
text stringlengths 0 30.5k | title stringclasses 1
value | embeddings listlengths 768 768 |
|---|---|---|
hardware department?
A reasonable setup supporting an "average" web application might evolve as follows:
1. Single combined application/database server
2. Separate database on a different machine
3. Second application server with DNS round-robin (poor man's load balancing) or, e.g. [Perlbal](http://www.danga.com/perlb... | [
0.3710804879665375,
-0.0046448251232504845,
0.3952028155326843,
0.2129419445991516,
-0.08812874555587769,
0.18376389145851135,
-0.10017234086990356,
-0.4288093149662018,
-0.389552503824234,
-0.2381374090909958,
-0.20967090129852295,
0.48162758350372314,
-0.21433378756046295,
0.305258989334... | |
avoid un-needed database reads, although you will need to consider how to maintain [cache coherency](http://en.wikipedia.org/wiki/Cache_coherency), typically in the application.
On the other hand, if content changes reasonably often, then you will probably prefer a more spread-out solution; introduce a few more applic... | [
0.26913630962371826,
0.10450809448957443,
0.15813666582107544,
0.2423093020915985,
0.10895328968763351,
-0.4013218283653259,
0.4507704973220825,
0.19386568665504456,
-0.5411790609359741,
-0.691707968711853,
-0.39651843905448914,
0.2932250499725342,
-0.09059973061084747,
0.07602674514055252... | |
load balancing to direct visitors to the closest "cluster". By that point, you'll probably be in a position to hire engineers who can really fine-tune things.
Probably the most valuable scaling advice I can think of would be to avoid worrying about it all far too soon; concentrate on developing a service people are go... | [
0.3181452453136444,
0.192861407995224,
0.15177874267101288,
0.11967384070158005,
0.10201568156480789,
-0.12502425909042358,
0.16970296204090118,
-0.2737383544445038,
-0.3664419651031494,
-0.36804887652397156,
-0.0416673868894577,
0.5943750143051147,
-0.3117852509021759,
-0.3389398455619812... | |
direct browsers on how to cache the data. Doing this sort of work early on in the design can yield benefits later, especially when you don't have to rework the entire thing to deal with cache coherency issues.
The second most valuable piece of advice I want to put across is that you shouldn't assume what works for som... | [
0.5280423164367676,
0.15083052217960358,
0.16693010926246643,
0.23945343494415283,
-0.04347093775868416,
-0.24851007759571075,
0.15317735075950623,
0.27499961853027344,
0.01860547624528408,
-0.7480985522270203,
-0.01999976858496666,
0.5647915005683899,
0.177736297249794,
-0.123380310833454... | |
I'm looking into writing a audio syntesizer in Java, and was wondering if anybody has any advice or good resources for writing such a program. I'm looking for info on generating raw sound waves, how to output them into a usable form (playing over speakers), as well as general theory on the topic. Thanks guys.
1. This p... | [
0.42813295125961304,
-0.12863031029701233,
0.01422051526606083,
0.2577553689479828,
-0.21401803195476532,
-0.20350699126720428,
-0.07486525177955627,
-0.16011278331279755,
0.01605418510735035,
-0.6577062606811523,
0.060936089605093,
0.8045747876167297,
-0.11275875568389893,
-0.111406624317... | |
canonical WAVE format is very simple, see <http://www.lightlink.com/tjweber/StripWav/Canon.html>. A header (first 44 bytes) + the wave-data. You don't need any library to implement that.
In C/C++, the corresponding data structure would look something like this:
```cpp
typedef struct _WAVstruct
{
char headertag[4]... | [
0.4117007553577423,
-0.2822487950325012,
0.9624142050743103,
-0.034399472177028656,
-0.4416990876197815,
-0.05893968045711517,
0.06493887305259705,
-0.5923241972923279,
-0.23380489647388458,
-0.33235040307044983,
-0.1577010154724121,
0.6019050478935242,
-0.33798646926879883,
0.185804650187... | |
char datatag[4];
unsigned int datalength;
void* data; //<--- that's where the raw sound-data goes
}* WAVstruct;
```
I'm not sure about Java. I guess you'll have to substitute "struct" with "class" and "void\* data" with "char[] data" or "short[] data" or "int[] data", corresponding to the number of bits per ... | [
0.3549184203147888,
0.11612988263368607,
0.19880232214927673,
-0.34100696444511414,
-0.040520381182432175,
0.2497275024652481,
0.4236273467540741,
-0.40825003385543823,
-0.04587069898843765,
-0.18360105156898499,
-0.03254882991313934,
0.6538658738136292,
-0.2007923424243927,
-0.00767655111... | |
= 'I';
result->headertag[2] = 'F';
result->headertag[3] = 'F';
result->remnantlength = 44 + datalength - 8;
result->fileid[0] = 'W';
result->fileid[1] = 'A';
result->fileid[2] = 'V';
result->fileid[3] = 'E';
result->fmtchunktag[0] = 'f';
result->fmtchunktag[1] = 'm';
result->fm... | [
0.2031753659248352,
-0.3706605136394501,
0.6926022171974182,
-0.0721343606710434,
-0.025470716878771782,
0.1489165872335434,
0.400796115398407,
-0.7349549531936646,
-0.23888631165027618,
-0.5763378143310547,
-0.4714972972869873,
0.33003178238868713,
-0.09517491608858109,
0.3134861886501312... | |
result->bipsa = bipsa;
result->ba = channels*bipsa / 8;
result->bypse = samplerate*result->ba;
result->datatag[0] = 'd';
result->datatag[1] = 'a';
result->datatag[2] = 't';
result->datatag[3] = 'a';
result->datalength = datalength;
result->data = data; // <--- that's were the data come... | [
0.30050456523895264,
-0.10567140579223633,
0.37049350142478943,
-0.4185601472854614,
-0.3962455093860626,
0.19108565151691437,
0.3389424681663513,
-0.8268718123435974,
-0.1825542449951172,
-0.42821916937828064,
-0.15332137048244476,
0.11608666181564331,
-0.6709200143814087,
-0.206025913357... | |
the bitrate.
Then simply write the entire structure to a file to get a playable wave file. | [
0.13835176825523376,
-0.45416441559791565,
0.3479747176170349,
0.18216615915298462,
0.021955817937850952,
-0.029176369309425354,
-0.2114618718624115,
-0.45894497632980347,
0.08401263505220413,
-0.4787335693836212,
0.08903492987155914,
0.8284010291099548,
0.15726608037948608,
0.046707578003... | |
I have a column which is of type nvarchar(max). How do I find the length of the string (or the number of bytes) for the column for each row in the table?
> SELECT LEN(columnName) AS MyLength
> FROM myTable | [
-0.19146446883678436,
-0.13402244448661804,
0.43445882201194763,
-0.05070109665393829,
-0.0016336519038304687,
0.23771752417087555,
0.023740991950035095,
-0.11445952951908112,
-0.325886607170105,
-0.3737712502479553,
0.24152792990207672,
0.2590678632259369,
-0.07023002207279205,
0.32788467... | |
I asked a question about Currying and closures were mentioned.
What is a closure? How does it relate to currying?
Variable scope
--------------
When you declare a local variable, that variable has a scope. Generally, local variables exist only within the block or function in which you declare them.
```js
function() {... | [
0.04678531363606453,
-0.003181945998221636,
0.30945461988449097,
-0.27343040704727173,
0.039080001413822174,
0.12379651516675949,
0.31522631645202637,
-0.18932627141475677,
-0.1343243271112442,
-0.5888481736183167,
-0.33664530515670776,
0.2921927869319916,
-0.3618201017379761,
0.0103053385... | |
console.log(a); // works
```
When a block or function is done with, its local variables are no longer needed and are usually blown out of memory.
This is how we normally expect things to work.
A closure is a persistent local variable scope
----------------------------------------------
A closure is a persistent sc... | [
-0.08606112748384476,
-0.0311565101146698,
0.4139980673789978,
0.10351571440696716,
0.17216894030570984,
-0.14803481101989746,
0.053374532610177994,
0.4340283274650574,
-0.21538741886615753,
-0.5597403049468994,
-0.44561636447906494,
0.3229526877403259,
-0.3450219929218292,
0.3761418461799... | |
you keep a reference to that block or function somewhere.
The scope object and all its local variables are tied to the function and will persist as long as that function persists.
This gives us function portability. We can expect any variables that were in scope when the function was first defined to still be in scop... | [
0.2893577218055725,
-0.03518471494317055,
0.02436121180653572,
-0.1866793930530548,
-0.10705479234457016,
-0.40260767936706543,
0.2757258117198944,
-0.17078261077404022,
-0.29573121666908264,
-0.3662458062171936,
-0.00239070737734437,
0.5742449164390564,
-0.45785263180732727,
0.16332404315... | |
console.log(a);
}
return inner; // this returns a function
}
var fnc = outer(); // execute outer to get inner
fnc();
```
Here I have defined a function within a function. The inner function gains access to all the outer function's local variables, including `a`. The variable `a` is in scope for the inner functi... | [
-0.16069991886615753,
-0.030909623950719833,
0.3317094147205353,
-0.1989973783493042,
0.4660451412200928,
-0.06746992468833923,
0.1829528510570526,
-0.1142386943101883,
-0.034755632281303406,
-0.48747703433036804,
-0.22322708368301392,
0.6972953081130981,
-0.3338877856731415,
0.36324867606... | |
The variable `a` has been closed over -- it is within a closure.
Note that the variable `a` is totally private to `fnc`. This is a way of creating private variables in a functional programming language such as JavaScript.
As you might be able to guess, when I call `fnc()` it prints the value of `a`, which is "1".
In... | [
-0.05058013275265694,
0.21852999925613403,
-0.09283663332462311,
-0.20947220921516418,
-0.06019585579633713,
-0.24491700530052185,
0.1917157769203186,
0.28110164403915405,
-0.22815294563770294,
-0.27565324306488037,
-0.33629411458969116,
0.3964289724826813,
-0.5029897689819336,
0.407538920... | |
when the function is first declared and persists for as long as the function continues to exist.
`a` belongs to the scope of `outer`. The scope of `inner` has a parent pointer to the scope of `outer`. `fnc` is a variable which points to `inner`. `a` persists as long as `fnc` persists. `a` is within the closure.
Furth... | [
0.3121528923511505,
-0.18427179753780365,
0.6392930150032043,
-0.32013264298439026,
0.28165364265441895,
-0.15134596824645996,
0.19004487991333008,
0.0847611203789711,
-0.2650395333766937,
-0.18939588963985443,
-0.19096508622169495,
0.6579676270484924,
-0.06015357747673988,
0.2369376420974... | |
Does anyone use [Phing](http://phing.info/trac/) to deploy PHP applications, and if so how do you use it? We currently have a hand-written "setup" script that we run whenever we deploy a new instance of our project. We just check out from SVN and run it. It sets some basic configuration variables, installs or reloads t... | [
0.8462305068969727,
0.06901517510414124,
0.13361860811710358,
0.1329049915075302,
-0.08045406639575958,
-0.28023821115493774,
0.040702760219573975,
0.2271515280008316,
-0.40895211696624756,
-0.3624246120452881,
0.28451359272003174,
0.35717955231666565,
-0.41703158617019653,
0.0840541049838... | |
one place to another much as our setup script does. What are some more advanced uses that you can give examples of to help me understand why we would or would not want to integrate [Phing](http://phing.info/trac/) into our process?
From Federico Cargnelutti's [blog post](http://phpimpact.wordpress.com/2007/06/30/phing-... | [
0.1618499457836151,
-0.28921768069267273,
0.18184520304203033,
0.1642608791589737,
-0.050198059529066086,
0.09006292372941971,
0.1392124891281128,
-0.002481271745637059,
-0.18613523244857788,
-0.8465995788574219,
-0.0941551998257637,
0.45564591884613037,
-0.1423352211713791,
0.048640869557... | |
a number of benefits. You'll be using a proven framework so instead of having to worry about setting up "infrastructure" you can focus on the code you need to write. Using Phing will also make it easier for when new members join your team, they'll be able to understand what is going on if they've used Phing (or Ant, wh... | [
0.47033411264419556,
0.04269539937376976,
-0.12702710926532745,
0.2597324550151825,
-0.04730699211359024,
-0.0881020799279213,
0.14085327088832855,
-0.0046233790926635265,
-0.20238269865512848,
-0.7661738395690918,
0.01431752648204565,
0.5852607488632202,
-0.010385708883404732,
-0.08982207... | |
Learning WPF nowadays. Found something new today with .Net dependency properties. What they bring to the table is
* Support for Callbacks (Validation, Change, etc)
* Property inheritance
* Attached properties
among others.
But my question here is why do they need to be declared as static in the containing class? Th... | [
0.3327682614326477,
-0.4028696119785309,
0.21960827708244324,
0.2161664068698883,
-0.2845529317855835,
-0.516624391078949,
0.36081963777542114,
0.009624426253139973,
-0.2783391773700714,
-0.6301646828651428,
0.08061941713094711,
0.25881680846214294,
-0.22781459987163544,
0.2270471006631851... | |
this constraint you should use static variable, it will be initialized only one time thus you will register DP one time only.
2. DP should be registered before any class (which uses that DB) instance created | [
0.11283755302429199,
-0.4089967608451843,
0.3183939456939697,
0.04148552566766739,
-0.34960678219795227,
-0.06277624517679214,
-0.011409862898290157,
-0.6042429804801941,
-0.12172326445579529,
-0.4831320345401764,
-0.05803428217768669,
0.24787472188472748,
-0.4667997360229492,
0.2454829663... | |
Is there a good yacc/bison type LALR parser generator for .NET ?
[Antlr](http://antlr.org/) supports C# code generation, though it is LL(k) not technically LALR. Its tree rewriting rules are an interesting feature though. | [
0.07120578736066818,
-0.131589874625206,
0.3169504702091217,
0.03368713706731796,
-0.28837355971336365,
-0.12271939218044281,
0.08550523221492767,
0.0991908386349678,
-0.2812032103538513,
-0.3106338083744049,
0.2179483324289322,
0.17072658240795135,
-0.2974911630153656,
-0.2357366532087326... | |
I'm writing C# code that uses the windows IP Helper API. One of the functions I'm trying to call is "[GetBestInterface](http://msdn.microsoft.com/en-us/library/aa365920(VS.85).aspx)" that takes a 'uint' representation of an IP. What I need is to parse a textual representation of the IP to create the 'uint' representati... | [
0.13759653270244598,
0.3119879961013794,
0.4070112407207489,
-0.0014546802267432213,
-0.09759350121021271,
-0.03434433788061142,
0.3031553626060486,
0.050109971314668655,
-0.2301936000585556,
-0.7555386424064636,
0.006550944875925779,
0.2659715712070465,
-0.308657705783844,
0.0048607746139... | |
is also a way of doing this using IP Helper, using the [ParseNetworkString](http://msdn.microsoft.com/en-us/library/bb408412(VS.85).aspx), but again, I'd rather use .NET - I believe the less I rely on pInvoke the better.
So, anyone knows of a standard way to do this in .NET?
MSDN [says](http://msdn.microsoft.com/en-us... | [
-0.15803949534893036,
0.14214970171451569,
0.57720547914505,
0.18991978466510773,
-0.12249338626861572,
-0.06934816390275955,
0.09898775070905685,
-0.1652173101902008,
-0.46890413761138916,
-0.9380972385406494,
-0.20866326987743378,
0.15844590961933136,
-0.14023634791374207,
0.232852861285... | |
code is for IPv4 addresses only.
IPv6 address is 128 bits long so it's impossible to convert it to 'uint' as question's author wanted. | [
-0.20245276391506195,
-0.02087281458079815,
0.34011656045913696,
0.10820192843675613,
0.10903636366128922,
-0.021342527121305466,
0.17210467159748077,
-0.15032491087913513,
0.24204018712043762,
-0.39499136805534363,
-0.21287816762924194,
0.01794060319662094,
-0.22682853043079376,
0.1051941... | |
With SVN, I had a single big repository I kept on a server, and checked-out on a few machines. This was a pretty good backup system, and allowed me easily work on any of the machines. I could checkout a specific project, commit and it updated the 'master' project, or I could checkout the entire thing.
Now, I have a bu... | [
0.6166478395462036,
0.08740843832492828,
0.04778996482491493,
0.23614178597927094,
-0.18208914995193481,
-0.2029738426208496,
-0.05831693112850189,
0.2971515655517578,
-0.397795170545578,
-0.6676263809204102,
0.04531333968043327,
0.4299793839454651,
-0.06310974806547165,
0.2484068274497985... | |
things like my CV, articles I've written, websites I've made and so on) in one big repository I can easily clone onto remote machines, or memory-sticks/harddrives as backup.
The problem is, since it's a private repository, and git doesn't allow checking out of a specific folder (that I could push to github as a separa... | [
0.43725669384002686,
0.18098674714565277,
0.14257021248340607,
0.22918656468391418,
0.39017853140830994,
-0.16921785473823547,
0.19690077006816864,
0.14131148159503937,
-0.355713814496994,
-0.5213797092437744,
-0.17952564358711243,
0.2588525712490082,
0.24442817270755768,
0.394038349390029... | |
I have a folder of git-repos (for example, ~/code\_projects/proj1/.git/ ~/code\_projects/proj2/.git/), and after doing changes to proj1 I do `git push github`, then I copy the files into ~/Documents/code/python/projects/proj1/ and do a single commit (instead of the numerous ones in the individual repos). Then do `git p... | [
0.5250263810157776,
0.023942168802022934,
0.2621825039386749,
0.094053715467453,
0.17377200722694397,
0.0936117097735405,
0.12646587193012238,
-0.21871180832386017,
-0.3254547119140625,
-0.6101093888282776,
-0.2727643847465515,
0.45694130659103394,
0.07150915265083313,
0.0580664798617363,
... | |
completely separate.
Fighting that idea means ending up with unnecessarily tangled history,
which renders administration more difficult and--more
importantly--"archeology" tools less useful because of the resulting
dilution. Also, as you mentioned, Git assumes that the "unit of
cloning" is the repository, and practica... | [
0.4082183539867401,
0.0881858766078949,
-0.06770437210798264,
0.40625816583633423,
0.1469515562057495,
-0.31411871314048767,
0.05411868542432785,
-0.07188501954078674,
-0.29275399446487427,
-0.3757547438144684,
-0.4640565812587738,
-0.0864211767911911,
-0.2761540412902832,
0.42052313685417... | |
to SVN workflows, with the addition that one
*can* use local commits and branches:
```
svn checkout --> git clone
svn update --> git pull
svn commit --> git push
```
You can have multiple remotes in each working clone, for the ease of
synchronizing between the multiple parties:
```
$ cd ~/dev
$ git clone ... | [
0.225656658411026,
-0.021501673385500908,
0.4789777994155884,
0.010577558539807796,
0.009999179281294346,
0.06666667014360428,
-0.12993697822093964,
-0.1863657534122467,
-0.3568319082260132,
-0.7642782330513,
-0.3200352191925049,
0.677710771560669,
-0.25902003049850464,
0.25609803199768066... | |
remotes when you
are ready with something like (note how that pushes the *same* commits
and history to each of the remotes!):
```
$ for remote in origin github memorystick; do git push $remote; done
```
The easiest way to turn an existing working repository `~/dev/foo`
into such a bare repository is probably:
```
$... | [
0.04389125481247902,
0.08741320669651031,
0.2987588047981262,
0.17039883136749268,
0.13488677144050598,
-0.4409877359867096,
0.056081634014844894,
-0.06037577614188194,
-0.1502874195575714,
-0.7302412986755371,
-0.3266424536705017,
0.4373517632484436,
-0.20262709259986877,
0.78462129831314... | |
I am using forms authentication. My users are redirected to a page (written in web.config) when they login, but some of them may not have the privilages to access this default page. In this case, I want them to redirect to another page but RedirectFromLoginPage method always redirects to the default page in web.config.... | [
0.41597798466682434,
-0.0036322507075965405,
0.8100370168685913,
0.06764883548021317,
0.17613732814788818,
-0.24627627432346344,
0.412610799074173,
-0.2571071684360504,
0.030535507947206497,
-0.8593907356262207,
-0.08822593837976456,
0.6648653745651245,
-0.26544153690338135,
0.023050090298... | |
ASP.NET redirect to wherever you want. | [
0.47324252128601074,
-0.5031808614730835,
0.38856637477874756,
0.2586662769317627,
-0.04753736034035683,
0.0000853084129630588,
0.12456655502319336,
0.40374302864074707,
-0.4606049954891205,
-0.8368046879768372,
-0.2743484079837799,
-0.001261546858586371,
-0.12522819638252258,
-0.074214980... | |
I'd like to add a method to my existing server's CORBA interface. Will that require recompiling all clients?
I'm using TAO.
Recompilation of clients is not required (and should not be, regardless of the ORB that you use). As Adam indicated, lookups are done by operation name (a straight text comparison).
I've done wh... | [
0.08978700637817383,
0.11674637347459793,
0.12230868637561798,
-0.1336544007062912,
-0.17551490664482117,
-0.13852447271347046,
0.34956851601600647,
-0.31710147857666016,
-0.10550505667924881,
-0.35383638739585876,
0.17423216998577118,
0.6219000220298767,
-0.5300431251525879,
-0.1362293064... | |
What do `*args` and `**kwargs` mean?
```
def foo(x, y, *args):
def bar(x, y, **kwargs):
```
The `*args` and `**kwargs` is a common idiom to allow arbitrary number of arguments to functions as described in the section [more on defining functions](http://docs.python.org/3/tutorial/controlflow.html#more-on-defining-func... | [
-0.05988980457186699,
0.26771071553230286,
0.7552351951599121,
-0.40982913970947266,
-0.4380694329738617,
0.41978105902671814,
0.025971096009016037,
-0.4475099742412567,
-0.18600407242774963,
-0.11751656234264374,
-0.520663857460022,
0.6372553110122681,
-0.6066203713417053,
-0.213479191064... | |
a in kwargs:
print(a, kwargs[a])
bar(name='one', age=27)
# name one
# age 27
```
Both idioms can be mixed with normal arguments to allow a set of fixed and some variable arguments:
```
def foo(kind, *args, **kwargs):
pass
```
It is also possible to use this the other way around:
```
def foo(a, b, c)... | [
0.3042471706867218,
0.4419231414794922,
0.31991246342658997,
-0.6870429515838623,
-0.0772530660033226,
0.4543241262435913,
0.2000577747821808,
-0.3403497636318207,
-0.14930126070976257,
-0.11925879120826721,
-0.39030396938323975,
0.3286202847957611,
-0.3135656416416168,
-0.0982417240738868... | |
on the left side of an assignment ([Extended Iterable Unpacking](http://www.python.org/dev/peps/pep-3132/)), though it gives a list instead of a tuple in this context:
```
first, *rest = [1,2,3,4]
first, *l, last = [1,2,3,4]
```
Also Python 3 adds new semantic (refer [PEP 3102](https://www.python.org/dev/peps/pep-31... | [
-0.450552761554718,
0.02942584827542305,
0.6542670130729675,
-0.16957996785640717,
-0.26459741592407227,
0.19420282542705536,
0.16225241124629974,
-0.22397398948669434,
-0.007893532514572144,
-0.3869416415691376,
-0.4041074812412262,
0.4474928677082062,
-0.26688170433044434,
-0.38348454236... | |
be passed as keyword arguments.
### Note:
* A Python `dict`, semantically used for keyword argument passing, are arbitrarily ordered. However, in Python 3.6, keyword arguments are guaranteed to remember insertion order.
* "The order of elements in `**kwargs` now corresponds to the order in which keyword arguments wer... | [
-0.1286846399307251,
-0.03480362519621849,
0.38549378514289856,
-0.2778494656085968,
-0.10479722917079926,
0.112897127866745,
0.285673052072525,
-0.39005833864212036,
0.041968513280153275,
-0.35834214091300964,
-0.5888199806213379,
0.45461294054985046,
-0.43649083375930786,
-0.089134417474... | |
We have been working with CVS for years, and frequently find it useful to "sticky" a single file here and there.
Is there any way to do this in subversion, specifically from TortoiseSVN?
The XOR method fails if a and b point to the same address. The first XOR will clear all of the bits at the memory address pointed to... | [
0.2993525564670563,
0.028236335143446922,
0.31499773263931274,
-0.18776175379753113,
0.06605727970600128,
-0.13841907680034637,
0.2280675619840622,
0.10499978065490723,
-0.21655254065990448,
-0.2527192533016205,
-0.1380438655614853,
0.6528830528259277,
-0.3812488913536072,
0.08186841756105... | |
that's guaranteed to work, not the clever method that fails at unexpected moments. | [
0.48030248284339905,
0.2169112116098404,
-0.09845560789108276,
0.20249846577644348,
0.291914701461792,
-0.12352260947227478,
0.2876950800418854,
-0.06515887379646301,
0.04582447558641434,
-0.2794440984725952,
0.01762503758072853,
0.4308035373687744,
0.2255239635705948,
-0.20876485109329224... | |
I'm mainly a C# developer, but I'm currently working on a project in Python.
How can I represent the equivalent of an Enum in Python?
[Enums](https://docs.python.org/3/library/enum.html) have been added to Python 3.4 as described in [PEP 435](http://www.python.org/dev/peps/pep-0435/). It has also been [backported to 3... | [
0.28146469593048096,
0.03624366596341133,
0.2851317226886749,
-0.1834477037191391,
-0.21201582252979279,
0.12130928039550781,
0.25036895275115967,
-0.22750259935855865,
-0.18905116617679596,
-0.685365617275238,
-0.10774819552898407,
0.4075792729854584,
-0.19069354236125946,
-0.154496297240... | |
will install a completely different and incompatible version.
---
```
from enum import Enum # for enum34, or the stdlib version
# from aenum import Enum # for the aenum version
Animal = Enum('Animal', 'ant bee cat dog')
Animal.ant # returns <Animal.ant: 1>
Animal['ant'] # returns <Animal.ant: 1> (string looku... | [
0.08456636220216751,
0.1345640867948532,
-0.031724680215120316,
-0.22340553998947144,
0.055718448013067245,
0.3244933485984802,
0.5069105625152588,
-0.6282334327697754,
0.11709802597761154,
-0.8526360392570496,
-0.19010646641254425,
0.4154617190361023,
-0.9350306987762451,
-0.0658662468194... | |
like so:
```
>>> Numbers = enum(ONE=1, TWO=2, THREE='three')
>>> Numbers.ONE
1
>>> Numbers.TWO
2
>>> Numbers.THREE
'three'
```
You can also easily support automatic enumeration with something like this:
```
def enum(*sequential, **named):
enums = dict(zip(sequential, range(len(sequential))), **named)
return... | [
-0.14020705223083496,
0.03137901797890663,
0.0622013621032238,
-0.2176189124584198,
-0.2907147705554962,
0.13806280493736267,
0.25911077857017517,
-0.5441717505455017,
-0.15724605321884155,
-0.657406747341156,
-0.30174142122268677,
0.24724671244621277,
-0.31124526262283325,
-0.047045510262... | |
it is useful for rendering your enums in output. It will throw a `KeyError` if the reverse mapping doesn't exist. With the first example:
```
>>> Numbers.reverse_mapping['three']
'THREE'
```
---
If you are using MyPy another way to express "enums" is with [`typing.Literal`](https://mypy.readthedocs.io/en/stable/lit... | [
0.10765848308801651,
-0.06075515225529671,
0.23863650858402252,
-0.16904780268669128,
-0.24611099064350128,
0.133209690451622,
0.15945695340633392,
-0.5993915796279907,
0.055424764752388,
-0.642524778842926,
0.08589771389961243,
0.4586202800273895,
-0.48653072118759155,
-0.0714318230748176... | |
I'm currently using and enjoying using the Flex MVC framework [PureMVC](http://www.puremvc.org). I have heard some good things about Cairngorm, which is supported by Adobe and has first-to-market momentum. And there is a new player called Mate, which has a good deal of buzz.
Has anyone tried two or three of these fram... | [
0.3050551414489746,
0.06718425452709198,
0.5596200227737427,
-0.40980610251426697,
0.0004294721002224833,
-0.18167909979820251,
0.20440919697284698,
-0.38689470291137695,
-0.14363862574100494,
-0.5591236352920532,
-0.056002698838710785,
0.7365782856941223,
-0.01240144856274128,
-0.03567646... | |
your application in using tags in what is called an event map -- basically a list of events that your application generates, and what actions to take when they occur. The event map gives a good overview of what your application does. Mate uses Flex' own event mechanism, it does not invent its own like most other framew... | [
0.21050435304641724,
-0.28229787945747375,
0.42700815200805664,
-0.057242244482040405,
-0.1976596564054489,
-0.34111884236335754,
0.5305812954902649,
-0.23823779821395874,
-0.31084468960762024,
-0.4343816339969635,
-0.1226389929652214,
0.3966488242149353,
-0.5045297741889954,
-0.1316183954... | |
(leveraging bindings) that makes it possible to connect your models to your views without either one knowing about the other. This is probably the most powerful feature of the framework.
In my view none of the other Flex application frameworks come anywhere near Mate. However, these are the contenders and why I consid... | [
0.5342945456504822,
0.06414549797773361,
0.2609294354915619,
0.16672144830226898,
-0.15151965618133545,
-0.15261206030845642,
0.14771954715251923,
-0.42524194717407227,
-0.1470928192138672,
-0.5192184448242188,
0.18316930532455444,
0.5270589590072632,
-0.3309102952480316,
0.328447639942169... | |
of your application depends on the framework. However, PureMVC isn't terrible, just not a very good fit for Flex. An alternative is [FlexMVCS](http://code.google.com/p/flexmvcs/), an effort to make PureMVC more suitable for Flex (unfortunately there's no documentation yet, just source).
Cairngorm is a bundle of anti-... | [
0.08814037591218948,
0.06523890793323517,
0.49129045009613037,
-0.10347237437963486,
-0.2252744734287262,
-0.034765616059303284,
0.5530444383621216,
-0.26843544840812683,
-0.29739534854888916,
-0.28342732787132263,
-0.06266459822654724,
0.4790416955947876,
-0.39759379625320435,
-0.01039911... | |
container and uses metadata to enable auto-wiring of dependencies. It is interesting, but a little bizzare in that goes to such lengths to avoid the global variables of Cairngorm by using dependency injection but then uses a global variable for central event dispatching.
Those are the ones I've tried or researched. Th... | [
0.3775580823421478,
-0.17113976180553436,
0.7006420493125916,
-0.050338178873062134,
-0.02310478687286377,
-0.4509096145629883,
-0.06558454781770706,
-0.1787859946489334,
-0.47498321533203125,
-0.17863944172859192,
-0.15851618349552155,
0.19635680317878723,
-0.23378106951713562,
0.36692711... | |
I'm trying to find out the 'correct' windows API for finding out the localized name of 'special' folders, specifically the Recycle Bin. I want to be able to prompt the user with a suitably localized dialog box asking them if they want to send files to the recycle bin or delete them directly.
I've found lots on the int... | [
0.20188593864440918,
-0.12531152367591858,
0.08656404912471771,
0.26175105571746826,
-0.10427292436361313,
-0.041727807372808456,
0.04492783918976784,
0.36069491505622864,
-0.43558067083358765,
-0.6896429657936096,
-0.44567787647247314,
0.2677319645881653,
-0.07365435361862183,
0.193790972... | |
you [Identify the Location of Special Folders with API Calls](http://msdn.microsoft.com/en-us/library/aa140088(office.10).aspx) | [
0.1452922523021698,
0.04637480527162552,
0.05102524533867836,
0.20161746442317963,
0.5530416369438171,
-0.2097439169883728,
0.21655341982841492,
0.2472507357597351,
-0.42146268486976624,
-0.6705837845802307,
-0.6841983199119568,
0.19185517728328705,
-0.12861138582229614,
0.0422576367855072... | |
I'm setting up a web application with a FreeBSD PostgreSQL back-end. I'm looking for some database performance optimization tool/technique.
[pgfouine](http://pgfouine.projects.postgresql.org/) works fairly well for me. And it looks like there's a [FreeBSD port](http://portsmon.freebsd.org/portoverview.py?category=datab... | [
0.12445987015962601,
0.19041387736797333,
0.2578224539756775,
0.007406524382531643,
0.01081904023885727,
0.016394997015595436,
0.061076439917087555,
0.3364204466342926,
-0.3941408693790436,
-0.5111998319625854,
0.0370887890458107,
0.6031740307807922,
0.047223348170518875,
0.084240697324275... | |
I've created a model for executing worker tasks in a server application using a thread pool associated with an IO completion port such as shown in the posts below:
<http://weblogs.asp.net/kennykerr/archive/2008/01/03/parallel-programming-with-c-part-4-i-o-completion-ports.aspx>
<http://blogs.msdn.com/larryosterman/ar... | [
0.2955890893936157,
0.22495795786380768,
-0.03203006461262703,
0.03366062045097351,
-0.08642225712537766,
0.07427877932786942,
0.07934170961380005,
0.15509289503097534,
-0.3772391080856323,
-0.41548246145248413,
0.41193920373916626,
0.5912612080574036,
-0.028115691617131233,
0.033205181360... | |
there doesn't really seem to be much benefit from that. | [
0.7736641764640808,
0.30100712180137634,
-0.07880780100822449,
0.047675736248493195,
-0.08388614654541016,
0.1000528559088707,
0.08359641581773758,
0.3915030062198639,
-0.05725351348519325,
-0.10292075574398041,
0.2692031264305115,
0.3320901095867157,
0.40407025814056396,
0.060322094708681... | |
On Mac OS X 10.5 I downloaded the latest version of Apache 2.2.9. After the usual configure, make, make install dance I had a build of apache without mod\_rewrite. This wasn't statically linked and the module was not built in the /modules folder either.
I had to do the following to build Apache and mod\_rewrite:
```
... | [
0.26387181878089905,
0.24096812307834625,
0.48239436745643616,
-0.06546185910701752,
-0.36557960510253906,
-0.2408159077167511,
0.5698162317276001,
-0.27822405099868774,
-0.27121374011039734,
-0.8463857769966125,
-0.04109157621860504,
0.6341602206230164,
-0.32790225744247437,
0.06473930180... | |
of Apache?
(The last time I built Apache (2.2.8) on Solaris, by default it built everything as a shared module.)
Try the `./configure` option `--enable-mods-shared="all"`, or `--enable-mods-shared="<list of modules>"` to compile modules as shared objects. See further [details in Apache 2.2 docs](http://httpd.apache.or... | [
0.5277608633041382,
-0.013621950522065163,
0.38487228751182556,
-0.17309582233428955,
-0.3898179233074188,
-0.46804746985435486,
0.43004390597343445,
-0.5431540012359619,
-0.2092779576778412,
-0.5375590920448303,
-0.33254510164260864,
0.3646937906742096,
-0.41301229596138,
-0.1529536098241... | |
When launching a thread or a process in .NET or Java, is there a way to choose which processor or core it is launched on? How does the shared memory model work in such cases?
If you're using multiple threads, the operating system will automatically take care of using multiple cores. | [
0.2615731358528137,
-0.22431409358978271,
-0.0894661396741867,
0.4207756817340851,
0.08804837614297867,
-0.004900928121060133,
-0.4166586697101593,
0.25469422340393066,
-0.43108561635017395,
-0.5624441504478455,
-0.045481156557798386,
0.15889804065227509,
0.0295405276119709,
0.136202216148... | |
I have a container div with a fixed `width` and `height`, with `overflow: hidden`.
I want a horizontal row of float: left divs within this container. Divs which are floated left will naturally push onto the 'line' below after they read the right bound of their parent. This will happen even if the `height` of the paren... | [
0.5926004648208618,
0.036063872277736664,
0.8402124047279358,
-0.3060324192047119,
0.07535663992166519,
-0.13280749320983887,
-0.15649724006652832,
-0.09957572817802429,
-0.10898380726575851,
-0.5980798602104187,
-0.015729203820228577,
0.3851315379142761,
-0.1331886500120163,
0.26472681760... | |
I did it in the image shown). This, however, is no good to me (for reasons too lengthy to explain here), as the child divs need to be floated block level elements.
You may put an inner div in the container that is enough wide to hold all the floated divs.
```css
#container {
background-color: red;
overflow: hidd... | [
0.37254321575164795,
-0.1594615876674652,
0.4737076461315155,
-0.02543688379228115,
0.1418062299489975,
0.318877249956131,
0.22018268704414368,
-0.3429965078830719,
-0.22248871624469757,
-0.503324568271637,
0.0807839184999466,
0.002904036547988653,
0.020280703902244568,
0.07359085977077484... | |
</div>
</div>
``` | [
-0.07190121710300446,
0.4921887218952179,
0.05531216040253639,
-0.17986783385276794,
-0.13135050237178802,
-0.0751023069024086,
0.28936469554901123,
0.20548641681671143,
-0.147556871175766,
-0.622516930103302,
-0.4902050495147705,
0.2702726721763611,
-0.10220156610012054,
0.330144584178924... | |
I have a large tree of Java Objects in my Desktop Application and am trying to decide on the best way of persisting them as a file to the file system.
Some thoughts I've had were:
* **Roll my own serializer using DataOutputStream**: This would give me the greatest control of what was in the file, but at the cost of m... | [
0.1547486037015915,
0.2688871920108795,
0.262561172246933,
-0.05604816600680351,
-0.19649364054203033,
-0.07275263965129852,
0.3638356924057007,
0.1611565500497818,
-0.5023411512374878,
-0.5871164202690125,
0.16112111508846283,
0.31923747062683105,
-0.19383388757705688,
0.4125656485557556,... | |
to be a horrible versioning nightmare.
* **XML Serialization**: It's not as brittle, but it's significantly slower that straight out serialization. It can be transformed outside of my program.
* **JavaDB**: I'd considered this since I'm comfortable writing JDBC applications. The difference here is that the database ins... | [
0.3257685899734497,
0.012512501329183578,
0.0945596918463707,
0.05874589458107948,
-0.22074811160564423,
-0.18720825016498566,
0.441087931394577,
0.44698745012283325,
-0.2739049792289734,
-0.8828182220458984,
0.08554669469594955,
0.4418222904205322,
-0.14950628578662872,
0.4203360974788666... | |
that I've missed some obvious, and simpler approach than the ones above.
---
Here are some more options culled from the answers below:
* **An Object Database** - Has significantly less infrastructure than ORM approaches and performs faster than an XML approach. thanks aku
[db4objects](http://www.db4o.com) might be t... | [
0.2866385281085968,
0.22808195650577545,
0.04711194708943367,
0.35137635469436646,
-0.23962661623954773,
-0.12257056683301926,
0.29666668176651,
0.08231460303068161,
-0.13724666833877563,
-0.39947187900543213,
-0.2694551348686218,
0.2602229118347168,
0.25280436873435974,
-0.026109201833605... | |
What is the SQL query to select all of the MSSQL Server's logins?
Thank you. More than one of you had the answer I was looking for:
```
SELECT * FROM syslogins
```
Is this what you're after?
```
select * from master.syslogins
``` | [
0.15076844394207,
0.061041127890348434,
0.031800296157598495,
0.25463971495628357,
-0.07242374122142792,
-0.13112984597682953,
-0.18104538321495056,
0.06786694377660751,
-0.35988274216651917,
-0.701154887676239,
-0.05228948965668678,
0.41101768612861633,
-0.41938143968582153,
-0.0697476938... | |
I'm working on a windows forms application (C#) where a user is entering data in a form. At any point while editing the data in the form the user can click one of the buttons on the form to perform certain actions. By default the focus goes to the clicked button so the user has to click back on to the control they want... | [
0.601314902305603,
0.21770673990249634,
0.3803613483905792,
-0.045376937836408615,
0.2759981155395508,
-0.2690907418727875,
-0.014434886164963245,
0.15232093632221222,
0.10693509876728058,
-0.7615164518356323,
-0.02698194794356823,
0.236429825425148,
-0.17288503050804138,
0.133678495883941... | |
processed. Here's a sample screenshot that illustrates what I'm talking about:
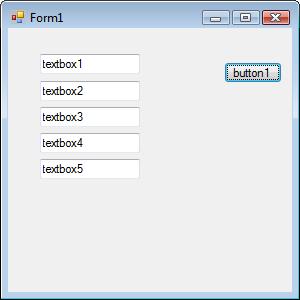
The user can be entering data in textbox1, textbox2, textbox3, etc and click the button. I need the button to return the ... | [
0.2115689218044281,
-0.04325827211141586,
0.42991170287132263,
0.06028217449784279,
0.18921175599098206,
-0.011952109634876251,
-0.040463004261255264,
-0.19971659779548645,
-0.41528475284576416,
-0.6358755230903625,
-0.10197290778160095,
0.3453361988067627,
-0.3726217746734619,
0.058615569... | |
private void textBox_Enter(object sender, EventArgs e)
{
_lastEnteredControl = (Control)sender;
}
private void button1_Click(object sender, EventArgs e)
{
MessageBox.Show("Do something here");
_lastEnteredControl.Focus();
}
}
```
So bas... | [
0.24808824062347412,
-0.25135186314582825,
0.34470224380493164,
-0.2246774435043335,
0.33344483375549316,
-0.14046454429626465,
0.3336353302001953,
0.11915351450443268,
-0.14353351294994354,
-0.5373477339744568,
-0.4800759255886078,
0.5583149790763855,
-0.5171821713447571,
0.14005267620086... | |
have here is a class variable that points to the last entered control. Each textbox on the form is setup so the textBox\_Enter method is fired when the control receives the focus. Then, when the button is clicked focus is returned to the control that had the focus before the button was clicked. Anybody have any more el... | [
0.3415038585662842,
0.03178631141781807,
0.6107541918754578,
-0.35252976417541504,
0.12124904990196228,
-0.3487449288368225,
0.10939816385507584,
-0.22766533493995667,
0.2641470730304718,
-0.6053633093833923,
-0.40541893243789673,
0.594891369342804,
-0.4475068747997284,
0.18977437913417816... | |
if (ctrl is TextBox)
{
ctrl.Enter += delegate(object sender, EventArgs e)
{ | [
-0.13657723367214203,
-0.25917577743530273,
0.19235314428806305,
0.11701113730669022,
0.08427167683839798,
-0.12475766986608505,
0.12201961874961853,
-0.18433110415935516,
0.0256632249802351,
-0.4186651110649109,
-0.3374108374118805,
0.4268295168876648,
-0.36324620246887207,
0.231205791234... | |
_lastEnteredControl = (Control)sender;
};
}
}
}
```
then you don't have to worry about decorating each textbox manually (or forgetting about one too). | [
0.11291173100471497,
-0.05257878452539444,
0.41191479563713074,
-0.16649480164051056,
0.21638305485248566,
-0.4074355661869049,
0.39609256386756897,
0.12906955182552338,
-0.2904207110404968,
-0.918468713760376,
-0.2475496232509613,
0.5152784585952759,
-0.24675491452217102,
0.08198896795511... | |
If I create a class like so:
```
// B.h
#ifndef _B_H_
#define _B_H_
class B
{
private:
int x;
int y;
};
#endif // _B_H_
```
and use it like this:
```
// main.cpp
#include <iostream>
#include <vector>
class B; // Forward declaration.
class A
{
public:
A() {
std::cout << v.size() << std::endl... | [
0.05471372231841087,
0.21797803044319153,
0.464576780796051,
-0.31327158212661743,
-0.07789847999811172,
0.12819024920463562,
0.23581475019454956,
-0.3011869490146637,
-0.33840861916542053,
-0.595963180065155,
-0.10144252330064774,
0.3471638560295105,
-0.47656670212745667,
0.13891641795635... | |
this matter.
The compiler needs to know how big "B" is before it can generate the appropriate layout information. If instead, you said `std::vector<B*>`, then the compiler wouldn't need to know how big B is because it knows how big a pointer is. | [
0.4008750021457672,
0.08795283734798431,
0.10209164768457413,
-0.10752018541097641,
-0.17865416407585144,
0.0031364092137664557,
0.0657874047756195,
0.04050442576408386,
-0.43265411257743835,
-0.60748690366745,
-0.014840802177786827,
0.39371708035469055,
-0.45927131175994873,
0.14832851290... | |
We have a whole bunch of DLLs that give us access to our database and other applications and services.
We've wrapped these DLLs with a thin WCF service layer which our clients then consume.
I'm a little unsure on how to write unit tests that only test the WCF service layer. Should I just write unit tests for the DLLs... | [
0.7235940098762512,
0.1664934605360031,
0.22706133127212524,
0.27425891160964966,
0.16554348170757294,
-0.19049961864948273,
0.1289810687303543,
-0.1591668426990509,
-0.02681136690080166,
-0.6380690932273865,
0.15590576827526093,
0.6140332221984863,
0.012884213589131832,
0.2624948024749756... | |
service host in a unit test.
So, I'm confused about exactly what to test and how.
The consumer of your service doesn't care what's underneath your service.
To really test your service layer, I think your layer needs to go down to DLLs and the database and write at least [CRUD](http://en.wikipedia.org/wiki/Create,_rea... | [
0.571892499923706,
0.08854407072067261,
0.41460466384887695,
0.1651177555322647,
-0.12983150780200958,
-0.17131246626377106,
0.35065561532974243,
-0.20078504085540771,
0.060430023819208145,
-0.9087833166122437,
-0.10231780260801315,
0.45417338609695435,
0.11142261326313019,
0.2410113066434... | |
I'm exploring the possibility of writing an application in Erlang, but it would need to have a portion written in Cocoa (presumably Objective-C). I'd like the front-end and back-end to be able to communicate easily. How can this best be done?
I can think of using C ports and connected processes, but I think I'd like a... | [
0.46939271688461304,
0.293992280960083,
0.2665105164051056,
0.19805175065994263,
0.030663415789604187,
-0.09995545446872711,
-0.10977564007043839,
0.11108184605836868,
-0.281691312789917,
-0.7083593010902405,
0.133249893784523,
0.5960749983787537,
-0.2322477549314499,
-0.06575272232294083,... | |
core of the application be a daemon that the Cocoa front-end communicates with over a Unix-domain socket using some simple protocol you devise.
The use of a Unix-domain socket means that the Erlang daemon could be launched on-demand by `launchd` and the Cocoa front-end could find the path to the socket to use via an e... | [
0.08707258850336075,
0.1941058188676834,
0.37746497988700867,
0.3117919862270355,
0.055852603167295456,
-0.20387977361679077,
-0.20657888054847717,
0.10101837664842606,
-0.23931047320365906,
-0.37937822937965393,
-0.3851567804813385,
0.3340238630771637,
-0.5022221803665161,
-0.030783422291... | |
that a job should be launched on-demand via a secure Unix-domain socket, `launchd` will actually create the socket itself with appropriate permissions, and advertise its location via the environment variable named in the job's property list. The job, when started, will actually be passed a file descriptor to the socket... | [
0.34701138734817505,
0.003925078548491001,
0.2545228600502014,
-0.11529721319675446,
0.17858871817588806,
0.009528346359729767,
-0.08785821497440338,
0.24976226687431335,
-0.23682089149951935,
-0.28096628189086914,
-0.6914604306221008,
0.5787167549133301,
-0.04180064797401428,
0.1487323790... | |
levels. | [
0.28834182024002075,
0.015883315354585648,
0.46071332693099976,
0.19537833333015442,
0.1881428062915802,
-0.06995560228824615,
0.3718017041683197,
-0.06551802903413773,
0.08553430438041687,
-0.7231647968292236,
-0.23589029908180237,
0.40711337327957153,
0.21764059364795685,
0.4823205769062... | |
Ok, so PHP isn't the best language to be dealing with arbitrarily large integers in, considering that it only natively supports 32-bit signed integers. What I'm trying to do though is create a class that could represent an arbitrarily large binary number and be able to perform simple arithmetic operations on two of the... | [
-0.12083430588245392,
0.24919922649860382,
-0.059255316853523254,
0.04373391717672348,
-0.36393803358078003,
0.1763622909784317,
-0.04546383023262024,
-0.07332754880189896,
-0.18891380727291107,
-0.45777106285095215,
0.213588148355484,
0.4789462089538574,
-0.33174774050712585,
-0.126065909... | |
that stores its integer internally as four 32-bit integers. The only problem with this approach is that I'm not sure how to go about handling overflow/underflow issues when manipulating individual chunks of the two operands.
**Approach #2:** Use the bcmath extension, as this looks like something it was designed to tac... | [
0.22589735686779022,
0.3047589957714081,
0.24183771014213562,
-0.17917850613594055,
-0.07824449986219406,
0.10826735198497772,
0.06096835061907768,
-0.4379892945289612,
-0.3850615620613098,
-0.4901815354824066,
0.0458766333758831,
0.5706034898757935,
-0.0912429690361023,
-0.043320931494235... | |
I'll later need to shove into some mcrypt encryption functions).
**Approach #3:** Store the numbers as binary strings (probably LSB first). Theoretically I should be able to store integers of any arbitrary size this way. All I would have to do is write the four basic arithmetic functions to perform add/sub/mult/div on... | [
0.21274958550930023,
0.2610761523246765,
0.613727867603302,
-0.1012725755572319,
-0.0729307234287262,
0.023970184847712517,
0.17667804658412933,
-0.19905255734920502,
-0.24274282157421112,
-0.5157085657119751,
-0.03726533055305481,
0.7285338044166565,
-0.07522062957286835,
-0.0853553712368... | |
that PHP doesn't offer me any way to manipulate the individual bits (that I know of). I believe I'd have to break it up into byte-sized chunks (no pun intended), at which point my questions about handling overflow/underflow from Approach #1 apply.
The [PHP GMP extension](http://us2.php.net/gmp) will be better for this.... | [
0.11732526123523712,
0.3438429534435272,
0.21366506814956665,
0.12224471569061279,
-0.17178836464881897,
0.19616034626960754,
-0.028034228831529617,
0.14469356834888458,
-0.24029091000556946,
-0.28612959384918213,
-0.10944448411464691,
0.22813749313354492,
-0.09260328114032745,
0.018406338... | |
I want to build a lightweight linux configuration to use for development. The first idea is to use it inside a Virtual Machine under Windows, or old Laptops with 1Gb RAM top. Maybe even a distributable environment for developers.
So the whole idea is to use a LAMP server, Java Application Server (Tomcat or Jetty) and ... | [
0.3609861135482788,
0.16410234570503235,
0.36736035346984863,
0.04574760049581528,
-0.09382057189941406,
-0.17685244977474213,
-0.0991939902305603,
0.1579369306564331,
-0.3591771125793457,
-0.7951753735542297,
-0.10094714909791946,
0.4211573302745819,
-0.30207207798957825,
-0.0969149097800... | |
base personal experiences on this matter. Info about the distros can be easily found in their sites. So please, focus on personal use of those systems
---
Distros
=======
Ubuntu / Xubuntu
----------------
**Pros**:
* Personal Experience in old systems or low RAM environment - @[Schroeder](https://stackoverflow.co... | [
-0.3373320996761322,
0.35307350754737854,
0.153413325548172,
-0.19853469729423523,
-0.09761710464954376,
0.36287540197372437,
0.10833216458559036,
-0.36951151490211487,
-0.4020540416240692,
-0.48753854632377625,
-0.23051434755325317,
0.6517655849456787,
-0.12704963982105255,
0.096005767583... | |
and lightweight computers - @[Ryan](https://stackoverflow.com/users/1811/ryan-guest)
* APT as package manager - @[Kyle](https://stackoverflow.com/users/658/kyle)
* Based on compatibility and usability - @[Kyle](https://stackoverflow.com/users/658/kyle)
---
-- Fell Free to add Prós and Cons on this, so we can compile ... | [
-0.010393881238996983,
0.19497764110565186,
0.180395245552063,
-0.09450343996286392,
-0.20914636552333832,
-0.17554529011249542,
-0.23618602752685547,
-0.07620474696159363,
-0.4534810781478882,
-0.5085896849632263,
-0.23878301680088043,
0.3724570870399475,
-0.18248485028743744,
-0.18170654... | |
Why are SQL distributions so non-standard despite an ANSI standard existing for SQL? Are there really that many meaningful differences in the way SQL databases work or is it just the two databases with which I have been working: MS-SQL and PostgreSQL? Why do these differences arise?
It's a form of "Stealth lock-in". Jo... | [
0.5472841262817383,
0.008597050793468952,
-0.061692509800195694,
0.1157560870051384,
-0.025186317041516304,
-0.15674731135368347,
0.03739599511027336,
0.2869469225406647,
0.01874622516334057,
-0.2777942717075348,
0.4011823236942291,
0.40746983885765076,
-0.08731690794229507,
0.443763673305... | |
will tend to abstract away the proprietary pieces, or avoid the lock-in altogether, if it gets too egregious. | [
0.2910591959953308,
0.32353684306144714,
0.2965453267097473,
0.17803479731082916,
0.6050704121589661,
-0.2264821082353592,
0.0414484441280365,
-0.2750769853591919,
-0.20551297068595886,
-0.3801723122596741,
-0.5466180443763733,
0.2215697020292282,
0.09666001051664352,
0.21282899379730225,
... | |
I have a site running in a Windows shared hosting environment. In their control panel for the shared hosting account I have it set to use ASP.NET version 3.0 but it doesn't say 3.5 SP1 specifically.
How can I view the installed version running on the server where my website is hosted in an asp.net page?
Thanks!
I jus... | [
0.40240979194641113,
0.17786680161952972,
0.28243693709373474,
-0.10016519576311111,
-0.06519860029220581,
-0.2197234332561493,
0.5804763436317444,
0.2619173526763916,
-0.2927359938621521,
-0.8864640593528748,
0.054375242441892624,
0.5515625476837158,
-0.18970730900764465,
0.32393756508827... | |
I suck at math. I need to figure out how to calculate a video duration with only a few examples of values. For example, a value of 70966 is displayed as 1:10 minutes. A value of 30533 displays as 30 seconds. A value of 7007 displays as 7 seconds.
Looks like the numbers are in milliseconds. So to convert to seconds, div... | [
0.3724974989891052,
-0.1772344410419464,
0.5439202785491943,
0.19503384828567505,
-0.16019456088542938,
0.11188610643148422,
0.39475637674331665,
0.09310252964496613,
-0.3364398777484894,
-0.1758643239736557,
0.09730923175811768,
0.16188672184944153,
0.26263076066970825,
0.3835389614105224... | |
Because regular expressions scare me, I'm trying to find a way to remove all HTML tags and resolve HTML entities from a string in Python.
Use [lxml](http://lxml.de/) which is the best xml/html library for python.
```
import lxml.html
t = lxml.html.fromstring("...")
t.text_content()
```
And if you just want to saniti... | [
0.325296550989151,
0.11905592679977417,
0.27104896306991577,
-0.10288386046886444,
-0.2708771824836731,
0.0017000844236463308,
0.6330149173736572,
-0.08079744875431061,
-0.25380125641822815,
-0.5745225548744202,
-0.05975063145160675,
0.5255934000015259,
-0.6793634295463562,
-0.145250931382... | |
Thanks to a Q&A on stackoverflow. I just found out how to determine the installed version on my hosting provider's server. Now I need to know what that number means.
Using `<%=Environment.Version%>` on my local machine returns 2.0.50727.3053.
Can someone give me a list of the version 1, 1.1, 2, etc. to the actual `En... | [
0.492403119802475,
0.20398060977458954,
0.3719651699066162,
-0.09797679632902145,
-0.13970910012722015,
-0.26209110021591187,
0.4728088676929474,
-0.09898508340120316,
-0.35386091470718384,
-0.7098109722137451,
0.002929960610345006,
0.47959479689598083,
-0.23243150115013123,
0.144356608390... | |
I used the LINQ to SQL designer in Visual Studio to create an object model of a database. Now, I want to add XML comments to each generated property but I can't figure out how to do it without erasing the properties the next time the dbml file is refreshed.
How can this be done?
> Is there a way to determine at what p... | [
0.10858386754989624,
0.15379595756530762,
0.2598622739315033,
0.159262016415596,
-0.01594218984246254,
-0.06108492985367775,
0.05658969655632973,
-0.387667715549469,
-0.2759236693382263,
-0.5484829545021057,
0.21258164942264557,
0.33648645877838135,
-0.23771126568317413,
0.2528029978275299... | |
How much of it is already used up depends on what your app (and the libraries your app uses) has previously done - this is often impossible to predict
* How much of the stack each call requires depends on what you do in your function. If you only allocate say 1 integer on the stack, you may be able to recurse an enourm... | [
0.16334810853004456,
0.04662151634693146,
0.2726637125015259,
0.20959247648715973,
0.25624680519104004,
0.3237251043319702,
0.20252777636051178,
-0.3088117241859436,
-0.4203858971595764,
-0.5466565489768982,
0.02773544378578663,
0.34959113597869873,
-0.14712834358215332,
-0.054994855076074... | |
far more prefereable for my app to just crash, than for it to loop forever using 100% CPU and have to be forcefully killed (this is a right PITA on a remote server over a bad connection as windows lacks SSH)
A rough guideline: Do you think your recursive function is likely to call itself more than say 10,000 times con... | [
0.23451027274131775,
-0.06705857813358307,
0.019104108214378357,
0.1468403935432434,
-0.03624218702316284,
-0.26707157492637634,
0.618577778339386,
0.143703892827034,
-0.4309260845184326,
-0.343205988407135,
-0.04871997982263565,
0.3963525593280792,
-0.19553528726100922,
-0.005433749873191... | |
I've got a bunch of FoxPro (VFP9) DBF files on my Ubuntu system, is there a library to open these in Python? I only need to read them, and would preferably have access to the memo fields too.
**Update**: Thanks @cnu, I used Yusdi Santoso's [`dbf.py`](http://www.physics.ox.ac.uk/users/santoso/dbf.py.src) and it works n... | [
0.40035101771354675,
0.36385369300842285,
-0.01959878019988537,
0.18096712231636047,
-0.05079982429742813,
0.11357201635837555,
0.15252330899238586,
0.04950623959302902,
0.025930307805538177,
-0.7911848425865173,
-0.019914550706744194,
0.3139578700065613,
-0.009990043938159943,
0.178032189... | |
How do I find duplicate addresses in a database, or better stop people already when filling in the form ? I guess the earlier the better?
Is there any good way of abstracting street, postal code etc so that typos and simple attempts to get 2 registrations can be detected? like:
```
Quellenstrasse 66/11
Quellenstr. ... | [
0.4060165584087372,
0.31325212121009827,
0.11060550808906555,
0.180979385972023,
0.08033916354179382,
-0.01908392645418644,
0.4851174056529999,
0.10654129832983017,
-0.16179271042346954,
-0.7348558902740479,
0.16396407783031464,
0.12259472906589508,
-0.14428137242794037,
0.1160225793719291... | |
approach was to take our existing corpus of addresses (150k or so), then apply the most common transformations for our domain (Ireland, so "Dr"->"Drive", "Rd"->"Road", etc). I'm afraid there was no comprehensive online resource for such things at the time, so we ended up basically coming up with a list ourselves, check... | [
0.27623939514160156,
0.3001490831375122,
0.032763104885816574,
0.07803136855363846,
0.16617436707019806,
0.11293070763349533,
0.12291523069143295,
0.06056138500571251,
-0.3600231409072876,
-0.6036750078201294,
0.017265012487769127,
0.10591919720172882,
-0.10700668394565582,
0.2211894840002... | |
of address abbreviations](https://sites.google.com/site/masteraddressfile//zp4/abbrev), although it's american english, so I'm not sure how useful it'd be in Germany! A quick google turned up a couple of sites, but they seemed like spammy newsletter sign-up traps. Although that was me googling in english, so you may ha... | [
0.4879385232925415,
0.5864309072494507,
0.36995428800582886,
-0.21365530788898468,
0.049921803176403046,
-0.3435557186603546,
0.8452845811843872,
0.1882731318473816,
-0.08989477902650833,
-0.41518494486808777,
-0.0638810470700264,
0.2391006499528885,
-0.046112243086099625,
0.02156558446586... | |
So I've been using InstantRails to check out Ruby on rails. I've been using Notepad++ for the editing. Now I don't want to install Ruby or Rails on my machine. Is there any walk through/tutorial on how to integrate Radrails or Netbeans with InstantRails?
Here's a tutorial: <http://ruby.meetup.com/73/boards/view/viewthr... | [
0.10259030759334564,
-0.1292758584022522,
-0.06425344198942184,
-0.10872503370046616,
-0.3269754648208618,
0.07154916226863861,
0.48022890090942383,
-0.01459822990000248,
-0.3332643210887909,
-0.6004514694213867,
0.38343414664268494,
0.3797781467437744,
-0.21127966046333313,
-0.03324139490... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.