
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 600M 2.05B | node_id stringlengths 18 32 | number int64 2 6.51k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association stringclasses 3
values | active_lock_reason float64 | draft float64 0 1 ⌀ | pull_request dict | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4963 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4963/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4963/comments | https://api.github.com/repos/huggingface/datasets/issues/4963/events | https://github.com/huggingface/datasets/issues/4963 | 1,368,201,188 | I_kwDODunzps5RjRfk | 4,963 | Dataset without script does not support regular JSON data file | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"Hi @julien-c,\r\n\r\nOut of the box, we only support JSON lines (NDJSON) data files, but your data file is a regular JSON file. The reason is we use `pyarrow.json.read_json` and this only supports line-delimited JSON. "
] | 2022-09-09T18:45:33Z | 2022-09-20T15:40:07Z | 2022-09-20T15:40:07Z | MEMBER | null | null | null | ### Link
https://huggingface.co/datasets/julien-c/label-studio-my-dogs
### Description
<img width="1115" alt="image" src="https://user-images.githubusercontent.com/326577/189422048-7e9c390f-bea7-4521-a232-43f049ccbd1f.png">
### Owner
Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4963/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4963/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5492 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5492/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5492/comments | https://api.github.com/repos/huggingface/datasets/issues/5492/events | https://github.com/huggingface/datasets/issues/5492 | 1,566,604,216 | I_kwDODunzps5dYHu4 | 5,492 | Push_to_hub in a pull request | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists... | null | [
"Assigned to myself and will get to it in the next week, but if someone finds this issue annoying and wants to submit a PR before I do, just ping me here and I'll reassign :). ",
"I would like to be assigned to this issue, @nateraw . #self-assign"
] | 2023-02-01T18:32:14Z | 2023-10-16T13:30:48Z | 2023-10-16T13:30:48Z | MEMBER | null | null | null | Right now `ds.push_to_hub()` can push a dataset on `main` or on a new branch with `branch=`, but there is no way to open a pull request. Even passing `branch=refs/pr/x` doesn't seem to work: it tries to create a branch with that name
cc @nateraw
It should be possible to tweak the use of `huggingface_hub` in `pus... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5492/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5492/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5577/comments | https://api.github.com/repos/huggingface/datasets/issues/5577/events | https://github.com/huggingface/datasets/issues/5577 | 1,598,587,665 | I_kwDODunzps5fSIMR | 5,577 | Cannot load `the_pile_openwebtext2` | {
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"events_url": "https://api.github.com/users/wjfwzzc/events{/privacy}",
"followers_url": "https://api.github.com/users/wjfwzzc/followers",
"following_url": "https://api.github.com/users/wjfwzzc/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Hi! I've merged a PR to use `int32` instead of `int8` for `reddit_scores`, so it should work now.\r\n\r\n"
] | 2023-02-24T13:01:48Z | 2023-02-24T14:01:09Z | 2023-02-24T14:01:09Z | NONE | null | null | null | ### Describe the bug
I met the same bug mentioned in #3053 which is never fixed. Because several `reddit_scores` are larger than `int8` even `int16`. https://huggingface.co/datasets/the_pile_openwebtext2/blob/main/the_pile_openwebtext2.py#L62
### Steps to reproduce the bug
```python3
from datasets import load... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5577/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5577/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4625/comments | https://api.github.com/repos/huggingface/datasets/issues/4625/events | https://github.com/huggingface/datasets/pull/4625 | 1,293,163,744 | PR_kwDODunzps46zELz | 4,625 | Unpack `dl_manager.iter_files` to allow parallization | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool thanks ! Yup it sounds like the right solution.\r\n\r\nIt looks like `_generate_tables` needs to be updated as well to fix the CI"
] | 2022-07-04T13:16:58Z | 2022-07-05T11:11:54Z | 2022-07-05T11:00:48Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4625.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4625",
"merged_at": "2022-07-05T11:00:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4625.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Iterate over data files outside `dl_manager.iter_files` to allow parallelization in streaming mode.
(The issue reported [here](https://discuss.huggingface.co/t/dataset-only-have-n-shard-1-when-has-multiple-shards-in-repo/19887))
PS: Another option would be to override `FilesIterable.__getitem__` to make it indexa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4625/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6016 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6016/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6016/comments | https://api.github.com/repos/huggingface/datasets/issues/6016/events | https://github.com/huggingface/datasets/pull/6016 | 1,798,968,033 | PR_kwDODunzps5VNEvn | 6,016 | Dataset string representation enhancement | {
"avatar_url": "https://avatars.githubusercontent.com/u/63643948?v=4",
"events_url": "https://api.github.com/users/Ganryuu/events{/privacy}",
"followers_url": "https://api.github.com/users/Ganryuu/followers",
"following_url": "https://api.github.com/users/Ganryuu/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6016). All of your documentation changes will be reflected on that endpoint.",
"It we could have something similar to Polars, that would be great.\r\n\r\nThis is what Polars outputs: \r\n* `__repr__`/`__str__` :\r\n```\r\nshape... | 2023-07-11T13:38:25Z | 2023-07-16T10:26:18Z | null | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6016.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6016",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6016.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6016"
} | my attempt at #6010
not sure if this is the right way to go about it, I will wait for your feedback | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6016/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6016/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2734/comments | https://api.github.com/repos/huggingface/datasets/issues/2734/events | https://github.com/huggingface/datasets/pull/2734 | 956,844,874 | MDExOlB1bGxSZXF1ZXN0NzAwMzc4NjI4 | 2,734 | Update BibTeX entry | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-07-30T15:22:51Z | 2021-07-30T15:47:58Z | 2021-07-30T15:47:58Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2734.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2734",
"merged_at": "2021-07-30T15:47:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2734.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Update BibTeX entry. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2734/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2734/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1506 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1506/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1506/comments | https://api.github.com/repos/huggingface/datasets/issues/1506/events | https://github.com/huggingface/datasets/pull/1506 | 763,846,074 | MDExOlB1bGxSZXF1ZXN0NTM4MTc1ODEz | 1,506 | Add nq_open question answering dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/28673745?v=4",
"events_url": "https://api.github.com/users/Nilanshrajput/events{/privacy}",
"followers_url": "https://api.github.com/users/Nilanshrajput/followers",
"following_url": "https://api.github.com/users/Nilanshrajput/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"@SBrandeis thanks for the review, I applied your suggested changes, but CI is failing now not sure about the error.",
"Many thanks @Nilanshrajput !\r\nThe failing tests on CI are not related to your changes, merging master on your branch should fix them :)\r\nIf you're interested in what causes the CI to fail,... | 2020-12-12T13:46:48Z | 2020-12-17T15:34:50Z | 2020-12-17T15:34:50Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1506.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1506",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1506.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1506"
} | Added nq_open Open-domain question answering dataset.
The NQ-Open task is currently being used to evaluate submissions to the EfficientQA competition, which is part of the NeurIPS 2020 competition track. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1506/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1506/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/469 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/469/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/469/comments | https://api.github.com/repos/huggingface/datasets/issues/469/events | https://github.com/huggingface/datasets/issues/469 | 671,876,963 | MDU6SXNzdWU2NzE4NzY5NjM= | 469 | invalid data type 'str' at _convert_outputs in arrow_dataset.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/30617486?v=4",
"events_url": "https://api.github.com/users/Murgates/events{/privacy}",
"followers_url": "https://api.github.com/users/Murgates/followers",
"following_url": "https://api.github.com/users/Murgates/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi ! Did you try to set the output format to pytorch ? (or tensorflow if you're using tensorflow)\r\nIt can be done with `dataset.set_format(\"torch\", columns=columns)` (or \"tensorflow\").\r\n\r\nNote that for pytorch, string columns can't be converted to `torch.Tensor`, so you have to specify in `columns=` the... | 2020-08-03T07:48:29Z | 2023-07-20T15:54:17Z | 2023-07-20T15:54:17Z | NONE | null | null | null | I trying to build multi label text classifier model using Transformers lib.
I'm using Transformers NLP to load the data set, while calling trainer.train() method. It throws the following error
File "C:\***\arrow_dataset.py", line 343, in _convert_outputs
v = command(v)
TypeError: new(): invalid data type ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/469/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/469/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/48 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/48/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/48/comments | https://api.github.com/repos/huggingface/datasets/issues/48/events | https://github.com/huggingface/datasets/pull/48 | 612,504,687 | MDExOlB1bGxSZXF1ZXN0NDEzNDM2MTgz | 48 | [Command Convert] remove tensorflow import | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-05-05T10:41:00Z | 2020-05-05T11:13:58Z | 2020-05-05T11:13:56Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/48.diff",
"html_url": "https://github.com/huggingface/datasets/pull/48",
"merged_at": "2020-05-05T11:13:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/48.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/48"
} | Remove all tensorflow import statements. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/48/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/48/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/350/comments | https://api.github.com/repos/huggingface/datasets/issues/350/events | https://github.com/huggingface/datasets/pull/350 | 652,398,691 | MDExOlB1bGxSZXF1ZXN0NDQ1NDczODYz | 350 | add from_pandas and from_dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-07-07T15:03:53Z | 2020-07-08T14:14:33Z | 2020-07-08T14:14:32Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/350.diff",
"html_url": "https://github.com/huggingface/datasets/pull/350",
"merged_at": "2020-07-08T14:14:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/350.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/350... | I added two new methods to the `Dataset` class:
- `from_pandas()` to create a dataset from a pandas dataframe
- `from_dict()` to create a dataset from a dictionary (keys = columns)
It uses the `pa.Table.from_pandas` and `pa.Table.from_pydict` funcitons to do so.
It is also possible to specify the features types v... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/350/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/350/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4417 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4417/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4417/comments | https://api.github.com/repos/huggingface/datasets/issues/4417/events | https://github.com/huggingface/datasets/issues/4417 | 1,251,933,091 | I_kwDODunzps5Knvuj | 4,417 | how to convert a dict generator into a huggingface dataset. | {
"avatar_url": "https://avatars.githubusercontent.com/u/32235549?v=4",
"events_url": "https://api.github.com/users/StephennFernandes/events{/privacy}",
"followers_url": "https://api.github.com/users/StephennFernandes/followers",
"following_url": "https://api.github.com/users/StephennFernandes/following{/other_... | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"@albertvillanova @lhoestq , could you please help me on this issue. ",
"Hi ! As mentioned on the [forum](https://discuss.huggingface.co/t/how-to-wrap-a-generator-with-hf-dataset/18464), the simplest for now would be to define a [dataset script](https://huggingface.co/docs/datasets/dataset_script) which can conta... | 2022-05-29T16:28:27Z | 2022-09-16T14:44:19Z | 2022-09-16T14:44:19Z | NONE | null | null | null | ### Link
_No response_
### Description
Hey there, I have used seqio to get a well distributed mixture of samples from multiple dataset. However the resultant output from seqio is a python generator dict, which I cannot produce back into huggingface dataset.
The generator contains all the samples needed for ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4417/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4417/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2580/comments | https://api.github.com/repos/huggingface/datasets/issues/2580/events | https://github.com/huggingface/datasets/pull/2580 | 935,767,421 | MDExOlB1bGxSZXF1ZXN0NjgyNjI2MTkz | 2,580 | Fix Counter import | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-07-02T13:21:48Z | 2021-07-02T14:37:47Z | 2021-07-02T14:37:46Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2580.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2580",
"merged_at": "2021-07-02T14:37:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2580.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Import from `collections` instead of `typing`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2580/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2580/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6464 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6464/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6464/comments | https://api.github.com/repos/huggingface/datasets/issues/6464/events | https://github.com/huggingface/datasets/pull/6464 | 2,020,860,462 | PR_kwDODunzps5g5djo | 6,464 | Add concurrent loading of shards to datasets.load_from_disk | {
"avatar_url": "https://avatars.githubusercontent.com/u/51880718?v=4",
"events_url": "https://api.github.com/users/kkoutini/events{/privacy}",
"followers_url": "https://api.github.com/users/kkoutini/followers",
"following_url": "https://api.github.com/users/kkoutini/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | [
"If we use multithreading no need to ask for `num_proc`. And maybe we the same numbers of threads as tqdm by default (IIRC it's `max(32, cpu_count() + 4)`) - you can even use `tqdm.contrib.concurrent.thread_map` directly to simplify the code\r\n\r\nAlso you can ignore the `IN_MEMORY_MAX_SIZE` config for this. This ... | 2023-12-01T13:13:53Z | 2023-12-07T12:47:02Z | null | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6464.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6464",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6464.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6464"
} | In some file systems (like luster), memory mapping arrow files takes time. This can be accelerated by performing the mmap in parallel on processes or threads.
- Threads seem to be faster than processes when gathering the list of tables from the workers (see https://github.com/huggingface/datasets/issues/2252).
- I'... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6464/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6464/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"events_url": "https://api.github.com/users/tuhinjubcse/events{/privacy}",
"followers_url": "https://api.github.com/users/tuhinjubcse/followers",
"following_url": "https://api.github.com/users/tuhinjubcse/following{/other_user}",
"gists_ur... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
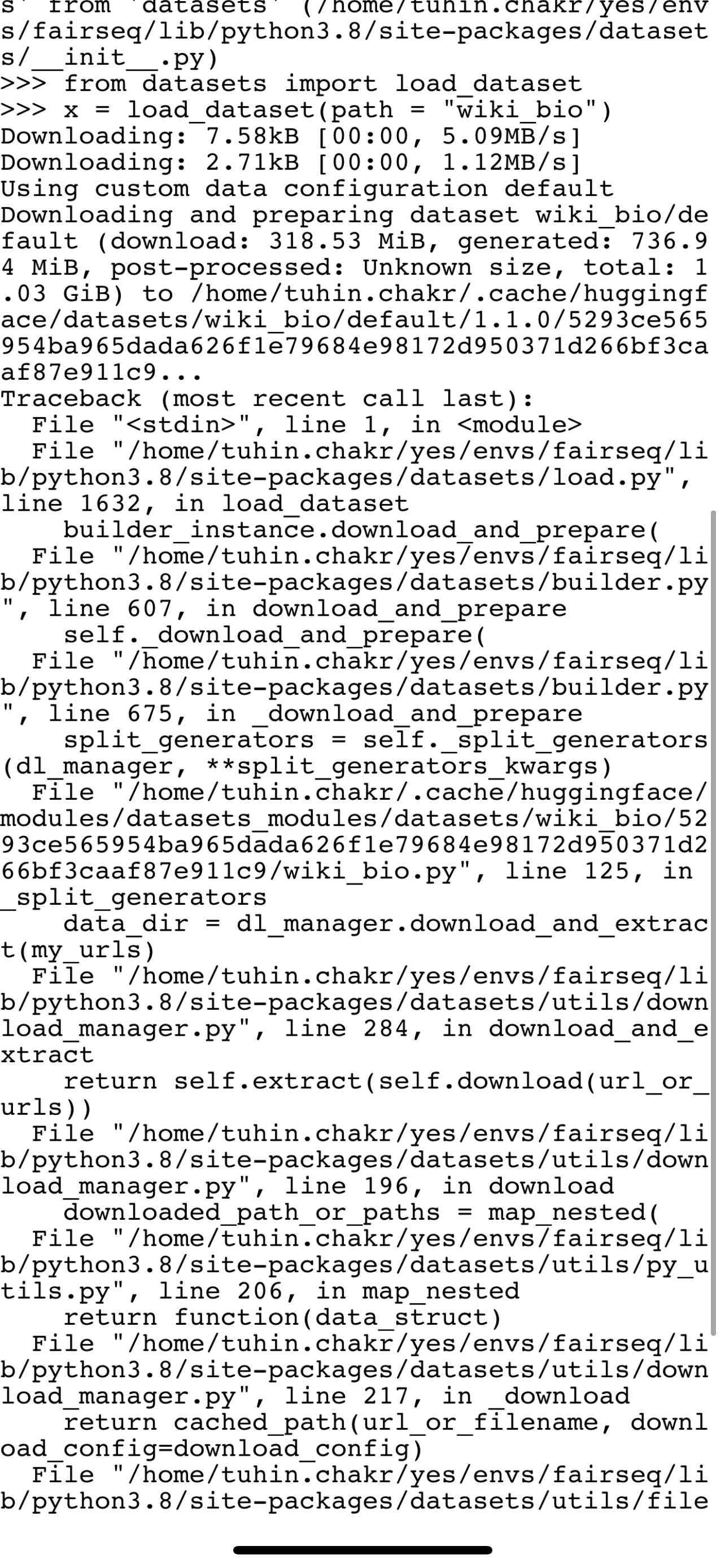
"+1, here's the error I got: \r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>>\r\n>>> load_dataset(\"wiki_bio\")\r\nDownloading: 7.58kB [00:00, 4.42MB/s]\r\nDownloading: 2.71kB [00:00, 1.30MB/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318... | 2022-01-15T10:04:33Z | 2022-01-31T08:38:09Z | 2022-01-31T08:38:09Z | NONE | null | null | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
: add initial loading script | {
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Hi @AmitMY, sorry for leaving you hanging for a minute :) \r\n\r\nWe've developed a new pipeline for adding datasets with a few extra steps, including adding a dataset card. You can find the full process [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md)\r\n\r\nWould you be up for addin... | 2020-11-02T06:50:10Z | 2020-12-01T13:41:37Z | 2020-12-01T13:41:36Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/789.diff",
"html_url": "https://github.com/huggingface/datasets/pull/789",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/789.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/789"
} | Its a small dataset, but its heavily annotated
https://www.bu.edu/asllrp/ncslgr.html

| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/789/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/789/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4363/comments | https://api.github.com/repos/huggingface/datasets/issues/4363/events | https://github.com/huggingface/datasets/issues/4363 | 1,238,897,652 | I_kwDODunzps5J2BP0 | 4,363 | The dataset preview is not available for this split. | {
"avatar_url": "https://avatars.githubusercontent.com/u/7584674?v=4",
"events_url": "https://api.github.com/users/roholazandie/events{/privacy}",
"followers_url": "https://api.github.com/users/roholazandie/followers",
"following_url": "https://api.github.com/users/roholazandie/following{/other_user}",
"gists... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"Hi! A dataset has to be streamable to work with the viewer. I did a quick test, and yours is, so this might be a bug in the viewer. cc @severo \r\n",
"Looking at it. The message is now:\r\n\r\n```\r\nMessage: cannot cache function '__shear_dense': no locator available for file '/src/services/worker/.venv/... | 2022-05-17T16:34:43Z | 2022-06-08T12:32:10Z | 2022-06-08T09:26:56Z | NONE | null | null | null | I have uploaded the corpus developed by our lab in the speech domain to huggingface [datasets](https://huggingface.co/datasets/Roh/ryanspeech). You can read about the companion paper accepted in interspeech 2021 [here](https://arxiv.org/abs/2106.08468). The dataset works fine but I can't make the dataset preview work. ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4363/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4306 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4306/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4306/comments | https://api.github.com/repos/huggingface/datasets/issues/4306/events | https://github.com/huggingface/datasets/issues/4306 | 1,231,137,204 | I_kwDODunzps5JYam0 | 4,306 | `load_dataset` does not work with certain filename. | {
"avatar_url": "https://avatars.githubusercontent.com/u/57242693?v=4",
"events_url": "https://api.github.com/users/whatever60/events{/privacy}",
"followers_url": "https://api.github.com/users/whatever60/followers",
"following_url": "https://api.github.com/users/whatever60/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Never mind. It is because of the caching of datasets..."
] | 2022-05-10T13:14:04Z | 2022-05-10T18:58:36Z | 2022-05-10T18:58:09Z | NONE | null | null | null | ## Describe the bug
This is a weird bug that took me some time to find out.
I have a JSON dataset that I want to load with `load_dataset` like this:
```
data_files = dict(train="train.json.zip", val="val.json.zip")
dataset = load_dataset("json", data_files=data_files, field="data")
```
## Expected results
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4306/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4306/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2163 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2163/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2163/comments | https://api.github.com/repos/huggingface/datasets/issues/2163/events | https://github.com/huggingface/datasets/pull/2163 | 849,669,366 | MDExOlB1bGxSZXF1ZXN0NjA4Mzk0NDMz | 2,163 | Concat only unique fields in DatasetInfo.from_merge | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi @mariosasko,\r\nJust came across this PR and I was wondering if we can use\r\n`description = \"\\n\\n\".join(OrderedDict.fromkeys([info.description for info in dataset_infos]))`\r\n\r\nThis will obviate the need for `unique` and is almost as fast as `set`. We could have used `dict` inplace of `OrderedDict` but ... | 2021-04-03T14:31:30Z | 2021-04-06T14:40:00Z | 2021-04-06T14:39:59Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2163.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2163",
"merged_at": "2021-04-06T14:39:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2163.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I thought someone from the community with less experience would be interested in fixing this issue, but that wasn't the case.
Fixes #2103 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2163/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2163/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2185 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2185/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2185/comments | https://api.github.com/repos/huggingface/datasets/issues/2185/events | https://github.com/huggingface/datasets/issues/2185 | 852,684,395 | MDU6SXNzdWU4NTI2ODQzOTU= | 2,185 | .map() and distributed training | {
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi, one workaround would be to save the mapped(tokenized in your case) file using `save_to_disk`, and having each process load this file using `load_from_disk`. This is what I am doing, and in this case, I turn off the ability to automatically load from the cache.\r\n\r\nAlso, multiprocessing the map function seem... | 2021-04-07T18:22:14Z | 2021-10-23T07:11:15Z | 2021-04-09T15:38:31Z | MEMBER | null | null | null | Hi,
I have a question regarding distributed training and the `.map` call on a dataset.
I have a local dataset "my_custom_dataset" that I am loading with `datasets = load_from_disk(dataset_path=my_path)`.
`dataset` is then tokenized:
```python
datasets = load_from_disk(dataset_path=my_path)
[...]
def tokeni... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2185/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2185/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1514 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1514/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1514/comments | https://api.github.com/repos/huggingface/datasets/issues/1514/events | https://github.com/huggingface/datasets/issues/1514 | 764,017,148 | MDU6SXNzdWU3NjQwMTcxNDg= | 1,514 | how to get all the options of a property in datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | [] | null | [
"In a dataset, labels correspond to the `ClassLabel` feature that has the `names` property that returns string represenation of the integer classes (or `num_classes` to get the number of different classes).",
"I think the `features` attribute of the dataset object is what you are looking for:\r\n```\r\n>>> datase... | 2020-12-12T16:24:08Z | 2022-05-25T16:27:29Z | 2022-05-25T16:27:29Z | CONTRIBUTOR | null | null | null | Hi
could you tell me how I can get all unique options of a property of dataset?
for instance in case of boolq, if the user wants to know which unique labels it has, is there a way to access unique labels without getting all training data lables and then forming a set i mean? thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1514/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1514/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5574/comments | https://api.github.com/repos/huggingface/datasets/issues/5574/events | https://github.com/huggingface/datasets/issues/5574 | 1,598,104,691 | I_kwDODunzps5fQSRz | 5,574 | c4 dataset streaming fails with `FileNotFoundError` | {
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"events_url": "https://api.github.com/users/krasserm/events{/privacy}",
"followers_url": "https://api.github.com/users/krasserm/followers",
"following_url": "https://api.github.com/users/krasserm/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"Also encountering this issue for every dataset I try to stream! Installed datasets from main:\r\n```\r\n- `datasets` version: 2.10.1.dev0\r\n- Platform: macOS-13.1-arm64-arm-64bit\r\n- Python version: 3.9.13\r\n- PyArrow version: 10.0.1\r\n- Pandas version: 1.5.2\r\n```\r\n\r\nRepro:\r\n```python\r\nfrom datasets ... | 2023-02-24T07:57:32Z | 2023-12-18T07:32:32Z | 2023-02-27T04:03:38Z | NONE | null | null | null | ### Describe the bug
Loading the `c4` dataset in streaming mode with `load_dataset("c4", "en", split="validation", streaming=True)` and then using it fails with a `FileNotFoundException`.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("c4", "en", split="train", ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5574/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5574/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1718 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1718/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1718/comments | https://api.github.com/repos/huggingface/datasets/issues/1718/events | https://github.com/huggingface/datasets/issues/1718 | 783,474,753 | MDU6SXNzdWU3ODM0NzQ3NTM= | 1,718 | Possible cache miss in datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/18296312?v=4",
"events_url": "https://api.github.com/users/ofirzaf/events{/privacy}",
"followers_url": "https://api.github.com/users/ofirzaf/followers",
"following_url": "https://api.github.com/users/ofirzaf/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Thanks for reporting !\r\nI was able to reproduce thanks to your code and find the origin of the bug.\r\nThe cache was not reusing the same file because one object was not deterministic. It comes from a conversion from `set` to `list` in the `datasets.arrrow_dataset.transmit_format` function, where the resulting l... | 2021-01-11T15:37:31Z | 2022-06-29T14:54:42Z | 2021-01-26T02:47:59Z | NONE | null | null | null | Hi,
I am using the datasets package and even though I run the same data processing functions, datasets always recomputes the function instead of using cache.
I have attached an example script that for me reproduces the problem.
In the attached example the second map function always recomputes instead of loading fr... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1718/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1718/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/738/comments | https://api.github.com/repos/huggingface/datasets/issues/738/events | https://github.com/huggingface/datasets/pull/738 | 723,033,923 | MDExOlB1bGxSZXF1ZXN0NTA0NjkxNjM4 | 738 | Replace seqeval code with original classification_report for simplicity | {
"avatar_url": "https://avatars.githubusercontent.com/u/6737785?v=4",
"events_url": "https://api.github.com/users/Hironsan/events{/privacy}",
"followers_url": "https://api.github.com/users/Hironsan/followers",
"following_url": "https://api.github.com/users/Hironsan/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"Hello,\r\n\r\nI ran https://github.com/huggingface/transformers/blob/master/examples/token-classification/run.sh\r\n\r\nAnd received this error:\r\n```\r\n100%|██████████| 407/407 [21:37<00:00, 3.44s/it]Traceback (most recent call last):\r\n File \"run_ner.py\", line 445, in <module>\r\n main()\r\n File \"ru... | 2020-10-16T08:51:45Z | 2021-01-21T16:07:15Z | 2020-10-19T10:31:12Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/738.diff",
"html_url": "https://github.com/huggingface/datasets/pull/738",
"merged_at": "2020-10-19T10:31:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/738.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/738... | Recently, the original seqeval has enabled us to get per type scores and overall scores as a dictionary.
This PR replaces the current code with the original function(`classification_report`) to simplify it.
Also, the original code has been updated to fix #352.
- Related issue: https://github.com/chakki-works/seq... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/738/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/738/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1636/comments | https://api.github.com/repos/huggingface/datasets/issues/1636/events | https://github.com/huggingface/datasets/issues/1636 | 774,574,378 | MDU6SXNzdWU3NzQ1NzQzNzg= | 1,636 | winogrande cannot be dowloaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.git... | [] | closed | false | null | [] | null | [
"I have same issue for other datasets (`myanmar_news` in my case).\r\n\r\nA version of `datasets` runs correctly on my local machine (**without GPU**) which looking for the dataset at \r\n```\r\nhttps://raw.githubusercontent.com/huggingface/datasets/master/datasets/myanmar_news/myanmar_news.py\r\n```\r\n\r\nMeanwhi... | 2020-12-24T22:28:22Z | 2022-10-05T12:35:44Z | 2022-10-05T12:35:44Z | NONE | null | null | null | Hi,
I am getting this error when trying to run the codes on the cloud. Thank you for any suggestion and help on this @lhoestq
```
File "./finetune_trainer.py", line 318, in <module>
main()
File "./finetune_trainer.py", line 148, in main
for task in data_args.tasks]
File "./finetune_trainer.py", ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1636/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1636/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4501 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4501/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4501/comments | https://api.github.com/repos/huggingface/datasets/issues/4501/events | https://github.com/huggingface/datasets/pull/4501 | 1,272,300,646 | PR_kwDODunzps45th2M | 4,501 | Corrected broken links in doc | {
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-06-15T14:12:17Z | 2022-06-15T15:11:05Z | 2022-06-15T15:00:56Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4501.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4501",
"merged_at": "2022-06-15T15:00:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4501.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4501/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4501/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2697/comments | https://api.github.com/repos/huggingface/datasets/issues/2697/events | https://github.com/huggingface/datasets/pull/2697 | 950,021,623 | MDExOlB1bGxSZXF1ZXN0Njk0NjMyODg0 | 2,697 | Fix import on Colab | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"@lhoestq @albertvillanova - It might be a good idea to have a patch release after this gets merged (presumably tomorrow morning when you're around). The Colab issue linked to this PR is a pretty big blocker. "
] | 2021-07-21T19:03:38Z | 2021-07-22T07:09:08Z | 2021-07-22T07:09:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2697.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2697",
"merged_at": "2021-07-22T07:09:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2697.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #2695, fix #2700. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2697/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2697/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2431/comments | https://api.github.com/repos/huggingface/datasets/issues/2431/events | https://github.com/huggingface/datasets/issues/2431 | 907,413,691 | MDU6SXNzdWU5MDc0MTM2OTE= | 2,431 | DuplicatedKeysError when trying to load adversarial_qa | {
"avatar_url": "https://avatars.githubusercontent.com/u/21348833?v=4",
"events_url": "https://api.github.com/users/hanss0n/events{/privacy}",
"followers_url": "https://api.github.com/users/hanss0n/followers",
"following_url": "https://api.github.com/users/hanss0n/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Thanks for reporting !\r\n#2433 fixed the issue, thanks @mariosasko :)\r\n\r\nWe'll do a patch release soon of the library.\r\nIn the meantime, you can use the fixed version of adversarial_qa by adding `script_version=\"master\"` in `load_dataset`"
] | 2021-05-31T12:11:19Z | 2021-06-01T08:54:03Z | 2021-06-01T08:52:11Z | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
dataset = load_dataset('adversarial_qa', 'adversarialQA')
```
## Expected results
The dataset should be loaded into memory
## Actual results
>DuplicatedKeysError: FAILURE TO GENERATE DATASET ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2431/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2600/comments | https://api.github.com/repos/huggingface/datasets/issues/2600/events | https://github.com/huggingface/datasets/issues/2600 | 938,086,745 | MDU6SXNzdWU5MzgwODY3NDU= | 2,600 | Crash when using multiprocessing (`num_proc` > 1) on `filter` and all samples are discarded | {
"avatar_url": "https://avatars.githubusercontent.com/u/4904985?v=4",
"events_url": "https://api.github.com/users/mxschmdt/events{/privacy}",
"followers_url": "https://api.github.com/users/mxschmdt/followers",
"following_url": "https://api.github.com/users/mxschmdt/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | 2021-07-06T16:53:25Z | 2021-07-07T12:50:31Z | 2021-07-07T12:50:31Z | CONTRIBUTOR | null | null | null | ## Describe the bug
If `filter` is applied to a dataset using multiprocessing (`num_proc` > 1) and all sharded datasets are empty afterwards (due to all samples being discarded), the program crashes.
## Steps to reproduce the bug
```python
from datasets import Dataset
data = Dataset.from_dict({'id': [0,1]})
dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2600/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6484 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6484/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6484/comments | https://api.github.com/repos/huggingface/datasets/issues/6484/events | https://github.com/huggingface/datasets/issues/6484 | 2,033,333,294 | I_kwDODunzps55MjQu | 6,484 | [Feature Request] Dataset versioning | {
"avatar_url": "https://avatars.githubusercontent.com/u/47979198?v=4",
"events_url": "https://api.github.com/users/kenfus/events{/privacy}",
"followers_url": "https://api.github.com/users/kenfus/followers",
"following_url": "https://api.github.com/users/kenfus/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [
"Hello @kenfus, this is meant to be possible to do yes. Let me ping @lhoestq or @mariosasko from the `datasets` team (`huggingface_hub` is only the underlying library to download files from the Hub but here it looks more like a `datasets` problem). ",
"Hi! https://github.com/huggingface/datasets/pull/6459 will fi... | 2023-12-08T16:01:35Z | 2023-12-11T19:13:46Z | null | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
I am working on a project, where I would like to test different preprocessing methods for my ML-data. Thus, I would like to work a lot with revisions and compare them. Currently, I was not able to make it work with the revision keyword because it was n... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6484/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6484/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4152 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4152/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4152/comments | https://api.github.com/repos/huggingface/datasets/issues/4152/events | https://github.com/huggingface/datasets/issues/4152 | 1,202,034,115 | I_kwDODunzps5HpZXD | 4,152 | ArrayND error in pyarrow 5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Where do we bump the required pyarrow version? Any inputs on how I fix this issue? ",
"We need to bump it in `setup.py` as well as update some CI job to use pyarrow 6 instead of 5 in `.circleci/config.yaml` and `.github/workflows/benchmarks.yaml`"
] | 2022-04-12T15:41:40Z | 2022-05-04T09:29:46Z | 2022-05-04T09:29:46Z | MEMBER | null | null | null | As found in https://github.com/huggingface/datasets/pull/3903, The ArrayND features fail on pyarrow 5:
```python
import pyarrow as pa
from datasets import Array2D
from datasets.table import cast_array_to_feature
arr = pa.array([[[0]]])
feature_type = Array2D(shape=(1, 1), dtype="int64")
cast_array_to_feature(a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4152/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4152/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2355/comments | https://api.github.com/repos/huggingface/datasets/issues/2355/events | https://github.com/huggingface/datasets/pull/2355 | 890,484,408 | MDExOlB1bGxSZXF1ZXN0NjQzNDk5NTIz | 2,355 | normalized TOCs and titles in data cards | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Oh right! I'd be in favor of still having the same TOC across the board, we can either leave it as is or add a `[More Info Needed]` `Contributions` Section wherever it's currently missing, wdyt?",
"(I thought those were programmatically updated based on git history :D )",
"Merging for now to avoid conflict sin... | 2021-05-12T20:59:59Z | 2021-05-14T13:23:12Z | 2021-05-14T13:23:12Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2355.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2355",
"merged_at": "2021-05-14T13:23:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2355.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I started fixing some of the READMEs that were failing the tests introduced by @gchhablani but then realized that there were some consistent differences between earlier and newer versions of some of the titles (e.g. Data Splits vs Data Splits Sample Size, Supported Tasks vs Supported Tasks and Leaderboards). We also ha... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2355/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2355/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1733/comments | https://api.github.com/repos/huggingface/datasets/issues/1733/events | https://github.com/huggingface/datasets/issues/1733 | 784,903,002 | MDU6SXNzdWU3ODQ5MDMwMDI= | 1,733 | connection issue with glue, what is the data url for glue? | {
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.git... | [] | closed | false | null | [] | null | [
"Hello @juliahane, which config of GLUE causes you trouble?\r\nThe URLs are defined in the dataset script source code: https://github.com/huggingface/datasets/blob/master/datasets/glue/glue.py"
] | 2021-01-13T08:37:40Z | 2021-08-04T18:13:55Z | 2021-08-04T18:13:55Z | NONE | null | null | null | Hi
my codes sometimes fails due to connection issue with glue, could you tell me how I can have the URL datasets library is trying to read GLUE from to test the machines I am working on if there is an issue on my side or not
thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1733/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1733/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/407/comments | https://api.github.com/repos/huggingface/datasets/issues/407/events | https://github.com/huggingface/datasets/issues/407 | 658,672,736 | MDU6SXNzdWU2NTg2NzI3MzY= | 407 | MissingBeamOptions for Wikipedia 20200501.en | {
"avatar_url": "https://avatars.githubusercontent.com/u/7490438?v=4",
"events_url": "https://api.github.com/users/mitchellgordon95/events{/privacy}",
"followers_url": "https://api.github.com/users/mitchellgordon95/followers",
"following_url": "https://api.github.com/users/mitchellgordon95/following{/other_user... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Fixed. Could you try again @mitchellgordon95 ?\r\nIt was due a file not being updated on S3.\r\n\r\nWe need to make sure all the datasets scripts get updated properly @julien-c ",
"Works for me! Thanks.",
"I found the same issue with almost any language other than English. (For English, it works). Will someone... | 2020-07-16T23:48:03Z | 2021-01-12T11:41:16Z | 2020-07-17T14:24:28Z | CONTRIBUTOR | null | null | null | There may or may not be a regression for the pre-processed Wikipedia dataset. This was working fine 10 commits ago (without having Apache Beam available):
```
nlp.load_dataset('wikipedia', "20200501.en", split='train')
```
And now, having pulled master, I get:
```
Downloading and preparing dataset wikipedia... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/407/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/407/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4733/comments | https://api.github.com/repos/huggingface/datasets/issues/4733/events | https://github.com/huggingface/datasets/issues/4733 | 1,314,479,616 | I_kwDODunzps5OWV4A | 4,733 | rouge metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/29248466?v=4",
"events_url": "https://api.github.com/users/asking28/events{/privacy}",
"followers_url": "https://api.github.com/users/asking28/followers",
"following_url": "https://api.github.com/users/asking28/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Fixed by:\r\n- #4735"
] | 2022-07-22T07:06:51Z | 2022-07-22T09:08:02Z | 2022-07-22T09:05:35Z | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Loading Rouge metric gives error after latest rouge-score==0.0.7 release.
Downgrading rougemetric==0.0.4 works fine.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
## Expected results
A clear and concis... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4733/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4733/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4569/comments | https://api.github.com/repos/huggingface/datasets/issues/4569/events | https://github.com/huggingface/datasets/issues/4569 | 1,284,833,694 | I_kwDODunzps5MlQGe | 4,569 | Dataset Viewer issue for sst2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @lewtun, thanks for reporting.\r\n\r\nI have checked locally and refreshed the preview and it seems working smooth now:\r\n```python\r\nIn [8]: ds\r\nOut[8]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 67349\r\n })\r\n validation: Datas... | 2022-06-26T07:32:54Z | 2022-06-27T06:37:48Z | 2022-06-27T06:37:48Z | MEMBER | null | null | null | ### Link
https://huggingface.co/datasets/sst2
### Description
Not sure what is causing this, however it seems that `load_dataset("sst2")` also hangs (even though it downloads the files without problem):
```
Status code: 400
Exception: Exception
Message: Give up after 5 attempts with Connectio... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4569/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4569/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4664/comments | https://api.github.com/repos/huggingface/datasets/issues/4664/events | https://github.com/huggingface/datasets/pull/4664 | 1,299,571,212 | PR_kwDODunzps47IvfG | 4,664 | Add stanford dog dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8711912?v=4",
"events_url": "https://api.github.com/users/khushmeeet/events{/privacy}",
"followers_url": "https://api.github.com/users/khushmeeet/followers",
"following_url": "https://api.github.com/users/khushmeeet/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi @khushmeeet, thanks for your contribution.\r\n\r\nBut wouldn't it be better to add this dataset to the Hub? \r\n- https://huggingface.co/docs/datasets/share\r\n- https://huggingface.co/docs/datasets/dataset_script",
"Hi @albertv... | 2022-07-09T04:46:07Z | 2022-07-15T13:30:32Z | 2022-07-15T13:15:42Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4664.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4664",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4664.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4664"
} | This PR is for adding dataset, related to issue #4504.
We are adding Stanford dog breed dataset. It is a multi class image classification dataset.
Details can be found here - http://vision.stanford.edu/aditya86/ImageNetDogs/
Tests on dummy data is failing currently, which I am looking into. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4664/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4664/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3995 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3995/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3995/comments | https://api.github.com/repos/huggingface/datasets/issues/3995/events | https://github.com/huggingface/datasets/pull/3995 | 1,178,232,623 | PR_kwDODunzps404054 | 3,995 | Close `PIL.Image` file handler in `Image.decode_example` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-23T14:51:48Z | 2022-03-23T18:24:52Z | 2022-03-23T18:19:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3995.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3995",
"merged_at": "2022-03-23T18:19:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3995.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Closes the file handler of the PIL image object in `Image.decode_example` to avoid the `Too many open files` error.
To pass [the image equality checks](https://app.circleci.com/pipelines/github/huggingface/datasets/10774/workflows/d56670e6-16bb-4c64-b601-a152c5acf5ed/jobs/65825) in CI, `Image.decode_example` calls `... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3995/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3995/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/327 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/327/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/327/comments | https://api.github.com/repos/huggingface/datasets/issues/327/events | https://github.com/huggingface/datasets/pull/327 | 648,312,858 | MDExOlB1bGxSZXF1ZXN0NDQyMTQyOTQw | 327 | set seed for suffling tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-30T16:21:34Z | 2020-07-02T08:34:05Z | 2020-07-02T08:34:04Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/327.diff",
"html_url": "https://github.com/huggingface/datasets/pull/327",
"merged_at": "2020-07-02T08:34:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/327.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/327... | Some tests were randomly failing because of a missing seed in a test for `train_test_split(shuffle=True)` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/327/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/327/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3042 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3042/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3042/comments | https://api.github.com/repos/huggingface/datasets/issues/3042/events | https://github.com/huggingface/datasets/pull/3042 | 1,020,047,289 | PR_kwDODunzps4s5Lxo | 3,042 | Improving elasticsearch integration | {
"avatar_url": "https://avatars.githubusercontent.com/u/5583410?v=4",
"events_url": "https://api.github.com/users/ggdupont/events{/privacy}",
"followers_url": "https://api.github.com/users/ggdupont/followers",
"following_url": "https://api.github.com/users/ggdupont/following{/other_user}",
"gists_url": "http... | [] | open | false | null | [] | null | [
"@lhoestq @albertvillanova Iwas trying to fix the failing tests in circleCI but is there a test elasticsearch instance somewhere? If not, can I launch a docker container to have one?"
] | 2021-10-07T13:28:35Z | 2022-07-06T15:19:48Z | null | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3042.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3042",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3042.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3042"
} | - adding murmurhash signature to sample in index
- adding optional credentials for remote elasticsearch server
- enabling sample update in index
- upgrade the elasticsearch 7.10.1 python client
- adding ElasticsearchBulider to instantiate a dataset from an index and a filtering query | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3042/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3042/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3796 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3796/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3796/comments | https://api.github.com/repos/huggingface/datasets/issues/3796/events | https://github.com/huggingface/datasets/pull/3796 | 1,154,298,629 | PR_kwDODunzps4zrOQ4 | 3,796 | Skip checksum computation if `ignore_verifications` is `True` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2022-02-28T16:28:45Z | 2022-02-28T17:03:46Z | 2022-02-28T17:03:46Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3796.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3796",
"merged_at": "2022-02-28T17:03:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3796.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This will speed up the loading of the datasets where the number of data files is large (can easily happen with `imagefoler`, for instance) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3796/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3796/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5268 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5268/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5268/comments | https://api.github.com/repos/huggingface/datasets/issues/5268/events | https://github.com/huggingface/datasets/pull/5268 | 1,455,633,978 | PR_kwDODunzps5DPIsp | 5,268 | Sharded save_to_disk + multiprocessing | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Added both num_shards and max_shard_size in push_to_hub/save_to_disk. Will take care of updating the tests later",
"It's ready for a final review @mariosasko and @albertvillanova, let me know what you think :)",
"Took your commen... | 2022-11-18T18:50:01Z | 2022-12-14T18:25:52Z | 2022-12-14T18:22:58Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5268.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5268",
"merged_at": "2022-12-14T18:22:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5268.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Added `num_shards=` and `num_proc=` to `save_to_disk()`
EDIT: also added `max_shard_size=` to `save_to_disk()`, and also `num_shards=` to `push_to_hub`
I also:
- deprecated the fs parameter in favor of storage_options (for consistency with the rest of the lib) in save_to_disk and load_from_disk
- always embed t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5268/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5268/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4083 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4083/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4083/comments | https://api.github.com/repos/huggingface/datasets/issues/4083/events | https://github.com/huggingface/datasets/pull/4083 | 1,190,025,878 | PR_kwDODunzps41gEbu | 4,083 | Add SacreBLEU Metric Card | {
"avatar_url": "https://avatars.githubusercontent.com/u/27527747?v=4",
"events_url": "https://api.github.com/users/emibaylor/events{/privacy}",
"followers_url": "https://api.github.com/users/emibaylor/followers",
"following_url": "https://api.github.com/users/emibaylor/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-04-01T16:24:56Z | 2022-04-12T20:45:00Z | 2022-04-12T20:38:40Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4083.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4083",
"merged_at": "2022-04-12T20:38:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4083.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4083/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4083/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4322 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4322/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4322/comments | https://api.github.com/repos/huggingface/datasets/issues/4322/events | https://github.com/huggingface/datasets/pull/4322 | 1,233,596,947 | PR_kwDODunzps43s1wy | 4,322 | Added stratify option to train_test_split function. | {
"avatar_url": "https://avatars.githubusercontent.com/u/48522685?v=4",
"events_url": "https://api.github.com/users/nandwalritik/events{/privacy}",
"followers_url": "https://api.github.com/users/nandwalritik/followers",
"following_url": "https://api.github.com/users/nandwalritik/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"> Nice thank you ! This will be super useful :)\r\n> \r\n> Could you also add some tests in test_arrow_dataset.py and add an example of usage in the `Example:` section of the `train_test_split` docstring ?\r\n\r\nI will try to do it, is there any documentation for adding test cases? I have never done it before.",
... | 2022-05-12T08:00:31Z | 2022-11-22T14:53:55Z | 2022-05-25T20:43:51Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4322.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4322",
"merged_at": "2022-05-25T20:43:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4322.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds `stratify` option to `train_test_split` method. I took reference from scikit-learn's `StratifiedShuffleSplit` class for implementing stratified split and integrated the changes as were suggested by @lhoestq.
It fixes #3452.
@lhoestq Please review and let me know, if any changes are required.
| {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4322/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4322/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1743/comments | https://api.github.com/repos/huggingface/datasets/issues/1743/events | https://github.com/huggingface/datasets/issues/1743 | 787,631,412 | MDU6SXNzdWU3ODc2MzE0MTI= | 1,743 | Issue while Creating Custom Metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Currently it's only possible to define the features for the two columns `references` and `predictions`.\r\nThe data for these columns can then be passed to `metric.add_batch` and `metric.compute`.\r\nInstead of defining more columns `text`, `offset_mapping` and `ground` you must include them in either references a... | 2021-01-17T07:01:14Z | 2022-06-01T15:49:34Z | 2022-06-01T15:49:34Z | CONTRIBUTOR | null | null | null | Hi Team,
I am trying to create a custom metric for my training as follows, where f1 is my own metric:
```python
def _info(self):
# TODO: Specifies the datasets.MetricInfo object
return datasets.MetricInfo(
# This is the description that will appear on the metrics page.
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1743/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1743/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6476 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6476/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6476/comments | https://api.github.com/repos/huggingface/datasets/issues/6476/events | https://github.com/huggingface/datasets/issues/6476 | 2,028,018,596 | I_kwDODunzps544Ruk | 6,476 | CI on windows is broken: PermissionError | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-12-06T08:32:53Z | 2023-12-06T09:17:53Z | 2023-12-06T09:17:53Z | MEMBER | null | null | null | See: https://github.com/huggingface/datasets/actions/runs/7104781624/job/19340572394
```
FAILED tests/test_load.py::test_loading_from_the_datasets_hub - NotADirectoryError: [WinError 267] The directory name is invalid: 'C:\\Users\\RUNNER~1\\AppData\\Local\\Temp\\tmpfcnps56i\\hf-internal-testing___dataset_with_script\... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6476/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6476/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/303 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/303/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/303/comments | https://api.github.com/repos/huggingface/datasets/issues/303/events | https://github.com/huggingface/datasets/pull/303 | 643,912,464 | MDExOlB1bGxSZXF1ZXN0NDM4NjI3Nzcw | 303 | allow to move files across file systems | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-23T14:56:08Z | 2020-06-23T15:08:44Z | 2020-06-23T15:08:43Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/303.diff",
"html_url": "https://github.com/huggingface/datasets/pull/303",
"merged_at": "2020-06-23T15:08:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/303.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/303... | Users are allowed to use the `cache_dir` that they want.
Therefore it can happen that we try to move files across filesystems.
We were using `os.rename` that doesn't allow that, so I changed some of them to `shutil.move`.
This should fix #301 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/303/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/303/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1617/comments | https://api.github.com/repos/huggingface/datasets/issues/1617/events | https://github.com/huggingface/datasets/pull/1617 | 772,084,764 | MDExOlB1bGxSZXF1ZXN0NTQzNDE5MTM5 | 1,617 | cifar10 initial commit | {
"avatar_url": "https://avatars.githubusercontent.com/u/75574105?v=4",
"events_url": "https://api.github.com/users/czabo/events{/privacy}",
"followers_url": "https://api.github.com/users/czabo/followers",
"following_url": "https://api.github.com/users/czabo/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"Yee a Computer Vision dataset!",
"Yep, the first one ! Thank @czabo "
] | 2020-12-21T11:18:50Z | 2020-12-22T10:18:05Z | 2020-12-22T10:11:28Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1617.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1617",
"merged_at": "2020-12-22T10:11:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1617.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | CIFAR-10 dataset. Didn't add the tagging since there are no vision related tags. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1617/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1617/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5334 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5334/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5334/comments | https://api.github.com/repos/huggingface/datasets/issues/5334/events | https://github.com/huggingface/datasets/pull/5334 | 1,477,421,927 | PR_kwDODunzps5EY9zN | 5,334 | Clean up docstrings | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks ! Let us know if we can help :)\r\n\r\nSmall pref for having multiple PRs",
"Awesome, thanks! Sorry this one is a little big, I'll open some smaller ones next :)"
] | 2022-12-05T20:56:08Z | 2022-12-09T01:44:25Z | 2022-12-09T01:41:44Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5334.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5334",
"merged_at": "2022-12-09T01:41:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5334.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As raised by @polinaeterna in #5324, some of the docstrings are a bit of a mess because it has both Markdown and Sphinx syntax. This PR fixes the docstring for `DatasetBuilder`.
I'll start working on cleaning up the rest of the docstrings and removing the old Sphinx syntax (let me know if you prefer one big PR with... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5334/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5334/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5945 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5945/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5945/comments | https://api.github.com/repos/huggingface/datasets/issues/5945/events | https://github.com/huggingface/datasets/issues/5945 | 1,754,084,577 | I_kwDODunzps5ojTTh | 5,945 | Failing to upload dataset to the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/77382661?v=4",
"events_url": "https://api.github.com/users/Ar770/events{/privacy}",
"followers_url": "https://api.github.com/users/Ar770/followers",
"following_url": "https://api.github.com/users/Ar770/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"Hi ! Feel free to re-run your code later, it will resume automatically where you left",
"Tried many times in the last 2 weeks, problem remains.",
"Alternatively you can save your dataset in parquet files locally and upload them to the hub manually\r\n\r\n```python\r\nfrom tqdm import tqdm\r\nnum_shards = 60\r\... | 2023-06-13T05:46:46Z | 2023-07-24T11:56:40Z | 2023-07-24T11:56:40Z | NONE | null | null | null | ### Describe the bug
Trying to upload a dataset of hundreds of thousands of audio samples (the total volume is not very large, 60 gb) to the hub with push_to_hub, it doesn't work.
From time to time one piece of the data (parquet) gets pushed and then I get RemoteDisconnected even though my internet is stable.
Please... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5945/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5945/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5895 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5895/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5895/comments | https://api.github.com/repos/huggingface/datasets/issues/5895/events | https://github.com/huggingface/datasets/issues/5895 | 1,725,467,252 | I_kwDODunzps5m2Ip0 | 5,895 | The dir name and split strings are confused when loading ArmelR/stack-exchange-instruction dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/45357817?v=4",
"events_url": "https://api.github.com/users/DongHande/events{/privacy}",
"followers_url": "https://api.github.com/users/DongHande/followers",
"following_url": "https://api.github.com/users/DongHande/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Thanks for reporting, @DongHande.\r\n\r\nI think the issue is caused by the metadata in the dataset card: in the header of the `README.md`, they state that the dataset has 4 splits (\"finetune\", \"reward\", \"rl\", \"evaluation\"). \r\n```yaml\r\n splits:\r\n - name: finetune\r\n num_bytes: 6674567576\r\... | 2023-05-25T09:39:06Z | 2023-05-29T02:32:12Z | 2023-05-29T02:32:12Z | NONE | null | null | null | ### Describe the bug
When I load the ArmelR/stack-exchange-instruction dataset, I encounter a bug that may be raised by confusing the dir name string and the split string about the dataset.
When I use the script "datasets.load_dataset('ArmelR/stack-exchange-instruction', data_dir="data/finetune", split="train", ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5895/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5895/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4607/comments | https://api.github.com/repos/huggingface/datasets/issues/4607/events | https://github.com/huggingface/datasets/pull/4607 | 1,290,171,941 | PR_kwDODunzps46pLnd | 4,607 | Align more metadata with other repo types (models,spaces) | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I just set a default value (None) for the deprecated licenses and languages fields, which should fix most of the CI failures.\r\n\r\nNote that the CI should still be red because you edited many dataset cards and they're still missing... | 2022-06-30T13:52:12Z | 2022-07-01T12:00:37Z | 2022-07-01T11:49:14Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4607.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4607",
"merged_at": "2022-07-01T11:49:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4607.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | see also associated PR on the `datasets-tagging` Space: https://huggingface.co/spaces/huggingface/datasets-tagging/discussions/2 (to merge after this one is merged) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4607/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4607/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2463 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2463/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2463/comments | https://api.github.com/repos/huggingface/datasets/issues/2463/events | https://github.com/huggingface/datasets/pull/2463 | 915,454,788 | MDExOlB1bGxSZXF1ZXN0NjY1MjY3NTA2 | 2,463 | Fix proto_qa download link | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-06-08T20:23:16Z | 2021-06-10T12:49:56Z | 2021-06-10T08:31:10Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2463.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2463",
"merged_at": "2021-06-10T08:31:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2463.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fixes #2459
Instead of updating the path, this PR fixes a commit hash as suggested by @lhoestq. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2463/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2463/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2086 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2086/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2086/comments | https://api.github.com/repos/huggingface/datasets/issues/2086/events | https://github.com/huggingface/datasets/pull/2086 | 836,249,587 | MDExOlB1bGxSZXF1ZXN0NTk2Nzg0Mjcz | 2,086 | change user permissions to -rw-r--r-- | {
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"I tried this with `ade_corpus_v2` dataset. `ade_corpus_v2-train.arrow` (downloaded dataset) and `cache-25d41a4d3c2d8a25.arrow` (ran a mapping function on the dataset) both had file permission with octal value of `0644`. "
] | 2021-03-19T18:14:56Z | 2021-03-24T13:59:04Z | 2021-03-24T13:59:04Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2086.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2086",
"merged_at": "2021-03-24T13:59:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2086.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix for #2065 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2086/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2086/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3647/comments | https://api.github.com/repos/huggingface/datasets/issues/3647/events | https://github.com/huggingface/datasets/pull/3647 | 1,117,383,675 | PR_kwDODunzps4xvGDQ | 3,647 | Fix `add_column` on datasets with indices mapping | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Sure, let's include this in today's release.",
"Cool ! The windows CI should be fixed on master now, feel free to merge :)"
] | 2022-01-28T13:06:29Z | 2022-01-28T15:35:58Z | 2022-01-28T15:35:58Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3647.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3647",
"merged_at": "2022-01-28T15:35:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3647.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | My initial idea was to avoid the `flatten_indices` call and reorder a new column instead, but in the end I decided to follow `concatenate_datasets` and use `flatten_indices` to avoid padding when `dataset._indices.num_rows != dataset._data.num_rows`.
Fix #3599 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3647/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1051 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1051/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1051/comments | https://api.github.com/repos/huggingface/datasets/issues/1051/events | https://github.com/huggingface/datasets/pull/1051 | 756,169,049 | MDExOlB1bGxSZXF1ZXN0NTMxNzU2OTQy | 1,051 | Add Facebook SimpleQuestionV2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [] | closed | false | null | [] | null | [
"I think @thomwolf may also be working on this one as part of the Babi benchmark in #945 "
] | 2020-12-03T12:53:20Z | 2020-12-03T17:31:59Z | 2020-12-03T17:31:58Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1051.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1051",
"merged_at": "2020-12-03T17:31:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1051.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add simple questions v2: https://research.fb.com/downloads/babi/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1051/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1051/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3284 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3284/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3284/comments | https://api.github.com/repos/huggingface/datasets/issues/3284/events | https://github.com/huggingface/datasets/issues/3284 | 1,055,502,909 | I_kwDODunzps4-6bI9 | 3,284 | Add VoxLingua107 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",... | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_use... | null | [
"#self-assign"
] | 2021-11-16T22:44:08Z | 2021-12-06T09:49:45Z | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** VoxLingua107
- **Description:** VoxLingua107 is a speech dataset for training spoken language identification models. The dataset consists of short speech segments automatically extracted from YouTube videos and labeled according the language of the video title and description, with som... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3284/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3284/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/6441 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6441/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6441/comments | https://api.github.com/repos/huggingface/datasets/issues/6441/events | https://github.com/huggingface/datasets/issues/6441 | 2,004,985,857 | I_kwDODunzps53gagB | 6,441 | Trouble Loading a Gated Dataset For User with Granted Permission | {
"avatar_url": "https://avatars.githubusercontent.com/u/124715309?v=4",
"events_url": "https://api.github.com/users/e-trop/events{/privacy}",
"followers_url": "https://api.github.com/users/e-trop/followers",
"following_url": "https://api.github.com/users/e-trop/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | [
"> Also when they try to click the url link for the dataset they get a 404 error.\r\n\r\nThis seems to be a Hub error then (cc @SBrandeis)",
"Could you report this to https://discuss.huggingface.co/c/hub/23, providing the URL of the dataset, or at least if the dataset is public or private?",
"Thanks for the rep... | 2023-11-21T19:24:36Z | 2023-12-13T08:27:16Z | 2023-12-13T08:27:16Z | NONE | null | null | null | ### Describe the bug
I have granted permissions to several users to access a gated huggingface dataset. The users accepted the invite and when trying to load the dataset using their access token they get
`FileNotFoundError: Couldn't find a dataset script at .....` . Also when they try to click the url link for the d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6441/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6441/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4864 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4864/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4864/comments | https://api.github.com/repos/huggingface/datasets/issues/4864/events | https://github.com/huggingface/datasets/issues/4864 | 1,344,410,043 | I_kwDODunzps5QIhG7 | 4,864 | Allow pathlib PoxisPath in Dataset.read_json | {
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"This same error will occur using `ds = datasets.load_dataset('json', data_files=['test.jsonl'])`",
"@cccntu I want to make a quick fix for this, but I am struggling to find where the json dataset builder is. Do you know?",
"@vvvm23 I think you mean think:\r\n```python\r\nds = datasets.load_dataset('json', data... | 2022-08-19T12:59:17Z | 2023-03-12T11:25:49Z | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
```
from pathlib import Path
from datasets import Dataset
ds = Dataset.read_json(Path('data.json'))
```
causes an error
```
AttributeError: 'PosixPath' object has no attribute 'decode'
```
**Describe the solution you'd like**
It should be... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4864/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4864/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/888 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/888/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/888/comments | https://api.github.com/repos/huggingface/datasets/issues/888/events | https://github.com/huggingface/datasets/issues/888 | 750,944,422 | MDU6SXNzdWU3NTA5NDQ0MjI= | 888 | Nested lists are zipped unexpectedly | {
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Yes following the Tensorflow Datasets convention, objects with type `Sequence of a Dict` are actually stored as a `dictionary of lists`.\r\nSee the [documentation](https://huggingface.co/docs/datasets/features.html?highlight=features) for more details",
"Thanks.\r\nThis is a bit (very) confusing, but I guess if ... | 2020-11-25T16:07:46Z | 2020-11-25T17:30:39Z | 2020-11-25T17:30:39Z | CONTRIBUTOR | null | null | null | I might misunderstand something, but I expect that if I define:
```python
"top": datasets.features.Sequence({
"middle": datasets.features.Sequence({
"bottom": datasets.Value("int32")
})
})
```
And I then create an example:
```python
yield 1, {
"top": [{
"middle": [
{"bottom": 1},
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/888/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/888/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5734/comments | https://api.github.com/repos/huggingface/datasets/issues/5734/events | https://github.com/huggingface/datasets/issues/5734 | 1,662,058,028 | I_kwDODunzps5jEP4s | 5,734 | Remove temporary pin of fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-04-11T09:04:17Z | 2023-04-11T11:04:52Z | 2023-04-11T11:04:52Z | MEMBER | null | null | null | Once root cause is found and fixed, remove the temporary pin introduced by:
- #5731 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5734/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5734/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3664/comments | https://api.github.com/repos/huggingface/datasets/issues/3664/events | https://github.com/huggingface/datasets/pull/3664 | 1,121,233,301 | PR_kwDODunzps4x7mg_ | 3,664 | [WIP] Return local paths to Common Voice | {
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Cool thanks for giving it a try @anton-l ! \r\n\r\nWould be very much in favor of having \"real\" paths to the audio files again for non-streaming use cases. At the same time it would be nice to make the audio data loading script as understandable as possible so that the community can easily add audio datasets in ... | 2022-02-01T21:48:27Z | 2022-02-22T09:14:06Z | 2022-02-22T09:14:06Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3664.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3664",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3664.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3664"
} | Fixes https://github.com/huggingface/datasets/issues/3663
This is a proposed way of returning the old local file-based generator while keeping the new streaming generator intact.
TODO:
- [ ] brainstorm a bit more on https://github.com/huggingface/datasets/issues/3663 to see if we can do better
- [ ] refactor th... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3664/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3664/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6186 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6186/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6186/comments | https://api.github.com/repos/huggingface/datasets/issues/6186/events | https://github.com/huggingface/datasets/issues/6186 | 1,869,431,457 | I_kwDODunzps5vbUKh | 6,186 | Feature request: add code example of multi-GPU processing | {
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url"... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
},
{
"color": "a2ee... | closed | false | null | [] | null | [
"That'd be a great idea! @mariosasko or @lhoestq, would it be possible to fix the code snippet or do you have another suggested way for doing this?",
"Indeed `if __name__ == \"__main__\"` is important in this case.\r\n\r\nNot sure about the imbalanced GPU usage though, but maybe you can try using the `torch.cuda.... | 2023-08-28T10:00:59Z | 2023-11-22T15:42:20Z | 2023-11-22T15:42:20Z | CONTRIBUTOR | null | null | null | ### Feature request
Would be great to add a code example of how to do multi-GPU processing with 🤗 Datasets in the documentation. cc @stevhliu
Currently the docs has a small [section](https://huggingface.co/docs/datasets/v2.3.2/en/process#map) on this saying "your big GPU call goes here", however it didn't work f... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6186/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6186/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2597/comments | https://api.github.com/repos/huggingface/datasets/issues/2597/events | https://github.com/huggingface/datasets/pull/2597 | 937,917,770 | MDExOlB1bGxSZXF1ZXN0Njg0Mzk0MDIz | 2,597 | Remove redundant prepare_module | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "B67A40",
"default": false,
"description": "Restructuring existing code without changing its external behavior",
"id": 2851292821,
"name": "refactoring",
"node_id": "MDU6TGFiZWwyODUxMjkyODIx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/refactoring"
}
] | closed | false | null | [] | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/... | [] | 2021-07-06T13:47:45Z | 2021-07-12T14:10:52Z | 2021-07-07T13:01:46Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2597.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2597",
"merged_at": "2021-07-07T13:01:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2597.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | I have noticed that after implementing `load_dataset_builder` (#2500), there is a redundant call to `prepare_module`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2597/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6090/comments | https://api.github.com/repos/huggingface/datasets/issues/6090/events | https://github.com/huggingface/datasets/issues/6090 | 1,825,865,043 | I_kwDODunzps5s1H1T | 6,090 | FilesIterable skips all the files after a hidden file | {
"avatar_url": "https://avatars.githubusercontent.com/u/10785413?v=4",
"events_url": "https://api.github.com/users/dkrivosic/events{/privacy}",
"followers_url": "https://api.github.com/users/dkrivosic/followers",
"following_url": "https://api.github.com/users/dkrivosic/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Thanks for reporting. We've merged a PR with a fix."
] | 2023-07-28T07:25:57Z | 2023-07-28T10:51:14Z | 2023-07-28T10:50:11Z | NONE | null | null | null | ### Describe the bug
When initializing `FilesIterable` with a list of file paths using `FilesIterable.from_paths`, it will discard all the files after a hidden file.
The problem is in [this line](https://github.com/huggingface/datasets/blob/88896a7b28610ace95e444b94f9a4bc332cc1ee3/src/datasets/download/download_manag... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6090/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3154 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3154/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3154/comments | https://api.github.com/repos/huggingface/datasets/issues/3154/events | https://github.com/huggingface/datasets/issues/3154 | 1,034,361,806 | I_kwDODunzps49pxvO | 3,154 | Sacrebleu unexpected behaviour/requirement for data format | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @BramVanroy!\r\n\r\nGood question. This project relies on PyArrow (tables) to store data too big to fit in RAM. In the case of metrics, this means that the number of predictions and references has to match to form a table.\r\n\r\nThat's why your example throws an error even though it matches the schema:\r\n```p... | 2021-10-24T08:55:33Z | 2021-10-31T09:08:32Z | 2021-10-31T09:08:31Z | CONTRIBUTOR | null | null | null | ## Describe the bug
When comparing with the original `sacrebleu` implementation, the `datasets` implementation does some strange things that I do not quite understand. This issue was triggered when I was trying to implement TER and found the datasets implementation of BLEU [here](https://github.com/huggingface/dataset... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3154/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3154/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2699 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2699/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2699/comments | https://api.github.com/repos/huggingface/datasets/issues/2699/events | https://github.com/huggingface/datasets/issues/2699 | 950,221,226 | MDU6SXNzdWU5NTAyMjEyMjY= | 2,699 | cannot combine splits merging and streaming? | {
"avatar_url": "https://avatars.githubusercontent.com/u/4436747?v=4",
"events_url": "https://api.github.com/users/eyaler/events{/privacy}",
"followers_url": "https://api.github.com/users/eyaler/followers",
"following_url": "https://api.github.com/users/eyaler/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi ! That's missing indeed. We'll try to implement this for the next version :)\r\n\r\nI guess we just need to implement #2564 first, and then we should be able to add support for splits combinations"
] | 2021-07-22T01:13:25Z | 2021-07-22T08:27:47Z | null | NONE | null | null | null | this does not work:
`dataset = datasets.load_dataset('mc4','iw',split='train+validation',streaming=True)`
with error:
`ValueError: Bad split: train+validation. Available splits: ['train', 'validation']`
these work:
`dataset = datasets.load_dataset('mc4','iw',split='train+validation')`
`dataset = datasets.load_d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2699/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2699/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5602/comments | https://api.github.com/repos/huggingface/datasets/issues/5602/events | https://github.com/huggingface/datasets/pull/5602 | 1,607,054,110 | PR_kwDODunzps5LJGfa | 5,602 | Return dict structure if columns are lists - to_tf_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_u... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5602). All of your documentation changes will be reflected on that endpoint.",
"This is a great PR! Thinking about the UX though, maybe we could do it without the extra argument? Before this PR, the logic in `to_tf_dataset` was... | 2023-03-02T15:51:12Z | 2023-04-12T15:54:53Z | null | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5602.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5602",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5602.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5602"
} | This PR introduces new logic to `to_tf_dataset` affecting the returned data structure, enabling a dictionary structure to be returned, even if only one feature column is selected.
If the passed in `columns` or `label_cols` to `to_tf_dataset` are a list, they are returned as a dictionary, respectively. If they are a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5602/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5602/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3311 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3311/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3311/comments | https://api.github.com/repos/huggingface/datasets/issues/3311/events | https://github.com/huggingface/datasets/issues/3311 | 1,060,387,957 | I_kwDODunzps4_NDx1 | 3,311 | Add WebSRC | {
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url"... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [] | 2021-11-22T16:58:33Z | 2021-11-22T16:58:33Z | null | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** WebSRC
- **Description:** WebSRC is a novel Web-based Structural Reading Comprehension dataset. It consists of 0.44M question-answer pairs, which are collected from 6.5K web pages with corresponding HTML source code, screenshots and metadata.
- **Paper:** https://arxiv.org/abs/2101.0... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3311/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3311/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5986 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5986/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5986/comments | https://api.github.com/repos/huggingface/datasets/issues/5986/events | https://github.com/huggingface/datasets/pull/5986 | 1,772,233,111 | PR_kwDODunzps5TygOZ | 5,986 | Make IterableDataset.from_spark more efficient | {
"avatar_url": "https://avatars.githubusercontent.com/u/134338709?v=4",
"events_url": "https://api.github.com/users/mathewjacob1002/events{/privacy}",
"followers_url": "https://api.github.com/users/mathewjacob1002/followers",
"following_url": "https://api.github.com/users/mathewjacob1002/following{/other_user}... | [] | closed | false | null | [] | null | [
"@lhoestq would you be able to review this please and also approve the workflow?",
"Sounds good to me :) feel free to run `make style` to apply code formatting",
"_The documentation is not available anymore as the PR was closed or merged._",
"cool ! I think we can merge once all comments have been addressed",... | 2023-06-23T22:18:20Z | 2023-07-07T10:05:58Z | 2023-07-07T09:56:09Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5986.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5986",
"merged_at": "2023-07-07T09:56:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5986.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Moved the code from using collect() to using toLocalIterator, which allows for prefetching partitions that will be selected next, thus allowing for better performance when iterating. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5986/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5986/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/258 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/258/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/258/comments | https://api.github.com/repos/huggingface/datasets/issues/258/events | https://github.com/huggingface/datasets/issues/258 | 635,859,525 | MDU6SXNzdWU2MzU4NTk1MjU= | 258 | Why is dataset after tokenization far more larger than the orginal one ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"Hi ! This is because `.map` added the new column `input_ids` to the dataset, and so all the other columns were kept. Therefore the dataset size increased a lot.\r\n If you want to only keep the `input_ids` column, you can stash the other ones by specifying `remove_columns=[\"title\", \"text\"]` in the arguments of... | 2020-06-10T01:27:07Z | 2020-06-10T12:46:34Z | 2020-06-10T12:46:34Z | CONTRIBUTOR | null | null | null | I tokenize wiki dataset by `map` and cache the results.
```
def tokenize_tfm(example):
example['input_ids'] = hf_fast_tokenizer.convert_tokens_to_ids(hf_fast_tokenizer.tokenize(example['text']))
return example
wiki = nlp.load_dataset('wikipedia', '20200501.en', cache_dir=cache_dir)['train']
wiki.map(token... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/258/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/258/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2870 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2870/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2870/comments | https://api.github.com/repos/huggingface/datasets/issues/2870/events | https://github.com/huggingface/datasets/pull/2870 | 988,276,859 | MDExOlB1bGxSZXF1ZXN0NzI3MjI4Njk5 | 2,870 | Fix three typos in two files for documentation | {
"avatar_url": "https://avatars.githubusercontent.com/u/25124853?v=4",
"events_url": "https://api.github.com/users/leny-mi/events{/privacy}",
"followers_url": "https://api.github.com/users/leny-mi/followers",
"following_url": "https://api.github.com/users/leny-mi/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-09-04T11:49:43Z | 2021-09-06T08:21:21Z | 2021-09-06T08:19:35Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2870.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2870",
"merged_at": "2021-09-06T08:19:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2870.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Changed "bacth_size" to "batch_size" (2x)
Changed "intsructions" to "instructions" | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2870/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2870/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4393/comments | https://api.github.com/repos/huggingface/datasets/issues/4393/events | https://github.com/huggingface/datasets/pull/4393 | 1,244,876,662 | PR_kwDODunzps44RxWN | 4,393 | Update CI deprecated legacy image | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-05-23T09:35:42Z | 2022-05-23T10:08:28Z | 2022-05-23T09:59:55Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4393.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4393",
"merged_at": "2022-05-23T09:59:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4393.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Now our CI still uses a deprecated legacy image:
> You’re using a [deprecated Docker convenience image.](https://discuss.circleci.com/t/legacy-convenience-image-deprecation/41034) Upgrade to a next-gen Docker convenience image.
This PR updates to next-generation convenience image.
Related to:
- #2955 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4393/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4393/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3349/comments | https://api.github.com/repos/huggingface/datasets/issues/3349/events | https://github.com/huggingface/datasets/pull/3349 | 1,067,853,601 | PR_kwDODunzps4vOF-s | 3,349 | raise exception instead of using assertions. | {
"avatar_url": "https://avatars.githubusercontent.com/u/153142?v=4",
"events_url": "https://api.github.com/users/manisnesan/events{/privacy}",
"followers_url": "https://api.github.com/users/manisnesan/followers",
"following_url": "https://api.github.com/users/manisnesan/following{/other_user}",
"gists_url": ... | [] | closed | false | null | [] | null | [
"@mariosasko - Thanks for the review & suggestions. Updated as per the suggestions. ",
"@mariosasko - Hello, Are there any additional changes required from my end??. Wondering if this PR can be merged or still pending on additional steps.",
"@mariosasko - The approved changes in the PR now has conflicts with th... | 2021-12-01T01:37:51Z | 2021-12-20T16:07:27Z | 2021-12-20T16:07:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3349",
"merged_at": "2021-12-20T16:07:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | fix for the remaining files https://github.com/huggingface/datasets/issues/3171 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3349/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3349/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2746/comments | https://api.github.com/repos/huggingface/datasets/issues/2746/events | https://github.com/huggingface/datasets/issues/2746 | 958,551,619 | MDU6SXNzdWU5NTg1NTE2MTk= | 2,746 | Cannot load `few-nerd` dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/28717374?v=4",
"events_url": "https://api.github.com/users/Mehrad0711/events{/privacy}",
"followers_url": "https://api.github.com/users/Mehrad0711/followers",
"following_url": "https://api.github.com/users/Mehrad0711/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @Mehrad0711,\r\n\r\nI'm afraid there is no \"canonical\" Hugging Face dataset named \"few-nerd\".\r\n\r\nThere are 2 kinds of datasets hosted at the Hugging Face Hub:\r\n- canonical datasets (their identifier contains no slash \"/\"): we, the Hugging Face team, supervise their implementation and we make sure th... | 2021-08-02T22:18:57Z | 2021-11-16T08:51:34Z | 2021-08-03T19:45:43Z | NONE | null | null | null | ## Describe the bug
Cannot load `few-nerd` dataset.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset('few-nerd', 'supervised')
```
## Actual results
Executing above code will give the following error:
```
Using the latest cached version of the module from /Users... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2746/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2746/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1236 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1236/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1236/comments | https://api.github.com/repos/huggingface/datasets/issues/1236/events | https://github.com/huggingface/datasets/pull/1236 | 758,263,012 | MDExOlB1bGxSZXF1ZXN0NTMzNDYzOTg2 | 1,236 | Opus finlex dataset of language pair Finnish and Swedish | {
"avatar_url": "https://avatars.githubusercontent.com/u/6419011?v=4",
"events_url": "https://api.github.com/users/spatil6/events{/privacy}",
"followers_url": "https://api.github.com/users/spatil6/followers",
"following_url": "https://api.github.com/users/spatil6/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [] | 2020-12-07T07:53:57Z | 2020-12-08T13:30:33Z | 2020-12-08T13:30:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1236.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1236",
"merged_at": "2020-12-08T13:30:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1236.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Added Opus_finlex dataset of language pair Finnish and Swedish
More info : http://opus.nlpl.eu/Finlex.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1236/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1236/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6056 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6056/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6056/comments | https://api.github.com/repos/huggingface/datasets/issues/6056/events | https://github.com/huggingface/datasets/pull/6056 | 1,815,086,963 | PR_kwDODunzps5WD4RY | 6,056 | Implement proper checkpointing for dataset uploading with resume function that does not require remapping shards that have already been uploaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/10792502?v=4",
"events_url": "https://api.github.com/users/AntreasAntoniou/events{/privacy}",
"followers_url": "https://api.github.com/users/AntreasAntoniou/followers",
"following_url": "https://api.github.com/users/AntreasAntoniou/following{/other_user}"... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6056). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq Reading the filenames is something I tried earlier, but I decided to use the yaml direction because:\r\n\r\n1. The yaml file name is const... | 2023-07-21T03:13:21Z | 2023-08-17T08:26:53Z | null | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6056.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6056",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6056.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6056"
} | Context: issue #5990
In order to implement the checkpointing, I introduce a metadata folder that keeps one yaml file for each set that one is uploading. This yaml keeps track of what shards have already been uploaded, and which one the idx of the latest one was. Using this information I am then able to easily get th... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6056/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6056/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5659/comments | https://api.github.com/repos/huggingface/datasets/issues/5659/events | https://github.com/huggingface/datasets/issues/5659 | 1,635,447,540 | I_kwDODunzps5hevL0 | 5,659 | [Audio] Soundfile/libsndfile requirements too stringent for decoding mp3 files | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"cc @polinaeterna @lhoestq ",
"@sanchit-gandhi can you please also post the logs of `pip install soundfile==0.12.1`? To check what wheel is being installed or if it's being built from source (I think it's the latter case). \r\nRequired `libsndfile` binary **should** be bundeled with `soundfile` wheel but I assume... | 2023-03-22T10:07:33Z | 2023-11-10T15:42:32Z | 2023-04-07T08:51:28Z | CONTRIBUTOR | null | null | null | ### Describe the bug
I'm encountering several issues trying to load mp3 audio files using `datasets` on a TPU v4.
The PR https://github.com/huggingface/datasets/pull/5573 updated the audio loading logic to rely solely on the `soundfile`/`libsndfile` libraries for loading audio samples, regardless of their file t... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5659/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5659/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6076 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6076/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6076/comments | https://api.github.com/repos/huggingface/datasets/issues/6076/events | https://github.com/huggingface/datasets/pull/6076 | 1,822,345,597 | PR_kwDODunzps5WcGVR | 6,076 | No gzip encoding from github | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-07-26T12:46:07Z | 2023-07-27T16:15:11Z | 2023-07-27T16:14:40Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6076.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6076",
"merged_at": "2023-07-27T16:14:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6076.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Don't accept gzip encoding from github, otherwise some files are not streamable + seekable.
fix https://huggingface.co/datasets/code_x_glue_cc_code_to_code_trans/discussions/2#64c0e0c1a04a514ba6303e84
and making sure https://github.com/huggingface/datasets/issues/2918 works as well | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6076/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6076/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2242/comments | https://api.github.com/repos/huggingface/datasets/issues/2242/events | https://github.com/huggingface/datasets/issues/2242 | 862,870,205 | MDU6SXNzdWU4NjI4NzAyMDU= | 2,242 | Link to datasets viwer on Quick Tour page returns "502 Bad Gateway" | {
"avatar_url": "https://avatars.githubusercontent.com/u/6735707?v=4",
"events_url": "https://api.github.com/users/martavillegas/events{/privacy}",
"followers_url": "https://api.github.com/users/martavillegas/followers",
"following_url": "https://api.github.com/users/martavillegas/following{/other_user}",
"gi... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"This should be fixed now!\r\n\r\ncc @srush "
] | 2021-04-20T14:19:51Z | 2021-04-20T15:02:45Z | 2021-04-20T15:02:45Z | NONE | null | null | null | Link to datasets viwer (https://huggingface.co/datasets/viewer/) on Quick Tour page (https://huggingface.co/docs/datasets/quicktour.html) returns "502 Bad Gateway"
The same error with https://huggingface.co/datasets/viewer/?dataset=glue&config=mrpc | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2242/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4243 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4243/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4243/comments | https://api.github.com/repos/huggingface/datasets/issues/4243/events | https://github.com/huggingface/datasets/pull/4243 | 1,217,689,909 | PR_kwDODunzps425Gkn | 4,243 | WIP: Initial shades loading script and readme | {
"avatar_url": "https://avatars.githubusercontent.com/u/69018523?v=4",
"events_url": "https://api.github.com/users/shayne-longpre/events{/privacy}",
"followers_url": "https://api.github.com/users/shayne-longpre/followers",
"following_url": "https://api.github.com/users/shayne-longpre/following{/other_user}",
... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Thanks for your contribution, @shayne-longpre.\r\n\r\nAre you still interested in adding this dataset? As we are transferring the dataset scripts from this GitHub repo, we would recommend you to add this to the Hugging Face Hub: https://huggingface.co/datasets"
] | 2022-04-27T17:45:43Z | 2022-10-03T09:36:35Z | 2022-10-03T09:36:35Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4243.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4243",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4243.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4243"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4243/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4243/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/647/comments | https://api.github.com/repos/huggingface/datasets/issues/647/events | https://github.com/huggingface/datasets/issues/647 | 704,734,764 | MDU6SXNzdWU3MDQ3MzQ3NjQ= | 647 | Cannot download dataset_info.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/33407613?v=4",
"events_url": "https://api.github.com/users/chiyuzhang94/events{/privacy}",
"followers_url": "https://api.github.com/users/chiyuzhang94/followers",
"following_url": "https://api.github.com/users/chiyuzhang94/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"Thanks for reporting !\r\nWe should add support for servers without internet connection indeed\r\nI'll do that early next week",
"Thanks, @lhoestq !\r\nPlease let me know when it is available. ",
"Right now the recommended way is to create the dataset on a server with internet connection and then to save it an... | 2020-09-19T01:35:15Z | 2020-09-21T08:28:42Z | 2020-09-21T08:28:42Z | NONE | null | null | null | I am running my job on a cloud server where does not provide for connections from the standard compute nodes to outside resources. Hence, when I use `dataset.load_dataset()` to load data, I got an error like this:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/text... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/647/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2865 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2865/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2865/comments | https://api.github.com/repos/huggingface/datasets/issues/2865/events | https://github.com/huggingface/datasets/pull/2865 | 986,460,698 | MDExOlB1bGxSZXF1ZXN0NzI1NjY1ODgx | 2,865 | Add MultiEURLEX dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1626984?v=4",
"events_url": "https://api.github.com/users/iliaschalkidis/events{/privacy}",
"followers_url": "https://api.github.com/users/iliaschalkidis/followers",
"following_url": "https://api.github.com/users/iliaschalkidis/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Hi @lhoestq, we have this new cool multilingual dataset coming at EMNLP 2021. It would be really nice if we could have it in Hugging Face asap. Thanks! ",
"Hi @lhoestq, I adopted most of your suggestions:\r\n\r\n- Dummy data files reduced, including the 2 smallest documents per subset JSONL.\r\n- README was upda... | 2021-09-02T09:42:24Z | 2021-09-10T11:50:06Z | 2021-09-10T11:50:06Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2865.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2865",
"merged_at": "2021-09-10T11:50:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2865.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | **Add new MultiEURLEX Dataset**
MultiEURLEX comprises 65k EU laws in 23 official EU languages (some low-ish resource). Each EU law has been annotated with EUROVOC concepts (labels) by the Publication Office of EU. As with the English EURLEX, the goal is to predict the relevant EUROVOC concepts (labels); this is mult... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2865/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2865/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1342/comments | https://api.github.com/repos/huggingface/datasets/issues/1342/events | https://github.com/huggingface/datasets/pull/1342 | 759,794,121 | MDExOlB1bGxSZXF1ZXN0NTM0NzM1MzAw | 1,342 | [yaml] Fix metadata according to pre-specified scheme | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [] | 2020-12-08T21:26:34Z | 2020-12-09T15:37:27Z | 2020-12-09T15:37:26Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1342.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1342",
"merged_at": "2020-12-09T15:37:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1342.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | @lhoestq @yjernite | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1342/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1342/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5880 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5880/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5880/comments | https://api.github.com/repos/huggingface/datasets/issues/5880/events | https://github.com/huggingface/datasets/issues/5880 | 1,719,090,101 | I_kwDODunzps5mdzu1 | 5,880 | load_dataset from s3 file system through streaming can't not iterate data | {
"avatar_url": "https://avatars.githubusercontent.com/u/59083384?v=4",
"events_url": "https://api.github.com/users/janineguo/events{/privacy}",
"followers_url": "https://api.github.com/users/janineguo/followers",
"following_url": "https://api.github.com/users/janineguo/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | [
"This sounds related to #5281.\r\n\r\nCan you try passing `storage_options=s3_client.storage_options` instead passing it to `use_auth_token=` ?",
"I tried `storage_options` before, but it doesn't work, I checked our source code and I found that we even didn't pass this parameter to the following process. if I use... | 2023-05-22T07:40:27Z | 2023-05-26T12:52:08Z | null | CONTRIBUTOR | null | null | null | ### Describe the bug
I have a JSON file in my s3 file system(minio), I can use load_dataset to get the file link, but I can't iterate it
<img width="816" alt="image" src="https://github.com/huggingface/datasets/assets/59083384/cc0778d3-36f3-45b5-ac68-4e7c664c2ed0">
<img width="1144" alt="image" src="https://github.c... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5880/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5880/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5498 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5498/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5498/comments | https://api.github.com/repos/huggingface/datasets/issues/5498/events | https://github.com/huggingface/datasets/issues/5498 | 1,568,190,529 | I_kwDODunzps5deLBB | 5,498 | TypeError: 'bool' object is not iterable when filtering a datasets.arrow_dataset.Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/91255010?v=4",
"events_url": "https://api.github.com/users/vmuel/events{/privacy}",
"followers_url": "https://api.github.com/users/vmuel/followers",
"following_url": "https://api.github.com/users/vmuel/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"Hi! Instead of a single boolean, your filter function should return an iterable (of booleans) in the batched mode like so:\r\n```python\r\ntrain_dataset = train_dataset.filter(\r\n function=lambda batch: [image is not None for image in batch[\"image\"]], \r\n batched=True,\r\n batc... | 2023-02-02T14:46:49Z | 2023-10-08T06:12:47Z | 2023-02-04T17:19:36Z | NONE | null | null | null | ### Describe the bug
Hi,
Thanks for the amazing work on the library!
**Describe the bug**
I think I might have noticed a small bug in the filter method.
Having loaded a dataset using `load_dataset`, when I try to filter out empty entries with `batched=True`, I get a TypeError.
### Steps to reproduce the ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5498/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5498/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/968 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/968/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/968/comments | https://api.github.com/repos/huggingface/datasets/issues/968/events | https://github.com/huggingface/datasets/pull/968 | 754,659,015 | MDExOlB1bGxSZXF1ZXN0NTMwNTIwMjEz | 968 | ADD Afrikaans NER | {
"avatar_url": "https://avatars.githubusercontent.com/u/7923902?v=4",
"events_url": "https://api.github.com/users/yvonnegitau/events{/privacy}",
"followers_url": "https://api.github.com/users/yvonnegitau/followers",
"following_url": "https://api.github.com/users/yvonnegitau/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [
"One trick if you want to add other datasets: consider running these commands each time you want to add a new dataset\r\n```\r\ngit checkout master\r\ngit fetch upstream\r\ngit rebase upstream/master\r\ngit checkout -b add-<my_dataset_name>\r\n```"
] | 2020-12-01T19:23:03Z | 2020-12-02T09:41:28Z | 2020-12-02T09:41:28Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/968.diff",
"html_url": "https://github.com/huggingface/datasets/pull/968",
"merged_at": "2020-12-02T09:41:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/968.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/968... | Afrikaans NER corpus | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/968/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/968/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2910 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2910/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2910/comments | https://api.github.com/repos/huggingface/datasets/issues/2910/events | https://github.com/huggingface/datasets/pull/2910 | 996,149,632 | PR_kwDODunzps4rvL9N | 2,910 | feat: 🎸 pass additional arguments to get private configs + info | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Included in https://github.com/huggingface/datasets/pull/2906"
] | 2021-09-14T15:24:19Z | 2021-09-15T16:19:09Z | 2021-09-15T16:19:06Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2910.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2910",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2910.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2910"
} | `use_auth_token` can now be passed to the functions to get the configs
or infos of private datasets on the hub | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2910/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2910/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/208 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/208/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/208/comments | https://api.github.com/repos/huggingface/datasets/issues/208/events | https://github.com/huggingface/datasets/pull/208 | 626,398,519 | MDExOlB1bGxSZXF1ZXN0NDI0Mzk0ODIx | 208 | [Dummy data] insert config name instead of config | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-05-28T10:28:19Z | 2020-05-28T12:48:01Z | 2020-05-28T12:48:00Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/208.diff",
"html_url": "https://github.com/huggingface/datasets/pull/208",
"merged_at": "2020-05-28T12:48:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/208.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/208... | Thanks @yjernite for letting me know. in the dummy data command the config name shuold be passed to the dataset builder and not the config itself.
Also, @lhoestq fixed small import bug introduced by beam command I think. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/208/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/208/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3707/comments | https://api.github.com/repos/huggingface/datasets/issues/3707/events | https://github.com/huggingface/datasets/issues/3707 | 1,132,741,903 | I_kwDODunzps5DhEUP | 3,707 | `.select`: unexpected behavior with `indices` | {
"avatar_url": "https://avatars.githubusercontent.com/u/36087158?v=4",
"events_url": "https://api.github.com/users/gabegma/events{/privacy}",
"followers_url": "https://api.github.com/users/gabegma/followers",
"following_url": "https://api.github.com/users/gabegma/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Hi! Currently, we compute the final index as `index % len(dset)`. I agree this behavior is somewhat unexpected and that it would be more appropriate to raise an error instead (this is what `df.iloc` in Pandas does, for instance).\r\n\r\n@albertvillanova @lhoestq wdyt?",
"I agree. I think `index % len(dset)` was ... | 2022-02-11T15:20:01Z | 2022-02-14T19:19:21Z | 2022-02-14T19:19:21Z | NONE | null | null | null | ## Describe the bug
The `.select` method will not throw when sending `indices` bigger than the dataset length; `indices` will be wrapped instead. This behavior is not documented anywhere, and is not intuitive.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"text": [... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3707/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/473 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/473/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/473/comments | https://api.github.com/repos/huggingface/datasets/issues/473/events | https://github.com/huggingface/datasets/pull/473 | 672,007,247 | MDExOlB1bGxSZXF1ZXN0NDYyMTIwNzU4 | 473 | add DoQA dataset (ACL 2020) | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-08-03T11:26:52Z | 2020-09-10T17:19:11Z | 2020-09-03T11:44:15Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/473.diff",
"html_url": "https://github.com/huggingface/datasets/pull/473",
"merged_at": "2020-09-03T11:44:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/473.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/473... | add DoQA dataset (ACL 2020) http://ixa.eus/node/12931 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/473/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/473/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6019 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6019/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6019/comments | https://api.github.com/repos/huggingface/datasets/issues/6019/events | https://github.com/huggingface/datasets/pull/6019 | 1,799,532,822 | PR_kwDODunzps5VPAlD | 6,019 | Improve logging | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-07-11T18:30:23Z | 2023-07-12T19:34:14Z | 2023-07-12T17:19:28Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6019.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6019",
"merged_at": "2023-07-12T17:19:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6019.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adds the StreamHandler (as `hfh` and `transformers` do) to the library's logger to log INFO messages and logs the messages about "loading a cached result" (and some other warnings) as INFO
(Also removes the `leave=False` arg in the progress bars to be consistent with `hfh` and `transformers` - progress bars serve as... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6019/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6019/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1732/comments | https://api.github.com/repos/huggingface/datasets/issues/1732/events | https://github.com/huggingface/datasets/pull/1732 | 784,874,490 | MDExOlB1bGxSZXF1ZXN0NTUzOTkzNTAx | 1,732 | [GEM Dataset] Added TurkCorpus, an evaluation dataset for sentence simplification. | {
"avatar_url": "https://avatars.githubusercontent.com/u/11708999?v=4",
"events_url": "https://api.github.com/users/mounicam/events{/privacy}",
"followers_url": "https://api.github.com/users/mounicam/followers",
"following_url": "https://api.github.com/users/mounicam/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Thank you for the feedback! I updated the code. "
] | 2021-01-13T07:50:19Z | 2021-01-14T10:19:41Z | 2021-01-14T10:19:41Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1732.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1732",
"merged_at": "2021-01-14T10:19:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1732.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | We want to use TurkCorpus for validation and testing of the sentence simplification task. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1732/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1732/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5491 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5491/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5491/comments | https://api.github.com/repos/huggingface/datasets/issues/5491/events | https://github.com/huggingface/datasets/pull/5491 | 1,566,235,012 | PR_kwDODunzps5JA9OD | 5,491 | [MINOR] Typo | {
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-02-01T14:39:39Z | 2023-02-02T07:42:28Z | 2023-02-02T07:35:14Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5491.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5491",
"merged_at": "2023-02-02T07:35:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5491.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5491/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5491/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6164 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6164/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6164/comments | https://api.github.com/repos/huggingface/datasets/issues/6164/events | https://github.com/huggingface/datasets/pull/6164 | 1,859,560,007 | PR_kwDODunzps5YZZAJ | 6,164 | Fix: Missing a MetadataConfigs init when the repo has a `datasets_info.json` but no README | {
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-08-21T14:57:54Z | 2023-08-21T16:27:05Z | 2023-08-21T16:18:26Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6164.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6164",
"merged_at": "2023-08-21T16:18:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6164.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | When I try to push to an arrow repo (can provide the link on Slack), it uploads the files but fails to update the metadata, with
```
File "app.py", line 123, in add_new_eval
eval_results[level].push_to_hub(my_repo, token=TOKEN, split=SPLIT)
File "blabla_my_env_path/lib/python3.10/site-packages/datasets/arro... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6164/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6164/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3761 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3761/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3761/comments | https://api.github.com/repos/huggingface/datasets/issues/3761/events | https://github.com/huggingface/datasets/issues/3761 | 1,144,830,702 | I_kwDODunzps5EPLru | 3,761 | Know your data for HF hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/20128202?v=4",
"events_url": "https://api.github.com/users/Muhtasham/events{/privacy}",
"followers_url": "https://api.github.com/users/Muhtasham/followers",
"following_url": "https://api.github.com/users/Muhtasham/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi @Muhtasham you should take a look at https://huggingface.co/blog/data-measurements-tool and accompanying demo app at https://huggingface.co/spaces/huggingface/data-measurements-tool\r\n\r\nWe would be interested in your feedback. cc @meg-huggingface @sashavor @yjernite "
] | 2022-02-19T19:48:47Z | 2022-02-21T14:15:23Z | 2022-02-21T14:15:23Z | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
Would be great to see be able to understand datasets with the goal of improving data quality, and helping mitigate fairness and bias issues.
**Describe the solution you'd like**
Something like https://knowyourdata.withgoogle.com/ for HF hub | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3761/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3761/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1516 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1516/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1516/comments | https://api.github.com/repos/huggingface/datasets/issues/1516/events | https://github.com/huggingface/datasets/pull/1516 | 764,032,327 | MDExOlB1bGxSZXF1ZXN0NTM4MjkzOTMw | 1,516 | adding wrbsc | {
"avatar_url": "https://avatars.githubusercontent.com/u/15803781?v=4",
"events_url": "https://api.github.com/users/kldarek/events{/privacy}",
"followers_url": "https://api.github.com/users/kldarek/followers",
"following_url": "https://api.github.com/users/kldarek/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"@lhoestq thanks for the comments! Should be fixed in the latest commit, I assume the CI errors are unrelated. ",
"merging since the CI is fixed on master"
] | 2020-12-12T16:38:40Z | 2020-12-18T09:41:33Z | 2020-12-18T09:41:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1516.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1516",
"merged_at": "2020-12-18T09:41:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1516.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1516/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1516/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/486 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/486/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/486/comments | https://api.github.com/repos/huggingface/datasets/issues/486/events | https://github.com/huggingface/datasets/issues/486 | 675,649,034 | MDU6SXNzdWU2NzU2NDkwMzQ= | 486 | Bookcorpus data contains pretokenized text | {
"avatar_url": "https://avatars.githubusercontent.com/u/99543?v=4",
"events_url": "https://api.github.com/users/orsharir/events{/privacy}",
"followers_url": "https://api.github.com/users/orsharir/followers",
"following_url": "https://api.github.com/users/orsharir/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Yes indeed it looks like some `'` and spaces are missing (for example in `dont` or `didnt`).\r\nDo you know if there exist some copies without this issue ?\r\nHow would you fix this issue on the current data exactly ? I can see that the data is raw text (not tokenized) so I'm not sure I understand how you would do... | 2020-08-09T06:53:24Z | 2022-10-04T17:44:33Z | 2022-10-04T17:44:33Z | CONTRIBUTOR | null | null | null | It seem that the bookcoprus data downloaded through the library was pretokenized with NLTK's Treebank tokenizer, which changes the text in incompatible ways to how, for instance, BERT's wordpiece tokenizer works. For example, "didn't" becomes "did" + "n't", and double quotes are changed to `` and '' for start and end q... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/486/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/486/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5379/comments | https://api.github.com/repos/huggingface/datasets/issues/5379/events | https://github.com/huggingface/datasets/pull/5379 | 1,504,010,639 | PR_kwDODunzps5F1r2k | 5,379 | feat: depth estimation dataset guide. | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
... | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the changes, looks good to me!",
"@stevhliu I have pushed some quality improvements both in terms of code and content. Would you be able to re-review? ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0... | 2022-12-20T05:32:11Z | 2023-01-13T12:30:31Z | 2023-01-13T12:23:34Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5379.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5379",
"merged_at": "2023-01-13T12:23:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5379.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds a guide for prepping datasets for depth estimation.
PR to add documentation images is up here: https://huggingface.co/datasets/huggingface/documentation-images/discussions/22 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5379/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5379/timeline | null | null | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.