
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I've got a wx.Toolbar and I'd like to make the buttons larger. I've searched and can't seem to find any concrete documentation on how to do this.
I'm also wondering how well this will translate across platforms; what will happen to the buttons and icons on OSX? | It depends on what you want to change: is it the size of the buttons or the size of the icons ?
To change the size of the buttons, use [SetToolBitmapSize](http://docs.wxwidgets.org/2.6/wx_wxtoolbar.html#wxtoolbarsettoolbitmapsize) (24x24 for instance):
```
toolbar.SetToolBitmapSize((24, 24))
```
This will only change the size of the buttons, though. If you want to change the size of the icons, simply use bigger ones. The easiest way is to use [wx.ArtProvider](http://docs.wxwidgets.org/2.6/wx_wxartprovider.html):
```
wx.ArtProvider.GetBitmap(wx.ART_FILE_SAVE, wx.ART_TOOLBAR, (24, 24))
```
So, summing it up:
```
# Define the size of the icons and buttons
iconSize = (24, 24)
# Set the size of the buttons
toolbar.SetToolBitmapSize(iconSize)
# Add some button
saveIcon = wx.ArtProvider.GetBitmap(wx.ART_FILE_SAVE, wx.ART_TOOLBAR, iconSize)
toolBar.AddSimpleTool(1, saveIcon, "Save", "Save current file")
```
**Remark:** As SetToolBitmapSize changes the size of the buttons, not the size of the icons, you can set the buttons to be larger than the icons. This should leave blank space around the icons. | Doesn't the size of the toolbar adapts itself automatically to the size of the bitmap icons? I think if you want a bigger toolbar, you need bigger bitmaps. | How to make a wx Toolbar buttons larger? | [
"",
"python",
"user-interface",
"wxpython",
"wxwidgets",
"toolbar",
""
] |
So I have been exploring different methods to clean up and test my JavaScript. I figured just like any other language one way to get better is to read good code. jQuery is very popular so it must have a certain degree of good coding.
So why when I run jQuery through JSLint's validation it gives me this message:
> Error:
>
> Problem at line 18 character 5:
> Expected an identifier and instead saw
> 'undefined' (a reserved word).
>
> undefined,
>
> Problem at line 24 character 27:
> Missing semicolon.
>
> jQuery = window.jQuery = window.$ =
> function( selector, context ) {
>
> Problem at line 24 character 28:
> Expected an identifier and instead saw
> '='.
>
> jQuery = window.jQuery = window.$ =
> function( selector, context ) {
>
> Problem at line 24 character 28:
> ***Stopping, unable to continue. (0%
> scanned)***.
This was done using [JSLint](http://jslint.com/) and [jquery-1.3.1.js](http://jqueryjs.googlecode.com/files/jquery-1.3.1.js) | JSLint tests one particular person's (Douglas Crockford) opinions regarding what makes good JavaScript code. Crockford is very good, but some of his opinions are anal retentive at best, like the underscore rule, or the use of the increment/decrement operators.
Many of the issues being tagged by JSLint in the above output are issues that Crockford feels leads to difficult to maintain code, or they are things that he feels has led him to doing 'clever' things in the past that can be hard to maintain.
There are some things Crockford identifies as errors that I agree with though, like the missing semicolons thing. Dropping semicolons forces the browser to guess where to insert the end-of-statement token, and that can sometimes be dangerous (it's always slower). And several of those errors are related to JSLint not expecting or supporting multiple assignments like jQuery does on line 24.
If you've got a question about a JSLint error, e-mail Crockford, he's really good about replying, and with his reply, you'll at least know why JSLint was implemented that way.
Oh, and just because a library is popular doesn't mean it's code is any good. JQuery is popular because it's a relatively fast, easy to use library. That it's well implemented is rather inconsequential to it's popularity among many. However, you should certainly be reading more code, we all should.
JSLint can be very helpful in identifying problems with the code, even if JQuery doesn't pass the standards it desires. | JSLint helps you catch problems, it isn't a test of validity or a replacement for thinking. jQuery is pretty advanced as js goes, which makes such a result understandable. I mean the first couple of lines are speed hacks, no wonder the most rigid js parser is going have a couple of errors.
In any case, the assumption that popular code is perfectly correct code or even 'good' is flawed. JQuery code is good, and you can learn a lot of from reading it. You should still run your stuff through JSLint, if only because it's good to hear another opinion on what you've written.
From JSLint's description:
> JSLint takes a JavaScript source and scans it. If it finds a problem, it returns a message describing the problem and an approximate location within the source. The problem is not necessarily a syntax error, although it often is. JSLint looks at some style conventions as well as structural problems. It does not prove that your program is correct. It just provides another set of eyes to help spot problems.
>
> JSLint defines a professional subset of JavaScript, a stricter language than that defined by Edition 3 of the ECMAScript Language Specification. The subset is related to recommendations found in Code Conventions for the JavaScript Programming Language. | What good is JSLint if jQuery fails the validation | [
"",
"javascript",
"jquery",
""
] |
I'm working on a website for a client, in PHP/MySQL. They are a publisher, and the site needs to show whether the book you are looking at is in stock with their distributor.
The stock file is a CSV file on the distributor's FTP. This file is updated at a certain time every evening. So far I've written a script in PHP that copies the contents of the file to the web server. I'll then get the stock information from this and stick it in the MySQL books database.
Is there a way to make the file-transfer PHP script only run once a day, after the file has updated on the distributor's FTP? Is this the best way to do this? | The conventional way to automate repeating tasks is to use **cron**. You can edit your cron configuration from the command line using `crontab -e`. The file follows the following format:
```
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
* * * * * command to be executed
``` | you will need to use a scheduled task if you are using a windows server, or a cronjob if you are on unix. Here is some info on using cron:
<http://www.clockwatchers.com/cron_main.html>
<http://www.clickmojo.com/code/cron-tutorial.html>
and the win task scheduler. | How best to display a stock file dynamicallly? | [
"",
"php",
"ftp",
"cron",
""
] |
I am intrigued by how the C++ exception handling mechanism works. Specifically, where is the exception object stored and how does it propagate through several scopes until it is caught? Is it stored in some global area?
Since this could be compiler specific could somebody explain this in the context of the g++ compiler suite? | Implementations may differ, but there are some basic ideas that follow from requirements.
The exception object itself is an object created in one function, destroyed in a caller thereof. Hence, it's typically not feasible to create the object on the stack. On the other hand, many exception objects are not very big. Ergo, one can create e.g a 32 byte buffer and overflow to heap if a bigger exception object is actually needed.
As for the actual transfer of control, two strategies exist. One is to record enough information in the stack itself to unwind the stack. This is basically a list of destructors to run and exception handlers that might catch the exception. When an exception happens, run back the stack executing those destructors until you find a matching catch.
The second strategy moves this information into tables outside the stack. Now, when an exception occurs, the call stack is used to find out which scopes are entered but not exited. Those are then looked up in the static tables to determine where the thrown exception will be handled, and which destructors run in between. This means there is less exception overhead on the stack; return addresses are needed anyway. The tables are extra data, but the compiler can put them in a demand-loaded segment of the program. | This is defined in 15.1 Throwing an exception of the standard.
The throw creates a temporary object.
How the memory for this temporary object is allocated is unspecified.
After creation of the temporary object control is passed to the closest handler in the call stack. unwinding the stack between throw and catch point. As the stack is unwind any stack variables are destroyed in reverse order of creation.
Unless the exception is re-thrown the temporary is destroyed at the end of the handler where it was caught.
Note: If you catch by reference the reference will refer to the temporary, If you catch by value the temporary object is copied into the value (and thus requires a copy constructor).
Advice from S.Meyers (Catch by const reference).
```
try
{
// do stuff
}
catch(MyException const& x)
{
}
catch(std::exception const& x)
{
}
``` | How is the C++ exception handling runtime implemented? | [
"",
"c++",
"exception",
"error-handling",
"language-implementation",
""
] |
Right now I have vector3 values represented as lists. is there a way to subtract 2 of these like vector3 values, like
```
[2,2,2] - [1,1,1] = [1,1,1]
```
Should I use tuples?
If none of them defines these operands on these types, can I define it instead?
If not, should I create a new vector3 class? | If this is something you end up doing frequently, and with different operations, you should probably create a class to handle cases like this, or better use some library like [Numpy](https://numpy.org/).
Otherwise, look for [list comprehensions](https://docs.python.org/3/tutorial/datastructures.html#list-comprehensions) used with the [zip](https://docs.python.org/3/library/functions.html#zip) builtin function:
```
[a_i - b_i for a_i, b_i in zip(a, b)]
``` | Here's an alternative to list comprehensions. Map iterates through the list(s) (the latter arguments), doing so simulataneously, and passes their elements as arguments to the function (the first arg). It returns the resulting list.
```
import operator
map(operator.sub, a, b)
```
This code because has less syntax (which is more aesthetic for me), and apparently it's 40% faster for lists of length 5 (see bobince's comment). Still, either solution will work. | Subtracting 2 lists in Python | [
"",
"python",
"list",
"tuples",
"vector",
""
] |
I'm running a python script on a shared hosting server which until this morning had MySQL version 4. Now it has version 5. My python script can no longer connect to MySQL, as it can't find libmysqlclient\_r.so.14:
```
$ python my_script.py
Traceback (most recent call last):
File "my_script.py", line 6, in ?
import MySQLdb
File "/home/lib/python2.4/site-packages/PIL-1.1.6-py2.4-linux-i686.egg/__init__.py", line 19, in ?
File "build/bdist.linux-i686/egg/_mysql.py", line 7, in ?
File "build/bdist.linux-i686/egg/_mysql.py", line 6, in __bootstrap__
ImportError: libmysqlclient_r.so.14: cannot open shared object file: No such file or directory
```
There are various other versions of libmysqlclient in /usr/lib:
```
/usr/lib/libmysqlclient.so.15
/usr/lib/libmysqlclient.so.14
/usr/lib/mysql/libmysqlclient.la
/usr/lib/mysql/libmysqlclient.so
/usr/lib/mysql/libmysqlclient_r.so
/usr/lib/mysql/libmysqlclient_r.a
/usr/lib/mysql/libmysqlclient_r.la
/usr/lib/mysql/libmysqlclient.a
/usr/lib/libmysqlclient.so
/usr/lib/libmysqlclient_r.so
/usr/lib/libmysqlclient_r.so.15
/usr/lib/libmysqlclient_r.so.15.0.0
/usr/lib/libmysqlclient.so.15.0.0
```
So my question is this: how can I tell python (version 2.4.3) which version of libmysqlclient to use? | You can't tell the dynamic linker which version of a library to use, because the SONAME (full name of the library + interface) is part of the binary.
In your case, you can try to upload libmysqlclient\_r.so.14 to the host and set `LD_LIBRARY_PATH` accordingly, so tell the dynamic linker which directories to search additionally to the system dirs when resolving shared objects.
You can use `ldd` to see if it `LD_LIBRARY_PATH` works:
```
$ ldd $path_to/_mysql.so
...
libmysqlclient_r.so.14 => $path_to_lib/libmysqlclient_r.so.14
...
```
Otherwise, there will be an error message about unresolved shared objects.
Of course that can only be a temporary fix until you rebuild MySQLdb to use the new libraries. | You will have to recompile python-mysql (aka MySQLdb) to get it to link to the new version of libmysqlclient.
If your host originally set up the environment rather than you compiling it, you'll have to pester them.
> /usr/lib/libmysqlclient.so.14
This looks like a remnant of the old libmysqlclient, and should be removed. The \_r and .a (static) versions are gone and you don't really want a mixture of libraries still around, it will only risk confusing automake.
Whilst you *could* make a symbolic link from libmysqlclient\_r.so.14 to .15, that'd only work if the new version of the client happened to have the same ABI for the functions you wanted to use as the old - and that's pretty unlikely, as that's the whole point of changing the version number. | How can I tell python which version of libmysqlclient.so to use? | [
"",
"python",
""
] |
* I tend to use [**POSIX Threads**](http://en.wikipedia.org/wiki/POSIX_Threads), when programming in C, under **Linux**.
* Without **MFC**
**Question:**
How would I then create threads in VC++?
Find more information on threads under win32?
### Edit:
* Brief illustrations
**I LOVE stackoverflow - best resource for students!**
Regards | You should not use the raw Win32 `CreateThread()` API.
Use the C runtime's [`_beginthreadex()`](http://msdn.microsoft.com/en-us/library/kdzttdcb.aspx) so the runtime has an opportunity to set up its own thread support. | if you're looking for a platform-independent method, use [boost](http://www.boost.org/)
there's also beginthread() and beginthreadex() functions. Both seem to be supplemental to Win32 API, in a sense that in many use cases, you still need to call some Win32 functions (such as CloseHandle for beginthreadex). So, if you don't care that much about platform compatibility, you might as well cut the foreplay and use CreateThread().
Win32 thread handling is documented here: <http://msdn.microsoft.com/en-us/library/ms684852(VS.85).aspx>
[edit1] example:
```
DWORD WINAPI MyThreadProc( void* pContext )
{
return 0;
}
HANDLE h = CreateThread( NULL, 0, MyThreadProc, this, 0L, NULL );
WaitForSingleObject(h, TIME); // wait for thread to exit, TIME is a DWORD in milliseconds
```
[edit2] CRT & CreateThread():
per MSDN:
A thread in an executable that calls the C run-time library (CRT) should use the \_beginthreadex and \_endthreadex functions for thread management rather than CreateThread and ExitThread; this requires the use of the multi-threaded version of the CRT. If a thread created using CreateThread calls the CRT, the CRT may terminate the process in low-memory conditions. | How to create threads in VC++ | [
"",
"c++",
"windows",
"visual-studio-2008",
""
] |
Where or when would one would use namespace aliasing like
```
using someOtherName = System.Timers.Timer;
```
It seems to me that it would just add more confusion to understanding the language. | That is a type alias, not a namespace alias; it is useful to disambiguate - for example, against:
```
using WinformTimer = System.Windows.Forms.Timer;
using ThreadingTimer = System.Threading.Timer;
```
(ps: thanks for the choice of `Timer` ;-p)
Otherwise, if you use both `System.Windows.Forms.Timer` and `System.Threading.Timer` in the same file, then you'd have to keep giving the full names (since `Timer` could be confusing).
It also plays a part with `extern` aliases for using types with the same fully-qualified type name from different assemblies - rare, but useful to be supported.
---
Actually, I can see another use: when you want quick access to a type but don't want to use a regular `using` because you can't import some conflicting extension methods. A bit convoluted but here's an example:
```
namespace RealCode {
//using Foo; // can't use this - it breaks DoSomething
using Handy = Foo.Handy;
using Bar;
static class Program {
static void Main() {
Handy h = new Handy(); // prove available
string test = "abc";
test.DoSomething(); // prove available
}
}
}
namespace Foo {
static class TypeOne {
public static void DoSomething(this string value) { }
}
class Handy {}
}
namespace Bar {
static class TypeTwo {
public static void DoSomething(this string value) { }
}
}
``` | I use it when I've got multiple namespaces with conflicting sub namespaces and/or object names you could just do something like [as an example]:
```
using src = Namespace1.Subspace.DataAccessObjects;
using dst = Namespace2.Subspace.DataAccessObjects;
...
src.DataObject source = new src.DataObject();
dst.DataObject destination = new dst.DataObject();
```
Which would otherwise have to be written:
```
Namespace1.Subspace.DataAccessObjects.DataObject source =
new Namespace1.Subspace.DataAccessObjects.DataObject();
Namespace2.Subspace.DataAccessObjects.DataObject dstination =
new Namespace2.Subspace.DataAccessObjects.DataObject();
```
It saves a ton of typing and can be used to make code a lot easier to read. | C# namespace alias - what's the point? | [
"",
"c#",
"namespaces",
""
] |
I have the following situation:
```
// A public interface of some kind
public interface IMyInterface {
int Something { get; set; }
}
// An internal class that implements the public interface.
// Despite the internal/public mismatch, this works.
internal class MyInternalConcrete : IMyInterface {
public int Something { get; set; }
}
// A generic class with an interface-restricted type parameter.
// Note that the constraint on T uses the *public* interface.
// The instance is *never* exposed as a public, or even protected member.
public class MyClass<T> where T : IMyInterface, new() {
T myInterfaceInstance;
public MyClass() {
myInterfaceInstance = new T();
}
}
// Attempting to implement concrete class... Inconsistent Accessibility Error!
public class MySpecificClass : MyClass<MyInternalConcrete>
{
}
```
When trying to implement MySpecificClass, I get the error:
> Inconsistent accessibility: base class 'App1.MyClass' is less accessible than class 'App1.MySpecificT'
Where it gets weird is that MyInternalConcrete, despite being **internal**, can still implement a **public** interface. And since it implements the interface, then it *should* be useable as a type parameter for MyClass - because T is constrained on the public interface and not the internal class.
I would understand it failing if MyClass exposed T, just as it would fail if we weren't using generics:
```
public class MyClass<T> where T : IMyInterface, new() {
T myInterfaceInstance;
public MyClass() {
myInterfaceInstance = new T();
}
// This will fail with an internal T - inconsistent accessibility!
public T Instance {
get { return myInterfaceInstance; }
}
}
```
And same as above, but without generics:
```
public class MyNonGenericClass {
MyInternalConcrete myInterfaceInstance;
public MyNonGenericClass() {
myInterfaceInstance = new MyInternalConcrete();
}
// This will fail - inconsistent accessibility!
// but removing it works, since the private instance is never exposed.
public MyInternalConcrete Instance {
get { return myInterfaceInstance; }
}
}
```
Is this a limitation of the C# generics or am I simply misunderstanding something fundamental about how generics work?
[I also posted this thread on MSDN](http://social.msdn.microsoft.com/Forums/en-US/csharpgeneral/thread/cfea0f0b-c0da-4381-a92f-54729279a8a8), but I'm being dismissed as not knowing what I'm talking about. Is my concern even valid? | This constraint you are facing makes sense for the following reason.
C# is strongly typed so...
To be able to reference the MySpecificClass outside the scope of the assembly it is defined in you must know its parameter types in order to generate a strong type reference to its instance; but an separate assembly than the internal definition does not know about MyInternalConcrete.
Thus the following wont work if in a separate assembly:
```
MyClass<MyInternalConcrete> myInstance = new MySpecificClass();
```
Here the separate assembly doesn't know of MyInternalConcrete, so how can you define a variable as such. | According to this article on [C# generics](http://www.codeguru.com/csharp/sample_chapter/article.php/c11637__2/)
> "The visibility of a generic type is
> the **intersection of the generic type
> with the visibility of the parameter
> types**. If the visibility of all the C,
> T1, T2 and T3 types is set to public,
> then the visibility of C is
> also public; but if the visibility of
> only one of these types is private,
> then the visibility of C is
> private."
So whilst your example could be possible, it doesn't fit with the rules as defined.
For a more definitive source see section 25.5.5 (page 399) of the [C# spec](http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-334.pdf).
> A constructed type C is
> accessible when all of its components
> C, T1, ..., TN are accessible. More
> precisely, the accessibility domain
> for a constructed type is the
> intersection of the accessibility
> domain of the unbound generic type and
> the accessibility domains of the type
> arguments. | Generics using public interfaces and internal type parameters | [
"",
"c#",
".net",
"generics",
"interface",
""
] |
Any suggestions for open source aspect-oriented library for c#. Thanks | [Post Sharp](http://www.postsharp.org/) | Spring.NET | Suggestions for open source aspect-oriented library for c# | [
"",
"c#",
"open-source",
"aop",
""
] |
Is there a way to make an `Oracle` query behave like it contains a MySQL `limit` clause?
In MySQL, I can do this:
```
select *
from sometable
order by name
limit 20,10
```
to get the 21st to the 30th rows (skip the first 20, give the next 10). The rows are selected after the `order by`, so it really starts on the 20th name alphabetically.
In Oracle, the only thing people mention is the `rownum` pseudo-column, but it is evaluated *before* `order by`, which means this:
```
select *
from sometable
where rownum <= 10
order by name
```
will return a random set of ten rows ordered by name, which is not usually what I want. It also doesn't allow for specifying an offset. | You can use a subquery for this like
```
select *
from
( select *
from emp
order by sal desc )
where ROWNUM <= 5;
```
Have also a look at the topic [On ROWNUM and limiting results](https://blogs.oracle.com/oraclemagazine/post/on-rownum-and-limiting-results) at Oracle/AskTom for more information.
**Update**:
To limit the result with both lower and upper bounds things get a bit more bloated with
```
select * from
( select a.*, ROWNUM rnum from
( <your_query_goes_here, with order by> ) a
where ROWNUM <= :MAX_ROW_TO_FETCH )
where rnum >= :MIN_ROW_TO_FETCH;
```
(Copied from specified AskTom-article)
**Update 2**:
Starting with Oracle 12c (12.1) there is a syntax available to limit rows or start at offsets.
```
-- only get first 10 results
SELECT *
FROM sometable
ORDER BY name
FETCH FIRST 10 ROWS ONLY;
-- get result rows 20-30
SELECT *
FROM sometable
ORDER BY name
OFFSET 20 ROWS FETCH NEXT 10 ROWS ONLY;
```
See [this answer](https://stackoverflow.com/a/26051830/57601) for more examples. Thanks to Krumia for the hint. | Starting from Oracle 12c R1 (12.1), there *is* a [row limiting clause](http://www.oracle-base.com/articles/12c/row-limiting-clause-for-top-n-queries-12cr1.php). It does not use familiar `LIMIT` syntax, but it can do the job better with more options. You can find the [full syntax here](http://docs.oracle.com/database/121/SQLRF/statements_10002.htm#BABBADDD). (Also read more on how this works internally in Oracle in [this answer](https://stackoverflow.com/a/57547541/1461424)).
To answer the original question, here's the query:
```
SELECT *
FROM sometable
ORDER BY name
OFFSET 20 ROWS FETCH NEXT 10 ROWS ONLY;
```
(For earlier Oracle versions, please refer to other answers in this question)
---
## Examples:
Following examples were quoted from [linked page](http://www.oracle-base.com/articles/12c/row-limiting-clause-for-top-n-queries-12cr1.php), in the hope of preventing link rot.
### Setup
```
CREATE TABLE rownum_order_test (
val NUMBER
);
INSERT ALL
INTO rownum_order_test
SELECT level
FROM dual
CONNECT BY level <= 10;
COMMIT;
```
### What's in the table?
```
SELECT val
FROM rownum_order_test
ORDER BY val;
VAL
----------
1
1
2
2
3
3
4
4
5
5
6
6
7
7
8
8
9
9
10
10
20 rows selected.
```
### Get first `N` rows
```
SELECT val
FROM rownum_order_test
ORDER BY val DESC
FETCH FIRST 5 ROWS ONLY;
VAL
----------
10
10
9
9
8
5 rows selected.
```
### Get first `N` rows, if `N`th row has ties, get all the tied rows
```
SELECT val
FROM rownum_order_test
ORDER BY val DESC
FETCH FIRST 5 ROWS WITH TIES;
VAL
----------
10
10
9
9
8
8
6 rows selected.
```
### Top `x`% of rows
```
SELECT val
FROM rownum_order_test
ORDER BY val
FETCH FIRST 20 PERCENT ROWS ONLY;
VAL
----------
1
1
2
2
4 rows selected.
```
### Using an offset, very useful for pagination
```
SELECT val
FROM rownum_order_test
ORDER BY val
OFFSET 4 ROWS FETCH NEXT 4 ROWS ONLY;
VAL
----------
3
3
4
4
4 rows selected.
```
### You can combine offset with percentages
```
SELECT val
FROM rownum_order_test
ORDER BY val
OFFSET 4 ROWS FETCH NEXT 20 PERCENT ROWS ONLY;
VAL
----------
3
3
4
4
4 rows selected.
``` | How do I limit the number of rows returned by an Oracle query after ordering? | [
"",
"sql",
"oracle",
"pagination",
"sql-limit",
""
] |
I am getting a compilation error when trying to build a C++ project which previously worked.
The code follows:
```
const wchar_t* pdest;
pdest = _tcsstr(ConnStr, Name);
```
The error follows:
Error 10 error C2440: '=' : cannot convert from 'const char \*' to 'const wchar\_t
I'm using Visual Studio 2008. The error message explains the problem well, but I know this program used to compile, what am I doing wrong? | Your code is dangerous. \_tcsstr is a TCHAR macro, so it's definition can change depending on whether or not UNICODE is defined. wchar\_t is fixed. The error you're seeing is due to this exact problem - the environment is using the single-byte version of \_tcsstr (likely becasue UNICODE is not defined).
Don't just define UNICODE. Fix the code first. Either use TCHAR macros for both, or the wide character functions. | \_tcsstr is for use with TCHAR. Depending on compile settings, this is either char or wchar\_t.
So either use `TCHAR`, or `wcsstr` | Compilation error when calling _tcsstr and assigning to a wchar_t* | [
"",
"c++",
"visual-studio-2008",
""
] |
In C++, what is the convention for including headers for class files in the "main" file. e.g.
```
myclass.h
class MyClass {
doSomething();
}
myclass.cpp
doSomething() {
cout << "doing something";
}
run.cpp
#include "myclass.h"
#include "myclass.cpp"
etc..
```
Is this relatively standard? | You don't include the .cpp file, only the .h file. The function definitions in the .cpp will be compiled to .obj files, which will then be linked into the final binary. If you include the .cpp file in other .cpp files, you will get two different .obj files with the same funciton definition compiled, which will lead to linker error. | See [Understanding C Compilers](https://stackoverflow.com/questions/533076/understanding-c-compilers-from-a-java-c-perspective/533138#533138) for a lot of good answers to this question. | What is the conventions for headers and cpp files in C++? | [
"",
"c++",
"header",
"include",
""
] |
I've started a new project and have decided to make sure it builds cleanly with the /Wall option enabled. The only problem is not all 3rd party libraries (like boost) compile without warnings, so I've resorted to doing this in a shared header:
```
#pragma warning(push)
#pragma warning(disable:4820)
#pragma warning(disable:4619)
#pragma warning(disable:4668)
#pragma warning(disable:4625)
#pragma warning(disable:4626)
#pragma warning(disable:4571)
#pragma warning(disable:4347)
#pragma warning(disable:4640)
#pragma warning(disable:4365)
#pragma warning(disable:4710)
#pragma warning(disable:4820)
#pragma warning(disable:4350)
#pragma warning(disable:4686)
#pragma warning(disable:4711)
#pragma warning(disable:4548)
#include <boost/array.hpp>
#include <boost/assert.hpp>
#include <boost/assign.hpp>
#include <boost/bind.hpp>
#include <boost/lexical_cast.hpp>
#include <boost/filesystem.hpp>
#include <boost/foreach.hpp>
#include <boost/format.hpp>
#include <boost/function.hpp>
#include <boost/integer.hpp>
#include <boost/optional.hpp>
#include <boost/regex.hpp>
#include <boost/smart_ptr.hpp>
#include <boost/algorithm/string.hpp>
#include <boost/tuple/tuple.hpp>
#include <boost/utility.hpp>
#include <boost/variant.hpp>
#pragma warning(pop)
```
This works well enough, but every time I add new boost headers I have to add whatever warnings they generate to the list. Is there a way to say disable all warnings for this stretch of code? | You can push/pop a low level of warning, like this:
```
#pragma warning(push, 0)
#include <boost/bind.hpp>
#include <boost/shared_ptr.hpp>
// ...
#pragma warning(pop)
```
But know that it's not possible to disable *all* warnings. For example, some linker warnings are impossible to turn off. | ```
#pragma warning(disable:4820)
#pragma warning(disable:4619)
#pragma warning(disable:4668)
```
for less lines....
```
#pragma warning (disable : 4820 4619 4668)
``` | Is there a way to disable all warnings with a pragma? | [
"",
"c++",
"visual-c++",
"pragma",
""
] |
My user have a password field such as “0!ZWQ2” saved in the database.
I must unscramble my User input password from “aA1234” to “0!ZWQ2” and compare it to data in a database.
The 2 strings that I compare is:
“abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890 ”
With
“9setybcpqwiuvxr108daj5'-`~!@#$%^&\*()\_+|}][{:.?/<>,;ZWQ2@#34KDA”
This way a = 9 and 0 = A
How would I do this in C#, any ideas?
I just need to take the password field from the user input and scramble it to funny text to compare it to the data in the Database.
Any help will be appreciated.
Regards
Etienne
Updates: (10 Feb 2009)
Thanks everyone for the replies. Please note that i do realize that there are much better ways of handeling this. But please note that I am creating an ASP.NET application thats goign to be sitting inside SharePoint connecting to Cobol flat file data and not a proper database. Using Transoft to connect my ASP.NET (ODBC connector) to the Cobol flat files. So i have to stick with this code, and this will not be used on my Private site. I also have no control on when the Password is created in Cobol. | Following is Quick, Fast, and lesser code example to convert.
Code in C#:
```
char[] OriginalChars = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890".ToCharArray();
char[] ScrambleChars = "9setybcpqwiuvxr108daj5'-`~!@#$%^&()+|}][{:.?/<>,;ZWQ2@#34KDART".ToCharArray();
string TextToTransfer = "Hello";
string NewText = "";
foreach (char c in TextToTransfer)
{
NewText = NewText + ScrambleChars[Array.IndexOf<char>(OriginalChars, c)].ToString();
}
Console.WriteLine(NewText);
```
Code in VB:
```
Dim OriginalChars() As Char = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890"
Dim ScrambleChars() As Char = "9setybcpqwiuvxr108daj5'-`~!@#$%^&()+|}][{:.?/<>,;ZWQ2@#34KDART"
Dim TextToTransfer As String = "Hello"
Dim NewText As String = ""
For Each c As Char In TextToTransfer
NewText += ScrambleChars(Array.IndexOf(OriginalChars, c))
Next
MsgBox(NewText)
``` | Any special reason not to use a standard hash + salt for storing the passwords, instead of a Caesars cipher?
One way that should solve it (untested code):
```
new string("aA1234".ToCharArray().Select(c => ScrambleChars[OriginalChars.IndexOf(c)]).ToArray());
``` | How to replace one value with another when comparing 2 strings? | [
"",
"c#",
"asp.net",
"cobol",
"transoft",
""
] |
I would like to know similar, concrete simulations, as the simulation about watering a field [here](https://stackoverflow.com/questions/494184/simulation-problem-with-mouse-in-pygame).
What is your favorite library/internet page for such simulations in Python?
I know little Simpy, Numpy and Pygame. I would like to get examples about them. | If you are looking for some *game* physics (collisions, deformations, gravity, etc.) which *looks* real and is reasonably *fast* consider re-using some *physics engine* libraries.
As a first reference, you may want to look into [pymunk](http://www.pymunk.org/), a Python wrapper of [Chipmunk](http://wiki.slembcke.net/main/published/Chipmunk) 2D physics library. You can find a list of various Open Source physics engines (2D and 3D) in Wikipedia.
If you are looking for *physically correct* simulations, no matter what language you want to use, it will be much *slower* (almost never real-time), and you need to use some *numerical analysis* software (and probably to write something yourself). Exact answer depends on the problem you want to solve. It is a fairly complicated field (of math).
For example, if you need to do simulations in continuum mechanics or electromagnetism, you probably need Finite Difference, Finite Volume or Finite Element methods. For Python, there are some ready-to-use libraries, for example: [FiPy](http://www.ctcms.nist.gov/fipy/) (FVM), [GetFem++](http://home.gna.org/getfem/) (FEM), [FEniCS/DOLFIN](http://www.fenics.org/wiki/FEniCS_Project) (FEM), and some other. | Here is some simple [astronomy related python](http://www.astro.sunysb.edu/mzingale/software/astro/). And here is a [hardcore code](http://www.astro.sunysb.edu/mzingale/pyro/) from the same guy.
And [Eagleclaw](http://kingkong.amath.washington.edu/claw/examples/index.html) solves and plots various hyperbolic equations using some python. However, most of the code is written in Fortran to do the computations and python to plot the results. If you are studying physics though you may have to get used to this kind of Fortran wrapped code. It is a reality. But this isn't really what your looking for I guess. The good thing it that it is documented in a literate programming style so it should be understandable. | Simple simulations for Physics in Python? | [
"",
"python",
"modeling",
"simulation",
""
] |
I use a datepicker for choosing an appointment day. I already set the date range to be only for the next month. That works fine. I want to exclude Saturdays and Sundays from the available choices. Can this be done? If so, how? | There is the `beforeShowDay` option, which takes a function to be called for each date, returning true if the date is allowed or false if it is not. From the docs:
---
**beforeShowDay**
The function takes a date as a parameter and must return an array with [0] equal to true/false indicating whether or not this date is selectable and [1](http://jqueryui.com/demos/datepicker/#event-beforeShowDay) equal to a CSS class name(s) or '' for the default presentation. It is called for each day in the datepicker before is it displayed.
Display some national holidays in the datepicker.
```
$(".selector").datepicker({ beforeShowDay: nationalDays})
natDays = [
[1, 26, 'au'], [2, 6, 'nz'], [3, 17, 'ie'],
[4, 27, 'za'], [5, 25, 'ar'], [6, 6, 'se'],
[7, 4, 'us'], [8, 17, 'id'], [9, 7, 'br'],
[10, 1, 'cn'], [11, 22, 'lb'], [12, 12, 'ke']
];
function nationalDays(date) {
for (i = 0; i < natDays.length; i++) {
if (date.getMonth() == natDays[i][0] - 1
&& date.getDate() == natDays[i][1]) {
return [false, natDays[i][2] + '_day'];
}
}
return [true, ''];
}
```
One built in function exists, called noWeekends, that prevents the selection of weekend days.
```
$(".selector").datepicker({ beforeShowDay: $.datepicker.noWeekends })
```
---
To combine the two, you could do something like (assuming the `nationalDays` function from above):
```
$(".selector").datepicker({ beforeShowDay: noWeekendsOrHolidays})
function noWeekendsOrHolidays(date) {
var noWeekend = $.datepicker.noWeekends(date);
if (noWeekend[0]) {
return nationalDays(date);
} else {
return noWeekend;
}
}
```
**Update**: Note that as of jQuery UI 1.8.19, the [beforeShowDay option](http://jqueryui.com/demos/datepicker/#event-beforeShowDay) also accepts an optional third paremeter, a popup tooltip | If you don't want the weekends to appear at all, simply:
CSS
```
th.ui-datepicker-week-end,
td.ui-datepicker-week-end {
display: none;
}
``` | Can the jQuery UI Datepicker be made to disable Saturdays and Sundays (and holidays)? | [
"",
"javascript",
"jquery",
"jquery-ui",
"jquery-ui-datepicker",
""
] |
I've got a number of scripts that use common definitions. How do I split them in multiple files? Furthermore, the application can not be installed in any way in my scenario; it must be possible to have an arbitrary number of versions concurrently running and it must work without superuser rights. Solutions I've come up with are:
* **Duplicate code** in every
script. Messy, and probably the worst
scheme.
* **Put all scripts and common
code in a single directory,** and
use `from . import` to load them.
The downside of this approach is that
I'd like to put my libraries in other
directory than the applications.
* **Put common
code in its own directory**, write a `__init__.py` that imports all submodules and finally use `from . import` to load them.
Keeps code organized, but it's a little bit of overhead to maintain `__init__.py` and qualify names.
* **Add the library directory to
`sys.path` and
`import`.** I tend to
this, but I'm not sure whether
fiddling with `sys.path`
is nice code.
* **Load using
`execfile`**
(`exec` in Python 3).
Combines the advantages of the
previous two approaches: Only one
line per module needed, and I can use
a dedicated. On the other hand, this
evades the python module concept and
polutes the global namespace.
* **Write and install a module using
`distutils`.** This
installs the library for all python
scripts and needs superuser rights
and impacts other applications and is hence not applicable in my case.
What is the best method? | Adding to sys.path (usually using site.addsitedir) is quite common and not particularly frowned upon. Certainly you will want your common working shared stuff to be in modules somewhere convenient.
If you are using Python 2.6+ there's already a user-level modules folder you can use without having to add to sys.path or PYTHONPATH. It's ~/.local/lib/python2.6/site-packages on Unix-likes - see [PEP 370](http://www.python.org/dev/peps/pep-0370/) for more information. | You can set the `PYTHONPATH` environment variable to the directory where your library files are located. This adds that path to the library search path and you can use a normal `import` to import them. | How to modularize a Python application | [
"",
"python",
""
] |
I have a C++ class that compiles fine on linux with gcc and on widows in visual studio.
boid.h:
```
#ifndef BOID_CLASS_HEADER_DEFINES_H
#define BOID_CLASS_HEADER_DEFINES_H
#include "defines.h"
class Boid {
public:
// Initialize the boid with random position, heading direction and color
Boid(float SceneRadius,float NormalVel);
.....
protected:
...
};
#endif
```
and in boid.cpp:
```
#include "Boid.h"
// Initialize the boid with random position, heading direction and color
Boid::Boid(float SceneRadius,float NormalVel)
{
....
}
```
However, I get the following error when I compile this code in Xcode:
```
Compiling Boid.h: "error: vector: No such file or directory"
```
Any ideas? I thought you could take C/C++ code and compile it in Xcode without issues?
Thanks
**EDIT**: Added defines.h (also added #endif to sample, but that was in the original code)
**EDIT 2**: I am getting a different error after a commenting out a couple of includes there were empty: the vector error above.
```
#ifndef BOID_NAV_DEFINES_H
#define BOID_NAV_DEFINES_H
#include <stdlib.h>
#include <vector>
#include "Vector3d.h"
#include "Point3d.h"
#include "win_layer.h"
#endif
``` | Are you including the C++ header in a .m file?
.m files are treated as .c files with Objective-C extensions.
.mm files are treated as .cpp files with Objective-C extensions, then it's called Objective-C++
Just rename any .m file to .mm, right-click or ctrl-click and select rename on the file in Xcode. | Without changing any .m to .mm or anything like that, if you click your project, click tagets->build settings
go all the way down to **"LLVM GCC 4.2 - Languages"** (new xcode says **"Apple LLVM compiler 4.2"**) you will see **Compile Sources As** change that value to **Objective-C++**; | compiling a C++ class in Xcode: error during compilation: stl vector | [
"",
"c++",
"xcode",
"porting",
""
] |
I was going to look up how to do this, but I don't really know what to call it to look it up, so I was hoping I could describe it here and someone could point me in the right direction.
Anyways, I'm looking for how to make it so on a website, when you click on something, a new sorta layer pops up and fades the background. I see sites do this all the time but I'm not sure how to do this. A little guidance would be great. | use [shadowbox](http://www.mjijackson.com/shadowbox/)!!! | It is called a light box. You can [Google for that term](http://www.google.com/search?q=light%20box). | How to fade the background | [
"",
"javascript",
"html",
"css",
""
] |
I need advice on this snippet
```
$text = preg_replace('|(A.*)?A(.*)C|', '$1foo$2bar', $text);
```
This will match ABC in "AB ABC D", and replace it with "AB fooBbar D"; as you can see this matches the "AB " part at the beginning as well, which I have to repeat in the replacement string with $1, in order not to lose it.
Is this the best way to get such a result?
Is there a flag X such that
```
$text = preg_replace('|A(.*)C|X', 'foo$1bar', $text);
```
produces the same result?
I hope I've been clear
Thank you!
**EDIT**: Consider A,B,C as atomic strings of arbitrary characters, they can contain whitespaces as well
Also, the presented example is in fact buggy, as it matches only the second "ABC" in "ABC ABC".
**EDIT2**: I'm sorry, I've probably explained the problem very badly. The point is I'd want to match **whatever** is between two A,C string, so that there is no substring A in the match
Again thanks | As the question has been clarified, try this expression:
```
preg_replace('/(?:A)+(.+?)(?:C)+/', 'foo$1bar', $text)
```
An example:
```
$A = 'abc'; $B = '123'; $C = 'xyz';
$text = "$A$B$C $A$A$B$C $A$B$C$C";
echo preg_replace("/(?:$A)+(.+?)(?:$C)+/", 'foo$1bar', $text);
``` | How about this:
```
$text = preg_replace('|A(\S*)C|', 'foo$1bar', $text);
```
The `\S` matches a non-whitespace character, so you won't replace across different words.
---
After seeing some of the OP's comments, I'll hazard another guess:
```
$text = preg_replace('|A(B)C|', 'foo$1bar', $text);
``` | RegEx: matching and replacing ABC in "AB ABC D" | [
"",
"php",
"regex",
"preg-replace",
""
] |
Is there a way to get an automatic feedback if an error (even syntax errors) occurs when running a JavaScript on the client side?
I was thinking of something like this:
```
<script src="debugger.js"></script>
<script>
// some script with an error in it
</script>
```
And every time the debugger notices an error it sends a feedback to the server. | EDIT: I misunderstood your question initially, this should work:
Also note, this needs to go BEFORE any javascript that might cause errors.
```
window.onerror = function(msg,u,l)
{
txt ="Error: " + msg + "\n";
txt+="URL: " + u + "\n";
txt+="Line: " + l + "\n\n";
//Insert AJAX call that passes data (txt) to server-side script
return true;
};
```
As for syntax errors, you're out of luck. Javascript simply dies when there's a syntax error. There's no way to handle it at all. | One technique is to use Ajax for [Javascript error logging](http://blog.inspired.no/javascript-error-logging-with-ajax-154)
*Every javascript error can be trapped in the window.onerror event. We can return true or false so we can choose if the user shall see the normal javascript error dialog.
This script will, in the very unlikely event of a javascript error, gather information about the error and send a httprequest to a page which will log the javascript error to the database.* | Automatic feedback on JavaScript error | [
"",
"javascript",
"debugging",
"feedback",
""
] |
is there a way to compile java files into executable with high quality free software and without going through using executable JAR files? | There's a nice page on [Javalobby](http://www.javalobby.org/articles/java2exe/) that discusses this in some detail, as well as going through several different styles you might want to do this and providing links to appropriate tools (broken down into free and commercial).
Some of the free EXE-generating tools are
1. [jstart32](http://jstart32.sourceforge.net/)
2. [Launch4j](http://launch4j.sourceforge.net/)
3. [JSmooth](http://jsmooth.sourceforge.net/)
and while I've never needed one of these so can't offer my opinion on their effectiveness, they all appear to do the simple task well. | There are [several ways](http://www.excelsior-usa.com/articles/java-to-exe.html) to do it. But you should in general avoid making a java application executable on one platform just because you don't like double clicking JAR files. That defeats the purpose of interoperable nature of Java. | Standalone Java Applications | [
"",
"java",
"compilation",
"executable",
""
] |
What are the possible return values from the following command?
```
import sys
print sys.platform
```
I know there is a lot of possibilities, so I'm mainly interested in the "main" ones (Windows, Linux, Mac OS) | Mac OS X (10.4, 10.5, 10.7, 10.8):
```
darwin
```
Linux (2.6 kernel):
```
linux2
```
Windows XP 32 bit:
```
win32
```
Versions in brackets have been checked - other/newer versions are likely to be the same. | ```
┍━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━┑
│ System │ Value │
┝━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━┥
│ Linux │ linux or linux2 (*) │
│ Windows │ win32 │
│ Windows/Cygwin │ cygwin │
│ Windows/MSYS2 │ msys │
│ Mac OS X │ darwin │
│ OS/2 │ os2 │
│ OS/2 EMX │ os2emx │
│ RiscOS │ riscos │
│ AtheOS │ atheos │
│ FreeBSD 7 │ freebsd7 │
│ FreeBSD 8 │ freebsd8 │
│ FreeBSD N │ freebsdN │
│ OpenBSD 6 │ openbsd6 │
│ AIX │ aix (**) │
┕━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━┙
```
(\*) Prior to Python 3.3, the value for any Linux version is always `linux2`; after, it is `linux`.
(\*\*) Prior Python 3.8 could also be `aix5` or `aix7`; use `sys.platform.startswith()` | Possible values from sys.platform? | [
"",
"python",
"cross-platform",
""
] |
I've read the manual many times, I've scoured the posts offered by Google on the subject, I have even bought a couple of books that deal with ZF. Now, why am I still confused?
I can, using Zend\_Form, make a form that validates and functions fine. What I cannot do it make a form that looks exactly like I want it to look with the error messages that I want it to have. I want custom buttons, I want funky layouts, I want to insert text in the midst of the form, etc.
Does anyone have a simple way of achieving these sorts of things? Something that makes me feel like the framework is saving me time rather than costing? I could forego Zend Form... make my own form, have its action hit a page to validate and process the posted data and I could do it about as fast as I can type but I really want to "get" this and be able to use it as it was apparently intended.
Any advice? Any simple "how to's" for custom buttons, funky layouts and basic (or rather advanced as there are tons of basic tutorials that skip over the harder issues) "getting things done" with zend form? | Barrett Conrad's advice is what I would have suggested. Also, keep in mind that you don't need to use a form object to render your form.
One thing you could do is create a form in your view script that has elements with the same name as a form class.
Your HTML form:
```
<form action="/login/" method="post">
<fieldset>
<label for="username">Username:</label>
<input type="text" size="10" name="username" />
<label for="password">Password:</label>
<input type="password" size="10" name="password" />
<input type="submit" />
</fieldset>
</form>
```
Your class:
```
class LoginForm extends Zend_Form
{
public function init()
{
$username = $this->createElement('text','username');
$username->setRequired(true);
$this->addElement($username);
$password = $this->createElement('password','password');
$password->setRequired(true);
$this->addElement($password);
}
}
```
Your form class reflects your HTML form, each element in your class has its own validators and requirements. Back in your action you can create an instance of your form class and validate your post/get vars against that form:
```
$form = new LoginForm();
if ($this->_request->isPost()) {
if ($form->isValid($this->_request->getParams())) {
// do whatever you need to do
} else {
$this->view->errors = $form->getMessages();
}
}
```
You can display the the error messages at the top of your form in one group, using this method.
This is a basic example, but it allows you to have total control over the presentation of your form without spending the time to learn to use decorators. Much of the strength of Zend\_Form is in its validation and filtering properties, in my opinion. This gives you that strength. The main draw back to a solution like this is that your view script HTML form can become out-of-sync with your form class. | Render each element individually in your view - for example
```
<!-- view script here -->
<form method="POST">
Name: <?php echo $this->myForm->getElement('name')->render(); ?>
some other text between the fields
Birthdate: <?php echo $this->myForm->getElement('birthdate')->render(); ?>
<input type="submit" />
</form>
```
This maintains the ability to use the Zend\_Form view helpers (i.e. to display error messages and maintain the values of the form fields when validation fails) but gives you full customization ability.
If you want to go further, then turn off the default decorators of the individual form elements and then either attach your own to further customize exactly what tags are used (i.e. for error messages and labels) or don't use decorators at all (other than to render the form element itself) and then write all the surrounding HTML manually. Complete customization ability without losing the benefits of Zend\_Form, both at the form level and at the view level. | Zend Form: How do I make it bend to my will? | [
"",
"php",
"zend-framework",
"zend-form",
""
] |
Is it a good idea to store large amounts of text (eg html pages) inside your SQL database? Or is it a better idea to store it as html files in the filesystem?
The same goes for images - is it a good idea to store image data in the database or better to put them on disk?
Will storing large amounts of data cause me performance problems for example? What are the pros and cons of each method of storage?
In terms of the size of data, in this case I am looking in the region of "a few pages" of HTML and images less than about 500kb in size (probably a lot smaller though). Enough to produce your average article/blog entry/etc scale web page. | Storing binary data (documents, images etc) in the database has some advantages.
* You can commit the update of the document itself in the same transaction as the information (name, date etc) you want to store about the document. This means you don't have to worry about writing your own two-phase commit (although ISTR that SQL Server 2008 has a solution for this).
* You can back up the whole lot (documents and metadata) at once, without worrying about having to synchronise the database with the file system
* You can deliver documents very simply over .NET web services, since they come straight out into DataTables, and are serialised effortlessly just by putting the DataTables into a DataSet and passing it.
* You can apply database security to the objects, as to the rest of your data, and not have to worry about network file permissions.
It does have some disadvantages too:
* Backups can get very large
* The size of the binary object in the database can be quite a bit larger than the file it originally came from, and therefore in a client-server environment, it can increase the time taken to open them across the network.
* Depending on the application, you might need to consider the load on the database server if it has to serve up a lot of large documents.
All that said, it's a technique I use extensively, and it works very well. | The more you put in, the more you will be moving around so the more overhead you will be creating.
If you have a great web server, no point in adding all of the extra stress to the database for no reason when you can delegate all of that stress to the web server.
Even from a maintenance point of view, it is a lot easier to move around and work with the files in a nice logical structure rather then constantly working with the database. | Large Text and Images In SQL | [
"",
"sql",
"mysql",
"sql-server",
""
] |
## Scenario:
* I load some data into a local MySQL database each day, about 2 million rows;
* I have to (*have* to - it's an audit/regulatory thing) move to a "properly" administered server, which currently looks to be Oracle 10g;
* The server is in a different country: a network round-trip current takes 60-70 ms;
* Input is a CSV file in a denormalised form: I normalise the data before loading, each line typically results in 3-8 INSERTs across up to 4 tables;
* The load script is currently implemented in Ruby, using ActiveRecord and fastercsv. I've tried the ar-extensions gem, but it assumes that the MySQL style multiple values clause idea will work. It doesn't.
**EDIT**: Extremely useful answers already - thank-you! More about that pesky input file. The number of fields is variable and positions have changed a few times - my current script determines content by analysing the header row (well, fastercsv and a cunning converter do it). So a straight upload and post-process SQL wouldn't work without several versions of the load file, which is horrible. Also it's a German CSV file: semi-colon delimited (no big deal) and decimals indicated by commas (rather bigger deal unless we load as VARCHAR and text-process afterwards - ugh).
## The problem:
Loading 2 million rows at about 7/sec is going to take rather more than 24 hours! That's likely to be a drawback with a daily process, not to mention that the users would rather like to be able to access the data about 5 hours after it becomes available in CSV form!
I looked at applying multiple inserts per network trip: the rather ungainly `INSERT ALL...` syntax would be fine, except that at present I'm applying a unique id to each row using a sequence. It transpires that
```
INSERT ALL
INTO tablea (id,b,c) VALUES (tablea_seq.nextval,1,2)
INTO tablea (id,b,c) VALUES (tablea_seq.nextval,3,4)
INTO tablea (id,b,c) VALUES (tablea_seq.nextval,5,6)
SELECT 1 FROM dual;
```
(did I say it was ungainly?) tries to use the same id for all three rows. Oracle docus appear to confirm this.
Latest attempt is to send multiple INSERTs in one execution, e.g.:
```
INSERT INTO tablea (id,b,c) VALUES (tablea_seq.nextval,1,2);
INSERT INTO tablea (id,b,c) VALUES (tablea_seq.nextval,3,4);
INSERT INTO tablea (id,b,c) VALUES (tablea_seq.nextval,5,6);
```
I haven't found a way to persuade Oracle to accept that.
## The Question(s)
* Have I missed something obvious? (I'd be *so* pleased if that turned out to be the case!)
* If I can't send multiple inserts, what else could I try?
## Why Accept That One?
For whatever reason, I prefer to keep my code as free from platform-specific constructs as possible: one reason this problem arose is that I'm migrating from MySQL to Oracle; it's possible another move could occur one day for geographical reasons, and I can't be certain about the platform. So getting my database library to the point where it can use a text SQL command to achieve reasonable scaling was attractive, and the PL/SQL block accomplishes that. Now if another platform does appear, the change will be limited to changing the adapter in code: a one-liner, in all probability. | You could use:
```
insert into tablea (id,b,c)
( select tablea_seq.nextval,1,2 from dual union all
select tablea_seq.nextval,3,4 from dual union all
select tablea_seq.nextval,3,4 from dual union all
select tablea_seq.nextval,3,4 from dual union all
...
)
```
This works until about up to 1024 lines when I remember correctly.
You could also send it as a PL/SQL batch instruction:
```
BEGIN
INSERT INTO tablea (id,b,c) VALUES (tablea_seq.nextval,1,2);
INSERT INTO tablea (id,b,c) VALUES (tablea_seq.nextval,3,4);
INSERT INTO tablea (id,b,c) VALUES (tablea_seq.nextval,5,6);
...
COMMIT;
END
``` | How about shipping the csv file to the oracle db server, use [SQLLoader](http://www.orafaq.com/wiki/SQL*Loader_FAQ) to load the csv file into a staging table and then running a stored procedure to transform and INSERT it in the final tables? | Can I send "batched" INSERTs to Oracle? | [
"",
"sql",
"ruby-on-rails",
"ruby",
"oracle",
""
] |
I need to load (de-serialize) a pre-computed list of integers from a file in a Python script (into a Python list). The list is large (upto millions of items), and I can choose the format I store it in, as long as loading is fastest.
Which is the fastest method, and why?
1. Using `import` on a .py file that just contains the list assigned to a variable
2. Using `cPickle`'s `load`
3. Some other method (perhaps `numpy`?)
Also, how can one benchmark such things reliably?
**Addendum:** measuring this reliably is difficult, because `import` is cached so it can't be executed multiple times in a test. The loading with pickle also gets faster after the first time probably because page-precaching by the OS. Loading 1 million numbers with `cPickle` takes 1.1 sec the first time run, and 0.2 sec on subsequent executions of the script.
Intuitively I feel `cPickle` should be faster, but I'd appreciate numbers (this is quite a challenge to measure, I think).
And yes, it's important for me that this performs quickly.
Thanks | I would guess [cPickle](http://docs.python.org/library/pickle.html#module-cPickle) will be fastest if you really need the thing in a list.
If you can use an [array](http://docs.python.org/library/array.html), which is a built-in sequence type, I timed this at a quarter of a second for 1 million integers:
```
from array import array
from datetime import datetime
def WriteInts(theArray,filename):
f = file(filename,"wb")
theArray.tofile(f)
f.close()
def ReadInts(filename):
d = datetime.utcnow()
theArray = array('i')
f = file(filename,"rb")
try:
theArray.fromfile(f,1000000000)
except EOFError:
pass
print "Read %d ints in %s" % (len(theArray),datetime.utcnow() - d)
return theArray
if __name__ == "__main__":
a = array('i')
a.extend(range(0,1000000))
filename = "a_million_ints.dat"
WriteInts(a,filename)
r = ReadInts(filename)
print "The 5th element is %d" % (r[4])
``` | For benchmarking, see the timeit module in the Python standard library. To see what is the fastest way, implement all the ways you can think of and measure them with timeit.
Random thought: depending on what you're doing exactly, you may find it fastest to store "sets of integers" in the style used in **.newsrc** files:
```
1, 3-1024, 11000-1200000
```
If you need to check whether something is in that set, then loading and matching with such a representation should be among the fastest ways. This assumes your sets of integers are reasonably dense, with long consecutive sequences of adjacent values. | Python list serialization - fastest method | [
"",
"python",
"serialization",
"caching",
""
] |
This is a .NET question for C# (or possibly VB.net), but I am trying to figure out what's the difference between the following declarations:
```
string hello = "hello";
```
vs.
```
string hello_alias = @"hello";
```
Printing out on the console makes no difference, the length properties are the same. | It marks the string as a [verbatim string literal](http://csharpindepth.com/Articles/General/Strings.aspx) - anything in the string that would normally be interpreted as an [escape sequence](http://en.wikipedia.org/wiki/Escape_sequence) is ignored.
So `"C:\\Users\\Rich"` is the same as `@"C:\Users\Rich"`
There is one exception: an escape sequence is needed for the double quote. To escape a double quote, you need to put two double quotes in a row. For instance, `@""""` evaluates to `"`. | It's a *verbatim string literal*. It means that escaping isn't applied. For instance:
```
string verbatim = @"foo\bar";
string regular = "foo\\bar";
```
Here `verbatim` and `regular` have the same contents.
It also allows multi-line contents - which can be very handy for SQL:
```
string select = @"
SELECT Foo
FROM Bar
WHERE Name='Baz'";
```
The one bit of escaping which is necessary for verbatim string literals is to get a double quote (") which you do by doubling it:
```
string verbatim = @"He said, ""Would you like some coffee?"" and left.";
string regular = "He said, \"Would you like some coffee?\" and left.";
``` | What's the @ in front of a string in C#? | [
"",
"c#",
".net",
"string",
"verbatim-string",
""
] |
Are there any language lawyers in the house?
Should the following code compile?
```
include <set>
bool fn( const std::set<int>& rSet )
{
if ( rSet.find( 42 ) != rSet.end() ) return true;
return false;
}
```
On one of the platforms (Sun Workshop) this does not compile. It reports that the find function returned an iterator and the end function that returned a const\_iterator and that it does not have a valid comparison operator between those types.
The following does compile:
```
include <set>
bool fn( std::set<int>& rSet )
{
if ( rSet.find( 42 ) != rSet.end() ) return true;
return false;
}
``` | It should compile. Set includes 2 find() functions and 2 end() functions (const and non-const versions). It sort of sounds like Sun's STL is broken somehow. Since you are passing in a const reference, the compiler should be able to select the correct find() and end() functions. | It's been a couple of years since I used a Sun C++ compiler, but at that time it had two STL versions. One was a legacy version, which wasn't anywhere near complete or correct, but which they kept to compile older programs, and one was stlport. Check to make sure you're using a correct STL version. | Problems with const set&. Compiler/STL bug or non-portable usage? | [
"",
"c++",
"stl",
"constants",
"set",
"standards",
""
] |
Say I have table with two columns: Name, Age.
I want to design a query that will return the names and ages sorted by age, but to also have an additional column which will run from 1 to N (the last row).
So for a table with the following rows:
```
John, 28
Jim, 30
Mike, 28
```
The following rows will be returned
```
John, 28, 1
Mike, 28, 2
Jim, 30, 3
```
How can I do this? (I'm using MySQL, btw, if it makes a diff). | In mysql you can:
```
SELECT Row,Name,Age
FROM (SELECT @row := @row + 1 AS Row, Name,Age FROM table1 )
As derived1
```
However , this next approach is generic (but you need to have unique values in one of the columns of the table , in this example I've used name but it could be any unique column)
```
select rank=count(*), a1.name, a1.age
from table1 a1, table1 a2
where a1.name >= a2.name
group by a1.name , a1.age
order by rank
``` | Don't know about MySQL, but in SQL Server you do it this way:
```
SELECT Name, Age, ROW_NUMBER() OVER (ORDER BY AGE) AS RunningCount
FROM MyTable
```
A quick google search on "mysql and ROW\_NUMBER()" I found this:
```
set @num = 0;
select *, @num := @num + 1 as row_number from TABLE
```
So presumably you could use that syntax instead | SQL query returning int column of relative order | [
"",
"sql",
"mysql",
""
] |
I'm novice with both JS and jQuery, and I'm a little bit confused about what situations would require you to pass `event` as an argument into the function, and what situations you would **not** need to.
For example:
```
$(document).ready(function() {
$('#foo').click(function() {
// Do something
});
});
```
versus
```
$(document).ready(function() {
$('#foo').click(function(event) {
// Do something
});
});
``` | The `event` argument has a few uses. You only need to specify it as an argument to your handler if you're actually going to make use of it -- JavaScript handles variable numbers of arguments without complaint.
The most common use you'll see is to prevent the default behavior of the action that triggered the event. So:
```
$('a.fake').click(function(e) {
e.preventDefault();
alert("This is a fake link!");
});
```
...would stop any links with the class `fake` from actually going to their `href` when clicked. Likewise, you can cancel form submissions with it, e.g. in validation methods. This is *like* `return false`, but rather more reliable.
jQuery's `event` object is actually a cross-browser version of the standard `event` argument provided in everything but IE. It's essentially a shortcut, that lets you use only one code path instead of having to check what browser you're using in every event handler.
(If you read non-jQuery code you'll see a lot of the following, which is done to work around IE's deficiency.
```
function(e) {
e = e || window.event; // For IE
```
It's a pain, and libraries make it so much easier to deal with.)
[There's a full accounting of its properties in the jQuery docs.](http://docs.jquery.com/Events/jQuery.Event) Essentially, include it if you see anything you need there, and don't worry otherwise. I like to include it always, just so I never have to remember to add it in later if I decide that it's needed after all. | You only need the event if you're going to use it in the body of the handler. | Passing 'event' into the function as an argument | [
"",
"javascript",
"jquery",
""
] |
I work for a large corporation that runs a **lot** of x86 based servers on which we run JVMs.
We have experimented successfully with VMWare ESX to get better usage out of our data center. But these still consume a lot of power per processing unit.
I had a mad idea that we should resurrect mainframes, we could host either lots of JVMs or virtual machines.
Has anyone tried this? Are there any good cost-benefits?
Do you lose flexibility? E.g. we have mainframes in other parts of the company but they seem to have much more rigid usage of the machines.. lots of change control, long lead times etc | All this assumes you’re talking about Java on Z/OS and not running Linux VM’s on the mainframe to take advantage of the cost savings that come with fewer machines.
My thoughts on virtualization are at the end of this and it’s probably the route you want to look at but I’ll start out with Z/OS since it’s what mainframes are traditionally associated with and what I have familiarity with. I have some experience with mainframe Java.
The short answer is, it depends, but probably not. What exactly are your applications? The mainframe is a difficult environment compared to x86 servers. If you're running I/O-intensive workloads under something like Websphere, it might be worth it, assuming your mainframe is underutilized.
In my experience, Java is horribly slow on a mainframe but that’s because the system I used was set up for developer flexibility rather than performance. That just goes to prove performance tuning on the mainframe is usually much more complicated then on an average server since mainframes will be running many more workloads then a generic x86 server.
Remember that the mainframe is designed primarily for I/O throughput and can outperform any normal x86 server at that. It was not designed to do a lot of computationally intensive calculations so won’t outperform a small cluster of x86 servers if your doing a lot of math.
The change controls on mainframes are there for a good reason - if one x86 server has a problem, you reboot it. If a mainframe has a problem, every second that it’s down is costing the company money. You also have to take into account any native code your apps depend on or third party libraries that may use native code. All that code would have to be ported.
Configuration of a mainframe also takes a lot longer on average then on an x86 server. I would suggest that, if you want to seriously look into this, you make a better business case than power savings, such as tight integration with current business apps and start out small either with a proof of concept or a new application. One that is not business critical, that can be implemented to take advantage of the mainframes strengths.
IBM mainframes can also run Linux in either native mode or a virtualized environment similar to VMWare. Unless your company is the exception to the rule, your Linux instances would run as virtual machines. I haven’t had much experience with this but, if your app depends on no native code and runs under Linux, it would probably work on a mainframe running Linux. For more info about Linux on mainframes see [this link](http://en.wikipedia.org/wiki/Linux_on_zSeries). | IBM makes a special Java co-processor that you should seriously consider. I would not run Java on the general engines as this may increase MPU charges for licensed software. | Java on mainframes | [
"",
"java",
"scalability",
"mainframe",
""
] |
What reasoning exists behind making C# case sensitive?
I'm considering switching from VB.NET to take advantage of some language features (CCR and yield), and understanding the reasoning behind this difference may make the transition easier.
[UPDATE]
Well I took the plunge three days ago. Learning C# hasn't been particularly hard, I could barely remember my C++ days in the late 90's though.
Is the Case Sensitivity annoying me? not as much as i'd thought... plus I am finding that it actually is advantageous. I'm actually really happy with the CCR as a asynchronous coordination programming model. If only I had more time on the current project i'd port the code base into C# to take full advantage. Wouldn't be fair to my client though.
Assessing my current project now and I'm seeing blocking threads EVERYWHERE! AHhhh!!!
**[UPDATE]**
Well i've been programming in C# for nearly a year now. I'm really enjoying the language, and I really REALLY hate crossing over to VB (especially when it is unavoidable!)
And the case sensitivity thing? not even an issue | C# is case sensistive because it takes after the C style languages which are all case sensitive. This is from memory here's an [MSDN link](http://msdn.microsoft.com/en-us/vcsharp/aa336811.aspx) which is not working for me right now I can't verify.
I would also like to point out that this is a very valid use case:
```
public class Child
{
private Person parent;
public Person Parent
{
get { return parent;}
}
}
```
Yes you can get around this using prefixes on your member variables but some people don't like to do that. | They were probably thinking "we don't want people using SoMeVaRiAbLe in one place and sOmEvArIaBlE in another. | Why is C# Case Sensitive? | [
"",
"c#",
"case-sensitive",
""
] |
I was thinking it be cool to have a simple matchmaker code in php. The idea is the app connect to the server or a specific webpage, the webpage takes it IP and the last X ips and prints it on page (his first)
problem is what happens when 5 ppl hit the page the same second. How do i handle it? i cant use global/shared memory? so i would need to write the IPs to a file and read/writing them everytime (10x the same second) would be bad? i guess its ok to be slow but i want this to be optimized if possible.
Is it better to store in a mysql db? | I would suggest using APC to memcache the information in memory.. This would only work for 1 server. With multiple servers, you should look at something like memCacheD. | I'm not quite sure why you'd bother doing this, except as a learning exercise, but you're basically going to be persisting the information somewhere, if only for a relatively short time, and you need reasonable transactional semantics.
Probably the simplest option would be to opt for a database; MySQL would be fine, and if you really don't need to store the data for a particularly long time, then you might as well use an in-memory table - use the `MEMORY` (or `HEAP`) storage engine for this. Using a database in this manner means you don't have to worry too much about conflicting concurrent writes, etc. | php matchmaker | [
"",
"php",
"tracking",
""
] |
I don't have whois installed on my server (apparently it's in the works but no real news on it). I was wondering if anybody knew a way to emulate the functionality of it though. I figured I'd be posting some data to a url but I don't know what, or where.
Basically I'm at a complete loss, and would appreciate any help or even something that I could look into. | You can use the [PHP Whois API](http://www.nott.org/blog/php-whois-script.html). This will allow you access to all the whois records. To use that function there is a link at the bottom of that page to [a class](http://www.phpclasses.org/browse/package/360.html). Make sure you include that too. | You can attempt to run it on your system, e.g. assuming you are using linux and you have the /usr/bin/whois lib installed then you can run php using the php exec
```
<?php exec("/usr/bin/whois $strDomain",$arrOutPut);?>
```
This will work only if php is allowed to use the exec function on your server and make sure to validate the arguments passed to the command...can end up ugly for the machine.
Alternatively you can try using an API
1. <http://www.nott.org/blog/php-whois-script.html>
2. <http://www.tevine.com/projects/whois/> | Is there a way to emulate the 'whois' tool using php? | [
"",
"php",
"whois",
""
] |
Using Python 2.5, I have some text in stored in a unicode object:
> Dinis e Isabel, uma difı´cil relac¸a˜o
> conjugal e polı´tica
This appears to be [decomposed Unicode](http://www.unicode.org/reports/tr15/#Decomposition). Is there a generic way in Python to reverse the decomposition, so I end up with:
> Dinis e Isabel, uma difícil relação
> conjugal e política | I think you are looking for this:
```
>>> import unicodedata
>>> print unicodedata.normalize("NFC",u"c\u0327")
ç
``` | > Unfortunately it seems I actually have (for example) \u00B8 (cedilla) instead of \u0327 (combining cedilla) in my text.
Eurgh, nasty! You can still do it automatically, though the process wouldn't be entirely lossless as it involves a compatibility decomposition (NFKD).
Normalise U+00B8 to NFKD and you'll get a space followed by the U+0327. You could then scan through the string looking for any case of space-followed-by-combining-character, and remove the space. Finally recompose to NFC to put the combining characters onto the previous character instead.
```
s= unicodedata.normalize('NFKD', s)
s= ''.join(c for i, c in enumerate(s) if c!=' ' or unicodedata.combining(s[i+1])==0)
s= unicodedata.normalize('NFC', s)
``` | How do I reverse Unicode decomposition using Python? | [
"",
"python",
"unicode",
""
] |
The following code compiles:
```
class Testing<TKey, TValue>
{
public bool Test(TKey key)
{
return key == null;
}
}
```
However, TKey can be a value type, and possibly not allow the value "null".
I know the results of this program, and how to add constraints. What I'm wondering is **why doesn't the compiler disallow this when TKey is not constrained to "class"?** | It's convenient to be able to do this in various cases. If `TKey` is a non-nullable value type, the result of the comparison will always be false. (It's possible that the JITter will remove that branch entirely - don't forget that although one version of the JITted code is shared for all reference types, it reJITs for each value type.)
EDIT: One interesting use for this is precisely to allow `Nullable<T>` comparisons with null. `TFoo=Nullable<T>` doesn't satisfy *either* the `where TFoo : class` *or* `where TFoo : struct` constraints. | As for the "why", I'm not sure. But to fix it, you can use `default(T)` instead of `null`. | Comparing an instance of a type param to null, even with no class constraint? | [
"",
"c#",
"generics",
"nullable",
""
] |
What are the real world pros and cons of executing a dynamic SQL command in a stored procedure in SQL Server using
```
EXEC (@SQL)
```
versus
```
EXEC SP_EXECUTESQL @SQL
```
? | `sp_executesql` is more likely to promote query plan reuse. When using `sp_executesql`, parameters are explicitly identified in the calling signature. This excellent article descibes this [process](http://technet.microsoft.com/en-au/library/cc966425.aspx).
The oft cited reference for many aspects of dynamic sql is Erland Sommarskog's must read: "[The Curse and Blessings of Dynamic SQL](http://www.sommarskog.se/dynamic_sql.html)". | The big thing about SP\_EXECUTESQL is that it allows you to create parameterized queries which is very good if you care about SQL injection. | Dynamic SQL - EXEC(@SQL) versus EXEC SP_EXECUTESQL(@SQL) | [
"",
"sql",
"sql-server",
"dynamic",
""
] |
I'm using 2005 Windows Forms in C#. I've only been working at this for a day, so go easy please.
I'd like to have a submit button that saves changes to a DataGridView. I've gotten data into the DGV and can edit, but am stuck on the Update().
I've created an .xsd named scDB and one DataTable called - SSIS Configurations Staging. I then added a new query that takes a parameter.
Here is my code so far:
```
//Declared at top of form class
scDBTableAdapters.SSIS_Configurations_StagingTableAdapter myStagingTableAdapter = new scDBTableAdapters.SSIS_Configurations_StagingTableAdapter();
//After a form event
stagingGrid.DataSource = myStagingTableAdapter.GetDataBy(filterName.Text.ToString());
//On Submit click:
myStagingTableAdapter.Update(?What Goes Here?);
```
What gets passed to the Update method? I know it needs a dataTable, but I don't know how to reference what is in the GridView. In most code examples people define the DataTable - but I do not. I assume this is being done behind the scenes when I created the TableAdapter. Thanks for the help. | Sam,
the update needs a table so you could try something like:
```
TableType table = (TableType) stagingGrid.DataSource;
myStagingTableAdapter.Update(table);
```
where you'll have to substitute TableType with something appropriate.
But a better approach would be to use drag-and-drop and learn form the code.
1. Select Data|View Datasources. Your
dataset should be visible in the
DataSources Window.
2. Drag a table to
a (new) form. VS2005 will add a load
of components and a few lines of
code.
The form will now have a instance of the dataset and that is your reference point for Adapter.Fill and .Update methods. | Update on a table-adapter needs a **DataSet**.
You need to instantiate a *scDB* *DataSet* with the table, update that table and call to *Update* for the table-adapter. | DataGridView Update | [
"",
"c#",
".net",
"datagridview",
""
] |
I want to make a function which moves items from one STL list to another if they match a certain condition.
This code is not the way to do it. The iterator will most likely be invalidated by the erase() function and cause a problem:
```
for(std::list<MyClass>::iterator it = myList.begin(); it != myList.end(); it++)
{
if(myCondition(*it))
{
myOtherList.push_back(*it);
myList.erase(it);
}
}
```
So can anyone suggest a better way to do this ? | `Erase` [returns an iterator](http://en.cppreference.com/w/cpp/container/list/erase) pointing to the element after the erased one:
```
std::list<MyClass>::iterator it = myList.begin();
while (it != myList.end())
{
if(myCondition(*it))
{
myOtherList.push_back(*it);
it = myList.erase(it);
}
else
{
++it;
}
}
``` | STL lists have an interesting feature: the **`splice()`** method lets you destructively move elements from one list to another.
`splice()` operates in constant time, and doesn't copy the elements or perform any free store allocations/deallocations. Note that both lists must be of the same type, and they must be separate list instances (not two references to the same list).
Here's an example of how you could use `splice()`:
```
for(std::list<MyClass>::iterator it = myList.begin(); it != myList.end(); ) {
if(myCondition(*it)) {
std::list<MyClass>::iterator oldIt = it++;
myOtherList.splice(myOtherList.end(), myList, oldIt);
} else {
++it;
}
}
``` | Erasing items from an STL list | [
"",
"c++",
"stl",
""
] |
Is it possible to do something like this
```
#ifdef SOMETHING
#define foo //
#else
#define foo MyFunction
#endif
```
The idea is that if SOMETHING is defined, then calls to foo(...) become comments (or something that doesn't get evaluated or compiled), otherwise it becomes a call to MyFunction.
I've seen \_\_noop used, but I don't believe I can use that.
EDIT(s):
I don't think I can really use a macro here, because MyFunction takes a variable number of arguments.
Also, I'd like to make it so the arguments are NOT evaluated! (So doing something like commenting out the body of MyFunction doesn't really give me what I need, as the arguments will still be evaluated) | Try this:
```
#ifdef SOMETHING
#define foo(x)
#else
#define foo(x) MyFunction(x)
#endif
```
If your function has several arguments, then:
```
#ifdef SOMETHING
#define foo(x,y,z)
#else
#define foo(x,y,z) MyFunction(x,y,z)
#endif
```
If your function has a variable number of arguments, then your compiler may support so-called "variadic macros", like this:
```
#ifdef SOMETHING
#define foo(...)
#else
#define foo(...) MyFunction(__VA_ARGS__)
#endif
```
The reason which I've seen this kind of thing used in practice is to get rid of logging functions from a release build. However, see also [Separate 'debug' and 'release' builds?](https://stackoverflow.com/questions/420343/separate-debug-and-release-builds) in which people question whether you *should* even *have* different builds.
---
Alternatively, instead of redefining the function call as nothing, Jonathan's comment to this answer suggested doing something like the following:
```
#ifdef SOMETHING
#define foo(...) do { if (false) MyFunction(__VA_ARGS__) } while (0)
#else
#define foo(...) do { if (true) MyFunction(__VA_ARGS__) } while (0)
#endif
```
The reasoning for doing this is so that the function call is always compiled (so it won't be left with gratuitous errors like references to deleted variables), but only called when needed: see Kernighan & Pike [The Practice of Programming](https://rads.stackoverflow.com/amzn/click/com/020161586X) and also the [Goddard Space Flight Center programming standards](http://software.gsfc.nasa.gov/assetsbytype.cfm?TypeAsset=Standard).
From a debug.h file (originating from 1990, and therefore not using `__VA_ARGS__`):
```
/*
** Usage: TRACE((level, fmt, ...))
** "level" is the debugging level which must be operational for the output
** to appear. "fmt" is a printf format string. "..." is whatever extra
** arguments fmt requires (possibly nothing).
** The non-debug macro means that the code is validated but never called.
** -- See chapter 8 of 'The Practice of Programming', by Kernighan and Pike.
*/
#ifdef DEBUG
#define TRACE(x) db_print x
#else
#define TRACE(x) do { if (0) db_print x; } while (0)
#endif /* DEBUG */
```
With C99, there's no longer a need for the double parentheses trick. New code should not use it unless C89 compatibility is an issue. | Maybe an easier way to do this would be to conditionally omit the body of the function?
```
void MyFunction() {
#ifndef SOMETHING
<body of function>
#endif
}
```
Unless you specifically don't want a function call to be made at all, this seems like a clean way to achieve your goal. | Use #ifdefs and #define to optionally turn a function call into a comment | [
"",
"c++",
"c",
"c-preprocessor",
"conditional-compilation",
""
] |
I have a class whose object must be created on the heap. Is there any better way of doing this other than this:
```
class A
{
public:
static A* createInstance(); //Allocate using new and return
static void deleteInstance(A*); //Free the memory using delete
private:
//Constructor and destructor are private so that the object can not be created on stack
A();
~A();
};
``` | This is pretty much the standard pattern for making the object heap-only.
Can't really be simplified much, except that you could just make the destructor private without forcing the use of a factory method for creation. | Check this at C++ FAQ lite:
[[16.21] How can I force objects of my class to always be created via new rather than as locals or global/static objects?](https://isocpp.org/wiki/faq/freestore-mgmt#static-create-methods) | Controlling object creation | [
"",
"c++",
"object",
""
] |
I'm porting a windows game to Mac OS X. I was wondering where I should store game data such as saved games, user profiles, etc and how I can retrieve that path programmatically in C++?
The game will be delivered as a "modern bundle" as specified [here](http://developer.apple.com/documentation/CoreFOundation/Conceptual/CFBundles/Concepts/BundleAnatomy.html) | Save it under
~/Library/Application Support/Your Game Name/
where "~" stands for the home directory of the user playing your game.
You may want to give this a read: <http://cocoadevcentral.com/articles/000084.php> | ```
~/Library/Application Support/GameName
```
You can access Cocoa objects using Objective-C++, this can be done by changing the suffix of to source code to `.mm` This enables you to combine both Objective-C and C++.
There are [several file system classes](http://developer.apple.com/documentation/Cocoa/Conceptual/LowLevelFileMgmt/index.html#//apple_ref/doc/uid/10000055i) you can use. | Mac OS X: Where should I store save games for a game delivered as a bundle? | [
"",
"c++",
"macos",
""
] |
I have some tabular data with some functionality to "view details" that fires off an ajax call to append a few new elements to the DOM (usually I insert another TR just after the selected row and innerHTML or append inside a TD with a colspan.
My question is this, in IE6/7 my columns flex. Currently I don't have a "static" width per column and wanted to avoid this if possible.
Any suggestions to avoid this "flex"? | This trick here is using the somewhat esoteric `table-layout:fixed` rule
Use it like this:
```
table {table-layout:fixed}
```
You also ought to specify explicit column widths for the `<td>`s.
The `table-layout:fixed` rule says "The cell widths of this table depend on what I say, not on the actual content in the cells". This is useful normally because the browser can begin displaying the table after it has received the first `<tr>`. Otherwise, the browser has to receive the entire table before it can compute the column widths. However, it is also useful in your case to maintain absolute column widths. | Tables resize dynamically based on content. That's their nature. You could always read the "natural" column width of the table when it is rendered, then apply a style to lock in in that shape before you make you Ajax call. | How to keep your table from "flexing" in IE6/7 | [
"",
"javascript",
"ajax",
"internet-explorer",
"client-side",
""
] |
I'm looking for a javascript that can limit the number of lines (by line I mean some text ended by user pressing enter on the keyboard) the user is able to enter in textarea. I've found some solutions but they simply don't work or behave really weird.
The best solution would be a jquery plugin that can do the work - something like [CharLimit](http://plugins.jquery.com/project/CharLimit), but it should be able to limit text line count not character count. | This *might* help (probably be best using jQuery, onDomReady and unobtrusively adding the keydown event to the textarea) but tested in IE7 and FF3:
```
<html>
<head><title>Test</title></head>
<body>
<script type="text/javascript">
var keynum, lines = 1;
function limitLines(obj, e) {
// IE
if(window.event) {
keynum = e.keyCode;
// Netscape/Firefox/Opera
} else if(e.which) {
keynum = e.which;
}
if(keynum == 13) {
if(lines == obj.rows) {
return false;
}else{
lines++;
}
}
}
</script>
<textarea rows="4" onkeydown="return limitLines(this, event)"></textarea>
</body>
</html>
```
\*Edit - explanation: It catches the keypress if the ENTER key is pressed and just doesn't add a new line if the lines in the textarea are the same number as the rows of the textarea. Else it increments the number of lines.
**Edit #2:** Considering people are still coming to this answer I thought I'd update it to handle paste, delete and cut, as best as I can.
```
<html>
<head>
<title>Test</title>
<style>
.limit-me {
height: 500px;
width: 500px;
}
</style>
</head>
<body>
<textarea rows="4" class="limit-me"></textarea>
<script>
var lines = 1;
function getKeyNum(e) {
var keynum;
// IE
if (window.event) {
keynum = e.keyCode;
// Netscape/Firefox/Opera
} else if (e.which) {
keynum = e.which;
}
return keynum;
}
var limitLines = function (e) {
var keynum = getKeyNum(e);
if (keynum === 13) {
if (lines >= this.rows) {
e.stopPropagation();
e.preventDefault();
} else {
lines++;
}
}
};
var setNumberOfLines = function (e) {
lines = getNumberOfLines(this.value);
};
var limitPaste = function (e) {
var clipboardData, pastedData;
// Stop data actually being pasted into div
e.stopPropagation();
e.preventDefault();
// Get pasted data via clipboard API
clipboardData = e.clipboardData || window.clipboardData;
pastedData = clipboardData.getData('Text');
var pastedLines = getNumberOfLines(pastedData);
// Do whatever with pasteddata
if (pastedLines <= this.rows) {
lines = pastedLines;
this.value = pastedData;
}
else if (pastedLines > this.rows) {
// alert("Too many lines pasted ");
this.value = pastedData
.split(/\r\n|\r|\n/)
.slice(0, this.rows)
.join("\n ");
}
};
function getNumberOfLines(str) {
if (str) {
return str.split(/\r\n|\r|\n/).length;
}
return 1;
}
var limitedElements = document.getElementsByClassName('limit-me');
Array.from(limitedElements).forEach(function (element) {
element.addEventListener('keydown', limitLines);
element.addEventListener('keyup', setNumberOfLines);
element.addEventListener('cut', setNumberOfLines);
element.addEventListener('paste', limitPaste);
});
</script>
</body>
</html>
``` | **How to do it with jQuery:**
Bind to keyDown event of textarea.
```
function limitTextareaLine(e) {
if(e.keyCode == 13 && $(this).val().split("\n").length >= $(this).attr('rows')) {
return false;
}
}
``` | Limiting number of lines in textarea | [
"",
"javascript",
"jquery",
"textarea",
""
] |
How can I do this in PHP
```
$myDBClass->users()->limit(5);//output you limited users to 5
$myDBClass->comments()->limit(3);//output you limited comments to 3
```
what I meant is nested methods or nested class (I don't know!)
so when I call the limit method as a child of users it will know that I am calling it from "users" method -or class- and when I call limit method -or class!- from comments It also knows that.
what is the possible structure for a PHP class to do this thing?
---
the reason for this question because I am working on my own class for database so I can easily use something like this
```
$DB->comments()->id(" > 3")->limit(10);
```
to generate the sql code "select \* from comments where id > 3 limit 10"
Thanks | Have the methods return objects with the methods described, and you get what you are after.
So, as long as `$DB` is an object that has a `comments()`-method, that part is valid. If that `comments()` returns an object that has an `id()`-method, that part is valid, too. Then, `id()` needs to return an object that has the `limit()`-method.
In your particular case, you might want to do something like this:
```
class DB {
public function comments() {
// do preparations that make the object select the "comments"-table...
return $this;
}
public function id($string) {
// handle this too...
return $this;
}
public function limit($int) {
// also this
return $this;
}
public function execute() {
$success = try_to_execute_accumulated_db_commands();
return $success;
}
}
$DB = new DB();
$DB->comments()->id(" > 3")->limit(10);
```
In my example, every method (also not depicted here) would return the object itself, so that commands can be chained together. When the construction of the database query is done, you actually evaluate the query by invoking `execute()` that (in my case) would return a boolean that would represent the success of the database execution.
User nickohm suggested that this is called a [fluent interface](http://en.wikipedia.org/wiki/Fluent_interface). I must admit that this is a new term for me, but that tells probably more of my knowledge, than the term's usage. (*"I just write code, you know..."*)
*Note:* `$this` is a 'magic' variable that points to the currently active object. As the name suggests, it just returns itself as the return value for the method. | The standard convention for this is to return the instance of $this at the end of each of the method call. So when returned to the caller we are then just referencing another method call.
```
class Foo
{
public function do_something()
{
return $this;
}
public function do_something_else()
{
return $this;
}
}
$foo = new Foo();
$foo->do_something()->do_something_else();
``` | How to do a PHP nested class or nested methods? | [
"",
"php",
"design-patterns",
"fluent-interface",
""
] |
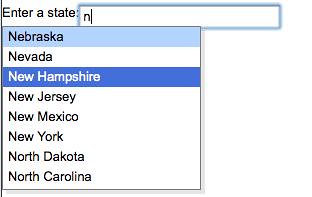
I am using the autocomplete YUI feature. However, as you can see I am having trouble aligning the suggestion drop down with the text input when I put a label in front of the text input. I am following [the example here](http://developer.yahoo.com/yui/examples/autocomplete/ac_basic_array_clean.html) exactly except for this snippet of code where I simply replace the H3 with a label element in the form:
```
<div id="myAutoComplete">
<label>Enter a state:</label>
<input id="myInput" type="text">
<div id="myContainer"></div>
</div>
<script type="text/javascript" src="http://developer.yahoo.com/yui/examples/autocomplete/assets/js/data.js"></script>
```
(I also had to change the data.js path from a relative to absolute path.)
What is the best way to have the suggestion drop down to line up with the text input? I would like a solution that works on all popular modern browsers (FF3, Safari, Chrome, IE), plus IE6. | AutoComplete doesn't automatically brute-force the position of your AC container every time it shows, because unless you're doing inline work this is unnecessary. However, now that you've moved your input field inline, you do need to take another step to align the container, either with custom CSS or brute force JS positioning.
Here's the brute force approach.
After you define your AC instance:
```
oAC.doBeforeExpandContainer = function() {
var Dom = YAHOO.util.Dom;
Dom.setXY("myContainer", [Dom.getX("myInput"), Dom.getY("myInput") + Dom.get("myInput").offsetHeight] );
return true;
}
```
Here's a working example:
<http://ericmiraglia.com/yui/demos/acalign.php> | Seems like this auto-complete plugin isn't using the infamous [element position](http://www.quirksmode.org/js/findpos.html) technique by quirksmode to find the *real* position of an element on the page.
Does the label need to be inline with the input box? You could very well fix this by either puttint a `<br>` after the `label`, or by actually setting a `margin-left` on the `<div id="myContainer">` element.
Otherwise you should probably file this as a bug, and tell them to use quirksmode way of doing this (it's cross-browser). | YUI autocomplete misalignment problem | [
"",
"javascript",
"html",
"css",
"yui",
""
] |
I've heard that "everyone" is using parameterized SQL queries to protect against SQL injection attacks without having to vailidate every piece of user input.
How do you do this? Do you get this automatically when using stored procedures?
So my understanding this is non-parameterized:
```
cmdText = String.Format("SELECT foo FROM bar WHERE baz = '{0}'", fuz)
```
Would this be parameterized?
```
cmdText = String.Format("EXEC foo_from_baz '{0}'", fuz)
```
Or do I need to do somethng more extensive like this in order to protect myself from SQL injection?
```
With command
.Parameters.Count = 1
.Parameters.Item(0).ParameterName = "@baz"
.Parameters.Item(0).Value = fuz
End With
```
Are there other advantages to using parameterized queries besides the security considerations?
Update: This great article was linked in one of the questions references by Grotok.
<http://www.sommarskog.se/dynamic_sql.html> | The `EXEC` example in the question would **NOT** be parameterized. You need parameterized queries (prepared statements in some circles) to prevent input like this from causing damage:
> ';DROP TABLE bar;--
Try putting that in your `fuz` variable (or don't, if you value the `bar` table). More subtle and damaging queries are possible as well.
Here's an example of how you do parameters with Sql Server:
```
Public Function GetBarFooByBaz(ByVal Baz As String) As String
Dim sql As String = "SELECT foo FROM bar WHERE baz= @Baz"
Using cn As New SqlConnection("Your connection string here"), _
cmd As New SqlCommand(sql, cn)
cmd.Parameters.Add("@Baz", SqlDbType.VarChar, 50).Value = Baz
Return cmd.ExecuteScalar().ToString()
End Using
End Function
```
Stored procedures are sometimes credited with preventing SQL injection. However, most of the time you still have to call them using query parameters or they don't help. If you use stored procedures *exclusively*, then you can turn off permissions for SELECT, UPDATE, ALTER, CREATE, DELETE, etc (just about everything but EXEC) for the application user account and get some protection that way. | Definitely the last one, i.e.
> Or do I need to do somethng more extensive ...? (Yes, `cmd.Parameters.Add()`)
Parametrized queries have two main advantages:
* Security: It is a good way to avoid [SQL Injection](http://en.wikipedia.org/wiki/SQL_injection) vulnerabilities
* Performance: If you regularly invoke the same query just with different parameters a parametrized query might allow the database to cache your queries which is a considerable source of performance gain.
* Extra: You won't have to worry about date and time formatting issues in your database code. Similarly, if your code will ever run on machines with a non-English locale, you will not have problems with decimal points / decimal commas. | How do I create a parameterized SQL query? Why Should I? | [
"",
"sql",
"vb.net",
"prepared-statement",
""
] |
I'm working on a javascript app that has a form with a button that processes inputs in the browser. It is important that the data never accidentally get sent to the server when the button is pushed. Situations where this might happen is the browser may not have javascript enabled or the DOM implementation may have a bug where the click binding on the button is lost briefly (I've seen this happen once in testing but not in a way that is reproducible).
The obvious way to do this seems to be to not have a button or a submit but some other structure which I would style to look like a button. Are there better ideas? Is there anything like a form attribute that disables data being sent from the form -- and is well implemented across browsers?
Thanks | ```
<input type="button">
```
does not submit a form, unlike
```
<input type="submit">
``` | Try using an `<input type="button">` that's not in the form. That way, even if the button is clicked, and even if the browser does somehow erroneously think that it should be submitting something, it will have no idea where to send the data for processing because there's no `action` attribute associated to the button.
Alternatively, you could look at [this question](https://stackoverflow.com/questions/520640/how-can-i-use-googles-new-imageless-button-how-could-i-reverse-engineer-or-rol) regarding imageless CSS buttons used in Gmail. | Safest way to make sure a HTML button does not send any information to the server | [
"",
"javascript",
"html",
""
] |
I am trying to inherit a non-static class by a static class.
```
public class foo
{ }
public static class bar : foo
{ }
```
And I get:
> Static class cannot derive from type.
> Static classes must derive from
> object.
**How can I derive it from object?**
The code is in C#. | There's no value in deriving static classes. The reasons to use inheritance are:
* Polymorphism
* Code reuse
You can't get polymorphism with static classes, obviously, because there is no instance to dynamically dispatch on (in other words, it's not like you can pass a Bar to a function expecting a Foo, since you don't *have* a Bar).
Code reuse is easily solved using composition: give Bar a static instance of Foo. | From the C# 3.0 specification, section 10.1.1.3:
> A static class may not include a
> *class-base* specification (§10.1.4) and
> cannot explicitly specify a base class
> or a list of implemented interfaces. A
> static class implicitly inherits from
> type `object`.
In other words, you can't do this. | How can a static class derive from an object? | [
"",
"c#",
"oop",
""
] |
I have seen video streaming to mobile phones. I would like to know whether we have a streaming server that can be installed on mobile phone and stream video to another device from the camera present on the phone. I would like to have on for my Nokia N70 phone. | [QIK](http://qik.com/) does something like that. They support a lot of Nokia phones, but unfortunately it looks like the N70 isn't among them. Probably not useful if you're looking to build your own application, but at least it shows that it can be done. | Yes, but due to processor limitations (often a 200-600MHz 32 bit ARM or similar) mobile phones can't compress high resolution video in realtime. Further, the bandwidth is very low, even with high speed 3G connections.
These two limitations mean that you can likely find CIF resolution, and occasionally slow frame rate VGA resolution streaming, but it's non trivial to get anything better than that.
-Adam | Video Streaming Server on Mobile | [
"",
"java",
"mobile",
"symbian",
"s60",
"rtsp",
""
] |
From [msdn](http://msdn.microsoft.com/en-us/library/441722ys(VS.80).aspx) I get this:
```
#pragma warning disable warning-list
#pragma warning restore warning-list
```
In the examples, both `disable` and `restore` are used. Is it necessary to `restore` if I want it disabled for a whole file?
Like, if I do not restore, how far does it carry? Are the warnings disabled for everything compiled after that? Or just for the rest of that file? Or is it ignored? | If you do not restore the disabling is active for the remainder of the file.
Interestingly this behaviour is **not** defined in the [language specification](http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-334.pdf).
(see section 9.5.8) However the 9.5.1 section on Conditional compilation symbols does indicate this "until end of file behaviour"
> The symbol remains defined until a
> #undef directive for that same symbol is processed, or until the end of the
> source file is reached.
Given the 'pre-processor' is actually part of the lexical analysis phase of compilation it is likely that this behaviour is an effective contract for Microsoft's and all other implementations for the foreseeable future (especially since the alternate would be hugely complex and non deterministic based on source file compilation order) | No, you'll find that the compiler will automatically restore any disabled warning once it's finished parsing a source file.
```
#pragma warning disable 649
struct MyInteropThing
{
int a;
int b;
}
#pragma warning restore 649
```
In the above example I've turned of warning CS00649 because I intend to use this struct in an unsafe manner. The compiler will not realize that I will be writing to memory that has this kind of layout so I'll want to ignore the warning:
> Field 'field' is never assigned to, and will always have its default value 'value'
But I don't want the entire file to not be left unchecked. | C#: Is pragma warning restore needed? | [
"",
"c#",
"compiler-warnings",
"pragma",
""
] |
What are the differences between the classic transaction pattern in LINQ to SQL like:
```
using(var context = Domain.Instance.GetContext())
{
try
{
context.Connection.Open();
context.Transaction = context.Connection.BeginTransaction();
/*code*/
context.Transaction.Commit();
}
catch
{
context.Transaction.Rollback();
}
}
```
vs the TransactionScope object
```
using (var context = Domain.Instance.GetContext())
using (var scope = new TransactionScope())
{
try
{
/*code*/
scope.Complete();
}
catch
{
}
}
``` | Linq2SQL will use an implicit transaction. If all of your updates are done within a single Submit, you may not need to handle the transaction yourself.
From the documentation (emphasis mine):
> When you call SubmitChanges, LINQ to SQL checks to see whether the call is in the scope of a Transaction or if the Transaction property (IDbTransaction) is set to a user-started local transaction. **If it finds neither transaction, LINQ to SQL starts a local transaction (IDbTransaction) and uses it to execute the generated SQL commands.** When all SQL commands have been successfully completed, LINQ to SQL commits the local transaction and returns. | It should be noted that when using the [`TransactionScope`](http://msdn.microsoft.com/en-us/library/system.transactions.transactionscope.aspx) there is no need for the `try/catch` construct you have. You simply have to call [`Complete`](http://msdn.microsoft.com/en-us/library/system.transactions.transactionscope.complete.aspx) on the scope in order to commit the transaction when the scope is exited.
That being said, `TransactionScope` is usually a better choice because it allows you to nest calls to other methods that might require a transaction without you having to pass the transaction state around.
When calling [`BeginTransaction`](http://msdn.microsoft.com/en-us/library/xfh66ye8.aspx) on the [`DbConnection`](http://msdn.microsoft.com/en-us/library/system.data.common.dbconnection.aspx) object, you have to pass that transaction object around if you want to perform other operations in the same transaction, but in a different method.
With `TransactionScope`, as long as the scope exists, it will handle everything that registers with the current [`Transaction`](http://msdn.microsoft.com/en-us/library/system.transactions.transaction.aspx) on the thread, making your code cleaner, and more maintainable.
On top of that, you have the added benefit of being able to use other resources that can participate in transactions, not just the connection to the database.
It should be noted that in situations where you need to squeeze the most out of your connections and database operations, you might not want to use `TransactionScope`; even against a single database, you run the possibility of the Distributed Transaction Coordinator being used and having the transaction being turned into a distributed transaction (even for a single database connection).
In these cases, while muddying up your design, you might want to consider passing a connection-specific transaction around.
*Or*, if you know you will use one resource consistently (and on the same thread), you might want to create a class that reference-counts your connection/transaction.
You would create a class that on construction, creates your resource/increments the count. It would also implement [`IDisposable`](http://msdn.microsoft.com/en-us/library/system.idisposable.aspx) (in which you would decrement/release/commit/abort when the count is zero), and store the count in a variable that has [`ThreadStaticAttribute`](http://msdn.microsoft.com/en-us/library/system.threadstaticattribute.aspx) applied to it.
This allows you to separate the transaction management from the logic code, and still hold onto a singular resource fairly efficiently (instead of escalating to a distributed transaction). | TransactionScope vs Transaction in LINQ to SQL | [
"",
"c#",
"linq",
"linq-to-sql",
"transactions",
""
] |
I've searched through google (maybe I didn't look hard enough) but I could not find how to turn Math.sqrt into an int.
I want to use Math.sqrt for a *for* loop and I guess I need it as an int but I can't seem to figure out how to cast the result to an int. So how do I do it?
I tried something similar to Java:
```
(int) Math.sqrt(num);
```
But it didn't work.
Thanks in advance :) | Use `Math.round`, `Math.ceil`, or `Math.floor` depending on your specific rounding needs.
*"For rounding numbers to integers one of Math.round, Math.ceil and Math.floor are preferable, and for a desired result that can be expressed as a 32 bit signed integer the bitwise operation described below might also suit."*
-<http://www.jibbering.com/faq/faq_notes/type_convert.html#tcNumber> | Someone suggested parseInt. That goes from a string to an int, but it's easy to turn a float into a string.
```
parseInt(Math.sqrt(num)+"")
```
Remember that no matter what you do, JavaScript is always using floats. There is no integer type. | Javascript: Cast Math.sqrt to int? | [
"",
"javascript",
"math",
"type-conversion",
"int",
"casting",
""
] |
I was wondering if I can somehow convert a column header text form MySQL into actial width size pixels. I am trying to generate a PDF from the database and I want it to automatically adjust column widths. As I will use it for many tables, the width must differ so I should be able to see it like: "The header for this column is called CompanyID so it should have the width of 40". Can I achieve something like this ? Can I convert text characters length to actual width ?
Thanks. | FPDF happens to have a [GetStringWidth()](http://www.fpdf.org/en/doc/getstringwidth.htm) method that predicts the width of a string. | You need to have some way of calculating the font metrics which will be used in the PDF - which PDF generation library are you using? | Get MySQL columns width? | [
"",
"php",
"pdf",
"text",
"width",
""
] |
I'm pretty sure this is possible, because I'm pretty sure I've seen it done. I think it is awesome, but I will gladly accept answers along the lines of "this is a terrible idea because \_\_\_\_".
Say we have a basic struct.
```
struct vertex
{
float x, y, z;
};
```
Now, I want to implement aliases on these variables.
```
vertex pos;
vertex col;
vertex arr;
pos.x = 0.0f; pos.y = 0.5f; pos.z = 1.0f;
col.r = 0.0f; col.g = 0.5f; col.b = 1.0f;
arr[0] = 0.0f; arr[1] = 0.5f; arr[2] = 1.0f;
```
Ideally the third syntax would be indistinguishable from an array. That is, if I sent `arr` as a reference parameter to a function expecting an array of floats into which it will store data (eg many of the OpenGL `glGet` functions), it would work fine.
What do you think? Possible? Possible but stupid? | What I would do is make accessors:
```
struct Vertex {
float& r() { return values[0]; }
float& g() { return values[1]; }
float& b() { return values[2]; }
float& x() { return values[0]; }
float& y() { return values[1]; }
float& z() { return values[2]; }
float operator [] (unsigned i) const { return this->values_[i]; }
float& operator [] (unsigned i) { return this->values_[i]; }
operator float*() const { return this->values_; }
private:
float[3] values_;
}
``` | Use a union?
```
union vertex
{
struct { float x, y, z; };
struct { float r, g, b; };
float arr[3];
};
```
I wouldn't recommend it - it will lead to confusion.
---
*Added*:
As noted by Adrian in his answer, this union with anonymous struct members is not supported by ISO C++. It works in GNU G++ (with complaints about not being supported when you turn on '`-Wall -ansi -pedantic`'). It is reminiscent of the pre-pre-standard C days (pre-K&R 1st Edn), when structure element names had to be unique across all structures, and you could use contracted notations to get to an offset within the structure, and you could use member names from other structure types - a form of anarchy. By the time I started using C (a long time ago, but post-K&R1), that was already historical usage.
The notation shown with anonymous union members (for the two structures) is supported by C11 (ISO/IEC 9899:2011), but not by earlier versions of the C standard. Section 9.5 of ISO/IEC 14882:2011 (C++11) provides for anonymous unions, but GNU `g++` (4.9.1) does not accept the code shown with `-pedantic`, identifying "`warning: ISO C++ prohibits anonymous structs [-Wpedantic]`".
Since the idea will lead to confusion, I'm not particularly concerned that it isn't standard; I would not use the mechanism for this task (and I'd be leery of using anonymous structures in a union even if it was beneficial).
---
A concern was raised:
> The three (x-y-z, r-g-b and the array) do not necessarily align.
It is a union with three elements; the three elements start at the same address. The first two are structures containing 3 float values. There's no inheritance and there are no virtual functions to give different layouts, etc. The structures will be laid out with the three elements contiguous (in practice, even if the standard permits padding). The array also starts at the same address, and subject to 'no padding' in the structures, the elements overlap the two structures. I really don't see that there would be a problem. | C++ member variable aliases? | [
"",
"c++",
"struct",
"variables",
"alias",
"member",
""
] |
I've got a string array in C# and I want to pop the top element off the array (ie. remove the first element, and move all the others up one). Is there a simple way to do this in C#? I can't find an Array.Pop method.
Would I need to use something like an ArrayList? The order of the items in my array is important. | Use a [List](http://msdn.microsoft.com/en-us/library/6sh2ey19.aspx), [Queue](http://msdn.microsoft.com/en-us/library/7977ey2c.aspx) or [Stack](http://msdn.microsoft.com/en-us/library/3278tedw.aspx) instead..
```
List<String>
Queue<String>
Stack<String>
``` | [`Queue<T>`](http://msdn.microsoft.com/en-us/library/7977ey2c.aspx) (first in, first out) or [`Stack<T>`](http://msdn.microsoft.com/en-us/library/3278tedw.aspx) (last in, first out) are what you're after.
Arrays in .NET are fixed length - you can't remove an element from them or indeed add elements to them. You *can* do this with a `List<T>` but `Queue<T>` and `Stack<T>` are more appropriate when you want queue/stack semantics. | Pop off array in C# | [
"",
"c#",
"arrays",
""
] |
I have a range of dates and a measurement on each of those dates. I'd like to calculate an exponential moving average for each of the dates. Does anybody know how to do this?
I'm new to python. It doesn't appear that averages are built into the standard python library, which strikes me as a little odd. Maybe I'm not looking in the right place.
So, given the following code, how could I calculate the moving weighted average of IQ points for calendar dates?
```
from datetime import date
days = [date(2008,1,1), date(2008,1,2), date(2008,1,7)]
IQ = [110, 105, 90]
```
(there's probably a better way to structure the data, any advice would be appreciated) | EDIT:
It seems that [`mov_average_expw()`](http://www.scipy.org/scipy/scikits/browser/trunk/timeseries/scikits/timeseries/lib/moving_funcs.py) function from [scikits.timeseries.lib.moving\_funcs](http://pytseries.sourceforge.net/lib/moving_funcs.html) submodule from [SciKits](http://scikits.appspot.com/) (add-on toolkits that complement [SciPy](http://scipy.org/)) better suits the wording of your question.
---
To calculate an [exponential smoothing](http://en.wikipedia.org/wiki/Exponential_smoothing) of your data with a smoothing factor `alpha` (it is `(1 - alpha)` in Wikipedia's terms):
```
>>> alpha = 0.5
>>> assert 0 < alpha <= 1.0
>>> av = sum(alpha**n.days * iq
... for n, iq in map(lambda (day, iq), today=max(days): (today-day, iq),
... sorted(zip(days, IQ), key=lambda p: p[0], reverse=True)))
95.0
```
The above is not pretty, so let's refactor it a bit:
```
from collections import namedtuple
from operator import itemgetter
def smooth(iq_data, alpha=1, today=None):
"""Perform exponential smoothing with factor `alpha`.
Time period is a day.
Each time period the value of `iq` drops `alpha` times.
The most recent data is the most valuable one.
"""
assert 0 < alpha <= 1
if alpha == 1: # no smoothing
return sum(map(itemgetter(1), iq_data))
if today is None:
today = max(map(itemgetter(0), iq_data))
return sum(alpha**((today - date).days) * iq for date, iq in iq_data)
IQData = namedtuple("IQData", "date iq")
if __name__ == "__main__":
from datetime import date
days = [date(2008,1,1), date(2008,1,2), date(2008,1,7)]
IQ = [110, 105, 90]
iqdata = list(map(IQData, days, IQ))
print("\n".join(map(str, iqdata)))
print(smooth(iqdata, alpha=0.5))
```
Example:
```
$ python26 smooth.py
IQData(date=datetime.date(2008, 1, 1), iq=110)
IQData(date=datetime.date(2008, 1, 2), iq=105)
IQData(date=datetime.date(2008, 1, 7), iq=90)
95.0
``` | I'm always calculating EMAs with Pandas:
Here is an example how to do it:
```
import pandas as pd
import numpy as np
def ema(values, period):
values = np.array(values)
return pd.ewma(values, span=period)[-1]
values = [9, 5, 10, 16, 5]
period = 5
print ema(values, period)
```
More infos about Pandas EWMA:
<http://pandas.pydata.org/pandas-docs/stable/generated/pandas.ewma.html> | calculate exponential moving average in python | [
"",
"python",
"signal-processing",
"average",
"digital-filter",
""
] |
I know that I have to use `SetConsoleCtrlHandler()` if I want to manage console closing events.
I do not know how to block the `CTRL_CLOSE_EVENT`. I've tried returning false/true if it catches that event, but no success
Here is what I have so far (thank you Anton Gogolev!):
```
[DllImport("Kernel32")]
public static extern bool SetConsoleCtrlHandler(HandlerRoutine Handler, bool Add);
public delegate bool HandlerRoutine(CtrlTypes CtrlType);
public enum CtrlTypes{
CTRL_C_EVENT = 0,
CTRL_BREAK_EVENT,
CTRL_CLOSE_EVENT,
CTRL_LOGOFF_EVENT = 5,
CTRL_SHUTDOWN_EVENT
}
private static bool ConsoleCtrlCheck(CtrlTypes ctrlType)
{
if(ctrlType == CtrlTypes.CTRL_CLOSE_EVENT)
return false;// I have tried true and false and viceversa with the return
// true/false but I cant seem to get it right.
return true;
}
//and then I use this to call it
SetConsoleCtrlHandler(new HandlerRoutine(ConsoleCtrlCheck), true);
```
Also, is it possible to run a new thread to monitor if the console is closing and block that close if the main thread is in the middle of doing something? | The documentation for [`SetConsoleCtrlHandler()`](http://msdn.microsoft.com/en-us/library/ms686016(VS.85).aspx) says:
> The system generates CTRL\_CLOSE\_EVENT, CTRL\_LOGOFF\_EVENT, and CTRL\_SHUTDOWN\_EVENT signals when the user closes the console, logs off, or shuts down the system so that the process has an opportunity to clean up before termination.
This implies that unlike when handling CTRL+C or CTRL+BREAK events, your process does not get the opportunity to cancel the close, logoff, or shutdown. | Actually you can block it (I have reproduced this on Windows XP at least). For example if in your handler you have an endless while loop with a sleep, this will stop this process from terminating forever (or at least for a long time, or until the user kills the process through task manager).
If you really needed to start a thread, you could use a wait condition (`AutoResetEvent` in C#) and start your thread (though a new thread probably isn't needed in most cases) then notify the wait condition when your thread is finished. However, just doing any cleanup in the handler would suffice in most cases.
If in the worst case you did wait forever, the process will remain running and you'll be able to see it when you log back in (at least on Windows XP). However, this causes the desktop to pause for around 20 seconds before going to the log out screen (while it waits for your applicaiton to exit), and then pauses again at the log out screen (I suppose while it tries for a 2nd time). Of course, I strongly advise against waiting forever; for any long running stuff you should really put this in a service. | How to use SetConsoleHandler() to block exit calls | [
"",
"c#",
"console",
"exit",
""
] |
I have a class A which implements many functions. Class A is very stable.
Now I have a new feature requirement, some of whose functionality matches that implemented by A. I cannot directly inherit my new class from class A, as that would bring lot of redundancy into my new class.
So, should i duplicate the common code in both the classes?
Or, should i create a new base class and move the common code to base class, and derive class A and the new class from it? But this will lead to changes in my existing class.
So, which would be a better approach? | Unless there is a very good reason not to modify class A, refactor and make a common base (or even better, a common class that both can use, but not necessarily derive from).
You can always use private inheritance to gain access to the shared functionality without modifying class As external interface - this change would require a rebuild, but nothing more. Leave all the functions on class A, and just have them forward to the shared implementation class.
One reason you might not want to refactor, but rather copy the code is if it's likely that the new class' functionality will change, but without the same change being needed in the old class. One of the reasons for not duplicating code is so that a fix or a change needs only to be made in one place. If changes are going to happen that will break the original class, then maybe you want to copy the code instead. Although in most cases, this will only happen if the two classes aren't as similar as you thought, and you'd be fighting to try and abstract a common set of functionality. | (1) Do not duplicate the common code in both classes unless you or your employer are prepared to maintain both copies indefinitely.
(2) Refactoring by definition changes classes you already have. The refactor you propose is called ["Extract SuperClass"](http://www.refactoring.com/catalog/extractSuperclass.html) followed by ["Pull Up Method"](http://www.refactoring.com/catalog/pullUpMethod.html) for each method that is common to the derived classes. This is a fine approach.
Edit: I remembered the real gem behind Refactoring: Within reason it is perfectly fluid and reversible. There is never a "Right" there is only a "Right for now". If you decide later that using inheritance for these classes isn't a good object model then you can refactor again to use composition (as superbly suggested by Josh). | Refactoring a class in C++ | [
"",
"c++",
"refactoring",
""
] |
I am pulling my ddl options from a database, which sets the order of the list. How do I keep the selected option to display when I Response.Redirect?
Page loads with Adidas -(ddl list order) **Adidas**, Nike, Puma
when Nike is selected -(ddl list order) Adidas, **Nike**, Puma
for Puma - -(ddl list order) Adidas, Nike, **Puma**
Right now, the redirect resets the displayed option to **Adidas**. How do I have it change accordingly? thanks | A response.redirect should clear viewstate, so the only way you'll be able to keep the selected item is to encode it somehow into the new request. Either use a query string (foo.aspx?currentSelectedShoes=Nike) or set a cookie with the same information before your response.redirect.
Then in your page load event handler check for the query string or cookie and set the selected item accordingly. | To add to what Randolpho has said, you could also use session state or the ASP.NET profile. These options have caveats but might be the right choice, particularly if the scope of this piece of data is greater than just this particular page. | How do I keep the Drop Down List option to be highlighted after a Redirect? | [
"",
"c#",
".net",
"asp.net",
""
] |
This is probably very simple, but I simply cannot find the answer myself :(
Basicaly, what I want is, given this string:
"<http://www.google.com/search?hl=en&q=c#> objects"
I want this output:
<http://www.google.com/search?hl=en&q=c%23+objects>
I'm sure there's some helper class somewhere buried in the Framework that takes care of that for me, but I'm having trouble finding it.
EDIT: I should add, that this is for a Winforms App. | HttpServerUtility.UrlEncode(string)
Should sort out any troublesome characters
To use it you'll need to add a reference to System.Web (Project Explorer > References > Add reference > System.Web)
Once you've done that you can use it to encode any items you wish to add to the querystring:
```
System.Web.HttpUtility.UrlEncode("c# objects");
``` | If you don't want a dependency on System.Web here is an implementation of "UrlEncode" I have in my C# OAuth Library (which requires a correct implementation - namely spaces should be encoded using percent encoding rather the "+" for spaces etc.)
```
private readonly static string reservedCharacters = "!*'();:@&=+$,/?%#[]";
public static string UrlEncode(string value)
{
if (String.IsNullOrEmpty(value))
return String.Empty;
var sb = new StringBuilder();
foreach (char @char in value)
{
if (reservedCharacters.IndexOf(@char) == -1)
sb.Append(@char);
else
sb.AppendFormat("%{0:X2}", (int)@char);
}
return sb.ToString();
}
```
For reference
<http://en.wikipedia.org/wiki/Percent-encoding> | How do I replace special characters in a URL? | [
"",
"c#",
"url",
"encoding",
""
] |
What would you realistically use OnItemDataBound for on a Repeater ? | "This event provides you with the last opportunity to access the data item before it is displayed on the client. After this event is raised, the data item is nulled out and no longer available."
~<http://msdn.microsoft.com/en-us/library/system.web.ui.webcontrols.datagrid.onitemdatabound.aspx> | One use could be dynamic control generation based on information that is only available from the bound data item at the time it is bound the Repeater. | Uses for OnItemDataBound | [
"",
"c#",
".net",
"events",
"event-binding",
""
] |
The Django apps come with their own features and design. If your requirements don't match 100% with the features of the contib app, you end up customizing and tweaking the app. I feel this involves more effort than just building your own app to fit your requirements.
What do you think? | It all depends. We had a need for something that was 98% similar to contrib.flatpages. We could have monkeypatched it, but we decided that the code was so straightforward that we would just copy and fork it. It worked out fine.
Doing this with contrib.auth, on the other hand, might be a bad move given its interaction with contrib.admin & contrib.session. | I'd also check out third-party re-usable apps before building my own. Many are listed on [Django Plug(g)ables](http://djangoplugables.com/), and most are hosted on [Google Code](http://code.google.com/search/?q=django#q=django), [GitHub](http://github.com/search?type=Repositories&language=python&q=django&repo=&langOverride=&x=15&y=15&start_value=1) or [BitBucket](http://bitbucket.org/repo/all/?name=django). | Should I use Django's contrib applications or build my own? | [
"",
"python",
"django",
"django-contrib",
""
] |
I have a c# .net winforms solution and I want to create two different builds: one that supports IE6 and one that supports IE7. A few of the files in one of my projects are different for the IE6 build versus the IE7 build, so I want to include the IE6 files when I build for IE6 and the IE7 files when I build for IE7. What's the best way of structuring my solution for this situation?
Due to other constraints I do not want to create a separate assembly that contains the shared items; I want the project to compile to a single assembly 'foo.dll' regardless of which build I'm making.
I thought I could just create two separate projects that compile to 'foo.dll', then create two Release Configurations and only include the relevant project in the relevant configuration. However I'd need to include the files that are the same for IE6 and IE7 in both projects, and I can't see how to use a single copy of a file in two projects (when I Add Existing Item it creates a copy in the project directory). I'm using SVN for source control so could perhaps use that to do the 'sharing' between folders, but doubt that's the best way..
NB: Different builds are needed due to API differences in IE, details of which aren't relevant to the question - just believe me that there are two builds required. | In MSBuild, you can specify conditions to item groups. You can then bind those conditions to the target device.
Example:
```
<!-- Declare the condition property at the beggining of the build file -->
<PropertyGroup Condition="$(Platform) == 'IE7'">
<UseNewLibrary>true</UseNewLibrary>
</PropertyGroup>
<PropertyGroup Condition="$(Platform) == 'IE6'">
<UseNewLibrary>false</UseNewLibrary>
</PropertyGroup>
<!-- Then those the property to select the right file -->
<ItemGroup Condition="$(UseNewLibrary)==true">
<Compile Include="Class1.cs"/>
<Compile Include="Class2.cs"/>
<Compile Include="Class3.cs"/>
<Compile Include="Class4.cs"/>
</ItemGroup>
<ItemGroup Condition="$(UseNewLibrary)==false">
<Compile Include="Class1Old.cs"/>
<Compile Include="Class2Old.cs"/>
<Compile Include="Class3Old.cs"/>
<Compile Include="Class4Old.cs"/>
</ItemGroup>
<!-- And now references -->
<ItemGroup Condition="$(UseNewLibrary)==true">
<Reference Include="MyAssembly, Version=1.1.7.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" />
</ItemGroup>
<ItemGroup Condition="$(UseNewLibrary)==false">
<Reference Include="MyAssembly, Version=1.0.6.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" />
</ItemGroup>
```
Note that all files will appear in the IDE, but at compile time everything should align correctly.
Then, all you need to do is create your platforms (IE6 and IE7) in the configuration management.
You can also directly use the platform property instead of creating an intermediate property. | In order to add the same file in two or more projects you can
Right click on the project and choose Add >> Existing Item
Choose the file in the filepicker
Click the little triangle on the right side of the Add button in the file picker
Choose Add As Link
This will add the file to the project without making a copy of it.
I don't know all the details of your situation, but you're solution sounds awkward. Two versions of the same dll is likely to lead to configuration problems on client computers eventurally. I encourage you to consider Kevin's idea of a single dll with all capabilities, and calling the appropriate code as needed. | How to use different files in a project for different build configurations - Visual Studio C# .net | [
"",
"c#",
".net",
"visual-studio",
"build",
""
] |
How do I best obfuscate my C#.net app Product Key verification code?
Is it enough to place it in a "INTERNAL SEALED CLASS CLASSNAME { };" or do I need to do more?
Thanks! | Access modifiers like `internal` and `sealed` don't have anything to do with obfuscation or code security, they just tell other classes how to interact (or not interact) with them.
At the end of the day, there's nothing you can do to prevent piracy. Anything created by one human can be broken by another. There are loads of questions on SO that deal with product keys, keeping software secure, etc. which you can find if you use the search mechanism in the upper-right. All the answers cover a few basic ideas that anyone with a little sense will tell you:
1. Only put enough effort into your anti-piracy measures to make cracking the software a little less convenient than breaking out the credit card. If that's really hard to do, you are charging way too much for your customer base.
2. If you focus on building positive relationships with your customers instead of assuming they are criminals, they will be more willing to give you money.
3. Most customers - individuals and especially companies - don't have any interest in cracking open your assemblies and trying to figure out how to get away with not paying you. For individuals, they wouldn't pay for it anyway so you're not losing a sale; and companies wouldn't risk mountains of cash in legal problems for the cost of some software licenses.
Research **public/private and elliptic key cryptography** and you'll find ways to secure your key algorithm, but it will only prevent cracking the *key*, not bypassing it. | I agree with Rex M, you should consider using an asymmetric encryption algorithm such as elliptic curves cryptography to avoid keygens. And if you are interested in a commercial solution then try [Ellipter](http://ellipter.com) - it uses elliptic curves and has some useful features like product info and expiration data embedding into generated serial keys. | How do I best obfuscate my C# product license verification code? | [
"",
"c#",
".net",
""
] |
I have a com.mysql.jdbc.exceptions.MySQLIntegrityConstraintViolationException in my code (using Hibernate and Spring) and I can't figure why.
My entities are Corpus and Semspace and there's a many-to-one relation from Semspace to Corpus as defined in my hibernate mapping configuration :
```
<class name="xxx.entities.Semspace" table="Semspace" lazy="false" batch-size="30">
<id name="id" column="idSemspace" type="java.lang.Integer" unsaved-value="null">
<generator class="identity"/>
</id>
<property name="name" column="name" type="java.lang.String" not-null="true" unique="true" />
<many-to-one name="corpus" class="xxx.entities.Corpus" column="idCorpus"
insert="false" update="false" />
[...]
</class>
<class name="xxx.entities.Corpus" table="Corpus" lazy="false" batch-size="30">
<id name="id" column="idCorpus" type="java.lang.Integer" unsaved-value="null">
<generator class="identity"/>
</id>
<property name="name" column="name" type="java.lang.String" not-null="true" unique="true" />
</class>
```
And the Java code generating the exception is :
```
Corpus corpus = Spring.getCorpusDAO().getCorpusById(corpusId);
Semspace semspace = new Semspace();
semspace.setCorpus(corpus);
semspace.setName(name);
Spring.getSemspaceDAO().save(semspace);
```
I checked and the corpus variable is not null (so it is in database as retrieved with the DAO)
The full exception is :
```
com.mysql.jdbc.exceptions.MySQLIntegrityConstraintViolationException: Cannot add or update a child row: a foreign key constraint fails (`xxx/Semspace`, CONSTRAINT `FK4D6019AB6556109` FOREIGN KEY (`idCorpus`) REFERENCES `Corpus` (`idCorpus`))
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:931)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:2941)
at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:1623)
at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:1715)
at com.mysql.jdbc.Connection.execSQL(Connection.java:3249)
at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:1268)
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1541)
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1455)
at com.mysql.jdbc.PreparedStatement.executeUpdate(PreparedStatement.java:1440)
at org.apache.commons.dbcp.DelegatingPreparedStatement.executeUpdate(DelegatingPreparedStatement.java:102)
at org.hibernate.id.IdentityGenerator$GetGeneratedKeysDelegate.executeAndExtract(IdentityGenerator.java:73)
at org.hibernate.id.insert.AbstractReturningDelegate.performInsert(AbstractReturningDelegate.java:33)
at org.hibernate.persister.entity.AbstractEntityPersister.insert(AbstractEntityPersister.java:2158)
at org.hibernate.persister.entity.AbstractEntityPersister.insert(AbstractEntityPersister.java:2638)
at org.hibernate.action.EntityIdentityInsertAction.execute(EntityIdentityInsertAction.java:48)
at org.hibernate.engine.ActionQueue.execute(ActionQueue.java:250)
at org.hibernate.event.def.AbstractSaveEventListener.performSaveOrReplicate(AbstractSaveEventListener.java:298)
at org.hibernate.event.def.AbstractSaveEventListener.performSave(AbstractSaveEventListener.java:181)
at org.hibernate.event.def.AbstractSaveEventListener.saveWithGeneratedId(AbstractSaveEventListener.java:107)
at org.hibernate.event.def.DefaultSaveOrUpdateEventListener.saveWithGeneratedOrRequestedId(DefaultSaveOrUpdateEventListener.java:187)
at org.hibernate.event.def.DefaultSaveEventListener.saveWithGeneratedOrRequestedId(DefaultSaveEventListener.java:33)
at org.hibernate.event.def.DefaultSaveOrUpdateEventListener.entityIsTransient(DefaultSaveOrUpdateEventListener.java:172)
at org.hibernate.event.def.DefaultSaveEventListener.performSaveOrUpdate(DefaultSaveEventListener.java:27)
at org.hibernate.event.def.DefaultSaveOrUpdateEventListener.onSaveOrUpdate(DefaultSaveOrUpdateEventListener.java:70)
at org.hibernate.impl.SessionImpl.fireSave(SessionImpl.java:535)
at org.hibernate.impl.SessionImpl.save(SessionImpl.java:523)
at org.hibernate.impl.SessionImpl.save(SessionImpl.java:519)
at org.springframework.orm.hibernate3.HibernateTemplate$12.doInHibernate(HibernateTemplate.java:642)
at org.springframework.orm.hibernate3.HibernateTemplate.execute(HibernateTemplate.java:373)
at org.springframework.orm.hibernate3.HibernateTemplate.save(HibernateTemplate.java:639)
at xxx.dao.impl.AbstractDAO.save(AbstractDAO.java:26)
at org.apache.jsp.functions.semspaceManagement_jsp._jspService(semspaceManagement_jsp.java:218)
[...]
```
The foreign key constraint has been created (and added to database) by hibernate and I don't see where the constraint can be violated. The table are innodb and I tried to drop all tables and recreate it the problem remains...
EDIT : Well I think I have a start of answer... I change the log level of hibernate to DEBUG and before it crash I have the following log
```
insert into Semspace (name, [...]) values (?, [...])
```
So it looks like it does not try to insert the idCorpus and as it is not null it uses the default value "0" which does not refers to an existing entry in Corpus table... | I get confused w/ the association mappings all the time. Review the association needed and the hibernate mapping config used to create the assiocation.
<http://docs.jboss.org/hibernate/core/3.5/reference/en/html/associations.html>
is a great recipe book of associations. | Seems simple enough. The first line of your exception clearly states that the violation is from the column `idCorpus` to another column in another table, `Corpus/idCorpus`.
You should be able to access the database directly to figure out what the constraint is. I suspect it's a simple lookup on the other table.
Then print out the value that you're using in the supplied Java code and, hopefully, voila, you'll know what value you're trying to insert in Semspace that isn't in Corpus.
`com.mysql.jdbc.exceptions.MySQLIntegrityConstraintViolationException: Cannot add or update a child row: a foreign key constraint fails (diaz/Semspace, CONSTRAINT FK4D6019AB6556109 FOREIGN KEY (idCorpus) REFERENCES Corpus (idCorpus))` | Hibernate : Foreign key constraint violation problem | [
"",
"java",
"mysql",
"hibernate",
"spring",
""
] |
my sql statement is something like this below
```
DECLARE @OLD_NAV_VALUE AS INT
DECLARE @FINAL AS INT
SELECT @OLD_NAV_VALUE = [col1] from TBL_BA where DATE = @id_Date
SET @FINAL = @OLD_NAV_VALUE * 50
```
But the problem i am haveing here is that the column name in the select statement which is given as [col1] is a dynamic value. So i am trying something like this below.
```
DECLARE @OLD_NAV_VALUE AS INT
DECLARE @FINAL AS INT
EXEC('SELECT @OLD_NAV_VALUE = [' + @DYNAMIC_COL_NAME + '] from TBL_BA where DATE = ' + @id_Date)
SET @FINAL = @OLD_NAV_VALUE * 50
```
this gives an error that @OLD\_NAV\_VALUE has to be declared. So i tried declaring @OLD\_NAV\_VALUE inside the EXEC statement. But if i do this i am not able to use the same outside the EXEC statement.
Please let me know how to do this. | This worked for me.
I declared a temp table and used it to receive the values from the select statement.
Something like below.
```
declare @i int
declare @v int
create table #t (val int)
insert into #t
exec ('declare @i int set @i = 0 select @i+1')
select * from #t
``` | You can also use the **sp\_executesql** statement with an output parameter:
```
declare @field nvarchar(50);
set @field = N'FieldToSelect';
declare @sql nvarchar(3000);
declare @parmDefinition nvarchar(500);
SET @parmDefinition = N'@returnValueOUT nvarchar(50) OUTPUT';
set @sql = N'SELECT @ReturnValueOUT = ' + @Field + ' FROM [TableName] WHERE [SomeCondition]'
declare @returnValue nvarchar(50);
EXECUTE sp_executesql @sql, @parmDefinition, @returnValueOut = @returnValue OUTPUT;
SELECT @returnValue
``` | Dynamic sql statement to update a variable | [
"",
"sql",
"sql-server",
"sql-server-2005",
""
] |
Please keep in mind that I'm new to C# and OOP so I apologize in advance if this seems like an easy question to some. I'm going back through my code and looking for ways to objectify repetitive code and create a class for it so that I can simply reuse the class. That being said, I'm not looking to learn NHibernate or any other ORM just yet. I'm not even looking to learn LINQ. I want to hack through this to learn.
Basically I use the same bit of code to access my database and populate a drop-down list with the values that I get. An example:
```
protected void LoadSchools()
{
SqlDataReader reader;
var connectionString = ConfigurationManager.ConnectionStrings["MyConnectionString"].ConnectionString;
var conn = new SqlConnection(connectionString);
var comm = new SqlCommand("SELECT * FROM [Schools] ORDER BY [SchoolName] ASC", conn);
try
{
conn.Open();
reader = comm.ExecuteReader();
cmbEditSchool.DataSource = reader;
cmbEditSchool.DataBind();
cmbEditSchool.Text = "Please select an existing school to edit...";
if (reader != null) reader.Close();
}
finally
{
conn.Dispose();
}
}
```
I use this same bit of code, over and over again throughout my program, on different pages. Most often, I'm populating a drop-down list or combo box, but sometimes I will populate a gridview, only slightly altering the query.
**My question is how can I create a class that will allow me to call a stored procedure**, instead of manually using queries like my example, and populate my different controls? Is it possible to do with only 1 method? I only need to start with selects. I've been reading up on IEnumerable which seems like the appropriate interface to use, but how do I use it?
***Edited to add:***
I marked Rorschach's answer as THE answer because s/he addressed my IEnumerable question. I also understand the need for a proper DAL and perhaps BLL layer. What I was trying to get to was that. I can build a DAL using datasets and table adapters which, in the end, gets me a strongly typed dataset. However, I feel a bit removed from the code. I was after a straight-forward way of building the DAL myself starting with the code that I gave above. Perhaps I'm not wording my question, or what I'm after, correctly.
At any rate, Rorschach came closest to answering my actual question. Thanks. | You can create a class that lets you call stored procedures (this is known as a Data Access Component (DAC) class, which is usually referenced by a Business Component (BC) class, but it is outside the scope of your question).
There are a few objects you will want to use in this new class:
Microsoft.Practices.EnterpriseLibrary.Data.Database
Microsoft.EnterpriseLibrary.Data.DatabaseFactory
System.Data.Common.DBCommand
The DAC class will look similar to what you have:
```
public class DataAccess
{
public DataAccess()
{
}
public System.Collections.IEnumerable GetSchoolData()
{
string connectionString = ConfigurationManager.ConnectionStrings["MyConnectionString"].ConnectionString;
Database db = DatabaseFactory.CreateDatabase(connectionString);
string sqlCommand = "GetSchoolData";
DbCommand comm = db.GetStoredProcCommand(sqlCommand);
//db.AddInParameter(comm, "SchoolId", DbType.Int32); // this is in case you want to add parameters to your stored procedure
return db.ExecuteDataSet(comm);
}
}
```
And your page code will look like this:
```
public class SchoolPage : Page
{
public void Page_Init(object sender, EventArgs e)
{
DataAccess dac = new DataAccess();
cmbEditSchool.DataSource = dac.GetSchoolData();
cmbEditSchool.DataBind();
}
}
```
Note that this is just to help you learn how to do this. It is not a good approach to development because you are opening up your Data Access Layer to the outside world (which is bad). | This is a down and dirty method of reducing your code duplication. It's not really the right way to go about setting up a Data Access Layer (DAL) and a Business Logic Layer (BLL), which I'd suggest learning about instead.
```
protected void FillFromDatabase( string sql, BaseDataBoundControl dataControl)
{
SqlDataReader reader = null;
var connectionString = ConfigurationManager.ConnectionStrings["MyConnectionString"].ConnectionString;
var conn = new SqlConnection( connectionString );
var comm = new SqlCommand( sql, conn );
try
{
conn.Open();
reader = comm.ExecuteReader();
dataControl.DataSource = reader;
dataControl.DataBind();
}
finally
{
if( reader != null )
reader.Dispose();
conn.Dispose();
}
}
```
then you could call it like
```
const string sql = "SELECT * FROM [Schools] ORDER BY [SchoolName] ASC";
FillFromDatabase( sql, cmbEditSchool );
``` | Creating a class to use for populating drop-down lists, grids, etc., in C# | [
"",
"c#",
"oop",
"ienumerable",
""
] |
I am actually having 100's of SP in my database. I have to find a set of 10 SP's in that which have a particular comment inside them. Is there any search query for this. | Found [this](http://www.knowdotnet.com/articles/storedprocfinds.html) article which does exactly what your after if your using SQL Server
I'll certainly be keeping a copy of this code for my own use :)
Also, It doesn't just work for comments but it appears to work for all text in an SP.
**Edit**
I've included a copy of the code for simplicity but all credit goes to Les Smith
```
CREATE PROCEDURE Find_Text_In_SP
@StringToSearch varchar(100)
AS
SET @StringToSearch = '%' +@StringToSearch + '%'
SELECT Distinct SO.Name
FROM sysobjects SO (NOLOCK)
INNER JOIN syscomments SC (NOLOCK) on SO.Id = SC.ID
AND SO.Type = 'P'
AND SC.Text LIKE @stringtosearch
ORDER BY SO.Name
GO
``` | Note that the syscomments search methods will fail if the String Search spans the boundary of records in syscomments.
To be 100% I guess you will have to Script the Sprocs out of the database
Suggest considering storing each Sproc in a separate file (and store in revision control repository etc.) rather than just Altering them in-situ in the DB - and then you can use your favourite editor to do a "Find" (and "Replace" if that is appropriate) | Search in SP | [
"",
"sql",
"sql-server",
"sql-server-2005",
""
] |
I heard you should never throw a string because there is a lack of information and you'll catch exceptions you dont expect to catch. What are good practice for throwing exceptions? do you inherit a base exception class? Do you have many exceptions or few? do you do MyExceptionClass& or const MyExceptionClass& ? etc. Also i know exceptions should never been thrown in destructors
i'll add that i understand design by contract and when to throw exception. I am asking how i should throw exceptions. | In my opinion, a function should throw an exception if it can't keep its "promise", if it has to break its "contract". The function's signature (name and parameters) determine its contract.
Given these two member functions:
```
const Apple* FindApple(const wchar_t* name) const;
const Apple& GetApple(const wchar_t* name) const;
```
The names of these functions as well as their return values indicate to me that in the case of **FindApple** the function is perfectly capable of returning NULL when the correct apple was not found, but in the case of **GetApple** you're expecting an apple to return. If that second function can't keep its promise, it must throw an exception.
Exceptions are meant for those exceptional conditions in which a function has no other way of reporting these conditions. If you decide to make it a part of the promise (read: function signature) then it can report that condition without throwing an exception.
Note that in the case of **FindApple**, it's up to the caller to decide how to handle the condition of "not finding the right apple" because it's no longer an exceptional condition.
You might be tempted to try to avoid all exceptions, but that means you have to account for all possible exceptional conditions, and you're placing the burden on the caller instead. The caller needs to check for "error conditions" then.
Ultimately, an exception needs to be handled, but only by the caller that **knows how to handle a particular condition in a useful way**. And I mean this in the widest possible interpretation: a service that gives up will try again later, a UI that provides a helpful error message, a web app that presents a "oops" screen but that recovers nicely, ... and so on.
Dave | One basic thing is to reserve exceptions for exceptional situations only. Don't use them for flow control. For instance, "file not found" should not be an exception, it should be an error code or return value (unless the file is something that *must* exist, e.g. a configuration file). But if a file suddenly disappears while you're processing it, then throwing an exception is a good choice.
When exceptions are used sparingly, you don't need to turn your code into a try-catch -spaghetti in order to avoid receiving incomprehensible-in-the-context exceptions from the deeper layers. | How to throw good exceptions? | [
"",
"c++",
"exception",
"throw",
""
] |
Having an HTML page with a simple table and js code to do show / hide on it:
```
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>title</title>
<script type="text/javascript">
function showErrorSteps()
{
var el = document.getElementById("t1");
if(el.style.display=="none")
{
el.style.display="block";
}
else
{
el.style.display="none";
}
}
</script>
</head>
<body>
<br />
<span onclick="showErrorSteps()">[click]</span>
<br />
<br />
<table id="t1" border="1" width="100%" style="table-layout: fixed">
<tr>
<td>s</td>
<td>d</td>
<td>a</td>
</tr>
</table>
</body>
</html>
```
What happens is that on Mozilla the table gets resized after you click twice(even with the table-layout: fixed css). IE works fine. | Tables shouldn't be set to `display: block`. Table rows and cells shouldn't either. They have different display values. My advice? Don't do it this way. Use a class:
```
.hidden {
display: none;
}
```
and dynamically add it and remove it from the table to avoid problems of setting the right display type on an element that you show.
**Edit:** To clarify the comment as to why do it this way and what's going on. Try this:
```
<table>
<tr>
<td>Cell 1</td>
<td style="display: block;">Cell 2</td>
</tr>
</table
```
It will (or should) screw up your table layout. Why because a `<td>` element, by default, has `display: table-cell` not `block`. Tables are the same. They have `display: table`.
Unsetting CSS attributes is... problematic.
Thus you are best off using classes to set and unset attributes. It's easier to change (the class resides in a CSS file and isn't code), avoids problems like setting the value back to the correct original value and generally provides a cleaner solution, especially when used with a library like jQuery. In jQuery, you can do:
```
$("table").toggleClass("hidden");
```
Done.
Or you can use `addClass()` and `removeClass()` if that's more appropriate. For example:
```
<input type="button" id="hide" value="Hide Table">
...
<table id="mytable">
...
```
and
```
$(function() {
$("#hide").click(function() {
if ($("#mytable").is(".hidden")) {
$("#hide").val("Hide Table");
$("#mytable").removeClass("hidden");
} else {
$("#hide").val("Show Table");
$("#mytable").addClass("hidden");
}
});
});
```
And there you have a robust, succinct and easy-to-understand solution (once you get your head around the jQuery syntax, which doesn't take that long).
Messing about with Javascript directly is so 2002. :-) | This is not a direct answer to your question, but a serious recommendation. I have recently discovered the joys of [JQuery](http://jquery.com/). All this kind of stuff can be done effortlessly and there is extensive online examples and references available.
If you haven’t got time to get into it now then I’m sure someone will offer a solution here, but I would recommend anyone who does anything beyond the most cursory JavaScript DOM manipulation to consider JQuery (or a similar framework).
JQuery offers browser independent Hide(), Show() and Toggle() methods. Here’s one of my favourite [references](http://www.gscottolson.com/jquery/jQuery1.2.cheatsheet.v1.0.pdf). | Hiding entire table resizes it | [
"",
"javascript",
"html",
"firefox",
""
] |
I have a project that uses the serial port, and it requires two files to run, the win32.dll file (which is in the java runtime environment bin folder) and the javax.comm.properties file (which is in the java runtime environment lib folder). When I run the project from eclipse it works, but when I try to build a jar file for distribution, it won't work. I suspect this is because the dll and properties files aren't included in the jar. How do I specify that they need to be there? | You generally don't put dll and properties files inside the jar. Properties files as well other jar files need to be added to the classpath. The jar file has a manifest file that defines the classpath used. You can't edit this with eclipse. You need to define an ant build.xml file and do something like this:
```
<jar jarfile="${dist}/MyJar.jar" basedir="${build}">
<manifest>
<attribute name="Main-Class" value="MyClass"/>
<attribute name="Class-Path" value="."/>
</manifest>
</jar>
```
Then put the properties file in the same folder as the jar. You can run the ant target by right clicking the build.xml and selecting the "Run as Ant target".
If I remember correctly, placing the dll file in the bin directory of the jre will work. | I think javax.comm.properties just need to be on your classpath. You may can add it to the top level of a jar you delivery.
InputStream is = MainClass.class.getResourceAsStream("javax.comm.properties");
if (is == null) {properties missing....}
I think win32.dll just need to be on the %PATH%(windows) or $LD\_LIBRARY\_PATH(unix)...... | How do I attach properties files to a jar? | [
"",
"java",
"jar",
"ant",
""
] |
I have this but there is an error, I don't get it :(. I'm relatively new to Java.
```
package hw;
import java.util.Scanner;
public class Problem1
{
public static void main (String [] args)
{
int cost; int number; double cost_unit; double total;
Scanner entrada = new Scanner(System.in);
System.out.println("Please enter the cost of the product.");
cost = entrada.nextInt();
while (cost>0){
System.out.println("Please enter the amount of units to be sold");
number = entrada.nextInt();
if (number>0);
cost_unit = cost * 1.4;
total = cost_unit*number;
System.out.printf("Cost per unit will be $ %d\n",cost_unit);
System.out.printf("Cost per unit will be $ %d\n",total);
}
}
}
```
// I just want the user to enter the cost for a product, give a number of units to be ordered, and I want the program find out the final price of the product with a 40% profit. | In printf, `%d` is for a signed decimal integer, whereas `cost_unit` and `total` are doubles. You should use `%f` instead.
```
System.out.printf("Cost per unit will be $ %f\n",cost_unit);
System.out.printf("Cost per unit will be $ %f\n",total);
``` | Try and actually describe the problem:
Did javac not compile it? That's a syntax problem.
Did the program not behave as you intended it to be? What parts is not behaving? That's a logic problem.
Without adequate description of the problem, how could you expect that you, or others, could locate the errors easily? You're going to need this skill as you go on learning more about programming.
Back to finding problems in your code:
* cost of the individual items are integers. Doesn't make sense if I want to sell gum that costs .75 cents
* the while loop would loop infinitely if you enter anything but 0 for the cost
* if condition does nothing... i.e. it makes no difference whether you've entered 0 or less units or more than 0 units
* `cost_unit = cost * 14` you probably want to name cost\_unit to something like retail\_unit - because that's the retail price. cost \* profit margin = retail price, no? | Help Need To Correct Java Code | [
"",
"java",
""
] |
I've looked up what this does, but does anyone actually have an example of when you would use the `strictfp` keyword in Java? Has anyone actually found a use for this?
Would there be any side-effects of just putting it on all my floating point operations? | Strictfp ensures that you get exactly the same results from your floating point calculations on every platform. If you don't use strictfp, the JVM implementation is free to use extra precision where available.
[From the JLS](http://java.sun.com/docs/books/jls/third_edition/html/expressions.html#249198):
> Within an FP-strict expression, all
> intermediate values must be elements
> of the float value set or the double
> value set, implying that the results
> of all FP-strict expressions must be
> those predicted by IEEE 754 arithmetic
> on operands represented using single
> and double formats. Within an
> expression that is not FP-strict, some
> leeway is granted for an
> implementation to use an extended
> exponent range to represent
> intermediate results; the net effect,
> roughly speaking, is that a
> calculation might produce "the correct
> answer" in situations where exclusive
> use of the float value set or double
> value set might result in overflow or
> underflow.
In other words, it's about making sure that *Write-Once-Run-Anywhere* actually means *Write-Once-Get-Equally-Wrong-Results-Everywhere*.
With strictfp your results are portable, without it they are more likely to be accurate. | Actually, there's a good [Wikipedia article about strictfp](http://en.wikipedia.org/wiki/Strictfp), with a link to the [Java specification's section on *Floating-Point Types, Formats, and Values*](https://docs.oracle.com/javase/specs/jls/se9/html/jls-4.html#jls-4.2.3).
Reading between the lines, the implication is that if you don't specify `strictfp`, then the JVM and JIT compiler have license to compute your floating-point calculations however they want. In the interest of speed, they will most likely delegate the computation to your processor. With `strictfp` on, the computations have to conform to IEEE 754 arithmetic standards, which, in practice, probably means that the JVM will do the computation.
So why would you want to use `strictfp`? One scenario I can see is in a distributed application (or multiplayer game) where all floating-point calculations need to be deterministic no matter what the underlying hardware or CPU is. What's the trade-off? Most likely execution time. | When should I use the "strictfp" keyword in java? | [
"",
"java",
"floating-point",
"strictfp",
""
] |
I'm having some problems to come up with a sane type naming scheme for our new line of applications. I want to follow the [.NET Framework Developer's Guide - Design Guidelines for Developing Class Libraries](http://msdn.microsoft.com/en-us/library/ms229042.aspx), but I'm starting to wonder if that's such a good idea.
I'd like to use the `Company.Product.Feature` namespace scheme as a basis.
**Problem 1:** We have our own control and form base classes, and I want these to go into the `Company.Product.Forms` namespace. However, according to the guidelines, we shouldn't let our type names be `Control` or `Form`, even if they are in our own `Company.Product.Forms` namespace, since they will clash with system types.
**Problem 2:** We have some distinct feature areas in the application and I want these to go into their own `Company.Product.Feature` namespace. Lots of these features have similar design, with a controller and some views, so under each `Company.Product.Feature` namespace I'd like to have types named `Controller`, `SomeView`, `AnotherView`, etc. However, according to the guidelines, we shouldn't have the same type names in different namespaces.
The only solution I see to overcome these problems is to prefix the types with something that in some way makes the namespaces redundant. Or not? | Microsoft clearly favors some redundancy. A common example is:
```
System.Xml.XmlDocument
```
General class names, even bound within a proper named namespace can cause headaches for the many programmers who like to avoid fully qualifying their class instantiations. "Document" could be an Xml, Html or word document. This ambiguity will cause endless confusion if you happen to import more than one namespace with a "Document" class. | I'd prefer Company.Product.UI, for some reason. I would use that naming for the web, too.
Regarding problem 1, if these are base types, you might include Base in the class name.
Then, you typically have a set of domain specific controls, which won't clash with built-in types.
If you also keep wrappers for common UI controls(TextBox, DropDownList etc), then i would actually recommend use a prefix for them,
maybe this prefix is an abbreviated name of the product.
And then, if you do that, then you might want to be consistent, and do it for all types,
regardless of whether they are ambigious names or not.
I tell you from my own experience.
You'll end up constantly hovering over variables to see their full type names, etc, you will use aliasing etc..
The code will be harder to read.
Problem 2: While at GUI layer, i tend to break these rules, because you will want naming consistency(common verbs; Show,Edit,List). If the guideline tells you otherwise, i would believe it is because it is simply not specific enough. | Naming types in a namespace by the .NET Framework Design Guidelines | [
"",
"c#",
"naming-conventions",
"namespaces",
"naming",
""
] |
Is there something similar to the Python utility [virtualenv](http://pypi.python.org/pypi/virtualenv)?
Basically it allows you to install Python packages into a sandboxed environment, so `easy_install django` doesn't go in your system-wide site-packages directory, it would go in the virtualenv-created directory.
For example:
```
$ virtualenv test
New python executable in test/bin/python
Installing setuptools...cd .........done.
$ cd test/
$ source bin/activate
(test)$ easy_install tvnamer
Searching for tvnamer
Best match: tvnamer 0.5.1
Processing tvnamer-0.5.1-py2.5.egg
Adding tvnamer 0.5.1 to easy-install.pth file
Installing tvnamer script to /Users/dbr/test/bin
Using /Library/Python/2.5/site-packages/tvnamer-0.5.1-py2.5.egg
Processing dependencies for tvnamer
Finished processing dependencies for tvnamer
(test)$ which tvnamer
/Users/dbr/test/bin/tvnamer
```
Is there something like this for RubyGems? | [RVM](http://rvm.io/) works closer to how virtualenv works since it lets you sandbox different ruby versions and their gems, etc. | Neither sandbox, RVM, nor rbenv manage the versions of your app's gem dependencies. The tool for that is [bundler](http://bundler.io/rationale.html).
* use a [Gemfile](http://bundler.io/v1.5/gemfile.html) as your application's dependency declaration
* use `bundle install` to install explicit versions of these dependencies into an isolated location
* use `bundle exec` to run your application | Ruby equivalent of virtualenv? | [
"",
"python",
"ruby",
"virtualenv",
""
] |
Let's imagine I have a collection of nodes that I use for my Renderer class later on. Then I have a Visitor class that can visit node or whole collection. It's simple because my collection of nodes it's simply a wrapper to the std::list with few extra methods.
The problem is I'd like to have a tree like structure for nodes(instead of simple list) so a node can have a parent and n children. That would be handy as I'd like to be able to pass to my Renderer a node and render everything "below" that node. The answer probably is Composite.
How can I use together Visitor and Composite? I've read that its often a good combo but my implementations look pretty bad... I'm missing sth. | I have something very similar implemented for our system. I wanted a way to compose hierarchy of geometrical object and render them into the volume. I used composite pattern to compose my description (root was Node and then derived child was compositeNode (list of Nodes).
CompositeNode has method accept() which accepts a visitor (Visitor) and then inside the accept() you do visitor->visit(this).
Thus your visitor hierarchy has base class as NodeVisitor and derived visitors like RenderVisitor (renders objects), ReportVisitor (dumped node info into text). Your base class will need to accept both base and specialized node types.
So yes, combo works and I have working code but I agree that design takes more effort than what you would read online (Wiki or toy example).
Hope this helps | Here's a simple example:
```
struct NodeVisitor;
struct Node
{
virtual ~Node() {}
virtual void accept(NodeVisitor &v);
};
struct CompositeNode : public Node
{
virtual void accept(NodeVisitor &v);
std::list<NodePtr> nodes_;
};
struct NodeVisitor
{
virtual ~NodeVisitor() {}
virtual void visit(Node &n) = 0;
virtual void visit(CompositeNode &cn)
{
for(std::list<NodePtr>::iterator it = cn.nodes_.begin(), end = cn.nodes_.end(); it != end; ++it)
{
(*it)->accept(*this);
}
}
};
``` | Iterating hierarchy of nodes - Visitor and Composite? | [
"",
"c++",
"oop",
"design-patterns",
"composite",
"visitor-pattern",
""
] |
In [this other question](https://stackoverflow.com/questions/541390/extracting-extension-from-filename-in-python), the votes clearly show that the `os.path.splitext` function is preferred over the simple `.split('.')[-1]` string manipulation. Does anyone have a moment to explain exactly why that is? Is it faster, or more accurate, or what? I'm willing to accept that there's something better about it, but I can't immediately see what it might be. Might importing a whole module to do this be overkill, at least in simple cases?
EDIT: The OS specificity is a big win that's not immediately obvious; but even I should've seen the "what if there isn't a dot" case! And thanks to everybody for the general comments on library usage. | Well, there are separate implementations for separate operating systems. This means that if the logic to extract the extension of a file differs on Mac from that on Linux, this distinction will be handled by those things. I don't know of any such distinction so there might be none.
---
**Edit**: [@Brian](https://stackoverflow.com/users/9493/brian) comments that an example like `/directory.ext/file` would of course not work with a simple `.split('.')` call, and you would have to know both that directories can use extensions, as well as the fact that on some operating systems, forward slash is a valid directory separator.
This just emphasizes the *use a library routine unless you have a good reason not to* part of my answer.
Thanks [@Brian](https://stackoverflow.com/users/9493/brian).
---
Additionally, where a file doesn't have an extension, you would have to build in logic to handle that case. And what if the thing you try to split is a directory name ending with a backslash? No filename nor an extension.
The rule should be that unless you have a specific reason not to use a library function that does what you want, use it. This will avoid you having to maintain and bugfix code others have perfectly good solutions to. | os.path.splitext will correctly handle the situation where the file has no extension and return an empty string. .split will return the name of the file. | Benefits of os.path.splitext over regular .split? | [
"",
"python",
""
] |
I would like to track messages sent and received though Windows Live Messenger. I would then like to collate these messages into a database (not in the scope of this question).
The question is how and where should I track these messages. The simplest way it to force all clients to keep history files and read those, but it is not really the solution that I am looking for. Is there a way to track them from a server running in the same domain, I have read a little into Windows Communicator, I have also seen a lot of people chat about <http://dev.live.com/messenger/> but I was hoping that someone may have addressed this problem already :)
I would like to do this using C# .NET 3.5 | I managed to find two ways of doing this, though both are not really programmatic solutions, so may not appeal to this audience.
1. Make use of a Jabber gateway to set up forwards between your jabber client and the other IM networks. Traffic flows between your jabber enabled client and the jabber server via the jabber server. The Jabber server then translates this to the destination networks protocol and forwards the message. Likewise messages from the external IM networks are routed and translated by the Jabber server. An example of this is PSI <-> IceWarp Merak <-> MSN
2. Make use of [Symantec IM Manager](http://www.symantec.com/business/im-manager) to intercept messages from the messaging clients on your network. You will need to either use host files or local DNS rules to convince the your local PCs that Messenger.hotmail.com is actually located at 192.168.0.59 and not at Microsoft.
Hope it helps other people that may want to do the same. | Check out MSNPSharp. Its a .NET msn library. Its very powerful and allows you to sign in from multiple locations. So you can sign in and listen to other conversations happening on a given account.
Its very straight forward to use. Download the full source code, there's a sample application that demonstrates its use in full detail.
<http://code.google.com/p/msnp-sharp/> | Track messages though Windows Live Messenger | [
"",
"c#",
".net",
"windows-live-messenger",
""
] |
I have a Unicode string in Python, and I would like to remove all the accents (diacritics).
I found on the web an elegant way to do this (in Java):
1. convert the Unicode string to its ***long normalized form*** (with a separate character for letters and diacritics)
2. remove all the characters whose Unicode type is "diacritic".
Do I need to install a library such as pyICU or is this possible with just the Python standard library? And what about python 3?
Important note: I would like to avoid code with an explicit mapping from accented characters to their non-accented counterpart. | How about this:
```
import unicodedata
def strip_accents(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
```
This works on greek letters, too:
```
>>> strip_accents(u"A \u00c0 \u0394 \u038E")
u'A A \u0394 \u03a5'
>>>
```
The [character category](http://www.unicode.org/reports/tr44/#GC_Values_Table) "Mn" stands for `Nonspacing_Mark`, which is similar to unicodedata.combining in MiniQuark's answer (I didn't think of unicodedata.combining, but it is probably the better solution, because it's more explicit).
And keep in mind, these manipulations may significantly alter the meaning of the text. Accents, Umlauts etc. are not "decoration". | [Unidecode](https://pypi.python.org/pypi/Unidecode) is the correct answer for this. It transliterates any unicode string into the closest possible representation in ascii text.
Example:
```
>>> from unidecode import unidecode
>>> unidecode('kožušček')
'kozuscek'
>>> unidecode('北亰')
'Bei Jing '
>>> unidecode('François')
'Francois'
``` | What is the best way to remove accents (normalize) in a Python unicode string? | [
"",
"python",
"python-3.x",
"unicode",
"python-2.x",
"diacritics",
""
] |
I have a function in my controller that has grown longer than I'd prefer and I'd like to refactor it to call a few discrete functions to make it easier to manage. How can I better organize a long function in a Codeigniter controller?
**What I've tried:**
I know you can create private functions in a controller by naming them with a leading underscore (\_myfunc), but then the variables in the function are out of scope for the calling controller function. So you have to return all the needed data from the function which is a hassle.
Is this the best option for managing a complex controller function? Is there an easier way where the variables could all be global to the controller class like a standard class member variable?
Suggestions? Thanks in advance!
EDIT: Someone requested the code so I added code for giant controller below. One opportunity for improvement is to move logic in switch statements to separate functions (delete, preview, order, etc). But I'm trying to decide on the next step after that. Moving the big validation setup code into it's own function would really take some weight out, but where should I move it to?
```
function categories() {
$this->load->library('upload');
$this->load->model('categories_m');
$this->load->model('products_m');
$this->load->model('pages_m');
$this->load->model('backoffice/backofficecategories_m');
$data['body'] = $this->load->view('backoffice/categories/navigation_v', '', TRUE);
$data['cat_tree'] = $this->categories_m->getCategoryTree();
$data['page_list'] = $this->pages_m->getPageList();
$data['category_dropdown'] = $this->load->view('backoffice/categories/category_dropdown_v',$data,TRUE);
switch ($this->uri->segment(3)) { //display views based on parameter in URL.
case 'delete':
$categoryTreeID = $this->sitewide_m->checkURLParam($this->uri->segment(4),'CategoryTree'); //if parameter is in URL, show 404 if invalid parameter is passed. Otherwise, set variable known to be safe.
if (isset($_POST['delete'])) {
$this->backofficecategories_m->deleteCategory($categoryTreeID);
$data['body'] .= '<span class="error">Category Deleted.</span>';
} else {
$data['cat_details'] = $this->categories_m->getCategoryDetails('',$categoryTreeID);
$data['parent_category'] = $this->categories_m->getParentCategory($categoryTreeID);
$data['products_to_reassign'] = $this->products_m->getProductsInCategory('',$categoryTreeID);
$data['body'] .= $this->load->view('backoffice/categories/delete_v',$data,TRUE); //pull fresh category tree data since tree was just updated.
}
break;
case 'preview':
if ($this->uri->segment(4)) $data['categoryTreeID'] = $this->sitewide_m->checkURLParam($this->uri->segment(4),'CategoryTree'); //if parameter is in URL, show 404 if invalid parameter is passed. Otherwise, set variable known to be safe.
$data['cat_details'] = $this->categories_m->getCategoryDetails(NULL,$data['categoryTreeID']); //get category ID being edited from the URL and store it. Returns false if category ID isn't found.
foreach ($data['cat_details']->result() as $detail) {
$data['categoryName'] = $detail->Name;
$data['categoryID'] = $detail->ID;
}
$data['body'] .= $this->load->view('backoffice/categories/preview_v', $data, TRUE);
break;
...cases continue...
default:
$this->load->library('table');
$data['body'] .= $this->load->view('backoffice/categories/categories_v', $data, TRUE);
break;
}
$this->load->view('backoffice/template_v',$data);
}
``` | Looking at your code, you are using one method for several actions. I would make each action its own method. Common resources could be class members and loaded in the constructor.
So instead of a url like "your\_controller/categories/add" you could change your url to "category\_controller/add" and have a method for each action. If you don't want to change your urls, then use a route:
```
$route['your_controller/categories/(.*)'] = 'your_controller/$1';
``` | Are you using models? Code igniter doesn't enforce this, but using models in addition to controllers and views is a good way to have a shorter controller function. Alternatively, you could place some of the functions in your own helper, then import it.
And if you want to set some default values for the entire constructor, you can use the class constructor. This is outlined here:
<http://codeigniter.com/user_guide/general/controllers.html#constructors> | How do you refactor a Codeigniter controller function that is too long? | [
"",
"php",
"codeigniter",
""
] |
This is new to me. I have a new boss at work who is insisting that every query we do from now on be a sproc with XML serialized parameters and return types.
I've not run any tests yet but this strikes me as overkill and possibly a performance killer in many ways. What is your experience? | Though being an obvious performance killer (imagine parsing several megs of XML returned from a sproc), it's even more a productivity, scalability and maintanability killer. Working with XML in T-SQL is not exactly painless neither seamless. Support will be a nightmare: imagine adding a single column to the resultset, which will lead to an avalanche of modifications in both serialization and deserialization code.
Plus, you'll not be able to use neither ORM tools, nor simple result-set mappers (iBATIS or BLToolkit). | Hey, lets take our least scalable component, and make it do intensive CPU work ;-p
OK, that was tongue in cheek. Xml as arguments and return values have uses in a few *specific* cases with structured data, but in general a flat TDS stream (i.e. grids) is far more efficient. For input, either CSV (split via udf) or table-valued-parameters (SQL 2008) are good options.
Sql/xml in 2005+ is much better than with openxml - and indeed, once xml is stored and indexed in the server (using the `xml` data type) it is quite efficient - but as input and output it can be a bottleneck if you aren't careful.
Don't make it the default, but consider it as one of the available options. | Opinions on using XML as a Stored Proc Parameter and Return Type | [
"",
"c#",
"xml",
"performance",
"stored-procedures",
""
] |
Is there any difference between typing:
```
<?php echo $_SERVER[REQUEST_URI] ?>
```
or
```
<?php echo $_SERVER['REQUEST_URI'] ?>
```
or
```
<?php echo $_SERVER["REQUEST_URI"] ?>
```
?
They all work... I use the first one.
Maybe one is faster than the other? | **Without quotes PHP interprets the `REQUEST_URI` as a constant** but corrects your typo error if there is no such constant and interprets it as string.
When [`error_reporting`](http://docs.php.net/manual/en/errorfunc.configuration.php#ini.error-reporting) includes [`E_NOTICE`](http://docs.php.net/manual/en/errorfunc.constants.php), you would probably get an error such as:
> Notice: Use of undefined constant REQUEST\_URI - assumed 'REQUEST\_URI' in *<file path>* on line *<line number>*
But if there is a constant with this name, PHP will use the constant’s value instead. (See also [Array do's and don'ts](http://docs.php.net/manual/en/language.types.array.php#language.types.array.donts))
**So always use quotes when you mean a string.** Otherwise it can have unwanted side effects.
And for the difference of single and double quoted strings, see the [PHP manual about strings](http://docs.php.net/manual/en/language.types.string.php). | The first one is wrong - you're actually looking for a constant `REQUEST_URI` that doesn't exist. This will generate a notice-level warning.
There's no difference between the other two. | How to use $_SERVER['REQUEST_URI'] | [
"",
"php",
""
] |
I'm trying to unpickle an object stored as a blob in a MySQL database. I've manually generated and stored the pickled object in the database, but when I try to unpickle the object, I get the following rather cryptic exception:
ImportError: No module named copy\_reg
Any ideas as to why this happens?
**Method of Reproduction**
Note: Must do step 1 on a Windows PC and steps 3 and 4 on a Linux PC.
1) On a Windows PC:
```
file = open("test.txt", "w")
thing = {'a': 1, 'b':2}
cPickle.dump(thing, file)
```
2) Manually insert contents of text.txt into blob field of MySQL database running on linux
3) In Python running on a linux machine, fetch the contents of column from MySQL
4) Assuming that you put the contents of the blob column into a variable called data, try this:
```
cPickle.loads(rawString)
``` | It seems this might be caused by my method of exporting the pickled object.
[This bug report](http://www.archivum.info/python-bugs-list@python.org/2007-04/msg00222.html "Bug report of similiar nature") seens to suggest that my issue can be resolved by exporting to a file writen in binary mode. I'm going to give this a go now and see if this solves my issue.
UPDATE: This works. The solution is to make sure you export your pickled object to a file open in binary mode, even if you are using the default protocol 0 (commonly referred to as being "text")
Correct code based on orignal example in question:
```
file = open("test.txt", 'wb')
thing = {'a': 1, 'b':2}
cPickle.dump(thing, file)
``` | Also, simply running dos2unix (under linux) over the (windows-created) pickle file solved the problem for me. (Haven't tried the open mode 'wb' thing.)
Dan | ImportError: No module named copy_reg pickle | [
"",
"python",
"pickle",
""
] |
Can anyone suggest a way of stripping tab characters ( "\t"s ) from a string? CString or std::string.
So that "1E10 " for example becomes "1E10". | [hackingwords' answer](https://stackoverflow.com/questions/556277/trim-remove-a-tab-t-from-a-string/556293#556293) gets you halfway there. But [`std::remove()`](http://en.cppreference.com/w/cpp/algorithm/remove) from `<algorithm>` doesn't actually make the string any shorter -- it just returns an iterator saying "the new sequence would end here." You need to call [`my_string().erase()`](http://en.cppreference.com/w/cpp/string/basic_string/erase) to do that:
```
#include <string>
#include <algorithm> // For std::remove()
my_str.erase(std::remove(my_str.begin(), my_str.end(), '\t'), my_str.end());
``` | If you want to remove all occurences in the string, then you can use the [erase/remove](http://en.wikibooks.org/wiki/More_C%2B%2B_Idioms/Erase-Remove) idiom:
```
#include <algorithm>
s.erase(std::remove(s.begin(), s.end(), '\t'), s.end());
```
If you want to remove only the tab at the beginning and end of the string, you could use the [boost string algorithms](http://www.boost.org/doc/libs/1_38_0/doc/html/string_algo.html):
```
#include <boost/algorithm/string.hpp>
boost::trim(s); // removes all leading and trailing white spaces
boost::trim_if(s, boost::is_any_of("\t")); // removes only tabs
```
If using Boost is too much overhead, you can roll your own trim function using `find_first_not_of` and `find_last_not_of` string methods.
```
std::string::size_type begin = s.find_first_not_of("\t");
std::string::size_type end = s.find_last_not_of("\t");
std::string trimmed = s.substr(begin, end-begin + 1);
``` | Trim / remove a tab ( "\t" ) from a string | [
"",
"c++",
"string",
"tabs",
""
] |
Is there any way I can separate a `List<SomeObject>` into several separate lists of `SomeObject`, using the item index as the delimiter of each split?
Let me exemplify:
I have a `List<SomeObject>` and I need a `List<List<SomeObject>>` or `List<SomeObject>[]`, so that each of these resulting lists will contain a group of 3 items of the original list (sequentially).
eg.:
* Original List: `[a, g, e, w, p, s, q, f, x, y, i, m, c]`
* Resulting lists: `[a, g, e], [w, p, s], [q, f, x], [y, i, m], [c]`
I'd also need the resulting lists size to be a parameter of this function. | Try the following code.
```
public static List<List<T>> Split<T>(IList<T> source)
{
return source
.Select((x, i) => new { Index = i, Value = x })
.GroupBy(x => x.Index / 3)
.Select(x => x.Select(v => v.Value).ToList())
.ToList();
}
```
The idea is to first group the elements by indexes. Dividing by three has the effect of grouping them into groups of 3. Then convert each group to a list and the `IEnumerable` of `List` to a `List` of `List`s | I just wrote this, and I think it's a little more elegant than the other proposed solutions:
```
/// <summary>
/// Break a list of items into chunks of a specific size
/// </summary>
public static IEnumerable<IEnumerable<T>> Chunk<T>(this IEnumerable<T> source, int chunksize)
{
while (source.Any())
{
yield return source.Take(chunksize);
source = source.Skip(chunksize);
}
}
``` | Split List into Sublists with LINQ | [
"",
"c#",
"linq",
"data-structures",
""
] |
I am planning to replace repeatedly executed Statement objects with `PreparedStatement` objects to improve performance. I am using arguments like the MySQL function `now()`, and string variables.
Most of the `PreparedStatement` queries I have seen contained constant values (like `10`, and strings like `"New York"`) as arguments used for the `?` in the queries. How would I go about using functions like `now()`, and variables as arguments? Is it necessary to use the `?`s in the queries instead of actual values? I am quite confounded. | If you have variables use the '?'
```
int temp = 75;
PreparedStatement pstmt = con.prepareStatement(
"UPDATE test SET num = ?, due = now() ");
pstmt.setInt(1, temp);
pstmt.executeUpdate():
```
Produces an sql statment that looks like:
```
UPDATE test SET num = 75, due = now();
``` | If you have a variable that comes from user input, it's essential that you use the ? rather than concatenating the strings. Users might enter a string maliciously, and if you drop the string straight into SQL it can run a command you didn't intend.
I realise this one is overused, but it says it perfectly:
 | How does Java's PreparedStatement work? | [
"",
"java",
"jdbc",
"prepared-statement",
""
] |
If I do SELECT a AS b and b is not a column in the table, would query create the "virtual" column?
in fact, I need to incorporate some virtual column into the query and process some information into the query so I can use it with each item later on. | Something like:
```
SELECT id, email, IF(active = 1, 'enabled', 'disabled') AS account_status FROM users
```
This allows you to make operations and show it as columns.
EDIT:
you can also use joins and show operations as columns:
```
SELECT u.id, e.email, IF(c.id IS NULL, 'no selected', c.name) AS country
FROM users u LEFT JOIN countries c ON u.country_id = c.id
``` | Try this one if you want to create a virtual column "age" within a select statement:
```
select brand, name, "10" as age from cars...
``` | How to create virtual column using MySQL SELECT? | [
"",
"php",
"mysql",
"select",
""
] |
I have a database where each row has an id, a URL, and an XML.
The IDs are unique, but URLs column can have duplicates.
I need all the URLs, without duplicates, and for each URL I need the id and XML.
If I ask only for the URL and the Id, I use the following query:
```
select URL, max(ID) as ID from T1 group by URL
```
And all is working great.
But when I want also the XML, and I use the following query:
```
select URL, max(ID) as ID, XML from T1 group by URL
```
I get the following error:
```
ISC ERROR CODE:335544569
ISC ERROR MESSAGE:
Dynamic SQL Error
SQL error code = -104
user name required
```
What am I doing wrong?
Thanks,
Dikla
Thanks for the answers. I want to add an explanation:
In case of duplicate URLs, I don't care which of them will be returned.
But I need to get them without duplicates, even if the XML is different between the rows.
Is it possible?
Thanks! | ```
select id, url, xml
from table1
where id in (
select min(id)
from table1
group by url)
```
would give you rows with duplicate urls removed (and only the first instance of duplicate urls included) | You need to reread your question and think about it.
You're asking for URLs (which can be duplicates) but you don't want duplicates and you also want the ID (which is not duplicated). Sample data:
```
1,http://www.google.com
2,http://www.yahoo.com
3,http://www.google.com
```
In this case what exactly do you want to return, bearing in mind that there are multiple IDs for google?
Same goes for the XML. If it's not unique for a given URL you need to specify how to get only one entry per URL and that's why your query doesn't work. | SQL "group by" question - I can't select every column | [
"",
"sql",
"group-by",
""
] |
Can I call `HttpContext.Current` from within a static class and Method?
I want to store a value on a per-user basis but want to be able to access it in a static manner.
e.g. Will this work?
```
public static class StaticClass
{
public static string SomeThing
{
get { return HttpContext.Current.Items["SomeItem"].ToString(); }
}
}
``` | Yes thats one way in which it is helpful, of course the thread on which it is called must currently be processing a request to make it useful. | Why don't you try?
Yes, it's perfectly possible (though is not necessarily a good design), just remember to reference `System.Web.dll` in your project and check `HttpContext.Current` for `null` in case you'll end up running in a non-ASP.NET environment. | HttpContext.Current accessed in static classes | [
"",
"c#",
"asp.net",
"static",
""
] |
This is a followup to [this question](https://stackoverflow.com/questions/262448/replace-non-numeric-with-empty-string#262466)
The first two answers are both correct and complete and at the end of the day, produce exactly the same result. However, one uses a Regex object and calls the aRegex.Replace(...) method (Joel's answer) and the other uses the static Regex.Replace(...) method. (CMS' answer).
Which method is preferred?
Under what circumstances would you change your mind? | Using the static instance will create a new `Regex` object each time so it is better to instantiate it yourself. Here is what I found using Reflector on System.dll:
```
public static string Replace(string input, string pattern, string replacement)
{
return new Regex(pattern, RegexOptions.None, true).Replace(input, replacement);
}
```
Plus if you instantiate your own instance you will be able to compile it as well and improve performance for multiple uses.
You *can* send `RegexOptions.Compiled` to one of the static `Replace` overloads but this is pointless as the `Regex` object that will be instantiated with this flag cannot be used again. | It's not as inefficient as it looks. Going into the Regex constructor with reflector, it caches the compiled regex code. That's probably the most time-consuming part.
I would generally use Regex.Replace() initially because it's more convenient and only change if it there's a performance problem.
Also you could write extension methods on string for convenience, eg:
```
public static string RegexReplace(this string source, string pattern, string replacement)
{
return Regex.Replace(source, pattern, replacement);
}
``` | Which is preferred: Regex.Replace() or. aRegexObject.Replace()? | [
"",
"c#",
"regex",
""
] |
As per [this](http://www.mazeworks.com/mazegen/mazetut/index.htm) website, I wish to represent a Maze with a 2 dimensional array of 16 bit integers.
Each 16 bit integer needs to hold the following information:
> Here's one way to do it (this is by no means the only way): a 12x16 maze grid can be represented as an array m[16][12] of 16-bit integers. Each array element would contains all the information for a single corresponding cell in the grid, with the integer bits mapped like this:
>
> [](https://i.stack.imgur.com/QmTW6.gif)
> (source: [mazeworks.com](http://www.mazeworks.com/mazegen/mazetut/tut5.gif))
>
> To knock down a wall, set a border, or create a particular path, all we need to do is flip bits in one or two array elements.
How do I use bitwise flags on 16 bit integers so I can set each one of those bits and check if they are set.
I'd like to do it in an easily readable way (ie, Border.W, Border.E, Walls.N, etc).
How is this generally done in C++? Do I use hexidecimal to represent each one (ie, Walls.N = 0x02, Walls.E = 0x04, etc)? Should I use an enum?
---
See also [How do you set, clear, and toggle a single bit?](https://stackoverflow.com/questions/47981/how-do-you-set-clear-and-toggle-a-single-bit-in-c). | Use [`std::bitset`](http://en.cppreference.com/w/cpp/utility/bitset) | If you want to use bitfields then this is an easy way:
```
typedef struct MAZENODE
{
bool backtrack_north:1;
bool backtrack_south:1;
bool backtrack_east:1;
bool backtrack_west:1;
bool solution_north:1;
bool solution_south:1;
bool solution_east:1;
bool solution_west:1;
bool maze_north:1;
bool maze_south:1;
bool maze_east:1;
bool maze_west:1;
bool walls_north:1;
bool walls_south:1;
bool walls_east:1;
bool walls_west:1;
};
```
Then your code can just test each one for true or false. | How do you use bitwise flags in C++? | [
"",
"c++",
"bit-manipulation",
""
] |
I was wondering why ad's still use the document.write approach to inserting the add into the page
```
<script language="javascript" type="text/javascript">
document.write("<script type='text/javascript' src='http://addomain/someadd.js'><\/sc" + "ript>");
</script>
```
Why is it that I can't just put
```
<script type='text/javascript' src='http://addomain/someadd.js'></script>
```
In place of the ad? | A traditional script tag will block the page while it is loading and executing. A script loaded with document.write will work asynchronously. That's why you see this on ads or analytics, as such scripts don't influence the page content directly. | I work with a web advertising company, and from what I've heard, certain browsers (don't know off hand which ones) will allow you to drop script tags into the page, but won't allow you to automatically execute their contents.
So, to pull this off, you need to break the script tag into pieces so the browser doesn't treat it as a script tag, but rather as any old HTML Data. Then, as the DOM is processed serially, the next thing it evaluates, after writing out the script tag is... hey, that script tag you just wrote out.
At this point the script tag is evaluated and executed. | Why use document.write? | [
"",
"javascript",
"document.write",
""
] |
I currently work for a social networking website.
My boss recently had the idea to show search results by random instead of normal results (registration date). The problem with that is simple and obvious: if you go from one page to another, it's going to show you different results each time as the list is randomized each time.
I had the idea to store results in database+cookies something like this:
* Cookie containing a serialized version of the $\_POST request (needed if we want to do a re-sort)
* A table which would serve as the base for the search id => searches (id,user`_id, creation`\_date)
* A table which would store the results and their order => searches`_results (search_id, order, user`\_id)
Flow chart would look like something like that:
* After each searches I store the "where" into a cookie or session
* Then I erase the previous search in "searches"
* Then I delete previous results in "searches\_results"
* Then I insert a row into "searches" for the key
* Then I insert each user row into "searches\_results"
* And finally I redirect the user to somethink like ?search\_id=[search\_key]
There is a big flaw here : performances .... it is definetly possible to make the system OR down OR very slow.
Any idea what would be the best to structure this ? | What if instead of ordering randomly, you ordered by some function where the order is known and repeatable, just non-obvious? You could seed such a function with some data from the search query to make it be even less obvious that it repeats. This way, you can page back and forth through your results and always get what you expect. Music players use this sort of function for their shuffle feature (so that if you click back, you get the previous song, and if you click next again, you're back where you started). I'm sure you can divine some function to accomplish this... [bitwise XORing](http://en.wikipedia.org/wiki/Bitwise_operation#XOR) ID values with some constant (from the query) and then sorting by the resulting number might be sufficient. I chose XOR arbitrarily because it's a trivially simple function that will get you repeatable and non-obvious results. | Hum maybe, but doesn't the xor operator only say if it is an OR exclusive ? I mean, there is no mathematical operation here, as far as I know of tho. | Database structure for saving search results | [
"",
"php",
"mysql",
"data-structures",
""
] |
I want to do the following:
Define a map between a string and any kind of object (may be a list, integer - anything).
The keys to the map can be as follow (the values are, again, not important):
"AAA/123" ==> 1
"AAA/*" ==> 2
"BBB/*" ==> 3
"CCC/\*" ==> 4
"CCC/123" ==> 5
Now, the trick is I want to find the right values given the following strings:
"AAA/123" should give 1.
"AAA/111" should give 2.
"CCC/111" should give 4.
"CCC/123" should give 5.
"BBB/AAA/123" should give 3.
Any idea how I do that with C++ and possibly STL/boost ? | Here's a variant of litb answer (which was somehow deleted from the answers list) which might work given the '\*' is removed:
```
template<typename Map> typename Map::const_iterator
find_prefix(Map const& map, typename Map::key_type const& key)
{
typename Map::const_iterator it = map.upper_bound(key);
while (it != map.begin())
{
--it;
if(key.substr(0, it->first.size()) == it->first)
return it;
}
return map.end(); // map contains no prefix
}
```
I forgot to add the code that uses it:
```
std::map<std::string, int> smap;
smap["AAA/"] = 1;
smap["BBB/"] = 2;
smap["AAA/AA"] = 3;
find_prefix(smap, "AAA/AB")->second; // ==> 1
find_prefix(smap, "AAA/AA")->second; // ==> 3
find_prefix(smap, "BBB/AB")->second; // ==> 2
find_prefix(smap, "CCC/AB"); // ==> smap.end()
```
any comment (and thanks to litb) ? | From your requirement it seems that you don't really want map data structure but may be set or something very simple.
I think structure like this std::map might help you. Boost::any will be able to store anything, but caveat is that you need to know that value type is to read it back.
Key is string and hence it can be regex expression too. With this structure you will need two pass algorithm as:
```
std::map<std::string, boost::any> _map;
if (_map.find(key) != _map.end)
{
// exact match
}
else
{
// Have to do sequential regex (use boost::regex) matching
}
```
Since regex evaluation at runtime might be costly, you may use std::vector>, such that for regex patterns you store compiled regex into one of the fields.
It might be useful to give more background what you want to accomplish, as it may help to decide on right data structure and search algorithm. | map complex find operation | [
"",
"c++",
"stl",
"boost",
"dictionary",
"find",
""
] |
Is there an existing function in numpy that will tell me if a value is either a numeric type or a numpy array? I'm writing some data-processing code which needs to handle numbers in several different representations (by "number" I mean any representation of a numeric quantity which can be manipulated using the standard arithmetic operators, +, -, \*, /, \*\*).
Some examples of the behavior I'm looking for
```
>>> is_numeric(5)
True
>>> is_numeric(123.345)
True
>>> is_numeric('123.345')
False
>>> is_numeric(decimal.Decimal('123.345'))
True
>>> is_numeric(True)
False
>>> is_numeric([1, 2, 3])
False
>>> is_numeric([1, '2', 3])
False
>>> a = numpy.array([1, 2.3, 4.5, 6.7, 8.9])
>>> is_numeric(a)
True
>>> is_numeric(a[0])
True
>>> is_numeric(a[1])
True
>>> is_numeric(numpy.array([numpy.array([1]), numpy.array([2])])
True
>>> is_numeric(numpy.array(['1'])
False
```
If no such function exists, I know it shouldn't be hard to write one, something like
```
isinstance(n, (int, float, decimal.Decimal, numpy.number, numpy.ndarray))
```
but are there other numeric types I should include in the list? | As others have answered, there could be other numeric types besides the ones you mention.
One approach would be to check explicitly for the capabilities you want, with something like
```
# Python 2
def is_numeric(obj):
attrs = ['__add__', '__sub__', '__mul__', '__div__', '__pow__']
return all(hasattr(obj, attr) for attr in attrs)
# Python 3
def is_numeric(obj):
attrs = ['__add__', '__sub__', '__mul__', '__truediv__', '__pow__']
return all(hasattr(obj, attr) for attr in attrs)
```
This works for all your examples except the last one, `numpy.array(['1'])`. That's because `numpy.ndarray` has the special methods for numeric operations but raises TypeError if you try to use them inappropriately with string or object arrays. You could add an explicit check for this like
```
... and not (isinstance(obj, ndarray) and obj.dtype.kind in 'OSU')
```
This may be good enough.
But... you can never be *100%* sure that somebody won't define another type with the same behavior, so a more foolproof way is to actually try to do a calculation and catch the exception, something like
```
def is_numeric_paranoid(obj):
try:
obj+obj, obj-obj, obj*obj, obj**obj, obj/obj
except ZeroDivisionError:
return True
except Exception:
return False
else:
return True
```
but depending on how often you plan to call use it and with what arguments, this may not be practical (it can be potentially slow, e.g. with large arrays). | Also, numpy has `numpy.isreal` and other similar functions (`numpy.is` + Tab should list them).
They all have their fun corner cases but one of those could be useful. | Identifying numeric and array types in numpy | [
"",
"python",
"numpy",
""
] |
I current use prototype library to handle ajax requests. I have been on stack overflow for a week or so, and have seen lot of jQuery questions. It seems like most of people choose to use that library to handle javascript part of the programming. Beside the ajax part, rest of my javascript part on my website is developed on my own written code.
I am wondering if it would be more useful to continue to write my own javascript code, or should I spend time learning JQuery library and use its functions to save myself time? I am thinking that by writing my own code, it would make me more aware of the cross browser issues, and increase my understanding of javascript. On the other hand, if I just use the library and not deal with those issues, then there is no point in learning about them. Just kinda confuse and wanted to hear others opinions. What do others choose to do and why? How heavily do you rely on a library for JavaScript? How much more time would you need to spend, if you can make hypothetical guess, if you did not had the option to use the library?
I don't do any commercial work. I only work on my personal websites.
(My functions collection, if it is helpful somehow in answering my question: <http://hsbsitez.com/js/hsb_functions.js> ) | Why would you want to reinvent the wheel? Well if you don't know how the wheel works, you can't do much about fixing your wheel when it breaks, or making better wheels entirely - jQuery is an extremely useful tool, but don't ever let it be a crutch, and raw JS is the only way to learn.(1)
fwiw, I believe your personal website is the ideal opportunity to be learning on.
oh, and (stupidly blatantly obviously) this completely depends on the domain.
For a small localised problem, loading up a library is an unnecessarily expensive thing to be doing. For a large generalised set of problems the only efficient way to solve that, let alone the only sensible way to manage it, is to use a library of code - yours if it exists / is good enough / is well understood, jQuery probably being the best third-party library on the grounds of familiarity for other/future developers.
*1. this is actually very debatable but my gut says JS -> jQuery will make obvious sense, but the reverse won't.* | People here will recommend jQuery, or other JavaScript libraries, by the "don't reinvent the wheel" logic. But, if you're making personal websites, it's *sometimes* quite fun to play with JavaScript yourself. Maybe reminding yourself that if you care about cross-browser issues, and are getting bored bug-fixing for different browsers, then jQuery (and other similar frameworks) does exist. | JavaScript library or Raw coding? | [
"",
"javascript",
"jquery",
""
] |
I wrote a twitter application in Python. Following is the code I used for a module where I find if x is following y. This code can be obviously improved upon. A pythonic way to do that?
```
import urllib2
import sys
import re
import base64
from urlparse import urlparse
import simplejson
def is_follows(follower, following):
theurl = 'http://twitter.com/friendships/exists.json?user_a='+follower+'&user_b='+following
username = 'uname1'
password = 'pwd1'
handle = urllib2.Request(theurl)
base64string = base64.encodestring('%s:%s' % (username, password))
authheader = "Basic %s" % base64string
handle.add_header("Authorization", authheader)
fol=True
try:
fol = simplejson.load(urllib2.urlopen(handle))
except IOError, e:
# here we shouldn't fail if the username/password is right
print "It looks like the username or password is wrong."
return fol
```
Update: Indentation fixed. | From your code it looks like you are trying to do a Basic HTTP Authentication. Is this right? Then you shouldn't create the HTTP headers by hand. Instead use the urllib2.HTTPBasicAuthHandler. An example from the [docs](http://docs.python.org/library/urllib2.html):
```
import urllib2
# Create an OpenerDirector with support for Basic HTTP Authentication...
auth_handler = urllib2.HTTPBasicAuthHandler()
auth_handler.add_password(realm='PDQ Application',
uri='https://mahler:8092/site-updates.py',
user='klem',
passwd='kadidd!ehopper')
opener = urllib2.build_opener(auth_handler)
# ...and install it globally so it can be used with urlopen.
urllib2.install_opener(opener)
urllib2.urlopen('http://www.example.com/login.html')
``` | Konrad gave you a good answer with changes you can make to make your code more Pythonic. All I want to add is if you are interested in seeing some **advanced** code to do this same thing check out [The Minimalist Twitter API for Python](http://mike.verdone.ca/twitter/).
It can show you a Pythonic way to write an API that doesn't repeat itself (in other words follows DRY [don't repeat yourself] principles) by using dynamic class method construction using \_\_getattr\_\_() and \_\_call\_\_(). Your example would be something like:
```
fol = twitter.friendships.exists(user_a="X", user_b="Y")
```
even though the twitter class doesn't have "friendships" or "exists" methods/properties.
(Warning: I didn't test the code above so it might not be quite right, but should be pretty close) | Python code to find if x is following y on twitter. More Pythonic way please | [
"",
"authentication",
"twitter",
"python",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.