
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I'm using a static code block to initialize some controllers in a registry I have. My question is therefore, can I guarantee that this static code block will only absolutely be called once when the class is first loaded? I understand I cannot guarantee when this code block will be called, I'm guessing its when the Classloader first loads it. I realize I could synchronize on the class in the static code block, but my guess is this is actually what happens anyway?
Simple code example would be;
```
class FooRegistry {
static {
//this code must only ever be called once
addController(new FooControllerImpl());
}
private static void addController(IFooController controller) {
// ...
}
}
```
or should I do this;
```
class FooRegistry {
static {
synchronized(FooRegistry.class) {
addController(new FooControllerImpl());
}
}
private static void addController(IFooController controller) {
// ...
}
}
``` | Yes, Java static initializers are thread safe (use your first option).
However, if you want to ensure that the code is executed exactly once you need to make sure that the class is only loaded by a single class-loader. Static initialization is performed once per class-loader. | This is a trick you can use for lazy initialization
```
enum Singleton {
INSTANCE;
}
```
or for pre Java 5.0
```
class Singleton {
static class SingletonHolder {
static final Singleton INSTANCE = new Singleton();
}
public static Singleton instance() {
return SingletonHolder.INSTANCE;
}
}
```
As the static block in SingletonHolder will run once in a thread safe manner you don't need any other locking. The class SingletonHolder will only get loaded when you call instance() | Are Java static initializers thread safe? | [
"",
"java",
"multithreading",
"static",
"synchronization",
"static-initializer",
""
] |
Could I run the query:
```
Select id, (
select count(*) from tableA as a where a.value < a.id
)
from tableA as a where id < 5
```
and get the results I wanted. If not is there a way to do the same thing without having to do 2 querys? | ```
SELECT id, COUNT(id) FROM tableA a WHERE id < 5 GROUP BY id HAVING a.value < a.id
``` | try
```
Select a.id, mycount
from tableA as a
join
(select a1.id, count(*) as mycount from tableA as a1 where a.value < a.id) b
on a.id = b.id
where a.id < 5
``` | Can you do a count query inside another query and use the results? | [
"",
"sql",
"join",
"count",
""
] |
I am wondering why in C#
```
0 == 0 // return true
(object) 0 == (object) 0 // return false
```
To me it looks like it compares the reference instead of comparing the value of the cast.
This came to me because with Reflection I am getting the default value of ValueType which return an object and when I am comparing it to the current value of my object it returns that both are not the same but have the same value.
Using Equals or ToString work on ValueType object but not with ReferenceType which can be null and therefore do not allow Equals or ToString.
If someone could tell me how can I compare different object that can be of any type, null or with a value since object == object seems to be the wrong way to go. Am oblige to recast my objects into their original type in this case will the ReferenceType always different? | Yes, it's boxing both sides, and comparing the references. Every time you box you create a new object, so the references are different.
Comparing with the `Equals` method is the way to go, taking account of nullity. The easiest way is to use the static [`object.Equals(object, object)`](http://msdn.microsoft.com/en-us/library/w4hkze5k.aspx) method:
```
if (object.Equals(x, y))
{
...
}
``` | You're boxing, so the 'cast' actually does create a NEW object for each one. If you're comparing against your object you may have to write your own .Equals implementation. | (object) 0 == (object) 0 | [
"",
"c#",
""
] |
How do I display the content of a JavaScript object in a string format like when we `alert` a variable?
The same formatted way I want to display an object. | If you want to print the object for debugging purposes, use the code:
```
var obj = {
prop1: 'prop1Value',
prop2: 'prop2Value',
child: {
childProp1: 'childProp1Value',
},
}
console.log(obj)
```
will display:
[](https://i.stack.imgur.com/x0Tvz.png)
**Note:** you must *only* log the object. For example, this won't work:
```
console.log('My object : ' + obj)
```
**Note '**: You can also use a comma in the `log` method, then the first line of the output will be the string and after that, the object will be rendered:
```
console.log('My object: ', obj);
``` | Use native `JSON.stringify` method.
Works with nested objects and all major browsers [support](http://caniuse.com/#search=json) this method.
```
str = JSON.stringify(obj);
str = JSON.stringify(obj, null, 4); // (Optional) beautiful indented output.
console.log(str); // Logs output to dev tools console.
alert(str); // Displays output using window.alert()
```
Link to [Mozilla API Reference](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/JSON/stringify) and other examples.
```
obj = JSON.parse(str); // Reverses above operation (Just in case if needed.)
```
---
Use a custom [JSON.stringify replacer](https://stackoverflow.com/a/11616993/218857) if you
encounter this Javascript error
```
"Uncaught TypeError: Converting circular structure to JSON"
``` | How can I display a JavaScript object? | [
"",
"javascript",
"serialization",
"javascript-objects",
""
] |
By text formatting I meant something more complicated.
At first I began manually adding the 5000 lines from the text file I'm asking this question for,into my project.
The text file has 5000 lines with different length.For example:
```
1 1 ITEM_ETC_GOLD_01 골드(소) xxx xxx xxx_TT_DESC 0 0 3 3 5 0 180000 3 0 1 0 0 255 1 1 0 0 0 0 0 0 0 0 0 0 -1 0 -1 0 -1 0 -1 0 -1 0 0 0 0 0 0 0 100 0 0 0 xxx item\etc\drop_ch_money_small.bsr xxx xxx xxx 0 2 0 0 1 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 0 0 0 0 0 0 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1 표현할 골드의 양(param1이상) -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx 0 0
1 4 ITEM_ETC_HP_POTION_01 HP 회복 약초 xxx SN_ITEM_ETC_HP_POTION_01 SN_ITEM_ETC_HP_POTION_01_TT_DESC 0 0 3 3 1 1 180000 3 0 1 1 1 255 3 1 0 0 1 0 60 0 0 0 1 21 -1 0 -1 0 -1 0 -1 0 -1 0 0 0 0 0 0 0 100 0 0 0 xxx item\etc\drop_ch_bag.bsr item\etc\hp_potion_01.ddj xxx xxx 50 2 0 0 1 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 0 0 0 0 0 0 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 120 HP회복양 0 HP회복양(%) 0 MP회복양 0 MP회복양(%) -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx 0 0
1 5 ITEM_ETC_HP_POTION_02 HP 회복약 (소) xxx SN_ITEM_ETC_HP_POTION_02 SN_ITEM_ETC_HP_POTION_02_TT_DESC 0 0 3 3 1 1 180000 3 0 1 1 1 255 3 1 0 0 1 0 110 0 0 0 2 39 -1 0 -1 0 -1 0 -1 0 -1 0 0 0 0 0 0 0 100 0 0 0 xxx item\etc\drop_ch_bag.bsr item\etc\hp_potion_02.ddj xxx xxx 50 2 0 0 2 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 0 0 0 0 0 0 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 220 HP회복양 0 HP회복양(%) 0 MP회복양 0 MP회복양(%) -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx -1 xxx 0 0
```
The text between the first character(1) and the second character(1/4/5) is not a whitespace,it's a tab.There's no whitespaces in that text file.
What I want:
I want to get the second integer(In the three lines I posted above,the second integers are 1,4 and 5) and the string in the middle of each line indicating the path(It starts with "item\" and ends with the file extension ".ddj").
My problem:
When I google "Text formatting C#" - all I get is how to open a text file and how to write a text file in C#.I don't know how to search for text inside a text file.Also I can't search for the first integer,because in case its a small integer like in the three lines I posted above,I wont be able to find the corrent location,because for example "1" might exist in a different location.
My question:
It would be the best If I write a program that would delete anything,but what I need.
The other way in my mind is to directly search inside that file,but as I mentioned above - I might get the wrong location of the second integer if its too low.
Please suggest something,I can't format all this by hand. | OK, here's what we do: open the file, read it line by line, and split it by tabs. Then we grab the second integer and loop through the rest to find the path.
```
StreamReader reader = File.OpenText("filename.txt");
string line;
while ((line = reader.ReadLine()) != null)
{
string[] items = line.Split('\t');
int myInteger = int.Parse(items[1]); // Here's your integer.
// Now let's find the path.
string path = null;
foreach (string item in items)
{
if (item.StartsWith("item\\") && item.EndsWith(".ddj"))
path = item;
}
// At this point, `myInteger` and `path` contain the values we want
// for the current line. We can then store those values or print them,
// or anything else we like.
}
``` | Another solution, this time making use of regular expressions:
```
using System.Text.RegularExpressions;
...
Regex parts = new Regex(@"^\d+\t(\d+)\t.+?\t(item\\[^\t]+\.ddj)");
StreamReader reader = FileInfo.OpenText("filename.txt");
string line;
while ((line = reader.ReadLine()) != null) {
Match match = parts.Match(line);
if (match.Success) {
int number = int.Parse(match.Group(1).Value);
string path = match.Group(2).Value;
// At this point, `number` and `path` contain the values we want
// for the current line. We can then store those values or print them,
// or anything else we like.
}
}
```
That expression's a little complex, so here it is broken down:
```
^ Start of string
\d+ "\d" means "digit" - 0-9. The "+" means "one or more."
So this means "one or more digits."
\t This matches a tab.
(\d+) This also matches one or more digits. This time, though, we capture it
using brackets. This means we can access it using the Group method.
\t Another tab.
.+? "." means "anything." So "one or more of anything". In addition, it's lazy.
This is to stop it grabbing everything in sight - it'll only grab as much
as it needs to for the regex to work.
\t Another tab.
(item\\[^\t]+\.ddj)
Here's the meat. This matches: "item\<one or more of anything but a tab>.ddj"
``` | How to parse a text file with C# | [
"",
"c#",
"parsing",
"text",
""
] |
I want to add a variable list of parameters to a Struts2 URL tag. I have a map of the parameters (name value pairs) in an object in the session. I'm struggling to find a good approach to this. Here is the relevant JSP code:
```
<s:iterator value="%{#session['com.strutsschool.interceptors.breadcrumbs']}" status="status">
<s:if test="#status.index > 0">
»
</s:if>
<s:url id="uri" action="%{action}" namespace="%{nameSpace}">
<s:param name="parameters" value="%{parameters}"/>
</s:url>
<nobr><s:a href="%{uri}"><s:property value="displayName"/></s:a></nobr>
</s:iterator>
```
The parameters variable is a Map that contains the params. This, of course does not work but I cannot see a way to approach this at the moment. I'm thinking at the moment that I might need a custom freemarker template for this. Can anyone suggest a better way? | The Parameter tag populates parameters only to its direct antecessor. Wrappings an iterator tag around the parameter tag has no effect. :)
To solve this you can easily write an alternative parameter tag wich can use a map direclty
The tag may look like this.
```
package my.taglibs;
import java.io.Writer;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.struts2.components.Component;
import org.apache.struts2.views.jsp.ComponentTagSupport;
import com.opensymphony.xwork2.util.ValueStack;
public class ParamTag extends ComponentTagSupport {
private String map;
private static final long serialVersionUID = 2522878390854066408L;
Log log = LogFactory.getLog(ParamTag.class);
@Override
public Component getBean(ValueStack stack, HttpServletRequest req, HttpServletResponse res) {
return new Param(stack);
}
@Override
protected void populateParams() {
super.populateParams();
Param param = (Param) component;
param.setMap(map);
}
public void setMap(String map) {
this.map = map;
}
public class Param extends Component {
private String map;
public Param(ValueStack stack) {
super(stack);
}
@Override
public boolean end(Writer writer, String body) {
Component component = findAncestor(Component.class);
if (this.map == null) {
log.warn("Attribute map is mandatory.");
return super.end(writer, "");
}
Object o = findValue(this.map); //find map in vs
if(o == null) {
log.warn("map not found in ValueStack");
return super.end(writer, "");
}
if(!(o instanceof Map)) {
log.warn("Error in JSP. Attribute map must evaluate to java.util.Map. Found type: " + o.getClass().getName());
return super.end(writer, "");
}
component.addAllParameters((Map) o);
return super.end(writer, "");
}
public void setMap(String map) {
this.map = map;
}
}
}
```
And you need a corresponding tld-entry
```
<tag>
<description><![CDATA[Parametrize other tags]]></description>
<name>param</name>
<tag-class>my.taglibs.ParamTag</tag-class>
<body-content>JSP</body-content>
<attribute>
<name>map</name>
<required>true</required>
<rtexprvalue>true</rtexprvalue>
</attribute>
<dynamic-attributes>false</dynamic-attributes>
</tag>
``` | Maybe you can use JSTL tags like this
```
<c:url var="uri" value="${namespace}/${action}.action">
<c:forEach items="${parameters}" var="p">
<c:param name="${p.key}" value="${p.value}"/>
</c:forEach>
</c:url>
<a href="${uri}">Your Link</a>
```
I know there is some hesitation to mix EL with OGNL etc but this works... | Adding parameters from a map to a URL tag | [
"",
"java",
"url",
"struts2",
"tags",
"param",
""
] |
This is what I need to do-
I have this equation-
Ax = y
Where A is a rational m\*n matrix (m<=n), and x and y are vectors of
the right size. I know A and y, I don't know what x is equal to. I
also know that there is no x where Ax equals exactly y.
I want to find the vector x' such that Ax' is as close as possible to
y. Meaning that (Ax' - y) is as close as possible to (0,0,0,...0).
I know that I need to use either the lstsq function:
<http://www.scipy.org/doc/numpy_api_docs/numpy.linalg.linalg.html#lstsq>
or the svd function:
<http://www.scipy.org/doc/numpy_api_docs/numpy.linalg.linalg.html#svd>
I don't understand the documentation at all. Can someone please show
me how to use these functions to solve my problem.
Thanks a lot!!! | SVD is for the case of m < n, because you don't really have enough degrees of freedom.
The docs for lstsq don't look very helpful. I believe that's least square fitting, for the case where m > n.
If m < n, you'll want [SVD](http://web.mit.edu/be.400/www/SVD/Singular_Value_Decomposition.htm). | The [updated documentation](http://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.lstsq.html#numpy.linalg.lstsq) may be a bit more helpful... looks like you want
```
numpy.linalg.lstsq(A, y)
``` | numpy linear algebra basic help | [
"",
"python",
"numpy",
"scipy",
"linear-algebra",
"svd",
""
] |
I am trying to count the number of days of the current week that do not have an event associated with them, but I don't know how to do it.
For example, I count the number of events happening this week with this query:
```
SELECT COUNT(e.event_id) FROM cali_events e
LEFT JOIN cali_dates d
ON e.event_id = d.event_id
WHERE YEARWEEK(d.date) = YEARWEEK(CURRENT_DATE())
```
But I only know how to count the days by counting each individual day and summing up the days that return 0, but that's not very elegant.
How could I do it with one query? | This query uses a subquery to find all the unique dates in the joined tables. Then the number of unique dates is subtracted from seven?
```
--assuming a 7 day week; no mention in the request about workweek.
SELECT 7 - COUNT(*) AS NumDaysWithoutEvents
FROM
(SELECT DAY(d.date)
FROM cali_events e
LEFT JOIN cali_dates d
ON e.event_id = d.event_id
WHERE YEARWEEK(d.date) = YEARWEEK(CURRENT_DATE())
GROUP BY DAY(d.date)
) AS UniqueDates
``` | This might be a case for one of those 'value tables' where you create a table with possible days/weeks/whatever and then join for those that DON'T match & count them. | How can I count this when there are no rows? | [
"",
"sql",
"mysql",
""
] |
I'm developing a retained mode drawing application in GDI+. The application can draw simple shapes to a canvas and perform basic editing. The math that does this is optimized to the last byte and is not an issue. I'm drawing on a panel that is using the built-in Controlstyles.DoubleBuffer.
Now, my problem arises if I run my app maximized on a big monitor (HD in my case). If I try to draw a line from one corner of the (big) canvas to the diagonally opposite other, it will start to lag and the CPU goes high up.
Each graphical object in my app has a boundingbox. Thus, when I invalidate the boundingbox of a line that goes from one corner of the maximized app to the oposite diagonal one, that boundingbox is virtually as big as the canvas. When a user is drawing a line, this invalidation of the boundingbox thus happens on the mousemove event, and there is a clear lag visible. This lag also exists if the line is the only object on the canvas.
I've tried to optimize this in many ways. If I draw a shorter line, the CPU and the lag goes down. If I remove the Invalidate() and keep all other code, the app is quick. If I use a Region (that only spans the figure) to invalidate instead of the boundingbox, it is just as slow. If I split the boundingbox into a range of smaller boxes that lie back to back, thus reducing the invalidation area, no visible performance gain can be seen.
Thus I'm at a loss here. How can I speed up the invalidation?
On a side note, both Paint.Net and Mspaint suffers from the same shortcommings. Word and PowerPoint however, seem to be able to paint a line as described above with no lag and no CPU load at all. Thus it's possible to achieve the desired results, the question is how? | For basic display items like lines, you should consider breaking them up into a few parts if you absolutely must invalidate their entire bounds per drawing cycle.
The reason for this is that GDI+ (as well as GDI itself) invalidates areas in rectangular shapes, just as you specify with your bounding box. You can verify this for yourself by testing some horizontal and vertical lines versus lines where the slope is similar to the aspect of your display area.
So, let's say your canvas is 640x480. If you draw a line from 0,0 to 639,479; Invalidate() will invalidate the entire region from 0,0 to 639,0 at the top down to 0,479 to 639,479 at the bottom. A horizontal line from, say, 0,100 to 639,100 results in a rectangle only 1 pixel high.
Regions will have the very same problem because regions are treated as sets of horizontal extents grouped together. So for a large diagonal line going from one corner to the other, in order to match the bounding box you have setup- a region would have to specify either every set of pixels on each vertical line or the entire bounding box.
So as a solution, if you have a very large line, break it into quarters or eighths and performance should increase considerably. Revisting the example above, if you just divide in half for two parts- you will reduce the total invalidated area to 0,0 x 319,239 plus 320,240 x 639,479.
Here is a visual example of a quarter splits. The pink area is what is invalidated. Unfortunately SO won't let me post images or more than 1 link, but this should be enough to explain everything.
(Line Split in Quarters, Total Invalidated Area is 1/4 of the surface)
[a 640x480 extent with 4 equal sized boxes carved behind a line drawn across the diagonal](http://www.amorph.com/stack-overflow/quarter-boxen.gif)
Or, instead of specifying a bounding box, you may want to consider rewriting your updates so that you only draw the portions of items that match the region that must be updated. It really depends on how many objects need to participate in a drawn update. If you have thousands of objects in a given frame, you might consider just ignoring all the invalidated areas and just redraw the entire scene. | You can't really speed up Invalidate. The reason why it is slow is because it posts a WM\_PAINT event onto the message queue. That then gets filtered down and eventually your OnPaint even is called. What you need to do is paint directly in your control during the MouseMove event.
In any control I do that requires some measure of fluid animation my OnPaint event generally only calls a PaintMe function. That way I can use that function to redraw the control at anytime. | Winforms: How to speed up Invalidate()? | [
"",
"c#",
".net",
"winforms",
"gdi+",
"gdi",
""
] |
I have a requirement where I have to select around 60 million plus records from database. Once I have all records in ResultSet then I have to formate some columns as per the client requirement(date format and number format) and then I have to write all records in a file(secondary memory).
* Currently I am selecting records on day basis (7 selects for 7 days) from DB and putting them in a HashMap. Reading from HashMap and formating some columns and finally writing in a file(separate file for 7 days).
* Finally I am merging all 7 files in a single file.
* But this whole process is taking 6 hrs to complete. To improve this process I have created 7 threads for 7 days and all threads are writing separate files.
* Finally I am merging all 7 files in a single file. This process is taking 2 hours. But my program is going to OutOfMemory after 1 hour and so.
Please suggest the best design for this scenario, should I used some caching mechanism, if yes, then which one and how?
Note: Client doesn't want to change anything at Database like create indexes or stored procedures, they don't want to touch database.
Thanks in advance. | Do you need to have all the records in memory to format them? You could try and stream the records through a process and right to the file. If your able to even break the query up further you might be able to start processing the results, while your still retrieving them.
Depending on your DB backend they might have tools to help with this such as SSIS for Sql Server 2005+.
**Edit**
I'm a .net developer so let me suggest what I would do in .net and hopefully you can convert into comparable technologies on the java side.
ADO.Net has a DataReader which is a forward only, read only (Firehose) cursor of a resultset. It returns data as the query is executing. This is very important. Essentially, my logic would be:
```
IDataReader reader=GetTheDataReader(dayOfWeek);
while (reader.Read())
{
file.Write(formatRow(reader));
}
```
Since this is executing while we are returning rows your not going to block on the network access which I am guessing is a huge bottleneck for you. The key here is we are not storing any of this in memory for long, as we cycle the reader will discard the results, and the file will write the row to disk. | I think what Josh is suggesting is this:
You have loops, where you currently go through all the result records of your query (just using pseudo code here):
```
while (rec = getNextRec() )
{
put in hash ...
}
for each rec in (hash)
{
format and save back in hash ...
}
for each rec in (hash)
{
write to a file ...
}
instead, do it like this:
while (rec = getNextRec() )
{
format fields ...
write to the file ...
}
```
then you never have more than 1 record in memory at a time ... and you can process an unlimited number of records. | Best Design for the scenario | [
"",
"java",
"database",
"performance",
"hashmap",
""
] |
I have a blog aggregation website
the stories are ordered by the number of visits
I think I am facing a spam of visits
because some blogs' stories receive a lot of visits in the same second with efferent ip address
my website does not allow visits from the same ip; however, my visitors somehow changing their ips.
is their any solution to detect this spam visits?, I wonder how Google adSense solves such a problem?
Thanks | The short answer is that it's impossible to stop a determined attacker if a single unverified visit is the only thing required to alter the order of your story.
You may want to think about implementing a registered user voting system.
However, You can collect several pieces of information and combine all of them:
1) User Agent
2) IP Address
3) X-Forwarded-For header (if available)
Often times attackers will be lazy and not cycle through different user agents. If you setup your system to process visit information at a certain interval (and not in real-time), you could potentially filter out large collections of visits occuring at the same time with the same exact user agent.
You could always download databases of proxies from websites such as antiproxy.com, but the truth is that most well planned attacks today come from botnet nodes which have yet to be documented. It is fully possible for your website to be targeted by an attack with heterogeneous traffic which is indistinguishable from normal visitors.
At the very least, I would suggest changing your implementation so that users can vote on stories and require a captcha. | With PHP you can check the $\_SERVER ["HTTP\_X\_FORWARDED\_FOR"] variable against the IP adress for a little more assurance that the client is who he says he is. This will help identify people through some proxies. | How to make sure about the ip of the visitor? | [
"",
"php",
"security",
"ip",
"spam-prevention",
"spam",
""
] |
Do you know any ways to run a C# project under Linux. Are there any framewoks or libraries for this? | You're looking for the [Mono Project](http://www.mono-project.com/Main_Page) - a cross-platform (but primarily targeted at Linux) implementation of the .NET Framework and CLR. It's capable of running binaries compiled for the CLR (MS .NET), or of creating its own native Linux binaries.
The project has been going a while now, and it's current version (2.4) is very usable, even for [production purposes](http://mono-project.com/Companies_Using_Mono). See the [project roadmap](http://www.mono-project.com/Roadmap) for details of the main features and milestones of current and future releases.
**Details about the current state:**
The great majority of the BCL (Base Class Library) is available on Mono, with the exception of some of the .NET 3.0/3.5 stuff, such as WPF (which has minimal support currently) and WCF (almost non-existent support). Silverlight 2.0 is however being supported via the [Moonlight](http://www.mono-project.com/Moonlight) project, and progress on that is going well. WinForms functionality (which uses GTK# as a backend) is however quite complete, as far as I know.
Implementation of the C# 3.0 language is effectively complete, including the C# 3.0 features such as *lambda expressions*, *LINQ*, and *automatic properties*. I believe the [C# compiler](http://www.mono-project.com/CSharp_Compiler) is mature to the point that its efficiency is at least comparable with that of the MS compiler, though not yet matching it in some respects. What's quite cool (and unique) about the Mono C# compiler is that is now offers a *compiler service* - in other words true dynamic compilation from code (without using the CodeDOM). This is something that MS will perhaps only add in .NET 5.0. | Like others have already said, you can run .NET applications on Mono. If your applications use Platform Invocation (P/Invoke) to call native code, you may run into some trouble if there is no Mono implementation of the native library. To check whether your application does that (or uses APIs that haven't been implemented in Mono yet), you can use the [Mono Migration Analyzer (MoMA)](http://www.mono-project.com/MoMA). | How to run C# project under Linux | [
"",
"c#",
".net",
"linux",
""
] |
Just curious. | This [blog post](http://dotnetdud.wordpress.com/2007/12/25/immediate-and-command-window-in-visual-studio/) offers a pretty decent overview of the users of the two windows. Quote from that page:
> The **Command window** is used to execute
> commands or aliases directly in the
> Visual Studio integrated development
> environment (IDE). You can execute
> both menu commands and commands that
> do not appear on any menu. To display
> the Command window, choose Other
> Windows from the View menu, and select
> Command Window
>
> The **Immediate window** is used to debug
> and evaluate expressions, execute
> statements, print variable values, and
> so forth. It allows you to enter
> expressions to be evaluated or
> executed by the development language
> during debugging. To display the
> Immediate window, open a project for
> editing, then choose Windows from the
> Debug menu and select Immediate.
It also includes a seemingly very complete list of commands and aliases that you can execute (for VS 2005 at least) - from either window, as far as I understand. Once of the nice features is that you can switch between the two windows simply by executing the `cmd` and `immed` commands.
In addition, see also the MSDN pages on the [Command Window](http://msdn.microsoft.com/en-us/library/c785s0kz.aspx) and the [Immediate Window](http://msdn.microsoft.com/en-us/library/f177hahy.aspx). | One difference between the two is that the Command Window will accept commands at any time (Visual Studio Commands) whereas the Immediate Window (Evaluations) only accepts commands during a debugging session. | What's the practical difference between the Command Window and the Immediate Window? | [
"",
"c#",
"visual-studio-2008",
""
] |
I am trying to use the various techniques with dynamic png images i.e. images added after the page has been loaded using javascript DOM.
All of the techniques I tried seem to fail. Is there a reliable technqiue for the same?
Thank you very much for your time. | I've used [this fix from TwinHelix](http://www.twinhelix.com/css/iepngfix/) on pretty complex websites with great success :)
One caveat through (this applies to all "fixes" i believe) is that you can not make a background image of an element be transparent. | <http://allinthehead.com/retro/338/supersleight-jquery-plugin>
Better yet, don't waste your time developing for IE6. I know this makes me flamebait, but the more new sites that work poorly on IE6, the more pressure we put on people to move on to at least IE7. The amount of hacking you will have to do around IE6 to make a *great* many things is something you really need to sit down and strongly consider. | IE6 transparency problem for dynamic images | [
"",
"javascript",
"internet-explorer-6",
"png",
""
] |
Helo
Can anybody explain me how to get configuration element from .config file.
I know how to handle attributes but not elements. As example, I want to parse following:
```
<MySection enabled="true">
<header><![CDATA[ <div> .... </div> ]]></header>
<title> .... </title>
</MySection>
```
My c# code looks like this so far:
```
public class MyConfiguration : ConfigurationSection
{
[ConfigurationProperty("enabled", DefaultValue = "true")]
public bool Enabled
{
get { return this["enabled"].ToString().ToLower() == "true" ? true : false; }
}
[ConfigurationProperty("header")]
public string header
{
???
}
}
```
It works with attributes, how do I do with elements (header property in above code) ? | I finally found one way to do it.
There is IConfigurationSectionHandler interface that allows for things I want. It requires the one to write the method
```
public object Create(object parent, object configContext, XmlNode section)
```
After it, u parse *section* on your own so I was able to fetch XmlElement's without a problem:
```
header = s["header"] != null ? s["header"].InnerText : String.Empty;
title = s["title"] != null ? s["title"].InnerText : String.Empty;
```
The down side of this is that interface is outdated but MSDN states that it will not be removed from future versions of the frameworks as it is used internally. | There is another approach for doing the same thing.
We could create an element by overriding `DeserializeElement` method to get string value:
```
public class EmailTextElement : ConfigurationElement {
public string Value { get; private set; }
protected override void DeserializeElement(XmlReader reader, bool s) {
Value = reader.ReadElementContentAs(typeof(string), null) as string;
}
}
``` | How to get configuration element | [
"",
"c#",
"configuration",
"web-config",
"app-config",
""
] |
I have the following situation:
If have a MySQL db with a InnoDB table which I use to store unique numbers.
I start a transaction, read the value (eg. 1000471), store this value in another table and update the incremented value (100472). Now I want to avoid that somebody else even reads the value while my transaction is running.
If I would use plain MySQL I would do something like this:
Exceute("LOCK tbl1 READ");
Execute("SELECT ... from tbl1");
Execute("INSERT into tbl2");
Execute("UNLOCK TABLES");
but since I am using SubSonic as a DAL and the code should be independent from mysql, I have to use the TransactionScope.
My code:
```
TransactionOptions TransOpt = new TransactionOptions();
TransOpt.IsolationLevel = System.Transactions.IsolationLevel.ReadCommitted;
TransOpt.Timeout = new TimeSpan(0, 2, 0);
using (TransactionScope ts = new TransactionScope(TransactionScopeOption.RequiresNew, TransOpt))
{
// Select Row from tbl1
// Do something
ts.Complete();
}
```
According to the help of TransactionOptions
[system.transactions.isolationlevel](http://msdn.microsoft.com/en-us/library/system.transactions.isolationlevel(VS.85).aspx)
The effect I want to reach could be implemented with IsolationLevel.ReadCommitted, but I can still read the row from outside the transaction (If I try to change it, I get a lock, so the transaction is working)
Does anybody has a suggestion? Is a read lock even possible with TransactionScope | Ok, I decided to use the "backdoor" and now use a inline query:
```
// start transaction
using (TransactionScope ts = new TransactionScope(TransactionScopeOption.RequiresNew))
{
using (SharedDbConnectionScope scope = new SharedDbConnectionScope(DB._provider))
{
try
{
Record r = new InlineQuery().ExecuteAsCollection<RecordCollection>(
String.Format("SELECT * FROM {0} WHERE {1} = ?param FOR UPDATE",
Record.Schema.TableName,
Record.Columns.Column1), "VALUE")[0];
// do something
r.Save();
}
}
}
```
I started 10 threads simultaniously and it works as expected. Thx to rudolfson for the "SELECT FOR UPDATE" hint. | If anyone is interested, this is how TransactionOptions affect MySql:
Lets say I have two methods.
Method1 starts a transaction, selects a row from my table, increments the value and updates the table.
Method2 is the same, but between select and update I added a sleep of 1000ms.
Now imagine I have the following code:
```
Private Sub Button1_Click(sender as Object, e as System.EventArgs) Handles Button1.Click
Dim thread1 As New Threading.Thread(AddressOf Method1)
Dim thread2 As New Threading.Thread(AddressOf Method2)
thread2.Start() // I start thread 2 first, because this one sleeps
thread1.Start()
End Sub
```
Without transactions this would happen:
thread2 starts, reads the value 5, then sleeps,
thread1 starts, reads the value 5, updates the value to 6,
thread2 updates the value to 6, too.
Effect: I have the unique number two times.
What I want:
thread2 starts, reads the value 5, then sleeps,
thread1 starts, trys to reads the value, but get a lock and sleeps,
thread2 updates the value to 6,
thread1 continues, reads the value 6, updates the value to 7
That's how to start transaction with the TransactionScope:
```
TransactionOptions Opts = new TransactionOptions();
Opts.IsolationLevel = IsolationLevel.ReadUncommitted;
// start Transaction
using (TransactionScope ts = new TransactionScope(TransactionScopeOption.RequiresNew, Opts))
{
// Do your work and call complete
ts.Complete();
}
```
That can even manage distributed transactions. If an Exception is thrown ts.Complete is never called and the Dispose() Part of the Scope rolls back the transaction.
Here's an overview how the different IsolationLevels affect the transaction:
* **IsolationLevel.Chaos**
Throws a NotSupportedException - Chaos isolation level is not supported
* **IsolationLevel.ReadCommited**
The transactions do not interfere each other (two identical reads, bad)
* **IsolationLevel.ReadUncommitted**
The transactions do not interfere each other (two identical reads, bad)
* **IsolationLevel.RepeatableRead**
The transactions do not interfere each other (two identical reads, bad)
* **IsolationLevel.Serializable**
Throws a MySqlException - Deadlock found when trying to get lock; try restarting transaction during Update
* **IsolationLevel.Snapshot**
Throws a MySqlException - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '' at line 1 during Connection.Open()
* **IsolationLevel.Unspecified**
Throws a MySqlException - Deadlock found when trying to get lock; try restarting transaction during Update
* **TransactionOptions not set**
Throws a MySqlException - Deadlock found when trying to get lock; try restarting transaction during Update | Using TransactionScope with MySQL and Read Lock | [
"",
"c#",
"mysql",
"subsonic",
"transactions",
"transactionscope",
""
] |
I have a class called ItemBase from which a number of classes inherit.
In this class I have a number of **one-line methods** which simply return a string or object and are available to all the inheriting classes. I use these quite a bit in inherited classes to make code more readable and so that I always have one and only one place that defines each calculation or piece of information.
**I used Getters like I do in PHP and Java** since this is the way I have always done it:
```
public class ItemBase
{
protected string GetApplicationPath()
{
return System.IO.Path.GetDirectoryName(System.Reflection.Assembly.GetExecutingAssembly().CodeBase);
}
protected string GetApplicationDataPath()
{
return GetApplicationPath() + @"..\..\..\TestServices\";
}
}
```
However, I've noticed that **Getters and Setters aren't really used in C#** as they are in Java or PHP and and I suspect that there is a better, more succinct/standard way to do this in C#.
But I don't want to use **class variables** since it doesn't seem right to define logic in the a class variable initializer, I assume that even though possible for some calculations it is probably frowned upon and causes problems in some cases:
```
protected string _applicationPath = System.IO.Path.GetDirectoryName(System.Reflection.Assembly.GetExecutingAssembly().CodeBase);
```
I stay away from **public fields** after reading about disadvantages you have with them down the road in [Jon Skeet's article](http://csharpindepth.com/Articles/Chapter8/PropertiesMatter.aspx). Plus this is too much code for just a simple definition.
```
protected string ApplicationPath
{
get
{
return System.IO.Path.GetDirectoryName(System.Reflection.Assembly.GetExecutingAssembly().CodeBase);
}
}
```
I could use C#'s **abbreviated properties** but then each little piece of information has code in two places and the name is used twice, just doesn't seem like a succinct solution.
```
protected string ApplicationPath { get; set; }
public ItemBase()
{
ApplicationPath = System.IO.Path.GetDirectoryName(System.Reflection.Assembly.GetExecutingAssembly().CodeBase);
}
```
So I've settled on **using these Getters just like I do in PHP and Java**, although this doesn't seem to be a very C# way to go about it.
**What conventions do you use in C#** for storing these "one-line class variables" that just hold a piece of information or do a little calculation?
# ANSWER:
```
protected string ApplicationPath
{
get { return System.IO.Path.GetDirectoryName(System.Reflection.Assembly.GetExecutingAssembly().CodeBase); }
}
protected string ApplicationDataPath
{
get { return ApplicationPath + @"..\..\..\TestServices\"; }
}
``` | "I could use C#'s abbreviated properties but then each little piece of information has code in two places and the name is used twice, just doesn't seem like a succinct solution"
What do you mean by that? Properties are just syntactic sugar for the getters / setter methods you would normally do in Java. Where do you see code in two places?
```
public string MyProp
{
get{return "MyProp";}
}
``` | > What conventions do you use in C# for storing these "one-line class variables" that just hold a piece of information or do a little calculation?
After your description: use read-only properties. This is *the* way to do it in C#, and in most cases it really is the only reasonable alternative. As you've said yourself:
> I've noticed that Getters and Setters aren't really used in C# as they are in Java or PHP
Yes, and the reason is simple: .NET's properties offer a special syntactic sugar to express getters and setters. In a way, the latter are just a workaround to compensate for the absence of the former.
Some cases where you might *not* want to use properties:
* Compile-time constants that are guaranteed to never, ever, change: use public constants (`const`) for these:
```
public const string Uuid = "D4D5DF8E-51DD-11DE-825A-1A5C55D89593";
```
* Cases where you want to make it clear for the consumer that the operation is (potentially) time-consuming and/or not free of side-effects: use a `Get`-prefixed method. However, in the case of side-effects it would probably be better to let the method name reflect that, too. | What is the best way to define semi-constant class variables in C#? | [
"",
"c#",
"naming-conventions",
""
] |
I am wondering what would be the best/preferred way to write a scanning app that lives in a web browser. The basic idea is I want to use a web page from where I can click a button which will scan a document on the client and upload that document to server. The first thought that came to mind is write a native (C++?) browser plug-in. However, I don't know what is required for a native plug-in to be cross-browsers. So here are few questions:
1. Is Silverlight a viable option? This is what I would prefer since all my code is C#, ASP.NET. The question is - can Silverlight talk to Windows Image Acquisition COM on the client?
2. Write something in flash, may be using Flex? Is this a viable option? Can it talk to WIA COM on the client?
3. And finally, if the answer is writing it in C++ then what are some of the high-level gotchas to make it cross-browser?
4. What else is out there? | Check out this:
<http://code.msdn.microsoft.com/silverlightwia> | Silverlight runs in a sandbox and cannot access any resources on a local machine (except isolated storage). It cannot access COM objects, It cannot access local hardware.
The option you may consider is to install little service on a client machine that will communicate with WIA and have SL talk with this service using ports. | WIA through web browser - ASP.NET | [
"",
"c#",
"asp.net",
"flash",
"silverlight",
"wia",
""
] |
I want to change sender PAGE URL to anything in my website.
For example I have a webpage named "DEFAULT.ASPX" thats got a Form tag action="http://otherpage.aspx". When I submit the form it's sending my values that are in the form to otherpage.aspx. This page is getting them and does its work.
But otherpage.aspx is looking for sender page url and see in there! Its DEFAULT.ASPX (my page thats got form in it ) . I want to change my page url thats got form to "YOUCANTSEEMYREALPAGENAME.ASPX" ..
WHY I NEED THIS...
There is a site that I want to link to. I have linked but if my URL is not "yrmypage.aspx" it's not working properly. So I need to hide my real page url and change it to yrmypage.aspx :) | The referrer is set by the browser. You cannot change it unless you are making the request from the server, yourself (in which case, you are essentially "the browser"). | Ibrahim, I'm not entirely familiar with this but I know that if you use Server.Transfer it would keep your URL as "Default.Aspx" I understand you are submitting and not redirecting but if you could somehow redirect instead it would look like this.
```
Server.Transfer("URL to go to",True)
```
This would redirect to the URL you need to go to but the URL would remain as Default.aspx.
It's the closest thing I can think of. Hope it helps sorry if it doesn't | Change Sender URL in ASP.NET | [
"",
"c#",
"asp.net",
""
] |
I am building my first wordpress theme and was hoping that when the user made a new category, there was a way of automatically generating a thumbnail for it from the first image uploaded as a post to this category (it is a portfolio theme).
Does anyone know how this might be coded?
It cannot rely on hard coding as the user does not know how to do this and I cannot do it for every category they make.
Any pointers for code or even plug-ins would be grerat. | Hook onto [an appropriate action](http://codex.wordpress.org/Plugin_API/Action_Reference) such as `publish_post` so that, when a new post is created and sent out to the world, you scour the HTML for image tags. If the post's category does not already have a thumbnail associated, use an image from this post to create a thumbnail and associate it with the category. If you only want this to occur for new categories and not existing categories, track which categories were already present when the plugin was installed.
You could use WordPress' existing media infrastructure to store the thumbnail and the `wp_postmeta` table to track your category-thumbnail associations. PHP comes with a library for image manipulation, and HTML scouring would be done with string manipulation. | It doesn't auto-create an icon based on the first post, but this is a "category icon" plugin which would enable your users to specify an icon for each category through a page in the control panel. It isn't *fully* automated in that users can't upload images directly through its admin page, but they could upload to the media library and then reference the URL.
Note that on the WP plugin page this plugin is listed as compatible up to 2.6.1 but if you search the compatibility list for 2.7 it's on there as working, and indeed I have it working on my 2.7.1 site.
<http://wordpress.org/extend/plugins/category-icons/>
Compatibility list: <http://codex.wordpress.org/Plugins/Plugin_Compatibility/2.7>
Hope this helps!
M | Assign thumbnail to new wordpress category | [
"",
"php",
"wordpress",
"wordpress-theming",
""
] |
I have an Address class in C# that looks like this:
```
public class Address
{
public string StreetAddress { get; set; }
public string RuralRoute { get; set; }
public string City { get; set; }
public string Province { get; set; }
public string Country { get; set; }
public string PostalCode { get; set; }
}
```
I'm implementing equality and so I need to override the hash code. At first I was going to use the hashcode formula from EJ but then I thought: These are all string fields, can't I just just use a StringBuilder to concatenate them and return the hash code from that string?
That is:
```
var str = new StringBuilder();
str.Append(StreetAddress)
.Append(RuralRoute)
...
return str.ToString().GetHashCode();
```
What are the advantages/disadvantages of this? Why shouldn't I do it? | I would avoid doing that simply on the grounds that it creates a bunch of strings pointlessly - although Kosi2801's point about making collisions simple is also relevant. (I suspect it wouldn't *actually* create many collisions, due to the nature of the fields, but...)
I would go for the "simple and easy to get right" algorithm I've previously [used in this answer](https://stackoverflow.com/questions/263400/what-is-the-best-algorithm-for-an-overridden-systemobjectgethashcode) (thanks for looking it up lance :) - and which is listed in Effective Java, as you said. In this case it would end up as:
```
public int GetHashCode()
{
int hash = 17;
// Suitable nullity checks etc, of course :)
hash = hash * 23 + StreetAddress.GetHashCode();
hash = hash * 23 + RuralRoute.GetHashCode();
hash = hash * 23 + City.GetHashCode();
hash = hash * 23 + Province.GetHashCode();
hash = hash * 23 + Country.GetHashCode();
hash = hash * 23 + PostalCode.GetHashCode();
return hash;
}
```
That's not null-safe, of course. If you're using C# 3 you might want to consider an extension method:
```
public static int GetNullSafeHashCode<T>(this T value) where T : class
{
return value == null ? 1 : value.GetHashCode();
}
```
Then you can use:
```
public int GetHashCode()
{
int hash = 17;
// Suitable nullity checks etc, of course :)
hash = hash * 23 + StreetAddress.GetNullSafeHashCode();
hash = hash * 23 + RuralRoute.GetNullSafeHashCode();
hash = hash * 23 + City.GetNullSafeHashCode();
hash = hash * 23 + Province.GetNullSafeHashCode();
hash = hash * 23 + Country.GetNullSafeHashCode();
hash = hash * 23 + PostalCode.GetNullSafeHashCode();
return hash;
}
```
You *could* create a parameter array method utility to make this even simpler:
```
public static int GetHashCode(params object[] values)
{
int hash = 17;
foreach (object value in values)
{
hash = hash * 23 + value.GetNullSafeHashCode();
}
return hash;
}
```
and call it with:
```
public int GetHashCode()
{
return HashHelpers.GetHashCode(StreetAddress, RuralRoute, City,
Province, Country, PostalCode);
}
```
In most types there are primitives involved, so that would perform boxing somewhat unnecessarily, but in this case you'd only have references. Of course, you'd end up creating an array unnecessarily, but you know what they say about premature optimization... | Don't do that because the objects can be different altough the hashcode is the same.
Think of
```
"StreetAddress" + "RuralRoute" + "City"
```
vs
```
"Street" + "AddressRural" + "RouteCity"
```
Both will have the same hashcode but different content in the fields. | Should I use a concatenation of my string fields as a hash code? | [
"",
"c#",
"string",
"hashcode",
"equality",
"iequatable",
""
] |
* Name of the file from where code is running
* Name of the class from where code is running
* Name of the method (attribute of the class) where code is running | Here is an example of each:
```
from inspect import stack
class Foo:
def __init__(self):
print __file__
print self.__class__.__name__
print stack()[0][3]
f = Foo()
``` | ```
import sys
class A:
def __init__(self):
print __file__
print self.__class__.__name__
print sys._getframe().f_code.co_name
a = A()
``` | How do I get the current file, current class, and current method with Python? | [
"",
"python",
"filenames",
""
] |
So I'm wiring up my first MasterPage, and everything is working great except for one thing. This is a legacy app, and I have an old BasePage class that all my content pages inherit. It inherits from System.Web.UI.Page, but has no content itself (no .aspx file). It runs a bunch of the user authentication/role granting menu building. I want to keep this functionality but use it to set controls on my MasterPage to build out the menus. I cannot for the life of me figure out how to reference the MasterPage properties without a MasterType declaration in a content page.
My MasterPage class is called NIMS\_Master, and I have the following in it (just trying to get started):
`public partial class NIMS_Master : System.Web.UI.MasterPage
{
public string MenuList { get; set; }`
```
protected void Page_Load(object sender, EventArgs e)
{}
}
```
With a MasterType declaration in one of my content pages:
`<%@ MasterType VirtualPath="~/NIMS_Master.master" %>`
I can access my property in Login.aspx.cs as follows:
`this.Master.MenuList = "this is the menu list";`
But in my BasePage.cs, I have nowhere to put the MasterType declaration. All the google searches indicate I have to cast my NIMS\_Master class as a Master, but I cannot get it to work to save my life. I've tried several different things, but my NIMS\_Master class just doesn't show up in BasePage.
`((this.Master)NIMS_Master).MenuList = "This is a menu list";`
BasePage.cs is in my App\_Code directory and my MasterPage file is in the application root, if that matters. | So I had my BasePage in App\_Code and was trying to set a property of my NIMS\_Master class which was in the application root directory. I had to create a MasterBase class that inherits from System.Web.UI.MasterPage in App\_Code and put my properties there. Sheesh, I'm not even sure why I thought I could access those class properties from within app\_code. | As I see it, your cast should be: ((NIMS\_Master)this.Master).MenuList | Accessing a Property of a Master Page from a class that's not part of a content page in ASP.NET | [
"",
"c#",
"asp.net",
"master-pages",
""
] |
Do you know how to check whether the mouse is over an element?
Somethnig like this?
```
setTimeout(function() {
if($(this).mouseover()) { // this not work
return false;
} else {
$(this).hide();
}
}, 1000);
```
Thanks. | You could use something like this:
```
var isMouseOver = false;
$(myitem).hover(function() {isMouseOver = true;},
function() {isMouseOver = false;});
``` | I'm assuming you're operating within a closure where 'this' represents a single element:
```
var mouseovered = false,
myElem = this;
$(myElem)
.mouseover(function(){
mouseovered = true;
})
.mouseout(function(){
mouseovered = false;
});
setTimeout(function() {
if(mouseovered) {
return false;
} else {
$(myElem).hide();
}
}, 1000);
```
---
Notice that I'm using "myElem" instead of the "this" keyword, which, in the context of the setTimeout callback will be a reference to the Window object - obviously not what you want. | How to verify that the mouse over an element? | [
"",
"javascript",
"jquery",
""
] |
The problem is that I need a little extra functionality to an object of a class that I can’t change (I’m trying to add data binding support).
The best solution that I can think of is to just write a derived class with this functionality. So I can use objects of this class instate. So now the problem is, how do I initialize the objects of the new class? I could make a constructor with the original object as a parameter and initialize the derived object with the values of this object, but to me this seems not to be the smartest solution.
It would be nice if I could do something like:
```
// MyDerivedClass is derived from ObjectOfAnUnchangeableClass.
MyDerivedClass Obj = ObjectOfAnUnchangeableClass as MyDerivedClass;
```
Of cause this would not work because the ObjectOfAnUnchangeableClass does not know of MyDerivedClass. Another idea would be to have a constructor that could be “initialized” with an object. Something like:
```
public MyDerivedClass(UnchangeableClass obj): base(obj){}
```
Here the idea would be that instead of having the base constructor build a new object; it could just take the existing object.
So I have two questions:
1. Is there some concept in .net the supports something like mentioned above?
2. What would be the best solution to have some extra functionality in a class that can’t be changed? | You have just about answered this yourself - the 'standard' way to do this is to take an instance of the base class in the constructor of your derived class. It's an example of the [decorator pattern](http://en.wikipedia.org/wiki/Decorator_pattern)
From the wikipedia page
> In object-oriented programming, the
> decorator pattern is a design pattern
> that allows new/additional behaviour
> to be added to an existing class
> dynamically. | I think [Duck Typing](http://haacked.com/archive/2007/08/19/why-duck-typing-matters-to-c-developers.aspx) could potentially help you. This will basically allow you to "cast" between classes that aren't related with inheritance, but are related in the way their fields look. It looks like they now use a dynamic proxy class to do the translation between the types. I am not exactly sure how this works under the covers, but I am going to find out.
The syntax would be something like this
```
MyDerivedClass Obj =
DuckTyping.Cast<MyDerivedClass>(ObjectOfAnUnchangeableClass);
```
Essentially it will copy all the fields from **ObjectOfAnUnchangeableClass** to **MyDerivedClass** which have the same name. You can archive the same behavior with the method you described, but if you don't like that, give [this library](http://www.deftflux.net/blog/page/Duck-Typing-Project.aspx) a go. | Is it possible to "cast" an object to a more specialized object? | [
"",
"c#",
".net",
"inheritance",
""
] |
I am programming a simple C# console application.
The spec is:
A game consists of ten frames, which start with a full rack of ten pins. In each frame, you have two deliveries of your ball, in which to knock down as many of the ten pins as you can. If you knock down all the pins on your first ball, it is called a strike. The score doesn't get added on straight away because for a strike you get the values of your next two balls as a bonus. For example, if you score a strike in the first frame, then a 7 and 1 in the second frame, you would score 18 (10+7+1) for the first frame, and 8 for the second frame, making a total of 26 after two frames. If you knock down some of the pins on the first ball, and knock down the remainder of the pins in the second ball, it is known as a spare. Again, the score doesn't get added on straight away because for a spare, you get the values of your next ball as a bonus. For example, if you score a spare in the first frame, say a 6 and a 4, then got an 8 and a 1 in the second frame, you would score 18 (6+4+8) for the first frame, and 9 for the second frame, making a total of 27 after two frames.
I understand how to write the code etc. etc.
However, I just cannot get my head around the best way of doing this scoring system and I need some advice.
Obviously a new object will be created for each player, however I am not sure of how to get round what seemed like a simple programming problem initially.
Any help would be greatly appreciated.
Regards | In bowling, strikes and spares are called "marks." Use this!
```
enum Marks { Open, Spare, Strike };
```
This way, you can determine what type of mark you have per frame. After a ball is thrown, check the last two frames, and update their scores. Then add up the scores.
Another note: If you're showing frame-by-frame scoring, do not show the frame score in a string of strikes (e.g.-four strikes in a row should not result in "30" being shown in frame 1). Wait for a spare or open to display the totals. It's improper scoring to do anything different, and it bugs the hell out of me when video games don't recognize that. | Well, if you want a real in-depth discussion that deals with OOP and TDD for a bowling game, I would suggest reading this entire article:
<http://www.objectmentor.com/resources/articles/xpepisode.htm>
Otherwise, you can just scroll to the bottom and see how they implemented it. | C# Console App - OO Math/Thought Problem | [
"",
"c#",
"console-application",
""
] |
Say for instance I have a table which has names of people and their ages. I want a generic query in MySQL which will pull out the n oldest people.
I could use something like this:
```
SELECT * FROM people ORDER BY age DESC LIMIT 1;
```
Say Frank and Emily are both 99 years old. The `limit 1` will only return one of their names. In psuedo-sql I would want the query to look like this:
```
SELECT * FROM people WHERE MAX(age);
```
I know you can also do this with a subquery, but there must be an easier, more generic way of achieving this? | Nope, subquery is it. For example, everyone with the top 3 ages:
```
SELECT * FROM people WHERE age IN (SELECT DISTINCT age FROM people ORDER BY age DESC LIMIT 3)
```
or just the top age:
```
SELECT * FROM people WHERE age = (SELECT MAX(age) FROM people)
``` | > I know you can also do this with a subquery, but there must be an easier, more generic way of achieving this?
Not in ANSI SQL.
```
SELECT * FROM people WHERE age =
(select MAX(age) from people);
``` | Generic way in MySQL to get the top results | [
"",
"sql",
"mysql",
""
] |
I have been coding using Visual Studio 2005, in VB.NET for a while. No problems.
Recently, I decided I wanted to start a New C# project. Upon attempting to do this, I noticed Visual Studio 2005 was missing this functionality entirely!
This is exactly what I get on my screen:
[](https://i.stack.imgur.com/1GAS6.png)
(source: [googlepages.com](http://jongallant.googlepages.com/Untitled-1.png))
Also note that I have both Visual Studio 2003 and 2005 installed on the same machine. Visual Studio 2003 has the C# templates available.
Any idea what I can do to solve this issue, without a re-install? | I think you did not include C# durting the time of installation? Restart the installation and add C# to it. | This might seem like a dumb question, but did you ever create a C# project with that version? In other words, did you install the C# personality? Because, you know, C# is not fundamental to Visual Studio ;)
You don't need to reinstall. If you are sure C# should be installed, just try Repair. If you didn't install it before, you can modify the installation. Takes much less time than a complete re-install. | C# Project Type not present in Visual Studio 2005 | [
"",
"c#",
"templates",
"visual-studio-2005",
""
] |
I am looking for a way to sort my xml data with javascript, and want to eventually filter out the data as well. I know all this is possible in the xsl file but i would like to do it client side.
I have searched multiple places for sorting with javascript but most of it was either too xml file specific or I couldn't figure out what was going on.
Would really appreciate any advice | The first part of this is performing the transformation in javascript:
```
function transformXML(_xml, _xsl) {
var
xml = typeof _xml == 'string'
? new DOMParser().parseFromString(_xml, 'text/xml')
: _xml // assume this is a node already
,xsl = typeof _xsl == 'string'
? new DOMParser().parseFromString(_xsl, 'text/xml')
: _xsl // assume this is a node already
,processor = new XSLTProcessor()
;
processor.importStylesheet(xsl);
return processor.transformToDocument(xml.firstChild);
}
```
This function accepts two params. The first is the xml that you want to transform. The second is the xslt that you want to use to transform the xml. Both params accept either strings that will be transformed to nodes or nodes themselves (such as XHR.responseXML).
The second part of the puzzle is sorting which you will use xsl's built-in `xsl:sort`.
```
<xsl:sort
select="expression"
lang="language-code"
data-type="text|number|qname"
order="ascending|descending"
case-order="upper-first|lower-first"/>
```
All parameters are optional besides the select statement.
**Sample sort usage:**
```
<xsl:for-each select="catalog/cd">
<xsl:sort select="artist"/>
<xsl:value-of select="artist"/>
<xsl:text> - </xsl:text>
<xsl:value-of select="title"/>
</xsl:for-each>
```
You can find more information about `xsl:sort` at [w3schools](http://www.w3schools.com/xsl/el_sort.asp). | I wouldn't sort in the xsl sheet.
I use the [tablesorter](http://tablesorter.com/docs/) [plugin](http://docs.jquery.com/Plugins/Authoring) to [jquery](http://jquery.com/).
The [Getting Started](http://tablesorter.com/docs/#Getting-Started) section is very straightforward(and is reproduced below).
To use the tablesorter plugin, include the jQuery library and the tablesorter plugin inside the tag of your HTML document:
```
<script type="text/javascript" src="/path/to/jquery-latest.js"></script>
<script type="text/javascript" src="/path/to/jquery.tablesorter.js"></script>
```
tablesorter works on standard HTML tables. You must include THEAD and TBODY tags:
```
<table id="myTable">
<thead>
<tr>
<th>Last Name</th>
<th>First Name</th>
<th>Email</th>
<th>Due</th>
<th>Web Site</th>
</tr>
</thead>
<tbody>
<tr>
<td>Smith</td>
<td>John</td>
<td>jsmith@gmail.com</td>
<td>$50.00</td>
<td>http://www.jsmith.com</td>
</tr>
<tr>
<td>Bach</td>
<td>Frank</td>
<td>fbach@yahoo.com</td>
<td>$50.00</td>
<td>http://www.frank.com</td>
</tr>
<tr>
<td>Doe</td>
<td>Jason</td>
<td>jdoe@hotmail.com</td>
<td>$100.00</td>
<td>http://www.jdoe.com</td>
</tr>
<tr>
<td>Conway</td>
<td>Tim</td>
<td>tconway@earthlink.net</td>
<td>$50.00</td>
<td>http://www.timconway.com</td>
</tr>
</tbody>
</table>
```
Start by telling tablesorter to sort your table when the document is loaded:
```
$(document).ready(function()
{
$("#myTable").tablesorter();
}
);
```
Click on the headers and you'll see that your table is now sortable! You can also pass in configuration options when you initialize the table. This tells tablesorter to sort on the first and second column in ascending order.
```
$(document).ready(function()
{
$("#myTable").tablesorter( {sortList: [[0,0], [1,0]]} );
}
);
``` | Xml, xsl Javascript sorting | [
"",
"javascript",
"xml",
"xslt",
""
] |
Is there any way to process all Windows messages while the UI thread is waiting on a WaitHandle or other threading primitive?
I realize that it could create very messy reentrancy problems; I want to do it anyway.
**EDIT**: The wait occurs in the middle of a complicated function that must run on the UI thread. Therefore, moving the wait to a background thread is not an option. (Splitting the function in two would make a complicated and unmaintainable mess) | I'd run the whole "Complicated-function-that-can-not-be-split" in a separate background thread, and have it to report to the GUI only when it needs to (using Invoke/BeginInvoke methods on a control).
In a more enhanced version, you should run your complicated function in a non-UI controller that does not depend on the UI, and is easier to unit test. Calling back to the UI and showing the result in the UI, can easily be reached by having the UI to subrscribe to events made available by the controller. | Why wouldn't you just spawn another thread to do the waiting and have him notify the UI thread via message (or whatever) at the appropriate juncture?
That's the usual approach to allow for UI thread message handling during a blocking event.
EDIT:
I see now -- you have that app logic logic built into the UI code. Well, this is really a design issue then. You're better off in the long-run breaking that functionality out from the UI into a self-contained object and using some mechanism to communicate status with the UI from your worker.
Aside from the benefit of keeping your UI code focused on UI, this allows you to unit-test the logic code separately. | Run Message Loop while waiting for WaitHandle | [
"",
"c#",
".net",
"multithreading",
"waithandle",
"message-loop",
""
] |
I don't think it makes any difference to the database, but when joining tables, which order do you prefer to write the condition:
```
SELECT
...
FROM AAA
INNER JOIN BBB ON AAA.ID=BBB.ID
WHERE ...
```
OR
```
SELECT
...
FROM AAA
INNER JOIN BBB ON BBB.ID=AAA.ID
WHERE ...
``` | I always do
```
From TABLE_A A
JOIN TABLE_B B ON A.Column = B.Column
``` | I prefer the second example (B=A) because in the join I am listing the criteria the determines which B rows should be included. In other words, I want all rows from B where "X" is true of B. This is also consistent when I need to check for criteria beyond just FKs. For example:
```
SELECT
some_columns
FROM
Table_A A
INNER JOIN Table_B B ON
B.a_id = A.a_id AND
B.active = 1
```
In my opinion it wouldn't have the same readability if I had:
```
1 = B.active
```
Also consider the cases where you're join criteria includes more than one table:
```
SELECT
some_columns
FROM
Table_A A
INNER JOIN Table_B B ON
B.a_id = A.a_id AND
B.active = 1
INNER JOIN Table_C C ON
C.a_id = A.a_id AND
C.b_id = B.b_id AND
C.category = 'Widgets'
```
To me that makes it very clear as to the criteria on which rows from C should be included. | SQL join condition A=B or reverse to B=A? | [
"",
"sql",
"join",
""
] |
I have an interesting situation and I'm wondering if there is a better way to do this. The situation is this, I have a tree structure (an abstract syntax tree, specifically) and some nodes can contain child nodes of various types but all extended from a given base class.
I want to frequently do queries on this tree and I'd like to get back the specific subtypes I'm interested in. So I created a predicate class that I can then pass into a generic query method. At first I had a query method that looked like this:
```
public <T extends Element> List<T> findAll(IElementPredicate pred, Class<T> c);
```
where the `Class` argument was used just to indicate the return type. What bothered me about this approach is that all of my predicates were already for specific types so there is redundant information here. A typical call might look like:
```
List<Declaration> decls =
scope.findAll(new DeclarationPredicate(), Declaration.class);
```
So I refactored it like this:
```
public <T extends Element> List<T> findAll(IElementPredicate<T> pred);
```
Where the `IElementPredicate` interface looks like this:
```
public interface IElementPredicate<T extends Element> {
public boolean match(T e);
public String getDescription();
public Class<T> getGenericClass();
}
```
The point here is that the predicate interface is expanded to provide the `Class` object instead. It makes writing the actual `findAll` method a little bit more work and it adds a bit more work in writing the predicate, but those are both essentially tiny "one-time" things and it makes the query call so much nicer because you don't have to add the extra (potentially redundant) argument, e.g.
```
List<Declaration> decls = scope.findAll(new DeclarationPredicate());
```
I haven't noticed this pattern before. Is this a typical way of dealing with the semantics of Java generics? Just curious if I'm missing some better pattern.
Commments?
UPDATE:
One question was what do you need the Class for? Here is the implementation of findAll:
```
public <T extends Element> List<T> findAll(IElementPredicate<T> pred) {
List<T> ret = new LinkedList<T>();
Class<T> c = pred.getGenericClass();
for(Element e: elements) {
if (!c.isInstance(e)) continue;
T obj = c.cast(e);
if (pred.match(obj)) {
ret.add(c.cast(e));
}
}
return ret;
}
```
While it is true that match only takes a T, I need to make sure the object is a T before I can call it. For that, I need the "isInstance" and "cast" methods of Class (as far as I can tell). | The closest "pattern" I think is **type token** and Generics Tutorial recommends them. You can also turn base predicate into [super-type-token](http://gafter.blogspot.com/2006/12/super-type-tokens.html) (a.k.a. Gafter gadget) and save the extra couple of lines when defining new predicates. | Your tree structure sounds very much like an XML DOM object. Have you considered translating your tree into a DOM structure and using XPath to do your queries? It might be a lot less custom code. | Type safety, Java generics and querying | [
"",
"java",
"generics",
""
] |
I wrote a library and want to test it. I wrote the following program, but I get an error message from eclipse.
```
#include <stdlib.h>
#include <stdio.h>
#include <dlfcn.h>
int main(int argc, char **argv) {
void *handle;
double (*desk)(char*);
char *error;
handle = dlopen ("/lib/CEDD_LIB.so.6", RTLD_LAZY);
if (!handle) {
fputs (dlerror(), stderr);
exit(1);
}
desk= dlsym(handle, "Apply"); // ERROR: cannot convert from 'void *' to 'double*(*)(char*)' for argument 1
if ((error = dlerror()) != NULL) {
fputs(error, stderr);
exit(1);
}
dlclose(handle);
}
```
What is wrong?
Regards. | In C++ you need the following:
```
typedef double (*func)(char*);
func desk = reinterpret_cast<func>( dlsym(handle, "Apply"));
``` | You need to explicitly cast the return value of dlsym(), it returns a void\* and desk is not of type void\*. Like this:
`desk = (double (*)(char*))dlsym(handle, "some_function");` | Using C++ Library in Linux (eclipse) | [
"",
"c++",
"c",
"linux",
""
] |
I have two IEnumerable
```
IEnumerable<MyObject> allowedObjects = MyService.GetAllowedObjects();
IEnumerable<MyOBject> preferedObjects = MyService.GetPreferedObjects();
```
We can safely assume that preferedObjects will always be a subset of allowedObjects.
I want to create an `IDictionary<MyObject, bool>`. Objects where the key is the set of MyObjects from the allowedObjects and the bool is true if the MyObject instance was also in the preferedObjects enumerable.
I can do this by enumerating them and adding them one by one, but I would like to be able to do something like this:
```
IDictionary<MyObject, bool> selectedObjects = allowedObjects
.ToDictionary(o => new KeyValuePair<MyObject, bool>()
{ Key = q,
Value = preferedObjects.Any(q)
}
);
```
**UPDATE**
Exchanged Contains with Any;
The solution that is suggested most was what I tried first, but it isn't accepted for some reason:
```
IDictionary<MyObject, bool> selectedObjects = allowedObjects
.ToDictionary<MyObject, bool>(o => o, preferedObjects.Any(o));
```
Visual studio says the first method does not return a bool. Which is true, but mainly because a bool would not be the correct result to start with...
And then it says it cannot infere the type of the second lambda...
As you can see I tried to explicitly define the types to help the inference, but it doesn't solve a thing..
Suggestions?
Disclaimer: names and code are snippyfied to keep the focus where it should be | I can't remember whether Linq provides a "Contains" extension method on `IEnumerable<T>`. If not, you could use Any:
```
var dict = allowedObjects.ToDictionary(o => o,
o => preferredObjects.Contains(o));
```
\*\* Edit \*\* Yep, just tested it and there is indeed a Contains() extension method, so the above code works. | [`Enumerable.ToDictionary`](http://msdn.microsoft.com/library/system.linq.enumerable.todictionary) has multiple overloads. Some of these take a second delegate (so you can pass a lambda) to return the value to go with the key.
Something like:
```
var secondDict = firstDictionary
.Where(p => SomeCondition(p))
.ToDictionary(p => p.Key, p => p.Value);
``` | Lambda way to fill the value field in the ToDictionary() method? | [
"",
"c#",
".net",
"dictionary",
"lambda",
""
] |
I have a primitive float and I need as a primitive double. Simply casting the float to double gives me weird extra precision. For example:
```
float temp = 14009.35F;
System.out.println(Float.toString(temp)); // Prints 14009.35
System.out.println(Double.toString((double)temp)); // Prints 14009.349609375
```
However, if instead of casting, I output the float as a string, and parse the string as a double, I get what I want:
```
System.out.println(Double.toString(Double.parseDouble(Float.toString(temp))));
// Prints 14009.35
```
Is there a better way than to go to String and back? | It's not that you're *actually* getting extra precision - it's that the float didn't accurately represent the number you were aiming for originally. The double *is* representing the original float accurately; `toString` is showing the "extra" data which was already present.
For example (and these numbers aren't right, I'm just making things up) suppose you had:
```
float f = 0.1F;
double d = f;
```
Then the value of `f` might be exactly 0.100000234523. `d` will have exactly the same value, but when you convert it to a string it will "trust" that it's accurate to a higher precision, so won't round off as early, and you'll see the "extra digits" which were already there, but hidden from you.
When you convert to a string and back, you're ending up with a double value which is closer to the string value than the original float was - but that's only good *if* you really believe that the string value is what you really wanted.
Are you sure that float/double are the appropriate types to use here instead of `BigDecimal`? If you're trying to use numbers which have precise decimal values (e.g. money), then `BigDecimal` is a more appropriate type IMO. | I find converting to the binary representation easier to grasp this problem.
```
float f = 0.27f;
double d2 = (double) f;
double d3 = 0.27d;
System.out.println(Integer.toBinaryString(Float.floatToRawIntBits(f)));
System.out.println(Long.toBinaryString(Double.doubleToRawLongBits(d2)));
System.out.println(Long.toBinaryString(Double.doubleToRawLongBits(d3)));
```
You can see the float is expanded to the double by adding 0s to the end, but that the double representation of 0.27 is 'more accurate', hence the problem.
```
111110100010100011110101110001
11111111010001010001111010111000100000000000000000000000000000
11111111010001010001111010111000010100011110101110000101001000
``` | Convert float to double without losing precision | [
"",
"java",
"floating-point",
"double",
""
] |
My sql statement is not working with Zend, its complaining about the Count(\*) field... what am I doing wrong?
```
// get open/closed
$stmt = $db->query('SELECT status, count(*) as total FROM reported_issues WHERE date_reported >= '.$today.' AND status IN (0,1) GROUP BY status');
while ($row = $stmt->fetch())
{
switch ($row['status'])
{
case 0:
$totalIssuesToday = $row['total'];
break;
case 1:
$totalIssuesClosedToday = $row['total'];
break;
}
}
```
and the errors...
```
Fatal error: Uncaught exception 'Zend_Db_Statement_Exception' with message
'SQLSTATE[42S22]: Column not found: 1054 Unknown column 'Y' in 'where clause''
in C:\xampp\htdocs\dating\trunk\library\Zend\Db\Statement\Pdo.php:238
Stack trace:
#0 C:\xampp\htdocs\dating\trunk\library\Zend\Db\Statement.php(283): Zend_Db_Statement_Pdo->_execute(Array)
#1 C:\xampp\htdocs\dating\trunk\library\Zend\Db\Adapter\Abstract.php(484): Zend_Db_Statement->execute(Array)
#2 C:\xampp\htdocs\dating\trunk\library\Zend\Db\Adapter\Pdo\Abstract.php(235): Zend_Db_Adapter_Abstract->query('SELECT status, ...', Array)
#3 C:\xampp\htdocs\dating\trunk\html\siteadmin.php(59): Zend_Db_Adapter_Pdo_Abstract->query('SELECT status, ...')
#4 {main} thrown in C:\xampp\htdocs\dating\trunk\library\Zend\Db\Statement\Pdo.php on line 238
``` | The complaint is actually about the `WHERE` -- looks like your `$today` variable does not contain what you think it should. Specifically, since it says:
```
'SQLSTATE[42S22]: Column not found: 1054 Unknown column 'Y' in 'where clause''
```
it seems your variable contains a `Y` that shouldn't be there. The `count` appears to have nothing to do with the issue. | Aside from what others have noted about the value you have in $today, you really should be using bound parameters with your queries
```
<?php
$stmt = $db->query(
"SELECT status, count(*) as total
FROM reported_issues
WHERE date_reported >= ?
AND status IN (0,1)
GROUP BY status"
,array( $today )
);
``` | Zend DB - Count(*) not working | [
"",
"php",
"mysql",
"zend-framework",
"zend-db-table",
"mysql-error-1054",
""
] |
Is there away to cause a script to prevent running if an if statement is true even with "GO"'s?
For example I want to do something similar to the following:
```
insert into table1 (col1, col2) value ('1', '2')
GO
if exists(select * from table1 where col1 = '1')
BEGIN
--Cause Script to fail
END
GO
insert into table1 (col1, col2) value ('1', '2') --Wont run
```
The actual purpose of doing this is to prevent table create scripts/inserts/deletes/updates from running more than once when we drop of packages for the DBA's to run. | According to the documentation, certain values passed for the severity to [RAISEERROR()](http://msdn.microsoft.com/en-us/library/ms178592.aspx) can cause varying levels of termination.
The ones of most interest (if you are running a script through SQL Management Studio or similar, and want to prevent any attempt to run any subsequent commands in a the file) may be:
> Severity levels from 20 through 25 are considered fatal. If a fatal severity level is encountered, the client connection is terminated after receiving the message, and the error is logged in the error and application logs. | GO is not a transact-sql keyword - it's actually a batch terminator understood by common SQL Server tools. If you use it in your application, your app wil fail.
Why wouldn't you do something like this?
```
IF NOT EXISTS (select * from table1 where col1 = '1')
BEGIN
--Do Some Stuff
END
```
Rather than abort the script if the condition *is* met, only run the script if the condition *isn't* met.
Alternatively, you could wrap the code in a proc and use RETURN to exit from the proc. | SQL Server: Terminate SQL From Running | [
"",
"sql",
"sql-server",
"t-sql",
""
] |
Is there a way to specify an ANT file to run only one/some/all of its sections? | Split your build into appropriate [targets](http://ant.apache.org/manual/using.html#targets) so that you can call individual targets separately, and then you can specify the target you want to run from the command line.
Personally I like having "real" targets without any dependencies (which I can run independently) and then "fake" targets which are *just* dependent on the real ones, for convenience (e.g. "clean-build"). The alternative of having test depend on compile etc always ends up getting in the way for me :( | You can group targets together using dependencies:
```
<target name="A">
<target name="B">
<target name="C" depends="A,B">
```
runs
A, B, then C.
You can also chain these to arbitrary depth. For example you could create an empty target "D" that depends on A, B which will only run A and B. | Run some or all sections of an ant file | [
"",
"java",
"ant",
""
] |
I keep getting a exception when I try to FTP to my Win 2008 Server from C# code using VS2008 as debugger.
My test class looks like this:
```
public class FTP
{
private string ftpServerIP = "192.168.10.35:21";
private string ftpUserID = "Administrator";
private string ftpPassword = "XXXXXXXX";
private string uploadToFolder = "uploadtest";
public void Upload(string filename)
{
FileInfo fileInf = new FileInfo(filename);
string uri = "ftp://" + ftpServerIP + "/" + uploadToFolder + "/" + fileInf.Name;
FtpWebRequest reqFTP;
reqFTP = (FtpWebRequest)FtpWebRequest.Create(new Uri(uri));
reqFTP.Credentials = new NetworkCredential(ftpUserID, ftpPassword);
reqFTP.KeepAlive = false;
reqFTP.Method = WebRequestMethods.Ftp.UploadFile;
reqFTP.UseBinary = true;
reqFTP.ContentLength = fileInf.Length;
int buffLength = 2048;
byte[] buff = new byte[buffLength];
int contentLen;
FileStream fs = fileInf.OpenRead();
try
{
Stream strm = reqFTP.GetRequestStream();
contentLen = fs.Read(buff, 0, buffLength);
while (contentLen != 0)
{
strm.Write(buff, 0, contentLen);
contentLen = fs.Read(buff, 0, buffLength);
}
strm.Close();
fs.Close();
}
catch (Exception ex)
{
throw new Exception(ex.Message);
}
}
}
```
When I execute the code I get a Connection Failed with FTP error 227 in the GetRequestStream() call.
In the exception I can see the connection fails to: 192.168.10.35:52184
I have no idea how it comes up with port 52184.
I specify in the ftpServerIP that it should be port 21.
I have found a few persons with the same issues on google but I haven't found a good example on how this is solved and I still don't understand why it happens.
Anyone know how to handle this issue??
UPDATE:
I have tried to connect to a different FTP account and there it all works fine. Therefore I tested my 192.168.10.35:21 FTP but it works fine in CuteFTP Pro and the likes.
This just makes it even more strange.. | My guess would be Windows firewall issues, FTP uses other ports than just port 21 - sometimes changing the FTP mode from active to passive helps to get things working.
```
reqFTP.UsePassive = false;
```
Look at this good article on FTP: [Active FTP vs. Passive FTP, a Definitive Explanation](http://slacksite.com/other/ftp.html) | Thies got it right, it had to do with passive mode
The fix in the code is so insanely simple :)
```
reqFTP.UsePassive = false;
```
And it worked fast and without errors! | Set Port number when using FtpWebRequest in C# | [
"",
"c#",
"ftpwebrequest",
""
] |
I have several CONST's defined on some classes, and want to get a list of them. For example:
```
class Profile {
const LABEL_FIRST_NAME = "First Name";
const LABEL_LAST_NAME = "Last Name";
const LABEL_COMPANY_NAME = "Company";
}
```
Is there any way to get a list of the CONST's defined on the `Profile` class? As far as I can tell, the closest option(`get_defined_constants()`) won't do the trick.
What I actually need is a list of the constant names - something like this:
```
array('LABEL_FIRST_NAME',
'LABEL_LAST_NAME',
'LABEL_COMPANY_NAME')
```
Or:
```
array('Profile::LABEL_FIRST_NAME',
'Profile::LABEL_LAST_NAME',
'Profile::LABEL_COMPANY_NAME')
```
Or even:
```
array('Profile::LABEL_FIRST_NAME'=>'First Name',
'Profile::LABEL_LAST_NAME'=>'Last Name',
'Profile::LABEL_COMPANY_NAME'=>'Company')
``` | You can use [Reflection](http://php.net/manual/en/book.reflection.php) for this. Note that if you are doing this a lot you may want to looking at caching the result.
```
<?php
class Profile {
const LABEL_FIRST_NAME = "First Name";
const LABEL_LAST_NAME = "Last Name";
const LABEL_COMPANY_NAME = "Company";
}
$refl = new ReflectionClass('Profile');
print_r($refl->getConstants());
```
Output:
```
Array
(
'LABEL_FIRST_NAME' => 'First Name',
'LABEL_LAST_NAME' => 'Last Name',
'LABEL_COMPANY_NAME' => 'Company'
)
``` | [This](http://www.php.net/manual/en/reflectionclass.getconstants.php)
```
$reflector = new ReflectionClass('Status');
var_dump($reflector->getConstants());
``` | Can I get CONST's defined on a PHP class? | [
"",
"php",
"constants",
"class-constants",
""
] |
I am a beginner to XML and XPath in C#. Here is an example of my XML doc:
```
<root>
<folder1>
...
<folderN>
...
<nodeMustExist>...
<nodeToBeUpdated>some value</nodeToBeUpdated>
....
</root>
```
What I need is to update the value of nodeToBeUdpated if the node exists or add this node after the nodeMustExist if nodeToBeUpdated is not there. The prototype of the function is something like this:
```
void UpdateNode(
xmlDocument xml,
string nodeMustExist,
string nodeToBeUpdte,
string newVal
)
{
/*
search for XMLNode with name = nodeToBeUpdate in xml
to XmlNodeToBeUpdated (XmlNode type?)
if (xmlNodeToBeUpdated != null)
{
xmlNodeToBeUpdated.value(?) = newVal;
}
else
{
search for nodeMustExist in xml to xmlNodeMustExist obj
if ( xmlNodeMustExist != null )
{
add xmlNodeToBeUpdated as next node
xmlNodeToBeUpdte.value = newVal;
}
}
*/
}
```
Maybe there are other better and simplified way to do this. Any advice?
By the way, if nodeToBeUpdated appears more than once in other places, I just want to update the first one. | This is to update all nodes in folder:
```
public void UpdateNodes(XmlDocument doc, string newVal)
{
XmlNodeList folderNodes = doc.SelectNodes("folder");
if (folderNodes.Count > 0)
foreach (XmlNode folderNode in folderNodes)
{
XmlNode updateNode = folderNode.SelectSingleNode("nodeToBeUpdated");
XmlNode mustExistNode = folderNode.SelectSingleNode("nodeMustExist"); ;
if (updateNode != null)
{
updateNode.InnerText = newVal;
}
else if (mustExistNode != null)
{
XmlNode node = folderNode.OwnerDocument.CreateNode(XmlNodeType.Element, "nodeToBeUpdated", null);
node.InnerText = newVal;
folderNode.AppendChild(node);
}
}
}
```
If you want to update a particular node, you cannot pass string nodeToBeUpdte, but you will have to pass the XmlNode of the XmlDocument.
I have omitted the passing of node names in the function since nodes names are unlikely to change and can be hardcoded. However, you can pass these to the functions and use the strings instead of hardcoded node names. | The XPath expression that selects all instances of `<nodeToBeUpdated>` would be this:
```
/root/folder[nodeMustExist]/nodeToBeUpdated
```
or, in a more generic form:
```
/root/folder[*[name() = 'nodeMustExist']]/*[name() = 'nodeToBeUpdated']
```
suitable for:
```
void UpdateNode(xmlDocument xml,
string nodeMustExist,
string nodeToBeUpdte,
string newVal)
{
string xPath = "/root/folder[*[name() = '{0}']]/*[name() = '{1}']";
xPath = String.Format(xPath, nodeMustExist, nodeToBeUpdte);
foreach (XmlNode n in xml.SelectNodes(xPath))
{
n.Value = newVal;
}
}
``` | Update or inserting a node in an XML doc | [
"",
"c#",
"xml",
"xpath",
""
] |
I am using the mod-rewrite router.
I am trying to add a Route to the router that will convert the following url:
baseurl/category/aaa/mycontroller/myaction/param/value
to be:
Controller=mycontroller
action=myaction
--parameters--
category=aaa
param=value
I am using the following (not working) in my bootstrap, \_front is the frontController
```
$Router=$this->_front->getRouter();
$CategoryRoute = new Zend_Controller_Router_Route('category/:category/:controller/:action/*');
$Router->addRoute('category', $CategoryRoute);
```
The error I get is a thrown router exception when I am using the Zend\_View::url() helper (with or without giving it the name of the new route).
The exception is thrown only when I have baseurl/category/....
What am I missing?
What I missed:
Since there was [category] in the url, The router that was used is the one defined above.
When I used the url() helper, I didn't give any value in it to the [category] hence there was no value for this key in the url parts->failure.
Giving a default, makes it work. | You should include the /\* as suggested by solomongaby.
If not supplying all of the required parameters (i.e. category, controller and action), you will need to specify defaults.
You can do so as follows:
```
$Router=$this->_front->getRouter();
$CategoryRoute = new Zend_Controller_Router_Route('category/:category/:controller/:action/*',
array(
'controller' => 'index',
'action' => 'index',
'category' => null
)
);
$Router->addRoute('category', $CategoryRoute);
``` | ```
$Router=$this->_front->getRouter();
$CategoryRoute = new Zend_Controller_Router_Route('category/:category/:controller/:action/*');
$Router->addRoute('category', $CategoryRoute);
```
Try adding a start to specify the existence of extra params | adding a Route to the a Router in Zend Framework | [
"",
"php",
"zend-framework",
"routes",
""
] |
> **Possible Duplicates:**
> [Visual Studio 6 tips and tricks](https://stackoverflow.com/questions/147339/visual-studio-6-tips-and-tricks)
> [Visual Studio 2005 Shortcuts](https://stackoverflow.com/questions/26452/visual-studio-2005-shortcuts)
> [Favorite Visual Studio keyboard shortcuts](https://stackoverflow.com/questions/98606/favorite-visual-studio-keyboard-shortcuts)
I am a big fan of shortcuts in VS2008, it can save a lot of time and keep your fingers on the keyboard instead of the mouse.
Recently I downloaded the entire list of [keyboard shortcuts for VS 2008](http://swami-k.blogspot.com/2009/01/visual-studio-2008-keyboard-shortcut.html) and went through them all finding my favourites.
Currently here are the top one's I use:
1. Shift + DEL: Deletes an entire line
2. Ctrl + Shift + F10: Brings up the Using / Resolution box
3. cw[tabx2]: Inserts Console.Writeline code
4. ctor[tabx2]: Inserts default constructor code
What other ones do people know that saves time / are actually useful? | `F12` Jump to definition
`SHIFT` + `F12`Find al references
`CTRL` + `MINUS` Jump back to previous cursor location
`CTRL` + `SHIFT` + `MINUS` Jump forward to last cursor location
`CTRL` + `K` , `C` Comment out currently selected code
`CTRL` + `K` , `U` Uncomment currently selected code
`CTRL` + `K` , `F` Format selected code
`CTRL` + `K` , `D` Format document
`F5` Start Debugging
`F6` Build Solution
`F7` Switch to code view
`Shift`+ `F7` Switch to design view
These are the ones I use most.
PS. Microsoft released keybinding posters for Visual Studio.
* VS C# 2005 Keyboard Shortcut [Reference Poster](http://www.microsoft.com/downloads/details.aspx?familyid=C15D210D-A926-46A8-A586-31F8A2E576FE&displaylang=en)
* VS C# 2008 Keyboard Shortcut [Reference Poster](http://www.microsoft.com/downloads/details.aspx?familyid=E5F902A8-5BB5-4CC6-907E-472809749973&displaylang=en) | Incremental Search - `Ctrl`+`I`
Search your code, just like in Firefox/IE8. Doesn't work with regions however. | What's your favourite VS 2008 shortcuts? | [
"",
"c#",
".net",
"visual-studio-2008",
""
] |
Have been scatching my head about this - and I reckon it's simple but my geometry/algebra is pretty rubbish, and I can't remember how to do this stuff from my school days!
EDITED:
I have a list of coordinates with people stood by them - I need an algorithm to order people from top left to bottom right in a list (array), and the second criteria demands that coordinates that are closer towards the top left origin take prescendance over all others - how would you do this?
The code should show the order as:
1. Tom
2. Harry
3. Bob
4. Dave
See diagram below:
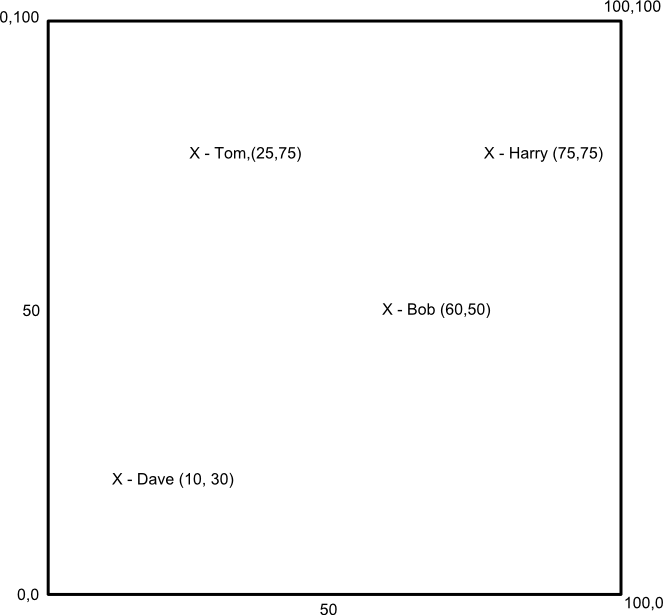 | From your ordering, it looks like you are putting y position at a higher priority than x position, so something like this would work when comparing two people:
```
if (a.y > b.y)
// a is before b
else if (a.x < b.x)
// a is before b
else
// b is before a
```
*edit for update*
This comparison still works with your new criteria. Y position is still has precedence over the X position. If the Y values are equal, the point closest to the top left corner would be the one with the smaller X value. If you want to make your object a comparator, implementing this as your comparator function would allow you to do ArrayList.sort() where negative means the first person is before the second:
```
public int compareTo(person a, person b) {
if (a.y == b.y)
return a.x-b.x
else
return b.y-a.y
}
//compareTo(Tom, Harry) == -50 (tom is before harry)
//compareTo(Tom, Bob) == -25 (tom is before bob)
//compareTo(Dave, Bob) == 30 (dave is after bob)
``` | Order them based on their distance from the top-left corner of your 2D-Space, in this case (0, 100).
EDIT:
Obviously this will mean that you will have cases where 2 people are equidistant from the top left corner, and yet they are nowhere near each other.
In this case, you need to specify how you want such people to be ordered. If you want to pick people who are higher up, you can order by y-coord first. Similarly you can choose some other criterion.
All other sorting algorithms will have the same problem, of what to do when 2 items have the same sort key. By definition then, they *are* considered identical until you come up with a secondary sorting criterion. | Ordering coordinates problem | [
"",
"java",
"arrays",
"algorithm",
"coordinates",
""
] |
Suppose I have table in my DB schema called TEST with fields (id, name, address, phone, comments). Now, I know that I'm going to perform a large set of different queries for that table, therefore my question is next, when and why I shall create indexes like ID\_NAME\_INDX (index for id and name) and when it's more efficient to create separately index for id and index for name field(by when I mean for what type of query)? | The general aim would be to "cover" all columns so the query only has to use the index.
```
-- An index on Name including ID would be ideal
SELECT
[id]
FROM
TEST
WHERE
[name] = 'bob'
```
Say you need name and indx but have separate indexes. You'll end up with a bookmark lookup from the index to the PK to get the other columns (assuming it doesn't just scan the PK)
Edit, after 1st comment:
```
select * from test where id='id1' and name='Name1'
```
For this query, the SELECT \* but mitigates against any index so the PK would be used.
If you had:
```
select address from test where id='id1' and name='Name1'
```
then an index on ID, name including address would "cover" it.
Using "OR" creates difficulties for any strategy. However,
```
select address from test where id='id1' and name='Name1'
```
would still use the "ID, name including address" inex most likely but scan it rather that seek
Read this: [Execution Plan Basics](http://www.simple-talk.com/sql/performance/execution-plan-basics/) | I'm not sure your example explains the actual question you're asking. You're saying if you should have an index on ID and and index on Name, as opposed to an index on both ID and Name. The thing is, I guess that ID is your primary key and so you're not likely to do a search on ID AND Name.
However, in the terms of a table with two ID's of which you would want to search on either one, or both together then having three indexes, one on each of the ID's and one combined will be the fastest. If you have two indexes then to find the record you're looking for both indexes will need to be searched. However, if you have one index covering both ID's then only that index will need to be searched.
As with all indexes though, as you add them, your database increases in size and you will get a reduction on insert / update performance. You always need to weigh up the gains / losses.
Add indexes to the absolutely obvious candidates, add indexes to the "maybe" ones as the need arises. Continue to monitor your database performance and run query analysers to see where any performance gains can be made over time. | RDBS when to use complex indexes for queries and when use simple? | [
"",
"sql",
"performance",
"indexing",
"rdbms",
""
] |
In trying to get up to speed with C++ (coming from a long experience with C), I am obviously trying to do the right thing, and use as much as is standard as is possible.
However, in my readings on the matter I come accross a lot of criticism for standard things, and praise for non-standard things. For example, even the the (I assume) poorly-thought-of MFC library has features in, for example, its `CString` class that some folks think useful enough to cause them to continue using it despite the fact that it's (a) non-standard and (b) that it's (I assume, from the wealth of criticism) deficient in many important ways.
My question is twofold, then:
A. What libraries that are poorly-thought-of contain features that nonetheless make it worth continuing to use them, what are those features, and what's so good about them?
B. Are there "adaptor" libraries out there that simplify and/or tighten up the use of such libraries, e.g. providing nice interfaces that abstract resources leaks, adaptors that go from a non-STL library interface to a STL, and so on
As a relative newbie to StackOverflow, I'm not 100% sure that this question is sufficiently on-point, so I apologise up-front if it's too open-ended.
Thanks in advance | My personal grunge is with [ACE](http://www.cs.wustl.edu/~schmidt/ACE.html). It was sort of the other way around - great idea, nothing else was available at the time for cross-platform threaded and network development in C++, wide deployment, books by the library authors, etc. But the implementation was terrible, usage patterns were complicated, almost all the useful features of C++ suppressed (or didn't exist at the time.) I think this library alone is responsible for good chunk of people thinking that C++ is hard and ugly. Very recently [Boost](http://www.boost.org) collection started catching up with threads, ipc, and networking, so there is at least an alternative. BUT with all that said, I still think it's worth to be familiar with ACE if you are in that space since, again, way too many people use it, the ideas are good, and it can serve as great negative example for library design. | IMO the best thing about MFC is that, historically, it was available before the STL was available, and something was better than nothing.
MFC is still good, if you're writing code to be compatible with an existing MFC code base.
Apart from that there's little merit in MFC, except that it's perhaps still one of the (if not the most) obvious C++ class library for Windows. | What are the good parts in the poorly-thought-of non-standard C++ libraries? | [
"",
"c++",
"c",
"standards-compliance",
""
] |
On this article ( <http://blogs.msdn.com/oldnewthing/archive/2008/08/13/8854601.aspx>), there is a pop question about iterators and one concerning a corner case:
> Exercise: Consider the following
> fragment: foreach (int i in
> CountTo100Twice()) { ... }
>
> Explain what happens on the 150th call
> to MoveNext() in the above loop.
> Discuss its consequences for recursive
> enumerators (such as tree traversal).
I haven't run this code, but I am assuming that this is a question supposedly with an answer from the articles (all links provided below), but I can't find the answer in the knowledge shared by the article or in the comments for this particular article.
Does anyone know what the answer is? What other corner cases are there?
1) <http://blogs.msdn.com/oldnewthing/archive/2008/08/12/8849519.aspx>
2) <http://blogs.msdn.com/oldnewthing/archive/2008/08/13/8854601.aspx>
3) <http://blogs.msdn.com/oldnewthing/archive/2008/08/14/8862242.aspx>
4) <http://blogs.msdn.com/oldnewthing/archive/2008/08/15/8868267.aspx>
Thanks | I suspect he *may* be referring to the fact that each call to `MoveNext()` invokes a state machine which in turn invokes `MoveNext()` on another state machine, making it all a bit inefficient.
This is blogged about [here by Wes Dyer](http://blogs.msdn.com/wesdyer/archive/2007/03/23/all-about-iterators.aspx) and [here by Eric Lippert](http://blogs.msdn.com/ericlippert/archive/2007/12/19/immutability-in-c-part-seven-more-on-binary-trees.aspx).
The main corner case I'd say with iterator blocks is that *nothing* is executed before the first call to `MoveNext()`. So this method:
```
public IEnumerable<string> ReadLines(string file)
{
if (file == null)
{
throw new ArgumentNullException("file");
}
using (TextReader reader = File.OpenText(file))
{
string line;
while ((line = reader.ReadLine()) != null)
{
yield return line;
}
}
}
```
doesn't actually throw the exception until you start iterating. Instead, you need to write something like this:
```
public static IEnumerable<string> ReadLines(string file)
{
if (file == null)
{
throw new ArgumentNullException("file");
}
return ReadLinesImpl(file);
}
public static IEnumerable<string> ReadLinesImpl(string file)
{
using (TextReader reader = File.OpenText(file))
{
string line;
while ((line = reader.ReadLine()) != null)
{
yield return line;
}
}
}
```
Again, Eric has blogged on this: [part 1](http://blogs.msdn.com/ericlippert/archive/2007/09/05/psychic-debugging-part-one.aspx), [part 2](http://blogs.msdn.com/ericlippert/archive/2007/09/06/psychic-debugging-part-two.aspx). I've blogged a [suggestion to make life easier](https://codeblog.jonskeet.uk/2008/03/02/c-4-idea-iterator-blocks-and-parameter-checking/) too, although I doubt it'll ever come to anything. | A few things.
(1) Jon is of course correct; the issue is that nesting iterators like this gives you a call stack of iterator logic. If you are iterating a deep recursively defined data structure, this can blow the stack, and there are easy ways to turn what ought to be a linear algorithm into a quadratic algorithm. See Wes's article for more details.
(2) We could build a new kind of iterator logic into the language that did not have the performance problem. I would love to implement this but it is not a high enough priority right now. If you're interested in the technical details of how to do so, read [this paper](http://citeseer.ist.psu.edu/cache/papers/cs2/355/http:zSzzSzwww.cs.kuleuven.ac.bezSz~frankzSzPAPERSzSzFTfJP2005.pdf/iterators-revisited-proof-rules.pdf).
(3) There are many corner cases; the ones already alluded to (deferred execution of bounds checks and deferred execution of finally blocks) are the two most common. Unfortunately, in many versions of C# there are bugs in the code generator that exacerbate the latter problem. Suppose you have try { try { ... yield ... } finally { X() } } finally { Y() } -- there are weird situations you can get into where the code we generate accidentally calls Y() before X() on the cleanup path, which is clearly wrong. We've fixed those for the service pack, but if you find others, please let me know.
(4) There are also some extant extremely obscure bugs involving the exact behaviour of the iterator when doing crazy things like a yield break out of a finally which then branches to an outer finally which does a second, redundant yield break. Again, if you happen to find bizarre-behaving iterators, feel free to bring them to my attention. | Yield/iterator corner cases | [
"",
"c#",
""
] |
Why on one system would the default time be 12:00:00 and on another 00:00:00
```
DateTime.Now.Date
```
Starting with string in a web ui, passing thru Nhibernate to SQL Server 2005.
For example 6/10/2009 is entered in a textbox on a web server by the time it is caught in sql profiler I see 2 different times
00:00:00 on my local system (XP), Dev, Test, Staging (2003)
12:00:00 on Prod (2003)
Thanks for the quick replies
Regional settings and DateTime format are the same. | Regional/display settings for date/time formats | In the control panel, you can define the way it displays in regional settings:
H:mm:ss -> 24 hours you will see 00:00
h:mm:ss -> 12 hours format with am/pm you will see 12:00 am | Why would DateTime.Now.Date formats differ between systems? | [
"",
"c#",
"datetime",
""
] |
I´m pretty new to programming in C++ and I´m using pthreads. I´m cross compiling my code for OpenWRT but for some reason I get segmentation fault when I run the program on my board but it runs fine on my PC. I suspect that the error occurs in the linking stage of the compilation because I tried a small C program and that worked fine. Also if I change the name of the file to .cpp and compile it with g++ it also works.
```
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
void *run(void *dummyPtr) {
printf("I am a thread...\n");
return NULL;
}
int main(int argc, char **argv) {
printf("Main start...\n");
pthread_t connector;
pthread_create(&connector, NULL, run, NULL);
printf("Main end...\n");
return 0;
}
```
The output from the eclipse compiler:
```
**** Build of configuration Release for project ThreadTest ****
make all
Building file: ../src/ThreadTest.cpp
Invoking: GCC C++ Compiler
mipsel-linux-g++ -O3 -Wall -c -fmessage-length=0 -MMD -MP -MF"src/ThreadTest.d" -MT"src/ThreadTest.d" -o"src/ThreadTest.o" "../src/ThreadTest.cpp" -lpthread
mipsel-linux-g++: -lpthread: linker input file unused because linking not done
Finished building: ../src/ThreadTest.cpp
Building target: ThreadTest
Invoking: GCC C++ Linker
mipsel-linux-g++ -o"ThreadTest" ./src/ThreadTest.o -lpthread -static
Finished building target: ThreadTest
```
Edit: Removed the old code and put in a new simpler example. This code runs if I compile it as a C program but no if I compile it as a c++ program. I´m runnig the 2.6.26.3 kernel on the board. | This could easily be due to a low memory condition. You should try to enable some form of page file and free up any other memory.
Also, why -static? if your using a dynamic `-lpthread`, wouldn't linking the shared library be preferable?
Also, it could be due to your C++ lib being mis-matched, make sure your `uclibc++` is the correct version, you may also want to install ldd if you have not already. Depends on your firmware. | It's not sufficient to simple link against pthread with -lpthread. You need gcc -pthread (as an option its own right) or gcc -D\_REENTRANT -lpthread (define a symbol named \_REENTRANT). I don't know if this necessary affects anything. | Compiling C++ using -pthreads for Openwrt Linux-Get segmentation fault | [
"",
"c++",
"linux",
"embedded",
"pthreads",
"segmentation-fault",
""
] |
Is it a replacement for if, then blocks? I have seen a lot of code where they are used like that. | No, it is not a replacement for an if, then block, it serves an entirely different purpose. The objective of a try, catch block is to try and do something which could fail and raise an exception (e.g., read a file from disk, but the file might not be there, etc.). After catching an exception, you can handle it.
```
try {
riskyOperation();
catch (ExpectedException) {
handleException();
}
``` | The purpose of try catch blocks to allow you to *try* to perform and action and then if an exception occurs, *catch* the exception and deal with it gracefully rather than crashing. | What is the purpose of using try, catch blocks? | [
"",
"c#",
".net",
"try-catch",
""
] |
I need to pass a few serialized form elements into a function to return them as a JSON object. I wrote the function, but **fieldName** ends up in the json object as "fieldName" instead of the actual field name ie; "PositionId", or "Series". The values however are correct. JS will not allow me to use field.name, but it does allow field.value, thats why I had to create var fieldName. Here is the function:
```
function SerializedFormToJSON(serializedForm){
var myJSONObject = {};
var fieldName = "";
$.each(serializedForm, function(i, field) {
fieldName = field.name;
if (field.value != "" && field.value != "ALL") {
myJSONObject = { fieldName: field.value };
}
});
return myJSONObject;
}
``` | Besides the problem you are experiencing, you're recreating the object in every iteration of the loop. The line where you set the property should read:
```
myJSONObject[fieldName] = field.Value;
```
Complete function:
```
function SerializedFormToJSON(serializedForm){
var myJSONObject = {};
var fieldName = "";
$.each(serializedForm, function(i, field) {
fieldName = field.name;
if (field.value != "" && field.value != "ALL") {
myJSONObject[fieldName] = field.value;
}
});
return myJSONObject;
``` | ```
myJSONObject[fieldName] = field.value;
``` | How do I build a custom object from Serialized form? | [
"",
"javascript",
"jquery",
"json",
""
] |
I need to pull data from two tables: `Neptune_FN_Analysis` and `Neptune_prem`
There will be 3 fields called `readings_miu_id` (comparable to a persons name or item #), `ReadDate`, `ReadTime` (all of which are in `Neptune_FN_Analysis`). Some `readings_miu_id`s have multiple `ReadTime`s for multiple days but I only want to pull the "last time" entered per `readings_miu_id`, per day.
I need all `readings_miu_id`s that have an entry date for the selected range but only the last `ReadTime` entered for each record I am pulling.
My solution so far, based on one table is:
```
SELECT readings_miu_id, Reading, ReadDate, ReadTime, MIUwindow, SN, Noise, RSSI, OriginCol, ColID, Ownage
FROM analyzed AS A
WHERE ReadDate Between #4/21/2009# and #4/29/2009#
AND ReadTime=
(SELECT TOP 1 analyzed.ReadTime FROM analyzed
where analyzed.readings_miu_id = A.readings_miu_id
AND analyzed.ReadDate = A.ReadDate
ORDER BY analyzed.ReadTime DESC);
```
When I try to adapt this solution, I can't do the `FROM [tableName] as A, INNER JOIN` because it gives me an error. The original code that my predecessor made (which is what I am trying to adapt/fix) is as follows:
```
SELECT readings_miu_id, Reading, ReadDate,Format([MIUtime],'hh:mm:ss') AS
ReadTime, MIUwindow, SN, Noise, RSSI, ColRSSI, MIURSSI, Firmware, CFGDate, FreqCorr,
Active, MeterType, OriginCol, ColID, Ownage, SiteID, PremID, Neptune_prem.prem_group1,
Neptune_prem.prem_group2, ReadID
INTO analyzed
FROM Neptune_FN_Analysis INNER JOIN
Neptune_prem ON Neptune_FN_Analysis.PremID = Neptune_prem.premice_id
WHERE SiteID = 36801 and ReadDate BETWEEN #04/21/09# AND #04/27/09#
and OriginCol = 'US 29' and ColID = 1 and ColID <> 0 and Active = 'Y'
``` | I don't quite get all of what you're trying to do, but if you inner join on a subquery which gets the MAX of date, it could eliminate all the records where the date was not the max
```
SELECT readings_miu_id, Reading, ReadDate, ReadTime, MIUwindow, SN,
Noise, RSSI, OriginCol, ColID, Ownage
FROM analyzed
INNER JOIN
(SELECT [whatever the id common to all like records is] as likeID, MAX(analyzed.ReadTime) as latestDate
FROM analyzed
GROUP BY likeID) AS maxDate ON analyzed.likeID=maxDate.likeID AND analyzed.latestDate = maxDate.latestDate
WHERE ReadDate Between #4/21/2009# and #4/29/2009#
```
modify as needed | I'm not sure what you imply by specifying "`INNER JOIN`" this time around. Other answers use a subquery, so here's a an example using two `INNER JOIN`s and no subquery. Rather than getting my head around your schema :) I'm using Northwind to return customers and the date of their most recent order:
```
SELECT C1.CustomerID, C1.CompanyName,
O1.OrderID, O1.OrderDate
FROM (Customers AS C1
INNER JOIN Orders AS O1
ON C1.CustomerID = O1.CustomerID)
INNER JOIN Orders AS O2
ON C1.CustomerID = O2.CustomerID
GROUP
BY C1.CustomerID, C1.CompanyName,
O1.OrderID, O1.OrderDate
HAVING O1.OrderDate = MAX(O2.OrderDate);
``` | How can I select only one record per “person”, per date with an inner join in an MS Access query? | [
"",
"sql",
"ms-access",
"select",
"subquery",
"inner-join",
""
] |
My question has two parts:
1) How can I search for a sentence (e.g., `Dell Canada`) in a string (e.g., `I am working in Dell Canada`, and I found it...) .
2)The second part is my string is text in a RichTextBox, so I would like to find the TextRange of that selected sentence and apply certain decoration.
thanks. | The first part is pretty simple as CK has pointed out.
Rich text formatting is dictated by certain predefined codes as defined in the RTF specification.
First get the underlying RTF raw string from the control using the RTF property
string rawString = richTextBox.Rtf;
For eg: the rtf for the phrase 'hello Bobby' will look like this. It is something like HTML, you have tags which define the formatting.
```
"{\\rtf1\\ansi\\ansicpg1252\\deff0\\deflang1033{\\fonttbl{\\f0\\fnil\\fcharset0 Microsoft Sans Serif;}}\r\n\\viewkind4\\uc1\\pard\\f0\\fs17 hello Bobby\\par\r\n\\par\r\n}\r\n"
```
Now suppose I want to make the phrase bold, I would set the Rtf property by replacing the string with
```
"{\\rtf1\\ansi\\ansicpg1252\\deff0\\deflang1033{\\fonttbl{\\f0\\fnil\\fcharset0 Microsoft Sans Serif;}}\r\n\\viewkind4\\uc1\\pard\\f0\\fs17
\\b hello Bobby\\par\r\n\\par\r\n}\r\n"
```
Note the \\b before the phrase. That's the code to make a given text bold.
To perform this formatting using code, find the string you want to format(using the first technique) and insert the rtf code in the required position.
Hope this helps.
For the codes refer MSDN <http://msdn.microsoft.com/en-us/library/aa140277.aspx>
PS: Jeff's version is the easy one. This verison gives you infinite control. If you can do something in WordPad, you can do the same using rtf codes. | Give this a whirl, it will set it to bold. There are many Selection... properties on the RichTextBox that you can use, also note that it is a case insensitive search:
```
string textToSearchFor = "Dell Canada";
int index = richTextBox1.Text.IndexOf(textToSearchFor, StringComparison.OrdinalIgnoreCase);
if (index >= 0)
{
richTextBox1.Select(index, textToSearchFor.Length);
richTextBox1.SelectionFont = new Font("Arial", 12f, FontStyle.Bold);
}
else
{
// not found
}
``` | Search a sentence in a string (C#) | [
"",
"c#",
"string",
""
] |
I'm working in C# and I'm starting to play with properties. One thing I don't know is what is the best way/where to put the logic for the set accessors of class properties and how to handle the errors.
For instance, say I have this (basic) class:
```
class Person
{
private int _Age = 18;
public Person()
{
}
public int Age
{
get
{
return _Age;
}
set
{
_Age = value;
}
}
}
```
Now say I have a requirement on the Age property, 0 < Age < 100. Where do I put the logic for this?
Should I put it in the property?
```
public int Age
{
get
{
return _Age;
}
set
{
if (value < 0 || value > 99)
// handle error
else
_Age = Convert.ToInt32(value);
}
}
```
or through class that is creating a Person object?
```
static void Main(string[] args)
{
Person him = new Person();
int NewAge = -10;
if (NewAge < 0 || NewAge > 100)
// handle error
else
him.Age = NewAge;
}
```
Now what if there is a problem with the NewAge (it doesn't meet my constraint)? Should I create a custom exception and throw that? Should I just print a message saying supply a valid age?
I've done some Googling and I cannot find anything that fully answers my questions. I need a book :-/ | Use the property setter, it is there for that reason (adding functionality to a field).
If out of range value is passed in, you can throw [ArgumentOutOfRangeException](http://msdn.microsoft.com/en-us/library/system.argumentoutofrangeexception.aspx) or just set it to minimum (or maximum) value, but this depends on your process requirement. | I'd implement it like this:
```
public int Age
{
get
{
return _Age;
}
set
{
if (IsValidAge(value))
_Age = value;
else
throw new ArgumentOutOfRangeException("value", string.Format("value should be between {0} and {1} inclusive.", MinAge, MaxAge));
}
}
private bool IsValidAge(int age)
{
return (age >= MinAge && age <= MaxAge);
}
```
A few things to note:
* Don't change their value instead of throwing an exception, this is unexpected behaviour.
* The .NET framework throws Argument\* exceptions in setters, so I'd say it's a good idea to follow this practice. In this case ArgumentOutOfRangeException is perfect, IMO.
* When referring to the argument in exception messages and xml docs, the standard is to call the argument "value", not the name of your property.
* I'd recommend MinAge and MaxAge as private consts in your class, don't fall into the trap of hardcoding error messages with range boundaries in them, there's nothing worse than being told "5 in invalid, please enter a number between 1 and 10" when someone changes the spec later on but forgets to update a string. | C# Properties - Set question | [
"",
"c#",
""
] |
I'd like to tinker with the auto-generated columns in a gridview a bit. What event would I want to override to modify them just after they are generated but before the control is rendered? | Check out this link for more information on Customizing the Auto-Generated Columns of a GridView Control:
<http://msdn.microsoft.com/en-us/library/cc903950(VS.95).aspx>
The particular event you are looking for would be the `AutoGeneratingColumn` event
[More information on the AutoGeneratingColumn event](http://msdn.microsoft.com/en-us/library/system.windows.controls.datagrid.autogeneratingcolumn(VS.95).aspx) | The columns are added to the GridView when the DataBind() method is called | When are the auto-generated columns in a gridview added? | [
"",
"c#",
"gridview",
""
] |
As I understand it, Windows #defines TCHAR as the correct character type for your application based on the build - so it is `wchar_t` in UNICODE builds and `char` otherwise.
Because of this I wondered if `std::basic_string<TCHAR>` would be preferable to `std::wstring`, since the first would theoretically match the character type of the application, whereas the second would always be wide.
So my question is essentially: Would `std::basic_string<TCHAR>` be preferable to `std::wstring` on Windows? And, would there be any caveats (i.e. unexpected behavior or side effects) to using `std::basic_string<TCHAR>`? Or, should I just use `std::wstring` on Windows and forget about it? | I believe the time when it was advisable to release non-unicode versions of your application (to support Win95, or to save a KB or two) is long past: nowadays the underlying Windows system you'll support are going to be unicode-based (so using char-based system interfaces will actually complicate the code by interposing a shim layer from the library) and it's doubtful whether you'd save any space at all. Go `std::wstring`, young man!-) | I have done this on very large projects and it works great:
```
namespace std
{
#ifdef _UNICODE
typedef wstring tstring;
#else
typedef string tstring;
#endif
}
```
You can use wstring everywhere instead though if you'd like, if you do not need to ever compile using a multi-byte character string. I don't think you need to ever support multi byte character strings though in any modern application.
Note: The `std` namespace is supposed to be off limits, but I have not had any problems with the above method for several years. | Would std::basic_string<TCHAR> be preferable to std::wstring on Windows? | [
"",
"c++",
"windows",
"unicode",
"stl",
""
] |
What is the best solution to convert PDF documents to be viewed in the browser as HTML? The site has several PDF documents and the visitor can click on view as HTML and this should be viewed on the screen as an HTML file.
Standard website running PHP, Linux, Apache. | pdftohtml works fine : fast, stable but the html result is ugly at best. I have used it for quite some time for a web site that has many job resumes.
It is a good solution for extracting textual content however.
I would give the [scribd API](http://www.scribd.com/developers) a try
or the google apps document API. GOogle does a great job a displaying and converting pdf files | If you have command line access at your hosting provider, there is a utility called pdftohtml inside of the poppler\_utils package.
<http://poppler.freedesktop.org/>
Looks quite easy to use, have not called it from inside of PHP, but it should work. | Convert PDF to HTML | [
"",
"php",
"html",
"pdf",
"pdf-to-html",
""
] |
I need to send an email to an Exchange distribution list called "DL-IT" using c#.
Does anyone know how to achieve this? | The simplest way would be to find the actual email address of the DL, and use that in your "To:" field. Exchange distribution lists actually have their own email addresses, so this should work fine. | Exchange server runs SMTP so one can use the [SmtpClient](http://msdn.microsoft.com/en-us/library/system.net.mail.smtpclient.aspx) to send an email.
One can lookup the SMTP address of the distribution list (manually) and use that as the "to" address on the [MailMessage](http://msdn.microsoft.com/en-us/library/system.net.mail.mailmessage.aspx) constructor. The constructor call will fail if you just pass in the name of the distribution list as it doesn't *look* like a *real* email address.
```
public void Send(string server, string from, string to)
{
// Client to Exchange server
SmtpClient client = new SmtpClient(server);
// Message
MailMessage message = new MailMessage(from, to);
message.Body = "This is a test e-mail message sent by an application. ";
message.Subject = "test message 1";
// Credentials are necessary if the server requires the client
// to authenticate before it will send e-mail on the client's behalf.
client.Credentials = CredentialCache.DefaultNetworkCredentials;
// Send
client.Send(message);
}
``` | How do I send an email to an Exchange Distribution list using c# | [
"",
"c#",
"email",
"exchange-server",
""
] |
I've been a web programmer for a while and I can also program in Java. I have an idea for a small, multiplayer RPG game that I want to work on. It will be played through a java applet in the user's web browser.
I have written the design document and specifications of the gameplay. What I'd like to know now is how I can develop the game? I've worked only with windows-like business apps in the past, with built-in widgets for textboxes, dropdowns, etc. With game programming it seems that I would have to build my own widget/controls for the UI of the game.
These are the specific questions I have in mind:
1) How to display a 'loading...' message with a progress bar while the game's images, sound, etc are being downloaded. (Using the java applet)
2) How to create the UI of the game with its own menu, controls, etc. Such as by clicking the map icon it would show up a map to them. Clicking the friends icon would let them chat to their friends, etc.
3) And other, general game development issues that i should know about, like whether I should use 2D or 3D graphics, physics in games, etc.
If there's a good recommendation for a book that will help me, do share. | 1. The easiest route is to package everything in a Jar file. The default screen does show a progress bar with some small ability to [customise](http://java.sun.com/javase/6/docs/technotes/guides/plugin/developer_guide/special_attributes.html). You can write custom code to keep track, manage and download files but I would personally advise against this route. If you search for applet loaders you will find more information.
2. I'm not 100% sure what you mean, but you can use [Swing components](http://java.sun.com/docs/books/tutorial/ui/features/components.html) in the same way you can use them in applications. Use a JButton with an image is quite trivial, then hook the event code in the actionPerformed method.
3. The biggest problem you will probably come across is animation and the [EDT](http://java.sun.com/docs/books/tutorial/uiswing/concurrency/dispatch.html). I asked about [this](https://stackoverflow.com/questions/686822/active-rendering-and-the-edt-swing-animation) earlier.
[This](http://www.coderanch.com/t/201085/Game-Development/java/Good-Java-Game-Tutorial) page has a whole bunch of useful links for game development. [Pulp core](http://www.interactivepulp.com/pulpcore/) is an open source framework worth checking out - even if you don't use the framework you can investigate the code.
Whether you should use Java applets or not seems out of scope of this question, but a lot of the above answers give objective (or no reasons at all) about whether to use Java applets. If it's a game for a personal exercise to learn Java then it's a great approach. If you wish to make it public you need to consider whether the current [adoption levels](http://www.riastats.com/) are high enough for your needs.
Things have changed in the applet world recently. Since [1.6 update 10](http://java.sun.com/developer/technicalArticles/javase/java6u10/) it is much more competitive with Flash - the download size is smaller (at typically under 4Mb), the startup time is reduced and a [new scaling look and feel](http://www.jasperpotts.com/blog/2007/09/nimbus-almost-done/) was introduced. | If this is your first game, a multiplayer project might be too ambitious.
Loading screens are not terribly hard - I implement them by counting up how many files I have to 'load' and then advancing the progress bar (and doing a screen refresh) every time another file has been loaded successfully. You can do this with as much granularity as you please - it might complicate your loading code to add the UI component. I wouldn't worry about it for now; maybe just throw up a basic "Loading..." frame and then implement a full progress bar later when the game is more solid. I've also seen some good implementations with multithreading.
The other two will come with experience; I think what you need more of is a general tutorial for game development than the specific answers. You should definitely start smaller. Once you understand the structure and problems of a smaller game, it will be easier to apply those to larger games.
Most reasonable game programming books will go over basic game structure; I like Game Coding Complete but it's quite complicated for a beginner (it covers more complex ways to approach large projects). Game Architecture and Design is similar, but might be better suited to what you're looking for since it also covers some minor project management "best practices."
There's a lot of different ways to do UI, from using the Java primitive UI types (depending on what other libraries you're using) to self-writing your own "HUD" implementation with just what you need. | How to learn game development? | [
"",
"java",
"applet",
"java-web-start",
""
] |
We had a line of code
```
if( !CreateFile( m_hFile, szFile, GENERIC_READ|GENERIC_WRITE, 0, OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL ) )
{
DWORD dwErr = GetLastError();
CString czInfo;
czInfo.Format ("CMemoryMapFile::OpenAppend SetFilePointer call failed - GetLastError returned %d", dwErr);
LOG(czInfo);
return false;
}
```
This code worked great for many years. A few weeks ago, we had a customer with a problem. Turns out, the problem could be traced to this line of code, where the function would return a INVALID\_HANDLE\_VALUE handle and GetLastError() returned ERROR\_FILE\_NOT\_FOUND(2).
Now, this is very confusing to us. OPEN\_ALWAYS should direct the file to be created if it does not exist. So, why are we getting a ERROR\_FILE\_NOT\_FOUND?
More confusion: For this customer, this only happened on one network share point (we were using a UNC path). Other UNC paths to other machines for this customer worked. Local paths worked. All our other customers (10000+ installs) have no problem at all.
The customer was using XP as the client OS, and the servers were running what appeared to be standard Windows Server 2003 (I think the Small Business Server version). We could not replicate their errors in our test lab using the same OS's. They could repeat the problem with several XP clients, but the problem was only on one server (other Server 2003 servers did not exhibit the problem).
We fixed the problem by nesting two CreateFile calls, the first with OPEN\_EXISTING, and the second with CREATE\_ALWAYS if OPEN\_EXISTING failed. So, we have no immediate need for a fix.
My question: Does anyone have any idea why this API call would fail in this particular way? We are puzzled.
Addendum:
The CreateFile function above is a wrapper on the Windows API function. Here's the code:
```
bool CMemoryMapFile::CreateFile( HANDLE & hFile, LPCSTR szFile, DWORD dwDesiredAccess, DWORD dwShareMode, DWORD dwCreationDisposition, DWORD dwFlagsAndAttributes )
{
hFile = ::CreateFile (szFile, dwDesiredAccess, dwShareMode, NULL,
dwCreationDisposition, dwFlagsAndAttributes, NULL);
return (hFile != INVALID_HANDLE_VALUE)
}
``` | Maybe the directory you wanted to create the file in did not exist?
Are you sure you fixed it by using 2 CreateFile calls? Or did you just not reproduce it? | First, you should always check for success of the CreateFile() API like this:
```
if (CreateFile(...) == INVALID_HANDLE_VALUE)
{
// handle the error
}
```
because CreateFile() doesn't return !=0 in case of success, but anything other than INVALID\_HANDLE\_VALUE (which is -1).
Then, the CreateFile() can fail in the situation you described if either the directory doesn't exist where you want to create/open the file in, or it can fail if the user has the rights to open and write files in that directory, but no rights to create new files. | CreateFile Win32 API Call with OPEN_ALWAYS failed in an Odd Way | [
"",
"c++",
"winapi",
""
] |
I'm trying to populate a Drop down list with pharmaceutical companies, like Bayer, Medley etc. And, I'm getting theses names from DB and theses names are repeated in DB, but with different id's.
I'm trying to use Linq Distinct(), but I don't want to use the equality comparer. Is there another way?
My drop down list must be filled with the id and the name of the company.
I'm trying something like:
```
var x = _partnerService
.SelectPartners()
.Select(c => new {codPartner = c.codPartner, name = c.name})
.Distinct();
```
This is showing repeated companies in ddl.
thanks! | The following expression will select only distinct companies and return the first occurence with its id.
```
partnerService.SelectPartners().GroupBy(p => p.Name).Select(g => g.First());
``` | ```
var distinctCompanies = Companies
.GroupBy(c => c.CompanyName)
.Select(g => g.First());
``` | Linq Distinct() by name for populate a dropdown list with name and value | [
"",
"c#",
"linq-to-sql",
"distinct",
""
] |
I have been trying to track down weird problems with my mod\_wsgi/Python web application. I have the application handler which creates an object and calls a method:
```
def my_method(self, file):
self.sapi.write("In my method for %d time"%self.mmcount)
self.mmcount += 1
# ... open file (absolute path to file), extract list of files inside
# ... exit if file contains no path/file strings
for f in extracted_files:
self.num_files_found += 1
self.my_method(f)
```
At the start and end of this, I write
```
obj.num_files_found
```
To the browser.
So this is a recursive function that goes down a tree of file-references inside files. Any references in a file are printed and then those references are opened and examined and so on until all files are leaf-nodes containing no files. Why I am doing this isn't really important ... it is more of a pedantic example.
**You would expect the output to be deterministic**
Such as
```
Files found: 0
In my method for the 0 time
In my method for the 1 time
In my method for the 2 time
In my method for the 3 time
...
In my method for the n time
Files found: 128
```
And **for the first few requests it is as expected.** Then I get the following for as long as I refresh
```
Files found: 0
In my method for the 0 time
Files found: 128
```
Even though I know, from previous refreshes and no code/file alterations that it takes *n* times to enumerate 128 files.
So the question then: **Does mod\_wsgi/Python include internal optimizations that would stop complete execution? Does it guess the output is deterministic and cache?**
As a note, in the refreshes when it is as expected, REMOTE\_PORT increments by one each time ... when it uses a short output, the increment of REMOTE\_PORT jumps wildly. Might be unrelated however.
**I am new to Python, be gentle**
**Solved**
Who knows what it was, but ripping out Apache, mod\_python, mod\_wsgi and nearly everything HTTP related and re-installing fixed the problem. Something was **pretty broken** but seems ok now :) | "Does mod\_wsgi/Python include internal optimizations that would stop complete execution? Does it guess the output is deterministic and cache?"
No.
The problem is (generally) that you have a global variable somewhere in your program that is not getting reset the way you hoped it would.
Sometimes this can be unintentional, since Python checks local namespace and global namespace for variables.
You can -- inadvertently -- have a function that depends on some global variable. I'd bet on this.
What you're likely seeing is a number of mod\_wsgi daemon processes, each with a global variable problem. The first request for each daemon works. Then your global variable is in a state that prevents work from happening. [File is left open, top-level directory variable got overwritten, who knows?]
After the first few, all the daemons are stuck in the "other" mode where they report the answer without doing the real work. | That Apache/mod\_wsgi may run in both multi process/multi threaded configurations can trip up code which is written with the assumption that it is run in a single process, with that process possibly being single threaded. For a discussion of different configuration possibilities and what that all means for shared data, see:
<http://code.google.com/p/modwsgi/wiki/ProcessesAndThreading> | Is mod_wsgi/Python optimizing things out? | [
"",
"python",
"debugging",
"caching",
"mod-wsgi",
""
] |
I'm working on an application that needs to run 24H a day, and am working on correctly implementing support for DST. All times are currently stored in UTC, but I'm having issues when I try to display in local time. Right now I'm using `savedDate.ToLocalTime()` to convert from DB values to local time for display. This seems to be working fine, except for when I change the time zone information in an effort to test DST. If I modify the timezone on the client pc, the display doesn't update with the new time zone. Is there a better way to test DST, or is my conversion to local time incorrect for this scenario? | I remember reading, perhaps regarding the Compact Framework, about .NET not being the most reliable when it comes to reporting about DST. More reliable was getting the current time in local time and UTC, and then determining (and using in future adjustments) the difference yourself. That seems like a horrible route to go if it's not really necessary. I'll see if I can find a reference backing up what I *think* I remember.
What are you doing, exactly, to change the timezone on the workstation? | Hmm. Do you expect to *actually* have to change time zone while the app is running? I wouldn't be surprised if the framework cached it after it's first fetched.
I would set the time zone on the device, change the time to "just before the change to DST", run the app and check that it's reporting times correctly. Then change the time to "just before the change out of DST".
Bear in mind that depending on your device and the age of its time zone database, it may not know about the change to DST in the US a few years ago. (Ah, time zones. Gotta love 'em.) | Handling DST in 24H Application | [
"",
"c#",
".net",
"timezone",
""
] |
I have an application that is scheduled and get some data from a another database table and dumps in my main applications database table,the number of records in this table increases daily and I assume it will grow daily as it is transactions event data that occur.This data is used for processing by the main application which takes each record and does the needed analysis and marks each record as processed.
What kind of solution can I provide so that I can keep the size of the database down in the future?
How would you go about it in this situation?
From my observation of a few enterprise applications,one provides an option that the user can
archive records 'older than 60 day' etc... to a text file.Well I could provide an option to archive the processed records to a text file and delete the records from the database,the text file could be later imported if necessary? Is this a solution? | If you need to occasionally access that older data then building a process to archive it to text and then to load back from text is probably not a great solution. Hard drives are cheap.
You could aggregate the older data. For example if the transaction data is at the millisecond grain now but when you report on older data you get it by the day then consider aggregating the data to "daily" as your archiving process. You may be able to collapse hundreds of thousands of rows into a just a few for each day.
Also consider a good partitioning scheme where you can keep the most recent transactions on one set of disks and the archived data to other disks, hopefully in a process where you can easily add new disks and create tables to those disks. | What kind of past data reporting needs does your company have? Dropping archived data into a text file is all well and good, assuming you don't need to be able to report off of that data in the future. However, having it in a text file means you have to have a manual process to import it on demand into a database when it is needed.
A better option would be to move archival data off into a data warehouse database which is not used for transaction processing (OLTP), and instead is used as the foundation of an analytical processing database (OLAP). When the time comes to report off of this archived data, its ready to go. If you are careful about how you structure data in this archival database, it should be very easy to aggregate all the data into an OLAP Cube, which makes reporting off of that data much faster and more flexible.
But again...depends on whether you report off the data or not, and how far back in time that reporting might go. | Managing huge transaction records? | [
"",
"c#",
"database",
"archive",
""
] |
How can I set the `java.library.path` for a whole Eclipse Project? I'm using a Java library that relies on OS specific files and need to find a `.dll/` `.so/` `.jnilib`. But the Application always exits with an error message that those files are not found on the library path.
I would like to configure this whole project to use the library path. I tried to add the path as a VM argument to some run configurations in eclipse but that didn't work. | Don't mess with the library path! Eclipse builds it itself!
Instead, go into the library settings for your projects and, for each jar/etc that requires a native library, expand it in the *Libraries* tab. In the tree view there, each library has items for source/javadoc and native library locations.
Specifically: select `Project`, right click -> *Properties* / *Java Build Path* / *Libraries* tab, select a .jar, expand it, select *Native library location*, click *Edit*, folder chooser dialog will appear)
Messing with the library path on the command line should be your last ditch effort, because you might break something that is already properly set by eclipse.
 | If you are adding it as a VM argument, make sure you prefix it with `-D`:
```
-Djava.library.path=blahblahblah...
``` | How to set the java.library.path from Eclipse | [
"",
"java",
"eclipse",
"configuration",
"buildpath",
""
] |
Is it possible to create an attribute on a generator object?
Here's a very simple example:
```
def filter(x):
for line in myContent:
if line == x:
yield x
```
Now say I have a lot of these filter generator objects floating around... maybe some of them are anonymous... I want to go back later and interrogate them for what they are filtering for. Is there a way I can a) interrogate the generator object for the value of x or b) set an attribute with the value of x that I can later interrogate?
Thanks | Unfortunately, generator objects (the results returned from calling a generator function) do not support adding arbitrary attributes. You can work around it to some extent by using an external dict indexed by the generator objects, since such objects *are* usable as keys into a dict. So where you'd *like* to do, say:
```
a = filter(23)
b = filter(45)
...
a.foo = 67
...
x = random.choice([a,b])
if hasattr(x, 'foo'): munge(x.foo)
```
you may instead do:
```
foos = dict()
a = filter(23)
b = filter(45)
...
foos[a] = 67
...
x = random.choice([a,b])
if x in foos: munge(foos[x])
```
For anything fancier, use a class instead of a generator (one or more of the class's methods can be generators, after all). | Yes.
```
class Filter( object ):
def __init__( self, content ):
self.content = content
def __call__( self, someParam ):
self.someParam = someParam
for line in self.content:
if line == someParam:
yield line
``` | python: attributes on a generator object | [
"",
"python",
""
] |
I have a jquery question about selecting Id.
Basically, I call a javascript function from an onClick function which I pass in control Id and LabelId.
If I use document.getElementById, it will work, however, if I use jQuery selector, it's NOT working.
```
<script type="text/javascript">
jQuery.noConflict();
function ToggleProgressEnable(valueofRadio, controlId, labelId) {
//Comments: the following will work.
// var control = document.getElementById(controlId);
// var label = document.getElementById(labelId);
//The following is not working.
var control = jQuery("'#" + controlId + "'");
var label = jQuery("'#" + labelId + "'");
if (control != null && label!=null) {
//alert(control.Id);
//alert(control.disabled);
if (valueofRadio == "yes") {
control.disabled = false;
label.disabled = false;
}
else if (valueofRadio == "no") {
control.disabled = true;
control.value = "";
label.disabled = true;
}
//alert(control.disabled);
}
}
</script>
``` | ```
var control = jQuery("'#" + controlId + "'");
var label = jQuery("'#" + labelId + "'");
```
you're doing your selectors wrong. get rid of your single quotes and just use your double quotes:
```
var control = $("#" + controlId);
var label = $("#" + labelId);
``` | Try
```
jQuery('#' + controlId);
```
Otherwise, you're searching for '#controlId', which is not a valid selector. | JQuery select Id question | [
"",
"javascript",
"jquery",
""
] |
In my application I need to know if the computer is the primary domain controller of a domain, so I need to know the domain of the computer to call NetGetDCName function.
Thanks.
EDIT: The problem is related with the DCOM authentication so I need to know the domain to use the DOMAIN\USERNAME in case of a PDC or COMPUTER\USERNAME if I need to use the local authentication database of the computer. | I would consider using [NetWkstaGetInfo()](http://msdn.microsoft.com/en-us/library/aa370663(VS.85).aspx) and pass the local computer name is that first parameter.
```
#include <Lmwksta.h>
#include <StrSafe.h>
WCHAR domain_name[256];
WKSTA_INFO_100 info = {0};
if (NERR_Success == NetWkstaGetInfo(L"THIS-COMPUTER", 100, &info) &&
SUCCEEDED(StringCchCopy(domain_name, ARRAYSIZE(domain_name), info.wki100_langroup))) {
// use domain_name here...
}
``` | The [`NetWkstaGetInfo()`](http://msdn.microsoft.com/en-us/library/aa370663%28VS.85%29.aspx) function returns either the domain name or the workgroup of the computer, and is therefore not a reliable way to determine if the computer is a member of a domain.
The [`GetComputerNameEx()`](http://msdn.microsoft.com/en-us/library/ms724301%28v=vs.85%29.aspx) function will help, used with the `ComputerNameDnsDomain` parameter, as shown below. This will return an empty string if the computer is in a workgroup, or the DNS name of the domain:
```
DWORD bufSize = MAX_PATH;
TCHAR domainNameBuf[ MAX_PATH ];
GetComputerNameEx( ComputerNameDnsDomain, domainNameBuf, &bufSize );
``` | Get the domain name of a computer from Windows API | [
"",
"c++",
"winapi",
""
] |
I have a page that will pull many headlines from multiple categories based off a category id.
I'm wondering if it makes more sense to pull all the headlines and then sort them out via PHP if/ifelse statements or it is better to run multiple queries that each contain the headlines from each category. | Why not do it in one query? Something like:
```
SELECT headline FROM headlines WHERE category_id IN (1, 2, 3, ...);
```
If you filter your headlines in PHP, think how many you'll be throwing away. If you end up with removing just 10% of the headlines, it won't matter as much as when you'd be throwing away 90% of the results. | These kinds of questions are always hard to answer because the situation determines the best course. There is never a truly correct answer, only better ways. In my experience doesn't really matter whether you attempt to do the work in PHP or in the database because you should always try to cache the results of any expensive operation using a caching engine such as [memcached](http://www.php.net/manual/en/book.memcached.php). That way you are not going to spend a lot of time in the db or in php itself since the results will be cached and ready instantaneously for use. When it comes down to it, unlss you profile your application using a tool like [xDebug](http://xdebug.org/), what you think are your performance bottlenecks are just guesses. | Faster to query in MYSQL or to use PHP logic | [
"",
"php",
"mysql",
"performance",
""
] |
In the actual C++ standard, creating collections satisfying following rules is hard if not impossible:
1. exception safety,
2. cheap internal operations (in actual STL containers: the operations are copies),
3. automatic memory management.
To satisfy (1), a collection can't store raw pointers. To satisfy (2), a collection must store raw pointers. To satisfy (3), a collection must store objects by value.
Conclusion: the three items conflict with each other.
Item (2) will not be satisfied when `shared_ptr`s are used because when a collection will need to move an element, it will need to make two calls: to a constructor and to a destructor. No massive, `memcpy()`-like copy/move operations are possible.
Am I correct that the described problem will be solved by `unique_ptr` and `std::move()`? Collections utilizing the tools will be able to satisfy all 3 conditions:
1. When a collection will be deleted as a side effect of an exception, it will call `unique_ptr`'s destructors. No memory leak.
2. * `unique_ptr` does not need any extra space for reference counter; therefore its body should be exact the same size, as wrapped pointer,
* I am not sure, but it looks like this allows to move groups of `unique_ptrs` by using `memmove()` like operations (**?**),
* even if it's not possible, the `std::move()` operator will allow to move each `unique_ptr` object without making the constructor/destructor pair calls.
3. `unique_ptr` will have exclusive ownership of given memory. No accidental memory leaks will be possible.
Is this true? What are other advantages of using `unique_ptr`? | I agree entirely. There's at last a natural way of handling heap allocated objects.
In answer to:
> I am not sure, but it looks like this allows to move groups of `unique_ptr`s by using `memmove()` like operations,
there was a [proposal](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2008/n2718.html) to allow this, but it hasn't made it into the C++11 Standard. | Yes, you are right. I would only add this is possible thanks to r-value references. | unique_ptr - major improvement? | [
"",
"c++",
"programming-languages",
"c++11",
"language-design",
""
] |
I am writing a C# console app. It's going to run as a scheduled task.
I want my EXE to exit quickly if it finds that another process is still running from the previous schedule task execution.
I can't seem to find the way to let my app detect the active processes, and so know whether it's already running or not.
Thanks for any ideas.
Peter | One very common technique is to create a mutex when your process starts. If you cannot create the mutex it means there is another instance running.
This is the sample from Nathan's Link:
```
//Declare a static Mutex in the main form or class...
private static Mutex _AppMutex = new Mutex(false, "MYAPP");
// Check the mutex before starting up another possible instance
[STAThread]
static void Main(string[] args)
{
if (MyForm._AppMutex.WaitOne(0, false))
{
Application.Run(new MyForm());
}
else
{
MessageBox.Show("Application Already Running");
}
Application.Exit();
}
``` | try
System.Diagnostics.Process
getProcesses() | How to detect if my program is running in Windows? | [
"",
"c#",
"windows",
"console",
""
] |
I work in Linux with C++ (Eclipse), and want to use a library.
Eclipse shows me an error:
```
undefined reference to 'dlopen'
```
Do you know a solution?
Here is my code:
```
#include <stdlib.h>
#include <stdio.h>
#include <dlfcn.h>
int main(int argc, char **argv) {
void *handle;
double (*desk)(char*);
char *error;
handle = dlopen ("/lib/CEDD_LIB.so.6", RTLD_LAZY);
if (!handle) {
fputs (dlerror(), stderr);
exit(1);
}
desk= dlsym(handle, "Apply");
if ((error = dlerror()) != NULL) {
fputs(error, stderr);
exit(1);
}
dlclose(handle);
}
``` | You have to link against libdl, add
> -ldl
to your linker options | @Masci is correct, but in case you're using C (and the `gcc` compiler) take in account that this doesn't work:
```
gcc -ldl dlopentest.c
```
But this does:
```
gcc dlopentest.c -ldl
```
Took me a bit to figure out... | Linux c++ error: undefined reference to 'dlopen' | [
"",
"c++",
"linux",
"eclipse",
""
] |
This bothers me a lot and I find I write stupid bugs when combined with Intellisense (VS 2008 Pro):
```
class Foo
{
public Foo(bool isAction)
{
this.IsAction = IsAction;
}
public bool IsAction { get; private set; }
}
```
Did you catch it? I certainly didn't until IsAction never changed, causing bugs.
Intellisense somehow converted "`isA<tab>`" to "IsAction" for me which means the property `Foo.IsAction` is *always* false regardless of the constructor input. Just brilliant.
I have to say that I particularly hate the "implicit `this`" (I don't know if that has a formal name) and I would like to turn it off so it never assumes it. **Is there a way to do this?** This also applies in calling static methods of the same class.
**Alternatively, what naming conventions avoid this little problem?** The property must remain "IsAction" so it has to be a convention on the constructor parameter name. Oddly enough, if I name it with the exact matching spelling then `this.IsAction = IsAction;` works out correctly.
The problem isn't case-sensitive languages but the implicitness of `this`. Now that I think about it, this also more of a VS 2008 Pro question than a C#. I can live with code already written without the `this` but I don't want to write new code without it which means telling In
---
Noldorin's answer got me thinking.
Now that I think about it, this also more of a VS 2008 question than a C#. I can live with code already written without the `this` (though I do change it if I'm in there mucking around) but I don't want to write new code without it which means telling Intellisense to stop doing it. **Can I tell Intellisense to knock it off?** | This is a common problem. Microsoft has some [recommendations for parameter names](http://msdn.microsoft.com/en-us/library/ab6a8y1b(VS.71).aspx) but they aren't terribly helpful in your case.
As other responders have mentioned, you cannot "disable" the C# language scope resolution behavior - your best approach is a naming conventions. Others have mentioned "Hungarian" notation - some people have a knee-jerk reaction to this because of the [confusion over the original intent](http://www.joelonsoftware.com/articles/Wrong.html) of the notation.
My personal approach, has been to use the character 'p' as a prefix to parameter names of public functions. It's unobtrusive, simple, readily identifiable, and easy to enforce with tools like [Resharper](http://www.jetbrains.com/resharper/index.html).
The particular naming convention you choose is a matter of preference and style; however, there is some benefit from being consistent in the practice you select.
Using my suggested naming convention, you would write your constructor to:
```
class Foo
{
public Foo(bool pIsAction)
{
this.IsAction = pIsAction;
}
public bool IsAction { get; private set; }
}
``` | I've just tried your code in Visual Studio 2008. Turning on the in built static analysis yields the following error:
> Warning 3 CA1801 : Microsoft.Usage :
> Parameter 'isAction' of
> 'Foo.Foo(bool)' is never used. Remove
> the parameter or use it in the method
> body.
My suggestion is by turning this on you will find errors like this early on. To enable this choose properties from the context menu on the project, then select the Code Analysis tab and select "Enable Code Analysis on Build" | How do I disable the implicit "this" in C#? | [
"",
"c#",
"visual-studio-2008",
".net-3.5",
"this",
""
] |
I haven't found any information on that topic and its [homepage](http://storm.canonical.com) doesn't mention it. | With storm 0.21, it supports Python 3.
You may refer to the [release notes](https://launchpad.net/storm/trunk/0.21) for details, or more specifically, refer to this [bug](https://bugs.launchpad.net/storm/+bug/1530734) for addressing this. | Even though planned, at the moment there is no support for Python 3, you can check it out more details about that reading this thread from the storm ml:
<https://lists.ubuntu.com/archives/storm/2009-January/000839.html> | Is storm Python 3 compatible? | [
"",
"python",
"python-3.x",
"storm-orm",
""
] |
I have two objects of the same type, and I want to loop through the public properties on each of them and alert the user about which properties don't match.
Is it possible to do this without knowing what properties the object contains? | Yes, with reflection - assuming each property type implements `Equals` appropriately. An alternative would be to use `ReflectiveEquals` recursively for all but some known types, but that gets tricky.
```
public bool ReflectiveEquals(object first, object second)
{
if (first == null && second == null)
{
return true;
}
if (first == null || second == null)
{
return false;
}
Type firstType = first.GetType();
if (second.GetType() != firstType)
{
return false; // Or throw an exception
}
// This will only use public properties. Is that enough?
foreach (PropertyInfo propertyInfo in firstType.GetProperties())
{
if (propertyInfo.CanRead)
{
object firstValue = propertyInfo.GetValue(first, null);
object secondValue = propertyInfo.GetValue(second, null);
if (!object.Equals(firstValue, secondValue))
{
return false;
}
}
}
return true;
}
``` | Sure you can with reflection. Here is the code to grab the properties off of a given type.
```
var info = typeof(SomeType).GetProperties();
```
If you can give more info on what you're comparing about the properties we can get together a basic diffing algorithmn. This code for intstance will diff on names
```
public bool AreDifferent(Type t1, Type t2) {
var list1 = t1.GetProperties().OrderBy(x => x.Name).Select(x => x.Name);
var list2 = t2.GetProperties().OrderBy(x => x.Name).Select(x => x.Name);
return list1.SequenceEqual(list2);
}
``` | Compare two objects' properties to find differences? | [
"",
"c#",
".net",
""
] |
Example, I want to specialize a class to have a member variable that is an stl container, say a vector or a list, so I need something like:
```
template <class CollectionType, class ItemType>
class Test
{
public:
CollectionType<ItemType> m_collection;
};
```
So I can do:
```
Test t = Test<vector, int>();
t.m_collection<vector<int>> = vector<int>();
```
But this generates
```
test.cpp:12: error: `CollectionType' is not a template
``` | Why not do it like this?
```
template <class CollectionType>
class Test
{
public:
CollectionType m_collection;
};
Test t = Test<vector<int> >();
t.m_collection = vector<int>();
```
If you need the itemtype you can use `CollectionType::value_type`.
EDIT: in response to your question about creating a member function returning the value\_type, you do it like this:
```
typename CollectionType::value_type foo();
```
You add the typename because CollectionType has not been bound to an actual type yet. So there isn't a value\_type it could look up. | What you want is a template template parameter:
```
template <template <typename> class CollectionType, class ItemType>
class Test
{
public:
CollectionType<ItemType> m_collection;
};
```
What we did here is specifying that the first template parameter, i.e. `CollectionType`, is a type template. Therefore, `Test` can only be instantiated with a type that is itself a template.
However, as @Binary Worrier pointed in the comments, this won't work with STL containers since they have **2** template parameters: one for the elements type, the other one for the type of the allocator used for managing storage allocation (which has a default value).
Consequently, you need to change the first template parameter so that it has two parameters:
```
template <template <typename,typename> class CollectionType, class ItemType>
class Test
{
public:
CollectionType<ItemType> m_collection;
};
```
But wait, that won't work either! Indeed, `CollectionType` awaits another parameter, the allocator... So now you have two solutions:
1 . Enforce the use of a particular allocator:
```
CollectionType<ItemType, std::allocator<ItemType> > m_collection
```
2 . Add a template parameter for the allocator to your class:
```
template <template <typename,typename> class CollectionType,
class ItemType,
class Allocator = std::allocator<ItemType> >
class Test
{
public:
CollectionType<ItemType, Allocator> m_collection;
};
```
So as you see, you end up with something rather complicated, which seems really twisted to deal with STL containers...
My advice: see Greg Rogers' answer for a better approach :)! | Can you use C++ templates to specify a collection type and the specialization of that type? | [
"",
"c++",
"templates",
"collections",
""
] |
I am trying to write a division method, which accepts 2 parameters.
```
public static decimal Divide(decimal divisor, decimal dividend)
{
return dividend / divisor;
}
```
Now, if divisor is 0, we get cannot divide by zero error, which is okay.
What I would like to do is check if the divisor is 0 and if it is, convert it to 1. Is there way to do this with out having a lot of if statements in my method? I think a lot of if()s makes clutter. I know mathematically this should not be done, but I have other functionality for this.
For example:
```
if(divisor == 0)
{
divisor = 1;
}
return dividend / divisor;
```
Can it be done without the `if()` statement? | You can do a conditional if statement like this. This is the same as IIF in VB.net
```
return dividend / ((divisor == 0) ? 1 : divisor);
```
Make sure you wrap your second half with () or you will get a divide error. | By using the `?:` operator
```
return (divisor == 0) ? dividend : dividend / divisor
``` | Decimal Value Check if Zero | [
"",
"c#",
"math",
"puzzle",
""
] |
I have only done databases without relations, but now I need to do something more serious and correct.
Here is my database design:
[](https://i.stack.imgur.com/ag55o.jpg)
1. Kunde = Customer
2. Vare = Product
3. Ordre = Order (*Read*: I want to make an order)
4. VareGruppe = ehm..type? (Read: Car, chair, closet etc.)
5. VareOrdre = Product\_Orders
Here is my SQL (SQLite) schema:
```
CREATE TABLE Post (
Postnr INTEGER NOT NULL PRIMARY KEY,
Bynavn VARCHAR(50) NOT NULL
);
CREATE TABLE Kunde (
CPR INTEGER NOT NULL PRIMARY KEY,
Navn VARCHAR(50) NOT NULL,
Tlf INTEGER NOT NULL,
Adresse VARCHAR(50) NOT NULL,
Postnr INTEGER NOT NULL
CONSTRAINT fk_postnr_post REFERENCES Post(Postnr)
);
CREATE TABLE Varegruppe (
VGnr INTEGER PRIMARY KEY,
Typenavn VARCHAR(50) NOT NULL
);
CREATE TABLE Vare (
Vnr INTEGER PRIMARY KEY,
Navn VARCHAR(50) NOT NULL,
Pris DEC NOT NULL,
Beholdning INTEGER NOT NULL,
VGnr INTEGER NOT NULL
CONSTRAINT fk_varegruppevgnr_vgnr REFERENCES Varegruppe(VGnr)
);
CREATE TABLE Ordre (
Onr INTEGER PRIMARY KEY,
CPR INTEGER NOT NULL
CONSTRAINT fk_kundecpr_cpr REFERENCES Kunde(CPR),
Dato DATETIME NOT NULL,
SamletPris DEC NOT NULL
);
CREATE TABLE VareOrdre (
VareOrdreID INTEGER PRIMARY KEY,
Onr INTEGER NOT NULL
CONSTRAINT fk_ordrenr_onr REFERENCES Ordre(Onr),
Vnr INTEGER NOT NULL
CONSTRAINT fk_varevnr_vnr REFERENCES Vare(Vnr),
Antal INTEGER NOT NULL
);
```
It should work correctly.
But I am confused about `Product_Orders`.
How do I create an order? For example, 2 products using `SQL INSERT INTO`?
I can get nothing to work.
So far:
Only when I manually insert products and data into `Product_Orders` and then add that data to `Orders =` which makes it complete. Or the other way around (create an order in with 1 SQL, then manually inserting products into `Product_orders - 1` SQL for each entry) | You should first create an order and then insert products in the table Product\_Orders. This is necessary because you need an actual order with an id to associate it with the table Product\_Orders.
You always should create a record in the foreign-key table before being able to create one in your current table. That way you should create a "Post", customer, type, product, order and product\_order. | Try this ...
first you have to insert a customer
```
insert into kunde values(1, 'navn', 1, 'adresse', 1)
```
then you insert a type
```
insert into VareGruppe values(1, 'Type1')
```
then you insert a product
```
insert into vare values(1, 'product1', '10.0', 1, 1)
```
then you add an order
```
insert into ordre values(1, 1, '20090101', '10.0')
```
then you insert a register to the product\_orders table
```
insert into VareOrdre values (1, 1, 1, 1)
```
I think this is it. :-)
As the primary keys are autoincrement, don't add them to the insert and specify the columns like this
```
insert into vare(Nav, Pris, Beholdning, VGnr) values('product1', '10.0', 1, 1)
```
Use `Select @@identity` to see the onr value | How can I insert into tables with relations? | [
"",
"sql",
"foreign-keys",
"primary-key",
"entity-relationship",
""
] |
I have a rather large project involving spring and hibernate. Right now, I'm backing certain objects out of hibernate and into memory, and I've hit a sort of snag. I have the following setup.
Class A contains a number of primitives and a class B. B contains primitives and a class C, which was previously **lazy-loaded**.
Now I have this
Service call 1:
1.) create object of class A
2.) get object of class B
3.) set B in A
4.) add A to memory
Service call 2:
1.) get A from memory
2.) get B from A
3.) get C from B
4.) operate on C
Because C is lazy loaded, it relied on a hibernate session existing to lazily load itself from B with hibernate, at least I believe this to be so. Now, however, I need to lazy load **without** modifying the DAO to return an ID, and there exists **no current** hibernate session to hijack into with OpenSessionInView. What's the best way to go about solving this problem, given the limitations? The only solutions I've found rely on unsuitable code change or an existing session, so I think that I could perhaps manually open a hibernate session. How would I go about doing this? Alternatively, is there a better solution to this problem? | If you can get a reference to your configured SessionFactory, you should be able to just call openSession() on it. | As a best practice, you'll want to use a session factory. Here is the one Netbeans generates.
```
public class HibernateUtil {
private static final SessionFactory sessionFactory;
private static final Configuration configuration = new Configuration().configure();
static {
try {
// Create the SessionFactory from standard (hibernate.cfg.xml)
// config file.
sessionFactory = new AnnotationConfiguration().configure().buildSessionFactory();
} catch (Throwable ex) {
// Log the exception.
System.err.println("Initial SessionFactory creation failed." + ex);
throw new ExceptionInInitializerError(ex);
}
}
public static SessionFactory getSessionFactory() {
return sessionFactory;
}
}
```
Once you have this, you can use this code for a transaction
```
Session session = HibernateUtil.getSessionFactory().getCurrentSession();
session.beginTransaction();
//Do something
session.getTransaction().commit();
```
Note that opening a transaction will open a session. I believe under pure Hibernate (unlike JPA) you need a transaction to do anything, even reads.
At the end of the program you want to make sure you do this
```
HibernateUtil.getSessionFactory().close();
```
For a more sophisticated solution, you may want to look into automatic session/transaction management with Spring or EJB. Which will handle the session behind the scenes once configured properly.
**EDIT:**
Just re-read your question and your point about IDs. I believe the sessionfactory approach will work for your purposes, unless you are doing a multiple threaded application. This is because, by default, Hibernate sessions and the ORM objects linked to that session are associated to one thread only. Let me know if I am wrong about this. | How do I manually open a hibernate session? | [
"",
"java",
"hibernate",
"spring",
"lazy-loading",
""
] |
What's wrong with this query:
```
SELECT co.*, mod.COUNT(*) as moduleCount, vid.COUNT(*) as vidCount
FROM courses as co, modules as mod, videos as vid
WHERE mod.course_id=co.id AND vid.course_id=co.id ORDER BY co.id DESC
```
In other words, how can I do it so with every record returned from 'courses', there's
an additional column called 'modCount' which shows the number of records in the modules table for that course\_id, and another called 'vidCount' which does the same thing for the videos table.
Error:
> Error Number: 1064
>
> You have an error in your SQL syntax;
> check the manual that corresponds to
> your MySQL server version for the
> right syntax to use near '*) as
> moduleCount, vid.COUNT(*) as vidCount
> FROM courses as co, ' at line 1 | Using subselects you can do:
```
SELECT co.*,
(SELECT COUNT(*) FROM modules mod WHERE mod.course_id=co.id) AS moduleCount,
(SELECT COUNT(*) FROM videos vid WHERE vid.course_id=co.id) AS vidCount
FROM courses AS co
ORDER BY co.id DESC
```
But be carefull as this is an expensive query when courses has many rows.
**EDIT:**
If your tables are quite large the following query should perform much better (in favor of being more complex to read and understand).
```
SELECT co.*,
COALESCE(mod.moduleCount,0) AS moduleCount,
COALESCE(vid.vidCount,0) AS vidCount
FROM courses AS co
LEFT JOIN (
SELECT COUNT(*) AS moduleCount, course_id AS courseId
FROM modules
GROUP BY course_id
) AS mod
ON mod.courseId = co.id
LEFT JOIN (
SELECT COUNT(*) AS vidCount, course_id AS courseId
FROM videos
GROUP BY course_id
) AS vid
ON vid.courseId = co.id
ORDER BY co.id DESC
``` | i have better solution and easy
```
SELECT COUNT(*),(SELECT COUNT(*) FROM table2) FROM table1
``` | Mysql COUNT(*) on multiple tables | [
"",
"sql",
"mysql",
""
] |
Now I know this has been asked before. But I've made doubly sure that all parameters are correct and there are no typos. I still get the error. Could somebody please guide me here? I am nearing my wit's end!
```
CREATE OR REPLACE PROCEDURE VWT.WUA_DELETE_FP_REQUEST
(i_pLDAPUserName IN varchar2,
i_pIReasonCode IN number,
i_pLastName IN varchar2,
i_pFirstName IN varchar2,
i_pDealerID IN number,
i_pAddr1 IN varchar2,
i_pAddr2 IN varchar2,
i_pCity IN varchar2,
i_pState IN varchar2,
i_pZip IN varchar2,
i_pBusinessEmail IN varchar2,
i_pBusinessPhone IN varchar2,
i_pReviewDate IN Date,
i_pReviewedByWhom IN varchar2,
i_pDealersRepID IN varchar2,
i_pComments IN varchar2,
i_pPrivacyUsageFlag IN varchar2,
i_pDealersBranchID IN varchar2,
i_pPrivacyUsageDate IN date,
i_pMarketingFlag IN varchar2,
i_pMarketingDate IN date,
i_pWorkCountry IN varchar2,
i_pOperator IN varchar2,
o_return_status OUT integer,
o_error_desc OUT varchar2
)
```
========================================================================
Code to run the procedure
```
OracleParameter ldapUserName = new OracleParameter
("i_pLDAPUserName", OracleType.VarChar, 1024);
ldapUserName.Direction = ParameterDirection.Input;
ldapUserName.Value = ldapUserName_;
command.Parameters.Add(ldapUserName);
OracleParameter reasonCode = new OracleParameter
("i_pIReasonCode", OracleType.Number);
reasonCode.Direction = ParameterDirection.Input;
reasonCode.Value = reasonCode_;
command.Parameters.Add(reasonCode);
OracleParameter lastName = new OracleParameter
("i_pLastName", OracleType.VarChar, 1024);
lastName.Direction = ParameterDirection.Input;
lastName.Value = userDetail.LastName ?? String.Empty;
command.Parameters.Add(lastName);
OracleParameter firstName = new OracleParameter
("i_pFirstName", OracleType.VarChar, 1024);
firstName.Direction = ParameterDirection.Input;
firstName.Value = userDetail.FirstName ?? String.Empty;
command.Parameters.Add(firstName);
OracleParameter dealerID = new OracleParameter
("i_pDealerID", OracleType.Number);
dealerID.Direction = ParameterDirection.Input;
dealerID.Value =
Int32.Parse(String.IsNullOrEmpty(userDetail.DealerID) ? "0" : userDetail.DealerID);
command.Parameters.Add(dealerID);
OracleParameter address1 = new OracleParameter
("i_pAddr1", OracleType.VarChar, 1024);
address1.Direction = ParameterDirection.Input;
address1.Value = userDetail.WorkAddress1 ?? String.Empty;
command.Parameters.Add(address1);
OracleParameter address2 = new OracleParameter
("i_pAddr2", OracleType.VarChar, 1024);
address2.Direction = ParameterDirection.Input;
address1.Value = userDetail.WorkAddress2 ?? String.Empty;
command.Parameters.Add(address2);
OracleParameter city = new OracleParameter
("i_pCity", OracleType.VarChar, 1024);
city.Direction = ParameterDirection.Input;
city.Value = userDetail.City ?? String.Empty;
command.Parameters.Add(city);
OracleParameter state = new OracleParameter
("i_pState", OracleType.VarChar, 1024);
state.Direction = ParameterDirection.Input;
state.Value = userDetail.State ?? String.Empty;
command.Parameters.Add(state);
OracleParameter zip = new OracleParameter
("i_pZip", OracleType.VarChar, 1024);
zip.Direction = ParameterDirection.Input;
zip.Value = userDetail.Zip ?? String.Empty;
command.Parameters.Add(zip);
OracleParameter email = new OracleParameter
("i_pBusinessEmail", OracleType.VarChar, 1024);
email.Direction = ParameterDirection.Input;
email.Value = userDetail.EMail ?? String.Empty;
command.Parameters.Add(email);
OracleParameter phone = new OracleParameter
("i_pBusinessPhone", OracleType.VarChar, 1024);
phone.Direction = ParameterDirection.Input;
phone.Value = userDetail.Phone ?? String.Empty;
command.Parameters.Add(phone);
OracleParameter reviewDate = new OracleParameter
("i_pReviewDate", OracleType.DateTime);
reviewDate.Direction = ParameterDirection.Input;
reviewDate.Value = userDetail.ReviewedDate ?? (object)DBNull.Value;
command.Parameters.Add(reviewDate);
OracleParameter reviewedbyWhom = new OracleParameter
("i_pReviewedByWhom", OracleType.VarChar, 1024);
reviewedbyWhom.Direction = ParameterDirection.Input;
reviewedbyWhom.Value = userDetail.ReviewedByWhom ?? String.Empty;
command.Parameters.Add(reviewedbyWhom);
OracleParameter repID = new OracleParameter
("i_pDealersRepID", OracleType.VarChar, 1024);
repID.Direction = ParameterDirection.Input;
repID.Value = userDetail.RepID ?? String.Empty;
command.Parameters.Add(repID);
OracleParameter comments = new OracleParameter
("i_pComments", OracleType.VarChar, 1024);
comments.Direction = ParameterDirection.Input;
comments.Value = userDetail.Comments ?? String.Empty + comments_;
command.Parameters.Add(comments);
OracleParameter privacyUsageFlag = new OracleParameter
("i_pPrivacyUsageFlag", OracleType.VarChar, 1024);
privacyUsageFlag.Direction = ParameterDirection.Input;
privacyUsageFlag.Value = userDetail.PrivacyAndUsageReadFlag ?? String.Empty;
command.Parameters.Add(privacyUsageFlag);
OracleParameter dealersBranchID = new OracleParameter
("i_pDealersBranchID", OracleType.VarChar, 1024);
dealersBranchID.Direction = ParameterDirection.Input;
dealersBranchID.Value = userDetail.DealerBranchID ?? String.Empty;
command.Parameters.Add(dealersBranchID);
OracleParameter privacyUsageDate = new OracleParameter
("i_pPrivacyUsageDate", OracleType.DateTime);
privacyUsageDate.Direction = ParameterDirection.Input;
privacyUsageDate.Value =
userDetail.PrivacyAndUsageReadDate ??(object)DBNull.Value;
command.Parameters.Add(privacyUsageDate);
OracleParameter marketingFlag = new OracleParameter
("i_pMarketingFlag", OracleType.VarChar, 1024);
marketingFlag.Direction = ParameterDirection.Input;
marketingFlag.Value = userDetail.SendMarketingEmailFlag ?? String.Empty;
command.Parameters.Add(marketingFlag);
OracleParameter marketingDate = new OracleParameter
("i_pMarketingDate", OracleType.DateTime);
marketingDate.Direction = ParameterDirection.Input;
marketingDate.Value =
userDetail.SendMarketingEmailDate ?? (object)DBNull.Value;
command.Parameters.Add(marketingDate);
OracleParameter country = new OracleParameter
("i_pWorkCountry", OracleType.VarChar, 1024);
country.Direction = ParameterDirection.Input;
country.Value = userDetail.Country ?? String.Empty;
command.Parameters.Add(country);
OracleParameter oper = new OracleParameter
("i_pOperator", OracleType.VarChar, 1024);
oper.Direction = ParameterDirection.Input;
oper.Value = operator_;
command.Parameters.Add(oper);
OracleParameter returnStatus = new OracleParameter
("o_return_status", OracleType.Int16);
returnStatus.Direction = ParameterDirection.Output;
command.Parameters.Add(returnStatus);
OracleParameter errorDesc = new OracleParameter
("o_error_desc", OracleType.VarChar, 1024);
errorDesc.Direction = ParameterDirection.Output;
command.Parameters.Add(errorDesc);
``` | Without a specific error that's occuring, its hard to give a specific answer. The code you've posted *could* be correct. There's nothing I see that is wrong in all scenarios. However, here are a few places I would start looking.
Is your command statement formatted properly? Do all the VarChar parameters accept 1024 characters? Are any of your strings going into a VarChar column longer than 1024? Is the returnStatus type of Int16 correct?
Anyway, those are some places to start, if you post some more detailed information on the issue, you may get some more responses. | I looked at your code and didn't see anything suspicious.
In similar circumstances I'd do a very stupid test: comment out all the parameters except the first one both in the procedure declaration and in the code running it, then test: if there's an error, you'll know that it's with the first parameter; if no error shows, then uncomment the second parameter in the procedure and in the code.
I know it's stupid, time consuming and annoying, but if you really feel you're closed in a corner, this could give you a more precise hint about where the problem is. | Oracle .NET error - Wrong number or type of arguments | [
"",
"c#",
".net",
"oracle",
"oracleclient",
""
] |
I've come across some code that I can't share here but it **declares** a method **WITHIN** the paramter list of another method. I didnt even know that was possible. I dont really understand why its doing that. Can someone please explain to me some possible uses that you as a programmer would have for doing that? (Note: Since I can't show the code I dont expect an in-context explanation just generally)
### Related:
> [What's the nearest substitute for a function pointer in Java?](https://stackoverflow.com/questions/122407/whats-the-nearest-substitute-for-a-function-pointer-in-java) | Did the code look something like this?
```
obj.someMethod(myVar,3,new FooObject() {
public void bar() {
return "baz";
}
});
```
If so, then the method is not being passed to the other method as an argument, but rather an [anonymous inner class](http://java.sun.com/docs/books/tutorial/java/javaOO/nested.html) is being created, and an instance of that class is being passed as the argument.
In the example above `FooObject` is an abstract class which doesn't implement the `bar()` method. Instead of creating a `private class` that extends `FooObject` we create an instance of the abstract class and provide the implementation of the abstract method in line with the rest of the code.
You can't create an instance of an abstract class so we have to provide the missing method to create a complete class defintion. As this new class is created on the fly it has no name, hence **anonymous**. As it's defined inside another class it's an anonymous **inner** class.
It can be a very handy shortcut, especially for `Listener` classes, but it can make your code hard to follow if you get carried away and the in line method definitions get too long. | In Java you can't pass methods as parameters. Could it have been passing not a method, but an anonymnous inner class?
This can be useful for passing behaviours between classes. Google "dependency injection" or "Inversion of control" for more information. | Java Methods - Taking a method AS AN ARGUMENT | [
"",
"java",
"methods",
""
] |
I was wondering if someone could explain what `Func<int, string>` is and how it is used with some clear examples. | Are you familiar with delegates in general? I have a page about [delegates and events](http://csharpindepth.com/Articles/Chapter2/Events.aspx) which may help if not, although it's more geared towards explaining the differences between the two.
[`Func<T, TResult>`](http://msdn.microsoft.com/en-us/library/bb549151.aspx) is just a generic delegate - work out what it means in any particular situation by replacing the *type parameters* (`T` and `TResult`) with the corresponding *type arguments* (`int` and `string`) in the declaration. I've also renamed it to avoid confusion:
```
string ExpandedFunc(int x)
```
In other words, `Func<int, string>` is a delegate which represents a function taking an `int` argument and returning a `string`.
`Func<T, TResult>` is often used in LINQ, both for projections and predicates (in the latter case, `TResult` is always `bool`). For example, you could use a `Func<int, string>` to project a sequence of integers into a sequence of strings. *Lambda expressions* are usually used in LINQ to create the relevant delegates:
```
Func<int, string> projection = x => "Value=" + x;
int[] values = { 3, 7, 10 };
var strings = values.Select(projection);
foreach (string s in strings)
{
Console.WriteLine(s);
}
```
Result:
```
Value=3
Value=7
Value=10
``` | A `Func<int, string>` eats ints and returns strings. So, what eats ints and returns strings? How about this ...
```
public string IntAsString( int i )
{
return i.ToString();
}
```
There, I just made up a function that eats ints and returns strings. How would I use it?
```
var lst = new List<int>() { 1, 2, 3, 4, 5 };
string str = String.Empty;
foreach( int i in lst )
{
str += IntAsString(i);
}
// str will be "12345"
```
Not very sexy, I know, but that's the simple idea that a lot of tricks are based upon. Now, let's use a Func instead.
```
Func<int, string> fnc = IntAsString;
foreach (int i in lst)
{
str += fnc(i);
}
// str will be "1234512345" assuming we have same str as before
```
Instead of calling IntAsString on each member, I created a reference to it called fnc (these references to methods are called [delegates](http://msdn.microsoft.com/en-us/library/ms173171(VS.80).aspx)) and used that instead. (Remember fnc eats ints and returns strings).
This example is not very sexy, but a ton of the clever stuff you will see is based on the simple idea of functions, delegates and [extension methods](http://msdn.microsoft.com/en-us/library/bb383977.aspx).
One of the best primers on this stuff I've seen is [here](http://blogs.msdn.com/ericwhite/pages/FP-Tutorial.aspx). He's got a lot more real examples. :) | Explanation of Func | [
"",
"c#",
".net",
"func",
""
] |
Can I configure IntelliJ on Windows to use `Ctrl` + `Tab` for switching between files?
Googling finds [this old thread](http://www.jetbrains.net/devnet/thread/943) that says "no". | You can't get a pop-up, but you can switch between open tabs with `Alt` + `→` and `Alt` + `←`, and you can press `Ctrl` + `E` to get a list of recently opened files, which is almost the same thing.
EDIT: (In response to comment) Oh, if that is what, it is just a question of changing the KeyMap. You go to `File -> Settings` and under there you have a keymap option. You will have to create a new KeyMap (can't change the default) by clicking copy, and then look in the other section for "Select Next Tab in multi-editor file" and change/add the keymap you want. `Ctrl` + `Tab` is legit - it is just defaulted to switching between splits.
EDIT 2: (In response to second comment) The function you are looking for in IDEA (at least as close as it gets) is Go Back, which is in the other group of the key map as well. That being said, you said you were looking for how it works in firefox (don't know about Visual Studio) and "Select Next Tab" is the firefox behavior. | Have you tried downloading and installing the TabSwitch plugin? It will allow you to cycle through your open editors and display them in a pop-up window when you hit `Alt` + `A`. This default keymapping is easy enough to change to `Ctrl` + `Tab` in the Keymap IDE Settings. | Ctrl-tab in IntelliJ IDEA | [
"",
"java",
"keyboard-shortcuts",
"intellij-idea",
""
] |
Can I open a PDF file in RichTextBox? | You need to use the Acrobat Control for ActiveX or at least the Adobe Reader 9 equivalent and use as
```
using PdfLib;
namespace WindowsFormsApplication1{
public partial class ViewerForm : Form{
public ViewerForm()
{
InitializeComponent();
PdfLib.AxAcroPDF axAcroPDF1;
axAcroPDF1.LoadFile(@"C:\Documents and Settings\jcrowe\Desktop\Medical Gas\_0708170240_001.pdf");
axAcroPDF1.Show(); }
private void richTextBox1_TextChanged(object sender, EventArgs e)
{ } } }
``` | You can write a simple app in a few seconds containing a WebBrowser control, and just call the navigate method and give it a URL pointing to the document you want.
XAML:
```
<Grid>
<WebBrowser x:Name="Browser"/>
</Grid>
```
C#:
```
private void Window1_Loaded(object sender, WindowLoadedArgs args)
{
Browser.Navigate(new URL("path to document.pdf");
}
```
Note: I am writing from memory so consider this pseudocode rather than something that will work as-is. | Open PDF file in RichTextBox in WPF | [
"",
"c#",
"wpf",
"pdf",
"richtextbox",
""
] |
I want to create a form on a second thread that will receive messages in it's WndProc method. What is the recommended way to create an invisible form like this? Is setting "ShowInTaskbar=false" and "Visible=false" enough, or is there a "cleaner" way? | I'm not sure what you mean by "cleaner". The standard way to create a form that is invisible to the user is to set Visible and ShowInTaskbar to false. | As far as I know, what you're doing is against the rules (although, these things do work sometimes) ... all UI stuff is supposed to be in the main thread.
As for your question, you should be able to just set Visible to false. Setting ShowInTaskbar would only be important for the main application form, I believe, and if you did that users wouldn't have a way to get back to your app from the taskbar. | WndProc with no visible form? | [
"",
"c#",
".net",
"winforms",
"wndproc",
""
] |
> **Duplicate:** [Should a function have only one return statement?](https://stackoverflow.com/questions/36707)
Often times you might have a method that checks numerous conditions and returns a status (lets say boolean for now). Is it better to define a flag, set it during the method, and return it at the end :
```
boolean validate(DomainObject o) {
boolean valid = false;
if (o.property == x) {
valid = true;
} else if (o.property2 == y) {
valid = true;
} ...
return valid;
}
```
or is it better/more correct to simply return once you know the method's outcome?
```
boolean validate(DomainObject o) {
if (o.property == x) {
return true;
} else if (o.property2 == y) {
return true;
} ...
return false;
}
```
Now obviously there could be try/catch blocks and all other kinds of conditions, but I think the concept is clear. Opinions? | If it's a method you'll be calling thousands of times, then early return is better to achieve a [slightly] increased performance.
If not, then I'd prefer late return, since it improves readability.
Remember programmers usually spend more time reading than writing code, so anything you can do to improve readability will be certainly welcome. | I prefer returning early and avoiding deep nesting. This is *particularly* true right at the start of the method: test anything that's simple, and get out (or throw an exception) if you can do so really early.
If it's right in the middle of a method, it's more of a judgement call.
Note that I'd refactor your example straight away to use a single `if`:
```
boolean validate(DomainObject o) {
if (o.property == x || o.property2 == y) {
return true;
} ...
return false;
}
```
I realise this was only a toy example, but my point is that it's always worth looking for more ways to simplify your code :) | Better Java method Syntax? Return early or late? | [
"",
"java",
"coding-style",
"return-path",
""
] |
I have a large set of data to be plotted on google map. Because of the data set size, google map always freezes for a few seconds before all the points are plotted. I used an animated spinning circle during the loading time to show it's in progress. But end users prefer to see actions. They want data plotted on the map step by step, instead of all at a once. Since javascript doesn't support multithreading, what's the best way to approach this? | Javascript engine executes functions one by one by taking them from sort of a queue. Functions can be put there either by your script or as result of user's actions (event handlers). So idea is to split long-running task into small short-running subtasks and feed them into this 'queue' in the manner so they can be mixed with functions responding to user's action.
This can be done by calling window's setTimeout with zero delay and passing your sub-task as a function. Thus you will give a chance for UI event handler to be executed earlier
```
function plotSpot(spot) {
// adding spots to map
};
var spots = [1,2,3,4,5,6,7,8,9,10,11,12];
var plotSpotsBatch;
plotSpotsBatch = function() {
var spotsInBatch = 10;
while(spots.length > 0 && spotsInBatch--) {
var spot = spots.shift();
plotSpot(spot);
}
if (spots.length > 0) {
setTimeout(plotSpotsBatch, 0);
}
};
plotSpotsBatch();
```
Here is extension for Array prototype:
```
Array.prototype.forEachInBatches = function(batchSize, func) {
var arr = this;
var i = 0;
var doer;
doer = function() {
setTimeout(function() {
for (var stopBatch = i + batchSize; i < stopBatch && i < arr.length; i++) {
func(arr[i], i);
}
if (i < arr.length) {
doer();
}
}, 0);
};
doer();
};
```
Usage example (you have to have div with id 'spots' somewhere in document). To see the difference, set batch size equal to number of spots:
```
var spots = [];
for (var i = 0; i < 10000; i++) {
spots.push('{x: ' + Math.ceil(Math.random() * 180) + ', y: ' + Math.ceil(Math.random() * 180) + '}');
}
spots.forEachInBatches(10, function(spot, i) {
document.getElementById('spots').innerHTML += spot + (i < spots.length ? '; ' : '');
});
``` | Could you plot them in batches, with a short delay (`setTimeout`) between each one? | UI responsiveness and javascript | [
"",
"javascript",
"user-interface",
""
] |
As a person who wanted to increase his fundamental programming skills, I chose to learn C++ instead of C. Which leads me to ask: Is there any fundamental skills that I leave in C that might not be obtained by learning C++?
**Related question:** [Should I learn C before learning C++?](https://stackoverflow.com/questions/598552/should-i-learn-c-before-learning-c) | If all you've ever used is object-oriented programming languages like C++ then it would be worthwhile to practice a little C. I find that many OO programmers tend to use objects like a crutch and don't know what to do once you take them away. C will give you the clarity to understand why OO programming emerged in the first place and help you to understand when its useful versus when its just overkill.
In the same vein, you'll learn what it's like to not rely on libraries to do things for you. By noting what features C++ developers turned into libraries, you get a better sense of how to abstract your own code when the time comes. It would be bad to just feel like you need to abstract everything in every situation.
That said, you don't have to learn C. If you know C++ you can drag yourself through most projects. However, by looking at the lower-level languages, you will improve your programming style, even in the higher-level ones. | I don't think there are any skills that you can learn in C but not C++, but I would definitely suggest learning C first still. *Nobody* can fit C++ in their head; it may be the most complex non-esoteric language ever created. C, on the other hand, is quite simple. It is relatively easy to fit C in your head. C will definitely help you get used to things like pointers and manual memory management much quicker than C++. C++ will help you understand OO.
Also, when I say learn C, it's okay to use a C++ compiler and possibly use things like iostreams if you want, just try to restrict yourself to mostly C features at first. If you go all out and learn all the weird C++ features like templates, RAII, exceptions, references, etc., you will be thoroughly confused. | What if any, programming fundamentals are better learned in C as opposed to C++? | [
"",
"c++",
"c",
""
] |
Python's list type has an index() method that takes one parameter and returns the index of the first item in the list matching the parameter. For instance:
```
>>> some_list = ["apple", "pear", "banana", "grape"]
>>> some_list.index("pear")
1
>>> some_list.index("grape")
3
```
Is there a graceful (idiomatic) way to extend this to lists of complex objects, like tuples? Ideally, I'd like to be able to do something like this:
```
>>> tuple_list = [("pineapple", 5), ("cherry", 7), ("kumquat", 3), ("plum", 11)]
>>> some_list.getIndexOfTuple(1, 7)
1
>>> some_list.getIndexOfTuple(0, "kumquat")
2
```
getIndexOfTuple() is just a hypothetical method that accepts a sub-index and a value, and then returns the index of the list item with the given value at that sub-index. I hope
Is there some way to achieve that general result, using list comprehensions or lambas or something "in-line" like that? I think I could write my own class and method, but I don't want to reinvent the wheel if Python already has a way to do it. | How about this?
```
>>> tuple_list = [("pineapple", 5), ("cherry", 7), ("kumquat", 3), ("plum", 11)]
>>> [x for x, y in enumerate(tuple_list) if y[1] == 7]
[1]
>>> [x for x, y in enumerate(tuple_list) if y[0] == 'kumquat']
[2]
```
As pointed out in the comments, this would get all matches. To just get the first one, you can do:
```
>>> [y[0] for y in tuple_list].index('kumquat')
2
```
There is a good discussion in the comments as to the speed difference between all the solutions posted. I may be a little biased but I would personally stick to a one-liner as the speed we're talking about is pretty insignificant versus creating functions and importing modules for this problem, but if you are planning on doing this to a very large amount of elements you might want to look at the other answers provided, as they are faster than what I provided. | Those list comprehensions are messy after a while.
### I like this Pythonic approach:
```
from operator import itemgetter
tuple_list = [("pineapple", 5), ("cherry", 7), ("kumquat", 3), ("plum", 11)]
def collect(l, index):
return map(itemgetter(index), l)
# And now you can write this:
collect(tuple_list,0).index("cherry") # = 1
collect(tuple_list,1).index("3") # = 2
```
### If you need your code to be all super performant:
```
# Stops iterating through the list as soon as it finds the value
def getIndexOfTuple(l, index, value):
for pos,t in enumerate(l):
if t[index] == value:
return pos
# Matches behavior of list.index
raise ValueError("list.index(x): x not in list")
getIndexOfTuple(tuple_list, 0, "cherry") # = 1
``` | Using Python's list index() method on a list of tuples or objects? | [
"",
"python",
"list",
"tuples",
"reverse-lookup",
""
] |
> prefix/dir1/dir2/dir3/dir4/..
How to parse the `dir1, dir2` values out of the above string in Java?
The prefix here can be:
/usr/local/apache2/resumes | If you want to split the `String` at the `/` character, the [`String.split`](http://java.sun.com/javase/6/docs/api/java/lang/String.html#split(java.lang.String)) method will work:
For example:
```
String s = "prefix/dir1/dir2/dir3/dir4";
String[] tokens = s.split("/");
for (String t : tokens)
System.out.println(t);
```
Output
```
prefix
dir1
dir2
dir3
dir4
```
**Edit**
Case with a `/` in the prefix, and we know what the prefix is:
```
String s = "slash/prefix/dir1/dir2/dir3/dir4";
String prefix = "slash/prefix/";
String noPrefixStr = s.substring(s.indexOf(prefix) + prefix.length());
String[] tokens = noPrefixStr.split("/");
for (String t : tokens)
System.out.println(t);
```
The substring without the prefix `"slash/prefix/"` is made by the [`substring`](http://java.sun.com/javase/6/docs/api/java/lang/String.html#substring(int)) method. That `String` is then run through `split`.
Output:
```
dir1
dir2
dir3
dir4
```
**Edit again**
If this `String` is actually dealing with file paths, using the [`File`](http://java.sun.com/javase/6/docs/api/java/io/File.html) class is probably more preferable than using string manipulations. Classes like `File` which already take into account all the intricacies of dealing with file paths is going to be more robust. | ```
...
String str = "bla!/bla/bla/"
String parts[] = str.split("/");
//To get fist "bla!"
String dir1 = parts[0];
``` | How to parse this string in Java? | [
"",
"java",
"string",
""
] |
Is there a way to get (from somewhere) the number of elements in a Javascript object?? (i.e. constant-time complexity).
I can't find a property or method that retrieves that information. So far I can only think of doing an iteration through the whole collection, but that's linear time.
It's strange there is no direct access to the size of the object, don't you think.
**EDIT:**
I'm talking about the `Object` object (not objects in general):
```
var obj = new Object ;
``` | Although JS implementations might keep track of such a value internally, there's no standard way to get it.
In the past, Mozilla's Javascript variant exposed the [non-standard `__count__`](https://developer.mozilla.org/en-US/docs/JavaScript/Reference/Global_Objects/Object#Properties_of_Object_instances), but it has been removed with version 1.8.5.
For cross-browser scripting you're stuck with explicitly iterating over the properties and checking `hasOwnProperty()`:
```
function countProperties(obj) {
var count = 0;
for(var prop in obj) {
if(obj.hasOwnProperty(prop))
++count;
}
return count;
}
```
In case of ECMAScript 5 capable implementations, this can also be written as (Kudos to [Avi Flax](https://stackoverflow.com/a/4889658/48015))
```
function countProperties(obj) {
return Object.keys(obj).length;
}
```
Keep in mind that you'll also miss properties which aren't enumerable (eg an array's `length`).
If you're using a framework like jQuery, Prototype, Mootools, $whatever-the-newest-hype, check if they come with their own collections API, which might be a better solution to your problem than using native JS objects. | To do this in any ES5-compatible environment
```
Object.keys(obj).length
```
(Browser support from [here](https://caniuse.com/mdn-javascript_builtins_object_keys))
(Doc on Object.keys [here](https://developer.mozilla.org/en/JavaScript/Reference/Global_Objects/Object/keys), includes method you can add to non-ECMA5 browsers) | Number of elements in a javascript object | [
"",
"javascript",
"collections",
"javascript-objects",
"element",
""
] |
I have these files with the extension ".adc". They are simply raw data files. I can open them with Audacity using File->Import->Raw data with encoding "Signed 16 bit" and sample rate "16000 Khz".
I would like to do the same with python. I think that audioop module is what I need, but I can't seem to find examples on how to use it for something that simple.
The main goal is to open the file and play a certain location in the file, for example from the second 10 to the second 20. Is there something out there for my task ?
Thanx in advance. | For opening the file, you just need `file()`.
For finding a location, you don't need audioop: you just need to convert seconds to bytes and get the required bytes of the file. For instance, if your file is 16 kHz 16bit mono, each second is 32,000 bytes of data. So the 10th second is 320kB into the file. Just seek to the appropriate place in the file and then read the appropriate number of bytes.
And audioop can't help you with the hardest part: namely, playing the audio. The correct way to do this very much depends on your OS.
EDIT: Sorry, I just noticed your username is "thelinuxer". Consider [pyAO](http://nixbit.com/cat/programming/libraries/pyao/) for playing audio from Python on Linux. You will probably need to change the sample format to play the audio---audioop will help you with this (see ratecv, tomono/tostereo, lin2lin, and bias) | Thanx a lot I was able to do the following:
```
def play_data(filename, first_sec, second_sec):
import ao
from ao import AudioDevice
dev = AudioDevice(2, bits=16, rate=16000,channels=1)
f = open(filename, 'r')
data_len = (second_sec-first_sec)*32000
f.seek(32000*first_sec)
data = f.read(data_len)
dev.play(data)
f.close()
play_data('AR001_3.adc', 2.5, 5)
``` | Python open raw audio data file | [
"",
"python",
"audio",
""
] |
Same as [oracle diff: how to compare two tables?](https://stackoverflow.com/questions/688537/) except in mysql.
> Suppose I have two tables, t1 and t2 which are identical in layout but which may contain different data.
>
> What's the best way to diff these two tables?
To be more precise, I'm trying to figure out a simple SQL query that tells me if data from one row in t1 is different from the data from the corresponding row in t2
It appears I cannot use the intersect nor minus. When I try
```
SELECT * FROM robot intersect SELECT * FROM tbd_robot
```
I get an error code:
> [Error Code: 1064, SQL State: 42000] You have an error in your SQL
> syntax; check the manual that corresponds to your MySQL server version
> for the right syntax to use near 'SELECT \* FROM tbd\_robot' at line 1
Am I doing something syntactically wrong? If not, is there another query I can use?
Edit: Also, I'm querying through a free version DbVisualizer. Not sure if that might be a factor. | `INTERSECT` needs to be emulated in `MySQL`:
```
SELECT 'robot' AS `set`, r.*
FROM robot r
WHERE ROW(r.col1, r.col2, …) NOT IN
(
SELECT col1, col2, ...
FROM tbd_robot
)
UNION ALL
SELECT 'tbd_robot' AS `set`, t.*
FROM tbd_robot t
WHERE ROW(t.col1, t.col2, …) NOT IN
(
SELECT col1, col2, ...
FROM robot
)
``` | You can construct the intersection manually using UNION. It's easy if you have some unique field in both tables, e.g. ID:
```
SELECT * FROM T1
WHERE ID NOT IN (SELECT ID FROM T2)
UNION
SELECT * FROM T2
WHERE ID NOT IN (SELECT ID FROM T1)
```
If you don't have a unique value, you can still expand the above code to check for all fields instead of just the ID, and use AND to connect them (e.g. ID NOT IN(...) AND OTHER\_FIELD NOT IN(...) etc) | MySQL: Compare differences between two tables | [
"",
"sql",
"mysql",
""
] |
I have a function in C++ that needs to be called after a period of time and this task is repeated. Do you know any built-in function or sample code in Win32 or pthread?
Thanks,
Julian | How about [SetTimer](http://msdn.microsoft.com/en-us/library/ms644906.aspx).
1. Create a wrapper function to use as the callback for set timer.
2. Wrapper function calls your function.
3. After your function finishes, wrapper function calls SetTimer again to re-set the timer. | Just as a side note, I hope that you aren't doing something in code which could be done via the OS. (I don't know enough about your requirements to say, but I thought I'd point it out).
Things such as task-scheduler (windows) are made for scheduling recurring tasks, and they often do a better job than hand-rolled solutions. | Win32 function for scheduled tasks in C++ | [
"",
"c++",
"multithreading",
"winapi",
""
] |
I'm building an MS Word add-in that has to gather all comment balloons from a document and summarize them in a list. My result will be a list of ReviewItem classes containing the Comment itself, the paragraph number and the page number on which the commented text resides.
Part of my code looks like this:
```
private static List<ReviewItem> FindComments()
{
List<ReviewItem> result = new List<ReviewItem>();
foreach (Comment c in WorkingDoc.Comments)
{
ReviewItem item = new ReviewItem()
{
Remark = c.Reference.Text,
Paragraph = c.Scope. ???, // How to determine the paragraph number?
Page = c.Scope. ??? // How to determine the page number?
};
result.Add(item);
}
return result;
}
```
The `Scope` property of the `Comment` class points to the actual text in the document the comment is about and is of type `Microsoft.Office.Interop.Word.Range`. I can't work out how to determine what page and which paragraph that range is located.
With paragraph number, I actually mean the "numbered list" number of the paragraph, such as "2.3" or "1.3.2".
Any suggestions? Thanks! | With the help Mike Regan gave me in his answer (thanks again Mike), I managed to work out a solution that I want to share here. Maybe this also clarifies what my goal was. In terms of performance, this might not be the fastest or most efficient solution. Feel free to suggest improvements.
The result of my code is a list of ReviewItem classes, that will be processed elsewhere. Without further ado, here's the code:
```
/// <summary>
/// Worker class that collects comments from a Word document and exports them as ReviewItems
/// </summary>
internal class ReviewItemCollector
{
/// <summary>
/// Working document
/// </summary>
private Word.Document WorkingDoc = new Word.DocumentClass();
/// <summary>
/// Extracts the review results from a Word document
/// </summary>
/// <param name="fileName">Fully qualified path of the file to be evaluated</param>
/// <returns></returns>
public ReviewResult GetReviewResults(string fileName)
{
Word.Application wordApp = null;
List<ReviewItem> reviewItems = new List<ReviewItem>();
object missing = System.Reflection.Missing.Value;
try
{
// Fire up Word
wordApp = new Word.ApplicationClass();
// Some object variables because the Word API requires this
object fileNameForWord = fileName;
object readOnly = true;
WorkingDoc = wordApp.Documents.Open(ref fileNameForWord,
ref missing, ref readOnly,
ref missing, ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing);
// Gather all paragraphs that are chapter headers, sorted by their start position
var headers = (from Word.Paragraph p in WorkingDoc.Paragraphs
where IsHeading(p)
select new Heading()
{
Text = GetHeading(p),
Start = p.Range.Start
}).ToList().OrderBy(h => h.Start);
reviewItems.AddRange(FindComments(headers));
// I will be doing similar things with Revisions in the document
}
catch (Exception x)
{
MessageBox.Show(x.ToString(),
"Error while collecting review items",
MessageBoxButtons.OK,
MessageBoxIcon.Error);
}
finally
{
if (wordApp != null)
{
object doNotSave = Word.WdSaveOptions.wdDoNotSaveChanges;
wordApp.Quit(ref doNotSave, ref missing, ref missing);
}
}
ReviewResult result = new ReviewResult();
result.Items = reviewItems.OrderBy(i => i.Position);
return result;
}
/// <summary>
/// Finds all comments in the document and converts them to review items
/// </summary>
/// <returns>List of ReviewItems generated from comments</returns>
private List<ReviewItem> FindComments(IOrderedEnumerable<Heading> headers)
{
List<ReviewItem> result = new List<ReviewItem>();
// Generate ReviewItems from the comments in the documents
var reviewItems = from Word.Comment c in WorkingDoc.Comments
select new ReviewItem()
{
Position = c.Scope.Start,
Page = GetPageNumberOfRange(c.Scope),
Paragraph = GetHeaderForRange(headers, c.Scope),
Description = c.Range.Text,
ItemType = DetermineCommentType(c)
};
return reviewItems.ToList();
}
/// <summary>
/// Brute force translation of comment type based on the contents...
/// </summary>
/// <param name="c"></param>
/// <returns></returns>
private static string DetermineCommentType(Word.Comment c)
{
// This code is very specific to my solution, might be made more flexible/configurable
// For now, this works :-)
string text = c.Range.Text.ToLower();
if (text.EndsWith("?"))
{
return "Vraag";
}
if (text.Contains("spelling") || text.Contains("spelfout"))
{
return "Spelling";
}
if (text.Contains("typfout") || text.Contains("typefout"))
{
return "Typefout";
}
if (text.ToLower().Contains("omissie"))
{
return "Omissie";
}
return "Opmerking";
}
/// <summary>
/// Determine the last header before the given range's start position. That would be the chapter the range is part of.
/// </summary>
/// <param name="headings">List of headings as identified in the document.</param>
/// <param name="range">The current range</param>
/// <returns></returns>
private static string GetHeaderForRange(IEnumerable<Heading> headings, Word.Range range)
{
var found = (from h in headings
where h.Start <= range.Start
select h).LastOrDefault();
if (found != null)
{
return found.Text;
}
return "Unknown";
}
/// <summary>
/// Identifies whether a paragraph is a heading, based on its styling.
/// Note: the documents we're reviewing are always in a certain format, we can assume that headers
/// have a style named "Heading..." or "Kop..."
/// </summary>
/// <param name="paragraph">The paragraph to be evaluated.</param>
/// <returns></returns>
private static bool IsHeading(Word.Paragraph paragraph)
{
Word.Style style = paragraph.get_Style() as Word.Style;
return (style != null && style.NameLocal.StartsWith("Heading") || style.NameLocal.StartsWith("Kop"));
}
/// <summary>
/// Translates a paragraph into the form we want to see: preferably the chapter/paragraph number, otherwise the
/// title itself will do.
/// </summary>
/// <param name="paragraph">The paragraph to be translated</param>
/// <returns></returns>
private static string GetHeading(Word.Paragraph paragraph)
{
string heading = "";
// Try to get the list number, otherwise just take the entire heading text
heading = paragraph.Range.ListFormat.ListString;
if (string.IsNullOrEmpty(heading))
{
heading = paragraph.Range.Text;
heading = Regex.Replace(heading, "\\s+$", "");
}
return heading;
}
/// <summary>
/// Determines the pagenumber of a range.
/// </summary>
/// <param name="range">The range to be located.</param>
/// <returns></returns>
private static int GetPageNumberOfRange(Word.Range range)
{
return (int)range.get_Information(Word.WdInformation.wdActiveEndPageNumber);
}
}
``` | Try this for page number:
```
Page = c.Scope.Information(wdActiveEndPageNumber);
```
Which should give you a page number for the end value of the range. If you want the page value for the beginning, try this first:
```
Word.Range rng = c.Scope.Collapse(wdCollapseStart);
Page = rng.Information(wdActiveEndPageNumber);
```
* [Range.Information Property](http://msdn.microsoft.com/en-us/library/bb256015.aspx)
* [WdInformation Enumeration](http://msdn.microsoft.com/en-us/library/bb213848.aspx)
For paragraph number, see what you can get from this:
```
c.Scope.Paragraphs; //Returns a paragraphs collection
```
My guess is to take the first paragraph object in the collection the above returns, get a new range from the end of that paragraph to the beginning of the document and grab the integer value of this:
```
[range].Paragraphs.Count; //Returns int
```
This should give the accurate paragraph number of the beginning of the comment range.
* [Range.Paragraphs](http://msdn.microsoft.com/en-us/library/bb256026.aspx)
* [Paragraph Object Members](http://msdn.microsoft.com/en-us/library/bb257689.aspx) | VSTO 2007: how do I determine the page and paragraph number of a Range? | [
"",
"c#",
"ms-word",
"vsto",
""
] |
How can I transform the following XML into a `List<string>` or `String[]`:
```
<Ids>
<id>1</id>
<id>2</id>
</Ids>
``` | It sounds like you're more after just parsing rather than full XML serialization/deserialization. If you can use LINQ to XML, this is pretty easy:
```
using System;
using System.Linq;
using System.Xml.Linq;
public class Test
{
static void Main()
{
string xml = "<Ids><id>1</id><id>2</id></Ids>";
XDocument doc = XDocument.Parse(xml);
var list = doc.Root.Elements("id")
.Select(element => element.Value)
.ToList();
foreach (string value in list)
{
Console.WriteLine(value);
}
}
}
```
In fact the call to `Elements` could omit the argument as there *are* only `id` elements, but I thought I'd demonstrate how to specify which elements you want.
Likewise I'd normally not bother calling [`ToList`](http://msdn.microsoft.com/en-us/library/bb342261.aspx) unless I really needed a `List<string>` - without it, the result is `IEnumerable<string>` which is fine if you're just iterating over it once. To create an array instead, use [`ToArray`](http://msdn.microsoft.com/en-us/library/bb298736.aspx). | Here is a way using XmlDocument :
```
// A string containing the XML data
string xml = "<Ids><id>1</id><id>2</id></Ids>";
// The list you want to fill
ArrayList list = new ArrayList();
XmlDocument doc = new XmlDocument();
// Loading from a XML string (use Load() for file)
doc.LoadXml(xml);
// Selecting node using XPath syntax
XmlNodeList idNodes = doc.SelectNodes("Ids/id");
// Filling the list
foreach (XmlNode node in idNodes)
list.Add(node.InnerText);
``` | How can I transform XML into a List<string> or String[]? | [
"",
"c#",
"xml",
"xml-serialization",
""
] |
I have something like this:
```
class Base
{
public:
static int Lolz()
{
return 0;
}
};
class Child : public Base
{
public:
int nothing;
};
template <typename T>
int Produce()
{
return T::Lolz();
}
```
and
```
Produce<Base>();
Produce<Child>();
```
both return 0, which is of course correct, but unwanted. Is there anyway to enforce the explicit declaration of the Lolz() method in the second class, or maybe throwing an compile-time error when using `Produce<Child>()`?
Or is it bad OO design and I should do something completely different?
**EDIT:**
What I am basically trying to do, is to make something like this work:
```
Manager manager;
manager.RegisterProducer(&Woot::Produce, "Woot");
manager.RegisterProducer(&Goop::Produce, "Goop");
Object obj = manager.Produce("Woot");
```
or, more generally, an external abstract factory that doesn't know the types of objects it is producing, so that new types can be added without writing more code. | There are two ways to avoid it. Actually, it depends on what you want to say.
(1) Making Produce() as an interface of Base class.
```
template <typename T>
int Produce()
{
return T::Lolz();
}
class Base
{
friend int Produce<Base>();
protected:
static int Lolz()
{
return 0;
}
};
class Child : public Base
{
public:
int nothing;
};
int main(void)
{
Produce<Base>(); // Ok.
Produce<Child>(); // error :'Base::Lolz' : cannot access protected member declared in class 'Base'
}
```
(2) Using template specialization.
```
template <typename T>
int Produce()
{
return T::Lolz();
}
class Base
{
public:
static int Lolz()
{
return 0;
}
};
class Child : public Base
{
public:
int nothing;
};
template<>
int Produce<Child>()
{
throw std::bad_exception("oops!");
return 0;
}
int main(void)
{
Produce<Base>(); // Ok.
Produce<Child>(); // it will throw an exception!
}
``` | There is no way to override a static method in a subclass, you can only hide it. Nor is there anything analogous to an abstract method that would force a subclass to provide a definition. If you really need different behaviour in different subclasses, then you should make Lolz() an instance method and override it as normal.
I suspect that you are treading close to a design problem here. One of the principals of object-oriented design is the substitution principal. It basically says that if B is a subclass of A, then it must be valid to use a B wherever you could use an A. | Enforce static method overloading in child class in C++ | [
"",
"c++",
"class",
"templates",
"oop",
"static",
""
] |
It appears, that in 32bit OS `ip2long` returns signed int, and in 64bit OS unsigned int is returned.
My application is working on 10 servers, and some are 32bit and some are 64bit, so I need all them to work same way.
In PHP documentation there is a trick to make that result always unsigned, but since I got my database already full of data, I want to have it signed.
So how to change an unsigned int into a signed one in PHP? | PHP does not support unsigned integers as a type, but what you can do is simply turn the result of [ip2long](http://php.net/ip2long) into an unsigned int *string* by having [sprintf](http://php.net/sprintf) interpret the value as unsigned with `%u`:
```
$ip="128.1.2.3";
$signed=ip2long($ip); // -2147417597 in this example
$unsigned=sprintf("%u", $signed); // 2147549699 in this example
```
Edit, since you really wanted it to be signed even on 64 bit systems - here's how you'd convert the 64 bit +ve value to a 32 bit signed equivalent:
```
$ip = ip2long($ip);
if (PHP_INT_SIZE == 8)
{
if ($ip>0x7FFFFFFF)
{
$ip-=0x100000000;
}
}
``` | Fwiw, if you're using MySQL it's usually a lot easier and cleaner if you just pass in the IPs as strings to the database, and let MySQL do the conversion using INET\_ATON() (when INSERTing/UPDAT(E)'ing) and INET\_NTOA() (when SELECTing). MySQL does not have any of the problems described here.
Examples:
```
SELECT INET_NTOA(ip_column) FROM t;
INSERT INTO t (ip_column) VALUES (INET_ATON('10.0.0.1'));
```
The queries are also much more readable.
Note that you can **not** mix INET\_NTOA()/INET\_ATON() in MySQL with ip2long()/long2ip() in PHP, since MySQL uses an INT UNSIGNED datatype, while PHP uses a **signed** integer. Mixing signed and unsigned integers will seriously mess up your data! | Unsigned int to signed in php | [
"",
"php",
"math",
"absolute-value",
""
] |
So I have a table that looks like this:
```
Name ID TaskID HoursAssigned
----------------------------------------------------------------
John Smith 4592 A01 40
Matthew Jones 2863 A01 20
Jake Adams 1182 A01 100
Matthew Jones 2863 A02 50
Jake Adams 2863 A02 10
```
and I want to return a data set that looks like this:
```
TaskID PeopleAssigned
------------------------------------------------------------
A01 Jake Adams, John Smith, Matthew Jones
A02 Matthew Jones, Jake Adams
```
The problem here is that I would have no idea how many people are assigned to a given task. Any suggestions would be great! | This question is asked daily here. [Here is yesterday's](https://stackoverflow.com/questions/941103/concat-groups-in-mssql). And [another one](https://stackoverflow.com/questions/273238/how-to-use-group-by-to-concatenate-strings-in-mssql)
<https://stackoverflow.com/questions/tagged/sql+string-concatenation> | TRY THIS:
```
declare @table table (name varchar(30), ID int, TaskID char(3), HoursAssigned int)
insert into @table values ('John Smith' ,4592 ,'A01' ,40)
insert into @table values ('Matthew Jones',2863 ,'A01' ,20)
insert into @table values ('Jake Adams' ,1182 ,'A01' ,100)
insert into @table values ('Matthew Jones',2863 ,'A02' ,50)
insert into @table values ('Jake Adams' ,2863 ,'A02' ,10)
--formatted so you can see what is happening
SELECT DISTINCT
t1.TaskID
,SUBSTRING(
replace(
replace(
(SELECT
t2.Name
FROM @Table AS t2
WHERE t1.TaskID=t2.TaskID
ORDER BY t2.Name
FOR XML PATH(''))
,'</NAME>','')
,'<NAME>',', ')
,3,2000) AS PeopleAssigned
FROM @table AS t1
```
BASED ON YESTERDAY'S ANSWER!
here is the output:
```
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
(1 row(s) affected)
TaskID PeopleAssigned
------ --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
A01 Jake Adams, John Smith, Matthew Jones
A02 Jake Adams, Matthew Jones
(2 row(s) affected)
``` | Combine Multiple Fields into One Text Field in SQL Server | [
"",
"sql",
"sql-server",
"t-sql",
"string-concatenation",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.