
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 600M 2.05B | node_id stringlengths 18 32 | number int64 2 6.51k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association stringclasses 3
values | active_lock_reason float64 | draft float64 0 1 ⌀ | pull_request dict | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/656/comments | https://api.github.com/repos/huggingface/datasets/issues/656/events | https://github.com/huggingface/datasets/pull/656 | 705,736,319 | MDExOlB1bGxSZXF1ZXN0NDkwNDEwODAz | 656 | Use multiprocess from pathos for multiprocessing | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"We can just install multiprocess actually, I'll change that",
"Just an FYI: I remember that I wanted to try pathos a couple of years back and I ran into issues considering cross-platform; the code would just break on Windows. If I can verify this PR by running CPU tests on Windows, let me know!",
"That's good ... | 2020-09-21T16:12:19Z | 2020-09-28T14:45:40Z | 2020-09-28T14:45:39Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/656.diff",
"html_url": "https://github.com/huggingface/datasets/pull/656",
"merged_at": "2020-09-28T14:45:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/656.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/656... | [Multiprocess](https://github.com/uqfoundation/multiprocess) (from the [pathos](https://github.com/uqfoundation/pathos) project) allows to use lambda functions in multiprocessed map.
It was suggested to use it by @kandorm.
We're already using dill which is its only dependency. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/656/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/656/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2061 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2061/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2061/comments | https://api.github.com/repos/huggingface/datasets/issues/2061/events | https://github.com/huggingface/datasets/issues/2061 | 832,596,228 | MDU6SXNzdWU4MzI1OTYyMjg= | 2,061 | Cannot load udpos subsets from xtreme dataset using load_dataset() | {
"avatar_url": "https://avatars.githubusercontent.com/u/55791365?v=4",
"events_url": "https://api.github.com/users/adzcodez/events{/privacy}",
"followers_url": "https://api.github.com/users/adzcodez/followers",
"following_url": "https://api.github.com/users/adzcodez/following{/other_user}",
"gists_url": "htt... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | null | [] | null | [
"@lhoestq Adding \"_\" to the class labels in the dataset script will fix the issue.\r\n\r\nThe bigger issue IMO is that the data files are in conll format, but the examples are tokens, not sentences.",
"Hi ! Thanks for reporting @adzcodez \r\n\r\n\r\n> @lhoestq Adding \"_\" to the class labels in the dataset scr... | 2021-03-16T09:32:13Z | 2021-06-18T11:54:11Z | 2021-06-18T11:54:10Z | NONE | null | null | null | Hello,
I am trying to load the udpos English subset from xtreme dataset, but this faces an error during loading. I am using datasets v1.4.1, pip install. I have tried with other udpos languages which also fail, though loading a different subset altogether (such as XNLI) has no issue. I have also tried on Colab and ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2061/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2061/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3304/comments | https://api.github.com/repos/huggingface/datasets/issues/3304/events | https://github.com/huggingface/datasets/issues/3304 | 1,059,130,494 | I_kwDODunzps4_IQx- | 3,304 | Dataset object has no attribute `to_tf_dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/59993678?v=4",
"events_url": "https://api.github.com/users/RajkumarGalaxy/events{/privacy}",
"followers_url": "https://api.github.com/users/RajkumarGalaxy/followers",
"following_url": "https://api.github.com/users/RajkumarGalaxy/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"The issue is due to the older version of transformers and datasets. It has been resolved by upgrading their versions.\r\n\r\n```\r\n# upgrade transformers and datasets to latest versions\r\n!pip install --upgrade transformers\r\n!pip install --upgrade datasets\r\n```\r\n\r\nRegards!"
] | 2021-11-20T12:03:59Z | 2021-11-21T07:07:25Z | 2021-11-21T07:07:25Z | NONE | null | null | null | I am following HuggingFace Course. I am at Fine-tuning a model.
Link: https://huggingface.co/course/chapter3/2?fw=tf
I use tokenize_function and `map` as mentioned in the course to process data.
`# define a tokenize function`
`def Tokenize_function(example):`
` return tokenizer(example['sentence'], truncat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3304/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3304/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/591/comments | https://api.github.com/repos/huggingface/datasets/issues/591/events | https://github.com/huggingface/datasets/pull/591 | 696,530,413 | MDExOlB1bGxSZXF1ZXN0NDgyNjAxMzc1 | 591 | fix #589 (backward compat) | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-09-09T07:33:13Z | 2020-09-09T08:57:56Z | 2020-09-09T08:57:55Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/591.diff",
"html_url": "https://github.com/huggingface/datasets/pull/591",
"merged_at": "2020-09-09T08:57:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/591.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/591... | Fix #589 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/591/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/591/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3691/comments | https://api.github.com/repos/huggingface/datasets/issues/3691/events | https://github.com/huggingface/datasets/pull/3691 | 1,127,629,306 | PR_kwDODunzps4yQThV | 3,691 | Upgrade black to version ~=22.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2022-02-08T18:45:19Z | 2022-02-08T19:56:40Z | 2022-02-08T19:56:39Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3691.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3691",
"merged_at": "2022-02-08T19:56:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3691.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Upgrades the `datasets` library quality tool `black` to use the first stable release of `black`, version 22.0. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3691/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3691/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/862 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/862/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/862/comments | https://api.github.com/repos/huggingface/datasets/issues/862/events | https://github.com/huggingface/datasets/pull/862 | 744,906,131 | MDExOlB1bGxSZXF1ZXN0NTIyNTUzMzY1 | 862 | Update head requests | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-11-17T16:49:06Z | 2020-11-18T14:43:53Z | 2020-11-18T14:43:50Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/862.diff",
"html_url": "https://github.com/huggingface/datasets/pull/862",
"merged_at": "2020-11-18T14:43:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/862.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/862... | Get requests and Head requests didn't have the same parameters. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/862/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/862/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4615/comments | https://api.github.com/repos/huggingface/datasets/issues/4615/events | https://github.com/huggingface/datasets/pull/4615 | 1,291,307,428 | PR_kwDODunzps46tADt | 4,615 | Fix `embed_storage` on features inside lists/sequences | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-01T11:52:08Z | 2022-07-08T12:13:10Z | 2022-07-08T12:01:36Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4615.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4615",
"merged_at": "2022-07-08T12:01:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4615.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add a dedicated function for embed_storage to always preserve the embedded/casted arrays (and to have more control over `embed_storage` in general).
Fix #4591
~~(Waiting for #4608 to be merged to mark this PR as ready for review - required for fixing `xgetsize` in private repos)~~ Done! | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4615/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5457/comments | https://api.github.com/repos/huggingface/datasets/issues/5457/events | https://github.com/huggingface/datasets/issues/5457 | 1,554,171,264 | I_kwDODunzps5cosWA | 5,457 | prebuilt dataset relies on `downloads/extracted` | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [
"Hi! \r\n\r\nThis issue is due to our audio/image datasets not being self-contained. This allows us to save disk space (files are written only once) but also leads to the issues like this one. We plan to make all our datasets self-contained in Datasets 3.0.\r\n\r\nIn the meantime, you can run the following map to e... | 2023-01-24T02:09:32Z | 2023-01-24T18:14:10Z | null | CONTRIBUTOR | null | null | null | ### Describe the bug
I pre-built the dataset:
```
python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
```
and it can be used just fine.
now I wipe out `downloads/extracted` and it no longer works.
```
rm -r ~/.cache/huggingface... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5457/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1356/comments | https://api.github.com/repos/huggingface/datasets/issues/1356/events | https://github.com/huggingface/datasets/pull/1356 | 759,994,457 | MDExOlB1bGxSZXF1ZXN0NTM0ODk3OTQ1 | 1,356 | Add StackOverflow StackSample dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7613470?v=4",
"events_url": "https://api.github.com/users/ncoop57/events{/privacy}",
"followers_url": "https://api.github.com/users/ncoop57/followers",
"following_url": "https://api.github.com/users/ncoop57/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"@lhoestq Thanks for the review and suggestions! I've added your comments and pushed the changes. I'm having issues with the dummy data still. When I run the dummy data test\r\n\r\n```bash\r\nRUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_all_configs_so_stacksample\r\n```\r\nI g... | 2020-12-09T04:59:51Z | 2020-12-21T14:48:21Z | 2020-12-21T14:48:21Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1356",
"merged_at": "2020-12-21T14:48:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds the StackOverflow StackSample dataset from Kaggle: https://www.kaggle.com/stackoverflow/stacksample
Ran through all of the steps. However, since my dataset requires manually downloading the data, I was unable to run the pytest on the real dataset (the dummy data pytest passed). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1356/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5550/comments | https://api.github.com/repos/huggingface/datasets/issues/5550/events | https://github.com/huggingface/datasets/pull/5550 | 1,591,409,475 | PR_kwDODunzps5KUl5i | 5,550 | Resolve four broken refs in the docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/37621491?v=4",
"events_url": "https://api.github.com/users/tomaarsen/events{/privacy}",
"followers_url": "https://api.github.com/users/tomaarsen/followers",
"following_url": "https://api.github.com/users/tomaarsen/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"See the resolved changes [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5550/en/package_reference/main_classes#datasets.Dataset.class_encode_column), [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5550/en/pa... | 2023-02-20T08:52:11Z | 2023-02-20T15:16:13Z | 2023-02-20T15:09:13Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5550.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5550",
"merged_at": "2023-02-20T15:09:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5550.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Hello!
## Pull Request overview
* Resolve 4 broken references in the docs
## The problems
Two broken references [here](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.class_encode_column):
 errors, which can arise when working with large datasets due to long-lasting HTTP connections, by repeating calls to `push_to_hub` to resume an upload.
To be able to check if an upload can be resumed, this PR mo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4402/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4402/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4554/comments | https://api.github.com/repos/huggingface/datasets/issues/4554/events | https://github.com/huggingface/datasets/pull/4554 | 1,283,369,453 | PR_kwDODunzps46Sv_f | 4,554 | Fix WMT dataset loading issue and docs update (Re-opened) | {
"avatar_url": "https://avatars.githubusercontent.com/u/8711912?v=4",
"events_url": "https://api.github.com/users/khushmeeet/events{/privacy}",
"followers_url": "https://api.github.com/users/khushmeeet/followers",
"following_url": "https://api.github.com/users/khushmeeet/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-06-24T07:26:16Z | 2022-07-08T15:39:20Z | 2022-07-08T15:27:44Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4554.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4554",
"merged_at": "2022-07-08T15:27:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4554.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR is a fix for #4354
Changes are made for `wmt14`, `wmt15`, `wmt16`, `wmt17`, `wmt18`, `wmt19` and `wmt_t2t`. And READMEs are updated for the corresponding datasets.
Let me know, if any additional changes are required.
Thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4554/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4554/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4594/comments | https://api.github.com/repos/huggingface/datasets/issues/4594/events | https://github.com/huggingface/datasets/issues/4594 | 1,288,070,023 | I_kwDODunzps5MxmOH | 4,594 | load_from_disk suggests incorrect fix when used to load DatasetDict | {
"avatar_url": "https://avatars.githubusercontent.com/u/11157811?v=4",
"events_url": "https://api.github.com/users/dvsth/events{/privacy}",
"followers_url": "https://api.github.com/users/dvsth/followers",
"following_url": "https://api.github.com/users/dvsth/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | 2022-06-29T01:40:01Z | 2022-06-29T04:03:44Z | 2022-06-29T04:03:44Z | NONE | null | null | null | Edit: Please feel free to remove this issue. The problem was not the error message but the fact that the DatasetDict.load_from_disk does not support loading nested splits, i.e. if one of the splits is itself a DatasetDict. If nesting splits is an antipattern, perhaps the load_from_disk function can throw a warning indi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4594/timeline | null | not_planned | false |
https://api.github.com/repos/huggingface/datasets/issues/3027 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3027/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3027/comments | https://api.github.com/repos/huggingface/datasets/issues/3027/events | https://github.com/huggingface/datasets/issues/3027 | 1,016,150,117 | I_kwDODunzps48kThl | 3,027 | Resolve data_files by split name | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Awesome @lhoestq I like the proposal and it works great on my JSON community dataset. Here is the [log](https://gist.github.com/vblagoje/714babc325bcbdd5de579fd8e1648892). ",
"From my discussion with @borisdayma it would be more general the files match if their paths contains the split name - not only if the fil... | 2021-10-05T10:24:36Z | 2021-11-05T17:49:58Z | 2021-11-05T17:49:57Z | MEMBER | null | null | null | This issue is about discussing the default behavior when someone loads a dataset that consists in data files. For example:
```python
load_dataset("lhoestq/demo1")
```
should return two splits "train" and "test" since the dataset repostiory is like
```
data/
├── train.csv
└── test.csv
```
Currently it returns ... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3027/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3027/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2855 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2855/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2855/comments | https://api.github.com/repos/huggingface/datasets/issues/2855/events | https://github.com/huggingface/datasets/pull/2855 | 983,858,229 | MDExOlB1bGxSZXF1ZXN0NzIzMzcxMTIy | 2,855 | Fix windows CI CondaError | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-08-31T13:22:02Z | 2021-08-31T13:35:34Z | 2021-08-31T13:35:33Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2855.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2855",
"merged_at": "2021-08-31T13:35:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2855.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | From this thread: https://github.com/conda/conda/issues/6057
We can fix the conda error
```
CondaError: Cannot link a source that does not exist.
C:\Users\...\Anaconda3\Scripts\conda.exe
```
by doing
```bash
conda update conda
```
before doing any install in the windows CI | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2855/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2855/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/554/comments | https://api.github.com/repos/huggingface/datasets/issues/554/events | https://github.com/huggingface/datasets/issues/554 | 690,173,214 | MDU6SXNzdWU2OTAxNzMyMTQ= | 554 | nlp downloads to its module path | {
"avatar_url": "https://avatars.githubusercontent.com/u/49398?v=4",
"events_url": "https://api.github.com/users/danieldk/events{/privacy}",
"followers_url": "https://api.github.com/users/danieldk/followers",
"following_url": "https://api.github.com/users/danieldk/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Indeed this is a known issue arising from the fact that we try to be compatible with cloupickle.\r\n\r\nDoes this also happen if you are installing in a virtual environment?",
"> Indeed this is a know issue with the fact that we try to be compatible with cloupickle.\r\n> \r\n> Does this also happen if you are in... | 2020-09-01T14:06:14Z | 2020-09-11T06:19:24Z | 2020-09-11T06:19:24Z | NONE | null | null | null | I am trying to package `nlp` for Nix, because it is now an optional dependency for `transformers`. The problem that I encounter is that the `nlp` library downloads to the module path, which is typically not writable in most package management systems:
```>>> import nlp
>>> squad_dataset = nlp.load_dataset('squad')
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/554/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/554/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2826 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2826/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2826/comments | https://api.github.com/repos/huggingface/datasets/issues/2826/events | https://github.com/huggingface/datasets/issues/2826 | 976,974,254 | MDU6SXNzdWU5NzY5NzQyNTQ= | 2,826 | Add a Text Classification dataset: KanHope | {
"avatar_url": "https://avatars.githubusercontent.com/u/46108405?v=4",
"events_url": "https://api.github.com/users/adeepH/events{/privacy}",
"followers_url": "https://api.github.com/users/adeepH/followers",
"following_url": "https://api.github.com/users/adeepH/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Hi ! In your script it looks like you're trying to load the dataset `bn_hate_speech,`, not KanHope.\r\n\r\nMoreover the error `KeyError: ' '` means that you have a feature of type ClassLabel, but for a certain example of the dataset, it looks like the label is empty (it's just a string with a space). Can you make ... | 2021-08-23T12:21:58Z | 2021-10-01T18:06:59Z | 2021-10-01T18:06:59Z | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** *KanHope*
- **Description:** *A code-mixed English-Kannada dataset for Hope speech detection*
- **Paper:** *https://arxiv.org/abs/2108.04616* (I am the author of the paper}
- **Author:** *[AdeepH](https://github.com/adeepH)*
- **Data:** *https://github.com/adeepH/KanHope/tree/main/d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2826/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2826/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6354/comments | https://api.github.com/repos/huggingface/datasets/issues/6354/events | https://github.com/huggingface/datasets/issues/6354 | 1,963,483,324 | I_kwDODunzps51CGC8 | 6,354 | `IterableDataset.from_spark` does not support multiple workers in pytorch `Dataloader` | {
"avatar_url": "https://avatars.githubusercontent.com/u/50199774?v=4",
"events_url": "https://api.github.com/users/NazyS/events{/privacy}",
"followers_url": "https://api.github.com/users/NazyS/followers",
"following_url": "https://api.github.com/users/NazyS/following{/other_user}",
"gists_url": "https://api.... | [] | open | false | null | [] | null | [
"I am having issues as well with this. \r\n\r\nHowever, the error I am getting is :\r\n`RuntimeError: It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transformation. SparkContext can only be used on the driver, not in code that it run on workers. For more informati... | 2023-10-26T12:43:36Z | 2023-11-14T18:46:03Z | null | NONE | null | null | null | ### Describe the bug
Looks like `IterableDataset.from_spark` does not support multiple workers in pytorch `Dataloader` if I'm not missing anything.
Also, returns not consistent error messages, which probably depend on the nondeterministic order of worker executions
Some exampes I've encountered:
```
File "/l... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6354/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4870 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4870/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4870/comments | https://api.github.com/repos/huggingface/datasets/issues/4870/events | https://github.com/huggingface/datasets/pull/4870 | 1,346,160,498 | PR_kwDODunzps49jGxD | 4,870 | audio folder check CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-22T10:15:53Z | 2022-11-02T11:54:35Z | 2022-08-22T12:19:40Z | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4870.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4870",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4870.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4870"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4870/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4870/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1474 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1474/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1474/comments | https://api.github.com/repos/huggingface/datasets/issues/1474/events | https://github.com/huggingface/datasets/pull/1474 | 762,083,706 | MDExOlB1bGxSZXF1ZXN0NTM2NjY4MjU3 | 1,474 | Create JSON dummy data without loading all dataset in memory | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | open | false | null | [] | null | [] | 2020-12-11T08:44:23Z | 2022-07-06T15:19:47Z | null | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1474.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1474",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1474.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1474"
} | See #1442.
The statement `json.load()` loads **all the file content in memory**.
In order to avoid this, file content should be parsed **iteratively**, by using the library `ijson` e.g.
I have refactorized the code into a function `_create_json_dummy_data` and I have added some tests. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1474/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1474/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1700/comments | https://api.github.com/repos/huggingface/datasets/issues/1700/events | https://github.com/huggingface/datasets/pull/1700 | 781,333,589 | MDExOlB1bGxSZXF1ZXN0NTUxMDc1NTg2 | 1,700 | Update Curiosity dialogs DatasetCard | {
"avatar_url": "https://avatars.githubusercontent.com/u/50873201?v=4",
"events_url": "https://api.github.com/users/vineeths96/events{/privacy}",
"followers_url": "https://api.github.com/users/vineeths96/followers",
"following_url": "https://api.github.com/users/vineeths96/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-01-07T13:59:27Z | 2021-01-12T18:51:32Z | 2021-01-12T18:51:32Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1700.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1700",
"merged_at": "2021-01-12T18:51:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1700.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Update Curiosity dialogs DatasetCard
There are some entries in the data fields section yet to be filled. There is little information regarding those fields. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1700/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1700/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3385/comments | https://api.github.com/repos/huggingface/datasets/issues/3385/events | https://github.com/huggingface/datasets/issues/3385 | 1,071,742,310 | I_kwDODunzps4_4X1m | 3,385 | None batched `with_transform`, `set_transform` | {
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! Thanks for the suggestion :)\r\nIt makes sense to me, and it can surely be implemented by wrapping the user's function to make it a batched function. However I'm not a big fan of the inconsistency it would create with `map`: `with_transform` is batched by default while `map` isn't.\r\n\r\nIs there something y... | 2021-12-06T05:20:54Z | 2022-01-17T15:25:01Z | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
A `torch.utils.data.Dataset.__getitem__` operates on a single example.
But 🤗 `Datasets.with_transform` doesn't seem to allow non-batched transform.
**Describe the solution you'd like**
Have a `batched=True` argument in `Datasets.with_transfor... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3385/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3385/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/487/comments | https://api.github.com/repos/huggingface/datasets/issues/487/events | https://github.com/huggingface/datasets/pull/487 | 676,143,029 | MDExOlB1bGxSZXF1ZXN0NDY1NTA1NjQy | 487 | Fix elasticsearch result ids returning as strings | {
"avatar_url": "https://avatars.githubusercontent.com/u/3595526?v=4",
"events_url": "https://api.github.com/users/sai-prasanna/events{/privacy}",
"followers_url": "https://api.github.com/users/sai-prasanna/followers",
"following_url": "https://api.github.com/users/sai-prasanna/following{/other_user}",
"gists... | [] | closed | false | null | [] | null | [
"It looks like you need to rebase from master to fix the CI. Could you do that please ?"
] | 2020-08-10T13:37:11Z | 2020-08-31T10:42:46Z | 2020-08-31T10:42:46Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/487.diff",
"html_url": "https://github.com/huggingface/datasets/pull/487",
"merged_at": "2020-08-31T10:42:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/487.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/487... | I am using the latest elasticsearch binary and master of nlp. For me elasticsearch searches failed because the resultant "id_" returned for searches are strings, but our library assumes them to be integers. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/487/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/487/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6270 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6270/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6270/comments | https://api.github.com/repos/huggingface/datasets/issues/6270/events | https://github.com/huggingface/datasets/issues/6270 | 1,920,329,373 | I_kwDODunzps5ydead | 6,270 | Dataset.from_generator raises with sharded gen_args | {
"avatar_url": "https://avatars.githubusercontent.com/u/53510?v=4",
"events_url": "https://api.github.com/users/hartmans/events{/privacy}",
"followers_url": "https://api.github.com/users/hartmans/followers",
"following_url": "https://api.github.com/users/hartmans/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"`gen_kwargs` should be a `dict`, as stated in the docstring, but you are passing a `list`.\r\n\r\nSo, to fix the error, replace the list of dicts with a dict of lists (and slightly modify the generator function):\r\n```python\r\nfrom pathlib import Path\r\nimport datasets\r\n\r\ndef process_yaml(files):\r\n for... | 2023-09-30T16:50:06Z | 2023-10-11T20:29:12Z | 2023-10-11T20:29:11Z | CONTRIBUTOR | null | null | null | ### Describe the bug
According to the docs of Datasets.from_generator:
```
gen_kwargs(`dict`, *optional*):
Keyword arguments to be passed to the `generator` callable.
You can define a sharded dataset by passing the list of shards in `gen_kwargs`.
```
So I'd expect that if gen_kwar... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6270/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6270/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5886 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5886/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5886/comments | https://api.github.com/repos/huggingface/datasets/issues/5886/events | https://github.com/huggingface/datasets/issues/5886 | 1,721,070,225 | I_kwDODunzps5mlXKR | 5,886 | Use work-stealing algorithm when parallel computing | {
"avatar_url": "https://avatars.githubusercontent.com/u/46060451?v=4",
"events_url": "https://api.github.com/users/1014661165/events{/privacy}",
"followers_url": "https://api.github.com/users/1014661165/followers",
"following_url": "https://api.github.com/users/1014661165/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Alternatively we could set the number of shards to be a factor than the number of processes (current they're equal) - this way it will be less likely to end up with a shard that is significantly slower than all the other ones."
] | 2023-05-23T03:08:44Z | 2023-05-24T15:30:09Z | null | NONE | null | null | null | ### Feature request
when i used Dataset.map api to process data concurrently, i found that
it gets slower and slower as it gets closer to completion. Then i read the source code of arrow_dataset.py and found that it shard the dataset and use multiprocessing pool to execute each shard.It may cause the slowest task ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5886/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5886/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/6446 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6446/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6446/comments | https://api.github.com/repos/huggingface/datasets/issues/6446/events | https://github.com/huggingface/datasets/issues/6446 | 2,007,092,708 | I_kwDODunzps53oc3k | 6,446 | Speech Commands v2 dataset doesn't match AST-v2 config | {
"avatar_url": "https://avatars.githubusercontent.com/u/18024303?v=4",
"events_url": "https://api.github.com/users/vymao/events{/privacy}",
"followers_url": "https://api.github.com/users/vymao/followers",
"following_url": "https://api.github.com/users/vymao/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"You can use `.align_labels_with_mapping` on the dataset to align the labels with the model config.\r\n\r\nRegarding the number of labels, only the special `_silence_` label corresponding to noise is missing, which is consistent with the model paper (reports training on 35 labels). You can run a `.filter` to drop ... | 2023-11-22T20:46:36Z | 2023-11-28T14:46:08Z | 2023-11-28T14:46:08Z | NONE | null | null | null | ### Describe the bug
[According](https://huggingface.co/MIT/ast-finetuned-speech-commands-v2) to `MIT/ast-finetuned-speech-commands-v2`, the model was trained on the Speech Commands v2 dataset. However, while the model config says the model should have 35 class labels, the dataset itself has 36 class labels. Moreover,... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6446/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6446/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6366/comments | https://api.github.com/repos/huggingface/datasets/issues/6366/events | https://github.com/huggingface/datasets/issues/6366 | 1,970,213,490 | I_kwDODunzps51bxJy | 6,366 | with_format() function returns bytes instead of PIL images even when image column is not part of "columns" | {
"avatar_url": "https://avatars.githubusercontent.com/u/17809020?v=4",
"events_url": "https://api.github.com/users/leot13/events{/privacy}",
"followers_url": "https://api.github.com/users/leot13/followers",
"following_url": "https://api.github.com/users/leot13/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Thanks for reporting! I've opened a PR with a fix."
] | 2023-10-31T11:10:48Z | 2023-11-02T14:21:17Z | 2023-11-02T14:21:17Z | NONE | null | null | null | ### Describe the bug
When using the with_format() function on a dataset containing images, even if the image column is not part of the columns provided in the function, its type will be changed to bytes.
Here is a minimal reproduction of the bug:
https://colab.research.google.com/drive/1hyaOspgyhB41oiR1-tXE3k_gJCdJU... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6366/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1716/comments | https://api.github.com/repos/huggingface/datasets/issues/1716/events | https://github.com/huggingface/datasets/pull/1716 | 782,819,006 | MDExOlB1bGxSZXF1ZXN0NTUyMjgzNzE5 | 1,716 | Add Hatexplain Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/48222101?v=4",
"events_url": "https://api.github.com/users/kushal2000/events{/privacy}",
"followers_url": "https://api.github.com/users/kushal2000/followers",
"following_url": "https://api.github.com/users/kushal2000/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2021-01-10T13:30:01Z | 2021-01-18T14:21:42Z | 2021-01-18T14:21:42Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1716.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1716",
"merged_at": "2021-01-18T14:21:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1716.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding Hatexplain - the first benchmark hate speech dataset covering multiple aspects of the issue | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1716/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1716/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4408/comments | https://api.github.com/repos/huggingface/datasets/issues/4408/events | https://github.com/huggingface/datasets/pull/4408 | 1,248,687,574 | PR_kwDODunzps44ecNI | 4,408 | Update imagenet gate | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-05-25T20:32:19Z | 2022-05-25T20:45:11Z | 2022-05-25T20:36:47Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4408.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4408",
"merged_at": "2022-05-25T20:36:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4408.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4408/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4408/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1004 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1004/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1004/comments | https://api.github.com/repos/huggingface/datasets/issues/1004/events | https://github.com/huggingface/datasets/issues/1004 | 755,325,368 | MDU6SXNzdWU3NTUzMjUzNjg= | 1,004 | how large datasets are handled under the hood | {
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/followin... | [] | closed | false | null | [] | null | [
"This library uses Apache Arrow under the hood to store datasets on disk.\r\nThe advantage of Apache Arrow is that it allows to memory map the dataset. This allows to load datasets bigger than memory and with almost no RAM usage. It also offers excellent I/O speed.\r\n\r\nFor example when you access one element or ... | 2020-12-02T14:32:40Z | 2022-10-05T12:13:29Z | 2022-10-05T12:13:29Z | NONE | null | null | null | Hi
I want to use multiple large datasets with a mapping style dataloader, where they cannot fit into memory, could you tell me how you handled the datasets under the hood? is this you bring all in memory in case of mapping style ones? or is this some sharding under the hood and you bring in memory when necessary, than... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1004/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1004/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4004 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4004/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4004/comments | https://api.github.com/repos/huggingface/datasets/issues/4004/events | https://github.com/huggingface/datasets/pull/4004 | 1,179,320,795 | PR_kwDODunzps408Onj | 4,004 | ASSIN 2 dataset: replace broken Google Drive _URLS by links on github | {
"avatar_url": "https://avatars.githubusercontent.com/u/14352388?v=4",
"events_url": "https://api.github.com/users/ruanchaves/events{/privacy}",
"followers_url": "https://api.github.com/users/ruanchaves/followers",
"following_url": "https://api.github.com/users/ruanchaves/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-24T10:37:39Z | 2022-03-28T14:01:46Z | 2022-03-28T13:56:39Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4004.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4004",
"merged_at": "2022-03-28T13:56:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4004.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Closes #4003 .
Fixes checksum error. Replaces Google Drive urls by the files hosted here: [Multilingual Transformer Ensembles for Portuguese Natural Language Tasks](https://github.com/ruanchaves/assin) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4004/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4004/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1230 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1230/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1230/comments | https://api.github.com/repos/huggingface/datasets/issues/1230/events | https://github.com/huggingface/datasets/pull/1230 | 758,119,342 | MDExOlB1bGxSZXF1ZXN0NTMzMzQxNTg0 | 1,230 | Add Urdu fake news dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/44389205?v=4",
"events_url": "https://api.github.com/users/chaitnayabasava/events{/privacy}",
"followers_url": "https://api.github.com/users/chaitnayabasava/followers",
"following_url": "https://api.github.com/users/chaitnayabasava/following{/other_user}"... | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | 2020-12-07T03:19:50Z | 2020-12-07T18:04:55Z | 2020-12-07T16:57:54Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1230.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1230",
"merged_at": "2020-12-07T16:57:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1230.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | @lhoestq opened a clean PR containing only relevant files.
old PR #1125 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1230/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1230/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3161 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3161/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3161/comments | https://api.github.com/repos/huggingface/datasets/issues/3161/events | https://github.com/huggingface/datasets/pull/3161 | 1,035,444,292 | PR_kwDODunzps4tpCsm | 3,161 | Add riddle_sense dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/44691149?v=4",
"events_url": "https://api.github.com/users/ziyiwu9494/events{/privacy}",
"followers_url": "https://api.github.com/users/ziyiwu9494/followers",
"following_url": "https://api.github.com/users/ziyiwu9494/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"@lhoestq \r\nI address all the comments, I think. Thanks! \r\n",
"The five test fails are unrelated to this PR and fixed on master so we can ignore them"
] | 2021-10-25T18:30:56Z | 2021-11-04T14:01:15Z | 2021-11-04T14:01:15Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3161.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3161",
"merged_at": "2021-11-04T14:01:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3161.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding a new dataset for QA with riddles. I'm confused about the tagging process because it looks like the streamlit app loads data from the current repo, so is it something that should be done after merging or off my fork? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3161/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3161/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3517 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3517/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3517/comments | https://api.github.com/repos/huggingface/datasets/issues/3517/events | https://github.com/huggingface/datasets/pull/3517 | 1,092,726,651 | PR_kwDODunzps4wemwU | 3,517 | Add CPPE-5 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Thanks so much, @mariosasko and @lhoestq , much appreciated!"
] | 2022-01-03T18:31:20Z | 2022-01-19T02:23:37Z | 2022-01-05T18:53:02Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3517.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3517",
"merged_at": "2022-01-05T18:53:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3517.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adds the recently released CPPE-5 dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3517/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3517/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/130 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/130/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/130/comments | https://api.github.com/repos/huggingface/datasets/issues/130/events | https://github.com/huggingface/datasets/issues/130 | 619,035,440 | MDU6SXNzdWU2MTkwMzU0NDA= | 130 | Loading GLUE dataset loads CoLA by default | {
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"As a follow-up to this: It looks like the actual GLUE task name is supplied as the `name` argument. Is there a way to check what `name`s/sub-datasets are available under a grouping like GLUE? That information doesn't seem to be readily available in info from `nlp.list_datasets()`.\r\n\r\nEdit: I found the info und... | 2020-05-15T14:55:50Z | 2020-05-27T22:08:15Z | 2020-05-27T22:08:15Z | NONE | null | null | null | If I run:
```python
dataset = nlp.load_dataset('glue')
```
The resultant dataset seems to be CoLA be default, without throwing any error. This is in contrast to calling:
```python
metric = nlp.load_metric("glue")
```
which throws an error telling the user that they need to specify a task in GLUE. Should the... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/130/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/130/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/712/comments | https://api.github.com/repos/huggingface/datasets/issues/712/events | https://github.com/huggingface/datasets/issues/712 | 714,242,316 | MDU6SXNzdWU3MTQyNDIzMTY= | 712 | Error in the notebooks/Overview.ipynb notebook | {
"avatar_url": "https://avatars.githubusercontent.com/u/850012?v=4",
"events_url": "https://api.github.com/users/subhrm/events{/privacy}",
"followers_url": "https://api.github.com/users/subhrm/followers",
"following_url": "https://api.github.com/users/subhrm/following{/other_user}",
"gists_url": "https://api... | [] | closed | false | null | [] | null | [
"Do this:\r\n``` python\r\nsquad_dataset = list_datasets(with_details=True)[datasets.index('squad')]\r\npprint(squad_dataset.__dict__) # It's a simple python dataclass\r\n```",
"Thanks! This worked. I have created a PR to fix this in the notebook. "
] | 2020-10-04T05:58:31Z | 2020-10-05T16:25:40Z | 2020-10-05T16:25:40Z | CONTRIBUTOR | null | null | null | Hi,
I got the following error in **cell number 3** while exploring the **Overview.ipynb** notebook in google colab. I used the [link ](https://colab.research.google.com/github/huggingface/datasets/blob/master/notebooks/Overview.ipynb) provided in the main README file to open it in colab.
```python
# You can acc... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/712/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/712/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/607/comments | https://api.github.com/repos/huggingface/datasets/issues/607/events | https://github.com/huggingface/datasets/pull/607 | 698,094,442 | MDExOlB1bGxSZXF1ZXN0NDgzOTcyMDg4 | 607 | Add transmit_format wrapper and tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-09-10T15:03:50Z | 2020-09-10T15:21:48Z | 2020-09-10T15:21:47Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/607.diff",
"html_url": "https://github.com/huggingface/datasets/pull/607",
"merged_at": "2020-09-10T15:21:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/607.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/607... | Same as #605 but using a decorator on-top of dataset transforms that are not in place | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/607/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/607/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1180 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1180/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1180/comments | https://api.github.com/repos/huggingface/datasets/issues/1180/events | https://github.com/huggingface/datasets/pull/1180 | 757,784,612 | MDExOlB1bGxSZXF1ZXN0NTMzMDk1MzI2 | 1,180 | Add KorQuAD v2 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/15624271?v=4",
"events_url": "https://api.github.com/users/cceyda/events{/privacy}",
"followers_url": "https://api.github.com/users/cceyda/followers",
"following_url": "https://api.github.com/users/cceyda/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"looks like this PR also includes the changes for the V1\r\nCould you only include the files of the V2 ?",
"hmm I have made the dummy data lighter retested on local and it passed not sure why it fails here?",
"merging since the CI is fixed on master"
] | 2020-12-05T21:33:34Z | 2020-12-16T16:10:30Z | 2020-12-16T16:10:30Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1180.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1180",
"merged_at": "2020-12-16T16:10:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1180.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | # The Korean Question Answering Dataset v2
Adding the [KorQuAD](https://korquad.github.io/) v2 dataset as part of the sprint 🎉
This dataset is very similar to SQuAD and is an extension of [squad_kor_v1](https://github.com/huggingface/datasets/pull/1178) which is why I added it as `squad_kor_v2`.
- Crowd generat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1180/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1180/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6171 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6171/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6171/comments | https://api.github.com/repos/huggingface/datasets/issues/6171/events | https://github.com/huggingface/datasets/pull/6171 | 1,862,922,767 | PR_kwDODunzps5Yk4AS | 6,171 | Fix typo in about_mapstyle_vs_iterable.mdx | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6171). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-08-23T09:21:11Z | 2023-08-23T09:32:59Z | 2023-08-23T09:21:19Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6171.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6171",
"merged_at": "2023-08-23T09:21:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6171.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6171/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6171/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"The preview is working OK:\r\n\r\n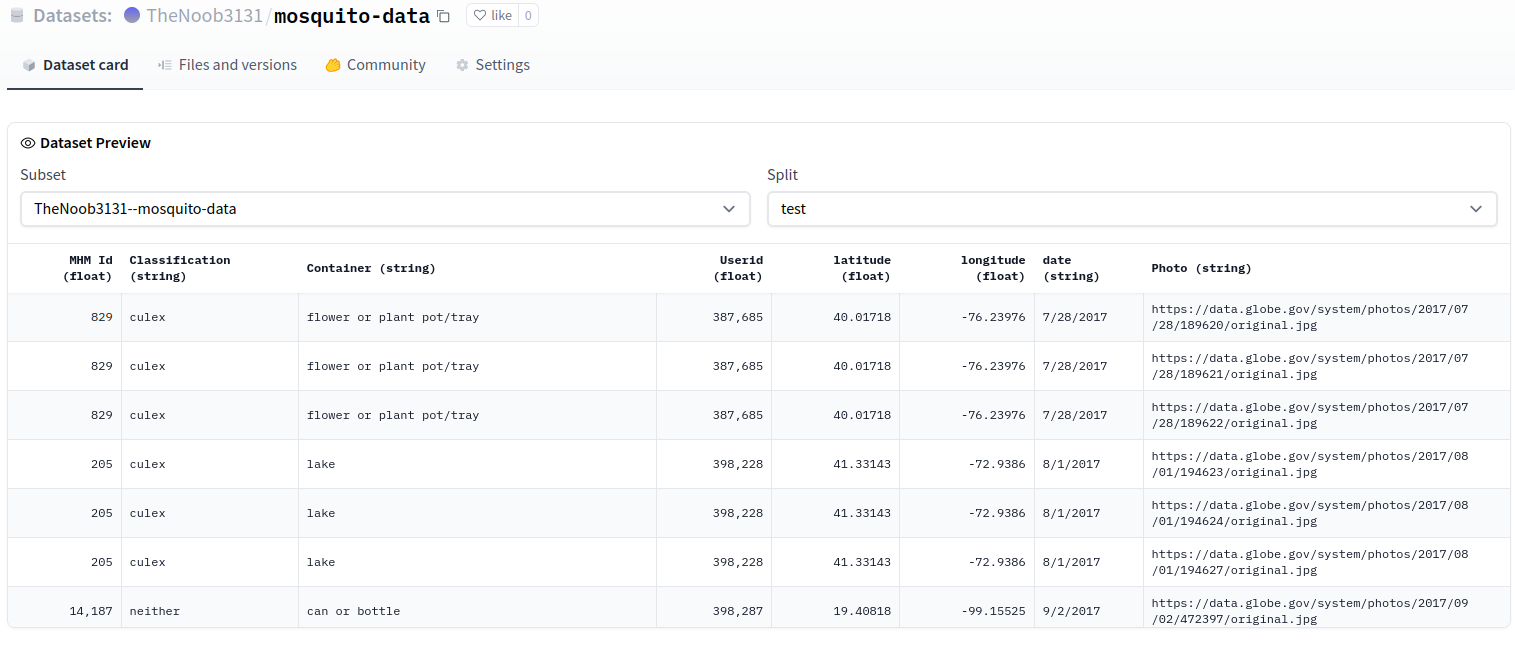\r\n\r\n"
] | 2022-07-21T05:24:48Z | 2022-07-21T07:51:56Z | 2022-07-21T07:45:01Z | NONE | null | null | null | ### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1000 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1000/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1000/comments | https://api.github.com/repos/huggingface/datasets/issues/1000/events | https://github.com/huggingface/datasets/pull/1000 | 755,292,066 | MDExOlB1bGxSZXF1ZXN0NTMxMDMxMTE1 | 1,000 | UM005: Urdu <> English Translation Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [] | closed | false | null | [] | null | [] | 2020-12-02T13:51:35Z | 2020-12-04T15:34:30Z | 2020-12-04T15:34:29Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1000.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1000",
"merged_at": "2020-12-04T15:34:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1000.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adds Urdu-English dataset for machine translation: http://ufal.ms.mff.cuni.cz/umc/005-en-ur/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1000/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1000/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/482 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/482/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/482/comments | https://api.github.com/repos/huggingface/datasets/issues/482/events | https://github.com/huggingface/datasets/issues/482 | 674,851,147 | MDU6SXNzdWU2NzQ4NTExNDc= | 482 | Bugs : dataset.map() is frozen on ELI5 | {
"avatar_url": "https://avatars.githubusercontent.com/u/56621342?v=4",
"events_url": "https://api.github.com/users/ratthachat/events{/privacy}",
"followers_url": "https://api.github.com/users/ratthachat/followers",
"following_url": "https://api.github.com/users/ratthachat/following{/other_user}",
"gists_url"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"This comes from an overflow in pyarrow's array.\r\nIt is stuck inside the loop that reduces the batch size to avoid the overflow.\r\nI'll take a look",
"I created a PR to fix the issue.\r\nIt was due to an overflow check that handled badly an empty list.\r\n\r\nYou can try the changes by using \r\n```\r\n!pip in... | 2020-08-07T08:23:35Z | 2023-04-06T09:39:59Z | 2020-08-11T23:55:15Z | NONE | null | null | null | Hi Huggingface Team!
Thank you guys once again for this amazing repo.
I have tried to prepare ELI5 to train with T5, based on [this wonderful notebook of Suraj Patil](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb)
However, when I run `dataset.map()` on ELI5 to prepare `input_text, ta... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/482/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/482/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1534 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1534/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1534/comments | https://api.github.com/repos/huggingface/datasets/issues/1534/events | https://github.com/huggingface/datasets/pull/1534 | 764,934,681 | MDExOlB1bGxSZXF1ZXN0NTM4Nzc1Njky | 1,534 | adding dataset for diplomacy detection | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Requested changes made and new PR submitted here: https://github.com/huggingface/datasets/pull/1580 "
] | 2020-12-13T04:38:43Z | 2020-12-15T19:52:52Z | 2020-12-15T19:52:25Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1534.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1534",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1534.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1534"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1534/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1534/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/2715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2715/comments | https://api.github.com/repos/huggingface/datasets/issues/2715/events | https://github.com/huggingface/datasets/pull/2715 | 952,845,229 | MDExOlB1bGxSZXF1ZXN0Njk2OTc5MjQ1 | 2,715 | Update PAN-X data URL in XTREME dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"Merging since the CI is just about missing infos in the dataset card"
] | 2021-07-26T12:21:17Z | 2021-07-26T13:27:59Z | 2021-07-26T13:27:59Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2715.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2715",
"merged_at": "2021-07-26T13:27:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2715.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Related to #2710, #2691. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2715/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2715/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3731/comments | https://api.github.com/repos/huggingface/datasets/issues/3731/events | https://github.com/huggingface/datasets/pull/3731 | 1,139,626,362 | PR_kwDODunzps4y5-hi | 3,731 | Fix Multi-News dataset metadata and card | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2022-02-16T07:14:57Z | 2022-02-16T08:48:47Z | 2022-02-16T08:48:47Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3731.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3731",
"merged_at": "2022-02-16T08:48:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3731.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #3730. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3731/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3731/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3194 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3194/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3194/comments | https://api.github.com/repos/huggingface/datasets/issues/3194/events | https://github.com/huggingface/datasets/pull/3194 | 1,041,999,535 | PR_kwDODunzps4t91Eg | 3,194 | Update link to Datasets Tagging app in Spaces | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-11-02T08:13:50Z | 2021-11-08T10:36:23Z | 2021-11-08T10:36:22Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3194.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3194",
"merged_at": "2021-11-08T10:36:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3194.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #3193. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3194/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3194/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/378/comments | https://api.github.com/repos/huggingface/datasets/issues/378/events | https://github.com/huggingface/datasets/issues/378 | 655,226,316 | MDU6SXNzdWU2NTUyMjYzMTY= | 378 | [dataset] Structure of MLQA seems unecessary nested | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"Same for the RACE dataset: https://github.com/huggingface/nlp/blob/master/datasets/race/race.py\r\n\r\nShould we scan all the datasets to remove this pattern of un-necessary nesting?",
"You're right, I think we don't need to use the nested dictionary. \r\n"
] | 2020-07-11T15:16:08Z | 2020-07-15T16:17:20Z | 2020-07-15T16:17:20Z | MEMBER | null | null | null | The features of the MLQA dataset comprise several nested dictionaries with a single element inside (for `questions` and `ids`): https://github.com/huggingface/nlp/blob/master/datasets/mlqa/mlqa.py#L90-L97
Should we keep this @mariamabarham @patrickvonplaten? Was this added for compatibility with tfds?
```python
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/378/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/6079 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6079/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6079/comments | https://api.github.com/repos/huggingface/datasets/issues/6079/events | https://github.com/huggingface/datasets/issues/6079 | 1,822,597,471 | I_kwDODunzps5soqFf | 6,079 | Iterating over DataLoader based on HF datasets is stuck forever | {
"avatar_url": "https://avatars.githubusercontent.com/u/5454868?v=4",
"events_url": "https://api.github.com/users/arindamsarkar93/events{/privacy}",
"followers_url": "https://api.github.com/users/arindamsarkar93/followers",
"following_url": "https://api.github.com/users/arindamsarkar93/following{/other_user}",... | [] | closed | false | null | [] | null | [
"When the process starts to hang, can you interrupt it with CTRL + C and paste the error stack trace here? ",
"Thanks @mariosasko for your prompt response, here's the stack trace:\r\n\r\n```\r\nKeyboardInterrupt Traceback (most recent call last)\r\nCell In[12], line 4\r\n 2 t = time.t... | 2023-07-26T14:52:37Z | 2023-10-05T02:58:43Z | 2023-07-30T14:09:06Z | NONE | null | null | null | ### Describe the bug
I am using Amazon Sagemaker notebook (Amazon Linux 2) with python 3.10 based Conda environment.
I have a dataset in parquet format locally. When I try to iterate over it, the loader is stuck forever. Note that the same code is working for python 3.6 based conda environment seamlessly. What shou... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6079/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6079/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3997 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3997/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3997/comments | https://api.github.com/repos/huggingface/datasets/issues/3997/events | https://github.com/huggingface/datasets/pull/3997 | 1,178,566,568 | PR_kwDODunzps4058xr | 3,997 | Sync Features dictionaries | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-03-23T19:23:51Z | 2022-04-13T15:52:27Z | 2022-04-13T15:46:19Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3997.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3997",
"merged_at": "2022-04-13T15:46:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3997.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds a wrapper to the `Features` class to keep the secondary dict, `_column_requires_decoding`, aligned with the main dict (as discussed in https://github.com/huggingface/datasets/pull/3723#discussion_r806912731).
A more elegant approach would be to subclass `UserDict` and override `__setitem__` and `__delit... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3997/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3997/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/388/comments | https://api.github.com/repos/huggingface/datasets/issues/388/events | https://github.com/huggingface/datasets/issues/388 | 656,707,497 | MDU6SXNzdWU2NTY3MDc0OTc= | 388 | 🐛 [Dataset] Cannot download wmt14, wmt15 and wmt17 | {
"avatar_url": "https://avatars.githubusercontent.com/u/2826602?v=4",
"events_url": "https://api.github.com/users/SamuelCahyawijaya/events{/privacy}",
"followers_url": "https://api.github.com/users/SamuelCahyawijaya/followers",
"following_url": "https://api.github.com/users/SamuelCahyawijaya/following{/other_u... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/followin... | null | [
"similar slow download speed here for nlp.load_dataset('wmt14', 'fr-en')\r\n`\r\nDownloading: 100%|██████████████████████████████████████████████████████████| 658M/658M [1:00:42<00:00, 181kB/s]\r\nDownloading: 100%|██████████████████████████████████████████████████████████| 918M/918M [1:39:38<00:00, 154kB/s]\r\nDow... | 2020-07-14T15:36:41Z | 2022-10-04T18:01:28Z | 2022-10-04T18:01:28Z | NONE | null | null | null | 1. I try downloading `wmt14`, `wmt15`, `wmt17`, `wmt19` with the following code:
```
nlp.load_dataset('wmt14','de-en')
nlp.load_dataset('wmt15','de-en')
nlp.load_dataset('wmt17','de-en')
nlp.load_dataset('wmt19','de-en')
```
The code runs but the download speed is **extremely slow**, the same behaviour is not ob... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/388/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/388/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2875 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2875/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2875/comments | https://api.github.com/repos/huggingface/datasets/issues/2875/events | https://github.com/huggingface/datasets/issues/2875 | 989,919,398 | MDU6SXNzdWU5ODk5MTkzOTg= | 2,875 | Add Congolese Swahili speech datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "d93f0b",... | open | false | null | [] | null | [] | 2021-09-07T12:13:50Z | 2021-09-07T12:13:50Z | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** Congolese Swahili speech corpora
- **Data:** https://gamayun.translatorswb.org/data/
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Also related: https://mobile.twitter.com/OktemAlp/status/14351963936... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2875/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2875/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4056 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4056/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4056/comments | https://api.github.com/repos/huggingface/datasets/issues/4056/events | https://github.com/huggingface/datasets/issues/4056 | 1,185,155,775 | I_kwDODunzps5GpAq_ | 4,056 | Unexpected behavior of _TempDirWithCustomCleanup | {
"avatar_url": "https://avatars.githubusercontent.com/u/22680696?v=4",
"events_url": "https://api.github.com/users/JonasGeiping/events{/privacy}",
"followers_url": "https://api.github.com/users/JonasGeiping/followers",
"following_url": "https://api.github.com/users/JonasGeiping/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"Hi ! Would setting TMPDIR at the beginning of your python script/session work ? I mean, even before importing transformers, datasets, etc. and using them ? I think this would be the most robust solution given any library that uses `tempfile`. I don't think we aim to support environment variables to be changed at r... | 2022-03-29T16:58:22Z | 2022-03-30T15:08:04Z | null | NONE | null | null | null | ## Describe the bug
This is not 100% a bug in `datasets`, but behavior that surprised me and I think this could be made more robust on the `datasets`side.
When using `datasets.disable_caching()`, cache files are written to a temporary directory. This directory should be based on the environment variable TMPDIR. I ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4056/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4056/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/6412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6412/comments | https://api.github.com/repos/huggingface/datasets/issues/6412/events | https://github.com/huggingface/datasets/issues/6412 | 1,992,401,594 | I_kwDODunzps52waK6 | 6,412 | User token is printed out! | {
"avatar_url": "https://avatars.githubusercontent.com/u/25702692?v=4",
"events_url": "https://api.github.com/users/mohsen-goodarzi/events{/privacy}",
"followers_url": "https://api.github.com/users/mohsen-goodarzi/followers",
"following_url": "https://api.github.com/users/mohsen-goodarzi/following{/other_user}"... | [] | closed | false | null | [] | null | [
"Indeed, this is not a good practice. I've opened a PR that removes the token value from the (deprecation) warning."
] | 2023-11-14T10:01:34Z | 2023-11-14T22:19:46Z | 2023-11-14T22:19:46Z | NONE | null | null | null | This line prints user token on command line! Is it safe?
https://github.com/huggingface/datasets/blob/12ebe695b4748c5a26e08b44ed51955f74f5801d/src/datasets/load.py#L2091 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6412/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6412/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5461 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5461/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5461/comments | https://api.github.com/repos/huggingface/datasets/issues/5461/events | https://github.com/huggingface/datasets/issues/5461 | 1,555,532,719 | I_kwDODunzps5ct4uv | 5,461 | Discrepancy in `nyu_depth_v2` dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/36858976?v=4",
"events_url": "https://api.github.com/users/awsaf49/events{/privacy}",
"followers_url": "https://api.github.com/users/awsaf49/followers",
"following_url": "https://api.github.com/users/awsaf49/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"Ccing @dwofk (the author of `fast-depth`). \r\n\r\nThanks, @awsaf49 for reporting this. I believe this is because the NYU Depth V2 shipped from `fast-depth` is already preprocessed. \r\n\r\nIf you think it might be better to have the NYU Depth V2 dataset from BTS [here](https://huggingface.co/datasets/sayakpaul/ny... | 2023-01-24T19:15:46Z | 2023-02-06T20:52:00Z | null | CONTRIBUTOR | null | null | null | ### Describe the bug
I think there is a discrepancy between depth map of `nyu_depth_v2` dataset [here](https://huggingface.co/docs/datasets/main/en/depth_estimation) and actual depth map. Depth values somehow got **discretized/clipped** resulting in depth maps that are different from actual ones. Here is a side-by-sid... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5461/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5461/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2209 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2209/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2209/comments | https://api.github.com/repos/huggingface/datasets/issues/2209/events | https://github.com/huggingface/datasets/pull/2209 | 855,638,232 | MDExOlB1bGxSZXF1ZXN0NjEzMzQwMTI2 | 2,209 | Add code of conduct to the project | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [] | 2021-04-12T07:16:14Z | 2021-04-12T17:55:52Z | 2021-04-12T17:55:52Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2209.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2209",
"merged_at": "2021-04-12T17:55:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2209.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add code of conduct to the project and link it from README and CONTRIBUTING.
This was already done in `transformers`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2209/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2209/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2231/comments | https://api.github.com/repos/huggingface/datasets/issues/2231/events | https://github.com/huggingface/datasets/pull/2231 | 859,850,488 | MDExOlB1bGxSZXF1ZXN0NjE2ODYyNTEx | 2,231 | Fix map when removing columns on a formatted dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-04-16T14:08:55Z | 2021-04-16T15:10:05Z | 2021-04-16T15:10:04Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2231.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2231",
"merged_at": "2021-04-16T15:10:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2231.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This should fix issue #2226
The `remove_columns` argument was ignored on formatted datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2231/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6300 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6300/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6300/comments | https://api.github.com/repos/huggingface/datasets/issues/6300/events | https://github.com/huggingface/datasets/pull/6300 | 1,940,153,432 | PR_kwDODunzps5cpIoG | 6,300 | Unpin `jax` maximum version | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-10-12T14:42:40Z | 2023-10-12T16:37:55Z | 2023-10-12T16:28:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6300.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6300",
"merged_at": "2023-10-12T16:28:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6300.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | fix #6299
fix #6202 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6300/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6300/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/594/comments | https://api.github.com/repos/huggingface/datasets/issues/594/events | https://github.com/huggingface/datasets/pull/594 | 696,816,893 | MDExOlB1bGxSZXF1ZXN0NDgyODQ1OTc5 | 594 | Fix germeval url | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-09-09T13:29:35Z | 2020-09-09T13:34:35Z | 2020-09-09T13:34:34Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/594.diff",
"html_url": "https://github.com/huggingface/datasets/pull/594",
"merged_at": "2020-09-09T13:34:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/594.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/594... | Continuation of #593 but without the dummy data hack | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/594/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1444/comments | https://api.github.com/repos/huggingface/datasets/issues/1444/events | https://github.com/huggingface/datasets/issues/1444 | 761,055,651 | MDU6SXNzdWU3NjEwNTU2NTE= | 1,444 | FileNotFound remotly, can't load a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/18331629?v=4",
"events_url": "https://api.github.com/users/sadakmed/events{/privacy}",
"followers_url": "https://api.github.com/users/sadakmed/followers",
"following_url": "https://api.github.com/users/sadakmed/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"This dataset will be available in version-2 of the library. If you want to use this dataset now, install datasets from `master` branch rather.\r\n\r\nCommand to install datasets from `master` branch:\r\n`!pip install git+https://github.com/huggingface/datasets.git@master`",
"Closing this, thanks @VasudevGupta7 "... | 2020-12-10T09:14:47Z | 2020-12-15T17:41:14Z | 2020-12-15T17:41:14Z | NONE | null | null | null | ```py
!pip install datasets
import datasets as ds
corpus = ds.load_dataset('large_spanish_corpus')
```
gives the error
> FileNotFoundError: Couldn't find file locally at large_spanish_corpus/large_spanish_corpus.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/large_spa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1444/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1444/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/954 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/954/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/954/comments | https://api.github.com/repos/huggingface/datasets/issues/954/events | https://github.com/huggingface/datasets/pull/954 | 754,362,012 | MDExOlB1bGxSZXF1ZXN0NTMwMjc1MDY4 | 954 | add prachathai67k | {
"avatar_url": "https://avatars.githubusercontent.com/u/15519308?v=4",
"events_url": "https://api.github.com/users/cstorm125/events{/privacy}",
"followers_url": "https://api.github.com/users/cstorm125/followers",
"following_url": "https://api.github.com/users/cstorm125/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Test failing for same issues as https://github.com/huggingface/datasets/pull/939\r\nPlease advise.\r\n\r\n```\r\n=========================== short test summary info ============================\r\nFAILED tests/test_dataset_common.py::RemoteDatasetTest::test_builder_class_flue\r\nFAILED tests/test_dataset_common.py... | 2020-12-01T12:40:55Z | 2020-12-02T05:12:11Z | 2020-12-02T04:43:52Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/954.diff",
"html_url": "https://github.com/huggingface/datasets/pull/954",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/954.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/954"
} | `prachathai-67k`: News Article Corpus and Multi-label Text Classificdation from Prachathai.com
The prachathai-67k dataset was scraped from the news site Prachathai.
We filtered out those articles with less than 500 characters of body text, mostly images and cartoons.
It contains 67,889 articles wtih 12 curated tags ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/954/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/954/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/585/comments | https://api.github.com/repos/huggingface/datasets/issues/585/events | https://github.com/huggingface/datasets/pull/585 | 695,191,209 | MDExOlB1bGxSZXF1ZXN0NDgxNDY4NTM4 | 585 | Fix select for pyarrow < 1.0.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-09-07T15:02:52Z | 2020-09-08T07:43:17Z | 2020-09-08T07:43:15Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/585.diff",
"html_url": "https://github.com/huggingface/datasets/pull/585",
"merged_at": "2020-09-08T07:43:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/585.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/585... | Fix #583 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/585/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/585/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4673/comments | https://api.github.com/repos/huggingface/datasets/issues/4673/events | https://github.com/huggingface/datasets/issues/4673 | 1,301,010,331 | I_kwDODunzps5Ni9eb | 4,673 | load_datasets on csv returns everything as a string | {
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @courtneysprouse, thanks for reporting.\r\n\r\nYes, you are right: by default the \"csv\" loader loads all columns as strings. \r\n\r\nYou could tweak this behavior by passing the `feature` argument to `load_dataset`, but it is also true that currently it is not possible to perform some kind of casts, due to la... | 2022-07-11T17:30:24Z | 2022-07-12T13:33:09Z | 2022-07-12T13:33:08Z | NONE | null | null | null | ## Describe the bug
If you use:
`conll_dataset.to_csv("ner_conll.csv")`
It will create a csv file with all of your data as expected, however when you load it with:
`conll_dataset = load_dataset("csv", data_files="ner_conll.csv")`
everything is read in as a string. For example if I look at everything in 'n... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4673/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5452 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5452/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5452/comments | https://api.github.com/repos/huggingface/datasets/issues/5452/events | https://github.com/huggingface/datasets/pull/5452 | 1,552,655,939 | PR_kwDODunzps5ITcA3 | 5,452 | Swap log messages for symbolic/hard links in tar extractor | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-01-23T07:53:38Z | 2023-01-23T09:40:55Z | 2023-01-23T08:31:17Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5452.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5452",
"merged_at": "2023-01-23T08:31:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5452.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The log messages do not match their if-condition. This PR swaps them.
Found while investigating:
- #5441
CC: @lhoestq | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5452/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5452/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5987 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5987/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5987/comments | https://api.github.com/repos/huggingface/datasets/issues/5987/events | https://github.com/huggingface/datasets/issues/5987 | 1,773,047,909 | I_kwDODunzps5prpBl | 5,987 | Why max_shard_size is not supported in load_dataset and passed to download_and_prepare | {
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Can you explain your use case for `max_shard_size`? \r\n\r\nOn some systems, there is a limit to the size of a memory-mapped file, so we could consider exposing this parameter in `load_dataset`.",
"In my use case, users may choose a proper size to balance the cost and benefit of using large shard size. (On azure... | 2023-06-25T04:19:13Z | 2023-06-29T16:06:08Z | 2023-06-29T16:06:08Z | CONTRIBUTOR | null | null | null | ### Describe the bug
https://github.com/huggingface/datasets/blob/a8a797cc92e860c8d0df71e0aa826f4d2690713e/src/datasets/load.py#L1809
What I can to is break the `load_dataset` and use `load_datset_builder` + `download_and_prepare` instead.
### Steps to reproduce the bug
https://github.com/huggingface/datasets/blo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5987/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5987/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4369/comments | https://api.github.com/repos/huggingface/datasets/issues/4369/events | https://github.com/huggingface/datasets/pull/4369 | 1,240,245,642 | PR_kwDODunzps44CpCe | 4,369 | Add redirect to dataset script in the repo structure page | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-05-18T17:05:33Z | 2022-05-19T08:19:01Z | 2022-05-19T08:10:51Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4369.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4369",
"merged_at": "2022-05-19T08:10:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4369.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Following https://github.com/huggingface/hub-docs/pull/146 I added a redirection to the dataset scripts documentation in the repository structure page. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4369/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4369/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4611/comments | https://api.github.com/repos/huggingface/datasets/issues/4611/events | https://github.com/huggingface/datasets/pull/4611 | 1,290,940,874 | PR_kwDODunzps46rxIX | 4,611 | Preserve member order by MockDownloadManager.iter_archive | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-01T05:48:20Z | 2022-07-01T16:59:11Z | 2022-07-01T16:48:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4611.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4611",
"merged_at": "2022-07-01T16:48:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4611.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Currently, `MockDownloadManager.iter_archive` yields paths to archive members in an order given by `path.rglob("*")`, which migh not be the same order as in the original archive.
See issue in:
- https://github.com/huggingface/datasets/pull/4579#issuecomment-1172135027
This PR fixes the order of the members yield... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4611/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/616/comments | https://api.github.com/repos/huggingface/datasets/issues/616/events | https://github.com/huggingface/datasets/issues/616 | 699,462,293 | MDU6SXNzdWU2OTk0NjIyOTM= | 616 | UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [] | open | false | null | [] | null | [
"I have the same issue",
"Same issue here when Trying to load a dataset from disk.",
"I am also experiencing this issue, and don't know if it's affecting my training.",
"Same here. I hope the dataset is not being modified in-place.",
"I think the only way to avoid this warning would be to do a copy of the n... | 2020-09-11T15:39:16Z | 2021-07-22T21:12:21Z | null | CONTRIBUTOR | null | null | null | I am trying out the library and want to load in pickled data with `from_dict`. In that dict, one column `text` should be tokenized and the other (an embedding vector) should be retained. All other columns should be removed. When I eventually try to set the format for the columns with `set_format` I am getting this stra... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/616/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/616/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/2474 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2474/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2474/comments | https://api.github.com/repos/huggingface/datasets/issues/2474/events | https://github.com/huggingface/datasets/issues/2474 | 917,622,055 | MDU6SXNzdWU5MTc2MjIwNTU= | 2,474 | cache_dir parameter for load_from_disk ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/7063207?v=4",
"events_url": "https://api.github.com/users/chbensch/events{/privacy}",
"followers_url": "https://api.github.com/users/chbensch/followers",
"following_url": "https://api.github.com/users/chbensch/following{/other_user}",
"gists_url": "http... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi ! `load_from_disk` doesn't move the data. If you specify a local path to your mounted drive, then the dataset is going to be loaded directly from the arrow file in this directory. The cache files that result from `map` operations are also stored in the same directory by default.\r\n\r\nHowever note than writing... | 2021-06-10T17:39:36Z | 2022-02-16T14:55:01Z | 2022-02-16T14:55:00Z | NONE | null | null | null | **Is your feature request related to a problem? Please describe.**
When using Google Colab big datasets can be an issue, as they won't fit on the VM's disk. Therefore mounting google drive could be a possible solution. Unfortunatly when loading my own dataset by using the _load_from_disk_ function, the data gets cache... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2474/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2474/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4601/comments | https://api.github.com/repos/huggingface/datasets/issues/4601/events | https://github.com/huggingface/datasets/pull/4601 | 1,289,924,715 | PR_kwDODunzps46oWF8 | 4,601 | Upgrade pip in WIN CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"It failed terribly"
] | 2022-06-30T10:25:42Z | 2023-09-24T10:04:25Z | 2022-06-30T10:43:38Z | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4601.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4601",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4601.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4601"
} | The windows CI is currently flaky: some dependencies like aiobotocore, multiprocess and seqeval sometimes fail to install.
In particular it seems that building the wheels fail. Here is an example of logs
```
Building wheel for seqeval (setup.py): started
Running command 'C:\tools\miniconda3\envs\py37\python.exe... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4601/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4601/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1593/comments | https://api.github.com/repos/huggingface/datasets/issues/1593/events | https://github.com/huggingface/datasets/issues/1593 | 769,611,386 | MDU6SXNzdWU3Njk2MTEzODY= | 1,593 | Access to key in DatasetDict map | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Indeed that would be cool\r\n\r\nAlso FYI right now the easiest way to do this is\r\n```python\r\ndataset_dict[\"train\"] = dataset_dict[\"train\"].map(my_transform_for_the_train_set)\r\ndataset_dict[\"test\"] = dataset_dict[\"test\"].map(my_transform_for_the_test_set)\r\n```",
"I don't feel like adding an extra... | 2020-12-17T07:02:20Z | 2022-10-05T13:47:28Z | 2022-10-05T12:33:06Z | NONE | null | null | null | It is possible that we want to do different things in the `map` function (and possibly other functions too) of a `DatasetDict`, depending on the key. I understand that `DatasetDict.map` is a really thin wrapper of `Dataset.map`, so it is easy to directly implement this functionality in the client code. Still, it'd be n... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1593/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1593/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3640/comments | https://api.github.com/repos/huggingface/datasets/issues/3640/events | https://github.com/huggingface/datasets/issues/3640 | 1,116,133,769 | I_kwDODunzps5ChtmJ | 3,640 | Issues with custom dataset in Wav2Vec2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/9079808?v=4",
"events_url": "https://api.github.com/users/peregilk/events{/privacy}",
"followers_url": "https://api.github.com/users/peregilk/followers",
"following_url": "https://api.github.com/users/peregilk/following{/other_user}",
"gists_url": "http... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Closed and moved to transformers."
] | 2022-01-27T12:09:05Z | 2022-01-27T12:29:48Z | 2022-01-27T12:29:48Z | NONE | null | null | null | We are training Vav2Vec using the run_speech_recognition_ctc_bnb.py-script.
This is working fine with Common Voice, however using our custom dataset and data loader at [NbAiLab/NPSC]( https://huggingface.co/datasets/NbAiLab/NPSC) it crashes after roughly 1 epoch with the following stack trace:
 | {
"avatar_url": "https://avatars.githubusercontent.com/u/57466294?v=4",
"events_url": "https://api.github.com/users/jeswan/events{/privacy}",
"followers_url": "https://api.github.com/users/jeswan/followers",
"following_url": "https://api.github.com/users/jeswan/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Thanks for opening this PR :) \r\n\r\nWe changed the name of the lib from nlp to datasets yesterday.\r\nCould you rebase from master and re-generate the dataset_info.json file to fix the name changes ?",
"Rebased changes here: https://github.com/huggingface/datasets/pull/626"
] | 2020-09-10T18:16:32Z | 2020-09-14T19:06:02Z | 2020-09-14T19:06:01Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/609.diff",
"html_url": "https://github.com/huggingface/datasets/pull/609",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/609.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/609"
} | NYU is switching dataset hosting from Google to FB. This PR closes https://github.com/huggingface/datasets/issues/608 and is necessary for https://github.com/jiant-dev/jiant/issues/161. This PR updates the data URLs based on changes made in https://github.com/nyu-mll/jiant/pull/1112. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/609/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/377/comments | https://api.github.com/repos/huggingface/datasets/issues/377/events | https://github.com/huggingface/datasets/issues/377 | 655,215,790 | MDU6SXNzdWU2NTUyMTU3OTA= | 377 | Iyy!!! | {
"avatar_url": "https://avatars.githubusercontent.com/u/68154535?v=4",
"events_url": "https://api.github.com/users/ajinomoh/events{/privacy}",
"followers_url": "https://api.github.com/users/ajinomoh/followers",
"following_url": "https://api.github.com/users/ajinomoh/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-07-11T14:11:07Z | 2020-07-11T14:30:51Z | 2020-07-11T14:30:51Z | NONE | null | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/377/timeline | null | completed | false | |
https://api.github.com/repos/huggingface/datasets/issues/2218 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2218/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2218/comments | https://api.github.com/repos/huggingface/datasets/issues/2218/events | https://github.com/huggingface/datasets/issues/2218 | 857,238,435 | MDU6SXNzdWU4NTcyMzg0MzU= | 2,218 | Duplicates in the LAMA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7276193?v=4",
"events_url": "https://api.github.com/users/amarasovic/events{/privacy}",
"followers_url": "https://api.github.com/users/amarasovic/followers",
"following_url": "https://api.github.com/users/amarasovic/following{/other_user}",
"gists_url":... | [] | open | false | null | [] | null | [
"Hi,\r\n\r\ncurrently the datasets API doesn't have a dedicated function to remove duplicate rows, but since the LAMA dataset is not too big (it fits in RAM), we can leverage pandas to help us remove duplicates:\r\n```python\r\n>>> from datasets import load_dataset, Dataset\r\n>>> dataset = load_dataset('lama', spl... | 2021-04-13T18:59:49Z | 2021-04-14T21:42:27Z | null | NONE | null | null | null | I observed duplicates in the LAMA probing dataset, see a minimal code below.
```
>>> import datasets
>>> dataset = datasets.load_dataset('lama')
No config specified, defaulting to: lama/trex
Reusing dataset lama (/home/anam/.cache/huggingface/datasets/lama/trex/1.1.0/97deffae13eca0a18e77dfb3960bb31741e973586f5c... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2218/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2218/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4583/comments | https://api.github.com/repos/huggingface/datasets/issues/4583/events | https://github.com/huggingface/datasets/pull/4583 | 1,286,790,871 | PR_kwDODunzps46d7xo | 4,583 | <code> implementation of FLAC support using torchaudio | {
"avatar_url": "https://avatars.githubusercontent.com/u/45745870?v=4",
"events_url": "https://api.github.com/users/rafael-ariascalles/events{/privacy}",
"followers_url": "https://api.github.com/users/rafael-ariascalles/followers",
"following_url": "https://api.github.com/users/rafael-ariascalles/following{/oth... | [] | closed | false | null | [] | null | [] | 2022-06-28T05:24:21Z | 2022-06-28T05:47:02Z | 2022-06-28T05:47:02Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4583",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4583"
} | I had added Audio FLAC support with torchaudio given that Librosa and SoundFile can give problems. Also, FLAC is been used as audio from https://mlcommons.org/en/peoples-speech/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4583/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3615/comments | https://api.github.com/repos/huggingface/datasets/issues/3615/events | https://github.com/huggingface/datasets/issues/3615 | 1,111,576,876 | I_kwDODunzps5CQVEs | 3,615 | Dataset BnL Historical Newspapers does not work in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"@albertvillanova let me know if there is anything I can do to help with this. I had a quick look at the code again and though I could try the following changes:\r\n- use `download` instead of `download_and_extract`\r\nhttps://github.com/huggingface/datasets/blob/d3d339fb86d378f4cb3c5d1de423315c07a466c6/datasets/bn... | 2022-01-22T14:12:59Z | 2022-02-04T14:05:21Z | 2022-02-04T14:05:21Z | MEMBER | null | null | null | ## Describe the bug
When trying to load in streaming mode, it "hangs"...
## Steps to reproduce the bug
```python
ds = load_dataset("bnl_newspapers", split="train", streaming=True)
```
## Expected results
The code should be optimized, so that it works fast in streaming mode.
CC: @davanstrien
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3615/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2134 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2134/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2134/comments | https://api.github.com/repos/huggingface/datasets/issues/2134/events | https://github.com/huggingface/datasets/issues/2134 | 843,242,849 | MDU6SXNzdWU4NDMyNDI4NDk= | 2,134 | Saving large in-memory datasets with save_to_disk crashes because of pickling | {
"avatar_url": "https://avatars.githubusercontent.com/u/5815801?v=4",
"events_url": "https://api.github.com/users/prokopCerny/events{/privacy}",
"followers_url": "https://api.github.com/users/prokopCerny/followers",
"following_url": "https://api.github.com/users/prokopCerny/following{/other_user}",
"gists_ur... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi !\r\nIndeed `save_to_disk` doesn't call pickle anymore. Though the `OverflowError` can still appear for in-memory datasets bigger than 4GB. This happens when doing this for example:\r\n```python\r\nimport pyarrow as pa\r\nimport pickle\r\n\r\narr = pa.array([0] * ((4 * 8 << 30) // 64))\r\ntable = pa.Table.from_... | 2021-03-29T10:43:15Z | 2021-05-03T17:59:21Z | 2021-05-03T17:59:21Z | NONE | null | null | null | Using Datasets 1.5.0 on Python 3.7.
Recently I've been working on medium to large size datasets (pretokenized raw text sizes from few gigabytes to low tens of gigabytes), and have found out that several preprocessing steps are massively faster when done in memory, and I have the ability to requisition a lot of RAM, so... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2134/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2134/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2382/comments | https://api.github.com/repos/huggingface/datasets/issues/2382/events | https://github.com/huggingface/datasets/issues/2382 | 895,610,216 | MDU6SXNzdWU4OTU2MTAyMTY= | 2,382 | DuplicatedKeysError: FAILURE TO GENERATE DATASET ! load_dataset('head_qa', 'en') | {
"avatar_url": "https://avatars.githubusercontent.com/u/75953751?v=4",
"events_url": "https://api.github.com/users/helloworld123-lab/events{/privacy}",
"followers_url": "https://api.github.com/users/helloworld123-lab/followers",
"following_url": "https://api.github.com/users/helloworld123-lab/following{/other_... | [] | closed | false | null | [] | null | [] | 2021-05-19T15:49:48Z | 2021-05-30T13:26:16Z | 2021-05-30T13:26:16Z | NONE | null | null | null | Hello everyone,
I try to use head_qa dataset in [https://huggingface.co/datasets/viewer/?dataset=head_qa&config=en](url)
```
!pip install datasets
from datasets import load_dataset
dataset = load_dataset(
'head_qa', 'en')
```
When I write above load_dataset(.), it throws the following:
```
Duplicated... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2382/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2382/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/163 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/163/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/163/comments | https://api.github.com/repos/huggingface/datasets/issues/163/events | https://github.com/huggingface/datasets/issues/163 | 620,534,307 | MDU6SXNzdWU2MjA1MzQzMDc= | 163 | [Feature request] Add cos-e v1.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Sounds good, @mariamabarham do you want to give a look?\r\nI think we should have two configurations so we can allow either version of the dataset to be loaded with the `1.0` version being the default maybe.\r\n\r\nCc some authors of the great cos-e: @nazneenrajani @bmccann",
"cos_e v1.0 is related to CQA v1.0 b... | 2020-05-18T22:05:26Z | 2020-06-16T23:15:25Z | 2020-06-16T18:52:06Z | NONE | null | null | null | I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](ht... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/163/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/163/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/356/comments | https://api.github.com/repos/huggingface/datasets/issues/356/events | https://github.com/huggingface/datasets/pull/356 | 653,537,388 | MDExOlB1bGxSZXF1ZXN0NDQ2NDM3MDQ5 | 356 | Add text dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists... | [] | closed | false | null | [] | null | [] | 2020-07-08T19:21:53Z | 2020-07-10T14:19:03Z | 2020-07-10T14:19:03Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/356.diff",
"html_url": "https://github.com/huggingface/datasets/pull/356",
"merged_at": "2020-07-10T14:19:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/356.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/356... | Usage:
```python
from nlp import load_dataset
dset = load_dataset("text", data_files="/path/to/file.txt")["train"]
```
I created a dummy_data.zip which contains three files: `train.txt`, `test.txt`, `dev.txt`. Each of these contains two lines. It passes
```bash
RUN_SLOW=1 pytest tests/test_dataset_common... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 3,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/356/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1440/comments | https://api.github.com/repos/huggingface/datasets/issues/1440/events | https://github.com/huggingface/datasets/pull/1440 | 760,973,057 | MDExOlB1bGxSZXF1ZXN0NTM1NzEyNDY1 | 1,440 | Adding english plaintext jokes dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22298787?v=4",
"events_url": "https://api.github.com/users/purvimisal/events{/privacy}",
"followers_url": "https://api.github.com/users/purvimisal/followers",
"following_url": "https://api.github.com/users/purvimisal/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi @purvimisal, thanks for your contributions!\r\n\r\nThis jokes dataset has come up before, and after a conversation with the initial submitter, we decided not to add it then. Humor is important, but looking at the actual data points in this set raises several concerns :) \r\n\r\nThe main issue is the Reddit part... | 2020-12-10T07:04:17Z | 2020-12-13T05:22:00Z | 2020-12-12T05:55:43Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1440.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1440",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1440.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1440"
} | This PR adds a dataset of 200k English plaintext Jokes from three sources: Reddit, Stupidstuff, and Wocka.
Link: https://github.com/taivop/joke-dataset
This is my second PR.
First was: [#1269 ](https://github.com/huggingface/datasets/pull/1269) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1440/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1801 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1801/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1801/comments | https://api.github.com/repos/huggingface/datasets/issues/1801/events | https://github.com/huggingface/datasets/pull/1801 | 797,814,275 | MDExOlB1bGxSZXF1ZXN0NTY0NzMwODYw | 1,801 | [GEM] Updated the source link of the data to update correct tokenized version. | {
"avatar_url": "https://avatars.githubusercontent.com/u/11708999?v=4",
"events_url": "https://api.github.com/users/mounicam/events{/privacy}",
"followers_url": "https://api.github.com/users/mounicam/followers",
"following_url": "https://api.github.com/users/mounicam/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"@mounicam we'll keep the original version in the Turk dataset proper, and use the updated file in the GEM aggregated dataset which I'll add later today\r\n\r\n@lhoestq do not merge, I'll close when I've submitted the GEM dataset PR :) ",
"Closed by https://github.com/huggingface/datasets/pull/1807"
] | 2021-01-31T21:17:19Z | 2021-02-02T13:17:38Z | 2021-02-02T13:17:28Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1801.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1801",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1801.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1801"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1801/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1801/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/2161 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2161/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2161/comments | https://api.github.com/repos/huggingface/datasets/issues/2161/events | https://github.com/huggingface/datasets/issues/2161 | 849,127,041 | MDU6SXNzdWU4NDkxMjcwNDE= | 2,161 | any possibility to download part of large datasets only? | {
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Not yet but it’s on the short/mid-term roadmap (requested by many indeed).",
"oh, great, really awesome feature to have, thank you very much for the great, fabulous work",
"We'll work on dataset streaming soon. This should allow you to only load the examples you need ;)",
"thanks a lot Quentin, this would be... | 2021-04-02T10:06:46Z | 2022-10-05T13:26:51Z | 2022-10-05T13:26:51Z | NONE | null | null | null | Hi
Some of the datasets I need like cc100 are very large, and then I wonder if I can download first X samples of the shuffled/unshuffled data without going through first downloading the whole data then sampling? thanks | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2161/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2161/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1754 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1754/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1754/comments | https://api.github.com/repos/huggingface/datasets/issues/1754/events | https://github.com/huggingface/datasets/pull/1754 | 789,881,730 | MDExOlB1bGxSZXF1ZXN0NTU4MTU5NjEw | 1,754 | Use a config id in the cache directory names for custom configs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-01-20T11:11:00Z | 2021-01-25T09:12:07Z | 2021-01-25T09:12:06Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1754.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1754",
"merged_at": "2021-01-25T09:12:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1754.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As noticed by @JetRunner there was some issues when trying to generate a dataset using a custom config that is based on an existing config.
For example in the following code the `mnli_custom` would reuse the cache used to create `mnli` instead of generating a new dataset with the new label classes:
```python
from ... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1754/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1754/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3576/comments | https://api.github.com/repos/huggingface/datasets/issues/3576/events | https://github.com/huggingface/datasets/pull/3576 | 1,102,059,651 | PR_kwDODunzps4w8sUm | 3,576 | Add PASS dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2022-01-13T17:16:07Z | 2022-01-20T16:50:48Z | 2022-01-20T16:50:47Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3576.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3576",
"merged_at": "2022-01-20T16:50:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3576.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds the PASS dataset.
Closes #3043 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3576/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3576/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4837 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4837/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4837/comments | https://api.github.com/repos/huggingface/datasets/issues/4837/events | https://github.com/huggingface/datasets/pull/4837 | 1,337,079,723 | PR_kwDODunzps49Fb6l | 4,837 | Add support for CSV metadata files to ImageFolder | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool thanks ! Maybe let's include this change after the refactoring from FolderBasedBuilder in #3963 to avoid dealing with too many unpleasant conflicts ?",
"@lhoestq I resolved the conflicts (AudioFolder also supports CSV metadata... | 2022-08-12T11:19:18Z | 2022-08-31T12:01:27Z | 2022-08-31T11:59:07Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4837.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4837",
"merged_at": "2022-08-31T11:59:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4837.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #4814 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4837/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4837/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5125 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5125/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5125/comments | https://api.github.com/repos/huggingface/datasets/issues/5125/events | https://github.com/huggingface/datasets/pull/5125 | 1,411,602,813 | PR_kwDODunzps5A7nr8 | 5,125 | Add `pyproject.toml` for `black` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-17T13:38:47Z | 2022-10-17T14:23:27Z | 2022-10-17T14:21:09Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5125.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5125",
"merged_at": "2022-10-17T14:21:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5125.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add `pyproject.toml` as a config file for the `black` tool to support VS Code's auto-formatting on save (and to be more consistent with the other HF projects).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5125/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5125/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6063 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6063/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6063/comments | https://api.github.com/repos/huggingface/datasets/issues/6063/events | https://github.com/huggingface/datasets/pull/6063 | 1,818,679,485 | PR_kwDODunzps5WPtxi | 6,063 | Release: 2.14.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-07-24T15:41:19Z | 2023-07-24T16:05:16Z | 2023-07-24T15:47:51Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6063.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6063",
"merged_at": "2023-07-24T15:47:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6063.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6063/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6063/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1875 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1875/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1875/comments | https://api.github.com/repos/huggingface/datasets/issues/1875/events | https://github.com/huggingface/datasets/pull/1875 | 807,887,267 | MDExOlB1bGxSZXF1ZXN0NTczMDM2NzE0 | 1,875 | Adding sari metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/6061911?v=4",
"events_url": "https://api.github.com/users/ddhruvkr/events{/privacy}",
"followers_url": "https://api.github.com/users/ddhruvkr/followers",
"following_url": "https://api.github.com/users/ddhruvkr/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2021-02-14T04:38:35Z | 2021-02-17T15:56:27Z | 2021-02-17T15:56:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1875.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1875",
"merged_at": "2021-02-17T15:56:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1875.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding SARI metric that is used in evaluation of text simplification. This is required as part of the GEM benchmark. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1875/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1875/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1596/comments | https://api.github.com/repos/huggingface/datasets/issues/1596/events | https://github.com/huggingface/datasets/pull/1596 | 770,260,531 | MDExOlB1bGxSZXF1ZXN0NTQyMDM3NTU0 | 1,596 | made suggested changes to hate-speech-and-offensive-language | {
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-12-17T18:09:26Z | 2020-12-17T18:36:02Z | 2020-12-17T18:35:53Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1596.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1596",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1596.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1596"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1596/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/3056 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3056/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3056/comments | https://api.github.com/repos/huggingface/datasets/issues/3056/events | https://github.com/huggingface/datasets/pull/3056 | 1,022,345,564 | PR_kwDODunzps4tAB9h | 3,056 | Fix meteor metric for version >= 3.6.4 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2021-10-11T07:11:44Z | 2021-10-11T07:29:20Z | 2021-10-11T07:29:19Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3056.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3056",
"merged_at": "2021-10-11T07:29:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3056.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | After `nltk` update, the meteor metric expects pre-tokenized inputs (breaking change).
This PR fixes this issue, while maintaining compatibility with older versions. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3056/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3056/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4071 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4071/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4071/comments | https://api.github.com/repos/huggingface/datasets/issues/4071/events | https://github.com/huggingface/datasets/issues/4071 | 1,187,587,683 | I_kwDODunzps5GySZj | 4,071 | Loading issue for xuyeliu/notebookCDG dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/46160972?v=4",
"events_url": "https://api.github.com/users/Jun-jie-Huang/events{/privacy}",
"followers_url": "https://api.github.com/users/Jun-jie-Huang/followers",
"following_url": "https://api.github.com/users/Jun-jie-Huang/following{/other_user}",
"g... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [
"Hi @Jun-jie-Huang,\r\n\r\nAs the error message says, \".pkl\" data files are not supported.\r\n\r\nIf you would like to share your dataset on the Hub, you would need:\r\n- either to create a Python loading script, that loads the data in any format\r\n- or to transform your data files to one of the supported format... | 2022-03-31T06:36:29Z | 2022-03-31T08:17:01Z | 2022-03-31T08:16:16Z | NONE | null | null | null | ## Dataset viewer issue for '*xuyeliu/notebookCDG*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/xuyeliu/notebookCDG)*
*Couldn't load the xuyeliu/notebookCDG with provided scripts: *
```
from datasets import load_dataset
dataset = load_dataset("xuyeliu/notebookCDG/dataset_note... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4071/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4071/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2016 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2016/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2016/comments | https://api.github.com/repos/huggingface/datasets/issues/2016/events | https://github.com/huggingface/datasets/pull/2016 | 825,965,493 | MDExOlB1bGxSZXF1ZXN0NTg4MDA5NjEz | 2,016 | Not all languages have 2 digit codes. | {
"avatar_url": "https://avatars.githubusercontent.com/u/13891775?v=4",
"events_url": "https://api.github.com/users/asiddhant/events{/privacy}",
"followers_url": "https://api.github.com/users/asiddhant/followers",
"following_url": "https://api.github.com/users/asiddhant/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [] | 2021-03-09T13:53:39Z | 2021-03-11T18:01:03Z | 2021-03-11T18:01:03Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2016.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2016",
"merged_at": "2021-03-11T18:01:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2016.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | . | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2016/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2016/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3431/comments | https://api.github.com/repos/huggingface/datasets/issues/3431/events | https://github.com/huggingface/datasets/issues/3431 | 1,079,866,083 | I_kwDODunzps5AXXLj | 3,431 | Unable to resolve any data file after loading once | {
"avatar_url": "https://avatars.githubusercontent.com/u/84694183?v=4",
"events_url": "https://api.github.com/users/LzyFischer/events{/privacy}",
"followers_url": "https://api.github.com/users/LzyFischer/followers",
"following_url": "https://api.github.com/users/LzyFischer/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi ! `load_dataset` accepts as input either a local dataset directory or a dataset name from the Hugging Face Hub.\r\n\r\nSo here you are getting this error the second time because it tries to load the local `wiki_dpr` directory, instead of `wiki_dpr` from the Hub. It doesn't work since it's a **cache** directory,... | 2021-12-14T15:02:15Z | 2022-12-11T10:53:04Z | 2022-02-24T09:13:52Z | NONE | null | null | null | when I rerun my program, it occurs this error
" Unable to resolve any data file that matches '['**train*']' at /data2/whr/lzy/open_domain_data/retrieval/wiki_dpr with any supported extension ['csv', 'tsv', 'json', 'jsonl', 'parquet', 'txt', 'zip']", so how could i deal with this problem?
thx.
And below is my code .
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3431/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3431/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/4192 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4192/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4192/comments | https://api.github.com/repos/huggingface/datasets/issues/4192/events | https://github.com/huggingface/datasets/issues/4192 | 1,210,692,554 | I_kwDODunzps5IKbPK | 4,192 | load_dataset can't load local dataset,Unable to find ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/33253979?v=4",
"events_url": "https://api.github.com/users/ahf876828330/events{/privacy}",
"followers_url": "https://api.github.com/users/ahf876828330/followers",
"following_url": "https://api.github.com/users/ahf876828330/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! :)\r\n\r\nI believe that should work unless `dataset_infos.json` isn't actually a dataset. For Hugging Face datasets, there is usually a file named `dataset_infos.json` which contains metadata about the dataset (eg. the dataset citation, license, description, etc). Can you double-check that `dataset_infos.json... | 2022-04-21T08:28:58Z | 2022-04-25T16:51:57Z | 2022-04-22T07:39:53Z | NONE | null | null | null |
Traceback (most recent call last):
File "/home/gs603/ahf/pretrained/model.py", line 48, in <module>
dataset = load_dataset("json",data_files="dataset/dataset_infos.json")
File "/home/gs603/miniconda3/envs/coderepair/lib/python3.7/site-packages/datasets/load.py", line 1675, in load_dataset
**config_kwa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4192/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4192/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1298 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1298/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1298/comments | https://api.github.com/repos/huggingface/datasets/issues/1298/events | https://github.com/huggingface/datasets/pull/1298 | 759,412,451 | MDExOlB1bGxSZXF1ZXN0NTM0NDIyODQy | 1,298 | Add OPUS Ted Talks 2013 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user... | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | 2020-12-08T12:38:38Z | 2020-12-16T16:57:50Z | 2020-12-16T16:57:49Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1298.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1298",
"merged_at": "2020-12-16T16:57:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1298.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1298/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1298/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/3453 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3453/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3453/comments | https://api.github.com/repos/huggingface/datasets/issues/3453/events | https://github.com/huggingface/datasets/issues/3453 | 1,084,515,911 | I_kwDODunzps5ApGZH | 3,453 | ValueError while iter_archive | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2021-12-20T08:46:18Z | 2021-12-20T10:04:59Z | 2021-12-20T10:04:59Z | MEMBER | null | null | null | ## Describe the bug
After the merge of:
- #3443
the method `iter_archive` throws a ValueError:
```
ValueError: read of closed file
```
## Steps to reproduce the bug
```python
for path, file in dl_manager.iter_archive(archive_path):
pass
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3453/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3453/timeline | null | completed | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.