
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"hwchase17",
"langchain"
] | I have two tools to manage credits from a bank
One calculate the loan payments and the other get the the interest rate from a table.
```
sql_tool = Tool(
name='Interest rate DB',
func=sql_chain.run,
description="Useful for when you need to answer questions about interest rate of credits"
)
cla... | Execute Actions when response has two actions | https://api.github.com/repos/langchain-ai/langchain/issues/3666/comments | 4 | 2023-04-27T17:44:40Z | 2023-08-31T17:06:46Z | https://github.com/langchain-ai/langchain/issues/3666 | 1,687,296,784 | 3,666 |
[
"hwchase17",
"langchain"
] | **Issue**
Sometimes when doing search similarity using chromaDB wrapper, I run into the following issue:
`RuntimeError(\'Cannot return the results in a contigious 2D array. Probably ef or M is too small\')`
**Some background info:**
ChromaDB is a library for performing similarity search on high-dimensional d... | Chroma DB : Cannot return the results in a contiguous 2D array | https://api.github.com/repos/langchain-ai/langchain/issues/3665/comments | 5 | 2023-04-27T16:44:01Z | 2024-06-27T09:44:47Z | https://github.com/langchain-ai/langchain/issues/3665 | 1,687,201,707 | 3,665 |
[
"hwchase17",
"langchain"
] | got the following error when running today:
``` File "venv/lib/python3.11/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "venv/lib/python3.11/site-packages/langchain/agents/__init__.py", line 2, in <module>
from l... | import error when importing `from langchain import OpenAI` on 0.0.151 | https://api.github.com/repos/langchain-ai/langchain/issues/3664/comments | 21 | 2023-04-27T16:24:30Z | 2023-04-28T17:54:02Z | https://github.com/langchain-ai/langchain/issues/3664 | 1,687,175,750 | 3,664 |
[
"hwchase17",
"langchain"
] | When i use other embedding model,the vector dimensions is always wrong. So i use 'None' to replace ADA_TOKEN_COUNT.
It will be auto compute how many dimensions when first time to use an embedding model.
I use 'GanymedeNil/text2vec-large-chinese' test and success.
so i change this :
embedding: Vector = sqlal... | pgvector embedding length error | https://api.github.com/repos/langchain-ai/langchain/issues/3660/comments | 3 | 2023-04-27T15:57:33Z | 2023-10-07T16:07:39Z | https://github.com/langchain-ai/langchain/issues/3660 | 1,687,134,800 | 3,660 |
[
"hwchase17",
"langchain"
] | have no idea, just install langchain and run code below, the error popup, any idea?
```python
from langchain.document_loaders import UnstructuredPDFLoader, OnlinePDFLoader, UnstructuredImageLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
------------------------------------------------... | ImportError: cannot import name 'Mapped' from 'sqlalchemy.orm' (/home/nvme2/kunzhong/anaconda3/lib/python3.8/site-packages/sqlalchemy/orm/__init__.py) | https://api.github.com/repos/langchain-ai/langchain/issues/3655/comments | 6 | 2023-04-27T14:55:35Z | 2023-09-24T16:07:06Z | https://github.com/langchain-ai/langchain/issues/3655 | 1,687,033,336 | 3,655 |
[
"hwchase17",
"langchain"
] | 
if return text is not str, there is nothing helpful info | logging Generation text type error | https://api.github.com/repos/langchain-ai/langchain/issues/3654/comments | 3 | 2023-04-27T14:48:41Z | 2023-09-10T16:26:05Z | https://github.com/langchain-ai/langchain/issues/3654 | 1,687,020,237 | 3,654 |
[
"hwchase17",
"langchain"
] | Hi there,
I'm using Langchain + AzureOpenAi api. Based on that I'm trying to use the sql agent to run queries against the postgresql table (15.2). In many cases it works fine but once in a while I'm getting an error:
```
Must provide an 'engine' or 'deployment_id' parameter to create a <class 'openai.api_resources... | AzureOpenAi - Sql Agent: must provide an `engine` or `deployment_id` | https://api.github.com/repos/langchain-ai/langchain/issues/3649/comments | 4 | 2023-04-27T12:28:05Z | 2023-04-28T14:14:46Z | https://github.com/langchain-ai/langchain/issues/3649 | 1,686,748,777 | 3,649 |
[
"hwchase17",
"langchain"
] | Hi, using the text-embedding-ada-002 model provided by Azure OpenAI doesnt seem to be working for me. Any fixes? | Azure OpenAI Embeddings model not working | https://api.github.com/repos/langchain-ai/langchain/issues/3648/comments | 5 | 2023-04-27T12:03:40Z | 2023-05-04T03:53:17Z | https://github.com/langchain-ai/langchain/issues/3648 | 1,686,708,535 | 3,648 |
[
"hwchase17",
"langchain"
] | Use my custom LLM model, got warning like this.
Token indices sequence length is longer than the specified maximum sequence length for this model (1266 > 1024). Running this sequence through the model will result in indexing errors
My model max support token is 8k.
Did anyone know what this mean?
``` python... | Token indices sequence length is longer than the specified maximum sequence length for this model | https://api.github.com/repos/langchain-ai/langchain/issues/3647/comments | 2 | 2023-04-27T11:59:19Z | 2023-10-05T16:10:38Z | https://github.com/langchain-ai/langchain/issues/3647 | 1,686,700,270 | 3,647 |
[
"hwchase17",
"langchain"
] | I am using Langchain package to connect to a remote DB. The problem is that it takes a lot of time (sometimes more than 3 minutes) to run the SQLDatabase class. To avoid that long time I am specifying just to load a table but still is taking up to a minute to do that work. Here the code:
```python
from langchain im... | Langchain connection to remote DB takes a lot of time | https://api.github.com/repos/langchain-ai/langchain/issues/3645/comments | 27 | 2023-04-27T11:35:12Z | 2024-07-30T09:27:42Z | https://github.com/langchain-ai/langchain/issues/3645 | 1,686,665,722 | 3,645 |
[
"hwchase17",
"langchain"
] | I think I have found an issue with using ChatVectorDBChain together with HuggingFacePipeline that uses Hugging Face Accelerate.
First, I successfully load and use a ~10GB model pipeline on an ~8GB GPU (setting it to use only ~5GB by specifying `device_map` and `max_memory`), and initialize the vectorstore:
```pyt... | Issue with ChatVectorDBChain and Hugging Face Accelerate | https://api.github.com/repos/langchain-ai/langchain/issues/3642/comments | 1 | 2023-04-27T10:28:29Z | 2023-09-10T16:26:11Z | https://github.com/langchain-ai/langchain/issues/3642 | 1,686,567,730 | 3,642 |
[
"hwchase17",
"langchain"
] | Follow the instruction: https://python.langchain.com/en/latest/modules/agents/tools/examples/bash.html
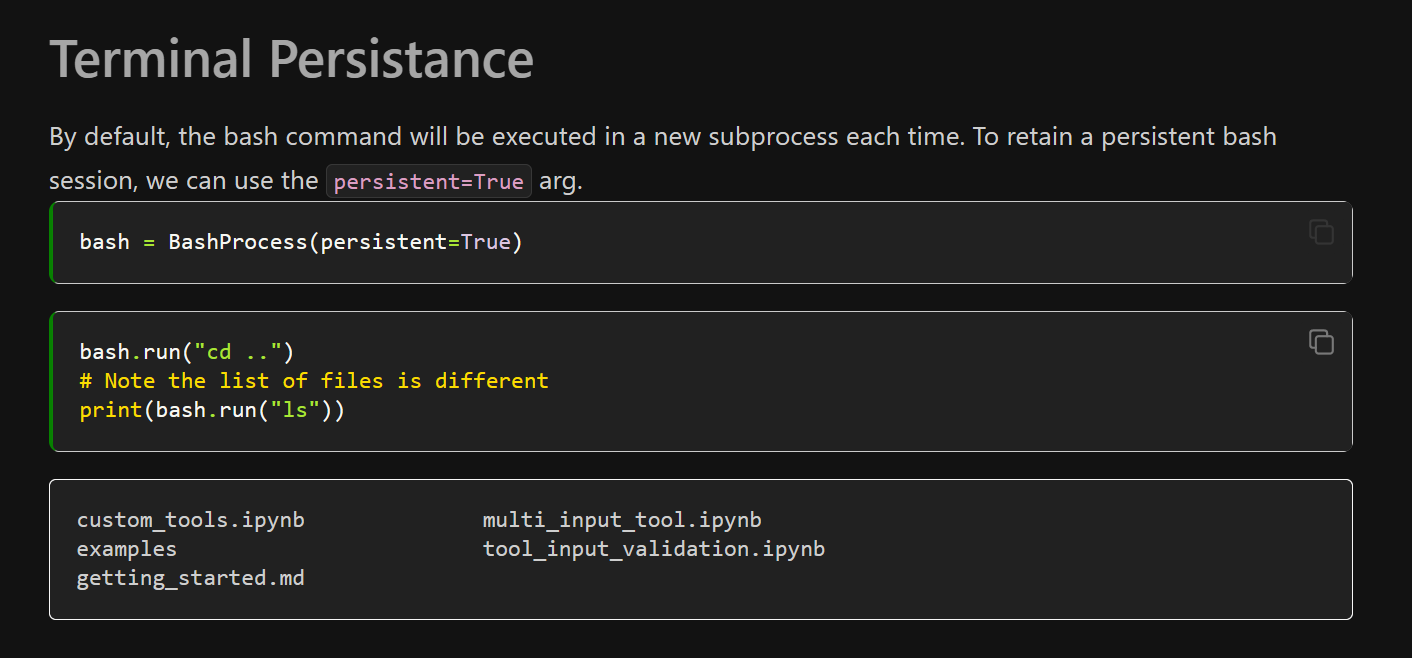
But I get the error:
```
bash = BashProcess(persistent=True)
TypeError: BashProcess.__ini... | no 'persistent=True' tag | https://api.github.com/repos/langchain-ai/langchain/issues/3641/comments | 1 | 2023-04-27T09:42:23Z | 2023-04-27T19:08:03Z | https://github.com/langchain-ai/langchain/issues/3641 | 1,686,495,917 | 3,641 |
[
"hwchase17",
"langchain"
] | I'm attempting to load some Documents and get a `TransformError` - could someone please point me in the right direction? Thanks!
I'm afraid the traceback doesn't mean much to me.
```python
db = DeepLake(dataset_path=deeplake_path, embedding_function=embeddings)
db.add_documents(texts)
```
```
tensor ... | deeplake.util.exceptions.TransformError | https://api.github.com/repos/langchain-ai/langchain/issues/3640/comments | 7 | 2023-04-27T09:03:57Z | 2023-11-27T04:56:27Z | https://github.com/langchain-ai/langchain/issues/3640 | 1,686,435,981 | 3,640 |
[
"hwchase17",
"langchain"
] | Brief summary:
Need to solve multiple tasks in sequence (eg: translate an input -> use it to answer question -> translate to different language)
Previously was making multiple LLMChain objects with different prompts and passing outputs of one chain into another.
Came across sequential chains, tried it.
I didnt... | Sequential chains vs multiple LLMChains (Why prefer one over the other?) | https://api.github.com/repos/langchain-ai/langchain/issues/3638/comments | 5 | 2023-04-27T07:12:50Z | 2023-10-21T16:09:41Z | https://github.com/langchain-ai/langchain/issues/3638 | 1,686,256,733 | 3,638 |
[
"hwchase17",
"langchain"
] | In the [docs](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/googledrive.html) of the GoogleDriveLoader says ``Currently, only Google Docs are supported``, but then, in the [code](https://github.com/hwchase17/langchain/blob/8e10ac422e4e6b193fc35e1d64d7f0c5208faa8d/langchain/document_l... | Document Loaders: GoogleDriveLoader hidden option to load spread sheets | https://api.github.com/repos/langchain-ai/langchain/issues/3637/comments | 3 | 2023-04-27T06:07:09Z | 2024-02-07T16:30:28Z | https://github.com/langchain-ai/langchain/issues/3637 | 1,686,176,243 | 3,637 |
[
"hwchase17",
"langchain"
] | Hello all,
I have been struggling for the past few days attempting to allow an agent.executor call to reference a text file as a VectorStore and determine the best response, then respond. When the agent eventually calls the VectorDBQAChain chain, it throws the below error stating the inability to redefine run().
... | Unable to call VectorDBQAChain from Executor | https://api.github.com/repos/langchain-ai/langchain/issues/3633/comments | 2 | 2023-04-27T05:25:14Z | 2023-04-27T17:40:28Z | https://github.com/langchain-ai/langchain/issues/3633 | 1,686,139,134 | 3,633 |
[
"hwchase17",
"langchain"
] | I am facing an issue when using the embeddings model that Azure OpenAI offers. Please help. Heres the code below. Assume the azure resource name is azure-resource. This issue is only arising with the text-embeddings-ada-002 model, nothing else
```
os.environ["OPENAI_API_KEY"] = API_KEY
# Loading the document usi... | KeyError: 'Could not automatically map azure-resource to a tokeniser. Arising when using the text-embeddings-ada-002 model. | https://api.github.com/repos/langchain-ai/langchain/issues/3632/comments | 0 | 2023-04-27T05:23:59Z | 2023-04-30T14:54:06Z | https://github.com/langchain-ai/langchain/issues/3632 | 1,686,138,122 | 3,632 |
[
"hwchase17",
"langchain"
] | Using MMR with Chroma currently does not work because the max_marginal_relevance_search_by_vector method calls self.__query_collection with the parameter "include:", but "include" is not an accepted parameter for __query_collection. This appears to be a regression introduced with #3372
Excerpt from max_marginal_rel... | Chroma.py max_marginal_relevance_search_by_vector method currently broken | https://api.github.com/repos/langchain-ai/langchain/issues/3628/comments | 4 | 2023-04-27T00:21:42Z | 2023-05-01T17:47:17Z | https://github.com/langchain-ai/langchain/issues/3628 | 1,685,907,595 | 3,628 |
[
"hwchase17",
"langchain"
] | Hi, i'm using deeplake with the ConversationalRetrievalBuffer (just like in this brand new guide [code understanding](https://python.langchain.com/en/latest/use_cases/code/code-analysis-deeplake.html#prepare-data) encountering the following error when calling:
`answer = chain({"question": user_input, "chat_history":... | Bug: deeplake cosine distance search error | https://api.github.com/repos/langchain-ai/langchain/issues/3623/comments | 1 | 2023-04-26T23:27:06Z | 2023-09-10T16:26:16Z | https://github.com/langchain-ai/langchain/issues/3623 | 1,685,870,712 | 3,623 |
[
"hwchase17",
"langchain"
] | It would be good to get some more documentation and examples of using models other than OpenAI. Currently the docs are really heavily skewed and in some areas such as conversation only offer an OpenAI option.
Thanks | Non OpenAI models | https://api.github.com/repos/langchain-ai/langchain/issues/3622/comments | 2 | 2023-04-26T23:06:51Z | 2023-09-17T17:22:03Z | https://github.com/langchain-ai/langchain/issues/3622 | 1,685,858,023 | 3,622 |
[
"hwchase17",
"langchain"
] | I am having issues with using ConversationalRetrievalChain to chat with a CSV file. It only recognizes the first four rows of a CSV file.
```
loader = CSVLoader(file_path=filepath, encoding="utf-8")
data = loader.load()
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_docu... | ConversationalRetrievalChain with CSV file limited to first 4 rows of data | https://api.github.com/repos/langchain-ai/langchain/issues/3621/comments | 14 | 2023-04-26T22:38:48Z | 2023-09-01T07:29:44Z | https://github.com/langchain-ai/langchain/issues/3621 | 1,685,837,569 | 3,621 |
[
"hwchase17",
"langchain"
] | if the line in BaseConversationalRetrievalChain::_call() (in chains/conversational_retrieval/base.py):
```
docs = self._get_docs(new_question, inputs)
```
returns an empty list of docs, then a subsequent line in the same method:
```
answer, _ = self.combine_docs_chain.combine_docs(docs, **new_inputs)
```
wi... | BaseConversationalRetrievalChain raising error when no Documents are matched | https://api.github.com/repos/langchain-ai/langchain/issues/3617/comments | 1 | 2023-04-26T20:15:11Z | 2023-09-10T16:26:25Z | https://github.com/langchain-ai/langchain/issues/3617 | 1,685,654,780 | 3,617 |
[
"hwchase17",
"langchain"
] | When executing the code for Human as a tool taken directly from documentation I get the following error:
```
ImportError Traceback (most recent call last)
[/Users/anonymous/Library/CloudStorage/OneDrive-UniversityCollegeLondon/Python_Projects/LangChain/delete.ipynb](https://file+.vsc... | Human as a Tool Documentation Out of Date | https://api.github.com/repos/langchain-ai/langchain/issues/3615/comments | 6 | 2023-04-26T19:58:50Z | 2023-04-26T22:11:05Z | https://github.com/langchain-ai/langchain/issues/3615 | 1,685,632,646 | 3,615 |
[
"hwchase17",
"langchain"
] | Hello all, I would like to clarify something regarding indexes, llama connectors etc... I made simple q/a AI app using lanchain with pinecone vector DB, the vector DB is updated from local files on change to that files.. Everything works ok.
Now, how or what is the logic when adding other connectors ? Do I just use ... | Multiple data sources logic ? | https://api.github.com/repos/langchain-ai/langchain/issues/3609/comments | 1 | 2023-04-26T18:23:02Z | 2023-09-17T17:22:08Z | https://github.com/langchain-ai/langchain/issues/3609 | 1,685,505,802 | 3,609 |
[
"hwchase17",
"langchain"
] | Hello, I and deploying RetrievalQAWithSourcesChain with ChatOpenAI model right now.
Unlike OpenAI model, you can provide system message for the model which is a great complement.
But I tried many times, it seems the prompt can not be insert into the chain.
Please suggest what should I do to my code:
```
#Prompt ... | How can I structure prompt temple for RetrievalQAWithSourcesChain with ChatOpenAI model | https://api.github.com/repos/langchain-ai/langchain/issues/3606/comments | 3 | 2023-04-26T18:02:39Z | 2023-09-17T17:22:13Z | https://github.com/langchain-ai/langchain/issues/3606 | 1,685,480,734 | 3,606 |
[
"hwchase17",
"langchain"
] | I am new to using Langchain and attempting to make it work with a locally running LLM (Alpaca) and Embeddings model (Sentence Transformer). When configuring the sentence transformer model with `HuggingFaceEmbeddings` no arguments can be passed to the encode method of the model, specifically `normalize_embeddings=True`.... | Embeddings normalization and similarity metric | https://api.github.com/repos/langchain-ai/langchain/issues/3605/comments | 0 | 2023-04-26T18:02:20Z | 2023-05-30T18:57:06Z | https://github.com/langchain-ai/langchain/issues/3605 | 1,685,480,283 | 3,605 |
[
"hwchase17",
"langchain"
] | I have a doubt if FAISS is a vector database or a search algorithm. The vectorstores.faiss mentions it as a vector database, but is it not a search algorithm? | The vectorstores says faiss as FAISS vector database | https://api.github.com/repos/langchain-ai/langchain/issues/3601/comments | 1 | 2023-04-26T16:28:37Z | 2023-09-10T16:26:41Z | https://github.com/langchain-ai/langchain/issues/3601 | 1,685,351,151 | 3,601 |
[
"hwchase17",
"langchain"
] | Hi Team, I am using opensearch as my vectorstore and trying to create index for documents vectors. but unable to create index:
Getting error:
`ERROR - The embeddings count, 501 is more than the [bulk_size], 500. Increase the value of [bulk_size]`
Can someone please advice ?
Thanks | Unable to create opensearch index. | https://api.github.com/repos/langchain-ai/langchain/issues/3595/comments | 2 | 2023-04-26T14:04:56Z | 2023-09-10T16:26:46Z | https://github.com/langchain-ai/langchain/issues/3595 | 1,685,103,449 | 3,595 |
[
"hwchase17",
"langchain"
] | null | load_qa_chain _ RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! | https://api.github.com/repos/langchain-ai/langchain/issues/3593/comments | 3 | 2023-04-26T14:02:08Z | 2023-10-18T21:42:47Z | https://github.com/langchain-ai/langchain/issues/3593 | 1,685,098,021 | 3,593 |
[
"hwchase17",
"langchain"
] | I am using RetrievalQAWithSourcesChain to get answers on documents that I previously embedded using pinecone. I notice that sometimes that the sources is not populated under the sources key when I run the chain.
I am using pinecone to embed the pdf documents like so:
```python
documents = loader.load()
text... | RetrievalQAWithSourcesChain sometimes does not return sources under sources key | https://api.github.com/repos/langchain-ai/langchain/issues/3592/comments | 7 | 2023-04-26T13:22:28Z | 2023-09-24T16:07:12Z | https://github.com/langchain-ai/langchain/issues/3592 | 1,685,024,756 | 3,592 |
[
"hwchase17",
"langchain"
] | I am using the DirectoryLoader, with the relevant loader class defined
```
DirectoryLoader('.\\src', glob="**/*.md", loader_cls=UnstructuredMarkdownLoader)`
```
I couldn't understand why the following step didn't chunk text into the relevant markdown sections:
```
markdown_splitter = MarkdownTextSplitter(chun... | UnstructuredMarkdownLoader strips Markdown formatting from documents, rendering MarkdownTextSplitter non-functional | https://api.github.com/repos/langchain-ai/langchain/issues/3591/comments | 3 | 2023-04-26T13:02:27Z | 2023-11-02T16:15:34Z | https://github.com/langchain-ai/langchain/issues/3591 | 1,684,990,072 | 3,591 |
[
"hwchase17",
"langchain"
] | So I'm just trying to write a custom agent using `LLMSingleActionAgent` based off the example from the official docs and I ran into this error
>
> File "/usr/local/lib/python3.9/site-packages/langchain/chains/base.py", line 118, in __call__
> return self.prep_outputs(inputs, outputs, return_only_outputs)
> ... | Did not get output keys that were expected. | https://api.github.com/repos/langchain-ai/langchain/issues/3590/comments | 1 | 2023-04-26T12:55:45Z | 2023-09-10T16:26:51Z | https://github.com/langchain-ai/langchain/issues/3590 | 1,684,978,281 | 3,590 |
[
"hwchase17",
"langchain"
] | I'm using OpenAPI agents to access my own APIs. and the LLM I'm using is OpenAI's GPT-4.
When I queried something, LLM just answered not only `Action` and `Action Input`, but also `Observation` and even `Final Answer` with fake data under API_ORCHESTRATOR_PROMPT.
So the agent did not work with `api_planner` and `a... | OpenAPI agents did not execute tools | https://api.github.com/repos/langchain-ai/langchain/issues/3588/comments | 3 | 2023-04-26T12:24:28Z | 2023-09-13T15:59:30Z | https://github.com/langchain-ai/langchain/issues/3588 | 1,684,928,287 | 3,588 |
[
"hwchase17",
"langchain"
] | I am facing an error when calling the OpenAIEmbeddings model. This is my code.
````
import os
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_BASE"] = "base-thing"
os.environ["OPENAI_API_KEY"] = "apikey"
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="m... | AttributeError when calling OpenAIEmbeddings model | https://api.github.com/repos/langchain-ai/langchain/issues/3586/comments | 12 | 2023-04-26T11:07:24Z | 2023-04-27T05:26:43Z | https://github.com/langchain-ai/langchain/issues/3586 | 1,684,804,005 | 3,586 |
[
"hwchase17",
"langchain"
] | Hi,
I have installed langchain-0.0.149 using pip. When trying to run the folloging code I get an import error.
from langchain.retrievers import ContextualCompressionRetriever
Traceback (most recent call last):
File ".../lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3460, in run_code
ex... | import error ContextualCompressionRetriever | https://api.github.com/repos/langchain-ai/langchain/issues/3585/comments | 2 | 2023-04-26T10:39:44Z | 2023-09-10T16:27:02Z | https://github.com/langchain-ai/langchain/issues/3585 | 1,684,762,823 | 3,585 |
[
"hwchase17",
"langchain"
] | Hello!
I am building an ai assistant, with the help of langchain's ConversationRetrievalChain. I built a FastAPI endpoint where users can ask questions from the ai. I store the previous messages in my db. My code:
```
def create_chat_agent():
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo... | ConversationRetrievalChain with memory | https://api.github.com/repos/langchain-ai/langchain/issues/3583/comments | 3 | 2023-04-26T09:40:35Z | 2023-09-27T16:07:31Z | https://github.com/langchain-ai/langchain/issues/3583 | 1,684,664,076 | 3,583 |
[
"hwchase17",
"langchain"
] | 
Token usage calculation is not working:

| Token usage calculation is not working for Asynchronous requests in ChatOpenA | https://api.github.com/repos/langchain-ai/langchain/issues/3579/comments | 2 | 2023-04-26T07:21:28Z | 2023-09-10T16:27:08Z | https://github.com/langchain-ai/langchain/issues/3579 | 1,684,427,942 | 3,579 |
[
"hwchase17",
"langchain"
] | ## Description
ref: https://python.langchain.com/en/latest/modules/agents/tools/examples/chatgpt_plugins.html
Thanks for the great tool.
I'm trying ChatGPT Plugin.
I get an error when I run the sample code in the document.
It looks like it's caused by single quotes.
### output
```
> Entering new Age... | ChatGPT Plugin sample code cannot be executed | https://api.github.com/repos/langchain-ai/langchain/issues/3577/comments | 1 | 2023-04-26T06:37:33Z | 2023-04-26T06:42:31Z | https://github.com/langchain-ai/langchain/issues/3577 | 1,684,371,023 | 3,577 |
[
"hwchase17",
"langchain"
] | I am trying to use the Pandas Agent create_pandas_dataframe_agent, but instead of using OpenAI I am replacing the LLM with LlamaCpp. I am running this in Python 3.9 on a SageMaker notebook, with a ml.g4dn.xlarge instance size. I am having trouble with running this agent and produces a weird error.
The code is as fo... | Issue with using LlamaCpp LLM in Pandas Dataframe Agent | https://api.github.com/repos/langchain-ai/langchain/issues/3569/comments | 9 | 2023-04-26T02:00:54Z | 2023-12-13T16:10:28Z | https://github.com/langchain-ai/langchain/issues/3569 | 1,684,129,288 | 3,569 |
[
"hwchase17",
"langchain"
] | I want to be able to pass pure string text, not as a text file. When I attempt to do so with long documents I get the error about the file name being too long:
```
Traceback (most recent call last):
File "/home/faizi/miniconda3/envs/langchain/lib/python3.10/site-packages/uvicorn/protocols/http/httptools_impl.py", ... | Can only load text as a text file, not as string input | https://api.github.com/repos/langchain-ai/langchain/issues/3561/comments | 8 | 2023-04-25T22:01:15Z | 2023-12-01T16:11:03Z | https://github.com/langchain-ai/langchain/issues/3561 | 1,683,936,827 | 3,561 |
[
"hwchase17",
"langchain"
] | We need a model gateway pattern support for Chains for following reasons:
- We may have external decision making elements that would help route which LLM model would need to handle a request. E.g. vector store.
- Agents don't always cut it with the customization that'd be needed. We will need custom tool building ... | Support for model router pattern for chains to allow for dynamic routing to right chains based on vector store semantics | https://api.github.com/repos/langchain-ai/langchain/issues/3555/comments | 3 | 2023-04-25T21:04:41Z | 2023-09-24T16:07:21Z | https://github.com/langchain-ai/langchain/issues/3555 | 1,683,865,609 | 3,555 |
[
"hwchase17",
"langchain"
] | See `langchain.vectorstores.milvus.Milvus._worker_search`
```python
# Decide to use default params if not passed in.
if param is None:
index_type = self.col.indexes[0].params["index_type"]
param = self.index_params[index_type]
``` | Milvus vector store may search failed when there are multiple indexes | https://api.github.com/repos/langchain-ai/langchain/issues/3546/comments | 0 | 2023-04-25T19:26:09Z | 2023-04-25T19:44:08Z | https://github.com/langchain-ai/langchain/issues/3546 | 1,683,732,337 | 3,546 |
[
"hwchase17",
"langchain"
] | Hello,
I am trying to use webbaseloader to ingest content from a list of urls.
```
from langchain.indexes import VectorstoreIndexCreator
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator().from_loaders([loader])
```
But I got an error like ,
... | VectorstoreIndexCreator cannot load data from WebBaseLoader | https://api.github.com/repos/langchain-ai/langchain/issues/3542/comments | 9 | 2023-04-25T18:25:55Z | 2024-01-30T00:41:19Z | https://github.com/langchain-ai/langchain/issues/3542 | 1,683,644,253 | 3,542 |
[
"hwchase17",
"langchain"
] | From this notebook: https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/zilliz.html
It doesn't work. I search in the issues and it seems someone are starting working on it. Not sure if it is fixed or not.
Here is the error:
`RPC error: [create_index], <MilvusException: (code=1, messag... | Can not connect to vector store in Zilliz | https://api.github.com/repos/langchain-ai/langchain/issues/3538/comments | 1 | 2023-04-25T17:58:38Z | 2023-09-10T16:27:11Z | https://github.com/langchain-ai/langchain/issues/3538 | 1,683,606,201 | 3,538 |
[
"hwchase17",
"langchain"
] | ```
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(template=system_template),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
llm = ChatOpenAI(temperature=0.9)
memory = ConversationB... | AI Prefix and Human Prefix not correctly reflected in | https://api.github.com/repos/langchain-ai/langchain/issues/3536/comments | 20 | 2023-04-25T17:14:29Z | 2024-04-10T13:48:20Z | https://github.com/langchain-ai/langchain/issues/3536 | 1,683,552,593 | 3,536 |
[
"hwchase17",
"langchain"
] | null | How can I add an identification while adding documents to Pinecone? Also, is there any way that I can update any document that I added to Pinecone before? | https://api.github.com/repos/langchain-ai/langchain/issues/3531/comments | 1 | 2023-04-25T15:52:43Z | 2023-09-10T16:27:16Z | https://github.com/langchain-ai/langchain/issues/3531 | 1,683,440,009 | 3,531 |
[
"hwchase17",
"langchain"
] | 
Getting this error While using faiss vector store methods.
Found that in code , the query embedding is wrapped around a List ,
 | https://api.github.com/repos/langchain-ai/langchain/issues/3529/comments | 2 | 2023-04-25T15:24:23Z | 2023-09-10T16:27:22Z | https://github.com/langchain-ai/langchain/issues/3529 | 1,683,394,463 | 3,529 |
[
"hwchase17",
"langchain"
] | How can I add custom prompt to:
```
qa_chain = load_qa_with_sources_chain(llm, chain_type="stuff",)
qa = RetrievalQAWithSourcesChain(combine_documents_chain=qa_chain, retriever=docsearch.as_retriever())
```
There is no prompt= for this class... | Custom prompt to RetrievalQAWithSourcesChain ? | https://api.github.com/repos/langchain-ai/langchain/issues/3523/comments | 26 | 2023-04-25T13:42:04Z | 2023-12-06T17:46:45Z | https://github.com/langchain-ai/langchain/issues/3523 | 1,683,202,939 | 3,523 |
[
"hwchase17",
"langchain"
] | code :
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(pages)
embeddings = OpenAIEmbeddings(openai_api_key=openAiKey)
vector_store = chroma_db.get_vector_store(file_hash_name, embeddings)
vector_store.add_... | thread '<unnamed>' panicked at 'assertion failed: encoder.len() == decoder.len()', src/lib.rs:458:9 | https://api.github.com/repos/langchain-ai/langchain/issues/3521/comments | 1 | 2023-04-25T13:05:54Z | 2023-09-15T22:12:52Z | https://github.com/langchain-ai/langchain/issues/3521 | 1,683,140,695 | 3,521 |
[
"hwchase17",
"langchain"
] | I am registering this issue out to request the addition of multilingual support for Langchain python repo
As the user base for Langchain grows, it is becoming increasingly important to accommodate users from different linguistic backgrounds.
Adding support for the multi-language would enable a wider audience to u... | Request for Multilingual Support in Langchain (docs + etc) | https://api.github.com/repos/langchain-ai/langchain/issues/3520/comments | 4 | 2023-04-25T12:58:27Z | 2023-09-24T16:07:27Z | https://github.com/langchain-ai/langchain/issues/3520 | 1,683,126,113 | 3,520 |
[
"hwchase17",
"langchain"
] | We define some callback manager and a chatbot:
```
from langchain.callbacks import OpenAICallbackHandler
from langchain.callbacks.base import CallbackManager
manager = CallbackManager([OpenAICallbackHandler()])
chatbot = ChatOpenAI(temperature=1, callback_manager=manager)
messages = [SystemMessage(content="")]
... | BaseChatModel.__call__() doesn't trigger any callback | https://api.github.com/repos/langchain-ai/langchain/issues/3519/comments | 2 | 2023-04-25T12:27:36Z | 2023-09-17T17:22:18Z | https://github.com/langchain-ai/langchain/issues/3519 | 1,683,076,298 | 3,519 |
[
"hwchase17",
"langchain"
] | I am using JASON Agent and currently, it is answering only from the JSON.
Even if I say 'hi' it is giving me some random answer from the given JSON.
My goal is to handle smalltalk normally, answer the questions from JSON, and if it is not sure then say I don't know.
I have achieved the I don't know part by modif... | Smalltalk in JSON Agent | https://api.github.com/repos/langchain-ai/langchain/issues/3515/comments | 1 | 2023-04-25T10:49:24Z | 2023-09-10T16:27:32Z | https://github.com/langchain-ai/langchain/issues/3515 | 1,682,922,264 | 3,515 |
[
"hwchase17",
"langchain"
] | I am facing a Warning similar to the one described here #3005
`WARNING:langchain.embeddings.openai:Retrying langchain.embeddings.openai.embed_with_retry.<locals>._completion_with_retry in 4.0 seconds as it raised Timeout: Request timed out: HTTPSConnectionPool(host='api.openai.com', port=443): Read timed out. (read... | Timeout Error OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/3512/comments | 31 | 2023-04-25T10:27:34Z | 2024-06-17T23:33:27Z | https://github.com/langchain-ai/langchain/issues/3512 | 1,682,889,147 | 3,512 |
[
"hwchase17",
"langchain"
] | I want to use from langchain.llms import AzureOpenAI with the following configuration:
os.environ["OPENAI_API_KEY"] = api_key_35
os.environ["OPENAI_API_VERSION"] = "2023-03-15-preview"
Where api_key_35 is the key for AzureOpenAI.
The code is:
llm = AzureOpenAI(
max_tokens=1024
,deployment_name = "gpt-35-turbo"... | Can not use AzureOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/3510/comments | 19 | 2023-04-25T10:09:52Z | 2023-10-05T16:10:49Z | https://github.com/langchain-ai/langchain/issues/3510 | 1,682,859,456 | 3,510 |
[
"hwchase17",
"langchain"
] | I've found that some recent langchain upgrade broke our detection of "agent exceeded max iterations error", returned in https://github.com/hwchase17/langchain/blob/bee59b4689fe23dce1450bde1a5d96b0aa52ee61/langchain/agents/agent.py#L92-L96.
The reason it broke is that we had to detect the response based on response t... | Agent early stopping is difficult to detect on the application level | https://api.github.com/repos/langchain-ai/langchain/issues/3509/comments | 1 | 2023-04-25T09:47:58Z | 2023-09-10T16:27:38Z | https://github.com/langchain-ai/langchain/issues/3509 | 1,682,823,125 | 3,509 |
[
"hwchase17",
"langchain"
] | I want to host a python agent on Gradio. It all works good. Im struggling when wanting to display not only the answer but also the AgentExecutor chain. How can I edit the code, so that also the AgentExecutor chain will be printed in the Gradio app. The Code snippet for that part is the following:
```
def answer_que... | Agent Executor Chain | https://api.github.com/repos/langchain-ai/langchain/issues/3506/comments | 3 | 2023-04-25T08:54:14Z | 2023-11-16T16:08:17Z | https://github.com/langchain-ai/langchain/issues/3506 | 1,682,728,591 | 3,506 |
[
"hwchase17",
"langchain"
] | Anthropic dose not support request timeout setting | Anthropic dose not support request timeout setting | https://api.github.com/repos/langchain-ai/langchain/issues/3502/comments | 1 | 2023-04-25T08:34:16Z | 2023-09-10T16:27:42Z | https://github.com/langchain-ai/langchain/issues/3502 | 1,682,697,890 | 3,502 |
[
"hwchase17",
"langchain"
] | oobabooga/text-generation-webui/ is a popular method of running various models including llama variants on GPU and via llama.cpp. It would be useful to be abl to call its api as it can run and configure LLaMA, llama.cpp, GPT-J, Pythia, OPT, and GALACTICA in various quantisations with LoRA etc.
I know you have just a... | text-generation-webui api | https://api.github.com/repos/langchain-ai/langchain/issues/3499/comments | 6 | 2023-04-25T07:06:54Z | 2023-09-24T16:07:32Z | https://github.com/langchain-ai/langchain/issues/3499 | 1,682,563,350 | 3,499 |
[
"hwchase17",
"langchain"
] | null | how can i modify own LLM to adapt initialize_agent(tools,llm)? | https://api.github.com/repos/langchain-ai/langchain/issues/3498/comments | 1 | 2023-04-25T06:43:20Z | 2023-09-10T16:27:47Z | https://github.com/langchain-ai/langchain/issues/3498 | 1,682,531,129 | 3,498 |
[
"hwchase17",
"langchain"
] | I'm running langchain on a 4xV100 rig on AWS. Currently it only utilizes a single GPU. I was able to get it to run on all GPUs by changing,
https://github.com/hwchase17/langchain/blob/a14d1c02f87d23d9ff5ab36a4c68aeb724499455/langchain/embeddings/huggingface.py#L71
to
```python
print('Using MultiGPU')
pool = self... | Multi GPU support | https://api.github.com/repos/langchain-ai/langchain/issues/3486/comments | 5 | 2023-04-25T03:52:39Z | 2023-10-26T16:08:39Z | https://github.com/langchain-ai/langchain/issues/3486 | 1,682,381,944 | 3,486 |
[
"hwchase17",
"langchain"
] | Start with the following tutorial:
https://python.langchain.com/en/latest/modules/agents/agents/custom_llm_agent.html
But instead of using SerpAPI, use the google search tool:
```python
from langchain.agents import load_tools
tools = load_tools(["google-search"])
```
The step that creates the CustomPromptTem... | Custom agent tutorial doesnt handle replacing SerpAPI with google search tool | https://api.github.com/repos/langchain-ai/langchain/issues/3485/comments | 9 | 2023-04-25T03:42:48Z | 2024-07-26T05:18:58Z | https://github.com/langchain-ai/langchain/issues/3485 | 1,682,376,132 | 3,485 |
[
"hwchase17",
"langchain"
] | With reference to the topic, I'm trying to build a chatbot to perform some action based on a conversation with a user. I believe I could use the "agent" module together with some "tools".
However, with this combination, it seems that the tools are used to provide context (in the form of a string) for the agent to ge... | What is the appropriate module to use if I want to just perform an action? | https://api.github.com/repos/langchain-ai/langchain/issues/3484/comments | 2 | 2023-04-25T03:24:43Z | 2023-09-10T16:27:53Z | https://github.com/langchain-ai/langchain/issues/3484 | 1,682,364,708 | 3,484 |
[
"hwchase17",
"langchain"
] | `class BaseOpenAI(BaseLLM):
"""Wrapper around OpenAI large language models."""
openai_api_base: Optional[str] = None`
Hope ChatOpenAi will support this configuration.
After all gpt-3.5-turbo model is much cheaper. | BaseOpenAI supports openai_api_base configuration but ChatOpenAI doesnot support | https://api.github.com/repos/langchain-ai/langchain/issues/3483/comments | 1 | 2023-04-25T03:22:22Z | 2023-09-10T16:27:57Z | https://github.com/langchain-ai/langchain/issues/3483 | 1,682,363,391 | 3,483 |
[
"hwchase17",
"langchain"
] | The _call function returns result["choices"][0]["text"]
For me result["choices"][0]["text"] includes both the prompt and the answer.
My use case: document summary:
llm = LlamaCpp(model_path=r"D:\AI\Model\vicuna-13B-1.1-GPTQ-4bit-128g.GGML.bin",n_ctx=4000, f16_kv=True)
chain = load_summarize_chain(llm, chain_type... | Llamacpp.py _call returns both prompt and generation | https://api.github.com/repos/langchain-ai/langchain/issues/3478/comments | 4 | 2023-04-25T02:31:49Z | 2023-09-24T16:07:41Z | https://github.com/langchain-ai/langchain/issues/3478 | 1,682,331,011 | 3,478 |
[
"hwchase17",
"langchain"
] | Name: langchain
Version: 0.0.146
Name: opensearch-py
Version: 2.2.0
Even if I build opensearch in docker and run it as per langchain's official documentation, the index is randomly numbered and data is created.
I am not sure if this is how it is supposed to work.
I was imagining that multiple documents are us... | The from_documents in opensensearch may not be working as expected. | https://api.github.com/repos/langchain-ai/langchain/issues/3473/comments | 4 | 2023-04-25T00:08:37Z | 2023-09-24T16:07:46Z | https://github.com/langchain-ai/langchain/issues/3473 | 1,682,215,942 | 3,473 |
[
"hwchase17",
"langchain"
] | Using Langchain, I used Milvus vector db to ingest all my document as per @ https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/milvus.html. Now later I want to get a handle to vector_db and start to query Milvus. How do I achieve this? In the example in the link, it is querying the vector_db i... | Persist pdf data in Milvus for later use | https://api.github.com/repos/langchain-ai/langchain/issues/3471/comments | 11 | 2023-04-24T23:55:18Z | 2023-10-16T16:08:30Z | https://github.com/langchain-ai/langchain/issues/3471 | 1,682,202,998 | 3,471 |
[
"hwchase17",
"langchain"
] | The [`PostgresChatMessageHistory` class](https://github.com/hwchase17/langchain/blob/master/langchain/memory/chat_message_histories/postgres.py). Uses `psygopg 3`; however, the [pyproject.toml file](https://github.com/hwchase17/langchain/blob/master/pyproject.toml) only includes `psycopg2-binary` instead of `psycopg[bi... | Missing Dependency for PostgresChatMessageHistory (dependent on psycopg 3, but psycopg 2 listed in requirements) | https://api.github.com/repos/langchain-ai/langchain/issues/3467/comments | 4 | 2023-04-24T23:23:46Z | 2023-12-22T12:47:05Z | https://github.com/langchain-ai/langchain/issues/3467 | 1,682,183,340 | 3,467 |
[
"hwchase17",
"langchain"
] | My query code is below:
```
pinecone.init(
api_key=os.environ.get('PINECONE_API_KEY'), # app.pinecone.io
environment=os.environ.get('PINECONE_ENV') # next to API key in console
)
index = pinecone.Index(index_name)
embeddings = OpenAIEmbeddings(openai_api_key=os.environ.get('OPENAI_API_KEY'))
vectord... | Pinecone retriever throwing: KeyError: 'text' | https://api.github.com/repos/langchain-ai/langchain/issues/3460/comments | 17 | 2023-04-24T18:02:53Z | 2024-05-19T00:22:40Z | https://github.com/langchain-ai/langchain/issues/3460 | 1,681,773,975 | 3,460 |
[
"hwchase17",
"langchain"
] | I get this error occasionally when running the calculator tool, and seems like lots of other people are dealing with weird outputs from agents [like here](https://github.com/hwchase17/langchain/issues/2276). I'm seeing just random junk on the end of my objects returned from agents:
```
File "c:\Users\djpec\Document... | Conversational Chat Agent: json.decoder.JSONDecodeError | https://api.github.com/repos/langchain-ai/langchain/issues/3455/comments | 4 | 2023-04-24T17:48:32Z | 2023-09-24T16:07:57Z | https://github.com/langchain-ai/langchain/issues/3455 | 1,681,753,632 | 3,455 |
[
"hwchase17",
"langchain"
] |
On `langchain==0.0.147`
I get
```python
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer,
model_kwargs=llm_kwargs, device=device)
hf = HuggingFacePipeline(pipeline=pipe)
print(hf.model_id)
```
always gives `gpt2`, irrespective of what `model` is.
| model_id remains set to 'gpt2' when creating HuggingFacePipeline from pipeline | https://api.github.com/repos/langchain-ai/langchain/issues/3451/comments | 6 | 2023-04-24T17:15:05Z | 2024-02-11T16:20:36Z | https://github.com/langchain-ai/langchain/issues/3451 | 1,681,712,468 | 3,451 |
[
"hwchase17",
"langchain"
] | I have been trying to stream the response using AzureChatOpenAI and it didn't call my MyStreamingCallbackHandler() until I finally set verbose=True and it started to work.
Is it a bug? I failed to find any indication in the docs about streaming requiring verbose=True when calling AzureChatOpenAI .
```
chat_m... | Streaming not working unless I set verbose=True in AzureChatOpenAI() | https://api.github.com/repos/langchain-ai/langchain/issues/3449/comments | 3 | 2023-04-24T16:20:34Z | 2023-08-22T17:50:42Z | https://github.com/langchain-ai/langchain/issues/3449 | 1,681,634,934 | 3,449 |
[
"hwchase17",
"langchain"
] | ```
Traceback (most recent call last):
File "/home/gptbot/cogs/search_service_cog.py", line 322, in on_message
response, stdout_output = await capture_stdout(
File "/home/gptbot/cogs/search_service_cog.py", line 79, in capture_stdout
result = await func(*args, **kwargs)
File "/usr/lib/python3.9/conc... | Broken intermediate output / parsing is grossly unreliable | https://api.github.com/repos/langchain-ai/langchain/issues/3448/comments | 22 | 2023-04-24T16:02:21Z | 2024-05-24T15:21:22Z | https://github.com/langchain-ai/langchain/issues/3448 | 1,681,601,217 | 3,448 |
[
"hwchase17",
"langchain"
] | I'm building a flow where I'm using both gpt-3.5 and gpt-4 based chains and I need to use different API keys for each (due to API access + external factors)
Both `ChatOpenAI` and `OpenAI` set `openai.api_key = openai_api_key` which is a global variable on the package.
This means that if I instantiate multiple Cha... | Encapsulate API keys | https://api.github.com/repos/langchain-ai/langchain/issues/3446/comments | 4 | 2023-04-24T15:12:21Z | 2023-09-24T16:08:02Z | https://github.com/langchain-ai/langchain/issues/3446 | 1,681,513,674 | 3,446 |
[
"hwchase17",
"langchain"
] | I wonder if this work: https://arxiv.org/abs/2304.11062
Could be integrated with LangChain | Possible Enhancement | https://api.github.com/repos/langchain-ai/langchain/issues/3445/comments | 1 | 2023-04-24T14:51:55Z | 2023-09-10T16:28:02Z | https://github.com/langchain-ai/langchain/issues/3445 | 1,681,468,911 | 3,445 |
[
"hwchase17",
"langchain"
] | Hi, I'm trying to use the examples for Azure OpenAI with langchain, for example this notebook in https://python.langchain.com/en/harrison-docs-refactor-3-24/modules/models/llms/integrations/azure_openai_example.html , but I always find this error:
Exception has occurred: InvalidRequestError Resource not found
I h... | Azure OpenAI - Exception has occurred: InvalidRequestError Resource not found | https://api.github.com/repos/langchain-ai/langchain/issues/3444/comments | 8 | 2023-04-24T14:31:33Z | 2023-09-24T16:08:07Z | https://github.com/langchain-ai/langchain/issues/3444 | 1,681,415,525 | 3,444 |
[
"hwchase17",
"langchain"
] | Hello, I came across a code snippet in the tutorial page on "Conversation Agent (for Chat Models)" that has left me a bit confused. The tutorial also mentioned a warning error like this:
`WARNING:root:Failed to default session, using empty session: HTTPConnectionPool(host='localhost', port=8000): Max retries exceeded ... | Question about setting LANGCHAIN_HANDLER environment variable | https://api.github.com/repos/langchain-ai/langchain/issues/3443/comments | 4 | 2023-04-24T14:08:05Z | 2024-01-06T18:09:31Z | https://github.com/langchain-ai/langchain/issues/3443 | 1,681,362,534 | 3,443 |
[
"hwchase17",
"langchain"
] | Aim::
aim.Text(outputs_res["output"]), name="on_chain_end", context=resp
KeyError: 'output'
Wandb::
resp.update({"action": "on_chain_end", "outputs": outputs["output"]})
KeyError: 'output'
Has anyone dealt with this issue yet while building custom agents with LLMSingleActionAgent, thank you | LLMOps integration of Aim and Wandb breaks when trying to parse agent output into dashboard for experiment tracking... | https://api.github.com/repos/langchain-ai/langchain/issues/3441/comments | 1 | 2023-04-24T12:07:58Z | 2023-09-10T16:28:08Z | https://github.com/langchain-ai/langchain/issues/3441 | 1,681,126,941 | 3,441 |
[
"hwchase17",
"langchain"
] | I think that among the actions that the agent can take, there may be actions without input. (e.g. return the current state in real time)
But in practice, LM often does that, but current MRKL parsers don't allow it. I'm a newbie so I don't know, but is there a special reason?
Will there be a problem if I change it... | [mrkl/output_parser.py] Behavior when there is no action input? | https://api.github.com/repos/langchain-ai/langchain/issues/3438/comments | 1 | 2023-04-24T10:19:03Z | 2023-09-10T16:28:13Z | https://github.com/langchain-ai/langchain/issues/3438 | 1,680,927,591 | 3,438 |
[
"hwchase17",
"langchain"
] | Just an early idea of an agent i wanted to share:
The cognitive interview is a police interviewing technique used to gather information from witnesses of specific events. It is based on the idea that witnesses may not remember everything they saw, but their memory can be improved by certain psychological techniques.... | Cognitive interview agent | https://api.github.com/repos/langchain-ai/langchain/issues/3436/comments | 1 | 2023-04-24T10:07:20Z | 2023-09-10T16:28:18Z | https://github.com/langchain-ai/langchain/issues/3436 | 1,680,907,446 | 3,436 |
[
"hwchase17",
"langchain"
] | I am building an agent toolkit for APITable, a SaaS product, with the ultimate goal of enabling natural language API calls. I want to know if I can dynamically import a tool?
My idea is to create a `tool_prompt.txt` file with contents like this:
```
Get Spaces
Mode: get_spaces
Description: This tool is useful ... | How to combine tools and vectorstores | https://api.github.com/repos/langchain-ai/langchain/issues/3435/comments | 1 | 2023-04-24T10:02:55Z | 2023-06-13T09:21:10Z | https://github.com/langchain-ai/langchain/issues/3435 | 1,680,898,670 | 3,435 |
[
"hwchase17",
"langchain"
] | BaseOpenAI's validate_environment does not set OPENAI_API_TYPE and OPENAI_API_VERSION from environment. As a result, the AzureOpenAI instance failed when called to run.
```
from langchain.llms import AzureOpenAI
from langchain.chains import RetrievalQA
model = RetrievalQA.from_chain_type(
llm=AzureOpenAI(... | AzureOpenAI instance fails because OPENAI_API_TYPE and OPENAI_API_VERSION are not inherited from environment | https://api.github.com/repos/langchain-ai/langchain/issues/3433/comments | 2 | 2023-04-24T08:41:56Z | 2023-04-25T10:02:39Z | https://github.com/langchain-ai/langchain/issues/3433 | 1,680,741,720 | 3,433 |
[
"hwchase17",
"langchain"
] | I am using the huggingface hosted vicuna-13b model ([link](https://huggingface.co/eachadea/vicuna-13b-1.1)) along with llamaindex and langchain to create a functioning chatbot on custom data ([link](https://github.com/jerryjliu/llama_index/blob/main/examples/chatbot/Chatbot_SEC.ipynb)). However, I'm always getting this... | ValueError: Could not parse LLM output: ` ` | https://api.github.com/repos/langchain-ai/langchain/issues/3432/comments | 1 | 2023-04-24T08:17:11Z | 2023-09-10T16:28:23Z | https://github.com/langchain-ai/langchain/issues/3432 | 1,680,704,272 | 3,432 |
[
"hwchase17",
"langchain"
] | Specifying max_iterations does not take effect when using create_json_agent. The following code is from [this page](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/json.html?highlight=JsonSpec#initialization), with max_iterations added:
```
import os
import yaml
from langchain.agents imp... | Cannot specify max iterations when using create_json_agent | https://api.github.com/repos/langchain-ai/langchain/issues/3429/comments | 4 | 2023-04-24T07:44:17Z | 2023-12-30T16:08:53Z | https://github.com/langchain-ai/langchain/issues/3429 | 1,680,648,980 | 3,429 |
[
"hwchase17",
"langchain"
] | I've noticed recently that the performance of the `zero-shot-react-description` agent has decreased significantly for various tasks and various tools. A very simple example attached, which a few weeks ago would pass perfectly maybe 80% of the time, but now hasn't managed a reasonable attempt in >10 tries. The main issu... | `zero-shot-react-description` performance has decreased? | https://api.github.com/repos/langchain-ai/langchain/issues/3428/comments | 1 | 2023-04-24T07:32:38Z | 2023-09-10T16:28:28Z | https://github.com/langchain-ai/langchain/issues/3428 | 1,680,632,696 | 3,428 |
[
"hwchase17",
"langchain"
] | Hi.
I try to run the following code
```
connection_string = "DefaultEndpointsProtocol=https;AccountName=<myaccount>;AccountKey=<mykey>"
container="<mycontainer>"
loader = AzureBlobStorageContainerLoader(
conn_str=connection_string,
container=container
)
documents = loader.load()
```
but the code `d... | AzureBlobStorageContainerLoader doesn't load the container | https://api.github.com/repos/langchain-ai/langchain/issues/3427/comments | 2 | 2023-04-24T07:22:28Z | 2023-04-25T01:20:11Z | https://github.com/langchain-ai/langchain/issues/3427 | 1,680,619,340 | 3,427 |
[
"hwchase17",
"langchain"
] | I like how it prints out the specific texts used in generating the answer (much better than just citing the sources IMO). How can I access it? Referring to here: https://python.langchain.com/en/latest/modules/chains/index_examples/chat_vector_db.html#conversationalretrievalchain-with-streaming-to-stdout
| In `ConversationalRetrievalChain` with streaming to `stdout` how can I access the text printed to `stdout` once it finishes streaming? | https://api.github.com/repos/langchain-ai/langchain/issues/3417/comments | 1 | 2023-04-24T03:59:25Z | 2023-09-10T16:28:33Z | https://github.com/langchain-ai/langchain/issues/3417 | 1,680,404,463 | 3,417 |
[
"hwchase17",
"langchain"
] | Current documentation text under Text Splitter throws error :
texts = text_splitter.create_documents([state_of_the_union])
<img width="968" alt="Screen Shot 2023-04-23 at 9 04 28 PM" src="https://user-images.githubusercontent.com/31634379/233891248-f3b5e187-272e-4822-8cd6-00a1cf56ffae.png">
The error is on both t... | Documentation error under Text Splitter | https://api.github.com/repos/langchain-ai/langchain/issues/3414/comments | 2 | 2023-04-24T03:06:47Z | 2023-09-28T16:07:35Z | https://github.com/langchain-ai/langchain/issues/3414 | 1,680,368,808 | 3,414 |
[
"hwchase17",
"langchain"
] | In the agent tutorials the memory_key is set as a fixed string, "chat_history", how do I make it a variable, that is different for each session_id, that is memory_key=str(session_id)? | memory_key as a variable | https://api.github.com/repos/langchain-ai/langchain/issues/3406/comments | 4 | 2023-04-23T23:05:24Z | 2023-09-17T17:22:23Z | https://github.com/langchain-ai/langchain/issues/3406 | 1,680,213,151 | 3,406 |
[
"hwchase17",
"langchain"
] | ---------------------------------------------------------------------------
InvalidRequestError Traceback (most recent call last)
[<ipython-input-26-5eed72c1ccb8>](https://localhost:8080/#) in <cell line: 3>()
2
----> 3 agent.run(["What were the winning boston marathon times for the... | marathon_times.ipynb: InvalidRequestError: This model's maximum context length is 4097 tokens. | https://api.github.com/repos/langchain-ai/langchain/issues/3405/comments | 5 | 2023-04-23T21:13:04Z | 2023-09-24T16:08:17Z | https://github.com/langchain-ai/langchain/issues/3405 | 1,680,179,456 | 3,405 |
[
"hwchase17",
"langchain"
] | Text mentions inflation and tuition:
Here is the prompt comparing inflation and college tuition.
Code is about marathon times:
agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."]) | marathon_times.ipynb: mismatched text and code | https://api.github.com/repos/langchain-ai/langchain/issues/3404/comments | 0 | 2023-04-23T21:06:49Z | 2023-04-24T01:14:13Z | https://github.com/langchain-ai/langchain/issues/3404 | 1,680,177,766 | 3,404 |
[
"hwchase17",
"langchain"
] | i tried out a simple custom model. as long as i am using only one "query" parameter everything is working fine. in this example i like to use two parameters (i searched the problem and i found this SendMessage usecase...)
unfortunately it does not work.. and throws this error.
`input_args.validate({key_: tool_i... | Custom Model with args_schema not working | https://api.github.com/repos/langchain-ai/langchain/issues/3403/comments | 7 | 2023-04-23T20:16:33Z | 2023-10-05T16:10:53Z | https://github.com/langchain-ai/langchain/issues/3403 | 1,680,154,536 | 3,403 |
[
"hwchase17",
"langchain"
] |
I have been trying multiple approaches to use headers in the requests chain. Here's my code:
I have been trying multiple approaches to use headers in the requests chain. Here's my code:
from langchain.utilities import TextRequestsWrapper
import json
requests = TextRequestsWrapper()
headers = {
... | Not able to Pass in Headers in the Requests module | https://api.github.com/repos/langchain-ai/langchain/issues/3402/comments | 2 | 2023-04-23T19:08:24Z | 2023-04-27T17:58:55Z | https://github.com/langchain-ai/langchain/issues/3402 | 1,680,133,937 | 3,402 |
[
"hwchase17",
"langchain"
] | Elastic supports generating embeddings using [embedding models running in the stack](https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding).
Add a the ability to generate embeddings with Elasticsearch in langchain similar to other embedding modules. | Add support for generating embeddings in Elasticsearch | https://api.github.com/repos/langchain-ai/langchain/issues/3400/comments | 1 | 2023-04-23T18:40:54Z | 2023-05-24T05:40:38Z | https://github.com/langchain-ai/langchain/issues/3400 | 1,680,125,057 | 3,400 |
[
"hwchase17",
"langchain"
] | Can you please help me with connecting my LangChain agent to a MongoDB database? I know that it's possible to directly connect to a SQL database using this resource [https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html](url) but I'm not sure if the same approach can be used with Mon... | Connection with mongo db | https://api.github.com/repos/langchain-ai/langchain/issues/3399/comments | 11 | 2023-04-23T18:03:33Z | 2024-02-15T16:12:00Z | https://github.com/langchain-ai/langchain/issues/3399 | 1,680,114,161 | 3,399 |
[
"hwchase17",
"langchain"
] | Hey
I'm getting `TypeError: 'StuffDocumentsChain' object is not callable`
the code snippet can be found here:
```
def main():
text_splitter = CharacterTextSplitter(chunk_size=2000, chunk_overlap=50)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(openai_api_key=api_... | object is not callable | https://api.github.com/repos/langchain-ai/langchain/issues/3398/comments | 2 | 2023-04-23T17:43:35Z | 2024-04-30T20:26:24Z | https://github.com/langchain-ai/langchain/issues/3398 | 1,680,107,688 | 3,398 |
[
"hwchase17",
"langchain"
] | The example in the documentation raises a `GuessedAtParserWarning`
To replicate:
```python
#!wget -r -A.html -P rtdocs https://langchain.readthedocs.io/en/latest/
from langchain.document_loaders import ReadTheDocsLoader
loader = ReadTheDocsLoader("rtdocs")
docs = loader.load()
```
```
/config/miniconda3/... | Read the Docs document loader documentation example raises warning | https://api.github.com/repos/langchain-ai/langchain/issues/3396/comments | 0 | 2023-04-23T15:50:35Z | 2023-04-25T04:54:40Z | https://github.com/langchain-ai/langchain/issues/3396 | 1,680,072,310 | 3,396 |
[
"hwchase17",
"langchain"
] | Hello, cloud you help me fix
Error fetching or processing https exeption: URL return an error: 403 when using UnstructuredURLLoader,I'm not sure if this error is a restricted access to the website or a problem with the use of the API, thank you very much | UnstructuredURLLoader Error | https://api.github.com/repos/langchain-ai/langchain/issues/3391/comments | 1 | 2023-04-23T14:45:09Z | 2023-09-10T16:28:50Z | https://github.com/langchain-ai/langchain/issues/3391 | 1,680,051,952 | 3,391 |
[
"hwchase17",
"langchain"
] | `MRKLOutputParser` strips quotes in "Action Input" without checking if they are present on both sides.
See https://github.com/hwchase17/langchain/blob/acfd11c8e424a456227abde8df8b52a705b63024/langchain/agents/mrkl/output_parser.py#L27
Test case that reproduces the problem:
```python
from langchain.agents.mrkl.o... | MRKLOutputParser strips quotes incorrectly and breaks LLM commands | https://api.github.com/repos/langchain-ai/langchain/issues/3390/comments | 1 | 2023-04-23T14:22:00Z | 2023-09-10T16:28:54Z | https://github.com/langchain-ai/langchain/issues/3390 | 1,680,044,740 | 3,390 |
[
"hwchase17",
"langchain"
] | ### The Problem
The `YoutubeLoader` is breaking when using the `from_youtube_url` function. The expected behaviour is to use this module to get transcripts from youtube videos and pass into them to an LLM. Willing to help if needed.
### Specs
```
- Machine: Apple M1 Pro
- Version: langchain 0.0.147
- conda-bui... | Youtube.py: urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1129)> | https://api.github.com/repos/langchain-ai/langchain/issues/3389/comments | 3 | 2023-04-23T13:47:11Z | 2023-09-24T16:08:22Z | https://github.com/langchain-ai/langchain/issues/3389 | 1,680,033,914 | 3,389 |
[
"hwchase17",
"langchain"
] | Hello everyone,
Is it possible to use IndexTree with a local LLM as for istance gpt4all or llama.cpp?
Is there a tutorial? | IndexTree and local LLM | https://api.github.com/repos/langchain-ai/langchain/issues/3388/comments | 1 | 2023-04-23T13:18:07Z | 2023-09-15T22:12:51Z | https://github.com/langchain-ai/langchain/issues/3388 | 1,680,025,245 | 3,388 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.