
Retry network requests on failure
In 1985 Jim Gray proposed the following conjecture1…
most production…faults are soft. If…reinitialized and…retried, the operation will usually not fail the second time.
This suggests that there are a large variety of bugs in software due to inexplicable and ephemeral causes. Many of our network connections experience these types of Heisenbugs which occur at random and are hard to debug. This pipeline processor exists to limit the extent to which these temporary failures impact Calypso and those developers writing code which interacts with HTTP requests.
What is a failed network request?
There are two reasons a network request can fail. The first is because the request was invalid and the remote server legitimately returned an error. The second is because something along the network path failed even though the request was legitimate. Network failures can occur on slow network connections, when transitioning from one network to another, when physical cables are cut, when routers crash, and in one of any number of different ways.
Because most of these failures are transient we can pause before considering a failed request as a true failure. A failed request is one which fails after we have given it every reasonable attempt to succeed.
What happens with failing requests?
We really don't want to have to write separate error handlers for these kinds of transient faults in every bit of code which interacts with HTTP requests.
Instead, we can apply policies to the request descriptions which indicate how failures should be treated and provide a default behavior.
When the request comes back as a failure we track its state and simply resend the request (if we determine that we can).
Repeated failures are compared against the state tracking to determine if we should continue to attempt resending it.
Once the reasonable effort has been exhausted we consider the request truly as a failure and re-inject it to the HTTP layer where the onFailure action will be dispatched.
How can we safely replay a failed network request?
Certain requests are assumed to be safe and idempotent if they are GET requests with matching path, version, and query parameters.
Usage
A default policy attaches to all failed network requests unless specifically overwritten with a custom policy.
At the time of writing the default is the exponential-backoff retry policy with an initial delay of 1000 ms and up to three retry attempts.
This means that nothing needs to be done explicitly in order to take advantage of this retry mechanism.
Custom policies can specify that we don't want to attempt a retry at all; and we can change the initial delay and max retry count.
These are added with the retryPolicy override in the HTTP request description.
// stop retry attempts
import {
noRetry,
exponentialBackoff,
} from 'calypso/state/data-layer/wpcom-http/pipeline/retry-on-failure/policies';
dispatch(
http(
{
path: '/sites',
method: 'GET',
onSuccess,
onFailure,
retryPolicy: noRetry(),
},
action
)
);
// moar attempts for a notoriously slow and buggy server
dispatch(
http(
{
path: '/sites',
method: 'GET',
onSuccess,
onFailure,
retryPolicy: exponentialBackoff( { delay: 4000, maxAttempts: 5 } ),
},
action
)
);
Delay calculation
The delay algorithm is designed to mitigate congestion which can occur as a side-effect of simple retry delays. For example, if a specific API endpoint were to unexpectedly fail and cascade to ten thousand clients, we would want to make sure that those ten thousand clients don't all attempt their retry at or around the same time. By introducing pseudo-randomness and jitter into the calculated delay times we can spread out the failure resolution and prevent further failure cascades.
The following histograms represent trial calculations for retry attempts numbered by graph, each containing five thousand delay computations. The shapes of the histograms illustrate what kinds of delay values are typical, normalized to the base delay.
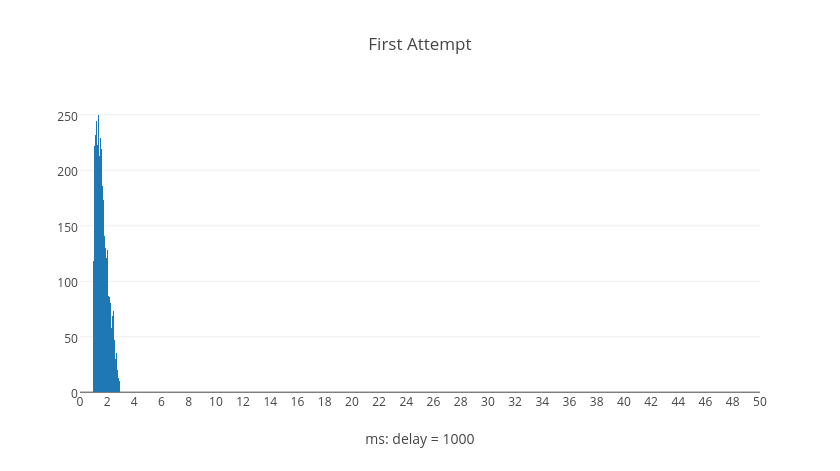
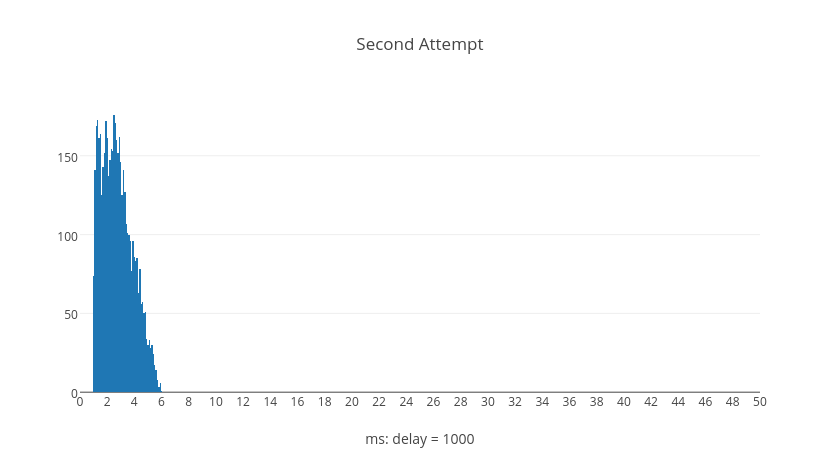
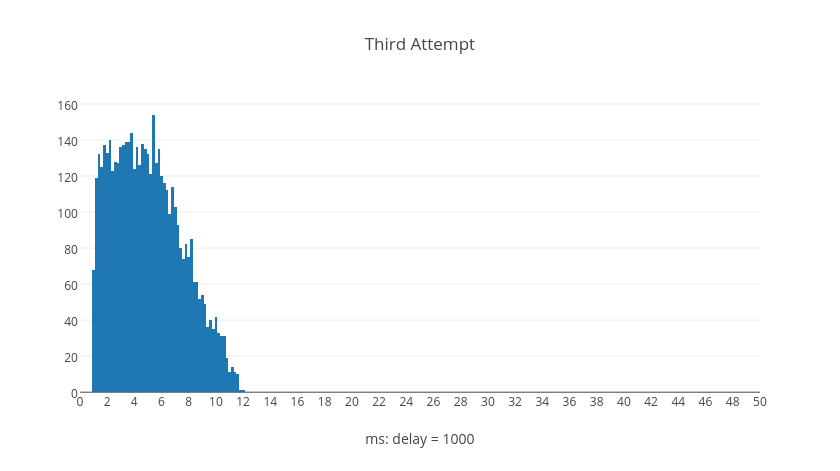
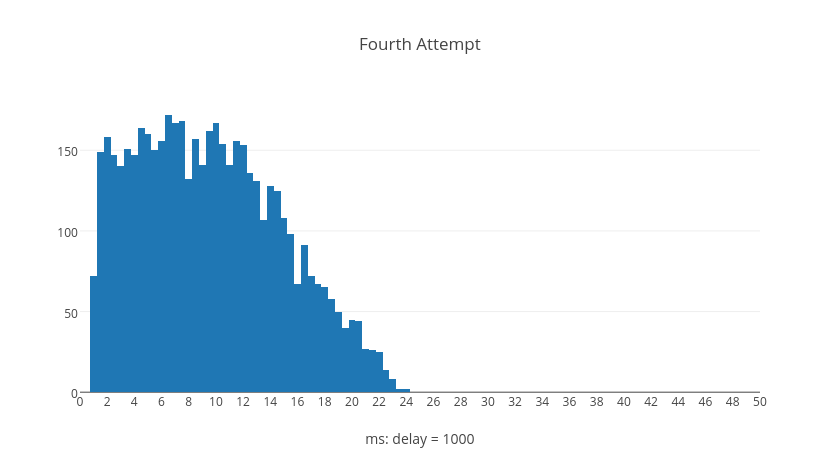
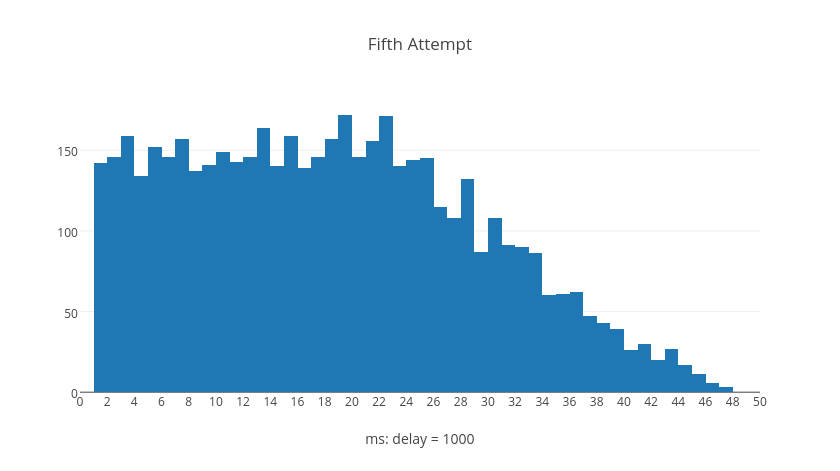
Surprisingly we can see from the graphs that it's possible for later retry attempts to have shorter delays than earlier retry attempts. However, if we examine what happens over the average total delay time when a request resolves after a given number of retries we can see a different picture. These next histograms show the total delay time for all requests given the number of retries, each with five thousand trial calculations.
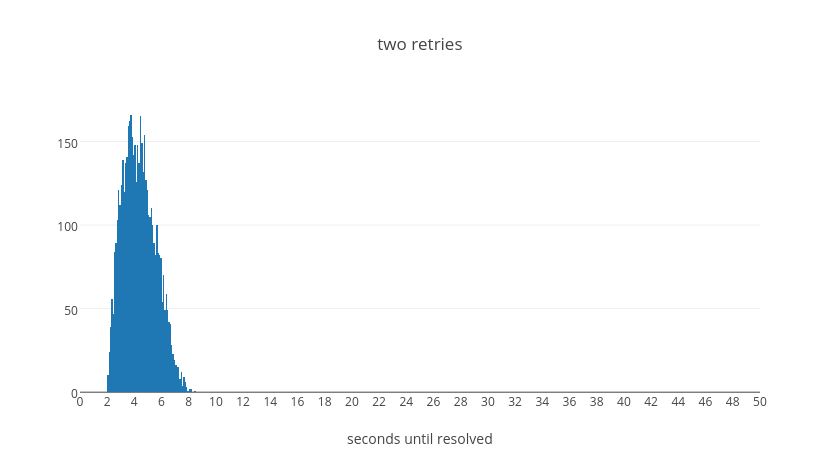
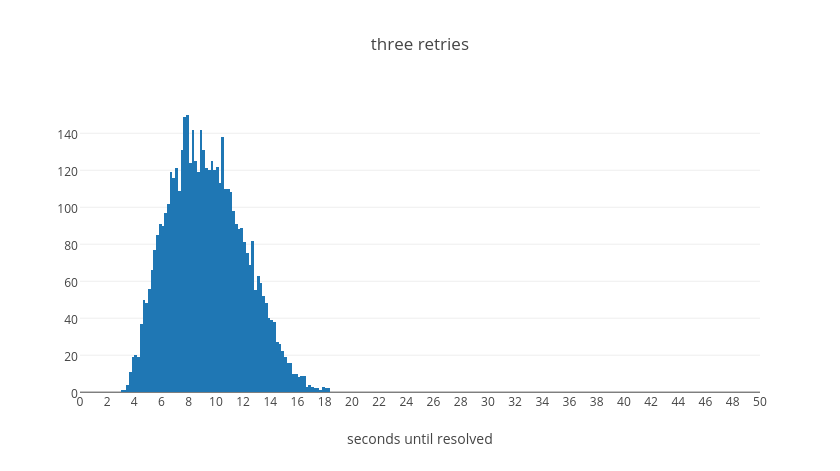
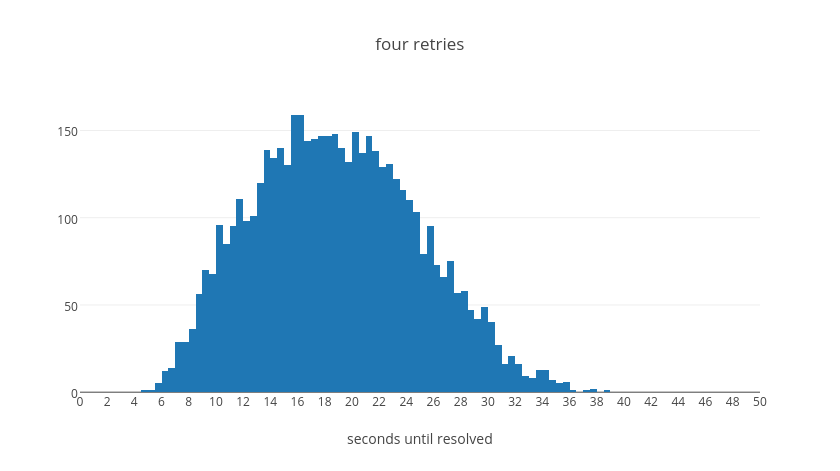
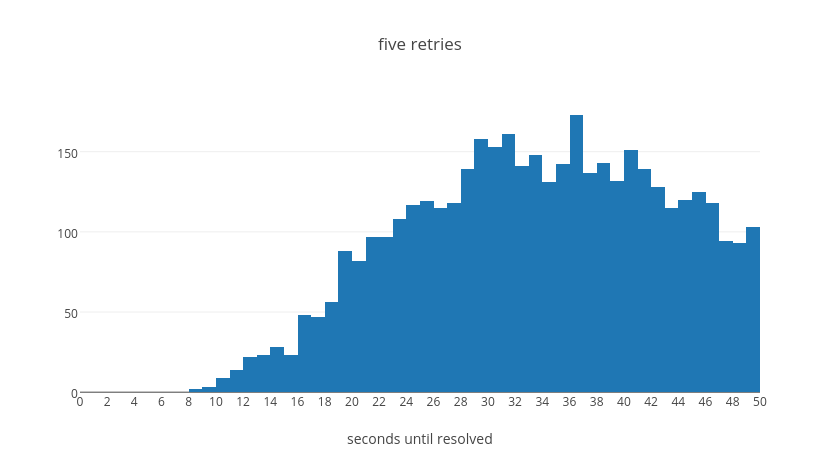
The entire expected wait time corresponds to an exponential shape. That is to say, we expect the total wait time to be exponential with the number of retry attempts it requires before resolution. The following table summaries then total average wait times for when a request resolves after the given number of retries, normalized to the base delay.
| # Retries | Expected Wait Time |
|---|---|
| 1 | 1.627 |
| 2 | 4.368 |
| 3 | 9.385 |
| 4 | 18.91 |
| 5 | 37.34 |
From this table we can see that in the average case even if a request takes five retry attempts it should be resolved within about 45 seconds. With four attempts, we can see that the vast majority will resolve within about 35s. With three attempts, almost everything will resolve within about 20s. With two attempts, everything within 10s. Finally with a single retry we will have resolution within 2s. These values were tuned experimentally to make a call on how long we believe it should take for a request to continue failing before we give up on it. We believe that if a request will succeed it should resolve in most cases in less than 40s overall.
1 Tandem Technical Report 85.7, June 1985, PN87614