
hexsha stringlengths 40 40 | size int64 5 1.04M | ext stringclasses 6
values | lang stringclasses 1
value | max_stars_repo_path stringlengths 3 344 | max_stars_repo_name stringlengths 5 125 | max_stars_repo_head_hexsha stringlengths 40 78 | max_stars_repo_licenses listlengths 1 11 | max_stars_count int64 1 368k ⌀ | max_stars_repo_stars_event_min_datetime stringlengths 24 24 ⌀ | max_stars_repo_stars_event_max_datetime stringlengths 24 24 ⌀ | max_issues_repo_path stringlengths 3 344 | max_issues_repo_name stringlengths 5 125 | max_issues_repo_head_hexsha stringlengths 40 78 | max_issues_repo_licenses listlengths 1 11 | max_issues_count int64 1 116k ⌀ | max_issues_repo_issues_event_min_datetime stringlengths 24 24 ⌀ | max_issues_repo_issues_event_max_datetime stringlengths 24 24 ⌀ | max_forks_repo_path stringlengths 3 344 | max_forks_repo_name stringlengths 5 125 | max_forks_repo_head_hexsha stringlengths 40 78 | max_forks_repo_licenses listlengths 1 11 | max_forks_count int64 1 105k ⌀ | max_forks_repo_forks_event_min_datetime stringlengths 24 24 ⌀ | max_forks_repo_forks_event_max_datetime stringlengths 24 24 ⌀ | content stringlengths 5 1.04M | avg_line_length float64 1.14 851k | max_line_length int64 1 1.03M | alphanum_fraction float64 0 1 | lid stringclasses 191
values | lid_prob float64 0.01 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
eeeb8c8f70d83488bd7f4ec6189410d56de56dff | 665 | md | Markdown | README.md | NCU-nwlab/training-plan | 52be9924d3a7ef0e6a4ee5021b82052e927e22cb | [
"MIT"
] | null | null | null | README.md | NCU-nwlab/training-plan | 52be9924d3a7ef0e6a4ee5021b82052e927e22cb | [
"MIT"
] | null | null | null | README.md | NCU-nwlab/training-plan | 52be9924d3a7ef0e6a4ee5021b82052e927e22cb | [
"MIT"
] | null | null | null | # training-plan
NWlab 新手任務區
目前想到可以寫的內容
## 常用工具
### Makefile
- [跟我一起寫Makefile](https://seisman.github.io/how-to-write-makefile/)
### CMake
- [CMake 入門實戰](https://www.hahack.com/codes/cmake/)
- CMake example
- [CMake example github](https://github.com/ttroy50/cmake-examples)
- [CMake example 電子書](https://s... | 17.051282 | 77 | 0.693233 | yue_Hant | 0.638673 |
eeec8bf6ab8a1f469ea860cc60cb81dabf92f835 | 1,276 | md | Markdown | problems/intersection-of-two-arrays/README.md | ecgan/leetcode | cd77308f4ab60bc6a0e9ec6796c075bf616d7cf8 | [
"MIT"
] | 9 | 2019-08-15T07:52:20.000Z | 2022-03-26T07:50:01.000Z | problems/intersection-of-two-arrays/README.md | ecgan/leetcode | cd77308f4ab60bc6a0e9ec6796c075bf616d7cf8 | [
"MIT"
] | 9 | 2019-12-29T16:50:39.000Z | 2021-05-29T12:23:46.000Z | problems/intersection-of-two-arrays/README.md | ecgan/leetcode | cd77308f4ab60bc6a0e9ec6796c075bf616d7cf8 | [
"MIT"
] | 2 | 2021-08-11T19:59:02.000Z | 2021-10-17T02:43:23.000Z | # Intersection of Two Arrays
[Link to LeetCode page](https://leetcode.com/problems/intersection-of-two-arrays/)
Difficulty: Easy
Topics: Hash table, two pointers, binary search, sort, set.
## Solution Explanation
We convert the arrays into two [Set](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference... | 34.486486 | 206 | 0.763323 | eng_Latn | 0.996235 |
eeec8efcbb818bd59f5eba24d331938b71cd9951 | 3,278 | md | Markdown | docs/outlook/mapi/iablogon-getlasterror.md | ManuSquall/office-developer-client-docs.fr-FR | 5c3e7961c204833485b8fe857dc7744c12658ec5 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-08-15T11:25:43.000Z | 2021-08-15T11:25:43.000Z | docs/outlook/mapi/iablogon-getlasterror.md | ManuSquall/office-developer-client-docs.fr-FR | 5c3e7961c204833485b8fe857dc7744c12658ec5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/outlook/mapi/iablogon-getlasterror.md | ManuSquall/office-developer-client-docs.fr-FR | 5c3e7961c204833485b8fe857dc7744c12658ec5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: IABLogonGetLastError
manager: soliver
ms.date: 11/16/2014
ms.audience: Developer
ms.topic: reference
ms.prod: office-online-server
localization_priority: Normal
api_name:
- IABLogon.GetLastError
api_type:
- COM
ms.assetid: d157e29e-7731-4e47-b4a7-e8622b223001
description: 'Derniére modification : samedi 23 j... | 38.116279 | 449 | 0.769677 | fra_Latn | 0.927929 |
eeec8f35882dd3868d6702f338b68d18499e558f | 12,688 | md | Markdown | articles/search/search-monitor-usage.md | YulelogPagoda/azure-docs | 467b6399197f039391e4091036a468bdbebf64d6 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-10-24T13:15:24.000Z | 2019-10-24T13:15:24.000Z | articles/search/search-monitor-usage.md | YulelogPagoda/azure-docs | 467b6399197f039391e4091036a468bdbebf64d6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/search/search-monitor-usage.md | YulelogPagoda/azure-docs | 467b6399197f039391e4091036a468bdbebf64d6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Monitor resource usage and query metrics for an search service - Azure Search
description: Enable logging, get query activity metrics, resource usage, and other system data from an Azure Search service.
author: HeidiSteen
manager: nitinme
tags: azure-portal
services: search
ms.service: search
ms.topic: conce... | 72.91954 | 645 | 0.779398 | eng_Latn | 0.990857 |
eeece856070127c1ca55627a9f874bd1d72b2d63 | 789 | md | Markdown | docs/debugger/debug-interface-access/idialoadcallback2-restrictdbgaccess.md | icnocop/visualstudio-docs | 61ee799c65dc6ccd0559e7872e168ab75387ed96 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-02-12T08:46:10.000Z | 2021-02-12T08:46:10.000Z | docs/debugger/debug-interface-access/idialoadcallback2-restrictdbgaccess.md | icnocop/visualstudio-docs | 61ee799c65dc6ccd0559e7872e168ab75387ed96 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/debugger/debug-interface-access/idialoadcallback2-restrictdbgaccess.md | icnocop/visualstudio-docs | 61ee799c65dc6ccd0559e7872e168ab75387ed96 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-02-21T21:24:15.000Z | 2021-02-21T21:24:15.000Z | ---
title: "IDiaLoadCallback2::RestrictDBGAccess | Microsoft Docs"
ms.date: "11/04/2016"
ms.topic: "reference"
dev_langs:
- "C++"
helpviewer_keywords:
- "IDiaLoadCallback2::RestrictDBGAccess method"
ms.assetid: 63b67a93-2910-4fff-aa70-6b2eaa08e5c8
author: "mikejo5000"
ms.author: "mikejo"
manager: jmartens
ms.worklo... | 24.65625 | 93 | 0.750317 | yue_Hant | 0.35753 |
eeed22c01392ebbbd0b64b02997a5a4b82a1e925 | 3,251 | md | Markdown | docs/content/releases/4.5.1.md | marekhanus/postgres-operator | b066320243b55d340b5af55313cdc62857ae887e | [
"Apache-2.0"
] | null | null | null | docs/content/releases/4.5.1.md | marekhanus/postgres-operator | b066320243b55d340b5af55313cdc62857ae887e | [
"Apache-2.0"
] | null | null | null | docs/content/releases/4.5.1.md | marekhanus/postgres-operator | b066320243b55d340b5af55313cdc62857ae887e | [
"Apache-2.0"
] | 1 | 2021-04-25T01:33:02.000Z | 2021-04-25T01:33:02.000Z | ---
title: "4.5.1"
date:
draft: false
weight: 69
---
Crunchy Data announces the release of the PostgreSQL Operator 4.5.1 on November 13, 2020.
The PostgreSQL Operator is released in conjunction with the [Crunchy Container Suite](https://github.com/CrunchyData/crunchy-containers/).
PostgreSQL Operator 4.5.1 release i... | 83.358974 | 280 | 0.794832 | eng_Latn | 0.994951 |
eeed757c19c6236c3cdaf5ec99364b52a4bdbcb4 | 29,680 | md | Markdown | etc/api/browser-ui.api.md | devmotiramani/jsplumb | ba0f68b1ff5aa86ef4dbd0c0390e9754ad557685 | [
"MIT"
] | 1 | 2021-12-16T02:25:26.000Z | 2021-12-16T02:25:26.000Z | etc/api/browser-ui.api.md | devmotiramani/jsplumb | ba0f68b1ff5aa86ef4dbd0c0390e9754ad557685 | [
"MIT"
] | null | null | null | etc/api/browser-ui.api.md | devmotiramani/jsplumb | ba0f68b1ff5aa86ef4dbd0c0390e9754ad557685 | [
"MIT"
] | null | null | null | ## API Report File for "@jsplumb/browser-ui"
> Do not edit this file. It is a report generated by [API Extractor](https://api-extractor.com/).
```ts
import { AbstractConnector } from '@jsplumb/core';
import { BehaviouralTypeDescriptor } from '@jsplumb/core';
import { BoundingBox } from '@jsplumb/util';
import { Comp... | 30.13198 | 161 | 0.697001 | eng_Latn | 0.220213 |
eeede13bffbdee0447f40d8c8b4faa6a1d80f85b | 3,002 | md | Markdown | README.md | LogInsight/tarantool | e060d243e5ecc6613056b9cea5cbdfae47e004aa | [
"BSD-2-Clause"
] | 2 | 2015-12-08T21:37:42.000Z | 2015-12-08T22:11:02.000Z | README.md | LogInsight/tarantool | e060d243e5ecc6613056b9cea5cbdfae47e004aa | [
"BSD-2-Clause"
] | null | null | null | README.md | LogInsight/tarantool | e060d243e5ecc6613056b9cea5cbdfae47e004aa | [
"BSD-2-Clause"
] | 1 | 2020-01-29T15:33:33.000Z | 2020-01-29T15:33:33.000Z | # tarantool [](https://travis-ci.org/tarantool/tarantool)
[](https://gitter.im/tarantool/tarantool?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
http://tarantool.... | 32.27957 | 166 | 0.768155 | eng_Latn | 0.971279 |
eeef9f2a1824b6deb4ecb0665c878fbde24d60d5 | 947 | md | Markdown | CHANGELOG.md | mmozeiko/CxxProfiler | 5836f2a948cf97ad87bef0e357fd39c95d07189f | [
"Unlicense"
] | 110 | 2016-05-06T09:17:55.000Z | 2022-03-30T02:34:41.000Z | CHANGELOG.md | mmozeiko/CxxProfiler | 5836f2a948cf97ad87bef0e357fd39c95d07189f | [
"Unlicense"
] | null | null | null | CHANGELOG.md | mmozeiko/CxxProfiler | 5836f2a948cf97ad87bef0e357fd39c95d07189f | [
"Unlicense"
] | 5 | 2017-10-27T10:59:53.000Z | 2022-01-10T02:24:41.000Z | # Change Log
## [v2] - 2015-08-27
### Bugfix and improvements for VS CRT source location
- Fixed potential crash when using links in source view
- Better support for VS CRT source detection (added VS2015 and Universal CRT)
- Upgraded Qt to 5.7.0
## [v1] - 2015-05-02
### First release!
- Allows to profile 32-bit or 64... | 39.458333 | 81 | 0.762408 | eng_Latn | 0.962124 |
eeefacbacd1b6807a682b73e47f48bcf302de5c5 | 1,644 | md | Markdown | charts/cerebro/README.md | vladlosev/wiremind-helm-charts | e3351be2593eb9d2310a1dc6b24de2c1eddd44c5 | [
"Apache-2.0"
] | 13 | 2020-12-01T22:33:58.000Z | 2022-03-23T10:50:33.000Z | charts/cerebro/README.md | vladlosev/wiremind-helm-charts | e3351be2593eb9d2310a1dc6b24de2c1eddd44c5 | [
"Apache-2.0"
] | 32 | 2020-11-23T21:23:10.000Z | 2022-03-24T13:37:48.000Z | charts/cerebro/README.md | vladlosev/wiremind-helm-charts | e3351be2593eb9d2310a1dc6b24de2c1eddd44c5 | [
"Apache-2.0"
] | 44 | 2021-03-02T05:33:18.000Z | 2022-03-30T13:05:49.000Z | # Cerebro
Cerebro is an open source (MIT License) elasticsearch web admin tool built using Scala, Play Framework, AngularJS and Bootstrap.
## Introduction
This chart deploys Cerebro to your cluster via a Deployment and Service.
Optionally you can also enable ingress.
Optionally you can use cerebro provided auth by u... | 27.864407 | 128 | 0.758516 | eng_Latn | 0.995395 |
eeefef26a8cd1e0d4c6200aed08216d728789389 | 10,328 | md | Markdown | articles/mobile-services-windows-store-dotnet-adal-sso-authentication.md | estei/azure-content | 9279b62c22abc4533b62a4803112b92fba118df9 | [
"CC-BY-3.0"
] | null | null | null | articles/mobile-services-windows-store-dotnet-adal-sso-authentication.md | estei/azure-content | 9279b62c22abc4533b62a4803112b92fba118df9 | [
"CC-BY-3.0"
] | null | null | null | articles/mobile-services-windows-store-dotnet-adal-sso-authentication.md | estei/azure-content | 9279b62c22abc4533b62a4803112b92fba118df9 | [
"CC-BY-3.0"
] | null | null | null | <properties
pageTitle="Authenticate your app with Active Directory Authentication Library Single Sign-On (Windows Store) | Mobile Dev Center"
description="Learn how to authentication users for single sign-on with ADAL in your Windows Store application."
documentationCenter="windows"
authors="wesmc7777"
manage... | 47.59447 | 525 | 0.737219 | eng_Latn | 0.848995 |
eef36a44df9db2bf39309c2c3bf3b5c2cad5d027 | 3,086 | md | Markdown | docs/t-sql/functions/upper-transact-sql.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/t-sql/functions/upper-transact-sql.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/t-sql/functions/upper-transact-sql.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: UPPER (Transact-SQL) | Microsoft Docs
ms.custom: ''
ms.date: 03/13/2017
ms.prod: sql
ms.prod_service: database-engine, sql-database, sql-data-warehouse, pdw
ms.reviewer: ''
ms.technology: t-sql
ms.topic: language-reference
f1_keywords:
- UPPER_TSQL
- UPPER
dev_langs:
- TSQL
helpviewer_keywords:
- UPPER funct... | 37.180723 | 264 | 0.725859 | ita_Latn | 0.414371 |
eef50d8483e67f0905626370a0b749a2c012cca1 | 1,033 | md | Markdown | README.md | ndukh/liver-segmentation | f46697719b78d11f8871048c7c3aaaf8d8f3777f | [
"MIT"
] | 2 | 2019-12-06T13:36:47.000Z | 2020-10-08T13:57:02.000Z | README.md | ndukh/liver-segmentation | f46697719b78d11f8871048c7c3aaaf8d8f3777f | [
"MIT"
] | null | null | null | README.md | ndukh/liver-segmentation | f46697719b78d11f8871048c7c3aaaf8d8f3777f | [
"MIT"
] | null | null | null | # Liver segmentation ([CHAOS](https://chaos.grand-challenge.org/Combined_Healthy_Abdominal_Organ_Segmentation/) challenge).
### An implementation of a CNN model, trained to segment liver on CT-scans.
##### Using:
```shell
$ python segment.py [-h] [-i INPUT_DIR] [-o OUTPUT_DIR]
optional arguments:
-h, --help ... | 36.892857 | 123 | 0.666989 | eng_Latn | 0.975862 |
eef5757cd55c8dad0820ccb782952bdde04d7b38 | 3,973 | md | Markdown | _posts/2020-12-07-Shallow-Neural-Networks.md | evfox9/minimal-mistakes | 8e340c76c9d97549ec4bc40e59760b5fde584b6e | [
"MIT"
] | null | null | null | _posts/2020-12-07-Shallow-Neural-Networks.md | evfox9/minimal-mistakes | 8e340c76c9d97549ec4bc40e59760b5fde584b6e | [
"MIT"
] | null | null | null | _posts/2020-12-07-Shallow-Neural-Networks.md | evfox9/minimal-mistakes | 8e340c76c9d97549ec4bc40e59760b5fde584b6e | [
"MIT"
] | null | null | null | ---
title: 1-3. Shallow Neural Networks
tags: AI Deep_Learning Coursera Deep_Learning_Specialization
---
## Shallow Neural Network
### Neural Network Representation
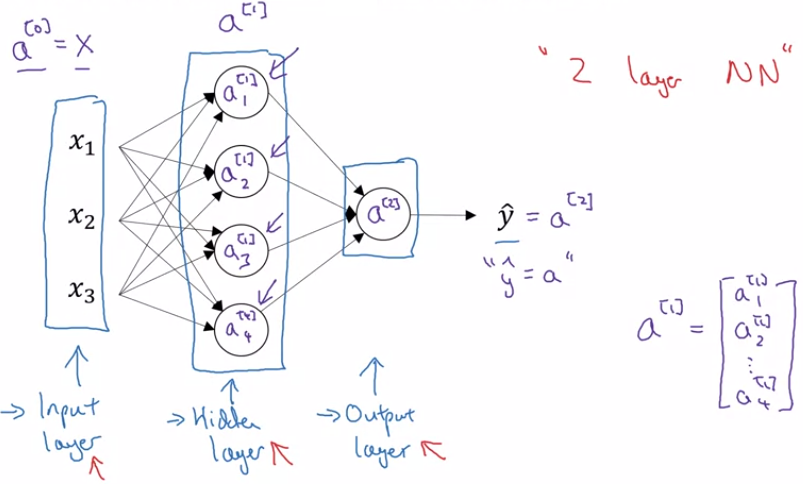
We call the layers with input features $x_1, x_2, x_3$ as ... | 31.784 | 200 | 0.593254 | eng_Latn | 0.495849 |
eef590b9337585327a6fe3f55f9eacd2b7691bce | 233 | md | Markdown | README.md | SayHello-Creator/2020-Miz-Game-Jamz | 973fecfce1ee0bf703b0fc935910320914cf185d | [
"MIT"
] | null | null | null | README.md | SayHello-Creator/2020-Miz-Game-Jamz | 973fecfce1ee0bf703b0fc935910320914cf185d | [
"MIT"
] | null | null | null | README.md | SayHello-Creator/2020-Miz-Game-Jamz | 973fecfce1ee0bf703b0fc935910320914cf185d | [
"MIT"
] | null | null | null | # 2020-Miz-Game-Jamz
Game for 2020 Miz Game Jam
Features:
- Pathfinding
- Turn based movement
- Inventory System
This game wasn't finished, however still has some mechanics and ideas I enjoyed. Will revisit in the future.
| 25.888889 | 110 | 0.746781 | eng_Latn | 0.989524 |
eef5c2a53287057b192b9ab035b214a41f7923fa | 1,284 | md | Markdown | .github/ISSUE_TEMPLATE/support-request.md | leon-anavi/transitions | ab2366accc5b54f70b13ec29193b4b2e429bde04 | [
"MIT"
] | 3,277 | 2017-06-09T15:03:15.000Z | 2022-03-31T15:46:01.000Z | .github/ISSUE_TEMPLATE/support-request.md | leon-anavi/transitions | ab2366accc5b54f70b13ec29193b4b2e429bde04 | [
"MIT"
] | 347 | 2017-06-13T22:50:35.000Z | 2022-03-31T11:37:34.000Z | .github/ISSUE_TEMPLATE/support-request.md | leon-anavi/transitions | ab2366accc5b54f70b13ec29193b4b2e429bde04 | [
"MIT"
] | 389 | 2017-06-16T00:54:31.000Z | 2022-03-23T06:35:10.000Z | ---
name: Support request
about: Ask for help
title: ''
labels: ''
assignees: ''
---
👋 Hello! If you have a question like "How do I do X with `transitions`" or "I have the following problem... Can `transitions` help me with that?", please consider [Stack Overflow](https://stackoverflow.com/questions/tagged/pytransit... | 64.2 | 448 | 0.764798 | eng_Latn | 0.99682 |
eef5c2ed62b61a2432ed7794680242e8b33c7cea | 748 | md | Markdown | _publications/2014-01-01-SonicData-Broadcasting-Data-via-Sound-for-Smartphones.md | hcilab/hcilab.github.io | 0e005266e317429cca60407163bed4d17250b8fb | [
"MIT"
] | 3 | 2016-05-09T16:08:32.000Z | 2019-05-09T14:47:00.000Z | _publications/2014-01-01-SonicData-Broadcasting-Data-via-Sound-for-Smartphones.md | hcilab/hcilab.github.io | 0e005266e317429cca60407163bed4d17250b8fb | [
"MIT"
] | 3 | 2021-05-17T23:23:40.000Z | 2022-02-26T01:23:33.000Z | _publications/2014-01-01-SonicData-Broadcasting-Data-via-Sound-for-Smartphones.md | hcilab/hcilab.github.io | 0e005266e317429cca60407163bed4d17250b8fb | [
"MIT"
] | 3 | 2019-01-22T17:37:21.000Z | 2020-05-08T13:33:50.000Z | ---
title: "SonicData: Broadcasting Data via Sound for Smartphones"
collection: publications
permalink: /publication/2014-01-01-SonicData-Broadcasting-Data-via-Sound-for-Smartphones
date: 2014-01-01
venue: 'University of Calgary, Department of Computer Science Technical Report'
citation: ' Aditya Nittala, Xing-Dong Ya... | 74.8 | 239 | 0.78877 | yue_Hant | 0.292645 |
eef62d02bc6cd0d983c91b7609d1bb2bf185d1b1 | 2,226 | md | Markdown | windows.networking.proximity/peerrole.md | TerryWarwick/winrt-api | 8067d355063938408e4d070241b1959dd62a295f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows.networking.proximity/peerrole.md | TerryWarwick/winrt-api | 8067d355063938408e4d070241b1959dd62a295f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows.networking.proximity/peerrole.md | TerryWarwick/winrt-api | 8067d355063938408e4d070241b1959dd62a295f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
-api-id: T:Windows.Networking.Proximity.PeerRole
-api-type: winrt enum
-api-device-family-note: xbox
---
<!-- Enumeration syntax
public enum Windows.Networking.Proximity.PeerRole : int
-->
# PeerRole
## -description
Describes the role of the peer app when connected to multiple peers.
## -enum-fields
### -field ... | 50.590909 | 582 | 0.756963 | eng_Latn | 0.966115 |
eef6eeaa367188837f9aca65a58b02f8637221da | 839 | md | Markdown | docs/manual-CN/0.about-this-manual.md | luobeichen/nebula-docs-cn | e7f11f24986e69a80683ba54af9c8e51879c8095 | [
"Apache-2.0"
] | null | null | null | docs/manual-CN/0.about-this-manual.md | luobeichen/nebula-docs-cn | e7f11f24986e69a80683ba54af9c8e51879c8095 | [
"Apache-2.0"
] | null | null | null | docs/manual-CN/0.about-this-manual.md | luobeichen/nebula-docs-cn | e7f11f24986e69a80683ba54af9c8e51879c8095 | [
"Apache-2.0"
] | 1 | 2021-10-08T08:21:19.000Z | 2021-10-08T08:21:19.000Z | # 关于本手册
此手册为 Nebula Graph 的用户手册,版本为 1.2。详细版本更新信息参见 [Release Notes](https://github.com/vesoft-inc/nebula/releases)。
## 面向的读者
本手册适用于 `算法工程师`、`数据科学家`、`软件开发人员`和 `DBA`,以及所有对`图数据库`感兴趣的人群。
如果在使用 Nebula Graph 的过程中有任何问题,欢迎在 [Nebula Graph Community Slack](https://join.slack.com/t/nebulagraph/shared_invite/enQtNjIzMjQ5MzE2OTQ... | 26.21875 | 274 | 0.753278 | yue_Hant | 0.751236 |
eef713c8bdf13bb5563e432a672d1637a4872a53 | 2,445 | md | Markdown | docs/framework/winforms/advanced/how-to-use-antialiasing-with-text.md | olifantix/docs.de-de | a31a14cdc3967b64f434a2055f7de6bf1bb3cda8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/winforms/advanced/how-to-use-antialiasing-with-text.md | olifantix/docs.de-de | a31a14cdc3967b64f434a2055f7de6bf1bb3cda8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/winforms/advanced/how-to-use-antialiasing-with-text.md | olifantix/docs.de-de | a31a14cdc3967b64f434a2055f7de6bf1bb3cda8 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 'Gewusst wie: Verwenden der Bildkantenglättung mit Text'
ms.date: 03/30/2017
dev_langs:
- csharp
- vb
helpviewer_keywords:
- strings [Windows Forms], smoothing drawn
- antialiasing [Windows Forms], using with text
- text [Windows Forms], smoothing
- text [Windows Forms], antialiasing
- strings [Win... | 64.342105 | 678 | 0.778323 | deu_Latn | 0.837557 |
eef720f468a4558e38421dc195112cb41cd327ac | 36 | md | Markdown | README.md | Ragnarokr45/LibraryWebApi | 0feb4e80ac845cde5fb3bf6ec1d283098f7438ab | [
"MIT"
] | null | null | null | README.md | Ragnarokr45/LibraryWebApi | 0feb4e80ac845cde5fb3bf6ec1d283098f7438ab | [
"MIT"
] | 1 | 2020-05-17T14:12:20.000Z | 2020-05-17T14:12:20.000Z | README.md | Ragnarokr45/LibraryWebApi | 0feb4e80ac845cde5fb3bf6ec1d283098f7438ab | [
"MIT"
] | null | null | null | # LibraryWebApi
Web API for Library
| 12 | 19 | 0.805556 | kor_Hang | 0.322886 |
eef7427081a237d4d405c6fa9256bf0c6f19b875 | 1,095 | md | Markdown | README.md | isek27/LocalizationClientHeroku | ae1ff2d885d7e261aa1218cefd4d72cf9943bb45 | [
"MIT"
] | null | null | null | README.md | isek27/LocalizationClientHeroku | ae1ff2d885d7e261aa1218cefd4d72cf9943bb45 | [
"MIT"
] | null | null | null | README.md | isek27/LocalizationClientHeroku | ae1ff2d885d7e261aa1218cefd4d72cf9943bb45 | [
"MIT"
] | null | null | null | # Localization App made with React (for [Heroku](https://www.heroku.com/) deployment)
This app was orinally made to help patients with hearing implants 'localize' sound. Works best with a left and right speakers.
Can also be used with headphones.
https://localization-client.herokuapp.com/
### INSTALL (Local/Developm... | 43.8 | 239 | 0.752511 | eng_Latn | 0.982508 |
eef7b83462d2645cef91d3beb1e7699a23d94838 | 907 | md | Markdown | doc/help/system-console/Team-Statistics.md | alexgaribay/platform | 178e30ecededae61eb727f30919b30358590e7f5 | [
"Apache-2.0"
] | 1 | 2021-03-16T14:06:32.000Z | 2021-03-16T14:06:32.000Z | doc/help/system-console/Team-Statistics.md | alexgaribay/platform | 178e30ecededae61eb727f30919b30358590e7f5 | [
"Apache-2.0"
] | null | null | null | doc/help/system-console/Team-Statistics.md | alexgaribay/platform | 178e30ecededae61eb727f30919b30358590e7f5 | [
"Apache-2.0"
] | null | null | null | # Team Statistics
Statistics on users, posts and channels are tracked for each team are viewable under **System Console** > **Teams** > **Statistics**.
## Total Users
The total number of accounts created, including both active and inactive accounts.
## Total Posts
The total number of posts made in a team, includin... | 36.28 | 134 | 0.776185 | eng_Latn | 0.99992 |
eef84bcc15d36c465360577a94173a66968a6024 | 2,716 | md | Markdown | content/en/user-manual/optimization/hardware-instancing.md | Viktor20012002/developcanvas.com | 30f04880962e752fed5b4faab782c517e9e2fbd5 | [
"MIT"
] | null | null | null | content/en/user-manual/optimization/hardware-instancing.md | Viktor20012002/developcanvas.com | 30f04880962e752fed5b4faab782c517e9e2fbd5 | [
"MIT"
] | null | null | null | content/en/user-manual/optimization/hardware-instancing.md | Viktor20012002/developcanvas.com | 30f04880962e752fed5b4faab782c517e9e2fbd5 | [
"MIT"
] | null | null | null | ---
title: Hardware Instancing
template: usermanual-page.tmpl.html
position: 5
---
Hardware instancing is a rendering technique which allows the GPU to render multiple identical meshes in a small number of draw calls. Each instance of the mesh can have a different limited amount of state (for example, position or colo... | 37.722222 | 317 | 0.762887 | eng_Latn | 0.966593 |
eef891be4d52c58593e0c1db5b9aa82764d3a933 | 1,808 | md | Markdown | website/docs/intro.md | asmengistu/flutter-facebook-auth | 4bf13cd4bcad4c5e7156b33ead546451a3406e5a | [
"MIT"
] | null | null | null | website/docs/intro.md | asmengistu/flutter-facebook-auth | 4bf13cd4bcad4c5e7156b33ead546451a3406e5a | [
"MIT"
] | null | null | null | website/docs/intro.md | asmengistu/flutter-facebook-auth | 4bf13cd4bcad4c5e7156b33ead546451a3406e5a | [
"MIT"
] | null | null | null | <!--  -->
<p align="center">
<a href="https://pub.dev/packages/flutter_facebook_auth"><img alt="pub version" src="https://img.shields.io/pub/v/flutter_facebook_auth?color=%2300b0ff&label=flutter_facebook_au... | 48.864865 | 382 | 0.755531 | eng_Latn | 0.623086 |
eef8fe8453df013768b3e6cbc2459be449d004c6 | 22,416 | md | Markdown | docs/reference/sql_reference/create-table.md | jiayuasu/snappydata-versus-tabula | 8c619dae370336334a0a6fed85b5404fbca20583 | [
"BSD-3-Clause-Open-MPI",
"PSF-2.0",
"Apache-2.0",
"BSD-2-Clause",
"MIT",
"MIT-0",
"BSD-3-Clause-No-Nuclear-License-2014",
"BSD-3-Clause-Clear",
"PostgreSQL",
"BSD-3-Clause"
] | null | null | null | docs/reference/sql_reference/create-table.md | jiayuasu/snappydata-versus-tabula | 8c619dae370336334a0a6fed85b5404fbca20583 | [
"BSD-3-Clause-Open-MPI",
"PSF-2.0",
"Apache-2.0",
"BSD-2-Clause",
"MIT",
"MIT-0",
"BSD-3-Clause-No-Nuclear-License-2014",
"BSD-3-Clause-Clear",
"PostgreSQL",
"BSD-3-Clause"
] | null | null | null | docs/reference/sql_reference/create-table.md | jiayuasu/snappydata-versus-tabula | 8c619dae370336334a0a6fed85b5404fbca20583 | [
"BSD-3-Clause-Open-MPI",
"PSF-2.0",
"Apache-2.0",
"BSD-2-Clause",
"MIT",
"MIT-0",
"BSD-3-Clause-No-Nuclear-License-2014",
"BSD-3-Clause-Clear",
"PostgreSQL",
"BSD-3-Clause"
] | 1 | 2021-08-10T01:55:55.000Z | 2021-08-10T01:55:55.000Z | # CREATE TABLE
**To Create Row/Column Table:**
```pre
CREATE TABLE [IF NOT EXISTS] table_name
( column-definition [ , column-definition ] * )
USING [row | column] // If not specified, a row table is created.
OPTIONS (
COLOCATE_WITH 'table-name', // Default none
PARTITION_BY 'column-name', // I... | 58.680628 | 666 | 0.752409 | eng_Latn | 0.984312 |
eef95ed8a9cfbb31a364fe5be42c41835113ce19 | 1,970 | md | Markdown | _posts/11/2021-04-06-jasmin-brown.md | chito365/ukdat | 382c0628a4a8bed0f504f6414496281daf78f2d8 | [
"MIT"
] | null | null | null | _posts/11/2021-04-06-jasmin-brown.md | chito365/ukdat | 382c0628a4a8bed0f504f6414496281daf78f2d8 | [
"MIT"
] | null | null | null | _posts/11/2021-04-06-jasmin-brown.md | chito365/ukdat | 382c0628a4a8bed0f504f6414496281daf78f2d8 | [
"MIT"
] | null | null | null | ---
id: 5589
title: Jasmin Brown
date: 2021-04-06T20:36:37+00:00
author: Laima
layout: post
guid: https://ukdataservers.com/jasmin-brown/
permalink: /04/06/jasmin-brown
tags:
- claims
- lawyer
- doctor
- house
- multi family
- online
- poll
- business
category: Guides
---
* some text
{: toc}
## Who i... | 20.102041 | 152 | 0.35533 | eng_Latn | 0.997715 |
eef9ca23c3ea61f46095d46f2dd9952448bbe914 | 142 | md | Markdown | README.md | davidsyntex/adventofcode2016csharp | 449ce24964296d41e1a2f72e0b9e9ad809503f26 | [
"MIT"
] | null | null | null | README.md | davidsyntex/adventofcode2016csharp | 449ce24964296d41e1a2f72e0b9e9ad809503f26 | [
"MIT"
] | null | null | null | README.md | davidsyntex/adventofcode2016csharp | 449ce24964296d41e1a2f72e0b9e9ad809503f26 | [
"MIT"
] | null | null | null | # My C#-solutions for Advent of Code 2016
Focus has been on finding a fast solution.
Refactoring for performance and beauty is in the future.
| 35.5 | 56 | 0.788732 | eng_Latn | 0.999627 |
eef9f03f3fbdf99ea2b539bf3bffdc3b56cbff6f | 2,119 | md | Markdown | source/webapp/README.md | chriscoombs/amazon-rekognition-shot-detection-demo-using-segment-api | 3bb5bb074436bbac7f29d46b1921c9220a2fb156 | [
"MIT-0"
] | null | null | null | source/webapp/README.md | chriscoombs/amazon-rekognition-shot-detection-demo-using-segment-api | 3bb5bb074436bbac7f29d46b1921c9220a2fb156 | [
"MIT-0"
] | null | null | null | source/webapp/README.md | chriscoombs/amazon-rekognition-shot-detection-demo-using-segment-api | 3bb5bb074436bbac7f29d46b1921c9220a2fb156 | [
"MIT-0"
] | null | null | null | # Webapp Component
The web application is written in ES6 and uses JQuery and Boostrap libraries.
___
# Limitations
The solution is designed to demonstrate how you can use Amazon Rekognition Segment Detection to extract shot boundaries from a given video. While the solut is fully functional, it is **not** meant to b... | 66.21875 | 471 | 0.787636 | eng_Latn | 0.97 |
eefa3d1c0d6ed26d0d8eba5b8535fbf831977604 | 21 | md | Markdown | README.md | tynashax36/shax | 5dc3b47b2fe7ea28fa773528f257d6b8f2ba4cf3 | [
"Apache-2.0"
] | null | null | null | README.md | tynashax36/shax | 5dc3b47b2fe7ea28fa773528f257d6b8f2ba4cf3 | [
"Apache-2.0"
] | null | null | null | README.md | tynashax36/shax | 5dc3b47b2fe7ea28fa773528f257d6b8f2ba4cf3 | [
"Apache-2.0"
] | null | null | null | # shax
my repository
| 7 | 13 | 0.761905 | eng_Latn | 0.999621 |
eefcf44bea6f6fc0d35df0c8ba097270fcb3d35d | 249 | md | Markdown | README.md | danerbland/Grun | ca19e8de7fb1ed67ee9126c758a2e4506e5313f3 | [
"MIT"
] | null | null | null | README.md | danerbland/Grun | ca19e8de7fb1ed67ee9126c758a2e4506e5313f3 | [
"MIT"
] | 2 | 2021-03-10T00:10:36.000Z | 2021-05-10T20:00:13.000Z | README.md | danerbland/Grun | ca19e8de7fb1ed67ee9126c758a2e4506e5313f3 | [
"MIT"
] | null | null | null | # GRUN
Grun is a social network for users to review NYC restaurants based on their sustability efforts and social responsibility. Users can easily look up their favorite restaurants, leave reviews, and find the top rated restaurants in their boro.
| 62.25 | 240 | 0.815261 | eng_Latn | 0.999143 |
eefd0916f7f8224a40863c56a5160084f97273d9 | 3,367 | md | Markdown | CONTRIBUTING.md | RPiAwesomeness/dephell | 993a212ce17dda04a878ceac64854d809f3dc47b | [
"MIT"
] | null | null | null | CONTRIBUTING.md | RPiAwesomeness/dephell | 993a212ce17dda04a878ceac64854d809f3dc47b | [
"MIT"
] | null | null | null | CONTRIBUTING.md | RPiAwesomeness/dephell | 993a212ce17dda04a878ceac64854d809f3dc47b | [
"MIT"
] | null | null | null | # Contributing to dephell
Thank you for deciding to contribute to DepHell! This guide is to assist you with contributing code. If you have a question that isn't answered here, please [open an issue][open issue].
## The basics
So you want to contribute some code? Great! Here are the basic steps:
1. Find an [issue... | 47.422535 | 483 | 0.761806 | eng_Latn | 0.994341 |
eefd4b873a483ada6d19186afb136e6829df6fb3 | 352 | md | Markdown | README.md | rukbrook/UOFDBot | 20d4efa566f73f508b8a3f42bd8214bd17a56839 | [
"Apache-2.0"
] | null | null | null | README.md | rukbrook/UOFDBot | 20d4efa566f73f508b8a3f42bd8214bd17a56839 | [
"Apache-2.0"
] | null | null | null | README.md | rukbrook/UOFDBot | 20d4efa566f73f508b8a3f42bd8214bd17a56839 | [
"Apache-2.0"
] | 1 | 2021-01-22T16:28:54.000Z | 2021-01-22T16:28:54.000Z | # UOFDBot - User of the day [bot]
<p align="center">
<img width="100px" src="https://user-images.githubusercontent.com/2866780/72239870-6a010c00-35f3-11ea-9d8f-9d499762e1bb.png"></img>
</p>
Веселый телеграм бот. Поможет определиться, кто сегодня 'пидор', а кто 'герой'. Каждая игра запускается отдельно. При необходим... | 50.285714 | 158 | 0.761364 | rus_Cyrl | 0.333533 |
eefd627497c9fa3389eb0e48596dd23a875b87c0 | 4,717 | md | Markdown | _technologies/apache-beam.md | boy007uk/OnDataEngineeringContent | bb88f85199fb4c1dbe84d4d2d8a0c5503c0c6f11 | [
"Apache-2.0"
] | 6 | 2017-02-25T19:38:56.000Z | 2021-06-08T16:21:51.000Z | _technologies/apache-beam.md | boy007uk/OnDataEngineeringContent | bb88f85199fb4c1dbe84d4d2d8a0c5503c0c6f11 | [
"Apache-2.0"
] | 17 | 2017-02-21T21:27:16.000Z | 2019-05-24T16:27:41.000Z | _technologies/apache-beam.md | boy007uk/OnDataEngineeringContent | bb88f85199fb4c1dbe84d4d2d8a0c5503c0c6f11 | [
"Apache-2.0"
] | 8 | 2017-02-12T02:22:53.000Z | 2020-01-07T11:54:20.000Z | ---
title: "Apache Beam"
description: "Unified batch and streaming programming model to define portable data processing pipelines and execute these using a range of different engines. Originating from the Google Dataflow model, focuses on unifying both styles of processing by treating static data sets as streams (which... | 120.948718 | 1,529 | 0.764893 | eng_Latn | 0.512567 |
eefe3343e16067182c049e56447efdc66ce6b660 | 4,273 | md | Markdown | README.md | amykep/Amy-Book-Search-Engine | 0b065d34ee6674fe07e1b062b747f2c1043bac8e | [
"MIT"
] | null | null | null | README.md | amykep/Amy-Book-Search-Engine | 0b065d34ee6674fe07e1b062b747f2c1043bac8e | [
"MIT"
] | null | null | null | README.md | amykep/Amy-Book-Search-Engine | 0b065d34ee6674fe07e1b062b747f2c1043bac8e | [
"MIT"
] | null | null | null | ## Description
This project takes a fully functioning Google Books API search engine built with a RESTful API, and refactor it to be a GraphQL API built with Apollo Server. The app was built using the MERN stack, with a React front end, MongoDB database, and Node.js/Express.js server and API. It's already set up to al... | 57.743243 | 352 | 0.74842 | eng_Latn | 0.975655 |
eefe576e20648069415939c36f13ed90134a264a | 33 | md | Markdown | README.md | umairq123/HelperiOS | e3df2ba6537b38e356b4e6529642c7ccaf9f0345 | [
"MIT"
] | 1 | 2016-09-24T06:11:50.000Z | 2016-09-24T06:11:50.000Z | README.md | umairq123/HelperiOS | e3df2ba6537b38e356b4e6529642c7ccaf9f0345 | [
"MIT"
] | null | null | null | README.md | umairq123/HelperiOS | e3df2ba6537b38e356b4e6529642c7ccaf9f0345 | [
"MIT"
] | null | null | null | # HelperiOS
helper files for ios
| 11 | 20 | 0.787879 | eng_Latn | 0.732311 |
eefe79dbe2b206ed8f9dbdecad9ddd6c49566cf4 | 1,295 | md | Markdown | _posts/2010-09-22-3287.md | TkTech/skins.tkte.ch | 458838013820531bc47d899f920916ef8c37542d | [
"MIT"
] | 1 | 2020-11-20T20:39:54.000Z | 2020-11-20T20:39:54.000Z | _posts/2010-09-22-3287.md | TkTech/skins.tkte.ch | 458838013820531bc47d899f920916ef8c37542d | [
"MIT"
] | null | null | null | _posts/2010-09-22-3287.md | TkTech/skins.tkte.ch | 458838013820531bc47d899f920916ef8c37542d | [
"MIT"
] | null | null | null | ---
title: >
Dig Dug
layout: post
permalink: /view/3287
votes: 2
preview: "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAACUAAAAgCAIAAAAaMSbnAAAABnRSTlMA/wD/AP5AXyvrAAAAfklEQVRIiWP8//8fAww8f/6CARuQlJTAKo4GiNHORIxBVAT0to8FmSPV8IyBgYFhlglD2hlkxv+ZRIUnMWAwhCfEc8gM2tpHS4ASf88apGhuH2P6OYL2Iav5P9MIlxQx2gdDehm1b9S+UftG7a... | 43.166667 | 322 | 0.836293 | yue_Hant | 0.51085 |
eefecfa8fe09096b3c92176b882fcd1d82fbb408 | 72 | md | Markdown | info/cnblogs/blog/start.md | BigShuang/python-introductory-exercises | 9b8d391ce5fcbd12a654aba1c62a746ddb52a42d | [
"MIT"
] | null | null | null | info/cnblogs/blog/start.md | BigShuang/python-introductory-exercises | 9b8d391ce5fcbd12a654aba1c62a746ddb52a42d | [
"MIT"
] | null | null | null | info/cnblogs/blog/start.md | BigShuang/python-introductory-exercises | 9b8d391ce5fcbd12a654aba1c62a746ddb52a42d | [
"MIT"
] | null | null | null | > [大爽Python入门练习题总目录](https://www.cnblogs.com/BigShuang/p/15664677.html)
| 36 | 71 | 0.777778 | yue_Hant | 0.941899 |
eefed49da84017f19f9e62d78f34f016e182a96a | 2,012 | md | Markdown | frontend/node_modules/ember-factory-for-polyfill/README.md | sahilpaudel/AfterGlow | 0859ec14b47c8c5704cc8e5cba86d39aa258fff5 | [
"MIT"
] | null | null | null | frontend/node_modules/ember-factory-for-polyfill/README.md | sahilpaudel/AfterGlow | 0859ec14b47c8c5704cc8e5cba86d39aa258fff5 | [
"MIT"
] | null | null | null | frontend/node_modules/ember-factory-for-polyfill/README.md | sahilpaudel/AfterGlow | 0859ec14b47c8c5704cc8e5cba86d39aa258fff5 | [
"MIT"
] | null | null | null | # ember-factory-for-polyfill
This addon provides a best effort polyfill for the `ember-factory-for` feature added in Ember 2.12.
Please review [emberjs/rfcs#150](https://github.com/emberjs/rfcs/blob/master/text/0150-factory-for.md) for more details.
## Installation
```sh
ember install ember-factory-for-polyfill
```... | 25.794872 | 155 | 0.736581 | eng_Latn | 0.922375 |
eeff5d7d31b6f33d4345ba23389291cf2c842b82 | 6,187 | md | Markdown | articles/finance/fixed-assets/acquire-assets-procurement.md | MicrosoftDocs/Dynamics-365-Operations.ja-jp | 821ba731df05b9c1d0b0947b8d7e66ae9a34c0b4 | [
"CC-BY-4.0",
"MIT"
] | 4 | 2020-05-18T17:14:25.000Z | 2021-11-13T07:27:21.000Z | articles/finance/fixed-assets/acquire-assets-procurement.md | MicrosoftDocs/Dynamics-365-Operations.ja-jp | 821ba731df05b9c1d0b0947b8d7e66ae9a34c0b4 | [
"CC-BY-4.0",
"MIT"
] | 37 | 2017-12-13T17:53:18.000Z | 2021-03-16T19:04:28.000Z | articles/finance/fixed-assets/acquire-assets-procurement.md | MicrosoftDocs/Dynamics-365-Operations.ja-jp | 821ba731df05b9c1d0b0947b8d7e66ae9a34c0b4 | [
"CC-BY-4.0",
"MIT"
] | 8 | 2017-11-06T03:10:26.000Z | 2020-03-21T18:08:51.000Z | ---
title: 調達によって取得される資産の取得
description: このトピックでは、固定資産と買掛金の統合を設定して、発注書または仕入先請求書から固定資産を自動作成する方法、また固定資産の取得および取得原価調整トランザクションの自動転記を実行する方法を説明します。
author: ShylaThompson
ms.date: 03/05/2019
ms.topic: article
ms.prod: ''
ms.technology: ''
ms.search.form: AssetParameters
audience: Application User
ms.reviewer: roschlom
ms.custo... | 55.738739 | 257 | 0.769517 | jpn_Jpan | 0.876333 |
eeffb275c7c9edf1291a5b31528e98e6a81f9f38 | 246 | md | Markdown | README.md | wf539/VB2005ExpressStarterKit | 48d8853692bc6fda5f9afd612388984ab1f08116 | [
"MIT"
] | null | null | null | README.md | wf539/VB2005ExpressStarterKit | 48d8853692bc6fda5f9afd612388984ab1f08116 | [
"MIT"
] | null | null | null | README.md | wf539/VB2005ExpressStarterKit | 48d8853692bc6fda5f9afd612388984ab1f08116 | [
"MIT"
] | null | null | null | # Example code for book: Wrox's Visual Basic 2005 Express Edition Starter Kit
Visual Basic 2005 Express Edition Starter Kit
Andrew Parsons
Copyright (c) 2006 by Wiley Publishing, Inc. Indianapolis IN 46256; Andrew Parsons
ISBN: 978-0764595738 | 27.333333 | 82 | 0.800813 | kor_Hang | 0.360636 |
eefff4c075d7aba5e05de032ec3c3d73d253ac65 | 3,220 | md | Markdown | docs/tutorials/train/detection.md | ZHUI/PaddleX | 27f21b7a1e4a209cf7cd9bb558410278e49e2806 | [
"Apache-2.0"
] | 3 | 2020-05-12T03:09:13.000Z | 2020-06-18T02:50:34.000Z | docs/tutorials/train/detection.md | wyc880622/PaddleX | f001960b7359f3a88b7dd96e1f34500b90566ceb | [
"Apache-2.0"
] | null | null | null | docs/tutorials/train/detection.md | wyc880622/PaddleX | f001960b7359f3a88b7dd96e1f34500b90566ceb | [
"Apache-2.0"
] | 1 | 2020-05-18T07:06:28.000Z | 2020-05-18T07:06:28.000Z | # 训练目标检测模型
------
更多检测模型在VOC数据集或COCO数据集上的训练代码可参考[代码tutorials/train/detection/faster_rcnn_r50_fpn.py](https://github.com/PaddlePaddle/PaddleX/blob/develop/tutorials/train/detection/faster_rcnn_r50_fpn.py)、[代码tutorials/train/detection/yolov3_darknet53.py](https://github.com/PaddlePaddle/PaddleX/blob/develop/tutorials/t... | 26.833333 | 336 | 0.762422 | yue_Hant | 0.128457 |
eefff5de95d70d8e59652e7d6a79cc3eade82c5b | 2,276 | md | Markdown | _kb/how-to-add-drop-map-location.md | Projectx-hub/projectx-live | 5d06ab212ead987935a5c7a6ee3bb0ea1bcf95e0 | [
"MIT"
] | null | null | null | _kb/how-to-add-drop-map-location.md | Projectx-hub/projectx-live | 5d06ab212ead987935a5c7a6ee3bb0ea1bcf95e0 | [
"MIT"
] | 1 | 2021-04-04T07:31:10.000Z | 2021-04-04T07:31:10.000Z | _kb/how-to-add-drop-map-location.md | Projectx-hub/projectx-live | 5d06ab212ead987935a5c7a6ee3bb0ea1bcf95e0 | [
"MIT"
] | 1 | 2020-12-26T11:37:37.000Z | 2020-12-26T11:37:37.000Z | ---
layout: kb
collection: kb
type: how-to
title: "Adding a Drop Map Location"
date: 2019-11-12
description: "How-to guide for accessing CloudCannon's visual editor to add a Google Maps location to the Drop Map page (standalone page)."
author: marklchaves
---
As of 15 November 2019, up to five map locations can be ente... | 51.727273 | 239 | 0.725395 | eng_Latn | 0.966023 |
e10062f7c139a56da8edb1e10fe297cad3041c21 | 2,276 | md | Markdown | README.md | YuriKovalchuk/Coworkee | 1ad3505cd65565faae6fe16c6fd3b6b7a2951796 | [
"MIT"
] | null | null | null | README.md | YuriKovalchuk/Coworkee | 1ad3505cd65565faae6fe16c6fd3b6b7a2951796 | [
"MIT"
] | null | null | null | README.md | YuriKovalchuk/Coworkee | 1ad3505cd65565faae6fe16c6fd3b6b7a2951796 | [
"MIT"
] | null | null | null | # Ext JS Employee Directory
Ext JS Sample Application - Employee Directory (Coworkee)
## Getting started
### Prerequisite
- Install [Node.js](https://nodejs.org/) (^6.9.2)
- Install [Sencha Cmd](https://www.sencha.com/products/sencha-cmd) (^6.5.1)
- Download [Sencha Ext JS](https://www.sencha.com/products/extjs) (^6.5... | 34.484848 | 114 | 0.721441 | eng_Latn | 0.930478 |
e101287ac78f1a694ce2d8ff977bd8cc2ffcea43 | 7,438 | md | Markdown | nodejs/pnpm.md | BillowsTao/Front-End-Knowledge-Base | 5590c055b86d38ebfa85674f07d56d7db580f16a | [
"MIT"
] | null | null | null | nodejs/pnpm.md | BillowsTao/Front-End-Knowledge-Base | 5590c055b86d38ebfa85674f07d56d7db580f16a | [
"MIT"
] | 5 | 2020-02-04T05:13:52.000Z | 2020-02-06T11:36:23.000Z | nodejs/pnpm.md | BillowsTao/Front-End-Knowledge-Base | 5590c055b86d38ebfa85674f07d56d7db580f16a | [
"MIT"
] | null | null | null | # pnpm - 快速的,节省磁盘空间的包管理工具
> Node.js 的包管理工具经历了从 npm, yarn 到 pnpm 的发展过程。截止目前 (2021.12),pnpm 为最新一代的包管理工具。pnpm 相较于其他包管理工具的优势有哪些,为何要选择 pnpm,本文为大家逐一介绍。
## 为什么不是 npm, Yarn
pnpm 是一个 Node.js 的另一种包管理工具,它是 npm, Yarn 的替代,但是更快、更高效。下面概述一下 npm, Yarn 的原理和问题,以及 Yarn 相对于 npm 的改进。
### pnpm 不是扁平化 `node_modules`
在 npm v3 之前的版本,`node_m... | 33.35426 | 250 | 0.628798 | yue_Hant | 0.642318 |
e1014a516797ad111748eeafaa065769777e3cf4 | 443 | md | Markdown | _posts/2016-7-4-Warden-blog-has-just-started.md | warden-stack/warden-stack.github.io | 57004bd53af4c0d4cb70d515be453ecda452c278 | [
"MIT"
] | 1 | 2016-07-01T06:05:24.000Z | 2016-07-01T06:05:24.000Z | _posts/2016-7-4-Warden-blog-has-just-started.md | warden-stack/warden-stack.github.io | 57004bd53af4c0d4cb70d515be453ecda452c278 | [
"MIT"
] | null | null | null | _posts/2016-7-4-Warden-blog-has-just-started.md | warden-stack/warden-stack.github.io | 57004bd53af4c0d4cb70d515be453ecda452c278 | [
"MIT"
] | null | null | null | ---
layout: post
title: Warden blog has just started!
---
Let me introduce a blog about the [Warden](https://getwarden.net) where the most important information and updates will be posted in order to keep you informed what's going on with the proejct.

Just make... | 40.272727 | 193 | 0.760722 | eng_Latn | 0.989725 |
e1014cbf73533ea854246247679abef6a97e6774 | 3,808 | md | Markdown | README.md | canhspokeo/rtask | 28ef0f05731874b63e2ef08e2c3bd080e76089c0 | [
"MIT"
] | null | null | null | README.md | canhspokeo/rtask | 28ef0f05731874b63e2ef08e2c3bd080e76089c0 | [
"MIT"
] | null | null | null | README.md | canhspokeo/rtask | 28ef0f05731874b63e2ef08e2c3bd080e76089c0 | [
"MIT"
] | null | null | null | # RTask
RTask mimicks Task class in .NET to allow writing asynchronous code in ruby easier.
## Installation
Add this line to your application's Gemfile:
```ruby
gem 'rtask'
```
And then execute:
$ bundle
Or install it yourself as:
$ gem install rtask
## Usage
Run a task
```ruby
# this is a non-blocking... | 23.949686 | 324 | 0.707983 | eng_Latn | 0.987067 |
e101d97500c919af214673e1095c6212959a7ab5 | 152 | md | Markdown | content/events/2017-riga/speakers.md | docent-net/devopsdays-web | 8056b7937e293bd63b43d98bd8dca1844eee8a88 | [
"Apache-2.0",
"MIT"
] | 6 | 2016-11-14T14:08:29.000Z | 2018-05-09T18:57:06.000Z | content/events/2017-riga/speakers.md | docent-net/devopsdays-web | 8056b7937e293bd63b43d98bd8dca1844eee8a88 | [
"Apache-2.0",
"MIT"
] | 461 | 2016-11-11T19:23:06.000Z | 2019-07-21T16:10:04.000Z | content/events/2017-riga/speakers.md | docent-net/devopsdays-web | 8056b7937e293bd63b43d98bd8dca1844eee8a88 | [
"Apache-2.0",
"MIT"
] | 15 | 2016-11-11T15:07:53.000Z | 2019-01-18T04:55:24.000Z | +++
date = "2017-05-23T00:00:00+02:00"
tags = ["riga","riga-2017"]
type = "speakers"
title = "Speakers"
heading = "DevOpsDays Riga 2017 - Speakers"
+++
| 19 | 43 | 0.638158 | eng_Latn | 0.276983 |
e102bcc09f038d1bef1da3633e06795912f7fda2 | 22 | md | Markdown | README.md | tutac/myplaybook | ab828f18233a32d8a3b558dbdff9af3d2b5fd9d3 | [
"Apache-2.0"
] | null | null | null | README.md | tutac/myplaybook | ab828f18233a32d8a3b558dbdff9af3d2b5fd9d3 | [
"Apache-2.0"
] | null | null | null | README.md | tutac/myplaybook | ab828f18233a32d8a3b558dbdff9af3d2b5fd9d3 | [
"Apache-2.0"
] | null | null | null | # myplaybook
playbook
| 7.333333 | 12 | 0.818182 | eng_Latn | 0.901663 |
e102bd28468501ee2f4cd1c6abbd43c80728a225 | 1,349 | md | Markdown | docs/generate-keys.md | joeabbey-anchor/flow-cli | ff9081f288eb544ff218b1f3ee77191c4e0a58fb | [
"Apache-2.0"
] | null | null | null | docs/generate-keys.md | joeabbey-anchor/flow-cli | ff9081f288eb544ff218b1f3ee77191c4e0a58fb | [
"Apache-2.0"
] | null | null | null | docs/generate-keys.md | joeabbey-anchor/flow-cli | ff9081f288eb544ff218b1f3ee77191c4e0a58fb | [
"Apache-2.0"
] | null | null | null | ---
title: Generate Keys with the Flow CLI
sidebar_title: Generate a Key
description: How to generate a Flow account key-pair from the command line
---
The Flow CLI provides a command to generate ECDSA key pairs
that can be [attached to new or existing Flow accounts](https://docs.onflow.org/concepts/accounts-and-keys)... | 29.326087 | 189 | 0.744255 | eng_Latn | 0.951452 |
e10355bfd9a19e22804dabc2e26f4e6bdab5b73a | 256 | md | Markdown | examples/README.md | integer32llc/tower-http | 53a312746f1467483f46741921e150d9aa639605 | [
"MIT"
] | 221 | 2018-01-22T22:52:19.000Z | 2022-03-29T08:26:29.000Z | examples/README.md | integer32llc/tower-http | 53a312746f1467483f46741921e150d9aa639605 | [
"MIT"
] | 148 | 2019-03-04T20:39:12.000Z | 2022-03-30T17:37:53.000Z | examples/README.md | integer32llc/tower-http | 53a312746f1467483f46741921e150d9aa639605 | [
"MIT"
] | 76 | 2018-04-07T17:29:17.000Z | 2022-03-15T04:27:05.000Z | # tower-http examples
This folder contains various examples of how to use tower-http.
- `warp-key-value-store`: A key/value store with an HTTP API built with warp.
- `tonic-key-value-store`: A key/value store with a gRPC API and client built with tonic.
| 36.571429 | 89 | 0.753906 | eng_Latn | 0.99287 |
e10395969dfb0e5c61398471503d75f93e23a17c | 5,096 | md | Markdown | A08.Dubbo/B01.DubboCoreTechnology/doc/sourcecode/A10_Server.md | huaxueyihao/NoteOfStudy | 061e62c97f4fa04fa417fd08ecf1dab361c20b87 | [
"Apache-2.0"
] | null | null | null | A08.Dubbo/B01.DubboCoreTechnology/doc/sourcecode/A10_Server.md | huaxueyihao/NoteOfStudy | 061e62c97f4fa04fa417fd08ecf1dab361c20b87 | [
"Apache-2.0"
] | 2 | 2020-05-12T02:05:50.000Z | 2022-01-12T23:04:55.000Z | A08.Dubbo/B01.DubboCoreTechnology/doc/sourcecode/A10_Server.md | huaxueyihao/NoteOfStudy | 061e62c97f4fa04fa417fd08ecf1dab361c20b87 | [
"Apache-2.0"
] | null | null | null | ### Server
#### 1 简介
> 服务器,dubbo远程暴露服务启动的服务器。
```
public interface Server extends Endpoint, Resetable, IdleSensible {
/**
* is bound.
*
* @return bound
*/
boolean isBound();
/**
* get channels.
*
* @return channels
*/
Collection<Channel> getChannels();
... | 30.698795 | 127 | 0.680141 | yue_Hant | 0.387646 |
e1042e9ffd41e4ec23c52581f58f5687274e8373 | 2,980 | md | Markdown | src/docs/external-data/actors/Frankenstein.md | swimlane/attck | dfff8c484c601633a47ad06a9da686571c21776f | [
"MIT"
] | 3 | 2020-05-16T05:22:34.000Z | 2020-06-30T16:59:10.000Z | src/docs/external-data/actors/Frankenstein.md | swimlane/attck | dfff8c484c601633a47ad06a9da686571c21776f | [
"MIT"
] | null | null | null | src/docs/external-data/actors/Frankenstein.md | swimlane/attck | dfff8c484c601633a47ad06a9da686571c21776f | [
"MIT"
] | 4 | 2020-05-06T02:08:05.000Z | 2021-06-21T18:10:05.000Z |
# Frankenstein
```
_____ __ __ .__
_/ ____\___________ ____ | | __ ____ ____ _______/ |_ ____ |__|
\ __\\_ __ \__ \ / \| |/ // __ \ / \ / ___/\ __\/ __ \| |
| | | | \// __ \| | \ <\ ___/| | \\___ \ | | \ ___/| |
|_... | 22.074074 | 277 | 0.625168 | yue_Hant | 0.537745 |
e10452bc93fa446d1558fbc258ecc282568a6107 | 1,537 | md | Markdown | _posts/2016-08-23-first.md | subdiff/subdiff.github.io | e5b683e434c2e260c52fe0c5ba83f08ce8f87eb7 | [
"MIT"
] | null | null | null | _posts/2016-08-23-first.md | subdiff/subdiff.github.io | e5b683e434c2e260c52fe0c5ba83f08ce8f87eb7 | [
"MIT"
] | null | null | null | _posts/2016-08-23-first.md | subdiff/subdiff.github.io | e5b683e434c2e260c52fe0c5ba83f08ce8f87eb7 | [
"MIT"
] | null | null | null | ---
layout: post
title: "First!"
date: 2016-08-23 19:43:00
tags:
- internal affairs
banner_image: 2016-08-23-first.jpg
comments: true
---
So, here we have one more programmer's blog. It's mainly for documenting my successes and defeats in the conquest of becoming better in [Linux][flip], [KDE][kde-dies], [Qt][cute... | 59.115385 | 191 | 0.766428 | eng_Latn | 0.272457 |
e104ac3af515fe6d5d70ae63c732a907a2c39524 | 1,879 | md | Markdown | _posts/2018-05-01-Edited_Media--2017-18.md | TheGuppyDude/TheGuppyDude.github.io | 396d37563e14ca4985a06b436927944766e9cd4f | [
"MIT"
] | null | null | null | _posts/2018-05-01-Edited_Media--2017-18.md | TheGuppyDude/TheGuppyDude.github.io | 396d37563e14ca4985a06b436927944766e9cd4f | [
"MIT"
] | null | null | null | _posts/2018-05-01-Edited_Media--2017-18.md | TheGuppyDude/TheGuppyDude.github.io | 396d37563e14ca4985a06b436927944766e9cd4f | [
"MIT"
] | null | null | null | ---
title: Edited_Media
layout: post
author: noah.mccall
permalink: /Edited_Media--2017-18/
source-id: 1-00iu-8QXgAphLsw_1hXoqPLNL3dn7wxqJiId4xD8c0
published: true
---
<table>
<tr>
<td>Title</td>
<td>Looking at things that are often edited in media</td>
<td>Date</td>
<td>01/05/18</td>
</tr>
</table>... | 23.78481 | 165 | 0.628526 | eng_Latn | 0.982001 |
e1050410caff8812e2049a90ab101bf2266ff3cb | 103 | md | Markdown | provisioning/roles/common/README.md | satoshi-hirayama/techtalk4 | 42483f2577c50ac06255c5da94a0362d53e9f461 | [
"MIT"
] | 8 | 2017-02-14T16:12:31.000Z | 2018-12-18T10:48:35.000Z | provisioning/roles/common/README.md | satoshi-hirayama/techtalk4 | 42483f2577c50ac06255c5da94a0362d53e9f461 | [
"MIT"
] | null | null | null | provisioning/roles/common/README.md | satoshi-hirayama/techtalk4 | 42483f2577c50ac06255c5da94a0362d53e9f461 | [
"MIT"
] | null | null | null | # common of role
サーバーの基本的な設定を行います。
* パッケージの更新
* ユーティリティパッケージのインストール
* wget
* ユーザーのディレクトリ調整
* sshの設定 | 11.444444 | 21 | 0.757282 | jpn_Jpan | 0.44409 |
e105206f3b834a552607f72cc6c14b11f3eef65d | 597 | md | Markdown | aspnet/visual-studio/overview/2017/index.md | terrajobst/AspNetDocs.pl-pl | 0fa8689494d61eeca5f7ddc52d218a22fe5b979f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | aspnet/visual-studio/overview/2017/index.md | terrajobst/AspNetDocs.pl-pl | 0fa8689494d61eeca5f7ddc52d218a22fe5b979f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | aspnet/visual-studio/overview/2017/index.md | terrajobst/AspNetDocs.pl-pl | 0fa8689494d61eeca5f7ddc52d218a22fe5b979f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
uid: visual-studio/overview/2017/index
title: ASP.NET i Visual Studio 2017
author: rick-anderson
description: Visual Studio 2017
ms.author: riande
ms.date: 08/25/2018
msc.type: chapter
ms.openlocfilehash: 46871b95709ae56c418dc8dd1a4466442da3bf3a
ms.sourcegitcommit: e7e91932a6e91a63e2e46417626f39d6b244a3ab
ms.transl... | 33.166667 | 107 | 0.812395 | pol_Latn | 0.255343 |
e1054a0f8e66d582efe1de95a1a8388c06c017b6 | 935 | md | Markdown | content/post/isca2020-dsagen/index.md | MaxwellWjj/homepage-academic | 27db23286fe9db6e0740f0ff039f33829f422940 | [
"MIT"
] | null | null | null | content/post/isca2020-dsagen/index.md | MaxwellWjj/homepage-academic | 27db23286fe9db6e0740f0ff039f33829f422940 | [
"MIT"
] | null | null | null | content/post/isca2020-dsagen/index.md | MaxwellWjj/homepage-academic | 27db23286fe9db6e0740f0ff039f33829f422940 | [
"MIT"
] | null | null | null | ---
title: ISCA 2020, DSAGEN - Synthesizing Programmable Spatial Accelerators
subtitle: To broaden the potential of acceleration, this work develops an approach and framework, DSAGEN, for programmable accelerator synthesis.
# Summary for listings and search engines
summary: To broaden the potential of acceleration, th... | 22.804878 | 145 | 0.763636 | eng_Latn | 0.968044 |
e1066da02ce078e25575adbc72297166145d373b | 10,764 | md | Markdown | articles/openshift/oshift-faq.md | ccouzens/documentation | d3e80f06a0727176721062c88835bd6e9dfa14c9 | [
"MIT"
] | null | null | null | articles/openshift/oshift-faq.md | ccouzens/documentation | d3e80f06a0727176721062c88835bd6e9dfa14c9 | [
"MIT"
] | null | null | null | articles/openshift/oshift-faq.md | ccouzens/documentation | d3e80f06a0727176721062c88835bd6e9dfa14c9 | [
"MIT"
] | null | null | null | ---
title: UKCloud for OpenShift FAQs
description: Frequently asked questions for UKCloud for OpenShift
services: openshift
author: Matt Warner
reviewer:
lastreviewed: 08/07/2019
toc_rootlink: FAQs
toc_sub1:
toc_sub2:
toc_sub3:
toc_sub4:
toc_title: UKCloud for OpenShift FAQs
toc_fullpath: FAQs/oshift-faq.md
toc_mdlink... | 59.8 | 455 | 0.802861 | eng_Latn | 0.998429 |
e107027ac4da038db1f699426d1a5020c021dbad | 4,547 | md | Markdown | ros/src/waypoint_updater/README.md | iamsumit16/CarND-Capstone | c18bc69f10c791fd680882bdbbca893bb9411827 | [
"MIT"
] | 2 | 2019-04-23T21:40:40.000Z | 2019-04-25T13:33:18.000Z | ros/src/waypoint_updater/README.md | iamsumit16/CarND-Capstone | c18bc69f10c791fd680882bdbbca893bb9411827 | [
"MIT"
] | null | null | null | ros/src/waypoint_updater/README.md | iamsumit16/CarND-Capstone | c18bc69f10c791fd680882bdbbca893bb9411827 | [
"MIT"
] | 4 | 2019-04-25T13:33:35.000Z | 2019-05-13T06:08:40.000Z | # TEAM MEMBERS
Steve Frazee - stevefrazee123@gmail.com
## Waypoint Updater (partial)
The goal of the first part of the waypoint updater is to publish a list of waypoints directly in front of the car for the car to follow. We are first given a list of waypoints that wraps around the entire track. From here we need to f... | 98.847826 | 979 | 0.768419 | eng_Latn | 0.999746 |
e10754896694eb3f472abafa3b03c286e0c8789f | 3,639 | md | Markdown | includes/vpn-gateway-add-local-network-gateway-portal-include.md | fuatrihtim/azure-docs.tr-tr | 6569c5eb54bdab7488b44498dc4dad397d32f1be | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/vpn-gateway-add-local-network-gateway-portal-include.md | fuatrihtim/azure-docs.tr-tr | 6569c5eb54bdab7488b44498dc4dad397d32f1be | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/vpn-gateway-add-local-network-gateway-portal-include.md | fuatrihtim/azure-docs.tr-tr | 6569c5eb54bdab7488b44498dc4dad397d32f1be | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: include dosyası
description: include dosyası
services: vpn-gateway
author: cherylmc
ms.service: vpn-gateway
ms.topic: include
ms.date: 10/22/2020
ms.author: cherylmc
ms.custom: include file
ms.openlocfilehash: 5358bbbca716f5152a943c90cb7a5f735ae12047
ms.sourcegitcommit: 910a1a38711966cb171050db245fc3b22abc8c... | 90.975 | 499 | 0.792251 | tur_Latn | 0.999959 |
e107815e0b91f9448d6a3ac39c5f2b9df154c7f4 | 7,927 | md | Markdown | README.md | Geogboe/xWindowsUpdate | e02aadb1a4d56ae2076f4e08037eb866059f8e73 | [
"MIT"
] | null | null | null | README.md | Geogboe/xWindowsUpdate | e02aadb1a4d56ae2076f4e08037eb866059f8e73 | [
"MIT"
] | null | null | null | README.md | Geogboe/xWindowsUpdate | e02aadb1a4d56ae2076f4e08037eb866059f8e73 | [
"MIT"
] | null | null | null | # xWindowsUpdate Module
master: [](https://ci.appveyor.com/project/PowerShell/xwindowsupdate/branch/master)
[](https://codecov.... | 35.388393 | 184 | 0.719061 | eng_Latn | 0.606525 |
e108030cfdce3915013a812d02e81f314a1890ff | 8,223 | md | Markdown | docs/ja/api_reference/services/TrafficEstimatorService.md | yahoojp-marketingsolutions/sponsored-search-api-documents | cf9af1cd623524e04d4e100a7de136840f269ee8 | [
"MIT"
] | null | null | null | docs/ja/api_reference/services/TrafficEstimatorService.md | yahoojp-marketingsolutions/sponsored-search-api-documents | cf9af1cd623524e04d4e100a7de136840f269ee8 | [
"MIT"
] | null | null | null | docs/ja/api_reference/services/TrafficEstimatorService.md | yahoojp-marketingsolutions/sponsored-search-api-documents | cf9af1cd623524e04d4e100a7de136840f269ee8 | [
"MIT"
] | 1 | 2019-10-03T09:56:04.000Z | 2019-10-03T09:56:04.000Z | # TrafficEstimatorService
TrafficEstimatorServiceは、ターゲットやキーワードなど、指定した条件で獲得できるトラフィックを見積る機能を提供します。
#### WSDL
| environment | url |
|---|---|
| production | https://ss.yahooapis.jp/services/V6.0/TrafficEstimatorService?wsdl|
| sandbox | https://sandbox.ss.yahooapis.jp/services/V6.0/TrafficEstimatorService?wsdl|
#... | 39.344498 | 334 | 0.578864 | yue_Hant | 0.187262 |
e1085c7db4dd38bfb9be8c1382c9f70ca8922e26 | 1,736 | md | Markdown | README.md | changlinli/diceware-generators | d39b2519482568db66e103b3c1e774c203488594 | [
"Unlicense"
] | null | null | null | README.md | changlinli/diceware-generators | d39b2519482568db66e103b3c1e774c203488594 | [
"Unlicense"
] | null | null | null | README.md | changlinli/diceware-generators | d39b2519482568db66e103b3c1e774c203488594 | [
"Unlicense"
] | null | null | null | Simple Diceware Password Generators
===================================
Tools for generating [diceware passwords]("Diceware homepage" http://world.std.com/~reinhold/diceware.html).
Because we don't always have dice by our side (nor do we want to roll them 30+
times).
Just download and execute.
If you don't want to ... | 31.563636 | 108 | 0.647465 | eng_Latn | 0.980354 |
e109c1c4a7edb0ae603a31674b03ad0aaf846413 | 244 | md | Markdown | menuler/yazarlar/sabahattin-ali.md | uguratmaca/edebiyatyarismalari | 1830b695819bcba72337f3c1ef1a46b38f54c88b | [
"MIT"
] | 4 | 2019-01-14T22:48:33.000Z | 2021-09-12T20:49:10.000Z | menuler/yazarlar/sabahattin-ali.md | uguratmaca/edebiyatyarismalari | 1830b695819bcba72337f3c1ef1a46b38f54c88b | [
"MIT"
] | 4 | 2018-10-10T09:07:58.000Z | 2020-10-29T21:06:07.000Z | menuler/yazarlar/sabahattin-ali.md | uguratmaca/edebiyatyarismalari | 1830b695819bcba72337f3c1ef1a46b38f54c88b | [
"MIT"
] | null | null | null | ---
layout: all
headline: "Sabahattin Ali Yarışmaları"
title: "Sabahattin Ali Yarışmaları"
key: "sabahattin ali"
description: "Ünlü Türk yazar Sabahattin Ali adına düzenlenen edebiyat yarışmalarıdır"
permalink: "sabahattin-ali-yarismalari/"
--- | 30.5 | 86 | 0.790984 | tur_Latn | 0.997051 |
e109d13c541c31f6ba1a38da0981d6f8c6f9332c | 65 | md | Markdown | source/about/index.md | tongjimirrors/mirrors.tongji.edu.cn | 3e5be3280d72a24737d6367e58d69678d19f3d3e | [
"MIT"
] | 13 | 2017-11-12T14:05:29.000Z | 2018-09-11T02:47:55.000Z | source/about/index.md | tongjimirrors/mirrors.tongji.edu.cn | 3e5be3280d72a24737d6367e58d69678d19f3d3e | [
"MIT"
] | 7 | 2017-12-23T13:04:53.000Z | 2021-02-27T06:24:04.000Z | source/about/index.md | tongjimirrors/mirrors.tongji.edu.cn | 3e5be3280d72a24737d6367e58d69678d19f3d3e | [
"MIT"
] | 2 | 2017-04-11T05:24:16.000Z | 2017-11-12T14:05:50.000Z | ---
type: page
title: about
date: 2017-01-13 23:08:56
---
About! | 9.285714 | 25 | 0.630769 | eng_Latn | 0.69651 |
e10a21c12b1aae8d371b83ebe903866120e2e6d5 | 1,574 | md | Markdown | views/blogs/healty.md | pgm-sybrdebo/Landingpage_Hiking_App | b28d58bc4bce32f1c54dfbcfe61f365e22440729 | [
"Apache-2.0"
] | null | null | null | views/blogs/healty.md | pgm-sybrdebo/Landingpage_Hiking_App | b28d58bc4bce32f1c54dfbcfe61f365e22440729 | [
"Apache-2.0"
] | null | null | null | views/blogs/healty.md | pgm-sybrdebo/Landingpage_Hiking_App | b28d58bc4bce32f1c54dfbcfe61f365e22440729 | [
"Apache-2.0"
] | null | null | null | ---
title: Nature can help!
author: Meaghan
release: March 16 2020
text: Hey friends – These are unusual times. While our day-to-day routines have changed pretty dramatically, it’s important to remember that we can still seek joy, peace, and health.
img: walkingHealty.jpg
alt: two people happily walking
highlighted: t... | 56.214286 | 523 | 0.78399 | eng_Latn | 0.99956 |
e10b9c06b28fb1b94897b90207fa50d7716bff56 | 1,003 | md | Markdown | .local/share/OpenSCAD/libraries/dotSCAD/docs/lib2x-shape_pie.md | IlyaMZP/dotfiles | b55e0cd63117c09778ea917b02313da74f7c1067 | [
"MIT"
] | null | null | null | .local/share/OpenSCAD/libraries/dotSCAD/docs/lib2x-shape_pie.md | IlyaMZP/dotfiles | b55e0cd63117c09778ea917b02313da74f7c1067 | [
"MIT"
] | null | null | null | .local/share/OpenSCAD/libraries/dotSCAD/docs/lib2x-shape_pie.md | IlyaMZP/dotfiles | b55e0cd63117c09778ea917b02313da74f7c1067 | [
"MIT"
] | null | null | null | # shape_pie
Returns shape points of a pie (circular sector) shape. They can be used with xxx_extrude modules of dotSCAD. The shape points can be also used with the built-in polygon module.
## Parameters
- `radius` : The radius of the circle.
- `angle` : A single value or a 2 element vector which defines the central... | 31.34375 | 192 | 0.692921 | eng_Latn | 0.967008 |
e10c88d755e521ca9537a447179ce22399ea725e | 155 | md | Markdown | README.md | lciolecki/php-library | f80e807ab9a27abf217cc0e7b57ecc4baba9d81e | [
"BSD-3-Clause"
] | null | null | null | README.md | lciolecki/php-library | f80e807ab9a27abf217cc0e7b57ecc4baba9d81e | [
"BSD-3-Clause"
] | null | null | null | README.md | lciolecki/php-library | f80e807ab9a27abf217cc0e7b57ecc4baba9d81e | [
"BSD-3-Clause"
] | null | null | null | PHP Extlib libray
===========
##Installation using Composer
{
"require": {
"lciolecki/php-library": "dev-master"
}
}
| 14.090909 | 49 | 0.483871 | kor_Hang | 0.316387 |
e10c8acde64b8efbfd522f8e45151a5c69dbc529 | 8,693 | md | Markdown | docs/ide/finding-and-replacing-text.md | monkey3310/visualstudio-docs.pl-pl | adc80e0d3bef9965253897b72971ccb1a3781354 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/ide/finding-and-replacing-text.md | monkey3310/visualstudio-docs.pl-pl | adc80e0d3bef9965253897b72971ccb1a3781354 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/ide/finding-and-replacing-text.md | monkey3310/visualstudio-docs.pl-pl | adc80e0d3bef9965253897b72971ccb1a3781354 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Znajdź i Zamień tekst i wybieranie wielu karetki
ms.date: 08/14/2018
ms.prod: visual-studio-dev15
ms.technology: vs-ide-general
ms.topic: conceptual
f1_keywords:
- vs.find
- vs.findreplacecontrol
- vs.findreplace.findsymbol
- vs.findreplace.symbol
- findresultswindow
- vs.findreplace.quickreplace
- vs.findsy... | 65.856061 | 514 | 0.777867 | pol_Latn | 0.999772 |
e10db90e46621a7ba92276e1cb62e83e58c41ef5 | 2,609 | md | Markdown | docs/mkdocs/docs/api/macros/json_throw_user.md | sthagen/nlohmann-json | 2b2d8b81ea3717385ac408e23aeda97326e506b5 | [
"MIT"
] | null | null | null | docs/mkdocs/docs/api/macros/json_throw_user.md | sthagen/nlohmann-json | 2b2d8b81ea3717385ac408e23aeda97326e506b5 | [
"MIT"
] | null | null | null | docs/mkdocs/docs/api/macros/json_throw_user.md | sthagen/nlohmann-json | 2b2d8b81ea3717385ac408e23aeda97326e506b5 | [
"MIT"
] | null | null | null | # JSON_CATCH_USER, JSON_THROW_USER, JSON_TRY_USER
```cpp
// (1)
#define JSON_CATCH_USER(exception) /* value */
// (2)
#define JSON_THROW_USER(exception) /* value */
// (3)
#define JSON_TRY_USER /* value */
```
Controls how exceptions are handled by the library.
1. This macro overrides [`#!cpp catch`](https://en.cppr... | 34.328947 | 123 | 0.68877 | eng_Latn | 0.910436 |
e10e8f5a129ea8a87fc0577d5f96ea8eddfd67cf | 3,267 | md | Markdown | docs/extensibility/debugger/reference/bp-passcount-style.md | MicrosoftDocs/visualstudio-docs.pt-br | b1882dc108a37c4caebbf5a80c274c440b9bbd4a | [
"CC-BY-4.0",
"MIT"
] | 5 | 2019-02-19T20:22:40.000Z | 2022-02-19T14:55:39.000Z | docs/extensibility/debugger/reference/bp-passcount-style.md | MicrosoftDocs/visualstudio-docs.pt-br | b1882dc108a37c4caebbf5a80c274c440b9bbd4a | [
"CC-BY-4.0",
"MIT"
] | 32 | 2018-08-24T19:12:03.000Z | 2021-03-03T01:30:48.000Z | docs/extensibility/debugger/reference/bp-passcount-style.md | MicrosoftDocs/visualstudio-docs.pt-br | b1882dc108a37c4caebbf5a80c274c440b9bbd4a | [
"CC-BY-4.0",
"MIT"
] | 25 | 2017-11-02T16:03:15.000Z | 2021-10-02T02:18:00.000Z | ---
description: Especifica a condição associada à contagem de passagem do ponto de interrupção que faz com que o ponto de interrupção seja a incêndio.
title: BP_PASSCOUNT_STYLE | Microsoft Docs
ms.date: 11/04/2016
ms.topic: reference
f1_keywords:
- BP_PASSCOUNT_STYLE
helpviewer_keywords:
- BP_PASSCOUNT_STYLE structure... | 41.35443 | 345 | 0.763085 | por_Latn | 0.942371 |
e10f25200c7181a991249c4a06f2ab2f1e653867 | 87 | md | Markdown | docs/pages/components/modal/fragments/import.md | imadilkhalil/rsuite | 2d7580d22a367a6b4e3a36989e59ee4bbaddf646 | [
"MIT"
] | 3 | 2021-01-12T01:39:44.000Z | 2021-01-12T01:39:48.000Z | docs/pages/components/modal/fragments/import.md | song-ran/rsuite | dd674d0b8a931387cef42c973213b05604b04e17 | [
"MIT"
] | 14 | 2022-01-11T19:37:32.000Z | 2022-03-31T11:32:01.000Z | docs/pages/components/modal/fragments/import.md | song-ran/rsuite | dd674d0b8a931387cef42c973213b05604b04e17 | [
"MIT"
] | null | null | null | ```js
import { Modal } from 'rsuite';
// or
import Modal from 'rsuite/lib/Modal';
```
| 12.428571 | 37 | 0.62069 | eng_Latn | 0.864523 |
e10fa518f8b1830607ce9cfd15f1413f0ad3df45 | 291 | md | Markdown | README.md | luke2m/BigSurBar | 93c2bb4d61e2d9cda2e48b43ac7c4474c215e228 | [
"MIT"
] | null | null | null | README.md | luke2m/BigSurBar | 93c2bb4d61e2d9cda2e48b43ac7c4474c215e228 | [
"MIT"
] | null | null | null | README.md | luke2m/BigSurBar | 93c2bb4d61e2d9cda2e48b43ac7c4474c215e228 | [
"MIT"
] | null | null | null | # MacOS Big Sur StatusBar
## For iPadOS
## Required the latest version of XenHTML from this repo https://xenpublic.incendo.ws/
# Installing:
- install it (From Repo) then add it as background widget from XenHTML
# Manual Install
- download deb from release page then install it with Filza
| 29.1 | 86 | 0.766323 | eng_Latn | 0.935308 |
e10ffc23b6c82f3e5de1d175b6524283fdeef2c1 | 153 | md | Markdown | CHANGELOG.md | walid-ashik/dartTwitterAPI | 51eb638eb7f0fffe902ba54c80a44c0e44427225 | [
"BSD-2-Clause"
] | 16 | 2020-02-03T22:56:01.000Z | 2021-12-23T10:02:28.000Z | CHANGELOG.md | kwe-k-u/toot | e73fec222f911a3cc9076ba702036d3e6901fb3b | [
"BSD-2-Clause"
] | 2 | 2020-02-02T20:05:21.000Z | 2021-08-22T03:14:42.000Z | CHANGELOG.md | kwe-k-u/toot | e73fec222f911a3cc9076ba702036d3e6901fb3b | [
"BSD-2-Clause"
] | 5 | 2020-02-07T16:36:37.000Z | 2022-01-07T10:43:14.000Z | # 0.1.2
* Fixing the changelog version titles
# 0.1.1
* Added example and fixed a couple suggested fixes
# 0.1.0
* Initial Version of package uploaded
| 17 | 50 | 0.732026 | eng_Latn | 0.997419 |
e110362b9ff63f69c603c6d62704c2a6f8932c08 | 422 | md | Markdown | README.md | polco-us/jupyter-notebook-heroku | 2990bfa8e9bbf22229d98315e80f3249e481e2ea | [
"MIT"
] | 4 | 2019-10-07T10:36:47.000Z | 2021-05-01T06:18:34.000Z | README.md | Bpowers4/jupyter-notebook-heroku | 3532cedc183aa7b04d0b7aed6a3d9278db2b93f7 | [
"MIT"
] | 2 | 2020-03-24T17:43:40.000Z | 2020-07-26T11:16:09.000Z | README.md | Bpowers4/jupyter-notebook-heroku | 3532cedc183aa7b04d0b7aed6a3d9278db2b93f7 | [
"MIT"
] | 22 | 2019-10-23T03:39:00.000Z | 2021-06-08T14:38:14.000Z | # jupyter-notebook-heroku
## Deployment
1. Generate a Secure password with [prepare_password.py](https://github.com/msimav/jupyter-notebook-heroku/blob/master/prepare_password.py)
```bash
curl -s https://raw.githubusercontent.com/msimav/jupyter-notebook-heroku/master/prepare_password.py | python
```
2. Click Deploy ... | 32.461538 | 139 | 0.774882 | kor_Hang | 0.099288 |
e11069ccedacc23be6562c7ece2df26ecbce870e | 2,044 | md | Markdown | docs/c-language/overview-of-functions.md | Mdlglobal-atlassian-net/cpp-docs.it-it | c8edd4e9238d24b047d2b59a86e2a540f371bd93 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/c-language/overview-of-functions.md | Mdlglobal-atlassian-net/cpp-docs.it-it | c8edd4e9238d24b047d2b59a86e2a540f371bd93 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/c-language/overview-of-functions.md | Mdlglobal-atlassian-net/cpp-docs.it-it | c8edd4e9238d24b047d2b59a86e2a540f371bd93 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-28T15:54:57.000Z | 2020-05-28T15:54:57.000Z | ---
title: Cenni preliminari sulle funzioni
ms.date: 11/04/2016
helpviewer_keywords:
- functions [C++]
- control flow, function calls
ms.assetid: b6f4637f-02b9-49d8-8601-1f886bd2cfb9
ms.openlocfilehash: 1c54dcdeec1bad1ffbd335d411e39c77be0ad961
ms.sourcegitcommit: 0ab61bc3d2b6cfbd52a16c6ab2b97a8ea1864f12
ms.translationt... | 73 | 583 | 0.819472 | ita_Latn | 0.999466 |
e110c1f39f364b5b29bef05155495af48484896f | 1,293 | md | Markdown | AlchemyInsights/blur-your-background-in-a-teams-meeting.md | isabella232/OfficeDocs-AlchemyInsights-pr.nb-NO | e72dad0e24e02cdcb7eeb3dd8c4fc4cf5ec56554 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-05-19T19:07:15.000Z | 2021-03-06T00:34:53.000Z | AlchemyInsights/blur-your-background-in-a-teams-meeting.md | isabella232/OfficeDocs-AlchemyInsights-pr.nb-NO | e72dad0e24e02cdcb7eeb3dd8c4fc4cf5ec56554 | [
"CC-BY-4.0",
"MIT"
] | 3 | 2020-06-02T23:25:08.000Z | 2022-02-09T06:52:49.000Z | AlchemyInsights/blur-your-background-in-a-teams-meeting.md | isabella232/OfficeDocs-AlchemyInsights-pr.nb-NO | e72dad0e24e02cdcb7eeb3dd8c4fc4cf5ec56554 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2019-10-09T20:30:02.000Z | 2020-06-02T23:24:46.000Z | ---
title: Redusere skarpheten på bakgrunnen i et Teams-møte
ms.author: pebaum
author: pebaum
manager: scotv
ms.audience: Admin
ms.topic: article
ms.service: o365-administration
ROBOTS: NOINDEX, NOFOLLOW
localization_priority: Priority
ms.collection: Adm_O365
ms.custom:
- "3815"
- "9001720"
ms.openlocfilehash: 7b553d5d... | 43.1 | 213 | 0.803558 | nob_Latn | 0.915228 |
e11175a95b6e9c34e546a0145522567ac19f1a2b | 38 | md | Markdown | README.md | wang-zihao/SmartButler | d74d614bc4ade587a647df1bce01189959516a8b | [
"Apache-2.0"
] | null | null | null | README.md | wang-zihao/SmartButler | d74d614bc4ade587a647df1bce01189959516a8b | [
"Apache-2.0"
] | 1 | 2018-05-18T07:47:37.000Z | 2018-05-18T07:47:37.000Z | README.md | wang-zihao/SmartButler | d74d614bc4ade587a647df1bce01189959516a8b | [
"Apache-2.0"
] | null | null | null | # SmartButler
Smart voice life butler
| 12.666667 | 23 | 0.815789 | kor_Hang | 0.875281 |
e11251adcb3914bd4d46d51fe93f7e94cc5d67fc | 1,615 | md | Markdown | README.md | evancharlton/spelling-bee-grid | 0518c04b7bddcfac1329ee4b8397e40d05432f90 | [
"MIT"
] | null | null | null | README.md | evancharlton/spelling-bee-grid | 0518c04b7bddcfac1329ee4b8397e40d05432f90 | [
"MIT"
] | null | null | null | README.md | evancharlton/spelling-bee-grid | 0518c04b7bddcfac1329ee4b8397e40d05432f90 | [
"MIT"
] | null | null | null | # Spelling Bee Grid
A simple Chrome extension to augment the [New York Times'][nyt] fantastic [Spelling Bee] game.
## Usage
When you reach the "Genius" level, a new button for "Today's Grid" will appear in the toolbar.

Clicking this button will bring up the grid for tod... | 32.3 | 104 | 0.749845 | eng_Latn | 0.882966 |
e1128a14bf706831c38456beb18a160e067fbefe | 17 | md | Markdown | _includes/01-name.md | nicolorossetti/markdown-portfolio | ee8a4209a189474ec2a8505fe7345f6c071ffc10 | [
"MIT"
] | null | null | null | _includes/01-name.md | nicolorossetti/markdown-portfolio | ee8a4209a189474ec2a8505fe7345f6c071ffc10 | [
"MIT"
] | 5 | 2021-06-25T13:54:35.000Z | 2021-06-25T14:49:44.000Z | _includes/01-name.md | nicolorossetti/markdown-portfolio | ee8a4209a189474ec2a8505fe7345f6c071ffc10 | [
"MIT"
] | null | null | null | ## My name
NRoss
| 5.666667 | 10 | 0.647059 | eng_Latn | 0.986017 |
e113c70d900e4b8370f1cd0c34419c22ab2dbe3a | 655 | md | Markdown | README.md | Morcki/android_raw2rinex | 6e53bef09b609f99af47786fce1879673191788f | [
"MIT"
] | 5 | 2020-07-11T02:42:47.000Z | 2021-01-11T17:51:42.000Z | README.md | Morcki/android_raw2rinex | 6e53bef09b609f99af47786fce1879673191788f | [
"MIT"
] | 1 | 2021-01-11T18:02:51.000Z | 2022-03-16T14:10:04.000Z | README.md | Morcki/android_raw2rinex | 6e53bef09b609f99af47786fce1879673191788f | [
"MIT"
] | 3 | 2020-10-24T10:27:41.000Z | 2021-01-11T17:51:46.000Z | # Usage
## function
convert raw/fix data generated by GnssLogger into standard observation format(Version Rinex 3.x)
## android_raw2rinex
`raw2rinex.py -c <confgure file>`
## configure file
- dir_path : directory of raw file
- raw_path : raw file name
- type : FIX / RAW
## mode
- FIX:
Get positioning resu... | 18.714286 | 159 | 0.732824 | eng_Latn | 0.512425 |
e11483a21bb5c93b945990e5a283f96706f16584 | 1,900 | md | Markdown | _posts/2015-03-28-how-to-add-custom-file-attributes.md | albertattard/blog | b451056bfc83edd206e371bdaedb0ded677ea213 | [
"Apache-2.0"
] | null | null | null | _posts/2015-03-28-how-to-add-custom-file-attributes.md | albertattard/blog | b451056bfc83edd206e371bdaedb0ded677ea213 | [
"Apache-2.0"
] | null | null | null | _posts/2015-03-28-how-to-add-custom-file-attributes.md | albertattard/blog | b451056bfc83edd206e371bdaedb0ded677ea213 | [
"Apache-2.0"
] | null | null | null | ---
layout: post
title: How to Add Custom File Attributes
description: The Files class, added in Java 7, provides an easy way to add and retrieve custom file's attributes
date: 2015-03-28 08:00:00 +0200
categories: IO
permalink: how-to-add-custom-file-attributes
author: Albert Attard
published: true
---
The `Files` cl... | 36.538462 | 272 | 0.735789 | eng_Latn | 0.608624 |
e114942aa8343ee6cb80a4eca5efd8a35d7e58b5 | 1,959 | md | Markdown | Vorlesungsbeispiele/MRT2_VL-8_OPCUA_FirstSteps_client/README.md | zmanjiyani/PLT_MRT_ARM-RPi2 | da77ab8ddf652a12ae6a6647c993daa2f94b39fb | [
"MIT"
] | 4 | 2015-11-11T14:02:17.000Z | 2021-11-29T16:07:38.000Z | Vorlesungsbeispiele/MRT2_VL-8_OPCUA_FirstSteps_client/README.md | zmanjiyani/PLT_MRT_ARM-RPi2 | da77ab8ddf652a12ae6a6647c993daa2f94b39fb | [
"MIT"
] | 6 | 2019-04-20T14:48:58.000Z | 2020-08-26T15:13:02.000Z | Vorlesungsbeispiele/MRT2_VL-8_OPCUA_FirstSteps_client/README.md | zmanjiyani/PLT_MRT_ARM-RPi2 | da77ab8ddf652a12ae6a6647c993daa2f94b39fb | [
"MIT"
] | 9 | 2016-01-10T15:14:28.000Z | 2021-10-13T22:45:19.000Z | # Erster OPC UA Client
Dieses Program erstellt einen neuen Client mit dem open62541 Stack und verbindet sich mit unserem Server auf dem Pi (der Server darf die Ampel oder das Erste-Schritte-Beispiel sein).
Der Client macht nichts, außer mit dem Stack verbunden zu bleiben. Er dient als erster Schritt für weitere Inter... | 55.971429 | 182 | 0.718224 | deu_Latn | 0.608708 |
e1157034e8ea8b721e697079da9a7bfed39b9216 | 2,029 | md | Markdown | README.md | iserveradmi/sendgrid-webhook-lambda | 22c6ff28e442cbbad4b22833cd5ec08e467a07bd | [
"MIT"
] | 8 | 2019-04-04T18:30:16.000Z | 2020-03-04T01:03:51.000Z | README.md | iserveradmin/sendgrid-webhook-lambda | 22c6ff28e442cbbad4b22833cd5ec08e467a07bd | [
"MIT"
] | null | null | null | README.md | iserveradmin/sendgrid-webhook-lambda | 22c6ff28e442cbbad4b22833cd5ec08e467a07bd | [
"MIT"
] | 5 | 2020-03-31T07:28:46.000Z | 2021-01-21T20:50:28.000Z | # sendgrid-webhook-lambda
A handler that saves Sendgrid's webhook events into DynamoDB
Requires
- SendGrid
- AWS: API Gateway, Lambda, DynamoDB
## SendGrid
In your SendGrid account, head to https://app.sendgrid.com/settings/mail_settings. Then find Event Notification. This section is where you will tell SendGrid wher... | 34.982759 | 318 | 0.647117 | eng_Latn | 0.950923 |
e1158312dd6a1a3b4b3be3fd67507c799cf9881f | 670 | md | Markdown | docs/release-notes/3.0.0.md | Ingridamilsina/Waffle | e93d80233394d1feae2acfdbf6f4c06abbf8ee86 | [
"MIT"
] | 750 | 2018-08-16T03:38:27.000Z | 2022-03-01T12:54:31.000Z | docs/release-notes/3.0.0.md | Ingridamilsina/Waffle | e93d80233394d1feae2acfdbf6f4c06abbf8ee86 | [
"MIT"
] | 394 | 2018-08-24T10:59:52.000Z | 2022-03-01T22:44:26.000Z | docs/release-notes/3.0.0.md | Ingridamilsina/Waffle | e93d80233394d1feae2acfdbf6f4c06abbf8ee86 | [
"MIT"
] | 149 | 2018-08-29T14:50:31.000Z | 2022-02-28T17:43:22.000Z | ## Changes:
* Introduced better ens support.
* Updated EthersJS version to ^5.0.0.
* Removed deprecated APIs from the provider.
* Swapped arguments for Fixture.
```ts
function createFixtureLoader(wallets: Wallet[], provider?: MockProvider);
```
* Added automatic recognising waffle.json config without cli argumen... | 16.341463 | 73 | 0.710448 | eng_Latn | 0.883513 |
e11597c4f138334305d1373a2876cfc92243a455 | 279 | md | Markdown | sharepoint-farm-solution-with-config/README.md | karamem0/samples | 0110c318390a99822ffc4997d548d065eafec77e | [
"MIT"
] | 2 | 2020-01-03T03:42:44.000Z | 2021-01-22T08:57:05.000Z | sharepoint-farm-solution-with-config/README.md | karamem0/samples | 0110c318390a99822ffc4997d548d065eafec77e | [
"MIT"
] | 5 | 2021-11-11T08:20:38.000Z | 2022-03-03T07:50:42.000Z | sharepoint-farm-solution-with-config/README.md | karamem0/samples | 0110c318390a99822ffc4997d548d065eafec77e | [
"MIT"
] | 1 | 2021-09-09T07:47:36.000Z | 2021-09-09T07:47:36.000Z | # sharepoint-farm-solution-with-config


[SharePoint 2013 アプリケーション ページで Web.config を使用する](https://blog.karamem0.dev/entry/2011/08/30/000000)
| 39.857143 | 100 | 0.752688 | yue_Hant | 0.658334 |
e116c97f37cce5e15efbf1ff822bc1f829101a67 | 819 | md | Markdown | products/network/advanced/getting-started.md | jb4free/docs | c1d122454c6c4b53e85b02d03221b0976fddae3e | [
"MIT"
] | null | null | null | products/network/advanced/getting-started.md | jb4free/docs | c1d122454c6c4b53e85b02d03221b0976fddae3e | [
"MIT"
] | 1 | 2021-06-25T17:45:00.000Z | 2021-06-25T17:45:00.000Z | products/network/advanced/getting-started.md | jb4free/docs | c1d122454c6c4b53e85b02d03221b0976fddae3e | [
"MIT"
] | 3 | 2020-10-29T13:28:41.000Z | 2021-06-10T18:56:34.000Z | <!-- <meta>
{
"title":"Advanced Network",
"description":"Using advanced network features",
"tag":["Layer2", "Native VLAN", "BGP"],
"seo-title": "Bare Metal Cloud Network - Packet Developer Docs",
"seo-description": "Using advanced network features",
"og-title": "Overview",
"og-description": ... | 48.176471 | 199 | 0.716728 | eng_Latn | 0.977067 |
e11706f0216057d9a79c5296e193f7cfadfbce3f | 1,828 | md | Markdown | wdk-ddi-src/content/usbscan/ns-usbscan-_channel_info.md | jazzdelightsme/windows-driver-docs-ddi | 793b0c96e117b1658144ba8b3939fdc31a49f6b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/usbscan/ns-usbscan-_channel_info.md | jazzdelightsme/windows-driver-docs-ddi | 793b0c96e117b1658144ba8b3939fdc31a49f6b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/usbscan/ns-usbscan-_channel_info.md | jazzdelightsme/windows-driver-docs-ddi | 793b0c96e117b1658144ba8b3939fdc31a49f6b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
UID: NS:usbscan._CHANNEL_INFO
title: _CHANNEL_INFO (usbscan.h)
description: The CHANNEL_INFO structure is used as a parameter to DeviceIoControl, when the specified I/O control code is IOCTL_GET_CHANNEL_ALIGN_RQST.
old-location: image\channel_info.htm
tech.root: image
ms.assetid: 1f1cb952-9a63-461f-b70f-4cc41b8d88f... | 25.746479 | 362 | 0.789387 | yue_Hant | 0.407509 |
e1174dc6e3c27690475e4e279fd6c1a6124a1a21 | 1,409 | md | Markdown | AlchemyInsights/restore-a-deleted-onedrive.md | isabella232/OfficeDocs-AlchemyInsights-pr.lv-LV | adf4768355ef570e9932eecb193599d2930398fb | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-19T19:07:08.000Z | 2020-05-19T19:07:08.000Z | AlchemyInsights/restore-a-deleted-onedrive.md | MicrosoftDocs/OfficeDocs-AlchemyInsights-pr.lv-LV | 96359061cbdf14f4c39b06fe9d9d29d8721dfcfb | [
"CC-BY-4.0",
"MIT"
] | 3 | 2020-06-02T23:28:33.000Z | 2022-02-09T06:51:14.000Z | AlchemyInsights/restore-a-deleted-onedrive.md | isabella232/OfficeDocs-AlchemyInsights-pr.lv-LV | adf4768355ef570e9932eecb193599d2930398fb | [
"CC-BY-4.0",
"MIT"
] | 3 | 2019-10-11T18:38:02.000Z | 2021-10-09T10:41:24.000Z | ---
title: Izdzēstas mapes OneDrive
ms.author: pebaum
author: pebaum
manager: scotv
ms.date: 04/21/2020
ms.audience: Admin
ms.topic: article
ms.service: o365-administration
ROBOTS: NOINDEX, NOFOLLOW
localization_priority: Normal
ms.collection: Adm_O365
ms.custom: ''
ms.assetid: 5298f192-326b-4820-b007-7e1a1c3c2b13
ms.o... | 48.586207 | 496 | 0.825408 | lvs_Latn | 0.993068 |
e117895766eac791619d7400701e6e27aedf56d1 | 5,488 | md | Markdown | articles/azure-signalr/signalr-concept-azure-functions.md | mtaheij/azure-docs.nl-nl | 6447611648064a057aae926a62fe8b6d854e3ea6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/azure-signalr/signalr-concept-azure-functions.md | mtaheij/azure-docs.nl-nl | 6447611648064a057aae926a62fe8b6d854e3ea6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/azure-signalr/signalr-concept-azure-functions.md | mtaheij/azure-docs.nl-nl | 6447611648064a057aae926a62fe8b6d854e3ea6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Real-time app-Azure Functions bouwen & Azure signalerings service
description: Meer informatie over het ontwikkelen van een realtime serverloze webtoepassing met de Azure signalerings service op het volgende voor beeld.
author: sffamily
ms.service: signalr
ms.topic: conceptual
ms.date: 11/13/2019
ms.author: ... | 70.358974 | 444 | 0.816691 | nld_Latn | 0.998578 |
e117e1652d8f8fdd36e75820f377c987660c3935 | 515 | md | Markdown | README.md | nwtgck/trans-server-http-knocking-docker-compose | eac5c295afd419628ff20438c2333bed711830de | [
"MIT"
] | null | null | null | README.md | nwtgck/trans-server-http-knocking-docker-compose | eac5c295afd419628ff20438c2333bed711830de | [
"MIT"
] | null | null | null | README.md | nwtgck/trans-server-http-knocking-docker-compose | eac5c295afd419628ff20438c2333bed711830de | [
"MIT"
] | null | null | null | # trans-server-http-knocking-docker-compose
[Trans server](https://github.com/nwtgck/trans-server-akka) on [http-knocking](https://github.com/nwtgck/http-knocking)
## Run the server
```bash
cd <this repo>
docker-compose up
```
## Knocking procedure
Visit the following order to open the server.
1. Access to http:/... | 23.409091 | 119 | 0.733981 | eng_Latn | 0.589902 |
e1182211f47dacb74a73c5fd9caa1df94ba2d3e9 | 154 | markdown | Markdown | _projects/Ghaya_Bin_Mesmar.markdown | SpaceTypeContinuum/generative-typography-gallery | f6acab2fed47d98ccf79c96a4427d8703d1d7968 | [
"CC-BY-4.0"
] | 3 | 2020-12-06T22:09:12.000Z | 2021-06-21T21:21:35.000Z | _projects/Ghaya_Bin_Mesmar.markdown | SpaceTypeContinuum/generative-typography-gallery | f6acab2fed47d98ccf79c96a4427d8703d1d7968 | [
"CC-BY-4.0"
] | null | null | null | _projects/Ghaya_Bin_Mesmar.markdown | SpaceTypeContinuum/generative-typography-gallery | f6acab2fed47d98ccf79c96a4427d8703d1d7968 | [
"CC-BY-4.0"
] | 1 | 2021-11-03T01:54:02.000Z | 2021-11-03T01:54:02.000Z | ---
layout: project
title: Ghaya Bin Mesmar
teaser: assets/img/Ghaya_Bin_Mesmar/00.png
link: https://editor.p5js.org/GhayaBinMesmar/present/Gwg_-qqtz
---
| 22 | 62 | 0.772727 | kor_Hang | 0.155691 |
e11b063ec7f71504216c83d310fb5f1760a00828 | 11,054 | md | Markdown | docs/linux/sql-server-linux-performance-best-practices.md | in4matica/sql-docs.de-de | b5a6c26b66f347686c4943dc8307b3b1deedbe7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/linux/sql-server-linux-performance-best-practices.md | in4matica/sql-docs.de-de | b5a6c26b66f347686c4943dc8307b3b1deedbe7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/linux/sql-server-linux-performance-best-practices.md | in4matica/sql-docs.de-de | b5a6c26b66f347686c4943dc8307b3b1deedbe7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Bewährte Methoden für die Leistung für SQL Server für Linux
description: Dieser Artikel enthält bewährte Methoden für die Leistung sowie Ausführungsrichtlinien für SQL Server für Linux.
author: tejasaks
ms.author: tejasaks
ms.reviewer: vanto
ms.date: 09/14/2017
ms.topic: conceptual
ms.prod: sql
ms.technology... | 61.071823 | 719 | 0.804505 | deu_Latn | 0.976148 |
e11ba56f9a63c77a706b56c003a2e56d84220af5 | 247 | md | Markdown | documentary/index.md | kumarikandam/control-style | 9d97b5e2055a2a6892d8a1d3db270e7550b5cba9 | [
"MIT"
] | 1 | 2019-09-16T21:19:55.000Z | 2019-09-16T21:19:55.000Z | documentary/index.md | kumarikandam/control-style | 9d97b5e2055a2a6892d8a1d3db270e7550b5cba9 | [
"MIT"
] | 1 | 2019-11-16T07:01:12.000Z | 2019-11-16T07:01:12.000Z | documentary/index.md | kumarikandam/control-style | 9d97b5e2055a2a6892d8a1d3db270e7550b5cba9 | [
"MIT"
] | null | null | null | # @lemuria/control-style
%NPM: @lemuria/control-style%
`@lemuria/control-style` is Extracts CSS Properties From Component Properties Map And Returns The Composed Style.
```sh
yarn add @lemuria/control-style
```
## Table Of Contents
%TOC%
%~% | 16.466667 | 113 | 0.732794 | eng_Latn | 0.621995 |
e11cbdd404779d928630b26c9967c529c900617e | 639 | md | Markdown | README.md | a24ma/msg2eml | dc5d23339cd231991918fc6956a94a30308b72d5 | [
"MIT"
] | 1 | 2020-10-11T14:21:30.000Z | 2020-10-11T14:21:30.000Z | README.md | a24ma/msg2eml | dc5d23339cd231991918fc6956a94a30308b72d5 | [
"MIT"
] | null | null | null | README.md | a24ma/msg2eml | dc5d23339cd231991918fc6956a94a30308b72d5 | [
"MIT"
] | null | null | null | # msg2eml
複数環境でのファイル互換性を保つために、
Outlook の .msg ファイルから、
情報交換に最低限必要な情報のみ抜き出して .eml ファイルに変換する。
* Microsoft Outlook 環境必須。
* 日本標準時(JST)のみ対応。
* ファイル名は ディレクトリ内序数・date・sender・subject 情報から自動生成。
* 書き換える必要がある場合はソースコード要変更。
* (余裕があればフォーマッタを実装するかも。)
# インストール
```
pip install pywin32 pathlib
pip install --upgrade PySimpleGUIQt
... | 19.363636 | 52 | 0.752739 | yue_Hant | 0.619184 |
e11d3826ccfbc7c8c755996199b62d7200f41547 | 181 | md | Markdown | readme.md | DesignPond/daemon | 5796f7d0a914b6e6bd339582ab76d7cb8306af33 | [
"MIT"
] | null | null | null | readme.md | DesignPond/daemon | 5796f7d0a914b6e6bd339582ab76d7cb8306af33 | [
"MIT"
] | null | null | null | readme.md | DesignPond/daemon | 5796f7d0a914b6e6bd339582ab76d7cb8306af33 | [
"MIT"
] | null | null | null | ## Site de documentation
Auteur: @designpond 2015
### License
The Laravel framework is open-sourced software licensed under the [MIT license](http://opensource.org/licenses/MIT)
| 22.625 | 115 | 0.773481 | eng_Latn | 0.902342 |
e11e51885c43e0f97b3285d6c87281098e1e3222 | 296 | md | Markdown | README.md | Stanleynista/Dataviz-for-BI | 094528ba870831bdbbfafd9e1e79053d66679893 | [
"MIT"
] | null | null | null | README.md | Stanleynista/Dataviz-for-BI | 094528ba870831bdbbfafd9e1e79053d66679893 | [
"MIT"
] | null | null | null | README.md | Stanleynista/Dataviz-for-BI | 094528ba870831bdbbfafd9e1e79053d66679893 | [
"MIT"
] | null | null | null | 
Status: Developing ⚠️
<h3> I gonna use this repo for Dataviz using PowerBi and Tableau for training and presentations </h3>
<h4> Technologies Used: </h4>
* Power BI
* Tableau
| 22.769231 | 113 | 0.756757 | eng_Latn | 0.380767 |
e11e9350428f3da6be5ed263cfb1dbdb949ca4ef | 4,212 | md | Markdown | _drafts/2021-04-06-watch-all-four-hunger-games-movies-free-on-our-favorite-netflix-rival.md | sergioafanou/smart-cv | dc522a19e38f5b55f9e4cda3e695a1a8dc087b4d | [
"MIT"
] | null | null | null | _drafts/2021-04-06-watch-all-four-hunger-games-movies-free-on-our-favorite-netflix-rival.md | sergioafanou/smart-cv | dc522a19e38f5b55f9e4cda3e695a1a8dc087b4d | [
"MIT"
] | 5 | 2020-01-09T10:46:58.000Z | 2021-11-03T15:13:42.000Z | _drafts/2021-04-06-watch-all-four-hunger-games-movies-free-on-our-favorite-netflix-rival.md | sergioafanou/smart-cv | 516b8ede13f74951c64f7390fa08c4f7a2344dd6 | [
"MIT"
] | null | null | null | ---
title : "Watch all four ‘Hunger Games’ movies free on our favorite Netflix rival"
layout: post
tags: tutorial labnol
post_inspiration: https://bgr.com/2021/04/01/free-movies-tubi-hunger-games-streaming/
image: "https://sergio.afanou.com/assets/images/image-midres-30.jpg"
---
<center><a href="https://bgr.com/2021/0... | 156 | 1,742 | 0.75831 | eng_Latn | 0.471267 |
e11ec73292533d566be89644f6c380a6de693a5b | 2,760 | md | Markdown | windows-driver-docs-pr/debugger/-wmitrace-logsave.md | Ryooooooga/windows-driver-docs.ja-jp | c7526f4e7d66ff01ae965b5670d19fd4be158f04 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows-driver-docs-pr/debugger/-wmitrace-logsave.md | Ryooooooga/windows-driver-docs.ja-jp | c7526f4e7d66ff01ae965b5670d19fd4be158f04 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows-driver-docs-pr/debugger/-wmitrace-logsave.md | Ryooooooga/windows-driver-docs.ja-jp | c7526f4e7d66ff01ae965b5670d19fd4be158f04 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: wmitrace.logsave
description: Wmitrace.logsave 拡張機能は、トレース セッションのトレース バッファーの現在の内容をファイルに書き込みます。
ms.assetid: 713fea09-d405-4142-b2e8-29c813a4c3b6
keywords:
- デバッグ wmitrace.logsave Windows
ms.date: 05/23/2017
topic_type:
- apiref
api_name:
- wmitrace.logsave
api_type:
- NA
ms.localizationpriority: medium
ms.open... | 37.297297 | 264 | 0.801812 | yue_Hant | 0.906488 |