
url stringlengths 62 66 | repository_url stringclasses 1
value | labels_url stringlengths 76 80 | comments_url stringlengths 71 75 | events_url stringlengths 69 73 | html_url stringlengths 50 56 | id int64 377M 2.15B | node_id stringlengths 18 32 | number int64 1 29.2k | title stringlengths 1 487 | user dict | labels list | state stringclasses 2
values | locked bool 2
classes | assignee dict | assignees list | comments list | created_at int64 1.54k 1.71k | updated_at int64 1.54k 1.71k | closed_at int64 1.54k 1.71k ⌀ | author_association stringclasses 4
values | active_lock_reason stringclasses 2
values | body stringlengths 0 234k ⌀ | reactions dict | timeline_url stringlengths 71 75 | state_reason stringclasses 3
values | draft bool 2
classes | pull_request dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/1109 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1109/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1109/comments | https://api.github.com/repos/huggingface/transformers/issues/1109/events | https://github.com/huggingface/transformers/issues/1109 | 485,386,684 | MDU6SXNzdWU0ODUzODY2ODQ= | 1,109 | keeping encoder fixed from pretrained model but changing classifier | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [] | closed | false | null | [] | [
"Closing this as it is a duplicate of the issue #1108 you opened 4 hours ago."
] | 1,566 | 1,566 | 1,566 | NONE | null | Hi
I need to pretrain the bert on one dataset and finetune it then on other datasets, so basically
removing classifier from first part and substitute it with a new one with the specific number of
labels, currently with current codes, it will be error to do it when loading pretrained model,
could you please assist ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1109/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1109/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1108 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1108/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1108/comments | https://api.github.com/repos/huggingface/transformers/issues/1108/events | https://github.com/huggingface/transformers/issues/1108 | 485,378,632 | MDU6SXNzdWU0ODUzNzg2MzI= | 1,108 | using BERT as pretraining with custom classifier | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, it seems you have saved a model with a classification head of dimension `174 x 768`. You're then trying to load this model with a different classification head of dimension `3 x 768`, is that correct?\r\n\r\nIf you are trying to save/load the model without the classification head, you can simply save the BertM... | 1,566 | 1,592 | 1,572 | NONE | null | Hi
I need to pretrain the bert on one dataset and finetune it then on other datasets, so basically
removing classifier from first part and substitute it with a new one with the specific number of
labels, currently with current codes, it will be error to do it when loading pretrained model,
could you please assist ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1108/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1108/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1107 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1107/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1107/comments | https://api.github.com/repos/huggingface/transformers/issues/1107/events | https://github.com/huggingface/transformers/issues/1107 | 485,372,189 | MDU6SXNzdWU0ODUzNzIxODk= | 1,107 | Changing the _read_tsv method in class DataProcessor | {
"login": "Sudeep09",
"id": 10047946,
"node_id": "MDQ6VXNlcjEwMDQ3OTQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/10047946?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sudeep09",
"html_url": "https://github.com/Sudeep09",
"followers_url": "https://api.github.com/users/Sud... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, we need more information about what script you are talking about.",
"The file path is: /examples/utils_glue.py\r\nThe class is DataProcessor(object):\r\n\r\n@classmethod\r\ndef _read_tsv(cls, input_file, quotechar=None)\r\n\"\"\"Reads a tab separated value file.\"\"\"\r\nlines = []\r\ndf = pd.read_csv(input_... | 1,566 | 1,573 | 1,573 | NONE | null | ## 🚀 Feature
I would request changing the class method to the following:
@classmethod
def _read_tsv(cls, input_file, quotechar=None)
"""Reads a tab separated value file."""
lines = []
df = pd.read_csv(input_file, delimiter='\t')
for line in (df.values):
lines.append(... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1107/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1107/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1106 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1106/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1106/comments | https://api.github.com/repos/huggingface/transformers/issues/1106/events | https://github.com/huggingface/transformers/issues/1106 | 485,332,581 | MDU6SXNzdWU0ODUzMzI1ODE= | 1,106 | sample_text.txt is broken (404 ERROR) | {
"login": "zbloss",
"id": 7165947,
"node_id": "MDQ6VXNlcjcxNjU5NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7165947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zbloss",
"html_url": "https://github.com/zbloss",
"followers_url": "https://api.github.com/users/zbloss/foll... | [] | closed | false | null | [] | [
"Hi, where did you retrieve this link from?",
"Hey this is listed on the huggingface.co documentation page here ([https://huggingface.co/pytorch-transformers/examples.html?highlight=sample_text](https://huggingface.co/pytorch-transformers/examples.html?highlight=sample_text))",
"This one is now in the tests at:... | 1,566 | 1,566 | 1,566 | NONE | null | ## ❓ Questions & Help
When I try to access the sample_text,txt file at this link, I find an nginx 404 server error.
https://huggingface.co/pytorch-transformers/samples/sample_text.txt | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1106/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1105 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1105/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1105/comments | https://api.github.com/repos/huggingface/transformers/issues/1105/events | https://github.com/huggingface/transformers/issues/1105 | 485,211,633 | MDU6SXNzdWU0ODUyMTE2MzM= | 1,105 | How to get pooler state's (corresponds to CLS token) attention vector? | {
"login": "Akella17",
"id": 16236287,
"node_id": "MDQ6VXNlcjE2MjM2Mjg3",
"avatar_url": "https://avatars.githubusercontent.com/u/16236287?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Akella17",
"html_url": "https://github.com/Akella17",
"followers_url": "https://api.github.com/users/Ake... | [] | closed | false | null | [] | [
"Hi, the pooler takes as input the last layer hidden-state of the first token of the sentence (the `[CLS]` token). So the attention used to compute the pooler input is just the attention for this token.",
"@thomwolf If my understanding is right, the last layer's attention vector should be of size ```[batch_size, ... | 1,566 | 1,567 | 1,567 | NONE | null | The following model definition returns the attention vector for tokens corresponding to the input sequence length, i.e. ```x.size(1)```. How do I procure the attention vector of the pooler state (output embedding corresponding to the CLS token)?
```Python
model = BertModel.from_pretrained('bert-base-uncased', outpu... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1105/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1105/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1104 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1104/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1104/comments | https://api.github.com/repos/huggingface/transformers/issues/1104/events | https://github.com/huggingface/transformers/pull/1104 | 485,192,464 | MDExOlB1bGxSZXF1ZXN0MzEwODgyODE4 | 1,104 | TensorFlow 2.0 - Testing with a few Bert architectures | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=h1) Report\n> Merging [#1104](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1104?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/df9d6effae43e92761eb92540bc45fac846789ee?... | 1,566 | 1,651 | 1,569 | MEMBER | null | This PR tests how easy it would be to incorporate TF 2.0 models in the current library:
- adds a few models: `TFBertPreTrainedModel`, `TFBertModel`, `TFBertForPretraining`, `TFBertForMaskedLM`, `TFBertForNextSentencePrediction`,
- weights conversion script to convert the PyTorch weights (only the `bert-base-uncased` ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1104/reactions",
"total_count": 5,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1104/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1104",
"html_url": "https://github.com/huggingface/transformers/pull/1104",
"diff_url": "https://github.com/huggingface/transformers/pull/1104.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1104.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1103 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1103/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1103/comments | https://api.github.com/repos/huggingface/transformers/issues/1103/events | https://github.com/huggingface/transformers/issues/1103 | 485,183,984 | MDU6SXNzdWU0ODUxODM5ODQ= | 1,103 | Roberta semantic similarity | {
"login": "subhamkhemka",
"id": 35528758,
"node_id": "MDQ6VXNlcjM1NTI4NzU4",
"avatar_url": "https://avatars.githubusercontent.com/u/35528758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/subhamkhemka",
"html_url": "https://github.com/subhamkhemka",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | [
"Hi, the provided `run_glue` example shows how to train/use `RoBERTa` for sentence pairs classification on the GLUE tasks (including MNLI).",
"Hi,\r\nThanks for your help\r\n\r\nI have executed the run_glue.py file on my custom data set by using the following command\r\n`\r\npython run_glue.py --model_type robert... | 1,566 | 1,698 | 1,568 | NONE | null | ## ❓ Questions & Help
Hi
I am trying to use Roberta for semantic similarity.
have 2 questions
Can you validate my code to check if its able to correctly execute sentence-pair classification ?
I want to train the roberta-large-mnli model on my own corpus, how do I do this?
Code :
```python
from p... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1103/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1102 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1102/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1102/comments | https://api.github.com/repos/huggingface/transformers/issues/1102/events | https://github.com/huggingface/transformers/issues/1102 | 485,176,756 | MDU6SXNzdWU0ODUxNzY3NTY= | 1,102 | Wrong documentation example for RoBERTa | {
"login": "CrafterKolyan",
"id": 9883873,
"node_id": "MDQ6VXNlcjk4ODM4NzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9883873?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CrafterKolyan",
"html_url": "https://github.com/CrafterKolyan",
"followers_url": "https://api.github.... | [] | closed | false | null | [] | [
"Hi, thank you for the bug report. It has been [changed](https://huggingface.co/pytorch-transformers/model_doc/roberta.html)."
] | 1,566 | 1,566 | 1,566 | CONTRIBUTOR | null | Documentation web page: https://huggingface.co/pytorch-transformers/model_doc/roberta.html#pytorch_transformers.RobertaModel
See `Inputs -> input_ids`:
`tokens: [CLS] is this jack ##son ##ville ? [SEP][SEP] no it is not . [SEP]`
and
`tokens: [CLS] the dog is hairy . [SEP]`
are wrong examples. Because `RobertaT... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1102/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1102/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1101 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1101/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1101/comments | https://api.github.com/repos/huggingface/transformers/issues/1101/events | https://github.com/huggingface/transformers/issues/1101 | 485,150,095 | MDU6SXNzdWU0ODUxNTAwOTU= | 1,101 | evaluate bert on Senteval dataset | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This should help you: https://medium.com/dsnet/running-pytorch-transformers-on-custom-datasets-717fd9e10fe2\r\nI did it for IMDB dataset which you should be able to customize for any other dataset.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if n... | 1,566 | 1,572 | 1,572 | NONE | null | Hi
I would like to evaluate bert on senteval datasets, with Senteval, I am not sure how to do it,
Do you provide any evaluation toolkit to evaluate the trained models?
thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1101/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1101/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1100 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1100/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1100/comments | https://api.github.com/repos/huggingface/transformers/issues/1100/events | https://github.com/huggingface/transformers/issues/1100 | 485,006,009 | MDU6SXNzdWU0ODUwMDYwMDk= | 1,100 | Writing predictions in a separate output file | {
"login": "vikas95",
"id": 25675079,
"node_id": "MDQ6VXNlcjI1Njc1MDc5",
"avatar_url": "https://avatars.githubusercontent.com/u/25675079?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vikas95",
"html_url": "https://github.com/vikas95",
"followers_url": "https://api.github.com/users/vikas9... | [] | closed | false | null | [] | [
"Solved it, apologies for raising this silly request.",
"Hi, how did u solve this?",
"Hi, I would like to know how can I do it. Thanks",
"You can access to label predictions thanks to the variable \"preds\" (line 318 after squeeze function). You can save it in a text file in a similar way of the line 323."
] | 1,566 | 1,587 | 1,567 | NONE | null | ## 🚀 Feature
Request for providing the final predictions (and probabilities of each class for classification task) on the validation/test set in a separate .txt or .json file
## Motivation
Since many of us will be using the provided models (RoBERTa, XLnet, BERT etc.) on various other NLP tasks and we will... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1100/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1099 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1099/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1099/comments | https://api.github.com/repos/huggingface/transformers/issues/1099/events | https://github.com/huggingface/transformers/issues/1099 | 485,002,298 | MDU6SXNzdWU0ODUwMDIyOTg= | 1,099 | Missing RobertaForMultipleChoice | {
"login": "malmaud",
"id": 987837,
"node_id": "MDQ6VXNlcjk4NzgzNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/987837?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/malmaud",
"html_url": "https://github.com/malmaud",
"followers_url": "https://api.github.com/users/malmaud/fo... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi @malmaud, no particular reason. But it's also super easy to just implement your own classifier on top of the model (and then you have full control)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your c... | 1,566 | 1,572 | 1,572 | NONE | null | Hi,
It seems like a `RobertaForMultipleChoice` class should exist to parallel `BertForMultipleChoice`. Or was there a particular reason it was elided? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1099/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1098 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1098/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1098/comments | https://api.github.com/repos/huggingface/transformers/issues/1098/events | https://github.com/huggingface/transformers/issues/1098 | 484,985,228 | MDU6SXNzdWU0ODQ5ODUyMjg= | 1,098 | Support multiprocessing when loading pretrained weights | {
"login": "rmrao",
"id": 6496605,
"node_id": "MDQ6VXNlcjY0OTY2MDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6496605?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rmrao",
"html_url": "https://github.com/rmrao",
"followers_url": "https://api.github.com/users/rmrao/follower... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi! Indeed, you have to be careful when downloading the models in a multiprocessing manner so that you do not download them several times. \r\n\r\nYou can see how we do it in our examples (like this [run_glue example)](https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_glue.py#L429-L438),... | 1,566 | 1,572 | 1,572 | NONE | null | ## 🐛 Bug
So this is an issue that probably won't crop up for *too* many people, but there's a synchronization issue in loading pretrained weights if doing so in a multiprocess setting if they are not present in the cache.
For context, I'm trying to use `torch.distributed.launch` and doing so inside a fresh docke... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1098/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1098/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1097 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1097/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1097/comments | https://api.github.com/repos/huggingface/transformers/issues/1097/events | https://github.com/huggingface/transformers/issues/1097 | 484,960,965 | MDU6SXNzdWU0ODQ5NjA5NjU= | 1,097 | modifying config | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi! What kind of values are you trying to add?\r\nThe configuration file is a simple python object, so you can handle it just as you would any Python object:\r\n\r\n```\r\nconfig = GPT2Config.from_pretrained(\"gpt2\")\r\nconfig.values = [1, 2]\r\n\r\nprint(config.values)\r\n# [1, 2]\r\n```",
"This issue has been... | 1,566 | 1,572 | 1,572 | NONE | null | Hi
I need to add more variables to the config file, while using pretrained models. I could not figure this out how to add parameters to config file, could you provide me please with examples?
very much appreciated! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1097/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1096 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1096/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1096/comments | https://api.github.com/repos/huggingface/transformers/issues/1096/events | https://github.com/huggingface/transformers/pull/1096 | 484,950,627 | MDExOlB1bGxSZXF1ZXN0MzEwNjk4MDkx | 1,096 | Temporary fix for RoBERTa's mismatch of vocab size and embedding size - issue #1091 | {
"login": "amirsaffari",
"id": 2384760,
"node_id": "MDQ6VXNlcjIzODQ3NjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2384760?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amirsaffari",
"html_url": "https://github.com/amirsaffari",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=h1) Report\n> Merging [#1096](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1096?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/df9d6effae43e92761eb92540bc45fac846789ee?... | 1,566 | 1,566 | 1,566 | NONE | null | I added an optional input argument so you can pass the starting index when adding new tokens. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1096/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1096/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1096",
"html_url": "https://github.com/huggingface/transformers/pull/1096",
"diff_url": "https://github.com/huggingface/transformers/pull/1096.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1096.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1095 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1095/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1095/comments | https://api.github.com/repos/huggingface/transformers/issues/1095/events | https://github.com/huggingface/transformers/issues/1095 | 484,884,662 | MDU6SXNzdWU0ODQ4ODQ2NjI= | 1,095 | some words not in xlnet vocabulary ,especially name | {
"login": "lagka",
"id": 18046874,
"node_id": "MDQ6VXNlcjE4MDQ2ODc0",
"avatar_url": "https://avatars.githubusercontent.com/u/18046874?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lagka",
"html_url": "https://github.com/lagka",
"followers_url": "https://api.github.com/users/lagka/follow... | [] | closed | false | null | [] | [
"Hi!\r\n\r\nXLNet uses a SentencePiece tokenizer which splits the words into subword units. In your case, it splits the two examples in different sized sequences, which can't be parsed as a Tensor which requires an input matrix (and not a list of lists).\r\n\r\nYou should pad your sequences after they have been tok... | 1,566 | 1,567 | 1,567 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
I face the problem when xlnet tokenizer encodes name
from pytorch_transformers import *
import torch
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
model = XLNetModel.from_pretrained('xlnet-base-c... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1095/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1094 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1094/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1094/comments | https://api.github.com/repos/huggingface/transformers/issues/1094/events | https://github.com/huggingface/transformers/issues/1094 | 484,854,416 | MDU6SXNzdWU0ODQ4NTQ0MTY= | 1,094 | Performing MRPC task after Fine Tuning | {
"login": "whitewolfos",
"id": 20001181,
"node_id": "MDQ6VXNlcjIwMDAxMTgx",
"avatar_url": "https://avatars.githubusercontent.com/u/20001181?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/whitewolfos",
"html_url": "https://github.com/whitewolfos",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"You can refer the code to run inference which I had written for sentiment classfication. HTH.\r\nhttps://github.com/nikhilno1/nlp_projects/blob/master/pytorch-transformers-extensions/examples/run_inference.py",
"Ah, that was exactly what I needed; thank you!\r\n\r\nOne final thing, though: I'm still a bit confus... | 1,566 | 1,566 | 1,566 | NONE | null | ## ❓ Questions & Help
Sorry if this is really basic; I'm new to BERT and machine learning in general. I want to perform the MRPC task. I went ahead and did the fine-tuning and got the files/model okay. But now that I have this fine-tuned model, I'm confused how to do the actual MRPC task (i.e. given two sentences, p... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1094/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1094/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1093 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1093/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1093/comments | https://api.github.com/repos/huggingface/transformers/issues/1093/events | https://github.com/huggingface/transformers/issues/1093 | 484,799,075 | MDU6SXNzdWU0ODQ3OTkwNzU= | 1,093 | fused_layer_norm_cuda.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN2at7getTypeERKNS_6TensorE | {
"login": "xijiz",
"id": 12234085,
"node_id": "MDQ6VXNlcjEyMjM0MDg1",
"avatar_url": "https://avatars.githubusercontent.com/u/12234085?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xijiz",
"html_url": "https://github.com/xijiz",
"followers_url": "https://api.github.com/users/xijiz/follow... | [] | closed | false | null | [] | [
"I am afraid we won't be able to help you if you do not provide any information on what caused the problem.",
"> I am afraid we won't be able to help you if you do not provide any information on what caused the problem.\r\n\r\nI am sorry that I provided the incompleted information. I have sovled this problem by c... | 1,566 | 1,567 | 1,566 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): BERT
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [ * ] my own modified scripts: (give details)
The tasks I am working on i... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1093/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1092 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1092/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1092/comments | https://api.github.com/repos/huggingface/transformers/issues/1092/events | https://github.com/huggingface/transformers/pull/1092 | 484,765,508 | MDExOlB1bGxSZXF1ZXN0MzEwNTc0NTQx | 1,092 | Added cleaned configuration properties for tokenizer with serialization - improve tokenization of XLM | {
"login": "shijie-wu",
"id": 2987758,
"node_id": "MDQ6VXNlcjI5ODc3NTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2987758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shijie-wu",
"html_url": "https://github.com/shijie-wu",
"followers_url": "https://api.github.com/users/sh... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=h1) Report\n> Merging [#1092](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1092?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/df9d6effae43e92761eb92540bc45fac846789ee?... | 1,566 | 1,567 | 1,567 | CONTRIBUTOR | null | This PR improve the tokenization of XLM. It's mostly the same as the [preprocessing](https://github.com/facebookresearch/XLM/blob/master/tools/tokenize.sh) in the original XLM. This PR also add `use_lang_emb` to config of XLM model, which makes adding the newly release [XLM-17 & XLM-100](https://github.com/facebookrese... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1092/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 4,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1092/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1092",
"html_url": "https://github.com/huggingface/transformers/pull/1092",
"diff_url": "https://github.com/huggingface/transformers/pull/1092.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1092.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1091 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1091/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1091/comments | https://api.github.com/repos/huggingface/transformers/issues/1091/events | https://github.com/huggingface/transformers/issues/1091 | 484,667,063 | MDU6SXNzdWU0ODQ2NjcwNjM= | 1,091 | Problem with mask token id in RoBERTa vocab | {
"login": "OlegPlatonov",
"id": 32016523,
"node_id": "MDQ6VXNlcjMyMDE2NTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/32016523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OlegPlatonov",
"html_url": "https://github.com/OlegPlatonov",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Just encountered this. You can verify the mismatch in dictionary sizes with: \r\n\r\n```Python\r\nimport pytorch_transformers as ptt\r\ntokeniser = ptt.RobertaTokenizer.from_pretrained('roberta-base')\r\nencoder = ptt.RobertaModel.from_pretrained('roberta-base')\r\nprint(len(tokeniser))\r\nprint(encoder.embeddings... | 1,566 | 1,572 | 1,572 | NONE | null | Hi! While looking into RoBERTa vocab files I came across the following issue:
There are only 50262 words in the vocab, but `<mask>` token is assigned to index 50264. In most cases, this will not lead to any problems, because the embedding matrix has 50265 embeddings. However, if I try adding several new tokens to th... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1091/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1090 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1090/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1090/comments | https://api.github.com/repos/huggingface/transformers/issues/1090/events | https://github.com/huggingface/transformers/issues/1090 | 484,533,073 | MDU6SXNzdWU0ODQ1MzMwNzM= | 1,090 | No such file or directory: '..\\VERSION' | {
"login": "balkon16",
"id": 28737437,
"node_id": "MDQ6VXNlcjI4NzM3NDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/28737437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/balkon16",
"html_url": "https://github.com/balkon16",
"followers_url": "https://api.github.com/users/bal... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"The same bug occurs when installing.",
"This looks like an issue with sentencepiece and python 3.5. Do you want to have a look there maybe? https://github.com/google/sentencepiece",
"> This looks like an issue with sentencepiece and python 3.5. Do you want to have a look there maybe? https://github.com/google/... | 1,566 | 1,585 | 1,577 | NONE | null | ## 🐛 Bug
<!-- Important information -->
While trying to install `pytorch-transformers` I get the following error:
```
ERROR: Command errored out with exit status 1:
command: 'c:\users\pawel.lonca\appdata\local\programs\python\python35\python.exe' -c 'import sys, setuptools, tokenize; sys.argv[0] = ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1090/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/1090/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1089 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1089/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1089/comments | https://api.github.com/repos/huggingface/transformers/issues/1089/events | https://github.com/huggingface/transformers/pull/1089 | 484,452,530 | MDExOlB1bGxSZXF1ZXN0MzEwMzI0MjM5 | 1,089 | change layernorm code to pytorch's native layer norm | {
"login": "dhpollack",
"id": 368699,
"node_id": "MDQ6VXNlcjM2ODY5OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/368699?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dhpollack",
"html_url": "https://github.com/dhpollack",
"followers_url": "https://api.github.com/users/dhpo... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=h1) Report\n> Merging [#1089](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1089?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?... | 1,566 | 1,567 | 1,567 | CONTRIBUTOR | null | The current code basically recreates pytorch's native [LayerNorm](https://pytorch.org/docs/stable/nn.html#layernorm) code. The only difference is that the default eps in the pytorch function is 1e-5 instead of 1e-12. PyTorch's native version is optimized for cudnn so it should be faster than this version. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1089/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1089/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1089",
"html_url": "https://github.com/huggingface/transformers/pull/1089",
"diff_url": "https://github.com/huggingface/transformers/pull/1089.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1089.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1088 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1088/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1088/comments | https://api.github.com/repos/huggingface/transformers/issues/1088/events | https://github.com/huggingface/transformers/issues/1088 | 484,291,183 | MDU6SXNzdWU0ODQyOTExODM= | 1,088 | ❓ Why in `run_squad.py` using XLNet, CLS token is not set at the end ? | {
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/ast... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Humm I think you are right.\r\n\r\nThe SquAD example looks a bit broken in pytorch-transformers, we will have to review it @LysandreJik.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\... | 1,566 | 1,572 | 1,572 | CONTRIBUTOR | null | ## ❓ Questions & Help
[This line](https://github.com/huggingface/pytorch-transformers/blob/e00b4ff1de0591d5093407b16e665e5c86028f04/examples/run_squad.py#L292) of the file `run_squad.py` create the features for the dataset.
No matter which model is used (BERT or XLNet), the function will create the format :
>... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1088/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1088/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1087 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1087/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1087/comments | https://api.github.com/repos/huggingface/transformers/issues/1087/events | https://github.com/huggingface/transformers/pull/1087 | 484,225,287 | MDExOlB1bGxSZXF1ZXN0MzEwMTUxMDMy | 1,087 | Decode now calls private property instead of public method | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=h1) Report\n> Merging [#1087](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1087?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?... | 1,566 | 1,576 | 1,567 | MEMBER | null | Removes the warning raised when the decode method is called. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1087/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1087/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1087",
"html_url": "https://github.com/huggingface/transformers/pull/1087",
"diff_url": "https://github.com/huggingface/transformers/pull/1087.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1087.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1086 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1086/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1086/comments | https://api.github.com/repos/huggingface/transformers/issues/1086/events | https://github.com/huggingface/transformers/issues/1086 | 484,068,626 | MDU6SXNzdWU0ODQwNjg2MjY= | 1,086 | ProjectedAdaptiveLogSoftmax log_prob computation dimensions error | {
"login": "tonyhqanguyen",
"id": 36124849,
"node_id": "MDQ6VXNlcjM2MTI0ODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/36124849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tonyhqanguyen",
"html_url": "https://github.com/tonyhqanguyen",
"followers_url": "https://api.githu... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): TransformerXL
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x]... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1086/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1085 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1085/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1085/comments | https://api.github.com/repos/huggingface/transformers/issues/1085/events | https://github.com/huggingface/transformers/issues/1085 | 483,983,439 | MDU6SXNzdWU0ODM5ODM0Mzk= | 1,085 | RuntimeError: Creating MTGP constants failed. at /opt/conda/conda-bld/pytorch_1533739672741/work/aten/src/THC/THCTensorRandom.cu:34 | {
"login": "dzhao123",
"id": 39663377,
"node_id": "MDQ6VXNlcjM5NjYzMzc3",
"avatar_url": "https://avatars.githubusercontent.com/u/39663377?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dzhao123",
"html_url": "https://github.com/dzhao123",
"followers_url": "https://api.github.com/users/dzh... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi! Could you provide us with the script that you use to add the cls and sep tokens? \r\nPlease be aware that RoBERTa already has those tokens that you can access using `tokenizer.sep_token` as well as `tokenizer.cls_token`.\r\n\r\nThe error you're showing often happens when you're trying to access an index that i... | 1,566 | 1,572 | 1,572 | NONE | null | Hi there, I am trying to fine tune the roberta model, but I meet the following errors below. Basically I use input_ids, token_type_ids, attention_ mask as inputs. Below are the command I use:
```
outputs_pos = model(input_ids=pos_data, token_type_ids=pos_segs, attention_mask=pos_mask)[0]
```
```
The data are... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1085/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1085/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1084 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1084/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1084/comments | https://api.github.com/repos/huggingface/transformers/issues/1084/events | https://github.com/huggingface/transformers/issues/1084 | 483,959,773 | MDU6SXNzdWU0ODM5NTk3NzM= | 1,084 | Xlnet for multi-label classification | {
"login": "ghaith-khlifi",
"id": 44617498,
"node_id": "MDQ6VXNlcjQ0NjE3NDk4",
"avatar_url": "https://avatars.githubusercontent.com/u/44617498?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghaith-khlifi",
"html_url": "https://github.com/ghaith-khlifi",
"followers_url": "https://api.githu... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"you can try fast-bert. https://github.com/kaushaltrivedi/fast-bert.\r\n\r\nits built on top of pytorch-transformers and supports multi-label classification for both BERT and XLNet.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activi... | 1,566 | 1,572 | 1,572 | NONE | null | Can you provide me with the xlnet code to deal with the multi-label classification task, please | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1084/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1083 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1083/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1083/comments | https://api.github.com/repos/huggingface/transformers/issues/1083/events | https://github.com/huggingface/transformers/issues/1083 | 483,932,147 | MDU6SXNzdWU0ODM5MzIxNDc= | 1,083 | hwo to get RoBERTaTokenizer vocab.json and also merge file | {
"login": "songtaoshi",
"id": 20240391,
"node_id": "MDQ6VXNlcjIwMjQwMzkx",
"avatar_url": "https://avatars.githubusercontent.com/u/20240391?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/songtaoshi",
"html_url": "https://github.com/songtaoshi",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"@thomwolf @LysandreJik @julien-c ",
"Hi! RoBERTa's tokenizer is based on the GPT-2 tokenizer. \r\n\r\n**Please note that except if you have completely re-trained RoBERTa from scratch, there is usually no need to change the `vocab.json` and `merges.txt` file.**\r\n\r\nCurrently we do not have a built-in way of c... | 1,566 | 1,666 | 1,572 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
hello, I trained the robert on my customized corpus following the fairseq instruction. I am confused how to generate the robert vocab.json and also merge.txt because I want to use the pytorch-transformer RoBERTaTokenizer. I only have ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1083/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1083/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1082 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1082/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1082/comments | https://api.github.com/repos/huggingface/transformers/issues/1082/events | https://github.com/huggingface/transformers/issues/1082 | 483,781,945 | MDU6SXNzdWU0ODM3ODE5NDU= | 1,082 | Getting tokenization ERROR while running run_generation.py | {
"login": "dxganta",
"id": 47485188,
"node_id": "MDQ6VXNlcjQ3NDg1MTg4",
"avatar_url": "https://avatars.githubusercontent.com/u/47485188?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dxganta",
"html_url": "https://github.com/dxganta",
"followers_url": "https://api.github.com/users/dxgant... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi! Yes currently there's a small issue with the tokenizer that outputs this warning during the decoding of the sentence. It will be fixed very shortly. \r\n\r\nIt won't affect your training however, as it is only a warning :)",
"This issue has been automatically marked as stale because it has not had recent act... | 1,566 | 1,572 | 1,572 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (GPT-2....):
Language I am using the model on (English):
The problem arise when using:
* [ ] the official example scripts: (give details)
pytorch-transformers/examples/run_generation.py \
The tasks I am working on is:
* [ ] my own task or dat... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1082/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1082/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1081 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1081/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1081/comments | https://api.github.com/repos/huggingface/transformers/issues/1081/events | https://github.com/huggingface/transformers/pull/1081 | 483,767,233 | MDExOlB1bGxSZXF1ZXN0MzA5Nzc4NTk5 | 1,081 | Fix distributed barrier hang | {
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | [
"Ok great, thanks a lot @VictorSanh "
] | 1,566 | 1,576 | 1,566 | MEMBER | null | This is bug reported in issue #998 (and is also valid for `run_squad.py`).
What is happening?
When launching a distributed training on one of the task of the GLUE benchmark (for instance this suggested command in the README [here](https://github.com/huggingface/pytorch-transformers#fine-tuning-bert-model-on-the-mrp... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1081/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1081/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1081",
"html_url": "https://github.com/huggingface/transformers/pull/1081",
"diff_url": "https://github.com/huggingface/transformers/pull/1081.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1081.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1080 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1080/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1080/comments | https://api.github.com/repos/huggingface/transformers/issues/1080/events | https://github.com/huggingface/transformers/pull/1080 | 483,763,064 | MDExOlB1bGxSZXF1ZXN0MzA5Nzc1Njg5 | 1,080 | 51 lm | {
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zh... | [] | closed | false | null | [] | [] | 1,566 | 1,566 | 1,566 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1080/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1080/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1080",
"html_url": "https://github.com/huggingface/transformers/pull/1080",
"diff_url": "https://github.com/huggingface/transformers/pull/1080.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1080.patch",
"merged_at": n... | |
https://api.github.com/repos/huggingface/transformers/issues/1079 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1079/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1079/comments | https://api.github.com/repos/huggingface/transformers/issues/1079/events | https://github.com/huggingface/transformers/pull/1079 | 483,747,768 | MDExOlB1bGxSZXF1ZXN0MzA5NzY0MDcz | 1,079 | Fix "No such file or directory" for SQuAD v1.1 | {
"login": "cooelf",
"id": 7037265,
"node_id": "MDQ6VXNlcjcwMzcyNjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7037265?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cooelf",
"html_url": "https://github.com/cooelf",
"followers_url": "https://api.github.com/users/cooelf/foll... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=h1) Report\n> Merging [#1079](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1079?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?... | 1,566 | 1,566 | 1,566 | CONTRIBUTOR | null | This solves the exception for SQuAD v1.1 evaluation without predicted null_odds file.
Traceback (most recent call last):
File "./examples/run_squad.py", line 521, in <module>
File "./examples/run_squad.py", line 510, in main
for checkpoint in checkpoints:
File "./examples/run_squad.py", line 257, in ev... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1079/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1079/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1079",
"html_url": "https://github.com/huggingface/transformers/pull/1079",
"diff_url": "https://github.com/huggingface/transformers/pull/1079.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1079.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1078 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1078/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1078/comments | https://api.github.com/repos/huggingface/transformers/issues/1078/events | https://github.com/huggingface/transformers/issues/1078 | 483,746,680 | MDU6SXNzdWU0ODM3NDY2ODA= | 1,078 | Index misplacement of Vocab.txt BUG BUG BUG | {
"login": "hackerxiaobai",
"id": 22817243,
"node_id": "MDQ6VXNlcjIyODE3MjQz",
"avatar_url": "https://avatars.githubusercontent.com/u/22817243?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hackerxiaobai",
"html_url": "https://github.com/hackerxiaobai",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | [] | 1,566 | 1,566 | 1,566 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (BertTokenizer):
Language I am using the model on (Chinese):
The problem arise when using:
**pytorch tokenizer**
```
t = tokenizer.tokenize('[CLS]哦我[SEP]')
i = tokenizer.convert_tokens_to_ids(t)
print(i)
[101, 1522, 2770, 102]
```
**tenso... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1078/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1078/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1077 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1077/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1077/comments | https://api.github.com/repos/huggingface/transformers/issues/1077/events | https://github.com/huggingface/transformers/pull/1077 | 483,725,067 | MDExOlB1bGxSZXF1ZXN0MzA5NzQ3MDM5 | 1,077 | Pruning changes so that deleted heads are kept on save/load | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=h1) Report\n> Merging [#1077](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1077?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/d7a4c3252ed5e630b7fb6e4b4616daddfe574fc5?... | 1,566 | 1,576 | 1,567 | MEMBER | null | The models saved with pruned heads will now be loaded correctly with a correct state dict and a correct configuration file. The changes in head structure are available in the config file via the property `config.pruned_heads`.
Pruned heads can be loaded from the config file:
```
config = GPT2Config(n_layer=4, n_... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1077/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1077",
"html_url": "https://github.com/huggingface/transformers/pull/1077",
"diff_url": "https://github.com/huggingface/transformers/pull/1077.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1077.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1076 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1076/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1076/comments | https://api.github.com/repos/huggingface/transformers/issues/1076/events | https://github.com/huggingface/transformers/issues/1076 | 483,722,853 | MDU6SXNzdWU0ODM3MjI4NTM= | 1,076 | can this project select the specific version of BERT? | {
"login": "bytekongfrombupt",
"id": 33115565,
"node_id": "MDQ6VXNlcjMzMTE1NTY1",
"avatar_url": "https://avatars.githubusercontent.com/u/33115565?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bytekongfrombupt",
"html_url": "https://github.com/bytekongfrombupt",
"followers_url": "https://... | [] | closed | false | null | [] | [
"Hi. You can check the documentation about the different checkpoints available for each model [here](https://huggingface.co/pytorch-transformers/pretrained_models.html).\r\n\r\nIf you're looking for BERT whole word masking, there are the following pretrained models that might be of interest: `bert-large-uncased-who... | 1,566 | 1,566 | 1,566 | NONE | null | ## ❓ Questions & Help
I dont know if this project can select the version of BERT which I need. For example, i want use BERT-wwm not BERT-basic, what should i do? Can you help me, plz.
<!-- A clear and concise description of the question. --> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1076/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1076/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1075 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1075/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1075/comments | https://api.github.com/repos/huggingface/transformers/issues/1075/events | https://github.com/huggingface/transformers/pull/1075 | 483,683,583 | MDExOlB1bGxSZXF1ZXN0MzA5NzEzODE1 | 1,075 | reraise EnvironmentError in modeling_utils.py | {
"login": "abhishekraok",
"id": 783844,
"node_id": "MDQ6VXNlcjc4Mzg0NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/783844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhishekraok",
"html_url": "https://github.com/abhishekraok",
"followers_url": "https://api.github.com/u... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=h1) Report\n> Merging [#1075](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1075?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/e00b4ff1de0591d5093407b16e665e5c86028f04?... | 1,566 | 1,566 | 1,566 | NONE | null | When an EnvironmentError occurs in modeling_utils.py, currently the code returns None. This causes a TypeError saying None is not iterable in the statement
config, model_kwargs = cls.config_class.from_pretrained(
pretrained_model_name_or_path, *model_args,
cache_dir=cach... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1075/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1075/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1075",
"html_url": "https://github.com/huggingface/transformers/pull/1075",
"diff_url": "https://github.com/huggingface/transformers/pull/1075.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1075.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1074 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1074/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1074/comments | https://api.github.com/repos/huggingface/transformers/issues/1074/events | https://github.com/huggingface/transformers/pull/1074 | 483,678,043 | MDExOlB1bGxSZXF1ZXN0MzA5NzA5MjM0 | 1,074 | Shortcut to special tokens' ids - fix GPT2 & RoBERTa tokenizers - improved testing for GPT/GPT-2 | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=h1) Report\n> Merging [#1074](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1074?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/f7978490b20ca3a8861bddb72689a464f0c59e84?... | 1,566 | 1,578 | 1,567 | MEMBER | null | This PR:
- Add shortcut to each special tokens with `_id` properties (e.g. `tokenizer.cls_token_id` for the id in the vocabulary of the `tokenizer.cls_token`)
- Fix GPT2 and RoBERTa tokenizer so that sentences to be tokenized always begins with at least one space (see note by fairseq authors: https://github.com/pytor... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1074/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1074/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1074",
"html_url": "https://github.com/huggingface/transformers/pull/1074",
"diff_url": "https://github.com/huggingface/transformers/pull/1074.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1074.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1073 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1073/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1073/comments | https://api.github.com/repos/huggingface/transformers/issues/1073/events | https://github.com/huggingface/transformers/issues/1073 | 483,572,599 | MDU6SXNzdWU0ODM1NzI1OTk= | 1,073 | Unable to get hidden states and attentions BertForSequenceClassification | {
"login": "delip",
"id": 347398,
"node_id": "MDQ6VXNlcjM0NzM5OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/347398?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/delip",
"html_url": "https://github.com/delip",
"followers_url": "https://api.github.com/users/delip/followers"... | [] | closed | false | null | [] | [
"Hi! \r\n\r\nThe two arguments `output_hidden_states` and `output_attentions` are arguments to be given to the configuration.\r\n\r\nHere, you would do as follows:\r\n\r\n```\r\nconfig = config_class.from_pretrained(name, output_hidden_states=True, output_attentions=True)\r\ntokenizer = tokenizer_class.from_pretrai... | 1,566 | 1,569 | 1,567 | NONE | null | I am able to instantiate the model etc. without the `output_` named arguments, but it fails when I include them. This is the latest master of pytorch_transformers installed via pip+git.
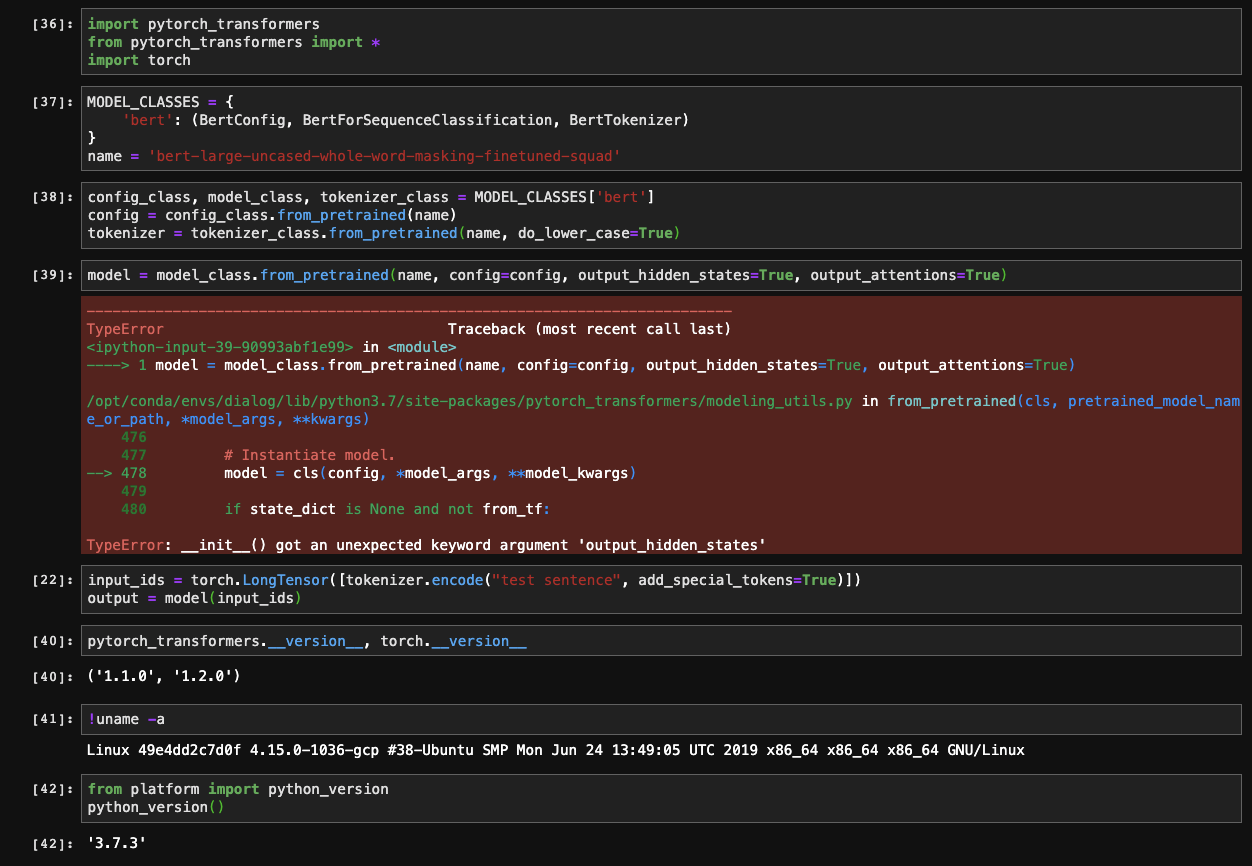
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1073/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1072 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1072/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1072/comments | https://api.github.com/repos/huggingface/transformers/issues/1072/events | https://github.com/huggingface/transformers/issues/1072 | 483,549,629 | MDU6SXNzdWU0ODM1NDk2Mjk= | 1,072 | Missing tf variables in convert_pytorch_checkpoint_to_tf.py | {
"login": "4everlove",
"id": 218931,
"node_id": "MDQ6VXNlcjIxODkzMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/218931?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/4everlove",
"html_url": "https://github.com/4everlove",
"followers_url": "https://api.github.com/users/4eve... | [] | closed | false | null | [] | [
"Indeed.\r\nBut I don't think we will aim for two-sided compatibility with the original Bert repo anyway.\r\nIn your case, you will need to adjust the original Bert repo code to be able to load the converted pytorch model (remove the unused variables or, more simple, tweak the checkpoint loading method).",
"Great... | 1,566 | 1,566 | 1,566 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): bert-base-uncased
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details)
* [ ] my own modified scripts: (give details)
The tasks I am w... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1072/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1072/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1071 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1071/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1071/comments | https://api.github.com/repos/huggingface/transformers/issues/1071/events | https://github.com/huggingface/transformers/issues/1071 | 483,432,464 | MDU6SXNzdWU0ODM0MzI0NjQ= | 1,071 | Support for Tensorflow (& or Keras) | {
"login": "victor-iyi",
"id": 24987474,
"node_id": "MDQ6VXNlcjI0OTg3NDc0",
"avatar_url": "https://avatars.githubusercontent.com/u/24987474?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/victor-iyi",
"html_url": "https://github.com/victor-iyi",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Probably not what you want to hear but you should probably look into rebuilding your infrastructure to also allow pytorch models. As someone who also uses tensorflow due to legacy systems, I wouldn't want the huggingface team to waste time struggling with tensorflow idiocracies and the currently in-flux API. ",
... | 1,566 | 1,573 | 1,573 | NONE | null | ## 🚀 Feature
pytorch-transformers the best NLP processing library based on the transformer model. However it has only extensive support for PyTorch, just like it's name suggests. It would be really helpful for the entire Machine Learning community to use it in their legacy project which might have been written in T... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1071/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1071/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1070 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1070/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1070/comments | https://api.github.com/repos/huggingface/transformers/issues/1070/events | https://github.com/huggingface/transformers/pull/1070 | 483,378,076 | MDExOlB1bGxSZXF1ZXN0MzA5NDY1Njgy | 1,070 | Fix the gpt2 quickstart example | {
"login": "oliverguhr",
"id": 3495355,
"node_id": "MDQ6VXNlcjM0OTUzNTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3495355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oliverguhr",
"html_url": "https://github.com/oliverguhr",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1070?src=pr&el=h1) Report\n> Merging [#1070](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1070?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/6f877d9daf36788bad4fd228930939fed6ab12bd?... | 1,566 | 1,567 | 1,567 | CONTRIBUTOR | null | You need to add the SEP (seperator) token to the tokenizer, otherwise the tokenizer.decode will fail with this error:
`ERROR:pytorch_transformers.tokenization_utils:Using sep_token, but it is not set yet.` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1070/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1070/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1070",
"html_url": "https://github.com/huggingface/transformers/pull/1070",
"diff_url": "https://github.com/huggingface/transformers/pull/1070.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1070.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1069 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1069/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1069/comments | https://api.github.com/repos/huggingface/transformers/issues/1069/events | https://github.com/huggingface/transformers/issues/1069 | 483,325,032 | MDU6SXNzdWU0ODMzMjUwMzI= | 1,069 | ru language | {
"login": "vvssttkk",
"id": 8581044,
"node_id": "MDQ6VXNlcjg1ODEwNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8581044?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vvssttkk",
"html_url": "https://github.com/vvssttkk",
"followers_url": "https://api.github.com/users/vvsst... | [] | closed | false | null | [] | [
"of course i can use bert aka multi-language but they work very bad in my mind for ru ",
"I think XLM models is better than mBERT. There are XLM models for 17 and 100 languages including ru.",
"cool\r\ncan u help me where i can download pre-trained xlm from ru because [here](https://huggingface.co/pytorch-tran... | 1,566 | 1,570 | 1,570 | NONE | null | which pre-trained model can work for russian language? i want get only vectors | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1069/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1069/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1068 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1068/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1068/comments | https://api.github.com/repos/huggingface/transformers/issues/1068/events | https://github.com/huggingface/transformers/issues/1068 | 483,307,600 | MDU6SXNzdWU0ODMzMDc2MDA= | 1,068 | LM fine-tuning for non-english dataset (hindi) | {
"login": "nikhilno1",
"id": 12153722,
"node_id": "MDQ6VXNlcjEyMTUzNzIy",
"avatar_url": "https://avatars.githubusercontent.com/u/12153722?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nikhilno1",
"html_url": "https://github.com/nikhilno1",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hello! Thanks for showcasing the library in your article!\r\n\r\nYou are totally correct about the auto-regressive models (XLNet, Transformer-XL, GPT-2 etc). Those models can efficiently predict the next work in a sequence as they attend to the left side of the sequence, usually trained with causal language modeli... | 1,566 | 1,572 | 1,572 | NONE | null | ## ❓ Questions & Help
Previously, I made this movie review sentiment classifier app using this wonderful library.
(Links:
https://deployment-247905.appspot.com/
https://towardsdatascience.com/battle-of-the-heavyweights-bert-vs-ulmfit-faceoff-91a582a7c42b)
Now I am looking to build a language model that will be... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1068/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1068/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1067 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1067/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1067/comments | https://api.github.com/repos/huggingface/transformers/issues/1067/events | https://github.com/huggingface/transformers/pull/1067 | 483,239,918 | MDExOlB1bGxSZXF1ZXN0MzA5MzU1MzI0 | 1,067 | Fix bug in run_openai_gpt.py file. | {
"login": "liyucheng09",
"id": 27999909,
"node_id": "MDQ6VXNlcjI3OTk5OTA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27999909?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liyucheng09",
"html_url": "https://github.com/liyucheng09",
"followers_url": "https://api.github.com/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"run_gpt2.py file has been test on ROCStories corpus, it runs fine and return auccuracy of 76%, lower than GPT1.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,575 | 1,575 | NONE | null | Add a example for add special tokens to OpenAIGPTTokenizer, and resize the embedding layer of OpenAIGPTModel. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1067/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1067/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1067",
"html_url": "https://github.com/huggingface/transformers/pull/1067",
"diff_url": "https://github.com/huggingface/transformers/pull/1067.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1067.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1066 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1066/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1066/comments | https://api.github.com/repos/huggingface/transformers/issues/1066/events | https://github.com/huggingface/transformers/issues/1066 | 483,188,319 | MDU6SXNzdWU0ODMxODgzMTk= | 1,066 | `run_squad.py` not using the dev cache | {
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/use... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 | MEMBER | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert (but it's independent of the model)
Language I am using the model on (English, Chinese....): English (but it's independent of the language)
The problem arise when using:
* [ X] the official example scripts: `examples/run_squa... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1066/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1066/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1065 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1065/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1065/comments | https://api.github.com/repos/huggingface/transformers/issues/1065/events | https://github.com/huggingface/transformers/issues/1065 | 483,147,671 | MDU6SXNzdWU0ODMxNDc2NzE= | 1,065 | Has anyone reproduced RoBERTa scores on Squad dataset? | {
"login": "Morizeyao",
"id": 25135807,
"node_id": "MDQ6VXNlcjI1MTM1ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/25135807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Morizeyao",
"html_url": "https://github.com/Morizeyao",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"@Morizeyao Were you able to find any answers to this?",
"Can you give us more info on what you tried and which results you obtained?",
"Sorry I was no longer working with the RoBERTa solution and switched to XLNet. Sadly the RoBERTa tries are overwritten. :(",
"This issue has been automatically marked as sta... | 1,566 | 1,574 | 1,574 | CONTRIBUTOR | null | I have been working on and made some modifications to run_squad.py in examples folder and is currently having problem reproduce the scores.
If we can have help (or even a PR) on RoBERTa in run_squad.py that would be great. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1065/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1065/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1064 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1064/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1064/comments | https://api.github.com/repos/huggingface/transformers/issues/1064/events | https://github.com/huggingface/transformers/pull/1064 | 483,142,889 | MDExOlB1bGxSZXF1ZXN0MzA5Mjc5NzEx | 1,064 | Adding gpt-2 large (774M parameters) model | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"Oops @LysandreJik forgot to add it in the [list of pretrained models of the doc](https://huggingface.co/pytorch-transformers/pretrained_models.html)",
"@thomwolf Added it with 2f93971\r\n",
"You're the best!"
] | 1,566 | 1,578 | 1,566 | MEMBER | null | Per request #1061
Also, fix a small restriction in a few conversion scripts (easier loading from original JSON configuration files). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1064/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 5,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1064/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1064",
"html_url": "https://github.com/huggingface/transformers/pull/1064",
"diff_url": "https://github.com/huggingface/transformers/pull/1064.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1064.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1063 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1063/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1063/comments | https://api.github.com/repos/huggingface/transformers/issues/1063/events | https://github.com/huggingface/transformers/issues/1063 | 483,113,043 | MDU6SXNzdWU0ODMxMTMwNDM= | 1,063 | Can't load the RobertaTokenizer from AutoTokenizer.from_pretrained interface | {
"login": "JohnGiorgi",
"id": 8917831,
"node_id": "MDQ6VXNlcjg5MTc4MzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8917831?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JohnGiorgi",
"html_url": "https://github.com/JohnGiorgi",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | [
"This should be fixed on master, can you try to install from master?\r\n(clone the repo and `pip install -e .`).",
"Ah, that solved it. Great, thanks a lot!\r\n\r\n",
"@thomwolf, is this fixed in the latest pip release version?",
"Yes, it is available in the latest pip release."
] | 1,566 | 1,582 | 1,566 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): `AutoModel`
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ ] the official example scripts: (give details)
* [x] my own modified scripts: (give details)
I tried to load a down... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1063/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1062 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1062/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1062/comments | https://api.github.com/repos/huggingface/transformers/issues/1062/events | https://github.com/huggingface/transformers/issues/1062 | 483,084,879 | MDU6SXNzdWU0ODMwODQ4Nzk= | 1,062 | Example in OpenAIGPTDoubleHeadsModel can't run | {
"login": "HaokunLiu",
"id": 35565210,
"node_id": "MDQ6VXNlcjM1NTY1MjEw",
"avatar_url": "https://avatars.githubusercontent.com/u/35565210?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HaokunLiu",
"html_url": "https://github.com/HaokunLiu",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"Yes, you need to resize the embeddings as well.\r\nThere is [an example](https://huggingface.co/pytorch-transformers/main_classes/tokenizer.html#pytorch_transformers.PreTrainedTokenizer.add_special_tokens) in the doc of the `add_special_tokens`method, that I copy here:\r\n```\r\n# Let's see how to add a new classi... | 1,566 | 1,566 | 1,566 | NONE | null | I tried to run the example from OpenAIGPTDoubleHeadsModel. But it went wrong.
Although the tokenizer added new index for special tokens, the embedding in OpenAIGPTDoubleHeadModel didn't add new embeddings for them, which leads to index out of range.
```
tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1062/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1061 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1061/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1061/comments | https://api.github.com/repos/huggingface/transformers/issues/1061/events | https://github.com/huggingface/transformers/issues/1061 | 482,955,459 | MDU6SXNzdWU0ODI5NTU0NTk= | 1,061 | GPT2 774M weights released! | {
"login": "moinnadeem",
"id": 813367,
"node_id": "MDQ6VXNlcjgxMzM2Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/813367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moinnadeem",
"html_url": "https://github.com/moinnadeem",
"followers_url": "https://api.github.com/users/m... | [] | closed | false | null | [] | [
"I did the following:\r\n\r\n1. Run `download_model.py 774` from [here](https://github.com/openai/gpt-2)\r\n2. Create a file named `config.json` with the following contents (Might be correct but I am not super sure):\r\n```json\r\n{\r\n \"vocab_size\": 50257,\r\n \"n_ctx\": 1024,\r\n \"n_embd\": 1280,\r\n ... | 1,566 | 1,566 | 1,566 | NONE | null | ## 🚀 Feature
Hi! OpenAI released the 774M weights in GPT2, is it possible to integrate this into pytorch-transformers?
https://twitter.com/OpenAI/status/1163843803884601344
Also, sorry for the obnoxiously quick ask! Thanks for all the great work you do for the community.
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1061/reactions",
"total_count": 35,
"+1": 20,
"-1": 1,
"laugh": 1,
"hooray": 0,
"confused": 0,
"heart": 7,
"rocket": 4,
"eyes": 2
} | https://api.github.com/repos/huggingface/transformers/issues/1061/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1060 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1060/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1060/comments | https://api.github.com/repos/huggingface/transformers/issues/1060/events | https://github.com/huggingface/transformers/pull/1060 | 482,837,836 | MDExOlB1bGxSZXF1ZXN0MzA5MDMxODc4 | 1,060 | Fix typo. configuratoin -> configuration | {
"login": "CrafterKolyan",
"id": 9883873,
"node_id": "MDQ6VXNlcjk4ODM4NzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9883873?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CrafterKolyan",
"html_url": "https://github.com/CrafterKolyan",
"followers_url": "https://api.github.... | [] | closed | false | null | [] | [
"Thanks!"
] | 1,566 | 1,566 | 1,566 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1060/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1060",
"html_url": "https://github.com/huggingface/transformers/pull/1060",
"diff_url": "https://github.com/huggingface/transformers/pull/1060.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1060.patch",
"merged_at": 1... | |
https://api.github.com/repos/huggingface/transformers/issues/1059 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1059/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1059/comments | https://api.github.com/repos/huggingface/transformers/issues/1059/events | https://github.com/huggingface/transformers/pull/1059 | 482,825,754 | MDExOlB1bGxSZXF1ZXN0MzA5MDIxOTcx | 1,059 | Better use of spacy tokenizer in open ai and xlm tokenizers | {
"login": "GuillemGSubies",
"id": 37592763,
"node_id": "MDQ6VXNlcjM3NTkyNzYz",
"avatar_url": "https://avatars.githubusercontent.com/u/37592763?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GuillemGSubies",
"html_url": "https://github.com/GuillemGSubies",
"followers_url": "https://api.gi... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=h1) Report\n> Merging [#1059](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1059?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/933841d903a032d93b5100220dc72db9d1283eca?... | 1,566 | 1,566 | 1,566 | CONTRIBUTOR | null | When you do: `spacy.load('en', disable=['parser', 'tagger', 'ner', 'textcat'])` There is a high risk of throwing an exception if the user did not install the model before.
Te easiest way to use the spaCy tokenizer is the one I propose here. This way there is no need for the user to download any spaCy model.
More ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1059/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1059",
"html_url": "https://github.com/huggingface/transformers/pull/1059",
"diff_url": "https://github.com/huggingface/transformers/pull/1059.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1059.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1058 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1058/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1058/comments | https://api.github.com/repos/huggingface/transformers/issues/1058/events | https://github.com/huggingface/transformers/issues/1058 | 482,763,755 | MDU6SXNzdWU0ODI3NjM3NTU= | 1,058 | Initialising XLMTokenizer | {
"login": "hiyingnn",
"id": 39294877,
"node_id": "MDQ6VXNlcjM5Mjk0ODc3",
"avatar_url": "https://avatars.githubusercontent.com/u/39294877?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hiyingnn",
"html_url": "https://github.com/hiyingnn",
"followers_url": "https://api.github.com/users/hiy... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"To pretrain XLM, you should use the original (PyTorch) codebase and training scripts which are [here](https://github.com/facebookresearch/XLM)",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contribut... | 1,566 | 1,572 | 1,572 | NONE | null | ## ❓ Questions & Help
To initialise the XLMTokenizer, both the vocab file and the merges.txt file are needed. If I am pre-training XLM, how do I obtain the merges.txt file?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1058/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1057 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1057/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1057/comments | https://api.github.com/repos/huggingface/transformers/issues/1057/events | https://github.com/huggingface/transformers/pull/1057 | 482,735,515 | MDExOlB1bGxSZXF1ZXN0MzA4OTQ3ODE3 | 1,057 | Add a few of typos corrections, bugs fixes and small improvements | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomw... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=h1) Report\n> Merging [#1057](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1057?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/c589862b783b94a8408b40c6dc9bf4a14b2ee391?... | 1,566 | 1,578 | 1,566 | MEMBER | null | - Add a `force_download` option to `from_pretrained` methods to override a corrupted file.
- Add a `proxies` option to `from_pretrained` methods to be able to use proxies.
- Update models doc (superseded #984)
- Fix a small bug when using Bert's `save_vocabulary` method with the path to a file instead of a directory... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1057/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1057",
"html_url": "https://github.com/huggingface/transformers/pull/1057",
"diff_url": "https://github.com/huggingface/transformers/pull/1057.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1057.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1056 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1056/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1056/comments | https://api.github.com/repos/huggingface/transformers/issues/1056/events | https://github.com/huggingface/transformers/pull/1056 | 482,705,334 | MDExOlB1bGxSZXF1ZXN0MzA4OTIzOTU5 | 1,056 | Swap of optimizer.step and scheduler.step for lm finetuning examples | {
"login": "Morizeyao",
"id": 25135807,
"node_id": "MDQ6VXNlcjI1MTM1ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/25135807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Morizeyao",
"html_url": "https://github.com/Morizeyao",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1056?src=pr&el=h1) Report\n> Merging [#1056](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1056?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/c589862b783b94a8408b40c6dc9bf4a14b2ee391?... | 1,566 | 1,566 | 1,566 | CONTRIBUTOR | null | Prior to PyTorch 1.1.0, the learning rate scheduler was expected to be called before the optimizer’s update; 1.1.0 changed this behavior in a BC-breaking way. If you use the learning rate scheduler (calling scheduler.step()) before the optimizer’s update (calling optimizer.step()), this will skip the first value of the... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1056/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1056/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1056",
"html_url": "https://github.com/huggingface/transformers/pull/1056",
"diff_url": "https://github.com/huggingface/transformers/pull/1056.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1056.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1055 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1055/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1055/comments | https://api.github.com/repos/huggingface/transformers/issues/1055/events | https://github.com/huggingface/transformers/pull/1055 | 482,502,376 | MDExOlB1bGxSZXF1ZXN0MzA4NzYyNjUw | 1,055 | Fix #1015 (tokenizer defaults to use_lower_case=True when loading from trained models) | {
"login": "qipeng",
"id": 1572802,
"node_id": "MDQ6VXNlcjE1NzI4MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1572802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qipeng",
"html_url": "https://github.com/qipeng",
"followers_url": "https://api.github.com/users/qipeng/foll... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1055?src=pr&el=h1) Report\n> Merging [#1055](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1055?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/c589862b783b94a8408b40c6dc9bf4a14b2ee391?... | 1,566 | 1,566 | 1,566 | CONTRIBUTOR | null | This PR fixes the issue where the tokenizer always defaults to `use_lower_case=True` when loading from trained models. It returns the control to the command-line arguments. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1055/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1055",
"html_url": "https://github.com/huggingface/transformers/pull/1055",
"diff_url": "https://github.com/huggingface/transformers/pull/1055.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1055.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1054 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1054/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1054/comments | https://api.github.com/repos/huggingface/transformers/issues/1054/events | https://github.com/huggingface/transformers/issues/1054 | 482,483,418 | MDU6SXNzdWU0ODI0ODM0MTg= | 1,054 | simple example of BERT input features : position_ids and head_mask | {
"login": "almugabo",
"id": 6864475,
"node_id": "MDQ6VXNlcjY4NjQ0NzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6864475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/almugabo",
"html_url": "https://github.com/almugabo",
"followers_url": "https://api.github.com/users/almug... | [] | closed | false | null | [] | [
"Hi,\r\n\r\nIf you read the documentation [here](https://huggingface.co/pytorch-transformers/model_doc/bert.html#bertfortokenclassification) you will see that `position_ids` and `head_mask` are not required inputs but are optional.\r\n\r\nNo need to give them if you don't want to (and you probably don't unless you ... | 1,566 | 1,566 | 1,566 | NONE | null | ## Background:
the documentation does a great job in explaining the particularities of BERT input features (input_ids, token_types_ids etc …) however for some (if not most) tasks other inputs features are required and I think it would help the users if they were explained with examples.
## Question:
could we a... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1054/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1054/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1053 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1053/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1053/comments | https://api.github.com/repos/huggingface/transformers/issues/1053/events | https://github.com/huggingface/transformers/issues/1053 | 482,283,584 | MDU6SXNzdWU0ODIyODM1ODQ= | 1,053 | reproducing bert results on snli and mnli | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,572 | 1,572 | NONE | null | Hi
I have finetuned bert for snli and mnli for 6 epochs for none of them I could reproduce bert results on these datasets. I also encountered degenerate solution which get around 47 accuracy, could you assist me how I can avoid this issue? so when there are several checkpoints, I always evaluate the last one after 6 e... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1053/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1053/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1052 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1052/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1052/comments | https://api.github.com/repos/huggingface/transformers/issues/1052/events | https://github.com/huggingface/transformers/pull/1052 | 482,104,194 | MDExOlB1bGxSZXF1ZXN0MzA4NDQzMTMz | 1,052 | Fix RobertaEmbeddings | {
"login": "DSKSD",
"id": 18030414,
"node_id": "MDQ6VXNlcjE4MDMwNDE0",
"avatar_url": "https://avatars.githubusercontent.com/u/18030414?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DSKSD",
"html_url": "https://github.com/DSKSD",
"followers_url": "https://api.github.com/users/DSKSD/follow... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=h1) Report\n> Merging [#1052](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1052?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/40acf6b52a5250608c2b90edd955835131971d5a?... | 1,566 | 1,575 | 1,575 | NONE | null | First of all, the original implementation can define `segment_embeddings` depending on `num_segments` argument. Actually, their model(Roberta) didn't use `segment_embeddings` because they found the effectiveness of `FULL/DOC SENTENCE` setting of inputs.
And `position_embeddings` should use `padding_idx` to ignore p... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1052/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1052/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1052",
"html_url": "https://github.com/huggingface/transformers/pull/1052",
"diff_url": "https://github.com/huggingface/transformers/pull/1052.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1052.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1051 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1051/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1051/comments | https://api.github.com/repos/huggingface/transformers/issues/1051/events | https://github.com/huggingface/transformers/issues/1051 | 482,068,075 | MDU6SXNzdWU0ODIwNjgwNzU= | 1,051 | BUG: run_openai_gpt.py load ROCStories data error | {
"login": "liyucheng09",
"id": 27999909,
"node_id": "MDQ6VXNlcjI3OTk5OTA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27999909?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liyucheng09",
"html_url": "https://github.com/liyucheng09",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"Hi @nine09, thanks for the report. Any way you could fix it cleanly and open a pull request?",
"> Hi @nine09, thanks for the report. Any way you could fix it cleanly and open a pull request?\r\n\r\nBien sur! But I want to have some clues about whether GPTTokenizer already have pad_token, otherwise add a new pad_... | 1,566 | 1,566 | 1,566 | NONE | null | ## 🐛 Bug
Model I am using (Bert, XLNet....): GPT
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [ 1 ] the official example scripts: run_openai_gpt.py
The tasks I am working on is:
* [ 1 ] an official GLUE/SQUaD task: ROCStories
**The method of preproce... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1051/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1051/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1050 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1050/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1050/comments | https://api.github.com/repos/huggingface/transformers/issues/1050/events | https://github.com/huggingface/transformers/issues/1050 | 481,993,922 | MDU6SXNzdWU0ODE5OTM5MjI= | 1,050 | Error in converting tensorflow checkpoints to pytorch | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"For me it worked to convert checkpoints without specifying the exact checkpoint. So only pointing to the folder of the checkpoint:\r\n`tf_checkpoint_path=\"pretrained_bert\"`",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occu... | 1,566 | 1,572 | 1,572 | NONE | null | @thomwolf
I downloaded tensorflow checkpoints for domain specific bert model and extracted the zip file into the folder **pretrained_bert** which contains the following the three files
model.ckpt.data-00000-of-00001
model.ckpt.index
model.ckpt.meta
I used the following code to convert tensorflow checkpoint... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1050/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1050/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1049 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1049/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1049/comments | https://api.github.com/repos/huggingface/transformers/issues/1049/events | https://github.com/huggingface/transformers/issues/1049 | 481,992,113 | MDU6SXNzdWU0ODE5OTIxMTM= | 1,049 | BUG: run_openai_gpt.py bug of GPTTokenizer and GPTDoubleHeadsModel | {
"login": "liyucheng09",
"id": 27999909,
"node_id": "MDQ6VXNlcjI3OTk5OTA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27999909?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liyucheng09",
"html_url": "https://github.com/liyucheng09",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [
"Yes, the `run_openai_gpt.py` example still needs to be updated to the new pytorch-transformers release. We haven't found time to do it yet.",
"I have pull request at #1067, this change fix the bug I mentioned above."
] | 1,566 | 1,566 | 1,566 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT
Language I am using the model on (English, Chinese....): ENGLISH
The problem arise when using:
* [ 1 ] the official example scripts: run_openai_gpt.py
The tasks I am working on is:
* [ 1 ] an official GLUE/SQUaD task: ROCSr... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1049/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1049/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1048 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1048/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1048/comments | https://api.github.com/repos/huggingface/transformers/issues/1048/events | https://github.com/huggingface/transformers/issues/1048 | 481,975,719 | MDU6SXNzdWU0ODE5NzU3MTk= | 1,048 | Very bad performances with BertModel on sentence classification | {
"login": "seo-95",
"id": 38254541,
"node_id": "MDQ6VXNlcjM4MjU0NTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/38254541?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/seo-95",
"html_url": "https://github.com/seo-95",
"followers_url": "https://api.github.com/users/seo-95/fo... | [] | closed | false | null | [] | [
"I still trying but the system seems to be in underfitting, i do not understand why it performs so poor",
"I've never used BERT for sentence classification tasks, but in regard to the batch size and memory constraints, you could use gradient accumulation to have a bigger effective batch size (see [examples/run_sq... | 1,566 | 1,566 | 1,566 | NONE | null | ## ❓ Questions & Help
I'm trying to use the raw BertModel for predictions over a dataset containing a set of dialogues. In the original work I had 3 different losses but I've noticed that the losses are very high and not going down epoch after epoch. So I started to take only one loss (intent classification) and I'v... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1048/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1048/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1047 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1047/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1047/comments | https://api.github.com/repos/huggingface/transformers/issues/1047/events | https://github.com/huggingface/transformers/issues/1047 | 481,946,693 | MDU6SXNzdWU0ODE5NDY2OTM= | 1,047 | Issue using Roberta | {
"login": "tuhinjubcse",
"id": 3104771,
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuhinjubcse",
"html_url": "https://github.com/tuhinjubcse",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"Hello!\r\n\r\nIt seems you're having trouble accessing the file on our S3 bucket. Could it be your firewall?\r\nIf you paste the URL in your browser: https://s3.amazonaws.com/models.huggingface.co/bert/roberta-base-pytorch_model.bin\r\n\r\nCan you download it or are you blocked?",
"Hi \r\nYou can close it . I ma... | 1,566 | 1,566 | 1,566 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Roberta
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (run_glue.py)
* [ ] my own modified scripts: (give details)
 Report\n> Merging [#1046](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1046?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/d8923270e6c497862f990a3c72e40cc1ddd01d4e?... | 1,566 | 1,566 | 1,566 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1046/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1046/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1046",
"html_url": "https://github.com/huggingface/transformers/pull/1046",
"diff_url": "https://github.com/huggingface/transformers/pull/1046.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1046.patch",
"merged_at": 1... | |
https://api.github.com/repos/huggingface/transformers/issues/1045 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1045/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1045/comments | https://api.github.com/repos/huggingface/transformers/issues/1045/events | https://github.com/huggingface/transformers/issues/1045 | 481,883,582 | MDU6SXNzdWU0ODE4ODM1ODI= | 1,045 | mnli results for BERT | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,566 | 1,571 | 1,571 | NONE | null | Hi
I cannot reproduce the MNLI results of BERT, for how many epochs I need to finetune bert?
thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1045/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1045/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1044 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1044/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1044/comments | https://api.github.com/repos/huggingface/transformers/issues/1044/events | https://github.com/huggingface/transformers/pull/1044 | 481,764,487 | MDExOlB1bGxSZXF1ZXN0MzA4MjAxMDg2 | 1,044 | Correct truncation for RoBERTa in 2-input GLUE | {
"login": "zphang",
"id": 1668462,
"node_id": "MDQ6VXNlcjE2Njg0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zphang",
"html_url": "https://github.com/zphang",
"followers_url": "https://api.github.com/users/zphang/foll... | [] | closed | false | null | [] | [
"Looks good to me, thanks!",
"Actually, for single-sentence inputs, do we expect one or two terminating `</s>`s? Currently we will generate two, I think.",
"@LysandreJik we can now update the GLUE scripts to use the newly added option `add_special_tokens` (added to all the tokenizers), don't you think?",
"Ind... | 1,565 | 1,566 | 1,565 | CONTRIBUTOR | null | Extend the truncation fix to the two-input case.
(Example: currently throws if running MRPC with `max_seq_length=32`.) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1044/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1044/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1044",
"html_url": "https://github.com/huggingface/transformers/pull/1044",
"diff_url": "https://github.com/huggingface/transformers/pull/1044.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1044.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1043 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1043/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1043/comments | https://api.github.com/repos/huggingface/transformers/issues/1043/events | https://github.com/huggingface/transformers/issues/1043 | 481,718,577 | MDU6SXNzdWU0ODE3MTg1Nzc= | 1,043 | Unable to load custom tokens | {
"login": "sashank06",
"id": 8636933,
"node_id": "MDQ6VXNlcjg2MzY5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8636933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashank06",
"html_url": "https://github.com/sashank06",
"followers_url": "https://api.github.com/users/sa... | [] | closed | false | null | [] | [
"Hello, thanks for the bug report. \r\n\r\nCould you please show me what's inside the directory `experiment1_conversation/runs/new` and `experiment1_conversation/runs/old`?",
"@LysandreJik the previous issue I had posted was due to a mistake on my side. I updated the issue. ",
"@LysandreJik This is the content ... | 1,565 | 1,565 | 1,565 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
I am unable to load the custom tokens that were added to GPT2 tokenizer while training.
Code used while training
```
SPECIAL_TOKENS = ["bos_token","eos_toke... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1043/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1043/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1042 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1042/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1042/comments | https://api.github.com/repos/huggingface/transformers/issues/1042/events | https://github.com/huggingface/transformers/pull/1042 | 481,671,513 | MDExOlB1bGxSZXF1ZXN0MzA4MTI2MzI1 | 1,042 | fix #1041 | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | [] | 1,565 | 1,566 | 1,565 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1042/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1042/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1042",
"html_url": "https://github.com/huggingface/transformers/pull/1042",
"diff_url": "https://github.com/huggingface/transformers/pull/1042.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1042.patch",
"merged_at": 1... | |
https://api.github.com/repos/huggingface/transformers/issues/1041 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1041/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1041/comments | https://api.github.com/repos/huggingface/transformers/issues/1041/events | https://github.com/huggingface/transformers/issues/1041 | 481,636,558 | MDU6SXNzdWU0ODE2MzY1NTg= | 1,041 | Issue in running run_glue.py in Roberta, XLNet, XLM in latest release | {
"login": "leslyarun",
"id": 5101854,
"node_id": "MDQ6VXNlcjUxMDE4NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5101854?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leslyarun",
"html_url": "https://github.com/leslyarun",
"followers_url": "https://api.github.com/users/le... | [] | closed | false | null | [] | [
"Thanks for the report! I'm looking into it.",
"Could you try the changes in [this commit ](https://github.com/huggingface/pytorch-transformers/commit/a93966e608cac8e80b4ff355d7c61f712b6da7f4)on your own dataset and tell me if you still have errors?",
"@LysandreJik Ya this code works fine. Thanks for the quick ... | 1,565 | 1,567 | 1,565 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Roberta, XLM, XLNet
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: run_glue.py
The tasks I am working on is:
* [x] my own task or dataset: bin... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1041/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1041/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1040 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1040/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1040/comments | https://api.github.com/repos/huggingface/transformers/issues/1040/events | https://github.com/huggingface/transformers/pull/1040 | 481,435,399 | MDExOlB1bGxSZXF1ZXN0MzA3OTM1MzIw | 1,040 | Fix bug of multi-gpu training in lm finetuning | {
"login": "FeiWang96",
"id": 19998174,
"node_id": "MDQ6VXNlcjE5OTk4MTc0",
"avatar_url": "https://avatars.githubusercontent.com/u/19998174?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FeiWang96",
"html_url": "https://github.com/FeiWang96",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1040?src=pr&el=h1) Report\n> Merging [#1040](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1040?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/9d0029e215f5ad0836d6be87458aab5142783af4?... | 1,565 | 1,566 | 1,566 | CONTRIBUTOR | null | Current code will raise error when running multi-gpu training (n_gpu > 1 & local_rank = -1).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1040/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1040/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1040",
"html_url": "https://github.com/huggingface/transformers/pull/1040",
"diff_url": "https://github.com/huggingface/transformers/pull/1040.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1040.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1039 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1039/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1039/comments | https://api.github.com/repos/huggingface/transformers/issues/1039/events | https://github.com/huggingface/transformers/issues/1039 | 481,377,776 | MDU6SXNzdWU0ODEzNzc3NzY= | 1,039 | Minor bug in evaluation phase in example code for SQUAD | {
"login": "aakanksha19",
"id": 6501707,
"node_id": "MDQ6VXNlcjY1MDE3MDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/6501707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aakanksha19",
"html_url": "https://github.com/aakanksha19",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | [
"I fixed it in #923 weeks ago.\r\nwaiting merge",
"Thanks, I did not come across it earlier! I'll close this issue."
] | 1,565 | 1,565 | 1,565 | NONE | null | In run_squad.py, the model saving code is outside the loop which performs training (if args.do_train - line 477).
Due to this, after finetuning a model with --do_train, if we only run --do_eval, the existing trained model gets overwritten before being loaded for testing.
**Simple fix:** Pushing model saving code in... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1039/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1039/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1038 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1038/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1038/comments | https://api.github.com/repos/huggingface/transformers/issues/1038/events | https://github.com/huggingface/transformers/issues/1038 | 481,338,732 | MDU6SXNzdWU0ODEzMzg3MzI= | 1,038 | Adding new tokens to GPT tokenizer | {
"login": "sashank06",
"id": 8636933,
"node_id": "MDQ6VXNlcjg2MzY5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8636933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashank06",
"html_url": "https://github.com/sashank06",
"followers_url": "https://api.github.com/users/sa... | [] | closed | false | null | [] | [] | 1,565 | 1,565 | 1,565 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
I am having saving GPT2Tokenizer when custom new tokens are added to it. Tried out two specific methods.
1. Using special_mapping dictionary and save_vocabular... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1038/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1038/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1037 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1037/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1037/comments | https://api.github.com/repos/huggingface/transformers/issues/1037/events | https://github.com/huggingface/transformers/issues/1037 | 481,273,080 | MDU6SXNzdWU0ODEyNzMwODA= | 1,037 | wrong generation of training sentence pairs. method: get_corpus_line, in finetune_on_pregenerated.py | {
"login": "Evgeneus",
"id": 7963274,
"node_id": "MDQ6VXNlcjc5NjMyNzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7963274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Evgeneus",
"html_url": "https://github.com/Evgeneus",
"followers_url": "https://api.github.com/users/Evgen... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi @Evgeneus, does your proposed solution solve the problem on your side?",
"> Hi @Evgeneus, does your proposed solution solve the problem on your side?\r\n\r\nHi @thomwolf, seems yes.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further a... | 1,565 | 1,572 | 1,572 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using:
BERT
Language I am using the model on (English, Chinese....):
The problem arise when using:
* [ ] the official example scripts: (give details)
The tasks I am working on is:
I am running on my own text corpus the official example to fine-tune B... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1037/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1037/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1036 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1036/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1036/comments | https://api.github.com/repos/huggingface/transformers/issues/1036/events | https://github.com/huggingface/transformers/issues/1036 | 481,129,840 | MDU6SXNzdWU0ODExMjk4NDA= | 1,036 | Customize BertTokenizer and Feature Extraction from Bert Model | {
"login": "hungph-dev-ict",
"id": 32316323,
"node_id": "MDQ6VXNlcjMyMzE2MzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/32316323?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hungph-dev-ict",
"html_url": "https://github.com/hungph-dev-ict",
"followers_url": "https://api.gi... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"1. ) Not really sure what your meaning here, but use whatever tokenizer that you used to tokenise your corpus; a tokenizer just converts words into integers anyways.\r\n\r\n2. ) You are pretty much right if all you want is the hidden states, `outputs = model(input_ids)` will create a tuple with the hidden layers... | 1,565 | 1,586 | 1,572 | NONE | null | ## ❓ Questions & Help
Hello everybody, I tuned Bert follow [this example](https://github.com/huggingface/pytorch-transformers/tree/master/examples/lm_finetuning) with my corpus in my country language - Vietnamese.
So now I have 2 question that concerns:
1. With my corpus, in my country language Vietnamese, I don't... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1036/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1036/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1035 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1035/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1035/comments | https://api.github.com/repos/huggingface/transformers/issues/1035/events | https://github.com/huggingface/transformers/pull/1035 | 481,005,443 | MDExOlB1bGxSZXF1ZXN0MzA3NTkwNjY5 | 1,035 | Merge pull request #1 from huggingface/master | {
"login": "pohanchi",
"id": 34079344,
"node_id": "MDQ6VXNlcjM0MDc5MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/34079344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pohanchi",
"html_url": "https://github.com/pohanchi",
"followers_url": "https://api.github.com/users/poh... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=h1) Report\n> Merging [#1035](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1035?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/a7b4cfe9194bf93c7044a42c9f1281260ce6279e?... | 1,565 | 1,566 | 1,566 | NONE | null | update | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1035/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1035/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1035",
"html_url": "https://github.com/huggingface/transformers/pull/1035",
"diff_url": "https://github.com/huggingface/transformers/pull/1035.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1035.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1034 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1034/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1034/comments | https://api.github.com/repos/huggingface/transformers/issues/1034/events | https://github.com/huggingface/transformers/issues/1034 | 480,870,072 | MDU6SXNzdWU0ODA4NzAwNzI= | 1,034 | Getting embedding from XLM in differnet languages | {
"login": "OfirArviv",
"id": 22588859,
"node_id": "MDQ6VXNlcjIyNTg4ODU5",
"avatar_url": "https://avatars.githubusercontent.com/u/22588859?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OfirArviv",
"html_url": "https://github.com/OfirArviv",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"Hi, are you referring to the sentence embeddings that are generated in the [XLM notebook](https://github.com/facebookresearch/XLM/blob/master/generate-embeddings.ipynb)?",
"Yes. Although I'm using it to get the word embeddings (see [here](https://github.com/facebookresearch/XLM/issues/17)).\r\nMaybe I'm missing ... | 1,565 | 1,566 | 1,566 | NONE | null | ## ❓ Questions & Help
Hi,
I'm trying to get a cross-lingual embedding from the XLM model, but can't figure out how.
In the project original github, you need to give the tokenizer the language of each of the tokens, but it doesn't seem the case here.
Will appreciated any help on the matter :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1034/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1034/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1033 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1033/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1033/comments | https://api.github.com/repos/huggingface/transformers/issues/1033/events | https://github.com/huggingface/transformers/issues/1033 | 480,832,406 | MDU6SXNzdWU0ODA4MzI0MDY= | 1,033 | GPT2 Tokenizer got an expected argument `skip_special_tokens` | {
"login": "sashank06",
"id": 8636933,
"node_id": "MDQ6VXNlcjg2MzY5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8636933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashank06",
"html_url": "https://github.com/sashank06",
"followers_url": "https://api.github.com/users/sa... | [] | closed | false | null | [] | [
"I'm having a hard time reproducing it on my side on a clean install. Could you provide a sample that throws the error?",
"@LysandreJik I will give you the code with sample input and output asap. "
] | 1,565 | 1,565 | 1,565 | NONE | null | ## 🐛 Bug
Model I am using -> GPT2
Language I am using the model on - >English
The problem arise when using:
I keep running into this error when trying to use the GPT2 model and GPT2 tokenizer while decoding.
Keep getting the following error when I run the piece of code below:
tokenizer.decode(response_ids... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1033/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1033/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1032 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1032/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1032/comments | https://api.github.com/repos/huggingface/transformers/issues/1032/events | https://github.com/huggingface/transformers/issues/1032 | 480,827,468 | MDU6SXNzdWU0ODA4Mjc0Njg= | 1,032 | GPT2 Tokenizer got an expected argument `skip_special_tokens` | {
"login": "sashank06",
"id": 8636933,
"node_id": "MDQ6VXNlcjg2MzY5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8636933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashank06",
"html_url": "https://github.com/sashank06",
"followers_url": "https://api.github.com/users/sa... | [] | closed | false | null | [] | [
"Could you please submit a bug report with the version of the library you're using?",
"will close this issue. Opened a bug report."
] | 1,565 | 1,565 | 1,565 | NONE | null | ## ❓ Questions & Help
I keep running into this error when trying to use the GPT2 model and GPT2 tokenizer while decoding.
Keep getting the following error when I run the piece of code below:
``tokenizer.decode(response_ids, skip_special_tokens=True)``
Error:
``TypeError: decode() got an unexpected keyword argum... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1032/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1032/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1031 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1031/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1031/comments | https://api.github.com/repos/huggingface/transformers/issues/1031/events | https://github.com/huggingface/transformers/issues/1031 | 480,783,335 | MDU6SXNzdWU0ODA3ODMzMzU= | 1,031 | Efficient data loading functionality | {
"login": "shubhamagarwal92",
"id": 7984532,
"node_id": "MDQ6VXNlcjc5ODQ1MzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/7984532?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shubhamagarwal92",
"html_url": "https://github.com/shubhamagarwal92",
"followers_url": "https://ap... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@thomwolf Is there an efficient implementation for this? Could you re-open the issue please. ",
"CSV generally has slower load times.... | 1,565 | 1,572 | 1,571 | CONTRIBUTOR | null | ## 🚀 Feature
Efficient data loader for huge dataset with lazy loading!
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too. -->
I am working... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1031/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1031/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1030 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1030/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1030/comments | https://api.github.com/repos/huggingface/transformers/issues/1030/events | https://github.com/huggingface/transformers/issues/1030 | 480,631,812 | MDU6SXNzdWU0ODA2MzE4MTI= | 1,030 | Tokenizer not found after conversion from TF checkpoint to PyTorch | {
"login": "HansBambel",
"id": 9060786,
"node_id": "MDQ6VXNlcjkwNjA3ODY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9060786?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HansBambel",
"html_url": "https://github.com/HansBambel",
"followers_url": "https://api.github.com/users... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, no the tokenizer is not trained. You can just load the original `gpt2` one.",
"Shouldn't the tokenizer then be loaded from `args.model_type` and not `args.model_name_or_path`? Or do they differ from `gpt2` to `gpt2-medium`?",
"This issue has been automatically marked as stale because it has not had recent ... | 1,565 | 1,572 | 1,572 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): GPT2
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: run_generation.py, convert_tf_checkpoint_to_pytorch.py
* [ ] my own modified scripts: (give d... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1030/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1030/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1029 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1029/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1029/comments | https://api.github.com/repos/huggingface/transformers/issues/1029/events | https://github.com/huggingface/transformers/issues/1029 | 480,574,887 | MDU6SXNzdWU0ODA1NzQ4ODc= | 1,029 | if cutoffs=[], convert_transfo_xl_checkpoint_to_pytorch.py has a bug | {
"login": "Pydataman",
"id": 17594431,
"node_id": "MDQ6VXNlcjE3NTk0NDMx",
"avatar_url": "https://avatars.githubusercontent.com/u/17594431?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Pydataman",
"html_url": "https://github.com/Pydataman",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi!\r\n\r\nYes, you should indeed specify `cutoffs` in your `TransfoXLConfig` or the adaptive softmax won't be able to create its clusters. We should probably put a more explicit error.",
"Hello, @LysandreJik\r\n\r\nThe checkpoint of https://github.com/kimiyoung/transformer-xl doesn't have cutoff_N when adaptive... | 1,565 | 1,573 | 1,573 | NONE | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): transformer_xl
Language I am using the model on (English, Chinese....): I train xl model base on own dataset
<!-- If you have a code sample, error messages, stack traces, please provide it here as well. -->
<!-- A clear and conc... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1029/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1029/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1028 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1028/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1028/comments | https://api.github.com/repos/huggingface/transformers/issues/1028/events | https://github.com/huggingface/transformers/pull/1028 | 480,570,434 | MDExOlB1bGxSZXF1ZXN0MzA3MjQwMTEx | 1,028 | add data utils | {
"login": "zhpmatrix",
"id": 4077026,
"node_id": "MDQ6VXNlcjQwNzcwMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/4077026?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhpmatrix",
"html_url": "https://github.com/zhpmatrix",
"followers_url": "https://api.github.com/users/zh... | [] | closed | false | null | [] | [] | 1,565 | 1,565 | 1,565 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1028/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1028",
"html_url": "https://github.com/huggingface/transformers/pull/1028",
"diff_url": "https://github.com/huggingface/transformers/pull/1028.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1028.patch",
"merged_at": n... | |
https://api.github.com/repos/huggingface/transformers/issues/1027 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1027/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1027/comments | https://api.github.com/repos/huggingface/transformers/issues/1027/events | https://github.com/huggingface/transformers/pull/1027 | 480,570,336 | MDExOlB1bGxSZXF1ZXN0MzA3MjQwMDMw | 1,027 | Re-implemented tokenize() iteratively in PreTrainedTokenizer. | {
"login": "samvelyan",
"id": 9724413,
"node_id": "MDQ6VXNlcjk3MjQ0MTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9724413?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/samvelyan",
"html_url": "https://github.com/samvelyan",
"followers_url": "https://api.github.com/users/sa... | [] | closed | false | null | [] | [
"The failed test log reads:\r\n``` \r\nERROR pytorch_transformers.modeling_utils:modeling_utils.py:160 Couldn't reach server at 'https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-whole-word-masking-config.json' to download pretrained model configuration file.\r\n```\r\n\r\nThis shouldn't be ... | 1,565 | 1,566 | 1,566 | CONTRIBUTOR | null | Firstly, Thanks a lot for this amazing library. Great work!
### Motivation
The `tokenize()` function in `PreTrainedTokenizer` uses the nested `split_on_tokens` recursive function which is called for all the added tokens (& special tokens). However, if the number of added tokens is large (e.g. > 1000), which is of... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1027/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1027/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1027",
"html_url": "https://github.com/huggingface/transformers/pull/1027",
"diff_url": "https://github.com/huggingface/transformers/pull/1027.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1027.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1026 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1026/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1026/comments | https://api.github.com/repos/huggingface/transformers/issues/1026/events | https://github.com/huggingface/transformers/pull/1026 | 480,563,765 | MDExOlB1bGxSZXF1ZXN0MzA3MjM0NzQ0 | 1,026 | loads the tokenizer for each checkpoint, to solve the reproducability… | {
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/... | [] | closed | false | null | [] | [
"# [Codecov](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=h1) Report\n> Merging [#1026](https://codecov.io/gh/huggingface/pytorch-transformers/pull/1026?src=pr&el=desc) into [master](https://codecov.io/gh/huggingface/pytorch-transformers/commit/a7b4cfe9194bf93c7044a42c9f1281260ce6279e?... | 1,565 | 1,567 | 1,567 | NONE | null | Hi
I observed that if you run "run_glue" code with the same parameters in the following ways:
1) run with both --do_train and --do_eval
2) run without --do_train but only --do_eval, but set the modelpath to use the trained models from step 1
The obtained evaluation results in these two cases are not the same, and... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1026/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1026/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1026",
"html_url": "https://github.com/huggingface/transformers/pull/1026",
"diff_url": "https://github.com/huggingface/transformers/pull/1026.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1026.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1025 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1025/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1025/comments | https://api.github.com/repos/huggingface/transformers/issues/1025/events | https://github.com/huggingface/transformers/issues/1025 | 480,551,291 | MDU6SXNzdWU0ODA1NTEyOTE= | 1,025 | puzzling issue regarding evaluation phase | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"f... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 | NONE | null | Hi
I observe that if you run the run_glue code on WNLI, and activate both do_train and do_eval once you get one accuracy, if you run_glue with only eval with the path to the trained model,
you get another accuracy. This is very puzzling, thanks for your help | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1025/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1025/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1024 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1024/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1024/comments | https://api.github.com/repos/huggingface/transformers/issues/1024/events | https://github.com/huggingface/transformers/issues/1024 | 480,513,962 | MDU6SXNzdWU0ODA1MTM5NjI= | 1,024 | fail to download vocabulary behind proxy server | {
"login": "jingjingli01",
"id": 8656202,
"node_id": "MDQ6VXNlcjg2NTYyMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8656202?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jingjingli01",
"html_url": "https://github.com/jingjingli01",
"followers_url": "https://api.github.com... | [] | closed | false | null | [] | [
"Put it in the same directory as your config.json file",
"Which directory is it by default?",
"> Which directory is it by default?\r\n\r\nHave you found the solution?"
] | 1,565 | 1,602 | 1,565 | NONE | null | ## ❓ Questions & Help
I work behind a proxy server. Following this [issue](https://github.com/huggingface/pytorch-transformers/issues/856), I manually download the `config.json` and `pytorch_model.bin` and the model can successfully load config and model weights.
However, in running `tokenizer = BertTokenizer.from_... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1024/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1024/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1023 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1023/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1023/comments | https://api.github.com/repos/huggingface/transformers/issues/1023/events | https://github.com/huggingface/transformers/pull/1023 | 480,221,465 | MDExOlB1bGxSZXF1ZXN0MzA2OTU5Njg0 | 1,023 | fix issue #824 | {
"login": "tuvuumass",
"id": 23730882,
"node_id": "MDQ6VXNlcjIzNzMwODgy",
"avatar_url": "https://avatars.githubusercontent.com/u/23730882?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuvuumass",
"html_url": "https://github.com/tuvuumass",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | [
"Thanks for this @tuvuumass!"
] | 1,565 | 1,566 | 1,566 | CONTRIBUTOR | null | fix issue #824 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1023/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1023/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1023",
"html_url": "https://github.com/huggingface/transformers/pull/1023",
"diff_url": "https://github.com/huggingface/transformers/pull/1023.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1023.patch",
"merged_at": 1... |
https://api.github.com/repos/huggingface/transformers/issues/1022 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1022/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1022/comments | https://api.github.com/repos/huggingface/transformers/issues/1022/events | https://github.com/huggingface/transformers/issues/1022 | 480,045,798 | MDU6SXNzdWU0ODAwNDU3OTg= | 1,022 | "mask_padding_with_zero" for xlnet | {
"login": "tbornt",
"id": 21997233,
"node_id": "MDQ6VXNlcjIxOTk3MjMz",
"avatar_url": "https://avatars.githubusercontent.com/u/21997233?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tbornt",
"html_url": "https://github.com/tbornt",
"followers_url": "https://api.github.com/users/tbornt/fo... | [] | closed | false | null | [] | [
"It is not. We've added an option to input a negative mask in XLNet so it can use the same input pattern as the other models.\r\n\r\nIf you take a look at the inputs of XLNetModel [here](https://huggingface.co/pytorch-transformers/model_doc/xlnet.html#pytorch_transformers.XLNetModel), you will see both possible mas... | 1,565 | 1,566 | 1,566 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
From the source code in [xlnet repo](https://github.com/zihangdai/xlnet/blob/master/classifier_utils.py) line113-115
I see the comment
`
The mask has 0 for real tokens and 1 for padding tokens. Only real
tokens are attended to.
... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1022/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1022/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1021 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1021/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1021/comments | https://api.github.com/repos/huggingface/transformers/issues/1021/events | https://github.com/huggingface/transformers/issues/1021 | 479,987,657 | MDU6SXNzdWU0Nzk5ODc2NTc= | 1,021 | When I set fp16_opt_level == O2 or O3, I can not use multiple GPU | {
"login": "liuyukid",
"id": 26139664,
"node_id": "MDQ6VXNlcjI2MTM5NjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/26139664?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liuyukid",
"html_url": "https://github.com/liuyukid",
"followers_url": "https://api.github.com/users/liu... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"We need more information, like a full error log and the detailed command line you used for instance.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,572 | 1,572 | NONE | null | ## ❓ Questions & Help
<!-- A clear and concise description of the question. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1021/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1021/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1020 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1020/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1020/comments | https://api.github.com/repos/huggingface/transformers/issues/1020/events | https://github.com/huggingface/transformers/issues/1020 | 479,922,203 | MDU6SXNzdWU0Nzk5MjIyMDM= | 1,020 | Intended Behaviour for Impossible (out-of-span) SQuAD Features | {
"login": "Shayne13",
"id": 12535144,
"node_id": "MDQ6VXNlcjEyNTM1MTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12535144?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shayne13",
"html_url": "https://github.com/Shayne13",
"followers_url": "https://api.github.com/users/Sha... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 | NONE | null | ## ❓ Questions & Help
Hello! We have a quick question regarding the featurization for BERT/XLNet Question Answering.
We noticed a confusing contradiction in your current `utils_squad` implementation: regardless of how the `version_2_with_negative` flag is set, you do not discard “impossible” features (chunks of a... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1020/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1020/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1019 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1019/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1019/comments | https://api.github.com/repos/huggingface/transformers/issues/1019/events | https://github.com/huggingface/transformers/issues/1019 | 479,878,162 | MDU6SXNzdWU0Nzk4NzgxNjI= | 1,019 | Fine-tuning approach for Bert and GPT2 classifiers | {
"login": "amity137",
"id": 48901019,
"node_id": "MDQ6VXNlcjQ4OTAxMDE5",
"avatar_url": "https://avatars.githubusercontent.com/u/48901019?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amity137",
"html_url": "https://github.com/amity137",
"followers_url": "https://api.github.com/users/ami... | [] | closed | false | null | [] | [
"AFAIK, BERT doesn't make use of gradual unfreezing. Instead, during fine-tuning all model parameters are trainable. It can result in catastrophic forgetting, if you train it for long enough/ large enough learning rate, which is why we usually fine tune for 1-2 epochs at a low learning rate.\r\n\r\nWhen it comes to... | 1,565 | 1,565 | 1,565 | NONE | null | ## ❓ Questions & Help
Hey folks, when we are fine-tuning BERT or GPT2 model for a classification task via classes like GPT2DoubleHeadsModel or BertForSequenceClassification, what is the recommended fine-tuning strategy? I assume all transformer layers of the base model are unfrozen for fine-tuning. Does this result ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1019/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1019/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1018 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1018/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1018/comments | https://api.github.com/repos/huggingface/transformers/issues/1018/events | https://github.com/huggingface/transformers/pull/1018 | 479,845,754 | MDExOlB1bGxSZXF1ZXN0MzA2NjU2NzY2 | 1,018 | Add LM-only finetuning script for GPT modules | {
"login": "ari-holtzman",
"id": 20871523,
"node_id": "MDQ6VXNlcjIwODcxNTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/20871523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ari-holtzman",
"html_url": "https://github.com/ari-holtzman",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | [
"Closing because I noticed this is a special case of #987 "
] | 1,565 | 1,565 | 1,565 | CONTRIBUTOR | null | A simple script adapted from `run_openai_gpt.py` to allow LM-only finetuning. Pre-processing is changed to accept arbitrary text files which are then chunked and a simple dataset caching scheme is added. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1018/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1018/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/1018",
"html_url": "https://github.com/huggingface/transformers/pull/1018",
"diff_url": "https://github.com/huggingface/transformers/pull/1018.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/1018.patch",
"merged_at": n... |
https://api.github.com/repos/huggingface/transformers/issues/1017 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1017/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1017/comments | https://api.github.com/repos/huggingface/transformers/issues/1017/events | https://github.com/huggingface/transformers/issues/1017 | 479,829,585 | MDU6SXNzdWU0Nzk4Mjk1ODU= | 1,017 | the execution order of `scheduler.step()` and `optimizer.step()` | {
"login": "boy2000-007man",
"id": 4197489,
"node_id": "MDQ6VXNlcjQxOTc0ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4197489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/boy2000-007man",
"html_url": "https://github.com/boy2000-007man",
"followers_url": "https://api.gith... | [] | closed | false | null | [] | [
"I believe the order doesn't actually matter as long as it reflects what you're trying to do with your learning rate.",
"Readme fixed, thanks!"
] | 1,565 | 1,566 | 1,566 | CONTRIBUTOR | null | ## ❓ Questions & Help
About current readme, related to the execution order of `scheduler.step()` and `optimizer.step()`
https://github.com/huggingface/pytorch-transformers#optimizers-bertadam--openaiadam-are-now-adamw-schedules-are-standard-pytorch-schedules
```python
### In PyTorch-Transformers, optimizer and sc... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1017/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1017/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1016 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1016/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1016/comments | https://api.github.com/repos/huggingface/transformers/issues/1016/events | https://github.com/huggingface/transformers/issues/1016 | 479,821,182 | MDU6SXNzdWU0Nzk4MjExODI= | 1,016 | inconsistent between class name (Pretrained vs PreTrained) | {
"login": "boy2000-007man",
"id": 4197489,
"node_id": "MDQ6VXNlcjQxOTc0ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4197489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/boy2000-007man",
"html_url": "https://github.com/boy2000-007man",
"followers_url": "https://api.gith... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, it isn't really expected and I agree that it can be a bit confusing, but now that it's like that we'll probably keep is so as to not make a breaking change.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you ... | 1,565 | 1,571 | 1,571 | CONTRIBUTOR | null | ## ❓ Questions & Help
https://github.com/huggingface/pytorch-transformers/blob/1b35d05d4b3c121a9740544aa6f884f1039780b1/pytorch_transformers/__init__.py#L37
I notice there are `Pre**t**rainedConfig`, `Pre**T**rainedModel` and `Pre**T**rainedTokenizer` have different naming case which is confusing.
Is this nami... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1016/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1016/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1015 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1015/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1015/comments | https://api.github.com/repos/huggingface/transformers/issues/1015/events | https://github.com/huggingface/transformers/issues/1015 | 479,801,422 | MDU6SXNzdWU0Nzk4MDE0MjI= | 1,015 | Logic issue with evaluating cased models in `run_squad.py` | {
"login": "qipeng",
"id": 1572802,
"node_id": "MDQ6VXNlcjE1NzI4MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1572802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qipeng",
"html_url": "https://github.com/qipeng",
"followers_url": "https://api.github.com/users/qipeng/foll... | [] | closed | false | null | [] | [
"Thanks for the bug report, will look into it.",
"Looks good to me, do you want to push a PR to fix this as you proposed @qipeng?",
"Done. See #1055!",
"Found another one: https://github.com/huggingface/pytorch-transformers/blob/master/examples/run_squad.py#L484\r\nIt seems like it should be \r\n```python\r\n... | 1,565 | 1,566 | 1,566 | CONTRIBUTOR | null | ## 🐛 Bug
<!-- Important information -->
Model I am using (Bert, XLNet....): Bert
Language I am using the model on (English, Chinese....): English
The problem arise when using:
* [x] the official example scripts: (give details) `run_squad.py` with cased models
* [ ] my own modified scripts: (give details)... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1015/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1015/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1014 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1014/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1014/comments | https://api.github.com/repos/huggingface/transformers/issues/1014/events | https://github.com/huggingface/transformers/issues/1014 | 479,799,546 | MDU6SXNzdWU0Nzk3OTk1NDY= | 1,014 | BertTokenizer.save_vocabulary() doesn't work as docstring described | {
"login": "boy2000-007man",
"id": 4197489,
"node_id": "MDQ6VXNlcjQxOTc0ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4197489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/boy2000-007man",
"html_url": "https://github.com/boy2000-007man",
"followers_url": "https://api.gith... | [] | closed | false | null | [] | [] | 1,565 | 1,566 | 1,566 | CONTRIBUTOR | null | ## 🐛 Bug
https://github.com/huggingface/pytorch-transformers/blob/1b35d05d4b3c121a9740544aa6f884f1039780b1/pytorch_transformers/tokenization_bert.py#L169-L174
## Expected behavior
It's obvious that when `vocab_path` is not a directory, the `vocab_file` is not defined.
I believe replacing all `vocab_path` with ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1014/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1014/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1013 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1013/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1013/comments | https://api.github.com/repos/huggingface/transformers/issues/1013/events | https://github.com/huggingface/transformers/issues/1013 | 479,772,666 | MDU6SXNzdWU0Nzk3NzI2NjY= | 1,013 | XLNet / sentence padding | {
"login": "cherepanovic",
"id": 10064548,
"node_id": "MDQ6VXNlcjEwMDY0NTQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/10064548?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cherepanovic",
"html_url": "https://github.com/cherepanovic",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi!\r\n\r\nBy concatenating the `<pad>` value to the end of your sentences you are successfully padding them. It can be observed by identifying the encoded sentence, which shows that a `5` value (which is the padding index in the tokenizer dictionary) is appended to the end of your token sequences.\r\n\r\nOnce you... | 1,565 | 1,702 | 1,572 | NONE | null | My samples have different lengths and I want to apply the padding to bring them to the same length, because my purpose is to create sentence embeddings batchwise. For that all sentences must have the same length, otherwise it is not possible to create a tensor.
How does padding work in use of XLNet model?
the s... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1013/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1013/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1012 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1012/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1012/comments | https://api.github.com/repos/huggingface/transformers/issues/1012/events | https://github.com/huggingface/transformers/issues/1012 | 479,635,274 | MDU6SXNzdWU0Nzk2MzUyNzQ= | 1,012 | inconsistency of the model (XLNet) output / related to #475 #735 | {
"login": "cherepanovic",
"id": 10064548,
"node_id": "MDQ6VXNlcjEwMDY0NTQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/10064548?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cherepanovic",
"html_url": "https://github.com/cherepanovic",
"followers_url": "https://api.github.c... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"if I don't load the config the results are consistent \r\n\r\n```\r\ntokenizer = XLNetTokenizer.from_pretrained(\"xlnet-base-cased\")\r\nmodel = XLNetLMHeadModel.from_pretrained(\"xlnet-base-cased\")\r\nmodel.eval()\r\n```\r\n",
"You should do this:\r\n```\r\ntokenizer = XLNetTokenizer.from_pretrained('xlnet-bas... | 1,565 | 1,576 | 1,576 | NONE | null | Related to #475 #735
Unfortunately, I lost the overview regarding this issue.
what is the final solution for that problem?
```
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
config = XLNetConfig.from_pretrained('xlnet-base-cased')
config.output_hidden_states=True
xlnet_model = XLNetMod... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1012/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1012/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1011 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1011/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1011/comments | https://api.github.com/repos/huggingface/transformers/issues/1011/events | https://github.com/huggingface/transformers/issues/1011 | 479,614,013 | MDU6SXNzdWU0Nzk2MTQwMTM= | 1,011 | run_classifier.py missing from examples dir | {
"login": "XinCode",
"id": 7126594,
"node_id": "MDQ6VXNlcjcxMjY1OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7126594?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/XinCode",
"html_url": "https://github.com/XinCode",
"followers_url": "https://api.github.com/users/XinCode/... | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"It is now replaced by run_glue.py in the /examples folder",
"@ningjize Got it, thanks.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,565 | 1,571 | 1,571 | NONE | null | Hi, it seems that run_classifier is removed (or changed name?) from the examples dir. I am working on NER task with bert, can anyone suggest where I can find the sample/tutorial training/prediction code? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1011/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1011/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/1010 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/1010/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/1010/comments | https://api.github.com/repos/huggingface/transformers/issues/1010/events | https://github.com/huggingface/transformers/issues/1010 | 479,580,099 | MDU6SXNzdWU0Nzk1ODAwOTk= | 1,010 | Order of inputs of forward function problematic for jit with Classification models | {
"login": "dhpollack",
"id": 368699,
"node_id": "MDQ6VXNlcjM2ODY5OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/368699?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dhpollack",
"html_url": "https://github.com/dhpollack",
"followers_url": "https://api.github.com/users/dhpo... | [] | closed | false | null | [] | [
"Thanks for giving such an in-depth review of the issue, it is very helpful. I indeed see this can be problematic, I'll have a look into it.",
"Thanks a lot for the details @dhpollack!\r\n\r\nAs you probably guessed, the strange order of the arguments is the results of trying to minimize the number of breaking ch... | 1,565 | 1,569 | 1,569 | CONTRIBUTOR | null | ## TL;DR
Due to order of args of `forward` in classification models, `device` gets hardcoded during jit tracing or causes unwanted overhead. Easy solution (but possibly breaking):
```
# change this
# classification BERT
class BertForSequenceClassification(BertPreTrainedModel):
...
def forward(self, ... | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/1010/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/1010/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.