
Training Details by Helios
🎉 Overview
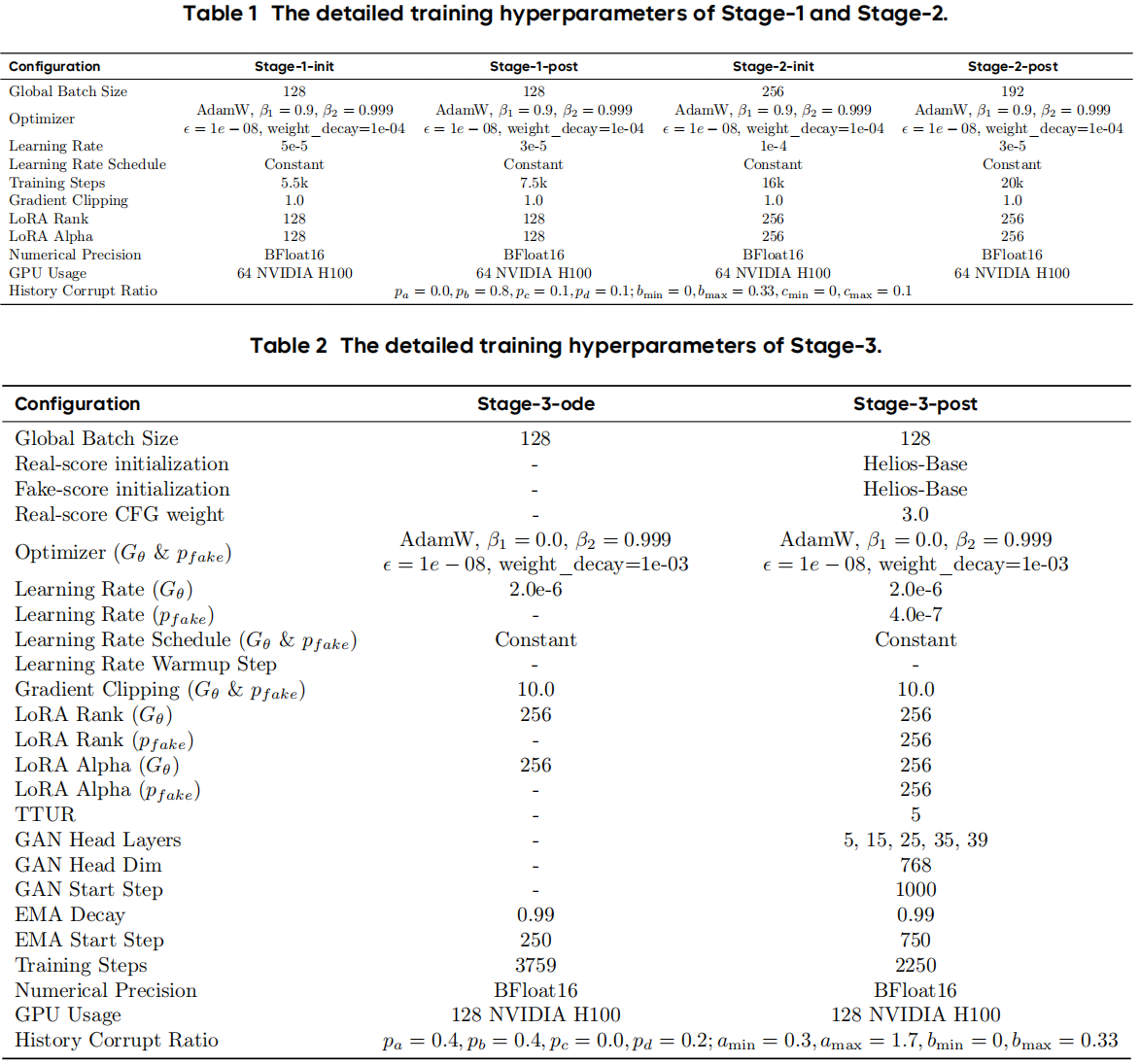
We use a three-stage progressive pipeline, all the setting can be found here. Stage-1 (Base) performs architectural adaptation: we apply Unified History Injection, Easy Anti-Drifting, and Multi-Term Memory Patchification to convert the bidirectional pretrained model into an autoregressive generator. Stage-2 (Mid) targets token compression by introducing Pyramid Unified Predictor Corrector, which aggressively reduces the number of noisy tokens and thus the overall computation. Stage-3 (Distilled) applies Adversarial Hierarchical Distillation, reducing the sampling steps from 50 to 3 and eliminating the need for classifier-free guidance (CFG). Throughout training, we apply dynamic shifting to all timestep-dependent operations to match the noise schedule to the latent size. For Stages 1 and 2, training is further divided into two phases: a high learning-rate phase for rapid convergence, followed by a low learning-rate phase for refinement.
Data Preparation
Please refer to this guide for how to obtain the training data required by Helios. And we prepare a toy training data here.
Run the model
# Use DDP
bash scripts/training/train_ddp.sh
# or
# Use DeepSpeed
bash scripts/training/train_deepspeed.sh
Training configuration can be adjusted in ./configs. You can use ./compare_yaml.py to check for configuration completeness or differences between stages.
Model Merging
After training, you can use this script to merge all the checkpoints and obtain the final safetensors file, similar to this.
💡 Important
Based on the findings in issue #38, we have identified several areas with potential for further improving Helios's performance. These include fixing the train-inference inconsistency in i2v to address the issue where i2v tends to produce very slow motion at the beginning, as well as fully enabling Easy Anti-Drifting to enhance Helios's resistance to quality degradation over time. For the relevant configuration details, please refer to correct.yaml.