
title stringlengths 1 100 | titleSlug stringlengths 3 77 | Java int64 0 1 | Python3 int64 1 1 | content stringlengths 28 44.4k | voteCount int64 0 3.67k | question_content stringlengths 65 5k | question_hints stringclasses 970
values |
|---|---|---|---|---|---|---|---|
An approach with generator | random-point-in-non-overlapping-rectangles | 0 | 1 | # Intuition\nfirst of all, this is only one limit; Any integer point inside the space covered by one of the given rectangles should be equally likely to be returned.\n\nso, what we have to do is return all the points when user calls pick without duplication. actually, we don\'t need to use random function here to avoid... | 0 | You are given an array of non-overlapping axis-aligned rectangles `rects` where `rects[i] = [ai, bi, xi, yi]` indicates that `(ai, bi)` is the bottom-left corner point of the `ith` rectangle and `(xi, yi)` is the top-right corner point of the `ith` rectangle. Design an algorithm to pick a random integer point inside th... | null |
An approach with generator | random-point-in-non-overlapping-rectangles | 0 | 1 | # Intuition\nfirst of all, this is only one limit; Any integer point inside the space covered by one of the given rectangles should be equally likely to be returned.\n\nso, what we have to do is return all the points when user calls pick without duplication. actually, we don\'t need to use random function here to avoid... | 0 | You are given an integer array `deck` where `deck[i]` represents the number written on the `ith` card.
Partition the cards into **one or more groups** such that:
* Each group has **exactly** `x` cards where `x > 1`, and
* All the cards in one group have the same integer written on them.
Return `true` _if such pa... | null |
Python3 solution with random utility | random-point-in-non-overlapping-rectangles | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nthe key idea solve the problem is drawing uniform probility arrording to rect area and after that draw a point inside the choised rect uniformly\nwe cant utilize python3 random library choices, randint fo that job\nps. also we can use dev... | 0 | You are given an array of non-overlapping axis-aligned rectangles `rects` where `rects[i] = [ai, bi, xi, yi]` indicates that `(ai, bi)` is the bottom-left corner point of the `ith` rectangle and `(xi, yi)` is the top-right corner point of the `ith` rectangle. Design an algorithm to pick a random integer point inside th... | null |
Python3 solution with random utility | random-point-in-non-overlapping-rectangles | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nthe key idea solve the problem is drawing uniform probility arrording to rect area and after that draw a point inside the choised rect uniformly\nwe cant utilize python3 random library choices, randint fo that job\nps. also we can use dev... | 0 | You are given an integer array `deck` where `deck[i]` represents the number written on the `ith` card.
Partition the cards into **one or more groups** such that:
* Each group has **exactly** `x` cards where `x > 1`, and
* All the cards in one group have the same integer written on them.
Return `true` _if such pa... | null |
Weighted Selection of Rect + Generate point in selected Rect | random-point-in-non-overlapping-rectangles | 0 | 1 | ```python\nfrom dataclasses import dataclass\nfrom functools import cached_property\nfrom itertools import accumulate\nfrom random import choices, randint\n\n\n@dataclass\nclass Rectangle:\n x: int\n y: int\n l: int\n b: int\n\n def generate(self) -> list[int]:\n return [\n self.x + ran... | 0 | You are given an array of non-overlapping axis-aligned rectangles `rects` where `rects[i] = [ai, bi, xi, yi]` indicates that `(ai, bi)` is the bottom-left corner point of the `ith` rectangle and `(xi, yi)` is the top-right corner point of the `ith` rectangle. Design an algorithm to pick a random integer point inside th... | null |
Weighted Selection of Rect + Generate point in selected Rect | random-point-in-non-overlapping-rectangles | 0 | 1 | ```python\nfrom dataclasses import dataclass\nfrom functools import cached_property\nfrom itertools import accumulate\nfrom random import choices, randint\n\n\n@dataclass\nclass Rectangle:\n x: int\n y: int\n l: int\n b: int\n\n def generate(self) -> list[int]:\n return [\n self.x + ran... | 0 | You are given an integer array `deck` where `deck[i]` represents the number written on the `ith` card.
Partition the cards into **one or more groups** such that:
* Each group has **exactly** `x` cards where `x > 1`, and
* All the cards in one group have the same integer written on them.
Return `true` _if such pa... | null |
Solution | diagonal-traverse | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n vector<int> findDiagonalOrder(vector<vector<int>>& mat) {\n int N = mat.size();\n int M = mat[0].size();\n vector<int> answer;\n\n int x = 0; \n int sum = 0; \n int dir = -1;\n\n auto addToAnswer = [&]() {\n int y = su... | 1 | Given an `m x n` matrix `mat`, return _an array of all the elements of the array in a diagonal order_.
**Example 1:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[1,2,4,7,5,3,6,8,9\]
**Example 2:**
**Input:** mat = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `m == mat.leng... | null |
Easy Python, NO DIRECTION CHECKING | diagonal-traverse | 0 | 1 | Hey guys, super easy solution here, with NO DIRECTION CHECKS!!!\nThe key here is to realize that the sum of indices on all diagonals are equal.\nFor example, in\n```\n[1,2,3]\n[4,5,6]\n[7,8,9]\n```\n2, 4 are on the same diagonal, and they share the index sum of 1. (2 is matrix[0][1] and 4 is in matrix[1][0]). 3,5,7 are... | 1,086 | Given an `m x n` matrix `mat`, return _an array of all the elements of the array in a diagonal order_.
**Example 1:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[1,2,4,7,5,3,6,8,9\]
**Example 2:**
**Input:** mat = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `m == mat.leng... | null |
Python Video Solution | diagonal-traverse | 0 | 1 | I have explained this in a [video](https://youtu.be/Njt7aZYq0wA).\n\n`row+col` for each element identifies which column it belongs to.\n\nWe can use this as a `diagonal_id` and store all elements corresponding to it in a HashMap.\n\nIf it is **even**, then we have to traverse the list in reverse order, else in forward ... | 3 | Given an `m x n` matrix `mat`, return _an array of all the elements of the array in a diagonal order_.
**Example 1:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[1,2,4,7,5,3,6,8,9\]
**Example 2:**
**Input:** mat = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `m == mat.leng... | null |
Python solution | diagonal-traverse | 0 | 1 | ```\nclass Solution:\n def findDiagonalOrder(self, mat: List[List[int]]) -> List[int]:\n M,N = len(mat), len(mat[0])\n diagonals = []\n \n # traverse first column\n for i in range(len(mat)):\n idx_i = i\n idx_j = 0\n diagonals.append([])\n ... | 2 | Given an `m x n` matrix `mat`, return _an array of all the elements of the array in a diagonal order_.
**Example 1:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[1,2,4,7,5,3,6,8,9\]
**Example 2:**
**Input:** mat = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `m == mat.leng... | null |
498: Time 97.90% and Space 98.87%, Solution with step by step explanation | diagonal-traverse | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize an empty list called result to store the elements in diagonal order.\n2. Get the dimensions of the matrix, m and n, and set the starting indices i and j to 0. Also initialize a variable direction to 0 to repres... | 6 | Given an `m x n` matrix `mat`, return _an array of all the elements of the array in a diagonal order_.
**Example 1:**
**Input:** mat = \[\[1,2,3\],\[4,5,6\],\[7,8,9\]\]
**Output:** \[1,2,4,7,5,3,6,8,9\]
**Example 2:**
**Input:** mat = \[\[1,2\],\[3,4\]\]
**Output:** \[1,2,3,4\]
**Constraints:**
* `m == mat.leng... | null |
✅Easy Python Code | keyboard-row | 0 | 1 | # Code\n```\nclass Solution:\n def findWords(self, words: List[str]) -> List[str]:\n row1 = list("qwertyuiop")\n row2 = list("asdfghjkl")\n row3 = list("zxcvbnm")\n\n ans = []\n\n for word in words:\n flag = 0\n temp = word\n word = word.lower()\n ... | 4 | Given an array of strings `words`, return _the words that can be typed using letters of the alphabet on only one row of American keyboard like the image below_.
In the **American keyboard**:
* the first row consists of the characters `"qwertyuiop "`,
* the second row consists of the characters `"asdfghjkl "`, and... | null |
Solution | keyboard-row | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n vector<string> findWords(vector<string>& words) {\n static const vector<unordered_set<char>> rows{{\'q\', \'w\', \'e\', \'r\', \'t\', \'y\', \'u\', \'i\', \'o\', \'p\'},\n {\'a\', \'s\', \'d\', \'f\', \'g\', \'h\', \'j... | 2 | Given an array of strings `words`, return _the words that can be typed using letters of the alphabet on only one row of American keyboard like the image below_.
In the **American keyboard**:
* the first row consists of the characters `"qwertyuiop "`,
* the second row consists of the characters `"asdfghjkl "`, and... | null |
Python easy solution no nested loop | keyboard-row | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 26 | Given an array of strings `words`, return _the words that can be typed using letters of the alphabet on only one row of American keyboard like the image below_.
In the **American keyboard**:
* the first row consists of the characters `"qwertyuiop "`,
* the second row consists of the characters `"asdfghjkl "`, and... | null |
Easy | Python Solution | Hashmap | keyboard-row | 0 | 1 | # Code\n```\nclass Solution:\n def findWords(self, words: List[str]) -> List[str]:\n hashmap = {}\n arr = [\'qwertyuiop\', \'asdfghjkl\', \'zxcvbnm\']\n\n for i in range(len(arr)):\n for j in arr[i]:\n hashmap[j] = i+1\n\n res = []\n\n for i in words:\n ... | 2 | Given an array of strings `words`, return _the words that can be typed using letters of the alphabet on only one row of American keyboard like the image below_.
In the **American keyboard**:
* the first row consists of the characters `"qwertyuiop "`,
* the second row consists of the characters `"asdfghjkl "`, and... | null |
Python 3 || 2 lines for fun | keyboard-row | 0 | 1 | ```\nrows = (set("qwertyuiop"), set("asdfghjkl"), set("zxcvbnm"))\n\nclass Solution:\n def findWords(self, words: list[str]) -> list[str]:\n \n return [w for w in words if any(set(w.lower()).issubset(row) for row in rows)]\n``` | 7 | Given an array of strings `words`, return _the words that can be typed using letters of the alphabet on only one row of American keyboard like the image below_.
In the **American keyboard**:
* the first row consists of the characters `"qwertyuiop "`,
* the second row consists of the characters `"asdfghjkl "`, and... | null |
python 3 set | keyboard-row | 0 | 1 | ```\nclass Solution:\n def findWords(self, words: List[str]) -> List[str]:\n #\n set1 = {\'q\',\'w\',\'e\',\'r\',\'t\',\'y\',\'u\',\'i\',\'o\',\'p\'}\n set2 = {\'a\',\'s\',\'d\',\'f\',\'g\',\'h\',\'j\',\'k\',\'l\'}\n set3 = {\'z\',\'x\',\'c\',\'v\',\'b\',\'n\',\'m\'}\n \n re... | 33 | Given an array of strings `words`, return _the words that can be typed using letters of the alphabet on only one row of American keyboard like the image below_.
In the **American keyboard**:
* the first row consists of the characters `"qwertyuiop "`,
* the second row consists of the characters `"asdfghjkl "`, and... | null |
✅ 99.87% 🏆 video walkthrough 🔥 optimal O(1) space solution | find-mode-in-binary-search-tree | 0 | 1 | https://youtu.be/A58XHd2Zo4M\n\nRecursion / DFS / BFS / Stack / Queue-based approaches **are NOT O(1) space**; **the cost to create the recursive callstack and/or data structures still has linear space complexity**. You can check for yourself by plugging in the code to https://pythontutor.com/ and seeing how the callst... | 90 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
Single BT traversal with if else cases to get resultant array/list. | find-mode-in-binary-search-tree | 0 | 1 | # Intuition\n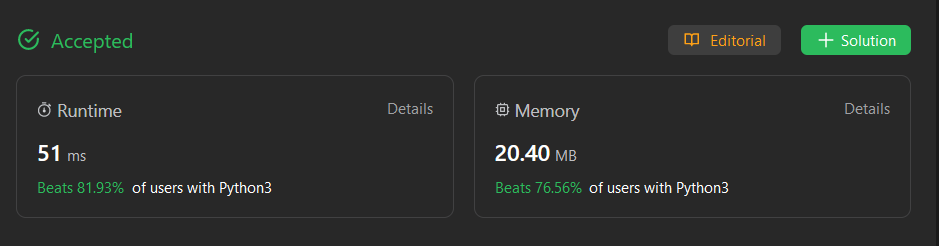\n2 parts:\n1. Traversal through BST\n2. Finding element count and adding elements of highest count to a list (Note that there can be multiple elements with highest count)\n\n<!-- Describe your... | 1 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
✅ 99.54% In-order Traversal Generator | find-mode-in-binary-search-tree | 1 | 1 | # Intuition\nWhen we are given a Binary Search Tree (BST) and asked about frequency or mode, the first thing that should come to mind is in-order traversal. This is because an in-order traversal of a BST gives a sorted sequence of its values. If we traverse the BST in-order, then same values will appear consecutively i... | 42 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
501. Find Mode in Binary Search Tree | find-mode-in-binary-search-tree | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
Python || Easiest Solution | find-mode-in-binary-search-tree | 0 | 1 | # Intuition\nTo find the mode(s) in a binary search tree with duplicates, you can use an in-order traversal of the BST. \n\n# Approach\nDuring the traversal, you\'ll keep track of the current element and its count while comparing it with the previous element. If the count of the current element is greater than the coun... | 1 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
Layman's Code in 🐍 | find-mode-in-binary-search-tree | 0 | 1 | # Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def findMode(self, root: Optional[TreeNode]) -> List[int]:\n # print(root)\n ... | 1 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
✅ Python3 | Recursion | 46ms | Beats 95% ✅ | find-mode-in-binary-search-tree | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\nFirst we need to count every value in the tree, and then return a list of those that are tied for teh most occurences.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\nRecursively traverse the tree, adding the v... | 1 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
【Video】Give me 5 minutes - How we think about a solution - Why do we use inorder traversal? | find-mode-in-binary-search-tree | 1 | 1 | # Intuition\nTraverse ascending order.\n\n---\n\n# Solution Video\n\nhttps://youtu.be/0i1Ze62pTuU\n\n\u25A0 Timeline of the video\n`0:04` Which traversal do you use for this question?\n`0:34` Properties of a Binary Search Tree\n`1:31` Key point of my solution code\n`3:09` How to write Inorder, Preorder, Postorder\n`4:0... | 24 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
✅ Beats 95.48% 🔥 || Inorder Traversal 🚀 | find-mode-in-binary-search-tree | 1 | 1 | \n\n# Intuition:\n**In this problem, we need to find the mode of the given BST. Mode is the element that occurs the most number of times in the given BST. We can solve thi... | 16 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
EASIEST solution💯💯 || C++ || Java || Python || JavaScript || Python || Ruby | find-mode-in-binary-search-tree | 1 | 1 | \n```C++ []\nclass Solution {\npublic:\n unordered_map<int,int>mp;\n\n void isValid(TreeNode* root) {\n\n if(root==NULL) return;\n\n isValid(root->left);\n mp[root->val]++;\n isValid(root->right);\n\n }\n\n vector<int> findMode(TreeNode* root) {\n\n isValid(root);\n\n ... | 8 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
Python Clean O(1) Space | find-mode-in-binary-search-tree | 0 | 1 | ```py\nclass Solution:\n def findMode(self, root: Optional[TreeNode]) -> List[int]:\n maxfreq = 0\n \n def dfs(node):\n if node:\n yield from dfs(node.left)\n yield node.val\n yield from dfs(node.right)\n \n for val, group in ... | 0 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
Really simple Python solution with explanation | find-mode-in-binary-search-tree | 0 | 1 | # Approach\n1. Get all the elements in the binary tree with `get_all`.\n2. Return the most common elements with `Counter.most_common()` + some filtering.\n\n# Code\n```\nfrom collections import Counter\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# ... | 1 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
[Python3] Inorder traversal without HashMap | find-mode-in-binary-search-tree | 0 | 1 | ```python3 []\nclass Solution:\n def findMode(self, root: Optional[TreeNode]) -> List[int]:\n res, prev, curStreak, maxStreak = [], None, 0, -1\n \n def dfs(node):\n if not node: return\n nonlocal prev, curStreak, maxStreak\n \n dfs(node.left)\n ... | 4 | Given the `root` of a binary search tree (BST) with duplicates, return _all the [mode(s)](https://en.wikipedia.org/wiki/Mode_(statistics)) (i.e., the most frequently occurred element) in it_.
If the tree has more than one mode, return them in **any order**.
Assume a BST is defined as follows:
* The left subtree of... | null |
Day 54 || C++ || Priority_Queue || Easiest Beginner Friendly Sol | ipo | 1 | 1 | # Intuition of this Problem:\nThe problem asks us to maximize the total capital by selecting at most k distinct projects. We have a limited amount of initial capital, and each project has a minimum capital requirement and a pure profit. We need to choose the projects in such a way that we can complete at most k distinc... | 305 | Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Help LeetCode design... | null |
Python3 👍||⚡97/97 T/M beats, only 13 lines 🔥|| Two heap || Optimization Simple explain || | ipo | 0 | 1 | \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nYou need two heap to solve this problem.\nFirst heap is used to pick projects until appear a project can\'t do at k steps.\nSecend he... | 1 | Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Help LeetCode design... | null |
[Python] sorting first, Daily Challenge Feb., Day 23 | ipo | 0 | 1 | # Intuition\nit\'s hard to deal with profits and capital at same time, we can sort one of them and see if we can gain benefits from it.\n\nsince we only can do projects whose capital is lower than ours, it\'s intuitively that we can try to sort projects by capital.\n\nthen, we can iterate through all the projects whose... | 1 | Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Help LeetCode design... | null |
Python Two Heaps | ipo | 0 | 1 | The strategy is greedy.\n1. Put all the profits you can pick with current w in a bag\n2. Pick the max profit from the bag\n```\nclass Solution:\n def findMaximizedCapital(self, k: int, w: int, profits: List[int], capital: List[int]) -> int:\n \n heap1 = [(c, -p) for c, p in zip(capital, profits)]\n ... | 1 | Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Help LeetCode design... | null |
🚀Simplest Solution🚀 Beginner Friendly||🔥Priority Queue||🔥C++|| Python3🔥 | ipo | 0 | 1 | # Consider\uD83D\uDC4D\n```\n Please Upvote If You Find It Helpful\n```\n\n# Intuition\nExplanation\nThis code will first create a vector of pairs containing the capital and profits of each project. It will then sort this vector based on the capital required for each project. Then, it will use a prio... | 17 | Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Help LeetCode design... | null |
Python short and clean. Greedy. Two heaps (PriorityQueues). | ipo | 0 | 1 | # Approach\nTLDR; Same as [Official solution](https://leetcode.com/problems/ipo/solutions/2959870/ipo/), except another heap is used instead of sorting the projects.\n\n# Complexity\n- Time complexity: $$O(n * log(n))$$\n\n- Space complexity: $$O(n)$$\n\nwhere, `n is the number of projects`.\n\n# Code\n```python\nclass... | 2 | Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Help LeetCode design... | null |
🔥🔥🔥 Heap + Greedy Solution (Beats 99.69%) 🔥Python 3🔥 | ipo | 0 | 1 | \n# Code\n```\nfrom heapq import heappush, heappop, nlargest\n\n\nclass Solution:\n def findMaximizedCapital(self, k: int, w: int, profits: List[int], capital: List[int]) -> int:\n if w >= max(capital):\n return w + sum(nlargest(k, profits))\n \n projects = [[capital[i],profits[i]] fo... | 9 | Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Help LeetCode design... | null |
Clean Example🔥🔥|| Full Explanation✅|| Priority Queue✅|| C++|| Java|| Python3 | ipo | 1 | 1 | # Intuition :\n- Here, We have to find maximum profit that can be achieved by selecting at most k projects to invest in, given an initial capital of W, a set of Profits and Capital requirements for each project.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach :\n- Here we are using tw... | 35 | Suppose LeetCode will start its **IPO** soon. In order to sell a good price of its shares to Venture Capital, LeetCode would like to work on some projects to increase its capital before the **IPO**. Since it has limited resources, it can only finish at most `k` distinct projects before the **IPO**. Help LeetCode design... | null |
Solution | next-greater-element-ii | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n vector<int> nextGreaterElements(vector<int>& nums) {\n int n = nums.size();\n stack<int> stk;\n vector<int> result(n);\n for(int i = 2 * n - 1; i >= 0; i--){\n while(!stk.empty() && stk.top() <= nums[i % n]) stk.pop();\n result[... | 1 | Given a circular integer array `nums` (i.e., the next element of `nums[nums.length - 1]` is `nums[0]`), return _the **next greater number** for every element in_ `nums`.
The **next greater number** of a number `x` is the first greater number to its traversing-order next in the array, which means you could search circu... | null |
🔥[Python 3] Monotonic stack 2 traversal approaches | next-greater-element-ii | 0 | 1 | ## Iteration from start to end:\n```python3\nclass Solution:\n def nextGreaterElements(self, nums: List[int]) -> List[int]:\n stack, L = [], len(nums)\n res = [-1] * L\n\n for i in range(L*2):\n idx = i % L\n while stack and nums[stack[-1]] < nums[idx]:\n res... | 4 | Given a circular integer array `nums` (i.e., the next element of `nums[nums.length - 1]` is `nums[0]`), return _the **next greater number** for every element in_ `nums`.
The **next greater number** of a number `x` is the first greater number to its traversing-order next in the array, which means you could search circu... | null |
Python Easy Solution | base-7 | 0 | 1 | # Code\n```\nclass Solution:\n def convertToBase7(self, num: int) -> str:\n if num==0:\n return "0"\n res=""\n flg=0\n if num<0:\n flg=1\n num=abs(num)\n while(num>0):\n res+=str(num%7)\n num//=7\n if flg==1:\n re... | 1 | Given an integer `num`, return _a string of its **base 7** representation_.
**Example 1:**
**Input:** num = 100
**Output:** "202"
**Example 2:**
**Input:** num = -7
**Output:** "-10"
**Constraints:**
* `-107 <= num <= 107` | null |
✅✅✅ Faster than 98% | Easy to understand | base-7 | 0 | 1 | ```\nclass Solution:\n def convertToBase7(self, num: int) -> str:\n if num==0: return "0"\n a=\'\'\n if num<0:\n num=-num\n a = \'-\'\n base7 = \'\'\n while num>0:\n base7+=str(num%7)\n num = num//7\n return a+base7[::-1]\n``` | 1 | Given an integer `num`, return _a string of its **base 7** representation_.
**Example 1:**
**Input:** num = 100
**Output:** "202"
**Example 2:**
**Input:** num = -7
**Output:** "-10"
**Constraints:**
* `-107 <= num <= 107` | null |
Solution | base-7 | 1 | 1 | ```C++ []\nclass Solution {\n public:\n string convertToBase7(int num) {\n if (num < 0)\n return "-" + convertToBase7(-num);\n if (num < 7)\n return to_string(num);\n return convertToBase7(num / 7) + to_string(num % 7);\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def convertToBase7(self, n:... | 2 | Given an integer `num`, return _a string of its **base 7** representation_.
**Example 1:**
**Input:** num = 100
**Output:** "202"
**Example 2:**
**Input:** num = -7
**Output:** "-10"
**Constraints:**
* `-107 <= num <= 107` | null |
Python 3 || 7 lines, modular arithmetic || T/M: 100% / 84% | base-7 | 0 | 1 | ```\nclass Solution:\n def convertToBase7(self, num: int) -> str:\n\n if num == 0: return \'0\'\n\n ans, n = \'\', abs(num)\n\n while n:\n n, m = divmod(n,7)\n ans+=str(m)\n\n if num < 0: ans+= \'-\'\n\n return ans[::-1]\n```\n[https://leetcode.com/problems/ba... | 4 | Given an integer `num`, return _a string of its **base 7** representation_.
**Example 1:**
**Input:** num = 100
**Output:** "202"
**Example 2:**
**Input:** num = -7
**Output:** "-10"
**Constraints:**
* `-107 <= num <= 107` | null |
504: Solution with step by step explanation | base-7 | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Check if the input number is 0, return "0" in this case.\n2. Initialize a flag to keep track of whether the number is negative or not.\n3. Convert the input number to a positive integer if it\'s negative by taking the abs... | 4 | Given an integer `num`, return _a string of its **base 7** representation_.
**Example 1:**
**Input:** num = 100
**Output:** "202"
**Example 2:**
**Input:** num = -7
**Output:** "-10"
**Constraints:**
* `-107 <= num <= 107` | null |
EFFICIENT PYTHON SOLUTION | base-7 | 0 | 1 | Given an integer num, return a string of its base 7 representation.\n\n \n# Code\n```\nclass Solution:\n def convertToBase7(self, num: int) -> str:\n \n ans=""\n temp=num\n num = abs(num)\n while(num>0):\n ans+=str(num%7)\n num//=7\n neg_case="-"+ans[::... | 2 | Given an integer `num`, return _a string of its **base 7** representation_.
**Example 1:**
**Input:** num = 100
**Output:** "202"
**Example 2:**
**Input:** num = -7
**Output:** "-10"
**Constraints:**
* `-107 <= num <= 107` | null |
python3 code | relative-ranks | 0 | 1 | \n\n# Approach\nThe approach of the code is to assign medals to the players based on their scores. The code first creates a copy of the scores list and then modifies it by replacing the top three scores with \'Gold Medal\', \'Silver Medal\', and \'Bronze Medal\'. The code then sorts the copy of the scores list in desce... | 1 | You are given an integer array `score` of size `n`, where `score[i]` is the score of the `ith` athlete in a competition. All the scores are guaranteed to be **unique**.
The athletes are **placed** based on their scores, where the `1st` place athlete has the highest score, the `2nd` place athlete has the `2nd` highest ... | null |
Readable Python solution | relative-ranks | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def findRelativeRanks(self, nums: List[int]) -> List[str]:\n d = defaultdict(int)\n place = ["Gold Medal", "Silver Medal", "Bronze Medal"]\n n = len(nums)\n a = [" "]*n\n for i in range(n): d[nums[i]] = i\n nums.sort(reverse=True)\n\n ... | 1 | You are given an integer array `score` of size `n`, where `score[i]` is the score of the `ith` athlete in a competition. All the scores are guaranteed to be **unique**.
The athletes are **placed** based on their scores, where the `1st` place athlete has the highest score, the `2nd` place athlete has the `2nd` highest ... | null |
Solution | relative-ranks | 1 | 1 | ```C++ []\nclass Solution {\n public:\n vector<string> findRelativeRanks(vector<int>& nums) {\n const int n = nums.size();\n vector<string> ans(n);\n vector<int> indices(n);\n\n iota(begin(indices), end(indices), 0);\n\n sort(begin(indices), end(indices),\n [&](const int a, const int b) { return... | 1 | You are given an integer array `score` of size `n`, where `score[i]` is the score of the `ith` athlete in a competition. All the scores are guaranteed to be **unique**.
The athletes are **placed** based on their scores, where the `1st` place athlete has the highest score, the `2nd` place athlete has the `2nd` highest ... | null |
Simpler solution with explanation | relative-ranks | 0 | 1 | \n\n# Code\n```\nclass Solution:\n def findRelativeRanks(self, score: List[int]) -> List[str]:\n score_positions = {score[i]: i for i in range(len(score))}\n \n # Sort the scores in descending order\n sorted_scores = sorted(score, reverse=True)\n \n # Create a dictionary to ... | 1 | You are given an integer array `score` of size `n`, where `score[i]` is the score of the `ith` athlete in a competition. All the scores are guaranteed to be **unique**.
The athletes are **placed** based on their scores, where the `1st` place athlete has the highest score, the `2nd` place athlete has the `2nd` highest ... | null |
🔥 [Python 3] 2 solutions: Heap and Sort | relative-ranks | 0 | 1 | # Sorting:\n```\nclass Solution:\n def findRelativeRanks(self, score: List[int]) -> List[str]:\n rank = ["Gold Medal", "Silver Medal", "Bronze Medal"] + list(map(str, range(4, len(score) + 1)))\n place = sorted(score, reverse = True)\n d = dict(zip(place, rank))\n\n return [d.get(s) for s... | 15 | You are given an integer array `score` of size `n`, where `score[i]` is the score of the `ith` athlete in a competition. All the scores are guaranteed to be **unique**.
The athletes are **placed** based on their scores, where the `1st` place athlete has the highest score, the `2nd` place athlete has the `2nd` highest ... | null |
Python Elegant & Short | O(n*log(n)) time | Sorting | relative-ranks | 0 | 1 | \tclass Solution:\n\t\t"""\n\t\tTime: O(n*log(n))\n\t\tMemory: O(n)\n\t\t"""\n\n\t\tMEDALS = {\n\t\t\t1: \'Gold Medal\',\n\t\t\t2: \'Silver Medal\',\n\t\t\t3: \'Bronze Medal\',\n\t\t}\n\n\t\tdef findRelativeRanks(self, nums: List[int]) -> List[str]:\n\t\t\tranks = {num: ind for ind, num in enumerate(sorted(nums, reve... | 4 | You are given an integer array `score` of size `n`, where `score[i]` is the score of the `ith` athlete in a competition. All the scores are guaranteed to be **unique**.
The athletes are **placed** based on their scores, where the `1st` place athlete has the highest score, the `2nd` place athlete has the `2nd` highest ... | null |
506: Time 99.42%, Solution with step by step explanation | relative-ranks | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define a function named findRelativeRanks that takes in an input list score and returns a list of strings as output.\n2. Create a copy of the input array and sort it in descending order, and store it in a new variable nam... | 8 | You are given an integer array `score` of size `n`, where `score[i]` is the score of the `ith` athlete in a competition. All the scores are guaranteed to be **unique**.
The athletes are **placed** based on their scores, where the `1st` place athlete has the highest score, the `2nd` place athlete has the `2nd` highest ... | null |
solution using hashmap-->python3 | relative-ranks | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 5 | You are given an integer array `score` of size `n`, where `score[i]` is the score of the `ith` athlete in a competition. All the scores are guaranteed to be **unique**.
The athletes are **placed** based on their scores, where the `1st` place athlete has the highest score, the `2nd` place athlete has the `2nd` highest ... | null |
The solution is in python3 | perfect-number | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | A [**perfect number**](https://en.wikipedia.org/wiki/Perfect_number) is a **positive integer** that is equal to the sum of its **positive divisors**, excluding the number itself. A **divisor** of an integer `x` is an integer that can divide `x` evenly.
Given an integer `n`, return `true` _if_ `n` _is a perfect number,... | null |
One Line of code Python-->Two Approaches | perfect-number | 0 | 1 | \n\n# 1. Only 5 perfect Number exist until 10^8\n```\nclass Solution:\n def checkPerfectNumber(self, num: int) -> bool:\n return num in [6,28,496,8128,33550336]\n//please upvote me it would encourage me alot\n\n```\n# 2. Rooting Approach [Accepted]\n```\nclass Solution:\n def checkPerfectNumber(self, num: ... | 34 | A [**perfect number**](https://en.wikipedia.org/wiki/Perfect_number) is a **positive integer** that is equal to the sum of its **positive divisors**, excluding the number itself. A **divisor** of an integer `x` is an integer that can divide `x` evenly.
Given an integer `n`, return `true` _if_ `n` _is a perfect number,... | null |
507: Solution with step by step explanation | perfect-number | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Check if the input number num is less than 2 (no even perfect number exists). If so, return False.\n2. Initialize the limit limit to the square root of num rounded up to the nearest integer, plus 1.\n3. Initialize the sum... | 3 | A [**perfect number**](https://en.wikipedia.org/wiki/Perfect_number) is a **positive integer** that is equal to the sum of its **positive divisors**, excluding the number itself. A **divisor** of an integer `x` is an integer that can divide `x` evenly.
Given an integer `n`, return `true` _if_ `n` _is a perfect number,... | null |
Solution | perfect-number | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n bool checkPerfectNumber(int num) {\n int sum = 1;\n for(int i = 2; i <= sqrt(num); ++i)\n if (num % i == 0) {\n sum += i + num/i;\n }\n if (sqrt(num)*sqrt(num)==num) sum -= sqrt(num);\n return sum==num;\n }\n};... | 2 | A [**perfect number**](https://en.wikipedia.org/wiki/Perfect_number) is a **positive integer** that is equal to the sum of its **positive divisors**, excluding the number itself. A **divisor** of an integer `x` is an integer that can divide `x` evenly.
Given an integer `n`, return `true` _if_ `n` _is a perfect number,... | null |
Easy to understand | perfect-number | 0 | 1 | # Solution\n```\nclass Solution:\n def checkPerfectNumber(self, num: int) -> bool:\n if num==1: return False\n answer = 1\n i = 2\n while i*i<num:\n if num%i==0: answer+=i+num//i\n i+=1\n if i*i==num: answer+=i\n return answer==num\n``` | 2 | A [**perfect number**](https://en.wikipedia.org/wiki/Perfect_number) is a **positive integer** that is equal to the sum of its **positive divisors**, excluding the number itself. A **divisor** of an integer `x` is an integer that can divide `x` evenly.
Given an integer `n`, return `true` _if_ `n` _is a perfect number,... | null |
Python simple solution fully explained | perfect-number | 0 | 1 | # Intuition\nThe intuition behind the solution is to iterate through all the numbers from 2 up to the square root of the given number. For each number, check if it is a divisor of the given number. If it is a divisor, add both the divisor and the quotient obtained by dividing the given number by the divisor to a runnin... | 4 | A [**perfect number**](https://en.wikipedia.org/wiki/Perfect_number) is a **positive integer** that is equal to the sum of its **positive divisors**, excluding the number itself. A **divisor** of an integer `x` is an integer that can divide `x` evenly.
Given an integer `n`, return `true` _if_ `n` _is a perfect number,... | null |
Python3 simple solution | perfect-number | 0 | 1 | ```\nclass Solution:\n def checkPerfectNumber(self, num: int) -> bool:\n if num == 1:\n return False\n res = 1\n for i in range(2,int(num**0.5)+1):\n if num%i == 0:\n res += i + num//i\n return res == num\n```\n**If you like this solution, please upvot... | 15 | A [**perfect number**](https://en.wikipedia.org/wiki/Perfect_number) is a **positive integer** that is equal to the sum of its **positive divisors**, excluding the number itself. A **divisor** of an integer `x` is an integer that can divide `x` evenly.
Given an integer `n`, return `true` _if_ `n` _is a perfect number,... | null |
[Python] it's kinda cheating but anyway it works | perfect-number | 0 | 1 | # Complexity\n- Time complexity: O(1)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def checkPerfectNumber(self, num: int) -> bool:\n pefectnum = [6, 28, 496, 8128, 33550336]\n ... | 4 | A [**perfect number**](https://en.wikipedia.org/wiki/Perfect_number) is a **positive integer** that is equal to the sum of its **positive divisors**, excluding the number itself. A **divisor** of an integer `x` is an integer that can divide `x` evenly.
Given an integer `n`, return `true` _if_ `n` _is a perfect number,... | null |
508: Solution with step by step explanation | most-frequent-subtree-sum | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define a dictionary \'freq\' to store the frequency of each subtree sum.\n2. Define a helper function \'subtree_sum\' to calculate the subtree sum of a node. The function takes a node as input and returns the sum of value... | 2 | Given the `root` of a binary tree, return the most frequent **subtree sum**. If there is a tie, return all the values with the highest frequency in any order.
The **subtree sum** of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself).
**Example 1:*... | null |
Simple solution with Binary Tree in Python3 | most-frequent-subtree-sum | 0 | 1 | # Intuition\nHere we have:\n- `root` as Binary Tree\n- our goal is to find **the most frequent** subtree sum\n\nThe algorithm is simple: traverse over tree, calculate subtree sum, store it into **HashMap** and extract **the most frequent**.\n\n# Approach\n1. declare `cache` and `maxFreq` to define max frequency of part... | 1 | Given the `root` of a binary tree, return the most frequent **subtree sum**. If there is a tie, return all the values with the highest frequency in any order.
The **subtree sum** of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself).
**Example 1:*... | null |
Python || DFS || Hashmap || Beats 98 % | most-frequent-subtree-sum | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nStore all the subtree sum using dfs then use a hashmap to count the occurance of all the sum then find the count which is the most frequent and the iterate through the values of hashmap and then use a result list to store the keys of the values which ... | 1 | Given the `root` of a binary tree, return the most frequent **subtree sum**. If there is a tie, return all the values with the highest frequency in any order.
The **subtree sum** of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself).
**Example 1:*... | null |
Solution | most-frequent-subtree-sum | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int dfs(TreeNode* root, unordered_map<int, int>& sums) {\n if(root == NULL) return 0;\n \n int sum = root->val;\n sum += dfs(root->left, sums);\n sum += dfs(root->right, sums);\n\n sums[sum]++;\n\n return sum;\n }\n vector<... | 1 | Given the `root` of a binary tree, return the most frequent **subtree sum**. If there is a tie, return all the values with the highest frequency in any order.
The **subtree sum** of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself).
**Example 1:*... | null |
Fast Python Recursive solution | most-frequent-subtree-sum | 0 | 1 | Hash map + DFS recursively.\n\n```python\nclass Solution:\n # 48 ms, 99%\n def findFrequentTreeSum(self, root: TreeNode) -> List[int]:\n if not root: return []\n \n D = collections.defaultdict(int)\n # DFS recursively\n\t\tdef cal_sum(node):\n if not node: return 0\n ... | 12 | Given the `root` of a binary tree, return the most frequent **subtree sum**. If there is a tie, return all the values with the highest frequency in any order.
The **subtree sum** of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself).
**Example 1:*... | null |
Easy Solution ✅ | fibonacci-number | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 2 | The **Fibonacci numbers**, commonly denoted `F(n)` form a sequence, called the **Fibonacci sequence**, such that each number is the sum of the two preceding ones, starting from `0` and `1`. That is,
F(0) = 0, F(1) = 1
F(n) = F(n - 1) + F(n - 2), for n > 1.
Given `n`, calculate `F(n)`.
**Example 1:**
**Input:** n = ... | null |
Easy Solution ✅ | fibonacci-number | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 2 | Given an array of integers `arr`, return `true` if we can partition the array into three **non-empty** parts with equal sums.
Formally, we can partition the array if we can find indexes `i + 1 < j` with `(arr[0] + arr[1] + ... + arr[i] == arr[i + 1] + arr[i + 2] + ... + arr[j - 1] == arr[j] + arr[j + 1] + ... + arr[ar... | null |
Easy java solution ,c,c++,python | fibonacci-number | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 3 | The **Fibonacci numbers**, commonly denoted `F(n)` form a sequence, called the **Fibonacci sequence**, such that each number is the sum of the two preceding ones, starting from `0` and `1`. That is,
F(0) = 0, F(1) = 1
F(n) = F(n - 1) + F(n - 2), for n > 1.
Given `n`, calculate `F(n)`.
**Example 1:**
**Input:** n = ... | null |
Easy java solution ,c,c++,python | fibonacci-number | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 3 | Given an array of integers `arr`, return `true` if we can partition the array into three **non-empty** parts with equal sums.
Formally, we can partition the array if we can find indexes `i + 1 < j` with `(arr[0] + arr[1] + ... + arr[i] == arr[i + 1] + arr[i + 2] + ... + arr[j - 1] == arr[j] + arr[j + 1] + ... + arr[ar... | null |
Beats 100% | Easy To Understand | 0ms 🚀🔥 | fibonacci-number | 1 | 1 | # Intuition\n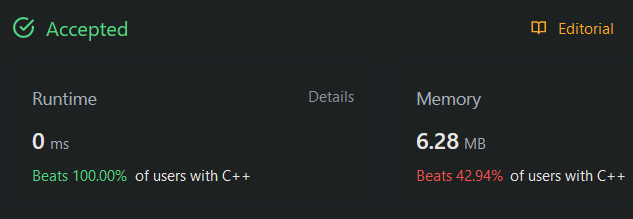\n\n\n\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n Upvote if you find this helpful!!\n<!-- Describe your approach to solving th... | 6 | The **Fibonacci numbers**, commonly denoted `F(n)` form a sequence, called the **Fibonacci sequence**, such that each number is the sum of the two preceding ones, starting from `0` and `1`. That is,
F(0) = 0, F(1) = 1
F(n) = F(n - 1) + F(n - 2), for n > 1.
Given `n`, calculate `F(n)`.
**Example 1:**
**Input:** n = ... | null |
Beats 100% | Easy To Understand | 0ms 🚀🔥 | fibonacci-number | 1 | 1 | # Intuition\n\n\n\n\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n Upvote if you find this helpful!!\n<!-- Describe your approach to solving th... | 6 | Given an array of integers `arr`, return `true` if we can partition the array into three **non-empty** parts with equal sums.
Formally, we can partition the array if we can find indexes `i + 1 < j` with `(arr[0] + arr[1] + ... + arr[i] == arr[i + 1] + arr[i + 2] + ... + arr[j - 1] == arr[j] + arr[j + 1] + ... + arr[ar... | null |
🧩 [VIDEO] Fast Mastering the Fibonacci Sequence with Dynamic Programming Unraveled | fibonacci-number | 1 | 1 | # Intuition\nUpon reading this problem, my first thoughts were to use the concept of dynamic programming. The problem requires us to find the \'n-th\' Fibonacci number which is a classic example where dynamic programming can be utilized. The Fibonacci sequence has a special property where each number is the sum of the ... | 8 | The **Fibonacci numbers**, commonly denoted `F(n)` form a sequence, called the **Fibonacci sequence**, such that each number is the sum of the two preceding ones, starting from `0` and `1`. That is,
F(0) = 0, F(1) = 1
F(n) = F(n - 1) + F(n - 2), for n > 1.
Given `n`, calculate `F(n)`.
**Example 1:**
**Input:** n = ... | null |
🧩 [VIDEO] Fast Mastering the Fibonacci Sequence with Dynamic Programming Unraveled | fibonacci-number | 1 | 1 | # Intuition\nUpon reading this problem, my first thoughts were to use the concept of dynamic programming. The problem requires us to find the \'n-th\' Fibonacci number which is a classic example where dynamic programming can be utilized. The Fibonacci sequence has a special property where each number is the sum of the ... | 8 | Given an array of integers `arr`, return `true` if we can partition the array into three **non-empty** parts with equal sums.
Formally, we can partition the array if we can find indexes `i + 1 < j` with `(arr[0] + arr[1] + ... + arr[i] == arr[i + 1] + arr[i + 2] + ... + arr[j - 1] == arr[j] + arr[j + 1] + ... + arr[ar... | null |
Python | Basic solution to Advanced ✅ | fibonacci-number | 0 | 1 | # Solution #1 (Basic)\n\n# Intuition and Approach\nUsing standard recursion. For n > 1, Fn should return Fn-1 + Fn-2.\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: 2^n (Exponential complexity)\n- Space complexity: O(n) since maximum depth of the recursion tree is n.\n<!-- ... | 4 | The **Fibonacci numbers**, commonly denoted `F(n)` form a sequence, called the **Fibonacci sequence**, such that each number is the sum of the two preceding ones, starting from `0` and `1`. That is,
F(0) = 0, F(1) = 1
F(n) = F(n - 1) + F(n - 2), for n > 1.
Given `n`, calculate `F(n)`.
**Example 1:**
**Input:** n = ... | null |
Python | Basic solution to Advanced ✅ | fibonacci-number | 0 | 1 | # Solution #1 (Basic)\n\n# Intuition and Approach\nUsing standard recursion. For n > 1, Fn should return Fn-1 + Fn-2.\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: 2^n (Exponential complexity)\n- Space complexity: O(n) since maximum depth of the recursion tree is n.\n<!-- ... | 4 | Given an array of integers `arr`, return `true` if we can partition the array into three **non-empty** parts with equal sums.
Formally, we can partition the array if we can find indexes `i + 1 < j` with `(arr[0] + arr[1] + ... + arr[i] == arr[i + 1] + arr[i + 2] + ... + arr[j - 1] == arr[j] + arr[j + 1] + ... + arr[ar... | null |
Find bottom left tree value | find-bottom-left-tree-value | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
Solution | find-bottom-left-tree-value | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n void calculate(TreeNode* head,int level,int &maxlevel,int &ans){\n if(level>maxlevel){\n ans=head->val;\n maxlevel=level;\n }\n if(head->left){\n calculate(head->left,level+1,maxlevel,ans);\n }\n if(head->right... | 1 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
python solution || Pre Order Traversal || Recursion || Easy to understand | find-bottom-left-tree-value | 0 | 1 | ```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:\n self.leftmostelm = root... | 1 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
Solution Python Easy | find-bottom-left-tree-value | 0 | 1 | # Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:\n q = [root]\n ... | 1 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
BFS || DFS || Python || SOlution | find-bottom-left-tree-value | 0 | 1 | \n\n# Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:\n if not root... | 1 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
Beats 95% with explanation | find-bottom-left-tree-value | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nCreate a queue within which we can iterate over the tree, while doing it, keep track of most left node, (because we prioritazing left over right), once we are done wit... | 1 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
513: Solution with step by step explanation | find-bottom-left-tree-value | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize a queue with the root node.\n2. Initialize a variable to store the leftmost node value as the value of the root node.\n3. Perform level-order traversal using a while loop until the queue becomes empty.\n4. Get ... | 7 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
python3 solution beats 96% | find-bottom-left-tree-value | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 1 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
Just do Level-Order -->Python solution | find-bottom-left-tree-value | 0 | 1 | \n# Code\n```\nclass Solution:\n def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:\n a = []\n\n def dfs(node, h):\n if not node: return\n if len(a) == h: a.append([])\n\n a[h].append(node.val)\n dfs(node.left, h+1)\n dfs(node.right, h... | 2 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
Pyhton3 BFS Solution || BGG | find-bottom-left-tree-value | 0 | 1 | ```\nclass Solution:\n def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:\n q=[[root]]\n nodes=[]\n while q:\n nodes = q.pop(0)\n t=[]\n for n in nodes:\n if n.left:\n t.append(n.left)\n if n.right:\n ... | 2 | Given the `root` of a binary tree, return the leftmost value in the last row of the tree.
**Example 1:**
**Input:** root = \[2,1,3\]
**Output:** 1
**Example 2:**
**Input:** root = \[1,2,3,4,null,5,6,null,null,7\]
**Output:** 7
**Constraints:**
* The number of nodes in the tree is in the range `[1, 104]`.
* `-... | null |
Solution | freedom-trail | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int dist(int size, int p, int t){\n return min(abs(t - p), size - abs(t - p));\n }\n int findRotateSteps(string ring, string key){\n int m[26][100] = {{0}};\n int cnt[26] = {0};\n int dp[100][100] = {{0}};\n\n const int rn = ring.size();... | 1 | In the video game Fallout 4, the quest **"Road to Freedom "** requires players to reach a metal dial called the **"Freedom Trail Ring "** and use the dial to spell a specific keyword to open the door.
Given a string `ring` that represents the code engraved on the outer ring and another string `key` that represents the... | null |
514: Solution with step by step explanation | freedom-trail | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define a function dp(i, j) that takes two parameters:\ni: index of the character in the ring that is currently aligned with the "12:00" direction.\nj: index of the character in the key that needs to be spelled.\n2. If the... | 4 | In the video game Fallout 4, the quest **"Road to Freedom "** requires players to reach a metal dial called the **"Freedom Trail Ring "** and use the dial to spell a specific keyword to open the door.
Given a string `ring` that represents the code engraved on the outer ring and another string `key` that represents the... | null |
Python 3 || 8 lines, dfs, dict || T/M: 67% / 28% | freedom-trail | 0 | 1 | ```\nclass Solution:\n def findRotateSteps(self, ring, key):\n \n rLen, kLen, d = len(ring), len(key), defaultdict(list)\n dist = lambda x,y : min((x-y)%rLen, (y-x)%rLen)\n\n for i, ch in enumerate(ring): d[ch].append(i)\n\n @lru_cache(None)\n def dfs(curr = 0,next = 0):\n\n... | 3 | In the video game Fallout 4, the quest **"Road to Freedom "** requires players to reach a metal dial called the **"Freedom Trail Ring "** and use the dial to spell a specific keyword to open the door.
Given a string `ring` that represents the code engraved on the outer ring and another string `key` that represents the... | null |
Python3 with explanation | freedom-trail | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ --... | 0 | In the video game Fallout 4, the quest **"Road to Freedom "** requires players to reach a metal dial called the **"Freedom Trail Ring "** and use the dial to spell a specific keyword to open the door.
Given a string `ring` that represents the code engraved on the outer ring and another string `key` that represents the... | null |
Python solution beats 98.67% | freedom-trail | 0 | 1 | # Code\n```\nclass Solution:\n def findRotateSteps(self, ring: str, key: str) -> int:\n ln=len(ring)\n kln=len(key)\n def getSetp(id1,id2):\n d=abs(id1-id2)\n return min(d,ln-d)+1\n \n mp=defaultdict(list)\n for i,n in enumerate(ring):\n mp[n].ap... | 0 | In the video game Fallout 4, the quest **"Road to Freedom "** requires players to reach a metal dial called the **"Freedom Trail Ring "** and use the dial to spell a specific keyword to open the door.
Given a string `ring` that represents the code engraved on the outer ring and another string `key` that represents the... | null |
Python DP, Beats 100%. Easy explained with comments. | freedom-trail | 0 | 1 | # Code\n```\nclass Solution:\n def findRotateSteps(self, ring: str, key: str) -> int:\n index = defaultdict(list)\n #Index Hashing\n for i in range(len(ring)):\n index[ring[i]].append(i)\n #DFS function + DP\n @lru_cache\n def dfs(r, k):\n if k == len(k... | 0 | In the video game Fallout 4, the quest **"Road to Freedom "** requires players to reach a metal dial called the **"Freedom Trail Ring "** and use the dial to spell a specific keyword to open the door.
Given a string `ring` that represents the code engraved on the outer ring and another string `key` that represents the... | null |
✅☑[C++/Java/Python/JavaScript] || 3 Approaches || EXPLAINED🔥 | find-largest-value-in-each-tree-row | 1 | 1 | # PLEASE UPVOTE IF IT HELPED\n\n---\n\n\n# Approaches\n**(Also explained in the code)**\n\n#### ***Approach 1 (BFS)***\n1. The function takes a pointer to the root of a binary tree as input, represented by the `TreeNode` class. The goal is to find the largest values at each level of the tree.\n\n1. The function starts ... | 4 | Given the `root` of a binary tree, return _an array of the largest value in each row_ of the tree **(0-indexed)**.
**Example 1:**
**Input:** root = \[1,3,2,5,3,null,9\]
**Output:** \[1,3,9\]
**Example 2:**
**Input:** root = \[1,2,3\]
**Output:** \[1,3\]
**Constraints:**
* The number of nodes in the tree will be... | null |
BFS Solution | find-largest-value-in-each-tree-row | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nTraverse through each of the level uisng BFS and find the maximum value.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nInstead of calculating the height of the tree to store the result, we directly traverse the t... | 1 | Given the `root` of a binary tree, return _an array of the largest value in each row_ of the tree **(0-indexed)**.
**Example 1:**
**Input:** root = \[1,3,2,5,3,null,9\]
**Output:** \[1,3,9\]
**Example 2:**
**Input:** root = \[1,2,3\]
**Output:** \[1,3\]
**Constraints:**
* The number of nodes in the tree will be... | null |
Python Solution using Queue and Map | find-largest-value-in-each-tree-row | 0 | 1 | \n\n# Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\n\ndef max_from_rows(root):\n if not root:\n return\n \n queue = []\n queue.append(root... | 1 | Given the `root` of a binary tree, return _an array of the largest value in each row_ of the tree **(0-indexed)**.
**Example 1:**
**Input:** root = \[1,3,2,5,3,null,9\]
**Output:** \[1,3,9\]
**Example 2:**
**Input:** root = \[1,2,3\]
**Output:** \[1,3\]
**Constraints:**
* The number of nodes in the tree will be... | null |
✅ 98.68% BFS | find-largest-value-in-each-tree-row | 1 | 1 | # Intuition\nWhen presented with this problem, the immediate thought is to traverse through the tree level by level. This is because we need to determine the maximum value in each row. Level order traversal, also known as breadth-first search (BFS) for trees, is the ideal strategy for this. Using a queue, we can explor... | 48 | Given the `root` of a binary tree, return _an array of the largest value in each row_ of the tree **(0-indexed)**.
**Example 1:**
**Input:** root = \[1,3,2,5,3,null,9\]
**Output:** \[1,3,9\]
**Example 2:**
**Input:** root = \[1,2,3\]
**Output:** \[1,3\]
**Constraints:**
* The number of nodes in the tree will be... | null |
Easiest Solution || Python | find-largest-value-in-each-tree-row | 0 | 1 | # Intuition\nVery easy approach by using BFS.\n\n# Approach\nAppending elements to queue by iterating through left and right childs of each element and poping and finding maximum at each level.\n\n# Complexity\n- Time complexity:\nO(n)\n- Space complexity:\nO(max_width)\n\n# Code\n```\n# Definition for a binary tree no... | 1 | Given the `root` of a binary tree, return _an array of the largest value in each row_ of the tree **(0-indexed)**.
**Example 1:**
**Input:** root = \[1,3,2,5,3,null,9\]
**Output:** \[1,3,9\]
**Example 2:**
**Input:** root = \[1,2,3\]
**Output:** \[1,3\]
**Constraints:**
* The number of nodes in the tree will be... | null |
Python3 DFS approach | find-largest-value-in-each-tree-row | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nI used a recursive approach to solve the question.In particular the dfs traversal.I started from the first node and traversed each node storing the maximum value on ea... | 1 | Given the `root` of a binary tree, return _an array of the largest value in each row_ of the tree **(0-indexed)**.
**Example 1:**
**Input:** root = \[1,3,2,5,3,null,9\]
**Output:** \[1,3,9\]
**Example 2:**
**Input:** root = \[1,2,3\]
**Output:** \[1,3\]
**Constraints:**
* The number of nodes in the tree will be... | null |
Beats 98% of the users in Python3 in both Time and Space, O(n^2) solution Clean Short Code. | longest-palindromic-subsequence | 0 | 1 | # Intuition\n\n\n# Complexity\n- Time complexity:\n- O(n^2)\n\n- Space complexity:\n- O(n)\n\n# Code\n```\nclass Solution:\n def longestPalindromeSubseq(self, s: str) -> int:\n \n l=[0]*... | 1 | Given a string `s`, find _the longest palindromic **subsequence**'s length in_ `s`.
A **subsequence** is a sequence that can be derived from another sequence by deleting some or no elements without changing the order of the remaining elements.
**Example 1:**
**Input:** s = "bbbab "
**Output:** 4
**Explanation:** On... | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.