
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
Official Javadoc [says](http://docs.oracle.com/javase/7/docs/api/java/lang/Math.html#floor(double)) that `Math.floor()` returns a `double` that is "equal to a mathematical integer", but then why shouldn't it return an `int`? | According to the same Javadoc:
If the argument is `NaN` or an infinity or positive zero or negative zero, then the result is the same as the argument. Can't do that with an `int`.
The largest `double` value is also larger than the largest `int`, so it would have to be a `long`. | It's for precision. The double data-type has a 53 bit mantissa. Among other things that means that a double can represent all whole up to 2^53 without precision loss.
If you store such a large number in an integer you will get an overflow. Integers only have 32 bits.
Returning the integer as a double is the right thing to do here because it offers a much wider usefull number-range than a integer could. | Why does Math.floor return a double? | [
"",
"java",
"math",
"types",
""
] |
I recently imported about 60k records into a table that relates data in one table to data in another table. However, my client has since requested that a sort order be added to all 60k records. My hope is there is a nice clean way to auto generate these sort orders in a SQL Update. The finished data should look something like this:
```
item1ID item2ID sortOrder
1 123 1
1 12 2
1 45 3
1 22 4
1 456 5
2 5 1
2 234 2
2 56 3
```
Can this be done? Any suggestions would be hugely appreciated.
--Anne | You could use [ROW\_NUMBER][1] and partition by Item1ID
```
UPDATE t1
SET t1.SortOrder = t2.SortOrder
FROM @t t1
INNER JOIN
(SELECT Item1ID, Item2ID, ROW_NUMBER() OVER
(PARTITION BY Item1ID ORDER BY Item1ID, Item2ID) AS SortOrder
from @t) t2
ON t1.Item1ID = t2.Item1ID
AND t1.Item2ID = t2.Item2ID
``` | You're touching on something fundamental about the relational model here. In databases on the whole, there's no such thing as an intrinsic ordering. If you want to get an ordering out of data whenever you look at a table, you must specify that order explicitly.
So in a *general* sense, you're asking for the impossible. You can't just `UPDATE` a table and get an automatic ordering out any query you make on it. But in a *query-by-query* sense, you could always put "`ORDER BY item1ID, sortOrder`" in any `SELECT` statement you apply to the table.
In SQL Server 2005, you could write a view and present it to your client, using this old hack:
```
SELECT TOP 100 PERCENT
item1ID, item2ID, sortOrder -- and all the other columns
FROM YourTable
ORDER BY item1ID, sortOrder;
```
There are ways of making such a view updateable, but you'll need to research that on your own. It's not too hard to do.
If you're never going to insert or change data in this table, and if you're willing to reimport the data into a table again, you could define your table with an identity, then insert your data into the table in the appropriate order. Then you would always order by the one identity column. That would work if your client always views the data in a program that allows sorting by a single column. *(BTW, never use the `IDENTITY`* function *for this purpose. It won't work.)*
```
CREATE TABLE YourTable (
SingleSortColumn INT IDENTITY(1,1) NOT NULL,
...
);
INSERT INTO YourTable (
item1ID, item2ID, sortOrder -- everything except the SingleSortColumn
)
SELECT -- all your columns
INTO YourTable
FROM yadda yadda yadda
ORDER BY item1ID, sortOrder;
```
Hope that's helpful. Sorry if I'm being pedantic. | Auto Generate Sort Orders with SQL UPDATE | [
"",
"sql",
"sql-server-2005",
""
] |
When i use this cmd line :
jar cmf arshad.mf ars.jar \*.class
i get this error :
```
invalid header field name:Manifest-version
```
This is my manifest file :
```
Manifest-Version: 1.0
Main-Class:t
```
i made the manifest file with notepad in UTF-8 encoding - is there any problem with the manifest ? | Add a space after the colons:
```
Manifest-Version: 1.0
Main-Class: t
``` | Yes,it is true.
A common mistake people make when writing their manifest files for jar's is that they don't put spaces after their colons. I don't know, based on what you wrote here, if that's it or not but give it a try.
Example:
```
Main-Class:someClass //wrong
Main-Class: someClass //correct
``` | invalid header file while using jar for archiving | [
"",
"java",
"jar",
""
] |
To interact with an external data feed I need to pass a rolling security key which has been MD5 hashed (every day we need to generate a new MD5 hashed key).
I'm trading up whether or not to do it every time we call the external feed or not. I need to has a string of about 10 characters for the feed.
It's for an ASP.NET (C#/ .NET 3.5) site and the feed is used on pretty much every page. Would I best off generating the hash once a day and then storing it in the application cache, and taking the memory hit, or generating it on each request? | The only acceptable basis for optimizations is data. Measure generating this inline and measure caching it.
My high-end workstation can calculate well over 100k MD5 hashes of a 10-byte data segment in a second. There would be zero benefit from caching this for me and I bet it's the same for you. | Generate some sample data. Well, a lot of it. Compute the MD5 of the sample data. Measure the time it takes. Decide for yourself. | How expensive is MD5 generation in .NET? | [
"",
"c#",
".net",
"asp.net",
"performance",
"md5",
""
] |
Windows has the "system tray" that houses the clock and alway-running services like MSN, Steam, etc.
I'd like to develop a wxPython tray application but I'm wondering how well this will port to other platforms. What is the tray equivalent on each platform, and how much manual work would be required to support Windows, OSX and Linux (which shells in particular would be friendliest). | wx is a cross-platform GUI and tools library that supports Win32, Mac OS X, GTK+, X11, Motif, WinCE, and more. And if you use it's classes then your application should work on all these platforms.
For system tray look at wxTaskBarIcon (<http://docs.wxwidgets.org/stable/wx_wxtaskbaricon.html#wxtaskbaricon>). | Under OS X you have the Status Menu bar - the right-most items are often status-related things (like battery status, WiFi connections, etc).
Try searching for [NSStatusBar](http://developer.apple.com/documentation/Cocoa/Reference/ApplicationKit/Classes/NSStatusBar_Class/Reference/Reference.html) and [NSMenuExtra](http://www.cocoadev.com/index.pl?NSMenuExtra). It's almost trivial to turn an application into one that has an NSStatusBar menu and doesn't appear in the Dock. There are [tutorials](http://www.mactech.com/articles/mactech/Vol.22/22.02/Menulet/) [around](http://files.semaja2.net/NSStatusItem%20-%20ObjC.html) on how to do it. | How would a system tray application be accomplished on other platforms? | [
"",
"python",
"cross-platform",
"operating-system",
"wxpython",
"system-tray",
""
] |
I need help in designing my PHP classes where I need to extend from multiple classes.
I have a general class, Pagination.php that does all sort of pagination and sorting. All other classes will use this for pagination.
To make my life easier, I made a class generator that generates a class from MySQL table. All the properties, getters, setters and common methods are created automatically, which really saves time and money.
As an example, class Staff\_Base in Staff\_Base.php is generated automatically from SQL table t\_staff.
Since class Staff\_Base is automatically generated from SQL table, any 'custom' methods / properties are located in another class that extends Staff\_Base.php. (So that whenever a new field is added, I can simply regenerate Staff\_Base class and overwrite in Staff\_Base.php).
So I have class Staff.php that extends Staff\_Base.php.
The problem is, Staff.php also needs to extend another class, Pagination.php.
(The current workaround is to put methods in Pagination.php into every class. This is really troublesome whenever I make changes to the pagination/sorting methods.)
How do I do this?
What is the best design pattern to achieve this?
I know common suggestions to restructure my classes, but I really think hard of other workaround/solution. Also, I may also need to extend other classes than Pagination.php.
Thanks! | I would recommend changing your `Staff_Base.php` generator to make that class extend Pagination by default. That way `Staff` extends `Staff_Base`, and `Staff_Base` extends `Pagination`. I think that's probably the cleanest (and most object-oriented) way of getting the results you want. | Can you have your generated Staff\_Base class inherit from Pagination? Or does Staff\_Base already inherit from another base class (that you do not have control over)...
Sounds like either Doctrine or Propel, I do not recall which uses the \*\_Base class system.
My suggestion would be to rewrite pagination to be able to be used by your entity classes instead of requiring your entity classes to extend it. | PHP classes: Need help to inherit two classes | [
"",
"php",
"class",
"oop",
""
] |
Alright I've spent a good three days trying this, here's the scenario:
I want to download a '.csv' file from Google and then do stuff with the data from the file. It's for a Win32 Console Application. I have the latter down, I just cannot for the life of me figure out how to download the file. I've heard of libcurl, curlpp, ptypes, rolling my own, just using the .NET api, and been told a bunch of times:
> ...it's just a GET request
Well that's all well and good, but I must be missing something because it seems like everyone was just born knowing how to do this. I have been combing through books looking to figure this out and even had a huge problem with LNKerrors after traveling down the road with "The Art of C++" for a while.
All that being said, I have learned a LOT from this, but at this point I just want to know how to do it. The API for C++ is seriously lacking, no example code to be found. Tutorials online are almost non-existent. And no book out there seems to think this is important.
Can someone please throw me a life raft? I'm a man on the edge here.
**edit**
By "from Google" I mean that I want to download a .csv file that they host. An example can be [found here.](http://finance.google.com/finance/historical?q=NASDAQ:AAPL) | You should be able to [bend this](http://www.luckyspin.org/?p=28) to your will.
Now that I have kinda answered your question. Why C++? Nothing against the language, but pick the best language for the job. Perl, PHP, and Python(and I am sure more) all have great documentation and support on this kind of operation.
In perl(the one I am familiar with) it's just about 3-5 lines of code.
---
Here is the code snippet [previously available in](http://www.luckyspin.org/?p=28) (from [WayBackMachine](https://web.archive.org/web/20060903181348/http://www.luckyspin.org/?p=28)):
```
/*
* This is a very simple example of how to use libcurl from within
* a C++ program. The basic idea is that you want to retrieve the
* contents of a web page as a string. Obviously, you can replace
* the buffer object with anything you want and adjust elsewhere
* accordingly.
*
* Hope you find it useful..
*
* Todd Papaioannou
*/
#include <string>
#include <iostream>
#include "curl/curl.h"
using namespace std;
// Write any errors in here
static char errorBuffer[CURL_ERROR_SIZE];
// Write all expected data in here
static string buffer;
// This is the writer call back function used by curl
static int writer(char *data, size_t size, size_t nmemb,
std::string *buffer)
{
// What we will return
int result = 0;
// Is there anything in the buffer?
if (buffer != NULL)
{
// Append the data to the buffer
buffer->append(data, size * nmemb);
// How much did we write?
result = size * nmemb;
}
return result;
}
// You know what this does..
void usage()
{
cout < < "curltest: \n" << endl;
cout << " Usage: curltest url\n" << endl;
}
/*
* The old favorite
*/
int main(int argc, char* argv[])
{
if (argc > 1)
{
string url(argv[1]);
cout < < "Retrieving " << url << endl;
// Our curl objects
CURL *curl;
CURLcode result;
// Create our curl handle
curl = curl_easy_init();
if (curl)
{
// Now set up all of the curl options
curl_easy_setopt(curl, CURLOPT_ERRORBUFFER, errorBuffer);
curl_easy_setopt(curl, CURLOPT_URL, argv[1]);
curl_easy_setopt(curl, CURLOPT_HEADER, 0);
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, writer);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &buffer);
// Attempt to retrieve the remote page
result = curl_easy_perform(curl);
// Always cleanup
curl_easy_cleanup(curl);
// Did we succeed?
if (result == CURLE_OK)
{
cout << buffer << "\n";
exit(0);
}
else
{
cout << "Error: [" << result << "] - " << errorBuffer;
exit(-1);
}
}
}
}
``` | Why not just using what's already there?
[UrlDownloadToFile()](http://msdn.microsoft.com/en-us/library/ms775123(VS.85).aspx) | C++ 'GET' request or how do you download files to work with in C++? | [
"",
".net",
"c++",
"visual-c++",
"curl",
"libcurl",
""
] |
What's difference between inner join, outer join, left join and right join? Which one has the best performance? | Check this article:
[A Visual Explanation of SQL Joins](http://blog.codinghorror.com/a-visual-explanation-of-sql-joins/)
**Inner Join:**

**Left Outer Join:**

**Right Outer Join:**
 | Performance comparisions between types of joins are irrelevant as they give differnt results sets. Even if an inner join is faster you wouldn't use it if you needed the results of a left join (which includes even the records which don't match the second table in the join). | What's difference between inner join, outer join, left join and right join? | [
"",
"sql",
"join",
""
] |
I am setting the value of Session["UserID"] to Id of logined user, so I can know who the user is. But I want to know all users logined my page, and show the list of them. | Generally, you ask "How to know who has been active in the last x minutes."
Record their last activity time on each page entry, and then query that list to see who's been active in the last couple of minutes. You could extend that and record the last page they visited too, to know how many people are online, and how many people are on a specific page.
You could do this by adding just a couple fields to your user-table in the database. One for the lastActivityTime, and one for lastVisitedLocation. | the main problem you have with logged in users is that there is no guaranteed way to ensure that the number is accurate, if someone closes their browser or kills it, or loses power, the only way you have of knowing that they aren't logged in, is when their session expires, so, by default this is 20 minutes... i'm not really into the idea of persisting this information into a database, although it is valid, the same problem remains, all you can accurately show is the number of sessions asp.net thinks are active not necessarily the number of users who are still using your site Jonathans answer is the best compromise as its a point in time measure rather than a guaranteed figure. | How can I know online users of my web site | [
"",
"c#",
"asp.net",
"session",
""
] |
I used to work for a company where some of the lead architect/developers had mandated on various projects that assertions were not to be used, and they would routinely be removed from code and replaced with exceptions.
I feel they are extremely important in writing correct code. Can anyone suggest how such a mandate could be justified? If so, what's wrong with assertions? | We use a modified version of assert, as per JaredPar's comment, that acts like a contract. This version is compiled into the release code so there is a small size overhead, but disabled unless a diagnostics switch is set, such that performance overhead is minimized. Our assert handler in this instance can be set to disabled, silent mode (e.g. log to file), or noisy mode (e.g. display on screen with abort / ignore, where abort throws an exception).
We used automated regression testing as part of our pre-release testing, and asserts are hugely important here as they allow us to find potential internal errors that cannot be picked up at a GUI level, and may not be initially fatal at a user level. With automation, we can run the tests both with and without diagnostics, with little overhead other than the execution time, so we can also determine if the asserts are having any other side effects.
One thing to be careful of with asserts is side effects. For example, you might see something like *assert(MyDatabasesIsOk())*, which inadvertently corrects errors in the database. This is a bug, as asserts should never change the state of the running application. | The only really negative thing I can say about assertions is they don't run in retail code. In our team we tend to avoid assertions because of this. Instead we use contracts, which are assertions that run in both retail and debug.
The only time we use assertions now is if one of the following are true.
1. The assertion code has a **noticable** performance impact
2. The particular condition is not fatal
3. Occasionally there is a piece of code that may or may not be dead. We will add an assertion that essentially says "how did you get here." Not firing does not mean the code is indeed dead but if QA emails me and says "what does this assertion mean," we now have a repro to get to a particular piece of code (it's immediately documented of course). | Are assertions always bad? | [
"",
"c++",
"exception",
"assertions",
""
] |
I have 2 files which are interacting with each other. I wanted to define an enum to make the code more readable, but if I define it in file 1, file 2 complains about having no knowledge of said enum. If I define ii in file 2, file 1 does the same. I am defining it as public too.
The solution was to define the enum in both files, but this doesn't seem right to me. Not only is it redundant, but I fear it may cause some conflict, even if the types have the same items.
What is the veredict on this? Am I doing something wrong or worrying too much?
EDIT
Well, given the comments here I found an alternative which seems to be doing what I want without having to create a new file. I had:
file 1
```
class myClass1
{
public enum MyEnum
{
...
}
...
}
```
file 2
```
class myClass2
{
public enum MyEnum
{
...
}
....
}
```
Now, I have:
file 1
```
enum myEnum
{
...
}
...
class myClass1
{
...
}
```
file 2
```
class myClass2
{
...
}
```
I didn't want to create another file just for the enum, so this works for me. Well, as long as there is nothing wrong with it, which I think there isn't. | You definitely shouldn't define the enum in both locations. I recommend defining the enum in its own file with public accessibility. Then everyone should have no trouble accessing it. However, assuming that you want to define the enum in one of the two classes, I'll continue...
You have to `import` the enum or use its fully qualified name. Assuming you are in the package `com.stackoverflow`, your classes should look like this, in the first file:
```
package com.stackoverflow;
public class A {
public enum MyEnum {
ONE,TWO,THREE;
}
...
}
```
and in another file:
```
package com.stackoverflow;
import com.stackoverflow.A.MyEnum;
public class B {
public void test(MyEnum mine) {
...
}
...
}
``` | No - it is wrong. The `enum` can be declared as a static inner class and referenced using the fully-qualified name
```
public class MyClass {
public static enum MyEnum { BOOK, DVD }
public void myMethod() {
MyEnum e = MyEnum.DVD;
}
}
public class B {
public void someMethod() {
MyClass.MyEnum enumVal = MyClass.MyEnum.BOOK;
}
}
``` | Question about Java enums | [
"",
"java",
"enums",
""
] |
why does this work..
```
<script type="text/javascript">
<!--
function myAlert(){
alert('magic!!!');
}
if(document.addEventListener){
myForm.addEventListener('submit',myAlert,false);
}else{
myForm.attachEvent('onsubmit',myAlert);
}
// -->
</script>
```
but not this ????
```
<script type="text/javascript">
<!--
function myAlert(){
alert('magic!!!');
}
if(document.addEventListener){
myForm.addEventListener('submit',myAlert(),false);
}else{
myForm.attachEvent('onsubmit',myAlert());
}
// -->
</script>
```
the difference being the use of parenthesis when calling the `myAlert` function.
the error I get..
> "htmlfile: Type mismatch." when compiling via VS2008. | The **()** after a function means to *execute* the function itself and return it's value. Without it you simply have the function, which can be useful to pass around as a callback.
```
var f1 = function() { return 1; }; // 'f1' holds the function itself, not the value '1'
var f2 = function() { return 1; }(); // 'f2' holds the value '1' because we're executing it with the parenthesis after the function definition
var a = f1(); // we are now executing the function 'f1' which return value will be assigned to 'a'
var b = f2(); // we are executing 'f2' which is the value 1. We can only execute functions so this won't work
``` | The [addEventListener](https://developer.mozilla.org/En/DOM/Element.addEventListener) function expects a function or an object implementing `EventListener` as the second argument, not a function call.
When the `()` are added to a function name, it is a function invocation rather than the function itself.
**Edit:** As indicated in the other responses and in the comments, it is possible to return functions in Javascript.
So, for something interesting, we could try the following. From the original `myAlert`, we can change it a little to return a different message, depending on the parameters:
```
function myAlert(msg)
{
return function()
{
alert("Message: " + msg);
}
}
```
Here, notice that the function actually returns a function. Therefore, in order to invoke that function, the extra `()` will be required.
I wrote a little HTML and Javascript to use the above function. (Please excuse my unclean HTML and Javascript, as it's not my domain):
```
<script type="text/javascript">
function myAlert(msg)
{
return function()
{
alert("Message: " + msg);
}
}
</script>
<html>
<body>
<form>
<input type="button" value="Button1" onclick="myAlert('Clicked Button1')()">
<input type="button" value="Button2" onclick="myAlert('Clicked Button2')()">
</form>
</body>
</html>
```
Two buttons are shown, and each will call the `myAlert` function with a different parameter. Once the `myAlert` function is called, it itself will return another `function` so that must be invoked with an extra set of parenthesis.
End result is, clicking on `Button1` will show a message box with the message `Message: Clicked Button1`, while clicking on `Button2` will show a message box saying `Message: Clicked Button2`. | javascript syntax: function calls and using parenthesis | [
"",
"javascript",
"syntax",
""
] |
I asked the opposite question [here](https://stackoverflow.com/questions/361135/sql-query-advice-most-recent-item), now I am faced with another problem. Assume I have the following tables (as per poster in previous post)
```
CustID LastName FirstName
------ -------- ---------
1 Woman Test
2 Man Test
ProdID ProdName
------ --------
123 NY Times
234 Boston Globe
ProdID IssueID PublishDate
------ ------- -----------
123 1 12/05/2008
123 2 12/06/2008
CustID OrderID OrderDate
------ ------- ---------
1 1 12/04/2008
OrderID ProdID IssueID Quantity
------- ------ ------- --------
1 123 1 5
2 123 2 12
```
How do I obtain the previous issue (publishdate) from table 3, of all issue, by WeekDay name? The presious issue of today (Wednesday) will not be yesterday Tuesday but last week Wednesday. The result will be 3 columns. The Product Name, current issue (PublishDate) and previous issue (PublishDate).
Thanks
Edit ~ Here is a problem I am facing. What if the previous issue doesn't exists, it has to go back to the pror week as well. I tried the following as a test but doesn't work
```
SELECT TOP 1 publishdate FROM dbo.issue
WHERE prodid = 123 AND datename(dw,publishdate) = datename(dw,'2008-12-31')
ORDER BY publishdate desc
```
This is on SQL Server 2000. | Can IssueIDs be assumed to be ordered correctly, ie. every next issue has ID that is larger by 1?
In that case something like this should work:
```
SELECT Curr.ProdID, Curr.PublishDate As CurrentIssue, Prev.PublishDate AS PrevIssue
FROM Issues Curr, Issues Prev
WHERE ProdID=123 AND Curr.PublishDate='12/06/2008' AND Prev.IssueID=Curr.IssueID - 1
```
Otherwise there needs to be a way to determine which date is correct for previous issue (last week, last month?) and use subselect with date subtraction.
P.S. It'd be nice if you also included the names of the tables for easier reference, and also specified which SQL server you are using, as, for exmample, date function syntax varies wildly among them. | I think you're saying that in this context, your definition of "previous issue" is "the issue that came out on the same day of the week in the previous week".
Does this accomplish what you want? (Calling your "table 2" products and your "table 3" issues.)
```
SELECT ProdName, current.IssueID, previous.IssueID
FROM products, issues current, issues previous
WHERE current.prodID = products.prodID
AND previous.prodID = current.prodID
AND previous.publishDate = current.publishDate - 7;
```
It's not clear if you want this information for the most recent issue, for all issues in the current week, or for all issues ever. You could add a condition on current.publishDate to restrict which "current" issues to look at.
I'm assuming that a previous issue always exists. If it is possible that it doesn't (some products skip days), you may want an outer join between "current" and "previous". | SQL Query Advice - Get Previous Item | [
"",
"sql",
"sql-server",
""
] |
I want to get a simple Python "hello world" web page script to run on Windows Vista/ Apache but hit different walls. I'm using WAMP. I've installed `mod_python` and the module shows, but I'm not quite sure what I'm supposed to do in e.g. http.conf (things like AddHandler mod\_python .py either bring me to a file not found, or a forbidden, or module not found errors when accessing <http://localhost/myfolder/index.py>). I can get `mod_python.publisher` to work but do I "want" this/ need this?
Can anyone help?
Thanks! | Stay away from `mod_python`. One common misleading idea is that `mod_python` is like `mod_php`, but for python. That is not true. [Wsgi](http://wsgi.org) is the standard to run python web applications, defined by [PEP 333](http://www.python.org/dev/peps/pep-0333/). So use [`mod_wsgi`](http://code.google.com/p/modwsgi/) instead.
Or alternatively, use some web framework that has a server. [Cherrypy](http://www.cherrypy.org/)'s one is particulary good. You will be able to run your application both standalone and through `mod_wsgi`.
An example of Hello World application using cherrypy:
```
import cherrypy
class HelloWorld(object):
def index(self):
return "Hello World!"
index.exposed = True
application = HelloWorld()
if __name__ == '__main__':
cherrypy.engine.start()
cherrypy.engine.block()
```
Very easy huh? Running this application directly on python will start a webserver. Configuring `mod_wsgi` to it will make it run inside apache. | You do not NEED mod\_python to run Python code on the web, you could use simple CGI programming to run your python code, with the instructions in the following link: <http://www.imladris.com/Scripts/PythonForWindows.html>
That should give you some of the configuration options you need to enable Python with CGI, and a google search should give you reams of other info on how to program in it and such.
Mod\_python is useful if you want a slightly more "friendly" interface, or more control over the request itself. You can use it to create request filters and other things for the Apache server, and with the publisher handler you get a simpler way of handling webpage requests via python.
The publisher handler works by mapping URLs to Python objects/functions. This means you can define a function named 'foo' in your python file, and any request to <http://localhost/foo> would call that function automatically. More info here: <http://www.modpython.org/live/current/doc-html/hand-pub-alg-trav.html>
As for the Apache config to make things work, something like this should serve you well
```
<Directory /var/www/html/python/>
SetHandler mod_python
PythonHandler mod_python.publisher
PythonDebug On
</Directory>
```
If you have /var/www/html/ set up as your web server's root and have a file called index.py in the python/ directory in there, then any request to <http://localhost/python/foo> should call the foo() function in index.py, or fail with a 404 if it doesn't exist. | Setting up Python on Windows/ Apache? | [
"",
"python",
"wamp",
"mod-python",
""
] |
When I print a webpage from Internet Explorer it will automatically add a header and footer including the website title, URL, date, and page number.
Is it possible to hide the header and footer programatically using Javascript or CSS?
Requirements:
* works in IE 6 (no other browser support necessary as its for an Intranet)
* may use ActiveX, Java Applet, Javascript, CSS
* preferably not something that the user needs to install (eg. <http://www.meadroid.com/scriptx>). feel free to list other third party available plug-ins though as I think this may be the only option
* don't require the user to manually update their browser settings
* don't render the pages as PDF or Word document or any other format
* don't write to the registry (security prevents this)
Thanks | In your print options you can disable this. The only way to do it programatically is with an activeX control which writes to the registry or a script block which is written in VB. The settings for your print options are stored in the registry. The user would have to allow your script to access the registry which most people wouldnt because of security.
If you want to control page content, you can use a css print stylesheet.
Edit: There are 3rd party active x controls which can programatically print for you, but once again, the user would have to choose to download and install it. | I think you can not control it with javascript.
In my opinion, there is only option to use ActiveX in IE.
I am still looking for the answer.
Good luck. | Hide header and footer when printing from Internet Explorer using Javascript or CSS | [
"",
"javascript",
"css",
"internet-explorer",
"printing",
""
] |
So I came across some code this morning that looked like this:
```
try
{
x = SomeThingDangerous();
return x;
}
catch (Exception ex)
{
throw new DangerousException(ex);
}
finally
{
CleanUpDangerousStuff();
}
```
Now this code compiles fine and works as it should, but it just doesn't feel right to return from within a try block, especially if there's an associated finally.
My main issue is what happens if the finally throws an exception of it's own? You've got a returned variable but also an exception to deal with... so I'm interested to know what others think about returning from within a try block? | No, it's not a bad practice. Putting `return` where it makes sense improves readability and maintainability and makes your code simpler to understand. You shouldn't care as `finally` block will get executed if a `return` statement is encountered. | The finally will be executed no matter what, so it doesn't matter. | Is it bad practice to return from within a try catch finally block? | [
"",
"c#",
"try-catch",
"try-catch-finally",
""
] |
I have a legacy class that the class itself is not a generic but one of its methods return type uses generics:
```
public class Thing {
public Collection<String> getStuff() { ... }
}
```
`getStuff()` uses generics to return a collection of strings. Therefore I can iterate over `getStuff()` and there's no need to cast the elements to a `String`:
```
Thing t = new Thing();
for (String s: t.getStuff()) // valid
{ ... }
```
However, if I change `Thing` itself to be a generic but keep everything else the same:
```
public class Thing<T> {
public Collection<String> getStuff() { ... }
}
```
and then keep using the non-generic reference to `Thing`, `getStuff()` no longer returns `Collection<String>` and instead returns a non-typed `Collection`. Thus the client code does not compile:
```
Thing t = new Thing();
for (String s: t.getStuff()) // compiler complains that Object can't be cast to String
{ ... }
```
Why is this? What are the workarounds?
My guess is that by using a non-generic reference to a generic class, Java turns off all generics for the entire class. This is pain, because now I've broken my client code by making Thing a generic.
**Edit:** I'm making Thing generic for another method which is not listed in the above example code. My question is educational as to why the above cannot be done. | Ok, take two, I misunderstood your question.
When you delcare `Thing` (this is called a **raw type**) instead of `Thing<?>` (**parameterized type**) the Java compiler strips out all generic arguments, even thogh (as in your case) the generic type of the method has nothing to do with the generic type of the class.
From the (excellent) [Java Generics FAQ](http://www.angelikalanger.com/GenericsFAQ/JavaGenericsFAQ.html):
[Can I use a raw type like any other type?](http://www.angelikalanger.com/GenericsFAQ/FAQSections/ParameterizedTypes.html#Can%20I%20use%20a%20raw%20type%20like%20any%20other%20type?)
> Methods or constructors of a raw type have the signature that they would have after type erasure.
This seemingly inocuous and unobtrusive sentence describes the behaviour in question. You're using `Thing` as a raw type so the return type is `Collection` (not `Collection<String>`) since this is the type after type erasure.
Confused? Not surprising. Just look at the size of that FAQ. There's probably about three people on earth who nderstand the full implications of Java Generics. Just consider my favourite declaration from the JDK:
```
Enum<T extends Enum<T>>
```
(Theres an explanation of that in the FAQ too). | It is failing because of erasure. You can read more about it in these [Java Tutorials](http://java.sun.com/docs/books/tutorial/java/generics/erasure.html) | Non-generic reference to generic class results in non-generic return types | [
"",
"java",
"generics",
""
] |
I have a variable, **$id**, which identifies the product category type to display on the page. I first need to check that the id variable has been set and if not, default the variable to category 0.
The code I have is as follows:
```
setdefault($id, 0);
function setdefault(&$var, $default="")
{
if (!isset($var))
{
$var = $default;
}
}
```
So with the address `www.website.com/browse.php`, I would expect it to default to `$id = 0`.
With the address `www.website.com/browse.php?id=3`, I would expect it to set `$id = 3` and display the relevant products.
However, despite setting `$id`, it still defaults to `0`. Is there something obviously incorrect with my code? | You are probably expecting PHP to use the $\_POST and $\_GET as global variables. PHP used to be setup this way, back in the day, but newer versions require you to explicitly reference these variables.
You could try this:
```
setdefault($_GET['id'], 0);
function setdefault(&$var, $default="")
{
if (!isset($var))
{
$var = $default;
}
}
```
or even more simply (using the ternary operator):
```
$id = array_key_exists('id', $_GET) ? $_GET['id'] : 0;
``` | First off, if this is PHP 5.X I highly recommend you do not pass variables by reference using the &. That being said. the isset function call will always be true withing the function. But you will receive an undefined variable warning on the setdefault($id, 0);
Try this instead.
```
$id = isset($id) ? $id : 0;
``` | Declare variable from value in query string of url and fallback to a default value if missing | [
"",
"php",
"variables",
"query-string",
"default-value",
"isset",
""
] |
I have a postfix server listening and receiving all emails received at mywebsite.com Now I want to show these postfix emails in a customized interface and that too for each user
To be clear, all the users of mywebsite.com will be given mail addresses like someguy@mywebsite.com who receives email on my production machine but he sees them in his own console built into his dashboard at mywebsite.com.
So to make the user see the mail he received, I need to create an email replica of the postfix mail so that mywebsite(which runs on django-python) will be reflecting them readily. How do I achieve this. To be precise this is my question, how do I convert a postfix mail to a python mail object(so that my system/website)understands it?
Just to be clear I have written psuedo code to achieve what I want:
```
email_as_python_object = postfix_email_convertor(postfix_email)
attachments_list = email_as_python_object.attachments
body = email_as_python_object.body # be it html or whatever
```
And by the way I have tried default email module which comes with python but thats not handy for all the cases. And even I need to deal with mail attachments manually(which I hate). I just need a simple way to deal with cases like these(I was wondering how postfix understands a email received. ie.. how it automatically figures out different headers,attachments etc..). Please help me. | First of all, Postfix mail routing rules can be very complex and your presumably preferred solution involves a lot of trickery in the wrong places. You do not want to accidentally show some user anothers mails, do you? Second, although Postfix can do almost anything, it shouldn't as it only is a MDA (mail delivery agent).
Your solution is best solved by using a POP3 or IMAP server (Cyrus IMAPd, Courier, etc). IMAP servers can have "superuser accounts" who can read mails of all users. Your web application can then connect to the users mailbox and retreive the headers and bodys.
If you only want to show the subject-line you can fetch those with a special IMAP command and very low overhead. The Python IMAP library has not the easiest to understand API though. I'll give it a shot (not checked!) with an example taken from the standard library:
```
import imaplib
sess = imaplib.IMAP4()
sess.login('superuser', 'password')
# Honor the mailbox syntax of your server!
sess.select('INBOX/Luke') # Or something similar.
typ, data = sess.search(None, 'ALL') # All Messages.
subjectlines = []
for num in data[0].split():
typ, msgdata = sess.fetch(num, '(RFC822.SIZE BODY[HEADER.FIELDS (SUBJECT)])')
subject = msgdata[0][1].lstrip('Subject: ').strip()
subjectlines.append(subject)
```
This logs into the IMAP server, selects the users mailbox, fetches all the message-ids then fetches (hopefully) only the subjectlines and appends the resulting data onto the *subjectlines* list.
To fetch other parts of the mail vary the line with *sess.fetch*. For the specific syntax of *fetch* have a look at [RFC 2060](http://www.faqs.org/rfcs/rfc2060.html) (Section 6.4.5).
**Good luck!** | You want to have postfix deliver to a local mailbox, and then use a webmail system for people to access that stored mail.
Don't get hung up on postfix - it just a transfer agent - it takes messages from one place, and puts them somewhere else, it doesn't store messages.
So postfix will take the messages over SMTP, and put them in local mail files.
Then IMAP or some webmail system will display those messages to your users.
If you want the mail integrated in your webapp, then you should probably run an IMAP server, and use python IMAP libraries to get the messages. | Integrate postfix mail into my (python)webapp | [
"",
"python",
"email",
"message",
"postfix-mta",
""
] |
In my application, I need to change some value ("Environment") in appSetting of app.config at runtime.
I use AppSettingsReader
```
private static AppSettingsReader _settingReader;
public static AppSettingsReader SettingReader
{
get
{
if (_settingReader == null)
{
_settingReader = new AppSettingsReader();
}
return _settingReader;
}
}
```
Then at some stage I do this
```
config.AppSettings.Settings[AppSettingString.Environment.ToString()].Value = newEnvironment.ToString();
config.Save(ConfigurationSaveMode.Modified);
ConfigurationManager.RefreshSection("appSettings");
```
However, next time I try to read "Environment" like this
```
string environment = (string)SettingReader.GetValue(AppSettingString.Environment.ToString(), typeof(System.String));
```
I end up with the old value of Environment.
I noticed that I can fix this by doing
```
_settingReader = new AppSettingsReader();
```
before I read "Environment".
But I think creating a new instance is not the proper approach.
Maybe there is a way to let my SettingReader know, that the values have changed to use the same instance of it, but with refreshed values?
(Not a project-breaking question obviously, more of an educational one) | AppSettingsReader doesn't seem to have any method to reload from disk. It just derives from Object. Creating a new instance seems to be the only thing that would work... I may be wrong, but AppSettings are supposed to be read-only values for your app. More like configuration parameters for your application that can be tweaked before startup.
For read-write application settings, I think the Settings mechanism with IDE support ([System.Configuration.ApplicationSettingsBase](http://msdn.microsoft.com/en-us/library/system.configuration.applicationsettingsbase.aspx)) would be the preferred approach. This has Save and [Reload](http://msdn.microsoft.com/en-us/library/system.configuration.applicationsettingsbase.reload.aspx) methods. The designer-gen class makes the code far more readable too..
*Double click on the Properties Node under your Project in Solution Explorer. Find the Settings tab.*
Instead of
```
sEnvironment = (string)SettingReader.GetValue(AppSettingString.Environment.ToString(), typeof(System.String));
```
you could have typed properties like
```
sEnvironment = Properties.Settings.Default.Environment;
```
The designer generated class exposes a synchronized singleton instance via the Default property.. which should mean you don't need to reload.. you'd always get the latest value within the application. | ```
System.Configuration.ApplicationSettingsBase.Reload
``` | C# AppSettingsReader: "reread" values into the AppSettingsReader (runtime)? | [
"",
"c#",
"configuration",
"app-config",
""
] |
I'm trying to create a bunch of entries in a database with a single script and the problem I'm encountering is how to reference the generated primary key of the previous entry I created.
For example if I created a customer, then tried to create an order for that customer, how do I get the primary key generated for the customer?
I'm using SQLServer. | Like so:
```
DECLARE @customerid int;
INSERT INTO customers(name) VALUES('Spencer');
SET @customerid = @@IDENTITY;
```
**EDIT:**
Apparently it needs to be SCOPE\_IDENTITY() in order to function as expected with triggers.
```
DECLARE @customerid int;
INSERT INTO customers(name) VALUES('Spencer');
SET @customerid = SCOPE_IDENTITY();
``` | If available in your version, use SCOPE\_IDENTITY() instead. Safer than @@IDENTITY. | Reference generated primary key in SQL script | [
"",
"sql",
"sql-server",
"primary-key",
""
] |
I know that according to C++ standard in case the new fails to allocate memory it is supposed to throw std::bad\_alloc exception. But I have heard that some compilers such as VC6 (or CRT implementation?) do not adhere to it. Is this true ? I am asking this because checking for NULL after each and every new statement makes code look very ugly. | VC6 was non-compliant by default in this regard. VC6's `new` returned `0` (or `NULL`).
Here's Microsoft's KB Article on this issue along with their suggested workaround using a custom `new` handler:
* [Operator new does not throw a bad\_alloc exception on failure in Visual C++](http://support2.microsoft.com/kb/167733/en-us)
If you have old code that was written for VC6 behavior, you can get that same behavior with newer MSVC compilers (something like 7.0 and later) by linking in a object file named `nothrownew.obj`. There's actually a [fairly complicated set of rules](http://msdn.microsoft.com/en-us/library/kftdy56f(VS.71).aspx) in the 7.0 and 7.1 compilers (VS2002 and VS2003) to determine whether they defaulted to non-throwing or throwing `new`.
It seems that [MS cleaned this up](http://msdn.microsoft.com/en-us/library/kftdy56f.aspx) in 8.0 (VS2005)—now it always defaults to a throwing new unless you specifically link to `nothrownew.obj`.
Note that you can specify that you want `new` to return `0` instead of throwing `std::bad_alloc` using the `std::nothrow` parameter:
```
SomeType *p = new(std::nothrow) SomeType;
```
This appears to work in VC6, so it could be a way to more or less mechanically fix the code to work the same with all compilers so you don't have to rework existing error handling. | I'd like to add the (somewhat controversial) opinion that checking for NULL after an allocation attempt is pretty much an exercise in futility. If your program ever runs into that situation, chances are you can't do much more than exiting fast. It's very likely that any subsequent allocation attempt will also fail.
Without checking for NULL, your subsequent code would attempt to dereference a NULL pointer, which tends to exit the program fast, with a relatively unique (and easily debuggable) exit condition.
I'm not trying to talk you out of checking for NULL, it's certainly conscientious programming. But you don't gain much from it, unless in very specific cases where you can perhaps store some recovery information (without allocating more memory), or free less important memory, etc. But those cases will be relatively rare for most people.
Given this, I'd just trust the compiler to throw bad\_alloc, personally - at least in most cases. | Will new return NULL in any case? | [
"",
"c++",
"visual-c++",
"memory-management",
"new-operator",
"visual-c++-6",
""
] |
I have the following code:
```
#include <iostream>
using namespace std;
class testing{
int test() const;
int test1(const testing& test2);
};
int testing::test() const{
return 1;
}
int testing::test1(const testing& test2){
test2.test();
return 1;
}
```
after compilation, it gives me the following error:
```
Undefined symbols:
"_main", referenced from:
start in crt1.10.5.o
ld: symbol(s) not found
collect2: ld returned 1 exit status
```
Why is it complaining about main? Can't i declare main in another file and include this one?
Thanks a lot! | You have tried to link it already:
```
g++ file.cpp
```
That will not only compile it, but try to already create the executable. The linker then is unable to find the main function that it needs. Well, do it like this:
```
g++ -c file.cpp
g++ -c hasmain.cpp
```
That will create two files file.o and hasmain.o, both only compiled so far. Now you can link them together with g++:
```
g++ -omy_program hasmain.o file.o
```
It will automatically figure out that those are files already compiled, and invoke the linker on them to create a file "my\_program" which is your executable. | If you declare the main function in another file, then you must compile the two files separately, and then link them into 1 executable.
Unless you include the entire contents of the file from the file with the main function, that will work too, though a bit odd. But, if you do this then you have to make sure that you compile the file which has the main() function. | Compile error: Undefined symbols: "_main", referenced from: start in crt1.10.5.o | [
"",
"c++",
""
] |
Can anyone suggest any open and free library for logging on Windows Mobile application written in C++?
It would be nice if it supports logging to files, syslog (would be nice) and logging level. | None that I know of.
You will most likely have to look for source code available logging libraries. Windows Mobile will pretty much compile most win32 code with no or little changes, so any win32 logging library should work.
Generally I build my own as I like fine gained control over my logging code. | Perhaps you could see if the logging from <http://pt-framework.sourceforge.net/> fits your needs. I don't know if syslog is supported. | Where can I find a flexible logging library for Windows Mobile? | [
"",
"c++",
"logging",
"windows-mobile",
""
] |
I am looking to write a small application that receives an SMS text message and records the results in an online database. I am most comfortable with php/mysql, but can use any suggestions you might have. | I wrote something cute and small like this last summer, but I cheated using an actual SMS server and used Twitter to receive my text messages in a specific format, then had a daemon service running through my RSS feed every *n* time units to pull in the data and store it in a flat file. It was a fun exercise, and free, and as far as I know no free SMS receivers are available. You can use MySQL if you want, but I feel like you'll need a language that's more designed for writing a service than a web application (i.e. PHP) | I've used [clickatell](http://www.clickatell.com/developers.php) for setting up SMS notification for Nagios. Never used them to receive text message though. My guess is you probably give them some magic URL and they hit it up with with a POST containing all the data in the message.
You'll ever find anything that is free though. In fact, you might find that SMS is rather expensive if you do a lot of volume. Even $0.01/message is a lot when you are sending 10k messages a week. | Looking for advice on updating an online database with SMS | [
"",
"php",
"mysql",
"database",
"sms",
""
] |
**DUPLICATE:** [How can I programmatically determine if my workstation is locked?](https://stackoverflow.com/questions/44980)
How can I detect (during runtime) when a Windows user has locked their screen (Windows+L) and unlocked it again. I know I could globally track keyboard input, but is it possible to check such thing with environment variables? | You can get this notification via a WM\_WTSSESSION\_CHANGE message. You must notify Windows that you want to receive these messages via WTSRegisterSessionNotification and unregister with WTSUnRegisterSessionNotification.
These posts should be helpful for a C# implementation.
<http://pinvoke.net/default.aspx/wtsapi32.WTSRegisterSessionNotification>
<http://blogs.msdn.com/shawnfa/archive/2005/05/17/418891.aspx>
<http://bytes.com/groups/net-c/276963-trapping-when-workstation-locked> | A [SessionSwitch](http://msdn.microsoft.com/en-us/library/microsoft.win32.sessionswitcheventhandler.aspx) event may be your best bet for this. Check the [SessionSwitchReason](http://msdn.microsoft.com/en-us/library/microsoft.win32.sessionswitchreason.aspx) passed through the [SessionSwitchEventArgs](http://msdn.microsoft.com/en-us/library/microsoft.win32.sessionswitcheventargs.aspx) to find out what kind of switch it is and react appropriately. | Checking for workstation lock/unlock change with c# | [
"",
"c#",
"windows",
"session-state",
"environment",
""
] |
I found this line of code in the Virtuemart plugin for Joomla on line 2136 in administrator/components/com\_virtuemart/classes/ps\_product.php
```
eval ("\$text_including_tax = \"$text_including_tax\";");
``` | Scrap my previous answer.
The reason this eval() is here is shown in the [php eval docs](http://www.php.net/eval)
This is what's happening:
```
$text_including_tax = '$tax <a href="...">...</a>';
...
$tax = 10;
...
eval ("\$text_including_tax = \"$text_including_tax\";");
```
At the end of this `$text_including_tax` is equal to:
```
"10 <a href="...">...</a>"
```
The single quotes prevents `$tax` being included in the original definition of the string. By using `eval()` it forces it to re-evaluate the string and include the value for `$tax` in the string.
I'm not a fan of this particular method, but it is correct. An alternative could be to use `sprintf()` | This code seems to be a bad way of forcing `$text_including_tax` to be a string.
The reason it is bad is because *if* `$text_including_tax` can contain data entered by a user it is possible for them to execute arbitrary code.
For example if `$text_include_tax` was set to equal:
```
"\"; readfile('/etc/passwd'); $_dummy = \"";
```
The eval would become:
```
eval("$text_include_tax = \"\"; readfile('/etc/passwd'); $_dummy =\"\";");
```
Giving the malicious user a dump of the passwd file.
A more correct method for doing this would be to cast the variable to string:
```
$text_include_tax = (string) $text_include_tax;
```
or even just:
```
$text_include_tax = "$text_include_tax";
```
If the data `$text_include_tax` is only an internal variable or contains already validated content there isn't a security risk. But it's still a bad way to convert a variable to a string because there are more obvious and safer ways to do it. | What is the point of this line of code? | [
"",
"php",
"virtuemart",
""
] |
I am using the Settings class in my .NET project. I notice in the editor that only certain types are available to be used as types for the individual properties in the Settings class. What if I wanted to have a property that was an enumeration from my code or a generic collection for instance? How would I implement that?
I'm guessing that I can do it in a separate file using the partial class mechanism (since Settings is already defined as a partial class) but I want to see if anyone agrees with that and if there may be a way to do it within the editor. | Create a new "Settings" file to add a complex/user-defined type of choice.
Here is a how-to for a Enum.
**Step 1**. Create a Settings file
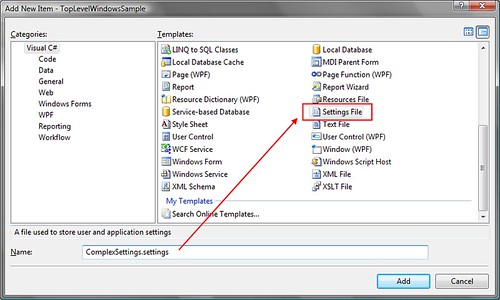
**Step 2**. Browse for type
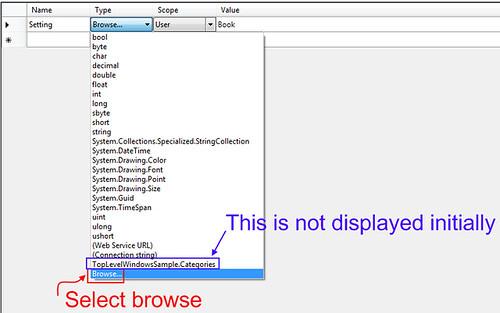
**Step 3**. Select type (Namespace.TypeName)
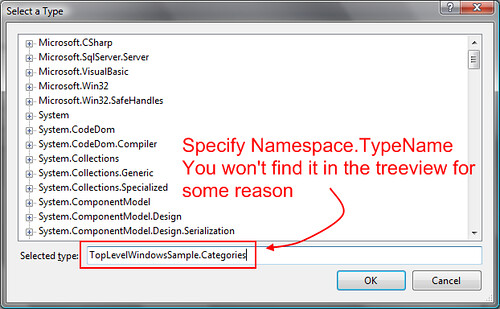
**Step 4**. Ta da - Done
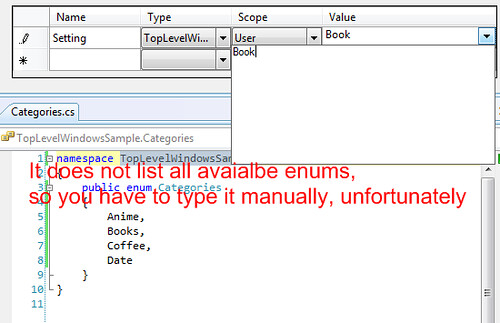 | To get a custom class to show in that list, make sure it has a default constructor as one of it's constructing options. I learned this the hard way | Using Settings with Complex Types | [
"",
"c#",
"configuration",
"settings",
""
] |
I'm doing some [Project Euler](http://projecteuler.net/) exercises and I've run into a scenario where I have want arrays which are larger than 2,147,483,647 (the upper limit of `int` in C#).
Sure these are large arrays, but for instance, I can't do this
```
// fails
bool[] BigArray = new BigArray[2147483648];
// also fails, cannot convert uint to int
ArrayList BigArrayList = new ArrayList(2147483648);
```
So, can I have bigger arrays?
EDIT:
It was for a [Sieve of Atkin](http://en.wikipedia.org/wiki/Sieve_of_Atkin), you know, so I just wanted a really big one :D | Anytime you are working with an array this big, you should probably try to find a better solution to the problem. But that being said I'll still attempt to answer your question.
As mentioned in this [article](http://msdn.microsoft.com/en-us/library/ms241064(VS.80).aspx) there is a 2 GB limit on any object in .Net. For all x86, x64 and IA64.
> As with 32-bit Windows operating
> systems, there is a 2GB limit on the
> size of an object you can create while
> running a 64-bit managed application
> on a 64-bit Windows operating system.
Also if you define an array too big on the stack, you will have a stack overflow. If you define the array on the heap, it will try to allocate it all in one big continuous block. It would be better to use an ArrayList which has implicit dynamic allocation on the heap. This will not allow you to get past the 2GB, but will probably allow you to get closer to it.
I think the stack size limit will be bigger only if you are using an x64 or IA64 architecture and operating system. Using x64 or IA64 you will have 64-bit allocatable memory instead of 32-bit.
If you are not able to allocate the array list all at once, you can probably allocate it in parts.
Using an array list and adding 1 object at a time on an x64 Windows 2008 machine with 6GB of RAM, the most I can get the ArrayList to is size: 134217728. So I really think you have to find a better solution to your problem that does not use as much memory. Perhaps writing to a file instead of using RAM. | The array limit is, afaik, fixed as int32 even on 64-bit. There is a cap on the maximum size of a single object. However, you could have a nice big jagged array quite easily.
Worse; because references are larger in x64, for ref-type arrays you actually get *less* elements in a single array.
See [here](http://www.twine.com/item/11qtqln9x-1s/josh-williams):
> I’ve received a number of queries as
> to why the 64-bit version of the 2.0
> .Net runtime still has array maximum
> sizes limited to 2GB. Given that it
> seems to be a hot topic of late I
> figured a little background and a
> discussion of the options to get
> around this limitation was in order.
>
> First some background; in the 2.0
> version of the .Net runtime (CLR) we
> made a conscious design decision to
> keep the maximum object size allowed
> in the GC Heap at 2GB, even on the
> 64-bit version of the runtime. This is
> the same as the current 1.1
> implementation of the 32-bit CLR,
> however you would be hard pressed to
> actually manage to allocate a 2GB
> object on the 32-bit CLR because the
> virtual address space is simply too
> fragmented to realistically find a 2GB
> hole. Generally people aren’t
> particularly concerned with creating
> types that would be >2GB when
> instantiated (or anywhere close),
> however since arrays are just a
> special kind of managed type which are
> created within the managed heap they
> also suffer from this limitation.
---
It should be noted that in .NET 4.5 the *memory size* limit is optionally removed by the [gcAllowVeryLargeObjects](http://msdn.microsoft.com/en-us/library/hh285054(v=vs.110).aspx) flag, however, this doesn't change the maximum *dimension* size. The key point is that if you have arrays of a custom type, or multi-dimension arrays, then you can now go beyond 2GB in memory size. | Is the size of an array constrained by the upper limit of int (2147483647)? | [
"",
"c#",
"arrays",
"int",
"integer-overflow",
""
] |
I'm working on a site where the images and other resources will be located on a separate domain from the main content of the site. We will use something like 'www.example.com' for the main site, and then 'images.example.com' for all extra resources for styles, etc.
When developing the site I will keep all of these resources on local dev. machines. The challenge here is keeping CSS references consistent between the production server and development environments.
What I was thinking of doing was creating a `web.config` key that would store the URL of the images server. Then, when switching from development to production I could just change the web.config value and everything would be done.
Is there any way to add a value to a CSS file, dynamically or otherwise, from some place in a config or C# class? Or am I going about this the wrong way?
Also, I'm limited to using .NET 2.0 if that makes a difference.
**UPDATE**
To expand on this a little more, I know I can use a web.config setting for server controls' URLs. Those are already generated dynamically. What I'm more interested in is what options I have for modifying (or doing "*something*") to static CSS files that will allow me to change URLs for things such as background image resources that would be referenced in CSS. Is there anything I can do besides find/replacing the values using my IDE? Perhaps something that can be done automatically with a deployment script? | Is keeping the CSS file on the image server an option? If that it possible, you could make all the image references relative, and then you just need to update the link to the css file.
```
<link rel="stylesheet" href="<%= ConfigurationManager.AppSettings("css-server") %>style.css" />
```
If you still want to send or generate a css file dynamically:
css files don't have to end in css. aspx is fine. You could do this:
```
<link rel="stylesheet" href="style.aspx" />
```
and then in your style.aspx page:
```
protected void page_load(){
Response.ContentType = "text/css";
if (ConfigurationManager.AppSettings("css-server") == "local") {
Server.Transfer("css/local.css");
} else {
Server.Transfer("css/production.css");
}
}
```
If you still want to dynamically generate a css file, I'd use an HttpHandler, set the contenttype to "text/css", then generate the css with Response.Write. If you insist on having the page end in css, you could always register css to go to asp.net in IIS, then on incoming requests in global.asax application\_Begin request, if the file ends in .css, use httpcontext.current.rewritepath to your handler.
This will have a net effect of style.css being dynamically generated at runtime. | Sounds like a job for a NAnt [[link](http://nant.sourceforge.net/)] script to me. They're pretty easy to work with and well documented.
That way your code has isn't changing your css links, they're being updated at deploy time. This isn't a code issue, it's a deployment issue, so addressing it as such feels more "right" to me. That way you know if it loads correctly (with the right images) the first time it will load every time. NAnt scripts are a good thing to have in your toolbox.
The other solutions will work, but that code will be running every time the page loads for a change that should have happened once -- when the app was deployed. | Dynamically setting CSS values using ASP.NET | [
"",
"c#",
"asp.net",
"css",
"configuration",
""
] |
Basically, I have a drop down list and a dynamically added user control. The user control loads a grid view depending on the choice that was made in the drop down list. The drop down list is not part of the user control.
Now, the question is, how do i simulate (isControlPostback = false) every time the user changes the selection in the drop down list? It looks like ViewState remembers the control.
Inside my user control I have:
```
protected bool IsUserControlPostBack
{
get
{
return this.ViewState["IsUserControlPostBack"] != null;
}
}
protected void Page_Load(object sender, EventArgs e)
{
if (!IsUserControlPostBack)
{
ViewState.Add("IsUserControlPostBack", true);
//load stuff in the grid view and bind it
}
}
```
When the user changes the selection on the drop down list, i have a javascript confirm box, and the page posts back. So OnSelectedIndexChanged event for drop down list doesn't get triggered. I would like to remove to do something like this every time the selected index changes:
ViewState.Remove("IsUserControlPostBack"); | For anyone who is interested to know the answer:
I ended up implementing a public property inside user control and load the control inside the server drop down list SelectedIndexChanged event rather than OnInit. This eliminated the need for explicit Viewstate use. | You can make changes to the control in prerender event. When this event is fired all other actions are made.
Or you can do public property in user control and when setting required to value react on appropriately. | ViewState, UserControl and IsPostback | [
"",
"c#",
".net",
"viewstate",
""
] |
My PHP script have to create a multi-tabs Excel file with a report in each tab, but those reports already exists as HTML pages, so I don't want to duplicate code and work.
I know I can rename a HTML file to .xls, and Excel/OpenOffice Calc will open it as a spreadsheet, but I don't know how to have severals tabs.
I do not even know if it is possible.
I already know Biffwriter and others PHP libs to create Excel file, but I am looking for a smarter solution.
Thanks,
Cédric | [Pear Excel Spreadsheet Writer](http://pear.php.net/package/Spreadsheet_Excel_Writer) has a function to create [new Worksheets](http://pear.php.net/manual/en/package.fileformats.spreadsheet-excel-writer.spreadsheet-excel-writer-workbook.addworksheet.php) if thats what you are looking for. | If you don't mind serving excel 2007 files, you can do this:
1. create an excel 2007 file
2. create all the tabs you need
3. save the file
4. rename the file as .zip
5. extract the contents of the zip file
Now you can use the file structure there to populate the file corresponding to each tab with the report you need. You may want to use them as templates, keep the same code and render different files depending on whether you generate the html report of the excel report.
In the end, zip up the entire directory structure and serve it with an xlsx extension. | Create a multi-tabs Excel file | [
"",
"php",
"html",
"tabs",
"export-to-excel",
""
] |
I am trying to structure my code in such a way to reduce/avoid code duplication and I have encountered an interesting problem. Every time my code invokes a stored proc, I need to pass few variables that are common to the stored proc: such as username, domain, server\_ip and client\_ip. These all come from either HttpRequest object or a system.environment object.
Since these are passed to every stored proc, my initial thought was to create a utility class that is a database wrapper and will initialize and pass these every time, so I don't have to do it in my code.
The problem is though that c# class (inside App\_Code folder) doesn't see Httprequest object. Of course, I could pass this as an argument to the wrapper, but that would defeat the whole purpose of creating the wrapper. Am I missing something here?
I realize it's not such a huge deal to repeat 4 lines of code each time I call a stored proc, but I would rather eliminate the code duplication at the very early stages. | Set up your data layer to inherit from a base class which contains 4 properties for those values. Make the public constructor require those 4 properties.
Then do something similar in the business layer - base class with those 4 properties in the constructor.
Then the UI does new BusObj( Request["username"], ... ).method()
Within the data layer you can have a method that builds a SQLParameter array with those 4 properties, then each method can add additional parameters to the array. | As a general rule regardless of programming language, if you can squint your eyes and the code looks the same you should make a function/method/message out of it and pass the parameters.
Another thing to look at once you have methods that take a large number of parameters (4 is a good rule of thumb, but it is definatly a case-by-case basis) it is time to make that method take an object as a parameter instead of individual parameters. 99.99999999999999999999% of the time such an object should be immutable (no writeable instance variables). | Best Practices on Code Duplication c# | [
"",
"c#",
"code-duplication",
""
] |
I work in an environment where, for historical reasons, we are using a hodgepodge of custom utility classes, most of which were written before STL arrived on the scene. There are many reasons why I think it is a good idea to at least write new code using STL, but the main one is that I believe it increases programmer productivity. Unfortunately, that is a point that I don't know how to prove.
Are there any studies out there that attempt to quantify, or even just hint at, a productivity gain from using STL?
**Update:** I guess I should have been more specific. I am *not* advocating rewriting existing code, and I am *not* worried about the new hires that will get a running start. The former would be foolish, and the latter by itself is not enough to convince people. | There are no studies that will show STL is more productive just because it is STL. Productivity gains from using it are due to it being a standard programmers are familiar with it, and because the code is already written and tested.
If your company already has utility classes that employees are familiar with, and this utility code is used throughout an existing codebase, then switching to STL could actually be detrimental to productivity.
That said for new code using STL would be a good move. I would not necessarily argue this from a productivity standpoint, but one of maintainability. If you have code that predates STL it sounds like code at your company has quite a long lifetime and is likely to be maintained by a number of new programmers over the years.
You may also want to broach the use of STL as a way for everyone to keep their C++ skillset sharp. While I wouldn't reject a C++ candidate who didn't know STL, I would definitely view it as a black mark. | The reason the STL is so "good" is simply because it's been around a long time now and the implementations have seen a lot of users and eyes. They're well debugged and the algorithms have been pretty well optimized by vendors.
STL will be more productive for new devs in your shop because it's likely they are already familiar with it. Your custom libs will be foreign and probably lacking in features that devs are accustomed to using. That's not a huge issue after the initial ramp-up period for new devs though.
There's no real pressing reason to shift to STL just because it is. If you have perfectly useful utility classes in your application I'd recommend sticking with them unless they're not workable for new code. Mixing STL with your custom libraries in new code is going to cause compatibility problems at some point and refactoring the code to use all STL is going to introduce bugs. Either way you'll be losing productivity.
Edit: By "new" code, I mean new code in existing applications using the older class libraries.
If you're developing new standalone apps that do not draw on any of the old applicaiton code I'd recommend STL because it's there, most every C++ dev knows how to use it and it's pretty stable (and you get support from your toolset vendor if it's not). | Programmer productivity with STL vs. custom utility classes | [
"",
"c++",
"stl",
""
] |
I am considering accessing some CLR code from a UDF in Sql Server 2005.
I've heard stories that unhandled exceptions thrown in CLR code can bring down the server.
Obviously my function would contain a try-catch block. However, certain exceptions (stackoverflow) can skip the catch.
Does anyone have a set of guidelines that can completely eliminate (or minimize) the risk of my CLR code bringing down the server. | Unhandled exceptions have an adverse effect on SQL Server, but just how adverse depends on the severity of the exception that is thrown.
Generally speaking, you use Constrained Execution Regions to indicate the scope (process, app domain, thread, etc, etc) that a piece of your code can impact when it fails. SQL Server uses this to determine whether or not to just abort the current query/request, or to go further in the case of a more severe error.
There is a good article in MSDN magazine that talks about CER, as well as how SQL Server utilizes them:
<http://msdn.microsoft.com/en-us/magazine/cc163716.aspx#>
Additionally, here is a list of best practices that is geared specifically towards developing CLR code for SQL Server:
<http://msdn.microsoft.com/en-us/library/ms228970.aspx#> | What does the code do?
I suggest you consider avoiding the risk entirely by achieving your goal without using CLR first, rather than using a technology that you know will quite possibly add coupling and complexity, and be completely non-portable. But I can't recommend anything if I don't know that the problem is, or whether you really need CLR. | Problems with CLR Code on Sql Server 2005 | [
"",
"c#",
"sql-server",
"sql-server-2005",
"sqlclr",
""
] |
Does dependency injection mean that you don't ever need the 'new' keyword? Or is it reasonable to directly create simple leaf classes such as collections?
In the example below I inject the comparator, query and dao, but the SortedSet is directly instantiated:
```
public Iterable<Employee> getRecentHires()
{
SortedSet<Employee> entries = new TreeSet<Employee>(comparator);
entries.addAll(employeeDao.findAll(query));
return entries;
}
``` | Just because Dependency Injection is a useful pattern doesn't mean that we use it for everything. Even when using DI, there will often be a need for *new*. Don't delete new just yet. | One way I typically decide whether or not to use dependency injection is whether or not I need to mock or stub out the collaborating class when writing a unit test for the class under test. For instance, in your example you (correctly) are injecting the DAO because if you write a unit test for your class, you probably don't want any data to actually be written to the database. Or perhaps a collaborating class writes files to the filesystem or is dependent on an external resource. Or the behavior is unpredictable or difficult to account for in a unit test. In those cases it's best to inject those dependencies.
For collaborating classes like TreeSet, I normally would not inject those because there is usually no need to mock out simple classes like these.
One final note: when a field cannot be injected for whatever reason, but I still would like to mock it out in a test, I have found the [Junit-addons PrivateAccessor](http://junit-addons.sourceforge.net/junitx/util/PrivateAccessor.html) class helpful to be able to switch the class's private field to a mock object created by [EasyMock](http://www.easymock.org/) (or jMock or whatever other mocking framework you prefer). | Is there ever a case for 'new' when using dependency injection? | [
"",
"java",
"oop",
"spring",
"dependency-injection",
"guice",
""
] |
I am trying to perform the following SQL using LINQ and the closest I got was doing cross joins and sum calculations. I know there has to be a better way to write it so I am turning to the stack team for help.
```
SELECT T1.Column1, T1.Column2, SUM(T3.Column1) AS Amount
FROM T1
INNER JOIN T2
ON T1.T1ID = T2.T1ID
INNER JOIN T3
ON T2.T3ID = T3.T3ID
GROUP BY T1.Column1, T1.Column2
```
What I have been trying is the following LINQ code
```
var qTotal = from T2 in context.T2
from T3 in context.T3
where T3.T3ID == T3.T3ID
group T3 by T2.T1ID into gT2T3
from T1 in context.T1
where gT2T3.Key.Equals(T1.T1ID)
select new { T1.Column1,T1.Column2,Amount = gT2T3.Sum(t => t.Column1)};
```
I know there has to be a better way to write it, I just do not know how, any help would be great! | Try this:
```
var total = from T1 in context.T1
join T2 in context.T2 on T1.T2ID equals T2.T2ID
join T3 in context.T3 on T2.T3ID equals T3.T3ID
group T3 by new { T1.Column1, T1.Column2 } into g
select new {
Column1 = T1.Column1,
Column2 = T2.Column2,
Amount = g.Sum(t3 => t3.Column1)
};
``` | For me (using 4.0), the following works.
```
var total = from T1 in context.T1
join T2 in context.T2 on T1.T2ID equals T2.T2ID
join T3 in context.T3 on T2.T3ID equals T3.T3ID
group T3 by new { T1.Column1, T1.Column2 } into g
select new {
Column1 = g.Key.Column1,
Column2 = g.Key.Column2,
Amount = g.Sum(t3 => t3.Column1)
};
``` | LINQ: Using INNER JOIN, Group and SUM | [
"",
"c#",
"linq",
".net-3.5",
""
] |
I read `Runtime.getRuntime().exec("perl script.pl")` is an option, but is this the best way to do it?
I'll need an answer from that script, so I'll have to read the script's return in some cases, although I might read it from a text file on other cases.
Anyway, is `exec()` a good way of calling a Perl Script from Java? I should note, I'm working on a Java Web Application, so security is an issue here. | You can use [`Runtime`](http://docs.oracle.com/javase/6/docs/api/java/lang/Runtime.html)[`.getRuntime()`](http://docs.oracle.com/javase/6/docs/api/java/lang/Runtime.html#getRuntime%28%29)[`.exec()`](http://docs.oracle.com/javase/6/docs/api/java/lang/Runtime.html#exec%28java.lang.String%29) or use the [Process API](http://docs.oracle.com/javase/6/docs/api/java/lang/Process.html).
The Process API allows you to get the output of the script, so you can have both communicate.
[`exitValue()`](http://docs.oracle.com/javase/6/docs/api/java/lang/Process.html#exitValue%28%29) and [`getInputStream()`](http://docs.oracle.com/javase/6/docs/api/java/lang/Process.html#getInputStream%28%29) seems to be what you need. | This outlines how to do it fairly elegantly, though it may be more effort than it's worth:
<http://search.cpan.org/~nwclark/perl-5.8.9/jpl/docs/Tutorial.pod>
Overview:
Well-supported by JPL, but it is a complicated process:
The JPL preprocessor parses the .jpl file and generates C code wrappers for Perl methods. It also generates Java and Perl source files.
The C compiler compiles the wrapper and links it to the libPerlInterpreter.so shared library, producing a shared library for the wrapper.
The Java compiler compiles the Java source file, which uses native methods to load the wrapper.
The wrapper connects the Java code to the Perl code in the Perl source file.
Fortunately, a generic Makefile.PL simplifies the process. This is a Perl script that generates a Makefile for you. | How should I call a Perl Script in Java? | [
"",
"java",
"perl",
""
] |
Is there an easy way to have JavaScript mimic a User clicking an anchor tag on a page? That means the Referrer Url needs to be set. Just setting the document.location.href doesn't set the Referrer Url.
```
<script>
$(document).ready(function () {
$("a").click();
});
</script>
<a href="http://example.com">Go here</a>
```
This doesn't work because there isn't a Click() event setup for the link. | You could do:
```
window.location = $("a").attr("href");
```
If you want to keep the referrer, you could do this:
```
var href = $('a').attr('href');
$('<form>').attr({action: href, method: 'GET'}).appendTo($('body')).submit();
```
It is hackish, but works in all browsers. | ```
document.location.href = "#wanted_Location";
``` | How to navigate href in anchor tag via JavaScript | [
"",
"javascript",
"jquery",
""
] |
I wrote the database schema (only one table so far), and the INSERT statements for that table in one file. Then I created the database as follows:
```
$ sqlite3 newdatabase.db
SQLite version 3.4.0
Enter ".help" for instructions
sqlite> .read ./schema.sql
SQL error near line 16: near "s": syntax error
```
Line 16 of my file looks something like this:
```
INSERT INTO table_name (field1, field2) VALUES (123, 'Hello there\'s');
```
The problem is the escape character for a single quote. I also tried double escaping the single quote (using `\\\'` instead of `\'`), but that didn't work either. What am I doing wrong? | Try doubling up the single quotes (many databases expect it that way), so it would be :
```
INSERT INTO table_name (field1, field2) VALUES (123, 'Hello there''s');
```
Relevant quote from [the documentation](http://www.sqlite.org/lang_expr.html):
> A string constant is formed by enclosing the string in single quotes ('). A single quote within the string can be encoded by putting two single quotes in a row - as in Pascal. C-style escapes using the backslash character are not supported because they are not standard SQL. BLOB literals are string literals containing hexadecimal data and preceded by a single "x" or "X" character. ... A literal value can also be the token "NULL". | I believe you'd want to escape by doubling the single quote:
```
INSERT INTO table_name (field1, field2) VALUES (123, 'Hello there''s');
``` | Escape single quote character for use in an SQLite query | [
"",
"sql",
"database",
"sqlite",
"escaping",
"single-quotes",
""
] |
I have some complicated object, such as a Cat, which has many properties, such as age, favorite cat food, and so forth.
A bunch of Cats are stored in a Java Collection, and I need to find all the Cats that are aged 3, or those whose favorite cat food is Whiskas. Surely, I can write a custom method that finds those Cats with a specific property, but this gets cumbersome with many properties; is there some generic way of doing this? | You could write a method that takes an instance of an interface which defines a `check(Cat)` method, where that method can be implemented with whatever property-checking you want.
Better yet, make it generic:
```
public interface Checker<T> {
public boolean check(T obj);
}
public class CatChecker implements Checker<Cat> {
public boolean check(Cat cat) {
return (cat.age == 3); // or whatever, implement your comparison here
}
}
// put this in some class
public static <T> Collection<T> findAll(Collection<T> coll, Checker<T> chk) {
LinkedList<T> l = new LinkedList<T>();
for (T obj : coll) {
if (chk.check(obj))
l.add(obj);
}
return l;
}
```
Of course, like other people are saying, this is what relational databases were made for... | Try the commons collections API:
```
List<Cat> bigList = ....; // master list
Collection<Cat> smallList = CollectionUtils.select(bigList, new Predicate() {
public boolean evaluate(Object o) {
Cat c = (Cat)o;
return c.getFavoriteFood().equals("Wiskas")
&& c.getWhateverElse().equals(Something);
}
});
```
Of course you don't have to use an anonymous class *every* time, you could create implementations of the `Predicate` interface for commonly used searchs. | Finding all objects that have a given property inside a collection | [
"",
"java",
"collections",
""
] |
Perl has the excellent module `Term::ANSIScreen` for doing all sorts of fancy cursor movement and terminal color control. I'd like to reimplement a program that's currently in Perl in Python instead, but the terminal ANSI colors are key to its function. Is anyone aware of an equivalent? | If you only need colors You may want to borrow the implementation from pygments. IMO it's much cleaner than the one from ActiveState
<http://dev.pocoo.org/hg/pygments-main/file/b2deea5b5030/pygments/console.py> | Here's a [cookbook recipe](http://code.activestate.com/recipes/574451/) on ActiveState to get you started. It covers colors and positioning.
*[Edit: The pygments code submitted above by Jorge Vargas is a better approach. ]* | Is there a Term::ANSIScreen equivalent for Python? | [
"",
"python",
"ansi-escape",
"ansi-colors",
""
] |
I'm looking at ORMs for Java and [Active Objects](http://java.net/projects/activeobjects/pages/Home) caught my eye. Apparently, it was [inspired by Rails' ActiveRecord](http://www.javalobby.org/articles/activeobjects/). Based on what I've read, this approach seems to solve a lot of problems with existing Java ORMs by embracing convention over configuration.
What's been your experience with it? | Be careful that you don't wander into "silver bullet syndrome"... I just hear devs saying "convention over configuration" and think it's a great thing...
[Daniel Spiewak](http://www.codecommit.com/blog/) is a solid programmer, I've learned a lot from his blog, but this is a fairly simple API. That means, don't expect a ton of experience with production usage, working in a high-load environment, etc. But sometimes, all you need is simple, and well, there are other projects, like [Databinder](http://databinder.net/) that integrate with Active Objects. (Wicket + Databinder is a pretty nice, lightweight web framework for Java.)
But, for example, I'd stay away from a persistence framework like this if I was doing a lot of batch processing. Mostly, because I want:
1. Immutable objects by default, which naturally flows into multi-threaded processing, because you force people to a "delete/create new" instead of "update" sort of paradigm, which saves a lot of disk usage in many DBs.
2. DB access that considers simplifying IO by using specialized commands like `COPY`
I've solved a lot of DB performance problems by just writing straight SQL code, replacing the use of an ORM that wasn't suited for the task. | DISCLAIMER: I am the primary developer working on a project called **ActiveJDBC** which shares some design goals with ActiveRecord and is actively in development:
<http://javalite.io> | Experiences With Active Objects ORM for Java? | [
"",
"java",
"orm",
"activerecord",
"persistence",
"active-objects",
""
] |
**Similar**: [Possible to assign a new IP address on every http request?](https://stackoverflow.com/questions/584272/possible-to-assign-a-new-ip-address-on-every-http-request)
---
Is it possible to display a different/spoofed IP address using CURL when you make requests to a server? If not, is there any alternative way of spoofing your IP address using PHP? | No. Unless of course you use proxies and route your traffic through them. | If you make a TCP/IP request, the other end needs to know your real address or you'll never receive a response back. | Hiding IP address using CURL | [
"",
"php",
"curl",
"libcurl",
""
] |
I'm developing a **Windows Mobile** app (**Compact Framework 2.0 SP1**) and this code it's generating me an error:
```
public Image Imagen
{
get
{
return imagen;
}
set
{
imagen = value;
this.Invalidate();
}
}
```
The code is called from a new thread. I've tried to solve using \*\*InvokeRequired:
```
public Image Imagen
{
get
{
return imagen;
}
set
{
imagen = value;
if (this.InvokeRequired)
this.Invoke(this.Invalidate);
else
this.Invalidate();
}
}
```
But the line **this.Invoke(this.Invalidate);** doesn't compile. How can I solve the problem? The first error is that you can interact with controls created on another thread.
Thank you! | Try this.
Long winded version of why this is necessary. Instead of taking a specific Delegate type as a parameter, the Invoke method takes the type System.Delegate. This type does not providing typing for a strongly typed signature. It's the base delegate class and instead provides a common mechanism for invoking all delegates.
Unfortunately when passing a method name as a Delegate source in C# it must be passed to a specific delegate type. Otherwise C# doesn't know what type of delegate to create under the hood and unlike VB it won't generate anonymous delegate types. This is why you need a specific delegate type like MethodInvoker in order to call the function.
**EDIT** Manually defined MethodInvoker since it doesn't exist in the Compact Framework
```
public delegate void MethodInvoker();
public Image Imagen
{
get { get return imagen; }
set {
imagen = value;
if (this.InvokeRequired)
this.Invoke(new MethodInvoker(this.Invalidate));
else
this.Invalidate();
}
}
``` | Invalidate doesn't need an invoke.
The invalidate only includes a paint message to be processed by the main thread with the rest of the pending messages. But the paint is not done when you call to invalidate and the control is not changed by this thread, so you don't need to use an invoke for it.
If you need to ensure that the control is refreshed, maybe the invalidate is not enough and you need to call to the update too. | C# Threads and this.Invalidate() | [
"",
"c#",
"winforms",
"multithreading",
"graphics",
""
] |
I've been trying to create a simple base class that encapsulates some of my conventions for database access. I generally create a sproc named "products\_retrieve\_product" to select a product based on productID. I would like the method "Retrieve" in the base class to return the type that the derived class supplies in it's definition. Is what I'm trying to accomplish possible with Generics?
```
public class MyBaseClass <T>
{
private string _className;
public MyBaseClass ()
{
_className = this.GetType().Name;
}
public virtual T Retrieve(int ID)
{
Database db = DatabaseFactory.CreateDatabase();
DbCommand dbCommand = db.GetStoredProcCommand(String.Format("{0}s_Retrieve_{0}", _className));
db.AddInParameter(dbCommand, String.Format("@{0}ID", _className), DbType.Int32, ID);
using (IDataReader dr = db.ExecuteReader(dbCommand))
{
if (dr.Read())
{
BOLoader.LoadDataToProps(this, dr);
}
}
return (T)this;
}
}
``` | I think that you want to do something like this:
```
class MyBaseClass<T> where T : MyBaseClass<T>, new()
{
public T Retrieve()
{
return new T();
}
}
class Foo : MyBaseClass<Foo>
{
}
class Program
{
public static void Main()
{
Foo f = new Foo();
Foo f2 = f.Retrieve();
Console.WriteLine(f2.ToString());
}
}
```
When you run this program, the type name of Foo is printed on the command line. Obviously this is a contrived example, but maybe you can do something more useful when loading from a database in `MyBaseClass.Retrieve()`.
The key is to add a constraint on T so that it must be an instance of the class itself. This way you can specify the subclass as the generic type when subclassing `MyBaseClass<T>.`
I'm not entirely sure if this is a good idea or not, but it looks like it can be done. | Sure. In your example, if I wanted my Foo class to return Bars when Retrieve(...) is called:
```
public class Foo : MyBaseClass<Bar>{}
``` | How do I return a Generic Type through a method in a base class? | [
"",
"c#",
".net",
"design-patterns",
"generics",
"activerecord",
""
] |
I want to understand how video and audio decoding works, specially the timing synchronization (how to get 30fps video, how to couple that with audio, etc.). I don't want to know ALL the details, just the essence of it. I want to be able to write a high level simplification of an actual video/audio decoder.
Could you provide pointers to me? An actual C/C++ source code of a MPEG2 video/audio decoder would be the fastest way to understand those things I think. | You can browse source code of [ffmpeg](https://git.ffmpeg.org/gitweb/ffmpeg.git) (available through svn), or its [API documentation](https://ffmpeg.org/doxygen/trunk/index.html). | Reading source code from a codec that works seems the right way to go.
I suggest the following :
<http://www.mpeg.org/MPEG/video/mssg-free-mpeg-software.html>
Given that it's mentionned on the mpeg.org website, i'd say you'll find what you need here.
In the past i've had some time to work on decoding mpeg videos (no audio though), and the principles are quite simple. There are some pure images included, some intermediary images that are described relatively to the closest main ones, and the rest are described using the closest main/intermediary images.
One time slot, one image. But recent codecs are much more complicated, I guess !
EDIT : synchronization
I am no expert in synchronizing audio and video, but the issue seems to be dealt with using a sync layer (see [there](https://mpeg.chiariglione.org/faq/which-layers-are-passed-mpeg-4-objects-are-composed) for a definition). | mpeg 2 decoding | [
"",
"c++",
"c",
"video",
"codec",
"mpeg",
""
] |
Among the wall of text that is a pages source; I need to get the video\_id,l and t without the quotes so for a section like this.
"video\_id": "lUoiKMxSUCw", "l": 105, "sk": "-2fL6AANk\_\_E49CRzF6\_Q8F7yBPWdb9QR", "fmt\_map": "35/640000/9/0/115,34/0/9/0/115,5/0/7/0/0", "t": "vjVQa1PpcFMbYtdhqxUip5Vtm856lwh7lXZ6lH6nZAg=",
i need the following
lUoiKMxSUCw
105
vjVQa1PpcFMbYtdhqxUip5Vtm856lwh7lXZ6lH6nZAg=
i was told to use "regular expressions" but I'm not to sure how to use them. any help would be nice :) | The Regex to use could be:
```
\"video_id\":\s*\"(?<videoID>.*?)\"(?:.*?)\"l\":\s*(?<l>.*?),(?:.*?)\"t\":\s*\"(?<t>.*?)\"
```
Here's some sample code to get you up and running:
```
string sample = "\"video_id\": \"lUoiKMxSUCw\", \"l\": 105, \"sk\": \"-2fL6AANk__E49CRzF6_Q8F7yBPWdb9QR\", \"fmt_map\": \"35/640000/9/0/115,34/0/9/0/115,5/0/7/0/0\", \"t\": \"vjVQa1PpcFMbYtdhqxUip5Vtm856lwh7lXZ6lH6nZAg=\",";
string regPattern = "\\\"video_id\\\":\\s*\\\"(?<videoID>.*?)\\\"(?:.*?)\\\"l\\\":\\s*(?<l>.*?),(?:.*?)\\\"t\\\":\\s*\\\"(?<t>.*?)\\\"";
Regex reg = new Regex(regPattern, RegexOptions.Singleline);
if (reg.IsMatch(sample))
{
Match m = reg.Match(sample);
GroupCollection gColl = m.Groups;
Console.WriteLine("VideoID:{0}", gColl["videoID"].Value);
Console.WriteLine("l:{0}", gColl["l"].Value);
Console.WriteLine("t:{0}", gColl["t"].Value);
}
```
Don't forget to import "System.Text.RegularExpressions". ;-) | I think this sites good for learning, but if you expect code to do your work, sorry..
this looks like a good start : [Regular Expressions Usage in C#](http://www.c-sharpcorner.com/UploadFile/prasad_1/RegExpPSD12062005021717AM/RegExpPSD.aspx)
And also [this site](http://www.regular-expressions.info/dotnet.html) is very helpful | C# Parsing a webpage's source | [
"",
"c#",
".net",
"asp.net",
"regex",
"data-mining",
""
] |
I am creating a multipage form in PHP, using a session. The `$stage` variable tracks the user's progress in filling out the form, **(UPDATE) and is normally set in $\_POST at each stage of the form.**
On the second page (stage 2), the form's submit button gets its value like this:
```
echo '<input type="hidden" name="stage" value="';
echo $stage + 1;
echo '" />;
```
That works fine - `$stage + 1` evaluates to 3 if I'm on page 2. But since I'm doing this more than once, I decided to pull this code out into a function, which I defined at the top of my code, before `$stage` is mentioned.
In the same spot where I previously used the code above, I call the function. I have verified that the function's code is the same, but now `$stage + 1` evaluates to 1.
**Is PHP evaluating my variable when the function is defined, rather than when it's called? If so, how can I prevent this?**
### Update 1
To test this theory, I set `$stage = 2` before defining my function, but it still evaluates to 1 when I call the function. What's going on?
### Problem Solved
Thanks to everyone who suggested variable scope as the culprit - I'm slapping my forehead now. **`$stage` was a global variable, and I didn't call it `$GLOBAL_stage`**, like I usually do, to prevent this sort of problem.
I added `global $stage;` to the function definition and it works fine. Thanks! | No, PHP will evaluate your variable when the function is called. But your function has a local [variable scope](http://de.php.net/global), i.e. without seeing your function I'd guess that you are operating on a local variable. You can import global variables into you function although this is discouraged:
```
function myfunction() {
global $stage;
...
}
```
It's really hard to say without knowledge of your code, but I'd go on to guess that you are using ['register globals'](http://de.php.net/register_globals) to inject your form parameters into global PHP variables ($state, in this case). You might want to consider turning `register_globals` off because it really is a security risk and using the so-called [superglobal](http://de.php.net/manual/en/language.variables.superglobals.php) variables instead.
---
**edit**
Ok, so you're seeing your stage in the $\_POST array. Still wildly guessing about your function, you might try the following:
```
function my_insert_stage_param() {
global $stage;
echo '<input type="hidden" name="stage" value="';
echo $_POST['stage'] + 1;
echo '" />';
}
```
Suberglobals like the $\_POST array don't need to be declared with `global`. | This is really hard to answer without more code. One thing to check is that you are saving stage back into the session before the next page loads. If stage is null, empty, or a string, stage + 1 will be 1.
To debug the session, put print\_r($\_SESSION); die; at the top of each page. | Does PHP evaluate variables when a function is defined? | [
"",
"php",
""
] |
**Outside of benefiting from Adaptive Rendering for alternate devices, does it ever make sense to write all of this code:**
```
writer.WriteBeginTag("table");
writer.WriteBeginTag("tr");
writer.WriteBeginTag("td");
writer.Write(HtmlTextWriter.TagRightChar);
writer.WriteEncodedText(someTextVariable);
writer.WriteEndTag("td");
writer.WriteEndTag("tr");
writer.WriteEndTag("table");
```
**When StringBuilder could build the same thing with simply this:**
```
sb.Append("<table><tr><td>");
sb.Append(someTextVariable);
sb.Append("</td></tr></table>");
``` | I can think of two reasons to use HtmlTextWriter:
1. You can use the writer to keep track of your indents, so that your outputted HTML is formatted nicely, rather than appearing on one line
2. HtmlTextWriter is usually associated with an output stream, so it should be more efficient than building up a long string in memory (depending upon how much HTML you are generating).
Neither of these are extraordinary reasons, but they are enough to convince me to use the writer when efficiency is needed, or if I am writing a base control that will be reused and should be as professional as possible. Your mileage may vary :-). | Another advantage could be that using HtmlTextWriter one could format code in a cleaner (more maintenance friendly) way, and that HtmlTextWriter supports encoding HTML automatically. Compare:
```
writer.AddAttribute(HtmlTextWriterAttribute.Id, "someId");
if (!string.IsNullOrEmpty(cssClass)) writer.AddAttribute(HtmlTextWriterAttribute.Class, cssClass);
writer.AddStyleAttribute(HtmlTextWriterStyle.Color, "Red");
writer.RenderBeginTag(HtmlTextWriterTag.Span);
writer.WriteEncodedText(text);
writer.RenderEndTag();
```
versus:
```
StringBuilder html = new StringBuilder();
html.Append("<span");
html.Append(" id=\"someId\"");
if (!string.IsNullOrEmpty(cssClass)) html.AppendFormat(" class=\"{0}\"", HttpUtility.HtmlAttributeEncode(cssClass));
html.Append(">");
html.Append(HttpUtility.HtmlEncode(text));
html.Append("</span>");
```
One may argue that the code in the second example can be written in a different, possibly cleaner, way, but this could be seen as an advantage of HtmlTextWriter because it basically enforces one canonical way of formatting (which again improves maintenance).
**Edit:** In fact, I actually made a mistake in the second snippet, and I needed to go back and fix the response. This confirms the point I wanted to make. | Are there any benefits to using HtmlTextWriter if you are not going to benefit from adaptive rendering? | [
"",
"c#",
"stream",
"conventions",
"htmltextwriter",
""
] |
Does assigning an unused object reference to `null` in Java improve the garbage collection process in any measurable way?
My experience with Java (and C#) has taught me that is often counter intuitive to try and outsmart the virtual machine or JIT compiler, but I've seen co-workers use this method and I am curious if this is a good practice to pick up or one of those voodoo programming superstitions? | Typically, no.
But like all things: it depends. The GC in Java these days is VERY good and everything should be cleaned up very shortly after it is no longer reachable. This is just after leaving a method for local variables, and when a class instance is no longer referenced for fields.
You only need to explicitly null if you know it would remain referenced otherwise. For example an array which is kept around. You may want to null the individual elements of the array when they are no longer needed.
For example, this code from ArrayList:
```
public E remove(int index) {
RangeCheck(index);
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
```
Also, explicitly nulling an object will not cause an object to be collected any sooner than if it just went out of scope naturally as long as no references remain.
Both:
```
void foo() {
Object o = new Object();
/// do stuff with o
}
```
and:
```
void foo() {
Object o = new Object();
/// do stuff with o
o = null;
}
```
Are functionally equivalent. | In my experience, more often than not, people null out references out of paranoia not out of necessity. Here is a quick guideline:
1. If object A references object B **and** you no longer need this reference **and** object A is not eligible for garbage collection then you should explicitly null out the field. There is no need to null out a field if the enclosing object is getting garbage collected anyway. Nulling out fields in a dispose() method is almost always useless.
2. There is no need to null out object references created in a method. They will get cleared automatically once the method terminates. The exception to this rule is if you're running in a very long method or some massive loop and you need to ensure that some references get cleared before the end of the method. Again, these cases are extremely rare.
I would say that the vast majority of the time you will not need to null out references. Trying to outsmart the garbage collector is useless. You will just end up with inefficient, unreadable code. | Does assigning objects to null in Java impact garbage collection? | [
"",
"java",
"null",
"garbage-collection",
""
] |
Let's say, for instance, I have the following extremely simple window:
```
<Window x:Class="CalendarGenerator.Window1"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Window1"
Height="300"
Width="447">
<Grid>
<ListBox Margin="12,40,0,12"
Name="eventList"
HorizontalAlignment="Left"
Width="134" />
</Grid>
</Window>
```
And a simple list defined as:
```
List<String> ListOfNames = new List<String>();
```
And let's assume that the list has several names in it. How would I go about binding the List to the ListBox using as much code-behind as possible? | First you'd need to give your ListBox a name so that it's accessible from your code behind (*edit* I note you've already done this, so I'll change my example ListBox's name to reflect yours):
```
<ListBox x:Name="eventList" ... />
```
Then it's as simple as setting the ListBox's [ItemsSource](http://msdn.microsoft.com/en-us/library/system.windows.controls.itemscontrol.itemssource.aspx) property to your list:
```
eventList.ItemsSource = ListOfNames;
```
Since you've defined your "ListOfNames" object as a `List<String>`, the ListBox won't automatically reflect changes made to the list. To get WPF's databinding to react to changes within the list, define it as an [ObservableCollection](http://msdn.microsoft.com/en-us/library/ms668604.aspx)`<String>` instead. | If the data list is created in code then you're going to have to bind it in code, like so:
```
eventList.ItemsSource = ListOfNames;
```
Now binding to a list of strings is a very simple example. Let's take a more complex one.
Say you have a person class:
```
public class Person {
public string FirstName { get; set; }
public string Surname { get; set; }
}
```
To display a list of persons you could bind a list to the ListBox, but you'll end up with a listbox that displays "Person" for each entry, because you haven't told WPF how to display a person object.
To tell WPF how to visually display data objects we define a DataTemplate like so:
```
<Window.Resources>
<DataTemplate DataType="{x:Type l:Person}">
<StackPanel Orientation="Horizontal">
<TextBlock Text="{Binding FirstName}"/>
<TextBlock Text=" "/>
<TextBlock Text="{Binding Surname}"/>
</StackPanel>
</DataTemplate>
</Window.Resources>
<Grid>
<ListBox Name="listBox" />
</Grid>
public Window1() {
InitializeComponent();
List<Person> people = new List<Person>();
people.Add(new Person() { FirstName = "Cameron", Surname = "MacFarland" });
people.Add(new Person() { FirstName = "Bea", Surname = "Stollnitz" });
people.Add(new Person() { FirstName = "Jason", Surname = "Miesionczek" });
listBox.ItemsSource = people;
}
```
This will nicely display "Firstname Surname" in the list.
If you wanted to change the look to be say "**Surname**, Firstname" all you need to do is change the XAML to:
```
<StackPanel Orientation="Horizontal">
<TextBlock FontWeight="Bold" Text="{Binding Surname}"/>
<TextBlock Text=", "/>
<TextBlock Text="{Binding FirstName}"/>
</StackPanel>
``` | Programmatically binding List to ListBox | [
"",
"c#",
"wpf",
"data-binding",
""
] |
I'd like to take a CSV file living server-side and display it dynamically as an html table.
E.g., this:
```
Name, Age, Sex
"Cantor, Georg", 163, M
```
should become this:
```
<html><body><table>
<tr> <td>Name</td> <td>Age</td> <td>Sex</td> </tr>
<tr> <td>Cantor, Georg</td> <td>163</td> <td>M</td> </td>
</table></body></html>
```
Solutions in any language are welcome. | The [previously linked solution](http://www.codewalkers.com/c/a/File-Manipulation-Code/Simple-CSV-to-HTML-Table/) is a horrible piece of code; nearly every line contains a bug. Use [fgetcsv](http://php.net/fgetcsv) instead:
```
<?php
echo "<html><body><table>\n\n";
$f = fopen("so-csv.csv", "r");
while (($line = fgetcsv($f)) !== false) {
echo "<tr>";
foreach ($line as $cell) {
echo "<td>" . htmlspecialchars($cell) . "</td>";
}
echo "</tr>\n";
}
fclose($f);
echo "\n</table></body></html>";
``` | Here is a simple function to convert csv to html table using php:
```
function jj_readcsv($filename, $header=false) {
$handle = fopen($filename, "r");
echo '<table>';
//display header row if true
if ($header) {
$csvcontents = fgetcsv($handle);
echo '<tr>';
foreach ($csvcontents as $headercolumn) {
echo "<th>$headercolumn</th>";
}
echo '</tr>';
}
// displaying contents
while ($csvcontents = fgetcsv($handle)) {
echo '<tr>';
foreach ($csvcontents as $column) {
echo "<td>$column</td>";
}
echo '</tr>';
}
echo '</table>';
fclose($handle);
}
```
One can call this function like `jj_readcsv('image_links.csv',true);`
if second parameter is true then the first row of csv will be taken as header/title.
Hope this helps somebody. Please comment for any flaws in this code. | Dynamically display a CSV file as an HTML table on a web page | [
"",
"php",
"html",
"csv",
""
] |
I've seen implementations of Singleton patterns where instance variable was declared as static variable in GetInstance method. Like this:
```
SomeBaseClass &SomeClass::GetInstance()
{
static SomeClass instance;
return instance;
}
```
I see following positive sides of this approach:
* The code is simpler, because it's compiler who responsible for creating this object only when GetInstance called for the first time.
* The code is safer, because there is no other way to get reference to instance, but with GetInstance method and there is no other way to change instance, but inside GetInstance method.
What are the negative sides of this approach (except that this is not very OOP-ish) ? Is this thread-safe? | In C++11 it is thread safe:
> §6.7 [stmt.dcl] p4 If control enters the declaration concurrently while the variable is being initialized, the concurrent execution shall wait for completion of the initialization.
In C++03:
* Under g++ it is thread safe.
But this is because g++ explicitly adds code to guarantee it.
One problem is that if you have two singletons and they try and use each other during construction and destruction.
Read this:
[Finding C++ static initialization order problems](https://stackoverflow.com/questions/335369/finding-c-static-initialization-order-problems#335746)
A variation on this problem is if the singleton is accessed from the destructor of a global variable. In this situation the singleton has definitely been destroyed, but the get method will still return a reference to the destroyed object.
There are ways around this but they are messy and not worth doing. Just don't access a singleton from the destructor of a global variable.
A Safer definition but ugly:
I am sure you can add some appropriate macros to tidy this up
```
SomeBaseClass &SomeClass::GetInstance()
{
#ifdef _WIN32
Start Critical Section Here
#elif defined(__GNUC__) && (__GNUC__ > 3)
// You are OK
#else
#error Add Critical Section for your platform
#endif
static SomeClass instance;
#ifdef _WIN32
END Critical Section Here
#endif
return instance;
}
``` | It is not thread safe as shown. The C++ language is silent on threads so you have no inherent guarantees from the language. You will have to use platform synchronization primitives, e.g. Win32 ::EnterCriticalSection(), to protect access.
Your particular approach would be problematic b/c the compiler will insert some (non-thread safe) code to initialize the static `instance` on first invocation, most likely it will be before the function body begins execution (and hence before any synchronization can be invoked.)
Using a global/static member pointer to `SomeClass` and then initializing within a synchronized block would prove less problematic to implement.
```
#include <boost/shared_ptr.hpp>
namespace
{
//Could be implemented as private member of SomeClass instead..
boost::shared_ptr<SomeClass> g_instance;
}
SomeBaseClass &SomeClass::GetInstance()
{
//Synchronize me e.g. ::EnterCriticalSection()
if(g_instance == NULL)
g_instance = boost::shared_ptr<SomeClass>(new SomeClass());
//Unsynchronize me e.g. :::LeaveCriticalSection();
return *g_instance;
}
```
I haven't compiled this so it's for illustrative purposes only. It also relies on the boost library to obtain the same lifetime (or there about) as your original example. You can also use std::tr1 (C++0x). | Singleton instance declared as static variable of GetInstance method, is it thread-safe? | [
"",
"c++",
"design-patterns",
"singleton",
""
] |
I'm trying to brush up on my LINQ by writing some simple extension methods. Is there any better way to write such a function as below that removes a given list of characters from a string (using LINQ)?
It helps me to think of the extension methods that LINQ relies on first:
```
public static string Remove(this string s, IEnumerable<char> chars)
{
string removeChars = string.Concat(chars);
return new string(s.ToCharArray().Where(c => !removeChars.Contains(c)).ToArray());
}
```
But that's pretty ugly. Ergo LINQ.
**The difference that I notice in the LINQ statement is that I have to use 'select' whereas with the extension method, I don't have to.**
```
/// <summary>Strip characters out of a string.</summary>
/// <param name="chars">The characters to remove.</param>
public static string Remove(this string s, IEnumerable<char> chars)
{
string removeChars = string.Concat(chars);
var stripped = from c in s.ToCharArray()
where !removeChars.Contains(c)
select c;
return new string(stripped.ToArray());
}
```
So I'm wondering if this (last snippet above) is the tersest LINQ statement to accomplish removal of characters. | I would prefer the first form with extension methods though simplified to
```
public static string Remove(this string s, IEnumerable<char> chars)
{
return new string(s.Where(c => !chars.Contains(c)).ToArray());
}
```
As for **select** keyword, it's obligatory in second form. The [documentation](http://msdn.microsoft.com/en-us/library/bb384087.aspx) says what "A query expression must terminate with either a select clause or a group clause". That's why I would avoid LINQ syntactic sugar. | try this for terseness
```
public static string Remove(this string source, IEnumerable<char> chars) {
return new String(source.Where(x => !chars.Contains(x)).ToArray());
}
```
**EDIT**
Updated to correct it removing duplicates from source | Removing characters from strings with LINQ | [
"",
"c#",
"linq",
""
] |
For example, let's say I want to find all instances of using the == operator with any string object, so that I can replace it with .equals() instead. How can I do such a search? Otherwise I'd have to pick through all my code line-by-line... Thanks :) | Eclipse doesn't have any special search capabilities for operators. That doesn't mean that you can't do a file search for them though.
You're probably better off running [PMD](http://pmd.sourceforge.net/rules/strings.html) to find issues like this for you. | FindBugs may produce warning for this type of coding as well. | Search for usage of a class object with a given operator? [Eclipse] | [
"",
"java",
"eclipse",
""
] |
I'm seeing a strange situation, that I'm trying to figure out if it's a PHP issue, file issue, or normal operation. I have some users complaining about very fast timeouts on our site (session expires?), and checking the php tmp directory, I see things like this:
```
-rw------- 1 www-data www-data 377 2009-01-15 22:46 sess_fc789ce04a3d54ce929a401cd33ea868
-rw------- 1 www-data www-data 1167 2009-01-15 23:21 sess_fcb67b1f44a3669d8ffee69d5fa9a2e8
-rw------- 1 www-data www-data 0 2009-01-15 23:22 sess_fe0ab79c78c612d71ecca575753afdc4
-rw------- 1 www-data www-data 0 2009-01-15 23:07 sess_fedd46db2b023215cb060d67a01d3382
-rw------- 1 www-data www-data 0 2009-01-15 23:21 sess_feec900e144c011303a9f06eb428574e
-rw------- 1 www-data www-data 0 2009-01-15 23:00 sess_ffb2ed75ca311d08e41ec69c7d708d08
-rw------- 1 www-data www-data 1142 2009-01-15 22:49 sess_ffc2c882af3b3ad39b844dc5a530dc44
-rw------- 1 www-data www-data 0 2009-01-15 22:51 sess_fffbd6f7734ce3b4ef9d8009a324a459
```
Is this normal behavior?
TIA
Mike | Two possibilities spring to mind, one is that your out of disk space in a shared hosting environment, if this is not the case then your website may be sharing its session directory with other websites that have a short timeout on their sessions.
The gc\_maxlifetime setting defaults to 1440 seconds, but if you share the same session dir with another website that has a lower setting than this then it will prematurely erase your sessions, this from the php manual:
> Note: If different scripts have different values of session.gc\_maxlifetime but share the same place for storing the session data then the script with the minimum value will be cleaning the data. In this case, use this directive together with session.save\_path.
so i recommend changing your session save path to a different directory that the web server will have write permissions on. | I'm not sure what you mean, exactly, but you could try putting:
```
<?php set_time_limit(100); ?>
```
at the top of every page. Maybe? Sorry =/ | PHP5: Some Session files 0 length? | [
"",
"php",
"session",
""
] |
I have written some code that makes use of an open source library to do some of the heavy lifting. This work was done in linux, with unit tests and cmake to help with porting it to windows. There is a requirement to have it run on both platforms.
I like Linux and I like cmake and I like that I can get visual studios files automatically generated. As it is now, on windows everything will compile and it will link and it will generate the test executables.
However, to get to this point I had to fight with windows for several days, learning all about manifest files and redistributable packages.
As far as my understanding goes:
With VS 2005, Microsoft created Side By Side dlls. The motivation for this is that before, multiple applications would install different versions of the same dll, causing previously installed and working applications to crash (ie "Dll Hell"). Side by Side dlls fix this, as there is now a "manifest file" appended to each executable/dll that specifies which version should be executed.
This is all well and good. Applications should no longer crash mysteriously. However...
Microsoft seems to release a new set of system dlls with every release of Visual Studios. Also, as I mentioned earlier, I am a developer trying to link to a third party library. Often, these things come distributed as a "precompiled dll". Now, what happens when a precompiled dll compiled with one version of visual studios is linked to an application using another version of visual studios?
From what I have read on the internet, bad stuff happens. Luckily, I never got that far - I kept running into the "MSVCR80.dll not found" problem when running the executable and thus began my foray into this whole manifest issue.
I finally came to the conclusion that the only way to get this to work (besides statically linking everything) is that all third party libraries must be compiled using the same version of Visual Studios - ie don't use precompiled dlls - download the source, build a new dll and use that instead.
Is this in fact true? Did I miss something?
Furthermore, if this seems to be the case, then I can't help but think that Microsoft did this on purpose for nefarious reasons.
Not only does it break all precompiled binaries making it unnecessarily difficult to use precompiled binaries, if you happen to work for a software company that makes use of third party proprietary libraries, then whenever they upgrade to the latest version of visual studios - your company must now do the same thing or the code will no longer run.
As an aside, how does linux avoid this? Although I said I preferred developing on it and I understand the mechanics of linking, I haven't maintained any application long enough to run into this sort of low level shared libraries versioning problem.
Finally, to sum up: Is it possible to use precompiled binaries with this new manifest scheme? If it is, what was my mistake? If it isn't, does Microsoft honestly think this makes application development easier?
Update - A more concise question: **How does Linux avoid the use of Manifest files?** | All components in your application must share the same runtime. When this is not the case, you run into strange problems like asserting on delete statements.
This is the same on all platforms. It is not something Microsoft invented.
You may get around this 'only one runtime' problem by being aware where the runtimes may bite back.
This is mostly in cases where you allocate memory in one module, and free it in another.
```
a.dll
dllexport void* createBla() { return malloc( 100 ); }
b.dll
void consumeBla() { void* p = createBla(); free( p ); }
```
When a.dll and b.dll are linked to different rumtimes, this crashes, because the runtime functions implement their own heap.
You can easily avoid this problem by providing a destroyBla function which must be called to free the memory.
There are several points where you may run into problems with the runtime, but most can be avoided by wrapping these constructs.
For reference :
* don't allocate/free memory/objects across module boundaries
* don't use complex objects in your dll interface. (e.g. std::string, ...)
* don't use elaborate C++ mechanisms across dll boundaries. (typeinfo, C++ exceptions, ...)
* ...
But this is not a problem with manifests.
A manifest contains the version info of the runtime used by the module and gets embedded into the binary (exe/dll) by the linker. When an application is loaded and its dependencies are to be resolved, the loader looks at the manifest information embedded in the exe file and uses the according version of the runtime dlls from the WinSxS folder. You cannot just copy the runtime or other modules to the WinSxS folder. You have to install the runtime offered by Microsoft. There are MSI packages supplied by Microsoft which can be executed when you install your software on a test/end-user machine.
So install your runtime before using your application, and you won't get a 'missing dependency' error.
---
(Updated to the "How does Linux avoid the use of Manifest files" question)
**What is a manifest file?**
Manifest files were introduced to place disambiguation information next to an existing executable/dynamic link library or directly embedded into this file.
This is done by specifying the specific version of dlls which are to be loaded when starting the app/loading dependencies.
(There are several other things you can do with manifest files, e.g. some meta-data may be put here)
**Why is this done?**
The version is not part of the dll name due to historic reasons. So "comctl32.dll" is named this way in all versions of it. (So the comctl32 under Win2k is different from the one in XP or Vista). To specify which version you really want (and have tested against), you place the version information in the "appname.exe.manifest" file (or embed this file/information).
**Why was it done this way?**
Many programs installed their dlls into the system32 directory on the systemrootdir. This was done to allow bugfixes to shared libraries to be deployed easily for all dependent applications. And in the days of limited memory, shared libraries reduced the memory footprint when several applications used the same libraries.
This concept was abused by many programmers, when they installed all their dlls into this directory; sometimes overwriting newer versions of shared libraries with older ones. Sometimes libraries changed silently in their behaviour, so that dependent applications crashed.
This lead to the approach of "Distribute all dlls in the application directory".
**Why was this bad?**
When bugs appeared, all dlls scattered in several directories had to be updated. (gdiplus.dll) In other cases this was not even possible (windows components)
**The manifest approach**
This approach solves all problems above. You can install the dlls in a central place, where the programmer may not interfere. Here the dlls can be updated (by updating the dll in the WinSxS folder) and the loader loads the 'right' dll. (version matching is done by the dll-loader).
**Why doesn't Linux have this mechanic?**
I have several guesses. (This is really just guessing ...)
* Most things are open-source, so recompiling for a bugfix is a non-issue for the target audience
* Because there is only one 'runtime' (the gcc runtime), the problem with runtime sharing/library boundaries does not occur so often
* Many components use C at the interface level, where these problems just don't occur if done right
* The version of libraries are in most cases embedded in the name of its file.
* Most applications are statically bound to their libraries, so no dll-hell may occur.
* The GCC runtime was kept very ABI stable so that these problems could not occur. | If a third party DLL will allocate memory and *you* need to free it, you need the same run-time libraries. If the DLL has allocate and deallocate functions, it can be ok.
It the third party DLL uses `std` containers, such as `vector`, etc. you could have issues as the layout of the objects may be completely different.
It is possible to get things to work, but there are some limitations. I've run into both of the problems I've listed above. | Working with Visual Studios C++ manifest files | [
"",
"c++",
"visual-studio",
"dll",
"manifest",
""
] |
When I have a markup error in my XHTML page, Mozilla Firefox displays the "Yellow Screen of Death", showing only a large red error message on a yellow background.
While these errors are rare, they are *extremely* user-unfriendly.
Is there a way I can detect these using Javascript, and thereby send a message back to the server?
What I've discovered so far:
- Scripts placed before the parsing error still run. (Of course.)
- Timeouts and intervals that were set in these scripts will still execute after the parsing error.
- In Firefox, the DOM is a `<parsererror>` with a `<sourcetext>` inside it. I can detect this if I query `document.firstChild.tagName`.
Remaining questions:
- What events are available that I could listen for to detect this happening? (Polling sucks.)
- How can I detect this in other browsers? | Catching parse errors on the client might be possible, but it's really solving the wrong problem.
I know this isn't what you asked for, but unless you're doing something truly XHTML-specific like embedding some other markup language, you should serve your page as text/html instead of application/xhtml+xml. Even if it's XHTML. By serving it as text/html you'll avoid the problem you're running into and allow your page to work in IE as well. Note that it's the MIME type and not the doctype declaration that determines which parser is used -- using a transitional doctype won't do it.
That said, if you're really sure you want your page parsed as XHTML, it's better to handle this kind of error on the server. Generate your page by building up a DOM and then send the result of serializing it. If that's not an option, then start by generating the page as you do now but don't transmit it to the client yet. Take the XHTML that you've generated and parse it server-side with a validating XHTML parser (or at the very least, a generic XML parser). If you get errors, display whatever error page you want. Otherwise, serialize the parsed DOM and send that to the client.
In summary, the basic rules for using application/xhtml+xml are:
1. Don't.
2. (For advanced users) Don't, unless you've proven that you're doing something that won't work if the page is served as text/html. This applies to a tiny, tiny fraction of a percent of XHTMl documents.
3. If you must serve your page as application/xhtml+xml, generate it with some method that guarantees validity.
4. Unless you *really* know what you're doing, *never* use application/xhtml+xml for a page that includes user input.
Remember that XHTML is just a reformulation of HTML 4 plus the ability to embed other languages. If you don't use the embedding, what you have is HTML 4 with a different but almost completely compatible syntax. The overwhelming majority of XHTML documents out there are served as text/html and thus treated like HTML 4 by browsers. | This doesn't answer your question but, instead, why not validate your XHTML on your server, after/when you generate it and before you send it to the browser? | Can I detect XHTML parsing errors using Javascript? | [
"",
"javascript",
"xhtml",
"error-logging",
"parsing-error",
""
] |
I've finally gotten around to learning Java and am looking for some documentation for Java that I can download and read offline. Something like [Sun's stuff](http://java.sun.com/docs/books/tutorial/) but zipped up or as a PDF or CHM.
I'm using Eclipse so something that integrates with that would be nice. It already seems to have some of what I want somewhere (the javadoc stuff) but I don't see how to search it and I'm not seeing a language ref. | Full Documentation in Windows Help Format
<http://javadoc.allimant.org/> | I'm not sure that I fully understand your question.
If you are interested in materials about learning Java (rather than API references), you can [download all of it as a zip file](http://java.sun.com/docs/books/tutorial/information/download.html). It will be multiple HTML files, but I've never seen a real problem with browsing them unless I wanted a printout. If you need a printout of the tutorial, just get the tutorial in book form.
If you are looking for the JavaDocs for a specific API, and you use Eclipse, your best bet might be to use the version of Eclipse that is specific for Java and comes packaged with the JDK source code (or just download the source code). You can then read the documentation of methods through different views like the Java Browsing view. | Offline Java Documentation | [
"",
"java",
"documentation",
"offline",
""
] |
I am starting a new Java Web Project which is using Hibernate and a standard MVC Architecture.
I have just started to layout the projects structure and while doing this I started to look around to see if there was any standards in this area, about where Controllers should go and generally the best way to lay everything out. However I have not really found any guidelines.
So what I am curious to know is
* Is anyone aware of any best practise guidelines for the layout of a Java Web Project?
* Does anyone have a particular set of hard rules that they always follow for different types of project?
* Do people tend to split packages by the different layers such as presentation, business, and application? | To continue my previous answer, I have many web projects. In all of them the structure under src is more or less the same. The packages are roughly separated to 3 logical layers.
First is the presentation layer, as you said, for servlets, app listeners, and helpers.
Second, there is a layer for the hibernate model/db access layer. The third layer for business logic. However, sometimes the boundary between these layers is not clear. If you are using hibernate for db access then the model is defined by hibernate classes so I put them in the same area as the dao objects. E.g. com.sample.model holds the hibernate data objects and com.sample.model.dao hold the dao objects.
If using straight jdbc (usually with Spring), then sometimes I find it more convenient to put the data objects closer to the business logic layer rather than with the db access layer.
(The rest of the stuff typically falls under the business layer). | It really depends on your web framework.
For example if you use Wicket, java files and webpages co-exist in the same directory while
in most other frameworks, pages (.jsp files or whatever is your presentation engine) and
code-behind stuff (java files ) are completely separate.
So read the documentation that comes with your framework (Spring MVC, Struts, JSF e.t.c).
Another good proposal is to use Maven Archetypes to generate a skeleton for your specific framework. Some web frameworks (such as seam) have even their own code generation tool that lays the foundations for your web project.
My only good suggestion (that is not mentioned by Yoni) for the src directory is
to make packages according to business purpose and NOT according to type/layer
That means packages for
* com.mycompany.myproject.customers
* com.mycompany.myproject.departments
* com.mycompany.myproject.billing
* com.mycompany.myproject.reports
* com.mycompany.myproject.admin
and NOT
* com.mycompany.myproject.entities
* com.mycompany.myproject.tables
* com.mycompany.myproject.graphs
* com.mycompany.myproject.dialogs
* com.mycompany.myproject.servlets
The second structure is too generic, tends to resolve around huge packages with unrelated stuff and is hard to maintain. | Java Web Project Structure Best Practice | [
"",
"java",
"model-view-controller",
"project",
"structure",
"package",
""
] |
I'm a big fan of Python's [for...else syntax](http://docs.python.org/reference/compound_stmts.html#the-for-statement) - it's surprising how often it's applicable, and how effectively it can simplify code.
However, I've not figured out a nice way to use it in a generator, for example:
```
def iterate(i):
for value in i:
yield value
else:
print 'i is empty'
```
In the above example, I'd like the `print` statement to be executed only if `i` is empty. However, as `else` only respects `break` and `return`, it is always executed, regardless of the length of `i`.
If it's impossible to use `for...else` in this way, what's the best approach to this so that the `print` statement is only executed when nothing is yielded? | You're breaking the definition of a generator, which should throw a StopIteration exception when iteration is complete (which is automatically handled by a return statement in a generator function)
So:
```
def iterate(i):
for value in i:
yield value
return
```
Best to let the calling code handle the case of an empty iterator:
```
count = 0
for value in iterate(range([])):
print value
count += 1
else:
if count == 0:
print "list was empty"
```
Might be a cleaner way of doing the above, but that ought to work fine, and doesn't fall into any of the common 'treating an iterator like a list' traps below. | There are a couple ways of doing this. You could always use the `Iterator` directly:
```
def iterate(i):
try:
i_iter = iter(i)
next = i_iter.next()
except StopIteration:
print 'i is empty'
return
while True:
yield next
next = i_iter.next()
```
But if you know more about what to expect from the argument `i`, you can be more concise:
```
def iterate(i):
if i: # or if len(i) == 0
for next in i:
yield next
else:
print 'i is empty'
raise StopIteration()
``` | Using for...else in Python generators | [
"",
"python",
"syntax",
"for-loop",
"generator",
"yield",
""
] |
I have some simple python code that searches files for a string e.g. `path=c:\path`, where the `c:\path` part may vary. The current code is:
```
def find_path(i_file):
lines = open(i_file).readlines()
for line in lines:
if line.startswith("Path="):
return # what to do here in order to get line content after "Path=" ?
```
What is a simple way to get the text after `Path=`? | Starting in `Python 3.9`, you can use [`removeprefix`](https://docs.python.org/3/library/stdtypes.html#str.removeprefix):
```
'Path=helloworld'.removeprefix('Path=')
# 'helloworld'
``` | If the string is fixed you can simply use:
```
if line.startswith("Path="):
return line[5:]
```
which gives you everything from position 5 on in the string (a string is also a sequence so these sequence operators work here, too).
Or you can split the line at the first `=`:
```
if "=" in line:
param, value = line.split("=",1)
```
Then param is "Path" and value is the rest after the first =. | How to remove the left part of a string? | [
"",
"python",
"string",
""
] |
I'm trying to figure out the best way take a ics file and convert it into a format I can put into a database. Can anyone recommend how to do this? | The commercial .NET library Aspose.iCal does the job
<http://www.aspose.com/community/blogs/salman.sarfraz/archive/2008/11/21/where-is-aspose-icalendar.aspx> (used to be <http://www.aspose.com/categories/file-format-components/aspose.network-for-.net/default.aspx>)
Or this open source parser (didn't try it)
<http://sourceforge.net/projects/icalparser/>
And this online iCal validator comes in handy
<http://severinghaus.org/projects/icv/>
Regards,
tamberg | There's an [example](http://www.codeproject.com/KB/macros/iCalendar1.aspx) of parsing iCalendar files. It is based on the [DDay.iCal](http://www.ddaysoftware.com/Pages/Projects/DDay.iCal/) library. | parser for ics files in .net | [
"",
"c#",
"calendar",
"icalendar",
""
] |
I'm trying to create an activity that presents some data to the user. The data is such that it can be divided into 'words', each being a widget, and sequence of 'words' would form the data ('sentence'?), the ViewGroup widget containing the words. As space required for all 'words' in a 'sentence' would exceed the available horizontal space on the display, I would like to wrap these 'sentences' as you would a normal piece of text.
The following code:
```
public class WrapTest extends Activity {
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
LinearLayout l = new LinearLayout(this);
LinearLayout.LayoutParams lp = new LinearLayout.LayoutParams(
LinearLayout.LayoutParams.FILL_PARENT,
LinearLayout.LayoutParams.WRAP_CONTENT);
LinearLayout.LayoutParams mlp = new LinearLayout.LayoutParams(
new ViewGroup.MarginLayoutParams(
LinearLayout.LayoutParams.WRAP_CONTENT,
LinearLayout.LayoutParams.WRAP_CONTENT));
mlp.setMargins(0, 0, 2, 0);
for (int i = 0; i < 10; i++) {
TextView t = new TextView(this);
t.setText("Hello");
t.setBackgroundColor(Color.RED);
t.setSingleLine(true);
l.addView(t, mlp);
}
setContentView(l, lp);
}
}
```
yields something like the left picture, but I would want a layout presenting the same widgets like in the right one.
Is there such a layout or combination of layouts and parameters, or do I have to implement my own ViewGroup for this? | Since May 2016 there is new layout called FlexboxLayout from Google, which is highly configurable for purpose you want.
FlexboxLayout is in Google GitHub repository at <https://github.com/google/flexbox-layout> at this moment.
You can use it in your project by adding dependency to your `build.gradle` file:
```
dependencies {
implementation 'com.google.android.flexbox:flexbox:3.0.0'
}
```
More about FlexboxLayout usage and all the attributes you can find in repository readme or in Mark Allison articles here:
<https://blog.stylingandroid.com/flexboxlayout-part-1/>
<https://blog.stylingandroid.com/flexboxlayout-part2/>
<https://blog.stylingandroid.com/flexboxlayout-part-3/> | I made my own layout that does what I want, but it is quite limited at the moment. Comments and improvement suggestions are of course welcome.
The activity:
```
package se.fnord.xmms2.predicate;
import se.fnord.android.layout.PredicateLayout;
import android.app.Activity;
import android.graphics.Color;
import android.os.Bundle;
import android.widget.TextView;
public class Predicate extends Activity {
/** Called when the activity is first created. */
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
PredicateLayout l = new PredicateLayout(this);
for (int i = 0; i < 10; i++) {
TextView t = new TextView(this);
t.setText("Hello");
t.setBackgroundColor(Color.RED);
t.setSingleLine(true);
l.addView(t, new PredicateLayout.LayoutParams(2, 0));
}
setContentView(l);
}
}
```
Or in an XML layout:
```
<se.fnord.android.layout.PredicateLayout
android:id="@+id/predicate_layout"
android:layout_width="fill_parent"
android:layout_height="wrap_content"
/>
```
And the Layout:
```
package se.fnord.android.layout;
import android.content.Context;
import android.util.AttributeSet;
import android.view.View;
import android.view.ViewGroup;
/**
* ViewGroup that arranges child views in a similar way to text, with them laid
* out one line at a time and "wrapping" to the next line as needed.
*
* Code licensed under CC-by-SA
*
* @author Henrik Gustafsson
* @see http://stackoverflow.com/questions/549451/line-breaking-widget-layout-for-android
* @license http://creativecommons.org/licenses/by-sa/2.5/
*
*/
public class PredicateLayout extends ViewGroup {
private int line_height;
public PredicateLayout(Context context) {
super(context);
}
public PredicateLayout(Context context, AttributeSet attrs){
super(context, attrs);
}
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
assert(MeasureSpec.getMode(widthMeasureSpec) != MeasureSpec.UNSPECIFIED);
final int width = MeasureSpec.getSize(widthMeasureSpec);
// The next line is WRONG!!! Doesn't take into account requested MeasureSpec mode!
int height = MeasureSpec.getSize(heightMeasureSpec) - getPaddingTop() - getPaddingBottom();
final int count = getChildCount();
int line_height = 0;
int xpos = getPaddingLeft();
int ypos = getPaddingTop();
for (int i = 0; i < count; i++) {
final View child = getChildAt(i);
if (child.getVisibility() != GONE) {
final LayoutParams lp = (LayoutParams) child.getLayoutParams();
child.measure(
MeasureSpec.makeMeasureSpec(width, MeasureSpec.AT_MOST),
MeasureSpec.makeMeasureSpec(height, MeasureSpec.UNSPECIFIED));
final int childw = child.getMeasuredWidth();
line_height = Math.max(line_height, child.getMeasuredHeight() + lp.height);
if (xpos + childw > width) {
xpos = getPaddingLeft();
ypos += line_height;
}
xpos += childw + lp.width;
}
}
this.line_height = line_height;
if (MeasureSpec.getMode(heightMeasureSpec) == MeasureSpec.UNSPECIFIED){
height = ypos + line_height;
} else if (MeasureSpec.getMode(heightMeasureSpec) == MeasureSpec.AT_MOST){
if (ypos + line_height < height){
height = ypos + line_height;
}
}
setMeasuredDimension(width, height);
}
@Override
protected LayoutParams generateDefaultLayoutParams() {
return new LayoutParams(1, 1); // default of 1px spacing
}
@Override
protected boolean checkLayoutParams(LayoutParams p) {
return (p instanceof LayoutParams);
}
@Override
protected void onLayout(boolean changed, int l, int t, int r, int b) {
final int count = getChildCount();
final int width = r - l;
int xpos = getPaddingLeft();
int ypos = getPaddingTop();
for (int i = 0; i < count; i++) {
final View child = getChildAt(i);
if (child.getVisibility() != GONE) {
final int childw = child.getMeasuredWidth();
final int childh = child.getMeasuredHeight();
final LayoutParams lp = (LayoutParams) child.getLayoutParams();
if (xpos + childw > width) {
xpos = getPaddingLeft();
ypos += line_height;
}
child.layout(xpos, ypos, xpos + childw, ypos + childh);
xpos += childw + lp.width;
}
}
}
}
```
With the result:
 | Line-breaking widget layout for Android | [
"",
"java",
"android",
"user-interface",
"layout",
""
] |
I'm currently refactoring some code on a project that is wrapping up, and I ended up putting a lot of business logic into service classes rather than in the domain objects. At this point most of the domain objects are data containers only. I had decided to write most of the business logic in service objects, and refactor everything afterwards into better, more reuseable, and more readable shapes. That way I could decide what code should be placed into domain objects, and which code should be spun off into new objects of their own, and what code should be left in a service class. So I have some code:
```
public decimal CaculateBatchTotal(VendorApplicationBatch batch)
{
IList<VendorApplication> applications = AppRepo.GetByBatchId(batch.Id);
if (applications == null || applications.Count == 0)
throw new ArgumentException("There were no applications for this batch, that shouldn't be possible");
decimal total = 0m;
foreach (VendorApplication app in applications)
total += app.Amount;
return total;
}
```
This code seems like it would make a good addition to a domain object, because it's only input parameter is the domain object itself. Seems like a perfect candidate for some refactoring. But the only problem is that this object calls another object's repository. Which makes me want to leave it in the service class.
My questions are thus:
1. Where would you put this code?
2. Would you break this function up?
3. Where would someone who's following strict Domain-Driven design put it?
4. Why?
Thanks for your time.
Edit Note: Can't use an ORM on this one, so I can't use a lazy loading solution.
Edit Note2: I can't alter the constructor to take in parameters, because of how the would-be data layer instantiates the domain objects using reflection (not my idea).
Edit Note3: I don't believe that a batch object should be able to total just any list of applications, it seems like it should only be able to total applications that are in that particular batch. Otherwise, it makes more sense to me to leave the function in the service class. | You shouldn't even have access to the repositories from the domain object.
What you can do is either let the service give the domain object the appropriate info or have a delegate in the domain object which is set by a service or in the constructor.
```
public DomainObject(delegate getApplicationsByBatchID)
{
...
}
``` | I'm no expert on DDD but I remember an article from the great Jeremy Miller that answered this very question for me. You would typically want logic related to your domain objects - inside those objects, but your service class would exec the methods that contain this logic. This helped me push domain specific logic into the entity classes, and keep my service classes less bulky (as I found myself putting to much logic inside the service classes like you mentioned)
**Edit: Example**
I use the enterprise library for simple validation, so in the entity class I will set an attribute like so:
```
[StringLengthValidator(1, 100)]
public string Username {
get { return mUsername; }
set { mUsername = value; }
}
```
The entity inherits from a base class that has the following "IsValid" method that will ensure each object meets the validation criteria
```
public bool IsValid()
{
mResults = new ValidationResults();
Validate(mResults);
return mResults.IsValid();
}
[SelfValidation()]
public virtual void Validate(ValidationResults results)
{
if (!object.ReferenceEquals(this.GetType(), typeof(BusinessBase<T>))) {
Validator validator = ValidationFactory.CreateValidator(this.GetType());
results.AddAllResults(validator.Validate(this));
}
//before we return the bool value, if we have any validation results map them into the
//broken rules property so the parent class can display them to the end user
if (!results.IsValid()) {
mBrokenRules = new List<BrokenRule>();
foreach (Microsoft.Practices.EnterpriseLibrary.Validation.ValidationResult result in results) {
mRule = new BrokenRule();
mRule.Message = result.Message;
mRule.PropertyName = result.Key.ToString();
mBrokenRules.Add(mRule);
}
}
}
```
Next we need to execute this "IsValid" method in the service class save method, like so:
```
public void SaveUser(User UserObject)
{
if (UserObject.IsValid()) {
mRepository.SaveUser(UserObject);
}
}
```
A more complex example might be a bank account. The deposit logic will live inside the account object, but the service class will call this method. | In domain-driven design, would it be a violation of DDD to put calls to other objects' repostiories in a domain object? | [
"",
"c#",
"design-patterns",
"service",
"domain-driven-design",
""
] |
I am using SQL and I have a table with three colums: account, transaction\_date, Points.
Each account will have multiple transaction\_dates and Points earned for each transaction.
How do I return the transaction\_date when each account reached a certain threshold (i.e. accumulatee 100 Points). Say the first account has 2000 transactions and the first five have each 21 Points. I would like the query to return transaction # 5 because that is when the account reached 100.
Can anybody help?
Thanks!
Cat | ```
select min(a.transaction_date), a.account from
(select sum(t1.points) as thesum, t2.transaction_date, t2.account
from table t1
inner join table t2 on t1.account = t2.account and t1.transaction_date <= t2.transaction_date
group by t2.transaction_date, t2.account
having thesum >= 100) a
group by a.account
``` | Use a triangular join:
In T-SQL:
```
SELECT account, MIN(dt), MIN(points)
FROM
(
SELECT t1.account, t1.date, sum(t2.points) AS points
FROM table t1
INNER JOIN table t2 ON t1.account = t2.account AND t1.dt >= t2.dt
GROUP BY t1.account, t1.date
HAVING SUM(t2.points) > 100
) iq
GROUP BY account
``` | How to return a record when the sum reached a certain threshold | [
"",
"sql",
""
] |
If you have several classes where you want them to inherit from a base class for common functionality, should you implement the base class using a class or an abstract class? | That depends, if you never want to be able to instantiate the base class then make it abstract. Otherwise leave it as a normal class. | If the base class ought not to be instantiated then make it an abstract class - if the base class needs to be instantiated then don't make it abstract.
In this example it makes sense to make the base class abstract as the base class does not have any concrete meaning:
```
abstract class WritingImplement
{
public abstract void Write();
}
class Pencil : WritingImplement
{
public override void Write() { }
}
```
However in this next example you can see how the base class does have concrete meaning:
```
class Dog
{
public virtual void Bark() { }
}
class GoldenRetriever : Dog
{
public override void Bark() { }
}
```
It is all pretty subjective really - you ought to be able to make a pretty good judgment call based on the needs of your particular domain. | Inherit from a class or an abstract class | [
"",
"c#",
".net",
"inheritance",
"class",
""
] |
I'm working with php and I want to do a next button that's step to the next 10 records (like when you browse question with stackoverflow)
I don't know how to do that but I'm thinking to do it with Top n record ? Do you think that's a good idea ? Any suggestion? | As for doing it in PHP, you can easily make the button send a POST or GET request for the starting amount. For instance, a user would make the initial request and that is just `yoursite.com/search.php`, and the next button would send them to the same page with the same search criteria only send an additional field of "start", (i.e. `yoursite.com/search.php?start=10`). And in the code, you can simply check for it:
```
if(isset($_POST['start'])) {
//code to add to the search string to start at $_POST['start']
}
```
**Edit 1:** [This article](http://www.select-sql.com/mssql/how-to-make-limit-from-to-in-mssql-2005.html) is the best I could find as to how to replicate MySQL's `LIMIT` function. Also, [this one](http://www.posteet.com/view/1567) has a more definitive query to reference, but it's the same idea. | I know in MySQL you can use LIMIT X, Y where X is the lower bound of the return and Y is the upper bound. So if you wanted to return 10-20 you would use LIMIT 10, 20. Not sure what the MS-SQL equivalent is. | How to browse results with php mssql? | [
"",
"php",
"sql-server",
""
] |
I need to undo the following ASP.Net processes in PHP so I can get at the username and expiration date in a ticket. I've decrypted the 3DES encryption (step 3 below) but I'm not sure what I need to do next. Is the string that results from decryption a byte array? Should I be able to convert it to ascii? (Because it doesn't).
What ASP.Net does to create ticket:
1. Serialize username, expiration, other data (which I don't care about). Create a byte array.
2. Sign the ticket using SHA1 (the sig is the last 20 bytes)
3. Encrypt the ticket with 3DES (which I've unencrypted).
I get back something that looks like this:
> 6E 85 A4 39 71 31 46 BB A3 F6 BE 1A 07 EE A4 CE 5F 03 C8 D1 4C 97 5D 6A 52 D1 C4 82 75 5E 53 06 7B 1D D2 4D BF 22 40 F7 F4 B8 8D B0 C3 EC E5 BE F7 52 C2 DF 00 7A D1 CB BC 76 4B 10 33 2D 1A B4 15 A7 BB D6 9D BF 41 69 D2 C4 43 4A 26 95 01 F2 06 AA 46 2C 96 CC AD DC 08 59 C0 64 B6 EE 2C 5F CA ED 8B 92 1C 80 FD FF DC 61 67 28 59 CB E6 71 C6 C3 72 0E D0 32 69 22 57 4E 40 2B DA 67 BA 7F F1 C5 78 BC DF 80 8C D8 F2 8B 19 E2 A4 4F 7C 8C D9 97 37 BD B5 5B 0A 66 9B DD E7 DC 7B 78 F4 F8
It doesn't map to ascii, what do I do next? I have the SHA1 validation key. Thanks for any help! | I've been working it out, and I have managed to get the forms authentication ticket contents in PHP.
1. Decrypt the ticket with the same key used to encrypt it on the .Net side. For this, I'm using <http://www.navioo.com/php/docs/function.mcrypt-encrypt.php>.
2. The decryption adds padding to the end of the string, I remove that.
3. I'm left with a string with a 20 byte SHA1 hash at the end. Those last 20 bytes (should) match the SHA1 hash of the first part of the string (string length - 20 bytes). I'm still working on this part, trying to figure out how .NET converts a byte array into a single clump of data that can be SHA1 hashed (so I can do the same on the PHP side).
That's really all there is to it. | I don't think this is possible...
**A few pre-requisite questions:**
* Are you sure you have decrypted the string correctly, with the correct `MachineKey` value and decryption algorithm? I know ASP.NET 1.0 used 3DES but newer versions generally use AES by default.
* Why are you accessing this data in the first place? The `FormsAuthenticationTicket` was not intended to be "broken", and if you were going to access these values from a different language you may consider rolling your own scheme.
**Some noteworthy observations:**
Buried `in FormsAuthentication.Decrypt()` is a call to `UnsafeNativeMethods.CookieAuthParseTicket(...)`. Here is the signature:
```
[DllImport("webengine.dll", CharSet=CharSet.Unicode)]
internal static extern int CookieAuthParseTicket(byte[] pData, int iDataLen, StringBuilder szName, int iNameLen, StringBuilder szData, int iUserDataLen, StringBuilder szPath, int iPathLen, byte[] pBytes, long[] pDates);
```
This parses what looks to be a byte array returned from `MachineKeySection.HexStringToByteArray()` (apparently a function that appears to decode the string using UTF-8) into the individual members of the `FormsAuthenticationTicket`.
I can only assume that no matter which decoding method you use (ASCII, UTF-16, etc.) you're not going to get the data back unless you know Microsoft's implementation hidden in this native method.
[MSDN](http://msdn.microsoft.com/en-us/library/ms998288.aspx#paght000007_formsauthenticationtickets) may also offer some help. | How to get at contents of Forms Authentication ticket with PHP | [
"",
"php",
".net",
"forms-authentication",
""
] |
I have this query with MySQL:
```
select * from table1 LIMIT 10,20
```
How can I do this with SQL Server? | Starting SQL SERVER 2005, you can do this...
```
USE AdventureWorks;
GO
WITH OrderedOrders AS
(
SELECT SalesOrderID, OrderDate,
ROW_NUMBER() OVER (ORDER BY OrderDate) AS 'RowNumber'
FROM Sales.SalesOrderHeader
)
SELECT *
FROM OrderedOrders
WHERE RowNumber BETWEEN 10 AND 20;
```
or something like this for 2000 and below versions...
```
SELECT TOP 10 * FROM (SELECT TOP 20 FROM Table ORDER BY Id) ORDER BY Id DESC
``` | Starting with SQL SERVER 2012, you can use the OFFSET FETCH Clause:
```
USE AdventureWorks;
GO
SELECT SalesOrderID, OrderDate
FROM Sales.SalesOrderHeader
ORDER BY SalesOrderID
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY;
GO
```
<http://msdn.microsoft.com/en-us/library/ms188385(v=sql.110).aspx>
This may not work correctly when the order by is not unique.
If the query is modified to ORDER BY OrderDate, the result set returned is not as expected. | How to implement LIMIT with SQL Server? | [
"",
"sql",
"sql-server",
"migration",
""
] |
I'm using a custom attribute inherited from an attribute class. I'm using it like this:
```
[MyCustomAttribute("CONTROL")]
[MyCustomAttribute("ALT")]
[MyCustomAttribute("SHIFT")]
[MyCustomAttribute("D")]
public void setColor()
{
}
```
But the "Duplicate 'MyCustomAttribute' attribute" error is shown.
How can I create a duplicate allowed attribute? | Stick an `AttributeUsage` attribute onto your Attribute class (yep, that's mouthful) and set `AllowMultiple` to `true`:
```
[AttributeUsage(AttributeTargets.Method, AllowMultiple = true)]
public sealed class MyCustomAttribute: Attribute
``` | AttributeUsageAttribute ;-p
```
[AttributeUsage(AttributeTargets.Method, AllowMultiple = true)]
public class MyAttribute : Attribute
{}
```
Note, however, that if you are using ComponentModel (`TypeDescriptor`), it only supports one attribute instance (per attribute type) per member; raw reflection supports any number... | How to create duplicate allowed attributes | [
"",
"c#",
"attributes",
""
] |
I'm working on an interactive interface using SVG and JavaScript/jQuery, and I'm trying to decide between [Raphael](http://raphaeljs.com/) and [jQuery SVG](http://keith-wood.name/svgRef.html). I'd like to know
1. What the trade-offs are between the two
2. Where the development momentum seems to be.
I don't need the VML/IE support in Raphael, or the plotting abilities of jQuery SVG. I'm primarily interested in the most elegant way to create, animate, and manipulate individual items on an SVG canvas. | I've recently used both Raphael and jQuery SVG - and here are my thoughts:
## Raphael
**Pros:** a good starter library, easy to do a LOT of things with SVG quickly. Well written and documented. Lots of examples and Demos. Very extensible architecture. Great with animation.
**Cons:** is a layer over the actual SVG markup, makes it difficult to do more complex things with SVG - such as grouping (it supports Sets, but not groups). Doesn't do great w/ editing of already existing elements.
## jQuery SVG
**Pros:** a jquery plugin, if you're already using jQuery. Well written and documented. Lots of examples and demos. Supports most SVG elements, allows native access to elements easily
**Cons:** architecture not as extensible as Raphael. Some things could be better documented (like configure of SVG element). Doesn't do great w/ editing of already existing elements. Relies on SVG semantics for animation - which is not that great.
## [SnapSVG](http://snapsvg.io/) as a pure SVG version of Raphael
SnapSVG is the successor of Raphael. It is supported only in the SVG enabled browsers and supports almost all the features of SVG.
## Conclusion
If you're doing something quick and easy, Raphael is an easy choice. If you're going to do something more complex, I chose to use jQuery SVG because I can manipulate the actual markup significantly easier than with Raphael. And if you want a non-jQuery solution then SnapSVG is a good option. | For posterity, I'd like to note that I ended up choosing Raphael, because of the clean API and "free" IE support, and also because the [active development](http://groups.google.com/group/raphaeljs) looks promising (event support was just added in 0.7, for instance). However, I'll leave the question unanswered, and I'd still be interested to hear about others' experiences using Javascript + SVG libraries. | jQuery SVG vs. Raphael | [
"",
"javascript",
"jquery",
"svg",
"raphael",
""
] |
Is there a standard way of laying out a C# file? As in, Fields, then Properties, then Constructors, etc?
Here's what I normally do, but I'm wondering if there's a standard way?
1. Nested Classes or Enums
2. Fields
3. Properties
4. Events
5. Constructors
6. Public Methods
7. Private Methods
Do people group their fields together, or do they put them with the properties? Or do people not worry about an order? Visual Studio seems to make it so hard to do.
**Edit**: Moved other part about ReSharper here: [Make Resharper respect your preference for code order.](https://stackoverflow.com/questions/603805/make-resharper-respect-your-preference-for-code-order) | I tend to use [Microsoft StyleCop](http://code.msdn.microsoft.com/sourceanalysis), which has a set order according to rule [SA1201](https://web.archive.org/web/20221229051138/https://github.com/DotNetAnalyzers/StyleCopAnalyzers/blob/master/documentation/SA1201.md):
> **Cause** An element within a C# code
> file is out of order in relation to
> the other elements in the code.
>
> **Rule Description** A violation of this
> rule occurs when the code elements
> within a file do not follow a standard
> ordering scheme.
>
> To comply with this rule, elements at
> the file root level or within a
> namespace must be positioned in the
> following order:
>
> * Extern Alias Directives
> * Using Directives
> * Namespaces
> * Delegates
> * Enums
> * Interfaces
> * Structs
> * Classes
>
> Within a class, struct, or interface,
> elements must be positioned in the
> following order:
>
> * Fields
> * Constructors
> * Finalizers (Destructors)
> * Delegates
> * Events
> * Enums
> * Interfaces
> * Properties
> * Indexers
> * Methods
> * Structs
> * Classes
>
> Complying with a standard ordering
> scheme based on element type can
> increase the readability and
> maintainability of the file and
> encourage code reuse.
>
> When implementing an interface, it is
> sometimes desirable to group all
> members of the interface next to one
> another. This will sometimes require
> violating this rule, if the interface
> contains elements of different types.
> This problem can be solved through the
> use of partial classes.
>
> 1. Add the partial attribute to the class, if the class is not already
> partial.
> 2. Add a second partial class with the same name. It is possible to place
> this in the same file, just below the
> original class, or within a second
> file.
> 3. Move the interface inheritance and all members of the interface
> implementation to the second part of
> the class. | I think there's no *best* way. There are two important things to consider when it comes to layout. The first most important thing is consistency. Pick an approach and make sure that the entire team agrees and applies the layout. Secondly, if your class gets big enough that you are searching for where those pesky properties live (or have to implement regions to make them easier to find), then your class is probably too large. Consider sniffing it, and refactoring based on what you smell.
To answer the reshaper question, check under **Type Members Layout** in **Options** (under the **C#** node). It's not simple, but it is possible to change the layout order. | What's the best way to layout a C# class? | [
"",
"c#",
"coding-style",
""
] |
I have a list of integers that I would like to convert to one number like:
```
numList = [1, 2, 3]
num = magic(numList)
print num, type(num)
>>> 123, <type 'int'>
```
What is the best way to implement the *magic* function?
**EDIT**
I did find [this](http://bytes.com/groups/python/722951-int-str-list-elements), but it seems like there has to be a better way. | ```
# Over-explaining a bit:
def magic(numList): # [1,2,3]
s = map(str, numList) # ['1','2','3']
s = ''.join(s) # '123'
s = int(s) # 123
return s
# How I'd probably write it:
def magic(numList):
s = ''.join(map(str, numList))
return int(s)
# As a one-liner
num = int(''.join(map(str,numList)))
# Functionally:
s = reduce(lambda x,y: x+str(y), numList, '')
num = int(s)
# Using some oft-forgotten built-ins:
s = filter(str.isdigit, repr(numList))
num = int(s)
``` | Two solutions:
```
>>> nums = [1, 2, 3]
>>> magic = lambda nums: int(''.join(str(i) for i in nums)) # Generator exp.
>>> magic(nums)
123
>>> magic = lambda nums: sum(digit * 10 ** (len(nums) - 1 - i) # Summation
... for i, digit in enumerate(nums))
>>> magic(nums)
123
```
The `map`-oriented solution actually comes out ahead on my box -- you definitely should not use `sum` for things that might be large numbers:
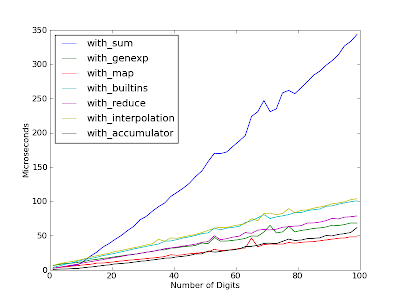
```
import collections
import random
import timeit
import matplotlib.pyplot as pyplot
MICROSECONDS_PER_SECOND = 1E6
FUNS = []
def test_fun(fun):
FUNS.append(fun)
return fun
@test_fun
def with_map(nums):
return int(''.join(map(str, nums)))
@test_fun
def with_interpolation(nums):
return int(''.join('%d' % num for num in nums))
@test_fun
def with_genexp(nums):
return int(''.join(str(num) for num in nums))
@test_fun
def with_sum(nums):
return sum(digit * 10 ** (len(nums) - 1 - i)
for i, digit in enumerate(nums))
@test_fun
def with_reduce(nums):
return int(reduce(lambda x, y: x + str(y), nums, ''))
@test_fun
def with_builtins(nums):
return int(filter(str.isdigit, repr(nums)))
@test_fun
def with_accumulator(nums):
tot = 0
for num in nums:
tot *= 10
tot += num
return tot
def time_test(digit_count, test_count=10000):
"""
:return: Map from func name to (normalized) microseconds per pass.
"""
print 'Digit count:', digit_count
nums = [random.randrange(1, 10) for i in xrange(digit_count)]
stmt = 'to_int(%r)' % nums
result_by_method = {}
for fun in FUNS:
setup = 'from %s import %s as to_int' % (__name__, fun.func_name)
t = timeit.Timer(stmt, setup)
per_pass = t.timeit(number=test_count) / test_count
per_pass *= MICROSECONDS_PER_SECOND
print '%20s: %.2f usec/pass' % (fun.func_name, per_pass)
result_by_method[fun.func_name] = per_pass
return result_by_method
if __name__ == '__main__':
pass_times_by_method = collections.defaultdict(list)
assert_results = [fun([1, 2, 3]) for fun in FUNS]
assert all(result == 123 for result in assert_results)
digit_counts = range(1, 100, 2)
for digit_count in digit_counts:
for method, result in time_test(digit_count).iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(digit_counts, pass_times, label=method)
pyplot.legend(loc='upper left')
pyplot.xlabel('Number of Digits')
pyplot.ylabel('Microseconds')
pyplot.show()
``` | Convert list of ints to one number? | [
"",
"python",
""
] |
I'm curious to know what the best way (best practice) to handle hierarchies are in regards to database design. Here is a small example of how I usually handle them.
**Node Table**
```
NodeId int PRIMARY KEY
NodeParentId int NULL
DisplaySeq int NOT NULL
Title nvarchar(255)
```
**Ancestor Table**
```
NodeId int
AncestorId int
Hops int
```
with Indexes on NodeId, AncestorId, Hops
Tables look like this:
**Node Table**
```
NodeId NodeParentId DisplaySeq Title
1 NULL 1 'Root'
2 1 1 'Child 1'
3 1 2 'Child 2'
4 2 1 'Grandchild 1'
5 2 2 'Grandchild 2'
```
**Ancestor Table**
```
NodeId AncestorId Hops
1 NULL 0
1 1 0
2 1 1
2 2 0
3 1 1
3 3 0
4 1 2
4 2 1
4 4 0
5 1 2
5 2 1
5 5 0
```
With this design, I've found that with large hierarchies I can get an entire section of the hierarchy very quickly by joining on the Ancestor table for AncestorId = target NodeId, like:
```
SELECT *
FROM Node n
INNER JOIN Ancestor a on a.NodeId=n.NodeId
WHERE a.AncestorId = @TargetNodeId
```
It's also easy to get direct children as well
```
SELECT *
FROM Node n
INNER JOIN Ancestor a on a.NodeId=n.NodeId
WHERE a.AncestorId = @TargetNodeId
AND Hops = 1
```
I'm interested in knowing what other solutions you may have used for this type of thing. In my experience, hierarchies can get pretty hairy, and any way to optimize their retrieval is very important. | As MarkusQ and n8wrl have already pointed out, Joe Celko has some good stuff on this. I'll just add that there are multiple ways to model a hierarchy (Joe's book contains several I believe, not just one that he considers the "best"). Your final decision will hopefully take into account your own specific needs. Some of the different ways to model it are better for write-intensive operations while others are better for frequent or fast reads up and down the hierarchy. Just keep in mind what your system will be doing with it. | There are some vendor-specific extensions to do this, but my favorite db-neutral way comes from Joe Celko - google 'Joe Celko Trees and Hierarchies' or buy this book: [link text](https://rads.stackoverflow.com/amzn/click/com/1558609202)
This is a very clever set-based way to go. Easy to query hierarchy. I added the 'parentID' field you have just because I ask the 'direct children' and 'parent' questions a lot and that speeds those up. But this is a wonderful way to get a 'ancestry' or 'descdent' query. | Handling Hierarchy Data in Database | [
"",
"sql",
"hierarchical-data",
""
] |
My problem is actually more nuanced than the question suggests, but wanted to keep the header brief.
I have a `HashMap<String, File>` of `File` objects as values. The keys are `String name` fields which are part of the `File` instances. I need to iterate over the values in the `HashMap` and return them as a single `String`.
This is what I have currently:
```
private String getFiles()
{
Collection<File> fileCollection = files.values();
StringBuilder allFilesString = new StringBuilder();
for(File file : fileCollection) {
allFilesString.append(file.toString());
}
return allFilesString.toString();
}
```
This does the job, but ideally I want the separate `File` values to be appended to the `StringBuilder` in order of `int fileID`, which is a field of the `File` class.
Hope I've made that clear enough. | Something like this should work:
```
List<File> fileCollection = new ArrayList<File>(files.values());
Collections.sort(fileCollection,
new Comparator<File>()
{
public int compare(File fileA, File fileB)
{
final int retVal;
if(fileA.fileID > fileB.fileID)
{
retVal = 1;
}
else if(fileA.fileID < fileB.fileID)
{
retVal = -1;
}
else
{
retVal = 0;
}
return (retVal);
}
});
``` | Unfortunately there is no way of getting data out of a HashMap in any recognizable order. You have to either put all the values into a TreeSet with a Comparator that uses the fileID, or put them into an ArrayList and sort them with Collections.sort, again with a Comparator that compares the way you want.
The TreeSet method doesn't work if there are any duplicates, and it may be overkill since you're not going to be adding things to or removing things from the Set. The Collections.sort method is a good solution for instances like this where you're going to take the whole HashSet, sort the results, and then toss away the sorted collection as soon as you've generated the result. | How can I form an ordered list of values extracted from HashMap? | [
"",
"java",
"iterator",
"hashmap",
""
] |
I'm hosting a website on Zymic (free host) that utilizes MySQL. I opened an account, and wrote the SIMPLEST function to connect to the DB. It looks like this:
```
<?php
$conn = mysql_connect("uuuq.com","paulasplace_sudo","mypassword");
if(!$con)
{
die("Could not connect: " . mysql_error());
}
else
{
echo("mysql connected successfully!");
}
?>
```
but it throws this error:
Warning: mysql\_connect() [function.mysql-connect]: Lost connection to MySQL server at 'reading initial communication packet', system error: 111 in /www/uuuq.com/p/a/u/paulasplace/htdocs/index.php on line 9
Could not connect: Lost connection to MySQL server at 'reading initial communication packet', system error: 111
Any ideas what might be wrong? | This may be just from when you copied the code into your post, but you store the results of mysql\_connect() into $conn, but the if statement checks a different variably $con... | For those like me that had this same problem with a virtual machine or where you have all the rights (priviliges as read in phpmyadmin) to make users, the problem for me was that my user for the database was created incorrectly . While creating my DB user i set incorrectly one the parametres right after the name there is an selector where you can choose the server: chosen as default was my error, that says "any server" and is set as % , i had to change it , infact , i had to create a new user with the same name and different server, there i set it to localhost. My problem got solved , i deleted my other user, restarted the server and it worked fine. | PHP/MySQL simple connection won't work | [
"",
"php",
"mysql",
"hosting",
""
] |
I have a list of files (stored as c style strings) that I will be performing a search on and I will remove those files that do not match my parameters. What is the best container to use for this purpose? I'm thinking Set as of now. Note the list of files will never be larger than when it is initialized. I'll only be deleting from the container. | I would definitely not use a set - you don't need to sort it so no point in using a set. Set is implemented as a self-balancing tree usually, and the self-balancing algorithm is unnecessary in your case.
If you're going to be doing this operation once, I would use a std::vector with remove\_if (from <algorithm>), followed by an erase. If you haven't used remove\_if before, what it does is go through and shifts all the relevant items down, overwriting the irrelevant ones in the process. You have to follow it with an erase to reduce the size of the vector. Like so:
```
std::vector<const char*> files;
files.erase(remove_if(files.begin(), files.end(), RemovePredicate()), files.end());
```
Writing the code to do the same thing with a std::list would be a little bit more difficult if you wanted to take advantage of its O(1) deletion time property. Seeing as you're just doing this one-off operation which will probably take so little time you won't even notice it, I'd recommend doing this as it's the easiest way.
And to be honest, I don't think you'll see that much difference in terms of speed between the std::list and std::vector approaches. The vector approach only copies each value once so it's actually quite fast, yet takes much less space. In my opinion, going up to a std::list and using three times the space is only really justified if you're doing a lot of addition and deletion throughout the entire application's lifetime. | Elements in a std::set must be unique, so unless the filenames are globally unique this won't suit your needs.
I would probably recommend a std::list. | Best c++ container to strip items away from? | [
"",
"c++",
"list",
"vector",
"set",
"containers",
""
] |
I've discovered [VB2Py](http://vb2py.sourceforge.net/), but it's been silent for almost 5 years. Are there any other tools out there which could be used to convert VB6 projects to Python, Ruby, Tcl, whatever? | Compile the VB code either into a normal DLL or a COM DLL. All Pythons on Windows, including the vanilla ActivePython distribution (IronPython isn't required) can connect to
both types of DLLs.
I think this is your best option. As Gustavo said, finding something that will compile arbitrary VB6 code into Python sounds like an unachievable dream. | I doubt there would be a good solution for that since VB6 relies too much on the windows API and VBRun libraries though you could translate code that does something else besides GUI operations
Is there something special you need to do with that code? You could compile your VB6 functionality and expose it as a COM object and connect it to python with [IronPython](http://www.codeplex.com/Wiki/View.aspx?ProjectName=IronPython) or [IronRuby](http://www.ironruby.net/) which are Python and Ruby implementations in .Net thus, allowing you to access .Net functionality although im not quite sure if COM exposed objects are easily pluggable to those interpreters.
Maybe if you explain a bit more what you want to do you would get a wiser response. | Is there a tool for converting VB to a scripting language, e.g. Python or Ruby? | [
"",
"python",
"vb6",
""
] |
I need to find a certain chunk from a group of HTML files and delete it from them all. The files are really hacked up HTML, so instead of parsing it with HtmlAgility pack as I was trying before, I would like to use a simple regex.
the section of html will always look like this:
```
<CENTER>some constant text <img src=image.jpg> more constant text:
variable section of text</CENTER>
```
All of the above can be any combination of upper and lower case, and notice that it is img src=image.jpg and not img src="image.jpg"... And there can be any number of white space characters in between the constant characters.
here are some examples:
```
<CENTER>This page has been visited
<IMG SRC=http://place.com/image.gif ALT="alt text">times since 10th July 2007
</CENTER>
```
or
```
<center>This page has been visited
<IMG src="http://place.com/image.gif" Alt="Alt Text">
times since 1st October 2005</center>
```
What do you think would be a good way to match this pattern? | How much of that text is needed to uniquely identify the target? I would try this first:
```
@"(?is)<center>\s*This\s+page\s+has\s+been\s+visited.*?</center>"
``` | It really depends on how simple you can make the regex and match the desired elements.
```
<center>[^<]+<img[^>]+>[^>]+</center>
```
Use the case-insensitive flag too (I don't know what C# uses). If you need something more developed because you'll have situations where an img tag sits within center tags and not match, then you can start hardcoding phrases like the other answer. | Matching a regex in html, ignoring spaces, and quotation marks | [
"",
"c#",
"regex",
""
] |
I was wondering if anyone knows about a good article which describes dividing workload on to several Threads? Preferebly it would be written for C# but it's really the concept I'm after, so it's not an issue if it's written for a different, similar, language.
I have a problem where I would have to divide a large amount of computing into several threads and then Sum the generated data after one iteration completes (so I would need to know that all threads have finished) and then start a new iteration, supplying all the threads with the data generated in the last iteration (the data would be modified before the end of each iteration).
I hope this makes sense, and is possible. Either way I would appreciate some advice on how to tackle the problem of computing large amounts of data divided on to several threads (so I can use more than one processor's core).
Thank you for your answers! | You should look at Parallel FX (PFX), you can find the blog [here](http://blogs.msdn.com/pfxteam/) and the download link [here](http://www.microsoft.com/downloads/details.aspx?FamilyId=348F73FD-593D-4B3C-B055-694C50D2B0F3) (Thanks Marc).
Unfortunately I don't know if this will be released for .NET 2.0/3.5 as it is currently slated for .NET 4.0.
If you're looking at implementing it yourself, look into [Work Stealing Algorithms](http://www.google.com/search?q=work+stealing+algorithms).
There is also a library named [Power Threading](http://www.wintellect.com/PowerThreading.aspx), by Jeffrey Richter from [Wintellect](http://www.wintellect.com/Resources.aspx) which has some rather good classes available for you. | Lasse and Marc have already spoken about Parallel Extensions. I have a couple of blog articles (with code) about using and benchmarking it:
* [Conway's Game of Life](http://msmvps.com/blogs/jon_skeet/archive/2008/06/01/more-parallelisation-fun-conway-s-game-of-life.aspx)
* [Visualising the Mandelbrot set](http://msmvps.com/blogs/jon_skeet/archive/2008/05/18/mandelbrot-revisited-benchmark-edition.aspx)
These might be helpful to show various different ways that work can be broken up. | Dividing workload on several threads | [
"",
"c#",
"multithreading",
"multicore",
""
] |
If I override Equals and GetHashCode, how do I decide which fields to compare? And what will happen if I have two objects with two fields each, but Equals only checks one field?
In other words, let's say I have this class:
```
class EqualsTestClass
{
public string MyDescription { get; set; }
public int MyId { get; set; }
public override bool Equals(object obj)
{
EqualsTestClass eq = obj as EqualsTestClass;
if(eq == null) {
return false;
} else {
return MyId.Equals(eq.MyId);
}
}
public override int GetHashCode()
{
int hashcode = 23;
return (hashcode * 17) + MyId.GetHashCode();
}
}
```
I consider two objects Equal if they have the same MyId. So if the Id is equal but the description is different, they are still considered equal.
I just wonder what the pitfalls of this approach are? Of course, a construct like this will behave as expected:
```
List<EqualsTestClass> test = new List<EqualsTestClass>();
EqualsTestClass eq1 = new EqualsTestClass();
eq1.MyId = 1;
eq1.MyDescription = "Des1";
EqualsTestClass eq2 = new EqualsTestClass();
eq2.MyId = 1;
eq2.MyDescription = "Des2";
test.Add(eq1);
if (!test.Contains(eq2))
{
// Will not be executed, as test.Contains is true
test.Add(eq2);
}
```
As eq2 is value-equal to eq1, it will not be added. But that is code that I control, but I wonder if there is code in the framework that could cause unexpected problems?
So, should I always add all public Fields in my Equals() Comparison, or what are the guidelines to avoid a nasty surprise because of some bad Framework-Mojo that was completely unexpected? | The reason for overriding `Equals()` is that you define, what it means for two instances to be equal. In some cases that means that all fields must be equal, but it doesn't have to. You decide.
For more information see the [documentation](http://msdn.microsoft.com/en-us/library/336aedhh.aspx) and this [post](http://blogs.msdn.com/jaredpar/archive/2009/01/15/if-you-implement-iequatable-t-you-still-must-override-object-s-equals-and-gethashcode.aspx). | I don't think you need to worry about the Framework in this instance.
If you as the Class Designer consider two instances of that class to be equal if they share the same MyId, then, you only need to test MyId in your overriden Equals() and GetHashCode() methods. | Overriding Equals() but not checking all fields - what will happen? | [
"",
"c#",
".net",
""
] |
I have recently learnt about namespaces in PHP, and was wondering, would it be bad practice to do this?
```
<?php
namespace String; // string helper functions
function match($string1, $string2)
{
$string1 = trim($string1);
$string2 = trim($string2);
if (strcasecmp($string1, $string2) == 0) // are equal
{
return true;
} else {
return false;
}
}
?>
```
Before I had this as a static method to a String class, but this always seemed *wrong* to me... Which is the better alternative? I have a desire to categorise my helper functions, and want to know which is the better way to do it.
**Edit**
So how do I then access the match function if I have declared it in a namespace? How do I *stop* the namespace declaration, say if I include a file beneath it which declared a new namespace, would it automatically stop references to the first? And how do I go about returning to global namespace? | I'd put it in a namespace. A class is a describes a type in php, and though you maybe operating over a type with a similar name, it's not the same type, strictly speaking. A namespace is just a way to logically group things, which is what you're using a class to do anyways. The only thing you lose is extensibility, but as you said, it's only a collection of static methods. | If they're all string-related functions, there's nothing wrong with making them static methods.
A namespace would be the better choice if you've got a bunch of global functions and/or variables which you don't want cluttering up global scope, but which wouldn't make sense in a class. (I've got a class in my own code which would be a lot better suited to a namespace).
It's good practice to stick everything in some sort of container if there's any chance your code will get reused elsewhere, so you don't scribble on other people's global vars...
As for your edit there:
* Namespaces are tied to the file they're defined in, IIRC. Not sure how this affects included files from there but I'd guess they aren't inherited.
* You can call the global scope by saying `::trim()`. | Is using namespaces to partition a project bad practice? | [
"",
"php",
""
] |
What is the **correct** way to log out of HTTP authentication protected folder?
There are workarounds that can achieve this, but they are potentially dangerous because they can be buggy or don't work in certain situations / browsers. That is why I am looking for correct and clean solution. | Mu. **No correct way exists**, not even one that's consistent across browsers.
This is a problem that comes from the [HTTP specification](http://www.w3.org/Protocols/rfc2616/rfc2616-sec15.html#sec15.6) (section 15.6):
> Existing HTTP clients and user agents typically retain authentication
> information indefinitely. HTTP/1.1. does not provide a method for a
> server to direct clients to discard these cached credentials.
On the other hand, section [10.4.2](http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.4.2) says:
> If the request already included Authorization credentials, then the 401
> response indicates that authorization has been refused for those
> credentials. If the 401 response contains the same challenge as the
> prior response, and the user agent has already attempted
> authentication at least once, then the user SHOULD be presented the
> entity that was given in the response, since that entity might
> include relevant diagnostic information.
In other words, **you may be able to show the login box again** (as [@Karsten](https://stackoverflow.com/questions/449788/htaccess-logout-through-php#449813) says), **but the browser doesn't have to honor your request** - so don't depend on this (mis)feature too much. | Method that works nicely in Safari. Also works in Firefox and Opera, but with a warning.
```
Location: http://logout@yourserver.example.com/
```
This tells browser to open URL with new username, overriding previous one. | HTTP authentication logout via PHP | [
"",
"php",
"authentication",
".htaccess",
"http-headers",
"password-protection",
""
] |
How would I load a dds texture file into an OpenGL 2dtexture or cube map texture? | I believe you use the glCompressedTexImage2DARB method and its friends.
[This PDF](http://www.oldunreal.com/editing/s3tc/ARB_texture_compression.pdf) seems to contain some promising info that may be helpful to you. | Depending on your needs, the [DevIL](http://openil.sourceforge.net/) library can take care of feeding OpenGL with a DDS file content. | DDS texture loading | [
"",
"c++",
"opengl",
"textures",
"directdraw",
""
] |
I have site that works fine but when i put it through Google translate my button that initiates a javascript function doesn't work.
However, some other Javascript calls via links work. Whats wrong?
[Example translation](http://translate.google.com/translate?prev=_t&hl=en&ie=UTF-8&u=http%3A%2F%2Fwww.videodownloadr.com%2F&sl=en&tl=pl&history_state0=&swap=1)
Thank you for any help.
## Update
The sister site is even worse, the whole left side goes white?? Wait for it to fully load.
[Example site 2](http://translate.google.com/translate?prev=_t&hl=en&ie=UTF-8&u=http%3A%2F%2Fwww.getaudiofromvideo.com%2F&sl=es&tl=en&history_state0=) | I think it's because when you use Google Translate, you're actually getting the page from Google's domain not your own. Your page then tries to make an AJAX request to your domain, which is now cross-domain, therefore blocked for security. | In order to avoid the translation of elements which should execute *JavaScript* you can give them a class of *notranslate*: `class=”notranslate”`. That should let google ignore these elements. | Google translate breaks button that makes javascript function call | [
"",
"javascript",
"html",
"button",
""
] |
In my class design, I use abstract classes and virtual functions extensively. I had a feeling that virtual functions affects the performance. Is this true? But I think this performance difference is not noticeable and looks like I am doing premature optimization. Right? | A good rule of thumb is:
> It's not a performance problem until you can prove it.
The use of virtual functions will have a very slight effect on performance, but it's unlikely to affect the overall performance of your application. Better places to look for performance improvements are in algorithms and I/O.
An excellent article that talks about virtual functions (and more) is [Member Function Pointers and the Fastest Possible C++ Delegates](http://www.codeproject.com/KB/cpp/FastDelegate.aspx). | Your question made me curious, so I went ahead and ran some timings on the 3GHz in-order PowerPC CPU we work with. The test I ran was to make a simple 4d vector class with get/set functions
```
class TestVec
{
float x,y,z,w;
public:
float GetX() { return x; }
float SetX(float to) { return x=to; } // and so on for the other three
}
```
Then I set up three arrays each containing 1024 of these vectors (small enough to fit in L1) and ran a loop that added them to one another (A.x = B.x + C.x) 1000 times. I ran this with the functions defined as `inline`, `virtual`, and regular function calls. Here are the results:
* inline: 8ms (0.65ns per call)
* direct: 68ms (5.53ns per call)
* virtual: 160ms (13ns per call)
So, in this case (where everything fits in cache) the virtual function calls were about 20x slower than the inline calls. But what does this really mean? Each trip through the loop caused exactly `3 * 4 * 1024 = 12,288` function calls (1024 vectors times four components times three calls per add), so these times represent `1000 * 12,288 = 12,288,000` function calls. The virtual loop took 92ms longer than the direct loop, so the additional overhead per call was 7 *nanoseconds* per function.
From this I conclude: **yes**, virtual functions are much slower than direct functions, and **no**, unless you're planning on calling them ten million times per second, it doesn't matter.
See also: [comparison of the generated assembly.](http://assemblyrequired.crashworks.org/code-for-testing-virtual-function-speed/) | Virtual functions and performance - C++ | [
"",
"c++",
"performance",
"optimization",
"virtual-functions",
""
] |
How do I remove all whitespace from the start and end of the string? | All browsers since IE9+ have [`trim()`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/trim) method for strings.
```
" \n test \n ".trim(); // returns "test" here
```
For those browsers who does not support `trim()`, you can use this polyfill from [MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/trim):
```
if (!String.prototype.trim) {
(function() {
// Make sure we trim BOM and NBSP
var rtrim = /^[\s\uFEFF\xA0]+|[\s\uFEFF\xA0]+$/g;
String.prototype.trim = function() {
return this.replace(rtrim, '');
};
})();
}
```
---
That said, if using `jQuery`, then `$.trim(str)` is always available, which handles undefined/null as well.
---
See this:
```
String.prototype.trim=function(){return this.replace(/^\s+|\s+$/g, '');};
String.prototype.ltrim=function(){return this.replace(/^\s+/,'');};
String.prototype.rtrim=function(){return this.replace(/\s+$/,'');};
String.prototype.fulltrim=function(){return this.replace(/(?:(?:^|\n)\s+|\s+(?:$|\n))/g,'').replace(/\s+/g,' ');};
``` | The trim from [jQuery](http://api.jquery.com/jQuery.trim/) is convenient if you are already using that framework.
```
$.trim(' your string ');
```
I tend to use jQuery often, so trimming strings with it is natural for me. But it's possible that there is backlash against jQuery out there? :) | Trim string in JavaScript | [
"",
"javascript",
"string",
"trim",
""
] |
Why do we need to use `int main` and not `void main` in C++? | The short answer, is because the C++ standard requires `main()` to return `int`.
As you probably know, the return value from the `main()` function is used by the runtime library as the exit code for the process. Both Unix and Win32 support the concept of a (small) integer returned from a process after it has finished. Returning a value from `main()` provides one way for the programmer to specify this value. | Most Operating Systems report back to the user, or the calling process, if an application was successful or not. This is especially useful in scripting, where the script can conditionally branch (if-then) on the results of a program. Something along the lines of:
```
// pseudo-code
screenscrape http://mydatasource.com > results.txt
if errorlevel == 0 then
processfile results.txt
else
echo Screen Scraping Failed!
end if
```
This result status is done via the return value of main.
While some compilers allow for void main, for the sake of consistency and simplicity, the ANSI standard requires one single prototype of main:
```
int main(int argc, char *argv[]);
```
Because in C, arguments are cleaned up by the caller, the author of main can neglect to declare or process the arguments argc & argv. However, if the setup-routines that call main expect an int return value, and instead don't find one, behavior can undefined.
Short answer:
* The return value of main is useful
for scripting.
* The setup and cleanup routines that invoke main need a consistent interface to use. | Why do we need to use `int main` and not `void main` in C++? | [
"",
"c++",
"function",
"return-value",
"program-entry-point",
""
] |
I have a place holder image saying something like:
```
Your rating is:
[rating here]
```
My PHP code is supposed to dynamically insert the rating number where there is a blank space left out for it on the placeholder image. How can I do that? | Here's a an example how you could do it - use [gd function](http://uk.php.net/manual/en/ref.image.php) calls to make your image, but play nice and cache the images. This sample plays *even nicer* by ensuring that if the browser already has the required image, it returns a 304...
```
#here's where we'll store the cached images
$cachedir=$_SERVER['DOCUMENT_ROOT'].'/imgcache/'
#get the score and sanitize it
$score=$_GET['score'];
if (preg_match('/^[0-9]\.[0-9]{1,2}$/', $score)
{
#figure out filename of cached file
$file=$cachedir.'score'.$score.'gif';
#regenerate cached image
if (!file_exists($file))
{
#generate image - this is lifted straight from the php
#manual, you'll need to work out how to make your
#image, but this will get you started
#load a background image
$im = imagecreatefrompng("images/button1.png");
#allocate color for the text
$orange = imagecolorallocate($im, 220, 210, 60);
#attempt to centralise the text
$px = (imagesx($im) - 7.5 * strlen($score)) / 2;
imagestring($im, 3, $px, 9, $score, $orange);
#save to cache
imagegif($im, $file);
imagedestroy($im);
}
#return image to browser, but return a 304 if they already have it
$mtime=filemtime($file);
$headers = apache_request_headers();
if (isset($headers['If-Modified-Since']) &&
(strtotime($headers['If-Modified-Since']) >= $mtime))
{
// Client's cache IS current, so we just respond '304 Not Modified'.
header('Last-Modified: '.gmdate('D, d M Y H:i:s', $mtime).' GMT', true, 304);
exit;
}
header('Content-Type:image/gif');
header('Content-Length: '.filesize($file));
header('Last-Modified: '.gmdate('D, d M Y H:i:s', $mtime).' GMT');
readfile($file);
}
else
{
header("HTTP/1.0 401 Invalid score requested");
}
```
If you put this in image.php, you would use as follows in an image tag
```
<img src="image.php?score=5.5" alt="5.5" />
``` | Use static images ranging from 0 to 9 and just combine them on the page to build large numbers:
`Your Rating: [image1.jpg][image2.jpg][image3.jpg]` | How to dynamically create an image with a specified number on it? | [
"",
"php",
"image",
"image-processing",
"image-manipulation",
"gd",
""
] |
Like I wrote [elsewhere](https://stackoverflow.com/questions/449760/dividing-workload-on-several-threads#449839), I seem to be sure that a white paper by Rick Brewster about multithreading used in
[Paint.NET](http://www.getpaint.net/) once existed. I am not able to find any reference to this white paper again however. Does it (still) exist? And if so, where?
**EDIT:** Found out in comments to an unrelated question that Paint.NET is still free, but code is no longer available? Is this related to the fact that I can't seem to find that white paper any more?
**EDIT2:** [Went straight to the horses mouth](http://paintdotnet.forumer.com/viewtopic.php?f=27&t=28502) on this and will return any answer that I get here. In the meantime any answer you guys might have is more than welcome! | I just received a private message reply on the [Paint.NET forum](http://paintdotnet.forumer.com) from [Rick Brewster](http://paintdotnet.forumer.com/memberlist.php?mode=viewprofile&u=3):
> No such whitepaper has ever existed.
That would at least explain why there seems to be no trace of it on Google. I must be going crazy after all? | Is it possible, that you found this whitepaper following a link on [Coding Horror](http://www.codinghorror.com/blog/archives/000169.html) to Rick Brewster's Blog? Seems he has cleaned up his blog and there are no entries before 2006 anymore.
The only "very little" explanation about threading in Paint.Net i could find anymore was on [CodeProject](http://www.codeproject.com/KB/graphics/pdnnoiseeffect.aspx). | Where to find Paint.NET multithreading white paper? | [
"",
"c#",
"multithreading",
"multicore",
"article",
""
] |
We are using the CString class throughout most of our code. However sometimes we need to convert to a char \*. at the moment we have been doing this using variable.GetBuffer(0) and this seems to work ( this mainly happens when passing the Csting into a function where the function requires a char \*). The function accepts this and we keep going.
However we have lately become worried about how this works, and whether there is a better way to do it.
The way i understand it to work is it passes a char pointer into the function that points at the first character in the CString and all works well.
I Guess we are just worried about memory leaks or any unforseen circumstances where this might not be a good idea. | If your functions only require reading the string and not modifying it, change them to accept `const char *` instead of `char *`. The `CString` will automatically convert for you, this is how most of the MFC functions work and it's really handy. (Actually MFC uses `LPCTSTR`, which is a synonym for `const TCHAR *` - works for both MBC and Unicode builds).
If you need to modify the string, `GetBuffer(0)` is very dangerous - it won't necessarily allocate enough memory for the resulting string, and you could get some buffer overrun errors.
As has been mentioned by others, you need to use `ReleaseBuffer` after `GetBuffer`. You don't need to do that for the conversion to `const char *`. | @ the OP:
*>>> I Guess we are just worried about memory leaks or any ...*
Hi, calling the GetBuffer method won't lead to any memory leaks. Because the destructor is going to deallocate the buffer anyway. However, others have already warned you about the potential issues with calling this method.
@Can >>> *when you call the getbuffer function it allocates memory for you.*
This statement is not completely true. GetBuffer(0) does NOT allocate any memory. It merely returns a pointer to the internal string buffer that can be used to manipulate the string directly from "outside" the CString class.
However, if you pass a number, say N to it like GetBuffer(N), and if N is larger than the current length of the buffer, then the function ensures that the returned buffer is at least as large as N by allocating more memory.
Cheers,
Rajesh.
MVP, Visual ++. | CString to char* | [
"",
"c++",
"mfc",
"memory-leaks",
"cstring",
""
] |
I'm doing a raytracer hobby project, and originally I was using structs for my Vector and Ray objects, and I thought a raytracer was the perfect situation to use them: you create millions of them, they don't live longer than a single method, they're lightweight. However, by simply changing 'struct' to 'class' on Vector and Ray, I got a very significant performance gain.
What gives? They're both small (3 floats for Vector, 2 Vectors for a Ray), don't get copied around excessively. I do pass them to methods when needed of course, but that's inevitable. So what are the common pitfalls that kill performance when using structs? I've read [this](http://msdn.microsoft.com/en-us/library/ms973839.aspx) MSDN article that says the following:
> When you run this example, you'll see that the struct loop is orders of magnitude faster. However, it is important to beware of using ValueTypes when you treat them like objects. This adds extra boxing and unboxing overhead to your program, and can end up costing you more than it would if you had stuck with objects! To see this in action, modify the code above to use an array of foos and bars. You'll find that the performance is more or less equal.
It's however quite old (2001) and the whole "putting them in an array causes boxing/unboxing" struck me as odd. Is that true? However, I did pre-calculate the primary rays and put them in an array, so I took up on this article and calculated the primary ray when I needed it and never added them to an array, but it didn't change anything: with classes, it was still 1.5x faster.
I am running .NET 3.5 SP1 which I believe fixed an issue where struct methods weren't ever in-lined, so that can't be it either.
So basically: any tips, things to consider and what to avoid?
EDIT: As suggested in some answers, I've set up a test project where I've tried passing structs as ref. The methods for adding two Vectors:
```
public static VectorStruct Add(VectorStruct v1, VectorStruct v2)
{
return new VectorStruct(v1.X + v2.X, v1.Y + v2.Y, v1.Z + v2.Z);
}
public static VectorStruct Add(ref VectorStruct v1, ref VectorStruct v2)
{
return new VectorStruct(v1.X + v2.X, v1.Y + v2.Y, v1.Z + v2.Z);
}
public static void Add(ref VectorStruct v1, ref VectorStruct v2, out VectorStruct v3)
{
v3 = new VectorStruct(v1.X + v2.X, v1.Y + v2.Y, v1.Z + v2.Z);
}
```
For each I got a variation of the following benchmark method:
```
VectorStruct StructTest()
{
Stopwatch sw = new Stopwatch();
sw.Start();
var v2 = new VectorStruct(0, 0, 0);
for (int i = 0; i < 100000000; i++)
{
var v0 = new VectorStruct(i, i, i);
var v1 = new VectorStruct(i, i, i);
v2 = VectorStruct.Add(ref v0, ref v1);
}
sw.Stop();
Console.WriteLine(sw.Elapsed.ToString());
return v2; // To make sure v2 doesn't get optimized away because it's unused.
}
```
All seem to perform pretty much identical. Is it possible that they get optimized by the JIT to whatever is the optimal way to pass this struct?
EDIT2: I must note by the way that using structs in my test project *is* about 50% faster than using a class. Why this is different for my raytracer I don't know. | Basically, don't make them too big, and pass them around by ref when you can. I discovered this the exact same way... By changing my Vector and Ray classes to structs.
With more memory being passed around, it's bound to cause cache thrashing. | An array of structs would be a single contiguous structure in memory, while items in an array of objects (instances of reference types) need to be individually addressed by a pointer (i.e. a reference to an object on the garbage-collected heap). Therefore if you address large collections of items at once, structs will give you a performance gain since they need fewer indirections. In addition, structs cannot be inherited, which might allow the compiler to make additional optimizations (but that is just a possibility and depends on the compiler).
However, structs have quite different assignment semantics and also cannot be inherited. Therefore I would usually avoid structs except for the given performance reasons when needed.
---
**struct**
An array of values v encoded by a struct (value type) looks like this in memory:
vvvv
**class**
An array of values v encoded by a class (reference type) look like this:
pppp
..v..v...v.v..
where p are the this pointers, or references, which point to the actual values v on the heap. The dots indicate other objects that may be interspersed on the heap. In the case of reference types you need to reference v via the corresponding p, in the case of value types you can get the value directly via its offset in the array. | When are structs the answer? | [
"",
"c#",
"performance",
"raytracing",
""
] |
How to determine what DLL's a binary depends on using programmatic methods?
To be clear, I am not trying to determine the DLL dependencies of the running exec, but of any arbitrary exec (that may be missing a required DLL). I'm looking for a solution to implement in a C/C++ application. This is something that needs to be done by my application at runtime and can't be done by a third party app (like depends). | Take a look at the [`IMAGE_LOAD_FUNCTION`](http://msdn.microsoft.com/en-us/library/ms680209(VS.85).aspx) API. It will return a pointer to a [`LOADED_IMAGE`](http://msdn.microsoft.com/en-us/library/ms680349(VS.85).aspx) structure, which you can use to access the various sections of a PE file.
You can find some articles that describe how the structures are laid out [here](http://msdn.microsoft.com/en-us/magazine/bb985992.aspx), and [here](http://msdn.microsoft.com/en-us/magazine/bb985994.aspx). You can download the source code for the articles [here](http://code.msdn.microsoft.com/mag200202Windows/Release/ProjectReleases.aspx?ReleaseId=1908).
I think this should give you everything you need.
**Update:**
I just downloaded the source code for the article. If you open up `EXEDUMP.CPP` and take a look at `DumpImportsSection` it should have the code you need. | 76 lines to do that based on [pedump](http://code.msdn.microsoft.com/mag200202Windows/Release/ProjectReleases.aspx?ReleaseId=1908) code (don't forget to add Imagehlp.lib as dependancy):
```
#include <stdio.h>
#include "windows.h" //DONT REMOVE IT
#include "ImageHlp.h"
#include "stdafx.h"
template <class T> PIMAGE_SECTION_HEADER GetEnclosingSectionHeader(DWORD rva, T* pNTHeader) // 'T' == PIMAGE_NT_HEADERS
{
PIMAGE_SECTION_HEADER section = IMAGE_FIRST_SECTION(pNTHeader);
unsigned i;
for ( i=0; i < pNTHeader->FileHeader.NumberOfSections; i++, section++ )
{
// This 3 line idiocy is because Watcom's linker actually sets the
// Misc.VirtualSize field to 0. (!!! - Retards....!!!)
DWORD size = section->Misc.VirtualSize;
if ( 0 == size )
size = section->SizeOfRawData;
// Is the RVA within this section?
if ( (rva >= section->VirtualAddress) &&
(rva < (section->VirtualAddress + size)))
return section;
}
return 0;
}
template <class T> LPVOID GetPtrFromRVA( DWORD rva, T* pNTHeader, PBYTE imageBase ) // 'T' = PIMAGE_NT_HEADERS
{
PIMAGE_SECTION_HEADER pSectionHdr;
INT delta;
pSectionHdr = GetEnclosingSectionHeader( rva, pNTHeader );
if ( !pSectionHdr )
return 0;
delta = (INT)(pSectionHdr->VirtualAddress-pSectionHdr->PointerToRawData);
return (PVOID) ( imageBase + rva - delta );
}
void DumpDllFromPath(wchar_t* path) {
char name[300];
wcstombs(name,path,300);
PLOADED_IMAGE image=ImageLoad(name,0);
if (image->FileHeader->OptionalHeader.NumberOfRvaAndSizes>=2) {
PIMAGE_IMPORT_DESCRIPTOR importDesc=
(PIMAGE_IMPORT_DESCRIPTOR)GetPtrFromRVA(
image->FileHeader->OptionalHeader.DataDirectory[1].VirtualAddress,
image->FileHeader,image->MappedAddress);
while ( 1 )
{
// See if we've reached an empty IMAGE_IMPORT_DESCRIPTOR
if ( (importDesc->TimeDateStamp==0 ) && (importDesc->Name==0) )
break;
printf(" %s\n", GetPtrFromRVA(importDesc->Name,
image->FileHeader,
image->MappedAddress) );
importDesc++;
}
}
ImageUnload(image);
}
//Pass exe or dll as argument
int _tmain(int argc, _TCHAR* argv[])
{
DumpDllFromPath(argv[1]);
return 0;
}
``` | How to determine a windows executables DLL dependencies programmatically? | [
"",
"c++",
"windows",
"dll",
"dependencies",
"executable",
""
] |
I need to send email via my C# app.
I come from a VB 6 background and had a lot of bad experiences with the MAPI control.
First of all, MAPI did not support HTML emails and second, all the emails were sent to my default mail outbox. So I still needed to click on send receive.
If I needed to send bulk html bodied emails (100 - 200), what would be the best way to do this in C#? | You could use the **System.Net.Mail.MailMessage** class of the .NET framework.
You can find the [MSDN documentation here](http://msdn.microsoft.com/en-us/library/system.net.mail.mailmessage(VS.80).aspx).
Here is a simple example (code snippet):
```
using System.Net;
using System.Net.Mail;
using System.Net.Mime;
...
try
{
SmtpClient mySmtpClient = new SmtpClient("my.smtp.exampleserver.net");
// set smtp-client with basicAuthentication
mySmtpClient.UseDefaultCredentials = false;
System.Net.NetworkCredential basicAuthenticationInfo = new
System.Net.NetworkCredential("username", "password");
mySmtpClient.Credentials = basicAuthenticationInfo;
// add from,to mailaddresses
MailAddress from = new MailAddress("test@example.com", "TestFromName");
MailAddress to = new MailAddress("test2@example.com", "TestToName");
MailMessage myMail = new System.Net.Mail.MailMessage(from, to);
// add ReplyTo
MailAddress replyTo = new MailAddress("reply@example.com");
myMail.ReplyToList.Add(replyTo);
// set subject and encoding
myMail.Subject = "Test message";
myMail.SubjectEncoding = System.Text.Encoding.UTF8;
// set body-message and encoding
myMail.Body = "<b>Test Mail</b><br>using <b>HTML</b>.";
myMail.BodyEncoding = System.Text.Encoding.UTF8;
// text or html
myMail.IsBodyHtml = true;
mySmtpClient.Send(myMail);
}
catch (SmtpException ex)
{
throw new ApplicationException
("SmtpException has occured: " + ex.Message);
}
catch (Exception ex)
{
throw ex;
}
``` | **Code:**
```
using System.Net.Mail
new SmtpClient("smtp.server.com", 25).send("from@email.com",
"to@email.com",
"subject",
"body");
```
**Mass Emails:**
SMTP servers usually have a limit on the number of connection hat can handle at once, if you try to send hundreds of emails you application may appear unresponsive.
**Solutions:**
* If you are building a WinForm then use a BackgroundWorker to process the queue.
* If you are using IIS SMTP server or a SMTP server that has an outbox folder then you can use SmtpClient().PickupDirectoryLocation = "c:/smtp/outboxFolder"; This will keep your system responsive.
* If you are not using a local SMTP server than you could build a system service to use Filewatcher to monitor a forlder than will then process any emails you drop in there. | Sending E-mail using C# | [
"",
"c#",
"email",
""
] |
I have found several open-source/freeware programs that allow you to convert .doc files to .pdf files, but they're all of the application/printer driver variety, with no SDK attached.
I have found several programs that do have an SDK allowing you to convert .doc files to .pdf files, but they're all of the proprietary type, $2,000 a license or thereabouts.
Does anyone know of any clean, inexpensive (preferably free) programmatic solution to my problem, using C# or VB.NET?
Thanks! | Use a foreach loop instead of a for loop - it solved my problem.
```
int j = 0;
foreach (Microsoft.Office.Interop.Word.Page p in pane.Pages)
{
var bits = p.EnhMetaFileBits;
var target = path1 +j.ToString()+ "_image.doc";
try
{
using (var ms = new MemoryStream((byte[])(bits)))
{
var image = System.Drawing.Image.FromStream(ms);
var pngTarget = Path.ChangeExtension(target, "png");
image.Save(pngTarget, System.Drawing.Imaging.ImageFormat.Png);
}
}
catch (System.Exception ex)
{
MessageBox.Show(ex.Message);
}
j++;
}
```
Here is a modification of a program that worked for me. It uses Word 2007 with the [Save As PDF add-in](http://www.microsoft.com/downloads/details.aspx?FamilyID=4d951911-3e7e-4ae6-b059-a2e79ed87041&displaylang=en) installed. It searches a directory for .doc files, opens them in Word and then saves them as a PDF. Note that you'll need to add a reference to Microsoft.Office.Interop.Word to the solution.
```
using Microsoft.Office.Interop.Word;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
...
// Create a new Microsoft Word application object
Microsoft.Office.Interop.Word.Application word = new Microsoft.Office.Interop.Word.Application();
// C# doesn't have optional arguments so we'll need a dummy value
object oMissing = System.Reflection.Missing.Value;
// Get list of Word files in specified directory
DirectoryInfo dirInfo = new DirectoryInfo(@"\\server\folder");
FileInfo[] wordFiles = dirInfo.GetFiles("*.doc");
word.Visible = false;
word.ScreenUpdating = false;
foreach (FileInfo wordFile in wordFiles)
{
// Cast as Object for word Open method
Object filename = (Object)wordFile.FullName;
// Use the dummy value as a placeholder for optional arguments
Document doc = word.Documents.Open(ref filename, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing);
doc.Activate();
object outputFileName = wordFile.FullName.Replace(".doc", ".pdf");
object fileFormat = WdSaveFormat.wdFormatPDF;
// Save document into PDF Format
doc.SaveAs(ref outputFileName,
ref fileFormat, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing,
ref oMissing, ref oMissing, ref oMissing, ref oMissing);
// Close the Word document, but leave the Word application open.
// doc has to be cast to type _Document so that it will find the
// correct Close method.
object saveChanges = WdSaveOptions.wdDoNotSaveChanges;
((_Document)doc).Close(ref saveChanges, ref oMissing, ref oMissing);
doc = null;
}
// word has to be cast to type _Application so that it will find
// the correct Quit method.
((_Application)word).Quit(ref oMissing, ref oMissing, ref oMissing);
word = null;
``` | To sum it up for vb.net users, the free option (must have office installed):
Microsoft office assembies download:
* [pia for office 2010](https://www.microsoft.com/en-us/download/details.aspx?id=3508)
* [pia for office 2007](https://www.microsoft.com/en-us/download/details.aspx?id=18346)
* Add reference to Microsoft.Office.Interop.Word.Application
* Add using or import (vb.net) statement to Microsoft.Office.Interop.Word.Application
VB.NET example:
```
Dim word As Application = New Application()
Dim doc As Document = word.Documents.Open("c:\document.docx")
doc.Activate()
doc.SaveAs2("c:\document.pdf", WdSaveFormat.wdFormatPDF)
doc.Close()
``` | How do I convert Word files to PDF programmatically? | [
"",
"c#",
"vb.net",
"pdf",
"ms-word",
""
] |
I need to set a PHP $\_SESSION variable using the jQuery. IF the user clicks on an image I want to save a piece of information associated with that image as a session variable in php.
I think I can do this by calling a php page or function and appending that piece of info to the query string.
Any ideas. I have found little help through google.
thanks
mike | You can't do it through jQuery alone; you'll need a combination of Ajax (which you can do with jQuery) and a PHP back-end. A very simple version might look like this:
**HTML:**
```
<img class="foo" src="img.jpg" />
<img class="foo" src="img2.jpg" />
<img class="foo" src="img3.jpg" />
```
**Javascript:**
```
$("img.foo").onclick(function()
{
// Get the src of the image
var src = $(this).attr("src");
// Send Ajax request to backend.php, with src set as "img" in the POST data
$.post("/backend.php", {"img": src});
});
```
**PHP (backend.php):**
```
<?php
// do any authentication first, then add POST variable to session
$_SESSION['imgsrc'] = $_POST['img'];
?>
``` | Might want to try putting the PHP function on another PHP page, and use an AJAX call to set the variable. | Setting a PHP $_SESSION['var'] using jQuery | [
"",
"php",
"jquery",
"session-variables",
""
] |
I'm trying to come up with an elegant way of creating a list from a function that yields values in both Python and Ruby.
In Python:
```
def foo(x):
for i in range(x):
if bar(i): yield i
result = list(foo(100))
```
In Ruby:
```
def foo(x)
x.times {|i| yield i if bar(i)}
end
result = []
foo(100) {|x| result << x}
```
Although I love working in both languages, I've always been a bit bothered by the Ruby version having to initialize the list and then fill it. Python's `yield` results in simple iteration, which is great. Ruby's `yield` invokes a block, which is also great, but when I just want to fill a list, it feels kinda clunky.
Is there a more elegant Ruby way?
**UPDATE** Reworked the example to show that the number of values yielded from the function isn't necessarily equal to x. | So, for your new example, try this:
```
def foo(x)
(0..x).select { |i| bar(i) }
end
```
Basically, unless you're writing an iterator of your own, you don't need `yield` very often in Ruby. You'll probably do a lot better if you stop trying to write Python idioms using Ruby syntax. | For the Python version I would use a generator expression like:
```
(i for i in range(x) if bar(i))
```
Or for this specific case of filtering values, even more simply
```
itertools.ifilter(bar,range(x))
``` | Creating lists using yield in Ruby and Python | [
"",
"python",
"ruby",
"list",
"yield",
""
] |
I am not completely sure that this is possible from within PHP or even the HTTP protocol in depth. Is it possible to receive PHP script to run when it is requested but then the script drops the connection? Without replying?
Hopefully my question makes sense.
(I am using Apache) | If you don't want to send any data *at all*, use a sleep in a loop. Eventually the client end will time out and close the connection. | When you serve php through Apache, there will always be a http response. Calling exit will just stop php from processing - not stop Apache. The proper thing to do in your case, is probably to send a http response-code other than 200 (OK). For example 404 or 500. Check [the specs](http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html) to find the one that applies to your situation.
You send a http response from within php, using:
```
<?php
header("HTTP/1.0 404 Not Found");
exit;
``` | Can I 'drop' a PHP request without replying? | [
"",
"php",
"http",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.