
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
Can someone explain to me why in .NET 2.0 if I have an interface, `IPackable` and a class that implements that interface `OrderItem`, when I have a method that takes in a `List<IPackable>`, passing in a list of `List<OrderItem>` does not work?
Does anyone know how I could accomplish this functionality?
Code:
```
public interface IPackable {
double Weight{ get; }
}
public class OrderItem : IPackable
public List<IShipMethod> GetForShipWeight(List<IPackable> packages) {
double totalWeight = 0;
foreach (IPackable package in packages) {
totalWeight += package.Weight;
}
}
```
The following code does not work.
```
List<OrderItem> orderItems = new List<OrderItem>();
List<IShipMethod> shipMethods = GetForShipWeight(orderItems);
``` | The feature is called covariance/contravariance and will be supported in c# 4.0. You can read about it here: <http://blogs.msdn.com/ericlippert/archive/tags/Covariance+and+Contravariance/default.aspx> | JMD is half correct. In fact, it's absolutely incorrect to say that we will be able to cast a generic list with C# 4.0. It's true that covariance and contravariance will be supported in C# 4.0 but it will only works with interface and delegate and there will have a lot of constraints. Therefore, it won't work with `List`.
The reason is really simple.
If B is a subclass of A, we cannot say that `List<B>` is a subclass of `List<A>`.
And here's why.
`List<A>` exposes some covariances methods (returning a value) and some contravariances methods (accepting a value as a parameter).
e.g.
* `List<A>` exposes `Add(A);`
* `List<B>` exposes `Add(B);`
If `List<B>` inherits from `List<A>`...than you would be able to do `List<B>.Add(A);`
Therefore, you would loose all type safety of generics. | .NET Casting Generic List | [
"",
"c#",
".net",
"generics",
"casting",
""
] |
For academic and performance sake, given this crawl recursive web-crawling function (which crawls only within the given domain) what would be the best approach to make it run iteratively? Currently when it runs, by the time it finishes python has climbed to using over 1GB of memory which isn't acceptable for running in a shared environment.
```
def crawl(self, url):
"Get all URLS from which to scrape categories."
try:
links = BeautifulSoup(urllib2.urlopen(url)).findAll(Crawler._match_tag)
except urllib2.HTTPError:
return
for link in links:
for attr in link.attrs:
if Crawler._match_attr(attr):
if Crawler._is_category(attr):
pass
elif attr[1] not in self._crawled:
self._crawled.append(attr[1])
self.crawl(attr[1])
``` | Use a BFS instead of crawling recursively (DFS): <http://en.wikipedia.org/wiki/Breadth_first_search>
You can use an external storage solution (such as a database) for BFS queue to free up RAM.
The algorithm is:
```
//pseudocode:
var urlsToVisit = new Queue(); // Could be a queue (BFS) or stack(DFS). (probably with a database backing or something).
var visitedUrls = new Set(); // List of visited URLs.
// initialization:
urlsToVisit.Add( rootUrl );
while(urlsToVisit.Count > 0) {
var nextUrl = urlsToVisit.FetchAndRemoveNextUrl();
var page = FetchPage(nextUrl);
ProcessPage(page);
visitedUrls.Add(nextUrl);
var links = ParseLinks(page);
foreach (var link in links)
if (!visitedUrls.Contains(link))
urlsToVisit.Add(link);
}
``` | Instead of recursing, you could put the new URLs to crawl into a queue. Then run until the queue is empty without recursing. If you put the queue into a file this uses almost no memory at all. | How can I make this recursive crawl function iterative? | [
"",
"python",
"recursion",
"web-crawler",
""
] |
I'm writing a game development IDE that creates and compiles .NET projects (which I've been working on for the past few years) and am in the process of updating it to generate output not only for Windows/Visual Studio, but also for Linux/MonoDevelop (a thrillingly simple process for .NET, but still requiring some tweaks).
As part of this, I have found it necessary to start generating an app.config file as part of this to map dependent DLL names to Linux dependency names with <dllmap> elements. I'm confused about who's responsible for copying the app.config file to the output name app.exe.config. In a Visual Studio project, the Build Action for app.config seems to normally be set to "None" and its settings indicate that it won't be copied anywhere, yet when Visual Studio compiles the project it generates app.exe.config (though I've sometimes found this to be unreliable). When I use MSBuild to build a solution file generated by the IDE (for debugging purposes), MSBuild copies app.config to app.exe.config. But when I compile the project with CSharpCodeProvider.CompileAssemblyFromFile it (naturally) doesn't like the config file being included as source code ("app.config(1,1) : error CS0116: A namespace does not directly contain members such as fields or methods"), and of course it doesn't copy it to the output when I don't include it as an input. Is it my responsibility to simply copy app.config to app.exe.config independently, or is there a more standard way of doing this?
Is it hardwired to take the first \*.config file? In my IDE it's conceivable that the app.config file would be renamed or another one added (just as in Visual Studio). It seems odd to me that the IDE has this secret action for config files (I think MonoDevelop behaves similarly in this regard because I couldn't find a special action for config files there either). I don't know how it even picks to what files this secret action applies. | The C# compiler does not care about the config file at all. Build environments (MSBuild and VS) will take care of copying that file themselves. | Order:
1. first app.config file with None build action, in the project directory
2. first app.config file with Content build action, in the project directory
3. first app.config file with None build action, in a subdirectory
4. first app.config file with Content build action, in a subdirectory
msbuild/xbuild also allow you to override this by setting the $(AppConfig) property. | Who copies app.config to app.exe.config? | [
"",
"c#",
".net",
"visual-studio",
"monodevelop",
""
] |
I recently had a security audit run against one of the sites I work on. This was done with the Acunetix Web Vulnerability Scanner. This came back with a bunch of results that I'm sorting through.
A lot of hits on XSS came up, but I'm not sure if they are false positives or not.
Code such as:
```
if(isset($_GET['variableNameX']))
$var_to_use_in_app = mysql_escape_string(trim($_GET['variableNameX']));
```
Is coming back as being open to XSS. Is any page with a querystring going to come back as being potentially open to XSS, or is it smart enough to know that I'm handling this server side?
Thanks for the help. | Acunetix is a decent tool but it is NOT a replacement for manual based App Penetration Testing. It doesn't have the logic to follow through potential exploits .....
It is certainly used in the banks and I've recommended it in Proposals (which have been approved) to conduct formal bits of work. If you have a fairly complex App that has lots of dynamically generated pages and budget /time is a concern, you would boot off with Acunetix, or similar tool to point you in the direction of potential hot spots with the App. You can then focus on those areas by manual means - whether this is manual testing or stepping through the code. This is where your Pen Test houses earn their stripes.
Clients simply don't have the resources to go through large App's thoroughly.
Oh, and bear in mind there's lots of false positives. | > $var\_to\_use\_in\_app = mysql\_escape\_string(trim($\_GET['variableNameX']));
That's generally the wrong thing to do. The string as used internally in your application should always be the plain text version. Then you can be sure than none of your string manipulations will break it, and you won't be outputting the wrong thing to the page.
For example, if you had the submitted string:
```
O'Reilly
```
mysql\_escape\_string would escape it to:
```
O\'Reilly
```
which, when you output that string to the HTML page, would look silly. And if you outputted it to a form field that was then submitted again, you'd get *another* backslash, which would turn into two blackslashes, which if edited again would turn into four, eight... and in not long you've got strings composed of hundreds of backslashes. This is a commonly-seen problem in poorly-written CMSs and servers with the evil magic\_quotes feature turned on.
If you then wanted to take the first two letters of the name to put in a database query, you'd snip the substring:
```
O\
```
and then concatenate that into the query:
```
SELECT * FROM users WHERE namefirst2='O\';
```
whoops, syntax error, that string is now unterminated. Variants of string-processing on pre-escaped strings can just as easily get you into security trouble.
Instead of this approach, keep your strings as simple unescaped text strings in your application everywhere except the final output stage where you concatenate them into a delimited literal in SQL or HTML. For SQL:
```
"SELECT * FROM users WHERE name='".mysql_real_escape_string($name)."';"
```
Note the ‘real’ function name — plain old mysql\_escape\_string fails for some corner cases like East Asian character sets and connections/databases with the ANSI SQL\_MODE set, so in general you should always use the ‘real’ version.
You can define a function that is the same as mysql\_real\_escape\_string but has a shorter name (eg. m()) to make this a bit less ugly. Or, better, look at mysqli's [parameterised queries](http://de.php.net/manual/en/mysqli.prepare.php).
For HTML, the escaping should be done using the htmlspecialchars() function:
```
<div id="greeting">
Hello, Mr. <?php echo htmlspecialchars($name); ?>!
</div>
```
You can define a function that does the echo(htmlspecialchars()) but has a shorter name (eg. h()) to make this a bit less ugly.
If you have missed out the call to htmlspecialchars, then your scanner is absolutely correct in telling you that your site is vulnerable to XSS. But don't feel too bad, almost every other PHP programmer makes the same mistake.
mysql\_[real\_]escape\_string doesn't help you at all here, because the characters that break out of text in HTML are ‘&’, ‘<’, and, in attributes, ‘"’. None of those are special in SQL string literals, so mysql\_escape\_string doesn't touch them at all. A malicious:
```
<script>alert("I'm stealing your cookies! "+document.cookie);</script>
```
Only gets escaped to:
```
<script>alert("I\'m stealing your cookies! "+document.cookie);</script>
```
Which, as far as security is concerned, is no help whatsoever. | Security Scan On Site | [
"",
"php",
"security",
"web-applications",
"xss",
""
] |
How can I translate this pseudo code into working JS [don't worry about where the end date comes from except that it's a valid JavaScript date].
```
var myEndDateTime = somedate; //somedate is a valid JS date
var durationInMinutes = 100; //this can be any number of minutes from 1-7200 (5 days)
//this is the calculation I don't know how to do
var myStartDate = somedate - durationInMinutes;
alert("The event will start on " + myStartDate.toDateString() + " at " + myStartDate.toTimeString());
``` | Once you know this:
* You can create a `Date` by calling the [constructor](http://www.java2s.com/Tutorial/JavaScript/0240__Date/CreateDateobjectbycalltheconstructor.htm) with milliseconds since Jan 1, 1970.
* The `valueOf()` a `Date` is the number of milliseconds since Jan 1, 1970
* There are `60,000` milliseconds in a minute :-]
In the code below, a new `Date` is created by subtracting the appropriate number of milliseconds from `myEndDateTime`:
```
var MS_PER_MINUTE = 60000;
var myStartDate = new Date(myEndDateTime - durationInMinutes * MS_PER_MINUTE);
``` | You can also use get and set minutes to achieve it:
```
var endDate = somedate;
var startdate = new Date(endDate);
var durationInMinutes = 20;
startdate.setMinutes(endDate.getMinutes() - durationInMinutes);
``` | How do I subtract minutes from a date in JavaScript? | [
"",
"javascript",
""
] |
If I define an array in PHP such as (I don't define its size):
```
$cart = array();
```
Do I simply add elements to it using the following?
```
$cart[] = 13;
$cart[] = "foo";
$cart[] = obj;
```
Don't arrays in PHP have an add method, for example, `cart.add(13)`? | Both [`array_push`](http://php.net/manual/en/function.array-push.php) and the method you described will work.
```
$cart = array();
$cart[] = 13;
$cart[] = 14;
// etc
//Above is correct. but below one is for further understanding
$cart = array();
for($i=0;$i<=5;$i++){
$cart[] = $i;
}
echo "<pre>";
print_r($cart);
echo "</pre>";
```
Is the same as:
```
<?php
$cart = array();
array_push($cart, 13);
array_push($cart, 14);
// Or
$cart = array();
array_push($cart, 13, 14);
?>
``` | It's better to not use [`array_push`](http://php.net/manual/en/function.array-push.php) and just use what you suggested. The functions just add overhead.
```
//We don't need to define the array, but in many cases it's the best solution.
$cart = array();
//Automatic new integer key higher than the highest
//existing integer key in the array, starts at 0.
$cart[] = 13;
$cart[] = 'text';
//Numeric key
$cart[4] = $object;
//Text key (assoc)
$cart['key'] = 'test';
``` | How to add elements to an empty array in PHP? | [
"",
"php",
"arrays",
"variables",
""
] |
I have JavaScript which performs a whole lot of calculations as well as reading/writing values from/to the DOM. The page is huge so this often ends up locking the browser for up to a minute (sometimes longer with IE) with 100% CPU usage.
Are there any resources on optimising JavaScript to prevent this from happening (all I can find is how to turn off Firefox's long running script warning)? | if you can turn your calculation algorithm into something which can be called iteratively, you could release control back the browser at frequent intervals by using [setTimeout](https://developer.mozilla.org/En/DOM/window.setTimeout) with a short timeout value.
For example, something like this...
```
function doCalculation()
{
//do your thing for a short time
//figure out how complete you are
var percent_complete=....
return percent_complete;
}
function pump()
{
var percent_complete=doCalculation();
//maybe update a progress meter here!
//carry on pumping?
if (percent_complete<100)
{
setTimeout(pump, 50);
}
}
//start the calculation
pump();
``` | Use timeouts.
By putting the content of your loop(s) into separate functions, and calling them from setTimeout() with a timeout of 50 or so, the javascript will yield control of the thread and come back some time later, allowing the UI to get a look-in.
There's a good workthrough [here](http://windyroad.org/2007/03/30/web-apps-the-new-single-threaded-gui/). | Prevent long running javascript from locking up browser | [
"",
"javascript",
""
] |
For some reason, it seems the `Add` operation on a `HashSet` is slower than the `Contains` operation when the element already exists in the `HashSet`.
Here is proof:
```
Stopwatch watch = new Stopwatch();
int size = 10000;
int iterations = 10000;
var s = new HashSet<int>();
for (int i = 0; i < size; i++) {
s.Add(i);
}
Console.WriteLine(watch.Time(() =>
{
for (int i = 0; i < size; i++) {
s.Add(i);
}
}, iterations));
s = new HashSet<int>();
for (int i = 0; i < size; i++) {
s.Add(i);
}
// outputs: 47,074,764
Console.WriteLine(watch.Time(() =>
{
for (int i = 0; i < size; i++) {
if (!s.Contains(i))
s.Add(i);
}
}, iterations));
// outputs: 41,125,219
```
Why is `Contains` faster than `Add` for already-existing elements?
Note: I'm using this `Stopwatch` extension from another SO question.
```
public static long Time(this Stopwatch sw, Action action, int iterations) {
sw.Reset();
sw.Start();
for (int i = 0; i < iterations; i++) {
action();
}
sw.Stop();
return sw.ElapsedTicks;
}
```
**UPDATE**: Internal testing has revealed that the big performance diff only happens on the x64 version of the .NET framework. With the 32 bit version of the framework Contains seems run at identical speed to add (in fact it appears that the version with the contains runs a percent slower in some test runs) On X64 versions of the framework, the version with the contains seems to run about 15% faster. | AddIfNotPresent does an additional divide that Contains doesn't perform. Take a look at the IL for Contains:
```
IL_000a: call instance int32 class System.Collections.Generic.HashSet`1<!T>::InternalGetHashCode(!0)
IL_000f: stloc.0
IL_0010: ldarg.0
IL_0011: ldfld int32[] class System.Collections.Generic.HashSet`1<!T>::m_buckets
IL_0016: ldloc.0
IL_0017: ldarg.0
IL_0018: ldfld int32[] class System.Collections.Generic.HashSet`1<!T>::m_buckets
IL_001d: ldlen
IL_001e: conv.i4
IL_001f: rem
IL_0020: ldelem.i4
IL_0021: ldc.i4.1
IL_0022: sub
IL_0023: stloc.1
```
This is computing the bucket location for the hash code. The result is saved at local memory location 1.
AddIfNotPresent does something similar, but it also saves the computed value at location 2, so that it can insert the item into the hash table at that position if the item doesn't exist. It does that save because one of the locations is modified later in the loop that goes looking for the item. Anyway, here's the relevant code for AddIfNotPresent:
```
IL_0011: call instance int32 class System.Collections.Generic.HashSet`1<!T>::InternalGetHashCode(!0)
IL_0016: stloc.0
IL_0017: ldloc.0
IL_0018: ldarg.0
IL_0019: ldfld int32[] class System.Collections.Generic.HashSet`1<!T>::m_buckets
IL_001e: ldlen
IL_001f: conv.i4
IL_0020: rem
IL_0021: stloc.1
IL_0022: ldarg.0
IL_0023: ldfld int32[] class System.Collections.Generic.HashSet`1<!T>::m_buckets
IL_0028: ldloc.0
IL_0029: ldarg.0
IL_002a: ldfld int32[] class System.Collections.Generic.HashSet`1<!T>::m_buckets
IL_002f: ldlen
IL_0030: conv.i4
IL_0031: rem
IL_0032: ldelem.i4
IL_0033: ldc.i4.1
IL_0034: sub
IL_0035: stloc.2
```
Anyway, I think the extra divide is what's causing Add to take more time than Contains. At first glance, it looks like that extra divide could be factored out, but I can't say for sure without spending a little more time deciphering the IL. | Interesting, on my machine (Dell Latitude D630, dual-core 2.2 Ghz) I am getting nearly identical results for both tests unless I run the stopwatch against a `null` action before the tests. For example:
I run the tests with the exact code you have given in the question:
```
Without Contains(): 8205794
With Contains(): 8207596
```
If I modify the code in this manner:
After:
```
Stopwatch watch = new Stopwatch();
int size = 10000;
int iterations = 10000;
```
Add:
```
watch.Time(null, 0);
```
My results become:
```
Without Contains(): 8019129
With Contains(): 8275771
```
This seems to me like something odd is going on inside of the `Stopwatch` that is causing these fluctuations. | HashSet performance Add vs Contains for existing elements | [
"",
"c#",
"performance",
"hashset",
""
] |
Can you please give me advise? I searched for questions but did not found something similiar to mine.
How do i make my user inputs automatically escaped when they are intended to use in SQL queries? I don't like in my code filled with something like
```
$var_x = $DB->Escape($_POST['var_x']);
$another_var = $DB->Escape($_POST['another_var']);
$some_string = $DB->Escape($_POST['some_string']);
...
```
*Assuming i have Database class with Escape method which performs mysql\_real\_escape\_string*
But i can't set auto escape on SQL query as well, because it breaks insert queries:
```
function Exec($sql){
$result = mysql_query($this->Escape($sql));
}
$q = $DB->Exec("SELECT * FROM table WHERE id = 'xxx'");
```
It makes them \'xxx\'. which is incorrect.
Last thing i want to do is make parameterized statements, as it will make system more complicated. I'll consider this option when nothing else will left.
In short - how to make smart auto-escape which works with whole query and escapes only values? | In fact, the one and the only thing you should ever consider (we're not speaking of test projects here, obviously) is to use parameterized statements. This is the only way (when SQL synax allows for them, of course). Properly done, these won't make your system more complicated, but they *will* make it more robust. | Sorry, you can't auto anything. When you are concatenating strings, you will always have character escaping issues there; this is not something you can ‘solve’ once and never have to think about again.
If you do:
```
$a= "a'b";
$query= "SELECT * FROM things WHERE name='$a'";
```
Then your query string contains both apostrophes that are real apostrophes in string literals, and apostrophes that are string delimiters:
```
SELECT * FROM things WHERE name='a'b'
```
One needs to be escaped; the other mustn't. How can you tell which is which? You can't, that information is lost forever. You must instead say:
```
$query= "SELECT * FROM things WHERE name='".mysql_real_escape_string($a)."'";
```
(or whichever other escape function is more suitable for the database you're using.)
Ugly? Hell yeah. That's why we use parameterised queries instead. This gets away from string concatenation with all its woes.
String concatenation looks easy. People think they understand clodging strings together. But really, they don't. | User provided input SQL-escaping | [
"",
"php",
"mysql",
"escaping",
"mysql-real-escape-string",
""
] |
Is it possible to access private members of a class in c++.
> provided you don't have a friend
> function and You don't have access to
> the class definition | You mean using some pointer arithmetic to gain the access ? It is possible but is definitely dangerous. Take a look at this question also: [Accessing private members](https://stackoverflow.com/questions/726096/accessing-private-members/726304#726304) | I think there was some old school trick like this:
```
#define private public
#include "header.h"
#define private private
```
But you are strongly discouraged to do this (I've read quickly that the said something about this in the C++ standard) - if you want to read more about this google for "#define private public" | Is it possible to access private members of a class? | [
"",
"c++",
"private",
"member",
""
] |
In my project I found a piece of code in which a method was getting called in constructor's initializer list.
```
Test2(Test* pTest):m_pTest(pTest), m_nDuplicateID(pTest->getTestID())
{
}
```
I observed that there is a chance that the users of Test2 might pass NULL to the constructor. Since the pointer is used without validation there are chances of Access Violation.
This triggered me to look into exception handling in constructor's initializers list. I found in one of the article that try can be used inside initializer list. I wrote small test program to test this concept:
```
//Test class stores the unique ID and returns the same with API getTestID
class Test
{
public:
Test(int nID):m_nID(nID){
}
int getTestID() const
{
return m_nID;
}
private:
int m_nID;
};
class Test2
{
public:
Test2(Test* pTest)
try :m_pTest(pTest), m_nDuplicateID(pTest->getTestID())
{
}
catch (...)
{
cout<<"exception cought "<< endl;
}
void printDupID()
{
cout<<"Duplicate ID" << m_nDuplicateID << endl;
}
private:
Test* m_pTest;
int m_nDuplicateID;
};
int main(int argc, char* argv[])
{
Test* pTest = new Test(10);
Test2 aTest2(pTest);
aTest2.printDupID();
delete pTest;
return 0;
}
```
This code is **not getting compiled in VC6.0**. Do I need to make any changes to make it compile in VC 6.0?
Also, in one of the article I found that using try in constructor's initializer list does not strictly confirms to C++ standards. In that case, how do we handle the exceptions in constructor's initializers list (standard way of handling )?
Thanks. | Firstly, if you dereference the NULL pointer standard C++ does not guarantee that that an exception will be thrown, so your code is useless for this case.
Secondly, if an exception were thrown, what would your exception handler do?
Thirdly, constructor/function exception blocks are widely considered to be awaste of time - take a look at this <http://www.gotw.ca/gotw/066.htm> and other articles on Herb Sutter's GotW site. | C++ Standard Section 15 / 3
> A function-try-block associates a
> handler-seqwith thector-initializer,
> if present, and the function-body. An
> exception thrown during the execution
> of the initializer expressions in the
> ctor-initializer or during the
> execution of the function-body
> transfers control to a handler in a
> function-try-block in the same way as
> an exception thrown during the
> execution of a try-block transfers
> control to other handlers.
```
class C
{
int i;
double d;
public:
C(int, double);
};
C::C(int ii, double id)
try : i(f(ii)), d(id)
{
//constructor function body
} catch (...)
{
//handles exceptions thrown from the ctor-initializer
//and from the constructor functionbody
}
``` | exception handling in constructor’s initializer list | [
"",
"c++",
"exception",
""
] |
Let's say I create and execute a `System.Net.FtpWebRequest`.
I can use `catch (WebException ex) {}` to catch any web-related exception thrown by this request. But what if I have some logic that I only want to execute when the exception is thrown due to `(550) file not found`?
What's the best way to do this? I could copy the exception message and test for equality:
```
const string fileNotFoundExceptionMessage =
"The remote server returned an error: (550) File unavailable (e.g., file not found, no access).";
if (ex.Message == fileNotFoundExceptionMessage) {
```
But theoretically it seems like this message could change down the road.
Or, I could just test to see if the exception message contains "550". This approach is probably more likely to work if the message is changed (it will likely still contain "550" somewhere in the text). But of course such a test would also return true if the text for some other `WebException` just happens to contain "550".
There doesn't seem to be a method for accessing just the *number* of the exception. Is this possible? | `WebException` exposes a [`StatusCode`](http://msdn.microsoft.com/en-us/library/system.net.webexception.status.aspx) property that you can check.
If you want the actual HTTP response code you can do something like this:
```
(int)((HttpWebResponse)ex.Response).StatusCode
``` | For reference, here's the actual code I ended up using:
```
catch (WebException ex) {
if (ex.Status == WebExceptionStatus.ProtocolError &&
((FtpWebResponse)ex.Response).StatusCode == FtpStatusCode.ActionNotTakenFileUnavailable) {
// Handle file not found here
}
``` | Catching a specific WebException (550) | [
"",
"c#",
".net",
"exception",
"http-status-codes",
""
] |
I have a test case that requires typing in a partial value into an ajax based textfield and verifying the list has the expected content. If it does, select the content. Any idea how to make this work? | The **type** command may not be enough to trigger the autocomplete. Dave Webb's suggestions are otherwise spot on. My only addition would be that you might need the **typeKeys** command, which causes slightly different JavaScript events to be fired, which may be more likely to trigger the autocomplete widget. | I'd do this as follows:
* `type` to enter the value in the text field.
* `waitForTextPresent` or `verifyTextPresent` to check the autocomplete content
* `click` or `mouseDown` to click on the item in the autocomplete list
The trick is going to be making the final `click` be just in the right place. You should be able to use an XPath expression that searches for the text you're expecting to find it. | Can selenium handle autocomplete? | [
"",
"java",
"firefox",
"junit",
"selenium",
""
] |
How to run an operation on a collection in Python and collect the results?
So if I have a list of 100 numbers, and I want to run a function like this for each of them:
```
Operation ( originalElement, anotherVar ) # returns new number.
```
and collect the result like so:
result = another list...
How do I do it? Maybe using lambdas? | [List comprehensions.](http://docs.python.org/tutorial/datastructures.html#list-comprehensions) In Python they look something like:
```
a = [f(x) for x in bar]
```
Where f(x) is some function and bar is a sequence.
You can define f(x) as a partially applied function with a construct like:
```
def foo(x):
return lambda f: f*x
```
Which will return a function that multiplies the parameter by x. A trivial example of this type of construct used in a list comprehension looks like:
```
>>> def foo (x):
... return lambda f: f*x
...
>>> a=[1,2,3]
>>> fn_foo = foo(5)
>>> [fn_foo (y) for y in a]
[5, 10, 15]
```
Although I don't imagine using this sort of construct in any but fairly esoteric cases. Python is not a true functional language, so it has less scope to do clever tricks with higher order functions than (say) Haskell. You may find applications for this type of construct, but it's not really *that* pythonic. You could achieve a simple transformation with something like:
```
>>> y=5
>>> a=[1,2,3]
>>> [x*y for x in a]
[5, 10, 15]
``` | Another (somewhat depreciated) method of doing this is:
def kevin(v):
return v\*v
vals = range(0,100)
map(kevin,vals) | How to run an operation on a collection in Python and collect the results? | [
"",
"python",
"list",
"lambda",
""
] |
We have a table in a database that has 35 rows, according to
```
exec sp_spaceused Department.
```
I am able to run
```
SELECT TOP 1 * FROM Department,
```
and get a result, but when I run
```
SELECT COUNT(*) FROM Department,
```
it runs longer than 2 minutes (I then cancelled it and did not wait for a result, since I expect this to be a simple and fast query).
What could the reason for this be? Do you have any suggestions? | Is there a lock open on the table that is stopping you from reading some of the rows?
Try:
```
sp_lock
``` | Does this query come back quickly?
```
SELECT COUNT(*) FROM Department WITH (NOLOCK)
```
If so I would definitely say there's a lock of some sort on your table / index, as has been suggested.
Marc | Sql table unresponsive when selecting or counting all rows | [
"",
"sql",
"sql-server",
"select",
""
] |
Is there a .NET obfuscation tool present for Linux? Or is there a class which can provide me a functionality of writing a obfuscation tool for byte code? | Do you want an obfuscator that executes under Mono or one that outputs assemblies that will run under Mono?
If you want one that runs under Mono I don't know of any whose GUI runs under Mono but I do know that we have tested the [Dotfuscator](http://www.preemptive.com/dotfuscator.html) command line interface internally under Mono and it works. This is not (yet) an officially supported or extensively tested solution so your mileage may vary.
Dotfuscator accepts any standard MSIL assembly and we only emit 100% PEverifiable assemblies out so as long as your source assembly is Mono compatible the Dotfuscator output should also be Mono compatible. This can be verified using the [Mono Migration Analyzer](http://www.mono-project.com/MoMA) on both your source assembly and the Dotfuscator output.
Disclaimer: I do work for PreEmptive Solutions, the makers of Dotfuscator. | Try this tool, its free : <http://www.foss.kharkov.ua/g1/projects/eazfuscator/dotnet/Default.aspx#downloads> and it does what commercial products do. | .Net Obfuscator | [
"",
"c#",
".net",
"linux",
"obfuscation",
""
] |
I have a query that returns a result set similar to the one below (in reality it is far bigger, thousands of rows):
```
A | B | C | D
-----|----|----|-----
1 NULL | d0 | d0 | NULL
2 NULL | d0 | d1 | NULL
3 NULL | d0 | d2 | a0
4 d0 | d1 | d1 | NULL
5 d0 | d2 | d2 | a0
```
Two of the rows are considered duplicates, 1 and 2, because A, B and D are the same. To eliminate this, I could use `SELECT DISTINCT A, B, D` but then I do not get column C in my result set. Column C is necessary information for rows 3, 4 and 5.
So how do I come from the result set above to this one (the result appearing in C4 can also be `NULL` instead of `d1`):
```
A | B | C | D
-----|----|------|-----
1 NULL | d0 | NULL | NULL
3 NULL | d0 | d2 | a0
4 d0 | d1 | d1 | NULL
5 d0 | d2 | d2 | a0
``` | ```
DECLARE @YourTable TABLE (
A VARCHAR(2)
, B VARCHAR(2)
, C VARCHAR(2)
, D VARCHAR(2))
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd0', NULL)
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd1', NULL)
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd2', 'a0')
INSERT INTO @YourTable VALUES ('d0', 'd1', 'd1', NULL)
INSERT INTO @YourTable VALUES ('d0', 'd2', 'd2', 'a0')
SELECT A, B, C = MIN(C), D
FROM @YourTable
GROUP BY A, B, D
```
---
```
SELECT A, B, CASE WHEN MIN(C) = MAX(C) THEN MIN(C) ELSE NULL END, D
FROM @YourTable
GROUP BY A, B, D
```
---
```
SELECT A, B, CASE WHEN MIN(COALESCE(C, 'dx')) = MAX(COALESCE(C, 'dx')) THEN MIN(C) ELSE NULL END, D
FROM @YourTable
GROUP BY A, B, D
``` | Use [Dense\_Rank()](http://msdn.microsoft.com/en-us/library/ms173825.aspx) to partition by A, B, and D
(Thanks Lieven, for the temp table query, I had to use it for demo to be consistent ;))
According to [MSDN](http://msdn.microsoft.com/en-us/library/ms173825.aspx),
> The rank of a row is one plus the number of distinct ranks that come before the row in question
Partitioning by `A, B, C` and then sorting by `A, B, C, D` will give you the rank of 1 for the first distinct value where uniqueness is defined by `A, B, D`. That is where filtering by `1` came from.
> where DenseRank = 1
Here is the result
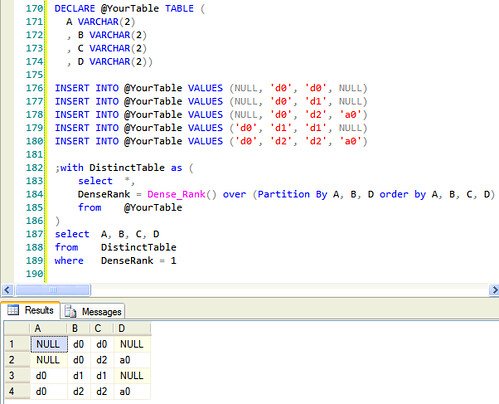
Here is the code:
```
DECLARE @YourTable TABLE (
A VARCHAR(2)
, B VARCHAR(2)
, C VARCHAR(2)
, D VARCHAR(2))
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd0', NULL)
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd1', NULL)
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd2', 'a0')
INSERT INTO @YourTable VALUES ('d0', 'd1', 'd1', NULL)
INSERT INTO @YourTable VALUES ('d0', 'd2', 'd2', 'a0')
;with DistinctTable as (
select *,
DenseRank = Dense_Rank() over (Partition By A, B, D order by A, B, C, D)
from @YourTable
)
select A, B, C, D
from DistinctTable
where DenseRank = 1
``` | Eliminate partial duplicate rows from result set | [
"",
"sql",
"sql-server",
"t-sql",
""
] |
I have a model Product
it has two fields size & colours among others
```
colours = models.CharField(blank=True, null=True, max_length=500)
size = models.CharField(blank=True, null=True, max_length=500)
```
In my view I have
```
current_product = Product.objects.get(slug=title)
if len(current_product.size) != 0 :
current_product.size = current_product.size.split(",")
```
and get this error:
object of type 'NoneType' has no len()
What is NoneType and how can I test for it? | `NoneType` is the type that the `None` value has. You want to change the second snippet to
```
if current_product.size: # This will evaluate as false if size is None or len(size) == 0.
blah blah
``` | NoneType is Pythons NULL-Type, meaning "nothing", "undefined". It has only one value: "None". When creating a new model object, its attributes are usually initialized to None, you can check that by comparing:
```
if someobject.someattr is None:
# Not set yet
``` | Django Model returning NoneType | [
"",
"python",
"django",
"django-views",
""
] |
I'm writing a js script that people will add to their web site by adding a single line of code to the header or end of the body part of their HTML.
My question is how to do the onload right on the external js file. Will the code below work? Can't it possibly run after the onload of the document and miss the onload event?
```
function c_onload () { alert ('onload'); }
if (window.attachEvent) {window.attachEvent('onload', c_onload);}
else if (window.addEventListener) {window.addEventListener('load', c_onload, false);}
else {document.addEventListener('load', c_onload, false);}
```
(I can't use Jquery or any other library) | I am afraid that if you can't use jQuery or some other library you need to reproduce a way good deal of their functionality. The reason is that browsers handle the onLoad event differently.
I recommend that you download jQuery's code and see how the documentready function is implemented. | What is your last `else`-clause
```
else {document.addEventListener('load', c_onload, false);
```
for? It's rather useless, imho.
The following should be a cross-browser solution: It first checks for `addEventListener()`, then `attachEvent()` and falls back to `onload = ...`
```
function chain(f1, f2) {
return typeof f1 !== 'function' ? f2 : function() {
var r1 = f1.apply(this, arguments),
r2 = f2.apply(this, arguments);
return typeof r1 === 'undefined' ? r2 : (r1 && r2);
};
}
function addOnloadListener(func) {
if(window.addEventListener)
window.addEventListener('load', func, false);
else if(window.attachEvent)
window.attachEvent('onload', func);
else window.onload = chain(window.onload, func);
}
```
Also, what kgiannakakis stated
> The reason is that browsers handle the onLoad event differently.
is not true: all major browsers handle `window.onload` the same way, ie the listener function gets executed after the external resources - **including your external script** - have been loaded. The problem lies with `DOMContentLoaded` - that's where the hacks with `doScroll()`, `defer`, `onreadystatechange` and whatever else someone has cooked up come to play.
---
Depending on your target audience, you may either want to drop the fallback code or even use it exclusively. My vote would go for dropping it. | onload from external js file | [
"",
"javascript",
"onload",
""
] |
This one is for Boost experts. Are there any gotchas or details that the programmer needs to be aware of before he goes in and replaces all his old C/C++ style loops with the lean-and-mean-looking `BOOST_FOREACH`?
(This question is partly derived from [here](https://stackoverflow.com/questions/716810).) | Take a look at:
* The [Conditional Love](http://www.artima.com/cppsource/foreach.html) article for an understanding of the rationale
* The [Pitfalls](http://www.boost.org/doc/libs/1_35_0/doc/html/foreach/pitfalls.html) section of documentation
* The [Portability](http://www.boost.org/doc/libs/1_35_0/doc/html/foreach/portability.html) section just in case you are developing cross-platform products
* The bugs page for [BOOST\_FOREACH](https://svn.boost.org/trac/boost/search?q=BOOST_FOREACH&noquickjump=1&ticket=on) | BOOST\_FOREACH - macro, I don't like macroses and prefer to use STL algorithms + lambda + bind.
Also [C++0x](http://en.wikipedia.org/wiki/C%2B%2B0x) will contain [for-loop](http://en.wikipedia.org/wiki/C%2B%2B0x#Range-based_for-loop) similar on BOOST\_FOREACH:
```
int my_array[5] = {1, 2, 3, 4, 5};
for(int &x : my_array)
{
x *= 2;
}
```
it is one additional reason for don't use partialy dead BOOST\_FOREACH. | C++ Boost: Any gotchas with BOOST_FOREACH? | [
"",
"c++",
"boost",
"loops",
""
] |
I have an HTML page which contains an Object tag to host an embedded HTML page.
```
<object style="border: none;" standby="loading" id="contentarea"
width="100%" height="53%" type="text/html" data="test1.html"></object>
```
However, I need to be to change the HTML page within the object tag. The current code seems to create a clone of the object and replaces the existing object with it, like so:
```
function changeObjectUrl(newUrl)
{
var oContentArea = document.getElementById("contentarea");
var oClone = oContentArea.cloneNode(true);
oClone.data = newUrl;
var oPlaceHolder = document.getElementById("contentholder");
oPlaceHolder.removeChild(oContentArea);
oPlaceHolder.appendChild(oClone);
}
```
This seems a rather poor way of doing this. Does anyone know the 'correct' way of changing the embedded page?
Thanks!
**EDIT**: In response to answers below, here is the full source for the page I am now using. Using the setAttribute does not seem to change the content of the Object tag.
```
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>Test</title>
<script language="JavaScript">
function doPage()
{
var objTag = document.getElementById("contentarea");
if (objTag != null)
{
objTag.setAttribute('data', 'Test2.html');
alert('Page should have been changed');
}
}
</script>
</head>
<body>
<form name="Form1" method="POST">
<p><input type="button" value="Click to change page" onclick="doPage();" /></p>
<object style="visibility: visible; border: none;" standby="loading data" id="contentarea" title="loading" width="100%" height="53%" type="text/html" data="test1.html"></object>
</form>
</body>
</html>
```
The Test1.html and Test2.html pages are just simple HTML pages displaying the text 'Test1' and 'Test2' respectively. | Here's how I finally achieved it. You can do
```
document.getElementById("contentarea").object.location.href = url;
```
or maybe
```
document.getElementById("contentarea").object.parentWindow.navigate(url);
```
The Object element also has a 'readyState' property which can be used to check whether the contained page is 'loading' or 'complete'. | This seems to be a browser bug, `setAttribute()` should work. I found this workaround, which seems to work in all browsers:
```
var newUrl = 'http://example.com';
var objectEl = document.getElementById('contentarea');
objectEl.outerHTML = objectEl.outerHTML.replace(/data="(.+?)"/, 'data="' + newUrl + '"');
``` | Changing data content on an Object Tag in HTML | [
"",
"javascript",
"html",
"object",
""
] |
In Sql Server 2005, I have a table with two integer columns, call them Id1 and Id2.
I need them to be unique with in the table (easy enough with a unique index that spans both columns). I also need them to be unique in the table if the values are transposed between the two columns.
For example, SELECT \* FROM MyTable returns
```
Id1 Id2
---------
2 4
5 8
7 2
4 2 <--- values transposed from the first row
```
How do I make a constraint that would prevent the last row from being entered into the table because they are the transposed values from the first row? | Create a check constraint that is bound to a user defined function that performs a select on the table to check for the transposed value.
```
Create table mytable(id1 int, id2 int)
go
create Function dbo.fx_Transposed(@id1 int, @id2 int)
returns bit as
Begin
Declare @Ret bit
Set @ret = 0
if exists(Select 1 from MyTable
Where id2 = @id1 and id1 = @id2)
Set @ret = 1
Return @ret
End
GO
Alter table mytable add
CONSTRAINT [CHK_TRANSPOSE] CHECK
(([dbo].[fx_Transposed]([ID1],[ID2])=(0)))
GO
Insert into mytable (id1, id2) values (1,2)
Insert into mytable (id1, id2) values (2,1)
``` | Does the order between Id1 and Id2 have any significance? If not and this is a large table it may be more performent to enforce Id1 < Id2 in addition to your unique index. This would impact any process inputing records so it may not be feasible. | SQL Constraints Question | [
"",
"sql",
"sql-server",
"constraints",
""
] |
*Edit:* This is not a conflict on the theoretical level but a conflict on an implementation level.
*Another Edit:*
The problem is not having domain models as data-only/DTOs versus richer, more complex object map where Order has OrderItems and some calculateTotal logic. The specific problem is when, for example, that Order needs to grab the latest wholesale prices of the OrderItem from some web service in China (for example). So you have some Spring Service running that allows calls to this PriceQuery service in China. Order has calculateTotal which iterates over every OrderItem, gets the latest price, and adds it to the total.
So how would you ensure that every Order has a reference to this PriceQuery service? How would you restore it upon de-serializations, loading from DBs, and fresh instantiations? This is my exact question.
The easy way would be to pass a reference to the calculateTotal method, but what if your Object uses this service internally throughout its lifetime? What if it's used in 10 methods? It gets messy to pass references around every time.
Another way would be to move calculateTotal out of the Order and into the OrderService, but that breaks OO design and we move towards the old "Transaction Script" way of things.
*Original post:*
**Short version:**
Rich domain objects require references to many components, but these objects get persisted or serialized, so any references they hold to outside components (Spring beans in this case: services, repositories, anything) are transient and get wiped out. They need to be re-injected when the object is de-serialized or loaded from the DB, but this is extremely ugly and I can't see an elegant way to do it.
**Longer version:**
For a while now I've practiced loose coupling and DI with the help of Spring. It's helped me a lot in keeping things manageable and testable. A while ago, however, I read Domain-Driven Design and some Martin Fowler. As a result, I've been trying to convert my domain models from simple DTOs (usually simple representations of a table row, just data no logic) into a more rich domain model.
As my domain grows and takes on new responsibilities, my domain objects are starting to require some of the beans (services, repositories, components) that I have in my Spring context. This has quickly become a nightmare and one of the most difficult parts of converting to a rich domain design.
Basically there are points where I am manually injecting a reference to the application context into my domain:
* when object is loaded from Repository or other responsible Entity since the component references are transient and obviously don't get persisted
* when object is created from Factory since a newly created object lacks the component references
* when object is de-serialized in a Quartz job or some other place since the transient component references get wiped
First, it's ugly because I'm passing the object an application context reference and expecting it to pull out by name references to the components it needs. This isn't injection, it's direct pulling.
Second, it's ugly code because in all of those mentioned places I need logic for injecting an appContext
Third, it's error prone because I have to remember to inject in all those places for all those objects, which is harder than it sounds.
There has got to be a better way and I'm hoping you can shed some light on it. | I've found the answer, at least for those using Spring:
[6.8.1. Using AspectJ to dependency inject domain objects with Spring](http://static.springsource.org/spring/docs/2.5.x/reference/aop.html#aop-atconfigurable) | I would venture to say that there are many shades of gray between having an "anemic domain model" and cramming all of your services into your domain objects. And quite often, at least in business domains and in my experience, an object might actually be nothing more than just the data; for example, whenever the operations that can be performed on that particular object depend on multitude of other objects and some localized context, say an address for example.
In my review of the domain-driven literature on the net, I have found a lot of vague ideas and writings, but I was not unable to find a proper, non-trivial example of where the boundaries between methods and operations should lie, and, what's more, how to implement that with current technology stack. So for the purpose of this answer, I will make up a small example to illustrate my points:
Consider the age-old example of Orders and OrderItems. An "anemic" domain model would look something like:
```
class Order {
Long orderId;
Date orderDate;
Long receivedById; // user which received the order
}
class OrderItem {
Long orderId; // order to which this item belongs
Long productId; // product id
BigDecimal amount;
BigDecimal price;
}
```
In my opinion, the point of the domain-driven design is to use classes to better model the relationships between entities. So, an non-anemic model would look something like:
```
class Order {
Long orderId;
Date orderDate;
User receivedBy;
Set<OrderItem> items;
}
class OrderItem {
Order order;
Product product;
BigDecimal amount;
BigDecimal price;
}
```
Supposedly, you would be using an ORM solution to do the mapping here. In this model, you would be able to write a method such as `Order.calculateTotal()`, that would sum up all the `amount*price` for each order item.
So, the model would be rich, in a sense that operations that make sense from a business perspective, like `calculateTotal`, would be placed in an `Order` domain object. But, at least in my view, domain-driven design does not mean that the `Order` should know about your persistence services. That should be done in a separate and independent layer. Persistence operations are not part of the business domain, they are the part of the implementation.
And even in this simple example, there are many pitfalls to consider. Should the entire `Product` be loaded with each `OrderItem`? If there is a huge number of order items, and you need a summary report for a huge number of orders, would you be using Java, loading objects in memory and invoking `calculateTotal()` on each order? Or is an SQL query a much better solution, from every aspect. That is why a decent ORM solution like Hibernate, offers mechanisms for solving precisely these kind of practical problems: lazy-loading with proxies for the former and HQL for the latter. What good would be a theoretically sound model be, if report generation takes ages?
Of course, the entire issue is quite complex, much more that I'm able to write or consider in one sitting. And I'm not speaking from a position of authority, but simple, everyday practice in deploying business apps. Hopefully, you'll get something out of this answer. Feel free to provide some additional details and examples of what you're dealing with...
**Edit**: Regarding the `PriceQuery` service, and the example of sending an email after the total has been calculated, I would make a distinction between:
1. the fact that an email should be sent after price calculation
2. what part of an order should be sent? (this could also include, say, email templates)
3. the actual method of sending an email
Furthermore, one has to wonder, is sending of an email an inherent ability of an `Order`, or yet another thing that can be done with it, like persisting it, serialization to different formats (XML, CSV, Excel) etc.
What I would do, and what I consider a good OOP approach is the following. Define an interface encapsulating operations of preparing and sending an email:
```
interface EmailSender {
public void setSubject(String subject);
public void addRecipient(String address, RecipientType type);
public void setMessageBody(String body);
public void send();
}
```
Now, inside `Order` class, define an operation by which an order "knows" how to send itself as an email, using an email sender:
```
class Order {
...
public void sendTotalEmail(EmailSender sender) {
sender.setSubject("Order " + this.orderId);
sender.addRecipient(receivedBy.getEmailAddress(), RecipientType.TO);
sender.addRecipient(receivedBy.getSupervisor().getEmailAddress(), RecipientType.BCC);
sender.setMessageBody("Order total is: " + calculateTotal());
sender.send();
}
```
Finally, you should have a facade towards your application operations, a point where the actual response to user action happens. In my opinion, this is where you should obtain (by Spring DI) the actual implementations of services. This can, for example, be the Spring MVC `Controller` class:
```
public class OrderEmailController extends BaseFormController {
// injected by Spring
private OrderManager orderManager; // persistence
private EmailSender emailSender; // actual sending of email
public ModelAndView processFormSubmission(HttpServletRequest request,
HttpServletResponse response, ...) {
String id = request.getParameter("id");
Order order = orderManager.getOrder(id);
order.sendTotalEmail(emailSender);
return new ModelAndView(...);
}
```
Here's what you get with this approach:
1. domain objects don't contain services, they **use** them
2. domain objects are decoupled from actual service implementation (e.g. SMTP, sending in separate thread etc.), by the nature of the interface mechanism
3. services interfaces are generic, reusable, but don't know about any actual domain objects. For example, if order gets an extra field, you need change only the `Order` class.
4. you can mock services easily, and test domain objects easily
5. you can test actual services implementations easily
I don't know if this is by standards of certain gurus, but it a down-to-earth approach that works reasonably well in practice. | How can I resolve the conflict between loose coupling/dependency injection and a rich domain model? | [
"",
"java",
"spring",
"dependency-injection",
"domain-driven-design",
""
] |
I work on a fairly complex Open Source project ([opensimulator.org](http://opensimulator.org/wiki/Main_Page)). It's currently sitting around 300 KLOC of C#, and there are a number of places where code has built up to trap and ignore exceptions, which end up disguising subtle bugs.
I'm wondering what tools are out there that can produce reports of overly general exception catching, and also if there are tools available that will log every thrown exception, whether it is suppressed or not, for examination later.
It would be ideal if the tools could be introduced into our CI build & test script, so that daily reports can be made, but isn't a requirement. | All righ, I agree with [@John Saunders](https://stackoverflow.com/questions/664935/tools-to-use-to-find-supressed-exceptions/664942#664942) but if there is a lot of code, you can write a simple analyzer or use some exisiting code to replace all the swallowed exception patterns with logging code. Very simple, like replace:
```
catch(Exception ex)
{
}
```
with:
```
catch(Exception ex)
{
System.Diagnostics.Debug.WriteLine(ex.ToString());
}
```
Note, you'd also want to check for catch(Exception), probably just use some regular expressions and this would not be difficult at all. I understand since it is a lot of code, you might want an automated way of getting basic logging in there. Replace the Debug.WriteLine() with whatever you want. This is kind of crude but simple. | Use FxCop, or the Code Analysis feature of Visual Studio Team System Developer Edition.
Also, I've found ReSharper useful for this. | Tools to use to find suppressed exceptions? | [
"",
"c#",
".net",
"exception",
""
] |
I'm about to jump into Java development again after a number of years. The language revision I worked with was 1.4.2. I know there have been significant changes to the language since then, and I'm looking for a site or a book that covers these in some detail. At the very least, I'm looking for a resource that indicates which language features were added in which revision, so I can at a glance skip the sections I'm already familiar with. Any suggestions ? | You could check out the Sun website. You can find the changes in [Java 5](http://java.sun.com/j2se/1.5.0/docs/relnotes/features.html) and [Java 6](http://java.sun.com/javase/6/webnotes/features.html). I think most of the significant language changes came in Java 5 with Generics, Autoboxing, Varargs, Enums etc. | The [Wikipedia entry](http://en.wikipedia.org/wiki/Java_version_history) seems concise enough for what you want to look at.
Extract:
## J2SE 5.0 (September 30, 2004)
Codename Tiger. (Originally numbered 1.5, which is still used as the internal version number.) Developed under JSR 176, Tiger added a number of significant new language features:
* Generics: Provides compile-time (static) type safety for collections and eliminates the need for most typecasts (type conversion). (Specified by JSR 14.)
* Metadata: Also called annotations; allows language constructs such as classes and methods to be tagged with additional data, which can then be processed by metadata-aware utilities. (Specified by JSR 175.)
* Autoboxing/unboxing: Automatic conversions between primitive types (such as int) and primitive wrapper classes (such as Integer). (Specified by JSR 201.)
* Enumerations: The enum keyword creates a typesafe, ordered list of values (such as Day.MONDAY, Day.TUESDAY, etc.). Previously this could only be achieved by non-typesafe constant integers or manually constructed classes (typesafe enum pattern). (Specified by JSR 201.)
* Swing: New skinnable look and feel, called synth.
* Varargs: The last parameter of a method can now be declared using a type name followed by three dots (e.g. void drawtext(String... lines)). In the calling code any number of parameters of that type can be used and they are then placed in an array to be passed to the method, or alternatively the calling code can pass an array of that type.
* Enhanced for each loop: The for loop syntax is extended with special syntax for iterating over each member of either an array or any Iterable, such as the standard Collection classes (Specified by JSR 201.)
* Fix the previously broken semantics of the Java Memory Model, which defines how threads interact through memory.
* Automatic stub generation for RMI objects.
* static imports
* 1.5.0\_17 (5u17) is the last release of Java to officially support the Microsoft Windows 9x line (Windows 95, Windows 98, Windows ME). [1](http://en.wikipedia.org/wiki/Java_version_history) Unofficially, Java SE 6 Update 7 (1.6.0.7) is the last version of Java to be shown working on this family of operating systems.
* The concurrency utilities in package java.util.concurrent.
J2SE 5.0 entered its end-of-life on 2008 April 8 and will be unsupported by Sun as of 2009 October 30.
## Java SE 6 (December 11, 2006)
Codename Mustang. As of this version, Sun replaced the name "J2SE" with Java SE and dropped the ".0" from the version number. Internal numbering for developers remains 1.6.0. This version was developed under JSR 270.
During the development phase, new builds including enhancements and bug fixes were released approximately weekly. Beta versions were released in February and June 2006, leading up to a final release that occurred on December 11, 2006. The current revision is Update 12 which was released in February 2009.
Major changes included in this version:
* Support for older Win9x versions dropped. Unofficially Java 6 Update 7 is the last release of Java shown to work on these versions of Windows. This is believed to be due to the major changes in Update 10.
* Scripting Language Support (JSR 223): Generic API for tight integration with scripting languages, and built-in Mozilla Javascript Rhino integration
* Dramatic performance improvements for the core platform[17][18], and Swing.
* Improved Web Service support through JAX-WS (JSR 224)
* JDBC 4.0 support (JSR 221).
* Java Compiler API (JSR 199): an API allowing a Java program to select and invoke a Java Compiler programmatically.
* Upgrade of JAXB to version 2.0: Including integration of a StAX parser.
* Support for pluggable annotations (JSR 269).
* Many GUI improvements, such as integration of SwingWorker in the API, table sorting and filtering, and true Swing double-buffering (eliminating the gray-area effect).
### Java SE 6 Update 10
Java SE 6 Update 10 (previously known as Java SE 6 Update N), while it does not change any public API, is meant as a major enhancement in terms of end-user usability. The release version is currently available for download.
Major changes for this update include:
* Java Deployment Toolkit, a set of JavaScript functions to ease the deployment of applets and Java Web Start applications.
* Java Kernel, a small installer including only the most commonly used JRE classes. Other packages are downloaded when needed.
* Enhanced updater.
* Enhanced versioning and pack200 support: server-side support is no longer required.
* Java Quick Starter, to improve cold start-up time.
* Improved performance of Java2D graphics primitives on Windows, using Direct3D and hardware acceleration.
* A new Swing look and feel called Nimbus and based on synth.[23]
* Next-Generation Java Plug-In: applets now run in a separate process and support many features of Web Start applications | Concise explanations of Java language changes in the major revisions | [
"",
"java",
"programming-languages",
"java-5",
"java1.4",
""
] |
I'm looking to scale an existing phpBB installation by separating the read queries from the write queries to two separate, replicated MySQL servers. Anyone succeeded in doing this, specifically with phpBB?
The biggest concern I have so far is that it seems like the queries are scattered haphazardly throughout the code. I'd love to hear if anyone else did this, and if so, how it went / what was the process. | Just add more RAM. Enough RAM to hold the entire database. You'll be surprised how fast your inefficient script will fly. Memory forgives a lot of database scaling mistakes. | You could try [MySQL Proxy](http://forge.mysql.com/wiki/MySQL_Proxy) which would be an easy way to split the queries without changing the application. | Scaling phpBB? | [
"",
"php",
"mysql",
"scaling",
"phpbb",
""
] |
I'm trying to use the Microsoft [Debug Interface Access SDK](http://msdn.microsoft.com/en-us/library/x93ctkx8(VS.80).aspx) from C#. This is installed with Visual Studio, but the docs don't seem to mention how you use this from C#.
I've found example code on interweb but no information on how to link to the DIA SDK. I.e. I can't import it as an assembly. I don't think I have to include it into a managed C++ application and use it as COM (that would be hell).
There is an IDL file, is this the correct way? If so, how?
---
**Edit:** The following will create the type library for use as a referenced assembly. Paste into a batch file.
```
call "%VS80COMNTOOLS%\vsvars32.bat"
midl /I "%VSINSTALLDIR%\DIA SDK\include" "%VSINSTALLDIR%\DIA SDK\idl\dia2.idl" /tlb dia2.tlb
tlbimp dia2.tlb
``` | You need to convert the IDL to a typelib first:
Something like:
```
midl /I "%VSINSTALLDIR%\DIA SDK\include" dia2.idl /tlb dia2.tlb
tlbimp dia2.tlb
```
Then you can import the tlb.
I've never used the DIA SDK this way, so don't know how friendly it would be. You could also consider using it directly from a managed C++ assembly and presenting a managed interface to the functionality you need. | The previous instructions worked, but needed some updating. VSINSTALLDIR doesn't exist anymore (and is ambiguous when you have multiple VS versions installed) so I generalized and corrected the instructions. Here is a VS 2015 version:
```
"%VS140COMNTOOLS%..\..\VC\vcvarsall.bat" amd64
set DIASDK=%VS140COMNTOOLS%..\..\DIA SDK
midl /I "%DIASDK%\include" "%DIASDK%\idl\dia2.idl" /tlb dia2.tlb
tlbimp dia2.tlb
```
Change VS140 to match whatever version you are trying to use.
This created dia2lib.dll which I added as a reference - right-click References, Add Reference, Browse, find the file. It works and I can now build and run symbolsort. | How do I use the MS DIA SDK from C#? | [
"",
"c#",
".net",
"debugging",
"dia-sdk",
""
] |
I am trying to write a cross-platform python program that would run in the background, monitor all keyboard events and when it sees some specific shortcuts, it generates one or more keyboard events of its own. For example, this could be handy to have Ctrl-@ mapped to "my.email@address", so that every time some program asks me for my email address I just need to type Ctrl-@.
I know such programs already exist, and I am reinventing the wheel... but my goal is just to learn more about low-level keyboard APIs. Moreover, the answer to this question might be useful to other programmers, for example if they want to startup an SSH connection which requires a password, without using pexpect.
Thanks for your help.
Note: there is [a similar question](https://stackoverflow.com/questions/310576/low-level-keyboard-input-on-windows) but it is limited to the Windows platform, and does not require python. I am looking for a cross-platform python api. There are also other questions related to keyboard events, but apparently they are not interested in system-wide keyboard events, just application-specific keyboard shortcuts.
Edit: I should probably add a disclaimer here: I do *not* want to write a keylogger. If I needed a keylogger, I could download one off the web a anyway. ;-) | There is no such API. My solution was to write a helper module which would use a different helper depending on the value of `os.name`.
On Windows, use the [Win32 extensions](http://python.net/crew/mhammond/win32/Downloads.html).
On Linux, things are a bit more complex since real OSes protect their users against keyloggers[\*]. So here, you will need a root process which watches one of[] the handles in `/dev/input/`. Your best bet is probably looking for an entry below `/dev/input/by-path/` which contains the strings `"kbd"` or `"keyboard"`. That should work in most cases.
[\*]: Jeez, not even my virus/trojan scanner will complain when I start a Python program which hooks into the keyboard events... | As the guy that wrote the original pykeylogger linux port, I can say there isn't really a cross platform one. Essentially I rewrote the pyhook API for keyboard events to capture from the xserver itself, using the record extension. Of course, this assumes the record extension is there, loaded into the x server.
From there, it's essentially just detecting if you're on windows, or linux, and then loading the correct module for the OS. Everything else should be identical.
Take a look at the pykeylogger source, in pyxhook.py for the class and implimentation. Otherwise, just load that module, or pyhook instead, depending on OS. | Is there a cross-platform python low-level API to capture or generate keyboard events? | [
"",
"python",
"cross-platform",
"keyboard-events",
"low-level-api",
""
] |
Is it possible to assign a base class object to a derived class reference with an explicit typecast in C#?.
I have tried it and it creates a run-time error. | No. A reference to a derived class must actually refer to an instance of the derived class (or null). Otherwise how would you expect it to behave?
For example:
```
object o = new object();
string s = (string) o;
int i = s.Length; // What can this sensibly do?
```
If you want to be able to convert an instance of the base type to the derived type, I suggest you write a method to create an appropriate derived type instance. Or look at your inheritance tree again and try to redesign so that you don't need to do this in the first place. | No, that's not possible since assigning it to a derived class reference would be like saying "Base class is a fully capable substitute for derived class, it can do everything the derived class can do", which is not true since derived classes in general offer more functionality than their base class (at least, that's the idea behind inheritance).
You could write a constructor in the derived class taking a base class object as parameter, copying the values.
Something like this:
```
public class Base {
public int Data;
public void DoStuff() {
// Do stuff with data
}
}
public class Derived : Base {
public int OtherData;
public Derived(Base b) {
this.Data = b.Data;
OtherData = 0; // default value
}
public void DoOtherStuff() {
// Do some other stuff
}
}
```
In that case you would copy the base object and get a fully functional derived class object with default values for derived members. This way you can also avoid the problem pointed out by Jon Skeet:
```
Base b = new Base();//base class
Derived d = new Derived();//derived class
b.DoStuff(); // OK
d.DoStuff(); // Also OK
b.DoOtherStuff(); // Won't work!
d.DoOtherStuff(); // OK
d = new Derived(b); // Copy construct a Derived with values of b
d.DoOtherStuff(); // Now works!
``` | Is it possible to assign a base class object to a derived class reference with an explicit typecast? | [
"",
"c#",
"casting",
"derived-class",
"base-class",
"downcast",
""
] |
Say you have a value like this:
```
n = 5
```
and a function that returns the factorial of it, like so:
```
factorial(5)
```
How do you handle multiple values:
```
nums = [1,2,3,4,5]
factorial (nums)
```
so it returns the factorials of all these values as a list?
What's the cleanest way to handle this, without writing 2 methods? Does Python have a good way to handle these kinds of situations? | This is done sometimes.
```
def factorial( *args ):
def fact( n ):
if n == 0: return 1
return n*fact(n-1)
return [ fact(a) for a in args ]
```
It gives an almost magical function that works with simple values as well as sequences.
```
>>> factorial(5)
[120]
>>> factorial( 5, 6, 7 )
[120, 720, 5040]
>>> factorial( *[5, 6, 7] )
[120, 720, 5040]
``` | ```
def Factorial(arg):
try:
it = iter(arg)
except TypeError:
pass
else:
return [Factorial(x) for x in it]
return math.factorial(arg)
```
If it's iterable, apply recursivly. Otherwise, proceed normally.
Alternatively, you could move the last `return` into the `except` block.
If you are sure the body of `Factorial` will never raise `TypeError`, it could be simplified to:
```
def Factorial(arg):
try:
return [Factorial(x) for x in arg]
except TypeError:
return math.factorial(arg)
``` | How to implement a function to cover both single and multiple values | [
"",
"python",
"list",
"function",
"vectorization",
""
] |
I've got a static class (DataFormSubject) that holds a generic List object, as follows:
```
private static List<DataForm> dataForms = new List<DataForm>();
```
Other classes that rely on this list need to be told when the list is updated, so I created a custom event, and associated methods that could trigger when an item is added or removed, as follows:
```
public delegate void DataFormsUpdatedHandler(object sender);
public static event DataFormsUpdatedHandler DataFormsUpdatedEvent;
public static void AddDataForm(DataForm df)
{
dataForms.Add(df);
if (DataFormsUpdatedEvent != null)
DataFormsUpdatedEvent(df);
}
public static void RemoveDataForm(DataForm df)
{
dataForms.Remove(df);
if (DataFormsUpdatedEvent != null)
DataFormsUpdatedEvent(df);
}
```
The List is available from the static class via a property, as follows:
```
public static List<DataForm> DataForms
{
get { return dataForms; }
//set { dataForms = value; }
}
```
But the problem here is that the client can now *bypass* the update event by accessing the property and doing a direct add or remove on the class! E.g.
```
DataFormSubject.DataForms.Add(new DataForm);
```
How can I prevent this, or is there a better way of acheiving what I want? Ideally what I would like is an update event on the List class that observers can subscribe to! | Consider using `BindingList<T>` or `ObservableCollection<T>`; both of these do what you want in standard ways.
You cannot do anything interesting by subclassing `List<T>` - the methods aren't virtual. `Collection<T>` is designed to be more extensible, but in this case everything you need is already provided (by `BindingList<T>`).
In particular, this provides:
* [IBindingList](http://msdn.microsoft.com/en-us/library/system.componentmodel.ibindinglist.aspx) (used by many UI binding components, such as grids)
* [ListChanged](http://msdn.microsoft.com/en-us/library/ms132742.aspx) - that your code can subscribe to for detailed notification | You want to look into using an `ObservableCollection` for such a purpose. See [this MSDN article](http://msdn.microsoft.com/en-us/library/ms748365.aspx) to get started. | Creating an event that triggers when a List is updated | [
"",
"c#",
"list",
"observer-pattern",
""
] |
I have a situation where before doing a particular task I have to check whether a particular flag is set in DB and if it is not set then rest of the processing is done and the same flag is set. Now, in case of concurrent access from 2 different transactions, if first transaction check the flag and being not set it proceeds further. At the same time, I want to restrict the 2nd transaction from checking the flag i.e. I want to restrict that transaction from executing a SELECT query and it can execute the same once the 1st transaction completes its processing and set the flag.
I wanted to implement it at the DB level with locks/hints. But no hint restrict SELECT queries and I cannot go for Isolation level restrictions. | You can create an [Application Lock](http://weblogs.sqlteam.com/mladenp/archive/2008/01/08/Application-Locks-or-Mutexes-in-SQL-Server-2005.aspx) to protect your flag, so the second transaction will not perform SELECT or access the flag if it cannot acquire the Application Lock | I believe that SQL Server 2005 does this natively by not permitting a dirty read. That is, as I understand it, as long as the update / insert occurs before the second user tries to do the select to check the flag, the db will wait for the update / insert to be committed before processing the select.
Here are some [common locks](http://blog.sqlauthority.com/2007/04/27/sql-server-2005-locking-hints-and-examples/) that may assist you as well, if you'd like more granularity.
edit : XLOCK may also be of some help. And, wrapping the SQL in a transaction may help as well. | Restricting a SELECT statement in SQL Server 2005 | [
"",
"java",
"sql-server",
"concurrency",
"locking",
""
] |
As I begin to develop more and more complicated JavaScript solutions, I wonder what sort of options JavaScript gives me to monitor changes in my environment. I've seen so many solutions that constantly ping whatever element they are wanting to monitor, but for any sort of resource heavy application (or for any case depending on the standards of the developer) that becomes bloated and too hackish to be a viable method. Which brings me to my question, "What are the limitations of JavaScript's `onchange` event?". Specifically, right now I'm trying to monitor the size of the window. Is there a way to utilize the `.onchange` event for things like this? How would you solve this?
I'm very interested to hear what everyone has to say. | The size of the window can be monitored with [onresize](http://www.w3schools.com/jsref/jsref_onresize.asp).
The onchange event, as Rahul says, applies to fileupload, select, text and textarea. However, it only fires once focus is shifted away from the item and onto something else, and the content has changed. | The onchange attribute is a DOM property. It is not provided by Javascript.
W3schools reports that only some elements support its use, per [their page about the onchange event](http://www.w3schools.com/jsref/jsref_onchange.asp):
> Supported by the following HTML tags:
```
<input type="text">, <select>,
<textarea>
```
> Supported by the following JavaScript
> objects:
>
> fileUpload, select, text, textarea
If you want to monitor the size of the window you basically have two options:
- use the onresize attribute
- set an interval that checks via polling. | Javascript .onchange limitations | [
"",
"javascript",
"dom-events",
""
] |
Why does C/C++ differentiate in case of an array index out of bound?
```
#include <stdio.h>
int main()
{
int a[10];
a[3] = 4;
a[11] = 3; // Does not give a segmentation fault
a[25] = 4; // Does not give a segmentation fault
a[20000] = 3; // Gives a segmentation fault
return 0;
}
```
I understand that it's trying to access memory allocated to a process or a thread in case of `a[11]` or `a[25]` and it's going out of stack bounds in case of `a[20000]`.
Why doesn't the compiler or linker give an error? Aren't they aware of the array size? If not, then how does `sizeof(a)` work correctly? | The problem is that C/C++ doesn't actually do any boundary checking with regards to arrays. It depends on the OS to ensure that you are accessing valid memory.
In this particular case, you are declaring a stack based array. Depending upon the particular implementation, accessing outside the bounds of the array will simply access another part of the already allocated stack space (most OS's and threads reserve a certain portion of memory for stack). As long as you just happen to be playing around in the pre-allocated stack space, everything will not crash (note i did not say work).
What's happening on the last line is that you have now accessed beyond the part of memory that is allocated for the stack. As a result you are indexing into a part of memory that is not allocated to your process or is allocated in a read only fashion. The OS sees this and sends a seg fault to the process.
This is one of the reasons that C/C++ is so dangerous when it comes to boundary checking. | The segfault is not an intended action of your C program that would tell you that an index is out of bounds. Rather, it is an unintended consequence of undefined behavior.
In C and C++, if you declare an array like
```
type name[size];
```
You are only allowed to access elements with indexes from `0` up to `size-1`. Anything outside of that range causes undefined behavior. If the index was near the range, most probably you read your own program's memory. If the index was largely out of range, most probably your program will be killed by the operating system. But you can't know, anything can happen.
Why does C allow that? Well, the basic gist of C and C++ is to not provide features if they cost performance. C and C++ has been used for ages for highly performance critical systems. C has been used as a implementation language for kernels and programs where access out of array bounds can be useful to get fast access to objects that lie adjacent in memory. Having the compiler forbid this would be for naught.
Why doesn't it warn about that? Well, you can put warning levels high and hope for the compiler's mercy. This is called *quality of implementation* (QoI). If some compiler uses open behavior (like, undefined behavior) to do something good, it has a good quality of implementation in that regard.
```
[js@HOST2 cpp]$ gcc -Wall -O2 main.c
main.c: In function 'main':
main.c:3: warning: array subscript is above array bounds
[js@HOST2 cpp]$
```
If it instead would format your hard disk upon seeing the array accessed out of bounds - which would be legal for it - the quality of implementation would be rather bad. I enjoyed to read about that stuff in the [ANSI C Rationale](http://www.lysator.liu.se/c/rat/a.html#1) document. | Array index out of bound behavior | [
"",
"c++",
"c",
"arrays",
""
] |
I know there are plenty of `upper()` methods in Java and other frameworks like Apache commons lang, which convert a String to all upper case.
Are there any common libraries that provide a method like `isUpper(String s)` and `isLower(String s)`, to check if all the characters in the String are upper or lower case?
EDIT:
Many good answers about converting to Upper and comparing to this. I guess I should have been a bit more specific, and said that I already had thought of that, but I was hoping to be able to use an existing method for this.
Good comment about possible inclusion of this in apache.commons.lang.StringUtils.
Someone has even submitted a patch (20090310). Hopefully we will see this soon.
<https://issues.apache.org/jira/browse/LANG-471>
EDIT:
What I needed this method for, was to capitalize names of hotels that sometimes came in all uppercase. I only wanted to capitalize them if they were all lower or upper case.
I did run in to the problems with non letter chars mentioned in some of the posts, and ended up doing something like this:
```
private static boolean isAllUpper(String s) {
for(char c : s.toCharArray()) {
if(Character.isLetter(c) && Character.isLowerCase(c)) {
return false;
}
}
return true;
}
```
This discussion and differing solutions (with different problems), clearly shows that there is a need for a good solid isAllUpper(String s) method in commons.lang
Until then I guess that the `myString.toUpperCase().equals(myString)` is the best way to go. | Guava's [CharMatchers](https://github.com/google/guava/wiki/StringsExplained#charmatcher) tend to offer very expressive and efficient solutions to this kind of problem.
```
CharMatcher.javaUpperCase().matchesAllOf("AAA"); // true
CharMatcher.javaUpperCase().matchesAllOf("A SENTENCE"); // false
CharMatcher.javaUpperCase().or(CharMatcher.whitespace()).matchesAllOf("A SENTENCE"); // true
CharMatcher.javaUpperCase().or(CharMatcher.javaLetter().negate()).matchesAllOf("A SENTENCE"); // true
CharMatcher.javaLowerCase().matchesNoneOf("A SENTENCE"); // true
```
A static import for `com.google.common.base.CharMatcher.*` can help make these more succinct.
```
javaLowerCase().matchesNoneOf("A SENTENCE"); // true
``` | Now in StringUtils [isAllUpperCase](http://commons.apache.org/proper/commons-lang/javadocs/api-3.1/org/apache/commons/lang3/StringUtils.html#isAllUpperCase(java.lang.CharSequence)) | Is there an existing library method that checks if a String is all upper case or lower case in Java? | [
"",
"java",
"string",
""
] |
I have iframe on a page, the iframe and the parent page are in different domain, can a javascript code on the parent page access elements inside this iframe? | It should not be able to if the pages are from different domains, the browsers security sandbox should prevent this type of access. It might work when the two pages are from different *sub* domains of the same domain, but that can and will differ between browsers (and possibly even versions of the same browser).
Accessing the child iframe might work, but the other way around will most certainly *not* work. | The easiest way would be through the frames object on window like this:
```
window.frames[0].document.getElementById('ElementId').style.backgroundColor="#000";
``` | Can javascript access iframe elements from the parent page? | [
"",
"javascript",
"jquery",
"html",
""
] |
OK, I should start this off by saying I'm not sure this is necessarily the right way to deal with this but...
Basically I have created a Window in WPF for displaying notifications in my application (a bit like Outlook New Mail notification). I would like to try and show this Window in it's own thread (it might do some work in the future).
I've created the Window using WPF because it's a bit nicer at handling things like AlwaysOnTop and Fading In and Out.
The application that shows the notification is a 3.5 Windows Forms App. I've seen examples similar to this [SOF: C# winforms startup (Splash) form not hiding](https://stackoverflow.com/questions/510765/510786#510786) for showing a Form in a different thread however I'm unable to start a new Message Loop with the WPF Window.
I've tried just calling Notification.Show() in a new thread however the Window never displays.
1. Is it possible to show this WPF in it's own thread?
2. Why do I see some resources say that you should not show any UI in a separate thread? | The [WPF Threading Model](https://msdn.microsoft.com/library/ms741870(v=vs.100).aspx) has details on this. Look for "Multiple Windows, Multiple Threads."
Basically, you start a new thread, which creates the relevant window and then calls
```
System.Windows.Threading.Dispatcher.Run();
```
in order to run a dispatcher for that window, on the new thread. | > 1. Is it possible to show this WPF in it's own thread?
Absolutely. Just create a new STA thread and create and display your `Window` from it. I've used this technique for a splash screen because the main (UI) thread got really tied up doing other things. It was completely out of my control how much work was being done on the UI thread because of a 3rd party framework we were using.
> 2. Why do I see some resources say that you should not show any UI in a separate thread?
Possibly because of the extra complexity involved. If one of your `Window`s wants to pass data to another, you need to remember that they're executing on separate threads. Therefore, each should use its Dispatcher to marshal calls to the correct thread. | Opening a WPF Window in another Thread from a Windows Forms App | [
"",
"c#",
"wpf",
"winforms",
"multithreading",
""
] |
I've got a Django-based site that allows users to register (but requires an admin to approve the account before they can view certain parts of the site). I'm basing it off of `django.contrib.auth`. I require users to register with an email address from a certain domain name, so I've overridden the `UserCreationForm`'s `save()` and `clean_email()` methods.
My registration page uses the following view. I'm interested in hearing about how I might improve this view—code improvements or process improvements (or anything else, really).
```
def register(request):
if request.method == 'POST':
form = UserCreationForm(request.POST)
if form.is_valid():
message = None
form.save()
username = form.cleaned_data['username']
password = form.cleaned_data['password1']
user = authenticate(username=username, password=password)
first_name = form.cleaned_data['first_name']
last_name = form.cleaned_data['last_name']
email = user.email
# If valid new user account
if (user is not None) and (user.is_active):
login(request, user)
message = "<strong>Congratulations!</strong> You have been registered."
# Send emails
try:
# Admin email
pk = None
try: pk = User.objects.filter(username=username)[0].pk
except: pass
admin_email_template = loader.get_template('accounts/email_notify_admin_of_registration.txt')
admin_email_context = Context({
'first_name': first_name,
'last_name': last_name,
'username': username,
'email': email,
'pk': pk,
})
admin_email_body = admin_email_template.render(admin_email_context)
mail_admins("New User Registration", admin_email_body)
# User email
user_email_template = loader.get_template('accounts/email_registration_success.txt')
user_email_context = Context({
'first_name': form.cleaned_data['first_name'],
'username': username,
'password': password,
})
user_email_body = user_email_template.render(user_email_context)
user.email_user("Successfully Registered at example.com", user_email_body)
except:
message = "There was an error sending you the confirmation email. You should still be able to login normally."
else:
message = "There was an error automatically logging you in. Try <a href=\"/login/\">logging in</a> manually."
# Display success page
return render_to_response('accounts/register_success.html', {
'username': username,
'message': message,
},
context_instance=RequestContext(request)
)
else: # If not POST
form = UserCreationForm()
return render_to_response('accounts/register.html', {
'form': form,
},
context_instance=RequestContext(request)
)
``` | You don't even need this code, but I think the style:
```
pk = None
try: pk = User.objects.filter(username=username)[0].pk
except: pass
```
is more naturally written like:
```
try:
user = User.objects.get(username=username)
except User.DoesNotExist:
user = None
```
and then in your admin notify template use `{{ user.id }}` instead of `{{ pk }}`.
But, like I said, you don't need that code at all because you already have a user object from your call to `authenticate()`.
Generally in Python, it's considered poor practice to have the exception handler in a try/except block be empty. In other words, always capture a specific exception such as `User.DoesNotExist` for this case.
It's also poor practice to have many lines inside the `try` part of the try/except block. It is better form to code this way:
```
try:
... a line of code that can generate exceptions to be handled ...
except SomeException:
... handle this particular exception ...
else:
... the rest of the code to execute if there were no exceptions ...
```
A final, minor, recommendation is to not send the email directly in your view because this won't scale if your site starts to see heavy registration requests. It is better add in the [django-mailer](http://code.google.com/p/django-mailer/) app to offload the work into a queue handled by another process. | I personally try to put the short branch of an if-else statement first. Especially if it returns. This to avoid getting large branches where its difficult to see what ends where. Many others do like you have done and put a comment at the else statement. But python doesnt always have an end of block statement - like if a form isn't valid for you.
So for example:
```
def register(request):
if request.method != 'POST':
form = UserCreationForm()
return render_to_response('accounts/register.html',
{ 'form': form, },
context_instance=RequestContext(request)
)
form = UserCreationForm(request.POST)
if not form.is_valid():
return render_to_response('accounts/register.html',
{ 'form': form, },
context_instance=RequestContext(request)
)
...
``` | How can I improve this "register" view in Django? | [
"",
"python",
"django",
"user-registration",
""
] |
I'm interested in MyLyn. I'm using Eclipse Ganymede and I have access to a BugZilla installation for the project I'm working on.
I wonder if the BugZilla installation will have to be changed/configured in any way or if I'm able to use MyLyn against it "out of the box"?
Will I have to setup some special kind of MyLyn server or could I simply install it on the client only?
And if configuration of BugZilla or a a special MyLyn service is needed on a server. Is it a difficult setup and will it take a long time to do? | It should work out of the box, just give it a try and specify the BugZilla server your tasks come from. | **Summary:** Mylyn will connect to Bugzilla 3.0 and requires **no** changes to Bugzilla. All you'll need is Mylyn (a client application) which is available as an Eclipse Plugin. Mylyn's Bugzilla Connector is one of the most stable and popular Mylyn Connectors.
**Details:** Mylyn is the leading ALM solution for the Eclipse ecosystem. It has recently become a top-level project on Eclipse. From a developer's point-of-view its primary purpose is to:
* Bring Tasks from different servers (Bugzilla, Trac, Mantis, etc.) into Eclipse [(certified connectors list)](http://tasktop.com/connectors/) [(full connectors list)](http://wiki.eclipse.org/index.php/Mylyn_Extensions)
* Provide a unified Task List for managing these tasks [(video)](http://tasktop.com/videos/1.6/setup/tasklist/)
* Focus the user interface on only the files relevant to the current task [(video)](http://tasktop.com/videos/1.6/setup/focus/)
While it provides many other great features these three points are among the most-cited reasons for using Mylyn (or Tasktop, which is the commercial Mylyn+).
To download Mylyn you can either download an Eclipse that includes Mylyn (e.g., the [Eclipse IDE for Java EE Developers](http://www.eclipse.org/downloads/packages/eclipse-ide-java-ee-developers/heliosr)) or you can use the update sites available on the [Mylyn Download Page](http://www.eclipse.org/mylyn/downloads/) to install into your existing Eclipse. The update sites should be of the format: <http://download.eclipse.org/tools/mylyn/update/e3.4>. Alternatively you can download [Tasktop Pro](http://tasktop.com/support/download/1.), a commercial product.
Once you've downloaded Mylyn it is easy to connect to Bugzilla. You'll need to:
1. Open the Task Repositories View.
2. Click on "Add Task Repository".
3. Select "Bugzilla" and press "Next".
4. Enter your repository settings, such as its URL and your credentials.
5. Open the Task List View.
6. Click on "New Query".
7. Use the dialog to create a query, which downloads your tasks from Bugzilla.
If you want more details about how to setup Mylyn to connect to Bugzilla try these tutorials on [connecting to a repository](http://tasktop.com/blog/mylyn/how-to-connect-task-repository) and [setting up your Task List](http://tasktop.com/blog/mylyn/track-tasks-with-queries-not-email).
David Shepherd, Tasktop Technologies
<http://www.twitter.com/davidcshepherd> | Eclipse MyLyn with BugZilla: Will the BugZilla installation need to be modified/configured? | [
"",
"java",
"eclipse",
"bugzilla",
"mylyn",
""
] |
I have a MS SQL table McTable with column BigMacs nvarchar(255). I would like to get rows with BigMacs value greater than 5.
What I do is:
```
select * from
(
select
BigMacs BigMacsS,
CAST(BigMacs as Binary) BigMacsB,
CAST(BigMacs as int) BigMacsL
from
McTable
where
BigMacs Like '%[0-9]%'
) table
where
Cast(table.BigMacsL as int) > 5
```
And in result I get an error:
> State 1, Line 67 Conversion failed
> when converting the nvarchar value
> '\*\*\*' to
> data type int.
But when I remove last filter `where Cast(table.BigMacsL as int) > 5` it works and I get this result:
```
6 0x360000000000000000000000000000000000000000000000000000000000 6
23 0x320033000000000000000000000000000000000000000000000000000000 23
22 0x320032000000000000000000000000000000000000000000000000000000 22
24 0x320034000000000000000000000000000000000000000000000000000000 24
25 0x320035000000000000000000000000000000000000000000000000000000 25
3 0x330000000000000000000000000000000000000000000000000000000000 3
17 0x310037000000000000000000000000000000000000000000000000000000 17
17 0x310037000000000000000000000000000000000000000000000000000000 17
19 0x310039000000000000000000000000000000000000000000000000000000 19
20 0x320030000000000000000000000000000000000000000000000000000000 20
659 0x360035003900000000000000000000000000000000000000000000000000 659
1 0x310000000000000000000000000000000000000000000000000000000000 1
43 0x340033000000000000000000000000000000000000000000000000000000 43
44 0x340034000000000000000000000000000000000000000000000000000000 44
45 0x340035000000000000000000000000000000000000000000000000000000 45
46 0x340036000000000000000000000000000000000000000000000000000000 46
47 0x340037000000000000000000000000000000000000000000000000000000 47
44 0x340034000000000000000000000000000000000000000000000000000000 44
44 0x340034000000000000000000000000000000000000000000000000000000 44
47 0x340037000000000000000000000000000000000000000000000000000000 47
43 0x340033000000000000000000000000000000000000000000000000000000 43
50 0x350030000000000000000000000000000000000000000000000000000000 50
44 0x340034000000000000000000000000000000000000000000000000000000 44
```
And when I change in first query 'select \* from' to 'select top 18 \* from' than I do not get error too!
I don't know what is the problem and how to make it work! Could you please help me?
Once again: what I try to accomplish here is to get these McTable rows that have BigMacs value greater than 5.
**UPDATE**
**Steps to reproduce this error:**
I've prepared queries so You can easily get this error on your database:
Create database TestDB, create table with:
```
USE [TestDB]
GO
/****** Object: Table [dbo].[TestTable] Script Date: 04/08/2009 16:27:40 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[TestTable](
[ID] [int] IDENTITY(1,1) NOT NULL,
[MyVal] [nvarchar](255) COLLATE Polish_CI_AS NOT NULL,
CONSTRAINT [PK_TestTable] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
```
insert values with:
```
delete from TestDB.dbo.TestTable
insert into TestDB.dbo.TestTable (MyVal) values ('fd')
insert into TestDB.dbo.TestTable (MyVal) values ('54543534')
insert into TestDB.dbo.TestTable (MyVal) values ('fat3tv3gv5')
insert into TestDB.dbo.TestTable (MyVal) values ('fdf4v43 4v434v')
insert into TestDB.dbo.TestTable (MyVal) values (' g dfg dfg df')
insert into TestDB.dbo.TestTable (MyVal) values ('f sd 4t4gsdf')
insert into TestDB.dbo.TestTable (MyVal) values ('f df 4 trwefg')
insert into TestDB.dbo.TestTable (MyVal) values ('f sd f4 fgsfg sd')
insert into TestDB.dbo.TestTable (MyVal) values ('54534534')
insert into TestDB.dbo.TestTable (MyVal) values ('454')
```
This query:
```
select
CAST(MyVal as int) MyValInt
from
dbo.TestTable
where
IsNumeric(MyVal) = 1
```
results in valid numbers as shown below:
> 54543534
>
> 54534534
>
> 454
And when you try to get filtered values with this query:
```
select
*
from
(
select
CAST(MyVal as int) MyValInt
from
dbo.TestTable
where
IsNumeric(MyVal) = 1
) tabela
where
tabela.MyValInt > 6
```
You should get this error that should not occur:
Msg 245, Level 16, State 1, Line 1
Conversion failed when converting the nvarchar value 'fd' to data type int. | New answer for your revised scripts. What is happening is that the SQL Server query optimiser is optimising out your subquery. It is performing a single scan of the test table, and combining the inner and outer WHERE clauses into one. That's why you get the error still. To see this, view the estimated execution plan for the query, and hover over the Clustered Index Scan icon to see what is actually being carried out. You will see the following predicate being applied on the scan:
```
CONVERT(int,[testdb].[dbo].[TestTable].[MyVal],0)>(6)
AND isnumeric(CONVERT_IMPLICIT(varchar(510),
[testdb].[dbo].[TestTable].[MyVal],0))=(1)
```
So regardless of the structure of your query, it is trying to do the CAST/CONVERT on every row in the table...
To avoid this, use a table variable or temporary table that can't be optimised out:
```
DECLARE @integers table (
MyValInt int
)
INSERT
INTO @integers
SELECT CAST(MyVal AS int)
FROM dbo.TestTable
WHERE ISNUMERIC(MyVal) = 1
SELECT *
FROM @integers
WHERE MyValInt > 6
```
The results set you actually want to return will be different, so I'd suggest storing the primary key along with the int value in the table variable, and then doing your final query as a join like this:
```
DECLARE @integers table (
ID int,
MyValInt int
)
INSERT
INTO @integers
SELECT ID, CAST(MyVal AS int)
FROM dbo.TestTable
WHERE ISNUMERIC(MyVal) = 1
SELECT b.*
FROM @integers t
INNER JOIN
TestTable b
ON b.ID = t.ID
WHERE t.MyValInt > 6
``` | > State 1, Line 67 Conversion failed when converting the nvarchar value '\*\*\*' to data type int.
You are getting this value since some of the values in `BigMacs.BigMac` contains a non-numeric value. In your case "\*\*\*".
> And when I change in first query 'select \* from' to 'select top 18 \* from' than I do not get error too!
It is because *at least* first returned 18 rows have numeric `BigMacs.BigMac` values.
Create a new User-Defined method called [isReallyNumeric()](http://classicasp.aspfaq.com/general/what-is-wrong-with-isnumeric.html), which addresses what is really numeric or not.
Filter out only numeric BigMac using [isReallyNumeric()](http://classicasp.aspfaq.com/general/what-is-wrong-with-isnumeric.html) function
I have also optimized the query to cast `BigMacs.BigMac` into integer once using CTE (Common Table Expression).
```
with NumericBigMacs as (
select
BigMacs as BigMacsS,
CAST(BigMacs as Binary) as BigMacsB,
CAST(BigMacs as int) as BigMacsL
from
McTable
where
-- Filter only numeric values to compare.
-- BigMacs Like '%[0-9]%'
dbo.isReallyNumeric(BigMacs) = 1
)
select *
from NumericBigMacs NBM
where BigMacsL > 5
``` | How to filter nvarchar greater than numeric value? | [
"",
"sql",
"sql-server-2005",
"t-sql",
"query-optimization",
""
] |
## Hi guys, ive got a stupid problem.
My Custom handler is working 100% on Asp.NET Development server but when i publish the site to IIS 5.1 whenever i try to run Comment/Find (which finds a user via an AJAX call) (i know the naming of my handler sux!!! :)
## I get this error:
The page cannot be displayed
The page you are looking for cannot be displayed because the page address is incorrect.
Please try the following:
```
* If you typed the page address in the Address bar, check that it is entered correctly.
* Open the home page and then look for links to the information you want.
```
HTTP 405 - Resource not allowed
Internet Information Services
Technical Information (for support personnel)
```
* More information:
Microsoft Support
```
## My code for the AJAX call is:
```
function findUser(skip, take) {
http.open("post", 'Comment/FindUser', true);
//make a connection to the server ... specifying that you intend to make a GET request
//to the server. Specifiy the page name and the URL parameters to send
http.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
http.setRequestHeader('Criteria', document.getElementById('SearchCriteria').value);
http.setRequestHeader("Skip", skip);
http.setRequestHeader("Take", take);
http.setRequestHeader("Connection", "close");
//display loading gif
document.getElementById('ctl00_ContentPlaceHolder1_DivUsers').innerHTML = 'Loading, Please Wait...<br /><img src="Images/loading.gif" /><br /><br />';
//assign a handler for the response
http.onreadystatechange = function() { findUserAction(); };
//actually send the request to the server
http.send(null);
}
```
Please can anyone help me?? | Make sure you have allowed the extension on the IIS server. The development server does this automatially for you.
If you open up the properties of the web site then go to the Home Directory Tab and click the configuration button.
In there try adding the extension you are using for the handler pointing. Set the executable to the aspnet\_isapi.dll (look at the standard .aspx extension to find where it is on your computer) and uncheck "Check that file exists".
I have been burned by this a couple of time and this sorted the problem
Colin G | On IIS not all calls will be processed by the asp.net handler (unlike cassini the development server) unless the call ends in .aspx, .ashx etc. the .NET isapi dll will not process the call.
The clue is in the
HTTP 405 - Resource not allowed Internet Information Services
You will need to also map the handler in the web.config if there is not a corresponding .ashx file in the file system. | Custom handler working on Asp.NET Development server but not on IIS 5.1? | [
"",
"c#",
"ajax",
"httphandler",
"iis-5",
""
] |
I'm using SQL Server 2005. I'm looking at opening a SQL connection, looping though a collection and running an update query (stored procedure or parameterized query) with the data from the collection item, then closing the connection.
Which is going to give me better performance and why? | It is difficult to say with certainty as there are a number of factors that can effect performance. In theory the Stored Procedure method should be faster.
There is another solution where you can pass XML to the stored procedure so you don’t have to call it multiple times. Assuming you can and know how to serialize your object into XML. Then you can use Xquery, Open XML or sp\_XML\_preparedocument to retrieve your data in a set based manner from the XML and perform the update statement. | In recent versions of SQL server, execution plans are cached for stored procedures and parametrized queries. The query will have a one time cost to create the execution plan, but this will be very minor and lost in the overhead of even a few calls.
From a performance perspective they will be almost identical.
The exception to this, is if you are doing recursive or nested queries (for each row in query 1, execute query 2), where the round trips between the client and server will add up. In this case, a proc will be much better.
Many companies still have "Everything as a proc" rules, but this is usually due to control of the database and not performance related. As LINQ grows in popularity, this may lessen.
If your application has a single (or few) points of deployment, then use whichever you prefer. On the other hand, if you are deploying to many many installations, then stored procs can in some (but not all) cases allow you to update database functionality without redeploying the client code. | Which is faster for multiple SQL calls - parameterized queries or stored procedures? | [
"",
"c#",
"sql-server",
"sql-server-2005",
"ado.net",
""
] |
I am designing a db application using a novel approach. (atleast novel to me... :) )
So I am doing some research for the same.
I am using .NET 3.5 ADO.NET Datasets to work with data and store it offline in XML.
First, is this approach any good for a serious (though a small db, 4-5 users, ~25 tables ~3-4k records in each) application?
Second, how do I exactly store a datarelation in an offline XML file?
Thanks!
Saurabh. | 25 tables with 3-4k rows in each is not what I'd call "small" for xml; in particular, it isn't easy to jump to just the right data in xml...
Have you considered a database, such as SQL Server Express Edition. Free, and more than up to this job.
---
Re storage; if you are using the inbuilt serialization a `DataSet`, this should just work automatically. Of course, the xml will then be specific to `DataSet`... I honestly don't recommend the `DataSet`/xml approach. | To answer your question (even though I agree with Marc, you shouldn't be using XML as a data storage layer).
Ids and hrefs are commonly used for creating relations in XML (which is hierarchical and not relational, again, you shouldn't use XML).
As a small example:
```
<region name="South Africa" id="region_1">
<manager ref="#employee_1"/>
</region>
<employee name="John Doe" id="employee_1" region="#region_1">
<manages>
<employee ref="#employee_2" />
</manages>
</employee>
<employee name="Cyril Smith" id="employee_2" region="#region_1">
<manages /> <!-- code monkey -->
</employee>
``` | Storing DataRelation in xml? | [
"",
"c#",
".net-3.5",
"ado.net",
""
] |
I am writing a LINQ provider to a hierarchal data source. I find it easiest to design my API by writing examples showing how I want to use it, and then coding to support those use cases.
One thing I am having trouble with is an easy/reusable/elegant way to express "deep query" or recursion in a LINQ statement. In other words, what is the best way to distinguish between:
```
from item in immediate-descendants-of-current-node where ... select item
```
versus:
```
from item in all-descendants-of-current-node where ... select item
```
(*Edit: please note neither of those examples above necessarily reflect the structure of the query I want. I am interested in **any** good way to express recursion/depth*)
**Please note** I am not asking how to implement such a provider, or how to write my IQueryable or IEnumerable in such a way that allows recursion. I am asking from the standpoint of a person writing the LINQ query and utilizing my provider - what is an intuitive way for them to express whether they want to recurse or not?
The data structure resembles a typical file system: a folder can contain a collection of subfolders, and a folder can also contain a collection of items. So myFolder.Folders represents all the folders who are immediate children of myFolder, and myFolder.Items contains all the items immediately within myFolder. Here's a basic example of a site hierachy, much like a filesystem with folders and pages:
```
(F)Products
(F)Light Trucks
(F)Z150
(I)Pictures
(I)Specs
(I)Reviews
(F)Z250
(I)Pictures
(I)Specs
(I)Reviews
(F)Z350
(I)Pictures
(I)Specs
(I)Reviews
(I)Splash Page
(F)Heavy Trucks
(F)Consumer Vehicles
(I)Overview
```
If I write:
```
from item in lightTrucks.Items where item.Title == "Pictures" select item
```
What is the most intuitive way to express an intent that the query get all items underneath Light Trucks, or only the immediate ones? The least-intrusive, lowest-friction way to distinguish between the two intents?
My #1 goal is to be able to turn this LINQ provider over to other developers who have an average understanding of LINQ and allow them to write both recursive and list queries without giving them a tutorial on writing recursive lambdas. Given a usage that looks good, I can code the provider against that.
**Additional clarification:** (I am really sucking at communicating this!) - This LINQ provider is to an external system, it is not simply walking an object graph, nor in this specific case does a recursive *expression* actually translate into any kind of true recursive activity under the hood. Just need a way to distinguish between a "deep" query and a "shallow" one.
So, what do you think is the best way to express it? Or is there a standard way of expressing it that I've missed out on? | Linq-toXml handles this fine, there is an XElement.Elements()/.Nodes() operation to get immediate children, and a XElement.Descendents()/DescendentNodes() operations to get all descendents. Would you consider that as an example?
To summarize Linq-to-Xml's behavior... The navigation functions each correspond to an axis type in XPath (<http://www.w3schools.com/xpath/xpath_axes.asp>). If the navigation function selects Elements, the axis name is used. If the navigation function selects Nodes, the axis name is used with Node appended.
For instance, there are functions Descendants() and DescendantsNode() correspond to XPath's descendants axis, returning either an XElement or an XNode.
The exception case is not surprisingly the most used case, the children axis. In XPath, this is the axis used if no axis is specified. For this, the linq-to-xml navigation functions are not Children() and ChildrenNodes() but rather Elements() and Nodes().
XElement is a subtype of XNode. XNode's include things like HTML tags, but also HTML comments, cdata or text. XElements are a type of XNode, but refer specifically to HTML tags. XElements therefore have a tag name, and support the navigation functions.
Now its not as easy to chain navigations in Linq-to-XML as it is XPath. The problem is that navigation functions return collection objects, while the navigation functions are applied to non-collections. Consider the XPath expression which selects a table tag as an immediate child then any descendant table data tag. I think this would look like "./children::table/descendants::td" or "./table/descendants::td"
Using IEnumerable<>::SelectMany() allows one to call the navigation functions on a collection. The equivalent to the above looks something like .Elements("table").SelectMany(T => T.Descendants("td")) | Well, the first thing to note is that actually, lambda expressions can be recursive. No, honestly! It isn't easy to do, and **certainly** isn't easy to read - heck, most LINQ providers (except LINQ-to-Objects, which is much simpler) will have a coughing fit just looking at it... but it ***is possible***. [See here](http://blogs.msdn.com/madst/archive/2007/05/11/recursive-lambda-expressions.aspx) for the full, gory details (warning - brain-ache is likely).
However!! That probably won't help much... for a practical approach, I'd look at the way `XElement` etc does it... note you can remove some of the recursion using a `Queue<T>` or `Stack<T>`:
```
using System;
using System.Collections.Generic;
static class Program {
static void Main() {
Node a = new Node("a"), b = new Node("b") { Children = {a}},
c = new Node("c") { Children = {b}};
foreach (Node node in c.Descendents()) {
Console.WriteLine(node.Name);
}
}
}
class Node { // very simplified; no sanity checking etc
public string Name { get; private set; }
public List<Node> Children { get; private set; }
public Node(string name) {
Name = name;
Children = new List<Node>();
}
}
static class NodeExtensions {
public static IEnumerable<Node> Descendents(this Node node) {
if (node == null) throw new ArgumentNullException("node");
if(node.Children.Count > 0) {
foreach (Node child in node.Children) {
yield return child;
foreach (Node desc in Descendents(child)) {
yield return desc;
}
}
}
}
}
```
---
An alternative would be to write something like `SelectDeep` (to mimic `SelectMany` for single levels):
```
public static class EnumerableExtensions
{
public static IEnumerable<T> SelectDeep<T>(
this IEnumerable<T> source, Func<T, IEnumerable<T>> selector)
{
foreach (T item in source)
{
yield return item;
foreach (T subItem in SelectDeep(selector(item),selector))
{
yield return subItem;
}
}
}
}
public static class NodeExtensions
{
public static IEnumerable<Node> Descendents(this Node node)
{
if (node == null) throw new ArgumentNullException("node");
return node.Children.SelectDeep(n => n.Children);
}
}
```
Again, I haven't optimised this to avoid recursion, but it could be done easily enough. | Expressing recursion in LINQ | [
"",
"c#",
".net",
"linq",
"recursion",
"hierarchical-data",
""
] |
I can get an object if it's moused over. I can get the coordinates of the mouse at any given time. How do I get an object given it's coordinates - if they are different from the mouse?
Essentially the user is dropping a div on a certain place on the screen. Since the div is wider than the mouse cursor, I need to know what object the corner of the div is over (not what the mouse is over). Is there a way to raise a mousemove event in JS - passing it the coordinates?
Thanks
---
Just a quick post script for others who read this post. Although I did not choose the jquery for my answer, it may be the answer for you. This appears to be a very flexible feature rich solution for many of the client side tools we want to offer. | There's no way to raise a mousemove and have it fill in the resulting target element properties, no.
There is a way to get an element from arbitrary co-ordinates, but you won't like it much. It involves walking over each page element and calculating its dimensions (from offsetLeft/Top/Parent) and which elements overlay which other elements (from calculated styles ‘position’ and ‘z-index’)... essentially, re-implementing part of the browser's own layout engine in script. And if you have elements with ‘overflow’ scroll/auto you have even more calculation to do.
If you have a limited case (eg. you can only drop the div somewhere amongst a set of other statically-positioned divs) it can be manageable, but the general case is quite hard and in no way fun. (Maybe someone somewhere has packaged such a feature up into a library or framework plugin, but I've not met one yet.)
If you can find another way to make your drag'n'drop behave nicely that doesn't require you to do this, then do that! | Not directly answering your question, but have you tried using a javascript library such as jQuery UI? It provides good drag/drop support & you can do the sorts of things your talking about... eg. you can make certain elements of your page draggable & others droppable & then handle the events when the user drags an element around. It provides a tolerance on the dropables that includes 'touch' (as well as 'fit', 'intersect', 'pointer'), so then you could handle the 'over' event of your dropable targets & you'd get an event handler that fires when the corner of your div is over a given element. This event handler gives you a reference to the element being dragged as well as the element its being dragged over. (a bit backwards to how you asked the question, but should be usable in solving the same problems).
Hope that's of some help... | raise javascript events or get an object from XY coords | [
"",
"javascript",
"dhtml",
""
] |
I keep getting an AccessViolationException when calling the following from an external DLL:
```
FILES_GetMemoryMapping(MapFile, out size, MapName, out PacketSize, pMapping, out PagePerSector);
```
Which has a prototype that I've setup as such:
```
[DllImport("Files.DLL", SetLastError = true)]
public static extern uint FILES_GetMemoryMapping(
[MarshalAs(UnmanagedType.LPStr)]
string pPathFile,
out ushort Size,
[MarshalAs(UnmanagedType.LPStr)]
string MapName,
out ushort PacketSize,
IntPtr pMapping,
out byte PagesPerSector);
```
Now, the argument that is causing this is most likely the 5th one (IntPtr pMapping). I've ported this code over from a C++ app into C#. The 5th argument above is a pointer to a struct which also contains a pointer to another struct. Below is how I have these sctructs setup:
```
[StructLayout(LayoutKind.Sequential)]
public struct MappingSector
{
[MarshalAs(UnmanagedType.LPStr)]
public string Name;
public uint dwStartAddress;
public uint dwAliasedAddress;
public uint dwSectorIndex;
public uint dwSectorSize;
public byte bSectorType;
public bool UseForOperation;
public bool UseForErase;
public bool UseForUpload;
public bool UseForWriteProtect;
}
[StructLayout(LayoutKind.Sequential)]
public struct Mapping
{
public byte nAlternate;
[MarshalAs(UnmanagedType.LPStr, SizeConst=260)]
public string Name;
public uint NbSectors;
public IntPtr pSectors;
}
```
The C++ equivalent of these are as follows:
```
typedef struct {
char* Name;
DWORD dwStartAddress;
DWORD dwAliasedAddress;
DWORD dwSectorIndex;
DWORD dwSectorSize;
BYTE bSectorType;
BOOL UseForOperation;
BOOL UseForErase;
BOOL UseForUpload;
BOOL UseForWriteProtect;
} MAPPINGSECTOR, *PMAPPINGSECTOR;
typedef struct {
BYTE nAlternate;
char Name[MAX_PATH]; // MAX_PATH = 260
DWORD NbSectors;
PMAPPINGSECTOR pSectors;
} MAPPING, *PMAPPING;
```
I have a feeling I did something wrong with either porting over these structs, or porting over the function prototype. A Marshaling issue of somesort.
The function all the way at the top of this post gets called twice in my code. Once with pMapping set to null (this puts a value in "size"). Memory is then allocated for a new struct using this size parameter and the function is called again now using a pointer to this allocated memory space for pMapping. (pMapping also has a pointer for the other struct which also gets some space allocated during this time).
Here is the old c++ code that accomplished this:
```
FILES_GetMemoryMapping((LPSTR)(LPCTSTR)MapFile, &Size, (LPSTR)MapName, &PacketSize, pMapping, &PagePerSector);
// Allocate the mapping structure memory
pMapping = (PMAPPING)malloc(sizeof(MAPPING));
pMapping->NbSectors = 0;
pMapping->pSectors = (PMAPPINGSECTOR) malloc((Size) * sizeof(MAPPINGSECTOR));
printf("mapsectorsize: <%d>\n", football);
printf("pMappingsize: <%d>\n", f2);
// Get the mapping info
FILES_GetMemoryMapping((LPSTR)(LPCTSTR)MapFile, &Size, (LPSTR)(LPCTSTR)MapName, &PacketSize, pMapping, &PagePerSector);
```
I initially thought I wasn't allocating the correct amount of space so I tried the old C++ code above and found out that:
```
sizeof(MAPPING) = 272
and
sizeof(PMAPPINGSECTOR) = 40
```
I did the same check in my C# code and found the following:
```
Marshal.SizeOf(new Mapping()) = 16
and
Marshal.SizeOF(new MappingSector()) = 40
```
We got a problem here. The Mapping struct should be of size 272, but its only 16. Thinking I could just do a quick fix, I manually allocated 272 instead of 16 here, but it still errored out with an AccessViolationException.
Any idea on how to fix this? Or what might still be going wrong? | 'prototype' was not the correct word, I like "DLLImport declaration" better.
And I've just got it working.
so in C++:
```
typedef struct {
BYTE nAlternate;
char Name[MAX_PATH]; // MAX_PATH = 260
DWORD NbSectors;
PMAPPINGSECTOR pSectors;
}
```
to C#:
```
[StructLayout(LayoutKind.Sequential, CharSet=CharSet.Ansi)]
public struct Mapping
{
public byte nAlternate;
[MarshalAs(UnmanagedType.ByValArray, SizeConst=260)]
public char[] Name;
public uint NbSectors;
public IntPtr pSectors;
}
```
A character Array is NOT a string, and should be treated as an array of characters.... Who would have guessed :P | [According to MSDN](http://msdn.microsoft.com/en-us/library/s9ts558h.aspx), you should pass a StringBuilder for a fixed-length buffer. Try the following, or some variant (untested):
```
[StructLayout(LayoutKind.Sequential)]
public struct Mapping
{
public byte nAlternate;
[MarshalAs(UnmanagedType.LPStr, SizeConst=260)]
public StringBuilder Name;
public uint NbSectors;
public IntPtr pSectors;
public Mapping()
{
Name = new StringBuilder(259);
//This will be a buffer of size 260 (259 chars + '\0')
}
}
``` | AccessViolationException during P/Invoke Help | [
"",
"c#",
"marshalling",
"sizeof",
"access-violation",
""
] |
Does anything like this exist?
What I am looking for is a control that is going to be client-side, with the Edit, Cancel row capabilities of a GridView.
I wish to use it to collect the data from the user and then save on the server after the user is done entering data.
EDITED:
Thanks for all the recommendations. One thing that I would like to ask all of you before I delve and spend time on learning these frameworks.
All of you seem to use ASP.net MVC and mention that these toolkits are good with this. I am however, using ASP.net web forms. Do these frameworks play well with old flavour of ASP.net? | Yes. [jqGrid](http://www.trirand.com/blog/) works well. Try [the demos](http://trirand.com/jqgrid/jqgrid.html). We use it with ASP.NET MVC.
**Update:** In your updated question, you asked about using frameworks such as jQuery with WebForms. Can you do this? Sure. Would you want to? That's a more difficult question. In WebForms, you *generally* let WebForms generate JavaScript for you. That's why you have UpdatePanel and the like. On one hand, this is easy, because you can focus your coding attention on C#, and you can use grid components which don't require you to write any JavaScript at all to make them work. On the other hand, you're limited to what the generated code can do. Yes, you can write JavaScript manually, even in WebForms, but you have to work around some of the things the framework does, like changing IDs on controls. Yes, you can write event handlers in C#, but this requires the use of postbacks, which do not fit naturally in HTTP, with consequences that are visible to the end-user.
It is common to use jQuery with ASP.NET MVC in no small part because it ships with the framework. But even before that happened, it was still very common to use the two together because jQuery makes it very easy to do things which are otherwise not directly supported within ASP.NET MVC, like making controls on a page interact with each other. Yes, this means you have to write JavaScript, but as long as you're OK with that, you get the huge advantage that you can write any kind of interaction you want to without having to postback to the server.
If you are just looking for a good grid control for WebForms, then I would suggest using a control designed for WebForms, rather than a grid designed for jQuery. The reason is that the code you will write will fit more naturally within the idioms of WebForms.
If you just want to learn jQuery, well, that's a really good idea, because the framework is interesting, useful, and well-designed, but I'm not sure that a great control is the best place to start. A better place to start might be adding visual flair to some of your existing pages. It is easier to start with known HTML and manipulate it with jQuery than it is to be generating new HTML and learning jQuery at the same time. | **Client-side frameworks**
In addition to jqGrid, there are several other javascript framework Grids that I've been playing with recently:
1. [Flexigrid](http://www.flexigrid.info/): jQuery-based, no
editing features yet, but planned.
2. [Ext's GridPanel](http://www.extjs.com/deploy/dev/docs/): Ext js is
another javascript framework which
interfaces with jQuery.
3. [YUI's DataTable](http://developer.yahoo.com/yui/datatable/): The Yahoo User
Interface (YUI) is yet another
framework with an editable Grid
control.
These are all client-side components: they operate in the user's browser, disconnected from your server code. Like Tracker1 and several others wrote, you'll have to either write Ajax methods yourself to wire the client-side grid to the server or you can try to take advantage of existing wrappers, such as:
**Server-side options**
1. [Coolite's Ext wrappers for .NET](http://www.coolite.com/)
2. One of the in-progress YUI .NET wrapper libraries (YuiDotNet or Yui.NET). I don't think either of these implements a wrapper for the DataTable yet, but they may show you the way to do so.
**Connecting the client and the server**
If you haven't worked with a lot of Ajax or done much with these javascript frameworks, be prepared for a bit of a learning curve: as you begin to use them, you'll need to constantly bear in mind what's happening on the server and what's happening on the client (and when!).
If you use one of the straight javascript libraries I listed above, as opposed to a .NET wrapper, you'd have to write a server-side method to handle data submission and expose it to the client using your choice of technology (MVC's JsonResult controller actions, establishing WebMethods / ScriptMethods, etc.).
**Related Stack Overflow Questions**
[Using ExtJS in ASP.NET](https://stackoverflow.com/questions/205720/using-extjs-in-asp-net) and [Returning data from ASP.net to an ExtJS Grid](https://stackoverflow.com/questions/221273/returning-data-from-asp-net-to-an-extjs-grid) - these are focused on Ext's controls, but the answers contain a lot of good general information about connecting the new generation of javascript framework controls to server applications.
[Good Asp.Net excel-like Grid control](https://stackoverflow.com/questions/587120/good-asp-net-excel-like-grid-control) - you may also be interested in the answers to this question, particularly since it sounds like you want solid editing capabilities. | JQuery GridView control | [
"",
"c#",
"asp.net",
"jquery",
"gridview",
""
] |
I need to calculate if someone is over 18 from their date of birth using JQuery.
```
var curr = new Date();
curr.setFullYear(curr.getFullYear() - 18);
var dob = Date.parse($(this).text());
if((curr-dob)<0)
{
$(this).text("Under 18");
}
else
{
$(this).text(" Over 18");
}
```
There must be some easier functions to use to compare dates rather than using the setFullYear and getFullYear methods.
Note: My actual reason for wanting to find a new method is length of the code. I have to fit this code into a database field that is limited to 250 chars. Changing the database is not something that can happen quickly or easily. | You might find the open source [Datejs](http://www.datejs.com/) library to be helpful. Specifically the the [`addYears`](http://code.google.com/p/datejs/wiki/APIDocumentation#addYears) function.
```
var dob = Date.parse($(this).text());
if (dob.addYears(18) < Date.today())
{
$(this).text("Under 18");
}
else
{
$(this).text(" Over 18");
}
```
In a more terse fashion:
```
$(this).text(
Date.parse($(this).text()).addYears(18) < Date.today() ?
"Under 18" :
" Over 18"
)
``` | ```
Date.prototype.age=function(at){
var value = new Date(this.getTime());
var age = at.getFullYear() - value.getFullYear();
value = value.setFullYear(at.getFullYear());
if (at < value) --age;
return age;
};
var dob = new Date(Date.parse($(this).text()));
if(dob.age(new Date()) < 18)
{
$(this).text("Under 18");
}
else
{
$(this).text(" Over 18");
}
``` | Age from Date of Birth using JQuery | [
"",
"javascript",
"jquery",
"datetime",
""
] |
I've been comparing a STL implementation of a popular XmlRpc library with an implementation that mostly avoids STL. The STL implementation is much slower - I got 47s down to 4.5s. I've diagnosed some of the reasons: it's partly due to std::string being mis-used (e.g. the author should have used "const std::string&" wherever possible - don't just use std::string's as if they were Java strings), but it's also because copy constructors were being constantly called each time the vector outgrew its bounds, which was exceedingly often. The copy constructors were very slow because they did deep-copies of trees (of XmlRpc values).
I was told by someone else on StackOverflow that std::vector implementations typically double the size of the buffer each time they outgrow. This does not seem to be the case on VisualStudio 2008: to add 50 items to a std::vector took 177 calls of the copy constructor. Doubling each time should call the copy constructor 64 times. If you were very concerned about keeping memory usage low, then increasing by 50% each time should call the copy constructor 121 times. So where does the 177 come from?
My question is: (a) why is the copy constructor called so often? (b) is there any way to avoid using the copy constructor if you're just *moving* an object from one location to another? (In this case and indeed most cases a memcpy() would have sufficed - and this makes a BIG difference).
(NB: I know about vector::reserve(), I'm just a bit disappointed that application programmers would need to implement the doubling trick when something like this is already part of any good STL implementation.)
My test program:
```
#include <string>
#include <iostream>
#include <vector>
using namespace std;
int constructorCalls;
int assignmentCalls;
int copyCalls;
class C {
int n;
public:
C(int _n) { n = _n; constructorCalls++; }
C(const C& orig) { copyCalls++; n = orig.n; }
void operator=(const C &orig) { assignmentCalls++; n = orig.n; }
};
int main(int argc, char* argv[])
{
std::vector<C> A;
//A.reserve(50);
for (int i=0; i < 50; i++)
A.push_back(i);
cout << "constructor calls = " << constructorCalls << "\n";
cout << "assignment calls = " << assignmentCalls << "\n";
cout << "copy calls = " << copyCalls << "\n";
return 0;
}
``` | The STL does tend to cause this sort of thing. The spec doesn't allow memcpy'ing because that doesn't work in all cases. There's a document describing [EASTL](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2007/n2271.html), a bunch of alterations made by EA to make it more suitable for their purposes, which does have a method of declaring that a type is safe to memcpy. Unfortunately it's not open source AFAIK so we can't play with it.
IIRC Dinkumware STL (the one in VS) grows vectors by 50% each time.
However, doing a series of push\_back's on a vector is a common inefficiency. You can either use reserve to alleviate it (at the cost of possibly wasting memory if you overestimate significantly) or use a different container - deque performs better for a series of insertions like that but is a little slower in random access, which may/may not be a good tradeoff for you.
Or you could look at storing pointers instead of values which will make the resizing much cheaper if you're storing large elements. If you're storing large objects this will always win because you don't have to copy them ever - you'll always save that one copy for each item on insertion at least. | Don't forget to count the copy constructor calls needed to `push_back` a temporary `C` object into the vector. Each iteration will call `C`'s copy constructor at least once.
If you add more printing code, it's a bit clearer what is going on:
```
std::vector<C> A;
std::vector<C>::size_type prevCapacity = A.capacity();
for (int i=0; i < 50; i++) {
A.push_back(i);
if(prevCapacity != A.capacity()) {
cout << "capacity " << prevCapacity << " -> " << A.capacity() << "\n";
}
prevCapacity = A.capacity();
}
```
This has the following output:
```
capacity 0 -> 1
capacity 1 -> 2
capacity 2 -> 3
capacity 3 -> 4
capacity 4 -> 6
capacity 6 -> 9
capacity 9 -> 13
capacity 13 -> 19
capacity 19 -> 28
capacity 28 -> 42
capacity 42 -> 63
```
So yes, the capacity increases by 50% each time, and this accounts for 127 of the copies:
```
1 + 2 + 3 + 4 + 6 + 9 + 13 + 19 + 28 + 42 = 127
```
Add the 50 additional copies from 50 calls to `push_back` and you have 177:
```
127 + 50 = 177
``` | std::vector on VisualStudio2008 appears to be suboptimally implemented - too many copy constructor calls | [
"",
"c++",
"stl",
""
] |
I’m looking for a trick about this. I know how to call a dynamic, arbitrary function in JavaScript, passing specific parameters, something like this:
```
function mainfunc(func, par1, par2){
window[func](par1, par2);
}
function calledfunc(par1, par2){
// Do stuff here
}
mainfunc('calledfunc', 'hello', 'bye');
```
I know how to pass optional, unlimited parameters using the `arguments` collection inside `mainfunc`, but, I can’t figure how to send an arbitrary number of parameters to `mainfunc` to be sent to `calledfunc` dynamically; how can I accomplish something like this, but with any number of optional arguments (not using that ugly `if`–`else`)?
```
function mainfunc(func){
if(arguments.length == 3)
window[func](arguments[1], arguments[2]);
else if(arguments.length == 4)
window[func](arguments[1], arguments[2], arguments[3]);
else if(arguments.length == 5)
window[func](arguments[1], arguments[2], arguments[3], arguments[4]);
}
function calledfunc1(par1, par2){
// Do stuff here
}
function calledfunc2(par1, par2, par3){
// Do stuff here
}
mainfunc('calledfunc1', 'hello', 'bye');
mainfunc('calledfunc2', 'hello', 'bye', 'goodbye');
``` | Use the apply method of a function:-
```
function mainfunc (func){
window[func].apply(null, Array.prototype.slice.call(arguments, 1));
}
```
**Edit**: It occurs to me that this would be much more useful with a slight tweak:-
```
function mainfunc (func){
this[func].apply(this, Array.prototype.slice.call(arguments, 1));
}
```
This will work outside of the browser (`this` defaults to the global space). The use of call on mainfunc would also work:-
```
function target(a) {
alert(a)
}
var o = {
suffix: " World",
target: function(s) { alert(s + this.suffix); }
};
mainfunc("target", "Hello");
mainfunc.call(o, "target", "Hello");
``` | Your code only works for global functions, ie. members of the `window` object. To use it with arbitrary functions, pass the function itself instead of its name as a string:
```
function dispatch(fn, args) {
fn = (typeof fn == "function") ? fn : window[fn]; // Allow fn to be a function object or the name of a global function
return fn.apply(this, args || []); // args is optional, use an empty array by default
}
function f1() {}
function f2() {
var f = function() {};
dispatch(f, [1, 2, 3]);
}
dispatch(f1, ["foobar"]);
dispatch("f1", ["foobar"]);
f2(); // calls inner-function "f" in "f2"
dispatch("f", [1, 2, 3]); // doesn't work since "f" is local in "f2"
``` | Calling dynamic function with dynamic number of parameters | [
"",
"javascript",
"function",
""
] |
I have a Windows Forms ListView in a form (C#, VS 2005) and have it anchored to all the edges of the form so that it entirely fills the form excluding the status bar. The ListView is in detail mode and the columns are very wide - definitely wider than the display area. I have a vertical scrollbar but no horizontal scrollbar.
I can scroll to the left and right with the keyboard when the control has the focus, but I cannot get the scrollbar to display.
Scrollable is set to true.
What am I missing? | It looks like the status bar is hiding the horizontal scroll bar, besides than changing the Dock property to Fill, you can check whether:
* Add a SplitContainer and arrange the Controls inside of them
* Modify your Status Bar's Dock to bottom
* Add a FlowLayoutPanel and put your Controls inside of it.
Hope these tips be useful | Rather than anchoring it to all four sides to fill the area, try setting the `Dock` property to `Fill`. | Windows Forms ListView missing horizontal scrollbar | [
"",
"c#",
".net",
"winforms",
"listview",
"scrollbar",
""
] |
I am using WorkflowMarkupSerializer to save a statemachine workflow - it saves the states OK, but does not keep their positions. The code to write the workflow is here:
```
using (XmlWriter xmlWriter = XmlWriter.Create(fileName))
{
WorkflowMarkupSerializer markupSerializer
= new WorkflowMarkupSerializer();
markupSerializer.Serialize(xmlWriter, workflow);
}
```
The code to read the workflow is:
```
DesignerSerializationManager dsm
= new DesignerSerializationManager();
using (dsm.CreateSession())
{
using (XmlReader xmlReader
= XmlReader.Create(fileName))
{
//deserialize the workflow from the XmlReader
WorkflowMarkupSerializer markupSerializer
= new WorkflowMarkupSerializer();
workflow = markupSerializer.Deserialize(
dsm, xmlReader) as Activity;
if (dsm.Errors.Count > 0)
{
WorkflowMarkupSerializationException error
= dsm.Errors[0]
as WorkflowMarkupSerializationException;
throw error;
}
}
}
``` | OK, [this tutorial](http://msdn.microsoft.com/en-us/library/aa480213.aspx) gives good information on how to do it - although so far I am only able to *save* the layout, I haven't been able to correctly *use* the layout. The information in question is about 2/3rds down (or just do a search for .layout)
(How does one close his own question?) | Open Control Panel -> "Regional and language options" and set list separator to ',' (comma)
and workflow serializer will use ',' (comma) as separator for X,Y coordinates for struct SizeF
then select ';' and workflow serializer will use ';' (semicolon) as separator.
This really stupid that serializer use regional setting for serialize markup. | WorkflowMarkupSerializer doesn't keep positions in a state machine workflow | [
"",
"c#",
".net",
"workflow",
""
] |
I have to be able to save a file, unfortunatly it can potentially be very large so saving it can potentially take minutes. As I need to do this from a GUI thread I don't want to block the GUI from executing. I was thinking about attempting the save operation on a seperate thread to allow the primary GUI thread to continue executing.
Is there a nice (easy) way to spawn a new thread, save the file, and destroy the thread without any nasty side effects?!
It must be said that I have NEVER had to use threads before so I am a complete novice! Any and all help would be greatly appreciated! | [`BackgroundWorker`](http://msdn.microsoft.com/en-us/library/system.componentmodel.backgroundworker.aspx) (as suggested by Frederik) is a good choice, particularly if you want to report progress to the UI while you're saving. A [search for BackgroundWorker tutorial](http://www.google.com/search?q=backgroundworker+tutorial) gets a lot of hits, so you should be able to follow one of those to get you started.
One thing to be careful of: would there be any way of changing the data structure that you'll be trying to save from the UI thread? If so, you should disable those aspects of the UI while you're saving - it would (probably!) be bad to be half way through saving the data, then allow the user to change some of it. If you can get away with effectively handing off the data to the background thread and then not touching it from the UI thread, that will make your life a lot easier. | You could maybe use the BackGroundWorker component, as it will abstract a bit the Threading part for you. | C# threads for file manipulation | [
"",
"c#",
"multithreading",
"io",
""
] |
When we used AppDomain.CreateInstance("Assembly name", Type name)
and my class inherits from MarshalByRefObject
what happen internally? Is it create a TransparetnProxy?
Code:
```
class Greet : MarshalByRefObejct
{
...
}
class test
{
public static void Main(string[] args)
{
AppDomain ad = AppDomain.CreateDomain("Second");
ObjectHandle hObj = ad.CreateInstance("Test", args[0]);
....
}
}
```
passing in args[0] = Greet | Yes, it creates a transparent proxy, which you get by unwrapping the object handle.
I find the [documentation and example for `ObjectHandle.Unwrap`](http://msdn.microsoft.com/en-us/library/system.runtime.remoting.objecthandle.unwrap.aspx) is quite informative, as is the general [`MarshalByRefObject` documentation](http://msdn.microsoft.com/en-us/library/system.marshalbyrefobject.aspx). | Yes.
You might also want to take a look at [CreateInstanceAndUnwrap](http://msdn.microsoft.com/en-us/library/system.appdomain.createinstanceandunwrap.aspx). If your code in Main and the Greet class were to share a common interface, you could cast hObj into your interface and call methods on it using the TransparentProxy. | AppDomain.CreateInstance | [
"",
"c#",
"appdomain",
""
] |
This is what I'm trying to do: I'm reading a file in from the command line.
The file contains a list of data,below this paragraph is what it looks like.
The problem I'm having is with the if statements.
```
import java.util.*;
import java.io.*;
public class VehicleTest {
public static void main(String[] args) throws FileNotFoundException {
String vehicle = "vehicle";
String car = "car";
String americanCar = "american car";
String foreignCar = "foreign car";
String truck = "truck";
String bicycle = "bicycle";
File file = new File(args[0]);
Scanner input = new Scanner(file);
String[] autos = new String[100];
ArrayList allVehicles = new ArrayList();
for (int i = 0; i < autos.length; i++) {
autos[i] = input.nextLine();
}
int j = 0;
int i = 0;
while (i++ < autos.length) {
if (vehicle.equalsIgnoreCase(autos[j++])) {
Vehicle v = new Vehicle();
v.setOwnerName(autos[j]);
allVehicles.add(v);
}else if(car.equalsIgnoreCase(autos[j++])){
Car c = new Car();
c.setOwnerName(autos[j]);
allVehicles.add(c);
}
}
for(Object a: allVehicles){
System.out.println(a);
}
}
}
```
In pseudo code this would be:
```
while i is less than the length of the string array
if you see the word vehicle create a new vehicle object and add it to the arrayList.
if you see the word car create a new car object and add it to the arrayList.
.....
```
The problems is that I get an arrayOutOfBounds exception with the code I'm using.
I understand that j++ is what is wrong, but how else am I supposed to iterate through the string array so that I can read each line and create the appropriate objects? I'm at a loss as to what to do. I need some help.
```
foreign car
aMarioy
Mario's house
(777) 777-7777
gmario@mario.com
false
black
Italy
4415.91
truck
aDougy
Doug's house
(123) 456-7890
hdoug@doug.com
30
61234.56
8/10/2003
vehicle
aRobby
Rob's house
(987) 654-3210
irob@rob.com
bicycle
bTommy
Tom's house
(246) 810-1214
jtom@tom.com
7
truck
bGeorge
George's house
(666) 666-6666
kgeorge@george.com
25
51234.56
12/4/2004
vehicle
bTim
Tim's house
(111) 111-1111
tim@tim.com
bicycle
bJim
Jim's house
(555) 555-5555
Ajim@jim.com
5
american car
bJohn
John's house
(888) 888-8888
Bjohn@john.com
true
green
false
true
car
cKen
Ken's house
(999) 999-9999
Cken@ken.com
false
orange
foreign car
cMario
Mario's house
(777) 777-7777
Dmario@mario.com
false
black
Italy
4415.91
american car
gSam
Sam's house
(333) 333-3333
Hsam@sam.com
false
blue
true
false
``` | A couple of problems:
* You're incrementing j in both "if" tests. I haven't checked to be certain (it's quite convoluted code, to be honest) but if you make sure that you only increment j when you've found a match, that will help.
* Your test using `i` basically means it will try to read as many vehicles as there are lines in the file, rather than stopping when you've reached the end of the file. Basically you don't need `i` here.
Here's one changed version:
```
while (j < autos.length) {
if (vehicle.equalsIgnoreCase(autos[j])) {
j++;
Vehicle v = new Vehicle();
v.setOwnerName(autos[j++]);
allVehicles.add(v);
} else if(car.equalsIgnoreCase(autos[j])){
j++;
Car c = new Car();
c.setOwnerName(autos[j++]);
allVehicles.add(c);
}
}
```
It would be slightly cleaner to extract the type once though - then you can do the comparisons separately:
```
while (j < autos.length) {
String type = autos[j++];
if (vehicle.equalsIgnoreCase(type)) {
Vehicle v = new Vehicle();
v.setOwnerName(autos[j++]);
allVehicles.add(v);
} else if(car.equalsIgnoreCase(type)){
Car c = new Car();
c.setOwnerName(autos[j++]);
allVehicles.add(c);
}
}
```
It's still not quite how I'd do it, but it's closer...
My next step would be to use the scanner more appropriately:
```
while (scanner.hasNext()) {
String type = scanner.nextLine();
if (type.equalsIgnoreCase("vehicle")) {
allVehicles.add(new Vehicle(scanner));
} else if (type.equalsIgnoreCase("car")) {
allVehicles.add(new Car(scanner));
}
// ...
}
```
Then make the constructor for Vehicle, Car etc do the parsing directly from the scanner.
The next step would be to separate out the construction from the iteration. Introduce a new method:
```
// Use a base type in real code
private static Object parseNextVehicle(Scanner scanner) {
String type = scanner.nextLine();
if (type.equalsIgnoreCase("vehicle")) {
return new Vehicle(scanner);
} else if (type.equalsIgnoreCase("car")) {
return new Car(scanner);
}
// ... throw an exception indicating an unknown vehicle type
}
// ... and then in the main method, use it like this:
while (scanner.hasNextLine()) {
allVehicles.add(parseNextVehicle(scanner));
}
``` | Every line that does not equal “vehicle” will (incorrectly) increment `j` so approximately after line 50 you will get the exception.
There are multiple solutions to this:
* Increment `j` only once per loop.
* Read the lines into another `ArrayList`.
* Don’t read the lines into a data structure but process them as they are being read. This way you are more independent of the size of your data. | Array Index out of bounds | [
"",
"java",
""
] |
I have a data reader. I want to compare the value in it with the value 42. I know it is an integral type (e.g., what MySQL calls `INT`, `TINYINT`, `SMALLINT`, `MEDIUMINT`, `BIGINT`, `JUMBODELUXEINT`, etc.). I do not want to hardwire the actual type in to the C# code. The best I have come up with is
```
object x = reader.GetValue(i);
uint k = x is byte ? (byte) x
: x is short ? (uint) (short) x
: x is ushort ? (ushort) x
: x is int ? (int) (int) x
: (uint) x;
if (k == 42) { ... }
```
This seems incredibly long-winded. I tried using `Equals` but different integral types with the same value do not appear to test as equal.
Is there a better way? | Just checking [`Convert.ToUInt32(object)`](http://msdn.microsoft.com/en-us/library/ec671dkh.aspx)... yup, it works fine:
```
using System;
class Test
{
static void Main()
{
Check((byte)10);
Check((short)10);
Check((ushort)10);
Check((int)10);
Check((uint)10);
}
static void Check(object o)
{
Console.WriteLine("Type {0} converted to UInt32: {1}",
o.GetType().Name, Convert.ToUInt32(o));
}
}
```
In other words, your code can be:
```
object x = reader.GetValue(i);
uint k = Convert.ToUInt32(x);
if (k == 42) { ... }
```
Alternatively, given that all `uint`s are representable as longs, if you're using a data reader could you try `reader.GetInt64(i)`? I don't know offhand whether the conversion will be done for you, but it's probably worth a try. | ```
if(Convert.ToUInt32(reader.GetValue(i)) == 42) { ... }
``` | This object is an integral type. Can I get its value in fewer than five lines of code? | [
"",
"c#",
"type-conversion",
""
] |
I tend to develop my apps in 'setup.py develop' -mode. I'd want the configuration to switch automagically on production mode when the program gets 'setup.py install'ed.
This can be done by poor hacks, like checking whether installation directory contains 'setup.py', but I wonder whether pkg\_resources can do this for me somehow. | Indeed, [`pkg_resources` will do that](http://peak.telecommunity.com/DevCenter/PkgResources#distribution-attributes):
```
dist = pkg_resources.get_distribution('your-app')
if dist.precedence == pkg_resources.DEVELOP_DIST:
# package is in development mode
...
``` | Isn't it easier, and cleaner, to just set an environment variable on your development machine, and test for `os.environ['development_mode']` (or a setting of your choice)? | figure out whether python module is installed or in develop mode programmatically | [
"",
"python",
"packaging",
""
] |
How can I have any uncaught exception get returned as a SOAP fault in my C# web service? It appears that IIS is 'catching' the exception and displaying it on the default error. Below is santized web.config.
```
<?xml version="1.0"?>
<configuration>
<configSections>
<section name="hibernate-configuration" type="NHibernate.Cfg.ConfigurationSectionHandler, NHibernate" />
</configSections>
<system.web>
<httpRuntime enableVersionHeader="false" />
<sessionState mode="Off" />
<compilation defaultLanguage="c#" debug="true" />
<authentication mode="None" />
<customErrors mode="RemoteOnly" defaultRedirect="GenericErrorPage.htm">
<error statusCode="403" redirect="NoAccess.htm" />
<error statusCode="404" redirect="FileNotFound.htm" />
</customErrors>
<webServices>
<protocols>
<remove name="HttpPost"/>
<remove name="HttpGet"/>
<remove name="Documentation"/>
<remove name="HttpSoap12" />
</protocols>
</webServices>
</system.web>
</configuration>
``` | it turns out some bad logic in an HttpModule was causing the application to error out. once this was resolved the application behaved as expected. | It turns out there was a code issue in the Application\_EndRequest method of an HttpModule that was causing the problem. | .NET Web Services - SOAP Faults | [
"",
"c#",
".net",
"asp.net",
"web-services",
""
] |
Is it possible to fill out an infopath form and submit it via a C# console application?
If yes, then how? | Yes, you can create a XML file within your C# application and push it to your Sharepoint Form Library. Sharepoint won't realize any difference.
Just ensure two things:
* Your XML must validate against the Infopath **schema**.
* Remember to add the XML **processing instructions**, so that Sharepoint and Infopath know how to handle the XML file. (Simply 'steal' it from an Infopath generated XML.) | MrFox is right, an Infopath Form is just an Xml document that conforms to certain rules, so as long as you create the text file with the correct Xml markups, then you've created an Infopath doc. There are, however, programmatical ways to manipulate a document using the Infopath space. In particular, you can create a new Infopath document from an Infopath template. Lookup more information on `XDocuments2.NewFromSolution()` to see some examples. | C# to fill out InfoPath Form programmatically? | [
"",
"c#",
"automation",
"infopath",
""
] |
I have an app which is very database and user intensive. The users are very keen on the browser history buttons for navigation.
Is there a way that I can absolutely guarantee that the page will reload if a user picks something out of their browser history?
What I regularly see is that a copy of the page will be shown from the browsers cache, rather than being reloaded.
I've tried:
```
this.Response.Cache.SetNoStore()
this.Response.Cache.SetNoServerCaching()
this.Response.Cache.SetCacheability(System.Web.HttpCacheability.NoCache)
```
And
```
this.Response.Cache.SetExpires(DateTime.Now.AddSeconds ( -1 ) );
```
None of these seems to help, sometimes the browser will load the old cached version anyway. | You need two statements to prevent caching:
`Response.Cache.SetCacheability(System.Web.HttpCacheability.NoCache); // For IE
Response.Cache.SetNoStore(); // For Firefox`
For more detail see:
<http://blog.httpwatch.com/2008/10/15/two-important-differences-between-firefox-and-ie-caching/>
Also, make sure that you always follow a POST with a redirect so that the back button works correctly:
<http://blog.httpwatch.com/2007/10/03/60-of-web-users-can%E2%80%99t-be-wrong-%E2%80%93-don%E2%80%99t-break-the-back-button/> | If you are using the 3.5 framework you can use the History server control to manager what goes into the browser history.
Here is a video and some blog articles with tips on using it:
[Video: How Do I Use the ASP.NET history control?](http://www.asp.net/learn/ajax-videos/video-149.aspx)
[Back Button Support for ASP.NET Update Panels](http://www.nikhilk.net/BackButtonSupport.aspx)
[ASP.NET: Managing Browser History with AJAX and UpdatePanels](http://blogs.interakting.co.uk/steve/archive/2008/01/25/ASP.NET-Managing-Browser-History-with-AJAX-and-UpdatePanels.aspx)
[Tip/Trick: Enabling Back/Forward-Button Support for ASP.NET AJAX UpdatePanel](http://weblogs.asp.net/scottgu/archive/2006/09/14/Tip_2F00_Trick_3A00_-Enabling-Back_2F00_Forward_2D00_Button-Support-for-ASP.NET-AJAX-UpdatePanel.aspx)
Update: As noted int he comments, you are using the 2.0 version of the framework. Here is a link explaining how to use this control on .NET 2.0 :
[Using ASP.NET 3.5 History Control with ASP.NET 2.0](http://weblogs.asp.net/brijmohan/archive/2008/09/11/using-asp-net-3-5-history-control-with-asp-net-2-0.aspx) | Whats the best way to deal with pages loaded via browser history in asp .net? | [
"",
"c#",
"asp.net",
""
] |
i have an application that records a date/time when the space bar is pressed
unfortunately, the window doesn't always have focus, for various reasons. eg virus checker popup, itunes update, windows update, etc
so what i though would be a cool idea is to use a joystick button, then regardless of which window has focus, i can always detect the button press event and record the date/time it was pressed.
now i had a look at a few game tutorials, but they seem to have the joystick polling tied into the screen refresh event, because in a game i guess if the computer is slow and the screen doesn't refresh often, having the joystick button pressed is going to make no difference anyway.
That doesn't really suit my need, so i am looking at running a thread that will poll the joystick every so often
My questions are
1. is a background thread the best solution
2. how often should i poll the joystick
3. what kind of timer should i use to determine the polling frequency.
I would like the responses to be at least equivalent to a keyboard. also need to make sure it doesn't auto-repeat if trigger is held down.
any sample code (C#) appreciated
thanks
alex | Your best bet would be to create a Timer object on your form, and tie the joystick check to the Tick event.
I've also found that running simple stuff like this every 100ms (10 times a second) has a negligible effect on CPU usage. | If you want to go for polling the joystick just because you are not able to capture the keyboard event, I think you need to re-work your strategy.
Even if your form doesn't have the focus there are ways that you can make sure you know of the keyboard state.
1. You could set up a system wide keyboard hook which can be done in C# using the SetWindowsHookEx API call.
This is delving a little in unmanaged code and Windows API, but I think it's a better idea than polling a joystick cause you won't need to add a joystick to your computer just because you need to capture datetime at the press of a spacebar.
Do a little search on google for keyboard hooks in C#. It's easier than many people believe.
I don't think using a timer object to do this is a good idea at all. Cause I believe you said you need to do it at the press of a key. | polling joystick C# | [
"",
"c#",
".net",
"multithreading",
"polling",
"input-devices",
""
] |
I'm using PHP and libtidy to attempt to screen scrape what might possibly be the most horrendous and malformed use of HTML tables in history. The site closes few table, tr, td, font, or bold tags and consistently nests many different layers of tables within tables.
Example snippet:
```
<center>
<table border="1" bordercolor="#000000" cellspacing="0" cellpadding="0">
<tr>
<td width="50%">
<center>
Home Team - <b>Wildcats<td>
<center>
Away Team - <b>Polar Bears<tr>
<td colspan="2">
<center>
<b><font size="+1">Rosters<tr>
<td valign="top">
<center>
<table border="0" cellspacing="0">
<tr>
<td>
<font size="2">1 <td>
<font size="2">Baird, T<tr>
<td>
<font size="2">2 <td>
<font size="2">Knight, P<tr>
<td>
<font size="2">8 <td>
<font size="2">Miller, B<tr>
<td>
<font size="2">9 <td>
<font size="2">Huebsch, B<tr>
<td>
<font size="2">11 <td>
<font size="2">Buschmann, C<tr>
<td>
<font size="2">12 <td>
<font size="2">Reding, J<tr>
<td>
<font size="2">14 <td>
<font size="2">Simpson, S<tr>
<td>
<font size="2">27 <td>
<font size="2">Kupferschmidt, M<tr>
<td>
<font size="2">28 <td>
<font size="2">Anderson, D<tr>
<td>
<font size="2">31 <td>
<font size="2">Gehrts, J<tr>
<td>
<font size="2">39 <td>
<font size="2">McGinnis, G<tr>
<td>
<font size="2">42 <td>
<font size="2">Temple, B<tr>
<td>
<font size="2">44 <td>
<font size="2">Kemplin, A<tr>
<td>
<font size="2">77 <td>
<font size="2">Weiner, B<tr>
<td>
<font size="2">95 <td>
<font size="2">
Zytkoskie, D</table>
<td valign="top">
<center>
<table border="0" cellspacing="0">
<tr>
<td>
<font size="2">5 <td>
<font size="2">Mack, A<tr>
<td>
<font size="2">8 <td>
<font size="2">Foucault, R<tr>
<td>
<font size="2">11 <td>
<font size="2">Oberpriller, D *<tr>
<td>
<font size="2">12 <td>
<font size="2">Underwood, J<tr>
<td>
<font size="2">15 <td>
<font size="2">Oberpriller, M<tr>
<td>
<font size="2">19 <td>
<font size="2">Langfus, B<tr>
<td>
<font size="2">25 <td>
<font size="2">Carroll, R<tr>
<td>
<font size="2">30 <td>
<font size="2">Hirdler, T<tr>
<td>
<font size="2">33 <td>
<font size="2">Gibson, S<tr>
<td>
<font size="2">35 <td>
<font size="2">Marthaler, C<tr>
<td>
<font size="2">44 <td>
<font size="2">Yurik, J<tr>
<td>
<font size="2">58 <td>
<font size="2">
Gronemeyer, S</table>
<tr>
<td colspan="2">
<center>
<b><font size="+1">Goals<tr>
<td valign="top">
<center>
<table border="1" cellspacing="0" width="100%">
<td>
<b><font size="2">Player<td>
<b><font size="2">Period<td>
<b><font size="2">Time<td>
<b><font size="2">Assist 1<td>
<b><font size="2">Assist 2<td>
<b><font size="2">SH<td>
<b><font size="2">PP<tr>
<td nowrap>
<font size="2">Kupferschmidt, M<td>
<font size="2">1<td>
<font size="2">12:51<td nowrap>
<font size="2">Kemplin, A<td nowrap>
<font size="2">None<td>
<font size="2">
<center>
<td>
<font size="2">
<center>
<tr>
<td nowrap>
<font size="2">McGinnis, G<td>
<font size="2">1<td>
<font size="2">12:33<td nowrap>
<font size="2">Huebsch, B<td nowrap>
<font size="2">None<td>
<font size="2">
<center>
<td>
<font size="2">
<center>
<tr>
<td nowrap>
<font size="2">Kupferschmidt, M<td>
<font size="2">2<td>
<font size="2">16:01<td nowrap>
<font size="2">None<td nowrap>
<font size="2">None<td>
<font size="2">
<center>
<td>
<font size="2">
<center>
<tr>
<td nowrap>
<font size="2">Buschmann, C<td>
<font size="2">3<td>
<font size="2">00:38<td nowrap>
<font size="2">None<td nowrap>
<font size="2">None<td>
<font size="2">
<center>
<td>
<font size="2">
<center>
</table>
<td valign="top">
<center>
<table border="1" cellspacing="0" width="100%">
<td>
<b><font size="2">Player<td>
<b><font size="2">Period<td>
<b><font size="2">Time<td>
<b><font size="2">Assist 1<td>
<b><font size="2">Assist 2<td>
<b><font size="2">SH<td>
<b><font size="2">PP<tr>
<td nowrap>
<font size="2">Oberpriller, D *<td>
<font size="2">3<td>
<font size="2">12:31<td nowrap>
<font size="2">Gronemeyer, S<td nowrap>
<font size="2">None<td>
<font size="2">
<center>
<td>
<font size="2">
<center>
</table>
<tr>
<td colspan="2">
<center>
<b><font size="+1">Penalties<tr>
<td valign="top">
<center>
<table border="1" cellspacing="0" width="100%">
<td>
<b><font size="2">Player<td>
<font size="2"><b>Period<td>
<font size="2"><b>Minutes<td>
<font size="2"><b>Offense<td>
<font size="2"><b>Start<td>
<font size="2"><b>Expired<tr>
<td nowrap>
<font size="2">Buschmann, C<td>
<font size="2">
<center>
3<td>
<font size="2">
<center>
2<td>
<font size="2">Interference<td>
<font size="2">11:11<td>
<font size="2">09:11<tr>
<td nowrap>
<font size="2">Buschmann, C<td>
<font size="2">
<center>
3<td>
<font size="2">
<center>
2<td>
<font size="2">Unsportmanlike Conduct<td>
<font size="2">03:26<td>
<font size="2">01:26<tr>
<td nowrap>
<font size="2">Bench<td>
<font size="2">
<center>
3<td>
<font size="2">
<center>
2<td>
<font size="2">Too Many Men<td>
<font size="2">01:46<td>
<font size="2">
00:00</table>
<td valign="top">
<center>
<table border="1" cellspacing="0" width="100%">
<td>
<b><font size="2">Player<td>
<font size="2"><b>Period<td>
<font size="2"><b>Minutes<td>
<font size="2"><b>Offense<td>
<font size="2"><b>Start<td>
<font size="2"><b>Expired<tr>
<td nowrap>
<font size="2">Marthaler, C<td>
<font size="2">
<center>
1<td>
<font size="2">
<center>
2<td>
<font size="2">Interference<td>
<font size="2">01:19<td>
<font size="2">16:19<tr>
<td nowrap>
<font size="2">Underwood, J<td>
<font size="2">
<center>
2<td>
<font size="2">
<center>
2<td>
<font size="2">Interference<td>
<font size="2">12:32<td>
<font size="2">10:32<tr>
<td nowrap>
<font size="2">Marthaler, C<td>
<font size="2">
<center>
3<td>
<font size="2">
<center>
2<td>
<font size="2">Interference<td>
<font size="2">11:39<td>
<font size="2">
09:39</table>
<tr>
<td colspan="2">
<center>
<font size="+1"><b>Goalies<tr>
<td>
<center>
<table border="1" cellspacing="0" width="100%">
<td>
<b><font size="2">Name<td>
<font size="2"><b>Shots<td>
<font size="2"><b>Goals<tr>
<td>
<font size="2">Baird, T<td>
<font size="2">20<td>
<font size="2">1<tr>
<td>
<font size="2"><b>Open Net<td>
<td>
<font size="2">
0</table>
<td>
<center>
<table border="1" cellspacing="0" width="100%">
<td>
<b><font size="2">Name<td>
<font size="2"><b>Shots<td>
<font size="2"><b>Goals<tr>
<td>
<font size="2">Hirdler, T<td>
<font size="2">42<td>
<font size="2">
```
Magically, all browsers seem to render this just fine.
PHPTidy manages to do a good sense of it all, but the tables are nested so deeply and almost randomly that it's really hard to traverse this using DOM XPath.
Does anyone have any recommendations for other approaches for taking this on?
**POST-MORTEM**: After way too many Belgian wheat beers and dirtying up my code real good I got great results by removing all tags via strip\_tags() except table, tr, and td, then running it through libtidy. It's now formatted beautifully and very easily traversed. Seems like it just needed a little massaging before sending it in to the parser. | There's a few tricks you can use to clean up highly-predictable structures like tables. Before running HTML tidy, you can use Regex or something to search for `<tr>`'s and `<td>`'s which are followed by another `<tr>` or `<td>`, and insert the corresponding closer immediately before it. There's some added trickery for accommodating tables inside of a `<td>` but nothing that's impossible to handle. Just start by locating the innermost structure and moving outward from there.
The real puzzle is things like unclosed `<div>`'s and `<p>`'s, which can be much harder to match up with their corresponding (or lacking) closers. | If you are open to other languages such as Python, [Beautiful Soup](http://www.crummy.com/software/BeautifulSoup/) is great at reconstructing poorly written HTML. I just tried running your HTML through the following snippet, and it's now quite readable.
```
#!/usr/bin/env python
from BeautifulSoup import BeautifulSoup
html = "long string of html"
soup = BeautifulSoup(html)
print soup.prettify()
``` | Screenscraping the ugliest HTML you've ever seen in your life | [
"",
"php",
"screen-scraping",
"tidy",
"htmltidy",
""
] |
I need to automate [FileMon.exe](http://technet.microsoft.com/en-us/sysinternals/bb896642.aspx) to startup with filters, save out the log it generates, and then exit.
My solution has been to write an assist application that will do all of this. Which has worked on starting up with specified filters and killing the process, but I still need it to save the log. Do you think it would be silly to send the application keystrokes to save the log? For instance I would send an Alt+F, Alt+S, type filepath, Enter.
How can you send keystrokes like above to another process that is running in C#? | Thanks for all the answers and help guys... I'm actually going to write and invoke a perl script using Win32::GuiTest. | As I know, you have to invoke some of native APIs:
-FindWindow to find parent windows you want to work with
-FindWindowEx to find true windows you'll send message to
-SendMessage to send key strokes to those windows
Details of these APIs, refer at MSDN :) | Send key strokes to another application C# | [
"",
"c#",
"input",
""
] |
I wrote a linked list implementation for my java class earlier this year. This is a generic class called LList. We now have to write out the merge sort algorithm for a lab. Instead of creating a new List implementation that takes Ints, I decided to just reuse the generic list I had created before.
The problem is how do I compare two generic objects?
java wont let me do something like
```
if(first.headNode.data > second.headNode.data)
```
So, my question is, is their a way to implement some sort of comparison function that will work on any type of data? I tried the following:
```
String one, two;
one = first.headNode.data.toString();
two = second.headNode.data.toString();
if(first.headNode.data.compareTo(second.headNode.data) < 0) {
result.add(first.headNode.data);
// remove head node. remove() takes care of list size.
first.remove(1);
} else {
// If compareTo returns 0 or higher, second.headNode is lower or
// equal to first.headNode. So it's safe to update the result
// list
result.add(second.headNode.data);
second.remove(1);
}
```
Which wont even work properly. I tested with the numbers 6 and 12, the above adds 12 to the result list.
Relevant stuff:
```
private LList<T> mergeSort(LList<T> list) {
LList<T> first = new LList();
LList<T> second = new LList();
if (list.length() == 1) {
return list;
}
int middle = list.length() / 2;
second.headNode = list.getNodeAt(middle + 1);
second.length = list.length() - (middle);
// Set first half to full list, then remove the "second" half.
first.headNode = list.headNode;
first.length = middle;
first.getNodeAt(middle).next = null;
// Get the splitted halves.
first = mergeSort(first);
second = mergeSort(second);
return merge(first, second);
}
private LList<T> merge(LList<T> first, LList<T> second) {
LList<T> result = new LList();
while((first.length > 0) && (second.length > 0)) {
// Ok, lets force toString to compare stuff since generics are a pain.
String one, two;
one = first.headNode.data.toString();
two = second.headNode.data.toString();
if(one.compareTo(two)) < 0) {
result.add(first.headNode.data);
// remove head node. remove() takes care of list size.
first.remove(1);
} else {
// If compareTo returns 0 or higher, second.headNode is lower or
// equal to first.headNode. So it's safe to update the result
// list
result.add(second.headNode.data);
second.remove(1);
}
}
return result;
}
```
NOTE: entire LList class can be found [here](<http://rapidshare.com/files/219112739/LList.java.html>
MD5: BDA8217D0756CC171032FDBDE1539478) | Look into the [Comparator](http://java.sun.com/j2se/1.5.0/docs/api/java/util/Comparator.html) and [Comparable](http://java.sun.com/j2se/1.5.0/docs/api/java/lang/Comparable.html) interfaces.
Your sort method should take [Comparator](http://java.sun.com/j2se/1.5.0/docs/api/java/util/Comparator.html) or you should specify < T extends Comparable > so that the Comparable interface can be used.
```
public void sort(Comparable<T> comparator) {
sort(SortType.MERGE, comparator);
}
....
private LList<T> merge(LList<T> first, LList<T> second) {
...
if(comparator.compare(first.headNode.data, second.headNode.data) < 0) {
...
}
``` | Note that Comparable is also a generic type, parameterized by what type it is comparable to. The most general, type-safe way to declare your mergeSort function above is:
```
private <T extends Comparable<? super T>> LList<T> mergeSort(LList<T> list) { }
```
This enforces that the type T's compareTo method can accept an argument of type T. (In theory, a type could implement Comparable, but not be comparable to itself, like `SomeClass implements Comparable<CompletelyDifferentClass>`, so it is important to have the requirement on the type parameter of Comparable. In practice, however, any well-designed Comparable class should be comparable to at least itself.)
We require that `<T extends Comparable<? super T>>` instead of just `<T extends Comparable<T>>` because it is okay if a type T's `compareTo` method accepts a more general type than T, because it would still be able to accept an argument of type T. This is important because, if you have a class A, which implements `Comparable<A>`; and then you have a subclass B which extends A, B cannot implement `Comparable<B>`, because B already implements `Comparable<A>`, inherited from A, and a class cannot implement an interface twice. So if we required `<T extends Comparable<T>>` above, B would not satisfy it, and we would not be able to sort `LList<B>` objects. | Comparing elements in a generic list | [
"",
"java",
"generics",
""
] |
I've been wrestling with Project Euler [Problem #16](http://projecteuler.net/index.php?section=problems&id=16) in C# 2.0. The crux of the question is that you have to calculate and then iterate through each digit in a number that is 604 digits long (or there-abouts). You then add up these digits to produce the answer.
This presents a problem: C# 2.0 *doesn't have* a built-in datatype that can handle this sort of calculation precision. I could use a [3rd party library](http://intx.codeplex.com/), but that would defeat the purpose of attempting to solve it programmatically without external libraries. I can solve it in Perl; but I'm trying to solve it in C# 2.0 (I'll attempt to use C# 3.0 in my next run-through of the [Project Euler](http://projecteuler.net) questions).
### Question
What suggestions (**not answers!**) do you have for solving project Euler #16 in C# 2.0? What methods would work?
> **NB**: If you decide to post an answer, please prefix your attempt with a blockquote that has ###Spoiler written before it. | A number of a series of digits. A 32 bit unsigned int is 32 binary digits. The string "12345" is a series of 5 digits. Digits can be stored in many ways: as bits, characters, array elements and so on. The largest "native" datatype in C# with complete precision is probably the decimal type (128 bits, 28-29 digits). Just choose your own method of storing digits that allows you to store much bigger numbers.
As for the rest, this will give you a clue:
21 = 2
22 = 21 + 21
23 = 22 + 22
Example:
```
The sum of digits of 2^100000 is 135178
Ran in 4875 ms
The sum of digits of 2^10000 is 13561
Ran in 51 ms
The sum of digits of 2^1000 is 1366
Ran in 2 ms
```
**SPOILER ALERT: Algorithm and solution in C# follows.**
Basically, as alluded to a number is nothing more than an array of digits. This can be represented easily in two ways:
* As a string;
* As an array of characters or digits.
As others have mentioned, storing the digits in reverse order is actually advisable. It makes the calculations much easier. I tried both of the above methods. I found strings and the character arithmetic irritating (it's easier in C/C++; the syntax is just plain annoying in C#).
The first thing to note is that you can do this with one array. You don't need to allocate more storage at each iteration. As mentioned you can find a power of 2 by doubling the previous power of 2. So you can find 21000 by doubling 1 one thousand times. The doubling can be done in place with the general algorithm:
```
carry = 0
foreach digit in array
sum = digit + digit + carry
if sum > 10 then
carry = 1
sum -= 10
else
carry = 0
end if
digit = sum
end foreach
```
This algorithm is basically the same for using a string or an array. At the end you just add up the digits. A naive implementation might add the results into a new array or string with each iteration. Bad idea. Really slows it down. As mentioned, it can be done in place.
But how large should the array be? Well that's easy too. Mathematically you can convert 2^a to 10^f(a) where f(a) is a simple logarithmic conversion and the number of digits you need is the next higher integer from that power of 10. For simplicity, you can just use:
```
digits required = ceil(power of 2 / 3)
```
which is a close approximation and sufficient.
Where you can really optimise this is by using larger digits. A 32 bit signed int can store a number between +/- 2 billion (approximately. Well 9 digits equals a billion so you can use a 32 bit int (signed or unsigned) as basically a base one billion "digit". You can work out how many ints you need, create that array and that's all the storage you need to run the entire algorithm (being 130ish bytes) with everything being done in place.
Solution follows (in fairly rough C#):
```
static void problem16a()
{
const int limit = 1000;
int ints = limit / 29;
int[] number = new int[ints + 1];
number[0] = 2;
for (int i = 2; i <= limit; i++)
{
doubleNumber(number);
}
String text = NumberToString(number);
Console.WriteLine(text);
Console.WriteLine("The sum of digits of 2^" + limit + " is " + sumDigits(text));
}
static void doubleNumber(int[] n)
{
int carry = 0;
for (int i = 0; i < n.Length; i++)
{
n[i] <<= 1;
n[i] += carry;
if (n[i] >= 1000000000)
{
carry = 1;
n[i] -= 1000000000;
}
else
{
carry = 0;
}
}
}
static String NumberToString(int[] n)
{
int i = n.Length;
while (i > 0 && n[--i] == 0)
;
String ret = "" + n[i--];
while (i >= 0)
{
ret += String.Format("{0:000000000}", n[i--]);
}
return ret;
}
``` | I solved this one using C# also, much to my dismay when I discovered that Python can do this in one simple operation.
Your goal is to create an adding machine using arrays of int values.
### Spoiler follows
> I ended up using an array of int
> values to simulate an adding machine,
> but I represented the number backwards
> - which you can do because the problem only asks for the sum of the digits,
> this means order is irrelevant.
>
> What you're essentially doing is
> doubling the value 1000 times, so you
> can double the value 1 stored in the
> 1st element of the array, and then
> continue looping until your value is
> over 10. This is where you will have
> to keep track of a carry value. The
> first power of 2 that is over 10 is
> 16, so the elements in the array after
> the 5th iteration are 6 and 1.
>
> Now when you loop through the array
> starting at the 1st value (6), it
> becomes 12 (so you keep the last
> digit, and set a carry bit on the next
> index of the array) - which when
> *that* value is doubled you get 2 ... plus the 1 for the carry bit which
> equals 3. Now you have 2 and 3 in your
> array which represents 32.
>
> Continues this process 1000 times and
> you'll have an array with roughly 600
> elements that you can easily add up. | Project Euler #16 - C# 2.0 | [
"",
"c#",
".net",
""
] |
Let's say there are 2 tables Table1 { ID, Name, Other } and Table2 { ID, Name, Other }. Both of them have identical records with the same IDs except that in Table1 all Name values are NULL. How can I import Name values from Table2 to Table1 using T-SQL (SQL Server 2008)? | ```
Update Table1
Set Table1.Name = Table2.Name
From
Table1 INNER JOIN Table2 on Table1.ID = Table2.ID
``` | You're looking for the MERGE command, which is like the UPSERT that you've probably read about elsewhere. Here's a [quick article](http://www.databasejournal.com/features/mssql/article.php/3739131/UPSERT-Functionality-in-SQL-Server-2008.htm) about it. | T-SQL for merging data from one table to another | [
"",
"sql",
"sql-server",
"sql-server-2008",
""
] |
I've made a quite big domain model with entity framework. I wanted to know if it is possible to map it so i create automaticly the tables in the database wanted?
I've looked up edmgen.exe but still couldn't find the right command.
thank's for helping!
Edit1: I know the tool LightSpeed from Mindscape ofer this features that's why i think that entity framework does the same.
Edit2 : Non one likes me... | currently this is not available but i thing this feature will be shipped with vs2010 | According to this [blog entry](http://blog.nakedobjects.net/?p=58), it's currently (v1) not possible to create the database from an entity model.
About half way down, under the heading of "2. Process and tooling issues", you'll find:
> * It is not currently possible to create the database schema
> automatically from the Entity Model.
> This is simply extraordinary - as it
> seems to easy to do!
Let's hope for EF v2 (in .NET 4.0 / VS2010).
Marc | Map entities to database with Entity Framework | [
"",
"c#",
".net",
"entity-framework",
"mapping",
""
] |
I'm looking for a string indexof function from the std namespace that returns an integer of a matching string similar to the java function of the same name. Something like:
```
std::string word = "bob";
int matchIndex = getAString().indexOf( word );
```
where getAString() is defined like this:
```
std::string getAString() { ... }
``` | Try the [`find`](http://www.cppreference.com/wiki/string/find) function.
Here is the example from the article I linked:
```
string str1( "Alpha Beta Gamma Delta" );
string::size_type loc = str1.find( "Omega", 0 );
if( loc != string::npos ) {
cout << "Found Omega at " << loc << endl;
} else {
cout << "Didn't find Omega" << endl;
}
``` | You are looking for the `std::basic_string<>` function template:
```
size_type find(const basic_string& s, size_type pos = 0) const;
```
This returns the index or `std::string::npos` if the string is not found. | How to do std::string indexof in C++ that returns index of matching string? | [
"",
"c++",
"string",
"stl",
""
] |
I have an RTF document that serves as a template for input data from a web page. I need to know how to break the base template into individual pages for display on the website. Is there a way to do this using PHP? I have tried searching through the RTF code inside the document, but cannot find anything that gives me a good breaking point. If anyone has a code snipit or and idea of how to do this I would be forever greatful. | There are no explicit page breaks in RTF files, unless the user put them there. "Paging" is computed when the document is rendered. No easy answer it seems, IIUC. | The RTF specification denotes \page as the command for a page break, but it seems to be ignored by most viewers. Google docs, for example, doesn't produce an RTF with page breaks when saving a document that contains page breaks. | How do I split an RTF document into individual pages using PHP | [
"",
"php",
"rtf",
"documents",
""
] |
I am having problem with escaping the single and double quotes inside the `href`s JavaScript function.
I have this JavaScript code inside `href`. It's like -
```
<a href = "javascript:myFunc("fileDir/fileName.doc", true)"> click this </a>
```
Now, since double quotes inside double quote is not valid, I need to escape the inner double quotes for it to be treated as part of the string -
so, I need to do this -
```
<a href = "javascript:myFunc(\"fileDir/fileName.doc\" , true)"> click this </a>
```
The problem is, even the above code is not working. The JavaScript code is getting truncated at -- `myFunc(`
I tried with the single quote variation too - but even that doesn't seem to work (meaning that if I have a single quote inside my string literal then the code gets truncated).
This is what I did with a single quote:
```
<a href = 'javascript:myFunc("fileDir/fileName.doc" , true)'> click this </a>
```
This works, but if I have a single quote inside the string then the code gets truncated in the same way as that of double quotes one. | Using backslashes to escape quotes is how it works in JavaScript, but you're not actually writing JavaScript code there: you're writing HTML. You can do it by using the HTML escaping method: character entities.
```
" // "
' // '
```
For example:
```
<a href="javascript: alert('John O'Brien says "Hi!"');">...</a>
``` | In case anyone needs to escape some thing like this:
```
<a href="www.google.com/search?q="how+to+escape+quotes+in+href""</a>
```
You can use ASCII code for double quotes `%22`:
```
<a href="www.google.com/search?q=%22how+to+escape+quotes+in+href%22"</a>
```
It is especially useful if you pass the link to JavaScript from PHP | Using JavaScript single and double quotes for href's | [
"",
"javascript",
"escaping",
""
] |
I have a Windows Forms application that allows only one instance to be running at the time. I have implemented Singleton by using Mutex. The Application must be startable from commandline (with or without parameters). Application is started and exited by script. User can not take any action on it.
So, application purpose is simple "indicator" application that will just display some visual and graphical information for the enduser. End user can not do anything with it, just see it. It is windows forms application because then visual and graphical appearance is relatively easy implement (you can get it topmost, borderless, etc.).
To put it simply:
How can I exit the current running application when someone tries to run same application with exit commandline parameter?
```
bool quit = (args.Length > 0 && args[0] == "quit") ? true : false;
using (Mutex mutex = new Mutex(false, sExeName))
{
if (!mutex.WaitOne(0, true))
{
if (quit)
{
// This is the tricky part?
// How can I get reference to "previous" launced
// Windows Forms application and call it's Exit() method.
}
}
else
{
if (!quit)
{
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run(new Form1());
}
}
}
``` | The .NET framework offers a very good generic solution for this. Check the bottom of this [MSDN magazine article](http://msdn.microsoft.com/en-us/magazine/cc163741.aspx). Use the StartupNextInstanceHandler() event handler to pass arbitrary commands to the running instance, like "quit". | Is this not over complicating things ? Rather than closing the existing instance and starting a new one, can you not just re-activate the existing instance? Either way round the code below should give you some ideas on how to go about it...?
```
Process thisProcess = Process.GetCurrentProcess();
Process[] allProcesses = Process.GetProcessesByName(thisProcess.ProcessName);
Process otherProcess = null;
foreach (Process p in allProcesses )
{
if ((p.Id != thisProcess.Id) && (p.MainModule.FileName == thisProcess.MainModule.FileName))
{
otherProcess = p;
break;
}
}
if (otherProcess != null)
{
//note IntPtr expected by API calls.
IntPtr hWnd = otherProcess.MainWindowHandle;
//restore if minimized
ShowWindow(hWnd ,1);
//bring to the front
SetForegroundWindow (hWnd);
}
else
{
//run your app here
}
```
There is another question about this [here](https://stackoverflow.com/questions/646480/is-using-a-mutex-to-prevent-multipule-instances-of-the-same-program-from-running) | Single instance windows forms application and how to get reference on it? | [
"",
"c#",
"winforms",
"singleton",
"mutex",
""
] |
I am trying to find some examples but no luck. Does anyone know of some examples on the net? I would like to know what it returns when it can't find, and how to specify from start to end, which I guess is going to be 0, -1. | you can use [`str.index`](http://docs.python.org/library/stdtypes.html?highlight=index#str.index) too:
```
>>> 'sdfasdf'.index('cc')
Traceback (most recent call last):
File "<pyshell#144>", line 1, in <module>
'sdfasdf'.index('cc')
ValueError: substring not found
>>> 'sdfasdf'.index('df')
1
``` | I'm not sure what you're looking for, do you mean [`find()`](http://docs.python.org/library/stdtypes.html#str.find)?
```
>>> x = "Hello World"
>>> x.find('World')
6
>>> x.find('Aloha');
-1
``` | Examples for string find in Python | [
"",
"python",
"string",
"find",
""
] |
Greetings Everyone.
I'm currently writing a multi-language programe in C, C++ and fortran on UNIX, unfortunatly I run into "Segmentation Error" when I try and execute after compiling.
I've narrowed down the problem to the interface between the C++ and C sections of my program. The first section consists of main.ccp and SA.cpp, and the second CFE.c.
A class called 'SimAnneal' exsists in SA.cpp, with public vectors DensityArray and ElementArray. The order of the program follows:
1. Create SimAnneal Object 'Obj1' and call function ObjFunction()
2. That function initializes the vector sizes
3. Call CFE(...) with pointers to both vectors and their length.
4. CFE.c edits the data elements of the vectors directly via use of the pointers
5. ObjFunction() uses EnergyArray (and possible DensityArray) data.
The relevant script is below for all sources:
main.cpp
```
#include "SA.h"
int main()
{
SimAnneal Obj1;
Obj1.ObjFunction();
return 0;
}
```
SA.h
```
class SimAnneal
{
void Initialize ();
...
public
std::vector<float> DensityArray;
std::vector<float> EnergyArray;
double ObjFunction ();
...
}
```
SA.cpp
```
#include "CFE.h"
void SimAnneal::Initialize ()
{
int length = 15;
EnergyArray.resize(length);
DensityArray.resize(length);
}
double SimAnneal::ObjFunction ()
{
Initialize ();
CFE(&DensityArray[0], &EnergyArray[0], DensityArray.size());
// sends pointers of both arrays to CFE.c, which will then
// directly modify the array
double SumStrainEnergy = 0;
for (int i = 0; i < EnergyArray.size(); i++)
{
SumStrainEnergy += EnergyArray[i]; //Effectively sum of array
//engy[] from CFE.c
}
return SumStrainEnergy;
}
```
CFE.h
```
#ifdef __cplusplus
extern "C" {
#endif
void CFE(float density[], float energy[], int NumElem);
#ifdef __cplusplus
}
#endif
```
CFE.c
```
void CFE(float density[], float energy[], int NumElem)
{
...
float * dens;
dens = density; //pass pointer of array density[0] in SA.cpp to CFE.c
for(n=0; n<NumElem; n++)
{ ... modify dens (e.g. DensityArray from SA.cpp) ... }
float * engy;
engy = energy; //pass pointer of array energy[0] in SA.cpp to CFE.c
for(n=0; n<NumElem; n++)
{ ... modify engy (e.g. EnergyArray from SA.cpp) ... }
}
```
Am I causing an illegal memory access by trying to access the vector elements from the C portion of my program? Is there any sure way to allow this?
Any help would be much appriciated. | Provided you stay within the bounds of the vector, what you are doing would seem to be OK.
**You can treat a std::vector exactly as if it were a C array by doing what you are doing - taking the address of the first element. The C++ Standard has been changed to specifically allow this kind of usage.**
Can't find a copy of C++ the Technical Corrigendum 2003 at present, but apparently the relevant section ref is 23.2.4, | The code you posted appears to be OK - you'll need to give more detail if you want the problem debugged. Actually, if you run the program in a debugger, it should be able to tell you exactly which line of code is causing the exception (you may have to look in a call stack), or simply step through the program until it crashes.
As for the confusion about whether vector can be treated as a C array, it definitely can by getting the address of the first element (ie., `&vect[0]`) - if the vector contains elements.
The C++03 standard says this about `vector<>` in 23.2.4:
> The elements of a vector are stored contiguously, meaning that if `v` is a `vector<T, Allocator>` where `T` is some type other than `bool`, then it obeys the identity `&v[n] == &v[0] + n` for all `0 <= n < v.size()`
Note that this was not explicitly stated in the C++98 standard (but was still the intent).
See also Herb Sutter's article:
* <http://herbsutter.wordpress.com/2008/04/07/cringe-not-vectors-are-guaranteed-to-be-contiguous/>
Note that `vector<bool>` cannot be treated as a C array - it a special case since the elements in `vector<bool>` are not stored as `bool`. | Accessing public class memory from C++ using C | [
"",
"c++",
"c",
"memory",
"class",
""
] |
I have an app that needs to fire off a couple of events at certain times during the day - the times are all defined by the users. I can think of a couple of ways of doing it but none of them sit too well. The timing doesn't have to be of a particularly high resolution - a minute or so each way is fine.
My ideas :
1. When the app starts up read all the times and start timers off that will Tick at the appropriate time
2. Start a timer off that'll check every minute or so for 'current events'
tia for any better solutions. | * Store/index the events sorted by when they next need attention. This could be in memory or not according to how many there are, how often you make changes, etc. If all of your events fire once a day, this list is basically a circular buffer which only changes when users change their events.
* Start a timer which will 'tick' at the time of the event at the head of the list. Round up to the next minute if you like.
* When the timer fires, process all events which are now in the past [edit - and which haven't already been processed], re-insert them into the list if necessary (i.e. if you don't have the "circular buffer" optimisation), and set a new timer.
Obviously, when you change the set of events, or change the time for an existing event, then you may need to reset the timer to make it fire earlier. There's usually no point resetting it to fire later - you may as well just let it go off and do nothing. And if you put an upper limit of one minute on how long the timer can run (or just have a 1 minute recurring timer), then you can get within 1-minute accuracy without ever resetting. This is basically your option 2.
Arguably you should use an existing framework rather than rolling your own, but I don't know C# so I have no idea what's available. I'm generally a bit wary of the idea of setting squillions of timers, because some environments don't support that (or don't support it well). Hence this scheme, which requires only one. I don't know whether C# has any problems in that respect, but this scheme can easily be arranged to use O(1) RAM if necessary, which can't be beat. | Have a look at [Quartz.Net](http://quartznet.sourceforge.net/). It is a scheduler framework (originally for Java). | Good way of firing an event at a particular time of day? | [
"",
"c#",
"events",
""
] |
I wanted to create an interface for copying an object to a destination object of the same class. The simple way is to use casting:
```
import org.junit.Test;
import org.junit.internal.runners.JUnit4ClassRunner;
import org.junit.runner.RunWith;
@RunWith(JUnit4ClassRunner.class)
public class TestGenerics {
public static interface Copyable {
public void copy(Copyable c);
}
public static class A implements Copyable {
private String aField = "--A--";
protected void innerCopy(Copyable c) {
A a = (A)c;
System.out.println(a.aField);
}
public void copy(Copyable c) {
innerCopy(c);
}
}
public static class B extends A {
private String bField = "--B--";
protected void innerCopy(Copyable c) {
B b = (B)c;
super.innerCopy(b);
System.out.println(b.bField);
}
}
@Test
public void testCopy() {
Copyable b1 = new B();
Copyable b2 = new B();
b1.copy(b2);
}
}
```
But also i've found a way it can be done using generics:
```
import org.junit.Test;
import org.junit.internal.runners.JUnit4ClassRunner;
import org.junit.runner.RunWith;
@RunWith(JUnit4ClassRunner.class)
public class TestGenerics {
public static interface Copyable<T> {
public void copy(T t);
}
public static class A<T extends A<?>> implements Copyable<T> {
private String a = "--A--";
public void copy(T t) {
System.out.println(t.a);
}
}
public static class B<T extends B<?>> extends A<T> {
private String b = "--B--";
public void copy(T t) {
super.copy(t);
System.out.println(t.b);
}
}
@Test
@SuppressWarnings("unchecked")
public void testCopy() {
Copyable b1 = new B();
Copyable b2 = new B();
b1.copy(b2);
}
}
```
Though the only way i've found to get rid of warnings is the annotation. And it feels like something is wrong.
So what's wrong? I can accept that something is wrong in the root of the problem. So any sort of clarification is welcome. | I've learned Scala and now i know that the thing i wanted 2 years ago could have been achieved with **contravariant type parameter** and Scala's type system:
```
trait CopyableTo[-T] {
def copyTo(t: T)
}
class A(private var a: Int) extends CopyableTo[A] {
override def copyTo(t: A) {
println("A:copy")
t.a = this.a
}
}
class B(private var a: Int, private var b: Int) extends A(a) with CopyableTo[B] {
def copyTo(t: B) {
println("B:copy")
super.copyTo(t)
t.b = this.b
}
}
@Test
def zzz {
val b1 = new B(1, 2)
val a1 = new A(3)
val b2 = new B(4, 5)
b1.copyTo(a1)
a1.copyTo(b1)
b1.copyTo(b2)
}
```
Java type system is too weak for this. | Your interface definition:
```
public interface Copyable<T extends Copyable<T>> {
void copy(T copyFrom);
}
```
Your implementation:
```
public class Example implements Copyable<Example> {
private Object data;
void copy(Example copyFrom) {
data = copyFrom.data;
}
//nontrivial stuff
}
```
That should take care of your warnings. | Overriding Java generic methods | [
"",
"java",
"generics",
"contravariance",
""
] |
If I have an XML document like
```
<root>
<element1>
<child attr1="blah">
<child2>blahblah</child2>
<child>
</element1>
</root>
```
I want to get an XML string with the first child element. My output string would be
```
<element1>
<child attr1="blah">
<child2>blahblah</child2>
<child>
</element1>
```
There are many approaches, would like to see some ideas. I've been trying to use Java XML APIs for it, but it's not clear that there is a good way to do this.
thanks | You're right, with the standard XML API, there's not a good way - here's one example (may be bug ridden; it runs, but I wrote it a long time ago).
```
import javax.xml.*;
import javax.xml.parsers.*;
import javax.xml.transform.*;
import javax.xml.transform.dom.*;
import javax.xml.transform.stream.*;
import org.w3c.dom.*;
import java.io.*;
public class Proc
{
public static void main(String[] args) throws Exception
{
//Parse the input document
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(new File("in.xml"));
//Set up the transformer to write the output string
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer();
transformer.setOutputProperty("indent", "yes");
StringWriter sw = new StringWriter();
StreamResult result = new StreamResult(sw);
//Find the first child node - this could be done with xpath as well
NodeList nl = doc.getDocumentElement().getChildNodes();
DOMSource source = null;
for(int x = 0;x < nl.getLength();x++)
{
Node e = nl.item(x);
if(e instanceof Element)
{
source = new DOMSource(e);
break;
}
}
//Do the transformation and output
transformer.transform(source, result);
System.out.println(sw.toString());
}
}
```
It would seem like you could get the first child just by using doc.getDocumentElement().getFirstChild(), but the problem with that is if there is any whitespace between the root and the child element, that will create a Text node in the tree, and you'll get that node instead of the actual element node. The output from this program is:
```
D:\home\tmp\xml>java Proc
<?xml version="1.0" encoding="UTF-8"?>
<element1>
<child attr1="blah">
<child2>blahblah</child2>
</child>
</element1>
```
I think you can suppress the xml version string if you don't need it, but I'm not sure on that. I would probably try to use a third party XML library if at all possible. | Since this is the top google answer and For those of you who just want the basic:
```
public static String serializeXml(Element element) throws Exception
{
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
StreamResult result = new StreamResult(buffer);
DOMSource source = new DOMSource(element);
TransformerFactory.newInstance().newTransformer().transform(source, result);
return new String(buffer.toByteArray());
}
```
I use this for debug, which most likely is what you need this for | How do I extract child element from XML to a string in Java? | [
"",
"java",
"xml",
""
] |
I know there is a Wizard control available but what I want is so simplistic I cannot figure out where I started veering off the deep end here. When a user puts in their name and hits next I want the calendar control to become selecatable for a start date. I have the ability to mark the start date as green. I want them to select away until they hit the continue button. Issue 1 is they can hit next without a date. I want to catch that. Issue two is they can reselect many times before hitting next. I want them to be able to do that. Once they hit next I want them to be able to chose and end date over and over until they hit next. Then I want them to confirm their coices. I guess the logic isn't so simple ... The code I wrote is so bad. :(. Even the proper fixes hurt my head because StartDateStartPart and EndDateStartPart just would become mental gibberish. I am obviously going to have to rethink and redo this from the ground up.
```
<script runat="server" enableviewstate="True">
DateTime begin;
DateTime end;
int iSelectedStart = 0;
int iSelectedEnd = 0;
int iPutName = 0;
protected void Button1_Click(object sender, EventArgs e)
{
if (iPutName == 0)
{
Label1.Text = TextBox1.Text + " you will be slecting your start and end dates.";
LabelInstructions1.Text = "Please select a begin date and hit next";
Calendar1.SelectionMode = System.Web.UI.WebControls.CalendarSelectionMode.Day;
iPutName = 1;
ViewState["iPutName"] = 1;
ViewState["Label1_Text"] = Label1.Text;
ViewState["LabelInstructions1_Text"] = LabelInstructions1.Text;
ViewState["Calendar1_SelectionMode"] = Calendar1.SelectionMode;
}
else
{
if (iSelectedStart <= 0)
{
LabelInstructions1.Text = "You have not selected a start date please do so.";
}
else if (iSelectedStart < 99)
{
iSelectedStart = 99;
Label1.Text = TextBox1.Text + " you will be slecting your start and end dates.";
LabelInstructions1.Text = "Please select an end date and hit confirm";
ViewState["begin"] = begin;
ViewState["iSelectedStart"] = iSelectedStart;
}
else
{
if (iSelectedEnd = 0)
{
LabelInstructions1.Text = "You have not selected a start date please do so.";
}
}
}
}
protected void Calendar1_SelectionChanged(object sender, EventArgs e)
{
if (iSelectedStart < 99)
{
iSelectedStart++;
begin = Calendar1.SelectedDate;
ViewState["iSelectedStart"] = iSelectedStart;
ViewState["begin"] = begin;
}
else
{
if (begin == Calendar1.SelectedDate)
{
LabelInstructions1.Text = "Error you cannot select the same start and end date";
LabelInstructions1.ForeColor = System.Drawing.Color.Red;
}
else
{
end = Calendar1.SelectedDate;
iSelectedEnd = 0;
ViewState["end"] = end;
}
}
}
protected void Calendar1_DayRender(object sender, DayRenderEventArgs e)
{
if (e.Day.Date == begin)
{
e.Cell.BackColor = System.Drawing.Color.Green;
}
if (e.Day.Date == end)
{
e.Cell.BackColor = System.Drawing.Color.Red;
}
}
protected void Page_Load(object sender, EventArgs e)
{
if (ViewState["iPutName"] != null)
iPutName = (int)ViewState["iPutName"];
if (ViewState["Label1_Text"] != null)
Label1.Text = ViewState["Label1_Text"].ToString();
if (ViewState["LabelInstructions1_Text"] != null)
LabelInstructions1.Text = ViewState["LabelInstructions1_Text"].ToString();
if (ViewState["Calendar1_SelectionMode"] != null)
Calendar1.SelectionMode = (CalendarSelectionMode) ViewState["Calendar1_SelectionMode"];
if (ViewState["begin"] != null)
begin = (DateTime)ViewState["begin"];
if (ViewState["end"] != null)
end = (DateTime)ViewState["end"];
}
``` | If you don't want to mess with AJAX, the more traditional way to do this sort of thing with web forms is to use a panel control for each page/form of the wizard, and then hide or reveal the various panels on postback. It's not as fun or cool as the AJAX approach, but if it's really just a simple little wizard then this is a quick and easy way to do that.
The web form might look something like this:
```
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="Default.aspx.cs" Inherits="PanelWizard._Default" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" >
<head runat="server">
<title>Untitled Page</title>
</head>
<body>
<form id="form1" runat="server">
<div>
<asp:Panel ID="wizForm1" runat="server" Height="50px" Width="125px">
<asp:TextBox ID="txtName" runat="server" OnTextChanged="TextBox1_TextChanged"></asp:TextBox></asp:Panel>
</div>
<asp:Panel ID="wizForm2" runat="server" Height="50px" Width="125px" Visible="False">
<asp:Calendar ID="calStart" runat="server"></asp:Calendar>
</asp:Panel>
<asp:Button ID="btnContinue" runat="server" OnClick="btnContinue_Click" Text="Continue" />
</form>
</body>
</html>
```
The page viewstate will manage the value of your controls, which you can then access in the code-behind to implement your business logic as you hide and reveal the panels. For example:
```
namespace PanelWizard
{
public partial class _Default : System.Web.UI.Page
{
protected void btnContinue_Click(object sender, EventArgs e)
{
// validate controls according to business logic
//...
// Hide and reveal panels based on the currently visible panel.
if (wizForm1.Visible)
{
wizForm1.Visible = false;
wizForm2.Visible = true;
}
else if (wizForm2.Visible)
{
// and so on...
}
}
}
}
``` | After much thought I think I need to make a finite state machine with a diagram showing all the possible state transitions. In addition the selection of good varible names and not writing as learning is probably necessary. | ASP.NET Are there good ways to design Wizards? | [
"",
"c#",
"asp.net",
"wizard",
""
] |
I have a FileUpload control (FileUpload1) on my web form, as well as a "Sumbit" button, a label, and a hidden field that contains a UserID. I have the following code in the button's click event:
```
string path = Server.MapPath("~/userfiles/");
if (FileUpload.HasFile)
{
try
{
FileUpload1.SaveAs(path + UserID.Value + "/image.jpg");
}
catch
{
Label1.Text = "* unable to upload file";
Label1.Visible = true;
}
}
```
It works great if I upload an actual file. However, if I type a non-existent filename (for example, "c:\a.jpg", which does not exist on my computer) into the FileUpload's textbox, and click the Sumbit button, HasFile still returns true. Furthermore, SaveAs() does not throw any exceptions, and it is a void function that returns no value indicating success or failure. How do I tell whether a file was actually uploaded? | Just check to see if it exists.
```
if(File.Exists(myFile)){
//it was uploaded.
}
``` | You could check FileUpload.PostedFile.ContentLength property | FileUpload - Verifying that an actual file was uploaded | [
"",
"c#",
".net",
"file-upload",
""
] |
There's a comment in another question that says the following:
> "When it comes to database queries,
> always try and use prepared
> parameterised queries. The mysqli and
> PDO libraries support this. This is
> infinitely safer than using escaping
> functions such as
> mysql\_real\_escape\_string."
[Source](https://stackoverflow.com/revisions/110576/list "source")
So, what i want to ask is: Why are prepared parameterized queries more secure? | An important point that I think people here are missing is that with a database that supports parameterized queries, there is no 'escaping' to worry about. The database engine doesn't combine the bound variables into the SQL statement and then parse the whole thing; The bound variables are kept separate and never parsed as a generic SQL statement.
That's where the security and speed comes from. The database engine knows the placeholder contains data only, so it is never parsed as a full SQL statement. The speedup comes when you prepare a statement once and then execute it many times; the canonical example being inserting multiple records into the same table. In this case, the database engine needs to parse, optimize, etc. only once.
Now, one gotcha is with database abstraction libraries. They sometimes fake it by just inserting the bound variables into the SQL statement with the proper escaping. Still, that is better than doing it yourself. | For one, you're leaving the escaping of dangerous characters to the database, which is a lot safer than you, the human.
... it won't forget to escape, or miss out on any special characters which could be used to inject some malicious SQL. Not to mention, you could possibly get a performance improvement to boot! | Why is using a mysql prepared statement more secure than using the common escape functions? | [
"",
"php",
"mysql",
"security",
"sql-injection",
"prepared-statement",
""
] |
I am using XNA and I want to save files to Vista's "Saved Games" folder.
I can get similar special folders like My Documents with `Environment.GetFolderPath(Environment.SpecialFolder.MyDocuments)` but I cannot find an equivalent for the Saved Games folder. How do I get to this folder? | <http://msdn.microsoft.com/en-us/library/bb200105.aspx#ID2EWD>
Looks like you'll need to use Microsoft.Xna.Framework.Storage and the StorageLocation class to do what you need to.
> Currently, the title location on a PC
> is the folder where the executable
> resides when it is run. Use the
> TitleLocation property to access the
> path.
>
> User storage is in the My Documents
> folder of the user who is currently
> logged in, in the SavedGames folder. A
> subfolder is created for each game
> according to the titleName passed to
> the OpenContainer method. When no
> PlayerIndex is specified, content is
> saved in the AllPlayers folder. When a
> PlayerIndex is specified, the content
> is saved in the Player1, Player2,
> Player3, or Player4 folder, depending
> on which PlayerIndex was passed to
> BeginShowStorageDeviceSelector. | There is no special folder const for it so just use System Variables. According to this Wikipedia article [Special Folders](http://en.wikipedia.org/wiki/Special_Folders), the saved games folder is just:
Saved Games %USERPROFILE%\saved games Vista
So the code would be:
```
string sgPath = System.IO.Path.Combine(Environment.GetEnvironmentVariable("USERPROFILE"), "saved games"));
```
...
EDIT: If, as per the comments, localization is an issue and as per your question you still want access to the Saved Games folder directly rather than using the API, then the following may be helpful.
Using RedGate reflector we can see that GetFolderPath is implemented as follows:
```
public static string GetFolderPath(SpecialFolder folder)
{
if (!Enum.IsDefined(typeof(SpecialFolder), folder))
{
throw new ArgumentException(string.Format(CultureInfo.CurrentCulture, GetResourceString("Arg_EnumIllegalVal"), new object[] { (int) folder }));
}
StringBuilder lpszPath = new StringBuilder(260);
Win32Native.SHGetFolderPath(IntPtr.Zero, (int) folder, IntPtr.Zero, 0, lpszPath);
string path = lpszPath.ToString();
new FileIOPermission(FileIOPermissionAccess.PathDiscovery, path).Demand();
return path;
}
```
So maybe you think all i need is to create my own version of this method and pass it the folder id for Saved Games. That wont work. Those folder ids pre-Vista were actually CSIDLs. A list of them can be found [here](http://msdn.microsoft.com/en-us/library/bb762494.aspx). Note the *Note:* however.
In releasing Vista, Microsoft replaced CLSIDLs with KNOWNFOLDERIDs. A list of KNOWNFOLDERIDs can be found [here](http://msdn.microsoft.com/en-us/library/bb762584(VS.85).aspx). And the Saved Games KNOWNFOLDERID is FOLDERID\_SavedGames.
But you don't just pass the new const to the old, CLSIDL based, SHGetFolderPath Win32 function. As per this article, [Known Folders](http://msdn.microsoft.com/en-us/library/bb776911(VS.85).aspx), and as you might expect, there is a new function called [SHGetKnownFolderPath](http://msdn.microsoft.com/en-us/library/bb762188(VS.85).aspx) to which you pass the new FOLDERID\_SavedGames constant and that will return the path to the Saved Games folder in a localized form. | How do you programatically find Vista's "Saved Games" folder? | [
"",
"c#",
".net",
"xna",
""
] |
I have a column in my table titled 'authorised'. Its default is 0. It needs to be changed to 1 when the user is authorised, but it must be able to be reset to 0. I know I could do this easily with two queries like so:
```
$authorised = Db::query('SELECT authorised FROM users WHERE id=2');
$newAuthValue = ($authorised['authorised']) ? 0 : 1;
Db::query('UPDATE users SET authorised=' . $newAuthValue . ' WHERE id=2');
```
Is there a way to do this with one query? To reverse a Boolean value? | ```
UPDATE users SET `authorised` = IF (`authorised`, 0, 1)
``` | ```
UPDATE `users` SET `authorised` = NOT `authorised` WHERE id = 2
```
This query will also work to negate the field, and is more inline with boolean syntax. | Is there a way in MySQL to reverse a Boolean field with one query? | [
"",
"php",
"mysql",
""
] |
When adding a user control or a project reference to a VS 2008 C# project, I can add only one configuration of the assembly. Is it possible to add separate configurations, depending on the configuration of the container project.
E.g. I am developing a user control, and I am working on a sample application. I want to add the user control so that a debug build of the sample will use the debug build of the user control, and the release build of the sample the release build of the user control.
Any suggestions? | You can do this by editing the csproj file; add a "Condition" attribute to the reference.
```
<Reference Include="Foo" Condition="'$(Configuration)'=='Debug'"/>
<Reference Include="Bar" Condition="'$(Configuration)'=='Release'"/>
```
However, I would have concerns about what this means for unit testing. | ```
<Reference Include="MyLibrary">
<HintPath>..\$(Configuration)\MyLibrary.dll</HintPath>
</Reference>
```
This add a reference "..\Debug\MyLibrary.dll" if compiled in debug mode or ..\Release\MyLibrary.dll" if compiled in release mode. | C# / VS2008: Add separate debug / release references to a project | [
"",
"c#",
"visual-studio-2008",
"project",
""
] |
**Updated:** The actual resolution that the compile box which served my compile request was different. In the slower instance I was running code compiled on a SuSE 9 but running on a SuSE 10 box. That was sufficient difference for me to drop it and compare apples to apples. When using the same compile box the results were as follows:
g++ was about two percent slower
delta real 4 minutes
delta user 4 mintues
delta system 5 seconds
Thanks!
gcc v4.3 vs g++ v4.3 reduced to simplest case used nothing but simple flags
```
#include <stdio.h>
#include <stdlib.h>
int main (int argc, char **argv)
{
int i=0;
int j=0;
int k=0;
int m=0;
int n=0;
for (i=0;i<1000;i++)
for (j=0;j<6000;j++)
for (k=0;k<12000;k++)
{
m = i+j+k;
n=(m+1+1);
}
return 0;
}
```
Is this a known issue? The 15% is very repro. and is across the board for real, system, and user time. I have to wait to post the assembly until tomorrow.
**Update:** I have only tried on one of my compile boxes. I am using SuSE 10. | When compiled with gcc and g++ the only difference I see is within the first 4 lines.
gcc:
```
.file "loops.c"
.def ___main; .scl 2; .type 32; .endef
.text
.globl _main
```
g++:
```
.file "loops.c"
.def ___main; .scl 2; .type 32; .endef
.text
.align 2
.globl _main
```
as you can see the only difference is that with g++, the alignment (2) occurs on a word boundary. This tiny difference seems to be making the significant performance difference.
Here is a page explaining structure alignment, although it is for ARM/NetWinder it is still applicable as it discusses how alignment works on modern CPUs. You will want to read section 7 specifically "What are the disadvantages of word alignment?" :
<http://netwinder.osuosl.org/users/b/brianbr/public_html/alignment.html>
and here is a reference on the .align operation:
<http://www.nersc.gov/vendor_docs/ibm/asm/align.htm>
Benchmarks as requested:
gcc:
```
john@awesome:~$ time ./loopsC
real 0m21.212s
user 0m20.957s
sys 0m0.004s
```
g++:
```
john@awesome:~$ time ./loopsGPP
real 0m22.111s
user 0m21.817s
sys 0m0.000s
```
I reduced the inner-most iteration to 1200. Results aren't as widespread as I had hoped, but then again the assembly output was generated on windows, and the timings done in Linux. Maybe something different is done behind the scenes in MinGW than it is with gcc for Linux alignment-wise. | In order to figure out why its slower you'll probably need to take a look at the assemblies that are produced by the compiler. The g++ compiler must be doing something different from the gcc compiler. | Why is the following program 15% slower when compiled with g++? | [
"",
"c++",
"c",
"performance",
""
] |
I have an application that keeps using up more and more memory as time goes by (while actively running), but there are no leaks. So I know the program isn't doing something totally wrong, which would be easy to find.
Instead I want to track allocations so I can start tracking down the issue, and on a Mac I'd use Instruments, which gives a detailed profile of what objects have been allocated, and by whom, but on Windows what would I use?
Currently I'm working with C/C++ on Windows XP, using VS2005. So any tools for this setup would be great, and hopefully tools that are free or at least provide a few weeks of trial, because it'll take a while to complete any purchase (corporate stuff) if necessary, and I have deadlines.
Thanks!
**Edit:** I'm using VLD, so I know the program has no Leaks, but it seems to be hogging more memory than needed, and not returning it, so I need to track allocations, not leaks. | Memory validator would be ideal for you.
<http://www.softwareverify.com/cpp/memory/index.html> | [Glowcode is here.](http://www.glowcode.com/) It has the worst user interface in the world. The internals have the stuff though, if you have the patience to struggle through the horror that is trying to get it to work right. There is a 21 day free trial. I've found it to be a lifesaver, but you really have to want to find that bug. | What are some good tools for measuring memory allocations on Windows? | [
"",
"c++",
"windows",
"allocation",
""
] |
The spate of questions regarding `BOOST_FOREACH` prompts me to ask users of the Boost library what (if anything) they are doing to prepare their code for portability to the proposed new C++ standard (aka C++0x). For example, do you write code like this if you use `shared_ptr`:
```
#ifdef CPPOX
#include <memory>
#else
#include "boost/shared_ptr.hpp"
#endif
```
There is also the namespace issue - in the future, `shared_ptr` will be part of the `std`, namespace - how do you deal with that?
I'm interested in these questions because I've decided to bite the bullet and start learning boost seriously, and I'd like to use best practices in my code.
**Not exactly a flood of answers - does this mean it's a non-issue? Anyway, thanks to those that replied; I'm accepting jalfs answer because I like being advised to do nothing!** | The simple answer is "do nothing". Boost is not going to remove the libraries that got adopted into 0x. So boost::shared\_ptr will still exist. So you don't need to do anything to maintain portability.
Of course, once 0x is here, a lot of code can be simplified, cleaned up and optimized, but since it's not yet here, that work can't really begin. All you can do is make sure your code will still compile when 0x hits... and it should, just like that. Boost isn't going to delete half their libraries. (I'm not guessing. They've stated this on their mailing list before)
(and if you want to switch to the standard shared\_ptr, I'd say it's probably easier to just do a simple search/replace when the time comes. Replace `#include <boost/shared_ptr.hpp>` with `#include <memory>`, and `boost::shared_ptr` with `std::shared_ptr`)
Or of course, you can just decide on the project that you're going to keep using Boost's `shared_ptr`. Just because it's been added to the standard library doesn't mean you *have* to use it, after all. | Nothing will need to be done because of namespaces. If you want to use the boost implementation you will still use the boost namesapce.
I don't think they would venture into breaking compatibility in such a big way with a previous version.
See my previous similar question here: [what will happen with the overlapping portion of boost once C++0x becomes mainstream?](https://stackoverflow.com/questions/405175/what-will-happen-with-the-overlapping-portion-of-boost-once-c0x-becomes-mainstr)
But of course if you do using namespace a lot in your code you may have some overlapping definitions. You'll have to go back to specifying the namespace explicitly on each use. | Preparing for the next C++ standard | [
"",
"c++",
"boost",
"c++11",
""
] |
I want to make my own malloc/free so I can make a precise copying allocator.
Any gurus have any tips and suggestions?
I have a few questions for now:
1. Should I just malloc large chunks of memory, and then distribute from that so I don't have to call the system calls?
2. How are copying collectors usually done? I would imagine that this part is a bit complicated to do efficiently. My naive implementation would just malloc a block the size of the remaining objects which would require 2x the space. | There's rather a lot of good literature on implementing malloc and similar things. but I notice that you include C++ here -- are you aware that you can write your own implementation of `new` and `delete` in C++? That might be useful as a way to do it easily.
In any case, the characteristics you want are going to depend pretty heavily on your workload, that is, on the pattern of usage over time. If you have only mallocs and new frees, it's easy, obviously. If you have only mallocs of one, or a few different, block sizes, that's also simple.
In other languages, you get some leverage by having the ability to chain memory together, but C isn't that smart.
The basic implementation of malloc simply allocates a header that contains the data length, an "in use flag", and the malloced memory. Malloc then constructs a new header at the end of its space, allocates the memory, and returns a pointer. When you free, it just resets the in use flag.
The trick is that when you do a lot of mallooc and free, you can quickly get a lot of small blobs that aren't in use, but are hard to allocate. So you need some kind of bumpo gc to merge blocks of memory.
You could do a more complicated gc, but remember that takes time; you don't want a free to take up a lot of time.
There's a [nice paper](http://developers.sun.com/solaris/articles/multiproc/multiproc.html) on Solaris malloc implementations you might find interesting. Here's another [on building an alternative malloc](http://www.steubentech.com/%7Etalon/dlmalloc.html), again in Solaris, but the basics are the same. And you should read the [Wikipedia article](http://en.wikipedia.org/wiki/Garbage_collection_(computer_science)) on garbage collection, and follow it to some of the more formal papers.
### Update
You know, you really should have a look at generational garbage collectors. The basic idea is that the longer something remains allocated, the more likely is it to *stay* allocated. This is an extension of the "copying" GC you mention. Basically, you allocate new stuff in one part of your memory pool, call it g0. When you reach a high water mark on that, you look through the allocated blocks and copy the ones that are still in use to another section of memory, call it g1, Then you can just clear the g0 space and start allocating there. Eventually g1 gets to its high water mark and you fix that by clearing g0, and clean up g1 moving stuff to g0, and when you're done, you rename the old g1 as g0 and vice versa and continue.
The trick is that in C especially, the handles you hand out to malloc'ed memory are straight raw pointers; you can't really move things around without some heap big medicine.
### Second update
In comments, @unknown asks "Wouldn't moving stuff around just be a memcpy()". And indeed it would. but consider this timeline:
**warning: this is not complete, and untested, just for illustration, for entertainment only, no warranty express or implied**
```
/* basic environment for illustration*/
void * myMemoryHdl ;
unsigned char lotsOfMemory[LOTS]; /* this will be your memory pool*/
```
You mallocate some memory
```
/* if we get past this, it succeded */
if((myMemoryHdl = newMalloc(SIZE)) == NULL)
exit(-1);
```
In your implementation of malloc, you create the memory and return a pointer to the buffer.
```
unsigned char * nextUnusued = &lotsOfMemory[0];
int partitionSize = (int)(LOTS/2);
int hwm = (int) (partition/2);
/* So g0 will be the bottom half and g1 the top half to start */
unsigned char * g0 = &lotsOfMemory[0];
unsigned char * g1 = &lotsOfMemory[partitionSize];
void * newMalloc(size_t size){
void * rtn ;
if( /* memory COMPLETELY exhausted */)
return NULL;
/* otherwise */
/* add header at nextUnused */
newHeader(nextUnused); /* includes some pointers for chaining
* and a field with values USED or FREE,
* set to USED */
nextUnused += HEADERLEN ; /* this could be niftier */
rtn = nextUnused ;
nextUnused += size ;
}
```
Some of the things are freed
```
newFree(void * aHandle){
*(aHandle-offset) = FREE ; /* set the flag in the header,
* using an offset. */
}
```
So now you do all the stuff and you get to your high water mark.
```
for( /* each block in your memory pool */ )
if( /* block header is still marked USED */ ) {
memcpy(/* block into other partition */);
}
/* clear the partition */
bzero(g0, partitionSize);
```
Now, go back to the original handle you saved in myMemHdl. What does it point to? (Answer, you just set it to 0x00 with bzero(3).)
That's where the magic comes in. In C at least, the pointer you returned from your malloc is no longer under your control -- you can't move it around after the fact. In C++, with user-defined pointer-like types, you can fix that. | It'd be helpful to know a little more about what you're trying to do. Is this for a single type? Or set of relatively uniform types?
* Memory pools are a tried-and-true technique if you need to speed up allocs for a give type (one possible downside is you can be hopping all over memory, affecting cache performance)
* Application-wide allocation techniques usually include rounding all allocs up to profile-driven bucket sizes so that you keep fragmentation down.
* Multi-threaded apps usually have per-thread pools that can be alloc'd from without risking contention with other threads
The doc's for tcmalloc are pretty good at describing the current state of the art for these techniques.
There isn't too much complicated stuff here, but you're probably reinventing
the wheel. There are a few open source libraries that do this. | I want to make my own Malloc | [
"",
"c++",
"c",
"garbage-collection",
"malloc",
""
] |
I'm understanding how events work in C# (am a fair newbie in this field). What I'm trying to understand is why we use events.
Do you know a well coded / architected app which uses events? | To provide a concrete normal world example....
You have a form, the form has a listbox. There's a nice happy class for the listbox. When the user selects something from the listbox, you want to know, and modify other things on the form.
Without events:
You derive from the listbox, overriding things to make sure that your parent is the form you expect to be on.
You override a ListSelected method or something, that manipulates other things on your parent form.
With events:
Your form listens for the event to indicate a user selected something, and manipulates other things on the form.
The difference being that in the without events case you've created a single-purpose class, and also one that is tightly bound to the environment it expects to be in. In the with events case, the code that manipulates your form is localized into your form, and the listbox is just, well, a listbox. | What would be very useful is a non trivial example of an app which uses events (guess it really helps testing too?)
Thoughts so far are:
**Why use Events or publish / subscribe?**
Any number of classes can be notified when an event is raised.
The subscribing classes do not need to know how the Metronome (see code below) works, and the Metronome does not need to know what they are going to do in response to the event
The publisher and the subscribers are decoupled by the delegate. This is highly desirable as it makes for more flexible and robust code. The metronome can change how it detects time without breaking any of the subscribing classes. The subscribing classes can change how they respond to time changes without breaking the metronome. The two classes spin independently of one another, which makes for code that is easier to maintain.
```
class Program
{
static void Main()
{
// setup the metronome and make sure the EventHandler delegate is ready
Metronome metronome = new Metronome();
// wires up the metronome_Tick method to the EventHandler delegate
Listener listener = new Listener(metronome);
ListenerB listenerB = new ListenerB(metronome);
metronome.Go();
}
}
public class Metronome
{
// a delegate
// so every time Tick is called, the runtime calls another method
// in this case Listener.metronome_Tick and ListenerB.metronome_Tick
public event EventHandler Tick;
// virtual so can override default behaviour in inherited classes easily
protected virtual void OnTick(EventArgs e)
{
// null guard so if there are no listeners attached it wont throw an exception
if (Tick != null)
Tick(this, e);
}
public void Go()
{
while (true)
{
Thread.Sleep(2000);
// because using EventHandler delegate, need to include the sending object and eventargs
// although we are not using them
OnTick(EventArgs.Empty);
}
}
}
public class Listener
{
public Listener(Metronome metronome)
{
metronome.Tick += new EventHandler(metronome_Tick);
}
private void metronome_Tick(object sender, EventArgs e)
{
Console.WriteLine("Heard it");
}
}
public class ListenerB
{
public ListenerB(Metronome metronome)
{
metronome.Tick += new EventHandler(metronome_Tick);
}
private void metronome_Tick(object sender, EventArgs e)
{
Console.WriteLine("ListenerB: Heard it");
}
}
```
Full article I'm writing on my site: [http://www.programgood.net/](http://www.programgood.net)
nb some of this text is from <http://www.akadia.com/services/dotnet_delegates_and_events.html>
Cheers. | Why use Events? | [
"",
"c#",
"winforms",
"architecture",
""
] |
In my Django app, I have a Newsletter model. Now I'd like to be able to ***send*** the newsletter (and even ***resend*** it) from Django Admin.
I could do this with a hook on the `Model.save()` method but is there another way that is not tied to the Model?
Thanks. | [Admin actions](http://docs.djangoproject.com/en/dev/ref/contrib/admin/actions/#ref-contrib-admin-actions) allow you to easily hook up custom actions which can be performed on selected items from the admin's list pages. | You can create [**custom django admin actions**](https://docs.djangoproject.com/en/4.1/ref/contrib/admin/actions/#admin-actions).
For example, I have `Person` model below:
```
# "my_app1/models.py"
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=30)
def __str__(self):
return self.name
```
Now, I created `uppercase()` and `lowercase()` admin actions in `Person` admin as shown below. \*`actions = ("uppercase", "lowercase")` is necessary to display `uppercase()` and `lowercase()` admin actions:
```
# "my_app1/admin.py"
from django.contrib import admin, messages
from .models import Person
@admin.register(Person)
class PersonAdmin(admin.ModelAdmin):
actions = ("uppercase", "lowercase") # Necessary
@admin.action(description='Make selected persons uppercase')
def uppercase(modeladmin, request, queryset):
for obj in queryset:
obj.name = obj.name.upper()
obj.save()
messages.success(request, "Successfully made uppercase!")
@admin.action(description='Make selected persons lowercase')
def lowercase(modeladmin, request, queryset):
for obj in queryset:
obj.name = obj.name.lower()
obj.save()
messages.success(request, "Successfully made lowercase!")
```
Then, if I select 2 persons and **Make selected persons uppercase** then click on **Go** as shown below:
[](https://i.stack.imgur.com/wQN1t.png)
I can make 2 persons uppercase as shown below:
[](https://i.stack.imgur.com/Ht0oz.png)
Then, if I select 2 persons and **Make selected persons lowercase** then click on **Go** as shown below:
[](https://i.stack.imgur.com/gpTcQ.png)
I can make 2 persons lowercase as shown below:
[](https://i.stack.imgur.com/lciir.png)
In addition, if I remove `@admin.action()` as shown below
```
# "my_app1/admin.py"
# ...
# @admin.action(description='Make selected persons uppercase')
def uppercase(modeladmin, request, queryset):
for obj in queryset:
obj.name = obj.name.upper()
obj.save()
messages.success(request, "Successfully made uppercase!")
# @admin.action(description='Make selected persons lowercase')
def lowercase(modeladmin, request, queryset):
for obj in queryset:
obj.name = obj.name.lower()
obj.save()
messages.success(request, "Successfully made lowercase!")
```
Actual function names are displayed as shown below:
[](https://i.stack.imgur.com/5sQhq.png) | Custom actions in Django Admin | [
"",
"python",
"django",
"django-admin",
"customization",
"django-admin-actions",
""
] |
I wrote a simple applet to have as a base fr making games, and it's already using up >50% of my CPU. I'm on a 3ghz P4 with 1.5gb ram, so I know it shouldn't take up THAT much.
```
import java.awt.*;
import java.applet.*;
public class applettest extends Applet implements Runnable {
long lastFrame;
public void init() {
(new Thread(this)).start();
}
public void paint(Graphics g) {
g.drawString("Welcome to Java!!", 50, 60 );
}
public void run() {
while(true) {
// code here
repaint();
try{
// wait 16 milliseconds to cap frame rate to 60 fps
while (System.nanoTime() < lastFrame + 160000000) {
Thread.yield();
}
lastFrame = System.nanoTime();
}
catch(Exception e){}
}
}
}
``` | Try replacing your [**busy wait**](http://en.wikipedia.org/wiki/Busy_waiting) with
```
lastFrame = System.currentTimeMillis();
while(true)
{
repaint();
long msSleep = 16 - (System.currentTimeMillis() - lastFrame);
lastFrame = System.currentTimeMillis();
if(nsToSleep > 0)
{
Thread.sleep(msSleep);
}
else
{
Thread.yield(); // Only necessary if you want to guarantee that
// the thread yields the CPU between every frame
}
}
```
This will guarantee that the time between frames is **at least 16ms**. If your render time is less than 16ms, and there aren't any other threads hogging the CPU, it will run at 60fps.
Your original solution will enforce the 16ms minimum, but it has to keep [polling](http://en.wikipedia.org/wiki/Busy_waiting) the system time over and over (which uses the CPU) until the necessary amount of time has passed.
**Notes:**
* `repaint()` is an asynchronous call (i.e. [it will return immediately](http://www.ryerson.ca/~dgrimsha/courses/cps840/repaint.html)) | Sorry that this post is more of the "and for further information..." type than a direct answer, which I think has now been given-- I just thought it was helpful not to get things lost inside comments.
This thread seems to show a lot of (admittedly typical) misunderstanding about what methods like Thread.sleep() and Thread.yield() actually do. I've previously written some material that people may find interesting where I've tried to clear some of these matters up: [Thread.sleep()](http://www.javamex.com/tutorials/threads/sleep.shtml) (including a graph of behaviour under different levels of load), [Thread.yield()](http://www.javamex.com/tutorials/threads/yield.shtml) and-- relatedly though it wasn't mentioned here, people might be interested in my look at [thread priorities](http://www.javamex.com/tutorials/threads/priority.shtml).
Incidentally, there is **generally no benefit in using System.nanoTime()** in this case: you'll just get a time rounded to the nearest millisecond in any case. I'd save yourslef the awkward calculations and potential overhead of retrieving the nanosecond clock time (though the latter is not so bad either) and just use good ole' traditional System.currentTimeMillis(). If your thread oversleeps, just compensate next time by sleeping for less. | Why is this simple applet using up >50% of my CPU? | [
"",
"java",
"applet",
"cpu",
""
] |
I have a base class for some kind of user controls, and in that base class and in its inherited classes I want to store some properties. I use
```
protected override object SaveControlState()
protected override void LoadControlState(object savedState)
```
methods to save or load my custom values. Since I can work only with 1 parameter of type object, I have to use some kind of list if I want to work with more than 1 variable.
I tried to do it with
```
[Serializable]
public class ControlSate : Dictionary<string, object>, ISerializable
{
void ISerializable.GetObjectData(SerializationInfo info,
StreamingContext context)
{
}
public ControlSate(SerializationInfo info, StreamingContext context)
: base(info, context)
{
}
public ControlSate()
: base()
{
}
}
```
but it didn't work, and looking for a solution I have read that Dictionary is not serializable.
So, my question *is what type should I use to work with a set of values in user control's state?* | While `LoadControlState` does pass you an `Object` it is possible for that `Object` to be an `Object[]`. In other words you are more than welcome to store an array of `Objects` in ControlState. I also believe that ControlState is optimized to work with the [`System.Web.UI.Pair`](http://msdn.microsoft.com/en-us/library/system.web.ui.pair.aspx) type so you can create trees of objects in ControlState if you wish.
Please read [this excellent article](http://haacked.com/archive/2007/03/16/gain-control-of-your-control-state.aspx) for the best way of storing multiple values in ControlState. | For storing complex state there is the IStateManager interface. | What type to use to save a set of values in user control's state? | [
"",
"c#",
"asp.net",
"serialization",
"user-controls",
""
] |
I am developing a grails application which uses lot of ajax.If the request is ajax call then it should give response(this part is working), however if I type in the URL in the browser it should take me to the home/index page instead of the requested page.Below is the sample gsp code for ajax call.
```
<g:remoteFunction action="list" controller="todo" update="todo-ajax">
<div id ="todo-ajax">
//ajax call rendered in this area
</div>
```
if we type <http://localhost:8080/Dash/todo/list> in the browser URL bar, the controller should redirect to <http://localhost:8080/Dash/auth/index>
How to validate this in controller. | It's quite a common practice to add this dynamic method in your BootStrap.init closure:
```
HttpServletRequest.metaClass.isXhr = {->
'XMLHttpRequest' == delegate.getHeader('X-Requested-With')
}
```
this allows you to test if the current request is an ajax call by doing:
```
if(request.xhr) { ... }
```
The simplest solution is to add something like this to your todo action:
```
if(!request.xhr) {
redirect(controller: 'auth', action: 'index')
return false
}
```
You could also use filters/interceptors. I've built a solution where I annotated all actions that are ajax-only with a custom annotation, and then validated this in a filter.
Full example of grails-app/conf/BootStrap.groovy:
```
import javax.servlet.http.HttpServletRequest
class BootStrap {
def init = { servletContext ->
HttpServletRequest.metaClass.isXhr = {->
'XMLHttpRequest' == delegate.getHeader('X-Requested-With')
}
}
def destroy = {
}
}
``` | Since Grails 1.1 an `xhr` property was added to the `request` object that allows you to detect AJAX requests. An example of it's usage is below:
```
def MyController {
def myAction() {
if (request.xhr) {
// send response to AJAX request
} else {
// send response to non-AJAX request
}
}
}
``` | Identifying ajax request or browser request in grails controller | [
"",
"java",
"ajax",
"grails",
"gsp",
""
] |
Often when I am coding I just like to print little things (mostly the current value of variables) out to console. I don't see anything like this for Google App Engine, although I note that the Google App Engine Launcher does have a Log terminal. Is there any way to write to said Terminal, or to some other terminal, using Google App Engine? | You'll want to use the Python's standard `logging` module.
```
import logging
logging.info("hello")
logging.debug("hi") # this won't show up by default
```
To see calls to `logging.debug()` in the GoogleAppEngineLauncher Logs console, you have to first add the flag `--dev_appserver_log_level=debug` to your app. However, beware that you're going to see a lot of debug noise from the App Engine SDK itself. The [full set of levels](https://cloud.google.com/appengine/docs/python/refdocs/modules/google/appengine/tools/devappserver2/devappserver2) are:
* `debug`
* `info`
* `warning`
* `error`
* `critical`
You can add the flag by double clicking the app and then dropping it into the **Extra Flags** field.
[](https://i.stack.imgur.com/2LZW5.png) | See <https://cloud.google.com/appengine/docs/python/requests#Python_Logging>
and <http://docs.python.org/library/logging.html>
You probably want to use something like:
```
logging.debug("value of my var is %s", str(var))
``` | How do I write to the console in Google App Engine? | [
"",
"python",
"google-app-engine",
"logging",
"python-logging",
""
] |
I grabbed the following code somewhere off the Internet, and I am using it to decompress gzip files, such as <http://wwwmaster.postgresql.org/download/mirrors-ftp/pgadmin3/release/v1.8.4/src/pgadmin3-1.8.4.tar.gz>, but when I run It, I get an exception, stating that the magic number doesn't match.
```
public byte[] Download(string pUrl) {
WebClient wc = new WebClient();
byte[] bytes = wc.DownloadData(pUrl);
return UnGzip(bytes, 0);
}
private static byte[] UnGzip(byte[] data, int start) {
int size = BitConverter.ToInt32(data, data.Length - 4);
byte[] uncompressedData = new byte[size];
MemoryStream memStream = new MemoryStream(data, start, (data.Length - start));
memStream.Position = 0;
GZipStream gzStream = new GZipStream(memStream, CompressionMode.Decompress);
try {
gzStream.Read(uncompressedData, 0, size);
} catch (Exception gzError) {
throw;
}
gzStream.Close();
return uncompressedData;
}
```
What's wrong with the code that would cause this problem? | The problem is that the URL you specified in your question doesn't actually give a gzip file. It takes the browser to a page where you select a mirror.
If you temporarily change your `Download` method to use:
```
string text = wc.DownloadString(pUrl);
Console.WriteLine(text);
```
you'll see all the HTML for mirror selection.
If you use a URL which is the *actual* gz file, e.g. <http://wwwmaster.postgresql.org/redir/170/h/pgadmin3/release/v1.8.4/src/pgadmin3-1.8.4.tar.gz> then it works fine. | I couldn't get the GZipStream to read the file you linked, but it seems to decompress other GZip files just fine. For example:
<ftp://gnu.mirror.iweb.com/gnu/bash/bash-1.14.0-1.14.1.diff.gz>
<ftp://gnu.mirror.iweb.com/gnu/emacs/elisp-manual-21-2.8.tar.gz>
Perhaps the file you linked is corrupt? Or maybe it uses a non-standard or new GZip format. | Problems decompressing a gzip archive in .NET | [
"",
"c#",
".net",
"compression",
"gzip",
""
] |
I need to send email notifications to users and I need to allow the admin to provide a template for the message body (and possibly headers, too).
I'd like something like `string.Format` that allows me to give named replacement strings, so the template can look like this:
```
Dear {User},
Your job finished at {FinishTime} and your file is available for download at {FileURL}.
Regards,
--
{Signature}
```
What's the simplest way for me to do that? | Use a templating engine. [StringTemplate](http://www.stringtemplate.org/) is one of those, and there are many.
Example:
```
using Antlr.StringTemplate;
using Antlr.StringTemplate.Language;
StringTemplate hello = new StringTemplate("Hello, $name$", typeof(DefaultTemplateLexer));
hello.SetAttribute("name", "World");
Console.Out.WriteLine(hello.ToString());
``` | Here is the version for those of you who can use a new version of C#:
```
// add $ at start to mark string as template
var template = $"Your job finished at {FinishTime} and your file is available for download at {FileURL}."
```
In a line - this is now a fully supported language feature (string interpolation). | What's a good way of doing string templating in .NET? | [
"",
"c#",
".net",
"string",
"templating",
""
] |
I have a program using 3 header files and 3 .cpp files in addition to main.cpp. I'm using VC++ 2008.
Here's the setup. All three headers are guarded with #ifndef HEADERNAME\_H, etc. Also all three headers have corresponding .cpp files, which #include their respective headers.
```
/* main.cpp */
#include "mainHeader.h"
/* mainHeader.h */
#include <windows.h>
#include <iostream>
//Others...
#include "Moo.h"
/* Moo.h */
#include "mainHeader.h"
#include "Foo.h"
class Moo {
private:
int varA;
Foo myFoo1;
Foo myFoo2;
Foo myFoo3;
Public:
void setVarA(int); // defined in Moo.cpp
//etc
};
/* Foo.h */
#include "mainHeader.h"
class Foo { ... };
```
I'm getting compiler errors for instantiating the three Foo's inside of Moo.h:
error C2079: 'Moo::setVarA' uses undefined class 'Foo'
I included Foo.h right there, so why is it undefined? This is the only file that includes Foo.h. I even tried declaring Foo by placing 'class Foo;' before my declaration of class Moo.
I also have #defines in my Foo.h file that are also causing compiler errors when I use them in Moo.h. (undeclared identifier error C2065).
It seems like Foo.h isn't getting included because Moo.h can't find anything defined/declared in it. What's going on?
My actual code is long, but here you go (it's a mario platformer game btw):
This would be Foo.h:
```
//**************************
// Animation.h
//**************************
// Header to Animation class
#ifndef ANIMATION_H
#define ANIMATION_H
#include "../Headers/MarioGame.h"
#define MAX_ANIMATIONS 58
extern char* fileAnimations[MAX_ANIMATIONS];
extern char marioAnims[MAX_ANIMATIONS][3000];
extern char background [3700000];
class Animation
{
private:
int imageCount;
public:
DWORD lastAnimTick;
int lastAnim;
int anims[4][2];
DWORD animsTime[4];
// Constructor
Animation();
// Mutators
void addImage(int left, int right, DWORD time);
void defaultAnimation();
// Accessors
int getImage(bool facingLeft);
int getImageCount();
int getCurLoc();
};
#endif // ANIMATION_H
```
This would be "Moo.h." Note the many private Animation members, all causing errors:
```
//**************************
// Mario.h
//**************************
// Header to Mario class
#ifndef MARIO_H
#define MARIO_H
#include "../Headers/MarioGame.h"
#include "../Headers/Animation.h"
enum { MARIO_TYPE_SMALL,
MARIO_TYPE_BIG,
MARIO_TYPE_LEAF };
class Animation;
class Mario
{
private:
#pragma region Variable Declarations
float xPos;
float yPos;
float xVel;
float yVel;
float lastXVel; //used for determining when walk/run decceleration is complete
float xAccel;
float yAccel;
float xSize;
float ySize;
float halfW;
float halfH;
bool grounded;
bool walking;
bool running;
bool pRunning;
bool jumping;
bool hunching;
bool gliding;
bool flying;
bool decelerating;
int facing;
DWORD pRunTimer;
int pChargeLevel;
DWORD jumpStart;
DWORD glideStart;
int type;
bool updateXMovement;
bool updateYMovement;
bool screenUpLock;
char marioAnims[MAX_ANIMATIONS][3000];
Animation smallStand;
Animation smallWalk;
Animation smallRun;
Animation smallPRun;
Animation smallJump;
Animation smallSkid;
Animation bigStand;
Animation bigWalk;
Animation bigRun;
Animation bigPRun;
Animation bigJump;
Animation bigSkid;
Animation bigHunch;
Animation leafStand;
Animation leafWalk;
Animation leafRun;
Animation leafPRun;
Animation leafJump;
Animation leafSkid;
Animation leafHunch;
Animation leafTailWhack;
Animation leafGlide;
Animation leafFly;
Animation leafFalling;
Animation* lastAnim;
#pragma endregion
public:
//Constructor
Mario();
//Mutators
void setGlideStart( DWORD g );
void setHunching( bool h );
void setGliding( bool g );
void setFlying( bool f );
void setType( int t );
void setPChargeLevel( int c );
void setPRunTimer( DWORD t );
void setScreenUpLock( bool s );
void setUpdateXMovement( bool m );
void setUpdateYMovement( bool m );
void setDecelerating( bool d );
void setPos( float x, float y );
void setVel( float x, float y );
void setAccel( float x, float y );
void setSize( float x, float y );
void setJumping( bool j );
void setJumpStart( DWORD s );
void setGrounded( bool g );
void setWalking( bool w );
void setRunning( bool r );
void setPRunning( bool r );
void setLastXVel( float l );
void setFacing( int f );
void defaultAnimations();
//Accessors
DWORD getGlideStart();
bool getHunching();
bool getGliding();
bool getFlying();
int getType();
int getPChargeLevel();
DWORD getPRunTimer();
bool getScreenUpLock();
bool getUpdateXMovement();
bool getUpdateYMovement();
bool getDecelerating();
float getXPos();
float getYPos();
float getXVel();
float getYVel();
float getXAccel();
float getYAccel();
bool getJumping();
DWORD getJumpStart();
float getXSize();
float getYSize();
float getHalfW();
float getHalfH();
bool getGrounded();
bool getWalking();
bool getRunning();
bool getPRunning();
float getLastXVel();
int getFacing();
int getAnimation();
};
#endif // MARIO_H
```
This would be "mainHeader.h":
```
//**************************
// MarioGame.h
//**************************
// Header to MarioGame functions
// Contains Includes, Defines, Function Declarations, Namespaces for program
#ifndef MARIOGAME_H
#define MARIOGAME_H
//*=====================
// Defines
//*=====================
#define WINDOWED 0 // predefined flags for initialization
#define FULLSCREEN 1
#define WNDCLASSNAME "MarioGame" // window class name
#define WNDNAME "Mario Game" // string that will appear in the title bar
#define NUM_OF_KEYS 5
#define KEY_SPACE 0
#define KEY_UP 1
#define KEY_DOWN 2
#define KEY_RIGHT 3
#define KEY_LEFT 4
#define KEY_CONTROL 5
#define GRIDW 2.0f
#define GRIDH 2.0f
#define PATHING_SIZE 33
//*=====================
// Includes
//*=====================
#include <windows.h>
#include <gl/gl.h>
#include <gl/glu.h>
#include <iostream>
#include <fstream>
#include <vector>
#include <math.h>
#include <WAVEMIX.H>
#include "../Console/guicon.h"
#include "../Headers/Mario.h"
//*=====================
// Function Declarations
//*=====================
LRESULT CALLBACK WinProc(HWND hwnd, UINT msg, WPARAM wparam, LPARAM lparam);
HWND createWindow(HINSTANCE &hinst, int width, int height, int depth);
void renderFrame();
void think();
void loadTextures();
void WMInit(HINSTANCE, HWND);
void resize (int width, int height);
void shutdown();
void keyLeft(bool);
void keyRight(bool);
void keySpace(bool);
void keyDownArrow(bool);
bool checkBoundary(float, float);
void onPlayerDeath();
class Mario;
//*=====================
// Namespaces
//*=====================
using namespace std;
//*=====================
// Global Variable Declarations
//*=====================
extern Mario Player;
extern HDC hdc;
extern HGLRC hglrc;
extern HWND hwnd;
extern int SCRW;
extern int SCRH;
extern int SCRD;
extern DWORD oldTick;
extern DWORD oldTick2;
extern DWORD oldPTime;
extern float pixelZoom;
extern float screenPosX;
extern float screenPosY;
extern float playerScrollMultiplier;
extern float playerTerminalWalkVel;
extern float playerWalkAccel;
extern float playerRunAccel;
extern float playerTerminalRunVel;
extern float playerDecel;
extern float playerPVel;
extern DWORD playerPRunAchieveTime;
extern float playerJumpUpVel;
extern float playerJumpTime;
extern float gravityAccel;
extern float playerTerminalFallVel;
extern float playerTerminalGlideFallVel;
extern bool keyDown[NUM_OF_KEYS];
extern bool lastSpace;
extern bool drawPathingMap;
extern float pathing [PATHING_SIZE][5][2];
#endif // MARIOGAME_H
```
Here's main.cpp:
```
//**************************
// main.cpp
//**************************
// Primary implementation file; handles Win32 interface
#include "../Headers/MarioGame.h"
//*=====================
// WinMain
//*=====================
int WINAPI WinMain(HINSTANCE hinstance, HINSTANCE hprevinstance, LPSTR lpcmdline, int nshowcmd)
{
...
}
//And other functions....
``` | You need a forward declaration for class Foo. For more information refer to item 31 of "Effective C++, Third Edition". Note: if you forward declare Foo that means your class Moo will only be able to have pointers of type Foo.
If something includes Foo.h this is what happens (the arrows show dependency):
Foo.h --includes--> mainHeader.h --includes--> Moo.h --includes--> Foo.h
Note that when class Moo is specified the second Foo.h is not included due to your guards, also class Foo has not been declared yet because that happens after including mainheader.h | The best tool for debugging these sorts of situations is the compiler's "dump preprocessed output to a file" option. If you enable this, you'll most likely see the problem right away. Check your compiler options for how to enable it. | What's wrong with my file dependencies? | [
"",
"c++",
"visual-c++",
"opengl",
"dependencies",
""
] |
I have ObservableCollection<Foo> that is bound to an ItemsControl (basically displaying a list).
Foo mostly looks like this (there are other members but it doesn't implement any interfaces or events):
```
class Foo
{
public string Name { get; set; }
//...
}
```
When the user clicks on an item I open a dialog where the user can edit Foo's properties (bound to a small viewmodel with a Foo property for the selected item), the Xaml looks like this:
```
<TextBox Text="{Binding Foo.Name,Mode=TwoWay}"
Grid.Column="1" Grid.Row="0" Margin="2" />
```
The really strange thing is, **when the user edits the name, the value in the list changes!** (not while typing but after the focus leaves the field)
How does it do that? I haven't implemented the INotifyPropertyChanged interface on the Foo object!
So far I checked that it doesn't just refresh the whole list - only the selected item. But I don't know where I could set a breakpoint to check who's calling.
---
Update: thanks to casperOne for the link to the solution! I'll add a summary here in case it goes 404:
[..] actually you are encountering a another hidden aspect of WPF, that's it WPF's data binding engine will data bind to PropertyDescriptor instance which wraps the source property if the source object is a plain CLR object and doesn't implement INotifyPropertyChanged interface. And the data binding engine will try to subscribe to the property changed event through PropertyDescriptor.AddValueChanged() method. And when the target data bound element change the property values, data binding engine will call PropertyDescriptor.SetValue() method to transfer the changed value back to the source property, and it will simultaneously raise ValueChanged event to notify other subscribers (in this instance, the other subscribers will be the TextBlocks within the ListBox.
And if you are implementing INotifyPropertyChanged, you are fully responsible to implement the change notification in every setter of the properties which needs to be data bound to the UI. Otherwise, the change will be not synchronized as you'd expect. | This is a total guess, but I'm thinking that because you have two-way binding enabled, WPF is now aware of when **it** makes changes, and will update other items it knows is bound to the same instance.
So because you have changed the value of the Name property through the textbox, and WPF knows when you have changed that value, it does its best to update whatever else it knows is bound to it. | Because they're databound to the same object. If you change the binding to
```
{Binding Foo.Name, Mode=TwoWay, UpdateSourceTrigger=PropertyChanged}
```
then they'll be in synch when the user types in the textbox. | WPF Databinding Magic | [
"",
"c#",
"wpf",
"data-binding",
""
] |
I have a web server which can run PHP and Ruby.
I would like to know if there is a PHP program which can do version control of my code similar to SVN?
I know there are already open source project hosting sites which provide this service already but I would like it to be installed on my own host.
I don't have the access to this server to install additional packages either | [<http://sourceforge.net/projects/asvcs/>](http://sourceforge.net/projects/asvcs/) - Haven't tried this. But this sounds like what you are after. | I'm not aware of any version-control system written in PHP. But even if there were one, I'd stay away from it. Version control isn't one of the things a scripting language is best used for.
Edit: I suggest installing Subversion on your local machine and develop all the code there, that way the SVN on your local computer can be used for version-control.
Edit 2: If you are collaborating with others and want them to have access to your repositry, I suggest getting subversion hosting somewhere for your project. There are some free hosts out there that support it, just google it and you should find some results. | Where can I find a good VCS written in PHP? | [
"",
"php",
"version-control",
""
] |
```
if (alMethSign[z].ToString().Contains(aClass.Namespace))
```
Here, I load an exe or dll and check its namespace. In some dlls, there is no namespace, so `aclass.namespace` is not present and it's throwing a `NullReferenceException`.
I have to just avoid it and it should continue with rest of the code. If I use try-catch, it executes the catch part; I want it to continue with the rest of the code. | Is `aClass` a `Type` instance? If so - just check it for null:
```
if (aClass != null && alMethSign[z].ToString().Contains(aClass.Namespace))
``` | Don't catch the exception. Instead, defend against it:
```
string nmspace = aClass.Namespace;
if (nmspace != null && alMethSign[z].ToString().Contains(nmspace))
{
...
}
``` | How to avoid a NullReferenceException | [
"",
"c#",
"exception",
"nullreferenceexception",
""
] |
I want to run the unittests of Jinja2 whenever I change something to make sure I'm not breaking something.
There's [a package full of unit tests](http://dev.pocoo.org/projects/jinja/browser/tests). Basically it's a folder full of Python files with the name "test\_xxxxxx.py"
How do I run all of these tests in one command? | It looks like Jinja uses the [py.test testing tool](http://codespeak.net/py/dist/test.html). If so you can run all tests by just running *py.test* from within the tests subdirectory. | You could also take a look at [nose](http://somethingaboutorange.com/mrl/projects/nose/) too. It's supposed to be a py.test evolution. | How can I run all unit tests of Jinja2? | [
"",
"python",
"unit-testing",
"jinja2",
""
] |
Is there a solution to use a final variable in a Java constructor?
The problem is that if I initialize a final field like:
```
private final String name = "a name";
```
then I cannot use it in the constructor. Java first runs the constructor and then the fields. Is there a solution that allows me to access the final field in the constructor? | I do not really understand your question. That
```
public class Test3 {
private final String test = "test123";
public Test3() {
System.out.println("Test = "+test);
}
public static void main(String[] args) {
Test3 t = new Test3();
}
}
```
executes as follows:
```
$ javac Test3.java && java Test3
Test = test123
``` | Do the initialization in the constructor, e.g.,
```
private final String name;
private YourObj() {
name = "a name";
}
```
Of course, if you actually know the value at variable declaration time, it makes more sense to make it a constant, e.g.,
```
private static final String NAME = "a name";
``` | Initialize final variable before constructor in Java | [
"",
"java",
"constructor",
"variables",
"initialization",
"final",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.