive watcher if available and needed.
- by default this is set to
true.
- the native recursive watcher is only available under macOS and Windows.
- when the native recursive watcher is used the
depthoption is ignored.
- setting it to
falsecan have a positive performance impact if you want to watch recursively a potentially very deep directory with a low
depthvalue.
persistent: whether to keep the Node process running as long as the watcher is not closed.
- by default this is set to
false.
pollingInterval: polling is used as a last resort measure when watching non-existent paths inside non-existent directories, this controls how often polling is performed, in milliseconds.
- by default this is set to
3000.
- you can set it to a lower value to make the app detect events much more quickly, but don't set it too low if you are watching many paths that require polling as polling is expensive.
pollingTimeout: sometimes polling will fail, for example if there are too many file descriptors currently open, usually eventually polling will succeed after a few tries though, this controls the amount of milliseconds the library should keep retrying for.
- by default this is set to
20000.
recursive: whether to watch recursively or not.
- by default this is set to
false.
- this is supported under all OS'.
- this is implemented natively by Node itself under macOS and Windows.
renameDetection: whether the library should attempt to detect renames and emit
rename/
renameDirevents.
- by default this is set to
false.
- rename detection may cause a delayed event emission, because the library may have to wait some more time for it.
- if disabled, the raw underlying
add/
addDirand
unlink/
unlinkDirevents will be emitted instead after a rename.
- if enabled, the library will check if each pair of
add/
unlinkor
addDir/
unlinkDirevents are actually
renameor
renameDirevents respectively, so it will wait for both of those events to be emitted.
- rename detection is fairly reliable, but it is fundamentally dependent on how long the file system takes to emit the underlying raw events, if it takes longer than the set rename timeout the app won't detect the rename and will instead emit the underlying raw events.
renameTimeout: amount of milliseconds to wait for a potential
rename/
renameDirevent to be detected.
- by default this is set to
1250.
- the higher this value is the more reliably renames will be detected.
- the higher this value is the longer the library will take to emit
add/
addDir/
unlink/
unlinkDirevents.
UsageUsage
Watcher returns an
EventEmitter instance, so all the methods inherited from that are supported, and the API is largely event-driven.
The following events are emitted:
- Watcher events:
error: Emitted whenever an error occurs.
ready: Emitted after the Watcher has finished instantiating itself. No events are emitted before this events, expect potentially for the
errorevent.
close: Emitted when the watcher gets explicitly closed and all its watching operations are stopped. No further events will be emitted after this event.
all: Emitted right before a file system event is about to get emitted.
- File system events:
add: Emitted when a new file is added.
addDir: Emitted when a new directory is added.
change: Emitted when an existing file gets changed, maybe its content changed, maybe its metadata changed.
rename: Emitted when a file gets renamed. This is only emitted when
renameDetectionis enabled.
renameDir: Emitted when a directory gets renamed. This is only emitted when
renameDetectionis enabled.
unlink: Emitted when a file gets removed from the watched tree.
unlinkDir: Emitted when a directory gets removed from the watched tree.
Basically it you have used
chokidar in the past Watcher emits pretty much the same exact events, except that it can also emit
rename/
renameDir events, it doesn't provide
stats objects but only paths, and in general it exposes a similar API surface, so switching from (or to)
chokidar should be easy.
The following interface is provided:
type Roots = string[] | string; type TargetEvent = 'add' | 'addDir' | 'change' | 'rename' | 'renameDir' | 'unlink' | 'unlinkDir'; type WatcherEvent = 'all' | 'close' | 'error' | 'ready'; type Event = TargetEvent | WatcherEvent; type Options = { debounce?: number, depth?: number, ignore?: ( targetPath: Path ) => boolean, ignoreInitial?: boolean, native?: boolean, persistent?: boolean, pollingInterval?: number, pollingTimeout?: number, recursive?: boolean, renameDetection?: boolean, renameTimeout?: number }; class Watcher { constructor ( roots: Roots, options?: Options, handler?: Handler ): this; on ( event: Event, handler: Function ): this; close (): void; }
You would use the library like this:
import Watcher from 'watcher'; // Watching a single path const watcher = new Watcher ( '/foo/bar' ); // Watching multiple paths const watcher = new Watcher ( ['/foo/bar', '/baz/qux'] ); // Passing some options const watcher = new Watcher ( '/foo/bar', { renameDetection: true } ); // Passing an "all" handler directly const watcher = new Watcher ( '/foo/bar', {}, ( event, targetPath, targetPathNext ) => {} ); // Attaching the "all" handler manually const watcher = new Watcher ( '/foo/bar' ); watcher.on ( 'all', ( event, targetPath, targetPathNext ) => { // This is what the library does internally when you pass it a handler directly }); // Listening to individual events manually const watcher = new Watcher ( '/foo/bar' ); watcher.on ( 'error', error => { console.log ( error instanceof Error ); // => true, "Error" instances are always provided on "error" }); watcher.on ( 'ready', () => { // The app just finished instantiation and may soon emit some events }); watcher.on ( 'close', () => { // The app just stopped watching and will not emit any further events }); watcher.on ( 'all', ( event, targetPath, targetPathNext ) => { }); watcher.on ( 'add', filePath => { console.log ( filePath ); // "filePath" just got created, or discovered by the watcher if this is an initial event }); watcher.on ( 'addDir', directoryPath => { console.log ( filePath ); // "directoryPath" just got created, or discovered by the watcher if this is an initial event }); watcher.on ( 'change', filePath => { console.log ( filePath ); // "filePath" just got modified }); watcher.on ( 'rename', ( filePath, filePathNext ) => { console.log ( filePath, filePathNext ); // "filePath" got renamed to "filePathNext" }); watcher.on ( 'renameDir', ( directoryPath, directoryPathNext ) => { console.log ( directoryPath, directoryPathNext ); // "directoryPath" got renamed to "directoryPathNext" }); watcher.on ( 'unlink', filePath => { console.log ( filePath ); // "filePath" got deleted, or at least moved outside the watched tree }); watcher.on ( 'unlinkDir', directoryPath => { console.log ( directoryPath ); // "directoryPath" got deleted, or at least moved outside the watched tree }); // Closing the watcher once you are done with it watcher.close (); // Updating watched roots by closing a watcher and opening an updated one watcher.close (); watcher = new Watcher ( /* Updated options... */ );
RelatedRelated
atomically: if you need to read and write files reliably do yourself a favor and use this library. Watcher internally uses this library for polling reliably the file system, so if you are using Watcher already using
atomicallytoo would add 0 extra weight to your bundles.
ThanksThanks
chokidar: for providing me a largely good-enough file system watcher for a long time.
node-watch: for providing a good base from with to make Watcher, and providing some good ideas for how to write good tests for it.
LicenseLicense
MIT © Fabio Spampinato | https://preview.npmjs.com/package/watcher | CC-MAIN-2021-31 | refinedweb | 2,264 | 54.63 |
.
In one of my recent projects we had a requirement where a user should have the possibility to save "favourites". In our case the item that the user should "save" was a WCM content item.
To implement that functionality we decided to use the tagging feature of WebSphere Portal. Since we wanted to avoid custom coding and at at the same time business users needed to be able to change the setup easily we chose to leverage the Portal Tagging REST API and use DDC to display the data.
Getting started
The ATOM feed we wanted to parse is the following:
/wps/mycontenthandler?uri=rm:empty?tmparam=tm:name:favorite&scope=PERSONAL
Our goal was to show the item name and the URL for the tagged content item. While most of the implementation was straight forward chosen the right URL for the data source was a bit tricky.
Displaying the data with DDC
We started of using the full URL including the host name. Since the REST call requires authentication this did not work since the LTPA token was not passed through. It turned out that it was good enough to just use the URI for the data source (uri=rm:empty?tmparam=tm:name:favorite&scope=PERSONAL).
To pass the variables use the following snipped in the presentation template:
[Plugin:ListRenderingContext extension-id="ibm.portal.ddc.xml" attribute="source=rm:empty" attribute1="sourceParams=tmparam=tm:name:favorite&scope=PERSONAL" profile="ibm.portal.atom"]
Showing the item name was easy since we just had to read the "title" element. To read the URL to the content item we had to parse the following with the atom:entry:
"/>
To do that we added the following expression to the resource environment properties:
Name: atom.ItemAttribute.repliesLink
Value: ./atom:link[@type='text/html']/@href
The other option would have been to read the URI - in that case the Portal namespace needs to be added to the properties
Name: atom.NamespaceMapping.portal
Value:
Open on the ToDo List is to implement the read operation also with DDC when someone is tagging an element.
Thanks also to Thomas Steinheber for his support during the implementation!.
The IBM Digital Data Connector is a very powerful integration framework in IBM WebSphere Portal and Web Content Manager. We know that much for quite a while now. In this very spirit, a team of IBMers has just released an integration sample for IBM Business Process Manager (BPM).
Just as some of the other samples that we mentioned in this blog in May (see also Integrating WebSphere Commerce using the Digital Data Connector framework), you can download this new sample from.
Enjoy this new and exciting example of DDC-based backend integration!
We are happy to share that our next sample for Digital Data Connector is available.
While DDC provides built-in support for consuming remote XML data, this sample shows how to write a custom DDC plugin to integrate arbitrary data sources.
The sample enumerates files and folders found on the local file system.
Please check out the sample available on the digitalExperience Developer sample site.
When we released the Digital Data Connector framework with its built-in support for XML, people kept asking us about a generic JSON support. Since IBM WebSphere Portal V8.5 CF06, you can also consume JSON via DDC!
It goes without saying that we also documented the JSON support in the knowledge center. You will find it here:
In addition, we just uploaded the latest version of the Digital Data Connector.pdf|View Details that we presented at the IBM Digital Experience Conference 2015 in Dublin last week. It also includes information on the generic JSON support and a few more samples that demonstrate the power of the DDC framework.
You might already know how versatile the Digital Data Connector for WebSphere Portal truly is and what benefits it gives you. In the past we have seen many different integration stories. For example, the integration of data from:
What you can see in an all new video on Youtube is another exciting example. Watch how Bryan Daniel (IBM) creates a bike shop with WebSphere Portal and WebSphere Commerce using the Digital Data Connector framework.
A fairly comprehensive example for the use of the Digital Data Connector framework is what we call Social Rendering. With IBM WebSphere Portal, you get this integration of IBM Connections into your portal site out-of-the-box. Additionally, we have released the IBM Social Rendering Templates for Digital Data Connector on the IBM Solutions Catalog in 2014 to extend the social integration beyond the built-in Social Rendering capabilties.
This month, we have released Update 2 of the templates. It includes the following minor changes:
How to render a list of colleagues in no time
i just wanted to share how easy it is starting from the IBM Social Rendering Templates for Digital Data Connector to come up with your own lists of social objects. Investigating the DDC profiles for Social Rendering, you can investigate the various profiles that are already available for reuse.
I would like to show the ease of realizing a list of colleagues for a user that is currently logged in to your portal.
This requires that you have the aforementioned IBM Social Rendering Templates installed and configured successfully.
To realize the list of colleagues requires only the existence of three items:
Create a Data Source Serving the Colleagues Feed
The data source that would serve the list of colleagues for the user that is currently logged in is very similar to the data source for the pending network invitations of the current user. Note that an additional parameter called 'outputType' is provided which means that the contents will be served as profile entries. The final URL would look something like this:
http://<yourserver>/profiles/atom/connections.do?outputType=profile&sortOrder=desc&sortBy=title&connectionType=colleague&ps=150&userid=8fd06c30-de54-40d9-9ee1-0ac01be0b198
Create a List Appearance Defining the Visual Appearance of Your List of Colleagues
As you want to control the look and feel of your list of colleagues, a new appearance will be created. You could for instance start of from the list of network invitations appearance component and alter it respectively. This is basically what i have done:
I did change the result design however to a newly created HTML Component representing a stripped down version of the user profile entry:
Create a Content Item bringing things together
Now that we have all at hand, the data source as well as the design component for the list of colleagues, the last step to perform is to create a content item that is making use of all this. Again you could copy one of the existing content items and alter the fields to represent what we have created here.
In short the following content item comprises:
Enjoy Your List of Colleagues
So this is how the list of colleagues looks like after roughly half an hour.
Our DDC journey continues with another great integration sample! This time, you will learn about the use of the DDC framework to connect to a Domino database and integrate its data into IBM WebSphere Portal.
Even if you are not that much into Domino, this all new sample is a fantastic DDC learning exercise, because it explains two different approaches for using DDC:
In addition, both approaches support a paging mechanism to present only clear subsets of data to the end user.
Links
This is to inform you about the latest update of the IBM Social Rendering Templates for Digital Data Connector. Right on time for the start of the IBM Digital Experience conference in Düsseldorf (see also) and the release of IBM WebSphere Portal V8.5 CF03, the IBM team has updated this solution. It is available from the Collaboration Solutions Catalog at.
A little over a year ago, we released an easy to use Digital Data Connector (DDC) sample to integrate WebSphere Commerce and IBM Digital Experience (specifically WebSphere Portal and IBM Web Content Manager). You can read about it here: Integrating WebSphere Commerce using the Digital Data Connector framework
Today, we are happy to announce a whole new maturity level of that integration. Last year's IBM WebSphere Commerce Sample has evolved to become IBM WebSphere Commerce Components for Digital Experience. You can drag and drop those components onto your portal pages from the portal site toolbar and they will pull data from your Commerce server right to your portal site.
Compared to the earlier sample, the new IBM WebSphere Commerce Components add:
Apart from those new features, the team also updated and improved the documentation. It is far more comprehensive now!
The following three tutorials are now available for you to take a peek:
Tutorial - DDC and CaaS Basics.zip|View Details
Tutorial - Commerce Integration - requires Commerce integration setup.pdf|View Details
Tutorial - Social Portal - requires Connections integration setup.pdf|View Details
Just note that only the first one is self contained. The other two assume a working integration with WebSphere Commerce and IBM Connections as well as an installation of the IBM WebSphere Commerce Components for Digital Experience and the IBM Social Rendering Templates for Digital Data Connector, respectively.
Enjoy! | https://www.ibm.com/developerworks/community/blogs/8422279e-6fe9-4534-9ea2-25f87e45434d?sortby=4&maxresults=15&lang=en | CC-MAIN-2017-34 | refinedweb | 1,540 | 50.67 |
XAS theory¶
Schematic illustration of XAS (from [Nil04]):
The oscillator strengths are proportional to \(|\langle \phi_{1s}| \mathbf{r} | \psi_n \rangle|^2\), where the one-center expansion of \(\psi_n\) for the core-hole atom can be used.
XAS examples¶
First we must create a core hole setup. This can be done with the gpaw-setup command:
gpaw-setup -f PBE N --name hch1s --core-hole=1s,0.5
or you can write a small script to do it:
from gpaw.atom.generator import Generator from gpaw.atom.configurations import parameters # Generate setups with 0.5, 1.0, 0.0 core holes in 1s elements = ['O', 'C', 'N'] coreholes = [0.5, 1.0, 0.0] names = ['hch1s', 'fch1s', 'xes1s'] functionals = ['LDA', 'PBE'] for el in elements: for name, ch in zip(names, coreholes): for funct in functionals: g = Generator(el, scalarrel=True, xcname=funct, corehole=(1, 0, ch), nofiles=True) g.run(name=name, **parameters[el])
Set the location of setups as described here: Installation of PAW datasets.
Spectrum calculation using unoccupied states¶
We do a “ground state” calculation with a core hole. Use a lot of unoccupied states.
from math import pi, cos, sin from ase import Atoms from gpaw import GPAW, setup_paths setup_paths.insert(0, '.') a = 12.0 # use a large cell d = 0.9575 t = pi / 180 * 104.51 atoms = Atoms('OH2', [(0, 0, 0), (d, 0, 0), (d * cos(t), d * sin(t), 0)], cell=(a, a, a)) atoms.center() calc = GPAW(nbands=-30, h=0.2, txt='h2o_xas.txt', setups={'O': 'hch1s'}) # the number of unoccupied stated will determine how # high you will get in energy atoms.set_calculator(calc) e = atoms.get_potential_energy() calc.write('h2o_xas.gpw')
To get the absolute energy scale we do a Delta Kohn-Sham calculation
where we compute the total energy difference between the ground state
and the first core excited state. The excited state should be spin
polarized and to fix the occupation to a spin up core hole and an
electron in the lowest unoccupied spin up state (singlet) we must set
the magnetic moment to one on the atom with the hole and fix the total
magnetic moment with
occupations=FermiDirac(0.0, fixmagmom=True):
from __future__ import print_function from math import pi, cos, sin from ase import Atoms from ase.parallel import paropen from gpaw import GPAW, setup_paths, FermiDirac setup_paths.insert(0, '.') a = 12.0 # use a large cell d = 0.9575 t = pi / 180 * 104.51 atoms = Atoms('OH2', [(0, 0, 0), (d, 0, 0), (d * cos(t), d * sin(t), 0)], cell=(a, a, a)) atoms.center() calc1 = GPAW(h=0.2, txt='h2o_gs.txt', xc='PBE') atoms.set_calculator(calc1) e1 = atoms.get_potential_energy() + calc1.get_reference_energy() calc2 = GPAW(h=0.2, txt='h2o_exc.txt', xc='PBE', charge=-1, spinpol=True, occupations=FermiDirac(0.0, fixmagmom=True), setups={0: 'fch1s'}) atoms[0].magmom = 1 atoms.set_calculator(calc2) e2 = atoms.get_potential_energy() + calc2.get_reference_energy() with paropen('dks.result', 'w') as fd: print('Energy difference:', e2 - e1, file=fd)
Plot the spectrum:
from gpaw import GPAW, setup_paths from gpaw.xas import XAS import matplotlib.pyplot as plt setup_paths.insert(0, '.') dks_energy = 532.774 # from dks calcualtion calc = GPAW('h2o_xas.gpw') xas = XAS(calc, mode='xas') x, y = xas.get_spectra(fwhm=0.5, linbroad=[4.5, -1.0, 5.0]) x_s, y_s = xas.get_spectra(stick=True) shift = dks_energy - x_s[0] # shift the first transition y_tot = y[0] + y[1] + y[2] y_tot_s = y_s[0] + y_s[1] + y_s[2] plt.plot(x + shift, y_tot) plt.bar(x_s + shift, y_tot_s, width=0.05) plt.savefig('xas_h2o_spectrum.png')
Haydock recursion method¶
For systems in the condensed phase it is much more efficient to use the Haydock recursion method to calculate the spectrum, thus avoiding to determine many unoccupied states. First we do a core hole calculation with enough k-points to converge the ground state density. Then we compute the recursion coefficients with a denser k-point mesh to converge the uncoccupied DOS. A Delta Kohn-Sham calculation can be done for the gamma point, and the shift is made so that the first unoccupied eigenvalue at the gamma point ends up at the computed total energy difference.
from ase import Atoms from gpaw import GPAW name = 'diamond333_hch' a = 3.574 atoms = Atoms('C8', [(0, 0, 0), (1, 1, 1), (2, 2, 0), (3, 3, 1), (2, 0, 2), (0, 2, 2), (3, 1, 3), (1, 3, 3)], cell=(4, 4, 4), pbc=True) atoms.set_cell((a, a, a), scale_atoms=True) atoms *= (3, 3, 3) calc = GPAW(h=0.2, txt=name + '.txt', xc='PBE', setups={0: 'hch1s'}) atoms.set_calculator(calc) e = atoms.get_potential_energy() calc.write(name + '.gpw')
Compute recursion coefficients:
from gpaw import GPAW from fpaw.xas import RecursionMethod name = 'diamond333_hch' calc = GPAW(name + '.gpw', kpts=(6, 6, 6), txt=name + '_rec.txt') calc.set_positions() r = RecursionMethod(calc) r.run(600) r.run(1400, inverse_overlap='approximate') r.write(name + '_600_1400a.rec', mode='all')
Compute the spectrum with the get_spectra method. delta is the HWHM (should we change it to FWHM???) width of the lorentzian broadening, and fwhm is the FWHM of the Gaussian broadening.
sys.setrecursionlimit(10000) name='diamond333_hch_600_1400a.rec' x_start=-20 x_end=100 dx=0.01 x_rec = x_start + npy.arange(0, x_end - x_start ,dx) r = RecursionMethod(filename=name) y = r.get_spectra(x_rec, delta=0.4, fwhm=0.4 ) y2 = sum(y) p.plot(x_rec + 273.44,y2) p.show()
Below the calculated spectrum of Diamond with half and full core holes are shown along with the experimental spectrum.
XES¶
To compute XES, first do a ground state calcualtion with an 0.0 core hole (an ‘xes1s’ setup as created above ). The system will not be charged so the setups can be placed on all atoms one wants to calculte XES for. Since XES probes the occupied states no unoccupied states need to be determined. Calculate the spectrum with
xas = XAS(calc, mode='xes', center=n)
Where n is the number of the atom in the atoms object, the center keyword is only necessary if there are more than one xes setup. The spectrum can be shifted by putting the first transition to the fermi level, or to compute the total energy diffrence between the core hole state and the state with a valence hole in HOMO.
Further considerations¶
For XAS: Gridspacing can be set to the default value. The shape of the spectrum is quite insensitive to the functional used, the DKS shifts are more sensitive. The absolute energy position can be shifted so that the calculated XPS energy matches the expreimental value [Leetmaa2006]. Use a large box, see convergence with box size for a water molecule below:
import numpy as np from ase.build import molecule from gpaw import GPAW, setup_paths setup_paths.insert(0, '.') atoms = molecule('H2O') h = 0.2 for L in np.arange(4, 14, 2) * 8 * h: atoms.set_cell((L, L, L)) atoms.center() calc = GPAW(xc='PBE', h=h, nbands=-40, eigensolver='cg', setups={'O': 'hch1s'}) atoms.set_calculator(calc) e1 = atoms.get_potential_energy() calc.write('h2o_hch_%.1f.gpw' % L)
and plot it
import numpy as np import matplotlib.pyplot as plt from gpaw import GPAW, setup_paths from gpaw.xas import XAS setup_paths.insert(0, '.') h = 0.2 offset = 0.0 for L in np.arange(4, 14, 2) * 8 * h: calc = GPAW('h2o_hch_%.1f.gpw' % L) xas = XAS(calc) x, y = xas.get_spectra(fwhm=0.4) plt.plot(x, sum(y) + offset, label='{:.1f}'.format(L)) offset += 0.005 plt.legend() plt.xlim(-6, 4) plt.ylim(-0.002, 0.03) plt.savefig('h2o_xas_box.png') | https://wiki.fysik.dtu.dk/gpaw/tutorials/xas/xas.html | CC-MAIN-2020-05 | refinedweb | 1,256 | 60.51 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.