
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I have these tables:
```
customer
--------
customer_id int
name varchar(255)
order
-----
order_id int
customer_id int
discount boolean
```
I can get the number of orders made by each customer with a query like:
```
select c.id, count(o.order_id)
from customer c
left join order as o using c.customer_id... | How about something like
```
select c.id, count(o.order_id),sum(if(o.discount,1,0))
from customer c
left join order as o using c.customer_id = o.customer_id
group by c.id
``` | You could do somethings like
```
select
c.id,
sum(case o.discount when true then 1 else 0 end) as 'total discounted',
count(o.order_id) as 'total orders'
from customer as c
left join order as o using c.customer_id = o.customer_id
group by c.id
``` | group by query challenge | [
"",
"sql",
"mysql",
""
] |
The .net framework provides in the Math class a method for powering double. But by precision requirement I need to raise a decimal to a decimal power [ Pow(decimal a, decimal b) ]. Does the framework have such a function? Does anyone know of a library with this kind of function? | To solve my problem I found some [expansion series](http://mathworld.wolfram.com/MaclaurinSeries.html "expansion series"), and them I had them implemented to solve the equation X^n = e^(n \* ln x).
```
// Adjust this to modify the precision
public const int ITERATIONS = 27;
// power series
public static decimal Decim... | This should be the fastest for a positive integer Exponent and a decimal base:
```
// From http://www.daimi.au.dk/~ivan/FastExpproject.pdf
// Left to Right Binary Exponentiation
public static decimal Pow(decimal x, uint y){
decimal A = 1m;
BitArray e = new BitArray(BitConverter.GetBytes(y));
int t = e.Coun... | Raising a decimal to a power of decimal? | [
"",
"c#",
"bigdecimal",
"decimal",
""
] |
I have a webpage on my site that displays a table, reloads the XML source data every 10 seconds (with an XmlHttpRequest), and then updates the table to show the user any additions or removals of the data. To do this, the JavaScript function first clears out all elements from the table and then adds a new row for each u... | 100 `<tr>`'s isn't really that much... are you still using that framework's `new Element()`? That might be the cause of it.
You should test the speed of `new Element()` vs `document.createElement()` vs `.innerHTML`
Also try building the dom tree "in memory" then append it to the document at the end.
Finally watch th... | I have experienced similar problems at round 3000 table rows of complex data, so there is something not entirely right with your code. How is it running in firefox ? Can you check in several different browsers.
Are you binding to onPropertyChange anywhere ? This is a really dangerous ie event that has caused me severe... | Possible to add large amount of DOM nodes without browser choking? | [
"",
"javascript",
"ajax",
"dom",
""
] |
Let's say I have two existing tables, "dogs" and "cats":
```
dog_name | owner
---------+------
Sparky | Bob
Rover | Bob
Snoopy | Chuck
Odie | Jon
cat_name | owner
---------+------
Garfield | Jon
Muffy | Sam
Stupid | Bob
```
How do I write a query with this output?
```
owner | num_dogs | ... | ```
select owner, sum(num_dogs), sum(num_cats) from
(select owner, 1 as num_dogs, 0 as num_cats from dogs
union
select owner, 0 as num_dogs, 1 as num_cats from cats)
group by owner
``` | I prefer this one:
```
select owner
, count(dog_name) dogs
, count(cat_name) cats
from cats FULL OUTER JOIN dogs ON (cats.owner = dogs.owner)
``` | Can SQL calculate aggregate functions across multiple tables? | [
"",
"sql",
""
] |
I can not figure out what all the parameters to the arc() function are (by experimentation) and I have not found any tutorial that seems to explain them. Where would a good explanation of the arc() function be? | ```
arc(x, y, radius, startAngle, endAngle, anticlockwise)
```
The first three parameters, x and y and radius, describe a circle, the arc drawn will be part of that circle.
startAngle and endAngle are where along the circle to start and stop drawing. 0 is east, Math.PI/2 is south, Math.PI is west, and Math.PI\*3/2 is ... | I was having the same problem and made a little interactive page to help make sense of it:
<http://www.scienceprimer.com/drawing-circles-javascript-html5-canvas-element>
All of the parameters can be adjusted and the resulting arc is rendered in real time. The page also demonstrates how the fill(), stroke() and closeP... | tutorial for HTML canvas's arc function | [
"",
"javascript",
"html",
"canvas",
""
] |
For some reason the following code fails. You can't simply erase a reverse\_iterator by using its base() method.
```
#include <set>
#include <iostream>
int main()
{
std::set<int> setOfInts;
setOfInts.insert(1);
setOfInts.insert(2);
setOfInts.insert(3);
std::set<int>::reverse_iterator rev_iter = s... | Apparently the solution is what base() returns is 1 off. The following identity holds for a reverse\_iterator:
```
&*(reverse_iterator(i)) == &*(i - 1)
```
Or in other words, the reverse\_iterator is always one pass the regular iterator it is the base of. Not sure why.
# In GCC
Simply change
```
// SEGFAUL... | When you iterate with a reverse iterator and want to use base() to modify its container, always keep in mind that a reverse\_iterator is always based on the next iterator from the original order. It's a little unintuitive but it actually makes the code simpler:
```
#include <set>
int main()
{
std::set<int> setOfIn... | How do I erase a reverse_iterator from an stl data structure? | [
"",
"c++",
"stl",
"iterator",
""
] |
I was just wondering if it is possible to capture the output of a separate process running on windows?
For instance if i have a console app running, could i run a second app, a forms app, and have that app capture the output from the console app and display it in a text box? | You can do this:
```
Process[] p = Process.GetProcessesByName("myprocess.exe");
StreamReader sr = p[0].StandardOutput;
while (sr.BaseStream.CanRead)
{
Console.WriteLine(sr.ReadLine());
}
``` | You can redirect the stdout / stderr (standary out put / error stream) of a process if you are the one starting it. For an example take a look at [this](http://channel9.msdn.com/forums/Coffeehouse/250664-C-Execute-External-App-and-capture-output/).
Capturing the output stream of a process which was not started by you,... | Capture output from unrelated process | [
"",
"c#",
""
] |
I'm wondering if it's possible to get a handle on running instances of a given class. The particular issue that triggered this was an application that doesn't exit nicely because of a number of running threads.
Yes, I know you can daemonize the theads, and they won't then hold up the application exit. But it did get m... | You can indeed get a stack trace of all running Threads dumped to the stdout by using `kill -QUIT <pid>` on a \*NIX like OS, or by running the application in a Windows console and pressing `Ctrl-Pause` (as another poster notes.)
However, it seems like you're asking for programmatic ways to do it. So, assuming what you... | From [this page](http://alek.xspaces.org/2005/08/11/how-does-a-java-profiler-work-ej-technologies-jprofiler),
> A Java profiler uses a native interface to the JVM (the JVMPI for Java <=1.4.2 or the [JVMTI for Java >=1.5.0](http://en.wikipedia.org/wiki/Java_Virtual_Machine_Tools_Interface)) to get profiling information... | Finding running instances in a running JVM | [
"",
"java",
"jvm",
"classloader",
""
] |
I'm wondering about the downsides of each servers in respect to a production environment. Did anyone have big problems with one of the features? Performance, etc. I also quickly took a look at the new Glassfish, does it match up the simple servlet containers (it seems to have a good management interface at least)? | I love Jetty for its low maintenance cost. It's just unpack and it's ready to roll. Tomcat is a bit high maintenance, requires more configuration and it's heavier. Besides, Jetty's continuations are very cool.
EDIT: In 2013, there are reports that Tomcat has gotten easier. See comments. I haven't verified that. | I think tomcat is more disscussed and supported by application, Jetty is portable and can be embedded in an application. and Jetty has good continuations. | Tomcat VS Jetty | [
"",
"java",
"tomcat",
"servlets",
"webserver",
"jetty",
""
] |
So I have a relatively large (enough code that it would be easier to write this CMS component from scratch than to rewrite the app to fit into a CMS) webapp that I want to add basic Page/Menu/Media management too, I've seen several Django pluggables addressing this issue, but many seem targeted as full CMS platforms.
... | I have worked with all three (and more) and they are all built for different use cases IMHO. I would agree that these are the top-teir choices.
The grid comparison at djangopluggables.com certainly can make evaluating each of these easier.
**django-cms** is the most full-featured and is something you could actually h... | If you do not necessarily want a finished CMS with a fixed feature set, but rather tools on top of Django to build your own CMS I recommend looking into FeinCMS. It follows a toolkit philosophy instead of trying to solve everything and (too) often failing to do so.
<http://github.com/matthiask/feincms/tree/master>
Di... | Best Django 'CMS' component for integration into existing site | [
"",
"python",
"django",
"content-management-system",
""
] |
I've seen a couple of web pages say that `a = b || 'blah'` should assign `'blah'` to `a` if `b` is `undefined` or `null`. But if I type that into Firebug or use it in code, it complains that `b` is not defined, at the list on FF3/win. Any hints?
Edit: I'm looking for the case where `b` may not exist at all. For exampl... | I think you're looking for this:
```
var a = typeof b == 'undefined' ? 'blah' : b;
``` | If b existed, and was false, null, etc, then it works in the way that you would expect. All you'll need to do is on the line above that, put `var b = null`;
This makes sense if you think about it. It basically does something like this...
```
a = function(){ if(b){return b;} else{ return 'blah' } }();
```
Note it is ... | Why doesn't || seem to work as a coalesce/default operator in JavaScript? | [
"",
"javascript",
"firefox-3",
"coalesce",
""
] |
I've just started looking into M-V-VM for a WPF application. Everything makes sense so far besides this particular issue...
I have a ViewModel I'll call Search. This ViewModel binds to a datagrid and lists results of items. Now, I have a command that needs to bring up **another view**, the item's details.
Putting the... | Views should never be instantiated anywhere "below" the UI layer. VMs exist below that realm, therefore this is not the place to put that logic (as you've already realized).
There will almost always be some UI level event that will indicate the need to create the view. In your example, it might be a row (double) click... | As Kiff noted:
> Views should never be instantiated anywhere "below" the UI layer. VMs exist below that realm, therefore this is not the place to put that logic (as you've already realized).
>
> There will almost always be some UI
> level event that will indicate the
> need to create the view. In your
> example, it mi... | M-V-VM Design Question. Calling View from ViewModel | [
"",
"c#",
"wpf",
"mvvm",
""
] |
How do I pass an array I have created on the server side onto the client side for manipulation by Javascript?
Any pseudo code will help | You'll need to embed it as a javascript array declaration into the page. There are a number of ways to do this, but it generally means turning the array into text that you write to the page, probably using the ClientScriptManager.
I'm hoping for better javascript integration in a upcoming verison of ASP.Net. Moving th... | Convert it to string representation of a javascript array ("['val1','val2','val3']") and shove it into the value field of a hidden input. | How to pass array from Asp.net server side to Javascript function on client side | [
"",
"asp.net",
"javascript",
""
] |
In C the following horror is valid:
```
myFunc()
{
return 42; // return type defaults to int.
}
```
But, what about in C++? I can't find a reference to it either way...
My compiler (Codegear C++Builder 2007) currently accepts it without warning, but I've had comments that this ***is*** an error in C++. | It's *ill-formed* in C++. Meaning that it doesn't compile with a standard conforming compiler. Paragraph **7.1.5/4** in Annex C of the Standard explains the change "Banning implicit int". | Implicit return types are valid in C89, but a lot of compilers warn about it.
They are not valid in C++, nor in C99. | Does C++ allow default return types for functions? | [
"",
"c++",
"c",
""
] |
I have a Linq to Entities query like this one:
```
var results = from r in entities.MachineRevision
where r.Machine.IdMachine == pIdMachine
&& r.Category == (int)pCategory
select r;
```
Usually, I use the code below to check if some results are returned:
```
if (results.C... | **EDIT**: Based on your update, the error may be related to an enum in your entity class. See this [blog entry](http://gmontrone.com/problem-with-casting-enums-in-linq-to-entities/) for more information and a work-around. I'm leaving my original answer as an improvement on your query syntax.
Try doing the selection of... | Why not just use FirstOrDefault() instead, and check for null? I can't see the benefit in querying for the count and then taking the first element. | Linq returns list or single object | [
"",
"c#",
"linq",
".net-3.5",
"enums",
""
] |
Can you guys tell me the difference between them?
By the way, is there something called C++ library or C library? | The `C++ Standard Library` and `C Standard Library` are the libraries that the C++ and C Standard define that is provided to C++ and C programs to use. That's a common meaning of those words, i haven't ever seen another definition of it, and C++ itself defines it as this:
> The *C++ Standard Library* provides an exten... | According to <https://en.wikibooks.org/wiki/C_Programming/Standard_libraries#Common_support_libraries>, there is a very important difference between Standard Library and Runtime Library. While the Standard Library defines functions that are (always) available to the programmer (but not part of the (initial) specificati... | Difference between C/C++ Runtime Library and C/C++ Standard Library | [
"",
"c++",
"c",
""
] |
I'm working on a Django-based application in a corporate environment and would like to use the existing Active Directory system for authentication of users (so they don't get yet another login/password combo). I would also like to continue to use Django's user authorization / permission system to manage user capabiliti... | Here's another more recent snippet (July 2008, updated Dec 2015):
[Authentication Against Active Directory (LDAP) over SSL](http://djangosnippets.org/snippets/901/) | The link provided by Jeff indeed works though it assumes you have a you have a default group where users are added to. I simply replaced:
```
group=Group.objects.get(pk=1)
```
by
```
group,created=Group.objects.get_or_create(name="everyone")
```
If you want tighter integration & more features there is also [django-... | Using AD as authentication for Django | [
"",
"python",
"django",
"active-directory",
"ldap",
""
] |
I've been reading [Filthy Rich Clients](http://filthyrichclients.org/) lately and noticed that, although the version of Java is 6, there is no mention of the Concurrent Framework. So, they talk about java.util.Timer and javax.swing.Timer but not about the ExecutorService.
I read about the advantages of ExecutorService... | Well the Swing Timer at least runs on the EDT so you do not have to wrap everything with calls to invokeLater. It also ties nicely in with Swing as it uses Actions, ActionListeners and other Swing related classes.
I'd stick with Swing Timer for Swing related tasks and use the new concurrent package for things that doe... | I would say that for simple swing related stuff the better choice is the `javax.swing.Timer` because of the advantages mentioned [here](http://java.sun.com/docs/books/tutorial/uiswing/misc/timer.html).
> Note that the Swing timer's task is
> performed in the event dispatch
> thread. This means that the task can
> safe... | ExecutorService vs Swing Timer | [
"",
"java",
"swing",
"timer",
""
] |
Is there any way to get a String[] with the roles a user has in the JSP or Servlet?
I know about request.isUserInRole("role1") but I also want to know all the roles of the user.
I searched the servlet source and it seems this is not possible, but this seems odd to me.
So... any ideas? | Read in all the possible roles, or hardcode a list. Then iterate over it running the isUserInRole and build a list of roles the user is in and then convert the list to an array.
```
String[] allRoles = {"1","2","3"};
HttpServletRequest request = ... (or from method argument)
List userRoles = new ArrayList(allRoles.len... | The answer is messy.
First you need to find out what type request.getUserPrincipal() returns in your webapp.
```
System.out.println("type = " + request.getUserPrincipal().getClass());
```
Let's say that returns org.apache.catalina.realm.GenericPrincipal.
Then cast the result of getUserPrincipal() to that type a... | How to get user roles in a JSP / Servlet | [
"",
"java",
"authentication",
"jsp",
"servlets",
"jboss",
""
] |
I am looking out for a good open source Reporting tool/framework for windows based application (WPF).
The database I am using is sql server 2005.
The typical reports format which I am interested is for e.g. Trial balance, balance sheet, etc (typical banking / finance reporting application).
There should be good supp... | Since this may form part of the answer, I thought of putting this in the answer section.
I just found this series of article
[WPF multipage reports](https://web.archive.org/web/20121214141444/http://janrep.blog.codeplant.net/post/WPF-Multipage-Reports-Part-I.aspx) **(note: original link dead, replaced with Wayback Mach... | Take a look at <http://wpfreports.codeplex.com/> | Good open source Reporting tool/framework for WPF (C#) | [
"",
"c#",
"wpf",
"open-source",
"reporting",
""
] |
I have a vector with 1000 "nodes"
```
if(count + 1 > m_listItems.capacity())
m_listItems.reserve(count + 100);
```
The problem is I also clear it out when I'm about to refill it.
```
m_listItems.clear();
```
The capacity doesn't change.
I've used the resize(1); but that doesn't seem to alter the capacity.
So ... | ```
vector<Item>(m_listItems).swap(m_listItems);
```
will shrink `m_listItems` again: <http://www.gotw.ca/gotw/054.htm> (Herb Sutter)
If you want to clear it anyway, swap with an empty vector:
```
vector<Item>().swap(m_listItems);
```
which of course is way more efficient. (Note that swapping vectors basicially mea... | You can swap the vector as others have suggested, and as described in <http://www.gotw.ca/gotw/054.htm> but be aware that it is *not* free, you're performing a copy of every element, because the vector has to allocate a new, smaller, chunk of memory, and copy all the old contents over. (The swap operation is essentiall... | Changing the reserve memory of C++ vector | [
"",
"c++",
"memory",
"stl",
"vector",
"resize",
""
] |
I'm working with an n-Tier application using WinForm and WCF
Engine Service (Windows Service) => WCF Service => Windows Form Client Application
The problem is that the WinForm Client Application need to be 100% available for work even if Engine Service is down.
So how can I make a disconnected architecture in order ... | Typically you implement a queue that's internal to your application.
The queue will forward the requests to the web service. In the event the web service is down, it stays queued. The queue mechanism should check every so often to see if the web service is alive, and when it is then forward everything it has stored up... | Have a look at Smart Client Factory: <http://msdn.microsoft.com/en-us/library/aa480482.aspx>
Just to highlight the goals (this is sniped from the above link):
* They have a rich user interface that
takes advantage of the power of the
Microsoft Windows desktop.
* They connect to multiple back-end
systems to exch... | Disconnected Architecture With .NET | [
"",
"c#",
".net",
"architecture",
""
] |
I need a solution to export a dataset to an excel file without any asp code (HttpResonpsne...) but i did not find a good example to do this...
Best thanks in advance | I've created a class that exports a `DataGridView` or `DataTable` to an Excel file. You can probably change it a bit to make it use your `DataSet` instead (iterating through the `DataTables` in it). It also does some basic formatting which you could also extend.
To use it, simply call ExcelExport, and specify a filena... | The following site demonstrates how to export a DataSet (or DataTable or List<>) into a "**genuine**" Excel 2007 .xlsx file.
It uses the *OpenXML* libraries, so you **don't** need to have Excel installed on your server.
[C# ExportToExcel library](https://www.codeproject.com/Articles/692121/Csharp-Export-data-to-Excel... | c# (WinForms-App) export DataSet to Excel | [
"",
"c#",
"winforms",
"excel",
"dataset",
"export",
""
] |
I'm trying to add a class to the selected radio input
and then remove that class when another radio of the same type is selected
The radio buttons have the class 'radio\_button' but i can't get
the class to change with the below code.
```
jQuery(".radio_button").livequery('click',function() {
$('input.radi... | Tre problem is caused by one extra space in your selectors.
Instead of:
```
$('input.radio_button :radio')
```
you wanted to write:
```
$('input.radio_button:radio')
``` | You might also want to take advantage of jQuery's chainability to reduce the amount of work you're doing. (Rather than re-finding these buttons over and over again.) Something like this:
```
jQuery(".radio_button").livequery('click',function() {
$('input.radio_button:radio')
.focus(updateSelectedStyle)
... | "Pin" a class to the selected radio button? | [
"",
"javascript",
"jquery",
"button",
"radio-button",
""
] |
I'm working on a new project and I'm using the repository pattern, I have my repository that pulls the data from the database and a "service" class which uses the repository and does all the business logic.
something similar to the following;
```
public class UserRepository : IUserRepository
{
public IQueryable<U... | You should test them both, because it's possible that someday there will be other clients of UserRepository than UserService, and those clients may use UserRepository differently than UserService. | test the features that you require:
* some features may reside in one class
* some may reside in the other class
* some may require both classes
from your description it looks like you get to define the features, so you can pretty much justify testing anything you like ;-)
if you're looking for minimal TDD efficienc... | TDD - How much do you test? | [
"",
"c#",
".net",
"unit-testing",
"tdd",
""
] |
I have a simple html page with a div. I am using jQuery to load the contents of an aspx app into the "content" div. Code looks like this:
```
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<script type="text/javascript" src="htt... | Is the code that is not executing rendered out as script blocks, I understand the libraries loaded but any script blocks or inline javascript will not execute when loaded dynamically like that. You have to come up witha solution that will evaluate the script blocks returned for any of it to be valid. I'll see if I can ... | I have code doing this, it might be more verbose than is needed, but nested js files shouldn't be a problem.
```
jQuery.get('default.aspx', null, function(data) {
$('#default').append(data);
}, 'html');
``` | Using jQuery .load breaks links to other library resources? | [
"",
"javascript",
"jquery",
"shadowbox",
""
] |
I was looking at ways to authenticate users in a web app, but in a way where the main web app doesn't need to process the password. Something like OpenId, but the authentication server would definitely need to be hosted on an intranet, internet services can't be accessed by the application server.
My environement is p... | You could [run your own OpenID server](http://wiki.openid.net/Run_your_own_identity_server).
You didn't mention your environment, but another option is to use Windows Authentication with Active Directory if you're running in a Windows domain situation. | Do you want to have single sign-on between applications? (That is, if the same user is using more than one of your web apps, if they've logged in on one, they don't need to log in again when they move to another one.)
If so, there are several options, The one I've used extensively is [CAS](http://www.ja-sig.org/produc... | Best way to authenticate users in a web application | [
"",
"java",
"security",
"authentication",
"web-applications",
"openid",
""
] |
I'm looking for a best way to implement common Windows keyboard shortcuts (for example `Ctrl`+`F`, `Ctrl`+`N`) in my [Windows Forms](http://en.wikipedia.org/wiki/Windows_Forms) application in C#.
The application has a main form which hosts many child forms (one at a time). When a user hits `Ctrl`+`F`, I'd like to show... | You probably forgot to set the form's [KeyPreview](http://msdn.microsoft.com/en-us/library/system.windows.forms.form.keypreview.aspx) property to True. Overriding the [ProcessCmdKey()](http://msdn.microsoft.com/en-us/library/system.windows.forms.control.processcmdkey.aspx) method is the generic solution:
```
protected... | On your Main form
1. Set `KeyPreview` to True
2. Add KeyDown event handler with the following code
```
private void MainForm_KeyDown(object sender, KeyEventArgs e)
{
if (e.Control && e.KeyCode == Keys.N)
{
SearchForm searchForm = new SearchForm();
searchForm.Show();
... | Best way to implement keyboard shortcuts in a Windows Forms application? | [
"",
"c#",
"winforms",
"keyboard-shortcuts",
""
] |
What is the purpose of `__builtin_offsetof` operator (or `_FOFF` operator in Symbian) in C++?
In addition what does it return? Pointer? Number of bytes? | It's a builtin provided by the GCC compiler to implement the `offsetof` macro that is specified by the C and C++ Standard:
[GCC - offsetof](http://gcc.gnu.org/onlinedocs/gcc/Offsetof.html#Offsetof)
It returns the offset in bytes that a member of a POD struct/union is at.
Sample:
```
struct abc1 { int a, b, c; };
un... | As @litb points out and @JesperE shows, offsetof() provides an integer offset in bytes (as a `size_t` value).
When might you use it?
One case where it might be relevant is a table-driven operation for reading an enormous number of diverse configuration parameters from a file and stuffing the values into an equally en... | what is the purpose and return type of the __builtin_offsetof operator? | [
"",
"c++",
"offsetof",
""
] |
I just purchased *C++ GUI Programming with Qt4* and after reading the code samples in this book I'm beginning to realize that my knowledge of C++ is incomplete. I learned C++ two years ago from online tutorials and a couple of ebooks I downloaded, and it turns out none of these resources were good enough. Since then I ... | I wouldn't hold my breath for C++0x. I doubt it will be out by the end of this decade. Even when it will be out, you should probably count a year or so for compilers to implement it. Learn the fundamentals now, and it should be relatively easy for you to learn most of the new features when the standard is out. The Stan... | It is certainly wise to buy the book. C++1x will hardly break with previous code. Nearly everything you learn is also possible with the next C++, and it will greatly help you understand the need of *why* C++1x will introduce what feature. For example, why will it have *variadic templates*, and why those *concepts*? | Is it Wise to Spend Cash on a C++ Book Keeping in View the Upcoming C++0x? | [
"",
"c++",
"c++11",
""
] |
I'm calling a SSIS package using LoadPackage(...).
Is it possible to make this call an Asynchronous call? | Yes, use an asynchronous delegate, as demostrated here:
<http://msdn.microsoft.com/en-us/library/h80ttd5f.aspx> | If you just want it to run in the background then yes, you can either spool up a thread or call some T-SQL to dynamically create a job (and remove it again afterwards). If you want to run it asynchronously and want a callback when it's done, then I think you're out of luck unfortunately. | Calling SSIS package Asynchronously | [
"",
"c#",
".net",
"ssis",
"asynchronous",
""
] |
I need a template like this, which work perfectly
```
template <typename container> void mySuperTempalte (const container myCont)
{
//do something here
}
```
then i want to specialize the above template for std::string so i came up with
```
template <typename container> void mySuperTempalte (const container<std:... | If I am understanding your problem correctly you have an algorithm that will work for STL containers vector, deque etc but are trying to write a template specialisation for string. If this is the case then you can write the generalised templated method that you defined in your question:-
```
template<typename containe... | To specialize:
```
template<> void mySuperTempalte<std:string>(const std::string myCont)
{
//check type of container
//do something here
}
```
To specialize for vector:
```
template<typename C> void mySuperTempalte (std::vector<C> myCont)
{
//check type of container
//do something here
}
```
To spec... | simple C++ templates suited for STL Containers | [
"",
"c++",
"templates",
"stl",
"containers",
""
] |
This is a(n) historical question, not a comparison-between-languages question:
[This article from 2005](http://tomayko.com/writings/no-rails-for-python) talks about the lack of a single, central framework for Python. For Ruby, this framework is clearly Rails. **Why, historically speaking, did this happen for Ruby but ... | As I see it, Rails put Ruby on the map. The simple fact is that before Rails, Ruby was a minor esoteric language, with very little adoption. Ruby owes its success to Rails. As such, Rails has a central place in the Ruby ecosystem. As slim points out, there are other web frameworks, but it's going to be very difficult t... | The real technical answer is that there are three major approaches to web-development in Python: one is CGI-based, where the application is built just like an old one-off Perl application to run through CGI or FastCGI, e.g. [Trac](http://trac.edgewall.org/); then there is [Zope](http://zope.org/), which is a bizarro ov... | Why does Ruby have Rails while Python has no central framework? | [
"",
"python",
"ruby-on-rails",
"ruby",
"frameworks",
"history",
""
] |
I have 2 textbox in my asp.net page and also have one hiddenfield in my asp.net page , my hiddenfield will always have numeric value like 123.00 , and in my one textbox also I will always have numeric value like 20.00 now I want to add this hiddenfield value and textbox value and display it into second textbox thru jav... | ```
amt.value = parseFloat(hiddenamt) + parseFloat(fee);
``` | the value of an input is just a string - [convert to float](http://www.w3schools.com/jsref/jsref_parseFloat.asp) `parseFloat(foo)` in JS and you'll be fine
*edited to make float as I notice it's probably important for you* | how to add 2 values of textbox in asp.net using javascript | [
"",
"asp.net",
"javascript",
""
] |
I have a class that parses very large file (that can't fit in memory) and I'm currently utilizing the IEnumerable interface to use foreach so I can easily grab the parsed contents of the file line by line. Currently, I'm trying to write this to file using an XMLSerializer. It insists on enumerating the class and in my ... | I managed to fix this problem without having to change my design. None of my code was relying on the IEnumerable interface, just the implementation of IEnumerable GetEnumerator() (apparently foreach doesn't check to see if IEnumerable is implemented). Just commenting out the interface in the class declaration did the t... | Well, you could implement `IXmlSerializable` and seize full control. It isn't entirely clear (without pseudo code) what the setup is - sometimes `[XmlIgnore]` can help, but I'm not sure in this case without an example of what you have, and what you do/don't want. | How can I use IEnumerable interface and at the same time, have XMLSerializer not use GetEnumerator()? | [
"",
"c#",
".net",
"xml-serialization",
"ienumerable",
""
] |
I was looking through my code and I found a couple of extension methods that I wrote in order to remove items from a System.Collections.Generic.Stack. I was curious, so I looked at the source of Stack with Reflector and I can see that they implemented it as an array instead of a linked list and I'm just wondering why? ... | Consider the size of a `Stack<byte>` with 1,000,000 items.
* With an array, size ~= 1,000,000 bytes. Usually more due to spare capacity, but probably not more than double.
* With a linked list, each entry needs its own object, the data itself, and at least one reference (for a singly-linked list, which is probably all... | A LIFO queue (a stack) is typically most efficient with an array, because you are pushing items onto the end of the array and pulling items off the same end of the array. So an array works well, without the memory and allocation overhead of a linked list. The cost of making and resizing an array is offset by not needin... | Why isn't System...Stack<T> implemented as a Linked List? | [
"",
"c#",
".net",
"data-structures",
""
] |
I'm trying to come up with a clean way of sorting a set of strings based on a "sorting template". I apologize if my wording is confusing, but I can't think of a better way to describe it (maybe someone can come up with a better way to describe it after reading what I'm trying to do?).
Consider the following list of st... | You could use a `Dictionary<string, int>` to store and retrieve your sorting template tokens. However, this basically does the same as your enum (only perhaps in a slightly more readable manner), because `Enum.Parse` here could be confusing.
```
var ordering = Dictionary<string, int>();
ordering.Add("FA", 0);
ordering... | Here is a very simple way to do it!
```
List<string> template = new List<string>{ "ZD", "AB", "GR"};
List<string> myList = new List<string>{"AB", "GR", "ZD", "AB", "AB"};
myList.Sort((a, b) => template.IndexOf(a).CompareTo(template.IndexOf(b)));
``` | String "Sort Template" in C# | [
"",
"c#",
"sorting",
""
] |
I see a lot of code like this:
```
function Base() {}
function Sub() {}
Sub.prototype = new Base();
```
However, if you do:
```
s = new Sub();
print(s.constructor == Sub);
```
This is false. This seems confusing to me, since s's constructor is, indeed, Sub. Is it conventional/better to do this?
```
function Base()... | 'constructor' doesn't do what it looks like it does. This, in addition to its non-standardness, is a good reason to avoid using it - stick with instanceof and prototype.
Technically: 'constructor' is not a property of the 's' instance, it is a property of the 'Sub' prototype object showing through. When you create the... | If you want to test whether an object is exactly an instance of Sub use the `instanceof` operator:-
```
print(s instanceof Sub);
```
If you want to know whether an object is an instance of Sub or an instance of a sub-class of Sub use the `isPrototypeOf` method:-
```
print(Sub.prototype.isPrototypeOf(s));
``` | Convention for prototype inheritance in JavaScript | [
"",
"javascript",
"inheritance",
"constructor",
"prototype",
""
] |
How can I have that functionality in my game through which the players can change their hairstyle, look, style of clothes, etc., and so whenever they wear a different item of clothing their avatar is updated with it.
Should I:
* Have my designer create all possible combinations of armor, hairstyles, and faces as spri... | 3D will not be necessary for this, but the painter algorithm that is common in the 3D world might IMHO save you some work:
The painter algorithm works by drawing the most distant objects first, then overdrawing with objects closer to the camera. In your case, it would boild down to generating the buffer for your sprit... | One major factor to consider is animation. If a character has armour with shoulder pads, those shoulderpads may need to move with his torso. Likewise, if he's wearing boots, those have to follow the same cycles as hid bare feet would.
Essentially what you need for your designers is a [Sprite Sheet](http://sdb.drshnaps... | Customizable player avatar in a 2D Game | [
"",
"java",
"3d",
"2d",
""
] |
After writing code to populate textboxes from an object, such as:
```
txtFirstName.Text = customer.FirstName;
txtLastName.Text = customer.LastName;
txtAddress.Text = customer.Address;
txtCity.Text = customer.City;
```
is there way in Visual Studio (or even something like Resharper) to copy and paste this code into a ... | Before VS2012:
* Copy and paste the original block of code
* Select it again in the place you want to switch
* Press Ctrl-H to get the "Replace" box up
* Under "Find what" put: `{[a-zA-Z\.]*} = {[a-zA-Z\.]*};`
* Under "Replace with" put: `\2 = \1;`
* Look in: "Selection"
* Use: "Regular expressions"
* Hit Replace All
... | None that I know of. Of course, if you use one of the many binding approaches available, then you won't have to - the binding will do the update in both directions (including change via notifications).
So for winforms:
```
txtFirstName.DataBindings.Add("Text", customer, "FirstName");
```
etc | How can I reverse code around an equal sign in Visual Studio? | [
"",
"c#",
"visual-studio-2008",
""
] |
I'm having difficulty getting widgets in a QDialog resized automatically when the dialog itself is resized.
In the following program, the textarea resizes automatically if you resize the main window. However, the textarea within the dialog stays the same size when the dialog is resized.
Is there any way of making the... | QMainWindow has special behavior for the central widget that a QDialog does not. To achieve the desired behavior you need to create a [layout](http://doc.trolltech.com/3.3/layout.html), add the text area to the layout and assign the layout to the dialog. | Just to add a little note about this - I was trying to have a child window spawned from an application, which is a `QDialog`, containing a single `QTextEdit` as a child/content - and I wanted the `QTextEdit` to resize automatically whenever the `QDialog` window size changes. This seems to have done the trick for me wit... | PyQt: getting widgets to resize automatically in a QDialog | [
"",
"python",
"qt",
"pyqt",
"qdialog",
""
] |
I'm probably missing something simple here, but I can't find the answer elsewhere. I just want to display an applet in my GWT code.
OS: Windows XP
Java: JDK 1.6.0\_10
Other: GWT, GWT-Ext 2.0.5
Here is the applet (obviously simplified for testing):
```
package foo.applet;
import javax.swing.JApplet;
import java.awt.... | Are you trying to GWT-compile your applet?
This won't work, as GWT compilation (which is just translation from Java to Javascript) supports only handful of Java libraries and certainly not applets.
Make sure that your applet is not on GWT source path (move it to another package).
Reference: <http://code.google.com/d... | Don't use the GWTCompiler to compile your applet code. I would recommend creating a second module (or project) that contains only the applet code. Compile this to a separate JAR using the standard Javac compiler (or your IDE/ant)
The GWTCompiler uses a subset of the Java libraries, and should only be used to generate ... | How to display java applet inside GWT page? | [
"",
"java",
"gwt",
"applet",
"gwt-ext",
""
] |
I have an application which had optional extras depending on if the user has the software installed.
On Linux what is the best way to determine if something like python and PyUsb is installed?
I am developing a C++ Qt application if that helps. | This is inefficient (requires forking and exec'ing */bin/sh*). There has to be a better way! But as a generic approach... There's always *system()*.
(Remember to use *WEXITSTATUS()*! Watch out for making programs uninterruptable!)
```
#define SHOW(X) cout << # X " = " << (X) << endl
int main()
{
int status;
SH... | You can require that they be in the path, etc. Check for the existence of the executable files you will require (using `which` or similar). You can also use the executable files' arguments and check for required versions as well, if needed. | What is the best way to check that external applications are available? | [
"",
"c++",
"linux",
"deployment",
"dependencies",
""
] |
I need to be able to programmatically transcode mpeg-2 files to .mp4, .mp3, .wmv, .rm (optional), and .flv (optional), and hopefully generate a thumbnail as well. I found the Java Media Framework, but it frankly looks pretty crappy. This will be running a Linux server, so I could shell out to ffmpeg using Commons Exec ... | Ffmpeg is the best and easiest. To output/convert video:
```
ffmpeg -i {input}.ext -r {target_frame_rate} -ar {target_audio_rate} -b {target_bitrate} -s {width}x{height} {target}.ext
```
And your screenshot:
```
ffmpeg -i {input}.ext -r 1 -ss 00:00:04:005 -t 00:00:01 -an -s {width}x{height} {target_name}%d.jpg
```
... | An interesting web service from [encoding.com](http://www.encoding.com/) will transcode files for you. | Programmatically transcode MPEG-2 videos | [
"",
"java",
"video",
"ffmpeg",
"mpeg",
"transcoding",
""
] |
I am constructing a large HTML document from fragments supplied by users that have the annoying habit of being malformed in various ways. Browsers are robust and forgiving enough but I want to be able to validate and (ideally) fix any malformed HTML if at all possible. For example:
```
<td><b>Title</td>
```
can be re... | You can use [HTML Tidy](http://devzone.zend.com/article/761-Tidying-up-your-HTML-with-PHP-5), man pages are [here](http://au.php.net/tidy). | I highly recommend [HTML Purifier](http://htmlpurifier.org/). From their site:
> HTML Purifier is a standards-compliant
> HTML filter library written in PHP.
> HTML Purifier will not only remove all
> malicious code (better known as XSS)
> with a thoroughly audited, secure yet
> permissive whitelist, it will also
> ma... | Fixing malformed HTML in PHP? | [
"",
"php",
"html",
"parsing",
""
] |
How do I get the actual value (or text) of the item selected in an HTML select box? Here are the main methods I've tried...
```
document.getElementById('PlaceNames').value
```
```
$("#PlaceNames option:selected").val()
```
```
$("#PlaceNames option:selected").text()
```
And I've tried various variations on these. A... | `$('#placeNames').val()` returns the [value](http://docs.jquery.com/Attributes/val) of the selected option in the latest version of jQuery. | Non-jQuery variant:
```
var select = document.getElementById('PlaceNames');
var value = select.options[select.selectedIndex].value;
```
Older jQuery variant:
```
var select = $('#PlaceNames:first')[0];
var value = select.options[select.selectedIndex].value;
```
Current jQuery variant:
```
var value = $('#PlaceName... | Checking to see what item is selected in an HTML select list via jQuery | [
"",
"javascript",
"jquery",
""
] |
I am going to start a C# project from scratch that will consist of several modules so it **can be sold by modules** of an existing PHP/ASP/MySQL/Oracle/MS SQL application that manages to show 3D objects and create 2D and 3D CAD files from a web app that the user can use to create all the stuff.
**My question is**, to ... | For a quick hit of each of your explicit questions I would say.
As for the how of integration, learn inversion of control principals and how it is used for extensibility purposes. Keep an eye on MEF, Microsoft Extensibility Framework. As for the what, your integration points will depend mostly on the type of applicati... | you'll rewrite any application at least once in its lifecycle. get something out to establish value then worry about how pretty your code is.
you can spend a year making the perfectly coded application that nobody wants to use, or you can spend a couple months and the rest of the year either improving it, or working o... | Creating an extensive project to be sold | [
"",
"c#",
"design-patterns",
"module",
""
] |
Basically this code below returns the right information, but I need to add the quantities together to bring back one record. Is there any way of doing this?
```
select category.category_name, (equipment.total_stock-equipment.stock_out) AS Current_Stock, equipment.stock_out
from
EQUIPMENT,
CATEGORY
WHERE EQUIPMENT.CAT... | You want to use the SUM function and a GROUP BY clause.
```
select category.category_name, SUM((equipment.total_stock-equipment.stock_out)) AS Current_Stock, SUM(equipment.stock_out) as stock_out
from EQUIPMENT, CATEGORY
WHERE EQUIPMENT.CATEGORY_ID = CATEGORY.CATEGORY_ID and category.category_name = 'Power Tools'
GRO... | 1 - Sum() and Group By will do the trick
2 - Post your questions only once, in one post, its easyer | sql help: how can I add quantities together? | [
"",
"sql",
"database",
""
] |
I have a windows service written in C# that acts as a proxy for a bunch of network devices to the back end database. For testing and also to add a simulation layer to test the back end I would like to have a GUI for the test operator to be able run the simulation. Also for a striped down version to send out as a demo. ... | You basically have two choices. Either expose an API on the service which you can then call from the UI app OR enable the service to run either as a winforms app or a service.
The first option is pretty easy - use remoting or WCF to expose the API.
The second option can be achieved by moving the "guts" of your app in... | If you use the below code:
```
[DllImport("advapi32.dll", CharSet=CharSet.Unicode)]
static extern bool StartServiceCtrlDispatcher(IntPtr services);
[DllImport("ntdll.dll", EntryPoint="RtlZeroMemory")]
static extern void ZeroMemory(IntPtr destination, int length);
static bool StartService(){
MySvc svc = new MySvc(... | How to write c# service that I can also run as a winforms program? | [
"",
"c#",
"winforms",
"windows-services",
"installation",
"service",
""
] |
Let's say I have a class that implements the **IDisposable** interface. Something like this:
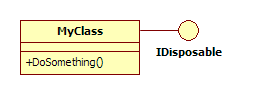
**MyClass** uses some unmanaged resources, hence the *Dispose()* method from **IDisposable** releases those... | So, my idea is to keep how many *AsyncDoSomething()* are pending to complete, and only dispose when this count reaches to zero. My initial approach is:
```
public class MyClass : IDisposable {
private delegate void AsyncDoSomethingCaller();
private delegate void AsyncDoDisposeCaller();
private int pendin... | It looks like you're using the event-based async pattern ([see here for more info about .NET async patterns](http://msdn.microsoft.com/en-us/library/ms228969.aspx)) so what you'd typically have is an event on the class that fires when the async operation is completed named `DoSomethingCompleted` (note that `AsyncDoSome... | How to dispose asynchronously? | [
"",
"c#",
"asynchronous",
"dispose",
""
] |
When trying to launch and run a flex/java project in eclipse I kept getting a "Out of Memory Exception" and "Java Heap Space" using Eclipse, Tomcat and a JRE.
While researching trying to adjust the memory settings I found three places to adjust these:
* Eclipse.ini
* The JRE Settings under Window > Preferences
* Cata... | -xms is the start memory (at the VM start), -xmx is the maximum memory for the VM
* eclipse.ini : the memory for the VM running eclipse
* jre setting : the memory for java programs run from eclipse
* catalina.sh : the memory for your tomcat server | First of all, I suggest that you narrow the problem to which component throws the "Out of Memory Exception".
This could be:
1. **Eclipse** itself (which I doubt)
2. **Your application** under **Tomcat**
The JVM parameters `-xms` and `-xmx` represent the heap's "start memory" and the "maximum memory". Forget the "sta... | Eclipse memory settings when getting "Java Heap Space" and "Out of Memory" | [
"",
"java",
"apache-flex",
"eclipse",
"memory",
""
] |
I'm pulling back a Date and a Time from a database. They are stored in separate fields, but I would like to combine them into a java.util.Date object that reflects the date/time appropriately.
Here is my original approach, but it is flawed. I always end up with a Date/Time that is 6 hours off what it should be. I thin... | I would put both the Date and the Time into Calendar objects, and then use the various Calendar methods to extract the time values from the second object and put them into the first.
```
Calendar dCal = Calendar.getInstance();
dCal.setTime(date);
Calendar tCal = Calendar.getInstance();
tCal.setTime(time);
dC... | Use Joda Time instead of Java's own Date classes when doing these types of things. It's a far superior date/time api that makes the sort of thing you are trying to do extremely easy and reliable. | How do I combine a java.util.Date object with a java.sql.Time object? | [
"",
"java",
"date",
"time",
""
] |
I'd like to create a workspace with status bar and menu, and within this workspace container have smaller windows of various types.
For example, if you un-maximise a worksheet in Excel but not the main window, it becomes a window in a larger workspace.
I've tried searching for the result but the main problem is in kn... | You want an MDI (Multiple Document Interface) Form
Just set the IsMdiContainer property of your main form to True, and you should be able to add other forms as mdi children. | Check into MDI programming. Here's a couple links
[Creating an MDI Application (CodeProject)](http://www.codeproject.com/KB/cs/myBestMDI.aspx)
[Developing MDI Application in C# (C-Sharp Corner)](http://www.c-sharpcorner.com/UploadFile/ggaganesh/DevelopingMDIAppplicationsinCSharp11272005225843PM/DevelopingMDIAppplicat... | How do I create a workspace window for other windows using c# in visual studio 2008? | [
"",
"c#",
"visual-studio",
"layout",
""
] |
I am a little confused here.
I would like to do something like this:
1. create some kind of buffer I can write into
2. clear the buffer
3. use a printf()-like function several times to append a bunch of stuff into the buffer based on some complicated calculations I only want to do once
4. use the contents of the buff... | ah: I think I've got it. The [`Formatter`](http://java.sun.com/j2se/1.5.0/docs/api/java/util/Formatter.html) class has a `format()` method that's like `printf()`, and it can be constructed to wrap around any kind of object that implements `Appendable`. [`CharBuffer`](http://java.sun.com/j2se/1.5.0/docs/api/java/nio/Cha... | Why is it a pain to create a new buffer in the loop? That's what the garbage collector is there for. There would need to be a new allocation under the covers in clear() anyway.
If you really want to implement your SuperBuffer, it would not be that hard at all. Just create a subclass of OutputStream with a clear() func... | printf() functionality in Java combined with a CharBuffer or something like it | [
"",
"java",
"stream",
"printf",
""
] |
We've a table with a `varchar2(100)` column, that occasionally contains carriage-return & line-feeds. We should like to remove those characters in the SQL query. We're using:
```
REPLACE( col_name, CHR(10) )
```
which has **no effect**, however replacing 'CHR(10)' for a more conventional 'letter' character proves tha... | Another way is to use [TRANSLATE](http://download.oracle.com/docs/cd/B19306_01/server.102/b14200/functions196.htm#i1501659):
```
TRANSLATE (col_name, 'x'||CHR(10)||CHR(13), 'x')
```
The 'x' is any character that you don't want translated to null, because TRANSLATE doesn't work right if the 3rd parameter is null. | Ahah! Cade is on the money.
An artifact in TOAD prints `\r\n` as two placeholder 'blob' characters, but prints a single `\r` also as two placeholders. The 1st step toward a solution is to use ..
```
REPLACE( col_name, CHR(13) || CHR(10) )
```
.. but I opted for the slightly more robust ..
```
REPLACE(REPLACE( col_n... | Oracle REPLACE() function isn't handling carriage-returns & line-feeds | [
"",
"sql",
"oracle",
""
] |
I've heard from a variety of places that global variables are inherently nasty and evil, but when doing some non-object oriented Javascript, I can't see how to avoid them. Say I have a function which generates a number using a complex algorithm using random numbers and stuff, but I need to keep using that particular nu... | To make a variable calculated in function A visible in function B, you have three choices:
* make it a global,
* make it an object property, or
* pass it as a parameter when calling B from A.
If your program is fairly small then globals are not so bad. Otherwise I would consider using the third method:
```
function ... | I think your best bet here may be to define a *single* global-scoped variable, and dumping your variables there:
```
var MyApp = {}; // Globally scoped object
function foo(){
MyApp.color = 'green';
}
function bar(){
alert(MyApp.color); // Alerts 'green'
}
```
No one should yell at you for doing something li... | Accessing variables from other functions without using global variables | [
"",
"javascript",
"global-variables",
""
] |
I need to call a const function from a non-const object. See example
```
struct IProcess {
virtual bool doSomeWork() const = 0L;
};
class Foo : public IProcess {
virtual bool doSomeWork() const {
...
}
};
class Bar
{
public:
const IProcess& getProcess() const {return ...;}
IProcess& getProcess() ... | Avoid the cast: assign this to a `const Bar *` or whatever and use that to call `getProcess()`.
There are some pedantic reasons to do that, but it also makes it more obvious what you are doing without forcing the compiler to do something potentially unsafe. Granted, you may never hit those cases, but you might as well... | `const_cast` is for casting **away** constness!
You're casting from non-const to const which is safe, so use `static_cast`:
```
static_cast<const Bar*>(this)->getProcess().doSomeWork();
```
*I mean techincally speaking you can cast in constness with `const_cast`, but it's not a pragmatic use of the operator. The ... | Calling a const function from a non-const object | [
"",
"c++",
"function",
"constants",
""
] |
This is the SP...
```
USE [EBDB]
GO
/****** Object: StoredProcedure [dbo].[delete_treatment_category] Script Date: 01/02/2009 15:18:12 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
/*
RETURNS 0 FOR SUCESS
1 FOR NO DELETE AS HAS ITEMS
2 FOR DELETE ERROR
*/
ALTER PROCEDURE [dbo].[delete_t... | I'm a little late to the game here, but for the sake of people who stumble upon this question...
If you're using ExecuteReader in ADO.Net, the return value will not be populated until you close either the Reader or the underlying connection to the database. ([See here](http://dhenztm.spaces.live.com/blog/cns!761D77A7A... | When you added the Parameter, did you set the Direction to [ReturnValue](http://msdn.microsoft.com/en-us/library/system.data.parameterdirection.aspx)? | Return value from SQL 2005 SP returns DBNULL - Where am I going wrong? | [
"",
"asp.net",
"sql",
"vb.net",
"t-sql",
"sql-server-2005",
""
] |
I have a Database table that I want to display in a DataGridView. However, it has several foreign keys and I don't want to show the integer that represents the other Table to the user.
I have this DataTable with a column userId
I have another DataTable with a column id, and a column username
I want the DataGridView t... | How are you populating the DataTable? You can specify custom SQL with the joins and appropriate columns to the .SelectCommand of a DataAdapter or specify the custom SQL in the .CommandText of a xxxCommand object.
Eg
```
myAdapter.SelectCommand = "Select a.column1, a.column2, b.username from tablea a inner join tableb... | Here are a couple options to consider...
1 - If you have access to the database, have a view or stored procedure created that returns the "denormalized" data. You can then bind your GridView directly to this and everything is done.
2 - Create template columns for those fields that you need to retrieve. Then in the Ro... | DataBinding with a DataGridView C# | [
"",
"c#",
"database",
"data-binding",
"datagridview",
""
] |
I saw this keyword for the first time and I was wondering if someone could explain to me what it does.
* What is the `continue` keyword?
* How does it work?
* When is it used? | A `continue` statement without a label will re-execute from the condition the innermost `while` or `do` loop, and from the update expression of the innermost `for` loop. It is often used to early-terminate a loop's processing and thereby avoid deeply-nested `if` statements. In the following example `continue` will get ... | `continue` is kind of like `goto`. Are you familiar with `break`? It's easier to think about them in contrast:
* `break` terminates the loop (jumps to the code below it).
* `continue` terminates the rest of the processing of the code within the loop for the current iteration, but continues the loop. | What is the "continue" keyword and how does it work in Java? | [
"",
"java",
"keyword",
"continue",
""
] |
I know that [CodeRush Xpress](http://www.devexpress.com/Products/Visual_Studio_Add-in/CodeRushX/) is intended to be used on VS 2008 and not on VS 2005.
But since I can't migrate to VS2008 yet, I want to install it on VS2005 and don't care it's not supposed to work.
My base assumption is that it can be done, this is ... | It is possible, and here what you need to do it.
Make sure VS is closed.
Install [RefactorCpp](http://devexpress.com/Products/Visual_Studio_Add-in/RefactorCPP/).
Install [CodeRush Xpress](http://www.devexpress.com/Products/Visual_Studio_Add-in/CodeRushX/).
Apply this registry patch:
```
Windows Registry Editor ... | Bad notice!
It's not possible because the plugin is for .NET Framework 3 and Visual Studio 2008 aka Orcas.
I try to install in Visual Studio 2005 but unsuccessfull. | How to install CodeRush Xpress on VS2005 | [
"",
"c#",
"visual-studio-2005",
"coderush-xpress",
""
] |
I am finishing off a C# ASP.NET program that allows the user to build their own computer by selecting hardware components such as memory, cpu, etc from a drop down lists. The SQL datatable has 3 columns; ComputerID, Attribute and Value. The computerID is an ID that corresponds to a certain computer in my main datatable... | You need to use Concat as a "Union All".
```
IQueryable<ComputerAttribute> results = null;
foreach(ComputerRequirement z in requirements)
{
//must assign to a locally scoped variable to avoid using
// the same reference in all of the where methods.
ComputerRequirement cr = z;
if (results == null)
{
resu... | I'm assuming you're asking:
> How do I refine the content of a search I've done using LINQ to SQL?
Or something similar right?
To my understanding, you have two options:
1. Filter your results in memory (if you have them cached).
2. Extend your SQL query and hit the DB again.
I'm not sure that LINQ to SQL allows y... | LINQ to SQL | [
"",
"sql",
"sql-server",
"linq",
""
] |
I am writing a library in standard C++ which does the phonetic conversion. I have used std::string as of now. But in future I may have to change this to someother (std::wstring or something else). So I need to write my library in such a way that I can switch this easily. I have done the following so far to achieve this... | You can write template functions that will work with either type of string, or for that matter anything that has the proper methods.
If you do the typedef as you suggest, you will need to change all your code in the future when you change the typedef. I'd recommend against it.
Edit: the point is that string and wstri... | I think typedeffing std::string is reasonable. You are still bound to an interface though. If you ever switch to a string implementation with an incompatible interface you can change the value of your typedef to some adapter class. In C++, you can do this with minimal to no overhead. Changing to a new string type then ... | typedef a std::string - Best practice | [
"",
"c++",
"typedef",
""
] |
I'd like to include **Python scripting** in one of my applications, that is written in Python itself.
My application must be able to call external Python functions (written by the user) as **callbacks**. There must be some control on code execution; for example, if the user provided code with syntax errors, the applic... | Use `__import__` to import the files provided by the user. This function will return a module. Use that to call the functions from the imported file.
Use `try..except` both on `__import__` and on the actual call to catch errors.
Example:
```
m = None
try:
m = __import__("external_module")
except:
# invalid m... | If you'd like the user to interactively enter commands, I can highly recommend the [code](http://docs.python.org/library/code.html) module, part of the standard library. The InteractiveConsole and InteractiveInterpreter objects allow for easy entry and evaluation of user input, and errors are handled very nicely, with ... | Scripting inside a Python application | [
"",
"python",
"scripting",
""
] |
Hey, im doing a little app for my smart phone, using Windows Mobile 6. I'm trying to get all currently running processec, but method CreateToolhelp32Snapshot always returns -1. So now im stuck. I tried to get error with invoking GetLastError() method, but that method returns 0 value.
Here is a snippet of my code.
```
... | * First, your handle check is wrong. It's common for the high bit to be on in a handle, causing it to look like a negative number when cast to a signed int. You should be checking that is isn't NULL (0) or INVALID\_HANDLE\_VALUE (-1 / 0xffffffff).
* You shouldn't be "invoking GetLastError" but calling Marshal.GetLastWi... | Instead of
```
CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
```
use
```
private const int TH32CS_SNAPNOHEAPS = 0x40000000;
CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS | TH32CS_SNAPNOHEAPS, 0);
```
By default CreateToolhelp32Snapshot will try to snapshot the heaps and that can cause an out of memory error.
Foun... | P/Invoking CreateToolhelp32Snapshot failing in Compact Framework | [
"",
"c#",
".net",
"compact-framework",
"windows-ce",
""
] |
Can anyone explain to me why I would want to use IList over List in C#?
*Related question: [Why is it considered bad to expose `List<T>`](https://stackoverflow.com/questions/387937)* | If you are exposing your class through a library that others will use, you generally want to expose it via interfaces rather than concrete implementations. This will help if you decide to change the implementation of your class later to use a different concrete class. In that case the users of your library won't need t... | The less popular answer is programmers like to pretend their software is going to be re-used the world over, when infact the majority of projects will be maintained by a small amount of people and however nice interface-related soundbites are, you're deluding yourself.
[Architecture Astronauts](http://www.joelonsoftwa... | List<T> or IList<T> | [
"",
"c#",
"list",
"generics",
""
] |
Simple question - In c++, what's the neatest way of getting which of two numbers (u0 and u1) is the smallest positive number? (that's still efficient)
Every way I try it involves big if statements or complicated conditional statements.
Thanks,
Dan
Here's a simple example:
```
bool lowestPositive(int a, int b, int& ... | I prefer clarity over compactness:
```
bool lowestPositive( int a, int b, int& result )
{
if (a > 0 && a <= b) // a is positive and smaller than or equal to b
result = a;
else if (b > 0) // b is positive and either smaller than a or a is negative
result = b;
else
result = a; // at least b is... | If the values are represented in twos complement, then
```
result = ((unsigned )a < (unsigned )b) ? a : b;
```
will work since negative values in twos complement are larger, when treated as unsigned, than positive values. As with Jeff's answer, this assumes at least one of the values is positive.
```
return result >... | Neatest / Fastest Algorithm for Smallest Positive Number | [
"",
"c++",
"algorithm",
"optimization",
""
] |
Does anyone ever use stopwatch benchmarking, or should a performance tool always be used? Are there any good free tools available for Java? What tools do you use?
To clarify my concerns, stopwatch benchmarking is subject to error due to operating system scheduling. On a given run of your program the OS might schedule ... | Stopwatch benchmarking is fine, provided you measure **enough** iterations to be meaningful. Typically, I require a total elapsed time of some number of single digit seconds. Otherwise, your results are easily significantly skewed by scheduling, and other O/S interruptions to your process.
For this I use a little set ... | It's totally valid as long as you measure large enough intervals of time. I would execute 20-30 runs of what you intend to test so that the total elapsed time is over 1 second. I've noticed that time calculations based off System.currentTimeMillis() tend to be either 0ms or ~30ms; I don't think you can get anything mor... | Is stopwatch benchmarking acceptable? | [
"",
"java",
"benchmarking",
""
] |
I've been trying to find a way to match a number in a Javascript string that is surrounded by parenthesis at the end of the string, then increment it.
Say I have a string:
```
var name = "Item Name (4)";
```
I need a RegExp to match the (4) part, and then I need to increment the 4 then put it back into the string.
... | The replace method can take a function as its second argument. It gets the match (including submatches) and returns the replacement string. Others have already mentioned that the parentheses need to be escaped.
```
"Item Name (4)".replace(/\((\d+)\)/, function(fullMatch, n) {
return "(" + (Number(n) + 1) + ")";
})... | I can can only think of a way of doing it in three steps: Extract, increment and replace.
```
// Tested on rhino
var name = "Item Name (4)";
var re = /\((\d+)\)/;
match = re.exec(name);
number = parseInt(match[1]) + 1;
name = name.replace(re, "(" + number + ")");
```
The important parts of the pattern:
1. You need ... | Use RegExp to match a parenthetical number then increment it | [
"",
"javascript",
"regex",
"string",
""
] |
I have a webpage that implements a set of tabs each showing different content. The tab clicks do not refresh the page but hide/unhide contents at the client side.
Now there is a requirement to change the page title according to the tab selected on the page ( for SEO reasons ). Is this possible? Can someone suggest a s... | **Update**: as per the comments and reference on [SearchEngineLand](https://searchengineland.com/tested-googlebot-crawls-javascript-heres-learned-220157)
most web crawlers will index the updated title. Below answer is obsolete, but the code is still applicable.
> You can just do something like, `document.title = "This... | I want to say hello from the future :) Things that happened recently:
1. Google now runs javascript that is on your website[1](http://searchengineland.com/tested-googlebot-crawls-javascript-heres-learned-220157)
2. People now use things like React.js, Ember and Angular to run complex javascript tasks on the page and i... | How to dynamically change a web page's title? | [
"",
"javascript",
"html",
""
] |
I want to store the username/password information of my windows service 'logon as' user in the app.config.
So in my Installer, I am trying to grab the username/password from app.config and set the property but I am getting an error when trying to install the service.
It works fine if I hard code the username/password... | The problem is that when your installer runs, you are still in installation phase and your application hasn't been fully installed. The app.config will only be available when the actual application is run.
You can however do the following:
1. Prompt the user for the username and password within the installer (or on t... | Just some ideas on accessing config files inside an installer.
```
Configuration config = ConfigurationManager.OpenExeConfiguration(assemblyPath);
ConnectionStringsSection csSection = config.ConnectionStrings;
```
Assembly Path can be gotten several ways:
Inside Installer class implementation with:
```
this.Context.... | Windows service, can't access app.config from within my Installer's constructor | [
"",
"c#",
".net",
"security",
"configuration",
"windows-services",
""
] |
I am working on project in Linux which involves
1) Static Lib in C++
2) GUI developed in C++/QT which uses static lib.
Now both the lib and gui are build from command prompt using makefiles.
I am trying to debug both like when I hit one button, call should go from GUI to lib.
Is it possible to do like this in Linux ... | Well I figured it out..
I am currently using Kdevelop..
With Kdevelp we can create QT project as well as c++(lib) project.
And there is option to attach process also.
So I can step through lib code by attaching GUI . | There shouldn't be any problem with debugging a static library as the relevant portions of it will be built in to the binary that you are debugging. If you are having problems then some things to check are that both the library and the binary are built with debugging information (usually the option `-g` to the compiler... | Debugging C++ lib with eclipse | [
"",
"c++",
"linux",
"debugging",
""
] |
I have a table with almost 800,000 records and I am currently using dynamic sql to generate the query on the back end. The front end is a search page which takes about 20 parameters and depending on if a parameter was chosen, it adds an " AND ..." to the base query. I'm curious as to if dynamic sql is the right way to ... | It is more likely that your indexing (or lack thereof) is causing the slowness than the dynamic SQL.
What does the execution plan look like? Is the same query slow when executed in SSMS? What about when it's in a stored procedure?
If your table is an unindexed heap, it will perform poorly as the number of records gro... | I'd just like to point out that if you use this style of optional parameters:
```
AND (@EarliestDate is Null OR PublishedDate < @EarliestDate)
```
The query optimizer will have no idea whether the parameter is there or not when it produces the query plan. I have seen cases where the optimizer makes bad choices in the... | Is a dynamic sql stored procedure a bad thing for lots of records? | [
"",
"sql",
"sql-server",
"t-sql",
"stored-procedures",
""
] |
* I have a *Client* and *Groupe* Model.
* A *Client* can be part of multiple *groups*.
* *Clients* that are part of a group can use its group's free rental rate at anytime but only once. That is where the intermediary model (*ClientGroupe*) comes in with that extra data.
For now, when I try to save the m2m data, it ju... | ```
…
if form.is_valid():
client_mod = form.save(commit=False)
client_mod.save()
for groupe in form.cleaned_data.get('groupes'):
clientgroupe = ClientGroupe(client=client_mod, groupe=groupe)
clientgroupe.save()
…
``` | If you use the save method right now, Django will try to save using the manager (which Django doesn't allow). Unfortunately, the behavior you want is a little bit trickier than what `ModelForm` does by default. What you need to do is create a *formset*.
First of all, you will need to change the options of your `Client... | What are the steps to make a ModelForm work with a ManyToMany relationship with an intermediary model in Django? | [
"",
"python",
"django",
"django-models",
"django-templates",
"django-forms",
""
] |
I prefer to use OOP in large scale projects like the one I'm working on right now. I need to create several classes in JavaScript but, if I'm not mistaken, there are at least a couple of ways to go about doing that. What would be the syntax and why would it be done in that way?
I would like to avoid using third-party ... | Here's the way to do it without using any external libraries:
```
// Define a class like this
function Person(name, gender){
// Add object properties like this
this.name = name;
this.gender = gender;
}
// Add methods like this. All Person objects will be able to invoke this
Person.prototype.speak = functio... | The best way to define a class in JavaScript is to not define a class.
Seriously.
There are several different flavors of object-orientation, some of them are:
* class-based OO (first introduced by Smalltalk)
* prototype-based OO (first introduced by Self)
* multimethod-based OO (first introduced by CommonLoops, I th... | What techniques can be used to define a class in JavaScript, and what are their trade-offs? | [
"",
"javascript",
"oop",
"class",
""
] |
Consider the following:
```
<div onclick="alert('you clicked the header')" class="header">
<span onclick="alert('you clicked inside the header');">something inside the header</span>
</div>
```
How can I make it so that when the user clicks the span, it does not fire the `div`'s click event? | Use [event.stopPropagation()](https://developer.mozilla.org/en/DOM/event.stopPropagation).
```
<span onclick="event.stopPropagation(); alert('you clicked inside the header');">something inside the header</span>
```
For IE: `window.event.cancelBubble = true`
```
<span onclick="window.event.cancelBubble = true; alert(... | There are two ways to get the event object from inside a function:
1. The first argument, in a W3C-compliant browser (Chrome, Firefox, Safari, IE9+)
2. The window.event object in Internet Explorer (<=8)
If you need to support legacy browsers that don't follow the W3C recommendations, generally inside a function you w... | How to stop event propagation with inline onclick attribute? | [
"",
"javascript",
"html",
"events",
"dom",
""
] |
From a web service (WCF), I want an endpoint to take 10 seconds to finish.
Is there a way I can do a `thread.sleep(10);` on the method? | You could create a wrapper method which does the appropriate sleep.
```
Thread.Sleep(TimeSpan.FromSeconds(10))
``` | Start a new thread that sleeps for 10 sec, then return, that way the time that the methos takes to run won't add to the 10 seconds
```
using System.Threading;
public static WCF(object obj)
{
Thread newThread =
new Thread(new ThreadStart(Work));
newThread.Start();
//do method... | Calling a C# method, and make it take 10 seconds to return | [
"",
"c#",
".net",
"wcf",
"multithreading",
""
] |
I am working with an object which has sub objects within (see example below). I am attempting to bind a `List<rootClass>` to the datagrid. When I bind the `List<>`, in the cell that contains the `subObject`, I see the following value `... "namespace.subObject" ...` the string values display correctly.
Ideally I would ... | If I'm not mistaken, it shows the result of calling .ToString() on your subObject, so you can override that to return the contents of Description.
Have you tried just binding to Value1.Description? (I'm guessing it doesn't work).
I have a class that can be used instead of List when binding, that will handle this, it ... | Since you mention `DataGridViewColumn` (tags), I assume you mean winforms.
Accessing sub-properties is a pain; the currency-manager is bound to the list, so you only have access to immediate properties by default; however, you can get past this *if you absolutely need* by using a custom type descriptor. You would need... | Binding a object with a sub objects as properties to a datagrid | [
"",
"c#",
"datagrid",
"binding",
"object",
"datagridviewcolumn",
""
] |
I'm currently writing a data access layer for an application. The access layer makes extensive use of linq classes to return data. Currently in order to reflect data back to the database I've added a private data context member and a public save method. The code looks something like this:
```
private DataContext myDb;... | It actually doesn't matter too much. I asked Matt Warren from the LINQ to SQL team about this a while ago, and here's the reply:
> There are a few reasons we implemented
> IDisposable:
>
> If application logic needs to hold
> onto an entity beyond when the
> DataContext is expected to be used or
> valid you can enforc... | Treat your datacontext as a resource. And the rule of using resource says
> "acquire a resource as late as
> possible, release it as soon as its
> safe" | When should I dispose of a data context | [
"",
"c#",
"linq",
"linq-to-sql",
""
] |
Is there a way to (ab)use the **C** preprocessor to emulate namespaces in **C**?
I'm thinking something along these lines:
```
#define NAMESPACE name_of_ns
some_function() {
some_other_function();
}
```
This would get translated to:
```
name_of_ns_some_function() {
name_of_ns_some_other_function();
}
``` | When using namespace prefixes, I normally add macros for the shortened names which can be activated via `#define NAMESPACE_SHORT_NAMES` before inclusion of the header. A header foobar.h might look like this:
```
// inclusion guard
#ifndef FOOBAR_H_
#define FOOBAR_H_
// long names
void foobar_some_func(int);
void foob... | Another alternative would be to declare a struct to hold all your functions, and then define your functions statically. Then you'd only have to worry about name conflicts for the global name struct.
```
// foo.h
#ifndef FOO_H
#define FOO_H
typedef struct {
int (* const bar)(int, char *);
void (* const baz)(void);... | Namespaces in C | [
"",
"c++",
"c",
"namespaces",
"c-preprocessor",
""
] |
Is there any way to have a Windows batch file directly input SQL statements without calling a script? I want the batch file to login to SQL and then enter in the statements directly.
**EDIT:** I'm using Oracle v10g | For a single command you can use this trick:
```
echo select * from dual; | sqlplus user/pw@db
``` | To run something on SQL server 2005/2008, you could use `sqlcmd` command line utility. `sqlcmd -h` prints the list of switches. | SQL Statements in a Windows Batch File | [
"",
"sql",
"batch-file",
""
] |
What's a good way to ensure that a temp file is deleted if my application closes or crashes? Ideally, I would like to obtain a temp file, use it, and then forget about it.
Right now, I keep a list of my temp files and delete them with an EventHandler that's triggered on Application.ApplicationExit.
Is there a better ... | Nothing is guaranteed if the process is killed prematurely, however, I use "`using`" to do this..
```
using System;
using System.IO;
sealed class TempFile : IDisposable
{
string path;
public TempFile() : this(System.IO.Path.GetTempFileName()) { }
public TempFile(string path)
{
if (string.IsNul... | Consider using the FileOptions.DeleteOnClose flag:
```
using (FileStream fs = new FileStream(Path.GetTempFileName(),
FileMode.OpenOrCreate, FileAccess.ReadWrite, FileShare.None,
4096, FileOptions.RandomAccess | FileOptions.DeleteOnClose))
{
// temp file exists
}
// temp file is gone
``` | How do I automatically delete temp files in C#? | [
"",
"c#",
".net",
"temporary-files",
""
] |
I have some data stored as `ArrayList`. And when I want to backup this data,java bounds two objects forever. Which means when I change values in data `ArrayList` this changes come to backup. I tried to copy values from data separately to backup in the loop, tried to use method `data.clone()` — nothing helps. | I think you need to `.clone()` the individual objects. Cloning the `ArrayList` is not "deep"; it will only clone the references to the object. | Your question isn't very clear. If you clone() an ArrayList, the clone will not be modified if you change the contents of the original (ie if you add or remove elements) but it's a "shallow copy" so if you change the actual objects in the original they will also be changed in the clone.
If you want to make a "deep cop... | How to backup ArrayList in Java? | [
"",
"java",
"arraylist",
""
] |
I recently ran across some 3rd party C# code which does the following:
```
public int RecvByteDataFromPrinter(ref byte[] byteData)
{
byte[] recvdata = new byte[1024];
///...fills recvdata array...
byteData = recvdata;
return SUCCESS;
}
```
What does the line "`byteData = recvdata`" actually d... | Yes, because of ref - it does modify the reference passed.
Stick around? you mean - not destroyed? Yes, it will not be GC'd because of a new reference. The old array (passed) might be GC'd though after this assignment if no more references...
Array.Copy will actually copy elements, then you don't need "ref", but this ... | You guessed right, the assignment is modifying the byteData array reference to point to the newly allocated array (because of the 'ref' keyword). The callers of the function will "see" the contents of the recvData array (whatever was filled in there).
And yes, the array sticks around as long as there's one reference t... | Modifications of arrays passed by reference | [
"",
"c#",
"arrays",
""
] |
I have a form that has a public property
```
public bool cancelSearch = false;
```
I also have a class which is sitting in my bll (business logic layer), in this class I have a method, and in this method I have a loop. I would like to know how can I get the method to recognise the form (this custom class and form1 ar... | When you are calling the business logic that needs to know the information pass a reference of the form to the method.
Something like.
```
public class MyBLClass
{
public void DoSomething(Form1 theForm)
{
//You can use theForm.cancelSearch to get the value
}
}
```
then when calling it from a Form... | Your question is really not clear. You might want to edit it.
## Advice
The form shouldn't pass to your business logic layer...
# Solutions to your problem
BUT if you really want to (BUT it's really not something to do), you need to pass the reference. You can do it by passing the reference in the constructor of yo... | C# Winforms: How to get a reference to Form1 design time | [
"",
"c#",
"winforms",
""
] |
Is it possible to somehow change the look/feel of NetBeans? I know it uses Swing and that usually apps using Swing for its UI can usually have their UI scheme changed.
The default appearence for OSX is vomitastic and would even settle for just some sort of barebones `default` look. The whole look is just too distracti... | See the answer to this question:
[Force look and feel on NetBeans 6.5](https://stackoverflow.com/questions/231738/force-look-and-feel-on-netbeans-65#233855) | Looks like this might be what I was looking for:
<http://wiki.netbeans.org/FaqCustomLaf> | Changing NetBeans UI Look/Feel | [
"",
"java",
"macos",
"swing",
"netbeans",
"interface",
""
] |
Are there any tools to give some sort of histogram of where most of the execution time of the program is spent at?
This is for a project using c++ in visual studio 2008. | The name you're after is a **profiler**. Try [Find Application Bottlenecks with Visual Studio Profiler](http://msdn.microsoft.com/en-gb/magazine/cc337887.aspx?pr=blog) | You need a [profiler](http://en.wikipedia.org/wiki/Profiler_(computer_science)).
Visual Studio Team edition includes a profiler (which is what you are looking for) but you may only have access to the Professional or Express editions. Take a look at these threads for alternatives:
[What's your favorite profiling tool ... | How do you find the least optimized parts of a program? | [
"",
"c++",
"visual-studio",
"optimization",
"profiler",
""
] |
Does SQL Server CheckSum calculate a CRC? If not how can I get SQL Server to calculate a CRC on an arbitrary varchar column? | I apologize for the crudity of the model, but this seems to do a correct CRC32 calculation.
I'm not a TSQL expert, and I'm sure that this could be improved mightily by a real SQL Server pro...
@input is the variable to calculate the CRC32 on.
It should be trivial to package this as a sproc or a udf, and the lookup tab... | I shortened Andrew Rollings' script to 11 lines, so he really gets the credit. This will run in SQL 2008 or higher. If you set the variable values after the DECLARE, it will run in SQL 2005. In 2005 and up the character limit is 2048, in SQL 2000 it's something like 512 (I can't remember how many spt\_values of type P ... | Does SQL Server CheckSum calculate a CRC? If not how can I get MS SQL to calculate a CRC on an arbitrary varchar column? | [
"",
"sql",
"sql-server",
""
] |
I typically use the below function to return the root URL if I ever need this, but thought to ask if jQuery had a "one liner" way to do this ...
```
function getRootURL()
{
var baseURL = location.href;
var rootURL = baseURL.substring(0, baseURL.indexOf('/', 7));
// if the r... | What about
```
document.location.hostname
``` | You can just do:
`alert(location.host)`
With **location.hostname**, you don't get the port (if there's a special port like :8080). | Does jQuery have a built in function to return the rootURL? | [
"",
"javascript",
"jquery",
""
] |
I need to store some values in the database, distance, weight etc.
In my model, I have field that contains quantity of something and `IntegerField` with choices option, that determines what this quantity means (length, time duration etc).
Should I create a model for units and physical quantity or should I use `Integ... | By `field(enum)`" do you mean you are using the [choices](http://docs.djangoproject.com/en/dev/ref/models/fields/#choices) option on a field?
A simple set of choices works out reasonably well for small lists of conversions. It allows you to make simplifying assumptions that helps your users (and you) get something tha... | It depends on how you want to use it. Let's say you have length value and two possible units, cm and mm. If you want only to print the value later, you can always print it as `[value] [unit]`.
However, if you want to do some calculations with the value, for instance, calculate the area, you need to convert the va... | Django and units conversion | [
"",
"python",
"django",
""
] |
When I'm moving through a file with a csv.reader, how do I return to the top of the file. If I were doing it with a normal file I could just do something like "file.seek(0)". Is there anything like that for the csv module?
Thanks ahead of time ;) | You can seek the file directly. For example:
```
>>> f = open("csv.txt")
>>> c = csv.reader(f)
>>> for row in c: print row
['1', '2', '3']
['4', '5', '6']
>>> f.seek(0)
>>> for row in c: print row # again
['1', '2', '3']
['4', '5', '6']
``` | You can still use file.seek(0). For instance, look at the following:
```
import csv
file_handle = open("somefile.csv", "r")
reader = csv.reader(file_handle)
# Do stuff with reader
file_handle.seek(0)
# Do more stuff with reader as it is back at the beginning now
```
This should work since csv.reader is working with t... | Python csv.reader: How do I return to the top of the file? | [
"",
"python",
"csv",
""
] |
I'd like to know if there is any .Net class that allows me to know the SSID of the wireless network I'm connected to.
So far I only found the library linked below. Is the best I can get or should I use something else?
[Managed WiFi](http://www.codeplex.com/managedwifi) (<http://www.codeplex.com/managedwifi>)
The metho... | I resolved using the library. It resulted to be quite easy to work with the classes provided:
First I had to create a WlanClient object
```
wlan = new WlanClient();
```
And then I can get the list of the SSIDs the PC is connected to with this code:
```
Collection<String> connectedSsids = new Collection<string>();
... | We were using the managed wifi library, but it throws exceptions if the network is disconnected during a query.
Try:
```
var process = new Process
{
StartInfo =
{
FileName = "netsh.exe",
Arguments = "wlan show interfaces",
UseShellExecute = false,
RedirectStandardOutput = true,
CreateNoWin... | Get SSID of the wireless network I am connected to with C# .Net on Windows Vista | [
"",
"c#",
"wifi",
"windows-vista",
"ssid",
""
] |
I have a master page with one form on it. It is a search form which must always be visible. When the button of that form is clicked I want the form data to be sent to search.aspx. The problem is, I don't know how. I cannot set the form action to search.aspx, because all my other pages which use the master form will go ... | In order to pass the values of the control "txtSearch", when Server.Transfer is executed, you could do many things, including passing it via a querystring variable or setting up a session variable, and then check either of those in the Page\_Load event of Search.aspx, and if it's populated, call the event that is fired... | You could create your search form in a separate form, and get it to use GET instead of POST.
Either that, or have the master form handle the search button click and use Server.Transfer to go to the search form. | Passing master page form data to another webform | [
"",
"c#",
"asp.net",
"forms",
"master-pages",
""
] |
I'm working with a start-up, mostly doing system administration and I've come across a some security issues that I'm not really comfortable with. I want to judge whether my expectations are accurate, so I'm looking for some insight into what others have done in this situation, and what risks/problems came up. In partic... | If security isn't thought of and built into the application and its infrastructure from day one it will be much more difficult to retrofit it in later. Now is the time to build the processes for regular OS/tool patching, upgrades, etc.
* What kind of data will users be creating/storing on the site?
* What effect will ... | Also, don't forget you need to have your server secured from current (that is, soon-to-be-past) employees. Several startups were totally wiped due to employee sabotage, e.g. <http://www.geek.com/articles/news/disgruntled-employee-kills-journalspace-with-data-wipe-2009015/> | What are the minimum security precautions to put in place for a startup? | [
"",
"java",
"security",
"lamp",
"infrastructure",
""
] |
What's the simplest way to get XmlSerializer to also serialize private and "public const" properties of a class or struct? Right not all it will output for me is things that are only public. Making it private or adding const is causing the values to not be serialized. | `XmlSerializer` only looks at public fields and properties. If you need more control, you can implement [IXmlSerializable](http://msdn.microsoft.com/en-us/library/system.xml.serialization.ixmlserializable.aspx) and serialize whatever you would like. Of course, serializing a constant doesn't make much sense since you ca... | Even though it's not possible to serialize private properties, you can serialize properties with an internal setter, like this one :
```
public string Foo { get; internal set; }
```
To do that, you need to pre-generate the serialization assembly with sgen.exe, and declare this assembly as friend :
```
[assembly:Inte... | Using XmlSerializer with private and public const properties | [
"",
"c#",
"xml-serialization",
""
] |
When I submit a form in HTML, I can pass a parameter multiple times, e.g.
```
<input type="hidden" name="id" value="2">
<input type="hidden" name="id" value="4">
```
Then in struts I can have a bean with property String[] id, and it'll populate the array correctly.
My question is, how can I do that in Javascript? Wh... | Is this what you're looking for? It generates a hidden form field for each element of a JavaScript array:
```
var el;
for (var i = 0; i < myArray.length) {
el = document.createElement("input");
el.type = "hidden";
el.name = "id";
el.value = myArray[i];
// Optional: give each input an id so they ca... | Not positive what you're trying to do but here's a go:
```
var inputs = document.getElementsByName('id');
for(var i=0; i<inputs.length; i++) {
var input = inputs[i];
input.value = myArray[i];
}
```
That iterates over all the inputs with name '`id`' and assigns the corresponding value from myArray.
You better... | Setting a multi-valued parameter in javascript | [
"",
"javascript",
"html",
"struts",
""
] |
This causes a compile-time exception:
```
public sealed class ValidatesAttribute<T> : Attribute
{
}
[Validates<string>]
public static class StringValidation
{
}
```
I realize C# does not support generic attributes. However, after much Googling, I can't seem to find the reason.
Does anyone know why generic types c... | Well, I can't answer why it's not available, but I *can* confirm that it's not a CLI issue. The CLI spec doesn't mention it (as far as I can see) and if you use IL directly you can create a generic attribute. The part of the C# 3 spec that bans it - section 10.1.4 "Class base specification" doesn't give any justificati... | An attribute decorates a class at compile-time, but a generic class does not receive its final type information until runtime. Since the attribute can affect compilation, it has to be "complete" at compile time.
See this [MSDN article](http://msdn.microsoft.com/en-us/library/ms379564.aspx) for more information. | Why does C# forbid generic attribute types? | [
"",
"c#",
"generics",
".net-attributes",
""
] |
I'm a little lost (still working with Ron Jeffries's book). Here's a simple class:
```
public class Model{
private String[] lines;
public void myMethod(){
String[] newLines = new String[lines.length + 2];
for (i = 0, i <= lines.length, i++) {
newLines[i] = lines[i];
}
}... | I think your example is probably not the same as your actual code based on your description. I think the problem is that arrays are zero-based and thus an array initialized as:
string[] lines = new string[0];
has no elements.
You need to change your loop so that you check that the index is strictly less than the len... | lines will be null, so lines.length will throw an exception.
I believe your other class initializing "Model" won't help since Lines itself is private. In fact, whatever you are doing to Model is probably illegal in at least 30 states. | How many dimensions in an array with no value | [
"",
"java",
"arrays",
""
] |
I am using Carbide (just upgraded to 2.0) to develop an S60 3rd Edition application.
I would like to know the easiest way to change the icon (both the application icon on the device menu **and** the icon at the top left of the main view) because I have the need to skin my application in many different ways as easily a... | To change the app icon when you run your app use (in the status bar):
```
CEikStatusPane* sp=iEikonEnv->AppUiFactory()->StatusPane();
CAknContextPane* cp=(CAknContextPane *)sp->ControlL(TUid::Uid(EEikStatusPaneUidContext));
_LIT(KContextBitMapFile, "my_bitmap_file.mbm");
CFbsBitmap* bitmap = iEikonEnv->CreateBitmapL(K... | <http://wiki.forum.nokia.com/index.php/CS000808_-_Creating_and_adding_an_icon_to_an_S60_3rd_Edition_application> | Carbide / Symbian C++ - Change Application Icon | [
"",
"c++",
"symbian",
"icons",
"s60",
"carbide",
""
] |
It's been suggested that this might be a reasonable approach, in order to minimize changes to an existing server configurations, but is it actually valid/supported? I've not been able to find anything specific either way.
In practice, with a JBoss Portal V2.4.2 server, there appears to be some class-loading issues, so... | The answer is that yes, it is valid, **but** the specific JBoss Portal V2.4.\* versions appear to have class-loader issues such that only the more basic web-apps will run correctly. | [JSR 286 (Portlet 2.0) spec](http://jcp.org/en/jsr/detail?id=286):
> PLT.2.7
>
> Relationship with Java 2
> Platform, Standard and Enterprise
> Edition
>
> The Portlet API v2.0 is based on the
> Java Platform, Standard Edition 5.0
> and Enterprise Edition v1.4. Portlet
> containers should at least meet the
> requireme... | Is it valid to expect a Java Portal Server to host 'standard' Java WebApps? | [
"",
"java",
"web-applications",
"portal",
"jboss-portal",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.