
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I have the following code on my site (using php and smarty) to try and avoid a form resubmitting when I hit f5:
```
if ($this->bln_added == false) {
if (isset($_POST['submit'])) {
$this->obj_site->obj_smarty->assign('title', $_POST['tas_heading']);
$this->obj_site->obj_smarty->assign('desc', $_POST['tas_description']);
}
} else {
$this->obj_site->obj_smarty->assign('title', '');
$this->obj_site->obj_smarty->assign('desc', '');
unset($_POST);
}
```
bln\_added is false by default, but changes to true once the form is successfully submitted. The smarty variables title and desc are used in the template to keep the form content there in case there is a user error and they need to change what they entered.
If the form is submitted successfully it sets bln\_added = true, so the second bit of code should not only clear the form fields, but also empty $\_POST. But if I press f5 the post data is still there.
Any ideas? | Your method could work in theory, but there's a much easier way.
After submitting the form successfully, perform a redirect. It doesn't matter where to, but it'll clear the $\_POST.
```
header('Location: http://www.example.com/form.php');
```
In your case, it sounds like you want to redirect to the page you're already on. Append a $\_GET parameter to the URL if you want to display a confirmation message.
Hope this helps,
Tom | The solution is a pattern commonly known as [Post/Redirect/Get](http://en.wikipedia.org/wiki/Post/Redirect/Get) | Avoiding form resubmit in php when pressing f5 | [
"",
"php",
"form-submit",
""
] |
I am playing with a Silverlight control that has a TextBox and Button. When I click the button (which calls SelectText below), I want to select all the text in the textbox.
Here's my code:
```
private void SelectText()
{
TextBox tb = this.txtFirstName;
tb.SelectionStart = 0;
tb.SelectionLength = 3;
// tb.Select(0, this.txtFirstName.Text.Trim().Length - 1);
// tb.SelectAll();
// tb.Text = String.Empty;
}
```
The commented code is what I tried already, but neither is working.
Anyone have suggestions on what I'm doing wrong? | You might need to give focus to the textbox to see the actual selection happening (either before or after selecting, it might not matter but you'll have to try):
```
private void SelectText()
{
TextBox tb = this.txtFirstName;
tb.SelectionStart = 0;
tb.SelectionLength = 3;
// tb.Select(0, this.txtFirstName.Text.Trim().Length - 1);
// tb.SelectAll();
// tb.Text = String.Empty;
tb.Focus();
}
``` | SelectAll() works -- I've used it more than once. Is something manipulating the text box after this method happens? | Silverlight Programmatically select text | [
"",
"c#",
"silverlight",
""
] |
This code compiles and does execute. It simply print the content
into a binary format. However the output differs from what I expected, namely:
1. Output file size should be much smaller that those created with std::cout.
2. The content of output file should be compressed, hence when we open it in editor,
we should not be able to see the content.
But why the code below doesn't do as I hope it does? How can I modify it accordingly?
```
#include <iostream>
#include <vector>
#include <fstream>
#include <string>
#include <sstream>
using namespace std;
void WriteStr2BinFh(const string& St, ostream &fn)
{
fn.write(St.c_str(), St.length());
}
int main ( int arg_count, char *arg_vec[] ) {
vector <string> Tags;
// In principle we have millions of such tags
// Hence we need to compress it into binary output.
Tags.push_back("0000000000");
Tags.push_back("0000101110");
Tags.push_back("0133030122");
Tags.push_back("0133132033");
Tags.push_back("1002013320");
Tags.push_back("1111111111");
Tags.push_back("1301013133");
Tags.push_back("3010112111");
Tags.push_back("3203012113");
Tags.push_back("3203012212");
//prn_vec<string>(Tags, "\t");
//cout << endl;
ofstream outfile;
outfile.open("MyOut.bin", ios::binary|ios::out);
for (unsigned i=0; i <Tags.size(); i++) {
WriteStr2BinFh(Tags[i]+"\t",outfile);
}
outfile.close();
return 0;
}
``` | You must write data in binary format (not text):
```
void WriteStr2BinFh(const string& St, ostream &fn)
{
char *p = 0;
long l = strtol(St.c_str(), &p);
fn << l;
}
```
You must be aware that types like long have some maximum values, so you will probably have to split your string into n pieces and save as n longs. | > Output file size should be much
> smaller that those created with
> std::cout
What you mean "created with std::cout"?
It could be a little smaller if you will save ints, not strings.
> The content of output file should be
> compressed, hence when we open it in
> editor, we should not be able to see
> the content.
No, it shouldn't be compressed. You could use Boost.Iostreams library <http://www.boost.org/doc/libs/1_38_0/libs/iostreams/doc/index.html> for create zipped files.
For easy understanding you could think that binary file contain information which you could see in debugger when will looking memory.
Also for outputting in binnary format you should use write stream method for all vector items (in case with `std::vector < int >` it will have difference). ( for output \t you could use operator << ) | Content of Binary Output File Created With Output Stream | [
"",
"c++",
"string",
"binaryfiles",
""
] |
How to get latest revision number using SharpSVN? | The least expensive way to retrieve the head revision from a repository
is the Info command.
```
using(SvnClient client = new SvnClient())
{
SvnInfoEventArgs info;
Uri repos = new Uri("http://my.server/svn/repos");
client.GetInfo(repos, out info);
Console.WriteLine(string.Format("The last revision of {0} is {1}", repos, info.Revision));
}
``` | I am checking the latest version of the working copy using SvnWorkingCopyClient:
```
var workingCopyClient = new SvnWorkingCopyClient();
SvnWorkingCopyVersion version;
workingCopyClient.GetVersion(workingFolder, out version);
```
The latest version of the local working repository is then available through
```
long localRev = version.End;
```
For a remote repository, use
```
var client = new SvnClient();
SvnInfoEventArgs info;
client.GetInfo(targetUri, out info);
long remoteRev = info.Revision;
```
instead.
This is similar to using the svnversion tool from the command line. Hope this helps. | How to get latest revision number from SharpSVN? | [
"",
"c#",
"svn",
"sharpsvn",
""
] |
Is there any way to get NHibernate to let me store multiple ChildObjects in the ChildObjectTable but refer them back to different ParentObjects? Or do I have to create a separate ChildObject class/table for each ParentObject type?
I've boiled this down to the following, I'm trying to map these objects:
```
public class ParentObjectA
{
public virtual Int64 Id { get; private set; }
public virtual IDictionary<int, ChildObject> Children { get; private set; }
}
public class ParentObjectB
{
public virtual Int64 Id { get; private set; }
public virtual IDictionary<int, ChildObject> Children { get; private set; }
}
public class ChildObject
{
public virtual Int64 Id { get; private set; }
}
```
into the following table structure:
```
ParentObjectTableA
Id bigint
ParentObjectTableB
Id bigint
ChildObjectTable
Id bigint
ParentId bigint
ParentQualifier varchar(50)
``` | The following maps seem to work from an object perspective. I'm not overly keen on the idea of using crosstables, but I think this might be cleaner than trying to deal with inheritance. I'm going to take a look at that option as well and I'll post my findings here for the sake of completion. Comments welcome.
Mapping of ParentObjectA
```
<map name="Children" table="ParentAxChildObject">
<key column="ParentId" />
<index column="ChildObjectNumber" type="Int32" />
<many-to-many class="ChildObject" />
</map>
```
Mapping of ParentObjectB
```
<map name="Children" table="ParentBxChildObject">
<key column="ParentId" />
<index column="ChildObjectNumber" type="Int32" />
<many-to-many class="ChildObject" />
</map>
```
These generate the following cross tables:
```
ParentAxChildObject
[ParentId] [bigint] NOT NULL,
[elt] [bigint] NOT NULL,
[ChildObjectNumber] [int] NOT NULL,
ParentBxChildObject
[ParentId] [bigint] NOT NULL,
[elt] [bigint] NOT NULL,
[ChildObjectNumber] [int] NOT NULL,
``` | Perhaps you could create an abstract base class for your parent classes? That way, a given child object could refer back to the abstract type for its parent.
For example, you can have a class called ParentBase, which ParentClassA and ParentClassB extend. Your child object will have a reference back to ParentBase.
This is all possible with NHibernate's various [inheritance models](http://www.hibernate.org/hib_docs/nhibernate/1.2/reference/en/html_single/#persistent-classes-inheritance). | NHibernate: How do I map mutiple parents' children of a common type into a single table? | [
"",
"c#",
"nhibernate",
""
] |
What is the best way to choose a random file from a directory in Python?
*Edit:* Here is what I am doing:
```
import os
import random
import dircache
dir = 'some/directory'
filename = random.choice(dircache.listdir(dir))
path = os.path.join(dir, filename)
```
Is this particularly bad, or is there a particularly better way? | ```
import os, random
random.choice(os.listdir("C:\\")) #change dir name to whatever
```
---
Regarding your edited question: first, I assume you know the risks of using a `dircache`, as well as the fact that it is [deprecated since 2.6, and removed in 3.0](http://docs.python.org/library/dircache.html).
Second of all, I don't see where any race condition exists here. Your `dircache` object is basically immutable (after directory listing is cached, it is never read again), so no harm in concurrent reads from it.
Other than that, I do not understand why you see any problem with this solution. It is fine. | The simplest solution is to make use of **os.listdir** & **random.choice** methods
```
random_file=random.choice(os.listdir("Folder_Destination"))
```
---
Let's take a look at it step by step :-
> 1} **os.listdir** method returns the list containing the name of
> entries (files) in the path specified.
>
> 2} This list is then passed as a parameter to **random.choice** method
> which returns a random file name from the list.
>
> 3} The file name is stored in **random\_file** variable.
---
***Considering a real time application***
*Here's a sample python code which will move random files from one directory to another*
```
import os, random, shutil
#Prompting user to enter number of files to select randomly along with directory
source=input("Enter the Source Directory : ")
dest=input("Enter the Destination Directory : ")
no_of_files=int(input("Enter The Number of Files To Select : "))
print("%"*25+"{ Details Of Transfer }"+"%"*25)
print("\n\nList of Files Moved to %s :-"%(dest))
#Using for loop to randomly choose multiple files
for i in range(no_of_files):
#Variable random_file stores the name of the random file chosen
random_file=random.choice(os.listdir(source))
print("%d} %s"%(i+1,random_file))
source_file="%s\%s"%(source,random_file)
dest_file=dest
#"shutil.move" function moves file from one directory to another
shutil.move(source_file,dest_file)
print("\n\n"+"$"*33+"[ Files Moved Successfully ]"+"$"*33)
```
You can check out the whole project on github
***[Random File Picker](https://github.com/THE-PHOENIX-777-TDW/Random-File-Picker.git)***
---
For addition reference about **os.listdir** & **random.choice** method you can refer to *tutorialspoint learn python*
os.listdir :- [Python listdir() method](https://www.tutorialspoint.com/python/os_listdir.htm)
random.choice :- [Python choice() method](https://www.tutorialspoint.com/python/number_choice.htm)
--- | Best way to choose a random file from a directory | [
"",
"python",
"file",
"random",
""
] |
I am trying to compare the length of a dictionary inside a django template
For example, I would like to know the correct syntax to do the following:
```
{% if error_messages %}
<div class="error">
{% if length(error_messages) > 1 %}
Please fix the following errors:
<div class="erroritem">
{% for key, value in error_messages.items %}
<br>{{ value }}
{% endfor %}
</div>
{% else %}
{% for key, value in error_messages.items %}
{{ value }}
{% endfor %}
{% endif %}
</div>
{% endif %}
``` | You could do this, using the [length](http://docs.djangoproject.com/en/dev/ref/templates/builtins/#length) filter and the [ifequal](https://docs.djangoproject.com/en/dev/ref/templates/builtins/#ifequal-and-ifnotequal) tag:
```
{% if error_messages %}
<div class="error">
{% ifequal error_messages|length 1 %}
error_messages[0]
{% else %}
Please fix the following errors:
<div class="erroritem">
{% for key, value in error_messages.items %}
<br>{{ value }}
{% endfor %}
</div>
{% endifequal %}
</div>
{% endif %}
```
Anything else will have to go down the path of [custom tags and filters](http://docs.djangoproject.com/en/dev/howto/custom-template-tags/#howto-custom-template-tags). | You can actually use both the `if` tag and the `length` filter
```
{% if page_detail.page_content|length > 2 %}
<strong><a class="see-more" href="#" data-prevent-default="">
Learn More</a></strong>{% endif %}
```
**NB**
Ensure no spaces between the dictionary/object and the `length` filter when used in the `if` tag so as not to throw an exception. | Django Template: Comparing Dictionary Length in IF Statement | [
"",
"python",
"django",
""
] |
Writing some XML documentation for a predicate helper class. But I can't figure out I can refer to an `Expression<Func<T, bool>>` without getting a syntax error. Is it even possible? I have tried this:
```
<see cref="Expression{Func{T, bool}}"/>
```
But I get a red squiggly line under `{T, bool}}`. This works though:
```
<see cref="Expression{TDelegate}"/>
```
Anyone have a clue?
---
**Update:**
The answer that was given (and I accepted) seemingly did work. But now I have started to get a lot of warnings about stuff not being able to resolve. I have a class called `ExpressionBuilder<T>` which works with `Expression<Func<T, bool>>` a lot. So I of course want to refer to that in my XML comments.
I have tried both versions that I know about:
```
<see cref="Expression<Func<T, Boolean>>"/>
<see cref="Expression{Func{T, Boolean}}"/>
```
But neither work. (And on the last one, ReSharper puts a blue squiggly under `{T,Boolean}}` I get two warnings under compilation everywhere I have used it which says that:
> 1. XML comment on 'blah blah' has cref attribute 'Expression>' that could not be resolved
> 2. Type parameter declaration must be an identifier not a type. See also error CS0081.
Have the same issue somewhere I tried to refer to `Range<Nullable<DateTime>>` (`Range<DateTime?>` didnt work either. Both with { } and with `< >`)
Am I not supposed to refer to these kinds of generics? | There seems to be no way to refer to a generic of a generic in XML documentation, because actually, there's no way to refer to a generic of any specific type.
Lasse V Karlsen's [answer](https://stackoverflow.com/questions/684982/c-xml-doc-how-to-refer-to-expressionfunct-bool-correctly/797364#797364) made it click for me:
If you write `<see cref="IEnumerable{Int32}" />`, the compiler just uses "Int32" as the type parameter name, not the type argument. Writing `<see cref="IEnumerable{HelloWorld}" />` would work just as well. This makes sense because there is no specific page in MSDN for "IEnumerable of int" that your documentation could link to.
To document your class properly, I think you'd have to write something like:
```
<summary>
Returns an <see cref="IEnumerable{T}" /> of <see cref="KeyValuePair{T,U}" />
of <see cref="String" />, <see cref="Int32" />.
</summary>
```
I hope you like text. | What exactly would you like it to link to?
There's no such thing in the documentation as a `Expression<Func<T>>`, so obviously a link to that would not work.
You can link to `Expression<TDelegate>` because that exists.
As for what works or not, neither of the following works in Visual Studio 2008 / .NET 3.5 for me:
```
/// <see cref="Expression<Func<T>>"/>.
/// <see cref="Expression{Func{T}}"/>.
```
But this works:
```
/// <see cref="Expression{T}"/>.
```
so apparently the generic type parameter doesn't have to the same as the one in the declaration. | Referring to a generic type of a generic type in C# XML documentation? | [
"",
"c#",
"visual-studio-2008",
"generics",
"resharper",
"xml-documentation",
""
] |
Our software is written in Java and comprise many (7) projects.
These projects are Netbeans ant projects.
I'm considering to converting them to maven2.
Where can I find some hints for doing such thing? | I discovered that the migration is not necessary. The real requirements that I need was automatic download of dependencies (libraries).
This is also achieved by [Ivy](http://ant.apache.org/ivy/) which nonetheless uses maven repositories.
I solved converting project from ant to ant+ivy with [IvyBeans](http://code.google.com/p/ivybeans/). | Don't read that book. It will only make you confused. Read this book instead: "Maven - The definitive guide" <http://www.sonatype.com/books/maven-book/reference/> .
Also, the maven site has a lot of information, but the structure is terrible so you'll need to use google to navigate in it.
Here is my suggestion:
1. Do this by hand, not with "automagic" "help" from the IDE. Maven integration doesn't work that good yet, not in any IDE.
2. Make sure you program project is divided into modules under a common umbrella module, so that each module produces a single binary artifact (jar, war,...) possibly accompanied by the javadoc of the source code behind that artifact, a zip with the source code etc. The basic principle is that each module produces a single artifact, containing all the non-test-code under that module. You can do this while the project is still built by ant.
3. Each module should conform to the standard maven directory layout. The build destination is under [module]/target/[output-type, e.g. "classes"]. The source code is under [module]/src/main/[src-type e.g. "java"] and [module]/test/[src-type]. The artifact consists of all the code under src/main, and none of the code under src/test, as it built to the target directories. You can do this while the is still built by ant.
4. Start by transforming the sub-module that has no dependencies on other modules in the project.
5. Now you can create the parent maven module pom.xml with artifact type "pom", consisting of one of the modules below. Make a child module for the first submodule (the one with only external dependencies), using the umbrella module as "parent". Remember that you need to specify version for the parent. Remember to add the child module as a "module" in the parent too. Always use ${project.version} as version in the child modules when you create multi-module projects like this. All modules under a parent must be released simultaneously in a single operation, and if you use this setting maven will make sure the version fields stay the same across all modules and gets updated everywhere during the release. This may make it difficult to re-use the existing numbering scheme, but that doesn't matter. You are never going to run out of version numbers anyway.
6. Add the necessary dependencies, and make sure you can build the parent and the child module together using the command "mvn clean install" from the parent module.
7. Proceed with the rest of the modules the same way. Dependencies to other modules under the same parent project should also use ${project.version} as the "version" they are depending on, meaning "the same version as this". NOTE THAT in order to build, the module you are depending on must be built using "mvn install", so that it gets deployed to you local (computer) repository. Otherwise the depending module will not be able to find the classes. There are NO source-code dependencies between modules in maven, only dependencies to built and packed versions installed in local and remote repositories. This can be very confusing if you come from ant-projects. Build from the root module until you get comfortable with this. It takes two days.
8. Don't use maven integration in IDEs. It is a bad idea. Use "mvn idea:idea" or "mvn eclipse:eclipse" to set up your workspace as a non-maven ordinary IDE project. The inter-module dependencies mechanisms in maven and the IDE aren't identical and will never be. Also, if you have several mavenized projects with dependencies in between, you want to have several of these in your workspace with dependencies set up between. You can do this with mvn idea:idea / eclipse:eclipse if you create a separate maven project file called "workspace.xml" (or whatever) in the same directory as parent module, set up as a multi-module project containing modules "." and "../otherproject" (only one-way reference here, no parent ref back). If you run "mvn idea:idea / eclipse:eclipse -f workspace.xml" you get a workspace with all these modules linked together. No IDE integration lets you do that. This sound like a lot of extra work, but the workspace.xml-file is really small. It doesn't have to contain all that dependency stuff and all that, only the reference to the modules you want to bind together in your IDE. | Migrating from ant to maven in Netbeans | [
"",
"java",
"maven-2",
"netbeans",
"ant",
""
] |
I am writing a library in C++ and have some functions that work with modules. An example would look like this:
```
void connect(Module *a, Module *b);
```
The problem is, that it would be sometimes handy if the function accepted also references (some of the Modules may be allocated on the stack and some on the heap and all the &s and \*s get boring and messy soon).
Now I have inlined function that takes references, turns them into pointers and calls the original function.
```
inline void connect(Module &a, Module &b){
connect(&a, &b);
}
```
I don't like this solution much, because for a few more functions it makes a lot of code to write, read, compile, ...
Another thing that was thinking about is adding `Module::operator Module *()` that would hust return `this`.
What are your thoughts on this? Isn't there any potential for epic failure that I missed?
Thanks. | Why not just call the function with
```
connect(&a, &b);
```
like in your inline function, whenever you have to call it with references? This makes it very clear that the function takes pointers, and that `a` and `b` are not pointers. You only have to type two more characters. | Any time you use operator overloading, you raise the possibility of epic fail. The problem is *you* know that you don't mean `*` as a standard pointer operator, but someone naively reading your code doesn't.
The best solution is to go back and refactor/rethink your code, so you don't need two interfaces for the same operation, | C++ functions accepting both pointers and references | [
"",
"c++",
"pointers",
"reference",
"overloading",
""
] |
I am working on a form with a GridView, pulling data from an SQL Express database. The last column will be a Button that I want to be able to change based on what data is bound to that column.
The button will act as an "Enable/Disable" toggle. Basically, if a user is enabled, I want the button to say "Disable" and have the OnClientClick property point to a disable function; if the user is disabled, I want the button to read "Enable" and point to an enable function.
My google-fu is weak today, hoping you all can be some help. Thanks in advance. | try this, i assume your Enabled/Disabled is a bit value in the DB
```
<asp:TemplateField>
<ItemTemplate>
<asp:Button runat="server" ID="btn" Text='<%# "1".Equals(Eval("Enabled").ToString()) ? "Enabled" : "Disabled" %>' OnClick='<%# "1".Equals(Eval("Enabled").ToString()) ? "DISABLE_METHOD" : "ENABLE_METHOD" %>' />
</ItemTemplate>
</asp:TemplateField>
``` | Have the text "Enabled/Disabled" in the dataset that's being used to bind the grid.
Then, utilizing a template column, define the button as thus:
```
<asp:button text='<%# Eval("IsEnabled") %>' runat=server commandname='<%# Eval("IsEnabled") %>' commandargument ='<%# Eval("UserId") %>' id="myButton" />
```
Then, on the grid's RowCommand event, do this:
```
dim btn as button = e.item.findcontrol("myButton")
select case e.Command
case "Enable"
myDisableFunction(e.commandargument)
btn.Text = 'Disable'
btn.Cmmand = 'Disable'
case "Disable"
myEnableFunction(e.commandArgument)
btn.Text = "Enable"
btn.Commandname="Enable"
end case
``` | Change properties of an ASP Button depending on data bound in a GridView? | [
"",
"c#",
".net",
"asp.net",
""
] |
I'm new to generics and all I could find in C# is List[T] - nothing else.
This is the C++ code I have to translate in C#
```
template <class type>
type Read()
{
type t;
int s = sizeof(type);
if(index + s > size)
throw(std::exception("error 101"));
memcpy(&t, stream + index, s);
index += s;
return t;
}
```
Its called like that
```
BYTE mode = Read<BYTE>();
DWORD mode1 = Read<DWORD>();
WORD mode2 = Read<WORD>();
```
Question:How to do that with C# Generics? | Your code seems to mimic the [ReadInt16](http://msdn.microsoft.com/en-us/library/system.io.binaryreader.readint16.aspx), [ReadInt32](http://msdn.microsoft.com/en-us/library/system.io.binaryreader.readint32.aspx) and [ReadInt64](http://msdn.microsoft.com/en-us/library/system.io.binaryreader.readint64.aspx) methods of the [BinaryReader](http://msdn.microsoft.com/en-us/library/system.io.binaryreader.aspx) class.
It's hard to provide a rewrite without knowledge about your global variables. Assuming that stream is a byte array the following code would work.
```
public T Read<T>() where T : struct {
// An T[] would be a reference type, and alot easier to work with.
T[] t = new T[1];
// Marshal.SizeOf will fail with types of unknown size. Try and see...
int s = Marshal.SizeOf(typeof(T));
if (_index + s > _size)
// Should throw something more specific.
throw new Exception("Error 101");
// Grab a handle of the array we just created, pin it to avoid the gc
// from moving it, then copy bytes from our stream into the address
// of our array.
GCHandle handle = GCHandle.Alloc(t, GCHandleType.Pinned);
Marshal.Copy(_stream, _index, handle.AddrOfPinnedObject(), s);
_index += s;
// Return the first (and only) element in the array.
return t[0];
}
``` | This is a function template. You need a class in C#, but something like:
```
public static class Utility
{
public static Type Read<Type>()
{
//Converted code to c# that returns a Type;
}
}
```
You'll probably want to use constraints for this, such as limiting to value-types.
You can call the function like this:
```
Utility.Read<int>();
``` | C#: How to make a Type generic method(byte/word/dword)? | [
"",
"c#",
"generics",
""
] |
If not, maybe you could tell me why.
I get NotSerializableException when my class is being serialized.
Inside the class I am passing this anonymous class to a method:
```
new org.apache.commons.collections.Closure() {
...
};
```
**The question is still unanswered. I want to know if there is a standard Closure interface that implements Serializable** | > Is there a standard closure interface
> that is Serializable?
I guess not. | All references in your class must be of the type Serializable as well, even the Closure type. Is it an interface? It must extend the java.io.Serializable interface.
I.e:
```
interface Closure extends java.io.Serializable {
...
}
class YourClass implements java.io.Serializable {
private Closure closure;
...
public void setClosure(Closure closure) {
this.closure = closure;
}
}
...
private static void main(String[] args) {
YourClass y = new YourClass();
y.setClosure(new Closure() {
...
});
...
```
Edit, clarifications. :) | Is there a standard closure interface that is Serializable? | [
"",
"java",
"serialization",
"closures",
""
] |
I ran across `enable_shared_from_this` while reading the Boost.Asio examples and after reading the documentation I am still lost for how this should correctly be used. Can someone please give me an example and explanation of when using this class makes sense. | It enables you to get a valid `shared_ptr` instance to `this`, when all you have is `this`. Without it, you would have no way of getting a `shared_ptr` to `this`, unless you already had one as a member. This example from the [boost documentation for enable\_shared\_from\_this](http://www.boost.org/doc/libs/1_38_0/libs/smart_ptr/enable_shared_from_this.html):
```
class Y: public enable_shared_from_this<Y>
{
public:
shared_ptr<Y> f()
{
return shared_from_this();
}
}
int main()
{
shared_ptr<Y> p(new Y);
shared_ptr<Y> q = p->f();
assert(p == q);
assert(!(p < q || q < p)); // p and q must share ownership
}
```
The method `f()` returns a valid `shared_ptr`, even though it had no member instance. Note that you cannot simply do this:
```
class Y: public enable_shared_from_this<Y>
{
public:
shared_ptr<Y> f()
{
return shared_ptr<Y>(this);
}
}
```
The shared pointer that this returned will have a different reference count from the "proper" one, and one of them will end up losing and holding a dangling reference when the object is deleted.
`enable_shared_from_this` has become part of C++ 11 standard. You can also get it from there as well as from boost. | from Dr Dobbs article on weak pointers, I think this example is easier to understand (source: <http://drdobbs.com/cpp/184402026>):
...code like this won't work correctly:
```
int *ip = new int;
shared_ptr<int> sp1(ip);
shared_ptr<int> sp2(ip);
```
Neither of the two `shared_ptr` objects knows about the other, so both will try to release the resource when they are destroyed. That usually leads to problems.
Similarly, if a member function needs a `shared_ptr` object that owns the object that it's being called on, it can't just create an object on the fly:
```
struct S
{
shared_ptr<S> dangerous()
{
return shared_ptr<S>(this); // don't do this!
}
};
int main()
{
shared_ptr<S> sp1(new S);
shared_ptr<S> sp2 = sp1->dangerous();
return 0;
}
```
This code has the same problem as the earlier example, although in a more subtle form. When it is constructed, the `shared_pt`r object `sp1` owns the newly allocated resource. The code inside the member function `S::dangerous` doesn't know about that `shared_ptr` object, so the `shared_ptr` object that it returns is distinct from `sp1`. Copying the new `shared_ptr` object to `sp2` doesn't help; when `sp2` goes out of scope, it will release the resource, and when `sp1` goes out of scope, it will release the resource again.
The way to avoid this problem is to use the class template `enable_shared_from_this`. The template takes one template type argument, which is the name of the class that defines the managed resource. That class must, in turn, be derived publicly from the template; like this:
```
struct S : enable_shared_from_this<S>
{
shared_ptr<S> not_dangerous()
{
return shared_from_this();
}
};
int main()
{
shared_ptr<S> sp1(new S);
shared_ptr<S> sp2 = sp1->not_dangerous();
return 0;
}
```
When you do this, keep in mind that the object on which you call `shared_from_this` must be owned by a `shared_ptr` object. This won't work:
```
int main()
{
S *p = new S;
shared_ptr<S> sp2 = p->not_dangerous(); // don't do this
}
``` | What is the usefulness of `enable_shared_from_this`? | [
"",
"c++",
"boost",
"boost-asio",
"tr1",
""
] |
I'm having a hard time trying to implement this method since array subscripts in C++ start with zero. The method add one element to the queue. You can use f (front) and r (rear) pointers and a sequential list of size n. If you find that additional variables are needed fell free. Thanks.
Thats my try but I know its wrong:
```
void QueueAr::enqueue(const Object& x){
prov = (r % n) + 1;
if(prov != f){
r = prov;
queueArray[r] = x;
if(f = -1){
f = 0
}
}else{
//queue is full
}
}
```
How do I work with the pointers? If I start them pointing to NULL I cant use pointer arithmetic. | To implement a queue using plain arrays, just treat it circularly - so as soon as you run out of space in the array, wrap back around to 0. You'll need to keep a record of front and rear, as you note. As an example (where X represents an item in the queue):
```
// Rear is where to enqueue into, Front is where to dequeue from
Empty Array:
| - - - |
Front = -1, Rear = 0
Enqueue()
| X - - |
Front = 0, Rear = 1
Enqueue()
| X X - |
Front = 0, Rear = 2
Dequeue()
| - X - |
Front = 1, Rear = 2
Enqueue()
| - X X |
Front = 1, Rear = 0 // Looped around
Dequeue()
| - - X |
Front = 2, Rear = 0
Enqueue()
| X - X |
Front = 2, Rear = 1
```
You just have to use modular arithmetic to wrap around. Of course, this is limited in size (once you run out of elements, you'd have to allocate more memory), but that's just what you get when dealing with arrays.
Here's some code as a start (I haven't checked it at all):
```
// Private class variables:
// These should be set in the constructor of your queue class
unsigned int rear = 0; // back of the queue
unsigned int front = -1; // front of the queue
unsigned int numStored = 0;
unsigned int length;
Object* array = new Object[length];
QueueAr::Enqueue(Object& obj)
{
if (front == rear)
{
// Throw an exception: queue is full!
}
else
{
array[rear] = obj; // Insert the object at the back
rear++;
rear = rear % length;
numStored++;
}
}
// For kicks, here's the queue code
QueueAr::Dequeue(Object& obj)
{
if (numStored == 0)
{
// Throw an exception: queue is empty!
}
front++;
front = front % length;
numStored--;
}
``` | If you're not using STL, you may want to use a linked list. To enqueue, add to the end of the list. To dequeue, remove from the beginning of the list. You should store pointers for either end of the list for performance and convenience. | enqueue() method adds one element to the queue: how to implement in C++? | [
"",
"c++",
"methods",
"queue",
""
] |
I need to check if some number of years have been since some date. Currently I've got `timedelta` from `datetime` module and I don't know how to convert it to years. | You need more than a `timedelta` to tell how many years have passed; you also need to know the beginning (or ending) date. (It's a leap year thing.)
Your best bet is to use the `dateutil.relativedelta` [object](http://labix.org/python-dateutil), but that's a 3rd party module. If you want to know the `datetime` that was `n` years from some date (defaulting to right now), you can do the following::
```
from dateutil.relativedelta import relativedelta
def yearsago(years, from_date=None):
if from_date is None:
from_date = datetime.now()
return from_date - relativedelta(years=years)
```
If you'd rather stick with the standard library, the answer is a little more complex::
```
from datetime import datetime
def yearsago(years, from_date=None):
if from_date is None:
from_date = datetime.now()
try:
return from_date.replace(year=from_date.year - years)
except ValueError:
# Must be 2/29!
assert from_date.month == 2 and from_date.day == 29 # can be removed
return from_date.replace(month=2, day=28,
year=from_date.year-years)
```
If it's 2/29, and 18 years ago there was no 2/29, this function will return 2/28. If you'd rather return 3/1, just change the last `return` statement to read::
```
return from_date.replace(month=3, day=1,
year=from_date.year-years)
```
Your question originally said you wanted to know how many years it's been since some date. Assuming you want an integer number of years, you can guess based on 365.2425 days per year and then check using either of the `yearsago` functions defined above::
```
def num_years(begin, end=None):
if end is None:
end = datetime.now()
num_years = int((end - begin).days / 365.2425)
if begin > yearsago(num_years, end):
return num_years - 1
else:
return num_years
``` | If you're trying to check if someone is 18 years of age, using `timedelta` will not work correctly on some edge cases because of leap years. For example, someone born on January 1, 2000, will turn 18 exactly 6575 days later on January 1, 2018 (5 leap years included), but someone born on January 1, 2001, will turn 18 exactly 6574 days later on January 1, 2019 (4 leap years included). Thus, you if someone is exactly 6574 days old, you can't determine if they are 17 or 18 without knowing a little more information about their birthdate.
The correct way to do this is to calculate the age directly from the dates, by subtracting the two years, and then subtracting one if the current month/day precedes the birth month/day. | Convert timedelta to years? | [
"",
"python",
"datetime",
"timedelta",
""
] |
I am working on a video processing library in C# and would like to display videos on Windows XP up. For this purpose, I currently use a custom double-buffered `UserControl` with overridden `OnPaint` that uses `Graphics.DrawImageUnscaled`. This works okay, but is not ideal.
Therefore I would like to implement a video display using [hardware overlay](http://en.wikipedia.org/wiki/Hardware_overlay), like so many other video players.
How do I do this? In C#? Or C/C++?
Any help is appreciated. | I ended up using OpenGL via the excellent [OpenTK](http://www.opentk.com) library which works on Windows, Linux and Mac OS X. In effect, I copy frames into a texture which is then mapped onto a quad that fills out the entire viewport. Works like an ace.
Thanks for all your suggestions,
Christian. | Have you looked at using WPF and the [MediaElement Class?](http://msdn.microsoft.com/en-us/library/system.windows.controls.mediaelement.aspx) | Video overlay on Windows (using C#?) | [
"",
"c#",
".net",
"windows",
"video-processing",
""
] |
I have a multi core cpu but the .net app i wrote only uses one of the cores. how can i make it use more than one core when that option is available. | This doesn't happen for free. Using multiple cores necessitates using multiple threads. You will have to explicitly add threading support to your program in order to use multiple cores simultaneously.
Here is a great article exploring how you can take advantage of multiple cores with managed code using the task parallel library (also known as the [parallel extensions framework](http://www.microsoft.com/downloads/details.aspx?FamilyId=348F73FD-593D-4B3C-B055-694C50D2B0F3&displaylang=en)).
<http://msdn.microsoft.com/en-us/magazine/cc163340.aspx> | You can try out the [Microsoft Parallel Extensions to .NET Framework 3.5](http://www.microsoft.com/downloads/details.aspx?FamilyId=348F73FD-593D-4B3C-B055-694C50D2B0F3&displaylang=en#filelist) as JaredPar mentioned, or create a multithread version of your program by yourself.
I would like to add a more concrete example here about how easy it is to convert a "for-loop" from existing program to use the System.Threading.Parallel from the Parallel Extension. For a for-loop that check for every prime between 0 to `maxnum`:
```
System.Threading.Parallel.For(0, maxNum + 1, x => IsPrime(x));
```
Easy, isn't it?
I also conduct a simple benchmark about performance improvement gained from System.Parallel. I hope SO peers don't mind if I post a link to my blog [here](http://m3rlinez.blogspot.com/2009/03/net-parallel-computation-made-easy.html).
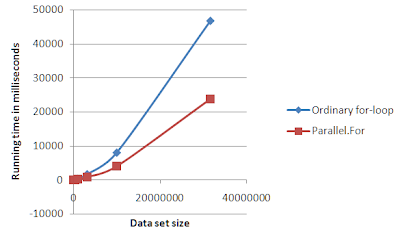 | .net application multi-threading | [
"",
"c#",
"multithreading",
""
] |
I've got a scipt executing in C# using the powershell async execution code on code project here:
<http://www.codeproject.com/KB/threads/AsyncPowerShell.aspx?display=PrintAll&fid=407636&df=90&mpp=25&noise=3&sort=Position&view=Quick&select=2130851#xx2130851xx>
I need to return the $lastexitcode and Jean-Paul describes how you can use a custom pshost class to return it. I can't find any method or property in pshost that returns the exit code.
This engine I have needs to ensure that script executes correctly.
Any help would be appreciated.
regards
Bob.
Its the $lastexitcode and the $? variables I need to bring back.
Hi,
Finally answered.
I found out about the $host variable. It implements a callback into the host, specifically a custom PSHost object, enabling you to return the $lastexitcode. Here is a link to an explanation of $host.
<http://mshforfun.blogspot.com/2006/08/do-you-know-there-is-host-variable.html>
It seems to be obscure, badly documented, as usual with powershell docs. Using point 4, calling $host.SetShouldExit(1) returns 1 to the SetShouldExit method of pshost, as described here.
<http://msdn.microsoft.com/en-us/library/system.management.automation.host.pshost.setshouldexit(VS.85).aspx>
Its really depends on defining your own exit code defintion. 0 and 1 suffixes I guess.
regards
Bob. | Here is a function you can try:
```
function run-process ($cmd, $params) {
$p = new-object System.Diagnostics.Process
$p.StartInfo = new-object System.Diagnostics.ProcessStartInfo
$exitcode = $false
$p.StartInfo.FileName = $cmd
$p.StartInfo.Arguments = $params
$p.StartInfo.UseShellExecute = $shell
$p.StartInfo.WindowStyle = 1; #hidden. Comment out this line to show output in separate console
$null = $p.Start()
$p.WaitForExit()
$exitcode = $p.ExitCode
$p.Dispose()
return $exitcode
}
```
Hope that helps | You can write in your script code that will check the $lastexitcode and will [throw an exception](http://huddledmasses.org/trap-exception-in-powershell/) if the exitcode is not what you excepted.
Exceptions are easier to catch. | How to extract $lastexitcode from c# powershell script execution | [
"",
"c#",
"powershell",
"scripting",
"exit-code",
"pshost",
""
] |
I'm trying to fix this ugly code.
```
RadGrid gv = (RadGrid) (((Control) e.CommandSource).Parent.Parent.Parent.Parent.Parent);
```
I often need to find the first grid that is the parent of the parent of... etc of a object that just raised an event.
The above tends to break when the layout changes and the number of .Parents increase or decreases.
I don't necessarily have a control Id, so I can't use FindControl().
Is there a better way to find the 1st parent grid? | ```
Control parent = Parent;
while (!(parent is RadGrid))
{
parent = parent.Parent;
}
``` | If you really have to find the grid, then you might something like this:
```
Control ct = (Control)e.CommandSource;
while (!(ct is RadGrid)) ct = ct.Parent;
RadGrid gv = (RadGrid)ct;
```
But maybe you can explain why you need a reference to the grid? Maybe there is another/better solution for your problem. | How do I avoid .Parent.Parent.Parent. etc. when referencing control hierarchies? | [
"",
"c#",
"asp.net",
""
] |
I have a Swing application, and even though I have everything in a `try`/`block`, the exception isn't caught.
```
public static void main(String[] args) {
try {
App app = new App();
app.setVisible(true);
} catch (Throwable e) {
System.err.println("never printed");
}
}
```
all I get is this stack trace:
```
Exception in thread "AWT-EventQueue-0"
java.lang.ArrayIndexOutOfBoundsException:
9 >= 9
at java.util.Vector.elementAt(Vector.java:427)
at javax.swing.table.DefaultTableModel.getValueAt(DefaultTableModel.java:633)
at javax.swing.JTable.getValueAt(JTable.java:2695)
at javax.swing.JTable.prepareRenderer(JTable.java:5712)
at javax.swing.plaf.basic.BasicTableUI.paintCell(BasicTableUI.java:2075)
at javax.swing.plaf.basic.BasicTableUI.paintCells(BasicTableUI.java:1977)
at javax.swing.plaf.basic.BasicTableUI.paint(BasicTableUI.java:1773)
at javax.swing.plaf.ComponentUI.update(ComponentUI.java:143)
at javax.swing.JComponent.paintComponent(JComponent.java:763)
at javax.swing.JComponent.paint(JComponent.java:1027)
at javax.swing.JComponent.paintChildren(JComponent.java:864)
at javax.swing.JComponent.paint(JComponent.java:1036)
at javax.swing.JViewport.paint(JViewport.java:747)
at javax.swing.JComponent.paintChildren(JComponent.java:864)
at javax.swing.JComponent.paint(JComponent.java:1036)
at javax.swing.JComponent.paintChildren(JComponent.java:864)
at javax.swing.JComponent.paint(JComponent.java:1036)
at javax.swing.JComponent.paintChildren(JComponent.java:864)
at javax.swing.JComponent.paint(JComponent.java:1036)
at javax.swing.JLayeredPane.paint(JLayeredPane.java:564)
at javax.swing.JComponent.paintChildren(JComponent.java:864)
at javax.swing.JComponent.paintToOffscreen(JComponent.java:5129)
at javax.swing.BufferStrategyPaintManager.paint
(BufferStrategyPaintManager.java:277)
at javax.swing.RepaintManager.paint(RepaintManager.java:1217)
at javax.swing.JComponent.paint(JComponent.java:1013)
at java.awt.GraphicsCallback$PaintCallback.run(GraphicsCallback.java:21)
at sun.awt.SunGraphicsCallback.runOneComponent(SunGraphicsCallback.java:60)
at sun.awt.SunGraphicsCallback.runComponents(SunGraphicsCallback.java:97)
at java.awt.Container.paint(Container.java:1780)
at javax.swing.RepaintManager.paintDirtyRegions(RepaintManager.java:814)
at javax.swing.RepaintManager.paintDirtyRegions(RepaintManager.java:714)
at javax.swing.RepaintManager.seqPaintDirtyRegions(RepaintManager.java:694)
at javax.swing.SystemEventQueueUtilities$ComponentWorkRequest.run
(SystemEventQueueUtilities.java:128)
at java.awt.event.InvocationEvent.dispatch(InvocationEvent.java:209)
at java.awt.EventQueue.dispatchEvent(EventQueue.java:597)
at java.awt.EventDispatchThread.pumpOneEventForFilters
(EventDispatchThread.java:269)
at java.awt.EventDispatchThread.pumpEventsForFilter
(EventDispatchThread.java:184)
at java.awt.EventDispatchThread.pumpEventsForHierarchy
(EventDispatchThread.java:174)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:169)
at java.awt.EventDispatchThread.pumpEvents(EventDispatchThread.java:161)
at java.awt.EventDispatchThread.run(EventDispatchThread.java:122)
``` | As mentioned by another poster, your problem is that the exception is being thrown in another thread, the event dispatch thread. A couple of solutions:
* put a try/catch around the actual code where the exception is occurring: e.g. if it's in response to a button click handled by an ActionListener, put the try/catch inside your actionPerformed() method;
* or, leave the exception as an uncaught exception, and add an [uncaught exception handler](http://www.javamex.com/tutorials/exceptions/exceptions_uncaught_handler.shtml). For example:
```
Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
public void uncaughtException(Thread t, Throwable e) {
// ... do something with exception here ...
}
});
```
On a side-note, you should in principle but your UI startup code in a [SwingUtilities.invokeLater()](http://www.javamex.com/tutorials/threads/invokelater.shtml). | Swing runs things in the event dispatching thread. You are trying to catch it in the main thread.
And note that swing is not thread safe, you too should be doing things in event dispatching thread.
To catch the exception, you can override some method from that stack trace, like the paint method from your component.
And for me that exception does look like a bug you should fix, not something you should hide by catching. | How do I catch this exception in Swing? | [
"",
"java",
"swing",
"exception",
""
] |
> **Possible Duplicate:**
> [Qt equivalent of PathAppend?](https://stackoverflow.com/questions/13014145/qt-equivalent-of-pathappend)
Is there a class that handles file paths in Qt? Particularly I'm looking for something like .NET's Path.Combine.
I know there's one in boost::filesystem but I was wondering if there's one in Qt. | There is [QDir](http://doc.qt.io/qt-4.8/qdir.html) which might be of help (see `QDir::relativeFilePath` and `QDir::canonicalPath` and others).
Quoting from QDir doc:
> A QDir is used to manipulate path
> names, access information regarding
> paths and files, and manipulate the
> underlying file system. | Another class that might be useful is `QFileInfo`.
From Qt documentation:
> The QFileInfo class provides
> system-independent file information.
>
> QFileInfo provides information about a
> file's name and position (path) in the
> file system, its access rights and
> whether it is a directory or symbolic
> link, etc. The file's size and last
> modified/read times are also
> available. QFileInfo can also be used
> to obtain information about a Qt
> resource. | Qt class for handling file paths | [
"",
"c++",
"qt",
""
] |
My study guide (for 70-536 exam) says this twice in the text and encoding chapter, which is right after the IO chapter.
All the examples so far are to do with simple file access using FileStream and StreamWriter.
It aslo says stuff like "If you don't know what encoding to use when you create a file, don't specify one and .NET will use UTF16" and "Specify different encodings using Stream constructor overloads".
Never mind the fact that the actual overloads are on the StreamWriter class but hey, whatever.
I am looking at StreamWriter right now in reflector and I am certain I can see that the default is actaully UTF8NoBOM.
But none of this is listed in the errata. It's an old book (cheked the errat of both editions) so if it was wrong I would have thought someone had picked up on it.....
Makes me think maybe I didn't understand it.
So.....any ideas what it is talking about? Some other place where there is a default?
It's just totally confused me. | “UTF-16” is an annoying term, as it has two meanings which are easily confused.
The first meaning is a series of 16-bit codepoints. Most of these correspond directly to the Unicode character of the same number; characters outside the Basic Multilingual Plane (U+10000 upwards) are stored as two 16-bit codepoints, each one of the [Surrogates](http://en.wikipedia.org/wiki/UTF-16#Encoding_of_characters_outside_the_BMP).
Many languages use UTF-16 in this sense for internal storage purposes, including as a native string type. This is the usual source of phrases like “.NET (or Java) uses UTF-16 as its default encoding”. .NET is accessing the elements of such a UTF-16 string 16 bits at a time (ie, at the implementation level, as a uint16).
The next thing to consider is the encoding of such a UTF-16 string into linear bytes, for storage in a file or network stream. As always when you store larger numbers into bytes, there are two possible encodings: little-endian or big-endian. So you can use “UTF-16LE”, the little-endian encoding of UTF-16 into bytes, or “UTF-16BE”, the big-endian encoding.
(“UTF-16LE” is the more commonly used. Just to add more confusion to the flames, Windows gives it the deeply misleading and ambiguous encoding name “Unicode”. In reality it is almost always better to use UTF-8 for file storage and network streams than either of UTF-16LE/BE.)
But if you don't know whether a bunch of bytes contains “UTF-16LE” or “UTF-16BE”, you can use the trick of looking at the first code point to work it out. This code point, the Byte Order Mark (BOM), is only valid when read one way around, so you can't mistake one encoding for the other.
This approach, of not caring what byte order you have but using a BOM to signal it, is usually referred to under the encoding name... “UTF-16”.
So, when someone says “UTF-16”, you can't tell whether they mean a sequence of short-int Unicode code points, or a sequence of bytes in unspecified order that will decode to one.
(“UTF-32” has the same problem.)
> If you don't know what encoding to use when you create a file, don't specify one and .NET will use UTF16
If that's the actual direct quote it is a lie. Constructing a StreamWriter without an encoding argument [is explicitly specified](http://msdn.microsoft.com/en-us/library/wtbhzte9.aspx) to give you UTF-8. | [The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
by Joel Spolsky](http://www.joelonsoftware.com/articles/Unicode.html) | What does "The .NET framework uses the UTF-16 encoding standard by default" mean? | [
"",
"c#",
".net",
"encoding",
"stream",
""
] |
Forgive me my C++ is incredibly rusty. But I am trying to take some old code and recompile it under Visual C++ 2008. It was originally written for Visual C++ 6.0
The error I am getting is this:
> error C4430: missing type specifier - int assumed. Note: C++ does not support default-int
Ok seems simple enough. But then I look at the offending line of code:
```
operator=(int i) {SetAsInt(i);};
```
And it appears the type IS declared. So what am I missing?
**FOLLOW UP:**
I took Micheals advice and added a return type of the function (the class), and added *return this;* to the end of each. Then I ran across this:
```
operator=(const CString& str);
```
There is no function body defined... what exactly does this mean? | You need to have the `operator=()` method return something (it would assume int if the diagnostic weren't an error, as the error message somewhat confusingly indicates).
Generally it would be a reference to the object the operator is working on so the assignments can be chained as in a normal assignment expression. Something like:
```
// where T is the class for this operator= implementation
T& operator=( int i) {
// ...
return *this;
}
``` | As michael has said, operator= needs a return type, but this type can be void:
```
class A {
...
void operator = ( int i ) {
SetAsInt(i);
}
};
```
although this means you won't be able to "daisy-chain" assignments.
Regarding the follow-up, it's probably saying that assignment for the class is forbidden:
```
class B {
private:
void operator =( const B & );
};
```
Making the assignment op (and usually the copy ctor) private and then not implementing them means it is impossible to assign (or copy) class instances, which is desirable behaviour for most business -oriented classes. | How to convert this VC++ 6 code to VC++ 2008? | [
"",
"c++",
"visual-studio",
"visual-studio-2008",
"visual-c++",
""
] |
I have an application where a bit of parallel processing would be of benefit. For the purposes of the discussion, let's say there is a directory with 10 text files in it, and I want to start a program, that forks off 10 processes, each taking one of the files, and uppercasing the contents of the file. I acknowledge that the parent program can wait for the children to complete using one of the **wait** functions, or using the **select** function.
What I would like to do is have the parent process monitor the progress of each forked process, and display something like a progress bar as the processes run.
My Question.
What would be a reasonable alternatives do I have for the forked processes to communicate this information back to the parent? What IPC techniques would be reasonable to use? | In this kind of situation where you only want to monitor the progress, the easiest alternative is to use shared memory. Every process updates it progress value (e.g. an integer) on a shared memory block, and the master process reads the block regularly. Basically, you don't need any locking in this scheme. Also, it is a "polling" style application because the master can read the information whenever it wants, so you do not need any event processing for handling the progress data. | If the only progress you need is "how many jobs have completed?", then a simple
```
while (jobs_running) {
pid = wait(&status);
for (i = 0; i < num_jobs; i++)
if (pid == jobs[i]) {
jobs_running--;
break;
}
printf("%i/%i\n", num_jobs - jobs_running, num_jobs);
}
```
will do. For reporting progress while, well, in progress, here's dumb implementations of some of the other suggestions.
Pipes:
```
#include <poll.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
int child(int fd) {
int i;
struct timespec ts;
for (i = 0; i < 100; i++) {
write(fd, &i, sizeof(i));
ts.tv_sec = 0;
ts.tv_nsec = rand() % 512 * 1000000;
nanosleep(&ts, NULL);
}
write(fd, &i, sizeof(i));
exit(0);
}
int main() {
int fds[10][2];
int i, j, total, status[10] = {0};
for (i = 0; i < 10; i++) {
pipe(fds[i]);
if (!fork())
child(fds[i][1]);
}
for (total = 0; total < 1000; sleep(1)) {
for (i = 0; i < 10; i++) {
struct pollfd pfds = {fds[i][0], POLLIN};
for (poll(&pfds, 1, 0); pfds.revents & POLLIN; poll(&pfds, 1, 0)) {
read(fds[i][0], &status[i], sizeof(status[i]));
for (total = j = 0; j < 10; j++)
total += status[j];
}
}
printf("%i/1000\n", total);
}
return 0;
}
```
Shared memory:
```
#include <semaphore.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <time.h>
#include <unistd.h>
int child(int *o, sem_t *sem) {
int i;
struct timespec ts;
for (i = 0; i < 100; i++) {
sem_wait(sem);
*o = i;
sem_post(sem);
ts.tv_sec = 0;
ts.tv_nsec = rand() % 512 * 1000000;
nanosleep(&ts, NULL);
}
sem_wait(sem);
*o = i;
sem_post(sem);
exit(0);
}
int main() {
int i, j, size, total;
void *page;
int *status;
sem_t *sems;
size = sysconf(_SC_PAGESIZE);
size = (10 * sizeof(*status) + 10 * sizeof(*sems) + size - 1) & size;
page = mmap(0, size, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1, 0);
status = page;
sems = (void *)&status[10];
for (i = 0; i < 10; i++) {
status[i] = 0;
sem_init(&sems[i], 1, 1);
if (!fork())
child(&status[i], &sems[i]);
}
for (total = 0; total < 1000; sleep(1)) {
for (total = i = 0; i < 10; i++) {
sem_wait(&sems[i]);
total += status[i];
sem_post(&sems[i]);
}
printf("%i/1000\n", total);
}
return 0;
}
```
Error handling etc. elided for clarity. | unix-fork-monitor-child-progress | [
"",
"c++",
"unix",
"parallel-processing",
"fork",
""
] |
I want to create a MathML document from an expression tree using Linq to xml, but I cannot figure out how to use the MathML xml entities (such as and &InvisibleTimes):
When I try to create directly a XElement using
```
XElement xe = new XElement("mo", "&InvisibleTimes");
```
it justs escapes the ampersand (which is no good).
I also tried to use XElement.Parse
```
XElement xe = new XElement.Parse("<mo>&InvisibleTimes</mo>");
```
but it fails with an System.XmlException: Reference to undeclared entity 'InvisibleTimes'
How can I declare the entity or ignore the checks? | As others have pointed out, there is no direct way to do it.
That said, you can try using the corresponding unicode caracther. According to <http://www.w3.org/TR/MathML2/mmlalias.html>, for ApplyFunction it is 02061, try new XElement("mo", "\u02061") | According to [this thread](http://social.msdn.microsoft.com/forums/en-US/linqprojectgeneral/thread/abd9d8cc-30cc-45f1-8bd9-652a15b2b491), LINQ to XML doesn't include entity references: it doesn't have any node type for them. It just expands them as it loads a file, and after that you've just got "normal" characters. | Linq to Xml and custom xml entities | [
"",
"c#",
"xml",
"linq",
"mathml",
""
] |
What would be the best way to see (in a 2 player) game of Tic Tac Toe who won? Right now I'm using something similar to the following:
```
if (btnOne.Text == "X" && btnTwo.Text == "X" && btnThree.Text == "X")
{
MessageBox.Show("X has won!", "X won!");
return;
}
else
// I'm not going to write the rest but it's really just a bunch
// if statements.
```
So how do I get rid of the multiple if's? | Something alongs:
```
rowSum == 3 || columnSum == 3 || diagnolSum == 3
```
.. ? | If you store your buttons in a multidimenstional array, you can write some extension methods to get the rows, columns and diagonals.
```
public static class MultiDimensionalArrayExtensions
{
public static IEnumerable<T> Row<T>(this T[,] array, int row)
{
var columnLower = array.GetLowerBound(1);
var columnUpper = array.GetUpperBound(1);
for (int i = columnLower; i <= columnUpper; i++)
{
yield return array[row, i];
}
}
public static IEnumerable<T> Column<T>(this T[,] array, int column)
{
var rowLower = array.GetLowerBound(0);
var rowUpper = array.GetUpperBound(0);
for (int i = rowLower; i <= rowUpper; i++)
{
yield return array[i, column];
}
}
public static IEnumerable<T> Diagonal<T>(this T[,] array,
DiagonalDirection direction)
{
var rowLower = array.GetLowerBound(0);
var rowUpper = array.GetUpperBound(0);
var columnLower = array.GetLowerBound(1);
var columnUpper = array.GetUpperBound(1);
for (int row = rowLower, column = columnLower;
row <= rowUpper && column <= columnUpper;
row++, column++)
{
int realColumn = column;
if (direction == DiagonalDirection.DownLeft)
realColumn = columnUpper - columnLower - column;
yield return array[row, realColumn];
}
}
public enum DiagonalDirection
{
DownRight,
DownLeft
}
}
```
And if you use a `TableLayoutPanel` with 3 rows and 3 columns, you can easily create your buttons programmably and store it into a `Button[3, 3]` array.
```
Button[,] gameButtons = new Button[3, 3];
for (int row = 0; column <= 3; row++)
for (int column = 0; column <= 3; column++)
{
Button button = new Button();
// button...
gameLayoutPanel.Items.Add(button);
gameButtons[row, column] = button;
}
```
And to check for a winner:
```
string player = "X";
Func<Button, bool> playerWin = b => b.Value == player;
gameButtons.Row(0).All(playerWin) ||
// ...
gameButtons.Column(0).All(playerWin) ||
// ...
gameButtons.Diagonal(DiagonalDirection.DownRight).All(playerWin) ||
// ...
``` | Checking for winner in TicTacToe? | [
"",
"c#",
"if-statement",
""
] |
In CodeIgniter, or core PHP; is there an equivalent of Rails's view partials and templates?
A partial would let me render another view fragment inside my view. I could have a common `navbar.php` view that I could point to the inside my `homepage.php` view. Templates would define the overall shell of an HTML page in one place, and let each view just fill in the body.
The closest thing I could find in the CodeIgniter documentation was [Loading multiple views](http://codeigniter.com/user_guide/general/views.html), where several views are rendered sequentially in the controller. It seems strange to be dictating the visual look of my page inside the controller. (i.e. to move the navbar my designer would have to edit the controller).
I've been searching on stack**overflow** for a PHP way to accomplish this. I have found [this page](https://stackoverflow.com/questions/761922/can-you-render-a-php-file-into-a-variable), which talks about simulating partials with [ob\_start](https://www.php.net/ob_start). Is that the recommended approach inside CodeIgniter? | I may be breaking some MVC rule, but I've always just placed my "fragments" in individual views and load them, CodeIgniter style, from within the other views that need them. Pretty much all of my views load a header and footer view at the top and bottom, respectively:
```
<? $this->load->view( "header" ); ?>
//Page content...
<? $this->load->view( "footer" ); ?>
```
The header could then include a NavBar in the same fashion, etc. | this is essentially what I use:
```
function render_partial($file, $data = false, $locals = array()) {
$contents = '';
foreach($locals AS $key => $value) {
${$key} = $value;
}
${$name . '_counter'} = 0;
foreach($data AS $object) {
${$name} = $object;
ob_start();
include $file;
$contents .= ob_get_contents();
ob_end_clean();
${$name . '_counter'}++;
}
return $contents;
}
```
this allows you to call something like:
```
render_partial('/path/to/person.phtml', array('dennis', 'dee', 'mac', 'charlie'), array('say_hello' => true));
```
and in /path/to/person.phtml have:
```
<?= if($say_hello) { "Hello, " } ?><?= $person ?> (<?= $person_counter ?>)
```
this is some magic going on though that may help you get a better picture of what's going on. full file: [view.class.php](http://vh1.cjb.net/gitweb/?p=gko.git;a=blob;f=core/lib/view.class.php;h=12ea5023ebbfaf16b41d10686a86c19796be198c;hb=HEAD) | CodeIgniter or PHP Equivalent of Rails Partials and Templates | [
"",
"php",
"codeigniter",
"partials",
""
] |
I was wondering which is the best way to turn a string (e.g. a post title) into a descriptive URL.
the simplest way that comes to mind is by using a regex, such in:
```
public static Regex regex = new Regex(
"\\W+",
RegexOptions.IgnoreCase
| RegexOptions.CultureInvariant
| RegexOptions.IgnorePatternWhitespace
| RegexOptions.Compiled
);
string result = regex.Replace(InputText,"_");
```
which turns
"my first (yet not so bad) cupcake!! :) .//\."
into
```
my_first_yet_not_so_bad_cupcake_
```
then I can strip the last "\_" and check it against my db and see if it's yet present. in that case I would add a trailing number to make it unique and recheck.
I could use it in, say
```
http://myblogsite.xom/posts/my_first_yet_not_so_bad_cupcake
```
but, is this way safe? should i check other things (like the length of the string)
is there any other, better method you prefer?
thanks | Here's what I do. regStripNonAlpha removes all the non-alpha or "-" characters. Trim() removes trailing and leading spaces (so we don't end up with dashes on either side). regSpaceToDash converts spaces (or runs of spaces) into a single dash. This has worked well for me.
```
static Regex regStripNonAlpha = new Regex(@"[^\w\s\-]+", RegexOptions.Compiled);
static Regex regSpaceToDash = new Regex(@"[\s]+", RegexOptions.Compiled);
public static string MakeUrlCompatible(string title)
{
return regSpaceToDash.Replace(
regStripNonAlpha.Replace(title, string.Empty).Trim(), "-");
}
``` | string result = regex.Replace(InputText,"-");
instead of under score put hypen (-) that would give added advantage for Google search engine.
See below post for more details
<http://www.mattcutts.com/blog/dashes-vs-underscores/> | best way to turn a post title into an URL in c# | [
"",
"c#",
"regex",
"url",
""
] |
Google search turns up some links to tsql questions. I was wondering what would SO experts would ask in an interview for TSQL. | Here are some of the most common questions I've been asked as an ASP.Net developer with strong SQL Server skills:
* Name and describe the different kinds of JOINs
* What is COALESCE?
* Explain primary and foreign keys
* What would you do to optimize slow-running queries?
* What is the difference between DELETE and TRUNCATE? | There are a bunch of questions here: [SQL Server Quiz, Can You Answer All These?](http://blogs.lessthandot.com/index.php/DataMgmt/DataDesign/sql-server-quiz-can-you-answer-all-these)
A biggie is of course how can you code to minimize deadlocks
Take the code below for example, 80% of people get that wrong
What will be the output of the following?
```
SELECT 3/2
``` | TSQL interview questions you ask | [
"",
"sql",
"sql-server",
"t-sql",
""
] |
In the course of my maintenance for an older application that badly violated the cross-thread update rules in winforms, I created the following extension method as a way to quickly fix illegal calls when I've discovered them:
```
/// <summary>
/// Execute a method on the control's owning thread.
/// </summary>
/// <param name="uiElement">The control that is being updated.</param>
/// <param name="updater">The method that updates uiElement.</param>
/// <param name="forceSynchronous">True to force synchronous execution of
/// updater. False to allow asynchronous execution if the call is marshalled
/// from a non-GUI thread. If the method is called on the GUI thread,
/// execution is always synchronous.</param>
public static void SafeInvoke(this Control uiElement, Action updater, bool forceSynchronous)
{
if (uiElement == null)
{
throw new ArgumentNullException("uiElement");
}
if (uiElement.InvokeRequired)
{
if (forceSynchronous)
{
uiElement.Invoke((Action)delegate { SafeInvoke(uiElement, updater, forceSynchronous); });
}
else
{
uiElement.BeginInvoke((Action)delegate { SafeInvoke(uiElement, updater, forceSynchronous); });
}
}
else
{
if (!uiElement.IsHandleCreated)
{
// Do nothing if the handle isn't created already. The user's responsible
// for ensuring that the handle they give us exists.
return;
}
if (uiElement.IsDisposed)
{
throw new ObjectDisposedException("Control is already disposed.");
}
updater();
}
}
```
Sample usage:
```
this.lblTimeDisplay.SafeInvoke(() => this.lblTimeDisplay.Text = this.task.Duration.ToString(), false);
```
I like how I can leverage closures to read, also, though forceSynchronous needs to be true in that case:
```
string taskName = string.Empty;
this.txtTaskName.SafeInvoke(() => taskName = this.txtTaskName.Text, true);
```
I don't question the usefulness of this method for fixing up illegal calls in legacy code, but what about new code?
Is it good design to use this method to update UI in a piece of new software when you may not know what thread is attempting to update the ui, or should new Winforms code generally contain a specific, dedicated method with the appropriate `Invoke()`-related plumbing for all such UI updates? (I'll try to use the other appropriate background processing techniques first, of course, e.g. BackgroundWorker.)
Interestingly this won't work for [ToolStripItems](http://msdn.microsoft.com/en-us/library/system.windows.forms.toolstripitem.aspx). I just recently discovered that they derive directly from [Component](http://msdn.microsoft.com/en-us/library/system.componentmodel.component.aspx) instead of from [Control](http://msdn.microsoft.com/en-us/library/system.windows.forms.control.aspx). Instead, the containing `ToolStrip`'s invoke should be used.
## Followup to comments:
Some comments suggest that:
```
if (uiElement.InvokeRequired)
```
should be:
```
if (uiElement.InvokeRequired && uiElement.IsHandleCreated)
```
Consider the following [msdn documentation](http://msdn.microsoft.com/en-us/library/system.windows.forms.control.invokerequired.aspx):
> This means that InvokeRequired can
> **return false** if Invoke is not required
> (the call occurs on the same thread),
> or **if the control was created on a
> different thread but the control's
> handle has not yet been created.**
>
> In the case where the control's handle
> has not yet been created, you should
> not simply call properties, methods,
> or events on the control. This might
> cause the control's handle to be
> created on the background thread,
> isolating the control on a thread
> without a message pump and making the
> application unstable.
>
> **You can protect against this case by
> also checking the value of
> IsHandleCreated when InvokeRequired
> returns false on a background thread.**
If the control was created on a different thread but the control's handle has not yet been created, `InvokeRequired` returns false. This means that if `InvokeRequired` returns `true`, `IsHandleCreated` will always be true. Testing it again is redundant and incorrect. | I like the general idea, but I do see one problem. It is important to process EndInvokes, or you can have resource leaks. I know a lot of people don't believe this, but it really is true.
[Here's one link talking about it](http://www.interact-sw.co.uk/iangblog/2005/05/16/endinvokerequired). There are others as well.
But the main response I have is: Yes, I think you've got a nice idea here. | You should create Begin and End extension methods as well. And if you use generics, you can make the call look a little nicer.
```
public static class ControlExtensions
{
public static void InvokeEx<T>(this T @this, Action<T> action)
where T : Control
{
if (@this.InvokeRequired)
{
@this.Invoke(action, new object[] { @this });
}
else
{
if (!@this.IsHandleCreated)
return;
if (@this.IsDisposed)
throw new ObjectDisposedException("@this is disposed.");
action(@this);
}
}
public static IAsyncResult BeginInvokeEx<T>(this T @this, Action<T> action)
where T : Control
{
return @this.BeginInvoke((Action)delegate { @this.InvokeEx(action); });
}
public static void EndInvokeEx<T>(this T @this, IAsyncResult result)
where T : Control
{
@this.EndInvoke(result);
}
}
```
Now your calls get a little shorter and cleaner:
```
this.lblTimeDisplay.InvokeEx(l => l.Text = this.task.Duration.ToString());
var result = this.BeginInvokeEx(f => f.Text = "Different Title");
// ... wait
this.EndInvokeEx(result);
```
And with regards to `Component`s, just invoke on the form or container itself.
```
this.InvokeEx(f => f.toolStripItem1.Text = "Hello World");
``` | Is it appropriate to extend Control to provide consistently safe Invoke/BeginInvoke functionality? | [
"",
"c#",
"winforms",
"controls",
"extension-methods",
"invoke",
""
] |
I'm not talking about generic classes that declare properties or fields with the type of a generic parameter. I'm talking about generic properties which could be applied to both generic and non-generic classes.
I'm not talking about this:
```
public class Base<T>
{
public T BaseProperty { get; set; }
}
```
I'm talking about this:
```
public class Base
{
public T BaseProperty<T>
{
get
{
// Insert magic
}
set
{
// Insert magic
}
}
}
```
Or this:
```
public class Base<U>
{
public T BaseProperty<T>
{
get
{
// Insert magic
}
set
{
// Insert magic
}
}
public U OtherBaseProperty { get; set; }
}
```
The usage would go something like this:
```
var b = new Base();
b.BaseProperty<int> = 42;
int i = b.BaseProperty<int>;
b.BaseProperty<string> = "Hi";
string s = b.BaseProperty<string>;
```
Or for the second example:
```
var b = new Base<string>();
b.BaseProperty<int> = 42;
int i = b.BaseProperty<int>;
b.OtherBaseProperty = "Hi";
string s = b.OtherBaseProperty;
```
The // Insert Magic refers to handling each call to the generic property getter or setter that has a different type for the type parameter.
For example this:
```
b.BaseProperty<int> = 42;
```
Needs to be handled differently to:
```
b.BaseProperty<string> = "Hi";
```
I would envisage that for each type T if the getter is called before the setter is called then default(T) is returned.
When the setter is called the value is stored per type T so that when the getter is subsequently called the previous value that was set for that type is returned.
Note that under the covers properties are just methods.
**Do you think this would be useful?** | I've had a couple of times where I would have liked the ability to do this, yes.
However, the syntax involved would be pretty ugly, and it's sufficiently rarely useful that I think I prefer to just suck it up and go with generic methods. | No . | Do you think generic properties would be useful in .NET? | [
"",
"c#",
".net",
"generics",
"c#-3.0",
"properties",
""
] |
How do I build a query in Subsonic that of this format
> (ConditionA OR ConditionB) AND
> ConditionC
Iv tried various approaches but I cant seem to get the desired result.
Here is one thing i tired:
```
Query q = Challenge.CreateQuery();
q.WHERE(Challenge.Columns.ChallengeeKey, playerKey)
.OR(Challenge.Columns.ChallengerKey, playerKey);
q.AND(Challenge.Columns.Complete, false);
``` | I'm using Subsonic 2.2, I tried a few variations on Rob's example but kept getting an exception with the message: "Need to have at least one From table specified"
In the end this achieved the desired result:
```
Challenge challenge = new Select().From(Challenge.Schema)
.WhereExpression(Challenge.Columns.ChallengerKey).IsEqualTo(playerKey)
.Or(Challenge.Columns.ChallengerKey).IsGreaterThan(playerKey)
.AndExpression(Challenge.Columns.Complete).IsEqualTo(false)
.ExecuteSingle<Challenge>();
``` | If you use 2.2 (or 2.1) you can open up expressions:
```
Northwind.ProductCollection products = new Select(Northwind.Product.Schema)
.WhereExpression("categoryID").IsEqualTo(5).And("productid").IsGreaterThan(10)
.OrExpression("categoryID").IsEqualTo(2).And("productID").IsBetweenAnd(2, 5)
.ExecuteAsCollection<Northwind.ProductCollection>();
```
You can read a bit more here:
<http://blog.wekeroad.com/subsonic/subsonic-version-21-pakala-preview-the-new-query-tool/> | Subsonic Query (ConditionA OR ConditionB) AND ConditionC | [
"",
"c#",
"subsonic",
""
] |
If you've used Memcheck (from Valgrind) you'll probably be familiar with this message...
> Conditional jump or move depends on uninitialized value(s)
~~I've read about this and it simply occurs when you use an uninitialized value.~~
```
MyClass s;
s.DoStuff();
```
This will work because `s` is automatically initialized... So if this is the case, and it works, why does Memcheck tell me that it's uninitialized? Should the message be ignored?
Perhaps I misunderstood where the error was directing me. From the Valgrind manual, the actual erroneous snippet is...
```
int main()
{
int x;
printf ("x = %d\n", x);
}
```
However, in my code, I can't see anything like that. I have noticed however that the function at the top of the stack trace Memcheck shows me is a virtual function; could this be something to do with it?
```
==14446== Conditional jump or move depends on uninitialised value(s)
==14446== at 0x414164: vimrid::glut::GlutApplication::FinishRender() (GlutApplication.cpp:120)
==14446== by 0x422434: vimrid::demos::filterdemos::FilterDemo3::Render() (FilterDemo3.cpp:260)
==14446== by 0x412D3D: vimrid::VimridApplication::UpdateAndRender() (VimridApplication.cpp:93)
==14446== by 0x4144BA: vimrid::glut::GlutApplication::glutHandleDisplay() (GlutApplication.cpp:201)
==14446== by 0x41486A: vimrid::glut::GlutApplication::glutCallbackDisplay() (GlutApplication.cpp:277)
==14446== by 0x54D9FAA: (within /usr/lib64/libglut.so.3.8.0)
==14446== by 0x54DDA4A: fgEnumWindows (in /usr/lib64/libglut.so.3.8.0)
==14446== by 0x54DA4A3: glutMainLoopEvent (in /usr/lib64/libglut.so.3.8.0)
==14446== by 0x54DAEB5: glutMainLoop (in /usr/lib64/libglut.so.3.8.0)
==14446== by 0x413FF8: vimrid::glut::GlutApplication::Run() (GlutApplication.cpp:112)
==14446== by 0x41249D: vimrid::Launcher::runDemo(vimrid::VimridSettings&) (Launcher.cpp:150)
==14446== by 0x412767: vimrid::Launcher::Launch(int, char**) (Launcher.cpp:62)
```
### Update 1:
I took a look at GlutApplication.cpp:120, and it looks like the uninitialized variable was being passed in to a function on that line. Simple! | Can you post a more complete sample? It's hard to see how there would be that particular error with out some form of goto or flow changing statement.
I most commonly see this error in code like the following
```
MyClass s1;
...
if ( someCondition ) {
goto Foo:
}
MyClass s2;
Foo:
cout << s2.GetName();
```
This code is fundamentally incorrect. The reason why is that even though s2 has a constructor, it's not executed if someCondition is true. The goto statement will jump over the initialization and at the last line of the program s2 will be uninitialized and essentially point to garbage.
**EDIT**
You may also want to check out this page which gives hints on how to decipher this particular valgrind error
<https://computing.llnl.gov/code/memcheck/#deciphering4>
**Addendum**
Another common cause for this I've just found is when you pass over some integer constants to a variadic function, which are put on the stack as ints, but when the callee gets it as longs, you've got a problem on 64-bit machines.
I was almost about to give up and just consider valgrind being stupid, then I've realised that simply casting it to long fixes it.
So my upshot is: take this messages seriously. | You can add the flag `--track-origins=yes` to valgrind and it will give you information on the sources of uninitialised data. It runs slower, but can be helpful.
Source: [Valgrind User Manual](http://valgrind.org/docs/manual/mc-manual.html#mc-manual.uninitvals) | Should I worry about "Conditional jump or move depends on uninitialised value(s)"? | [
"",
"c++",
"valgrind",
"memcheck",
""
] |
Assume I have this barebones structure:
```
project/
main.py
providers/
__init.py__
acme1.py
acme2.py
acme3.py
acme4.py
acme5.py
acme6.py
```
Assume that `main.py` contains (partial):
```
if complexcondition():
print providers.acme5.get()
```
Where `__init__.py` is empty and `acme*.py` contain (partial):
```
def get():
value=complexcalculation()
return value
```
How do I change these files to work?
Note: If the answer is "import acme1", "import acme2", and so on in `__init__.py`, is there a way to accomplish that without listing them all by hand? | This question asked today, [Dynamic Loading of Python Modules](https://stackoverflow.com/questions/769534/dynamic-loading-of-python-modules), should have your answer. | hey! two years later but... maybe could be helpfull to some one
make your **providers/\_\_init\_\_.py** like that:
```
import os
import glob
module_path = os.path.dirname(__file__)
files = glob.glob(os.path.join(module_path, 'acme*.py'))
__all__ = [os.path.basename(f)[:-3] for f in files]
```
you don't have to change it later if add or remove any **providers/acme\*.py**
then use `from providers import *` in **main.py** | How do I structure Python code into modules/packages? | [
"",
"python",
"module",
"package",
""
] |
I have a asp.net website where the users have the possibility to print a document. This document is first written to a folder on the server and then opened/printed by the client.
When deploying the website on IIS server I did encounter a few times issues when a user tried to print the document. Apparently the IIS user on the server had insufficient access rights to write to the local folder and thus throwing an unauthorized access exception.
which one is the IIS user and how do I give it write access to a folder on the server in .net ? | I would give write / modify access to the IUSR\_MACHINE and NETWORK SERVICE accounts. To actually change the permissions, find the folder in Windows Explorer, get the Folder Properties. On the security tab, click the user in the list (you may have to "ADD" a user to the list first), then check the appropriate checkboxes under the Allow column.
As an aside, when ever I am stumped by a permissions issue, Sysinternals Process Monitor nearly always solves it. Run procmon.exe, set up the filters by excluding processes of known good processes (Right click on the process name, and select "Exclude 'explorer.exe'"). I also typically exclude known results like SUCCESS, and a few others.
You can then reproduce the problem, and a bright shining "ACCESS DENIED" entry will be listed at the bottom of the list, including the name of the user account, and the specific asset it was trying to access.
Download Link: <http://technet.microsoft.com/en-us/sysinternals/bb896645.aspx> | Usially it's NETWORK SERVICE user, grand to it write permissions on the required folder. | Unauthorized access when writing to file | [
"",
"c#",
".net-2.0",
""
] |
So when I write something like this
```
Action action = new Action(()=>_myMessage = "hello");
```
Refactor Pro! Highlights this as a redundant delegate creation and allows me to to shorten it to
```
Action action = () => _myMessage="hello";
```
And this usually works great. **Usually**, but not always. For example, Rhino Mocks has an extension method named Do:
```
IMethodOptions<T> Do(Delegate action);
```
Here, passing in the first version works, but the second doesn't. What exactly is going on under the covers here? | The first version is effectively doing:
```
Action tmp = () => _myMessage = "hello";
var action = new Action(tmp);
```
The problem you're running into is that the compiler has to know what kind of delegate (or expression tree) the lambda expression should be converted into. That's why this:
```
var action = () => _myMessage="hello";
```
actually doesn't compile - it could be *any* delegate type with no parameters and either no return value or the same return type as `_myMessage` (which is presumably `string`). For instance, all of these are valid:
```
Action action = () => _myMessage="hello";
Func<string> action = () => _myMessage="hello";
MethodInvoker action = () => _myMessage="hello";
Expression<Action> = () => _myMessage="hello";
// etc
```
How could the C# compiler work out what type `action` was meant to be, if it were declared with `var`?
The simplest way to get round this when calling a method (for your Rhino Mocks example) is to cast:
```
methodOptions.Do((Action) (() => _myMessage = "hello"));
``` | Have you verified the second line actually compiles? It should not compile because C# does not support assigning a lambda expression to an implicitly typed variable (CS0815). This line will work in VB.Net though because it supports anonymous delegate creation (starting in VB 9.0).
The Rhino Mocks version does not compile for the same reason the second line should not compile. C# will not automatically infer a type for a lambda expression. Lambda expressions must be used in a context where it is possible to determine the delegate type they are intended to fulfill. The first line works great because the intended type is clear: Action. The Rhino Mocks version does not work because Delegate is more akin to an abstract delegate type. It must be a concrete delegate type such as Action or Func.
For a detailed discussion on this topic, you should read Eric Lippert's blog entries on the subject: <http://blogs.msdn.com/ericlippert/archive/2007/01/11/lambda-expressions-vs-anonymous-methods-part-two.aspx> | What is the difference between new Action() and a lambda? | [
"",
"c#",
".net-3.5",
"delegates",
"lambda",
""
] |
I'm 99% certain the answer to this is a blinding **no**. Please validate my proposition that the following code will produce a memory leak.
```
Data &getData()
{
Data *i = new Data();
return *i;
}
void exampleFunc()
{
Data d1 = getData();
Data d2;
/* d1 is not deallocated because it is on the heap, and d2 is
* because it is on the stack. */
}
```
Please note that this is an oversimplified example, so clearly you wouldn't actually use the above code... So no need to point this out thanks.
### Update 1:
To add to this, what if I assign the pointer to a reference? In this case, I assume that the data is not copied...
```
Data &getData()
{
Data *i = new Data();
return *i;
}
void exampleFunc()
{
// Does copying occur here?
Data &d1 = getData();
// Does this deallocate the memory assigned to the pointer?
delete &d;
}
```
### Update 2:
I guess to answer my own question (in update 1) the following code proves that assigning a reference to a reference does not cause a copy...
```
#include <iostream>
#include <string>
using namespace std;
class Data
{
public:
string mName;
Data(const string &name) : mName(name)
{ cout << mName << " default ctor" << endl; }
Data(const Data& other)
{
mName = other.mName + " (copy)";
cout << mName << " copy ctor" << endl;
}
~Data()
{ cout << mName << " dtor" << endl; }
static Data &getData(const string &name)
{
Data *d = new Data(name);
return *d;
}
};
int main()
{
cout << "d1..." << endl;
Data d1 = Data::getData("d1");
cout << "d2..." << endl;
Data d2("d2");
cout << "d3..." << endl;
Data &d3 = Data::getData("d3");
cout << "return..." << endl;
return 0;
}
```
Yields the following result...
```
d1...
d1 default ctor
d1 (copy) copy ctor
d2...
d2 default ctor
d3...
d3 default ctor
return...
d2 dtor
d1 (copy) dtor
```
Thanks to Eric Melski for [a great answer](https://stackoverflow.com/questions/765971/is-memory-allocated-with-new-ever-automatically-freed/766002#766002) (my code in update 2 is a modified copy of his exmaple code). | Actually both `d1` and `d2` will be deallocated, because they are both on the stack. What is not deallocated is the `Data` object you allocated in your `getData()` function. You can see this a little more clearly if you flesh out your `Data` class with instrumentation in the constructors and destructor. For example:
```
class Data {
public:
Data() { cout << "Data default ctor" << endl; }
Data(const Data& other) { cout << "Data copy ctor" << endl; }
~Data() { cout << "Data dtor" << endl; }
static Data& getData()
{
Data *i = new Data();
return *i;
}
};
```
Note that I have explicitly declared the copy constructor for `Data`. In your example you are implicitly calling that constructor when you do `Data d1 = getData();`, and I suspect this is where your confusion is coming from. Now if I run this simple program:
```
#include <iostream>
using namespace std;
int main(int argc, char *argv[])
{
Data d1 = Data::getData();
Data d2;
return 0;
}
```
The output is as follows:
```
Data default ctor
Data copy ctor
Data default ctor
Data dtor
Data dtor
```
Line-by-line, here's what you're seeing:
1. The default constructor is invoked when you allocate a new `Data` in `getData()`.
2. The copy constructor is invoked to create `d1` from the dynamically allocated `Data` you just made.
3. The default constructor is invoked to create `d2`.
4. The destructor is invoked for `d2` when it goes out of scope at the end of `main()`.
5. The destructor is invoked for `d1` when it goes out of scope at the end of `main()`.
Note that there are three constructor calls, but only two destructor calls -- indicating that you have leaked exactly one `Data` object. | `d1` is a stack object, copy-constructed from the reference returned from `getData()`. `d1` is freed, but the object created in `getData()` is leaked. | Is memory allocated with new ever automatically freed? | [
"",
"c++",
"memory-management",
""
] |
Lets say I have this class:
```
class MyList<T>
{
}
```
What must I do to that class, to make the following possible:
```
var list = new MyList<int> {1, 2, 3, 4};
``` | Have an Add method and implement IEnumerable.
```
class MyList<T> : IEnumerable
{
public void Add(T t)
{
}
public IEnumerator GetEnumerator()
{
//...
}
}
public void T()
{
MyList<int> a = new MyList<int>{1,2,3};
}
``` | Implementing ICollection on MyList will let the initalizer syntax work
```
class MyList<T> : ICollection<T>
{
}
```
Although the bare minimum would be:
```
public class myList<T> : IEnumerable<T>
{
public void Add(T val)
{
}
public IEnumerator<T> GetEnumerator()
{
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
}
}
``` | C#: List add object initializer | [
"",
"c#",
"initialization",
""
] |
In my application, the client is a Javascript set of functions in the browser, and it does some work - for example, playing a clip.
It uses XmlHttpRequest to talk to the server.
However, the server is allowed to abruptly close the connection since there is no other way it seems, to interrupt the client.
Can the client detect, while it is playing the clip, that the connection was closed, and so print a message and erase the page?
Any help appreciated.
thanks,
Anil | It does seem that the server **cannot** notify the client that the connection is closed; however the polling method suggested is not as efficient as a notification would have been.
I solved it by specifying that at the NEXT Get request, the client would be told that its session is invalid.
This was implemented by URL rewriting - appending "jsessionid=[id]" on each request sent by the Javascript functions. the servlet stores the current session id. | If the clip is streamed to the client, you could just stop serving it.
However, it seems like the clip is being downloaded and then played through the browser. In this instance it's probably best to use a watchdog approach as described by CookieOfFortune: Poll the server regularly (once a second or so) and get it to respond with tiny message of confirmation. When the connection is closed, get the server to respond with a negative messgage.
Unfortunately, without using a comet-like system, it's very hard to get the server to 'send' a message indicating session closure.
Bear in mind though, that as soon as the client has downloaded a clip they will be able to play it in full if they want to. Unfortunately there's no way to stop this besides switching to a streaming approach. If securing your content is a priority, I'd suggest making this change. | can client side Javascript detect when server has closed http connection while client is working? | [
"",
"javascript",
"connection",
"detect",
""
] |
What is the best way to create a parallax effect in an XNA game? I would like the camera to follow my sprite as it moves across the world, that way I can build in effects like zoom, panning, shake, and other effects. Anybody have a solid example of how this is done, preferably in a GameComponent? | So I figured it out using a combination of the tutorials above and have created the class below. It tweens towards your target and follows it around. Try it out.
```
public interface IFocusable
{
Vector2 Position { get; }
}
public interface ICamera2D
{
/// <summary>
/// Gets or sets the position of the camera
/// </summary>
/// <value>The position.</value>
Vector2 Position { get; set; }
/// <summary>
/// Gets or sets the move speed of the camera.
/// The camera will tween to its destination.
/// </summary>
/// <value>The move speed.</value>
float MoveSpeed { get; set; }
/// <summary>
/// Gets or sets the rotation of the camera.
/// </summary>
/// <value>The rotation.</value>
float Rotation { get; set; }
/// <summary>
/// Gets the origin of the viewport (accounts for Scale)
/// </summary>
/// <value>The origin.</value>
Vector2 Origin { get; }
/// <summary>
/// Gets or sets the scale of the Camera
/// </summary>
/// <value>The scale.</value>
float Scale { get; set; }
/// <summary>
/// Gets the screen center (does not account for Scale)
/// </summary>
/// <value>The screen center.</value>
Vector2 ScreenCenter { get; }
/// <summary>
/// Gets the transform that can be applied to
/// the SpriteBatch Class.
/// </summary>
/// <see cref="SpriteBatch"/>
/// <value>The transform.</value>
Matrix Transform { get; }
/// <summary>
/// Gets or sets the focus of the Camera.
/// </summary>
/// <seealso cref="IFocusable"/>
/// <value>The focus.</value>
IFocusable Focus { get; set; }
/// <summary>
/// Determines whether the target is in view given the specified position.
/// This can be used to increase performance by not drawing objects
/// directly in the viewport
/// </summary>
/// <param name="position">The position.</param>
/// <param name="texture">The texture.</param>
/// <returns>
/// <c>true</c> if the target is in view at the specified position; otherwise, <c>false</c>.
/// </returns>
bool IsInView(Vector2 position, Texture2D texture);
}
public class Camera2D : GameComponent, ICamera2D
{
private Vector2 _position;
protected float _viewportHeight;
protected float _viewportWidth;
public Camera2D(Game game)
: base(game)
{}
#region Properties
public Vector2 Position
{
get { return _position; }
set { _position = value; }
}
public float Rotation { get; set; }
public Vector2 Origin { get; set; }
public float Scale { get; set; }
public Vector2 ScreenCenter { get; protected set; }
public Matrix Transform { get; set; }
public IFocusable Focus { get; set; }
public float MoveSpeed { get; set; }
#endregion
/// <summary>
/// Called when the GameComponent needs to be initialized.
/// </summary>
public override void Initialize()
{
_viewportWidth = Game.GraphicsDevice.Viewport.Width;
_viewportHeight = Game.GraphicsDevice.Viewport.Height;
ScreenCenter = new Vector2(_viewportWidth/2, _viewportHeight/2);
Scale = 1;
MoveSpeed = 1.25f;
base.Initialize();
}
public override void Update(GameTime gameTime)
{
// Create the Transform used by any
// spritebatch process
Transform = Matrix.Identity*
Matrix.CreateTranslation(-Position.X, -Position.Y, 0)*
Matrix.CreateRotationZ(Rotation)*
Matrix.CreateTranslation(Origin.X, Origin.Y, 0)*
Matrix.CreateScale(new Vector3(Scale, Scale, Scale));
Origin = ScreenCenter / Scale;
// Move the Camera to the position that it needs to go
var delta = (float) gameTime.ElapsedGameTime.TotalSeconds;
_position.X += (Focus.Position.X - Position.X) * MoveSpeed * delta;
_position.Y += (Focus.Position.Y - Position.Y) * MoveSpeed * delta;
base.Update(gameTime);
}
/// <summary>
/// Determines whether the target is in view given the specified position.
/// This can be used to increase performance by not drawing objects
/// directly in the viewport
/// </summary>
/// <param name="position">The position.</param>
/// <param name="texture">The texture.</param>
/// <returns>
/// <c>true</c> if [is in view] [the specified position]; otherwise, <c>false</c>.
/// </returns>
public bool IsInView(Vector2 position, Texture2D texture)
{
// If the object is not within the horizontal bounds of the screen
if ( (position.X + texture.Width) < (Position.X - Origin.X) || (position.X) > (Position.X + Origin.X) )
return false;
// If the object is not within the vertical bounds of the screen
if ((position.Y + texture.Height) < (Position.Y - Origin.Y) || (position.Y) > (Position.Y + Origin.Y))
return false;
// In View
return true;
}
}
```
And Here is how you would use it with `SpriteBatch`:
```
spriteBatch.Begin(SpriteBlendMode.AlphaBlend,
SpriteSortMode.FrontToBack,
SaveStateMode.SaveState,
Camera.Transform);
spriteBatch.Draw(_heliTexture,
_heliPosition,
heliSourceRectangle,
Color.White,
0.0f,
new Vector2(0,0),
0.5f,
SpriteEffects.FlipHorizontally,
0.0f);
spriteBatch.End();
```
Let Me know if this helps you out, and thanks to StackOverflow and the community. W00t! | Here are some tutorials on implementing a 2D camera in XNA:
1. <http://www.paradeofrain.com/?page_id=32>
2. <http://gamecamp.no/blogs/tutorials/archive/2008/01/29/creating-a-simple-xna-camera-class.aspx> | XNA 2D Camera Engine That Follows Sprite | [
"",
"c#",
"xna",
"camera",
"sprite",
""
] |
I'm trying to detect line segments in an image.
From what I gather, the Hough algorithm detects lines but not segments.
Does anyone know of how I would go about this, or any libraries suitable for this?
Im my case, I'm trying to detect star trails (which for these purposes are all straight) from a photograph so I can reduce them back to points.
If it's important, I'm trying to implement this in C#
Any ideas? | For unsmearing motion blur, you should look at [deconvolution](http://en.wikipedia.org/wiki/Deconvolution). The Hough transform might be helpful in finding the original motion vector (I suspect it would work fine for a bunch of parallel line segments), but deconvolution is what you'd use to get the original stars back out of it, and these guys use a different method for estimating the original motion vector:
* [Removing Motion Blur from Astrophotographic Images](http://www.sweaglesw.com/cs448/)
[](https://i.stack.imgur.com/Y73tm.jpg)
[](https://i.stack.imgur.com/agOZg.jpg) | The openCV Hough transform cvHoughLines2 has a probabilistic mode that detects line segments:
* CV\_HOUGH\_PROBABILISTIC - probabilistic Hough transform (more efficient in case if picture contains a few long linear segments). It returns line segments rather than the whole lines. Every segment is represented by starting and ending points, and the matrix must be (the created sequence will be) of CV\_32SC4 type.
I have tested it and it works | Detect line segments in an image | [
"",
"c#",
"image-recognition",
""
] |
From this string:
```
$input = "Some terms with spaces between";
```
how can I produce this array?
```
$output = ['Some', 'terms', 'with', 'spaces', 'between'];
``` | You could use [`explode`](http://docs.php.net/explode), [`split`](http://docs.php.net/split) or [`preg_split`](http://docs.php.net/preg_split).
`explode` uses a fixed string:
```
$parts = explode(' ', $string);
```
while `split` and `preg_split` use a regular expression:
```
$parts = split(' +', $string);
$parts = preg_split('/ +/', $string);
```
An example where the regular expression based splitting is useful:
```
$string = 'foo bar'; // multiple spaces
var_dump(explode(' ', $string));
var_dump(split(' +', $string));
var_dump(preg_split('/ +/', $string));
``` | ```
$parts = explode(" ", $str);
``` | How can I convert a sentence to an array of words? | [
"",
"php",
"arrays",
"string",
"split",
""
] |
The combination of coroutines and resource acquisition seems like it could have some unintended (or unintuitive) consequences.
The basic question is whether or not something like this works:
```
def coroutine():
with open(path, 'r') as fh:
for line in fh:
yield line
```
Which it does. (You can test it!)
The deeper concern is that `with` is supposed to be something an alternative to `finally`, where you ensure that a resource is released at the end of the block. Coroutines can suspend and resume execution from *within* the `with` block, so **how is the conflict resolved?**
For example, if you open a file with read/write both inside and outside a coroutine while the coroutine hasn't yet returned:
```
def coroutine():
with open('test.txt', 'rw+') as fh:
for line in fh:
yield line
a = coroutine()
assert a.next() # Open the filehandle inside the coroutine first.
with open('test.txt', 'rw+') as fh: # Then open it outside.
for line in fh:
print 'Outside coroutine: %r' % repr(line)
assert a.next() # Can we still use it?
```
### Update
I was going for write-locked file handle contention in the previous example, but since most OSes allocate filehandles per-process there will be no contention there. (Kudos to @Miles for pointing out the example didn't make too much sense.) Here's my revised example, which shows a real deadlock condition:
```
import threading
lock = threading.Lock()
def coroutine():
with lock:
yield 'spam'
yield 'eggs'
generator = coroutine()
assert generator.next()
with lock: # Deadlock!
print 'Outside the coroutine got the lock'
assert generator.next()
``` | I don't really understand what conflict you're asking about, nor the problem with the example: it's fine to have two coexisting, independent handles to the same file.
One thing I didn't know that I learned in response to your question it that there is a new close() method on generators:
> `close()` raises a new `GeneratorExit` exception inside the generator to terminate the iteration. On receiving this exception, the generator’s code must either raise `GeneratorExit` or `StopIteration`.
>
> `close()` is called when a generator is garbage-collected, so this means the generator’s code gets one last chance to run before the generator is destroyed. This last chance means that `try...finally` statements in generators can now be guaranteed to work; the `finally` clause will now always get a chance to run. This seems like a minor bit of language trivia, but using generators and `try...finally` is actually necessary in order to implement the `with` statement described by PEP 343.
>
> <http://docs.python.org/whatsnew/2.5.html#pep-342-new-generator-features>
So that handles the situation where a `with` statement is used in a generator, but it yields in the middle but never returns—the context manager's `__exit__` method will be called when the generator is garbage-collected.
---
**Edit**:
With regards to the file handle issue: I sometimes forget that there exist platforms that aren't POSIX-like. :)
As far as locks go, I think Rafał Dowgird hits the head on the nail when he says "You just have to be aware that the generator is just like any other object that holds resources." I don't think the `with` statement is really that relevant here, since this function suffers from the same deadlock issues:
```
def coroutine():
lock.acquire()
yield 'spam'
yield 'eggs'
lock.release()
generator = coroutine()
generator.next()
lock.acquire() # whoops!
``` | I don't think there is a real conflict. You just have to be aware that the generator is just like any other object that holds resources, so it is the creator's responsibility to make sure it is properly finalized (and to avoid conflicts/deadlock with the resources held by the object). The only (minor) problem I see here is that generators don't implement the context management protocol (at least as of Python 2.5), so you cannot just:
```
with coroutine() as cr:
doSomething(cr)
```
but instead have to:
```
cr = coroutine()
try:
doSomething(cr)
finally:
cr.close()
```
The garbage collector does the `close()` anyway, but it's bad practice to rely on that for freeing resources. | Is it safe to yield from within a "with" block in Python (and why)? | [
"",
"python",
"resources",
"coroutine",
""
] |
I am trying to load an image in the background and then update the UI. I have been playing with this all day and I don't know what I am missing. I keep getting the following error:
> "The calling thread cannot access this object because a different thread owns it."
I've hunted around following example after example, but I cannot seem to find an answer. I also wrapped the code that is touching the UI in another BeginInvoke.
Update 3: The moral of the story. ImageSource is not thread safe for access.
Update 2: This has got to be a simple solution :). I tried the cloning, but that didn't result in success, but I did get a different error: "Exception has been thrown by the target of an invocation."
Update 1: I tried the BackgroundWorker, but I am still getting the same error, but it is occurring on the brush.ImageSource.Height. Am I signaling the UI correctly? Any suggestions?
Here is my XAML:
```
<Window x:Class="Slideshow.Show"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml">
<DockPanel>
<Canvas Background="Black" Name="canvas">
<Viewbox Name="background" Stretch="Uniform">
<Rectangle name="background" />
</Viewbox>
</Canvas>
</DockPanel>
</Window>
```
Here is some of the code behind:
```
namespace Slideshow
{
public class Show
{
public Show()
{
BackgroundWorker bw = new BackgroundWorker();
bw.DoWork += new DoWorkEventHandler(bw_DoWork);
bw.RunWorkerCompleted +=
new RunWorkerCompletedEventHandler(bw_RunWorkerCompleted);
bw.RunWorkerAsync();
}
void bw_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
BitmapSource bitmap = e.Result as BitmapSource;
if (bitmap != null)
{
this.Dispatcher.BeginInvoke(DispatcherPriority.Normal
(ThreadStart)delegate()
{
Image image = new Image();
image.Source = bitmap;
background.Child = image;
});
}
}
void bw_DoWork(object sender, DoWorkEventArgs e)
{
BitmapSource bitmapSource = CreateBrush(GetRandomFile());
e.Result = bitmapSource;
}
}
}
``` | What I tend to use the [`ThreadPool.QueueUserWorkItem`](http://msdn.microsoft.com/en-us/library/system.threading.threadpool.queueuserworkitem.aspx) to load the image, then when the operation completes I call back to the UI thread using the thread-safe [`Dispatcher`](http://msdn.microsoft.com/en-us/library/system.windows.threading.dispatcherobject.aspx) object. The image source is not thread safe, you will have to use something like the `JpegBitmapDecoder`, there is also a `PngBitmapDecoder`.
For Example:
```
public Window()
{
InitializeComponent();
ThreadPool.QueueUserWorkItem(LoadImage,
"http://z.about.com/d/animatedtv/1/0/1/m/simp2006_HomerArmsCrossed_f.jpg");
}
public void LoadImage(object uri)
{
var decoder = new JpegBitmapDecoder(new Uri(uri.ToString()), BitmapCreateOptions.PreservePixelFormat, BitmapCacheOption.OnLoad);
decoder.Frames[0].Freeze();
this.Dispatcher.Invoke(DispatcherPriority.Send, new Action<ImageSource>(SetImage), decoder.Frames[0]);
}
public void SetImage(ImageSource source)
{
this.BackgroundImage.Source = source;
}
``` | One more thing we had in our project. Since ImageSource is placed into UI you have to check if it is frozen:
```
public void SetImage(ImageSource source)
{
ImageSource src = null;
if(!source.IsFrozen)
src = source.GetAsFrozen();
else
src = source;
this.BackgroundImage.Source = src;
}
``` | How do I load images in the background? | [
"",
"c#",
"wpf",
"image",
"delegates",
""
] |
I am looking for the simplest way to get notified when successful installation of a program takes place somewhere. My application is Java based and has Java installer, I could easily put up a client to do any http call with any parameters, this is not an issue. My problem is on the other side - I've got hosted web site and I want direct all traffic there, but I'm not familiar with that part of the programming world :) It would be nice if each successful installation would dump a records in the database (I've got MySql integrated on site). Another options is to send me an email, or at least tail into a log file. The simpler the better. Either would be fine. Can anybody suggest an approach? I know a little bit of PHP and perhaps would be able to do some simple stuff, but without an example or starting point, it's very easy to get lost in today's web technologies maze :) | Does your web site have logging already? If so, you've already got a log file which you could grep for the appropriate URL. No programming required :) Just don't link to that URL from anywhere else, and you shouldn't end up with any false positives. | I think Jon Skeet has already answered the questions well enough but..
If you do phone home - for politeness sake make sure that you inform the user and ask their permission.
If you don't you may find that you get a bad reputation. | How to go about "Calling home" in minimalistic way? | [
"",
"java",
"web",
"installation",
""
] |
I need to prompt a user to save their work when they leave a page. I've tried onbeforeunload but I need to show a styled prompt not the usual dialog box. Facebook has managed to achieve this (if you have a Facebook account, edit your profile info and go to another page without saving and you get a styled prompt). I've also tried jquery unload but there doesn't seem to be a way to stop the unload event from propagating. | Take a closer look at what Facebook is doing: you get a prompt if you click a link *on the page*, but nothing when entering a new URL in the address bar, clicking a bookmark, or navigating Back in your browser's history.
If that works for you, it's easy enough to do: simply add a `click` event handler to every link on the page, and trigger your stylized confirmation from it. Since these handlers will get called prior to the *start* of any navigation events triggered from within the page itself, you can pretty much do whatever you want in the handler - save data, cancel the event entirely, record the intended destination and postpone it 'till after they confirm...
However, if you do need or want to respond to navigation events triggered externally, you'll have to use `onbeforeunload`. And yes, the dialog is crappy, and you can't cancel the event - that's the price we pay for all the scandalous idiots abusing such features back in the '90s. Sorry... | The selected answer is good but I still had to dig around for the details. If you want to use the onbeforeunload event, here's some sample code:
```
<script>
window.onbeforeunload= function() { return "Custom message here"; };
</script>
``` | Prompting user to save when they leave a page | [
"",
"javascript",
"jquery",
"html",
""
] |
Is the a short syntax for joining a list of lists into a single list( or iterator) in python?
For example I have a list as follows and I want to iterate over a,b and c.
```
x = [["a","b"], ["c"]]
```
The best I can come up with is as follows.
```
result = []
[ result.extend(el) for el in x]
for el in result:
print el
``` | ```
import itertools
a = [['a','b'], ['c']]
print(list(itertools.chain.from_iterable(a)))
```
This gives
```
['a', 'b', 'c']
``` | ```
x = [["a","b"], ["c"]]
result = sum(x, [])
``` | join list of lists in python | [
"",
"python",
""
] |
Currently, I'm able to load in a static sized texture which I have created. In this case it's 512 x 512.
This code is from the header:
```
#define TEXTURE_WIDTH 512
#define TEXTURE_HEIGHT 512
GLubyte textureArray[TEXTURE_HEIGHT][TEXTURE_WIDTH][4];
```
Here's the usage of glTexImage2D:
```
glTexImage2D(
GL_TEXTURE_2D, 0, GL_RGBA,
TEXTURE_WIDTH, TEXTURE_HEIGHT,
0, GL_RGBA, GL_UNSIGNED_BYTE, textureArray);
```
And here's how I'm populating the array (rough example, not exact copy from my code):
```
for (int i = 0; i < getTexturePixelCount(); i++)
{
textureArray[column][row][0] = (GLubyte)pixelValue1;
textureArray[column][row][1] = (GLubyte)pixelValue2;
textureArray[column][row][2] = (GLubyte)pixelValue3;
textureArray[column][row][3] = (GLubyte)pixelValue4;
}
```
How do I change that so that there's no need for TEXTURE\_WIDTH and TEXTURE\_HEIGHT? Perhaps I could use a pointer style array and dynamically allocate the memory...
### Edit:
I think I see the problem, in C++ it can't really be done. The work around as pointed out by Budric is to use a single dimensional array but use all 3 dimensions multiplied to represent what would be the indexes:
```
GLbyte *array = new GLbyte[xMax * yMax * zMax];
```
And to access, for example x/y/z of 1/2/3, you'd need to do:
```
GLbyte byte = array[1 * 2 * 3];
```
However, the problem is, I don't think the `glTexImage2D` function supports this. Can anyone think of a workaround that would work with this OpenGL function?
### Edit 2:
Attention OpenGL developers, this can be overcome by using a single dimensional array of pixels...
> [0]: column 0 > [1]: row 0 > [2]: channel 0 ... n > [n]: row 1 ... n > [n]: column 1 .. n
... no need to use a 3 dimensional array. In this case I've had to use this work around as 3 dimensional arrays are apparently not strictly possible in C++. | You can use
```
int width = 1024;
int height = 1024;
GLubyte * texture = new GLubyte[4*width*height];
...
glTexImage2D(
GL_TEXTURE_2D, 0, GL_RGBA,
width, height,
0, GL_RGBA, GL_UNSIGNED_BYTE, textureArray);
delete [] texture; //remove the un-needed local copy of the texture;
```
However you still need to specify the width and height to OpenGL in glTexImage2D call. This call copies texture data and that data is managed by OpenGL. You can delete, resize, change your original texture array all you want and it won't make a different to the texture you specified to OpenGL.
**Edit:**
C/C++ deals with only 1 dimensional arrays. The fact that you can do texture[a][b] is hidden and converted by the compiler at compile time. The compiler must know the number of columns and will do texture[a\*cols + b].
Use a class to hide the allocation, access to the texture.
For academic purposes, if you really want dynamic multi dimensional arrays the following should work:
```
int rows = 16, cols = 16;
char * storage = new char[rows * cols];
char ** accessor2D = new char *[rows];
for (int i = 0; i < rows; i++)
{
accessor2D[i] = storage + i*cols;
}
accessor2D[5][5] = 2;
assert(storage[5*cols + 5] == accessor2D[5][5]);
delete [] accessor2D;
delete [] storage;
```
Notice that in all the cases I'm using 1D arrays. They are just arrays of pointers, and array of pointers to pointers. There's memory overhead to this. Also this is done for 2D array without colour components. For 3D dereferencing this gets really messy. Don't use this in your code. | Ok since this took me ages to figure this out, here it is:
My task was to implement the example from the OpenGL Red Book (9-1, p373, 5th Ed.) with a dynamic texture array.
The example uses:
```
static GLubyte checkImage[checkImageHeight][checkImageWidth][4];
```
Trying to allocate a 3-dimensional array, as you would guess, won't do the job. Someth. like this does ***NOT*** work:
```
GLubyte***checkImage;
checkImage = new GLubyte**[HEIGHT];
for (int i = 0; i < HEIGHT; ++i)
{
checkImage[i] = new GLubyte*[WIDTH];
for (int j = 0; j < WIDTH; ++j)
checkImage[i][j] = new GLubyte[DEPTH];
}
```
You have to use a ***one dimensional array***:
```
unsigned int depth = 4;
GLubyte *checkImage = new GLubyte[height * width * depth];
```
You can access the elements using this loops:
```
for(unsigned int ix = 0; ix < height; ++ix)
{
for(unsigned int iy = 0; iy < width; ++iy)
{
int c = (((ix&0x8) == 0) ^ ((iy&0x8)) == 0) * 255;
checkImage[ix * width * depth + iy * depth + 0] = c; //red
checkImage[ix * width * depth + iy * depth + 1] = c; //green
checkImage[ix * width * depth + iy * depth + 2] = c; //blue
checkImage[ix * width * depth + iy * depth + 3] = 255; //alpha
}
}
```
Don't forget to delete it properly:
```
delete [] checkImage;
```
Hope this helps... | How can I use a dynamically sized texture array with glTexImage2D? | [
"",
"c++",
"opengl",
"glteximage2d",
""
] |
If an invalid value is passed to a property setter and an `ArgumentException` (or possibility a class derived from it) is thrown, what value should be assigned to the `paramName` parameter?
`value`, since it seemingly is the actual argument?
Wouldn't it be more clear to pass the name of the property instead? | ArgumentExceptions contain the name of the parameter which is not valid. For a property setter the actual parameter is named value (in both source and generated code). It's more consistent to use this name. | After extensive poking around with Reflector (trying to find a CLR object with a writable Property), the first one I found (FileStream.Position) using "value" as the argument name:
```
if (value < 0L)
{
throw new ArgumentOutOfRangeException("value",
Environment.GetResourceString("NeedNonNegNum"));
}
``` | Value to assign to 'paramName' parameter for ArgumentException in C# property setter? | [
"",
"c#",
"exception",
"naming-conventions",
""
] |
does anyone have an idea how to hide the hourglass icon when you execute an application from another?
E.g. App-A with pretty background screen starts App-B. While App-B is loading windows puts this ugly grey block with the rotating hourglass in the middle of App-A.
I have tried calling System.Windows.Forms.Cursor.Hide(); but that did not seem to deter windows. It is possible that I did not use it correctly. Any ideas most welcome.
TIA (Thanks in Advance),
Ends | The fact you're calling it an "hourglass" indicates to me that this is not a Windows Mobile device but instead a generic CE device. Unfortunately the CF loader tells the OS to display the hourglass when it starts up and there is actually no way to prevent that from a CF perspective. You can remove the hourglass cursor altogether in the OS itself if you control the OS, but you can't prevent the CF from showing it if it's there. | Did you try to set the `Cursor.Current` property to Cursors to `Cursors.Default`?
Here you can find the [documentation for this property on MSDN](http://msdn.microsoft.com/en-us/library/system.windows.forms.cursor.current.aspx) and for the [Cursor class here](http://msdn.microsoft.com/en-us/library/system.windows.forms.cursor.aspx). | How to hide the hourglass icon in C# (.NET Compact Framework) | [
"",
"c#",
"compact-framework",
"cursor",
""
] |
I am looking for a way to have a script run every day at 5am to delete the contents of a Temp folder. The following is the method I am considering. I would appreciate any thoughts on this or suggestions for other methods. I want to keep everything local, so that there are no external dependencies from outside my account on Discount ASP hosting.
* Have a textfile containing the datetime of the next desired run (5:00am tomorrow).
* Have a Datetime cache value that expires after (one hour?)
* When someone hits the website and the cache is expired, reload the datetime into cache
* If the Datetime has passed, run the script to be "scheduled" and add 24 hours to the DateTime in the file
Your comments are appreciated. | You are on the right way. [Here](http://www.codeproject.com/KB/aspnet/ASPNETService.aspx) is a good article how to achieve this.
Also, based on your comment, why not use session end event to purge? Also, you can hook to application end as well, just in case. | You could also create a web service to perform the task, then have a scheduled task call the web service periodically. | ASP.NET script "scheduling" question | [
"",
"c#",
"asp.net",
"asp.net-mvc",
""
] |
I am trying to understand how best to extend the `ListBox` control. As a learning experience, I wanted to build a `ListBox` whose `ListBoxItem`s display a `CheckBox` instead of just text. I got that working in a basic fashion using the `ListBox.ItemTemplate`, explicitly setting the names of the properties I wanted to databind to. An example is worth a thousand words, so...
I've got a custom object for databinding:
```
public class MyDataItem {
public bool Checked { get; set; }
public string DisplayName { get; set; }
public MyDataItem(bool isChecked, string displayName) {
Checked = isChecked;
DisplayName = displayName;
}
}
```
(I build a list of those and set `ListBox.ItemsSource` to that list.) And my XAML looks like this:
```
<ListBox Name="listBox1">
<ListBox.ItemTemplate>
<DataTemplate>
<CheckBox IsChecked="{Binding Path=Checked}" Content="{Binding Path=DisplayName}" />
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
```
This works. But I want to make this template reusable, i.e. I'll want to bind to other objects with properties other than "Checked" and "DisplayName". How can I modify my template such that I could make it a resource, reuse it on multiple `ListBox` instances, and for each instance, bind `IsChecked` and `Content` to arbitrary property names? | The easiest way is probably to put the `DataTemplate` as a *resource* somewhere in your application with a `TargetType` of `MyDataItem` like this
```
<DataTemplate DataType="{x:Type MyDataItem}">
<CheckBox IsChecked="{Binding Path=Checked}" Content="{Binding Path=DisplayName}" />
</DataTemplate>
```
You'll probably also have to include an `xmlns` to your local assembly and reference it through that. Then whenever you use a `ListBox` (or anything else that uses a `MyDataItem` in a `ContentPresenter` or `ItemsPresenter`) it will use this `DataTemplate` to display it. | Create your DataTemplate as a resource and then reference it using the ItemTemplate property of the ListBox. [MSDN has a good example](http://msdn.microsoft.com/en-us/library/ms742521.aspx)
```
<Windows.Resources>
<DataTemplate x:Key="yourTemplate">
<CheckBox IsChecked="{Binding Path=Checked}" Content="{Binding Path=DisplayName}" />
</DataTemplate>
...
</Windows.Resources>
...
<ListBox Name="listBox1"
ItemTemplate="{StaticResource yourTemplate}"/>
``` | How to make a ListBox.ItemTemplate reusable/generic | [
"",
"c#",
"wpf",
"data-binding",
"itemtemplate",
""
] |
Grettings!
I have some XML that looks like this:
```
<Root>
<SectionA>
<Item id="111">
<Options>
<Option val="a" cat="zzz">
<Package value="apple" />
<Feature value="avacado" />
</Option>
<Option val="b" cat="yyy">
<Package value="banana" />
<Feature value="blueberry" />
</Option>
</Options>
</Item>
<Item id="222">
<Options>
<Option val="c" cat="xxx">
<Package value="carrot" />
<Feature value="cucumber" />
</Option>
<Option val="d" cat="www">
<Package value="dairy" />
<Feature value="durom" />
</Option>
</Options>
</Item>
</SectionA>
<SectionB>
.
.
.
</SectionB>
</Root>
```
I'd like to get the PACKAGE and FEATURE values based on the ID attribute of ITEM being "111" and the VAL attribute of OPTION being "a".
I'm not sure where to start. I'm able to select the ITEM node using a where, but I'm not sure how to combine that with a where clause on the OPTION node. Any ideas? | This works for me.
```
var doc = XDocument.Parse(s);
var items = from item in doc.Descendants("Item")
where item.Attribute("id").Value == "111"
from option in item.Descendants("Option")
where option.Attribute("val").Value == "a"
let package = option.Element("Package").Attribute("value")
let feature = option.Element("Feature").Attribute("value")
select new { Package = package.Value, Feature = feature.Value };
items.First().Feature; // = "avacado"
items.First().Package; // = "apple"
```
You can omit the `let` parts if you want, they are only to make the anonymous type thinner.
```
var items = from item in doc.Descendants("Item")
where item.Attribute("id").Value == "111"
from option in item.Descendants("Option")
where option.Attribute("val").Value == "a"
select new
{
Package = option.Element("Package").Attribute("value").Value,
Feature = option.Element("Feature").Attribute("value").Value
};
```
Actually, I kind of like the second one more.
---
And the non query Linq style.
```
var items = doc.Descendants("Item")
.Where(item => item.Attribute("id").Value == "111")
.SelectMany(item => item.Descendants("Option"))
.Where(option => option.Attribute("val").Value == "a")
.Select(option => new
{
Package = option.Element("Package").Attribute("value").Value,
Feature = option.Element("Feature").Attribute("value").Value
});
``` | alternate implementation using SelectMany
```
var doc = XDocument.Parse(xml);
var items = from i in doc.Descendants("Item")
from o in i.Descendants("Option")
where i.Attribute("id").Value == "111"
&& o.Attribute("val").Value == "a"
select new {
Package = i.Descendants("Package").Attribute("value").Value,
Feature = i.Descendants("Feature").Attribute("value").Value
};
``` | Linq Question: Combined Where Clauses | [
"",
"c#",
".net",
"linq",
"linq-to-xml",
""
] |
**Exact Duplicate:** [User Images: Database or filesystem storage?](https://stackoverflow.com/questions/585224/user-images-database-vs-filesystem-storage)
**Exact Duplicate:** [Storing images in database: Yea or nay?](https://stackoverflow.com/questions/3748/storing-images-in-db-yea-or-nay)
**Exact Duplicate:** [Should I store my images in the database or folders?](https://stackoverflow.com/questions/713243/should-i-store-my-images-in-the-database-or-folders/713292%5C)
**Exact Duplicate:** [Would you store binary data in database or folders?](https://stackoverflow.com/questions/662488/would-you-store-binary-data-in-database-or-in-file-system)
**Exact Duplicate:** [Store pictures as files or or the database for a web app?](https://stackoverflow.com/questions/561447/store-pictures-as-files-or-in-the-database-for-a-web-app)
**Exact Duplicate:** [Storing a small number of images: blob or fs?](https://stackoverflow.com/questions/325126/storing-a-small-number-of-images-blob-or-fs)
I have to store user's profile image (100px \* 100px) what is the best way to store it ? database or system file ? which one is better , faster ,safer ... ? | **Always** store images, music files etc in system files on disk, and then store the url:s to them in the database. That will make it
1) faster
2) easier to configure security settings
3) better in any ways I can imagine | SQL Server 2008 offers the [best of both worlds](http://technet.microsoft.com/en-us/library/bb933993.aspx). | store image in database or in a system file? | [
"",
".net",
"sql",
"database",
""
] |
How can I get the following JavaScript to return `row` so I can access it outside the transaction? All of Apple's example code seems to have HTML written to the browser within the transaction instead of ever passing data back to a calling function.
Along the lines of:
```
function getData() {
db.transaction(function(tx) {
tx.executeSql("SELECT id FROM table LIMIT 1", [], function(tx, result) {
row = result.rows.item(0);
}, function(tx, error) {
});
});
return row;
}
```
Is this even possible? Can the Webkit storage API be set to synchronous instead of asynchronous execution? | I think you want to create a closure here as values are being garbage collected/moved away from the scope chain before you can access them. Pass `row` to a closure for access later or to some other function that can handle the value while it's still in scope.
More info: [Working With Closures](https://developer.mozilla.org/en/Core_JavaScript_1.5_Guide/Working_with_Closures) | I realise this is a very old question but I found it when searching for how to deal with JavaScript asynchronous SQLite calls. And the question is the same as mine and I've found a better answer (Expands on the selected answer, using closures)
my version of your getData function is as follows:
```
function get_option (option, get_option_callback){
if (db === null){
open_database();
}
db.transaction(function (tx) {
tx.executeSql("SELECT rowid,* FROM app_settings WHERE option = ? ", [option],
function(tx, result){
item = result.rows.item(0);
get_option_callback(item.value);
return;
}
}, sql_err);
});
}
```
Then to call the method I would use:
```
get_option("option name", function(val){
// set the html element value here with val
// or do whatever
$('input[name="some_input"]').val(val);
});
``` | getting a Webkit executeSql transaction to return a value | [
"",
"javascript",
"sqlite",
"webkit",
""
] |
I would like to compare two SQL Server databases including schema (table structure) and data in tables too. What is best tool to do this? | I am using Red-Gate's software:
[http://www.red-gate.com](http://www.red-gate.com/) | I use schema and data comparison functionality built into the latest version **Microsoft Visual Studio** Community Edition (Free) or Professional / Premium / Ultimate edition. Works like a charm!
<http://channel9.msdn.com/Events/Visual-Studio/Launch-2013/VS108>
**Red-Gate's SQL data comparison tool** is my second alternative:
[](https://i.stack.imgur.com/hHI5m.png)
(source: [spaanjaars.com](http://imar.spaanjaars.com/Images/Articles/NLayer45/Part10/Figure10-5_Red_Gate_SQL_Compare_Results.png))
* <http://www.red-gate.com/products/sql-development/sql-compare/>
* <http://www.red-gate.com/products/sql-development/sql-data-compare/> | What is best tool to compare two SQL Server databases (schema and data)? | [
"",
"sql",
"sql-server",
"database",
"compare",
""
] |
I'm using some `JTextArea` in my Swing application. The surrounded `JScrollPane` is added to a `JPanel` using the `GridBagLayout` manager.
```
// Pseudo Code ----
JTextArea area = new JTextArea();
area.setRows(3);
JScrollPane sp = new JScrollPane(area);
JPanel p = new JPanel(new GridBagLayout());
p.add(sp, new GridBagConstraints(
0, 0, 1, 1, 1, 0, WEST, HORIZONTAL, new Insets(4, 4, 4, 4), 0, 0));
// ----------------
```
Everything works fine. No problem at all until I will resize the `JFrame`. Then **both `JTextArea` will collapse to one row**. However there is enough place for at least one of them.
Why the element collapse to one row?
Does anyone know a solution? Has anyone an idea? | If I use a `BorderLayout` around my elements, it works.
Pete, MrWiggles, Thank you for your help!! | I believe this is because you have your weighty set to 0 (6th argument to the GridBagConstraints constructor). You'll need to increase this if you want your component to grow vertically. | JTextArea with strange behaviour when resizing the JFrame | [
"",
"java",
"user-interface",
"swing",
""
] |
I'm in the process of porting a large C++ application from Linux (gcc) to Windows (Visual C++ 2008) and am having linker issues with plugins. On Linux this wasn't an issue, as .so supports runtime symbol lookup, but dll does not seem to support this.
Some background information:
The application (the host), which hosts a scripting environment, provides interfaces to plugins (shared libraries that are loaded at runtime by script API calls), allowing the host and the scripting API to be extended without recompiling the host application. On Linux this is just a matter of including the host application's headers in the plugin source, but on Windows I'm receiving linker errors. I'm not sure exactly what I need to link with for Visual C++ to resolve these symbols.
One of our dependencies (open source, LGPL) has preprocessor declarations that it uses to insert \_\_declspec(dllexport) and \_\_declspec(dllimport) into it's headers. Some prior research indicates that I may have to do this as well, but I'd like to be sure before I go modifying a whole bunch of core headers. (I was previously able to get this working on MinGW, but we've decided that supporting Visual Studio is a requirement for this sort of commercial project.)
My question, in a nutshell: **How do I link runtime-loaded dlls against a host exe in Visual C++?**
Edit: To clarify the problem with an example, I have a class in my host application, **Object**, which represents the base type of an object that may be accessed by a script. In my plugins I have a number of classes which extend **Object** to perform other functions, such as integrating networking support or new visual elements. This means that my dll must link with symbols in the host exe, and I am not sure how to do that. | What do you mean by "runtime symbol lookup"? Do you mean dynamically loading libraries using `dlopen` and `dlsym` and [so on](http://linux.die.net/man/3/dlopen)? The [equivalents in Windows](http://msdn.microsoft.com/en-us/library/ms684175(VS.85).aspx) are called `LoadLibrary` and `GetProcAddress`.
In windows, you don't export symbols from a executable. You should only export them from a dll. The right way to solve your problem is to rearchitect so that the exported symbols are in a dll that the executable and other plugin dlls can link against. | You can't, easily. The windows loader isn't designed to export symbols out of an EXE and bind them to symbols in a DLL.
One pattern that I have seen is the DLL export a certain function that the EXE calls. It takes as a parameter a structure which contains addresses of functions in the EXE for the DLL to call. | Visual C++ - Linking plugin DLL against EXE? | [
"",
"c++",
"visual-studio-2008",
"visual-c++",
"dll",
"plugins",
""
] |
When I've uploaded content from my C# app to a website in the past, I've used a POST request like so:
```
HttpWebRequest wr = (HttpWebRequest)WebRequest.Create("http://" + this.server + "/log.php");
wr.Method = "POST";
wr.ContentType = "application/x-www-form-urlencoded";
string paramString = "v=" + this.version + "&m=" + this.message;
wr.ContentLength = paramString.Length;
StreamWriter stOut = new StreamWriter(wr.GetRequestStream(), System.Text.Encoding.ASCII);
stOut.Write(paramString);
stOut.Close();
```
My problem is that now I'm in a situation where `this.message` will very likely contain newlines, tabs, and special characters including "&" and "=". Do I need to escape this content. If so, how? | You can use HttpUtility.HtmlEncode/HtmlDecode or UrlEncode/UrlDecode as appropriate. | Just for reference, the solution to my problem was in:
[`System.Web.HttpUtility.UrlEncode`](http://msdn.microsoft.com/en-us/library/system.web.httputility.urlencode.aspx)
Which is supported by all versions of the .Net framework =p
Specifically, I'm using the overload that takes a [string as an argument](http://msdn.microsoft.com/en-us/library/4fkewx0t.aspx). Running this on all parameter values will make them safe for POSTing. | C# HttpWebReqest - escape POST content? | [
"",
"c#",
"httpwebrequest",
"escaping",
""
] |
I am developing a desktop app using Java and Swing Application Framework. I have an application about box and I'd like to have that box contain some indication of what version is being tested. My preference is for that value to be changed in an automated fashion. I'm using CruiseControl to build the application triggered off the commits to SVN.
What mechanism to others use to do this job? Is there an about box version number library or set of ant related tools that I can just drop in place in my build process?
I'm not looking for deployment options or anyway to automatically check for updates or anything like that. I just want to be able to ask a tester what version is in the about box and get a reliable answer. | I will start this post off by stating that I use [Apache Maven](http://maven.apache.org/) to build. You could also do a similar sort of thing with Ant or another tool, but this is what I have done using maven.
The best way I have found to handle this is to use the version of your project plus the subversion revision as the build number. From maven you can include the following. This will give you the subversion revision number as ${scm.revision}.
```
<build>
<plugins>
<plugin>
<artifactId>maven-scm-plugin</artifactId>
<executions>
<execution>
<id>getting-scm.revision</id>
<phase>validate</phase>
<goals>
<goal>update</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
```
After you have then, I then use this as part of the jar file manifest as the Implementation Version.
```
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>2.1</version>
<configuration>
<archive>
<manifestEntries>
<Implementation-Version>${this.version}.${scm.revision}</Implementation-Version>
</manifestEntries>
</archive>
</configuration>
</plugin>
```
The nice thing about this is that you can access this from code by using the following:
```
Package p = getClass().getPackage();
String version = p.getImplementationVersion();
```
That gives you the full build number like "1.0.13525" where the last number is the subversion revision. For more information on setting this up you can check out the full [blog post](http://chrisdail.com/2008/04/17/building-with-maven/) I did a while back on this very issue. | Have the build script create a property file holding the version. It's good idea to grab the revision # directly from SVN. This way you can refer to it in tests. Place this property file into the packaged jar and read it in run time. We usually have major and minor versions set as parameters to ant scrpt while revision is managed automatically by SVN and gives consistent build number for the references.
This snippet target runs svn command line and outputs into a temp file (svndump).
Then constructing xx.yy.zz string, place it in another file which will be later included into jar.
Note that xx.yy are taken from external parameters, this is major-minor version.
```
<target name="getrev">
<exec executable="svn" output="svndump">
<arg value="info"/>
<arg value="${my.svn.url}"/>
</exec>
<property file="svndump"/>
<property name="my.build" value="${Revision}"/>
<property name="my.rev" value="${my.ver}.${my.build}"/>
<echo message="current revision is ${my.rev}"/>
<property name="my.dir.dist" value="${my.dir.root}/dist/${my.rev}"/>
<echo message="${my.rev}" file="${my.dir.projects}/revision"/>
<delete file="svndump"/>
</target>
``` | What is a good way to handle a version number in a Java application? | [
"",
"java",
"version",
""
] |
My site is rather extensive, and I just recently made the switch to PHP5 (call me a late bloomer).
All of my MySQL query's before were built as such:
```
"SELECT * FROM tablename WHERE field1 = 'value' && field2 = 'value2'";
```
This made it very easy, simple and friendly.
I am now trying to make the switch to mysqli for obvious security reasons, and I am having a hard time figuring out how to implement the same `SELECT * FROM` queries when the `bind_param` requires specific arguments.
Is this statement a thing of the past?
If it is, how do I handle a query with tons of columns involved? Do I really need to type them all out every time? | ```
"SELECT * FROM tablename WHERE field1 = 'value' && field2 = 'value2'";
```
becomes
```
"SELECT * FROM tablename WHERE field1 = ? && field2 = ?";
```
which is passed to the `$mysqli::prepare`:
```
$stmt = $mysqli->prepare(
"SELECT * FROM tablename WHERE field1 = ? && field2 = ?");
$stmt->bind_param( "ss", $value, $value2);
// "ss' is a format string, each "s" means string
$stmt->execute();
$stmt->bind_result($col1, $col2);
// then fetch and close the statement
```
OP comments:
> so if i have 5 parameters, i could potentially have "sssis" or something (depending on the types of inputs?)
Right, one type specifier per `?` parameter in the prepared statement, all of them positional (first specifier applies to first `?` which is replaced by first actual parameter (which is the second parameter to `bind_param`)). | I could be wrong, but for your question I get the feeling that `bind_param()` isn't really the problem here. You always need to define some conditions, be it directly in the query string itself, of using `bind_param()` to set the `?` placeholders. That's not really an issue.
The problem I had using MySQLi `SELECT *` queries is the `bind_result()` part. Therefore, just use `get_result()` which is much more convenient:
```
$result = $stmt->get_result();
$row = $result->fetch_assoc();
```
As you can see, all familiar fetch functions can be used.
For historical reasons, here is how to fetch arrays with `bind_result()`. That's where it gets interesting. I came across this post from Jeffrey Way: <http://jeff-way.com/2009/05/27/tricky-prepared-statements/>(This link is no longer active). The script basically loops through the results and returns them as an array — no need to know how many columns there are, and you can still use prepared statements.
In this case it would look something like this:
```
$stmt = $mysqli->prepare(
'SELECT * FROM tablename WHERE field1 = ? AND field2 = ?');
$stmt->bind_param('ss', $value, $value2);
$stmt->execute();
```
Then use the snippet from the site:
```
$meta = $stmt->result_metadata();
while ($field = $meta->fetch_field()) {
$parameters[] = &$row[$field->name];
}
call_user_func_array(array($stmt, 'bind_result'), $parameters);
while ($stmt->fetch()) {
foreach($row as $key => $val) {
$x[$key] = $val;
}
$results[] = $x;
}
```
And `$results` now contains all the info from `SELECT *`. So far I found this to be an ideal solution. | SELECT * FROM in MySQLi | [
"",
"php",
"mysqli",
""
] |
how could I request Java garbage collection externally, starting the program from JAR (Windows BAT used)?
* From the Java code I can do it with `System.gc()`
* When running a JNLP distribution, I get this "Java console" turned on from Control Panel / Java / ... and this Java console provides manual garbage collection.
But... When I'm running the jar from command-line / bat the java console doesn't seem to open. Couldn't find help with a brief googling, maybe somebody here? | You can use [jconsole](http://java.sun.com/j2se/1.5.0/docs/guide/management/jconsole.html) to connect to a JVM that is running locally - This provides a "Perform GC" button on the GUI.
You'll need to specify **-Dcom.sun.management.jmxremote** when you kick off your java process. | For a purely command-line approach, you should be able to use [`jcmd`](http://docs.oracle.com/javase/7/docs/technotes/tools/windows/jcmd.html). I believe jcmd has been part of the standard JDK install since at least Java 1.7. The command would be something like this:
```
jcmd <process-id> GC.run
```
You can get a list of available diagnostic commands that jcmd provides for a particular process like this:
```
jcmd <process-id> help
``` | How to request JVM garbage collection (not from code) when run from Windows command-line | [
"",
"java",
"windows",
"command-line",
"garbage-collection",
""
] |
I need to draw [ternary/triangle plots](http://en.wikipedia.org/wiki/Ternary_plot) representing mole fractions (*x*, *y*, *z*) of various substances/mixtures (*x* + *y* + *z* = 1). Each plot represents iso-valued substances, e.g. substances which have the same melting point. The plots need to be drawn on the same triangle with different colors/symbols and it would be nice if I could also connect the dots.
I have looked at matplotlib, R and gnuplot, but they don't seem to be able to draw this kind of plot. The 3rd party [ade4](http://cran.r-project.org/web/packages/ade4/) package for R seems to be able to draw it, but I'm not sure if I can draw multiple plots on the same triangle.
I need something that runs under Linux or Windows. I'm open to any suggestions, including libraries for other languages, e.g. Perl, PHP, Ruby, C# and Java. | R has an external package called [VCD](http://www.math.yorku.ca/SCS/vcd/) which should do what you want.
The documentation is very good (122 page manual distributed w/ the package); there's also a book by the same name, *Visual Display of Quantitative Information*, by the package's author (Prof. Michael Friendly).
To create ternary plots using **vcd**, just call ***ternaryplot()*** and pass in an m x 3 matrix, i.e., a matrix with three columns.
The method signature is very simple; only a single parameter (the m x 3 data matrix) is required; and all of the keyword parameters relate to the plot's aesthetics, except for scale, which when set to 1, normalizes the data column-wise.
To plot data points on the ternary plot, the coordinates for a given point are calculated as the *gravity center of mass points* in which each feature value comprising the data matrix is a separate *weight*, hence the coordinates of a point V(a, b, c) are
```
V(b, c/2, c * (3^.5)/2
```
To generate the diagram below, i just created some fake data to represent four different chemical mixtures, each comprised of varying fractions of three substances (x, y, z). I scaled the input (so x + y + z = 1) but the function will do it for you if you pass in a value for its 'scale' parameter (in fact, the default is 1, which i believe is what your question requires). I used different colors & symbols to represent the four data points, but you can also just use a single color/symbol and label each point (via the 'id' argument).
[](https://i.stack.imgur.com/MujXH.png) | Created a very basic script for generating ternary (or more) plots. No gridlines or ticklines, but those wouldn't be too hard to add using the vectors in the "basis" array.
```
from pylab import *
def ternaryPlot(
data,
# Scale data for ternary plot (i.e. a + b + c = 1)
scaling=True,
# Direction of first vertex.
start_angle=90,
# Orient labels perpendicular to vertices.
rotate_labels=True,
# Labels for vertices.
labels=('one','two','three'),
# Can accomodate more than 3 dimensions if desired.
sides=3,
# Offset for label from vertex (percent of distance from origin).
label_offset=0.10,
# Any matplotlib keyword args for plots.
edge_args={'color':'black','linewidth':2},
# Any matplotlib keyword args for figures.
fig_args = {'figsize':(8,8),'facecolor':'white','edgecolor':'white'},
):
'''
This will create a basic "ternary" plot (or quaternary, etc.)
'''
basis = array(
[
[
cos(2*_*pi/sides + start_angle*pi/180),
sin(2*_*pi/sides + start_angle*pi/180)
]
for _ in range(sides)
]
)
# If data is Nxsides, newdata is Nx2.
if scaling:
# Scales data for you.
newdata = dot((data.T / data.sum(-1)).T,basis)
else:
# Assumes data already sums to 1.
newdata = dot(data,basis)
fig = figure(**fig_args)
ax = fig.add_subplot(111)
for i,l in enumerate(labels):
if i >= sides:
break
x = basis[i,0]
y = basis[i,1]
if rotate_labels:
angle = 180*arctan(y/x)/pi + 90
if angle > 90 and angle <= 270:
angle = mod(angle + 180,360)
else:
angle = 0
ax.text(
x*(1 + label_offset),
y*(1 + label_offset),
l,
horizontalalignment='center',
verticalalignment='center',
rotation=angle
)
# Clear normal matplotlib axes graphics.
ax.set_xticks(())
ax.set_yticks(())
ax.set_frame_on(False)
# Plot border
ax.plot(
[basis[_,0] for _ in range(sides) + [0,]],
[basis[_,1] for _ in range(sides) + [0,]],
**edge_args
)
return newdata,ax
if __name__ == '__main__':
k = 0.5
s = 1000
data = vstack((
array([k,0,0]) + rand(s,3),
array([0,k,0]) + rand(s,3),
array([0,0,k]) + rand(s,3)
))
color = array([[1,0,0]]*s + [[0,1,0]]*s + [[0,0,1]]*s)
newdata,ax = ternaryPlot(data)
ax.scatter(
newdata[:,0],
newdata[:,1],
s=2,
alpha=0.5,
color=color
)
show()
``` | Library/tool for drawing ternary/triangle plots | [
"",
"python",
"r",
"plot",
"gnuplot",
""
] |
Given a time (eg. currently 4:24pm on Tuesday), I'd like to be able to select all businesses that are currently open out of a set of businesses.
* I have the open and close times for every business for every day of the week
* Let's assume a business can open/close only on 00, 15, 30, 45 minute marks of each hour
* I'm assuming the same schedule each week.
* I am most interested in being able to quickly look up a set of businesses that is open at a certain time, not the space requirements of the data.
* Mind you, some my open at 11pm one day and close 1am the next day.
* Holidays don't matter - I will handle these separately
What's the most efficient way to store these open/close times such that with a single time/day-of-week tuple I can **speedily** figure out which businesses are open?
I am using Python, SOLR and mysql. I'd like to be able to do the querying in SOLR. But frankly, I'm open to any suggestions and alternatives. | If you are willing to just look at single week at a time, you can canonicalize all opening/closing times to be set numbers of minutes since the start of the week, say Sunday 0 hrs. For each store, you create a number of tuples of the form [startTime, endTime, storeId]. (For hours that spanned Sunday midnight, you'd have to create two tuples, one going to the end of the week, one starting at the beginning of the week). This set of tuples would be indexed (say, with a tree you would pre-process) on both startTime and endTime. The tuples shouldn't be that large: there are only ~10k minutes in a week, which can fit in 2 bytes. This structure would be graceful inside a MySQL table with appropriate indexes, and would be very resilient to constant insertions & deletions of records as information changed. Your query would simply be "select storeId where startTime <= time and endtime >= time", where time was the canonicalized minutes since midnight on sunday.
If information doesn't change very often, and you want to have lookups be very fast, you could solve every possible query up front and cache the results. For instance, there are only 672 quarter-hour periods in a week. With a list of businesses, each of which had a list of opening & closing times like Brandon Rhodes's solution, you could simply, iterate through every 15-minute period in a week, figure out who's open, then store the answer in a lookup table or in-memory list. | The bitmap field mentioned by another respondent would be incredibly efficient, but gets messy if you want to be able to handle half-hour or quarter-hour times, since you have to increase arithmetically the number of bits and the design of the field each time you encounter a new resolution that you have to match.
I would instead try storing the values as datetimes inside a list:
```
openclosings = [ open1, close1, open2, close2, ... ]
```
Then, I would use Python's "bisect\_right()" function in its built-in "bisect" module to find, in fast O(log n) time, where in that list your query time "fits". Then, look at the index that is returned. If it is an even number (0, 2, 4...) then the time lies between one of the "closed" times and the next "open" time, so the shop is closed then. If, instead, the bisection index is an odd number (1, 3, 5...) then the time has landed between an opening and a closing time, and the shop is open.
Not as fast as bitmaps, but you don't have to worry about resolution, and I can't think of another O(log n) solution that's as elegant. | Efficiently determining if a business is open or not based on store hours | [
"",
"python",
"mysql",
"performance",
"solr",
""
] |
I am trying to use the getJSON function in jQuery to import some data and trigger a callback function. The callback function doesn't run. However, if I try the same thing with the get function, it works fine. Strangely, it works with the get function even when I pass "json" as the type. Why is this happening? I tested the following file in Firefox 3 and IE 7:
```
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html><head>
<meta http-equiv='Content-Type' content='text/html; charset=UTF-8'>
<title>ajax test</title>
<script type="text/javascript" src="/jquery-1.3.2.min.js"></script>
</head>
<body>
<input type="button" id="test1" value="get">
<input type="button" id="test2" value="getJSON">
<input type="button" id="test3" value="get with json type">
<script type="text/javascript">
$("#test1").click(function() {
$.get("index.html",
function(response) {
alert('hi');
//works
}
)
});
$("#test2").click(function() {
$.getJSON("index.html",
function(response) {
alert('hi');
//doesn't work
}
)
});
$("#test3").click(function() {
$.get("index.html",
function(response) {
alert('hi');
//works
},
"json"
)
});
</script>
</body></html>
```
This seems to happen no matter what URL I access, as long as it's on the same domain. I tried passing some data and that doesn't make a difference.
Of course I can work around the problem by using the get function like I did in my 3rd test function, but I am still curious as to why this is happening.
I know there is a [similar question](https://stackoverflow.com/questions/572991/jquery-getjson-doesnt-trigger-callback) asked here but it didn't answer my question. | The json needs to be valid, otherwise the callback will not fire. | $.getJSON() is JSONP, so change it this way:
```
$("#test2").click(function() {
$.getJSON("index.html?callback=?",
function(response) {
alert('hi');
}
)
});
```
Server receives param callback filled with something like: jsonp1291077863309.
In a response write back callback function jsonp1291077863309( PUT\_JSON\_HERE). | callback function doesn't work when using getJSON function in jQuery | [
"",
"javascript",
"jquery",
"ajax",
""
] |
Can I easily swap two elements with jQuery?
I'm looking to do this with one line if possible.
I have a select element and I have two buttons to move up or down the options, and I already have the selected and the destination selectors in place, I do it with an if, but I was wondering if there is an easier way. | Here's an interesting way to solve this using only jQuery (if the 2 elements are **next to each other**):
```
$("#element1").before($("#element2"));
```
or
```
$("#element1").after($("#element2"));
``` | Paulo's right, but I'm not sure why he's cloning the elements concerned. This isn't really necessary and will lose any references or event listeners associated with the elements and their descendants.
Here's a non-cloning version using plain DOM methods (since jQuery doesn't really have any special functions to make this particular operation easier):
```
function swapNodes(a, b) {
var aparent = a.parentNode;
var asibling = a.nextSibling === b ? a : a.nextSibling;
b.parentNode.insertBefore(a, b);
aparent.insertBefore(b, asibling);
}
``` | Is there a native jQuery function to switch elements? | [
"",
"jquery",
"swap",
"javascript",
""
] |
Any know how can I get the mode value from an array? For example, if I have a array with difference number, how can I use Java to search out which number is appears the most? | Completes in O(n) as opposed to O(n^2). Requires arrays of length > 0.
```
public static int getMode(int[] values) {
HashMap<Integer,Integer> freqs = new HashMap<Integer,Integer>();
for (int val : values) {
Integer freq = freqs.get(val);
freqs.put(val, (freq == null ? 1 : freq+1));
}
int mode = 0;
int maxFreq = 0;
for (Map.Entry<Integer,Integer> entry : freqs.entrySet()) {
int freq = entry.getValue();
if (freq > maxFreq) {
maxFreq = freq;
mode = entry.getKey();
}
}
return mode;
}
``` | This is a little out there, and I don't know about it's performance, but if you were willing to try a little Groovy with your Java...
```
static int modal( ArrayList values ) {
use(Collections){
values.max{ values.frequency(it) }
}
}
``` | Get mode value in java | [
"",
"java",
""
] |
I am trying to access a static *variable* within a class by using a variable class name. I'm aware that in order to access a *function* within the class, you use `call_user_func()`:
```
class foo {
function bar() { echo 'hi'; }
}
$class = 'foo';
call_user_func(array($class, 'bar')); // prints hi
```
However, this does not work when trying to access a static *variable* within the class:
```
class foo {
public static $bar = 'hi';
}
$class = "foo";
call_user_func(array($class, 'bar')); // nothing
echo $foo::$bar; // invalid
```
How do I get at this variable? Is it even possible? I have a bad feeling this is only available in PHP 5.3 going forward and I'm running PHP 5.2.6. | You can use [reflection](https://www.php.net/language.oop5.reflection) to do this. Create a [ReflectionClass](http://php.net/manual/en/class.reflectionclass.php) object given the classname, and then use the getStaticPropertyValue method to get the static variable value.
```
class Demo
{
public static $foo = 42;
}
$class = new ReflectionClass('Demo');
$value=$class->getStaticPropertyValue('foo');
var_dump($value);
``` | I think there is much better (more elegant) way then creating ReflectionClass instance. I also edited this code (and my answer) after few comments. I added example for protected variables (you can't of course access them from outside the class, so I made static getter and call it using variable pattern as well). You can use it in few different ways:
```
class Demo
{
public static $foo = 42;
protected static $boo = 43;
public static function getProtected($name) {
return self::$$name;
}
}
$var1 = 'foo';
$var2 = 'boo';
$class = 'Demo';
$func = 'getProtected';
var_dump(Demo::$$var1);
var_dump($class::$foo);
var_dump($class::$$var1);
//var_dump(Demo::$$var2); // Fatal error: Cannot access protected property Demo::$boo
var_dump(Demo::getProtected($var2));
var_dump($class::getProtected($var2));
var_dump($class::$func($var2));
```
Documentation is here:
<http://php.net/manual/en/language.variables.variable.php> | Access a static variable by $var::$reference | [
"",
"php",
""
] |
java.lang.NoClassDefFoundError: happens sporadically on Resin sever start up
This is on Resin 3.0.21
Using Java 1.5 on Linux machine...
I have a servlet defined on the web.xml to load the log4j.properties.
This is thrown when the servlet is trying to load on start up..
log4j-init: init log4j:ERROR Could not instantiate class [org.apache.log4j.DailyRollingFileAppender].
java.lang.ClassNotFoundException: org.apache.log4j.DailyRollingFileAppender [java.lang.NoClassDefFoundError: org/apache/log4j/FileAppender]
at com.caucho.loader.DynamicClassLoader.loadClass(DynamicClassLoader.java:1264)
at com.caucho.loader.DynamicClassLoader.findClass(DynamicClassLoader.java:1149)
at com.caucho.loader.DynamicClassLoader.loadClass(DynamicClassLoader.java:1072)
at com.caucho.loader.DynamicClassLoader.loadClass(DynamicClassLoader.java:1021)
at java.lang.ClassLoader.loadClassInternal(ClassLoader.java:319)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:164)
at org.apache.log4j.helpers.Loader.loadClass(Loader.java:160)
at org.apache.log4j.helpers.OptionConverter.instantiateByClassName(OptionConverter.java:309)
at org.apache.log4j.helpers.OptionConverter.instantiateByKey(OptionConverter.java:112)
at org.apache.log4j.PropertyConfigurator.parseAppender(PropertyConfigurator.java:620) | We found out that this usually happens when there is no free disk space on the server | Most likely, the file `log4j.jar` is found on the classpath twice, causing Classpath problems. If log4J gets loaded twice, once in the Web Application and once in Resin, then you can get this kind of confusion. Assuming log4j is already present in Resin, if it is also present in your web application's classpath (lib directory), then try removing it from your application's lib directory. | java.lang.NoClassDefFoundError: happens sporadically on Resin sever start up | [
"",
"java",
"resin",
""
] |
Can someone show me the simplest way of perform a parametrized SQL query using Classic ASP in VBscript?
A compilable example would be best. | Use the adodb.command object.
```
with createobject("adodb.command")
.activeConnection = application("connectionstring")
.commandText = "select * from sometable where id=?"
set rs = .execute( ,array(123))
end with
```
I would also advise to use a custom db access object instead of using adodb directly. This allows you to build a nicer api, improves testability and add hooks for debuging/logging/profiling. Secondly you can add request scoped transactions with implicit rollback's on errors using the class\_terminiate event. Oure db access object offers the following query api
```
call db.execute("update some_table set column=? where id=?", array(value, id))
set rs = db.fetch_rs("select * from some_table where id=?", array(id))
count = db.fetch_scalar("select count(*) from some_table where column > ?", array(value))
``` | I'm assuming you are referring to a parameterized SQL Query. If this is the case, then the VBScript code would look something like this:
```
Set adoCon = Server.CreateObject("ADODB.Connection")
adoCon.Open "connectionstring"
SET cmd = Server.CreateObject("ADODB.Command")
cmd.ActiveConnection = adoCon
cmd.CommandType= adCmdStoredProc
cmd.CommandText = "GetCustomerByFirstName"
cmd.Parameters.Append cmd.CreateParameter("@FirstName",adVarchar,adParamInput,50,"John")
Set Rec = cmd.Execute()
While NOT Rec.EOF
'code to iterate through the recordset
Rec.MoveNext
End While
```
**UPDATE:** You need to include the ADOVBS.inc file for the constants to be recognized.
Here's a link: [ADOVBS.inc](http://www.asp101.com/articles/john/adovbs/adovbs.inc.txt) | How to make a parametrized SQL Query on Classic ASP? | [
"",
"sql",
"asp-classic",
"vbscript",
""
] |
We're in the process of planning a large, enterprise application. We're focusing our efforts on evaluating hibernate after experiencing the pains of J2EE.
It looks like the new Java EE API is simpler. I've also read some good things about Hibernate and iBatis. Our team has little experience with any of the frameworks.
There are 5 main comparisong points I'd like to determine
* Learning Curve/Ease of Use
* Productivity
* Maintainability/Stability
* Performance/Scalability
* Ease of Troubleshooting
If you were to manage a team of ~6 developers with J2EE experience which ORM tool would you use and why? | Let me take a crack at this. First of, I've written some on this subject in [Using an ORM or plain SQL?](https://stackoverflow.com/questions/494816/using-an-orm-or-plain-sql/494853#494853). Specifically to address your points:
**Learning Curve/Ease of Use**
Ibatis is about SQL. If you know SQL the learning curve for ibatis is trivial. Ibatis does some things on top of SQL such as:
* group by;
* discriminated types; and
* dynamic SQL.
that you'll still need to learn but the biggest hurdle is SQL.
JPA (which includes Hibernate) on the other hand tries to distance itself from SQL and present things in an object rather than a relational way. As Joel points out however, [abstractions are leaky](http://www.joelonsoftware.com/articles/LeakyAbstractions.html) and JPA is no exception. To do JPA you'll still need to know about relational models, SQL, performance tuning of queries and so forth.
Whereas Ibatis will simply having you apply the SQL you know or are learning, JPA will require you to know something else: how to configure it (either XML or annotations). By this I mean figuring out that foreign key relationships are a relationship (one-to-one, one-to-many or many-to-many) of some kind, the type mapping, etc.
If you know SQL I would say the barrier to learning JPA is actually higher. If you don't, it's more of a mixed result with JPA allowing you to effectively defer learning SQL for a time (but it doesn't put it off indefinitely).
With JPA once you setup your entities and their relationships then other developers can simply use them and don't need to learn everything about configuring JPA. This could be an advantage but a developer will still need to know about entity managers, transaction management, managed vs unmanaged objects and so on.
It's worth noting that JPA also has its own query language (JPA-SQL), which you will need to learn whether or not you know SQL. You will find situations where JPA-SQL just can't do things that SQL can.
**Productivity**
This is a hard one to judge. Personally I think I'm more productive in ibatis but I'm also really comfortable with SQL. Some will argue they're way more productive with Hibernate but this is possibly due--at least in part--to unfamiliarity with SQL.
Also the productivity with JPA is deceptive because you will occasionally come across a problem with your data model or queries that takes you a half a day to a day to solve as you turn up logging and watch what SQL your JPA provider is producing and then working out the combination of settings and calls to get it to produce something that's both correct and performant.
You just don't have this kind of problem with Ibatis because you've written the SQL yourself. You test it by running the SQL inside PL/SQL Developer, SQL Server Management Studio, Navicat for MySQL or whatever. After the query is right, all you're doing is mapping inputs and outputs.
Also I found JPA-QL to be more awkward than pure SQL. You need separate tools to just run a JPA-QL query to see the results and it's something more you have to learn. I actually found this whole part of JPA rather awkward and unwieldy although some people love it.
**Maintainability/Stability**
The danger with Ibatis here is proliferation meaning your dev team may just keep adding value objects and queries as they need them rather than looking for reuse whereas JPA has one entitty per table and once you have that entity, that's it. Named queries tend to go on that entity so are hard to miss. Ad-hoc queries can still be repeated but I think it's less of a potential problem.
That comes at the cost of rigidity however. Often in an application you will need bits and pieces of data from different tables. With SQL it's easy because you can write a single query (or a small number of queries) to get all that data in one hit and put it in a custom value object just for that purpose.
With JPA you are moving up that logic into your business layer. Entities are basically all or nothing. Now that's not strictly true. Various JPA providers will allow you to partially load entities and so forth but even there you're talking about the same discrete entitites. If you need data from 4 tables you either need 4 entities or you need to combine the data you want into some kind of custom value object in the business or presentation layer.
One other thing I like about ibatis is that all your SQL is external (in XML files). Some will cite this is as a disadvantage but not me. You can then find uses of a table and/or column relatively easy by searching your XML files. With SQL embedded in code (or where there is no SQL at all) it can be a lot harder to find. You can also cut and paste SQL into a database tool and run it. I can't overstate enough how many times this has been useful to me over the years.
**Performance/Scalability**
Here I think ibatis wins hands down. It's straight SQL and low cost. By its nature JPA simply won't be able to manage the same level of latency or throughput. Now what JPA has going for it is that latency and throughput are only rarely problems. High performance systems however do exist and will tend to disfavour more heavyweight solutions like JPA.
Plus with ibatis you can write a query that returns exactly the data you want with the exact columns that you need. Fundamentally there's no way JPA can beat (or even match) that when it's returning discrete entities.
**Ease of Troubleshooting**
I think this one is a win for Ibatis too. Like I mentioned above, with JPA you will sometimes spend half a day getting a query or entity produce the SQL you want or diagnosing a problem where a transaction fails because the entity manager tried to persist an unmanaged object (which could be part of a batch job where you've committed a lot of work so it might be nontrivial to find).
Both of them will fail if you try to use a table or column that doesn't exist, which is good.
**Other criteria**
Now you didn't mention portability as one of your requirements (meaning moving between database vendors). It's worth noting that here JPA has the advantage. The annotations are less portable than, say, Hibernate XML (eg standard JPA annotations don't have an equivalent for Hibernate's "native" ID type) but both of them are more portable than ibatis / SQL.
Also I've seen JPA / Hibernate used as a form of portable DDL, meaning you run a small Java program that creates the database schema from JPA configuration. With ibatis you'll need a script for each supported database.
The downside of portability is that JPA is, in some ways, lowest common denominator, meaning the supported behaviour is largely the common supported behaviour across a wide range of database vendors. If you want to use Oracle Analytics in ibatis, no problem. In JPA? Well, that's a problem. | A simplistic rule of thumb between iBatis and Hibernate is that if you want more SQL/relational view of the world, iBatis is better fit; and for more complex inheritance chain, and less direct view to SQL, Hibernate.
Both are widely used and solid good frameworks. So I think both would probably work well. Perhaps read a tutorial for both, see if one sounds better than the other, and just pick one.
Of things you list, I don't think performance is very different -- bottleneck will almost invariably be the database, not framework. For other things I think different developers would prefer one or the other, i.e. there's no commonly accepted priority (for iBatis vs Hibernate). | Hibernate, iBatis, Java EE or other Java ORM tool | [
"",
"java",
"hibernate",
"orm",
"jakarta-ee",
"ibatis",
""
] |
The "party model" is a "pattern" for relational database design. At least part of it involves finding commonality between many entities, such as Customer, Employee, Partner, etc., and factoring that into some more "abstract" database tables.
I'd like to find out your thoughts on the following:
1. What are the core principles and motivating forces behind the party model?
2. What does it prescribe you do to your data model? (My bit above is pretty high level and quite possibly incorrect in some ways. I've been on a project that used it, but I was working with a separate team focused on other issues).
3. What has your experience led you to feel about it? Did you use it, and if so, would you do so again? What were the pros and cons?
4. Did the party model limit your choice of ORMs? For example, did you have to eliminate certain ORMs because they didn't allow for enough of an "abstraction layer" between your domain objects and your physical data model?
I'm sure every response won't address every one of those questions ... but anything touching on one or more of them is going to help me make some decisions I'm facing.
Thanks. | > 1. What are the core principles and motivating forces behind the party
> model?
To the extent that I've used it, it's mostly about code reuse and flexibility. We've used it before in the guest / user / admin model and it certainly proves its value when you need to move a user from one group to another. Extend this to having organizations and companies represented with users under them, and it's really providing a form of abstraction that isn't particularly inherent in SQL.
> 2. What does it prescribe you do to your data model? (My bit above is
> pretty high level and quite possibly
> incorrect in some ways. I've been on a
> project that used it, but I was
> working with a separate team focused
> on other issues).
You're pretty correct in your bit above, though it needs some more detail. You can imagine a situation where an entity in the database (call it a Party) contracts out to another Party, which may in turn subcontract work out. A party might be an Employee, a Contractor, or a Company, all subclasses of Party. From my understanding, you would have a Party table and then more specific tables for each subclass, which could then be further subclassed (Party -> Person -> Contractor).
> 3. What has your experience led you to feel about it? Did you use it, and if
> so, would you do so again? What were
> the pros and cons?
It has its benefits if you need flexibly to add new types to your system and create relationships between types that you didn't expect at the beginning and architect in (users moving to a new level, companies hiring other companies, etc). It also gives you the benefit of running a single query and retrieving data for multiple types of parties (Companies,Employees,Contractors). On the flip side, you're adding additional layers of abstraction to get to the data you actually need and are increasing load (or at least the number of joins) on the database when you're querying for a specific type. If your abstraction goes too far, you'll likely need to run multiple queries to retrieve the data as the complexity would start to become detrimental to readability and database load.
> 4. Did the party model limit your choice of ORMs? For example, did you
> have to eliminate certain ORMs because
> they didn't allow for enough of an
> "abstraction layer" between your
> domain objects and your physical data
> model?
This is an area that I'm admittedly a bit weak in, but I've found that using views and mirrored abstraction in the application layer haven't made this too much of a problem. The real problem for me has always been a "where is piece of data X living" when I want to read the data source directly (it's not always intuitive for new developers on the system either). | The idea behind the party models (aka entity schema) is to define a database that leverages some of the scalability benefits of schema-free databases. The party model does that by defining its entities as party type records, as opposed to one table per entity. The result is an extremely normalized database with very few tables and very little knowledge about the semantic meaning of the data it stores. All that knowledge is pushed to the data access in code. Database upgrades using the party model are minimal to none, since the schema never changes. It’s essentially a glorified key-value pair data model structure with some fancy names and a couple of extra attributes.
Pros:
* Kick-ass horizontal scalability. Once your 5-6 tables are defined in your entity model, you can go to the beach and sip margaritas. You can virtually scale this database out as much as you want with minimum efforts.
* The database supports any data structure you throw at it. You can also change data structures and party/entities definitions on the fly without affecting your application. This is very very powerful.
* You can model any arbitrary data entity by adding records, not changing the schema. Meaning you can say goodbye to schema migration scripts.
* This is programmers’ paradise, since the code they write will define the actual entities they use in code, and there are no mappings from Objects to Tables or anything like that. You can think of the Party table as the base object of your framework of choice (System.Object for .NET)
Cons:
* Party/Entity models never play well with ORMs, so forget about using EF or NHibernate to get semantically meaningful entities out of your entity database.
* Lots of joins. Performance tuning challenges. This ‘con’ is relative to the practices you use to define your entities, but is safe to say that you’ll be doing a lot more of those mind-bending queries that will bring you nightmares at night.
* Harder to consume. Developers and DB pros unfamiliar with your business will have a harder time to get used to the entities exposed by these models. Since everything is abstract, there no diagram or visualization you can build on top of your database to explain what is stored to someone else.
* Heavy data access models or business rules engines will be needed. Basically you have to do the work of understanding what the heck you want out of your database at some point, and your database model is not going to help you this time around.
If you are considering a party or entity schema in a relational database, you should probably take a look at other solutions like a NoSql data store, BigTable or KV Stores. There are some great products out there with massive deployments and traction such as MongoDB, DynamoDB, and Cassandra that pioneered this movement. | What are the principles behind, and benefits of, the "party model"? | [
"",
"sql",
"database-design",
"orm",
"data-modeling",
""
] |
**Short question:**
Is there a simple way in LINQ to objects to get a distinct list of objects from a list based on a key property on the objects.
**Long question:**
I am trying to do a [`Distinct()`](http://www.hookedonlinq.com/DistinctOperator.ashx) operation on a list of **objects** that have a key as one of their properties.
```
class GalleryImage {
public int Key { get;set; }
public string Caption { get;set; }
public string Filename { get; set; }
public string[] Tags {g et; set; }
}
```
I have a list of `Gallery` objects that contain `GalleryImage[]`.
Because of the way the webservice works [sic] I have duplicates of the
`GalleryImage` object. i thought it would be a simple matter to use `Distinct()` to get a distinct list.
This is the LINQ query I want to use :
```
var allImages = Galleries.SelectMany(x => x.Images);
var distinctImages = allImages.Distinct<GalleryImage>(new
EqualityComparer<GalleryImage>((a, b) => a.id == b.id));
```
The problem is that `EqualityComparer` is an abstract class.
I dont want to :
* implement IEquatable on `GalleryImage` because it is generated
* have to write a separate class to implement `IEqualityComparer` as [shown here](http://www.hookedonlinq.com/DistinctOperator.ashx)
Is there a concrete implementation of `EqualityComparer` somewhere that I'm missing?
I would have thought there would be an easy way to get 'distinct' objects from a set based on a key. | (There are two solutions here - see the end for the second one):
My [MiscUtil](http://pobox.com/~skeet/csharp/miscutil) library has a `ProjectionEqualityComparer` class (and two supporting classes to make use of type inference).
Here's an example of using it:
```
EqualityComparer<GalleryImage> comparer =
ProjectionEqualityComparer<GalleryImage>.Create(x => x.id);
```
Here's the code (comments removed)
```
// Helper class for construction
public static class ProjectionEqualityComparer
{
public static ProjectionEqualityComparer<TSource, TKey>
Create<TSource, TKey>(Func<TSource, TKey> projection)
{
return new ProjectionEqualityComparer<TSource, TKey>(projection);
}
public static ProjectionEqualityComparer<TSource, TKey>
Create<TSource, TKey> (TSource ignored,
Func<TSource, TKey> projection)
{
return new ProjectionEqualityComparer<TSource, TKey>(projection);
}
}
public static class ProjectionEqualityComparer<TSource>
{
public static ProjectionEqualityComparer<TSource, TKey>
Create<TKey>(Func<TSource, TKey> projection)
{
return new ProjectionEqualityComparer<TSource, TKey>(projection);
}
}
public class ProjectionEqualityComparer<TSource, TKey>
: IEqualityComparer<TSource>
{
readonly Func<TSource, TKey> projection;
readonly IEqualityComparer<TKey> comparer;
public ProjectionEqualityComparer(Func<TSource, TKey> projection)
: this(projection, null)
{
}
public ProjectionEqualityComparer(
Func<TSource, TKey> projection,
IEqualityComparer<TKey> comparer)
{
projection.ThrowIfNull("projection");
this.comparer = comparer ?? EqualityComparer<TKey>.Default;
this.projection = projection;
}
public bool Equals(TSource x, TSource y)
{
if (x == null && y == null)
{
return true;
}
if (x == null || y == null)
{
return false;
}
return comparer.Equals(projection(x), projection(y));
}
public int GetHashCode(TSource obj)
{
if (obj == null)
{
throw new ArgumentNullException("obj");
}
return comparer.GetHashCode(projection(obj));
}
}
```
**Second solution**
To do this just for Distinct, you can use the [`DistinctBy`](http://code.google.com/p/morelinq/source/browse/trunk/MoreLinq/DistinctBy.cs) extension in [MoreLINQ](http://code.google.com/p/morelinq/):
```
public static IEnumerable<TSource> DistinctBy<TSource, TKey>
(this IEnumerable<TSource> source,
Func<TSource, TKey> keySelector)
{
return source.DistinctBy(keySelector, null);
}
public static IEnumerable<TSource> DistinctBy<TSource, TKey>
(this IEnumerable<TSource> source,
Func<TSource, TKey> keySelector,
IEqualityComparer<TKey> comparer)
{
source.ThrowIfNull("source");
keySelector.ThrowIfNull("keySelector");
return DistinctByImpl(source, keySelector, comparer);
}
private static IEnumerable<TSource> DistinctByImpl<TSource, TKey>
(IEnumerable<TSource> source,
Func<TSource, TKey> keySelector,
IEqualityComparer<TKey> comparer)
{
HashSet<TKey> knownKeys = new HashSet<TKey>(comparer);
foreach (TSource element in source)
{
if (knownKeys.Add(keySelector(element)))
{
yield return element;
}
}
}
```
In both cases, `ThrowIfNull` looks like this:
```
public static void ThrowIfNull<T>(this T data, string name) where T : class
{
if (data == null)
{
throw new ArgumentNullException(name);
}
}
``` | Building on Charlie Flowers' answer, you can create your own extension method to do what you want which internally uses grouping:
```
public static IEnumerable<T> Distinct<T, U>(
this IEnumerable<T> seq, Func<T, U> getKey)
{
return
from item in seq
group item by getKey(item) into gp
select gp.First();
}
```
You could also create a generic class deriving from EqualityComparer, but it sounds like you'd like to avoid this:
```
public class KeyEqualityComparer<T,U> : IEqualityComparer<T>
{
private Func<T,U> GetKey { get; set; }
public KeyEqualityComparer(Func<T,U> getKey) {
GetKey = getKey;
}
public bool Equals(T x, T y)
{
return GetKey(x).Equals(GetKey(y));
}
public int GetHashCode(T obj)
{
return GetKey(obj).GetHashCode();
}
}
``` | Can you create a simple 'EqualityComparer<T>' using a lambda expression | [
"",
"c#",
"linq",
"distinct",
""
] |
We've got some data (10-50 columns, hundreds of thousands of rows) that we usually visualize in Excel as a line graph or stacked bar chart.
Users want to be able to zoom in and out of the graph to get down to the individual samples, but these kind of operations really bring Excel to its knees.
I'm thinking about embedding the data into an HTML page, with inline JavaScript to handle the visualization in the browser. Something like the flotr JS charting lib would be leveraged for the charts.
1. Is this a stupid idea?
2. Is the browser ready for this kind of load?
3. Is this a solved problem that I just should have googled more thoroughly before asking? | Javascript is probably ready for it, since javascript itself has gotten to be quite fast. In my experience browsers are generally *not* ready to handle very large DOM structures. At the least you can expect to be spending a lot of time trying to find out why things are slow. You'll also discover that a lot of "standard" javascript libraries (prototype/jquery come to mind) are not suitable for working with "excessively" large DOM structures.
Be prepared to find out that a given operation is slow on *all* browsers, but in the end it turns out to be for 3-4 different reasons on the different browsers. This is based on experience from working with moderately oversized DOMs. While certainly possible, it's going to cost a fair amount of work to get a decent result. | I highly recommend Adam's suggestion to perform some benchmarking and optimisation. I've recently done some work on plotting large datasets with Flot and experienced less than acceptable performance with Internet Explorer (e.g. the entire browser hanging for ~20s on my developer box while plotting charts).
Flot uses the [`canvas`](http://en.wikipedia.org/wiki/Canvas_(HTML_element)) element for charting which is only supported from Internet Explorer 9+. Flot provides support for older versions of Internet Explorer using the [ExplorerCanvas](http://code.google.com/p/explorercanvas/) library. This library uses [VML](http://en.wikipedia.org/wiki/Vector_Markup_Language), drawing graphics by manipulating VML elements through the DOM.
Using the [Internet Explorer 8 script profiler](http://msdn.microsoft.com/en-nz/library/dd565629(en-us,VS.85).aspx) I discovered most of the time taken rendering the plot was spent calling the native [insertAdjacentHTML method](http://msdn.microsoft.com/en-us/library/ms536452.aspx) to create the VML elements. Because there was nothing that can be done to improve performance of calls to native methods I instead worked on reducing the number of data points plotted (in turn reducing the VML elements created in the DOM) to get acceptable performance.
If you don't need or care about support for older versions of Internet Explorer when you should find Flot/Flotr is quite capable of handling large datasets. But if you do need to support these versions be prepared to run into performance problems when charting large datasets. | Is JavaScript ready for visualizing large datasets? | [
"",
"javascript",
"dom",
"browser",
"visualization",
"flot",
""
] |
I'm new to JQuery and web development in general. I'm trying to load some data from an XML file and build an unordered list. I've got that part working, now I'm trying to use the [TreeView](http://plugins.jquery.com/project/treeview) plugin so I can collapse/expand the data. The data is loaded like this:
```
$(document).ready(function(){
$.ajax({
type: "GET",
url: "solutions.xml",
dataType: ($.browser.msie) ? "text" : "xml",
success: function(data) {
var xml;
if (typeof data == "string") {
// Work around IE6 lameness
xml = new ActiveXObject("Microsoft.XMLDOM");
xml.async = false;
xml.loadXML(data);
} else {
xml = data;
}
list = ""
$(xml).find("Group").each(function() {
group = $(this).attr("name");
list += "<li><span>" + group + "</span><ul>";
$(this).find("Solution").each(function() {
solution = $(this).attr("name");
list += "<li><span>" + solution + "</span></li>";
});
list += "</ul></li>";
});
$("#groups").html(list);
},
error: function(x) {
alert("Error processing solutions.xml.");
}
});
$("#groups").treeview({
toggle: function() {
console.log("%s was toggled.", $(this).find(">span").text());
}
});
});
```
and the HTML looks like this:
```
<html>
...
<body>
<ul id="groups">
</ul>
</body>
</html>
```
The unordered list shows correctly, but the little [+] and [-] signs don't show up and the sections aren't collapsible/expandable. If I get rid of my Ajax loading and insert an unordered list inside of #groups manually it works as expected.
What am I doing wrong? Is there any other plugins or Javascript libs that could make this easier? The solution needs to work on IE6 locally (i.e. webserver).
**Update**: I found a work-around: If I define my treeview stuff like this it works:
```
function makeTreeview() {
$("#container").treeview({
toggle: function() {
console.log("%s was toggled.", $(this).find(">span").text());
}
});
}
setTimeout('makeTreeview();', 50);
```
I think the problem is, when I create the treeview, the ajax stuff hasn't done it's work yet, so when treeview() is called, the unordered list hasn't been created yet. I haven't tested this with IE6 yet. Is there a nicer way to do this, without using SetTimeout()? | I made the same type of call for another project.
For other reasons you will probably want to wrap your ajax call in an anonymous function to create a closure so that your variables remain what you expect them to...
The success method is a callback function that happens after your call is complete , just create your treeview inside that method, or break it out into a seperate fumction if you need to for clarity.
in the example that you show - your treeview will still fail if the ajax call takes longer than 50ms - which could easily happen during initial load if more than two objects are being loaded from that same server.
This example used JSON, and concurrently loaded html data from a page method into a series of divs.
```
$(document).ready(function() {
for (i= 1;i<=4;i++)
{
(function (){
var divname ="#queuediv"+i;
$.ajax({
type: "POST",
contentType: "application/json; charset=utf-8",
dataType: "json",
url: "test12.aspx/GetHtmlTest",
data: "{}",
error: function(xhr, status, error) {
alert("AJAX Error!");
},
success: function(msg) {
$(divname).removeClass('isequeue_updating');
$(divname).html(msg);
$("#somethingfromthemsg").treeview();
}
});
})();
}
});
```
Hope that helps! | You need to get FireBug (Firefox add-in) and then you can see in the console what is being returned, and make sure it matches what you expect (And that it is actually doing the request..).
Once you get it working in FF, you can support the ancient 10-year old IE6 browser.
---
There's also some other things you may want to consider:
The whole ActiveXObject("Microsoft.XMLDOM") jumps out as me as unnecessary. If you pass XML in a string to $(), jQuery turns it into a DOM object.
Additionally, .Find can be replaced by:
```
$('Element', this);
```
So for example:
```
var xmlDoc = '<Group><Solution name="foo" /><Solution name="bar" /></Group>';
$('Solution', xmlDoc).each(function() {
document.write( $(this).attr('name') );
});
```
would spit out:
```
foo
bar
```
Also, with firebug, stick a console.log(list); at the end, to be sure you're generating the HTML you think you are. If you're really stuck in IE6, alert(list) somewhat works as a poor man's equivalent (as long as your file isn't too big).
---
In short, I think you're on the right track, you just need the tools to debug properly. | JQuery Treeview not working with Ajax | [
"",
"javascript",
"jquery",
"jquery-plugins",
""
] |
I have a project for which we are extending some functionality from an existing client into a web portal in ASP.NET 2.0. The client is windows forms based (in .NET 2.0). It has some settings that are kept in the Project > Properties > Settings.settings system, including a generated settings.Designer.cs file. This file provides nice automatic wrappers for each of the settings.
In trying to set up the website I have been frustrated by an apparent lack of parity for this feature. I have a web.config, and it can have an section. This means access via code with strings, for example:
```
WebConfigurationManager.AppSettings["mySetting"];
```
I can even have the settings refer to another file this way, affording a little abstraction, and easier check-ins to source control:
```
<appSettings configSource="web.settings.config"/>
```
but ultimately this lacks some of the functionality of the client projects settings system.
Particularly I would very much like these features if at all possible:
* Autogenerated accessor class (for convenience, intellisense..)
+ Convenient
+ Strongly Typed
+ Provides Intellisense
+ Code will not compile against typos/mistakes in settings names
* Easy Interface
+ The settings.Settings before provided a nice grid
+ All options represented
+ Showed dropdown choices for certain options
+ Don't have to edit XML
+ Can't fat-finger an angle bracket
I know that it would be possible to create a class that wrapped these, but it would not stay in sync with the settings automatically, and would have to be manually edited on any change. It would provide some of the above however.
Can I get parity with the project settings like we do in our client?
What is the best way to manage settings for an ASP.NET 2.0 website? | You should use Web Application, not Website and you'll have access to settings in the same way as Windows applications | By default, using the appSettings section in your web.config is the simplest way to manage your application settings for the web application. You can cast the values within the application settings as needed. However, you will lose strong typing in this case, which sounds like a deal breaker to you.
If you do need to retain the strong typing, go into the project settings (similar to the WinForms application) and set your values there. You'll notice that settings.settings files exists within a MyProjects folder, but you'll also find the following code snippet down at the bottom of your web.config file (swiped from one of my applications):
```
<applicationSettings>
<EAF.My.MySettings>
<setting name="EAF_AS400EmployeeServices_EmployeeServices" serializeAs="String">
<value>http://countynetappsdev/AS400DataService/EmployeeServices.asmx</value>
</setting>
</applicationSettings>
```
Notice the serializeAs property in this section. Once you have things in this section, you can access the settings through the My.Settings library using VB.NET. However, since you're using C#, you need a smidge more work, but a simple code solution can be found [here](http://www.knowdotnet.com/articles/accessappconfigfromdll.html). | What is the best way to manage settings (configuration) in ASP.NET 2.0? | [
"",
"c#",
"asp.net",
"settings",
""
] |
What is the relation between word length, character size, integer size, and byte in C++? | The standard requires that certain types have *minimum* sizes (short is at least 16 bits, int is at least 16 bits, etc), and that some groups of type are ordered (`sizeof(int)` >= `sizeof(short)` >= `sizeof(char)`). | In C++ a char must be large enough to hold any character in the implemetation's basic character set.
`int` has the "natural size suggested by the architecture of the execution environment". Note that this means that an int does *not* need to be at least 32-bits in size. Implementations where `int` is 16 bits are common (think embedded ot MS-DOS).
The following are taken from various parts of the C++98 and C99 standards:
* `long int` has to be at least as large as `int`
* `int` has to be at least as large as `short`
* `short` has to be at least as large as `char`
Note that they could all be the same size.
Also (assuming a two's complement implementation):
* `long int` has to be at least 32-bits
* `int` has to be at least 16-bits
* `short` has to be at least 16-bits
* `char` has to be at least 8 bits | Relation between word length, character size, integer size and byte | [
"",
"c++",
"cpu-word",
"int",
"byte",
""
] |
Let's say if I have wrapper div which includes some links and images,
is there any way I can deactivate it at once with CSS only?
---
After review of answers:
I dropped the idea that can make it with CSS only.
jQuery blockUI plug in works like charm. | if you are going to use jQuery, you can easily accomplish this with the blockUI plugin. ...or to answer your question with CSS, you'll have to absolutely position the div over the content you wish to block. just make sure the absolutely positioned div comes after the content to be blocked for z-indexing purposes.
```
<div style="position:relative;width: 200px;height: 200px;background-color:green">
<div>
<a href="#">Content to be blocked.</a>
</div>
<div style="position: absolute;top:0;left:0;width: 200px;height:200px;background-color: blue;z-index:2;opacity:0.4;filter: alpha(opacity = 50)"></div>
</div>
```
sorry for all the inline css. you'll have to make some nice classes. Also, this has only been tested in firefox and IE7. | There is a CSS rule for that:
`pointer-events: none;`
Check browser support: <https://caniuse.com/pointer-events> | How do I make an area unclickable with CSS? | [
"",
"javascript",
"jquery",
"css",
""
] |
I am currently using the directory walker from [Here](http://effbot.org/librarybook/os-path-walk-example-3.py)
```
import os
class DirectoryWalker:
# a forward iterator that traverses a directory tree
def __init__(self, directory):
self.stack = [directory]
self.files = []
self.index = 0
def __getitem__(self, index):
while 1:
try:
file = self.files[self.index]
self.index = self.index + 1
except IndexError:
# pop next directory from stack
self.directory = self.stack.pop()
self.files = os.listdir(self.directory)
self.index = 0
else:
# got a filename
fullname = os.path.join(self.directory, file)
if os.path.isdir(fullname) and not os.path.islink(fullname):
self.stack.append(fullname)
return fullname
for file in DirectoryWalker(os.path.abspath('.')):
print file
```
This minor change allows you to have the full path within the file.
Can anyone help me how to find just the filename as well using this? I need both the full path, and just the filename. | Rather than using '.' as your directory, refer to its absolute path:
```
for file in DirectoryWalker(os.path.abspath('.')):
print file
```
Also, I'd recommend using a word other than 'file', because it means something in the python language. Not a keyword, though so it still runs.
As an aside, when dealing with filenames, I find the os.path module to be incredibly useful - I'd recommend having a look through that, especially
```
os.path.normpath
```
Normalises paths (gets rid of redundant '.'s and 'theFolderYouWereJustIn/../'s)
```
os.path.join
```
Joins two paths | Why do you want to do such boring thing yourself?
```
for path, directories, files in os.walk('.'):
print 'ls %r' % path
for directory in directories:
print ' d%r' % directory
for filename in files:
print ' -%r' % filename
```
Output:
```
'.'
d'finction'
d'.hg'
-'setup.py'
-'.hgignore'
'./finction'
-'finction'
-'cdg.pyc'
-'util.pyc'
-'cdg.py'
-'util.py'
-'__init__.pyc'
-'__init__.py'
'./.hg'
d'store'
-'hgrc'
-'requires'
-'00changelog.i'
-'undo.branch'
-'dirstate'
-'undo.dirstate'
-'branch'
'./.hg/store'
d'data'
-'undo'
-'00changelog.i'
-'00manifest.i'
'./.hg/store/data'
d'finction'
-'.hgignore.i'
-'setup.py.i'
'./.hg/store/data/finction'
-'util.py.i'
-'cdg.py.i'
-'finction.i'
-'____init____.py.i'
```
But if you insist, there's path related tools in [os.path](http://docs.python.org/library/os.path.html), os.basename is what you are looking at.
```
>>> import os.path
>>> os.path.basename('/hello/world.h')
'world.h'
``` | Directory Walker for Python | [
"",
"python",
"directory-listing",
""
] |
I have this java code which does this
```
ResulSet rs = stmt.executeQuery();
while (rs.next()) {
.... //do regular processing
if (rs.last()) {
//do last record processing
}
}
``` | You should use: [isLast()](http://java.sun.com/javase/6/docs/api/java/sql/ResultSet.html#isLast()) instead.
Be warned, not all the JDCB drivers support this feature. Obviously you have to check it with your installation.
Most major DB work fine.
The fixed code should look like this.
```
if( rs.isLast() ) {
// do last record processing
}
``` | Personally, I would declare the variables that are retrieved from the query outside the loop, and then do the "last record processing" after the loop.
```
ResulSet rs = stmt.executeQuery();
long primaryKey;
while (rs.next()) {
primaryKey = rs.getLong(1);
.... //do regular processing
}
// Do last record processing.
System.out.println("last primary key = " + primaryKey);
``` | ResultSet method "last" is this an optimal way? | [
"",
"java",
"jdbc",
""
] |
I have a method which needs to be as fast as it possibly can, it uses unsafe memory pointers and its my first foray into this type of coding so I know it can probably be faster.
```
/// <summary>
/// Copies bitmapdata from one bitmap to another at a specified point on the output bitmapdata
/// </summary>
/// <param name="sourcebtmpdata">The sourcebitmap must be smaller that the destbitmap</param>
/// <param name="destbtmpdata"></param>
/// <param name="point">The point on the destination bitmap to draw at</param>
private static unsafe void CopyBitmapToDest(BitmapData sourcebtmpdata, BitmapData destbtmpdata, Point point)
{
// calculate total number of rows to draw.
var totalRow = Math.Min(
destbtmpdata.Height - point.Y,
sourcebtmpdata.Height);
//loop through each row on the source bitmap and get mem pointers
//to the source bitmap and dest bitmap
for (int i = 0; i < totalRow; i++)
{
int destRow = point.Y + i;
//get the pointer to the start of the current pixel "row" on the output image
byte* destRowPtr = (byte*)destbtmpdata.Scan0 + (destRow * destbtmpdata.Stride);
//get the pointer to the start of the FIRST pixel row on the source image
byte* srcRowPtr = (byte*)sourcebtmpdata.Scan0 + (i * sourcebtmpdata.Stride);
int pointX = point.X;
//the rowSize is pre-computed before the loop to improve performance
int rowSize = Math.Min(destbtmpdata.Width - pointX, sourcebtmpdata.Width);
//for each row each set each pixel
for (int j = 0; j < rowSize; j++)
{
int firstBlueByte = ((pointX + j)*3);
int srcByte = j *3;
destRowPtr[(firstBlueByte)] = srcRowPtr[srcByte];
destRowPtr[(firstBlueByte) + 1] = srcRowPtr[srcByte + 1];
destRowPtr[(firstBlueByte) + 2] = srcRowPtr[srcByte + 2];
}
}
}
```
So is there anything that can be done to make this faster? Ignore the todo for now, ill fix that later once I have some baseline performance measurements.
**UPDATE:** Sorry, should have mentioned that the reason i'm using this instead of Graphics.DrawImage is because im implementing multi-threading and because of that I cant use DrawImage.
**UPDATE 2:** I'm still not satisfied with the performance and i'm sure there's a few more ms that can be had. | There was something fundamentally wrong with the code that I cant believe I didn't notice until now.
```
byte* destRowPtr = (byte*)destbtmpdata.Scan0 + (destRow * destbtmpdata.Stride);
```
This gets a pointer to the destination row but it does not get the column that it is copying to, that in the old code is done inside the rowSize loop. It now looks like:
```
byte* destRowPtr = (byte*)destbtmpdata.Scan0 + (destRow * destbtmpdata.Stride) + pointX * 3;
```
So now we have the correct pointer for the destination data. Now we can get rid of that for loop. Using suggestions from [Vilx-](https://stackoverflow.com/questions/740555/lockbits-performance-critical-code/857480#857480) and [Rob](https://stackoverflow.com/questions/740555/lockbits-performance-critical-code/857932#857932) the code now looks like:
```
private static unsafe void CopyBitmapToDestSuperFast(BitmapData sourcebtmpdata, BitmapData destbtmpdata, Point point)
{
//calculate total number of rows to copy.
//using ternary operator instead of Math.Min, few ms faster
int totalRows = (destbtmpdata.Height - point.Y < sourcebtmpdata.Height) ? destbtmpdata.Height - point.Y : sourcebtmpdata.Height;
//calculate the width of the image to draw, this cuts off the image
//if it goes past the width of the destination image
int rowWidth = (destbtmpdata.Width - point.X < sourcebtmpdata.Width) ? destbtmpdata.Width - point.X : sourcebtmpdata.Width;
//loop through each row on the source bitmap and get mem pointers
//to the source bitmap and dest bitmap
for (int i = 0; i < totalRows; i++)
{
int destRow = point.Y + i;
//get the pointer to the start of the current pixel "row" and column on the output image
byte* destRowPtr = (byte*)destbtmpdata.Scan0 + (destRow * destbtmpdata.Stride) + point.X * 3;
//get the pointer to the start of the FIRST pixel row on the source image
byte* srcRowPtr = (byte*)sourcebtmpdata.Scan0 + (i * sourcebtmpdata.Stride);
//RtlMoveMemory function
CopyMemory(new IntPtr(destRowPtr), new IntPtr(srcRowPtr), (uint)rowWidth * 3);
}
}
```
Copying a 500x500 image to a 5000x5000 image in a grid 50 times took: 00:00:07.9948993 secs. Now with the changes above it takes 00:00:01.8714263 secs. Much better. | Well... I'm not sure whether .NET bitmap data formats are *entirely* compatible with Windows's GDI32 functions...
But one of the first few Win32 API I learned was BitBlt:
```
BOOL BitBlt(
HDC hdcDest,
int nXDest,
int nYDest,
int nWidth,
int nHeight,
HDC hdcSrc,
int nXSrc,
int nYSrc,
DWORD dwRop
);
```
And it was the **fastest** way to copy data around, if I remember correctly.
Here's the BitBlt PInvoke signature for use in C# and related usage information, a great read for any one working with high-performance graphics in C#:
* <http://www.pinvoke.net/default.aspx/gdi32/BitBlt.html>
Definitely worth a look. | LockBits Performance Critical Code | [
"",
"c#",
"performance",
"image-processing",
"image-manipulation",
"unsafe",
""
] |
Im getting a weird error when running my spring2.5.6,jpa(hibernate3.4) webapp in weblogic 10.3
---
```
[ERROR] Javassist Enhancement failed: com.xxx.domain.model.Scheme
java.lang.NoSuchMethodError: pcGetManagedFieldCount
at com.xxx.domain.model.Fund.<clinit>(Fund.java)
at sun.misc.Unsafe.ensureClassInitialized(Native Method)
at sun.reflect.UnsafeFieldAccessorFactory.newFieldAccessor(UnsafeFieldAc
cessorFactory.java:25)
```
---
The com.xxx.domain.model.Scheme class is a mapped subclass entity of the abstract fund entity on a single\_table inheritance hierarchy, and I'm getting this error for all entities on the hierarchy. I'm using both annotated classes and xml metadata to define the mappings for my persistence classes.
I only get this error when the app is deployed to weblogic, so everything runs fine using junit. I have tried upgrading to the latest version on javaassit.jar.
Problem Looks to me like an issue with classloading order, but I cant figure it out.
PS. As suggested by bea I have added the following to the weblogic.xml
```
<container-descriptor>
<prefer-web-inf-classes>true</prefer-web-inf-classes>
</container-descriptor>
```
Anyone got any ideas, other config tips, or directions I should take my investigation? | I had the same problem.
My entities extended a class (@MappedSuperClass) which lived inside a jar dependency. I had to move that class from the jar into my project. Only then it would work and deployed fine.
Also another way to solve this is to specify your entities explicitly in the persistence.xml | I'm sorry, I only have WebLogic 10.0 on my machine, and it doesn't have any javassist JARs in the distro. Looks like javassist was only added in 10.3 for AOP byte code generation.
It might be worth a try to remove the javassist JAR from your WebLogic deployment and use the version that it supports. Take the "prefer-web-inf-classes" tag out of your web.xml and see if it can work with the version that WebLogic prefers. | Hibernate/JPA inheritance issue on weblogic | [
"",
"java",
"hibernate",
"spring",
"jpa",
"weblogic-10.x",
""
] |
I have this code from an HTML form:
```
<select name="history12">
<option value="Gov/Econ">Government & Economics</option>
<option value="AP Gov/Econ">AP Government & Economics</option>
</select>
```
...and this code, in a mailer form:
```
$history12 = $_REQUEST['history12'] ;
```
However, when I try to echo() $history12, it always returns blank. I can't figure out what I'm doing wrong since other inputs work fine (text and radio) but it seems like it's bonking on selects. | A few things to check
* Is there a form element around it
* Does the form element use POST
* Do you get anything from print\_r($\_REQUEST);
* And as a last resort, do you see the value anywhere in [`get_defined_vars()`](http://is.php.net/manual/en/function.get-defined-vars.php) | Perhaps you could try outputting the entire $\_REQUEST variable, to ensure everything you're expecting is showing up. That might at least indicate if the 'history12' key is set.
```
print_r($_REQUEST);
``` | Why does my form value not appear in $_REQUEST? | [
"",
"php",
"html",
"forms",
""
] |
I have a CRUD-heavy ASP.NET application with all the business logic in Stored Procedures.
As an example, there is an UPDATE stored procedure that's ~500 lines long and contains large amounts of conditional logic, referencing multiple tables & UDFs. The proc takes in the field name being updated and the new value, sets a bunch of declared variables, does a bunch of validation and creates a dynamic SQL statement to do the update. Once size fits all. It's big and confusing.
I would like to move the business logic over to the .NET side to make it easier to manage/update, test and put under source control.
My question is this: where should this business logic go?
Say I have a PurchaseOrder object with a property called 'Factory'. If the Factory gets changed, I need to make sure the new factory assigned makes the product that's on the PurchaseOrder, that it has pricing, and that there is a minimum quantity requested based upon that factory, etc. All these validations require inquiries in the database.
Should I have the PurchaseOrder object's Factory setter be responsible for doing the data validation via an 'isFactoryValid' method/property that makes the multiple calls to a generic data access object then do the update if it is?
Or do I create a PurchaseOrder/Database 'proxy' object that's responsible for handling just PurchaseOrder-related data access. In this case, would I have an 'isFactoryValid' method in the proxy that's called by the PurchaseOrder's setter and then a call to the proxy's update method?
How do I determine if I need to worry about increasing traffic to the database with all these extra calls? | There are two main patterns that are widely used to implement persistence logic out of the DB:
* [ActiveRecord Pattern](http://www.martinfowler.com/eaaCatalog/activeRecord.html) - Persistence logic is in your domain object.
* [Repository Pattern](http://www.martinfowler.com/eaaCatalog/repository.html) - A separate object or layer handles the data access -- your "proxy" concept addresses this.
The trick with both objects is *knowing when to make a trip to the database and knowing when not to*. For example, there *will* be redundant validations that will be done between the DB and the domain layer, e.g., even before you make a DB call you should evaluate for not null values, truncate strings to length, etc. Only after these checks have been made should a call to Save in the db be made.
There are also a wide range of strategies available to increase performance or minimize database trips, like lazy loading, transactions, and the like. | **One way to do it:**
You have a data layer in .net (one or multiple data classes) with an interface for the layer... then you have a business layer that performs the business logic using the interface. <http://en.wikipedia.org/wiki/Multitier_architecture> | Where to move the business logic when moving it out of the database | [
"",
".net",
"sql",
"sql-server-2005",
"business-logic",
""
] |
In my experience teaching C++, operator overloading is one of those topics that causes the most grief to students. Even looking at questions here at stackoverflow: for example, make the + operator external or a member? How to handle symmetry, etc., it seems like it's a lot of trouble.
When I moved from C++ to Java, I was worried I would miss that ability, but with the exception of operators like [] or (), I haven't really ever felt the need to overload operators. In fact, I feel programs without them are more readable.
Note: I put this as a community wiki. Let's discuss this. I want to hear opinions. | Overloaded operators are like spice. A little can make something better; too much can make it unpalatable. | Some examples of overloading that every C++ programmer should know about, even if they don't approve:
* operator=() is required in order to allow C++ objects to behave like values.
* operator->() is required in order to implement smart pointers
* operator<<() and operator>>() are required to integrate types into the iostream framework
* operator<() is used by default when comparing objects stored in standard library containers
* operator()() is used to implement functors used by standard library algorithms
* operator++() is expected to be available if you implement your own iterator | Are operator overloadings in C++ more trouble than they're worth? | [
"",
"c++",
"operator-overloading",
""
] |
Trying to get past a class cast exception here:
```
FooClass fooClass = (FooClass ) unmarshaller.unmarshal(inputStream);
```
throws this exception:
```
java.lang.ClassCastException: javax.xml.bind.JAXBElement
```
I don't understand this - as the class was generated by the xjc.bat tool - and the classes it generated I have not altered at all - so there should be no casting problems here - the unmarshaller should really be giving me back a class that CAN be cast to FooClass.
Any ideas as to what I am doing wrong? | Does `FooClass` have the `XmlRootElement` annotation? If not, try:
```
Source source = new StreamSource(inputStream);
JAXBElement<FooClass> root = unmarshaller.unmarshal(source, FooClass.class);
FooClass foo = root.getValue();
```
That's based on the [Unofficial JAXB Guide](https://javaee.github.io/jaxb-v2/doc/user-guide/ch03.html#unmarshalling-xmlrootelement-and-unmarshalling). | Use JAXBIntrospector on the JAXBElement to get the schemaObject like >>
```
JAXBContext jaxbContext = JAXBContext.newInstance(Class.forName(className));
Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
Object schemaObject = JAXBIntrospector.getValue(unmarshaller.unmarshal(new ByteArrayInputStream(xmlString.getBytes())));
```
Refer: [when does JAXB unmarshaller.unmarshal returns a JAXBElement<MySchemaObject> or a MySchemaObject?](https://stackoverflow.com/questions/10243679/when-does-jaxb-unmarshaller-unmarshal-returns-a-jaxbelementmyschemaobject-or-a/10253282#10253282) | Class Cast Exception when trying to unmarshall xml? | [
"",
"java",
"jaxb",
"jaxb2",
""
] |
In my web application I have a treeview with documents. The NavigateUrl of a treenode looks like this:
```
viewDocument.aspx?id=1&doctype=type
```
In the load event of `ViewDocument.asp.cs` I check whether `id` and `doctype` are set. If so, check `doctype` has a valid value and check the `id` is a number. After that, i create a document object. Then I call it's `Load(int id)` function which will load all the data in the object. If the `id` doesn't exists in the database the return value is `false`, otherwhise `true`.
Is it possible to use MVC pattern? And if so, how do I start? | There is an official ASP.NET MVC framework. Check it out [here](http://www.asp.net/mvc/). You can read up the tutorials there to get you started. | It is, but MVC is the second issue you have to address.
It would make sense if you used URL rewriting here to rewrite your urls into this template:
documents/type/id
Here is a good blog post on how to enable URL rewriting for your site hosted in IIS7:
<http://blogs.iis.net/bills/archive/2008/05/31/urlrewrite-module-for-iis7.aspx>
Once you have that in place, MVC is an EXCELLENT candidate for handing this scenario. You would simply declare a route with this pattern:
{controller}/{action}/{id}
The controller would be a class (most likely, DocumentsController), the action would be the type in this case. You don't have to use that, you could use a type, but then you would have to set a default action when setting up the route. Finally, the id would be a parameter into the method that is specified by action. | ASP C# Can I use MVC? | [
"",
"c#",
"model-view-controller",
""
] |
I need to create an application that can be activated with a batch file.
The application would accept a single string parameter of a file name. It will then run some processing with this file and drop another file in a predetermined location and exit.
The application does not need to interact with an actual user.
My preferred platform is .net using C#.
I originally planned on writing a console application but am not sure that this is the best idea.
What is the best way to accomplish this task? Is there a way to create a windows service that would be triggered by a batch file? Is this more desirable? Would a Windows Form project be more desirable? | Option one: Console App. Use Windows Scheduler to run it at schedule times. (recommended)
Option two: Windows Service that has some inbuilt scheduler or poller. | My favorite option, and one which I convinced my previous employer to adopt as a company policy, is as follows:
All server-type applications are written with no directly-attached UI of any sort. Whether this compiles as a console application, as a windows application, or otherwise is irrelevant at the design stage -- with .NET the difference comes down to flipping a compiler switch. Generally, though, since the program is running without direct human intervention, we usually designed it to run as a service -- the Service Control Manager takes care of startup and shutdown, can restart the application when it fails, and does a lot of good stuff that is difficult to do on your own when writing a desktop application.
Next, you have the server application listen over the network for an "admin" to connect. This admin connection is your UI. Things like SSL encryption and authentication are up to you and your company, but at the base of it I would recommend building a line-based human-readable interface. That way you can connect to it with telnet and issue commands like "`show connections`", "`drop user 52`", and "`restart`". Any sort of administrative behavior, and any sort of status and statistics should be exposed using this interface. First of all, this helps with debugging, and second of all, it leads to the next step...
Last you build a UI. A simple one probably. Part of the configuration for this UI is to specify a host and port for it to connect to, as well as any authentication bits. The UI application connects to the machine running the service and issues commands over the network admin interface, and interprets the results. At our company, each new UI was a snap-in module as part of a larger project. This project would show little red and green lights representing the various servers and their statuses. Clicking on a server would allow you to "drill-down" to that server and examine various aspects of it state or configuration.
Though the project started as my little program on only one or two servers, it quickly grew to include dozens of servers running a handful of services each, running on diverse operating systems and in numerous cities around the world. This simple UI policy allowed us to easily track and control hundreds of these services from one single seat, or simultaneously at different desks in different offices.
Scalability mean not requiring someone in front of the computer to hit a button on a program you wrote. | What kind of Application would be best for running non interactively? | [
"",
"c#",
".net",
""
] |
I am having a hard time using the MySQLdb module to insert information into my database. I need to insert 6 variables into the table.
```
cursor.execute ("""
INSERT INTO Songs (SongName, SongArtist, SongAlbum, SongGenre, SongLength, SongLocation)
VALUES
(var1, var2, var3, var4, var5, var6)
""")
```
Can someone help me with the syntax here? | Beware of using string interpolation for SQL queries, since it won't escape the input parameters correctly and will leave your application open to SQL injection vulnerabilities. **The difference might seem trivial, but in reality it's huge**.
### Incorrect (with security issues)
```
c.execute("SELECT * FROM foo WHERE bar = %s AND baz = %s" % (param1, param2))
```
### Correct (with escaping)
```
c.execute("SELECT * FROM foo WHERE bar = %s AND baz = %s", (param1, param2))
```
It adds to the confusion that the modifiers used to bind parameters in a SQL statement varies between different DB API implementations and that the mysql client library uses `printf` style syntax instead of the more commonly accepted '?' marker (used by eg. `python-sqlite`). | You have a few options available. You'll want to get comfortable with python's string iterpolation. Which is a term you might have more success searching for in the future when you want to know stuff like this.
Better for queries:
```
some_dictionary_with_the_data = {
'name': 'awesome song',
'artist': 'some band',
etc...
}
cursor.execute ("""
INSERT INTO Songs (SongName, SongArtist, SongAlbum, SongGenre, SongLength, SongLocation)
VALUES
(%(name)s, %(artist)s, %(album)s, %(genre)s, %(length)s, %(location)s)
""", some_dictionary_with_the_data)
```
Considering you probably have all of your data in an object or dictionary already, the second format will suit you better. Also it sucks to have to count "%s" appearances in a string when you have to come back and update this method in a year :) | MySQL parameterized queries | [
"",
"python",
"mysql",
"bind-variables",
""
] |
I am using **jQuery.autocomplete(1.02)** on my search box and I want **exact** string and substring matching. I don't care (yet!) about the database load, I'm happy for it to fire off a query every keystroke and bypass the caching entirely - I just don't want anything missed.
To this end I have tried setting *cacheLength=1*, the minimum permitted, but the autocomplete function refuses to fire off a GET request for each key up.
```
searchbox GET_request
'a' -> http://localhost/service_search_request?q=a
'ar' -> http://localhost/service_search_request?q=ar
'ars' -> http://localhost/service_search_request?q=ars
```
Instead, it sends the first and the third and misses the second, giving me the wrong results for 'ar' :-/ I've cleared my cache and sessions but it looks like some sort of caching is still going on. AFAIK I have no proxying going on and I'm shift-refreshing each time. It looks likely then that this behavior is from jQuery.autocomplete itself.
**So my questions are...**
**A)** Does this seem likely? i.e. is it a feature, or maybe a bug?
**B)** If so is there a clean way around it?...
**C)** If not, what autocomplete would you use instead?
Naturally *D) No you're just using it incorrectly you douche!* is always a possibility, and indeed the one I'd prefer having spent time going down this road - assuming it comes with a link to the docs I've failed to find / read!
Cheers,
Roger :) | I wonder why **cacheLength** doesn't work, but had trouble with autocomplete too. IMHO, there are errors in it. However, in the [list of options](http://docs.jquery.com/Plugins/Autocomplete/autocomplete#url_or_dataoptions), there is a **matchSubset** you could set to false.
**EDIT:**
somewhere around line 335 is a function called "request". You could add some debug messages to it, to see what happens: (note: you need [firebug](http://getfirebug.com/) installed or "console" will be unknown)
```
function request(term, success, failure) {
console.debug("ac request...");
if (!options.matchCase)
term = term.toLowerCase();
var data = cache.load(term);
console.debug("ac request 1, loaded data from cache: " + data + " term: " + term);
// recieve the cached data
if (data && data.length) {
success(term, data);
// if an AJAX url has been supplied, try loading the data now
} else if( (typeof options.url == "string") && (options.url.length > 0) ){
console.debug("ac request 2, data is not in the cache, request it");
```
"flushCache" can easily be used in the function you can attach / set as options. I used this, to clear the Cache, if there could be more data in the backend:
```
formatItem: function (data,i,n,value){
if(i === (this.max -1)){
console.debug("flushCache");
jQuery(this).flushCache();
}
return data[1] + " (" + data[0] + ")";
}
``` | I am having the same problem. Caching doesn't work although I have set the option cacheLength to 1.
With your solution to call the flushCache function after each printed term it works. I couldn't use the:
```
if(i === (this.max -1)){
```
since 'i' was e.g 1 after filtering but 'this.max' still 25 as the original backend query resulted in 25 returned rows.
**However**, this bug **ONLY** appears when typing words that contain the swedish characters 'å', 'ä' or 'ö'. So maybe the cashing works as expected but not with these special characters.
Anyway. the solution for me was to always call the flushCache control in the formatItem() function:
```
function formatItem(row, position, n, term) {
if($("#keywords-h").length > 0){
$("#keywords-h").flushCache();
}
// format Item
return "<span>" + row[0] + "</span>";
}
```
Hope this helps someone and if someone is having the same problems with special characters please post a reply. | Bypass all cacheing on jQuery.autocomplete(1.02) | [
"",
"javascript",
"jquery",
"caching",
"autocomplete",
"autofill",
""
] |
consider the following algorithm with arrays:
```
class MyType;
{
// some stuff
}
class MySubType:MyType
{
// some stuff
}
void foo(MyType** arr, int len)
{
for (int i = 0;i<len;i++)
// do something on arr[i]->
}
void bar()
{
MySubType* arr[10];
// initialize all MySubType*'s in arr
foo(&arr, 10);
}
```
Nothing too fancy here. My question is - how do I do this with templates?
```
void foo(std::vector<MyType>& s)
{
std::vector<MyType>::iterator i;
for (i = s.begin(); i != s.end(); i++)
// do stuff on *i
}
```
so, in bar, I can't do this:
```
void bar()
{
std::vector<MySubType> s;
foo(s); // compiler error
}
```
error: invalid initialization of reference of type `std::vector<MyType, std::allocator<MyType> >&` from expression of type `std::vector<MySubType, std::allocator<MySubType> >`
Is there some way to do something like this?
Basically, if there's a way to do this:
```
std::vector<MySubType> s;
std::vector<MyType>& t = s;
```
I'd be happy... | This might fix your problem
```
template <typename T>
void foo(std::vector<T>& s)
{
typename std::vector<T>::iterator i;
for (i = s.begin(); i != s.end(); i++)
// do stuff on *i
}
``` | To expand on [kuoson's answer](https://stackoverflow.com/questions/775325/how-do-i-do-this-in-c/775343#775343), the idiomatic C++ style is to pass iterators to a function rather than containers.
```
template<typename Iterator>
void foo(const Iterator & begin, const Iterator & end)
{
Iterator i;
for (i = begin; i != end; ++i)
// do stuff on *i
}
``` | Function for manipulating container of Base/Derived objects | [
"",
"c++",
"generics",
"stl",
"templates",
""
] |
I am using a lot of `STL` code with `std::for_each`, `bind`, and so on, but I noticed that sometimes `STL` usage is not good idea.
For example if you have a `std::vector` and want to do one action on each item of the vector, your first idea is to use this:
```
std::for_each(vec.begin(), vec.end(), Foo())
```
and it is elegant and ok, for a while. But then comes the first set of bug reports and you have to modify code. Now you should add parameter to call `Foo()`, so now it becomes:
```
std::for_each(vec.begin(), vec.end(), std::bind2nd(Foo(), X))
```
but that is only temporary solution. Now the project is maturing and you understand business logic much better and you want to add new modifications to code. It is at this point that you realize that you should use old good:
```
for(std::vector::iterator it = vec.begin(); it != vec.end(); ++it)
```
Is this happening only to me? Do you recognise this kind of pattern in your code? Have you experience similar anti-patterns using `STL`? | Using [boost::bind](http://www.boost.org/doc/libs/1_38_0/libs/bind/bind.html) with std::for\_each solves this problem in a clean way. Or you can use [BOOST\_FOREACH](http://www.boost.org/doc/libs/1_35_0/doc/html/foreach.html).
Example of std::for\_each:
```
std::for_each(v.begin(), v.end(), boost::bind(&C::f, _1, param));
```
Example of BOOST\_FOREACH:
```
std::list<int> list_int( /*...*/ );
BOOST_FOREACH( int i, list_int )
{
// do something with i
}
``` | It can go the opposite way too though. Suppose you start out with an operation that only takes a couple of lines. You don't want to bother creating a function that will only be called once, just to condense the loop, so you write something like:
```
for ()
{
// do
// some
// stuff
}
```
Then as the operation you need to perform gets more complex, you realize that pulling it into a separate function makes sense so you end up with
```
for ()
do_alot_more_stuff();
```
And then modifying it to be like your original method makes sense to condense it down further:
```
std::for_each(begin, end, do_alot_more_stuff);
```
*In the end, how hard is it to really change a for\_each to a for loop, or vice versa? Don't beat yourself up over tiny details!* | How much of STL is too much? | [
"",
"c++",
"stl",
"coding-style",
""
] |
I need the ability to monitor for and read e-mail from a particular mailbox on a MS Exchange Server (internal to my company). I also need to be able to read the sender's e-mail address, subject, message body and download an attachment, if any.
What is the best way to do this using C# (or VB.NET)? | It's a mess. MAPI or CDO via a .NET interop DLL is [officially unsupported by Microsoft](http://blogs.msdn.com/mstehle/archive/2007/10/03/fyi-why-are-mapi-and-cdo-1-21-not-supported-in-managed-net-code.aspx)--it will appear to work fine, but there are problems with memory leaks due to their differing memory models. You could use CDOEX, but that only works on the Exchange server itself, not remotely; useless. You could interop with Outlook, but now you've just made a dependency on Outlook; overkill. Finally, you could use [Exchange 2003's WebDAV support](http://msdn.microsoft.com/en-us/library/aa143161.aspx), but WebDAV is complicated, .NET has poor built-in support for it, and (to add insult to injury) Exchange 2007 *nearly completely drops* WebDAV support.
What's a guy to do? I ended up using [AfterLogic's IMAP component](http://www.afterlogic.com/products/net-imap-component) to communicate with my Exchange 2003 server via IMAP, and this ended up working very well. (I normally seek out free or open-source libraries, but I found all of the .NET ones wanting--especially when it comes to some of the quirks of 2003's IMAP implementation--and this one was cheap enough and worked on the first try. I know there are others out there.)
If your organization is on Exchange 2007, however, you're in luck. [Exchange 2007 comes with a SOAP-based Web service interface](http://msdn.microsoft.com/en-us/library/bb204119.aspx) that finally provides a unified, language-independent way of interacting with the Exchange server. If you can make 2007+ a requirement, this is definitely the way to go. (Sadly for me, my company has a "but 2003 isn't broken" policy.)
If you need to bridge both Exchange 2003 and 2007, IMAP or POP3 is definitely the way to go. | Um,
I might be a bit too late here but isn't this kinda the point to EWS ?
<https://msdn.microsoft.com/en-us/library/dd633710(EXCHG.80).aspx>
Takes about 6 lines of code to get the mail from a mailbox:
```
ExchangeService service = new ExchangeService(ExchangeVersion.Exchange2007_SP1);
//service.Credentials = new NetworkCredential( "{Active Directory ID}", "{Password}", "{Domain Name}" );
service.AutodiscoverUrl( "First.Last@MyCompany.com" );
FindItemsResults<Item> findResults = service.FindItems(
WellKnownFolderName.Inbox,
new ItemView( 10 )
);
foreach ( Item item in findResults.Items )
{
Console.WriteLine( item.Subject );
}
``` | Read MS Exchange email in C# | [
"",
"c#",
"email",
"exchange-server",
"mapi",
""
] |
I really hope someone can help with this problem. I have an ajax pagination script that works great on the first page but the click events will not work on any other pages from the paging.
This is how I have it setup:
jQuery script
```
<script type="text/javascript">
// prepare when the DOM is ready
$().ready(function() {
//popup div
$(".wsbutton_pop").click(function(e){
//getting height and width of the message box
var height = $('#popuup_div').height();
var width = $('#popuup_div').width();
//calculating offset for displaying popup message
leftVal=e.pageX-(width/2)+"px";
topVal=e.pageY-(height/2)+"px";
//show the popup message and hide with fading effect
$('#popuup_div').css({left:leftVal,top:topVal}).show();
$('#popuup_div').html("<img src='images/ajaximg.gif' border='0'>");
$.ajax({
type: "get",
url: $(this).attr("href"),
success: function(r){
$('#popuup_div').html("")
$('#popuup_div').prepend(r);
}
});
});
//close div on mouse click
$(".popup_msg").click(function(e){
$('#popuup_div').fadeOut();
});
});
</script>
```
That should popup a div with content from another page.
Now my link:
`<a href="http://mysite.com/file.php?content=1" class="wsbutton_pop">Load content</a>`
That works great on the initial page but the problem now is when I click to visit page 2 which has the exact same link, the link doesn't work anymore.
As a note, my pages should load in a div with id="paging". The ajax paging itself works great, its just that any jquery click event on the resulting pages does not work. I think the problem may be that I need to rebind the script but I do not know how to accomplish that.
Thanks for any help on this. | I would guess you are overwriting the link with the pagination so the click event is no longer bound. If you are using jquery 1.3 you can use the [live events](http://docs.jquery.com/Events/live) to fix this.
```
$(".wsbutton_pop").live("click", function(e) { ...
```
Or if you're using an earlier version of jQuery you can just reattach the event handler when you get the new page data back. | You are correct about rebinding the script. The reason is that the elements on the page are getting recreated during the ajax postback.
If you are using jQuery 1.3 or higher you can use live events (for click) like this:
```
$(".wsbutton_pop").live("click", function(e){
...
});
```
Note that live events do not work with the following events: change, blur, focus, mouseenter, mouseleave, and submit.
If you are not using jQuery 1.3, or you need to use one of the events above, you should follow the advice in the following article to avoid memory leaks:
[Code-Project Article](http://www.codeproject.com/KB/ajax/jqmemleak.aspx) | Click event does not work after ajax paging | [
"",
"javascript",
"jquery",
""
] |
Following up on my [question about jQuery.get()](https://stackoverflow.com/questions/765698/jquery-get-practical-uses) I was wondering if there is a list of DOM properties and methods that aren't available in jQuery that can only be accessible if you were working with the raw DOM object (i.e. $("#someID").get().scrollHeight; ) | I haven't encountered a list but if one existed it would probably be quite lengthy. In addition to browser-specific (proprietary) properties there's a bunch of other less useful properties and methods not currently abstracted by jQuery. But then, I don't really see this as a problem, or even a valid point of discussion because jQuery IS JavaScript; if you need access to something beyond what jQuery provides then you can use **`get()`** or access a specified element within one of your "jQuery collections" like an array:
```
jQuery(elem)[0].someDOMProperty;
```
Plus jQuery provides absolutely no support for non-element nodes within the DOM. If, for whatever reason, you need direct access to comment nodes, text nodes etc. then you'll need to use the "raw" DOM. | I don't know of a compiled list of DOM operations/properties that are NOT available in jQuery (and a quick google search didn't turn anything up), but if you go to <http://api.jquery.com/> you can see the entire API, and even download it as an Adobe AIR app in case you don't have internet when you need it. | DOM properties/methods that aren't available in jQuery? | [
"",
"javascript",
"jquery",
"dom",
""
] |
I commonly use `os.path.exists()` to check if a file is there before doing anything with it.
I've run across a situation where I'm calling a executable that's in the configured env path, so it can be called without specifying the `abspath`.
Is there something that can be done to check if the file exists before calling it?
(I may fall back on `try/except`, but first I'm looking for a replacement for `os.path.exists()`)
btw - I'm doing this on windows. | You could get the PATH environment variable, and try "exists()" for the .exe in each dir in the path. But that could perform horribly.
example for finding notepad.exe:
```
import os
for p in os.environ["PATH"].split(os.pathsep):
print os.path.exists(os.path.join(p, 'notepad.exe'))
```
more clever example:
```
if not any([os.path.exists(os.path.join(p, executable) for p in os.environ["PATH"].split(os.pathsep)]):
print "can't find %s" % executable
```
Is there a specific reason you want to avoid exception? (besides dogma?) | Extending Trey Stout's search with Carl Meyer's comment on PATHEXT:
```
import os
def exists_in_path(cmd):
# can't search the path if a directory is specified
assert not os.path.dirname(cmd)
extensions = os.environ.get("PATHEXT", "").split(os.pathsep)
for directory in os.environ.get("PATH", "").split(os.pathsep):
base = os.path.join(directory, cmd)
options = [base] + [(base + ext) for ext in extensions]
for filename in options:
if os.path.exists(filename):
return True
return False
```
EDIT: Thanks to Aviv (on my blog) I now know there's a Twisted implementation: [twisted.python.procutils.which](http://twistedmatrix.com/trac/browser/tags/releases/twisted-8.2.0/twisted/python/procutils.py)
EDIT: In Python 3.3 and up there's [shutil.which()](https://docs.python.org/3/library/shutil.html#shutil.which) in the standard library. | os.path.exists() for files in your Path? | [
"",
"python",
"windows",
""
] |
Would prefer an answer in C#, .Net 3.5 using WPF (Windows Forms also okay)
I have an application that is essentially a toolbar window or tray icon. It needs to detect if a user locks his/her workstation and walks away in order to update the person's status in a centralized system.
I can detect a session switch or a logout easily enough, using the SystemEvents, but I cannot for the life of me figure out how to detect or receive an event on Lock.
Thanks for any assistance. | When you handle the [`Microsoft.Win32.SystemEvents.SessionSwitch`](http://msdn.microsoft.com/en-us/library/microsoft.win32.systemevents.sessionswitch(VS.85).aspx) event (which it sounds like you're already doing to detect logout), check to see if the `Reason` is [`SessionSwitchReason`](http://msdn.microsoft.com/en-us/library/microsoft.win32.sessionswitchreason.aspx)`.SessionLock`:
```
using Microsoft.Win32;
// ...
// Somewhere in your startup, add your event handler:
SystemEvents.SessionSwitch +=
new SessionSwitchEventHandler(SystemEvents_SessionSwitch);
// ...
void SystemEvents_SessionSwitch(object sender, SessionSwitchEventArgs e)
{
switch(e.Reason)
{
// ...
case SessionSwitchReason.SessionLock:
// Do whatever you need to do for a lock
// ...
break;
case SessionSwitchReason.SessionUnlock:
// Do whatever you need to do for an unlock
// ...
break;
// ...
}
}
``` | You need to [P/Invoke](https://learn.microsoft.com/en-us/dotnet/framework/interop/platform-invoke-examples) [`WTSRegisterSessionNotification`](http://pinvoke.net/default.aspx/wtsapi32.WTSRegisterSessionNotification "Samples here"). | How do I detect a Lock This Computer command from a WPF application? | [
"",
"c#",
"wpf",
"desktop",
"locking",
""
] |
I can't find any thorough explanation of the Ivy dependency tag's *conf* attribute:
```
<dependency org="hibernate" name="hibernate" rev="3.1.3" conf="runtime, standalone -> runtime(*)"/>
```
See that *conf* attribute? I can't find any explanation (that I can understand) about the right hand side of the `->` symbol. PLEASE keep in mind I don't know the first thing about Maven so please explain this attribute with that consideration.
Yes, I've already looked at this: <http://ant.apache.org/ivy/history/latest-milestone/ivyfile/dependency.html>
Thanks,
Dan | First of all, [Ivy is not Maven](http://ant.apache.org/ivy/m2comparison.html) ;)
Maven2 is a software project management and comprehension tool, whereas Ivy is only a dependency management tool.
Ivy heavily relies on a unique concept called **configuration**.
In Ivy, a module configuration is a **way to use or to see the module**.
For instance, you can have a test and runtime configuration in your module. But you can also have a MySQL and an Oracle configuration. Or an Hibernate and a JDBC configuration.
In each configuration, you can declare:
* what artifacts (jar, war, ...) are required.
* your dependencies on other modules, and describe which configuration of the dependency you need. This is called configuration mapping.
So the [conf](http://ant.apache.org/ivy/history/latest-milestone/ivyfile/dependency-conf.html) attribute does precisely that: Describes a configuration mapping for a dependency.
The [mapped child element](http://ant.apache.org/ivy/history/latest-milestone/ivyfile/mapped.html) is your "right hand side of the `->` symbol" and represents the name of the dependency configuration mapped. `'*'` wildcard can be used to designate all configurations of this module.
See more at "[Simplest Explanation of Ivy Configuration](http://wrongnotes.blogspot.com/2014/02/simplest-explanation-of-ivy.html)" from [Charlie Hubbard](https://sourceforge.net/u/charliehubbard/profile/)
> The important part of that is Ivy downloads dependencies and organizes them.
>
> An ivy-module (ie `ivy.xml` file) has two main parts:
>
> * What dependencies do you need?
> * How do you want them organized?
>
> The first part is configured under the `<dependencies>` element.
> The 2nd is controlled by the `<configurations>` element
>
> When Ivy is downloading these dependencies it needs to know what scopes to use when pulling these transitive dependencies (are we pulling this for testing, runtime, compilation, etc?). We have to tell Ivy how to map our configurations to Maven scopes so it knows what to pull.
---
Maven2 on its side has something called the **scope**.
You can declare a dependency as being part of the test scope, or the buildtime scope.
Then depending on this scope you will get the dependency artifact (only one artifact per module in maven2) with its dependencies depending on their scope. Scopes are predefined in maven2 and you can't change that.
That means :
> There are a *lot* of unnecessary dependencies downloaded for many libraries.
> For example, Hibernate downloads a bunch of JBoss JARs and the Display Tag downloads all the various web framework JARs. I found myself excluding almost as many dependencies as I added.
The problem is that hibernate can be used with several cache implementations, several connection pool implementation, ... And this can't be managed with scopes, wheres Ivy configurations offers an elegant solution to this kind of problem.
For instance, in Ivy, **assuming hibernate has an Ivy file like this one**, then you can declare a dependency like that:
```
<dependency org="hibernate" name="hibernate" rev="2.1.8" conf="default->proxool,oscache"/>
```
to get hibernate with its proxool and oscache implementations, and like that:
```
<dependency org="hibernate" name="hibernate" rev="2.1.8" conf="default->dbcp,swarmcache"/>
```
to get hibernate with dbcp and swarmcache.
By mapping your default `master` configuration to "`proxool,oscache`" or to "`dbcp,swarmcache`", you specify what you need *exactly* from the module "hibernate".
---
You can find those "proxool,..." arguments by listing the Ivy configuration defined for each modules associate with the library. For instance:
```
<ivy-module version="2.0">
<info organisation="ssn-src" module="pc"/>
<configurations defaultconfmapping="default->default">
<conf name="default" />
<conf name="provided" description="they are provided by the env." />
<conf name="compile" extends="default,provided" />
<conf name="war" extends="default"/>
</configurations>
<dependencies>
```
[Example](http://mail-archives.apache.org/mod_mbox/ant-ivy-user/200812.mbox/%3C7916a6a60812030821u6f831ad2ub0921b2bfac8ec63@mail.gmail.com%3E):
> let's suppose `modA` has two configurations, default and test.
> As a practical matter, it's going to be highly unusual to want to leave out the `conf` attribute of the dependency element.
> The `ivy.xml` for `modA` might have a dependency:
```
<dependency org="theteam" name="modB" rev="1.0" conf="default->*" />
```
> You're starting from default, rather than from both default and test.
>
> The above example makes modA's default depend on modB's conf1, conf2, and conf3.
> Or you might want to say that modA's default only depends on modB's conf1:
```
<dependency org="theteam" name="modB" rev="1.0" conf="default->*conf1*" />
``` | I've read these answers and quite frankly I don't find them very helpful. I think they could be improved so I wrote down how I use and understand configurations by showing a practical example:
<http://wrongnotes.blogspot.com/2014/02/simplest-explanation-of-ivy.html>
Unfortunately, you have to understand a little about maven, and its dependencies because Ivy is using Maven repositories to download those jar files. Therefore, Ivy has to understand Maven and it passes that back to you. But, I think I kept it real simple without going into too much detail about maven. | Can someone explain the ivy.xml dependency's conf attribute? | [
"",
"java",
"apache",
"ant",
"ivy",
""
] |
I'm declaring a struct inside my code and then trying to insert it into a data structure that I have written. However, I'm concerned that since I declare the struct inside the function, once the function ends, the data structure will be pointing to garbage. Can anyone help with this?
Here's the code:
```
void Class::function()
{
// do some stuff
node newNode;
newNode.memAddr = tempNode.memAddr+totalSize;
newNode.size = tempNode.size-totalSize;
lists[newNode.size>=512?64:(newNode.size>>3)].insert(&newNode);
}
```
Edit: I'm actually trying to re-write malloc, so calling malloc() or new will not work here. Is there some way that I could move this code into the insert method and then make it work in a way that it would not fall out of scope in insert? | It will be out of scope after function returns, yes. That is not valid. You want to allocate it on the heap.
Edit: Unless you copy the memory you point to in insert, of course. | This will almost certainly cause an error. The problem is that you're passing in an address to a value on the stack to a list that will live beyond the value. If the list is storing `node*` types then this will be incorrect.
To get this to work you need to do one of the following
1. Have the list instance store node values instead of `node*`.
2. Allocate the `node*` on the heap before passing it in. This means you will have to free it later. | Will this be out of scope and not function properly? | [
"",
"c++",
"struct",
"scope",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.