
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
In my project, I'm using [HTML\_ToPDF](http://rustyparts.com/pdf.php) PHP class, which uses [html2ps](http://user.it.uu.se/~jan/html2ps.html) script to convert from HTML to PDF file.
Recently I upgraded my production server to Debian 5 (Lenny) and, after that, `HTML_ToPDF` is no longer working:
`convert()` method from `HTML_ToPDF` class is returning this error:
```
Error: there was a problem running the html2ps command. Error code returned: 127. setDebug() for more information.
```
And, the output from html2ps call is:
```
/usr/bin/perl: symbol lookup error: /usr/lib/perl5/auto/Compress/Zlib/Zlib.so: undefined symbol: Perl_Tstack_sp_ptr
```
Any help would be appreciated, thanks!
**[Edited]**
After some tests, I've found that the problem happens only with HTML containing images ( tags). When html2ps founds the first image it crashes. Converting HTML without images works fine. Any idea? Thanks! | Try this
apt-get install perl=5.8.8-7etch6 perl-base=5.8.8-7etch6 perl-modules=5.8.8-7etch6 debconf-i18n=1.5.11etch2 liblocale-gettext-perl=1.05-1 libtext-iconv-perl=1.4-3 libtext-wrapi18n-perl=0.06-5 libtext-charwidth-perl=0.04-4 html2ps=1.0b5-2 libapache2-mod-perl2=2.0.2-2.4 libcompress-zlib-perl=1.42-2 libfuse-perl=0.07-2+b2 libhtml-parser-perl=3.55-1 libhtml-tree-perl=3.19.01-2 libio-zlib-perl=1.04-1 libwww-perl=5.805-1 perlmagick=7:6.2.4.5.dfsg1-0.14 snmpd=5.2.3-7etch4 xhtml2ps mysql-client=5.0.32-7etch8 mysql-client-5.0=5.0.32-7etch8 libdbd-mysql-perl=3.0008-1 libdbi-perl=1.53-1etch1
<http://www.deberias.com> | This is an issue with the initial conversion from HTML to PS. Usually due to poorly written HTML.
Can you show some examples of what you are trying to convert? | Convert HTML to PDF with HTML_ToPDF class (PHP) | [
"",
"php",
"pdf-generation",
"debian",
""
] |
I am subclassing the Process class, into a class I call EdgeRenderer. I want to use `multiprocessing.Pool`, except instead of regular Processes, I want them to be instances of my EdgeRenderer. Possible? How? | From Jesse Noller:
> It is not currently supported in the
> API, but would not be a bad addition.
> I'll look at adding it to
> python2.7/2.6.3 3.1 this week | This seems to work:
```
import multiprocessing as mp
ctx = mp.get_context() # get the default context
class MyProcess(ctx.Process):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
print("Hi, I'm custom a process")
ctx.Process = MyProcess # override the context's Process
def worker(x):
print(x**2)
p = ctx.Pool(4)
nums = range(10)
p.map(worker, nums)
``` | Python multiprocessing: Pool of custom Processes | [
"",
"python",
"multiprocessing",
"pool",
""
] |
I would like to implement a text box with a 140 character limit in Javascript such that when the 141st character is added that character is erased.
I don't want to show any message or alert to user they have exceeded the limit. There is already a counter.re.
Here is an example of what I want to do: <http://titletweets.com/category/games/michigan-state-vs-north-carolina/>
I am using jQuery, if it already has this functionality please let me know. | A bank in Scandinavia recently had a lawsuit because a customer accidentally transferred a pile of money to the wrong account because she typed in too many zeros into the account number. This made the resulting account number invalid, however she didn't notice because the web-application silently erased her extra digit. So she entered something like
```
1223300045
```
but should have entered
```
122330045
```
and consequently account
```
122330004
```
received her money. **This is a major usability flaw.**
In the case of something like a text-area, take a look at StackOverflow's own comments UI. It shows you how much text is in your textbox, and you have the opportunity to edit your text, but the really sweet part is that you can type as much as you want, then edit down to the bare limit, letting you ensure you can say all you like. If your text box erases the user's text:
* They may not notice it happening, if they type by looking at the keyboard
* They have to erase text before they can add new, more concise wording
* They will be annoyed
Thus, my recommendation is to let the user type as much they want, but let them know when they are over the limit, and let them edit. The following sample can get you started. You should change the selectors as appropriate to only manipulate the textareas/text inputs you need to. And don't forget to do the appropriate thing if the limit is wrong. This sample sets a class; the class attribute lets you change the colour of the textarea (or whatever). You might want to show a message or something. They key is to let the user keep typing.
```
function checkTALength(event) {
var text = $(this).val();
if(text.length > 140) {
$(this).addClass('overlimit');
} else {
$(this).removeClass('overlimit');
}
}
function checkSubmit(event) {
if($('.overlimit', this).length > 0) { return false; }
}
$(document).ready(function() {
$('textarea').change(checkTALength);
$('textarea').keyup(checkTALength);
$('form').submit(checkSubmit);
});
``` | If it's a single line textbox then you can use the `maxlength` attribute:
```
<input type="text" maxlength="140" />
```
It's also worth noting that whatever your solution, you *still need to repeat validation on the server-side*. Whether you report back to the user that their entry was too long or you simply truncate the data is up to you. | How do I remove characters from a textbox when the number of characters exceeds a certain limit? | [
"",
"javascript",
"jquery",
""
] |
What is the general guidance on when you should use `CAST` versus `CONVERT`? Is there any performance issues related to choosing one versus the other? Is one closer to ANSI-SQL? | `CONVERT` is SQL Server specific, `CAST` is ANSI.
`CONVERT` is more flexible in that you can format dates etc. Other than that, they are pretty much the same. If you don't care about the extended features, use `CAST`.
EDIT:
As noted by @beruic and @C-F in the comments below, there is possible loss of precision when an implicit conversion is used (that is one where you use neither CAST nor CONVERT). For further information, see [CAST and CONVERT](http://msdn.microsoft.com/en-us/library/ms187928.aspx) and in particular this graphic: [SQL Server Data Type Conversion Chart](https://learn.microsoft.com/en-us/sql/t-sql/data-types/media/cast-and-convert-transact-sql/data-type-conversions.png). With this extra information, the original advice still remains the same. Use CAST where possible. | `CONVERT` has a *style* parameter for date to string conversions.
<https://learn.microsoft.com/en-us/sql/t-sql/functions/cast-and-convert-transact-sql> | T-SQL Cast versus Convert | [
"",
"sql",
"sql-server",
"database",
"t-sql",
""
] |
I've apparently worked myself into a bad coding habit. Here is an example of the code I've been writing:
```
using(StreamReader sr = new StreamReader(File.Open("somefile.txt", FileMode.Open)))
{
//read file
}
File.Move("somefile.txt", "somefile.bak"); //can't move, get exception that I the file is open
```
I thought that because the `using` clause explicitly called `Close()` and `Dispose()` on the `StreamReader` that the `FileStream` would be closed as well.
The only way I could fix the problem I was having was by changing the above block to this:
```
using(FileStream fs = File.Open("somefile.txt", FileMode.Open))
{
using(StreamReader sr = new StreamReader(fs))
{
//read file
}
}
File.Move("somefile.txt", "somefile.bak"); // can move file with no errors
```
Should closing the `StreamReader` by disposing in the first block also close the underlying `FileStream`? Or, was I mistaken?
## Edit
I decided to post the actual offending block of code, to see if we can get to the bottom of this. I am just curious now.
I thought I had a problem in the `using` clause, so I expanded everything out, and it still can't copy, every time. I create the file in this method call, so I don't think anything else has a handle open on the file. I've also verified that the strings returned from the `Path.Combine` calls are correct.
```
private static void GenerateFiles(List<Credit> credits)
{
Account i;
string creditFile = Path.Combine(Settings.CreditLocalPath, DateTime.Now.ToString("MMddyy-hhmmss") + ".credits");
StreamWriter creditsFile = new StreamWriter(File.Open(creditFile, FileMode.Create));
creditsFile.WriteLine("code\inc");
foreach (Credit c in credits)
{
if (DataAccessLayer.AccountExists(i))
{
string tpsAuth = DataAccessLayer.GetAuthCode(i.Pin);
creditsFile.WriteLine(String.Format("{0}{1}\t{2:0.00}", i.AuthCode, i.Pin, c.CreditAmount));
}
else
{
c.Error = true;
c.ErrorMessage = "NO ACCOUNT";
}
DataAccessLayer.AddCredit(c);
}
creditsFile.Close();
creditsFile.Dispose();
string dest = Path.Combine(Settings.CreditArchivePath, Path.GetFileName(creditFile));
File.Move(creditFile,dest);
//File.Delete(errorFile);
}
``` | Yes, `StreamReader.Dispose` closes the underlying stream (for all public ways of creating one). However, there's a nicer alternative:
```
using (TextReader reader = File.OpenText("file.txt"))
{
}
```
This has the added benefit that it opens the underlying stream with a hint to Windows that you'll be accessing it sequentially.
Here's a test app which shows the first version working for me. I'm not trying to say that's proof of anything in particular - but I'd love to know how well it works for you.
```
using System;
using System.IO;
class Program
{
public static void Main(string[] args)
{
for (int i=0; i < 1000; i++)
{
using(StreamReader sr = new StreamReader
(File.Open("somefile.txt", FileMode.Open)))
{
Console.WriteLine(sr.ReadLine());
}
File.Move("somefile.txt", "somefile.bak");
File.Move("somefile.bak", "somefile.txt");
}
}
}
```
If that works, it suggests that it's something to do with what you do while reading...
And now here's a shortened version of your edited question code - which again works fine for me, even on a network share. Note that I've changed `FileMode.Create` to `FileMode.CreateNew` - as otherwise there *could* still have been an app with a handle on the old file, potentially. Does this work for you?
```
using System;
using System.IO;
public class Test
{
static void Main()
{
StreamWriter creditsFile = new StreamWriter(File.Open("test.txt",
FileMode.CreateNew));
creditsFile.WriteLine("code\\inc");
creditsFile.Close();
creditsFile.Dispose();
File.Move("test.txt", "test2.txt");
}
}
``` | Note - your using blocks do not need to be nested in their own blocks - they can be sequential, as in:
```
using(FileStream fs = File.Open("somefile.txt", FileMode.Open))
using(StreamReader sr = new StreamReader(fs))
{
//read file
}
```
The order of disposal in this case is still the same as the nested blocks (ie, the StreamReader will still dispose before the FileStream in this case). | Will a using clause close this stream? | [
"",
"c#",
"filestream",
"dispose",
"streamreader",
""
] |
In python when running scripts is there a way to stop the console window from closing after spitting out the traceback? | If you doing this on a Windows OS, you can prefix the target of your shortcut with:
```
C:\WINDOWS\system32\cmd.exe /K <command>
```
This will prevent the window from closing when the command exits. | You can register a top-level exception handler that keeps the application alive when an unhandled exception occurs:
```
def show_exception_and_exit(exc_type, exc_value, tb):
import traceback
traceback.print_exception(exc_type, exc_value, tb)
raw_input("Press key to exit.")
sys.exit(-1)
import sys
sys.excepthook = show_exception_and_exit
```
This is especially useful if you have exceptions occuring inside event handlers that are called from C code, which often do not propagate the errors. | Stop python from closing on error | [
"",
"python",
"debugging",
""
] |
I have an integer column that may have a number or nothing assigned to it (i.e. null in the database). How can I check if it is null or not?
I have tried
```
if(data.ColumnName == null)
{
...
}
```
This doesn't work either (as SubSonic does not use nullable types (when applicable) for ActiveRecord)
```
if(data.ColumnName.HasValue)
{
...
}
```
If the value stored in the database is 0, then this wouldn't help:
```
if(data.ColumnName == 0 /* or 0x000? */)
{
...
}
```
The same problem could also occur with DateTime fields as well. | Found out how to do it. SubSonic has a method for getting the value as an object to allow a null check:
```
if(data.GetColumnValue("Column Name") == null)
{
...
}
``` | Try:
If (data == System.DBNull) | How to check for null values? | [
"",
"c#",
".net",
"subsonic",
""
] |
I am writing a Huffman encoding/decoding tool and am looking for an efficient way to store the Huffman tree that is created to store inside of the output file.
Currently there are two different versions I am implementing.
1. This one reads the entire file into memory character by character and builds a frequency table for the whole document. This would only require outputting the tree once, and thus efficiency is not that big of a concern, other than if the input file is small.
2. The other method I am using is to read a chunk of data, about 64 kilobyte in size and run the frequency analysis over that, create a tree and encode it. However, in this case before every chunk I will need to output my frequency tree so that the decoder is able to re-build its tree and properly decode the encoded file. This is where the efficiency does come into place since I want to save as much space as possible.
In my searches so far I have not found a good way of storing the tree in as little space as possible, I am hoping the StackOverflow community can help me find a good solution! | Since you already have to implement code to handle a bit-wise layer on top of your byte-organized stream/file, here's my proposal.
Do not store the actual frequencies, they're not needed for decoding. You do, however, need the actual tree.
So for each node, starting at root:
1. If leaf-node: Output 1-bit + N-bit character/byte
2. If not leaf-node, output 0-bit. Then encode both child nodes (left first then right) the same way
To read, do this:
1. Read bit. If 1, then read N-bit character/byte, return new node around it with no children
2. If bit was 0, decode left and right child-nodes the same way, and return new node around them with those children, but no value
A leaf-node is basically any node that doesn't have children.
With this approach, you can calculate the exact size of your output before writing it, to figure out if the gains are enough to justify the effort. This assumes you have a dictionary of key/value pairs that contains the frequency of each character, where frequency is the actual number of occurrences.
Pseudo-code for calculation:
```
Tree-size = 10 * NUMBER_OF_CHARACTERS - 1
Encoded-size = Sum(for each char,freq in table: freq * len(PATH(char)))
```
The tree-size calculation takes the leaf and non-leaf nodes into account, and there's one less inline node than there are characters.
SIZE\_OF\_ONE\_CHARACTER would be number of bits, and those two would give you the number of bits total that my approach for the tree + the encoded data will occupy.
PATH(c) is a function/table that would yield the bit-path from root down to that character in the tree.
Here's a C#-looking pseudo-code to do it, which assumes one character is just a simple byte.
```
void EncodeNode(Node node, BitWriter writer)
{
if (node.IsLeafNode)
{
writer.WriteBit(1);
writer.WriteByte(node.Value);
}
else
{
writer.WriteBit(0);
EncodeNode(node.LeftChild, writer);
EncodeNode(node.Right, writer);
}
}
```
To read it back in:
```
Node ReadNode(BitReader reader)
{
if (reader.ReadBit() == 1)
{
return new Node(reader.ReadByte(), null, null);
}
else
{
Node leftChild = ReadNode(reader);
Node rightChild = ReadNode(reader);
return new Node(0, leftChild, rightChild);
}
}
```
An example (simplified, use properties, etc.) Node implementation:
```
public class Node
{
public Byte Value;
public Node LeftChild;
public Node RightChild;
public Node(Byte value, Node leftChild, Node rightChild)
{
Value = value;
LeftChild = leftChild;
RightChild = rightChild;
}
public Boolean IsLeafNode
{
get
{
return LeftChild == null;
}
}
}
```
---
Here's a sample output from a specific example.
Input: AAAAAABCCCCCCDDEEEEE
Frequencies:
* A: 6
* B: 1
* C: 6
* D: 2
* E: 5
Each character is just 8 bits, so the size of the tree will be 10 \* 5 - 1 = 49 bits.
The tree could look like this:
```
20
----------
| 8
| -------
12 | 3
----- | -----
A C E B D
6 6 5 1 2
```
So the paths to each character is as follows (0 is left, 1 is right):
* A: 00
* B: 110
* C: 01
* D: 111
* E: 10
So to calculate the output size:
* A: 6 occurrences \* 2 bits = 12 bits
* B: 1 occurrence \* 3 bits = 3 bits
* C: 6 occurrences \* 2 bits = 12 bits
* D: 2 occurrences \* 3 bits = 6 bits
* E: 5 occurrences \* 2 bits = 10 bits
Sum of encoded bytes is 12+3+12+6+10 = 43 bits
Add that to the 49 bits from the tree, and the output will be 92 bits, or 12 bytes. Compare that to the 20 \* 8 bytes necessary to store the original 20 characters unencoded, you'll save 8 bytes.
The final output, including the tree to begin with, is as follows. Each character in the stream (A-E) is encoded as 8 bits, whereas 0 and 1 is just a single bit. The space in the stream is just to separate the tree from the encoded data and does not take up any space in the final output.
```
001A1C01E01B1D 0000000000001100101010101011111111010101010
```
---
For the concrete example you have in the comments, AABCDEF, you will get this:
Input: AABCDEF
Frequencies:
* A: 2
* B: 1
* C: 1
* D: 1
* E: 1
* F: 1
Tree:
```
7
-------------
| 4
| ---------
3 2 2
----- ----- -----
A B C D E F
2 1 1 1 1 1
```
Paths:
* A: 00
* B: 01
* C: 100
* D: 101
* E: 110
* F: 111
Tree: 001A1B001C1D01E1F = 59 bits
Data: 000001100101110111 = 18 bits
Sum: 59 + 18 = 77 bits = 10 bytes
Since the original was 7 characters of 8 bits = 56, you will have too much overhead of such small pieces of data. | If you have enough control over the tree generation, you could make it do a canonical tree (the same way [DEFLATE](https://en.wikipedia.org/wiki/DEFLATE) does, for example), which basically means you create rules to resolve any ambiguous situations when building the tree. Then, like DEFLATE, all you actually have to store are the lengths of the codes for each character.
That is, if you had the tree/codes Lasse mentioned above:
* A: 00
* B: 110
* C: 01
* D: 111
* E: 10
Then you could store those as:
2, 3, 2, 3, 2
And that's actually enough information to regenerate the huffman table, assuming you're always using the same character set -- say, ASCII. (Which means you couldn't skip letters -- you'd have to list a code length for each one, even if it's zero.)
If you also put a limitation on the bit lengths (say, 7 bits), you could store each of these numbers using short binary strings. So 2,3,2,3,2 becomes 010 011 010 011 010 -- Which fits in 2 bytes.
If you want to get *really* crazy, you could do what DEFLATE does, and make another huffman table of the lengths of these codes, and store its code lengths beforehand. Especially since they add extra codes for "insert zero N times in a row" to shorten things further.
The RFC for DEFLATE isn't too bad, if you're already familiar with huffman coding: <http://www.ietf.org/rfc/rfc1951.txt> | Efficient way of storing Huffman tree | [
"",
"c++",
"performance",
"huffman-code",
""
] |
My search for the meaning of DCO was quite fruitless, so I decided to ask here. In my Java application, there are many classes like EmployeeDetailsDto, EmployeeDetailsDao, but recently I also came across EmployeeDetailsDco. Does anyone know what does the DCO stand for? | I just spoke to the guy who used to remember what this stands for. It's pretty ironic that he no longer does. Nor do any other people here in this company.
The explanation I could find was, that it's basically a DTO, but they wanted to use DCO to differentiate between DTOs used by Hibernate and DCOs used by external systems, in this case LDAP.
So I believe the meaning of DCO could really be, as Bhushan suggests, Data Carrying object or the like, and in this case it was indeed intended to be just another name for DTO. Answer accepted. Thanks for your time! I thought DCO was an accepted acronym widely used by developers but it turned out to be just this... sorry.
**Edit**
---
THE answer is Data Container Object, for those interested. I have caused enough stir in the company so eventually a colleague emailed the local originator of the DCO term and, if anyone still cares to find out, it stands for **Data Container Object**. | > DTO = [Data Transfer Object](http://msdn.microsoft.com/en-us/library/ms978717.aspx)
>
> DAO = [Data Access Object](http://java.sun.com/blueprints/patterns/DAO.html)
>
> DCO =
> [Dynamically Configurable Object](http://209.85.229.132/search?q=cache:21UeLR983rEJ:legion.virginia.edu/WinterWorkshop/slides/Class_System/class_system.PPT+Dynamically+Configurable+object+dco&cd=2&hl=en&ct=clnk)?
From the [article](http://209.85.229.132/search?q=cache:21UeLR983rEJ:legion.virginia.edu/WinterWorkshop/slides/Class_System/class_system.PPT+Dynamically+Configurable+object+dco&cd=2&hl=en&ct=clnk)
### Dynamically configurable object (DCO)
an object whose implementation can change incrementally after it is running
* consists of interface elements
* public function
* private function
* private data along with all accessor functions
* member functions support incremental changes to interface elements
* adding, removing, or altering | DTO, DAO, and DCO. What is a DCO? | [
"",
"java",
"terminology",
"acronym",
""
] |
If I do an online `onload` event for embedded objects, that seems to work but I can't seem to get the `load` event working through `addEventListener`. Is this expected? | Probably, but it may be browser dependent.
windows and images and iframes define their load events with addEventListener and attachEvent, but other load events are browser specific.
A script or link element's onload doesn't attach in IE, for instance. | try
`$("embed").ready(function(){ ... });` | Load events for embedded elements | [
"",
"javascript",
"dom-events",
""
] |
When deploying my OSGi web application using the [equinox servlet bridge](http://www.eclipse.org/equinox/server/http_in_container.php) i get the following:
```
log4j:WARN No appenders could be found for logger (org.springframework.osgi.extender.internal.activator.ContextLoaderListener).
log4j:WARN Please initialize the log4j system properly.
```
I tried several ways of supplying the necessary "log4j.properties" file, including:
* adding the context-param "log4jConfigLocation" to the servlet bridge web.xml
* creating a folder "classes" in the WEB-INF folder and copying my log4j.properties file there (and copying it in several other locations)
* removing my log4j bundle and setting "extendedFrameworkExports" to org.apache.log4j so (I guess) the tomcat log4j is used ... this did not work because my dependencies need some slf4j classes which are provided as a fragment for the log4j bundle ... which isn't there anymore ...
Of course I also have a fragment bundle which extends the log4j bundle with a log4j.properties file, but it looks like this log4j bundle is not used.
**ADDED:** I should add that I'm developing the application in Eclipse... and my fragment bundle which configures log4j / slf4j works there.
Has anyone solved this? Any ideas? | I found my error. The fragment which should provide the log4j.properties file did not include it, because I did not add it to the binary build in build.properties. | I had the same issue and I added `log4j.properties` to my `/src` folder. | How to configure Log4J when deploying an OSGi app with the Equinox Servle Bridge to Tomcat? | [
"",
"java",
"tomcat",
"log4j",
"osgi",
"equinox",
""
] |
Does anyone know of any tools that allow you to extract comments directly from a .cs file in to some simple text or even the clipboard? Even better if such a tool could work at the method level too.
I am **not** looking for something like Sandcastle that works at build time, I am looking for something that works on single source code files. Basically I need to copy a chunk of method signatures and the associated doc comments in to a text file, but I am getting bored of removing the "///" and reformating the lines. I'd love to be able to right click on a method and have a context menu item along the lines of "Copy documentation to Clipboard".
Do any such tools exist? | No need to roll your own, have a look at [cr-documentor](http://code.google.com/p/cr-documentor/).
> CR\_Documentor is a plugin for
> [DXCore](http://www.devexpress.com/Downloads/NET/IDETools/DXCore/) that allows you to preview
> what the documentation will look like
> when it's rendered - in a tool window
> inside Visual Studio.
It works quite well, but I suspect it running along with Resharper is a bit shaky, so I disable it until I use it. | I have just written a tool that does that. It's just a few lines of code, and it is not finished yet, but very simple to extend (I might do that tomorrow somewhere).
The result : just click extract from a menu, and the result will be on the **clipboard**.
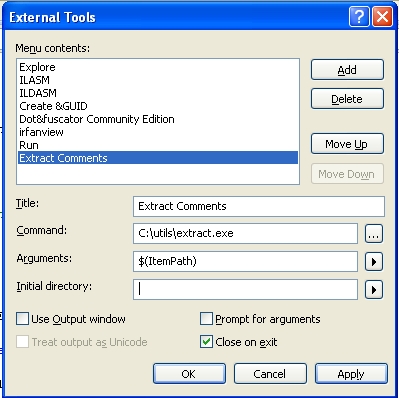
Two very easy steps :
1. Write a program that takes a file as argument, takes some text from that file and paste them to the clipboard.
2. Integrate that program into your IDE.
**STEP 1, part 1**
Main program, take a file, send it to an 'extractor' and write results to clipboard.
```
class Program
{
[STAThread]
static void Main(string[] args)
{
if (args.Length == 0) return;
FileInfo f = new FileInfo(args[0]);
Extracter e = new Extracter(f.OpenText().ReadToEnd());
Clipboard.SetText(e.GetExtractedText());
}
}
```
**STEP 1, part 2**
The extracter : get all the textpatterns you need out of it using regex of course, and return the conforming string. I have ommitted comments for density of post, and since the principle is simple and explained already.
```
public class Extracter
{
private Regex re;
// extend/adapt regex patterns for better result.
const String RE_COMMENT_AND_NEXT_LINE= @"(?<=([\/]{3})).+";
public string FileText { get; set; }
public Extracter(String FileText)
{
this.FileText = FileText;
}
public String GetExtractedText()
{
StringBuilder sb = new StringBuilder(String.Empty);
re = new Regex(RE_COMMENT_AND_NEXT_LINE);
foreach (Match match in re.Matches(FileText))
{
sb.Append(match.ToString());
}
return sb.ToString();
}
}
```
**STEP 2 : Add to IDE**
That IDE dependent of course, but always easy. See my screenshot for VS2008 :
 | Extracting doc comments from C# source file | [
"",
"c#",
"visual-studio",
"documentation",
"comments",
""
] |
I want to fetch the records from MySQL for the current year and month.
I am passing to get the today records
Today:
("recDate","=", new Date());
Like that, how to fetch for current Month and current Year ?
Thanks in advance
* Gnaniyar Zubair | ```
import java.util.Calendar;
public class CalendarExample
{
public static void main(String[] args)
{
Calendar cal = Calendar.getInstance();
int day = cal.get(Calendar.DATE);
int month = cal.get(Calendar.MONTH) + 1;
int year = cal.get(Calendar.YEAR);
int dow = cal.get(Calendar.DAY_OF_WEEK);
int dom = cal.get(Calendar.DAY_OF_MONTH);
int doy = cal.get(Calendar.DAY_OF_YEAR);
System.out.println("Current Date: " + cal.getTime());
System.out.println("Day: " + day);
System.out.println("Month: " + month);
System.out.println("Year: " + year);
System.out.println("Day of Week: " + dow);
System.out.println("Day of Month: " + dom);
System.out.println("Day of Year: " + doy);
}
}
```
Here is the result of this example:
Current Date: Thu Dec 29 13:41:09 ICT 2005
Day: 29
Month: 12
Year: 2005
Day of Week: 5
Day of Month: 29
Day of Year: 363 | There's no need to pass parameters, MySQL can work out for itself what the current year and month is:
```
SELECT * FROM table
WHERE YEAR(recDate) = YEAR(CURDATE())
AND MONTH(recDate) = MONTH(CURDATE())
```
or, alternatively,
```
SELECT * FROM table
WHERE DATE_FORMAT(recDate, '%Y%m') = DATE_FORMAT(NOW(), '%Y%m')
``` | How to fetch current year and month from MySQL in JAVA? | [
"",
"java",
"mysql",
""
] |
I know about the PDF report generator, but I need to use RTF instead. | There is [PyRTF](http://pypi.python.org/pypi/PyRTF/0.45) but it hasn't been updated in a while.
If that doesn't work and you are willing to do some hacking then I can also point you to the [GRAMPS Project](http://www.gramps-project.org/wiki/index.php?title=Main_Page) that has an RTF report generator (look in gramps/docgen/RTFDoc.py). This code is very specific to their genealogy reporting needs, but it is clean and decently documented so could make a good starting point. | `(can't comment yet so I post it as an answer)`
There's a fork of PyRTF called [pyrtf-ng](http://code.google.com/p/pyrtf-ng/), it's maintained and has Unicode support.
Documentation doesn't exist from what I've seen, but api looks nice, and you can figure out a lot from tests in `tests` dir. | Does any one know of an RTF report generator in Django? | [
"",
"python",
"django",
"report",
"rtf",
""
] |
I've created simple annotation in Java
```
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Column {
String columnName();
}
```
and class
```
public class Table {
@Column(columnName = "id")
private int colId;
@Column(columnName = "name")
private String colName;
private int noAnnotationHere;
public Table(int colId, String colName, int noAnnotationHere) {
this.colId = colId;
this.colName = colName;
this.noAnnotationHere = noAnnotationHere;
}
}
```
I need to iterate over all fields, that are annotated with `Column` and get **name** and **value** of field and annotation. But I've got problem with getting **value** of each field, since all of them are of different **data type**.
Is there anything that would return collection of fields that have certain **annotation**?
I managed to do it with this code, but I don't think that reflection is good way to solve it.
```
Table table = new Table(1, "test", 2);
for (Field field : table.getClass().getDeclaredFields()) {
Column col;
// check if field has annotation
if ((col = field.getAnnotation(Column.class)) != null) {
String log = "colname: " + col.columnName() + "\n";
log += "field name: " + field.getName() + "\n\n";
// here i don't know how to get value of field, since all get methods
// are type specific
System.out.println(log);
}
}
```
Do I have to wrap every field in object, which would implement method like `getValue()`, or is there some better way around this? Basicly all I need is string representation of each field that is annotated.
edit: yep `field.get(table)` works, but only for `public` fields, is there any way how to do this even for `private` fields? Or do I have to make getter and *somehow* invoke it? | Every object should has toString() defined. (And you can override this for each class to get a more meaningful representation).
So you where your "// here I don't know" comment is, you could have:
```
Object value = field.get(table);
// gets the value of this field for the instance 'table'
log += "value: " + value + "\n";
// implicitly uses toString for you
// or will put 'null' if the object is null
``` | Reflection is *exactly* the way to solve it. Finding out things about types and their members at execution time is pretty much the definition of reflection! The way you've done it looks fine to me.
To find the value of the field, use [`field.get(table)`](http://java.sun.com/javase/6/docs/api/java/lang/reflect/Field.html#get()) | Java annotations | [
"",
"java",
"annotations",
""
] |
How do I check if the user clicked with a mouse or with a pen stylus on a C# control.
For eg. If the user clicks a text box with a pen button then I want an input panel to pop up but if he clicks with a mouse then it shouldn't. So how do I check whether he was using a mouse or a pen?
Edit: Using Windows Forms not WPF | I wrote an article for MSDN that never got published, I guess because Tablet PC development fizzled out by the time I got it to them. But it described how to do this. Long story short, you'll want the GetMessageExtraInfo API. Here's the definitions:
```
// [DllImport( "user32.dll" )]
// private static extern uint GetMessageExtraInfo( );
uint extra = GetMessageExtraInfo();
bool isPen = ( ( extra & 0xFFFFFF00 ) == 0xFF515700 );
```
Email me at my first name at Einstein Tech dot net if you want me to send you the article. | If you're using WPF then there's a whole host of Stylus events. E.g. [UIElement.StylusDown](http://msdn.microsoft.com/en-us/library/system.windows.uielement.stylusdown.aspx).
[This](http://msdn.microsoft.com/en-us/library/ms754010.aspx) has more details about how stylus and mouse events interact.
If you're not using WPF, why not? :p | When developing for a tablet PC, how do I determine if the user clicked a mouse or a pen? | [
"",
"c#",
"winforms",
"tablet-pc",
""
] |
I have a generic function:
```
void ImageAlbum::ExpressButtonPressed(
boost::function<
void (
thumb::PhotoPrintThumbnail*,
thumb::PhotoPrintFormat,
thumb::PhotoPrintQuantity
)
> memberToCall
) {
...
BOOST_FOREACH(thumb::PhotoPrintThumbnail *pThumbnail, m_thumbs.GetSelected()) {
memberToCall(
pThumbnail,
m_expressSel.GetSelectedFormat(),
m_expressSel.GetSelectedQuantity()
);
}
...
}
```
I can successfully call:
```
ExpressButtonPressed(boost::bind(&thumb::PhotoPrintThumbnail::AddQuantity, _1, _2, _3));
```
Then, instead of adding a quantity of a certain format to a thumbnail, I need to replace them all with a single format. More precise, with a list of 1 element, like that:
```
ExpressButtonPressed(
boost::lambda::bind(
&thumb::PhotoPrintThumbnail::SetFormats,
_1,
boost::lambda::bind(
boost::lambda::constructor<thumb::PhotoPrintThumbnail::LoadedFormats>(),
1,
boost::lambda::bind(
boost::lambda::constructor<thumb::PhotoPrintThumbnail::LoadedFormat>(),
_2,
_3
)
)
)
);
```
Which results in "boost/lambda/detail/actions.hpp(96) : error C2665: 'boost::lambda::function\_adaptor::apply' : none of the 2 overloads could convert all the argument types".
What am I doing wrong here?
BTW
```
class PhotoPrintThumbnail {
public:
...
typedef std::pair<PhotoPrintFormat, PhotoPrintQuantity> LoadedFormat;
typedef std::list<LoadedFormat> LoadedFormats;
void SetFormats(const LoadedFormats &formats);
``` | Do you happen to #include boost/bind.hpp in your lambda-using code? This would cause unqualified use of the placeholders (\_1, \_2, etc) to resolve to those defined by Boost.Bind, and these don't mix well with Boost.Lambda.
Rewriting your code to explicitly use boost::lambda::\_[1,2,3] instead of the unqualified names compiles fine on my VC 7.1 setup. | Not sure what version of Boost or what compiler are you using. With boost 1.37 and VS2005 i can get the same error. I suspect it may be that an error at the heart of the template expansion is causing a SFINAE issue.
For instance taking the innermost expression out:
```
boost::function<
PhotoPrintThumbnail::LoadedFormat (
PhotoPrintFormat,
PhotoPrintQuantity
)
> func = boost::lambda::bind
( boost::lambda::constructor<PhotoPrintThumbnail::LoadedFormat>()
, _1
, _2
);
```
That looks ok to me yet also fails, albeit with a :
std::pair<\_Ty1,\_Ty2>::pair' : none of the 3 overloads could convert all the argument types
error.
Of course you could just use:
```
void func
( PhotoPrintThumbnail* ppt
, const PhotoPrintFormat& ppf
, const PhotoPrintQuantity& ppq
)
{
ppt->SetFormats (PhotoPrintThumbnail::LoadedFormats (1, PhotoPrintThumbnail::LoadedFormat (ppf, ppq)));
}
ExpressButtonPressed (func);
```
which is clearer *and compiles*. | Problem nesting boost::lambda::bind-s | [
"",
"c++",
"boost-lambda",
""
] |
I want to get the next element in a list and if the list is at it's end I want the first element.
So I just want it to circle in other words.
```
List<int> agents = taskdal.GetOfficeAgents(Branches.aarhusBranch);
if (lastAgentIDAarhus != -1)
{
int index = agents.IndexOf(lastAgentIDAarhus);
if (agents.Count > index + 1)
{
lastAgentIDAarhus = agents[index + 1];
}
else
{
lastAgentIDAarhus = agents[0];
}
}
else
{
lastAgentIDAarhus = agents[0];
}
```
I am fairly displeased with my own solution shown above, let me know if you have a better one :) | ```
lastAgentIDAarhus = agents[index == -1 ? 0 : index % agents.Count];
```
The use of the MOD operator **%** atuomatically chops the index to the range of possible indexes.
The modulo operator is the compliment to the DIV (/) operator and returns the remainder of a division of two whole numbers. For example if you divide 9 by 6 the result is 1 with a remainder of 3. The MOD operator asks for the 3. | Or simply:
```
public static T NextOf<T>(this IList<T> list, T item)
{
var indexOf = list.IndexOf(item);
return list[indexOf == list.Count - 1 ? 0 : indexOf + 1];
}
```
Example:
```
List<string> names = new List<string>();
names.Add("jonh");
names.Add("mary");
string name = String.Empty;
name = names.NextOf(null); //name == jonh
name = names.NextOf("jonh"); //name == mary
name = names.NextOf("mary"); //name == jonh
``` | List<> Get Next element or get the first | [
"",
"c#",
""
] |
Hoping someone can help me out with this.
Lets say I have a table called incoming\_data with 4 columns:
```
primary_key_id
serial_number
counter
selected_color
```
I get data from a source that fills this table. The primary key has its identity
turned on so it is not repeating. I will get duplicate serial numbers with different selected colors.
The counter is ever increasing coming from the device.
So what I want to do is select all the data I received today, group the data by serial number and only get the record
with the highest counter value.
Simple:
```
SELECT serial_number, MAX(counter)
FROM incoming_data
GROUP BY serial number
```
This works perfectly, except that I want to do something with the color information
that I received.
If I add color to the select, then I get ALL the records since all
the colors I received that day are different. That wont work.
If I could get the primary\_key\_id of the record then I could just
query for the color but this doesn't work either since each primary\_key\_id
value is different I get them all.
Any suggestions on a better technique for doing this?
Thanks! | Extract the relevant key, then join back to get "non key".
This works in MS SQL Server and later Sybase.
```
SELECT
i.serial_number, i.counter, i.selected_color
FROM
(
SELECT serial_number, MAX(counter) AS maxc
FROM incoming_data
GROUP BY serial number
) max
JOIN
incoming_data i ON max.serial_number = i.serial_number AND max.maxc = i.counter
``` | EDIT: t odeal with cases where multiple records have same serial number and max counter value.. This will extract the one of those multiples with the biggest primary\_key\_id
```
Select * From incoming_data
Where primary_key_id In
(Select Max(primary_key_id) From incoming_data I
Where Counter =
(Select Max(counter) From incoming_data
Where SerialNumber = I.SerialNumber)
Group By SerialNumber)
``` | SQL - Getting more data with a GROUP BY | [
"",
"sql",
""
] |
Can you advice best way to rectify timezone issues in .Net. Recently I developed a simlple website by using asp.net C# as codebehind adn MS Access as backend.
My production server and live servers are in different date time setting. My producttion server date format is dd-mm-yyyy
live server format is mm-dd-yyyy.
I am facing an error when i tried to cast the datetime in front end. "String was not recognized as a valid DateTime."
The date i try to cast was populated in my production server it works fine in production server. but when i push the access file into live server I am facing the above error. any help would much appreciated | this is what i do ALWAYS while working with datetimes in my front end: specify my own exact format (which is usually DD/MMM/YYYY - that way i am sure my day part is always numeric, month part string and year part a 4 digit number
also - USE DateTime.ParseExact instead of DateTime.Parse. this way there is no ambiguity with front end code.
1 more tip - if you are using c# 3.5, i would really recommend you to create an extension method on the datetime class where you actually HARDCODE your specific format for a given application, and then instead of supplying your format at 10 different places where you are converting, simply make a call on this extension method
this way if for any reason you want to change your format later, you just have to change 1 extension method :-) | Convert the date to an ISO Date format instead - YYYY-MM-DD. When you put it in that format, there is ZERO ambiguity, and MS's date functions always understands it. | How we can resolve the datetime problem shifting the Access DB from production server to live | [
"",
"c#",
"ms-access",
""
] |
I was wondering if there's a language feature in Java in which methods of a superclass would be invisible for members of a subclass:
```
public class Subclass extends protected Superclass
```
or something. I'll give an example.
Here is your superclass.
```
public class A{
public String getA(){...}
public String getB(){...}
public String getC(){...}
public void setA(String a){...}
public void setB(String b){...}
public void setC(String c){...}
}
```
If you want to subclass A while protecting some of its methods, and you can't change access modifyers in methods unless you override them, you'd end up with something like this-
```
public class B extends A{
private String getA(){return super.getA();}
private String getB(){return super.getB();}//These four methods have
private void setA(String a){super.setA(a);}//to be redeclared.
private void setB(String b){super.setB(b);}
public String getC(){return super.getC();}//These two methods can be
public void setC(String c){super.setC(c);}//removed.
public String getD(){...}
public void setD(String d){...}
}
```
Either that or you can keep a private instance of A and have something like this:
```
public class B{
private A obj;
private String getA(){return obj.getA();}
private String getB(){return obj.getB();}//These four methods can also
private void setA(String a){obj.setA(a);}//be removed.
private void setB(String b){obj.setB(b);}
public String getC(){return obj.getC();}//These two methods are
public void setC(String c){obj.setC(c);}//redeclared.
public String getD(){...}
public void setD(String d){...}
}
```
Can you have something that takes both in a way that you don't have to redeclare any methods? | There is no "non-public" inheritance in Java, unlike the situation in C++.
Inheritance creates a subtyping relation. Any instance of B is also an instance of A, and should respond to the same messages. If instances of B clearly don't respond to all messages that instances of A respond to, then inheritance would be inappropriate anyway.
Your last solution (B does not inherit from A) is the appropriate one: you don't create a subtyping relation, just use one type to (secretly) implement the other. | I don't think it is or should be possible.
If you use inheritance so that B extends A, you should be able to use a B object as an A object. For instance, this would be possible:
```
A obj = new B();
```
Now the program has no way of knowing that you can't call some of A's public methods.
And without inheritance, redefinition of functions is unavoidable. | Protected class structure in Java? | [
"",
"java",
"oop",
"class",
"inheritance",
""
] |
I'm trying to write a Greasemonkey script, and would like to use the jQuery library to do so, but I'm not quite sure how I would include jQuery from a web address to get rolling.
**How would I include jQuery (from Google's web server) into the greasemonkey script** so that I can just go:
```
$(document).ready(function(){
// Greasemonkey stuff here
});
```
I'd prefer to get it from this source:
```
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.3.2/jquery.min.js" type="text/javascript" charset="utf-8"></script>
```
**Update:** Thanks for the help, the answers were very informative. I did, however, utilize my GoogleFu a little more and came across this *solution*: <http://joanpiedra.com/jquery/greasemonkey/>
Works like a charm.. just update the source to google's hosted version of jQuery to complete. | The recommended way in recent versions of greasemonkey is to use the @require comment tag.
E.g.
```
// ==UserScript==
// @name Hello jQuery
// @namespace http://www.example.com/
// @description jQuery test script
// @include *
// @require http://ajax.googleapis.com/ajax/libs/jquery/1.3.2/jquery.min.js
// ==/UserScript==
```
**However... be aware that jQuery 1.4.1 and 1.4.2 are incompatible with this method**
Thanks Paul Tarjan, for pointing this out. See [jQuery forum thread](http://forum.jquery.com/topic/importing-jquery-1-4-1-into-greasemonkey-scripts-generates-an-error).
**Also be aware of these @require semantics**
At the time that the user script is installed, Greasemonkey will download and keep a locally cached copy of the remote file that can be read almost instantly. The cached copy is kept in the same folder as your installed user-script. The remote file is not monitored for changes.
Please be aware that, at the time of writing this answer, this @require tag is only read at install-time. If you edit an existing user script to add this tag, it will be ignored. You need to uninstall and re-install your user script to pick up the change. | From [here](http://www.nabble.com/Loading-jQuery-UI-dialogs-from-GreaseMonkey--td19897312s27240.html):
```
// ==UserScript==
// @name jQueryTest
// @namespace http://www.example.com/
// @include *
// ==/UserScript==
// Add jQuery
var GM_JQ = document.createElement('script');
GM_JQ.src = 'http://jquery.com/src/jquery-latest.js';
GM_JQ.type = 'text/javascript';
document.getElementsByTagName('head')[0].appendChild(GM_JQ);
// Check if jQuery's loaded
function GM_wait() {
if(typeof unsafeWindow.jQuery == 'undefined')
{ window.setTimeout(GM_wait,100); }
else { $ = unsafeWindow.jQuery; letsJQuery(); }
}
GM_wait();
// All your GM code must be inside this function
function letsJQuery() {
alert($); // check if the dollar (jquery) function works
// the next call fails
$("<div id='example' class='flora' title='This is my title'>I'm in
a dialog!</div>").dialog({
buttons: {
"Ok": function() {
alert("Ok");
},
"Cancel": function() {
$(this).dialog("close");
}
}
});
}
```
It works perfectly, but you may want to limit the sites it runs on or host the jQuery js file on your own site so as not to steal their bandwidth. | How do I include a remote javascript file in a Greasemonkey script? | [
"",
"javascript",
"jquery",
"greasemonkey",
""
] |
I recently started playing with C#, but I am finding it very frustrating. It seems every time I want to add what I think is a simple control, I end up either scouring the internet or writing my own. I just feel like I spend more time recreating controls to get them to work the way they should, and less time actually creating applications.
For example: [In another question](https://stackoverflow.com/questions/745974/remove-the-border-from-a-combobox), I asked if it was possible to remove the border on a combobox; something I thought should be built into the control, but alas I had to build my own control for this simple alteration.
Am I just too new to C#/.net, or am I just expecting too much? I know SO loves C# so don't bite my head off for feeling this way, just help me understand what I am missing and whether I should continue learning and working with C#. | You're not the first, nor the last developer to have this sentiment. It always seemed to me that every time I needed to do something that wasn't part of a demo, I had to spend hours trying to figure out how to accomplish one small task. Much of my frustration was with ASP.NET web controls.
That being said, I found that once I got over the (steep IMHO) learning curve of control development, many of my frustrations were eliminated. I feel that using inheritance and overriding virtual members to create new behavior is a very clean approach. Plus, it creates output that can be very easily reused. Using OO practices just always seemed better to me than pasting JavaScript snippets all over the place.
Microsoft does a good job of providing many base controls to use out of the box, but every application always seems to need something that's missing. I would recommend learning control development, or looking to third party solutions if possible. There are many companies that exist solely to fill the voids. Either way, I wouldn't judge the whole language based off of the default control set. | I spent 4+ hours today tracking down an 8 byte memory leak in a C++ program. There are threads involved and attaching the debugger would alter the thread timing so I couldn't do even something as simple as breaking on the Nth alloc to see where the leak was. Additionally I knew generally in between which two events the memory was allocated. Unfortunately both threads thought that was a great time to allocate lots and lots of 8 byte size objects. At the end of the investigation I found a ref count error on a COM pointer was leading to the leak.
Not having to pull your hair out over investigations like this is why you should move to C#. | .Net is increasing my development time - am I missing something? | [
"",
"c#",
".net",
""
] |
Is there any library that can be used for analyzing (nlp) simple english text. For example it would be perfect if it can do that;
Input: "I am going"
Output: I, go, present continuous tense | How about the [Natural Language Toolkit](http://www.nltk.org/)? | Try StanFord's NLP stuff [here](http://nlp.stanford.edu/software/index.shtml). | How to analyze simple English sentences | [
"",
"java",
"nlp",
""
] |
What kind of open-source libraries are available to convert XML into a java value object?
In .Net, there is a way to easily do this with xml serialization and attributes. I would imagine there some parallel in java. I know how to do this with a DOM or SAX parser, but I was wondering if there was an easier way.
I have a predefined XML format that looks something like this.
```
<FOOBAR_DATA>
<ID>12345</ID>
<MESSAGE>Hello World!</MESSAGE>
<DATE>22/04/2009</DATE>
<NAME>Fred</NAME>
</FOOBAR_DATA>
```
In .Net, I can do something like this to bind my object to the data.
```
using System;
using System.Xml.Serialization;
namespace FooBarData.Serialization
{
[XmlRoot("FOOBAR_DATA")]
public class FooBarData
{
private int _ID = 0;
[XmlElement("ID")]
public int ID
{
get { return this._ID; }
set { this._ID = value; }
}
private string _Message = "";
[XmlElement("MESSAGE")]
public string Message
{
get { return this._Message; }
set { this._Message = value; }
}
private string _Name = "";
[XmlElement("NAME")]
public string Name
{
get { return this._Name; }
set { this._Name = value; }
}
private Date _Date;
[XmlElement("DATE")]
public Date Date
{
get { return this._Date; }
set { this._Date= value; }
}
public FooBarData()
{
}
}
}
```
I was wondering if there was a method using annotations, similar to .Net or perhaps Hibernate, that will allow me to bind my value object to the predefined-XML. | I like [XStream](http://xstream.codehaus.org/) alot, especially compared to JAXB - unlike JAXB, XStream doesn't need you to have an XSD. It's great if you have a handful of classes you want to serialize and deserialize to XML, without the heavy-handed-ness of needing to create a XSD, run jaxc to generate classes from that schema, etc. XStream on the other hand is pretty lightweight.
(Of course, there are plenty of times where JAXB is appropriate, such as when you have a pre-existing XSD that fits the occasion...) | [JAXB](http://jaxb.java.net/) allows you to convert an XML Schema (XSD) file into a collection of Java classes. This may be more "structured" than the `XMLEncoder`/`Serializable` approach that Andy's (excellent, by the way) answer provides. | How do I convert XML into a java value object? | [
"",
"java",
"xml",
"xml-parsing",
""
] |
I have the following class in C++/CLI and an explicit template instantiation for the int primitive..
```
template<typename T>
public ref class Number
{
T _value;
public:
static property T MinValue
{
T get()
{
return T::MinValue;
}
}
static property T MaxValue
{
T get()
{
return T::MaxValue;
}
}
property T Value
{
T get()
{
return _value;
}
void set(T value)
{
if( value<MinValue || value > MaxValue)
throw gcnew System::ArgumentException("Value out of range");
_value = value;
}
}
};
template ref class Number<int>;
```
On compiling this and inspecting the generated assembly using reflector I am able to see a class called `Number<int>` but while trying to instantiate this same class in C# the compiler complains about some `System::Number` class not taking a template argument. What am I doing wrong? Can this be done at all? | I have a work around, declare an additional class inheriting the `Number<int>` class. This class is now visible in C# and can be instantiated.
```
public ref class MyInt32 : public Number<int>
{
};
``` | Reflector is *lying* a little bit here. The name of the class is not actually Number<int>. It is actually 'Number<int>'. Notice the single quotes. These are only visible when you view the type name with ildasm.
I **believe** this is done to make the type unbindable in most languages as they have no way of understanding how a C++ template actually works. This makes it effectively only visible to the C++ compiler which is appropriate since it's the only MS compiler that actually supports templates (templates != generics). | Use C++ CLI template class in C# | [
"",
"c#",
".net",
"c++-cli",
""
] |
I'm trying to include a vCard export function in an existing page full of account information.
The ugly methods would involve 1, submitting a form to the same page, processing it and re-rendering the whole page, or 2, a GET targeting an iframe on the page. I'd really like to avoid both of those, but I may have to use #2 to achieve the goal.
Right now I have:
```
<input type="image" src="/intra/imgs/icons/vcard.png" onclick="$.post('/intra/vcard.php', { id: '992772', type: 'sponsor'});">
```
Which works in the sense that if I watch XHR activity in Firebug I see the request come back with the correct response, full of vCard formatted data. However it does not prompt the user to download the response as a file, even though the card is sent with:
```
header('Content-Type: text/x-vcard');
header("Content-Disposition: attachment; filename={$this->name_first}{$this->name_last}.vcf");
```
Am I doing something wrong, or is this just not possible? | I'm confused as to what exactly the problem is. Why not just do something like:
```
<input type="image"
src="/intra/imgs/icons/vcard.png"
onclick="window.location='/intra/vcard.php?id=992772&type=sponsor';">
```
And then return the appropriate download headers on `vcard.php`? When the browser gets those, it will stay on the same page and prompt for download. You will have to change your code to handle the variables as `$_GET` instead of `$_POST` but you should be using GET for this anyways.
**EDIT** as pointed out in the comments, it would be even more appropriate to do this:
```
<a href="/intra/vcard.php?id=992772&type=sponsor"><img src="/intra/imgs/icons/vcard.png"></a>
```
As then it would be accessible to users with javascript disabled. | Yeah, you can't trigger a download from xhr. Only way I've found is option #2, use an iframe.
Perhaps a jquery plugin (I'm assuming you're using jquery) is an overkill for just this purpose, but [this](http://www.nicolas.rudas.info/jQuery/xajaSubmit.js) may be of use to you. | How do I offer an Ajax POST response to the user as a download? | [
"",
"php",
"jquery",
"download",
""
] |
I am using IBM Websphere Application Server v6 and Java 1.4 and am trying to write large CSV files to the `ServletOutputStream` for a user to download. Files are ranging from a 50-750MB at the moment.
The smaller files aren't causing too much of a problem but with the larger files it appears that it is being written into the heap which is then causing an OutOfMemory error and bringing down the entire server.
These files can only be served out to authenticated users over HTTPS which is why I am serving them through a Servlet instead of just sticking them in Apache.
The code I am using is (some fluff removed around this):
```
resp.setHeader("Content-length", "" + fileLength);
resp.setContentType("application/vnd.ms-excel");
resp.setHeader("Content-Disposition","attachment; filename=\"export.csv\"");
FileInputStream inputStream = null;
try
{
inputStream = new FileInputStream(path);
byte[] buffer = new byte[1024];
int bytesRead = 0;
do
{
bytesRead = inputStream.read(buffer, offset, buffer.length);
resp.getOutputStream().write(buffer, 0, bytesRead);
}
while (bytesRead == buffer.length);
resp.getOutputStream().flush();
}
finally
{
if(inputStream != null)
inputStream.close();
}
```
The `FileInputStream` doesn't seem to be causing a problem as if I write to another file or just remove the write completely the memory usage doesn't appear to be a problem.
What I am thinking is that the `resp.getOutputStream().write` is being stored in memory until the data can be sent through to the client. So the entire file might be read and stored in the `resp.getOutputStream()` causing my memory issues and crashing!
I have tried Buffering these streams and also tried using Channels from `java.nio`, none of which seems to make any bit of difference to my memory issues. I have also flushed the `OutputStream` once per iteration of the loop and after the loop, which didn't help. | The average decent servletcontainer itself flushes the stream by default every ~2KB. You should really not have the need to explicitly call `flush()` on the `OutputStream` of the `HttpServletResponse` at intervals when sequentially streaming data from the one and same source. In for example Tomcat (and Websphere!) this is configureable as `bufferSize` attribute of the HTTP connector.
The average decent servletcontainer also just streams the data in [chunks](https://en.wikipedia.org/wiki/Chunked_transfer_encoding) if the content length is unknown beforehand (as per the [Servlet API specification](https://jakarta.ee/specifications/servlet/4.0/apidocs/javax/servlet/http/HttpServlet.html#doGet-javax.servlet.http.HttpServletRequest-javax.servlet.http.HttpServletResponse-)!) and if the client supports HTTP 1.1.
The problem symptoms at least indicate that the servletcontainer is buffering the entire stream in memory before flushing. This can mean that the content length header is not set and/or the servletcontainer does not support chunked encoding and/or the client side does not support chunked encoding (i.e. it is using HTTP 1.0).
To fix the one or other, just set the content length beforehand:
```
response.setContentLengthLong(new File(path).length());
```
Or when you're not on Servlet 3.1 yet:
```
response.setHeader("Content-Length", String.valueOf(new File(path).length()));
``` | I have used a class that wraps the outputstream to make it reusable in other contexts. It has worked well for me in getting data to the browser faster, but I haven't looked at the memory implications. (please pardon my antiquated m\_ variable naming)
```
import java.io.IOException;
import java.io.OutputStream;
public class AutoFlushOutputStream extends OutputStream {
protected long m_count = 0;
protected long m_limit = 4096;
protected OutputStream m_out;
public AutoFlushOutputStream(OutputStream out) {
m_out = out;
}
public AutoFlushOutputStream(OutputStream out, long limit) {
m_out = out;
m_limit = limit;
}
public void write(int b) throws IOException {
if (m_out != null) {
m_out.write(b);
m_count++;
if (m_limit > 0 && m_count >= m_limit) {
m_out.flush();
m_count = 0;
}
}
}
}
``` | Using ServletOutputStream to write very large files in a Java servlet without memory issues | [
"",
"java",
"servlets",
"stream",
"websphere",
""
] |
I am currently using jQuery to write an online application, that started off with a couple of lines of code, and have quickly now become over a 1000 lines.
My code's structure is simple. I have a window.load which wraps my javascript, and inside it I start adding my click event handlers, and the various functions that makeup my application.
```
$(window).load(function(){
// Code goes here...
});
```
My code functions can definitely be grouped into categories; e.g. 5 functions perform animation, 12 are event handlers, etc.
I would like to group the functions in their own js files, and import them individually. I can later use my CMS engine to concatenate and compress the files on the fly.
What is the best way in doing so. I am thinking that maybe I can give some of my functions their own namespace for further clarity; e.g. all animation functions are prefixed with ANIMATION - ANIMATION.moveDiv1(), ANIMATION.moveDiv2, MYEVENT.div1Clicked, etc. | I generally stick all related items into their own file, with a namespace that matches the file for readability sake.
An example file could look like:
Example.js
```
var Animation = {}; // create the namespace-like object
Animation.moveDiv1 = function() {...};
Animation.moveDiv2 = function() {...};
```
There's really a lot of ways to do this. Speaking of compression, there are some nice tools that you can use to compress things. Check out [YUI Compressor](http://developer.yahoo.com/yui/compressor/)
Modularity is a good goal with Javascript, but I would say the next level would be to actually use some Javascript OO techniques. If your app is simple enough, you can probably do without it though. | 1. Your code files should mirror your classes.
2. Your classes should follow principles of good OO design.
In terms of load-time within the browser, kekoav and knut have the right idea - just use YUI or another script compressor/minifier (and optionally an obfuscator), combine them into a single file and load them all from a single script include directive.
I'd also have a look at JS the prototype property of your classes - if they're getting large and you're creating multiple instances of them, you'll start to see significant performance gains by putting your public (and optionally, private/privileged) methods into the class prototype.
You should definitely be using fully-qualified namespaces for your classes, either using Microsoft's Type.registerNamespace if you're using their AJAX solution, by declaring your own namespace functions as per kekoav's post, or using a squillion other similar approaches that Google will offer. | Splitting code in to multiple files for easier management | [
"",
"javascript",
"jquery",
""
] |
If I have a local variable like so:
```
Increment()
{
int i = getFromDb(); // get count for a customer from db
};
```
And this is an instance class which gets incremented (each time a customer - an instance object - makes a purchase), is this variable thread safe? I hear that local variables are thread safe because each thread gets its own stack, etc etc.
Also, am I right in thinking that this variable is shared state? What I'm lacking in the thinking dept is that this variable will be working with different customer objects (e.g. John, Paul, etc) so is thread safe but this is flawed thinking and a bit of inexperience in concurrent programming. This sounds very naive, but then I don't have a lot of experience in concurrent coding like I do in general, synchronous coding.
EDIT: Also, the function call getFromDb() isn't part of the question and I don't expect anyone to guess on its thread safety as it's just a call to indicate the value is assigned from a function which gets data from the db. :)
EDIT 2: Also, getFromDb's thread safety is guaranteed as it only performs read operations. | `i` is declared as a local (method) variable, so it only **normally** exists in the stack-frame of `Increment()` - so yes, `i` is thread safe... (although I can't comment on `getFromDb`).
*except* if:
* `Increment` is an iterator block (i.e. uses `yield return` or `yield break`)
* `i` is used in an anonymous method ( `delegate { i = i + 1;}` ) or lambda (`foo => {i=i+foo;}`
In the above two scenarios, there are some cases when it can be exposed outside the stack. But I doubt you are doing either.
Note that *fields* (variables on the class) are **not** thread-safe, as they are trivially exposed to other threads. This is even more noticeable with `static` fields, since all threads automatically share the same field (except for thread-static fields). | Your statement has two separate parts - a function call, and an assignment.
The assignment is thread safe, because the variable is local. Every different invocation of this method will get its own version of the local variable, each stored in a different stack frame in a different place in memory.
The call to getFromDb() may or may not be threadsafe - depending on its implementation. | Thread safety and local variables | [
"",
"c#",
""
] |
I have a class containing a number of double values. This is stored in a vector where the indices for the classes are important (they are referenced from elsewhere). The class looks something like this:
## Vector of classes
```
class A
{
double count;
double val;
double sumA;
double sumB;
vector<double> sumVectorC;
vector<double> sumVectorD;
}
vector<A> classes(10000);
```
The code that needs to run as fast as possible is something like this:
```
vector<double> result(classes.size());
for(int i = 0; i < classes.size(); i++)
{
result[i] += classes[i].sumA;
vector<double>::iterator it = find(classes[i].sumVectorC.begin(), classes[i].sumVectorC.end(), testval);
if(it != classes[i].sumVectorC.end())
result[i] += *it;
}
```
The alternative is instead of one giant loop, split the computation into two separate loops such as:
```
for(int i = 0; i < classes.size(); i++)
{
result[i] += classes[i].sumA;
}
for(int i = 0; i < classes.size(); i++)
{
vector<double>::iterator it = find(classes[i].sumVectorC.begin(), classes[i].sumVectorC.end(), testval);
if(it != classes[i].sumVectorC.end())
result[i] += *it;
}
```
or to store each member of the class in a vector like so:
## Class of vectors
```
vector<double> classCounts;
vector<double> classVal;
...
vector<vector<double> > classSumVectorC;
...
```
and then operate as:
```
for(int i = 0; i < classes.size(); i++)
{
result[i] += classCounts[i];
...
}
```
Which way would usually be faster (across x86/x64 platforms and compilers)? Are look-ahead and cache lines are the most important things to think about here?
## Update
The reason I'm doing a linear search (i.e. find) here and not a hash map or binary search is because the sumVectors are very short, around 4 or 5 elements. Profiling showed a hash map was slower and a binary search was slightly slower. | As lothar says, you really should test it out. But to answer your last question, yes, cache misses will be a major concern here.
Also, it seems that your first implementation would run into load-hit-store stalls as coded, but I'm not sure how much of a problem that is on x86 (it's a big problem on XBox 360 and PS3). | As the implementation of both variants seems easy enough I would build both versions and profile them to find the fastest one.
Empirical data usually beats speculation. | Performance: vector of classes or a class containing vectors | [
"",
"c++",
"performance",
"arrays",
"stl",
""
] |
I would like to get to query Windows Vista Search service directly ( or indirectly ) from Java.
I know it is possible to query using the search-ms: protocol, but I would like to consume the result within the app.
I have found good information in the [Windows Search API](http://msdn.microsoft.com/en-us/library/aa906096.aspx) but none related to Java.
I would mark as accepted the answer that provides useful and definitive information on how to achieve this.
Thanks in advance.
**EDIT**
Does anyone have a JACOB sample, before I can mark this as accepted?
:) | You may want to look at one of the Java-COM integration technologies. I have personally worked with JACOB (JAva COm Bridge):
* <http://danadler.com/jacob/>
Which was rather cumbersome (think working exclusively with reflection), but got the job done for me (quick proof of concept, accessing MapPoint from within Java).
The only other such technology I'm aware of is Jawin, but I don't have any personal experience with it:
* <http://jawinproject.sourceforge.net/>
**Update 04/26/2009:**
Just for the heck of it, I did more research into Microsoft Windows Search, and found an easy way to integrate with it using OLE DB. Here's some code I wrote as a proof of concept:
```
public static void main(String[] args) {
DispatchPtr connection = null;
DispatchPtr results = null;
try {
Ole32.CoInitialize();
connection = new DispatchPtr("ADODB.Connection");
connection.invoke("Open",
"Provider=Search.CollatorDSO;" +
"Extended Properties='Application=Windows';");
results = (DispatchPtr)connection.invoke("Execute",
"select System.Title, System.Comment, System.ItemName, System.ItemUrl, System.FileExtension, System.ItemDate, System.MimeType " +
"from SystemIndex " +
"where contains('Foo')");
int count = 0;
while(!((Boolean)results.get("EOF")).booleanValue()) {
++ count;
DispatchPtr fields = (DispatchPtr)results.get("Fields");
int numFields = ((Integer)fields.get("Count")).intValue();
for (int i = 0; i < numFields; ++ i) {
DispatchPtr item =
(DispatchPtr)fields.get("Item", new Integer(i));
System.out.println(
item.get("Name") + ": " + item.get("Value"));
}
System.out.println();
results.invoke("MoveNext");
}
System.out.println("\nCount:" + count);
} catch (COMException e) {
e.printStackTrace();
} finally {
try {
results.invoke("Close");
} catch (COMException e) {
e.printStackTrace();
}
try {
connection.invoke("Close");
} catch (COMException e) {
e.printStackTrace();
}
try {
Ole32.CoUninitialize();
} catch (COMException e) {
e.printStackTrace();
}
}
}
```
To compile this, you'll need to make sure that the JAWIN JAR is in your classpath, and that jawin.dll is in your path (or java.library.path system property). This code simply opens an ADO connection to the local Windows Desktop Search index, queries for documents with the keyword "Foo," and print out a few key properties on the resultant documents.
Let me know if you have any questions, or need me to clarify anything.
**Update 04/27/2009:**
I tried implementing the same thing in JACOB as well, and will be doing some benchmarks to compare performance differences between the two. I may be doing something wrong in JACOB, but it seems to consistently be using 10x more memory. I'll be working on a jcom and com4j implementation as well, if I have some time, and try to figure out some quirks that I believe are due to the lack of thread safety somewhere. I may even try a JNI based solution. I expect to be done with everything in 6-8 weeks.
**Update 04/28/2009:**
This is just an update for those who've been following and curious. Turns out there are no threading issues, I just needed to explicitly close my database resources, since the OLE DB connections are presumably pooled at the OS level (I probably should have closed the connections anyway...). I don't think I'll be any further updates to this. Let me know if anyone runs into any problems with this.
**Update 05/01/2009:**
Added JACOB example per Oscar's request. This goes through the exact same sequence of calls from a COM perspective, just using JACOB. While it's true JACOB has been much more actively worked on in recent times, I also notice that it's quite a memory hog (uses 10x as much memory as the Jawin version)
```
public static void main(String[] args) {
Dispatch connection = null;
Dispatch results = null;
try {
connection = new Dispatch("ADODB.Connection");
Dispatch.call(connection, "Open",
"Provider=Search.CollatorDSO;Extended Properties='Application=Windows';");
results = Dispatch.call(connection, "Execute",
"select System.Title, System.Comment, System.ItemName, System.ItemUrl, System.FileExtension, System.ItemDate, System.MimeType " +
"from SystemIndex " +
"where contains('Foo')").toDispatch();
int count = 0;
while(!Dispatch.get(results, "EOF").getBoolean()) {
++ count;
Dispatch fields = Dispatch.get(results, "Fields").toDispatch();
int numFields = Dispatch.get(fields, "Count").getInt();
for (int i = 0; i < numFields; ++ i) {
Dispatch item =
Dispatch.call(fields, "Item", new Integer(i)).
toDispatch();
System.out.println(
Dispatch.get(item, "Name") + ": " +
Dispatch.get(item, "Value"));
}
System.out.println();
Dispatch.call(results, "MoveNext");
}
} finally {
try {
Dispatch.call(results, "Close");
} catch (JacobException e) {
e.printStackTrace();
}
try {
Dispatch.call(connection, "Close");
} catch (JacobException e) {
e.printStackTrace();
}
}
}
``` | As few posts here suggest you can bridge between Java and .NET or COM using commercial or free frameworks like JACOB, JNBridge, J-Integra etc..
Actually I had an experience with with one of these third parties (an expensive one :-) ) and I must say I will do my best to avoid repeating this mistake in the future. The reason is that it involves many "voodoo" stuff you can't really debug, it's very complicated to understand what is the problem when things go wrong.
The solution I would suggest you to implement is to create a simple .NET application that makes the actual calls to the windows search API. After doing so, you need to establish a communication channel between this component and your Java code. This can be done in various ways, for example by messaging to a small DB that your application will periodically pull. Or registering this component on the machine IIS (if exists) and expose simple WS API to communicate with it.
I know that it may sound cumbersome but the clear advantages are: a) you communicate with windows search API using the language it understands (.NET or COM) , b) you control all the application paths. | Query Windows Search from Java | [
"",
"java",
"windows-search",
""
] |
If I have a parametrized stored procedure which takes a varchar(10) value and converts it to an int, I currently have to ensure that the value is not greater than the varchar equivalent of the maximum int value.
```
IF @Criteria <= '2147483647'
SET @Id = CONVERT(int, @Criteria)
```
My question: Is there a better way to prevent overflowing an int column when converting from a varchar value?
Edit: Yes obviously if I felt that a the value was going to legitimately contain something close to the max value I could expand to BigInt. This is really meant to handle improper calls to this stored proc, and was just a general-purpose question about using Convert() in cases where the resulting value might overflow the desired data type. | To deal with the various conditions (spaces, decimals etc) wrap the convert in a TRY/CATCH if you can't clean on the client. Assumes SQL Server 2005
```
...
BEGIN TRY
SET @Id = CONVERT(int, @Criteria)
END TRY
BEGIN CATCH
SET @Id = NULL
END CATCH
...
``` | Your test won't work reliably.
If @Criteria contains '11111111111111111111', it sorts less than your magic number, because you are doing a string comparison. | Preventing Sql column overflows | [
"",
"sql",
"sql-server",
"database",
"stored-procedures",
""
] |
The **java.lang.System** class defines a number of [well-known properties](http://java.sun.com/j2se/1.5.0/docs/api/java/lang/System.html#getProperties()).
For example, you can obtain the JVM's temporary directory by looking up the "java.io.tmpdir" property:
```
... = System.getProperty("java.io.tmpdir");
```
What I don't understand is why these properties aren't defined as constants (e.g. in the java.lang.System class). This would be a lot less error-prone than using literal Strings. In other words, I would like to be able to do this:
```
... = System.getProperty(System.JAVA_IO_TMPDIR);
```
Any ideas why this wasn't done? It could even be added in a future release of Java without breaking backward compatibility. Or am I missing something obvious? | All the properties documented under [System.getProperties()](http://java.sun.com/javase/6/docs/api/java/lang/System.html#getProperties() "System.getProperties()") are standardised - every Java SE implementation must provide them. There is no reason that Java 7 could not introduce constants for these standard property names. It would not prevent the introduction of new properties. I think it's just no one has thought it worth the effort (even trivial additions to core Java APIs have to go through processes I think). | My guess is that Sun did not want to commit to a predefined set of system properties. If they are not defined as contants they can add system properties at any time (even if they only release an incremental version of the JDK like from 1.4.1 to 1.4.2).
**Edit:**
Any predefined constants must be considered part of the API. Thus even changing the number of constants is an API change. By not defining any constants Sun is allowed to define new system properties without introducing an API change. | Why doesn't Java have constants for well-known system property names? | [
"",
"java",
"api",
"properties",
"constants",
""
] |
im trying to change the text of a label from a class but have been unsuccessful.
what i have is that im updating a variable in the class using get{} and set{}. i understand that i need to put or do something within set{} to get it to send the update value from the class back into the form1 class so that it can update the label.
could anyone tell me how i could accomplish this? or if there is a way to update the label from within the class, that would be even better.
i hope this makes sense and thanks in advance. | You might want to consider using delegates or events and having your classes raise events back to the form, that way your classes will have no knowledge of your form.
**EXAMPLE**
```
class SomeClass
{
public delegate void UpdateLabel(string value);
public event UpdateLabel OnLabelUpdate;
public void Process()
{
if (OnLabelUpdate != null)
{
OnLabelUpdate("hello");
}
}
}
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void UpdateLabelButton_Click(object sender, EventArgs e)
{
SomeClass updater = new SomeClass();
updater.OnLabelUpdate += new SomeClass.UpdateLabel(updater_OnLabelUpdate);
updater.Process();
}
void updater_OnLabelUpdate(string value)
{
this.LabelToUpdateLabel.Text = value;
}
}
``` | If I understand your question, you have a form class, "form1". An instance of that class is being displayed. That form has a label on it. You are running a method in a different class. You want that method to update the label that's on form1.
If that is correct, then, this is just like any other situation where a method needs to change a property of another class instance. Your method in the other class needs a reference to the form instance. When you call your method, instead of doing this:
```
OtherClass oc = new OtherClass();
oc.OtherMethod();
```
do this:
```
OtherClass oc = new OtherClass();
oc.OtherMethod(this);
```
Change the definition of Othermethod:
```
public void Othermethod(form1 theForm) {
theForm.TheLabel.Text = "New Text!";
}
```
Then everything should be happy! | C#: How can i change the text of a label thats in form1 from another class? | [
"",
"c#",
"visual-studio-2008",
""
] |
In JavaScript, it doesn't seem to matter whether you use single quotes or double quotes when writing strings. However, some programming languages treat them differently.
Is one more reliable than the other across multiple programming languages? Are there any pros or cons using one rather than the other (apart from when apostrophes or quotes are in the string)?
I would like to choose one and then be able to use it across multiple programming languages—with it meaning the same thing (if that's possible). | In a lot of scripting and shell languages, there is a significant difference between double and single quotes. For example, in Perl and a lot of Unix shells, when you use double quotes, the interpreter will parse through your string and try to do any substitutions for any variables in the string. If you use single quotes, the interpreter will not try to do anything fancy with the string; it will treat it as a plain literal.
In other languages like C++ or Java, double quotes are used for strings, and single for single character literals.
Every language might treat quotes differently. I think in Javascript it might not matter which one you use, but it would be best to do some research on the best practices, then just pick one methodology and be consistent. I've seen some examples where the person chose to use double quotes in HTML and single in Javascript, but I'm not sure if that's the "standard." | The meaning is completely dependent on the language you are using, so what you want is not possible. | Should I use double-quotes or single-quotes for quoting strings if I want to be consistent across multiple languages? | [
"",
"javascript",
"programming-languages",
"syntax",
""
] |
I have an HTML layout based on tabs (say 5).
In each tab I load an iframe. The iframe contents are variations of one another that the user can compare by switching tabs.
How can I, in javascript, synchronize the scrolling of all iframes vertically and horizontally?
In other words, scrolling in one iframe should scroll by the same amount all other iframes, allowing the user to compare the same data.
Bonus points: iframe content is loaded only when the user opens the tab for the first time. So newly opened iframes should directly scroll to the same place as already opened iframes.
Thanks. | While this works for divs, it does not work for iframes.
Here's what you can do,
```
$($('#iframe1').contents()).scroll(function(){
$($('#iframe2').contents()).scrollTop($(this).scrollTop());
});
```
With [jQuery's scroll event](http://docs.jquery.com/Events/scroll), you should be able to synchronize them.
**Edit**: No plugins required. Here's the code that worked for me:
```
<html>
<head>
<SCRIPT language="javascript" type="text/javascript" src="jquery-1.3.2.js"></SCRIPT>
<SCRIPT>
$(document).ready(function()
{
$("#div1").scroll(function () {
$("#div2").scrollTop($("#div1").scrollTop());
$("#div2").scrollLeft($("#div1").scrollLeft());
});
$("#div2").scroll(function () {
$("#div1").scrollTop($("#div2").scrollTop());
$("#div1").scrollLeft($("#div2").scrollLeft());
});
});
</SCRIPT>
</head>
<body>
<div id="div1" style="overflow:auto;height:100px;width:200px;border:1px solid black;">
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
</div>
<div id="div2" style="overflow:auto;height:100px;width:200px;border:1px solid black;">
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
Test..................................................................................................................................................................................................................................................................................test
<BR/><BR/>
</div>
</body>
</html>
``` | I synchronize overflowed div's using code like this:
```
frame1.onscroll = function(e) {
frame2.scrollTop = frame1.scrollTop;
frame2.scrollLeft = frame1.scrollLeft;
};
``` | How to synchronize scrolling positions for several iframes | [
"",
"javascript",
"html",
"iframe",
""
] |
I'm using [WMI to start a process on a remote machine](https://stackoverflow.com/questions/677867/run-application-or-process-on-a-remote-computer). The call to create the process returns immediately and I also get the id of the process on the remote machine.
I would like to wait for the remote process to be completed. One option would be to poll whether a process on the remote machine with the given id still exists.
However, I was wondering whether there is a better way to achieve this, maybe using native WinAPI functions?
Just for additional information, this is the code that I am currently using to start the remote process:
```
ConnectionOptions connOptions = new ConnectionOptions();
connOptions.Impersonation = ImpersonationLevel.Impersonate;
connOptions.EnablePrivileges = true;
connOptions.Username = domainUserName;
connOptions.Password = password;
ManagementScope manScope = new ManagementScope(String.Format(@"\\{0}\ROOT\CIMV2", host), connOptions);
manScope.Connect();
ObjectGetOptions objectGetOptions = new ObjectGetOptions();
ManagementPath managementPath = new ManagementPath("Win32_Process");
ManagementClass processClass = new ManagementClass(manScope, managementPath, objectGetOptions);
ManagementBaseObject inParams = processClass.GetMethodParameters("Create");
inParams["CommandLine"] = commandLine;
ManagementBaseObject outParams = processClass.InvokeMethod("Create", inParams, null);
``` | I don't know how effective this can be, you can use [ManagementEventWatcher](http://msdn.microsoft.com/en-us/library/system.management.managementeventwatcher.aspx) to watch a query.
Here is something I found on the net.
```
WqlEventQuery wQuery =
new WqlEventQuery("Select * From __InstanceDeletionEvent Within 1 Where TargetInstance ISA 'Win32_Process'");
using (ManagementEventWatcher wWatcher = new ManagementEventWatcher(scope, wQuery))
{
bool stopped = false;
while (stopped == false)
{
using (ManagementBaseObject MBOobj = wWatcher.WaitForNextEvent())
{
if (((ManagementBaseObject)MBOobj["TargetInstance"])["ProcessID"].ToString() == ProcID)
{
// the process has stopped
stopped = true;
}
}
}
wWatcher.Stop();
}
``` | The native Win32 way of achieving this would be to perform a `WaitForSingleObject()` on the process handle returned by `CreateProcess()`, however I don't think this handle is made available to you from WMI.
[This article](http://www.microsoft.com/technet/scriptcenter/resources/qanda/dec06/hey1208.mspx) offers another option you could consider - instead of polling the process list and waiting for your process to disappear, it repeatedly queries for process deletion events matching your process ID:
```
strComputer = "."
Set objWMIService = GetObject("winmgmts:\\" & strComputer & "\root\cimv2:Win32_Process")
objWMIService.Create "notepad.exe", null, null, intProcessID
Set objWMIService = GetObject("winmgmts:\\" & strComputer & "\root\cimv2")
Set colMonitoredProcesses = objWMIService.ExecNotificationQuery _
("Select * From __InstanceDeletionEvent Within 1 Where TargetInstance ISA 'Win32_Process'")
Do Until i = 1
Set objLatestProcess = colMonitoredProcesses.NextEvent
If objLatestProcess.TargetInstance.ProcessID = intProcessID Then
i = 1
End If
Loop
```
---
You could also improve on this by using a `ManagementEventWatcher` object and its `WaitForNextEvent` method to avoid having to poll for the deletion events. | WaitForExit for a process on a remote computer | [
"",
"c#",
"process",
""
] |
I'm trying to build a regular expression that will detect any character that Windows does not accept as part of a file name (are these the same for other OS? I don't know, to be honest).
These symbols are:
```
\ / : * ? " |
```
Anyway, this is what I have: `[\\/:*?\"<>|]`
The tester over at <http://gskinner.com/RegExr/> shows this to be working.
For the string `Allo*ha`, the `*` symbol lights up, signalling it's been found. Should I enter `Allo**ha` however, only the first `*` will light up. So I think I need to modify this regex to find all appearances of the mentioned characters, but I'm not sure.
You see, in Java, I'm lucky enough to have the function [String.replaceAll(String regex, String replacement)](http://java.sun.com/javase/6/docs/api/java/lang/String.html#replaceAll%28java.lang.String,%20java.lang.String%29).
The description says:
> Replaces each substring of this string that matches the given regular expression with the given replacement.
So in other words, even if the regex only finds the first and then stops searching, this function will still find them all.
For instance: `String.replaceAll("[\\/:*?\"<>|]","")`
However, I don't feel like I can take that risk. So does anybody know how I can extend this? | Windows filename rules are *tricky*. You're only scratching the surface.
For example here are some things that are not valid filenames, in addition to the chracters you listed:
```
(yes, that's an empty string)
.
.a
a.
a (that's a leading space)
a (or a trailing space)
com
prn.txt
[anything over 240 characters]
[any control characters]
[any non-ASCII chracters that don't fit in the system codepage,
if the filesystem is FAT32]
```
Removing special characters in a single regex sub like String.replaceAll() isn't enough; you can easily end up with something invalid like an empty string or trailing ‘.’ or ‘ ’. Replacing something like “[^A-Za-z0-9\_.]\*” with ‘\_’ would be a better first step. But you will still need higher-level processing on whatever platform you're using. | since no answer was good enough i did it myself. hope this helps ;)
```
public static boolean validateFileName(String fileName) {
return fileName.matches("^[^.\\\\/:*?\"<>|]?[^\\\\/:*?\"<>|]*")
&& getValidFileName(fileName).length()>0;
}
public static String getValidFileName(String fileName) {
String newFileName = fileName.replace("^\\.+", "").replaceAll("[\\\\/:*?\"<>|]", "");
if(newFileName.length()==0)
throw new IllegalStateException(
"File Name " + fileName + " results in a empty fileName!");
return newFileName;
}
``` | Regex to replace characters that Windows doesn't accept in a filename | [
"",
"java",
"regex",
""
] |
I have a thread in which I catch all errors in a big, all-encompassing catch block. I do this so that I can report any error, not just expected ones, in my application. My Runnable looks like this:
```
public final void run()
{
try
{
System.out.println("Do things"); /* [1] */
doUnsafeThings();
}
catch (Throwable t)
{
System.out.println("Catch"); /* [2] */
recover();
}
finally
{
System.out.println("Finally"); /* [3] */
}
}
```
I would expect the NPE to be caught by the Throwable catch block. Instead, the output at [2] is not printed, and neither is [3]. The output at [1] is printed.
What I do get on the console, is this:
```
Uncaught exception java/lang/NullPointerException.
```
What on earth is going on here?
For the court records, I'm using J2ME, and this is running in Sun's WTK v2.5.2 emulator.
I'm tempted to put it down to JVM implementation dodginess but I can't help feeling that I'm just missing something.
To clarify for the avoidance of doubt (Since the example code is obviously altered from my production code)
* There is nothing outside of the try/catch/finally block in the run method.
* There is a System.out.println at the start of each of those blocks - What follows those console statements should not matter. | The answer turns out that I'm an idiot. I'd explain what went wrong, but let's just call it "one of those bugs".
I had momentarily forgotten that the thread that ran the runnable was a custom thread class (To get round some Nokia bugs). It called `run()` repeatedly between calls to a `canWait()` method.
The canWait method was responsible for the failure, and run wasn't failing at all. To top it off, I have console-blindness and completely but accidentally misquoted the sequence of events in my question. | Sounds like you'll need some trial and error. May I suggest:
```
try {
doEvilStuff();
} catch (NullPointerException ex) {
System.out.println("NPE encountered in body");
} catch (Throwable ex) {
System.out.println("Regular Throwable: " + ex.getMessage());
} finally {
etc...
}
```
By having an explicit catch for NullPointerException, it should become obvious if the exception is from within the try block or a catch/finally block. | Why is my NullPointerException not being caught in my catch block? | [
"",
"java",
"exception",
"java-me",
"try-catch",
"java-wireless-toolkit",
""
] |
Can anyone conjure from this code why the ItemsSource line would be getting a
> **Items collection must be empty before**
> **using ItemsSource.**
error? Most solutions I've found point to ill-composed XAML, e.g. an extra element etc. which I don't seem to have. When I take out
> ItemsSource="{Binding Customers}"
it runs without an error (but of course doesn't display my list of customers).
Customers is defines thusly in the ViewModel and has 3 CustomerViewModels in it:
```
Customer[] customers = Customer.GetCustomers();
IEnumerable<CustomerViewModel> customersViewModels = customers.Select(c => new CustomerViewModel(c));
this.Customers = new ReadOnlyCollection<CustomerViewModel>(customersViewModels.ToArray());
```
**Any suggestions of where to look?**
```
<UserControl x:Class="TestCommandSink123.View.CustomersView"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:local="clr-namespace:TestCommandSink123"
xmlns:view="clr-namespace:TestCommandSink123.View"
xmlns:vm="clr-namespace:TestCommandSink123.ViewModel"
xmlns:sink="clr-namespace:TestCommandSink123.CommandSinkClasses"
sink:CommandSinkBinding.CommandSink="{Binding}"
>
<UserControl.CommandBindings>
<sink:CommandSinkBinding Command="vm:CustomersViewModel.CloseAllCustomersCommand"/>
</UserControl.CommandBindings>
<DockPanel>
<ItemsControl
DockPanel.Dock="Bottom" ItemsSource="{Binding Customers}">
<ItemsControl.ItemTemplate>
<DataTemplate>
<view:CustomerView/>
</DataTemplate>
</ItemsControl.ItemTemplate>
<Button
Command="vm:CustomersViewModel.CloseAllCustomersCommand"
Content="Close All"
Margin="0,0,0,8"
/>
</ItemsControl>
</DockPanel>
</UserControl>
```
# ANSWER:
I did indeed have malformed XAML, just overlooked it, **the Button should be outside the ItemsControl**:
```
<ItemsControl
DockPanel.Dock="Bottom" ItemsSource="{Binding Customers}">
<ItemsControl.ItemTemplate>
<DataTemplate>
<view:CustomerView/>
</DataTemplate>
</ItemsControl.ItemTemplate>
</ItemsControl>
<Button
Command="vm:CustomersViewModel.CloseAllCustomersCommand"
Content="Close All"
Margin="0,0,0,8"
/>
``` | You are trying to set the ItemsSource of the ItemsControl but you already have children. Which of those two should apply? The Button you put inside the ItemsControl or the collection you are handing into it as ItemsSource? The error message is perfectly reasonable.
You would have to either remove the button from the ItemsControl or remove the ItemsSource attribute. You can't insert items and set ItemsSource at the same time. | Your ItemsControl has a Button in it. Since there's already an item in the ItemsControl, it's not letting you set its ItemsSource property.
Move the Button declaration down under the `</ItemsControl>` closing tag. | Why is this XAML getting the error: Items collection must be empty before using ItemsSource | [
"",
"c#",
"wpf",
"mvvm",
""
] |
Let's say I have this base class:
```
abstract public class Base {
abstract public Map save();
abstract public void load(Map data);
}
```
to my surprise I could do this in a derived class:
```
public class Derived extends Base {
@Override
public Map<String, String> save() { //Works
...
}
...
}
```
but I couldn't do this:
```
public class Derived extends Base {
@Override
public void load(Map<String, String> data) { // Fails
...
}
...
}
```
What is happening here? Why can I use a specialized return type but not a specialized parameter type?
What's even more confusing is that if I keep the original declaration of `load`, I can just assign it to the more special type:
```
public class Derived extends Base {
@Override
public void load(Map data) {
Map<String, String> myData = data; // Works without further casting
...
}
...
}
``` | There's an implicit conversion from the specialized type to the raw type - that's always "safe" because someone using the raw type can't make any assumptions. So someone expecting to get a raw `Map` back from a method doesn't mind if they get a `Map<String, String>`.
There *isn't* an implicit conversion from the raw type to the specialized type - if someone passes a raw `Map` into `load` it may have non-string keys and values. That's completely legal by the base type declaration of `load`.
Leaving generics aside, your methods are a bit like this:
```
public abstract class Base
{
public abstract Object save();
public abstract void load(Object x);
}
public class Derived extends Base
{
@Override
public String save() { ... } // Valid
@Override
public void load(String x) // Not valid
}
```
With the generics removed, is it clear why the `save` call is okay here, but the `load` call isn't? Consider this:
```
Base b = new Derived();
Object x = b.save(); // Fine - it might return a string
b.load (new Integer(0)); // Has to compile - but the override wouldn't work!
``` | You can't change the parameters to `load(Map<String, String> data)` because you could easily violate this if you used the base class instead of the specialized class like so:
```
Base base = new Derived()
base.load(new HashMap<Integer, Integer>());
```
This would call the load-method of derived but in violation to the declaration. Because generics are only checked at compile-time it wouldn't be possible to detect that error.
Return values are no problem as long as they are more specialized in subclasses than in superclasses. | Why can derived classes only sometimes have specialized types in overridden methods? | [
"",
"java",
"polymorphism",
""
] |
In Javascript, you can extend existing classes by using its prototype object:
```
String.prototype.getFirstLetter = function() {
return this[0];
};
```
Is it possible to use this method to extend DOM elements? | you can extend the DOM by using the Element's prototype. However, this does not work in IE7 and earlier. You will need to extend the specific element, one at a time. The Prototype library does this. I recommend looking through the [source](http://prototypejs.org/assets/2008/9/29/prototype-1.6.0.3.js) to see exactly how it's done. | I found the answer just as I was writing the question, but thought I'd post anyway to share the info.
The object you need to extend is `Element.prototype`.
```
Element.prototype.getMyId = function() {
return this.id;
};
``` | In Javascript, can you extend the DOM? | [
"",
"javascript",
"dom",
""
] |
How can I pass a arbitrary number of arguments to the class constructor using the Object() function defined below?
```
<?php
/*
./index.php
*/
function Object($object)
{
static $instance = array();
if (is_file('./' . $object . '.php') === true)
{
$class = basename($object);
if (array_key_exists($class, $instance) === false)
{
if (class_exists($class, false) === false)
{
require('./' . $object . '.php');
}
/*
How can I pass custom arguments, using the
func_get_args() function to the class constructor?
$instance[$class] = new $class(func_get_arg(1), func_get_arg(2), ...);
*/
$instance[$class] = new $class();
}
return $instance[$class];
}
return false;
}
/*
How do I make this work?
*/
Object('libraries/DB', 'DATABASE', 'USERNAME', 'PASSWORD')->Query(/* Some Query */);
/*
./libraries/DB.php
*/
class DB
{
public function __construct($database, $username, $password, $host = 'localhost', $port = 3306)
{
// do stuff here
}
}
?>
``` | ```
$klass = new ReflectionClass($classname);
$thing = $klass->newInstanceArgs($args);
```
Although the need to use reflection suggests that you are overcomplicating something in your design. Why do you want to write this function in the first place? | Instead of your class taking separated parameters I'd have it take an array.
```
class DB
{
public function __construct(array $params)
{
// do stuff here
}
}
```
That way you can pass the direct result of the func\_get\_args into your constructor. The only problem now is being able to figure out the array key / values.
If anyone else has any ideas I'd also be delighted to know :) | Passing arguments to the Class Constructor | [
"",
"php",
"class",
"object",
""
] |
I have a lot of JavaScript/ jQuery code blocks to handle asynchronous
data processing in my page. Each code block has three functions (code is incomplete and for illustrative purpose only):
1. encapsulates `$.ajax` call:
```
function doSomething(data){
// do some preprocessing
$.ajax({}); // some JQuery Ajax operation that accepts data
// do some postprocessing
return false;
}
```
2. handles the response:
```
function handleResponse(result){
// process the result
return false;
}
```
3. handles any error:
```
function handleError(XMLHttpRequest, textStatus, errorThrown){
// gracefully handle the Error and present relevant information to user
return false;
}
```
In a page that requires a lot of data processing I end up having a lot
of these blocks which seems to be duplication, so I decided to do some
refactoring.
I figure there would be different ways to go about this.
1. One could have one error handler that can be reused across Ajax calls (obvious).
2. One could maybe reuse some response handlers, but this would be akward as responses are very different depending on call.
3. Maybe create some kind of prototype object that provides base functionality and have a static method for error handling (can this be done in JavaScript?).
I was just wondering if anyone has come across this and/or if there is a best practice solution for this? | You can use the $.ajaxSetup({}) method in jQuery to setup some common ajax settings.
For instance, if you are going to be posting to the same URL over and over again on some page, you can just set that in the ajaxSetup. This would mean you would have to pass less parameters to a function like what Richard provided. Any property of the ajax method's first parameter can be set as a default in $.ajaxSetup().
```
$.ajaxSetup({
url: 'my/ajax/url'
success: function() {
// Do some default stuff on success
},
error: function() {
// Do some default stuff on a failure
}
// etc...
});
```
They can be overridden in any ajax call. So, now you can just do:
```
$.ajax({data:{foo:'bar',bar:'foo'}});
```
And you can override the URL, for instance like this:
```
$.ajax({url:'different/ajax/url',data:{foo:'bar',bar:'foo'}});
``` | We have often used a wrapper function for the Ajax call in order to simplify the usage so you could do this:
```
function NewAjax(url, data, success)
{
$.ajax({
url: url,
data: data,
success: success,
fail: function ()
{
// Do generic failure handling here
}
}
```
But I often prefer to bind to every ajax event using the jQuery ajax events:
<http://docs.jquery.com/Ajax>
so you could bind to every failure or success of every ajax call such as:
ajaxError( callback )
ajaxSuccess( callback ) | Refactoring many jQuery Ajax calls - best practice? | [
"",
"javascript",
"jquery",
"ajax",
""
] |
I want to have a JSON object with the value of an attribute as a string with the character `"`.
For example:
```
{
"Dimensions" : " 12.0" x 9.6" "
}
```
Obviously this is not possible. How do I do this?
With Python. | Isaac is correct.
As for how to do it in python, you need to provide a more detailed explanation of how you are building your `JSON` object. For example, let's say you're using no external libraries and are doing it manually (ridiculous, I know), you would do this:
```
>>> string = "{ \"Dimensions\" : \" 12.0\\\" x 9.6\\\" \" }"
>>> print string
{ "Dimensions" : " 12.0\" x 9.6\" " }
```
Obviously this is kind of silly. If you are using the standard python json module, try this:
```
from json import JSONEncoder
encoder = JSONEncoder()
string = encoder.encode({ "Dimensions":" 12.0\" x 9.6\" " })
>>> print string
{"Dimensions": " 12.0\" x 9.6\" "}
```
which is the desired result. | Python has two symbols you can use to specify string literals, the single quote and the double quote.
For example:
my\_string = "I'm home!"
Or, more relevant to you,
```
>>> string = '{ "Dimensions" : " 12.0\\\" x 9.6\\\" " }'
>>> print string
{ "Dimensions" : " 12.0\" x 9.6\" " }
```
You can also prefix the string with 'r' to specify it is a raw string, so backslash escaped sequences are not processed, making it cleaner.
```
>>> string = r'{ "Dimensions" : " 12.0\" x 9.6\" " }'
>>> print string
{ "Dimensions" : " 12.0\" x 9.6\" " }
``` | How do I store a string with a `"` in it? | [
"",
"python",
"json",
""
] |
I was changing my for loop to increment using `++i` instead of `i++` and got to thinking, is this really necessary anymore? Surely today's compilers do this optimization on their own.
In this article, <http://leto.net/docs/C-optimization.php>, from 1997 Michael Lee goes into other optimizations such as inlining, loop unrolling, loop jamming, loop inversion, strength reduction, and many others. Are these still relevant?
**What low level code optimizations should we be doing, and what optimizations can we safely ignore?**
Edit: This has nothing to do with premature optimization. **The decision to optimize has already been made.** Now the question is what is the most effective way to do it.
anecdote: I once reviewed a requirements spec that stated: "The programmer shall left shift by one instead of multiplying by 2". | If there is no cost to the optimization, do it. When writing the code, `++i` is just as easy to write as `i++`, so prefer the former. There is no cost to it.
On the other hand, going back and making this change *afterwards* takes time, and it most likely won't make a noticeable difference, so you probably shouldn't bother with it.
But yes, it can make a difference. On built-in types, probably not, but for complex classes, the compiler is unlikely to be able to optimize it away. The reason for this is that the increment operation no is no longer an intrinsic operation, built into the compiler, but a function defined in the class. The compiler may be able to optimize it like any other function, but it can not, in general, assume that pre-increment can be used instead of post-increment. The two functions may do entirely different things.
So when determining which optimizations can be done by the compiler, consider whether it has enough information to perform it. In this case, the compiler doesn't know that post-increment and pre-increment perform the same modifications to the object, so it can not assume that one can be replaced with the other. But you have this knowledge, so you can safely perform the optimization.
Many of the others you mention can usually be done very efficiently by the compiler:
Inlining can be done by the compiler, and it's usually better at it than you. All it needs to know is how large a proportion of the function consists of function call over head, and how often is it called? A big function that is called often probably shouldn't be inlined, because you end up copying a lot of code, resulting in a larger executable, and more instruction cache misses. Inlining is always a tradeoff, and often, the compiler is better at weighing all the factors than you.
Loop unrolling is a purely mechanic operation, and the compiler can do that easily. Same goes for strength reduction. Swapping inner and outer loops is trickier, because the compiler has to prove that the changed order of traversal won't affect the result, which is difficult to do automatically. So here is an optimization you should do yourself.
But even in the simple ones that the compiler is able to do, you sometimes have information your compiler doesn't. If you know that a function is going to be called extremely often, even if it's only called from one place, it may be worth checking whether the compiler automatically inlines it, and do it manually if not.
Sometimes you may know more about a loop than the compiler as well (for example, that the number of iterations will always be a multiple of 4, so you can safely unroll it 4 times). The compiler may not have this information, so if it were to inline the loop, it would have to insert an epilog to ensure that the last few iterations get performed correctly.
So such "small-scale" optimizations can still be necessary, if 1) you actually need the performance, and 2) you have information that the compiler doesn't.
You can't outperform the compiler on purely mechanical optimizations. But you may be able to make assumptions that the compiler can't, and *that* is when you're able to optimize better than the compiler. | This is a well-worn subject, and SO contains oodles of good and bad advice on it.
Let me just tell you what I have found from much experience doing performance tuning.
There are tradeoff curves between performance and other things like memory and clarity, right? And you would expect that to get better performance you would have to give something up, right?
That is only true if the program is *on the tradeoff curve*. Most software, as first written, is *miles away from the tradeoff curve*. Most of the time, it is irrelevant and ignorant to talk about giving up one thing to get another.
The method I use is not measurement, it is [diagnosis](https://stackoverflow.com/questions/375913/what-can-i-use-to-profile-c-code-in-linux/378024#378024). I don't care how fast various routines are or how often they are called. I want to know precisely which instructions are causing slowness, and *why*.
The dominant and primary cause of poor performance in good-sized software efforts (not little one-person projects) is ***galloping generality***. Too many layers of abstraction are employed, each of which extracts a performance penalty. This is not usually a problem - until it is a problem - and then it's a killer.
So what I do is tackle one issue at a time. I call these "slugs", short for "slowness bugs". Each slug that I remove yields a speedup of anywhere from 1.1x to 10x, depending on how bad it is. Every slug that is removed makes the remaining ones take a larger fraction of the remaining time, so they become easier to find. In this way, all the "low-hanging fruit" can be quickly disposed of.
At that point, I know what is costing the time, but the fixes may be more difficult, such as partial redesign of the software, possibly by removing extraneous data structure or using code generation. If it is possible to do this, that can set off a new round of slug-removal until the program is many times not only faster than it was to begin with, but smaller and clearer as well.
I recommend getting experience like this for yourself, because then when you design software you will know what *not* to do, and you will make better (and simpler) designs to begin with. At the same time, you will find yourself at odds with less experienced colleagues who can't begin thinking about a design without conjuring up a dozen classes.
ADDED: Now, to try to answer your question, low-level optimization should be done when diagnosis says you have a hot-spot (i.e. some code at the bottom of the call stack appears on enough call stack samples (10% or more) to be known to be costing significant time). AND if the hot-spot is in code you can edit. If you've got a hot-spot in "new", "delete", or string-compare, look higher up the stack for things to get rid of.
Hope that helps. | Should we still be optimizing "in the small"? | [
"",
"c++",
"c",
"optimization",
""
] |
Is there a way to use a namespace and then have it automatically use all sub namespaces?
Example:
```
namespace Root.Account
{
//code goes here
}
namespace Root.Orders
{
//code goes here
}
//New File:
using Root;
```
In order for me to use the code in Root.Account, I would need to add using Root.Account to my code.
I would like to be able to just say using Root and have it pick up any sub namespace classes for use.
If this makes sense, is this possible?
Thanks | No, there's nothing working that way *down* the tree. However, you don't need to include using directives to go *up* the tree. In other words, if you use:
```
namespace Root.Orders
{
// Code
}
```
then any types in `Root` are already visible. | No, `using` directive in C# [does not allow](http://msdn.microsoft.com/en-us/library/sf0df423(VS.80).aspx) this:
> Create a using directive to use the types in a namespace without having to specify the namespace. A using directive does not give you access to any namespaces that are nested in the namespace you specify.
VB.NET, however, [supports](http://msdn.microsoft.com/en-us/library/7f38zh8x(VS.71).aspx) somewhat closer behavior with `Imports` statement:
> The scope of the elements made available by an Imports statement depends on how specific you are when using the Imports statement. For example, if only a namespace is specified, all uniquely named members of that namespace, and members of modules within that namespace, are available without qualification. If both a namespace and the name of an element of that namespace are specified, only the members of that element are available without qualification.
That is, if you say
```
Imports Root
```
then you'll be able to just say `Orders.Whatever`. | Namespace and Sub Namespaces | [
"",
"c#",
"namespaces",
""
] |
I have been googling around looking for a advantages that one might gain in nesting classes. There are plenty of examples as to how to do this but none that I can find as to the reasons for declaring a class within another. I even consulted my newly arrived “Code Complete” but there was no mention there either. I can see the disadvantage of it being harder to read. | Usually, a nested class is only there to support the functionality of its container class, and has no viability on its own. For instance, it may serve to collect a larger number of parameters for initialization keeping the constructor of the main class manageable; or it may inherit to define a specialized collection that supports the main class.
Semantically, there's no difference to a separate class, but nesting sends a clear message that the class is not to be used on its own. | there are several design decision that ends with making a nested class:
* you want to make more explicit the relation between two class; a . name is more explicit that two classes in the same namespace
* context-dependent classes as top-level nested classes enclosed by the context-serving class makes this dependency clearer **"these things goes togheter"**
* avoids namespace pollution
* reduces the number of source files
so there are two principles behind nested classes: **dependency** and **better organization** | What reasons would there be for nesting classes | [
"",
"c#",
"oop",
""
] |
Is there a way to force a browser window to always be on top and in focus? I am working on a project that I need to have the browser window on top and in focus all the time except when closing the browser window. I have tried a few things through javascript, but have not had any success keeping the window in focus.
I am not trying to do this to be forceful to the user. I am working on a project to implement online testing and I don't want the user to be able to switch away to look up answers on the web. | You will need to install a windows application on the clients machine which will force the browser to be on top. This is the only way.
If you are using IE, you can open a Modal dialog which will always be on top and in focus but only while in that browser session, the user is free to switch applications.
Edit: If you are writing a testing application, you are honestly better off just putting a reasonable time limit on each question. trying to prevent them from looking up the answers is worthless. What if they have two machines side by side? What if they have their buddy next to them helping with the answers. You are going to have to go with the honor system on this one. | I commented on the question, but realized this is worth posting as an answer...
Find another solution. Think a little about it. If a user is off looking at answers in another window/tab/browser, what would be the side-effects of that? Detect those side-effects, and penalize/block in those cases.
For instance, you can detect the `blur` event on the `window` and then poll for activity (`focus`, `click`, `mousemove`, `keypress` and so on) to determine "idle" time for the user. If the user is "idle" long enough to have gone elsewhere to find an answer, they are more than likely "cheating". You can otherwise simply impose time constraints on questions, and skip those questions if the time allotted runs out.
You can't guarantee that your user is not "cheating". Either construct the "physical" rules of the test such that the chance of "cheating" is minimized, or construct the test itself so that "cheating" is less consequential. Do not try to circumvent in-built user protections in browsers that disallow users from operating their browser as they would any other application. | How do I force a browser window to always be on top and in focus | [
"",
"javascript",
"windows",
"web-applications",
"browser",
""
] |
We have taken on a site written in Zend framework. We didn't write the site and haven't use the Zend framework before so I'm interested in finding three things.
1. How do I add new views to the site, adding in a new folder to the application/views/scripts directory seems to do nothing
2. Are there any tutorials on how to add affiliate feeds and setups to a zend site that you can recomend?
3. Are there any good tutorials on learning the framework? So far all I've found is vast amounts of material that confuses me | to answer your questions in order:
1. You have to find the controller, that will emerge the view you want to add. There are two ways to get a view script rendered. The first one is a naming convention on the view script. The view has to be the same name as the action name of the controller. Like "indexAction" and index.phtml. The other way is to instanciate a view object within the controller and give a string with the view name at runtime. You may want to look at this excerpt:
$view = new Zend\_View();
$view->a = "Hay";
$view->b = "Bee";
$view->c = "Sea";
echo $view->render('someView.php');
which I took from <http://framework.zend.com/manual/en/zend.view.controllers.html#zend.view.controllers.render>
2. I don't think that I understand what you mean by "affiliate feed"... are you talking about advertising or is it more like content syndication?
3. The first thing you should read may be the Zend Framework Study Guide which you find here: <http://www.zend.com/community/downloads>. There are many tutorials an howtos out there but, this guide is made from Zend directly and should cover the main topics.
Regards,
Mario | Are you adding the appropriate Zend\_Controller as well? The [Zend\_Controller QuickStart](http://framework.zend.com/manual/en/zend.controller.html#zend.controller.quickstart.go) is a good place to get started with MVC.
You might also look at [Zend\_Tool](http://framework.zend.com/manual/en/zend.tool.project.html "Zend_Tool"), which provides a script to help create the necessary structure. | Adding a new view to the a Zend Framework site | [
"",
"php",
"zend-framework",
""
] |
I get a string from a array list:
```
array.get(0).toString()
```
gives TITLE = "blabla"
I want the string blabla, so I try this :
```
Pattern p = Pattern.compile("(\".*\")");
Matcher m = p.matcher(array.get(0).toString());
System.out.println("Title : " + m.group(0));
```
It doesn't work: `java.lang.IllegalStateException: No match found`
I also try:
```
Pattern p = Pattern.compile("\".*\"");
Pattern p = Pattern.compile("\".*\"");
Pattern p = Pattern.compile("\\\".*\\\"");
```
Nothing matches in my program but ALL patterns work on <http://www.fileformat.info/tool/regex.htm>
Any Idea? Thanks in advance. | A couple of points:
The Javadoc for [Matcher#group](http://java.sun.com/javase/6/docs/api/java/util/regex/Matcher.html) states:
> IllegalStateException - If no match has yet been attempted, or if the previous match operation failed
That is, before using group, you must first use `m.matches` (to match the entire sequence), or `m.find` (to match a subsequence).
Secondly, you actually want `m.group(1)`, since `m.group(0)` is the whole pattern.
Actually, this isn't so important here since the regexp in question starts and ends with the capture parentheses, so that group(0) is the same string as group(1), but it would matter if your regexp looked like: `"TITLE = (\".*\")"`
Example code:
```
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.junit.Test;
@SuppressWarnings("serial")
public class MatcherTest {
@Test(expected = IllegalStateException.class)
public void testIllegalState() {
List<String> array = new ArrayList<String>() {{ add("Title: \"blah\""); }};
Pattern p = Pattern.compile("(\".*\")");
Matcher m = p.matcher(array.get(0).toString());
System.out.println("Title : " + m.group(0));
}
@Test
public void testLegal() {
List<String> array = new ArrayList<String>() {{ add("Title: \"blah\""); }};
Pattern p = Pattern.compile("(\".*\")");
Matcher m = p.matcher(array.get(0).toString());
if (m.find()) {
System.out.println("Title : " + m.group(1));
}
}
}
``` | You need to call `find()` or `matches()` on the Matcher instance first: these actually execute the regular expression and return whether it matched or not. And then only if it matched you can call the methods to get the match groups. | Question about Java regex | [
"",
"java",
"regex",
""
] |
I have a main application class, which contains a logger, plus some general app configurations, etc.
Now I will display a lot of GUI windows and so on (that will use the logger and configs), and I don't want to pass the logger and configurations to every single constructor.
I have seen some variants, like declaring the main class extern everywhere, but that doesn't feel very object oriented. What is the "standard" C++ way to make elements in the main class accessible to all (or most) other classes? | Use the [singleton design pattern](http://en.wikipedia.org/wiki/Singleton_pattern).
Basically you return a static instance of an object and use that for all of your work.
Please see this [link about how to use a singleton](http://www.ibm.com/developerworks/webservices/library/co-single.html) and also this [stackoverflow link about when you should not use it](https://stackoverflow.com/questions/137975/what-is-so-bad-about-singletons)
Warning: The singleton pattern involves promoting global state. Global state is bad for many reasons.
For example: unit testing. | It is not so bad idea to pass the logger and config to all the constructors if your logger and config is abstract enough.
Singleton can be a problem in the future. But it seams like a right choice in the project begin. Your choice. If your project is small enough - go with singleton. If not - dependency injection. | What's the proper "C++ way" to do global variables? | [
"",
"c++",
"design-patterns",
"oop",
""
] |
I have a test method that is run. When the method generates an exception I want to know what the name of the test was and the exception content.
In the teardown for the test I want to get access to this information. How would I get access to it from the `[TearDown]` attributed method? | **OPTION 1:** I don't think you can. Or rather, I don't know that you can. How I approach this need is to use a try/catch on the specific tests, do what I want with the exception and then throw again within the catch block so that the test could fail.
```
try{
// do something that can potentially throw;
}
catch(Exception ex){
// do something interesting with the ex;
throw;
}
```
**OPTION 2:** If you've not gone too far along, you may want to use xUnit which has a different exception expectation model and may provide some of the control you are looking for. | You can access text context objects in test tear down method
```
[TearDown]
public void TestTearDown()
{
// inc. class name
var fullNameOfTheMethod = NUnit.Framework.TestContext.CurrentContext.Test.FullName;
// method name only
var methodName = NUnit.Framework.TestContext.CurrentContext.Test.Name;
// the state of the test execution
var state = NUnit.Framework.TestContext.CurrentContext.Result.State; // TestState enum
}
```
I don't know which version was first to support it, but mine is 24. | In the teardown event during an NUnit test how can I get to the attribute applied to the method that was just tested? | [
"",
"c#",
"nunit",
""
] |
I'm trying to build a SQL query that will count both the total number of rows for each id, and the number of 'FN%' and 'W%' grades grouped by id. If those numbers are equal, then the student only has either all 'FN%' or all 'W%' or a combination of both.
**I need a list of all the id's who only have stats of 'FN%' or 'W%'**
example id # 683 & 657 would make it into the result set of the query, but 603, 781 & 694 would not
```
id stat
683 WF
683 WF
683 WF
683 WF
683 W
683 W
657 W
657 W
657 W
657 W
781 B+
781 IP
781 WP
781 WP
603 FN
603 FN
603 F
603 FN
603 FN
694 B
694 B+
694 CI
694 LAB
694 WF
694 WF
```
sample output:
683
657 | Here are two possible solutions that I can think of. I'm not sure if they'll work in Informix:
```
SELECT id
FROM foo a
GROUP BY id
HAVING COUNT(*) = (
SELECT COUNT(*)
FROM foo b
WHERE a.id = b.id
AND (b.stat LIKE 'FN%' OR b.stat LIKE 'W%')
);
```
And if subqueries in the `HAVING` clause are verboten, maybe this will work instead:
```
SELECT id
FROM (
SELECT id, COUNT(*) stat_count
FROM foo
WHERE (stat LIKE 'FN%' OR stat LIKE 'W%')
GROUP BY id
) a
WHERE stat_count = (SELECT COUNT(*) FROM foo b WHERE a.id = b.id);
```
Update: I just tried these in Oracle, and both work. | This was written against the original question:
```
select first 50
c.id,
(select trim(fullname) from entity where id = c.id) fullname,
count(*),
(select count(*) from courses where id = c.id and grd like 'FN%') FN,
(select count(*) from courses where id = c.id and grd like 'W%') W
from courses c
group by 1
```
The subquery to retrieve the name is much faster than using a join for some reason.
Edit:
The following will have the same behavior as yukondude's answer but performs better on our HPUX / Informix v10.00.HC5 box.
```
select c.id
from courses c
where not exists (
select id
from courses
where (grd not like 'W%' and grd not like 'FN%')
and id = c.id
)
group by 1
``` | Informix SQL count() comparisons | [
"",
"sql",
"count",
"grouping",
"informix",
""
] |
What's the best way to convert a list/tuple into a dict where the keys are the distinct values of the list and the values are the the frequencies of those distinct values?
In other words:
```
['a', 'b', 'b', 'a', 'b', 'c']
-->
{'a': 2, 'b': 3, 'c': 1}
```
(I've had to do something like the above so many times, is there anything in the standard lib that does it for you?)
EDIT:
Jacob Gabrielson points out there is [something coming in the standard lib](http://svn.python.org/view/python/trunk/Lib/collections.py?view=markup&pathrev=68559#Counter) for the 2.7/3.1 branch | Kind of
```
from collections import defaultdict
fq= defaultdict( int )
for w in words:
fq[w] += 1
```
That usually works nicely. | I find that the easiest to understand (while might not be the most efficient) way is to do:
```
{i:words.count(i) for i in set(words)}
``` | Best way to turn word list into frequency dict | [
"",
"python",
""
] |
I'm probably doing this wrong, so please be nice.
I'm developing a Java game, and I'm at the stage of testing character movement / animation.
The "person" can move up down left and right on a grid.
The class the grid is drawn in is the gamePanel class.
The buttons are in the gameControlPanel class.
I have a button which spawns a person on the grid.
I then have a button to move the person up down left and right.
When the move up button is pressed, it calls the move up method from the person class.
(At the moment, I'm only testing one "person" at a time.)
In that method is the following code...
```
int move = 10;
while(move!=0)
{
setTopLeftPoint(new Point((int)getTopLeftPoint().getX(),
(int)getTopLeftPoint().getY() - 3));
try
{
Thread.sleep(300);
} catch (InterruptedException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}
move-=1;
}
```
The problem is that I can't seem to call the repaint method for the gamePanel class from within the Person class.
To get around this, I created a timer in the gamePanel class which repaints every 20ms.
When I press the up button after the person is spawned, the button remains pressed down until the cycles of the while loop have been completed, and then the circle representation of the person is displayed in the grid square above.
I will try to answer any questions regarding this. | If you want to repaint at a certain interval, `javax.swing.Timer` is probably the class for you. In the specific case of `repaint` you can call it from a non-EDT thread, but you may get yourself into difficulty as you are now dealing with multiple threads. | repaint() does not immediately repaint the GUI. Rather, it posts a message to the AWT thread telling it to paint at the next convenient opportunity. When it gets the chance, it will repaint your app. However, if you do this in an event handler, then the AWT thread is already busy and you need to exit the handler to give control back to the AWT handler.
As a general rule of thumb, you *don't* want to do any long-running calculations on the AWT thread (including in event handlers) since these will stop the app from responding to other events until your calculations are done. This will often appear to the user as stuck buttons like you described. To get around this, use a [SwingWorker](http://java.sun.com/javase/6/docs/api/javax/swing/SwingWorker.html) which can do the calculations on a separate thread.
Finally, something to be aware (but not necessarily to change) is that timers and sleeps do not guarantee when they will awaken. Rather, they guarantee that they will not waken before the amount of time elapses, but can theoretically sleep indefinitely. Also, not all machines have 1 ms timer resolution. In particular, on many windows machines the timers only have 55 ms resolution, so a 20 ms timer may give weird results. | Call repaint from another class in Java? | [
"",
"java",
"multithreading",
"swing",
"animation",
"timer",
""
] |
*This is a significant edit from the original question, making it more concise and covering the points raised by existing answers...*
Is it possible to have mulitple changes made to multiple tables, inside a single transaction, and rollback only some of the changes?
In the TSQL below, I would NOT want any of the changes made by "myLogSP" to ever be rolled back. But all changes made by the various myBusinessSPs should rollback if necessary.
```
BEGIN TRANSACTION
EXEC myLogSP
EXEC @err = myBusinessSPa
IF (@err <> 0) BEGIN ROLLBACK TRANSACTION RETURN -1 END
EXEC myLogSP
EXEC @err = myBusinessSPb
IF (@err <> 0) BEGIN ROLLBACK TRANSACTION RETURN -1 END
EXEC myLogSP
EXEC @err = myBusinessSPc
IF (@err <> 0) BEGIN ROLLBACK TRANSACTION RETURN -1 END
EXEC myLogSP
COMMIT TRANSACTION
RETURN 0
```
The order is important, the myLogSPs must happen between and after the myBusinessSPs (the myLogSPs pick up on the changes made by the myBusinessSPs)
It is also important that all the myBusinessSPs happen inside one transaction to maintain database integrity, and allow all their changes to rollback if necessary.
It's as if I want the myLogSPs to behave as if they're not part of the transaction. It is just an inconvenient fact that they happen to be inside one (by virtue of needing to be called between the myBusinessSPs.)
EDIT:
Final answer is "no", the only option is to redesign the code. Either to using table variables for the logging (as variables don't get rolled back) or redesign the business logic to Not require Transactions... | Use [`SAVEPOINT`s](http://msdn.microsoft.com/en-us/library/ms188378.aspx), e.g.
```
BEGIN TRANSACTION
EXEC myLogSP
SAVE TRANSACTION savepointA
EXEC @err = myBusinessSPa
IF (@err <> 0) BEGIN
ROLLBACK TRANSACTION savepointA
COMMIT
RETURN -1
END
EXEC myLogSP
SAVE TRANSACTION savepointB
EXEC @err = myBusinessSPb
IF (@err <> 0) BEGIN
ROLLBACK TRANSACTION savepointB
COMMIT
RETURN -1
END
EXEC myLogSP
SAVE TRANSACTION savepointC
EXEC @err = myBusinessSPc
IF (@err <> 0) BEGIN
ROLLBACK TRANSACTION savepointC
COMMIT
RETURN -1
END
EXEC myLogSP
COMMIT TRANSACTION
```
---
**EDIT**
Based on the information provided so far (and my understanding of it) it appears that you will have to re-engineer you logging SPs, either to use variables, or to use files, or to allow them to run 'after the fact' as follows:
```
BEGIN TRANSACTION
SAVE TRANSACTION savepointA
EXEC @err = myBusinessSPa
IF (@err <> 0) BEGIN
ROLLBACK TRANSACTION savepointA
EXEC myLogSPA -- the call to myBusinessSPa was attempted/failed
COMMIT
RETURN -1
END
SAVE TRANSACTION savepointB
EXEC @err = myBusinessSPb
IF (@err <> 0) BEGIN
ROLLBACK TRANSACTION savepointB
EXEC myLogSPA -- the call to myBusinessSPa originally succeeded
EXEC myLogSPB -- the call to myBusinessSPb was attempted/failed
COMMIT
RETURN -1
END
SAVE TRANSACTION savepointC
EXEC @err = myBusinessSPc
IF (@err <> 0) BEGIN
ROLLBACK TRANSACTION savepointC
EXEC myLogSPA -- the call to myBusinessSPa originally succeeded
EXEC myLogSPB -- the call to myBusinessSPb originally succeeded
EXEC myLogSPC -- the call to myBusinessSPc was attempted/failed
COMMIT
RETURN -1
END
EXEC myLogSPA -- the call to myBusinessSPa succeeded
EXEC myLogSPB -- the call to myBusinessSPb succeeded
EXEC myLogSPC -- the call to myBusinessSPc succeeded
COMMIT TRANSACTION
``` | We have had luck with putting the log entries into table variables and then inserting to the real tables after the commit or rollback.
OK if you aren't on SQL Server 2008, then try this method. It's messy and a workaround but it should work. The #temp table and the table variable would have to be set up with the structure of what is returned by the sp.
```
create table #templog (fie1d1 int, field2 varchar(10))
declare @templog table (fie1d1 int, field2 varchar(10))
BEGIN TRANSACTION
insert into #templog
Exec my_proc
insert into @templog (fie1d1, field2)
select t.* from #templog t
left join @templog t2 on t.fie1d1 = t2.fie1d1 where t2.fie1d1 is null
insert into templog
values (1, 'test')
rollback tran
select * from #templog
select * from templog
select * from @templog
``` | Commiting only Specific Changes made inside a TRANSACTION which may ROLLBACK | [
"",
"sql",
"sql-server-2005",
"transactions",
"locking",
"transaction-isolation",
""
] |
Here is a sample soap response from my SuperDuperService:
```
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<soap:Body>
<MyResponse xmlns="http://mycrazyservice.com/SuperDuperService">
<Result>32347</Result>
</MyResponse>
</soap:Body>
</soap:Envelope>
```
For some reason when I try to grab the Descendant or Element of "Result" I get null. Does it have something to do with the Namespace? Can someone provide a solution to retrieve Result from this? | You might want to try something like this:
```
string myNamespace= "http://mycrazyservice.com/SuperDuperService";
var results = from result in yourXml.Descendants(XName.Get("MyResponse", myNamespace))
select result.Element("Result").value
```
Don't have VS on this laptop so I can't double check my code, but it should point you in the right direction using LINQ to SQL. | to extend Justin's answer with tested code with a return that excpects a boolean and that the response and result start with the method name (BTW - a surprise is even thought the XML element does not show the NS it requires it when parsing):
```
private string ParseXml(string sXml, string sNs, string sMethod, out bool br)
{
br = false;
string sr = "";
try
{
XDocument xd = XDocument.Parse(sXml);
if (xd.Root != null)
{
XNamespace xmlns = sNs;
var results = from result in xd.Descendants(xmlns + sMethod + "Response")
let xElement = result.Element(xmlns + sMethod + "Result")
where xElement != null
select xElement.Value;
foreach (var item in results)
sr = item;
br = (sr.Equals("true"));
return sr;
}
return "Invalid XML " + Environment.NewLine + sXml;
}
catch (Exception ex)
{
return "Invalid XML " + Environment.NewLine + ex.Message + Environment.NewLine + sXml;
}
}
``` | Using C# and XDocument/XElement to parse a Soap Response | [
"",
"c#",
"xml",
"soap",
"parsing",
""
] |
I'm in the process of building an web app that will, besides other things, need to connect to a FTP server to download or upload files. The application is written in PHP and it's hosted on a Linux server.
What I was wondering is whether or not it would be possible to also provide support for SFTP servers, but after some quick searches on Google it seems that this is not all that simple.
So, the question is: What would be the best way to use SFTP from within PHP? Is there a class that could also provide support for FTP as well as SFTP so that same functions could be used for both? | Yes, you can do that with [cURL](http://www.php.net/manual/en/book.curl.php). To switch from FTP to SFTP all you have to do is to change protocol option form `CURLPROTO_FTP` to `CURLPROTO_SFTP`.
cURL supports following protocols: HTTP, HTTPS , FTP, FTPS, SCP, SFTP, TELNET, LDAP, LDAPS, DICT, FILE, TFTP.
BTW. SFTP is not to be confused with FTPS. SFTP is SSH File Transfer Protocol, while FTPS is FTP over SSL. | if you don't have cURL installed (my host doesn't), you can use phpseclib:
<http://phpseclib.sourceforge.net/documentation/net.html#net_sftp> | SFTP from within PHP | [
"",
"php",
"ftp",
"curl",
"sftp",
""
] |
I'm showing images from other websites as thumbnails. To do this I display them in a smaller img tag so the browser does the size decrease.
The problem is that the quality of these images (which I have no control of) is diminished.
Also they look much better in FF and Safari than in IE.
Is there a way to make these images look better without caching them on my server? (e.g a javascript library that does the resize with better quality)? Any idea is highly appreciated. | IE's default image resizing algorithm is not that nice - it can be changed by tweaking a registry entry, but of course that is outside of your control.
However, apparently it can also be triggered to do a better image resize through css
```
img { -ms-interpolation-mode: bicubic; }
```
source: <http://edmondcho.com/blog/2009/03/17/internet-explorer-image-resizing-tip/> | A quick Google search shows that in IE7 you can fix the image quality problem:
<http://devthought.com/tumble/2009/03/tip-high-quality-css-thumbnails-in-ie7/> | better quality thumbnails from larger image files | [
"",
"javascript",
"internet-explorer",
"firefox",
"image",
"resize",
""
] |
I'm passing a large dataset into a MySQL table via PHP using insert commands and I'm wondering if it's possible to insert approximately 1000 rows at a time via a query other than appending each value on the end of a mile-long string and then executing it. I am using the CodeIgniter framework so its functions are also available to me. | Assembling one `INSERT` statement with multiple rows is much faster in MySQL than one `INSERT` statement per row.
That said, it sounds like you might be running into string-handling problems in PHP, which is really an algorithm problem, not a language one. Basically, when working with large strings, you want to minimize unnecessary copying. Primarily, this means you want to avoid concatenation. The fastest and most memory efficient way to build a large string, such as for inserting hundreds of rows at one, is to take advantage of the `implode()` function and array assignment.
```
$sql = array();
foreach( $data as $row ) {
$sql[] = '("'.mysql_real_escape_string($row['text']).'", '.$row['category_id'].')';
}
mysql_query('INSERT INTO table (text, category) VALUES '.implode(',', $sql));
```
The advantage of this approach is that you don't copy and re-copy the SQL statement you've so far assembled with each concatenation; instead, PHP does this *once* in the `implode()` statement. This is a *big* win.
If you have lots of columns to put together, and one or more are very long, you could also build an inner loop to do the same thing and use `implode()` to assign the values clause to the outer array. | Multiple insert/ batch insert is now supported by CodeIgniter.
```
$data = array(
array(
'title' => 'My title' ,
'name' => 'My Name' ,
'date' => 'My date'
),
array(
'title' => 'Another title' ,
'name' => 'Another Name' ,
'date' => 'Another date'
)
);
$this->db->insert_batch('mytable', $data);
// Produces: INSERT INTO mytable (title, name, date) VALUES ('My title', 'My name', 'My date'), ('Another title', 'Another name', 'Another date')
``` | How to insert multiple rows from array using CodeIgniter framework? | [
"",
"php",
"mysql",
"codeigniter",
"insert",
"bulkinsert",
""
] |
My question is simple: what to write into a log.
Are there any conventions?
What do I have to put in?
Since my app has to be released, I'd like to have friendly logs, which could be read by most people without asking what it is.
I already have some ideas, like a timestamp, a unique identifier for each function/method, etc..
I'd like to have several log levels, like tracing/debugging, informations, errors/warnings.
Do you use some pre-formatted log resources?
Thank you | **Here are some suggestions for content:**
* timestamp
* message
* log message type (such as error, warning, trace, debug)
* thread id ( so you can make sense of the log file from a multi threaded application)
**Best practices for implementation:**
* Put a mutex around the write method so that you can be sure that each write is thread safe and will make sense.
* Send 1 message at at a time to the log file, and specify the type of log message each time. Then you can set what type of logging you want to take on program startup.
* Use no buffering on the file, or flush often in case there is a program crash.
**Edit:** I just noticed the question was tagged with Python, so please see S. Lott's answer before mine. It may be enough for your needs. | It's quite pleasant, and already implemented.
Read this: <http://docs.python.org/library/logging.html>
---
**Edit**
"easy to parse, read," are generally contradictory features. English -- easy to read, hard to parse. XML -- easy to parse, hard to read. There is no format that achieves easy-to-read and easy-to-parse. Some log formats are "not horrible to read and not impossible to parse".
Some folks create multiple handlers so that one log has several formats: a summary for people to read and an XML version for automated parsing. | What to write into log file? | [
"",
"python",
"logging",
"methodology",
""
] |
I realized that i was using a varchar attribute as a index/key in a query, and that is killing my query performance. I am trying to look in my precienct table and get the integer ID, and then update my record in the household table with the new int FK, placed in a new column. this is the sql i have written thus far. but i am getting a
Error 1093 You can't specify target table 'voterfile\_household' for update in FROM clause, and i am not sure how to fix it.
```
UPDATE voterfile_household
SET
PrecID = (SELECT voterfile_precienct.ID
FROM voterfile_precienct INNER JOIN voterfile_household
WHERE voterfile_precienct.PREC_ID = voterfile_household.Precnum);
``` | Try:
```
update voterfile_household h, voterfile_precienct p
set h.PrecID = p.ID
where p.PREC_ID = h.Precnum
```
Take a look at update reference [here](http://dev.mysql.com/doc/refman/5.0/en/update.html).
Similarly, you can use **inner join** syntax as well.
```
update voterfile_household h inner join voterfile_precienct p on (h.Precnum = p.PREC_id)
set h.PrecID = p.ID
``` | What if the subquery returns more than one result? That's why it doesn't work.
On SQL Server you can get this type of thing to work if the subquery does "SELECT TOP 1 ...", not sure if mysql will also accept it if you add a "limit 1" to the subquery.
I also think this is pretty much a duplicate of [this question ("Can I have an inner SELECT inside of an SQL UPDATE?")](https://stackoverflow.com/questions/778307/can-i-have-an-inner-select-inside-of-an-sql-update) from earlier today. | Update Value in Table from another table | [
"",
"mysql",
"sql",
"mysql-error-1093",
""
] |
I have a base class DockedToolWindow : Form, and many classes that derive from DockedToolWindow. I have a container class that holds and assigns events to DockedToolWindow objects, however I want to invoke the events from the child class.
I actually have a question about how to implement what this [MSDN site](http://msdn.microsoft.com/en-us/library/hy3sefw3(VS.80).aspx) is telling me to do. This section below is giving me the problem:
```
// The event. Note that by using the generic EventHandler<T> event type
// we do not need to declare a separate delegate type.
public event EventHandler<ShapeEventArgs> ShapeChanged;
public abstract void Draw();
//The event-invoking method that derived classes can override.
protected virtual void OnShapeChanged(ShapeEventArgs e)
{
// Make a temporary copy of the event to avoid possibility of
// a race condition if the last subscriber unsubscribes
// immediately after the null check and before the event is raised.
EventHandler<ShapeEventArgs> handler = ShapeChanged;
if (handler != null)
{
handler(this, e);
}
}
```
Sure this example compiles and works, but when I replace "ShapeChanged" with "Move" (an event I acquired from deriving from Form), it errors saying I cannot have Move on the right side without += or -=. I also removed the ShapeEventArgs generic tags.
Any incite on why this isn't working? What's the difference between an event declared within the class and one that is inherited? | You cannot directly fire base class events. This is exactly the reason why you had to make your `OnShapeChanged` method `protected` instead of `private`.
Use [base.OnMove()](http://msdn.microsoft.com/en-us/library/system.windows.forms.control.onmove.aspx) instead. | From the C# language spec, section 10.7 (emphasis added):
> **Within the program text of the class or struct that contains the declaration of an event, certain events can be used like fields**. To be used in this way, an event must not be abstract or extern, and must not explicitly include event-accessor-declarations. Such an event can be used in any context that permits a field. The field contains a delegate (§15) which refers to the list of event handlers that have been added to the event. If no event handlers have been added, the field contains null.
Thus, the reason you can't treat the Move event like a field is that it is defined in a different type (in this case, your superclass). I agree with @womp's speculation that the designers made this choice to prevent unintended monkeying with the event. It seems obviously bad to allow unrelated types (types not derived from the type declaring the event) to do this, but even for derived types, it might not be desirable. They probably would have had to include syntax to allow the event declaration to be made `private` or `protected` with respect to field-style usage, so my guess is that they opted to just disallow it entirely. | Raise Base Class Events in Derived Classes C# | [
"",
"c#",
"events",
"base-class",
""
] |
I have some source code and I would like to auto generate class diagrams in PHP.
What software can I use to do this?
**Duplicate**
* [PHP UML Generator](https://stackoverflow.com/questions/393603/php-uml-generator)
* [UML tool for php](https://stackoverflow.com/questions/704957/uml-tool-for-php) | Doxygen can do class diagrams, too (if what I'm thinking of are "class diagrams" :) ). | [Umbrello](http://uml.sourceforge.net/) can do it. | What software can I use to auto generate class diagrams in PHP? | [
"",
"php",
""
] |
Calling all Oracle Gurus!
I am in the process of clustering a well tested application on WebSphere. The application in question made it about half way through processing 1k of JMS messages from a queue before this happened.
```
---- Begin backtrace for Nested Throwables
java.sql.SQLException: ORA-01654: unable to extend index DABUAT.INDEX1 by 128 in tablespace DABUAT_TBLSP
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:112)
at oracle.jdbc.driver.T4CTTIoer.processError(T4CTTIoer.java:331)
at oracle.jdbc.driver.T4CTTIoer.processError(T4CTTIoer.java:288)
at oracle.jdbc.driver.T4C8Oall.receive(T4C8Oall.java:745)
```
I have had a quick look online and found a few possible suggestions as to why this could have happend, if anyone could give a clear explanation as to why this may have occurred now my application has been clusterd I would be most grateful.
Regards Karl | You are out of disk space.
Increase your `TABLESPACE`:
```
ALTER TABLESPACE DABUAT_TBLSP
ADD DATAFILE 'C:\FolderWithPlentyOfSpace\DABUAT_TBLSP001.DBF'
SIZE 4M
AUTOEXTEND ON NEXT 4M
MAXSIZE 64G;
-- Put your own size parameters here
``` | IF you are using ASM then you can add with below comment
you can run below command to get size of datafile
```
SELECT
file_name,
bytes / 1024 / 1024 mb
FROM
dba_data_files
WHERE
tablespace_name = 'APP_DATA'
ORDER BY
file_name;
FILE_NAME mb
------------------------------------------------------------ -------
+DATA/SID/datafile/app_data.dbf 20000
+DATA/SID/datafile/app_data.dbf 28100
```
Resizing and adding
```
+DATA/path/indx_operational_00.dbf
alter database datafile '+DATA/path/indx_operational_00.dbf' resize 3000m;
``` | ORA-01654: unable to extend index | [
"",
"java",
"oracle",
"cluster-computing",
""
] |
I noticed some not so old VM languages like Lua, NekoVM, and Potion written in C.
It looked like they were reimplementing many C++ features.
Is there a benefit to writing them in C rather than C++? | I know something about Lua.
* Lua is written in pure ANSI Standard C and compiles on any ANSI platform with no errors and no warnings. Thus **Lua runs on almost any platform in the world**, including things like [Canon PowerShot cameras](http://chdk.wikia.com/wiki/LUA). It's a lot harder to get C++ to run on weird little embedded platforms.
* Lua is a high-performance VM, and because C cannot express method calls (which might be virtual or might not) and operator overloading, it is much **easier to predict the performance of C code** just by looking at the code. C++, especially with the template library, makes it a little too easy to burn resources without being aware of it. (A full implementation of Lua including not only VM but libraries fits in 145K of x86 object code. The whole language fits even in a tiny 256K cache, which you find at L2 on Intel i7 and L1 on older chips. Unless you really know what you're doing, it's much harder to write C++ that compiles to something this small.)
These are two good reasons to write a VM in C. | > It looked like they were reimplementing many C++ features.
Are you suggesting it's easier to implement polymorphism in C++ rather than C? I think you are greatly mistaken.
If you write a VM in C++, you wouldn't implement polymorphism in terms of C++'s polymorphism. You'd roll your own virtual table which maps function names to pointers, or something like that. | Why are many VMs written in C when they look like they have C++ features? | [
"",
"c++",
"c",
"programming-languages",
"vm-implementation",
""
] |
I am new to C# and programming in general my question is how do you call a variable that is in a different namespace? if I have this code
```
public void servicevalues(string _servicename)
{
string servicename = _servicename;
string query = string.Format("SELECT * FROM Win32_Service WHERE Name ='{0}'", servicename);
ManagementObjectSearcher moquery = new ManagementObjectSearcher(query);
ManagementObjectCollection queryCollection = moquery.Get();
foreach (ManagementObject service in queryCollection)
{
string serviceId = Convert.ToString(service["DisplayName"]);
bool serviceResult = Convert.ToBoolean(service["Started"]);
}
```
and I am passing in service name how would I call one or multiple variable values from a different namespace? | Normally, variables don't live in a namespace alone, they live inside another class that could be in another namespace. If you need to access a variable in another class (in another namespace), your other class needs to expose the variable somehow. The common practice for this is to use a public Property (static if you only need access to that variable) for the variable.
```
namespace My.Namespace
{
public class MyClassA
{
public void MyMethod()
{
// Use value from MyOtherClass
int myValue = My.Other.Namespace.MyOtherClass.MyInt;
}
}
}
namespace My.Other.Namespace
{
public class MyOtherClass
{
private static int myInt;
public static int MyInt
{
get {return myInt;}
set {myInt = value;}
}
// Can also do this in C#3.0
public static int MyOtherInt {get;set;}
}
}
``` | To add to Andy's answer you can also shorten the call to the MyInt property by adding this above the My.Namespace declaration:
```
using My.Other.Namespace
```
If you do that then your call to the MyInt property would look like this:
```
int MyValue = MyOtherClass.MyInt
``` | Accessing variables from other namespaces | [
"",
"c#",
"variables",
"namespaces",
""
] |
This is odd, but for some reason the `$_SERVER["SCRIPT_URI"]` will not return the domain name when I am in child/sub-pages but will only work on the main page. Not sure if its due to the script (WordPress) or host, but please can you suggest any reliable solution to retrieve the domain name with PHP? | If you need domain name, use:
```
$_SERVER['HTTP_HOST']
``` | When in doubt
```
var_dump($_SERVER);
``` | $_SERVER["SCRIPT_URI"] not working? alternative? | [
"",
"php",
""
] |
I have built a web proxy from scratch (using `Socket` and `NetworkStream` classes). I am now trying to implement SSL support for it so that it can handle HTTPS requests and responses. I have a good idea of what I need to do (using `SslStream`) but I don't know how to determine if the request I get from the client is SSL or not.
I have searched for hours on this subject and have been unable to find a suitable solution.
After I do this:
```
TcpListener pServer = new TcpListener(localIP, port);
pServer.Start(256);
Socket a_socket = pServer.AcceptSocket();
```
How do I know if I need to read the information using `SslStream` or `NetworkStream`? | Client will send you a **CONNECT** method request after this point you need to just redirect the traffic.
Sample Connect :
```
CONNECT www.google.com:443 HTTP/1.1
```
After seeing this just switch to data redirect mode. You can not intercept or read the data so you don't need to worry about SSLStream anyway, you won't touch it.
However if you want to MITM (man in the middle) then you need to switch to SSL otherwise just **redirect whatever comes to the target** URL and port, that's it.
Obviously client browser will popup with an SSL certificate exception if you intercept the request. | You need to add support for the CONNECT command.
<http://www.codeproject.com/KB/IP/akashhttpproxy.aspx> | SSL in a C# Web Proxy; how do I determine if the request is SLL or not? | [
"",
"c#",
"sockets",
"ssl",
"proxy",
""
] |
```
List<int> a = 11,2,3,11,3,22,9,2
//output
11
``` | This may not be the most efficient way, but it will get the job done.
```
public static int MostFrequent(IEnumerable<int> enumerable)
{
var query = from it in enumerable
group it by it into g
select new {Key = g.Key, Count = g.Count()} ;
return query.OrderByDescending(x => x.Count).First().Key;
}
```
And the fun single line version ...
```
public static int MostFrequent(IEnumerable<int> enumerable)
{
return (from it in enumerable
group it by it into g
select new {Key = g.Key, Count = g.Count()}).OrderByDescending(x => x.Count).First().Key;
}
``` | ```
a.GroupBy(item => item).
Select(group => new { Key = group.Key, Count = group.Count() }).
OrderByDescending(pair => pair.Count).
First().
Key;
``` | how would i use linq to find the most occured data in a data set? | [
"",
"c#",
"linq",
""
] |
I'm working with UDP sockets in C++ for the first time, and I'm not sure I understand how they work. I know that `sendto`/`recvfrom` and `send`/`recv` normally return the number of bytes actually sent or received. I've heard this value can be arbitrarily small (but at least 1), and depends on how much data is in the socket's buffer (when reading) or how much free space is left in the buffer (when writing).
If `sendto` and `recvfrom` only guarantee that 1 byte will be sent or received at a time, and datagrams can be received out of order, how can any UDP protocol remain coherent? Doesn't this imply that the bytes in a message can be arbitrarily shuffled when I receive them? Is there a way to guarantee that a message gets sent or received all at once? | It's a *little* stronger than that. UDP does deliver a full package; the buffer size can be arbitrarily small, but it has to include all the data sent in the packet. But there's also a size limit: if you want to send a lot of data, you have to break it into packets and be able to reassemble them yourself. It's also no guaranteed delivery, so you have to check to make sure everything comes through.
But since you can implement all of TCP with UDP, it has to be possible.
usually, what you do with UDP is you make small packets that are discrete.
Metaphorically, think of UDP like sending postcards and TCP like making a phone call. When you send a postcard, you have no guarantee of delivery, so you need to do something like have an acknowledgement come back. With a phone call, you know the connection exists, and you hear the answers right away. | Actually you can send a UDP datagram of 0 bytes length. All that gets sent is the IP and UDP headers. The UDP recvfrom() on the other side will return with a length of 0. Unlike TCP this does not mean that the peer closed the connection because with UDP there is no "connection". | Confusion about UDP/IP and sendto/recvfrom return values | [
"",
"c++",
"networking",
"udp",
""
] |
Is there a way to get the last number from the `range()` function?
I need to get the last number in a Fibonacci sequence for first 20 terms or should I use a list instead of `range()`? | Not quite sure what you are after here but here goes:
```
rangeList = range(0,21)
lastNumber = rangeList[len(rangeList)-1:][0]
```
or:
```
lastNumber = rangeList[-1]
``` | by *in a range*, do you mean last value provided by a generator? If so, you can do something like this:
```
def fibonacci(iterations):
# generate your fibonacci numbers here...
[x for x in fibonacci(20)][-1]
```
That would get you the last generated value. | How do I get the last number from the range() function? | [
"",
"python",
"range",
"fibonacci",
""
] |
Is there a rule of thumb to follow when to use the `new` keyword and when not to when declaring objects?
```
List<MyCustomClass> listCustClass = GetList();
```
OR
```
List<MyCustomClass> listCustClass = new List<MyCustomClass>();
listCustClass = GetList();
``` | In your scenario it seems that the actual creation of the object is being performed inside your `GetList()` method. So your first sample would be the correct usage.
When created, your `List<MyCustomClass>` is stored in the heap, and your `listCustClass` is simply a reference to that new object. When you set listCustClass to `GetList()` the reference pointer of `listCustClass` is discarded and replaced with a reference pointer to whatever `GetList()` returns (could be null). When this happens your original `List<MyCustomClass>` is still in the heap, but no objects point to it, so its just wasting resources until the Garbage Collector comes around and cleans it up.
To sum it up everytime you create a new object then abandon it, like the second example, you're essentially wasting memory by filling the heap with useless information. | In your second case you are creating a new object on the first line just to throw it away on the second line. Completely unnecessary. | To "new" or not to "new" | [
"",
"c#",
".net",
"new-operator",
"allocation",
""
] |
I am less than satisfied in my HTML/CSS/JS debugging of pages with IE6 and 7 specific bugs.
I am aware that IE8 has a Firebug clone, called 'Developer Tools' installed.
Is it possible to have IE8 installed (maybe on a VM, i don't mind), set it to compatibility mode (is there one for IE6?), then perform JS debugging and live HTML changes, **using the IE8 Developer Tools**, just like we can in Firebug?
many many thanks
mieze | There are differences between native IE6/7 and the IE8 compatibility mode:
<http://blogs.msdn.com/ie/archive/2009/03/12/site-compatibility-and-ie8.aspx>
The best option I've found to debug in IE6/7 is to install the Microsoft Script Editor (not Debugger), that is bundled with Microsoft Office. It's an optional install, so you probably have to open Add remove programs in Control panel and go through setup again. Here's a guide to configure IE after you've installed the Microsoft Script Editor.
<http://www.jonathanboutelle.com/mt/archives/2006/01/howto_debug_jav.html>
The default view doesn't have breakpoints and such, so take a look at the menu to add the views you like. It's not as good as Firebug, but it's a lot better than alert-debugging ;) | I've said it before, and I'll say it again:
[Firebug Lite](http://getfirebug.com/lite.html)
That'll let you use Firebug features in whatever browser you feel like using that day... | Using the IE8 'Developer Tools' to debug earlier IE versions | [
"",
"javascript",
"internet-explorer-6",
"internet-explorer-8",
"internet-explorer-7",
"firebug",
""
] |
I am creating an audit table for tracking changes done on a record in main table.
Here audit table is the exact duplicate of main table (say Employee Table) but will only have 'inserts' for every changes happens in the main table. So it will have duplicates (same EmployeeIDs), so should I add separate Audit\_ID for each entry? | Sure you need some kind of a primary key in the table.
It will be easier to remove duplicates and to track the 'reason of insert' (for debugging purposes) if you have one.
Some `RDBMS`'s (like `MySQL` with `InnoDB`) actually create a hidden primary key for you if you didn't do it explicitly, so just do it yourself and make if visible and usable. | You pretty much *have* to, as while the EmployeeID in Employee will be unique (an update will not add a new row, just modify the existing row), the audit table will have multiple rows with the same EmployeeId (one for the initial insert, one for each subsequent update, of that employee).
Besides, the entities in Employee are employees. But the entities in audit are audit records. They shoulld have their own id.
You'll want this if ever something goes wrong and you need to actually update or delete an audit record. Indeed, if an employee is inserted, then one column's value is updated, then updated again to be the original value, you now have two identical records in audit. Which would have to be deleted or updated together (unless you used a limit clause in your update or delete.) Messy.
Which also points up the usefulness of adding a timestamp to the audit table too. But don't think you should use that and employeeid as a composite key. First, composite keys suck. Second, it's entirely possible a timestamp's granularity is less than the time it would take your system to perform two updates (two updates of the same employee, as in, say, a batch operation). (A Sybase datetime has a three millisecond granularity; an Intel Core 2 Extreme can do nearly 200 *million* instructions in that time.) | Should I include primary key for Audit Table in SQL? | [
"",
"sql",
"audit",
""
] |
I'd like to be able to append some data to a binary field in a MS SQL 2005 server from C# without reading the original data, concatenating it, and then setting it all back.
Is this possible?
Cheers!
Steve | Read about the UPDATETEXT sql statement at <http://msdn.microsoft.com/en-us/library/3517w44b.aspx>. The Msdn article contains example code that appends binary data to a blob in the StorePhoto method. | I don't know if this option exists in MSSQL 2005, but if someone is searching for appending info into varbinary(max) in MSSQL2008 it can be done like this:
```
UPDATE [dbo].[Files] SET [FileContent].WRITE('0x',NULL,0)
WHERE Id = 1
```
Hope this will help someone. | Can I append to a BLOB in MSSQL database from C# without reading the original data? | [
"",
"c#",
"sql-server",
"blob",
""
] |
I'm looking at the function `trim` but that unfortunately does not remove "0"s how do I add that to it? Should I use `str_replace`?
EDIT:
The string I wanted to modify was a message number which looks like this: 00023460
The function `ltrim("00023460", "0")` does just what I need :) obviously I would not want to use the regular `trim`because it would also remove the ending 0 but since I forgot to add that the answer I got is great :) | ```
$ php -r 'echo trim("0string0", "0") . "\n";'
string
```
For the zero padded number in the example:
```
$ php -r 'echo ltrim("00023460", "0") . "\n";'
23460
``` | This should have been here from the start.
> EDIT: The string I wanted to modify
> was a message number which looks like
> this: 00023460
The best solution is probably this for any integer lower then PHP\_INT\_MAX
$number = (int) '00023460'; | How to remove 0's from a string | [
"",
"php",
""
] |
I'm trying to serialize my business objects into JSON for consumption by a Javascript application. The problem is is that I'm trying to keep my business objects "pure" in the sense they are not aware of data access or persistence. It seems to me that "diluting" my objects with a toJSON() function would go against this goal. On the other hand, using an external object to serialize my business objects would not work since I keep all my instance variables private.
Am I approaching this totally the wrong way? | If the instance variables are private, they should not appear in a serialization that is being sent to a JavaScript application. By definition, if you're serializing them and sending them to a separate application, they are public. So, an external object should have some way of accessing them, probably through some sort of getter methods. | What purpose does searializing the data in JSON serve? Is it purely for reporting? If so, then Brian is correct, those variables should have getter methods.
If the purpose of serialization is to transport the data to a JavaScript app where it can be manipulated and then returned to the originating application, then perhaps you would be best served by creating a related class that serves the purpose of serialization while still maintaining strong encapsulation.
For example, in Java you could define an inner class. An inner class instance has direct access to all fields of the enclosing class instance without the need of getter methods. Or you could group with a package (or namespace) using the correct access modifiers to permit access by the serializer, but not by any other class.
Or you could use reflection. Or hijack the toString method. (Or shine it all and create a toJson method.) | Serializing business objects as JSON | [
"",
"javascript",
"json",
"domain-driven-design",
"business-objects",
""
] |
I have a generic class which takes two type parameters, `Generic<A, B>`. This class has methods with signatures that are distinct so long and `A` and `B` are distinct. However, if `A == B` the signatures match exactly and overload resolution cannot be performed. Is it possible to somehow specify a specialisation of the method for this case? Or force the compiler to arbitrarily choose one of the matching overloads?
```
using System;
namespace Test
{
class Generic<A, B>
{
public string Method(A a, B b)
{
return a.ToString() + b.ToString();
}
public string Method(B b, A a)
{
return b.ToString() + a.ToString();
}
}
class Program
{
static void Main(string[] args)
{
Generic<int, double> t1 = new Generic<int, double>();
Console.WriteLine(t1.Method(1.23, 1));
Generic<int, int> t2 = new Generic<int, int>();
// Following line gives:
// The call is ambiguous between the following methods
// or properties: 'Test.Generic<A,B>.Method(A, B)' and
// 'Test.Generic<A,B>.Method(B, A)'
Console.WriteLine(t2.Method(1, 2));
}
}
}
``` | Thanks for the good answers, they prompted me into this solution:
```
using System;
namespace Test
{
class Generic<A, B>
{
public string Method(A a, B b)
{
return this.DefaultMethod(a, b);
}
protected string DefaultMethod(A a, B b)
{
return a.ToString() + b.ToString();
}
public string Method(B b, A a)
{
return b.ToString() + a.ToString();
}
}
class Generic<A> : Generic<A, A>
{
public new string Method(A a, A b)
{
return base.DefaultMethod(a, b);
}
}
class Program
{
static void Main(string[] args)
{
Generic<int, double> t1 = new Generic<int, double>();
Console.WriteLine(t1.Method(1.23, 1));
Generic<int> t2 = new Generic<int>();
Console.WriteLine(t2.Method(1, 2));
}
}
}
``` | Given the purely generic definition there is no way to force the compiler to choose an overload. It has no way to distinguish a winner between the two methods.
It may seem a good idea to just pick one or the other but the decision needs to be deterministic. Even something as simple as the first one in the file is not really doable because you must consider partial classes. How would the compiler choose the first method if each were in a different file?
What you can do though is add a non-generic version of the method which accepts int. The compiler will choose the non-generic version over the generic version and it will produce a win in this very limited scenario. You would have to repeat that for every type which may have a conflict though.
For example. Adding this method will solve your compilation error, but only for int.
```
public string Method(int b, int a)
{
return b.ToString() + a.ToString();
}
``` | Specialize implementation of GenericType<A,B> for case A == B? | [
"",
"c#",
"generics",
"overloading",
""
] |
When you have 5 dropdowns for date selection (Y, m,d, H,i) how do you insert the selected date and time into a single column of a mySQL table as a datetime using PHP5?
I know they need to be combined in a string such as:
```
$DateTime="$Year-$Month-$Day $Hour:$Minute:00";
```
and then maybe use strtotime:
```
$Date=date('Y-m-d H:i:s', strtotime($DateTime)) ;
```
but where do I declare the variables and how do I build it into a query such as:
```
if ((isset($_POST["MM_insert"])) && ($_POST["MM_insert"] == "details")) {
$insertSQL = sprintf("INSERT INTO sessions (Location1, Location2, Date)
VALUES (%s, %s, $s)",
GetSQLValueString($_POST['Location1'], "text"),
GetSQLValueString($_POST['Location2'], "text"),
GetSQLValueString($_POST[' ???? '], "date"));
``` | Thanks to all who tried to help - the answer was a lot less complicated
(blonde moment I guess! lol)
Just needed to declare the post variables as:
$\_POST['startDate'] ="$Year-$Month-$Day $Hour:$Minute:00";
No need for time conversions as it's already in Mysql format (YEY!) | You might also look into the mktime() function: <http://ca.php.net/mktime>
You would then just need to declare your date variable like:
```
$date = mktime($_POST['H'],$_POST['i'],0,$_POST['m'],$_POST['d'],$_POST['Y']);
$location1 = mysql_real_escape_string( $_POST['Location1'];
$location2 = mysql_real_escape_string( $_POST['Location2'];
$insertSQL = "INSERT INTO sessions (Location1, Location2, Date) VALUES ('$location1', '$location2', $date)";
mysql_query( $insertSQL );
```
**EDIT:**
Or, using the sprintf format you're using:
```
$date = mktime($_POST['H'],$_POST['i'],0,$_POST['m'],$_POST['d'],$_POST['Y']);
$insertSQL = sprintf("INSERT INTO sessions (Location1, Location2, Date)
VALUES (%s, %s, $s)",
GetSQLValueString($_POST['Location1'], "text"),
GetSQLValueString($_POST['Location2'], "text"),
GetSQLValueString($date, "date"));
```
I have never used the GetSQLValueString function before though, so I can only assume that's the correct way to use it. | How to insert dates selected from drop downs into mySQL table using php? | [
"",
"php",
"mysql",
"date",
"insert",
"drop-down-menu",
""
] |
I'm decoding some JSON (from the Youtube data API) with json\_decode and it gives me an object that looks like this when var\_dump()ed:
```
object(stdClass)[29]
public 'type' => string 'text' (length=4)
public '$t' => string 'Miley and Mandy! KCA VIDEO WINNERS' (length=34)
```
How can I access the $t member? | Try
```
$member = '$t';
$obj->$member
``` | You may use the second argument of json\_decode
```
$data = json_decode($text, true);
echo $data['$t'];
``` | How to access/escape PHP object member with a $ character in its name? | [
"",
"php",
""
] |
We are trying to debug some web services code we're running in C# on IIS. I am new to Windows programming and have no idea how to view output to the console. We've got some write statements in the code, but I can't figure out how to view the console while this thing is running. Help? | You'll want to take a look at ASP.NET tracing
here is a handy link to get you started: <http://www.asp101.com/articles/robert/tracing/default.asp>
you can enable application wide tracing if you place the following in your web.config, then you will have access to your trace.axd
```
<trace enabled="true"
localOnly="false"
pageOutput="false"
requestLimit="500"
traceMode="SortByTime"
/>
``` | I have found the Trace feature extremely helpful. You can get there by going to:
<http://mysiteurl/trace.axd>
In your web.config, place the following within the System.Web tag:
```
<trace enabled="true"
localOnly="false"
pageOutput="false"
requestLimit="500"
traceMode="SortByTime"
/>
```
Now from your code behind, you can inject some logging by doing:
```
HttpContext.Current.Trace.Warn("I Made It Here!");
``` | Outputting to the Console in C# on IIS | [
"",
"c#",
"iis",
"console",
""
] |
In Eclipse you can configure numerous servers to run inside the IDE, including Tomcat. Depending on your Tomcat configuration, at some point in the life cycle of a webapp your JSP files will get compiled into servlets. These new servlet *.class* files are stored in the `%TOMCAT_HOME%/work` directory along with the *.java* intermediate file created from the JSP. This *.java* file is very helpful when your JSPs throw exceptions and cite a line number corresponding to the *.java* and not the *.jsp*
**Update:** On my environment (Windows), it is located here:
> C:/Documents and Settings/**%USER%**/workspace/.metadata/.plugins/org.eclipse.wst.server.core/tmp0/work
Perhaps to answer more completely somebody could post the location for \*nix environments. | You will find it in
```
projectworkspace/.metadata/.plugins/org.eclipse.wst.server.core/tmp0
```
This is the default place where Eclipse 3.4 publishes the project. However, this can be changed by changing the settings in your 'Server' view. | Go to "Servers" window -> double click on your tomcat instance -> clik "Open launch configuration" -> go to "Arguments" tab.
Look for variable definition like this:
```
-Dcatalina.base="/Users/dirtyaffairs/Documents/workspace/.metadata/.plugins/org.eclipse.wst.server.core/tmp0"
``` | Where is the "work" directory located for a Tomcat instance running in Eclipse? | [
"",
"java",
"eclipse",
"jsp",
"tomcat",
""
] |
Sometimes checking of arguments in Python is necessary. e.g. I have a function which accepts either the address of other node in the network as the raw string address or class Node which encapsulates the other node's information.
I use type() function as in:
```
if type(n) == type(Node):
do this
elif type(n) == type(str)
do this
```
Is this a good way to do this?
**Update 1:** Python 3 has annotation for function parameters. These can be used for type checks using tool: <http://mypy-lang.org/> | Use `isinstance()`. Sample:
```
if isinstance(n, unicode):
# do this
elif isinstance(n, Node):
# do that
...
``` | ```
>>> isinstance('a', str)
True
>>> isinstance(n, Node)
True
``` | Type checking of arguments Python | [
"",
"python",
"typechecking",
""
] |
I'm curious if any developers use string.IsNullOrEmpty() more often with a negative than with a positive
e.g.
```
if (!string.IsNullOrEmpty())
```
This is how I use the method 99% of the time. What was the design decision for this? | Because "IsNullOrEmpty" is easier to understand than "NotNullOrEmpty". The latter could be interpreted as:
1. It's not null and it's not empty
2. It's not null or it is empty | Double negatives are usually discouraged in naming stuff. `!string.NotNullOrEmpty(...)` would make one. | string.IsNullOrEmpty() vs string.NotNullOrEmpty() | [
"",
"c#",
".net",
"string",
""
] |
I am wondering if there is a cross-platform allocator that is one step lower than malloc/free.
For example, I want something that would simply call sbrk in Linux and VirtualAlloc in Windows (There might be two more similar syscalls, but its just an example). | I'm not familiar with the functions in question but:
```
#if defined (__WIN32__)
#define F(X) VirtualAlloc(X)
#elif defined (__LINUX__) /* or whatever linux's define is */
#define F(X) sbrk(X)
#endif
```
Not sure if the syntax is 100% (I'm new to macros & c), but the general idea should work. | C gives you `malloc` and `free`, C++ adds `new`, `new[]`, `delete` and `delete[]` and the placement forms in addition to what C provides.
Anything more and you are out of the realms of the language proper. You are either treading in OS-land or murking in assembler. There is no question of such things being cross platform.
> I am wondering what good would it do if such allocator existed?
>
> You could implement your own malloc/free without worrying about the underlying OS
And you'd want another cross-platform solution to implement this and another ... you get the point. This is not a viable scheme. | Cross-platform memory allocator sbrk/virtualalloc | [
"",
"c++",
"c",
"memory",
"cross-platform",
""
] |
If you have a collection of methods in a file, is there a way to include those files in another file, but call them without any prefix (i.e. file prefix)?
So if I have:
```
[Math.py]
def Calculate ( num )
```
How do I call it like this:
```
[Tool.py]
using Math.py
for i in range ( 5 ) :
Calculate ( i )
``` | You will need to import the other file as a module like this:
```
import Math
```
If you don't want to prefix your `Calculate` function with the module name then do this:
```
from Math import Calculate
```
If you want to import all members of a module then do this:
```
from Math import *
```
**Edit:** [Here is a good chapter](https://linux.die.net/diveintopython/html/object_oriented_framework/importing_modules.html) from [Dive Into Python](https://linux.die.net/diveintopython/html/toc/index.html) that goes a bit more in depth on this topic. | Just write the "include" command :
```
import os
def include(filename):
if os.path.exists(filename):
execfile(filename)
include('myfile.py')
```
@Deleet :
@bfieck remark is correct, for python 2 and 3 compatibility, you need either :
Python 2 and 3: alternative 1
```
from past.builtins import execfile
execfile('myfile.py')
```
Python 2 and 3: alternative 2
```
exec(compile(open('myfile.py').read()))
``` | How to include external Python code to use in other files? | [
"",
"python",
""
] |
We are shopping for Business Rules Engines.
We want to make our core application customizable to different customers with slightly different requirements.
The people who would actually do the customizations are analysts. I.e. non-programmers who are technically skilled (usually have a degree in sciences).
What are the criteria to evaluate business rules engines?
Are there open source and comercial ones?
What are your experiences in ease of use, documentation, support, price, etc.
Our app is in Java. | [Drools](http://www.jboss.org/drools/) (used to be Drools then JBoss Rules then Drools again) is a very good open-source rules engine and definitely worth a look.
To my mind the best criteria to evaluate a rules engine are:
* Is it configurable (otherwise you'd just code it instead)
* Is it performant.
* How easy is it for non technical people to change rules
* How easy is it for new rule sets to be deployed (and old ones undeployed).
Several Rules Engines have [Business Rules Management](http://en.wikipedia.org/wiki/BRMS) Systems (BRMS) and Drools is no exception. This makes deployment much easier for non-techies.
There is good support for Drools via docs and tutorials on the web and even via the IRC channel.
I've also used the Rules Engine that comes with IBM Websphere Process Server and found that to be quite good as well (although pricey). | I worked as a consultant for a leading rule engine in the industry for close to three years. You will pay a LOT of money for a commercial rule engine and need to decide if the features and support you potentially receive are worth the price. All rule engine vendors will claim theirs is the best hands down; the best advice I can give you is to do a prototype with each rule engine you're considering that is limited in scope, but representative of the features you need. Do NOT let sales people just show you a fancy demo; YOU should actively build the prototype. I have seen too many people buy a rule engine that really have no idea what it is they're buying. Personally, I would opt for one of the open source rule engines (someone has already mentioned Drools) if you have your heart set on a rule engine. However, I would seriously consider alongside rule engines the possibility of not using a rule engine. You may save time initially with a rule engine (ignoring the learning curve), but a custom solution is likely to be superior in the long term to meet you specific needs.
Here are a couple links from Martin Fowler's website that are relevant to your question:
* <http://www.martinfowler.com/bliki/RulesEngine.html>
* <http://www.martinfowler.com/bliki/DomainSpecificLanguage.html> | Criteria to Evaluate Business Rules Engines | [
"",
"java",
"enterprise",
"rule-engine",
"business-rules",
""
] |
I need to generate a list of all the files which are enough to run my application on any machine. I need this for a setup program. When i go to bin/release folder i'm able to see some pdb files and some configuration files, which i think will not be needed. I tried to disable generation of pdb files too but it still generates pdb for the other projects present in the solution.
So i need a way in visual studio 2008, which can get me all the files (the .exe and .dll and other files) required by my application to run.
Thanks. | Have you tried publishing the application (Build > Publish [app])?
This should just copy all the essential files to the specified folder. | The pdb files are used for debugging. Building in "Release" mode should exclude these files.
You can also create a setup project within the solution. Using that project it is possible to see a list of included files. | Find out all the files required to run a c# application | [
"",
"c#",
"visual-studio-2008",
"all-files",
""
] |
I'm trying to re-order a HTML table when the user clicks on the table header. Here is all I can do, but still doesn't work.
in the HTML:
```
// onClick on table header
var par='ASC';
sort(par);
```
from: ajax.js
```
function sort(orderByType)
{
$.ajax({
url: "sort.php",
type: "get",
data: "orderby="+orderByType,
success: function(data){
alert(data);
$("t1").text(data);
}
});
}
```
sort.php
```
$con = mysql_connect("localhost","root","root");
if (!$con) {
die('Could not connect: ' . mysql_error());
}
$orderBy = $_GET['orderby'];
mysql_select_db("icrisis", $con);
$result = mysql_query("SELECT * FROM messages,user
where user_id = from_user
ORDER BY user_name".$orderBy);
while($row = mysql_fetch_array($result))
{
echo "<tbody><tr><td>"."•"."</td><td>".
$row["Time_Date"]."</td><td>".
$row["player_name"]."</td><td></td><td></td><tr><td></td><td colspan='4'>".
$row["msg_desc"]."</td></tr></tbody>";
}
mysql_close($con);
```
It doesn't see the `$orderBy`. And then I want to add the new order to my page - how could that be done?
Could the variable sent to function sort be dynamic, i.e. to be ASC or DESC on click? | I'm not sure if that is the cause of your problem, but I believe you miss a space.
The last line of your query is now:
```
ORDER BY user_name".$orderBy);
```
But should be:
```
ORDER BY user_name ".$orderBy);
``` | You should try: [tablesorter](http://tablesorter.com/docs/) its for sorting tables. And you don't even need to use php with this solution just jquery. Hope its usefull.
To reply to your comment on Daan's anwser you could update tablesorter with ajax as described [here](http://tablesorter.com/docs/example-ajax.html). | Sort using php and jquery | [
"",
"php",
"jquery",
"sorting",
""
] |
I would like to display 100000 records on browser / multiple pages with minimal impact on memory. ie Per page 100 records.
I would like to move page back and forth. My doubts are
1. Can I maintain all the record inside the memory ? Is this good Idea ?
2) Can I make database connection/query for ever page ? If so how do write a query?
Could anyone please help me.. | It's generally not a good idea to maintain so much records in memory. If the application is accessed by several users at the same time, the memory impact will be huge.
I don't know what DBMS are you using, but in MySQL and several others, you can rely on the DB for pagination with a query such as:
```
SELECT * FROM MyTable
LIMIT 0, 100
```
The first number after limit is the offset (how many records it will skip) and the second is the number of records it will fetch.
Bear in mind that this is SQL does not have the same syntax on every DB (some don't even support it). | I would not hold the data in memory (either in the browser or in the serving application). Instead I'd page through the results using SQL.
How you do this can be database-specific. See [here](http://www.plus2net.com/sql_tutorial/sql_limit.php) for one example in MySql. Mechanisms will exist for other databases. | Display 100000 records on browser / multiple pages | [
"",
"java",
"jsp",
"jdbc",
""
] |
I have written a bunch of Perl libraries (actually Perl classes) and I want to use some of them in my Python application. Is there a natural way to do this without using SWIG or writing Perl API for Python. I am asking for a similar way of PHP's Perl [interface](http://devzone.zend.com/node/view/id/1712). If there is no such kind of work for Perl in Python. What is the easiest way to use Perl classes in python? | Personally, I would expose the Perl libs as services via XML/RPC or some other such mechanism. That way you can call them from your Python application in a very natural manner. | I haven't tried it, but [Inline::Python](http://search.cpan.org/dist/Inline-Python/Python.pod) lets you call Python from Perl.
You should be able to use a thin bit of perl to load your python app and then use the `perl` python package that comes with I::P to access your Perl objects. | How can I use Perl libraries from Python? | [
"",
"python",
"perl",
"api",
""
] |
Is there a better way to require that an argument is not null in a method? I keep checking if any of the arguments that my method requires are null, as show below. But I'm wondering if there is a better way.
```
public void MyMethod(string a, int b)
{
if(a==null){throw new ArgumentNullException("a");}
if(b==null){throw new ArgumentNullException("b");}
//more stuff here
}
``` | Rick Brewster (author of Paint.NET) blogged about a Fluent API alternative:
<http://blog.getpaint.net/2008/12/06/a-fluent-approach-to-c-parameter-validation/> | You can write some utility methods. This is the common pattern in java.
user code:
```
public void MyMethod(string a, int b)
{
//validate each
Objects.RequireNotNull(a);
Objects.RequireNotNull(b);
//or validate in single line as array
Objects.RequireNotNullArray(a, b);
}
```
implementation code:
```
public static class Objects
{
public static T RequireNotNull<T>(T arg)
{
if(arg == null)
{
throw new ArgumentNullException();
}
return arg;
}
public static object[] RequireNotNullArray(params object[] args)
{
return RequireNotNullArray<object>(args);
}
public static T[] RequireNotNullArray<T>(params T[] args)
{
Objects.RequireNotNull(args);
for(int i=0; i<args.Length; i++)
{
T arg = args[i];
if(arg == null)
{
throw new ArgumentNullException($"null entry at position:{i}");
}
}
return args;
}
}
```
You cannot get the variable name in the exception. but with the stack trace and your source code, it should be possible to easily track down. | Is there a way to require that an argument provided to a method is not null? | [
"",
"c#",
"null",
"methods",
"arguments",
""
] |
I requested 100 pages that all 404. I wrote
```
{
var s = DateTime.Now;
for(int i=0; i < 100;i++)
DL.CheckExist("http://google.com/lol" + i.ToString() + ".jpg");
var e = DateTime.Now;
var d = e-s;
d=d;
Console.WriteLine(d);
}
static public bool CheckExist(string url)
{
HttpWebRequest wreq = null;
HttpWebResponse wresp = null;
bool ret = false;
try
{
wreq = (HttpWebRequest)WebRequest.Create(url);
wreq.KeepAlive = true;
wreq.Method = "HEAD";
wresp = (HttpWebResponse)wreq.GetResponse();
ret = true;
}
catch (System.Net.WebException)
{
}
finally
{
if (wresp != null)
wresp.Close();
}
return ret;
}
```
Two runs show it takes 00:00:30.7968750 and 00:00:26.8750000. Then i tried firefox and use the following code
```
<html>
<body>
<script type="text/javascript">
for(var i=0; i<100; i++)
document.write("<img src=http://google.com/lol" + i + ".jpg><br>");
</script>
</body>
</html>
```
Using my comp time and counting it was roughly 4 seconds. 4 seconds is 6.5-7.5faster then my app. I plan to scan through a thousands of files so taking 3.75hours instead of 30mins would be a big problem. How can i make this code faster? I know someone will say firefox caches the images but i want to say 1) it still needs to check the headers from the remote server to see if it has been updated (which is what i want my app to do) 2) I am not receiving the body, my code should only be requesting the header. So, how do i solve this? | Probably Firefox issues multiple requests at once whereas your code does them one by one. Perhaps adding threads will speed up your program. | I noticed that an `HttpWebRequest` hangs on the first request. I did some research and what seems to be happening is that the request is configuring or auto-detecting proxies. If you set
```
request.Proxy = null;
```
on the web request object, you might be able to avoid an initial delay.
With proxy auto-detect:
```
using (var response = (HttpWebResponse)request.GetResponse()) //6,956 ms
{
}
```
Without proxy auto-detect:
```
request.Proxy = null;
using (var response = (HttpWebResponse)request.GetResponse()) //154 ms
{
}
``` | Why is this WebRequest code slow? | [
"",
"c#",
"httpwebrequest",
"httpwebresponse",
""
] |
I have two questions concerning the `sleep()` function in PHP:
1. Does the sleep time affect the maximum execution time limit of my PHP scripts? Sometimes, PHP shows the message "maximum execution time of 30 seconds exceeded". Will this message appear if I use `sleep(31)`?
2. Are there any risks when using the `sleep()`function? Does it cost a lot of CPU performance? | You should try it, just have a script that sleeps for more than your maximum execution time.
```
<?php
sleep(ini_get('max_execution_time') + 10);
?>
```
Spoiler: [Under Linux, sleeping time is ignored, but under Windows, it counts as execution time.](http://www.php.net/manual/en/function.set-time-limit.php#75557) | From the [PHP sleep() page](http://www.php.net/sleep), there's this user-contributed note:
> Note: The set\_time\_limit() function
> and the configuration directive
> max\_execution\_time only affect the
> execution time of the script itself.
> Any time spent on activity that
> happens outside the execution of the
> script such as system calls using
> system(), the sleep() function,
> database queries, etc. is not included
> when determining the maximum time that
> the script has been running. | Does sleep time count for execution time limit? | [
"",
"php",
"sleep",
"execution",
"max",
""
] |
Item is a simple model class.
ItemComponent is a view for an Item which just draws simple rectangles in a given spot. A bunch of ItemComponent instances are put into a parent component that is added to the JFrame of the application (just a simple shell right now).
The view has two different display styles. I want to adjust some properties of the model, and possibly change the state (which controls the style), and then call update() to repaint.
The problem is, as far as I can tell... paint() is only EVER called once. repaint() seems to have no effect.
What's wrong?
I'm not a Swing programmer and cobbled this together from examples, so I expect it may be something trivial here I don't understand.
```
public class ItemComponent extends JComponent implements ItemView {
private static final Color COLOR_FILL_NORMAL = new Color(0x008080ff);
private static final Color COLOR_FILL_TARGET = Color.LIGHT_GRAY;
private static final Color COLOR_OUTLINE = new Color(0x00333333);
Item item;
RoundRectangle2D rect;
State state = State.NORMAL;
float alpha = 1.0f;
public ItemComponent(Item item) {
this.item = item;
this.rect = new RoundRectangle2D.Double(0, 0, 0, 0, 5, 5);
item.setView(this);
}
public void setState(State state) {
this.state = state;
}
public void update() {
System.out.println("ItemComponent.update");
setLocation(item.getLeft(), 1);
setSize(item.getWidth(), getParent().getHeight()-1);
rect.setRoundRect(0, 0, getWidth()-1, getHeight()-1, 5, 5);
repaint();
//paintImmediately(getBounds());
}
@Override
public void addNotify() {
update();
}
@Override
public void paint(Graphics g) {
System.out.println("paint");
Graphics2D g2 = (Graphics2D)g;
g2.setComposite(AlphaComposite.getInstance(AlphaComposite.SRC_OVER, alpha));
if (state == State.NORMAL) {
System.out.println("draw normal");
g2.setPaint(COLOR_FILL_NORMAL); // light blue
g2.fill(rect);
g2.setPaint(COLOR_OUTLINE);
g2.draw(rect);
}
else if (state == State.TARGET) {
System.out.println("draw target");
g2.setPaint(COLOR_FILL_TARGET);
g2.fill(rect);
float[] dashPattern = { 8, 5 };
g2.setStroke(new BasicStroke(2, BasicStroke.CAP_BUTT, BasicStroke.JOIN_MITER, 10, dashPattern, 0));
g.setColor(COLOR_OUTLINE);
g2.draw(rect);
}
}
}
```
---
**Hint:**
I traced into repaint() and found a point where isDisplayable() was being checked, and it's returning false. It makes sure that getPeer() != null.
So my component has no peer? What's up with that? It's been added to a container which itself is added to the rest of the app. And it gets painted once, so I know it's visible. | My apologies to people who looked at this already. I trimmed down the code a bit for posting and inadvertently left out a key part:
```
@Override
public void addNotify() {
update();
}
```
I was using this to do some setup as soon as it's been added. Turns out it's pretty critical that you don't override this, or at least you need to call super.addNotify(), or a whole bunch of important initialization doesn't happen.
Changing it to this fixed the problem:
```
@Override
public void addNotify() {
super.addNotify();
update();
}
``` | The answer is somewhere [here](http://java.sun.com/products/jfc/tsc/articles/painting/index.html). Particularly the section on [Painting in Swing](http://java.sun.com/products/jfc/tsc/articles/painting/index.html#swing). I'm puzzled that moving the rendering code into paintComponent() didn't work as suggested by Johannes Rössel. As the documentation there says..
> The Paint Methods
>
> The rules that apply to AWT's
> lightweight components also apply to
> Swing components -- for instance,
> paint() gets called when it's time to
> render -- except that Swing further
> factors the paint() call into three
> separate methods, which are invoked in
> the following order:
>
> ```
> protected void paintComponent(Graphics g)
> protected void paintBorder(Graphics g)
> protected void paintChildren(Graphics g)
> ```
>
> Swing programs should override
> paintComponent() instead of overriding
> paint(). | Swing: why wont my custom component repaint? | [
"",
"java",
"user-interface",
"swing",
""
] |
```
/**
* Returns a number between kLowerBound and kUpperBound
* e.g.: Wrap(-1, 0, 4); // Returns 4
* e.g.: Wrap(5, 0, 4); // Returns 0
*/
int Wrap(int const kX, int const kLowerBound, int const kUpperBound)
{
// Suggest an implementation?
}
``` | The sign of `a % b` is only defined if `a` and `b` are both non-negative.
```
int Wrap(int kX, int const kLowerBound, int const kUpperBound)
{
int range_size = kUpperBound - kLowerBound + 1;
if (kX < kLowerBound)
kX += range_size * ((kLowerBound - kX) / range_size + 1);
return kLowerBound + (kX - kLowerBound) % range_size;
}
``` | The following should work independently of the implementation of the mod operator:
```
int range = kUpperBound - kLowerBound + 1;
kx = ((kx-kLowerBound) % range);
if (kx<0)
return kUpperBound + 1 + kx;
else
return kLowerBound + kx;
```
An advantage over other solutions is, that it uses only a single % (i.e. division), which makes it pretty efficient.
*Note (Off Topic):*
It's a good example, why sometimes it is wise to define intervals with the upper bound being being the first element not in the range (such as for STL iterators...). In this case, both "+1" would vanish. | Clean, efficient algorithm for wrapping integers in C++ | [
"",
"c++",
"algorithm",
"math",
"word-wrap",
"integer",
""
] |
I hope that made sense, let me elaborate:
There is a table of tracking data for a quiz program where each row has..
QuestionID and AnswerID (there is a table for each). So because of a bug there were a bunch of QuestionIDs set to NULL, but the QuestionID of a related AnswerID is in the Answers table.
So say QuestionID is NULL and AnswerID is 500, if we go to the Answers table and find AnswerID 500 there is a column with the QuestionID that should have been where the NULL value is.
So basically I want to set each NULL QuestionID to be equal to the QuestionID found in the Answers table on the Answer row of the AnswerID that is in the trackings table (same row as the NULL QuestionID that is being written).
How would I do this?
```
UPDATE QuestionTrackings
SET QuestionID = (need some select query that will get the QuestionID from the AnswerID in this row)
WHERE QuestionID is NULL AND ... ?
```
Not sure how I will be able to make it assign the QuestionID to the QuestionID from the matching AnswerID... | ```
update QuestionTrackings q
inner join QuestionAnswers a
on q.AnswerID = a.AnswerID
set q.QuestionID = a.QuestionID
where q.QuestionID is null -- and other conditions you might want
```
I recommend to check what the result set to update is before running the update (same query, just with a select):
```
select *
from QuestionTrackings q
inner join QuestionAnswers a
on q.AnswerID = a.AnswerID
where q.QuestionID is null -- and other conditions you might want
```
Particularly whether each answer id has definitely only 1 associated question id. | Without the update-and-join notation (not all DBMS support that), use:
```
UPDATE QuestionTrackings
SET QuestionID = (SELECT QuestionID
FROM AnswerTrackings
WHERE AnswerTrackings.AnswerID = QuestionTrackings.AnswerID)
WHERE QuestionID IS NULL
AND EXISTS(SELECT QuestionID
FROM AnswerTrackings
WHERE AnswerTrackings.AnswerID = QuestionTrackings.AnswerID)
```
Often in a query like this, you need to qualify the WHERE clause with an EXISTS clause that contains the sub-query. This prevents the UPDATE from trampling over rows where there is no match (usually nulling all the values). In this case, since a missing question ID would change the NULL to NULL, it arguably doesn't matter. | SQL UPDATE SET one column to be equal to a value in a related table referenced by a different column? | [
"",
"sql",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.