
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 600M 2.05B | node_id stringlengths 18 32 | number int64 2 6.51k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association stringclasses 3
values | active_lock_reason float64 | draft float64 0 1 ⌀ | pull_request dict | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4811 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4811/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4811/comments | https://api.github.com/repos/huggingface/datasets/issues/4811/events | https://github.com/huggingface/datasets/issues/4811 | 1,333,043,421 | I_kwDODunzps5PdKDd | 4,811 | Bug in function validate_type for Python >= 3.9 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-08-09T10:25:21Z | 2022-08-12T13:27:05Z | 2022-08-12T13:27:05Z | MEMBER | null | null | null | ## Describe the bug
The function `validate_type` assumes that the type `typing.Optional[str]` is automatically transformed to `typing.Union[str, NoneType]`.
```python
In [4]: typing.Optional[str]
Out[4]: typing.Union[str, NoneType]
```
However, this is not the case for Python 3.9:
```python
In [3]: typing.Opt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4811/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4811/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5640/comments | https://api.github.com/repos/huggingface/datasets/issues/5640/events | https://github.com/huggingface/datasets/pull/5640 | 1,625,896,057 | PR_kwDODunzps5MID3I | 5,640 | Less zip false positives | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-03-15T16:48:59Z | 2023-03-16T13:47:37Z | 2023-03-16T13:40:12Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5640.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5640",
"merged_at": "2023-03-16T13:40:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5640.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | `zipfile.is_zipfile` return false positives for some Parquet files. It causes errors when loading certain parquet datasets, where some files are considered ZIP files by `zipfile.is_zipfile`
This is a known issue: https://github.com/python/cpython/issues/72680
At first I wanted to rely only on magic numbers, but t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5640/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5640/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4465 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4465/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4465/comments | https://api.github.com/repos/huggingface/datasets/issues/4465/events | https://github.com/huggingface/datasets/pull/4465 | 1,265,754,479 | PR_kwDODunzps45X0XY | 4,465 | Fix bigbench config names | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-06-09T08:06:19Z | 2022-06-09T14:38:36Z | 2022-06-09T14:29:19Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4465.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4465",
"merged_at": "2022-06-09T14:29:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4465.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix https://github.com/huggingface/datasets/issues/4462 in the case of bigbench | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4465/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4465/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4178 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4178/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4178/comments | https://api.github.com/repos/huggingface/datasets/issues/4178/events | https://github.com/huggingface/datasets/pull/4178 | 1,207,787,073 | PR_kwDODunzps42ZfFN | 4,178 | [feat] Add ImageNet dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3616806?v=4",
"events_url": "https://api.github.com/users/apsdehal/events{/privacy}",
"followers_url": "https://api.github.com/users/apsdehal/followers",
"following_url": "https://api.github.com/users/apsdehal/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the comments. I believe I have addressed all of them and also decreased the size of the dummy data file, so it should be ready for a re-review. I also made a change to allow adding synset mapping and valprep script in conf... | 2022-04-19T06:01:35Z | 2022-04-29T21:43:59Z | 2022-04-29T21:37:08Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4178.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4178",
"merged_at": "2022-04-29T21:37:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4178.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | To use the dataset download the tar file
[imagenet_object_localization_patched2019.tar.gz](https://www.kaggle.com/competitions/imagenet-object-localization-challenge/data?select=imagenet_object_localization_patched2019.tar.gz) from Kaggle and then point the datasets library to it by using:
```py
from datasets impo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4178/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4178/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4366/comments | https://api.github.com/repos/huggingface/datasets/issues/4366/events | https://github.com/huggingface/datasets/issues/4366 | 1,239,534,165 | I_kwDODunzps5J4cpV | 4,366 | TypeError: __init__() missing 1 required positional argument: 'scheme' | {
"avatar_url": "https://avatars.githubusercontent.com/u/99231535?v=4",
"events_url": "https://api.github.com/users/jffgitt/events{/privacy}",
"followers_url": "https://api.github.com/users/jffgitt/followers",
"following_url": "https://api.github.com/users/jffgitt/following{/other_user}",
"gists_url": "https:... | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | null | [] | null | [
"Duplicate of:\r\n- #3956\r\n\r\nI think you should report that issue to `elasticsearch` library: https://github.com/elastic/elasticsearch-py"
] | 2022-05-18T07:17:29Z | 2022-05-18T16:36:22Z | 2022-05-18T16:36:21Z | NONE | null | null | null | "name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "",
"version" : {
"number" : "7.5.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "",
"build_date" : "2019-11-26T01:06:52.518245Z",
"build_snapshot" : false,
"lucene_version" : "8.3.0... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4366/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/92 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/92/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/92/comments | https://api.github.com/repos/huggingface/datasets/issues/92/events | https://github.com/huggingface/datasets/pull/92 | 617,341,505 | MDExOlB1bGxSZXF1ZXN0NDE3Mjc1ODky | 92 | [WIP] add wmt14 | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-05-13T10:42:03Z | 2020-05-16T11:17:38Z | 2020-05-16T11:17:37Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/92.diff",
"html_url": "https://github.com/huggingface/datasets/pull/92",
"merged_at": "2020-05-16T11:17:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/92.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/92"
} | WMT14 takes forever to download :-/
- WMT is the first dataset that uses an abstract class IMO, so I had to modify the `load_dataset_module` a bit. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/92/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/92/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1703/comments | https://api.github.com/repos/huggingface/datasets/issues/1703/events | https://github.com/huggingface/datasets/pull/1703 | 781,395,146 | MDExOlB1bGxSZXF1ZXN0NTUxMTI2MjA5 | 1,703 | Improvements regarding caching and fingerprinting | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"I few comments here for discussion:\r\n- I'm not convinced yet the end user should really have to understand the difference between \"caching\" and 'fingerprinting\", what do you think? I think fingerprinting should probably stay as an internal thing. Is there a case where we want cahing without fingerprinting or ... | 2021-01-07T15:26:29Z | 2021-01-19T17:32:11Z | 2021-01-19T17:32:10Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1703.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1703",
"merged_at": "2021-01-19T17:32:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1703.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds these features:
- Enable/disable caching
If disabled, the library will no longer reload cached datasets files when applying transforms to the datasets.
It is equivalent to setting `load_from_cache` to `False` in dataset transforms.
```python
from datasets import set_caching_enabled
set_cach... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1703/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1859 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1859/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1859/comments | https://api.github.com/repos/huggingface/datasets/issues/1859/events | https://github.com/huggingface/datasets/issues/1859 | 805,479,025 | MDU6SXNzdWU4MDU0NzkwMjU= | 1,859 | Error "in void don't know how to serialize this type of index" when saving index to disk when device=0 (GPU) | {
"avatar_url": "https://avatars.githubusercontent.com/u/3995321?v=4",
"events_url": "https://api.github.com/users/corticalstack/events{/privacy}",
"followers_url": "https://api.github.com/users/corticalstack/followers",
"following_url": "https://api.github.com/users/corticalstack/following{/other_user}",
"gi... | [] | closed | false | null | [] | null | [
"Hi @corticalstack ! Thanks for reporting. Indeed in the recent versions of Faiss we must use `getDevice` to check if the index in on GPU.\r\n\r\nI'm opening a PR",
"I fixed this issue. It should work fine now.\r\nFeel free to try it out by installing `datasets` from source.\r\nOtherwise you can wait for the next... | 2021-02-10T12:41:00Z | 2021-02-10T18:32:12Z | 2021-02-10T18:17:47Z | NONE | null | null | null | Error serializing faiss index. Error as follows:
`Error in void faiss::write_index(const faiss::Index*, faiss::IOWriter*) at /home/conda/feedstock_root/build_artifacts/faiss-split_1612472484670/work/faiss/impl/index_write.cpp:453: don't know how to serialize this type of index`
Note:
`torch.cuda.is_availabl... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1859/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1859/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5686/comments | https://api.github.com/repos/huggingface/datasets/issues/5686/events | https://github.com/huggingface/datasets/pull/5686 | 1,646,308,228 | PR_kwDODunzps5NMXdu | 5,686 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5686). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-03-29T18:24:13Z | 2023-03-29T18:33:49Z | 2023-03-29T18:24:22Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5686.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5686",
"merged_at": "2023-03-29T18:24:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5686.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5686/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5686/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3583/comments | https://api.github.com/repos/huggingface/datasets/issues/3583/events | https://github.com/huggingface/datasets/issues/3583 | 1,105,195,144 | I_kwDODunzps5B3_CI | 3,583 | Add The Medical Segmentation Decathlon Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",... | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/64613009?v=4",
"events_url": "https://api.github.com/users/pri1311/events{/privacy}",
"followers_url": "https://api.github.com/users/pri1311/followers",
"following_url": "https://api.github.com/users/pri1311/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/64613009?v=4",
"events_url": "https://api.github.com/users/pri1311/events{/privacy}",
"followers_url": "https://api.github.com/users/pri1311/followers",
"following_url": "https://api.github.com/users/pri1311/following{/other_user}",
"gists... | null | [
"Hello! I have recently been involved with a medical image segmentation project myself and was going through the `The Medical Segmentation Decathlon Dataset` as well. \r\nI haven't yet had experience adding datasets to this repository yet but would love to get started. Should I take this issue?\r\nIf yes, I've got ... | 2022-01-16T21:42:25Z | 2022-03-18T10:44:42Z | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** *The Medical Segmentation Decathlon Dataset*
- **Description:** The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data, and small objects.
- **Paper:*... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3583/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/6259 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6259/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6259/comments | https://api.github.com/repos/huggingface/datasets/issues/6259/events | https://github.com/huggingface/datasets/issues/6259 | 1,911,965,758 | I_kwDODunzps5x9kg- | 6,259 | Duplicated Rows When Loading Parquet Files from Root Directory with Subdirectories | {
"avatar_url": "https://avatars.githubusercontent.com/u/141304309?v=4",
"events_url": "https://api.github.com/users/MF-FOOM/events{/privacy}",
"followers_url": "https://api.github.com/users/MF-FOOM/followers",
"following_url": "https://api.github.com/users/MF-FOOM/following{/other_user}",
"gists_url": "https... | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Thanks for reporting this issue! We should be able to avoid this by making our `glob` patterns more precise. In the meantime, you can load the dataset by directly assigning splits to the data files: \r\n```python\r\nfrom datasets import load_dataset\r\nds = load_dataset(\"parquet\", data_files={\"train\": \"testin... | 2023-09-25T17:20:54Z | 2023-09-26T17:54:08Z | null | NONE | null | null | null | ### Describe the bug
When parquet files are saved in "train" and "val" subdirectories under a root directory, and datasets are then loaded using `load_dataset("parquet", data_dir="root_directory")`, the resulting dataset has duplicated rows for both the training and validation sets.
### Steps to reproduce the bug... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6259/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6259/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4628/comments | https://api.github.com/repos/huggingface/datasets/issues/4628/events | https://github.com/huggingface/datasets/pull/4628 | 1,293,361,308 | PR_kwDODunzps46zvFJ | 4,628 | Fix time type `_arrow_to_datasets_dtype` conversion | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-04T16:20:15Z | 2022-07-07T14:08:38Z | 2022-07-07T13:57:12Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4628.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4628",
"merged_at": "2022-07-07T13:57:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4628.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix #4620
The issue stems from the fact that `pa.array([time_data]).type` returns `DataType(time64[unit])`, which doesn't expose the `unit` attribute, instead of `Time64Type(time64[unit])`. I believe this is a bug in PyArrow. Luckily, the both types have the same `str()`, so in this PR I call `pa.type_for_alias(str(... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4628/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4628/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/551/comments | https://api.github.com/repos/huggingface/datasets/issues/551/events | https://github.com/huggingface/datasets/pull/551 | 690,034,762 | MDExOlB1bGxSZXF1ZXN0NDc2OTkwNjAw | 551 | added HANS dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2020-09-01T10:42:02Z | 2020-09-01T12:17:10Z | 2020-09-01T12:17:10Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/551.diff",
"html_url": "https://github.com/huggingface/datasets/pull/551",
"merged_at": "2020-09-01T12:17:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/551.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/551... | Adds the [HANS](https://github.com/tommccoy1/hans) dataset to evaluate NLI systems. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/551/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/551/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6195 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6195/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6195/comments | https://api.github.com/repos/huggingface/datasets/issues/6195/events | https://github.com/huggingface/datasets/issues/6195 | 1,874,195,585 | I_kwDODunzps5vtfSB | 6,195 | Force to reuse cache at given path | {
"avatar_url": "https://avatars.githubusercontent.com/u/43507393?v=4",
"events_url": "https://api.github.com/users/Luosuu/events{/privacy}",
"followers_url": "https://api.github.com/users/Luosuu/followers",
"following_url": "https://api.github.com/users/Luosuu/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"realized that need to pass the path at `cache_file_name` like\r\n\r\n```python\r\ntokenized_datasets = raw_datasets[\"train\"].map(\r\n tokenize_function,\r\n batched=True,\r\n num_proc=data_args.preprocessing_num_workers,\r\n remove_columns=[text_column_... | 2023-08-30T18:44:54Z | 2023-11-03T10:14:21Z | 2023-08-30T19:00:45Z | NONE | null | null | null | ### Describe the bug
I have run the official example of MLM like:
```bash
python run_mlm.py \
--model_name_or_path roberta-base \
--dataset_name togethercomputer/RedPajama-Data-1T \
--dataset_config_name arxiv \
--per_device_train_batch_size 10 \
--preprocessing_num_workers 20 ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6195/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6195/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1868 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1868/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1868/comments | https://api.github.com/repos/huggingface/datasets/issues/1868/events | https://github.com/huggingface/datasets/pull/1868 | 807,138,159 | MDExOlB1bGxSZXF1ZXN0NTcyNDM2MjA0 | 1,868 | Update oscar sizes | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-02-12T10:55:35Z | 2021-02-12T11:03:07Z | 2021-02-12T11:03:06Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1868.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1868",
"merged_at": "2021-02-12T11:03:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1868.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This commit https://github.com/huggingface/datasets/commit/837a152e4724adc5308e2c4481908c00a8d93383 removed empty lines from the oscar deduplicated datasets. This PR updates the size of each deduplicated dataset to fix possible `NonMatchingSplitsSizesError` errors. cc @cahya-wirawan | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1868/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1868/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5040 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5040/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5040/comments | https://api.github.com/repos/huggingface/datasets/issues/5040/events | https://github.com/huggingface/datasets/pull/5040 | 1,390,566,428 | PR_kwDODunzps4_11O2 | 5,040 | Fix NonMatchingChecksumError in hendrycks_test dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-29T09:37:43Z | 2022-09-29T10:06:22Z | 2022-09-29T10:04:19Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5040.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5040",
"merged_at": "2022-09-29T10:04:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5040.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Update metadata JSON.
Fix #5039. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5040/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5040/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2620/comments | https://api.github.com/repos/huggingface/datasets/issues/2620/events | https://github.com/huggingface/datasets/pull/2620 | 940,893,389 | MDExOlB1bGxSZXF1ZXN0Njg2ODk3MDky | 2,620 | Add speech processing tasks | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Are there any `task_categories:automatic-speech-recognition` dataset for which we should update the tags ?",
"> Are there any `task_categories:automatic-speech-recognition` dataset for which we should update the tags ?\r\n\r\nYes there's a few - I'll fix them tomorrow :)"
] | 2021-07-09T16:07:29Z | 2021-07-12T18:32:59Z | 2021-07-12T17:32:02Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2620.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2620",
"merged_at": "2021-07-12T17:32:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2620.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR replaces the `automatic-speech-recognition` task category with a broader `speech-processing` category.
The tasks associated with this category are derived from the [SUPERB benchmark](https://arxiv.org/abs/2105.01051), and ASR is included in this set. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2620/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2620/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/988 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/988/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/988/comments | https://api.github.com/repos/huggingface/datasets/issues/988/events | https://github.com/huggingface/datasets/issues/988 | 755,069,159 | MDU6SXNzdWU3NTUwNjkxNTk= | 988 | making sure datasets are not loaded in memory and distributed training of them | {
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"my implementation of sharding per TPU core: https://github.com/google-research/ruse/blob/d4dd58a2d8efe0ffb1a9e9e77e3228d6824d3c3c/seq2seq/trainers/t5_trainer.py#L316 \r\nmy implementation of dataloader for this case https://github.com/google-research/ruse/blob/d4dd58a2d8efe0ffb1a9e9e77e3228d6824d3c3c/seq2seq/tasks... | 2020-12-02T08:45:15Z | 2022-10-05T13:00:42Z | 2022-10-05T13:00:42Z | CONTRIBUTOR | null | null | null | Hi
I am dealing with large-scale datasets which I need to train distributedly, I used the shard function to divide the dataset across the cores, without any sampler, this does not work for distributed training and does not become any faster than 1 TPU core. 1) how I can make sure data is not loaded in memory 2) in cas... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/988/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/988/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/31 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/31/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/31/comments | https://api.github.com/repos/huggingface/datasets/issues/31/events | https://github.com/huggingface/datasets/pull/31 | 610,677,641 | MDExOlB1bGxSZXF1ZXN0NDEyMDczNDE4 | 31 | [Circle ci] Install a virtual env before running tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-05-01T10:11:17Z | 2020-05-01T22:06:16Z | 2020-05-01T22:06:15Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/31.diff",
"html_url": "https://github.com/huggingface/datasets/pull/31",
"merged_at": "2020-05-01T22:06:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/31.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/31"
} | Install a virtual env before running tests to not running into sudo issues when dynamically downloading files.
Same number of tests now pass / fail as on my local computer:
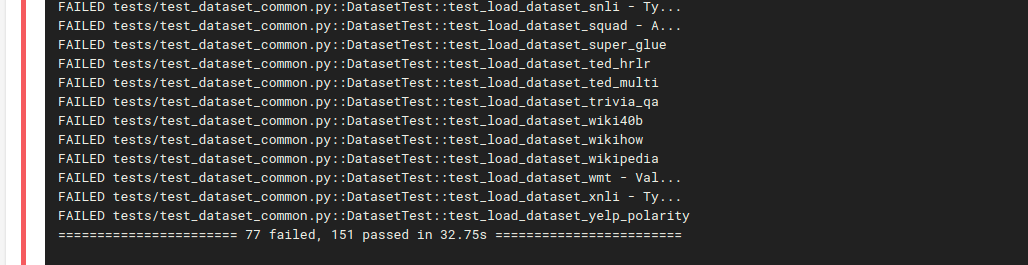
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/31/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/31/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4724/comments | https://api.github.com/repos/huggingface/datasets/issues/4724/events | https://github.com/huggingface/datasets/pull/4724 | 1,311,127,404 | PR_kwDODunzps47vLrP | 4,724 | Download and prepare as Parquet for cloud storage | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Added some docs for dask and took your comments into account\r\n\r\ncc @philschmid if you also want to take a look :)",
"Just noticed that it would be more convenient to pass the output dir to download_and_prepare directly, to bypa... | 2022-07-20T13:39:02Z | 2022-09-05T17:27:25Z | 2022-09-05T17:25:27Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4724.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4724",
"merged_at": "2022-09-05T17:25:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4724.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Download a dataset as Parquet in a cloud storage can be useful for streaming mode and to use with spark/dask/ray.
This PR adds support for `fsspec` URIs like `s3://...`, `gcs://...` etc. and ads the `file_format` to save as parquet instead of arrow:
```python
from datasets import *
cache_dir = "s3://..."
build... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4724/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4724/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2843 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2843/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2843/comments | https://api.github.com/repos/huggingface/datasets/issues/2843/events | https://github.com/huggingface/datasets/pull/2843 | 981,317,775 | MDExOlB1bGxSZXF1ZXN0NzIxMzkwODA5 | 2,843 | Fix extraction protocol inference from urls with params | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"merging since the windows error is just a CircleCI issue",
"It works, eg https://observablehq.com/@huggingface/datasets-preview-backend-client#{%22datasetId%22%3A%22discovery%22} and https://datasets-preview.huggingface.tech/rows?dataset=discovery&config=discovery&split=train",
"Nice !"
] | 2021-08-27T14:40:57Z | 2021-08-30T17:11:49Z | 2021-08-30T13:12:01Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2843.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2843",
"merged_at": "2021-08-30T13:12:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2843.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Previously it was unable to infer the compression protocol for files at URLs like
```
https://foo.bar/train.json.gz?dl=1
```
because of the query parameters.
I fixed that, this should allow 10+ datasets to work in streaming mode:
```
"discovery",
"emotion",
"grail_qa",
"guardian_authorship",
"pra... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2843/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2843/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4751 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4751/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4751/comments | https://api.github.com/repos/huggingface/datasets/issues/4751/events | https://github.com/huggingface/datasets/pull/4751 | 1,319,440,903 | PR_kwDODunzps48LJ7U | 4,751 | Added dataset information in clinic oos dataset card | {
"avatar_url": "https://avatars.githubusercontent.com/u/84362194?v=4",
"events_url": "https://api.github.com/users/arnav-ladkat/events{/privacy}",
"followers_url": "https://api.github.com/users/arnav-ladkat/followers",
"following_url": "https://api.github.com/users/arnav-ladkat/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-27T11:44:28Z | 2022-07-28T10:53:21Z | 2022-07-28T10:40:37Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4751.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4751",
"merged_at": "2022-07-28T10:40:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4751.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR aims to add relevant information like the Description, Language and citation information of the clinic oos dataset card. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4751/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4751/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3697/comments | https://api.github.com/repos/huggingface/datasets/issues/3697/events | https://github.com/huggingface/datasets/pull/3697 | 1,129,795,724 | PR_kwDODunzps4yXeXo | 3,697 | Add code-fill datasets for pretraining/finetuning/evaluating | {
"avatar_url": "https://avatars.githubusercontent.com/u/49989029?v=4",
"events_url": "https://api.github.com/users/rgismondi/events{/privacy}",
"followers_url": "https://api.github.com/users/rgismondi/followers",
"following_url": "https://api.github.com/users/rgismondi/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hi ! Thanks for adding this dataset :)\r\n\r\nIt looks like your PR contains many changes in files that are unrelated to your changes, I think it might come from running `make style` with an outdated version of `black`. Could you try opening a new PR that only contains your additions ? (or force push to this PR)"
... | 2022-02-10T10:31:48Z | 2022-07-06T15:19:58Z | 2022-07-06T15:19:58Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3697.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3697",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3697.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3697"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3697/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3697/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/422 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/422/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/422/comments | https://api.github.com/repos/huggingface/datasets/issues/422/events | https://github.com/huggingface/datasets/pull/422 | 663,028,497 | MDExOlB1bGxSZXF1ZXN0NDU0NTE3MDU2 | 422 | - Corrected encoding for IMDB. | {
"avatar_url": "https://avatars.githubusercontent.com/u/25091538?v=4",
"events_url": "https://api.github.com/users/ghazi-f/events{/privacy}",
"followers_url": "https://api.github.com/users/ghazi-f/followers",
"following_url": "https://api.github.com/users/ghazi-f/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-07-21T13:46:59Z | 2020-07-22T16:02:53Z | 2020-07-22T16:02:53Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/422.diff",
"html_url": "https://github.com/huggingface/datasets/pull/422",
"merged_at": "2020-07-22T16:02:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/422.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/422... | The preparation phase (after the download phase) crashed on windows because of charmap encoding not being able to decode certain characters. This change suggested in Issue #347 fixes it for the IMDB dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/422/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/422/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1207 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1207/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1207/comments | https://api.github.com/repos/huggingface/datasets/issues/1207/events | https://github.com/huggingface/datasets/pull/1207 | 757,953,830 | MDExOlB1bGxSZXF1ZXN0NTMzMjE3MDA4 | 1,207 | Add msr_genomics_kbcomp Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/6687858?v=4",
"events_url": "https://api.github.com/users/manandey/events{/privacy}",
"followers_url": "https://api.github.com/users/manandey/followers",
"following_url": "https://api.github.com/users/manandey/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-12-06T15:40:05Z | 2020-12-07T15:55:17Z | 2020-12-07T15:55:11Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1207.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1207",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1207.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1207"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1207/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1207/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/3375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3375/comments | https://api.github.com/repos/huggingface/datasets/issues/3375/events | https://github.com/huggingface/datasets/pull/3375 | 1,070,454,913 | PR_kwDODunzps4vWrXz | 3,375 | Support streaming zipped dataset repo by passing only repo name | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"I just tested and I think this only opens one file ? If there are several files in the ZIP, only the first one is opened. To open several files from a ZIP, one has to call `open` several times.\r\n\r\nWhat about updating the CSV loader to make it `download_and_extract` zip files, and open each extracted file ?",
... | 2021-12-03T10:43:05Z | 2021-12-16T18:03:32Z | 2021-12-16T18:03:31Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3375",
"merged_at": "2021-12-16T18:03:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Proposed solution:
- I have added the method `iter_files` to DownloadManager and StreamingDownloadManager
- I use this in modules: "csv", "json", "text"
- I test for CSV/JSONL/TXT zipped (and non-zipped) files, both in streaming and non-streaming modes
Fix #3373. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3375/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5703/comments | https://api.github.com/repos/huggingface/datasets/issues/5703/events | https://github.com/huggingface/datasets/pull/5703 | 1,653,158,955 | PR_kwDODunzps5NjCCV | 5,703 | [WIP][Test, Please ignore] Investigate performance impact of using multiprocessing only | {
"avatar_url": "https://avatars.githubusercontent.com/u/1535968?v=4",
"events_url": "https://api.github.com/users/hvaara/events{/privacy}",
"followers_url": "https://api.github.com/users/hvaara/followers",
"following_url": "https://api.github.com/users/hvaara/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"`multiprocess` uses `dill` instead of `pickle` for pickling shared objects and, as such, can pickle more types than `multiprocessing`. And I don't think this is something we want to change :).",
"That makes sense to me, and I don't think you should merge this change. I was only curious about the performance impa... | 2023-04-04T04:37:49Z | 2023-04-20T03:17:37Z | 2023-04-20T03:17:32Z | NONE | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5703.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5703",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5703.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5703"
} | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5703/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1100 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1100/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1100/comments | https://api.github.com/repos/huggingface/datasets/issues/1100/events | https://github.com/huggingface/datasets/pull/1100 | 756,998,433 | MDExOlB1bGxSZXF1ZXN0NTMyNDQ2ODc1 | 1,100 | Urdu fake news | {
"avatar_url": "https://avatars.githubusercontent.com/u/44389205?v=4",
"events_url": "https://api.github.com/users/chaitnayabasava/events{/privacy}",
"followers_url": "https://api.github.com/users/chaitnayabasava/followers",
"following_url": "https://api.github.com/users/chaitnayabasava/following{/other_user}"... | [] | closed | false | null | [] | null | [] | 2020-12-04T10:41:20Z | 2020-12-04T11:19:00Z | 2020-12-04T11:19:00Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1100.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1100",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1100.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1100"
} | Added Bend the Truth urdu fake news dataset. More inforation <a href="https://github.com/MaazAmjad/Datasets-for-Urdu-news">here</a>. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1100/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1100/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4559 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4559/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4559/comments | https://api.github.com/repos/huggingface/datasets/issues/4559/events | https://github.com/huggingface/datasets/pull/4559 | 1,283,544,937 | PR_kwDODunzps46TV7- | 4,559 | Add action names in schema_guided_dstc8 dataset card | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-06-24T10:00:01Z | 2022-06-24T10:54:28Z | 2022-06-24T10:43:47Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4559.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4559",
"merged_at": "2022-06-24T10:43:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4559.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | As aseked in https://huggingface.co/datasets/schema_guided_dstc8/discussions/1, I added the action names in the dataset card | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4559/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4559/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/362/comments | https://api.github.com/repos/huggingface/datasets/issues/362/events | https://github.com/huggingface/datasets/issues/362 | 653,766,245 | MDU6SXNzdWU2NTM3NjYyNDU= | 362 | [dateset subset missing] xtreme paws-x | {
"avatar_url": "https://avatars.githubusercontent.com/u/50871412?v=4",
"events_url": "https://api.github.com/users/jerryIsHere/events{/privacy}",
"followers_url": "https://api.github.com/users/jerryIsHere/followers",
"following_url": "https://api.github.com/users/jerryIsHere/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"You're right, thanks for pointing it out. We will update it "
] | 2020-07-09T05:04:54Z | 2020-07-09T12:38:42Z | 2020-07-09T12:38:42Z | CONTRIBUTOR | null | null | null | I tried nlp.load_dataset('xtreme', 'PAWS-X.es') but get the value error
It turns out that the subset for Spanish is missing
https://github.com/google-research-datasets/paws/tree/master/pawsx | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/362/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3545 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3545/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3545/comments | https://api.github.com/repos/huggingface/datasets/issues/3545/events | https://github.com/huggingface/datasets/pull/3545 | 1,096,189,889 | PR_kwDODunzps4wpziv | 3,545 | fix: 🐛 pass token when retrieving the split names | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Currently, it does not work with https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0/blob/main/common_voice_7_0.py#L146 (which was the goal), because `dl_manager.download_config.use_auth_token` is ignored, and the authentication is required to be use `huggingface-cli login`.\r\nIn my use case (data... | 2022-01-07T10:29:22Z | 2022-01-10T10:51:47Z | 2022-01-10T10:51:46Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3545.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3545",
"merged_at": "2022-01-10T10:51:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3545.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3545/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3545/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5255 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5255/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5255/comments | https://api.github.com/repos/huggingface/datasets/issues/5255/events | https://github.com/huggingface/datasets/issues/5255 | 1,452,631,517 | I_kwDODunzps5WlWXd | 5,255 | Add a Depth Estimation dataset - DIODE / NYUDepth / KITTI | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
... | null | [
"Also cc @mariosasko and @lhoestq ",
"Cool ! Let us know if you have questions or if we can help :)\r\n\r\nI guess we'll also have to create the NYU CS Department on the Hub ?",
"> I guess we'll also have to create the NYU CS Department on the Hub ?\r\n\r\nYes, you're right! Let me add it to my profile first, a... | 2022-11-17T03:22:22Z | 2022-12-17T12:20:38Z | 2022-12-17T12:20:37Z | MEMBER | null | null | null | ### Name
NYUDepth
### Paper
http://cs.nyu.edu/~silberman/papers/indoor_seg_support.pdf
### Data
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
### Motivation
Depth estimation is an important problem in computer vision. We have a couple of Depth Estimation models on Hub as well:
* [GLPN... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5255/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5255/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5566/comments | https://api.github.com/repos/huggingface/datasets/issues/5566/events | https://github.com/huggingface/datasets/issues/5566 | 1,595,916,674 | I_kwDODunzps5fH8GC | 5,566 | Directly reading parquet files in a s3 bucket from the load_dataset method | {
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "htt... | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
},
{
"color": "a2eeef",
... | open | false | null | [] | null | [
"Hi ! I think is in the scope of this other issue: to https://github.com/huggingface/datasets/issues/5281 "
] | 2023-02-22T22:13:40Z | 2023-02-23T11:03:29Z | null | NONE | null | null | null | ### Feature request
Right now, we have to read the get the parquet file to the local storage. So having ability to read given the bucket directly address would be benificial
### Motivation
In a production set up, this feature can help us a lot. So we do not need move training datafiles in between storage.
### Yo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5566/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5566/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3646/comments | https://api.github.com/repos/huggingface/datasets/issues/3646/events | https://github.com/huggingface/datasets/pull/3646 | 1,116,544,627 | PR_kwDODunzps4xsX66 | 3,646 | Fix streaming datasets that are not reset correctly | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Works smoothly with the `transformers.Trainer` class now, thank you!"
] | 2022-01-27T17:21:02Z | 2022-01-28T16:34:29Z | 2022-01-28T16:34:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3646.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3646",
"merged_at": "2022-01-28T16:34:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3646.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Streaming datasets that use `StreamingDownloadManager.iter_archive` and `StreamingDownloadManager.iter_files` had some issues. Indeed if you try to iterate over such dataset twice, then the second time it will be empty.
This is because the two methods above are generator functions. I fixed this by making them return... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3646/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3646/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/7 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7/comments | https://api.github.com/repos/huggingface/datasets/issues/7/events | https://github.com/huggingface/datasets/pull/7 | 601,780,534 | MDExOlB1bGxSZXF1ZXN0NDA0OTgyMzA2 | 7 | Fix issue 5: allow empty datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | [] | closed | false | null | [] | null | [] | 2020-04-17T07:59:56Z | 2020-04-29T09:27:13Z | 2020-04-20T13:23:48Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7",
"merged_at": "2020-04-20T13:23:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/5193 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5193/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5193/comments | https://api.github.com/repos/huggingface/datasets/issues/5193/events | https://github.com/huggingface/datasets/issues/5193 | 1,433,883,780 | I_kwDODunzps5Vd1SE | 5,193 | "One or several metadata. were found, but not in the same directory or in a parent directory" | {
"avatar_url": "https://avatars.githubusercontent.com/u/20109584?v=4",
"events_url": "https://api.github.com/users/lambda-science/events{/privacy}",
"followers_url": "https://api.github.com/users/lambda-science/followers",
"following_url": "https://api.github.com/users/lambda-science/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Also unrelated but still: https://huggingface.co/docs/datasets/image_dataset#generate-the-dataset\r\n```If your loading script passed the test, you should now have a dataset_infos.json file in your dataset folder.```\r\nIt's not the case anymore as it's now in the readme.md, it was confusing to me",
"And here is... | 2022-11-02T22:46:25Z | 2022-11-03T13:39:16Z | 2022-11-03T13:35:44Z | NONE | null | null | null | ### Describe the bug
When loading my own dataset, on loading it I get an error.
Here is my dataset link: https://huggingface.co/datasets/corentinm7/MyoQuant-SDH-Data
And the error after loading with:
```python
from datasets import load_dataset
load_dataset("corentinm7/MyoQuant-SDH-Data")
```
```python
Downlo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5193/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5193/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3781 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3781/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3781/comments | https://api.github.com/repos/huggingface/datasets/issues/3781/events | https://github.com/huggingface/datasets/pull/3781 | 1,148,599,680 | PR_kwDODunzps4zXr_O | 3,781 | Reddit dataset card additions | {
"avatar_url": "https://avatars.githubusercontent.com/u/56791604?v=4",
"events_url": "https://api.github.com/users/anna-kay/events{/privacy}",
"followers_url": "https://api.github.com/users/anna-kay/followers",
"following_url": "https://api.github.com/users/anna-kay/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hello! I added the tags and created a PR. Just to note, regarding the paperswithcode_id tag, that currently has the value \"reddit\"; the dataset described as reddit in paperswithcode is https://paperswithcode.com/dataset/reddit and it isn't the Webis-tldr-17. I could not find Webis-tldr-17 in paperswithcode neith... | 2022-02-23T21:29:16Z | 2022-02-28T18:00:40Z | 2022-02-28T11:21:14Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3781.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3781",
"merged_at": "2022-02-28T11:21:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3781.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The changes proposed are based on the "TL;DR: Mining Reddit to Learn Automatic Summarization" paper & https://zenodo.org/record/1043504#.YhaKHpbQC38
It is a Reddit dataset indeed, but the name given to the dataset by the authors is Webis-TLDR-17 (corpus), so perhaps it should be modified as well.
The task at which t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3781/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3781/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1149 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1149/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1149/comments | https://api.github.com/repos/huggingface/datasets/issues/1149/events | https://github.com/huggingface/datasets/pull/1149 | 757,504,068 | MDExOlB1bGxSZXF1ZXN0NTMyODY5ODUz | 1,149 | Fix typo in the comment in _info function | {
"avatar_url": "https://avatars.githubusercontent.com/u/34424769?v=4",
"events_url": "https://api.github.com/users/vinaykudari/events{/privacy}",
"followers_url": "https://api.github.com/users/vinaykudari/followers",
"following_url": "https://api.github.com/users/vinaykudari/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2020-12-05T01:26:20Z | 2020-12-05T16:19:26Z | 2020-12-05T16:19:26Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1149.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1149",
"merged_at": "2020-12-05T16:19:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1149.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1149/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1149/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/5811 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5811/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5811/comments | https://api.github.com/repos/huggingface/datasets/issues/5811/events | https://github.com/huggingface/datasets/issues/5811 | 1,689,919,046 | I_kwDODunzps5kuh5G | 5,811 | load_dataset: TypeError: 'NoneType' object is not callable, on local dataset filename changes | {
"avatar_url": "https://avatars.githubusercontent.com/u/50685483?v=4",
"events_url": "https://api.github.com/users/durapensa/events{/privacy}",
"followers_url": "https://api.github.com/users/durapensa/followers",
"following_url": "https://api.github.com/users/durapensa/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | [
"This error means a `DatasetBuilder` subclass that generates the dataset could not be found inside the script, so make sure `dushowxa-characters/dushowxa-characters.py `is a valid dataset script (assuming `path_or_dataset` is `dushowxa-characters`)\r\n\r\nAlso, we should improve the error to make it more obvious wh... | 2023-04-30T13:27:17Z | 2023-05-05T17:44:03Z | null | NONE | null | null | null | ### Describe the bug
I've adapted Databrick's [train_dolly.py](/databrickslabs/dolly/blob/master/train_dolly.py) to train using a local dataset, which has been working. Upon changing the filenames of the `.json` & `.py` files in my local dataset directory, `dataset = load_dataset(path_or_dataset)["train"]` throws th... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5811/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5811/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1828 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1828/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1828/comments | https://api.github.com/repos/huggingface/datasets/issues/1828/events | https://github.com/huggingface/datasets/pull/1828 | 802,449,234 | MDExOlB1bGxSZXF1ZXN0NTY4NTkwNDM2 | 1,828 | Add CelebA Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Hi @gchhablani! Thanks for all the contributions! We definitely want more image datasets, but Face datasets are tricky in general, in this one includes predicting attributes such as Attractiveness, Gender, or Race, which can be pretty problematic.\r\n\r\nWould you be up for starting with only object classification... | 2021-02-05T20:20:55Z | 2021-02-18T14:17:07Z | 2021-02-18T14:17:07Z | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1828.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1828",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1828.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1828"
} | Trying to add CelebA Dataset.
Need help with testing. Loading examples takes a lot of time so I am unable to generate the `dataset_infos.json` and unable to test. Also, need help with creating `dummy_data.zip`.
Additionally, trying to load a few examples using `load_dataset('./datasets/celeb_a',split='train[10:20]... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1828/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1828/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6120 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6120/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6120/comments | https://api.github.com/repos/huggingface/datasets/issues/6120/events | https://github.com/huggingface/datasets/issues/6120 | 1,836,026,938 | I_kwDODunzps5tb4w6 | 6,120 | Lookahead streaming support? | {
"avatar_url": "https://avatars.githubusercontent.com/u/17175484?v=4",
"events_url": "https://api.github.com/users/PicoCreator/events{/privacy}",
"followers_url": "https://api.github.com/users/PicoCreator/followers",
"following_url": "https://api.github.com/users/PicoCreator/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"In which format is your dataset? We could expose the `pre_buffer` flag for Parquet to use PyArrow's background thread pool to speed up loading. "
] | 2023-08-04T04:01:52Z | 2023-08-17T17:48:42Z | null | NONE | null | null | null | ### Feature request
From what I understand, streaming dataset currently pulls the data, and process the data as it is requested.
This can introduce significant latency delays when data is loaded into the training process, needing to wait for each segment.
While the delays might be dataset specific (or even mappi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6120/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6120/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1299 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1299/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1299/comments | https://api.github.com/repos/huggingface/datasets/issues/1299/events | https://github.com/huggingface/datasets/issues/1299 | 759,414,566 | MDU6SXNzdWU3NTk0MTQ1NjY= | 1,299 | can't load "german_legal_entity_recognition" dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/59837137?v=4",
"events_url": "https://api.github.com/users/nataly-obr/events{/privacy}",
"followers_url": "https://api.github.com/users/nataly-obr/followers",
"following_url": "https://api.github.com/users/nataly-obr/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Please if you could tell me more about the error? \r\n\r\n1. Please check the directory you've been working on\r\n2. Check for any typos",
"> Please if you could tell me more about the error?\r\n> \r\n> 1. Please check the directory you've been working on\r\n> 2. Check for any typos\r\n\r\nError happens during t... | 2020-12-08T12:42:01Z | 2020-12-16T16:03:13Z | 2020-12-16T16:03:13Z | NONE | null | null | null | FileNotFoundError: Couldn't find file locally at german_legal_entity_recognition/german_legal_entity_recognition.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/german_legal_entity_recognition/german_legal_entity_recognition.py or https://s3.amazonaws.com/datasets.huggingface.co... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1299/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1299/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/868 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/868/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/868/comments | https://api.github.com/repos/huggingface/datasets/issues/868/events | https://github.com/huggingface/datasets/pull/868 | 745,889,882 | MDExOlB1bGxSZXF1ZXN0NTIzMzc2MzQ3 | 868 | Consistent metric outputs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "E3165C",
"default": false,
"description": "",
"id": 4190228726,
"name": "transfer-to-evaluate",
"node_id": "LA_kwDODunzps75wdD2",
"url": "https://api.github.com/repos/huggingface/datasets/labels/transfer-to-evaluate"
}
] | closed | false | null | [] | null | [
"I keep this PR in stand-by for next week's datasets sprint. If the next release is 2.0.0 then we can include it given that it's breaking for many metrics",
"Metrics are deprecated in `datasets` and `evaluate` should be used instead: https://github.com/huggingface/evaluate"
] | 2020-11-18T18:05:59Z | 2023-09-24T09:50:25Z | 2023-07-11T09:35:52Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/868.diff",
"html_url": "https://github.com/huggingface/datasets/pull/868",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/868.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/868"
} | To automate the use of metrics, they should return consistent outputs.
In particular I'm working on adding a conversion of metrics to keras metrics.
To achieve this we need two things:
- have each metric return dictionaries of string -> floats since each keras metrics should return one float
- define in the metric ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/868/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/868/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3468 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3468/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3468/comments | https://api.github.com/repos/huggingface/datasets/issues/3468/events | https://github.com/huggingface/datasets/pull/3468 | 1,085,871,301 | PR_kwDODunzps4wIozO | 3,468 | Add COCO dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"The CI failures other than a missing dummy data file and missing fields in the card are unrelated to this PR. ",
"Thanks a lot for this great work and fixing TFDS based script @mariosasko 🤗 will generate the dummy dataset and write the model card tomorrow!",
"@mariosasko I added the dataset card, I'm on the d... | 2021-12-21T14:07:50Z | 2023-09-24T09:33:31Z | 2022-10-03T09:36:08Z | CONTRIBUTOR | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3468.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3468",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3468.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3468"
} | This PR adds the MS COCO dataset. Compared to the [TFDS](https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/object_detection/coco.py) script, this implementation adds 8 additional configs to cover the tasks other than object detection.
Some notes:
* the data exposed by TFDS is contained in the `... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3468/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3468/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5791 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5791/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5791/comments | https://api.github.com/repos/huggingface/datasets/issues/5791/events | https://github.com/huggingface/datasets/issues/5791 | 1,683,473,943 | I_kwDODunzps5kV8YX | 5,791 | TIFF/TIF support | {
"avatar_url": "https://avatars.githubusercontent.com/u/31293221?v=4",
"events_url": "https://api.github.com/users/sebasmos/events{/privacy}",
"followers_url": "https://api.github.com/users/sebasmos/followers",
"following_url": "https://api.github.com/users/sebasmos/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"The issue with multichannel TIFF images has already been reported in Pillow (https://github.com/python-pillow/Pillow/issues/1888). We can't do much about it on our side.\r\n\r\nStill, to avoid the error, you can bypass the default Pillow decoding and define a custom one as follows:\r\n```python\r\nimport tifffile ... | 2023-04-25T16:14:18Z | 2023-05-05T16:22:50Z | null | NONE | null | null | null | ### Feature request
I currently have a dataset (with tiff and json files) where I have to do this:
`wget path_to_data/images.zip && unzip images.zip`
`wget path_to_data/annotations.zip && unzip annotations.zip`
Would it make sense a contribution that supports these type of files?
### Motivation
instead o... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5791/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5791/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4191 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4191/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4191/comments | https://api.github.com/repos/huggingface/datasets/issues/4191/events | https://github.com/huggingface/datasets/issues/4191 | 1,210,028,090 | I_kwDODunzps5IH5A6 | 4,191 | feat: create an `Array3D` column from a list of arrays of dimension 2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @SaulLu, thanks for your proposal.\r\n\r\nJust I got a bit confused about the dimensions...\r\n- For the 2D case, you mention it is possible to create an `Array2D` from a list of arrays of dimension 1\r\n- However, you give an example of creating an `Array2D` from arrays of dimension 2:\r\n - the values of `da... | 2022-04-20T18:04:32Z | 2022-05-12T15:08:40Z | 2022-05-12T15:08:40Z | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
It is possible to create an `Array2D` column from a list of arrays of dimension 1. Similarly, I think it might be nice to be able to create a `Array3D` column from a list of lists of arrays of dimension 1.
To illustrate my proposal, let's take the... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4191/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4191/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2676/comments | https://api.github.com/repos/huggingface/datasets/issues/2676/events | https://github.com/huggingface/datasets/pull/2676 | 947,734,909 | MDExOlB1bGxSZXF1ZXN0NjkyNjc2NTg5 | 2,676 | Increase json reader block_size automatically | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2021-07-19T14:51:14Z | 2021-07-19T17:51:39Z | 2021-07-19T17:51:38Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2676.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2676",
"merged_at": "2021-07-19T17:51:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2676.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Currently some files can't be read with the default parameters of the JSON lines reader.
For example this one:
https://huggingface.co/datasets/thomwolf/codeparrot/resolve/main/file-000000000006.json.gz
raises a pyarrow error:
```python
ArrowInvalid: straddling object straddles two block boundaries (try to increa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2676/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/34 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/34/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/34/comments | https://api.github.com/repos/huggingface/datasets/issues/34/events | https://github.com/huggingface/datasets/pull/34 | 611,385,516 | MDExOlB1bGxSZXF1ZXN0NDEyNTg0OTM0 | 34 | [Tests] add slow tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-05-03T11:01:22Z | 2020-05-03T12:18:30Z | 2020-05-03T12:18:29Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/34.diff",
"html_url": "https://github.com/huggingface/datasets/pull/34",
"merged_at": "2020-05-03T12:18:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/34.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/34"
} | This PR adds a slow test that downloads the "real" dataset. The test is decorated as "slow" so that it will not automatically run on circle ci.
Before uploading a dataset, one should test that this test passes, manually by running
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/34/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/34/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4959 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4959/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4959/comments | https://api.github.com/repos/huggingface/datasets/issues/4959/events | https://github.com/huggingface/datasets/pull/4959 | 1,367,924,429 | PR_kwDODunzps4-rx6l | 4,959 | Fix data URLs of compguesswhat dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-09T14:36:10Z | 2022-09-09T16:01:34Z | 2022-09-09T15:59:04Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4959.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4959",
"merged_at": "2022-09-09T15:59:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4959.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | After we informed the `compguesswhat` dataset authors about an error with their data URLs, they have updated them:
- https://github.com/CompGuessWhat/compguesswhat.github.io/issues/1
This PR updates their data URLs in our loading script.
Related to:
- #3191 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4959/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4959/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/145 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/145/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/145/comments | https://api.github.com/repos/huggingface/datasets/issues/145/events | https://github.com/huggingface/datasets/pull/145 | 619,480,549 | MDExOlB1bGxSZXF1ZXN0NDE4OTcxMjg0 | 145 | [AWS Tests] Follow-up PR from #144 | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-05-16T13:53:46Z | 2020-05-16T13:54:23Z | 2020-05-16T13:54:22Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/145.diff",
"html_url": "https://github.com/huggingface/datasets/pull/145",
"merged_at": "2020-05-16T13:54:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/145.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/145... | I forgot to add this line in PR #145 . | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/145/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/145/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1187 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1187/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1187/comments | https://api.github.com/repos/huggingface/datasets/issues/1187/events | https://github.com/huggingface/datasets/pull/1187 | 757,826,707 | MDExOlB1bGxSZXF1ZXN0NTMzMTI1NjU3 | 1,187 | Added AQUA-RAT (Algebra Question Answering with Rationales) Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/14899066?v=4",
"events_url": "https://api.github.com/users/arkhalid/events{/privacy}",
"followers_url": "https://api.github.com/users/arkhalid/followers",
"following_url": "https://api.github.com/users/arkhalid/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | 2020-12-06T02:12:52Z | 2020-12-07T15:37:12Z | 2020-12-07T15:37:12Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1187.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1187",
"merged_at": "2020-12-07T15:37:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1187.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1187/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1187/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/3397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3397/comments | https://api.github.com/repos/huggingface/datasets/issues/3397/events | https://github.com/huggingface/datasets/pull/3397 | 1,073,502,444 | PR_kwDODunzps4vgh1U | 3,397 | add BNL newspapers | {
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [
"\r\n> Also, maybe calling the dataset as \"bnl_historical_newspapers\" and setting \"processed\" as one configuration name?\r\n\r\nThis sounds like a good idea but my only question around this is how easy it would be to use the same approach for processing the other newspaper collections [https://data.bnl.lu/data/... | 2021-12-07T15:43:21Z | 2022-01-17T18:35:34Z | 2022-01-17T18:35:34Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3397",
"merged_at": "2022-01-17T18:35:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This pull request adds the BNL's [processed newspaper collections](https://data.bnl.lu/data/historical-newspapers/) as a dataset. This is partly done to support BigScience see: https://github.com/bigscience-workshop/data_tooling/issues/192.
The Datacard is more sparse than I would like but I plan to make a separate... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3397/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3397/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3085 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3085/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3085/comments | https://api.github.com/repos/huggingface/datasets/issues/3085/events | https://github.com/huggingface/datasets/pull/3085 | 1,026,467,384 | PR_kwDODunzps4tNFza | 3,085 | Fixes to `to_tf_dataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Hi ! Can you give some details about why you need these changes ?",
"Hey, sorry, I should have explained! I've been getting a lot of `VisibleDeprecationWarning` from Numpy, due to an issue in the formatter, see #3084 . This is a temporary workaround (since I'm using these methods in the upcoming course) until I ... | 2021-10-14T14:25:56Z | 2021-10-21T15:05:29Z | 2021-10-21T15:05:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3085.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3085",
"merged_at": "2021-10-21T15:05:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3085.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3085/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3085/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1007 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1007/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1007/comments | https://api.github.com/repos/huggingface/datasets/issues/1007/events | https://github.com/huggingface/datasets/pull/1007 | 755,364,078 | MDExOlB1bGxSZXF1ZXN0NTMxMDg4NTk5 | 1,007 | Include license file in source distribution | {
"avatar_url": "https://avatars.githubusercontent.com/u/589279?v=4",
"events_url": "https://api.github.com/users/synapticarbors/events{/privacy}",
"followers_url": "https://api.github.com/users/synapticarbors/followers",
"following_url": "https://api.github.com/users/synapticarbors/following{/other_user}",
"... | [] | closed | false | null | [] | null | [] | 2020-12-02T15:17:43Z | 2020-12-02T17:58:05Z | 2020-12-02T17:58:05Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1007.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1007",
"merged_at": "2020-12-02T17:58:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1007.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | It would be helpful to include the license file in the source distribution. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1007/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1007/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3947 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3947/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3947/comments | https://api.github.com/repos/huggingface/datasets/issues/3947/events | https://github.com/huggingface/datasets/pull/3947 | 1,171,452,854 | PR_kwDODunzps40jfLq | 3,947 | BLEU metric card | {
"avatar_url": "https://avatars.githubusercontent.com/u/27527747?v=4",
"events_url": "https://api.github.com/users/emibaylor/events{/privacy}",
"followers_url": "https://api.github.com/users/emibaylor/followers",
"following_url": "https://api.github.com/users/emibaylor/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Some thoughts:\r\n- For values, e.g. \"Defaults to False\", I would put False in code: `False`. Same for : \"Defaults to `4`.\"\r\n- I would put the following remark in \"Limitations\": \r\n> \"BLEU's output is always a number betwee... | 2022-03-16T19:20:07Z | 2022-03-29T14:59:50Z | 2022-03-29T14:54:14Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3947.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3947",
"merged_at": "2022-03-29T14:54:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3947.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add BLEU metric card | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3947/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3947/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5582/comments | https://api.github.com/repos/huggingface/datasets/issues/5582/events | https://github.com/huggingface/datasets/pull/5582 | 1,600,932,092 | PR_kwDODunzps5K0ZcN | 5,582 | Add column_names to IterableDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/50772274?v=4",
"events_url": "https://api.github.com/users/patrickloeber/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickloeber/followers",
"following_url": "https://api.github.com/users/patrickloeber/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-02-27T10:50:07Z | 2023-03-13T19:10:22Z | 2023-03-13T19:03:32Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5582.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5582",
"merged_at": "2023-03-13T19:03:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5582.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR closes #5383
* Add column_names property to IterableDataset
* Add multiple tests for this new property | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5582/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5582/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5948 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5948/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5948/comments | https://api.github.com/repos/huggingface/datasets/issues/5948/events | https://github.com/huggingface/datasets/pull/5948 | 1,754,794,611 | PR_kwDODunzps5S4dUt | 5,948 | Fix sequence of array support for most dtype | {
"avatar_url": "https://avatars.githubusercontent.com/u/45557362?v=4",
"events_url": "https://api.github.com/users/qgallouedec/events{/privacy}",
"followers_url": "https://api.github.com/users/qgallouedec/followers",
"following_url": "https://api.github.com/users/qgallouedec/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-06-13T12:38:59Z | 2023-06-14T15:11:55Z | 2023-06-14T15:03:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5948.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5948",
"merged_at": "2023-06-14T15:03:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5948.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fixes #5936
Also, a related fix to #5927 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5948/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5948/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/899 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/899/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/899/comments | https://api.github.com/repos/huggingface/datasets/issues/899/events | https://github.com/huggingface/datasets/pull/899 | 752,191,227 | MDExOlB1bGxSZXF1ZXN0NTI4NTYzNzYz | 899 | Allow arrow based builder in auto dummy data generation | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-11-27T11:39:38Z | 2020-11-27T13:30:09Z | 2020-11-27T13:30:08Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/899.diff",
"html_url": "https://github.com/huggingface/datasets/pull/899",
"merged_at": "2020-11-27T13:30:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/899.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/899... | Following #898 I added support for arrow based builder for the auto dummy data generator | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/899/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/899/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1127 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1127/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1127/comments | https://api.github.com/repos/huggingface/datasets/issues/1127/events | https://github.com/huggingface/datasets/pull/1127 | 757,229,684 | MDExOlB1bGxSZXF1ZXN0NTMyNjQwMjMx | 1,127 | Add wikiqaar dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/15667714?v=4",
"events_url": "https://api.github.com/users/zaidalyafeai/events{/privacy}",
"followers_url": "https://api.github.com/users/zaidalyafeai/followers",
"following_url": "https://api.github.com/users/zaidalyafeai/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2020-12-04T16:26:18Z | 2020-12-07T16:39:41Z | 2020-12-07T16:39:41Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1127.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1127",
"merged_at": "2020-12-07T16:39:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1127.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Arabic Wiki Question Answering Corpus. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1127/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1127/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6438 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6438/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6438/comments | https://api.github.com/repos/huggingface/datasets/issues/6438/events | https://github.com/huggingface/datasets/issues/6438 | 2,002,032,804 | I_kwDODunzps53VJik | 6,438 | Support GeoParquet | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Thank you, @severo ! I would be more than happy to help in any way I can. I am not familiar with this repo's codebase, but I would be eager to contribute. :)\r\n\r\nFor the preview in Datasets Hub, I think it makes sense to just display the geospatial column as text. If there were a dataset loader, though, I think... | 2023-11-20T11:54:58Z | 2023-12-18T07:33:06Z | null | CONTRIBUTOR | null | null | null | ### Feature request
Support the GeoParquet format
### Motivation
GeoParquet (https://geoparquet.org/) is a common format for sharing vectorial geospatial data on the cloud, along with "traditional" data columns.
It would be nice to be able to load this format with datasets, and more generally, in the Datasets Hub... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6438/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6438/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3936 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3936/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3936/comments | https://api.github.com/repos/huggingface/datasets/issues/3936/events | https://github.com/huggingface/datasets/pull/3936 | 1,170,713,473 | PR_kwDODunzps40hE-P | 3,936 | Fix Wikipedia version and re-add tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3936). All of your documentation changes will be reflected on that endpoint."
] | 2022-03-16T08:48:04Z | 2022-03-16T17:04:07Z | 2022-03-16T17:04:05Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3936.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3936",
"merged_at": "2022-03-16T17:04:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3936.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | To keep backward compatibility when loading using "wikipedia" dataset ID (https://huggingface.co/datasets/wikipedia), we have created the pre-processed data for the same languages we were offering before, but with updated date "20220301":
- de
- en
- fr
- frr
- it
- simple
These pre-processed data can be acces... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3936/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3936/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/923/comments | https://api.github.com/repos/huggingface/datasets/issues/923/events | https://github.com/huggingface/datasets/pull/923 | 753,569,220 | MDExOlB1bGxSZXF1ZXN0NTI5NjIyMDQx | 923 | Add CC-100 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"Hello @lhoestq, I would like just to ask you if it is OK that I include this feature 9f32ba1 in this PR or you would prefer to have it in a separate one.\r\n\r\nI was wondering whether include also a test, but I did not find any test for the other file formats...",
"Hi ! Sure that would be valuable to support .x... | 2020-11-30T15:23:22Z | 2021-04-20T13:34:17Z | 2021-04-20T13:34:17Z | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/923.diff",
"html_url": "https://github.com/huggingface/datasets/pull/923",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/923.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/923"
} | Add CC-100.
Close #773 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/923/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5430/comments | https://api.github.com/repos/huggingface/datasets/issues/5430/events | https://github.com/huggingface/datasets/issues/5430 | 1,535,856,503 | I_kwDODunzps5bi093 | 5,430 | Support Apache Beam >= 2.44.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Some of the shard files now have 0 number of rows.\r\n\r\nWe have opened an issue in the Apache Beam repo:\r\n- https://github.com/apache/beam/issues/25041"
] | 2023-01-17T06:42:12Z | 2023-01-17T16:12:18Z | null | MEMBER | null | null | null | Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5430/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5430/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3843 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3843/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3843/comments | https://api.github.com/repos/huggingface/datasets/issues/3843/events | https://github.com/huggingface/datasets/pull/3843 | 1,161,397,812 | PR_kwDODunzps40Cm0D | 3,843 | Fix Google Drive URL to avoid Virus scan warning in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3843). All of your documentation changes will be reflected on that endpoint.",
"Cool ! Looks like it breaks `test_streaming_gg_drive_gzipped` for some reason..."
] | 2022-03-07T13:09:19Z | 2022-03-15T12:30:25Z | 2022-03-15T12:30:23Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3843.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3843",
"merged_at": "2022-03-15T12:30:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3843.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | The streaming version of https://github.com/huggingface/datasets/pull/3787.
Fix #3835
CC: @albertvillanova | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3843/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3843/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2376/comments | https://api.github.com/repos/huggingface/datasets/issues/2376/events | https://github.com/huggingface/datasets/pull/2376 | 894,852,264 | MDExOlB1bGxSZXF1ZXN0NjQ3MTU1NDE4 | 2,376 | Improve task api code quality | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Looks good thanks, what do you think @lewtun ?",
"thanks for including the lazy `ClassLabel` class @mariosasko ! from my side this LGTM!"
] | 2021-05-18T23:13:40Z | 2021-06-02T20:39:57Z | 2021-05-25T15:30:54Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2376.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2376",
"merged_at": "2021-05-25T15:30:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2376.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Improves the code quality of the `TaskTemplate` dataclasses.
Changes:
* replaces `return NotImplemented` with raise `NotImplementedError`
* replaces `sorted` with `len` in the uniqueness check
* defines `label2id` and `id2label` in the `TextClassification` template as properties
* replaces the `object.__setatt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2376/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5112 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5112/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5112/comments | https://api.github.com/repos/huggingface/datasets/issues/5112/events | https://github.com/huggingface/datasets/issues/5112 | 1,409,143,409 | I_kwDODunzps5T_dJx | 5,112 | Bug with filtered indices | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"The issue is here:\r\nhttps://github.com/huggingface/datasets/blob/3ad9644b9a2e4558dd1d0f1e43c67658674e6228/src/datasets/arrow_dataset.py#L2964",
"@PartiallyTyped, @Muennighoff: the issue is fixed.\r\n\r\nWe are planning to make a patch release today.",
"Thanks a lot for the swift response! For a brief moment ... | 2022-10-14T10:35:47Z | 2022-10-14T13:55:03Z | 2022-10-14T12:11:45Z | MEMBER | null | null | null | ## Describe the bug
As reported by @PartiallyTyped (and by @Muennighoff):
- https://github.com/huggingface/datasets/issues/5111#issuecomment-1278652524
There is an issue with the indices of a filtered dataset.
## Steps to reproduce the bug
```python
ds = Dataset.from_dict({"num": [0, 1, 2, 3]})
ds = ds.filte... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5112/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5112/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5774 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5774/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5774/comments | https://api.github.com/repos/huggingface/datasets/issues/5774/events | https://github.com/huggingface/datasets/pull/5774 | 1,676,716,662 | PR_kwDODunzps5OxIMe | 5,774 | Fix style | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-04-20T13:21:32Z | 2023-04-20T13:34:26Z | 2023-04-20T13:24:28Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5774.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5774",
"merged_at": "2023-04-20T13:24:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5774.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Fix C419 issues | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5774/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5774/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2384 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2384/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2384/comments | https://api.github.com/repos/huggingface/datasets/issues/2384/events | https://github.com/huggingface/datasets/pull/2384 | 896,866,461 | MDExOlB1bGxSZXF1ZXN0NjQ4OTI4NTQ0 | 2,384 | Add args description to DatasetInfo | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Thanks for the suggestions! I've included them and made a few minor tweaks along the way",
"Please merge master into this branch to fix the CI, I just fixed metadata validation tests."
] | 2021-05-20T13:53:10Z | 2021-05-22T09:26:16Z | 2021-05-22T09:26:14Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2384.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2384",
"merged_at": "2021-05-22T09:26:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2384.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Closes #2354
I am not sure what `post_processed` and `post_processing_size` correspond to, so have left them empty for now. I also took a guess at some of the other fields like `dataset_size` vs `size_in_bytes`, so might have misunderstood their meaning. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2384/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2384/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5399/comments | https://api.github.com/repos/huggingface/datasets/issues/5399/events | https://github.com/huggingface/datasets/issues/5399 | 1,515,548,427 | I_kwDODunzps5aVW8L | 5,399 | Got disconnected from remote data host. Retrying in 5sec [2/20] | {
"avatar_url": "https://avatars.githubusercontent.com/u/46427957?v=4",
"events_url": "https://api.github.com/users/alhuri/events{/privacy}",
"followers_url": "https://api.github.com/users/alhuri/followers",
"following_url": "https://api.github.com/users/alhuri/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [] | 2023-01-01T13:00:11Z | 2023-01-02T07:21:52Z | 2023-01-02T07:21:52Z | NONE | null | null | null | ### Describe the bug
While trying to upload my image dataset of a CSV file type to huggingface by running the below code. The dataset consists of a little over 100k of image-caption pairs
### Steps to reproduce the bug
```
df = pd.read_csv('x.csv', encoding='utf-8-sig')
features = Features({
'link': Ima... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5399/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5399/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3421/comments | https://api.github.com/repos/huggingface/datasets/issues/3421/events | https://github.com/huggingface/datasets/pull/3421 | 1,077,966,571 | PR_kwDODunzps4vuvJK | 3,421 | Adding mMARCO dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/17603035?v=4",
"events_url": "https://api.github.com/users/lhbonifacio/events{/privacy}",
"followers_url": "https://api.github.com/users/lhbonifacio/followers",
"following_url": "https://api.github.com/users/lhbonifacio/following{/other_user}",
"gists_u... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Hi @albertvillanova we've made a major overhaul of the loading script including all configurations we're making available. Could you please review it again?",
"@albertvillanova :ping_pong: ",
"Thanks @lhbonifacio for adding this dataset.\r\nHi there, i got an error about mmarco:\r\nConnectionError: Couldn't re... | 2021-12-13T00:56:43Z | 2022-10-03T09:37:15Z | 2022-10-03T09:37:15Z | NONE | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3421.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3421",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3421.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3421"
} | Adding mMARCO (v1.1) to HF datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3421/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3421/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4441 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4441/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4441/comments | https://api.github.com/repos/huggingface/datasets/issues/4441/events | https://github.com/huggingface/datasets/issues/4441 | 1,258,568,656 | I_kwDODunzps5LBDvQ | 4,441 | Dataset Viewer issue for aeslc | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"Not sure what happened 😬, but it's fixed"
] | 2022-06-02T18:57:12Z | 2022-06-07T18:50:55Z | 2022-06-07T18:50:55Z | MEMBER | null | null | null | ### Link
https://huggingface.co/datasets/aeslc
### Description
The dataset viewer can't find `dataset_infos.json` in it's cache:
```
Server error
Status code: 400
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: '/cache/modules/datasets_modules/datasets/aeslc/eb8e30234cf9... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4441/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4441/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5463 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5463/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5463/comments | https://api.github.com/repos/huggingface/datasets/issues/5463/events | https://github.com/huggingface/datasets/pull/5463 | 1,557,021,041 | PR_kwDODunzps5IiGWb | 5,463 | Imagefolder docs: mention support of CSV and ZIP | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-01-25T17:24:01Z | 2023-01-25T18:33:35Z | 2023-01-25T18:26:15Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5463.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5463",
"merged_at": "2023-01-25T18:26:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5463.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5463/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5463/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4339 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4339/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4339/comments | https://api.github.com/repos/huggingface/datasets/issues/4339/events | https://github.com/huggingface/datasets/pull/4339 | 1,234,496,289 | PR_kwDODunzps43v0WT | 4,339 | Dataset loader for the MSLR2022 shared task | {
"avatar_url": "https://avatars.githubusercontent.com/u/8917831?v=4",
"events_url": "https://api.github.com/users/JohnGiorgi/events{/privacy}",
"followers_url": "https://api.github.com/users/JohnGiorgi/followers",
"following_url": "https://api.github.com/users/JohnGiorgi/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | [
"I think the underlying issue is in https://github.com/huggingface/datasets/blob/c0ed6fdc29675b3565b01b77fde5ab5d9d8b60ec/src/datasets/commands/dummy_data.py#L124 - where `CSV`s are considered to be in the same class of file as text, jsonl, and tsv.\r\n\r\nI think this is an error because CSVs can have newlines wit... | 2022-05-12T21:23:41Z | 2022-07-18T17:19:27Z | 2022-07-18T16:58:34Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4339.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4339",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4339.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4339"
} | This PR adds a dataset loader for the [MSLR2022 Shared Task](https://github.com/allenai/mslr-shared-task). Both the MS^2 and Cochrane datasets can be loaded with this dataloader:
```python
from datasets import load_dataset
ms2 = load_dataset("mslr2022", "ms2")
cochrane = load_dataset("mslr2022", "cochrane")
``... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4339/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4339/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/640/comments | https://api.github.com/repos/huggingface/datasets/issues/640/events | https://github.com/huggingface/datasets/pull/640 | 704,311,758 | MDExOlB1bGxSZXF1ZXN0NDg5MjYwNTc1 | 640 | Make shuffle compatible with temp_seed | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-09-18T11:38:58Z | 2020-09-18T11:47:51Z | 2020-09-18T11:47:50Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/640.diff",
"html_url": "https://github.com/huggingface/datasets/pull/640",
"merged_at": "2020-09-18T11:47:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/640.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/640... | This code used to return different dataset at each run
```python
import dataset as ds
dataset = ...
with ds.temp_seed(42):
shuffled = dataset.shuffle()
```
Now it returns the same one since the seed is set | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/640/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/640/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3198 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3198/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3198/comments | https://api.github.com/repos/huggingface/datasets/issues/3198/events | https://github.com/huggingface/datasets/pull/3198 | 1,042,679,548 | PR_kwDODunzps4t_5G8 | 3,198 | Add Multi-Lingual LibriSpeech | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2021-11-02T18:23:59Z | 2021-11-04T17:09:22Z | 2021-11-04T17:09:22Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3198.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3198",
"merged_at": "2021-11-04T17:09:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3198.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Add https://www.openslr.org/94/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3198/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3198/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/6083 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6083/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6083/comments | https://api.github.com/repos/huggingface/datasets/issues/6083/events | https://github.com/huggingface/datasets/pull/6083 | 1,824,832,348 | PR_kwDODunzps5WkgAI | 6,083 | set dev version | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6083). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-07-27T17:10:41Z | 2023-07-27T17:22:05Z | 2023-07-27T17:11:01Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6083.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6083",
"merged_at": "2023-07-27T17:11:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6083.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6083/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6083/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/928/comments | https://api.github.com/repos/huggingface/datasets/issues/928/events | https://github.com/huggingface/datasets/pull/928 | 753,722,324 | MDExOlB1bGxSZXF1ZXN0NTI5NzQ1OTIx | 928 | Add the Multilingual Amazon Reviews Corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/9353833?v=4",
"events_url": "https://api.github.com/users/joeddav/events{/privacy}",
"followers_url": "https://api.github.com/users/joeddav/followers",
"following_url": "https://api.github.com/users/joeddav/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [] | 2020-11-30T18:58:06Z | 2020-12-01T16:04:30Z | 2020-12-01T16:04:27Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/928.diff",
"html_url": "https://github.com/huggingface/datasets/pull/928",
"merged_at": "2020-12-01T16:04:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/928.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/928... | - **Name:** Multilingual Amazon Reviews Corpus* (`amazon_reviews_multi`)
- **Description:** A collection of Amazon reviews in English, Japanese, German, French, Spanish and Chinese.
- **Paper:** https://arxiv.org/abs/2010.02573
### Checkbox
- [x] Create the dataset script `/datasets/my_dataset/my_dataset.py` us... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/928/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/99 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/99/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/99/comments | https://api.github.com/repos/huggingface/datasets/issues/99/events | https://github.com/huggingface/datasets/pull/99 | 618,026,700 | MDExOlB1bGxSZXF1ZXN0NDE3ODMxNjky | 99 | [Cmrc 2018] fix cmrc2018 | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-05-14T08:22:03Z | 2020-05-14T08:49:42Z | 2020-05-14T08:49:41Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/99.diff",
"html_url": "https://github.com/huggingface/datasets/pull/99",
"merged_at": "2020-05-14T08:49:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/99.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/99"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/99/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/99/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/4974 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4974/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4974/comments | https://api.github.com/repos/huggingface/datasets/issues/4974/events | https://github.com/huggingface/datasets/pull/4974 | 1,371,682,020 | PR_kwDODunzps4-4Iri | 4,974 | [GH->HF] Part 2: Remove all dataset scripts from github | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"So this means metrics will be deleted from this repo in favor of the \"evaluate\" library? Maybe you guys could just redirect metrics to that library.",
"We are deprecating the metrics in `datasets` indeed and suggest users to swit... | 2022-09-13T16:01:12Z | 2022-10-03T17:09:39Z | 2022-10-03T17:07:32Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4974.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4974",
"merged_at": "2022-10-03T17:07:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4974.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Now that all the datasets live on the Hub we can remove the /datasets directory that contains all the dataset scripts of this repository
- [x] Needs https://github.com/huggingface/datasets/pull/4973 to be merged first
- [x] and PR to be enabled on the Hub for non-namespaced datasets | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4974/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4974/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/168 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/168/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/168/comments | https://api.github.com/repos/huggingface/datasets/issues/168/events | https://github.com/huggingface/datasets/issues/168 | 620,959,819 | MDU6SXNzdWU2MjA5NTk4MTk= | 168 | Loading 'wikitext' dataset fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/25987633?v=4",
"events_url": "https://api.github.com/users/itay1itzhak/events{/privacy}",
"followers_url": "https://api.github.com/users/itay1itzhak/followers",
"following_url": "https://api.github.com/users/itay1itzhak/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Hi, make sure you have a recent version of pyarrow.\r\n\r\nAre you using it in Google Colab? In this case, this error is probably the same as #128",
"Thanks!\r\n\r\nYes I'm using Google Colab, it seems like a duplicate then.",
"Closing as it is a duplicate",
"Hi,\r\nThe squad bug seems to be fixed, but the l... | 2020-05-19T13:04:29Z | 2020-05-26T21:46:52Z | 2020-05-26T21:46:52Z | NONE | null | null | null | Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError Traceback (most rece... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/168/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/168/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/989 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/989/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/989/comments | https://api.github.com/repos/huggingface/datasets/issues/989/events | https://github.com/huggingface/datasets/pull/989 | 755,079,394 | MDExOlB1bGxSZXF1ZXN0NTMwODYwNDMw | 989 | Fix SV -> NO | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | [] | closed | false | null | [] | null | [] | 2020-12-02T08:59:59Z | 2020-12-02T09:18:21Z | 2020-12-02T09:18:14Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/989.diff",
"html_url": "https://github.com/huggingface/datasets/pull/989",
"merged_at": "2020-12-02T09:18:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/989.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/989... | This PR fixes the small typo as seen in #956 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/989/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/989/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3551/comments | https://api.github.com/repos/huggingface/datasets/issues/3551/events | https://github.com/huggingface/datasets/pull/3551 | 1,096,561,111 | PR_kwDODunzps4wq_AO | 3,551 | Add more compression types for `to_json` | {
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"@lhoestq, I looked into how to compress with `zipfile` for which few methods exist, let me know which one looks good:\r\n1. create the file in normal `wb` mode and then zip it separately\r\n2. use `ZipFile.write_str` to write file into the archive. For this we'll need to change how we're writing files from `_write... | 2022-01-07T18:25:02Z | 2022-07-10T14:36:55Z | 2022-02-21T15:58:15Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3551.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3551",
"merged_at": "2022-02-21T15:58:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3551.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds `bz2`, `xz`, and `zip` (WIP) for `to_json`. I also plan to add `infer` like how `pandas` does it | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3551/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3551/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1362/comments | https://api.github.com/repos/huggingface/datasets/issues/1362/events | https://github.com/huggingface/datasets/pull/1362 | 760,138,233 | MDExOlB1bGxSZXF1ZXN0NTM1MDIwMDAz | 1,362 | adding opus_infopankki | {
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Thanks Quentin !"
] | 2020-12-09T08:57:10Z | 2020-12-09T18:16:20Z | 2020-12-09T18:13:48Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1362.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1362",
"merged_at": "2020-12-09T18:13:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1362.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Adding opus_infopankki
http://opus.nlpl.eu/infopankki-v1.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1362/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1520 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1520/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1520/comments | https://api.github.com/repos/huggingface/datasets/issues/1520/events | https://github.com/huggingface/datasets/pull/1520 | 764,140,938 | MDExOlB1bGxSZXF1ZXN0NTM4MzU5MTA5 | 1,520 | ru_reviews dataset adding | {
"avatar_url": "https://avatars.githubusercontent.com/u/44197177?v=4",
"events_url": "https://api.github.com/users/darshan-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/darshan-gandhi/followers",
"following_url": "https://api.github.com/users/darshan-gandhi/following{/other_user}",
... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"Hi @lhoestq \r\n\r\nI have added the readme as well \r\n\r\nPlease do have a look at it when suitable ",
"Chatted with @darshan-gandhi on Slack about parsing examples into a separate text and sentiment field",
"Thanks for your contribution, @darshan-gandhi. Are you still interested in adding this dataset?\r\n... | 2020-12-12T18:13:06Z | 2022-10-03T09:38:42Z | 2022-10-03T09:38:42Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1520.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1520",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1520.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1520"
} | RuReviews: An Automatically Annotated Sentiment Analysis Dataset for Product Reviews in Russian | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1520/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1520/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/396/comments | https://api.github.com/repos/huggingface/datasets/issues/396/events | https://github.com/huggingface/datasets/pull/396 | 657,477,952 | MDExOlB1bGxSZXF1ZXN0NDQ5NTg3MDQ4 | 396 | Fix memory issue when doing select | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-07-15T16:15:04Z | 2020-07-16T08:07:32Z | 2020-07-16T08:07:31Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/396.diff",
"html_url": "https://github.com/huggingface/datasets/pull/396",
"merged_at": "2020-07-16T08:07:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/396.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/396... | We were passing the `nlp.Dataset` object to get the hash for the new dataset's file name.
Fix #395 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/396/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/396/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/983 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/983/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/983/comments | https://api.github.com/repos/huggingface/datasets/issues/983/events | https://github.com/huggingface/datasets/pull/983 | 754,966,620 | MDExOlB1bGxSZXF1ZXN0NTMwNzY4MTMw | 983 | add mc taco | {
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"events_url": "https://api.github.com/users/VictorSanh/events{/privacy}",
"followers_url": "https://api.github.com/users/VictorSanh/followers",
"following_url": "https://api.github.com/users/VictorSanh/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2020-12-02T05:54:55Z | 2020-12-02T15:37:47Z | 2020-12-02T15:37:46Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/983.diff",
"html_url": "https://github.com/huggingface/datasets/pull/983",
"merged_at": "2020-12-02T15:37:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/983.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/983... | MC-TACO
Temporal commonsense knowledge | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/983/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/983/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5495 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5495/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5495/comments | https://api.github.com/repos/huggingface/datasets/issues/5495/events | https://github.com/huggingface/datasets/issues/5495 | 1,566,803,452 | I_kwDODunzps5dY4X8 | 5,495 | to_tf_dataset fails with datetime UTC columns even if not included in columns argument | {
"avatar_url": "https://avatars.githubusercontent.com/u/2512762?v=4",
"events_url": "https://api.github.com/users/dwyatte/events{/privacy}",
"followers_url": "https://api.github.com/users/dwyatte/followers",
"following_url": "https://api.github.com/users/dwyatte/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "7057ff",
"default": true,
"descript... | closed | false | null | [] | null | [
"Hi! This is indeed a bug in our zero-copy logic.\r\n\r\nTo fix it, instead of the line:\r\nhttps://github.com/huggingface/datasets/blob/7cfac43b980ab9e4a69c2328f085770996323005/src/datasets/features/features.py#L702\r\n\r\nwe should have:\r\n```python\r\nreturn pa.types.is_primitive(pa_type) and not (pa.types.is_b... | 2023-02-01T20:47:33Z | 2023-02-08T14:33:19Z | 2023-02-08T14:33:19Z | CONTRIBUTOR | null | null | null | ### Describe the bug
There appears to be some eager behavior in `to_tf_dataset` that runs against every column in a dataset even if they aren't included in the columns argument. This is problematic with datetime UTC columns due to them not working with zero copy. If I don't have UTC information in my datetime column... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5495/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5495/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/561 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/561/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/561/comments | https://api.github.com/repos/huggingface/datasets/issues/561/events | https://github.com/huggingface/datasets/pull/561 | 690,871,415 | MDExOlB1bGxSZXF1ZXN0NDc3Njk1NDQy | 561 | Made `share_dataset` more readable | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2020-09-02T09:34:48Z | 2020-09-03T09:00:30Z | 2020-09-03T09:00:29Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/561.diff",
"html_url": "https://github.com/huggingface/datasets/pull/561",
"merged_at": "2020-09-03T09:00:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/561.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/561... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/561/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/561/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/4300 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4300/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4300/comments | https://api.github.com/repos/huggingface/datasets/issues/4300/events | https://github.com/huggingface/datasets/pull/4300 | 1,230,272,761 | PR_kwDODunzps43iA86 | 4,300 | Add API code examples for loading methods | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-05-09T21:30:26Z | 2022-05-25T16:23:15Z | 2022-05-25T09:20:13Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4300.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4300",
"merged_at": "2022-05-25T09:20:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4300.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | This PR adds API code examples for loading methods, let me know if I've missed any important parameters we should showcase :)
I was a bit confused about `inspect_dataset` and `inspect_metric`. The `path` parameter says it will accept a dataset identifier from the Hub. But when I try the identifier `rotten_tomatoes`,... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4300/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4300/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4067 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4067/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4067/comments | https://api.github.com/repos/huggingface/datasets/issues/4067/events | https://github.com/huggingface/datasets/pull/4067 | 1,186,731,905 | PR_kwDODunzps41U7qc | 4,067 | Update datasets task tags to align tags with models | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Looks good, but I think we are missing some scripts with outdated tags (RedCaps, MNIST, ...).",
"Just updated the tags of vision datasets :)\r\nWe can figure out one for image datasets without labels like PASS - not sure how to nam... | 2022-03-30T16:49:32Z | 2022-04-13T17:37:27Z | 2022-04-13T17:31:11Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4067.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4067",
"merged_at": "2022-04-13T17:31:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4067.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | **Requires https://github.com/huggingface/datasets/pull/4066 to be merged first**
Following https://github.com/huggingface/datasets/pull/4066 we need to update many dataset tags to use the new ones. This PR takes case of this and is quite big - feel free to review only certain tags if you don't want to spend too muc... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4067/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4067/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3007 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3007/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3007/comments | https://api.github.com/repos/huggingface/datasets/issues/3007/events | https://github.com/huggingface/datasets/pull/3007 | 1,014,775,450 | PR_kwDODunzps4sns-n | 3,007 | Correct a typo | {
"avatar_url": "https://avatars.githubusercontent.com/u/35955430?v=4",
"events_url": "https://api.github.com/users/Yann21/events{/privacy}",
"followers_url": "https://api.github.com/users/Yann21/followers",
"following_url": "https://api.github.com/users/Yann21/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [] | 2021-10-04T06:15:47Z | 2021-10-04T09:27:57Z | 2021-10-04T09:27:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/3007.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3007",
"merged_at": "2021-10-04T09:27:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3007.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3007/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3007/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3444/comments | https://api.github.com/repos/huggingface/datasets/issues/3444/events | https://github.com/huggingface/datasets/issues/3444 | 1,082,078,961 | I_kwDODunzps5Afzbx | 3,444 | Align the Dataset and IterableDataset processing API | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Yes I agree, these should be as aligned as possible. Maybe we can also check the feedback in the survey at http://hf.co/oss-survey and see if people mentioned related things on the API (in particular if we go the breaking change way, it would be good to be sure we are taking the right direction for the community).... | 2021-12-16T11:26:11Z | 2023-08-16T09:28:17Z | null | MEMBER | null | null | null | ## Intro
items marked like <s>this</s> are done already :)
Currently the two classes have two distinct API for processing:
### The `.map()` method
Both have those parameters in common: function, batched, batch_size
- IterableDataset is missing those parameters:
<s>with_indices</s>, with_rank, <s>input_c... | {
"+1": 13,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 13,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3444/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3444/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3172 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3172/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3172/comments | https://api.github.com/repos/huggingface/datasets/issues/3172/events | https://github.com/huggingface/datasets/issues/3172 | 1,038,351,587 | I_kwDODunzps494_zj | 3,172 | `SystemError 15` thrown in `Dataset.__del__` when using `Dataset.map()` with `num_proc>1` | {
"avatar_url": "https://avatars.githubusercontent.com/u/9859840?v=4",
"events_url": "https://api.github.com/users/vlievin/events{/privacy}",
"followers_url": "https://api.github.com/users/vlievin/followers",
"following_url": "https://api.github.com/users/vlievin/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"NB: even if the error is raised, the dataset is successfully cached. So restarting the script after every `map()` allows to ultimately run the whole preprocessing. But this prevents to realistically run the code over multiple nodes.",
"Hi,\r\n\r\nIt's not easy to debug the problem without the script. I may be wr... | 2021-10-28T10:29:00Z | 2023-09-04T14:20:49Z | 2021-11-03T11:26:10Z | NONE | null | null | null | ## Describe the bug
I use `datasets.map` to preprocess some data in my application. The error `SystemError 15` is thrown at the end of the execution of `Dataset.map()` (only with `num_proc>1`. Traceback included bellow.
The exception is raised only when the code runs within a specific context. Despite ~10h spent ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3172/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3172/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/1816 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1816/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1816/comments | https://api.github.com/repos/huggingface/datasets/issues/1816/events | https://github.com/huggingface/datasets/pull/1816 | 800,660,995 | MDExOlB1bGxSZXF1ZXN0NTY3MTExMjEx | 1,816 | Doc2dial rc update to latest version | {
"avatar_url": "https://avatars.githubusercontent.com/u/2062185?v=4",
"events_url": "https://api.github.com/users/songfeng/events{/privacy}",
"followers_url": "https://api.github.com/users/songfeng/followers",
"following_url": "https://api.github.com/users/songfeng/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"- update data loader and readme for latest version 1.0.1"
] | 2021-02-03T20:08:54Z | 2021-02-15T15:15:24Z | 2021-02-15T15:04:33Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1816.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1816",
"merged_at": "2021-02-15T15:04:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1816.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1816/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1816/timeline | null | null | true | |
https://api.github.com/repos/huggingface/datasets/issues/5767 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5767/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5767/comments | https://api.github.com/repos/huggingface/datasets/issues/5767/events | https://github.com/huggingface/datasets/issues/5767 | 1,672,433,979 | I_kwDODunzps5jr1E7 | 5,767 | How to use Distill-BERT with different datasets? | {
"avatar_url": "https://avatars.githubusercontent.com/u/109907638?v=4",
"events_url": "https://api.github.com/users/sauravtii/events{/privacy}",
"followers_url": "https://api.github.com/users/sauravtii/followers",
"following_url": "https://api.github.com/users/sauravtii/following{/other_user}",
"gists_url": ... | [] | closed | false | null | [] | null | [
"Closing this one in favor of the same issue opened in the `transformers` repo."
] | 2023-04-18T06:25:12Z | 2023-04-20T16:52:05Z | 2023-04-20T16:52:05Z | NONE | null | null | null | ### Describe the bug
- `transformers` version: 4.11.3
- Platform: Linux-5.4.0-58-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.12.0+cu102 (True)
- Tensorflow version (GPU?): 2.10.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxL... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5767/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5767/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3051 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3051/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3051/comments | https://api.github.com/repos/huggingface/datasets/issues/3051/events | https://github.com/huggingface/datasets/issues/3051 | 1,021,852,234 | I_kwDODunzps486DpK | 3,051 | Non-Matching Checksum Error with crd3 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8942987?v=4",
"events_url": "https://api.github.com/users/RylanSchaeffer/events{/privacy}",
"followers_url": "https://api.github.com/users/RylanSchaeffer/followers",
"following_url": "https://api.github.com/users/RylanSchaeffer/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I got the same error for another dataset (`multi_woz_v22`):\r\n\r\n```\r\ndatasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:\r\n['https://github.com/budzianowski/multiwoz/raw/master/data/MultiWOZ_2.2/dialog_acts.json', 'https://github.com/budzianowski/multiwoz/raw/... | 2021-10-10T01:32:43Z | 2022-03-15T15:54:26Z | 2022-03-15T15:54:26Z | NONE | null | null | null | ## Describe the bug
When I try loading the crd3 dataset (https://huggingface.co/datasets/crd3), an error is thrown.
## Steps to reproduce the bug
```python
dataset = load_dataset('crd3', split='train')
```
## Expected results
I expect no error to be thrown.
## Actual results
A non-matching checksum err... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3051/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3051/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/2986 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2986/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2986/comments | https://api.github.com/repos/huggingface/datasets/issues/2986/events | https://github.com/huggingface/datasets/pull/2986 | 1,010,792,783 | PR_kwDODunzps4scSHR | 2,986 | Refac module factory + avoid etag requests for hub datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"> One thing is that I still don't know at what extent we want to keep backward compatibility for prepare_module. For now I just kept it (except I removed two parameters) just in case, but it's not used anywhere anymore.\r\n\r\nFYI, various other projects currently use it, thus clearly a major version would be requ... | 2021-09-29T10:42:00Z | 2021-10-11T11:05:53Z | 2021-10-11T11:05:52Z | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2986.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2986",
"merged_at": "2021-10-11T11:05:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2986.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | ## Refactor the module factory
When trying to extend the `data_files` logic to avoid doing unnecessary ETag requests, I noticed that the module preparation mechanism needed a refactor:
- the function was 600 lines long
- it was not readable
- it contained many different cases that made it complex to maintain
- i... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2986/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2986/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/2261 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2261/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2261/comments | https://api.github.com/repos/huggingface/datasets/issues/2261/events | https://github.com/huggingface/datasets/pull/2261 | 867,088,818 | MDExOlB1bGxSZXF1ZXN0NjIyODIxNzQw | 2,261 | Improve ReadInstruction logic and update docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Ready for the final review"
] | 2021-04-25T19:07:26Z | 2021-05-17T18:24:44Z | 2021-05-17T16:48:57Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/2261.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2261",
"merged_at": "2021-05-17T16:48:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2261.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Improve ReadInstruction logic and docs. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2261/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2261/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4971 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4971/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4971/comments | https://api.github.com/repos/huggingface/datasets/issues/4971/events | https://github.com/huggingface/datasets/pull/4971 | 1,370,319,516 | PR_kwDODunzps4-zk3g | 4,971 | Preserve non-`input_colums` in `Dataset.map` if `input_columns` are specified | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-12T18:08:24Z | 2022-09-13T13:51:08Z | 2022-09-13T13:48:45Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4971.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4971",
"merged_at": "2022-09-13T13:48:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4971.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Currently, if the `input_columns` list in `Dataset.map` is specified, the columns not in that list are dropped after the `map` transform.
This makes the behavior inconsistent with `IterableDataset.map`.
(It seems this issue was introduced by mistake in https://github.com/huggingface/datasets/pull/2246)
Fix h... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4971/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4971/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/1490 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1490/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1490/comments | https://api.github.com/repos/huggingface/datasets/issues/1490/events | https://github.com/huggingface/datasets/pull/1490 | 762,915,346 | MDExOlB1bGxSZXF1ZXN0NTM3NDE2MDU5 | 1,490 | ADD: opus_rf dataset for translation | {
"avatar_url": "https://avatars.githubusercontent.com/u/29649801?v=4",
"events_url": "https://api.github.com/users/akshayb7/events{/privacy}",
"followers_url": "https://api.github.com/users/akshayb7/followers",
"following_url": "https://api.github.com/users/akshayb7/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"merging since the CI is fixed on master"
] | 2020-12-11T21:16:43Z | 2020-12-13T19:12:24Z | 2020-12-13T19:12:24Z | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1490.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1490",
"merged_at": "2020-12-13T19:12:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1490.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | Passed all local tests. Hopefully passes all Circle CI tests too. Tried to keep the commit history clean. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1490/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1490/timeline | null | null | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.