
url stringlengths 61 61 | repository_url stringclasses 1
value | labels_url stringlengths 75 75 | comments_url stringlengths 70 70 | events_url stringlengths 68 68 | html_url stringlengths 49 51 | id int64 1.12B 1.61B | node_id stringlengths 18 19 | number int64 3.68k 5.61k | title stringlengths 1 290 | user dict | labels list | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees list | milestone dict | comments sequence | created_at timestamp[s] | updated_at timestamp[s] | closed_at timestamp[s] | author_association stringclasses 3
values | active_lock_reason null | draft bool 2
classes | pull_request dict | body stringlengths 2 33.9k ⌀ | reactions dict | timeline_url stringlengths 70 70 | performed_via_github_app null | state_reason stringclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5614/comments | https://api.github.com/repos/huggingface/datasets/issues/5614/events | https://github.com/huggingface/datasets/pull/5614 | 1,611,896,357 | PR_kwDODunzps5LZOTd | 5,614 | Fix archive fs test | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5614). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-03-06T17:28:09 | 2023-03-06T17:34:25 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5614",
"html_url": "https://github.com/huggingface/datasets/pull/5614",
"diff_url": "https://github.com/huggingface/datasets/pull/5614.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5614.patch",
"merged_at": null
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5614/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5614/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5613/comments | https://api.github.com/repos/huggingface/datasets/issues/5613/events | https://github.com/huggingface/datasets/issues/5613 | 1,611,875,473 | I_kwDODunzps5gE0SR | 5,613 | Version mismatch with multiprocess and dill on Python 3.10 | {
"login": "adampauls",
"id": 1243668,
"node_id": "MDQ6VXNlcjEyNDM2Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adampauls",
"html_url": "https://github.com/adampauls",
"followers_url": "https://api.github.com/users/ad... | [] | closed | false | null | [] | null | [
"Sorry, I just found https://github.com/apache/beam/issues/24458. It seems this issue is being worked on. "
] | 2023-03-06T17:14:41 | 2023-03-06T17:47:18 | 2023-03-06T17:47:17 | NONE | null | null | null | ### Describe the bug
Grabbing the latest version of `datasets` and `apache-beam` with `poetry` using Python 3.10 gives a crash at runtime. The crash is
```
File "/Users/adpauls/sc/git/DSI-transformers/data/NQ/create_NQ_train_vali.py", line 1, in <module>
import datasets
File "/Users/adpauls/Library/Caches/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5613/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5613/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5612/comments | https://api.github.com/repos/huggingface/datasets/issues/5612/events | https://github.com/huggingface/datasets/issues/5612 | 1,611,262,510 | I_kwDODunzps5gCeou | 5,612 | Arrow map type in parquet files unsupported | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/... | [] | open | false | null | [] | null | [] | 2023-03-06T12:03:24 | 2023-03-06T12:32:10 | null | MEMBER | null | null | null | ### Describe the bug
When I try to load parquet files that were processed with Spark, I get the following issue:
`ValueError: Arrow type map<string, string ('warc_headers')> does not have a datasets dtype equivalent.`
Strangely, loading the dataset with `streaming=True` solves the issue.
### Steps to reproduce ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5612/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5612/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5611/comments | https://api.github.com/repos/huggingface/datasets/issues/5611/events | https://github.com/huggingface/datasets/pull/5611 | 1,611,197,906 | PR_kwDODunzps5LW2Lx | 5,611 | add Dataset.to_list | {
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5611). All of your documentation changes will be reflected on that endpoint.",
"Hi, thanks for working on this! `Table.to_pylist` requires PyArrow 7.0+, and our minimal version requirement is 6.0, so we need to bump the version... | 2023-03-06T11:21:57 | 2023-03-06T16:37:37 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5611",
"html_url": "https://github.com/huggingface/datasets/pull/5611",
"diff_url": "https://github.com/huggingface/datasets/pull/5611.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5611.patch",
"merged_at": null
} | close https://github.com/huggingface/datasets/issues/5606
This PR is for adding the `Dataset.to_list` method.
Thank you in advance.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5611/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5610/comments | https://api.github.com/repos/huggingface/datasets/issues/5610/events | https://github.com/huggingface/datasets/issues/5610 | 1,610,698,006 | I_kwDODunzps5gAU0W | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | {
"login": "gromzhu",
"id": 15223544,
"node_id": "MDQ6VXNlcjE1MjIzNTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/15223544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gromzhu",
"html_url": "https://github.com/gromzhu",
"followers_url": "https://api.github.com/users/gromzh... | [] | open | false | null | [] | null | [] | 2023-03-06T05:26:49 | 2023-03-06T05:37:10 | null | NONE | null | null | null | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, Sequenti... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5610/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5610/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5609/comments | https://api.github.com/repos/huggingface/datasets/issues/5609/events | https://github.com/huggingface/datasets/issues/5609 | 1,610,062,862 | I_kwDODunzps5f95wO | 5,609 | `load_from_disk` vs `load_dataset` performance. | {
"login": "davidgilbertson",
"id": 4443482,
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidgilbertson",
"html_url": "https://github.com/davidgilbertson",
"followers_url": "https://api.g... | [] | open | false | null | [] | null | [] | 2023-03-05T05:27:15 | 2023-03-05T05:27:15 | null | NONE | null | null | null | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_di... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5609/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5609/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5608/comments | https://api.github.com/repos/huggingface/datasets/issues/5608/events | https://github.com/huggingface/datasets/issues/5608 | 1,609,996,563 | I_kwDODunzps5f9pkT | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | {
"login": "jcho19",
"id": 107211437,
"node_id": "U_kgDOBmPqrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcho19",
"html_url": "https://github.com/jcho19",
"followers_url": "https://api.github.com/users/jcho19/follower... | [] | open | false | null | [] | null | [
"Hi!\r\n\r\n> naming convention of mp3 files\r\n\r\nYes, this could be the problem. MP3 files should end with `.mp3`/`.MP3` to be recognized as audio files.\r\n\r\nIf the file names are not the culprit, can you paste the audio folder's directory structure to help us reproduce the error (e.g., by running the `tree ... | 2023-03-05T00:14:45 | 2023-03-05T23:07:36 | null | NONE | null | null | null | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the b... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5608/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5607/comments | https://api.github.com/repos/huggingface/datasets/issues/5607/events | https://github.com/huggingface/datasets/pull/5607 | 1,609,166,035 | PR_kwDODunzps5LQPbG | 5,607 | Don't save dataset info to cache dir when skipping verifications | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5607). All of your documentation changes will be reflected on that endpoint."
] | 2023-03-03T19:50:29 | 2023-03-06T18:35:14 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5607",
"html_url": "https://github.com/huggingface/datasets/pull/5607",
"diff_url": "https://github.com/huggingface/datasets/pull/5607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5607.patch",
"merged_at": null
} | I think it makes sense not to save `dataset_info.json` file to a dataset cache directory when loading dataset with `verification_mode="no_checks"` because otherwise when next time the dataset is loaded **without** `verification_mode="no_checks"`, it will be loaded successfully, despite some values in info might not cor... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5607/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5606/comments | https://api.github.com/repos/huggingface/datasets/issues/5606/events | https://github.com/huggingface/datasets/issues/5606 | 1,608,911,632 | I_kwDODunzps5f5gsQ | 5,606 | Add `Dataset.to_list` to the API | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | open | false | {
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://api.github.com/users/... | [
{
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://a... | null | [
"Hello, I have an interest in this issue.\r\nIs the `Dataset.to_dict` you are describing correct in the code here?\r\n\r\nhttps://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/arrow_dataset.py#L4633-L4667",
"Yes, this is where `Dataset.to_dict` is defined.",
"#self-a... | 2023-03-03T16:17:10 | 2023-03-06T11:33:20 | null | CONTRIBUTOR | null | null | null | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5606/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5606/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5605/comments | https://api.github.com/repos/huggingface/datasets/issues/5605/events | https://github.com/huggingface/datasets/pull/5605 | 1,608,865,460 | PR_kwDODunzps5LPPf5 | 5,605 | Update README logo | {
"login": "gary149",
"id": 3841370,
"node_id": "MDQ6VXNlcjM4NDEzNzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3841370?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gary149",
"html_url": "https://github.com/gary149",
"followers_url": "https://api.github.com/users/gary149/... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Are you sure it's safe to remove? https://github.com/huggingface/datasets/pull/3866",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benc... | 2023-03-03T15:46:31 | 2023-03-03T21:57:18 | 2023-03-03T21:50:17 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5605",
"html_url": "https://github.com/huggingface/datasets/pull/5605",
"diff_url": "https://github.com/huggingface/datasets/pull/5605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5605.patch",
"merged_at": "2023-03-03T21:50... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5605/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"login": "sentialx",
"id": 11065386,
"node_id": "MDQ6VXNlcjExMDY1Mzg2",
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sentialx",
"html_url": "https://github.com/sentialx",
"followers_url": "https://api.github.com/users/sen... | [] | open | false | null | [] | null | [] | 2023-03-03T09:52:08 | 2023-03-03T09:52:08 | null | NONE | null | null | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
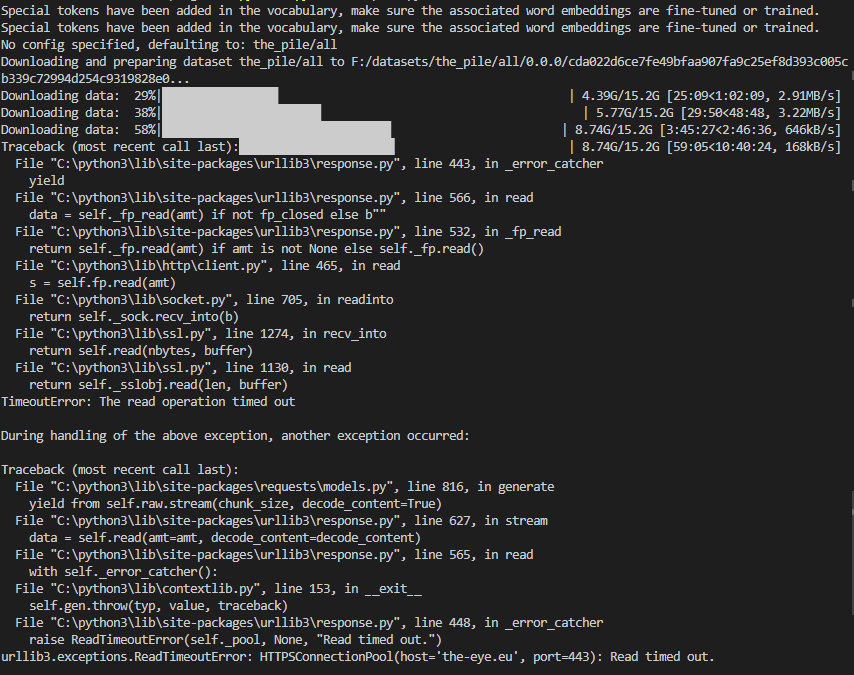
Here are the downloaded files:
. All of your documentation changes will be reflected on that endpoint.",
"This is a great PR! Thinking about the UX though, maybe we could do it without the extra argument? Before this PR, the logic in `to_tf_dataset` was... | 2023-03-02T15:51:12 | 2023-03-06T18:07:04 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5602",
"html_url": "https://github.com/huggingface/datasets/pull/5602",
"diff_url": "https://github.com/huggingface/datasets/pull/5602.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5602.patch",
"merged_at": null
} | This PR introduces new logic to `to_tf_dataset` affecting the returned data structure, enabling a dictionary structure to be returned, even if only one feature column is selected.
If the passed in `columns` or `label_cols` to `to_tf_dataset` are a list, they are returned as a dictionary, respectively. If they are a... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5602/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5602/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5601/comments | https://api.github.com/repos/huggingface/datasets/issues/5601/events | https://github.com/huggingface/datasets/issues/5601 | 1,606,685,976 | I_kwDODunzps5fxBUY | 5,601 | Authorization error | {
"login": "OleksandrKorovii",
"id": 107404835,
"node_id": "U_kgDOBmbeIw",
"avatar_url": "https://avatars.githubusercontent.com/u/107404835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OleksandrKorovii",
"html_url": "https://github.com/OleksandrKorovii",
"followers_url": "https://api.gi... | [] | open | false | null | [] | null | [] | 2023-03-02T12:08:39 | 2023-03-03T07:32:54 | null | NONE | null | null | null | ### Describe the bug
Get `Authorization error` when try to push data into hugginface datasets hub.
### Steps to reproduce the bug
I did all steps in the [tutorial](https://huggingface.co/docs/datasets/share),
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingfa... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5601/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"login": "salahiguiliz",
"id": 76955987,
"node_id": "MDQ6VXNlcjc2OTU1OTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salahiguiliz",
"html_url": "https://github.com/salahiguiliz",
"followers_url": "https://api.github.c... | [] | open | false | null | [] | null | [
"Hi! \r\n\r\n> (see example of DreamboothDatasets)\r\n\r\n\r\nCould you please provide a link to it? If you are referring to the example in the `diffusers` repo, your issue is unrelated to `datasets` as that example uses `Dataset` from PyTorch to load data."
] | 2023-03-02T11:00:27 | 2023-03-05T18:25:44 | null | NONE | null | null | null | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5598/comments | https://api.github.com/repos/huggingface/datasets/issues/5598/events | https://github.com/huggingface/datasets/pull/5598 | 1,605,018,478 | PR_kwDODunzps5LCMiX | 5,598 | Fix push_to_hub with no dataset_infos | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-01T13:54:06 | 2023-03-02T13:47:13 | 2023-03-02T13:40:17 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5598",
"html_url": "https://github.com/huggingface/datasets/pull/5598",
"diff_url": "https://github.com/huggingface/datasets/pull/5598.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5598.patch",
"merged_at": "2023-03-02T13:40... | As reported in https://github.com/vijaydwivedi75/lrgb/issues/10, `push_to_hub` fails if the remote repository already exists and has a README.md without `dataset_info` in the YAML tags
cc @clefourrier | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5598/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5598/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5597/comments | https://api.github.com/repos/huggingface/datasets/issues/5597/events | https://github.com/huggingface/datasets/issues/5597 | 1,604,928,721 | I_kwDODunzps5fqUTR | 5,597 | in-place dataset update | {
"login": "speedcell4",
"id": 3585459,
"node_id": "MDQ6VXNlcjM1ODU0NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/speedcell4",
"html_url": "https://github.com/speedcell4",
"followers_url": "https://api.github.com/users... | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
}
] | closed | false | null | [] | null | [
"We won't support in-place modifications since `datasets` is based on the Apache Arrow format which doesn't support in-place modifications.\r\n\r\nIn your case the old dataset is garbage collected pretty quickly so you won't have memory issues.\r\n\r\nNote that datasets loaded from disk (memory mapped) are not load... | 2023-03-01T12:58:18 | 2023-03-02T13:30:41 | 2023-03-02T03:47:00 | NONE | null | null | null | ### Motivation
For the circumstance that I creat an empty `Dataset` and keep appending new rows into it, I found that it leads to creating a new dataset at each call. It looks quite memory-consuming. I just wonder if there is any more efficient way to do this.
```python
from datasets import Dataset
ds = Datas... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5597/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5597/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5596/comments | https://api.github.com/repos/huggingface/datasets/issues/5596/events | https://github.com/huggingface/datasets/issues/5596 | 1,604,919,993 | I_kwDODunzps5fqSK5 | 5,596 | [TypeError: Couldn't cast array of type] Can only load a subset of the dataset | {
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [
"Apparently some JSON objects have a `\"labels\"` field. Since this field is not present in every object, you must specify all the fields types in the README.md\r\n\r\nEDIT: actually specifying the feature types doesn’t solve the issue, it raises an error because “labels” is missing in the data",
"We've updated t... | 2023-03-01T12:53:08 | 2023-03-02T11:12:11 | 2023-03-02T11:12:11 | NONE | null | null | null | ### Describe the bug
I'm trying to load this [dataset](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues) which consists of jsonl files and I get the following error:
```
casted_values = _c(array.values, feature[0])
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 1839, in wr... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5596/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5595/comments | https://api.github.com/repos/huggingface/datasets/issues/5595/events | https://github.com/huggingface/datasets/pull/5595 | 1,604,070,629 | PR_kwDODunzps5K--V9 | 5,595 | Unpins sqlAlchemy | {
"login": "lazarust",
"id": 46943923,
"node_id": "MDQ6VXNlcjQ2OTQzOTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/46943923?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lazarust",
"html_url": "https://github.com/lazarust",
"followers_url": "https://api.github.com/users/laz... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5595). All of your documentation changes will be reflected on that endpoint.",
"It looks like this issue hasn't been fixed yet, so let's wait a bit more."
] | 2023-03-01T01:33:45 | 2023-03-06T16:41:39 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5595",
"html_url": "https://github.com/huggingface/datasets/pull/5595",
"diff_url": "https://github.com/huggingface/datasets/pull/5595.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5595.patch",
"merged_at": null
} | Closes #5477 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5595/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5595/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5594/comments | https://api.github.com/repos/huggingface/datasets/issues/5594/events | https://github.com/huggingface/datasets/issues/5594 | 1,603,980,995 | I_kwDODunzps5fms7D | 5,594 | Error while downloading the xtreme udpos dataset | {
"login": "simran-khanuja",
"id": 24687672,
"node_id": "MDQ6VXNlcjI0Njg3Njcy",
"avatar_url": "https://avatars.githubusercontent.com/u/24687672?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simran-khanuja",
"html_url": "https://github.com/simran-khanuja",
"followers_url": "https://api.gi... | [] | open | false | null | [] | null | [
"Hi! I cannot reproduce this error on my machine.\r\n\r\nThe raised error could mean that one of the downloaded files is corrupted. To verify this is not the case, you can run `load_dataset` as follows:\r\n```python\r\ntrain_dataset = load_dataset('xtreme', 'udpos.English', split=\"train\", cache_dir=args.cache_dir... | 2023-02-28T23:40:53 | 2023-03-01T22:07:07 | null | NONE | null | null | null | ### Describe the bug
Hi,
I am facing an error while downloading the xtreme udpos dataset using load_dataset. I have datasets 2.10.1 installed
```Downloading and preparing dataset xtreme/udpos.Arabic to /compute/tir-1-18/skhanuja/multilingual_ft/cache/data/xtreme/udpos.Arabic/1.0.0/29f5d57a48779f37ccb75cb8708d1... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5594/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5592/comments | https://api.github.com/repos/huggingface/datasets/issues/5592/events | https://github.com/huggingface/datasets/pull/5592 | 1,603,619,124 | PR_kwDODunzps5K9dWr | 5,592 | Fix docstring example | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-02-28T18:42:37 | 2023-02-28T19:26:33 | 2023-02-28T19:19:15 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5592",
"html_url": "https://github.com/huggingface/datasets/pull/5592",
"diff_url": "https://github.com/huggingface/datasets/pull/5592.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5592.patch",
"merged_at": "2023-02-28T19:19... | Fixes #5581 to use the correct output for the `set_format` method. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5592/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5592/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5591/comments | https://api.github.com/repos/huggingface/datasets/issues/5591/events | https://github.com/huggingface/datasets/pull/5591 | 1,603,571,407 | PR_kwDODunzps5K9S79 | 5,591 | set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5591). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-02-28T18:09:05 | 2023-02-28T18:16:31 | 2023-02-28T18:09:15 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5591",
"html_url": "https://github.com/huggingface/datasets/pull/5591",
"diff_url": "https://github.com/huggingface/datasets/pull/5591.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5591.patch",
"merged_at": "2023-02-28T18:09... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5591/timeline | null | null | true |
End of preview. Expand in Data Studio
- Downloads last month
- 12