
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I'm writing a web applicaion in Eclipse, and I'm using the XStream Serialization Library to generate My JSON.
I've encapsulated the Code that builds up the JSON in a class which is called by my servelet. Then encapsulated class has a main method for testing and when I run it everything seems to work fine.
However when I use the call the class from my servelet I get a `java.lang.NoClassDefFoundError` error, sayying that I've not loaded the XStream libraries. I assume I've got my build path wrong, but I've set the XStream libraries to be in the build path for the project, so as far as I know it should work.
What is likely to be going wrong here?
Following is the exact exception:
```
java.lang.ClassNotFoundException: com.thoughtworks.xstream.io.HierarchicalStreamDriver
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1387)
at org.apache.catalina.loader.WebappClassLoader.loadClass(WebappClassLoader.java:1233)
at java.lang.ClassLoader.loadClassInternal(ClassLoader.java:320)
at SecurePaymentAjaxData.doPost(SecurePaymentAjaxData.java:44)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:637)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:717)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:290)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:233)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:191)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:128)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:102)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:109)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:286)
at org.apache.coyote.http11.Http11Processor.process(Http11Processor.java:845)
at org.apache.coyote.http11.Http11Protocol$Http11ConnectionHandler.process(Http11Protocol.java:583)
at org.apache.tomcat.util.net.JIoEndpoint$Worker.run(JIoEndpoint.java:447)
at java.lang.Thread.run(Thread.java:619)
```
And here is the relavant code that uses the xstream class:
```
XStream xstream = new XStream(new JettisonMappedXmlDriver());
xstream.setMode(XStream.NO_REFERENCES);
xstream.alias("CallDataUpdate", CallDataUpdate.class);
xstream.alias("CardStatus", CardStatus.class);
String jsonData = xstream.toXML(updateData);
```
I stress that this code works fine when run as a java application, I'm sure it's something to do with loading the libraries, I just don't know where I've gone wrong. | I found the issue:
If you right click on the project and select properties you can set the "Java EE Module dependencies" to include the modules you are using.
Hey Presto it works. | Don't forget that there's a difference between how you **build** and how you **deploy**. That is, you may be building against XStream, but you should also package it in the .war file for deployment.
Explode your resultant .war file (`jar tvf {filename}` to see the contents) and check whether it's there (a .jar file under `WEB-INF/lib`). I suspect it's not. | Under Tomcat java.lang.NoClassDefFoundError when accessing a servlet? | [
"",
"java",
"eclipse",
"tomcat",
"xstream",
""
] |
How do i blink the text in console using C#? | Person-b was on the right track, but their code needs some changes:
```
static void Main()
{
string txt = "Hello, world!";
while (true)
{
WriteBlinkingText(txt, 500, true);
WriteBlinkingText(txt, 500, false);
}
}
private static void WriteBlinkingText(string text, int delay, bool visible)
{
if (visible)
Console.Write(text);
else
for (int i = 0; i < text.Length; i++)
Console.Write(" ");
Console.CursorLeft -= text.Length;
System.Threading.Thread.Sleep(delay);
}
``` | To do this you will have to use:
```
console.clear
```
which will clear all the information in the console, but allow you to simulate a blinking text, by doing the following code you can do this:
(This is in VB but its easily translated)
```
Dim Flash As Integer
Flash = 0
While Flash < 100 (Any number can be put here for duration)
Flash = Flash + 1
console.Backgroundcolor = consolecolor.Black
console.clear
system.threading.thread.sleep(25)
console.Backgroundcolor = consolecolor.White
console.clear
system.threading.thread.sleep(25)
End While
```
And that would give a blinking screen for example, for the blinking text simply adjust it:
```
Dim FlashWord As Integer
FlashWord = 0
While FlashWord < 100 (Any number can be put here for duration)
FlashWord = FlashWord + 1
console.Foregroundcolor = consolecolor.Black
console.clear
Console.Writeline("Hello World")
system.threading.thread.sleep(25)
console.Foregroundcolor = consolecolor.White
console.clear
Console.Writeline("Hello World")
system.threading.thread.sleep(25)
End While
```
And this will simulate 'flashing', the only down side is that you lose your previous on-screen info, but nothing else, and for an effect this is pretty good! | Blink text in C# | [
"",
"c#",
""
] |
I often find myself doing quick checks like this:
```
if (!eregi('.php', $fileName)) {
$filename .= '.php';
}
```
But as [`eregi()`](http://php.net/eregi) was deprecated in PHP 5.3 the code now throws errors.
Is there another function that behaves exactly the same way as `eregi()`? I don't know anything about regexps and don't want to learn, so `preg_match()` etc won't work for me. | [stristr](http://php.net/stristr) achieves exactly the same result as eregi (at least when you don't use regular expressions):
```
if (!stristr($fileName, '.php'))
$filename.='.php';
```
You could also make a "fake" eregi this way:
```
if (!function_exists('eregi')) {
function eregi($find, $str) {
return stristr($str, $find);
}
}
```
**Update**: Note that `stristr` doesn't accept regular expressions as `eregi` does, and for this specific case (checking the extension), you'd better go with vartec's solution. | Of course you are aware, that this doesn't do what you expect it do do?
In regexp '.' means any character, so `eregi('.php',$fileName)` means filename with any character followed by 'php'. Thus for example "blabla2PHP.txt" will match your regexp.
Now what you want to do is this:
```
$file_ext = pathinfo($filename, PATHINFO_EXTENSION);
if(strtolower($file_ext) != 'php')
$filename .= '.php';
``` | Good alternative to eregi() in PHP | [
"",
"php",
"string",
""
] |
Is there a way for js code to force Selenium testing to fail? For (a probably bad) example, if I had the following:
```
return document.getElementById('foo').innerHTML == 'hello'
```
is there a way I could make the 'runScript' command fail depending on if the js code returned true or false? (I know that example could be used by other Selenium commands, but I wanted a more general solution.)
Do I need to learn how to extend Selenium to add another command?
I'm also relatively new to Selenium so is this something that using Selenium-rc will solve? | `assertExpression` will give you what you're asking for.
For instance, the following line would cause your test to fail if the JavaScript expression you mention did not evaluate to true.
```
<tr>
<td>assertExpression</td>
<td>javascript{this.browserbot.getCurrentWindow().document.getElementById('foo').innerHTML == 'hello'}</td>
<td>true</td>
</tr>
``` | It depends how you want to use selenium. In selenese suite there are calls for verifyText, etc (just google for selenese suite and verifyText, waitForCondition). If you are using the selenium remote control in e.g. java than you do the assertions in the java code. With the remote control you send scripts to the page and you get back what the evaluation of the code returns. The comparsion/assertion is done in the java client. | having javascript force a Selenium test to fail | [
"",
"javascript",
"selenium",
"assertions",
"testcase",
""
] |
What are the reasons behind the decision to not have a fully generic get method
in the interface of [`java.util.Map<K, V>`](http://java.sun.com/javase/6/docs/api/java/util/Map.html#get(java.lang.Object)).
To clarify the question, the signature of the method is
`V get(Object key)`
instead of
`V get(K key)`
and I'm wondering why (same thing for `remove, containsKey, containsValue`). | As mentioned by others, the reason why `get()`, etc. is not generic because the key of the entry you are retrieving does not have to be the same type as the object that you pass in to `get()`; the specification of the method only requires that they be equal. This follows from how the `equals()` method takes in an Object as parameter, not just the same type as the object.
Although it may be commonly true that many classes have `equals()` defined so that its objects can only be equal to objects of its own class, there are many places in Java where this is not the case. For example, the specification for `List.equals()` says that two List objects are equal if they are both Lists and have the same contents, even if they are different implementations of `List`. So coming back to the example in this question, according to the specification of the method is possible to have a `Map<ArrayList, Something>` and for me to call `get()` with a `LinkedList` as argument, and it should retrieve the key which is a list with the same contents. This would not be possible if `get()` were generic and restricted its argument type. | An awesome Java coder at Google, Kevin Bourrillion, wrote about exactly this issue in a [blog post](http://smallwig.blogspot.com/2007/12/why-does-setcontains-take-object-not-e.html) a while ago (admittedly in the context of `Set` instead of `Map`). The most relevant sentence:
> Uniformly, methods of the Java
> Collections Framework (and the Google
> Collections Library too) never
> restrict the types of their parameters
> except when it's necessary to prevent
> the collection from getting broken.
I'm not entirely sure I agree with it as a principle - .NET seems to be fine requiring the right key type, for example - but it's worth following the reasoning in the blog post. (Having mentioned .NET, it's worth explaining that part of the reason why it's not a problem in .NET is that there's the *bigger* problem in .NET of more limited variance...) | What are the reasons why Map.get(Object key) is not (fully) generic | [
"",
"java",
"generics",
"collections",
"dictionary",
""
] |
Often, when searching for answers, I have found that certain websites will allow you to read the information they offer if the referer is, for example, google.com. Yet, if you link directly to the information, it will be unavailable.
What I am looking for is the smallest PHP script that will set a referer of my choice, and a destination, like so:
```
http://example.com/ref_red.php?referer=http://google.com/&end=http://example.net/
```
Notes:
* **ref\_red.php** is the name of the script on my example.
* **referer** and **end** should accept *http*, *https*, *ftp*.
* **referer** and **end** can contain an URI of any type, as simple as <http://end.com> or as complicated as:
`http://example.com/some/rr/print.pl?document=rr`, for example.
**NOTE:** As recommended on a reply, I am adding this. The script isn't a full proxy per se. **Only initial HTTP request would be proxied** (not subsequent requests like images,etc) for the **sole purpose** of setting the **referer**. | this function should give you a starting point
it will fetch any http url with the specified referrer
handling the query parms should be pretty trivial, so i will leave that part for you to do
```
<?php
echo geturl('http://some-url', 'http://referring-url');
function geturl($url, $referer) {
$headers[] = 'Accept: image/gif, image/x-bitmap, image/jpeg, image/pjpeg,text/html,application/xhtml+xml';
$headers[] = 'Connection: Keep-Alive';
$headers[] = 'Content-type: application/x-www-form-urlencoded;charset=UTF-8';
$useragent = 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 1.0.3705; .NET CLR 1.1.4322; Media Center PC 4.0)';
$process = curl_init($url);
curl_setopt($process, CURLOPT_HTTPHEADER, $headers);
curl_setopt($process, CURLOPT_HEADER, 0);
curl_setopt($process, CURLOPT_USERAGENT, $useragent);
curl_setopt($process, CURLOPT_REFERER, $referer);
curl_setopt($process, CURLOPT_TIMEOUT, 30);
curl_setopt($process, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($process, CURLOPT_FOLLOWLOCATION, 1);
$return = curl_exec($process);
curl_close($process);
return $return;
}
?>
``` | You can use one of the services available on Internet which allow hiding referrers (by setting their address), but you cannot impose a specific referrer that ain't the actual referrer. The user must actually be redirected to that website (which will appear as a referrer) before he is redirected to the target website.
One of such services: <http://linkanon.com>
edit:
Since you changed your question now, my comment about writing a user agent in PHP which acts like a proxy, applies, but then this gets close to a criminal activity, because you will be displaying a third party website to a user who might think that she is in the actual website, while in fact she will have loaded your content (the content you have passed on). To perform this close-to-criminal activity (you are one step away from trying to read a username and password), you load the third party's website content with PHP by using your own written user agent which specifies the fake referrer and simply passes the output to visitor of your website. The function in PHP which lets one send HTTP headers, is header($header):
```
header("Referer: http://example.org");
```
Instead of shouting at people who try to help, you could try to read HTTP (that's the protocol according to which the world turns around) specification regarding Referer header: <http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html> (See Section 14.36).
You also might want to read <http://en.wikipedia.org/wiki/Referrer_spoofing> where you can see that it's all about client side. PHP is server side. All you can do is try to write a client code (Javascript) generated by PHP, but if you have any luck, then you're breaking into user's world. | PHP - Referer redirect script | [
"",
"php",
"http-referer",
""
] |
I have a `Dictionary` that contains items and prices. The items are unique but slowly get added and updated through the lifetime of the application (that is, I don't know the item strings in advance). I would like to bind this structure to a DataGridView, so I can show updates on my Form, something like:
```
Dictionary<string, double> _priceData = new Dictionary<string, double>();
BindingSource _bindingSource = new BindingSource();
dataGridView1.DataSource = _bindingSource;
_bindingSource.DataSource = _priceData;
```
But cannot, since `Dictionary` does not implement `IList` (or `IListSource`, `IBindingList`, or `IBindingListView`).
Is there a way to achieve this? I need to keep a unique list of items, but also update the price for an existing item, so a `Dictionary` is the ideal data structure I think, but I cannot find a way to display the data on my Form.
---
Update:
Marc's suggestion below works very nicely, but I'm still not sure how to update the DataGridView during execution.
I have a class-level variable:
```
private DictionaryBindingList<string, decimal> bList;
```
Then instantiate that in `Main()`:
```
bList = new DictionaryBindingList<string,decimal>(prices);
dgv.DataSource = bList;
```
Then during program execution if a new entry is added to the dictionary:
```
prices.Add("foobar", 234.56M); bList.ResetBindings();
```
I thought that would refresh the DataGridView. Why not? | There are a couple of issues with `Dictionary`; the first is (as you've found) it doesn't implement the necessary `IList`/`IListSource`. The second is that there is no guaranteed order to the items (and indeed, no indexer), making random access by index (rather than by key) impossible.
However... it is probably doable with some some smoke and mirrors; something like below:
```
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Windows.Forms;
static class Program
{
[STAThread]
static void Main()
{
Dictionary<string, decimal> prices =
new Dictionary<string, decimal>();
prices.Add("foo", 123.45M);
prices.Add("bar", 678.90M);
Application.EnableVisualStyles();
Form form = new Form();
DataGridView dgv = new DataGridView();
dgv.Dock = DockStyle.Fill;
form.Controls.Add(dgv);
var bl = prices.ToBindingList();
dgv.DataSource = bl;
Button btn = new Button();
btn.Dock = DockStyle.Bottom;
btn.Click += delegate
{
prices.Add(new Random().Next().ToString(), 0.1M);
bl.Reset();
};
form.Controls.Add(btn);
Application.Run(form);
}
public static DictionaryBindingList<TKey, TValue>
ToBindingList<TKey, TValue>(this IDictionary<TKey, TValue> data)
{
return new DictionaryBindingList<TKey, TValue>(data);
}
public sealed class Pair<TKey, TValue>
{
private readonly TKey key;
private readonly IDictionary<TKey, TValue> data;
public Pair(TKey key, IDictionary<TKey, TValue> data)
{
this.key = key;
this.data = data;
}
public TKey Key { get { return key; } }
public TValue Value
{
get
{
TValue value;
data.TryGetValue(key, out value);
return value;
}
set { data[key] = value; }
}
}
public class DictionaryBindingList<TKey, TValue>
: BindingList<Pair<TKey, TValue>>
{
private readonly IDictionary<TKey, TValue> data;
public DictionaryBindingList(IDictionary<TKey, TValue> data)
{
this.data = data;
Reset();
}
public void Reset()
{
bool oldRaise = RaiseListChangedEvents;
RaiseListChangedEvents = false;
try
{
Clear();
foreach (TKey key in data.Keys)
{
Add(new Pair<TKey, TValue>(key, data));
}
}
finally
{
RaiseListChangedEvents = oldRaise;
ResetBindings();
}
}
}
}
```
Note that the use of a custom extension method is entirely optional, and can be removed in C# 2.0, etc. by just using `new DictionaryBindingList<string,decimal>(prices)` instead. | Or, in LINQ, it's nice and quick:
```
var _priceDataArray = from row in _priceData select new { Item = row.Key, Price = row.Value };
```
That should then be bindable, to the columns 'Item' and 'Price'.
To use it as a data source in a grid view, you just have to follow it with `ToArray()`.
```
dataGridView1.DataSource = _priceDataArray.ToArray();
``` | DataGridView bound to a Dictionary | [
"",
"c#",
".net",
"winforms",
"datagridview",
"dictionary",
""
] |
I was doing some performance metrics and I ran into something that seems quite odd to me. I time the following two functions:
```
private static void DoOne()
{
List<int> A = new List<int>();
for (int i = 0; i < 200; i++) A.Add(i);
int s=0;
for (int j = 0; j < 100000; j++)
{
for (int c = 0; c < A.Count; c++) s += A[c];
}
}
private static void DoTwo()
{
List<int> A = new List<int>();
for (int i = 0; i < 200; i++) A.Add(i);
IList<int> L = A;
int s = 0;
for (int j = 0; j < 100000; j++)
{
for (int c = 0; c < L.Count; c++) s += L[c];
}
}
```
Even when compiling in release mode, the timings results were consistently showing that DoTwo takes ~100 longer then DoOne:
```
DoOne took 0.06171706 seconds.
DoTwo took 8.841709 seconds.
```
Given the fact the List directly implements IList I was very surprised by the results. Can anyone clarify this behavior?
## The gory details
Responding to questions, here is the full code and an image of the project build preferences:
> [Dead Image Link](http://img178.imageshack.us/img178/9456/projpref.tif)
```
using System;
using System.Collections.Generic;
using System.Text;
using System.Diagnostics;
using System.Collections;
namespace TimingTests
{
class Program
{
static void Main(string[] args)
{
Stopwatch SW = new Stopwatch();
SW.Start();
DoOne();
SW.Stop();
Console.WriteLine(" DoOne took {0} seconds.", ((float)SW.ElapsedTicks) / Stopwatch.Frequency);
SW.Reset();
SW.Start();
DoTwo();
SW.Stop();
Console.WriteLine(" DoTwo took {0} seconds.", ((float)SW.ElapsedTicks) / Stopwatch.Frequency);
}
private static void DoOne()
{
List<int> A = new List<int>();
for (int i = 0; i < 200; i++) A.Add(i);
int s=0;
for (int j = 0; j < 100000; j++)
{
for (int c = 0; c < A.Count; c++) s += A[c];
}
}
private static void DoTwo()
{
List<int> A = new List<int>();
for (int i = 0; i < 200; i++) A.Add(i);
IList<int> L = A;
int s = 0;
for (int j = 0; j < 100000; j++)
{
for (int c = 0; c < L.Count; c++) s += L[c];
}
}
}
}
```
Thanks for all the good answers (especially @kentaromiura). I would have closed the question, though I feel we still miss an important part of the puzzle. Why would accessing a class via an interface it implements be so much slower? The only difference I can see is that accessing a function via an Interface implies using virtual tables while the normally the functions can be called directly. To see whether this is the case I made a couple of changes to the above code. First I introduced two almost identical classes:
```
public class VC
{
virtual public int f() { return 2; }
virtual public int Count { get { return 200; } }
}
public class C
{
public int f() { return 2; }
public int Count { get { return 200; } }
}
```
As you can see VC is using virtual functions and C doesn't. Now to DoOne and DoTwo:
```
private static void DoOne()
{ C a = new C();
int s=0;
for (int j = 0; j < 100000; j++)
{
for (int c = 0; c < a.Count; c++) s += a.f();
}
}
private static void DoTwo()
{
VC a = new VC();
int s = 0;
for (int j = 0; j < 100000; j++)
{
for (int c = 0; c < a.Count; c++) s += a.f();
}
}
```
And indeed:
```
DoOne took 0.01287789 seconds.
DoTwo took 8.982396 seconds.
```
This is even more scary - virtual function calls 800 times slower?? so a couple of question to the community:
1. Can you reproduce? (given the
fact that all had worse performance
before, but not as bad as mine)
2. Can you explain?
3. (this may be the
most important) - can you think of
a way to avoid?
Boaz | First I want to thank all for their answers. It was really essential in the path figuring our what was going on. Special thanks goes to @kentaromiura which found the key needed to get to the bottom of things.
The source of the slow down of using List<T> via an IList<T> interface is the lack of the ability of the JIT complier to inline the Item property get function. The use of virtual tables caused by accessing the list through it's IList interface prevents that from happening.
As a proof , I have written the following code:
```
public class VC
{
virtual public int f() { return 2; }
virtual public int Count { get { return 200; } }
}
public class C
{
//[MethodImpl( MethodImplOptions.NoInlining)]
public int f() { return 2; }
public int Count
{
// [MethodImpl(MethodImplOptions.NoInlining)]
get { return 200; }
}
}
```
and modified the DoOne and DoTwo classes to the following:
```
private static void DoOne()
{
C c = new C();
int s = 0;
for (int j = 0; j < 100000; j++)
{
for (int i = 0; i < c.Count; i++) s += c.f();
}
}
private static void DoTwo()
{
VC c = new VC();
int s = 0;
for (int j = 0; j < 100000; j++)
{
for (int i = 0; i < c.Count; i++) s += c.f();
}
}
```
Sure enough the function times are now very similar to before:
```
DoOne took 0.01273598 seconds.
DoTwo took 8.524558 seconds.
```
Now, if you remove the comments before the MethodImpl in the C class (forcing the JIT not to inline) - the timing becomes:
```
DoOne took 8.734635 seconds.
DoTwo took 8.887354 seconds.
```
Voila - the methods take almost the same time. You can stil see that method DoOne is still slightly fast , which is consistent which the extra overhead of a virtual function. | A note to everyone out there who is trying to benchmark stuff like this.
Do not forget that **the code is not jitted until the first time it runs**. That means that the first time you run a method, the cost of running that method could be dominated by the time spent loading the IL, analyzing the IL, and jitting it into machine code, particularly if it is a trivial method.
If what you're trying to do is compare the "marginal" runtime cost of two methods, it's a good idea to run both of them twice and *consider only the second runs* for comparison purposes. | Why does casting List<T> into IList<T> result in reduced performance? | [
"",
"c#",
"list",
"generics",
""
] |
Hello guys first of all apologize for asking such a simple and yet redundant question but it seems my case is kinda bit different where googling failed to provide answers.
I have a solution with 2 projects say proj1 and proj2 where proj1 is a winform application and proj2 is a classlibrary application.proj1 is sitting here
> C:\Documents and Settings\myname\My Documents\Visual Studio 2005\Projects\proj1\proj1
ane the classlibrary is here
> C:\Documents and Settings\myname\My Documents\Visual Studio 2005\Projects\proj1\proj2
Now i have a report in a subfolder Report where i have my crystalreport and other stuffs
i need to have this root path of proj1
> C:\Documents and Settings\myname\My Documents\Visual Studio 2005\Projects\proj1\proj1
so that i append `@"Report\myreport.rpt"` to it. I believe with that it's supposed to be relative path on the deployed machine.correct me if I'm wrong.the main idea is to have relative path to the Report folder at
> C:\Documents and Settings\myname\My Documents\Visual Studio 2005\Projects\proj1\proj\Report.
from all i searched online
like `Environment.CurrentDirectory`or `Application.StartupPath` or `Application.ExecutablePath` or `System.Reflection.Assembly.GetExecutingAssembly().Location` are just given me either the bin/proj1.exe or the debug folder.
i just can't figure out how to do that
thank you for reading this.oh yeah! and for your kind answer.
PS: using C#2.0 | You just have to set the property `Copy to Output Directory` of the report file to `Copy allways` or "Copy if newer". This will copy the report below the actual output directory during a build and you can access it with `Path.Combine(Application.StartupPath, "Reports", "report.rpt")`. | You're not going to get the *project* folder from the compiled assembly because (as far as I know) it has no idea where it was compiled from. You are, however, going to get the folder *where the assembly is running from*, which is the "debug folder" you're getting from `Application.ExecutablePath`.
You would be better off to copy the reports into a Reports folder into the bin/debug folder and access them from there (you could use `Application.ExecutablePath` to get this). Then when you need to move the compiled files, you can move the Reports folder with it.
When you deploy, you would then have following structure:
```
C:\Program Files\proj1\proj1.exe
C:\Program Files\proj1\Reports\myreport.rpt
```
and not the following (which is what you're suggesting?):
```
C:\Program Files\proj1\proj1.exe
C:\Documents and Settings\myname\My Documents\Visual Studio 2005\Projects\proj1\Reports\myreport.rpt
``` | Winform root directory path.How to again! | [
"",
"c#",
"winforms",
"deployment",
""
] |
How do I find out about the memory used by each object in a program?
For example : I want to know how much memory(in Kb) is used by this object "someclassinstance"..
someclass someclassinstance=new someclass();
I can see the total memory used by the application in the task manager...But Is there a way to see detailed report about memory usage for each object instance?
Note:I've tried CLR profiler..but it only shows total memory used by strings as far as i know...It does not show the memory used by each string object.
Thanks | [CLR profiler](http://www.microsoft.com/downloads/details.aspx?FamilyId=A362781C-3870-43BE-8926-862B40AA0CD0&displaylang=en) is free and can do this. It has a learning curve, but comes with the documentation you will need. | [.NET Memory Profiler is excellent](http://memprofiler.com/) It's got a 14 day trial and is pretty cheap after that. It lets you track all the instances you have, graph them and see how much memory each is taking. It gives you a tremendous amount of insight into exactly what is happening in your application. | How to find memory used by each object in a program? | [
"",
"c#",
"memory",
"object",
""
] |
I am making a prompt in C# that instructs the user how to use the program before they can access it.
What is the best way to display multiple lines of static text? Using a bunch labels doesn't seem like it would be the proper way... xD | Use a text input box marked as read-only and multi-line. | If you're using WinForms, you might want to consider adding a WebBrowser control to your form - you can then point the browser to an html file you send with the program. This allows you to use all of html to instruct your users, as well as point them to, say, your web site for more help or information. | Best way to display multiple lines of static text in C#? | [
"",
"c#",
"text",
"lines",
""
] |
I want to extract two consecutive words starting from each word in a string.
```
$string = "This is my test case for an example."
```
If I explode on each space, I get every word individually, but I don't want that.
```
[
'This',
'is',
'my',
'test',
'case',
'for',
'an',
'example.'
];
```
What I want is to get each word and its next word including the delimiting space.
Desired output:
```
[
'This is'
'is my'
'my test'
'test case'
'case for'
'for an',
'an example.'
]
``` | this will provide the output you're looking for
```
$string = "This is my test case for an example.";
$tmp = explode(' ', $string);
$result = array();
//assuming $string contains more than one word
for ($i = 0; $i < count($tmp) - 1; ++$i) {
$result[$i] = $tmp[$i].' '.$tmp[$i + 1];
}
print_r($result);
```
Wrapped in a function:
```
function splitWords($text, $cnt = 2)
{
$words = explode(' ', $text);
$result = array();
$icnt = count($words) - ($cnt-1);
for ($i = 0; $i < $icnt; $i++)
{
$str = '';
for ($o = 0; $o < $cnt; $o++)
{
$str .= $words[$i + $o] . ' ';
}
array_push($result, trim($str));
}
return $result;
}
``` | An alternative, making use of 'chasing pointers', would be this snippet.
```
$arr = explode( " ", "This is an example" );
$result = array();
$previous = $arr[0];
array_shift( $arr );
foreach( $arr as $current ) {
$result[]=$previous." ".$current;
$previous = $current;
}
echo implode( "\n", $result );
```
It's always fun to not need indices and counts but leave all these internal representational stuff to the foreach method (or array\_map, or the like). | Get each word with its next word from a space-delimited string | [
"",
"php",
"split",
"explode",
"cpu-word",
"pairwise",
""
] |
I am currently asking myself some questions about exception handling and eventhandlers, and i hope some of you will give me some help.
I will start to explain what i would like to achieve in my c# application:
I have a top-level method (lets call it the main method). This method calls an asynchronous method (wich is called connect), which connect to a FTP server.
An EventHandler object is associated to this connection, and a "callback" method is called when the connection is successful.
I want to handle exceptions that can be launched during the whole process. So i would like to catch it in the top level method. It works fine for exceptions launched by the connect method (which is called inside the top level method).
However, it does not work for exceptions called inside the "callback" method: the top level method does not catch them and the execution fails.
What can I do to make these exceptions beeing caught by the top level method ? I don't want to handle these exceptions in the callback. | Take a look at how the Backgroundworker deals with this: the Exception is propagated to the Completed event handler.
I assume you have some form of State object that is passed to/from the delegate, that's where you can add such a property. And you will have to catch all exceptions in the thread, at the outermost scope. But 'handling' just means passing it along.
There is a standard pattern for the RunWorkerCompleted event, see [this MSDN page](http://msdn.microsoft.com/en-us/library/system.componentmodel.backgroundworker.runworkercompleted.aspx). | Consider the below code fragment for wrapping all of your code in a global exception handler:
```
namespace MyClient
{
class Program
{
static void Main(string[] args)
{
try
{
bool isSuccess = SubMain(string[] args);
}
catch (Exception e)
{
HandleExceptionGracefully(e);
}
}
static bool SubMain(string[] agrs)
{
// Do something
}
static void HandleExceptionGracefully(Exception e)
{
// Display/Send the exception in a graceful manner to the user/admin.
}
}
}
```
Also, don't forget to make your error handling [user-friendly.](http://www.codinghorror.com/blog/archives/001238.html) | top-level exception handling with event handlers in c# | [
"",
"c#",
"exception",
"events",
"asynchronous",
""
] |
What do you suggest for JS development IDE. Is there something similar to VisualStudio IDE, so I can run/debug my application in it? | A few options:
* Visual Studio 2008 (including VWD Express, <http://blog.berniesumption.com/software/how-to-debug-javascript-in-internet-explorer/>)
* Adobe Dreamweaver CS4
* Notepad++ (or any other text editor), Firefox and Firebug | At JetBrains we've just developed lightweight [HTML/Javascript/CSS IDE WebStorm](http://www.jetbrains.com/webstorm/) that includes very smart JavaScript Editor with DOM-based autocompletion and HTML5 API support.
It allows you to debug(breakpoints supported) and run your scripts directly from IDE. | IDE for JavaScript development | [
"",
"javascript",
"ide",
""
] |
I'm new to using Hibernate with Java. I'm getting the following exception. The stuff that I found online regarding this error didn't seem to help. Any ideas? The Exception:
```
java.lang.IllegalArgumentException: org.hibernate.hql.ast.QuerySyntaxException:
ApplPerfStats is not mapped [select count(c) from ApplPerfStats c]
at org.hibernate.ejb.AbstractEntityManagerImpl.throwPersistenceException(AbstractEntityManagerImpl.java:601)
at org.hibernate.ejb.AbstractEntityManagerImpl.createQuery(AbstractEntityManagerImpl.java:96)
at com.icesoft.icefaces.samples.datatable.jpa.CustomerDAO.findTotalNumberCustomers(CustomerDAO.java:89)
at com.icesoft.icefaces.samples.datatable.ui.SessionBean.getDataPage(SessionBean.java:189)
at com.icesoft.icefaces.samples.datatable.ui.SessionBean.access$0(SessionBean.java:185)
at com.icesoft.icefaces.samples.datatable.ui.SessionBean$LocalDataModel.fetchPage(SessionBean.java:245)
at com.icesoft.icefaces.samples.datatable.ui.PagedListDataModel.getPage(PagedListDataModel.java:121)
at com.icesoft.icefaces.samples.datatable.ui.PagedListDataModel.getRowCount(PagedListDataModel.java:100)
at com.icesoft.faces.component.datapaginator.DataPaginator.isModelResultSet(DataPaginator.java:1091)
at com.icesoft.faces.component.datapaginator.DataPaginatorRenderer.encodeBegin(DataPaginatorRenderer.java:201)
```
The place where this is called:
```
@SuppressWarnings("unchecked")
public Long findTotalNumberCustomers() {
EntityManagerHelper.log("finding number of Customer instances", Level.INFO, null);
try {
String queryString = "select count(c) from ApplPerfStats c";
return (Long) getEntityManager().createQuery(queryString).getSingleResult();
} catch (RuntimeException re) {
EntityManagerHelper.log("find number of Appl_perf_stats failed",
Level.SEVERE, re);
throw re;
}
}
```
The class that maps to the database table:
```
package com.icesoft.icefaces.samples.datatable.jpa;
import java.sql.Timestamp;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "Appl_perf_stats", uniqueConstraints = {})
public class ApplPerfStats implements java.io.Serializable {
.....
```
Thanks,
Tam | Try adding a `class` element under `persistence-unit`, in your `persistence.xml` file.
```
<?xml version="1.0" encoding="UTF-8"?>
<persistence ...>
<persistence-unit name="unit">
<class>com.icesoft.icefaces.samples.datatable.jpa.ApplPerfStats</class>
...
</persistence-unit>
<persistence>
```
I haven't done much more than that with JPA/EntityManager, so I don't know if there's a way to add an entire package. AFAIK, when using `hibernate.cfg.xml`, each persistent class has to be specified directly. | It happened to me until I started to use the full class name, e.g.:
```
String queryString = "select count(c) from com.my.classes.package.ApplPerfStats c";
```
But I don't like this approach, because it's refactoring-unfirendly. A more tractable one would be:
```
String queryString = "select count(c) from " + ApplPerfStats.class.getName() + c";
```
javashlook's solution seems to be a shortcut for that - but it adds more XML configuration, which I try to avoid. If only there was an annotation-based way to specify that... | org.hibernate.hql.ast.QuerySyntaxException with Hibernate | [
"",
"java",
"hibernate",
""
] |
i have 3 hidden fields in 1 div. when I have reference to this div, how to get 1 of the hidden fields in this div. | This will also work (jQuery):
```
$('#my_div').find('input[type=hidden]:first')
``` | Assuming you have a DIV, like so:
```
<div id="mydiv">
<input type="hidden">
<input type="hidden">
<input type="hidden">
</div>
```
You can use jQuery to do something like this to select all of them:
```
$('input:hidden','#mydiv');
```
With that selector, now you have all 3 hidden fields in a jQuery collection. You can pick and choose from there which one you want to use by using several methods:
```
$('input:hidden:first','#mydiv'); // get first one using first
$('input:hidden:last','#mydiv'); // get last one using last
$('input:hidden','#mydiv').eq(0); // get first one using eq
$('input:hidden','#mydiv').eq(1); // get second one using eq
$('input:hidden','#mydiv').eq(2); // get third one using eq
$('input:hidden:eq(0)','#mydiv'); // get first one using eq in selector
```
The options are:
* [`first`](http://docs.jquery.com/Selectors/first) - get the first matched element in the collection.
* [`last`](http://docs.jquery.com/Selectors/last) - get the last matched element in the collection.
* [`eq(N)`](http://docs.jquery.com/Traversing/eq#index) - get the Nth matched element, 0 based.
* [`:eq(N)`](http://docs.jquery.com/Selectors/eq#index) - get the Nth matched element, 0 based, inside the selector string.
I am personally a fan of option 3 as I don't like having too much crap in my selector.
One caveat of the above is that by using the `:hidden` selector we might match other input elements that are hidden (ie, not visible). If you expect that to happen, or even if you don't, you could do this:
```
$('input[type=hidden]', '#mydiv').eq(0);
``` | how to get 1 hidden field among several within div | [
"",
"javascript",
"jquery",
""
] |
I obviously do not 'grok' C++.
On this programming assignment, I have hit a dead end. A runtime error occurs at this line of code:
```
else if (grid[i][j]->getType() == WILDEBEEST) { ...
```
with the message "Runtime Error - pure virtual function call."
From my understanding, this error occurs if the function reference attempts to call the (virtual) base class while the child class is not currently instantiated. However, I do not see where I have made this mistake.
Relevant Code:
Professor's Code:
```
const int LION = 1;
const int WILDEBEEST = 2;
//
// .
// .
// .
//
class Animal {
friend class Savanna; // Allow savanna to affect animal
public:
Animal();
Animal(Savanna *, int, int);
~Animal();
virtual void breed() = 0; // Breeding implementation
virtual void move() = 0; // Move the animal, with appropriate behavior
virtual int getType() = 0; // Return if wildebeest or lion
virtual bool starve() = 0; // Determine if animal starves
protected:
int x,y; // Position in the savanna, using the XY coordinate plane
bool moved; // Bool to indicate if moved this turn
int breedTicks; // Number of ticks since breeding
Savanna *savanna;
};
//
// .
// .
// .
//
void Savanna::Display()
{
int i,j;
cout << endl << endl;
for (j=0; j<SAVANNASIZE; j++)
{
for (i=0; i<SAVANNASIZE; i++)
{
if (grid[i][j]==NULL){
setrgb(0);
cout << " ";
}
else if (grid[i][j]->getType()==WILDEBEEST) // RUNTIME ERROR HERE
{
setrgb(7);
cout << "W";
}
else {
setrgb(3);
cout << "L";
}
}
cout << endl;
}
setrgb(0);
}
```
My Code:
```
class Wildebeest: public Animal {
friend class Savanna; // Allow the Savanna to affect the animal, as per spec
public:
Wildebeest();
Wildebeest(Savanna *, int, int); // accepts (pointer to a Savanna instance, X Position, Y Position)
void breed(); // Perform breeding, and check breedTick
void move(); // move the animal.
int getType(); // returns WILDEBEEST
bool starve(); // if starving, returns 0. (counterintuitive, I know.)
};
int Wildebeest::getType() {
return WILDEBEEST;
}
```
I've read [The Old New Thing: What is \_\_purecall?](http://blogs.msdn.com/oldnewthing/archive/2004/04/28/122037.aspx) and [Description of the R6025 run-time error in Visual C++](http://support.microsoft.com/kb/125749) but I do not fully understand why this is occurring in the above code.
[edit] Full listing of main.c (yes, all one file... part of the assignment requirements.)
```
//
// This program simulates a 2D world with predators and prey.
// The predators (lions) and prey (wildebeest) inherit from the
// Animal class that keeps track of basic information about each
// animal (time ticks since last bred, position on the savanna).
//
// The 2D world is implemented as a separate class, Savanna,
// that contains a 2D array of pointers to type Animal.
//
// ****************************************************************
#include <iostream>
#include <string>
#include <vector>
#include <cstdlib>
#include <time.h>
#include "graphics.h"
using namespace std;
int wrapTo20 (int value) {
if (0 > value) {
value = 19;
} else if (20 == value) {
value = 0;
}
return value;
}
const int SAVANNASIZE = 20;
const int INITIALBEEST = 100;
const int INITIALLIONS = 5;
const int LION = 1;
const int WILDEBEEST = 2;
const int BEESTBREED = 3;
const int LIONBREED = 8;
const int LIONSTARVE = 3;
// Forward declaration of Animal classes so we can reference it
// in the Savanna class
class Animal;
class Lion;
class Wildebeest;
// ==========================================
// The Savana class stores data about the savanna by creating a
// SAVANNASIZE by SAVANNASIZE array of type Animal.
// NULL indicates an empty spot, otherwise a valid object
// indicates an wildebeest or lion. To determine which,
// invoke the virtual function getType of Animal that should return
// WILDEBEEST if the class is of type Wildebeest, and Lion otherwise.
// ==========================================
class Savanna
{
friend class Animal; // Allow Animal to access grid
friend class Lion; // Allow Animal to access grid
friend class Wildebeest; // Allow Animal to access grid
public:
Savanna();
~Savanna();
Animal* getAt(int, int);
void setAt(int, int, Animal *);
void Display();
void SimulateOneStep();
private:
Animal* grid[SAVANNASIZE][SAVANNASIZE];
};
// ==========================================
// Definition for the Animal base class.
// Each animal has a reference back to
// the Savanna object so it can move itself
// about in the savanna.
// ==========================================
class Animal
{
friend class Savanna; // Allow savanna to affect animal
public:
Animal();
Animal(Savanna *, int, int);
~Animal();
virtual void breed() = 0; // Whether or not to breed
virtual void move() = 0; // Rules to move the animal
virtual int getType() = 0; // Return if wildebeest or lion
virtual bool starve() = 0; // Determine if animal starves
protected:
int x,y; // Position in the savanna
bool moved; // Bool to indicate if moved this turn
int breedTicks; // Number of ticks since breeding
Savanna *savanna;
};
// ======================
// Savanna constructor, destructor
// These classes initialize the array and
// releases any classes created when destroyed.
// ======================
Savanna::Savanna()
{
// Initialize savanna to empty spaces
int i,j;
for (i=0; i<SAVANNASIZE; i++)
{
for (j=0; j<SAVANNASIZE; j++)
{
grid[i][j]=NULL;
}
}
}
Savanna::~Savanna()
{
// Release any allocated memory
int i,j;
for (i=0; i<SAVANNASIZE; i++)
{
for (j=0; j<SAVANNASIZE; j++)
{
if (grid[i][j]!=NULL) delete (grid[i][j]);
}
}
}
// ======================
// getAt
// Returns the entry stored in the grid array at x,y
// ======================
Animal* Savanna::getAt(int x, int y)
{
if ((x>=0) && (x<SAVANNASIZE) && (y>=0) && (y<SAVANNASIZE))
return grid[x][y];
return NULL;
}
// ======================
// setAt
// Sets the entry at x,y to the
// value passed in. Assumes that
// someone else is keeping track of
// references in case we overwrite something
// that is not NULL (so we don't have a memory leak)
// ======================
void Savanna::setAt(int x, int y, Animal *anim)
{
if ((x>=0) && (x<SAVANNASIZE) && (y>=0) && (y<SAVANNASIZE))
{
grid[x][y] = anim;
}
}
// ======================
// Display
// Displays the savanna in ASCII. Uses W for wildebeest, L for lion.
// ======================
void Savanna::Display()
{
int i,j;
cout << endl << endl;
for (j=0; j<SAVANNASIZE; j++)
{
for (i=0; i<SAVANNASIZE; i++)
{
if (grid[i][j]==NULL){
setrgb(0);
cout << " ";
}
else if (grid[i][j]->getType()==WILDEBEEST)
{
setrgb(7);
cout << "W";
}
else {
setrgb(3);
cout << "L";
}
}
cout << endl;
}
setrgb(0);
}
// ======================
// SimulateOneStep
// This is the main routine that simulates one turn in the savanna.
// First, a flag for each animal is used to indicate if it has moved.
// This is because we iterate through the grid starting from the top
// looking for an animal to move . If one moves down, we don't want
// to move it again when we reach it.
// First move lions, then wildebeest, and if they are still alive then
// we breed them.
// ======================
void Savanna::SimulateOneStep()
{
int i,j;
// First reset all animals to not moved
for (i=0; i<SAVANNASIZE; i++)
for (j=0; j<SAVANNASIZE; j++)
{
if (grid[i][j]!=NULL) grid[i][j]->moved = false;
}
// Loop through cells in order and move if it's a Lion
for (i=0; i<SAVANNASIZE; i++)
for (j=0; j<SAVANNASIZE; j++)
{
if ((grid[i][j]!=NULL) && (grid[i][j]->getType()==LION))
{
if (grid[i][j]->moved == false)
{
grid[i][j]->moved = true; // Mark as moved
grid[i][j]->move();
}
}
}
// Loop through cells in order and move if it's an Wildebeest
for (i=0; i<SAVANNASIZE; i++)
for (j=0; j<SAVANNASIZE; j++)
{
if ((grid[i][j]!=NULL) && (grid[i][j]->getType()==WILDEBEEST))
{
if (grid[i][j]->moved == false)
{
grid[i][j]->moved = true; // Mark as moved
grid[i][j]->move();
}
}
}
// Loop through cells in order and check if we should breed
for (i=0; i<SAVANNASIZE; i++)
for (j=0; j<SAVANNASIZE; j++)
{
// Kill off any lions that haven't eaten recently
if ((grid[i][j]!=NULL) &&
(grid[i][j]->getType()==LION))
{
if (grid[i][j]->starve())
{
delete (grid[i][j]);
grid[i][j] = NULL;
}
}
}
// Loop through cells in order and check if we should breed
for (i=0; i<SAVANNASIZE; i++)
for (j=0; j<SAVANNASIZE; j++)
{
// Only breed animals that have moved, since
// breeding places new animals on the map we
// don't want to try and breed those
if ((grid[i][j]!=NULL) && (grid[i][j]->moved==true))
{
grid[i][j]->breed();
}
}
}
// ======================
// Animal Constructor
// Sets a reference back to the Savanna object.
// ======================
Animal::Animal()
{
savanna = NULL;
moved = false;
breedTicks = 0;
x=0;
y=0;
}
Animal::Animal(Savanna *savana, int x, int y)
{
this->savanna = savana;
moved = false;
breedTicks = 0;
this->x=x;
this->y=y;
savanna->setAt(x,y,this);
}
// ======================
// Animal destructor
// No need to delete the savanna reference,
// it will be destroyed elsewhere.
// ======================
Animal::~Animal()
{ }
// Start with the Wildebeest class and its required declarations
class Wildebeest: public Animal {
friend class Savanna; // Allow savanna to affect animal
public:
Wildebeest();
Wildebeest(Savanna *, int, int);
void breed(); // Whether or not to breed
void move(); // Rules to move the animal
int getType(); // Return if wildebeest or lion
bool starve();
};
bool Wildebeest::starve() {
return 1;
}
// ======================
// Wildebeest constructors
// ======================
Wildebeest::Wildebeest() {
}
Wildebeest::Wildebeest(Savanna * sav, int x, int y) : Animal(sav, x, y) {
}
// ======================
// Wldebeest Move
// Look for an empty cell up, right, left, or down and
// try to move there.
// ======================
void Wildebeest::move() {
int loc1, loc2, loc3, loc4;
int x1, x2, x3, x4;
int y1, y2, y3, y4;
x1 = wrapTo20(x);
y1 = wrapTo20(y + 1);
x2 = wrapTo20(x + 1);
y2 = wrapTo20(y);
x3 = wrapTo20(x);
y3 = wrapTo20(y - 1);
x4 = wrapTo20(x - 1);
y4 = wrapTo20(y);
loc1 = savanna->getAt(x1, y1)->getType();
loc2 = (int)savanna->getAt(x2, y2)->getType();
loc3 = savanna->getAt(x3, y3)->getType();
loc4 = savanna->getAt(x4, y4)->getType();
while (!moved) {
int x = 1 + (rand() % 4);
switch (x) {
case 1:
if (!loc1) savanna->setAt(x1, y1, this);
break;
case 2:
if (!loc2) savanna->setAt(x2, y2, this);
break;
case 3:
if (!loc3) savanna->setAt(x3, y3, this);
break;
case 4:
if (!loc4) savanna->setAt(x4, y4, this);
break;
default:
break;
}
}
}
// ======================
// Wildebeest getType
// This virtual function is used so we can determine
// what type of animal we are dealing with.
// ======================
int Wildebeest::getType() {
return WILDEBEEST;
}
// ======================
// Wildebeest breed
// Increment the tick count for breeding.
// If it equals our threshold, then clone this wildebeest either
// above, right, left, or below the current one.
// ======================
void Wildebeest::breed() {
breedTicks++;
if (2 == breedTicks) {
breedTicks = 0;
}
}
// *****************************************************
// Now define Lion Class and its required declarations
// *****************************************************
class Lion: public Animal {
friend class Savanna; // Allow savanna to affect animal
public:
Lion();
Lion(Savanna *, int, int);
void breed(); // Whether or not to breed
void move(); // Rules to move the animal
int getType(); // Return if wildebeest or lion
bool starve();
};
// ======================
// Lion constructors
// ======================
Lion::Lion() {
}
Lion::Lion(Savanna * sav, int x, int y) : Animal(sav, x, y) {
}
// ======================
// Lion move
// Look up, down, left or right for a lion. If one is found, move there
// and eat it, resetting the starveTicks counter.
// ======================
void Lion::move() {
int loc1, loc2, loc3, loc4;
int x1, x2, x3, x4;
int y1, y2, y3, y4;
x1 = wrapTo20(x);
y1 = wrapTo20(y + 1);
x2 = wrapTo20(x + 1);
y2 = wrapTo20(y);
x3 = wrapTo20(x);
y3 = wrapTo20(y - 1);
x4 = wrapTo20(x - 1);
y4 = wrapTo20(y);
loc1 = savanna->getAt(x1, y1)->getType();
loc2 = (int)savanna->getAt(x2, y2)->getType();
loc3 = savanna->getAt(x3, y3)->getType();
loc4 = savanna->getAt(x4, y4)->getType();
while (!moved) {
int x = 1 + (rand() % 4);
switch (x) {
case 1:
if (!loc1) savanna->setAt(x1, y1, this);
break;
case 2:
if (!loc2) savanna->setAt(x2, y2, this);
break;
case 3:
if (!loc3) savanna->setAt(x3, y3, this);
break;
case 4:
if (!loc4) savanna->setAt(x4, y4, this);
break;
default:
break;
}
}
}
// ======================
// Lion getType
// This virtual function is used so we can determine
// what type of animal we are dealing with.
// ======================
int Lion::getType() {
return LION;
}
// ======================
// Lion breed
// Creates a new lion adjacent to the current cell
// if the breedTicks meets the threshold.
// ======================
void Lion::breed() {
breedTicks++;
if (2 == breedTicks) {
breedTicks = 0;
}
}
// ======================
// Lion starve
// Returns true or false if a lion should die off
// because it hasn't eaten enough food.
// ======================
bool Lion::starve() {
return 1;
}
// ======================
// main function
// ======================
int main()
{
string s;
srand((int)time(NULL)); // Seed random number generator
Savanna w;
int initialWildebeest=0;
int initialLions=0;
// enter initial number of wildebeest
int beestcount = 0;
while(initialWildebeest <= 0 || initialWildebeest > INITIALBEEST){
cout << "Enter number of initial Wildebeest (greater than 0 and less than " << INITIALBEEST << ") : ";
cin >> initialWildebeest;
}
// Randomly create wildebeests and place them in a randomly choosen empty spot in savanna
int i;
bool placed = 0;
for ( i = 0; i < initialWildebeest; i++) {
while (!placed) {
int x = 1 + (rand() % 20);
int y = 1 + (rand() % 20);
if (!(w.getAt(x, y))){
Wildebeest fred(&w, x, y);
placed = 1;
}
}
placed = 0;
}
// Enter initial number of lions
int lioncount = 0;
while(initialLions <= 0 || initialLions > INITIALLIONS){
cout << "Enter number of initial Lions (greater than 0 and less than " << INITIALLIONS << ") : ";
cin >> initialLions;
}
// Randomly create lions and place them in a randomly choosen empty spot in savanna
placed = 0;
for ( i = 0; i < initialLions; i++) {
while (!placed) {
int x = 1 + (rand() % 20);
int y = 1 + (rand() % 20);
if (!(w.getAt(x, y))){
Lion ronald(&w, x, y);
placed = 1;
}
}
placed = 0;
}
// Run simulation forever, until user cancels
int count=0;
while (true)
{
gotoxy(0,0);
w.Display();
w.SimulateOneStep();
Sleep(500);
count++;
if(count == 20){
count=0;
cout << endl << "Press enter for next step, ctrl-c to quit" << endl;
getline(cin,s);
clearline(23);
}
}
return 0;
}
``` | What is the definition of `grid` and how are you populating it? I bet you are doing it from the Animal constructor. At this time, the dynamic type of this is `Animal`, and not the type of the object that is eventually created.
```
Animal::Animal()
{
grid[i][j] = this; // the type of this is Animal
}
```
Until the object is fully constructed, you cannot use the `this` pointer in a dynamic way, this includes calling virtual functions, or using the virtual function table.
To be more specific, you need to postpone using the `this` pointer, that is to say, storing it in the `grid` array, until after the object is fully constructed.
Here in the Animal constructor:
```
Animal::Animal(Savanna *savana, int x, int y)
{
this->savanna = savana;
moved = false;
breedTicks = 0;
this->x=x;
this->y=y;
savanna->setAt(x,y,this);
}
```
Note that you are calling `Savanna::setAt` with the `this` parameter. At this point, the dynamic type of `this` is Animal, not Wildebeest or some other thing. setAt does this:
```
void Savanna::setAt(int x, int y, Animal *anim)
{
if ((x>=0) && (x<SAVANNASIZE) && (y>=0) && (y<SAVANNASIZE))
{
grid[x][y] = anim;
}
}
```
The value of `anim` is the this pointer from the Animal constructor.
Note a few more things. When you are constructing the list of Wildebeest, you are causing a dangling pointer:
```
for ( i = 0; i < initialWildebeest; i++) {
while (!placed) {
int x = 1 + (rand() % 20);
int y = 1 + (rand() % 20);
if (!(w.getAt(x, y))){
**** Wildebeest fred(&w, x, y);
placed = 1;
}
}
placed = 0;
}
```
The WildeBeest named `fred` will go out of scope on the next line and be destroyed. You need to allocate it dynamically via `new`:
```
for ( i = 0; i < initialWildebeest; i++) {
while (!placed) {
int x = 1 + (rand() % 20);
int y = 1 + (rand() % 20);
if (!(w.getAt(x, y))){
Wildebeest *fred = new Wildebeest(&w, x, y);
placed = 1;
}
}
placed = 0;
}
```
In the destrcuctor of the Savanna, there is a matching call to delete so that we do not leak memory:
```
Savanna::~Savanna()
{
// Release any allocated memory
int i,j;
for (i=0; i<SAVANNASIZE; i++)
{
for (j=0; j<SAVANNASIZE; j++)
{
**** if (grid[i][j]!=NULL) delete (grid[i][j]);
}
}
}
```
You will have exactly the same problem with the Lion instances as well. | One of your problems is these lines ...
```
if (!(w.getAt(x, y))){
Wildebeest fred(&w, x, y);
placed = 1;
}
```
... create a Wildebeest on the stack, and in the constructor the *address* of that stack-dwelling Wildebeest is stuffed into w's grid, and then the Wildebeest goes out of scope.
Your Wildebeests and Lions need to live in the heap ...
if (!(w.getAt(x, y))){
```
// hey maintenance programmer, this looks like I'm leaking the Wildebeest,
// but chillax, the Savannah is going to delete them
Wildebeest *fred = new Wildebeest(&w, x, y);
placed = 1;
```
}
... and you need the comment because what you're doing is far, far away from idiomatic C++. | Pure Virtual Function Call | [
"",
"c++",
"runtime",
"pure-virtual",
""
] |
I wrote a VB.NET windows service and I'd like to know if there is some library or something that will provide me with a very simple mini web server. If my service is running, I'd just like to be able to type, in my browser:
<http://localhost:1234>
And have a status page popup. It will only be one single page and very simple html. Anyone know an easy way to do this before I attempt it on my own and over-engineer? lol | I actually found a pretty good library of what I was looking for at:
<http://www.codeproject.com/cs/internet/minihttpd.asp>
If anyone else needs a small mini web site, check out that link. I tried it and liked it. | Look into the System.Net.HttpListener class. You can specify what port to listen to, and it's up and running pretty quickly. | Mini Web Server for .NET | [
"",
"c#",
".net",
"vb.net",
"windows-services",
""
] |
How I can find all extension methods in solution ? | If I were doing it I would search all files for the string "( this " -- your search string may differ based on your formatting options.
**EDIT**: After a little bit of experimentation, the following seems to work for me with high precision using "Find in Files" (Ctrl-Shift-F)
* Search string: "`\( this [A-Za-z]`" (minus quotes, of course)
* Match case: unchecked
* Match whole word: unchecked
* Use: Regular Expressions
* Look at these file types: "\*.cs" | I'd look at the generated assemblies using reflection; iterate through the static types looking for methods with `[ExtensionAttribute]`...
```
static void ShowExtensionMethods(Assembly assembly)
{
foreach (Type type in assembly.GetTypes())
{
if (type.IsClass && !type.IsGenericTypeDefinition
&& type.BaseType == typeof(object)
&& type.GetConstructors().Length == 0)
{
foreach (MethodInfo method in type.GetMethods(
BindingFlags.Static |
BindingFlags.Public | BindingFlags.NonPublic))
{
ParameterInfo[] args;
if ((args = method.GetParameters()).Length > 0 &&
HasAttribute(method,
"System.Runtime.CompilerServices.ExtensionAttribute"))
{
Console.WriteLine(type.FullName + "." + method.Name);
Console.WriteLine("\tthis " + args[0].ParameterType.Name
+ " " + args[0].Name);
for (int i = 1; i < args.Length; i++)
{
Console.WriteLine("\t" + args[i].ParameterType.Name
+ " " + args[i].Name);
}
}
}
}
}
}
static bool HasAttribute(MethodInfo method, string fullName)
{
foreach(Attribute attrib in method.GetCustomAttributes(false))
{
if (attrib.GetType().FullName == fullName) return true;
}
return false;
}
``` | How I can find all extension methods in solution? | [
"",
"c#",
"visual-studio-2008",
"extension-methods",
""
] |
We are thinking to use **Dotnetnuke(ASP.NET)** as platform for creating asp.net based social networking site. Surprisingly, Its difficult to find webhost with **unlimited diskspace/badnwidth** to store/stream lots of photos/videos.
On the other hand, *PHP based webhosting companies do provide unlimited diskspace/bandwidth*. Check it [here](http://www.top10webhosting.com)
So, I have two questions:
1) Does Diskspace/Bandwidth in webhosting scenario have anything to do with technology(PHP/ASP.NET) and OS(Windows/Linux)?
2) Recommendation of hosting providers with diskspace/Bandwidth for hosting ASP.NET website. | The reason you can't find one is because there aren't any hosts who can offer you unlimited bandwidth because it is a finite resource. Check the terms of all these offerings and you will see that they generally mean "there's no arbitrary limit" when they say "unlimited" but that's not the same as "you can use any amount of bandwidth".
Using that list you gave, I went to HostMonster who happened to be top of the list and they state in their terms:
> **What "Unlimited" means**. HostMonster.Com does not set an arbitrary limit or cap on the amount of resources a single Subscriber can use.
> ...snip ...
> As a result, **a typical website may experience periods of great popularity and resulting increased storage without experiencing any associated increase in hosting charges**.
Basically, if you get slashdotted then they won't cut you off. That's not the same as being permanently busy.
> **What "Unlimited" DOES NOT mean.** ... snip ... HostMonster.Com's offering of "unlimited" services is not intended to allow the actions of a single or few Subscribers to unfairly or adversely impact the experience of other Subscribers.
>
> HostMonster.Com's service is a shared hosting service, which means that **multiple Subscriber web sites are hosted from the same server and share server resources**. HostMonster.Com's service is designed to meet the typical needs of small business and home business website Subscribers in the United States. **It is NOT intended to support the sustained demand of large enterprises, internationally based businesses, or non-typical applications better suited to a dedicated server**.
If you want as much bandwidth as you will need, you need to pay for it. | For something as large as a social networking site, you want to look into your own server. | Unlimited diskspace/Bandwidth for hosting ASP.NET vs PHP website? | [
"",
"php",
"asp.net",
"hosting",
"bandwidth",
"diskspace",
""
] |
I have been asked to write an app which screen scrapes info from an intranet web page and presents the certain info from it in a nice easy to view format. The web page is a real mess and requires the user to click on half a dozen icons to discover if an ordered item has arrived or has been receipted. As you can imagine users find this irritating to say the least and it would be nice to have an app anyone can use that lists the state of their orders in a single screen.
Yes I know a better solution would be to re-write the web app but that would involve calling in the vendor and would cost us as small fortune.
Anyway while looking into this I discovered the web page I want to scrape is mostly Javascript (although it doesn't use any AJAX techniques). Does anyone know if a library or program exists which I could feed with the Javascript and which would then spit out the DOM for my app to parse ?
I can pretty much write the app in any language but my preference would be JavaFX just so I could have a play with it.
Thanks for your time.
Ian | You may consider using [HTMLunit](http://htmlunit.sourceforge.net)
It's a java class library made to automate browsing without having to control a browser, and it integrates the Mozilla Rhino Javascript engine to process javascript on the pages it loads. There's also a JRuby wrapper for that, named Celerity. Its javascript support is not really perfect right now, but if your pages don't use many hacks things should work fine the performance should be way better than controlling a browser. Furthermore, you don't have to worry about cookies being persisted after your scraping is over and all the other nasty things connected to controlling a browser (history, autocomplete, temp files etc). | Since you say that no AJAX is used, then all the info is present at the HTML source. The javascript just renders it based on user clicks. So you need to reverse engineer the way the application works, parse the html and the javascript code and extract the useful information. It is strictly business of text parsing - you shouldn't deal with running javascript and producing a new DOM. This would be much more difficult to do.
If AJAX was used, your job would be easier. You could easily find out how the AJAX services work (probably by receiving JSON and XML) and extract the information. | Screen Scraping from a web page with a lot of Javascript | [
"",
"javascript",
"html",
"dom",
"screen-scraping",
""
] |
I have a union that is defined like this:
```
typedef union {
enum {
REVISION = 0,
CURRENT_VERSION = REVISION
};
enum FLAGS{
FLAG_DEFAULT = 0x00000000,
FLAG_EOD = 0x00000001,
FLAG_OUTOFORDER = 0x00000002
};
CHAR _filler[32];
struct INTERNAL_STRUCTURE {
UINT16 type;
UINT16 flags;
};
}CORRHDR
```
How do I access the member's of INTERNAL\_STRUCTURE from my code?
I've thought I could just do this:
```
CORRHDR hdr;
hdr.INTERNAL_STRUCTURE.type = 1;
```
I'm wrong. I can see the enums in the union, but nothing else. Could someone explain the structure (or benefit) of this type to me? | You have declared the *type* called `INTERNAL_STRUCTURE`, but not an actual instance of that type. Try this:
```
typedef union {
//...
CHAR _filler[32];
struct {
UINT16 type;
UINT16 flags;
} INTERNAL_STRUCTURE;
}CORRHDR;
```
Then to access the field:
```
CORRHDR ch;
printf("%u\n", ch.INTERNAL_STRUCTURE.type);
``` | You need to define an object of type `INTERNAL_STRUCTURE` before you can try to access it. Your union as of now does not have one. Try:
```
struct INTERNAL_STRUCTURE {
UINT16 type;
UINT16 flags;
};
struct INTERNAL_STRUCTURE is;
```
... | How do I access internal members of a union? | [
"",
"c++",
"struct",
"unions",
""
] |
I'm trying to delete all digits from a string.
However the next code deletes as well digits contained in any word, and obviously I don't want that.
I've been trying many regular expressions with no success.
Thanks!
---
```
s = "This must not b3 delet3d, but the number at the end yes 134411"
s = re.sub("\d+", "", s)
print s
```
Result:
> This must not b deletd, but the number at the end yes | Add a space before the \d+.
```
>>> s = "This must not b3 delet3d, but the number at the end yes 134411"
>>> s = re.sub(" \d+", " ", s)
>>> s
'This must not b3 delet3d, but the number at the end yes '
```
Edit: After looking at the comments, I decided to form a more complete answer. I think this accounts for all the cases.
```
s = re.sub("^\d+\s|\s\d+\s|\s\d+$", " ", s)
``` | Try this:
```
"\b\d+\b"
```
That'll match only those digits that are not part of another word. | Delete digits in Python (Regex) | [
"",
"python",
"regex",
"digits",
""
] |
I have a web app(ASP.NET 2.0 C#). On my Masterpage, I have a menu control, and I am using a css stylesheet to style the different parts of the menu. For some reason, when I hover over the menu, it jumps a little. I think somehow the borders become larger when I hover over it.
Heres the styling for the whole menu:
```
.menu
{
width:110%;
height:25px;
border: 1px solid gray;
text-align:center;
}
```
Heres my style for the StaticHoverStyle:
```
.staticMenuHover
{
background-color:#CCCCCC;
border-style:solid;
border-color:#888888;
text-decoration: underline;
border-width:thin;
}
```
I don't know why this is happening, can someone help?
Thanks | You could always add an underline to the link (not a text-decoration) and adjust the padding. Working example:
```
#menu ul li a {
display: block;
width: 95%;
padding: 0px 2px 2px 4px;
text-decoration: none;
color: rgb(30%,30%,60%); background: transparent;
}
#menu ul li a:visited {
color: rgb(50%,10%,100%);
}
#menu ul li a:hover {
color: #000;
border-bottom: 2px solid #c63;
background: #fcf;
padding-bottom: 0px; }
```
What makes this work is changing the 2px bottom padding to 0 px and adding a 2px border-bottom in the **same rule**. The color change is extraneous to the question at hand. | Your border width on your hover class is set to thin which is rendering as a 2 pixel border in my test. Set it to 1px.
```
border-width:1px;
```
You can also collapse that second class's border rule to a single line to make it consistent with your first class like this:
```
border:1px solid #888888;
``` | Menu Jumping on Hover | [
"",
"c#",
"asp.net",
"css",
"menu",
"border",
""
] |
I need to get the event args as a `char`, but when I try casting the Key enum I get completely different letters and symbols than what was passed in.
How do you properly convert the Key to a char?
This is what I've tried
```
ObserveKeyStroke(this, new ObervableKeyStrokeEvent((char)((KeyEventArgs)e.StagingItem.Input).Key));
```
Edit: I also don't have the KeyCode property on the args. I'm getting them from the InputManager.Current.PreNotifyInput event. | See [How to convert a character in to equivalent System.Windows.Input.Key Enum value?](https://stackoverflow.com/questions/544141/how-to-convert-a-character-in-to-equivalent-system-windows-input-key-enum-value)
Use `KeyInterop.VirtualKeyFromKey` instead. | It takes a little getting used to, but you can just use the key values themselves. If you're trying to limit input to alphanumerics and maybe a little extra, the code below may help.
```
private bool bLeftShiftKey = false;
private bool bRightShiftKey = false;
private bool IsValidDescriptionKey(Key key)
{
//KEYS ALLOWED REGARDLESS OF SHIFT KEY
//various editing keys
if (
key == Key.Back ||
key == Key.Tab ||
key == Key.Up ||
key == Key.Down ||
key == Key.Left ||
key == Key.Right ||
key == Key.Delete ||
key == Key.Space ||
key == Key.Home ||
key == Key.End
) {
return true;
}
//letters
if (key >= Key.A && key <= Key.Z)
{
return true;
}
//numbers from keypad
if (key >= Key.NumPad0 && key <= Key.NumPad9)
{
return true;
}
//hyphen
if (key == Key.OemMinus)
{
return true;
}
//KEYS ALLOWED CONDITITIONALLY DEPENDING ON SHIFT KEY
if (!bLeftShiftKey && !bRightShiftKey)
{
//numbers from keyboard
if (key >= Key.D0 && key <= Key.D9)
{
return true;
}
}
return false;
}
private void cboDescription_PreviewKeyDown(object sender, KeyEventArgs e)
{
if (e.Key == Key.LeftShift)
{
bLeftShiftKey = true;
}
if (e.Key == Key.RightShift)
{
bRightShiftKey = true;
}
if (!IsValidDescriptionKey(e.Key))
{
e.Handled = true;
}
}
private void cboDescription_PreviewKeyUp(object sender, KeyEventArgs e)
{
if (e.Key == Key.LeftShift)
{
bLeftShiftKey = false;
}
if (e.Key == Key.RightShift)
{
bRightShiftKey = false;
}
}
``` | Convert a System.Windows.Input.KeyEventArgs key to a char | [
"",
"c#",
"wpf",
"keyeventargs",
""
] |
I've seen the common setup for cross threading access to a GUI control, such as discussed here:
[Shortest way to write a thread-safe access method to a windows forms control](https://stackoverflow.com/questions/571706/shortest-way-to-write-a-thread-safe-access-method-to-a-windows-forms-control)
All the web hits I found describe a similar thing.
However, why do we need to check InvokeRequired? Can't we just call Invoke directly?
I assume the answer is no, so my real question is 'why'? | From non-UI threads we can't touch the UI - very bad things can happen, since controls have thread affinity. So from a non-UI thread we must (at a minumum) call `Invoke` or `BeginInvoke`.
For UI-threads, however - we *don't* want to call `Invoke` lots of time; the issue is that if you *are* already on the UI thread, it still has the unnecessary overhead of sending a message to the form's pump and processing it.
In reality, in most threading code you *know* you expect a specific method to be called on a **non**-UI thread, so in those cases, there is no additional overhead: just call `Invoke`. | If you try to invoke before a window handle is created (for example, when calling form constructor), you will get an `InvalidOperationException`. So, generally `InvokeRequired` check is required.
See [MSDN](http://msdn.microsoft.com/en-us/library/zyzhdc6b.aspx) for details. | What's wrong with calling Invoke, regardless of InvokeRequired? | [
"",
"c#",
"user-interface",
"event-handling",
"invoke",
"invokerequired",
""
] |
I have a code base that makes extensive use of files to represent a single data object. I have refactored the code so that the data object is now an explicit java object that mostly hides interaction with the underlying file system. However, we use a few external tools (like Weka), that read and write files.
Ideally, I would like to have a subclass of File that I can pass to these other libraries that is backed by an in- memory array of bytes -- either for reading or writing.
My google searches turned up memory-mapped files, but this is not the problem I have as I don't want any actual file on the file system. Are there any solutions already out there, or should I just subclass File myself and over-ride all the methods that refer to the real file system? | This is generally why you should never write methods to take a File unless it's really necessary. Do your libraries not provide methods that take an arbitrary InputStream? In this case, it's trivial to pass a ByteArrayInputStream or any input stream that reads from memory.
The problem with overriding File is it's unlikely that you can override it in a way that will help you. For example, if the library opens it with a FileInputStream, then where the bytes come from at that point is really controlled by the FileInputStream implementation, not by your File. | `java.io.File` is essentially a wrapper around a `String` that represent a file path (it should have been a `final` class, but there you go). So you are out of luck with that approach. You can, of course, create temporary files and files on "RAM discs". | What is the easiest way to have a custom file implementation that only uses memory in Java | [
"",
"java",
"file",
"memory",
""
] |
I'm trying to convert some code from C# to C so that it can be burnt onto a microcontroller.
Could someone please tell me how I would convert a two dimensional string array in C# into something in C?
My C# code looks like this:
```
string[,] DirectionPosition = {{"00", "10", "", "01", ""},
{"01", "11", "", "02", "00"},
{"02", "12", "", "03", "01"},
{"03", "13", "", "04", "02"},
{"04", "14", "", "", "03"},
{"10", "20", "00", "11", ""},
{"11", "21", "01", "12", "10"},
{"12", "22", "02", "13", "11"},
.
.
.
.
{"44", "", "34", "", "43"},};
```
And moreover, how would I access the elements?
In C# if I wanted the second element in the third row it would simply be DirectionPosition[2,1] but what is the equivalent of that when there is no string in C much less 2-D string arrays? | ```
char DirectionPosition[][ 5 ][ 3 ] = {{"00", "10", "", "01", ""},
{"01", "11", "", "02", "00"},
{"02", "12", "", "03", "01"},
{"03", "13", "", "04", "02"},
{"04", "14", "", "", "03"},
{"10", "20", "00", "11", ""},
{"11", "21", "01", "12", "10"},
{"12", "22", "02", "13", "11"},
.
.
.
.
{"44", "", "34", "", "43"},};
```
C has no inbuilt string class, you have to make do with character arrays. You could alternatively use pointers to pointer to char. | The easiest way to do it is with char pointers as follows:
```
char *DirectionPosition[9][5] = {
{"00", "10", "", "01", "" },
{"01", "11", "", "02", "00"},
{"02", "12", "", "03", "01"},
{"03", "13", "", "04", "02"},
{"04", "14", "", "", "03"},
{"10", "20", "00", "11", "" },
{"11", "21", "01", "12", "10"},
{"12", "22", "02", "13", "11"},
{"44", "", "34", "", "43"}
};
```
The element "10" in the first line is referenced as `DirectionPosition[0][1]` (zero-based, first index is line, second is column). | How to Initialize a Multidimensional Char Array in C? | [
"",
"c#",
"c",
"arrays",
"multidimensional-array",
""
] |
this editor is horizontal <http://tinymce.moxiecode.com/examples/simple.php>
and I seem to find only horizonal editors, has anyone came across a vertical editor? any examples? how long would it take to build?
I mean the toolbar is horizontal and I want to use a vertical one instead? (I don't mean for languages)
I heard it's very difficult to do
I believe this is the problem they have:
<http://tinymce.moxiecode.com/punbb/viewtopic.php?id=13834> | Picking up on Karsten’s suggestion to amend TinyMCE’s layout so that it has a vertical toolbar, [Googling “wysiwyg editor vertical toolbar”](http://www.google.co.uk/search?q=wysiwyg+editor+vertical+toolbar&ie=utf-8&oe=utf-8&aq=t&rls=org.mozilla:en-US:official&client=firefox-a) turned up this page on the TinyMCE forums:
<http://tinymce.moxiecode.com/punbb/viewtopic.php?id=13834>
Looks like you’re allowed to change TinyMCE, but that achieving the vertical toolbar involves doing a custom layout:
<http://wiki.moxiecode.com/index.php/TinyMCE:Configuration/theme_advanced_custom_layout>
I think you’ll need someone with HTML, CSS and JavaScript skills for this. No idea how long it’d take. Someone might have already done it, but [Googling “tinymce "vertical toolbar"”](http://www.google.co.uk/search?q=tinymce+%22vertical+toolbar%22&ie=utf-8&oe=utf-8&aq=t&rls=org.mozilla:en-US:official&client=firefox-a) only turns up 9 results. | If it is only the toolbar, you could try to move it (i.e. with tinymce) via css. I just overlooked the html code and i see a simple table construct there. | How difficult/time consuming is to build a vertical editor? | [
"",
"javascript",
"editor",
""
] |
Why doesn't Java support a copy constructor like in C++? | Java does. They're just not called implicitly like they are in C++ and I suspect that's your real question.
Firstly, a copy constructor is nothing more than:
```
public class Blah {
private int foo;
public Blah() { } // public no-args constructor
public Blah(Blah b) { foo = b.foo; } // copy constructor
}
```
Now C++ will implicitly call the copy constructor with a statement like this:
```
Blah b2 = b1;
```
Cloning/copying in that instance simply makes no sense in Java because all b1 and b2 are references and not value objects like they are in C++. In C++ that statement makes a copy of the object's state. In Java it simply copies the **reference**. The object's state is not copied so implicitly calling the copy constructor makes no sense.
And that's all there is to it really. | From [Bruce Eckel](http://www.codeguru.com/java/tij/tij0128.shtml):
> **Why does [a copy constructor] work in C++ and not Java?**
>
> The copy constructor is a fundamental
> part of C++, since it automatically
> makes a local copy of an object. Yet
> the example above proves that it does
> not work for Java. Why? In Java
> everything that we manipulate is a
> handle, while in C++ you can have
> handle-like entities and you can also
> pass around the objects directly.
> That’s what the C++ copy constructor
> is for: when you want to take an
> object and pass it in by value, thus
> duplicating the object. So it works
> fine in C++, but you should keep in
> mind that this scheme fails in Java,
> so don’t use it.
(I recommend reading the entire page -- actually, start [here](http://www.codeguru.com/java/tij/tij0127.shtml) instead.) | Why doesn't Java have a copy constructor? | [
"",
"java",
"copy-constructor",
""
] |
We have the following object
```
int [,] oGridCells;
```
which is only used with a fixed first index
```
int iIndex = 5;
for (int iLoop = 0; iLoop < iUpperBound; iLoop++)
{
//Get the value from the 2D array
iValue = oGridCells[iIndex, iLoop];
//Do something with iValue
}
```
Is there a way in .NET to convert the values at a fixed first index into a single dimension array (other than by looping the values)?
I doubt it would speed up the code (and it may well make it slower) if the array is only being looped once. But if the array was being heavily manipulated then a single dimension array would be more efficient than a multi dimension array.
My main reason for asking the question is to see if it can be done and how, rather than using it for production code. | The following code demonstrates copying 16 bytes (4 ints) from a 2-D array to a 1-D array.
```
int[,] oGridCells = {{1, 2}, {3, 4}};
int[] oResult = new int[4];
System.Buffer.BlockCopy(oGridCells, 0, oResult, 0, 16);
```
You can also selectively copy just 1 row from the array by providing the correct byte offsets. This example copies the middle row of a 3-row 2-D array.
```
int[,] oGridCells = {{1, 2}, {3, 4}, {5, 6}};
int[] oResult = new int[2];
System.Buffer.BlockCopy(oGridCells, 8, oResult, 0, 8);
``` | You can try this:
```
int[,] twoD = new int[2,2];
twoD[0, 0] = 1;
twoD[0, 1] = 2;
twoD[1, 0] = 3;
twoD[1, 1] = 4;
int[] result = twoD.Cast<int>().Select(c => c).ToArray();
```
The result will be an integer array with data:
```
1, 2, 3, 4
``` | How to copy a row of values from a 2D array into a 1D array? | [
"",
"c#",
".net",
"arrays",
"multidimensional-array",
""
] |
When and why to `return false` in JavaScript? | Often, in event handlers, such as `onsubmit`, returning false is a way to tell the event to not actually fire. So, say, in the `onsubmit` case, this would mean that the form is not submitted. | I'm guessing that you're referring to the fact that you often have to put a 'return false;' statement in your event handlers, i.e.
```
<a href="#" onclick="doSomeFunction(); return false;">...
```
The 'return false;' in this case stops the browser from jumping to the current location, as indicated by the href="#" - instead, only doSomeFunction() is executed. It's useful for when you want to add events to anchor tags, but don't want the browser jumping up and down to each anchor on each click | When and why to 'return false' in JavaScript? | [
"",
"javascript",
"jquery",
""
] |
I need a status column that will have about a dozen possible values.
Is there any reason why I should choose int (StatusID) over char(4) (StatusCode)?
Since sql server doesn't support named constants, char is far more descriptive than int when used in stored procedure and views as constants.
To clarify, I would still use a lookup table either way. Since the I will need a more descriptive text for the UI. So this decision is only to help me as the developer when I'm maintaining the stored procedures and views.
Right now I'm leaning toward char(4). Especially since designing views in SQL Server Management Studio prevents me from adding comments (I know it's possible to add it in the script editor, but realistically I will use the View Designer far more often, especially if the view is trivial). StateCODE = 'NEW' is much more readable than StateID = 1000.
I guess the question is will there be cases where char(4) is problematic, and since the database is pretty small, I'm not too concerned about slight performance hit (like using TinyInt versus int), but more afraid of code maintenance problems. | Database purists will say a key should have no meaning in the business domain, and that you should create a status table where you look up the description and other meanings of the status.
But for operators and end users, having a descriptive status code can be a blessing. And it doesn't even have to be char(4), you can make it varchar(20). This allows them to query without joins, and inspect the database in an easier way.
In the end, I think the char(20) organization will run more smoothly, and go home earlier on Friday. But the int organization has a better abstraction of the database, and they can enjoy meta programming on friday evening (or boosting on forums.)
(All of this assuming that you're writing business support software. One of the more succesful business support systems, SAP, makes successful use of meaningful keys.) | There are many pro's and con's to each method. I'm sure other arguments will come up in favour of using a char(4). My reasons for choosing an int over a char include:
1. I always use lookup tables. They allow for an audit trail of the value to be retained and easily examined. For example, if one of your status codes is 'MING' and a business decision is made to change it from 'MING' to 'MONG' from a certain date, my lookup table handles this.
2. Smaller index - if you need to index this column, it will be thinner.
3. Extendability - OK, I made that word up, but if you need to go from 4 chars to 5 chars for example, a lookup table would be a blessing.
4. Descriptions: We use a lot of TLA's here which once you know what they are is great but if I gave a business user a report that said "GDA's 2007 1001", they wouldn't necessarily twig that GDA = Good Dead on Arrival. With a lookup table, I can add this description.
5. Best practice: Can't find the link to hand but it might be something I read in a K.Tripp article. Aim to make your clustered primary key incrementing integers to optimise the index.
Of course if you are absolutely positive that you will never need any more than a handful of 4 characters, there is no reason not to bang it in the table. | Char(4) versus int as StatusID/StatusCode column in a table | [
"",
"sql",
"sql-server",
""
] |
I want to create a HashMap in java for users with preferences. This would be easy to do in a database, but unfortunately I can't use a database. What I need is a way to find a user by name in the HashMap, and to find all the users with a certain interest (e.g. golf). If I delete a user, then all their interests should be deleted.
Anyone know a nice way to make this data structure? | Do you know you really need to have a second index. You may find that a search of every user is fast enough, unless you have millions of users.
The following example takes 51 micro-second to scan 1,000 users. It takes 557 micro-seconds to scan 10,000 users.
I wouldn't suggest optimising the collection until your know whether it would make a difference.
```
import java.util.*;
import java.io.*;
public class TestExecutor {
public static void main(String[] args) throws IOException {
Map<String, User> users = new LinkedHashMap<String, User>();
generateUsers(users, 1000, 0.1);
// warmup.
int count = 10000;
for(int i=0;i< count;i++)
getAllUsersWithInterest(users, Interest.Golf);
long start = System.nanoTime();
for(int i=0;i< count;i++)
getAllUsersWithInterest(users, Interest.Golf);
long time = System.nanoTime() - start;
System.out.printf("Average search time %,d micro-seconds%n", time/ count/1000);
}
private static Set<User> getAllUsersWithInterest(Map<String, User> users, Interest golf) {
Set<User> ret = new LinkedHashSet<User>();
for (User user : users.values()) {
if (user.interests.contains(golf))
ret.add(user);
}
return ret;
}
private static void generateUsers(Map<String, User> users, int count, double interestedInGolf) {
Random rand = new Random();
while(users.size() < count) {
String name = Long.toString(rand.nextLong(), 36);
EnumSet<Interest> interests = rand.nextFloat() < interestedInGolf
? EnumSet.of(Interest.Golf) : EnumSet.noneOf(Interest.class);
users.put(name, new User(name, interests));
}
}
static class User {
private final String name;
private final Set<Interest> interests;
User(String name, Set<Interest> interests) {
this.name = name;
this.interests = interests;
}
}
enum Interest {
Golf
}
}
``` | I would suggest you create your own data structure for holding the information. Inside that class you could have two HashMaps storing the relevant information. Then write your own methods to insert and delete a user.
This way you have control over the insert/delete-operations while being able to query each attribute separately. | Java HashMap indexed on 2 keys | [
"",
"java",
"data-structures",
"dictionary",
"hashmap",
""
] |
Yahoo best practices states that [putting JavaScript files on bottom](http://developer.yahoo.com/performance/rules.html#js_bottom) might make your pages load faster. What is the experience with this? What are the side effects, if any? | It has a couple of advantages:
* **Rendering begins sooner.** The browser cannot layout elements it hasn't received yet. This avoids the "blank white screen" problem.
* **Defers connection limits.** Usually your browser won't try to make more than a couple of connections to the same server at a time. If you have a whole queue of scripts waiting to be downloaded from a slow server, it can really wreck the user experience as your page appears to grind to a halt. | If you get a copy of Microsoft's [Visual Round Trip Analyzer](http://www.microsoft.com/Downloads/details.aspx?FamilyID=119f3477-dced-41e3-a0e7-d8b5cae893a3&displaylang=en), you can profile exactly what is happening.
What I have seen more often that not is that most browsers **STOP PIPELINING** requests when they encounter a JavaScript file, and dedicate their entire connection to downloading the single file, rather than downloading in parallel.
The reason the pipelining is stopped, is to allow immediate inclusion of the script into the page. Historically, a lot of sites used to use document.write to add content, and downloading the script immediately allowed for a slightly more seamless experience.
This is most certainly the behavior that Yahoo is optimizing against. (I have seen the very same recommendation in MSDN magazine with the above explanation.)
It is important to note that IE 7+ and FF 3+ are less likely to exhibit the bad behavior. (Mostly since using document.write has fallen out of practice, and there are now better methods to pre-render content.) | Does putting scripts on the bottom of a web page speed up page load? | [
"",
"javascript",
""
] |
Background:
PHPDoc ( <http://www.phpdoc.org/> ) is a brilliant tool for extracting
html documentation of your classes or methods from comments in your
files. Adding PHPDoc comments also has other advantages - if you use
an IDE like Zend or Netbeans, it will use the PHPDocs to show you
autocompletion tips.
Most Issue trackers have a feature where you can commit into your
version control system with a special comment, and it will
automatically link that commit to that issue.
So here's what I want in a system: I commit some code with a special
comment, my issue tracker links it to an issue. It then looks at the
commit and works out what Methods and Classes I have changed. It then
says "If you are looking for documentation around this issue, try
these bits of PHPDoc: ClassX.FunctionY, ClassZ.VariableP". It
automatically points users to documentation that might be relevant. I think this would be a great feature.
Question:
So the piece that is missing is something to take a PHP code diff, and
work out what classes and methods have changed. Anyone got any
pointers on some code that can do that?
Thanks in advance,
James | <https://www.php.net/reflection>
PHP5 has methods to take a class apart and examine all the methods, including giving me the line numbers I need to match against the diff. Using this I can start to hand roll my own solution. | If you are using [subversion](http://subversion.tigris.org/), you can see a diff of all the files that have changed in the project. And see how they are different.
There are software with integrated subversion support, like [Trac.](http://trac.edgewall.org/)
[Here's a picture of TracDiff](http://tracker.moodle.org/secure/attachment/12747/trac_diff.png) | From a PHP Code Diff, can you tell which Classes and Functions have changed? | [
"",
"php",
"svn",
"diff",
"phpdoc",
""
] |
How can an iterator over a non-empty sequence, with no filtering and no aggregation (`sum()`, etc.), yield nothing?
Consider a simple example:
```
sequence = ['a', 'b', 'c']
list((el, ord(el)) for el in sequence)
```
This yields `[('a', 97), ('b', 98), ('c', 99)]` as expected.
Now, just swap the `ord(el)` out for an expression that takes the first value out of some generator using `(...).next()` — forgive the contrived example:
```
def odd_integers_up_to_length(str):
return (x for x in xrange(len(str)) if x%2==1)
list((el, odd_integers_up_to_length(el).next()) for el in sequence)
```
This yields `[]`. Yeah, empty list. No `('a',`stuff`)` tuples. Nothing.
But we're not filtering or aggregating or reducing. A generator expression over `n` objects without filtering or aggregation must yield `n` objects, right? What's going on? | `odd_integers_up_to_length(el).next()` will raise StopIteration, which isn't caught there, but is caught for the generator expression within it, stopping it without ever yielding anything.
look at the first iteration, when the value is 'a':
```
>>> odd_integers_up_to_length('a').next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
``` | What happens is that the `next()` call raises a `StopIteration` exception, which bubbles up the stack to the outer generator expression and stops *that* iteration.
A `StopIteration` is the normal way for an iterator to signal that it's done. Generally we don't see it, because generally the `next()` call occurs within a construct that consumes the iterator, e.g. `for x in iterator` or `sum(iterator)`. But when we call `next()` directly, we are the ones responsible for catching the `StopIteration`. Not doing so springs a leak in the abstraction, which here leads to unexpected behavior in the outer iteration.
The lesson, I suppose: be careful about direct calls to `next()`. | Python: an iteration over a non-empty list with no if-clause comes up empty. Why? | [
"",
"python",
"iterator",
"generator",
"leaky-abstraction",
""
] |
I'm looking to implement a synchronous and asynchronous version of a method within a class library. Currently I've done this so that the Async method fires off a new Thread and does it's processing. To determine if the action has completed the user should poll a property to see if it has finished.
I'd like to improve it, I think it would be better to use some form of Async callback or result, but I'm not really sure how to go about implementing it, or, if indeed it is necessary. Can anyone offer any advice? | ```
public static void Queue(Action action, Action done) {
ThreadPool.QueueUserWorkItem(_ =>
{
try {
action();
}
catch (ThreadAbortException) { /* dont report on this */ }
catch (Exception ex) {
Debug.Assert(false, "Async thread crashed! This must be fixed. " + ex.ToString());
}
// note: this will not be called if the thread is aborted
if (done != null) done();
});
}
```
Usage:
```
Queue( () => { Console.WriteLine("doing work"); },
() => { Console.WriteLine("work was done!"); } );
``` | You can use a callback method instead of polling.
Check out my answer on [AsyncCallback](https://stackoverflow.com/questions/1047662/asynccallback/1047677#1047677)
**Edited:**
Example of FileCopy using own async delegates with callback:
```
public class AsyncFileCopier
{
public delegate void FileCopyDelegate(string sourceFile, string destFile);
public static void AsynFileCopy(string sourceFile, string destFile)
{
FileCopyDelegate del = new FileCopyDelegate(FileCopy);
IAsyncResult result = del.BeginInvoke(sourceFile, destFile, CallBackAfterFileCopied, null);
}
public static void FileCopy(string sourceFile, string destFile)
{
// Code to copy the file
}
public static void CallBackAfterFileCopied(IAsyncResult result)
{
// Code to be run after file copy is done
}
}
```
You can call it as:
```
AsyncFileCopier.AsynFileCopy("abc.txt", "xyz.txt");
``` | Implementing Asynchronous method | [
"",
"c#",
"asynchronous",
""
] |
What I would like to do is to pass an arbitrary audio file to a DirectShow filtergraph and receive a (PCM audio) stream object in the end using .NET 3.5 C# and DirectShow.NET. I would like to reach the point that I can just say:
```
Stream OpenFile(string filename) {...}
```
and
```
stream.Read(...)
```
I have been reading up on DirectShow for a couple of days and think I have started to grasp the idea of filters and filtergraphs. I found examples ([to file](http://www.informikon.com/directshow-tutorials/yet-another-capture-sample-in-c.html) / [to device](http://replay.waybackmachine.org/20091021154718/http://geocities.com/contactgirish/DirectShow.html)) how to play audio or write it to a file, but cannot seem to find the solution for a Stream object. Is this even possible? Could you point me in the right direction in case I missed something, please?
Best,
Hauke | I would like to share my solution to my own problem with you (my focus was on the exotic bwf file format. hence the name.):
```
using System;
using System.Collections.Generic;
using System.Text;
using DirectShowLib;
using System.Runtime.InteropServices;
using System.IO;
namespace ConvertBWF2WAV
{
public class BWF2WavConverter : ISampleGrabberCB
{
IFilterGraph2 gb = null;
ICaptureGraphBuilder2 icgb = null;
IBaseFilter ibfSrcFile = null;
DsROTEntry m_rot = null;
IMediaControl m_mediaCtrl = null;
ISampleGrabber sg = null;
public BWF2WavConverter()
{
// Initialize
int hr;
icgb = (ICaptureGraphBuilder2)new CaptureGraphBuilder2();
gb = (IFilterGraph2) new FilterGraph();
sg = (ISampleGrabber)new SampleGrabber();
#if DEBUG
m_rot = new DsROTEntry(gb);
#endif
hr = icgb.SetFiltergraph(gb);
DsError.ThrowExceptionForHR(hr);
}
public void reset()
{
gb = null;
icgb = null;
ibfSrcFile = null;
m_rot = null;
m_mediaCtrl = null;
}
public void convert(object obj)
{
string[] pair = obj as string[];
string srcfile = pair[0];
string targetfile = pair[1];
int hr;
ibfSrcFile = (IBaseFilter)new AsyncReader();
hr = gb.AddFilter(ibfSrcFile, "Reader");
DsError.ThrowExceptionForHR(hr);
IFileSourceFilter ifileSource = (IFileSourceFilter)ibfSrcFile;
hr = ifileSource.Load(srcfile, null);
DsError.ThrowExceptionForHR(hr);
// the guid is the one from ffdshow
Type fftype = Type.GetTypeFromCLSID(new Guid("0F40E1E5-4F79-4988-B1A9-CC98794E6B55"));
object ffdshow = Activator.CreateInstance(fftype);
hr = gb.AddFilter((IBaseFilter)ffdshow, "ffdshow");
DsError.ThrowExceptionForHR(hr);
// the guid is the one from the WAV Dest sample in the SDK
Type type = Type.GetTypeFromCLSID(new Guid("3C78B8E2-6C4D-11d1-ADE2-0000F8754B99"));
object wavedest = Activator.CreateInstance(type);
hr = gb.AddFilter((IBaseFilter)wavedest, "WAV Dest");
DsError.ThrowExceptionForHR(hr);
// manually tell the graph builder to try to hook up the pin that is left
IPin pWaveDestOut = null;
hr = icgb.FindPin(wavedest, PinDirection.Output, null, null, true, 0, out pWaveDestOut);
DsError.ThrowExceptionForHR(hr);
// render step 1
hr = icgb.RenderStream(null, null, ibfSrcFile, (IBaseFilter)ffdshow, (IBaseFilter)wavedest);
DsError.ThrowExceptionForHR(hr);
// Configure the sample grabber
IBaseFilter baseGrabFlt = sg as IBaseFilter;
ConfigSampleGrabber(sg);
IPin pGrabberIn = DsFindPin.ByDirection(baseGrabFlt, PinDirection.Input, 0);
IPin pGrabberOut = DsFindPin.ByDirection(baseGrabFlt, PinDirection.Output, 0);
hr = gb.AddFilter((IBaseFilter)sg, "SampleGrabber");
DsError.ThrowExceptionForHR(hr);
AMMediaType mediatype = new AMMediaType();
sg.GetConnectedMediaType(mediatype);
hr = gb.Connect(pWaveDestOut, pGrabberIn);
DsError.ThrowExceptionForHR(hr);
// file writer
FileWriter file_writer = new FileWriter();
IFileSinkFilter fs = (IFileSinkFilter)file_writer;
fs.SetFileName(targetfile, null);
hr = gb.AddFilter((DirectShowLib.IBaseFilter)file_writer, "File Writer");
DsError.ThrowExceptionForHR(hr);
// render step 2
AMMediaType mediatype2 = new AMMediaType();
pWaveDestOut.ConnectionMediaType(mediatype2);
gb.Render(pGrabberOut);
// alternatively to the file writer use the NullRenderer() to just discard the rest
// assign control
m_mediaCtrl = gb as IMediaControl;
// run
hr = m_mediaCtrl.Run();
DsError.ThrowExceptionForHR(hr);
}
//
// configure the SampleGrabber filter of the graph
//
void ConfigSampleGrabber(ISampleGrabber sampGrabber)
{
AMMediaType media;
// set the media type. works with "stream" somehow...
media = new AMMediaType();
media.majorType = MediaType.Stream;
//media.subType = MediaSubType.WAVE;
//media.formatType = FormatType.WaveEx;
// that's the call to the ISampleGrabber interface
sg.SetMediaType(media);
DsUtils.FreeAMMediaType(media);
media = null;
// set BufferCB as the desired Callback function
sg.SetCallback(this, 1);
}
public int SampleCB(double a, IMediaSample b)
{
return 0;
}
/// <summary>
/// Called on each SampleGrabber hit.
/// </summary>
/// <param name="SampleTime">Starting time of the sample, in seconds.</param>
/// <param name="pBuffer">Pointer to a buffer that contains the sample data.</param>
/// <param name="BufferLen">Length of the buffer pointed to by pBuffer, in bytes.</param>
/// <returns></returns>
public int BufferCB(double SampleTime, IntPtr pBuffer, int BufferLen)
{
byte[] buffer = new byte[BufferLen];
Marshal.Copy(pBuffer, buffer, 0, BufferLen);
using (BinaryWriter binWriter = new BinaryWriter(File.Open(@"C:\directshowoutput.pcm", FileMode.Append)))
{
binWriter.Write(buffer);
}
return 0;
}
}
}
``` | This ([AVILibrary Wrapper](http://www.codeproject.com/KB/audio-video/avifilewrapper.aspx)) may lead you to a solution, it's not DirectSound based (which I get the feeling is very much biased to interfacing your code with the playback hardware) but could be the answer.
Another approach can be found [here](http://www.csharp-home.com/index/tiki-read_article.php?articleId=110). | How to access an audio stream using DirectShow.NET C# | [
"",
"c#",
".net-3.5",
"streaming",
"directshow",
"directshow.net",
""
] |
I have a TreeCtrl in which more than one Item can be assigned the same object as PyData. When the object is updated, I want to update all of the items in the tree which have that object as their PyData.
I thought the following code would solve the problem quite neatly, but for some reason the logical test (current != self.GetFirstVisibleItem()) always returns true leading to infinite recursion. Can anyone explain why?
```
def RefreshNodes(self, obj, current=None):
print "Entered refresh"
current = current or self.GetFirstVisibleItem()
if current.IsOk():
print self.GetPyData(current).name
if self.GetPyData(current) == obj:
self.RefreshNode(current)
current = self.GetNextVisible(current)
if current != self.GetFirstVisibleItem():
self.RefreshNodes(obj, current)
```
Edit: the above is obviously part of a class based on wx.TreeCtrl | Just realised the problem: if current is not a valid item, it's logical value is False.
Hence the line current = current or self.GetFirstVisibleItem() wraps back to the first item before current.IsOk() is called... | How is the "next" item ever going to be the first item?
This appears to be a tautology. The next is never the first.
```
current = self.GetNextVisible(current)
current != self.GetFirstVisibleItem()
```
It doesn't appear that next wraps around to the beginning. It appears that next should return an invalid item (IsOk is False) at the end.
See <http://wxpython.org/onlinedocs.php> for information on this. | Infinite recursion trying to check all elements of a TreeCtrl | [
"",
"python",
"wxpython",
""
] |
I have been doing some refactoring and reorganization and I have moved a bunch of files around.
I want to update each file so it has the "correct" namespace according to its new location. With ReSharper, I can go into each file and it shows me that the namespaces is incorrect but that way I have to do it each file at a time.
Is there anyway to update namespaces across every file in a folder or a project? | **UPDATE: Anyone reading this question with R#5.0 and above should note that [this is now a feature](http://www.jetbrains.com/resharper/webhelp/Refactorings__Adjust_Namespaces.html):**
ReSharper -> Refactor -> Adjust Namespaces... | This isn't quite what you want to do ... but hopefully it's helpful.
Go to the class view, and rename the namespace using Ctrl+R,R. It will update that namespace in all the files/folders that it's used in. As long as your namespaces are consistant, it should acheive the same result as changing all the namespaces in a folder.
If your namespaces aren't consistant, and you're just tidying up then I'm afraid you've got a lot of clicking in front of you (or behind you as you've probably already done this). | Fastest way to update namespaces with ReSharper? | [
"",
"c#",
"resharper",
""
] |
In the .net 3.5 project that I am working on right now, I was writing some tests for a service class.
```
public class ServiceClass : IServiceClass
{
private readonly IRepository _repository;
public ServiceClass(IRepository repository)
{
_repository = repository;
}
#region IServiceClass Members
public IEnumerable<ActionType> GetAvailableActions()
{
IQueryable<ActionType> actionTypeQuery = _repository.Query<ActionType>();
return actionTypeQuery.Where(x => x.Name == "debug").AsEnumerable();
}
#endregion
}
```
and I was having a hard time figuring out how to stub or mock the
```
actionTypeQuery.Where(x => x.Name == "debug")
```
part.
Here's what I got so far:
```
[TestFixture]
public class ServiceClassTester
{
private ServiceClass _service;
private IRepository _repository;
private IQueryable<ActionType> _actionQuery;
[SetUp]
public void SetUp()
{
_repository = MockRepository.GenerateMock<IRepository>();
_service = new ServiceClass(_repository);
}
[Test]
public void heres_a_test()
{
_actionQuery = MockRepository.GenerateStub<IQueryable<ActionType>>();
_repository.Expect(x => x.Query<ActionType>()).Return(_actionQuery);
_actionQuery.Expect(x => x.Where(y => y.Name == "debug")).Return(_actionQuery);
_service.GetAvailableActions();
_repository.VerifyAllExpectations();
_actionQuery.VerifyAllExpectations();
}
}
```
[Note: class names have been changed to protect the innocent]
But this fails with a `System.NullReferenceException` at
```
_actionQuery.Expect(x => x.Where(y => y.Name == "debug")).Return(_actionQuery);
```
So my question is:
How do I mock or stub the IQueryable.Where function with RhinoMocks and get this test to pass?
If my current setup won't allow me to mock or stub IQueryable, then give a reasoned explanation why.
Thanks for reading this epically long question. | I initially wanted to mock out calls like 'IQueryable.Where(Func)' too but I think it is testing at the wrong level. Instead in my tests I just mocked out IQueryable and then check the result:
```
// Setup a dummy list that will be filtered, queried, etc
var actionList = new List<ActionType>()
{
new ActionType() { Name = "debug" },
new ActionType() { Name = "other" }
};
_repository.Expect(x => x.Query<ActionType>()).Return(actionList);
var result = _service.GetAvailableActions().ToList();
// Check the logic of GetAvailableActions returns the correct subset
// of actionList, etc:
Assert.That(result.Length, Is.EqualTo(1));
Assert.That(result[0], Is.EqualTo(actionList[0]);
_repository.VerifyAllExpectations();
``` | Without using Rhino mocks, you can create a List and then call .AsQueryable() on it. e.g.
```
var actionTypeList = new List<ActionType>() {
new ActionType {}, //put your fake data here
new ActionType {}
};
var actionTypeRepo = actionTypeList.AsQueryable();
```
That will at least get you a fake repository, but it won't let you verify that methods were called. | How do you stub IQueryable<T>.Where(Func<T, bool>) with Rhino Mocks? | [
"",
"c#",
"unit-testing",
"nunit",
"rhino-mocks",
"iqueryable",
""
] |
I'm a little confused about HTML classes and IDs, as I'd like to use them BOTH to describe an HTML element. Is this valid and supported by most browsers?
The motivation for me to use both is this:
1. I have a CSS style that I would like applied to multiple elements.
2. I have some AJAX and Javascript that will manipulate those same elements, so I need a way to identify which element is which using an ID.
3. So I'd like to use an id to identify each element for JS manipulation AND at the same time I would like to specify a class so that the same style is applied from the same css. | An ID would be unique to only one item, where a class can be used to group many items together. You can use them together as you stated, ID as a unique identifier for Javascript and the class to markup with CSS.
Search for [html class vs id](http://www.google.com/search?q=html+classes+vs+id) to get many articles about this topic.
Example:
```
<ul>
<li class="odd" id="item1">First Item in the List</li>
<li class="even" id="item2">Second Item in the List</li>
<li class="odd" id="item3">Third Item in the List</li>
</ul>
``` | Yes, it is perfectly valid to use both the ID and Class properties in one element. Example:
```
<div class="infoBox" id="myUniqueStyle"> *content* </div>
```
Still, keep in mind that an ID can only be used once (hence its name), while you can use classes as many times as you'd like througout a document. You can still use both the ID and the class to apply styles, while only the ID is a simple way of reaching the element through javascript.
A good way of doing it is applying IDs to all elements that you know are unique (header, navigation, main containers etc.), and classes to everything else.
"Is *the*" applies to elements using ID: "This *is the* navigation bar", "this *is the* header"
"Is *a*" or "is *an*" applies to elements using classes: "This *is a* blogPost", "this *is an* infoBox" etc. | HTML Classes WITH IDs | [
"",
"javascript",
"html",
"css",
"ajax",
""
] |
I am attempting to create a REST API in PHP and I'd like to implement an authentication scheme similar to Amazon's S3 approach. This involves setting a custom 'Authorization' header in the request.
I had thought I would be able to access the header with $\_SERVER['HTTP\_AUTHORIZATION'], but it's nowhere to be found in var\_dump($\_SERVER). The apache\_request\_headers() function would solve my problem, but my host implements PHP as CGI, so it's unavailable.
Is there another way I can access the complete request headers in PHP? | You'll need to do some `mod_rewrite` wizardry to get your headers past the CGI barrier, like so:
```
RewriteEngine on
RewriteRule .? - [E=HTTP_AUTHORIZATION:%{HTTP:Authorization}]
<?php
$auth = $_SERVER['HTTP_AUTHORIZATION'];
?>
```
Note that if you're using `mod_rewrite` for other purposes, it could end up being `$_SERVER['REDIRECT_HTTP_AUTHORIZATION']`. | Try
```
$_ENV['HTTP_AUTHORIZATION']
```
When using CGI interface instead of Apache Module interface, HTTP headers should be available as environment variables. | How can I access request headers that don't appear in $_SERVER? | [
"",
"php",
"http",
"http-headers",
""
] |
Is there a simple way to create a copy of a database or schema in PostgreSQL 8.1?
I'm testing some software which does a lot of updates to a particular schema within a database, and I'd like to make a copy of it so I can run some comparisons against the original. | If it's on the same server, you just use the CREATE DATABASE command with the TEMPLATE parameter. For example:
```
CREATE DATABASE newdb WITH TEMPLATE olddb;
``` | [`pg_dump`](http://www.postgresql.org/docs/current/static/app-pgdump.html) with the `--schema-only` option. | PostgreSQL how to create a copy of a database or schema? | [
"",
"sql",
"database",
"postgresql",
""
] |
In C# when I want to call a static method of a class from another static method of that class, is there a **generic prefix** that I can use such as PHP's `self::` instead of the class name?
So in the below example, instead of saying **`Customer.DatabaseConnectionExists()`**, how can I say something like **`Self.DatabaseConnectionExists()`** so e.g. later if I change the name of the class I don't have to go change all the prefixes?
```
class Customer
{
public string FirstName { get; set; }
public string LastName { get; set; }
public static Customer GetCurrentCustomer()
{
if (Customer.DatabaseConnectionExists())
{
return new Customer { FirstName = "Jim", LastName = "Smith" };
}
else
{
throw new Exception("Database connection does not exist.");
}
}
public static bool DatabaseConnectionExists()
{
return true;
}
}
``` | There's no real equivalent - you have to either specify the class name, i.e.
```
Customer.DatabaseConnectionExists()
```
or miss out the qualifier altogether, i.e.
```
DatabaseConnectionExists()
```
The latter style of calling is advisable since it's simpler and doesn't lose any meaning. Also, it's more inline with method calling in instances (i.e. calling by `InstanceMethod()` and *not* `this.InstanceMethod()`, which is overly verbose). | If you're calling the method from inside the class, you don't need to specify anything like ::Self, just the method name will do.
```
class Customer
{
public string FirstName { get; set; }
public string LastName { get; set; }
public static Customer GetCurrentCustomer()
{
if (DatabaseConnectionExists())
{
return new Customer { FirstName = "Jim", LastName = "Smith" };
}
else
{
throw new Exception("Database connection does not exist.");
}
}
public static bool DatabaseConnectionExists()
{
return true;
}
}
``` | What is the C# equivalent to PHP's "self::"? | [
"",
"c#",
"oop",
""
] |
How do I use progress bar with percentage for EVERY AJAX request on the page?
I've already asked about loading a whole page with one progress bar [here](https://stackoverflow.com/questions/796792/ajax-progress-bar-dispaying-loading-progress-percentage-for-page-load)
But,now I want to know if its possible to use a separate progressbars for each AJAX request on the same page?
Any ideas?
Thanks. | try these following demos
* [west-wind](http://www.west-wind.com/wconnect/webcontrols/progressBar.wcsx)
* [Matt Berseth](http://mattberseth2.com/demo/Default.aspx?Name=ASP.NET+AJAX+Progress+Bar+Control&Filter=All)
* [SingingEels](http://www.singingeels.com/Articles/RealTime_Progress_Bar_With_ASPNET_AJAX.aspx) | Having a progress bar **with percentage** depends very much on your server environment. The %age isn't returned as part of a normal HTTP request process, so you need to simultaneously poll the server to obtain a response about the %age transfer process.
This is what some of the examples above do. Other ones appear just to spoof a %age?
Obviously this needs a server capable of delivering this information. You are also adding to the load by using continual requests to poll the server - if you have multiple progress bars, then you are talking about multiple requests + multiple pollings, which will cause quite an additional load. Particularly as simultaneous HTTP connections are limited in the browser.
You could also investigate COMET type approaches, which do various things by keeping requests alive and feeding data asynchronously that way. | Using progressbars with percentage for AJAX requests | [
"",
"c#",
"ajax",
"asp.net-ajax",
""
] |
I've got a LINQ query going against an Entity Framework object. Here's a summary of the query:
```
//a list of my allies
List<int> allianceMembers = new List<int>() { 1,5,10 };
//query for fleets in my area, including any allies (and mark them as such)
var fleets = from af in FleetSource
select new Fleet
{
fleetID = af.fleetID,
fleetName = af.fleetName,
isAllied = (allianceMembers.Contains(af.userID) ? true : false)
};
```
Basically, what I'm doing is getting a set of fleets. The allianceMembers list contains INTs of all users who are allied with me. I want to set isAllied = true if the fleet's owner is part of that list, and false otherwise.
When I do this, I am seeing an exception: "LINQ to Entities does not recognize the method 'Boolean Contains(Int32)' method"
I can understand getting this error if I had used the contains in the where portion of the query, but why would I get it in the select? By this point I would assume the query would have executed and returned the results. This little ditty of code does nothing to constrain my data at all.
Any tips on how else I can accomplish what I need to with setting the isAllied flag?
Thanks | ```
var fleets = from af in FleetSource;
var x = from u in fleets.ToList()
select new Fleet
{
fleetID = u.fleetID,
fleetName = u.fleetName,
isAllied = (allianceMembers.Contains(u.userID) ? true : false)
}
```
calling `ToList()` on fleets the query is executed, later you can use `Contains()`. | This poached from a previous answer...
Contains not supported.
IN and JOIN are not the same operator (Filtering by IN never changes the cardinality of the query).
Instead of doing it that way use the join method. It's somewhat difficult to understand without using the query operators, but once you get it, you've got it.
```
var foo =
model.entitySet.Join( //Start the join
values, //Join to the list of strings
e => e.Name, // on entity.Name
value => value, //equal to the string
(ModelItem ent, String str) => ent);//select the entity
```
Here it is using the query operators
```
var foo = from e in model.entitySet
join val in values on
e.Name equals val
select e;
``` | LINQ to Entity: using Contains in the "select" portion throws unexpected error | [
"",
"c#",
"entity-framework",
"linq-to-entities",
""
] |
I need to do an inverse calculation, which consists bitwise AND operation,how do I do it?
I tried exclusive OR, but it didn't help.
```
int i = 254 & 2;
Console.Write("254 & 2 ={0}", i + "\n");
Console.Write("{0} ^ 2 ={1}",i, (i ^ 2) + "\n");
```
Doesn't work. How do I do that calculation? | Given `i`, you cannot get back `254`. By `&`ing it you have destroyed what data was not stored in the second bit.
```
1111 1110
&0000 0010
----------
0000 0010
```
How would you recover the 6 lost bits? For `x & 2 == 2`, you could put almost any `x` and it would be true.
```
0010 1010 // = 42
&0000 0010
----------
0000 0010
```
Is `x` 254 or 42? You cannot tell. | Technically the opposite of AND is NAND:
> ~( 254 & 2 )
Note that the ~ is the complement operator, and does a bitwise NOT (toggle each bit to its opposite).
What exactly do you want, though? What are you trying to accomplish?
If you're trying to undo the calculation, you can't - there is no inverse function such that inverseand(and(x, y)) will return x or y, even if inverse is given one of them. | What is the inverse of bitwise AND in C#? | [
"",
"c#",
"bitwise-operators",
""
] |
Why does nobody seem to use tuples in C++, either the [Boost Tuple Library](http://www.boost.org/doc/libs/1_39_0/libs/tuple/doc/tuple_users_guide.html) or the standard library for TR1? I have read a lot of C++ code, and very rarely do I see the use of tuples, but I often see lots of places where tuples would solve many problems (usually returning multiple values from functions).
Tuples allow you to do all kinds of cool things like this:
```
tie(a,b) = make_tuple(b,a); //swap a and b
```
That is certainly better than this:
```
temp=a;
a=b;
b=temp;
```
Of course you could always do this:
```
swap(a,b);
```
But what if you want to rotate three values? You can do this with tuples:
```
tie(a,b,c) = make_tuple(b,c,a);
```
Tuples also make it much easier to return multiple variable from a function, which is probably a much more common case than swapping values. Using references to return values is certainly not very elegant.
Are there any big drawbacks to tuples that I'm not thinking of? If not, why are they rarely used? Are they slower? Or is it just that people are not used to them? Is it a good idea to use tuples? | Because it's not yet standard. Anything non-standard has a much higher hurdle. Pieces of Boost have become popular because programmers were clamoring for them. (hash\_map leaps to mind). But while tuple is handy, it's not such an overwhelming and clear win that people bother with it. | A cynical answer is that many people program in C++, but do not understand and/or use the higher level functionality. Sometimes it is because they are not allowed, but many simply do not try (or even understand).
As a non-boost example: how many folks use functionality found in `<algorithm>`?
In other words, many C++ programmers are simply C programmers using C++ compilers, and perhaps `std::vector` and `std::list`. That is one reason why the use of `boost::tuple` is not more common. | Why is the use of tuples in C++ not more common? | [
"",
"c++",
"tuples",
""
] |
My SUT looks like:
```
foo.py
bar.py
tests/__init__.py [empty]
tests/foo_tests.py
tests/bar_tests.py
tests/integration/__init__.py [empty]
tests/integration/foo_tests.py
tests/integration/bar_tests.py
```
When I run `nosetests --with-coverage`, I get details for all sorts of
modules that I'd rather ignore. But I can't use the
`--cover-package=PACKAGE` option because `foo.py` & `bar.py` are not in a
package. (See the thread after
<http://lists.idyll.org/pipermail/testing-in-python/2008-November/001091.html>
for my reasons for not putting them in a package.)
Can I restrict coverage output to just foo.py & bar.py?
**Update** - Assuming that there isn't a better answer than [Nadia](https://stackoverflow.com/users/97828/nadia)'s below, I've asked a follow up question: ["How do I write some (bash) shell script to convert all matching filenames in directory to command-line options?"](https://stackoverflow.com/questions/855265/how-do-i-write-some-bash-shell-script-to-convert-all-matching-filenames-in-dire) | You can use it like this:
```
--cover-package=foo --cover-package=bar
```
I had a quick look at nose source code to confirm: [This is the line](https://github.com/nose-devs/nose/blob/master/nose/plugins/cover.py)
```
if options.cover_packages:
for pkgs in [tolist(x) for x in options.cover_packages]:
``` | You can use:
```
--cover-package=.
```
or even set environment variable
```
NOSE_COVER_PACKAGE=.
```
Tested with nose 1.1.2 | Can I restrict nose coverage output to directory (rather than package)? | [
"",
"python",
"code-coverage",
"nose",
"nosetests",
""
] |
When I feed a utf-8 encoded xml to an ExpatParser instance:
```
def test(filename):
parser = xml.sax.make_parser()
with codecs.open(filename, 'r', encoding='utf-8') as f:
for line in f:
parser.feed(line)
```
...I get the following:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "test.py", line 72, in search_test
parser.feed(line)
File "/System/Library/Frameworks/Python.framework/Versions/2.5/lib/python2.5/xml/sax/expatreader.py", line 207, in feed
self._parser.Parse(data, isFinal)
UnicodeEncodeError: 'ascii' codec can't encode character u'\xb4' in position 29: ordinal not in range(128)
```
I'm probably missing something obvious here. How do I change the parser's encoding from 'ascii' to 'utf-8'? | Your code fails in Python 2.6, but works in 3.0.
This does work in 2.6, presumably because it allows the parser itself to figure out the encoding (perhaps by reading the encoding optionally specified on the first line of the XML file, and otherwise defaulting to utf-8):
```
def test(filename):
parser = xml.sax.make_parser()
parser.parse(open(filename))
``` | The SAX parser in Python 2.6 should be able to parse utf-8 without mangling it. Although you've left out the ContentHandler you're using with the parser, if that content handler attempts to print any non-ascii characters to your console, that will cause a crash.
For example, say I have this XML doc:
```
<?xml version="1.0" encoding="utf-8"?>
<test>
<name>Champs-Élysées</name>
</test>
```
And this parsing apparatus:
```
import xml.sax
class MyHandler(xml.sax.handler.ContentHandler):
def startElement(self, name, attrs):
print "StartElement: %s" % name
def endElement(self, name):
print "EndElement: %s" % name
def characters(self, ch):
#print "Characters: '%s'" % ch
pass
parser = xml.sax.make_parser()
parser.setContentHandler(MyHandler())
for line in open('text.xml', 'r'):
parser.feed(line)
```
This will parse just fine, and the content will indeed preserve the accented characters in the XML. The only issue is that line in `def characters()` that I've commented out. Running in the console in Python 2.6, this will produce the exception you're seeing because the print function must convert the characters to ascii for output.
You have 3 possible solutions:
**One**: Make sure your terminal supports unicode, then create a `sitecustomize.py` entry in your `site-packages` and set the default character set to utf-8:
import sys
sys.setdefaultencoding('utf-8')
**Two**: Don't print the output to the terminal (tongue-in-cheek)
**Three**: Normalize the output using `unicodedata.normalize` to convert non-ascii chars to ascii equivalents, or `encode` the chars to ascii for text output: `ch.encode('ascii', 'replace')`. Of course, using this method you won't be able to properly evaluate the text.
Using option one above, your code worked just fine for my in Python 2.5. | Setting the encoding for sax parser in Python | [
"",
"python",
"unicode",
"sax",
""
] |
I am running into a road block on a larger problem.
As part of a large query I need to solve a "night watchman" problem.
I have a table with schedule shifts as such:
```
ID | Start | End
1 | 2009-1-1 06:00 | 2009-1-1 14:00
2 | 2009-1-1 10:00 | 2009-1-1 18:00
3 | 2009-2-1 20:00 | 2009-2-2 04:00
4 | 2009-2-2 06:00 | 2009-2-2 14:00
```
As part of a query, I need to determine if there is at least 1 watchman in a room at all times for a given time range.
So if I specified the range `2009-1-1 06:00` to `2009-1-1 12:00`, the result is true, because shifts 1 and 2 merge to cover this time period - in fact any number of shifts could be chained to keep the watch up. However if I checked `2009-2-1 22:00` to `2009-1-2 10:00`, the result is false because there is a break between 4 and 6am the following morning.
I would like to implement this *either* in LINQ, or as a user defined function in SQL Server (2005), as in both cases this is just a part of the logic of a larger query that must be run to identify elements that need attention. The real dataset involves about a hundred shift records intersecting any given time period, but not always covering the whole range.
The closest I've found is
[How to group ranged values using SQL Server](https://stackoverflow.com/questions/472732/how-to-group-ranged-values-using-sql-server)
for number ranges, however it depends on each range ending just before the next range starts. If I could construct the same unified view of the watches, only taking overlapping watches into consideration, then it would be trivial to check if a specific time was covered. A unified view would look like this:
```
Start | End
2009-1-1 06:00 | 2009-1-1 18:00
2009-2-1 20:00 | 2009-2-2 04:00
2009-2-2 06:00 | 2009-2-2 14:00
```
Note: This whole thing would be relatively easy to implement by just pulling all the data and running some manual loop on it, however that is the current system, and its rather slow because of the number of shifts and the number of time ranges that must be checked. | Here is a way to flatten date range like this
```
Start | End
2009-1-1 06:00 | 2009-1-1 18:00
2009-2-1 20:00 | 2009-2-2 04:00
2009-2-2 06:00 | 2009-2-2 14:00
```
You have to compare *previous* **and** *next* dates in each row and see whether
* Current row's **Start** date falls between previous row's date range.
* Current row's **End** date falls between next row's date range.
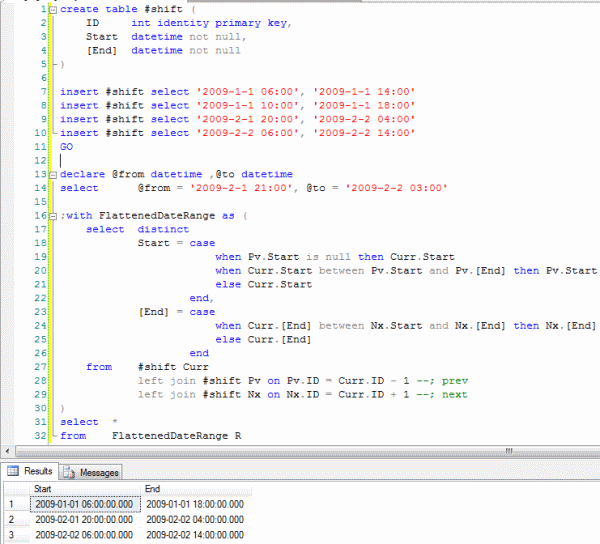
Using above code, implementing UDF is as simple as followed.
```
create function fnThereIsWatchmenBetween(@from datetime, @to datetime)
returns bit
as
begin
declare @_Result bit
declare @FlattenedDateRange table (
Start datetime,
[End] datetime
)
insert @FlattenedDateRange(Start, [End])
select distinct
Start =
case
when Pv.Start is null then Curr.Start
when Curr.Start between Pv.Start and Pv.[End] then Pv.Start
else Curr.Start
end,
[End] =
case
when Curr.[End] between Nx.Start and Nx.[End] then Nx.[End]
else Curr.[End]
end
from shift Curr
left join shift Pv on Pv.ID = Curr.ID - 1 --; prev
left join shift Nx on Nx.ID = Curr.ID + 1 --; next
if exists( select 1
from FlattenedDateRange R
where @from between R.Start and R.[End]
and @to between R.Start and R.[End]) begin
set @_Result = 1 --; There is/are watchman/men during specified date range
end
else begin
set @_Result = 0 --; There is NO watchman
end
return @_Result
end
``` | An unguarded interval obviously starts either at the end of a watched period or at the beginning of the whole time range that you are checking. So you need a query that selects all elements from this set that don't have an overlapping shift. The query would look like:
```
select 1
from shifts s1 where not exists
(select 1 from shifts s2
where s2.start<=s1.end and s2.end > s1.end
)
and s1.end>=start_of_range and s1.end< end_of_range
union
select 1
where not exists
(select 1 from shifts s2
where s2.start<=start_of_range and s2.end > start_of_range
)
```
If this is non-empty, then you have an unguarded interval. I suspect it will run in quadratic time, so it might be slower than "sort, fetch and loop". | Checking for time range overlap, the watchman problem [SQL] | [
"",
"sql",
"sql-server-2005",
"algorithm",
"linq-to-sql",
"t-sql",
""
] |
I would like to darken an existing color for use in a gradient brush. Could somebody tell me how to do this please?
C#, .net 2.0, GDI+ | As a simple approach, you can just factor the RGB values:
```
Color c1 = Color.Red;
Color c2 = Color.FromArgb(c1.A,
(int)(c1.R * 0.8), (int)(c1.G * 0.8), (int)(c1.B * 0.8));
```
(which should darken it; or, for example, \* 1.25 to brighten it) | You could also try using
```
ControlPaint.Light(baseColor, percOfLightLight)
```
[ControlPaint.Light](http://msdn.microsoft.com/en-us/library/3wz9t9fy(VS.80).aspx)
or
```
ControlPaint.Dark(baseColor, percOfDarkDark)
```
[ControlPaint.Dark](http://msdn.microsoft.com/en-us/library/h3fxkc2x.aspx) | How do I adjust the brightness of a color? | [
"",
"c#",
"gdi+",
""
] |
I need to prevent the automatic scroll-to behavior in the browser when using link.html#idX and <div id="idX"/>.
The problem I am trying to solve is where I'm trying to do a custom scroll-to functionality on page load by detecting the anchor in the url, but so far have not been able to prevent the automatic scrolling functionality (specifically in Firefox).
Any ideas? I have tried preventDefault() on the $(window).load() handler, which did not seem to work.
Let me reiterate this is for links that are not clicked within the page that scrolls; it is for links that scroll on page load. Think of clicking on a link from another website with an #anchor in the link. What prevents that autoscroll to the id?
Everyone understand I'm not looking for a workaround; I need to know if (and how) it's possible to prevent autoscrolling to #anchors on page load.
---
## **NOTE**
This isn't *really* an answer to the question, just a simple race-condition-style kluge.
Use jQuery's scrollTo plugin to scroll back to the top of the page, then reanimate the scroll using something custom. If the browser/computer is quick enough, there's no "flash" on the page.
I feel dirty just suggesting this...
```
$(document).ready(function(){
// fix the url#id scrollto "effect" (that can't be
// aborted apparently in FF), by scrolling back
// to the top of the page.
$.scrollTo('body',0);
otherAnimateStuffHappensNow();
});
```
Credit goes to [wombleton](https://stackoverflow.com/users/22419/wombleton) for pointing it out. Thanks! | [This](http://www.inmotiondesign.nl/playground/?p=20) seems the only option I can see with ids:
```
$(document).ready(function() {
$.scrollTo('0px');
});
```
It doesn't automatically scroll to classes.
So if you identify your divs with unique classes you will lose a bit of speed with looking up elements but gain the behaviour you're after.
(Thanks, by the way, for pointing out the scroll-to-id feature! Never knew it existed.)
EDIT: | 1. Scroll first to top (fast, no effects pls), and then call your scroll function. (I know its not so pretty)
2. or just use a prefix | Prevent/stop auto anchor link from occurring | [
"",
"javascript",
"jquery",
""
] |
In a project I'm working on in C++, I need to create objects for messages as they come in over the wire. I'm currently using the [factory method pattern](http://www.parashift.com/c++-faq-lite/ctors.html#faq-10.12) to hide the creation of objects:
```
// very psuedo-codey
Message* MessageFactory::CreateMessage(InputStream& stream)
{
char header = stream.ReadByte();
switch (header) {
case MessageOne::Header:
return new MessageOne(stream);
case MessageTwo::Header:
return new MessageTwo(stream);
// etc.
}
}
```
The problem I have with this is that I'm lazy and don't like writing the names of the classes in two places!
In C# I would do this with some reflection on first use of the factory (bonus question: that's an OK use of reflection, right?) but since C++ lacks reflection, this is off the table. I thought about using a registry of some sort so that the messages would register themselves with the factory at startup, but this is hampered by the [non-deterministic (or at least implementation-specific) static initialization order problem](http://www.parashift.com/c++-faq-lite/ctors.html#faq-10.12).
So the question is, is it possible to implement this type of factory in C++ while respecting the open/closed principle, and how?
EDIT: Apparently I'm overthinking this. I intended this question to be a "how would you do this in C++" since it's really easy to do with reflection in other languages. | I think that the open/closed approach and DRY are good principles. But they are not sacred. The goal should be making the code reliable and maintainable. If you have to perform unnatural acts to adhere to O/C or DRY, then you may simply be making your code needlessly more complex with no material benefit.
Here is [something I wrote](http://www.io.com/~richardr/writing/Engineering/SoftwareQuality/index.htm) a few years ago on how I make these judgment calls. | I have answered in another SO question about C++ factories. Please see [there](https://stackoverflow.com/questions/410823/factory-method-implementation-c/534396#534396) if a flexible factory is of interest. I try to describe an old way from ET++ to use macros which has worked great for me.
The method is macro based and are easily extensible.
[ET++](http://www.ubilab.org/publications/wei94.html) was a project to port old MacApp to C++ and X11. In the effort of it Eric Gamma etc started to think about *Design Patterns* | Is it possible to make a factory in C++ that complies with the open/closed principle? | [
"",
"c++",
""
] |
I have a thread that appends rows to self.output and a loop that runs until self.done is True (or the max execution time is reached).
Is there a more efficient way to do this other than using a while loop that constantly checks to see if it's done. The while loop causes the CPU to spike to 100% while it's running..
```
time.clock()
while True:
if len(self.output):
yield self.output.pop(0)
elif self.done or 15 < time.clock():
if 15 < time.clock():
yield "Maximum Execution Time Exceeded %s seconds" % time.clock()
break
``` | Are your threads appending to self.output here, with your main task consuming them? If so, this is a tailor-made job for [Queue.Queue](http://docs.python.org/library/queue.html). Your code should become something like:
```
import Queue
# Initialise queue as:
queue = Queue.Queue()
Finished = object() # Unique marker the producer will put in the queue when finished
# Consumer:
try:
while True:
next_item = self.queue.get(timeout=15)
if next_item is Finished: break
yield next_item
except Queue.Empty:
print "Timeout exceeded"
```
Your producer threads add items to the queue with `queue.put(item)`
**[Edit]** The original code has a race issue when checking self.done (for example multiple items may be appended to the queue before the flag is set, causing the code to bail out at the first one). Updated with a suggestion from ΤΖΩΤΖΙΟΥ - the producer thread should instead append a special token (Finished) to the queue to indicate it is complete.
Note: If you have multiple producer threads, you'll need a more general approach to detecting when they're all finished. You could accomplish this with the same strategy - each thread a Finished marker and the consumer terminates when it sees num\_threads markers. | Use a semaphore; have the working thread release it when it's finished, and block your appending thread until the worker is finished with the semaphore.
ie. in the worker, do something like `self.done = threading.Semaphore()` at the beginning of work, and `self.done.release()` when finished. In the code you noted above, instead of the busy loop, simply do `self.done.acquire()`; when the worker thread is finished, control will return.
Edit: I'm afraid I don't address your needed timeout value, though; this [issue](http://bugs.python.org/issue850728) describes the need for a semaphore timeout in the standard library. | Python - Threading and a While True Loop | [
"",
"python",
"multithreading",
"loops",
""
] |
If there anyway allows AJAX between two own domains without proxy hacking, JSONP, Flash or browser security changes? Maybe SSL or something? | A signed Java applet might be able to do it, but that is the same principle as Flash so probably would not meet your requirements.
There is [a specification for cross domain requests](http://www.w3.org/TR/access-control/), but it is still in the development stages. | As far as I know, your best bet here is to create a server resource that you can direct your AJAX calls to that will forward them on to the second server on a different domain and then tunnel the results back to your application. | AJAX cross site scripting between own domains | [
"",
"javascript",
"ajax",
"xss",
""
] |
Is there any way to group tests in JUnit, so that I can run only some groups?
Or is it possible to annotate some tests and then globally disable them?
I'm using **JUnit 4**, I can't use TestNG.
**edit:** @RunWith and @SuiteClasses works great. But is it possible to annotate like this only some tests in test class? Or do I have to annotate whole test class? | Do you want to group tests inside a test class or do you want to group test classes? I am going to assume the latter.
It depends on how you are running your tests. If you run them by Maven, it is possible to specify exactly what tests you want to include. See [the Maven surefire documentation](http://maven.apache.org/plugins/maven-surefire-plugin/examples/inclusion-exclusion.html) for this.
More generally, though, what I do is that I have a tree of test suites. A test suite in JUnit 4 looks something like:
```
@RunWith(Suite.class)
@SuiteClasses({SomeUnitTest1.class, SomeUnitTest2.class})
public class UnitTestsSuite {
}
```
So, maybe I have a FunctionTestsSuite and a UnitTestsSuite, and then an AllTestsSuite which includes the other two. If you run them in Eclipse you get a very nice hierarchical view.
The problem with this approach is that it's kind of tedious if you want to slice tests in more than one different way. But it's still possible (you can for example have one set of suites that slice based on module, then another slicing on the type of test). | JUnit 4.8 supports grouping:
```
public interface SlowTests {}
public interface IntegrationTests extends SlowTests {}
public interface PerformanceTests extends SlowTests {}
```
And then...
```
public class AccountTest {
@Test
@Category(IntegrationTests.class)
public void thisTestWillTakeSomeTime() {
...
}
@Test
@Category(IntegrationTests.class)
public void thisTestWillTakeEvenLonger() {
...
}
@Test
public void thisOneIsRealFast() {
...
}
}
```
And lastly,
```
@RunWith(Categories.class)
@ExcludeCategory(SlowTests.class)
@SuiteClasses( { AccountTest.class, ClientTest.class })
public class UnitTestSuite {}
```
Taken from here: <https://community.oracle.com/blogs/johnsmart/2010/04/25/grouping-tests-using-junit-categories-0>
Also, Arquillian itself supports grouping:
<https://github.com/weld/core/blob/master/tests-arquillian/src/test/java/org/jboss/weld/tests/Categories.java> | Grouping JUnit tests | [
"",
"java",
"unit-testing",
"junit",
""
] |
When a user selects a file in a web page I want to be able to extract just the filename.
I did try str.search function but it seems to fail when the file name is something like this: **c:\uploads\ilike.this.file.jpg**.
How can we extract just the file name without extension? | Assuming your **<input type="file" >** has an id of **upload** this should hopefully do the trick:
```
var fullPath = document.getElementById('upload').value;
if (fullPath) {
var startIndex = (fullPath.indexOf('\\') >= 0 ? fullPath.lastIndexOf('\\') : fullPath.lastIndexOf('/'));
var filename = fullPath.substring(startIndex);
if (filename.indexOf('\\') === 0 || filename.indexOf('/') === 0) {
filename = filename.substring(1);
}
alert(filename);
}
``` | To split the string ({filepath}/{filename}) and get the file name you could use something like this:
```
str.split(/(\\|\/)/g).pop()
```
> "The pop method removes the last element from an array and returns that
> value to the caller."
> [Mozilla Developer Network](https://developer.mozilla.org/en/JavaScript/Reference/Global_Objects/Array/pop)
Example:
from: `"/home/user/file.txt".split(/(\\|\/)/g).pop()`
you get: `"file.txt"` | Javascript - How to extract filename from a file input control | [
"",
"javascript",
"browser",
"extract",
""
] |
Does anyone know a Library which provides a Thread.sleep() for Java which has an error not higher than 1-2 Millisecond?
I tried a mixture of Sleep, error measurement and BusyWait but I don't get this reliable on different windows machines.
It can be a native implementation if the implementation is available for Linux and MacOS too.
**EDIT**
The link Nick provided ( <http://blogs.oracle.com/dholmes/entry/inside_the_hotspot_vm_clocks> ) is a really good resource to understand the issues all kinds of timers/sleeps/clocks java has. | To improve granularity of sleep you can try the following from this [Thread.sleep](http://www.javamex.com/tutorials/threads/sleep.shtml) page.
> **Bugs with Thread.sleep() under Windows**
>
> If timing is crucial to your
> application, then an inelegant but
> practical way to get round these bugs
> is to leave a daemon thread running
> throughout the duration of your
> application that simply sleeps for a
> large prime number of milliseconds
> (Long.MAX\_VALUE will do). This way,
> the interrupt period will be set once
> per invocation of your application,
> minimising the effect on the system
> clock, and setting the sleep
> granularity to 1ms even where the
> default interrupt period isn't 15ms.
The page also mentions that it causes a system-wide change to Windows which may cause the user's clock to run fast due to this [bug](http://support.microsoft.com/?id=821893).
**EDIT**
More information about this is available
[here](http://blogs.oracle.com/dholmes/entry/inside_the_hotspot_vm_clocks) and an associated [bug report](https://bugs.java.com/bugdatabase/view_bug?bug_id=6435126) from Sun. | This is ~5 months late but might be useful for people reading this question. I found that `java.util.concurrent.locks.LockSupport.parkNanos()` does the same as `Thread.sleep()` but with nanosecond precision (in theory), and much better precision than `Thread.sleep()` in practice. This depends of course on the Java Runtime you're using, so YMMV.
Have a look: [LockSupport.parkNanos](http://java.sun.com/javase/6/docs/api/java/util/concurrent/locks/LockSupport.html#parkNanos(long))
(I verified this on Sun's 1.6.0\_16-b01 VM for Linux) | Accurate Sleep for Java on Windows | [
"",
"java",
"windows",
"sleep",
""
] |
Is there a good profiler for javascript? I know that firebug has some support for profiling code. But I want to determine stats on a longer scale.
Imagine you are building a lot of javascript code and you want to determine what are actually the bottlenecks in the code. At first I want to see profile stats of every javascript function and execution time. Next would be including DOM functions. This combined with actions that slows things down like operation on the rendering tree would be perfect. I think this would give a good impression if the performance is killed in my code, in DOM preparation or in updates to the rendering tree/visual.
Is there something close to what I want? Or what would be the best tool to achieve the most of what I've described? Would it be a self compiled browser plus javascript engine enhanced by profile functionality? | # [Firebug](http://getfirebug.com/docs.html)
Firebug provides a highly detailed profiling report. It will tell you how long each method invocation takes in a giant (detailed) table.
```
console.profile([title])
//also see
console.trace()
```
You need to call `console.profileEnd ()` to end your profile block. See the console API here: <http://getfirebug.com/wiki/index.php/Console_API>
# Blackbird
Blackbird also has a simpler profiler
* [Blackbird official site from Wayback Machine](https://web.archive.org/web/20130509011712/http://www.gscottolson.com/blackbirdjs/)
* [Source from Google Code Archive](https://code.google.com/archive/p/blackbirdjs/)
* [Source from Github (pockata/blackbird-js: A fork of the cool Blackbird logging utility)](https://github.com/pockata/blackbird-js)
* [Source from Github (louisje/blackbirdjs: Blackbird offers a dead-simple way to log messages)](https://github.com/louisje/blackbirdjs) | Chrome's Developer Tools has a built-in profiler. | What is the best way to profile javascript execution? | [
"",
"javascript",
"performance",
"browser",
"profiling",
""
] |
I'm developing a Java application that uses java.util.logging for its logging needs. This application uses a multitude of external libraries (JDBC, JMS clients, JSR-160 implementation, etc), some of which also use java.util.logging.
I want to set the log level for *my* Loggers to ALL when I specify a flag on the command line, but so far I have only found ways to set the level for all loggers, not just mine.
My loggers are all called "com.mycompany.myapp.SomeClass" and when I set the level for "com.mycompany.myapp" to ALL, no extra information is logged. When I set the level for the root logger to ALL, all information for all loggers is logged to the console, which is way too much information!
How can I set my own loggers to ALL without having all those other loggers flood my logfiles? | Actually, I'm not sure why your having the problems you've described. I've created a simple JUnit test (below) and setting the log levels works exactly as I expect (which also seems inline with the way you expected them to work).
Are you trying to log messages with levels set below INFO in your custom logger? As you can see from the tests I've included, the default logging handler is set to INFO by default. You need to change *that Handler's* level to see FINE messages (also shown).
```
import java.util.logging.Handler;
import java.util.logging.Level;
import java.util.logging.Logger;
import org.junit.Test;
public class SimpleLoggerTest {
private void logMessages(Logger logger) {
logger.warning(getLoggerName(logger) + ": warning message");
logger.info(getLoggerName(logger) + ": info message");
logger.fine(getLoggerName(logger) + ": fine message");
}
private String getLoggerName(Logger logger) {
String loggerName = logger.getName();
if (loggerName.isEmpty()) {
return "[root logger]";
}
return loggerName;
}
private void listHandlerLevels(Logger logger) {
for (Handler handler : logger.getHandlers()) {
logger.info(getLoggerName(logger) + ": handler level = " + handler.getLevel());
}
Logger parentLogger = logger.getParent();
if (null != parentLogger) {
for (Handler handler : parentLogger.getHandlers()) {
logger.info("parent logger handler (" + getLoggerName(parentLogger) + "): handler level = " + handler.getLevel());
}
}
}
private void setHandlerLevels(Logger logger, Level level) {
for (Handler handler : logger.getHandlers()) {
handler.setLevel(level);
}
Logger parentLogger = logger.getParent();
if (null != parentLogger) {
for (Handler handler : parentLogger.getHandlers()) {
handler.setLevel(level);
}
}
}
@Test
public void testLoggingLevel() {
Logger myLogger = Logger.getLogger(SimpleLoggerTest.class.getName());
Logger rootLogger = myLogger.getParent();
// list the default handler levels
listHandlerLevels(myLogger);
listHandlerLevels(rootLogger);
// log some messages
logMessages(myLogger);
logMessages(rootLogger);
// change the logger levels
myLogger.setLevel(Level.ALL);
rootLogger.setLevel(Level.WARNING);
// list the handler levels again
listHandlerLevels(myLogger);
listHandlerLevels(rootLogger);
// log some messages (again)
logMessages(myLogger);
logMessages(rootLogger);
// change Handler levels to FINE
setHandlerLevels(myLogger, Level.FINE);
// list the handler levels (last time)
listHandlerLevels(myLogger);
listHandlerLevels(rootLogger);
// log some messages (last time)
logMessages(myLogger);
logMessages(rootLogger);
}
}
```
Produces this output...
```
May 13, 2009 10:46:53 AM SimpleLoggerTest listHandlerLevels
INFO: parent logger handler ([root logger]): handler level = INFO
May 13, 2009 10:46:53 AM java.util.logging.LogManager$RootLogger log
INFO: [root logger]: handler level = INFO
May 13, 2009 10:46:53 AM SimpleLoggerTest logMessages
WARNING: SimpleLoggerTest: warning message
May 13, 2009 10:46:53 AM SimpleLoggerTest logMessages
INFO: SimpleLoggerTest: info message
May 13, 2009 10:46:53 AM java.util.logging.LogManager$RootLogger log
WARNING: [root logger]: warning message
May 13, 2009 10:46:53 AM java.util.logging.LogManager$RootLogger log
INFO: [root logger]: info message
May 13, 2009 10:46:53 AM SimpleLoggerTest listHandlerLevels
INFO: parent logger handler ([root logger]): handler level = INFO
May 13, 2009 10:46:53 AM SimpleLoggerTest logMessages
WARNING: SimpleLoggerTest: warning message
May 13, 2009 10:46:53 AM SimpleLoggerTest logMessages
INFO: SimpleLoggerTest: info message
May 13, 2009 10:46:53 AM java.util.logging.LogManager$RootLogger log
WARNING: [root logger]: warning message
May 13, 2009 10:46:53 AM SimpleLoggerTest listHandlerLevels
INFO: parent logger handler ([root logger]): handler level = FINE
May 13, 2009 10:46:53 AM SimpleLoggerTest logMessages
WARNING: SimpleLoggerTest: warning message
May 13, 2009 10:46:53 AM SimpleLoggerTest logMessages
INFO: SimpleLoggerTest: info message
May 13, 2009 10:46:53 AM SimpleLoggerTest logMessages
FINE: SimpleLoggerTest: fine message
May 13, 2009 10:46:53 AM java.util.logging.LogManager$RootLogger log
WARNING: [root logger]: warning message
```
This is what I was trying to convey in [my other response](https://stackoverflow.com/questions/857634/set-loglevel-for-some-loggers-but-not-others/857746#857746). | Each [Logger](https://docs.oracle.com/javase/8/docs/api/java/util/logging/Logger.html) has a [Handler](https://docs.oracle.com/javase/8/docs/api/java/util/logging/Handler.html) with it's own log [Level](https://docs.oracle.com/javase/8/docs/api/java/util/logging/Level.html).
Is it possible that the Handler for your logger is not also set to ALL and is ignoring the messages? (This is messy, I know).
Here's [a 2002 article on Java logging](https://web.archive.org/web/20180506084006/http://www.onjava.com/pub/a/onjava/2002/06/19/log.html) from O'Reilly. | Set loglevel for some Loggers, but not others | [
"",
"java",
"logging",
""
] |
I am a newbie to web-services. What is a good way to learn web-services implementation using java, xml and spring? Are there any good books which cover this topic in good width?
Or, are there any online resources, tutorials, etc.?
Also, what would be good projects to understand this hands-on?
Any recommendations>? | I originally learned Web Services concepts without books, so my opinions may be biased, but I don't think books would help much in the beginning. Once you get to some intermediate state where you need to study security, SOA, etc, maybe books would help.
I needed to get an intern up to speed on Web Services, so I made him implement a two-player game of [Reversi](http://en.wikipedia.org/wiki/Reversi) using Web Services as the business logic layer with SQL Server underneath it. The UI layer was a desktop executable hitting the service.
You can do something like that using Axis2 and Swing. Once you've built the first UI, you can then try to consume the same service using .NET/Ruby/jQuery or something too to demonstrate the interoperability. | 
[Spring in Action Second Edition](http://www.manning.com/walls3/) has a fair bit of information about using Spring and web services with examples. It worked for me anyway. | Best book/ tutorial to learn/implement web services using java, xml and spring | [
"",
"java",
"xml",
"spring",
""
] |
I would like to emulate the pass-by-value behaviour in python. In other words, I would like to make absolutely sure that the function I write do not modify user supplied data.
One possible way is to use deep copy:
```
from copy import deepcopy
def f(data):
data = deepcopy(data)
#do stuff
```
is there more efficient or more *pythonic* way to achieve this goal, making as few assumptions as possible about the object being passed (such as .clone() method)
**Edit**
I'm aware that technically everything in python is passed by value. I was interested in *emulating* the behaviour, i.e. making sure I don't mess with the data that was passed to the function. I guess the most general way is to clone the object in question either with its own clone mechanism or with deepcopy. | There is no pythonic way of doing this.
Python provides very few facilities for *enforcing* things such as private or read-only data. The pythonic philosophy is that "we're all consenting adults": in this case this means that "the function shouldn't change the data" is part of the spec but not enforced in the code.
---
If you want to make a copy of the data, the closest you can get is your solution. But `copy.deepcopy`, besides being inefficient, also has caveats [such as](http://docs.python.org/library/copy.html):
> Because deep copy copies everything it may copy too much, e.g., administrative data structures that should be shared even between copies.
>
> [...]
>
> This module does not copy types like module, method, stack trace, stack frame, file, socket, window, array, or any similar types.
So i'd only recommend it if you know that you're dealing with built-in Python types or your own objects (where you can customize copying behavior by defining the `__copy__` / `__deepcopy__` special methods, there's no need to define your own `clone()` method). | You can make a decorator and put the cloning behaviour in that.
```
>>> def passbyval(func):
def new(*args):
cargs = [deepcopy(arg) for arg in args]
return func(*cargs)
return new
>>> @passbyval
def myfunc(a):
print a
>>> myfunc(20)
20
```
This is not the most robust way, and doesn't handle key-value arguments or class methods (lack of self argument), but you get the picture.
Note that the following statements are equal:
```
@somedecorator
def func1(): pass
# ... same as ...
def func2(): pass
func2 = somedecorator(func2)
```
You could even have the decorator take some kind of function that does the cloning and thus allowing the user of the decorator to decide the cloning strategy. In that case the decorator is probably best implemented as a class with `__call__` overridden. | Emulating pass-by-value behaviour in python | [
"",
"python",
"pass-by-value",
""
] |
I often do vector addition of Python lists.
Example: I have two lists like these:
```
a = [0.0, 1.0, 2.0]
b = [3.0, 4.0, 5.0]
```
I now want to add b to a to get the result `a = [3.0, 5.0, 7.0]`.
Usually I end up doing like this:
```
a[0] += b[0]
a[1] += b[1]
a[2] += b[2]
```
Is there some efficient, standard way to do this with less typing?
UPDATE: It can be assumed that the lists are of length 3 and contain floats. | I don't think you will find a faster solution than the 3 sums proposed in the question. The advantages of numpy are visible with larger vectors, and also if you need other operators. numpy is specially useful with matrixes, witch are trick to do with python lists.
Still, yet another way to do it :D
```
In [1]: a = [1,2,3]
In [2]: b = [2,3,4]
In [3]: map(sum, zip(a,b))
Out[3]: [3, 5, 7]
```
**Edit**: you can also use the izip from itertools, a generator version of zip
```
In [5]: from itertools import izip
In [6]: map(sum, izip(a,b))
Out[6]: [3, 5, 7]
``` | If you need efficient vector arithmetic, try [Numpy](https://numpy.org/).
```
>>> import numpy
>>> a=numpy.array([0,1,2])
>>> b=numpy.array([3,4,5])
>>> a+b
array([3, 5, 7])
>>>
```
Or (thanks, Andrew Jaffe),
```
>>> a += b
>>> a
array([3, 5, 7])
>>>
``` | Concise vector adding in Python? | [
"",
"python",
""
] |
i have some file test.php
```
<?PHP
$config_key_security = "test";
?>
```
and i have some class
test5.php
```
include test.php
class test1 {
function test2 {
echo $config_key_security;
}
}
``` | ```
class test1 {
function test2 {
global $config_key_security;
echo $config_key_security;
}
}
```
or
```
class test1 {
function test2 {
echo $GLOBALS['config_key_security'];
}
}
```
Having your class rely on a global variable isn't really best practice - you should consider passing it in to the constructor instead. | Have your config file create an array of config items. Then include that file in your class's constructor, and save its value as a member variable. This way, all your config settings are available to the class.
test.php:
```
<?
$config["config_key_security"] = "test";
$config["other_config_key"] = true;
...
?>
```
test5.php:
```
<?
class test1 {
private $config;
function __construct() {
include("test.php");
$this->config = $config;
}
public function test2{
echo $this->config["config_key_security"];
}
}
?>
``` | How to Include Variable inside Class in php | [
"",
"php",
""
] |
I have been reading the descriptions of referencing in Java, and, while I feel I understand them, I am not sure if Java allows me to do the following: we have two threads in the same JVM communicating via sockets, and we would like to pass what is essentially the address of a large chunk of data across the socket, without copying the data itself. The solution may be quite obvious to the initiated, but I can't figure it out! Help would be appreciated. | What else travels on this socket? If it is your own protocol then add a verb to the protocol that says "get that big thing from a known location" and just send the verb. How many of these objects are there? Can you make a map - string, object - and just pass the string over the socket? | AFAIK Java does not provide the means to get the memory reference of an object. What might work for you though is to use a shared array or shared vector into which you place the data as an object into the vector/array and pass the index of the object over the socket. | Passing a reference to a (large) data area across a socket | [
"",
"java",
"sockets",
"reference",
""
] |
I have a COM server with a method currently returning an integer:
```
[
object,
uuid("..."),
dual,
helpstring("IMyCOMServer Interface"),
pointer_default(unique)
]
__interface IMyCOMServer : IDispatch
{
[id(1), helpstring("method MyQuery")]
HRESULT MyQuery([in] BSTR instr, [out,retval] int* outint);
};
```
This compiles fine, but I'd rather return an enum: *(this code is actually above the interface definition)*
```
typedef
[
uuid("..."),
v1_enum,
helpstring("Enum")
]
enum {
value_a,
value_b,
value_c
} MyEnum;
```
Which again compile fine of its own right, but as soon as I change the `int*` to `MyEnum*` in the interface and implementation, I get linker errors:
```
[id(1), helpstring("method MyQuery")]
HRESULT MyQuery([in] BSTR instr, [out,retval] MyEnum* outint);
error MIDL2025 : syntax error : expecting a type specification near "MyEnum"
```
Whichever way I do it, I can't get it to compile.
---
Thanks to [Euro Micelli](https://stackoverflow.com/users/2230/euro-micelli) it turns out that the real problem is that my User Defined Type (the enum) wasn't making it into the generated .IDL file. Judging by forum queries online, this seems to be a common problem.
A blog article [Star Tech: UDT (User Defined Types) and COM](http://startech-journey.blogspot.com/2007/06/udt-user-defined-types-and-com.html) guided me down the right path. It seems that a workaround is needed when using attributed ATL.
In summary, I made the following changes:
Created `udt.idl`:
```
import "oaidl.idl";
import "ocidl.idl";
[
uuid("..."),
v1_enum,
helpstring("Enum")
]
typedef enum MyEnum {
value_a,
value_b,
value_c
} MyEnum_t;
[
version(1.0),
uuid(...),
helpstring(...)
]
library MyLibrary
{
enum MyEnum;
}
```
Added the following line prior to the module attribute in the main `.cpp` file so that the above IDL gets imported into the generated file:
```
[importidl("udt.idl")];
``` | (This is adapted from an actual IDL, so I know it works)
```
[uuid(XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX), v1_enum, helpstring("Enum")]
enum MyEnum {
value_a,
value_b,
value_c
} ;
```
Plus, in your Library section you must include the enum as well, or the enum won't be exported to the type library:
```
library MyLib
{
enum MyEnum;
...
};
``` | This is very compiler-dependent, since enums don't have a fixed storage size.
There's also the compatibility angle - how would you represent that enum in, say, Visual Basic, or C#? The underlying storage is something like an integer, so that's what COM allows. | How can I use a User Defined Type (UDT) in a COM server? | [
"",
"c++",
"com",
"enums",
""
] |
Can anybody give me some sample source code showing how to connect to a SQL Server 2005 database from JavaScript locally? I am learning web programming on my desktop.
Or do I need to use any other scripting language? Suggest some alternatives if you have them, but I am now trying to do it with JavaScript. My SQL Server is locally installed on my desktop — SQL Server Management Studio 2005 and IE7 browser. | You shouldn´t use client javascript to access databases for several reasons (bad practice, security issues, etc) but if you really want to do this, here is an example:
```
var connection = new ActiveXObject("ADODB.Connection") ;
var connectionstring="Data Source=<server>;Initial Catalog=<catalog>;User ID=<user>;Password=<password>;Provider=SQLOLEDB";
connection.Open(connectionstring);
var rs = new ActiveXObject("ADODB.Recordset");
rs.Open("SELECT * FROM table", connection);
rs.MoveFirst
while(!rs.eof)
{
document.write(rs.fields(1));
rs.movenext;
}
rs.close;
connection.close;
```
A better way to connect to a sql server would be to use some server side language like PHP, Java, .NET, among others. Client javascript should be used only for the interfaces.
And there are rumors of an ancient legend about the existence of server javascript, but this is another story. ;) | This would be really bad to do because sharing your connection string opens up your website to so many vulnerabilities that you can't simply patch up, you have to use a different method if you want it to be secure. Otherwise you are opening up to a huge audience to take advantage of your site. | How to connect to SQL Server database from JavaScript in the browser? | [
"",
"javascript",
"sql-server",
"database-connection",
""
] |
I'd like a regexp or other string which can replace everything except alphanumeric chars (`a-z` and `0-9`) from a string. All things such as `,@#$(@*810` should be stripped. Any ideas?
Edit: I now need this to strip everything but allow dots, so everything but `a-z, 1-9, .`. Ideas? | ```
$string = preg_replace("/[^a-z0-9.]+/i", "", $string);
```
Matches one or more characters not a-z 0-9 [case-insensitive], or "." and replaces with "" | I like using [^[:alnum:]] for this, less room for error.
```
preg_replace('/[^[:alnum:]]/', '', "(ABC)-[123]"); // returns 'ABC123'
``` | Stripping everything but alphanumeric chars from a string in PHP | [
"",
"php",
"regex",
"string",
""
] |
I am using a file stream to write out a file.
I was hoping to be able to write the file to the desktop.
If I have something like
```
tw = new StreamWriter("NameOflog file.txt");
```
I would like to be able to have some sort of @desktop identified in front of the file name that would automatically insert the path to the desktop.
Does this exist in C#? Or do I have to look for desktop paths on a computer by computer (or OS by OS) basis? | Quick google search reveals this one:
```
string strPath = Environment.GetFolderPath(
System.Environment.SpecialFolder.DesktopDirectory);
```
**EDIT**: This will work for Windows, but [Mono supports it](http://www.go-mono.com/docs/index.aspx?link=T%3ASystem.Environment.SpecialFolder), too. | You want to use [Environment.GetFolderPath](http://msdn.microsoft.com/en-us/library/system.environment.getfolderpath.aspx), passing in [`SpecialFolder.DesktopDirectory`](http://msdn.microsoft.com/en-us/library/system.environment.specialfolder.aspx).
There's also `SpecialFolder.Desktop` which represents the *logical* desktop location - it's not clear what the difference between the two is though. | C# reference to the desktop | [
"",
"c#",
"special-folders",
""
] |
Is it possible to create a complete fork of a 'PROGRAM' in execution into two sub-programs from a single execution sequence ?
The sub-programs produced are completely identical. They have the same execution sequences and values but now they are two different programs. It is like creating a clone of an Object, thus giving us two different objects of the same type to work on. But instead of just an object and some values, here we want to create a completely parallel execution sequence of a Program already loaded in the JVM (would prefer an answer for Java). | You seem to be looking for the Java equivalent of the [fork system call](http://en.wikipedia.org/wiki/Fork_(operating_system)) from Unix.
That does not exist in Java, and it's unclear whether it would even be possible, as processes in Unix don't have a direct equivalent in the JVM (threads are less independent than processes).
There is however a fork framework planned for Java 7:
<http://www.ibm.com/developerworks/java/library/j-jtp11137.html>
It's not the same as Unix'es fork/join, but it shares some ideas and might be useful.
Of course you can do concurrent programming in Java, it's just not done via fork(), but using Threads. | I'm not sure exactly what you're trying to do here. It sounds to me like you have a solution in mind to a problem that would best be solved in another way. Would something like this accomplish your **end goal**?
```
public class MyApp implements Runnable
{
public MyApp(int foo, String bar)
{
// Set stuff up...
}
@Override
public void run()
{
// Do stuff...
}
public static void main(String[] argv)
{
// Parse command line args...
Thread thread0 = new Thread(new MyApp(foo, bar));
Thread thread1 = new Thread(new MyApp(foo, bar));
thread0.start();
thread1.start();
}
}
```
Though I would probably put `main()` in another object in a real app, since life-cycle management is a separate concern. | Forking a process in Java | [
"",
"java",
"runtime",
""
] |
I am displaying a form using `xForm.ShowDialog(this);`.
This form has a button which has its `DialogResult` set to OK. Now when I click on the OK button, there is some validation performed. If it fails I want the form to remain as it but but the form closes and returns an `DialogResult.OK` to the main form. So how do I prevent that from happening?
For e.g.
```
Button_click
{
If validation fails pretend we never came here
else some code.. return DialogResult.OK
}
``` | Don't assign a DialogResult to the button. A Method that returns a DialogResult can be used that calls the Form.ShowDialog method. If the Validate button is hit, validate the form and if the validation succeeds return the expected DialogResult. | ```
Button_click()
{
if (this.Validate())
{
this.DialogResult = DialogResult.OK ;
}
}
``` | Cancel a click event in ShowDialog form | [
"",
"c#",
""
] |
I've current got a line at the top of all my tests that looks like this:
```
Console.WriteLine(System.Reflection.MethodBase.GetCurrentMethod().Name);
```
Seems like it'd be nice if I could just put this in my Init method (the one tagged with `[Setup]`). I thought this would work but no matter what number I put in for the stack frame the closest I can get is `Init`. Not what I want, but very close:
```
string methodName = new StackFrame(0).GetMethod().Name;
Console.WriteLine(methodName);
```
I think this just might not be possible, given the way that Nunit runs tests.
Why do this, you say? Because in my console output it'd be nice to see where a new test started so if they both hit the same code and output different values, I'll know which one did what, without having to debug. | TestCaseAttribute wasn't added until NUnit 2.5, which could be why you can't find it. But it wouldn't help anyway -- unfortunately, the SetUp method is called before the test method, not from within the context of the test method (so it won't show up in the call stack).
Fortunately, NUnit already supports what you're trying to do! From the GUI, go to Tools > Options > GUI > General > Text Output and check 'Display TestCase Labels'. Or, for the console runner, just add `/labels` to the parameters. | The following could help me:
```
string testName = NUnit.Framework.TestContext.CurrentContext.Test.Name;
string testFullName = NUnit.Framework.TestContext.CurrentContext.Test.FullName;
``` | output the name of the current test via use of code in [Setup] method | [
"",
"c#",
"nunit",
""
] |
In Python, how big can a list get? I need a list of about 12000 elements. Will I still be able to run list methods such as sorting, etc? | According to the [source code](https://svn.python.org/projects/python/trunk/Objects/listobject.c?revision=69227&view=markup), the maximum size of a list is `PY_SSIZE_T_MAX/sizeof(PyObject*)`.
`PY_SSIZE_T_MAX` is defined in [pyport.h](https://svn.python.org/projects/python/trunk/Include/pyport.h?revision=70489&view=markup) to be `((size_t) -1)>>1`
On a regular 32bit system, this is (4294967295 / 2) / 4 or 536870912.
Therefore the maximum size of a python list on a 32 bit system is **536,870,912** elements.
As long as the number of elements you have is equal or below this, all list functions should operate correctly. | As the [Python documentation says](http://docs.python.org/2/library/sys.html#sys.maxsize):
**sys.maxsize**
> The largest positive integer supported by the platform’s Py\_ssize\_t type, and thus the maximum size lists, strings, dicts, and many other containers can have.
In my computer (Linux x86\_64):
```
>>> import sys
>>> print sys.maxsize
9223372036854775807
``` | How Big can a Python List Get? | [
"",
"python",
"list",
"size",
""
] |
I'm having trouble writing a query. I have a support tabled called 'MYTABLE' and it has a column called 'TABLENAME' that can have one or many table names in it. Multiple Tables are separated with commas.
Example:
```
TBLUSER
TBLUSER, TBLACCOUNT
```
I'm trying to write an query that will identify any entries in the MYTABLE table that are not valid tables in the database. I was able to write the follow....
```
SELECT *
FROM MYTABLE T1
LEFT outer JOIN ALL_TAB_COLS T2
ON ( upper(T1.TABLENAME) = upper(t2.Table_Name)
AND T2.Owner = 'ME'
)
WHERE TABLE_NAME IS NULL;
```
And it works exactly how I want - but it only works when the entry in MYTABLE contains a single table. When there are multiple tables separated by commas - it fails. My SQL skills are somewhat lacking and my natural instinct is to 'Do a For Each' but I feel that's not the right approach (and I have no idea how to do that in SQL). | You're storing a string in MYTABLE.TABLENAME and trying to match it against a string in ALL\_TAB\_COLS.TABLE\_NAME (which btw, I don't see any reason you would use ALL\_TAB\_COLS instead of ALL\_TABLES in this case).
If your string is 'TBLUSER, TBLACCOUNT', it's not going to be equal to the string 'TBLUSER' or the string 'TBLACCOUNT'. That's all the expression `upper(T1.TABLENAME) = upper(t2.Table_Name)` is testing -- are these two string equal? You seem to be expecting that it somehow "knows" that your data happens to be a comma-separated list of table names.
The brute-force method to make what you have work using string comparisons is to change the condition to `','||upper(T1.TABLENAME)||',' LIKE '%,'||upper(t2.Table_Name)||',%`. So you basically would be looking at whether TABLE\_NAME is a substring of your TABLENAME column value.
However, the real point is that this is a not very good database design. First of all, from a simple point of clarity, why would you name a column "TABLENAME" (singular) and then put values in it that represent multiple table names? If you're going to do that, you should at least call it something like "TABLENAMELIST".
More importantly, this is not generally the way we do things in relational databases. If your MYTABLE looks like this:
```
ID TABLENAME
1 TBLUSER
2 TBLUSER, TBLACCOUNT
```
then a more proper relational way to design the table would be:
```
ID TBL_NUM TABLENAME
1 1 TBLUSER
2 1 TBLUSER
2 2 TBLACCOUNT
```
Then your query would work as-is, more or less, because the TABLENAME column would always contain the name of a single table. | You seriously need to rethink your database design there. Keeping multiple entries on a single record in a table that is supposed to keep track of those entries is a big giant WTF.
You need to change your design so that instead of what you describe you have something like:
```
ID TABLENAME
----------------------
1 TBLUSER
2 TBLUSER
2 TBLACCOUNT
```
Where the ID + Tablename is a composite primary key. This would make your query you have wrote work (although not work based on the bare-bones example I provided above).
**NOTE** I know that this may not be what you are looking for in your exact problem, but I feel it is important to say anyway because future users may come and find this problem and need a better understanding of database normalization practices (which you may not be able to do since the application is as it is because "that's just how it is"). | Trouble Writing SQL Query | [
"",
"sql",
"oracle",
""
] |
I am using the DatabasePublishingWizard to generate a large create script, containing both data and schema. The file it produces is ginormous so opening the script to fix any syntax errors is next to impossible and machines with less than 4gb have a hard time getting it to run! What should I do and how should I do it? Thanks everyone for any help you can provide. | With the Database Publishing Wizard, you can have all the objects created as separate files instead of one big one. Then you can put all the files in source control and track all changes.
My current project uses a script to recreate a database for development. The script deletes all existing objects and then readds them using the following statement for each object file.
sqlcmd -S %1 -d THRIVEHQ -E -b -i "../Tables/Schema.sql"
if %ERRORLEVEL% NEQ 0 goto errors | Just want to add to Kevin's comment. Breaking the scripts into separate files THEN write the script to put all the files in order of execution.
When dumping a large database that has a lot of inter-dependencies as one large file won't do you much good as in most cases the script won't execute without errors. In my world I use a naming convention that helps me quickly see which, in this case, views are dependent on other views. For example, if I have a view that just produces a dump of data I'd use something like this v\_VIEW\_NAME\_ORIGINATING-TABLE\_Dump, then I'd change the suffix to something like \_weekly or \_weekly\_Summary for views that are derived off of the main dump table.
I learned my lesson many years ago and have since follow this naming schema in all my databases. | How do I split a .sql script into multiple files? | [
"",
"sql",
"sql-server-2005",
"t-sql",
""
] |
I have a folder pulled from a wordpress installation, >1000 files. Some php code is throwing an error due to trailing spaces on the very last line (I cleaned up an iframe injection on some final lines of pages, and did find/replace with a space, but didn't know that that would throw off all my code).
What's the most efficient way to chop those spaces? I've never run a regex before, but know that's what I would use. Help! | Something like:
find -type f |xargs sed -i '$s/[[:space:]]+$//'
That should remove trailing spaces on the last line of any file anywhere within the cwd. The first $ is the sed address for "last line" and the second is the regex for end of line.
As always, be sure to backup first. | If you're certain it's a trailing space on the last line of the file, then you'd want a bash script (I'm assuming you're using Linux) to, for each file (use "find ." to get a list), tail -1 the file, and then grep that line for space or tab.
Tangentially, it's useful to know that the closing ?> is unnecessary at the end of PHP files, and it's best to omit it there. I can't count the number of times I've seen a PHP file that ends with "?> " and people go nuts trying to find that one extra space that's causing output/header problems. | Regex question to find a trailing space in a whole folder | [
"",
"php",
"regex",
"directory",
""
] |
I've been using C++ for a few years, and today I saw some code, but how can this be perfectly legal?
```
int main(int argc, char **argv)
{
size_t size;
cin >> size;
int array[size];
for(size_t i = 0; i < size; i++)
{
array[i] = i;
cout << i << endl;
}
return 0;
}
```
Compiled under GCC.
How can the size be determined at run-time without `new` or `malloc`?
Just to double check, I've googled some and all similar codes to mine are claimed to give storage size error.
Even Deitel's C++ How To Program p. 261 states under Common Programming Error 4.5:
> Only constants can be used to declare the size of automatic and static arrays.
Enlight me. | This is valid in C99.
C99 standard supports variable sized arrays on the stack. Probably your compiler has chosen to support this construct too.
Note that this is different from `malloc` and `new`. `gcc` allocates the array on the stack, just like it does with `int array[100]` by just adjusting the stack pointer. No heap allocation is done. It's pretty much like [`_alloca`](https://learn.microsoft.com/en-us/cpp/c-runtime-library/reference/alloca?view=vs-2019). | This is known as VLAs (variable length arrays). It is standard in c99, but gcc allows it in c++ code as an extension. If you want it to reject the code, try experimenting with `-std=standard`, `-ansi` and `-pedantic` options. | Array size at run time without dynamic allocation is allowed? | [
"",
"c++",
"array-initialization",
""
] |
I have the ViewValue class defined as follows:
```
class ViewValue {
private Long id;
private Integer value;
private String description;
private View view;
private Double defaultFeeRate;
// getters and setters for all properties
}
```
Somewhere in my code i need to convert a list of ViewValue instances to a list containing values of id fields from corresponding ViewValue.
I do it using foreach loop:
```
List<Long> toIdsList(List<ViewValue> viewValues) {
List<Long> ids = new ArrayList<Long>();
for (ViewValue viewValue : viewValues) {
ids.add(viewValue.getId());
}
return ids;
```
}
Is there a better approach to this problem? | EDIT: This answer is based on the idea that you'll need to do similar things for different entities and different properties elsewhere in your code. If you *only* need to convert the list of ViewValues to a list of Longs by ID, then stick with your original code. If you want a more reusable solution, however, read on...
I would declare an interface for the projection, e.g.
```
public interface Function<Arg,Result>
{
public Result apply(Arg arg);
}
```
Then you can write a single generic conversion method:
```
public <Source, Result> List<Result> convertAll(List<Source> source,
Function<Source, Result> projection)
{
ArrayList<Result> results = new ArrayList<Result>();
for (Source element : source)
{
results.add(projection.apply(element));
}
return results;
}
```
Then you can define simple projections like this:
```
private static final Function<ViewValue, Long> ID_PROJECTION =
new Function<ViewValue, Long>()
{
public Long apply(ViewValue x)
{
return x.getId();
}
};
```
And apply it just like this:
```
List<Long> ids = convertAll(values, ID_PROJECTION);
```
(Obviously using K&R bracing and longer lines makes the projection declaration a bit shorter :)
Frankly all of this would be a lot nicer with lambda expressions, but never mind... | We can do it in a single line of code using java 8
```
List<Long> ids = viewValues.stream().map(ViewValue::getId).collect(Collectors.toList());
```
For more info : **[Java 8 - Streams](https://www.tutorialspoint.com/java8/java8_streams.htm)** | Java - map a list of objects to a list with values of their property attributes | [
"",
"java",
"list",
"properties",
""
] |
Firstly, I realise that this is a very similar question to this one: [Which are the good open source libraries for Collective Intelligence in .net/java?](https://stackoverflow.com/questions/345982/which-are-the-good-open-source-libraries-for-collective-intelligence-in-net-java)
... but all the answers to that one were Java centric so I am asking again, this time looking more for .Net (idealy C#) ideas.
A little background; I recently read [Toby Segran's excellent book on CI](https://rads.stackoverflow.com/amzn/click/com/0596529325), and I just got hold of [Satnam Alag's book](https://rads.stackoverflow.com/amzn/click/com/1933988312) (which I am sure is also excellent, but I have only just opened it). These are Python and Java centric, I don't have any trouble reading the code samples, but as I am a C# developer it would be fun to play with some of these ideas in my native language. I've had a search of the web and SO and not come up with too much. In a way this is great news, maybe I could port something to .Net (suggestions welcome), but I'd also really like to take a look at any existing projects before I do this.
So, are there an CI fans out there working in .Net with OS projects, have I missed some glaringly obvious and interesting books/sites/blogs?
I realise CI is a pretty broad field, so to narrow it down a little I am primarily interested in the clustering / prediction /recommendations areas, but am open to other ideas.
**Edit**: Just spotted this book about to be published by Manning which may interest CI fans: [Algorithms of the Intelligent Web](http://www.manning.com/marmanis/).
**Edit** Clarification in response to comment by Moose; what I am looking for really is libraries, frameworks or larger-scale projects (idealy OS) that use CI techniques with .Net. Code samples are great, but as Moose said in his comment it is easy enough to take Java examples and port them. For example, there is an interesting looking project written in Java called [WEKA](http://en.wikipedia.org/wiki/Weka_%28machine_learning%29), there is no reason I can't use this and experiment with it, I was just curious to know if there were similar things going on in .Net. I have just been browsing info on [Lucene](http://en.wikipedia.org/wiki/Lucene) and I see that there is a C# port of that, so that's a start... are there any more out there?
**Edit** This is not C#, but it is .Net; Robert Pickering has started collection F# CI resources [here](http://github.com/robertpi/fscollintelli/tree/master). Looks interesting, but I'm still looking for C# info too. | Microsoft Research ( full disclosure: I work at Microsoft, though not in the group that released this tool ) has just released a machine learning library in .NET called Infer.NET.
[link text](http://research.microsoft.com/en-us/um/cambridge/projects/infernet/default.aspx)
You might want to check it out. | Here's a link for a slope one predictor for rating-based collaborative filtering:
[C# Implementation of Slope One](http://www.cnblogs.com/kuber/articles/SlopeOne_CSharp.html) | Looking for collective intelligence .Net / C# resources | [
"",
"c#",
".net",
"algorithm",
"cluster-analysis",
"collective-intelligence",
""
] |
I am changing the Visibility of a Form to false during the load event AND the form still shows itself. What is the right event to tie this.Visible = false; to? I'd like to instantiate the Form1 without showing it.
```
using System;
using System.Windows.Forms;
namespace TestClient
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
private void Form1_Load(object sender, EventArgs e)
{
this.Visible = false;
}
}
}
``` | Regardless of how much you try to set the Visible property before the form has been shown, it will pop up. As I understand it, this is because it is the MainForm of the current ApplicationContext. One way to have the form automatically load, but not show at application startup is to alter the Main method. By default, it looks something like this (.NET 2.0 VS2005):
```
[STAThread]
static void Main()
{
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run(new Form1());
}
```
If you instead do something like this, the application will start, load your form and run, but the form will not show:
```
[STAThread]
static void Main()
{
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Form1 f = new Form1();
Application.Run();
}
```
I am not entirely sure how this is useful, but I hope you know that ;o)
Update: it seems that you do not need to set the Visible property to false, or supply an ApplicationContext instance (that will be automatically created for you "under the hood"). Shortened the code accordingly. | I know this is an old question, but I just stumbled upon it and am pretty surprised no one has mentioned [`SetVisibleCore`](http://msdn.microsoft.com/en-us/library/system.windows.forms.control.setvisiblecore%28v=vs.90%29.aspx):
```
bool isVisibleCore = false;
protected override void SetVisibleCore(bool value)
{
base.SetVisibleCore(isVisibleCore);
}
```
In that code snippet, as long as `isVisibleCore` remains false, the form will remain invisible. If it's set to false when the form is instantiated, you won't get that brief flash of visibility that you'd get if you set `Visible = false` in the Shown event. | C#/.NET - WinForms - Instantiate a Form without showing it | [
"",
"c#",
".net",
"winforms",
"events",
"visibility",
""
] |
I'm trying to use Ajax to fetch an HTML page and then pull out a div by it's ID, and insert that DIV into the current page. So the current page loads (via Ajax) a second page, pulls the div out of the Ajax response and inserts into the current page. However I am at a loss as unless the response is text/xml, I cannot use any DOM functions on it... can I? | Jquery (or other libraries??) will basically do all this for you. I highly recommend looking into this and not reinventing the wheel.
For query it would probably like:
```
// Make a call to url, with data
$.ajax(
{ url: $url,
data: $data,
dataType: 'xml',
callback: function(returnData) {
// Jquery find <mytag attribute="foo">...</mytag> and store it in mydata
var mydata = $(returnData).find('mytag[attribute=foo]');
// Insert into current page to somewhere with class="after-me"
$('.after-me').html(mydata);
}
});
```
I may have the syntax wrong. But here is the docs: <http://docs.jquery.com/Ajax/jQuery.ajax#options> | Yes you can. [Here](http://www.w3schools.com/Xml/xml_parser.asp) you will find a resource for how to parse XML responses.
If you are loading it into the DOM tree that already exists (`innerHTML`), you should be able to call the standard DOM traversal functions you are used to. | Can Javascript access the DOM of an Ajax text/html response? | [
"",
"javascript",
"html",
"ajax",
"dom",
""
] |
I've just completed the very very nice django tutorial and it all went swimmingly. One of the first parts of the tutorial is that it says not to use their example server thingie in production, my first act after the tutorial was thus to try to run my app on apache.
I'm running OSX 10.5 and have the standard apache (which refuses to run python) and MAMP (which begrudgingly allows it in cgi-bin). The problem is that I've no idea which script to call, in the tutorial it was always localhost:8000/polls but I've no idea how that's meant to map to a specific file.
Have I missed something blatantly obvious about what to do with a .htaccess file or does the tutorial not actually explain how to use it somewhere else? | You probably won't find much joy using `.htaccess` to configure Django through Apache (though I confess you probably could do it if you're determined enough... but for production I suspect it will be more complicated than necessary). I develop and run Django in OS X, and it works quite seamlessly.
The secret is that you must configure `httpd.conf` to pass requests to Django via one of three options: `mod_wsgi` (the most modern approach), `mod_python` (second best, but works fine on OS X's Python 2.5), `fastcgi` (well... if you must to match your production environment).
Django's [deployment docs](http://docs.djangoproject.com/en/dev/howto/deployment/#howto-deployment-index) have good advice and instruction for all three options.
If you are using the default OS X apache install, edit `/etc/apache2/httpd.conf` with the directives found in the Django docs above. I can't speak for MAMP, but if you build Apache from source (which is so easy on OS X I do wonder why anyone bothers with MAMP... my insecurities are showing), edit `/usr/local/apache2/conf/httpd.conf`. | Unless you are planning on going to production with OS X you might not want to bother. If you must do it, go straight to mod\_wsgi. Don't bother with mod\_python or older solutions. I did mod\_python on Apache and while it runs great now, it took countless hours to set up.
Also, just to clarify something based on what you said: You're not going to find a mapping between the url path (like /polls) and a script that is being called. Django doesn't work like that. With Django your application is loaded into memory waiting for requests. Once a request comes in it gets dispatched through the url map that you created in urls.py. That boils down to a function call somewhere in your code.
That's why for a webserver like Apache you need a module like mod\_wsgi, which gives your app a spot in memory in which to live. Compare that with something like CGI where the webserver executes a specific script on demand at a location that is physically mapped between the url and the filesystem.
I hope that's helpful and not telling you something you already knew. :) | Running django on OSX | [
"",
"python",
"django",
"macos",
""
] |
Confusing title, hopefully some code will clarify:
```
struct MyNestedType {
void func();
};
struct MyType {
MyNestedType* nested;
}
std::vector<MyType> vec;
// ... populate vec
// I want something approximating this line, but that doesn't use made-up C++!
std::for_each(vec.begin(), vec.end(), std::mem_fun_ref(&MyType::nested->func));
```
So basically I want to call a method on each element of the container, but it's not actually a method of the type, it's some method on a contained type... I know I could write a function object to 'pass on' the call but there are a few methods I'd like to call and that will get messy.
Any ideas? | You can use such functor
```
template <typename T, T* MyType::* TMember, void (T::* TNestedMember)() >
struct Caller {
Caller() {
}
template <typename TObject>
void operator()(TObject object) {
(object.*TMember->*TNestedMember)();
}
};
```
To solve your problem
```
struct MyNestedType {
MyNestedType(int a):
a_(a){
}
void func() {
std::cout << "MyNestedType::func " << a_ << std::endl;
}
void foo() {
std::cout << "MyNestedType::foo " << a_ << std::endl;
}
int a_;
};
struct MyType {
MyNestedType* nested;
};
int main()
{
std::vector<MyType> vec;
std::auto_ptr<MyNestedType> nt1(new MyNestedType(2));
std::auto_ptr<MyNestedType> nt2(new MyNestedType(5));
MyType t1 = {nt1.get()};
MyType t2 = {nt2.get()};
vec.push_back(t1);
vec.push_back(t2);
std::for_each(vec.begin(), vec.end(),
Caller<MyNestedType, &MyType::nested, &MyNestedType::func>());
std::for_each(vec.begin(), vec.end(),
Caller<MyNestedType, &MyType::nested, &MyNestedType::foo>());
}
``` | Why don't you just use a simple for-loop?
```
for(vector<MyType>::iterator i = vec.begin(); i != vec.end(); ++i)
i->nested->func();
```
Alternatively, you could use lambda expressions or boost::foreach
```
FOREACH(MyType x, vec)
x.nested->func();
```
You can build your up expression with binders and mem\_funs, but this will get very messy and confusing! There is no advantage in putting everything in one std::foreach line. | Call member functions of members of elements of a container with for_each? | [
"",
"c++",
"stl",
"functor",
"foreach",
""
] |
How can I get the list of logial drives (C#) on a system as well as their capacity and free space? | [`System.IO.DriveInfo.GetDrives()`](http://msdn.microsoft.com/library/system.io.driveinfo.getdrives) | ```
foreach (var drive in DriveInfo.GetDrives())
{
double freeSpace = drive.TotalFreeSpace;
double totalSpace = drive.TotalSize;
double percentFree = (freeSpace / totalSpace) * 100;
float num = (float)percentFree;
Console.WriteLine("Drive:{0} With {1} % free", drive.Name, num);
Console.WriteLine("Space Remaining:{0}", drive.AvailableFreeSpace);
Console.WriteLine("Percent Free Space:{0}", percentFree);
Console.WriteLine("Space used:{0}", drive.TotalSize);
Console.WriteLine("Type: {0}", drive.DriveType);
}
``` | Getting a list of logical drives | [
"",
"c#",
"hard-drive",
""
] |
I use the following code to compile a cpp file to object file.
```
g++ -c main.cpp
```
Above code generates the .o fles in same directory where main.cpp resides.
1. Suppose I have a folder named obj and need to generate the object files there, how could I write it?
2. How can I see the compiler switches supported by g++ and it's usages?
Any help would be great | > Suppose I have a folder named obj and need to generate the object files there, how do I write?
Use:
```
g++ -c main.cpp -o obj/main.o
```
> How can I see the compiler switches supported by g++ and it's usages?
If you are on a \*nix system use:
```
man g++
```
or use `info g++` | If you type
```
$man g++
```
Here's the [man page online](http://linux.die.net/man/1/g++) You'll probably get gobs of good information there. You can also try
```
$g++ --help
```
To your question. If you used the -o switch, you can specify the output file to use. So you could probably do something like
```
$g++ -c main.cpp -o obj/main.obj
``` | Generating object file to separate directory using g++ compiler - C++ | [
"",
"c++",
"g++",
""
] |
What are the big advantages from JMS over Webservices or vice versa?
(Are webservices bloated? Is JMS overall better for providing interfaces?) | EDITED after correction from erickson:
JMS requires that you have a JMS provider, a Java class that implements the MessageListener interface for processing messages, and a client that knows how to connect to the JMS queue. JMS means asynchronous processing - the client sends the message and doesn't necessarily wait for a response. JMS can be used in a point-to-point queue fashion or publish/subscribe.
"Service" is a fluid term. I think of a service as a component that lives out on a network and advertises a contract: "If you send me X I'll perform this task for you and return Y."
Distributed components have been around for a long time. Each one communicated using a different protocol (e.g., COM, Corba, RMI, etc.) and exposed their contract in different ways.
Web services are the latest trend in distributed services. They use HTTP as their protocol and can interoperate with any client that can connect via TCP/IP and make an HTTP request.
You can use SOAP or RPC-XML or REST or "contract first" styles, but the underlying idea of a distributed component using HTTP as its protocol remains.
If you accept all this, web services are usually synchronous calls. They need not be bloated, but you can write bad components in any style or language.
You can start designing any distributed component by designing the request and responses first. Given those, you choose JMS or web services based on what kind of clients you want to have and whether or not the communication is synchronous or asynchronous. | Message based systems, including JMS, provide the ability to be "chronologically decoupled" from the other end. A message can be sent without the other end being available.
All other common A2A approaches require the partner to be able to respond immediately, requiring them to be able to handle peak loads, with little ability to spread processing. | JMS vs Webservices | [
"",
"java",
"web-services",
"jms",
""
] |
I am having a problem where a routine (that I cannot modify) is returning me either a 3 nested array -or- a 2 nested array. The key values are never the same, however, I'd like to normalize the nesting so that I can make the 2 nested array 3 levels deep every time to avoid "Notice: Undefined index:" errors. Or if possible, have a routine to count the number of levels deep the array is so I can code accordingly. | You can use isset() to determine if a particular level is present in the array. If not, add it. | ```
function get_depth($arr) {
foreach ( $arr as $arr2 ) {
if ( is_array($arr2) ) {
return 1+get_depth($arr2);
}
break;
}
return 1;
}
``` | Problem with array values | [
"",
"php",
"arrays",
""
] |
I need to do a search and replace on long text strings. I want to find all instances of broken links that look like this:
```
<a href="http://any.url.here/%7BlocalLink:1369%7D%7C%7CThank%20you%20for%20registering">broken link</a>
```
and fix it so that it looks like this:
```
<a href="/{localLink:1369}" title="Thank you for registering">link</a>
```
There may be a number of these broken links in the text field. My difficulty is working out how to reuse the matched ID (in this case 1369). In the content this ID changes from link to link, as does the url and the link text.
Thanks,
David
EDIT: To clarify, I am writing C# code to run through hundreds of long text fields to fix broken links in them. Each single text field contains html that can have any number of broken links in there - the regex needs to find them all and replace them with the correct version of the link. | Take this with a grain of salt, HTML and Regex don't play well together:
```
(<a\s+[^>]*href=")[^"%]*%7B(localLink:\d+)%7D%7C%7C([^"]*)("[^>]*>[^<]*</a>)
```
When applied to your input and replaced with
```
$1/{$2}" title="$3$4
```
the following is produced:
```
<a href="/{localLink:1369}" title="Thank%20you%20for%20registering">broken link</a>
```
This is as close as it gets with regex alone. You'll need to use a [`MatchEvaluator` delegate](http://msdn.microsoft.com/en-us/library/system.text.regularexpressions.matchevaluator.aspx) to remove the URL encoding from the replacement. | I'm assuming that you already have the element and the attributes parsed. So to process the URL, use something like this:
```
string url = "http://any.url.here/%7BlocalLink:1369%7D%7C%7CThank%20you%20for%20registering";
Match match = Regex.Match(HttpUtility.UrlDecode(url), @"^http://[^/]+/\{(?<local>[^:]+):(?<id>\d+)\}\|\|(?<title>.*)$");
if (match.Success) {
Console.WriteLine(match.Groups["local"].Value);
Console.WriteLine(match.Groups["id"].Value);
Console.WriteLine(match.Groups["title"].Value);
} else {
Console.WriteLine("Not one of those URLs");
}
``` | c# regex to find and replace reusing part of the matched text | [
"",
"c#",
"regex",
""
] |
> **Possible Duplicate:**
> [How do I generate a hashcode from a byte array in c#](https://stackoverflow.com/questions/16340/how-do-i-generate-a-hashcode-from-a-byte-array-in-c-sharp)
In C#, I need to create a Hash of an image to ensure it is unique in storage.
I can easily convert it to a byte array, but unsure how to proceed from there.
Are there any classes in the .NET framework that can assist me, or is anyone aware of some *efficient* algorithms to create such a unique hash? | There's plenty of hashsum providers in .NET which create cryptographic hashes - which satisifies your condition that they are unique (for most purposes collision-proof). They are all *extremely* fast and the hashing definitely won't be the bottleneck in your app unless you're doing it a trillion times over.
Personally I like SHA1:
```
public static string GetHashSHA1(this byte[] data)
{
using (var sha1 = new System.Security.Cryptography.SHA1CryptoServiceProvider())
{
return string.Concat(sha1.ComputeHash(data).Select(x => x.ToString("X2")));
}
}
```
Even when people say one method might be slower than another, it's all in relative terms. A program dealing with images definitely won't notice the microsecond process of generating a hashsum.
And regarding collisions, for most purposes this is also irrelevant. Even "obsolete" methods like MD5 are still highly useful in most situations. Only recommend not using it when the security of your system *relies* on preventing collisions. | The part of [Rex M's answer](https://stackoverflow.com/a/800469/50776) about using SHA1 to generate a hash is a good one (MD5 is also a popular option). zvolkov's suggestion about not constantly creating new crypto providers is also a good one (as is the suggestion about using CRC if speed is more important than virtually-guaranteed uniqueness.
However, do *not* use [Encoding.UTF8.GetString()](http://msdn.microsoft.com/en-us/library/744y86tc.aspx) to convert a byte[] into a string (unless of course you know from context that it is valid UTF8). For one, it will [reject invalid surogates](http://blogs.msdn.com/oldnewthing/archive/2004/09/07/226306.aspx). A method guaranteed to always give you a valid string from a byte[] is [Convert.ToBase64String()](http://msdn.microsoft.com/en-us/library/dhx0d524.aspx). | C# Create a hash for a byte array or image | [
"",
"c#",
".net",
"image",
"hash",
""
] |
I'm attempting to provide a script-only solution for reading the contents of a file on a client machine through a browser.
I have a solution that works with Firefox and Internet Explorer. It's not pretty, but I'm only trying things at the moment:
```
function getFileContents() {
var fileForUpload = document.forms[0].fileForUpload;
var fileName = fileForUpload.value;
if (fileForUpload.files) {
var fileContents = fileForUpload.files.item(0).getAsBinary();
document.forms[0].fileContents.innerHTML = fileContents;
} else {
// try the IE method
var fileContents = ieReadFile(fileName);
document.forms[0].fileContents.innerHTML = fileContents;
}
}
function ieReadFile(filename)
{
try
{
var fso = new ActiveXObject("Scripting.FileSystemObject");
var fh = fso.OpenTextFile(filename, 1);
var contents = fh.ReadAll();
fh.Close();
return contents;
}
catch (Exception)
{
return "Cannot open file :(";
}
}
```
I can call `getFileContents()` and it will write the contents into the `fileContents` text area.
**Is there a way to do this in other browsers?**
I'm most concerned with Safari and Chrome at the moment, but I'm open to suggestions for any other browser.
**Edit:** In response to the question, "Why do you want to do this?":
Basically, I want to hash the file contents together with a one-time-password on the client side so I can send this information back as a verification. | **Edited to add information about the File API**
Since I originally wrote this answer, the [File API](http://dev.w3.org/2006/webapi/FileAPI/) has been proposed as a standard and [implemented in most browsers](http://caniuse.com/#feat=fileapi) (as of IE 10, which added support for `FileReader` API described here, though not yet the `File` API). The API is a bit more complicated than the older Mozilla API, as it is designed to support asynchronous reading of files, better support for binary files and decoding of different text encodings. There is [some documentation available on the Mozilla Developer Network](https://developer.mozilla.org/en/using_files_from_web_applications) as well as various examples online. You would use it as follows:
```
var file = document.getElementById("fileForUpload").files[0];
if (file) {
var reader = new FileReader();
reader.readAsText(file, "UTF-8");
reader.onload = function (evt) {
document.getElementById("fileContents").innerHTML = evt.target.result;
}
reader.onerror = function (evt) {
document.getElementById("fileContents").innerHTML = "error reading file";
}
}
```
**Original answer**
There does not appear to be a way to do this in WebKit (thus, Safari and Chrome). The only keys that a [File](http://trac.webkit.org/export/42566/trunk/WebCore/html/File.idl) object has are `fileName` and `fileSize`. According to the [commit message](http://trac.webkit.org/changeset/34702) for the File and FileList support, these are inspired by [Mozilla's File object](https://developer.mozilla.org/en/nsIDOMFile), but they appear to support only a subset of the features.
If you would like to change this, you could always [send a patch](http://webkit.org/coding/contributing.html) to the WebKit project. Another possibility would be to propose the Mozilla API for inclusion in [HTML 5](http://www.whatwg.org/specs/web-apps/current-work/); the [WHATWG](http://lists.whatwg.org/listinfo.cgi/whatwg-whatwg.org) mailing list is probably the best place to do that. If you do that, then it is much more likely that there will be a cross-browser way to do this, at least in a couple years time. Of course, submitting either a patch or a proposal for inclusion to HTML 5 does mean some work defending the idea, but the fact that Firefox already implements it gives you something to start with. | There's a modern native alternative: [File](https://developer.mozilla.org/en-US/docs/Web/API/File) implements [Blob](https://developer.mozilla.org/en-US/docs/Web/API/Blob), so we can call [Blob.text()](https://developer.mozilla.org/en-US/docs/Web/API/Blob/text).
```
async function readText(event) {
const file = event.target.files.item(0)
const text = await file.text();
document.getElementById("output").innerText = text
}
```
```
<input type="file" onchange="readText(event)" />
<pre id="output"></pre>
```
Currently (September 2020) this is supported in Chrome and Firefox, for other Browser you need to load a polyfill, e.g. [blob-polyfill](https://www.npmjs.com/package/blob-polyfill). | Reading file contents on the client-side in javascript in various browsers | [
"",
"javascript",
"html",
"file-io",
"sandbox",
""
] |
This is a silly question, but you can use this code to check if something is a particular type...
```
if (child is IContainer) { //....
```
Is there a more elegant way to check for the "NOT" instance?
```
if (!(child is IContainer)) { //A little ugly... silly, yes I know...
//these don't work :)
if (child !is IContainer) {
if (child isnt IContainer) {
if (child aint IContainer) {
if (child isnotafreaking IContainer) {
```
Yes, yes... silly question....
**Because there is some question** on what the code looks like, it's just a simple return at the start of a method.
```
public void Update(DocumentPart part) {
part.Update();
if (!(DocumentPart is IContainer)) { return; }
foreach(DocumentPart child in ((IContainer)part).Children) {
//...etc...
``` | ```
if(!(child is IContainer))
```
is the only operator to go (there's no `IsNot` operator).
You can build an extension method that does it:
```
public static bool IsA<T>(this object obj) {
return obj is T;
}
```
and then use it to:
```
if (!child.IsA<IContainer>())
```
And you could follow on your theme:
```
public static bool IsNotAFreaking<T>(this object obj) {
return !(obj is T);
}
if (child.IsNotAFreaking<IContainer>()) { // ...
```
---
### Update (considering the OP's code snippet):
Since you're actually casting the value afterward, you could just use `as` instead:
```
public void Update(DocumentPart part) {
part.Update();
IContainer containerPart = part as IContainer;
if(containerPart == null) return;
foreach(DocumentPart child in containerPart.Children) { // omit the cast.
//...etc...
``` | You can do it this way:
```
object a = new StreamWriter("c:\\temp\\test.txt");
if (a is TextReader == false)
{
Console.WriteLine("failed");
}
``` | C# : 'is' keyword and checking for Not | [
"",
"c#",
"casting",
"keyword",
""
] |
I'm currently using Vim as a lightweight IDE. I have NERDTree, bufexplorer, supertab, and ctags plugins which do *almost* everything I want. Only big thing missing for me is auto code formatting.
I'm working with some messy PHP code which has inconsistent indenting and code formatting, ideally I could highlight the code I want formatted (whole files would be fine too) and run a command to tidy it.
Does anybody have a nice solution for this working in Vim? | Quick way to fix PHP indentation in vim is to visually select the lines you want to work with using `shift`-`v`, and then press equals (`=`) to trigger auto-formatting.
As for other formatting issues you're probably looking at employing some regex search and replaces, such as `:%s/^M/\r/g` (that's `ctrl`-`V` `ctrl`-`m`, not `caret`-`M`) to fix line endings | Enter normal mode in vim and then type
```
1GVG=
``` | Formatting PHP Code within Vim | [
"",
"php",
"vim",
"code-formatting",
"tidy",
""
] |
I keep ending up at this situation where I want to use a dictionary very much like the one 'locals' gives back, but that only contains the variables in the limited scope of the function. Is there a way to do this in python?
A bit more about why I want to do this: I'm playing with Django and when I go to give my templates context, I am forced either to either manually make a dictionary (In violation with DRY principles) or pass in locals() which contains far more entries then are needed (wasteful). Is there perhaps something I'm missing with django which would alleviate the need of a python level solution?
To Clarify:
So, the case that I've hit repeatedly is where I have:
```
@render_to('my_template.html')
def myview(request):
var1 = #blahblah
var2 = #...
# do stuff with vars
return {'var1': val1,'var2':val2}
```
So instead of repeating those variables and naming conventions, I'll do:
```
@render_to('my_template.html')
def myview(request):
var1 = #blahblah
var2 = #...
# do stuff with vars
return locals()
```
Which I find cleaner, but I know its kind of sloppy since there are about 30 more entries in locals() then I actually need. | I'm not sure I agree that making a dictionary is a violation of DRY, but if you really don't want to repeat anything at all, you could just define a 'context' dictionary at the top of the view and use dictionary keys instead of variables throughout the view.
```
def my_view(request):
context = {}
context['items'] = Item.objects.all()
context['anothervalue'] = context['items'][2].name
return render_to_response('template.html', context)
``` | How is passing a dictionary a violation of DRY? [Django is all about DRY](http://docs.djangoproject.com/en/dev/misc/design-philosophies/#don-t-repeat-yourself-dry), so I doubt the standard behavior of it would directly violate it. In either case, however, I use a modified version of [django-annoying](http://bitbucket.org/offline/django-annoying/wiki/Home) to make the whole thing easier:
```
@render_to('my_template.html')
def myview(request):
# figure stuff out...
return {'var1':'val1','var2','val2'}
```
The `render_to` decorator takes care of the request context and all that good stuff. Works well.
If this doesn't help, I suggest rephrasing your question. Whatever you want to do messing around with `locals()` and such is rarely necessary especially in this kind of situation with Django. | Getting local dictionary for function scope only in Python | [
"",
"python",
"django",
"scope",
"django-views",
"locals",
""
] |
I have a webpage with a form element and a popup window (opened by window.open).
Both have jQuery available.
The popup window has a javascript that can change the form element in the opener window. That works perfectly by doing...
```
$(opener.document.formelement).val(vals[0]);
```
However by doing that the onChange event will not fire. That would be required by some other page elements, though. So I tried to fire the onChange event myself with
```
$(opener.document.formelement).change();
```
But that doesn't do anything.
Any hints? I definitely have to have that onChange event fired due to the architecture of other page elements.
This question is similar to [Call Javascript onchange event by programatically changing textbox value](https://stackoverflow.com/questions/735462/call-javascript-onchange-event-by-programatically-changing-textbox-value), but the suggested solutions from that question don't seem to work for me. Maybe that's because of the popup. | Perhaps its the cross-window that is hurting you... Try making a function inside of opener that you call instead. Might help?
In opener:
```
window.changeMyElement = function(value) {
$(formelement).val(value).change();
}
```
From popup:
```
opener.changeMyElement(value);
``` | This line is supposed to work:
```
$(opener.document.formelement).change();
```
According to the jQuery [documentation](http://docs.jquery.com/Events/change) this line triggers the change event of each matched element.
If it's not working for you then there is a problem in your code somewhere. Can you trigger the onchange event by changing in the form element by hand? | Raise "onChange" event when Input Element changed by JavaScript from Popup Window | [
"",
"javascript",
"jquery",
"popup",
"onchange",
""
] |
I spent about 4 hours yesterday trying to fix this issue in my code. I simplified the problem to the example below.
The idea is to store a string in a `stringstream` ending with `std::ends`, then retrieve it later and compare it to the original string.
```
#include <sstream>
#include <iostream>
#include <string>
int main( int argc, char** argv )
{
const std::string HELLO( "hello" );
std::stringstream testStream;
testStream << HELLO << std::ends;
std::string hi = testStream.str();
if( HELLO == hi )
{
std::cout << HELLO << "==" << hi << std::endl;
}
return 0;
}
```
As you can probably guess, the above code when executed will not print anything out.
Although, if printed out, or looked at in the debugger (VS2005), `HELLO` and `hi` look identical, their `.length()` in fact differs by 1. That's what I am guessing is causing the `==` operator to fail.
My question is why. I do not understand why `std::ends` is an invisible character added to string `hi`, making `hi` and `HELLO` different lengths even though they have identical content. Moreover, this invisible character does not get trimmed with boost trim. However, if you use `strcmp` to compare `.c_str()` of the two strings, the comparison works correctly.
The reason I used `std::ends` in the first place is because I've had issues in the past with `stringstream` retaining garbage data at the end of the stream. `std::ends` solved that for me. | `std::ends` inserts a null character into the stream. Getting the content as a `std::string` will retain that null character and create a string with that null character at the respective positions.
So indeed a std::string can contain embedded null characters. The following std::string contents *are* different:
```
ABC
ABC\0
```
A binary zero is not whitespace. But it's also not printable, so you won't see it (unless your terminal displays it specially).
Comparing using `strcmp` will interpret the content of a `std::string` as a C string when you pass `.c_str()`. It will say
> Hmm, characters before the first `\0` (terminating null character) are *ABC*, so i take it the string is *ABC*
And thus, it will not see any difference between the two above. You are probably having this issue:
```
std::stringstream s;
s << "hello";
s.seekp(0);
s << "b";
assert(s.str() == "b"); // will fail!
```
The assert will fail, because the sequence that the stringstream uses is still the old one that contains "hello". What you did is just overwriting the first character. You want to do this:
```
std::stringstream s;
s << "hello";
s.str(""); // reset the sequence
s << "b";
assert(s.str() == "b"); // will succeed!
```
Also read this answer: [How to reuse an ostringstream](https://stackoverflow.com/questions/624260/how-to-reuse-an-ostringstream/624291#624291) | `std::ends` is simply a null character. Traditionally, strings in C and C++ are terminated with a null (ascii 0) character, however it turns out that `std::string` doesn't really require this thing. Anyway to step through your code point by point we see a few interesting things going on:
```
int main( int argc, char** argv )
{
```
The string literal `"hello"` is a traditional zero terminated string constant. We copy that whole into the `std::string` HELLO.
```
const std::string HELLO( "hello" );
std::stringstream testStream;
```
We now put the `string` HELLO (including the trailing 0) into the `stream`, followed by a second null which is put there by the call to `std::ends`.
```
testStream << HELLO << std::ends;
```
We extract out a copy of the stuff we put into the `stream` (the literal string "hello", plus the two null terminators).
```
std::string hi = testStream.str();
```
We then compare the two strings using the `operator ==` on the `std::string` class. This operator (probably) compares the length of the `string` objects - including how ever many trailing null characters. Note that the `std::string` class does not require the underlying character array to end with a trailing null - put another way it allows the string to contain null characters so the first of the two trailing null characters is treated as part of the string `hi`.
Since the two strings are different in the number of trailing nulls, the comparison fails.
```
if( HELLO == hi )
{
std::cout << HELLO << "==" << hi << std::endl;
}
return 0;
}
```
> Although, if printed out, or looked at
> in the debugger (VS2005), HELLO and hi
> look identical, their .length() in
> fact differs by 1. That's what I am
> guessing is causing the "==" operator
> to fail.
Reason being, the length is different by one trailing null character.
> My question is why. I do not
> understand why std::ends is an
> invisible character added to string
> hi, making hi and HELLO different
> lengths even though they have
> identical content. Moreover, this
> invisible character does not get
> trimmed with boost trim. However, if
> you use strcmp to compare .c\_str() of
> the two strings, the comparison works
> correctly.
`strcmp` is different from `std::string` - it is written from back in the early days when strings were terminated with a null - so when it gets to the first trailing null in `hi` it stops looking.
> The reason I used std::ends in the
> first place is because I've had issues
> in the past with stringstream
> retaining garbage data at the end of
> the stream. std::ends solved that for
> me.
Sometimes it is a good idea to understand the underlying representation. | Why does std::ends cause string comparison to fail? | [
"",
"c++",
"stl",
"boost",
""
] |
I've see this sort of thing in Java code quite often...
```
try
{
fileStream.close();
}
catch (IOException ioe)
{
/* Ignore. We do not care. */
}
```
Is this reasonable, or cavalier?
When would I care that closing a file failed? What are the implications of ignoring this exception? | I would *at the very least* log the exception.
I've seen it happen occasionally, if the attempt to close the file fails due to it not being able to flush the data. If you just swallow the exception, then you've lost data without realizing it.
Ideally, you should probably swallow the exception if you're already in the context of another exception (i.e. you're in a finally block, but due to another exception rather than having completed the try block) but throw it if your operation is otherwise successful. Unfortunately that's somewhat ugly to sort out :(
But yes, you should at least log it. | You would care if the `close()` method flushes written content from a buffer to the filesystem, and that fails. e.g. if the file you're writing to is on a remote filesystem that has become unavailable.
Note that the above re. flushing applies to any output stream, not just files. | Why would I care about IOExceptions when a file is closed? | [
"",
"java",
"file",
"io",
""
] |
We are about to start a new Web2/AJAX app and are trying to decide if its worth the time and effort learning Ruby/RubyOnRails instead of PHP, CodeIgnitor and JQuery we currently use.
The key issues are clean/fast/modern AJAX UI, robust error handling, ans maintainability.
I would appreciate unbiased (if thats at all possible talking languages/frameworks) comments from experienced PHP and RUBY developers. | PHP has a terrible reputation because it is so accessible. Anyone can start writing PHP, and most hosting solutions offer PHP these days, so there are a lot of non-programmer types writing programs in PHP. These programs lack proper computer science discipline.
There is a very widespread movement within the PHP community to move toward readable, well formed code as PHP starts to adopt modern language features. With PHP5, OOP became a practical reality and with that an explosion of books and material written about OOP best practices and development patterns. While PHP is often used to write malformed sloppy spaghetti code, the language facilities are there to allow developers to program in development paradigms like MVC, OOP, and TDD.
Not to mention, PEAR has greatly improved the quality and accessibility of community scripts. PHP's strongest asset is its community, and it has been becoming stronger and more disciplined. In many ways, PHP is very much like JavaScript--it had a very sloppy beginning from which the developers and community have been trying to recover. JavaScript is a very sloppy language, but there are some extremely powerful parts of that language that have brought it some well deserved respect in the age of Ajax and interactive web applications.
Languages like Ruby and Python are chock full of things geared toward computer programmers. If you hire a Python or a Ruby programmer, just by virtue of knowing the language that programmer is many, many times more likely to appreciate clean, well organized code than a PHP developer. That is part of the culture of those languages, and the people who evangelize them.
There is nothing inherently better about Ruby or Ruby on Rails in my opinion. Rails was the first mainstream MVC development framework, but its popularity and success has catalyzed the development of similar frameworks in every language imaginable. The choice to write Rails in Ruby isn't an indication that Ruby is better than PHP, which many could argue. Considering the time in which Rails was written and 37signals' fascination with obscure things, I can understand the move completely. At the time, web scripting languages were pretty lame, and 37signals was looking for a language that catered more to the needs of application programmers, not scripters.
You're not being held back using a PHP framework like Zend Framework, CakePHP, or symfony. CakePHP and symfony are both directly modelled after Rails, even if they aren't direct ports. Akelos is an actual port of Rails to PHP. Zend Framework is the most fully featured framework I've used so far. Don't be afraid to experiment, but jumping ship to a completely different platform isn't necessary and it won't change the way you do business. It's the same business in a different dialect. | I can't say too much about Ruby, but I can say that I often feel like PHP gets a bad rap. PHP is what you make of it. Yes, there is a lot of awful PHP code out there, but you know, it was mostly written by people who would have written awful Ruby, or awful Python. PHP has such a wide audience that programmers of all stripes and abilities are using it, and many of them are writing bad programs.
That said, you can write good programs in PHP. Do you have good developers? If so, you can certainly write good code in PHP. | What are main advantages of RUBY and RAILS to PHP and CODEIGNITER | [
"",
"php",
"jquery",
"ruby-on-rails",
"ruby",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.