
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/17974
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17974/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17974/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17974/events
|
https://github.com/huggingface/transformers/issues/17974
| 1,290,577,149
|
I_kwDOCUB6oc5M7KT9
| 17,974
|
openai's CLIP model not working with pytorch 1.12 in some environments
|
{
"login": "buhrmann",
"id": 190342,
"node_id": "MDQ6VXNlcjE5MDM0Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/190342?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/buhrmann",
"html_url": "https://github.com/buhrmann",
"followers_url": "https://api.github.com/users/buhrmann/followers",
"following_url": "https://api.github.com/users/buhrmann/following{/other_user}",
"gists_url": "https://api.github.com/users/buhrmann/gists{/gist_id}",
"starred_url": "https://api.github.com/users/buhrmann/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/buhrmann/subscriptions",
"organizations_url": "https://api.github.com/users/buhrmann/orgs",
"repos_url": "https://api.github.com/users/buhrmann/repos",
"events_url": "https://api.github.com/users/buhrmann/events{/privacy}",
"received_events_url": "https://api.github.com/users/buhrmann/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
|
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hey @buhrmann, there are some known issues with torch 1.12. Torch 1.12.1 was released 4 days ago, do you get the same issues with it?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,662
| 1,662
|
NONE
| null |
### System Info
- `transformers` version: 4.20.1
- Platform: Linux-5.4.170+-x86_64-with-glibc2.31
- Python version: 3.9.12
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.11.0+cu113 (True)
- Tensorflow version (GPU?): 2.7.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help?
@patil-suraj
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
The following works as expected with torch 1.11, but generates the below error in version 1.12:
``` python
import io
import requests
import torch
from PIL import Image
from transformers import CLIPModel, CLIPProcessor
def load_image(bytes, max_width=100, max_height=100, force_rgb=True):
"""Create and optionally resize an image from bytes."""
img = Image.open(io.BytesIO(bytes))
width, height = img.size
if width > max_width or height > max_height:
img.thumbnail(size=(max_width, max_height))
if img.mode != "RGB" and force_rgb:
img = img.convert("RGB")
return img
urls = [
"https://placekitten.com/408/287",
"https://placekitten.com/200/138"
]
images = [load_image(requests.get(url).content) for url in urls]
name = "openai/clip-vit-base-patch32"
proc = CLIPProcessor.from_pretrained(name)
model = CLIPModel.from_pretrained(name)
model.to(torch.device("cuda"))
inputs = proc(images=images, return_tensors="pt").to(torch.device("cuda"))
embeddings = model.get_image_features(**inputs).detach().cpu().numpy()
```
This results in:
``` log
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [1], in <cell line: 41>()
38 model.to(torch.device("cuda"))
40 inputs = proc(images=images, return_tensors="pt").to(torch.device("cuda"))
---> 41 embeddings = model.get_image_features(**inputs).detach().cpu().numpy()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
```
Here is how I test the different versions, keep all else the same:
```
!pip uninstall -y torch torchvision torchaudio
!pip install --no-cache-dir torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# !pip install --no-cache-dir torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
```
And here some more info about the hardware environment:
``` log
┌─────────── System Report ────────────┐
│ Linux │
│ Linux-5.4.170+-x86_64-with-glibc2.31 │
│ │
│ CPUs │
│ ┌──────────┬────────┐ │
│ │ cores │ # │ │
│ ├──────────┼────────┤ │
│ │ logical │ 2 │ │
│ │ physical │ 1 │ │
│ │ usable │ [0, 1] │ │
│ └──────────┴────────┘ │
│ RAM │
│ ┌───────────┬──────┐ │
│ │ kind │ gb │ │
│ ├───────────┼──────┤ │
│ │ total │ 7.3 │ │
│ │ available │ 5.6 │ │
│ │ used │ 1.5 │ │
│ │ free │ 3.1 │ │
│ │ active │ 2.7 │ │
│ │ inactive │ 1.1 │ │
│ │ buffers │ 0.4 │ │
│ │ cached │ 2.4 │ │
│ │ shared │ 0.0 │ │
│ │ slab │ 0.3 │ │
│ └───────────┴──────┘ │
│ Disk (/home) │
│ ┌───────┬──────┐ │
│ │ kind │ gb │ │
│ ├───────┼──────┤ │
│ │ total │ 48.9 │ │
│ │ used │ 2.3 │ │
│ │ free │ 46.6 │ │
│ └───────┴──────┘ │
│ GPU │
│ ┌────────────────┬─────────────────┐ │
│ │ property │ value │ │
│ ├────────────────┼─────────────────┤ │
│ │ name │ Tesla K80 │ │
│ │ driver_version │ 450.119.04 │ │
│ │ vbios_version │ 80.21.25.00.04 │ │
│ │ memory.total │ 11441 MiB │ │
│ │ memory.free │ 11438 MiB │ │
│ │ memory.used │ 3 MiB │ │
│ └────────────────┴─────────────────┘ │
│ Packages │
│ ┌──────────────┬──────────────┐ │
│ │ Package │ Version │ │
│ ├──────────────┼──────────────┤ │
│ │ numpy │ 1.22.0 │ │
│ │ torch │ 1.12.0+cu113 │ │
│ │ transformers │ 4.20.1 │ │
│ └──────────────┴──────────────┘ │
└──────────────────────────────────────┘
```
### Expected behavior
The code should run without CUDA errors.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17974/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17974/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17973
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17973/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17973/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17973/events
|
https://github.com/huggingface/transformers/pull/17973
| 1,290,556,914
|
PR_kwDOCUB6oc46qenB
| 17,973
|
XLA train step fixes
|
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"I'd be interested in having @ydshieh's review as well",
"> If I understand correctly, this changes the loss returned by TensorFlow models from a matrix to a vector, which is obviously breaking. While I don't know how many TensorFlow users rely on the current structure of the loss, we at least need to have a flag (probably `use_xla=False`) to enable the previous behavior for users who relied on it.\r\n> \r\n> Could you confirm first that my understanding is correct?\r\n\r\nI believe both prev. and current version return a vector. The difference is on the size: \r\n\r\n- prev: number of active tokens (non-padding tokens)\r\n- now: batch size",
"@ydshieh I was completely wrong earlier - `SparseCategoricalCrossentropy` only returns `nan` for invalid labels when running on GPU! On CPU, inputs are validated and TensorFlow throws an error.\r\n\r\nI'll rewrite my loss functions to not depend on that behaviour, and change the loss computation tests to mask some positions to ensure that gets tested, so I don't miss anything like this in future.",
"@Rocketknight1 \r\n\r\nhttps://github.com/huggingface/transformers/blob/f17136c80dfec2a78890d012105634079531dcd9/src/transformers/modeling_tf_utils.py#L211-L213\r\n\r\nAs in an earlier comment, I think this loss value is incorrect. Imagine we have 2 sequences of length 100.\r\n- 1st sentence: 1 active token + 99 pad tokens (somehow non-sense 😄 )\r\n- 2nd sentence: 20 active token + 80 pad tokens\r\n\r\nIn this latest version, the unique token in sentence 1 get an weight (when computing the loss) 20 times larger than each token in the 2nd sentence. (As you first average the loss along sequence dimension).\r\n\r\nFurthermore, this doesn't correspond to PyTorch's computation, which leads to test failures (I didn't check in detail if this is the cause, but I believe it is).\r\n\r\n**Q: Is there any reason we don't want to sum each token's loss value?**\r\n\r\ncc @gante @patrickvonplaten @sgugger \r\n\r\n",
"Hi @ydshieh I'm sorry, I think you're right there! Let me investigate and see if I can make a PR to weight tokens properly, which should hopefully resolve the issue.",
"@patrickvonplaten Agreed! I fixed that in https://github.com/huggingface/transformers/pull/18013"
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
This PR makes a bunch of changes to the TF codebase to improve XLA support, in preparation for our upcoming big TF release. The goal is to allow users to use `jit_compile` on the vast majority of our models, which should yield large performance improvements for TF. In particular:
- Rewrites to the `train_step` and `test_step` so that any mutable Python input dicts are not modified in the step. This was a bad idea anyway, but it causes particular problems with XLA, which is very functional and hates side effects, like JAX.
- Rewrites to the common `hf_compute_loss` functions to ensure that static shapes are maintained throughout, so that XLA compilation is possible.
- Add a test to ensure that we can still fit models when XLA compilation is used. XLA compilation is quite expensive, which makes this test quite slow, so it's restricted to `core` models for now and tagged as `@slow`.
Left to do:
- [x] Fix XLA-incompatible model-specific `hf_compute_loss` functions. On a quick search it looked like there were 4-5 of these, so it shouldn't take too long. Any use of `tf.boolean_mask` is a surefire sign that XLA compilation will break, because output shapes become data-dependent.
- [x] See if there's a way to test non-core models for XLA fit support without crippling performance. (No, but we're using the XLA losses in non-XLA tests by default, so that partially tests it for all models)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17973/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17973/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17973",
"html_url": "https://github.com/huggingface/transformers/pull/17973",
"diff_url": "https://github.com/huggingface/transformers/pull/17973.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17973.patch",
"merged_at": 1656699074000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17972
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17972/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17972/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17972/events
|
https://github.com/huggingface/transformers/pull/17972
| 1,290,530,982
|
PR_kwDOCUB6oc46qZCw
| 17,972
|
[Do NOT merge 🙏 ] Skip a particular exception in `test_sample_generate`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Let's maybe put this PR on hold for 1,2 weeks to see if #18053 has solved the issue or not :-)",
"OK, thank you for taking time on this."
] | 1,656
| 1,662
| 1,657
|
COLLABORATOR
| null |
# What does this PR do?
A continuation of #17937 to fix a CI failure
```
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
> next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
E RuntimeError: probability tensor contains either `inf`, `nan` or element < 0
```
As @patrickvonplaten , when a broken generation happens due to all `-inf` scores along the vocab dimension, nothing we can do. This is likely to happen only with random models however.
Let's say goodbye to this flaky situation!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17972/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17972/timeline
| null | true
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17972",
"html_url": "https://github.com/huggingface/transformers/pull/17972",
"diff_url": "https://github.com/huggingface/transformers/pull/17972.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17972.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17971
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17971/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17971/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17971/events
|
https://github.com/huggingface/transformers/issues/17971
| 1,290,520,931
|
I_kwDOCUB6oc5M68lj
| 17,971
|
TrainingArguments does not support `mps` device (Mac M1 GPU)
|
{
"login": "saattrupdan",
"id": 47701536,
"node_id": "MDQ6VXNlcjQ3NzAxNTM2",
"avatar_url": "https://avatars.githubusercontent.com/u/47701536?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/saattrupdan",
"html_url": "https://github.com/saattrupdan",
"followers_url": "https://api.github.com/users/saattrupdan/followers",
"following_url": "https://api.github.com/users/saattrupdan/following{/other_user}",
"gists_url": "https://api.github.com/users/saattrupdan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/saattrupdan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/saattrupdan/subscriptions",
"organizations_url": "https://api.github.com/users/saattrupdan/orgs",
"repos_url": "https://api.github.com/users/saattrupdan/repos",
"events_url": "https://api.github.com/users/saattrupdan/events{/privacy}",
"received_events_url": "https://api.github.com/users/saattrupdan/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"A simple hack fixed the issue, by simply overwriting the `device` attribute of `TrainingArguments`:\r\n\r\n```python\r\nimport torch\r\nfrom transformers import TrainingArguments\r\n\r\n\r\nclass TrainingArgumentsWithMPSSupport(TrainingArguments):\r\n\r\n @property\r\n def device(self) -> torch.device:\r\n if torch.cuda.is_available():\r\n return torch.device(\"cuda\")\r\n elif torch.backends.mps.is_available():\r\n return torch.device(\"mps\")\r\n else:\r\n return torch.device(\"cpu\")\r\n```\r\n\r\nThis at least shows that it might just be the aforementioned `_setup_devices` that needs changing.",
"Another observation: Some PyTorch operations have not been implemented in `mps` and will throw an error. One way to get around that is to set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1`, which will fallback to CPU for these operations. It still throws a `UserWarning` however.",
"This is not supported yet, as this has been introduced by PyTorch 1.12, which also breaks all speech models due to a regression there. We will look into the support for Mac M1 GPUs once we officially support PyTorch 1.12 (probably won't be before they do a patch 1.12.1).",
"@sgugger And it's not possible to add a `use_mps` flag to `TrainingArguments`, which just requires PyTorch 1.12.x, alongside a warning of some kind? Or is that too unstable?",
"I have no idea, since we haven't tried and tested it out yet. And as I said our whole CI is constrained by PyTorch < 1.12 right now, so until that pin is dropped we can't test the integration :-). You can certainly try it on your own fork in the meantime!",
"I'm seeing this odd behavior. I'm trying a code from [here](https://github.com/nlp-with-transformers/notebooks/blob/main/02_classification.ipynb), adapted with @saattrupdan solution. It runs but the problem is that I'm getting very different results when using `cpu` and `mps`. With `device_type = \"cpu\"` I get the expected results (`f1=0.92`) but when using `device_type = \"mps\"` I'm getting a very low f1 (~0.3), likely as a result a random guess. \r\n\r\n\r\n```python\r\ndevice_type = \"mps\"\r\ndevice = torch.device(device_type)\r\n# Tokenizer\r\nfrom transformers import AutoTokenizer\r\nmodel_ckpt = \"distilbert-base-uncased\"\r\ntokenizer = AutoTokenizer.from_pretrained(model_ckpt)\r\ndef tokenize(batch):\r\n return tokenizer(batch[\"text\"],padding = True,truncation = True)\r\n\r\n# Load Data\r\nfrom datasets import list_datasets\r\nfrom datasets import load_dataset\r\nemotions = load_dataset(\"emotion\")\r\nemotions_encoded = emotions.map(tokenize,batched = True,batch_size = None)\r\n\r\n#Model\r\nfrom transformers import AutoModelForSequenceClassification\r\nnum_labels = 6\r\nmodel = (AutoModelForSequenceClassification.from_pretrained(model_ckpt,num_labels = num_labels).to(device))\r\n\r\n#Metric\r\nfrom sklearn.metrics import accuracy_score,f1_score\r\ndef compute_metrics(pred):\r\n labels = pred.label_ids\r\n preds = pred.predictions.argmax(1)\r\n f1 = f1_score(labels,preds,average = \"weighted\")\r\n acc = accuracy_score(labels,preds)\r\n return {\"accuracy\":acc,\"f1\":f1}\r\n\r\n#Train\r\nfrom transformers import Trainer,TrainingArguments\r\nclass TrainingArgumentsWithMPSSupport(TrainingArguments):\r\n @property\r\n def device(self) -> torch.device:\r\n if device_type == \"mps\":\r\n return torch.device(\"mps\")\r\n else:\r\n return torch.device(\"cpu\")\r\nbatch_size = 64\r\nloggin_steps = len(emotions_encoded[\"train\"])\r\nmodel_name = f\"{model_ckpt}-finetuned-emotion\"\r\ntrain_args = TrainingArgumentsWithMPSSupport(output_dir = model_name,\r\n num_train_epochs = 2,\r\n learning_rate = 2e-5,\r\n per_device_train_batch_size = batch_size,\r\n per_device_eval_batch_size = batch_size,\r\n weight_decay = 0.01,\r\n evaluation_strategy = \"epoch\",\r\n disable_tqdm = False,\r\n logging_steps = loggin_steps,\r\n push_to_hub = False,\r\n log_level = \"error\"\r\n )\r\ntrainer = Trainer(model = model,args = train_args,\r\n compute_metrics = compute_metrics,\r\n train_dataset = emotions_encoded[\"train\"],\r\n eval_dataset = emotions_encoded[\"validation\"],\r\n tokenizer = tokenizer)\r\n\r\nprint(\"Trainner device:\",trainer.args.device)\r\n\r\ntrainer.train()\r\n```\r\n",
"We've also observed a drop in metrics when training, see [this issue](https://github.com/pytorch/pytorch/issues/82707).",
"Now that PyTorch `1.12.1` is out I think we should reopen this issue! cc @pacman100 ",
"Note that on the inference side, pipelines now support `device=\"mps\"` since #18494",
"@julien-c That's great to hear! In my own scripts I've used [this implementation](https://github.com/saattrupdan/ScandEval/blob/main/src/scandeval/training_args_with_mps_support.py), just tweaking the `TrainingArguments._setup_devices` method.\n\nI also guess that the `no_cuda` training argument has to either be changed to `no_gpu`, if the current functionality should be preserved, or otherwise the handling of this keyword needs to be changed in the method (potentially adding a `no_mps` argument as well then, but I'm not sure if that's desirable). \n\nI can open a PR if needed 🙂 \n\n",
"Hi Team. Thanks for the mac integration. Quick question - Is this not part of the most recent `pip install`? Because I have the latest pip package version (`4.21.2`) but couldn't find `--use_mps_device` function parameter in it.\r\n\r\nHere's a simple snippet from the jupyter notebook \r\n```\r\nfrom transformers import TrainingArguments\r\nargs = TrainingArguments(use_mps_device=False)\r\n```\r\nand the error message:\r\n```\r\nTypeError Traceback (most recent call last)\r\n/var/folders/_p/8spsq7dj5mg51p7kdrqzlmgr0000gn/T/ipykernel_2337/1658168950.py in <module>\r\n----> 1 args = TrainingArguments(use_mps_device=False)\r\n\r\nTypeError: __init__() got an unexpected keyword argument 'use_mps_device'",
"Hello @V-Sher, it is yet to be released. For time being, you can install transformers from the source to use this feature via the below command\r\n```bash\r\npip install git+https://github.com/huggingface/transformers\r\n```",
"Hi All:\r\nI am finetuning a BERT model with HuggingFace Trainer API in Mac OS Ventura (Intel), Python 3.10 and Torch 2.0.0.\r\nIt takes 14 min in a simple scenery with CPU, with no problem.\r\nI changed to GPU with mps. Initially, GPU was not used, but after redefining TrainingArguments in this way, it worked\r\n\r\n```\r\nclass TrainingArgumentsWithMPSSupport(TrainingArguments):\r\n @property\r\n def device(self) -> torch.device:\r\n return torch.device(device)\r\n\r\ntraining_args = TrainingArgumentsWithMPSSupport(...)\r\n```\r\n\r\nBut the problem is that improvement over CPU is scarce (barely from 14 min to 10 min). Monitor says %GPU is only 15% peak.\r\n\r\nAny idea about why such poor improvement?\r\n\r\nThanks for any help\r\nAlberto\r\n\r\nThe is the full code\r\n\r\n```\r\nfrom transformers import BertForSequenceClassification, BertTokenizerFast, Trainer, TrainingArguments\r\nimport nlp\r\nimport torch\r\nfrom torch.utils.data import Dataset, DataLoader\r\n\r\ndevice = torch.device(\"mps:0\")\r\n\r\n_DATASET = '../IMDB.csv'\r\n\r\ndataset = nlp.load_dataset('csv', data_files=[_DATASET], split='train[:1%]')\r\n\r\ndataset = dataset.train_test_split(test_size=0.3)\r\ntrain_set = dataset['train'] \r\ntest_set = dataset['test']\r\n\r\n\r\nclass CustomDataset(Dataset):\r\n\r\n def __init__(self, dataset, mytokenizer):\r\n self.tokenizer = mytokenizer\r\n self.dataset = dataset\r\n self.texts = dataset[\"text\"] \r\n\r\n def __len__(self):\r\n return len(self.dataset)\r\n\r\n def __getitem__(self, index):\r\n theText = self.dataset[index]['text']\r\n theLabel = self.dataset[index]['label']\r\n inputs = self.tokenizer(theText, max_length=512, padding='max_length', truncation=True)\r\n ids = inputs['input_ids']\r\n mask = inputs['attention_mask']\r\n token_type_ids = inputs[\"token_type_ids\"]\r\n\r\n ids = torch.tensor(ids, dtype=torch.long).to(device)\r\n mask = torch.tensor(mask, dtype=torch.long).to(device)\r\n theLabel = torch.tensor(theLabel, dtype=torch.long).to(device)\r\n\r\n result = {\r\n 'input_ids': ids,\r\n 'attention_mask': mask,\r\n 'label': theLabel\r\n }\r\n\r\n return result\r\n\r\n\r\nmodel = BertForSequenceClassification.from_pretrained('bert-base-uncased')\r\ntokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')\r\n\r\ntraining_set = CustomDataset(train_set, tokenizer)\r\ntesting_set = CustomDataset(test_set, tokenizer)\r\n\r\nbatch_size = 8\r\nepochs = 2\r\nwarmup_steps = 500\r\nweight_decay = 0.01\r\n\r\n\r\nclass TrainingArgumentsWithMPSSupport(TrainingArguments):\r\n @property\r\n def device(self) -> torch.device:\r\n return torch.device(device)\r\n\r\n\r\n\r\ntraining_args = TrainingArgumentsWithMPSSupport(\r\n\toutput_dir='./results',\r\n\tnum_train_epochs=epochs,\r\n\tper_device_train_batch_size=batch_size,\r\n\tper_device_eval_batch_size=batch_size,\r\n\twarmup_steps=warmup_steps,\r\n\tweight_decay=weight_decay,\r\n\t# evaluate_during_training=True,\r\n\tevaluation_strategy='steps',\r\n\tlogging_dir='./logs',\r\n)\r\n\r\ntrainer = Trainer(\r\n\tmodel=model.to(device),\r\n\targs=training_args,\r\n\ttrain_dataset=training_set,\r\n\teval_dataset=testing_set\r\n)\r\n\r\ntrainer.train() # full finetune\r\ntrainer.evaluate()\r\n```\r\n\r\n\r\n",
"After installing `transformers` package from source as suggested by @pacman100 like this:\r\n```bash\r\npip install git+https://github.com/huggingface/transformers\r\n``` \r\nthe `mps` device is used with the standard `TrainingArguments` class. Does not require the custom `TrainingArgumentsWithMPSSupport` class.\r\n\r\nNow the M1 Mac GPU is ~90% utilized.\r\n\r\n\r\n",
"> After installing `transformers` package from source as suggested by @pacman100 like this:\r\n> \r\n> ```shell\r\n> pip install git+https://github.com/huggingface/transformers\r\n> ```\r\n> \r\n> the `mps` device is used with the standard `TrainingArguments` class. Does not require the custom `TrainingArgumentsWithMPSSupport` class.\r\n> \r\n> Now the M1 Mac GPU is ~90% utilized. 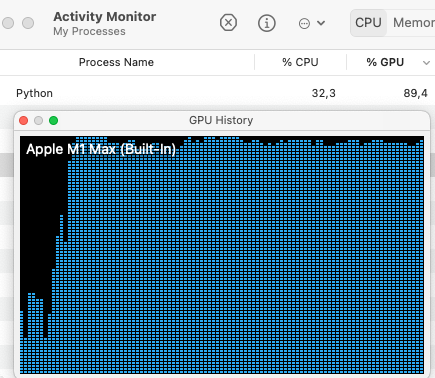\r\n\r\nComfirm, it works for me too.",
"Hi, \r\n\r\nStill getting the same error on apple Macbook Pro M1 \r\nValueError: BF16 Mixed precision training with AMP (`--bf16`) and BF16 half precision evaluation (`--bf16_full_eval`) can only be used on CUDA or CPU/TPU/NeuronCore devices.\r\ncurrent python libs versions accelerate==0.22.0.dev0 peft==0.4.0 bitsandbytes==00.41.1 transformers==4.31.0 trl==0.4.7 torch==2.1.0.dev20230820\r\nupgrade to the latest transformers start getting errors on the \r\nmodel loading\r\nImportError: Using `load_in_8bit=True` requires Accelerate: `pip install accelerate` and the latest version of bitsandbytes `pip install -i https://test.pypi.org/simple/ bitsandbytes` or pip install bitsandbytes` \r\n\r\nany recommendations",
"I'm also on Macbook Pro M1 and is getting the same error as the post above me by @inaim .\r\n\r\nSimilar problem here: https://stackoverflow.com/questions/76589840/cant-run-transformer-fine-tuning-with-m1-mac-cpu",
"My recommendation is to install `bitsandbytes` and `accelerate`",
"Hello, `load_in_8bit` isn't supported for Mac devices. So, load the model without that param. @younesbelkada, who has better idea about bitsandbytes.",
"Hi @pacman100 , \r\n\r\nThe config used for quantization\r\n# bitsandbytes parameters\r\n\r\nuse_4bit = True\r\n\r\nbnb_4bit_compute_dtype = \"float16\"\r\n\r\nbnb_4bit_quant_type = \"nf4\"\r\n\r\nuse_nested_quant = False",
"Hi @ArthurZucker ,\r\n\r\nThey are already installed"
] | 1,656
| 1,692
| 1,660
|
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.21.0.dev0
- Platform: macOS-12.4-arm64-arm-64bit
- Python version: 3.8.9
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.12.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help?
@sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```bash
export TASK_NAME=wnli
python run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/
```
### Expected behavior
When running the `Trainer.train` on a machine with an MPS GPU, it still just uses the CPU. I expected it to use the MPS GPU. This is supported by `torch` in the newest version 1.12.0, and we can check if the MPS GPU is available using `torch.backends.mps.is_available()`.
It seems like the issue lies in the [`TrainingArguments._setup_devices` method](https://github.com/huggingface/transformers/blob/49cd736a288a315d741e5c337790effa4c9fa689/src/transformers/training_args.py#L1266), which doesn't appear to allow for the case where `device = "mps"`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17971/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17971/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17970
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17970/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17970/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17970/events
|
https://github.com/huggingface/transformers/pull/17970
| 1,290,505,440
|
PR_kwDOCUB6oc46qThI
| 17,970
|
Ensure PT model is in evaluation mode and lightweight forward pass done
|
{
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
Small update to the `pt-to-tf` CLI. Sets the pytorch model into evaluate model and uses `no_grad` context to make the memory requirements lighter.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17970/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17970/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17970",
"html_url": "https://github.com/huggingface/transformers/pull/17970",
"diff_url": "https://github.com/huggingface/transformers/pull/17970.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17970.patch",
"merged_at": 1656700428000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17969
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17969/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17969/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17969/events
|
https://github.com/huggingface/transformers/pull/17969
| 1,290,494,107
|
PR_kwDOCUB6oc46qRGF
| 17,969
|
TF: T5 can now handle a padded past (i.e. XLA generation)
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"related issue: https://github.com/huggingface/transformers/issues/17935",
"_The documentation is not available anymore as the PR was closed or merged._",
"Great job on finding and fixing the bug here @gante - cool that T5 works now :-)"
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
# What does this PR do?
In TF T5, we now fetch the correct slice of `position_bias` -- [the same way we do it in FLAX](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_flax_t5.py#L339). The key difference is that FLAX relies on an [external variable](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_flax_t5.py#L312) for the generated length that gets incremented every time past gets updated, and here the same value is obtained dynamically from the past array (latest filled past index = generated length - 1, where latest filled past index corresponds to the maximum index with non-0 values).
All slow tests are passing and we no longer have length restrictions on the XLA beam search test, which means that:
1. Although the code for eager execution was changed, all outputs remain the same;
2. XLA generation matches non-XLA generation.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17969/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17969/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17969",
"html_url": "https://github.com/huggingface/transformers/pull/17969",
"diff_url": "https://github.com/huggingface/transformers/pull/17969.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17969.patch",
"merged_at": 1656960464000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17968
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17968/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17968/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17968/events
|
https://github.com/huggingface/transformers/pull/17968
| 1,290,490,147
|
PR_kwDOCUB6oc46qQRe
| 17,968
|
Mask t5 relative position bias then head pruned
|
{
"login": "hadaev8",
"id": 20247085,
"node_id": "MDQ6VXNlcjIwMjQ3MDg1",
"avatar_url": "https://avatars.githubusercontent.com/u/20247085?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hadaev8",
"html_url": "https://github.com/hadaev8",
"followers_url": "https://api.github.com/users/hadaev8/followers",
"following_url": "https://api.github.com/users/hadaev8/following{/other_user}",
"gists_url": "https://api.github.com/users/hadaev8/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hadaev8/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hadaev8/subscriptions",
"organizations_url": "https://api.github.com/users/hadaev8/orgs",
"repos_url": "https://api.github.com/users/hadaev8/repos",
"events_url": "https://api.github.com/users/hadaev8/events{/privacy}",
"received_events_url": "https://api.github.com/users/hadaev8/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the PR @hadaev8! \r\n\r\nCould you add a test for the newly added functionality ? :-) ",
"@patrickvonplaten \r\nNever did it, how it should looks like?",
"Hey @hadaev8,\r\n\r\nThe test should be added to this file here: https://github.com/huggingface/transformers/blob/main/tests/models/t5/test_modeling_t5.py\r\n\r\nIn this test it would be great if you could do the following for example:\r\nCreate a dummy T5 model and run a forward pass with `output_attentions=True`. The prune a head and run a forward pass again with `output_attentions=True`. Then you can compare that the attentions returned by the second forward pass will be 0 or just have fewer tensors because the head was pruned",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"@patrickvonplaten \r\nI spotted another thing.\r\nIn encoder-decoder only one broken function to prune. Should I split in two?",
"@hadaev8 let's maybe do this in another PR :-) ",
"Okay, i only will make test",
"Hey @hadaev8, \r\n\r\nSorry last thing - could you maybe remove the accidently added `datasets` folder? See: https://github.com/huggingface/transformers/pull/17968/files#diff-714284abfa95a1447d7c34554c2d65b16fcfb1af22a44fc15489d13b76e951e5",
"@patrickvonplaten \r\nSorry, still had no time to write the test.\r\nRemoved datasets folder.",
"It seems there is an issue with your CircleCI permissions, the tests won't run.\r\nCould you try refreshing your permissions as shown [here](https://support.circleci.com/hc/en-us/articles/360048210711-How-to-Refresh-User-Permissions-)?",
"Seems I can't register account at CircleCI because sanctioned country.",
"Arf that's super annoying, sorry about that @hadaev8. I'll look into triggering it for you.",
"I pushed the same commits under a different branch: https://github.com/huggingface/transformers/tree/fix_t5_pruning-lysandre\r\nIt used my token permissions so it could run. Sorry you're experiencing this, I'll handle the triggers if some tests need to be fixed.",
"All tests pass, thank you @hadaev8! Merging the PR.",
"@LysandreJik \r\nCool, thank you."
] | 1,656
| 1,662
| 1,662
|
CONTRIBUTOR
| null |
# What does this PR do?
Fixes #17886
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [X] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17968/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17968/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17968",
"html_url": "https://github.com/huggingface/transformers/pull/17968",
"diff_url": "https://github.com/huggingface/transformers/pull/17968.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17968.patch",
"merged_at": 1662453571000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17967
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17967/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17967/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17967/events
|
https://github.com/huggingface/transformers/pull/17967
| 1,290,447,162
|
PR_kwDOCUB6oc46qHE3
| 17,967
|
Drop columns after loading samples in prepare_tf_dataset
|
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"I think this PR is ready to go, but it's waiting on https://github.com/huggingface/datasets/pull/4553 to be merged and a release in Datasets. Tests will fail until that makes it through, so I won't merge until then!"
] | 1,656
| 1,657
| 1,657
|
MEMBER
| null |
Another super-small fix to `prepare_tf_dataset()` - this time we apply the same fix we applied to `to_tf_dataset()`, and keep columns until after samples have been loaded from the dataset. This ensures that columns that are needed to compute the transform aren't dropped.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17967/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17967/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17967",
"html_url": "https://github.com/huggingface/transformers/pull/17967",
"diff_url": "https://github.com/huggingface/transformers/pull/17967.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17967.patch",
"merged_at": 1657213342000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17966
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17966/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17966/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17966/events
|
https://github.com/huggingface/transformers/pull/17966
| 1,290,361,658
|
PR_kwDOCUB6oc46p0vl
| 17,966
|
[Flax] Bump to v0.4.1
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"Nice finding! I am not competent regarding which versions we want to always support, but LGTM",
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks @patil-suraj! The latest version would be v0.5.2 (see https://github.com/google/flax/releases). Is the best way to test this by setting `flax>=0.5.2` and observe if the tests past?",
"IMO we should also try to stay compatible with older Flax versions, so let's not go as high as we can but only as high as we have to! PR looks good to me - but let's try to not always use the most recent Flax features in order to stay compatible with older versions as well ",
"Thanks for the details @patrickvonplaten. I'm in agreement that we should avoid potentially breaking use cases purely for the sake of being on the latest version, but try and integrate the latest features where applicable.\r\n\r\nInterestingly, I actually went away and had a play with three different versions of Flax on my personal research project https://github.com/sanchit-gandhi/seq2seq-speech:\r\n\r\n1. **v0.3.5:** issues regarding the `sep` arg of `flatten_dict` in `modeling_flax_utils` (described above)\r\n2. **v0.4.2:** no apparent issues\r\n3. **v0.5.2:** (latest) had issues with Flax's `scan` not working depending on JAX version\r\n\r\nSeems like v0.4.2 sits in the sweet spot for newer Flax version whilst providing backwards compatibility!",
"Yes, but it's often worth to also not directly implement all the new features of Flax since:\r\n- a) they might not work very well because they are new\r\n- b) it breaks backwards comp"
] | 1,656
| 1,657
| 1,657
|
CONTRIBUTOR
| null |
# What does this PR do?
The `flatten_dict` operator with the kwarg argument `sep` was added to `modeling_flax_utils` in https://github.com/huggingface/transformers/pull/17760:
https://github.com/huggingface/transformers/blob/f25457b273348733bfeb19a51ab0d21bd30a08b8/src/transformers/modeling_flax_utils.py#L127
This kwarg was only added to Flax in v0.4.1: https://github.com/google/flax/releases/tag/v0.4.1
This PR bumps the required Flax version in Transformers from v0.3.5 to v0.4.1.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
cc @ArthurZucker
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17966/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17966/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17966",
"html_url": "https://github.com/huggingface/transformers/pull/17966",
"diff_url": "https://github.com/huggingface/transformers/pull/17966.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17966.patch",
"merged_at": 1657030637000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17965
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17965/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17965/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17965/events
|
https://github.com/huggingface/transformers/pull/17965
| 1,290,318,688
|
PR_kwDOCUB6oc46prdr
| 17,965
|
time series forecasting model
|
{
"login": "kashif",
"id": 8100,
"node_id": "MDQ6VXNlcjgxMDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8100?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kashif",
"html_url": "https://github.com/kashif",
"followers_url": "https://api.github.com/users/kashif/followers",
"following_url": "https://api.github.com/users/kashif/following{/other_user}",
"gists_url": "https://api.github.com/users/kashif/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kashif/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kashif/subscriptions",
"organizations_url": "https://api.github.com/users/kashif/orgs",
"repos_url": "https://api.github.com/users/kashif/repos",
"events_url": "https://api.github.com/users/kashif/events{/privacy}",
"received_events_url": "https://api.github.com/users/kashif/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"cc'ing @mishig25 here - there seems to be an issue with the docs being built. The model is added to the toctree, but it's saying:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/doc-builder\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/usr/local/lib/python3.8/site-packages/doc_builder/commands/doc_builder_cli.py\", line 47, in main\r\n args.func(args)\r\n File \"/usr/local/lib/python3.8/site-packages/doc_builder/commands/build.py\", line 96, in build_command\r\n build_doc(\r\n File \"/usr/local/lib/python3.8/site-packages/doc_builder/build_doc.py\", line 427, in build_doc\r\n sphinx_refs = check_toc_integrity(doc_folder, output_dir)\r\n File \"/usr/local/lib/python3.8/site-packages/doc_builder/build_doc.py\", line 482, in check_toc_integrity\r\n raise RuntimeError(\r\nRuntimeError: The following files are not present in the table of contents:\r\n- model_doc/time_series_transformer\r\nAdd them to ../transformers/docs/source/en/_toctree.yml.\r\n```",
"Mishig the failure on the doc was due to a typo (comment is hidden now since the suggestion was accepted) nothing to do for you :-)"
] | 1,656
| 1,664
| 1,664
|
CONTRIBUTOR
| null |
# What does this PR do?
This PR implements a vanilla encoder-decoder Transformer for time-series forecasting.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17965/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17965/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17965",
"html_url": "https://github.com/huggingface/transformers/pull/17965",
"diff_url": "https://github.com/huggingface/transformers/pull/17965.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17965.patch",
"merged_at": 1664566380000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17964
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17964/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17964/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17964/events
|
https://github.com/huggingface/transformers/pull/17964
| 1,290,309,359
|
PR_kwDOCUB6oc46ppbu
| 17,964
|
skip some ipex tests until it works with torch 1.12
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
skip some ipex tests until it works with torch 1.12
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17964/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17964/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17964",
"html_url": "https://github.com/huggingface/transformers/pull/17964",
"diff_url": "https://github.com/huggingface/transformers/pull/17964.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17964.patch",
"merged_at": 1656605129000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17963
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17963/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17963/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17963/events
|
https://github.com/huggingface/transformers/pull/17963
| 1,290,304,677
|
PR_kwDOCUB6oc46poa1
| 17,963
|
BLOOM - modifying slow tests
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17963). All of your documentation changes will be reflected on that endpoint.",
"Hi, @younesbelkada \r\n\r\nCould you explain a bit more on ` One should always use padding_side=left when doing batched generations`?\r\nAnd what are examples of test failures when using `padding=right` ? I couldn't find you mentioning this on Slack.\r\n\r\nThanks!\r\n",
"Hi @ydshieh !\r\nFrom the internal discussions here is a summary of why one should always use `padding_side=left` (cc @patrickvonplaten ):\r\n- Imagine: `[\"hello my name is\", \"hey <pad> <pad> <pad>\"]`\r\nFor the first input the correct token will be sampled from \"is\" - however for the second input, generate would incorrectly sample from `\"<pad>\"` where as it should sample from `\"hey\"`. Making sure everything is batched on the left circumvents this problem !",
"@younesbelkada - IMO we should not expect the generation to be flaky ever, why is this the case here?",
"Hi @younesbelkada : I have 3 questions 🙏 \r\n\r\n- with fp16:\r\n - do we get stable results in a specific torch version (i.e. the same result across many runs)\r\n- after changing to fp32 (without reducing the seq length)\r\n - do we get the same results across torch 1.11 and 1.12?\r\n - do we get stable results in a specific torch version (i.e. the same result across many runs)",
"Hi @ydshieh !\r\nAfter merging this PR: https://github.com/huggingface/transformers/pull/17866 the slow tests are now passing. Our conclusion is that:\r\n1- In half precision mode we might not get the same results across batched generation and it should be expected \r\n2- This behavior is observed ONLY on small models !",
"I'm still a bit confused by this PR - generations are not flaky for pretrained models normally and it's a bit weird to me that all this test does is modifying slow generation tests",
"Closing as it has been fixed by https://github.com/huggingface/transformers/pull/18344"
] | 1,656
| 1,660
| 1,660
|
CONTRIBUTOR
| null |
# What does this PR do?
- changed the non passing tests to fp32
- reduced sequence length
- remove padding test
All these matters have been discussed on Slack but mainly:
1- Generations tests were not passing because the linear layers does not give the same results between torch 1.11 and torch 1.12
2- batched generation can be flaky sometimes in half precision mode, this should be expected. Therefore we reduce the sequence length of the generated output
3- One should **always** use `padding_side=left` when doing batched generations
cc @ydshieh @patrickvonplaten
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17963/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17963/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17963",
"html_url": "https://github.com/huggingface/transformers/pull/17963",
"diff_url": "https://github.com/huggingface/transformers/pull/17963.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17963.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17962
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17962/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17962/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17962/events
|
https://github.com/huggingface/transformers/issues/17962
| 1,290,176,053
|
I_kwDOCUB6oc5M5oY1
| 17,962
|
IPEX integration in Trainer breaks with PyTorch 1.12
|
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"@sgugger Thanks for reporting. IPEX v1.12 will be releasing to support latest PyTorch version by next week. The team will look into the issue and let you know whether the issue is getting fixed in upcoming release. cc @jianan-gu ",
"@sgugger , this is Eikan from IPEX team. This is a version-mismatch issue. IPEX 1.11 is on top of PyTorch 1.11. And the upcoming release of IPEX(1.12) will resolve this issue as the latest PyTorch is 1.12. I will keep you posted as long as the IPEX is released.",
"Hi @sgugger,\r\nIPEX 1.12 release is available https://intel.github.io/intel-extension-for-pytorch/1.12.0/tutorials/installation.html ;\r\nAnd we also open a PR https://github.com/huggingface/transformers/pull/18072 to enhance the integration for this version mismatch issue to avoid breaking Trainer;\r\nThanks!"
] | 1,656
| 1,657
| 1,657
|
COLLABORATOR
| null |
All the tests for the IPEX integration in Trainer started to break with the latest PyTorch release. Error is:
```
ImportError: /usr/local/lib/python3.8/dist-packages/intel_extension_for_pytorch/lib/libintel-ext-pt-cpu.so: undefined symbol: _ZNK3c1010TensorImpl5sizesEv
```
cc @hshen14
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17962/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17962/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17961
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17961/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17961/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17961/events
|
https://github.com/huggingface/transformers/pull/17961
| 1,290,082,664
|
PR_kwDOCUB6oc46o4OQ
| 17,961
|
add ONNX support for BLOOM
|
{
"login": "NouamaneTazi",
"id": 29777165,
"node_id": "MDQ6VXNlcjI5Nzc3MTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/29777165?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NouamaneTazi",
"html_url": "https://github.com/NouamaneTazi",
"followers_url": "https://api.github.com/users/NouamaneTazi/followers",
"following_url": "https://api.github.com/users/NouamaneTazi/following{/other_user}",
"gists_url": "https://api.github.com/users/NouamaneTazi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NouamaneTazi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NouamaneTazi/subscriptions",
"organizations_url": "https://api.github.com/users/NouamaneTazi/orgs",
"repos_url": "https://api.github.com/users/NouamaneTazi/repos",
"events_url": "https://api.github.com/users/NouamaneTazi/events{/privacy}",
"received_events_url": "https://api.github.com/users/NouamaneTazi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"As you told me offline that the slow tests were passing (under torch1.11.0), looks good to me! Thanks for working on that 🔥 ",
"I'm not too sure about the changes in `modeling_bloom.py`. Looks like not leveraging the bool type and converting to int32 will hurt performance. Wdyt @younesbelkada ?",
"I think the changes in `modeling_bloom.py` come from the fact that boolean tensors cannot be added in ONNX (not 100% sure). Two suggestions then:\r\n\r\n- Reformulate the addition to [torch.logical_or](https://pytorch.org/docs/stable/generated/torch.logical_or.html#torch-logical-or)\r\n- Cast the input to int8\r\n\r\nI think that the first solution is both faster and more aligned with the original implementation.\r\nWDYT?",
"@sgugger I do not think this will hurt performances in terms of logits since slow tests are passing, but might hurt indeed the inference time performance for large and/or batched sequences.. We need to benchmark that though to be sure",
"@michaelbenayoun I think option 1 sounds good, yes!",
"Also make sure all the tests pass before merging.",
"All tests for `tests/onnx/test_onnx_v2.py -k \"bloom\"` and `tests/models/bloom` are passing.\r\nHere are the ones that are skipped (which is fine according to @younesbelkada)\r\n```\r\n================================================================================= short test summary info =================================================================================\r\nSKIPPED [1] tests/test_modeling_common.py:2006: test is PT+FLAX test\r\nSKIPPED [1] tests/test_modeling_common.py:1934: test is PT+FLAX test\r\nSKIPPED [1] tests/test_modeling_common.py:1758: test is PT+TF test\r\nSKIPPED [1] tests/test_tokenization_common.py:1960: This test is only for slow tokenizers\r\nSKIPPED [1] tests/test_tokenization_common.py:2189: test is PT+TF test\r\n================================================================= 159 passed, 5 skipped, 35 warnings in 449.50s (0:07:29)\r\n```",
"There is a difference between a copy in BLOOM and the original in GPT-2 which is why the CI is failing. Make sure to run `make fic-copies` or remove the `Copied from`."
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
# What does this PR do?
add ONNX support for BLOOM
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [X] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [X] Did you write any new necessary tests?
## Who can review?
@michaelbenayoun
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17961/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17961/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17961",
"html_url": "https://github.com/huggingface/transformers/pull/17961",
"diff_url": "https://github.com/huggingface/transformers/pull/17961.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17961.patch",
"merged_at": 1656686682000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17960
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17960/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17960/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17960/events
|
https://github.com/huggingface/transformers/issues/17960
| 1,289,999,740
|
I_kwDOCUB6oc5M49V8
| 17,960
|
Suggestion for introducing "shift_labels" argument for Trainer
|
{
"login": "seungeunrho",
"id": 8207326,
"node_id": "MDQ6VXNlcjgyMDczMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8207326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/seungeunrho",
"html_url": "https://github.com/seungeunrho",
"followers_url": "https://api.github.com/users/seungeunrho/followers",
"following_url": "https://api.github.com/users/seungeunrho/following{/other_user}",
"gists_url": "https://api.github.com/users/seungeunrho/gists{/gist_id}",
"starred_url": "https://api.github.com/users/seungeunrho/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/seungeunrho/subscriptions",
"organizations_url": "https://api.github.com/users/seungeunrho/orgs",
"repos_url": "https://api.github.com/users/seungeunrho/repos",
"events_url": "https://api.github.com/users/seungeunrho/events{/privacy}",
"received_events_url": "https://api.github.com/users/seungeunrho/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"I don't think a new TrainingArgument is the right answer here. Some models shift the labels internally, I think it's all the models for causal LM (not jsut GPT-2), so I think instead of a flag, there should be a check when the loss is computed by the `Trainer` for label smoothing to see if the model class name is inside the `MODEL_FOR_CAUSAL_LM_MAPPING_NAMES` (to import from the auto module) and then shift the labels.\r\n\r\nLet me know if you'd like to proceed with a PR for this fix!",
"Thanks for quick reply. Your approach seems plausible and I'd like to proceed it. \r\nI've read the document for contribution guide thoroughly. Can I just start now? or is there anything I should know before begin?",
"You can start, good luck! :-)",
"> ### Feature request\r\n> Add an argument to determine shifting the `labels` or not.\r\n> \r\n> In [TrainingArguments](https://github.com/huggingface/transformers/blob/v4.20.1/src/transformers/training_args.py#L104) class, an argument named `shift_labels` should be added.\r\n> \r\n> During training, at [here](https://github.com/huggingface/transformers/blob/v4.20.1/src/transformers/models/gpt2/modeling_gpt2.py#L1073) and [here](https://github.com/huggingface/transformers/blob/d0acc9537829e7d067edbb791473bbceb2ecf056/src/transformers/models/gpt2/modeling_gpt2.py#L1280), `model` must check both `labels is not None` and `self.shift_labels is True`\r\n> \r\n> e.g.\r\n> \r\n> ```\r\n> if labels is not None and self.shift_labels: # changed\r\n> # Shift so that tokens < n predict n\r\n> shift_logits = lm_logits[..., :-1, :].contiguous()\r\n> shift_labels = labels[..., 1:].contiguous()\r\n> ```\r\n> \r\n> Default values for `shift_labels` is `False`, except for causal language models such as `GPT2PreTrainedModel`\r\n> \r\n> Related to gpt2 : @patil-suraj and trainer @sgugger\r\n> \r\n> ### Motivation\r\n> In the current state of the code, the shifting of `labels` for training GPT2LMHeadModel is changing under the use of `label_smoothing`, which I assume is unintended.\r\n> \r\n> Specifically, training a GPT2LMHeadModel with `args.label_smoothing_factor==0` (which is default), the [code](https://github.com/huggingface/transformers/blob/d0acc9537829e7d067edbb791473bbceb2ecf056/src/transformers/models/gpt2/modeling_gpt2.py#L1075) shifts the `labels` and computes the loss inside the `model.forward()`. This assumes that `labels` have not been shifted to be properly aligned with corresponding `input_ids`.\r\n> \r\n> However, if I train GPT2LMHeadModel with `args.label_smoothing_factor > 0`, then the loss is computed [here](https://github.com/huggingface/transformers/blob/692e61e91a0b83f5b847902ed619b7c74c0a5dda/src/transformers/trainer.py#L2384), inside the `compute_loss()` function of the `Trainer`. This part assumes `labels` are already shifted, and does not proceed to shift the labels.\r\n> \r\n> I believe whether to shift `labels` or not should be explicitly determined by its own argument, not by another argument like `label_smoothing_factor`. In my case, our team was very frustrated that our training results were totally different by only changing the `label_smoothing` with same given `labels` and `input_ids`. The reason was due to the misalignment of `labels` and `input_ids` when turning on the `label_smoothing`.\r\n> \r\n> ### Your contribution\r\n> I'm willing to make PR after your confirmation.\r\n\r\nI want to know more about how the prediction text looks like under the label-smoothing case before the bug-fix. Does the model learn an indentity transformation and always predict the last input token repeatedly? I am curious about this. "
] | 1,656
| 1,702
| 1,656
|
CONTRIBUTOR
| null |
### Feature request
Add an argument to determine shifting the `labels` or not.
In [TrainingArguments](https://github.com/huggingface/transformers/blob/v4.20.1/src/transformers/training_args.py#L104) class, an argument named `shift_labels` should be added.
During training, at [here](https://github.com/huggingface/transformers/blob/v4.20.1/src/transformers/models/gpt2/modeling_gpt2.py#L1073) and [here](https://github.com/huggingface/transformers/blob/d0acc9537829e7d067edbb791473bbceb2ecf056/src/transformers/models/gpt2/modeling_gpt2.py#L1280), `model` must check both `labels is not None` and `self.shift_labels is True`
e.g.
```
if labels is not None and self.shift_labels: # changed
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
```
Default values for `shift_labels` is `False`, except for causal language models such as `GPT2PreTrainedModel`
Related to gpt2 : @patil-suraj and trainer @sgugger
### Motivation
In the current state of the code, the shifting of `labels` for training GPT2LMHeadModel is changing under the use of `label_smoothing`, which I assume is unintended.
Specifically, training a GPT2LMHeadModel with `args.label_smoothing_factor==0` (which is default), the [code](https://github.com/huggingface/transformers/blob/d0acc9537829e7d067edbb791473bbceb2ecf056/src/transformers/models/gpt2/modeling_gpt2.py#L1075) shifts the `labels` and computes the loss inside the `model.forward()`.
This assumes that `labels` have not been shifted to be properly aligned with corresponding `input_ids`.
However, if I train GPT2LMHeadModel with `args.label_smoothing_factor > 0`, then the loss is computed [here](https://github.com/huggingface/transformers/blob/692e61e91a0b83f5b847902ed619b7c74c0a5dda/src/transformers/trainer.py#L2384), inside the `compute_loss()` function of the `Trainer`.
This part assumes `labels` are already shifted, and does not proceed to shift the labels.
I believe whether to shift `labels` or not should be explicitly determined by its own argument, not by another argument like `label_smoothing_factor`. In my case, our team was very frustrated that our training results were totally different by only changing the `label_smoothing` with same given `labels` and `input_ids`.
The reason was due to the misalignment of `labels` and `input_ids` when turning on the `label_smoothing`.
### Your contribution
I'm willing to make PR after your confirmation.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17960/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17960/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17959
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17959/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17959/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17959/events
|
https://github.com/huggingface/transformers/pull/17959
| 1,289,991,645
|
PR_kwDOCUB6oc46okjN
| 17,959
|
CLI: convert sharded PT models
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"BTW could we add 2 tests, `test_load_sharded_tf_to_pt` and `load_sharded_pt_to_tf` ",
"TF shards -> PT probably won't work, but I will add the test for PT shards -> TF 👍 "
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
# What does this PR do?
This PR adds a major upgrade and a minor change to the `pt-to-tf` CLI.
Major upgrade: we can now convert sharded PT models. It updates how the `from_pt` loading works so as to be able to load from shards. It also updates how the `pt-to-tf` CLI stores the models, so it uses sharding capabilities when needed.
Minor change: adds a flag to control the maximum hidden layer admissible error. It is relatively common to find models where the outputs from the PT and TF models are nearly the same, but the hidden layers have a larger mismatch. This flag allows us to temporarily increase the admissible error if the model seems to be behaving properly (for instance, all RegNet models had a hidden layer difference between 1e-4 and 1e-2, but the outputs were behaving properly).
Example of sharded TF model PR, using the updated tools: https://huggingface.co/facebook/regnet-y-10b-seer-in1k/discussions/1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17959/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17959/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17959",
"html_url": "https://github.com/huggingface/transformers/pull/17959",
"diff_url": "https://github.com/huggingface/transformers/pull/17959.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17959.patch",
"merged_at": 1656604264000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17958
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17958/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17958/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17958/events
|
https://github.com/huggingface/transformers/pull/17958
| 1,289,961,715
|
PR_kwDOCUB6oc46oeEt
| 17,958
|
[wip] testing new docstring ui
|
{
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17958). All of your documentation changes will be reflected on that endpoint.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17958/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17958/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17958",
"html_url": "https://github.com/huggingface/transformers/pull/17958",
"diff_url": "https://github.com/huggingface/transformers/pull/17958.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17958.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17957
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17957/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17957/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17957/events
|
https://github.com/huggingface/transformers/issues/17957
| 1,289,620,312
|
I_kwDOCUB6oc5M3gtY
| 17,957
|
ERORR: "Missing XLA Configuration" while running the script?
|
{
"login": "karndeepsingh",
"id": 49562460,
"node_id": "MDQ6VXNlcjQ5NTYyNDYw",
"avatar_url": "https://avatars.githubusercontent.com/u/49562460?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/karndeepsingh",
"html_url": "https://github.com/karndeepsingh",
"followers_url": "https://api.github.com/users/karndeepsingh/followers",
"following_url": "https://api.github.com/users/karndeepsingh/following{/other_user}",
"gists_url": "https://api.github.com/users/karndeepsingh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/karndeepsingh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/karndeepsingh/subscriptions",
"organizations_url": "https://api.github.com/users/karndeepsingh/orgs",
"repos_url": "https://api.github.com/users/karndeepsingh/repos",
"events_url": "https://api.github.com/users/karndeepsingh/events{/privacy}",
"received_events_url": "https://api.github.com/users/karndeepsingh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
NONE
| null |
Hi,
I was trying to train the clip model on the images and text. And using clip-Italian repository and they are using HFScripts to train the model and got the error related to torch_xla.
Please help me to remove the following error. I am trying to train it on GPU device, it seems that error is due to torch_xla which is trying to look TPU. Please help me to train it on GPU.
```
comet_ml is installed but `COMET_API_KEY` is not set.
Traceback (most recent call last):
File "run_hybrid_clip.py", line 832, in <module>
main()
File "run_hybrid_clip.py", line 472, in main
) = parser.parse_args_into_dataclasses()
File "/opt/conda/lib/python3.7/site-packages/transformers/hf_argparser.py", line 214, in parse_args_into_dataclasses
obj = dtype(**inputs)
File "<string>", line 101, in __init__
File "/opt/conda/lib/python3.7/site-packages/transformers/training_args.py", line 1066, in __post_init__
and (self.device.type != "cuda")
File "/opt/conda/lib/python3.7/site-packages/transformers/utils/import_utils.py", line 829, in wrapper
return func(*args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/training_args.py", line 1357, in device
return self._setup_devices
File "/opt/conda/lib/python3.7/site-packages/transformers/utils/generic.py", line 49, in __get__
cached = self.fget(obj)
File "/opt/conda/lib/python3.7/site-packages/transformers/utils/import_utils.py", line 829, in wrapper
return func(*args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/training_args.py", line 1299, in _setup_devices
device = xm.xla_device()
File "/opt/conda/lib/python3.7/site-packages/torch_xla/core/xla_model.py", line 232, in xla_device
devkind=devkind if devkind is not None else None)
File "/opt/conda/lib/python3.7/site-packages/torch_xla/core/xla_model.py", line 137, in get_xla_supported_devices
xla_devices = _DEVICES.value
File "/opt/conda/lib/python3.7/site-packages/torch_xla/utils/utils.py", line 32, in value
self._value = self._gen_fn()
File "/opt/conda/lib/python3.7/site-packages/torch_xla/core/xla_model.py", line 19, in <lambda>
_DEVICES = xu.LazyProperty(lambda: torch_xla._XLAC._xla_get_devices())
RuntimeError: tensorflow/compiler/xla/xla_client/computation_client.cc:273 : Missing XLA configuration
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17957/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17957/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17956
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17956/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17956/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17956/events
|
https://github.com/huggingface/transformers/issues/17956
| 1,289,521,596
|
I_kwDOCUB6oc5M3Im8
| 17,956
|
`dlopen: cannot load any more object with static TLS` after installing sentencepiece
|
{
"login": "cyk1337",
"id": 13767887,
"node_id": "MDQ6VXNlcjEzNzY3ODg3",
"avatar_url": "https://avatars.githubusercontent.com/u/13767887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cyk1337",
"html_url": "https://github.com/cyk1337",
"followers_url": "https://api.github.com/users/cyk1337/followers",
"following_url": "https://api.github.com/users/cyk1337/following{/other_user}",
"gists_url": "https://api.github.com/users/cyk1337/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cyk1337/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cyk1337/subscriptions",
"organizations_url": "https://api.github.com/users/cyk1337/orgs",
"repos_url": "https://api.github.com/users/cyk1337/repos",
"events_url": "https://api.github.com/users/cyk1337/events{/privacy}",
"received_events_url": "https://api.github.com/users/cyk1337/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hi @cyk1337,\r\n\r\n`\"./t5-v1_1-base\"` looks like a local path, could you share its content with us so that we can reproduce the error please?",
"> Hi @cyk1337,\r\n> \r\n> `\"./t5-v1_1-base\"` looks like a local path, could you share its content with us so that we can reproduce the error please?\r\n\r\nHi @SaulLu , please refer to [https://huggingface.co/google/t5-v1_1-base/tree/main](https://huggingface.co/google/t5-v1_1-base/tree/main) for tokenizer files.",
"Thanks, unfortunately I didn't succeed in reproducing your error.\r\n\r\nI see in your stack trace the mention of `t5_mlm/run_t5_mlm.py`, are you running this code? If yes, can you try to just run the snippet you shared with me? :smile: ",
"I have rerun the provided snippet separately but find it works. The whole script seems not work due to some dependency conflicts. I just tried to adjust their import orders and temporarily resolved it. I suspect it results from some conflicts from common dependencies that the libraries require. Thank you for your help and will reopen it if it reoccurs.🤝"
] | 1,656
| 1,656
| 1,656
|
NONE
| null |
### System Info
- `transformers` version: 4.19.2 (tried 4.20 / 4.21dev)
- Platform: Linux-3.10.0_3-0-0-12-x86_64-with-centos-6.3-Final
- Python version: 3.7.11
- PyTorch version (GPU?): 1.7.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Y
- Using distributed or parallel set-up in script?: N
### Who can help?
@SaulLu
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
from transformers import AutoTokenizer
model_name_or_path="./t5-v1_1-base" # `path to t5-v1_1-base`
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, cache_dir=None, use_fast=True)
```
### Expected behavior
Expected error:
```bash
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/models/auto/tokenization_auto.py", line 573, in from_pretrained
return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1791, in from_pretrained
**kwargs,
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1929, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/models/t5/tokenization_t5_fast.py", line 141, in __init__
**kwargs,
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/tokenization_utils_fast.py", line 119, in __init__
"Couldn't instantiate the backend tokenizer from one of: \n"
ValueError: Couldn't instantiate the backend tokenizer from one of:
(1) a `tokenizers` library serialization file,
(2) a slow tokenizer instance to convert or
(3) an equivalent slow tokenizer class to instantiate and convert.
You need to have sentencepiece installed to convert a slow tokenizer to a fast one.
```
Then I try to install sentencepiece 0.1.96 via `pip install sentencepiece`
```bash
Installing collected packages: sentencepiece
Successfully installed sentencepiece-0.1.96
```
But the OSError occurs.
```bash
Traceback (most recent call last):
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/utils/import_utils.py", line 872, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/models/t5/modeling_t5.py", line 24, in <module>
import torch
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/torch/__init__.py", line 189, in <module>
_load_global_deps()
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/torch/__init__.py", line 142, in _load_global_deps
ctypes.CDLL(lib_path, mode=ctypes.RTLD_GLOBAL)
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/ctypes/__init__.py", line 364, in __init__
self._handle = _dlopen(self._name, mode)
OSError: dlopen: cannot load any more object with static TLS
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "t5_mlm/run_t5_mlm.py", line 35, in <module>
from transformers import (
File "<frozen importlib._bootstrap>", line 1032, in _handle_fromlist
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/utils/import_utils.py", line 863, in __getattr__
value = getattr(module, name)
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/utils/import_utils.py", line 862, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/home/cyk/anaconda3/envs/pt1.7/lib/python3.7/site-packages/transformers/utils/import_utils.py", line 876, in _get_module
) from e
RuntimeError: Failed to import transformers.models.t5.modeling_t5 because of the following error (look up to see its traceback):
dlopen: cannot load any more object with static TLS
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17956/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17956/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17955
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17955/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17955/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17955/events
|
https://github.com/huggingface/transformers/issues/17955
| 1,289,416,235
|
I_kwDOCUB6oc5M2u4r
| 17,955
|
tune save checkpoint throwing error due to float32
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Bump",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"I am getting the same error almost a year later. It seems that noone is using PB2 with transformers...",
"> I am getting the same error almost a year later. It seems that noone is using PB2 with transformers...\r\n\r\nme too"
] | 1,656
| 1,686
| 1,662
|
COLLABORATOR
| null |
### System Info
- `transformers` version: 4.21.0.dev0
- Platform: Linux-5.13.0-27-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.12.0+cu113 (True)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no, although Ray tune runs in parallel
### Who can help?
@richardliaw @amogkam
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I run a hyperparameter search with ray[tune] which consists of these parts:
```python
hp_space = {
"num_train_epochs": tune.choice([1, 2, 3, 4]),
}
scheduler = PB2(
metric="eval_f1",
mode="max",
hyperparam_bounds={
"weight_decay": [0.0, 0.3], # default (in transformers): 0.
"learning_rate": [1e-4, 1e-5],
"gradient_accumulation_steps": [4, 8],
"adam_epsilon": [1e-07, 1e-9], # default: 1e-8
"adam_beta1": [0.85, 0.9999], # default: 0.9
"adam_beta2": [0.95, 0.9999], # default: 0.999
},
)
resources_per_trial = {"cpu": min(4, (os.cpu_count() - 1) // device_count), "gpu": 1}
best_params = trainer.hyperparameter_search(hp_space=lambda _: hpspace,
backend="ray",
n_trials=8,
resources_per_trial=resources_per_trial,
keep_checkpoints_num=1,
scheduler=scheduler,
compute_objective=compute_objective)
```
However, after the processes have been running for a long time (async 4x V100), I get the following error trace:
```
ray::ImplicitFunc.train()ESC[39m (pid=3354338, ip=157.193.228.18, repr=_objective)
File "/home/bram/.local/share/virtualenvs/transformers-finetuner-rzmJjOSV/lib/python3.8/site-packages/ray/tune/trainable.py", line 360, in train
result = self.step()
File "/home/bram/.local/share/virtualenvs/transformers-finetuner-rzmJjOSV/lib/python3.8/site-packages/ray/tune/function_runner.py", line 404, in step
self._report_thread_runner_error(block=True)
File "/home/bram/.local/share/virtualenvs/transformers-finetuner-rzmJjOSV/lib/python3.8/site-packages/ray/tune/function_runner.py", line 574, in _report_thread_runner_error
raise e
File "/home/bram/.local/share/virtualenvs/transformers-finetuner-rzmJjOSV/lib/python3.8/site-packages/ray/tune/function_runner.py", line 277, in run
self._entrypoint()
File "/home/bram/.local/share/virtualenvs/transformers-finetuner-rzmJjOSV/lib/python3.8/site-packages/ray/tune/function_runner.py", line 349, in entrypoint
return self._trainable_func(
File "/home/bram/.local/share/virtualenvs/transformers-finetuner-rzmJjOSV/lib/python3.8/site-packages/ray/tune/function_runner.py", line 645, in _trainable_func
output = fn()
File "/home/bram/Python/projects/transformers-finetuner/transformers/src/transformers/integrations.py", line 288, in dynamic_modules_import_trainable
return trainable(*args, **kwargs)
File "/home/bram/.local/share/virtualenvs/transformers-finetuner-rzmJjOSV/lib/python3.8/site-packages/ray/tune/utils/trainable.py", line 410, in inner
trainable(config, **fn_kwargs)
File "/home/bram/Python/projects/transformers-finetuner/transformers/src/transformers/integrations.py", line 189, in _objective
local_trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
File "/home/bram/Python/projects/transformers-finetuner/transformers/src/transformers/trainer.py", line 1410, in train
return inner_training_loop(
File "/home/bram/Python/projects/transformers-finetuner/transformers/src/transformers/trainer.py", line 1729, in _inner_training_loop
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/home/bram/Python/projects/transformers-finetuner/transformers/src/transformers/trainer.py", line 1914, in _maybe_log_save_evaluate
self._report_to_hp_search(trial, epoch, metrics)
File "/home/bram/Python/projects/transformers-finetuner/transformers/src/transformers/trainer.py", line 1153, in _report_to_hp_search
self._tune_save_checkpoint()
File "/home/bram/Python/projects/transformers-finetuner/transformers/src/transformers/trainer.py", line 1165, in _tune_save_checkpoint
self.state.save_to_json(os.path.join(output_dir, TRAINER_STATE_NAME))
File "/home/bram/Python/projects/transformers-finetuner/transformers/src/transformers/trainer_callback.py", line 97, in save_to_json
json_string = json.dumps(dataclasses.asdict(self), indent=2, sort_keys=True) + "\n"
File "/home/bram/.pyenv/versions/3.8.10/lib/python3.8/json/__init__.py", line 234, in dumps
return cls(
File "/home/bram/.pyenv/versions/3.8.10/lib/python3.8/json/encoder.py", line 201, in encode
chunks = list(chunks)
File "/home/bram/.pyenv/versions/3.8.10/lib/python3.8/json/encoder.py", line 431, in _iterencode
yield from _iterencode_dict(o, _current_indent_level)
File "/home/bram/.pyenv/versions/3.8.10/lib/python3.8/json/encoder.py", line 405, in _iterencode_dict
yield from chunks
File "/home/bram/.pyenv/versions/3.8.10/lib/python3.8/json/encoder.py", line 405, in _iterencode_dict
yield from chunks
File "/home/bram/.pyenv/versions/3.8.10/lib/python3.8/json/encoder.py", line 438, in _iterencode
o = _default(o)
File "/home/bram/.pyenv/versions/3.8.10/lib/python3.8/json/encoder.py", line 179, in default
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type float32 is not JSON serializable
```
This occurs at around step 1840/2500. I do not know if it is relevant, but I am also running in `fp16`. If I had to guess, I'd think that during the duping of the [TrainerState](https://github.com/huggingface/transformers/blob/692e61e91a0b83f5b847902ed619b7c74c0a5dda/src/transformers/trainer_callback.py#L97), one of the [trial_params](https://github.com/huggingface/transformers/blob/692e61e91a0b83f5b847902ed619b7c74c0a5dda/src/transformers/trainer_callback.py#L89) was a np/torch float32 rather than a Python primitive, which could not be serialized. It is unclear to me why this would only happen already far into the training, though. Maybe it's a nan, or another kind of overflow of some kind?
### Expected behavior
No errors. It would also be nice if the error message could tell us which key is causing this issue, but I am not sure how feasible that is.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17955/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17955/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17954
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17954/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17954/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17954/events
|
https://github.com/huggingface/transformers/issues/17954
| 1,289,271,338
|
I_kwDOCUB6oc5M2Lgq
| 17,954
|
codegen-16B-mono (Salesforce) fails to load tokenizer and model
|
{
"login": "weidotwisc",
"id": 3663272,
"node_id": "MDQ6VXNlcjM2NjMyNzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/3663272?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weidotwisc",
"html_url": "https://github.com/weidotwisc",
"followers_url": "https://api.github.com/users/weidotwisc/followers",
"following_url": "https://api.github.com/users/weidotwisc/following{/other_user}",
"gists_url": "https://api.github.com/users/weidotwisc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/weidotwisc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/weidotwisc/subscriptions",
"organizations_url": "https://api.github.com/users/weidotwisc/orgs",
"repos_url": "https://api.github.com/users/weidotwisc/repos",
"events_url": "https://api.github.com/users/weidotwisc/events{/privacy}",
"received_events_url": "https://api.github.com/users/weidotwisc/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hi @weidotwisc ,\r\n\r\nYou get these errors because CodeGen was only merged onto the master branch of the repo 5 days ago (PR https://github.com/huggingface/transformers/pull/17443) and therefore has not been released yet. :smile: \r\n\r\nIf you want to use it now without waiting for a release, you can install a transformers version on master. For example with pip by running `pip install git+https://github.com/huggingface/transformers.git`\r\n",
"@SaulLu Thanks for the help! I am now able to load its tokenizer and model and follow through the model card example. \r\n\r\nThanks,\r\n\r\nWei"
] | 1,656
| 1,656
| 1,656
|
NONE
| null |
### System Info
- `transformers` version: 4.20.1
- Platform: Linux-4.18.0-193.19.1.el8_2.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.10
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.7.1+cu110 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <N/A>
- Using distributed or parallel set-up in script?: <N/A>
### Who can help?
Per https://huggingface.co/Salesforce/codegen-16B-mono?text=What+is+projection+matrix, I should be able to load the codegen tokenizer and model by doing
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-16B-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-16B-mono")
@SaulLu When I do tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-16B-mono"), I got this error:
"...huggingface_py3.9/lib/python3.9/site-packages/transformers/models/auto/tokenization_auto.py", line 576, in from_pretrained
raise ValueError(
ValueError: Tokenizer class CodeGenTokenizer does not exist or is not currently imported.
@LysandreJik When I do model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-16B-mono"), I got this error:
"... huggingface_py3.9/lib/python3.9/site-packages/transformers/models/auto/configuration_auto.py", line 725, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/Volume0/userhomes/weiz/venvs/huggingface_py3.9/lib/python3.9/site-packages/transformers/models/auto/configuration_auto.py", line 432, in __getitem__
raise KeyError(key)
KeyError: 'codegen'
"
Thanks!
Wei
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Follow the model card at https://huggingface.co/Salesforce/codegen-16B-mono?text=What+is+projection+matrix
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-16B-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-16B-mono")
I then got the Errors:
"...huggingface_py3.9/lib/python3.9/site-packages/transformers/models/auto/tokenization_auto.py", line 576, in from_pretrained
raise ValueError(
ValueError: Tokenizer class CodeGenTokenizer does not exist or is not currently imported.
"... huggingface_py3.9/lib/python3.9/site-packages/transformers/models/auto/configuration_auto.py", line 725, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/Volume0/userhomes/weiz/venvs/huggingface_py3.9/lib/python3.9/site-packages/transformers/models/auto/configuration_auto.py", line 432, in __getitem__
raise KeyError(key)
KeyError: 'codegen'
"
### Expected behavior
The tokenizer and Model should be loaded successfully.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17954/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17954/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17953
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17953/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17953/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17953/events
|
https://github.com/huggingface/transformers/pull/17953
| 1,289,167,711
|
PR_kwDOCUB6oc46l1Lg
| 17,953
|
Add ONNX support for LayoutLMv3
|
{
"login": "regisss",
"id": 15324346,
"node_id": "MDQ6VXNlcjE1MzI0MzQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/15324346?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/regisss",
"html_url": "https://github.com/regisss",
"followers_url": "https://api.github.com/users/regisss/followers",
"following_url": "https://api.github.com/users/regisss/following{/other_user}",
"gists_url": "https://api.github.com/users/regisss/gists{/gist_id}",
"starred_url": "https://api.github.com/users/regisss/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/regisss/subscriptions",
"organizations_url": "https://api.github.com/users/regisss/orgs",
"repos_url": "https://api.github.com/users/regisss/repos",
"events_url": "https://api.github.com/users/regisss/events{/privacy}",
"received_events_url": "https://api.github.com/users/regisss/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"@NielsRogge The supported tasks are question answering, token classification and sequence classification. Is there any other use case that should be supported?\r\n\r\nAlso, the order of input arguments for the `forward` method of `LayoutLMv3ForSequenceClassification` and `LayoutLMv3ForQuestionAnswering` is different from `LayoutLMv3ForTokenClassification` and `LayoutLMv3Model`. This is taken care of in the ONNX config because I guess modifying it in `modeling_layoutlmv3.py` is not an option since it would break backwards compatibility right?",
"_The documentation is not available anymore as the PR was closed or merged._",
"@lewtun All slow tests passed",
"CI fails because of the following error:\r\n```shell\r\nTraceback (most recent call last):\r\n File \"utils/check_repo.py\", line 768, in <module>\r\n check_repo_quality()\r\n File \"utils/check_repo.py\", line 762, in check_repo_quality\r\n check_all_objects_are_documented()\r\n File \"utils/check_repo.py\", line 675, in check_all_objects_are_documented\r\n + \"\\n - \".join(undocumented_objs)\r\nException: The following objects are in the public init so should be documented:\r\n - OptionalDependencyNotAvailable\r\n - dummy_scatter_objects\r\n - sys\r\n```\r\nIt seems to come from the following line in `configuration_layoutlmv3.py`:\r\n```python\r\nfrom ...processing_utils import ProcessorMixin\r\n```",
"Wow thanks a lot @sgugger for the clear explanation, it makes complete sense!",
"CI and slow tests all passed. It should be ready now @sgugger @lewtun ",
"Thanks!",
"@regisss Thank you for your great work, when convert layoutxlm LayoutLMv2ForRelationExtraction to onnx, we are blocked by relation extraction layer for some reasons, can you try to export LayoutLMv2ForRelationExtraction model to onnx and give us for some help? gret thanks for you!",
"@NielsRogge Thanks for your great work, when I convert LayoutLMv2ForRelationExtraction to onnx, I can not export relation extraction layer to onnx, can you help me to solve it? because the deadline is coming for the project, I hope you can help me, Thank you very much.",
"> @regisss Thank you for your great work, when convert layoutxlm LayoutLMv2ForRelationExtraction to onnx, we are blocked by relation extraction layer for some reasons, can you try to export LayoutLMv2ForRelationExtraction model to onnx and give us for some help? gret thanks for you!\r\n\r\n@githublsk Where did you find `LayoutLMv2ForRelationExtraction`? I cannot find it in Transformers",
"@regisss it is just in microsoft/unlim,please refer to the link:\r\nhttps://github.com/microsoft/unilm/blob/master/layoutlmft/layoutlmft/models/layoutlmv2/modeling_layoutlmv2.py\r\n\r\nit is useful for relation extraction, but when running onnx,some question occur as below:\r\n\r\nthe onnx graph is as below:\r\n\r\nI can not find any reason, which confused me, I meet the deadline for my project, it is so urgent....",
"@regisss if you have time, please help us, I am a newer to it, great thanks for you!",
"> @regisss if you have time, please help us, I am a newer to it, great thanks for you!\r\n\r\n@githublsk Open an issue because it is not related to this PR. And provide the command/script you ran with the complete error message please, screenshots are not very helpful. ",
"@regisss Thank you for your great help, I open an issue in the link, can you help me? because the deadline is coming, it bothers me a lot, we hope you can help us to reslove it, great thanks.\r\n\r\nhttps://github.com/huggingface/transformers/issues/17999",
"@githublsk \r\nhow did you solve onnx convert error:\r\n **Exporting the operator bilinear to ONNX opset version 13 is not supported**\r\n super(BiaffineAttention, self).__init__()\r\n self.in_features = in_features\r\n self.out_features = out_features\r\n **self.bilinear = torch.nn.Bilinear(in_features, in_features, out_features, bias=False)**",
"@gjj123 replace torch.nn.Bilinear with this one\r\n```\r\nclass Bilinear(nn.Module):\r\n def __init__(self, in1_features, in2_features, out_features):\r\n super(Bilinear, self).__init__()\r\n self.weight = torch.nn.Parameter(torch.zeros((in1_features, in2_features, out_features)))\r\n self.bias = torch.nn.Parameter(torch.zeros((out_features)))\r\n nn.init.xavier_uniform_(self.weight)\r\n\r\n def forward(self, x, y):\r\n t = x @ self.weight.permute(2,0,1)\r\n output = (t * y).sum(dim=2).t()\r\n return output\r\n```"
] | 1,656
| 1,673
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR adds ONNX support for LayoutLMv3. Linked to #16308.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17953/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17953/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17953",
"html_url": "https://github.com/huggingface/transformers/pull/17953",
"diff_url": "https://github.com/huggingface/transformers/pull/17953.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17953.patch",
"merged_at": 1656605392000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17952
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17952/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17952/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17952/events
|
https://github.com/huggingface/transformers/issues/17952
| 1,289,162,913
|
I_kwDOCUB6oc5M1xCh
| 17,952
|
Trainer.predict multiple progress bars
|
{
"login": "neverix",
"id": 46641404,
"node_id": "MDQ6VXNlcjQ2NjQxNDA0",
"avatar_url": "https://avatars.githubusercontent.com/u/46641404?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/neverix",
"html_url": "https://github.com/neverix",
"followers_url": "https://api.github.com/users/neverix/followers",
"following_url": "https://api.github.com/users/neverix/following{/other_user}",
"gists_url": "https://api.github.com/users/neverix/gists{/gist_id}",
"starred_url": "https://api.github.com/users/neverix/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neverix/subscriptions",
"organizations_url": "https://api.github.com/users/neverix/orgs",
"repos_url": "https://api.github.com/users/neverix/repos",
"events_url": "https://api.github.com/users/neverix/events{/privacy}",
"received_events_url": "https://api.github.com/users/neverix/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"\r\n\r\nThe cause of the issue is that `Trainer.predict()` calls `on_prediction_step` but not `on_evaluate` for `predict()`, so every prediction run after the first one will reuse the progress bar object because `on_evaluate` is the callback responsible for destroying it.",
"A simple fix would be to add an `on_predict` method to the `ProgressCallback`.\r\n\r\nAlternatively, `Trainer.predict` could just call `on_evaluate` in the end.",
"There is no `on_predict` event, but I guess we can reuse `on_evaluate` here. Do you want to make a PR?",
"I wrote a draft, but it breaks in Jupyter because `NotebookProgressBar` adds [custom logic](https://github.com/huggingface/transformers/blob/3f936df66287f557c6528912a9a68d7850913b9b/src/transformers/utils/notebook.py#L318) to `on_evaluate`. Creating `on_predict` might be necessary.",
"Feel free to create it then!"
] | 1,656
| 1,657
| 1,657
|
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.21.0.dev0
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.11.0+cu113 (False)
- Tensorflow version (GPU?): 2.8.2 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
trainer = Trainer(model)
trainer.predict([{"input_ids": torch.zeros(20).long()} for _ in range(48)]) # [6/6 00:03]
trainer.predict([{"input_ids": torch.zeros(20).long()} for _ in range(96)]) # [6/6 00:12] despite having more examples
```
### Expected behavior
Two progress bars, one of length 6 and the other of length 12.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17952/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17952/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17951
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17951/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17951/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17951/events
|
https://github.com/huggingface/transformers/pull/17951
| 1,289,108,302
|
PR_kwDOCUB6oc46loFQ
| 17,951
|
Fix number of examples for iterable dataset in distributed training
|
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
As pointed out in #17913, when training in distributed mode with iterable datasets, the number of examples displayed is wrong. This is because we need to go grab the length of the underlying dataset of the `IterableDatasetShard`, not the length of the `IterableDatasetShard` itself.
Fixes #17913
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17951/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17951/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17951",
"html_url": "https://github.com/huggingface/transformers/pull/17951",
"diff_url": "https://github.com/huggingface/transformers/pull/17951.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17951.patch",
"merged_at": 1656601300000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17950
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17950/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17950/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17950/events
|
https://github.com/huggingface/transformers/pull/17950
| 1,289,091,269
|
PR_kwDOCUB6oc46lkM6
| 17,950
|
Fix for prepare_tf_dataset when drop_remainder is not supplied
|
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"It's the same behaviour as Keras and `to_tf_dataset()`, so I think people will expect it!"
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
Super-minor fix for an oversight that causes a crash when `drop_remainder` is left at the default `None`!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17950/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17950/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17950",
"html_url": "https://github.com/huggingface/transformers/pull/17950",
"diff_url": "https://github.com/huggingface/transformers/pull/17950.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17950.patch",
"merged_at": 1656527020000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17949
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17949/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17949/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17949/events
|
https://github.com/huggingface/transformers/pull/17949
| 1,289,014,101
|
PR_kwDOCUB6oc46lS0l
| 17,949
|
PyTorch 1.12.0 for scheduled CI
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
After the slack discussion, using PyTorch 1.12.0 for scheduled CI is a better idea, so we can see what to fix.
Another reason is that this (messy) block
https://github.com/huggingface/transformers/blob/39dad9768e75460d8bf92fc27d407562eaeb6bd0/docker/transformers-pytorch-gpu/Dockerfile#L19-L22
will change torch 1.11 (if specified) back to 1.12, as torchvision and torchaudio are installed separately from torch without specifying versions. It's better to avoid such situations.
Regarding the torch/torchvision/torchaudio correspondence, I have better approach in my past-ci PR.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17949/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17949/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17949",
"html_url": "https://github.com/huggingface/transformers/pull/17949",
"diff_url": "https://github.com/huggingface/transformers/pull/17949.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17949.patch",
"merged_at": 1656523939000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17948
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17948/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17948/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17948/events
|
https://github.com/huggingface/transformers/pull/17948
| 1,289,012,939
|
PR_kwDOCUB6oc46lSkB
| 17,948
|
PyTorch 1.12.0
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,657
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Change to PyTorch 1.12.0 for scheduled CI.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17948/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17948/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17948",
"html_url": "https://github.com/huggingface/transformers/pull/17948",
"diff_url": "https://github.com/huggingface/transformers/pull/17948.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17948.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17947
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17947/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17947/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17947/events
|
https://github.com/huggingface/transformers/issues/17947
| 1,289,007,037
|
I_kwDOCUB6oc5M1K-9
| 17,947
|
Consider adding "middle" option for tokenizer truncation_side argument
|
{
"login": "AndreaSottana",
"id": 48888970,
"node_id": "MDQ6VXNlcjQ4ODg4OTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/48888970?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AndreaSottana",
"html_url": "https://github.com/AndreaSottana",
"followers_url": "https://api.github.com/users/AndreaSottana/followers",
"following_url": "https://api.github.com/users/AndreaSottana/following{/other_user}",
"gists_url": "https://api.github.com/users/AndreaSottana/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AndreaSottana/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AndreaSottana/subscriptions",
"organizations_url": "https://api.github.com/users/AndreaSottana/orgs",
"repos_url": "https://api.github.com/users/AndreaSottana/repos",
"events_url": "https://api.github.com/users/AndreaSottana/events{/privacy}",
"received_events_url": "https://api.github.com/users/AndreaSottana/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"WDYT @SaulLu @Narsil ?",
"Hi @AndreaSottana,\r\n\r\nThank you very much for sharing a feature proposal! :hugs: \r\n\r\nI understand your use case, my feeling is that for the moment I will not push for the addition of this feature. My feeling is that at the moment it is something that can be implemented on-top of transformers and touches a problem where a user may want many different variants depending on their specific use case.\r\n\r\nOf course, if this is a feature for which there is a lot of demand, I will gladly come back to my opinion! (so please if you are passing by feel free to share what you think :smiley:)\r\n\r\nIn terms of implementation, my opinion is that it is not a very simple addition because it will affect all tokenizers (and some are really particular like those of LayoutLM-like models) whether they are slow or fast. This also means that it would require a new feature in the rust tokenizers library.\r\n\r\nI'm also very curious to know what you think @Narsil !",
"Ok that's fine, thanks a lot for getting back to me @SaulLu \r\nLet's see if there is more appetite, if not we can leave it here for now. I can always implement the truncation myself for my specific model and tokenizer, I just thought it may be a helpful feature to have, but as you said we'd need to see how much demand there is.\r\nFeel free to close the issue if appropriate",
"100% agree with @SaulLu .\r\n\r\nThere might be a use case, but it doesn't seem as a blatant missing feature (and we try to focus on those).\r\nFuture reader, make yourself heard so that we can revisit our opinion :)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"It is needed indeed! :)\r\nTo add the motivation to this, take a look at the article \"How to Fine-Tune BERT for Text Classification?\": https://arxiv.org/pdf/1905.05583.pdf\r\nThey show that using head+tail achieved the best results. I think that the case when the most important content is in the beginning and\\or the end is relevant to a lot of fields, including sentiment detection, hate-speech detection and more."
] | 1,656
| 1,674
| 1,660
|
CONTRIBUTOR
| null |
### Feature request
At the moment, thanks to this PR https://github.com/huggingface/transformers/pull/14947 the option to truncate the text from the left instead of just from the right has been added. However, for some NLP tasks like summarization of long documents, it might also be advantageous to truncate the middle part of the document instead. For example if our sequence length is 512 tokens and a document exceeds this length, we might want to keep the first 256 and the last 256 tokens of the document, and truncate everything in between. Therefore this issue is to request implementation of this option.
### Motivation
The reason this feature might be helpful is is because when dealing in particular with long documents (for example for longformer summarization tasks), depending on the documents domain, the start of the document might set out relevant information, and the end of the document might contain a useful recap of the main points discussed, therefore both can be very relevant and valuable to keep, whereas the text in the middle may not be as important. Therefore adding an option `truncation_side="middle"`, allowing retention of the first 256 and the last 256 tokens, might be very helpful for certain use cases.
### Your contribution
I have limited bandwidth right now, but might consider contributing if this can be done as a quick fix and someone from HuggingFace can provide overview.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17947/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17947/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17946
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17946/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17946/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17946/events
|
https://github.com/huggingface/transformers/issues/17946
| 1,288,972,965
|
I_kwDOCUB6oc5M1Cql
| 17,946
|
Decision Transformer Position Embedding Incorrect Implementation
|
{
"login": "charlesjsun",
"id": 16947871,
"node_id": "MDQ6VXNlcjE2OTQ3ODcx",
"avatar_url": "https://avatars.githubusercontent.com/u/16947871?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/charlesjsun",
"html_url": "https://github.com/charlesjsun",
"followers_url": "https://api.github.com/users/charlesjsun/followers",
"following_url": "https://api.github.com/users/charlesjsun/following{/other_user}",
"gists_url": "https://api.github.com/users/charlesjsun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/charlesjsun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/charlesjsun/subscriptions",
"organizations_url": "https://api.github.com/users/charlesjsun/orgs",
"repos_url": "https://api.github.com/users/charlesjsun/repos",
"events_url": "https://api.github.com/users/charlesjsun/events{/privacy}",
"received_events_url": "https://api.github.com/users/charlesjsun/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
|
{
"login": "edbeeching",
"id": 7275864,
"node_id": "MDQ6VXNlcjcyNzU4NjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7275864?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/edbeeching",
"html_url": "https://github.com/edbeeching",
"followers_url": "https://api.github.com/users/edbeeching/followers",
"following_url": "https://api.github.com/users/edbeeching/following{/other_user}",
"gists_url": "https://api.github.com/users/edbeeching/gists{/gist_id}",
"starred_url": "https://api.github.com/users/edbeeching/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/edbeeching/subscriptions",
"organizations_url": "https://api.github.com/users/edbeeching/orgs",
"repos_url": "https://api.github.com/users/edbeeching/repos",
"events_url": "https://api.github.com/users/edbeeching/events{/privacy}",
"received_events_url": "https://api.github.com/users/edbeeching/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "edbeeching",
"id": 7275864,
"node_id": "MDQ6VXNlcjcyNzU4NjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7275864?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/edbeeching",
"html_url": "https://github.com/edbeeching",
"followers_url": "https://api.github.com/users/edbeeching/followers",
"following_url": "https://api.github.com/users/edbeeching/following{/other_user}",
"gists_url": "https://api.github.com/users/edbeeching/gists{/gist_id}",
"starred_url": "https://api.github.com/users/edbeeching/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/edbeeching/subscriptions",
"organizations_url": "https://api.github.com/users/edbeeching/orgs",
"repos_url": "https://api.github.com/users/edbeeching/repos",
"events_url": "https://api.github.com/users/edbeeching/events{/privacy}",
"received_events_url": "https://api.github.com/users/edbeeching/received_events",
"type": "User",
"site_admin": false
}
] |
[
"cc @edbeeching @simoninithomas ",
"Thanks for highlighting this, we set the position_ids to all zeros in the forward pass of the Decision Transformer Model: \r\nhttps://github.com/huggingface/transformers/blob/9fe2403bc52e342022ed132561655f84a6b6b7f3/src/transformers/models/decision_transformer/modeling_decision_transformer.py#L935-L942\r\n\r\nIn additional, the weights of this layer are loaded with zeros. This is equivalent to not using the position embeddings. \r\nI just went through the Decision Transformer models on the hub to ensure that the model.encoder.wpe weights are indeed zeros and that is the case.\r\n\r\nWe left position embeddings in the implementation in case researchers wish to experiment with the inclusion of position embeddings. Please let us know if you find any other examples of potential bugs or require further clarification."
] | 1,656
| 1,656
| 1,656
|
NONE
| null |
### System Info
Not necessary (source code issue)
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
From the code for decision transformer: https://github.com/huggingface/transformers/blob/9fe2403bc52e342022ed132561655f84a6b6b7f3/src/transformers/models/decision_transformer/modeling_decision_transformer.py#L821-L822
But the actual implementation did not remove the position embedding from the GPT2 model
https://github.com/huggingface/transformers/blob/9fe2403bc52e342022ed132561655f84a6b6b7f3/src/transformers/models/decision_transformer/modeling_decision_transformer.py#L497
https://github.com/huggingface/transformers/blob/9fe2403bc52e342022ed132561655f84a6b6b7f3/src/transformers/models/decision_transformer/modeling_decision_transformer.py#L610-L611
### Expected behavior
The expected implementation should be
https://github.com/kzl/decision-transformer/blob/e2d82e68f330c00f763507b3b01d774740bee53f/gym/decision_transformer/models/trajectory_gpt2.py#L680-L681
from the official decision transformer repo
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17946/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17946/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17945
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17945/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17945/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17945/events
|
https://github.com/huggingface/transformers/issues/17945
| 1,288,937,959
|
I_kwDOCUB6oc5M06Hn
| 17,945
|
Unable to fine-tune WMT model
|
{
"login": "tatiana-iazykova",
"id": 70767376,
"node_id": "MDQ6VXNlcjcwNzY3Mzc2",
"avatar_url": "https://avatars.githubusercontent.com/u/70767376?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tatiana-iazykova",
"html_url": "https://github.com/tatiana-iazykova",
"followers_url": "https://api.github.com/users/tatiana-iazykova/followers",
"following_url": "https://api.github.com/users/tatiana-iazykova/following{/other_user}",
"gists_url": "https://api.github.com/users/tatiana-iazykova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tatiana-iazykova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tatiana-iazykova/subscriptions",
"organizations_url": "https://api.github.com/users/tatiana-iazykova/orgs",
"repos_url": "https://api.github.com/users/tatiana-iazykova/repos",
"events_url": "https://api.github.com/users/tatiana-iazykova/events{/privacy}",
"received_events_url": "https://api.github.com/users/tatiana-iazykova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hi Tatiana,\r\nI am just a user and just came across your issue. I have experienced similar things and I finally found out it was due to incompatibility between tokenizer's vocabulary and the vocabulary sizes of the encoder & decoder (check in the config). Not sure if the same reason, but maybe you could check it, too :)",
"Apologies I wasn't able to attend to many things transformers as of recently due to BLOOM training. I had a quick look and the problem stems from the padding id being `-100` here for some reason which is the wrong negative index and `torch.embedding` fails to look it up as its keys are all positive indices. \r\n\r\nWill try to find some time hopefully in the next few days to dive deeper and resolve this.",
"I apologize again for taking so long. Please try with this PR: https://github.com/huggingface/transformers/pull/18592\r\n",
"Thanks"
] | 1,656
| 1,660
| 1,660
|
NONE
| null |
### System Info
- `transformers` version: 4.20.1
- Platform: Darwin-21.5.0-x86_64-i386-64bit
- Python version: 3.7.2
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.12.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@stas00 @sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Hi!
I'm trying to fine-tune WMT model on my dataset, but running into strange behaviour. The code was taken from official notebook listed on website https://github.com/huggingface/notebooks/blob/main/examples/translation.ipynb
Data: https://www.kaggle.com/datasets/nltkdata/wmt15-eval
Code to reproduce:
```python
import pandas as pd
from datasets import Dataset, load_metric
import transformers
from transformers import AutoTokenizer
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
import numpy as np
with open('newstest-2015-100sents.en-ru.ref.ru') as f:
en = f.read()
with open('newstest-2015-100sents.en-ru.src.en') as f:
ru = f.read()
en = en.split('\n')
ru = ru.split('\n')
df_all = pd.DataFrame({'en': en, 'ru': ru})
df = Dataset.from_pandas(df_all)
metric = load_metric("sacrebleu")
dataset_splitted = df.shuffle(1337).train_test_split(0.1)
model_checkpoint = 'facebook/wmt19-en-ru'
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
max_input_length = 128
max_target_length = 128
def preprocess_function(examples):
inputs = [ex for ex in examples["en"]]
targets = [ex for ex in examples["ru"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_datasets = dataset_splitted.map(preprocess_function, batched=True)
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
batch_size = 16
model_name = model_checkpoint.split("/")[-1]
args = Seq2SeqTrainingArguments(
"./tmp",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
predict_with_generate=True
)
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
```
The traceback I get:
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
/var/folders/cv/dmhc689x3gn9vgg44b67yl2c0000gq/T/ipykernel_29677/4032920361.py in <module>
----> 1 trainer.train()
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1411 resume_from_checkpoint=resume_from_checkpoint,
1412 trial=trial,
-> 1413 ignore_keys_for_eval=ignore_keys_for_eval,
1414 )
1415
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/transformers/trainer.py in _inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
1649 tr_loss_step = self.training_step(model, inputs)
1650 else:
-> 1651 tr_loss_step = self.training_step(model, inputs)
1652
1653 if (
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/transformers/trainer.py in training_step(self, model, inputs)
2343
2344 with self.compute_loss_context_manager():
-> 2345 loss = self.compute_loss(model, inputs)
2346
2347 if self.args.n_gpu > 1:
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/transformers/trainer.py in compute_loss(self, model, inputs, return_outputs)
2375 else:
2376 labels = None
-> 2377 outputs = model(**inputs)
2378 # Save past state if it exists
2379 # TODO: this needs to be fixed and made cleaner later.
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/transformers/models/fsmt/modeling_fsmt.py in forward(self, input_ids, attention_mask, decoder_input_ids, decoder_attention_mask, head_mask, decoder_head_mask, cross_attn_head_mask, encoder_outputs, past_key_values, labels, use_cache, output_attentions, output_hidden_states, return_dict)
1175 output_attentions=output_attentions,
1176 output_hidden_states=output_hidden_states,
-> 1177 return_dict=return_dict,
1178 )
1179 lm_logits = outputs[0]
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/transformers/models/fsmt/modeling_fsmt.py in forward(self, input_ids, attention_mask, decoder_input_ids, decoder_attention_mask, head_mask, decoder_head_mask, cross_attn_head_mask, encoder_outputs, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
1079 output_attentions=output_attentions,
1080 output_hidden_states=output_hidden_states,
-> 1081 return_dict=return_dict,
1082 )
1083
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/transformers/models/fsmt/modeling_fsmt.py in forward(self, input_ids, encoder_hidden_states, encoder_padding_mask, decoder_padding_mask, decoder_causal_mask, head_mask, cross_attn_head_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
722 # assert input_ids.ne(self.padding_idx).any()
723
--> 724 x = self.embed_tokens(input_ids) * self.embed_scale
725 x += positions
726 x = nn.functional.dropout(x, p=self.dropout, training=self.training)
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/torch/nn/modules/sparse.py in forward(self, input)
158 return F.embedding(
159 input, self.weight, self.padding_idx, self.max_norm,
--> 160 self.norm_type, self.scale_grad_by_freq, self.sparse)
161
162 def extra_repr(self) -> str:
~/pet_projects/fairseq_experiments/venv/lib/python3.7/site-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
2197 # remove once script supports set_grad_enabled
2198 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)
-> 2199 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
2200
2201
IndexError: index out of range in self
```
### Expected behavior
Could you please help me figure out what's wrong with the trainer?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17945/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17945/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17944
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17944/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17944/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17944/events
|
https://github.com/huggingface/transformers/pull/17944
| 1,288,901,259
|
PR_kwDOCUB6oc46k6dM
| 17,944
|
[Bigscience] Non-causal Decoder Generation
|
{
"login": "haileyschoelkopf",
"id": 65563625,
"node_id": "MDQ6VXNlcjY1NTYzNjI1",
"avatar_url": "https://avatars.githubusercontent.com/u/65563625?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/haileyschoelkopf",
"html_url": "https://github.com/haileyschoelkopf",
"followers_url": "https://api.github.com/users/haileyschoelkopf/followers",
"following_url": "https://api.github.com/users/haileyschoelkopf/following{/other_user}",
"gists_url": "https://api.github.com/users/haileyschoelkopf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/haileyschoelkopf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/haileyschoelkopf/subscriptions",
"organizations_url": "https://api.github.com/users/haileyschoelkopf/orgs",
"repos_url": "https://api.github.com/users/haileyschoelkopf/repos",
"events_url": "https://api.github.com/users/haileyschoelkopf/events{/privacy}",
"received_events_url": "https://api.github.com/users/haileyschoelkopf/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17944). All of your documentation changes will be reflected on that endpoint.",
"Demonstration still here: https://gist.github.com/haileyschoelkopf/33b9e41d07b9222e995c6cce155724de\r\n\r\nPR now updated to include `BloomForPrefixLM` and passing in a mask tensor of size `[batch_size, 1, input_length, input_length]` \r\n\r\nRunning the bigscience lm-eval-harness fork with Bloom Prefix LM should be as simple as just swapping the (\"bloom\", \"BloomForCausalLM\") entry in MODEL_FOR_CAUSAL_LM_MAPPING_NAMES to (\"bloom\", \"BloomForPrefixLM\").",
"I proposed some adjustments here: https://github.com/haileyschoelkopf/transformers/pull/1\r\n@haileyschoelkopf @thomasw21 ",
"You should create a test that shows that whatever invariances your model has, it should be tested in the test:\r\n - changing a value in the input part changes all the input logits as well as target.\r\n - changing a value in the targer only changes logies before and not after (same as language modeling)\r\n - `generate` actually works with this function.",
"Thanks for the input. Will make above into tests. ",
"Thanks for the edits and comments Lintang!\r\n\r\nI may not get to testing these today because of the holiday, but I will do so tomorrow if not.\r\n\r\n@lintangsutawika I'm happy to also turn your `tests/models/bloom/test_noncausal_attention_bloom.py` test script into unit tests in huggingface/transformers if you'd like.",
"@younesbelkada since you're the author of the architecture in `transformers`",
"Update on the status of this: I started looking at Lintang's edits today. Commit [0f692c07788a536fec103d83c8acdd5565cccb05](https://github.com/huggingface/transformers/pull/17944/commits/0f692c07788a536fec103d83c8acdd5565cccb05) from me is the last one I had checked for generation; I will continue editing Lintang's changes as necessary tomorrow.\r\n\r\n\r\nIf necessary, happy to discuss further the merits of using `prefix_length` vs. passing `prefix_mask` to the model as a design choice--Lintang switched it back to `prefix_length`, and I think I agree with this because it'd be easier to just feed a prefix length to the model when training it on a batch of concatenated input-target sequences using a prefix LM objective.",
"I think we'd be much happier is the `attention_mask` was explicitely passed to the model. Typically one of the thing we're using in MTF right now is packing. I don't think packing exists as a technique under current bloom implementation.",
"Is the goal for the Transformers version of Bloom to also support packing? My understanding is that even transformers version of T5 doesn't have packing.\n\nHaving to input an attention mask means there would be two attention masks to input? The regular attention masks that the PretrainedModel object requires and the NonCausal Attention mask? I figured it would be easier for users to just declare the length of the prefix and let the model build the mask?\n\nI suppose a compromise would be to have a NonCausalAttentionMask argument but allow the model to accept prefix length as well of the former is not provided.",
"I don't have a strong opinion but setting an attention mask explictely vs having `n` different mechanism to update an attention_mask is annoying. Today we're handling prefix, tomorrow we're handling another weird thing. One use-case I can think of is like `{input} <pad> <pad> <pad> {target} <pad> <pad> <pad>` I think this case can happen when you generate. \r\n\r\nAlso @patrickvonplaten if you have any input about this. For context, we're going to train a prefix lm and so naturally we have bidirectional attention in the input, and casaul in the target. The current solution are:\r\n - pass a prefix length and update the attention mask\r\n - pass an explicit attention mask everytime.",
"If there is another attention formula, we could always add another BloomFor<Attention Type>LM? \n\nIn the case for prefix LM, it seems easier to have a prefix length and modify the attention mask. ",
"I think there's a way to do both. We can allow `prefix_length` as an extra argument to `BloomForPrefixLM`, which will take care of creating the noncausal attention mask if no mask is given as an argument, and pass this mask to the base `BloomModel` forward and use it for attention computation in the forward pass. (`prefix_length` will never be passed to the `BloomModel` this way)\r\n\r\nI'll start implementing this if there aren't any objections. ",
"Nice, I would suggest to do it differently though:\r\n- Just have one additional kwarg in all forward funcs called `causal_mask` next to attention_mask\r\n- If `causal_mask` is None set it to the `torch.tril` default directly in `BloomPreTrainedModel` (i.e. dont recreate it in every layer)\r\n- Have one test checking that if it's set with prefixes it's different than the default like `test_equivalence_prefix_causal_lm`\r\n\r\nI think this is all we would need & then the user just creates its own causal mask which has prefixes. There's no need for separate models to allow users to pass prefix masks or bidirectional masks with skipping like `[1,0,1]` or any other mechanism one may come up with like @thomasw21 said. What do you think?\r\n\r\n",
"I like the idea of having a single `BloomForCausalLM` that can handle the causal_masks be it causal or non causal. \r\n\r\nI just think that handling the non-causal mask could be done automatically inside the model especially during generation when the intention is to process the input prompt with non-causal mask. \r\n\r\n",
"What if `causal_mask` has 3 possible input options?\n- `None`: a causal mask is generated in the model\n- `torch.Tensor` with shape same as input_ids: a manual causal mask (which can also be non-causal) is used.\n- `torch.Tensor` with shape `batch size * 1`: is a prefix length matrix, a non-causal attention mask is generated in the model",
"Hi all,\n\nI just went through the comments of this PR but did not checked the modifications yet. We are currently trying to refactor the modeling code in this PR: https://github.com/huggingface/transformers/pull/17866 - one thing that we are doing is to create the mask only once at the `_prepare_attn_mask` function that we pass to all submodules. It might be easier in your use case. I cannot give a fixed timeline on when the refactoring PR will get merged but if you merge this PR before I will take care of refactoring a bit your code ;) ! ",
"Thanks @Muennighoff for the comments! \r\n\r\nThey make sense and I’ll work on addressing them, but I agree with @lintangsutawika that we should have some way of automatically creating a PrefixLM non-causal mask.\r\n\r\nIf we’re planning on users using Bloom0++ for generation then I think there should be some way of setting causal_mask to a non-causal mask without manually creating it, whether that’s a PrefixLM class or just a flag passed to the CausalLM forward or similar.",
"Addressed points 1 and 2 from @Muennighoff ! I left the BloomForPrefixLM class for now.\r\n\r\nThe tests I added (including slow tests locally) pass—it’s unrelated tests that fail currently.",
"@thomasw21 @Muennighoff \r\n\r\nFYI, I'm in the middle of refactoring this PR after pulling from main. So for now, if you could use commit `6538564ee1e3f1689ab71b01866aa7771b82edc7` that's the last one that still works.\r\n\r\n",
"> Nice, I would suggest to do it differently though:\r\n> \r\n> * Just have one additional kwarg in all forward funcs called `causal_mask` next to attention_mask\r\n> * If `causal_mask` is None set it to the `torch.tril` default directly in `BloomPreTrainedModel` (i.e. dont recreate it in every layer)\r\n> * Have one test checking that if it's set with prefixes it's different than the default like `test_equivalence_prefix_causal_lm`\r\n> \r\n> I think this is all we would need & then the user just creates its own causal mask which has prefixes. There's no need for separate models to allow users to pass prefix masks or bidirectional masks with skipping like `[1,0,1]` or any other mechanism one may come up with like @thomasw21 said. What do you think?\r\n\r\nVery much agree with your idea here @Muennighoff ! Think this is the way to go which will be 100% backwards compatible (we could btw also add this to GPT2 etc...)\r\n\r\nFollowing @Muennighoff thoughts' here I think we should make the behavior crystal clear in the docstring:\r\n\r\n```\r\nIf 'causal_mask' is set to 'None' the model will automatically create the conventional causal (unidirectional) attention mask to prevent past tokens to attend to future tokens. If you would like to overwrite this behavior, *e.g.* to create a Prefix-LM architecture, please pass a tensor different to 'None'\r\n```\r\n\r\nAlso cc @sgugger @LysandreJik here to hear their input on this (since this functionality might be extended to GPT2)",
"I also agree that @Muennighoff options sounds better than adding a new model which is very very similar to the causal LM architecture. It also will make the functionality more accessible (since users often use the auto-classes to load their models).",
"Thanks for the feedback! Especially since we probably aren't going with Prefix-LM for Bloom-T0, removing the class and just making this an optional argument sounds like a good idea. \r\n\r\nI'll ping you all after I get around to making these changes!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,661
| 1,661
|
CONTRIBUTOR
| null |
@thomasw21 @Muennighoff
As we discussed, here's a quick hack to try out Prefix-LM on BLOOM via swapping out the mask for one that always attends to the first `prefix_length` tokens (as in this figure from the pretraining objectives paper).

EDIT: I extended this for cleaner interface + drop-in support for `bigscience/lm-eval-harness`
[Minimal script I was using to test outputs using this code](https://gist.github.com/haileyschoelkopf/33b9e41d07b9222e995c6cce155724de)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17944/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17944/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17944",
"html_url": "https://github.com/huggingface/transformers/pull/17944",
"diff_url": "https://github.com/huggingface/transformers/pull/17944.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17944.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17943
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17943/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17943/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17943/events
|
https://github.com/huggingface/transformers/pull/17943
| 1,288,860,502
|
PR_kwDOCUB6oc46kxwR
| 17,943
|
fix regexes with escape sequence
|
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
This PR fixes:
```
src/transformers/dynamic_module_utils.py:81
/workspace/transformers/src/transformers/dynamic_module_utils.py:81: DeprecationWarning: invalid escape sequence \s
relative_imports = re.findall("^\s*import\s+\.(\S+)\s*$", content, flags=re.MULTILINE)
src/transformers/dynamic_module_utils.py:83
/workspace/transformers/src/transformers/dynamic_module_utils.py:83: DeprecationWarning: invalid escape sequence \s
relative_imports += re.findall("^\s*from\s+\.(\S+)\s+import", content, flags=re.MULTILINE)
src/transformers/dynamic_module_utils.py:125
/workspace/transformers/src/transformers/dynamic_module_utils.py:125: DeprecationWarning: invalid escape sequence \s
imports = re.findall("^\s*import\s+(\S+)\s*$", content, flags=re.MULTILINE)
src/transformers/dynamic_module_utils.py:127
/workspace/transformers/src/transformers/dynamic_module_utils.py:127: DeprecationWarning: invalid escape sequence \s
imports += re.findall("^\s*from\s+(\S+)\s+import", content, flags=re.MULTILINE)
src/transformers/modeling_utils.py:222
/workspace/transformers/src/transformers/modeling_utils.py:222: DeprecationWarning: invalid escape sequence \d
bit_search = re.search("[^\d](\d+)$", str(dtype))
```
@sgugger
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17943/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17943/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17943",
"html_url": "https://github.com/huggingface/transformers/pull/17943",
"diff_url": "https://github.com/huggingface/transformers/pull/17943.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17943.patch",
"merged_at": 1656518122000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17942
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17942/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17942/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17942/events
|
https://github.com/huggingface/transformers/pull/17942
| 1,288,781,077
|
PR_kwDOCUB6oc46kgp7
| 17,942
|
Use explicit torch version in deepspeed CI
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"OK for me to use 1.12. We might see more test failures (for scheduled daily CI). Current CircleCI pings 1.11 to have green CI."
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Use explicit torch version in DeepSpeed CI docker file, as we do in
https://github.com/huggingface/transformers/blob/d49c43e93fedc1ff7d58a3617fc8a3532af054ba/docker/transformers-all-latest-gpu/Dockerfile#L12
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17942/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17942/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17942",
"html_url": "https://github.com/huggingface/transformers/pull/17942",
"diff_url": "https://github.com/huggingface/transformers/pull/17942.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17942.patch",
"merged_at": 1656519635000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17941
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17941/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17941/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17941/events
|
https://github.com/huggingface/transformers/issues/17941
| 1,288,761,418
|
I_kwDOCUB6oc5M0PBK
| 17,941
|
Getting only <|endoftext|> token in GPT-NEOX-20B model
|
{
"login": "pragnakalpdev11",
"id": 68984286,
"node_id": "MDQ6VXNlcjY4OTg0Mjg2",
"avatar_url": "https://avatars.githubusercontent.com/u/68984286?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pragnakalpdev11",
"html_url": "https://github.com/pragnakalpdev11",
"followers_url": "https://api.github.com/users/pragnakalpdev11/followers",
"following_url": "https://api.github.com/users/pragnakalpdev11/following{/other_user}",
"gists_url": "https://api.github.com/users/pragnakalpdev11/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pragnakalpdev11/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pragnakalpdev11/subscriptions",
"organizations_url": "https://api.github.com/users/pragnakalpdev11/orgs",
"repos_url": "https://api.github.com/users/pragnakalpdev11/repos",
"events_url": "https://api.github.com/users/pragnakalpdev11/events{/privacy}",
"received_events_url": "https://api.github.com/users/pragnakalpdev11/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
NONE
| null |
### System Info
Transformer Version: 4.20.1
Python : 3.8
ubuntu : 18.04
### Who can help?
@patil-suraj
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
- We are creating a streaming app using HF transformer generate() but during the token decoding we are only getting " <|endoftext|> " . when an input prompt is passed, No tokens are generated from the model. The model we are using is GPT-NEOX-20B.
- We have tried 3 Tokenizers, GPTNeoXTokenizerFast, AutoTokenizer, and GPT2TokenizerFast but all of them returned the same output.
``
- Below is the generate parameters.
```
output_sequences = model.generate(
input_ids=input_ids,
max_length=200,
temperature=temperature,
top_k=k,
top_p=p,
repetition_penalty=repetition_penalty,
do_sample=False,
num_return_sequences=num_return_sequences,
filename=filename,
tokenizer=tokenizer,
num_beams=1,
use_cache=False
)
```
- where we are receiving Empty tokens, is https://github.com/huggingface/transformers/blob/main/src/transformers/generation_utils.py line 1740,
We are trying to decode the next tokens.
# finished sentences should have their next token be a padding token
```
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
tensor_text = tokenizer.decode(next_tokens, clean_up_tokenization_spaces=True)
```
- A confirmation for the code in file https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt_neox/modeling_gpt_neox.py
and line 146. what logic should be there. if use or if not?
`present = None if use_cache else (key, value)`
### Expected behavior
The above code works well with all the models of the GPT-NEO but with GPT-NEOX we are facing the <|endoftext|> tokens issues. Instead of <|endoftext|> tokens. we need to generate the correct tokens.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17941/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17941/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17940
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17940/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17940/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17940/events
|
https://github.com/huggingface/transformers/pull/17940
| 1,288,760,399
|
PR_kwDOCUB6oc46kcJA
| 17,940
|
fix `bias` keyword argument in TFDebertaEmbeddings
|
{
"login": "WissamAntoun",
"id": 44616226,
"node_id": "MDQ6VXNlcjQ0NjE2MjI2",
"avatar_url": "https://avatars.githubusercontent.com/u/44616226?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WissamAntoun",
"html_url": "https://github.com/WissamAntoun",
"followers_url": "https://api.github.com/users/WissamAntoun/followers",
"following_url": "https://api.github.com/users/WissamAntoun/following{/other_user}",
"gists_url": "https://api.github.com/users/WissamAntoun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/WissamAntoun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WissamAntoun/subscriptions",
"organizations_url": "https://api.github.com/users/WissamAntoun/orgs",
"repos_url": "https://api.github.com/users/WissamAntoun/repos",
"events_url": "https://api.github.com/users/WissamAntoun/events{/privacy}",
"received_events_url": "https://api.github.com/users/WissamAntoun/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Can you review and approve this PR ? @sgugger @LysandreJik \r\nThank you"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes an issue (caused by a typo) that occurs when attempting to create TF Deberta models (v1 and v2) where the `embedding_size` and `hidden_size` are different.
here is a link to a colab demo that highlights the issue and checks if it was fixed. https://colab.research.google.com/drive/1dScSEBeaBnvgV9504MG0OKUokeDVgBia?usp=sharing
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [X] Did you write any new necessary tests?
No test was needed
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17940/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17940/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17940",
"html_url": "https://github.com/huggingface/transformers/pull/17940",
"diff_url": "https://github.com/huggingface/transformers/pull/17940.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17940.patch",
"merged_at": 1656683323000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17939
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17939/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17939/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17939/events
|
https://github.com/huggingface/transformers/pull/17939
| 1,288,747,657
|
PR_kwDOCUB6oc46kZWX
| 17,939
|
Fix img seg tests (load checkpoints from `hf-internal-testing`)
|
{
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@sgugger please feel free to merge it 😊 (the merge btn is not available)"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
Tests use `tiny-detr` checkpoints from `hf-internal-testing` org from hub
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17939/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17939/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17939",
"html_url": "https://github.com/huggingface/transformers/pull/17939",
"diff_url": "https://github.com/huggingface/transformers/pull/17939.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17939.patch",
"merged_at": 1656512378000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17938
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17938/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17938/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17938/events
|
https://github.com/huggingface/transformers/pull/17938
| 1,288,737,423
|
PR_kwDOCUB6oc46kXGy
| 17,938
|
Add OWL-ViT model for zero-shot object detection
|
{
"login": "alaradirik",
"id": 8944735,
"node_id": "MDQ6VXNlcjg5NDQ3MzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8944735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alaradirik",
"html_url": "https://github.com/alaradirik",
"followers_url": "https://api.github.com/users/alaradirik/followers",
"following_url": "https://api.github.com/users/alaradirik/following{/other_user}",
"gists_url": "https://api.github.com/users/alaradirik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alaradirik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alaradirik/subscriptions",
"organizations_url": "https://api.github.com/users/alaradirik/orgs",
"repos_url": "https://api.github.com/users/alaradirik/repos",
"events_url": "https://api.github.com/users/alaradirik/events{/privacy}",
"received_events_url": "https://api.github.com/users/alaradirik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Any plan to extend it for TensorFlow version? \r\nThere seems to be [conversion script](https://github.com/google-research/scenic/tree/a41d24676f64a2158bfcd7cb79b0a87673aa875b/scenic/projects/owl_vit#conversion-to-tensorflow) officially. ",
"Hi @innat. Yes, @alaradirik is already working on it! The PR is here: https://github.com/huggingface/transformers/pull/18450\r\n\r\nYou can find out which models are being implemented by searching the open issues and PRs [for example](https://github.com/huggingface/transformers/pulls?q=is%3Apr+is%3Aopen+owlvit)"
] | 1,656
| 1,659
| 1,658
|
CONTRIBUTOR
| null |
# What does this PR do?
- Adds OwlViT model for open-vocabulary object detection. Model takes in one or multiple text queries per image as input.
Original repo:
https://github.com/google-research/scenic/tree/a41d24676f64a2158bfcd7cb79b0a87673aa875b/scenic/projects/owl_vit
Test notebook:
https://colab.research.google.com/drive/1IMPWZcnlMy-tdnTDrUcOZU3oiGg-hTem?usp=sharing
@sgugger could you review my draft PR, please?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17938/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17938/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17938",
"html_url": "https://github.com/huggingface/transformers/pull/17938",
"diff_url": "https://github.com/huggingface/transformers/pull/17938.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17938.patch",
"merged_at": 1658486132000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17937
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17937/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17937/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17937/events
|
https://github.com/huggingface/transformers/pull/17937
| 1,288,716,431
|
PR_kwDOCUB6oc46kSlU
| 17,937
|
Avoid nan during sampling in generate()
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"I have some doubts here, as this will make all tokens having equal probability to be sampled. But with all `-inf`, nothing could be sampled which leads to error. I feel there is no well-defined expected results in such edge cases.",
"_The documentation is not available anymore as the PR was closed or merged._",
"Yes, that happens only when all `-inf` along the vocab dim. I will close this PR, and we have to maybe create a doc with all possible flaky tests :-)"
] | 1,656
| 1,662
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Fix CI test error
```bash
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
> next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
E RuntimeError: probability tensor contains either `inf`, `nan` or element < 0
```
in
https://github.com/huggingface/transformers/runs/6959698965?check_suite_focus=true
The test `test_sample_generate` may still fail at
https://github.com/huggingface/transformers/blob/8f400775fc5bc1011a2674dcfd5408d30d69f678/tests/generation/test_generation_utils.py#L711
for some unknown reason. I think it is better to investigate this in another PR.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17937/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17937/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17937",
"html_url": "https://github.com/huggingface/transformers/pull/17937",
"diff_url": "https://github.com/huggingface/transformers/pull/17937.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17937.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17936
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17936/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17936/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17936/events
|
https://github.com/huggingface/transformers/pull/17936
| 1,288,696,358
|
PR_kwDOCUB6oc46kOPf
| 17,936
|
Fix all is_torch_tpu_available issues
|
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2155169140,
"node_id": "MDU6TGFiZWwyMTU1MTY5MTQw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/trainer",
"name": "trainer",
"color": "2ef289",
"default": false,
"description": ""
},
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
This PR should fix up all `torch_xla` initialization caused on import with the new check for if a TPU is available by following the same structure as [accelerate](https://github.com/huggingface/accelerate/pull/469)
Fixes # (issue)
Fixes #17752
Fixes #17900
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sgugger
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17936/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17936/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17936",
"html_url": "https://github.com/huggingface/transformers/pull/17936",
"diff_url": "https://github.com/huggingface/transformers/pull/17936.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17936.patch",
"merged_at": 1656515013000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17935
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17935/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17935/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17935/events
|
https://github.com/huggingface/transformers/issues/17935
| 1,288,615,260
|
I_kwDOCUB6oc5MzrVc
| 17,935
|
TF: XLA generation not working properly in some models
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1834054694,
"node_id": "MDU6TGFiZWwxODM0MDU0Njk0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/TensorFlow",
"name": "TensorFlow",
"color": "FF6F00",
"default": false,
"description": "Anything TensorFlow"
},
{
"id": 2392046359,
"node_id": "MDU6TGFiZWwyMzkyMDQ2MzU5",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20Second%20Issue",
"name": "Good Second Issue",
"color": "dd935a",
"default": false,
"description": "Issues that are more difficult to do than \"Good First\" issues - give it a try if you want!"
}
] |
open
| false
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
] |
[
"@gante do you require any help with this issue? Happy to contribute",
"Hi @anmolsjoshi 👋 \r\n\r\nIf you are comfortable with debugging XLA, absolutely :) My recommendation would be to pick a model from \"Models failing complex tests\" (the others might require significant architecture changes), and to start debugging. The number 1 suspect is always the position embeddings, which may not be handling the case where `past` is padded. Let me know if you are up to it, and which model would you like to take! ",
"Hi @gante, I did have a bit of a poke around. I think the complex tests all fail for the same reason: those models have a setting `max_position_embeddings` that is set to 20 by default during testing and which is too short for the “slow” tests. Here’s a simple fix for those: https://github.com/dsuess/transformers/commit/4a3e27164ae941fcd649b8565d7d92a4552d689f. I’ll give the other ones a shot now",
"Hello @gante, may I ask if there is anything that I can contribute?\r\n",
"Hi JuheonChu 👋 Actually yes! I have a few unchecked models at the top, but I wouldn't recommend spending time there unless you plan to use those architectures -- they are infrequently used.\r\n\r\nHowever, two popular models are currently failing their XLA tests with beam search:\r\n- Marian\r\n- OPT\r\n\r\nYou can see the failing test if you install from `main` (`pip install --upgrade git+https://github.com/huggingface/transformers.git`) and run it e.g. for OPT `NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 py.test -vv tests/models/opt/test_modeling_tf_opt.py::TFOPTModelTest::test_xla_generate_slow`\r\n\r\nI haven't dived in yet, so I don't know what's the cause for the failure. You'll have to hop into debug mode and see what is breaking :)",
"Can @katiele47 and I try working on them? ",
"@JuheonChu of course!",
"> @JuheonChu of course!\r\n@gante Are we figuring out the cause of the testing failures based on the clues as follows?\r\n\r\n\r\n\r\n\r\n",
"@JuheonChu yes. My suggestion would be to attempt to find where the numerical differences start from (between the XLA and the non-XLA version), using a debugger. Please note that you can't print variables with `jit_compile=True`, so you should set it to `False`. From there, the root cause is typically apparent.\r\n\r\nBe warned, these sort of tasks sometimes are very time-consuming to complete :)",
"> @JuheonChu yes. My suggestion would be to attempt to find where the numerical differences start from (between the XLA and the non-XLA version), using a debugger. Please note that you can't print variables with `jit_compile=True`, so you should set it to `False`. From there, the root cause is typically apparent.\r\n> \r\n> Be warned, these sort of tasks sometimes are very time-consuming to complete :)\r\n\r\nThank you very much for your valuable guidance! We will try and keep you updated!",
"Hi @gante, I've attempted to reproduce the failed XLA test on the OPT model using your suggested commands. The cause of error I had was somehow different from @JuheonChu's. Would you be able to verify if the following is the expected failing test output? If not, I assume it could be due to my local repo. Thanks!\r\n<img width=\"1015\" alt=\"Screen Shot 2023-02-21 at 11 20 44 PM\" src=\"https://user-images.githubusercontent.com/54815905/220521074-6ab355c4-fe0b-42b5-88fa-cbd15de82b8a.png\">\r\n<img width=\"1125\" alt=\"Screen Shot 2023-02-21 at 11 21 24 PM\" src=\"https://user-images.githubusercontent.com/54815905/220521160-946a03db-cf80-4fbc-818c-3be337df3983.png\">\r\n<img width=\"1135\" alt=\"Screen Shot 2023-02-21 at 11 21 43 PM\" src=\"https://user-images.githubusercontent.com/54815905/220521210-981d6099-e093-4b8b-9913-2dafe5bef905.png\">\r\n",
"@gante working on XLNet"
] | 1,656
| 1,677
| null |
MEMBER
| null |
This issue is used to track TensorFlow XLA generation issues, arising from #17857. There are three categories of issues, sorted in descending order by severity:
### Key model issues
These are heavily-used models, whose quality should be prioritized.
- [x] T5 -- The quality of the results decreases with `max_length`. See [here](https://github.com/huggingface/transformers/pull/17857/files#r906702367).
- [x] GPT-J -- fails simple generate tests with numerical issues
### Models failing basic tests
These models are failing `test_xla_generate_fast` -- a short greedy generation.
- [ ] LED
- [ ] Speech2Text
- [ ] XLNet
- [ ] XGLM
### Models failing complex tests
These are models failing `test_xla_generate_slow` -- a long beam search generation.
- [x] Bart
- [x] Blenderbot
- [x] Marian
- [x] mbart
- [x] OPT
- [x] Pegasus
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17935/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17935/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/17934
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17934/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17934/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17934/events
|
https://github.com/huggingface/transformers/pull/17934
| 1,288,542,199
|
PR_kwDOCUB6oc46jspb
| 17,934
|
Unifying training argument type annotations
|
{
"login": "jannisborn",
"id": 15703818,
"node_id": "MDQ6VXNlcjE1NzAzODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/15703818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jannisborn",
"html_url": "https://github.com/jannisborn",
"followers_url": "https://api.github.com/users/jannisborn/followers",
"following_url": "https://api.github.com/users/jannisborn/following{/other_user}",
"gists_url": "https://api.github.com/users/jannisborn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jannisborn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jannisborn/subscriptions",
"organizations_url": "https://api.github.com/users/jannisborn/orgs",
"repos_url": "https://api.github.com/users/jannisborn/repos",
"events_url": "https://api.github.com/users/jannisborn/events{/privacy}",
"received_events_url": "https://api.github.com/users/jannisborn/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"I understand that the tests are failing because of:\r\n\r\n```txt\r\nValueError: Only `Union[X, NoneType]` (i.e., `Optional[X]`) is allowed for `Union` because\r\nthe argument parser only supports one type per argument. Problem encountered in field 'evaluation_strategy'.\r\n```\r\n\r\nCould this issue of not supporting multiple types be fixed in HF itself? I guess no since it's introduced upstream by `arparse.add_argument` not allowing multiple types? @sgugger \r\n\r\nUltimately, this is inconsistency between the type annotations and the actually possible types is caused by HF. I think it's quite problematic because it's a systematic inconsistency that makes things appear more complex as they are. If the annotation has to be a single type, then should it not be the simplest type that can actually be used, in this case `str`? \r\nIn that way, HF would be minimally invasive wrt downstream packages that indeed have stricter type annotation requirements.",
"The type is not perfectly exact, but note that:\r\n1. the argument will be converted to that type in the post-init, so while the init of the dataclass accepts both `str` and `IntervalStrategy` (or other enum types), the attribute will always be of the enum type.\r\n2. having the enum has main type allows us to properly fill the `choices` part of the parser for CLI help.\r\n\r\nSo to be able to accept the change in type, we would need some custom code in `HfArgumentParser` to not only stop erroring on those types, but also properly fill the `choices` part. If you're interested in exploring this further, those are the missing steps we would need in order to merge this PR.",
"Looking at this from the surface, it seems that this PR is (partially?) covered by the PR that was merged earlier today? https://github.com/huggingface/transformers/pull/17933\r\n\r\nThere:\r\n\r\n- \"Complex\" enumtypes like IntervalStrategy (all that subclass `ExplicitEnum`) now also subclass `str`. As a consequence, the argparse equivalents also accept any string value\r\n- `HfArgumentParser._parse_dataclass_field` (that gives you the Union error) has been updated to allow Union's that include a `str`, because the `str` type is never an issue for argparse (as its the default)",
"We don't have the error anymore, but we are still losing the autofill of \"choices\" and all the custom logic we had for enums [here](https://github.com/huggingface/transformers/blob/fbc7598babd06a49797db7142016f0029cdc41b2/src/transformers/hf_argparser.py#L105).",
"Thanks a lot @BramVanroy, that's a nice coincidence!!\r\n\r\n@sgugger: Could we move up that logic about the autofill to an `elif` starting at L94?",
"I think there should be an if at line 94 that replaces the `field.dtype` by the `field.type.__args__` which is not `str` (like we replace the `field.dtype` that is not None below line 95 for `Optional`), then line 105 and the test for enums will be triggered properly.\r\n\r\nBasically something like:\r\n```py\r\nif type(None) not in field.type.__args__:\r\n # filter `str` in Union\r\n field.type = field.type.__args__[0] if field.type.__args__[1] == str else field.type.__args__[1]\r\n origin_type = getattr(field.type, \"__origin__\", field.type)\r\nelif bool not in field.type.__args__:\r\n``` \r\nbefore and replacing the line \r\n```py\r\nif bool not in field.type.__args__:\r\n```\r\n",
"Just did that!",
"Thanks! Will play a bit with it tomorrow morning to triple-check nothing breaks then it should be good to merge!",
"All good in my tests, thanks again for your work on this!"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR fixes the incorrect type annotations in the `TrainingArguments` class. Some arguments can handle complex types like `evaluation_strategy: IntervalStrategy`. However, when calling from CLI, they can be initialized using a `str` as well which is not reflected in the type annotations.
**Solution**: Fix the type annotations to `Union[ComplexType, str]`.
Note that this PR simply ensures consistency between the docstrings and the annotated types. E.g., the docstring for `evaluation_strategy` is already:
```txt
evaluation_strategy (`str` or [`~trainer_utils.IntervalStrategy`], *optional*, defaults to `"no"`):
The evaluation strategy...
```
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
Please have a look @sgugger!
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17934/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17934/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17934",
"html_url": "https://github.com/huggingface/transformers/pull/17934",
"diff_url": "https://github.com/huggingface/transformers/pull/17934.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17934.patch",
"merged_at": 1656593613000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17933
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17933/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17933/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17933/events
|
https://github.com/huggingface/transformers/pull/17933
| 1,288,505,707
|
PR_kwDOCUB6oc46jkx0
| 17,933
|
ExplicitEnum subclass str (JSON dump compatible)
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"The following tests are failing but that seems unrelated:\r\n\r\ntests/pipelines/test_pipelines_object_detection.py::ObjectDetectionPipelineTests::test_small_model_pt\r\ntests/pipelines/test_pipelines_image_segmentation.py::ImageSegmentationPipelineTests::test_small_model_pt\r\n",
"Yes, I skipped those tests on main for now. Let me play a little bit with this, it seems like a good idea but I want to make sure it doesn't break anything before merging.",
"Tested and it all looks good, thanks a lot!"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
I found that when I wanted to write the parsed dataclasses that I get from `HfArgumentParser.parse_args_into_dataclasses()` to JSON, that I would get JSON errors. The reason being that `TypeError: Object of type IntervalStrategy is not JSON serializable`. While this is understandable (Enum members are not serializable), this is not ideal within `transformers`.
I checked all items in `transformers` that subclass `ExplicitEnum` and it seems that they are all `str`-only Enums. That would allow us to have them inherit from `str`, too, which solves the JSON issue. JSON can then make use of its `str` class for serialization. Below is a minimal - but full - example to show how this would work:
```
from enum import Enum
from json import dump, loads
from pathlib import Path
class ExplicitEnum(str, Enum): # If you remove `str` you'll get a serialization error
"""
Enum with more explicit error message for missing values.
"""
@classmethod
def _missing_(cls, value):
raise ValueError(
f"{value} is not a valid {cls.__name__}, please select one of {list(cls._value2member_map_.keys())}"
)
class IntervalStrategy(ExplicitEnum):
NO = "no"
STEPS = "steps"
EPOCH = "epoch"
if __name__ == "__main__":
strat = IntervalStrategy("no")
print(strat)
p = Path("strat_dump.json")
with p.open("w", encoding="utf-8") as out:
dump({"strategy": strat}, out, indent=4, sort_keys=True)
loaded = loads(p.read_text(encoding="utf-8"))
strat = IntervalStrategy(loaded["strategy"])
print(strat)
```
A consequence is that now these ExplicitEnums will have a Union type, which originally lead to issues when using `HfArgumentParser._parse_dataclass_field`. Therefore, I added an exception to `_parse_dataclass_field` to allow for a Union if one of the types is `str`, assuming that a given string value to the argparser will be resolved correctly, because it is one of the accepted types.
## Who can review?
@sgugger
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17933/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17933/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17933",
"html_url": "https://github.com/huggingface/transformers/pull/17933",
"diff_url": "https://github.com/huggingface/transformers/pull/17933.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17933.patch",
"merged_at": 1656524971000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17932
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17932/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17932/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17932/events
|
https://github.com/huggingface/transformers/pull/17932
| 1,288,405,667
|
PR_kwDOCUB6oc46jPa4
| 17,932
|
Fix LayoutLMv3 documentation
|
{
"login": "pocca2048",
"id": 10275397,
"node_id": "MDQ6VXNlcjEwMjc1Mzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/10275397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pocca2048",
"html_url": "https://github.com/pocca2048",
"followers_url": "https://api.github.com/users/pocca2048/followers",
"following_url": "https://api.github.com/users/pocca2048/following{/other_user}",
"gists_url": "https://api.github.com/users/pocca2048/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pocca2048/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pocca2048/subscriptions",
"organizations_url": "https://api.github.com/users/pocca2048/orgs",
"repos_url": "https://api.github.com/users/pocca2048/repos",
"events_url": "https://api.github.com/users/pocca2048/events{/privacy}",
"received_events_url": "https://api.github.com/users/pocca2048/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Applied your suggestions!",
"Thanks, could you run `make style` and `make quality` from the root of the repo? This ensures the code quality check will pass. ",
"Applied and all checks are passing!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"@sgugger I change into two versions. Could you re-open this pull request?\r\n"
] | 1,656
| 1,660
| 1,660
|
CONTRIBUTOR
| null |
# What does this PR do?
- Fixes documentation of LayoutLMv3Model and some other typos.
Fixes # (issue)
#17833
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@NielsRogge
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17932/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17932/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17932",
"html_url": "https://github.com/huggingface/transformers/pull/17932",
"diff_url": "https://github.com/huggingface/transformers/pull/17932.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17932.patch",
"merged_at": 1660222300000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17931
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17931/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17931/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17931/events
|
https://github.com/huggingface/transformers/pull/17931
| 1,288,354,706
|
PR_kwDOCUB6oc46jEjc
| 17,931
|
Large model loading: add link to existing documentation
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hmmm yes, I agree, but this is still linking to `from_pretrained`, just a part of the documentation that contains more information about the `low_cpu_mem_usage`. The part I have removed glosses over it quickly, whereas the part I link to has extensive documentation covering both `low_cpu_mem_usage` and the `device_map` argument to pass to `from_pretrained`.\r\n\r\nReading the documentation right now, if we're interested in big models and we open the \"Instantiating a big model\" page in the toctree, there are no mention of the `device_map`. This is what this PR aims to fix."
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
The documentation for large model loading is in two different places. This adds a link from one to the other, showing the auto device map.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17931/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17931/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17931",
"html_url": "https://github.com/huggingface/transformers/pull/17931",
"diff_url": "https://github.com/huggingface/transformers/pull/17931.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17931.patch",
"merged_at": 1656922385000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17930
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17930/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17930/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17930/events
|
https://github.com/huggingface/transformers/pull/17930
| 1,288,263,086
|
PR_kwDOCUB6oc46ixHh
| 17,930
|
Fix typo
|
{
"login": "Dobatymo",
"id": 7647594,
"node_id": "MDQ6VXNlcjc2NDc1OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7647594?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dobatymo",
"html_url": "https://github.com/Dobatymo",
"followers_url": "https://api.github.com/users/Dobatymo/followers",
"following_url": "https://api.github.com/users/Dobatymo/following{/other_user}",
"gists_url": "https://api.github.com/users/Dobatymo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dobatymo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dobatymo/subscriptions",
"organizations_url": "https://api.github.com/users/Dobatymo/orgs",
"repos_url": "https://api.github.com/users/Dobatymo/repos",
"events_url": "https://api.github.com/users/Dobatymo/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dobatymo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
Only a typo, but it can lead to confusion
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17930/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17930/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17930",
"html_url": "https://github.com/huggingface/transformers/pull/17930",
"diff_url": "https://github.com/huggingface/transformers/pull/17930.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17930.patch",
"merged_at": 1656921856000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17929
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17929/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17929/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17929/events
|
https://github.com/huggingface/transformers/issues/17929
| 1,288,233,900
|
I_kwDOCUB6oc5MyOOs
| 17,929
|
"zero-shot-image-classification" pipeline with `VisionTextDualEncoderModel` needs manual feature_extractor and tokenizer input
|
{
"login": "Bing-su",
"id": 37621276,
"node_id": "MDQ6VXNlcjM3NjIxMjc2",
"avatar_url": "https://avatars.githubusercontent.com/u/37621276?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Bing-su",
"html_url": "https://github.com/Bing-su",
"followers_url": "https://api.github.com/users/Bing-su/followers",
"following_url": "https://api.github.com/users/Bing-su/following{/other_user}",
"gists_url": "https://api.github.com/users/Bing-su/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Bing-su/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Bing-su/subscriptions",
"organizations_url": "https://api.github.com/users/Bing-su/orgs",
"repos_url": "https://api.github.com/users/Bing-su/repos",
"events_url": "https://api.github.com/users/Bing-su/events{/privacy}",
"received_events_url": "https://api.github.com/users/Bing-su/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
|
{
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
}
] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"hi sorry for long reply, didn't see this until today:\r\n\r\nThe model `https://huggingface.co/Bingsu/vitB32_bert_ko_small_clip` is a VisionTextDualEncoder, but it's not defined within the `AutoFeatureExtractor` meta class (@NielsRogge ) so the pipeline doesn't know about it and cannot load the `feature_extractor` that's why passing it manually works.\r\n\r\nBasically the issue lies in transformers when we added this model, it wasn't properly configured.\r\n\r\nCheers.",
"@NielsRogge I also cannot find a small testing model here: https://huggingface.co/hf-internal-testing\r\n\r\nFor this dual model, is that normal ?",
"> Basically the issue lies in transformers when we added this model, it wasn't properly configured.\r\n\r\nThis was an incorrect assumption on my end. Those types of models are more generic, so they don't provide and `AutoFeatureExtractor`/`AutoTokenizer` property, so it's **normal** for them to fail.\r\n\r\nWill update the pipeline loading to make it work",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Fixed per #18392 "
] | 1,656
| 1,661
| 1,661
|
NONE
| null |
### System Info
```shell
transformers: 4.20.1
platform: windows 11, google colab
```
### Who can help?
@Narsil
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```python
# works
from transformers import pipeline
pipe = pipeline("zero-shot-image-classification", model="openai/clip-vit-base-patch32")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
pipe(images=url, candidate_labels=["a photo of one cat", "a photo of two cats"], hypothesis_template="{}")
```
```python
# error
from transformers import pipeline
pipe2 = pipeline("zero-shot-image-classification", model="Bingsu/vitB32_bert_ko_small_clip")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
pipe2(images=url, candidate_labels=["고양이 한 마리", "고양이 두 마리"], hypothesis_template="{}")
```
```sh
TypeError Traceback (most recent call last)
[<ipython-input-8-c1bcb0faaf45>](https://localhost:8080/#) in <module>()
----> 1 pipe2(images=url, candidate_labels=["고양이 한 마리", "고양이 두 마리"], hypothesis_template="{}")
3 frames
[/usr/local/lib/python3.7/dist-packages/transformers/pipelines/zero_shot_image_classification.py](https://localhost:8080/#) in preprocess(self, image, candidate_labels, hypothesis_template)
90 for i, candidate_label in enumerate(candidate_labels):
91 image = load_image(image)
---> 92 images = self.feature_extractor(images=[image], return_tensors=self.framework)
93 sequence = hypothesis_template.format(candidate_label)
94 inputs = self.tokenizer(sequence, return_tensors=self.framework)
TypeError: 'NoneType' object is not callable
```
[Colab](https://colab.research.google.com/drive/1CHrjJ7f7JcyMrEIcK18ieUHvS_1xKJKm?usp=sharing)
Currently I'm using it like this:
```python
from transformers import AutoModel, AutoProcessor, pipeline
model = AutoModel.from_pretrained("Bingsu/vitB32_bert_ko_small_clip")
processor = AutoProcessor.from_pretrained("Bingsu/vitB32_bert_ko_small_clip")
pipe = pipeline("zero-shot-image-classification", model=model, feature_extractor=processor.feature_extractor, tokenizer=processor.tokenizer)
```
### Expected behavior
work with `pipeline("zero-shot-image-classification", model="Bingsu/vitB32_bert_ko_small_clip")`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17929/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17929/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17928
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17928/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17928/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17928/events
|
https://github.com/huggingface/transformers/pull/17928
| 1,288,157,853
|
PR_kwDOCUB6oc46ia9Z
| 17,928
|
Fix trainer seq2seq qa.py evaluate log
|
{
"login": "iamtatsuki05",
"id": 92259109,
"node_id": "U_kgDOBX_DJQ",
"avatar_url": "https://avatars.githubusercontent.com/u/92259109?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iamtatsuki05",
"html_url": "https://github.com/iamtatsuki05",
"followers_url": "https://api.github.com/users/iamtatsuki05/followers",
"following_url": "https://api.github.com/users/iamtatsuki05/following{/other_user}",
"gists_url": "https://api.github.com/users/iamtatsuki05/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iamtatsuki05/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iamtatsuki05/subscriptions",
"organizations_url": "https://api.github.com/users/iamtatsuki05/orgs",
"repos_url": "https://api.github.com/users/iamtatsuki05/repos",
"events_url": "https://api.github.com/users/iamtatsuki05/events{/privacy}",
"received_events_url": "https://api.github.com/users/iamtatsuki05/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,664
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
This PR fix the If eval tries to log eval logs with prediction_loss_only and logging_dir, it will not be logged, so I changed it so that logs will be saved.
-->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger @patil-suraj
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17928/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17928/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17928",
"html_url": "https://github.com/huggingface/transformers/pull/17928",
"diff_url": "https://github.com/huggingface/transformers/pull/17928.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17928.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17927
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17927/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17927/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17927/events
|
https://github.com/huggingface/transformers/pull/17927
| 1,288,144,797
|
PR_kwDOCUB6oc46iYPU
| 17,927
|
fix: eval logs is not saved
|
{
"login": "iamtatsuki05",
"id": 92259109,
"node_id": "U_kgDOBX_DJQ",
"avatar_url": "https://avatars.githubusercontent.com/u/92259109?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iamtatsuki05",
"html_url": "https://github.com/iamtatsuki05",
"followers_url": "https://api.github.com/users/iamtatsuki05/followers",
"following_url": "https://api.github.com/users/iamtatsuki05/following{/other_user}",
"gists_url": "https://api.github.com/users/iamtatsuki05/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iamtatsuki05/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iamtatsuki05/subscriptions",
"organizations_url": "https://api.github.com/users/iamtatsuki05/orgs",
"repos_url": "https://api.github.com/users/iamtatsuki05/repos",
"events_url": "https://api.github.com/users/iamtatsuki05/events{/privacy}",
"received_events_url": "https://api.github.com/users/iamtatsuki05/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"Sorry, I forgot to ping reviewers @patil-suraj @sgugger",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
This PR fix the If eval tries to log eval logs with prediction_loss_only and logging_dir, it will not be logged, so I changed it so that logs will be saved.
-->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger @patil-suraj
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17927/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17927/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17927",
"html_url": "https://github.com/huggingface/transformers/pull/17927",
"diff_url": "https://github.com/huggingface/transformers/pull/17927.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17927.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17926
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17926/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17926/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17926/events
|
https://github.com/huggingface/transformers/pull/17926
| 1,287,799,872
|
PR_kwDOCUB6oc46hSay
| 17,926
|
Remove imports and use forward references in ONNX feature
|
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Type annotations should not be responsible for imports, so moving the pretrained models import in the onnx feature file inside a TYPE_CHECKING block and using fast-forward references instead.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17926/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17926/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17926",
"html_url": "https://github.com/huggingface/transformers/pull/17926",
"diff_url": "https://github.com/huggingface/transformers/pull/17926.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17926.patch",
"merged_at": 1656507774000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17925
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17925/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17925/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17925/events
|
https://github.com/huggingface/transformers/pull/17925
| 1,287,772,700
|
PR_kwDOCUB6oc46hNKe
| 17,925
|
Fix compatibility with 1.12
|
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"We'll need a fix for all Wav2Vec2-like models it seems. Opened an issue here: https://github.com/pytorch/pytorch/issues/80569",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Should this be merged or closed @sgugger?",
"We're still not supporting PyTorch 1.12, so this shouldn't be closed.",
"Good news: we can go for `torch 1.12.1`. But FYI:\r\n\r\n`https://pytorch-geometric.com/whl/torch-1.12.1+cpu.html` page doesn't exist, so I keep it as `1.12.0`"
] | 1,656
| 1,659
| 1,659
|
COLLABORATOR
| null |
# What does this PR do?
Fixes the scatter tests by installing torch_scatter wheels for PyTorch 1.12.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17925/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17925/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17925",
"html_url": "https://github.com/huggingface/transformers/pull/17925",
"diff_url": "https://github.com/huggingface/transformers/pull/17925.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17925.patch",
"merged_at": 1659966788000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17924
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17924/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17924/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17924/events
|
https://github.com/huggingface/transformers/pull/17924
| 1,287,314,719
|
PR_kwDOCUB6oc46fqr5
| 17,924
|
Add ViltForTokenClassification e.g. for Named-Entity-Recognition (NER)
|
{
"login": "gilad19",
"id": 11805822,
"node_id": "MDQ6VXNlcjExODA1ODIy",
"avatar_url": "https://avatars.githubusercontent.com/u/11805822?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gilad19",
"html_url": "https://github.com/gilad19",
"followers_url": "https://api.github.com/users/gilad19/followers",
"following_url": "https://api.github.com/users/gilad19/following{/other_user}",
"gists_url": "https://api.github.com/users/gilad19/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gilad19/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gilad19/subscriptions",
"organizations_url": "https://api.github.com/users/gilad19/orgs",
"repos_url": "https://api.github.com/users/gilad19/repos",
"events_url": "https://api.github.com/users/gilad19/events{/privacy}",
"received_events_url": "https://api.github.com/users/gilad19/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hey @gilad19, the implementation and internals look good to me! \r\n\r\nI'll defer to @NielsRogge regarding the forward call implementation and documentation.",
"Regarding the use case - exactly, apply NER on a piece of text for which you also have a visual information. ",
"Hi @NielsRogge - a gentle reminder :) ",
"Feel free to merge when satisfied @NielsRogge "
] | 1,656
| 1,658
| 1,658
|
CONTRIBUTOR
| null |
# What does this PR do?
Adding ViltForTokenClassification in order to be able to fine-tune ViLT for a token classification task (e.g. as Named-Entity-Recognition). This allows leveraging both image and text for token classification tasks using ViLT.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [X] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [X] Did you write any new necessary tests?
## Who can review?
@xhluca , @LysandreJik, @NielsRogge, @ydshieh
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17924/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17924/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17924",
"html_url": "https://github.com/huggingface/transformers/pull/17924",
"diff_url": "https://github.com/huggingface/transformers/pull/17924.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17924.patch",
"merged_at": 1658823093000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17923
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17923/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17923/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17923/events
|
https://github.com/huggingface/transformers/pull/17923
| 1,287,263,018
|
PR_kwDOCUB6oc46ffpB
| 17,923
|
skip some gpt_neox tests that require 80G RAM
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"What Sylvain said and I'd ask an even more different question - why are we running the same test on many identical models of different sizes. The purpose of our test suite is not to test models on the hub, it's to test the model's code. So such tests should never be there in the first place.\r\n\r\n- 99% of the time the tests should be run against tiny random models, most of which reside under https://huggingface.co/hf-internal-testing - these are functional tests.\r\n- 1% of tests should be against the smallest non-random model to test the quality of the results. And typically these are `@slow` tests.\r\n\r\nOf course, the % breakdown is symbolic, the point I was trying to convey is that most tests should be really fast in download and execution.\r\n\r\n---------------\r\n\r\nIf there is a need to test models on the hub, there should be another CI that all it does is loading the models and performs some basic test on them. That CI would need to have a ton of CPU and GPU memory and # of GPUs for obvious reasons - e.g. t5-11b and other huge models.",
"Hi @stas00 \r\n\r\nThe related tests here are decorated with `@slow` and run in the daily scheduled CI, not push CI. And only one size is tested `GPT_NEOX_PRETRAINED_MODEL_ARCHIVE_LIST[:1]`.\r\n\r\nFor `test_model_from_pretrained`, I think we can use tiny random models in `hf-internal-testing` for `GPTNeoX` if we want to keep the test. However, we always have integration tests (like `GPTNeoXModelIntegrationTest`) which are important to have.\r\n\r\nNote that on scheduled CI, we use a cache server (FileStore on GCP), so there is no real downloading (e.g. the downloading is very fast, happening between GCP's network).\r\n\r\nThey also have 16 vCPUs and 60G RAM.",
"Ah, good point, I missed `[:1]` - why then there is a loop then?\r\n\r\n```\r\nfor model_name in GPT_NEOX_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:\r\n```\r\n\r\nprobably should write out explicitly the desired smallest real model then and perhaps it's small enough to fit?\r\n\r\n",
"The main point is that GPT-Neo-X does not come with a smaller pretrained model, there is only the 20B version.",
"> Ah, good point, I missed `[:1]` - why then there is a loop then?\r\n> \r\n> ```\r\n> for model_name in GPT_NEOX_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:\r\n> ```\r\n> \r\n> probably should write out explicitly the desired smallest real model then and perhaps it's small enough to fit?\r\n\r\nI think this is from old code. We don't want to maintain `...PRETRAINED_MODEL_ARCHIVE_LIST` anymore, and for some models, we do use the explicit checkpoint name.\r\n\r\nI will just remove the 2 tests here.",
"Removed. Will rebase on main later to see if tests all pass",
"I am ready for the merge :-)"
] | 1,656
| 1,662
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
GPT-NeoX requires ~80G RAM to run. Our CI runners have only 60G RAM. Skip a few tests for now.
Do you think it's better to use something like
```python
@unittest.skipUnless(psutil.virtual_memory().total / 1024 ** 3 > 80, "GPT-NeoX requires 80G RAM for testing")
```
The problem is that `psutil` is not in the requirements.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17923/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17923/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17923",
"html_url": "https://github.com/huggingface/transformers/pull/17923",
"diff_url": "https://github.com/huggingface/transformers/pull/17923.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17923.patch",
"merged_at": 1656680678000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17922
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17922/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17922/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17922/events
|
https://github.com/huggingface/transformers/pull/17922
| 1,287,216,808
|
PR_kwDOCUB6oc46fVtU
| 17,922
|
fixing fsdp autowrap functionality
|
{
"login": "pacman100",
"id": 13534540,
"node_id": "MDQ6VXNlcjEzNTM0NTQw",
"avatar_url": "https://avatars.githubusercontent.com/u/13534540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pacman100",
"html_url": "https://github.com/pacman100",
"followers_url": "https://api.github.com/users/pacman100/followers",
"following_url": "https://api.github.com/users/pacman100/following{/other_user}",
"gists_url": "https://api.github.com/users/pacman100/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pacman100/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pacman100/subscriptions",
"organizations_url": "https://api.github.com/users/pacman100/orgs",
"repos_url": "https://api.github.com/users/pacman100/repos",
"events_url": "https://api.github.com/users/pacman100/events{/privacy}",
"received_events_url": "https://api.github.com/users/pacman100/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks for the fix. I think we should proceed differently to still support the previous nightly builds, and import the old name as the new name then.\r\n\r\nHello, I have updated the version requirement to the stable torch version `1.12.0` and this version has the updated name for the function. The support in `1.11.0` couldn't allow for saving model when using FSDP."
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
### What does this PR do?
1. PyTorch has renamed default_auto_wrap_policy to size_based_auto_wrap_policy. This PR updates the same.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17922/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17922/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17922",
"html_url": "https://github.com/huggingface/transformers/pull/17922",
"diff_url": "https://github.com/huggingface/transformers/pull/17922.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17922.patch",
"merged_at": 1656684656000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17921
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17921/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17921/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17921/events
|
https://github.com/huggingface/transformers/pull/17921
| 1,287,101,909
|
PR_kwDOCUB6oc46e8-U
| 17,921
|
Update notification service
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"To make this PR visible again, @LysandreJik .\r\n\r\n**More context**: this is mainly for past CI - the summary table(s) could be very long as there are many more test failures.\r\n\r\n**Update**: I will try to save a complete table as an artifacts, so we have it.\r\n\r\n\r\n",
"PR ready again for review.",
"Perfect!"
] | 1,656
| 1,658
| 1,658
|
COLLABORATOR
| null |
# What does this PR do?
~~**Let me run a dummy test before merge**~~
- Fix failure report blocks (the tables) with too long text (might happen for past CI) - similar to #17630
- A complete version of (long) tables are saved as artifacts
- Still send successful report if it is not push CI (we are close to 0 failure now)
A dummy run with very long blocks
https://github.com/huggingface/transformers/runs/7094507618?check_suite_focus=true
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17921/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17921/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17921",
"html_url": "https://github.com/huggingface/transformers/pull/17921",
"diff_url": "https://github.com/huggingface/transformers/pull/17921.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17921.patch",
"merged_at": 1658408630000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17920
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17920/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17920/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17920/events
|
https://github.com/huggingface/transformers/pull/17920
| 1,287,061,808
|
PR_kwDOCUB6oc46e0jE
| 17,920
|
Fix DisjunctiveConstraint edge case and add ConjunctiveDisjunctiveConstraint
|
{
"login": "boy2000-007man",
"id": 4197489,
"node_id": "MDQ6VXNlcjQxOTc0ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4197489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/boy2000-007man",
"html_url": "https://github.com/boy2000-007man",
"followers_url": "https://api.github.com/users/boy2000-007man/followers",
"following_url": "https://api.github.com/users/boy2000-007man/following{/other_user}",
"gists_url": "https://api.github.com/users/boy2000-007man/gists{/gist_id}",
"starred_url": "https://api.github.com/users/boy2000-007man/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/boy2000-007man/subscriptions",
"organizations_url": "https://api.github.com/users/boy2000-007man/orgs",
"repos_url": "https://api.github.com/users/boy2000-007man/repos",
"events_url": "https://api.github.com/users/boy2000-007man/events{/privacy}",
"received_events_url": "https://api.github.com/users/boy2000-007man/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17920). All of your documentation changes will be reflected on that endpoint.",
"Hey @boy2000-007man,\r\n\r\nThanks for the fix proposal! @cwkeam could you take a look here as well? :-) \r\n\r\n@boy2000-007man - it'd be really nice if you could add a test that would have failed without your fix, but will now pass. \r\n\r\nThanks a lot for working on this!",
"Hey @boy2000-007man, \r\n\r\nThanks a lot for the PR - I'm a bit worried about adding so much new code to main transformers to catch an edge case and wonder if it's really worth it. The problem is that this function will quickly become unmaintainable (it already sadly is to some extent) - in your opinion is it absolutely necessary to add this edge case? Also could you maybe provide a \"real\" generation example that shows how the current implementation fails?",
"Hi, @patrickvonplaten, the current code implementation is complex to support both the existing `DisjunctiveConstraint` and newly added `ConjunctiveDisjunctiveConstraint` at the same time. I can add a much-simplified version dedicated to back `DisjunctiveConstraint` only, and the new `ConjunctiveDisjunctiveConstraint` is not used by the library default but requires manual import, so won't break any existing works by chance.\r\nFinding a failure case is not that straightforward especially without deep understanding of specific model preference, but I can image some constraints like `the small cat/small cats`, `the united states/united kingdom` may be influenced.",
"Hey @boy2000-007man,\r\n\r\nSorry to reply so late here. Will gently ask @cwkeam in private if he could take a quick look because he's the most familiar with the current code. if there is no answer, I'll come back to it and dive deeper into the code to be able to better answer here. \r\n\r\nAlso cc @gante if you're feeling curios on complex code ;-)",
"Hi @boy2000-007man 👋 I was having a look into this PR, and one thing I noticed was that the objective of the PR was not immediately clear -- it says at the top that it fixes an edge case but... what edge case? We can find the answer to that in the code, especially in the docstring of `ConjunctiveDisjunctiveConstraint`.\r\n\r\nI do think we should fix the edge case, as the documented behavior does not match the actual behavior. However, adding clear examples (as in #15761) will be extremely useful for our future selves 🙏 It will also helps the reviewers seeing the value of the PR :D ",
"Hi, @gante , Sorry for the late reply. The edge case is mentioned in the associated bug report, https://github.com/huggingface/transformers/issues/17831. Do you mean to mention it again in the docstring?",
"> Do you mean to mention it again in the docstring\r\n\r\nYes please, but with input strings (as opposed to tokens). \r\n\r\nIt's hard to justify adding so many new lines of code without a clear example of why it matters :) We have very limited maintenance capacity, so sometimes it's preferable to have an incomplete short solution that we can maintain than a complete long solution that will accumulate bugs as we introduce new features.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,664
| 1,664
|
CONTRIBUTOR
| null |
# What does this PR do?
- implement [`AC automaton`](https://en.wikipedia.org/wiki/Aho%E2%80%93Corasick_algorithm) to supersede Trie to fix DisjunctiveConstraint edge case
- add ConjunctiveDisjunctiveConstraint to handle the complex combinations between multiple conjunctive and disjunctive constraints
- update stronger unit tests
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
#17831
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten, @cwkeam
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17920/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17920/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17920",
"html_url": "https://github.com/huggingface/transformers/pull/17920",
"diff_url": "https://github.com/huggingface/transformers/pull/17920.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17920.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17919
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17919/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17919/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17919/events
|
https://github.com/huggingface/transformers/pull/17919
| 1,287,040,722
|
PR_kwDOCUB6oc46ewFb
| 17,919
|
Enable Past CI
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"> merge it ... and monitor failures. \r\n\r\nI read your comment too quickly. So far the Past CI will be triggered only on pushing to `run-past-ci*` branches. I ran it ~ June 20 however, and I opened #18181 today.\r\n\r\nI think we can launch past CI monthly or even bimonthly. Please let me know if you have different opinion, @LysandreJik. Thanks."
] | 1,656
| 1,658
| 1,657
|
COLLABORATOR
| null |
# What does this PR do?
Enable Past CI
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17919/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17919/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17919",
"html_url": "https://github.com/huggingface/transformers/pull/17919",
"diff_url": "https://github.com/huggingface/transformers/pull/17919.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17919.patch",
"merged_at": 1657037316000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17918
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17918/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17918/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17918/events
|
https://github.com/huggingface/transformers/pull/17918
| 1,286,981,633
|
PR_kwDOCUB6oc46ejt4
| 17,918
|
Pin black to 22.3.0 to benefit from a stable --preview flag
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"Merging now as the code quality passes so that as few PRs are impacted as possible.",
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks a lot!"
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
Pins black to 22.3.0 in order to benefit from the `--preview` flag continuously. This flag adds reformats for strings, exceptions, logs, and others.
The recent black 22.6.0 version's `--preview` flag isn't compatible with the 22.3.0 and results in line changes.
This PR pins 22.3.0 as it was deemed the path with the least friction.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17918/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17918/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17918",
"html_url": "https://github.com/huggingface/transformers/pull/17918",
"diff_url": "https://github.com/huggingface/transformers/pull/17918.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17918.patch",
"merged_at": 1656405139000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17917
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17917/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17917/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17917/events
|
https://github.com/huggingface/transformers/pull/17917
| 1,286,968,288
|
PR_kwDOCUB6oc46eg7N
| 17,917
|
Fix #17893, removed dead code
|
{
"login": "clefourrier",
"id": 22726840,
"node_id": "MDQ6VXNlcjIyNzI2ODQw",
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clefourrier",
"html_url": "https://github.com/clefourrier",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_url": "https://api.github.com/users/clefourrier/gists{/gist_id}",
"starred_url": "https://api.github.com/users/clefourrier/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clefourrier/subscriptions",
"organizations_url": "https://api.github.com/users/clefourrier/orgs",
"repos_url": "https://api.github.com/users/clefourrier/repos",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"received_events_url": "https://api.github.com/users/clefourrier/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hey @clefourrier! The code quality error comes from a new release from `black`. Rebasing on `main` should solve the issue as you'll benefit from https://github.com/huggingface/transformers/pull/17918.",
"Regarding the test\r\n\r\nfrom Lysandre on Slack\r\n\r\n_There was a new release from black that has a slightly different behavior for the --preview flag that we use in the CI._\r\n\r\n_If you see failures in the CI for the code quality test, with a large number of file changes (>500), please mention to the author that they just need to rebase on/merge main in order to benefit from the fix._\r\n",
"@LysandreJik @ydshieh Should be good now! :smiley: \r\nTy both, I had missed it on the slack",
"@sgugger Done :)"
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
# What does this PR do?
Fixes #17893
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@ydshieh
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17917/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17917/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17917",
"html_url": "https://github.com/huggingface/transformers/pull/17917",
"diff_url": "https://github.com/huggingface/transformers/pull/17917.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17917.patch",
"merged_at": 1656539667000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17916
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17916/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17916/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17916/events
|
https://github.com/huggingface/transformers/pull/17916
| 1,286,965,681
|
PR_kwDOCUB6oc46egY5
| 17,916
|
[M2M100] update conversion script
|
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
# What does this PR do?
Update the m2m100 conversion script for newer checkpoints.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17916/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17916/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17916",
"html_url": "https://github.com/huggingface/transformers/pull/17916",
"diff_url": "https://github.com/huggingface/transformers/pull/17916.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17916.patch",
"merged_at": 1656404107000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17915
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17915/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17915/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17915/events
|
https://github.com/huggingface/transformers/pull/17915
| 1,286,961,444
|
PR_kwDOCUB6oc46efgm
| 17,915
|
Compute min_resolution in prepare_image_inputs
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
If `feature_extract_tester.min_resolution` is specified, the images have to be at least that large, otherwise we will get image width and/or height `0` and it gives error.
An error is [here](https://github.com/huggingface/transformers/runs/7071766841?check_suite_focus=true):
```
> return self._new(self.im.resize(size, resample, box))
E ValueError: height and width must be > 0
```
So far, we have the following in `GLPNFeatureExtractionTester` and other testers
```
min_resolution=30,
...
size_divisor=32,
```
issue spotted by @Rocketknight1 , thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17915/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17915/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17915",
"html_url": "https://github.com/huggingface/transformers/pull/17915",
"diff_url": "https://github.com/huggingface/transformers/pull/17915.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17915.patch",
"merged_at": 1656491420000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17914
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17914/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17914/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17914/events
|
https://github.com/huggingface/transformers/pull/17914
| 1,286,932,981
|
PR_kwDOCUB6oc46eZkg
| 17,914
|
Fix typo in serialization.mdx
|
{
"login": "eltociear",
"id": 22633385,
"node_id": "MDQ6VXNlcjIyNjMzMzg1",
"avatar_url": "https://avatars.githubusercontent.com/u/22633385?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eltociear",
"html_url": "https://github.com/eltociear",
"followers_url": "https://api.github.com/users/eltociear/followers",
"following_url": "https://api.github.com/users/eltociear/following{/other_user}",
"gists_url": "https://api.github.com/users/eltociear/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eltociear/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eltociear/subscriptions",
"organizations_url": "https://api.github.com/users/eltociear/orgs",
"repos_url": "https://api.github.com/users/eltociear/repos",
"events_url": "https://api.github.com/users/eltociear/events{/privacy}",
"received_events_url": "https://api.github.com/users/eltociear/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17914). All of your documentation changes will be reflected on that endpoint.",
"Hey @eltociear! The code quality error comes from a new release from `black`. Rebasing on `main` should solve the issue as you'll benefit from https://github.com/huggingface/transformers/pull/17918.\r\n\r\nLet us know if we can help!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
CONTRIBUTOR
| null |
# What does this PR do?
overriden -> overridden
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17914/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17914/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17914",
"html_url": "https://github.com/huggingface/transformers/pull/17914",
"diff_url": "https://github.com/huggingface/transformers/pull/17914.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17914.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17913
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17913/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17913/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17913/events
|
https://github.com/huggingface/transformers/issues/17913
| 1,286,871,833
|
I_kwDOCUB6oc5MtBsZ
| 17,913
|
"num_examples" incorrect when using IterableDataset
|
{
"login": "Vicky-Meng",
"id": 32586021,
"node_id": "MDQ6VXNlcjMyNTg2MDIx",
"avatar_url": "https://avatars.githubusercontent.com/u/32586021?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Vicky-Meng",
"html_url": "https://github.com/Vicky-Meng",
"followers_url": "https://api.github.com/users/Vicky-Meng/followers",
"following_url": "https://api.github.com/users/Vicky-Meng/following{/other_user}",
"gists_url": "https://api.github.com/users/Vicky-Meng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Vicky-Meng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vicky-Meng/subscriptions",
"organizations_url": "https://api.github.com/users/Vicky-Meng/orgs",
"repos_url": "https://api.github.com/users/Vicky-Meng/repos",
"events_url": "https://api.github.com/users/Vicky-Meng/events{/privacy}",
"received_events_url": "https://api.github.com/users/Vicky-Meng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
|
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Thanks for flagging! Could you double-check the PR above fixes your issue?"
] | 1,656
| 1,656
| 1,656
|
NONE
| null |
When using ```torch.utils.data.IterableDataset```, logging ```num_examlpes``` (as in https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L1518) is not the actual num_examples, but the number of examples processed on a single process.
For example, when I have 2000 training samples and 2 gpus, with and IterableDataset, current output be like:
```
[INFO|trainer.py:1519] 2022-06-28 12:51:44,666 >> ***** Running training *****
[INFO|trainer.py:1520] 2022-06-28 12:51:44,666 >> Num examples = 1000
[INFO|trainer.py:1521] 2022-06-28 12:51:44,666 >> Num Epochs = 1
[INFO|trainer.py:1522] 2022-06-28 12:51:44,666 >> Instantaneous batch size per device = 8
[INFO|trainer.py:1523] 2022-06-28 12:51:44,666 >> Total train batch size (w. parallel, distributed & accumulation) = 16
[INFO|trainer.py:1524] 2022-06-28 12:51:44,666 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1525] 2022-06-28 12:51:44,666 >> Total optimization steps = 125
```
Here's the possible cause I've found:
as defined in
https://github.com/huggingface/transformers/blob/e02037b3524686b57c5a861ea49ac751f15568af/src/transformers/trainer.py#L1085
```num_examples``` is equal to ``` len(dataloader.dataset)```.
However, when ```isinstance(dataset, torch.utils.data.IterableDataset)```, the```dataloader.dataset``` is an instance of ```IterableDatasetShard```, which "generate samples for one of the processes only", whose ```__len__``` is the length of dataset on a single process, not the entire project.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17913/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17913/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17912
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17912/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17912/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17912/events
|
https://github.com/huggingface/transformers/issues/17912
| 1,286,820,374
|
I_kwDOCUB6oc5Ms1IW
| 17,912
|
Training loss doesn't decrease on TPU while works fine on GPU
|
{
"login": "AbuUbaida",
"id": 39676946,
"node_id": "MDQ6VXNlcjM5Njc2OTQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/39676946?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AbuUbaida",
"html_url": "https://github.com/AbuUbaida",
"followers_url": "https://api.github.com/users/AbuUbaida/followers",
"following_url": "https://api.github.com/users/AbuUbaida/following{/other_user}",
"gists_url": "https://api.github.com/users/AbuUbaida/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AbuUbaida/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AbuUbaida/subscriptions",
"organizations_url": "https://api.github.com/users/AbuUbaida/orgs",
"repos_url": "https://api.github.com/users/AbuUbaida/repos",
"events_url": "https://api.github.com/users/AbuUbaida/events{/privacy}",
"received_events_url": "https://api.github.com/users/AbuUbaida/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"Maybe @sgugger has an idea or knows someone who does!",
"This is more of a question for the PyTorch XLA folks, since you're not using any of our tools for training.",
"> This is more of a question for the PyTorch XLA folks, since you're not using any of our tools for training.\r\n\r\nThanks I have asked them and here's the solution: https://github.com/pytorch/xla/issues/3675#issuecomment-1171702988",
"Ah yes, I missed it but it's indeed a common mistake on TPUs!\r\n(FYI: by using Accelerate to power your training loop, your mistake would have been automatically fixed ;-) )",
"Nice to know! Thanks for the information @sgugger. Actually, I started with the HF Trainer but facing [this](https://github.com/huggingface/transformers/issues/14989#issue-1091070983) issue I moved to [this](https://github.com/huggingface/transformers/issues/14989#issuecomment-1003349939) solution which used PyTorch loop instead though I am using v4.18.0."
] | 1,656
| 1,656
| 1,656
|
NONE
| null |
For the summarization task, where I train with an encoder-decoder model on GPU, it works fine and the loss gets lower over iterations. But when I change the device to `device = xm.xla_device()` and optimizer to `xm.optimizer_step(optimizer, barrier=True)` on single-core TPU, the training loss remains nearly unchanged!!
**Here's the reproducible code:** https://colab.research.google.com/drive/1pC2CF3ipWt0eJrfXdznwAZD3zs0sX1kd?usp=sharing
Is it a bug or I am missing something?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17912/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17912/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17911
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17911/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17911/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17911/events
|
https://github.com/huggingface/transformers/issues/17911
| 1,286,798,797
|
I_kwDOCUB6oc5Msv3N
| 17,911
|
Silero Models License Infringement
|
{
"login": "snakers4",
"id": 12515440,
"node_id": "MDQ6VXNlcjEyNTE1NDQw",
"avatar_url": "https://avatars.githubusercontent.com/u/12515440?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/snakers4",
"html_url": "https://github.com/snakers4",
"followers_url": "https://api.github.com/users/snakers4/followers",
"following_url": "https://api.github.com/users/snakers4/following{/other_user}",
"gists_url": "https://api.github.com/users/snakers4/gists{/gist_id}",
"starred_url": "https://api.github.com/users/snakers4/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/snakers4/subscriptions",
"organizations_url": "https://api.github.com/users/snakers4/orgs",
"repos_url": "https://api.github.com/users/snakers4/repos",
"events_url": "https://api.github.com/users/snakers4/events{/privacy}",
"received_events_url": "https://api.github.com/users/snakers4/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] |
closed
| false
| null |
[] |
[
"closing as duplicate of https://github.com/huggingface/hub-docs/issues/216 let's address the issue there"
] | 1,656
| 1,656
| 1,656
|
NONE
| null |
### Model description
Hi,
My name is Alexander, I am writing to you on behalf of Silero, a company maintaining our project [silero-models](https://github.com/snakers4/silero-models).
We noticed that our models are rehosted here - https://huggingface.co/spaces/pytorch/silero_tts or here https://huggingface.co/spaces?search=silero.
We did not explicitly grant Hugging Face, Inc. any sort of permission to rehost, relicense and profit from our work and models.
Moreover it openly disregards our CC BY-NC-SA license.
Please immediately remove any of our models from your website and / or any of your resources.
Best,
Alexander
### Open source status
- [ ] The model implementation is available
- [ ] The model weights are available
### Provide useful links for the implementation
_No response_
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17911/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17911/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17910
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17910/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17910/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17910/events
|
https://github.com/huggingface/transformers/pull/17910
| 1,286,791,801
|
PR_kwDOCUB6oc46d7-R
| 17,910
|
[SegFormer] TensorFlow port
|
{
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hey @sayakpaul! The code quality error comes from a new release from `black`. Rebasing on `main` should solve the issue as you'll benefit from https://github.com/huggingface/transformers/pull/17918.",
"@Rocketknight1 @sgugger this PR is now ready for your review. Some things to note:\r\n\r\n* This is the first segmentation model on the TF side that has pre-trained segmentation checkpoints available. Hopefully, it serves as a good foundation for devs contributing TF segmentation models in the future. \r\n* @deep-diver and I will work on creating a Space and Colab notebook (for off-the-shelf inference and fine-tuning) to allow users to take advantage of a state-of-the-art segmentation model like this one in TF via `transformers`. \r\n\r\n~@NielsRogge even though the error in the CI is coming from `run_tests_pipelines_tf` it seems like the PT test is what is originating the error. Do you mind taking a look?~",
"Yes @Rocketknight1's comments are needed [here](https://github.com/huggingface/transformers/pull/17910#discussion_r910724119) as well. ",
"Yes, I'm sorry! I went deep on a couple of PRs yesterday and today - one for `datasets`, the other for XLA in `transformers`, and haven't had time to review this properly yet. I'll get to it ASAP, though!",
"Thanks, @gante. There were no changes except that. Those were reviewed and approved by @Rocketknight1 and @ydshieh. "
] | 1,656
| 1,658
| 1,658
|
MEMBER
| null |
This PR adds the SegFormer model in TensorFlow (probably the first Transformer-based segmentation model in TensorFlow for which we have PT weights available).
## TODOs
- [x] Write the foundation components
- [x] Write the image classification layer
- [x] Write components w.r.t semantic segmentation
- [x] Write the semantic segmentation layer
- [x] Add code examples after `call()` methods where relevant
- [x] Write tests
- [x] Modify other related utilities
- [x] Create Space to allow users to try out the models (preferably with ONNX to reduce the time?)
- [x] Create a Colab Notebook
The final two points are unrelated to the merging of this PR.
Cc: @deep-diver
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17910/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17910/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17910",
"html_url": "https://github.com/huggingface/transformers/pull/17910",
"diff_url": "https://github.com/huggingface/transformers/pull/17910.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17910.patch",
"merged_at": 1658424158000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17909
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17909/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17909/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17909/events
|
https://github.com/huggingface/transformers/issues/17909
| 1,286,746,439
|
I_kwDOCUB6oc5MsjFH
| 17,909
|
Wav2vec model further training [RuntimeError: you can only change requires_grad flags of leaf variables]
|
{
"login": "xinghua-qu",
"id": 36146785,
"node_id": "MDQ6VXNlcjM2MTQ2Nzg1",
"avatar_url": "https://avatars.githubusercontent.com/u/36146785?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xinghua-qu",
"html_url": "https://github.com/xinghua-qu",
"followers_url": "https://api.github.com/users/xinghua-qu/followers",
"following_url": "https://api.github.com/users/xinghua-qu/following{/other_user}",
"gists_url": "https://api.github.com/users/xinghua-qu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xinghua-qu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xinghua-qu/subscriptions",
"organizations_url": "https://api.github.com/users/xinghua-qu/orgs",
"repos_url": "https://api.github.com/users/xinghua-qu/repos",
"events_url": "https://api.github.com/users/xinghua-qu/events{/privacy}",
"received_events_url": "https://api.github.com/users/xinghua-qu/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hey @xinghua-qu,\r\n\r\nCould you please provide a fully reproducible code snippet here? E.g. something along the lines:\r\n\r\n```python\r\nfrom transformers import Wav2Vec2Model\r\n....\r\n```\r\n\r\nMore than happy to look into solving it then - thanks!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"@patrickvonplaten I am facing the same issue! Here is the snippet:\r\n`from transformers import Wav2Vec2ForSequenceClassification\r\nmodel = Wav2Vec2ForSequenceClassification.from_pretrained(\"facebook/wav2vec2-base-960h\")`\r\nwhen I freeze the FE `self.model.freeze_feature_extractor()` training is fine otherwise I get:\r\n`RuntimeError: you can only change requires_grad flags of leaf variables.`"
] | 1,656
| 1,684
| 1,659
|
NONE
| null |
### System Info
```shell
Latest version
```
### Who can help?
@patrickvonplaten, @anton-l
I use wav2vec model as part of my own pytorch model.
`self.configuration = Wav2Vec2Config()
self.wav2vec_feature = Wav2Vec2Model(self.configuration)
self.wav2vec_feature = self.wav2vec_feature.train()`
However, it raises error when I call wav2vec model in my own forward function.
The error is:
`File "/home/tiger/.local/lib/python3.7/site-packages/transformers/models/wav2vec2/modeling_wav2vec2.py", line 440, in forward
hidden_states.requires_grad = True`
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
`configuration = Wav2Vec2Config()
model = Wav2Vec2Model(configuration)
model = model.train()`
put this 'model' into a forward function in pytorch.
### Expected behavior
```shell
The wav2vec model inserted in my own model is expected to be trainable.
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17909/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17909/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17908
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17908/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17908/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17908/events
|
https://github.com/huggingface/transformers/pull/17908
| 1,286,596,385
|
PR_kwDOCUB6oc46dThl
| 17,908
|
In group_texts function, drop last block if smaller than block_size
|
{
"login": "billray0259",
"id": 31375073,
"node_id": "MDQ6VXNlcjMxMzc1MDcz",
"avatar_url": "https://avatars.githubusercontent.com/u/31375073?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/billray0259",
"html_url": "https://github.com/billray0259",
"followers_url": "https://api.github.com/users/billray0259/followers",
"following_url": "https://api.github.com/users/billray0259/following{/other_user}",
"gists_url": "https://api.github.com/users/billray0259/gists{/gist_id}",
"starred_url": "https://api.github.com/users/billray0259/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/billray0259/subscriptions",
"organizations_url": "https://api.github.com/users/billray0259/orgs",
"repos_url": "https://api.github.com/users/billray0259/repos",
"events_url": "https://api.github.com/users/billray0259/events{/privacy}",
"received_events_url": "https://api.github.com/users/billray0259/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
Adds one line to both the English and Spanish versions of the [Language modeling task documentation](https://huggingface.co/docs/transformers/tasks/language_modeling) in the `group_texts` function which drops the last block if the block is smaller than `block_size`. The absence of this line causes this exception to be thrown later when training the model:
`ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.`
This line is present in the related documentation, [Fine-tuning a masked language model](https://huggingface.co/course/chapter7/3?fw=pt).
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes [# 17882](https://github.com/huggingface/transformers/issues/17882)
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
@SaulLu, @sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17908/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17908/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17908",
"html_url": "https://github.com/huggingface/transformers/pull/17908",
"diff_url": "https://github.com/huggingface/transformers/pull/17908.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17908.patch",
"merged_at": 1656419695000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17907
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17907/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17907/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17907/events
|
https://github.com/huggingface/transformers/pull/17907
| 1,286,443,952
|
PR_kwDOCUB6oc46cyxa
| 17,907
|
[WIP] Add VQA docs
|
{
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1834067346,
"node_id": "MDU6TGFiZWwxODM0MDY3MzQ2",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Documentation",
"name": "Documentation",
"color": "77cc3b",
"default": false,
"description": ""
}
] |
closed
| false
| null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_17907). All of your documentation changes will be reflected on that endpoint.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
MEMBER
| null |
This PR adds visual question answering to the pipeline tutorial (under a more general multimodal header) and the fine-tune section of the guides. It would also be nice to create a VQA Tasks video similar to the other fine-tune guides, but this is not a super high priority right now :)
## TODO
- [ ] Create fine-tune guide for VQA.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17907/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17907/timeline
| null | true
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17907",
"html_url": "https://github.com/huggingface/transformers/pull/17907",
"diff_url": "https://github.com/huggingface/transformers/pull/17907.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17907.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17906
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17906/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17906/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17906/events
|
https://github.com/huggingface/transformers/pull/17906
| 1,286,424,595
|
PR_kwDOCUB6oc46cub8
| 17,906
|
Fixing a regression with `return_all_scores` introduced in #17606
|
{
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@sgugger Do you mind just re-reviewing, I pushed the PR a little early yesterday (forgot WIP tag).\r\n\r\nThe real edge case (present in `4.19.4`) is when there's a single incoming item and `return_all_scores=True`, somehow we are always returning `[CLASS_DICT]` but when using `return_all_scores` we're returning `[[CLASS_DICT, CLASS_DICT]]` .\r\n\r\nI don't fully remember why the second list popped from the very old legacy code (before the pipeline rework) but that's the reason for the weird return type in the beginning.\r\n\r\nIMO, we should return ALWAYS a list when classifying a single text ( containing only the top element by default `, which is fully backward compatible).\r\n\r\nThen, we keep the odd LIST of LIST when using `return_all_scores=True` (BC, + add a warning to move to `top_k`.)\r\n\r\nThen we change the return when using `top_k=None` or `top_k=n` to contain a single LIST of the classes (so more aligned with the return type without any parameters).\r\n\r\nWDYT about this solution ?\r\n\r\nDo you think we should be more conservative and keep LIST of LISTS all the time (even when using the new parameter )?.\r\n(The API itself will maintain that return legacy type, while I go look if we can update the widget itself)\r\n\r\nAlso, when sending a LIST of str as an input the output will ALWAYS be a list of list of classes in all scenarios.\r\n",
"PS: Failing tests seem to be linked with new `black` version so I am going to ignore them and rebase later.",
"Mmm I see weird changes in `molideng_utils` and `gpt2` now. I think your solution is sensible.",
"Wrong rebase on my end."
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
Fixing a regression with `return_all_scores` introduced in #17606
- The legacy test actually tested `return_all_scores=False` (the actual
default) instead of `return_all_scores=True` (the actual weird case).
This commit adds the correct legacy test and fixes it.
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@sgugger
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17906/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17906/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17906",
"html_url": "https://github.com/huggingface/transformers/pull/17906",
"diff_url": "https://github.com/huggingface/transformers/pull/17906.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17906.patch",
"merged_at": 1656451485000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17905
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17905/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17905/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17905/events
|
https://github.com/huggingface/transformers/pull/17905
| 1,286,423,493
|
PR_kwDOCUB6oc46cuL0
| 17,905
|
feat: add pipeline registry abstraction
|
{
"login": "aarnphm",
"id": 29749331,
"node_id": "MDQ6VXNlcjI5NzQ5MzMx",
"avatar_url": "https://avatars.githubusercontent.com/u/29749331?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aarnphm",
"html_url": "https://github.com/aarnphm",
"followers_url": "https://api.github.com/users/aarnphm/followers",
"following_url": "https://api.github.com/users/aarnphm/following{/other_user}",
"gists_url": "https://api.github.com/users/aarnphm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aarnphm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aarnphm/subscriptions",
"organizations_url": "https://api.github.com/users/aarnphm/orgs",
"repos_url": "https://api.github.com/users/aarnphm/repos",
"events_url": "https://api.github.com/users/aarnphm/events{/privacy}",
"received_events_url": "https://api.github.com/users/aarnphm/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"> Note that this is only to customize preprocessing and/or postprocessing as this still relies on existing auto-model classes.\r\n\r\nShould I include inside the docs to use an `AutoModel` class for better readability?",
"@Narsil CI failed due to the recent `black` versioning locked?",
"Super nice PR thanks for this addition !\r\n\r\nLeft a few NITs about the structure. Feel free to ignore if you don't agree with them",
"> @Narsil CI failed due to the recent `black` versioning locked?\r\n\r\nSeems like `black` released a new version and the CI is not locking it, right @sgugger ?\r\nhttps://pypi.org/project/black/",
"Yes, you'll need to rebase on main to fix the tests. Failures are due to new releases of black and PyTorch.",
"> Yes, you'll need to rebase on main to fix the tests. Failures are due to new releases of black and PyTorch.\r\n\r\nunderstood. Address accordingly.\r\n\r\ncc @LysandreJik @sgugger @Narsil when you guys have time.",
"That's very nice, love this approach! Should make it much much simpler to add custom pipelines.\r\n\r\nI only have one request: please add tests :smile: ",
"cc @LysandreJik for tests. I'm thinking to add a test for log capture output, but I'm not too familiar with transformers logging structure.",
"If you want to test outputs, we have a util for this called `CaptureStd`. You can see an example of use in [this test](https://github.com/huggingface/transformers/blob/9fe2403bc52e342022ed132561655f84a6b6b7f3/tests/utils/test_cli.py#L30).",
"> If you want to test outputs, we have a util for this called `CaptureStd`. You can see an example of use in [this test](https://github.com/huggingface/transformers/blob/9fe2403bc52e342022ed132561655f84a6b6b7f3/tests/utils/test_cli.py#L30).\n\nThanks. Will update accordingly.",
"tests are finished. lmk if any additional testing is required. cc @LysandreJik ",
"Failure is flaky, so merging. Thanks again for your contribution!"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
- added `PipelineRegistry` abstraction for better supports for custom pipeline.
- updates `add_new_pipeline.mdx` (english docs) to reflect the api addition
- migrate `check_task` and `get_supported_tasks` from
`transformers/pipelines/__init__.py` to
` transformers/pipelines/base.py#PipelineRegistry.{check_task,get_supported_tasks}`
Address #17762
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@LysandreJik and @sgugger, would be great if you guys can provide feedback.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17905/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17905/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17905",
"html_url": "https://github.com/huggingface/transformers/pull/17905",
"diff_url": "https://github.com/huggingface/transformers/pull/17905.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17905.patch",
"merged_at": 1656605468000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17904
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17904/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17904/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17904/events
|
https://github.com/huggingface/transformers/pull/17904
| 1,286,363,904
|
PR_kwDOCUB6oc46cgqn
| 17,904
|
Add ONNX support for DETR
|
{
"login": "regisss",
"id": 15324346,
"node_id": "MDQ6VXNlcjE1MzI0MzQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/15324346?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/regisss",
"html_url": "https://github.com/regisss",
"followers_url": "https://api.github.com/users/regisss/followers",
"following_url": "https://api.github.com/users/regisss/following{/other_user}",
"gists_url": "https://api.github.com/users/regisss/gists{/gist_id}",
"starred_url": "https://api.github.com/users/regisss/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/regisss/subscriptions",
"organizations_url": "https://api.github.com/users/regisss/orgs",
"repos_url": "https://api.github.com/users/regisss/repos",
"events_url": "https://api.github.com/users/regisss/events{/privacy}",
"received_events_url": "https://api.github.com/users/regisss/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"All slow tests passed @lewtun ",
"Pinging @sgugger for approval"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR adds ONNX support for DETR and for object-detection models in general. Linked to #16308 and discussed [here](https://huggingface.co/facebook/detr-resnet-50/discussions/1).
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17904/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17904/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17904",
"html_url": "https://github.com/huggingface/transformers/pull/17904",
"diff_url": "https://github.com/huggingface/transformers/pull/17904.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17904.patch",
"merged_at": 1656420523000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17903
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17903/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17903/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17903/events
|
https://github.com/huggingface/transformers/pull/17903
| 1,286,272,755
|
PR_kwDOCUB6oc46cMS0
| 17,903
|
Mrbean/codegen onnx
|
{
"login": "sam-h-bean",
"id": 43734688,
"node_id": "MDQ6VXNlcjQzNzM0Njg4",
"avatar_url": "https://avatars.githubusercontent.com/u/43734688?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sam-h-bean",
"html_url": "https://github.com/sam-h-bean",
"followers_url": "https://api.github.com/users/sam-h-bean/followers",
"following_url": "https://api.github.com/users/sam-h-bean/following{/other_user}",
"gists_url": "https://api.github.com/users/sam-h-bean/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sam-h-bean/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sam-h-bean/subscriptions",
"organizations_url": "https://api.github.com/users/sam-h-bean/orgs",
"repos_url": "https://api.github.com/users/sam-h-bean/repos",
"events_url": "https://api.github.com/users/sam-h-bean/events{/privacy}",
"received_events_url": "https://api.github.com/users/sam-h-bean/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
Codegen was added with an ONNX config but not with the model added to the features manager so trying to actually export an ONNX config is failing.
```bash
11497 ± RUN_SLOW=1 pytest tests/onnx/test_onnx_v2.py -k "codegen" -v
===================================================================================== test session starts ======================================================================================
platform darwin -- Python 3.9.10, pytest-7.1.2, pluggy-1.0.0 -- /Users/marklar/workspace/transformers/venv/bin/python3
cachedir: .pytest_cache
hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/Users/marklar/workspace/transformers/.hypothesis/examples')
rootdir: /Users/marklar/workspace/transformers, configfile: setup.cfg
plugins: xdist-2.5.0, forked-1.4.0, timeout-2.1.0, hypothesis-6.47.0, dash-2.5.0
collected 371 items / 367 deselected / 4 selected
tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_029_codegen_causal_lm PASSED [ 25%]
tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_030_codegen_default PASSED [ 50%]
tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_on_cuda_029_codegen_causal_lm PASSED [ 75%]
tests/onnx/test_onnx_v2.py::OnnxExportTestCaseV2::test_pytorch_export_on_cuda_030_codegen_default PASSED [100%]
```
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@patil-suraj @JingyaHuang
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17903/reactions",
"total_count": 10,
"+1": 10,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17903/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17903",
"html_url": "https://github.com/huggingface/transformers/pull/17903",
"diff_url": "https://github.com/huggingface/transformers/pull/17903.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17903.patch",
"merged_at": 1656421073000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17902
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17902/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17902/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17902/events
|
https://github.com/huggingface/transformers/pull/17902
| 1,286,243,005
|
PR_kwDOCUB6oc46cFxl
| 17,902
|
Adding support for `device_map` directly in `pipeline(..)` function.
|
{
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,657
| 1,657
|
CONTRIBUTOR
| null |
# What does this PR do?
Fixes #17663
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@younes @sgugger
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17902/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17902/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17902",
"html_url": "https://github.com/huggingface/transformers/pull/17902",
"diff_url": "https://github.com/huggingface/transformers/pull/17902.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17902.patch",
"merged_at": 1657893266000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17901
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17901/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17901/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17901/events
|
https://github.com/huggingface/transformers/pull/17901
| 1,286,196,966
|
PR_kwDOCUB6oc46b79L
| 17,901
|
`bitsandbytes` - `Linear8bitLt` integration into `transformers` models
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"cc-ing also @michaelbenayoun in case you want to have a look as well ;) ",
"Nice, thanks for working on it @younesbelkada! Also quite interested in the feature. I'd be particularly interested in seeing a bit of documentation so that we may understand better how it works under the hood and how to use the feature to its best.\r\n\r\nThanks!",
"Hi all!\r\nJust to summarise a bit about what is happening and the solution we came up to implement this!\r\nIn the previous version, we found out 2 major bugs: 1- the function `set_module_tensor_to_device` seems to overwrite the `Int8Params` modules by `nn.Parameter` modules. 2- `init_empty_weights` seems also to replace the `Int8Params` modules by `nn.Parameter` modules.\r\n\r\nI see two solutions to this\r\n1- Open a PR in `accelerate` to support the correct overwriting into `Int8Params` class as the following: https://github.com/huggingface/accelerate/compare/main...TimDettmers:accelerate:integration_8bit - only 2 functions are modified and should not break backward compatibility but I am not sure\r\n2- Manually redefine the functions `set_module_tensor_to_device` and `init_empty_weights`as two new function `set_module_8bit_tensor_to_device` and `init_8bit_empty_weights` as proposed in this PR. \r\n\r\nI personally found the option 1 cleaner but the option 2 might be safer for `accelerate` - Let us know what do you think !\r\ncc @LysandreJik @sgugger @TimDettmers",
"Thank you very much for your comments!\r\n`has_fp16_weights` comes from the class `bnb.Int8Params` that is currently being developed in a WIP branch that should be merged soon on the main branch of `bitsandbytes`. Basically the logic behind it is that if the module contain this attribute then it has to be a `bnb.Int8Params` module.\r\nI will refactor the code with your proposed changes and ask for a second batch of review 🚀 ",
"I think before merging we need:\r\n- [x] Memory footprint benchmarking\r\n- [x] Infrence speed benchmarking\r\n- [x] `lm-eval` benchmarking for large models (it has been done for small models)\r\n- [x] Merging the WIP branch of `bitsandbytes` into `main`",
"Added another PR to support int8 quantization + `accelerate` on multi-GPU setup here: https://github.com/huggingface/accelerate/pull/539 ! ",
"Thanks @sgugger for your review ! Fixed the suggestions ;) \r\nI think that we are good to go to merge https://github.com/huggingface/accelerate/pull/539 if you don't mind 🙏 \r\nI just need to wait the release of `bitsandbytes` to be more stable (facing some issues when installing the library but should be fixed very soon, I am syncing with @TimDettmers). Once this is fixed I think that we should be good to go for merging 🚀 ",
"Merged the PR in Accelerate! Don't forget to add some documentation and also setup some tests for this so it doesn't get broken by future PRs :-)",
"TODOs:\r\n- [x] Have a working colab demo for inference\r\n- [x] Add more documentation\r\n- [x] Implement tests",
"Before moving forward, I would like to have a comment from @michaelbenayoun @mfuntowicz and @echarlaix \r\n\r\n## About this PR\r\n\r\nWe replace all the `nn.Linear` modules by the `bnb.Linear8bitLt` modules from the recent release of `bitsandbytes` that proposes a new post-training quantization technique for 0 performance degradation on large-scale models (>1b parameters). With that we have managed to fit BLOOM-176B on 3xA100 80GB instead of 6xA100 GB with no performance degradation. \r\n\r\n## About the mixed quantization method in few words\r\n\r\nIn this technique the operations on the outliers are done in `fp16` and the rest of the operations are done in `int8` to achieve 0 performance degradation on large-scale models. \r\n\r\n## Usage\r\n\r\nThis does not run on CPU, you will need a GPU that supports 8-bit core tensors operations (T4 and A100) to make it run. Here is a tutorial on Google Colab on how to run the mixed-int8 model: https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4#scrollTo=YJlldexxwnhM ",
"Can confirm the slow tests that I have designed are passing on my testing machine (2x Tesla T4 15GB). But for now it is not possible to load saved int8 checkpoints because you need to load the quantization statistics that are not saved when doing `model.state_dict()` in `bitsandbytes`. For now I propose to just raise an error message if int8 weights are loaded and tell users that the feature is not supported (as proposed in 1326a42795033410dae6c5a8a07b81f12ee7a41c). \r\nNo strong opinions but I personally advocate to keep this feature inside `transformers` since the method relies also on `accelerate` + an additional lib (`bitsandbytes`), but I am not the best knowledgable person regarding `optimum` integration that might be a bit different than the `transformers` one. \r\ncc @sgugger @mfuntowicz @TimDettmers🙏 ",
"Thank you for all the work on this PR @younesbelkada, @sgugger, @michaelbenayoun! \r\n\r\nRegarding the `transformers` vs `optimum` question: From my understanding of the libraries, I think if people want to deploy models or run them with high efficiency `optimum` seems to be the right tool, whereas general purpose \"inefficient\" access of models is more suitable for `transformers`. \r\n\r\nAs such, I think it's best to keep this feature in `transformers`. I think it fits better into there since it is not meant for fast inference but memory-efficient inference for as many use-cases as possible. ",
"Forgive me for jumping the gun - \r\n\r\nOn Colab(T4, 12G RAM) I tried:\r\n\r\n```\r\n!nvidia-smi\r\n\r\n| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |\r\n| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |\r\n| N/A 58C P8 10W / 70W | 0MiB / 15109MiB | 0% Default |\r\n| No running processes found |\r\n```\r\n\r\nThen\r\n\r\n```\r\n!pip install https://github.com/younesbelkada/transformers/archive/refs/heads/integration-8bit.zip accelerate \r\n!pip install -i https://test.pypi.org/simple/ bitsandbytes-cuda112\r\n```\r\n\r\nLoading model with\r\n\r\n```\r\nimport torch\r\nfrom transformers import AutoTokenizer, AutoModelForCausalLM\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(\"Salesforce/codegen-2B-mono\")\r\nmodel = AutoModelForCausalLM.from_pretrained(\"Salesforce/codegen-2B-mono\", load_in_8bit=True, device_map=\"auto\")\r\n```\r\n\r\nAnd got this error:\r\n\r\n```\r\nRuntimeError Traceback (most recent call last)\r\n[<ipython-input-8-40073518cc86>](https://localhost:8080/#) in <module>()\r\n----> 1 model = AutoModelForCausalLM.from_pretrained(\"Salesforce/codegen-2B-mono\", load_in_8bit=True, device_map=\"auto\")\r\n\r\n7 frames\r\n[/usr/local/lib/python3.7/dist-packages/transformers/models/auto/auto_factory.py](https://localhost:8080/#) in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)\r\n 444 elif type(config) in cls._model_mapping.keys():\r\n 445 model_class = _get_model_class(config, cls._model_mapping)\r\n--> 446 return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, config=config, **kwargs)\r\n 447 raise ValueError(\r\n 448 f\"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\\n\"\r\n\r\n[/usr/local/lib/python3.7/dist-packages/transformers/modeling_utils.py](https://localhost:8080/#) in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)\r\n 2282 # Dispatch model with hooks on all devices if necessary\r\n 2283 if device_map is not None:\r\n-> 2284 dispatch_model(model, device_map=device_map, offload_dir=offload_folder)\r\n 2285 \r\n 2286 if output_loading_info:\r\n\r\n[/usr/local/lib/python3.7/dist-packages/accelerate/big_modeling.py](https://localhost:8080/#) in dispatch_model(model, device_map, main_device, state_dict, offload_dir, offload_buffers, preload_module_classes)\r\n 246 offload_buffers=offload_buffers,\r\n 247 weights_map=weights_map,\r\n--> 248 preload_module_classes=preload_module_classes,\r\n 249 )\r\n 250 model.hf_device_map = device_map\r\n\r\n[/usr/local/lib/python3.7/dist-packages/accelerate/hooks.py](https://localhost:8080/#) in attach_align_device_hook_on_blocks(module, execution_device, offload, weights_map, offload_buffers, module_name, preload_module_classes)\r\n 446 place_submodules=True,\r\n 447 )\r\n--> 448 add_hook_to_module(module, hook)\r\n 449 attach_execution_device_hook(module, execution_device[module_name])\r\n 450 elif module_name in execution_device:\r\n\r\n[/usr/local/lib/python3.7/dist-packages/accelerate/hooks.py](https://localhost:8080/#) in add_hook_to_module(module, hook)\r\n 136 module._old_forward = old_forward\r\n 137 \r\n--> 138 module = hook.init_hook(module)\r\n 139 module._hf_hook = hook\r\n 140 \r\n\r\n[/usr/local/lib/python3.7/dist-packages/accelerate/hooks.py](https://localhost:8080/#) in init_hook(self, module)\r\n 219 if not self.offload and self.execution_device is not None:\r\n 220 for name, _ in named_module_tensors(module, recurse=self.place_submodules):\r\n--> 221 set_module_tensor_to_device(module, name, self.execution_device)\r\n 222 elif self.offload:\r\n 223 self.original_devices = {\r\n\r\n[/usr/local/lib/python3.7/dist-packages/accelerate/utils/modeling.py](https://localhost:8080/#) in set_module_tensor_to_device(module, tensor_name, device, value)\r\n 128 module._buffers[tensor_name] = new_value\r\n 129 else:\r\n--> 130 new_value = nn.Parameter(new_value, requires_grad=old_value.requires_grad)\r\n 131 module._parameters[tensor_name] = new_value\r\n 132 \r\n\r\n[/usr/local/lib/python3.7/dist-packages/torch/nn/parameter.py](https://localhost:8080/#) in __new__(cls, data, requires_grad)\r\n 40 t = data.detach().requires_grad_(requires_grad)\r\n 41 if type(t) is not type(data):\r\n---> 42 raise RuntimeError(f\"Creating a Parameter from an instance of type {type(data).__name__} \"\r\n 43 \"requires that detach() returns an instance of the same type, but return \"\r\n 44 f\"type {type(t).__name__} was found instead. To use the type as a \"\r\n\r\nRuntimeError: Creating a Parameter from an instance of type Int8Params requires that detach() returns an instance of the same type, but return type Tensor was found instead. To use the type as a Parameter, please correct the detach() semantics defined by its __torch_dispatch__() implementation.\r\n```\r\n\r\nInterestingly on AWS Sagemaker(T4, 16G RAM) -\r\n\r\n```\r\n!pip install -i https://test.pypi.org/simple/ bitsandbytes-cuda114\r\n\r\nimport torch\r\nfrom transformers import AutoTokenizer, AutoModelForCausalLM\r\ntokenizer = AutoTokenizer.from_pretrained(\"Salesforce/codegen-6B-mono\")\r\nmodel = AutoModelForCausalLM.from_pretrained(\"Salesforce/codegen-6B-mono\", load_in_8bit=True, device_map=\"auto\")\r\n```\r\n\r\ngot me\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nNameError Traceback (most recent call last)\r\n/tmp/ipykernel_141/3855166932.py in <cell line: 1>()\r\n----> 1 model = AutoModelForCausalLM.from_pretrained(\"Salesforce/codegen-6B-mono\", load_in_8bit=True, device_map=\"auto\")\r\n\r\n~/.conda/envs/default/lib/python3.9/site-packages/transformers/models/auto/auto_factory.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)\r\n 444 elif type(config) in cls._model_mapping.keys():\r\n 445 model_class = _get_model_class(config, cls._model_mapping)\r\n--> 446 return model_class.from_pretrained(pretrained_model_name_or_path, *model_args, config=config, **kwargs)\r\n 447 raise ValueError(\r\n 448 f\"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\\n\"\r\n\r\n~/.conda/envs/default/lib/python3.9/site-packages/transformers/modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)\r\n 2177 init_contexts = [deepspeed.zero.Init(config_dict_or_path=deepspeed_config())] + init_contexts\r\n 2178 elif load_in_8bit:\r\n-> 2179 init_contexts = [init_empty_weights()] # Force enable init empty weights\r\n 2180 logger.info(\"Detected 8-bit loading: activating 8-bit loading for this model\")\r\n 2181 elif low_cpu_mem_usage:\r\n\r\nNameError: name 'init_empty_weights' is not defined\r\n```\r\n\r\nI suppose the 2nd case may have something to do with environment setup - but what would trigger the first issue?\r\n\r\nThanks,",
"Hi @cnbeining !\r\nThanks for your interest in this feature and happy to see that you are already excited to run it on Codegen! 🚀 \r\nInitially your problem is related to `accelerate` that you are installing. Make sure you install the latest version from source using a command like:\r\n```\r\npip install git+https://github.com/huggingface/accelerate.git@24c28a1adc284db0126b7c17ebef275597ddc6b7\r\n```\r\nWith `24c28a1adc284db0126b7c17ebef275597ddc6b7` being the latest commit hash from accelerate. The most recent release (aka `accelerate` library that you will get from `pip install accelerate`) is not compatible with this PR at the time I wrote this message. Therefore you will need the latest version of it.\r\n\r\nHowever, when using `load_in_8bit`, `torch_dtype=torch.float16` is internally called. It happens that there might be a small bug in Codegen when using `torch_dtype=torch.float16` that we propose to fix in https://github.com/huggingface/transformers/pull/18467 . if you are interested to reproduce the issue you can run this small snippet:\r\n\r\n```\r\nimport torch\r\nfrom transformers import AutoTokenizer, AutoModelForCausalLM\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(\"Salesforce/codegen-2B-mono\")\r\nmodel = AutoModelForCausalLM.from_pretrained(\"Salesforce/codegen-2B-mono\", device_map=\"auto\", torch_dtype=torch.float16)\r\n\r\ntext = \"def quicksort(l):\"\r\n\r\nencoded_input = tokenizer(text, return_tensors='pt')\r\noutput_sequences = model.generate(input_ids=encoded_input['input_ids'], attention_mask=encoded_input['attention_mask'])\r\nprint(tokenizer.decode(output_sequences[0], skip_special_tokens=True))\r\n```\r\n\r\nSince this might take time to be merged and as I saw that you wanted to run on Google Colab I made a special branch that you can build from Colab and should work (tested it) here: [](https://colab.research.google.com/drive/1IUAn97Zsfiiz7B1-vAAOSGsWE96yAiNM#scrollTo=1mNklAh5trGY). Just run those cells and everything should work.\r\n\r\nIf you follow the same installation instructions as this Colab I think that everything should work smoothly in SageMaker as well but we never know! \r\nLet us know if this helps, and happy to help you again if necessary 💪 \r\nAlso if you face any other issues, I think that it would be better to move this discussion into an issue! 🐛 \r\n\r\nThanks\r\nYounes",
"@LysandreJik I have a question regarding slow tests for this feature! \r\nI prefer to build another Docker image for these tests and run them separately because it happens sometimes that the import of `bitsandbytes` fails on some specific configurations. We found an issue that will be fixed on `bitsandbytes` asap but I think that having a separate image and running the tests independently is safer to not affect other tests. Since `bitsandbytes` is [always being imported](https://github.com/younesbelkada/transformers/blob/31fce94e8a3983dfa65222311b340460ccff05f7/src/transformers/modeling_utils.py#L95) if it is available if the docker image installs it all tests will fail at import time. I can also try to come up with a solution where we import this library only if `load_in_8bit` is triggered. What do you think is the best in this case?",
"Slow tests are now [all passing on our docker image](https://github.com/huggingface/transformers/actions/runs/2816407110) with the latest fix of `bitsandbytes`\r\nI would love to have a potential final round of review! cc @sgugger @LysandreJik ",
"Thanks for the review!\r\nGoing to do a last sanity check - testing with Docker and see if the slow tests passes on our Docker and merge once it's green! 🟢 ",
"GJ!\r\n\r\nNon blocking comment: How about incorporating (optional) `bnb.nn.StableEmbedding ` as [recommended by authors](https://github.com/facebookresearch/bitsandbytes#using-the-8-bit-optimizers) or added benefit is limited?",
"Thanks @cnbeining !\r\nI think that this can be done in a separate PR since we need to release the beta version of this feature probably ASAP! Also I am not sure how the current implementation will handle tied weights if we replace Embedding layers with StableEmbedding. So this needs further tests/investigations ",
"Yeah let's get this rolled out to unleash GPT-J-6B and CodeGen to ordinary folks :-) I will continue with my testing with `StableEmbedding` and will report results as they come by.\r\n\r\nAgain thanks so much for all the effort!",
"Great that would be awesome! I would be definitely interested in seeing the results and comparison against the current approach (aka without StableEmbedding)\r\nLet's maybe keep the results in this thread even after merging the PR",
"Ultimate checks are passing: https://github.com/huggingface/transformers/actions/runs/2830688091 Merging!",
"Looks nice, will try it out :)",
"You can check the Google Colab: https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4#scrollTo=W8tQtyjp75O_ to see how to run it! We will publish that today with the beta release on Twitter ",
"Great work! Can big models such us models used in the example colab be fine-tuned just loading it as `int8`?\r\nAre you thinking about release a colab for fine-tuning a model not just for inference?\r\nThanks in adavace",
"Thanks for the remark @mrm8488 ! Indeed it would be very nice to have a fine-tuning demo on colab\r\nAfter discussing with @TimDettmers it appears that the current implementation would support classic `torch` optimizers.\r\nAlso I think that @justheuristic has some experience with finetuning int8 models using `Linear8bitLt` modules for prompt tuning ;) so I will let him answer on the feasibility of that! 🚀 ",
"tl;dr soon :)\r\n\r\nRight now you can fine-tune with bitsandbytes, but it's gonna take up the same memory as 16bit - but we hope this can soon be fixed.\r\n\r\n@timdettmers and @dbaranchuk are working on memory-efficient fine-tuning on the bitsandbytes side.\r\nAfter they're done, you'll be able to write trainable adapters, soft-prompts and other parameter-efficient methods.\r\n\r\nThere is also a group in BigScience that works on 8-bit finetuning for very large models (think bloom-176B) in colab, but we are still polishing the code. I'll tag you once it becomes public.",
"@younesbelkada, thank you for integrating this awesome feature - may I suggest that all these cool features will remain hidden unless we expose them in the docs where users are likely to search for those and not in the API docs.\r\n\r\nI propose to add a new section at https://huggingface.co/docs/transformers/main/perf_train_gpu_one so that those searching for performance improvement will find it. Thank you!",
"Thanks for the comment ! Sounds really good for me 💪 \r\nI was planning to open a PR by the beginning of next week to add the link to blogpost + paper, I will most likely use this PR to propose your refactoring as well "
] | 1,656
| 1,660
| 1,660
|
CONTRIBUTOR
| null |
# What does this PR do?
Adding the `bitsandbytes` - `Linear8bitLt` integration for large language models! 🚀
This feature could reduce the size of the large models by up to 2, without a high loss in precision
Paper and main implementations from: @TimDettmers
# Usage:
Anyone with a GPU that supports mixed 8 bit quantization could load a model using
`AutoModel.from_pretrained(xxx, load_in_8bit=True, device_map="auto")`
And works like charm. Could work on *any* HF model!
## Requirements
Needs the latest version of `bitsandbytes` (that is compiled manually) and `accelerate`
## TODOs:
- [x] Add custom tests
- [x] Discuss potential improvements
- [x] Verify that the weights are still in 8bit after the loading (once there are more advances on Tim's side)
- [x] Add documentation (Younes first and then Tim)
- [x] Add a demo / few lines to explain how to use it
- [ ] Add flag that loads directly to 8bit @TimDettmers
Resources:
- WIP branch of bitsandbytes: https://github.com/TimDettmers/bitsandbytes/tree/cublaslt
Many thanks to @justheuristic and @TimDettmers !! 🎉
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17901/reactions",
"total_count": 9,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 6,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17901/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17901",
"html_url": "https://github.com/huggingface/transformers/pull/17901",
"diff_url": "https://github.com/huggingface/transformers/pull/17901.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17901.patch",
"merged_at": 1660115617000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17900
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17900/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17900/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17900/events
|
https://github.com/huggingface/transformers/issues/17900
| 1,286,122,370
|
I_kwDOCUB6oc5MqKuC
| 17,900
|
new Transformer update causes an error with TPU XLA implementation
|
{
"login": "salrowili",
"id": 56635735,
"node_id": "MDQ6VXNlcjU2NjM1NzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/56635735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salrowili",
"html_url": "https://github.com/salrowili",
"followers_url": "https://api.github.com/users/salrowili/followers",
"following_url": "https://api.github.com/users/salrowili/following{/other_user}",
"gists_url": "https://api.github.com/users/salrowili/gists{/gist_id}",
"starred_url": "https://api.github.com/users/salrowili/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/salrowili/subscriptions",
"organizations_url": "https://api.github.com/users/salrowili/orgs",
"repos_url": "https://api.github.com/users/salrowili/repos",
"events_url": "https://api.github.com/users/salrowili/events{/privacy}",
"received_events_url": "https://api.github.com/users/salrowili/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
|
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Maybe of interest to @sgugger ",
"cc @muellerzr It's probably linked to your recent changes for selecting the TPU device."
] | 1,656
| 1,656
| 1,656
|
NONE
| null |
Hi,
I notice the new release of the Transformer model (4.20) causes an issue with PyTorch XLA implementation and the new error message says "Cannot replicate if number of devices (1) is different from 8" appears.
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [x] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
`!pip install cloud-tpu-client==0.10 torch==1.11.0 https://storage.googleapis.com/tpu-pytorch/wheels/colab/torch_xla-1.11-cp37-cp37m-linux_x86_64.whl`
```
!pip3 install git+https://github.com/huggingface/transformers
!git clone https://github.com/huggingface/transformers
```
`!pip3 install -r /content/transformers/examples/pytorch/question-answering/requirements.txt`
```
!python /content/transformers/examples/pytorch/xla_spawn.py --num_cores=8 /content/transformers/examples/pytorch/question-answering/run_qa.py --model_name_or_path sultan/BioM-ELECTRA-Large-Discriminator \
--dataset_name squad_v2 \
--do_train \
--do_eval \
--dataloader_num_workers 4 \
--preprocessing_num_workers 4 \
--version_2_with_negative \
--num_train_epochs 2 \
--learning_rate 5e-5 \
--max_seq_length 384 \
--doc_stride 128 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--logging_steps 500 \
--save_steps 1000 \
--overwrite_output_dir \
--output_dir out
```
To fix the issue we git clone and git+install with 4.19 release:
```
!pip3 install git+https://github.com/huggingface/transformers.git@v4.19.4
!git clone --depth 1 --branch v4.19.4 https://github.com/huggingface/transformers
```
### Expected behavior
```shell
A new error message says "Cannot replicate if number of devices (1) is different from 8" appears.
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17900/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17900/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17899
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17899/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17899/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17899/events
|
https://github.com/huggingface/transformers/pull/17899
| 1,285,939,007
|
PR_kwDOCUB6oc46bF10
| 17,899
|
Move logic into pixelshuffle layer
|
{
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Moves logic relating to PixelShuffle layer into layer class. This is to provide a consistent usage wrt the PyTorch pixel shuffle layer and makes sure all necessary logic is ported if any `#Copied from ` statements are used.
Also renamed layer `PixelShuffle` -> `TFSwinPixelShuffle` to reflect naming in the rest of the repo. The following was run to make sure the models are still compatible with current weights:
```
from transformers import AutoFeatureExtractor, TFSwinForImageClassification
checkpoint = "microsoft/swin-tiny-patch4-window7-224"
# relative_position_index isn't updated during training. In TF set as instance param
print("\nTFSwinForImageClassification - from PyTorch checkpoint")
tf_model = TFSwinForImageClassification.from_pretrained(checkpoint, from_pt=True)
print("\nTFSwinForImageClassification - from TF checkpoint")
tf_model = TFSwinForImageClassification.from_pretrained(checkpoint)
```
With the following output. Note: `relative_position_index` isn't updated during training and is set as an instance param in the TF model
```
TFSwinForImageClassification - from PyTorch checkpoint
Some weights of the PyTorch model were not used when initializing the TF 2.0 model TFSwinForImageClassification: ['swin.encoder.layers.3.blocks.1.attention.self.relative_position_index', 'swin.encoder.layers.2.blocks.0.attention.self.relative_position_index', 'swin.encoder.layers.2.blocks.4.attention.self.relative_position_index', 'swin.encoder.layers.1.blocks.0.attention.self.relative_position_index', 'swin.encoder.layers.2.blocks.2.attention.self.relative_position_index', 'swin.encoder.layers.1.blocks.1.attention.self.relative_position_index', 'swin.encoder.layers.3.blocks.0.attention.self.relative_position_index', 'swin.encoder.layers.0.blocks.1.attention.self.relative_position_index', 'swin.encoder.layers.0.blocks.0.attention.self.relative_position_index', 'swin.encoder.layers.2.blocks.1.attention.self.relative_position_index', 'swin.encoder.layers.2.blocks.3.attention.self.relative_position_index', 'swin.encoder.layers.2.blocks.5.attention.self.relative_position_index']
- This IS expected if you are initializing TFSwinForImageClassification from a PyTorch model trained on another task or with another architecture (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFSwinForImageClassification from a PyTorch model that you expect to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFSwinForImageClassification were initialized from the PyTorch model.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFSwinForImageClassification for predictions without further training.
TFSwinForImageClassification - from TF checkpoint
All model checkpoint layers were used when initializing TFSwinForImageClassification.
All the layers of TFSwinForImageClassification were initialized from the model checkpoint at microsoft/swin-tiny-patch4-window7-224.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFSwinForImageClassification for predictions without further training.
```
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17899/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17899/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17899",
"html_url": "https://github.com/huggingface/transformers/pull/17899",
"diff_url": "https://github.com/huggingface/transformers/pull/17899.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17899.patch",
"merged_at": 1656417860000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17898
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17898/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17898/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17898/events
|
https://github.com/huggingface/transformers/pull/17898
| 1,285,815,403
|
PR_kwDOCUB6oc46arp2
| 17,898
|
Fix loss computation in TFBertForPreTraining
|
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@sgugger I believe it's unique to BERT, because I tried searching the codebase for any similar lines and it couldn't find any. I suspect this is how it stayed undetected for so long - it uses the NSP loss and people generally don't train with that anymore."
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
With thanks to @sreyan88 for writing up a clean bug report and reproducer, and to @ydshieh for locating the problematic code!
Our `hf_compute_loss()` function for `TFBertForPreTraining` was incorrect. However, it still appeared to work when the number of masked positions was evenly divisible by the batch size. Other, more commonly-used models like `TFBertForMaskedLM` do not have this issue.
The problem was incorrect handling of the reduction for the masked loss, so I took the opportunity to rewrite the function in modern TF. All shapes are now static in the rewritten function as well, which means it should now compile with XLA.
Fixes #17883
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17898/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17898/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17898",
"html_url": "https://github.com/huggingface/transformers/pull/17898",
"diff_url": "https://github.com/huggingface/transformers/pull/17898.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17898.patch",
"merged_at": 1656416697000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17897
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17897/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17897/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17897/events
|
https://github.com/huggingface/transformers/pull/17897
| 1,285,814,338
|
PR_kwDOCUB6oc46arbJ
| 17,897
|
[Issue template] Remove render tags
|
{
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
This PR makes sure that people's comments on Github issues regarding "System info" and "Expected behaviour" aren't rendered as shell.
This makes them a lot more readable (at least for me).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17897/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17897/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17897",
"html_url": "https://github.com/huggingface/transformers/pull/17897",
"diff_url": "https://github.com/huggingface/transformers/pull/17897.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17897.patch",
"merged_at": 1656497202000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17896
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17896/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17896/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17896/events
|
https://github.com/huggingface/transformers/issues/17896
| 1,285,767,078
|
I_kwDOCUB6oc5Moz-m
| 17,896
|
Deploying a pytorch-pretrained-bert on mobile
|
{
"login": "CowryCode",
"id": 23655212,
"node_id": "MDQ6VXNlcjIzNjU1MjEy",
"avatar_url": "https://avatars.githubusercontent.com/u/23655212?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CowryCode",
"html_url": "https://github.com/CowryCode",
"followers_url": "https://api.github.com/users/CowryCode/followers",
"following_url": "https://api.github.com/users/CowryCode/following{/other_user}",
"gists_url": "https://api.github.com/users/CowryCode/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CowryCode/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CowryCode/subscriptions",
"organizations_url": "https://api.github.com/users/CowryCode/orgs",
"repos_url": "https://api.github.com/users/CowryCode/repos",
"events_url": "https://api.github.com/users/CowryCode/events{/privacy}",
"received_events_url": "https://api.github.com/users/CowryCode/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"Hi,\r\n\r\nRegarding exporting Transformers models, refer to the guide here: https://huggingface.co/docs/transformers/serialization.\r\n\r\nAlso cc'ing @hollance who's an expert on mobile ML.",
"Thanks @NielsRogge I will explore it.\r\n\r\n@hollance, I just sent you an email at [mail@hollance.com]",
"It would be helpful to know what mobile platform you're trying to export to, how you've tried to do the export, and what errors you're running into. There are too many unknowns here to give an answer.",
"Thanks @hollance for your response, I just saw the message now. I will drop detail of both the code and screenshot shortly ",
"@hollance below are the codes and errors they threw. What I want to achieve is to use the model on edge device (mobile) developed in flutter. \r\n\r\n**Output of the training**\r\n\r\n**First Approach I tried**\r\n`model_class = OpenAIGPTDoubleHeadsModel\r\nmodel = model_class.from_pretrained('./themodel')\r\nScripted_model = torch.jit.script(model)\r\nopt_model = optimize_for_mobile(Scripted_model)\r\nopt_model._save_for_lite_interpreter(\"Mobile_model.ptl\")`\r\n\r\n**Error from Approach 1**\r\n\r\n\r\n\r\n**Approach 2**\r\n`from itertools import chain\r\npersona = [[\"i\", \"like\", \"playing\", \"football\", \".\"],\r\n [\"i\", \"am\", \"from\", \"NYC\", \".\"]]\r\nhistory = [[\"hello\", \"how\", \"are\", \"you\", \"?\"],\r\n [\"i\", \"am\", \"fine\", \"thanks\", \".\"]]\r\nreply = [\"great\", \"to\", \"hear\"]\r\nbos, eos, speaker1, speaker2 = \"<bos>\", \"<eos>\", \"<speaker1>\", \"<speaker2>\"\r\n\r\ndef build_inputs(persona, history, reply):\r\n sequence = [[bos] + list(chain(*persona))] + history + [reply + [eos]]\r\n sequence = [sequence[0]] + [ [speaker2 if (len(sequence)-i) % 2 else speaker1] + s\r\n for i, s in enumerate(sequence[1:])]\r\n words = list(chain(*sequence)) # word tokens\r\n segments = [speaker2 if i % 2 else speaker1 # segment tokens\r\n for i, s in enumerate(sequence) for _ in s]\r\n position = list(range(len(words))) # position tokens\r\n return words, segments, position, sequence\r\n\r\nwords, segments, position, sequence = build_inputs(persona, history, reply)\r\n\r\nwords = tokenizer.convert_tokens_to_ids(words)\r\nsegments = tokenizer.convert_tokens_to_ids(segments)\r\n\r\ntokenizer_class, model_class = (OpenAIGPTTokenizer, OpenAIGPTDoubleHeadsModel)\r\ntokens_tensor = torch.tensor([words])\r\nsegments_tensors = torch.tensor([segments])\r\nmodel = torch.load('./themodel/pytorch_model.bin')\r\nScripted_model = torch.jit.trace(model,[tokens_tensor, segments_tensors])\r\nopt_model = optimize_for_mobile(Scripted_model)\r\nopt_model._save_for_lite_interpreter(\"Mobile_model.ptl\")`\r\n\r\n**Error of the Second Approach**\r\n\r\n",
"The second approach of tracing the model (rather than scripting it), is what I would prefer. However, you need to load the model using `model = OpenAIGPTDoubleHeadsModel.from_pretrained(\"themodel\", torchscript=True)` instead of `torch.load`.",
"**Thank you @hollance, I really appreciate your effort. I tried it, and below were the error I got.**\r\n\r\n**When I changed the model load, I got the error below:**\r\n\r\n\r\n**When I removed the torchscript argument, I got the error below:**\r\n\r\n\r\n",
"That looks like you're not giving it inputs of the correct size. It's a good idea to using your input tensors first in a normal inference call:\r\n\r\n```\r\nwith torch.no_grad():\r\n outputs = model(inputs, return_dict=False)\r\n```\r\n\r\nwhere `inputs` are the input tensors this model needs. I expect this to also give an error message, so first make sure that works without problems.",
"Thank you @hollance for your support, I tried it and that failed. Below is a link to the google colab file perhaps that will explain the scenario better than I can do, I really appreciate your effort to help a newbie in ML. \r\n\r\nhttps://drive.google.com/file/d/1jKjmO0gh94i57zuPV0rvMyTmRgiyBBFG/view?usp=sharing",
"Sorry but there's just way too much stuff in that notebook for me to make sense of. Could you create a notebook that has the minimum amount of code in it to reproduce the problem?",
"Hi @hollance, kindly find below as requested to recreate the problem:\r\n**This is link to the minimized version of the colable file**\r\nhttps://drive.google.com/file/d/1CTVA6wD26BMHXlU6JY2VJ3S5TW5dI2Ac/view?usp=sharing\r\n\r\n**Below is a link to training output (i.e content of \"themodel\" folder)**\r\nhttps://drive.google.com/file/d/1ppib_rexC6_XsOlUQeOf3goD-v2uhqad/view?usp=sharing\r\n\r\n**Below is a link to the dataset (in case you may want to take a look)**\r\nhttps://s3.amazonaws.com/datasets.huggingface.co/personachat/personachat_self_original.json\r\n\r\n\r\nThank you for your support so far I am grateful. I feel really excited and relieved knowing that I am getting the needed help.",
"@CowryCode The problem is that the following code doesn't work:\r\n\r\n```python\r\nwith torch.no_grad():\r\n outputs = model(tokens_tensor, segments_tensors)\r\n```\r\n\r\nThe error message is \"Index tensor must have the same number of dimensions as input tensor\". The same thing happens when you try to do a `torch.jit.trace`. That's why the JIT trace fails.\r\n\r\nNow I'm not sure what `segments_tensors` is supposed to be but I think you mean to pass this into the `token_type_ids` argument. However, writing the following doesn't work:\r\n\r\n```python\r\nwith torch.no_grad():\r\n outputs = model(tokens_tensor, token_type_ids=segments_tensors)\r\n```\r\n\r\nThis is because the OpenAIGPTDoubleHeadsModel from the pytorch-pretrained-bert package expects there to be a `mc_token_ids` argument. \r\n\r\nAssuming that you actually meant to use OpenAIGPTDoubleHeadsModel from 🤗 Transformers, the above code does work, so I suggest you use that instead.\r\n\r\nHowever, there is another argument, `attention_mask`, in between the `input_ids` and `token_type_ids` arguments. When you call `torch.jit.trace`, you have to supply that attention mask argument too.\r\n\r\nThe easiest way around this is to create a helper class:\r\n\r\n```python\r\nfrom torch import nn\r\n\r\nclass Wrapper(nn.Module):\r\n def __init__(self, model):\r\n super().__init__()\r\n self.model = model\r\n\r\n def forward(self, input_ids, token_type_ids):\r\n return self.model(input_ids, None, token_type_ids, return_dict=False)\r\n```\r\n\r\nAnd then call it like so:\r\n\r\n```python\r\nwrapper = Wrapper(model)\r\ntraced_model = torch.jit.trace(wrapper, [tokens_tensor, segments_tensors])\r\n```\r\n\r\nThis will trace the model into a TorchScript object. Now you can do whatever you need to in order to load it into PyTorch mobile etc.\r\n\r\nTo verify this traced model gives the same outputs as the original, do this:\r\n\r\n```python\r\nwith torch.no_grad():\r\n traced_outputs = traced_model(tokens_tensor, segments_tensors)\r\n```\r\n\r\nThen the following should print a very small number (around 1e-6 or 1e-7):\r\n\r\n```python\r\ntorch.max(torch.abs(outputs[0] - traced_outputs[0])) / torch.max(torch.abs(traced_outputs[0]))\r\n```\r\n\r\nP.S. Ideally, you should load the original model as follows, with the `torchscript` argument:\r\n\r\n```python\r\nmodel = OpenAIGPTDoubleHeadsModel.from_pretrained(\"openai-gpt\", torchscript=True)\r\n```\r\n",
"Thank you @hollance, I will explore the solution you gave.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"@hollance hi, I wanted to deploy pix2struct into mobile. Do you have advice on which mobile platform, libraries, model format, etc to use and steps on deploying it? "
] | 1,656
| 1,707
| 1,659
|
NONE
| null |
### System Info
```shell
I use google colab
```
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Code here https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313
### Expected behavior
```shell
I want to export the model for use in a mobile app (flutter). I am new to this and I just can't figure it out. Have tried many recommendations online, but something seems off. Kindly help
```
### Checklist
- [X] I have read the migration guide in the readme. ([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers); [pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [X] I checked if a related official extension example runs on my machine.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17896/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17896/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17895
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17895/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17895/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17895/events
|
https://github.com/huggingface/transformers/pull/17895
| 1,285,709,776
|
PR_kwDOCUB6oc46aUsd
| 17,895
|
Fix tf pytorch test in auto
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Reopen #16044 by force push: fix some tests in `TFPTAutoModelTest`.
This is probably the last fix to have ` models_rembert` the only test failure (intended) in the CI report.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17895/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17895/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17895",
"html_url": "https://github.com/huggingface/transformers/pull/17895",
"diff_url": "https://github.com/huggingface/transformers/pull/17895.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17895.patch",
"merged_at": 1656399385000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17894
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17894/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17894/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17894/events
|
https://github.com/huggingface/transformers/issues/17894
| 1,285,660,877
|
I_kwDOCUB6oc5MoaDN
| 17,894
|
Trainer in `run_image_classification.py` removes necessary `"image"` column for evaluation
|
{
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https://api.github.com/users/fxmarty/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fxmarty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fxmarty/subscriptions",
"organizations_url": "https://api.github.com/users/fxmarty/orgs",
"repos_url": "https://api.github.com/users/fxmarty/repos",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"received_events_url": "https://api.github.com/users/fxmarty/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hi,\r\n\r\nIf `set_transform` (or `with_transform`) is used, you have to specificy `--remove_unused_columns False` to the script.\r\n\r\nElse, the error you show above occurs. Cc @nateraw",
"@NielsRogge Thank you for your quick reply, I missed it!",
"To quote @nateraw from his [blog post](https://huggingface.co/blog/fine-tune-vit):\r\n\r\n> What I'm trying to say is that you'll have a bad time if you forget to set remove_unused_columns=False.\r\n\r\n😂 ",
"\r\n\r\n> Hi,\r\n> \r\n> If `set_transform` (or `with_transform`) is used, you have to specificy `--remove_unused_columns False` to the script.\r\n> \r\n> Else, the error you show above occurs. Cc @nateraw\r\n\r\nThank you. I also meet this error. Another solution is to modify the parameter \"label_names = ['image', 'labels']\", so that the two fields can be registered in \"signature_columns\". Is there a description in the code? Because the default parameter 'remove_unused_columns' is True. It's easy to run into this problem. I think it would be better if adding a description in the \"set_transform\" function or after the parameter \"remove_unused_columns\" "
] | 1,656
| 1,692
| 1,656
|
COLLABORATOR
| null |
### System Info
```shell
- `transformers` version: 4.21.0.dev0
- Platform: Linux-5.15.0-39-generic-x86_64-with-glibc2.35
- Python version: 3.9.12
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.11.0+cu113 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
```
### Who can help?
@sgugger @patil-suraj
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Reproduce:
* Run `python examples/pytorch/image-classification/run_image_classification.py --model_name_or_path nateraw/vit-base-beans --dataset_name beans --output_dir ./beans_outputs/ --do_eval`
Error:
```
[INFO|trainer.py:661] 2022-06-27 13:15:34,641 >> The following columns in the evaluation set don't have a corresponding argument in `ViTForImageClassification.forward` and have been ignored: image. If image are not expected by `ViTForImageClassification.forward`, you can safely ignore this message.
[INFO|trainer.py:2753] 2022-06-27 13:15:34,642 >> ***** Running Evaluation *****
[INFO|trainer.py:2755] 2022-06-27 13:15:34,642 >> Num examples = 133
[INFO|trainer.py:2758] 2022-06-27 13:15:34,642 >> Batch size = 8
Traceback (most recent call last):
File "/home/fxmarty/hf_internship/transformers/examples/pytorch/image-classification/run_image_classification.py", line 388, in <module>
main()
File "/home/fxmarty/hf_internship/transformers/examples/pytorch/image-classification/run_image_classification.py", line 370, in main
metrics = trainer.evaluate()
File "/home/fxmarty/hf_internship/transformers/src/transformers/trainer.py", line 2621, in evaluate
output = eval_loop(
File "/home/fxmarty/hf_internship/transformers/src/transformers/trainer.py", line 2788, in evaluation_loop
for step, inputs in enumerate(dataloader):
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 530, in __next__
data = self._next_data()
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 570, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/torch/utils/data/_utils/fetch.py", line 49, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/torch/utils/data/_utils/fetch.py", line 49, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 2154, in __getitem__
return self._getitem(
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 2139, in _getitem
formatted_output = format_table(
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/datasets/formatting/formatting.py", line 532, in format_table
return formatter(pa_table, query_type=query_type)
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/datasets/formatting/formatting.py", line 281, in __call__
return self.format_row(pa_table)
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/datasets/formatting/formatting.py", line 387, in format_row
formatted_batch = self.format_batch(pa_table)
File "/home/fxmarty/anaconda3/envs/hf-inf/lib/python3.9/site-packages/datasets/formatting/formatting.py", line 418, in format_batch
return self.transform(batch)
File "/home/fxmarty/hf_internship/transformers/examples/pytorch/image-classification/run_image_classification.py", line 318, in val_transforms
example_batch["pixel_values"] = [_val_transforms(pil_img.convert("RGB")) for pil_img in example_batch["image"]]
KeyError: 'image'
```
This error is expected because the trainer remove unused columns ( https://github.com/huggingface/transformers/blob/ee0d001de71f0da892f86caa3cf2387020ec9696/src/transformers/trainer.py#L652-L676 ).
However, the evaluation dataset (and I reckon training as well) uses `set_transforms`, that requires keeping the `"image"` column: https://github.com/huggingface/transformers/blob/ee0d001de71f0da892f86caa3cf2387020ec9696/examples/pytorch/image-classification/run_image_classification.py#L338
and
https://github.com/huggingface/transformers/blob/ee0d001de71f0da892f86caa3cf2387020ec9696/examples/pytorch/image-classification/run_image_classification.py#L315-L318
### Expected behavior
No error. We should somehow be able to tell to the trainer that the `"image"` column is necessary. An alternative is to load all images in memory before calling the trainer so that we have the `pixel_values` column from the very start, but this is costly.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17894/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17894/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17893
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17893/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17893/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17893/events
|
https://github.com/huggingface/transformers/issues/17893
| 1,285,518,543
|
I_kwDOCUB6oc5Mn3TP
| 17,893
|
Ambiguous positional embedding management in LongformerEmbeddings
|
{
"login": "clefourrier",
"id": 22726840,
"node_id": "MDQ6VXNlcjIyNzI2ODQw",
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clefourrier",
"html_url": "https://github.com/clefourrier",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_url": "https://api.github.com/users/clefourrier/gists{/gist_id}",
"starred_url": "https://api.github.com/users/clefourrier/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clefourrier/subscriptions",
"organizations_url": "https://api.github.com/users/clefourrier/orgs",
"repos_url": "https://api.github.com/users/clefourrier/repos",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"received_events_url": "https://api.github.com/users/clefourrier/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hi @clefourrier \r\n\r\nLooking the PR #7352, `LongformerEmbeddings` was originally using (or being) `RobertaEmbeddings` at that time, and both had the line `if position_ids is None:`.\r\n\r\nLooking current `RobertaEmbeddings`, there is no more such line. So I think we can remove it too for `LongformerEmbeddings` without any doubt (actually, it is already very obvious, but I just to find more evidence 😄 )\r\n\r\nWould you like to open a PR?\r\n\r\n\r\n"
] | 1,656
| 1,656
| 1,656
|
MEMBER
| null |
### System Info
```shell
Current main version of the transformer lib (4.20.1?)
```
### Who can help?
@ydshieh
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Hi!
In the code of the LongformerEmbeddings ([here](https://github.com/huggingface/transformers/blob/401fcca6c561d61db6ce25d9b1cebb75325a034f/src/transformers/models/longformer/modeling_longformer.py#L459)), there is unreachable code for the `position_ids` in `forward`.
```python
def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
if position_ids is None:
if input_ids is not None:
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx).to(input_ids.device)
else:
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
...
# Here, code is unreachable
# as both create_position_ids_from_input_ids and create_position_ids_from_inputs_embeds always return stg
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
```
So, what is the actual expected behavior of this layer for the positional embeddings ids?
Is it supposed to use self.position_ids or not?
(If yes, then this is indeed a bug, if not, then some code could be removed for clarity)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17893/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17893/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17892
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17892/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17892/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17892/events
|
https://github.com/huggingface/transformers/pull/17892
| 1,285,361,614
|
PR_kwDOCUB6oc46ZKre
| 17,892
|
Fix job links in Slack report
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
The current `notification_service.py` doesn't take `artifact_path['gpu']` (`single` or `multi`) into account when storing the `job_link` information, which leads to wrong pages (sometimes) when we click the `GitHub Action Job` button on Slack.
This PR fixes this issue.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17892/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17892/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17892",
"html_url": "https://github.com/huggingface/transformers/pull/17892",
"diff_url": "https://github.com/huggingface/transformers/pull/17892.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17892.patch",
"merged_at": 1656507194000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17891
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17891/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17891/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17891/events
|
https://github.com/huggingface/transformers/pull/17891
| 1,285,341,113
|
PR_kwDOCUB6oc46ZGUP
| 17,891
|
Remove DT_DOUBLE from the T5 graph
|
{
"login": "szutenberg",
"id": 37601244,
"node_id": "MDQ6VXNlcjM3NjAxMjQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/37601244?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/szutenberg",
"html_url": "https://github.com/szutenberg",
"followers_url": "https://api.github.com/users/szutenberg/followers",
"following_url": "https://api.github.com/users/szutenberg/following{/other_user}",
"gists_url": "https://api.github.com/users/szutenberg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/szutenberg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/szutenberg/subscriptions",
"organizations_url": "https://api.github.com/users/szutenberg/orgs",
"repos_url": "https://api.github.com/users/szutenberg/repos",
"events_url": "https://api.github.com/users/szutenberg/events{/privacy}",
"received_events_url": "https://api.github.com/users/szutenberg/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1834054694,
"node_id": "MDU6TGFiZWwxODM0MDU0Njk0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/TensorFlow",
"name": "TensorFlow",
"color": "FF6F00",
"default": false,
"description": "Anything TensorFlow"
}
] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi @szutenberg 👋 Have you confirmed that the slow tests pass after this change? (you can run the slow tests with `NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 py.test -vv tests/models/t5/test_modeling_tf_t5.py`)\r\n\r\nIt looks good to me if it passes the tests :)",
"@gante - my change passes tests\r\n```\r\n(venv28) msz@G4:~/transformers$ NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 pytest -vv tests/models/t5/test_modeling_tf_t5.py\r\n============================================================================================================================= test session starts =============================================================================================================================\r\nplatform linux -- Python 3.8.5, pytest-7.1.2, pluggy-1.0.0 -- /home/msz/venv28/bin/python\r\ncachedir: .pytest_cache\r\nrootdir: /home/msz/transformers, configfile: setup.cfg\r\nplugins: typeguard-2.13.3\r\ncollected 86 items \r\n\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_attention_outputs <- tests/test_modeling_tf_common.py PASSED [ 1%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_compile_tf_model <- tests/test_modeling_tf_common.py PASSED [ 2%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_config PASSED [ 3%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_dataset_conversion <- tests/test_modeling_tf_common.py PASSED [ 4%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_determinism <- tests/test_modeling_tf_common.py PASSED [ 5%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_forward_signature <- tests/test_modeling_tf_common.py PASSED [ 6%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_generate_with_headmasking PASSED [ 8%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_headmasking <- tests/test_modeling_tf_common.py PASSED [ 9%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_hidden_states_output <- tests/test_modeling_tf_common.py PASSED [ 10%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_initialization <- tests/test_modeling_tf_common.py PASSED [ 11%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_inputs_embeds <- tests/test_modeling_tf_common.py PASSED [ 12%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_int64_inputs <- tests/test_modeling_tf_common.py PASSED [ 13%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_keras_fit <- tests/test_modeling_tf_common.py PASSED [ 15%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_keras_save_load SKIPPED (The inputs of the Main Layer are different.) [ 16%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_keyword_and_dict_args <- tests/test_modeling_tf_common.py PASSED [ 17%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_lm_head_model_beam_search_generate_dict_outputs <- tests/test_modeling_tf_common.py PASSED [ 18%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_lm_head_model_no_beam_search_generate_dict_outputs <- tests/test_modeling_tf_common.py PASSED [ 19%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_lm_head_model_random_beam_search_generate <- tests/test_modeling_tf_common.py PASSED [ 20%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_lm_head_model_random_no_beam_search_generate <- tests/test_modeling_tf_common.py PASSED [ 22%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_load_with_mismatched_shapes <- tests/test_modeling_tf_common.py PASSED [ 23%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_loss_computation <- tests/test_modeling_tf_common.py PASSED [ 24%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_model_common_attributes PASSED [ 25%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_model_from_pretrained PASSED [ 26%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_model_main_input_name <- tests/test_modeling_tf_common.py PASSED [ 27%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_model_outputs_equivalence <- tests/test_modeling_tf_common.py PASSED [ 29%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_numpy_arrays_inputs <- tests/test_modeling_tf_common.py PASSED [ 30%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_onnx_compliancy <- tests/test_modeling_tf_common.py PASSED [ 31%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_onnx_runtime_optimize <- tests/test_modeling_tf_common.py SKIPPED (test requires tf2onnx) [ 32%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_pt_tf_model_equivalence <- tests/test_modeling_tf_common.py SKIPPED (test is PT+TF test) [ 33%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_resize_embeddings PASSED [ 34%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_resize_token_embeddings <- tests/test_modeling_tf_common.py PASSED [ 36%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_save_load <- tests/test_modeling_tf_common.py PASSED [ 37%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_save_load_config <- tests/test_modeling_tf_common.py PASSED [ 38%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_saved_model_creation PASSED [ 39%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_t5_decoder_model_past PASSED [ 40%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_t5_decoder_model_past_large_inputs PASSED [ 41%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_t5_decoder_model_past_with_attn_mask PASSED [ 43%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_t5_model PASSED [ 44%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_t5_model_v1_1 PASSED [ 45%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_t5_model_xla_generate_fast PASSED [ 46%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_with_lm_head PASSED [ 47%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_attention_outputs <- tests/test_modeling_tf_common.py PASSED [ 48%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_compile_tf_model <- tests/test_modeling_tf_common.py PASSED [ 50%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_config PASSED [ 51%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_dataset_conversion <- tests/test_modeling_tf_common.py PASSED [ 52%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_determinism <- tests/test_modeling_tf_common.py PASSED [ 53%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_forward_signature <- tests/test_modeling_tf_common.py PASSED [ 54%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_generate_with_headmasking <- tests/test_modeling_tf_common.py PASSED [ 55%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_headmasking <- tests/test_modeling_tf_common.py PASSED [ 56%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_hidden_states_output <- tests/test_modeling_tf_common.py PASSED [ 58%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_initialization <- tests/test_modeling_tf_common.py PASSED [ 59%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_inputs_embeds <- tests/test_modeling_tf_common.py PASSED [ 60%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_int64_inputs <- tests/test_modeling_tf_common.py PASSED [ 61%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_keras_fit <- tests/test_modeling_tf_common.py PASSED [ 62%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_keras_save_load <- tests/test_modeling_tf_common.py PASSED [ 63%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_keyword_and_dict_args <- tests/test_modeling_tf_common.py PASSED [ 65%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_lm_head_model_beam_search_generate_dict_outputs <- tests/test_modeling_tf_common.py PASSED [ 66%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_lm_head_model_no_beam_search_generate_dict_outputs <- tests/test_modeling_tf_common.py PASSED [ 67%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_lm_head_model_random_beam_search_generate <- tests/test_modeling_tf_common.py PASSED [ 68%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_lm_head_model_random_no_beam_search_generate <- tests/test_modeling_tf_common.py PASSED [ 69%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_load_with_mismatched_shapes <- tests/test_modeling_tf_common.py PASSED [ 70%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_loss_computation <- tests/test_modeling_tf_common.py PASSED [ 72%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_model PASSED [ 73%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_model_common_attributes <- tests/test_modeling_tf_common.py PASSED [ 74%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_model_main_input_name <- tests/test_modeling_tf_common.py PASSED [ 75%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_model_outputs_equivalence <- tests/test_modeling_tf_common.py PASSED [ 76%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_numpy_arrays_inputs <- tests/test_modeling_tf_common.py PASSED [ 77%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_onnx_compliancy <- tests/test_modeling_tf_common.py PASSED [ 79%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_onnx_runtime_optimize <- tests/test_modeling_tf_common.py SKIPPED (test requires tf2onnx) [ 80%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_pt_tf_model_equivalence <- tests/test_modeling_tf_common.py SKIPPED (test is PT+TF test) [ 81%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_resize_token_embeddings <- tests/test_modeling_tf_common.py PASSED [ 82%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_save_load <- tests/test_modeling_tf_common.py PASSED [ 83%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_save_load_config <- tests/test_modeling_tf_common.py PASSED [ 84%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5EncoderOnlyModelTest::test_train_pipeline_custom_model PASSED [ 86%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_beam_search_generate PASSED [ 87%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_greedy_generate PASSED [ 88%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_greedy_xla_generate_simple PASSED [ 89%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_sample_generate PASSED [ 90%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_sample_xla_generate_simple PASSED [ 91%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_small_byt5_integration_test PASSED [ 93%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_small_integration_test PASSED [ 94%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_small_v1_1_integration_test PASSED [ 95%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_summarization PASSED [ 96%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_translation_en_to_de PASSED [ 97%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_translation_en_to_fr PASSED [ 98%]\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_translation_en_to_ro PASSED [100%]\r\n\r\n============================================================================================================================== warnings summary ===============================================================================================================================\r\n../venv28/lib/python3.8/site-packages/flatbuffers/compat.py:19\r\n /home/msz/venv28/lib/python3.8/site-packages/flatbuffers/compat.py:19: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses\r\n import imp\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:23\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:23: DeprecationWarning: NEAREST is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.NEAREST or Dither.NONE instead.\r\n 'nearest': pil_image.NEAREST,\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:24\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:24: DeprecationWarning: BILINEAR is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BILINEAR instead.\r\n 'bilinear': pil_image.BILINEAR,\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:25\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:25: DeprecationWarning: BICUBIC is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BICUBIC instead.\r\n 'bicubic': pil_image.BICUBIC,\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:28\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:28: DeprecationWarning: HAMMING is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.HAMMING instead.\r\n if hasattr(pil_image, 'HAMMING'):\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:29\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:29: DeprecationWarning: HAMMING is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.HAMMING instead.\r\n _PIL_INTERPOLATION_METHODS['hamming'] = pil_image.HAMMING\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:30\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:30: DeprecationWarning: BOX is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BOX instead.\r\n if hasattr(pil_image, 'BOX'):\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:31\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:31: DeprecationWarning: BOX is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.BOX instead.\r\n _PIL_INTERPOLATION_METHODS['box'] = pil_image.BOX\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:33\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:33: DeprecationWarning: LANCZOS is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.LANCZOS instead.\r\n if hasattr(pil_image, 'LANCZOS'):\r\n\r\n../venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:34\r\n /home/msz/venv28/lib/python3.8/site-packages/keras_preprocessing/image/utils.py:34: DeprecationWarning: LANCZOS is deprecated and will be removed in Pillow 10 (2023-07-01). Use Resampling.LANCZOS instead.\r\n _PIL_INTERPOLATION_METHODS['lanczos'] = pil_image.LANCZOS\r\n\r\ntests/models/t5/test_modeling_tf_t5.py: 1116 warnings\r\n /home/msz/venv28/lib/python3.8/site-packages/datasets/formatting/formatting.py:197: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. \r\n Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\r\n (isinstance(x, np.ndarray) and (x.dtype == np.object or x.shape != array[0].shape))\r\n\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelTest::test_resize_embeddings\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_beam_search_generate\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_greedy_generate\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_greedy_xla_generate_simple\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_sample_generate\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5GenerationIntegrationTests::test_sample_xla_generate_simple\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_small_integration_test\r\n /home/msz/transformers/src/transformers/models/t5/tokenization_t5.py:164: FutureWarning: This tokenizer was incorrectly instantiated with a model max length of 512 which will be corrected in Transformers v5.\r\n For now, this behavior is kept to avoid breaking backwards compatibility when padding/encoding with `truncation is True`.\r\n - Be aware that you SHOULD NOT rely on t5-small automatically truncating your input to 512 when padding/encoding.\r\n - If you want to encode/pad to sequences longer than 512 you can either instantiate this tokenizer with `model_max_length` or pass `max_length` when encoding/padding.\r\n - To avoid this warning, please instantiate this tokenizer with `model_max_length` set to your preferred value.\r\n warnings.warn(\r\n\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_summarization\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_translation_en_to_de\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_translation_en_to_fr\r\ntests/models/t5/test_modeling_tf_t5.py::TFT5ModelIntegrationTests::test_translation_en_to_ro\r\n /home/msz/transformers/src/transformers/models/t5/tokenization_t5.py:164: FutureWarning: This tokenizer was incorrectly instantiated with a model max length of 512 which will be corrected in Transformers v5.\r\n For now, this behavior is kept to avoid breaking backwards compatibility when padding/encoding with `truncation is True`.\r\n - Be aware that you SHOULD NOT rely on t5-base automatically truncating your input to 512 when padding/encoding.\r\n - If you want to encode/pad to sequences longer than 512 you can either instantiate this tokenizer with `model_max_length` or pass `max_length` when encoding/padding.\r\n - To avoid this warning, please instantiate this tokenizer with `model_max_length` set to your preferred value.\r\n warnings.warn(\r\n\r\n-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html\r\n========================================================================================================== 81 passed, 5 skipped, 1137 warnings in 680.12s (0:11:20) ===========================================================================================================\r\n(venv28) msz@G4:~/transformers$ git log -n 2\r\ncommit 004812a999675881da07e5ffb253b80c95883941 (HEAD -> remove_float64, origin/remove_float64)\r\nAuthor: Michal Szutenberg <michal@szutenberg.pl>\r\nDate: Mon Jun 27 08:52:46 2022 +0200\r\n\r\n Remove DT_DOUBLE from the T5 graph\r\n\r\ncommit cc5c061e346365252458126abb699b87cda5dcc0 (origin/master, origin/HEAD, master)\r\nAuthor: Joao Gante <joaofranciscocardosogante@gmail.com>\r\nDate: Sat Jun 25 16:17:11 2022 +0100\r\n\r\n CLI: handle multimodal inputs (#17839)\r\n(venv28) msz@G4:~/transformers$ pip list | grep transformers\r\ntransformers 4.21.0.dev0\r\nWARNING: You are using pip version 21.1; however, version 22.1.2 is available.\r\nYou should consider upgrading via the '/home/msz/venv28/bin/python -m pip install --upgrade pip' command.\r\n```",
"@szutenberg awesome! Thank you for double-checking the tests -- merging :)"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
This PR removes DT_DOUBLE aka tf.float64 from T5 TF graph. It comes from https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/math_ops.py#L1510 , two operands are int32 so TF casts them to float64 (`_TRUEDIV_TABLE[dtypes.int32] = dtypes.float64`).
Some accelerators do not support doubles so it's important to avoid them wherever possible.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten, @LysandreJik
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17891/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17891/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17891",
"html_url": "https://github.com/huggingface/transformers/pull/17891",
"diff_url": "https://github.com/huggingface/transformers/pull/17891.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17891.patch",
"merged_at": 1656494629000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17890
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17890/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17890/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17890/events
|
https://github.com/huggingface/transformers/pull/17890
| 1,285,306,283
|
PR_kwDOCUB6oc46Y_D_
| 17,890
|
Ignore `test_multi_gpu_data_parallel_forward` for `LayoutLMV2`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Ok, so it's always advised to avoid using `add_module`?",
"@NielsRogge Not really. The test `test_multi_gpu_data_parallel_forward` uses `nn.DataParallel`, but PyTorch recommendes to use `DistributedDataParallel`, see [here](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html`.)\r\n\r\nHowever, I don't know if `add_module` works well with `DistributedDataParallel`. It would be good to avoid `add_module` until we decide to remove all `nn.DataParallel`. But in the cases where you really need `add_module`, don't hesitate.",
"@NielsRogge I guess I need to add more meaningful commit message, so you don't have to double check when clicking the merge button :-)"
] | 1,656
| 1,662
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Ignore test_multi_gpu_data_parallel_forward for LayoutLMV2.
The reason to skip is the same as in #17864. (The usage of `add_module`)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17890/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17890/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17890",
"html_url": "https://github.com/huggingface/transformers/pull/17890",
"diff_url": "https://github.com/huggingface/transformers/pull/17890.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17890.patch",
"merged_at": 1656333371000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17889
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17889/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17889/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17889/events
|
https://github.com/huggingface/transformers/pull/17889
| 1,285,303,977
|
PR_kwDOCUB6oc46Y-lO
| 17,889
|
Fix `test_number_of_steps_in_training_with_ipex`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Fix `test_number_of_steps_in_training_with_ipex`.
## Details
This test uses `no_cuda=True`, which will change `n_gpu` to `0` (see `_setup_devices`), and `train_batch_size` will be `8` (with the default training args). However this line
https://github.com/huggingface/transformers/blob/93f48da2740ab69fd14e6bbb38d53c87b4809eda/tests/trainer/test_trainer.py#L590
is computed (earlier) with GPUs, and therefore the (total) batch size is `16` when 2 GPUs is available.
This cause the following error.
#### Currently test error
```bash
tests/trainer/test_trainer.py::TrainerIntegrationTest::test_number_of_steps_in_training_with_ipex
(line 652) AssertionError: 24 != 12.0
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17889/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17889/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17889",
"html_url": "https://github.com/huggingface/transformers/pull/17889",
"diff_url": "https://github.com/huggingface/transformers/pull/17889.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17889.patch",
"merged_at": 1656399303000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17888
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17888/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17888/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17888/events
|
https://github.com/huggingface/transformers/pull/17888
| 1,285,302,302
|
PR_kwDOCUB6oc46Y-PQ
| 17,888
|
Update expected values in CodeGen tests
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"kindly ping @patil-suraj as I am eager toward 0 test failure 🚀 on CI report "
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Update expected values in CodeGen test `test_codegen_sample`. The currently value works for other GPU, but for Nvidia T4, we need the values in this PR.
Note that `do_sample` will call `self.sample` (in `generatioin_utils.py`) which uses `torch.multinomial`, which is not 100% reproducible across different accelerators.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17888/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17888/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17888",
"html_url": "https://github.com/huggingface/transformers/pull/17888",
"diff_url": "https://github.com/huggingface/transformers/pull/17888.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17888.patch",
"merged_at": 1656682417000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17887
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17887/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17887/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17887/events
|
https://github.com/huggingface/transformers/pull/17887
| 1,285,299,326
|
PR_kwDOCUB6oc46Y9oi
| 17,887
|
Update expected values in constrained beam search tests
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks the corrections sound better as well :-)"
] | 1,656
| 1,656
| 1,656
|
COLLABORATOR
| null |
# What does this PR do?
Update expected values in constrained beam search tests.
#17814 changed `generation_utils.py` which gives new expected values in the test.
(otherwise test failed - as in the current CI report)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17887/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17887/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17887",
"html_url": "https://github.com/huggingface/transformers/pull/17887",
"diff_url": "https://github.com/huggingface/transformers/pull/17887.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17887.patch",
"merged_at": 1656399233000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17886
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17886/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17886/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17886/events
|
https://github.com/huggingface/transformers/issues/17886
| 1,285,078,995
|
I_kwDOCUB6oc5MmL_T
| 17,886
|
Pruning function in T5Attention doesnt affect _relative_position_bucket
|
{
"login": "hadaev8",
"id": 20247085,
"node_id": "MDQ6VXNlcjIwMjQ3MDg1",
"avatar_url": "https://avatars.githubusercontent.com/u/20247085?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hadaev8",
"html_url": "https://github.com/hadaev8",
"followers_url": "https://api.github.com/users/hadaev8/followers",
"following_url": "https://api.github.com/users/hadaev8/following{/other_user}",
"gists_url": "https://api.github.com/users/hadaev8/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hadaev8/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hadaev8/subscriptions",
"organizations_url": "https://api.github.com/users/hadaev8/orgs",
"repos_url": "https://api.github.com/users/hadaev8/repos",
"events_url": "https://api.github.com/users/hadaev8/events{/privacy}",
"received_events_url": "https://api.github.com/users/hadaev8/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"@hadaev8 \r\n\r\nIt is not clear to me about this.\r\n\r\n`_relative_position_bucket` is a `staticmethod` without using any model weight in it, and IMO there is no need to do anything when pruning a model.\r\n\r\ncc @patrickvonplaten ",
"@ydshieh \r\n\r\nRelative position bias have shape (dim, heads).\r\nFor example I have 6 heads and pruned one, would be mismatch, (dim, 5) + (dim, 6)\r\n\r\nHere this line\r\nhttps://github.com/huggingface/transformers/blob/3ccff0d400ffd1b0c5074e15afb2b1f2af0e7b44/src/transformers/models/t5/modeling_t5.py#L529\r\n\r\nI realized all layers use same positional bias, so it should be masked in forward, not pruned.",
"After looking the 2 blocks below, I think there is indeed a shape issue when we prune the heads.\r\n\r\nWould you like to try to make a minimal code snippet that could confirm the issue, @hadaev8?\r\n\r\nhttps://github.com/huggingface/transformers/blob/3ccff0d400ffd1b0c5074e15afb2b1f2af0e7b44/src/transformers/models/t5/modeling_t5.py#L432\r\n\r\nhttps://github.com/huggingface/transformers/blob/3ccff0d400ffd1b0c5074e15afb2b1f2af0e7b44/src/transformers/models/t5/modeling_t5.py#L351",
"@ydshieh \r\nHere it is\r\nhttps://colab.research.google.com/drive/1HYu-yzmmbumbskGZExXlOP0WFmDYdgAp?usp=sharing\r\n\r\nI fixed rel pos bias, but where is some other error",
"Hey @hadaev8,\r\n\r\nThis is quite an edge case and I don't think it'll be to find an easy fix here because usually one only prunes some heads of some layers (not of all layers), where as the same `position_bias` is applied to **all** layers. So pruning some heads of only some layers will necessarily lead to problems here. The solution I see it to dynamically discard the superfluous dimensions of `relative_attention_bias`at every attention layer if the corresponding head has been discarded. @hadaev8 would you be interested in opening a PR for this? I won't have the time to dive deeper here for this sadly in the near future, but more than happy to review! ",
"@patrickvonplaten \r\nMy fix looks like this and seems to work, but I'm not satisfied with it, idk if it worth adding to codebase.\r\n\r\n```\r\n if self.pruned_heads:\r\n mask = torch.ones(position_bias.shape[1])\r\n mask[list(self.pruned_heads)] = 0\r\n position_bias_masked = position_bias[:,mask.bool()]\r\n else:\r\n position_bias_masked = position_bias\r\n\r\n scores += position_bias_masked\r\n```",
"Hey @hadaev8,\r\n\r\nThat's actually quite a smart fix :-) Think I'd be ok with adding this! Do you want to open a PR for it ? :-)",
"@patrickvonplaten \r\nOkay, if you think its ok, i will do pr tomorrow.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
CONTRIBUTOR
| null |
### Who can help?
@patrickvonplaten
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Run pruning function in t5 model, then run inference.
### Expected behavior
Relative position head should be pruned too.
Here it is
https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/modeling_t5.py#L355
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17886/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17886/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17885
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17885/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17885/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17885/events
|
https://github.com/huggingface/transformers/issues/17885
| 1,285,052,186
|
I_kwDOCUB6oc5MmFca
| 17,885
|
Replicating RoBERTa-base GLUE results
|
{
"login": "markblee",
"id": 3402571,
"node_id": "MDQ6VXNlcjM0MDI1NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3402571?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/markblee",
"html_url": "https://github.com/markblee",
"followers_url": "https://api.github.com/users/markblee/followers",
"following_url": "https://api.github.com/users/markblee/following{/other_user}",
"gists_url": "https://api.github.com/users/markblee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/markblee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/markblee/subscriptions",
"organizations_url": "https://api.github.com/users/markblee/orgs",
"repos_url": "https://api.github.com/users/markblee/repos",
"events_url": "https://api.github.com/users/markblee/events{/privacy}",
"received_events_url": "https://api.github.com/users/markblee/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"Another option would be to open a discussion in the community tab in https://huggingface.co/roberta-base/discussions and tag the model authors there",
"Thanks for the suggestion, that's a neat feature! I opened a discussion [here](https://huggingface.co/roberta-base/discussions/1) (although, it's not quite clear how to discover the model authors by handle).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
NONE
| null |
Hello! I had originally posted this on the [forums](https://discuss.huggingface.co/t/replicating-roberta-base-glue-results/19328) but it seems like there's not much foot traffic there, so hoping to get more visibility here.
I'm trying to replicate RoBERTa-base GLUE results as reported in the [model card](https://huggingface.co/roberta-base#evaluation-results). The numbers in the model card look like they were copied from the paper. Has anyone made an attempt to actually match these numbers with `run_glue.py`? If so, what configuration was used for the trainer?
If I follow the original configs from [fairseq](https://github.com/facebookresearch/fairseq/tree/fcca32258c8e8bcc9f9890bf4714fa2f96b6b3e1/examples/roberta/config/finetuning), I am unable to match the reported numbers for RTE, CoLA, STS-B, and MRPC.
Any pointers would be much appreciated, thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17885/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17885/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17884
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17884/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17884/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17884/events
|
https://github.com/huggingface/transformers/issues/17884
| 1,285,030,784
|
I_kwDOCUB6oc5MmAOA
| 17,884
|
Attention gradients for models
|
{
"login": "Rachneet",
"id": 16959771,
"node_id": "MDQ6VXNlcjE2OTU5Nzcx",
"avatar_url": "https://avatars.githubusercontent.com/u/16959771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rachneet",
"html_url": "https://github.com/Rachneet",
"followers_url": "https://api.github.com/users/Rachneet/followers",
"following_url": "https://api.github.com/users/Rachneet/following{/other_user}",
"gists_url": "https://api.github.com/users/Rachneet/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rachneet/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rachneet/subscriptions",
"organizations_url": "https://api.github.com/users/Rachneet/orgs",
"repos_url": "https://api.github.com/users/Rachneet/repos",
"events_url": "https://api.github.com/users/Rachneet/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rachneet/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"Hi @Rachneet ,\r\n\r\nModel interpretability is indeed interesting and useful!\r\n\r\nHowever, I think currently we don't have a plan to integrate the mechanism of getting gradients into `transformers`. There is an library [Captum](https://captum.ai/) which might be useful in this area though.\r\n\r\ncc @LysandreJik ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
NONE
| null |
### Feature request
Hi, I was wondering if there is a way to get the gradients of the attention weights. In PyTorch, we can do this via hooks and it works perfectly for getting embeddings gradients. But, I had an issue doing this for the transformer attention weights. Is there any way we can make this possible?
### Motivation
This can help with model interpretability with the scaled attention method.
### Your contribution
I can attach my current codebase if you guys would be interested. It works partly but sometimes the gradients are zeroed. I am not sure if this is the correct behavior though.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17884/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17884/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17883
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17883/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17883/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17883/events
|
https://github.com/huggingface/transformers/issues/17883
| 1,284,995,987
|
I_kwDOCUB6oc5Ml3uT
| 17,883
|
Exception encountered when calling layer "tf_bert_for_pre_training" (type TFBertForPreTraining)
|
{
"login": "Sreyan88",
"id": 36225987,
"node_id": "MDQ6VXNlcjM2MjI1OTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/36225987?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sreyan88",
"html_url": "https://github.com/Sreyan88",
"followers_url": "https://api.github.com/users/Sreyan88/followers",
"following_url": "https://api.github.com/users/Sreyan88/following{/other_user}",
"gists_url": "https://api.github.com/users/Sreyan88/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sreyan88/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sreyan88/subscriptions",
"organizations_url": "https://api.github.com/users/Sreyan88/orgs",
"repos_url": "https://api.github.com/users/Sreyan88/repos",
"events_url": "https://api.github.com/users/Sreyan88/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sreyan88/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"This line seems strange to me\r\n\r\nhttps://github.com/huggingface/transformers/blob/401fcca6c561d61db6ce25d9b1cebb75325a034f/src/transformers/models/bert/modeling_tf_bert.py#L146\r\n\r\nI don't think it makes sense to reshape `masked_lm_loss ` using `next_sentence_loss`. cc @Rocketknight1 ",
"@ydshieh This is true. I suspect this is done because 1) During loss calculation no \"reduction\" is being done 2) Since no reduction is being done the code is trying to add loss sample/instance wise (for example `masked_lm_loss` + `next_sentence_loss` for each sentence in a batch).\r\n\r\nThe fix might be to do reduction but then I see no loss calculation with reduction anywhere in HF.",
"Investigating this now - I think this bug is real, but does not occur for most of our models, and might be specific to `BertForPreTraining()` and the next sentence prediction loss. As a workaround for now, you can use a language model that doesn't have a next sentence prediction loss, like `TFBertForMaskedLM` or `TFRobertaForMaskedLM` - the current consensus is that this loss isn't that helpful for training a language model anyway, and models more recent than BERT generally don't use it.",
"Hi @Rocketknight1 ,\r\n\r\nThank You for your reply. Actually, I am planning to make a community notebook for Tensorflow BERT pre-training (it's been a problem to figure out according to the [discussion](https://discuss.huggingface.co/t/pre-train-bert-from-scratch/1245/30)) since BERT still serves as a baseline for a lot of the research and very recent [work](https://arxiv.org/pdf/2203.15827.pdf) also shows variations of NSP to help in pre-training. \r\n\r\nSo I thought this might be a nice feature to have. Thank You for the help!",
"Bug post-mortem: The bug is in the line that @ydshieh identified. The code here is quite old and was obviously trying to reshape the masked LM loss before reduction so that a per-sample loss tensor would result. However, the loss vector does not reshape cleanly after masking, because random positions are removed from each sample. I rewrote everything with static shapes to fix the issue, and add XLA compilation as a bonus!",
"@Sreyan88 We have now pushed a fix, so you can try installing from `main` and see if this fixes your problem. If it doesn't, please feel free to post the new error and reopen this issue!",
"Hi @Rocketknight1 ,\r\n\r\nThe code works perfectly fine on colab now! However, in my personal server, it's giving me `nan` loss since the beginning of training. Do you think there is a reason for this? I have the same tf version (2.8.0) on both and the same hf version too. The only difference is GPUs (Tesla T4 on Colab and RTX 3090 on person system). Any clues?",
"Hi @Sreyan88, we're in the process of rewriting some loss functions in preparation for our next release, so things are changing quite quickly on `main`. Can you try updating to the most recent commit on your personal server and let me know if you still get the error? Use\r\n`pip install --upgrade git+https://github.com/huggingface/transformers.git`",
"The problem persists :( .\r\n\r\nIs there anything more I should do beyond checking that both are on `4.21.0.dev0`?",
"It finally worked, I had to force-reinstall. Thank You!",
"Hi @Rocketknight1 ,\r\n\r\nJust a question, can `prediction_logits` keyword in [this](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_tf_bert.py#L1247) line be converted to `logits`? a.k.a the `prediction_logits` in `TFBertForPreTrainingOutput` be converted to `logits`. This way the model gets compatible with `pipeline(\"fill-mask\")` which will be useful since Pre-training also has MLM as a task!\r\n\r\nP.S. - `pipeline(\"fill-mask\")` currently errors out with `TFBertForPreTraining` because it expects `logits`.\r\n\r\nThank You! If you suggest doing this would be correct I can create a PR!",
"Hi @Sreyan88, I'm not sure - like I said, `TFBertForPreTraining` is mostly not used anymore because the next sentence loss doesn't seem to be helpful! If you'd like to use a model you trained with `TFBertForPreTraining` with the `fill_mask` pipeline, I suggest loading the checkpoint with `TFBertForMaskedLM.from_pretrained()` - this will give you a model without the next sentence prediction head, which `fill_mask` doesn't use anyway. "
] | 1,656
| 1,657
| 1,656
|
CONTRIBUTOR
| null |
### System Info
```shell
`transformers` version: 4.20.0
- Platform: Linux-5.13.0-48-generic-x86_64-with-glibc2.31
- Python version: 3.7.13
- PyTorch version (GPU?): 1.11.0 (False)
- Tensorflow version (GPU?): 2.9.1 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
### Who can help?
@Rocketknight1 @gante
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Colab link to reproduce: https://colab.research.google.com/drive/1tusV1pNe7sV2To9y7tep4l2LTPunEd5h?usp=sharing
```
InvalidArgumentError: Exception encountered when calling layer "tf_bert_for_pre_training" (type TFBertForPreTraining).
Input to reshape is a tensor with 61 values, but the requested shape requires a multiple of 2 [Op:Reshape]
Call arguments received by layer "tf_bert_for_pre_training" (type TFBertForPreTraining):
• input_ids={'input_ids': 'tf.Tensor(shape=(2, 512), dtype=int64)', 'token_type_ids': 'tf.Tensor(shape=(2, 512), dtype=int64)', 'attention_mask': 'tf.Tensor(shape=(2, 512), dtype=int64)', 'next_sentence_label': 'tf.Tensor(shape=(2,), dtype=int64)', 'labels': 'tf.Tensor(shape=(2, 512), dtype=int64)'}
• attention_mask=None
• token_type_ids=None
• position_ids=None
• head_mask=None
• inputs_embeds=None
• output_attentions=None
• output_hidden_states=None
• return_dict=None
• labels=None
• next_sentence_label=None
• training=True
```
### Expected behavior
```shell
The pre-training should start. I suspect the problem occurs when the number of masked tokens is not divisible by the batch size because of the reshape operation here: https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_tf_bert.py#L146.
The solution doesn't look trivial as it would need loss to be reduced before addition, because the current implementation adds loss for each item/sample separately.
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17883/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17883/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17882
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17882/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17882/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17882/events
|
https://github.com/huggingface/transformers/issues/17882
| 1,284,995,173
|
I_kwDOCUB6oc5Ml3hl
| 17,882
|
Copied "Fine-tuning a masked language model" tutorial, got error on last step - training
|
{
"login": "billray0259",
"id": 31375073,
"node_id": "MDQ6VXNlcjMxMzc1MDcz",
"avatar_url": "https://avatars.githubusercontent.com/u/31375073?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/billray0259",
"html_url": "https://github.com/billray0259",
"followers_url": "https://api.github.com/users/billray0259/followers",
"following_url": "https://api.github.com/users/billray0259/following{/other_user}",
"gists_url": "https://api.github.com/users/billray0259/gists{/gist_id}",
"starred_url": "https://api.github.com/users/billray0259/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/billray0259/subscriptions",
"organizations_url": "https://api.github.com/users/billray0259/orgs",
"repos_url": "https://api.github.com/users/billray0259/repos",
"events_url": "https://api.github.com/users/billray0259/events{/privacy}",
"received_events_url": "https://api.github.com/users/billray0259/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hi @billray0259 ,\r\n\r\nI believe that in your notebook you have modified the `group_texts` function a little, in particular by removing the following line:\r\n\r\n```python\r\n # We drop the last chunk if it's smaller than chunk_size\r\n total_length = (total_length // chunk_size) * chunk_size\r\n```\r\n\r\nI think the error you are getting is due to the fact that you have kept this last chunk which will not be at the right size. Reintroducing this line should solve your problem. Keep me informed :relaxed: ",
"Thank you @SaulLu! That line of code solves my issue! When putting together this issue, I made a different mistake; I linked to a similar but different tutorial. \r\n\r\n[This is the tutorial I was following](https://huggingface.co/docs/transformers/tasks/language_modeling)\r\n\r\nIt appears this tutorial is missing the line that solves the issue.\r\n\r\n`group_texts` function from tutorial:\r\n```block_size = 128\r\n\r\n\r\ndef group_texts(examples):\r\n concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}\r\n total_length = len(concatenated_examples[list(examples.keys())[0]])\r\n result = {\r\n k: [t[i : i + block_size] for i in range(0, total_length, block_size)]\r\n for k, t in concatenated_examples.items()\r\n }\r\n result[\"labels\"] = result[\"input_ids\"].copy()\r\n return result\r\n```\r\n\r\nIt is also entirely possible that I have made an error when copying the code.\r\n \r\nThank you again for your help, apologies that I didn't realize I was linking to a different page (which happened to contain the solution 😳)\r\n ",
"Ahah, funny! No worries! \r\n\r\nDo you want to suggest changing in a PR the snippet for the `group_texts` method in the documentation (the page is [here](https://github.com/huggingface/transformers/blob/main/docs/source/en/tasks/language_modeling.mdx)) so that other people testing the guide don't run into the problem you encountered?",
"Great idea! I have [submitted a PR](https://github.com/huggingface/transformers/pull/17908) and I'll close this issue."
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
### System Info
```shell
- `transformers` version: 4.20.1
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.11.0+cu113 (True)
- Tensorflow version (GPU?): 2.8.2 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
```
### Who can help?
@sgugger, @SaulLu
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Run the PyTorch code provided in the [FIne-tuning a masked language model](https://huggingface.co/course/chapter7/3?fw=pt) tutorial or the linked Colab notebook.
I copied the code into [this Colab notebook](https://colab.research.google.com/drive/1Wqjg3gDaSmFCww6ZRkixsCYr-QPjwGgf?usp=sharing) and have experienced the error here and when I run the code locally.
The last cell trains the model for a handful of iterations before throwing the following exception:
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py](https://localhost:8080/#) in convert_to_tensors(self, tensor_type, prepend_batch_axis)
706 if not is_tensor(value):
--> 707 tensor = as_tensor(value)
708
ValueError: expected sequence of length 128 at dim 1 (got 28)
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
10 frames
[<ipython-input-13-8bea5af68eb3>](https://localhost:8080/#) in <module>()
17 )
18
---> 19 trainer.train()
[/usr/local/lib/python3.7/dist-packages/transformers/trainer.py](https://localhost:8080/#) in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1411 resume_from_checkpoint=resume_from_checkpoint,
1412 trial=trial,
-> 1413 ignore_keys_for_eval=ignore_keys_for_eval,
1414 )
1415
[/usr/local/lib/python3.7/dist-packages/transformers/trainer.py](https://localhost:8080/#) in _inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
1623
1624 step = -1
-> 1625 for step, inputs in enumerate(epoch_iterator):
1626
1627 # Skip past any already trained steps if resuming training
[/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py](https://localhost:8080/#) in __next__(self)
528 if self._sampler_iter is None:
529 self._reset()
--> 530 data = self._next_data()
531 self._num_yielded += 1
532 if self._dataset_kind == _DatasetKind.Iterable and \
[/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py](https://localhost:8080/#) in _next_data(self)
568 def _next_data(self):
569 index = self._next_index() # may raise StopIteration
--> 570 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
571 if self._pin_memory:
572 data = _utils.pin_memory.pin_memory(data)
[/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/fetch.py](https://localhost:8080/#) in fetch(self, possibly_batched_index)
50 else:
51 data = self.dataset[possibly_batched_index]
---> 52 return self.collate_fn(data)
[/usr/local/lib/python3.7/dist-packages/transformers/data/data_collator.py](https://localhost:8080/#) in __call__(self, features, return_tensors)
40 return self.tf_call(features)
41 elif return_tensors == "pt":
---> 42 return self.torch_call(features)
43 elif return_tensors == "np":
44 return self.numpy_call(features)
[/usr/local/lib/python3.7/dist-packages/transformers/data/data_collator.py](https://localhost:8080/#) in torch_call(self, examples)
727 # Handle dict or lists with proper padding and conversion to tensor.
728 if isinstance(examples[0], Mapping):
--> 729 batch = self.tokenizer.pad(examples, return_tensors="pt", pad_to_multiple_of=self.pad_to_multiple_of)
730 else:
731 batch = {
[/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py](https://localhost:8080/#) in pad(self, encoded_inputs, padding, max_length, pad_to_multiple_of, return_attention_mask, return_tensors, verbose)
2892 batch_outputs[key].append(value)
2893
-> 2894 return BatchEncoding(batch_outputs, tensor_type=return_tensors)
2895
2896 def create_token_type_ids_from_sequences(
[/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py](https://localhost:8080/#) in __init__(self, data, encoding, tensor_type, prepend_batch_axis, n_sequences)
207 self._n_sequences = n_sequences
208
--> 209 self.convert_to_tensors(tensor_type=tensor_type, prepend_batch_axis=prepend_batch_axis)
210
211 @property
[/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py](https://localhost:8080/#) in convert_to_tensors(self, tensor_type, prepend_batch_axis)
722 )
723 raise ValueError(
--> 724 "Unable to create tensor, you should probably activate truncation and/or padding "
725 "with 'padding=True' 'truncation=True' to have batched tensors with the same length."
726 )
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length.
```
### Expected behavior
```shell
The code fine-tunes `distilroberta-base` on the `eli5` dataset without error.
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17882/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17882/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17881
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17881/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17881/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17881/events
|
https://github.com/huggingface/transformers/pull/17881
| 1,284,966,762
|
PR_kwDOCUB6oc46X5V3
| 17,881
|
Test fix job link in report
|
{
"login": "rahul-patil-08",
"id": 106728070,
"node_id": "U_kgDOBlyKhg",
"avatar_url": "https://avatars.githubusercontent.com/u/106728070?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rahul-patil-08",
"html_url": "https://github.com/rahul-patil-08",
"followers_url": "https://api.github.com/users/rahul-patil-08/followers",
"following_url": "https://api.github.com/users/rahul-patil-08/following{/other_user}",
"gists_url": "https://api.github.com/users/rahul-patil-08/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rahul-patil-08/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rahul-patil-08/subscriptions",
"organizations_url": "https://api.github.com/users/rahul-patil-08/orgs",
"repos_url": "https://api.github.com/users/rahul-patil-08/repos",
"events_url": "https://api.github.com/users/rahul-patil-08/events{/privacy}",
"received_events_url": "https://api.github.com/users/rahul-patil-08/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"needed",
"_The documentation is not available anymore as the PR was closed or merged._",
"@rahulpatil6886 \r\n\r\nThis is a temporary branch to test another PR. This is not meant to be a PR itself."
] | 1,656
| 1,658
| 1,656
|
NONE
| null |
1. > [`**_**#**_**`](url) What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17881/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17881/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17881",
"html_url": "https://github.com/huggingface/transformers/pull/17881",
"diff_url": "https://github.com/huggingface/transformers/pull/17881.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17881.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/17880
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17880/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17880/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17880/events
|
https://github.com/huggingface/transformers/issues/17880
| 1,284,665,816
|
I_kwDOCUB6oc5MknHY
| 17,880
|
KeyError: 'logits'
|
{
"login": "kkavyashankar0009",
"id": 47808165,
"node_id": "MDQ6VXNlcjQ3ODA4MTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/47808165?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kkavyashankar0009",
"html_url": "https://github.com/kkavyashankar0009",
"followers_url": "https://api.github.com/users/kkavyashankar0009/followers",
"following_url": "https://api.github.com/users/kkavyashankar0009/following{/other_user}",
"gists_url": "https://api.github.com/users/kkavyashankar0009/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kkavyashankar0009/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kkavyashankar0009/subscriptions",
"organizations_url": "https://api.github.com/users/kkavyashankar0009/orgs",
"repos_url": "https://api.github.com/users/kkavyashankar0009/repos",
"events_url": "https://api.github.com/users/kkavyashankar0009/events{/privacy}",
"received_events_url": "https://api.github.com/users/kkavyashankar0009/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hi,\r\n\r\nYou're loading the pipeline with a `BertModel`, which doesn't include a head on top (like a sequence classification head for instance). Hence, no `logits` are computed.\r\n\r\nThe zero-shot classification pipeline makes use of sequence classifiers fine-tuned on an [NLI task](http://nlpprogress.com/english/natural_language_inference.html) (natural language inference). Hence, you'll need to provide an `xxxForSequenceClassification` model fine-tuned on such a dataset.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"> Hi,\r\n> \r\n> You're loading the pipeline with a `BertModel`, which doesn't include a head on top (like a sequence classification head for instance). Hence, no `logits` are computed.\r\n> \r\n> The zero-shot classification pipeline makes use of sequence classifiers fine-tuned on an [NLI task](http://nlpprogress.com/english/natural_language_inference.html) (natural language inference). Hence, you'll need to provide an `xxxForSequenceClassification` model fine-tuned on such a dataset.\r\n\r\nThank you for the response!\r\n\r\nIt's the same even if I use the pre-trained zero-shot classification model from Huggingface.\r\n\r\nExample:\r\nbert_name = ‘facebook/bart-large-mnli’\r\nmodel = AutoModel.from_pretrained(bert_name)\r\ntokenizer = AutoTokenizer.from_pretrained(bert_name)\r\nclassifier = pipeline(“zero-shot-classification”, model = model , tokenizer=tokenizer)",
"You need to replace `AutoModel` with `AutoModelForSequenceClassification` and use a model that supports `AutoModelForSequenceClassification`.\r\n\r\nOr use directly \r\n```\r\npipe = pipeline(model=\"facebook/bart-large-mnli\")\r\nprint(pipe(\"Is this ok?\", candidate_labels=[\"Science\", \"politics\"])\r\n```",
"> You need to replace `AutoModel` with `AutoModelForSequenceClassification` and use a model that supports `AutoModelForSequenceClassification`.\r\n> \r\n> Or use directly\r\n> \r\n> ```\r\n> pipe = pipeline(model=\"facebook/bart-large-mnli\")\r\n> print(pipe(\"Is this ok?\", candidate_labels=[\"Science\", \"politics\"])\r\n> ```\r\n\r\nIts working. Thanks alot. "
] | 1,656
| 1,658
| 1,658
|
NONE
| null |
### System Info
```shell
`transformers` version: 4.16.2
- Platform: Linux-5.13.0-48-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- PyTorch version (GPU?): 1.9.1+cu111 (True)
- Tensorflow version (GPU?): 2.4.1 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
### Who can help?
@Narsil
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
bert_name = 'bert-base-cased'
bert_ = AutoModel.from_pretrained(bert_name)
tokenizer_= AutoTokenizer.from_pretrained(bert_name)
classifier = pipeline("zero-shot-classification",model=bert_,tokenizer=tokenizer_)
for d in tqdm(data_loader):
text=d['text']
true_label = d["label"]
for i in range(len(text)):
tl=c.index(true_label[i])
Ground_Truth.append(tl)
output=classifier(text[i],label)
print('output',output)
high_score=max(output['scores'])
Error:::
File "/home/kshankar/Desktop/Project/Zero_Shot_updated/Fine-tuning/BBC_distilbert-base-uncased-finetuned-sst-2-english.py", line 187, in eval_model
output=classifier(text[i],label)
File "/home/kshankar/miniconda3/lib/python3.9/site-packages/transformers/pipelines/zero_shot_classification.py", line 182, in __call__
return super().__call__(sequences, **kwargs)
File "/home/kshankar/miniconda3/lib/python3.9/site-packages/transformers/pipelines/base.py", line 1006, in __call__
return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
File "/home/kshankar/miniconda3/lib/python3.9/site-packages/transformers/pipelines/base.py", line 1030, in run_single
outputs = self.postprocess(all_outputs, **postprocess_params)
File "/home/kshankar/miniconda3/lib/python3.9/site-packages/transformers/pipelines/zero_shot_classification.py", line 214, in postprocess
logits = np.concatenate([output["logits"].numpy() for output in model_outputs])
File "/home/kshankar/miniconda3/lib/python3.9/site-packages/transformers/pipelines/zero_shot_classification.py", line 214, in <listcomp>
logits = np.concatenate([output["logits"].numpy() for output in model_outputs])
KeyError: 'logits'
### Expected behavior
```shell
logits is assigned before assignment
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17880/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17880/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17879
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17879/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17879/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17879/events
|
https://github.com/huggingface/transformers/issues/17879
| 1,284,640,520
|
I_kwDOCUB6oc5Mkg8I
| 17,879
|
Wav2Vec2ProcessorWithLM degraded performance when transcribing multiple files
|
{
"login": "falcaopetri",
"id": 8387736,
"node_id": "MDQ6VXNlcjgzODc3MzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8387736?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/falcaopetri",
"html_url": "https://github.com/falcaopetri",
"followers_url": "https://api.github.com/users/falcaopetri/followers",
"following_url": "https://api.github.com/users/falcaopetri/following{/other_user}",
"gists_url": "https://api.github.com/users/falcaopetri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/falcaopetri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/falcaopetri/subscriptions",
"organizations_url": "https://api.github.com/users/falcaopetri/orgs",
"repos_url": "https://api.github.com/users/falcaopetri/repos",
"events_url": "https://api.github.com/users/falcaopetri/events{/privacy}",
"received_events_url": "https://api.github.com/users/falcaopetri/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Pool creation might be required to be platform-dependent in the future (https://github.com/huggingface/transformers/pull/17070#issuecomment-1117695494), which means this would be users' responsibility if we go with a user-managed pool scenario.",
"Hey @falcaopetri,\r\n\r\nThanks for the well-explained issue here! I agree that it would be nicer to let the user pass the pool to the function as an argument. Would you be interested in opening a PR for this? :-)",
"Sure, I'd be glad to help. I'll add some tests and docs and create a PR over the next few days.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,656
| 1,659
| 1,659
|
CONTRIBUTOR
| null |
### System Info
```shell
- `transformers` version: 4.21.0.dev0
- Platform: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.13
- Huggingface_hub version: 0.8.1
- PyTorch version (GPU?): 1.11.0+cu113 (True)
- Tensorflow version (GPU?): 2.8.2 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
```
### Who can help?
@patrickvonplaten, @anton-l
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
This snippet uses https://github.com/falcaopetri/transformers/commit/4d0d36ef66b1fd52942721096665f8bc9574c2b0 to allow setting a pool in `batch_decode`. Full colab example [here](https://colab.research.google.com/drive/1j4UNdqcafKH8WQUYIr871xc8h2A97B_z?usp=sharing).
```python
# based on https://huggingface.co/patrickvonplaten/wav2vec2-large-960h-lv60-self-4-gram
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torch
from jiwer import wer
model_id = "patrickvonplaten/wav2vec2-base-100h-with-lm"
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
model = AutoModelForCTC.from_pretrained(model_id).to("cuda")
processor = AutoProcessor.from_pretrained(model_id)
def map_to_pred(batch, pool=None):
inputs = processor(batch["audio"]["array"], sampling_rate=16_000, return_tensors="pt")
inputs = {k: v.to("cuda") for k,v in inputs.items()}
with torch.no_grad():
logits = model(**inputs).logits
transcription = processor.batch_decode(logits.cpu().numpy(), pool=pool).text[0]
batch["transcription"] = transcription
return batch
# Current implementation. Pool with 2 workers will be created for each dataset instance
# Running this a second time to reuse cache does not significantly improve runtime (it's still > 15s)
result = ds.map(map_to_pred, remove_columns=["audio"])
print(wer(result["text"], result["transcription"]))
# 100% 73/73 [00:29<00:00, 3.48ex/s]
# 0.057391304347826085
from multiprocessing import get_context
# Alternative implementation. User-managed pool is reused for all instances
with get_context("fork").Pool(None) as pool:
result = ds.map(map_to_pred, remove_columns=["audio"], fn_kwargs={"pool": pool})
print(wer(result["text"], result["transcription"]))
# 100% 73/73 [00:04<00:00, 17.12ex/s]
# 0.057391304347826085
```
### Expected behavior
I'd expect that instantiating a `Wav2Vec2ProcessorWithLM` allowed me to apply it to multiple audio instances, and that increasing `batch_decode`'s `num_processes` would bring performance improvements for all calls. Current implementation of `batch_decode` creates a `multiprocessing.Pool` at every call, leading to an overhead when decoding multiple files and when increasing `num_processes`.
-----
https://github.com/falcaopetri/transformers/commit/4d0d36ef66b1fd52942721096665f8bc9574c2b0 implements a POC that allows `Wav2Vec2ProcessorWithLM` to reuse the same `multiprocessing.Pool` across multiple `batch_decode` calls. Performance gains can be checked in the previous Colab link.
Allowing the user to manage their own `Pool` is equivalent to how `pyctcdecode` implements [decode_batch](https://github.com/kensho-technologies/pyctcdecode/blob/33478761427b3faad2652ca5b46b158566d88bab/pyctcdecode/decoder.py#L609), but we could also consider having a `Wav2Vec2ProcessorWithLM`-managed pool. For example, as a user I'd expect out-of-the-box performance gains when using more `num_processes`. We should be aware about docs on [multiprocessing.pool.Pool](https://docs.python.org/3/library/multiprocessing.html#multiprocessing.pool.Pool) though:
> Note that it is not correct to rely on the garbage collector to destroy the pool as CPython does not assure that the finalizer of the pool will be called (see [object.__del__()](https://docs.python.org/3/reference/datamodel.html#object.__del__) for more information).
> ...
> A frequent pattern found in other systems (such as Apache, mod_wsgi, etc) to free resources held by workers is to allow a worker within a pool to complete only a set amount of work before being exiting, being cleaned up and a new process spawned to replace the old one. The maxtasksperchild argument to the [Pool](https://docs.python.org/3/library/multiprocessing.html#multiprocessing.pool.Pool) exposes this ability to the end user.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17879/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17879/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17878
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17878/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17878/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17878/events
|
https://github.com/huggingface/transformers/pull/17878
| 1,284,640,134
|
PR_kwDOCUB6oc46W4-k
| 17,878
|
Add type hints for RoFormer models
|
{
"login": "donelianc",
"id": 7807897,
"node_id": "MDQ6VXNlcjc4MDc4OTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7807897?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/donelianc",
"html_url": "https://github.com/donelianc",
"followers_url": "https://api.github.com/users/donelianc/followers",
"following_url": "https://api.github.com/users/donelianc/following{/other_user}",
"gists_url": "https://api.github.com/users/donelianc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/donelianc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/donelianc/subscriptions",
"organizations_url": "https://api.github.com/users/donelianc/orgs",
"repos_url": "https://api.github.com/users/donelianc/repos",
"events_url": "https://api.github.com/users/donelianc/events{/privacy}",
"received_events_url": "https://api.github.com/users/donelianc/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,656
| 1,660
| 1,656
|
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Adding type hints for `RoFormer` model (PyTorch). Issue related: #16059.
This is my second PR in the 🤗 Transformers repo, please let me know if any change is required.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? _Task requested in [comment](https://github.com/huggingface/transformers/issues/16059#issuecomment-1165783174) for issue #16059._
- [x] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests? _Ran `make fixup` before last commit._
## Who can review?
@Rocketknight1 for review or assign reviewer. Thanks!
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17878/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17878/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17878",
"html_url": "https://github.com/huggingface/transformers/pull/17878",
"diff_url": "https://github.com/huggingface/transformers/pull/17878.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17878.patch",
"merged_at": 1656337844000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17877
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17877/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17877/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17877/events
|
https://github.com/huggingface/transformers/pull/17877
| 1,284,396,415
|
PR_kwDOCUB6oc46WF8P
| 17,877
|
Fix bug in gpt2's (from-scratch) special scaled weight initialization
|
{
"login": "karpathy",
"id": 241138,
"node_id": "MDQ6VXNlcjI0MTEzOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/241138?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/karpathy",
"html_url": "https://github.com/karpathy",
"followers_url": "https://api.github.com/users/karpathy/followers",
"following_url": "https://api.github.com/users/karpathy/following{/other_user}",
"gists_url": "https://api.github.com/users/karpathy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/karpathy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/karpathy/subscriptions",
"organizations_url": "https://api.github.com/users/karpathy/orgs",
"repos_url": "https://api.github.com/users/karpathy/repos",
"events_url": "https://api.github.com/users/karpathy/events{/privacy}",
"received_events_url": "https://api.github.com/users/karpathy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false
| null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Coming to this PR a bit late (sorry!) and this is a nice fix! I think @karpathy raises a good point about maybe factoring out a special post-init (probably not for GPT-2 since folks are used to this API, but for future models others may want to hack on) that prevent the extra initialization calls.\r\n\r\nFWIW this code does only execute once at the beginning of a from-scratch training run; I could see this becoming a problem if we tried to naively scale to much larger models. I'll see if we can come up with a better fix for other models.\r\n\r\nThanks for the PR @karpathy - super excited to see you contributing to `transformers`!"
] | 1,656
| 1,656
| 1,656
|
CONTRIBUTOR
| null |
I randomly noticed a minor bug in the (from-scratch) weight initialization of gpt2, where the same tensor gets re-initialized over and over many times. I don't believe the significantly more common `from_pretrained` is impacted. The original discussion and explanation is here https://github.com/huggingface/transformers/pull/13573#discussion_r906288955 .
The simplest reproduction is
```python
from transformers import GPT2Model, GPT2Config
configuration = GPT2Config()
model = GPT2Model(configuration)
```
Then if you insert `print(id(p), name)` inside the if statement you'll see 4 inits of the same tensor, at each layer of the onion, e.g.:
```
139851709684832 c_proj.weight
139851709684832 attn.c_proj.weight
139851709684832 0.attn.c_proj.weight
139851709684832 h.0.attn.c_proj.weight
```
I verified that original code triggers the `if` statement 96 times, while this version triggers it 24 times, which is correct for a 12-layer model. I also ran `pytest tests/models/gpt2/test_modeling_gpt2.py`, without issues. The code is still not super satisfying (e.g. there is still one layer of overwriting present due the init in code block above, it only happens in the right order because of the way `self.apply` iterates depth-first over children, and we're "hard-coding" variable names present in different modules all the way up, but fixing this would be a bit bigger refactor.
cc potential gpt2 reviewers @patrickvonplaten, @LysandreJik and @sgugger, @siddk from original thread
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17877/reactions",
"total_count": 38,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 28,
"rocket": 10,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17877/timeline
| null | false
|
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/17877",
"html_url": "https://github.com/huggingface/transformers/pull/17877",
"diff_url": "https://github.com/huggingface/transformers/pull/17877.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/17877.patch",
"merged_at": 1656356509000
}
|
https://api.github.com/repos/huggingface/transformers/issues/17876
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17876/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17876/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17876/events
|
https://github.com/huggingface/transformers/issues/17876
| 1,284,373,165
|
I_kwDOCUB6oc5Mjfqt
| 17,876
|
Inference API failing: `"Unknown error in run_once : postprocess() got an unexpected keyword argument 'return_all_scores'`
|
{
"login": "sergeyf",
"id": 1874668,
"node_id": "MDQ6VXNlcjE4NzQ2Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1874668?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sergeyf",
"html_url": "https://github.com/sergeyf",
"followers_url": "https://api.github.com/users/sergeyf/followers",
"following_url": "https://api.github.com/users/sergeyf/following{/other_user}",
"gists_url": "https://api.github.com/users/sergeyf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sergeyf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sergeyf/subscriptions",
"organizations_url": "https://api.github.com/users/sergeyf/orgs",
"repos_url": "https://api.github.com/users/sergeyf/repos",
"events_url": "https://api.github.com/users/sergeyf/events{/privacy}",
"received_events_url": "https://api.github.com/users/sergeyf/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
| null |
[] |
[
"Hello again. Any ideas here? ",
"Perhaps this has something to do with the `.bin` file being \"unsafe\" for some reason?\r\n\r\n\r\n",
"Looks like the error is different now:\r\n\r\n\r\n",
"I am no longer getting an error when running this code:\r\n\r\n```python\r\nimport requests\r\n\r\nAPI_URL = \"https://api-inference.huggingface.co/models/guidecare/feelings_and_issues_large\"\r\nheaders = {\"Authorization\": \"Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\"} # i just put my own in here\r\n\r\ndef query(payload):\r\n\tresponse = requests.post(API_URL, headers=headers, json=payload)\r\n\treturn response.json()\r\n\t\r\noutput = query({\r\n\t\"inputs\": \"I like you. I love you\",\r\n})\r\n```",
"Closing in favor of https://github.com/huggingface/huggingface_hub/issues/932",
"Hi @sergeyf ,\r\n\r\nThanks for reporting this issue, \r\n` 'warnings': [\"Unknown error in run_once : postprocess() got an unexpected keyword argument 'return_all_scores'\"]}` was fixed yesterday (linked to a small customization in the API in regards with pipelines that had to be updated. (By default the API returns all scores while the pipeline returns only the top score)\r\n",
"We've been using Inference API in production and it was down for multiple days for us. We didn't see any updates on https://status.huggingface.co under Inference API.\r\n\r\nHow can we get notified of downtimes in the future? Is Inference API recommended for production use?",
"> How can we get notified of downtimes in the future?\r\n\r\nUnfortunately this wasn't picked as downtime since the API was responding correctly. Sometimes errors do happen on models because of configuration issues sometimes and the API just cannot run it, neither can the `pipeline` object within `transformers` which is what powers the API basically).\r\n\r\n> Is Inference API recommended for production use?\r\n\r\nVery much so. Breaking like so is definitely not great and I do apologize for this experience.\r\nChanges like this in `transformers` are very rare. But we definitely should have caught and fixed it earlier, again apologies here.\r\n\r\nFor production use/issues we also recommend contacting api-enterprise@huggingface.co (Issues on github do work but it requires some internal routing to make it to the correct person).\r\n"
] | 1,656
| 1,656
| 1,656
|
NONE
| null |
This model doesn't seem to work on the Hub: https://huggingface.co/guidecare/feelings_and_issues_large?text=I+like+you.+I+love+you
Note the Unknown Error in red. It worked fine last week.
Further, if I try to use the Accelerated Inference API via
```python
import requests
API_URL = "https://api-inference.huggingface.co/models/guidecare/feelings_and_issues_large"
headers = {"Authorization": "Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"} # i just put my own in here
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "I like you. I love you",
})
```
I get this:
```
{'error': 'unknown error',
'warnings': ["Unknown error in run_once : postprocess() got an unexpected keyword argument 'return_all_scores'"]}
```
### Who can help?
_No response_
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
Clearly defined above.
### Expected behavior
```shell
No error!
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17876/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17876/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/17875
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/17875/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/17875/comments
|
https://api.github.com/repos/huggingface/transformers/issues/17875/events
|
https://github.com/huggingface/transformers/issues/17875
| 1,284,219,267
|
I_kwDOCUB6oc5Mi6GD
| 17,875
|
run_clm with gpt2 and wiki103 throws ValueError: expected sequence of length 1024 at dim 1 (got 1012) during training.
|
{
"login": "TrentBrick",
"id": 12433427,
"node_id": "MDQ6VXNlcjEyNDMzNDI3",
"avatar_url": "https://avatars.githubusercontent.com/u/12433427?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TrentBrick",
"html_url": "https://github.com/TrentBrick",
"followers_url": "https://api.github.com/users/TrentBrick/followers",
"following_url": "https://api.github.com/users/TrentBrick/following{/other_user}",
"gists_url": "https://api.github.com/users/TrentBrick/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TrentBrick/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TrentBrick/subscriptions",
"organizations_url": "https://api.github.com/users/TrentBrick/orgs",
"repos_url": "https://api.github.com/users/TrentBrick/repos",
"events_url": "https://api.github.com/users/TrentBrick/events{/privacy}",
"received_events_url": "https://api.github.com/users/TrentBrick/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3817266200,
"node_id": "MDU6TGFiZWwzODE3MjY2MjAw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": null
}
] |
closed
| false
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hi @TrentBrick ,\r\n\r\nI think you can assign a custom padding token to GPT2, or discard the sequences that are too short (i.e. having < 1024 tokens)",
"@ydshieh is this common practice for GPT2? \r\n\r\nAnd I think the bigger issue is that an error is only thrown if my number of workers is not to the power of 2? ",
"Hi, I don't know if this is a common practice, but it is a reasonable approach. The important thing is to make sure the attention masks for those (meant to be padded) tokens to have mask value `0` when doing training.\r\n\r\nOtherwise, you can always discard the short sequences (if it is the rare case).\r\n\r\nI don't think the issue is coming from the number of workers, it is more about the sequence length.\r\n\r\nSee previous discussion\r\nhttps://github.com/huggingface/transformers/issues/12594\r\nhttps://github.com/huggingface/transformers/issues/2630",
"I'm telling you that empirically when I use `--preprocessing_num_workers n` where n is the power of 2 there is no error that gets thrown. It is only when it is not to a power of 2 that this problem appears. ",
"@TrentBrick \r\n\r\nI still believe it is not about `preprocessing_num_workers` being the power of 2 or not. However, this value might indeed have some effect. This method in `clm.py`\r\nhttps://github.com/huggingface/transformers/blob/b424f0b4a301abcbf3c282114159371ee44c3e01/examples/pytorch/language-modeling/run_clm.py#L440\r\n\r\ntries to group texts and split them into `block_size` (1024 here). So there should be no shorter sequence.\r\n\r\nHowever, there is a condition\r\nhttps://github.com/huggingface/transformers/blob/b424f0b4a301abcbf3c282114159371ee44c3e01/examples/pytorch/language-modeling/run_clm.py#L446\r\n\r\nIn some cases, it might happen a batched examples has very few number of examples, and `total_length < block_size`, so it is not thrown away. This indeed depends on `preprocessing_num_workers`. I think you can set a breakpoint around this place and use try /except to verify the situation.\r\n\r\nI could talk to my colleague about this though - probably we can improve this condition here.",
"Hi @TrentBrick Could you try if the following change will work? Thanks.\r\n\r\nChange\r\nhttps://github.com/huggingface/transformers/blob/b424f0b4a301abcbf3c282114159371ee44c3e01/examples/pytorch/language-modeling/run_clm.py#L446-L448\r\nto \r\n```python\r\n\r\nif total_length >= block_size: \r\n total_length = (total_length // block_size) * block_size \r\nelse:\r\n total_length = 0\r\n # Split by chunks of max_len. \r\n```",
"Hi @TrentBrick, if you get the chance to verify it works, don't hesitate to open a PR if you would like to :-). Otherwise, I will open a PR later. Thank you for finding this issue!\r\n\r\nAs mentioned, it actually depends on the batches of examples received in the preprocessing function, and I don't try to run with 30 processes.",
"Close this issue - see [this comment](https://github.com/huggingface/transformers/pull/18304#pullrequestreview-1051141051)"
] | 1,656
| 1,658
| 1,658
|
NONE
| null |
### System Info
```shell
transformers 4.20.0.dev0 dev_0
python 3.7.11 h12debd9_0
linux os (docker container).
```
### Who can help?
@patil-suraj, @patrickvonplaten, @LysandreJik
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I run the following code using `run_clm.py`
`python run_clm.py --train_name testing-gpt2 --output_dir ../data/training_outputs/ --model_type gpt2 --dataset_name wikitext --dataset_config_name wikitext-103-v1 --tokenizer_name gpt2 --preprocessing_num_workers 30 --do_train --overwrite_output_dir --save_steps 100000000 --save_total_limit 2 --num_train_epochs 175 --config_overrides n_layer=3`
The error is:
```
{'loss': 7.0678, 'learning_rate': 4.998998477686083e-05, 'epoch': 0.04}
0%| | 1000/2496200 [03:17<138:25:20, 5.01it/s]{'loss': 6.2992, 'learning_rate': 4.997996955372166e-05, 'epoch': 0.07} | 0/1 [00:00<?, ?ba/s]
0%| | 1500/2496200 [04:57<138:30:20, 5.00it/s]{'loss': 6.0153, 'learning_rate': 4.9969954330582484e-05, 'epoch': 0.11}
0%| | 2000/2496200 [06:35<137:22:45, 5.04it/s]{'loss': 5.8504, 'learning_rate': 4.995993910744331e-05, 'epoch': 0.14} | 0/1 [00:00<?, ?ba/s]
0%| | 2500/2496200 [08:14<136:41:10, 5.07it/s]{'loss': 5.6997, 'learning_rate': 4.994992388430414e-05, 'epoch': 0.18}
{'loss': 5.5797, 'learning_rate': 4.993990866116497e-05, 'epoch': 0.21}
0%| | 3500/2496200 [11:32<135:57:45, 5.09it/s]{'loss': 5.4796, 'learning_rate': 4.99298934380258e-05, 'epoch': 0.25}
{'loss': 5.3864, 'learning_rate': 4.991987821488663e-05, 'epoch': 0.28}
0%|▏ | 4500/2496200 [14:50<137:03:49, 5.05it/s]{'loss': 5.3007, 'learning_rate': 4.990986299174746e-05, 'epoch': 0.32}
0%|▏ | 5000/2496200 [16:29<139:10:06, 4.97it/s]{'loss': 5.2367, 'learning_rate': 4.989984776860829e-05, 'epoch': 0.35}
0%|▏ | 5500/2496200 [18:08<137:22:34, 5.04it/s]{'loss': 5.16, 'learning_rate': 4.988983254546912e-05, 'epoch': 0.39}
0%|▏ | 6000/2496200 [19:47<138:31:23, 4.99it/s]{'loss': 5.109, 'learning_rate': 4.987981732232994e-05, 'epoch': 0.42}
{'loss': 5.0511, 'learning_rate': 4.986980209919077e-05, 'epoch': 0.46}
0%|▏ | 7000/2496200 [23:06<138:01:44, 5.01it/s]{'loss': 5.0114, 'learning_rate': 4.98597868760516e-05, 'epoch': 0.49}
0%|▏ | 7500/2496200 [24:45<136:05:20, 5.08it/s]{'loss': 4.957, 'learning_rate': 4.984977165291243e-05, 'epoch': 0.53}
0%|▏ | 8000/2496200 [26:24<137:43:44, 5.02it/s]{'loss': 4.8985, 'learning_rate': 4.983975642977326e-05, 'epoch': 0.56}
0%|▎ | 8500/2496200 [28:04<136:25:23, 5.07it/s]{'loss': 4.8615, 'learning_rate': 4.982974120663408e-05, 'epoch': 0.6}
0%|▎ | 9000/2496200 [29:43<137:32:41, 5.02it/s]{'loss': 4.8158, 'learning_rate': 4.981972598349491e-05, 'epoch': 0.63}
0%|▎ | 9259/2496200 [30:35<137:00:18, 5.04it/s]Traceback (most recent call last):
File "run_clm.py", line 649, in <module>
main()
File "run_clm.py", line 597, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/workspace/transformers/src/transformers/trainer.py", line 1327, in train
ignore_keys_for_eval=ignore_keys_for_eval,
File "/workspace/transformers/src/transformers/trainer.py", line 1539, in _inner_training_loop
for step, inputs in enumerate(epoch_iterator):
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 521, in __next__
data = self._next_data()
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 561, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 52, in fetch
return self.collate_fn(data)
File "/workspace/transformers/src/transformers/data/data_collator.py", line 67, in default_data_collator
return torch_default_data_collator(features)
File "/workspace/transformers/src/transformers/data/data_collator.py", line 131, in torch_default_data_collator
batch[k] = torch.tensor([f[k] for f in features])
ValueError: expected sequence of length 1024 at dim 1 (got 1012)
```
Where every time I am getting this same error. I tried following https://stackoverflow.com/questions/71166789/huggingface-valueerror-expected-sequence-of-length-165-at-dim-1-got-128 by adding `padding='max_length'` to my tokenizer but then I get an error where this tokenizer does not have a padding token.
NB. I think this only happens when `--preprocessing_num_workers 30` is not to a power of 2? Using 8, 16 or 128 avoids the problem.
### Expected behavior
```shell
Model should keep training and not throw an error at training step: 9259
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/17875/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/17875/timeline
|
completed
| null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.