
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 600M 2.05B | node_id stringlengths 18 32 | number int64 2 6.51k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association stringclasses 3
values | active_lock_reason float64 | draft float64 0 1 ⌀ | pull_request dict | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5976 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5976/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5976/comments | https://api.github.com/repos/huggingface/datasets/issues/5976/events | https://github.com/huggingface/datasets/pull/5976 | 1,768,503,913 | PR_kwDODunzps5TmAFp | 5,976 | Avoid stuck map operation when subprocesses crashes | {
"avatar_url": "https://avatars.githubusercontent.com/u/1213561?v=4",
"events_url": "https://api.github.com/users/pappacena/events{/privacy}",
"followers_url": "https://api.github.com/users/pappacena/followers",
"following_url": "https://api.github.com/users/pappacena/following{/other_user}",
"gists_url": "h... | [] | closed | false | null | [] | null | [
"Hi ! Do you think this can be fixed at the Pool level ? Ideally it should be the Pool responsibility to handle this, not the `map` code. We could even subclass Pool if needed (at least the one from `multiprocess`)",
"@lhoestq it makes sense to me. Just pushed a refactoring creating a `class ProcessPool(multiproc... | 2023-06-21T21:18:31Z | 2023-07-10T09:58:39Z | 2023-07-10T09:50:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5976.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5976",
"merged_at": "2023-07-10T09:50:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5976.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I've been using Dataset.map() with `num_proc=os.cpu_count()` to leverage multicore processing for my datasets, but from time to time I get stuck processes waiting forever. Apparently, when one of the subprocesses is abruptly killed (OOM killer, segfault, SIGKILL, etc), the main process keeps waiting for the async task ... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5976/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5976/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4713/comments | https://api.github.com/repos/huggingface/datasets/issues/4713/events | https://github.com/huggingface/datasets/pull/4713 | 1,309,184,756 | PR_kwDODunzps47ojC1 | 4,713 | Document installation of sox OS dependency for audio | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-19T08:42:35Z | 2022-07-21T08:16:59Z | 2022-07-21T08:04:15Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4713.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4713",
"merged_at": "2022-07-21T08:04:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4713.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The `sox` OS package needs being installed manually using the distribution package manager.
This PR adds this explanation to the docs. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4713/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4713/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3957 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3957/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3957/comments | https://api.github.com/repos/huggingface/datasets/issues/3957/events | https://github.com/huggingface/datasets/pull/3957 | 1,172,401,455 | PR_kwDODunzps40magW | 3,957 | Fix xtreme s metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [
"Sorry for the commit history mess, but will be squashed anyways so should be fine",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-17T13:39:04Z | 2022-03-18T13:46:19Z | 2022-03-18T13:42:16Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3957.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3957",
"merged_at": "2022-03-18T13:42:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3957.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | We in fact do need BABEL in xtreme-s | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3957/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3957/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4946 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4946/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4946/comments | https://api.github.com/repos/huggingface/datasets/issues/4946/events | https://github.com/huggingface/datasets/pull/4946 | 1,364,692,069 | PR_kwDODunzps4-g0Hz | 4,946 | Introduce regex check when pushing as well | {
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Let me take over this PR if you don't mind"
] | 2022-09-07T13:45:58Z | 2022-09-13T10:19:01Z | 2022-09-13T10:16:34Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4946.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4946",
"merged_at": "2022-09-13T10:16:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4946.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Closes https://github.com/huggingface/datasets/issues/4945 by adding a regex check when pushing to hub.
Let me know if this is helpful and if it's the fix you would have in mind for the issue and I'm happy to contribute tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4946/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4946/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3656/comments | https://api.github.com/repos/huggingface/datasets/issues/3656/events | https://github.com/huggingface/datasets/issues/3656 | 1,120,510,823 | I_kwDODunzps5CyaNn | 3,656 | checksum error subjqa dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/9828683?v=4",
"events_url": "https://api.github.com/users/RensDimmendaal/events{/privacy}",
"followers_url": "https://api.github.com/users/RensDimmendaal/followers",
"following_url": "https://api.github.com/users/RensDimmendaal/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @RensDimmendaal, \r\n\r\nI'm sorry but I can't reproduce your bug:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: ds = load_dataset(\"subjqa\", \"electronics\")\r\nDownloading builder script: 9.15kB [00:00, 4.10MB/s] ... | 2022-02-01T10:53:33Z | 2022-02-10T10:56:59Z | 2022-02-10T10:56:38Z | NONE | null | null | null | ## Describe the bug
I get a checksum error when loading the `subjqa` dataset (used in the transformers book).
## Steps to reproduce the bug
```python
from datasets import load_dataset
subjqa = load_dataset("subjqa","electronics")
```
## Expected results
Loading the dataset
## Actual results
```
---... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3656/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3656/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/677/comments | https://api.github.com/repos/huggingface/datasets/issues/677/events | https://github.com/huggingface/datasets/pull/677 | 710,055,239 | MDExOlB1bGxSZXF1ZXN0NDkzOTczNDE3 | 677 | Move cache dir root creation in builder's init | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-09-28T08:22:46Z | 2020-09-28T14:42:43Z | 2020-09-28T14:42:42Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/677.diff",
"html_url": "https://github.com/huggingface/datasets/pull/677",
"merged_at": "2020-09-28T14:42:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/677.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/677... | We use lock files in the builder initialization but sometimes the cache directory where they're supposed to be was not created. To fix that I moved the builder's cache dir root creation in the builder's init.
Fix #671 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/677/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/677/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3663/comments | https://api.github.com/repos/huggingface/datasets/issues/3663/events | https://github.com/huggingface/datasets/issues/3663 | 1,121,067,647 | I_kwDODunzps5C0iJ_ | 3,663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Having talked to @lhoestq, I see that this feature is no longer supported. \r\n\r\nI really don't think this was a good idea. It is a major breaking change and one for which we don't even have a working solution at the moment, which is bad for PyTorch as we don't want to force people to have `datasets` decode audi... | 2022-02-01T18:40:10Z | 2022-09-21T15:03:09Z | 2022-09-21T14:56:22Z | MEMBER | null | null | null | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3663/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3663/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5820 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5820/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5820/comments | https://api.github.com/repos/huggingface/datasets/issues/5820/events | https://github.com/huggingface/datasets/issues/5820 | 1,695,892,811 | I_kwDODunzps5lFUVL | 5,820 | Incomplete docstring for `BuilderConfig` | {
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"events_url": "https://api.github.com/users/Laurent2916/events{/privacy}",
"followers_url": "https://api.github.com/users/Laurent2916/followers",
"following_url": "https://api.github.com/users/Laurent2916/following{/other_user}",
"gists_u... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | [
"Thanks for reporting! You are more than welcome to improve `BuilderConfig`'s docstring.\r\n\r\nThis class serves an identical purpose as `tensorflow_datasets`'s `BuilderConfig`, and its docstring is [here](https://github.com/tensorflow/datasets/blob/a95e38b5bb018312c3d3720619c2a8ef83ebf57f/tensorflow_datasets/core... | 2023-05-04T12:14:34Z | 2023-05-05T12:31:56Z | 2023-05-05T12:31:56Z | CONTRIBUTOR | null | null | null | Hi guys !
I stumbled upon this docstring while working on a project.
Some of the attributes have missing descriptions.
https://github.com/huggingface/datasets/blob/bc5fef5b6d91f009e4101684adcb374df2c170f6/src/datasets/builder.py#L104-L117 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5820/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5820/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2757 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2757/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2757/comments | https://api.github.com/repos/huggingface/datasets/issues/2757/events | https://github.com/huggingface/datasets/issues/2757 | 959,984,081 | MDU6SXNzdWU5NTk5ODQwODE= | 2,757 | Unexpected type after `concatenate_datasets` | {
"avatar_url": "https://avatars.githubusercontent.com/u/32683010?v=4",
"events_url": "https://api.github.com/users/JulesBelveze/events{/privacy}",
"followers_url": "https://api.github.com/users/JulesBelveze/followers",
"following_url": "https://api.github.com/users/JulesBelveze/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @JulesBelveze, thanks for your question.\r\n\r\nNote that 🤗 `datasets` internally store their data in Apache Arrow format.\r\n\r\nHowever, when accessing dataset columns, by default they are returned as native Python objects (lists in this case).\r\n\r\nIf you would like their columns to be returned in a more... | 2021-08-04T07:10:39Z | 2021-08-04T16:01:24Z | 2021-08-04T16:01:23Z | NONE | null | null | null | ## Describe the bug
I am trying to concatenate two `Dataset` using `concatenate_datasets` but it turns out that after concatenation the features are casted from `torch.Tensor` to `list`.
It then leads to a weird tensors when trying to convert it to a `DataLoader`. However, if I use each `Dataset` separately everythi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2757/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2757/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1689/comments | https://api.github.com/repos/huggingface/datasets/issues/1689/events | https://github.com/huggingface/datasets/pull/1689 | 779,107,313 | MDExOlB1bGxSZXF1ZXN0NTQ5MTEwMDgw | 1,689 | Fix ade_corpus_v2 config names | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-01-05T14:33:28Z | 2021-01-05T14:55:09Z | 2021-01-05T14:55:08Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1689.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1689",
"merged_at": "2021-01-05T14:55:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1689.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | There are currently some typos in the config names of the `ade_corpus_v2` dataset, I fixed them:
- Ade_corpos_v2_classificaion -> Ade_corpus_v2_classification
- Ade_corpos_v2_drug_ade_relation -> Ade_corpus_v2_drug_ade_relation
- Ade_corpos_v2_drug_dosage_relation -> Ade_corpus_v2_drug_dosage_relation | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1689/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1689/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5721/comments | https://api.github.com/repos/huggingface/datasets/issues/5721/events | https://github.com/huggingface/datasets/issues/5721 | 1,659,680,682 | I_kwDODunzps5i7Leq | 5,721 | Calling datasets.load_dataset("text" ...) results in a wrong split. | {
"avatar_url": "https://avatars.githubusercontent.com/u/1841186?v=4",
"events_url": "https://api.github.com/users/cyrilzakka/events{/privacy}",
"followers_url": "https://api.github.com/users/cyrilzakka/followers",
"following_url": "https://api.github.com/users/cyrilzakka/following{/other_user}",
"gists_url":... | [] | open | false | null | [] | null | [] | 2023-04-08T23:55:12Z | 2023-04-08T23:55:12Z | null | NONE | null | null | null | ### Describe the bug
When creating a text dataset, the training split should have the bulk of the examples by default. Currently, testing does.
### Steps to reproduce the bug
I have a folder with 18K text files in it. Each text file essentially consists in a document or article scraped from online. Calling the follo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5721/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5721/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4329 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4329/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4329/comments | https://api.github.com/repos/huggingface/datasets/issues/4329/events | https://github.com/huggingface/datasets/pull/4329 | 1,233,991,207 | PR_kwDODunzps43uIcF | 4,329 | Adding eval metadata for AG News | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2022-05-12T13:30:32Z | 2022-05-12T21:02:41Z | 2022-05-12T21:02:40Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4329.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4329",
"merged_at": "2022-05-12T21:02:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4329.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding eval metadata for AG News | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4329/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4329/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6040 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6040/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6040/comments | https://api.github.com/repos/huggingface/datasets/issues/6040/events | https://github.com/huggingface/datasets/pull/6040 | 1,807,410,238 | PR_kwDODunzps5VptVf | 6,040 | Fix legacy_dataset_infos | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-07-17T09:56:21Z | 2023-07-17T10:24:34Z | 2023-07-17T10:16:03Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6040.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6040",
"merged_at": "2023-07-17T10:16:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6040.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | was causing transformers CI to fail
https://circleci.com/gh/huggingface/transformers/855105 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6040/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6040/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5926 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5926/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5926/comments | https://api.github.com/repos/huggingface/datasets/issues/5926/events | https://github.com/huggingface/datasets/issues/5926 | 1,743,922,028 | I_kwDODunzps5n8iNs | 5,926 | Uncaught exception when generating the splits from a dataset that miss data | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @severo.\r\n\r\nThis is a known issue with `fsspec`:\r\n- #5862\r\n- https://github.com/fsspec/filesystem_spec/issues/1265"
] | 2023-06-06T13:51:01Z | 2023-06-07T07:53:16Z | null | CONTRIBUTOR | null | null | null | ### Describe the bug
Dataset https://huggingface.co/datasets/blog_authorship_corpus has an issue with its hosting platform, since https://drive.google.com/u/0/uc?id=1cGy4RNDV87ZHEXbiozABr9gsSrZpPaPz&export=download returns 404 error.
But when trying to generate the split names, we get an exception which is now corr... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5926/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5926/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3337 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3337/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3337/comments | https://api.github.com/repos/huggingface/datasets/issues/3337/events | https://github.com/huggingface/datasets/issues/3337 | 1,066,232,936 | I_kwDODunzps4_jWxo | 3,337 | Typing of Dataset.__getitem__ could be improved. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https:/... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_... | null | [
"Hi ! Thanks for the suggestion, I didn't know about this decorator.\r\n\r\nIf you are interesting in contributing, feel free to open a pull request to add the overload methods for each typing combination :) To assign you to this issue, you can comment `#self-assign` in this thread.\r\n\r\n`Dataset.__getitem__` is ... | 2021-11-29T16:20:11Z | 2021-12-14T10:28:54Z | 2021-12-14T10:28:54Z | CONTRIBUTOR | null | null | null | ## Describe the bug
The newly added typing for Dataset.__getitem__ is Union[Dict, List]. This makes tools like mypy a bit awkward to use as we need to check the type manually. We could use type overloading to make this easier. [Documentation](https://docs.python.org/3/library/typing.html#typing.overload)
## Steps... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3337/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3337/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/430/comments | https://api.github.com/repos/huggingface/datasets/issues/430/events | https://github.com/huggingface/datasets/pull/430 | 664,583,837 | MDExOlB1bGxSZXF1ZXN0NDU1ODAxOTI2 | 430 | add DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"I did the changes in the docstrings and I added a type check in each `DatasetDict` method to make sure all values are of type `Dataset`",
"Awesome, do you mind adding these in the doc as well?",
"I added it to the docs (processing + main classes)",
"I'm trying to follow along with the following about dataset... | 2020-07-23T15:43:49Z | 2020-08-04T01:01:53Z | 2020-07-29T09:06:22Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/430.diff",
"html_url": "https://github.com/huggingface/datasets/pull/430",
"merged_at": "2020-07-29T09:06:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/430.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/430... | ## Add DatasetDict
### Overview
When you call `load_dataset` it can return a dictionary of datasets if there are several splits (train/test for example).
If you wanted to apply dataset transforms you had to iterate over each split and apply the transform.
Instead of returning a dict, it now returns a `nlp.Dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/430/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/430/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4586/comments | https://api.github.com/repos/huggingface/datasets/issues/4586/events | https://github.com/huggingface/datasets/pull/4586 | 1,287,105,636 | PR_kwDODunzps46e9xB | 4,586 | Host pn_summary data on the Hub instead of Google Drive | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-06-28T10:05:05Z | 2022-06-28T14:52:56Z | 2022-06-28T14:42:03Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4586.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4586",
"merged_at": "2022-06-28T14:42:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4586.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #4581. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4586/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/331 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/331/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/331/comments | https://api.github.com/repos/huggingface/datasets/issues/331/events | https://github.com/huggingface/datasets/issues/331 | 648,533,199 | MDU6SXNzdWU2NDg1MzMxOTk= | 331 | Loading CNN/Daily Mail dataset produces `nlp.utils.info_utils.NonMatchingSplitsSizesError` | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"I couldn't reproduce on my side.\r\nIt looks like you were not able to generate all the examples, and you have the problem for each split train-test-validation.\r\nCould you try to enable logging, try again and send the logs ?\r\n```python\r\nimport logging\r\nlogging.basicConfig(level=logging.INFO)\r\n```",
"he... | 2020-06-30T22:21:33Z | 2020-07-09T13:03:40Z | 2020-07-09T13:03:40Z | CONTRIBUTOR | null | null | null | ```
>>> import nlp
>>> nlp.load_dataset('cnn_dailymail', '3.0.0')
Downloading and preparing dataset cnn_dailymail/3.0.0 (download: 558.32 MiB, generated: 1.26 GiB, total: 1.81 GiB) to /u/jm8wx/.cache/huggingface/datasets/cnn_dailymail/3.0.0/3.0.0...
Traceback (most recent call last):
File "<stdin>", line 1, in... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/331/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/331/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/556/comments | https://api.github.com/repos/huggingface/datasets/issues/556/events | https://github.com/huggingface/datasets/pull/556 | 690,218,423 | MDExOlB1bGxSZXF1ZXN0NDc3MTQ0MTky | 556 | Add DailyDialog | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [] | 2020-09-01T15:01:15Z | 2020-09-03T15:42:03Z | 2020-09-03T15:38:39Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/556.diff",
"html_url": "https://github.com/huggingface/datasets/pull/556",
"merged_at": "2020-09-03T15:38:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/556.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/556... | http://yanran.li/dailydialog.html
https://arxiv.org/pdf/1710.03957.pdf
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/556/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/556/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2403/comments | https://api.github.com/repos/huggingface/datasets/issues/2403/events | https://github.com/huggingface/datasets/pull/2403 | 900,059,014 | MDExOlB1bGxSZXF1ZXN0NjUxNjcxMTMw | 2,403 | Free datasets with cache file in temp dir on exit | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-05-24T22:15:11Z | 2021-05-26T17:25:19Z | 2021-05-26T16:39:29Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2403.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2403",
"merged_at": "2021-05-26T16:39:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2403.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR properly cleans up the memory-mapped tables that reference the cache files inside the temp dir.
Since the built-in `_finalizer` of `TemporaryDirectory` can't be modified, this PR defines its own `TemporaryDirectory` class that accepts a custom clean-up function.
Fixes #2402 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2403/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2403/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1815 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1815/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1815/comments | https://api.github.com/repos/huggingface/datasets/issues/1815/events | https://github.com/huggingface/datasets/pull/1815 | 800,610,017 | MDExOlB1bGxSZXF1ZXN0NTY3MDY3NjU1 | 1,815 | Add CCAligned Multilingual Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi !\r\n\r\nWe already have some datasets that can have many many configurations possible.\r\nTo be able to support that, we allow to subclass BuilderConfig to add as many additional parameters as you may need.\r\nThis way users can load any language they want. For example the [bible_para](https://github.com/huggi... | 2021-02-03T18:59:52Z | 2021-03-01T12:33:03Z | 2021-03-01T10:36:21Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1815.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1815",
"merged_at": "2021-03-01T10:36:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1815.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Hello,
I'm trying to add [CCAligned Multilingual Dataset](http://www.statmt.org/cc-aligned/). This has the potential to close #1756.
This dataset has two types - Document-Pairs, and Sentence-Pairs.
The datasets are huge, so I won't be able to test all of them. At the same time, a user might only want to downlo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1815/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1815/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6434 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6434/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6434/comments | https://api.github.com/repos/huggingface/datasets/issues/6434/events | https://github.com/huggingface/datasets/pull/6434 | 1,999,554,915 | PR_kwDODunzps5fxgUO | 6,434 | Use `ruff` for formatting | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-11-17T16:53:22Z | 2023-11-21T14:19:21Z | 2023-11-21T14:13:13Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6434.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6434",
"merged_at": "2023-11-21T14:13:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6434.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Use `ruff` instead of `black` for formatting to be consistent with `transformers` ([PR](https://github.com/huggingface/transformers/pull/27144)) and `huggingface_hub` ([PR 1](https://github.com/huggingface/huggingface_hub/pull/1783) and [PR 2](https://github.com/huggingface/huggingface_hub/pull/1789)). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6434/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6434/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6490 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6490/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6490/comments | https://api.github.com/repos/huggingface/datasets/issues/6490/events | https://github.com/huggingface/datasets/issues/6490 | 2,037,204,892 | I_kwDODunzps55bUec | 6,490 | `load_dataset(...,save_infos=True)` not working without loading script | {
"avatar_url": "https://avatars.githubusercontent.com/u/114978051?v=4",
"events_url": "https://api.github.com/users/morganveyret/events{/privacy}",
"followers_url": "https://api.github.com/users/morganveyret/followers",
"following_url": "https://api.github.com/users/morganveyret/following{/other_user}",
"gis... | [] | open | false | null | [] | null | [
"Also, once the README.md exists in the python environment it is used when loading another dataset in the same format (e.g. json) since it always resolves the path to the same directory.\r\nThe consequence here is any other dataset won't load because of infos mismatch.\r\nTo reproduce this aspect:\r\n1. Do a `load_... | 2023-12-12T08:09:18Z | 2023-12-12T08:36:22Z | null | NONE | null | null | null | ### Describe the bug
It seems that saving a dataset infos back into the card file is not working for datasets without a loading script.
After tracking the problem a bit it looks like saving the infos uses `Builder.get_imported_module_dir()` as its destination directory.
Internally this is a call to `inspect.getfil... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6490/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6490/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3243 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3243/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3243/comments | https://api.github.com/repos/huggingface/datasets/issues/3243/events | https://github.com/huggingface/datasets/pull/3243 | 1,048,630,754 | PR_kwDODunzps4uSWtB | 3,243 | Remove redundant isort module placement | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-11-09T13:50:30Z | 2021-11-12T14:02:45Z | 2021-11-12T14:02:45Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3243.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3243",
"merged_at": "2021-11-12T14:02:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3243.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | `isort` can place modules by itself from [version 5.0.0](https://pycqa.github.io/isort/docs/upgrade_guides/5.0.0.html#module-placement-changes-known_third_party-known_first_party-default_section-etc) onwards, making the `known_first_party` and `known_third_party` fields in `setup.cfg` redundant (this is why our CI work... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3243/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3243/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4702/comments | https://api.github.com/repos/huggingface/datasets/issues/4702/events | https://github.com/huggingface/datasets/issues/4702 | 1,307,793,811 | I_kwDODunzps5N81mT | 4,702 | Domain specific dataset discovery on the Hugging Face hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi! I added a link to this issue in our internal request for adding keywords/topics to the Hub, which is identical to the `topic tags` solution. The `collections` solution seems too complex (as you point out). Regarding the `domain tags` solution, we primarily focus on machine learning, so I'm not sure if it's a g... | 2022-07-18T11:14:03Z | 2022-07-19T15:18:11Z | null | MEMBER | null | null | null | **Is your feature request related to a problem? Please describe.**
## The problem
The datasets hub currently has `8,239` datasets. These datasets span a wide range of different modalities and tasks (currently with a bias towards textual data).
There are various ways of identifying datasets that may be releva... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4702/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4702/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2758 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2758/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2758/comments | https://api.github.com/repos/huggingface/datasets/issues/2758/events | https://github.com/huggingface/datasets/pull/2758 | 960,206,575 | MDExOlB1bGxSZXF1ZXN0NzAzMjQ5Nzky | 2,758 | Raise ManualDownloadError when loading a dataset that requires previous manual download | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-08-04T10:19:55Z | 2021-08-04T11:36:30Z | 2021-08-04T11:36:30Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2758.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2758",
"merged_at": "2021-08-04T11:36:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2758.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR implements the raising of a `ManualDownloadError` when loading a dataset that requires previous manual download, and this is missing.
The `ManualDownloadError` is raised whether the dataset is loaded in normal or streaming mode.
Close #2749.
cc: @severo | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2758/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2758/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1450 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1450/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1450/comments | https://api.github.com/repos/huggingface/datasets/issues/1450/events | https://github.com/huggingface/datasets/pull/1450 | 761,102,429 | MDExOlB1bGxSZXF1ZXN0NTM1ODIwNjg0 | 1,450 | Fix version in bible_para | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [] | closed | false | null | [] | null | [] | 2020-12-10T10:13:55Z | 2020-12-11T16:40:41Z | 2020-12-11T16:40:40Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1450.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1450",
"merged_at": "2020-12-11T16:40:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1450.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1450/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1450/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/1274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1274/comments | https://api.github.com/repos/huggingface/datasets/issues/1274/events | https://github.com/huggingface/datasets/pull/1274 | 758,943,174 | MDExOlB1bGxSZXF1ZXN0NTM0MDI0MTQx | 1,274 | oclar-dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26907161?v=4",
"events_url": "https://api.github.com/users/alaameloh/events{/privacy}",
"followers_url": "https://api.github.com/users/alaameloh/followers",
"following_url": "https://api.github.com/users/alaameloh/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | 2020-12-07T23:56:45Z | 2020-12-09T15:36:08Z | 2020-12-09T15:36:08Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1274.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1274",
"merged_at": "2020-12-09T15:36:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1274.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Opinion Corpus for Lebanese Arabic Reviews (OCLAR) corpus is utilizable for Arabic sentiment classification on reviews, including hotels, restaurants, shops, and others. : [homepage](http://archive.ics.uci.edu/ml/datasets/Opinion+Corpus+for+Lebanese+Arabic+Reviews+%28OCLAR%29#) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1274/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4635/comments | https://api.github.com/repos/huggingface/datasets/issues/4635/events | https://github.com/huggingface/datasets/issues/4635 | 1,294,475,931 | I_kwDODunzps5NKCKb | 4,635 | Dataset Viewer issue for vadis/sv-ident | {
"avatar_url": "https://avatars.githubusercontent.com/u/20404466?v=4",
"events_url": "https://api.github.com/users/e-tornike/events{/privacy}",
"followers_url": "https://api.github.com/users/e-tornike/followers",
"following_url": "https://api.github.com/users/e-tornike/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @e-tornike \r\n\r\nSome context:\r\n- #4527 \r\n\r\nThe dataset loads locally in streaming mode:\r\n```python\r\nIn [2]: from datasets import load_dataset; ds = load_dataset(\"vadis/sv-ident\", split=\"validation\", streaming=True); item = next(iter(ds)); item\r\nUsing custom data configurati... | 2022-07-05T15:48:13Z | 2022-07-06T07:13:33Z | 2022-07-06T07:12:14Z | NONE | null | null | null | ### Link
https://huggingface.co/datasets/vadis/sv-ident/viewer/default/validation
### Description
Error message when loading validation split in the viewer:
```
Status code: 400
Exception: Status400Error
Message: The split cache is empty.
```
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4635/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4635/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1952 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1952/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1952/comments | https://api.github.com/repos/huggingface/datasets/issues/1952/events | https://github.com/huggingface/datasets/pull/1952 | 817,428,160 | MDExOlB1bGxSZXF1ZXN0NTgwOTIyNjQw | 1,952 | Handle timeouts | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"I never said the calls were hanging indefinitely, what we need is quite different - in the firewalled env with a network, there should be no network calls or they should fail instantly.\r\n\r\nTo make this work I suppose on top of this PR we need:\r\n1. `DATASETS_OFFLINE` env var to force set timeout to 0 globally... | 2021-02-26T15:02:07Z | 2021-03-01T14:29:24Z | 2021-03-01T14:29:24Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1952.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1952",
"merged_at": "2021-03-01T14:29:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1952.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As noticed in https://github.com/huggingface/datasets/issues/1939, timeouts were not properly handled when loading a dataset.
This caused the connection to hang indefinitely when working in a firewalled environment cc @stas00
I added a default timeout, and included an option to our offline environment for tests to... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1952/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1952/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2127 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2127/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2127/comments | https://api.github.com/repos/huggingface/datasets/issues/2127/events | https://github.com/huggingface/datasets/pull/2127 | 843,017,199 | MDExOlB1bGxSZXF1ZXN0NjAyNDYxMzc3 | 2,127 | make documentation more clear to use different cloud storage | {
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-03-29T06:24:06Z | 2021-03-29T12:16:24Z | 2021-03-29T12:16:24Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2127.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2127",
"merged_at": "2021-03-29T12:16:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2127.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR extends the cloud storage documentation. To show you can use a different `fsspec` implementation. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2127/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2127/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1262 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1262/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1262/comments | https://api.github.com/repos/huggingface/datasets/issues/1262/events | https://github.com/huggingface/datasets/pull/1262 | 758,637,124 | MDExOlB1bGxSZXF1ZXN0NTMzNzc3OTcy | 1,262 | Adding msr_genomics_kbcomp dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/6687858?v=4",
"events_url": "https://api.github.com/users/manandey/events{/privacy}",
"followers_url": "https://api.github.com/users/manandey/followers",
"following_url": "https://api.github.com/users/manandey/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-12-07T16:01:30Z | 2020-12-08T18:08:55Z | 2020-12-08T18:08:47Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1262.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1262",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1262.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1262"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1262/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1262/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/152 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/152/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/152/comments | https://api.github.com/repos/huggingface/datasets/issues/152/events | https://github.com/huggingface/datasets/pull/152 | 619,971,900 | MDExOlB1bGxSZXF1ZXN0NDE5MzA4OTE2 | 152 | Add GLUE config name check | {
"avatar_url": "https://avatars.githubusercontent.com/u/13381361?v=4",
"events_url": "https://api.github.com/users/bharatr21/events{/privacy}",
"followers_url": "https://api.github.com/users/bharatr21/followers",
"following_url": "https://api.github.com/users/bharatr21/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"If tests are being added, any guidance on where to add tests would be helpful!\r\n\r\nTagging @thomwolf for review",
"Looks good to me. Is this compatible with the way we are doing tests right now @patrickvonplaten ?",
"If the tests pass it should be fine :-) \r\n\r\n@Bharat123rox could you check whether the t... | 2020-05-18T07:23:43Z | 2020-05-27T22:09:12Z | 2020-05-27T22:09:12Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/152.diff",
"html_url": "https://github.com/huggingface/datasets/pull/152",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/152.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/152"
} | Fixes #130 by adding a name check to the Glue class | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/152/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/152/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1242/comments | https://api.github.com/repos/huggingface/datasets/issues/1242/events | https://github.com/huggingface/datasets/pull/1242 | 758,370,579 | MDExOlB1bGxSZXF1ZXN0NTMzNTU0MzAx | 1,242 | adding bprec | {
"avatar_url": "https://avatars.githubusercontent.com/u/15803781?v=4",
"events_url": "https://api.github.com/users/kldarek/events{/privacy}",
"followers_url": "https://api.github.com/users/kldarek/followers",
"following_url": "https://api.github.com/users/kldarek/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"looks like this PR includes changes to many files other than the ones related to bprec\r\nCan you create another branch and another PR please ?",
"> looks like this PR includes changes to many files other than the ones related to bprec\r\n> Can you create another branch and another PR please ?\r\n\r\nYes, I real... | 2020-12-07T10:15:49Z | 2020-12-08T14:33:49Z | 2020-12-08T14:33:48Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1242.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1242",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1242.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1242"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1242/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/453 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/453/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/453/comments | https://api.github.com/repos/huggingface/datasets/issues/453/events | https://github.com/huggingface/datasets/pull/453 | 667,728,247 | MDExOlB1bGxSZXF1ZXN0NDU4MzQwNzky | 453 | add builder tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-07-29T10:22:07Z | 2020-07-29T11:14:06Z | 2020-07-29T11:14:05Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/453.diff",
"html_url": "https://github.com/huggingface/datasets/pull/453",
"merged_at": "2020-07-29T11:14:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/453.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/453... | I added `as_dataset` and `download_and_prepare` to the tests | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/453/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/453/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4763 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4763/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4763/comments | https://api.github.com/repos/huggingface/datasets/issues/4763/events | https://github.com/huggingface/datasets/pull/4763 | 1,321,295,876 | PR_kwDODunzps48RMKi | 4,763 | More rigorous shape inference in to_tf_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-28T18:04:15Z | 2022-09-08T19:17:54Z | 2022-09-08T19:15:41Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4763.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4763",
"merged_at": "2022-09-08T19:15:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4763.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | `tf.data` needs to know the shape of tensors emitted from a `tf.data.Dataset`. Although `None` dimensions are possible, overusing them can cause problems - Keras uses the dataset tensor spec at compile-time, and so saying that a dimension is `None` when it's actually constant can hurt performance, or even cause trainin... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4763/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4763/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6465 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6465/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6465/comments | https://api.github.com/repos/huggingface/datasets/issues/6465/events | https://github.com/huggingface/datasets/issues/6465 | 2,022,212,468 | I_kwDODunzps54iIN0 | 6,465 | `load_dataset` uses out-of-date cache instead of re-downloading a changed dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3391297?v=4",
"events_url": "https://api.github.com/users/mnoukhov/events{/privacy}",
"followers_url": "https://api.github.com/users/mnoukhov/followers",
"following_url": "https://api.github.com/users/mnoukhov/following{/other_user}",
"gists_url": "http... | [] | open | false | null | [] | null | [
"Hi, thanks for reporting! https://github.com/huggingface/datasets/pull/6459 will fix this."
] | 2023-12-02T21:35:17Z | 2023-12-04T16:13:10Z | null | NONE | null | null | null | ### Describe the bug
When a dataset is updated on the hub, using `load_dataset` will load the locally cached dataset instead of re-downloading the updated dataset
### Steps to reproduce the bug
Here is a minimal example script to
1. create an initial dataset and upload
2. download it so it is stored in cache
3. c... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6465/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6465/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3621/comments | https://api.github.com/repos/huggingface/datasets/issues/3621/events | https://github.com/huggingface/datasets/issues/3621 | 1,112,720,434 | I_kwDODunzps5CUsQy | 3,621 | Consider adding `ipywidgets` as a dependency. | {
"avatar_url": "https://avatars.githubusercontent.com/u/1019791?v=4",
"events_url": "https://api.github.com/users/koaning/events{/privacy}",
"followers_url": "https://api.github.com/users/koaning/followers",
"following_url": "https://api.github.com/users/koaning/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! We use `tqdm` to display progress bars, so I suggest you open this issue in their repo.",
"It depends on how you use `tqdm`, no? \r\n\r\nDoesn't this library import via; \r\n\r\n```\r\nfrom tqdm.notebook import tqdm\r\n```",
"Hi! Sorry for the late reply. We import `tqdm` as `from tqdm.auto import tqdm`, w... | 2022-01-24T14:27:11Z | 2022-02-24T09:04:36Z | 2022-02-24T09:04:36Z | NONE | null | null | null | When I install `datasets` in a fresh virtualenv with jupyterlab I always see this error.
```
ImportError: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
```
It's a bit of a nuisance, because I need to run shut down the jupyterlab ser... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3621/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3621/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2978 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2978/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2978/comments | https://api.github.com/repos/huggingface/datasets/issues/2978/events | https://github.com/huggingface/datasets/issues/2978 | 1,009,521,419 | I_kwDODunzps48LBML | 2,978 | Run CI tests against non-production server | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | open | false | null | [] | null | [
"Hey @albertvillanova could you provide more context, including extracts from the discussion we had ?\r\n\r\nLet's ping @Pierrci @julien-c and @n1t0 for their opinion about that",
"@julien-c increased the huggingface.co production workers in order to see if it solve [the 502 you had this morning](https://app.circ... | 2021-09-28T09:41:26Z | 2021-09-28T15:23:50Z | null | MEMBER | null | null | null | Currently, the CI test suite performs requests to the HF production server.
As discussed with @elishowk, we should refactor our tests to use the HF staging server instead, like `huggingface_hub` and `transformers`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2978/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2978/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3623/comments | https://api.github.com/repos/huggingface/datasets/issues/3623/events | https://github.com/huggingface/datasets/pull/3623 | 1,112,835,239 | PR_kwDODunzps4xgWig | 3,623 | Extend support for streaming datasets that use os.path.relpath | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2022-01-24T16:00:52Z | 2022-02-04T14:03:55Z | 2022-02-04T14:03:54Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3623.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3623",
"merged_at": "2022-02-04T14:03:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3623.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR extends the support in streaming mode for datasets that use `os.path.relpath`, by patching that function.
This feature will also be useful to yield the relative path of audio or image files, within an archive or parent dir.
Close #3622. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3623/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3623/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3277 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3277/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3277/comments | https://api.github.com/repos/huggingface/datasets/issues/3277/events | https://github.com/huggingface/datasets/pull/3277 | 1,054,122,656 | PR_kwDODunzps4ujk11 | 3,277 | f-string formatting | {
"avatar_url": "https://avatars.githubusercontent.com/u/56029953?v=4",
"events_url": "https://api.github.com/users/Mehdi2402/events{/privacy}",
"followers_url": "https://api.github.com/users/Mehdi2402/followers",
"following_url": "https://api.github.com/users/Mehdi2402/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hello @lhoestq, ```make style``` is applied as asked. :)"
] | 2021-11-15T21:37:05Z | 2021-11-19T20:40:08Z | 2021-11-17T16:18:38Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3277.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3277",
"merged_at": "2021-11-17T16:18:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3277.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | **Fix #3257**
Replaced _.format()_ and _%_ by f-strings in the following modules :
- [x] **tests**
- [x] **metrics**
- [x] **benchmarks**
- [x] **utils**
- [x] **templates**
- [x] **src/Datasets/\*.py**
Modules in **_src/Datasets/_**:
- [x] **commands**
- [x] **features**
- [x] **formatting**
- [x] **... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3277/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3277/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6479 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6479/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6479/comments | https://api.github.com/repos/huggingface/datasets/issues/6479/events | https://github.com/huggingface/datasets/pull/6479 | 2,029,040,121 | PR_kwDODunzps5hVLom | 6,479 | More robust preupload retry mechanism | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6479). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2023-12-06T17:19:38Z | 2023-12-06T19:47:29Z | 2023-12-06T19:41:06Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6479.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6479",
"merged_at": "2023-12-06T19:41:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6479.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6479/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6479/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5291 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5291/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5291/comments | https://api.github.com/repos/huggingface/datasets/issues/5291/events | https://github.com/huggingface/datasets/pull/5291 | 1,462,983,472 | PR_kwDODunzps5DoKNC | 5,291 | [build doc] for v2.7.1 & v2.6.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"doc versions are built https://huggingface.co/docs/datasets/index"
] | 2022-11-24T08:54:47Z | 2022-11-24T09:14:10Z | 2022-11-24T09:11:15Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5291.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5291",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5291.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5291"
} | Do NOT merge. Using this PR to build docs for [v2.7.1](https://github.com/huggingface/datasets/pull/5291/commits/f4914af20700f611b9331a9e3ba34743bbeff934) & [v2.6.2](https://github.com/huggingface/datasets/pull/5291/commits/025f85300a0874eeb90a20393c62f25ac0accaa0) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5291/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5291/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1953 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1953/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1953/comments | https://api.github.com/repos/huggingface/datasets/issues/1953/events | https://github.com/huggingface/datasets/pull/1953 | 817,498,869 | MDExOlB1bGxSZXF1ZXN0NTgwOTgyMDMz | 1,953 | Documentation for to_csv, to_pandas and to_dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-02-26T16:35:49Z | 2021-03-01T14:03:48Z | 2021-03-01T14:03:47Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1953.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1953",
"merged_at": "2021-03-01T14:03:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1953.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I added these methods to the documentation with a small paragraph.
I also fixed some formatting issues in the docstrings | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1953/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1953/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4795 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4795/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4795/comments | https://api.github.com/repos/huggingface/datasets/issues/4795/events | https://github.com/huggingface/datasets/issues/4795 | 1,329,525,732 | I_kwDODunzps5PPvPk | 4,795 | Missing MBPP splits | {
"avatar_url": "https://avatars.githubusercontent.com/u/2452384?v=4",
"events_url": "https://api.github.com/users/stadlerb/events{/privacy}",
"followers_url": "https://api.github.com/users/stadlerb/followers",
"following_url": "https://api.github.com/users/stadlerb/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Thanks for reporting this as well, @stadlerb.\r\n\r\nI suggest waiting for the answer of the data owners... ",
"@albertvillanova The first author of the paper responded to the upstream issue:\r\n> Task IDs 11-510 are the 500 test problems. We use 90 problems (511-600) for validation and then remaining 374 for fi... | 2022-08-05T06:51:01Z | 2022-09-13T12:27:24Z | 2022-09-13T12:27:24Z | NONE | null | null | null | (@albertvillanova)
The [MBPP dataset on the Hub](https://huggingface.co/datasets/mbpp) has only a test split for both its "full" and its "sanitized" subset, while the [paper](https://arxiv.org/abs/2108.07732) states in subsection 2.1 regarding the full split:
> In the experiments described later in the paper, we hold... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4795/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4795/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4183 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4183/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4183/comments | https://api.github.com/repos/huggingface/datasets/issues/4183/events | https://github.com/huggingface/datasets/pull/4183 | 1,208,449,335 | PR_kwDODunzps42bjXn | 4,183 | Document librispeech configs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"I think the main purpose of #4179 was how to be able to load both configs into one, so should we maybe add this part of the code: https://github.com/huggingface/datasets/issues/4179#issuecomment-1102383717 \r\n\r\nto the doc? \r\n\r\nActually @lhoestq would this work given that they have different split names: htt... | 2022-04-19T14:26:59Z | 2023-09-24T10:02:24Z | 2022-04-19T15:15:20Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4183.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4183",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4183.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4183"
} | Added an example of how to load one config or the other | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4183/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4183/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1257 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1257/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1257/comments | https://api.github.com/repos/huggingface/datasets/issues/1257/events | https://github.com/huggingface/datasets/pull/1257 | 758,550,490 | MDExOlB1bGxSZXF1ZXN0NTMzNzA2NDQy | 1,257 | Add Swahili news classification dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7923902?v=4",
"events_url": "https://api.github.com/users/yvonnegitau/events{/privacy}",
"followers_url": "https://api.github.com/users/yvonnegitau/followers",
"following_url": "https://api.github.com/users/yvonnegitau/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [] | 2020-12-07T14:15:13Z | 2020-12-08T14:44:19Z | 2020-12-08T14:44:19Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1257.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1257",
"merged_at": "2020-12-08T14:44:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1257.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add Swahili news classification dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1257/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1257/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2932 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2932/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2932/comments | https://api.github.com/repos/huggingface/datasets/issues/2932/events | https://github.com/huggingface/datasets/issues/2932 | 999,317,750 | I_kwDODunzps47kGD2 | 2,932 | Conda build fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Why 1.9 ?\r\n\r\nhttps://anaconda.org/HuggingFace/datasets currently says 1.11",
"Alright I added 1.12.0 and 1.12.1 and fixed the conda build #2952 "
] | 2021-09-17T12:49:22Z | 2021-09-21T15:31:10Z | 2021-09-21T15:31:10Z | MEMBER | null | null | null | ## Describe the bug
Current `datasets` version in conda is 1.9 instead of 1.12.
The build of the conda package fails.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2932/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2932/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/477 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/477/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/477/comments | https://api.github.com/repos/huggingface/datasets/issues/477/events | https://github.com/huggingface/datasets/issues/477 | 673,142,143 | MDU6SXNzdWU2NzMxNDIxNDM= | 477 | Overview.ipynb throws exceptions with nlp 0.4.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/23109219?v=4",
"events_url": "https://api.github.com/users/mandy-li/events{/privacy}",
"followers_url": "https://api.github.com/users/mandy-li/followers",
"following_url": "https://api.github.com/users/mandy-li/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Thanks for reporting this issue\r\n\r\nThere was a bug where numpy arrays would get returned instead of tensorflow tensors.\r\nThis is fixed on master.\r\n\r\nI tried to re-run the colab and encountered this error instead:\r\n\r\n```\r\nAttributeError: 'tensorflow.python.framework.ops.EagerTensor' object has no at... | 2020-08-04T23:18:15Z | 2021-08-03T06:02:15Z | 2021-08-03T06:02:15Z | NONE | null | null | null | with nlp 0.4.0, the TensorFlow example in Overview.ipynb throws the following exceptions:
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-5-48907f2ad433> in <module>
----> 1 features = {x: trai... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/477/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/477/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5955 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5955/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5955/comments | https://api.github.com/repos/huggingface/datasets/issues/5955/events | https://github.com/huggingface/datasets/issues/5955 | 1,756,827,133 | I_kwDODunzps5otw39 | 5,955 | Strange bug in loading local JSON files, using load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/73934131?v=4",
"events_url": "https://api.github.com/users/Night-Quiet/events{/privacy}",
"followers_url": "https://api.github.com/users/Night-Quiet/followers",
"following_url": "https://api.github.com/users/Night-Quiet/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"This is the actual error:\r\n```\r\nFailed to read file '/home/lakala/hjc/code/pycode/glm/temp.json' with error <class 'pyarrow.lib.ArrowInvalid'>: cannot mix list and non-list, non-null values\r\n```\r\nWhich means some samples are incorrectly formatted.\r\n\r\nPyArrow, a storage backend that we use under the hoo... | 2023-06-14T12:46:00Z | 2023-06-21T14:42:15Z | 2023-06-21T14:42:15Z | NONE | null | null | null | ### Describe the bug
I am using 'load_dataset 'loads a JSON file, but I found a strange bug: an error will be reported when the length of the JSON file exceeds 160000 (uncertain exact number). I have checked the data through the following code and there are no issues. So I cannot determine the true reason for this err... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5955/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5955/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1374/comments | https://api.github.com/repos/huggingface/datasets/issues/1374/events | https://github.com/huggingface/datasets/pull/1374 | 760,288,291 | MDExOlB1bGxSZXF1ZXN0NTM1MTQ1Mzgw | 1,374 | Add OPUS Tilde Model Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | 2020-12-09T12:29:23Z | 2020-12-10T16:11:29Z | 2020-12-10T16:11:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1374.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1374",
"merged_at": "2020-12-10T16:11:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1374.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1374/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/3036 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3036/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3036/comments | https://api.github.com/repos/huggingface/datasets/issues/3036/events | https://github.com/huggingface/datasets/issues/3036 | 1,017,687,944 | I_kwDODunzps48qK-I | 3,036 | Protect master branch to force contributions via Pull Requests | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"It would be nice to protect the master from direct commits, but still having a way to merge our own PRs when no review is required (for example when updating a dataset_infos.json file, or minor bug fixes - things that happen quite often actually).\r\nDo you know if there's a way ?",
"you can if you're an admin o... | 2021-10-06T07:34:17Z | 2021-10-07T06:51:47Z | 2021-10-07T06:49:52Z | MEMBER | null | null | null | In order to have a clearer Git history in the master branch, I propose to protect it so that all contributions must be done through a Pull Request and no direct commits to master are allowed.
- The Pull Request allows to give context, discuss any potential issues and improve the quality of the contribution
- The Pull... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3036/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3036/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2181 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2181/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2181/comments | https://api.github.com/repos/huggingface/datasets/issues/2181/events | https://github.com/huggingface/datasets/issues/2181 | 852,261,607 | MDU6SXNzdWU4NTIyNjE2MDc= | 2,181 | Error when loading a HUGE json file (pyarrow.lib.ArrowInvalid: straddling object straddles two block boundaries) | {
"avatar_url": "https://avatars.githubusercontent.com/u/29157715?v=4",
"events_url": "https://api.github.com/users/hwijeen/events{/privacy}",
"followers_url": "https://api.github.com/users/hwijeen/followers",
"following_url": "https://api.github.com/users/hwijeen/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Hi ! Can you try to increase the block size ? For example\r\n```python\r\nblock_size_10MB = 10<<20\r\nload_dataset(\"json\", ..., block_size=block_size_10MB)\r\n```\r\nThe block size corresponds to how much bytes to process at a time from the input stream.\r\nThis will determine multi-threading granularity as well... | 2021-04-07T10:26:46Z | 2021-04-12T07:15:55Z | 2021-04-12T07:15:55Z | NONE | null | null | null | Hi, thanks for the great library. I have used the brilliant library for a couple of small projects, and now using it for a fairly big project.
When loading a huge json file of 500GB, pyarrow complains as follows:
```
Traceback (most recent call last):
File "/home/user/.pyenv/versions/3.7.9/lib/python3.7/site-pack... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2181/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2181/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/148 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/148/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/148/comments | https://api.github.com/repos/huggingface/datasets/issues/148/events | https://github.com/huggingface/datasets/issues/148 | 619,590,555 | MDU6SXNzdWU2MTk1OTA1NTU= | 148 | _download_and_prepare() got an unexpected keyword argument 'verify_infos' | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"Same error for dataset 'wiki40b'",
"Should be fixed on master :)"
] | 2020-05-17T01:48:53Z | 2020-05-18T07:38:33Z | 2020-05-18T07:38:33Z | CONTRIBUTOR | null | null | null | # Reproduce
In Colab,
```
%pip install -q nlp
%pip install -q apache_beam mwparserfromhell
dataset = nlp.load_dataset('wikipedia')
```
get
```
Downloading and preparing dataset wikipedia/20200501.aa (download: Unknown size, generated: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/w... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/148/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/148/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2368 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2368/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2368/comments | https://api.github.com/repos/huggingface/datasets/issues/2368/events | https://github.com/huggingface/datasets/pull/2368 | 893,411,076 | MDExOlB1bGxSZXF1ZXN0NjQ1OTI5NzM0 | 2,368 | Allow "other-X" in licenses | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-05-17T14:47:54Z | 2021-05-17T16:36:27Z | 2021-05-17T16:36:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2368.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2368",
"merged_at": "2021-05-17T16:36:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2368.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR allows "other-X" licenses during metadata validation.
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2368/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2368/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3086 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3086/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3086/comments | https://api.github.com/repos/huggingface/datasets/issues/3086/events | https://github.com/huggingface/datasets/pull/3086 | 1,026,481,905 | PR_kwDODunzps4tNIvp | 3,086 | Remove _resampler from Audio fields | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-10-14T14:38:50Z | 2021-10-14T15:13:41Z | 2021-10-14T15:13:40Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3086.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3086",
"merged_at": "2021-10-14T15:13:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3086.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The `_resampler` Audio attribute was implemented to optimize audio resampling, but it should not be cached.
This PR removes `_resampler` from Audio fields, so that it is not returned by `fields()` or `asdict()`.
Fix #3083. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3086/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3086/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1350/comments | https://api.github.com/repos/huggingface/datasets/issues/1350/events | https://github.com/huggingface/datasets/pull/1350 | 759,879,789 | MDExOlB1bGxSZXF1ZXN0NTM0ODA1OTY3 | 1,350 | add LeNER-Br dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"I don't know what happened, my first commit passed on all checks, but after just a README.md update one of the scripts failed, is it normal? 😕 ",
"Looks like a flaky connection error, I've launched a re-run, it should be fine :)",
"The RemoteDatasetTest error in the CI is just a connection error, we can ignor... | 2020-12-09T00:06:38Z | 2020-12-10T14:11:33Z | 2020-12-10T14:11:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1350.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1350",
"merged_at": "2020-12-10T14:11:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1350.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding the LeNER-Br dataset, a Portuguese language dataset for named entity recognition | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1350/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1350/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6147 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6147/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6147/comments | https://api.github.com/repos/huggingface/datasets/issues/6147/events | https://github.com/huggingface/datasets/issues/6147 | 1,848,914,830 | I_kwDODunzps5uNDOO | 6,147 | ValueError when running BeamBasedBuilder with GCS path in cache_dir | {
"avatar_url": "https://avatars.githubusercontent.com/u/13844767?v=4",
"events_url": "https://api.github.com/users/ktrk115/events{/privacy}",
"followers_url": "https://api.github.com/users/ktrk115/followers",
"following_url": "https://api.github.com/users/ktrk115/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"The cause of the error seems to be that `datasets` adds \"gcs://\" as a schema, while `beam` checks only \"gs://\".\r\n\r\ndatasets: https://github.com/huggingface/datasets/blob/c02a44715c036b5261686669727394b1308a3a4b/src/datasets/builder.py#L822\r\n\r\nbeam: [link](https://github.com/apache/beam/blob/25e1a64641b... | 2023-08-14T03:11:34Z | 2023-08-14T03:19:43Z | null | NONE | null | null | null | ### Describe the bug
When running the BeamBasedBuilder with a GCS path specified in the cache_dir, the following ValueError occurs:
```
ValueError: Unable to get filesystem from specified path, please use the correct path or ensure the required dependency is installed, e.g., pip install apache-beam[gcp]. Path spec... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6147/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6147/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3956 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3956/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3956/comments | https://api.github.com/repos/huggingface/datasets/issues/3956/events | https://github.com/huggingface/datasets/issues/3956 | 1,172,272,327 | I_kwDODunzps5F33TH | 3,956 | TypeError: __init__() missing 1 required positional argument: 'scheme' | {
"avatar_url": "https://avatars.githubusercontent.com/u/1645137?v=4",
"events_url": "https://api.github.com/users/amirj/events{/privacy}",
"followers_url": "https://api.github.com/users/amirj/followers",
"following_url": "https://api.github.com/users/amirj/following{/other_user}",
"gists_url": "https://api.g... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @amirj, thanks for reporting.\r\n\r\nAt first sight, your issue seems a version incompatibility between your Elasticsearch client and your Elasticsearch server.\r\n\r\nFeel free to have a look at Elasticsearch client docs: https://www.elastic.co/guide/en/elasticsearch/client/python-api/current/overview.html#_co... | 2022-03-17T11:43:13Z | 2023-11-21T04:26:20Z | 2022-03-28T08:00:01Z | NONE | null | null | null | ## Describe the bug
Based on [this tutorial](https://huggingface.co/docs/datasets/faiss_es#elasticsearch) the provided code should add Elasticsearch index but raised the following error, probably the new Elasticsearch version is not compatible though the tutorial doesn't provide any information about the supporting El... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3956/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3956/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2946 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2946/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2946/comments | https://api.github.com/repos/huggingface/datasets/issues/2946/events | https://github.com/huggingface/datasets/pull/2946 | 1,000,754,824 | PR_kwDODunzps4r89f8 | 2,946 | Update meteor score from nltk update | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-09-20T09:28:46Z | 2021-09-20T09:35:59Z | 2021-09-20T09:35:59Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2946.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2946",
"merged_at": "2021-09-20T09:35:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2946.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | It looks like there were issues in NLTK on the way the METEOR score was computed.
A fix was added in NLTK at https://github.com/nltk/nltk/pull/2763, and therefore the scoring function no longer returns the same values.
I updated the score of the example in the docs | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2946/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2946/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3480 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3480/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3480/comments | https://api.github.com/repos/huggingface/datasets/issues/3480/events | https://github.com/huggingface/datasets/issues/3480 | 1,088,267,110 | I_kwDODunzps5A3aNm | 3,480 | the compression format requested when saving a dataset in json format is not respected | {
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Thanks for reporting @SaulLu.\r\n\r\nAt first sight I think the problem is caused because `pandas` only takes into account the `compression` parameter if called with a non-null file path or buffer. And in our implementation, we call pandas `to_json` with `None` `path_or_buf`.\r\n\r\nWe should fix this:\r\n- either... | 2021-12-24T09:23:51Z | 2022-01-05T13:03:35Z | 2022-01-05T13:03:35Z | CONTRIBUTOR | null | null | null | ## Describe the bug
In the documentation of the `to_json` method, it is stated in the parameters that
> **to_json_kwargs – Parameters to pass to pandas’s pandas.DataFrame.to_json.
however when we pass for example `compression="gzip"`, the saved file is not compressed.
Would you also have expected compression t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3480/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3480/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3816 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3816/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3816/comments | https://api.github.com/repos/huggingface/datasets/issues/3816/events | https://github.com/huggingface/datasets/pull/3816 | 1,158,589,913 | PR_kwDODunzps4z5owP | 3,816 | Doc new UI test workflows2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"<img src=\"https://www.bikevillastravel.com/cms/static/images/loading.gif\" alt=\"Girl in a jacket\" width=\"50\" >"
] | 2022-03-03T15:59:14Z | 2022-10-04T09:35:53Z | 2022-03-03T16:42:15Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3816.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3816",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3816.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3816"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3816/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3816/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4511 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4511/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4511/comments | https://api.github.com/repos/huggingface/datasets/issues/4511/events | https://github.com/huggingface/datasets/pull/4511 | 1,273,336,874 | PR_kwDODunzps45w7RN | 4,511 | Support all negative values in ClassLabel | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for this fix! I'm not sure what the release timeline is, but FYI #4508 is a breaking issue for transformer token classification using Trainer and PyTorch. PyTorch defaults to -100 as the ignored label for [negative log loss](h... | 2022-06-16T09:59:39Z | 2022-07-28T16:03:27Z | 2022-06-16T13:54:07Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4511.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4511",
"merged_at": "2022-06-16T13:54:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4511.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | We usually use -1 to represent a missing label, but we should also support any negative values (some users use -100 for example). This is a regression from `datasets` 2.3
Fix https://github.com/huggingface/datasets/issues/4508 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4511/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4511/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1571/comments | https://api.github.com/repos/huggingface/datasets/issues/1571/events | https://github.com/huggingface/datasets/pull/1571 | 766,981,721 | MDExOlB1bGxSZXF1ZXN0NTM5ODM5OTEw | 1,571 | Fixing the KILT tasks to match our current standards | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-12-14T22:26:12Z | 2020-12-14T23:07:41Z | 2020-12-14T23:07:41Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1571.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1571",
"merged_at": "2020-12-14T23:07:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1571.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This introduces a few changes to the Knowledge Intensive Learning task benchmark to bring it more in line with our current datasets, including adding the (minimal) dataset card and having one config per sub-task | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1571/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1571/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5952 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5952/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5952/comments | https://api.github.com/repos/huggingface/datasets/issues/5952/events | https://github.com/huggingface/datasets/pull/5952 | 1,756,481,591 | PR_kwDODunzps5S-OIh | 5,952 | Add Arrow builder docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-06-14T09:42:46Z | 2023-06-14T14:42:31Z | 2023-06-14T14:34:39Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5952.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5952",
"merged_at": "2023-06-14T14:34:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5952.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | following https://github.com/huggingface/datasets/pull/5944 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5952/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5952/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5434 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5434/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5434/comments | https://api.github.com/repos/huggingface/datasets/issues/5434/events | https://github.com/huggingface/datasets/issues/5434 | 1,536,090,042 | I_kwDODunzps5bjt-6 | 5,434 | sample_dataset module not found | {
"avatar_url": "https://avatars.githubusercontent.com/u/15816213?v=4",
"events_url": "https://api.github.com/users/nickums/events{/privacy}",
"followers_url": "https://api.github.com/users/nickums/followers",
"following_url": "https://api.github.com/users/nickums/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Hi! Can you describe what the actual error is?",
"working on the setfit example script\r\n\r\n from setfit import SetFitModel, SetFitTrainer, sample_dataset\r\n\r\nImportError: cannot import name 'sample_dataset' from 'setfit' (C:\\Python\\Python38\\lib\\site-packages\\setfit\\__init__.py)\r\n\r\n apart from t... | 2023-01-17T09:57:54Z | 2023-01-19T13:52:12Z | 2023-01-19T07:55:11Z | NONE | null | null | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5434/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5434/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1114 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1114/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1114/comments | https://api.github.com/repos/huggingface/datasets/issues/1114/events | https://github.com/huggingface/datasets/pull/1114 | 757,123,638 | MDExOlB1bGxSZXF1ZXN0NTMyNTUyMjE1 | 1,114 | Add sesotho ner corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/7923902?v=4",
"events_url": "https://api.github.com/users/yvonnegitau/events{/privacy}",
"followers_url": "https://api.github.com/users/yvonnegitau/followers",
"following_url": "https://api.github.com/users/yvonnegitau/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [] | 2020-12-04T13:59:41Z | 2020-12-04T15:02:07Z | 2020-12-04T15:02:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1114.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1114",
"merged_at": "2020-12-04T15:02:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1114.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Clean Sesotho PR | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1114/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1114/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | https://api.github.com/repos/huggingface/datasets/issues/5362/events | https://github.com/huggingface/datasets/issues/5362 | 1,497,643,744 | I_kwDODunzps5ZRDrg | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | {
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"events_url": "https://api.github.com/users/shaoyuta/events{/privacy}",
"followers_url": "https://api.github.com/users/shaoyuta/followers",
"following_url": "https://api.github.com/users/shaoyuta/following{/other_user}",
"gists_url": "htt... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @shaoyuta.\r\n\r\nWe have checked and yes, apparently there is an issue with the server hosting the data of the \"enron_emails\" subset of \"the_pile\" dataset: http://eaidata.bmk.sh/data/enron_emails.jsonl.zst\r\nIt seems to be down: The connection has timed out.\r\n\r\nPlease note that at t... | 2022-12-15T01:23:03Z | 2022-12-15T07:45:54Z | 2022-12-15T07:45:53Z | NONE | null | null | null | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
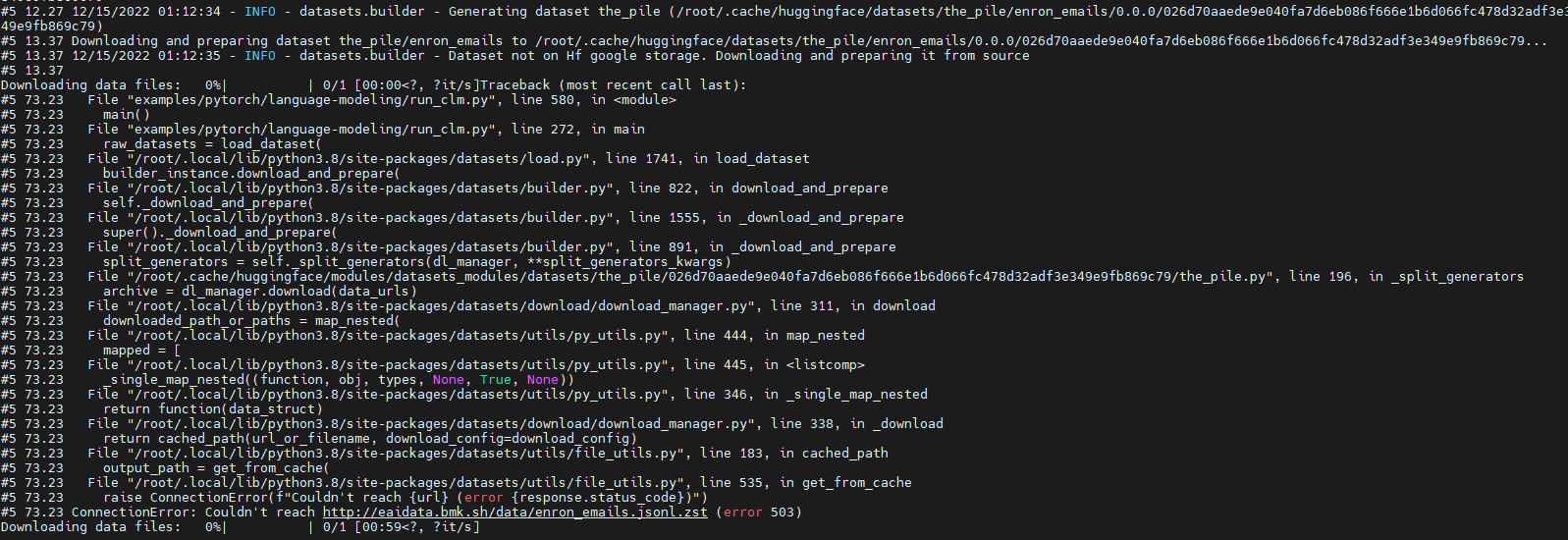
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5362/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/478 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/478/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/478/comments | https://api.github.com/repos/huggingface/datasets/issues/478/events | https://github.com/huggingface/datasets/issues/478 | 673,178,317 | MDU6SXNzdWU2NzMxNzgzMTc= | 478 | Export TFRecord to GCP bucket | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Nevermind, I restarted my python session and it worked fine...\r\n\r\n---\r\n\r\nI had an authentification error, and I authenticated from another terminal. After that, no more error but it was not working. Restarting the sessions makes it work :)"
] | 2020-08-05T01:08:32Z | 2020-08-05T01:21:37Z | 2020-08-05T01:21:36Z | NONE | null | null | null | Previously, I was writing TFRecords manually to GCP bucket with : `with tf.io.TFRecordWriter('gs://my_bucket/x.tfrecord')`
Since `0.4.0` is out with the `export()` function, I tried it. But it seems TFRecords cannot be directly written to GCP bucket.
`dataset.export('local.tfrecord')` works fine,
but `dataset.... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/478/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/478/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/828 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/828/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/828/comments | https://api.github.com/repos/huggingface/datasets/issues/828/events | https://github.com/huggingface/datasets/pull/828 | 740,008,683 | MDExOlB1bGxSZXF1ZXN0NTE4NTcwMjY3 | 828 | Add writer_batch_size attribute to GeneratorBasedBuilder | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-11-10T15:28:19Z | 2020-11-10T16:27:36Z | 2020-11-10T16:27:36Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/828.diff",
"html_url": "https://github.com/huggingface/datasets/pull/828",
"merged_at": "2020-11-10T16:27:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/828.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/828... | As specified in #741 one would need to specify a custom ArrowWriter batch size to avoid filling the RAM. Indeed the defaults buffer size is 10 000 examples but for multimodal datasets that contain images or videos we may want to reduce that. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/828/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/828/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5680/comments | https://api.github.com/repos/huggingface/datasets/issues/5680/events | https://github.com/huggingface/datasets/pull/5680 | 1,645,430,103 | PR_kwDODunzps5NJYNz | 5,680 | Fix a description error for interleave_datasets. | {
"avatar_url": "https://avatars.githubusercontent.com/u/55624066?v=4",
"events_url": "https://api.github.com/users/QizhiPei/events{/privacy}",
"followers_url": "https://api.github.com/users/QizhiPei/followers",
"following_url": "https://api.github.com/users/QizhiPei/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_a... | 2023-03-29T09:50:23Z | 2023-03-30T13:14:19Z | 2023-03-30T13:07:18Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5680.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5680",
"merged_at": "2023-03-30T13:07:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5680.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | There is a description mistake in the annotation of interleave_dataset with "all_exhausted" stopping_strategy.
``` python
d1 = Dataset.from_dict({"a": [0, 1, 2]})
d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
d3 = Dataset.from_dict({"a": [20, 21, 22, 23, 24]})
dataset = interleave_datasets([d1, d2, d3], stopping... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5680/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5680/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3916/comments | https://api.github.com/repos/huggingface/datasets/issues/3916/events | https://github.com/huggingface/datasets/pull/3916 | 1,168,869,191 | PR_kwDODunzps40a-cR | 3,916 | Create README.md for GLUE | {
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3916). All of your documentation changes will be reflected on that endpoint."
] | 2022-03-14T20:27:22Z | 2022-03-15T17:06:57Z | 2022-03-15T17:06:56Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3916.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3916",
"merged_at": "2022-03-15T17:06:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3916.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I still have a hesitation regarding the format of inputs -- whether it's a list or a list of lists? -- hopefully @lhoestq will be able to clarify.
Also tagging @yjernite for the Limitations section. Happy to hear your thoughts! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3916/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/93 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/93/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/93/comments | https://api.github.com/repos/huggingface/datasets/issues/93/events | https://github.com/huggingface/datasets/pull/93 | 617,522,029 | MDExOlB1bGxSZXF1ZXN0NDE3NDIxODUy | 93 | Cleanup notebooks and various fixes | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-05-13T14:58:58Z | 2020-05-13T15:01:48Z | 2020-05-13T15:01:47Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/93.diff",
"html_url": "https://github.com/huggingface/datasets/pull/93",
"merged_at": "2020-05-13T15:01:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/93.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/93"
} | Fixes on dataset (more flexible) metrics (fix) and general clean ups | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/93/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/93/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2150 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2150/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2150/comments | https://api.github.com/repos/huggingface/datasets/issues/2150/events | https://github.com/huggingface/datasets/pull/2150 | 844,776,448 | MDExOlB1bGxSZXF1ZXN0NjAzOTg3OTcx | 2,150 | Allow pickling of big in-memory tables | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-03-30T15:51:56Z | 2021-03-31T10:37:15Z | 2021-03-31T10:37:14Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2150.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2150",
"merged_at": "2021-03-31T10:37:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2150.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This should fix issue #2134
Pickling is limited to <4GiB objects, it's not possible to pickle a big arrow table (for multiprocessing for example).
For big tables, we have to write them on disk and only pickle the path to the table. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2150/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2150/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6493 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6493/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6493/comments | https://api.github.com/repos/huggingface/datasets/issues/6493/events | https://github.com/huggingface/datasets/pull/6493 | 2,038,221,490 | PR_kwDODunzps5h0XJK | 6,493 | Lazy data files resolution and offline cache reload | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6493). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"> Naive question: is there any breaking change when loading?\r\n\r\nNo breaking changes... | 2023-12-12T17:15:17Z | 2023-12-15T18:16:18Z | null | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6493.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6493",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6493.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6493"
} | Includes both https://github.com/huggingface/datasets/pull/6458 and https://github.com/huggingface/datasets/pull/6459
This PR should be merged instead of the two individually, since they are conflicting
## Offline cache reload
it can reload datasets that were pushed to hub if they exist in the cache.
examp... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6493/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6493/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4680/comments | https://api.github.com/repos/huggingface/datasets/issues/4680/events | https://github.com/huggingface/datasets/issues/4680 | 1,304,534,770 | I_kwDODunzps5NwZ7y | 4,680 | Dataset Viewer issue for codeparrot/xlcost-text-to-code | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"There seems to be an issue with the `C++-snippet-level` config:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"codeparrot/xlcost-text-to-code\", \"C++-snippet-level\")\r\nTraceback (most recent call last):\r\n File \"/home/slesage/hf/datasets-server/services/... | 2022-07-14T09:45:50Z | 2022-07-18T16:37:00Z | 2022-07-18T16:04:36Z | NONE | null | null | null | ### Link
https://huggingface.co/datasets/codeparrot/xlcost-text-to-code
### Description
Error
```
Server Error
Status code: 400
Exception: TypeError
Message: 'NoneType' object is not iterable
```
Before I did a minor change in the dataset script (removing some comments), the viewer was working but... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4680/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4680/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5091 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5091/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5091/comments | https://api.github.com/repos/huggingface/datasets/issues/5091/events | https://github.com/huggingface/datasets/pull/5091 | 1,401,112,552 | PR_kwDODunzps5AZCm9 | 5,091 | Allow connection objects in `from_sql` + small doc improvement | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-07T12:39:44Z | 2022-10-09T13:19:15Z | 2022-10-09T13:16:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5091.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5091",
"merged_at": "2022-10-09T13:16:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5091.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Allow connection objects in `from_sql` (emit a warning that they are cachable) and add a tip that explains the format of the con parameter when provided as a URI string.
PS: ~~This PR contains a parameter link, so https://github.com/huggingface/doc-builder/pull/311 needs to be merged before it's "ready for review".~... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5091/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5091/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1562/comments | https://api.github.com/repos/huggingface/datasets/issues/1562/events | https://github.com/huggingface/datasets/pull/1562 | 765,981,749 | MDExOlB1bGxSZXF1ZXN0NTM5MTc5ODc3 | 1,562 | Add dataset COrpus of Urdu News TExt Reuse (COUNTER). | {
"avatar_url": "https://avatars.githubusercontent.com/u/14899066?v=4",
"events_url": "https://api.github.com/users/arkhalid/events{/privacy}",
"followers_url": "https://api.github.com/users/arkhalid/followers",
"following_url": "https://api.github.com/users/arkhalid/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Just a small revision from simon's review: 20KB for the dummy_data.zip is fine, you can keep them this way.",
"Also the CI is failing because of an error `tests/test_file_utils.py::TempSeedTest::test_tensorflow` that is not related to your dataset and is fixed on master. You can ignore it",
"merging since the ... | 2020-12-14T06:32:48Z | 2020-12-21T13:14:46Z | 2020-12-21T13:14:46Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1562.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1562",
"merged_at": "2020-12-21T13:14:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1562.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1562/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/2110 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2110/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2110/comments | https://api.github.com/repos/huggingface/datasets/issues/2110/events | https://github.com/huggingface/datasets/pull/2110 | 840,794,995 | MDExOlB1bGxSZXF1ZXN0NjAwNjI1NDQ5 | 2,110 | Fix incorrect assertion in builder.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/2340721?v=4",
"events_url": "https://api.github.com/users/dreamgonfly/events{/privacy}",
"followers_url": "https://api.github.com/users/dreamgonfly/followers",
"following_url": "https://api.github.com/users/dreamgonfly/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [
"Hi ! The SplitInfo is not always available. By default you would get `split_info.num_examples == 0`\r\nSo unfortunately we can't use this assertion you suggested",
"> Hi ! The SplitInfo is not always available. By default you would get `split_info.num_examples == 0`\r\n> So unfortunately we can't use this assert... | 2021-03-25T10:39:20Z | 2021-04-12T13:33:03Z | 2021-04-12T13:33:03Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2110.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2110",
"merged_at": "2021-04-12T13:33:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2110.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix incorrect num_examples comparison assertion in builder.py | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2110/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2110/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/49 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/49/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/49/comments | https://api.github.com/repos/huggingface/datasets/issues/49/events | https://github.com/huggingface/datasets/pull/49 | 612,545,483 | MDExOlB1bGxSZXF1ZXN0NDEzNDY5ODg0 | 49 | fix flatten nested | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-05-05T11:55:13Z | 2020-05-05T13:59:26Z | 2020-05-05T13:59:25Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/49.diff",
"html_url": "https://github.com/huggingface/datasets/pull/49",
"merged_at": "2020-05-05T13:59:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/49.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/49"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/49/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/49/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/74 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/74/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/74/comments | https://api.github.com/repos/huggingface/datasets/issues/74/events | https://github.com/huggingface/datasets/pull/74 | 616,511,101 | MDExOlB1bGxSZXF1ZXN0NDE2NjA3MDcy | 74 | fix overflow check | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-05-12T09:38:01Z | 2020-05-12T10:04:39Z | 2020-05-12T10:04:38Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/74.diff",
"html_url": "https://github.com/huggingface/datasets/pull/74",
"merged_at": "2020-05-12T10:04:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/74.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/74"
} | I did some tests and unfortunately the test
```
pa_array.nbytes > MAX_BATCH_BYTES
```
doesn't work. Indeed for a StructArray, `nbytes` can be less 2GB even if there is an overflow (it loops...).
I don't think we can do a proper overflow test for the limit of 2GB...
For now I replaced it with a sanity check on... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/74/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/74/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3020/comments | https://api.github.com/repos/huggingface/datasets/issues/3020/events | https://github.com/huggingface/datasets/pull/3020 | 1,015,406,105 | PR_kwDODunzps4sprfa | 3,020 | Add a metric for the MATH dataset (competition_math). | {
"avatar_url": "https://avatars.githubusercontent.com/u/91226467?v=4",
"events_url": "https://api.github.com/users/hacobe/events{/privacy}",
"followers_url": "https://api.github.com/users/hacobe/followers",
"following_url": "https://api.github.com/users/hacobe/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"I believe the only failed test related to this PR is tests/test_metric_common.py::LocalMetricTest::test_load_metric_competition_math. It gives the following error:\r\n\r\nImportError: To be able to use this dataset, you need to install the following dependencies['math_equivalence'] using 'pip install git+https://g... | 2021-10-04T16:52:16Z | 2021-10-22T10:29:31Z | 2021-10-22T10:29:31Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3020.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3020",
"merged_at": "2021-10-22T10:29:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3020.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This metric computes accuracy for the MATH dataset (https://arxiv.org/abs/2103.03874) after canonicalizing the prediction and the reference (e.g., converting "1/2" to "\\\\frac{1}{2}"). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3020/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2067 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2067/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2067/comments | https://api.github.com/repos/huggingface/datasets/issues/2067/events | https://github.com/huggingface/datasets/issues/2067 | 833,559,940 | MDU6SXNzdWU4MzM1NTk5NDA= | 2,067 | Multiprocessing windows error | {
"avatar_url": "https://avatars.githubusercontent.com/u/47894090?v=4",
"events_url": "https://api.github.com/users/flozi00/events{/privacy}",
"followers_url": "https://api.github.com/users/flozi00/followers",
"following_url": "https://api.github.com/users/flozi00/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Hi ! Thanks for reporting.\r\nThis looks like a bug, could you try to provide a minimal code example that reproduces the issue ? This would be very helpful !\r\n\r\nOtherwise I can try to run the wav2vec2 code above on my side but probably not this week..",
"```\r\nfrom datasets import load_dataset\r\n\r\ndatase... | 2021-03-17T09:12:28Z | 2021-08-04T17:59:08Z | 2021-08-04T17:59:08Z | CONTRIBUTOR | null | null | null | As described here https://huggingface.co/blog/fine-tune-xlsr-wav2vec2
When using the num_proc argument on windows the whole Python environment crashes and hanging in loop.
For example at the map_to_array part.
An error occures because the cache file already exists and windows throws and error. After this the log c... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2067/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2067/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3549 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3549/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3549/comments | https://api.github.com/repos/huggingface/datasets/issues/3549/events | https://github.com/huggingface/datasets/pull/3549 | 1,096,426,996 | PR_kwDODunzps4wqkGt | 3,549 | Fix sem_eval_2018_task_1 download location | {
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"events_url": "https://api.github.com/users/maxpel/events{/privacy}",
"followers_url": "https://api.github.com/users/maxpel/followers",
"following_url": "https://api.github.com/users/maxpel/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Hi ! Thanks for pushing this :)\r\n\r\nIt seems that you created this PR from an old version of `datasets` that didn't have the sem_eval_2018_task_1.py file.\r\n\r\nCan you try merging `master` into your branch ? Or re-create your PR from a branch that comes from a more recent version of `datasets` ?\r\n\r\nAnd so... | 2022-01-07T15:37:52Z | 2022-01-27T15:52:03Z | 2022-01-27T15:52:03Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3549.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3549",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3549.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3549"
} | This changes the download location of sem_eval_2018_task_1 files to include the test set labels as discussed in https://github.com/huggingface/datasets/issues/2745#issuecomment-954588500_ with @lhoestq. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3549/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3549/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2881 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2881/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2881/comments | https://api.github.com/repos/huggingface/datasets/issues/2881/events | https://github.com/huggingface/datasets/pull/2881 | 991,639,142 | MDExOlB1bGxSZXF1ZXN0NzMwMDc1OTAy | 2,881 | Add BIOSSES dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/6764450?v=4",
"events_url": "https://api.github.com/users/bwang482/events{/privacy}",
"followers_url": "https://api.github.com/users/bwang482/followers",
"following_url": "https://api.github.com/users/bwang482/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2021-09-09T00:35:36Z | 2021-09-13T14:20:40Z | 2021-09-13T14:20:40Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2881.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2881",
"merged_at": "2021-09-13T14:20:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2881.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding the biomedical semantic sentence similarity dataset, BIOSSES, listed in "Biomedical Datasets - BigScience Workshop 2021" | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2881/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2881/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2445 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2445/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2445/comments | https://api.github.com/repos/huggingface/datasets/issues/2445/events | https://github.com/huggingface/datasets/pull/2445 | 911,577,578 | MDExOlB1bGxSZXF1ZXN0NjYxODMzMTky | 2,445 | Fix broken URLs for bn_hate_speech and covid_tweets_japanese | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Thanks ! To fix the CI you just have to rename the dummy data file in the dummy_data.zip files",
"thanks for the tip with the dummy data - all fixed now!"
] | 2021-06-04T14:53:35Z | 2021-06-04T17:39:46Z | 2021-06-04T17:39:45Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2445.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2445",
"merged_at": "2021-06-04T17:39:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2445.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Closes #2388 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2445/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2445/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1188 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1188/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1188/comments | https://api.github.com/repos/huggingface/datasets/issues/1188/events | https://github.com/huggingface/datasets/pull/1188 | 757,827,407 | MDExOlB1bGxSZXF1ZXN0NTMzMTI2MTcw | 1,188 | adding hind_encorp dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/56379013?v=4",
"events_url": "https://api.github.com/users/rahul-art/events{/privacy}",
"followers_url": "https://api.github.com/users/rahul-art/followers",
"following_url": "https://api.github.com/users/rahul-art/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"help needed in dummy data",
"extension of the file is .plaintext so dummy data generation is failing\r\n",
"you can add the `--match_text_file \"*.plaintext\"` flag when generating the dummy data\r\n\r\nalso it looks like the PR is empty, is this expected ?",
"yes it is expected because I made all my change... | 2020-12-06T02:18:45Z | 2020-12-11T17:40:41Z | 2020-12-11T17:40:41Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1188.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1188",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1188.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1188"
} | adding Hindi_Encorp05 dataset | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1188/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1188/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1215 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1215/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1215/comments | https://api.github.com/repos/huggingface/datasets/issues/1215/events | https://github.com/huggingface/datasets/pull/1215 | 758,002,885 | MDExOlB1bGxSZXF1ZXN0NTMzMjUyNjUx | 1,215 | Add irc disentanglement | {
"avatar_url": "https://avatars.githubusercontent.com/u/32560035?v=4",
"events_url": "https://api.github.com/users/dhruvjoshi1998/events{/privacy}",
"followers_url": "https://api.github.com/users/dhruvjoshi1998/followers",
"following_url": "https://api.github.com/users/dhruvjoshi1998/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"looks like this PR includes changes about many files other than the ones for irc_disentanglement\r\n\r\nCould you please create a new branch and create another PR please ?",
"closing in favor of #1586 "
] | 2020-12-06T19:30:46Z | 2020-12-16T16:18:25Z | 2020-12-16T16:18:25Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1215.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1215",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1215.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1215"
} | added files for irc disentanglement dataset
was unable to test dummy data as a result of vpn/proxy issues | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1215/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1215/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/649/comments | https://api.github.com/repos/huggingface/datasets/issues/649/events | https://github.com/huggingface/datasets/issues/649 | 704,838,415 | MDU6SXNzdWU3MDQ4Mzg0MTU= | 649 | Inconsistent behavior in map | {
"avatar_url": "https://avatars.githubusercontent.com/u/10166085?v=4",
"events_url": "https://api.github.com/users/krandiash/events{/privacy}",
"followers_url": "https://api.github.com/users/krandiash/followers",
"following_url": "https://api.github.com/users/krandiash/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Thanks for reporting !\r\n\r\nThis issue must have appeared when we refactored type inference in `nlp`\r\nBy default the library tries to keep the same feature types when applying `map` but apparently it has troubles with nested structures. I'll try to fix that next week"
] | 2020-09-19T08:41:12Z | 2020-09-21T16:13:05Z | 2020-09-21T16:13:05Z | NONE | null | null | null | I'm observing inconsistent behavior when applying .map(). This happens specifically when I'm incrementally adding onto a feature that is a nested dictionary. Here's a simple example that reproduces the problem.
```python
import datasets
# Dataset with a single feature called 'field' consisting of two examples
d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/649/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/649/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1349/comments | https://api.github.com/repos/huggingface/datasets/issues/1349/events | https://github.com/huggingface/datasets/pull/1349 | 759,870,664 | MDExOlB1bGxSZXF1ZXN0NTM0Nzk4NDQ3 | 1,349 | initial commit for MultiReQA | {
"avatar_url": "https://avatars.githubusercontent.com/u/13200370?v=4",
"events_url": "https://api.github.com/users/Karthik-Bhaskar/events{/privacy}",
"followers_url": "https://api.github.com/users/Karthik-Bhaskar/followers",
"following_url": "https://api.github.com/users/Karthik-Bhaskar/following{/other_user}"... | [] | closed | false | null | [] | null | [
"looks like this dataset includes changes about many other files than the ones for multi_re_qa\r\n\r\nCan you create another branch and another PR please ?",
"> looks like this dataset includes changes about many other files than the ones for multi_re_qa\r\n> \r\n> Can you create another branch and another PR ple... | 2020-12-08T23:44:34Z | 2020-12-09T16:46:37Z | 2020-12-09T16:46:37Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1349",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1349"
} | Added MultiReQA, which is a dataset containing the sentence boundary annotation from eight publicly available QA datasets including SearchQA, TriviaQA, HotpotQA, NaturalQuestions, SQuAD, BioASQ, RelationExtraction, and TextbookQA. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1349/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1349/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1182 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1182/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1182/comments | https://api.github.com/repos/huggingface/datasets/issues/1182/events | https://github.com/huggingface/datasets/pull/1182 | 757,804,877 | MDExOlB1bGxSZXF1ZXN0NTMzMTA5Nzgx | 1,182 | ADD COVID-QA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4341867?v=4",
"events_url": "https://api.github.com/users/olinguyen/events{/privacy}",
"followers_url": "https://api.github.com/users/olinguyen/followers",
"following_url": "https://api.github.com/users/olinguyen/following{/other_user}",
"gists_url": "h... | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master",
"Wow, thanks for including this dataset from my side as well!"
] | 2020-12-05T23:31:56Z | 2020-12-28T13:23:14Z | 2020-12-07T14:23:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1182.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1182",
"merged_at": "2020-12-07T14:23:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1182.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds the COVID-QA dataset, a question answering dataset consisting of 2,019 question/answer pairs annotated by volunteer biomedical experts on scientific articles related to COVID-19
Link to the paper: https://openreview.net/forum?id=JENSKEEzsoU
Link to the dataset/repo: https://github.com/deepset-ai/COVID-... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1182/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1182/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3264/comments | https://api.github.com/repos/huggingface/datasets/issues/3264/events | https://github.com/huggingface/datasets/issues/3264 | 1,052,663,513 | I_kwDODunzps4-vl7Z | 3,264 | Downloading URL change for WikiAuto Manual, jeopardy and definite_pronoun_resolution | {
"avatar_url": "https://avatars.githubusercontent.com/u/22296717?v=4",
"events_url": "https://api.github.com/users/slyviacassell/events{/privacy}",
"followers_url": "https://api.github.com/users/slyviacassell/followers",
"following_url": "https://api.github.com/users/slyviacassell/following{/other_user}",
"g... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"#take\r\nI am willing to fix this. Links can be replaced for WikiAuto Manual and jeopardy with new ones provided by authors.\r\n\r\nAs for the definite_pronoun_resolution URL, a certificate error seems to be preventing a download. I have the files on my local machine. I can include them in the dataset folder as th... | 2021-11-13T11:47:12Z | 2022-06-01T17:38:16Z | 2022-06-01T17:38:16Z | NONE | null | null | null | ## Describe the bug
- WikiAuto Manual
The original manual datasets with the following downloading URL in this [repository](https://github.com/chaojiang06/wiki-auto) was [deleted](https://github.com/chaojiang06/wiki-auto/commit/0af9b066f2b4e02726fb8a9be49283c0ad25367f) by the author.
```
https://github.com/chaoj... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3264/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3264/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2347 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2347/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2347/comments | https://api.github.com/repos/huggingface/datasets/issues/2347/events | https://github.com/huggingface/datasets/issues/2347 | 887,404,868 | MDU6SXNzdWU4ODc0MDQ4Njg= | 2,347 | Add an API to access the language and pretty name of a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi ! With @bhavitvyamalik we discussed about having something like\r\n```python\r\nfrom datasets import load_dataset_card\r\n\r\ndataset_card = load_dataset_card(\"squad\")\r\nprint(dataset_card.metadata.pretty_name)\r\n# Stanford Question Answering Dataset (SQuAD)\r\nprint(dataset_card.metadata.languages)\r\n# [\... | 2021-05-11T14:10:08Z | 2022-10-05T17:16:54Z | 2022-10-05T17:16:53Z | CONTRIBUTOR | null | null | null | It would be super nice to have an API to get some metadata of the dataset from the name and args passed to `load_dataset`. This way we could programmatically infer the language and the name of a dataset when creating model cards automatically in the Transformers examples scripts. | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2347/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2347/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4566/comments | https://api.github.com/repos/huggingface/datasets/issues/4566/events | https://github.com/huggingface/datasets/issues/4566 | 1,284,397,594 | I_kwDODunzps5Mjloa | 4,566 | Document link #load_dataset_enhancing_performance points to nowhere | {
"avatar_url": "https://avatars.githubusercontent.com/u/11674033?v=4",
"events_url": "https://api.github.com/users/subercui/events{/privacy}",
"followers_url": "https://api.github.com/users/subercui/followers",
"following_url": "https://api.github.com/users/subercui/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! This is indeed the link the docstring should point to. Are you interested in submitting a PR to fix this?",
"https://github.com/huggingface/datasets/blame/master/docs/source/cache.mdx#L93\r\n\r\nThere seems already an anchor here. Somehow it doesn't work. I am not very familiar with how this online documenta... | 2022-06-25T01:18:19Z | 2023-01-24T16:33:40Z | 2023-01-24T16:33:40Z | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.

The [load_dataset_enhancing_performance](https://huggingface.co/docs/datasets/v2.3.2/en/package_reference/main_classes#load_dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4566/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4566/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5780 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5780/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5780/comments | https://api.github.com/repos/huggingface/datasets/issues/5780/events | https://github.com/huggingface/datasets/issues/5780 | 1,679,367,149 | I_kwDODunzps5kGRvt | 5,780 | TypeError: 'NoneType' object does not support item assignment | {
"avatar_url": "https://avatars.githubusercontent.com/u/38179632?v=4",
"events_url": "https://api.github.com/users/v-yunbin/events{/privacy}",
"followers_url": "https://api.github.com/users/v-yunbin/followers",
"following_url": "https://api.github.com/users/v-yunbin/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2023-04-22T06:22:43Z | 2023-04-23T08:49:18Z | 2023-04-23T08:49:18Z | NONE | null | null | null | command:
```
def load_datasets(formats, data_dir=datadir, data_files=datafile):
dataset = load_dataset(formats, data_dir=datadir, data_files=datafile, split=split, streaming=True, **kwargs)
return dataset
raw_datasets = DatasetDict()
raw_datasets["train"] = load_datasets(“csv”, args.datadir, "train.csv", s... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5780/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5780/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6274/comments | https://api.github.com/repos/huggingface/datasets/issues/6274/events | https://github.com/huggingface/datasets/issues/6274 | 1,921,036,328 | I_kwDODunzps5ygLAo | 6,274 | FileNotFoundError for dataset with multiple builder config | {
"avatar_url": "https://avatars.githubusercontent.com/u/97120485?v=4",
"events_url": "https://api.github.com/users/LouisChen15/events{/privacy}",
"followers_url": "https://api.github.com/users/LouisChen15/followers",
"following_url": "https://api.github.com/users/LouisChen15/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Please tell me if the above info is not enough for solving the problem. I will then make my dataset public temporarily so that you can really reproduce the bug. "
] | 2023-10-01T23:45:56Z | 2023-10-02T20:09:38Z | 2023-10-02T20:09:38Z | NONE | null | null | null | ### Describe the bug
When there is only one config and only the dataset name is entered when using datasets.load_dataset(), it works fine. But if I create a second builder_config for my dataset and enter the config name when using datasets.load_dataset(), the following error will happen.
FileNotFoundError: [Errno 2... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6274/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4244 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4244/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4244/comments | https://api.github.com/repos/huggingface/datasets/issues/4244/events | https://github.com/huggingface/datasets/pull/4244 | 1,217,732,221 | PR_kwDODunzps425Po6 | 4,244 | task id update | {
"avatar_url": "https://avatars.githubusercontent.com/u/3278583?v=4",
"events_url": "https://api.github.com/users/nazneenrajani/events{/privacy}",
"followers_url": "https://api.github.com/users/nazneenrajani/followers",
"following_url": "https://api.github.com/users/nazneenrajani/following{/other_user}",
"gi... | [] | closed | false | null | [] | null | [
"Reverted the multi-input-text-classification tag from task_categories and added it as task_ids @lhoestq ",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-04-27T18:28:14Z | 2022-05-04T10:43:53Z | 2022-05-04T10:36:37Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4244.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4244",
"merged_at": "2022-05-04T10:36:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4244.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | changed multi input text classification as task id instead of category | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4244/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4244/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3423 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3423/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3423/comments | https://api.github.com/repos/huggingface/datasets/issues/3423/events | https://github.com/huggingface/datasets/issues/3423 | 1,078,049,638 | I_kwDODunzps5AQbtm | 3,423 | data duplicate when setting num_works > 1 with streaming data | {
"avatar_url": "https://avatars.githubusercontent.com/u/16486492?v=4",
"events_url": "https://api.github.com/users/cloudyuyuyu/events{/privacy}",
"followers_url": "https://api.github.com/users/cloudyuyuyu/followers",
"following_url": "https://api.github.com/users/cloudyuyuyu/following{/other_user}",
"gists_u... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "fef2c0",
"default": false,
"descrip... | closed | false | null | [] | null | [
"Hi ! Thanks for reporting :)\r\n\r\nWhen using a PyTorch's data loader with `num_workers>1` and an iterable dataset, each worker streams the exact same data by default, resulting in duplicate data when iterating using the data loader.\r\n\r\nWe can probably fix this in `datasets` by checking `torch.utils.data.get_... | 2021-12-13T03:43:17Z | 2022-12-14T16:04:22Z | 2022-12-14T16:04:22Z | NONE | null | null | null | ## Describe the bug
The data is repeated num_works times when we load_dataset with streaming and set num_works > 1 when construct dataloader
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import pandas as pd
import numpy as np
import os
from datasets import load_dataset
from tor... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3423/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3423/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2048 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2048/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2048/comments | https://api.github.com/repos/huggingface/datasets/issues/2048/events | https://github.com/huggingface/datasets/issues/2048 | 830,953,431 | MDU6SXNzdWU4MzA5NTM0MzE= | 2,048 | github is not always available - probably need a back up | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [] | 2021-03-13T18:03:32Z | 2022-04-01T15:27:10Z | 2022-04-01T15:27:10Z | CONTRIBUTOR | null | null | null | Yesterday morning github wasn't working:
```
:/tmp$ wget https://raw.githubusercontent.com/huggingface/datasets/1.4.1/metrics/sacrebleu/sacrebleu.py--2021-03-12 18:35:59-- https://raw.githubusercontent.com/huggingface/datasets/1.4.1/metrics/sacrebleu/sacrebleu.py
Resolving raw.githubusercontent.com (raw.githubuser... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2048/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2048/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2799 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2799/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2799/comments | https://api.github.com/repos/huggingface/datasets/issues/2799/events | https://github.com/huggingface/datasets/issues/2799 | 970,507,351 | MDU6SXNzdWU5NzA1MDczNTE= | 2,799 | Loading JSON throws ArrowNotImplementedError | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @lewtun, thanks for reporting.\r\n\r\nApparently, `pyarrow.json` tries to cast timestamp-like fields in your JSON file to pyarrow timestamp type, and it fails with `ArrowNotImplementedError`.\r\n\r\nI will investigate if there is a way to tell pyarrow not to try that timestamp casting.",
"I think the issue is... | 2021-08-13T15:31:48Z | 2022-01-10T18:59:32Z | 2022-01-10T18:59:32Z | MEMBER | null | null | null | ## Describe the bug
I have created a [dataset](https://huggingface.co/datasets/lewtun/github-issues-test) of GitHub issues in line-separated JSON format and am finding that I cannot load it with the `json` loading script (see stack trace below).
Curiously, there is no problem loading the dataset with `pandas` which... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2799/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2799/timeline | null | completed | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.