
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
What I'm looking for is a clean method to round the corners of all inputs with the class "submit". I've experimented with a number of javascript techniques, but none worked well for form elements. Pure CSS would be great, but, note, the button needs to expand, and will have arbitrary text. Other methods required really ugly HTML cruft around the inputs, which I don't want.
Any ideas? | Try [CurvyCorners](http://www.curvycorners.net/) (30,100 bytes, minified) for this solution because IE browser will not make it rounded. I haven't tried adding an image though.
```
<style type="text/css">
.input-rounded-button {
-webkit-border-radius: 5px;
-moz-border-radius: 5px;
border-radius: 5px;
border: 1px solid gray;
padding:0 3px 0 3px;
display:inline-block;
text-decoration:none;
background:#595651;
color:#FFFFFF;
cursor:pointer;
font:11px sans-serif;
}
.input-rounded-button:hover {
text-decoration:none;
color:#ADD8E6;
cursor:pointer;
border:1px solid #FF2B06;
}
</style>
<input class="input-rounded-button" type="button" value="SEARCH" />
``` | I've been using this method for a while -
<http://www.oscaralexander.com/tutorials/how-to-make-sexy-buttons-with-css.html>
It works pretty well | Method to render rounded corners on form submit buttons | [
"",
"javascript",
"html",
"css",
"user-interface",
"rounded-corners",
""
] |
The company I work for creates applications for the Blackberry platform.
We've been working on a proprietary "analytics system" that allows us to embed code within our applications and have the applications report back some stats to our central servers every time they're run. Currently, the system works ok; however it's only in beta with 100-200 hits per hour. The "hits" are sent to the servers without a problem. We've built a very solid API to handle the acceptance and storage of the hits (in a MySQL DB). We've tested the load and we should be able to accommodate hundreds of thousands of hits per hour without a problem. That's not really a problem.
The problem is showing the stats. We've built a display panel similar to Mint's (haveamint.com), it shows the hits over each hour, the past days, months, weeks, years...etc. The fist version ran straight queries pulling data from the hits table and interpreting it on the fly. That didn't work for very long. Our current solution is that the hits are "queued" for processing and we have a cron come through every 5 minutes taking the hits and sorting them into "caches" for each hour, day, week, month, year...etc. This works amazing and it's incredibly scalable; however, it only works for 1 timezone. Since the entire company has access to this, we're dealing with a few hundred users in various timezones. What I define as "Today" in San Jose is MUCH different than what my colleague in London defines as Today. Since the current solution is only cached to 1 timezone, it's a nightmare for anyone who's checking the data outside of our timezone.
Our current plan to fix this is to create caches for every timezone (40 in total); however, that would mean that we're multiplying the amount of data by 40...that's terrible to me and given that the caches can be very large, multiplying it just sounds like a bad idea; plus, when we go to process the queue, it's going to take a lot more CPU time to put them in 40 different caches.
Any one else have a better idea of how to solve this problem?
(Sorry for such a long question..it's not exactly easy to explain. Thanks all!) | The solution you are proposing has too much redundancy. I would suggest you store the data in at least 30-minute buckets instead of hourly and the time zone be normalized to UTC.
With 30-minute buckets, if a user requests hourly data for 1 - 2PM from -4.5 UTC you can fetch data for 5:30 - 6:30PM from your system and show that. If you store data in one-hour increments you can't service requests to users in time zones with N + 0.5 hour differences.
For daily numbers you would need to aggregate 48 half-hour slots. The slots to pick would be determined by the user's time zone.
It gets interesting when you get to annual data because you end up having to aggregate 17,520 half-hour buckets. To ease that computation I would suggest you get the pre-aggregated annual data per UTC time and the subtract aggregate data for the first for 4.5 hours of the year and add aggregate data for the first 4.5 hours of the next year. This will essentially shift the whole year by 4.5 hours and the work is not that much. Working from here, you can tweak the system further.
EDIT: Turns out Kathmandu is +5.45 GMT so you would need to store the data in 15-minute buckets instead of 30-minute buckets.
EDIT 2: Another easy improvement is around aggregating annual so you don't have to add 17,520 buckets each time and without requiring one aggregate per country. Aggregate the annual data from Jan 02 - Dec 30. Since the maximum time-zone difference between any two countries is 23 hours, this means that you can take the annual data (Jan 02 - Dec 30) and add a few buckets before and after as appropriate. For example for a -5 UTC timezone you would add all buckets on Jan 01 after 0500, all buckets on Dec 31, and on Jan 01 the following year up to 0500 hours. | When designing software that touches multiple timezones, I'd say to always store your date/times in [UTC](http://en.wikipedia.org/wiki/Coordinated_Universal_Time) with another field for the original timezone and have a function that takes the time and converts it to and from UTC/timezone. You'll save yourself a lot of trouble to handle the different cases of day switch, daylight savings, people looking at stats from a country from the other side of the earth and so on....
In your case, having the caches in UTC and just adjusting the requests to be converted in UTC should help. Don't store a stat as being "today", store it for hours 00:00:00UTC to 23:59:59UTC and when someone asks for the stats for today in New York, do the conversion. | Best way to design a scaleable hits/analytics system? | [
"",
"php",
"mysql",
"date",
"time",
"analytics",
""
] |
If Python had a macro facility similar to Lisp/Scheme (something like [MetaPython](https://code.google.com/p/metapython/)), how would you use it?
If you are a Lisp/Scheme programmer, what sorts of things do you use macros for (other than things that have a clear syntactic parallel in Python such as a while loop)? | Some examples of lisp macros:
* [ITERATE](http://common-lisp.net/project/iterate) which is a funny and extensible loop facility
* [CL-YACC](http://www.pps.jussieu.fr/~jch/software/cl-yacc/)/[FUCC](http://common-lisp.net/project/fucc) that are parser generators that generate parsers at compile time
* [CL-WHO](http://www.weitz.de/cl-who/) which allows specifying html documents with static and dynamic parts
* [Parenscript](http://common-lisp.net/project/parenscript/) which is a javascript code generator
* Various simple code-wrappers, e.g., error handlers (I have a with-gtk-error-message-handler that executes code and shows GtkMessageDialog if unhandled error occurs), executors (e.g., given a code, execute it in different thread; I have a within-main-thread macro that executes code in different threads; [PCall](http://marijn.haverbeke.nl/pcall/) library uses macros to wrap code to be executed concurrently)
* GUI builders with macros (e.g., specify widgets hierarchy and widgets' properties and have a macro generate code for creation of all widgets)
* Code generators that use external resources during compilation time. E.g., a macro that processes C headers and generates FFI code or a macro that generates classes definitions based on database schema
* Declarative FFI. E.g., specifying the foreign structures, functions, their argument types and having macros to generate corresponding lisp structures, functions with type mapping and marshaling code
* Continuations-based web frameworks for Common Lisp use macros that transform the code into CPS (continuation passing style) form. | This is a somewhat late answer, but [MacroPy](https://github.com/lihaoyi/macropy) is a new project of mine to bring macros to Python. We have a pretty substantial list of demos, all of which are use cases which require macros to implement, for example providing an extremely concise way of declaring classes:
```
@case
class Point(x, y)
p = Point(1, 2)
print p.x # 1
print p # Point(1, 2)
```
MacroPy has been used to implement features such as:
* Case Classes, easy [Algebraic Data Types](https://en.wikipedia.org/wiki/Algebraic_data_type) from Scala
* Pattern Matching from the Functional Programming world
* Tail-call Optimization
* Quasiquotes, a quick way to manipulate fragments of a program
* String Interpolation, a common feature in many languages, and Pyxl.
* Tracing and Smart Asserts
* PINQ to SQLAlchemy, a clone of LINQ to SQL from C#
* Quick Lambdas from Scala and Groovy,
* Parser Combinators, inspired by [Scala's](http://www.suryasuravarapu.com/2011/04/scala-parser-combinators-win.html).
Check out the linked page to find out more; I think I can confidently say that the use cases we demonstrate far surpass anything anyone's suggested so far on this thread =D | Python Macros: Use Cases? | [
"",
"python",
"macros",
"lisp",
"scheme",
""
] |
I have a JTable that stores the results of a database query, so far so good. What I want is for the last column in each table to have a clickible JButton that will open the edit screen for the object represented in that row, and that means the button will need to know the details of the first column in the table from its own row (the ID from the database).
Any advice? I already tried just adding JButtons but they turned into Text when I tried to run it. | Contrary to the tutorial above, there is a way to do this without a complicated positioning math, custom mouse listeners, and custom table models. Instead, it can be done with a single simple custom class following the pattern described here:
<http://web.archive.org/web/20100623105810/http://ivolo.mit.edu/post/A-Simple-Pattern-for-Embedding-Components-into-a-Swing-JTable.aspx> | You may also find my tutorial on a similar subject (in this case, using a JPanel) helpful as well: [Custom JPanel cell with JButtons in JTable](http://pekalicious.com/blog/custom-jpanel-cell-with-jbuttons-in-jtable/) | Is it possible to include JButton in a JTable? | [
"",
"java",
"swing",
"jtable",
"jbutton",
""
] |
How can i put the result of a sql server query into a "comma delimited" format? | You should be able to go to `Tools->Options->Query Results` in SQL Server Management Studio and set the preferences there to output to a text file.
Then expand that and in "Result to Text" you can set the output format there. | Check out [this answer](http://forums.mysql.com/read.php?79,11324,13062#msg-13062) on the MySQL forums.
Here's the snippet.
```
SELECT a,b INTO OUTFILE '/tmp/result.text'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM test_table;
``` | Comma delimited output from SQL query | [
"",
"sql",
"csv",
""
] |
How do I remove leading and trailing whitespace from a string in Python?
```
" Hello world " --> "Hello world"
" Hello world" --> "Hello world"
"Hello world " --> "Hello world"
"Hello world" --> "Hello world"
``` | To remove all whitespace surrounding a string, use [`.strip()`](https://docs.python.org/library/stdtypes.html#str.strip). Examples:
```
>>> ' Hello '.strip()
'Hello'
>>> ' Hello'.strip()
'Hello'
>>> 'Bob has a cat'.strip()
'Bob has a cat'
>>> ' Hello '.strip() # ALL consecutive spaces at both ends removed
'Hello'
```
Note that [`str.strip()`](https://docs.python.org/library/stdtypes.html#str.strip) removes all whitespace characters, including tabs and newlines. To remove only spaces, specify the specific character to remove as an argument to `strip`:
```
>>> " Hello\n ".strip(" ")
'Hello\n'
```
---
To remove only one space at most:
```
def strip_one_space(s):
if s.endswith(" "): s = s[:-1]
if s.startswith(" "): s = s[1:]
return s
>>> strip_one_space(" Hello ")
' Hello'
``` | As pointed out in answers above
```
my_string.strip()
```
will remove all the leading and trailing whitespace characters such as `\n`, `\r`, `\t`, `\f`, space .
For more flexibility use the following
* Removes only **leading** whitespace chars: [`my_string.lstrip()`](https://docs.python.org/library/stdtypes.html#str.lstrip)
* Removes only **trailing** whitespace chars: [`my_string.rstrip()`](https://docs.python.org/library/stdtypes.html#str.rstrip)
* Removes **specific** whitespace chars: `my_string.strip('\n')` or `my_string.lstrip('\n\r')` or `my_string.rstrip('\n\t')` and so on.
More details are available in the [docs](https://docs.python.org/library/stdtypes.html#string-methods). | How do I trim whitespace from a string? | [
"",
"python",
"string",
"trim",
""
] |
I got a user control which implements a reference to a css file, now I want to use this user control many times on page, and this will lead to duplication of inclusion of the css file.
With javascript files it is simple by using the `ScriptManager`.
So what is your suggestion for a solution or similar approach to the `ScriptManager`? | There is no easy way to check if the styles are registered to the page like ClientScript utility.
If you register your styles as an external css file to page like that :
```
HtmlLink link = new HtmlLink();
link.Href = relativePath;
link.Attributes["type"] = "text/css";
link.Attributes["rel"] = "stylesheet";
Page.Header.Controls.Add(link);
```
You can then check if it exists by looping the page header's Controls collection and looking for the path of the CSS file. | Here's a technique I've used before, although it may not be the best one:
```
Dim cssLink As String = String.Format("<link rel='stylesheet' type='text/css' href='{0}/css/cssLink.css' />", Request.ApplicationPath)
If (From c As LiteralControl In Page.Header.Controls.OfType(Of LiteralControl)() Where c.Text = cssLink).Count = 0 Then
Page.Header.Controls.Add(New LiteralControl(cssLink))
End If
``` | Preventing the duplication of CSS files? | [
"",
"c#",
"asp.net",
"css",
""
] |
I'm new to PHP/MySQL and super-new to CodeIgniter..
I have information in many MySQL tables. I want to retrieve it with JOIN where the tables primary keys are equal to $variable... How can I do it and get all the fields without the primary key field???
What I'm doing now is this (only two tables joined here):
```
function getAll($id) {
$this->db->select('*');
$this->db->from('movies');
$this->db->join('posters', 'movies.id= posters.id');
// WHERE id = $id ... goes here somehow...
$q = $this->db->get();
if ($q->num_rows() == 1) {
$row = $q->row();
$data = array(
'id' => $row->id,
'title' => $row->title,
'year' => $row->year,
'runtime' => $row->runtime,
'plotoutline' => $row->plotoutline,
'poster_url' => $row->poster_url
);
}
$q->free_result();
return $data;
```
id (PK), title, year, runtime and plotoutline are columns from the first table and poster\_url is a field from the second table. The second table also contains an ID (PK) column that I don't want to Retrieve because I already have. | Jon is right. Here's an example:
```
$this->db->select('movies.id,
movies.title,
movies.year,
movies.runtime as totaltime,
posters.poster_url');
$this->db->from('movies');
$this->db->join('posters', 'movies.id= posters.id');
$this->db->where('movies.id', $id);
$q = $this->db->get();
```
This will return objects that have ->id, ->title, ->year, ->totaltime, and ->poster\_url properties. You won't need the additional code to fetch the data from each row.
Don't forget, if the Active Record syntax gets a little unwieldy, you can use full SQL queries and get the same results:
```
$sql = "SELECT movies.id,
movies.title,
movies.year,
movies.runtime as totaltime,
posters.poster_url
FROM movies
INNER JOIN posters ON movies.id = posters.id
WHERE movies.id = ?"
return $this->db->query($sql, array($id))->result();
```
Both forms will ensure that your data is escaped properly.
[CodeIgniter Active Record](http://codeigniter.com/user_guide/database/active_record.html)
[Query Binding in CodeIgniter](http://codeigniter.com/user_guide/database/queries.html) | An asterisk will return all the fields. To return a subset of these, i.e. all fields apart form the repeated id field, simply list the columns which you require rather than use '\*'.
It is often a good idea to not use asterisk anyway. In the future of the app, someone may add a large field to the table which will be surplus to your requirements, and will slow your queries. | CodeIgniter/PHP/MySQL: Retrieving data with JOIN | [
"",
"php",
"mysql",
"codeigniter",
""
] |
Is there a library available for AES 256-bits encryption in Javascript? | JSAES is a powerful implementation of AES in JavaScript.
<http://point-at-infinity.org/jsaes/> | Here's [a demonstration page](http://cheeso.members.winisp.net/AES-Encryption.htm) that uses slowAES.
[slowAES](http://code.google.com/p/slowaes) was easy to use. Logically designed. Reasonable OO packaging. Supports knobs and levers like IV and Encryption mode. Good compatibility with .NET/C#. The name is tongue-in-cheek; it's called "**slow** AES" because it's not implemented in C++. But in my tests it was not impractically slow.
It lacks an ECB mode. Also lacks a CTR mode, although you could build one pretty easily given an ECB mode, I guess.
It is solely focused on encryption. A nice complementary class that does [RFC2898](http://www.ietf.org/rfc/rfc2898.txt)-compliant password-based key derivation, in Javascript, is [available from Anandam](http://anandam.name/pbkdf2/). This pair of libraries works well with the analogous .NET classes. Good interop. Though, in contrast to SlowAES, the Javascript PBKDF2 is noticeably slower than the [Rfc2898DeriveBytes](http://msdn.microsoft.com/en-us/library/system.security.cryptography.rfc2898derivebytes.aspx) class when generating keys.
It's not surprising that technically there is good interop, but the key point for me was the model adopted by SlowAES is familiar and easy to use. I found some of the other Javascript libraries for AES to be hard to understand and use. For example, in some of them I couldn't find the place to set the IV, or the mode (CBC, ECB, etc). Things were not where I expected them to be. SlowAES was not like that. The properties were right where I expected them to be. It was easy for me to pick up, having been familiar with the Java and .NET crypto programming models.
Anandam's PBKDF2 was not quite on that level. It supported only a single call to DeriveBytes function, so if you need to derive both a key and an IV from a password, this library won't work, unchanged. Some slight modification, and it is working just fine for that purpose.
**EDIT**: I put together [an example](http://cheeso.members.winisp.net/srcview.aspx?dir=AES-example) of packaging [SlowAES](http://code.google.com/p/slowaes) and a modified version of Anandam's [PBKDF2](http://anandam.name/pbkdf2/) into Windows Script Components. Using this AES with a password-derived key shows good interop with the .NET RijndaelManaged class.
**EDIT2**: [the demo page](http://cheeso.members.winisp.net/AES-Encryption.htm) shows how to use this AES encryption from a web page. Using the same inputs (iv, key, mode, etc) supported in .NET gives you good interop with the .NET Rijndael class. You can do a "view source" to get the javascript for that page.
**EDIT3**
a late addition: [Javascript Cryptography considered harmful.](https://web.archive.org/web/20160323100711/https://www.nccgroup.trust/us/about-us/newsroom-and-events/blog/2011/august/javascript-cryptography-considered-harmful/) Worth the read. | Javascript AES encryption | [
"",
"javascript",
"encryption",
"aes",
""
] |
I need to convert markdown text to plain text format to display summary in my website. I want the code in python. | The [Markdown](https://pypi.org/project/Markdown/) and [BeautifulSoup](https://pypi.org/project/beautifulsoup4/) (now called *beautifulsoup4*) modules will help do what you describe.
Once you have converted the markdown to HTML, you can use a HTML parser to strip out the plain text.
Your code might look something like this:
```
from bs4 import BeautifulSoup
from markdown import markdown
html = markdown(some_html_string)
text = ''.join(BeautifulSoup(html).findAll(text=True))
``` | Despite the fact that this is a very old question, I'd like to suggest a solution I came up with recently. This one neither uses BeautifulSoup nor has an overhead of converting to html and back.
The **markdown** module core class Markdown has a property **output\_formats** which is not configurable but otherwise patchable like almost anything in python is. This property is a dict mapping output format name to a rendering function. By default it has two output formats, 'html' and 'xhtml' correspondingly. With a little help it may have a plaintext rendering function which is easy to write:
```
from markdown import Markdown
from io import StringIO
def unmark_element(element, stream=None):
if stream is None:
stream = StringIO()
if element.text:
stream.write(element.text)
for sub in element:
unmark_element(sub, stream)
if element.tail:
stream.write(element.tail)
return stream.getvalue()
# patching Markdown
Markdown.output_formats["plain"] = unmark_element
__md = Markdown(output_format="plain")
__md.stripTopLevelTags = False
def unmark(text):
return __md.convert(text)
```
**unmark** function takes markdown text as an input and returns all the markdown characters stripped out. | Python : How to convert markdown formatted text to text | [
"",
"python",
"parsing",
"markdown",
""
] |
I essentially have a database layer that is totally isolated from any business logic. This means that whenever I get ready to commit some business data to a database, I have to pass all of the business properties into the data method's parameter. For example:
`Public Function Commit(foo as object) as Boolean`
This works fine, but when I get into commits and updates that take dozens of parameters, it can be a lot of typing. Not to mention that two of my methods--update and create--take the same parameters since they essentially do the same thing. What I'm wondering is, what would be an optimal solution for passing these parameters so that I don't have to change the parameters in both methods every time something changes as well as reduce my typing :) I've thought of a few possible solutions. One would be to move all the sql parameters to the class level of the data class and then store them in some sort of array that I set in the business layer. Any help would be useful! | Thanks for the responses, but I think I've figured out a better way for what I'm doing. It's similar to using the upsert, but what I do is have one method called Commit that looks for the given primary key. If the record is found in the database, then I execute an update command. If not, I do an insert command. Since the parameters are the same, you don't have to worry about changing them any. | For your problem I guess Iterator design pattern is the best solution. Pass in an Interface implementation say ICommitableValues you can pass in a key pair enumeration value like this. Keys are the column names and values are the column commitable values. A property is even dedicated as to return the table name in which to insert these value and or store procedures etc.
To save typing you can use declarative programming syntax (Attributes) to declare the commitable properties and a main class in middleware can use reflection to extract the values of these commitable properties and prepare a ICommitableEnumeration implementation from it. | Best Way to Handle SQL Parameters? | [
"",
"sql",
".net",
"parameters",
"data-access-layer",
""
] |
I've been studying up on static reflection with LINQ expressions - very cool!
One thought I had - is it possible for one class to 'generate' fields on one class based on static reflection done on another class? I'm thinking specifically of the Builder pattern I've seen here many times. I would like to do a fluent-nhibernate-style property registration that 'generates' fields on the builder that match the class I want to build. Soemthing like this:
```
public class Color
{
private Color()
{
}
public string Name { get; private set; }
public class Builder : BuilderBase<Color>
{
public Builder()
{
Property(x => x.Name);
}
public Build()
{
return built_up_color;
}
}
}
```
and support constructor syntax like this:
```
Color c = new Color.Builder() { Name = "Red" }.Build();
```
The point of all this is to reduce the number of times I have to repeat defining the properies of Color. I played with this:
```
public class Color
{
private Color()
{
}
public string Name { get; private set; }
public class Builder
{
private Color _color = new Color();
public string Name
{
get { return _color.Name; }
set { _color.Name = value; }
}
public Build()
{
return _color;
}
}
}
```
which certainly works AND lists the properties the same # of times but feels wordier and less flexible. It seems like I should be able to do something anonymous-type-y here? | Worth pointing out that Having a class called Color clashing with the System.Drawing.Color is probably a bad idea.
It is *very* likely to lead to confusion in others (worse still System.Drawring.Color has value semantics whereas your class has reference semantics which can lead to further confusion)
I would point out that what you really want is [Named Optional Arguments](http://blogs.msdn.com/samng/archive/2009/02/03/named-arguments-optional-arguments-and-default-values.aspx). I would suggest that putting in cumbersome Builder classes now will be more effort and made it more painful to move to these once you get to c# 4.0. Instead make the constructors that are required (or if need be to avoid type signature collisions static factory methods on the class) | I think it's impossible, you can't generate members except by declaring them explicitly. Bite the bullet and declare a constructor for `Color`.
PS: I think static reflection is a misnomer, the only thing that's static is the lookup of the member you want to reference — a good thing as far as it goes, but that's not very far. | On-the-fly fields from Static Reflection? | [
"",
"c#",
"reflection",
"static-reflection",
""
] |
I am fairly new to reflection and I would like to know, if possible, how to create an instance of a class then add properties to the class, set those properties, then read them later. I don't have any code as i don't even know how to start going about this. C# or VB is fine.
Thank You
EDIT: (to elaborate)
My system has a dynamic form creator. one of my associates requires that the form data be accessible via web service. My idea was to create a class (based on the dynamic form) add properties to the class (based on the forms fields) set those properties (based on the values input for those fields) then return the class in the web service.
additionally, the web service will be able to set the properties in the class and eventually commit those changes to the db. | I know this is being overly simplified by why not just KISS and generate the required Xml to return through the Web Service and then parse the returned Xml to populate the database.
My reasoning is that for the expanded reason you suggest doing this I can see the value or reason for wanting a dynamic class? | If you mean dynamically create a class, then the two options are:
* [Reflection.Emit](http://msdn.microsoft.com/en-us/library/3y322t50.aspx) - Difficult, Fast to create the class
* [CodeDom](http://msdn.microsoft.com/en-us/library/y2k85ax6.aspx) - Less Difficult, Slower to create the class
If you mean create an instance of an existing class, then start with [Activator.CreateInstance](http://msdn.microsoft.com/en-us/library/system.activator.createinstance.aspx) to create an instance of the object, and then look at the methods on [Type](http://msdn.microsoft.com/en-us/library/system.type.aspx) such as [GetProperty](http://msdn.microsoft.com/en-us/library/system.type.getproperty.aspx) which will return a [PropertyInfo](http://msdn.microsoft.com/en-us/library/system.type.getproperty.aspx) that you can call [GetValue](http://msdn.microsoft.com/en-us/library/system.reflection.propertyinfo.getvalue.aspx) and [SetValue](http://msdn.microsoft.com/en-us/library/system.reflection.propertyinfo.setvalue.aspx) on.
---
Update: For the scenario you describe, returning dynamic data from a web service, then I'd recommend against this approach as it's hard for you to code, and hard for statically-typed languages to consume. Instead, as suggested in the comments and one of the other answers, some sort of dictionary would likely be a better option.
(Note that when I say return some sort of dictionary, I am speaking figuratively rather than literally, i.e. return something which is conceptually the same as a dictionary such as a list of key-value pairs. I wouldn't recommend directly returning one (even if you're using WCF which does support this) because it's typically better to have full control over the XML you return.) | .NET Reflection Create Class Properties | [
"",
"c#",
".net",
"vb.net",
"reflection",
""
] |
I would like to somehow log every time `Thread.interrupt()` is called, logging which Thread issued the call (and its current stack) as well as identifying information about which Thread is being interrupted.
Is there a way to do this? Searching for information, I saw someone reference the possibility of implementing a security manager. Is this something that can be done at runtime (e.g., in an Applet or Web Start client), or do you need to tool the installed JVM to do this?
Or is there a better way to do this? | As a quick hack, this was a *lot* easier to do than I thought it would be. Since this is a quick hack, I didn't do things like ensure that the stack trace is deep enough before dereferencing the array, etc. I inserted the following in my signed Applet's constructor:
```
log.info("Old security manager = " + System.getSecurityManager());
System.setSecurityManager(new SecurityManager() {
@Override
public void checkAccess(final Thread t) {
StackTraceElement[] list = Thread.currentThread().getStackTrace();
StackTraceElement element = list[3];
if (element.getMethodName().equals("interrupt")) {
log.info("CheckAccess to interrupt(Thread = " + t.getName() + ") - "
+ element.getMethodName());
dumpThreadStack(Thread.currentThread());
}
super.checkAccess(t);
}
});
```
and the `dumpThreadStack` method is as follows:
```
public static void dumpThreadStack(final Thread thread) {
StringBuilder builder = new StringBuilder('\n');
try {
for (StackTraceElement element : thread.getStackTrace()) {
builder.append(element.toString()).append('\n');
}
} catch (SecurityException e) { /* ignore */ }
log.info(builder.toString());
}
```
I could never, of course, leave this in production code, but it sufficed to tell me exactly which thread was causing an `interrupt()` that I didn't expect. That is, with this code in place, I get a stack dump for every call to `Thread.interrupt()`. | Before trying anything too wild, have you considered using the [Java debugging](http://docs.rinet.ru/JaTricks/ch26.htm) [API](http://download.java.net/jdk7/docs/jdk/api/jpda/jdi/index.html)? I'd think that capturing MethodEntryEvents on Thread.interrupt() would do it.
Eeek, that's the old interface, you should also check oout the new [JVM Tool](http://java.sun.com/j2se/1.5.0/docs/guide/jvmti/jvmti.html) [Interface](http://java.sun.com/j2se/1.5.0/docs/guide/jpda/enhancements.html). | Is there any way in Java to log *every* Thread interrupt? | [
"",
"java",
"multithreading",
"debugging",
"interrupt",
""
] |
In the post [Enum ToString](https://stackoverflow.com/questions/479410/enum-tostring), a method is described to use the custom attribute `DescriptionAttribute` like this:
```
Enum HowNice {
[Description("Really Nice")]
ReallyNice,
[Description("Kinda Nice")]
SortOfNice,
[Description("Not Nice At All")]
NotNice
}
```
And then, you call a function `GetDescription`, using syntax like:
```
GetDescription<HowNice>(NotNice); // Returns "Not Nice At All"
```
But that doesn't really help me **when I want to simply populate a ComboBox with the values of an enum, since I cannot force the ComboBox to call `GetDescription`**.
What I want has the following requirements:
* Reading `(HowNice)myComboBox.selectedItem` will return the selected value as the enum value.
* The user should see the user-friendly display strings, and not just the name of the enumeration values. So instead of seeing "`NotNice`", the user would see "`Not Nice At All`".
* Hopefully, the solution will require minimal code changes to existing enumerations.
Obviously, I could implement a new class for each enum that I create, and override its `ToString()`, but that's a lot of work for each enum, and I'd rather avoid that.
Any ideas?
Heck, I'll even throw in a [hug](https://stackoverflow.com/questions/795979/retrieve-a-list-of-the-most-popular-get-param-variations-for-a-given-url) as a bounty :-) | You could write an TypeConverter that reads specified attributes to look them up in your resources. Thus you would get multi-language support for display names without much hassle.
Look into the TypeConverter's ConvertFrom/ConvertTo methods, and use reflection to read attributes on your enum *fields*. | `ComboBox` has everything you need: the `FormattingEnabled` property, which you should set to `true`, and `Format` event, where you'll need to place desired formatting logic. Thus,
```
myComboBox.FormattingEnabled = true;
myComboBox.Format += delegate(object sender, ListControlConvertEventArgs e)
{
e.Value = GetDescription<HowNice>((HowNice)e.Value);
}
``` | How do I have an enum bound combobox with custom string formatting for enum values? | [
"",
"c#",
"combobox",
"enums",
""
] |
Hello i want to make something on classes
i want to do a super class which one is my all class is extended on it
```
____ database class
/
chesterx _/______ member class
\
\_____ another class
```
i want to call the method that is in the database class like this
```
$this->database->smtelse();
class Hello extends Chesterx{
public function ornekFunc(){
$this->database->getQuery('popularNews');
$this->member->lastRegistered();
}
}
```
and i want to call a method with its parent class name when i extend my super class to any class | I'm not quite sure what you mean by your last sentence but this is perfectly valid:
```
class Chesterx{
public $database, $member;
public function __construct(){
$this->database = new database; //Whatever you use to create a database
$this->member = new member;
}
}
``` | Consider the Singleton pattern - it usually fits better for database interactions. <http://en.wikipedia.org/wiki/Singleton_pattern>. | $this->a->b->c->d calling methods from a superclass in php | [
"",
"php",
"oop",
""
] |
Trying to persist Guid's in a MySQL db from C# (.NET). MySQL column is of type BINARY(16). Any sugestion on how to persist the guid and later get the guid back to from MySQL? Looking for a code answer here :-) | Figured it out. Here's how ...
Database schema
```
CREATE TABLE `test` (
`id` BINARY(16) NOT NULL,
PRIMARY KEY (`id`)
)
```
Code
```
string connectionString = string.Format("Server={0};Database={1};Uid={2};pwd={3}", "server", "database", "user", "password");
Guid orgId = Guid.NewGuid();
Guid fromDb = Guid.Empty;
using (MySqlConnection conn = new MySqlConnection(connectionString))
{
conn.Open();
using (MySqlCommand cmd = new MySqlCommand("INSERT INTO test (id) VALUES (?id)", conn))
{
cmd.Parameters.Add("id", MySqlDbType.Binary).Value = orgId.ToByteArray();
cmd.ExecuteNonQuery();
}
using (MySqlCommand cmd = new MySqlCommand("SELECT id FROM test", conn))
{
using (MySqlDataReader r = cmd.ExecuteReader())
{
r.Read();
fromDb = new Guid((byte[])r.GetValue(0));
}
}
}
``` | Apparently, the `GetGuid()` method in MySQL .NET Connector v5.2.6+ should be fixed so you can [use this example](http://bugs.mysql.com/bug.php?id=41452). | Store GUID in MySQL from C# | [
"",
"c#",
"mysql",
""
] |
I use vectors, lists, strings and wstrings obsessively in my code. Are there any catch 22s involved that should make me more interested in using arrays from time to time, chars and wchars instead?
Basically, if working in an environment which supports the standard template library is there any case using the primitive types is actually better? | For 99% of the time and for 99% of Standard Library implementations, you will find that std::vectors will be fast enough, and the convenience and safety you get from using them will more than outweigh any small performance cost.
For those very rare cases when you really need bare-metal code, you can treat a vector like a C-style array:
```
vector <int> v( 100 );
int * p = &v[0];
p[3] = 42;
```
The C++ standard guarantees that vectors are allocated contiguously, so this is guaranteed to work.
Regarding strings, the convenience factor becomes almnost overwhelming, and the performance issues tend to go away. If you go beack to C-style strings, you are also going back to the use of functions like strlen(), which are inherently very inefficent themselves.
As for lists, you should think twice, and probably thrice, before using them at all, whether your own implementation or the standard. The vast majority of computing problems are better solved using a vector/array. The reason lists appear so often in the literature is to a large part because they are a convenient data structure for textbook and training course writers to use to explain pointers and dynamic allocation in one go. I speak here as an ex training course writer. | I would stick to STL classes (vectors, strings, etc). They are safer, easier to use, more productive, with less probability to have memory leaks and, AFAIK, they make some additional, run-time checking of boundaries, at least at DEBUG time (Visual C++).
Then, measure the performance. If you identify the bottleneck(s) is on STL classes, then move to C style strings and arrays usage.
From my experience, the chances to have the bottleneck on vector or string usage are very low. | Are there any practical limitations to only using std::string instead of char arrays and std::vector/list instead of arrays in c++? | [
"",
"c++",
"arrays",
"list",
"vector",
"std",
""
] |
I've got files on Amazon's S3. They are named with a unique ID so there are no duplicates. I am accessing them using an authorized URL. I need to be able to pass them through to the browser, but I need to rename them. Right now I'm using fopen, but it is downloading the file to my server before serving the file to the browser. How can I have the files 'pass through' my server to the browser? Or how do I buffer the download - downloading a small chunk to my server and pass that to the browser while downloading the next chunk?
Also - I would really like to use CloudFront but they don't offer authenticated URLs. I believe I can use CURL to send credentials for the request - can I do this sort of 'pass through' file serving with CURL?
Thanks! | I'm not familiar with how S3 works, so I don't know if this solution is possible. But couldn't you simply redirect the user's browser to the file? If I understand correctly, S3 allows you to create web URLs for any of the files in your bucket. So if, say, these are paid downloads, then you could [have S3 generate a temporary URL for that download](http://bart.motd.be/using-amazon-s3-serve-static-files) and then remove that once the user has downloaded it.
If that is not an option, you can try these PHP Classes:
* [HTTP protocol client](http://www.phpclasses.org/browse/package/3.html) - A class that implements requests to HTTP resources (used by the below stream wrapper). Allows requests to be streamed.
* [gHttp](http://www.phpclasses.org/browse/package/4040.html) - An HTTP stream wrapper that lets you treat remote HTTP resources as files, using functions like `fopen()`, `fread()`, etc.
* [Amazon S3 Stream Wrapper](http://www.phpclasses.org/browse/package/4144.html) - An Amazon S3 stream wrapper by the same developer as gHttp. Also allows remote resources to be accessed like ordinary files via `fopen('s3://...')`.
---
Edit:
[This page](http://docs.amazonwebservices.com/AmazonS3/latest/index.html?RESTAuthentication.html) has the info on how to "pre-authenticate" a request by encoding the authentication key in the URL. It's under the section titled: **Query String Request Authentication Alternative**.
```
// I'm only implementing the parts required for GET requests.
// POST uploads will require additional components.
function getStringToSign($req, $expires, $uri) {
return "$req\n\n\n$expires\n$uri";
}
function encodeSignature($sig, $key) {
$sig = utf8_encode($sig);
$sig = hash_hmac('sha1', $sig, $key);
$sig = base64_encode($sig);
return urlencode($sig);
}
$expires = strtotime('+1 hour');
$stringToSign = getStringToSign('GET', $expires, $uri);
$signature = encodeSignature($stringToSign, $awsKey);
$url .= '?AWSAccessKeyId='.$awsKeyId
.'&Expires='.$expires
.'&Signature='.$signature;
```
Then just redirect the user to `$url`, and they should be able to download the file. The signature is encoded by a one-way encryption scheme (sha1), so there's no risk of your AWS Secret Access Key being uncovered. | Have you tried using http\_get, with request\_options to specify the httpauth and httpauthtype? Although I don't remember if this method assumes a string valid type, which might not work for well binary.
If that is successful, then you should be able to provide the correct MIME type and write out to the browser. | In php, I want to download an s3 file to the browser without storing it on my server | [
"",
"php",
"download",
"amazon-s3",
"fopen",
"buffering",
""
] |
ReSharper suggests changing the accessibility of a `public` constructor in an `abstract` class to `protected`, but it does not state the rationale behind this.
Can you shed some light? | Simply because being public makes no sense in an abstract class. An abstract class by definition cannot be instantiated directly. It can only be instantiated by an instance of a derived type. Therefore the only types that should have access to a constructor are its derived types and hence protected makes much more sense than public. It more accurately describes the accessibility. | It technically makes no difference whatsoever if you make the constructor `public` instead of `protected` on an abstract class. The accessibility/visibility of the constructor is still exactly the same: the same class or derived classes. The two keywords have indistinguishable effects for all intents and purposes.
So, this choice is only a matter of style: type `protected` to satisfy the Object Oriented savvy people.
---
Reflection will by default only include the constructor when it is `public`, but you cannot call that constructor anyway.
IntelliSense will show the `public` constructor when typing `new`, but you cannot call that constructor anyway.
The assembly's metadata will reflect the fact that the constructor is public or protected. | Why should constructors on abstract classes be protected, not public? | [
"",
"c#",
".net",
"oop",
"inheritance",
"access-modifiers",
""
] |
C# 2008
I have developed a softphone application.
However, I have to test for a constant internet connection.
I was thinking of having a function that runs in another thread that constantly pings a IP address. However, what IP address can I used to determine if my application is still connected to the Internet.
Many thanks, | Do you just want to check if there is a network connection, or if the network actually goes out to the internet.
In the first case, then do as it says in the ["How do I check for an network connection question"](https://stackoverflow.com/questions/520347/c-how-do-i-check-for-a-network-connection/520352#520352). This will let you know if the cable gets pulled out of the back of your PC, but its won't tell you if your modem or phone line is malfunctioning (for example)
The second case is more complicated, as far as I know, there is no way to check this apart from constantly polling some IP address. In the simple case, you could just have a Timer ping some website every 30 seconds in a separate thread, and raise events when it decides the internet is down. Be aware that ICMP pings are not 100% reliable though, occasionally they will get dropped even if your connection is ok.
If you really wanted to get complicated you could create a windows service raising these events, then multiple applications could hook in and consume the information, but thats a bit beyond my knowlage of windows programming though. | Please see this SO question and answer: [C# - How do I check for a network connection](https://stackoverflow.com/questions/520347/c-how-do-i-check-for-a-network-connection/520352#520352)
If you are restricted to the .NET Compact Framework, check out the free [OpenNETCF library](http://www.opennetcf.com/). | C# Test a constant internet connection | [
"",
"c#",
"networking",
""
] |
**My question is this:** Is string concatenation in C# safe? If string concatenation leads to unexpected errors, and replacing that string concatenation by using StringBuilder causes those errors to disappear, what might that indicate?
**Background:** I am developing a small command line C# application. It takes command line arguments, performs a slightly complicated SQL query, and outputs about 1300 rows of data into a formatted XML file.
My initial program would always run fine in debug mode. However, in release mode it would get to about the 750th SQL result, and then die with an error. The error was that a certain column of data could not be read, even through the Read() method of the SqlDataReader object had just returned true.
This problem was fixed by using StringBuilder for all operations in the code, where previously there had been "string1 + string2". I'm not talking about string concatenation inside the SQL query loop, where StringBuilder was already in use. I'm talking about simple concatenations between two or three short string variables earlier in the code.
I had the impression that C# was smart enough to handle the memory management for adding a few strings together. Am I wrong? Or does this indicate some other sort of code problem? | Apart from what you're doing is probably best done with XML APIs instead of strings or StringBuilder I doubt that the error you see is due to string concatenation. Maybe switching to StringBuilder just masked the error or went over it gracefully, but I doubt using strings really was the cause. | **To answer your question:**
String contatenation in C# (and .NET in general) *is* "safe", but doing it in a tight loop as you describe is likely to cause severe memory pressure and put strain on the garbage collector.
I would hazard a guess that the errors you speak of were related to resource exhaustion of some sort, but it would be helpful if you could provide more detail — for example, did you receive an exception? Did the application terminate abnormally?
**Background:**
.NET strings are immutable, so when you do a concatenation like this:
```
var stringList = new List<string> {"aaa", "bbb", "ccc", "ddd", //... };
string result = String.Empty;
foreach (var s in stringList)
{
result = result + s;
}
```
This is roughly equivalent to the following:
```
string result = "";
result = "aaa"
string temp1 = result + "bbb";
result = temp1;
string temp2 = temp1 + "ccc";
result = temp2;
string temp3 = temp2 + "ddd";
result = temp3;
// ...
result = tempN + x;
```
The purpose of this example is to emphasise that each time around the loop results in the allocation of a new temporary string.
Since the strings are immutable, the runtime has no alternative options but to allocate a new string each time you add another string to the end of your result.
Although the `result` string is constantly updated to point to the latest and greatest intermediate result, you are producing a lot of these un-named temporary string that become eligible for garbage collection almost immediately.
At the end of this concatenation you will have the following strings stored in memory (assuming, for simplicity, that the garbage collector has not yet run).
```
string a = "aaa";
string b = "bbb";
string c = "ccc";
// ...
string temp1 = "aaabbb";
string temp2 = "aaabbbccc";
string temp3 = "aaabbbcccddd";
string temp4 = "aaabbbcccdddeee";
string temp5 = "aaabbbcccdddeeefff";
string temp6 = "aaabbbcccdddeeefffggg";
// ...
```
Although all of these implicit temporary variables are eligible for garbage collection almost immediately, they still have to be allocated. When performing concatenation in a tight loop this is going to put a lot of strain on the garbage collector and, if nothing else, will make your code run very slowly. I have seen the performance impact of this first hand, and it becomes truly dramatic as your concatenated string becomes larger.
**The recommended approach is to always use a `StringBuilder` if you are doing more than a few string concatenations.** `StringBuilder` uses a mutable buffer to reduce the number of allocations that are necessary in building up your string. | String Concatenation unsafe in C#, need to use StringBuilder? | [
"",
"c#",
"string",
"stringbuilder",
"string-concatenation",
""
] |
There are various ways to take screenshots of a running application in Windows. However, I hear that an application can be tailored such that it can notice when a screenshot is being taken of it, through some windows event handlers perhaps? Is there any way of taking a screenshot such that it is impossible for the application to notice? (Maybe even running the application inside a VM, and taking a screenshot from the host?) I'd prefer solutions in Python, but anything will do. | *> I hear that an application can be tailored such that it can notice when a screenshot is being taken of it*
Complete nonsense.
Don't repeat what kids say...
Read MSDN about screenshots. | There will certainly be no protection against a screenshot taken with a digital camera. | Programmatically taking screenshots in windows without the application noticing | [
"",
"python",
"windows",
"events",
"operating-system",
"screenshot",
""
] |
I am trying to get some simple UDP communication working on my local network.
All i want to do is do a multicast to all machines on the network
Here is my sending code
```
public void SendMessage(string message)
{
var data = Encoding.Default.GetBytes(message);
using (var udpClient = new UdpClient(AddressFamily.InterNetwork))
{
var address = IPAddress.Parse("224.100.0.1");
var ipEndPoint = new IPEndPoint(address, 8088);
udpClient.JoinMulticastGroup(address);
udpClient.Send(data, data.Length, ipEndPoint);
udpClient.Close();
}
}
```
and here is my receiving code
```
public void Start()
{
udpClient = new UdpClient(8088);
udpClient.JoinMulticastGroup(IPAddress.Parse("224.100.0.1"), 50);
receiveThread = new Thread(Receive);
receiveThread.Start();
}
public void Receive()
{
while (true)
{
var ipEndPoint = new IPEndPoint(IPAddress.Any, 0);
var data = udpClient.Receive(ref ipEndPoint);
Message = Encoding.Default.GetString(data);
// Raise the AfterReceive event
if (AfterReceive != null)
{
AfterReceive(this, new EventArgs());
}
}
}
```
It works perfectly on my local machine but not across the network.
-Does not seem to be the firewall. I disabled it on both machines and it still did not work.
-It works if i do a direct send to the hard coded IP address of the client machine (ie not multicast).
Any help would be appreciated. | Does your local network hardware support [IGMP](http://en.wikipedia.org/wiki/Internet_Group_Management_Protocol)?
It's possible that your switch is multicast aware, but if IGMP is disabled it won't notice if any attached hardware subscribes to a particular multicast group so it wouldn't forward those packets.
To test this, temporarily connect two machines directly together with a cross-over cable. That should (AFAICR) always work.
Also, it should be the *server* half of the code that has the TTL argument supplied to `JoinMulticastGroup()`, not the client half. | I've just spent 4 hours on something similar (I think), the solution for me was:
```
client.Client.Bind(new IPEndPoint(IPAddress.Any, SSDP_PORT));
client.JoinMulticastGroup(SSDP_IP,IP.ExternalIPAddresses.First());
client.MulticastLoopback = true;
```
Using a specific (first external) IP address on the multicast group. | How to do a UDP multicast across the local network in c#? | [
"",
"c#",
".net",
"networking",
"messaging",
""
] |
I'm wondering how I get a smooth zoom in animation with the Google Maps API.
I have 2 points, one in, let say China, and one in France. When I'm zoomed in on China, and click the button France. I want it to gradually zoom out smooth, one zoom level at the time. When it's zoomed out it should pan to the new location, and then zoom in on the new location one zoom level at the time.
How can I do this? | You need the [`zoomOut`](http://code.google.com/apis/maps/documentation/reference.html#GMap2.zoomOut) method with the continuous zoom parameter set to do the zoom and the [`panTo`](http://code.google.com/apis/maps/documentation/reference.html#GMap2.panTo) method to do the smooth panning to the new centerpoint.
You can listen to the [`zoomEnd`](http://code.google.com/apis/maps/documentation/reference.html#GMap2.zoomend) and [`moveEnd`](http://code.google.com/apis/maps/documentation/reference.html#GMap2.moveend) events on the map object to chain together your `zoomOut`, `panTo` and `zoomIn` methods.
EDIT:
So in the course of implementing a sample for this problem, I discovered that the `doContinuousZoom` param on `ZoomIn` and `ZoomOut` (or just `EnableContinuousZoom` on the map) doesn't quite work as expected. It works ok when zooming out, if the tiles are in the cache (this is an important point, if the tiles aren't cached then it is not really possible to get the smooth animation you are after) then it does some nice scaling on the tiles to simulate a smooth zoom animation and introduces a ~500 ms delay on each zoom step so you can do it asynchronously (unlike `panTo`, which you will see in my example I use a setTimeout to call async).
Unfortunately the same is not true for the `zoomIn` method, which just jumps to the target zoom level without the scaling animation for each zoom level. I haven't tried explicitly setting the version for the google maps code, so this might be something that is fixed in later versions. Anyway, here is the [sample code](http://www.cannonade.net/geo2.js) which is mostly just javascript hoop jumping and not so much with the Google Maps API:
<http://www.cannonade.net/geo.php?test=geo2>
Because this approach seems a bit unreliable, I think it would make more sense to do the async processing for setZoom explicitly (Same as the panning stuff).
EDIT2:
So I do the async zooming explicitly now (using `setTimeout` with a single zoom at a time). I also have to fire events when each zoom happens so that my events chain correctly. It seems like the zoomEnd and panEnd events are being called synchronously.
Setting enableContinuousZoom on the map doesn't seem to work, so I guess calling zoomOut, zoomIn with the param is the only way to get that to work. | Here's my approach.
```
var point = markers[id].getPosition(); // Get marker position
map.setZoom(9); // Back to default zoom
map.panTo(point); // Pan map to that position
setTimeout("map.setZoom(14)",1000); // Zoom in after 1 sec
``` | Google Maps zoomOut-Pan-zoomIn animation | [
"",
"javascript",
"google-maps",
"settimeout",
""
] |
I know that BEA was working on LiquidVM which didn't require an underlying operating system, but would like to know if anyone in the open source community is working on something similar.
Ideally I would like to find an implementation where the VM is directly loaded by the OS boot loader. | What is it you need?
Perhaps Sanos can give you a small chunk of code between the hardware and the JVM which you can use?
<http://www.jbox.dk/sanos/> | Unlike SANOS, the [JNode](http://www.jnode.org) operating system is a full operating system with many supported devices, file systems, a network stack, a GUI stack, a command shell and 50 or so commands, and much more. JNode currently runs on x86 (32 bit) with one processor enabled, but x86-64 and multi-processor versions are in development. (JNode is 99.99% Java. Porting to a new architecture would entail rewriting the 0.01% of code that is in assembler, creating / modifying hardware specific drivers ... and writing a native code compiler for the new architecture.)
We currently have ~7 active developers, but we are always looking for new people to join the team, especially people who understand Java AND code generation, garbage collectors, drivers and so on.
(And for what it is worth, we use a recent version of the OpenJDK class libraries: 1.6u24 at the last count.) | Java VMs that do not require an operating system? | [
"",
"java",
"jvm",
"vmware",
"virtualization",
"xen",
""
] |
Named function parameters can be emulated in PHP if I write functions like this
```
function pythonic(array $kwargs)
{
extract($kwargs);
// .. rest of the function body
}
// if params are optional or default values are required
function pythonic(array $kwargs = array('name'=>'Jon skeet'))
{
extract($kwargs);
// .. rest of the function body
}
```
Apart from losing intellisense in IDEs what are the other possible downsides of this approach?
Edit:
**Security:** Shouldn't security be a non-issue in this case, as the extracted variables are limited to function scope? | I would suggest using the associative array to pass named parameters, but keep them in the array without extracting them.
```
function myFunc(array $args) {
echo "Hi, " . $args['name'];
// etc
}
```
There's a couple of reasons for this. Looking at that function, you can quite clearly see that I'm referring to one of the arguments passed into the function. If you extract them, and don't notice the `extract()` you (or the next guy) will be there scratching your head wondering where this "`$name`" variable came from. Even if you *do* know you're extracting the arguments to local variables, it's still a guessing game to a certain degree.
Secondly, it ensures that other code doesn't overwrite the args. You may have written your function expecting only to have arguments named `$foo` and `$bar`, so in your other code, you define `$baz = 8;`, for example. Later on, you might want to expand your function to take a new parameter called "baz" but forget to change your other variables, so no matter what gets passed in the arguments, `$baz` will always be set to 8.
There are some benefits to using the array too (these apply equally to the methods of extracting or leaving in the array): you can set up a variable at the top of each function called `$defaults`:
```
function myFunc (array $args) {
$default = array(
"name" => "John Doe",
"age" => "30"
);
// overwrite all the defaults with the arguments
$args = array_merge($defaults, $args);
// you *could* extract($args) here if you want
echo "Name: " . $args['name'] . ", Age: " . $args['age'];
}
myFunc(array("age" => 25)); // "Name: John Doe, Age: 25"
```
You could even remove all items from `$args` which don't have a corresponding `$default` value. This way you know exactly which variables you have. | Here's another way you could do this.
```
/**
* Constructor.
*
* @named string 'algorithm'
* @named string 'mode'
* @named string 'key'
*/
public function __construct(array $parameter = array())
{
$algorithm = 'tripledes';
$mode = 'ecb';
$key = null;
extract($parameter, EXTR_IF_EXISTS);
//...
}
```
With this set up, you get default params, you don't lose intellisense in IDEs and EXTR\_IF\_EXISTS makes it secure by just extracting array keys that are already existing as variables.
(By the way, creating default values from the example you provided is not good, because if an array of param is provided without a 'name' index, your default value is lost.) | Emulating named function parameters in PHP, good or bad idea? | [
"",
"php",
"function",
"named-parameters",
""
] |
This is almost similar question to this one: -
[Dealing with timezones in PHP](https://stackoverflow.com/questions/346770/dealing-with-timezones-in-php)
I read that thread, and have some more issues, and not sure of how to elegantly build timezone support in PHP/MySQL application.
I am writing an application in PHP, where users can select their timezone.
Here, all timestamps are stored in GMT in MySQL. And I am converting the timezone back to users timezone, when presenting the data.
Now these are the problems I am facing: -
1)
I show the user, a list of timezones populated from MySQL's timezone tables, it is a HUGE list and is difficult to chose from.
So, I want to implement something like windows time zone list. Offset with region info.
2)
The PHP and MySQL may have different set of list.
3)
Where should I convert timezones, in PHP or in MySQL? I have combination of coding.
Sometimes it is easy to select a column converted from MySQL, sometimes it is easy to convert in PHP.
So, here the previous point becomes very important. For example, in MySQL's time\_zone tables
Asia/Kolkata, and Asia/Calcutta both were there, but in PHP 5.2.6's default timezonedb, only Asia/Calcutta is present. | When faced with this exact issue, I found [this reference](http://www.unicode.org/cldr/data/docs/design/formatting/zone_log.html#windows_ids), which maps the succinct, Windows-style timezone list to a subset of the ridiculously exhaustive Unix-style timezone list.
Users are presented with a dropdown of these windows-style names (e.g., (GMT-05:00) Eastern Time (US & Canada)), and their selection is stored in the db in the unix-style format (e.g. America/New\_York)
The work of applying the user's timezone preference is done in PHP at display time, using the [DateTime class](http://www.php.net/manual/en/class.datetime.php). I think I'd recommend this, so you can be confident that the dates you're manipulating in SQL/PHP are always in UTC, until they're displayed. | 1. Choosing a time zone from a large list isn't that difficult. Sort the list by standard-time offset so that users can quickly scroll to the correct offset, and from there, look for their exact location.
2. Choose one list. I would tend to go for whichever list is shorter. Only present those choices to the user.
3. Do the math where the list that was chosen is. If you're presenting the MySQL list, have MySQL do the date math, if you're using PHP's list, have PHP do the math. This will make so that you don't need to figure out some weird mapping for missing zones in one implementation.
A fancy solution could involve asking the user's location and extrapolating their timezone. (However, have the option to explicitly set it as well) | building timezone feature in PHP web application | [
"",
"php",
"mysql",
"timezone",
""
] |
I'm so tired of having to learn yet another Java web framework every other day.
JSP, Struts, Wicket, JSF, JBoss Seam, Spring MVC to name just a few - all this countless frameworks out there try to address the same issues. However, none of them really solves the fundamental problems - that's why there are still coming up more and more new ones all the time.
Most do look very bright and shiny on the first impression because they simplify doing simple things.
But as soon as it comes to the implementation of a real world use case one is running into problems.
Often the frameworks don't provide any help but are hindering one and limiting the options by forcing things to be implemented according to the frameworks own logic and environment.
In short, I see the following disadvantages when using a framework:
1. There mostly is a steep learning curve and you first need to understand sometimes quite academic concepts and know meaning and location of a bunch of configuration files before you can get started.
2. The documentation usually is more or less awful, either missing a public accessible online reference, is helpless outdated, confuses different incompatible versions or all of this together and often doesn't provide any helpful examples.
3. The framework consist of zillions of classes which makes it practically impossible to understand the intended use only by browsing the sources.
4. Therefore you need to buy some "XYZ in action for dummies in 21 days" kind of books which have a bad user interface because they are missing a full text search and are heavy to carry around.
5. To really use one of this frameworks you need to learn by heart how things can be done the way the framework requires it by remembering the adequate classes and method names until your head is full of stupid and useless information you can't use for anything else.
6. There is a big overhead, slowing down your applications performance and making your brain feeling numb when try to understand what really is going on.
7. In the real world there is usually no time to get well familiar with something new because of the pressure of being productive. As a consequence of this learning by doing approach one always looks only for the fastest way to get the next task done rather than really understanding the new tool and it's possibilities.
8. The argument that following a standard would allow people who are new to a project to quickly get started is not valid in my view because every project uses a different framework even within the same company (at least in my case).
It seems to me that the following quote from Albert Einstein fits here very well:
> “We can't solve problems by using the same kind of thinking we used when we created them.”
Back in my good old PHP coding days when coding still was fun and productive, I used to write my own frameworks for most things and just copy-pasted and adopted them from one project to the next.
This approach paid out very well, resulting in fast development, no overhead at all and a framework which actually was mightier than most Java frameworks out there but with only a few hundred lines of code in a single file plus some simple mod\_rewrite rules.
This certainly wasn't solving all problems of web development, but it was simple, fast and straight to the point.
While perfectly adjusted to the requirements of the current project, it also was easy expandable and had a very high performance due to zero overhead.
So why all that hassle with using this frameworks, why not throwing them all away and going back to the roots?
What should I say to my boss when we're starting tomorrow the next project with a new framework again?
Or are there maybe frameworks which really make a difference?
Or some hidden advantages I have ignored? | Here is a quote from [Kev](https://stackoverflow.com/users/16777/kev) from the thread [What’s your most controversial programming opinion?](https://stackoverflow.com/questions/406760/whats-your-most-controversial-programming-opinion/) which fit's in here really well:
> I think that the whole "Enterprise" frameworks thing is smoke and mirrors. J2EE, .NET, the majority of the Apache frameworks and most abstractions to manage such things create far more complexity than they solve.
>
> Take any regular Java or .NET OMR, or any supposedly modern MVC framework for either which does "magic" to solve tedious, simple tasks. You end up writing huge amounts of ugly XML boilerplate that is difficult to validate and write quickly. You have massive APIs where half of those are just to integrate the work of the other APIs, interfaces that are impossible to recycle, and abstract classes that are needed only to overcome the inflexibility of Java and C#. We simply don't need most of that.
>
> How about all the different application servers with their own darned descriptor syntax, the overly complex database and groupware products?
>
> The point of this is not that complexity==bad, it's that unnecessary complexity==bad. I've worked in massive enterprise installations where some of it was necessary, but even in most cases a few home-grown scripts and a simple web frontend is all that's needed to solve most use cases.
>
> I'd try to replace all of these enterprisey apps with simple web frameworks, open source DBs, and trivial programming constructs. | > Back in my good old PHP coding days
> when coding still was fun and
> productive, I used to write my own
> frameworks for most things and just
> copy-pasted and adopted them from one
> project to the next. This approach
> paid out very well, resulting in fast
> development, no overhead at all and a
> framework which actually was mightier
> than most Java frameworks out there
Forgive me for believing that not one second.
> but with only a few hundred lines of
> code in a single file plus some simple
> mod\_rewrite rules. This certainly
> wasn't solving all problems of web
> development, but it was simple, fast
> and straight to the point.
So basically you developed your own framework over the course of months or years, tailored to your own needs, and could work very fast with it because you knew it intimately.
And yet you can't understand why others do the same and then try to turn the result into something useable by everyone?
Where's this great framework you developed? If it's so powerful and easy to use, where are the dedicated communities, thousands of users and hundreds of sites developed with it?
> every project uses a different
> framework even within the same company
> (at least in my case)
Well, that's your problem right there. Why would you throw away the expertise gained with each framework after each project?
The idea is to choose one framework and stick with it over multiple projects so that you get proficient in it. You have to invest some time to learn the framework, and then it saves you time by allowing you to work on a higher level. | Making life better by not using Java web frameworks? | [
"",
"java",
"web-applications",
"web-frameworks",
""
] |
Is it because of string pooling by CLR or by the GetHashCode() method of both strings return same value?
```
string s1 = "xyz";
string s2 = "xyz";
Console.WriteLine(" s1 reference equals s2 : {0}", object.ReferenceEquals(s1, s2));
```
Console writes : **"s1 reference equals s2 : True"**
I believe that, it's not because of the GetHashCode() returns same value for both string instance. Because, I tested with custom object and overridden the GetHasCode() method to return a single constant every time. The two separate instances of this object does not equal in the reference.
Please let me know, what is happening behind the scene.
thanks
123Developer | It sounds like [string interning](http://en.wikipedia.org/wiki/String_intern_pool) - a method of storing only one copy of a string. It requires strings to be an immutable type in the language you are dealing with, and .Net satisfies that and uses string interning.
In string interning a string "xyz" is stored in the intern pool, and whenever you say "xyz" internally it references the entry in the pool. This can save space by only storing the string once. So a comparison of "xyz" == "xyz" will get interpreted as [pointer to 34576] == [pointer to 34576] which is true. | This is definitely due to string interning. Hash codes are *never* calculated when comparing references with `object.ReferenceEquals`.
From the C# spec, section 2.4.4.5:
> Each string literal does not
> necessarily result in a new string
> instance. When two or more string
> literals that are equivalent according
> to the string equality operator
> (§7.9.7) appear in the same program,
> these string literals refer to the
> same string instance.
Note that string *constant expressions* count as literals in this case, so:
```
string x = "a" + "b";
string y = "ab";
```
It's guaranteed that `x` and `y` refer to the same object too (i.e. they are the same references).
When the spec says "program" by the way, it really means "assembly". The behaviour of equal strings in different assemblies depends on things like `CompilationRelaxations.NoStringInterning` and the precise CLR implementation and execution time situation (e.g. whether the assembly is ngen'd or not). | Is it because of string pooling by CLR or by the GetHashCode() method? | [
"",
"c#",
"string",
""
] |
I've got a set of models that look like this:
```
class Page(models.Model):
title = models.CharField(max_length=255)
class LinkSection(models.Model):
page = models.ForeignKey(Page)
title = models.CharField(max_length=255)
class Link(models.Model):
linksection = models.ForeignKey(LinkSection)
text = models.CharField(max_length=255)
url = models.URLField()
```
and an admin.py that looks like this:
```
class LinkInline(admin.TabularInline):
model = Link
class LinkSectionInline(admin.TabularInline):
model = LinkSection
inlines = [ LinkInline, ]
class PageAdmin(admin.ModelAdmin):
inlines = [ LinkSectionInline, ]
```
My goal is to get an admin interface that lets me edit everything on one page. The end result of this model structure is that things are generated into a view+template that looks more or less like:
```
<h1>{{page.title}}</h1>
{% for ls in page.linksection_set.objects.all %}
<div>
<h2>{{ls.title}}</h2>
<ul>
{% for l in ls.link_set.objects.all %}
<li><a href="{{l.url}}">{{l.title}}</a></li>
{% endfor %}
</ul>
</div>
{% endfor %}
```
I know that the inline-in-an-inline trick fails in the Django admin, as I expected. Does anyone know of a way to allow this kind of three level model editing? Thanks in advance. | You need to create a custom [form](http://docs.djangoproject.com/en/dev/ref/contrib/admin/#form) and [template](http://docs.djangoproject.com/en/dev/ref/contrib/admin/#template) for the `LinkSectionInline`.
Something like this should work for the form:
```
LinkFormset = forms.modelformset_factory(Link)
class LinkSectionForm(forms.ModelForm):
def __init__(self, **kwargs):
super(LinkSectionForm, self).__init__(**kwargs)
self.link_formset = LinkFormset(instance=self.instance,
data=self.data or None,
prefix=self.prefix)
def is_valid(self):
return (super(LinkSectionForm, self).is_valid() and
self.link_formset.is_valid())
def save(self, commit=True):
# Supporting commit=False is another can of worms. No use dealing
# it before it's needed. (YAGNI)
assert commit == True
res = super(LinkSectionForm, self).save(commit=commit)
self.link_formset.save()
return res
```
(That just came off the top of my head and isn't tested, but it should get you going in the right direction.)
Your template just needs to render the form and form.link\_formset appropriately. | [Django-nested-inlines](https://pypi.python.org/pypi/django-nested-inlines/0.1) is built for just this. Usage is simple.
```
from django.contrib import admin
from nested_inlines.admin import NestedModelAdmin, NestedStackedInline, NestedTabularInline
from models import A, B, C
class MyNestedInline(NestedTabularInline):
model = C
class MyInline(NestedStackedInline):
model = B
inlines = [MyNestedInline,]
class MyAdmin(NestedModelAdmin):
pass
admin.site.register(A, MyAdmin)
``` | Django admin - inline inlines (or, three model editing at once) | [
"",
"python",
"django",
"django-models",
"django-admin",
"inlines",
""
] |
I have an xml string which is very long in one line. I would like to save the xml string to a text file in a nice indent format:
```
<root><app>myApp</app><logFile>myApp.log</logFile><SQLdb><connection>...</connection>...</root>
```
The format I prefer:
```
<root>
<app>myApp</app>
<logFile>myApp.log</logFile>
<SQLdb>
<connection>...</connection>
....
</SQLdb>
</root>
```
What are .Net libraries available for C# to do it? | This will work for what you want to do ...
```
var samp = @"<root><app>myApp</app><logFile>myApp.log</logFile></root>";
var xdoc = XDocument.Load(new StringReader(samp), LoadOptions.None);
xdoc.Save(@"c:\temp\myxml.xml", SaveOptions.None);
```
Same result with System.Xml namespace ...
```
var xdoc = new XmlDocument();
xdoc.LoadXml(samp);
xdoc.Save(@"c:\temp\myxml.xml");
``` | I'm going to assume you don't mean that you have a System.String instance with some XML in it, and I'm going to hope you don't create it via string manipulation.
That said, all you have to do is set the proper settings when you create your XmlWriter:
```
var sb = new StringBuilder();
var settings = new XmlWriterSettings {Indent = true};
using (var writer = XmlWriter.Create(sb, settings))
{
// write your XML using the writer
}
// Indented results available in sb.ToString()
``` | Save xml string or XmlNode to text file in indent format? | [
"",
"c#",
".net",
"xml",
""
] |
I have a sequence of functions that look very similar but for a single line, like the following two (but I have many more of them):
```
private static int HowManyHoursInTheFirstYear(IList<T> samples)
{
DateTime firstDate = samples[0].Date;
int count = 0;
while (count < samples.Count &&
samples[count].Date.Year == firstDate.Year)
{
count++;
}
return count;
}
private static int HowManyDaysInTheFirstMonth(IList<T> samples)
{
DateTime firstDate = samples[0].Date;
int count = 0;
while (count < samples.Count &&
samples[count].Date.Month == firstDate.Month) // <--- only change!
count++;
}
return count;
}
```
I was thinking about using delegates to remove this repetition in code in some elegant way, that would have allowed me to invoke something like:
```
HowManyDaysInTheFirstPeriod(
samples,
delegate(DateTime d1, DateTime d2) { return d1.Month == d2.Month; });
```
thereby declaring a delegate like the following:
```
delegate bool DateComparer(DateTime first, DateTime second);
```
and where HowManyDaysInTheFirstPeriod whould be something like the following:
```
private static int HowManySamplesInFirstPeriod
IList<T> samples,
DateComparer comparer)
{
DateTime firstDate = samples[0].Date;
int count = 0;
while (count < samples.Count && comparer())
{
count++;
}
}
```
Unfortunately, the compiler complains that comparer needs two parameters.
I am relatively new to C# and hit a road-block here.
How would you solve this? | You're almost there! The `comparer` delegate parameter is just like any other function: **You still need to pass the appropriate arguments to invoke it.** In your case, that's going to mean this change:
```
while (count < samples.Count && comparer(samples[count].Date, firstDate))
{
count++;
}
```
**(Also, note that `samples` should probably be `samples.Count`, as I have written above.)** | You can do it a bit simpler. Simply provide the function a delegate which extracts whatever should be compared from a DateTime:
```
private static int HowManySamplesInFirstPeriod<T>
IList<T> samples,
Func<DateTime, int> f // a function which takes a DateTime, and returns some number
{
DateTime firstDate = samples[0].Date;
int count = 0;
while (count < samples && f(samples[count].Date) == f(firstDate))
{
count++;
}
}
```
and it can then be called as such:
```
HowManySamplesInFirstPeriod(samples, (dt) => dt.Year); // to get the year
HowManySamplesInFirstPeriod(samples, (dt) => dt.Month); // to get the month
```
The `(dt) => dt.year` syntax may be new to you, but it's a cleaner way of writing "an anonymous delegate which takes an object dt of some generic type, and returns dt.year".
You could write an old-fashioned delegate instead, but this is nicer. :)
We can make it a bit more general than that though, by adding another generic type parameter:
```
private static int HowManySamplesInFirstPeriod<T, U>
IList<T> samples,
Func<DateTime, U> f // Let's generalize it a bit, since the function may return something other than int (some of the DateTime members return doubles, as I recall)
```
As usual though, LINQ provides a nicer still alternative:
```
private static int HowManySamplesInFirstPeriod<T>
IList<T> samples,
Func<DateTime, int> f)
{
var firstVal = f(samples.First().Date);
return samples.Count(dt => f(dt.Date) = firstVal)
}
``` | Passing a delegate with two parameters as a parameter function | [
"",
"c#",
"delegates",
""
] |
In a textbox.TextChanged event I want to prevent some specific (processor intensive) functionality from executing if a key is still held down. E.g. while the user is deleting large regions of text by holding down the delete key I want to prevent the code from firing if the delete key is still held down.
I looked into `Control.ModifierKeys` which is the closest thing a google search kicks up, but in my specific case I want to trap if the delete or backspace key are pressed - which ModifierKeys doesn't provide.
Does anyone know how to do this? Ideally something which doesn't involve me having to track the state of keyup/keydown for each and every textbox (although if there is no other way I'll do it like that) | In the end I've resorted to the external function `GetKeyboardState`
So for future reference i'm doing something along the lines:
```
[DllImport("user32.dll")] public static extern int GetKeyboardState(byte[] lpKeyState);
private void myFunc()
{
byte[] keyboardState = new byte[255];
int keystate = GetKeyboardState(keyboardState);
if (keyboardState[(int)Keys.Back] == 128)
{
// backspace still pressed
return;
}
else if (keyboardState[(int)Keys.Delete] == 128)
{
// Delete key still pressed
return;
}
// More processor intensive code ...
}
```
I am not sure of the function call overhead, but I'm pretty sure it will be less than the processing the function would perform were it not there. | Why not handle the [KeyUp event](http://msdn.microsoft.com/en-us/library/system.windows.forms.control.keyup(VS.80,loband).aspx) instead of handling `KeyPress`. That way you can always be sure that the key has already been depressed and is in the process of being... errr.. released (for lack of a better word!) | Determine state of keyboard in non-keyboard-event method call | [
"",
"c#",
"winforms",
".net-2.0",
""
] |
I am learning C++ and I was wondering if I could gain some insight into the preferred way of creating binary operators that work on instances of two different types. Here is an example that I've made to illustrate my concerns:
```
class A;
class B;
class A
{
private:
int x;
public:
A(int x);
int getX() const;
int operator + (const B& b);
};
class B
{
private:
int x;
public:
B(int x);
int getX() const;
int operator + (const A& A);
};
A::A(int x) : x(x) {}
int A::getX() const { return x; }
// Method 1
int A::operator + (const B& b) { return getX() + b.getX(); }
B::B(int x) : x(x) {}
int B::getX() const { return x; }
// Method 1
int B::operator + (const A& a) { return getX() + a.getX(); }
// Method 2
int operator + (const A& a, const B& b) { return a.getX() + b.getX(); }
int operator + (const B& b, const A& a) { return a.getX() + b.getX(); }
#include <iostream>
using namespace std;
int main()
{
A a(2);
B b(2);
cout << a + b << endl;
return 0;
};
```
If I would like to have symmetry among the two types, which method is the best approach in the above code. Are there any possible dangers in choosing one method over the other? Does this vary with the return type? Please explain! Thank you! | The best way is to define (outside of either class) `int operator+ (const A& a, const B& b)`, and make it a friend function of both classes if needed. In addition, define
```
int operator+(const B& b, const A& a) {return a + b;}
```
To make it symmetric. | The big risk with this approach is that people tend to perceive + as a symmetric operator. The way this is written, it is not (unless your implementations re the same).
At a minimum, you should overload + as an external binary operator (not as a member), and then play with overloading it several times.
You have to be careful, though, to make sure that nothing becomes ambiguous.
Can you explain what you're trying to do? I can't think of many cases of different types where it makes sense to have the symmetric heterogenous operators. | C++ Symmetric Binary Operators with Different Types | [
"",
"c++",
"operator-overloading",
"symmetric",
""
] |
Example:
```
template<class T>
class Base {
public:
Base();
friend class T;
};
```
Now this doesn't work... Is there a way of doing this?
I'm actually trying to make a general class sealer like this:
```
class ClassSealer {
private:
friend class Sealed;
ClassSealer() {}
};
class Sealed : private virtual ClassSealer
{
// ...
};
class FailsToDerive : public Sealed
{
// Cannot be instantiated
};
```
I found this example on this site somewhere but I can't find it... ([here](https://stackoverflow.com/questions/656224/when-should-i-use-c-private-inheritance/656523#656523))
I know there are [other ways](http://www.gamedev.net/reference/programming/features/cppseal/) of doing this but just now I'm curious if you actually can do something like this. | It is explicitly disallowed in the standard, even if some versions of VisualStudio do allow it.
C++ Standard 7.1.5.3 Elaborated type specifiers, paragraph 2
> 3.4.4 describes how name lookup proceeds for the identifier in an
> elaborated-type-specifier. If the
> identifier resolves to
> a class-name or enum-name,
> the elaborated-type-specifier introduces
> it into the declaration the same
> way a simple-type-specifier introduces
> its type-name. If the identifier resolves
> to a typedef-name or a
> template type-parameter,
> the elaborated-type-specifier is
> ill-formed. [Note: this implies that,
> within a class template with a
> template type-parameter T, the
> declaration *friend class T*; is
> ill-formed. ]
I recognize the code above as a pattern to seal (disallow the extension of) a class. There is another solution, that does not really block the extension but that will flag unadvertidly extending from the class. As seen in [ADOBE Source Library](http://stlab.adobe.com/group__adobe__final.html):
```
namespace adobe { namespace implementation {
template <class T>
class final
{
protected:
final() {}
};
}}
#define ADOBE_FINAL( X ) private virtual adobe::implementation::final<T>
```
with the usage:
```
class Sealed : ADOBE_FINAL( Sealed )
{//...
};
```
While it allows extension if you really force it:
```
class SealBreaker : public Sealed, ADOBE_FINAL( Sealed )
{
public:
SealBreaker() : adobe::implementation::final<Sealed>(), Sealed() {}
};
```
It will restrict users from mistakenly do it.
**EDIT**:
The upcoming C++11 standard does allow you to befriend a type argument with a slightly different syntax:
```
template <typename T>
class A {
// friend class T; // still incorrect: elaborate type specifier
friend T; // correct: simple specifier, note lack of "class"
};
``` | I found a simple trick to declare template parameters as friends:
```
template < typename T>
struct type_wrapper
{
typedef T type;
};
template < typename T> class foo
{
friend class type_wrapper < T>::type
}; // type_wrapper< T>::type == T
```
However I do not know how this could help to define an alternative version of a class sealer. | Making a template parameter a friend? | [
"",
"c++",
"templates",
"friend",
""
] |
How do I get the 'default' param if not specified?
Consider the following:
```
http://localhost/controller/action/id/123
```
In my controller, I can get the value of 'id' using
```
$request = $this->getRequest();
$id = $request->getParam('id');
```
If the URL is
```
http://localhost/controller/action/456
```
how do I get the value of 456?
What is the 'param' name? | By default ZF URL have to follow pattern:
```
/controller/action/param1Name/param1Val/param2Name/param2Val ...
```
You should use [router](http://framework.zend.com/manual/en/zend.controller.router.html). For example in `bootstrap.php`:
```
$frontController = Zend_Controller_Front::getInstance();
//^^^this line should be already there
$router = $frontController->getRouter();
$route = new Zend_Controller_Router_Route(
'yourController/yourAction/:id',
array(
'id' => 1, //default value
'controller' => 'yourController',
'action' => 'yourAction'
),
array('id' => '\d+')
);
$router->addRoute('yourController', $route);
``` | Just want to share.
The above router setting must be used with the $frontController.
And be sure put it before the controller dispatches.
```
<..above router code goes here...>
// Dispatch the request using the front controller.
$frontController->dispatch ();
```
Hope don't waste time like myself. ;-) | Zend Framework: How to get default param? | [
"",
"php",
"zend-framework",
"url-routing",
""
] |
If I'm writing a class library, and at some point in that library I have code to catch an exception and deal with it, then I don't want anyone using my library to know that it even happened - it should be invisible from the outside world.
However, if they have "Catch Thrown Exceptions" turned on in Visual Studio (as opposed to "Catch User Unhandled Exceptions") then the exception *will* be visible to them.
Is there any way to avoid this? | The only way you can pull this off is if you put a [[DebuggerHidden]](http://msdn.microsoft.com/en-us/library/system.diagnostics.debuggerhiddenattribute.aspx) attribute on the method that may throw the exception. Like others have pointed out, better to avoid the exception altogether, but this attribute will accomplish what you want. | No. This is by design: as a developer, I run with "Catch Thrown Exceptions" turned on, so that I can see exceptions thrown in library code (and hopefully avoid them). The situation you're in applies equally to the .NET framework's own libraries too.
The best way would be to avoid throwing the exception in the first place. As a side benefit, you library code will be faster, since throwing an exception has a noticeable impact on performance (and should only be used in 'exceptional' circumstances). | How to prevent exceptions bubbling up in C#? | [
"",
"c#",
"visual-studio-2005",
"exception",
""
] |
Well I have been thinking about this for a while, ever since I was introduced to TDD.
Which would be the best way to build a "Hello World" application ? which would print "Hello World" on the console - using Test Driven Development.
What would my Tests look like ? and Around what classes ?
**Request:** No "*wikipedia-like*" links to what TDD is, I'm familiar with TDD. Just curious about how this can be tackled. | You need to hide the Console behind a interface. (This could be considered to be useful anyway)
**Write a Test**
```
[TestMethod]
public void HelloWorld_WritesHelloWorldToConsole()
{
// Arrange
IConsole consoleMock = MockRepository.CreateMock<IConsole>();
// primitive injection of the console
Program.Console = consoleMock;
// Act
Program.HelloWorld();
// Assert
consoleMock.AssertWasCalled(x => x.WriteLine("Hello World"));
}
```
**Write the program**
```
public static class Program
{
public static IConsole Console { get; set; }
// method that does the "logic"
public static void HelloWorld()
{
Console.WriteLine("Hello World");
}
// setup real environment
public static void Main()
{
Console = new RealConsoleImplementation();
HelloWorld();
}
}
```
**Refactor** to something more useful ;-) | Well...I've not seen a TDD version of hello world. But, to see a similarly simple problem that's been approached with TDD and manageability in mind, you could take a look at [Enterprise FizzBuzz](http://wolfbyte-net.blogspot.com/2007/09/if-something-is-worth-doing.html) ([code](http://code.google.com/p/fizzbuzz/)). At least this will allow you to see the level of over-engineering you could possibly achieve in a hello world. | "Hello World" - The TDD way? | [
"",
"c#",
"unit-testing",
"tdd",
"nunit",
""
] |
When executing some command(let's say 'x') from cmd line, I get the following message:
"....Press any key to continue . . .". So it waits for user input to unblock.
But when I execute the same command ('x') from java:
```
Process p = Runtime.getRuntime().exec(cmd, null, cmdDir);
// here it blocks and cannot use outputstream to write somnething
p.getOutputStream().write(..);
```
the code blocks...
I tried to write something into the process's output stream, but how can i do that sice the code never reaches that line ? | I think (although can't be certain) that you're talking about Windows rather than Unix?
If so, it's possible that the command line process isn't actually waiting for a key press (or input) on `stdin` but instead doing the equivalent of the old DOS `kbhit()` function.
AFAIK there's no way to make that function believe that the keyboard has been pressed without actually pressing a key.
To test this theory, create a text file "input.txt" with some blank lines in it, and run:
```
foo.exe < input.txt
```
That will show whether your program is waiting on `stdin` or on something else. | You should read the ouput and error streams of your subprocess simultaneously. The buffer size of these streams is limited. If one of the buffers gets full the subprocess will block. I think that is what happens in your case. | How can I unblock from a Java started process? | [
"",
"java",
"process",
""
] |
Can any one tell me how can i implement a auto slider/scroller in my web page. The slider should show dynamic data from a database. (Ex : Hot jobs tab in the plipl.com site's home page (www.plipl.com) . Is there any easy way to do this with jQuery ? | The following is nothing special, just quickly tried it. There's 2 div's that it continously switches between, hopefully give you a head start. You could use the same idea and load content into div's via AJAX.
Code snippet:
css:
```
div{width:100px;height:100px;}
#container{overflow:hidden;border:1px solid black;}
#left{background:red;float:left;}
#right{background:green;float:right;}
```
jScript:
```
$(function() {
//Call scrollContent function every 3secs
var timerUp = setInterval(scrollContent, 3000);
function scrollContent(){
//Toggle top between 100 and 0
var top = $("#container").scrollTop() == 0 ? 100 : 0;
$("#container").scrollTop(top);
}
});
```
markup:
```
<div id="container">
<div id="left">
<ul>
<li>One</li>
<li>Two</li>
<li>Three</li>
<li>Four</li>
</ul>
</div>
<div id="right">
<ul>
<li>Five</li>
<li>Six</li>
<li>Seven</li>
<li>Eight</li>
</ul>
</div>
</div>
``` | yes. this is easy.
grab your data from the database. lets say its a list of HotJob objects, each object containing some String fields. Convert each object to a JSON object (which is a hash). Make a list of these JSON objects. use your web framework X to print out the JSON.
Use jquery's getJSON to grab the JSON object. Iterate over each HotJob and write out the information.
Google for "jquery json scroller" and find something that supports JSON out of the box. this does:
<http://www.logicbox.net/jquery/simplyscroll/flickr.html>
sure, its images, but you can modify it to support text. | Auto Slider / Scroller to display dynamic content | [
"",
"javascript",
"jquery",
""
] |
> ## Duplicate
>
> [How do I adjust the brightness of a color?](https://stackoverflow.com/questions/737217/how-do-i-adjust-the-brightness-of-a-color)
> [How do I determine darker or lighter color variant of a given color?](https://stackoverflow.com/questions/97646/how-do-i-determine-darker-or-lighter-color-variant-of-a-given-color)
> [Programmatically Lighten a Color](https://stackoverflow.com/questions/141855/programmatically-lighten-a-color)
---
Say I have
```
var c = Color.Red;
```
Now I want to create a new `Color` that is lighter or darker than that color. How can I do that without too much hassle? | [ControlPaint](http://msdn.microsoft.com/en-us/library/system.windows.forms.controlpaint(VS.85).aspx).Light .Dark .DarkDark, etc.
```
Color lightRed = ControlPaint.Light( Color.Red );
``` | I recently [**blogged about this**](http://www.pvladov.com/2012/09/make-color-lighter-or-darker.html). The main idea is to apply a given correction factor to each of the color components. The following static method modifies the brightness of a given color with a specified correction factor and produces a darker or a lighter variant of that color:
```
/// <summary>
/// Creates color with corrected brightness.
/// </summary>
/// <param name="color">Color to correct.</param>
/// <param name="correctionFactor">The brightness correction factor. Must be between -1 and 1.
/// Negative values produce darker colors.</param>
/// <returns>
/// Corrected <see cref="Color"/> structure.
/// </returns>
public static Color ChangeColorBrightness(Color color, float correctionFactor)
{
float red = (float)color.R;
float green = (float)color.G;
float blue = (float)color.B;
if (correctionFactor < 0)
{
correctionFactor = 1 + correctionFactor;
red *= correctionFactor;
green *= correctionFactor;
blue *= correctionFactor;
}
else
{
red = (255 - red) * correctionFactor + red;
green = (255 - green) * correctionFactor + green;
blue = (255 - blue) * correctionFactor + blue;
}
return Color.FromArgb(color.A, (int)red, (int)green, (int)blue);
}
``` | C#: Create a lighter/darker color based on a system color | [
"",
"c#",
"colors",
""
] |
I want to have a `List` or `Array` of some sort, storing this information about each country:
* 2 letter code
* Country name such as Brazil
* Continent/region of the world such as Eastern Europe, North America, etc.
I will classify each country into the region/continent manually (but if there exists a way to do this automatically, do let me know). This question is about how to store and access the countries. For example, I want to be able to retrieve all the countries in North America.
I don't want to use local text files or such because this project will be converted to javascript using Google Web Toolkit. But storing in an Enum or another resource file of some sort, keeping it separate from the rest of the code, is what I'm really after. | There is 246 countries in ISO 3166, you might get a relay big enum on back of this. I prefer to use XML file with list of countries, you can download one from [http://www.iso.org/](http://www.iso.org/iso/country_codes/iso_3166_code_lists.htm) and load them (e.g. when app is starting).
Than, as you need them in GWT load them in back as RPC call, but remember to cache those (some kind of lazy loading) so you wont finish with loading them each time.
I think this would be anyway better than holding them in code, as you will finish with loading full list each time module is accessed, even if user will not need to use this list.
So you need something which will hold country:
```
public class Country
{
private final String name;
private final String code;
public Country(String name, String code)
{
this.name = name;
this.code = code;
}
public String getName()
{
return name;
}
public String getCode()
{
return code;
}
public boolean equals(Object obj)
{
if (this == obj)
{
return true;
}
if (obj == null || getClass() != obj.getClass())
{
return false;
}
Country country = (Country) obj;
return code.equals(country.code);
}
public int hashCode()
{
return code.hashCode();
}
}
```
For GWT this class would need to implement IsSerializable.
And you can load those, on server side using:
```
import java.util.ArrayList;
import java.util.List;
import java.io.InputStream;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class CountriesService
{
private static final String EL_COUNTRY = "ISO_3166-1_Entry";
private static final String EL_COUNTRY_NAME = "ISO_3166-1_Country_name";
private static final String EL_COUNTRY_CODE = "ISO_3166-1_Alpha-2_Code_element";
private List<Country> countries = new ArrayList<Country>();
public CountriesService(InputStream countriesList)
{
parseCountriesList(countriesList);
}
public List<Country> getCountries()
{
return countries;
}
private void parseCountriesList(InputStream countriesList)
{
countries.clear();
try
{
Document document = parse(countriesList);
Element root = document.getRootElement();
//noinspection unchecked
Iterator<Element> i = root.elementIterator(EL_COUNTRY);
while (i.hasNext())
{
Element countryElement = i.next();
Element countryName = countryElement.element(EL_COUNTRY_NAME);
Element countryCode = countryElement.element(EL_COUNTRY_CODE);
String countryname = countryName.getText();
countries.add(new Country(countryname, countryCode.getText()));
}
}
catch (DocumentException e)
{
log.error(e, "Cannot read countries list");
}
catch (IOException e)
{
log.error(e, "Cannot read countries list");
}
}
public static Document parse(InputStream inputStream) throws DocumentException
{
SAXReader reader = new SAXReader();
return reader.read(inputStream);
}
}
```
Of course, if you need to find country by ISO 2 letter code you might wont to change List to Map probably.
If, as you mentioned, you need separate countries by continent, you might extend XML from ISO 3166 and add your own elements. Just check their (ISO website) license. | Just make an enum called Country. Java enums can have properties, so there's your country code and name. For the continent, you pobably want another enum.
```
public enum Continent
{
AFRICA, ANTARCTICA, ASIA, AUSTRALIA, EUROPE, NORTH_AMERICA, SOUTH_AMERICA
}
public enum Country
{
ALBANIA("AL", "Albania", Continent.EUROPE),
ANDORRA("AN", "Andorra", Continent.EUROPE),
...
private String code;
private String name;
private Continent continent;
// get methods go here
private Country(String code, String name, Continent continent)
{
this.code = code;
this.name = name;
this.continent = continent;
}
}
```
As for storing and access, one Map for each of the fields you'll be searching for, keyed on that that field, would be the standard solution. Since you have multiple values for the continent, you'll either have to use a `Map<?, List<Country>>`, or a Multimap implementation e.g. from Apache commons. | Best way to store Country codes, names, and Continent in Java | [
"",
"java",
"arrays",
"linked-list",
"hashmap",
"treemap",
""
] |
There's no way to do something like this, in C++ is there?
```
union {
{
Scalar x, y;
}
Scalar v[2];
};
```
Where `x == v[0]` and `y == v[1]`? | I've used something like this before. I'm not sure its 100% OK by the standard, but it seems to be OK with any compilers I've needed to use it on.
```
struct Vec2
{
float x;
float y;
float& operator[](int i) { return *(&x+i); }
};
```
You can add bounds checking etc to operator[] if you want ( you probably should want) and you can provide a const version of operator[] too.
If you're concerned about padding (and don't want to add the appropriate platform specific bits to force the struct to be unpadded) then you can use:
```
struct Vec2
{
float x;
float y;
float& operator[](int i) {
assert(i>=0);
assert(i<2);
return (i==0)?x:y;
}
const float& operator[](int i) const {
assert(i>=0);
assert(i<2);
return (i==0)?x:y;
}
};
``` | Since you are using C++ and not C, and since they are of the same types, why not just make x a reference to v[0] and y a reference to v[1] | C++ union array and vars? | [
"",
"c++",
"unions",
""
] |
I find java starts up and runs practically instantly for me - but javac takes a few seconds, and ant makes it slower again. It's only a few seconds, but my edit-compile-test loop would be smoother without it. :-)
BTW: I've already used vim's ":make" with ant.
Is there a way to speed up javac and/or ant? I'm thinking of special switches, or tricks? Or maybe an alternative java compiler (I'm using 1.6, in linux) | [Eclipse](http://www.eclipse.org/) does that for you ... but it's probably a bit big as a "patch" for your problem.
That aside, you can roll your own compiler plugin. There are two approaches:
1. Run the java compiler from within ant (instead of creating a new process). Not sure if ant already does that; if not, that will save you a bit of time. Look at the [Java 6 compiler API](http://java.sun.com/javase/6/docs/technotes/guides/javac/index.html) for details.
2. Run javac in a server process which listens for options on a socket. In ant, send the process the command line and wait for the output to be sent back. Saves you starting a new process all the time.
3. Try to use the eclipse compiler. Unlike the original javac, the Eclipse compiler is pretty good at "ignoring" errors, so it can produce class files even when they contain errors. That doesn't seem to mean much but it allows you to compile all the time in the background. When you do your last save (wrapping everything up), the compiler will have been able to compile *everything else* and will just have to look at a single file. | Google found these two (I haven't tried either yet)
1. `javac` [`-J-client -J-Xms100m -J-Xmx100m`](http://blogs.oracle.com/ahe/entry/javac_performance_problems) `<src>`
2. [JBrownie](http://www.onyxbits.de/jbrownie) "monitors Java sourcecode and automatically recompiles any files found changed" along the lines of Aaron Digulla's (2) | Faster javac/ant? | [
"",
"java",
"ant",
"time",
"build",
"javac",
""
] |
I'm just teaching myself C++ namespaces (coming from a C# background) and I'm really starting to think that even with all the things that C++ does better than most other languages, nested namespaces isn't one of them!
Am I right in thinking that in order to declare some nested namespaces I have to do the following:
```
namespace tier1
{
namespace tier2
{
namespace tier3
{
/* then start your normal code nesting */
}
}
}
```
As opposed to:
```
namespace tier1::tier2::tier3
{
}
```
à la C#?
This becomes even more demented when I need to forward declare:
```
namespace tier1
{
namespace tier2
{
namespace forward_declared_namespace
{
myType myVar; // forward declare
}
namespace tier3
{
/* then start your normal code nesting */
class myClass
{
forward_declared_namespace::myType myMember;
}
}
}
}
```
Bearing in mind that a typical system that I develop consists of:
```
MyCompany::MySolution::MyProject::System::[PossibleSections]::Type
```
Is this why you don't tend to see much use of namespaces in C++ examples? Or usually only single (not nested) namespaces?
**UPDATE**
For anyone interested, [this is how I ended up](http://www.adamjamesnaylor.com/2012/10/23/NestedNamespacesInC.aspx) tackling this issue. | C++ namespaces were not intended to be a design mechanism - they are there simply to prevent name clashes. You really don't want or need to use nested namespaces in 99.99% of situations.
A good example of the correct use of namespaces in C++ is the C++ Standard Library. Everything in this quite large library is placed in a single namespace called **std** - there is no attempt or need to break the library up into (for example) an I/O sub-namespace, a math sub-namespace, a container sub-namespace etc.
The basic tool for modelling in C++ is the class (and to some extent the template), not the namespace. If you feel the need for nesting, you should consider using nested classes, which have the following advantages over namespaces:
* they have methods
* they can control access
* they cannot be re-opened
Having considered these, if you still wish to use nested namespaces by all means do so - there is nothing technically wrong with using them in this way. | C++ namespaces were a vast improvement over the previous offering (i.e. no namespaces at all). C# namespaces have extended the concept and ran with it. I would advise you to keep your namespaces in a simple flat structure.
**EDIT** *Do you advise that due to the short comings i've outlined here?*
Simply "Yes". C++ namespaces weren't designed to help you partition your logic & libraries the way they do in C#.
The purpose of C++ namespaces is to stop the real world problem encountered by C developers, where they experience name collisions when using two third party libs that export the same function name(s). C developers had various workarounds for it, but it could be a serious pain.
The idea was that the STL etc has the `std::` namespace, libs provided by "XYZ Corp" would have an `xyz::` namespace, you working for "ABC corp" would put *all* your stuff in a single `abc::` namespace. | C++ namespaces advice | [
"",
"c++",
"namespaces",
""
] |
```
char[] a = { 'o', 'r', 'a', 'n', 'g', 'e' };
for (int i = 0; i < a.Length/2; i++)
{
a[i] = (char)(((uint)a[i])|((uint)a[a.Length-(i+1)]));
a[a.Length-(i+1)] = (char)(((uint)a[i])^((uint)a[a.Length-(i+1)]));
a[i] = (char)(((uint)a[i])^((uint)a[a.Length-(i+1)]));
}
```
I know how to implement this using standard .NET functionality and temp vars. I am just curious what specifically I am doing wrong in the above example that causes it not to work when the following works fine:
```
int a = 5;
int b = 10;
a = a | b;
b = a ^ b;
a = a ^ b;
```
Isn't the above string version just a series of those? | Hehe, there's no such thing as an OR/XOR/XOR swap - it should be a "triple xor" swap.
```
int a = 8, b = 10;
a ^= b;
b ^= a;
a ^= b;
```
I don't see why you want to use it (aside from the novelty value) | The reason it's not working is that you're using a bad example. You can't swap two values by using OR then XOR then XOR. It only worked in your example because 5 and 10 have no bits in common, so the first OR doesn't destroy any information:
```
a = 0101 #5
b = 1010 #10
# step 1 (OR into a)
a = 1111
b = 1010
# step 2 (XOR into b)
a = 1111
b = 0101
# step 3 (XOR into a)
a = 1010 #10
b = 0101 #5
```
But it won't work if they have any bits in common - let's try with 13 and 10:
```
a = 1101 #13
b = 1010 #10
# step 1 (OR into a)
a = 1111
b = 1010
# step 2 (XOR into b)
a = 1111
b = 0101
# step 3 (XOR into a)
a = 1010 #10
b = 0101 #5
```
Note that we now have the values 5 and 10 still, even though we started with 13 and 10. What you're looking for is a thrice-XOR swap:
```
a = 1101 #13
b = 1010 #10
# step 1 (XOR into a)
a = 0111
b = 1010
# step 2 (XOR into b)
a = 0111
b = 1101
# step 3 (XOR into a)
a = 1010 # 10
b = 1101 #13
``` | What's wrong with my string reversal function? (C#) | [
"",
"c#",
""
] |
In TSQL I can state:
```
insert into myTable (ID) values (5)
GO
select * from myTable
```
In MySQL I can't write the same query.
What is the correct way to write this query in MySQL? | Semicolon at the end of the statement.
```
INSERT INTO myTable (ID) values (5);
``` | The semicolon is the default delimiter.
You can however redefine it to whatever you want with the DELIMITER keyword. From the MySQL manual:
```
mysql> delimiter //
mysql> CREATE PROCEDURE simpleproc (OUT param1 INT)
-> BEGIN
-> SELECT COUNT(*) INTO param1 FROM t;
-> END;
-> //
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
mysql> CALL simpleproc(@a);
Query OK, 0 rows affected (0.00 sec)
```
This is not limited to stored procedure definitions of course. | What is the equivalent of 'go' in MySQL? | [
"",
"sql",
"mysql",
"t-sql",
""
] |
Are you aware of an open source implementation of [force-directed layout](http://en.wikipedia.org/wiki/Force-based_algorithms) in C++ used for GUIs? Preferably BSD/MIT/Apache or other (non-GPL) license. | The excellent [Boost.Graph library](http://www.boost.org/doc/libs/1_38_0/libs/graph/doc/table_of_contents.html) provides a wide range of algorithms, among which a few layout algorithms. I'd recommend using either [Kamada-Kawai spring layout](http://www.boost.org/doc/libs/1_38_0/libs/graph/doc/kamada_kawai_spring_layout.html) or [Fruchterman-Reingold force-directed layout](http://www.boost.org/doc/libs/1_38_0/libs/graph/doc/fruchterman_reingold.html).
[Boost licence](http://www.boost.org/LICENSE_1_0.txt) is very permissive so don't worry about that. | The first Google result is [VTK](http://vtk.org/). Another takes me to [vtkGraphLayoutView](http://www.vtk.org/doc/nightly/html/classvtkGraphLayoutView.html). | Force-directed layout implementation in C++ | [
"",
"c++",
"user-interface",
"force-layout",
"force-based-algorithm",
""
] |
I've been self-learning C++ for about 4 months now. I'm enjoying it, and I think I'm doing quite well. However, an answer to [a question of mine](https://stackoverflow.com/questions/711350/learning-to-work-with-audio-in-c/711447#711447) got me thinking that I might be setting myself up for a fall.
So, what do people here think about C++ as a first language to learn? And is it worth me just carrying on now that I've made a good start? | I don't understand why people still confuse "language" with "library". (Referring to the linked answer.) So what if C++ doesn't have a "native" concept of audio? There are lots of libraries out there, which you can readily use with C++, and which are probably better suited to your specific needs than any "catch-all" "standard-library" audio processing API could be.
</rant>
C++ is a difficult language. There are others that are easier to learn. I would never argue about that.
But C++ is easily one of the most *powerful* languages around. It can be highly efficient, and highly elegant, *at once*. Of course, nothing keeps you from making a fine big mess of everything, either.
If I recommend C++ as a first programming language? Actually, I don't know any better. Others might protect you from making mistakes, and make initial success (e.g. your first GUI application) easier. But if you build on a foundation of C++, you will always be on a secure footing. You might never have to chose another language at all, actually. But if you want / have to, you will find it ridiculously easy.
An experienced C++ coder can do e.g. Java at full speed in a matter of weeks. The other way round? Much, *much* more difficult.
---
Many years later, I felt like I should amend this answer. Since my kids asked me to teach them programming, I started to do so. I found myself actually **not** starting with C++... because I showed them [BF](https://en.wikipedia.org/wiki/Brainfuck) first. In absolutely no time at all, they understood about memory and pointers. Then I went on with C++, and we're enjoying ourselves immensely so far.
---
Yet some more years later, and I felt I really should add this excellent lecture by Kate Gregory from CppCon 2015 to this answer:
[Stop Teaching C](https://www.youtube.com/watch?v=YnWhqhNdYyk). | Let me put it this way:
I took and passed with a 94%, the Sun Java Certification *without ever having compiled a line of Java* (that was nine years ago). I was able to do this, because I knew C++ very well.
On my first professional job, I was hired as a tester. On my second day, I was told I could program instead of test, if I learned enough PowerBuilder to be useful -- in two weeks. Because I knew C++ so well, PowerBuilder was easy.
C++ is *hard*, but if you learn it well -- read Stroustrup's *The C++ Programming Language*, do the exercises too, read his *Design and Evolution of C++*, read the C++ Faq and the Meyers books and Herb Sutter's books, read comp.lang.c++.moderated, read Coplien's *Advanced C++ Programming Styles and Idioms* no matter what OO language you want to code in -- if you learn it well, every other OO language is easy.
Learning C++ is excellent preparation for learning to code. (And you'll become a fair C programmer too, but read K&R to get to be a good C programmer.)
Oh. And C++ is really fun to program in, *much* less verbose than Java, and much more flexible. You're really in charge, not the IDE or the language. You can shoot off your own foot, but you'll be in charge of doing it. And read Alexandrescu's book once you know
templates, it'll amaze and dumbfound and delight you.
C++ is *fun*. Read the "Curiously Recurring Template Pattern": it looks like this
```
template< class T> struct base {};
struct derived: base< derived > {};
```
Yeah, you got that right: it's a class that derives from a base that's templated on the deriving class. Now that sounds just obscure and silly, but there are many good uses for it, and just the other day I was beating my head because *you can't do this in Java* (because Java uses type erase, not templates, for generics), but if I could have used it, I could have saved lots and lots of code repeated in lots of classes.
There's so much more in C++, and if you limit yourself to Java or .Net, you'll never discover it. | C++ as a first language | [
"",
"c++",
""
] |
I have a dictionary of type
```
Dictionary<Guid,int>
```
I want to return the first instance where a condition is met using
```
var available = m_AvailableDict.FirstOrDefault(p => p.Value == 0)
```
However, how do I check if I'm actually getting back a KeyValuePair? I can't seem to use != or == to check against default(KeyValuePair) without a compiler error. There is a similar thread [here](https://stackoverflow.com/questions/648115/how-can-an-object-not-be-compared-to-null) that doesn't quite seem to have a solution. I'm actually able to solve my particular problem by getting the key and checking the default of Guid, but I'm curious if there's a good way of doing this with the keyvaluepair. Thanks | If you just care about existence, you could use `ContainsValue(0)` or `Any(p => p.Value == 0)` instead? Searching by *value* is unusual for a `Dictionary<,>`; if you were searching by key, you could use `TryGetValue`.
One other approach:
```
var record = data.Where(p => p.Value == 1)
.Select(p => new { Key = p.Key, Value = p.Value })
.FirstOrDefault();
```
This returns a *class* - so will be `null` if not found. | I suggest you change it in this way:
```
var query = m_AvailableDict.Where(p => p.Value == 0).Take(1).ToList();
```
You can then see whether the list is empty or not, and take the first value if it's not, e.g.
```
if (query.Count == 0)
{
// Take action accordingly
}
else
{
Guid key = query[0].Key;
// Use the key
}
```
Note that there's no real concept of a "first" entry in a dictionary - the order in which it's iterated is not well-defined. If you want to get the key/value pair which was *first* entered with that value, you'll need an order-preserving dictionary of some kind.
(This is assuming you actually want to know the key - if you're just after an existence check, [Marc's solution](https://stackoverflow.com/a/793918/3649914) is the most appropriate.) | Check if KeyValuePair exists with LINQ's FirstOrDefault | [
"",
"c#",
"linq",
"null",
""
] |
I've had quite a long discussion with a friend of mine about the correct and good use of the main method in Java. Basically we have a class like this:
```
public class AnImporter implements Runnable {
// some methods, attributes, etc.
}
```
But where to put the main method? I concider it a good practice to "keep code where it belongs", thus turning the above code into
```
public class AnImporter implements Runnable {
public static void main(String [] args){
// Startup code for Importer App here
}
// some methods, attributes, etc.
}
```
While my buddy argues that "the startup code has nothing to do with the application itself", thus it should be placed in another class, like this:
```
public class AnImporter implements Runnable {
// some methods, attributes, etc.
}
public class AnApplication {
// Nothing here
public static void main(String [] args){
AnImporter a = new AnImporter();
// Startup code here
}
// Nothing here
}
```
Despite the fact that we discussed the matter for some time we both ended up with no conclusion on which way is the better approach in Java. What's your oppinion on this topic? Where and most importantly, why, do you place your main method where you placed it? | I agree with your friend. You're building up a potentially reusable service in AnImporter that could potentially be used in multiple programs with multiple main's. So, making one main special and embedding it in AnImporter doesn't make much sense. | I'd probably go with your friend as I'd prefer to get out of the class with the main method as quickly as possible. It helps facilitate testing when you want to test atomically (just the runnable class) or you want to mock things out. The sooner you get out of the main method, the more options you have. If you have one class with the main method and other things in it, it could get messy quickly. (even if it might not seem that way with a simple example such as the one you describe)
But I'd say readability and testability are two good reasons for getting out of the main method (and its encompassing class) ASAP. But hey..that's just me ;) | Java Main Method, Good Coding Style | [
"",
"java",
"coding-style",
""
] |
I am writing a report to return details about an object ('files') in my database. My application lets users create their own flags for use against file objects. Flags basically consist of a name, then flag instances store a bit value to indicate whether it is set for the parent file object.
I want to write a query that returns one row per file in the database, where the first few columns in the result set contain the file details (id, name, size etc) and the remaining columns are the flag names, with bit values returned to indicate whether the flag is set for the given file row.
Does that make sense? How do i go about writing the query?
Thanks for any help.
Edit: Clarification..
As part of this query, I need to run a sub query that returns the flags that have been created by the user (I do not know these at design time), then incorporate a check for each flag value in the main query to return details about the files.
Simplified schema as follows:
* File {Id, Name}
* Flag {Id, Name}
* FileFlags {FileId, FlagId} - a row in this table indicates that the flag is set for the file
I need the query to return a result set with columns something like this:
**FileId** **FileName** **Flag1Name** **Flag2Name** .... **FlagNName** | You could start by looking at the [Pivot](http://msdn.microsoft.com/en-us/library/ms177410.aspx) function available in SQL Server 2005+. With that and some string concatenation you should be able to assemble a query for any number of columns
Based on your comment your select would look something like this:
```
SELECT <non-pivoted column>,
[first pivoted column] AS <column name>,
[second pivoted column] AS <column name>, ...
From Table
PIVOT (
...
FOR
...
)
``` | Why not create a stored procedure with the required logic - querying user-specific flags, etc - and on that basis dynamically build a query string with the variables you need?
You can then use `EXECUTE` to return the dynamic query set to the user. See <http://msdn.microsoft.com/en-us/library/ms188332.aspx> | sql question .. how can i dynamically add columns to a sql query result set? | [
"",
"sql",
"t-sql",
"dynamic-sql",
""
] |
I am connecting to a 3rd party server. I know right now they allow 8 connections from the same remote user. However i dont know if they will raise or lower the connection limit. So i want my app to dynamically find out. How can i do this?
## I'm using C#, MSVS 2008
I started a bounty for anyone who can give me working C#. If no one does then i'll give it to the best answer.
I find this very difficult to do and had a few failed attempts :( | I will take this bounty good sir. Not exactly sure why you want to do this and why someone allows 8 connections.
> Defined in 1999 (RFC 2616) “clients
> that use persistent connections should
> limit the number of simultaneous
> connections that they maintain to a
> given server. A single-user client
> SHOULD NOT maintain more than 2
> connections with any server or proxy.
> A proxy SHOULD use up to 2\*N
> connections to another server or
> proxy, where N is the number of
> simultaneously active users. These
> guidelines are intended to improve
> HTTP response times and avoid
> congestion.” Since developers are
> using AJAX or AJAX-like requests to
> update a Web page the http limits are
> discussed more and more.
Like the RFC says, I was only able to get 2 open connections to web servers.
But here's the code:
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net;
using System.Threading;
namespace ConnectionTest
{
public class RequestCounter
{
public int Counter = 0;
public void Increment()
{
Interlocked.Increment(ref Counter);
}
}
public class RequestThread
{
public AutoResetEvent AsyncWaitHandle { get; private set; }
public RequestCounter RequestCounter;
public String Url;
public HttpWebRequest Request;
public HttpWebResponse Response;
public RequestThread(AutoResetEvent r, String u, RequestCounter rc)
{
Url = u;
AsyncWaitHandle = r;
RequestCounter = rc;
}
public void Close()
{
if (Response != null)
Response.Close();
if (Request != null)
Request.Abort();
}
}
public class ConnectionTest
{
static void Main()
{
string url = "http://www.google.com/";
int max = GetMaxConnections(25, url);
Console.WriteLine(String.Format("{0} Max Connections to {1}",max,url));
Console.ReadLine();
}
private static int GetMaxConnections(int maxThreads, string url)
{
RequestCounter requestCounter = new RequestCounter();
List<RequestThread> threadState = new List<RequestThread>();
for (int i = 0; i < maxThreads; i++)
threadState.Add(new RequestThread(new AutoResetEvent(false), url, requestCounter));
List<Thread> threads = new List<Thread>();
foreach (RequestThread state in threadState)
{
Thread t = new Thread(StartRequest);
t.Start(state);
threads.Add(t);
}
WaitHandle[] handles = (from state in threadState select state.AsyncWaitHandle).ToArray();
WaitHandle.WaitAll(handles, 5000); // waits seconds
foreach (Thread t in threads)
t.Abort();
foreach(RequestThread rs in threadState)
rs.Close();
return requestCounter.Counter;
}
public static void StartRequest(object rt)
{
RequestThread state = (RequestThread) rt;
try
{
state.Request = (HttpWebRequest)WebRequest.Create(state.Url);
state.Request.ReadWriteTimeout = 4000; //Waits 4 seconds
state.Response = (HttpWebResponse)state.Request.GetResponse();
if (state.Response.StatusDescription.Equals("OK", StringComparison.InvariantCultureIgnoreCase))
state.RequestCounter.Increment();
//Do not close, or you will free a connection. Close Later
//response.Close();
}
catch (WebException e)
{
//Console.WriteLine("Message:{0}", e.Message);
state.Close();
}
catch (ThreadAbortException e)
{
//Console.WriteLine("Thread Aborted");
state.Close();
}
catch(Exception e)
{
//Console.WriteLine("Real Exception");
state.Close();
}
finally
{
state.AsyncWaitHandle.Set();
}
}
}
}
``` | That's not information which a server gives out to clients by default. The only way to know is keep opening connections until it fails (bad idea), or ask the server owner to offer a service you can poll which returns this information.
Edit: after thinking some more about this question, I'm not sure if it's possible to determine this via "probing" with any real degree of accuracy. If the server returned `503 Server Busy` when it reached its connection limit (which I assumed would happen when I made my original suggestion), it would be easier to test. But generally when servers go over their connection limit, they simply don't respond until a new connection is available. The client simply waits for a response. There is no hard way to distinguish between a server which took 10 seconds to respond because its connection limit had been reached, and a server which took 10 seconds to respond for any other reason.
In addition, even if you still attempted to test it in this manner, the requests you make to the server would need to stay open long enough to ensure that the *first* connection you create (and all subsequent ones) are still open when the nth request times out. That would mean either calling a service which takes an arbitrarily long time to return - a long-running process or a Thread.Sleep(); or download an inconveniently large file. Either approach is extremely inefficient at best. | Amount of Connections per server? C#, web | [
"",
"c#",
".net",
"httpwebrequest",
""
] |
In std::string there are only const members to fetch the data like c\_str(). However I can get a reference to the first element of the string via `operator[]` and I can write to it.
For example, if I have function:
```
void toupper(char *first,char *last_plus_one);
```
I can write directly to vector getting a pointer to the first element:
```
vector<char> message // has "Some Message";
toupper(&message[0],&message[0]+message.size());
```
Can I do same thing with std::string?
```
string message="Some Message";
toupper(&message[0],&message[0]+message.size());
```
Does the standard guarantee that the location of the memory is actually linear? ie:
```
&(*(message.begin()+n)) == &message[n]
```
Thanks. | std::string will be required to have contiguous storage with the new c++0x standard. Currently that is undefined behavior. | Herb Sutter has this to say (<http://herbsutter.wordpress.com/2008/04/07/cringe-not-vectors-are-guaranteed-to-be-contiguous/#comment-483>):
> current ISO C++ does require &str[0] to cough up a pointer to contiguous string data (but not necessarily null-terminated!), so there wasn’t much leeway for implementers to have non-contiguous strings, anyway. For C++0x we have already adopted the guarantee that std::string contents must indeed be stored contiguously. For details, see <http://www.open-std.org/jtc1/sc22/wg21/docs/lwg-defects.html#530>
And Matt Austern says similar in the referenced document (<http://www.open-std.org/jtc1/sc22/wg21/docs/lwg-defects.html#530>).
So, it seems that you can assume that once you call str[0] you do get a modifyable array of characters (but note that it is not required to be null terminated). | Is it legal to write to std::string? | [
"",
"c++",
"string",
"standards",
""
] |
The function code:
```
# Connect to the DB
try:
dbi = MySQLdb.connect(host='localhost', \
user='user', \
passwd='pass', \
db='dbname', \
port=3309)
print "Connected to DB ..."
except MySQLdb.Error, e:
apiErr = 2
apiErrMsg = "Error %d: %s" % (e.args[0], e.args[1])
return
# To prevent try..finally bug in python2.4,
# one has to nest the "try: except:" part.
try:
try:
sql = dbi.cursor()
sql.execute("""
SELECT *
FROM table
WHERE idClient = %s
""", (key, ))
access = sql.fetchall()
# [some more code here]
except MySQLdb.Error, e:
apiErr = 2
apiErrMsg = "Error %d: %s" % (e.args[0], e.args[1])
return
finally:
sql.close()
dbi.close()
```
I understand that in a try .. except .. finally, the finally block will always execute.
In the above code, I don't want the finally in the second try block to execute if there is an exception in the first try block. What am I doing wrong?
(Note: Using python 2.4)
Clarification: I am not aware if MySQLdb closes connections automatically when an error occurs. The problem I am facing with the above code is, when there is an error in establishing a connection (the first try block of the code), calling dbi.close() in the finally block raises "AttributeError: 'NoneType' object has no attribute 'close'" with reference to dbi ...
**Solution**:
This worked as desired -
```
# define at the start
dbi = None
sql = None
```
In the finally block,
```
if sql is not None:
sql.close()
if dbi is not None:
dbi.close()
```
Thanks to those who replied. I learned something new from all of you. (I'll try to phrase my questions more clearly the next time :). | I think in this case you do want to use finally, because you want to close those connections.
I disagree with the notion that you should have two try blocks in the same method.
I think the flaw in the design is acquiring the connection and performing the query in the same method. I would recommend separating the two. A service class or method knows about the unit of work. It should acquire the connection, pass it to another class that performs the query, and closes the connection when it's done. That way the query method can throw any exception it encounters and leave the cleanup to the class or method that's responsible for the connection. | Use `else:` instead of `finally:`. See the [Exception Handling](http://docs.python.org/tutorial/errors.html#handling-exceptions) part of the docs:
> The `try ... except` statement has an optional else clause, which, when present, must follow all except clauses. It is useful for code that must be executed if the try clause does not raise an exception.
```
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except IOError:
print 'cannot open', arg
else:
print arg, 'has', len(f.readlines()), 'lines'
f.close()
```
..basically:
```
try:
[code that might error]
except IOError:
[This code is only ran when IOError is raised]
else:
[This code is only ran when NO exception is raised]
finally:
[This code is always run, both if an exception is raised or not]
``` | Python Beginner: How to Prevent 'finally' from executing? | [
"",
"python",
""
] |
I'm using v2.0 of ClassTextile.php, with the following call:
```
$testimonial_text = $textile->TextileRestricted($_POST['testimonial']);
```
... and all of my apostrophes (ex. It's hot in here) are being translated to ASCII `‘` (which is a single quote, which slopes the wrong way). What it should be is ASCII `’`. I've also tried using `TextileThis()` and I have the same problem.
If I go and try it on Textile's website (<http://textile.thresholdstate.com/>), it gives the correct ASCII code. So why isn't it working with the downloadable library? Or am I doing something wrong? | Tried this again and it works. Weird.
Have since switched to Markdown, regardless. Ah well. | Have you really copy-pasted the text from your source code to the form on their website? If this still yields the same result, you should probably upgrade your version. | PHP: Textile giving me single quotes instead of apostrophes | [
"",
"php",
"textile",
""
] |
Let A and B be two tables in a database schema. A and B are related by a many-to-one relationship. There exists many B's for each A, and B has a foreign key column a\_id. Both tables have a primary key column id.
Which of the following two queries performs better for large data sets in A and B?
```
SELECT A.* FROM A,B WHERE A.id = B.a_id
```
or
```
SELECT A.* FROM A INNER JOIN B ON A.id = B.a_id
```
Or are they equivalent? | They are equivalent for all `4` major database systems: `Oracle`, `SQL Server`, `MySQL`, `PostgreSQL`.
Using `JOIN` syntax (to be more exact, using `STRAIGHT_JOIN` instead of `JOIN`) will help to enforce the join order you need in `MySQL`.
See this answer for details:
* [**Does the order of tables matter?**](https://stackoverflow.com/questions/785583/does-the-order-of-tables-referenced-in-the-on-clause-of-the-join-matter/785626#785626)
It's also generally considered more clean and readable to use the `JOIN` syntax.
Though I'm grown on `Oracle` code samples which generally use the `WHERE` syntax. | I would agree with the other answers that performance wise the two statements are equivalent on the major systems but I would also throw out there that the second statement is preferable from a code readability standpoint. I would also say that specifying the column list instead of using an asterisk would increase performance as well as readability. | Which of these approaches has better performance for large tables? | [
"",
"sql",
"performance",
""
] |
I have a JSP page running on Tomcat 5.5. I have the following code:
```
<c:forEach var="i" begin="1" end="10" step="1">
<c:out value="${i}" />
<br />
</c:forEach>
```
The output I am getting is:
```
${i}
${i}
${i}
${i}
${i}
${i}
${i}
${i}
${i}
${i}
```
I cant work out why the forEach loop is working but the output is not working. Any help any one could give would be great. | I know it's supposed to be on by default, but I run across pages now and again (or even the same page that changes behavior) where the EL processing doesn't happen. Adding the following to the top of any such pages should resolve the issue:
```
<%@ page isELIgnored="false" %>
```
I add it to every page because it doesn't hurt, and I still don't know the root cause that occasionally causes a page to stop interpreting the EL expressions. | I just had this same problem and spent forever trying to figure out what was wrong.
I've developed lots of web apps from scratch. Why suddenly was this one not cooperating?
One difference was this time I used the maven webapp archetype to generate the project structure. It created a web.xml file that looked like this:
```
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd" >
<web-app>
<display-name>Archetype Created Web Application</display-name>
</web-app>
```
Once I realized that as my problem, I was sure I had the answer. So I copied one of my 2.5 web.xml headers, rebuilt, and redeployed. No cigar. Couldn't believe that wasn't the problem. Cleaned the project, restarted tomcat. Nope.
RHSeeger's answer led me to try putting in the <%@ page isELIgnored="false" %>. That resolved the problem. But I still wanted to know why el started getting ignored to begin with.
I figured the el was being ignored because of something wrong with my web.xml, so I closely inspected it in comparison with another webapp's web.xml that I knew worked fine. No noticeable differences.
Then I removed the <%@ page isELIgnored="false" %> from my JSP, and redeployed, assuming the el would not be evaluated again, but much to my surprise, the el was evaluated fine!
Then, figuring it must be some sort of caching problem, I undid my changes to the web.xml to recreate the problem. I redeployed, but still the el was being evaluated correctly, even with the bad web.xml. Then I cleaned my entire project (I'm using an exploded deployment), blowing away the exploded directory and recreating it. I then restarted tomcat. Still, the el appeared to be getting evaluated correctly in spite of the bad web.xml.
Finally it dawned on me. I simply added a space to some place in the JSP, repackaged it, and refreshed the page. Bingo! Now the el was not getting evaluated.
So the problem *was* with the web.xml. It would further complicated by the fact that the JSPs weren't getting recompiled unless they had changed. Not sure if tomcat uses an MD5 sum to decide if the JSPs need to be recompiled or what. Another possibility is that I'm using tiles, which I know has a caching mechanism, but I wouldn't expect that to survive an tomcat restart.
Anyway, unless you modify your JSPs AFTER fixing the web.xml, all bets are off as to whether the EL will start working again. Hope this saves someone else a headache. I'm also interested if anyone can tell me whether it was tomcat not recompiling the JSPs or tiles caching the output of the JSP. I'm pretty sure it's the recompile, because at compile time is when the JSP should have to figure out what to do with the ${} el expressions, right? Tiles can't actually cache what gets substituted into the el expressions, otherwise all kinds of problems would arise. | JSP: EL expression is not evaluated | [
"",
"java",
"jsp",
"el",
"taglib",
""
] |
My application requires an on-drive map as there will be no internet access during operation. I've kind of settled on using MapPoint 2009, but the map 'style' really clashes with my overall UI look and feel.
I'm wondering if there's some way to custom draw everything on the map (roads, labels, etc.)? It's crossed my mind that perhaps there's some themeing in the MapPoint application itself, but I don't have it handy right now :(
I'd totally prefer a WPF method but really, anything at this point helps :) | I don't believe the MapPoint COM API exposes any method of overriding the default rendering. You can add your own objects on top (via shapes, etc), but I don't believe it will do exactly what you are asking for.
The only C# mapping framework I know of that would do this is [SharpMap v2](http://sharpmap.codeplex.com/Wiki/View.aspx?title=SharpMap%20v2). The plans were to provide a WPF rendering stack in addition to the current GDI+ one. | No, basically. The most you can do is add push-pins, lines, shapes etc. There is a usenet forum (microsoft.public.mappoint) that might have more, but I can pretty much guarantee the answer is "no". | Custom-drawing MapPoint maps in C#? | [
"",
"c#",
"wpf",
"mappoint",
""
] |
What do people mean when they say this? What are the implications for programmers and compilers? | This is related to the fact that C++'s template system is [Turing complete](https://stackoverflow.com/questions/189172/c-templates-turing-complete). This means (theoretically) that you can compute anything at compile time with templates that you could using any other Turing complete language or system.
This has the side effect that some apparently valid C++ programs cannot be compiled; the compiler will never be able to decide whether the program is valid or not. If the compiler could decide the validity of all programs, it would be able to solve the [Halting problem](http://en.wikipedia.org/wiki/Halting_problem).
Note this has nothing to do with the ambiguity of the C++ grammar.
---
**Edit:** Josh Haberman pointed out in the comments below and in a [blog post](http://blog.reverberate.org/2013/08/parsing-c-is-literally-undecidable.html) with an excellent example that constructing a parse tree for C++ actually is undecideable. Due to the ambiguity of the grammar, it's impossible to separate syntax analysis from semantic analysis, and since semantic analysis is undecideable, so is syntax analysis.
See also (links from Josh's post):
* [C++ grammar: the type name vs object name issue](http://yosefk.com/c++fqa/web-vs-c++.html#misfeature-2)
* [C++ grammar: type vs object and template specializations](http://yosefk.com/c++fqa/web-vs-c++.html#misfeature-3) | What it probably means is that C++ grammar is syntactically ambiguous, that you can write down some code that could mean different things, depending on context. (The grammar is a description of the syntax of a language. It's what determines that `a + b` is an addition operation, involving variables a and b.)
For example, `foo bar(int(x));`, as written, could be a declaration of a variable called bar, of type foo, with int(x) being an initializer. It could also be a declaration of a function called bar, taking an int, and returning a foo. This is defined within the language, but not as a part of the grammar.
The grammar of a programming language is important. First, it's a way to understand the language, and, second, it's part of compiling that can be made fast. Therefore, C++ compilers are harder to write and slower to use than if C++ had an unambiguous grammar. Also, it's easier to make certain classes of bugs, although a good compiler will provide enough clues. | What do people mean when they say C++ has "undecidable grammar"? | [
"",
"c++",
"compiler-construction",
""
] |
Consider the following code:
```
Class Demo
{
Person person = new Person("foo"); // assume Person class has a 'name' field.
//Now, how do I get the value of a field, using some expression.
String expression = "person.name";
}
```
Now, I want to evaluate the 'expression' to get the value of the 'name' attribute. Can anyone tell how it can be done?
--
Updated: the 'expression' string I'll be getting it from an XML file. So, will it be possible to use 'Reflection' in that scenario also? the 'expression' string may go into deeper levels also, like 'person.birthday.date'. | There's no native way in Java to do this. A variety of other options exist.
One approach is to use [JXPath](http://commons.apache.org/jxpath/). This uses XPath-style syntax to query objects. It may be a little overkill for your purposes, but is undoubtedly powerful.
e.g. from the JXPath home page:
```
Address address = (Address)JXPathContext.newContext(vendor).
getValue("locations[address/zipCode='90210']/address");
```
which asks the given vendor object for it's address given a zip code of 90210. So you can navigate object hierarchies and provide predicates to perform 'SELECT .. WHERE' type queries.
See also [this](http://today.java.net/pub/a/today/2006/08/03/java-object-querying-using-jxpath.html) java.net article for more examples (shameless plug of something I wrote). | Typically in Java you create getters to retrieve this information. However, if you need to get the value of a field by name you should be using [reflection](http://java.sun.com/docs/books/tutorial/reflect/index.html).
Yet, there is something about your question that nags me that your problem has more to do with design than reflection. Can you tell us more? | Accessing an Object's attribute value using an expression | [
"",
"java",
""
] |
The Windows API DuplicateHandle()
<http://msdn.microsoft.com/en-us/library/ms724251(VS.85).aspx>
Requires the Object handle to be duplicated and a handle to both the original process AND the other process that you want to use the duplicated handle in.
I am assuming that if I have two UNRELATED processes, I could call DuplicateHandle() in either one so long as I had the required handles available?
My Question is about using a Pipe to communicate between the two processes to achieve this with an Event.
In the first process I CreateEvent(). Now I want to use WaitForSingleObject() in the second process.
If I try to duplicate the handle in the first process, I will need to first send the second process handle to the first process via the pipe, duplicate the handle and then send the handle over to the second process?
Alternativly, I could begin by sending the first process handle and the Event handle to the second process and just duplicate it there.
Is there a reason I should choose one over the other?
To add a wrinkle, the Event handle is actually inherited from the parent process that actually called the first process (which is a CGI application). If that Event handle was created with HANDLE\_DO\_NOT\_DUPLICATE (something like that) then can I in fact use DuplicateHandle() to duplicate it for the second process?
Response:
Well I could create a new NAMED event in the first process and find it in the second process as suggested, but I am trying to DUPLICATE the event that was created in the parent of the first process and foreward it to the second process. This event is not a named event so I need to use DuplicateHandle().
I am using a pipe for the IPC. I am realizing that DuplicateHandle() will have to be called in the first process because the event handle is out of context when sent to the second process.
```
hProcPseudo = GetCurrentProcess()
//Then call either:
lpRealHandle = OpenProcess( PROCESS_DUP_HANDLE, 0, hProcPseudo )
//This fails with GetLastError= 87 - The parameter is incorrect ???
// same thing with PROCESS_ALL_ACCESS ??
//OR
lRet = DuplicateHandle( hProcPseudo, hProcPseudo, hProcPseudo, lpRealHandle, DUPLICATE_SAME_ACCESS, 0, 0 )
//then I can Duplicate my Event Handle in the first thread with:
lRet = DuplicateHandle( hLocalProcess, hEvent, lpRealHandle, hDupEvent, DUPLICATE_SAME_ACCESS, 0, 0)
```
The second process converts its handle with DuplicateHandle() detailed above converting
hProcPseudo= 4294967295
to
hProcess= 152
Then I pass this process handle to the first process via the named pipe.
In the first process (where the event handle is valid) I call Duplicate handle:
```
DuplicateHandle( hFirstProcess, hEvent, hSecondProc, hDupEvent, DUPLICATE_SAME_ACCESS, 0, 0)
```
Unfortunatly I get the error:
DuplicateHandle hPipeFCGI GetLastError= 6 - The handle is invalid.
Further testing (substituting hFirstProcess) reveals it is hSecondProc that is invalid!??
Big Mystery. | Use a [named pipe](http://msdn.microsoft.com/en-us/library/aa365590(VS.85).aspx) or [mailslots](http://msdn.microsoft.com/en-us/library/aa365576(VS.85).aspx) for IPC, this should work reliably for your purpose. If you need to wait, use named wait handles.
Otherwise, I'd choose to do DuplicateHandle in the second process in order to set the handle ownership correctly. | Process Handle is different from process id. OpenProcess takes process id. Use something like...
HANDLE hProcess = OpenProcess(PROCESS\_DUP\_HANDLE, FALSE, GetCurrentProcessId()); | DuplicateHandle(), use in first or second process? | [
"",
"c++",
"winapi",
"ipc",
""
] |
I am using the code below
```
Thread.Sleep(5);
```
at the end of a while loop. To try and get a 5ms delay between iterations.
Sometimes it sleeps for 16ms. This I understand and accept, since it depends on when the CPU gets around to servicing the thread. However once it has woken the next iteration it seems to wake immediately after the sleep call (I am logging with timestamps). Is there a problem with using such a short sleep interval that it is treated as zero? | Your problem is like that on most modern machines, [DateTime.UtcNow](http://msdn.microsoft.com/en-us/library/system.datetime.utcnow.aspx) has a resolution of about 10-15ms (though I see the documentation says it's about 10ms since NT 3.5). If you want higher resolution timing, see the [Stopwatch](http://msdn.microsoft.com/en-us/library/system.diagnostics.stopwatch.aspx) class, specifically [Stopwatch.GetTimestamp()](http://msdn.microsoft.com/en-us/library/system.diagnostics.stopwatch.gettimestamp.aspx).
Also note that Stopwatch will only use the high-resolution timers if they are available ([Stopwatch.IsHighResolution](http://msdn.microsoft.com/en-us/library/system.diagnostics.stopwatch.ishighresolution.aspx) will tell you at run-time). If not, it falls back to DateTime.UtcNow.Ticks. | Most likely, the problem is simply that your timer has limited resolution. If it only updates, say, every 10ms, you're going to see the same timestamp on some iterations, even if 5ms have passed.
Which timer are you using to generate your timestamps? | C# Thread.Sleep waking immediately | [
"",
"c#",
"multithreading",
""
] |
I have a web app that currently uses the current HttpContext to store a LINQ Data Context. The context is persisted for the current request, on a per user basis, per [Rick Strahl's blog](http://www.west-wind.com/weblog/posts/246222.aspx):
```
string ocKey = "ocm_" + HttpContext.Current.GetHashCode().ToString("x")
Thread.CurrentContext.ContextID.ToString();
if (!HttpContext.Current.Items.Contains(ocKey))
{
// Get new Data Context and store it in the HTTP Context
}
```
However, I have some scripts that execute from the global.asax file, that **don't have** an HttpContext. **The HttpContext.Current is NULL**, because the server is the one making the "request".
Is there an equivalent object that I can use to store the Data Context? So I don't have to worry about re-creating it, and attaching/detaching objects? I only want to persist the context for the lifetime of my processes.
**UPDATED:**
I am currently trying to use a static variable in my DAL helper class. on the first call to one of the methods in the class the DataContext is instantiated, and stored in the static variable. At the end of my process, I call another method that calls Dispose on the DataContext, and sets the static variable to NULL. | Can you not just use a static variable specifically for those scripts? That will have the same life-time as the `AppDomain`. You should probably think carefully about any concurrency concerns, but it sounds like the simplest way to keep a value around.
(I've just checked, and although one instance of `HttpApplication` can be used to service multiple requests, each one only serves one request at a time - which suggests that multiple instances are created for concurrent request processing. I haven't validated this, but it does sound like it wouldn't be safe to keep it in an instance variable.)
EDIT: Josh's answer suggests that you want this to be per-thread. That sounds slightly odd to me, as unless you've got a *lot* of these events occurring, you're quite likely to only ever see them execute on different threads, making the whole sharing business pointless. If you really do want that sort of thing, I'd suggest just using an instance variable in the `HttpApplication`-derived class - for exactly the reason described in the paragraph above :) | Why not use the current HttpContext? The scripts in your global.asax file are all the result of a request coming into the server, so there should be a context associated with that request which you can grab.
I don't understand the need for generating the key based on the hashcode or the thread. There is going to be a separate instance of HttpContext for each request that comes in, and that instance is going to be specific to the thread that is processing the request. Because of that, the key is pretty much worthless when it's based on the instance of HttpContext and the thread.
Also, how do you dispose of the DataContext when you are done? It implements IDisposable for a reason, so I would recommend against a shared instance like this.
---
**UPDATE**
In the comments, it indicates that there is a timer that is running that is executing the scripts. Instead of the timer, I would recommend setting up a Scheduled Task which will call a webservice or predetermined page on the site which will perform the task. Then you will always have an HttpContext to work with. | Server-side equivalent of HttpContext? | [
"",
"c#",
"asp.net",
"linq",
"linq-to-entities",
"httpcontext",
""
] |
How can I shorten the definition of my custom routes in Zend Framework? I currently have this as definition:
```
$route = new Zend_Controller_Router_Route(
":module/:id",
array(
"controller" => "index",
"action" => "index"
),
array("id" => "\d+")
);
self::$frontController->getRouter()->addRoute('shortcutOne', $route);
$route = new Zend_Controller_Router_Route(
":module/:controller/:id",
array("action" => "index"),
array("id" => "\d+")
);
self::$frontController->getRouter()->addRoute('shortcutTwo', $route);
$route = new Zend_Controller_Router_Route(
":module/:controller/:action/:id",
null,
array("id" => "\d+")
);
self::$frontController->getRouter()->addRoute('shortcutThree', $route);
```
Is there a way to better combine these rules?
And what are your best practices in where to place these? I currently have them in my bootstrap class right after the Front Controller initialization. | When it comes to setting up routes like this, I use a config file. As a preference, I use XML to store my config data, however these could just as easily be stored in another supported format. I then add the routes from the config, to the router in my bootstrap.
**Config:**
```
<config>
<routes>
<shortcutone type="Zend_Controller_Router_Route">
<route>:module/:id</route>
<defaults>
<controller>index</controller>
<action>index</action>
</defaults>
<reqs id="\d+">
</shortcutone>
<shortcuttwo type="Zend_Controller_Router_Route">
<route>:module/:controller/:id</route>
<defaults>
<controller>index</controller>
</defaults>
<reqs id="\d+">
</shortcuttwo>
<shortcutthree type="Zend_Controller_Router_Route">
<route>:module/:controller/:action/:id</route>
<defaults>
<controller>index</controller>
<action>index</action>
</defaults>
<reqs id="\d+">
</shortcutthree>
</routes>
</config>
```
**Bootstrap**
```
$config = new Zend_Config_Xml('config.xml');
$router = Zend_Controller_Front::getInstance()->getRouter();
$router->addConfig($config, 'routes');
```
Obviously, there are other options and I'd encourage you to read the [documentation](http://framework.zend.com/manual/en/zend.controller.router.html) on this, however, this fits for your example. | My routes.ini file started to get really large, so I decided to use Zend Caching to cache the routes after they had been parsed. I used Xcache for the backend caching solution. Here's the code, which should be put in the Bootstrap.php file:
```
protected function _initRoutes()
{
$backendType = 'Xcache';
$backendOptions = array();
// Instantiate a caching object for caching the routes
$cache = Zend_Cache::factory('File', $backendType,
array(
'automatic_serialization' => true,
'master_files'=>array(APPLICATION_PATH . '/configs/routes.ini')
),
$backendOptions
);
$frontController = Zend_Controller_Front::getInstance();
if(! $router = $cache->load('router')) {
// Load up .ini file and put the results in the cache
$routes = new Zend_Config_Ini (APPLICATION_PATH . '/configs/routes.ini', 'production');
$router = $frontController->getRouter();
$router->addConfig( $routes, 'routes' );
$cache->save($router, 'router');
}
else {
// Use cached version
$frontController->setRouter($router);
}
}
``` | Shorten Zend Framework Route Definitions | [
"",
"php",
"zend-framework",
"routes",
""
] |
I am trying to create a general method for disposing an object that implements [IDisposable](http://msdn.microsoft.com/en-us/library/system.idisposable(loband).aspx), called `DisposeObject()`
To make sure I am disposing an object pointed by original reference, I am trying to pass an object by reference.
But I am getting a compilation error that says
> The 'ref' argument type doesn't match parameter type
In the below (simplified) code, both `_Baz` and `_Bar` implement [IDisposable](http://msdn.microsoft.com/en-us/library/system.idisposable(loband).aspx).
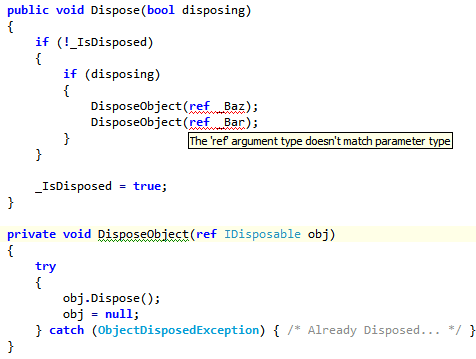
So the questions are,
1. Why am I getting this error?
2. Is there a way to get around it?
**[UPDATE]**
From provided answers so far, as long as I do not set an IDisposable argument to null, I can simply pass an object by value without using `ref`.
I am now having another trouble whether to set disposable objects to `null` or not within `DisposeObject` method.
Here is the full source for completeness:
```
public class Foo : IDisposable
{
private Bar _Bar;
private Baz _Baz;
private bool _IsDisposed;
~Foo() { Dispose(false); }
public void Dispose(bool disposing)
{
if (!_IsDisposed)
{
if (disposing)
{
DisposeObject(ref _Baz);
DisposeObject(ref _Bar);
}
}
_IsDisposed = true;
}
private void DisposeObject(ref IDisposable obj)
{
try
{
if (obj == null)
return;
obj.Dispose();
obj = null;
} catch (ObjectDisposedException) { /* Already Disposed... */ }
}
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
}
public class Bar : IDisposable
{
public void Dispose() {}
}
public class Baz : IDisposable
{
public void Dispose() {}
}
```
**[RESULT]**
I removed the code that sets argument to null (`obj = null;`) within `DisposeObject`
So the final code became.
```
public void Dispose(bool disposing)
{
if (!_IsDisposed)
{
if (disposing)
{
DisposeObject(_Baz);
DisposeObject(_Bar);
}
}
_IsDisposed = true;
}
private void DisposeObject(IDisposable obj)
{
try
{
if (obj == null)
return;
obj.Dispose();
} catch (ObjectDisposedException) { /* Already Disposed... */ }
}
``` | There is no need for you to pass by reference, as you're passing a reference type. You should remove the `ref` keyword from your method definition. Do this and you shouldn't have any issues, though I'm not sure how this is more effective or clearer than simply calling `Dispose()` (other than the fact that you don't have to cast it for explicit implementations and this does a `null` check for you).
**Edit**
Dance, while I hope the discussion that's surrounded this topic has been helpful to you, your original intent doesn't seem to be something that's doable. In order to pass something as `ref`, you can't pass a variable that has a type other than what the `ref` parameter expects (in other words, you can't pass a variable declared as a `class` or other `interface` that implements `IDisposable` if the `ref` parameter is `IDisposable`). Because `ref` parameters allow assignments to propagate back to the caller, you would open up the possibility of allowing incompatible types being stored in your variable.
Your best bet here is to assign `null` yourself if that's what you want. If you want to encapsulate the `null` check and ignoring exceptions in to the function that's fine, but `ref` will not work for you in this scenario no matter how you slice it, unfortunately. | Here's an option for your example (can't verify it against a compiler right now, but you'll get the idea):
```
private void DisposeObject<T>(ref T obj) where T : class, IDisposable
{
// same implementation
}
```
To call it, use
```
DisposeObject<Baz>(ref _Baz);
DisposeObject<Bar>(ref _Bar);
```
As pointed in the other comments, the compiler error you get has its own purpose (preventing you to assign some other type of IDisposable inside your method, leading to an inconsistent state). | Passing an IDisposable object by reference causes an error? | [
"",
"c#",
"dispose",
"idisposable",
"pass-by-reference",
""
] |
I am developing in python a file class that can read and write a file, containing a list of xyz coordinates. In my program, I already have a Coord3D class to hold xyz coordinates.
My question is relative to the design of a getCoordinate(index) method. Should I return a tuple of floats, or a Coord3D object?
In the first case, I get very low coupling, but then I will probably have to instantiate a Coord3D object with the obtained values anyway, although outside of the file class. In the second case, I will have the file class tightly coupled with the Coord3D class.
Please note that I think there's not a huge difference between the two solutions, but I would like to read your answer and the reason behind it.
---
**Edit**: to recap the answers I got until now, it looks like there's no clearcut choice. It has been said (appropriately) that python is not Java, and you don't need a specialized class for everything just because you need it by language architecture. In my case, however, I have the following conditions:
1. I am working on a library, where the Coord3D object is used as is. Using it would increase the cohesiveness of my library, as the data types will be uniformly used.
2. The Coord3D object has state and behavior. Indeed, the Coord3D object aggregate the coordinates and the units in a single entity. Operations among Coord3D objects will keep into account the potentially different units, and act accordingly.
3. I can put centralize control code into the Coord3D class instantiation to refuse, for example, arrays of length 4, or non units. If I use a tuple, I cannot perform this check. Moreover, if a method accepts a Coord3D, is sort of guaranteed that it's well formed upfront (you could be bold and check for isinstance, or check the interface). A tuple can contain invalid data. Although python approach to error handling is done where the trouble happen, a class preventing me to have an xyz coordinate made out of three strings is somehow beneficial (correct me if wrong, please)
On the other hand, using a tuple has the following advantages:
1. Less occupation of resources, quite critical in case of huge
2. Simpler design. More classes means more complex design. A tuple is a standard data type which is well understood and can be unpacked easily. A personalized class is not.
3. Using a tuple, the XYZFile class is totally decoupled from the rest of the library (because it does not use the Coord3D object). This means that it can be reused totally as an independent entity.
further comments very welcome! | I've asked myself the same question, albeit while doing 2D geometry stuff.
The answer I found for myself was that if I was planning to write a larger library, with more functions and whatnot, go ahead and return the Point, or in your case the Coord3D object. If it's just a hacky implementation, the tuple will get you going faster. In the end, it's just what you're going to do with it, and is it worth the effort. | Compromise solution: Instead of a class, make Coord3D a [`namedtuple`](http://docs.python.org/library/collections.html#namedtuple-factory-function-for-tuples-with-named-fields) and return that :-)
Usage:
```
Coord3D = namedtuple('Coord3D', 'x y z')
def getCoordinate(index):
# do stuff, creating variables x, y, z
return Coord3D(x, y, z)
```
The return value can be used exactly as a tuple, and has the same speed and memory properties, so you don't lose any genericity. But you can also access its values by name: if `c` is the result of `getCoordinate(index)`, then you can work with `c.x`, `c.y`, etc, for increased readibility.
(obviously this is a bit less useful if your Coord3D class needs other functionality too)
[if you're not on python2.6, you can get namedtuples from the [cookbook recipe](http://code.activestate.com/recipes/500261/)] | Returning an object vs returning a tuple | [
"",
"python",
""
] |
I see that there are two options that I know can be used in web services... WCF obviously, and ASP.NET Web Services. What's the difference? I just started picking up WCF recently and had a little exposure to web services in the past, but I'm certainly not an expert. | it is quite easy to know the differences.
ASP.NET Web Method is called ASMX [because of the file extension] (check 4GuysFromRolla about this, they have a [good tutorial](https://web.archive.org/web/20210802160731/https://aspnet.4guysfromrolla.com/articles/100803-1.aspx))
This technology makes you expose methods as a Web Service so you can connect it (to the WS) from everywhere and use it (the methods). But... **you can't protect** the data between server and client, like, you can send big files in a clear mode, etc...
[Note] you can protect the access to the web service using certificates, but it is a pain and quite complicated, normally in ASMX we use username / passsword to give access to a method (once again... in plain text!)
In **WCF**, you are in the different world about Web Services, and this is the best technology in .NET (so far) to expose Services (*can you see the difference...* **Services**! not **Web Services**), WCF does not need IIS to run, it can run as a System Service on the server, using a console ambient (like command line), in TCP/IP mode, etc, so we say that WCF is a **Service**, not a Web Service. Remember ASMX need IIS to run and will only run hosted in a Web Server.
With WCF you can use SSL to encrypt the communication (to do that in ASMX you need to use **WSE** - Web Services Enhancements) and it is quite easy to implement it, you can send big files and securely (to do that in ASMX you need to use **MTOM** - Message Transmission Optimization Mechanism).
you can set the transmission preferences just changing one line of code, or even, if you prefer, change the XML configuration file, the security is much higher, etc, etc :)
hope you get a better general overview with this, but there is much more.
bottom line: to expose Web Services that you do not need to protect, you can use ASMX, no problem at all, but if you need to protect the communication somehow, do it in WCF!
**link**: [you can read here some performance comparative between the 2 services](https://web.archive.org/web/20200804033236/http://geekswithblogs.net/khanna/archive/2006/01/06/65067.aspx) | ASP.NET web services was Microsoft's first attempt at web services.
WCF replaces ASP.NET web servies and .NET remoting. WCF provides a common programming model that enables you to do what the two older technologies where capable of and much more including support for a wide range of protocols and security models.
Go with WCF if you have the choice. | What is the difference between the Visual Studio Options: ASP.NET Web Service and WCF Service | [
"",
"c#",
"asp.net",
"wcf",
"web-services",
"asmx",
""
] |
I need to look up thousands of rows by ID, but the IDs come from outside the DB, so I can't get them from other tables like so:
> SELECT \* FROM some\_table WHERE ID IN (
> SELECT KnownID FROM some\_other\_table WHERE someCondition
> )
Is there anything better than this:
> SELECT \* FROM some\_table WHERE ID IN ('1001', '1002', '1003', ...)
Can I parametrize such a query where the number of id's isn't fixed? Or do I just end up concatenating a big string together each time?
(I'm using sqlite, btw, but I'm curious about other databases too.) | I would create a temp table with the variable values and do a "`select were in`". | > (I'm using sqlite, btw, but I'm curious about other db's too.)
in sql server you could have a linked server and then just do a join between the two if it is on a different server. If it is on the same server but in different database then you would just do a regular join and add the dbname in from if the table and schema names | SQL: efficiently look up many IDs coming from outside the DB | [
"",
"sql",
""
] |
Can a model have multiple tables in CakePHP? | Guessing from this sentence in the manual:
> A model is generally an access point to the database, and more specifically, to a certain table in the database. By default, each model uses the table who's name is plural of its own, i.e. a 'User' model uses the 'users' table.
I don't think so, but you can make relationships maybe thats what you need.
[Check this](http://book.cakephp.org/view/312/Models) | Sure it can, it is convenient when you have a lot identical tables.
```
class SomeModel extends Model
{
var $useTable = false;
public function ReadData()
{
// select table
if($a == 1)
$this->setSource('tableName1');
else if($a == 2)
$this->setSource('tableName2');
// ...
else if($a == N)
$this->setSource('tableNameN');
// now perform operations with selected table
return $this->find('all');
}
}
``` | Can a model have multiple tables in CakePHP? | [
"",
"php",
"cakephp",
""
] |
I asked a [question](https://stackoverflow.com/questions/482431/which-local-database-fits-my-situation) a while ago about which local DB was right for my situation. I needed to access the DB from both .NET code and VB6. The overwhelming response was SQLite. However, I decided to pass on SQLite, because the only OLE DB provider for it charges royalties for every deployed copy of my software. It also requires an activation procedure to be run on every single PC.
After evaluating other options (SQL Server Compact edition - barely functional OLE DB provider, Firebird - don't want to have to pay for another driver, etc...), I've come to conclusion that the only viable choice is using .MDB files created by Microsoft Access (or the Jet engine).
I haven't used it since late 90s, so I have the following questions to those who have experience with it.
1. Have they resolved the problem where the database would corrupt every now and then.
2. Is access to the MDB from c# accomplished via the ADO.NET OLEDB Provider or is there a native solution (i can't seem to find it).
3. Is there a viable alternative to the really crappy SQL Editor in Access?
Thanks. | Rather then going "back" to Access, I'd stick with SQLite and use the System.Data.SQLite provider for SQLite data access within the .NET code.
Then I'd just create a simple COM interop .NET class for use by VB6 that wraps any required SQLite data access functionality. Finally, just reference and use it like a standard COM object from your VB6 projects.
My knowledge of Access is probably a bit dated and biased by bad experiences, but within reason I would try most other options before resorting to the Access route. | Have you considered [SQL Server 2008 Express Edition](http://www.microsoft.com/express/sql/) (as oppose to SQL Server CE)?
1) Personally, I found that most times that Access DBs corrupted it was due to code that didn't clean up after it self, or there was a faulty Network card involved.
2)
```
string connectionString = @“Provider = Microsoft.Jet.OLEDB.4.0; " +
@"Data Source = C:\data\northwind.mdb; " +
@"User Id = guest; Password = abc123”
using (OleDbConnection oleDbConnection = New OleDbConnection())
{
oleDbConnection.ConnectionString = connectionString;
oleDbConnection.Open();
...
}
```
3) SQL Server 2008 Express Edition | Pros and cons of the Access database engine. Life after SQLite | [
"",
"c#",
"vb6",
"ms-jet-ace",
""
] |
i have a class which looks like this
```
public class Process_Items
{
String Process_Name;
int Process_ID;
//String Process_Title;
public string ProcessName
{
get { return Process_Name; }
set { this.Process_Name = value; }
}
public int ProcessID
{
get { return Process_ID; }
set { this.Process_ID = value; }
}
}
```
now i want to create a Process\_Items[] Array and display all the elements in a multi column listbox. Such that first column must have the processName and 2nd must have the processID. How can i achieve this in C# 2.0? | You should use a ListView control and add two columns (ListBox only has one column)
```
Process_Items[] items = new Process_Items[] // Initialize array
foreach(Process_Items p in items) {
listView.Items.Add(p.ProcessName).Subitems.Add(p.ProcessID.ToString());
}
``` | A list box has a single ListItem (string) displayed to the user.
So you could override ToString() as
```
public override string ToString()
{
return string.Format("{0} [ProcID: {1}]", this.Process_Name , this.ProcessID);
}
```
If this is for a winforms app, have a look at the ListView Control or a DataGridView | Adding custom class objects to listbox in c# | [
"",
"c#",
"class",
".net-2.0",
""
] |
This is a question in response to thise: [Javascript AJAX function not working in IE?](https://stackoverflow.com/questions/760628/javascript-function-not-working-in-ie)
I need jQuery to do something like this:
```
function render_message(id)
{
var xmlHttp;
xmlHttp=new XMLHttpRequest();
xmlHttp.onreadystatechange=function()
{
if(xmlHttp.readyState==4)
{
document.getElementById('message').innerHTML=xmlHttp.responseText;
document.getElementById('message').style.display='';
}
}
var url="include/javascript/message.php";
url=url+"?q="+id;
xmlHttp.open("GET",url,true);
xmlHttp.send(null);
}
```
Can someone write the function for me quickly? | You can use the handy [`load()`](http://docs.jquery.com/Ajax/load#urldatacallback) function for this:
```
$('#message').load("include/javascript/message.php", {q: id}, function() {
$(this).show();
});
```
The callback function is assuming the `message` div is hidden and you only want it show once the request is complete. | See `$.ajax()` to retrieve pages and access the content. [Documentation here](http://docs.jquery.com/Ajax).
Then use e.g. `$("#yourElementId").html( myHtmlContent )` to replace the HTML. [More doc here](http://docs.jquery.com/Manipulation). | How would I use jQuery to grab the contents of a page and render it within a div? | [
"",
"javascript",
"jquery",
""
] |
How can I rebind my events (jquery) when I perform a partial page postback?
I am wiring everything up using:
```
$(document).ready(function(){};
```
After a partial page postback, my events are not firing. | You can either tap into the [PageRequestManager](http://msdn.microsoft.com/en-us/library/bb383810.aspx) endRequestEvent:
```
Sys.WebForms.PageRequestManager.getInstance().add_endRequest(function(){});
```
Or if it is control events you're trying to attach, you can use jQuery [live events](http://docs.jquery.com/Events/live#typefn).
Another option is to do the event delegation manually. It is what the "live" event are doing under the covers. Attach the event handler to the document itself, then conditionally execute your method if the sender of the event was element you expect.
```
$(document).click(function(e){
if($(e.target).is(".collapseButton")){
$(this).find(".collapsePanel").slideToggle(500);
}
})
``` | I'm guessing from 'partial page postback' you're working in Asp.net land.
Try using
```
Sys.Application.add_load(function() { });
```
You should still be able to use all the normal jQuery stuff inside that func. | jquery needs to rebind events on partial page postback | [
"",
"javascript",
"jquery",
"binding",
"postback",
""
] |
I've found the common way to get image metadata in WPF is to create a `BitmapFrame` object and inspect the Metadata property on it. However I can't seem to create a `BitmapFrame` object that fulfills these two requirements:
1. Does not lock the file
2. Does not throw weird, undocumented exceptions when given certain files
Using these lines seems to create the `BitmapImage` reliably:
```
BitmapFrame.Create(new Uri(imageName));
BitmapFrame.Create(new Uri(imageName), BitmapCreateOptions.DelayCreation, BitmapCacheOption.None);
```
However they leave the file locked for an indeterminate amount of time. There is no dispose method on the `BitmapFrame` as far as I can tell.
This keeps the file from being locked:
```
BitmapFrame.Create(new Uri(imageName), BitmapCreateOptions.None, BitmapCacheOption.OnLoad);
```
However on Vista it throws `ArgumentException`s and `InvalidOperationException`s on certain files and on Win7 it throws `FileFormatException`s and `IOException`s. This makes me think that caching the `BitmapFrame` is unsupported/untested.
Can you get metadata from an image in WPF without leaving a lock on the file for an indeterminate length of time? | Have you tried using a converter approach? For example, my [Intuipic](http://intuipic.codeplex.com) application does this. See [`BitmapFrameConverter`](http://intuipic.codeplex.com/SourceControl/changeset/view/7348#114513) for details on loading without locking, and [`BitmapOrientationConverter`](http://intuipic.codeplex.com/SourceControl/changeset/view/7348#114514) for getting at metadata. | I don't know if an answer at this time can still be useful to anybody but since I got here only today, I assume that somebody else may be interested.
I had a similar problem when trying to use BitmapFrame to test if an image is valid, then trying to rename the image file. With this code, the image is locked and the Move command does not work:
```
bool isImageValid = true;
try
{
BitmapFrame bmpFrame = BitmapFrame.Create(new Uri("C:\\Images\\Test.jpg"));
}
catch
{
isImageValid = false;
}
File.Move("C:\\Images\\Test.jpg", "C:\\Images\\Test0.jpg");
```
However, when I first read the image file in a file stream, the file is released as soon as the using block is done and the Move command works:
```
bool isImageValid = true;
try
{
using (FileStream fs = new FileStream("C:\\Images\\Test.jpg", FileMode.Open))
{
BitmapFrame bmpFrame = BitmapFrame.Create(fs);
}
}
catch
{
isImageValid = false;
}
File.Move("C:\\Images\\Test.jpg", "C:\\Images\\Test0.jpg");
``` | Using BitmapFrame for metadata without locking the file | [
"",
"c#",
".net",
"wpf",
"image-processing",
""
] |
I'd like to add "IDLE-like functionality" to C# WinForms application, but I don't quite have an idea how to do that and couldn't find anything useful with Google.
So basically I want interactive command line interface, where user could enter some Python code and execute it (not just expressions, should be possible to define new functions).
So, where to start? Are there any good tutorials or samples available? | Thru IronPython mailing list I found [IronTextBox2](http://www.codeproject.com/KB/edit/irontextbox2.aspx), which is good example how things are done. It needs a little tweaking, to get it running, but otherwise is good solution. | If my memory serves me correctly there's a chapter on embedding Python in the book [Python in a Nutshell](http://oreilly.com/catalog/9780596001889/). Perhaps you can find some useful information there, but since the book is not Windows specific, you may have to adapt it yourself. | How to create IDLE -like functionality to WinForms application | [
"",
"c#",
"winforms",
"ironpython",
""
] |
I'm writing a Cake component and it seems to make sense that I use it for saving data rather than doing so in a controller. In the manual it says using models in a component is discouraged, but the other way of doing it would mean I'd be repeating code in the controller.
The component basically analyses a load of data from various sources and will then insert data for various models. | If the component *analyses a load of data from various sources*, it can probably be written as a behaviour.
If not, and you have no other choice but to use a model in your component, be sure to do it properly:
```
$this->ModelName = ClassRegistry::init('ModelName');
```
I personally don't see a problem with this, since the core components (such as the Acl component) do that. As long as your component handles the *application logic* and models handle *data*, you'll be just fine. | In my opinion, DRY is the critical path. To that end, I see two options:
1. Instead of saving the data in the component, return it to the controller in a raw form that can be saved from the controller.
2. Go ahead and import the model into the component and do what you need to do. It's not encouraged, but they do make it reasonably easy.
If it comes down to a hard choice, I'd err on the side of keeping my application DRY rather than maintaining a strict MVC discipline. | Best practice in CakePHP for saving data, using models in component | [
"",
"php",
"cakephp",
""
] |
I'd like to do a search for folders/directories from java, and go into those folders/directories in java. I guess it's called system utilities? Any tutorials out there, or books on the subject?
Thanks ;) | I use this code to get all ZIP files in a folder. Call this recursively checking for the file object to be a sub directory again and again.
```
public List<String> getFiles(String folder) {
List<String> list = new ArrayList<String>();
File dir = new File(folder);
if(dir.isDirectory()) {
FileFilter filter = new FileFilter() {
public boolean accept(File file) {
boolean flag = false;
if(file.isFile() && !file.isDirectory()) {
String filename = file.getName();
if(!filename.endsWith(".zip")) {
return true;
}
return false;
}
};
File[] fileNames = dir.listFiles(filter);
for (File file : fileNames) {
list.add(file.getName());
}
return list;
```
} | You could use Apache Commons FileUtils (see: <http://commons.apache.org/io/api-release/org/apache/commons/io/FileUtils.html>) and specifically the listFiles method there, which can do this recursively and use filters (so it saves you the writing of the recursion yourself and answers the search you mentioned). | How to "walk around" in the File System with Java | [
"",
"java",
"linux",
"filesystems",
""
] |
I get a JS error and I can't figure out how to fix it.
When my page loads up, IE7 notifies me of a run time error. In addition, my Firebug on Firefox warns me of an error:
```
$ is not defined
(?)
[Break on this error] $(document).ready(function() { $("a#sin...Out': 300, 'overlayShow': false }); });
```
When I go to the lines in question its this:
```
<script type="text/javascript" src="/templates/magazeen/js/jquery/jquery.dropdown.js"></script>
<script type="text/javascript">
$(document).ready(function() { $("a#single_image").fancybox(); $("a#inline").fancybox({ 'hideOnContentClick': false }); $("a.group").fancybox({ 'zoomSpeedIn': 300, 'zoomSpeedOut': 300, 'overlayShow': false }); });
</script>
```
Any help please. | You may have only included the dropdown part of jQuery, and not the whole thing. Try including just the JQuery.js file, without specification as to what part. | Do you have a script reference to jQuery above the script block in question? The reason you are seeing this error is because you are using the jQuery function **`$`** without referencing jQuery itself.
You need to add a script reference to jQuery like this:
```
<script type="text/javascript" src="/yourJsDir/jQuery.js"></script>
```
if you have a local copy of jQuery.js. Otherwise you can use Google's hosted version like this:
```
<script type="text/javascript"
src="http://ajax.googleapis.com/ajax/libs/jqueryui/1.7.1/jquery-ui.min.js"></script>
```
Just make sure that these script references live above the script block in question as that way your jQuery plugin will have **`$`** defined for it. | $ is not defined: What does this mean? | [
"",
"javascript",
"jquery",
""
] |
```
public bool IsList(object value)
{
Type type = value.GetType();
// Check if type is a generic list of any type
}
```
What's the best way to check if the given object is a list, or can be cast to a list? | ```
using System.Collections;
if(value is IList && value.GetType().IsGenericType) {
}
``` | For you guys that enjoy the use of extension methods:
```
public static bool IsGenericList(this object o)
{
var oType = o.GetType();
return (oType.IsGenericType && (oType.GetGenericTypeDefinition() == typeof(List<>)));
}
```
So, we could do:
```
if(o.IsGenericList())
{
//...
}
``` | How do I check if a given value is a generic list? | [
"",
"c#",
"reflection",
"list",
"generics",
""
] |
I know regex is [dangerous](http://www.perlmonks.org/index.pl?node_id=221512) for validating IP addresses because of the different forms an IP address can take.
I've seen similar questions for C and C++, and those were resolved with a function that doesn't exist in C# [inet\_ntop()](http://beej.us/guide/bgnet/output/html/multipage/inet_ntopman.html)
The .NET solutions I've found only handle the standard "ddd.ddd.ddd.ddd" form. Any suggestions? | You can use this to try and parse it:
```
IPAddress.TryParse
```
Then check `AddressFamily` which
> Returns System.Net.Sockets.AddressFamily.InterNetwork for IPv4 or System.Net.Sockets.AddressFamily.InterNetworkV6 for IPv6.
EDIT: some sample code. change as desired:
```
string input = "your IP address goes here";
IPAddress address;
if (IPAddress.TryParse(input, out address))
{
switch (address.AddressFamily)
{
case System.Net.Sockets.AddressFamily.InterNetwork:
// we have IPv4
break;
case System.Net.Sockets.AddressFamily.InterNetworkV6:
// we have IPv6
break;
default:
// umm... yeah... I'm going to need to take your red packet and...
break;
}
}
``` | Just a warning about using `System.Net.IpAddress.TryParse()`:
If you pass it an string containing an integer (e.g. "3") the TryParse function will convert it to "0.0.0.3" and, therefore, a valid InterNetworkV4 address. So, at the very least, the reformatted "0.0.0.3" should be returned to the user application so the user knows how their input was interpreted. | How to determine if a string is a valid IPv4 or IPv6 address in C#? | [
"",
"c#",
".net",
"ip-address",
""
] |
I've got a complex SQL where clause that just got more complex because of a requirements change. There are four basic sets of cases, each with a different combination of other factors. It's more readable (in my opinion) to have the four cases as separate branches of the where clause, and to repeat the redundant criteria in each branch. But I don't know how well the database engine will optimize that.
Here's the expression in its redundant form. I've replaced the actual criteria with letters. A is the "branching" criterion, which comes in four forms. All of the expressions are in the form `field='value'`, unless otherwise noted.
```
A1 AND B AND C AND D
OR A2 AND B AND C AND D AND E AND F1 AND G
OR A3 AND A3a AND B AND C AND D AND E AND F1 AND G
OR A4 AND B AND C AND D AND F2
```
All of the A's except A4 are in the form `field in ('value1','value2')`. D is `field > 'value'`. G is in the form `field not in (subquery)`.
Here's the expression, factored to (I think) its least redundant form.
```
B AND C AND D AND (
A1
OR (
E AND F1 AND G AND (
A2
OR (A3 AND A3a)
)
)
OR (A4 AND F2)
```
My question is whether I should factor this expression into its simplest (least redundant) *logical* form, or whether it's OK to keep it in it's more redundant but also more readable form. The target database is Sybase, but I'd like to know the answer for RDMBSs generally. | In an `RDBMS` world I wouldn't bother of redundancy much, efficiency is more important here.
In your case, I would `UNION` all the four queries using `A`'s as a top condition, like this:
```
SELECT *
FROM mytable
WHERE A1 AND B AND C
UNION
SELECT *
FROM mytable
WHERE A2 AND B AND C AND D AND E AND F1 AND G
…
```
I didn't look into `Sybase` for more than `7` years, but in all major `RDBMS`'s `UNION`'s are more efficient than `OR`'s.
See this article in my blog for approach to a silimar problem in `Oracle`:
* [**Selecting lowest value**](http://explainextended.com/2009/04/24/selecting-lowest-value/): efficient usage of `UNION` in `Oracle`
and also this article for comparison of `UNION` versus `OR` in `MySQL`:
* [**Selecting friends**](http://explainextended.com/2009/03/07/selecting-friends/): efficiency of `UNION` compared to one of `OR` in `MySQL`
I think these approaches will work well for `Sybase` too.
You also need to create indexes on columns used in your conditions to benefit from `UNION`'s
**Update:**
Since condition `G` is a subquery, it may probably happen that it needs a `HASH JOIN` to perform fast. `HASH JOIN` requires a full scan on all unfiltered values, that's why it may probable be better to filter all values in a single fullscan and then perform a `HASH JOIN`:
```
SELECT *
FROM (
SELECT *
FROM foo
WHERE condition_set_1
UNION
SELECT *
FROM foo
WHERE condition_set_2_but_no_g
…
) q
WHERE G
```
To make any further judgements, it will be much better to see the query itself, really. | If I were attacking this problem on M$ SQL Server, I would write it the way I wanted and look at the query execution plan. If it (a) ran slow and (b) had a bad execution plan, then I would refactor and document. Not sure what the mechanism is in Sybase for viewing HOW the optimizer executes the query. | Complex SQL where clause: whether to factor logic | [
"",
"sql",
"database",
"optimization",
"boolean",
"boolean-logic",
""
] |
In Java, is there a way to know that a `StackOverflow` error or `OutOfMemory` exception may happen soon?
The `OutOfMemory` exception might be an easier one to catch, if one is capable of getting memory usage statistics programmatically, and if one knows ahead of time how much memory needs to be used before the `OutOfMemory` exception is thrown. But are those values knowable?
For the `StackOverflow` error, is there a way to get recursion depth, and how does one know what value for recursion depth would cause the error to occur?
By knowing ahead of time whether these errors will happen, I feel I can recover the application more gracefully, instead of watching it crash. | ### Anticipating Out of Memory Errors
I'm surprised I didn't see this mentioned in the other posts, but you can use [ManagementFactory](http://java.sun.com/javase/6/docs/api/java/lang/management/ManagementFactory.html) in Java 5/6 to get at a lot of the memory usage information.
Look at the [platform mbean server page](http://java.sun.com/j2se/1.5.0/docs/guide/management/mxbeans.html#low_memory) for more information on detecting low memory conditions in Java. I believe you can setup notifiers to call code when memory usage reaches a certain threshold. | You can anticipate out-of-memory conditions with [`Runtime.freeMemory()`](http://java.sun.com/javase/6/docs/api/java/lang/Runtime.html#freeMemory()) and [`Runtime.maxMemory()`](http://java.sun.com/javase/6/docs/api/java/lang/Runtime.html#maxMemory()). Most times it'll be hard recovering gracefully, but I leave that to you. | How to know about OutOfMemory or StackOverflow errors ahead of time | [
"",
"java",
"exception",
""
] |
Do you know of any open-source Zend Framework applications besides Magento that show in a good OOP-way how to develop big apps with Zend Framework?
My problem right now is, that I'm pretty good at PHP and OOP, but I don't have enough knowledge of the Zend Framework and how things should be solved in it.
So do you know any good applications that showcase best-practices for ZF?
Thanks! | Have a look at:
* JotBug (from 2009): <http://www.ohloh.net/p/jotbug> ([zip file of code](http://akrabat.com/wp-content/uploads/jotbug.zip))
* Pastebin: <http://github.com/weierophinney/pastebin/>
* 'ZF 1.8 Web Application Development' code: <http://code.google.com/p/zendframeworkstorefront/>
* Enygma's Ext-JS with ZF example app: <https://github.com/enygma/Agile-ExtJS-ZF>
* MTD issues: <https://github.com/mtd/issues> | Magento is a good example of the Zend Framework, Until you start looking at how they decided to go about templating! Wow.. wonder how late that meeting was when they decided to depart from logic and create their highly nested template components.. fun times (from a designers perspective) :) | Good Zend Framework example apps to learn from | [
"",
"php",
"zend-framework",
"open-source",
""
] |
I don't mean how to connect to a socket. What should I know about UDP programming?
* Do I need to worry about bad data in my socket?
* I should assume if I send 200bytes I may get 120 and 60 bytes separately?
* Should I worry about another connection sending me bad data on the same port?
* If data doesnt arrive typically how long may I (typically) not see data for (250ms? 1 second? 1.75sec?)
What do I really need to know? | > "i should assume if i send 200bytes i
> may get 120 and 60bytes separately?"
When you're sending UDP datagrams your read size will equal your write size. This is because UDP is a **datagram** protocol, vs TCP's **stream** protocol. However, you can only write data up to the size of the MTU before the packet could be fragmented or dropped by a router. For general internet use, the safe MTU is 576 bytes including headers.
> "i should worry about another
> connection sending me bad data on the
> same port?"
You don't have a connection, you have a port. You will receive any data sent to that port, regardless of where it's from. It's up to you to determine if it's from the right address.
> If data doesnt arrive typically how
> long may i (typically) not see data
> for (250ms? 1 second? 1.75sec?)
Data can be lost forever, data can be delayed, and data can arrive out of order. **If any of those things bother you, use TCP.** Writing a reliable protocol on top of UDP is a very non trivial task and there is no reason to do so for almost all applications. | > Should I worry about another
> connection sending me bad data on the
> same port?
Yes you should worry about it. Any application can send data to your open UDP port at any time. One of the big uses of UDP is many to one style communications where you multiplex communications with several peers on a single port using the addressed passed back during the `recvfrom` to differentiate between peers.
However, if you want to avoid this and only accept packets from a single peer you can actually call `connect` on your UDP socket. This cause the IP stack to reject packets coming from any host:port combo ( socket ) other than the one you want to talk to.
A second advantage of calling `connect` on your UDP socket is that in many OS's it gives a significant speed / latency improvement. When you call `sendto` on an unconnected UDP socket the OS actually temporarily connects the socket, sends your data and then disconnects the socket adding significant overhead.
A third advantage of using connected UDP sockets is it allows you to receive ICMP error messages back to your application, such as routing or host unknown due to a crash. If the UDP socket isn't connected the OS won't know where to deliver ICMP error messages from the network to and will silently discard them, potentially leading to your app hanging while waiting for a response from a crashed host ( or waiting for your select to time out ). | What should i know about UDP programming? | [
"",
"c++",
"sockets",
"udp",
""
] |
I have a table of reports that has these relevant fields:
```
user_id (int 11)
submitted_date (datetime)
approved_flag (shortint 1)
```
There are multiple rows per `user_id`, some with `approved_flag` = 0 and some with `approved_flag` = 1 and each with a unique `submitted_date`.
I need to get a count of the approved and unapproved reports. But I only want to count the most recent submitted report per user (most recent `submitted_date`), regardless of `approved_flag`.
So, if there was 4 records like this:
```
user_id, submitted_date, approved_flag
1, 2009-04-01 01:00, 1
1, 2009-04-01 02:00, 0
1, 2009-04-01 03:00, 1 (using this record)
2, 2009-04-02 01:00, 1 (using this record)
```
the count would be 2 approved and no unapproved, and if we had
```
user_id, submitted_date, approved_flag
1, 2009-04-01 01:00, 1
1, 2009-04-01 02:00, 0
1, 2009-04-01 03:00, 0 (using this record)
2, 2009-04-02 01:00, 0
2, 2009-04-02 02:00, 1 (using this record)
```
the count would be 1 approved (user id 2) and 1 unapproved (user id 1).
To summarize one more time because it is not easy to describe: I want the total number of unique users in the table (regardless of # rows per user) and I want it broken down in to 'approved' and 'not approved' based on the `approved_flag` of the most recent report per user.
Any help would be greatly appreciated, thanks! | ```
SELECT approved_flag, COUNT(*)
FROM
Table t
INNER JOIN (
SELECT user_id, submitted_date = MAX(submitted_date)
FROM Table
GROUP BY user_id
) latest ON latest.user_id = t.user_id
AND latest.submitted_date = t.submitted_date
GROUP BY approved_flag
``` | Can think of two ways to do this. The first is perhaps the most readable, search for the last submitted\_date per user, and then display the approval with that timestamp:
```
select a.user_id, a.submitted_date, a.approved_flag
from approvals a
inner join (
select user_id, maxdt = max(submitted_date)
from approvals
group by user_id
) latest on latest.user_id = a.user_id
and latest.maxdt = a.submitted_date
```
The second is to join the table on it's future rows for the same user, and specify in the where clause that these don't exist. This gives you the latest entry for each user:
```
select cur.user_id, cur.submitted_date, cur.approved_flag
from approvals cur
left join approvals next
on next.user_id = cur.user_id
and next.submitted_date > cur.submitted_date
where next.user_id is null
``` | counting records from a grouped query with additional criteria | [
"",
"sql",
"mysql",
""
] |
I have an array of doubles and need to do a calculation on that array and then find the min and max value that results from that calculation. Here is basically what I have:
```
double * array;
double result;
double myMin;
double myMax;
// Assume array is initialized properly...
for (int i = 0; i < sizeOfArray; ++i) {
result = transmogrify(array[i]);
if (i == 0) {
myMin = result;
myMax = result;
}
else if (result < myMin) {
myMin = result;
}
else if (result > myMax) {
myMax = result;
}
}
```
I'm getting a warning that the value computed for `result` is never used, and since we treat all warnings as errors, this doesn't compile. How can I fix this code to avoid the warning? I'm using g++ for my compiler.
Here's the warning text:
```
cc1plus: warnings being treated as errors
foo.cc:<lineno of transmogrify call>: error: value computed is not used
```
Edit: I don't understand the down votes, but I've got things working now. Thanks to everyone for taking the time to help me out. | Assuming you don't need `result` outside of the loop, you could declare `result` inside the loop thusly:
```
for( int i=0; i < sizeOfArray; ++i ) {
double result = transmogrify( array[i] );
...
}
``` | > I'm getting a warning that the value computed for `result` is never used because (theoretically) it's possible that none of the if/else branches will be selected
That can't be the reason for the warning, because `result` is also used in the if conditions. Even if none of the branches are taken, `result` is still used to decide that they should not be taken. | How should I correct this code that causes "value computed not used" warning? | [
"",
"c++",
"g++",
""
] |
This isn't about the different methods I could or should be using to utilize the queues in the best manner, rather something I have seen happening that makes no sense to me.
```
void Runner() {
// member variable
queue = Queue.Synchronized(new Queue());
while (true) {
if (0 < queue.Count) {
queue.Dequeue();
}
}
}
```
This is run in a single thread:
```
var t = new Thread(Runner);
t.IsBackground = true;
t.Start();
```
Other events are "Enqueue"ing else where. What I've seen happen is over a period of time, the Dequeue will actually throw InvalidOperationException, queue empty. This should be impossible seeing as how the count guarantees there is something there, and I'm positive that nothing else is "Dequeue"ing.
The question(s):
1. Is it possible that the Enqueue actually increases the count before the item is fully on the queue (whatever that means...)?
2. Is it possible that the thread is somehow restarting (expiring, reseting...) at the Dequeue statement, but immediately after it already removed an item?
**Edit (clarification):**
These code pieces are part of a Wrapper class that implements the background helper thread. The Dequeue here is the only Dequeue, and all Enqueue/Dequeue are on the Synchronized member variable (queue). | Using Reflector, you can see that no, the count does not get increased until after the item is added.
As Ben points out, it does seem as you do have multiple people calling dequeue.
You say you are positive that nothing else is calling dequeue. Is that because you only have the one thread calling dequeue? Is dequeue called anywhere else at all?
EDIT:
I wrote a little sample code, but could not get the problem to reproduce. It just kept running and running without any exceptions.
How long was it running before you got errors? Maybe you can share a bit more of the code.
```
class Program
{
static Queue q = Queue.Synchronized(new Queue());
static bool running = true;
static void Main()
{
Thread producer1 = new Thread(() =>
{
while (running)
{
q.Enqueue(Guid.NewGuid());
Thread.Sleep(100);
}
});
Thread producer2 = new Thread(() =>
{
while (running)
{
q.Enqueue(Guid.NewGuid());
Thread.Sleep(25);
}
});
Thread consumer = new Thread(() =>
{
while (running)
{
if (q.Count > 0)
{
Guid g = (Guid)q.Dequeue();
Console.Write(g.ToString() + " ");
}
else
{
Console.Write(" . ");
}
Thread.Sleep(1);
}
});
consumer.IsBackground = true;
consumer.Start();
producer1.Start();
producer2.Start();
Console.ReadLine();
running = false;
}
}
``` | Here is what I think the problematic sequence is:
1. `(0 < queue.Count)` evaluates to true, the queue is not empty.
2. This thread gets [preempted](http://en.wikipedia.org/wiki/Preemption_(computing)) and another thread runs.
3. The other thread removes an item from the queue, emptying it.
4. This thread resumes execution, but is now within the if block, and attempts to dequeue an empty list.
However, you say nothing else is dequeuing...
Try outputting the count inside the if block. If you see the count jump numbers downwards, someone else is dequeuing. | C# Threading and Queues | [
"",
"c#",
"multithreading",
""
] |
I'm aiming to learn about concurrency in Java. Currently my state of knowledge is poor. I'm pretty sure I know what "volatile" means. I sort of know what "synchronized" means. Sometimes. I've never written code that starts threads or manages them. Outside of this issue, I feel confident and at home working in Java.
I'm looking for suggestions for a small project or program which will require understanding concurrency to work correctly and efficiently. | If you're really just starting then probably the producer-consumer problem is a good way to start:
<http://en.wikipedia.org/wiki/Producer-consumer_problem>
Don't read too much because the Wikipedia article also contains a solution to the problem :-) | Write a matrix-multiply algorithm. Parallelize it. Optimize it. See how it scales especially if you have a multi-core machine. That would be a fun project. | Any suggestions for a program or small project to learn about concurrency in Java? | [
"",
"java",
"multithreading",
"concurrency",
""
] |
I'm having a debate with a co-worker about throwing exceptions from constructors, and thought I would like some feedback.
Is it OK to throw exceptions from constructors, from a design point of view?
Lets say I'm wrapping a POSIX mutex in a class, it would look something like this:
```
class Mutex {
public:
Mutex() {
if (pthread_mutex_init(&mutex_, 0) != 0) {
throw MutexInitException();
}
}
~Mutex() {
pthread_mutex_destroy(&mutex_);
}
void lock() {
if (pthread_mutex_lock(&mutex_) != 0) {
throw MutexLockException();
}
}
void unlock() {
if (pthread_mutex_unlock(&mutex_) != 0) {
throw MutexUnlockException();
}
}
private:
pthread_mutex_t mutex_;
};
```
My question is, is this the standard way to do it? Because if the `pthread mutex_init` call fails the mutex object is unusable so throwing an exception ensures that the mutex won't be created.
Should I rather create a member function init for the Mutex class and call `pthread mutex_init` within which would return a bool based on `pthread mutex_init`'s return? This way I don't have to use exceptions for such a low level object. | Yes, throwing an exception from the failed constructor is the standard way of doing this. Read this FAQ about [Handling a constructor that fails](https://isocpp.org/wiki/faq/exceptions#ctors-can-throw) for more information. Having a init() method will also work, but everybody who creates the object of mutex has to remember that init() has to be called. I feel it goes against the [RAII](http://en.wikipedia.org/wiki/Resource_Acquisition_Is_Initialization) principle. | If you do throw an exception from a constructor, keep in mind that you need to use the function try/catch syntax if you need to catch that exception in a constructor initializer list.
e.g.
```
func::func() : foo()
{
try {...}
catch (...) // will NOT catch exceptions thrown from foo constructor
{ ... }
}
```
vs.
```
func::func()
try : foo() {...}
catch (...) // will catch exceptions thrown from foo constructor
{ ... }
``` | Throwing exceptions from constructors | [
"",
"c++",
"exception",
"constructor",
"throw",
""
] |
I have a javascript variable which is referencing a complex object (it is a slideshow control but that's not important)
```
e.g.
var slideshow = new SlideShow();
```
Because i have multiple slideshows on the page and I want to make accessing certain operations generic/reuse code in different pages.
I WANT TO BE ABLE TO ACCESS DIFFERENT VARIABLES CONTAINING DIFFERENT INSTANCES OF THE SLIDESHOWS IN THE SAME JAVASCRIPT ROUTINE. THE VARIABLE USED IS DIFFERENT DEPENDING ON WHAT SLIDESHOW IS BEING CONTROLLED AT THE TIME.
So instead of
```
slideshow.playSlides();
```
do something like
```
[dynamically get reference to variable containing slideshow].playSlides();
```
I've looked into this before in JavaScript and not found a solution, I'm wondering if this can be done in JQUERY somehow? | Well... something has to contain the variable, so that's the question you need to answer first. My thought would be to store it in a hash, which, may not look much different to you at first:
```
var slideshows = {};
slideshows['someslideshowName'] = new SlideShow();
```
But now you can reference by name with no issues.
or it could look like....
```
window.slideshows = {};
var slideShowName = 'someSlideShowName';
window.slideshows[slideShowName] = new SlideShow();
``` | If I understand the question, why not create an array of slideshows and enum them so you have 0 to N slide shows and not need to recode.
```
var slideshows = [new SlideShow()];
function playSlides() {
for(var i=0; i < slideshows.length; i++) {
slideshows[i].playSlides();
}
}
``` | Javascript / JQUery Dynamic Variable Access | [
"",
"javascript",
"jquery",
""
] |
How do I find out which function or target is modifying the items in a foreach loop in a multithreaded application?
I continously keep getting the error "Collection was modified; enumeration operation may not execute". I'm not removing or adding any items to the generic list within the for loop.
I want to find out how it is getting modified.
What is the best way to do this?
Thanks | **Wait a minute** - I think we've all missed the point.
The collection classes are not thread-safe. If the collection is being accessed by multiple threads without thread-locking, then you need to fix that. It's a particularly insidious problem because it will work correctly *[edit - or throw a predictable exception]* 99.999% of the time, and 0.001% of the time it will do something totally unpredictable and nearly impossible to reproduce.
A simple approach is to use lock{} statements around EVERY place where ANY code accesses the collection. That may be slight overkill but it is the safest plan. For iteration you can either put a lock around the whole loop or if you don't want to block out other threads that long, just lock it long enough to make a snapshot:
```
object[] snap;
lock (list)
{
snap = list.ToArray();
}
foreach (object x in snap) ...
``` | This is not a direct answer, just a suggestion that might help - in a multithreaded situation where a collection might get modified during iteration, I usually use the ToArray method to create a snapshot of the list for iteration:
```
foreach (object x in list.ToArray()) ...
``` | Finding how a foreach collection gets modified | [
"",
"c#",
"function",
"loops",
"for-loop",
""
] |
We are developing a Java EE application backed by any database of customer choice.
We will sell to customers based on per user license price. How do I make sure, the application is getting used as per our conditions, i.e., not easily hackable? Are there any tutorials available? | [Bill Karwin's answer](https://stackoverflow.com/questions/475216/python-applications-can-you-secure-your-code-somehow/475394#475394) was the most useful of the answers from the question mentioned in the comments. Assuming that you will go ahead with a "protection" scheme, try to do the bare minimum. Anything else tends to frustrate users immensely and leads to lower repeat business and/or an increased desire to hack around your frustrating system.
From your question, it's tough to tell if each user will install the application. If so, you probably just need to require a license code that they must contact you in some way to get. If it's a client-server thing, then your options are a lot more limited; in fact, I can't think of a single solution I've ever designed in my head or come across in practice that isn't *massively* frustrating. You could probably do a license code solution here, too, except the license code would somehow carry a payload that indicated the number of users they paid for and then disallow the creation/use of users in excess of that number. At that point, though, you're really walking that frustration line I mentioned. | If you can obfuscate - this is the way to go for a start. But it could be painful if you use inversion of control frameworks (e.g. spring). I heard that it's possible to obfuscate spring context as well, never tried it though. Also (just guessing) there could be some surprises with reflections, dynamic proxies and such. As to the licensing, I can suggest using **[TrueLicense](https://truelicense.dev.java.net/)**. It has very flexible means of handling various aspects of protection as well as free trial periods out of the box. Works very well and has great documentation. | How to create a secure licensed Java EE application? | [
"",
"java",
"jakarta-ee",
"licensing",
"security",
""
] |
Is this ValueStore class threadsafe? Does the lock scope in GetInt(string key) need to be extended around the yield return?
```
public class ValueStore
{
private readonly object _locker = new object();
private readonly Dictionary<string, int> _data =
new Dictionary<string, int>();
public ValueStore(Dictionary<string, int> data)
{
_data = data;
}
public IEnumerable<int> GetInt(string key)
{
IEnumerable<KeyValuePair<string, int>> selected;
lock(_locker)
{
selected = _data.Where(x => x.Key.Equals(key));
}
foreach (KeyValuePair<string, int> pair in selected)
{
yield return pair.Value;
}
}
}
```
The unit test seems to be fine:
```
[TestFixture]
public class ValueStoreTest
{
[Test]
public void test1()
{
Dictionary<string, int> data = new Dictionary<string, int>();
for (int i = 0; i < 100000; i++)
{
data.Add(i.ToString(),i);
}
ValueStore vs = new ValueStore(data);
for (int i = 0; i < 900000; i++)
{
ThreadPool.QueueUserWorkItem(delegate
{
for (int j = 0; j < 100000; j++)
{
IEnumerable<int> d = vs.GetInt(j.ToString());
}
});
}
}
}
``` | No, it's definitely not thread-safe.
The fact that it uses a dictionary passed in by the client means you have no control over when the client changes it. You're also only locking it when you apply the `Where` clause - but that doesn't actually perform any iteration at all. You'd need to hold the lock while iterating over the results - but as I said before, it doesn't stop the client from changing the dictionary at any time anyway.
If you created the dictionary in the class and only ever exposed the data within it (i.e. protected it from the outside world) you could make it fully thread-safe. If you insist that the client code doesn't mutate the dictionary, you don't need the lock at all, as dictionaries are safe to read from multiple threads when there are no writers. | I can tell you that the statement in the lock isn't executed until after the lock is released. If you must lock the collection during iteration then move the yield into the lock statement. | Is this class threadsafe? | [
"",
"c#",
"multithreading",
""
] |
It's very annoying that `copy_if` is not in C++. Does anyone know if it will be in C++0x? | Since the C++0x is not yet finalized, you can only take a look at the most recent [draft](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2009/n2857.pdf). | In the meantime, it's not very hard to make your own `copy_if()` using `remove_copy_if()`:
```
#include <functional>
struct my_predicate : std::unary_function<my_arg_type, bool> {
bool operator()(my_arg_type const& x) const { ... }
};
// To perform "copy_if(x, y, z, my_predicate())", write:
remove_copy_if(x, y, z, std::not1(my_predicate()));
```
Using `not1()` requires your predicate class to supply a nested type, `argument_type`, identifying the type of the argument -- as shown above, one convenient way to do this is to derive from `unary_function<T, U>`, where `T` is the argument type. | are they adding copy_if to c++0x? | [
"",
"c++",
"algorithm",
"c++11",
""
] |
By default, Tomcat sends some HTML content back to the client if it encounters something like an HTTP 404. I know that via `web.xml` an `<error-page>` [can be configured](http://wiki.apache.org/tomcat/FAQ/Miscellaneous#Q6) to customize this content.
However, I'd just like for Tomcat to **not send anything** in terms of response content (I'd still like the status code, of course). Is there any way to easily configure this?
I'm trying to avoid A) explicitly sending empty content on the response stream from my Servlet, and B) configuring custom error pages for a whole bunch of HTTP error statuses in my `web.xml`.
For some background, I'm developing an HTTP API and am controlling my own response content. So for an HTTP 500, for example, I'm populating some XML content on the response containing error information. For situations like an HTTP 404, the HTTP response status is sufficient for clients, and the content tomcat is sending is unnecessary. If there's a different approach, I'm open to hearing it.
**Edit:**
After continued investigation, I still can't find much in the way of a solution. If someone can definitively say this is not possible, or provide a resource with evidence that it will not work, I'll accept that as an answer and try and work around it. | If you do not want tomcat to show an error page, do not use sendError(...). Instead, use setStatus(...).
e.g. if you want to give a 405 response, then you do
```
response.setStatus(HttpServletResponse.SC_METHOD_NOT_ALLOWED);
response.getWriter().println("The method " + request.getMethod() +
" is not supported by this service.");
```
Also, remember not to throw any Exceptions from your servlet. Instead, catch the Exception and, again, set the statusCode yourself.
i.e.
```
protected void service(HttpServletRequest request,
HttpServletResponse response) throws IOException {
try {
// servlet code here, e.g. super.service(request, response);
} catch (Exception e) {
// log the error with a timestamp, show the timestamp to the user
long now = System.currentTimeMillis();
log("Exception " + now, e);
response.setStatus(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);
response.getWriter().println("Guru meditation: " + now);
}
}
```
Of course, if you do not want any content, just don't write anything to the writer, and just set the status. | Although this doesn't respond exactly to the "not send anything" statement on the question, and on the wave of [Clive Evans' answer](https://stackoverflow.com/a/8166149/1504300), I found out that, in tomcat, you can make those overly verbose texts go away from error pages without creating a custom ErrorReportValve.
You can accomplish this by customizing ErrorReportValve through the 2 params "showReport" and "showServerInfo" in your "server.xml":
```
<Valve className="org.apache.catalina.valves.ErrorReportValve" showReport="false" showServerInfo="false" />
```
[Link to official documentation](https://tomcat.apache.org/tomcat-7.0-doc/config/valve.html#Error_Report_Valve).
Worked for me on tomcat 7.0.55, didn't work for me on tomcat 7.0.47 (because of something reported on the following link, I think - <http://www.mail-archive.com/users@tomcat.apache.org/msg113856.html>) | Disable all default HTTP error response content in Tomcat | [
"",
"java",
"http",
"tomcat",
"servlets",
"httpresponse",
""
] |
I'm trying to compare two Xml files using C# code.
I want to ignore Xml syntax differences (i.e. prefix names).
For that I am using Microsoft's [XML Diff and Patch](http://www.microsoft.com/downloads/details.aspx?FamilyID=3471df57-0c08-46b4-894d-f569aa7f7892&DisplayLang=en) C# API.
It works for some Xml's but I couldn't find a way to configure it to work with the following two Xml's:
XML A:
```
<root xmlns:ns="http://myNs">
<ns:child>1</ns:child>
</root>
```
XML B:
```
<root>
<child xmlns="http://myNs">1</child>
</root>
```
My questions are:
1. Am I right that these two xml's are semantically equal (or isomorphic)?
2. Can Microsoft's XML Diff and Patch API be configured to support it?
3. Are there any other C# utilities to to this? | I've got [an answer by Martin Honnen](http://social.msdn.microsoft.com/Forums/en-US/xmlandnetfx/thread/3f2bb47f-356d-48f3-866c-b2533e5731f8/) in XML and the .NET Framework MSDN Forum.
In short he suggests to use XQuery 1.0's deep-equal function and supplies some C# implementations. Seems to work. | The documents are isomorphic as can be shown by the program below. I think if you use `XmlDiffOptions.IgnoreNamespaces` and `XmlDiffOptions.IgnorePrefixes` to configure `Microsoft.XmlDiffPatch.XmlDiff`, you get the result you want.
```
using System.Linq;
using System.Xml.Linq;
namespace SO_794331
{
class Program
{
static void Main(string[] args)
{
var docA = XDocument.Parse(
@"<root xmlns:ns=""http://myNs""><ns:child>1</ns:child></root>");
var docB = XDocument.Parse(
@"<root><child xmlns=""http://myNs"">1</child></root>");
var rootNameA = docA.Root.Name;
var rootNameB = docB.Root.Name;
var equalRootNames = rootNameB.Equals(rootNameA);
var descendantsA = docA.Root.Descendants();
var descendantsB = docB.Root.Descendants();
for (int i = 0; i < descendantsA.Count(); i++)
{
var descendantA = descendantsA.ElementAt(i);
var descendantB = descendantsB.ElementAt(i);
var equalChildNames = descendantA.Name.Equals(descendantB.Name);
var valueA = descendantA.Value;
var valueB = descendantB.Value;
var equalValues = valueA.Equals(valueB);
}
}
}
}
``` | Xml Comparison in C# | [
"",
"c#",
"xml",
""
] |
I'm trying to generate Java classes from the FpML (Finanial Products Markup Language) version 4.5. A ton of code is generated, but I cannot use it. Trying to serialize a simple document I get this:
```
javax.xml.bind.MarshalException
- with linked exception: [com.sun.istack.SAXException2: unable
to marshal type
"org.fpml._2008.fpml_4_5.PositionReport"
as an element because it is missing an
@XmlRootElement annotation]
```
In fact **no** classses have the @XmlRootElement annotation, so what can I be doing wrong?. I'm pointing xjc (JAXB 2.1) to fpml-main-4-5.xsd, which then includes all types. | To tie together what others have already stated or hinted at, the rules by which JAXB XJC decides whether or not to put the `@XmlRootElement` annotation on a generated class are non trivial ([see this article](http://web.archive.org/web/20160117210900/https://community.oracle.com/blogs/kohsuke/2006/03/03/why-does-jaxb-put-xmlrootelement-sometimes-not-always)).
`@XmlRootElement` exists because the JAXB runtime requires certain information in order to marshal/unmarshal a given object, specifically the XML element name and namespace. You can't just pass any old object to the Marshaller. `@XmlRootElement` provides this information.
The annotation is just a convenience, however - JAXB does not require it. The alternative to is to use `JAXBElement` wrapper objects, which provide the same information as `@XmlRootElement`, but in the form of an object, rather than an annotation.
However, `JAXBElement` objects are awkward to construct, since you need to know the XML element name and namespace, which business logic usually doesn't.
Thankfully, when XJC generates a class model, it also generates a class called `ObjectFactory`. This is partly there for backwards compatibility with JAXB v1, but it's also there as a place for XJC to put generated factory methods which create `JAXBElement` wrappers around your own objects. It handles the XML name and namespace for you, so you don't need to worry about it. You just need to look through the `ObjectFactory` methods (and for large schema, there can be hundreds of them) to find the one you need. | This is mentioned at the bottom of the blog post already linked above but this works like a treat for me:
```
Marshaller marshaller = jc.createMarshaller();
marshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE);
marshaller.marshal(new JAXBElement<MyClass>(new QName("uri","local"), MyClass.class, myClassInstance), System.out);
``` | No @XmlRootElement generated by JAXB | [
"",
"java",
"jaxb",
"xjc",
"fpml",
""
] |
I have the below code for returning back an instance of my WCF Service `ServiceClient`:
```
var readerQuotas = new XmlDictionaryReaderQuotas()
{
MaxDepth = 6000000,
MaxStringContentLength = 6000000,
MaxArrayLength = 6000000,
MaxBytesPerRead = 6000000,
MaxNameTableCharCount = 6000000
};
var throttlingBehaviour = new ServiceThrottlingBehavior(){MaxConcurrentCalls=500,MaxConcurrentInstances=500,MaxConcurrentSessions = 500};
binding = new WSHttpBinding(SecurityMode.None) {MaxReceivedMessageSize = 6000000, ReaderQuotas = readerQuotas};
dualBinding = new WSDualHttpBinding(WSDualHttpSecurityMode.None)
{MaxReceivedMessageSize = 6000000, ReaderQuotas = readerQuotas};
endpointAddress = new EndpointAddress("http://localhost:28666/DBInteractionGateway.svc");
return new MusicRepo_DBAccess_ServiceClient(new InstanceContext(instanceContext), dualBinding, endpointAddress);
```
Lately I was having some trouble with timeouts and so I decided to add a throttling behavior, like such:
```
var throttlingBehaviour = new ServiceThrottlingBehavior () {
MaxConcurrentCalls=500,
MaxConcurrentInstances=500,
MaxConcurrentSessions = 500
};
```
My question is, **where in the above code should I add this `throttlingBehaviour` to my `MusicRepo_DBAccess_ServiceClient` instance?**
---
From some of the examples I found on the web, they are doing something like this:
```
ServiceHost host = new ServiceHost(typeof(MyService));
ServiceThrottlingBehavior throttleBehavior = new ServiceThrottlingBehavior
{
MaxConcurrentCalls = 40,
MaxConcurrentInstances = 20,
MaxConcurrentSessions = 20,
};
host.Description.Behaviors.Add(throttleBehavior);
host.Open();
```
Notice that in the above code they are using a `ServiceHost` whereas I am not, and they are then opening it (with `Open()`) whereas I open the `MusicRepo_DBAccess_ServiceClient` instance...and this is what got me confused. | You can specify the behavior in the configuration file afaik, and the generated client will obey, using behaviors.
Some configuration sections excluded for brevity
```
<service
behaviorConfiguration="throttleThis" />
<serviceBehaviors>
<behavior name="throttleThis">
<serviceMetadata httpGetEnabled="True" />
<serviceThrottling
maxConcurrentCalls="40"
maxConcurrentInstances="20"
maxConcurrentSessions="20"/>
</behavior>
</serviceBehaviors>
``` | Can be done in code for those, like me, who configure at runtime.
vb version:
```
Dim stb As New ServiceThrottlingBehavior
stb.MaxConcurrentSessions = 100
stb.MaxConcurrentCalls = 100
stb.MaxConcurrentInstances = 100
ServiceHost.Description.Behaviors.Add(stb)
```
c# version:
```
ServiceThrottlingBehavior stb = new ServiceThrottlingBehavior {
MaxConcurrentSessions = 100,
MaxConcurrentCalls = 100,
MaxConcurrentInstances = 100
};
ServiceHost.Description.Behaviors.Add(stb);
``` | WCF: How do I add a ServiceThrottlingBehavior to a WCF Service? | [
"",
"c#",
"wcf",
"web-services",
"throttling",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.