
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I have some code which populates a hashtable with a question as the key and an arraylist of answers as the value.
I want to then print out these values from the hashtable so that it displays the question and corresponding solutions for each individual question in the hashtable.
I know I have done something totally stupid with the foreach loop to printout the hashtable contents, but i've been coding for a good few hours straight and I can't think of the logic to printout my nested arraylist.
Help appreciated greatly.
Here is the code:
```
//Hashtable Declaration
static Hashtable sourceList = new Hashtable();
//Class For Storing Question Information
public class QuestionAnswerClass
{
public string simonQuestion;
public ArrayList simonAnswer = new ArrayList();
}
//Foreach loop which populates a hashtable with results from
//a linq query that i need to print out.
foreach (var v in linqQueryResult)
{
Debug.WriteLine(v.question);
newques.simonQuestion = v.question;
//Debug.WriteLine(v.qtype);
//newques.simonQType = v.qtype;
foreach (var s in v.solution)
{
Debug.WriteLine(s.Answer);
newques.simonAnswer.Add(s.Answer);
}
}
sourceList.Add(qTextInput,newques);
//foreach loop to print out contents of hashtable
foreach (string key in sourceList.Keys)
{
foreach(string value in sourceList.Values)
{
Debug.WriteLine(key);
Debug.WriteLine(sourceList.Values.ToString());
}
}
``` | As you are using LINQ you are obviously not constrained to framework 1.1, so you should not be using the `HashTable` and `ArrayList` classes. You should use the strictly typed generic `Dictionary` and `List` classes instead.
You don't need a class to keep the question and answers in as you have the `Dictionary`. The class would only be an extra container with no real purpose.
```
//Dictionary declaration
static Dictionary<string, List<string>> sourceList = new Dictionary<string, List<string>>();
//Foreach loop which populates a Dictionary with results from
//a linq query that i need to print out.
foreach (var v in linqQueryResult) {
List<string> answers = v.solution.Select(s => s.Answer).ToList();
sourceList.Add(v.question, answers);
}
//foreach loop to print out contents of Dictionary
foreach (KeyValuePair<string, List<string>> item in sourceList) {
Debug.WriteLine(item.Key);
foreach(string answer in item.Value) {
Debug.WriteLine(answer);
}
}
```
If you need the class for some other reason, that could look like below.
(Note that the question string is both referenced in the class and used as key in the dictionary, but the dictionary key isn't really used for anything in this code.)
```
//Class For Storing Question Information
public class QuestionAnswers {
public string Question { get; private set; }
public List<string> Answers { get; private set; }
public QuestionAnswers(string question, IEnumerable<string> answers) {
Question = question;
Answers = new List<string>(answers);
}
}
//Dictionary declaration
static Dictionary<string, QuestionAnswers> sourceList = new Dictionary<string, QuestionAnswers>();
//Foreach loop which populates a Dictionary with results from
//a linq query that i need to print out.
foreach (var v in linqQueryResult) {
QuestionAnswers qa = new QuestionAnswers(v.question, v.solution.Select(s => s.Answer));
sourceList.Add(qa.Question, qa);
}
//foreach loop to print out contents of Dictionary
foreach (QustionAnswers qa in sourceList.Values) {
Debug.WriteLine(qa.Question);
foreach(string answer in qa.Answers) {
Debug.WriteLine(answer);
}
}
``` | Try this
```
foreach (DictionaryEntry entry in sourceList)
{
Debug.WriteLine(entry.Key);
foreach (object item in (ArrayList)entry.Value)
{
Debug.WriteLine(item.ToString());
}
}
``` | C# Foreach Loop Hashtable Issue | [
"",
"c#",
"hashtable",
"foreach",
""
] |
I have this error message:
> Msg 8134, Level 16, State 1, Line 1 Divide by zero error encountered.
What is the best way to write SQL code so that I will never see this error message again?
I could do either of the following:
* Add a where clause so that my divisor is never zero
Or
* I could add a case statement, so that there is a special treatment for zero.
Is the best way to use a `NULLIF` clause?
Is there better way, or how can this be enforced? | In order to avoid a "Division by zero" error we have programmed it like this:
```
Select Case when divisor=0 then null
Else dividend / divisor
End ,,,
```
But here is a much nicer way of doing it:
```
Select dividend / NULLIF(divisor, 0) ...
```
Now the only problem is to remember the NullIf bit, if I use the "/" key. | In case you want to return zero, in case a zero devision would happen, you can use:
```
SELECT COALESCE(dividend / NULLIF(divisor,0), 0) FROM sometable
```
For every divisor that is zero, you will get a zero in the result set. | How to avoid the "divide by zero" error in SQL? | [
"",
"sql",
"sql-server",
"sql-server-2008",
"sql-server-2005",
"dividebyzeroexception",
""
] |
I am used to the c-style `getchar()`, but it seems like there is nothing comparable for java. I am building a lexical analyzer, and I need to read in the input character by character.
I know I can use the scanner to scan in a token or line and parse through the token char-by-char, but that seems unwieldy for strings spanning multiple lines. Is there a way to just get the next character from the input buffer in Java, or should I just plug away with the Scanner class?
The input is a file, not the keyboard. | Use [Reader.read()](http://java.sun.com/javase/6/docs/api/java/io/Reader.html#read()). A return value of -1 means end of stream; else, cast to *char*.
This code reads character data from a list of file arguments:
```
public class CharacterHandler {
//Java 7 source level
public static void main(String[] args) throws IOException {
// replace this with a known encoding if possible
Charset encoding = Charset.defaultCharset();
for (String filename : args) {
File file = new File(filename);
handleFile(file, encoding);
}
}
private static void handleFile(File file, Charset encoding)
throws IOException {
try (InputStream in = new FileInputStream(file);
Reader reader = new InputStreamReader(in, encoding);
// buffer for efficiency
Reader buffer = new BufferedReader(reader)) {
handleCharacters(buffer);
}
}
private static void handleCharacters(Reader reader)
throws IOException {
int r;
while ((r = reader.read()) != -1) {
char ch = (char) r;
System.out.println("Do something with " + ch);
}
}
}
```
The bad thing about the above code is that it uses the system's default character set. Wherever possible, prefer a known encoding (ideally, a Unicode encoding if you have a choice). See the [Charset](http://java.sun.com/javase/6/docs/api/java/nio/charset/Charset.html) class for more. *(If you feel masochistic, you can read [this guide to character encoding](http://illegalargumentexception.blogspot.com/2009/05/java-rough-guide-to-character-encoding.html).)*
*(One thing you might want to look out for are supplementary Unicode characters - those that require two char values to store. See the [Character](http://java.sun.com/javase/6/docs/api/java/lang/Character.html) class for more details; this is an edge case that probably won't apply to homework.)* | Combining the recommendations from others for specifying a character encoding and buffering the input, here's what I think is a pretty complete answer.
Assuming you have a `File` object representing the file you want to read:
```
BufferedReader reader = new BufferedReader(
new InputStreamReader(
new FileInputStream(file),
Charset.forName("UTF-8")));
int c;
while((c = reader.read()) != -1) {
char character = (char) c;
// Do something with your character
}
``` | How do I read input character-by-character in Java? | [
"",
"java",
"character",
"tokenize",
""
] |
I want to get title of shortcut, not file name, not description, but title.
how to get it?
I have learn to resolve its target path from here, [How to resolve a .lnk in c#](https://stackoverflow.com/questions/139010/how-to-resolve-a-lnk-in-c)
but i don't find any method to get its title.
[](https://i.stack.imgur.com/qzpvM.jpg)
(source: [ggpht.com](http://lh4.ggpht.com/_2HeweEMiLbg/SfkeMXlpbmI/AAAAAAAAIDE/eucex2mloOo/s912/vista-lnk.jpg))
[](https://i.stack.imgur.com/CbQfo.jpg)
(source: [ggpht.com](http://lh6.ggpht.com/_2HeweEMiLbg/Sfkf5eerapI/AAAAAAAAIDM/u5GqEWvgc74/lnk-properties-dlg.jpg)) | There is a Desktop.ini hidden file in shortcuts directory, the Desktop.ini file records display strings info of shortcuts.
Desktop.ini file sample:
```
[LocalizedFileNames]
Windows Update.lnk=@%SystemRoot%\system32\wucltux.dll,-1
Default Programs.lnk=@%SystemRoot%\system32\sud.dll,-1
``` | It sounds like you might be trying to get the title of the file the link points to, as JRL suggests.
If you're *not* trying to do that, I'd recommend opening up one of these .lnk files in a hex editor like [XVI32](http://www.chmaas.handshake.de/delphi/freeware/xvi32/xvi32.htm). You can probably tell from there whether the Chinese name displayed is embedded in the .lnk file or is somewhere else.
If it's somewhere else, it may be an Extended File Property. There's some source code that may help with retrieving that info: [Extended File Properties](http://www.planet-source-code.com/vb/scripts/ShowCode.asp?txtCodeId=683&lngWId=10)
If by some chance it *is* inside the .lnk file, I recommend looking at the [Windows Shortcut Specification](http://mediasrv.ns.ac.yu/extra/fileformat/windows/lnk/shortcut.pdf) to get offset information and such on the location of that data. | c#, How to solve the *.lnk file title? | [
"",
"c#",
"shortcut",
""
] |
The criteria is basically this:
* folders will exist for about 24-48hrs
* folders names can not be readily guessable by a user (if used in a URL)
* folder names should be short 5-15 chars
Initial thoughts:
```
printf('%u',crc32(microtime(true)));
```
Details:
When uploading a file, I basically want to keep the unique file name as named by the uploader, so to avoid any naming collision I would like to put it in a uniquely named directory ... | [Edit] Wait a second. PHP includes right in the standard library a [unique id generator function](http://us.php.net/uniqid). There are [other approaches](http://phpgoogle.blogspot.com/2007/08/four-ways-to-generate-unique-id-by-php.html) too. | The classic technique looks something like
```
+ uploader-name
+ 20090401
+ 010000 // hhmmss
+ 013000 // hhmmss
+ 014500 // hhmmss
...
+ 20090402
```
adding levels, appending "a", "b", "c", ... etc. based on desired granularity.
This works esp. well if the user relates to the files at all chronologically.
You end up doing a few existence enumerations, but it's not that painful. I've used this many times (including with PHP), primarily because user resistance is lower than for any alternative I've found.
If you are so inclined you can beautify the date expressions - "2009-Apr-01", "01:45AM", etc. | What is a good way to generate short and unique file/folder names? | [
"",
"php",
"string",
"unique",
""
] |
I am currently designing a class library that will provide data to a web application graph rendering engine in C#. I am currently defining the interfaces of this library.
I have a IGraphData interface which I would like to cache using a service that accesses the cache, this is called IGraphDataCacheService and has set and get methods to add and retrieve IGraphData objects to and from the cache. the cache service will be a singleton.
I am confused about the correct way to implement this, so that there is only one cache service that can get and set generic IgraphData objects.
I came up with this:
```
interface IGraphDataCacheService {
IGraphData<object> Get(string identifier);
void Set(IGraphData<object> graphData);}
```
or this:
```
T Get<T, P>(string identifier) where T : IGraphData<P>;
void Set<T,P>(T graphData) where T : IGraphData<P>;
```
Can any one offer any advice help?
Thanks | Why don't you just make the interface generic instead?
```
interface ICacheService<T> {
T Get(string identifier);
void Set(T graphData);
}
```
if you wanted, you could type-constrain T to be of type IGraphData, or you could write it as:
```
interface IGraphDataCacheService<T> {
IGraphData<T> Get(string identifier);
void Set(IGraphData<T> graphData);
}
``` | A few points:
1. I'd probably rename the interface methods to be more emblematic of a caching service. For example, `Fetch` and `Store` instead of `Get` and `Set`, which makes it sound like you're getting or setting the provider rather than the data to be cached.
2. Ensuring that there is only one cache is an implementation detail, not an interface one.
To implement a singleton, try something like:
```
public class SingletonCacheService : IGraphDataCacheService {
private static Singleton instance;
private Singleton() {}
// snip implementation of IGraphDataCacheService methods ...
public static Singleton Instance {
get {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
}
```
Note that this simple version isn't threadsafe. | Interface design using C# Generics | [
"",
"c#",
"generics",
"interface",
""
] |
I am using Apache Commons Email library to send emails, but I am not able to send them via GMail SMTP server.
Can anyone provide sample code which works with GMail SMTP server and others?
I am using the following code which does not work:
```
String[] recipients = {"receiver@gmail.com"};
SimpleEmail email = new SimpleEmail();
email.setHostName("smtp.gmail.com");
email.setAuthentication("sender@gmail.com", "mypasswd");
email.setDebug(true);
email.setSmtpPort(465);
for (int i = 0; i < recipients.length; i++)
{
email.addTo(recipients[i]);
}
email.setFrom("sender@gmail.com", "Me");
email.setSubject("Test message");
email.setMsg("This is a simple test of commons-email");
email.send();
``` | Sending emails to the GMail SMTP server requires authentication and SSL. The username and password is pretty straight forward. Make sure you have the following properties set to enable authentication and SSL and it should work.
```
mail.smtp.auth=true
mail.smtp.starttls.enable=true
```
To the sample code add the following to enabled TLS.
For API-Versions < 1.3 use:
`email.setTSL(true);`
the method is deprecated for versions >= 1.3, and instead you should use: `email.setStartTLSEnabled(true);` | Please find below a code which works. Obviously, you have to add the apache jar to your project's build path.
```
public static void sendSimpleMail() throws Exception {
Email email = new SimpleEmail();
email.setSmtpPort(587);
email.setAuthenticator(new DefaultAuthenticator("your gmail username",
"your gmail password"));
email.setDebug(false);
email.setHostName("smtp.gmail.com");
email.setFrom("me@gmail.com");
email.setSubject("Hi");
email.setMsg("This is a test mail ... :-)");
email.addTo("you@gmail.com");
email.setTLS(true);
email.send();
System.out.println("Mail sent!");
}
```
Regards,
Sergiu | Sending email in Java using Apache Commons email libs | [
"",
"java",
"email",
"smtp",
"gmail",
"apache-commons-email",
""
] |
I trying to understand if a isset is required during form processing when i check $\_REQUEST["input\_name"] if no value is passed it doesn't cry about it and php doesn't throw out an error if you are trying to access a array item which doesn't exist....i can use if($\_REQUEST["input\_name"])..
what about "empty" even in those cases i can use if()
THnks | ```
if($_REQUEST["input_name"])
```
will throw a notice (error) if "input\_name" doesn't exist, so isset() is recommended. | I wouldn't recommend using the `$_REQUEST` superglobal for capturing form input, unless you're testing a form. Use `$_GET` or `$_POST` instead, unless you have a really good reason.
Also, `isset()` and `array_key_exists()` both do the same trick with regard to array keys, although `array_key_exists()` is clearer in an arrays context.
I recommend using:
```
error_reporting(E_ALL); //E_ALL - All errors and warnings
```
within your development environment, as that can expose where better practices might be applied, such failure to declare variables before they are used, etc. | php isset do you need it in a form check? | [
"",
"php",
"isset",
""
] |
I have several complex data structures like
```
Map< A, Set< B > >
Set< Map< A, B > >
Set< Map< A, Set< B > > >
Map< A, Map< B, Set< C > > >
and so on (more complex data structures)
```
*Note: In my case it doesn't really matter if I use Set or List.*
Now I know that JAXB let me define **XmlAdapter**'s, that's fine,
but I don't want to define an XmlAdapter for every of the given data structures
(it would be just too much copy-and-paste code).
I tried to achieve my goal by declaring two generalizing XmlAdapters:
* one for Map: `MapAdapter<K,V>`
* one for Set: `SetAdapter<V>`
**The problem**:
JAXB complains as following:
```
javax.xml.bind.JAXBException:
class java.util.Collections$UnmodifiableMap nor any of its
super class is known to this context.
```
**Here is my adapter class:**
```
import java.util.*;
import javax.xml.bind.annotation.*;
import javax.xml.bind.annotation.adapters.*;
public class Adapters {
public final static class MapAdapter<K, V>
extends XmlAdapter<MapAdapter.Adapter<K, V>, Map<K, V>> {
@XmlType
@XmlRootElement
public final static class Adapter<K, V> {
@XmlElement
protected List<MyEntry<K, V>> key = new LinkedList<MyEntry<K, V>>();
private Adapter() {
}
public Adapter(Map<K, V> original) {
for (Map.Entry<K, V> entry : original.entrySet()) {
key.add(new MyEntry<K, V>(entry));
}
}
}
@XmlType
@XmlRootElement
public final static class MyEntry<K, V> {
@XmlElement
protected K key;
@XmlElement
protected V value;
private MyEntry() {
}
public MyEntry(Map.Entry<K, V> original) {
key = original.getKey();
value = original.getValue();
}
}
@Override
public Adapter<K, V> marshal(Map<K, V> obj) {
return new Adapter<K, V>(obj);
}
@Override
public Map<K, V> unmarshal(Adapter<K, V> obj) {
throw new UnsupportedOperationException("unmarshalling is never performed");
}
}
}
```
**Here is my JUnit test case:**
```
import java.io.*;
import java.util.*;
import javax.xml.bind.*;
import javax.xml.bind.annotation.*;
import javax.xml.bind.annotation.adapters.*;
import org.junit.*;
import static java.lang.System.*;
public class SomeTest {
@Test
public void _map2()
throws Exception {
Map<String, Map<String, String>> dataStructure =
new HashMap<String, Map<String, String>>();
Map<String, String> inner1 = new HashMap<String, String>();
Map<String, String> inner2 = new HashMap<String, String>();
dataStructure.put("a", inner1);
dataStructure.put("b", inner1);
inner1.put("a1", "1");
inner1.put("a2", "2");
inner2.put("b1", "1");
inner2.put("b2", "2");
JAXBContext context = JAXBContext.newInstance(Adapters.XMap.class,
Adapters.XCount.class, Adapters.XEntry.class);
Marshaller marshaller = context.createMarshaller();
marshaller.setProperty(Marshaller.JAXB_FRAGMENT, true);
marshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, true);
marshaller.setAdapter(new Adapters.MapAdapter());
StringWriter sw = new StringWriter();
marshaller.marshal(dataStructure, sw);
out.println(sw.toString());
}
}
``` | I've solved the problem **without XmlAdapter's**.
I've written JAXB-annotated objects for **Map**, **Map.Entry** and **Collection**.
The main idea is inside the method **xmlizeNestedStructure(...)**:
Take a look at the code:
```
public final class Adapters {
private Adapters() {
}
public static Class<?>[] getXmlClasses() {
return new Class<?>[]{
XMap.class, XEntry.class, XCollection.class, XCount.class
};
}
public static Object xmlizeNestedStructure(Object input) {
if (input instanceof Map<?, ?>) {
return xmlizeNestedMap((Map<?, ?>) input);
}
if (input instanceof Collection<?>) {
return xmlizeNestedCollection((Collection<?>) input);
}
return input; // non-special object, return as is
}
public static XMap<?, ?> xmlizeNestedMap(Map<?, ?> input) {
XMap<Object, Object> ret = new XMap<Object, Object>();
for (Map.Entry<?, ?> e : input.entrySet()) {
ret.add(xmlizeNestedStructure(e.getKey()),
xmlizeNestedStructure(e.getValue()));
}
return ret;
}
public static XCollection<?> xmlizeNestedCollection(Collection<?> input) {
XCollection<Object> ret = new XCollection<Object>();
for (Object entry : input) {
ret.add(xmlizeNestedStructure(entry));
}
return ret;
}
@XmlType
@XmlRootElement
public final static class XMap<K, V> {
@XmlElementWrapper(name = "map")
@XmlElement(name = "entry")
private List<XEntry<K, V>> list = new LinkedList<XEntry<K, V>>();
public XMap() {
}
public void add(K key, V value) {
list.add(new XEntry<K, V>(key, value));
}
}
@XmlType
@XmlRootElement
public final static class XEntry<K, V> {
@XmlElement
private K key;
@XmlElement
private V value;
private XEntry() {
}
public XEntry(K key, V value) {
this.key = key;
this.value = value;
}
}
@XmlType
@XmlRootElement
public final static class XCollection<V> {
@XmlElementWrapper(name = "list")
@XmlElement(name = "entry")
private List<V> list = new LinkedList<V>();
public XCollection() {
}
public void add(V obj) {
list.add(obj);
}
}
}
```
**It works!**
Let's look at a **demo output**:
```
<xMap>
<map>
<entry>
<key xsi:type="xCount" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<count>1</count>
<content xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">a</content>
</key>
<value xsi:type="xCollection" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<list>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">a1</entry>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">a2</entry>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">a3</entry>
</list>
</value>
</entry>
<entry>
<key xsi:type="xCount" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<count>2</count>
<content xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">b</content>
</key>
<value xsi:type="xCollection" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<list>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">b1</entry>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">b3</entry>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">b2</entry>
</list>
</value>
</entry>
<entry>
<key xsi:type="xCount" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<count>3</count>
<content xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">c</content>
</key>
<value xsi:type="xCollection" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<list>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">c1</entry>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">c2</entry>
<entry xsi:type="xs:string" xmlns:xs="http://www.w3.org/2001/XMLSchema">c3</entry>
</list>
</value>
</entry>
</map>
</xMap>
```
Sorry, the demo output uses also a data structure called **"count"**
which is not mentioned in the Adapter's source code.
**BTW:** does anyone know how to remove all these annoying
and (in my case) unnecessary **xsi:type** attributes? | I had the same requirement to use a Map< String,Map< String,Integer>>. I used the XMLAdapter and it worked fine. Using XMLAdaptor is the cleanest solution I think. Below is the code of the adaptor.
This is the jaXb class code snippet.
```
@XmlJavaTypeAdapter(MapAdapter.class)
Map<String, Map<String, Integer>> mapOfMap = new HashMap<String,Map<String, Integer>>();
```
MapType Class :
```
public class MapType {
public List<MapEntryType> host = new ArrayList<MapEntryType>();
}
```
MapEntry Type Class:
```
public class MapEntryType {
@XmlAttribute
public String ip;
@XmlElement
public List<LinkCountMapType> request_limit = new ArrayList<LinkCountMapType>();
}
```
LinkCountMapType Class:
```
public class LinkCountMapType {
@XmlAttribute
public String service;
@XmlValue
public Integer count;
}
```
Finally the MapAdaptor Class:
```
public final class MapAdapter extends XmlAdapter<MapType, Map<String, Map<String, Integer>>> {
@Override
public Map<String, Map<String, Integer>> unmarshal(MapType v) throws Exception {
Map<String, Map<String, Integer>> mainMap = new HashMap<String, Map<String, Integer>>();
List<MapEntryType> myMapEntryTypes = v.host;
for (MapEntryType myMapEntryType : myMapEntryTypes) {
Map<String, Integer> linkCountMap = new HashMap<String, Integer>();
for (LinkCountMapType myLinkCountMapType : myMapEntryType.request_limit) {
linkCountMap.put(myLinkCountMapType.service, myLinkCountMapType.count);
}
mainMap.put(myMapEntryType.ip, linkCountMap);
}
return mainMap;
}
@Override
public MapType marshal(Map<String, Map<String, Integer>> v) throws Exception {
MapType myMapType = new MapType();
List<MapEntryType> entry = new ArrayList<MapEntryType>();
for (String ip : v.keySet()) {
MapEntryType myMapEntryType = new MapEntryType();
Map<String, Integer> linkCountMap = v.get(ip);
List<LinkCountMapType> linkCountList = new ArrayList<LinkCountMapType>();
for (String link : linkCountMap.keySet()) {
LinkCountMapType myLinkCountMapType = new LinkCountMapType();
Integer count = linkCountMap.get(link);
myLinkCountMapType.count = count;
myLinkCountMapType.service = link;
linkCountList.add(myLinkCountMapType);
}
myMapEntryType.ip = ip;
myMapEntryType.request_limit = linkCountList;
entry.add(myMapEntryType);
}
myMapType.host = entry;
return myMapType;
}
```
}
Marshalling a Jaxb Object will give the below XML
```
<mapOfmap>
<host ip="127.0.0.1">
<request_limit service="service1">7</request_limit>
<request_limit service="service2">8</request_limit>
</host>
</mapOfmap>
``` | JAXB: How should I marshal complex nested data structures? | [
"",
"java",
"xml",
"data-binding",
"data-structures",
"jaxb",
""
] |
Based on a previous stack overflow question and contribution by cgoldberg, I came up with this regex using the python re module:
```
import re
urls = re.finditer('http://(.*?).mp3', htmlcode)
```
The variable urls is an iterable object and I can use a loop to access each mp3 file url individually if there is more than one :
```
for url in urls:
mp3fileurl = url.group(0)
```
This technique, however, only works sometimes. I realize regular expressions will not be as reliable as a fully fledged parser module. But, sometimes, this is not reliable for the same page.
I sometimes receive everything before http for some url entries.
I am relatively new to regular expressions. So, I am just wondering if there is a more reliable way to go about it.
Thanks in advance.
New to stackoverflow and looking forward to contributing some answers as well. | As always I suggest using a html parser like [lxml.html](http://codespeak.net/lxml/lxmlhtml.html) instead of regular expressions to extract informations from html files:
```
import lxml.html
tree = lxml.html.fromstring(htmlcode)
for link in tree.findall(".//a"):
url = link.get("href")
if url.endswith(".mp3"):
print url
``` | As pointed out by the other answers, using regular expressions to parse HTML = bad, bad idea.
With that in mind, I will add in code of my favorite parser: [BeautifulSoup](http://www.crummy.com/software/BeautifulSoup/):
```
from BeautifulSoup import BeautifulSoup
soup = BeautifulSoup(htmlcode)
links = soup.findAll('a', href=True)
mp3s = [l for l in links if l['href'].endswith('.mp3')]
for song in mp3s:
print link['href']
``` | I need a regex for the href attribute for an mp3 file url in python | [
"",
"python",
"regex",
""
] |
Given a date range how to calculate the number of weekends partially or wholly within that range?
(A few definitions as requested:
take 'weekend' to mean Saturday and Sunday.
The date range is inclusive i.e. the end date is part of the range
'wholly or partially' means that any part of the weekend falling within the date range means the whole weekend is counted.)
To simplify I imagine you only actually need to know the duration and what day of the week the initial day is...
I darn well now it's going to involve doing integer division by 7 and some logic to add 1 depending on the remainder but I can't quite work out what...
extra points for answers in Python ;-)
**Edit**
Here's my final code.
Weekends are Friday and Saturday (as we are counting nights stayed) and days are 0-indexed starting from Monday. I used onebyone's algorithm and Tom's code layout. Thanks a lot folks.
```
def calc_weekends(start_day, duration):
days_until_weekend = [5, 4, 3, 2, 1, 1, 6]
adjusted_duration = duration - days_until_weekend[start_day]
if adjusted_duration < 0:
weekends = 0
else:
weekends = (adjusted_duration/7)+1
if start_day == 5 and duration % 7 == 0: #Saturday to Saturday is an exception
weekends += 1
return weekends
if __name__ == "__main__":
days = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
for start_day in range(0,7):
for duration in range(1,16):
print "%s to %s (%s days): %s weekends" % (days[start_day], days[(start_day+duration) % 7], duration, calc_weekends(start_day, duration))
print
``` | General approach for this kind of thing:
For each day of the week, figure out how many days are required before a period starting on that day "contains a weekend". For instance, if "contains a weekend" means "contains both the Saturday and the Sunday", then we have the following table:
Sunday: 8
Monday: 7
Tuesday: 6
Wednesday: 5
Thursday: 4
Friday: 3
Saturday: 2
For "partially or wholly", we have:
Sunday: 1
Monday: 6
Tuesday: 5
Wednesday: 4
Thursday: 3
Friday: 2
Saturday: 1
Obviously this doesn't have to be coded as a table, now that it's obvious what it looks like.
Then, given the day-of-week of the start of your period, subtract[\*] the magic value from the length of the period in days (probably start-end+1, to include both fenceposts). If the result is less than 0, it contains 0 weekends. If it is equal to or greater than 0, then it contains (at least) 1 weekend.
Then you have to deal with the remaining days. In the first case this is easy, one extra weekend per full 7 days. This is also true in the second case for every starting day except Sunday, which only requires 6 more days to include another weekend. So in the second case for periods starting on Sunday you could count 1 weekend at the start of the period, then subtract 1 from the length and recalculate from Monday.
More generally, what's happening here for "whole or part" weekends is that we're checking to see whether we start midway through the interesting bit (the "weekend"). If so, we can either:
* 1) Count one, move the start date to the end of the interesting bit, and recalculate.
* 2) Move the start date back to the beginning of the interesting bit, and recalculate.
In the case of weekends, there's only one special case which starts midway, so (1) looks good. But if you were getting the date as a date+time in seconds rather than day, or if you were interested in 5-day working weeks rather than 2-day weekends, then (2) might be simpler to understand.
[\*] Unless you're using unsigned types, of course. | My general approach for this sort of thing: don't start messing around trying to reimplement your own date logic - it's hard, ie. you'll screw it up for the edge cases and look bad. **Hint:** if you have mod 7 arithmetic anywhere in your program, or are treating dates as integers anywhere in your program: ***you fail***. If I saw the "accepted solution" anywhere in (or even near) my codebase, someone would need to start over. It beggars the imagination that anyone who considers themselves a programmer would vote that answer up.
Instead, use the built in date/time logic that comes with Python:
First, get a list of all of the days that you're interested in:
```
from datetime import date, timedelta
FRI = 5; SAT = 6
# a couple of random test dates
now = date.today()
start_date = now - timedelta(57)
end_date = now - timedelta(13)
print start_date, '...', end_date # debug
days = [date.fromordinal(d) for d in
range( start_date.toordinal(),
end_date.toordinal()+1 )]
```
Next, filter down to just the days which are weekends. In your case you're interested in Friday and Saturday nights, which are 5 and 6. (Notice how I'm not trying to roll this part into the previous list comprehension, since that'd be hard to verify as correct).
```
weekend_days = [d for d in days if d.weekday() in (FRI,SAT)]
for day in weekend_days: # debug
print day, day.weekday() # debug
```
Finally, you want to figure out how many weekends are in your list. This is the tricky part, but there are really only four cases to consider, one for each end for either Friday or Saturday. Concrete examples help make it clearer, plus this is really the sort of thing you want documented in your code:
```
num_weekends = len(weekend_days) // 2
# if we start on Friday and end on Saturday we're ok,
# otherwise add one weekend
#
# F,S|F,S|F,S ==3 and 3we, +0
# F,S|F,S|F ==2 but 3we, +1
# S|F,S|F,S ==2 but 3we, +1
# S|F,S|F ==2 but 3we, +1
ends = (weekend_days[0].weekday(), weekend_days[-1].weekday())
if ends != (FRI, SAT):
num_weekends += 1
print num_weekends # your answer
```
Shorter, clearer and easier to understand means that you can have more confidence in your code, and can get on with more interesting problems. | Given a date range how to calculate the number of weekends partially or wholly within that range? | [
"",
"python",
"date",
"date-arithmetic",
""
] |
So lets say I have an **N** sized server array set up like so:
[alt text http://www.terracotta.org/web/download/attachments/43909161/ServerArrayMirrorGroup.png](http://www.terracotta.org/web/download/attachments/43909161/ServerArrayMirrorGroup.png)
I have a simple JavaBean/POJO:
```
package example;
public class Person {
private OtherObject obj;
public void setObj(OtherObject theObj) {
synchronized (this) {
obj = theObj;
}
}
public OtherObject getObj() {
synchronized (this) {
return obj;
}
}
}
```
Now if one of the Clients calls Person.setObj(OtherObject) on a Person Object in the TC root (data structure), is the **synchronized block** (in Person.setObj(OtherObject)) on that client held:
1) Until all **N** of the Servers in the **N** sized server array have been synchronized/updated with that Person.obj attribute?
**or**
2) Until the "active" server has been synchronized with that updated Person.obj attribute? Then the other (**N-1**) servers in the array are synchronized as possible?
**or**
3) Some other method that I am over looking? | The answer is not really 1 or 2. Objects are striped across the server mirror groups. The first time this field is set, a transaction is created and that mirror group chosen for that first transaction will "own" the object after that.
With respect to both 1 and 2, not all active server groups need to be updated so there is no need to to wait for either of those conditions.
You can find more info at the Terracotta documentation about configuring the Terracotta server array:
* <http://terracotta.org/web/display/docs/Terracotta+Server+Arrays>
From a locking point of view, the clustered lock on this Person object would be held (mutual exclusion across the cluster) while performing the object modification. The scope of the synchronized block forms the transaction mentioned above. In the getObj() method, you could configure this as a read lock which would allow multiple concurrent readers across the cluster. | Assume that everyone else has a reference to your object and can touch it while/before/after you do. Thus the solution would be to add locks, and
* obtain lock
* modify the object
* release lock
And that's exactly what *synchronized* does... it creates a queue and the *synchronized method* can't be called more than once... but the underlying object might be touched if it's referenced somewhere.
see:
* <http://www.terracotta.org/web/display/orgsite/Hello+Clustered+World>
* <http://www.terracotta.org/web/display/orgsite/Tutorials> | How does Terracotta work in this situation? | [
"",
"java",
"failover",
"high-availability",
"terracotta",
""
] |
I have a class that implements the IDisposable interface. I am using a webclient to download some data using the AsyncDownloadString.
I am wondering have I correctly declared my event handlers in the constructor and within the using statement of the web client? And is this correct way to remove the event handlers in the Dispose method?
Overrule is this the correct way to use the IDisposable interface?
```
public class Balance : IDisposable
{
//Constructor
WebClient wc;
public Balance()
{
using (wc = new WebClient())
{
//Create event handler for the progress changed and download completed events
wc.DownloadProgressChanged += new DownloadProgressChangedEventHandler(wc_DownloadProgressChanged);
wc.DownloadStringCompleted += new DownloadStringCompletedEventHandler(wc_DownloadStringCompleted);
}
}
~Balance()
{
this.Dispose(false);
}
//Get the current balance for the user that is logged in.
//If the balance returned from the server is NULL display error to the user.
//Null could occur if the DB has been stopped or the server is down.
public void GetBalance(string sipUsername)
{
//Remove the underscore ( _ ) from the username, as this is not needed to get the balance.
sipUsername = sipUsername.Remove(0, 1);
string strURL =
string.Format("https://www.xxxxxxx.com",
sipUsername);
//Download only when the webclient is not busy.
if (!wc.IsBusy)
{
// Download the current balance.
wc.DownloadStringAsync(new Uri(strURL));
}
else
{
Console.Write("Busy please try again");
}
}
//return and display the balance after the download has fully completed
void wc_DownloadStringCompleted(object sender, DownloadStringCompletedEventArgs e)
{
//Pass the result to the event handler
}
//Dispose of the balance object
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
//Remove the event handlers
private bool isDisposed = false;
private void Dispose(bool disposing)
{
if (!this.isDisposed)
{
if (disposing)
{
wc.DownloadProgressChanged -= new DownloadProgressChangedEventHandler(wc_DownloadProgressChanged);
wc.DownloadStringCompleted -= new DownloadStringCompletedEventHandler(wc_DownloadStringCompleted);
wc.Dispose();
}
isDisposed = true;
}
}
}
``` | That is mostly correct except `wc` is being disposed twice and `GetBalance` will always be using `wc` after it's disposed!
Edit: a version with that correction:
```
public class Balance : IDisposable
{
//Constructor
WebClient wc;
public Balance()
{
wc = new WebClient();
//Create event handler for the progress changed and download completed events
try {
wc.DownloadProgressChanged += new DownloadProgressChangedEventHandler(wc_DownloadProgressChanged);
wc.DownloadStringCompleted += new DownloadStringCompletedEventHandler(wc_DownloadStringCompleted);
} catch {
wc.Dispose();
throw;
}
}
~Balance()
{
this.Dispose(false);
}
//Get the current balance for the user that is logged in.
//If the balance returned from the server is NULL display error to the user.
//Null could occur if the DB has been stopped or the server is down.
public void GetBalance(string sipUsername)
{
//Remove the underscore ( _ ) from the username, as this is not needed to get the balance.
sipUsername = sipUsername.Remove(0, 1);
string strURL =
string.Format("https://www.xxxxxxx.com",
sipUsername);
//Download only when the webclient is not busy.
if (!wc.IsBusy)
{
// Download the current balance.
wc.DownloadStringAsync(new Uri(strURL));
}
else
{
Console.Write("Busy please try again");
}
}
//return and display the balance after the download has fully completed
void wc_DownloadStringCompleted(object sender, DownloadStringCompletedEventArgs e)
{
//Pass the result to the event handler
}
private bool isDisposed = false;
//Dispose of the balance object
public void Dispose()
{
if (!isDisposed)
Dispose(true);
GC.SuppressFinalize(this);
}
//Remove the event handlers
private void Dispose(bool disposing)
{
isDisposed = true;
if (disposing)
{
wc.DownloadProgressChanged -= new DownloadProgressChangedEventHandler(wc_DownloadProgressChanged);
wc.DownloadStringCompleted -= new DownloadStringCompletedEventHandler(wc_DownloadStringCompleted);
wc.Dispose();
}
}
}
``` | There are two correct ways to use an IDisposable object:
1. put it in a `using` block
**OR**
2. Wrap it in a class that also *correctly* implements IDisposable and dispose it when this new class is disposed. You now expect that all instances of your new class are created with `using` blocks.
Note that I said "or", not "and". Do one or the other, but not both.
Here, when you create your WebClient instance with a `using` block in the constructor, you dispose it before you ever have a chance to use it anywhere else. You should do just option two, in this case. | Is this correct for disposing an object using IDisposable | [
"",
"c#",
"idisposable",
""
] |
I was trying to debug a sorting issue with the jquery plugin *tablesorter* which uses the following code to check for digits:
```
this.isDigit = function(s,config) {
var DECIMAL = '\\' + config.decimal;
var exp = '/(^[+]?0(' + DECIMAL +'0+)?$)|(^([-+]?[1-9][0-9]*)$)|(^([-+]?((0?|[1-9][0-9]*)' + DECIMAL +'(0*[1-9][0-9]*)))$)|(^[-+]?[1-9]+[0-9]*' + DECIMAL +'0+$)/';
return RegExp(exp).test($.trim(s));
};
```
the value for config.decimal is '.'
Now if s='0' this fails, but if you run match instead the RegEx appears to be responding positively as expected.
```
return exp.match($.trim(s)) != null
```
How is this processing differently in order to return different results?
Just in case you wanted the HTML where s is derived (The last column is viewed as text):
```
<tr class="">
<td><a href="#">Click</a></td>
<td>Annen Woods</td>
<td>131</td>
<td>20</td>
<td>5</td>
<td>3</td>
<td>12</td>
<td>6</td>
<td>50%</td>
<td>0</td>
</tr>
```
I understand that test returns a boolean value and match returns a string or null.
The ultimate question is why isn't for this regular expression:
```
return RegExp(exp).test($.trim(s));
```
equivalent to :
```
return exp.match($.trim(s)) != null
``` | I think it's a bit of an odd coincidence due to the function used to construct the regular expression.
Match is a member of String.
Test is a member of RegExp.
However, in the function there, exp is defined as a string. So, technically, you're running String's match() using exp as a string value, not as a regular expression.
Running exp through a RegExp constructor should return the same result as test() would. | match returns array of values, test returns boolean, on some engine test returns first result | Why would match find a result while test returns false for a regular expression in JavaScript? | [
"",
"javascript",
"regex",
"tablesorter",
""
] |
When I load data in my code-behind, I find that often I want to run several javascript functions based on my data. It it more efficient to use a StringBuilder to compile all of my function calls and issue RegisterStartupScript one time, or is performance the same if I issue RegisterStartupScript everytime I need it? | I would think that your implementation with a `StringBuilder` would be a bit more efficient as you are not creating any controls and only register the script once you are finished. The other reason that you may want to stay with your `StringBuilder` approach is if the order of the registered scripts is important.
From [MSDN:](http://msdn.microsoft.com/en-us/library/asz8zsxy(loband).aspx)
> The script block added by the RegisterStartupScript method executes when the page finishes loading but before the page's OnLoad event is raised. ***The script blocks are not guaranteed to be output in the order they are registered.*** If the order of the script blocks is important, use a StringBuilder object to gather the scripts together in a single string, and then register them all in a single client script block. | If you are worried about the inefficient reallocation of memory that would occur if you built up the scripts using string concatenation, then don't worry. The scripts that you register are stored in a ListDictionary (System.Collections.Specialized namespace), so the allocation of memory for this list could actually be faster than using a StringBuilder if the StringBuilder weren't instantiated with an appropriate amount of memory. There is also the benefit of not having to build up all your scripts in the one place.
The ListDictionary works like a singly linked list, so while I am not certain, I can't imagine any reason why scripts would not be added to the page in the order they are registered. | Efficient Use of the ASP.NET RegisterStartupScript method | [
"",
"asp.net",
"javascript",
""
] |
I am looking for the simplest php framework that comes integrated with dojo. I do not need MVC or to learn a giant framework all over again. Does anyone have suggestions or examples? | "the simplest PHP framework" does not tell us at all what you're looking for.
To field a guess, however, I'd still say Zend is the best in most cases...It includes MVC capabilities, but does not *require* the use of an MVC pattern. | Maybe <http://www.comodojo.org> can fit your needs... it's still in alpha, but it works in most cases. | PHP Framework that integrates with dojo | [
"",
"php",
"dojo",
""
] |
In EJB 3.0 you can write your domain objecs, then convert them into entitities (adding @Entity attribute, etc.) and underlying JPA mechanism (let's say Hibernate) can automaticly generate db schema. What's better it will also update db when you update you domain model in Java code.
I'm looking for equivalent of that functionality on .NET platform. Is is possible with ADO.NET Entity Framework? | DataObjects.Net also automatically generates and upgrades database schema according to domain model. But the most interesting thing is how to upgrade stored data if model and database schema are changed. **Is it possible to do it on entity level, rather then using low-level SQL?** | Mindscape LightSpeed supports this - full schema round tripping with model first or database first development. It is a commercial product but there is a free version for small databases.
As mentioned, Entity Framework will add some of these features in their next release but that is some time away.
[Details of the LightSpeed designer with the model first support](http://www.mindscape.co.nz/products/lightspeed/features/designer.aspx) | Create db schema from domain objects in .NET | [
"",
"c#",
".net",
"orm",
""
] |
I'm new to Scala and don't know Java. I want to create a jar file out of a simple Scala file. So I have my HelloWorld.scala, generate a HelloWorld.jar.
Manifest.mf:
```
Main-Class: HelloWorld
```
In the console I run:
```
fsc HelloWorld.scala
jar -cvfm HelloWorld.jar Manifest.mf HelloWorld\$.class HelloWorld.class
java -jar HelloWorld.jar
=> "Exception in thread "main" java.lang.NoClassDefFoundError: HelloWorld/jar"
java -cp HelloWorld.jar HelloWorld
=> Exception in thread "main" java.lang.NoClassDefFoundError: scala/ScalaObject
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:675)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:124)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:260)
at java.net.URLClassLoader.access$100(URLClassLoader.java:56)
at java.net.URLClassLoader$1.run(URLClassLoader.java:195)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:188)
at java.lang.ClassLoader.loadClass(ClassLoader.java:316)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:280)
at java.lang.ClassLoader.loadClass(ClassLoader.java:251)
at java.lang.ClassLoader.loadClassInternal(ClassLoader.java:374)
at hoppity.main(HelloWorld.scala)
``` | Sample directory structure:
```
X:\scala\bin
X:\scala\build.bat
X:\scala\MANIFEST.MF
X:\scala\src
X:\scala\src\foo
X:\scala\src\foo\HelloWorld.scala
```
HelloWorld.scala:
```
//file: foo/HelloWorld.scala
package foo {
object HelloWorld {
def main(args: Array[String]) {
println("Hello, world!")
}
}
}
```
MANIFEST.MF:
```
Main-Class: foo.HelloWorld
Class-Path: scala-library.jar
```
build.bat:
```
@ECHO OFF
IF EXIST hellow.jar DEL hellow.jar
IF NOT EXIST scala-library.jar COPY %SCALA_HOME%\lib\scala-library.jar .
CALL scalac -sourcepath src -d bin src\foo\HelloWorld.scala
CD bin
jar -cfm ..\hellow.jar ..\MANIFEST.MF *.*
CD ..
java -jar hellow.jar
```
---
In order to successfully use the *-jar* switch, you need two entries in the *META-INF/MANIFEST.MF* file: the main class; relative URLs to any dependencies. The documentation notes:
> **-jar**
>
> Execute a program encapsulated in a
> JAR file. The first argument is the
> name of a JAR file instead of a
> startup class name. In order for this
> option to work, the manifest of the
> JAR file must contain a line of the
> form Main-Class: classname. Here,
> classname identifies the class having
> the public static void main(String[]
> args) method that serves as your
> application's starting point. See the
> Jar tool reference page and the Jar
> trail of the Java Tutorial for
> information about working with Jar
> files and Jar-file manifests.
>
> When you use this option, the JAR file
> is the source of all user classes,
> **and other user class path settings are ignored.**
* [java command line usage](http://java.sun.com/javase/6/docs/technotes/tools/windows/java.html)
* [manifest spec](http://java.sun.com/javase/6/docs/technotes/guides/jar/jar.html#JAR%20Manifest)
*(Notes: JAR files can be inspected with most ZIP applications; I probably neglect handling spaces in directory names in the batch script; Scala code runner version 2.7.4.final .)*
---
For completeness, an equivalent bash script:
```
#!/bin/bash
if [ ! $SCALA_HOME ]
then
echo ERROR: set a SCALA_HOME environment variable
exit
fi
if [ ! -f scala-library.jar ]
then
cp $SCALA_HOME/lib/scala-library.jar .
fi
scalac -sourcepath src -d bin src/foo/HelloWorld.scala
cd bin
jar -cfm ../hellow.jar ../MANIFEST.MF *
cd ..
java -jar hellow.jar
``` | Because Scala scripts require the Scala libraries to be installed, you will have to include the Scala runtime along with your JAR.
There are many strategies for doing this, such as [jar jar](http://code.google.com/p/jarjar/), but ultimately the issue you're seeing is that the Java process you've started can't find the Scala JARs.
For a simple stand-alone script, I'd recommend using jar jar, otherwise you should start looking at a dependency management tool, or require users to install Scala *in the JDK*. | Creating a jar file from a Scala file | [
"",
"java",
"scala",
"jar",
""
] |
Can anyone suggest me any library/jar files which I can use to export my table to excel/pdf/word.
Please tell me if there is any library by which I can create reports in jsp. | It should also be mentioned that you can export tables to Excel simply by outputting an HTML table, and setting response-type to `application/vnd.ms-excel`. No external libraries whatsoever needed.
Something like this:
```
<%@ page language="java" session="true" %>
<%@ taglib uri="/WEB-INF/tld/response.tld" prefix="res" %>
<res:setHeader name="Content-Type">application/vnd.ms-excel</res:setHeader>
<res:setHeader name="Content-Disposition">attachment; filename=excel-test.xls</res:setHeader>
<table>
<tr>
<td>foo</td>
<td>bar</td>
</tr>
</table>
```
*Note*: this answer is meant to supplement [this](https://stackoverflow.com/questions/845439/exporting-jsp-tables-to-excel-word-pdf/845444#845444) and [this](https://stackoverflow.com/questions/845439/exporting-jsp-tables-to-excel-word-pdf/845455#845455) as it covers only one of the cases (Excel). | I'd say [JasperReports](http://jasperforge.org/plugins/project/project_home.php?group_id=102) - which is [open source](http://sourceforge.net/projects/jasperreports) - is your best bet. It would allow you to code the report once, but export it to the various formats you need. It even supports direct streaming of HTML to the browser, so it really is a code-once, use anywhere type thing. It can also scale up nicely via JasperServer. | Exporting jsp tables to excel, word, pdf | [
"",
"java",
"jsp",
"pdf",
"ms-word",
"export-to-excel",
""
] |
Which constitutes better object oriented design?
```
Class User {
id {get;set}
}
Class Office {
id {get;set}
List<User> Managers(){ }//search for users, return list of them
}
```
or this one
```
Class User {
id {get;set}
List<User> Managers(){ }//search for users, return list of them
}
Class Office {
id {get;set}
}
``` | ```
User john;
List<User> managers = fred.Managers(); //get managers of this user
Office london;
List<User> managers = london.Managers(); //get managers of this office
```
Unless it's a static method, make it a method of a class of which you have an instance: no point in making getUsers a non-static method of the User class, because then you'd need a user instance in order to invoke the getUsers method. | The first solution is the better one, because `User` does not/should not know how `Office` works and how to obtain a list of managers. | Should an object searcher method be in the a parent object, or the same as the object beign searched? | [
"",
"c#",
"oop",
"coupling",
""
] |
I trid to use an upload plugin for jQuery.
<http://valums.com/ajax-upload/>
When I set the returning respond type to json, firefox will popup a dialog asking how I like to handle the returning json object.
People have asked the same question at the upload script's author's page but no answer so far. Hopefully javascript guys here can figure out how we can handle this.
Thanks.
```
<script type= "text/javascript">
/*<![CDATA[*/
$(document).ready(function(){
/* example 1 */
var button = $('#button1'), interval;
new AjaxUpload(button, {
//action: 'upload-test.php', // I disabled uploads in this example for security reasons
action: '/posts/upload_images/',
name: 'myfile',
responseType: 'json',
onSubmit : function(file, ext){
// change button text, when user selects file
button.text('Uploading');
// If you want to allow uploading only 1 file at time,
// you can disable upload button
this.disable();
// Uploding -> Uploading. -> Uploading...
interval = window.setInterval(function(){
var text = button.text();
if (text.length < 13){
button.text(text + '.');
} else {
button.text('Uploading');
}
}, 200);
},
onComplete: function(file, response){
var json = response;
alert(json);
button.text('Upload');
window.clearInterval(interval);
// enable upload button
this.enable();
// add file to the list
// $('<li></li>').appendTo('#example1 .files').text(json.response_text);
$('<li></li>').appendTo('#example1 .files').text(file);
}
});
});
/*]]>*/
</script>
``` | I was looking for a solution for the same script and stumbled upon this page. I didn't found a solution online so here's how I fixed it:
@ `upload-file.php`:
replace
```
echo "success".$cc;
```
with
```
echo json_encode(array(
status' => 'success',
'id' => $picid,
'image' => $imgurl
));
```
@ `front end`:
replace
```
var bb=response.substr(0,7)
var idd=response.replace('success',' ');
var idb =idd.replace(/^\s*|\s*$/g,'');
if(bb==="success")
{
$('<span></span>').appendTo('#files').html('<img src="images/'+file+'" alt="" width="120" height="120" style="margin:5px;" />').addClass('success');
}
else
{
$('<span></span>').appendTo('#files').text(file).addClass('error');
}
```
with
```
var what = jQuery.parseJSON(response);
if(what.status == 'success')
{
$('<span id='+what.id+'></span>').appendTo('#files').html('<img src="'+what.image+'" alt="" width="120" height="120" style="margin:5px;" /><br><a href="javascript:void(0)" onClick="deleteFile('+what.id+');">Delete</a>').addClass('success');
}
else
{
$('<span></span>').appendTo('#files').text(response).addClass('error');
}
```
And to actually answer this question.
`jQuery.parseJSON(response);`
does.. | <http://api.jquery.com/jQuery.parseJSON/>
```
var obj = jQuery.parseJSON('{"name":"John"}');
alert( obj.name === "John" );
``` | How to use jquery to decode the return json object? | [
"",
"javascript",
"json",
"jquery-plugins",
""
] |
In my Java project, I have a vector of various types of Traders. These different types of traders are subclasses of the Trader class. Right now, I have a method that takes a Trader as an argument and stores it 50 or so times in the vector. I am having problems because storing the same object 50 times is just storing 50 *references* of the same object. I need to store 50 *copies* of the object. I've researched about implementing [Clone](http://en.wikipedia.org/wiki/Clone_(Java_method)), but I don't want the programmers defining a type of Trader to have to worry about making their class cloneable. Also, as pointed out by [this page](http://www.javapractices.com/topic/TopicAction.do?Id=71), implementing clone creates all sorts of problems. I don't think a copy constructor would work either because if I defined one in the Trader class, it would not know the type of Trader it was copying and just make a generic Trader. What can I do?
Edit: I am not really wanting to make exact copies of a certain object. What I am really trying to do is to add a certain number of Traders to the vector. The problem is that the user needs to specify in an argument which type of Trader he wants to add. Here is an example of what I am trying to do: (although my syntax is completely imaginary)
```
public void addTraders(*traderType*)
{
tradervect.add(new *traderType*())
}
```
How can I achieve something like this in Java? | Just add an abstract copy method. You can use covariant return types so that the derived type is specified to return a derived instance, which may or may not be important.
```
public interface Trader {
Trader copyTrader();
...
}
public final class MyTrader implements Trader {
MyTrader copyTrader() {
return new MyTrader(this);
}
...
}
```
Sometimes you might want to generically deal with a collection of derived type of `Trader` that needs to clone and then return the a properly typed collection. For that you can use generics in an idiomatic way:
```
public interface Trader<THIS extends Trader> {
THIS copyTrader();
...
}
public final class MyTrader implements Trader<MyTrader> {
public MyTrader copyTrader() {
return new MyTrader(this);
}
...
}
``` | I am a little unclear as to why you would want to store 50 or so clones of the same object unless they the original trader serves as a prototype (see pattern) for later traders.
If you want to make an exact copy of an object, you have to take into account the issue of polymorphism. If people subclassing your given class are allowed to add state members, then you already have enough of a headache with functions like equals and compareTo, that clone is jut one more case where you need to require special handling.
I disagree that clone is always evil, it is sometimes necessary. However, in situations of subclassing, a lot of things become tricky.
I would recommend you read (when you get a chance) Bloch's "Effective Java", which covers a lot of his topics. Bracha's view is that it is not a good idea to let others extend your classes, and that if you do, you need to document very well what they would have to do and hope that they follow your instructions. There really isn't a way to bypass that. You may also want to make your Traders immutable.
Go ahead an implement Clone normally, and indicate very clearly in the class header that anybody inheriting from your Trader and adding state members must implement X methods (specify which).
Finding tricks to bypass an actual Cloneable and still Clone isn't going to overcome the problem of inheritance. There is no silver bullet here. | Are there any alternatives to implementing Clone in Java? | [
"",
"java",
"reference",
"vector",
"clone",
"subclass",
""
] |
Any idea why this code:
```
extern "C" __declspec(dllexport) void Transform(double x[], double y[], int iterations, bool forward)
{
long n, i, i1, j, k, i2, l, l1, l2;
double c1, c2, tx, ty, t1, t2, u1, u2, z;
/* Calculate the number of points */
n = (long)pow((double)2, (double)iterations);
/* Do the bit reversal */
i2 = n >> 1;
j = 0;
for (i = 0; i < n - 1; ++i)
{
if (i < j)
{
tx = x[i];
ty = y[i];
x[i] = x[j];
y[i] = y[j];
x[j] = tx;
y[j] = ty;
}
k = i2;
while (k <= j)
{
j -= k;
k >>= 1;
}
j += k;
}
/* Compute the FFT */
c1 = -1.0;
c2 = 0.0;
l2 = 1;
for (l = 0; l < iterations; ++l)
{
l1 = l2;
l2 <<= 1;
u1 = 1;
u2 = 0;
for (j = 0; j < l1; j++)
{
for (i = j; i < n; i += l2)
{
i1 = i + l1;
t1 = u1 * x[i1] - u2 * y[i1];
t2 = u1 * y[i1] + u2 * x[i1];
x[i1] = x[i] - t1;
y[i1] = y[i] - t2;
x[i] += t1;
y[i] += t2;
}
z = u1 * c1 - u2 * c2;
u2 = u1 * c2 + u2 * c1;
u1 = z;
}
c2 = sqrt((1.0 - c1) / 2.0);
if (forward)
c2 = -c2;
c1 = sqrt((1.0 + c1) / 2.0);
}
/* Scaling for forward transform */
if (forward)
{
for (i = 0; i < n; ++i)
{
x[i] /= n;
y[i] /= n;
}
}
}
```
runs 20% faster than this code?
```
public static void Transform(DataSet data, Direction direction)
{
double[] x = data.Real;
double[] y = data.Imag;
data.Direction = direction;
data.ExtremeImag = 0.0;
data.ExtremeReal = 0.0;
data.IndexExtremeImag = 0;
data.IndexExtremeReal = 0;
long n, i, i1, j, k, i2, l, l1, l2;
double c1, c2, tx, ty, t1, t2, u1, u2, z;
/* Calculate the number of points */
n = (long)Math.Pow(2, data.Iterations);
/* Do the bit reversal */
i2 = n >> 1;
j = 0;
for (i = 0; i < n - 1; ++i)
{
if (i < j)
{
tx = x[i];
ty = y[i];
x[i] = x[j];
y[i] = y[j];
x[j] = tx;
y[j] = ty;
}
k = i2;
while (k <= j)
{
j -= k;
k >>= 1;
}
j += k;
}
/* Compute the FFT */
c1 = -1.0;
c2 = 0.0;
l2 = 1;
for (l = 0; l < data.Iterations; ++l)
{
l1 = l2;
l2 <<= 1;
u1 = 1;
u2 = 0;
for (j = 0; j < l1; j++)
{
for (i = j; i < n; i += l2)
{
i1 = i + l1;
t1 = u1 * x[i1] - u2 * y[i1];
t2 = u1 * y[i1] + u2 * x[i1];
x[i1] = x[i] - t1;
y[i1] = y[i] - t2;
x[i] += t1;
y[i] += t2;
}
z = u1 * c1 - u2 * c2;
u2 = u1 * c2 + u2 * c1;
u1 = z;
}
c2 = Math.Sqrt((1.0 - c1) / 2.0);
if (direction == Direction.Forward)
c2 = -c2;
c1 = Math.Sqrt((1.0 + c1) / 2.0);
}
/* Scaling for forward transform */
if (direction == Direction.Forward)
{
for (i = 0; i < n; ++i)
{
x[i] /= n;
y[i] /= n;
if (Math.Abs(x[i]) > data.ExtremeReal)
{
data.ExtremeReal = x[i];
data.IndexExtremeReal = (int)i;
}
if (Math.Abs(y[i]) > data.ExtremeImag)
{
data.ExtremeImag = y[i];
data.IndexExtremeImag = (int)i;
}
}
}
}
```
[FFT http://www.rghware.com/fft.png](http://www.rghware.com/fft.png)
I created the drop in CPU seen in the middle of the graph by selecting the “Native DLL FFT” in my app:
<http://www.rghware.com/InstrumentTuner.zip> (source code)
I think this will run on most PCs. You’ll need to have DirectX installed. I had some issues using the capture settings for certain hardware. The capture settings were supposed to be configurable, but the app’s development has been sidetracked by this interesting find.
Anyway, why I’m seeing a 20% increase in speed using the native code? This seems to fly in the face of some of the assumptions I previously had.
**UPDATE**
After converting the function to an unsafe method and fixing the long/int issue. The new unsafe method actually runs faster than the native method (pretty cool).
[Profile http://www.rghware.com/profile.png](http://www.rghware.com/profile.png)
It's obvious that the array bound checking is the cause of the 20% slow down in this FFT method. Due to it's nature, the for-loops in this method cannot be optimized.
Thanks everyone for the help. | Just looking at this code, I'd suspect from my experience a fairly significant slowdown going from C++ -> C#.
One major issue you're going to face in a naive port of a routine like this to C# is that C# is going to add bounds checking on every array check here. Since you're never looping through the arrays in a way that will get optimized ([see this question for details](https://stackoverflow.com/questions/631123/what-is-the-special-case-with-the-foreach-loop-that-eliminates-bounds-checking)), just about every array access is going to receive bounds checking.
In addition, this port is pretty close to a 1->1 mapping from C. If you run this through a good .NET profiler, you'll probably find some great spots that can be optimized to get this back to near C++ speed with one or two tweaks (that's nearly always been my experience in porting routines like this).
If you want to get this to be at nearly identical speed, though, you'll probably need to convert this to unsafe code and use pointer manipulation instead of directly setting the arrays. This will eliminate all of the bounds checking issues, and get your speed back.
---
Edit: I see one more huge difference, which may be the reason your C# unsafe code is running slower.
Check out [this page about C# compared to C++](http://msdn.microsoft.com/en-us/library/yyaad03b.aspx), in particular:
"The long type: In C#, the long type is 64 bits, while in C++, it is 32 bits."
You should convert the C# version to use int, not long. In C#, long is a 64bit type. This may actually have a profound effect on your pointer manipulation, because I believe you are inadvertantly adding a long->int conversion (with overflow checking) on every pointer call.
Also, while you're at it, you may want to try wrapping the entire function in an [unchecked block](http://msdn.microsoft.com/en-us/library/a569z7k8.aspx). C++ isn't doing the overflow checking you're getting in C#. | This is most likely due to the JIT compiler generating code that's not as efficient as the code generated by the native compiler.
Profiling the code should probably be your next step if you care about the 20% decrease in performance, or you might consider using an off the shelf optimized library. | Why would I see ~20% speed increase using native code? | [
"",
"c#",
"winforms",
""
] |
I'am aware there has been a generic question about a "best IDE in C++" but I would like to stress I'm a **new** to C++ and programming in general. This means I have the needs of a student:
* relatively easy and unbloated working environment
* things just work, focus on the code
* color coding to show the different language features (comments, etc)
* not *too* unfriendly (not a simple editor, something to handle projects from start to finish)
* cross-platform so not to be bound with specific system practices
I think the above are relatively reasonable demands for an **educational IDE**, perhaps excluding the last as such universal tool might not exist. Any ideas? | If you are using both windows and linux (as your comment indicates), I'd recommend [Qt Creator](https://web.archive.org/web/20090727072714/http://www.qtsoftware.com:80/products/developer-tools). Qt is cross platform so your apps will work on linux, windows, and mac. Qt has excellent documentation, too, so it's very newbie friendly. Signals and Slots take a bit of getting used to, but IMO it's worth it. | It depends on which world are you coming from to learn C++.
* Do you have previous Java experience? - Use Eclipse CDT.
* Have used .NET previously? - Go with Visual Studio C++ Express Edition (and then throw it away if you really need multiplatform *IDE*, not just code).
* Are you an Unix guy? Use just a syntax-highlighting editor + Makefile. When you want to learn basics of the C++, the project should not be complicated and it is well invested time to learn how the C++ compiler is called with preprocessor options, etc. | Educational IDE to start programming in C++? | [
"",
"c++",
"ide",
""
] |
I'd like to properly close some sockets, and be able to tell the server that we're closing, but if the application is closed then the sockets are all just closed and on occasion files are left locked. How can I run a method when my application is closed?
This is going to go into a library that will be used in a forms app. | I would implement [IDisposable](http://msdn.microsoft.com/en-us/library/system.idisposable.aspx) on the classes that use these resources. Dispose can then be called explicitly from whichever shutdown method the application type supports (OnFormClose, OnStop, Application\_End, ...). | If its a Windows Forms application you can give focus to the form, click the events lightning bolt in the properties window, and use the Form Closing event.
```
this.FormClosing += new System.Windows.Forms.FormClosingEventHandler(OnFormClosing);
private void OnFormClosing(object sender, FormClosingEventArgs e)
{
// Your socket logic here
}
```
Also if you need to intercept the form being closed set the Cancel property to true:
```
e.Cancel = true;
``` | Intercepting application close in c# | [
"",
"c#",
"resource-cleanup",
""
] |
I'm working on a little something and I am trying to figure out whether I can load an XDocument from a string. `XDocument.Load()` seems to take the string passed to it as a path to a physical XML file.
I want to try and bypass the step of first having to create the physical XML file and jump straight to populating the XDocument.
Any ideas? | You can use [`XDocument.Parse`](http://msdn.microsoft.com/en-us/library/system.xml.linq.xdocument.parse.aspx) for this. | You can use [`XDocument.Parse(string)`](http://msdn.microsoft.com/en-us/library/bb345532.aspx) instead of `Load(string)`. | Populate XDocument from String | [
"",
"c#",
"xml",
"c#-3.0",
"linq-to-xml",
""
] |
I'm researching the development of Enterprise Applications in Java, .NET and Groovy. For each platform, we're going to try how hard it is to realize a simple SOAP web service. We'll use the tools and libraries that are most commonly used, to research the real world as accurately as possible.
In this regard, when using Hibernate for persistence, would it better reflect the real world to use the new JPA (Java Persistence API), or the Hibernate custom API that existed before JPA came around? | As you're probably already aware, as of 3.2 Hibernate is JPA certified. You can easily use Hibernate as your JPA provider without having to use any of Hibernate's "custom" APIs.
I'd recommend using straight JPA with Hibernate as the provider. And use annotations rather than XML (much nicer).
Then when you need a little something extra you can always get the Hibernate Session. For example I often find I need to do this in order to pass a collection to a query as a parameter (setParameterList). | It's funny how you worded your question
> *new* JPA ... or *plain old* Hibernate
Sounds like one has been around forever and the other has just been released. Of course it's not true. JPA was influenced not just by Hibernate but also by TopLink and by J2EE entity beans. The first reference to JSR 220 draft is back from 2003 - how is that for new?
If you use JPA with Hibernate you still use Hibernate and is free to apply any proprietary extensions Hibernate has.
So the choice is yours: use proprietary API or use equivalent established and standard API... | JPA or Hibernate for Java Persistence? | [
"",
"java",
"hibernate",
"jpa",
"persistence",
""
] |
In C#, I am developing several Windows Services which have some standard functionality so I have put all this common functionality into a separate referenced utility project.
I have a situation where I need to create instances of business classes which reside in my Windows Service project from the utility project using Activator.CreateInstance.
My utility project is aware of the namespace and the class name for the Type.GetType call but the type is always null and when I think about it, it won’t be able to get the type from the project it’s referenced to, or can it?
In short:
Project A references Utility Project.
Utility Project wants to create class from Project A, its aware of the namespace and class name.
Is there a Design Pattern or an approach that I should be following to achieve this functionality? Or does this look like a no, no and I should be refactoring?
Thanks for looking | You need to specify the fully-qualified assembly name (including version etc, if it's strongly named) if you want `Type.GetType` to find a type which isn't in either `mscorlib` or the calling assembly.
For example:
```
// Prints nothing
Console.WriteLine(Type.GetType("System.Linq.Enumerable"));
// Prints the type name (i.e. it finds it)
Console.WriteLine(Type.GetType("System.Linq.Enumerable, System.Core, "
+ "Version=3.5.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"));
```
Alternatively, can you make this a generic method in the utility project, and get the caller to specify the type as a type argument? | You can solve the circular reference problem using reflection, as Jon pointed out, but I suggest rethinking the design and refactoring it. Two suggestions.
* Use interfaces to decuple A and B. (prefered solution)
* Move the part needed by A and B into C and reference only C from A and B. | C#, accessing classes from a referenced project | [
"",
"c#",
"design-patterns",
"inheritance",
"types",
"reference",
""
] |
I'm just trying to quickly debug a webservice by printing out the contents of an int and string array. Is there anyway to do this in one method?
I tried
```
public static string ArrayToString(object[] array)
{
StringBuilder sb = new StringBuilder();
foreach (Object item in array)
{
sb.Append(item.ToString());
sb.Append(" ");
}
return sb.ToString();
}
```
But this chokes when I try and send it a primative array (int[]) due to it not being an Object.
Which I find strange as sending an int to the method below works
```
static void PrintObject(object obj)
{
Console.WriteLine(obj.ToString());
}
```
Is there anyway to do this in one method or am I just going to have to man up and create two separate methods?
---
Of course whether I should be using arrays at all is questionable, but the web service is already in place.
**See also:**
* [When to use a Array() over
Generic.Lists in .NET](https://stackoverflow.com/questions/413174/when-to-use-a-array-over-generic-lists-in-net)
* [Arrays considered somewhat harmful](http://blogs.msdn.com/ericlippert/archive/2008/09/22/arrays-considered-somewhat-harmful.aspx) | ```
public static string ArrayToString<T>(T[] array)
{
StringBuilder sb = new StringBuilder();
foreach (T item in array)
{
sb.Append(item.ToString());
sb.Append(" ");
}
return sb.ToString();
}
```
Then
```
int[] x = new int[] { 1, 2, 3 };
string[] y = new string[] { "a", "b", "c" };
Console.WriteLine(ArrayToString(x));
Console.WriteLine(ArrayToString(y));
``` | Try something like this:
```
static String toString<T>(IEnumerable<T> list)
{
StringBuilder sb = new StringBuilder();
foreach (T item in list)
{
sb.Append(item.ToString());
sb.Append(" ");
}
return sb.ToString();
}
```
The compiler will happily infer the type of `T` by the type of the list you pass in like this:
```
toString(new int[] { 1, 2, 3 });
toString(new String[] { "1", "2", "3" });
``` | How do I build a generic C# array content printer that accepts both objects and primitives? | [
"",
"c#",
".net",
"arrays",
"tostring",
""
] |
I'm writing a simple web app in PHP that needs to have write access to a directory on the server, if the directory isn't writable I want to display an error message explaining to set the owner of the directory to whoever the webserver is being run as (eg. www-data, nobody) but as most people don't know this it would be nice to be able to tell them who to chown the directory to. Is it possible to find this from PHP? | Check out [shell\_exec()](http://www.php.net/shell_exec) | ```
<?php
echo exec('whoami');
?>
``` | Can I find which user the web server is being run as in PHP? | [
"",
"php",
"apache",
""
] |
I have implemented in my python code a callback for variable arguments similar to what can be found here:
<https://docs.python.org/library/optparse.html#callback-example-6-variable-arguments>
Adding the option like this:
```
parser.add_option("-c", "--callback", dest="vararg_attr", action="callback", callback=vararg_callback)
```
The problem is, that there is no indication for the user that the option requires extra input:
```
Options:
-h, --help show this help message and exit
-c, --callback
```
Is there any way to change optparse's usage so that the usage will print something like:
```
-c=LIST, --callback=LIST
``` | This involves monkeypatching and might not be the best solution. On the other hand, it seems to work.
```
from optparse import OptionParser, Option
# Complete hack.
Option.ALWAYS_TYPED_ACTIONS += ('callback',)
def dostuff(*a):
pass
parser = OptionParser()
parser.add_option("-c",
"--callback",
dest="filename",
action="callback",
callback=dostuff,
metavar='LIST',
help='do stuff',
)
(options, args) = parser.parse_args()
```
Output:
```
Usage: opt.py [options]
Options:
-h, --help show this help message and exit
-c LIST, --callback=LIST
do stuff
``` | user the `metavar` keyword argument:
```
parser.add_option("-c", "--callback", dest="vararg_attr", action="callback", callback=vararg_callback, metavar='LIST')
```
Reference: <http://docs.python.org/library/optparse.html> | Optparse: Usage on variable arg callback action does not indicate that extra params are needed | [
"",
"python",
"callback",
"optparse",
""
] |
Can somebody explain to me why the following works:
```
template<class T> class MyTemplateClass {
public:
T * ptr;
};
int main(int argc, char** argv) {
MyTemplateClass<double[5]> a;
a.ptr = new double[10][5];
a.ptr[2][3] = 7;
printf("%g\n", a.ptr[2][3]);
return 0;
}
```
But this doesn't:
```
class MyClass {
public:
double[5] * ptr;
// double(*ptr)[5]; // This would work
};
int main(int argc, char** argv) {
MyClass a;
a.ptr = new double[10][5];
a.ptr[2][3] = 7;
printf("%g\n", a.ptr[2][3]);
return 0;
}
```
Obviously there is more to template instantiation than just a textual replacement by the arguments to the template - is there a simple explanation of this magic?
For the latter the compiler (g++ 4.1.2) spits out the following error:
```
test.cxx:13: error: expected unqualified-id before '[' token
```
Where line 13 is the `double[5] * ptr;` line.
The question is not:
"Why does the MyClass example fail? - because C++ doesn't allow Java style array declarations ;-)".
But is:
"Why does the MyTemplateClass example succeed?" | The difference lies in the C++ grammar. A simple-declaration is formed like this:
```
declaration-specifier-seq init-declarator-list
```
Where declaration-specifier-seq is a sequence of declaration specifiers:
```
simple-type-specifier: int, bool, unsigned, typedef-name, class-name ...
class-specifiers: class X { ... }
type-qualifier: const, volatile
function-specifier: inline, virtual, ...
storage-class-specifier: extern, static, ...
typedef
```
You get the idea. And init-declarator-list is a list of declarators with an optional initializer for each:
```
a
*a
a[N]
a()
&a = someObj
```
So a full simple-declaration could look like this, containing 3 declarators:
```
int a, &b = a, c[3] = { 1, 2, 3 };
```
Class members have special rules to account for the different context in which they appear, but they are very similar. Now, you can do
```
typedef int A[3];
A *a;
```
Since the first uses the typedef specifier and then simple-type-specifier and then a declarator like "a[N]". The second declaration then uses the typedef-name "A" (simple-type-specifier) and then a declarator like "\*a". However, you of course cannot do
```
int[3] * a;
```
Since "int[3]" is not a valid declaration-specifier-seq as shown above.
And now, of course, a template is **not** just like a macro text substitution. A template type parameter of course is treated like any other type-name which is interpreted as just the type it names and can appear where a simple-type-specifier can appear. Some C# folks tend to say C++ templates are "just like macros", but of course they are not :) | ```
template<class T> MyTemplateClass {
...
}
```
is closer to
```
template<class T> MyTemplateClass {
typedef {actual type} T;
...
}
```
than to a simple text substitution. | Why is this C++ class not equivalent to this template? | [
"",
"c++",
"templates",
""
] |
At work, we have migrated from Windows XP to Windows Vista. After the migration, some of my unit tests, using nUnit, started to randomly fail with the System.UnauthorizedAccessException being thrown. The failing tests each involve writing files used for tests stored as embedded resources in the test DLL to the current directory, running the tests, then deleting them, typically in the setup/teardown or the fixture setup/teardown, in rapid succession. I do this so that my tests are agnostic to the location on each developer's drive that they are ran from and not worrying about relative file paths.
While troubleshooting this, I found that it related to the creation and deletion of the files. On deletion, each delete follows the pattern:
```
if( File.Exists(path) ) { File.Delete(path) }
```
When I surround this with a try-catch block and breakpoint on the catch (if the exception was thrown), the file would already be deleted from the disk. For the failures of file creation, usually using XmlWriter or StreamWriter, each are specified to overwrite the file if it exists.
Odd thing is, while investigating, I created this C# program that seems to recreate the exception:
```
class Program
{
static void Main(string[] args)
{
int i = 0;
try
{
while (true)
{
System.IO.TextWriter writer = new System.IO.StreamWriter("file.txt");
i++;
System.Console.Out.WriteLine(i);
writer.Write(i);
writer.Close();
System.IO.File.Delete("file.txt");
}
}
catch (System.UnauthorizedAccessException ex)
{
System.Console.Out.WriteLine("Boom at: " + i.ToString());
}
}
}
```
On one of our machines that still has XP on it, it will keep iterating into the hundreds of thousands without excepting until I kill it. On any of our Vista machines, it will print "Boom" anywhere between 150 and 500 iterations.
Since I do not have access to a Vista machine outside of work, I can't determine whether this particular 'quirk' is because of my employer's security configuration of Vista or Vista itself.
Suffice to say, I am quite stumped.
EDIT:
I would like to thank everyone for their responses. I used the Process Monitor suggested by Christian and found that the Windows Vista SearchIndexer and TortoiseSVN's TSVNCache processes were trying to access the target file while my code was running, as suggested by Martin.
Thanks again. | Do you have any virus scanners? Try to disable them or watch the file activity with ProcMon from <http://www.sysinternals.com> | In vista, go to Performace Monitor (controlpanrl->Administrative tools) and observe the virtual bytes(for memory leaks) for your application when it is running. Performance monitor gives you a lot of details about the process you want to investigate. I suspect that your application is not releasing resources since it is working heavily on file system.
Also play around with performance monitor to try and see other measures that might have caused your issue. It is difficult to blame one or the other service with out doing little investigation. | UnauthorizedAccessException in Vista from frequent file I/O with .Net 2.0 | [
"",
"c#",
"vb.net",
"windows-vista",
"windows-xp",
"unauthorized",
""
] |
I have two stored procedures I wish to use in my stored procedure, but once I do that it fails to load with the error: "Invalid Argument provided, no rowset retrieved." If I remove either one of them it starts working again.
I have the crystal report set up something like this:
```
Report:
Group By Tenant.ReferedBy
stored proc here that calculates the tenant's balance
```
and the second stored proc is in the Select for the report. I only want to select tenant's by a status flag, and I'm getting the status flag from a stored proc.
Neither of the two procedures are linked together in anyway. One returns one value (the one in the select), the other returns multiple (the one in the group by). Neither take any parameters and are both just simple SQL statements stored on the database.
First Proc: GetAllTenantBalances
```
SELECT (SUM(tblTransaction.AmountPaid) - SUM(tblTransaction.AmountCharged)) AS TenantBalance, tblTransaction.TenantID
FROM tblTransaction
GROUP BY tblTransaction.TenantID
```
Second Proc: [GetTenantStatusID\_Current]
```
SELECT ID FROM tblTenantStatus WHERE Description = 'Current'
```
Can anyone tell me why I can't do this, and how to get around it? | You could change the first sp to only sum 'Current' tenants. Or, if you must keep two sp you will have to go to the database expert and join them by the tenant\_id. | You could also use sub-reports to give you the data you want. Use on SP on the main, and then another SP on a sub-report.
-JFV | How can I use more than one Stored Procedure in a crystal report? | [
"",
"sql",
"stored-procedures",
"crystal-reports",
""
] |
Is there any way to validate the contents of a CEdit box without subclassing?
I want to check for invalid filename characters in a CEdit box and not allow the user to input it at all (keypress should not be recorded, if pasted in the box, the invalid characters should just not make it to the edit box)..
Is there any easy way to do this?
On a side note, how do I make a variable that is tied to this box? If I add a variable that is not a control one, would this variable always contain what is in the edit control?
Thanks.. | Per <http://msdn.microsoft.com/en-us/library/f7yhsd2b(VS.80).aspx> , "If you want to handle Windows notification messages sent by an edit control to its parent (usually a class derived from CDialog), add a message-map entry and message-handler member function to the parent class for each message." and "ON\_EN\_UPDATE The edit control is about to display altered text. Sent after the control has formatted the text but before it screens the text so that the window size can be altered, if necessary." -- so, without subclassing CEdit, you can vet and possibly block updates via the windows message-map/message-handler in the parent. | Some time long ago I created [this](http://www.codeproject.com/KB/library/Validators.aspx). Granted, this is very dated but ideas still hold:
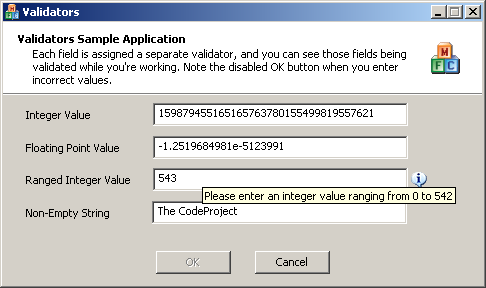 | validating CEdit without subclassing | [
"",
"c++",
"mfc",
"cedit",
""
] |
Is there any way that I can create a new delegate type based on an existing one? In my case, I'd like to create a delegate `MyMouseEventDelegate` which would have the same functionality as `EventHandler<MouseEventArgs>`.
Why do I want this? To take advantage of **compile-time type-checking**, of course! This way, I can have two different delegates: `MyRightClickHandler` and `MyLeftClickHandler`, and never the twain shall be confused - even if they are both functionally identical to `EventHandler<MouseEventArgs>`.
Is there syntax to do this sort of thing?
Oh, and code like:
```
using MyRightClickHandler = EventHandler<MouseEventArgs>
```
isn't good enough. It doesn't do any type-checking, since it doesn't actually create a new type. And I'd have to paste such a line into every code file in which I would refer to `MyRightClickHandler`. | Well, it's as simple as copying the delegate declaration from the original. There's nothing in C# to do this automatically, but I can't see it's much of a burden:
```
public delegate void MyLeftClickHandler(object sender, MouseEventArgs e);
public delegate void MyRightClickHandler(object sender, MouseEventArgs e);
```
It's not like `MouseEventHandler` is going to change any time soon...
Have you actually been bitten by bugs due to using the wrong delegates in the wrong places though? I can't remember ever having found this a problem myself, and it seems to me you're introducing more work (and an unfamiliar set of delegates for other developers) - are you sure it's worth it? | I you only want to achieve compile time type checking I guess it would be enough to create specialized EventArgs classes for the cases that you describe. That way you can still take advantage of the pre-defined delegates:
```
class RightMouseButtonEventArgs : MouseEventArgs {}
class LeftMouseButtonEventArgs : MouseEventArgs {}
EventHandler<RightMouseButtonEventArgs>
EventHandler<LeftMouseButtonEventArgs>
``` | How do I create a new delegate type based on an existing one, in C#? | [
"",
"c#",
"inheritance",
"delegates",
""
] |
What the difference between jQuery's functions `val()` and `text()`?
Where would you use one over the other? | `.val()` works on input elements (or any element with a value attribute?) and `.text()` will not work on input elements. `.val()` gets the value of the input element -- regardless of type. `.text()` gets the innerText (not HTML) of all the matched elements:
[`.text()`](http://docs.jquery.com/Attributes/text)
> The result is a string that contains
> the combined text contents of all
> matched elements. This method works on
> both HTML and XML documents. Cannot be
> used on input elements. For input
> field text use the val attribute.
[`.val()`](http://docs.jquery.com/Attributes/val)
> Get the content of the value attribute
> of the first matched element | text() return the combined text contents of all matched elements (such as p, div, and so on)
val() is used to obtain the value of an input element (such as input, select, and so on)
according to the official documentation text() should not be used with input elements | Difference between val() and text() | [
"",
"javascript",
"jquery",
"html",
""
] |
Consider this scenario: I've an XML file called person.xml with the following data in it.
```
<person>
<name>MrFoo</name>
<age>28</age>
</person>
```
If I want to read this XML into a Java object, I would be creating a Java bean called PersonBean (with getters/setters for the attributes) as:
```
class Person{
String name;
int age;
}
```
And I could use any APIs for reading the XML and populating the Java Bean.
But the real question here is, suppose if the structure of the XML file changes, i.e. if an new attribute 'email' is added to the XML file, then I have to modify the Java Bean also to add a new attribute. But, I want to avoid changing the Java code even if the XML structure changes.
So, what I'm trying to do is, I'm creating another XML file called PersonStructure.xml with the content as:
```
<class name="Person">
<attributes>
<attribute>
<name>personName</name>
<type>java.lang.String</type>
</attribute>
... and it goes like this...
</attribute>
</class>
```
Is it possible to read the PersonStructure.XML file and convert it into Person.Java class file? The approach what I'm trying to do is correct or is there any other way to do the same? | While this is not exactly what you are trying to do, you should have a look at JAXB. It can generate a set of Java classes from a Schema definition. Your PersonStructure.xml file looks quite a bit like an XSD with a different syntax, so you could reuse JAXB.
<https://jaxb.dev.java.net/> | Not very familiar with Java (I'm mostly a .NET guy), but common sense applies: there's actually very little use in dynamically generated beans (unless you'll be binding those to some control, in which case array of `Object`s will do just fine).
What is more logical is codegen'ing Java beans from this XML definitions, which can be done with [XSLT](http://en.wikipedia.org/wiki/XSLT).
PS. Do not try to make a programming language out of XML. Hell will definitely break loose if you do so. | Generating Java Classes dynamically from an XML document | [
"",
"java",
"xml",
"reflection",
""
] |
How do I convert the XML in an XDocument to a MemoryStream, without saving anything to disk? | Have a look at the [XDocument.WriteTo](http://msdn.microsoft.com/en-us/library/system.xml.linq.xdocument.writeto.aspx) method; e.g.:
```
using (MemoryStream ms = new MemoryStream())
{
XmlWriterSettings xws = new XmlWriterSettings();
xws.OmitXmlDeclaration = true;
xws.Indent = true;
using (XmlWriter xw = XmlWriter.Create(ms, xws))
{
XDocument doc = new XDocument(
new XElement("Child",
new XElement("GrandChild", "some content")
)
);
doc.WriteTo(xw);
}
}
``` | In .NET 4 and later, you can Save it to a `MemoryStream`:
```
Stream stream = new MemoryStream();
doc.Save(stream);
// Rewind the stream ready to read from it elsewhere
stream.Position = 0;
```
In .NET 3.5 and earlier, you would need to create an `XmlWriter` based on a `MemoryStream` and save to that, as shown in [dtb's answer](https://stackoverflow.com/a/750250). | Convert XDocument to Stream | [
"",
"c#",
".net",
"xml",
"linq-to-xml",
""
] |
I'm writing a basic push messaging system. A small change has caused it to stop workingly properly. Let me explain. In my original version, I was able to put the code in the of a document something like this:
```
<head>
...text/javascript">
$(document).ready(function(){
$(document).ajaxStop(check4Updates);
check4Updates();
});
function check4Updates(){
$.getJSON('%PATH%', callback);
};
...
</head>
```
This worked nicely and would keep the connection open even if the server return null (which it would after say a 2 minute timeout). It would just keep calling the getJSON function over and over indefinitely. Happy Panda.
Now, I must put the code segment in between tags. Access to the $(document).ready() function pretty much won't work.
```
<body>
...
check4Updates();
$("body").ajaxStop(check4Updates);
...
</body>
```
This works... for a while. Shortly thereafter, it will stop calling check4Updates and get into an infinite loop and use 100% processor time.
I'm trying to get it so that check4Updates is repeatedly called until the page is closed. If anyone has any insights as to why my simple change is no longer functioning as expected, PLEASE let me know. Thank you for taking the time to read and help me out.
Best Regards,
Van Nguyen | Yeah, you're not going to want to use that loop, you're pretty much [DOSing](http://en.wikipedia.org/wiki/Denial-of-service_attack) yourself not to mention locking the client.
Simple enough, create a polling plugin:
Source: <http://web.archive.org/web/20081227121015/http://buntin.org:80/2008/sep/23/jquery-polling-plugin/>
Usage:
```
$("#chat").poll({
url: "/chat/ajax/1/messages/",
interval: 3000,
type: "GET",
success: function(data){
$("#chat").append(data);
}
});
```
The code to back it up:
```
(function($) {
$.fn.poll = function(options){
var $this = $(this);
// extend our default options with those provided
var opts = $.extend({}, $.fn.poll.defaults, options);
setInterval(update, opts.interval);
// method used to update element html
function update(){
$.ajax({
type: opts.type,
url: opts.url,
success: opts.success
});
};
};
// default options
$.fn.poll.defaults = {
type: "POST",
url: ".",
success: '',
interval: 2000
};
})(jQuery);
``` | Use a timeout, these types of loops are a really bad idea, so if you must employ polling for whatever reason, make sure you don't keep hammering your backend. | Keeping a jQuery .getJSON() connection open and waiting while in body of a page? | [
"",
"javascript",
"jquery",
"comet",
"server-push",
""
] |
This should be a elementary question but why is better to use something like this:
```
$pwd = filter_input(INPUT_POST, 'pwd');
```
Instead of just:
```
$pwd = $_POST['pwd'];
```
PS: I understand that the filter extension can be used with more arguments to provide an additional level of sanitization. | It's not. `$_GET`, `$_POST`, `$_COOKIE` and `$_REQUEST` are [filtered with default filter](http://www.php.net/manual/en/filter.configuration.php). `filter_input(INPUT_POST, 'pwd')` without additional parameters also uses the default filter. So there is no difference at all. | Any data which is sent from the client (such as POST data) should be sanitized and escaped (and even better, sanity-checked) to ensure that it isn't going to kill your website.
[SQL Injection](http://en.wikipedia.org/wiki/SQL_injection) and [Cross-site scripting](http://en.wikipedia.org/wiki/Cross-site_scripting) are the two largest threats for failing to sanitize your user-sent data. | Why is better to use filter_input()? | [
"",
"php",
"security",
"filter",
""
] |
I'm nearly done with a trackback system for my website, but have one last niggling regular expression I just can't get right.
What I'm after is an excerpt of the referring page, where I'm defining the most relevant excerpt as:
The first paragraph (marked by `<p></p>` tags) that follows either an `<h1></h1>`, `<h2></h2>` or `<h3></h3>` in the HTML Source of the page.
For instance, I can successfully fetch the `<title></title>` tag for the HTML as follows:
```
Regex reTITLE = new Regex( @"(?<=<title.*>)([\s\S]*)(?=</title>)",
RegexOptions.IgnoreCase );
Match match = reTITLE.Match( strHTMLSource );
if (match.Success)
{
strReferringPageTitle = match.Value.Trim( );
}
```
My question -- what Regular Expression can I use to fetch the string described in the first part of my post?
PS: I love StackOverflow and this community -- great job, Joel & Co.! | ```
Match m = Regex.Match(strHTMLSource, "^.*?</h[123]>.*?<p>(.*?)</p>",
RegexOptions.Compiled | RegexOptions.IgnoreCase);
string para = m.Success ? m.Groups[1].Value.Trim() : string.Empty;
``` | Personally I would use XPath queries to do what you're trying to achieve, much easier imo than fiddling with regexes. | Regular Expression (C# flavor) to fetch first <p></p> after heading tag | [
"",
"c#",
"asp.net",
"regex",
""
] |
I have a .Net object (in C#) which has properties named event1, event2 and so on.
I have to do some if-else on each of these. is there way i can loop over these. If these were controls i could have used the controls collection, but these are properties of an object.
Any help? | Assuming you know how many properties you're dealing with
```
for(int eventIndex = 0; eventIndex < NUM_EVENTS; eventIndex++)
{
PropertyInfo eventPropertyInfo =
this.GetType().GetProperty("Event" + eventIndex);
if (eventPropertyInfo.GetValue(this, null) == yourValue)
{
//Do Something here
}
}
``` | It is probably clearest just to write it out manually.
However, it is possible to do using reflection. | Accessing similar named properties in a loop | [
"",
"c#",
".net",
""
] |
I have a block of text that im taking from a Gedcom ([Here](http://en.wikipedia.org/wiki/GEDCOM) and [Here](https://stackoverflow.com/questions/836146/gedcom-reader-for-c)) File
The text is flat and basically broken into "nodes"
I am splitting each node on the \r char and thus subdividing it into each of its parts( amount of "lines" can vary)
I know the 0 address will always be the ID but after that everything can be anywhere so i want to test each Cell of the array to see if it contains the correct tag for me to proccess
an example of what two nodes would look like
```
0 @ind23815@ INDI <<<<<<<<<<<<<<<<<<< Start of node 1
1 NAME Lawrence /Hucstepe/
2 DISPLAY Lawrence Hucstepe
2 GIVN Lawrence
2 SURN Hucstepe
1 POSITION -850,-210
2 BOUNDARY_RECT (-887,-177),(-813,-257)
1 SEX M
1 BIRT
2 DATE 1521
1 DEAT Y
2 DATE 1559
1 NOTE * Born: Abt 1521, Kent, England
2 CONT * Marriage: Jane Pope 17 Aug 1546, Kent, England
2 CONT * Died: Bef 1559, Kent, England
2 CONT
1 FAMS @fam08318@
0 @ind23816@ INDI <<<<<<<<<<<<<<<<<<<<<<< Start of Node 2
1 NAME Jane /Pope/
2 DISPLAY Jane Pope
2 GIVN Jane
2 SURN Pope
1 POSITION -750,-210
2 BOUNDARY_RECT (-787,-177),(-713,-257)
1 SEX F
1 BIRT
2 DATE 1525
1 DEAT Y
2 DATE 1609
1 NOTE * Born: Abt 1525, Tenterden, Kent, England
2 CONT * Marriage: Lawrence Hucstepe 17 Aug 1546, Kent, England
2 CONT * Died: 23 Oct 1609
2 CONT
1 FAMS @fam08318@
0 @ind23817@ INDI <<<<<<<<<<< start of Node 3
```
So a when im done i have an array that looks like
```
address , string
0 = "1 NAME Lawrence /Hucstepe/"
1 = "2 DISPLAY Lawrence Hucstepe"
2 = "2 GIVN Lawrence"
3 = "2 SURN Hucstepe"
4 = "1 POSITION -850,-210"
5 = "2 BOUNDARY_RECT (-887,-177),(-813,-257)"
6 = "1 SEX M"
7 = "1 BIRT "
8 = "1 FAMS @fam08318@"
```
So my question is what is the best way to search the above array to see which Cell has the SEX tag or the NAME Tag or the FAMS Tag
this is the code i have
```
private int FindIndexinArray(string[] Arr, string search)
{
int Val = -1;
for (int i = 0; i < Arr.Length; i++)
{
if (Arr[i].Contains(search))
{
Val = i;
}
}
return Val;
}
```
But it seems inefficient because i end up calling it twice to make sure it doesnt return a -1
Like so
`if (FindIndexinArray(SubNode, "1 BIRT ") != -1)
{
// add birthday to Struct
I.BirthDay = SubNode[FindIndexinArray(SubNode, "1 BIRT ") + 1].Replace("2 DATE ", "").Trim();
}`
sorry this is a longer post but hopefully you guys will have some expert advice | Can use the static method FindAll of the Array class:
It will return the string itself though, if that works..
```
string[] test = { "Sex", "Love", "Rock and Roll", "Drugs", "Computer"};
Array.FindAll(test, item => item.Contains("Sex") || item.Contains("Drugs") || item.Contains("Computer"));
```
The => indicates a lamda expression. Basically a method without a concrete implementation.
You can also do this if the lamda gives you the creeps.
```
//Declare a method
private bool HasTag(string s)
{
return s.Contains("Sex") || s.Contains("Drugs") || s.Contains("Computer");
}
string[] test = { "Sex", "Love", "Rock and Roll", "Drugs", "Computer"};
Array.FindAll(test, HasTag);
``` | What about a simple [regular expression](http://msdn.microsoft.com/en-us/library/kweb790z.aspx)?
```
^(\d)\s=\s\"\d\s(SEX|BIRT|FAMS){1}.*$
```
First group captures the address, second group the tag.
Also, it might be quicker to dump all array items into a string and do your regex on the whole lot at once. | Best way to Find which cell of string array contins text | [
"",
"c#",
"arrays",
"methods",
"find",
"gedcom",
""
] |
I'm reviewing some code from one of our contractors:
```
if (userLists != null)
{
Int32 numberOfItems = userLists.Count;
if ((numberOfItems & 1) == 1)
{
var emptyList = new tblList();
userLists.Add(emptyList);
}
}
```
Now, I'm trying to understand this, so, can someone please confirm with me if I have got this right or not?
1. Do we have an instance of a userList?
2. Yes. Get a the number of items in the userLists object.
3. if (the number of items equals 1 (Yes/true) AND 1 equals 1 (yes/True) ) AND that result equals 1 (Yes/True), then add an empty list object to the list.
4. Else: nothing.
If so (W.T.FFFFFFFFFFFFFFFFFFFF !!!!!!!!!!), that can be refactored to
```
if (numberOfItems == 1)
{
..
}
```
but even that's crap because I don't want a list with 'empty' items.
So did I read that piece of code correctly?
Oh, one more sigh at the use of `Int32` vs `Int` :( (but I digress). | The `&` is what is called a bitwise operator. Whereas the operator `&&` tests two boolean values:
```
TRUE && FALSE => FALSE
TRUE && TRUE => TRUE
```
the `&` operator can work on integer values:
```
00101101 (45)
& 01011011 (91)
---------------
= 00001001 (9)
```
**Each bit** has the boolean operation (and) done on it. So in the case of your code sample, it is asking "is the last bit a 1?" - that is to say "is it odd?" For instance, if the number is 23:
```
00010111 (23)
& 00000001 (1)
---------------
= 00000001 (1)
```
So it adds to the list because 1 == 1. But if the number was 22:
```
00010110 (22)
& 00000001 (1)
---------------
= 00000000 (0)
```
So it does not add to the list. | Bitwise-ANDing a number with 1 checks whether the number is odd or even (returns 1 if odd). What this code is doing is making sure the list has an even number of items by adding another item if there is an odd number of items. | Is my understanding of this piece of code correct? | [
"",
"c#",
""
] |
Does the IFRAME's onload event fire when the HTML has fully downloaded, or only when all dependent elements load as well? (css/js/img) | The latter: `<body onload=` fires only when all dependent elements (css/js/img) have been loaded as well.
If you want to run JavaScript code when the HTML has been loaded, do this at the end of your HTML:
```
<script>alert('HTML loaded.')</script></body></html>
```
Here is a [relevant e-mail thread](http://groups.google.com/group/mochikit/browse_thread/thread/ecd1ff24a780ae2f/1dc3eafb37b1e7b7?pli=1) about the difference between *load* and *ready* (jQuery supports both). | The above answer (using onload event) is correct, however in certain cases this seems to misbehave. Especially when dynamically generating a print template for web-content.
I try to print certain contents of a page by creating a dynamic iframe and printing it. If it contains images i cant get it to fire when the images are loaded. It always fires too soon when the images are still loading resulting in a incomplete print:
```
function printElement(jqElement){
if (!$("#printframe").length){
$("body").append('<iframe id="printframe" name="printframe" style="height: 0px; width: 0px; position: absolute" />');
}
var printframe = $("#printframe")[0].contentWindow;
printframe.document.open();
printframe.document.write('<html><head></head><body onload="window.focus(); window.print()">');
printframe.document.write(jqElement[0].innerHTML);
printframe.document.write('</body></html>');
// printframe.document.body.onload = function(){
// printframe.focus();
// printframe.print();
// };
printframe.document.close();
// printframe.focus();
// printframe.print();
// printframe.document.body.onload = function()...
}
```
as you can see i tried out several methods to bind the onload handler... in any case it will fire too early. I know that because the browser print preview (google chrome) contains broken images. When I cancel the print and call that function again (images are now cached) the print preview is fine.
... fortunately i found a solution. not pretty but suitable. What it does that it scans the subtree for 'img' tags and checking the 'complete' state of those. if uncomplete it delays a recheck after 250ms.
```
function delayUntilImgComplete(element, func){
var images = element.find('img');
var complete = true;
$.each(images, function(index, image){
if (!image.complete) complete = false;
});
if (complete) func();
else setTimeout(function(){
delayUntilImgComplete(element, func);}
, 250);
}
function printElement(jqElement){
delayUntilImgComplete(jqElement, function(){
if (!$("#printframe").length){
$("body").append('<iframe id="printframe" name="printframe" style="height: 0px; width: 0px; position: absolute" />');
}
var printframe = $("#printframe")[0].contentWindow;
printframe.document.open();
printframe.document.write(jqElement[0].innerHTML);
printframe.document.close();
printframe.focus();
printframe.print();
});
}
``` | Exactly when does an IFRAME onload event fire? | [
"",
"javascript",
"html",
"iframe",
"onload",
""
] |
I need a TextBox or some type of Multi-Line Label control which will automatically adjust the font-size to make it as large as possible and yet have the entire message fit inside the bounds of the text area.
I wanted to see if anyone had implemented a user control like this before developing my own.
Example application: have a TextBox which will be half of the area on a windows form. When a message comes in which is will be approximately 100-500 characters it will put all the text in the control and set the font as large as possible. An implementation which uses Mono Supported .NET libraries would be a plus.
If know one has implemented a control already... If someone knows how to test if a given text completely fits inside the text area that would be useful for if I roll my own control.
Edit: I ended up writing an extension to RichTextBox. I will post my code shortly once i've verified that all the kinks are worked out. | The solution i came up with was to write a control which extends the standard RichTextBox control.
Use the extended control in the same way you would a regular RichTextBox control with the following enhancements:
* Call the ScaleFontToFit() method after resizing or text changes.
* The Horizontal Alignment field can be used to center align the text.
* The Font attributes set in the designer will be used for the entire region. It is not possible to mix fonts as they will changed once the ScaleFontToFit method is called.
This control combines several techniques to determine if the text still fits within it's bounds. If the text area is multiline, it detects if scrollbars are visible. I found a clever way to detect whether or not the scrollbars are visible without requiring any winapi calls using a clever technique I found on one of [Patrick Smacchia's posts.](http://codebetter.com/blogs/patricksmacchia/archive/2008/07/07/some-richtextbox-tricks.aspx). When multiline isn't true, vertical scrollbars never appear so you need to use a different technique which relies on rendering the text using a the Graphics object. The Graphic rendering technique isn't suitable for Multiline boxes because you would have to account for word wrapping.
Here are a few snippets which shows how it works (link to source code is provided below). This code could easily be used to extend other controls.
```
/// <summary>
/// Sets the font size so the text is as large as possible while still fitting in the text
/// area with out any scrollbars.
/// </summary>
public void ScaleFontToFit()
{
int fontSize = 10;
const int incrementDelta = 5; // amount to increase font by each loop iter.
const int decrementDelta = 1; // amount to decrease to fine tune.
this.SuspendLayout();
// First we set the font size to the minimum. We assume at the minimum size no scrollbars will be visible.
SetFontSize(MinimumFontSize);
// Next, we increment font size until it doesn't fit (or max font size is reached).
for (fontSize = MinFontSize; fontSize < MaxFontSize; fontSize += incrementDelta)
{
SetFontSize(fontSize);
if (!DoesTextFit())
{
//Console.WriteLine("Text Doesn't fit at fontsize = " + fontSize);
break;
}
}
// Finally, we keep decreasing the font size until it fits again.
for (; fontSize > MinFontSize && !DoesTextFit(); fontSize -= decrementDelta)
{
SetFontSize(fontSize);
}
this.ResumeLayout();
}
#region Private Methods
private bool VScrollVisible
{
get
{
Rectangle clientRectangle = this.ClientRectangle;
Size size = this.Size;
return (size.Width - clientRectangle.Width) >= SystemInformation.VerticalScrollBarWidth;
}
}
/**
* returns true when the Text no longer fits in the bounds of this control without scrollbars.
*/
private bool DoesTextFit()
{
if (VScrollVisible)
{
//Console.WriteLine("#1 Vscroll is visible");
return false;
}
// Special logic to handle the single line case... When multiline is false, we cannot rely on scrollbars so alternate methods.
if (this.Multiline == false)
{
Graphics graphics = this.CreateGraphics();
Size stringSize = graphics.MeasureString(this.Text, this.SelectionFont).ToSize();
//Console.WriteLine("String Width/Height: " + stringSize.Width + " " + stringSize.Height + "form... " + this.Width + " " + this.Height);
if (stringSize.Width > this.Width)
{
//Console.WriteLine("#2 Text Width is too big");
return false;
}
if (stringSize.Height > this.Height)
{
//Console.WriteLine("#3 Text Height is too big");
return false;
}
if (this.Lines.Length > 1)
{
//Console.WriteLine("#4 " + this.Lines[0] + " (2): " + this.Lines[1]); // I believe this condition could be removed.
return false;
}
}
return true;
}
private void SetFontSize(int pFontSize)
{
SetFontSize((float)pFontSize);
}
private void SetFontSize(float pFontSize)
{
this.SelectAll();
this.SelectionFont = new Font(this.SelectionFont.FontFamily, pFontSize, this.SelectionFont.Style);
this.SelectionAlignment = HorizontalAlignment;
this.Select(0, 0);
}
#endregion
```
ScaleFontToFit could be optimized to improve performance but I kept it simple so it'd be easy to understand.
[Download the latest source code here.](http://www.blakerobertson.com/code/csharp/AutoScalingRichTextBox "Click here to get the source code and demo application") I am still actively working on the project which I developed this control for so it's likely i'll be adding a few other features and enhancements in the near future. So, check the site for the latest code.
My goal is to make this control work on Mac using the Mono framework. | I had to solve the same basic problem. The iterative solutions above were very slow. So, I modified it with the following. Same idea. Just uses calculated ratios instead of iterative. Probably, not quite as precise. But, much faster.
For my one-off need, I just threw an event handler on the label holding my text.
```
private void PromptLabel_TextChanged(object sender, System.EventArgs e)
{
if (PromptLabel.Text.Length == 0)
{
return;
}
float height = PromptLabel.Height * 0.99f;
float width = PromptLabel.Width * 0.99f;
PromptLabel.SuspendLayout();
Font tryFont = PromptLabel.Font;
Size tempSize = TextRenderer.MeasureText(PromptLabel.Text, tryFont);
float heightRatio = height / tempSize.Height;
float widthRatio = width / tempSize.Width;
tryFont = new Font(tryFont.FontFamily, tryFont.Size * Math.Min(widthRatio, heightRatio), tryFont.Style);
PromptLabel.Font = tryFont;
PromptLabel.ResumeLayout();
}
``` | Autoscale Font in a TextBox Control so that its as big as possible and still fits in text area bounds | [
"",
"c#",
".net",
"winforms",
""
] |
```
interface I { int J(); }
class A : I
{
public int J(){return 0; } // note NOT virtual (and I can't change this)
}
class B : A, I
{
new public int J(){return 1; }
}
B b = new B();
A a = b;
I ib = b, ia = a;
b.J(); // should give 1
a.J(); // should give 0 (IMHO)
ia.J(); // ???
ib.J(); // ???
```
I know I could just try it but I'm looking for a good *authoritative* source for this whole corner and I'd rather not just start myopically digging through the MSDN texts (I haven't a clue what to Google for). | It does not matter that you are talking to the contract provided by a base class or interface they will all return 1 because you are talking to an instance of class B. | **Rewritten:** Since we're talking about implementing IDisposable what *really* matters is ensuring that both the Derived and Base classes have the opportunity to run their respective cleanup code. This example will cover 2/3 of the scenario's; however since it derives from Base() and Base.Dispose() is not virtual, calls made to ((Base)Child).Dispose() will not provide the Child class with the chance to cleanup.
The only workaround to that is to not derive Child from Base; however that's been ruled out. Calls to ((IDisposable)Child).Dispose() and Child.Dispose() will allow both Child and Base to execute their cleanup code.
```
class Base : IDisposable
{
public void Dispose()
{
// Base Dispose() logic
}
}
class Child : Base, IDisposable
{
// public here ensures that Child.Dispose() doesn't resolve to the public Base.Dispose()
public new void Dispose()
{
try
{
// Child Dispose() logic
}
finally
{
// ensure that the Base.Dispose() is called
base.Dispose();
}
}
void IDisposable.Dispose()
{
// Redirect IDisposable.Dispose() to Child.Dispose()
Dispose();
}
}
``` | How will this work? (interfaces and non virtual functions) | [
"",
"c#",
".net",
"interface",
""
] |
What are the advantages and when is it appropriate to use a static constructor?
```
public class MyClass
{
protected MyClass()
{
}
public static MyClass Create()
{
return new MyClass();
}
}
```
and then creating an instance of the class via
```
MyClass myClass = MyClass.Create();
```
as opposed to just having a public constructor and creating objects using
```
MyClass myClass = new MyClass();
```
I can see the first approach is useful if the Create method returns an instance of an interface that the class implements...it would force callers create instances of the interface rather than the specific type. | This is the factory pattern, and it could often be used to produce a subclass, but allow the parameters to the static method determine which one.
It could also be used if a new object isn't always required, for example in a pooling implementation.
It can also be used if all instances of the object needs to be cached or otherwise registered upon creation. This ensures that the client doesn't forget to do that.
And of course, it is part and parcel of the Singleton pattern. | This is not a singleton...Create would return the same instance every time if it was.
This is a factory pattern. I would normally do this with interfaces not classes, so I have to stretch here, but a contrived example would be:
```
public static MyClass Create()
{
if(OS == Windows)
return new MyDerivedClassForWindows();
else if(OS == Linux)
return new MyDerivedClassForLinux();
etc....
}
``` | Why have a Create method instead of using "new"? | [
"",
"c#",
"constructor",
""
] |
I have a Javascript object that requires 2 calls out to an external server to build its contents and do anything meaningful. The object is built such that instantiating an instance of it will automatically make these 2 calls. The 2 calls share a common callback function that operates on the returned data and then calls another method. The problem is that the next method should not be called until both methods return. Here is the code as I have implemented it currently:
```
foo.bar.Object = function() {
this.currentCallbacks = 0;
this.expectedCallbacks = 2;
this.function1 = function() {
// do stuff
var me = this;
foo.bar.sendRequest(new RequestObject, function(resp) {
me.commonCallback(resp);
});
};
this.function2 = function() {
// do stuff
var me = this;
foo.bar.sendRequest(new RequestObject, function(resp) {
me.commonCallback(resp);
});
};
this.commonCallback = function(resp) {
this.currentCallbacks++;
// do stuff
if (this.currentCallbacks == this.expectedCallbacks) {
// call new method
}
};
this.function1();
this.function2();
}
```
As you can see, I am forcing the object to continue after both calls have returned using a simple counter to validate they have both returned. This works but seems like a really poor implementation. I have only worked with Javascript for a few weeks now and am wondering if there is a better method for doing the same thing that I have yet to stumble upon.
Thanks for any and all help. | There is barely another way than to have this counter. Another option would be to use an object {} and add a key for every request and remove it if finished. This way you would know immediately which has returned. But the solution stays the same.
You can change the code a little bit. If it is like in your example that you only need to call another function inside of commonCallback (I called it otherFunction) than you don't need the commonCallback. In order to save the context you did use closures already. Instead of
```
foo.bar.sendRequest(new RequestObject, function(resp) {
me.commonCallback(resp);
});
```
you could do it this way
```
foo.bar.sendRequest(new RequestObject, function(resp) {
--me.expectedCallbacks || me.otherFunction(resp);
});
``` | Unless you're willing to serialize the AJAX there is no other way that I can think of to do what you're proposing. That being said, I think what you have is fairly good, but you might want to clean up the structure a bit to not litter the object you're creating with initialization data.
Here is a function that might help you:
```
function gate(fn, number_of_calls_before_opening) {
return function() {
arguments.callee._call_count = (arguments.callee._call_count || 0) + 1;
if (arguments.callee._call_count >= number_of_calls_before_opening)
fn.apply(null, arguments);
};
}
```
This function is what's known as a higher-order function - a function that takes functions as arguments. This particular function returns a function that calls the passed function when it has been called `number_of_calls_before_opening` times. For example:
```
var f = gate(function(arg) { alert(arg); }, 2);
f('hello');
f('world'); // An alert will popup for this call.
```
You could make use of this as your callback method:
```
foo.bar = function() {
var callback = gate(this.method, 2);
sendAjax(new Request(), callback);
sendAjax(new Request(), callback);
}
```
The second callback, whichever it is will ensure that `method` is called. But this leads to another problem: the `gate` function calls the passed function without any context, meaning `this` will refer to the global object, not the object that you are constructing. There are several ways to get around this: You can either close-over `this` by aliasing it to `me` or `self`. Or you can create *another* higher order function that does just that.
Here's what the first case would look like:
```
foo.bar = function() {
var me = this;
var callback = gate(function(a,b,c) { me.method(a,b,c); }, 2);
sendAjax(new Request(), callback);
sendAjax(new Request(), callback);
}
```
In the latter case, the other higher order function would be something like the following:
```
function bind_context(context, fn) {
return function() {
return fn.apply(context, arguments);
};
}
```
This function returns a function that calls the passed function in the passed context. An example of it would be as follows:
```
var obj = {};
var func = function(name) { this.name = name; };
var method = bind_context(obj, func);
method('Your Name!');
alert(obj.name); // Your Name!
```
To put it in perspective, your code would look as follows:
```
foo.bar = function() {
var callback = gate(bind_context(this, this.method), 2);
sendAjax(new Request(), callback);
sendAjax(new Request(), callback);
}
```
In any case, once you've made these refactorings you will have cleared up the object being constructed of all its members that are only needed for initialization. | Javascript - synchronizing after asynchronous calls | [
"",
"javascript",
"asynchronous",
"callback",
"synchronous",
""
] |
I'm having an issue with pulling a Spring bean from an application context.
When I try;
```
InnerThread instance = (InnerThread) SpringContextFactory.getApplicationContext().getBean("innerThread", InnerThread.class);
```
I get;
```
org.springframework.beans.factory.BeanNotOfRequiredTypeException: Bean named 'innerThread' must be of type [com.generic.InnerThread], but was actually of type [$Proxy26]
```
Without the specified class in the getBean() call I get a ClassCastException (which you can see in detail below).
The InnerThread bean is being initialized as a non-singleton, because I need multiple instances. The InnerThread class also extends Thread. The interesting thing is that this error shows up within OuterThread, which is set up in the exact same way the InnerThread is.
I've tried to include all relevant code listings/stack traces below. Could someone with more Spring experience tell me what is going on here?
---
## Code/Configuration Listing
*OuterThread.java snippet:*
```
public class OuterThread extends Thread {
private Queue<InnerThread> createInnerThreads() {
Queue<InnerThread> threads = new ArrayBlockingQueue();
ApplicationContext ctx = SpringContextFactory.getApplicationContext();
int i = 0;
for (SearchRule search : searches) {
logger.debug("Number of times looped " + i++);
//Seprated lines to get a better sense of what is going on
Object proxy = ctx.getBean("innerThread", InnerThread.class);
logger.debug(ReflectionToStringBuilder.toString(proxy));
logger.debug("proxy.getClass(): " + proxy.getClass());
logger.debug("proxy.getClass().getClassLoader(): " + proxy.getClass().getClassLoader());
logger.debug("proxy.getClass().getDeclaringClass(): " + proxy.getClass().getDeclaringClass());
logger.debug("InnerThread.class.getClassLoader(): " + InnerThread.class.getClassLoader());
//---Exception here---
InnerThread cst = (InnerThread) proxy;
threads.add(cst);
}
return threads;
}
public static void main(String[] args) throws Exception {
try {
OuterThread instance = (OuterThread) SpringContextFactory.getApplicationContext().getBean("outerThread", OuterThread.class);
instance.run();
} catch (Exception ex) {
logger.error("Fatal exception.", ex);
throw ex;
}
}
}
```
*SpringContextFactory.java:*
```
public class SpringContextFactory {
static final Logger logger = LoggerFactory.getLogger(SpringContextFactory.class);
private static ApplicationContext ctx;
private static final String DEFAULT_PATH = "META-INF/app-context.xml";
public static ApplicationContext getApplicationContext() {
return getApplicationContext(DEFAULT_PATH);
}
public static synchronized ApplicationContext getApplicationContext(String path) {
if (ctx == null) return createApplicationContext(path);
else return ctx;
}
private static ApplicationContext createApplicationContext(String path) {
if (logger.isDebugEnabled()) logger.debug("Loading Spring Context...");
ctx = new ClassPathXmlApplicationContext(path);
if (logger.isDebugEnabled()) logger.debug("Spring Context Loaded");
return ctx;
}
}
```
*app-context.xml:*
```
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd">
<!-- persistence context from separate jar -->
<import resource="persistence-context.xml"/>
<bean id="outerThread" class="com.generic.OuterThread" scope="prototype"/>
<bean id="innerThread" class="com.generic.InnerThread" scope="prototype"/>
</beans>
```
## Stack Trace
```
2009-05-08 14:34:37,341 [main] DEBUG com.generic.OuterThread.init(OuterThread.java:59) - Initializing OuterThread object, com.generic.OuterThread@1c8fb4b[em=org.hibernate.ejb.EntityManagerImpl@e2892b,currentTime=java.util.GregorianCalendar[time=1241634874841,areFieldsSet=true,areAllFieldsSet=true,lenient=true,zone=sun.util.calendar.ZoneInfo[id="America/New_York",offset=-18000000,dstSavings=3600000,useDaylight=true,transitions=235,lastRule=java.util.SimpleTimeZone[id=America/New_York,offset=-18000000,dstSavings=3600000,useDaylight=true,startYear=0,startMode=3,startMonth=2,startDay=8,startDayOfWeek=1,startTime=7200000,startTimeMode=0,endMode=3,endMonth=10,endDay=1,endDayOfWeek=1,endTime=7200000,endTimeMode=0]],firstDayOfWeek=1,minimalDaysInFirstWeek=1,ERA=1,YEAR=2009,MONTH=4,WEEK_OF_YEAR=19,WEEK_OF_MONTH=2,DAY_OF_MONTH=6,DAY_OF_YEAR=126,DAY_OF_WEEK=4,DAY_OF_WEEK_IN_MONTH=1,AM_PM=1,HOUR=2,HOUR_OF_DAY=14,MINUTE=34,SECOND=34,MILLISECOND=841,ZONE_OFFSET=-18000000,DST_OFFSET=3600000],maxConcurrentThreads=5,reconId=3,reportUsername=TEST,useOffset=false,username=removed,uuid=bf61494d-ff96-431c-a41f-1e292d0c9fbe,name={T,h,r,e,a,d,-,1},priority=5,threadQ=<null>,eetop=0,single_step=false,daemon=false,stillborn=false,target=<null>,group=java.lang.ThreadGroup[name=main,maxpri=10],contextClassLoader=sun.misc.Launcher$AppClassLoader@11b86e7,inheritedAccessControlContext=java.security.AccessControlContext@1524d43,threadLocals=<null>,inheritableThreadLocals=java.lang.ThreadLocal$ThreadLocalMap@2cbc86,stackSize=0,nativeParkEventPointer=0,tid=9,threadStatus=0,parkBlocker=<null>,blocker=<null>,blockerLock=java.lang.Object@a68fd8,stopBeforeStart=false,throwableFromStop=<null>,uncaughtExceptionHandler=<null>]
2009-05-08 14:34:37,341 [main] DEBUG org.springframework.orm.jpa.ExtendedEntityManagerCreator$ExtendedEntityManagerInvocationHandler.doJoinTransaction(ExtendedEntityManagerCreator.java:385) - No local transaction to join
2009-05-08 14:34:37,529 [main] DEBUG com.generic.OuterThread.createInnerThreads(OuterThread.java:139) - Number of times looped 0
2009-05-08 14:34:37,529 [main] DEBUG org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory$1.run(AbstractAutowireCapableBeanFactory.java:458) - Creating instance of bean 'searchThread' with merged definition [Root bean: class [com.generic.InnerThread]; scope=prototype; abstract=false; lazyInit=false; autowireCandidate=true; autowireMode=0; dependencyCheck=0; factoryBeanName=null; factoryMethodName=null; initMethodName=null; destroyMethodName=null; defined in class path resource [META-INF/app-context.xml]]
2009-05-08 14:34:37,545 [main] DEBUG com.generic.InnerThread.<init>(InnerThread.java:50) - Constructing InnerThread object, com.generic.InnerThread@1080876[em=<null>,coolScheme=<null>,coolUrl=<null>,date=<null>,error=<null>,millisecondsTaken=0,thresholdMet=false,reconId=0,result=-2,searchId=0,username=<null>,uuid=<null>,name={T,h,r,e,a,d,-,2},priority=5,threadQ=<null>,eetop=0,single_step=false,daemon=false,stillborn=false,target=<null>,group=java.lang.ThreadGroup[name=main,maxpri=10],contextClassLoader=sun.misc.Launcher$AppClassLoader@11b86e7,inheritedAccessControlContext=java.security.AccessControlContext@1524d43,threadLocals=<null>,inheritableThreadLocals=java.lang.ThreadLocal$ThreadLocalMap@3aef16,stackSize=0,nativeParkEventPointer=0,tid=10,threadStatus=0,parkBlocker=<null>,blocker=<null>,blockerLock=java.lang.Object@126c6ea,stopBeforeStart=false,throwableFromStop=<null>,uncaughtExceptionHandler=<null>]
2009-05-08 14:34:37,545 [main] DEBUG org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:203) - Returning cached instance of singleton bean 'entityManagerFactory'
2009-05-08 14:34:37,545 [main] DEBUG org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:203) - Returning cached instance of singleton bean 'org.springframework.transaction.config.internalTransactionAdvisor'
2009-05-08 14:34:37,560 [main] DEBUG org.springframework.transaction.interceptor.AbstractFallbackTransactionAttributeSource.getTransactionAttribute(AbstractFallbackTransactionAttributeSource.java:108) - Adding transactional method [report] with attribute [PROPAGATION_REQUIRED,ISOLATION_DEFAULT]
2009-05-08 14:34:37,560 [main] DEBUG org.springframework.aop.framework.autoproxy.AbstractAutoProxyCreator.buildAdvisors(AbstractAutoProxyCreator.java:494) - Creating implicit proxy for bean 'searchThread' with 0 common interceptors and 1 specific interceptors
2009-05-08 14:34:37,560 [main] DEBUG org.springframework.aop.framework.JdkDynamicAopProxy.getProxy(JdkDynamicAopProxy.java:113) - Creating JDK dynamic proxy: target source is SingletonTargetSource for target object [com.generic.InnerThread@1080876]
2009-05-08 14:34:37,591 [main] DEBUG com.generic.OuterThread.createInnerThreads(OuterThread.java:141) - $Proxy26@1594a88[h=org.springframework.aop.framework.JdkDynamicAopProxy@1f0cf51]
2009-05-08 14:34:37,591 [main] DEBUG com.generic.OuterThread.createInnerThreads(OuterThread.java:142) - proxy.getClass(): class $Proxy26
2009-05-08 14:34:37,591 [main] DEBUG com.generic.OuterThread.createInnerThreads(OuterThread.java:143) - proxy.getClass().getClassLoader(): sun.misc.Launcher$AppClassLoader@11b86e7
2009-05-08 14:34:37,591 [main] DEBUG com.generic.OuterThread.createInnerThreads(OuterThread.java:144) - proxy.getClass().getDeclaringClass(): null
2009-05-08 14:34:37,591 [main] DEBUG com.generic.OuterThread.createInnerThreads(OuterThread.java:145) - InnerThread.class.getClassLoader(): sun.misc.Launcher$AppClassLoader@11b86e7
2009-05-08 14:34:37,591 [main] ERROR com.generic.OuterThread.run(OuterThread.java:101) - Exception in OuterThread, ending reconciliation.
java.lang.ClassCastException: $Proxy26 cannot be cast to com.generic.InnerThread
at com.generic.OuterThread.createInnerThreads(OuterThread.java:148)
at com.generic.OuterThread.run(OuterThread.java:65)
at com.generic.OuterThread.main(OuterThread.java:170)
```
---
## Similar questions that do not answer my question
* [Auto-cast Spring Beans](https://stackoverflow.com/questions/812178/auto-cast-spring-beans)
* [ClassCastException when casting to the same class.](https://stackoverflow.com/questions/826319/classcastexception-when-casting-to-the-same-class) | Once again, after spending hours trying to debug this I find the answer right after posting on StackOverflow.
A key point that I left out from my question is that InnerThread has a transactional method (sorry thought this was irrelevant). This is the important difference between OuterThread and InnerThread.
From the [Spring documentation](http://static.springframework.org/spring/docs/2.5.x/reference/index.html):
> Note
>
> Multiple sections are collapsed into a single unified auto-proxy creator at runtime, which applies the strongest proxy settings that any of the sections (typically from different XML bean definition files) specified. This also applies to the and elements.
>
> To be clear: **using 'proxy-target-class="true"'** on , or elements will force the use of [CGLIB proxies](http://static.springframework.org/spring/docs/2.5.x/reference/aop-api.html#aop-pfb-proxy-types) for all three of them.
Adding the above to my configuration (based in persistance-context.xml, which you can see loaded above) line seems to fix the problem. However, I think this may be a quick fix workaround as opposed to real solution.
I think I've got a few deeper issues here, number one being that I find Spring as confusing as expletive deleted. Second I should probably be using [Spring's TaskExecutor](http://static.springframework.org/spring/docs/2.5.x/reference/scheduling.html#scheduling-task-executor) to kick off my threads. Third my threads should implement Runnable instead of extending Thread (See SO question below).
**See Also**
* [BeanNotOfRequiredTypeException using
ServiceLocatorFactoryBean and
@Transactional](http://forum.springsource.org/showthread.php?t=66083)
(Nothing better then finding a thread off Google after hours of searching to have a response that says "This has already been answered a million times.")
* [Section 6.6 in the Spring
Docs.](http://static.springframework.org/spring/docs/2.5.x/reference/aop.html#aop-proxying)
* [Java: “implements Runnable” vs. “extends Thread”](https://stackoverflow.com/questions/541487/java-implements-runnable-vs-extends-thread) | Annotate your `@Configuration` class with
```
@EnableAspectJAutoProxy(proxyTargetClass = true)
```
You also have to add the following dependency:
```
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.7.2</version>
</dependency>
``` | Fixing BeanNotOfRequiredTypeException on Spring proxy cast on a non-singleton bean? | [
"",
"java",
"spring",
"casting",
"aop",
"proxy-classes",
""
] |
I have the following code in a Runnable that gets passed to a thread t:
```
public void run() {
logger.debug("Starting thread " + Thread.currentThread());
try {
doStuff();
} catch (Exception e) {
logger.debug("Exception in Thread " + Thread.currentThread());
}
logger.debug("End of thread " + Thread.currentThread());
}
```
I've hit a bug where I see deadlock with the following conditions
* only the start of thread message has been printed by my logs
* A thread dump shows that the thread t (supposed to be executing this) is no longer running
Is there some magical way this thread could have terminated early without either logging an end of thread message OR throwing an exception? | Are you sure that `doStuff()` did not throw an `Error`? Change `catch (Exception e)` to `catch (Throwable t)`. It's possible to kill threads in Java with `Thread.stop()`, but that is highly unlikely. | Are you sure that where you **start()** the Thread, you also **join()** it afterwards?
```
Runnable myRunnable=new Runnable(){
@Override
public void run(){
// your original code goes here
}
};
Thread myThread=new Thread(myRunnable);
myThread.start();
myThread.join(); // magic happens here! it waits for the thread to finish ;)
```
By the way, **join()** may throw an **InterruptedException**,
so if something interrupts your thread while it's running,
join will inform you about this by throwing this exception.
Hope this helps. | java thread terminating early and suspiciously | [
"",
"java",
"multithreading",
""
] |
**EDIT:** I used, finally, inotify. As stefanB says, inotify is the thing to use. I found a tail clone that uses inotify to implement the -f mode, [inotail](http://distanz.ch/inotail/).
Original question text:
I'm trying to implement the "tail -f" logic in a C project, for prototyping purposes I developed it in python as follow:
```
# A forever loop, each 5 seconds writes a line into file.txt
from time import *
while 1:
sleep(5)
file = open("file.txt", "a")
file.write("This is a test\n")
file.close()
```
The next code follows the eof of file.txt (updated by the code above)
```
# tail -f
from time import *
file = open("file.txt", "r")
file.seek(0, 2)
while 1:
line = file.readline()
if not line:
sleep(1)
else:
print line
file.close()
```
All works fine but the C implementation is not working (there are no check-error code). The inclusion of stdio.h, string.h and unistd.h is omitted (the colorization hides the header inclusion code).
```
#define LINE_LEN 256
int main(int argc, char **argv)
{
FILE *f;
char line[LINE_LEN];
f = fopen("file.txt", "r");
fseek(f, 0, SEEK_END);
while (1)
{
fgets(line, LINE_LEN, f);
if (strlen(line) == 0)
{
sleep(1);
}
else
{
printf("Readed: %s", line);
}
}
fclose(f);
return 0;
}
```
Some idea?
Is a good idea implement it with a poll() instead the presented solution?.
Thanks in advance. | **EDIT**:
Seems like [inotify](http://www.linuxjournal.com/article/8478) is the thing to use. It should be included in linux kernel since 2.6.13 . [An article from IBM developerworks about inotify](http://www.ibm.com/developerworks/linux/library/l-ubuntu-inotify/index.html?ca=drs-).
Previous answer:
Have a look at Linux [File Alteration Monitor](http://oss.sgi.com/projects/fam/faq.html) (in linux kernels 2.4.x >). It's a framework that let's you subscribe for file changes and you get callback from kernel when change happens. This should be better than polling.
[Examples](http://techpubs.sgi.com/library/tpl/cgi-bin/getdoc.cgi?coll=0650&db=bks&fname=/SGI_Developer/books/IIDsktp_IG/sgi_html/ch08.html) how to poll for file changes, check out sections **Waiting for file changes** and **Polling for file changes**.
I haven't tried it yet. | Once a FILE \* has seen an error or eof, it has its internal status set so that it continues to return error or eof on subsequent calls. You need to call `clearerr(f);` after the sleep returns to clear the eof setting and get it to try to read more data from the file. | Custom implementation of "tail -f" functionality in C | [
"",
"python",
"c",
""
] |
I'm executing an external script, using a `<script>` inside `<head>`.
Now since the script executes **before** the page has loaded, I can't access the `<body>`, among other things. I'd like to execute some JavaScript after the document has been "loaded" (HTML fully downloaded and in-RAM). Are there any events that I can hook onto when my script executes, that will get triggered on page load? | These solutions will work:
As mentioned in comments use [defer](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/script#attr-defer):
```
<script src="deferMe.js" defer></script>
```
or
```
<body onload="script();">
```
or
```
document.onload = function ...
```
or even
```
window.onload = function ...
```
Notes
* `window.onload` is [considered more standard](https://stackoverflow.com/questions/807878/javascript-that-executes-after-page-load#comment617710_807891) than `document.onload`
* Using `defer` or `window.onload` is [unobstrusive](http://en.wikipedia.org/wiki/Unobtrusive_JavaScript). | # Triggering scripts in the right moment
A quick overview on how to load / run the script at the moment in which they intend to be loaded / executed.
## Using "defer"
```
<script src="script.js" defer></script>
```
Using defer will trigger after domInteractive (document.readyState = "interactive") and just before "DOMContentLoaded" Event is triggered. If you need to execute the script after all resources (images, scripts) are loaded use "load" event or target one of the document.readyState states. Read further down for more information about those events / states, as well as async and defer attributes corresponding to script fetching and execution timing.
> This Boolean attribute is set to indicate to a browser that the script
> is meant to be executed after the document has been parsed, but before
> firing DOMContentLoaded.
>
> Scripts with the defer attribute will prevent the DOMContentLoaded
> event from firing until the script has loaded and finished evaluating.
Resource: <https://developer.mozilla.org/en-US/docs/Web/HTML/Element/script#attributes>
\* See the images at the bottom for feather explanation.
## Event Listeners - Keep in mind that loading of the page has more, than one event:
### "DOMContentLoaded"
This event is fired when the *initial HTML document has been completely loaded and parsed*, without waiting for style sheets, images, and subframes to finish loading. At this stage you could programmatically optimize loading of images and CSS based on user device or bandwidth speed.
Executes after DOM is loaded (before images and CSS):
```
document.addEventListener("DOMContentLoaded", function(){
//....
});
```
> Note: Synchronous JavaScript pauses parsing of the DOM.
> If you want the DOM to get parsed as fast as possible after the user requested the page, you could **turn your JavaScript asynchronous** and [optimize loading of style sheets](https://developers.google.com/speed/docs/insights/OptimizeCSSDelivery)
### "load"
A very different event, \*\*load\*\*, should only be used to detect a \*fully-loaded page\*. It is an incredibly popular mistake to use load where DOMContentLoaded would be much more appropriate, so be cautious.
Executes after everything is loaded and parsed:
```
window.addEventListener("load", function(){
// ....
});
```
---
*MDN Resources:*
<https://developer.mozilla.org/en-US/docs/Web/Events/DOMContentLoaded>
<https://developer.mozilla.org/en-US/docs/Web/Events/load>
*MDN list of all events:*
<https://developer.mozilla.org/en-US/docs/Web/Events>
## Event Listeners with readyStates - Alternative solution (readystatechange):
You can also track document.readystatechange states to trigger script execution.
```
// Place in header (do not use async or defer)
document.addEventListener('readystatechange', event => {
switch (document.readyState) {
case "loading":
console.log("document.readyState: ", document.readyState,
`- The document is still loading.`
);
break;
case "interactive":
console.log("document.readyState: ", document.readyState,
`- The document has finished loading DOM. `,
`- "DOMContentLoaded" event`
);
break;
case "complete":
console.log("document.readyState: ", document.readyState,
`- The page DOM with Sub-resources are now fully loaded. `,
`- "load" event`
);
break;
}
});
```
MDN Resources: <https://developer.mozilla.org/en-US/docs/Web/API/Document/readyState>
## Where to place your script (with & without async/defer)?
This is also very important to know where to place your script and how it positions in HTML as well as parameters like defer and async will affects script fetching, execution and HTML blocking.
\* On the image below the yellow label “Ready” indicates the moment of ending loading HTML DOM. Then it fires: document.readyState = "interactive" >>> defered scripts >>> DOMContentLoaded event (it's sequential);
[](https://i.stack.imgur.com/jsHK7.jpg)
[](https://i.stack.imgur.com/b3ixy.jpg)
[](https://i.stack.imgur.com/GkezA.jpg)
[](https://i.stack.imgur.com/zx3fh.jpg)
If your script uses **async** or **defer** read this: <https://flaviocopes.com/javascript-async-defer/>
## And if all of the above points are still to early...
What if you need your script to run *after* other scripts are run, including those scheduled to run at the very end (e.g. those scheduled for the "load" event)? See [Run JavaScript after all window.onload scripts have completed?](https://stackoverflow.com/q/1593527/8910547)
What if you need to make sure your script runs *after* some other script, regardless of when it is run? [This answer](https://stackoverflow.com/a/74956907/8910547) to the above question has that covered too. | How to make JavaScript execute after page load? | [
"",
"javascript",
"html",
"dom",
"dom-events",
"pageload",
""
] |
There are now so many ways to write windows apps, win32, MFC, ATL, .NET, WinForms, and probably some others that I don't know of. Which one should I choose? I'd like one that works on a fresh install of Vista, and is modern and easy to use. | If you are amateur with C++ you'll have much easier time learning WinForms than any of the native Visual C++ frameworks (Win32, MVC, etc.). WPF will give you best versatily. It's a bit harder to master than WinForms but managed and so keeps you away from the nasty Win32 stuff.
The native frameworks are good mainly if you want to crunch the last bits of performance or need to keep the footprint small for stuff such as shell extensions.
I'd recommend checking WinForms at least first to get some quick understanding of the principles. If WinForms doesn't suit you, you can then move to either C++ if you feel you need more low level control or WPF if you wish more shiny features like skinning and theming.
**Edit:**
Though if you have a look at WPF, remember that fresh Vista contains only .Net 3.0 so 3.5 and 3.5 SP1 features require a separate runtime installation. | I highly recommend [Qt](http://qt.nokia.com/). It's cross-platform, very easy to use and LGPL licensed. | Which Windows GUI system should I choose with C++? | [
"",
"c++",
""
] |
I've had some problems with a Django application after I deployed it. I use a Apache + mod-wsgi on a ubuntu server. A while after I reboot the server the time goes foobar, it's wrong by around -10 hours. I made a Django view that looks like:
```
def servertime():
return HttpResponse( datetime.now() )
```
and after I reboot the server and check the url that shows that view it first looks alright. Then at one point it sometimes gives the correct time and sometimes not and later it gives the wrong time always. The server time is corect though.
Any clues? I've googled it without luck. | I found that putting wsgi in daemon mode works. Not sure why, but it did. Seems like some of the newly created processes gets the time screwed up. | Can I see your urls.py as well?
Similar behaviors stumped me once before...
What it turned out to be was the way that my urls.py called the view. Python ran the datetime.now() once and stored that for future calls, never really calling it again. This is why django devs had to implement the ability to pass a function, not a function call, to a model's default value, because it would take the first call of the function and use that until python is restarted.
Your behavior sounds like the first time is correct because its the first time the view was called. It was incorrect at times because it got that same date again. Then it was randomly correct again because your apache probably started another worker process for it, and the craziness probably happens when you get bounced in between which process was handling the request. | datetime.now() in Django application goes bad | [
"",
"python",
"django",
"apache",
"datetime",
"mod-wsgi",
""
] |
I wonder when we write a program in PHP, Ruby, or Python, how do we make it easily downloadable and installable by general users like a Win32 app?
and is it possible to make it a Mac app easily too? | ## Ruby
[RubyScript2Exe](http://www.erikveen.dds.nl/rubyscript2exe/)
> RubyScript2Exe transforms your Ruby application into a standalone, compressed Windows, Linux or Mac OS X (Darwin) executable.
There's also a decent [blog post about it](http://redhanded.hobix.com/inspect/churningRubyIntoExe.html)
Another possible option is the [Shoes GUI framework](http://shoooes.net/), which can create Widows, Linux and OS X executables from your Shoes application.
## Python
[py2exe](http://www.py2exe.org/)
> py2exe is a Python Distutils extension which converts Python scripts into executable Windows programs, able to run without requiring a Python installation.
>
> py2exe is used by BitTorrent, SpamBayes, and thousands more
## PHP
[Bambalam PHP EXE Compiler/Embedder](http://www.bambalam.se/bamcompile/)
> Bambalam PHP EXE Compiler/Embedder is a free command line tool to convert PHP applications to standalone Windows .exe applications. The exe files produced are totally standalone, no need for php dlls etc.
## and is it possible to make it a Mac app easily too?
[Py2App](http://svn.pythonmac.org/py2app/py2app/trunk/doc/index.html)
> py2app is a Python setuptools command which will allow you to make standalone application bundles and plugins from Python scripts. py2app is similar in purpose and design to py2exe for Windows.
Also, there is a utility "Build Applet" included with the Developer Tools.. Drag-and-drop a Python script on to it and it becomes a `.app`. The utility is in `/Developer/Applications/Utilities/MacPython 2.5/`
---
*Note*, all of the above basically take your script, package it up along with a Python interpreter and any dependancies, and on launch run your script. If you use a GUI platform that does not work on Windows, running it through Py2EXE will not make it work!
Also as [Peter D](https://stackoverflow.com/questions/858017/how-to-write-a-program-in-php-ruby-or-python-and-make-it-easily-downloadable-a/858059#858059) mentioned, you need to be careful about dependancies - if your application requires a MySQL database, your users will have to install that separately to use your application, and every library you use will add size to your executables. | I think your question should be, "How do I write PHP/Ruby/Python apps to be able to be easily downloaded and installed on Windows machines?".
If I write a PHP application to take advantage of a MySQL database I now have to take into consideration (when packaging the app) if the user will install and setup the database themselves or not. Maybe I will use the SQLite database instead to save the user from having to run a database themselves.
So I think the important thing here is not to understand how to package your app so users can download it easily. It's how to create the app to make it as portable as possible. | how to write a program in PHP, Ruby, or Python, and make it easily downloadable and installable by general users like a Win32 app? | [
"",
"php",
"windows",
"ruby",
"user-interface",
""
] |
How do I determine, without using jQuery or any other JavaScript library, if a div with a vertical scrollbar is scrolled all the way to the bottom?
My question is not how to scroll to the bottom. I know how to do that. I want to determine if the the div is scrolled to the bottom already.
This does not work:
```
if (objDiv.scrollTop == objDiv.scrollHeight)
``` | You're pretty close using `scrollTop == scrollHeight`.
`scrollTop` refers to the top of the scroll position, which will be `scrollHeight - offsetHeight`
Your if statement should look like so (don't forget to use triple equals):
```
if( obj.scrollTop === (obj.scrollHeight - obj.offsetHeight))
{
}
```
Edit: Corrected my answer, was completely wrong | In order to get the correct results when taking into account things such as the possibility of a border, horizontal scrollbar, and/or floating pixel count, you should use...
```
el.scrollHeight - el.scrollTop - el.clientHeight < 1
```
**NOTE:** You MUST use clientHeight instead of offsetHeight if you want to get the correct results. offsetHeight will give you correct results only when el doesn't have a border or horizontal scrollbar | How can I determine if a div is scrolled to the bottom? | [
"",
"javascript",
"scroll",
"scrollbar",
""
] |
I am looking for an ECMAScript alternative to work as a scripting language for custom application logic. There are things I like about ECMA, especially the syntax for the newer spec(like AS3).
Unfortunately, the AS3 engine is not open source to be able to integrate in a project. I would like a scripting language that was designed for object oriented use.
Specifically, is there a language that has:
* Statically typed variables(optional)
* Classes, including public/private members
* Inheritance, including Interfaces
* Packages(optional)
* Clean syntax
* Must be able to interface as an internal scripting language for an application(like Javascript for a browser), can not be an external system call.
Things I would rather do without
* The messy ECMA `prototype` object
What languages that you know about fit this profile? I've had difficulty finding a quality scripting language that was designed for good object oriented design. | In Java the best ECMAScript (Javascript) option is to embed [Rhino](http://www.mozilla.org/rhino/). I don't find the prototype-based inheritance a deal killer, as with a bit of discipline you can make it behave almost like class-based inheritance.
If you want something that interoperates very closely with Java, go with [Groovy](http://groovy.codehaus.org/). If you need JVM compatibility, also look into [Jython](http://www.jython.org/Project/) (python on the JVM), [Jruby](http://jruby.codehaus.org/) (Ruby on the JVM) and [Scala](http://www.scala-lang.org/) (a functional language on the JVM). If you don't care about Java and JVM compatibility, look at [Ruby](http://www.ruby-lang.org/en/), [Python](http://www.python.org/), and [Erlang](http://erlang.org/). [Clojure](http://clojure.org/) is a dialect of Lisp on the JVM.
Going further afield, TCL (Tool Command Language) lets you embed an interpreter in C/C++ code, there are many embeddable Lisp and Scheme interpreters, etc. | If you want a scripting language that works like ECMAScript, why not use ECMAScript? There are many Open Source implementations, just take a look at the list on [Wikipedia](http://en.wikipedia.org/wiki/List_of_ECMAScript_engines). | What scripting languages are similar to ECMA? | [
"",
"javascript",
"actionscript-3",
"dynamic-languages",
"scripting-language",
"ecma262",
""
] |
Hey all, I want to change a value in a table (in a mysql database) via PHP code. I have a row in the table called 'approved' and there are two options it can be set to, "0" (not approved) and "1" (approved). I am creating a script that will change an individual approved from "0" to "1".
For example, there is a different value called 'position' and 'approved' sets the 'position' as approved or not approved (where approved is set to 1 or 0). If that is worded wrong, I will try to make it more clear.
I guess my question is can I make an individual 'position' value have its 'approved' data be switched from 0 to 1 and vice versa.
Thanks!
EDIT/UPDATE:
here's the info from the dump for this specific table:
```
CREATE TABLE `positions` (
`posID` int(10) unsigned NOT NULL auto_increment,
`postitle` varchar(500) NOT NULL default '',
`addtitletext` varchar(35) default NULL,
`description` text NOT NULL,
`print_website` enum('1','2') NOT NULL default '1',
`userID` tinyint(4) unsigned NOT NULL default '0',
`submitted_on` datetime NOT NULL default '0000-00-00 00:00:00',
`approved_date` date NOT NULL default '0000-00-00',
`approved` enum('0','1') NOT NULL default '0',
PRIMARY KEY (`posID`)
) ENGINE=MyISAM AUTO_INCREMENT=464 DEFAULT CHARSET=latin1;
LOCK TABLES `positions` WRITE;
/*!40000 ALTER TABLE `positions` DISABLE KEYS */;
INSERT INTO `positions` (`posID`,`postitle`,`addtitletext`,`description`,`print_website`,`userID`,`submitted_on`,`approved_date`,`approved`)
VALUES
```
and I was trying to edit this code here to make it change from not approved to approved (or vice versa)
```
<?
include('secure.php');
include('config.php');
if (isset($_POST['submitted'])) {
foreach($_POST AS $key => $value) { $_POST[$key] = mysql_real_escape_string($value); }
$sql = "UPDATE `positions` SET `approved` = '{$_POST['approved']}'";
mysql_query($sql) or die(mysql_error());
echo (mysql_affected_rows()) ? "Edited row.<br />" : "Nothing changed. <br />";
echo "<a href='list.php'>Back To Listing</a>";
}
$row = mysql_fetch_array ( mysql_query("SELECT * FROM `positions` WHERE `posID` = '$posID' "));
?>
<form action='' method='POST'>
<p><b>Approved:</b><br /><input type='text' name='approved' value='<?= stripslashes($row['approved']) ?>' />
<p><input type='submit' value='Edit Row' /><input type='hidden' value='1' name='submitted' />
</form>
```
If it helps, awesome, but sorry if it is more confusing haha.
EDIT: Here's what I have, but getting a blank page (errors I know)
```
<?
include('secure.php');
include('config.php');
if (isset($_GET['posID']) ) {
$posID = (int) $_GET['posID'];
if (isset($_POST['submitted'])) {
foreach($_POST AS $key => $value) { $_POST[$key] = mysql_real_escape_string($value); }
$sql = "UPDATE `positions` SET `approved` = '{$_POST['approved']}' WHERE `posID` = '$posID'";
mysql_query($sql) or die(mysql_error());
echo (mysql_affected_rows()) ? "Edited row.<br />" : "Nothing changed. <br />";
echo "<a href='list.php'>Back To Listing</a>";
}
<form action='' method='POST'>
<p><b>Approved:</b><br /><input type='text' name='approved' value='<?= stripslashes($row['approved']) ?>' />
<p><input type='submit' value='Edit Row' /><input type='hidden' value='1' name='submitted' />
</form>
<? } ?>
``` | I'm not entirely sure what you are trying to do, because it sounds like approved is a column, not a row, in the table. If you wanted to do something like the following:
```
function toggle_approved($position_id) {
$query = "UPDATE positions SET approved = !approved WHERE posID = '$position_id'";
// execute the query here with your mysql_query() call
}
```
I am assuming you have some method of executing mysql queries, if not see [this link](http://www.w3schools.com/PHP/php_mysql_intro.asp). Also make sure you use your table name and position field names. | yes. you would do something like:
```
UPDATE table_name
SET approved=value
WHERE position=some_value
```
A good place for learning SQL and PHP is w3schools: <http://www.w3schools.com/sql/default.asp> | Change value in Mysql database via PHP | [
"",
"php",
"mysql",
""
] |
I'm using `std::map` to store a lot of elements (pairs of elements) and I have a "little" doubt. What is more efficient to iterate all elements over my `std::map`, `iterator` or `reverse_iterator`? | Does it really matter? these are the types of the micro optimizations you must try to avoid IMHO. Also, even if the iteration time changes for very large number of elements in the map, the fact that you are trying to iterate through all the elements of such a big map means that most probably you have chosen a wrong data structure. | For the record, **dereferencing `reverse_iterator`** on `std::map` and `std::set` containers is **twice as slow** as using `iterator` -- with both -O3 gcc 3.4.6 and MSVC on Intel/AMD processors (almost 3x as slow on PPC architectures.) Same holds for `const_reverse_iterator` vs. `const_iterator`. This is due to the fact that `reverse_iterator` *actually* points to the tree node immediately following the tree node to be dereferenced, hence the extra work. `std::vector` iterators exhibit a much milder difference (`reverse_iterator` is only ~30% slower on PPC, virtually indistinguishable on Intel/AMD.) Incidentally, a `std::vector` iterator is about 20x faster than a `std::map` or `std::set` iterator.
```
#include <set>
#include <vector>
#include <stdio.h>
#ifdef _WIN32
#include <sys/timeb.h>
#else
#include <sys/time.h>
#endif
#include <time.h>
#define CONTAINER std::set< int >
double
mygettime(void) {
# ifdef _WIN32
struct _timeb tb;
_ftime(&tb);
return (double)tb.time + (0.001 * (double)tb.millitm);
# else
struct timeval tv;
if(gettimeofday(&tv, 0) < 0) {
perror("oops");
}
return (double)tv.tv_sec + (0.000001 * (double)tv.tv_usec);
# endif
}
int main() {
int i, x = 0;
CONTAINER bla;
for (i = 0; i < 10000; bla.insert(bla.end(), i++)) ;
double t1 = mygettime();
for (i = 0; i < 100; ++i) {
for (CONTAINER::iterator it = bla.begin(); it != bla.end(); ++it) {
x ^= *it;
}
}
printf("forward: %f\n", mygettime() - t1);
double t2 = mygettime();
for (i = 0; i < 100; ++i) {
for (CONTAINER::reverse_iterator it = bla.rbegin(); it != bla.rend(); ++it) {
x ^= *it;
}
}
printf("reverse: %f\n", mygettime() - t2);
return 0;
}
``` | iterator vs reverse_iterator | [
"",
"c++",
"performance",
"stl",
"stdmap",
""
] |
I'm trying to be a good CF web developer and use `<cfqueryparam>` around all FORM or URL elements that make it to my SQL queries.
In this case, I'm trying to allow a user to control the ORDER BY clause dynamically.
```
<cfquery datasource="MyDSN" name="qIncidents">
SELECT IncidentID, AnimalID, IntakeDate, DxDate, OutcomeDate
FROM Incidents
WHERE ShelterID = <cfqueryparam cfsqltype="cf_sql_integer" value="#Arguments.ShelterID#">
ORDER BY <cfqueryparam cfsqltype="cf_sql_varchar" value="#SortBy#">
</cfquery>
```
When I do this, I get the following error:
> The SELECT item identified by the ORDER BY number 1 contains a variable as part of the expression identifying a column position. Variables are only allowed when ordering by an expression referencing a column name.
Any suggestions on how to do this safely? | Unfortunately, you can't use CFQUERYPARAM directly in the Order By clause.
If you want to use the Order By dynamically but still do so safely, you can set up a CFSWITCH or similar structure to change your SortBy variable depending on some condition (say, a URL variable). As always, don't pass any values directly from the user, just look at the user's input and select from a predetermined list of possible values based on that. Then, just use the standard syntax:
```
ORDER BY #SortBy#
``` | I'll just expand on Aaron's answer. One of the things that I do is to use listfindnocase() to make sure that the arguments passed to the order by clause are valid:
```
<cfset variables.safeSortColumn = "name">
<cfset variables.safeSortOrder = "desc">
<cfparam name="url.sortcolumn" type="string" default="#variables.safeSortColumn#">
<cfparam name="url.sortorder" type="string" default="#variables.safeSortOrder#">
<cfif listfindnocase("name,age,address", url.sortcolumn)>
<cfset variables.safeSortColumn = url.sortcolumn>
</cfif>
<cfif listfindnocase("desc,asc", url.sortorder)>
<cfset variables.safeSortOrder = url.sortorder>
</cfif>
<cfquery>
select *
from mytable
order by #variables.safeSortcolumn# #variables.safeSortorder#
</cfquery>
``` | How do you use cfqueryparam in the ORDER BY clause? | [
"",
"sql",
"coldfusion",
"cfquery",
"cfqueryparam",
""
] |
**Question 1)**
I have a control to which I add an attribute from the server side by using a sentence like:
```
ControlName.Attributes.Add("myTestAttribute", "")
```
From the client side I modify the value of this attribute by using the Javascript function:
```
Document.getElementById(ControlName).setAttribute("myTestAttribute", “Hello Server!!”);
```
My problem is that when I try to acces to the attribute value on the Postback treatment function the attribute is empty.
Am I missing some step?
**Question 2)**
Is it possible to obtain the full HTML code of the page in the server side from inside a Postback treatment function? | If javascript modifies elemants on a page, they will not be visible to the server. When a postback occurs, the only data that is available to the server is the data that is sent in the form on the page.
ASP.net handles standard form elements such as textboxes, drop down lists etc. by putting their values into a hidden field called viewstate (this is normally encoded so cannot be read directly).
If you want page elements modified by javascript to be visible to the server, you can write new hidden form elements and retrieve them from the Request[string name] array. | 1. Put that attribute add code in Page\_Init
2. Nope | Two ASP.NET Postback related questions | [
"",
"asp.net",
"javascript",
""
] |
When using reflection it is possible to obtain the call stack (apart from that it can be a crude approximation due to JIT optimizations) using System.Diagnostics.StackTrace and examine the StackFrame objects contained.
How can I get a reference to the object (the this-pointer) on which a method in a stack frame is executing?
I know I can get the MethodBase by calling GetMethod() on the stack frame object, but what I'm looking for is something along the lines of GetObject() (which'd naturally return null if the method is static). It seems like the stack frame object can only be queried for statically determined info such as method info, originating file etc.
The VS debugger knows (although it probably use another method of obtaining the call stack trace), as one can double click any stack frame in the call stack window and look at the values of the locals and class fields.
EDIT:
To clarify: I want the *object **instance*** on which the method was called. I.e.: If method Foo() is called on object instance A somewhere on the call stack, and it cascades to the method I do the stack trace, I'd like to obtain a reference to A from where I perform the stack trace. (Not the declaring type of the method base) | I'm pretty sure that this is not possible. Here's why:
1. This could break type safety, since anyone can lookup a frame, get the object regardless of which AppDomain\Thread they are executing on or permission they have.
2. The '`this`' (C#) identifier is really just an argument to the instance method (the first), so in reality there is no difference between static methods and instance methods, the compiler does its magic to pass the right `this` to an instance method, which of course means that you will need to have access to all method arguments to get the `this` object. (which `StackFrame` does not support)
It might be possible by using `unsafe` code to get the pointer of the first argument to an instance method and then casting it to the right type, but I have no knowledge of how to do that, just an idea.
BTW you can imagine instance methods after being compiled to be like C# 3.0 extension methods, they get the `this` pointer as their first argument. | It's possible to obtain reference to `thiscall` object, but not with .NET code only. Native code must be involved. Even with using dynamic classes and System.Relection.Emit namespace .NET does not have instruments to access another methods evaluation stack and arguments.
On other side if you disassemble your .NET method you can see that this reference does not passed on physical stack at all. `Thiscall` reference is stored in `ECX`(`RCX` for x64) register instead. So it is possible climb up on stack from your method to method from which you want to obtain `thiscall` object. And then lookup inside that method's machine codes for instruction which save register ECX (RCX) in stack, and get from that instruction relative address where that reference lies.
Of course, the method of climbing is severely different in x32 and x64 application. To produce such function you must use not only C# but assembly code, and keep in mind that inline assembler is not allowed under x64; it must be a full assembler module. | How do I get the executing object for a stackframe? | [
"",
"c#",
"reflection",
"stack-trace",
"stack-frame",
""
] |
So:
```
@fopen($file);
```
Ignores any errors and continues
```
fopen($file) or die("Unable to retrieve file");
```
Ignores error, kills program and prints a custom message
Is there an easy way to ignore errors from a function, print a custom error message and not kill the program? | Typically:
```
if (!($fp = @fopen($file))) echo "Unable to retrieve file";
```
or using your way (which discards file handle):
```
@fopen($file) or printf("Unable to retrieve file");
``` | Use Exceptions:
```
try {
fopen($file);
} catch(Exception $e) {
/* whatever you want to do in case of an error */
}
```
More information at <http://php.net/manual/language.exceptions.php> | Ignoring PHP error, while still printing a custom error message | [
"",
"php",
"error-handling",
""
] |
Please your opinion on the following code.
I need to calculate the diff in days between 2 Date objects. It is assured that both Date objects are within the same TimeZone.
```
public class DateUtils {
public final static long DAY_TIME_IN_MILLIS = 24 * 60 * 60 * 1000;
/**
* Compare between 2 dates in day resolution.
*
* @return positive integer if date1 > date2, negative if date1 < date2. 0 if they are equal.
*/
public static int datesDiffInDays(final Date date1, final Date date2){
long date1DaysMS = date1.getTime() - (date1.getTime() % DAY_TIME_IN_MILLIS);
long date2DaysMS = date2.getTime() - (date2.getTime() % DAY_TIME_IN_MILLIS);
long timeInMillisDiff = (date1DaysMS - date2DaysMS);
int ret = (int) (timeInMillisDiff / DAY_TIME_IN_MILLIS);
return ret;
}
```
Can you point to a problem that I might have missed ?
EDIT: @mmyers asked if pass my unit test. Well - Yes. But I have no real experience with dates and I know that is a big subject. Posted below the unit test that I'm using.
```
public class TestMLDateUtils {
@Test
public final void testDatesDiffInDays() {
TimeZone.setDefault(TimeZone.getTimeZone("UTC"));
// 00:00:00.000 1.1.1970
Calendar cal1970 = Calendar.getInstance();
cal1970.setTimeInMillis(0);
Calendar tested = Calendar.getInstance();
tested.setTimeInMillis(0);
// Add 1 millisecond, date = 00:00:00.001 1.1.1970
tested.add(Calendar.MILLISECOND, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == 0);
// Add 1 second, date = 00:00:01.001 1.1.1970
tested.add(Calendar.SECOND, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == 0);
// Add 1 minute, date = 00:01:01.001 1.1.1970
tested.add(Calendar.MINUTE, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == 0);
// Add 1 hour, date = 01:01:01.001 1.1.1970
tested.add(Calendar.HOUR_OF_DAY, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == 0);
// date = 23:59:59.999 1.1.1970
tested.setTimeInMillis(0);
tested.add(Calendar.MILLISECOND, 999);
tested.add(Calendar.SECOND, 59);
tested.add(Calendar.MINUTE, 59);
tested.add(Calendar.HOUR_OF_DAY, 23);
//System.out.println("D: " + tested.getTime());
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == 0);
// date = 00:00:00.000 2.1.1970
tested.setTimeInMillis(0);
tested.add(Calendar.DAY_OF_MONTH, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == -1);
assertTrue(DateUtils.datesDiffInDays(tested.getTime(), cal1970.getTime()) == 1);
// date = 00:00:00.001 2.1.1970
tested.add(Calendar.MILLISECOND, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == -1);
assertTrue(DateUtils.datesDiffInDays(tested.getTime(), cal1970.getTime()) == 1);
// date = 00:00:01.001 2.1.1970
tested.add(Calendar.SECOND, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == -1);
assertTrue(DateUtils.datesDiffInDays(tested.getTime(), cal1970.getTime()) == 1);
// date = 00:01:01.001 2.1.1970
tested.add(Calendar.MINUTE, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == -1);
assertTrue(DateUtils.datesDiffInDays(tested.getTime(), cal1970.getTime()) == 1);
// date = 01:01:01.001 2.1.1970
tested.add(Calendar.HOUR_OF_DAY, 1);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == -1);
assertTrue(DateUtils.datesDiffInDays(tested.getTime(), cal1970.getTime()) == 1);
// date = 13:01:01.001 2.1.1970
tested.add(Calendar.HOUR_OF_DAY, 12);
assertTrue(DateUtils.datesDiffInDays(cal1970.getTime(), tested.getTime()) == -1);
assertTrue(DateUtils.datesDiffInDays(tested.getTime(), cal1970.getTime()) == 1);
}
}
``` | * Immediate problem: days can have less than or more than 24 hours due to daylight saving time changes.
* Secondary problem: normally when people think in days, they really mean "human days" rather than "periods of 24 hours". In other words, many people would say that 7pm-7am the next day is a difference of a day, whereas 7am-7pm the same day is a difference of zero days. Both are 12 hours. At that point, you really need to know the calendar that is being considered.
Of course, this may not matter for your situation, but we don't really know what that is.
* Third problem: you're using the built-in calendar API instead of [Joda Time](http://joda-time.sourceforge.net/). That's almost never a good idea - it's horrible and riddled with gotchas and problems. And yes, the regulars here will tell you that's *always* part of my answer when it comes to Java dates and times - and for good reason. It's really that important.
EDIT: Your test sets the default time zone to be UTC. That's not really a good idea (especially without resetting it in a finally statement). Time zones are tricky, but you should really think about what values you've got, what they mean, and what time zones are involved. | The time zone, if any, within the Date object is irrelevant, since you're using `getTime()`; that "[r]eturns the number of milliseconds since January 1, 1970, 00:00:00 GMT represented by this Date object."
However, you aren't accounting for leap seconds, which some implementations may return. Thus, if the day range you give has one or more leap seconds in it, and your times are near enough to the same time of day, your calculation may be wrong by a day. That said, there appears to be no way to see if any particular implementation accounts for leap seconds or not (I expect that most don't), and the difference is pretty darn trivial anyway. | CodeReview: java Dates diff (in day resolution) | [
"",
"java",
"datetime",
""
] |
I am currently using PIL.
```
from PIL import Image
try:
im = Image.open(filename)
# do stuff
except IOError:
# filename not an image file
```
However, while this sufficiently covers most cases, some image files like, xcf, svg and psd are not being detected. PSD files throw an `OverflowError` exception.
Is there someway I could include them as well? | A lot of times the first couple chars will be a magic number for various file formats. You could check for this in addition to your exception checking above. | You can use the builtin [imghdr](https://docs.python.org/library/imghdr.html) module. From its documentation:
> The imghdr module determines the type
> of image contained in a file or byte
> stream.
This is how you use it:
```
>>> import imghdr
>>> imghdr.what('/tmp/bass')
'gif'
```
**Note:** imghdr is [deprecated as of Python 3.11](https://peps.python.org/pep-0594/#imghdr) because it only supported a small number of file formats. | How to check if a file is a valid image file? | [
"",
"python",
"image",
"identification",
"imghdr",
""
] |
I have a folder called Etc which has an image I want to use in another file in the same folder, Example.java. So I have Etc\image.png and Etc\Example.java. I've tried using "Etc/image.png" as the image path, but that didn't work. How should I go about this?
Also, suppose the files were in different packages, how would I do it?
My main .java classes are in a package called Main, for the record.
**EDIT:**
I used this:
ClassLoader.getSystemClassLoader().getResource("Etc\image.png"); | You can use `Class.getResource()`, which uses the class loader to obtain a URL to the resource. For example:
```
import java.net.URL;
import javax.swing.ImageIcon;
public class Example {
public ImageIcon getImage() {
URL url = Example.class.getResource( "image.png" );
if( url != null ) {
return new ImageIcon( url );
}
return null; // TODO: Better error handling
}
}
```
The important part is `Example.class.getResource( "image.png" )` - the image path is specified relative to the named class; in this case, it's in the same directory as the class file. You could also use this line in any other class, leaving the reference to `Example.class` intact. | First things first.
Is Etc a package? In other words at the top of your Example file do you have a
package Etc;
???
Usually package names are lower case, which is why I ask.
Second, although you can use relative paths to access resources, I would recommend always using absolute paths.
So
URL url = Example.class.getResource("/Etc/image.png");
if Etc is a package, otherwise
URL url = Example.class.getResource("/image.png");
if it is not. | Problem with paths in a java jar | [
"",
"java",
"path",
"jar",
"classpath",
""
] |
I understand that letting any anonymous user upload any sort of file in general can be dangerous, especially if it's code. However, I have an idea to let users upload custom AI scripts to my website. I would provide the template so that the user could compete with other AI's in an online web game I wrote in Python. I either need a solution to ensure a user couldn't compromise any other files or inject malicious code via their uploaded script or a solution for client-side execution of the game. Any suggestions? (I'm looking for a solution that will work with my Python scripts) | Have an extensive API for the users and strip all other calls upon upload (such as import statements). Also, strip everything that has anything to do with file i/o.
(You might want to do multiple passes to ensure that you didn't miss anything.) | I am in no way associated with this site and I'm only linking it because it tries to achieve what you are getting after: jailing of python. The site is [code pad](http://codepad.org/about).
According to the about page it is ran under [geordi](http://www.xs4all.nl/~weegen/eelis/geordi/) and traps all sys calls with ptrace. In addition to be chroot'ed they are on a virtual machine with firewalls in place to disallow outbound connections.
Consider it a starting point but I do have to chime in on the whole danger thing. Gotta CYA myself. :) | Letting users upload Python scripts for execution | [
"",
"python",
"cgi",
""
] |
public IList GetClientsByListofID(IList ids) where T : IClient
{
IList clients = new List();
clients.Add( new Client(3));
}
I am getting a compiler error here:
**cannot convert from 'Bailey.Objects.Client' to 'T'**
The client object implements the IClient interface. My goal here is to try and loosen the coupling between my classes (learning DI stuff atm). I was thinking that I can say it can use any type of client object and that would be returned.
Am I completely off base here?
Thanks
Jon Hawkins | You cannot use generic constraints in this way. How can the compiler guarantee that the type parameter is a `Client` simply because it implements the `IClient` interface? Couldn't many types implement that interface?
In this case (*that is in the case where you need to work with the type, not the interface*) it is better to constrain the type parameter with the type itself like this:
```
public IList<T> GetClientsByListofID<T>(IList<int> ids) where T : Client
{
IList<T> clients = new List<T>();
clients.Add(new Client(3));
// ...
}
```
and once doing that I am wondering if you need a generic method at all:
```
public IList<Client> GetClientsByListofID(IList<int> ids)
{
IList<Client> clients = new List<Client>();
clients.Add(new Client(3));
// ...
}
``` | `Client` is a `IClient`.
`T` is a `IClient`.
Where did you specify that `T` is a `Client`? Nowhere!
I think you need a `IClientFactory` or `IClientRepository` that will create/retrieve IClient instances for you. You will then be able to use different implementations of this factory/repository. | IList<IClient> method<T>() where T : Iclient can not add client object to list | [
"",
"c#",
".net",
"generics",
"generic-method",
""
] |
Not exactly about programming, but I need help with this.
I'm running a development sever with WampServer. I want to install Python (because I prefer to use Python over PHP), but it seems there isn't an obvious choice. I've read about mod\_python and WSGI, and about how the latter is better.
However, from what I gathered (I may be wrong) you have to do more low-level stuff with WSGI than with PHP. So I researched about Django, but it seems too complex for what I want.
So, what recommendations would you give to a newbie in this area?
Again, sorry if this isn't about programming, but it's related, and this seems like a nice place to ask. | [Werkzeug](http://werkzeug.pocoo.org/) is a great little python tool (werkzeug) that works with mod\_wsgi for creating simple apps that dont need database backends with CMS's, such as calculators .. They've even got a nifty [screencast](http://werkzeug.pocoo.org/wiki30/) where they create a simple wiki in 30 minutes.
You can always add something like SQLAlchemy/FormAlchemy later on if you eventually do want to have a ORM and CMS.
Avoid mod\_python tho, it's got a pretty big memory footprint and it's actually a bit harder to install and set up than mod\_wsgi, in my opinion. | Django is not a web server, but a web application framework.
If you want a bare-bones Python webserver capable of some dynamic and some static content, have a look at [CherryPy](http://www.cherrypy.org/). | How to set up Python in a web server? | [
"",
"python",
"windows",
"django",
""
] |
I was wondering about caching dynamic PHP pages. Is it really about pre-compiling the PHP code and storing it in byte-code? Something similar to Python's .pyc which is a more compiled and ready to execute version and so that if the system sees that the .pyc file is newer than the .py file, then it won't bother to re-compile to .py file.
So is PHP caching mainly about this? Can someone offer a little bit more information on this? | Depends on the type of caching you are talking about. Opcode caching does exactly like you are saying. It takes the opcode and caches it so that whenever a user visits a particular page, that page does not need to be re-compiled if its opcode is already compiled and in the cache. If you modify a php file the caching mechanism will detect this and re-compile the code and put it in the cache.
If you're talking about caching the data on the page itself this is something different altogether.
Take a look at the [Alternative PHP Cache](https://www.php.net/apc/) for more info on opcode caching. | What you're describing is a [PHP accelerator](http://en.wikipedia.org/wiki/PHP_accelerator) and they do exactly what you said; store the cached, compiled bytecode so that multiple executions of the same script require only one compilation.
It's also possible to cache the results of executing the PHP script. This usually requires at least a little bit of logic, since the content of the page might have changed since it was cached. For example, you can have a look at the [general cache feature provided by CodeIgniter](http://codeigniter.com/user_guide/general/caching.html). | Can someone explain a little bit about caching dynamic PHP pages? | [
"",
"php",
"caching",
"webserver",
""
] |
I would like to produce a character list of all of the first letters of column in my database. The SQL below illistrats what I would like to return.
```
SELECT DISTINCT first_character(name) FROM mydatabase
```
Is there a way to do this in MySQL?
**EDIT**
What is the advantage of using SUBSTRING over LEFT and vice versa?
**EDIT**
Currently there are about 1700 records in the table and growing. | Sorry to do this, but I figured out exactly what I needed to do just now.
```
SELECT DISTINCT LEFT(name, 1) FROM table;
```
This returned a list of the first, distinct, single characters that each row in the column started with. I changed it to the following to get the list in alphanumeric order:
```
SELECT DISTINCT LEFT(name, 1) AS letter FROM table ORDER BY letter;
```
Works like a charm. | Sounds simple:
```
select distinct substring(field,1,1) as char
from mytable
``` | Returning the DISTINCT first character of a field (MySQL) | [
"",
"sql",
"mysql",
""
] |
I'm trying to a draw a more-or-less smooth multi-segment line in OpenGL. However I find that if the line is over a thickness about 3 then the joins between the segments are not seamless. They sometimes have gaps between them. Is there a good way of making these joins smooth and gapless? I'm looking for something like the equivalent of BasicStroke.JOIN\_MITER in Java. | The most consistent and portable way to draw think lines using OpenGL is to use camera aligned (otherwise know as billboarded) polygons. Different implementations of the OpenGL API handle the end points of the lines differently and `GL_LINE_SMOOTH` produces drastically different results depending on the platform. Some implementations consider lines of thickness greater then 1 to be ill-defined. As stated in the glLineWidth manpages: [For anti-aliased lines] only width 1 is guaranteed to be supported; others depend on the implementation.
That being said, I have used a simple 2 pass hack to address this very problem.
1. Disable writing to the depth buffer glDepthMask(GL\_FALSE)
2. Draw smoothed lines of desired thickness
3. Draw smoothed points at the endpoints of all the lines that are the same size at the lines. (this step may not be needed to fill the gap, however it should round out the points where the lines meet and make everything look a little smoother)
4. Re-enable the depth buffer for writing glDepthMask(GL\_TRUE)
You may also want to play around with the depth buffer settings. The "gap" between the lines may be due to the 2nd line failing a depth test on pixels that have been alpha blended with the background. | Depending of the quality of the OpenGL implementation, the results may vary. I've noticed a lot of differences for smooth lines on different implementations.
You may want to use a different strategy to draw your line segments, such as using thin polygons. | Smooth lines in OpenGL | [
"",
"java",
"opengl",
"jogl",
""
] |
When changing the selected item in a ListBox, I'm getting a weird error where the changed item appears selected but I cannot deselect it or reselect it.
Is there a way to fix this?
Here's a sample app that demonstrates the problem.
```
public partial class Window1 : Window
{
public Window1()
{
InitializeComponent();
this.DataContext = new WindowViewModel();
lst.SelectedIndex = 0;
}
private void Button_Click(object sender, RoutedEventArgs e)
{
((WindowViewModel)this.DataContext).Items[0] = "New Item";
}
}
public class WindowViewModel
{
public WindowViewModel()
{
Items = new ObservableCollection<string>();
Items.Add("Item1");
Items.Add("Item2");
Items.Add("Item3");
}
public ObservableCollection<string> Items { get; set; }
}
<Window x:Class="WpfSelectionIssue.Window1"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Title="Window1" Height="300" Width="300">
<StackPanel>
<Button Content="Change" Click="Button_Click" />
<ListBox x:Name="lst" ItemsSource="{Binding Items}" />
</StackPanel>
</Window>
```
[ImageOfIssue http://img136.imageshack.us/img136/9396/wpfselectionissue.jpg](http://img136.imageshack.us/img136/9396/wpfselectionissue.jpg) | After searching a bit more I found the solution. Adding an IsSynchronizedWithCurrentItem to the ListBox solved the problem.
```
<ListBox
x:Name="lst"
ItemsSource="{Binding Items}"
IsSynchronizedWithCurrentItem="True"
/>
``` | I also had this problem where I couldn't deselect any items. It seems that the listbox doesn't understand when you have multiple items in the list which are exactly the same. (And thus it selects them all, but doesn't deselect them)
This also happens when you change the value of the selected item when your binding. You have to first deselect the index (ex: listBox.SelectedIndex = -1;) and then change the value.
I hope this helps anyone with the same problem as me. | WPF ListBox Selection Problem when changing an item | [
"",
"c#",
".net",
"wpf",
"xaml",
"listbox",
""
] |
I want to detect in a script, which could be deployed beyond my control, whether the page was delivered with a HTTP status of 200, 404 or 500 etc.
This can't be done, right? | Have the page make a XMLHttpRequest to itself (using `location.href` or `document.URL`) and check the HTTP status you get. Seems to be pretty portable way to me. Why you would do a thing like this is beyond my understanding though ;) | Page A can be a Javascript that loads page B via AJAX and displays it with
document.write or in a pop up window or however.
In such a strategy, you can check return code for success/failure in the AJAX handler and send different things to the output window depending on status.
Most Ajax libraries provide a way to examine the return code....
See for instance "transport.status" with Ajax.Request in Prototype.js | How to detect HTTP status from JavaScript | [
"",
"javascript",
"http",
"dom",
""
] |
I have been given the following request.
Please give 7% of the current contacts registered to each of the sales associates to the new sales associate ('Peter').
What I decided to do was to get the total records for each sales associate and calculate 7% of the records.
For example
David has 200
200/7% = 14
```
SELECT TOP 14 ContactAssociate
FROM tb_Contact
WHERE tb_Contact.ContactAssociate = 'David'
ORDER BY NEWID()
```
Now, I can select the data but am struggling to update them;
I thought this would do it but no joy.
```
UPDATE tb_Contact
SET ContactAssociate = 'Peter'
IN
(
SELECT TOP 14 ContactAssociate
FROM tb_Contact
WHERE tb_Contact.ContactAssociate = 'David'
ORDER BY NEWID()
)
```
Any ideas where, I'm going wrong?
Any help, much appreciated. | PK\_Of\_tb\_Contact - primary key in your tb\_Contact table
```
UPDATE tb_Contact
SET ContactAssociate = 'Peter'
where PK_Of_tb_Contact
IN
(
SELECT TOP 14 PK_Of_tb_Contact
FROM tb_Contact
WHERE tb_Contact.ContactAssociate = 'David'
ORDER BY NEWID()
)
``` | Try this:
```
UPDATE c
SET ContactAssociate = 'Peter'
FROM tb_Contact c
INNER JOIN (
SELECT TOP 14 ContactAssociate FROM tb_Contact
WHERE tb_Contact.ContactAssociate = 'David'
) q ON c.ContactAssociate = q.ContactAssociate
```
If you want to try if you are updating the records you want, you may do this:
```
SELECT c.*
FROM tb_Contact c
INNER JOIN (
SELECT TOP 14 ContactAssociate FROM tb_Contact
WHERE tb_Contact.ContactAssociate = 'David'
) q ON c.ContactAssociate = q.ContactAssociate
```
As you can see, the only change between updates or checks are the lines before the FROM clause. | Update subset of data in sqlserver | [
"",
"sql",
"sql-server",
""
] |
I have a project that I'm building in C++ in Release mode in Visual Studio 2008 SP1 on Windows 7 and when I build it I keep getting:
> fatal error C1047: The object or
> library file '.\Release\foobar.obj'
> was created with an older compiler
> than other objects; rebuild old
> objects and libraries.
The error occurs while linking.
I've tried deleting the specific object file and rebuilding but that doesn't fix it. I've also tried blowing away the whole release build folder and rebuilding but that also didn't fix it. Any ideas? | I would suggest reinstalling VS 2008 SP1. Have you installed a different VS (e.g. VS Express) in the meantime? This is known to cause interference with an existing VS installation.
You could try checking the compiler and linker versions by running `cl.exe` and `link.exe` from the Visual Studio command prompt. | I had this problem but my solution differs:
For me the culprit was that an included external library was compiled with
```
/GL (=Enable link-time code generation under
C/C++/ Optimization / Whole Program Optimization)
```
using an older visual studio (2005). I rebuild said library in 2005 without /GL and the linker error disappeared in 2008. As MSDN states it has to do with the /LTCG setting, this is set automatically by the /GL flag:
<http://msdn.microsoft.com/en-us/library/ms173554%28v=vs.80%29.aspx> | Error C1047: Object file created with an older compiler than other objects | [
"",
"c++",
"visual-studio-2008",
""
] |
In the tutorials for ASP.Net MVC, the LINQ to Entities code looks like:
```
public class MyController : Controller
{
private Models db;
public ActionResult Index()
{
db = new Models();
var foo = (from f in db.foo select f).ToList();
return View(foo);
}
}
```
I'm guessing this has something to do with thread safety/connection pooling, but I just wanted to know if anyone knew of any good reasons not to do it this way:
```
public class MyController : Controller
{
private readonly Models db = new Models();
public ActionResult Index()
{
var foo = (from f in db.foo select f).ToList();
return View(foo);
}
}
``` | I just put together a tip that covers this in quite a lot of detail.
Your educated guess of threading is just one of the many reasons why it is generally better to construct/dispose of the Context in the method that needs it.
There are some situations where this rule of thumb doesn't hold but they are pretty rare.
See this: [Tip 18 - How to decide on a lifetime for your ObjectContext](http://blogs.msdn.com/alexj/archive/2009/05/07/tip-18-how-to-decide-on-a-lifetime-for-your-objectcontext.aspx) | From the code samples I've seen you should write the code your looking for as follows:
```
public class MyController : Controller{
public ActionResult Index()
{
using (var db = new Models())
{
var foo = db.Foo.ToList();
return View(foo);
}
}
}
```
There are two main changes here.
1. The EF Model is an IDisposable object and should be disposed of properly. It's not going to destroy your app if you don't (GC will clean it up later), but it's best to clean it up early if you can.
2. There is really no need for the from/select stuff in your LINQ, it's not doing anything in this scenario.
Although you should consider your application architecture as a whole and think about abstracting your data access outside of your controller. | LINQ to Entities Entity Initialization | [
"",
"c#",
".net",
"asp.net-mvc",
"linq",
"linq-to-entities",
""
] |
I've been trying to learn about metaclasses in Python. I get the main idea, but I can't seem to activate the mechanism. As I understand it, you can specify M to be as the metaclass when constructing a class K by setting `__metaclass__` to M at the global or class level. To test this out, I wrote the following program:
```
p = print
class M(type):
def __init__(*args):
type.__init__(*args)
print("The rain in Spain")
p(1)
class ClassMeta:
__metaclass__ = M
p(2)
__metaclass__ = M
class GlobalMeta: pass
p(3)
M('NotMeta2', (), {})
p(4)
```
However, when I run it, I get the following output:
```
C:\Documents and Settings\Daniel Wong\Desktop>python --version
Python 3.0.1
C:\Documents and Settings\Daniel Wong\Desktop>python meta.py
1
2
3
The rain in Spain
4
```
Shouldn't I see "The rain in Spain" after 1 and 2? What's going on here? | In Python 3 (which you are using) metaclasses are specified by a keyword parameter in the class definition:
```
class ClassMeta(metaclass=M):
pass
```
Specifying a `__metaclass__` class property or global variable is old syntax from Python 2.x and not longer supported. See also ["What's new in Python 3"](http://docs.python.org/3.0/whatsnew/3.0.html#changed-syntax) and [PEP 2115](http://www.python.org/dev/peps/pep-3115/). | This works as you expect in Python 2.6 (and earlier), but in 3.0 metaclasses are specified differently:
```
class ArgMeta(metaclass=M): ...
``` | Shouldn't __metaclass__ force the use of a metaclass in Python? | [
"",
"python",
"oop",
"python-3.x",
"metaclass",
""
] |
Can somebody tell me how I can find out "how many threads are in deadlock condition" in a Java multi-threading application? What is the way to find out the list of deadlocked threads?
I heard about Thread Dump and Stack Traces, but I don't know how to implement it.
* I also want to know what new features have been introduced in Java 5 for Threading?
Please let me know with your comments and suggestions. | Way of obtaining thread dumps:
* ctrl-break (Windows) or ctrl-\, possibly ctrl-4 and `kill -3` on Linux/UNIX
* `jstack` and your process id (use `jps`)
* `jconsole` or `visualvm`
* just about any debugger
Major new threading features in J2SE 5.0 (released 2004, in End Of Service Life Period):
* `java.util.concurrent`
* New Java Memory Model. | use kill -3 on the process id
this will print out to the console a thread dump and an overview of thread contention | Dead Lock Thread Check | [
"",
"java",
"multithreading",
""
] |
I have been putting off developing this part of my app for sometime purely because I want to do this in a circular way but get the feeling its a bad idea from what I remember my lecturers telling me back in school.
I have a design for an order system, ignoring the everything that doesn't pertain to this example I'm left with:
* CreditCard
* Customer
* Order
I want it so that,
* Customers can have credit cards (0-n)
* Customers have orders (1-n)
* Orders have one customer(1-1)
* Orders have one credit card(1-1)
* Credit cards can have one customer(1-1) (unique ids so we can ignore uniqueness of cc number, husband/wife may share cc instances ect)
Basically the last part is where the issue shows up, sometimes credit cards are declined and they wish to use a different one, this needs to update which their 'current' card is but this can only change the current card used for that order, not the other orders the customer may have on disk.
Effectively this creates a circular design between the three tables.
Possible solutions:
Either
Create the circular design, give references:
* cc ref to order,
* customer ref to cc
* customer ref to order
or
* customer ref to cc
* customer ref to order
* create new table that references all three table ids and put unique on the order so that only one cc may be current to that order at any time
Essentially both model the same design but translate differently, I am liking the latter option best at this point in time because it seems less circular and more central. (If that even makes sense)
My questions are,
* What if any are the pros and cons of each?
* What is the pitfalls of circular relationships/dependancies?
* Is this a valid exception to the rule?
* Is there any reason I should pick the former over the latter?
Thanks and let me know if there is anything you need clarified/explained.
--Update/Edit--
I have noticed an error in the requirements I stated. Basically dropped the ball when trying to simplify things for SO. There is another table there for Payments which adds another layer. The catch, Orders can have multiple payments, with the possibility of using different credit cards. (if you really want to know even other forms of payment).
Stating this here because I think the underlying issue is still the same and this only really adds another layer of complexity. | A customer can have 0 or more credit cards associated, but the association is dynamic - it can come and go. And as you point out a credit card can be associated with more than one customer. So this ends up being an n:m table, maybe with a flag column for "active".
An order has a static relationship to 0 or 1 credit card, and after a sale is complete, you can't mess with the cc value, no matter what happens to the relationship between the cc and the customer. The order table should independently store all the associated info about the cc at the time of the sale. There's no reason to associate the sale with any other credit card column in any other table (which might change - but it wouldn't affect the sale). | Hmm?
A customer has several credit cards, but only a current one. An order has a single assigned card. When a customer puchases something, his default card is tried first, otherwise, he may change his main card?
I see no circular references here; when a user's credit card changes, his orders' stay the same. Your tables would end up as:
* Customer: id, Current Card
* Credit Cards: id, number, customer\_id
* Order: id, Card\_id, Customer\_id
**Edit:** Oops, forgot a field, thanks. | Circular database relationships. Good, Bad, Exceptions? | [
"",
"sql",
"rdbms",
"entity-relationship",
"relational-model",
""
] |
I would like a span to update when a value is entered into a text field using jquery.
My form field has a text box with the name "userinput" and i have a span with the id "inputval".
Any help would be greatly appreciated. | **UPDATE:
although you marked this as the correct answer, note that you should use the keyup event rather than the change event or the keydown**
```
$(document).ready(function() {
$('input[name=userinput]').keyup(function() {
$('#inputval').text($(this).val());
});
});
``` | Try the following, you have to call again `keyup()` to trigger for the last char:
```
$(".editable_input").keyup(function() {
var value = $(this).val();
var test = $(this).parent().find(".editable_label");
test.text(value);
}).keyup();
``` | How to update span when text is entered in form text field with jquery | [
"",
"javascript",
"jquery",
"ajax",
""
] |
I tried to solve problems from Project Euler. I know my method would work logically (it returns answers to the small scale problem almost instantly). However, it scales horribly. I already attempted changing the .ini file, but to no avail.
Here's my code:
```
public class Number28 {
static int SIZE = 101; //this should be an odd number, i accidentally posted 100
/**
* @param args
*/
public static void main(String[] args) {
double start = System.currentTimeMillis();
long spiral[][]= spiral(SIZE);
long sum = 0;
for(int i = 0; i < SIZE; i++)
{
sum += spiral[i][i];
sum += spiral[i][SIZE - 1 - i];
}
System.out.println(sum - 1);
double time = System.currentTimeMillis() - start;
System.out.println(time);
}
public static long[][] spiral(int size){
long spiral[][]= new long[size][size];
if(size == 1){
spiral[0][0] = 1;
return spiral;
}
else{
long subspiral[][]= new long[size - 2][size - 2];
subspiral = spiral(size - 2);
for(int r = 0; r < size - 2; r++){
for(int c = 0; c < size - 2; c++){
spiral[r + 1][c + 1] = subspiral[r][c];
}
}
long counter = subspiral[0][size - 3];
for(int r = 1; r < size ; r++){
counter++;
spiral[r][size - 1] = counter;
}
for(int c = size - 2; c >= 0; c--){
counter++;
spiral[size - 1][c] = counter;
}
for(int r = size - 2 ; r >= 0 ; r--){
counter++;
spiral[r][0] = counter;
}
for(int c = 1; c < size ; c++){
counter++;
spiral[0][c] = counter;
}
return spiral;
}
}
}
```
Here's the edited code, worked like a gem:
```
public class Number28 {
static int SIZE = 1001;
static long spiral[][]= new long[SIZE][SIZE];
/**
* @param args
*/
public static void main(String[] args) {
double start = System.currentTimeMillis();
long spiral[][]= spiral(SIZE);
long sum = 0;
for(int i = 0; i < SIZE; i++)
{
sum += spiral[i][i];
sum += spiral[i][SIZE - 1 - i];
}
System.out.println(sum - 1);
double time = System.currentTimeMillis() - start;
System.out.println(time);
}
public static long[][] spiral(int size){
if(size == 1){
spiral[SIZE / 2][SIZE / 2] = 1;
return spiral;
}
else{
long subspiral[][]= spiral(size - 2);
int edge = (SIZE - size) / 2;
long counter = subspiral[edge + 1][edge + size - 2];
for(int r = 1; r < size ; r++){
counter++;
spiral[edge + r][edge + size - 1] = counter;
}
for(int c = size - 2; c >= 0; c--){
counter++;
spiral[edge + size - 1][edge + c] = counter;
}
for(int r = size - 2 ; r >= 0 ; r--){
counter++;
spiral[edge + r][edge] = counter;
}
for(int c = 1; c < size ; c++){
counter++;
spiral[edge][edge + c] = counter;
}
return spiral;
}
}
}
``` | Not familiar with the Euler problems, but the horror appears to be your continual allocation and re-allocation of what are basically throwaway intermediate spirals, as you call down recursively to the base case.
Restructure so that you allocate your full spiral up front. Then call your recursive function, passing your full spiral in as a parameter by reference, along with a "level" parameter, which will change with each recursive call. E.g., initial call is with 100x100 spiral and level 100; next (recursive) call is with same spiral, by reference, and level 98. Operations within the function will all be done on the one-and-only-allocated spiral.
In a nutshell: allocate your data structure once, even if you operate on that data structure recursively. | As a general piece of Project Euler advice, if your solution doesn't scale, there's almost certainly a better way to solve it. If you've used the same type of solution on an earlier problem you can go through the posts from other users on the earlier question to get ideas for solving the problem in different ways. | Overcoming heap overflow issues | [
"",
"java",
"heap-memory",
""
] |
If I am on a page such as
<http://somesite.com/somepage.php?param1=asdf>
In the JavaScript of that page, I would like to set a variable to the value of the parameter in the GET part of the URL.
So in JavaScript:
```
<script>
param1var = ... // ... would be replaced with the code to get asdf from URI
</script>
```
What would "..." be? | Here's some **[sample code](http://www.zrinity.com/developers/code_samples/code.cfm/CodeID/59/JavaScript/Get_Query_String_variables_in_JavaScript)** for that.
```
<script>
var param1var = getQueryVariable("param1");
function getQueryVariable(variable) {
var query = window.location.search.substring(1);
var vars = query.split("&");
for (var i=0;i<vars.length;i++) {
var pair = vars[i].split("=");
if (pair[0] == variable) {
return pair[1];
}
}
alert('Query Variable ' + variable + ' not found');
}
</script>
``` | You can get the "search" part of the location object - and then parse it out.
```
var matches = /param1=([^&#=]*)/.exec(window.location.search);
var param1 = matches[1];
``` | Using the GET parameter of a URL in JavaScript | [
"",
"javascript",
"url",
"get",
""
] |
Is there a way in Python to list all the currently in-use drive letters in a Windows system?
(My Google-fu seems to have let me down on this one)
A `C++` equivalent: [Enumerating all available drive letters in Windows](https://stackoverflow.com/questions/286534/enumerating-all-available-drive-letters-in-windows) | ```
import win32api
drives = win32api.GetLogicalDriveStrings()
drives = drives.split('\000')[:-1]
print drives
```
Adapted from:
<http://www.faqts.com/knowledge_base/view.phtml/aid/4670> | Without using any external libraries, if that matters to you:
```
import string
from ctypes import windll
def get_drives():
drives = []
bitmask = windll.kernel32.GetLogicalDrives()
for letter in string.uppercase:
if bitmask & 1:
drives.append(letter)
bitmask >>= 1
return drives
if __name__ == '__main__':
print get_drives() # On my PC, this prints ['A', 'C', 'D', 'F', 'H']
``` | Is there a way to list all the available Windows' drives? | [
"",
"python",
"windows",
""
] |
SQL Server reports can embed vbscript and execute client side, but can the same be done with javascript? I think there would be great utility to be able to execute jQuery and CSS manipulation client side to create a more interactive drill down experience. | May be late reply , but it will help for others
<http://direit.wordpress.com/2012/07/24/ssrs-use-custom-javascript-to-call-a-report-in-a-new-tabwindow/> | Are we talking about SQL Server Reporting Services?
If so, I have not ever seen a method to do it. I will admit that the notion makes my skin crawl, though.
**Edit**
Here is a [small example](https://web.archive.org/web/20120109030937/http://blogs.msdn.com/b/mab/archive/2007/05/17/how-to-create-a-hyperlink-in-reporting-services-that-opens-in-a-new-window.aspx) of using JavaScript to open a separate window in a hyperlink.
This [blog article](https://web.archive.org/web/20170514231429/http://geekswithblogs.net:80/mnf/archive/2007/11/25/sql-server-reporting-services-notes.aspx) may contain even better information for some interesting JavaScript techniques in reporting services. | Is it possible to embed javascript into an SSRS Report? | [
"",
"javascript",
"jquery",
"sql-server",
"report",
""
] |
Assuming I have a column called A and I want to check if A is null or blank, what is the proper way to check for this using the DataView's RowFilter:
```
DataTable dt = GetData();
DataView dv = new DataView(dt);
dv.RowFilter = "A IS NOT NULL OR A IS NOT ''";
```
The above doesn't seem to work though. | Are you tied to .net < 3.5? If not you can use linq to check the state of a column.
Otherwise there is an `Isnull(,)` function like in T-SQL:
```
dv.RowFilter = "Isnull(a,'') <> ''";
``` | I am assuming you need to retrieve all the records where the value in column A is neither null nor ''
The correct expr is:
```
dv.RowFilter = "A IS NOT NULL AND A <> ''";
```
And to retrieve the filtered records loop on dv.ToTable() like this:
```
foreach (DataRow dr in dv.ToTable().Rows)
Console.WriteLine(dr["A"]);
```
This should work ... cheers!! | How do I check for blank in DataView.RowFilter | [
"",
"c#",
"asp.net",
"dataview",
""
] |
Anyone know of an easy way to parse a Lua datastructure in C# or with any .Net library? This would be similar to JSON decoding, except for Lua instead of javascript.
At this point it looks like I'll need to write my own, but hoping there's something already out there. | What Alexander said. The lab is the home of Lua, after all.
Specifically, [LuaInterface](http://code.google.com/p/luainterface/) can allow a Lua interpreter to be embedded in your application so that you can use Lua's own parser to read the data. This is analogous to embedding Lua in a C/C++ application for use as a config/datafile language. The [LuaCLR](http://code.google.com/p/luaclr/) project might be fruitful at some point as well, but it may not be quite as mature. | Thanks to both of you, I found what I was looking for using LuaInterface
Here's a datastructure in Lua I wanted to read ("c:\sample.lua"):
```
TestValues = {
NumbericOneMillionth = 1e-006,
NumbericOnehalf = 0.5,
NumbericOne = 1,
AString = "a string"
}
```
Here's some sample code reading that Lua datastructure using LuaInterface:
```
Lua lua = new Lua();
var result = lua.DoFile("C:\\sample.lua");
foreach (DictionaryEntry member in lua.GetTable("TestValues")) {
Console.WriteLine("({0}) {1} = {2}",
member.Value.GetType().ToString(),
member.Key,
member.Value);
}
```
And here's what that sample code writes to the console:
```
(System.String) AString = a string
(System.Double) NumbericOneMillionth = 1E-06
(System.Double) NumbericOnehalf = 0.5
(System.Double) NumbericOne = 1
```
To figure out how to use the library I opened up the LuaInterface.dll in Reflector and google'd the member functions. | Easiest way to parse a Lua datastructure in C# / .Net | [
"",
"c#",
"parsing",
"lua",
""
] |
I get confused when I see examples of self invoked anonymous functions in Javascript such as this:
```
(function () { return val;}) ();
```
Is there a difference between this syntax and the following:
```
function() { return val;} ();
```
If someone can give me a concrete difference, it would help put to rest a question that's been bugging me for ages... | Javascript doesn't have a block scope, so this is a way to create a temporary local scope that doesn't pollute the global namespace. The parentheses serve two purposes:
1. Some implementations of javascript flip out if they're missing.
2. It signals to readers that something different from a normal function declaration is going on. So as a convention, it signals that this function is being used as a scope.
see here:
<http://peter.michaux.ca/articles/an-important-pair-of-parens> | In Safari 4, the following code (without the parentheses) results in "SyntaxError: Parse error":
```
function() { alert("Test"); }();
```
...but the following code works as expected:
```
(function() { alert("Test"); })();
```
**Update**: I also tried the code in Firefox 3 (via Firebug), and it behaved just like Safari. | Does parenthetical notation for self-invoked functions serve a purpose in Javascript? | [
"",
"javascript",
"functional-programming",
"scope",
""
] |
**Note:** This question and most of its answers date to before the release of Java 7. Java 7 provides [Automatic Resource Management](https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html) functionality for doing this easilly. If you are using Java 7 or later you should advance to [the answer of Ross Johnson](https://stackoverflow.com/a/21723193).
---
What is considered the best, most comprehensive way to close nested streams in Java? For example, consider the setup:
```
FileOutputStream fos = new FileOutputStream(...)
BufferedOS bos = new BufferedOS(fos);
ObjectOutputStream oos = new ObjectOutputStream(bos);
```
I understand the close operation needs to be insured (probably by using a finally clause). What I wonder about is, is it necessary to explicitly make sure the nested streams are closed, or is it enough to just make sure to close the outer stream (oos)?
One thing I notice, at least dealing with this specific example, is that the inner streams only seem to throw FileNotFoundExceptions. Which would seem to imply that there's not technically a need to worry about closing them if they fail.
Here's what a colleague wrote:
---
Technically, if it were implemented right, closing the outermost
stream (oos) should be enough. But the implementation seems flawed.
Example:
BufferedOutputStream inherits close() from FilterOutputStream, which defines it as:
```
155 public void close() throws IOException {
156 try {
157 flush();
158 } catch (IOException ignored) {
159 }
160 out.close();
161 }
```
However, if flush() throws a runtime exception for some reason, then
out.close() will never be called. So it seems "safest" (but ugly) to
mostly worry about closing FOS, which is keeping the file open.
---
What is considered to be the hands-down best, when-you-absolutely-need-to-be-sure, approach to closing nested streams?
And are there any official Java/Sun docs that deal with this in fine detail? | I usually do the following. First, define a template-method based class to deal with the try/catch mess
```
import java.io.Closeable;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
public abstract class AutoFileCloser {
// the core action code that the implementer wants to run
protected abstract void doWork() throws Throwable;
// track a list of closeable thingies to close when finished
private List<Closeable> closeables_ = new LinkedList<Closeable>();
// give the implementer a way to track things to close
// assumes this is called in order for nested closeables,
// inner-most to outer-most
protected final <T extends Closeable> T autoClose(T closeable) {
closeables_.add(0, closeable);
return closeable;
}
public AutoFileCloser() {
// a variable to track a "meaningful" exception, in case
// a close() throws an exception
Throwable pending = null;
try {
doWork(); // do the real work
} catch (Throwable throwable) {
pending = throwable;
} finally {
// close the watched streams
for (Closeable closeable : closeables_) {
if (closeable != null) {
try {
closeable.close();
} catch (Throwable throwable) {
if (pending == null) {
pending = throwable;
}
}
}
}
// if we had a pending exception, rethrow it
// this is necessary b/c the close can throw an
// exception, which would remove the pending
// status of any exception thrown in the try block
if (pending != null) {
if (pending instanceof RuntimeException) {
throw (RuntimeException) pending;
} else {
throw new RuntimeException(pending);
}
}
}
}
}
```
Note the "pending" exception -- this takes care of the case where an exception thrown during close would mask an exception we might really care about.
The finally tries to close from the outside of any decorated stream first, so if you had a BufferedWriter wrapping a FileWriter, we try to close the BuffereredWriter first, and if that fails, still try to close the FileWriter itself. (Note that the definition of Closeable calls for close() to ignore the call if the stream is already closed)
You can use the above class as follows:
```
try {
// ...
new AutoFileCloser() {
@Override protected void doWork() throws Throwable {
// declare variables for the readers and "watch" them
FileReader fileReader =
autoClose(fileReader = new FileReader("somefile"));
BufferedReader bufferedReader =
autoClose(bufferedReader = new BufferedReader(fileReader));
// ... do something with bufferedReader
// if you need more than one reader or writer
FileWriter fileWriter =
autoClose(fileWriter = new FileWriter("someOtherFile"));
BufferedWriter bufferedWriter =
autoClose(bufferedWriter = new BufferedWriter(fileWriter));
// ... do something with bufferedWriter
}
};
// .. other logic, maybe more AutoFileClosers
} catch (RuntimeException e) {
// report or log the exception
}
```
Using this approach you never have to worry about the try/catch/finally to deal with closing files again.
If this is too heavy for your use, at least think about following the try/catch and the "pending" variable approach it uses. | When closing chained streams, you only need to close the outermost stream. Any errors will be propagated up the chain and be caught.
Refer to [Java I/O Streams](http://java.sun.com/developer/technicalArticles/Streams/ProgIOStreams/) for details.
To address the issue
> However, if flush() throws a runtime exception for some reason, then out.close() will never be called.
This isn't right. After you catch and ignore that exception, execution will pick back up after the catch block and the `out.close()` statement will be executed.
Your colleague makes a good point about the **Runtime**Exception. If you absolutely need the stream to be closed, you can always try to close each one individually, from the outside in, stopping at the first exception. | Correct way to close nested streams and writers in Java | [
"",
"java",
"java-io",
""
] |
A **Map** maps from keys to values and provides quick access based on the knowledge of the key.
Does there exist a data structure like Maps which supports both key to value and value to key access? Sometimes I may want to derefence the Map via the value, while other times by the key. | Not in the JDK, but you can find a good BiMap implementation in the Google Collections : <http://google-collections.googlecode.com/svn/trunk/javadoc/com/google/common/collect/BiMap.html> | [Apache Commons Collections](http://commons.apache.org/collections/index.html) provides a [BidiMap](http://commons.apache.org/collections/apidocs/org/apache/commons/collections/package-use.html#org.apache.commons.collections.bidimap) which serves this purpose. | Looking a data structure that is a Map but in which keys can be values, values can be keys | [
"",
"java",
"algorithm",
"data-structures",
"dictionary",
""
] |
I'm looking at the article *[C# - Data Transfer Object](http://www.codeproject.com/KB/cs/datatransferobject.aspx)* on serializable DTOs.
The article includes this piece of code:
```
public static string SerializeDTO(DTO dto) {
try {
XmlSerializer xmlSer = new XmlSerializer(dto.GetType());
StringWriter sWriter = new StringWriter();
xmlSer.Serialize(sWriter, dto);
return sWriter.ToString();
}
catch(Exception ex) {
throw ex;
}
}
```
The rest of the article looks sane and reasonable (to a noob), but that try-catch-throw throws a WtfException... **Isn't this exactly equivalent to not handling exceptions at all?**
Ergo:
```
public static string SerializeDTO(DTO dto) {
XmlSerializer xmlSer = new XmlSerializer(dto.GetType());
StringWriter sWriter = new StringWriter();
xmlSer.Serialize(sWriter, dto);
return sWriter.ToString();
}
```
Or am I missing something fundamental about error handling in C#? It's pretty much the same as Java (minus checked exceptions), isn't it? ... That is, they both refined C++.
The Stack Overflow question *[The difference between re-throwing parameter-less catch and not doing anything?](https://stackoverflow.com/questions/717489)* seems to support my contention that try-catch-throw is-a no-op.
---
**EDIT:**
Just to summarise for anyone who finds this thread in future...
**DO NOT**
```
try {
// Do stuff that might throw an exception
}
catch (Exception e) {
throw e; // This destroys the strack trace information!
}
```
The stack trace information can be crucial to identifying the root cause of the problem!
**DO**
```
try {
// Do stuff that might throw an exception
}
catch (SqlException e) {
// Log it
if (e.ErrorCode != NO_ROW_ERROR) { // filter out NoDataFound.
// Do special cleanup, like maybe closing the "dirty" database connection.
throw; // This preserves the stack trace
}
}
catch (IOException e) {
// Log it
throw;
}
catch (Exception e) {
// Log it
throw new DAOException("Excrement occurred", e); // wrapped & chained exceptions (just like java).
}
finally {
// Normal clean goes here (like closing open files).
}
```
Catch the more specific exceptions before the less specific ones (just like Java).
---
**References:**
* [MSDN - Exception Handling](http://msdn.microsoft.com/en-us/library/ms229005.aspx)
* [MSDN - try-catch (C# Reference)](http://msdn.microsoft.com/en-us/library/0yd65esw.aspx) | First, the way that the code in the article does it is evil. `throw ex` will reset the call stack in the exception to the point where this throw statement is losing the information about where the exception actually was created.
Second, if you just catch and re-throw like that, I see no added value. The code example above would be just as good (or, given the `throw ex` bit, even better) without the try-catch.
However, there are cases where you might want to catch and rethrow an exception. Logging could be one of them:
```
try
{
// code that may throw exceptions
}
catch(Exception ex)
{
// add error logging here
throw;
}
``` | Don't do this,
```
try
{
...
}
catch(Exception ex)
{
throw ex;
}
```
You'll lose the stack trace information...
Either do,
```
try { ... }
catch { throw; }
```
OR
```
try { ... }
catch (Exception ex)
{
throw new Exception("My Custom Error Message", ex);
}
```
One of the reason you might want to rethrow is if you're handling different exceptions, for
e.g.
```
try
{
...
}
catch(SQLException sex)
{
//Do Custom Logging
//Don't throw exception - swallow it here
}
catch(OtherException oex)
{
//Do something else
throw new WrappedException("Other Exception occured");
}
catch
{
System.Diagnostics.Debug.WriteLine("Eeep! an error, not to worry, will be handled higher up the call stack");
throw; //Chuck everything else back up the stack
}
``` | Why catch and rethrow an exception in C#? | [
"",
"c#",
"exception",
"try-catch",
""
] |
We have a form that hosts the WebBrowser control. That is the only control on the form.
We pass the form the file path of a temporary PDF file and it does:
```
WebBrowser1.Navigate(Me._PathToPdf)
```
When the form is closing, it navigates away from the PDF file:
```
WebBrowser1.Hide()
WebBrowser1.Navigate("about:blank")
Do Until WebBrowser1.ReadyState = WebBrowserReadyState.Complete
Application.DoEvents()
System.Threading.Thread.Sleep(50)
Loop
```
Once the form is closed, the calling class then deletes the temporary PDF file.
This process works great... until we installed Internet Explorer 8. For some reason, the combination of IE8 and Adobe Acrobat 8 (or 9) causes an extra file lock handle to be placed on the temporary PDF file. The extra lock handle does not go away until the entire application is shut down. I should also mention that there are no locks on the file until the file is opened by Acrobat.
We can reproduce this on multiple machines and it is always the combination of IE8 and Adobe Acrobat Reader. We can install Foxit Reader 3 instead of Adobe Acrobat and things work fine. Likewise, we can run the app on a machine with IE7 and Adobe Acrobat, and things work fine. But, when you mix the magic potion of IE 8 and Acrobat, you end up with a mess.
Can anyone tell me why I'm getting an extra file lock that persists until the end of the application?
Thanks.
An example application that demonstrates my problem can be found here: [PDFLockProblemDemo.zip](http://www.centrolutions.com/downloads/PDFLockProblemDemo.zip) | Seems to me the real problems is using a `WebBrowser` control to host the Adobe Reader web browser plugin to display PDFs. Isn't there a better way to display PDFs directly without introducing a dependency on a web browser? Doesn't Adobe provide an SDK or an ActiveX control you can host directly inside your form?
---
UPDATE: I looked around and found [this post](http://www.ureader.com/message/819807.aspx) where they access an Adobe ActiveX control (`AxAcroPDFLib.AxAcroPDF`) and simply call:
```
axAcroPDF1.LoadFile("mypdf.pdf");
axAcroPDF1.Show();
``` | Still no solution found, but more info:
Previously I had tested with XP Pro, Acrobat \*.x and .NET 2.0 (built with VS 2005). Since then, I have also tested in a variety of scenarios that include Vista, Acrobat 9.x and .NET 3.5 (built with VS 2008).
Same results though: as long as the browser is IE8, the PDF file doesn't get released when you call Dispose() on the WebBrowser control. It does get released when the app is closed, but that doesn't help us...
Hope this helps. | Hosting IE 8 In WinForms and Opening a PDF | [
"",
"c#",
"vb.net",
"file",
"internet-explorer-8",
"acrobat",
""
] |
Can't download adventure works database 2005 from codeplex. Where else can I find and download it??? I've been searching it online, I found some results but i can't download any of them. Any help is appreciated | No response or solution found. Just gave up findin it. | it's usually bundled with sql installation disks
Try this link for online download of sqlserver samples
[1](http://www.codeplex.com/MSFTDBProdSamples/Release/ProjectReleases.aspx?ReleaseId=4004)
[2](http://codeplex.com/SqlServerSamples) | Can't download adventure works database 2005 from codeplex | [
"",
"sql",
"sql-server-2005",
"database",
"sample",
"adventureworks",
""
] |
How do I create a namespace in JavaScript so that my objects and functions aren't overwritten by other same-named objects and functions? I've used the following:
```
if (Foo == null || typeof(Foo) != "object") { var Foo = new Object();}
```
Is there a more elegant or succinct way of doing this? | I like this:
```
var yourNamespace = {
foo: function() {
},
bar: function() {
}
};
...
yourNamespace.foo();
``` | I use [the approach found on the Enterprise jQuery site](https://web.archive.org/web/20181005005954/https://appendto.com/2010/10/how-good-c-habits-can-encourage-bad-javascript-habits-part-1/):
Here is their example showing how to declare private & public properties and functions. Everything is done as a self-executing anonymous function.
```
(function( skillet, $, undefined ) {
//Private Property
var isHot = true;
//Public Property
skillet.ingredient = "Bacon Strips";
//Public Method
skillet.fry = function() {
var oliveOil;
addItem( "\t\n Butter \n\t" );
addItem( oliveOil );
console.log( "Frying " + skillet.ingredient );
};
//Private Method
function addItem( item ) {
if ( item !== undefined ) {
console.log( "Adding " + $.trim(item) );
}
}
}( window.skillet = window.skillet || {}, jQuery ));
```
So if you want to access one of the public members you would just go `skillet.fry()` or `skillet.ingredients`.
What's really cool is that you can now extend the namespace using the exact same syntax.
```
//Adding new Functionality to the skillet
(function( skillet, $, undefined ) {
//Private Property
var amountOfGrease = "1 Cup";
//Public Method
skillet.toString = function() {
console.log( skillet.quantity + " " +
skillet.ingredient + " & " +
amountOfGrease + " of Grease" );
console.log( isHot ? "Hot" : "Cold" );
};
}( window.skillet = window.skillet || {}, jQuery ));
```
# The third `undefined` argument
> The third, `undefined` argument is the source of the variable of value `undefined`. I'm not sure if it's still relevant today, but while working with older browsers / JavaScript standards (ecmascript 5, javascript < 1.8.5 ~ firefox 4), the global-scope variable `undefined` is writable, so anyone could rewrite its value. The third argument (when not passed a value) creates a variable named `undefined` which is scoped to the namespace/function. Because no value was passed when you created the name space, it defaults to the value `undefined`. | How do I declare a namespace in JavaScript? | [
"",
"javascript",
"namespaces",
"javascript-namespaces",
""
] |
I need to create a block of unique lines to test a different project I am working on.
So I created a simple program to generate a random string of X length.
The issue is that if I call it once, I get a random string, if I call it again (in a for loop for example) I get the same string for the entire execution of the loop.
I have a feeling that it's being cached or something but I didn't know .net did that and I am just confused at this point.
**calling code:**
```
StreamWriter SW = new StreamWriter("c:\\test.txt");
int x = 100;
while (x >0)
{
SW.WriteLine(RandomString(20));
x--;
}
```
**here is the method:**
```
private static string RandomString(int Length)
{
StringBuilder sb = new StringBuilder();
Random randomNumber = new Random();
for (int i = 0; i <= Length; ++i)
{
int x = randomNumber.Next(65, 122);
sb.Append(Convert.ToChar(x));
}
return sb.ToString();
}
```
**and here is the output:**
```
"VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB
..................
VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB
VEWMCQ`Fw]TvSFQawYnoB"
```
So what gives i thought Random.next() would always return a new random number? | You are creating the `Random` instances too close in time. Each instance is initialised using the system clock, and as the clock haven't changed you get the same sequence of random numbers over and over.
Create a single instance of the `Random` class and use it over and over.
Use the `using` keyword so that the `StreamWriter` is closed and disposed when you are done with it. The code for a loop is easier to recognise if you use the `for` keyword.
```
using (StreamWriter SW = new StreamWriter("c:\\test.txt")) {
Random rnd = new Random();
for (int x = 100; x > 0; x--) {
SW.WriteLine(RandomString(rnd, 20));
}
}
```
The method takes the `Random` object as a parameter.
Also, use the length to initialise the StringBuilder with the correct capacity, so that it doesn't have to reallocate during the loop. Use the < operator instead of <= in the loop, otherwise you will create a string that is one character longer than the `length` parameter specifies.
```
private static string RandomString(Random rnd, int length) {
StringBuilder sb = new StringBuilder(length);
for (int i = 0; i < length; i++) {
int x = rnd.Next(65, 122);
sb.Append((char)x);
}
return sb.ToString();
}
``` | See [Random constructor description](http://msdn.microsoft.com/en-us/library/h343ddh9.aspx) at MSN, this part:
> The default seed value is derived from
> the system clock and has finite
> resolution. As a result, different
> Random objects that are created in
> close succession by a call to the
> default constructor will have
> identical default seed values and,
> therefore, will produce identical sets
> of random numbers.
So either call the Random() constructor only once at the beginning of your program or use the Random(int32) constructor and define a varying seed yourself. | why does this method return the same random string each time? | [
"",
"c#",
".net",
"text",
"random",
"char",
""
] |
I'm wondering what Data Structure people would recommend to do the following. I have a Class which has three main properties eg.
```
public class Example {
public Object One { get; }
public Object Two { get; }
public Object Three { get; }
}
```
Another class contains a collection of these Objects and frequently needs to enumerate over these which I do mainly with LINQ. A lot of the time though I need to lookup/enumerate only a subset of these objects based mainly on the value of property One so what I'd like to do is store these in an efficient data structure based on that property. I could do something like the following:
```
Dictionary<Object,List<Example>>
```
But this strikes me as being very inefficient, I know I need some kind of Hash Table but having never used one before in C# I'm unsure of what there is to use.
Some other requirements/notes:
* All the Objects are immutable and have fixed Hash Codes which are computed from the values the class gets instantiated with in the constructors
* Must be able to store multiple items that have the same value (and thus Hash Code) for property One in the same 'slot' in the data structure
* Must be able to freely add and remove Objects from the collection | PowerCollections (<http://www.codeplex.com/PowerCollections>) has a MultiDictionary container - perhaps you could try that? | [Indexed LINQ](http://www.codeplex.com/i4o) may be able to help you here. It provides an in-memory collection, but lets you attribute properties on your objects as Indexable so that it can create efficient queries against them. | Data Structure for enumeration in c# where lookup is often predicated on one property of the Objects being stored | [
"",
"c#",
"data-structures",
"hashtable",
"hashcode",
""
] |
I started to use Json.NET to convert a string in JSON format to object or viceversa. I am not sure in the Json.NET framework, is it possible to convert a string in JSON to XML format and viceversa? | Yes. Using the JsonConvert class which contains helper methods for this precise purpose:
```
// To convert an XML node contained in string xml into a JSON string
XmlDocument doc = new XmlDocument();
doc.LoadXml(xml);
string jsonText = JsonConvert.SerializeXmlNode(doc);
// To convert JSON text contained in string json into an XML node
XmlDocument doc = JsonConvert.DeserializeXmlNode(json);
```
Documentation here: [**Converting between JSON and XML with Json.NET**](http://james.newtonking.com/projects/json/help/index.html?topic=html/ConvertingJSONandXML.htm) | Yes, you [can](http://www.newtonsoft.com/json/help/html/ConvertJsonToXml.htm) do it (I do) but Be aware of some paradoxes when converting, and handle appropriately. You cannot automatically conform to all interface possibilities, and there is limited built-in support in controlling the conversion- many JSON structures and values cannot automatically be converted both ways. Keep in mind I am using the default settings with Newtonsoft JSON library and MS XML library, so your mileage may vary:
### XML -> JSON
1. All data becomes string data (for example you will always get *"false"* not *false* or *"0"* not *0*) Obviously JavaScript treats these differently in certain cases.
2. Children elements can become nested-object `{}` OR nested-array `[ {} {} ...]` depending if there is only one or more than one XML child-element. You would consume these two differently in JavaScript, etc. Different examples of XML conforming to the same schema can produce actually different JSON structures this way. You can add the attribute [*json:Array='true'*](http://www.newtonsoft.com/json/help/html/ConvertXmlToJsonForceArray.htm) to your element to workaround this in some (but not necessarily all) cases.
3. Your XML must be *fairly* well-formed, I have noticed it doesn't need to perfectly conform to W3C standard, but 1. you must have a root element and 2. you cannot start element names with numbers are two of the enforced XML standards I have found when using Newtonsoft and MS libraries.
4. In older versions, Blank elements do not convert to JSON. They are ignored. A blank element does not become *"element":null*
A new update changes how null can be handled (Thanks to Jon Story for pointing it out): <https://www.newtonsoft.com/json/help/html/T_Newtonsoft_Json_NullValueHandling.htm>
### JSON -> XML
1. You need a top level object that will convert to a root XML element or the parser will fail.
2. Your object names cannot start with a number, as they cannot be converted to elements (XML is technically even more strict than this) but I can 'get away' with breaking some of the other element naming rules.
Please feel free to mention any other issues you have noticed, I have developed my own custom routines for preparing and cleaning the strings as I convert back and forth. Your situation may or may not call for prep/cleanup. As StaxMan mentions, your situation may actually require that you convert between objects...this could entail appropriate interfaces and a bunch of case statements/etc to handle the caveats I mention above. | How to convert JSON to XML or XML to JSON in C#? | [
"",
"c#",
"json",
"xml",
"json.net",
""
] |
I'm looking for an effective way to execute a method everyday at 3PM regardless of when the application was initially run or how long it has been running.
This must be done entirely from the application with no OS intervention (ex. Windows Task Scheduler)
I have been experimenting with java.util.Timer in varies configurations but I have had no success.
Any help would be appreciated.
Thanks. | You should take a look at [Quartz](http://www.quartz-scheduler.org/) which is a Java-based job scheduling system. | A built-in JDK way is to do what others suggested and first calculate :
* currentTime - desiredTime
Then you can use something like [a schedule executor](http://java.sun.com/javase/6/docs/api/java/util/concurrent/ScheduledExecutorService.html) to submit the tasks, and run them with a particular delay. This is far simpler than the options you have with frameworks like [Quartz](http://www.quartz-scheduler.org/), but doesn't require an external dependency.
Also, you should always list which JDK you're using, so people can provide solutions for your version of the JDK. | Java - Scheduling a daily task | [
"",
"java",
"scheduling",
"timer",
"task",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.