
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
Why does it (apparently) make a difference whether I pass `null` as an argument directly, or pass an `Object` that I assigned the *value* `null`?
```
Object testVal = null;
test.foo(testVal); // dispatched to foo(Object)
// test.foo(null); // compilation problem -> "The method foo(String) is ambiguous"
publi... | Which version of Java are you using? With 1.6.0\_11 the code (pasted below) compiles and runs.
I am sure its obvious why `foo(testVal)` goes to `foo(Object)`.
The reason why `foo(null)` goes to `foo(String)` is a little complex. The constant `null` is of type `nulltype`, which is a subtype of all types. So, this `nul... | Because the second commented out invocation with null is ambiguous to the compiler. The literal null could be a string or an object. Whereas the assigned value has a definite type. You need to cast the null, e.g. test.foo((String)null) to remove the ambiguity. | Java method dispatch with null argument | [
"",
"java",
"null",
"method-dispatch",
""
] |
Is there any way that I could get the source of a website (as a string preferably), let's say www.google.com, from some c# code inside code behind of asp.net website?
edit: of course i mean html code - in every browser you can view it using "view **source**" in context menu. | Assuming you want to retrieve the html:
```
class Program
{
static void Main(string[] args)
{
using (WebClient client = new WebClient())
using (Stream stream = client.OpenRead("http://www.google.com"))
using (StreamReader reader = new StreamReader(stream))
{
Console.... | For C#, I prefer to use [HttpWebRequest](http://www.codeproject.com/KB/IP/httpwebrequest_response.aspx) over WebClient because you can have more option in the future like having GET/POST parameter, using Cookies, etc.
You can have a shortest explication at [MSDN](http://msdn.microsoft.com/en-us/library/system.net.http... | Get the source of some website from asp.net code | [
"",
"c#",
"asp.net-2.0",
""
] |
I posted this [question](https://stackoverflow.com/questions/385442/linq-submitchanges-not-updating-certain-fields) yesterday evening, which has led me to discover a **huge** problem!
I have a decimal column in my database called Units, anytime I set the value of the column to a NON ZERO, and SubmitChanges the column ... | I figured out my problem with the help of the SO community. My problem was being caused by the fact when I created my entity to attach, the default value of the column was set to zero, so when it tried to assign the value to zero ... LinqToSql says hey ... nothing changed, so I am not updating the value.
What I am doi... | I have tried to reproduce this with a the following code, but for me it works.
```
using (DataClasses1DataContext ctx = new DataClasses1DataContext())
{
var obj = ctx.DecimalColumnTables.First();
Debug.Assert(obj.B != 0);
obj.B = 0;
ctx.SubmitChanges();
}
```
So I think there must be something special... | Linq-to-Sql SubmitChanges not updating fields ... why? | [
"",
"c#",
".net",
"linq",
"linq-to-sql",
""
] |
I am using the following methods:
```
public void M1(Int32 a)
{
// acquire MyMutex
DoSomething(a);
// release MyMutex
}
```
and
```
public void M2(String s, String t)
{
// acquire MyMutex
DoSomethingElse(s, t);
// release MyMutex
}
```
From what I have found so far it seems that it is not possible to us... | Absolutely you can mix delegates with generics. In 2.0, `Predicate<T>` etc are good examples of this, but you must have the same number of args. In this scenario, perhaps an option is to use captures to include the args in the delegate?
i.e.
```
public delegate void Action();
static void Main()
{
... | Yes, it's possible to combine generics with delegates.
```
public delegate void Action<T>(T x);
public delegate void Action<T,U>(T x, U y);
public void UsingMutex<T>(Action<T> x, T t) {
// acquire mutex...
x(t);
// release mutex...
}
public void UsingMutex<T,U>(Action<T,U> x, T t, U u) {
// acquire mu... | C# delegate for two methods with different parameters | [
"",
"c#",
"generics",
"delegates",
""
] |
How do I handle the scenario where I making a synchronous request to the server using XMLHttpRequest and the server is not available?
```
xmlhttp.open("POST","Page.aspx",false);
xmlhttp.send(null);
```
Right now this scenario results into a JavaScript error:
"The system cannot locate the resource specified" | Ok I resolved it by using try...catch around xmlhttprequest.send
:
```
xmlhttp.open("POST","Page.aspx",false);
try
{
xmlhttp.send(null);
}
catch(e)
{
alert('there was a problem communicating with the server');
}
``` | Try the timeout property.
```
xmlHTTP.TimeOut= 2000
``` | Problem: XMLHttpRequest - handle server connection lost | [
"",
"javascript",
"xmlhttprequest",
""
] |
The [C# 3.0 spec](http://msdn.microsoft.com/en-us/vcsharp/aa336809.aspx) has the following code example in section 10.6.1.3 "Output parameters":
```
using System;
class Test
{
static void SplitPath(string path, out string dir, out string name) {
int i = path.Length;
while (i > 0) {
char... | It is an invalid character '–'. Change '–' to '-' | What error are you getting?
System.String has had [] accessors since .NET v1.0 | String as char[] array in C# 3.0? | [
"",
"c#",
".net",
"c#-3.0",
""
] |
I wonder if people (meaning the company/developers) really care about having [SuppressMessage] attributes lying around in the shipping assemblies.
Creating separate configs in the Project files that include CODE\_ANALYSIS in Release mode and then yanking it off in the final build seems kind of an avoidable overhead to... | In the grand scheme of things, I don't think it really matters. Since this is an attribute (effectively meta-data), it doesn't impact code performance. That being said, do remember that the information in the attribute is available to anyone using a disassember like Reflector.
The problem with storing them in the FxCo... | The SuppressMessage attribute will only be added to your code if the CODE\_ANALYSIS preprocessor definition is present during a compile. You can verify this by looking at the definition of the attribute in Reflector.exe. By default this is not defined in Release so it won't affect production code.
Typically, I only ru... | .NET [SuppressMessage] attributes in shipping assemblies fxcop | [
"",
"c#",
".net",
"fxcop",
""
] |
I want to list (a sorted list) all my entries from an attribute called streetNames in my table/relation Customers.
eg. I want to achieve the following order:
Street\_1A
Street\_1B
Street\_2A
Street\_2B
Street\_12A
Street\_12B
A simple order by streetNames will do a lexical comparision and then Street\_12A a... | The reliable way to do it (reliable in terms of "to sort your data correctly", not "to solve your general problem") is to split the data into street name and house number and sort both of them on their own. But this requires knowing where the house number starts. And this is the tricky part - making the assumption best... | Select street\_name from tablex
order by udf\_getStreetNumber(street\_name)
in your udf\_getStreetNumber - write your business rule for stripping out the number
EDIT
I think you can use regex functionality in SQL Server now. I'd just strip out all non-number characters from the input. | SQL query (order by) | [
"",
"sql",
"sorting",
""
] |
```
function holiday_hitlist($tablename, $hit_user){
global $host, $user, $pass, $dbname;
$link = mysql_connect($host, $user, $pass, $dbname);
print "<div class=\"hit_list\">
<h3>My Holiday Hitlist</h3>
<p>Five things I want the most, based on my desirability ratings.<br/>You can'... | See the line
```
$output = print "<li><a href=\"$url\" target=\"_blank\">$title</a> $price</li>";
```
you should probably remove the print after the $output =
Or maybe you just need to remove the $output =
I am not quite sure what you intend.
To explain, $output is getting the return value of print "..." | From php.net Reference:
"Return Values
Returns 1, always."
<http://ca.php.net/manual/en/function.print.php>
You should assign $output to be the output that you would like, then use print to display that output. | PHP is generating a numeral "1" on output of a function. I've never seen it do this before | [
"",
"php",
""
] |
I am considering using Maven for a Java open source project I manage.
In the past, however, Maven has not always had the best reputation. What are your impressions of Maven, at this time? | For an open-source project, Maven has some advantages, especially for your contributors (eg mvn eclipse:eclipse).
If you do go with Maven, the one rule you must follow religiously is: don't fight the tool. Layout your project exactly how Maven recommends, follow all its conventions and best practices. Every little fig... | Personally, I'm not a fan. I agree with most of what Charles Miller [says about it being broken by design](http://fishbowl.pastiche.org/2007/12/20/maven_broken_by_design/). It does solve some problems, but it also [introduces others](http://tapestryjava.blogspot.com/2007/11/maven-wont-get-fooled-again.html).
[Ant](htt... | What are your impressions of Maven? | [
"",
"java",
"open-source",
"maven-2",
""
] |
Using the code below, I am returning an nvarchar field from *MS SQL 2005* and keep getting a System.InvalidCastException.
```
vo.PlacementID = dr.IsDBNull(0) ? null : dr.GetString(0);
```
The vo.PlacementID variable is of type String so there shouldn't be a problem.
The values I am trying to return are like this (num... | If you read the exception again it gives you a clue as to the problem:
> System.**InvalidCastException**:
> ***Unable to cast object of type 'System.Int32' to type
> 'System.String'***. at
> System.Data.SqlClient.SqlBuffer.get\_String()
> at
> System.Data.SqlClient.SqlDataReader.GetString(Int32
> i)
Basically the und... | the cast exception is not raised in the assignment, but in the datareader's GetString().
try dr.GetValue(0).ToString() | Problem returning field in ms sql 2005 - System.InvalidCastException: | [
"",
"sql",
"sql-server",
""
] |
Compiling a C++ file takes a very long time when compared to C# and Java. It takes significantly longer to compile a C++ file than it would to run a normal size Python script. I'm currently using VC++ but it's the same with any compiler. Why is this?
The two reasons I could think of were loading header files and runni... | Several reasons
# Header files
Every single compilation unit requires hundreds or even thousands of headers to be (1) loaded and (2) compiled.
Every one of them typically has to be recompiled for every compilation unit,
because the preprocessor ensures that the result of compiling a header *might* vary between every ... | Parsing and code generation are actually rather fast. The real problem is opening and closing files. Remember, even with include guards, the compiler still have open the .H file, and read each line (and then ignore it).
A friend once (while bored at work), took his company's application and put everything -- all sourc... | Why does C++ compilation take so long? | [
"",
"c++",
"performance",
"compilation",
""
] |
I hope someone can guide me as I'm stuck... I need to write an emergency broadcast system that notifies workstations of an emergency and pops up a little message at the bottom of the user's screen. This seems simple enough but there are about 4000 workstations over multiple subnets. The system needs to be almost realti... | Consider using WCF callbacks mechanism and events. There is [good introduction](http://msdn.microsoft.com/en-us/magazine/cc163537.aspx) by Juval Lowy.
Another pattern is to implement [blocking web-service calls](http://xmpp.org/extensions/xep-0124.html). This is how GMail chat works, for example. However, you will hav... | This is exactly what [Multicast](http://en.wikipedia.org/wiki/Multicast) was designed for.
A normal network broadcast (by definition) stays on the local subnet, and will not be forwarded through routers.
Multicast transmissions on the other hand can have various scopes, ranging from subnet local, through site local, ... | Whats the best way to send an event to all workstations | [
"",
"c#",
"wcf",
"web-services",
"tcp",
"udp",
""
] |
I've seen a lot of example c++ code that wraps function calls in a FAILED() function/method/macro.
Could someone explain to me how this works? And if possible does anyone know a c# equivalent? | It generally checks COM function errors. But checking any function that returns a `HRESULT` is what it's meant for, specifically. `FAILED` returns a true value if the `HRESULT` value is negative, which means that the function failed ("error" or "warning" severity). Both `S_OK` and `S_FALSE` are >= 0 and so they are not... | [This page](http://msdn.microsoft.com/en-us/library/ms819775.aspx) shows the half of the WinError.h include file that defines `FAILED()`. It's actually just a very simple macro, the entire definition goes like this:
```
#define FAILED(Status) ((HRESULT)(Status)<0)
``` | Can someone explain the c++ FAILED function? | [
"",
"c++",
"windows",
"com",
""
] |
suppose I have an enum
```
[Flags]
public enum E {
zero = 0,
one = 1
}
```
then I can write
```
E e;
object o = 1;
e = (E) o;
```
and it will work.
BUT if I try to do that at runtime, like
```
(o as IConvertible).ToType(typeof(E), null)
```
it will throw InvalidCastException.
So, is there something tha... | ```
object o = 1;
object z = Enum.ToObject(typeof(E), o);
``` | You can also use
```
Enum.Parse(typeof(E), (int)o)
``` | what's the runtime equivalent of c# 'bracketed' type cast | [
"",
"c#",
"casting",
"enums",
"runtime",
""
] |
Can all .NET exception objects be serialized? | Yes and no. As other answers here have pointed out, the all exception classes should and almost always are serializable. If you run across a particular exception class that is not serializable, it is quite possibly a bug.
But when considering serializability you need to consider both the immediate class and all types ... | Yes, but historically there have been (no pun intended) exceptions.
In other words, **all Exceptions SHOULD be serializable**, but some custom Exceptions from third party code may *not* be, depending on how they're implemented.
For example, in the .NET 1.0 era, exceptions from the official Microsoft Oracle database p... | Are all .NET exceptions serializable? | [
"",
"c#",
".net",
"exception",
""
] |
At my current job, we're looking to implement our own odbc driver to allow many different applications to be able to connect to our own app as a datasource. Right now we are trying to weigh the options of developing our own driver to the implementation spec, which is massive, *or* using an SDK that allows for programme... | I have not, but I once interviewed at a company that had done exactly this. They made
a 4GL/DBMS product called AMPS of the same sort of architecture as MUMPS - a hierarchical database with integrated 4GL (a whole genre of such systems came out during the 1970s). They had quite a substantial legacy code base and custom... | Another option: Instead of creating a ODBC driver, implement a back end that talks the wire protocol that another database (Postgresql or MySQL for instance) uses.
Your users can then download and use for instance the Postgresql ODBC driver.
Exactly what back-end database you choose to emulate should probably depend ... | Creating a custom ODBC driver | [
"",
"sql",
"database",
"sdk",
"odbc",
"odbc-bridge",
""
] |
In a C# program, I have an abstract base class with a static "Create" method. The Create method is used to create an instance of the class and store it locally for later use. Since the base class is abstract, implementation objects will always derive from it.
I want to be able to derive an object from the base class, ... | Try using generics:
```
public static BaseClass Create<T>() where T : BaseClass, new()
{
T newVar = new T();
// Do something with newVar
return T;
}
```
Sample use:
```
DerivedClass d = BaseClass.Create<DerivedClass>();
``` | ## Summary
There are two main options. The nicer and newer one is to use generics, the other is to use reflection. I'm providing both in case you need to develop a solution that works prior to .NET 2.0.
## Generics
```
abstract class BaseClass
{
public static BaseClass Create<T>() where T : BaseClass, new()
{
... | C#: Determine derived object type from a base class static method | [
"",
"c#",
"static-methods",
"derived-class",
""
] |
In my Java application I would like to download a JPEG, transfer it to a PNG and do something with the resulting bytes.
I am almost certain I remember a library to do this exists, I cannot remember its name. | [ImageIO](http://docs.oracle.com/javase/6/docs/api/javax/imageio/ImageIO.html) can be used to load JPEG files and save PNG files (also into a `ByteArrayOutputStream` if you don't want to write to a file). | This is what I ended up doing, I was thinking toooo far outside of the box when I asked the question..
```
// these are the imports needed
import java.awt.image.BufferedImage;
import java.io.File;
import javax.imageio.ImageIO;
import java.io.ByteArrayOutputStream;
// read a jpeg from a inputFile
BufferedImage buffere... | Image transcoding (JPEG to PNG) with Java | [
"",
"java",
"png",
"jpeg",
"image-transcoding",
""
] |
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Linq.Expressions;
using System.Text;
namespace ConsoleApplication1
{
public class Class1
{
static void Main(string[] args)
{
List<Car> mylist = new List<Car>();
Car car1;
Car ca... | Everything leppie said - plus:
```
int index = mylist.FindIndex(p => p.id == 1);
if(index<0) {
mylist.Add(car3);
} else {
mylist[index] = car3;
}
```
This just uses the existing FindIndex to locate a car with id 1, then replace or add it. No LINQ; no SQL - just a lambda and `List<T>`. | If you wanted to do an update to multiple elements...
```
foreach (var f in mylist.FindAll(x => x.id == 1))
{
f.id = car3.id;
f.color = car3.color;
f.make = car3.make;
}
``` | List Manipulation in C# using Linq | [
"",
"c#",
"linq",
""
] |
Answers provided have all been great, I mentioned in the comments of Alnitak's answer that I would need to go take a look at my CSV Generation script because for whatever reason it wasn't outputting UTF-8.
As was correctly pointed out, it WAS outputting UTF-8 - the problem existed with Ye Olde Microsoft Excel which wa... | What you're seeing is [UTF-8](http://en.wikipedia.org/wiki/UTF-8) encoding - it's a way of storing Unicode characters in a relatively compact format.
The pound symbol has value `0x00a3` in Unicode, but when it's written in UTF-8 that becomes `0xc2 0xa3` and that's what's stored in the database. It seems that your data... | £ is 0xC2 0xA3 which is the UTF-8 encoding for £ symbol - so you're storing it as UTF-8, but presumably viewing it as Latin-1 or something other than UTF-8
It's useful to know how to spot and decode UTF-8 by hand - check the [wikipedia page](http://en.wikipedia.org/wiki/UTF-8) for info on how the encoding works:
* 0... | MySQL or PHP is appending a  whenever the £ is used | [
"",
"php",
"mysql",
"character",
""
] |
I'm trying to write rules for detecting some errors in *annotated* multi-threaded java programs. As a toy example, I'd like to detect if any method annotated with @ThreadSafe calls a method without such an annotation, without synchronization. I'm looking for a tool that would allow me to write such a test.
I've looked... | Have you tried [FindBugs](http://findbugs.sourceforge.net/)? It actually supports a set of [annotations for thread safety](http://www.javaconcurrencyinpractice.com/annotations/doc/net/jcip/annotations/package-summary.html) (the same as those used in [Java Concurrency in Practice](http://www.javaconcurrencyinpractice.co... | You can do [cross-class analysis in PMD](http://pmd.sourceforge.net/howtowritearule.html#I_want_to_implement_a_rule_that_analyse_more_than_the_class__) (though I've never used it for this specific purpose). I think it's possible using this visitor pattern that they document, though I'll leave the specifics to you. | Cross-class-capable extendable static analysis tool for java? | [
"",
"java",
"multithreading",
"annotations",
"static-analysis",
""
] |
I had this question earlier and it was concluded it was a bug in 5.2.5. Well, it's still broken in 5.2.6, at least for me:
Please let me know if it is broken or works for you:
```
$obj = new stdClass();
$obj->{"foo"} = "bar";
$obj->{"0"} = "zero";
$arr = (array)$obj;
//foo -- bar
//0 -- {error: undefined index}
f... | Definitely seems like a bug to me (PHP 5.2.6).
You can fix the array like this:
```
$arr = array_combine(array_keys($arr), array_values($arr));
```
It's been reported in [this bug report](http://bugs.php.net/bug.php?id=45346) but marked as bogus... [the documentation](http://www.php.net/manual/en/language.types.arra... | A bit of experimentation shows phps own functions don't persist this fubarity.
```
function noopa( $a ){ return $a; }
$arr = array_map('noopa', $arr );
$arr[0]; # no error!
```
This in effect, just creates a copy of the array, and the fix occurs during the copy.
Ultimately, its a design failure across the board, tr... | PHP bug with converting object to arrays | [
"",
"php",
"arrays",
"stdclass",
""
] |
Which version of JavaScript does Google Chrome support in relation to Mozilla Firefox? In other words, does Chrome support JavaScript 1.6, 1.7, or 1.8 which Firefox also supports or some combination of them? | While Chrome will execute Javascript marked as "javascript1.7", it does not support JS1.7 features like the "let" scoped variable operator.
This code will run on Firefox 3.5 but not on Chrome using V8:
```
<script language="javascript" type="application/javascript;version=1.7">
function foo(){ let a = 4; alert(a)... | This thread is still relevant. As of 2012, Chrome supports most of Javascript 1.6, not including string and array generics. It supports none of 1.7. It supports reduce and reduceRight from 1.8, all of 1.8.1, and Getters and setters and all the non-version specific things listed on [this page](http://robertnyman.com/jav... | Google Chrome - JavaScript version | [
"",
"javascript",
"firefox",
"google-chrome",
""
] |
Ok, I'm doing a bunch of RIA/AJAX stuff and need to create a "pretty", custom confirm box which is a DIV (not the built-in javascript confirm). I'm having trouble determining how to accomplish a pause in execution to give the user a chance to accept or decline the condition before either resuming or halting execution. ... | I'm afraid to say that it's not possible to pause the Javascript runtime in the same way that the "confirm" and "alert" dialogs pause it. To do it with a DIV you're going to have to break up your code into multiple chunks and have the event handler on the custom confirm box call the next section of code.
There have be... | The way how I did this:
1. Create your own confirm dialog box
with buttons, let's say "Yes" and
"No".
2. Create function that triggers the
dialog box, let's say `confirmBox(text,
callback)`.
3. Bind events on "Yes" and "No"
buttons - "Yes" - `callback(true)`,
"No" - `callback(false)`.
4. When you are... | How to create a custom "confirm" & pause js execution until user clicks button? | [
"",
"jquery",
"ajax",
"ria",
"javascript",
""
] |
I'm trying to animate a block level element using jQuery. The page loads with the element styled with `display: none`. Id like it to `slideDown` whilst transparent and then `fadeIn` the content using the callback, however `slideDown` appears to set the visibility to full before `fadeIn` is called, resulting in the cont... | a few probable issues with your code: are you setting the content to hide as well in the beginning? are you calling `fadeIn` during the `slideDown` callback?
here's some example HTML/code that will `fadeIn` after the `slideDown`
```
$('div').hide(); // make sure you hide both container/content
$('#container').slideD... | Your description sounds like a variation of [this](http://dev.jquery.com/ticket/2423) problem, which I had to deal with the other day.
It only happens in IE, and only if you are rendering in quirks mode. So the easy solution, is to switch to standards mode. You can find a table of doctypes [here](http://hsivonen.iki.f... | How do I slideDown whilst maintaining transparency in jQuery? | [
"",
"javascript",
"jquery",
"animation",
""
] |
I am wondering if it is possible to validate parameters to (custom) .net attributes. eg: If I had an attribute that takes a positive integer, could I force a compile time error when a negative value was supplied?
[DonkeyAttribute(1)] //OK
[DonkeyAttribute(-828)] //error
In this example I could use an unsigned intege... | I don't think it is normally, however [this](http://karlagius.wordpress.com/2008/01/29/validating-attribute-usage-with-postsharp-aspects/) article details a solution using [PostSharp](http://www.postsharp.org/). Not sure if it's fit for your purpose, but give it go! | You could enforce this with unit tests; a similar solution to the one I proposed for [this question](https://stackoverflow.com/questions/19454/enforce-attribute-decoration-of-classesmethods#19455), maybe. | Possible to validate a .NET Attibute parameter? | [
"",
"c#",
"attributes",
""
] |
Avast there fellow programmers!
I have the following problem:
I have two rectangles overlapping like shown on the picture below.
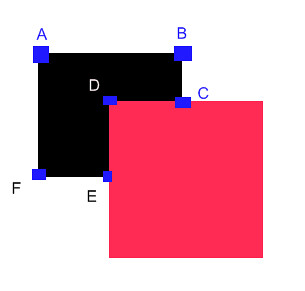
I want to figure out the polygon consisting of point ABCDEF.
Alternate christmas description: The red cookie c... | This is a special case of general 2D polygon clipping. A good place to start is the Weiler-Atherton algorithm. [Wikipedia has a summary](http://en.wikipedia.org/wiki/Weiler-Atherton) and [links to the original paper](http://www.cs.drexel.edu/~david/Classes/CS430/HWs/p214-weiler.pdf). The algorithm seems to match the da... | [constructive solid geometry](http://en.wikipedia.org/wiki/Constructive_solid_geometry) | Boolean operations on rectangle polygons | [
"",
"c++",
"algorithm",
"geometry",
"boolean",
""
] |
Does anyone know how to calculate time difference in C++ in milliseconds?
I used [`difftime`](http://linux.die.net/man/3/difftime) but it doesn't have enough precision for what I'm trying to measure. | You have to use one of the more specific time structures, either timeval (microsecond-resolution) or timespec (nanosecond-resolution), but you can do it manually fairly easily:
```
#include <time.h>
int diff_ms(timeval t1, timeval t2)
{
return (((t1.tv_sec - t2.tv_sec) * 1000000) +
(t1.tv_usec - t2.t... | I know this is an old question, but there's an updated answer for C++0x. There is a new header called `<chrono>` which contains modern time utilities. Example use:
```
#include <iostream>
#include <thread>
#include <chrono>
int main()
{
typedef std::chrono::high_resolution_clock Clock;
typedef std::chrono::mi... | Time difference in C++ | [
"",
"c++",
"time",
""
] |
So I have a client who's current host does not allow me to use tar via exec()/passthru()/ect and I need to backup the site periodicly and programmaticly so is there a solution?
This is a linux server. | At <http://pear.php.net/package/Archive_Tar> you can donload the PEAR tar package and use it like this to create the archive:
```
<?php
require 'Archive/Tar.php';
$obj = new Archive_Tar('archive.tar');
$path = '/path/to/folder/';
$handle=opendir($path);
$files = array();
while(false!==($file = readdir($handle)))
{
... | PHP 5.3 offers a much easier way to solve this issue.
Look here: <http://www.php.net/manual/en/phardata.buildfromdirectory.php>
```
<?php
$phar = new PharData('project.tar');
// add all files in the project
$phar->buildFromDirectory(dirname(__FILE__) . '/project');
?>
``` | Build Tar file from directory in PHP without exec/passthru | [
"",
"php",
"linux",
"backup",
"archive",
""
] |
Do you know a good source to learn how to design SQL solutions?
Beyond the basic language syntax, I'm looking for something to help me understand:
1. What tables to build and how to link them
2. How to design for different scales (small client APP to a huge distributed website)
3. How to write effective / efficient /... | I started with this book: [Relational Database Design Clearly Explained (The Morgan Kaufmann Series in Data Management Systems) (Paperback)](http://www.amazon.co.uk/Relational-Database-Explained-Kaufmann-Management/dp/1558608206/ref=sr_1_3?ie=UTF8&s=books&qid=1229597641&sr=8-3) by Jan L. Harrington and found it very cl... | I started out with this article
<http://en.tekstenuitleg.net/articles/software/database-design-tutorial/intro.html>
It's pretty concise compared to reading an entire book and it explains the basics of database design (normalization, types of relationships) very well. | A beginner's guide to SQL database design | [
"",
"sql",
"database",
"database-design",
"scalability",
""
] |
I was hoping to automate some tasks related to SubVersion, so I got SharpSvn. Unfortunately I cant find much documentation for it.
I want to be able to view the changes after a user commits a new revision so I can parse the code for special comments that can then be uploaded into my ticket system. | If you just want to browse SharpSvn you can use [<http://docs.sharpsvn.net/>](http://docs.sharpsvn.net/current/). The documentation there is far from complete as the focus is primarily on providing features. Any help on enhancing the documentation (or SharpSvn itself) is welcome ;-)
To use log messages for your issue ... | Is this of any use?
<http://blogs.open.collab.net/svn/2008/04/sharpsvn-brings.html> | How can I view the changes made after a revision is committed and parse it for comments? | [
"",
"c#",
"svn",
"sharpsvn",
""
] |
I've recently bumped into facelift, an alternative to sIFR and I was wondering if those who have experience with both sIFR and FLIR could shed some light on their experience with FLIR.
For those of you who've not yet read about how FLIR does it, FLIR works by taking the text from targeted elements using JavaScript to ... | Over the long term, sIFR should cache better because rendering is done on the client side, from one single Flash movie. Flash text acts more like browser text than an image, and it's easy to style the text within Flash (different colors, font weights, links, etc). You may also prefer the quality of text rendered in Fla... | I know that with sIFR, and I assume with FLIR that you perform your markup in the same way as usual, but with an extra class tag or similar, so it can find the text to replace. Search engines will still read the markup as regular text so that shouldn't be an issue.
Performance-wise: if you're just using this for headi... | sIFR or FLIR? | [
"",
"php",
"seo",
"sifr",
"gd",
"flir",
""
] |
I want to convert a string into a series of Keycodes, so that I can then send them via PostMessage to a control. I need to simulate actual keyboard input, and I'm wondering if a massive switch statement is the only way to convert a character into the correct keycode, or if there's a simpler method.
====
Got my soluti... | Got my solution - <http://msdn.microsoft.com/en-us/library/ms646329(VS.85).aspx>
VkKeyScan will return the correct keycode for any character.
(And yes, I wouldn't do this in general, but when doing automated testing, and making sure that keyboard presses are responded to correctly, it works reliably enough). | Raymond says this is a bad idea.
<http://blogs.msdn.com/oldnewthing/archive/2005/05/30/423202.aspx> | How do I convert a Char into a Keycode in .Net? | [
"",
"c#",
"winapi",
""
] |
Currently I`m using Visual Studio for writing code in C++. But it seems so weighty that I decided to switch for another one, preferably free, not so strict to system resources (I mean memory, of course) as VS to learn libraries, such as Boost and Qt. What compiler do you suggest? | Code::blocks is exactly what you are after. You can can download it here: <http://www.codeblocks.org/downloads/5>
Choose the version with the mingw compiler bundled with it (Windows port of GCC). You can switch between that and the VC++ compiler as and when you like.
Code::Blocks has all the stuff you want, debugger ... | I'd suggest using Visual Studio's compiler from the command-line. You get the same high-quality compiler, without the resource-hogging IDE.
Although the IDE is pretty good too, and probably worth the resources it uses. | Need a c++ compiler to work with libraries (boost, ...) | [
"",
"c++",
"compiler-construction",
""
] |
I am trying to use the actual numerical value for the month on a sql query to pull results. Is there any way to do this without having a function to change the numbers to actual month names, then back to month numbers? The following code works for Names, what works for numbers?
> datename(month,(convert(datetime,DTSTA... | month,(convert(datetime,DTSTAMP)) should do it, but why on earth are you not storing the data correctly as a datetime to begin with? All that additional conversion stuff to use the dates adds unnecessary load to your server and slows down your application. | [Datepart](http://msdn.microsoft.com/en-us/library/aa258265(SQL.80).aspx) is an alternative to the month command and it is more flexable as you can extract other parts of the date.
```
DATEPART(mm, convert(datetime,DTSTAMP))
``` | Is there a way to search a SQL Query with Month Numbers, and not Month Name? | [
"",
"sql",
"mysql",
"sql-server",
""
] |
Ok, i have simple scenario:
have two pages:
login and welcome pages.
im using FormsAuthentication with my own table that has four columns: ID, UserName, Password, FullName
When pressed login im setting my username like:
```
FormsAuthentication.SetAuthCookie(userName, rememberMe ?? false);
```
on the welcome page i ... | I would store the user's full name in the session cookie after your call to FormsAuth
```
FormsAuth.SetAuthCookie(userName, rememberme);
// get the full name (ex "John Doe") from the datbase here during login
string fullName = "John Doe";
Response.Cookies["FullName"].Value = fullName;
Response.Cookies["FullName"].ex... | Forms authentication works using cookies. You could construct your own auth cookie and put the full name in it, but I think I would go with putting it into the session. If you use a cookie of any sort, you'll need to extract the name from it each time. Tying it to the session seems more natural and makes it easy for yo... | FormsAuthentication after login | [
"",
"c#",
"asp.net",
"asp.net-mvc",
""
] |
I was shocked to find out today that C# does not support dynamic sized arrays. How then does a [VB.NET](http://en.wikipedia.org/wiki/Visual_Basic_.NET) developer used to using [ReDim Preserve](http://msdn.microsoft.com/en-us/library/w8k3cys2.aspx) deal with this in C#?
At the beginning of the function I am not sure of... | Use ArrayLists or Generics instead | VB.NET doesn't have the idea of dynamically sized arrays, either - the CLR doesn't support it.
The equivalent of "Redim Preserve" is [`Array.Resize<T>`](http://msdn.microsoft.com/en-us/library/bb348051.aspx) - but you *must* be aware that if there are other references to the original array, they won't be changed at al... | Redim Preserve in C#? | [
"",
"c#",
"arrays",
""
] |
How do I get my Python program to sleep for 50 milliseconds? | Use [`time.sleep()`](https://docs.python.org/library/time.html#time.sleep)
```
from time import sleep
sleep(0.05)
``` | Note that if you rely on sleep taking *exactly* 50 ms, you won't get that. It will just be about it. | How do I get my program to sleep for 50 milliseconds? | [
"",
"python",
"timer",
"sleep",
""
] |
I'm trying to write some C# code that calls a method from an unmanaged DLL. The prototype for the function in the dll is:
```
extern "C" __declspec(dllexport) char *foo(void);
```
In C#, I first used:
```
[DllImport(_dllLocation)]
public static extern string foo();
```
It seems to work on the surface, but I'm getti... | You must return this as an IntPtr. Returning a System.String type from a PInvoke function requires great care. The CLR must transfer the memory from the native representation into the managed one. This is an easy and predictable operation.
The problem though comes with what to do with the native memory that was return... | You can use the Marshal.PtrToStringAuto method.
```
IntPtr ptr = foo();
string str = Marshal.PtrToStringAuto(ptr);
``` | PInvoke for C function that returns char * | [
"",
"c#",
"pinvoke",
""
] |
Academia has it that table names should be the singular of the entity that they store attributes of.
I dislike any T-SQL that requires square brackets around names, but I have renamed a `Users` table to the singular, forever sentencing those using the table to sometimes have to use brackets.
My gut feel is that it is... | Others have given pretty good answers as far as "standards" go, but I just wanted to add this... Is it possible that "User" (or "Users") is not actually a full description of the data held in the table? Not that you should get too crazy with table names and specificity, but perhaps something like "Widget\_Users" (where... | I had same question, and after reading all answers here I definitely stay with ***SINGULAR***, reasons:
~~**Reason 1** (Concept). You can think of bag containing apples like "AppleBag", it doesn't matter if contains 0, 1 or a million apples, it is always the same bag. Tables are just that, containers, the table name m... | Table Naming Dilemma: Singular vs. Plural Names | [
"",
"sql",
"sql-server",
"naming-conventions",
""
] |
We have a large (about 580,000 loc) application which in Delphi 2006 builds (on my machine) in around 20 seconds. When you have build times in seconds, you tend to use the compiler as a tool. i.e. write a little code, build, write some more code and build some more etc etc As we move some of our stuff over to C#, does ... | Visual Studio 2008 SP1 now has background compilation for C# (it's always had it for VB.NET). Back in my VB days, I often used this to find where something was referenced by changing the name and then seeing where the background compiler said there was an error.
I never worked on anything quite this large. At my last ... | I used to use the compiler as you describe, but since I've been using [ReSharper](http://www.jetbrains.com/resharper) I do this a lot less.
Also, for things like rename, the refactoring support (both in Visual Studio 2005 upwards and, even better, from ReSharper) mean I don't have to do search + replace to rename thing... | Do you use regular builds as a coding tool? | [
"",
"c#",
"performance",
"delphi",
"compiler-construction",
""
] |
I've built the x86 Boost libraries many times, but I can't seem to build x64 libraries. I start the "Visual Studio 2005 x64 Cross Tools Command Prompt" and run my usual build:
```
bjam --toolset=msvc --build-type=complete --build-dir=c:\build install
```
But it still produces x86 .lib files (I verified this with dump... | You need to add the `address-model=64` parameter.
Look e.g. [here](http://devsql.blogspot.com/2007/05/building-boost-134-for-x86-x64-and-ia64.html). | The accepted answer is correct. Adding this in case somebody else googles this answer and still fails to produce x64 version.
Following is what I had to do to build Boost 1.63 on Visual Studio 15 2017 Community Edition.
Commands executed from VS environment cmd shell. Tools -> Visual Studio Command Prompt
```
C:\Wor... | How do you build the x64 Boost libraries on Windows? | [
"",
"c++",
"visual-studio-2005",
"boost",
"64-bit",
"boost-build",
""
] |
If I am posting a question about a query against an Oracle database, what should I include in my question so that people have a chance to answer me? How should I get this information?
Simply providing the poorly performing query may not be enough. | Ideally, get the full query plan using DBMS\_XPLAN.DISPLAY\_CURSOR using the sql\_id and child\_cursor\_id from v$sql. Failing that (ie on older versions), try v$sql\_plan and include filter and access predicates. EXPLAIN PLAN is fine if it actually shows the plan that was used.
DB version and edition (Express/Standar... | * The schema definition of the tables involved.
* The indexes defined on those tables.
* The query you are executing.
* The resulting query execution plan | If I'm posting a question about Oracle SQL query performance, what should I include in my question? | [
"",
"sql",
"performance",
"oracle",
"database-design",
""
] |
```
SaveFileDialog savefileDialog1 = new SaveFileDialog();
DialogResult result = savefileDialog1.ShowDialog();
switch(result == DialogResult.OK)
case true:
//do something
case false:
MessageBox.Show("are you sure?","",MessageBoxButtons.YesNo,MessageBoxIcon.Question);
```
How to show the messag... | If the reason for needing the message box on Cancel of the File Save dialogue is because you're shutting things down with unsaved changes, then I suggest putting the call to the File Save dialogue in a loop that keeps going until a flag is set to stop the loop and call the message box if you don't get OK as the result.... | You can't do that with `SaveFileDialog` class. | Show messagebox over Save dialog in C# | [
"",
"c#",
"winforms",
""
] |
I've got a simple class that inherits from Collection and adds a couple of properties. I need to serialize this class to XML, but the XMLSerializer ignores my additional properties.
I assume this is because of the special treatment that XMLSerializer gives ICollection and IEnumerable objects. What's the best way aroun... | Collections generally don't make good places for extra properties. Both during serialization and in data-binding, they will be ignored if the item looks like a collection (`IList`, `IEnumerable`, etc - depending on the scenario).
If it was me, I would encapsulate the collection - i.e.
```
[Serializable]
public class ... | If you do encapsulate, as Marc Gravell suggests, the beginning of this post explains how to get your XML to look exactly like you describe.
<http://blogs.msdn.com/youssefm/archive/2009/06/12/customizing-the-xml-for-collections-with-xmlserializer-and-datacontractserializer.aspx>
That is, instead of this:
```
<MyColle... | XmlSerialize a custom collection with an Attribute | [
"",
"c#",
".net",
"xml-serialization",
""
] |
In your workplace, where do you store your common, non-database specific scripts that you use in SQL Server? Do you keep them in .SQL scripts on the file server, do you store them in the Master database, or do you keep them in a database you defined specifically for these kinds of things? | We store them as regular source code, so in version-control.
You have then available previous versions of script, and you avoid "someone deleted the XY script" risk. | We store them in a wiki where everyone can access them. | Where do you keep your common sql task scripts? | [
"",
"sql",
"sql-server",
"scripting",
""
] |
I keep seeing people say that exceptions are slow, but I never see any proof. So, instead of asking if they are, I will ask how do exceptions work behind the scenes, so I can make decisions of when to use them and whether they are slow.
From what I know, exceptions are the same as doing a return bunch of times, except... | Instead of guessing, I decided to actually look at the generated code with a small piece of C++ code and a somewhat old Linux install.
```
class MyException
{
public:
MyException() { }
~MyException() { }
};
void my_throwing_function(bool throwit)
{
if (throwit)
throw MyException();
}
void another... | Exceptions being slow **was** true in the old days.
In most modern compiler this no longer holds true.
Note: Just because we have exceptions does not mean we do not use error codes as well. When error can be handled locally use error codes. When errors require more context for correction use exceptions: I wrote it m... | How do exceptions work (behind the scenes) in c++ | [
"",
"c++",
"performance",
"exception",
"throw",
"try-catch",
""
] |
We have a large enterprise consisting of many apps both old and new backed by Oracle 10G. When blocking sessions or deadlocks occur and we get trace reports it would be super handy to be able to have embedded some details in the sql so that we know both what app, and specifically where it was executed from. In addition... | You can tag chunks of SQL being executed via the Oracle [DBMS\_APPLICATION\_INFO](http://download.oracle.com/docs/cd/B28359_01/appdev.111/b28419/d_appinf.htm) package. This works in any application language, works within the database engine itself, and does not clutter your SQL statements with comments (smart comments ... | We dynamically modify our SQL statements so that the command which executed them is in a comment at the start of the query. This works because we do our own transaction management and have a strict framework. But the base code is simple (in Java... not sure how other languages will deal with this):
```
String sql = "S... | Tagging sql statements for tracing and debugging | [
"",
"sql",
"oracle",
"debugging",
"tags",
"trace",
""
] |
I need to delete a temporary file from my C++ windows application (developed in Borland C++ Builder). Currently I use a simple:
```
system("del tempfile.tmp");
```
This causes a console window to flash in front of my app and it doesn't look very professional. How do I do this without the console window? | It sounds like you need the Win32 function [DeleteFile](http://msdn.microsoft.com/en-us/library/aa363915(VS.85).aspx)(). You will need to `#include <windows.h>` to use it. | Or, even the standard C library function `int remove( const char *path );`. | How to delete a file from a C++ app without console window in Windows? | [
"",
"c++",
"windows",
"winapi",
"file-io",
""
] |
This sure seems like a simple error to fix. However, I somehow can't figure it out. Found some posts here and went thru them and couldn't get it to work. Sure seems like a famous error.
The error I'm getting is : Unable to start debugging on the web server. An Authentication error occured while communicating with the ... | After looking around, I noticed there were 537 - 'An error occurred during logon' security events every time i tried to launch in debug mode. I found this article on M$-
<http://support.microsoft.com/?id=896861>
After setting a key in the reg to disable the loopback check per the article and a reboot, problem solved!... | Make sure to check that in IIS, the authentication mode is set properly. If you're on a Domain, make sure to note such, and make sure that Anonymous access is checked (if required for your application).
[This MSDN Link](http://msdn.microsoft.com/en-us/library/aa292114(VS.71).aspx) has more details.
There are a few ot... | Getting 'unable to start debugging' 'An authentication error occurred while...' | [
"",
"c#",
"asp.net",
"debugging",
""
] |
I'd like to be able to detect Vista IE7 Protected Mode within a page using javascript, preferably. My thinking is to perform an action that would violate protected mode, thus exposing it. The goal is to give appropriate site help messaging to IE7 Vista users. | What are you trying to accomplish that is substantially different for protected users? I've seen some window popup issues, but otherwise, clean JavaScript tends to be less affected. If you're finding that a block of code won't execute, why not do a check after attempted execution to see if the document is the state you... | I reviewed the MSDN documentation of the [Protected Mode API](http://msdn.microsoft.com/en-us/library/ms537316) from [6t7m4](https://stackoverflow.com/users/42608/meyahoocoma6t7m4awxtoekdfhpitmg2nk224sinfwk3st), and if I could call the ieframe.dll from javascript, such as:
```
var axo = new ActiveXObject("ieframe.dll"... | Detecting Vista IE7 Protected Mode with Javascript | [
"",
"javascript",
"windows-vista",
"internet-explorer-7",
"protected",
"mode",
""
] |
Can we use Java in Silverlight? | In short: No. Silverlight only supports [.NET languages](http://en.wikipedia.org/wiki/.NET_languages), such as Visual Basic, C#, Managed JavaScript, IronPython and IronRuby.
However, J# or IKVM.NET could be of use to you. | According to [Wikipedia - Future of J#](http://en.wikipedia.org/wiki/J_Sharp#Future_of_J.23), Microsoft's own major Java support is soon to be retired.
Since J# will gets removed from the full .NET CLR itself...
I don't think there is much hope for Silverlight. | Java in Silverlight? | [
"",
"java",
"silverlight",
""
] |
Modern browsers have multi-tab interface, but JavaScript function `window.showModalDialog()` creates a modal dialog that blocks *all* of the tabs.
I'd like to know if there is a way to create a modal dialog that blocks only the tab it's been created in? | You could use one of the more 'Ajax-like' modal dialogs, which are just absolute positioned divs, floating on top of everything else.
Those are modal to the 'document' and not the browser.
For instance take a look it [this jQuery plugin](http://www.ericmmartin.com/projects/simplemodal/)
P.S. `showModalDialog()` is a... | Nope. It's conceivable IE8's ‘loose coupling’ might behave like this at some point, but it doesn't in the current betas.
I second Michiel's recommendation. A pseudo-modal-dialogue working by obscuring the rest of the page, floating a div on top, and calling the script back when it's finished, is both:
* much more usa... | Can a JavaScript modal dialog be modal only to the tab and not to the whole browser window? | [
"",
"javascript",
"modal-dialog",
""
] |
In F#, you can generate a set of numbers, just by saying [1..100].
I want to do something similar in C#. This is what I have come up with so far:
```
public static int[] To(this int start, int end)
{
var result = new List<int>();
for(int i = start; i <= end; i++)
result.Add(i);
return result.ToArr... | Enumerable.Range(1, 100); | I like the idea of using `To`. The alternative `Enumerable.Range` has a subtle flaw imo. The second parameter is **not** the *value* of the last element, it is the *length* of the enumeration. This is what I've done in the past:
```
public IEnumerable<int> To(this int start, int stop)
{
while (start <= stop)
yie... | Generating sets of integers in C# | [
"",
"c#",
"set",
""
] |
I'm building a small web app in PHP that stores some information in a plain text file. However, this text file is used/modified by all users of my app at some given point in time and possible at the same time.
So the questions is. What would be the best way to make sure that only one user can make changes to the file ... | You should put a lock on the file
```
$fp = fopen("/tmp/lock.txt", "r+");
if (flock($fp, LOCK_EX)) { // acquire an exclusive lock
ftruncate($fp, 0); // truncate file
fwrite($fp, "Write something here\n");
fflush($fp); // flush output before releasing the lock
flock($fp, LOCK_UN); ... | My suggestion is to use SQLite. It's fast, lightweight, stored in a file, and has mechanisms for preventing concurrent modification. Unless you're dealing with a preexisting file format, SQLite is the way to go. | PHP and concurrent file access | [
"",
"php",
"file",
"concurrency",
""
] |
I have had a few problems with log files growing too big on my SQL Servers (2000). Microsoft doesn't recommend using auto shrink for log files, but since it is a feature it must be useful in some scenarios. Does anyone know when is proper to use the auto shrink property? | Your problem is not that you need to autoshrink periodically but that you need to backup the log files periodically. (We back ours up every 15 minutes.) Backing up the database itself is not sufficient, you must do the log as well. If you do not back up the transaction log, it will grow until it takes up all the space ... | My take on this is that auto-shrink is useful when you have many fairly small databases that frequently get larger due to added data, and then have a lot of empty space afterwards. You also need to not mind that the files will be fragmented on the disk when they frequently grow and shrink. I'd never use auto-shrink on ... | When should one use auto shrink on log files in SQL Server? | [
"",
"sql",
"sql-server",
"database",
""
] |
Is it possible to use any chart modules with wxpython? And are there any good ones out there?
I'm thinking of the likes of PyCha (<http://www.lorenzogil.com/projects/pycha/>) or any equivalent. Many modules seem to require PyCairo, but I can't figure out if I can use those with my wxpython app.
My app has a notebook ... | I recently revisited [matplotlib](http://matplotlib.sourceforge.net/index.html), and am pretty happy with the results.
If you're on windows, there are windows installers available to make your installation process a little less painful.
One potential drawback though is that it requires [numpy](http://sourceforge.net/p... | Use matplotlib. It integrates nicely with wxPython. [Here's a sample](http://eli.thegreenplace.net/2008/08/01/matplotlib-with-wxpython-guis/) of an interactive chart with wxPython and matplotlib. | Can I use chart modules with wxpython? | [
"",
"python",
"wxpython",
""
] |
What's the best way to extract the key and value from a string like this:
```
var myString = 'A1234=B1234';
```
I originally had something like this:
```
myString.split('=');
```
And that works fine, BUT an equal (=) sign could be used as a key or value within the string plus the string could have quotes, like this... | What I've tended to do in config files is ensure that there's **no** possibility that the separator character can get into either the key or value.
Sometimes that's easy if you can just say "no '=' characters allowed" but I've had to resort to encoding those characters in some places.
I generally hex them up so that ... | can't help with a one-liner, but I'll suggest the naive way:
```
var inQuote = false;
for(i=0; i<str.length; i++) {
if (str.charAt(i) == '"') {
inQuote = !inQuote;
}
if (!inQuote && str.charAt(i)=='=') {
key = str.slice(0,i);
value = str.slice(i+1);
break;
}
}
``` | Easiest way to split string into Key / value | [
"",
"javascript",
"regex",
""
] |
How can I get the (physical) installed path of a DLL that is (may be) registered in GAC? This DLL is a control that may be hosted in things other than a .Net app (including IDEs other than VS...).
When I use `System.Reflection.Assembly.GetExecutingAssembly().Location`, it gives path of GAC folder in winnt\system32 - o... | If something gets put in the GAC, it actually gets copied into a spot under %WINDIR%\assembly, like
```
C:\WINDOWS\assembly\GAC_32\System.Data\2.0.0.0__b77a5c561934e089\System.Data.dll
```
I assume you're seeing something like that when you check the Location of the assembly in question when it's installed in the GAC... | After the assembly is shadow copied into the Global Assembly cache, i don't think there is any metadata to traceback the location of the source assemblies.
What are you trying to achieve by deploying in GAC? If its just for the sake of CLR for resolving purposes, then there is an alternate way that solves your problem... | Path of DLL installed to the GAC | [
"",
"c#",
"dll",
"file",
"gac",
""
] |
Whats the other option we can use for multiple inheritance other than implementing interface | A direct answer is to use inner classes. That gives you two (or more) objects that are intimately linked but cover independent base classes.
In general, prefer composition over inheritance. It's a common mistake to use inheritance everywhere. However, that leaves inflexible solutions that are difficult to follow. | At first, it's better to avoid multiple inheritance and use interfaces. And Java actually does not support multiple inheritance.
But you can use mixins to fake the multiple inheritance. There are some manuals about this:
[Multiple Inheritance in Java](http://csis.pace.edu/~bergin/patterns/multipleinheritance.html)
[... | option for inheritance | [
"",
"java",
"multiple-inheritance",
""
] |
I've looking to find a simple recommended "minimal" c++ makefile for linux which will use g++ to compile and link a single file and h file. Ideally the make file will not even have the physical file names in it and only have a .cpp to .o transform. What is the best way to generate such a makefile without diving into th... | If it is a single file, you can type
```
make t
```
And it will invoke
```
g++ t.cpp -o t
```
This doesn't even require a Makefile in the directory, although it will get confused if you have a t.cpp and a t.c and a t.java, etc etc.
Also a real Makefile:
```
SOURCES := t.cpp
# Objs are all the sources, with .cpp r... | Here is a generic makefile from my code snippets directory:
```
SOURCES=$(wildcard *.cpp)
OBJECTS=$(SOURCES:.cpp=.o)
DEPS=$(SOURCES:.cpp=.d)
BINS=$(SOURCES:.cpp=)
CFLAGS+=-MMD
CXXFLAGS+=-MMD
all: $(BINS)
.PHONY: clean
clean:
$(RM) $(OBJECTS) $(DEPS) $(BINS)
-include $(DEPS)
```
As long as you have one .cpp s... | minimum c++ make file for linux | [
"",
"c++",
"makefile",
"compilation",
""
] |
I'm trying to figure out if I should start using more of `internal` access modifier.
I know that if we use `internal` and set the assembly variable `InternalsVisibleTo`, we can test functions that we don't want to declare public from the testing project.
This makes me think that I should just always use `internal` be... | Internal classes need to be tested and there is an assembly attribute:
```
using System.Runtime.CompilerServices;
[assembly:InternalsVisibleTo("MyTests")]
```
Add this to the project info file, e.g. `Properties\AssemblyInfo.cs`, for the project under test. In this case "MyTests" is the test project. | Adding to Eric's answer, you can also configure this in the `csproj` file:
```
<ItemGroup>
<AssemblyAttribute Include="System.Runtime.CompilerServices.InternalsVisibleTo">
<_Parameter1>MyTests</_Parameter1>
</AssemblyAttribute>
</ItemGroup>
```
Or if you have one test project per project to be tested, y... | C# "internal" access modifier when doing unit testing | [
"",
"c#",
".net",
"unit-testing",
"tdd",
""
] |
I am trying to talk to a device using python. I have been handed a tuple of bytes which contains the storage information. How can I convert the data into the correct values:
response = (0, 0, 117, 143, 6)
The first 4 values are a 32-bit int telling me how many bytes have been used and the last value is the percentage... | See [Convert Bytes to Floating Point Numbers in Python](https://stackoverflow.com/questions/5415/)
You probably want to use the struct module, e.g.
```
import struct
response = (0, 0, 117, 143, 6)
struct.unpack(">I", ''.join([chr(x) for x in response[:-1]]))
```
Assuming an unsigned int. There may be a better way t... | Would,
```
num = (response[0] << 24) + (response[1] << 16) + (response[2] << 8) + response[3]
```
meet your needs?
aid | How do I convert part of a python tuple (byte array) into an integer | [
"",
"python",
"tuples",
""
] |
I have a class called DatabaseHelper that wraps a DbConnection. What's the proper way to setup this class for a using statement? I have implemented IDisposible, but I'm not sure when and where I should be calling Connection.Close() or Connection.Dispose().
When I simply call Connection.Dispose() in my own Dispose() me... | Call connection.Dispose() from within your dispose method. You should look at the standard pattern for implementing IDisposable, which goes above and beyond simply implementing the IDisposable interface and allows for disposing unmanaged objects etc:
```
public void Dispose()
{
Dispose(true);
GC.SuppressFinali... | According to [this](http://www.devnewsgroups.net/group/microsoft.public.dotnet.framework.adonet/topic41208.aspx) newsgroup:
Here is how IDbConnection.Dispose() is implemented (as Reflector utility shows):
SqlClient:
```
protected override void Dispose(bool disposing)
{
if (disposing)
{
swi... | Properly disposing of a DbConnection | [
"",
"c#",
"dispose",
"dbconnection",
""
] |
**JavaFX** is now out, and there are promises that Swing will improve along with JavaFX. Gone will be the days of ugly default UI, and at long last we can create engaging applications that are comparable to **Flash, Air, and Silverlight** in terms of quality.
1. Will this mean that **Java Applets** that hail from 1990... | In my opinion Java Applets have been dead for years. I wrote some in the late 90s - a Tetris game during an internship to demonstrate on a 40MHz ARM Acorn Set Top Box for example. Of course I bet there are some casual game sites that have tonnes of them still, and thus it will remain supported, but active development w... | I think this discussion is somewhat misleading. I an no fan of applet technology either (and I have been underwhelmed by JavaFX). But the point that this thread is missing is that, unless I am mistaken, **JavaFX is built on top of applet technology**. They are not competing or mutually exclusive. See these articles [he... | JavaFX is now out: Are Applets and Java Desktop officially dead/dying? | [
"",
"java",
"applet",
"javafx",
""
] |
I've got several function where I need to do a one-to-many join, using count(), group\_by, and order\_by. I'm using the sqlalchemy.select function to produce a query that will return me a set of id's, which I then iterate over to do an ORM select on the individual records. What I'm wondering is if there is a way to do ... | I've found the best way to do this. Simply supply a `from_statement` instead of a `filter_by` or some such. Like so:
```
meta.Session.query(Location).from_statement(query).all()
``` | What you're trying to do maps directly to a SQLAlchemy join between a subquery [made from your current select call] and a table. You'll want to move the ordering out of the subselect and create a separate, labeled column with count(desc); order the outer select by that column.
Other than that, I don't see much that's ... | SQLAlchemy with count, group_by and order_by using the ORM | [
"",
"python",
"sqlalchemy",
""
] |
I have an XP client that is experiencing an issue. My dev box is Vista Home 64. I start up the debugger on the client machine and when i try to run on the dev box, it says 'Unable to debug. Remote debugger doesn't support this version of windows'.
Looks like I'm sol. is there another way to find out how to debug this?... | Turns out the .net framework was hosed on the client. I couldn't get a stacktrace or nothing. Removed and reinstalled .net framework and everything worked great!
Thanks for all the help! | You may be running into issues with the 64-bit debugger not being able to deal with the 32-bit debugger client.
There was a question a while ago talking about problems connecting a 32-bit debugger to a 64-bit target (which I think is the opposite from your situation):
* [x86 Remote Debugger Service on x64](https://st... | Remote debugging - Remote debugger doesn't support this version of Windows error | [
"",
"c#",
".net",
"debugging",
"remote-debugging",
""
] |
I'm writing some RSS feeds in PHP and stuggling with character-encoding issues. Should I utf8\_encode() before or after htmlentities() encoding? For example, I've got both ampersands and Chinese characters in a description element, and I'm not sure which of these is proper:
```
$output = utf8_encode(htmlentities($sour... | It's important to pass the character set to the htmlentities function, as the default is ISO-8859-1:
```
utf8_encode(htmlentities($source,ENT_COMPAT,'utf-8'));
```
You should apply htmlentities first as to allow utf8\_encode to encode the entities properly.
(EDIT: I changed from my opinion before that the order didn... | First: The [`utf8_encode` function](http://docs.php.net/utf8_encode) converts from ISO 8859-1 to UTF-8. So you only need this function, if your input encoding/charset is ISO 8859-1. But why don’t you use UTF-8 in the first place?
Second: You don’t need [`htmlentities`](http://docs.php.net/htmlentities). You just need ... | utf-8 and htmlentities in RSS feeds | [
"",
"php",
"utf-8",
"rss",
""
] |
I know that the compiler will sometimes initialize memory with certain patterns such as `0xCD` and `0xDD`. What I want to know is **when** and **why** this happens.
## When
Is this specific to the compiler used?
Do `malloc/new` and `free/delete` work in the same way with regard to this?
Is it platform specific?
Wi... | A quick summary of what Microsoft's compilers use for various bits of unowned/uninitialized memory when compiled for debug mode (support may vary by compiler version):
```
Value Name Description
------ -------- -------------------------
0xCD Clean Memory Allocated memory via malloc or ne... | One nice property about the fill value 0xCCCCCCCC is that in x86 assembly, the opcode 0xCC is the [int3](https://pdos.csail.mit.edu/6.828/2008/readings/i386/INT.htm) opcode, which is the software breakpoint interrupt. So, if you ever try to execute code in uninitialized memory that's been filled with that fill value, y... | When and why will a compiler initialise memory to 0xCD, 0xDD, etc. on malloc/free/new/delete? | [
"",
"c++",
"c",
"memory",
"memory-management",
""
] |
I'm working with a Java program that has multiple components (with Eclipse & Ant at the moment).
Is there some way to start multiple programs with one launch configuration? I have an Ant target that does the job (launches multiple programs) but there are things I would like to do:
* I would like to debug the programs... | ['multiple launch part':]
If you have an ant launch configuration which does what you want, you can always transform it into a java launcher calling ant.
```
Main Class: org.apache.tools.ant.Main
-Dant.home=${resource_loc:/myPath/apache_ant}
-f ${resource_loc:/myProject/config/myFile-ant.xml}
```
You can then laun... | The question and selected answer here are both 6 years old.
[Eclipse Launch Groups](http://help.eclipse.org/juno/index.jsp?topic=%2Forg.eclipse.cdt.doc.user%2Freference%2Fcdt_u_run_dbg_launch_group.htm) provides UI to run multiple launch configs. Launch Groups is apparently part of CDT but can be [installed separately... | How to launch multiple Java programs with one configuration on separate consoles (with Eclipse) | [
"",
"java",
"eclipse",
"launch",
""
] |
In Java 1.4 you could use ((SunToolkit) Toolkit.getDefaultToolkit()).getNativeWindowHandleFromComponent() but that was removed.
It looks like you have to use JNI to do this now. Do you have the JNI code and sample Java code to do this?
I need this to call the Win32 GetWindowLong and SetWindowLong API calls, which can... | The following code lets you pass a Component to get the window handle (HWND) for it. To make sure that a Component has a corresponding window handle call isLightWeight() on the Component and verify that it equals false. If it doesn't, try it's parent by calling Component.getParent().
Java code:
```
package win32;
pub... | You don't have write any C/JNI code. From Java:
```
import sun.awt.windows.WComponentPeer;
public static long getHWnd(Frame f) {
return f.getPeer() != null ? ((WComponentPeer) f.getPeer()).getHWnd() : 0;
}
```
Caveats:
* This uses a sun.\* package. Obviously this is not public API. But it is unlikely to change (... | In Java Swing how do you get a Win32 window handle (hwnd) reference to a window? | [
"",
"java",
"winapi",
"swing",
"java-native-interface",
"hwnd",
""
] |
SQL Server 2005
I have 10 million rows in DB, and run a select (with lots of "where" and joints.. pretty complex). The results are presented in grid (think goolge results) and because of that, the user cannot possibly use more then 1000 results.
So I limit my SQL with a TOP 1000.
**Problem**: User still wants to kno... | ```
SELECT TOP 1000 x, y, z, COUNT(*) OVER () AS TotalCount
FROM dbo.table
``` | Personally I'd opt for two statements hitting the database. One to retrieve the count, one to retrieve the first 1000 records.
You could run both queries in a batch to squeeze a little extra performance by saving a round-trip to the database.
```
-- Get the count
select count(*) from table where [criteria]
-- Get th... | select top 1000, but know how many rows are there? | [
"",
"sql",
"sql-server-2005",
"performance",
""
] |
My MS Visual C# program was compiling and running just fine.
I close MS Visual C# to go off and do other things in life.
I reopen it and (before doing anything else) go to "Publish" my program and get the following error message:
> Program C:\myprogram.exe does not contain a static 'Main' method suitable for an entry... | Are the properties on the file set to Compile? | I was struggle with this error just because **one of my `class library` projects** `was set acceddentaly` to be an **console application**
so make sure your class library projects is class library in Output type
[](https://i.stack.imgur.com/pzRCw.png... | Troubleshooting "program does not contain a static 'Main' method" when it clearly does...? | [
"",
"c#",
"compilation",
""
] |
Does anyone know of a link to a reference on the web that contains a sample English dictionary word script, that can be used to populate a dictionary table in SQL Server?
I can handle a .txt or .csv file, or something similar.
Alternatively, I'm adding custom spellchecking functionality to my web apps...but I don't w... | [Downloadable Dictionaries](http://www.dicts.info/uddl.php)
[GNU version of The Collaborative International Dictionary of English (XML)](http://www.ibiblio.org/webster/) | As used on [Debian](http://packages.debian.org/changelogs/pool/main/s/scowl/scowl_6-2.3/wamerican-large.copyright) and [Ubuntu](http://changelogs.ubuntu.com/changelogs/pool/main/s/scowl/scowl_6-2.1/wbritish.copyright):
[SCOWL (Spell Checker Oriented Word Lists)](http://wordlist.sourceforge.net/) is a collection of Eng... | Sample [English] Dictionary SQL Script to populate table? | [
"",
"sql",
"dictionary",
"scripting",
"spell-checking",
""
] |
This seems to me to be the kind of issue that would crop up all the time with SQL/database development, but then I'm new to all this, so forgive my ignorance.
I have 2 tables:
```
CREATE TABLE [dbo].[Tracks](
[TrackStringId] [bigint] NOT NULL,
[Id] [bigint] IDENTITY(1,1) NOT NULL,
[Time] [datetime] NOT NU... | First, insert into `TrackStrings`, omitting the primary key column from the column list. This invokes its `IDENTITY` column which generates a value automatically.
```
INSERT INTO [dbo].[TrackStrings] ([String])
VALUES ('some string');
```
Second, insert into `Tracks` and specify as its `TrackStringId` the function... | If you are using SQL Server 2005 or later and are inserting a lot of records in a single `INSERT`, you can look into `OUTPUT` or `OUTPUT INTO` options [here](http://msdn.microsoft.com/en-us/library/ms177564.aspx) to use the identities from the first insert in the second without haveing to "re-find" the rows to get all ... | SQL insert into related tables | [
"",
"sql",
"sql-server",
"insert",
""
] |
How do you gracefully handle failed future feature imports? If a user is running using Python 2.5 and the first statement in my module is:
```
from __future__ import print_function
```
Compiling this module for Python 2.5 will fail with a:
```
File "__init__.py", line 1
from __future__ import print_function
Sy... | "I'd like to inform the user that they need to rerun the program with Python >= 2.6 and maybe provide some instructions on how to do so."
Isn't that what a README file is for?
Here's your alternative. A "wrapper": a little blob of Python that checks the environment before running your target aop.
File: appwrapper.py... | A rather hacky but simple method I've used before is to exploit the fact that byte literals were introduced in Python 2.6 and use something like this near the start of the file:
```
b'This module needs Python 2.6 or later. Please do xxx.'
```
This is harmless in Python 2.6 or later, but a `SyntaxError` in any earlier... | How to gracefully deal with failed future feature (__future__) imports due to old interpreter version? | [
"",
"python",
"python-import",
""
] |
Setup is following:
Drupal project, one svn repo with trunk/qa/production-ready branches, vhosts for every branch, post-commit hook that copies files from repository to docroots.
Problem is following: Drupal website often relies not only on source code but on DB data too (node types, their settings, etc.).
I'm lookin... | It sounds like you've already got some infrastructure there that you've written.
So I'd start coding! There's not anything that I'm aware of thats especially good for this at the moment. And if there is, I imagine that it would take some effort to get it going with your existing infrastructure. So starting coding seem... | Did a presentation on this at a recent conference ([slideshare link](http://www.slideshare.net/eaton/drupal-deployment-presentation)) -- I would STRONGLY suggest that you use a site-specific custom module whose .install file contains versioned 'update' functions that do the heavy lifting for database schema changes and... | Drupal deployment/testing/don't-how-to-call it tool | [
"",
"php",
"deployment",
"drupal",
"continuous-integration",
""
] |
I have searched high and low and cannot find a Samsung Omnia SDK.
I know its possible to use the .net framework for development , but i want more , specifically being able to access the motion sensor and maybe the GPS as well.
Any idea or directions are welcome. | [Here](http://innovator.samsungmobile.com/down/cnts/category.main.list.do?cateId=147&cateAll=all&platformId=2) you can find SDK and Emulators for Samsung's Omnia, the [second](http://innovator.samsungmobile.com/down/cnts/detail.view.do?platformId=2&cateId=147&childCateId=All&childCateId2=&cntsId=1641&imgType=&parentCat... | You should be able to access the GPS with the GPS intermediate driver. Have a look at the GPS sample from Windows Mobile SDK.
I don't know where to find the Omnia SDK, but if you can't find something in [xda-developers](http://www.xda-developers.com/), it would be very hard to locate it.
EDIT: Little bit of search an... | How or where to obtain the Official Samsung Omnia's SDK | [
"",
"c#",
"windows-mobile",
""
] |
You can do it in .NET by using the keyword "ref". Is there any way to do so in Java? | What are you doing in your method? If you're merely populating an existing array, then you don't need pass-by-reference semantics - either in .NET or in Java. In both cases, the reference will be passed by value - so changes to the *object* will be visible by the caller. That's like telling someone the address of your ... | Actually, in Java, the **references are passed-by-value**.
In this case, the reference is a `byte[]` object. Any changes that affect the object itself will be seen from the caller method.
However, if you try to replace the reference, for example using `new byte[length]`, you are only replacing the reference that you ... | Java: How to pass byte[] by reference? | [
"",
"java",
"pass-by-reference",
""
] |
I have an action handling a form post, but I want to make sure they are authenticated before the action. The problem is that the post data is lost because they user is redirected to the login page, and then back.
```
[AcceptVerbs(HttpVerbs.Post)]
[Authorize]
public ActionResult AskQuestion(string question)... | You need to serialize your form values and a RedirectUrl to a hidden field.
After authentication deserialize the data in your hidden field and redirect based on the value of the RedirectUrl.
You will need a custom Authorize class to handle this. | A POST is usually used for an add, update, or delete of data. By the time the user is doing this, if authentication is needed, you should have already authenticated them. So I would suggest that you change the flow of your app to authenticate before the POST. | ASP.NET MVC Preserve Post Data After Authorize | [
"",
"c#",
"asp.net-mvc",
""
] |
I keep a cache of transactions to flush (to persistent storage) on the event of a watermark or object finalization. Since `__del__` is [no longer guaranteed to be called](http://docs.python.org/reference/datamodel.html?highlight=__del__#object.__del__) on every object, is the appropriate approach to hook a similar func... | If you don't need your object to be alive at the time you perform the flush, you could use [weak references](http://docs.python.org/library/weakref.html)
This is similar to your proposed solution, but rather than using a real reference, store a list of weak references, with a callback function to perform the flush. Th... | If you have to handle ressources the prefered way is to have an explicit call to a `close()` or `finalize()` method. Have a look at the `with` statement to abstract that. In your case the `weakref` module might be an option. The cached object can be garbage collected by the system and have their `__del__()` method call... | Python: flush a buffer before program termination via a finalizer | [
"",
"python",
"buffer",
"destructor",
"finalizer",
""
] |
for the following:
```
( a != b ) ? cout<<"not equal" : cout<<"equal";
```
suppose I don't care if it's equal, how can I use the above statement by substituting `cout<<"equal"` with a no-op. | If it really is for a ternary operator that doesn't need a second action, the best option would be to replace it for an if:
```
if (a!=b) cout << "not equal";
```
it will smell a lot less. | Simple: I would code it as
```
if (a != b)
cout << "not equal";
```
The ternary operator requires the two results to be of the same type. So you might also be able to get away with
```
(a != b) ? cout << "not equal" : cout;
```
because the stream operator (<<) just returns the ostream reference. That's ugly and ... | How does one execute a no-op in C/C++? | [
"",
"c++",
""
] |
I'm working on a PHP CMS like project and I'm trying to find out what's the most convenient way of dealing with the CRUD functionality in PHP.
The CMS is programmed completely in procedural PHP (no OOP - I know that many of you will not agree with this...) and was designed keeping everything as simple and light as pos... | By CRUD operations do you mean just the (tedious) database queries?
You could just as easily setup your database so that except for a few common fields amongst content types, all data for a particular content type is stored as a serialized associative array in a TEXT field.
This way you only need 1 set of queries to ... | > Though as a personal aside I would highly suggest you look into grabbing Zend\_Form (with Zend\_Validate and Zend\_Config) as well as using Doctrine as a ORM/database abstraction layer. You might find that at least Doctrine will make your life so much easier when it comes to running operations on the database.
I agr... | Simple / reusable CRUD in PHP (NO famework or big classes) | [
"",
"php",
"crud",
"code-reuse",
""
] |
I've written a PHP script that handles file downloads, determining which file is being requested and setting the proper HTTP headers to trigger the browser to actually download the file (rather than displaying it in the browser).
I now have a problem where some users have reported certain files being identified incorr... | Acoording to [RFC 2046 (Multipurpose Internet Mail Extensions)](http://www.rfc-editor.org/rfc/rfc2046.txt):
> The recommended action for an
> implementation that receives an
> "application/octet-stream" entity is
> to simply offer to put the data in
> a file
So I'd go for that one. | As explained by Alex's link you're probably missing the header `Content-Disposition` on top of `Content-Type`.
So something like this:
```
Content-Disposition: attachment; filename="MyFileName.ext"
``` | HTTP Headers for File Downloads | [
"",
"php",
"http-headers",
"download",
"content-type",
""
] |
Are there any scientific packages for Lua comparable to Scipy? | There is the basis for one in [Numeric Lua](http://numlua.luaforge.net/). | You should try **[Torch7](http://www.torch.ch)** ([github](https://github.com/andresy/torch)).
Torch7 has a very nice and efficient vector/matrix/tensor numerical library
with a Lua front-end. It also has a bunch of functions for computer vision
and machine learning.
It's pretty recent but getting better quickly. | Scientific libraries for Lua? | [
"",
"python",
"lua",
"scipy",
"scientific-computing",
"torch",
""
] |
Is there a way to tidy-up the following code, rather than a series of nested try/except statements?
```
try:
import simplejson as json
except ImportError:
try:
import json
except ImportError:
try:
from django.utils import simplejson as json
except:
raise "Req... | I found the following function at <http://mail.python.org/pipermail/python-list/2007-May/441896.html>. It seems to work quite well, and I'm pretty sure the way its importing won't stomp on any existing imports you might already have.
```
def module_exists(module_name):
try:
mod = __import__(module_name)
... | ```
def import_any(*mod_list):
res = None
for mod in mod_list:
try:
res = __import__(mod)
return res
except ImportError:
pass
raise ImportError("Requires one of " + ', '.join(mod_list))
json = import_any('simplejson', 'json', 'django.utils.simplejson')
``... | Tidier way of trying to import a module from multiple locations? | [
"",
"python",
"refactoring",
"python-import",
""
] |
We are porting an app which formerly used Openbase 7 to now use MySQL 5.0.
OB 7 did have quite badly defined (i.e. undocumented) behavior regarding case-sensitivity. We only found this out now when trying the same queries with MySQL.
It appears that OB 7 treats lookups using "=" differently from those using "LIKE": I... | Another idea .. does MySQL offer something like User Defined Functions? You could then write a UDF-version of like that is case insesitive (ci\_like or so) and change all like's to ci\_like. Probably easier to do than regexing a call to lower in .. | These two articles talk about case sensitivity in mysql:
* [Case Sensitive mysql](http://dev.mysql.com/doc/refman/5.1/en/case-sensitivity.html)
* [mySql docs "Case Sensitivity"](http://dev.mysql.com/doc/refman/5.1/en/case-sensitivity.html)
Both were early hits in this Google search:
* [case sensitive mysql](http://w... | Openbase SQL case-sensitivity oddities ('=' vs. LIKE) - porting to MySQL | [
"",
"sql",
"mysql",
"case-sensitive",
"case-insensitive",
"openbase",
""
] |
I've done quite a bit of programming on Windows but now I have to write my first Linux app.
I need to talk to a hardware device using UDP. I have to send 60 packets a second with a size of 40 bytes. If I send less than 60 packets within 1 second, bad things will happen.
The data for the packets may take a while to gen... | I posted this answer to illustrate a quite different approach to the "obvious" one, in the hope that someone discovers it to be exactly what they need. I didn't expect it to be selected as the best answer! Treat this solution with caution, because there are potential dangers and concurrency issues...
You can use the [... | I've done a similar project: a simple software on an embedded Linux computer, sending out CAN messages at a regular speed.
I would go for the two threads approach. Give the sending thread a slightly higher priority, and make it send out the same data block once again if the other thread is slow in computing those bloc... | Architectural Suggestions in a Linux App | [
"",
"c++",
"c",
"linux",
"structure",
"ethernet",
""
] |
How do I properly set the default character encoding used by the JVM (1.5.x) programmatically?
I have read that `-Dfile.encoding=whatever` used to be the way to go for older JVMs. I don't have that luxury for reasons I wont get into.
I have tried:
```
System.setProperty("file.encoding", "UTF-8");
```
And the proper... | Unfortunately, the `file.encoding` property has to be specified as the JVM starts up; by the time your main method is entered, the character encoding used by `String.getBytes()` and the default constructors of `InputStreamReader` and `OutputStreamWriter` has been permanently cached.
As [another user points out,](https... | From the [JVM™ Tool Interface](http://java.sun.com/javase/6/docs/platform/jvmti/jvmti.html#tooloptions) documentation…
> Since the command-line cannot always be accessed or modified, for example in embedded VMs or simply VMs launched deep within scripts, a `JAVA_TOOL_OPTIONS` variable is provided so that agents may be... | Setting the default Java character encoding | [
"",
"java",
"utf-8",
"character-encoding",
""
] |
I wanna stop the reading of my text input file when the word "synonyms" appears. I'm using ifstream and I don't know how to break the loop. I tried using a stringstream "synonyms" but it ended up junking my bst. I included the complete project files below in case you wanna avoid typing.
Important part:
```
for(;;) ... | You can do it like
```
/* here, it stops when reading "synonyms" or when failing to extract a word. */
while(inStream >> word && word != "synonym") {
wordTree.insert(word);
}
wordTree.graph(cout);
```
Note that when it fails to read a sequence of non-whitespace characters, it sets the fail-bit of the stream. inSt... | You should make an operator == on WordInfo to compare it to a string, then you can just this in the reading loop:
```
if ( word == "synonyms" ) break;
``` | How can I break the reading this text file (using ifstream)? C++ | [
"",
"c++",
"ifstream",
""
] |
I'm having issues getting Firefox to update a webpage when its class is changed dynamically.
I'm using an HTML `table` element. When the user clicks a cell in the table header, my script toggles the class back and forth between `sorted_asc` and `sorted_des`. I have pseudo element which adds an arrow glyph (pointing up... | It's kind of cheesy, but since you're using javascript anyway, try this after you changed the className:
```
document.body.style.display = 'none';
document.body.style.display = 'block';
```
This will re-render the layout and often solves these kind of bugs. Not always, though. | This is 2014 and none of the proposed solutions on this page seem to work. I found another way : detach the element from the DOM and append it back where it was. | How can I convince Firefox to redraw CSS Pseudo-elements? | [
"",
"javascript",
"html",
"css",
"firefox",
""
] |
Having a table with a column like: `mydate DATETIME` ...
I have a query such as:
```
SELECT SUM(foo), mydate FROM a_table GROUP BY a_table.mydate;
```
This will group by the full `datetime`, including hours and minutes. I wish to make the group by, only by the date `YYYY/MM/DD` not by the `YYYY/MM/DD/HH/mm`.
How to... | Cast the datetime to a date, then GROUP BY using this syntax:
```
SELECT SUM(foo), DATE(mydate) FROM a_table GROUP BY DATE(a_table.mydate);
```
Or you can GROUP BY the alias as @orlandu63 suggested:
```
SELECT SUM(foo), DATE(mydate) DateOnly FROM a_table GROUP BY DateOnly;
```
Though I don't think it'll make any di... | I found that I needed to group by the month and year so neither of the above worked for me. Instead I used date\_format
```
SELECT date
FROM blog
GROUP BY DATE_FORMAT(date, "%m-%y")
ORDER BY YEAR(date) DESC, MONTH(date) DESC
``` | Group by date only on a Datetime column | [
"",
"sql",
"mysql",
""
] |
A few weeks back I was using std::ifstream to read in some files and it was failing immediately on open because the file was larger than 4GB. At the time I couldnt find a decent answer as to why it was limited to 32 bit files sizes, so I wrote my own using native OS API.
So, my question then: Is there a way to handle ... | Apparently it depends on how `off_t` is implemented by the library.
```
#include <streambuf>
__int64_t temp=std::numeric_limits<std::streamsize>::max();
```
gives you what the current max is.
[STLport](http://stlport.sourceforge.net/) supports larger files. | I ran into this problem several years ago using gcc on Linux. The OS supported large files, and the C library (fopen, etc) supported it, but the C++ standard library didn't. I turned out that I had to recompile the C++ standard library using the correct compiler flags. | Reading files larger than 4GB using c++ stl | [
"",
"c++",
"file-io",
"iostream",
""
] |
Is there a way to configure Velocity to use something other than toString() to convert an object to a string in a template? For example, suppose I'm using a simple date class with a format() method, and I use the same format every time. If all of my velocity code looks like this:
```
$someDate.format('M-D-yyyy')
```
... | You could also create your own ReferenceInsertionEventHandler that watches for your dates and automatically does the formatting for you. | Velocity allows for a JSTL like utility called velocimacros:
<http://velocity.apache.org/engine/devel/user-guide.html#Velocimacros>
This would allow you to define a macro like:
```
#macro( d $date)
$date.format('M-D-yyyy')
#end
```
And then call it like so:
```
#d($someDate)
``` | Configure velocity to render an object with something other than toString? | [
"",
"java",
"templates",
"velocity",
"tostring",
"webwork",
""
] |
I'm reading "[Pro JavaScript Techniques](http://jspro.org/)" by [John Resig](https://en.wikipedia.org/wiki/John_Resig), and I'm confused with an example. This is the code:
```
// Create a new user object that accepts an object of properties
function User( properties ) {
// Iterate through the properties of the objec... | I started this post with the sole purpose of learning why that things happened, and I finally did. So in case there's someone else interested in the "whys", here they are:
**Why does 'this' changes inside the anonymous function?**
A new function, even if it is an anonymous, declared inside an object or another functi... | **I think it's best not to use the `new` keyword at all when working in JavaScript.**
This is because if you then instantiate the object **without** using the new keyword (ex: `var user = User()`) by mistake, \*very bad things will happen...\*reason being that in the function (if instantiated without the `new` keyword... | JavaScript automatic getter/setters (John Resig book) | [
"",
"javascript",
"metaprogramming",
""
] |
i m trying to design a mmo game using python...
I have evaluated stackless and since it is not the general python and it is a fork, i dont want to use it
I am trying to chose between
pysage
candygram
dramatis
and
parley
any one try any of these libraries?
Thanks a lot for your responses | I would go for [pysage](http://code.google.com/p/pysage/).
It has the highest level of abstraction and a lightweight messaging API which will give you lots of flexibility. I would imagine when designing an MMO you will want as much flexibility as possible.
It also takes a page from Erlang's Actor model which is reall... | Initially [Twisted Python](http://twistedmatrix.com/trac/) was designed to write MMOs, but it not really easy to use. I don't know if there is an Actor implementation for it, perhaps in the [tx project in Launchpad](https://launchpad.net/tx) ? | Good python library for designing a mmo? Actor based design | [
"",
"python",
"stackless",
"python-stackless",
"mmo",
""
] |
I have been learning more and more javascript; it's a necessity at my job. We have a web application that uses a lot of javascript and I will be doing more and more every day. I have read bits and pieces about design patterns, but was wondering if someone could just give me a cut and dry example and definition. Are the... | Design patterns are generic and usually elegant solutions to well-known programming problems. Without knowing what problem you're working in, I would say "Yes" they can help make your code more manageable.
[This link](https://addyosmani.com/resources/essentialjsdesignpatterns/book/) and [this link](https://www.oreilly... | One of the most practical and easy to use JavaScript-specific design pattern I've encountered is the [Module Pattern](http://yuiblog.com/blog/2007/06/12/module-pattern/), which is a modified [Singleton pattern](http://en.wikipedia.org/wiki/Singleton_pattern) that "namespaces" related code and prevents the global scope ... | Are design patterns in JavaScript helpful? And what exactly are they? | [
"",
"javascript",
"design-patterns",
""
] |
How can I send keyboard input messages to either the currently selected window or the previously selected window?
I have a program which I use to type some characters which are not present on my keyboard and I would like it if I could just send the input directly rather than me having to copy and paste all the time.
... | [SendKeys.Send](http://msdn.microsoft.com/en-us/library/system.windows.forms.sendkeys.send.aspx) will help you with that. | Look at System.Windows.Forms.SendKeys.Send( string ). This allows key presses to be sent to the currently active application.
Update: just found this on MSDN forums: [MSDN Forum](http://forums.microsoft.com/MSDN/ShowPost.aspx?PostID=2766639&SiteID=1) | C# Sending Keyboard Input | [
"",
"c#",
"windows",
""
] |
Does Java 6 consume more memory than you expect for largish applications?
I have an application I have been developing for years, which has, until now taken about 30-40 MB in my particular test configuration; now with Java 6u10 and 11 it is taking several hundred while active. It bounces around a lot, anywhere between... | Over the last few weeks I had cause to investigate and correct a problem with a thread pooling object (a pre-Java 6 multi-threaded execution pool), where is was launching far more threads than required. In the jobs in question there could be up to 200 unnecessary threads. And the threads were continually dying and new ... | In response to a discussion in the comments to Ran's answer, here's a test case that proves that the JVM *will* release memory back to the OS under certain circumstances:
```
public class FreeTest
{
public static void main(String[] args) throws Exception
{
byte[][] blob = new byte[60][1024*1024];
... | Java 6 Excessive Memory Usage | [
"",
"java",
"memory-management",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.