
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I want to post ($\_GET as well as $\_POST) data by clicking on links (enclosed with `<a>`) and not the regular form 'submit' button. preferred language : PHP
I have seen this in a lot of todays websites,
where forms are submitted by clicking on buttons looking like hyperlinks.
so was wondering how it could be done.
Thanks in advance | [This post](http://ajaxian.com/archives/styling-buttons-as-links-allowing-you-to-post-away) on Ajaxian might help. It links to a pretty in depth blog post that shows you how to apply css to buttons so that they look like links.
The advantage here over using a proper link is the "fake link" really **is** a button, so it behaves exactly like a button, only it looks like a link. Spiders won't follow it, screen readers will treat it differently, it's a more "correct" thing to do in terms of launching a http post. | Forms are designed to be submitted with buttons. You can use JavaScript to make a link submit it, but this will break when JS is not available. Even if JavaScript is available, using a link will be using a control which won't show up when a screen reader is in "Forms Mode", leaving screen reader users without any obvious way to submit the form.
CSS is a safer alternative (see <http://tom.me.uk/scripting/submit.html>). | Posting data through hyperlinks | [
"",
"php",
"post",
"hyperlink",
""
] |
I would like to change a string in php from all upper case to normal cases. So that every sentence would start with an upper case and the rest would be in lower case.
Is there a simple way to do this ? | A simple way is to use [strtolower](http://php.net/strtolower) to make the string lower case, and [ucfirst](http://php.net/ucfirst) to upper case the first char as follows:
```
$str=ucfirst(strtolower($str));
```
If the string contains multiple sentences, you'll have to write your own algorithm, e.g. explode on sentence separators and process each sentence in turn. As well as the first char, you might need some heuristics for words like "I" and any common proper nouns which appear in your text. E.g, something like this:
```
$sentences=explode('.', strtolower($str));
$str="";
$sep="";
foreach ($sentences as $sentence)
{
//upper case first char
$sentence=ucfirst(trim($sentence));
//now we do more heuristics, like turn i and i'm into I and I'm
$sentence=preg_replace('/i([\s\'])/', 'I$1', $sentence);
//append sentence to output
$str=$sep.$str;
$sep=". ";
}
``` | Here's a function that will do it:
```
function sentence_case($s) {
$str = strtolower($s);
$cap = true;
for($x = 0; $x < strlen($str); $x++){
$letter = substr($str, $x, 1);
if($letter == "." || $letter == "!" || $letter == "?"){
$cap = true;
}elseif($letter != " " && $cap == true){
$letter = strtoupper($letter);
$cap = false;
}
$ret .= $letter;
}
return $ret;
}
```
Source:
<http://codesnippets.joyent.com/posts/show/715> | Change input from all upper case into a normal case | [
"",
"php",
""
] |
I am attempting to load document files into a document library in SharePoint using the CopyIntoItems method of the SharePoint Copy web service.
The code below executes and returns 0 (success). Also, the CopyResult[] array returns 1 value with a "Success" result. However, I cannot find the document anywhere in the library.
I have two questions:
1. Can anyone see anything wrong with my code or suggest changes?
2. Can anyone suggest how I could debug this on the server side. I don't have a tremendous amount of experience with SharePoint. If I can track what is going on through logging or some other method on the server side it may help me figure out what is going on.
**Code Sample:**
```
string[] destinationUrls = { Uri.EscapeDataString("https://someaddress.com/Reports/Temp") };
SPCopyWebService.FieldInformation i1 = new SPCopyWebService.FieldInformation { DisplayName = "Name", InternalName = "Name", Type = SPListTransferSpike1.SPCopyWebService.FieldType.Text, Value = "Test1Name" };
SPCopyWebService.FieldInformation i2 = new SPCopyWebService.FieldInformation { DisplayName = "Title", InternalName = "Title", Type = SPListTransferSpike1.SPCopyWebService.FieldType.Text, Value = "Test1Title" };
SPCopyWebService.FieldInformation[] info = { i1, i2 };
SPCopyWebService.CopyResult[] result;
byte[] data = File.ReadAllBytes("C:\\SomePath\\Test1Data.txt");
uint ret = SPCopyNew.CopyIntoItems("", destinationUrls, info, data, out result);
```
**Edit that got things working:**
I got my code working by adding "<http://null>" to the SourceUrl field. Nat's answer below would probably work for that reason. Here is the line I changed to get it working.
```
// Change
uint ret = SPCopyNew.CopyIntoItems("http://null", destinationUrls, info, data, out result);
``` | I think the issue may be in trying to set the "Name" property using the webservice. I have had some fail doing that.
Given the "Name" is the name of the document, you may have some success with
```
string targetDocName = "Test1Name.txt";
string destinationUrl = Uri.EscapeDataString("https://someaddress.com/Reports/Temp/" + targetDocName);
string[] destinationUrls = { destinationUrl };
SPCopyWebService.FieldInformation i1 = new SPCopyWebService.FieldInformation { DisplayName = "Title", InternalName = "Title", Type = SPListTransferSpike1.SPCopyWebService.FieldType.Text, Value = "Test1Title" };
SPCopyWebService.FieldInformation[] info = { i1};
SPCopyWebService.CopyResult[] result;
byte[] data = File.ReadAllBytes("C:\\SomePath\\Test1Data.txt");
uint ret = SPCopyNew.CopyIntoItems(destinationUrl, destinationUrls, info, data, out result);
```
Note: I have used the "target" as the "source" property. [Don't quite know why, but it does the trick](https://stackoverflow.com/questions/787610/how-do-you-copy-a-file-into-sharepoint-using-a-webservice/791847#791847). | I didn't understand very well what you're tying to do, but if you're trying to upload a file from a local directory into a sharepoint library, i would suggest you create a webclient and use uploadata:
Example (VB.NET):
```
dim webclient as Webclient
webClient.UploadData("http://srvasddress/library/filenameexample.doc", "PUT", filebytes)
```
Then you just have to check in the file using the lists web service, something like:
```
listService.CheckInFile("http://srvasddress/library/filenameexample.doc", "description", "1")
```
Hope it was of some help.
EDIT: Don't forget to set credentials for the web client, etc.
EDIT 2: Update metada fields using this:
```
listService.UpdateListItems("Name of the Library, batchquery)
```
You can find info on building batch query's in here: [link](http://msdn.microsoft.com/en-us/library/dd586543(office.11).aspx) | How do you use the CopyIntoItems method of the SharePoint Copy web service? | [
"",
"c#",
".net",
"web-services",
"sharepoint",
""
] |
I am trying to insert new lines into an Excel XML document. The entity that I need to insert is ` ` but whenever I insert that into PHP DOM, it just converts it to a normal line break.
This is what I am getting:
```
<Cell><Data>text
text2
</Data></Cell>
```
This is what I want:
```
<Cell><Data>text text2 </Data></Cell>
```
I cannot figure out how to insert a new line and get it to encode that way, or add that character without it either double encoding it, or converting it to a new line.
Thanks for the help! | Use a CDATA section... | The correct format for this appears to be " ". Note the trailing space. It works in our applications when the trailing space is entered. | Excel XML Line Breaks within Cell from PHP DOM | [
"",
"php",
"xml",
"excel",
"dom",
""
] |
I'm trying to replicate some image filtering software on the Android platform. The desktop version works with bmps but crashes out on png files.
When I come to xOr two pictures (The 32 bit ints of each corresponding pixel) I get very different results for the two pieces of software.
I'm sure my code isn't wrong as it's such a simple task but here it is;
```
const int aMask = 0xFF000000;
int xOrPixels(int p1, int p2) {
return (aMask | (p1 ^ p2) );
}
```
The definition for the JAI library used by the Java desktop software can be found [here](http://java.sun.com/products/java-media/jai/forDevelopers/jai-apidocs/javax/media/jai/operator/XorDescriptor.html) and states;
```
The destination pixel values are defined by the pseudocode:
dst[x][y][b] = srcs[0][x][y][b] ^ srcs[1][x][y][b];
```
Where the b is for band (i.e. R,G,B).
Any thoughts? I have a similar problem with AND and OR.
Here is an image with the two source images xOr'd at the bottom on Android using a png. The same file as a bitmap xOr'd gives me a bitmap filled with 0xFFFFFFFF (White), no pixels at all. I checked the binary values of the Android ap and it seems right to me....
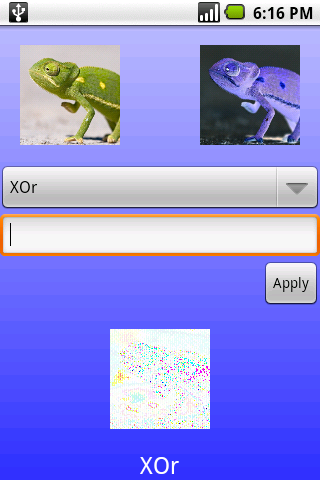
Gav
NB When i say (Same 32 bit ARGB representation) I mean that android allows you to decode a png file to this format. Whilst this might give room for some error (Is png lossless?) I get completely different colours on the output. | I checked a couple of values from your screenshot.
The input pixels:
* Upper left corners, 0xc3cbce^0x293029 = 0xeafbe7
* Nape of the neck, 0xbdb221^0x424dd6 = 0xfffff7
are very similar to the corresponding output pixels.
Looks to me like you are XORing two images that are closely related (inverted in each color channel), so, necessarily, the output is near 0xffffff.
If you were to XOR two dissimilar images, perhaps you will get something more like what you expect.
The question is, why do you want to XOR pixel values? | The png could have the wrong gamma or color space, and it's getting converted on load, affecting the result. Some versions of Photoshop had a bug where they saved pngs with the wrong gamma. | Bitwise operations on a png and bmp give different results? (Same 32 bit ARGB representation) | [
"",
"java",
"image-processing",
""
] |
I'm looking for a simple method to check if only one variable in a list of variables has a True value.
I've looked at this [logical xor post](https://stackoverflow.com/questions/432842/how-do-you-get-the-logical-xor-of-two-variables-in-python) and is trying to find a way to adapt to multiple variables and only one true.
Example
```
>>>TrueXor(1,0,0)
True
>>>TrueXor(0,0,1)
True
>>>TrueXor(1,1,0)
False
>>>TrueXor(0,0,0,0,0)
False
``` | There isn't one built in but it's not to hard to roll you own:
```
def TrueXor(*args):
return sum(args) == 1
```
Since "[b]ooleans are a subtype of plain integers" ([source](http://docs.python.org/library/stdtypes.html#numeric-types-int-float-long-complex)) you can sum the list of integers quite easily and you can also pass true booleans into this function as well.
So these two calls are homogeneous:
```
TrueXor(1, 0, 0)
TrueXor(True, False, False)
```
If you want explicit boolean conversion: `sum( bool(x) for x in args ) == 1`. | I think the sum-based solution is fine for the given example, but keep in mind that boolean predicates in python always short-circuit their evaluation. So you might want to consider something more consistent with [all and any](http://docs.python.org/library/functions.html#all).
```
def any_one(iterable):
it = iter(iterable)
return any(it) and not any(it)
``` | Check if only one variable in a list of variables is set | [
"",
"python",
"xor",
""
] |
In other words, does it matter whether I use <http://www.example.com/> or <http://wwW.exAmPLe.COm/> ?
I've been running into strange issues with host-names lately: I have an Apache2.2+PHP5.1.4 webserver, accessed by all kinds of browsers. IE6 users in particular (esp. when their UA string is burdened with numerous BHOs, no pattern yet) seem to have problems accessing the site (cookies disappear, JS refuses to load) when entering via <http://www.Example.com/>, but not <http://www.example.com/>
I've checked the [HTTP](http://www.faqs.org/rfcs/rfc2616.html) and [DNS](http://www.dns.net/dnsrd/rfc/) RFCs, my [P3P policies](https://stackoverflow.com/questions/389456/cookie-blocked-not-saved-in-iframe-in-internet-explorer), cookie settings and [SOP](http://en.wikipedia.org/wiki/Same_origin_policy); yet nowhere I've seen even a mention of domain names being case-sensitive.
(I know path and query string are case sensitive ( `?x=foo` is different from `?x=Foo` ) and treat them appropriately; am doing no parsing/processing on domain name in my code)
Am I doing something wrong or is this just some browser+toolbar crap I should work around? | Domain names are **not** case-sensitive; `Example.com` will resolve to the same IP as `eXaMpLe.CoM`. If a web server or browser treats the `Host` header as case-sensitive, that's a bug. | No, this shouldn't make any difference.
Check out the URL RFC Spec (<http://www.ietf.org/rfc/rfc1738.txt>). From section 2.1:
> For resiliency, programs interpreting
> URLs should treat upper case letters
> as equivalent to lower case in scheme
> names | Does HTTP hostname case (upper/lower) matter? | [
"",
"php",
"http",
"dns",
"case-sensitive",
""
] |
Hey all, just a quick question (should be an easy fix I think). In a WHERE statement in a query, is there a way to have multiple columns contained inside? Here is my code:
```
$sql="SELECT * FROM $tbl_name WHERE username='$myusername' and pwd='$pass'";
```
What I want to do is add another column after the WHERE (called priv\_level = '$privlevel'). I wasn't sure of the syntax on how to do that however.
Thanks for the help! | Read up on SQL. But anyways, to do it just add `AND priv_level = '$privlevel'` to the end of the SQL.
This might be a pretty big step if you're new to PHP, but I think you should read up on the [`mysqli` class in PHP](http://se.php.net/manual/en/mysqli.prepare.php) too. It allows much safer execution of queries.
Otherwise, here's a safer way:
```
$sql = "SELECT * FROM $tbl_name WHERE " .
"username = '" . mysql_real_escape_string($myusername) . "' AND " .
"pwd = '" . mysql_real_escape_string($pass) . "' AND " .
"priv_level = '" . mysql_real_escape_string($privlevel) . "'";
``` | Wrapped for legibility:
```
$sql="
SELECT *
FROM $tbl_name
WHERE username='$myusername' and pwd='$pass' and priv_level = '$privlevel'
";
```
Someone else will warn you about how dangerous the statement is. :-) Think [SQL injection](http://en.wikipedia.org/wiki/SQL_injection). | Multiple columns after a WHERE in PHP? | [
"",
"php",
"mysql",
"where-clause",
""
] |
I have a baseclass, `Statement`, which several other classes inherit from, named `IfStatement`, `WhereStatement`, etc... What is the best way to perform a test in an `if` statement to determine which sort of `Statement` class an instance is derived from? | ```
if (obj.getClass().isInstance(Statement.class)) {
doStuffWithStatements((Statement) obj));
}
```
The nice thing about this technique (as opposed to the "instanceof" keyword) is that you can pass the test-class around as an object. But, yeah, other than that, it's identical to "instanceof".
NOTE: I've deliberately avoided editorializing about whether or not type-instance-checking is the *right* thing to do. Yeah, in most cases, it's better to use polymorphism. But that's not what the OP asked, and I'm just answering his question. | ```
if(object instanceof WhereStatement) {
WhereStatement where = (WhereStatement) object;
doSomething(where);
}
```
Note that code like this usually means that your base class is missing a polymorphic method. i.e. `doSomething()` should be a method of `Statement`, possibly abstract, that is overridden by sub-classes. | Does Java have an "is kind of class" test method | [
"",
"java",
"reflection",
"inheritance",
"evaluation",
""
] |
I'm using BufferedReader and PrintWriter to go through each line of an input file, make a change to some lines, and output the result. If a line doesn't undergo a change, it's just printed as is to the output file. For some reason however, the process ends prematurely. The code looks something like this:
```
BufferedReader in = new BufferedReader(new FileReader("in.txt"));
FileOutputStream out = new FileOutputStream("out.txt");
PrintWriter p = new PrintWriter(out);
String line = in.readLine();
while(line!=null)
{
if(line is special)
do edits and p.println(edited_line);
else
p.println(line);
line = in.readLine();
}
```
However, for some odd reason, this process ends prematurely (actually prints out a half of a line) towards the very end of my input file. Any obvious reason for this? The while loop is clearly being ended by a null. And it's towards the end of my 250k+ line txt file. Thanks! | Where do you flush/close your PrintWriter or FileOutputStream ? If the program exits and this is not done, not all your results will be written out.
You need `out.close()` (possibly a `p.flush()` as well?) at the end of your process to close the file output stream | Try adding a p.flush() after the loop. | Problems with BufferedReader / PrintWriter? | [
"",
"java",
"file",
"bufferedreader",
""
] |
I'd like to write an applet (or a java Web start application) calling its server (servlet?) to invoke some methods and to send/retrieve data. What would be the best way/technology to send and to retrieve those message ? | Protocol:
If you don't care about interoperability with other languages, I'd go with RMI over HTTP. It has support right from the JRE, quite easy to setup and very easy to use once you have the framework.
For applicative logic, I'd use either:
1. The command pattern, passing objects that, when invoked, invoke methods on the server. This is good for small projects, but tends to over complicate as time goes by and more commands are added. Also, it require the client to be coupled to server logic.
2. Request by name + DTO approach. This has the benefit of disassociating server logic from the client all together, leaving the server side free to change as needed. The overhead of building a supporting framework is a bit greater than the first option, but the separation of client from server is, in my opinion, worth the effort.
Implementation:
If you have not yet started, or you have and using Spring, then Spring remoting is a great tool. It works from everywhere (including applets) even if you don't use the IOC container.
If you do not want to use Spring, the basic RMI is quite easy to use as well and has an abundance of examples over the web. | HTTP requests? Parameters in, xml out. | Applet (or WebStart application) calling a server : best practices? | [
"",
"java",
"applet",
"java-web-start",
""
] |
Having been googling for hours, I realize that users can use either xml file(orm.xml, I suppose?) or annotations in JPA, or both of them at the same time. I'm i correct?
So, My project use the second-level cache, which is not in the JPA specification. And I use annotations like:
**@org.hibernate.annotations.Cache(usage =
org.hibernate.annotations.CacheConcurrencyStrategy.READ\_WRITE
)**
for each entities.
However, I guess that the annotation above doesn't belongs to be JPA annotation, therefore, I don't know if there is anything equivalent in orm.xml? I have had a look at the xml schema of orm.xml, and there is not such hibernate element permitted in the schema.
If I can't do the second-level cache config in the orm.xml, is there any way other than in the annotation? The reason that I don't want to do it the annotation is because I have two applications, one use READ\_WRITE concurrency strategy and another use READ\_ONLY concurrency strategy.
Thanks in advance!!!
Kewei | So Therefore, I think the current solution for my problem is to replace all the annotations of each entities with Hibernate mapping files, so that for different deployment (application as well), we could use different Hibernate mapping files. | you can use the hibernate.cfg.xml, hibernate.properties or \*.hbm.xml files to turn on caching on specific objects with different caching strategies | Hibernate second-level cache in orm.xml? | [
"",
"java",
"xml",
"hibernate",
"orm",
"second-level-cache",
""
] |
I have some code:
```
int CalculateAckermann(int x, int y)
{
if(!x)
{
return y++;
}
if(!y)
{
return CalculateAckermann(x--,1);
}
else
{
return CalculateAckermann(x--, CalculateAckermann(x, y--));
}
}
```
Designed to calculate the ackermann function. Above a fairly low number of x and y the application causes a stack overflow because it recurses too deeply and results in pretty big numbers. How would I go about slowly calculating a solution? | As a note if you wish to just used the closed form, then the algorithms for m<4 are straightforward. If you wish to extend to tetration, then I suggest you write a fastpower algorithm probably using the binary method and then with that method you can write a tetration function. Which would look something like:
```
int Tetration(int number, int tetrate)
{
long int product=1;
if(tetrate==0)
return product;
product=number;
while(tetrate>1)
{
product=FastPower(number,product);
tetrate--;
}
return product;
}
```
Then you can cover cases up to n==4 and after that use the recursive definition and values of A(5,n) overflow at a ridiculous rate, so it's really of no concern. Although your teacher probably won't be satisfied with an algorithm such as this, but it will run much faster. In one of my discrete classes when I asked to write an algorithm to compute the fibonacci numbers and then find its O(n), I wrote the closed form and then wrote O(1) and got full credit, some professors appreciate clever answers.
What is important to note about the Ackerman function is it essentially defines the heirachy of additive functions on the integers, A(1,n) is addition , A(2,n) is multiplication, A(3,n) is exponentiation, A(4,n) is tetration and after 5 the functions grow too fast to be applicable to very much.
Another way to look at addition, multiplication, etc is:
```
Φ0 (x, y ) = y + 1
Φ1 (x, y ) = +(x, y )
Φ2 (x, y ) = ×(x, y )
Φ3 (x, y ) = ↑ (x, y )
Φ4 (x, y ) = ↑↑ (x, y )
= Φ4 (x, 0) = 1 if y = 0
= Φ4 (x, y + 1) = Φ3 (x, Φ4 (x, y )) for y > 0
```
(Uses prefix notation ie +(x,y)=x+y, *(x,y)=x*y. | IIRC, one interesting property of the Ackermann function is that the maximum stack depth needed to evaluate it (in levels of calls) is the same as the answer to the function. This means that there will be severe limits on the actual calculation that can be done, imposed by the limits of the virtual memory of your hardware. It is not sufficient to have a multi-precision arithmetic package; you rapidly need more bits to store the logarithms of the logarithms of the numbers than there are sub-atomic particles in the universe.
Again, IIRC, you can derive relatively simply closed formulae for A(1, N), A(2, N), and A(3, N), along the lines of the following (I seem to remember 3 figuring in the answer, but the details are probably incorrect):
* A(1, N) = 3 + N
* A(2, N) = 3 \* N
* A(3, N) = 3 ^ N
The formula for A(4, N) involves some hand-waving and stacking the exponents N-deep. The formula for A(5, N) then involves stacking the formulae for A(4, N)...it gets pretty darn weird and expensive very quickly.
As the formulae get more complex, the computation grows completely unmanageable.
---
The Wikipedia article on the [Ackermann function](http://en.wikipedia.org/wiki/Ackermann_function) includes a section 'Table of Values'. My memory is rusty (but it was 20 years ago I last looked at this in any detail), and it gives the closed formulae:
* A(0, N) = N + 1
* A(1, N) = 2 + (N + 3) - 3
* A(2, N) = 2 \* (N + 3) - 3
* A(3, N) = 2 ^ (N + 3) - 3
And A(4, N) = 2 ^ 2 ^ 2 ^ ... - 3 (where that is 2 raised to the power of 2, N + 3 times). | Calculating larger values of the ackermann function | [
"",
"c++",
"math",
""
] |
Iam using borland 2006 c++
```
class A
{
private:
TObjectList* list;
int myid;
public:
__fastcall A(int);
__fastcall ~A();
};
__fastcall A::A(int num)
{
myid = num;
list = new TObjectList();
}
__fastcall A::~A()
{
}
int main(int argc, char* argv[])
{
myfunc();
return 0;
}
void myfunc()
{
vector<A> vec;
vec.push_back(A(1));
}
```
when i add a new object A to the vector, it calls its destructor twice, and then once when vec goes out of scope , so in total 3 times.
I was thinking it should call once when object is added, and then once when vec goes out scope. | The expression `A(1)` is an r-value and constructs a new `A` value, the compiler may then copy this into a temporary object in order to bind to the `const` reference that push\_back takes. This temporary that the reference is bound to is then copied into the storage managed by `vector`.
The compiler is allowed to elide temporary objects in many situations but it isn't required to do so. | Try this:
```
#include <iostream>
#include <vector>
class A
{
private:
public:
A(int num)
{
std::cout << "Constructor(" << num << ")\n";
}
A(A const& copy)
{
std::cout << "Copy()\n";
}
A& operator=(A const& copy)
{
std::cout << "Assignment\n";
return *this;
}
A::~A()
{
std::cout << "Destroyed\n";
}
};
int main(int argc, char* argv[])
{
std::vector<A> vec;
vec.push_back(A(1));
}
```
The output on my machine is:
```
> ./a.exe
Constructor(1)
Copy()
Destroyed
Destroyed
>
``` | stl vectors add sequence | [
"",
"c++",
""
] |
I have an array of strings that are valid jQuery selectors (i.e. IDs of elements on the page):
```
["#p1", "#p2", "#p3", "#p4", "#p5"]
```
I want to select elements with those IDs into a jQuery array. This is probably elementary, but I can't find anything online. I could have a for-loop which creates a string `"#p1,#p2,#p3,#p4,#p5"` which could then be passed to jQuery as a single selector, but isn't there another way? Isn't there a way to pass an array of strings as a selector?
**EDIT:** Actually, there is [an answer out there already](https://stackoverflow.com/questions/201724/easy-way-to-turn-javascript-array-into-comma-separated-list/201733). | Well, there's 'join':
```
["#p1", "#p2", "#p3", "#p4", "#p5"].join(", ")
```
EDIT - Extra info:
It is possible to select an array of elements, problem is here you don't have the elements yet, just the selector strings. Any way you slice it you're gonna have to execute a search like .getElementById or use an actual jQuery select. | Try the [Array.join method](https://developer.mozilla.org/en/Core_JavaScript_1.5_Reference/Global_Objects/Array/join):
```
var a = ["#p1", "#p2", "#p3", "#p4", "#p5"];
var s = a.join(", ");
//s should now be "#p1, #p2, #p3, ..."
$(s).whateverYouWant();
``` | an array of strings as a jQuery selector? | [
"",
"javascript",
"jquery",
""
] |
A third party programm allows me to ask data from his ip:port. I ask the stuff via this classic code. Here is the constructor of my connection class:
```
public TcpConnection(String adress, Integer port) {
this.adress = adress;
this.port = port;
try {
socket = new Socket(adress, port);
System.out.println("Opening connection");
out = new PrintWriter(socket.getOutputStream(), true);
InputStream r = new DataInputStream(socket.getInputStream());
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
} catch (UnknownHostException e) {
// TODO: handle exception
} catch (IOException e) {
e.printStackTrace();
}
}
```
Then I read my socket with `in.read()` in a while loop.
It allows me to read the socket int by int,but I need a finner granularity. (Some info in the answer are encoded in 2 bytes, some in bit, some in 64 bytes ....). So i need to read 2 byte, then a bit. then another bit, then 1 byte and inspect each bit of this byte.
First I was thinking : "Fine, I convert the int I get in a String Binary representation",
( via `Integer.toBinaryString(whatIget)` )
buts it's just stupid and error prone.
I'm sure I'm missing something to address this casual problem.
Some idea ?
Edit2 : i remove the "when i read a int, i read 32 bit ( 4 bytes )" , because it's wrong and not the point of the question. Thus, Reader.read() read a int, if this method only read a byte, she's reading a 1/4 int ??!? | No. read() reads 8 bits / 1 byte at a time.
You can get byte, word, int, long, utf-8 string etc. from DataInputStream if you use a DataInputStream typed reference further on. Have
```
DataInputStream r = new DataInputStream(socket.getInputStream());
r.readLong();
r.readShort();
```
instead of
```
InputStream r = new DataInputStream(socket.getInputStream());
```
However, for words, int and long the the 'Endiannes' of the data matters. DataInputStream combines bytes in Big endian format where as you might have your data in little endian format. You might need to swap the bytes in the short/int/long after you read from the DIS. This is where [Integer.reverseBytes()](http://java.sun.com/javase/6/docs/api/java/lang/Integer.html#reverseBytes(int)) and its friends come in handy.
If you need bit sized data retrieval (for example read 6 bits, then 4, then 12, etc) you might want to check out the answers to [this recent question](https://stackoverflow.com/questions/1034473/java-iterate-bits-in-byte-array).
**Edit:** Removed the 8 bits as it is misleading in this context.
**Edit 2:** Rephrased my 3rd sentence. | You can not read only a bit: socket/TCP/IP work with byte as the smallest unit.
You'll have to read the byte containing the bit and use some bit shifting/masking to get the value of one bit:
```
int byte = r.read();
boolean bit1 = (byte && 0x01) != 0; // first bit (least significatn)
boolean bit2 = (byte && 0x02) != 0; // second bit
boolean bit3 = (byte && 0x04) != 0; // thrid bit
...
``` | read bits and not int from a socket | [
"",
"java",
"sockets",
""
] |
I'm using a convention of prefixing field names with an underscore. When I generate annotate entity classes with such fields I am stuck to using the underscore-prefixed property names in queries. I want to avoid that, and be able to do:
```
@Entity
public class Container {
private String _value;
}
// in a lookup method
executeQuery("from Container where value = ?", value);
```
Is that possible with JPA in general or Hibernate in particular?
---
**Update:** Still trying to remember why, but I need this to be annotated on fields rather than on getters. | You can annotate the getter:
```
@Entity
public class Container {
private String _value;
@Column
public String getValue()
{
return _value;
}
public void setValue( String value )
{
this._value = value;
}
}
``` | You could perhaps write subclasses of your generated entity classes, which have getter methods on them, and then configure the entity manager to use getter/setter access instead if field access? Then your getters/setters could have any name you liked. | Modifying property names in JPA queries | [
"",
"java",
"hibernate",
"jpa",
"annotations",
""
] |
What should be the most recommended datatype for storing an IPv4 address in SQL server?
**Or maybe someone has already created a user SQL data-type (.Net assembly) for it?**
I don't need sorting. | Storing an IPv4 address as a [`binary`](http://msdn.microsoft.com/en-us/library/ms188362.aspx)(4) is truest to what it represents, and allows for easy subnet mask-style querying. However, it requires conversion in and out if you are actually after a text representation. In that case, you may prefer a string format.
A little-used SQL Server function that might help if you are storing as a string is [`PARSENAME`](http://msdn.microsoft.com/en-us/library/ms188006.aspx), by the way. Not designed for IP addresses but perfectly suited to them. The call below will return '14':
```
SELECT PARSENAME('123.234.23.14', 1)
```
(numbering is right to left). | I normally just use varchar(15) for IPv4 addresses - but sorting them is a pain unless you pad zeros.
I've also stored them as an INT in the past. [`System.Net.IPAddress`](http://msdn.microsoft.com/en-us/library/system.net.ipaddress.aspx) has a [`GetAddressBytes`](http://msdn.microsoft.com/en-us/library/system.net.ipaddress.getaddressbytes.aspx) method that will return the IP address as an array of the 4 bytes that represent the IP address. You can use the following C# code to convert an [`IPAddress`](http://msdn.microsoft.com/en-us/library/system.net.ipaddress.aspx) to an `int`...
```
var ipAsInt = BitConverter.ToInt32(ip.GetAddressBytes(), 0);
```
I had used that because I had to do a lot of searching for dupe addresses, and wanted the indexes to be as small & quick as possible. Then to pull the address back out of the int and into an [`IPAddress`](http://msdn.microsoft.com/en-us/library/system.net.ipaddress.aspx) object in .net, use the [`GetBytes`](http://msdn.microsoft.com/en-us/library/system.bitconverter.getbytes.aspx) method on [`BitConverter`](http://msdn.microsoft.com/en-us/library/system.bitconverter.aspx) to get the int as a byte array. Pass that byte array to the [constructor](http://msdn.microsoft.com/en-us/library/t4k07yby.aspx) for [`IPAddress`](http://msdn.microsoft.com/en-us/library/system.net.ipaddress.aspx) that takes a byte array, and you end back up with the [`IPAddress`](http://msdn.microsoft.com/en-us/library/system.net.ipaddress.aspx) that you started with.
```
var myIp = new IPAddress(BitConverter.GetBytes(ipAsInt));
``` | What is the most appropriate data type for storing an IP address in SQL server? | [
"",
"sql",
"sql-server",
"types",
"ip-address",
"ipv4",
""
] |
After setting up a table model in Qt 4.4 like this:
```
QSqlTableModel *sqlmodel = new QSqlTableModel();
sqlmodel->setTable("Names");
sqlmodel->setEditStrategy(QSqlTableModel::OnFieldChange);
sqlmodel->select();
sqlmodel->removeColumn(0);
tableView->setModel(sqlmodel);
tableView->show();
```
the content is displayed properly, but editing is not possible, error:
```
QSqlQuery::value: not positioned on a valid record
``` | I can confirm that the bug exists exactly as you report it, in Qt 4.5.1, AND that the documentation, e.g. [here](https://doc.qt.io/qt-5/qsqltablemodel.html#details), still gives a wrong example (i.e. one including the `removeColumn` call).
As a work-around I've tried to write a slot connected to the `beforeUpdate` signal, with the idea of checking what's wrong with the QSqlRecord that's about to be updated in the DB and possibly fixing it, but I can't get that to work -- any calls to methods of that record parameter are crashing my toy-app with a BusError.
So I've given up on that idea and switched to what's no doubt the right way to do it (visibility should be determined by the view, not by the model, right?-): lose the `removeColumn` and in lieu of it call `tableView->setColumnHidden(0, true)` instead. This way the IDs are hidden and everything works.
So I think we can confirm there's a documentation error and open an issue about it in the Qt tracker, so it can be fixed in the next round of docs, right? | It seems that the cause of this was in line
```
sqlmodel->removeColumn(0);
```
After commenting it out, everything work perfectly.
Thus, I'll have to find another way not to show ID's in the table ;-)
**EDIT**
I've said "it seems", because in the example from "Foundations of Qt development" Johan Thelin also removed the first column. So, it would be nice if someone else also tries this and reports results. | Problem with QSqlTableModel -- no automatic updates | [
"",
"sql",
"database",
"qt",
"qt4",
""
] |
If a form is submitted but not by any specific button, such as
* by pressing `Enter`
* using `HTMLFormElement.submit()` in JS
how is a browser supposed to determine which of multiple submit buttons, if any, to use as the one pressed?
This is significant on two levels:
* calling an `onclick` event handler attached to a submit button
* the data sent back to the web server
My experiments so far have shown that:
* when pressing `Enter`, Firefox, Opera and Safari use the first submit button in the form
* when pressing `Enter`, IE uses either the first submit button or none at all depending on conditions I haven't been able to figure out
* all these browsers use none at all for a JS submit
What does the standard say?
If it would help, here's my test code (the PHP is relevant only to my method of testing, not to my question itself)
```
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Test</title>
</head>
<body>
<h1>Get</h1>
<dl>
<?php foreach ($_GET as $k => $v) echo "<dt>$k</dt><dd>$v</dd>"; ?>
</dl>
<h1>Post</h1>
<dl>
<?php foreach ($_POST as $k => $v) echo "<dt>$k</dt><dd>$v</dd>"; ?>
</dl>
<form name="theForm" method="<?php echo isset($_GET['method']) ? $_GET['method'] : 'get'; ?>" action="<?php echo $_SERVER['SCRIPT_NAME']; ?>">
<input type="text" name="method" />
<input type="submit" name="action" value="Button 1" onclick="alert('Button 1'); return true" />
<input type="text" name="stuff" />
<input type="submit" name="action" value="Button 2" onclick="alert('Button 2'); return true" />
<input type="button" value="submit" onclick="document.theForm.submit();" />
</form>
</body></html>
``` | If you submit the form via JavaScript (i.e., `formElement.submit()` or anything equivalent), then *none* of the submit buttons are considered successful and none of their values are included in the submitted data. (Note that if you submit the form by using `submitElement.click()` then the submit that you had a reference to is considered active; this doesn't really fall under the remit of your question since here the submit button is unambiguous but I thought I'd include it for people who read the first part and wonder how to make a submit button successful via JavaScript form submission. Of course, the form's onsubmit handlers will still fire this way whereas they wouldn't via `form.submit()` so that's another kettle of fish...)
If the form is submitted by hitting Enter while in a non-textarea field, then it's actually down to the user agent to decide what it wants here. [The specifications](http://www.w3.org/TR/html401/interact/forms.html#submit-button) don't say anything about submitting a form using the `Enter` key while in a text entry field (if you tab to a button and activate it using space or whatever, then there's no problem as that specific submit button is unambiguously used). All it says is that a form must be submitted when a submit button is activated. It's not even a requirement that hitting `Enter` in e.g. a text input will submit the form.
I believe that Internet Explorer chooses the submit button that appears first in the source; I have a feeling that Firefox and Opera choose the button with the lowest tabindex, falling back to the first defined if nothing else is defined. There's also some complications regarding whether the submits have a non-default value attribute IIRC.
The point to take away is that there is no defined standard for what happens here and it's entirely at the whim of the browser - so as far as possible in whatever you're doing, try to avoid relying on any particular behaviour. If you really must know, you can probably find out the behaviour of the various browser versions, but when I investigated this a while back there were some quite convoluted conditions (which of course are subject to change with new browser versions) and I'd advise you to avoid it if possible! | HTML 4 does not make it explicit. HTML 5 [specifies that the first submit button must be the default](https://html.spec.whatwg.org/multipage/form-control-infrastructure.html#implicit-submission):
> 4.10.21.2 Implicit submission
>
> A `form` element's **default button** is the first [submit button](https://html.spec.whatwg.org/multipage/forms.html#concept-submit-button) in [tree order](https://dom.spec.whatwg.org/#concept-tree-order) whose [form owner](https://html.spec.whatwg.org/multipage/form-control-infrastructure.html#form-owner) is that `form` element.
>
> If the user agent supports letting the user submit a form implicitly
> (for example, on some platforms hitting the "enter" key while a text
> control is [focused](https://html.spec.whatwg.org/multipage/interaction.html#focused) implicitly submits the form), then doing so for a
> form, whose [default button](https://html.spec.whatwg.org/multipage/form-control-infrastructure.html#default-button) has [activation behavior](https://dom.spec.whatwg.org/#eventtarget-activation-behavior) and is not
> [disabled](https://html.spec.whatwg.org/multipage/form-control-infrastructure.html#concept-fe-disabled), must cause the user agent to [fire a `click` event](https://html.spec.whatwg.org/multipage/webappapis.html#fire-a-click-event) at that
> [default button](https://html.spec.whatwg.org/multipage/form-control-infrastructure.html#default-button).
If you want to influence which one is "first" while maintaining the visual order then there are a couple of approaches you could take.
An off-screen, unfocusable button.
```
.hidden-default {
position: absolute;
left: -9999px;
}
```
```
<form>
<input name="text">
<button name="submit" value="wanted" class="hidden-default" tabindex="-1"></button>
<button name="submit" value="not wanted">Not the default</button>
<button name="submit" value="wanted">Looks like the default</button>
</form>
```
Flexbox order:
```
.ordering {
display: inline-flex;
}
.ordering button {
order: 2;
}
.ordering button + button {
order: 1;
}
```
```
<form>
<input name="text">
<div class="ordering">
<button name="submit" value="wanted">First in document order</button>
<button name="submit" value="not wanted">Second in document order</button>
</div>
</form>
``` | How is the default submit button on an HTML form determined? | [
"",
"javascript",
"html",
"cross-browser",
"standards",
""
] |
I have the following code
```` ```
void reportResults()
{
wstring env(_wgetenv(L"ProgramFiles"));
env += L"\Internet Explorer\iexplore.exe";
wstringstream url;
url << "\"\"" << env.c_str() << "\" http://yahoo.com\"";
wchar_t arg[BUFSIZE];
url.get(arg, BUFSIZE);
wcout << arg << endl;
_wsystem(arg);
}
``` ````
Where arg is:
""C:\Program Files\Internet Explorer\iexplore.exe" <http://yahoo.com>"
The program functions as expected, launching IE and navigating to Yahoo, but the calling function (reportResults) never exits. How do I get the program to exit leaving the browser alive?
Thanks. | You want to use \_wspawn() instead of \_wsystem(). This will spawn a new process for the browser process. \_wsystem() blocks on the command that you create; this is why you're not getting back to your code. \_wspawn() creates a new, separate process, which should return to your code immediately. | The \_wsystem command will wait for the command in arg to return and returns the return value of the command. If you close the Internet Explorer window it will return command back to your program. | C++ system function hangs application | [
"",
"c++",
"process",
""
] |
i am using a ThreadPoolExecutor with a thread pool size of one to sequentially execute swing workers. I got a special case where an event arrives that creates a swing worker that does some client-server communication and after that updates the ui (in the done() method).
This works fine when the user fires (clicks on an item) some events but not if there occur many of them. But this happens so i need to cancel all currently running and scheduled workers. The problem is that the queue that is backing the ThreadPoolExecutor isnt aware of the SwingWorker cancellation process (at least it seems like that). So scheduled worker get cancelled but already running workers get not.
So i added a concurrent queue of type `<T extends SwingWorker>` that holds a reference of all workers as long as they are not cancelled and when a new event arrives it calls .cancel(true) on all SwingWorkers in the queue and submits the new SwingWorker to the ThreadPoolExecutor.
Summary: SwingWorkers are created and executed in a ThreadPoolExecutor with a single Thread. Only the worker that was submitted last should be running.
Are there any alternatives to solve this problem, or is it "ok" to do it like this?
Just curious... | One way to create a Single thread ThreadPoolExecutor that only executes last incoming Runnable is to subclass a suitable queue class and override all adding methods to clear the queue before adding the new runnable. Then set that queue as the ThreadPoolExecutor's work queue. | Why do you need a ThreadPoolExecutor to do this kind of job?
How many sources of different SwingWorkers you have? Because if the source is just one you should use a different approach.
For example you can define a class that handles one kind of working thread and it's linked to a single kind of item on which the user can fire actions and care inside that class the fact that a single instance of the thread should be running (for example using a singleton instance that is cleared upon finishing the task) | SwingWorker cancellation with ThreadPoolExecutor | [
"",
"java",
"multithreading",
"swing",
"threadpool",
""
] |
Is there a method built into .NET that can write all the properties and such of an object to the console?
One could make use of reflection of course, but I'm curious if this already exists...especially since you can do it in Visual Studio in the Immediate Window. There you can type an object name (while in debug mode), press enter, and it is printed fairly prettily with all its stuff.
Does a method like this exist? | The `ObjectDumper` class has been known to do that. I've never confirmed, but I've always suspected that the immediate window uses that.
EDIT: I just realized, that the code for `ObjectDumper` is actually on your machine. Go to:
```
C:/Program Files/Microsoft Visual Studio 9.0/Samples/1033/CSharpSamples.zip
```
This will unzip to a folder called *LinqSamples*. In there, there's a project called *ObjectDumper*. Use that. | You can use the [`TypeDescriptor`](https://learn.microsoft.com/en-us/dotnet/api/system.componentmodel.typedescriptor) class to do this:
```
foreach(PropertyDescriptor descriptor in TypeDescriptor.GetProperties(obj))
{
string name = descriptor.Name;
object value = descriptor.GetValue(obj);
Console.WriteLine("{0}={1}", name, value);
}
```
`TypeDescriptor` lives in the `System.ComponentModel` namespace and is the API that Visual Studio uses to display your object in its property browser. It's ultimately based on reflection (as any solution would be), but it provides a pretty good level of abstraction from the reflection API. | C#: Printing all properties of an object | [
"",
"c#",
"object",
"serialization",
"console",
""
] |
Hey people... trying to get my mocking sorted with asp.net MVC.
I've found this example on the net using Moq, basically I'm understanding it to say: when ApplyAppPathModifier is called, return the value that was passed to it.
I cant figure out how to do this in Rhino Mocks, any thoughts?
```
var response = new Mock<HttpResponseBase>();
response.Expect(res => res.ApplyAppPathModifier(It.IsAny<string>()))
.Returns((string virtualPath) => virtualPath);
``` | As I mentioned above, sods law, once you post for help you find it 5 min later (even after searching for a while). Anyway for the benefit of others this works:
```
SetupResult
.For<string>(response.ApplyAppPathModifier(Arg<String>.Is.Anything)).IgnoreArguments()
.Do((Func<string, string>)((arg) => { return arg; }));
``` | If you are using the stub method as opposed to the SetupResult method, then the syntax for this is below:
```
response.Stub(res => res.ApplyAppPathModifier(Arg<String>.Is.Anything))
.Do(new Func<string, string>(s => s));
``` | What would this Moq code look like in RhinoMocks | [
"",
"c#",
"asp.net-mvc",
"mocking",
"rhino-mocks",
"moq",
""
] |
I have the following situation in JavaScript:
```
<a onclick="handleClick(this, {onSuccess : 'function() { alert(\'test\') }'});">Click</a>
```
The `handleClick` function receives the second argument as a object with a `onSuccess` property containing the function definition...
**How do I call the `onSuccess` function (which is stored as string) -and- pass `otherObject` to that function? (jQuery solution also fine...)?**
This is what I've tried so far...
```
function handleClick(element, options, otherObject) {
options.onSuccess = 'function() {alert(\'test\')}';
options.onSuccess(otherObject); //DOES NOT WORK
eval(options.onSuccess)(otherObject); //DOES NOT WORK
}
``` | You really don't need to do this. Pass the function around as a string, i mean. JavaScript functions are first-class objects, and can be passed around directly:
```
<a onclick="handleClick(this, {onSuccess : function(obj) { alert(obj) }}, 'test');">
Click
</a>
```
...
```
function handleClick(element, options, otherObject) {
options.onSuccess(otherObject); // works...
}
```
But if you *really* want to do it your way, then [cloudhead's solution](https://stackoverflow.com/questions/984138/javascript-execute-anonymous-function-stored-in-string-with-argument/984171#984171) will do just fine. | Try this:
```
options.onSuccess = eval('function() {alert(\'test\')}');
options.onSuccess(otherObject);
``` | How can I call an anonymous function (stored in string) with an argument in JavaScript? | [
"",
"javascript",
"jquery",
""
] |
> **Possible Duplicate:**
> [Detect file encoding in PHP](https://stackoverflow.com/questions/505562/detect-file-encoding-in-php)
How can I figure out with PHP what file encoding a file has? | Detecting the encoding is really hard for all 8 bit character sets but utf-8 (because not every 8 bit byte sequence is valid utf-8) and usually requires semantic knowledge of the text for which the encoding is to be detected.
Think of it: Any particular plain text information is just a bunch of bytes with no encoding information associated. If you look at any particular byte, it could mean *anything*, so to have a chance at detecting the encoding, you would have to look at that byte in context of other bytes and try some heuristics based on possible *language* combination.
For 8bit character sets you can never be sure though.
A demonstration of heuristics going wrong is here for example:
<http://www.hoax-slayer.com/bush-hid-the-facts-notepad.html>
Some 16bit sets, you have a chance at detecting because they might include a byte order mark or have every second byte set to 0.
If you just want to detect UTF-8, you can either use mb\_detect\_encoding as already explained, or you can use this handy little function:
```
function isUTF8($string){
return preg_match('%(?:
[\xC2-\xDF][\x80-\xBF] # non-overlong 2-byte
|\xE0[\xA0-\xBF][\x80-\xBF] # excluding overlongs
|[\xE1-\xEC\xEE\xEF][\x80-\xBF]{2} # straight 3-byte
|\xED[\x80-\x9F][\x80-\xBF] # excluding surrogates
|\xF0[\x90-\xBF][\x80-\xBF]{2} # planes 1-3
|[\xF1-\xF3][\x80-\xBF]{3} # planes 4-15
|\xF4[\x80-\x8F][\x80-\xBF]{2} # plane 16
)+%xs', $string);
}
``` | mb\_detect\_encoding should be able to do the job.
<http://us.php.net/manual/en/function.mb-detect-encoding.php>
In it's default setup, it'll only detect ASCII, UTF-8, and a few Japanese JIS variants. It can be configured to detect more encodings, if you specify them manually. If a file is both ASCII and UTF-8, it'll return UTF-8. | Get file encoding | [
"",
"php",
"encoding",
"utf-8",
""
] |
```
<body>
<div> <?= $_POST['msg'] ?> </div>
<form id="frm" method="post">
<input type="hidden" name='msg' value='{"field0": "Im a string", "field1": 84, "field3": "so am I"}' />
<input type="submit" value="test" />
</form>
</body>
```
When the form is posted, the following string is displayed between the div tags.
> {\"field0\": \"Im a string\",
> \"field1\": 84, \"field3\": \"so am
> I\"}
Why are the escape characters being added?
Are they being added by the PHP server or the web client?
Can I do anything to prevent this?
Someone already mentioned the PHP function stripslashes. I'm using it for now but I want to get rid of the slashes all together. | Check whether your PHP configuration has [`magic_quotes_gpc`](http://www.php.net/manual/en/function.get-magic-quotes-gpc.php) activated, in such case the PHP server automatically adds slashes to GET/POST/cookie values... | I believe the problem is just one of escaping done by the tools you are using to output the string. For example:
```
var msg = dojo.toJson({field1: 'string', field2: 84, field3: 'another string'});
alert(msg);
```
will show the double quotes as unescaped. Similarly, running your first example while the browser is hooked up to a proxy like Charles, shows the double qoutes as unescaped.
So I believe this is just an auto-escape that Firebug/PHP does when showing you strings. | Why are escape characters being added to the value of the hidden input | [
"",
"php",
"html",
"json",
""
] |
Is there any way to prevent the `gethostbyname()` function not to read the nscd cache on Linux? | Not really an answer, but use `getaddrinfo(3)` instead :)
As far as `nscd` is concerned, here's from the `nscd.conf(5)` manual page:
```
enable-cache service <yes|no>
Enables or disables the specified service cache.
```
You'll have to find out what the correct `service` for DNS is. | Call `res_init()` before `gethostbyname()`. It seems ok. | Forcing non-cached gethostbyname() | [
"",
"c++",
"linux",
"caching",
""
] |
I'm working on a C# object copy constructor, part of which involves copying the contents of a KeyedCollection into a new KeyedCollection. This is what I have implemented currently:
```
class MyKeyedCollection : KeyedCollection<uint, DataObject>
{
protected override uint GetKeyForItem( DataObject do )
{
return do.Key;
}
}
class MyObject
{
private MyKeyedCollection kc;
// Copy constructor
public MyObject( MyObject that )
{
this.kc = new MyKeyedCollection();
foreach ( DataObject do in that.kc )
{
this.kc.Add( do );
}
}
}
```
This does the correct thing -- the collection is copied as expected. The problem is that it's also a bit slow. I'm guessing that the problem is that each .Add(do) requires a uniqueness check on the existing data, even though I know it's coming from a source that guarantees uniqueness.
How can I make this copy constructor as fast as possible? | Ok, how about a solution with a little unsafe code? Just for fun?
WARNINGS! This is coded for windows OS and 32 bit, but there is no reason this technique can't be modified to work for 64 bit or other OS's. Finally, I tested this on 3.5 framework. I think it will work on 2.0 and 3.0 but I didn't test. If Redmond changes the number, type, or order of instance variables between the revisions or patches, then this won't work.
But this is fast!!!
This hacks into the KeyedCollection, its underlying List<> and Dictionary<> and copies all the internal data and properties. Its a hack because to do this you have to access private internal variables. I basicly made some structures for KeyedCollection, List, and Dictionary that are those classes' private variables in the right order. I simply point an these structures to where the classes are and voila...you can mess with the private variables!! I used the RedGate reflector to see what all the code was doing so I could figure out what to copy. Then its just a matter of copying some value types and using Array.Copy in a couple places.
The result is **CopyKeyedCollection**<,>, **CopyDict**<> and **CopyList**<>. You get a function that can quick copy a Dictionary<> and one that can quick copy a List<> for free!
One thing I noticed when working this all out was that KeyedCollection contains a list and a dictionary all pointing to the same data! I thought this was wasteful at first, but commentors pointed out KeyedCollection is expressly for the case where you need an ordered list and a dictionary at the same time.
Anyway, i'm an assembly/c programmer who was forced to use vb for awhile, so I am not afraid of doing hacks like this. I'm new to C#, so tell me if I have violated any rules or if you think this is cool.
By the way, I researched the garbage collection, and this should work just fine with the GC. I think it would be prudent if I added a little code to fix some memory for for the ms we spend copying. You guys tell me. I'll add some comments if anyone requests em.
```
using System;
using System.Collections.Generic;
using System.Text;
using System.Runtime.InteropServices;
using System.Collections.ObjectModel;
using System.Reflection;
namespace CopyCollection {
class CFoo {
public int Key;
public string Name;
}
class MyKeyedCollection : KeyedCollection<int, CFoo> {
public MyKeyedCollection() : base(null, 10) { }
protected override int GetKeyForItem(CFoo foo) {
return foo.Key;
}
}
class MyObject {
public MyKeyedCollection kc;
// Copy constructor
public MyObject(MyObject that) {
this.kc = new MyKeyedCollection();
if (that != null) {
CollectionTools.CopyKeyedCollection<int, CFoo>(that.kc, this.kc);
}
}
}
class Program {
static void Main(string[] args) {
MyObject mobj1 = new MyObject(null);
for (int i = 0; i < 7; ++i)
mobj1.kc.Add(new CFoo() { Key = i, Name = i.ToString() });
// Copy mobj1
MyObject mobj2 = new MyObject(mobj1);
// add a bunch more items to mobj2
for (int i = 8; i < 712324; ++i)
mobj2.kc.Add(new CFoo() { Key = i, Name = i.ToString() });
// copy mobj2
MyObject mobj3 = new MyObject(mobj2);
// put a breakpoint after here, and look at mobj's and see that it worked!
// you can delete stuff out of mobj1 or mobj2 and see the items still in mobj3,
}
}
public static class CollectionTools {
public unsafe static KeyedCollection<TKey, TValue> CopyKeyedCollection<TKey, TValue>(
KeyedCollection<TKey, TValue> src,
KeyedCollection<TKey, TValue> dst) {
object osrc = src;
// pointer to a structure that is a template for the instance variables
// of KeyedCollection<TKey, TValue>
TKeyedCollection* psrc = (TKeyedCollection*)(*((int*)&psrc + 1));
object odst = dst;
TKeyedCollection* pdst = (TKeyedCollection*)(*((int*)&pdst + 1));
object srcObj = null;
object dstObj = null;
int* i = (int*)&i; // helps me find the stack
i[2] = (int)psrc->_01_items;
dstObj = CopyList<TValue>(srcObj as List<TValue>);
pdst->_01_items = (uint)i[1];
// there is no dictionary if the # items < threshold
if (psrc->_04_dict != 0) {
i[2] = (int)psrc->_04_dict;
dstObj = CopyDict<TKey, TValue>(srcObj as Dictionary<TKey, TValue>);
pdst->_04_dict = (uint)i[1];
}
pdst->_03_comparer = psrc->_03_comparer;
pdst->_05_keyCount = psrc->_05_keyCount;
pdst->_06_threshold = psrc->_06_threshold;
return dst;
}
public unsafe static List<TValue> CopyList<TValue>(
List<TValue> src) {
object osrc = src;
// pointer to a structure that is a template for
// the instance variables of List<>
TList* psrc = (TList*)(*((int*)&psrc + 1));
object srcArray = null;
object dstArray = null;
int* i = (int*)&i; // helps me find things on stack
i[2] = (int)psrc->_01_items;
int capacity = (srcArray as Array).Length;
List<TValue> dst = new List<TValue>(capacity);
TList* pdst = (TList*)(*((int*)&pdst + 1));
i[1] = (int)pdst->_01_items;
Array.Copy(srcArray as Array, dstArray as Array, capacity);
pdst->_03_size = psrc->_03_size;
return dst;
}
public unsafe static Dictionary<TKey, TValue> CopyDict<TKey, TValue>(
Dictionary<TKey, TValue> src) {
object osrc = src;
// pointer to a structure that is a template for the instance
// variables of Dictionary<TKey, TValue>
TDictionary* psrc = (TDictionary*)(*((int*)&psrc + 1));
object srcArray = null;
object dstArray = null;
int* i = (int*)&i; // helps me find the stack
i[2] = (int)psrc->_01_buckets;
int capacity = (srcArray as Array).Length;
Dictionary<TKey, TValue> dst = new Dictionary<TKey, TValue>(capacity);
TDictionary* pdst = (TDictionary*)(*((int*)&pdst + 1));
i[1] = (int)pdst->_01_buckets;
Array.Copy(srcArray as Array, dstArray as Array, capacity);
i[2] = (int)psrc->_02_entries;
i[1] = (int)pdst->_02_entries;
Array.Copy(srcArray as Array, dstArray as Array, capacity);
pdst->_03_comparer = psrc->_03_comparer;
pdst->_04_m_siInfo = psrc->_04_m_siInfo;
pdst->_08_count = psrc->_08_count;
pdst->_10_freeList = psrc->_10_freeList;
pdst->_11_freeCount = psrc->_11_freeCount;
return dst;
}
// these are the structs that map to the private variables in the classes
// i use uint for classes, since they are just pointers
// statics and constants are not in the instance data.
// I used the memory dump of visual studio to get these mapped right.
// everything with a * I copy. I Used RedGate reflector to look through all
// the code to decide what needed to be copied.
struct TKeyedCollection {
public uint _00_MethodInfo; // pointer to cool type info
// Collection
public uint _01_items; // * IList<T>
public uint _02_syncRoot; // object
// KeyedCollection
public uint _03_comparer; // IEqualityComparer<TKey>
public uint _04_dict; // * Dictionary<TKey, TItem>
public int _05_keyCount; // *
public int _06_threshold; // *
// const int defaultThreshold = 0;
}
struct TList {
public uint _00_MethodInfo; //
public uint _01_items; // * T[]
public uint _02_syncRoot; // object
public int _03_size; // *
public int _04_version; //
}
struct TDictionary {
// Fields
public uint _00_MethodInfo; //
public uint _01_buckets; // * int[]
public uint _02_entries; // * Entry<TKey, TValue>[]
public uint _03_comparer; // IEqualityComparer<TKey>
public uint _04_m_siInfo; // SerializationInfo
public uint _05__syncRoot; // object
public uint _06_keys; // KeyCollection<TKey, TValue>
public uint _07_values; // ValueCollection<TKey, TValue>
public int _08_count; // *
public int _09_version;
public int _10_freeList; // *
public int _11_freeCount; // *
}
}
}
``` | I just ran a test adding 10,000,000 items and to various collections, and the KeyedCollection took about 7x as long as a list, but only about 50% longer than a Dictionary object. Considering that the KeyedCollection is a combination of these two, the performance of Add is perfectly reasonable, and the duplicate-key check it runs is clearly not taking **that** much time. You might want to run a similar test on your KeyedCollection, and if it's going significantly slower, you can start looking elsewhere (check your `MyObject.Key` getter to make sure you're not getting overhead from that).
---
## Old Response
Have you tried:
```
this.kc = that.kc.MemberwiseClone() as MyKeyedCollection;
```
More info on MemberwiseClone [here](http://msdn.microsoft.com/en-us/library/system.object.memberwiseclone(VS.80).aspx). | Fastest way to copy a KeyedCollection | [
"",
"c#",
".net",
"optimization",
"collections",
"keyedcollection",
""
] |
Let's say I have a class:
```
class String
{
public:
String(char *str);
};
```
And two functions:
```
void DoSomethingByVal(String Str);
void DoSomethingByRef(String &Str);
```
If I call DoSomethingByVal like this:
```
DoSomethingByVal("My string");
```
the compiler figures out that it should create a temporary String object and call the char\* constructor.
However, if I try to use DoSomethingByRef the same way, I get a "Can't convert parameter from 'char \*' to 'String &'" error.
Instead, I have to explicitly create an instance:
```
DoSomethingByRef(String("My string"));
```
which can get preety annoying.
Is there any way to avoid this? | You need to pass by const reference:
For:
```
void DoSomethingByVal(String Str);
```
In this situation the compiler first creates a temporary variable. Then the temporary variable is copy constructed into the parameter.
For:
```
void DoSomethingByRef(String const& Str);
```
In this situation the compiler creates a temporary variable. But temporary variables can not be bound to a reference they can only be bound to a const reference so your original function can not be called. Note the std::string objects constructor takes a const reference is the parameter to the copy constructor and that is why the first version works as the temporary is bound to the const reference parameter of the copy constructor only. | Hmm, I'm not sure if
```
void DoSomethingByRef(String &Str);
DoSomethingByRef(String("My string"));
```
would actually compile. An rvalue can't bind to a reference to non-const (because a ref to non-const is stating you will modify the value, and it wouldn't make sense to modify a temporary). Are you sure you aren't doing:
```
String str("My string");
DoSomethingByRef(str);
```
If you want DoSomethingByVal to take an rvalue, the parameter has to be a reference to const:
```
void DoSomethingByRef(const String &Str);
``` | How to avoid explicitly calling a constructor when passing temporary object by reference in C++? | [
"",
"c++",
"pass-by-reference",
""
] |
I'm busy with programming a class that creates an index out of a text-file ASCII/BINARY.
My problem is that I don't really know how to start. I already had some tries but none really worked well for me.
I do NOT need to find the address of the file via the MFT. Just loading the file and finding stuff much faster by searching for the key in the index-file and going in the text-file to the address it shows.
The index-file should be built up as follows:
```
KEY ADDRESS
1 0xABCDEF
2 0xFEDCBA
. .
. .
```
We have a text-file with the following example value:
```
1, 8752 FW,
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++,
******************************************************************************,
------------------------------------------------------------------------------;
```
I hope that this explains my question a bit better.
Thanks! | It seems to me that all your class needs to do is store an array of pointers or file start offsets to the key locations in the file.
It really depends on what your Key locations represent.
I would suggest that you access the file through your class using some public methods. You can then more easily tie in Key locations with the data written.
For example, your Key locations may be where each new data block written into the file starts from. e.g. first block 1000 bytes, key location 0; second block 2500 bytes, key location 1000; third block 550 bytes; key location 3500; the next block will be 4050 all assuming that 0 is the first byte.
Store the Key values in a variable length array and then you can easily retrieve the starting point for a data block.
If your Key point is signified by some key character then you can use the same class, but with a slight change to store where the Key value is stored. The simplest way is to step through the data until the key character is located, counting the number of characters checked as you go. The count is then used to produce your key location. | Your code snippet isn't so much of an idea as it is the functionality you wish to have in the end.
Recognize that "indexing" merely means "remembering" where things are located. You can accomplish this using any data structure you wish... B-Tree, Red/Black tree, BST, or more advanced structures like suffix trees/suffix arrays.
I recommend you look into such data structures.
edit:
with the new information, I would suggest making your own key/value lookup. Build an array of keys, and associate their values somehow. this may mean building a class or struct that contains both the key and the value, or instead contains the key and a pointer to a struct or class with a value, etc.
Once you have done this, sort the key array. Now, you have the ability to do a binary search on the keys to find the appropriate value for a given key.
You could build a hash table in a similar manner. you could build a BST or similar structure like i mentioned earlier. | Making an index-creating class | [
"",
"c++",
"binary",
"indexing",
"ascii",
""
] |
I'm working on a web project that is multilingual. For example, one portion of the project involves some custom google mapping that utilizes a client-side interace using jquery/.net to add points to a map and save them to the database.
There will be some validation and other informational messaging (ex. 'Please add at least one point to the map') that will have to be localized.
The only options I can think of right now are:
1. Use a code render block in the javascript to pull in the localized message from a resource file
2. Use hidden fields with meta:resourcekey to automatically grab the proper localized message from the resource file using the current culture, and get the .val() in jquery when necessary.
3. Make a webservice call to get the correct message by key/language each time a message is required.
Any thoughts, experiences?
EDIT:
I'd prefer to use the .net resource files to keep things consistent with the rest of the application. | Ok, I built a generic web service to allow me to grab resources and return them in a dictionary (probably a better way to convert to the dictionary)...
```
<WebMethod()> _
<ScriptMethod(ResponseFormat:=ResponseFormat.Json, UseHttpGet:=False, XmlSerializeString:=True)> _
Public Function GetResources(ByVal resourceFileName As String, ByVal culture As String) As Dictionary(Of String, String)
Dim reader As New System.Resources.ResXResourceReader(String.Format(Server.MapPath("/App_GlobalResources/{0}.{1}.resx"), resourceFileName, culture))
If reader IsNot Nothing Then
Dim d As New Dictionary(Of String, String)
Dim enumerator As System.Collections.IDictionaryEnumerator = reader.GetEnumerator()
While enumerator.MoveNext
d.Add(enumerator.Key, enumerator.Value)
End While
Return d
End If
Return Nothing
End Function
```
Then, I can grab this json result and assign it to a local variable:
```
// load resources
$.ajax({
type: "POST",
url: "mapping.asmx/GetResources",
contentType: "application/json; charset=utf-8",
dataType: "json",
data: '{"resourceFileName":"common","culture":"en-CA"}',
cache: true,
async: false,
success: function(data) {
localizations = data.d;
}
});
```
Then, you can grab your value from the local variable like so:
localizations.Key1
The only catch here is that if you want to assign the localizations to a global variable you have to run it async=false, otherwise you won't have the translations available when you need them. I'm trying to use 'get' so I can cache the response, but it's not working for me. See this question:
[Can't return Dictionary(Of String, String) via GET ajax web request, works with POST](https://stackoverflow.com/questions/1033305/cant-return-dictionaryof-string-string-via-get-ajax-web-request-works-with-p) | I've done this before where there are hidden fields that have their values set on Page\_Init() and Page\_Load() with the appropriate values from the global and local resource files. The javascript code would then work with those hidden values.
**Code Behind**
```
this.hfInvalidCheckDateMessage.Value = this.GetLocalResourceObject("DatesRequired").ToString();
```
**Page.aspx**
```
$('#<%= btnSearch.ClientID %>').click(function(e) {
if (!RequiredFieldCheck()) {
var message = $("#<%= hfInvalidCheckDateMessage.ClientID %>").val();
alert(message);
e.preventDefault();
$("#<%= txtAuthDateFrom.ClientID %>").focus();
}
});
```
***Disclaimer***... Not sure if this was the best route or not, but it does seem to work well. | Localize javascript messages and validation text | [
"",
"asp.net",
"javascript",
"jquery",
"localization",
""
] |
Currently many of the links on our pages get changed to `href="javascript:void(0);"` on pageload, but if you're impatient (as most users are) you can click the links before the page loads and land on the clunkier, non-javascript, non-ajax pages.
I'm thinking about progressive enhancement a lot these days, and I predict the majority of our users will have javascript enabled (no data yet, we havn't yet launched alpha)
**Is it a bad idea to generate some indicator that a user has javascript enabled for the session, and then serve pages that assume javascript? (ie. have the server put `href="javascript:void(0);"` from the start)** | Why not just do this?
```
<a href="oldversion.htm" onclick="...something useful......; return false;">link</a>
```
`return false` tells the browser not to carry on to the url in the href.
Now js visitors get fancy js, and non-js users fall back silently; and there is no need for changing links on pageload. | Do you do your progressive enhancement on load? You could try to move it to (a cross-browser version of) DOMReady. | progressive enhancement on the server side? | [
"",
"javascript",
"server-side",
"progressive-enhancement",
""
] |
In Python 2.6 (and earlier) the `hex()` and `oct()` built-in functions can be overloaded in a class by defining `__hex__` and `__oct__` special functions. However there is not a `__bin__` special function for overloading the behaviour of Python 2.6's new `bin()` built-in function.
I want to know if there is any way of flexibly overloading `bin()`, and if not I was wondering why the inconsistent interface?
I do know that the `__index__` special function can be used, but this isn't flexible as it can only return an integer. My particular use case is from the [bitstring](http://code.google.com/p/python-bitstring/) module, where leading zero bits are considered significant:
```
>>> a = BitString(length=12) # Twelve zero bits
>>> hex(a)
'0x000'
>>> oct(a)
'0o0000'
>>> bin(a)
'0b0' <------ I want it to output '0b000000000000'
```
I suspect that there's no way of achieving this, but I thought it wouldn't hurt to ask! | I think the short answer is 'No, `bin()` can't be overloaded like `oct()` and `hex()`.'
As to why, the answer must lie with Python 3.0, which uses `__index__` to overload `hex()`, `oct()` and `bin()`, and has removed the `__oct__` and `__hex__` special functions altogether.
So the Python 2.6 `bin()` looks very much like it's really a Python 3.0 feature that has been back-ported without much consideration that it's doing things the new Python 3 way rather than the old Python 2 way. I'd also guess that it's unlikely to get fixed, even if it is considered to be a bug. | As you've already discovered, you can't override `bin()`, but it doesn't sound like you need to do that. You just want a 0-padded binary value. Unfortunately in python 2.5 and previous, you couldn't use "%b" to indicate binary, so you can't use the "%" string formatting operator to achieve the result you want.
Luckily python 2.6 does offer what you want, in the form of the new [str.format()](http://docs.python.org/library/string.html#string-formatting) method. I believe that this particular bit of line-noise is what you're looking for:
```
>>> '{0:010b}'.format(19)
'0000010011'
```
The syntax for this mini-language is under "[format specification mini-language](http://docs.python.org/library/string.html#format-specification-mini-language)" in the docs. To save you some time, I'll explain the string that I'm using:
1. parameter zero (i.e. `19`) should be formatted, using
2. a magic "`0`" to indicate that I want 0-padded, right-aligned number, with
3. 10 digits of precision, in
4. binary format.
You can use this syntax to achieve a variety of creative versions of alignment and padding. | Can bin() be overloaded like oct() and hex() in Python 2.6? | [
"",
"python",
"binary",
"overloading",
"python-2.6",
""
] |
I use a php checkbox and I want to retrieve marked values.
My checkbox code :
```
<label for="cours">Je suis intéressé par un ou plusieurs cours :</label><br><br>
<input type="checkbox" name="cours" value="individuel">Individuel<br>
<input type="checkbox" name="cours" value="semiprive">Semi-privé<br>
<input type="checkbox" name="cours" value="minigroupe">Mini-groupe<br>
<input type="checkbox" name="cours" value="intensif">Intensif<br>
<input type="checkbox" name="cours" value="entreprise">Entreprises<br>
<input type="checkbox" name="cours" value="distance">A distance<br>
<input type="checkbox" name="cours" value="telephone">Par téléphone<br>
<input type="checkbox" name="cours" value="coaching">Coaching<br>
<input type="checkbox" name="cours" value="soutien">Soutien scolaire<br>
<input type="checkbox" name="cours" value="diplome">Diplômes officiels<br>
```
php :
```
<?php
if(isset($_POST['envoyer']))
{
if(get_magic_quotes_gpc())
{
$cours = stripslashes(trim($_POST['cours']));
}
}
?>
```
I want to put it in the variable msg :
```
$msg = 'Cours : '.$cours."\r\n";
```
and sending the message throw the php email function.
But when I do that like this a receive just the first checked choice...
Thank you for your help.
Michaël | You have to change the name attribute to cours[] and then php will treat it as an array.
Read up at <http://docs.php.net/faq.html> | Change name to `cours[`*checkbox-value*`]`.
This will make an associative array full over selected checkboxes. | Retrieving values from a checkbox | [
"",
"php",
"html",
"checkbox",
""
] |
Setting aside the heap's capacity, are there ways to go beyond Integer.MAX\_VALUE constraints in Java?
Examples are:
1. Collections limit themselves to Integer.MAX\_VALUE.
2. StringBuilder / StringBuffer limit themselves to Integer.MAX\_VALUE. | If you have a huge Collection you're going to hit all sorts of practical limits before you ever have [231 - 1](http://java.sun.com/j2se/1.4.2/docs/api/java/lang/Integer.html#MAX_VALUE) items in it. A Collection with a million items in it is going to be pretty unwieldy, let alone one with more than a thousands times more than that.
Similarly, a StringBuilder can build a String that's 2GB in size before it hits the `MAX_VALUE` limit which is more than adequate for any practical purpose.
If you truly think that you might be hitting these limits your application should be storing your data in a different way, probably in a database. | You can create your own collections which have a long size() based on the source code for those collections. To have larger arrays of Objects for example, you can have an array of arrays (and stitch these together)
This approach will allow almost 2^62 elements. | go beyond Integer.MAX_VALUE constraints in Java | [
"",
"java",
"collections",
"integer",
"stringbuilder",
"max",
""
] |
I am creating some custom exceptions in my application.
If I have an exception that gets thrown after testing the state of an argument, Or I have an Exception that gets thrown after testing that an int is within the proper range, should my exceptions inherit ArgumentException and IndexOutOfRangeException or should they just inherit Exception? | Since inheritance is used to specify which exceptions to catch, you should respect this primarily when taking a decision.
Think of an IOException which carries additional information, or a ArgumentException other than ArgumentOutOfRangeException or ArgumentNullException. | Presuming that you really need a custom exception, I would inherit from the Exception most like what you're looking for, rather than just from Exception.
That said, I have found that, under most conditions, using correct wording in you Exception message will normally suffice over creating a whole new exception.
How, for instance is `throw new IntOutOfProperRangeException();` significantly different from `throw new ArgumentOutOfRangeException("The int value was too large?");` | Should my custom Exceptions Inherit an exception that is similar to them or just inherit from Exception? | [
"",
"c#",
"exception",
""
] |
I have 8 sorted lists that I need to merge into 1 sorted list. I don't know the best way to do this. I was thinking of the following:
```
void merge_lists_inplace(list<int>& l1, const list<int>& l2)
{
list<int>::iterator end_it = l1.end();
--end_it;
copy(l2.begin(), l2.end(), back_inserter(l1));
++end_it;
inplace_merge(l1.begin(), end_it, l1.end());
}
list<int> merge_8_lists(list<int>[8] lists)
{
merge_lists_inplace(lists[0], lists[1]);
merge_lists_inplace(lists[2], lists[3]);
merge_lists_inplace(lists[4], lists[5]);
merge_lists_inplace(lists[6], lists[7]);
merge_lists_inplace(lists[0], lists[2]);
merge_lists_inplace(lists[4], lists[6]);
merge_lists_inplace(lists[0], lists[4]);
return lists[0];
}
```
But would it be better to just worry about the sorting last?
```
list<int> merge_8_lists(list<int>[8] lists)
{
for (int i = 1; i < 8; ++i)
copy(lists[i].begin(), lists[i].end(), back_inserter(lists[0]));
lists[0].sort();
return lists[0];
}
```
Side note: I don't care that the lists are modified. | A simple extension of merge sort's merge phase can do this in O(n lg m) time (where n = total number of items and m = number of lists), using a [priority queue](http://en.wikipedia.org/wiki/Priority_queue) (eg, a [heap](http://en.wikipedia.org/wiki/Heap_(data_structure))). Pseudocode:
```
Let P = a priority queue of the sorted lists, sorted by the smallest element in each list
Let O = an empty output list
While P is not empty:
Let L = remove the minimum element from P
Remove the first element from L and add it to O
If L is not empty, add L to P
```
And a simple (untested!) concrete implementation in C++:
```
#include <list>
#include <set>
template<typename T>
struct cmp_list {
bool operator()(const std::list<T> *a, const std::list<T> *b) const {
return a->front() < b->front();
}
};
template<typename T>
void merge_sorted_lists(std::list<T> &output, std::list<std::list<T> > &input)
{
// Use a std::set as our priority queue. This has the same complexity analysis as
// a heap, but has a higher constant factor.
// Implementing a min-heap is left as an exercise for the reader,
// as is a non-mutating version
std::set<std::list<T> *, cmp_list<T> > pq;
for ( typename std::list<std::list<T> >::iterator it = input.begin();
it != input.end(); it++)
{
if (it->empty())
continue;
pq.insert(&*it);
}
while (!pq.empty()) {
std::list<T> *p = *pq.begin();
pq.erase(pq.begin());
output.push_back(p->front());
p->pop_front();
if (!p->empty())
pq.insert(p);
}
}
``` | You could try applying the merge sort one at a time to each of the lists:
<http://en.wikipedia.org/wiki/Merge_sort>
This has the algorithm for the merge sort. Essentially you'd go with list 1 and 2 and merge sort those. Then you'd take that new combined list and sort with list 3, and this continues until you have one fully sorted list.
EDIT:
Actually, because your lists are already sorted, only the last part of the merge sort would be needed. I would iteratively combine the lists into bigger and bigger parts all the while sorting each of those bigger lists until you have your full list, which is essentially what the merge sort does after it's done with its divide and conquer approach. | Merging 8 sorted lists in c++, which algorithm should I use | [
"",
"c++",
"sorting",
"stl",
"merge",
""
] |
I have put together an [example page detailing my problem](http://tinyurl.com/lgk9ny)
My website is going to have a main wrapper that is set to a max-width property for compatible browsers. It will stretch to 940px across at max. When scaled down I would like the swf to scale proportionately with it. Like an image with width percent applied. The flash movie has the dimensions of 940 × 360 pixels.
I can't seem to figure out the correct attributes to add to the embed tag to get it to do this.
I am currently using jquery flash embed, but am open to other options, though this is my ideal.
In the example I have set the flash background to black.
When resize the browser window the flash movie doesn't scale proportionately to the div, only the photo does, leaving a blank canvas (black), while the div height stays the same. I can't add a height value in the CSS.

How do I make this scale correctly? Adding a noscale param only crops the image. The swf's height doesn't scale also.
All of my code can be viewed in the [linked examples source](http://tinyurl.com/lgk9ny). | Thanks George Profenza for giving me all the actionscript codes. There was too much flicker and I am not familiar enough with actionscript to know how to fix it. Big props for putting that much together though.
**I created a solution using jquery. It's very simple.**
First I embed the flash movie with the max possible height, for folks with css disabled. It will still scale with the width but will show canvas background like in the linked examples.
```
$(selector).flash({
src: swf,
width: '100%',
height: '360',
});
//get ratio from native width and height
var nativeWidth = 940;
var nativeHeight = 360;
var ratio = nativeWidth/nativeHeight;
var containerWidth = $(selector).width();
var containerHeight = containerWidth/ratio;
$(selector+' embed').height(containerHeight);
//resize flash movie
$(window).resize(function() {
containerWidth = $(selector).width();
containerHeight = containerWidth/ratio;
$(selector+' embed', selector+' object').height(containerHeight);
$(selector).height(containerHeight);
});
```
Then pretty much resize the movie as the browser window is resized and calculate the height from the new width divided by the original aspect ratio. This code could be cleaned up a lot, but I hope it helps someone else avoid hours of annoyance. | This article will hopefully cover what you need: <http://www.alistapart.com/articles/creating-intrinsic-ratios-for-video/>. It's pure CSS too! | How to make flash movie to scale proportunatly to div width? | [
"",
"javascript",
"jquery",
"css",
"flash",
"actionscript",
""
] |
I'd like one general purpose function that could be used with any Flags style enum to see if a flag exists.
This doesn't compile, but if anyone has a suggestion, I'd appreciate it.
```
public static Boolean IsEnumFlagPresent<T>(T value,T lookingForFlag)
where T:enum
{
Boolean result = ((value & lookingForFlag) == lookingForFlag);
return result ;
}
``` | No, you can't do this with C# generics. However, you *could* do:
```
public static bool IsEnumFlagPresent<T>(T value, T lookingForFlag)
where T : struct
{
int intValue = (int) (object) value;
int intLookingForFlag = (int) (object) lookingForFlag;
return ((intValue & intLookingForFlag) == intLookingForFlag);
}
```
This will only work for enums which have an underlying type of `int`, and it's somewhat inefficient because it boxes the value... but it should work.
You may want to add an execution type check that T is actually an enum type (e.g. `typeof(T).BaseType == typeof(Enum)`)
Here's a complete program demonstrating it working:
```
using System;
[Flags]
enum Foo
{
A = 1,
B = 2,
C = 4,
D = 8
}
class Test
{
public static Boolean IsEnumFlagPresent<T>(T value, T lookingForFlag)
where T : struct
{
int intValue = (int) (object) value;
int intLookingForFlag = (int) (object) lookingForFlag;
return ((intValue & intLookingForFlag) == intLookingForFlag);
}
static void Main()
{
Console.WriteLine(IsEnumFlagPresent(Foo.B | Foo.C, Foo.A));
Console.WriteLine(IsEnumFlagPresent(Foo.B | Foo.C, Foo.B));
Console.WriteLine(IsEnumFlagPresent(Foo.B | Foo.C, Foo.C));
Console.WriteLine(IsEnumFlagPresent(Foo.B | Foo.C, Foo.D));
}
}
``` | You're looking to replace one line of code with a function that wraps one line of code? I'd say to just use the one line of code... | C#, Flags Enum, Generic function to look for a flag | [
"",
"c#",
"enums",
"enum-flags",
""
] |
For various reasons, I need to play the intermediary between an HTTP Request and a file on disk. My approach has been to populate headers and then perform a readfile('/path/to/file.jpg');
Now, everything works fine, except that it returns even a medium sized image very slowly.
Can anyone provide me with a more efficient way of streaming the file to the client once the headers have been sent?
Note: it's a linux box in a shared hosting environment if it matters | Several web servers allow an external script to tell them to do exactly this. [X-Sendfile](http://blog.adaniels.nl/articles/how-i-php-x-sendfile/) on Apache (with mod\_xsendfile) is one.
In a nutshell, all you send is headers. The special `X-Sendfile` header instructs the web server to send the named file as the body of the response. | You could start with implementing conditional GET request support.
Send out a "Last-Modified" header with the file and reply with "304 Not Modified" whenever the client requests the file with "If-Modified-Since" and you see that the file has not been modified. Some sensible freshness-information (via "Cache-Control" / "Expires" headers) also is advisable to prevent repeated requests for an unchanged resource in the first place.
This way at least the perceived performance can be improved, even if you should find that you can do nothing about the actual performance. | PHP passthrough slow | [
"",
"php",
""
] |
I need to write a report that generates summary totals against a table with date ranges for each record.
```
table data:
option start_date end_date
opt1 6/12/2009 6/19/2009
opt1 6/3/2009 6/13/2009
opt2 6/5/2009 6/6/2009
```
What I want out is basically this:
```
date option count
6/1/2009 opt1 0
6/1/2009 opt2 0
6/2/2009 opt1 0
6/2/2009 opt2 0
6/3/2009 opt1 0
6/3/2009 opt2 1
```
I am having a hard time figuring out how to iterate over a date range. I am sure this is some simple cursor that could be created for this but I am at a loss. Preferably in PL/SQL
UPDATE:
I ended up using the example [here](http://www.adp-gmbh.ch/ora/plsql/date_range.html) to accomplish what I wanted to do. This creates a function that generates a table of dates. | You will need some sort of calendar to loop through a range of date. I have built one using the [connect by level](http://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:40476301944675 "Infinite Dual") trick. You can then join the calendar with your data (cross join since you want a row even when there is no option for that day):
```
SQL> WITH calendar AS (
2 SELECT to_date(:begin_date, 'mm/dd/yyyy') + ROWNUM - 1 c_date
3 FROM dual
4 CONNECT BY LEVEL <= to_date(:end_date, 'mm/dd/yyyy')
- to_date(:begin_date, 'mm/dd/yyyy') + 1
5 )
6 SELECT c_date "date", d_option "option", COUNT(one_day)
7 FROM (SELECT c.c_date, d.d_option,
8 CASE
9 WHEN c.c_date BETWEEN d.start_date AND d.end_date THEN
10 1
11 END one_day
12 FROM DATA d, calendar c)
13 GROUP BY c_date, d_option
14 ORDER BY 1,2;
date option COUNT(ONE_DAY)
----------- ------ --------------
01/06/2009 opt1 0
01/06/2009 opt2 0
02/06/2009 opt1 0
02/06/2009 opt2 0
03/06/2009 opt1 1
03/06/2009 opt2 0
04/06/2009 opt1 1
04/06/2009 opt2 0
05/06/2009 opt1 1
05/06/2009 opt2 1
06/06/2009 opt1 1
06/06/2009 opt2 1
12 rows selected
``` | One solution that I use for this is to convert the date range into an integer range that you can use in a for loop, then convert back to a date to do stuff with it. You can't do any joins or anything this way, but it's a much smaller solution that those already posted:
```
declare
start_date number;
end_date number;
business_date varchar2(8);
begin
start_date := to_number(to_char(to_date('2013-04-25', 'yyyy-MM-dd'), 'j'));
end_date := to_number(to_char(to_date('2013-05-31', 'yyyy-MM-dd'), 'j'));
for cur_r in start_date..end_date loop
business_date := to_char(to_date(cur_r, 'j'), 'yyyy-MM-dd');
dbms_output.put_line(business_date);
end loop;
end;
``` | How to iterate over a date range in PL/SQL | [
"",
"sql",
"database",
"oracle",
"plsql",
""
] |
```
Box buttonBox = new Box(BoxLayout.Y_AXIS);
Name1 name2 = new Name1();
```
there are two Name1s
```
checkboxList = new ArrayList<JCheckBox>();
name2 = new Name1();
```
there is only one Name1
It works, but why? | The first time, the `Name1 name2` declares a variable of type `Name1` called `name2`, then it is immediately assigned to `new Name1()`. The second time, the variable already exists; you're just reassigning it.
Some people like to use:
```
Name1 name2;
name2 = new Name1();
```
instead of the equivalent:
```
Name1 name2 = new Name1();
```
but I find the second one much easier to read.
I suggest you go through the [Java tutorials](http://java.sun.com/docs/books/tutorial/), especially [Getting Started](http://java.sun.com/docs/books/tutorial/getStarted/index.html) and [Learning the Java Language](http://java.sun.com/docs/books/tutorial/java/index.html). They cover all sorts of beginner questions like this one. | ```
Name1 name2 = new Name1();
```
In this line, you are doing two things:
1. declare a variable named `name2` of type `Name1`
2. create an object by calling the no-argument constructor of the class `Name1` and assign a reference to the newly-create object to the variable `name2`
You can also separate the steps:
```
Name1 name2;
name2 = new Name1();
```
In your second piece of code, you are only doing step 2, and *reusing* (i.e. overwriting) the already existing variable `name2`. This is possible because once declared, variables can be used (read from *and* written to) as often as you want within the same scope. The exception are `final` variables, which you can only write to once. If you do this:
```
final Name1 name2 = new Name1();
name2 = new Name1();
```
You'll get a compiler error because you're trying to the same variable a second time. This can be useful because it prevents programmer errors that occur when you reuse variables. | Creating an object | [
"",
"java",
"object",
""
] |
I often use regex expression validators that are also a required field. Which leads to what seems like redundant controls on the page. There is no "Required" property of the regex validator which means I need another control. Like this:
```
<asp:TextBox ID="tbCreditCardNumber" runat="server" Width="200"></asp:TextBox>
<asp:RegularExpressionValidator ID="revCreditCardNumber" runat="server"
ControlToValidate="tbCreditCardNumber" ValidationGroup="CheckoutGroup" ErrorMessage="Invalid Credit Card Number!"
ValidationExpression="^(3[47][0-9]{13}|5[1-5][0-9]{14}|4[0-9]{12}(?:[0-9]{3})?)$">*</asp:RegularExpressionValidator>
<asp:RequiredFieldValidator ID="rfvCreditCardNumber" runat='server' ControlToValidate="tbCreditCardNumber" ValidationGroup="CheckoutGroup"
ErrorMessage="Credit Card Number Required">*</asp:RequiredFieldValidator>
```
Is there a way to combine the two controls so I don't have to type so much code? | You can roll your own CustomValidator, combining the functionality. Other than that, no not to my knowledge. | One common problem is that the validator component still takes space when it is not shown, which looks odd if you have several and i.e. the last one is triggered leaving a larger gap to the asterisk or other error marker. This can be easily solved by adding:
```
display="Dynamic"
```
...to the validator.
But it does not solve the problem of several trigging at the same time which will still show many validator errors in a row. A custom validator would then probably be the best solution. | How to combine RegularExpressionValidator control and RequiredFieldValidator? | [
"",
"c#",
"asp.net",
"regex",
"validation",
""
] |
Do any versions of SQL Server support deferrable constraints (DC)?
Since about version 8.0, [Oracle has supported deferrable constraints](http://www.oracle.com/technology/oramag/oracle/03-nov/o63asktom.html) - constraints that are only evaluated when you commit a statement group, not when you insert or update individual tables. Deferrable constraints differ from just disabling/enabling constraints, in that the constraints are still active - they are just evaluated later (when the batch is committed).
The benefit of DC is that they allow updates that individually would be illegal to be evaluated that cummulatively result in a valid end state. An example is creating circular references in a table between two rows where each row requires a value to exist. No individual insert statement would pass the constraint - but the group can.
To clarify my goal, I am looking to port an ORM implementation in C# to SQLServer - unfortunately the implementation relies on Oracle DC to avoid computing insert/update/delete orders amongst rows. | So far SQL Server does not support them. What is the problem you are solving? | OT: There are IMHO quite a few things SQL Server does not support, but would make sense in an enterprise environment:
* Deferrable constraints as mentioned here
* MARS: Just why do you need to set an option for something entirely natural?
* CASCADE DELETE constraints: SQL Server does only allow one single cascadation path for a given CASCADE DELETE constraint. Again, I don't see a reason why it shouldn't be allowed to cascade on deletion through multiple possible paths: In the end, at the time it really is executed, there will always be only one path being actually used, so why is this restriction?
* Prevention of parallel transactions on a single ADO.NET connection.
* Forcing of every command executed on a connection that has a transaction to be executed within this transaction.
* When creating a UNIQUE index, NULL is treated as if it was an actual value, and allowed to appear only once in the index. SQL's notion of NULL as an "unknown value" would, however, indicate, that NULL values be ignored altogether when creating the index...
All these little things make many of the referential integrity and transactional features you would expect from a full-sized RDBMS nearly useless in SQL Server. For example, since deferrable constraints are not supported, the notion of a "transaction" as an externally consistent Unit Of Work is partly negated, the only viable solution - except fro some dirty workarounds - being to not define referential integrity constraints at all. I would expect, the natural behavior of a transaction be that you can work inside it in the way and order of operations you like, and the system will make sure it is consistent at the time you commit it.
Similar problems arise from the restriction, that a referential integrity constraint with ON DELETE CASCADE may only be defined in a way that only one single constraint can lead to the cascaded deletion of an object. This really doesn't fit most real-world scenarios. | Deferrable Constraints in SQL Server | [
"",
"sql",
"sql-server",
"database",
"oracle",
"constraints",
""
] |
I'm trying to develop/port a game to Android, but it's in C, and Android supports Java, but I'm sure there must be a way to get a C app on there, anyone knows of a way to accomplish this? | For anyone coming to this via Google, note that starting from SDK 1.6 Android now has an official native SDK.
You can download the Android NDK (Native Development Kit) from here:
<https://developer.android.com/ndk/downloads/index.html>
Also there is an blog post about the NDK:
<http://android-developers.blogspot.com/2009/06/introducing-android-15-ndk-release-1.html> | The [Android NDK](https://developer.android.com/ndk/index.html) is a toolset that lets you implement parts of your app in native code, using languages such as C and C++. For certain types of apps, this can help you reuse code libraries written in those languages.
For more info on how to get started with native development, follow [this link](https://developer.android.com/ndk/guides/index.html).
Sample applications can be found [here](https://developer.android.com/ndk/samples/index.html). | Write applications in C or C++ for Android? | [
"",
"c++",
"c",
"android",
""
] |
I'm using Netbeans to develop my RoR project so it is managing the SQL database. How can I make quick changes (i.e. edit row-by-row) to my DB, preferably in command line?
i'm thinking - changing temporary passwords and users for testing purposes. Thanks for your input! | Try using `ruby script/console` in your rails application directory. From there, you can do things like:
```
u = User.find(:first)
u.password = 'something_else'
u.save
```
or
```
users = User.find(:all)
users.each { |u| u.password = 'something'; u.save }
```
which will update all users' passwords. | Two ways:
* run `script/console` and manipulate your Rails' model objects directly from the command line
* run `script/dbconsole` which will drop you into the command line for your RDBMS (assuming that your `database.yml` file is configured to access your database correctly). Then use SQL to do what you need to do
([Railscast on Console Tricks](http://railscasts.com/episodes/48-console-tricks)) | quick method to save ruby objects on command line? | [
"",
"sql",
"ruby-on-rails",
"command-line",
""
] |
I know everyone who reads the question will think "Firebug!" right away. Maybe some will think "YSlow!" and "Google Page Speed!"
While I really like these tools, I'm more concerned with how the quickly the page will render in IE 6/7/8. All of the above tools require Firefox. That's all fine and you can definitely test the underlying speed of getting the page to the browser but what about when it comes to actually rendering the page?
I haven't seen any really good answers on how to test optimization at the browser level. How do you write performance tests for HTML/JS across difference browsers? | I am not sure it is a useful endeavor to optimize for only one vendor:
* regarding HTML, most browsers are written to optimize for standard layout techniques (tables, table-less, etc.)
* the rendering engines are quite
different between IE6 and IE8, so
already that is like two different
browsers
* most of the techniques for optimizing
are standard across browsers (put
javascript at bottom so you don't
block page loads, move javascript to
external file, use multiple hostnames
for images etc. to take advantage of
parallel loading, don't use tables
for overall layout, make sure caching
headers are correct, etc.)
* once you have a site optimized for Firefox, I would argue there is little more to be gained as far as tweaking it for IE; there is probably more you can do at the application level at this point (optimize queries, etc.), unless your site is largely static content, in which case you can investigate caching, HTTP compression, etc.
* if your concern is actually in optimizing Javascript code for IE, then there are many good cross-browser Javascript libraries that are in an arms-race for best execution times across browser platforms, so again, picking a cross-browser solution is the way to go
* the browser landscape is constantly evolving, and your customers are likely to move on to another platform at some point down the road; optimizing for several different browsers now will end up with more compatible code that is more likely to perform well when a platform change is made at some point in the future
* I would argue that writing cross-browser optimized code will result in a more maintainable code base with fewer magic IE hacks, whose reason for existence will soon be lost in the mists of time | You can use the IE [high performance tester](http://www.codeplex.com/IEJst). | How do you do page performance tests? | [
"",
"javascript",
"html",
"performance",
"testing",
""
] |
I see endless examples that involve "**Url.Action**" in a view to generate a URL dynamically. (See example code below.)
The problem: The type/class "Url" doesn't exist in my views! No IntelliSense, and compiling the site results in a "Type expected" exception. How do I get it in there?
Source Code Snippet (this is from an example):
```
<form id="register-form" action="<%= Url.Action(new(action="Register")) %>" method="post">
//inputs etc
</form>
```
**I'm using the latest version of MVC.**
Here is the entire page (which was generates through "generate view"):
```
<%@ Page Title="" Language="C#" MasterPageFile="~/Views/Shared/Site.Master" Inherits="System.Web.Mvc.ViewPage" %>
<asp:Content ID="Content1" ContentPlaceHolderID="TitleContent" runat="server">Register</asp:Content>
<asp:Content ID="Content2" ContentPlaceHolderID="MainContent" runat="server">
<h2>Register</h2>
<form id="register-form" action="<%= Url.Action(new(action="Register")) %>" method="post">
<fieldset>
<label for="emailAddress"><%= Resources.Labels.EmailAddress %>: </label> <input id="emailAddress" type="text" />
<label for="password"><%= Resources.Labels.Password %>: </label> <input id="password" type="password" />
<input id="register-submit" value="<%= Resources.Labels.SubmitRegistration %>" type="submit" />
</fieldset>
</form>
``` | Solved it. The Url.Action(**new("Register"))**) was the problem. Url.Action("Register") works.
Thanks for your help though. This was hard to tackle because VS underlines the wrong code and gives confusion statements about problems. Glad its solved. | The `Url` class in the examples is actually a [property](http://msdn.microsoft.com/en-us/library/system.web.mvc.viewpage.url.aspx) of the [ViewPage](http://msdn.microsoft.com/en-us/library/system.web.mvc.viewpage_members.aspx), and [also](http://msdn.microsoft.com/en-us/library/system.web.mvc.viewusercontrol.url.aspx) of the [ViewUserControl](http://msdn.microsoft.com/en-us/library/system.web.mvc.viewusercontrol_members.aspx), so if your application builds and you have your inheritances correctly set up, this shouldn't be possible.
Try rebuilding your solution a couple of times, and if that not helps restarting Visual Studio. (I used to have the same problem with the `Html` property, but I believe that was on one of the Preview releases, and I could solve it by upgrading to the next preview/the beta.) | Url type not available in my view? | [
"",
"c#",
"asp.net-mvc",
""
] |
## Background
I am writing a class library assembly in C# .NET 3.5 which is used for integration with other applications including third-party Commercial-Off-The-Shelf (COTS) tools. Therefore, sometimes this class library will be called by applications (EXEs) that I control while other times it will be called by other DLLs or applications that I do **not** control.
## Assumptions
* I am using C# 3.0, .NET 3.5 SP1, and Visual Studio 2008 SP1
* I am using log4net 1.2.10.0 or greater
## Constraints
Any solution must:
* Allow for the class library to enable and configure logging via it's own configuration file, if the calling application does not configure log4net.
* Allow for the class library to enable and configuring logging via the calling applications configuration, if it specifies log4net information
OR
* Allow for the class library to enable and configuring logging using it's own configuration file at all times.
## Problem
When my stand-alone class library is called by a DLL or application that I do not control (such as a third-party COTS tool) and which doesn't specify log4net configuration information, my class library is unable to do any of it's logging.
---
## Question
**How do you configure and enable log4net for a stand-alone class library assembly so that it will log regardless if the calling application provides log4net configuration?** | ## Solution 1
A solution for the first set of constraints is to basically wrap the [log4net.LogManager](http://logging.apache.org/log4net/release/sdk/log4net.LogManagerMembers.html) into your own custom LogManager class like [Jacob](https://stackoverflow.com/questions/1028375/how-do-you-configure-and-enable-log4net-for-a-stand-alone-class-library-assembly/1028425#1028425), [Jeroen](https://stackoverflow.com/questions/1028375/how-do-you-configure-and-enable-log4net-for-a-stand-alone-class-library-assembly/1028445#1028445), and [McWafflestix](https://stackoverflow.com/questions/1028375/how-do-you-configure-and-enable-log4net-for-a-stand-alone-class-library-assembly/1028406#1028406) have suggested (see code below).
Unfortunately, the [log4net.LogManager](https://stackoverflow.com/questions/1028375/how-do-you-configure-and-enable-log4net-for-a-stand-alone-class-library-assembly/1028425#1028425) class is static and C# doesn't support static inheritance, so you couldn't simply inherit from it and override the GetLogger method.
There aren't too many methods in the [log4net.LogManager](https://stackoverflow.com/questions/1028375/how-do-you-configure-and-enable-log4net-for-a-stand-alone-class-library-assembly/1028425#1028425) class however, so this is certainly a possibility.
The other drawback to this solution is that if you have an existing codebase (which I do in my case) you would have to replace all existing calls to log4net.LogManager with your wrapper class. Not a big deal with today's refactoring tools however.
For my project, these drawbacks outweighed the benefits of using a logging configuration supplied by the calling application so, I went with Solution 2.
## Code
First, you need a LogManager wrapper class:
```
using System;
using System.IO;
using log4net;
using log4net.Config;
namespace MyApplication.Logging
{
//// TODO: Implement the additional GetLogger method signatures and log4net.LogManager methods that are not seen below.
public static class LogManagerWrapper
{
private static readonly string LOG_CONFIG_FILE= @"path\to\log4net.config";
public static ILog GetLogger(Type type)
{
// If no loggers have been created, load our own.
if(LogManager.GetCurrentLoggers().Length == 0)
{
LoadConfig();
}
return LogManager.GetLogger(type);
}
private void LoadConfig()
{
//// TODO: Do exception handling for File access issues and supply sane defaults if it's unavailable.
XmlConfigurator.ConfigureAndWatch(new FileInfo(LOG_CONFIG_FILE));
}
}
```
Then in your classes, instead of:
```
private static readonly ILog log = LogManager.GetLogger(typeof(MyApp));
```
Use:
```
private static readonly ILog log = LogManagerWrapper.GetLogger(typeof(MyApp));
```
---
# Solution 2
For my purposes, I have decided to settle on a solution that meets the second set of constraints. See the code below for my solution.
From the [Apache log4net document](http://logging.apache.org/log4net/release/manual/repositories.html):
*"An assembly may choose to utilize a named logging repository rather than the default repository. This completely separates the logging for the assembly from the rest of the application. This can be very useful to component developers that wish to use log4net for their components but do not want to require that all the applications that use their component are aware of log4net. It also means that their debugging configuration is separated from the applications configuration. The assembly should specify the RepositoryAttribute to set its logging repository."*
## Code
I placed the following lines in the AssemblyInfo.cs file of my class library:
> ```
> // Log4Net configuration file location
> [assembly: log4net.Config.Repository("CompanyName.IntegrationLibName")]
> [assembly: log4net.Config.XmlConfigurator(ConfigFile = "CompanyName.IntegrationLibName.config", Watch = true)]
> ```
##
# References
* [LogManagerMembers](http://logging.apache.org/log4net/release/sdk/log4net.LogManagerMembers.html)
* [Jacob's Answer](https://stackoverflow.com/questions/1028375/how-do-you-configure-and-enable-log4net-for-a-stand-alone-class-library-assembly/1028425#1028425)
* [Jeroen's Answer](https://stackoverflow.com/questions/1028375/how-do-you-configure-and-enable-log4net-for-a-stand-alone-class-library-assembly/1028445#1028445)
* [McWafflestix's Answer](https://stackoverflow.com/questions/1028375/how-do-you-configure-and-enable-log4net-for-a-stand-alone-class-library-assembly/1028406#1028406)
* [log4net Manual - Repositories](http://logging.apache.org/log4net/release/manual/repositories.html)
* [log4NET from a class library (dll)](http://www.l4ndash.com/Log4NetMailArchive/tabid/70/forumid/1/postid/17276/view/topic/Default.aspx) | You can probably code something around the [XmlConfigurator](http://logging.apache.org/log4net/release/manual/configuration.html#Reading%20Files%20Directly) class:
```
public static class MyLogManager
{
// for illustration, you should configure this somewhere else...
private static string configFile = @"path\to\log4net.config";
public static ILog GetLogger(Type type)
{
if(log4net.LogManager.GetCurrentLoggers().Length == 0)
{
// load logger config with XmlConfigurator
log4net.Config.XmlConfigurator.Configure(configFile);
}
return LogManager.GetLogger(type);
}
}
```
Then in your classes, instead of:
```
private static readonly ILog log = LogManager.GetLogger(typeof(MyApp));
```
Use:
```
private static readonly ILog log = MyLogManager.GetLogger(typeof(MyApp));
```
Of course, it would be preferable to make this class a service and dynamically configure it with the IoC container of your choice, but you get the idea?
**EDIT:** Fixed Count() problem pointed out in comments. | How do you configure and enable log4net for a stand-alone class library assembly? | [
"",
"c#",
".net",
"log4net",
""
] |
```
public class Buddy
{
public string[] Sayings;
}
Buddy one = new Buddy();
one.Sayings = new[] {"cool", "wicked", "awesome"};
Buddy two = new Buddy();
two.Sayings = new[] {"bad", "lame", "boring"};
Buddy[] buddies = new[] {one, two};
IEnumerable<string[]> something =
from b in buddies
select b.Sayings;
```
So basically I would like to get a single array or list that contains {"cool, wicked, awesome, "bad", "lame", "boring"} the sayings for each Buddy using linq.
I tried everything I could think of and am starting to doubt it can be done with just a single linq expression. I could go through each buddy in buddies and do an addrange on the Sayings into a list but I figured since I am learning linq I would try it this way. Is it possible and if so how? This could also apply if I wanted to get some other objects inside of a Buddy in this case its just the list of strings. | How about this:
```
var result2 = buddies.SelectMany(b => b.Sayings);
``` | Jakers is right - this is *exactly* what [`SelectMany`](http://msdn.microsoft.com/en-us/library/system.linq.enumerable.selectmany.aspx) does, in its simplest form. Alternative overloads allow you to get different results, e.g. including the "source" item in the projection as well.
Note that the query expression syntax for this is to have more than one `from` clause - each clause after the first one adds another call to `SelectMany`. Jakers code is *similar* to:
```
var result2 = from buddy in buddies
from saying in buddy.Sayings
select saying;
```
except the dot-notation version is more efficient - it only projects once. The above code compiles to:
```
var result2 = buddies.SelectMany(buddy => buddy.Sayings,
(buddy, saying) => saying);
``` | Use a linq expression to get a single array or list of strings from inside a collection of objects without using foreach and addrange | [
"",
"c#",
"linq-to-objects",
""
] |
I have two tables
`(1) MonthlyTarget {SalesManCode, TargetMonthYear, TargetValue};` this table has 1966177 rows.
```
(2) MonthlySales {SalesManCode, SaleDate, AchievedValue};
```
this table has 400310 rows.
I have to make a query that produces a result like the following table:
```
{SalesManCode, JanTar, JanAch, FebTar, FebAch,....., DecTar, DecAch}
```
The problem is, joining these two tables taking a long time.
What should be the query?
How can the query be optimized?
I don't want to consider indexing. | It looks like you're missing some columns in your MonthlyTarget table, namely a "TargetDate" column.
In addition to what everyone has already said about indexing, sometimes a divide-and-conquer approach can really help. Rather than joining a 1966177 row table to a 400310 row table, create to tiny temp tables and join them together instead:
```
CREATE TABLE #MonthlySalesAgg
(
SalesManCode int,
JanTar money,
FebTar money,
MarTar money,
AprTar money,
MayTar money,
JunTar money,
JulTar money,
AugTar money,
SepTar money,
OctTar money,
NovTar money,
DecTar money
PRIMARY KEY CLUSTERED (SalesManCode)
)
INSERT INTO #MonthlySalesAgg
SELECT *
FROM
(SELECT SalesManCode, TargetValue, SaleMonth = Month(TargetDate) FROM MonthlyTarget) as temp
PIVOT
(
Max(TargetValue)
FOR [SaleMonth] IN ([1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])
) as p
CREATE TABLE #MonthlyTargetAgg
(
SalesManCode int,
JanAch money,
FebAch money,
MarAch money,
AprAch money,
MayAch money,
JunAch money,
JulAch money,
AugAch money,
SepAch money,
OctAch money,
NovAch money,
DecAch money
PRIMARY KEY CLUSTERED (SalesManCode)
)
INSERT INTO #MonthlyTargetAgg
SELECT * FROM
(SELECT SalesManCode, AchievedValue, SaleMonth = Month(SaleDate) FROM MonthlySales) as temp
PIVOT
(
Sum(AchievedValue)
FOR [SaleMonth] IN ([1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])
) as p
```
The queries above create two intermediate tables which should contain the same number of records as your SalesMan table. Joining them is straightforward:
```
SELECT *
FROM #MonthlyTargetAgg target
INNER JOIN #MonthlySalesAgg sales ON target.SalesManCode = sales.SalesManCode
```
If you find yourself needing to pull out data by month all the time, move the code into a view instead.
PIVOT requires SQL Server 2005 or higher, and its often a very useful operator. Hopefully SQL Server 2008 will allow users to pivot on more than one column at a time, which will result in an even simpler query than shown above.
Using SQL Server 2000:
PIVOT is syntax sugar. For example,
```
SELECT * FROM
(SELECT SalesManCode, AchievedValue, SaleMonth = Month(SaleDate) FROM MonthlySales) as temp
PIVOT
(
Sum(AchievedValue)
FOR [SaleMonth] IN ([1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])
) as p
```
Becomes
```
SELECT
SalesManCode,
[1] = Sum(case SaleMonth when 1 then AchievedValue else 0 end),
[2] = Sum(case SaleMonth when 2 then AchievedValue else 0 end),
[3] = Sum(case SaleMonth when 3 then AchievedValue else 0 end),
[4] = Sum(case SaleMonth when 4 then AchievedValue else 0 end),
[5] = Sum(case SaleMonth when 5 then AchievedValue else 0 end),
[6] = Sum(case SaleMonth when 6 then AchievedValue else 0 end),
[7] = Sum(case SaleMonth when 7 then AchievedValue else 0 end),
[8] = Sum(case SaleMonth when 8 then AchievedValue else 0 end),
[9] = Sum(case SaleMonth when 9 then AchievedValue else 0 end),
[10] = Sum(case SaleMonth when 10 then AchievedValue else 0 end),
[11] = Sum(case SaleMonth when 11 then AchievedValue else 0 end),
[12] = Sum(case SaleMonth when 12 then AchievedValue else 0 end)
FROM
(SELECT SalesManCode, AchievedValue, SaleMonth = Month(SaleDate) FROM MonthlySales) as temp
GROUP BY SalesManCode
``` | Well, if you don't want to consider indexing, then you will always be preforming full table scans and performance will not be improved. | SQL Join taking long time | [
"",
"sql",
"sql-server",
"t-sql",
"sql-server-2000",
""
] |
I'm using Microsoft Visual Studio 2008 with a Windows target deployment. How would I make a file "update itself"? I've already got the "transmitting over a network" part down, but how do I make an executable write over itself?
Basically, I want to write an auto-updater for a directory that also includes the auto-updater, and the updater needs to update EVERYTHING in the directory.
Maybe a ways to pend the changes to the file for until the file lock is released would work. If I were to do that though, I'd probably follow it up with a hot-patch. | Write a new executable and delete or save a copy of the old one -- you could send a diff over the network and have a third program, the update monitor or whatever, to apply it. It would be just a small script that could be started from the remote app when it realizes an update is available. The updater could rename itself to $UPDATER\_OLD\_VERSION or whatever, write an updated copy of itself with the appropriate name, and then when the new updater is run you check if there is a file named $UPDATER\_OLD\_VERSION in the app directory and delete it. All other files could just be updated/overwritten. | This is how I did it recently. There is a brief overlap of the old program running and the new programming running. It makes use of the trick that you can rename the current executable and bring the new file in place before you shut down the old one. This is not 100% fail safe, but the only way this could "brick" your application is if CopyFile fails.
```
#include <windows.h>
#include <iostream>
#include <fstream>
void UpgradeService::UpgradeSelf() {
std::string temp = root + "\\myprogram_tmp.exe";
remove(temp.c_str()); // ignore return code
std::string src = upgradeFolder + "\\myprogram.exe";
std::string dst = root + "\\myprogram.exe";
rename(dst.c_str(),temp.c_str());
CopyFile(src.c_str(),dst.c_str(),false);
static char buffer[512];
strcpy(buffer,dst.c_str());
/* CreateProcess API initialization */
STARTUPINFO siStartupInfo;
PROCESS_INFORMATION piProcessInfo;
memset(&siStartupInfo, 0, sizeof(siStartupInfo));
memset(&piProcessInfo, 0, sizeof(piProcessInfo));
siStartupInfo.cb = sizeof(siStartupInfo);
::CreateProcess(buffer, // application name/path
NULL, // command line (optional)
NULL, // no process attributes (default)
NULL, // default security attributes
false,
CREATE_DEFAULT_ERROR_MODE | CREATE_NEW_CONSOLE,
NULL, // default env
NULL, // default working dir
&siStartupInfo,
&piProcessInfo);
::TerminateProcess( GetCurrentProcess(),0);
::ExitProcess(0); // exit this process
// this does not return.
}
``` | How do I make a file self-update (Native C++) | [
"",
"c++",
"windows",
"native",
""
] |
I've read a lot of the SCJP questions here, and all the tips and tricks from Sun and the Head First publishers, and I wonder if I am missing something.
I'm having trouble moving from knowledge about a component of Java to being able to answer a question that applies that knowledge. If you asked me a specific question about the language or API, I could answer it. However, when I am looking to apply that knowledge to answer the mock coding questions, it takes me forever to process the question, and I have trouble connecting the dots. It's like nothing clicks. Is there a process by which I can better draw conclusions about questions based upon what I know? | Simple: you use it.
That may sound trite but there is no substitute for learning something new in programming than trying to do something with it. As in writing code.
If it's *really* new, you might start by taking an existing program and modifying it to do something you want. This will usually break it and you'll spend the next 2 hours working out why. In that 2 hours you'll have learnt more about the basics of program structure (in that language/framework), how a program is put to together and so on than 5 times that long reading it from a book.
Not that I'm suggesting books are worthless: far from it. But programming is ultimately a pragmatic discipline. | **When encountering a new concept, come up with a use case, and actually write some code.**
For example, if we learn about `Runnable`s and how they can be used to make new `Thread`s, actually write some code and try it out:
```
Thread t = new Thread(new Runnable() {
public void run() {
// Do something.
}
});
t.start();
```
**When learning something new, there's really no substitute for actually trying things out.**
Actually, I believe that going through questions on Stack Overflow and trying to answer them would be pretty good way to try to apply learned concepts. Even if one doesn't actually post an answer, going through the process of writing an answer would itself work to re-enforce the learned concept. | Studying for SCJP, and how to move from knowledge to the application of knowledge | [
"",
"java",
"scjp",
""
] |
Here's an argument for SPs that I haven't heard. Flamers, be gentle with the down tick,
Since there is overhead associated with each trip to the database server, I would suggest that a POSSIBLE reason for placing your SQL in SPs over embedded code is that you are more insulated to change without taking a performance hit.
For example. Let's say you need to perform Query A that returns a scalar integer.
Then, later, the requirements change and you decide that it the results of the scalar is > x that then, and only then, you need to perform another query. If you performed the first query in a SP, you could easily check the result of the first query and conditionally execute the 2nd SQL in the same SP.
How would you do this efficiently in embedded SQL w/o perform a separate query or an unnecessary query?
Here's an example:
```
--This SP may return 1 or two queries.
SELECT @CustCount = COUNT(*) FROM CUSTOMER
IF @CustCount > 10
SELECT * FROM PRODUCT
```
Can this/what is the best way to do this in embedded SQL? | [A very persuasive article](http://sqlblog.com/blogs/paul_nielsen/archive/2009/05/09/why-use-stored-procedures.aspx)
SQL and stored procedures will be there for the duration of your data.
Client languages come and go, and you'll have to re-implement your embedded SQL every time. | In the example you provide, the time saved is sending a single scalar value and a single follow-up query over the wire. This is insignificant in any reasonable scenario. That's not to say there might not be other valid performance reasons to use SPs; just that this isn't such a reason. | Is this a valid benefit of using embedded SQL over stored procedures? | [
"",
"sql",
"performance",
"stored-procedures",
""
] |
Has anyone here used [Sigma Grid](http://www.sigmawidgets.com/products/sigma_grid2/) for JavaScript-based data grids? It was the only grid I could find that would allow fast data entry and use of the keypad, but before we spend a lot of development time I wanted to learn about the community's experience with it.
(Note: we need dozens of fast, sortable, and editable grids that can be used with the arrow keys and minimal mouse use ... otherwise we'd just pop in an ASP.NET control) | We decided to go with Sigma Grid after the folks at the other ASP.NET control companies said they couldn't provide the required functionality. | it is a good dat grid to use over desktop and web..
it is light weight and very efficient,but the problem is very little help found on internet regarding sigma data.
before starting implementing grid,you must read its documentation. | Has anyone used Sigma Grid (Javascript-based editable data grid)? | [
"",
"javascript",
"ajax",
"grid",
"data-entry",
"sigma-grid-control",
""
] |
Is there a way in my code that I can link to the library files I need so that I do not have to setup each individual compiler I use?
I want to be able to use Visual C++.net 2005, G++, etc. I am trying to make a cross platform game engine, but some platforms use a custom compiler and I want to make my engine as versatile as possible. | There is a tool called [mpc](http://www.ociweb.com/products/mpc) that can create both makefiles and VC projects from the same [mpc DSL](http://en.wikipedia.org/wiki/Domain-specific_language). If you would use that tool you would specify the link dependencies (libraries) once in the pmc files and it would generate makefiles for g++ and project files for Visual Studio that contain the necessary information on how to link your libraries.
From the [mpc](http://www.ociweb.com/products/mpc) homepage:
> supports multiple versions of make (GNU, Microsoft, Borland, Automake), Visual C++ 6.0 and Visual Studio 2003, 2005 and 2008. | I don't fully understand your problem sure there is a way to specify your libraries in UNIX via -L dir option
for visual C++ it seems that you can use /LIBPATH to override the environment library path.
I doubt you would want to do it in your code as the library path is often not static same as header files.
You would want to create a custom make file setting up the correct compiler options and paths for the different platforms and tools you are using. seems that is what the mpc tool that was suggested is trying to accomplish. | How do you link a .lib file without putting them into the compilers library folder? | [
"",
"c++",
"linker",
""
] |
I have a custom class (call i Field) that that implements several properties. One of the properties is MaximumLength that spcifies the maximum length that the value can be. The Value property is an object so i can be set to string, int, double, etc. Then I have a class that has multiple properties of type Field in it. All the Field properties are initialized in the constructor and only the Field.Value property can be written to. What I want to do is throw an error if the an attempt is made to set the Field.Value to a value that is too long for the field and implement INotifyPropertyChanged. My problem is the Value property is a member of the generic Field class and I do not know how to get the name of the property inside that class.
an example:
```
public class Customer
{
private Field _firstName = new Field(typeof(string), 20);
public Field FirstName
{
get
{
return _firstName;
}
}
}
public class Field
{
private Type _type;
private int _maximumLength;
object _value;
public Field(Type type, int maximumLength)
{
_type = type;
_maximumLength = maximumLength;
}
public Object Value
{
get
{
return _value;
}
set
{
if (value.ToString().Length > _maximumLength)
{
throw(string.Format("{0} cannot exceed {1} in length.", property name, _maximumValue);
}
else
{
_value = value;
OnPropertyChanged(property name);
}
}
}
}
```
Hopefully that is clear enough. | It seems to me that, yes, there might be a way using reflection to get to this information, but I'm not certain that this will be a foolproof method, and might expose you to a more cumbersome debugging phase later on. It just seems excessively... clever.
In my opinion, and based on what I've implemented in the past, Fredrik and Micahtan are pointing you in the correct direction. Your Field class should implement a Name property, set on instantiation. One reason that I can point to for this being a good idea is that this is the way that Microsoft does this very same thing. If you look at the generated code for any of the visual designers, controls implement a Name property that is set by the designer. If there were a foolproof way to do this under the covers, you'd have to believe that this would be done.
An additional boon to using a Name property is that it allows for you to come up with an "English" translation for your properties. i.e. "First Name" instead of "FirstName" this is a friendlier approach to the user interface, and decouples the user from your implementation (to overload the word "decouple"). | What you want to do is not really possible the way that you have it designed. It seems like it should be, but really there isn't much of a relationship between the two classes.
**I would just add the name property and change it to a generic class because walking stack is not efficient at ALL**, but to try to answer your question you could do this to get most of what you are asking for...
If you contained the field class and made the properties of the actual type you could do it walking the stack to get the property name (and if you added the change that many others have suggested to make it a generic class, it would make it an even better solution because you wouldn't need to cast anything).
If you wrote the customer class like this:
```
public class Customer
{
private Field _firstName = new Field(typeof(string), 20);
public string FirstName
{
get
{
return _firstName.Value as string;
}
set
{
_firstName.Value = value;
}
}
}
```
This would allow you to walk the stack to get the calling method name in your field class (in this case property)
```
string name = "<unknown>";
StackTrace st = new StackTrace();
name = st.GetFrame(1).GetMethod().Name;
```
name would now have the value
> set\_FirstName
so you would just have to strip the set\_ off it to get the property name, but if you are using the INotifyPropertyChanged event, you are still going to have a problem because the sender is going to be the Field object and not the Customer object. | How to get the name of a property of type myClass? | [
"",
"c#",
".net",
""
] |
Say I have a table like this in my MsSql server 2005 server
```
Apples
+ Id
+ Brand
+ HasWorms
```
Now I want an overview of the number of apples that have worms in them per brand.
Actually even better would be a list of all the apple brands with a flag if they are unspoiled or not.
So if I had the data
```
ID| Brand | HasWorms
---------------------------
1 | Granny Smith | 1
2 | Granny Smith | 0
3 | Granny Smith | 1
4 | Jonagold | 0
5 | Jonagold | 0
6 | Gala | 1
7 | Gala | 1
```
I want to end up with
```
Brand | IsUnspoiled
--------------------------
Granny Smith | 0
Jonagold | 1
Gala | 0
```
I figure I should first
```
select brand, numberOfSpoiles =
case
when count([someMagic]) > 0 then 1
else 0
end
from apples
group by brand
```
I can't use a having clause, because then brands without valid entries would dissapear from my list (I wouldn't see the entry Gala).
Then I thought a subquery of some kind should do it, but then I can't link the apple id of the outer (grouped) query to the inner (count) query...
Any ideas? | SQL server version, I did spoiled instead of unspoiled, this way I could use the SIGN function and make the code shorter
table + data (DML + DDL)
```
create table Apples(id int,brand varchar(20),HasWorms bit)
insert Apples values(1,'Granny Smith',1)
insert Apples values(2,'Granny Smith',0)
insert Apples values(3,'Granny Smith',1)
insert Apples values(4,'Jonagold',0)
insert Apples values(5,'Jonagold',0)
insert Apples values(6,'Gala',1)
insert Apples values(7,'Gala',1)
```
Query
```
select brand, IsSpoiled = sign(sum(convert(int,hasworms)))
from apples
group by brand
```
Output
```
brand IsSpoiled
----------------------
Gala 1
Granny Smith 1
Jonagold 0
``` | ```
select brand, case when sum(hasworms)>0 then 0 else 1 end IsUnSpoiled
from apples
group by brand
``` | Group by with count | [
"",
"sql",
"sql-server",
""
] |
I've always been used to using String instead of string and Int32 instead of int. Mainly because everything is a class, so I like to keep consistent and treat so called 'primitives' just like every other class/object.
I just saw an article on coding standards where it mentioned "Always use C# predefined types rather than the aliases in the System Namespace."
It didn't say why though. | The types are completely interchangeable, and compile to the same IL. There should be one key rule in your coding standards - if you are editing a shared file, use the same style as the existing code. Nothing is more annoying than trying to fix a file where the style changes every other function.
So - pick one and be consistent. | There is no reason that would affect the behavior or performance of your application. It is a recommended style guideline - and as with all style guidelines you can ignore it if you see fit. Nearly all OSS and corporate style policies will stipulate that you need to use the aliases - so keep that in mind. | Is there any reason not to use Aliases in the System namespace? | [
"",
"c#",
"types",
"aliases",
""
] |
How can I select an entire row of a ListView control in Details view-mode?
Or alternatively, how can I select a row in a ListView by clicking on any subItem? | The [FullRowSelect](http://msdn.microsoft.com/en-us/library/system.windows.forms.listview.fullrowselect.aspx) Property is what you are looking for to highlight the entire row when it is selected. | use property FullRowSelect of ListView | C# ListView - control | [
"",
"c#",
".net",
"winforms",
"listview",
"controls",
""
] |
I have some old code like this:
```
private int ParseByte(byte theByte)
{
byte[] bytes = new byte[1];
bytes[0] = theByte;
BitArray bits = new BitArray(bytes);
if (bits[0])
return 1;
else
return 0;
}
```
It's long and I figured I could trim it down like this:
```
private int ParseByte(byte theByte)
{
return theByte >> 7;
}
```
But, I'm not getting the same values as the first function. The byte either contains 00000000 or 10000000. What am I missing here? Am I using an incorrect operator? | The problem is that, in the first function, bits[0] returns the least significant bit, but the second function is returning the most significant bit. To modify the second function to get the least significant bit:
```
private int ParseByte(byte theByte)
{
return theByte & 00000001;
}
```
To modify the first function to return the most significant bit, you should use bits[7] -- not bits[0]. | The equivalent function to the first snipet is:
```
return theByte & 1 == 1
```
In the second snipet you were chechink the most significative bit and in the first snipet the least significant. | Bit shifting confusion in C# | [
"",
"c#",
"bit-shift",
""
] |
What is the best/most reliable way of detecting if a PC has Microsoft ActiveSync installed? My PC program uses RAPI to get files off of the device and if it isn't installed there is an error that RAPI.dll cannot be found. | You can read the registry to detect if ActiveSync is installed
```
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows CE Services
``` | ```
/// <summary>
/// Checks to see if ActiveSync/Windows Mobile Device Center
/// is installed on the PC.
/// </summary>
/// <param name="syncVersion">The version of the synchronization tool installed.</param>
/// <returns>True: Either ActiveSync or Windows Mobile Device Center is
/// installed. False: version is null
/// </returns>
private static bool isActiveSyncInstalled(out Version syncVersion)
{
using (RegistryKey reg =
Registry.LocalMachine.OpenSubKey(@"SOFTWARE\Microsoft\Windows CE Services"))
{
if (reg == null)
{
syncVersion = null;
return false;
}
int majorVersion = (int)reg.GetValue("MajorVersion", 0);
int minorVersion = (int)reg.GetValue("MinorVersion", 0);
int buildNumber = (int)reg.GetValue("BuildNumber", 0);
syncVersion = new Version(majorVersion, minorVersion, buildNumber);
}
return true;
}
``` | How to detect if Microsoft ActiveSync is installed on a PC | [
"",
"c#",
"windows-mobile",
"activesync",
""
] |
I'm getting this strange error while processing a large number of data...
```
Error Number: 1267
Illegal mix of collations (latin1_swedish_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE) for operation '='
SELECT COUNT(*) as num from keywords WHERE campaignId='12' AND LCASE(keyword)='hello again 昔 ã‹ã‚‰ ã‚ã‚‹ å ´æ‰€'
```
What can I do to resolve this? Can I escape the string somehow so this error wouldn't occur, or do I need to change my table encoding somehow, and if so, what should I change it to? | ```
SET collation_connection = 'utf8_general_ci';
```
then for your databases
```
ALTER DATABASE your_database_name CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE your_table_name CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
```
MySQL sneaks swedish in there sometimes for no sensible reason. | ```
CONVERT(column1 USING utf8)
```
Solves my problem. Where column1 is the column which gives me this error. | Illegal mix of collations MySQL Error | [
"",
"mysql",
"sql",
"mysql-error-1267",
""
] |
On one hand, I'm told that exceptions in C# are 'expensive', but on the other, I'm stuck on how to implement this.
My problem is this: I'm making a `Stream` derivitive, that wraps a `NetworkStream`. Now, the problem I'm facing is this: `Read(byte[] buffer, int offset, int count)`. From the `Stream` docs for the function:
> Returns:
>
> ... or zero (0) if the end of the stream has been reached.
The problem is, in the protocol I'm implementing the remote side can send an "end of record" token, or a "please respond" token. Obviously, if this happens at the start of the `Read()` this causes problems, since I need to return from the function, and I havn't read anything, so I need to return 0, which means the stream is finished, but it isn't... is a `EndOfRecordException` or similar justified in this case? And in this case, should it aways be thrown when this token is encountered (at the start of the `Read()` call and make sure these tokens are always at the start by returning early) so that there is some sort of pattern to how these tokens should be handled.
**Edit:** For what it's worth, these tokens generally come through 3-10 times a second. At the most, I wouldn't expect more than 25 a second. | Exceptions aren't really all that expensive - but they also aren't necessarily the best way to manage expected/normal flow.
To me, it sounds like you aren't actually *implementing* a `Stream` - you are *encapsulating* a stream into a "reader". I might be inclined to write a protocol-specific reader class with suitable methods to detect the end of a record, or `Try...` methods to get data or return false. | It sounds like you shouldn't really be deriving from `Stream` if your class is concerned with records. Streams don't generally *interpret* their data at all - they're just a transport mechanism of data from one place to another.
There have been cases like `ZipInputStream` in Java which end up being very confusing when a single `InputStream` effectively has several streams within it, and you can skip between them. Such APIs have been awful to use in my experience. Providing a separate class to implement the "record splitting" which can provide a stream for the data *within* a record sounds cleaner to me. Then each stream can behave consistently with normal streams. No need for new exceptions.
However, I'm just guessing at your context based on the limited information available. If you could give more details of the bigger picture, that would help. | Should I use exceptions in C# to enforce base class compatibility? | [
"",
"c#",
"design-patterns",
"exception",
""
] |
I want to count both the total # of records in a table, and the total # of records that match certain conditions. I can do these with two separate queries:
```
SELECT COUNT(*) AS TotalCount FROM MyTable;
SELECT COUNT(*) AS QualifiedCount FROM MyTable
{possible JOIN(s) as well e.g. JOIN MyOtherTable mot ON MyTable.id=mot.id}
WHERE {conditions};
```
Is there a way to combine these into one query so that I get two fields in one row?
```
SELECT {something} AS TotalCount,
{something else} AS QualifiedCount
FROM MyTable {possible JOIN(s)} WHERE {some conditions}
```
If not, I can issue two queries and wrap them in a transaction so they are consistent, but I was hoping to do it with one.
edit: I'm most concerned about atomicity; if there are two sub-SELECT statements needed that's OK as long as if there's an INSERT coming from somewhere it doesn't make the two responses inconsistent.
edit 2: The CASE answers are helpful but in my specific instance, the conditions may include a JOIN with another table (forgot to mention that in my original post, sorry) so I'm guessing that approach won't work. | One way is to join the table against itself:
```
select
count(*) as TotalCount,
count(s.id) as QualifiedCount
from
MyTable a
left join
MyTable s on s.id = a.id and {some conditions}
```
Another way is to use subqueries:
```
select
(select count(*) from Mytable) as TotalCount,
(select count(*) from Mytable where {some conditions}) as QualifiedCount
```
Or you can put the conditions in a case:
```
select
count(*) as TotalCount,
sum(case when {some conditions} then 1 else 0 end) as QualifiedCount
from
MyTable
```
Related:
[SQL Combining several SELECT results](https://stackoverflow.com/questions/843642/sql-combining-several-select-results/843666#843666) | In Sql Server or MySQL, you can do that with a CASE statement:
```
select
count(*) as TotalCount,
sum(case when {conditions} then 1 else 0 end) as QualifiedCount
from MyTable
```
Edit: This also works if you use a JOIN in the condition:
```
select
count(*) as TotalCount,
sum(case when {conditions} then 1 else 0 end) as QualifiedCount
from MyTable t
left join MyChair c on c.TableId = t.Id
group by t.id, t.[othercolums]
```
The GROUP BY is there to ensure you only find one row from the main table. | two SQL COUNT() queries? | [
"",
"sql",
""
] |
I have a string, how do I convert it to an array?
After manipulating that array, how do I again make it into a string?
Do strings in PHP behave the same way as in Java?
is there a dupe for this? | as in C, strings are arrays in php
then
```
<?php
$a = "hola";
for($i=0; $i < strlen($a); $i++) {
echo $a[$i] . "\n";
}
$a[2] = "-"; // will print ho-a
?>
```
what operation do you want to do? | ```
explode ( string $delimiter , string $string [, int $limit ] )
```
... and after changes ...
```
implode ( string $glue , array $pieces )
```
check out <http://php.net/explode>
and <http://php.net/implode>
You can also use split or join which, as far as I know, support regex | String to Array and Back | [
"",
"php",
"arrays",
"string",
""
] |
I'm trying to use a Year-Week format in oracle SQL to return results only from a range of Year-Weeks.
Here's what I'm trying
```
SELECT * FROM widsys.train trn WHERE trn.WID_DATE>=TO_DATE('2008-13', 'YYYY-IW') AND trn.WID_DATE<=TO_DATE('2008-15', 'YYYY-IW') ORDER BY trn.wid_date
```
but it shoots this error.
ORA-01820: format code cannot appear in date input format but fails on ORA
Any suggestions on what I can use?
Thanks kindly,
Thomas | You could flip it around and do a string compare.
```
SELECT *
FROM widsys.train trn
WHERE to_char(trn.WID_DATE, 'YYYY-IW') ='2008-13'
ORDER BY trn.wid_date;
```
I suppose it makes sense that to\_date() doesn't work with IW, as the start of the week is somewhat ambiguous - some locales start the week on Sunday, others Monday, etc. Generating a truncated week of the year, unlike a truncated day, month, or year, would therefore be difficult.
**edit:**
I agree that the natural sort should suffice, but you got me thinking. How would you compare a given date and a formatted YYYY-IW string? I took a stab at it. This attempt could be fashioned into a function that takes a date and a YYYY-IW formatted varchar, but you would need to replace the hard coded strings and the to\_date() function calls, and perform some clean up.
It returns a -1 if the passed in date is before the year/weekofyear, 0 if the date falls within the specified weekofyear, and 1 if it is after. It works on ISO week of year, as does the 'IW' format token.
```
select (case
when input.day < a.startofweek then -1
when input.day < a.startofweek+7 then 0
else 1 end)
from
(select
-- //first get the iso offset for jan 1, this could be removed if you didn't want iso
(select (max(to_number(to_char(to_date('2008','YYYY') + level,'DDD'))))
from dual
where to_number(to_char(to_date('2008','YYYY') + level,'IW'))
<2 connect by level <= 6) -6
+
-- //next get the days in the year to the month in question
(select ((to_number(substr('2008-13', 6,2))-1)*7) from dual) startofweek
from dual) a,
-- //this is generating a test date
(select to_number(to_char(to_date('2008-07-19', 'YYYYMMDD'), 'DDD')) day
from dual) input,
dual
``` | How about
```
select * from widsys.train trn
where to_char(trn.wid_date, 'YYYY-IW') = ?
order by trn.wid_date
```
and for ranges
```
select * from widsys.train trn
where to_char(trn.wid_date, 'YYYY-IW') between ? and ?
order by trn.wid_date
```
The range will use string comparisons, which works fine if smaller numbers are zero-padded:
"2009-08" and not "2009-8". But the 'IW' format does this padding. | SQL to Return Results from Week 13 Year 2008 (not grouped) | [
"",
"sql",
"oracle",
"date",
"week-number",
""
] |
I am thinking of executing multiple instances of same java binary (a socket application) with different configuration files (As a command line parameter). Does the JVM correctly handles this situation? In other words If I haven't any common resources (Files that can be locked etc.) will this approach make any problems? If so what are things that I need to be careful. | If you start multiple instances of java from the command line you get multiple running JVMs (one per instance).
If there are no shared resources you should have no problems at all. | As Matthew pointed out earlier, as long as there are no shared resources we should see no problems.
Just to add a bit more, JVM is like a container that provides an execution environment for a java program and a JVM created each time we invoke java from the command line.
<http://en.wikipedia.org/wiki/Java_Virtual_Machine> | Can I execute multiple instances of a Java class file? | [
"",
"java",
"binary",
"jvm",
"multiple-instances",
""
] |
Is it possible to cache a binary file in .NET and do normal file operations on cached file? | The way to do this is to read the entire contents from the `FileStream` into a `MemoryStream` object, and then use this object for I/O later on. Both types inherit from `Stream`, so the usage will be effectively identical.
Here's an example:
```
private MemoryStream cachedStream;
public void CacheFile(string fileName)
{
cachedStream = new MemoryStream(File.ReadAllBytes(fileName));
}
```
So just call the `CacheFile` method once when you want to cache the given file, and then anywhere else in code use `cachedStream` for reading. (The actual file will been closed as soon as its contents was cached.) Only thing to remember is to dispose `cachedStream` when you're finished with it. | Any modern OS has a caching system built in, so in fact whenever you interact with a file, you are interacting with an in-memory cache of the file.
Before applying custom caching, you need to ask an important question: what happens when the underlying file changes, so my cached copy becomes invalid?
You can complicate matters further if the cached copy is allowed to change, and the changes need to be saved back to the underlying file.
If the file is small, it's simpler just to use `MemoryStream` as suggested in another answer.
If you need to save changes back to the file, you could write a wrapper class that forwards everything on to `MemoryStream`, but additionally has an IsDirty property that it sets to true whenever a write operation is performed. Then you can have some management code that kicks in whenever you choose (at the end of some larger transaction?), checks for `(IsDirty == true)` and saves the new version to disk. This is called "lazy write" caching, as the modifications are made in memory and are not actually saved until sometime later.
If you really want to complicate matters, or you have a very large file, you could implement your own paging, where you pick a buffer size (maybe 1 MB?) and hold a small number of `byte[]` pages of that fixed size. This time you'd have a dirty flag for each page. You'd implement the Stream methods so they hide the details from the caller, and pull in (or discard) page buffers whenever necessary.
Finally, if you want an easier life, try:
<http://www.microsoft.com/Sqlserver/2005/en/us/compact.aspx>
It lets you use the same SQL engine as SQL Server but on a file, with everything happening inside your process instead of via an external RDBMS server. This will probably give you a much simpler way of querying and updating your file, and avoid the need for a lot of hand-written persistence code. | Caching a binary file in C# | [
"",
"c#",
"file",
"caching",
"filestream",
""
] |
This question in mainly pointed at C/C++, but I guess other languages are relevant as well.
I can't understand why is switch/case still being used instead of if/else if. It seems to me much like using goto's, and results in the same sort of messy code, while the same results could be acheived with if/else if's in a much more organized manner.
Still, I see these blocks around quite often. A common place to find them is near a message-loop (WndProc...), whereas these are among the places when they raise the heaviest havoc: variables are shared along the entire block, even when not propriate (and can't be initialized inside it). Extra attention has to be put on not dropping break's, and so on...
Personally, I avoid using them, and I wonder wether I'm missing something?
Are they more efficient than if/else's?
Are they carried on by tradition? | Summarising my initial post and comments - there are several advantages of `switch` statement over `if`/`else` statement:
1. Cleaner code. Code with multiple chained `if`/`else if ...` looks messy and is difficult to maintain - `switch` gives cleaner structure.
2. Performance. For dense `case` values compiler generates jump table, for sparse - binary search or series of `if`/`else`, so in worst case `switch` is as fast as `if`/`else`, but typically faster. Although some compilers can similarly optimise `if`/`else`.
3. Test order doesn't matter. To speed up series of `if`/`else` tests one needs to put more likely cases first. With `switch`/`case` programmer doesn't need to think about this.
4. Default can be anywhere. With `if`/`else` default case must be at the very end - after last `else`. In `switch` - `default` can be anywhere, wherever programmer finds it more appropriate.
5. Common code. If you need to execute common code for several cases, you may omit `break` and the execution will "fall through" - something you cannot achieve with `if`/`else`. (There is a good practice to place a special comment `/* FALLTHROUGH */` for such cases - lint recognises it and doesn't complain, without this comment it does complain as it is common error to forgot `break`).
Thanks to all commenters. | Well, one reason is clarity....
if you have a switch/case, then the expression can't change....
i.e.
```
switch (foo[bar][baz]) {
case 'a':
...
break;
case 'b':
...
break;
}
```
whereas with if/else, if you write by mistake (or intent):
```
if (foo[bar][baz] == 'a') {
....
}
else if (foo[bar][baz+1] == 'b') {
....
}
```
people reading your code will wonder "were the foo expressions supposed to be the same", or "why are they different"? | Why Switch/Case and not If/Else If? | [
"",
"c++",
"c",
"switch-statement",
"conditional-statements",
""
] |
I have a MySQL `member` table, with a `DOB` field which stores all members' dates of birth in `DATE` format (Notice: it has the "Year" part)
I'm trying to find the correct SQL to:
* List all birthdays within the next 14 days
and another query to:
* List all birthdays within the previous 14 days
Directly comparing the current date by:
```
(DATEDIFF(DOB, now()) <= 14 and DATEDIFF(DOB, now()) >= 0)
```
will fetch nothing since the current year and the DOB year is different.
However, transforming the DOB to 'this year' won't work at all, because today could be Jan 1 and the candidate could have a DOB of Dec 31 (or vice versa)
It will be great if you can give a hand to help, many thanks! :) | My first thought was it would be easy to just to use DAYOFYEAR and take the difference, but that actually gets kinda trick near the start/end of a yeay. However:
```
WHERE
DAYOFYEAR(NOW()) - DAYOFYEAR(dob) BETWEEN 0 AND 14
OR DAYOFYEAR(dob) - DAYOFYEAR(NOW()) > 351
```
Should work, depending on how much you care about leap years. A "better" answer would probably be to extract the DAY() and MONTH() from the dob and use MAKEDATE() to build a date in the current (or potential past/following) year and compare to that. | Here's the simplest code to get the upcoming birthdays for the next x days and previous x days
this query is also not affected by leap-years
```
SELECT name, date_of_birty
FROM users
WHERE DATE(CONCAT(YEAR(CURDATE()), RIGHT(date_of_birty, 6)))
BETWEEN
DATE_SUB(CURDATE(), INTERVAL 14 DAY)
AND
DATE_ADD(CURDATE(), INTERVAL 14 DAY)
``` | SQL that list all birthdays within the next and previous 14 days | [
"",
"sql",
"mysql",
"date",
""
] |
When you have multiple projects that all use the same set of JAR libraries, it's tedious to include the same JARs over and over again with each project. If I'm working on 20 different projects, I'd rather not have 20 of the same exact set of JAR files lying around. What's the best way to make all those projects (and new projects as well) reference the same set of JARs?
I have some ideas, but each of them has some disadvantages:
* Place all the JARs in a folder and have each project look in that folder.
* Using Eclipse, create a "User Library" and have each project reference that user library.
* Create a "Library" project that references each JAR, and have each project reference that library project. | Use [Maven](http://maven.apache.org/) or [Ivy](http://ant.apache.org/ivy/) to handle these shared jars. If you're wary of changing your projects too much, you can simply use [Ivy](http://ant.apache.org/ivy/) to manage the extra classpath for you.
---
Both have good Eclipse plugins:
## [m2eclipse](http://m2eclipse.codehaus.org/)
[Maven classpath container http://img229.imageshack.us/img229/4848/mavendependencies.png](http://img229.imageshack.us/img229/4848/mavendependencies.png)
## [IvyDE](http://ant.apache.org/ivy/ivyde/)
[IvyDE classpath container http://img76.imageshack.us/img76/3180/cpnode.jpg](http://img76.imageshack.us/img76/3180/cpnode.jpg)
which I've used with good results.
You'll note that both of them reference jars *outside* the workspace, so the duplication is removed.
---
**Update** ( prompted by comments ):
My reason for recommending this approach is that I strongly believe that it's simpler and clearer to *declare* dependencies rather then manually include them. There is a small one-time cost associated with this - smaller for Ivy than for Maven - but in the long run it does pay off.
Another, smaller, benefit is the handling of transitive and conflicting dependencies. It's easy to forget *why* you need that commons-logging-1.1.jar in the classpath and whether you need to upgrade to 1.1.1. And also it's no fun to pull in all the depencies required for *e.g.* a Hibernate + Annotation + Spring combo. Focus on programming, not building. | Believe it or not, your 'tedious' approach is probably the simplest, cleanest and least time-consuming approach there is.
Before jumping on the maven bandwagon you should consider what is really wrong with doing things the way you are currently doing them. You mentioned that it is tedious and that you have a lot of jar files lying around. I created the build process on a large multi-module project using Maven then spent the next 18 months battling with it constantly. Believe me it was tedious and there were a lot of jar files lying around.
Since going back to Ant and committing jars to source control alongside the projects that use them it has been a much smoother ride.
I store a bunch of jar files in a single directory on my machine and then when I create a new project or need to add a new jar to an existing project it only takes about 30 seconds:
* Copy the jar from JAR\_REPO to project lib dir.
* Add jar to build.properties
* Add jar to classpath in build.xml
* Add jar to build path in Eclipse.
Over the course of a project, that 30 seconds is insignificant, but it means I have a project that can be checked out of source control and just works without requiring any custom Eclipse configuration or Maven installations or user-specific setup.
This approach has saved me and my project team a huge amount of time, mainly because it is simple, reliable and easy to understand.
---
**Update**: Clarification prompted by comments
@Robert Munteanu: Thanks for the feedback and updated comments. This might sound a bit argumentative but I'm afraid I can't agree with you that Maven is simpler and clearer, or that it will save you time in the long run.
From your posting:
"I strongly believe that it's simpler and clearer to declare dependencies rather then manually include them. There is a small one-time cost associated with this - smaller for Ivy than for Maven - but in the long run it does pay off."
It may be easier to have Maven download a jar file for you than having to download it yourself but that's the only advantage. Otherwise Maven is not simpler, not clearer and its complexities and limitations will cost you in the long run.
**Clarity**
The two dependency declarations below do the same thing. I find the Ant one much clearer than the Maven one.
Ant Style:
```
<path id="compile.classpath">
<pathelement location="${log4j.jar}" />
<pathelement location="${spring.jar}" />
</path>
```
Maven Style:
```
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring</artifactId>
<version>${spring.version}</version>
<scope>compile</scope>
</dependency>
```
**Simplicity**
With the Ant version you can hover over the ${log4j.jar} property and it will show you the absolute path to the jar file. You can search for usage of compile.classpath. There's not a whole lot more you need to know.
There is no question that Maven is more complex than the approach I'm suggesting. When you start out with Maven these are just some of the questions that need to be answered.
* What does groupId mean?
* What does artifactId mean?
* Where does the jar come from?
* Where is the jar now?
* What is provided scope? Who's providing it?
* How did that jar file end up in my WAR file?
* Why does this dependency not have a version element?
* I don't understand this error message. What on Earth does it mean?
* Where on Earth did that jar file come from? I didn't declare it.
* Why do I have 2 versions of the same jar file on my classpath?
* Why does the project not build any more? Nothing has changed since the last time I built it.
* How do I add a third-party jar that's not in the Maven repository?
* Tell me again where I get that Eclipse plugin from.
**Transitive Dependencies**
"Another, smaller, benefit is the handling of transitive and conflicting dependencies."
In my experience, transitive dependencies are more trouble than they're worth. You end up with multiple versions of the same jar file and you end up with optional jar files that you don't want. I ended up declaring just about everything with provided scope to avoid the hassle.
**The Long Term Payoff**
"Focus on programming, not building."
I agree. Since going back to Ant and putting my jar files in source control I have been able to spend *far* less time dealing with build issues.
These are the things I spend less time doing:
* Reading poor Maven documentation.
* Reading even poorer Codehaus Mojo documentation.
* Setting up shared internal repositories.
* Educating team members.
* Writing Maven plugins to fill the gaps.
* Trying to workaround defective plugins (release, assembly).
* Installing Eclipse plugins for Maven.
* Waiting for the plugin to give me back control of Eclipse.
Anyways, sorry about the long posting. Maybe now that I've got that off my chest I can bring some closure to my long and painful Maven experience. :) | What's the best way to share JARs across multiple projects? | [
"",
"java",
"eclipse",
"jar",
"include",
""
] |
I'm reviewing a collegue's code, and I see he has several constants defined in the global scope as:
```
const string& SomeConstant = "This is some constant text";
```
Personally, this smells bad to me because the reference is referring to what I'm assuming is an "anonymous" object constructed from the given char array.
Syntactically, it's legal (at least in VC++ 7), and it seems to run, but really I'd rather have him remove the & so there's no ambiguity as to what it's doing.
So, is this TRULY safe and legal and I'm obsessing? Does the temp object being constructed have a guaranteed lifetime? I had always assumed anonymous objects used in this manner were destructed after use...
---
So my question could also be generalized to anonymous object lifetime. Does the standard dictate the lifetime of an anonymous object? Would it have the same lifetime as any other object in that same scope? Or is it only given the lifetime of the expression?
---
Also, when doing it as a local, it's obviously scoped differently:
```
class A
{
string _str;
public:
A(const string& str) :
_str(str)
{
cout << "Constructing A(" << _str << ")" << endl;
}
~A()
{
cout << "Destructing A(" << _str << ")" << endl;
}
};
void TestFun()
{
A("Outer");
cout << "Hi" << endl;
}
```
Shows:
Constructing A(Outer);
Destructing A(Outer);
Hi | It's completely legal. It will not be destructed until the program ends.
EDIT: *Yes*, it's guaranteed:
> "All objects which do not have dynamic
> storage duration, do not have thread
> storage duration, and are not local
> have static storage duration. The
> storage for these objects shall last
> for the duration of the program
> (3.6.2, 3.6.3)."
-- [2008 Working Draft, Standard for Programming Language C++](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2008/n2798.pdf), § 3.7.1 p. 63
As Martin noted, this is not the whole answer. The standard draft further notes (§ 12.2, p. 250-1):
> "Temporaries of class type are created
> in various contexts: binding an rvalue
> to a reference (8.5.3) [...] Even when
> the creation of the temporary object
> is avoided (12.8), all the semantic
> restrictions shall be respected as if
> the temporary object had been created.
> [...] Temporary objects are destroyed
> as the last step in evaluating the
> full-expression (1.9) that (lexically)
> contains the point where they were
> created. [...] There are two contexts
> in which temporaries are destroyed at
> a different point than the end of the
> full-expression. [...] The second
> context is when a reference is bound
> to a temporary. The temporary to which
> the reference is bound or the
> temporary that is the complete object
> of a subobject to which the reference
> is bound persists for the lifetime of
> the reference except as specified
> below."
I tested in g++ if that makes you feel any better. ;) | Yes it is valid and legal.
```
const string& SomeConstant = "This is some constant text";
// Is equivalent too:
const string& SomeConstant = std::string("This is some constant text");
```
Thus you are creating a temporary object.
This temporary object is bound to a const& and thus has its lifetime extended to the lifespan of the variable it is bound too (ie longer than the expression in which it was created).
This is guranteed by the standard.
### Note:
Though it is legal. I would not use it. The easist solution would be to convert it into a const std::string.
### Usage:
In this situation because the variable is in global scope it is valid for the full length of the program. So it can be used as soon as execution enters main() and should not be accessed after executiuon exits main().
Though it technically may be avilable before this your usage of it in constructors/destructors of global objects should be tempered with the known problem of global variable initialization order.
### Extra Thoughts:
This on the other hand will not suffer from the problem:
```
char const* SomeConstant = "This is some constant text";
```
And can be used at any point. Just a thought. | Global const string& smells bad to me, is it truly safe? | [
"",
"c++",
"string",
"object",
"constants",
"anonymous",
""
] |
I'm trying to get the following to work, but I'm at a loss...
```
class Foo {
public $somethingelse;
function __construct() {
echo 'I am Foo';
}
function composition() {
$this->somethingelse =& new SomethingElse();
}
}
```
```
class Bar extends Foo {
function __construct() {
echo 'I am Bar, my parent is Foo';
}
}
```
```
class SomethingElse {
function __construct() {
echo 'I am some other class';
}
function test() {
echo 'I am a method in the SomethingElse class';
}
}
```
What I'd like to do is create an instance of the SomethingElse class within the class Foo. This works using `=&`. But when I extend class Foo with class Bar, I thought that the child inherits all the data attributes and methods from the parent class. However, it seems that `$this->somethingelse` doesn't work in child class Bar:
```
$foo = new Foo(); // I am Foo
$foo->composition(); // I am some other class
$foo->somethingelse->test(); // I am a method in the SomethingElse class
$bar = new Bar(); // I am Bar, my parent is Foo
$bar->somethingelse->test(); // Fatal error: Call to a member function test() on a non-object
```
So, is it not possible to inherit in such a way? And should I create a new instance of class SomethingElse from within class Bar if I want to use it there? Or am I missing something?
Thanks in advance for your help. | > I thought that the child inherits all the data attributes and methods from the parent class.
This is true - the child class inherits the static variables and static methods from the parent class. Additionally, any child objects will inherit the static and instance variables and methods.
One possibility to get what you want with your existing class structure is this:
```
$bar = new Bar();
$bar->composition();// here you are calling the parent method, sets instance var $somethineelse
$bar->somethingelse->test();// now you can call methods
```
Another way to accomplish inheriting an variable (in this case an object) in child instances would be like so:
```
class Foo {
protected $somethingelse;
public function __construct() {
$this->somethingelse = new SomethingElse();
}
}
class Bar extends Foo {
public function __construct() {
parent::__construct();
// now i've got $somethingelse
}
}
```
For a very good overview of classes and objects in PHP 5, take a look here:
<http://php.net/manual/en/language.oop5.php>
Make sure to read it all, maybe a couple times if OO is new for you. | bar has a member variable named somethingelse, which is inherited from foo.
you are mixing object and class scope.
if you really want to achieve the effect described, you have to make your variable static, so its context is class based | PHP5 Classes: inheriting a composed class? | [
"",
"php",
"inheritance",
"composition",
""
] |
C# VS 2005.
I have developed an application that run perfectly on my development machine when I install it. However, it doesn't run on any of the clients machines.
I have tested with VMWare with a fresh install of windows, and still the application doesn't run.
I have added logging to try and determine where the application is failing. My previous versions worked, and after a week of development I gave to the client and then experienced this problem.
I have entered logging at the start and end of the constructor and form\_load event. The constructor runs ok. However, at the end of the constructor it doesn't run in the form\_load event as I have a log statement that should print out.
When the application runs it displays for a few seconds in task manager then fails to load.
I think this could be a very difficult problem to solve. So if anyone has experienced this before or could point me in the right direction to solve this problem.
The code in the form load event.
```
private void CATDialer_Load(object sender, EventArgs e)
{
my_logger.Info("Start of form load event"); // Doesn't display this.
.
.
}
```
===== Edit static main ====
```
[STAThread]
static void Main()
{
Application.SetCompatibleTextRenderingDefault(false);
// Get the language and set this cultureUI in the statusdisplay that will
// change the language for the whole program.
string language = CATWinSIP.Properties.Settings.Default.Language;
if (language == "th-TH")
{
StatusDisplay.StatusDisplay status_display = new StatusDisplay.StatusDisplay(true);
}
else if(language == "en-GB")
{
StatusDisplay.StatusDisplay status_display = new StatusDisplay.StatusDisplay(false);
}
try
{
Application.Run(new CATDialer());
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
```
=== Constructor ===
```
public CATDialer()
{
//Set the language for all the controls on the form.
//Has to be done before all components are initialized.
//If not Thai language then must be using English.
if (Settings.Default.Language == "th-TH")
{
Thread.CurrentThread.CurrentUICulture = new CultureInfo("th-TH");
}
else
{
Thread.CurrentThread.CurrentUICulture = new CultureInfo("en-GB");
}
InitializeComponent();
this.statusDisplay1.BalanceStatus = CATWinSIP_MsgStrings.BalanceStatus;
this.statusDisplay1.RedialHistory = CATWinSIP_MsgStrings.RedialHistory;
this.statusDisplay1.LoginStatus = CATWinSIP_MsgStrings.LoginSuccessful;
// Enable logging
XmlConfigurator.Configure();
logger.Info("CATDialer Constructor(): XmlConfigurator.Configure() Loaded [ OK ]");
// MessageBox.Show("Balance Status: " + this.statusDisplay1.BalanceStatus);
//Short cut menu.
this.SetupShortCutMenu();
this.fill_properties();
logger.Debug("CATDialer Constructor(): Fill properties loaded [ OK ]");
}
```
--
Hello,
Thanks for all the advice.
I have problem with one of my class libraries I created that used a crypto stream.
I found the answer when I added this to my program.cs
The message box displayed the information for the failed assembly.
Thanks,
```
try
{
Application.Run(new CATDialer());
}
catch (Exception ex)
{
MessageBox.Show(ex.ToString());
}
``` | Have you checked on a different development machine? Are your systems running same version of the .net framework? Is the .net framework installed correctly on the remote system? Have you tested your application in a different environment?
edit: have you tried spamming your log? Wrap the entire thing in a try catch and see what you can capture. Sometimes I found using the messagebox useful for this kind of logging (MessageBox.Show()) | You probably need to post a bit more detail about the type of exception that is being thrown to get the most help.
If all the obvious checks such as having the correct framework version pass, the next thing to fail can often be a missing assembly.
If this is the case you may want to troubleshoot assembly loading in your app.
The [MS Assembly Binding Log Viewer (fuslogvw)](http://msdn.microsoft.com/en-us/library/e74a18c4(vs.71).aspx) is a valuable piece of kit for this task. | C# Application not run | [
"",
"c#",
""
] |
The project I'm working on has an Oracle backend, and we use [SQL Navigator](http://www.quest.com/sql-navigator/) 5.5 for SQL development and it really sucks: the intellisense doesn't work for queries with more than one table and you can't browse the schema and write a query on the screen at the same time. Not fun.
I also tried using [Oracle SQL Developer](http://www.oracle.com/technology/products/database/sql_developer/index.html). That's not much of an improvement either - the graphics on the query results window get all fudged up and have to be repainted frequently by clicking around the screen.
The extent to which I'm writing SQL is pretty basic: a procedure here and there, mostly queries. Can someone recommend a decent tool, preferably one with a low cost? | All IDE:s for Oracle DB are more or less bad, TOAD is the best but still nothing comapared to real IDE like Visual Studio or Eclipse.
Main problem with TOAD is the default texteditor. Find is nightmare and you can't change shortcuts and auto alignment uses spaces even if you configure it to use tabs and other annoying features. Also cancelling queries or making query to disconnected session might crash it. Also the intellisense is kinda slow imo but it works which is better than what others offer. | You may want to check out PL/SQL Developer (<http://www.allroundautomations.com/plsqldev.html>). It does more than just PL/SQL. Cost is pretty reasonable. On Linux try Tora It is suppose to be a replacement for Toad. Have used to other 2 personally but not the latter. | What's a quality development environment for writing Oracle SQL? | [
"",
"sql",
"oracle",
"ide",
""
] |
Let's say the page TestPage.aspx has two controls. The first control is an address control that has a validation group called "AddressGroup". This group contains several validation controls which are colated in the validation summary on that control. The second control is a credit card control and has a validation group called "CreditCardGroup". It also has several validators and a summary to display the results. To add to the problem, there are some random controls on the page that also have validators which are tied to a third ValidatorSummary control.
When the user presses the "Do it all" button, I would like the page to trigger all three validation groups. The button itself can be tied to a single group or an unlabeled group. It can not be tied to multiple groups as far as I can tell.
The solution is not to extract the validation from the controls as that would deminish the value of having them in seperate controls. Thanks for your thoughts. | Are you talking client side or server side validation? Jamie's answer is spot on for server side, but for client side validation you will probably need to write your own JS function that will trigger validation on all three groups in concert. | Call the Validate method for each validation group individually inside the button's click handler:
```
bool isValidTest = false;
Validate("AddressGroup");
isValidTest = IsValid;
Validate("CreditCardGroup");
isValidTest &= IsValid;
// etc.
if (!isValidTest) return;
```
The next problem you may encounter is that the ValidationSummary control is linked to a single validation group. The only way that I've found to display all the error messages for multiple groups (without walking the control tree) is use multiple ValidationSummary controls.
With user controls, you may want to have its Validate method perform validation for all the controls it contains and display its own summary.
Edited to add: The isValidTest variable is not needed. According to the docs:
> Note that when you call the Validate
> method, the IsValid property reflects
> the validity of all groups validated
> so far. | Triggering multiple validation groups with a single button? | [
"",
"c#",
"asp.net",
"validation",
""
] |
This question came up in Spring class, which has some rather long class names. Is there a limit in the language for class name lengths? | The [Java Language Specification](http://docs.oracle.com/javase/specs/jls/se5.0/html/lexical.html#3.8) states that identifiers are unlimited in length.
In practice though, the filesystem will limit the length of the resulting file name. | 65535 characters I believe. From the Java virtual machine specification:
> The length of field and method names,
> field and method descriptors, and
> other constant string values is
> **limited to 65535** characters by the
> 16-bit unsigned length item of the
> CONSTANT\_Utf8\_info structure (§4.4.7).
> Note that the limit is on the number
> of bytes in the encoding and not on
> the number of encoded characters.
> UTF-8 encodes some characters using
> two or three bytes. Thus, strings
> incorporating multibyte characters are
> further constrained.
here:
<https://docs.oracle.com/javase/specs/jvms/se6/html/ClassFile.doc.html#88659> | Does Java have a limit on the class name length? | [
"",
"java",
"name-length",
""
] |
I'm building a web application with Django. The reasons I chose Django were:
* I wanted to work with free/open-source tools.
* I like Python and feel it's a **long-term** language, whereas regarding Ruby I wasn't sure, and PHP seemed like a huge hassle to learn.
* I'm building a prototype for an idea and wasn't thinking too much about the future. Development speed was the main factor, and I already knew Python.
* I knew the migration to Google App Engine would be easier should I choose to do so in the future.
* I heard Django was "nice".
Now that I'm getting closer to thinking about publishing my work, I start being concerned about scale. The only information I found about the scaling capabilities of Django is provided by the Django team (I'm not saying anything to disregard them, but this is clearly not objective information...).
**Has an independent development team reported building a Django-based site that reliably handles an excess of 100k daily visits?** | 1. **"What are the largest sites built on Django today?"**
There isn't any single place that collects information about traffic on Django built sites, so I'll have to take a stab at it using data from various locations. First, we have a list of Django sites on the front page of [the main Django project page](http://www.djangoproject.com/) and then a list of Django built sites at [djangosites.org](http://www.djangosites.org/). Going through the lists and picking some that I know have decent traffic we see:
* **[Instagram](http://instagram.com)**: [What Powers Instagram: Hundreds of Instances, Dozens of Technologies](http://instagram-engineering.tumblr.com/post/13649370142/what-powers-instagram-hundreds-of-instances).
* **[Pinterest](http://pinterest.com/)**: [Alexa rank 37 (21.4.2015)](http://www.alexa.com/siteinfo/Pinterest.com) and 70 Million users in 2013
* **[Bitbucket](http://bitbucket.org/)**: [200TB of Code and 2.500.000 Users](https://blog.bitbucket.org/2015/02/05/bitbucket-2014-in-review/)
* **[Disqus](http://disqus.com)**: [Serving 400 million people with Python](http://pyvideo.org/video/418/pycon-2011--disqus--serving-400-million-people-wi).
* **[curse.com](http://curse.com/)**: [600k daily visits](http://www.quantcast.com/curse.com).
* **[tabblo.com](http://tabblo.com/)**: [44k daily visits](http://www.quantcast.com/tabblo.com), see Ned Batchelder's posts [Infrastructure for modern web sites](http://nedbatchelder.com/blog/200902/infrastructure_for_modern_web_sites.html).
* **[chesspark.com](http://chesspark.com/)**: [Alexa](http://www.alexa.com/siteinfo/chesspark.com) rank about 179k.
* **[pownce.com](http://pownce.com/)** (no longer active): [alexa](http://www.alexa.com/siteinfo/pownce.com) rank about 65k.
Mike Malone of Pownce, in his EuroDjangoCon presentation on **[Scaling Django Web Apps](http://www.slideshare.net/road76/scaling-django)** says "hundreds of hits per second". This is a very good presentation on how to scale Django, and makes some good points including (current) shortcomings in Django scalability.
* HP had a site built with Django 1.5: [ePrint center](http://www.eprintcenter.com). However, as for novemer/2015 the entire website was migrated and this link is just a redirect. This website was a world-wide service attending subscription to Instant Ink and related services HP offered (\*).
2. **"Can Django deal with 100,000 users daily, each visiting the site for a couple of hours?"**
Yes, see above.
3. **"Could a site like Stack Overflow run on Django?"**
My gut feeling is yes but, as others answered and Mike Malone mentions in his presentation, database design is critical. Strong proof might also be found at www.cnprog.com if we can find any reliable traffic stats. Anyway, it's not just something that will happen by throwing together a bunch of Django models :)
There are, of course, many more sites and bloggers of interest, but I have got to stop somewhere!
---
Blog post about [Using Django to build high-traffic site michaelmoore.com](http://web.archive.org/web/20130307032621/http://concentricsky.com/blog/2009/oct/michaelmoorecom) described as a [top 10,000 website](http://www.alexa.com/siteinfo/http%3A%2F%2Fmichaelmoore.com). [Quantcast stats](http://www.quantcast.com/michaelmoore.com) and [compete.com stats](http://siteanalytics.compete.com/michaelmoore.com/).
---
(\*) The author of the edit, including such reference, used to work as outsourced developer in that project. | We're doing load testing now. We think we can support 240 concurrent requests (a sustained rate of 120 hits per second 24x7) without any significant degradation in the server performance. That would be 432,000 hits per hour. Response times aren't small (our transactions are large) but there's no degradation from our baseline performance as the load increases.
We're using Apache front-ending Django and MySQL. The OS is Red Hat Enterprise Linux (RHEL). 64-bit. We use mod\_wsgi in daemon mode for Django. We've done no cache or database optimization other than to accept the defaults.
We're all in one VM on a 64-bit Dell with (I think) 32Gb RAM.
Since performance is almost the same for 20 or 200 concurrent users, we don't need to spend huge amounts of time "tweaking". Instead we simply need to keep our base performance up through ordinary SSL performance improvements, ordinary database design and implementation (indexing, etc.), ordinary firewall performance improvements, etc.
What we do measure is our load test laptops struggling under the insane workload of 15 processes running 16 concurrent threads of requests. | Has Django served an excess of 100k daily visits? | [
"",
"python",
"django",
"web-applications",
"scalability",
""
] |
Why is this the extended ascii character (â, é, etc) getting replaced with <?> characters?
I attached a pic... but I am using PHP to pull the data from MySQL, and some of these locations have extended characters... I am using the Font Arial.
You can see the screen shot here: <http://img269.imageshack.us/i/funnychar.png/>
Still happening after the suggestions, here is what I did:
My firefox (view->encoding) is set to UTF-8 after adding the line, however, the text inside the option tags is still showing the funny character instead of the actual accented one. What should I look for now?
**UPDATE:**
I have the following in the PHP program that is giving my those <?> characters...
```
ini_set( 'default_charset', 'UTF-8' );
```
And right after my zend db object creation, I am setting the following query:
```
$db->query("SET NAMES utf8;");
```
I changed all my tables over to UTF-8 and reinserted all the data (waste of time) as it never helped. It was latin1 prior.
Also STATUS is reporting:
```
Connection: Localhost via UNIX socket
Server characterset: latin1
Db characterset: latin1
Client characterset: utf8
Conn. characterset: utf8
UNIX socket: /var/run/mysqld/mysqld.sock
Uptime: 4 days 20 hours 59 min 41 sec
```
Looking at the source of the page, I see
<option value="Br�l� Lake"> Br�l� Lake
**OK- NEW UPDATE-**
I Changed everything in my PHP and HTML to:
and
header('Content-Type: text/html; charset=latin1');
Now it works, what gives?? How do I convert it all to UTF-8? | That's what the browser does when it doesn't know the encoding to use for a character. Make sure you specify the encoding type of the text you send to the client either in headers or markup meta.
In HTML:
```
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
```
In PHP (before any other content is sent to the client):
```
header('Content-Type: text/html; charset=utf-8');
```
I'm assuming you'll want UTF-8 encoding. If your site uses another encoding for text, then you should replace UTF-8 with the encoding you're using.
One thing to note about using HTML to specify the encoding is that the browser will restart rendering a page once it sees the `Content-Type` meta tag, so you should include the `<meta />` tag immediately after the `<head />` tag in your page so the browser doesn't do any more extra processing than it needs.
Another common charset is "iso-8859-1" (Basic Latin), which you may want to use instead of UTF-8. You can find more detailed info from this awesome article on [character encodings and the web](http://unicode.org/faq/unicode_web.html). You can also get an exhaustive [list of character encodings here](http://www.iana.org/assignments/character-sets) if you need a specific type.
---
If nothing else works, another (rare) possibility is that you may not have a font installed on your computer with the characters needed to display the page. I've tried [repeating your results on my own server](http://dan-herbert.com/unicode.htm) and had no luck, possibly because I have a lot of fonts installed on my machine so the browser can always substitute unavailable characters from one font with another font.
What I did notice by investigating further is that if text is sent in an encoding different than the encoding the browser reports as, Unicode characters can render unexpectedly. To work around this, I used the [HTML character entity representation](http://en.wikipedia.org/wiki/List_of_XML_and_HTML_character_entity_references) of special characters, so `â` becomes `â` in my HTML and `é` becomes `é`. Once I did this, no matter what encoding I reported as, my characters rendered correctly.
Obviously you don't want to modify your database to HTML encode Unicode characters. Your best option if you must do this is to use a PHP function, [`htmlentities()`](http://php.net/manual/en/function.htmlentities.php). You should use this function on any data-driven text you expect to have Unicode characters in. This may be annoying to do, but if specifying the encoding doesn't help, this is a good last resort for forcing Unicode characters to work. | There is no such standard called "extended ASCII", just a bunch of [proprietary extensions](http://en.wikipedia.org/wiki/Extended_ASCII).
Anyway, there are a variety of possible causes, but it's not your font. You can start by checking the character set in MySQL, and then see what PHP is doing. As Dan said, you need to make sure PHP is specifying the character encoding it's actually using. | Why is this the extended ascii character (â, é, etc) getting replaced with <?> characters? | [
"",
"php",
"html",
"character-encoding",
""
] |
I have a web site with users and their data accordingly.
What is the safest way to implement web services / API such that users' login credentials and in turn data are secure? oAuth isn't really an option, because usage will not necessarily be in other web apps.
My concern is that having the username and password as an input is dangerous to be transmitted plainly, and a token could also be stolen and reused maliciously.
Do I need to come up with my own method of encrypting and decrypting data, or is there a common practice(s) already in use?
The whole point is that it's as open as possible for anyone in the world to use, but safe by definition nonetheless. Documentation will be available to everyone to use. | There's always the WS-Security standard:
[WS-Security (Wikipedia)](http://en.wikipedia.org/wiki/Web_Services_Security)
.NET has its implementations in .NET 1.1 and .NET 2.0 via the Microsoft Web Service Enhancements:
[WSE 2.0 (.NET 1.1)](http://www.microsoft.com/downloads/details.aspx?familyid=fc5f06c5-821f-41d3-a4fe-6c7b56423841&displaylang=en)
[WSE 3.0 (.NET 2.0)](http://www.microsoft.com/downloads/details.aspx?FamilyID=018a09fd-3a74-43c5-8ec1-8d789091255d&displaylang=en)
It provides various methods on encrypting the SOAP Envelope before it is sent over the wire, safely transmitting the data inside. | What about using an SSL connection? | What is the safest way to implement Web Services / API? | [
"",
"c#",
".net",
"web-services",
"api",
"soap",
""
] |
I'd be more than interesting for me to understand which technique is being used here to persist sensible data since I'm needing to implement a similar solution. Here's a sample connection configuration and the resulting exported snippet:
[](https://i.stack.imgur.com/NHmpl.gif)
```
<?xml version = '1.0' encoding = 'UTF-8'?>
<References xmlns="http://xmlns.oracle.com/adf/jndi">
<Reference name="My Connection" className="oracle.jdeveloper.db.adapter.DatabaseProvider" xmlns="">
<Factory className="oracle.jdeveloper.db.adapter.DatabaseProviderFactory"/>
<RefAddresses>
<StringRefAddr addrType="user">
<Contents>username</Contents>
</StringRefAddr>
<StringRefAddr addrType="password">
<Contents>054D4844D8549C0DB78EE1A98FE4E085B8A484D20A81F7DCF8</Contents>
</StringRefAddr>
<SKIPPED />
</RefAddresses>
</Reference>
</References>
```
Any advice would be really appreciated. | For the curious, what you're actually seeing is the secret key concatenated with the encrypted password. For example, I tried encrypting the password "SAILBOAT" using:
```
DatabaseProviderHelper.goingOut("SAILBOAT")
```
In this particular instance, the result was:
```
0527C290B40C41D71139B5E7A4446E94D7678359087249A463
```
The first byte is constant:
```
05
```
The next 8 bytes represent the randomly generated secret key (for the DES cipher):
```
27C290B40C41D711
```
The remaining bytes are the encrypted password:
```
39B5E7A4446E94D7678359087249A463
```
Therefore, to decrypt the password, you simply use this:
```
public static byte[] decryptPassword(byte[] result) throws GeneralSecurityException {
byte constant = result[0];
if (constant != 5) {
throw new IllegalArgumentException();
}
byte[] secretKey = new byte[8];
System.arraycopy(result, 1, secretKey, 0, 8);
byte[] encryptedPassword = new byte[result.length - 9];
System.arraycopy(result, 9, encryptedPassword, 0, encryptedPassword.length);
byte[] iv = new byte[8];
for (int i = 0; i < iv.length; i++) {
iv[i] = 0;
}
Cipher cipher = Cipher.getInstance("DES/CBC/PKCS5Padding");
cipher.init(Cipher.DECRYPT_MODE, new SecretKeySpec(secretKey, "DES"), new IvParameterSpec(iv));
return cipher.doFinal(encryptedPassword);
}
``` | Note that Tim's password hash above is not for "apps\_ro" - presumably he cut and pasted from the wrong place... I won't post the real password in case it's something he doesn't want shared!
I had a similar problem, trying to store my db credentials centrally (for non-secure databases!) and then exporting sql developer xml files. I have no idea what the algorithm is - however, you don't really need to know the algorithm, as you can just call the Oracle java API yourself. If you have SQLDeveloper, just grab the right Jar files:
```
cp /Applications/SQLDeveloper.App/Contents/Resources/sqldeveloper/BC4J/lib/db-ca.jar .
cp /Applications/SQLDeveloper.App/Contents/Resources/sqldeveloper/jlib/ojmisc.jar .
```
Then either load them in your Java app, or use something like JRuby as I do:
```
$jirb
> require 'java'
> require 'ojmisc.jar'
> require 'db-ca.jar'
> Java::oracle.jdevimpl.db.adapter.DatabaseProviderHelper.goingOut("password")
=> "059D45F5EB78C99875F6F6E3C3F66F71352B0EB4668D7DEBF8"
> Java::oracle.jdevimpl.db.adapter.DatabaseProviderHelper.goingOut("password")
=> "055CBB58B69B477714239157A1F95FDDD6E5B453BEB69E5D49"
> Java::oracle.jdevimpl.db.adapter.DatabaseProviderHelper.comingIn("059D45F5EB78C99875F6F6E3C3F66F71352B0EB4668D7DEBF8")
=> "password"
> Java::oracle.jdevimpl.db.adapter.DatabaseProviderHelper.comingIn("055CBB58B69B477714239157A1F95FDDD6E5B453BEB69E5D49")
=> "password"
```
Note that the algorithm, whatever it is, has a random factor so the same password used twice can produce two different hex strings. | Does anybody know what encrypting technique is JDeveloper/SQL Developer using to persist credentials? | [
"",
"java",
"oracle",
"oracle-sqldeveloper",
"jdeveloper",
""
] |
I'm writing a Java [servlet](http://en.wikipedia.org/wiki/Java_Servlet) in Eclipse (to be hosted on Google App Engine) and need to process an XML document. What libraries are available that are easy to add to an Eclipse project and have good example code? | I ended up using [JAXP](http://en.wikipedia.org/wiki/Java_API_for_XML_Processing) with the SAX API.
Adding something like the following to my servlet:
```
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
....
InputStream in = connection.getInputStream();
InputSource responseXML = new InputSource(in);
final StringBuilder response = new StringBuilder();
DefaultHandler myHandler = new DefaultHandler() {
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if (localName.equals("elementname")) {
response.append(attributes.getValue("attributename"));
inElement = true;
}
}
public void characters(char [] buf, int offset, int len) {
if (inElement) {
inElement = false;
String s = new String(buf, offset, len);
response.append(s);
response.append("\n");
}
}
};
SAXParserFactory factory = SAXParserFactory.newInstance();
try {
SAXParser parser = factory.newSAXParser();
parser.parse(responseXML, myHandler);
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
in.close();
connection.disconnect();
....
``` | Xerces (that provides both SAX and DOM implementations) and Xalan (that provides support for transformations) - both have been bundled with the JDK since 1.5 and are therefore already configured in a standard Java install | What libraries are there for processing XML on Google App Engine/Java Servlet | [
"",
"java",
"xml",
"eclipse",
"servlets",
""
] |
I have a simple Indexed View. When I query against it, it's pretty slow. First I show you the schema's and indexes. Then the simple queries. Finally a query plan screnie.
### Update: Proof of Solution at the bottom of this post.
### Schema
This is what it looks like :-
```
CREATE view [dbo].[PostsCleanSubjectView] with SCHEMABINDING AS
SELECT PostId, PostTypeId,
[dbo].[ToUriCleanText]([Subject]) AS CleanedSubject
FROM [dbo].[Posts]
```
My udf `ToUriCleanText` just replaces various characters with an empty character. Eg. replaces all '#' chars with ''.
Then i've added two indexes on this :-
### Indexes
Primary Key Index (ie. Clustered Index)
```
CREATE UNIQUE CLUSTERED INDEX [PK_PostCleanSubjectView] ON
[dbo].[PostsCleanSubjectView]
(
[PostId] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
```
And a Non-Clustered Index
```
CREATE NONCLUSTERED INDEX [IX_PostCleanSubjectView_PostTypeId_Subject] ON
[dbo].[PostsCleanSubjectView]
(
[CleanedSubject] ASC,
[PostTypeId] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
```
Now, this has around 25K rows. Nothing big at all.
When i do the following queries, they both take around 4 odd seconds. WTF? This should be.. basically instant!
### Query 1
```
SELECT a.PostId
FROM PostsCleanSubjectView a
WHERE a.CleanedSubject = 'Just-out-of-town'
```
### Query 2 (added another where clause item)
```
SELECT a.PostId
FROM PostsCleanSubjectView a
WHERE a.CleanedSubject = 'Just-out-of-town' AND a.PostTypeId = 1
```
What have I done wrong? Is the UDF screwing things up? I thought that, because i have index'd this view, it would be materialised. As such, it would not have to calculate that string column.
Here's a screenie of the query plan, if this helps :-

Also, notice the index it's using? Why is it using that index?
That index is...
```
CREATE NONCLUSTERED INDEX [IX_Posts_PostTypeId_Subject] ON [dbo].[Posts]
(
[PostTypeId] ASC,
[Subject] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
```
So yeah, any ideas folks?
### Update 1: Added schema for the udf.
```
CREATE FUNCTION [dbo].[ToUriCleanText]
(
@Subject NVARCHAR(300)
)
RETURNS NVARCHAR(350) WITH SCHEMABINDING
AS
BEGIN
<snip>
// Nothing insteresting in here.
//Just lots of SET @foo = REPLACE(@foo, '$', ''), etc.
END
```
### Update 2: Solution
Yep, it was because i wasn't using the index on the view and had to manually make sure i didn't expand the view. The server is Sql Server 2008 Standard Edition. The full answer is below.
Here's the proof, `WITH (NOEXPAND)`

Thank you all for helping me solve this problem :) | What edition of SQL Server? I believe that only Enterprise and Developer Edition will use indexed views automatically, while the others support it using query hints.
```
SELECT a.PostId
FROM PostsCleanSubjectView a WITH (NOEXPAND)
WHERE a.CleanedSubject = 'Just-out-of-town' AND a.PostTypeId = 1
```
From [Query Hints (Transact SQL) on MSDN](http://msdn.microsoft.com/en-us/library/ms181714.aspx):
> The indexed view is not expanded only if the view is directly referenced in the SELECT part of the query and WITH (NOEXPAND) or WITH (NOEXPAND, INDEX( index\_value [ ,...n ] ) ) is specified. | I see an @ sign in the query code in your execution plan. There's a string variable involved.
Sql Server has a NASTY behavior if the string variable's type does not match the type of the string column in the index. Sql Server will ... **convert the whole column** to that type, perform the fast lookup, and then throw away the converted index so it can do the whole thing again next query.
---
Simon figured it out - but here's more helpful detail: <http://msdn.microsoft.com/en-us/library/ms187373.aspx>
> If a query contains references to columns that are present both in an indexed view and base tables, and the query optimizer determines that using the indexed view provides the best method for executing the query, the query optimizer uses the index on the view. This function is called **indexed view matching**, and is supported only in the SQL Server Enterprise and Developer editions.
>
> However, for the optimizer to consider indexed views for matching or use an indexed view that is referenced with the NOEXPAND hint, the following SET options must be set to ON:
So, what's happening here is that **indexed view matching** is not working. Make sure you're using Enterprise or Developer editions of Sql Server (pretty likely). Then check your SET options according to the article. | How can i speed up this Indexed View? | [
"",
"sql",
"sql-server",
"t-sql",
"sql-server-2008",
"indexed-view",
""
] |
I have recently been going through some of our windows python 2.4 code and come across this:
```
self.logfile = open(self.logfile_name, "wua")
```
I know what `w`, `u` and `a` do on their own, but what happens when you combine them? | The `a` is superfluous. `wua` is the same as `wu` since `w` comes first and will thus truncate the file. If you would reverse the order, that is, `auw`, that would be the same as `au`. Visualized:
```
>>> f = open('test.txt', 'r')
>>> f.read()
'Initial contents\n'
>>> f.close()
>>> f = open('test.txt', 'wua')
>>> print >> f, 'writing'
>>> f.close()
>>> f = open('test.txt', 'r')
>>> f.read()
'writing\n'
>>> f.close()
>>> f = open('test.txt', 'auw')
>>> print >> f, 'appending'
>>> f.close()
>>> f = open('test.txt', 'r')
>>> f.read()
'writing\nappending\n'
>>> f.close()
```
(Reminder: both `a` and `w` [open the file for writing](http://docs.python.org/3.0/library/functions.html#open), but the former appends while the other truncates.) | I did not notice that you knew what the modifiers did. Combined they will do the following:
A and W together is superfluous since both will open for writing. When using W, the file will be overwritten. When using A, all new text is appended after the existing content.
U means "open file XXX for input as a text file with universal newline interpretation".
* W is for Write
* A is for Append
* U will
convert the file to use the defined
newline character.
More here:
<http://codesnippets.joyent.com/posts/show/1969> | What is "wua" mode when opening a file in python? | [
"",
"python",
"file",
""
] |
I'm using JDK 1.4...so I don't have access to the nice concurrency stuff in 1.5+.
Consider the following class fragment:
```
private Map map = Collections.EMPTY_MAP;
public Map getMap() {
return map;
}
public synchronized void updateMap(Object key, Object value) {
Map newMap = new HashMap(map);
newMap.put(key, value);
map = Collections.unmodifiableMap(newMap);
}
```
Is it necessary to synchronize (or volatile) the map reference given that I will only be allowed to update the map via the updateMap method (which is synchronized)?
The map object will be accessed (read) in multiple threads, especially via Iterators. Knowing that Iterators will throw an exception if the back-end map's structure is changed, I figured I would make the map unmodifiable. So as I change the structure of the map via updateMap, the existing iterators will continue working on the "old" map (which is fine for my purposes).
The side effect is, I don't have to worry about synchronizing reads. In essense, I'm going to have a much greater magnitude of reads compared to writes. The threads that are currently iterating over the map object will continue to do so and any new threads that kick off will grab the latest map. (well, I *assume* it will considering erickson's comments here - [Java concurrency scenario -- do I need synchronization or not?](https://stackoverflow.com/questions/300316/java-concurrency-scenario-do-i-need-synchronization-or-not))
Can somebody comment on whether or not this idea is a good one?
Thanks! | You **should** use the `volatile` keyword, to ensure that Threads will see the most recent `Map` version. Otherwise, without synchronization, there is no *guarantee* that other threads will ever see anything except the empty map.
Since your `updateMap()` is synchronized, each access to it will see the latest value for `map`. Thus, you won't lose any updates. This is guaranteed. However, since your `getMap()` is not synchronized and `map` is not `volatile`, there is no guarantee that a thread will see the latest value for `map` unless that thread itself was the most recent thread to update the map. Use of `volatile` will fix this.
However, you **do** have access to the Java 1.5 and 1.6 concurrency additions. A [backport](http://backport-jsr166.sourceforge.net/) exists. I highly recommend use of the backport, as it will allow easy migration to the JDK concurrency classes when you are able to migrate to a later JDK, and it allows higher performance than your method does. (Although if updates to your `map` are rare, your performance should be OK.) | Technically, if you use volatile map, you don't need to synchronize updateMap (updating 'map' is atomic, and all other instructions in that method operate on objects local to the current thread). | Is synchronization necessary for unmodifiable maps? | [
"",
"java",
"concurrency",
""
] |
I was sure that there would be a one liner to convert a list to a dictionary where the items in the list were keys and the dictionary had no values.
The only way I could find to do it was argued against.
"Using list comprehensions when the result is ignored is misleading and inefficient. A `for` loop is better"
```
myList = ['a','b','c','d']
myDict = {}
x=[myDict.update({item:None}) for item in myList]
>>> myDict
{'a': None, 'c': None, 'b': None, 'd': None}
```
It works, but is there a better way to do this? | Use `dict.fromkeys`:
```
>>> my_list = [1, 2, 3]
>>> dict.fromkeys(my_list)
{1: None, 2: None, 3: None}
```
Values default to `None`, but you can specify them as an optional argument:
```
>>> my_list = [1, 2, 3]
>>> dict.fromkeys(my_list, 0)
{1: 0, 2: 0, 3: 0}
```
From the docs:
> a.fromkeys(seq[, value]) Creates a new
> dictionary with keys from seq and
> values set to value.
>
> dict.fromkeys is a class method that
> returns a new dictionary. value
> defaults to None. New in version 2.3. | You could use a [set](http://docs.python.org/library/stdtypes.html#set-types-set-frozenset) instead of a dict:
```
>>> myList=['a','b','c','d']
>>> set(myList)
set(['a', 'c', 'b', 'd'])
```
This is better if you never need to store values, and are just storing an unordered collection of unique items. | Is there a better way to convert a list to a dictionary in Python with keys but no values? | [
"",
"python",
"list",
"dictionary",
"list-comprehension",
""
] |
The syntax for disabling warnings is as follows:
```
#pragma warning disable 414, 3021
```
Or, expressed more generally:
```
#pragma warning disable [CSV list of numeric codes]
```
Is there a list of these numeric codes and the description of the warning that they're suppressing? Much to my chagrin, I can't seem to locate it via Google. | You shouldn't need a list. The compiler will tell you. If you get a compiler error that says "warning CS0168", then add 168 to the list (or, better yet, fix the code). | [MSDN has a list](http://msdn.microsoft.com/en-us/library/ms228296.aspx) of warning codes. Unfortunately, you have to click each link to view what the code actually means. | List of #pragma warning disable codes and what they mean | [
"",
"c#",
"c-preprocessor",
"pragma",
""
] |
Our existing compile-time assert implementation is based on negative array index, and it provides poor diagnostic output on GCC. C++0x's `static_assert` is a very nice feature, and the diagnostic output it provides is much better. I know GCC has already implemented some C++0x features. Does anyone know if `static_assert` is among them and if it is then since what GCC version? | According to [this page](https://gcc.gnu.org/projects/cxx-status.html#cxx11), gcc has had `static_assert` since 4.3. | If you need to use a `GCC` version which does not support `static_assert` you can use:
```
#include <boost/static_assert.hpp>
BOOST_STATIC_ASSERT( /* assertion */ )
```
Basically, what boost does is this:
Declare (but don't define!) a
```
template< bool Condition > struct STATIC_ASSERTION_FAILURE;
```
Define a specialization for the case that the assertion holds:
```
template <> struct STATIC_ASSERTION_FAILURE< true > {};
```
Then you can define STATIC\_ASSERT like this:
```
#define STATIC_ASSERT(Condition) \
enum { dummy = sizeof(STATIC_ASSERTION_FAILURE< (bool)(Condition) > ) }
```
The trick is that if Condition is false the compiler needs to instantiate the struct
```
STATIC_ASSERTION_FAILURE< false >
```
in order to compute its size, and this fails since it is not defined. | Does GCC have a built-in compile time assert? | [
"",
"c++",
"gcc",
"static-assert",
""
] |
Just wondering if there is anyway to represent the following code in C# 3.5:
```
public struct Foo<T> {
public Foo(T item) {
this.Item = item;
}
public T Item { get; set; }
public static explicit operator Foo<U> ( Foo<T> a )
where U : T {
return new Foo<U>((U)a.Item)
}
}
```
Thanks | Conversion operators can't be generic. From the spec section 10.10, here's the format of a conversion-operator-declarator:
> ```
> conversion-operator-declarator:
> implicit operator type ( type identifier )
> explicit operator type ( type identifier )
> ```
Compare this with, say, a method-header:
> *method-header*:
> *attributesopt* *method-modifiersopt* partial*opt* *return-type*
> *member-name* *type-parameter-listopt* ( *formal-parameter-listopt* )
> *type-parameter-constraints-clausesopt*
(Sorry about the formatting - not sure how to do it better.)
Note that the operator format doesn't include a type parameter list or type parameter constraints. | Your code boils down to the line: `return new Foo<U>((U)a.Item)`
Where you try to assign a baseclass to an inherited class, which is impossible.
Let's say T (base-class) is of type `Stream` and U is of type `MemoryStream` (inherited class), you cannot assign a `Stream` to a variable of type `MemoryStream`. | Is it possible in C# to overload a generic cast operator in the following way? | [
"",
"c#",
"generics",
"casting",
"operator-overloading",
""
] |
I have 100+ channels of video streams to process all at the same time. I need to capture the video, generate thumbnails, and serve them out as a web service. For the generation of thumbnail, I can use JMF etc.(I noticed there is another post talking about how to generate and access: [better quality thumbnails from larger image files](https://stackoverflow.com/questions/772715/better-quality-thumbnails-from-larger-image-files)). But my concern is: how to scale? Java EE EJB or simply Java SE Threads? What's the cons and pros? How to scale horizontally using EJB?
I am not that familiar with scalability issue, and I really appreciate your kind suggestions.
Thanks. | Agree... threads should help to scale on single machine. If you want to scale across different machines - use Terracotta. | Java SE Threads can help you scale on a single machine, but if you are going to need to scale horizontally across different machines, EJB would be one way to do it.
If it was me, I'd probably farm it out to a separate web service tier that could run on as many machines as needed, and then load balance between those machines. | How to scale up in Java | [
"",
"java",
"video-processing",
""
] |
I know you can use both `$_GET` and `$_POST` at the same time, but is this a required "feature"? I am writing a framework, where you can access input through:
```
$value = $this->input->get('name','');
$value = $this->input->post('name','');
$value = $this->input->cookies('name','');
```
I'm just thinking here, is there a need for having GET and POST at the same time? Couldn't I just do:
```
$value = $this->input('name','default value if not set');
```
To obtain GET/POST data according to which HTTP request was made? Cookies will be only accessible through `->cookies()`, but should I use `->get()` and `->post()` instead of doing something like `->input()` ?
Thanks for your input! | Yes!
I think you ***must*** allow access to both `$_GET` and `$_POST` at the same time. And I don't think you can just merge them together either. (You can have the option to, like PHP and the ill concieved `$_REQUEST`.) You could get a request like:
```
POST /validator?type=strict HTTP/1.1
type=html/text
body=<h1>Hello World</h1>
```
Note that the variable name **`type`** is used twice, but in different scopes! (Once in the URI defining the resource that should handle the POST, and then in the posted entity itself.) In PHP this looks like:
```
$_GET => ('type' => 'strict')
$_POST => ('type' => 'html/text', 'body' => '<H1>Hellow World</h1>')
```
PHP:s way of just parsing the URI and putting the parameters there into `$_GET` is somewhat confusing. A URI is used with most (all?) of the HTTP methods, like POST, GET, PUT, DELETE etc. (Not just GET, like PHP would have you believe.) Maybe you could be revolutionary and use some of your own lingo:
```
$a = $this->uri('name');//param passed in the URI (same as PHP:s $_GET)
$b = $this->entity('body');//var passed in an entity (same as PHP:s $_POST)
$c = $this->method(); //The HTTP method in question ('GET', 'POST' etc.)
```
And maybe even some utility functions:
```
if($this->isGET()){
...
}elseif($this->isPOST()){
...
)
```
I know, wild and crazy :)
Good luck and have fun!
cheers! | It's conceivable that in a REST architecture I'd add a product like so:
```
POST /products?location=Ottawa HTTP/1.0
name=Book
```
And the product would automatically be associated with the location in the query params.
In a nutshell: there are semantically valid reasons for allowing both, but they can always be transformed into one or the other. That being said, do you want to enforce that usage on your users? | Should my framework allow access to $_GET and $_POST at the same time? | [
"",
"php",
"post",
"input",
"get",
""
] |
My application will have a per machine (not per user) Startup shortcut. I can create a shortcut during the installer process no problem. My problem comes when the user later removes it and then tries to re-enable. In otherwords, they turn off RunOnStartup (which deletes the Startup ink) and at a later time they decide they do want it to run on startup so they go back into preferences and re-enable.
Apparently, this is a pretty common gripe with .NET that there isn't a native way to create shortcuts. But, haven't found a very good solution.
Solutions I've Found/Considered:
* Rather then create a shortcut. Just copy one. This might be a good solution. I can't depend on there being a Start Menu link. But, I guess I could probably create one and keep it in Program Directory... This shifts the problem over to my installer to have to create the shortcut with the appropriate path which would be specified at install time.
* Do what [this other stackoverflow answer](https://stackoverflow.com/questions/234231/how-do-you-create-an-application-shortcut-lnk-file-in-c-or-net) is and use a COM wrapper object. I'd like to avoid COM. It was also written in 2003. So, I'm not sure how well it's going to support vista. I'd give it a shot but don't have a vista box handy.
* Use the registry instead. This is how I currently do it... but run into issues on Vista. It seems the general consensus that Startup Menu shortcuts are the proper way to do this so that's what my goal is.
Also, I have to handle the case that a regular user (not an admin) tries to change this preference. In this case, I need to gracefully fail or in the case of vista allow the user to enter the Admin password to get a Admin security token. An answer which already properly takes into consider this case would be awesome.
I apologize if this topic has already been covered. I searched around before posting.
**UPDATE**: Copying a shortcut which your installer created is the best solution. I'll post code once finished... ran into some hurdles with a) Environment.GetSpecialFolder not having a reference to the StartMenu which has been resolved... But, now i'm dealing with elevating permissions to copy the file to the proper location. I created a new stackoverflow question for this topic: [How can I copy a file as a "Standard User" in Vista (ie "An Administrative Choice Application") by prompting user for admin credentials?](https://stackoverflow.com/questions/1039875/how-can-i-copy-a-file-as-a-standard-user-in-vista-ie-an-administrative-choice) | As suggested by Joel, the proper solution is to install a shortcut in your program files folder at install time and then copy the .lnk to the startup folder. Trying to create a shortcut is more difficult.
The code below does the following:
* It gets the path to the All Users Startup Folder for you. Environment.GetSpecialFolder is fairly limited and doesn't have a reference to this folder and as a result you need to make a system call.
* Has methods to copy and remove a shortcut.
Ultimately, I wanted to also make sure that it was gracefully handled on vista if the user running the application was a regular user they would be prompted to enter their credentials. I created a post here on the subject so check into that here if that's important to you.
[How can I copy a file as a "Standard User" in Vista (ie "An Administrative Choice Application") by prompting user for admin credentials?](https://stackoverflow.com/questions/1039875/how-can-i-copy-a-file-as-a-standard-user-in-vista-ie-an-administrative-choice)
```
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Security.Principal;
using System.Windows.Forms;
using System.Runtime.InteropServices;
namespace BR.Util
{
public class StartupLinkUtil
{
[DllImport("shell32.dll")]
static extern bool SHGetSpecialFolderPath(IntPtr hwndOwner, [Out] StringBuilder lpszPath, int nFolder, bool fCreate);
public static string getAllUsersStartupFolder()
{
StringBuilder path = new StringBuilder(200);
SHGetSpecialFolderPath(IntPtr.Zero, path, CSIDL_COMMON_STARTUP, false);
return path.ToString();
}
private static string getStartupShortcutFilename()
{
return Path.Combine(getAllUsersStartupFolder(), Application.ProductName) + ".lnk";
}
public static bool CopyShortcutToAllUsersStartupFolder(string pShortcutName)
{
bool retVal = false;
FileInfo shortcutFile = new FileInfo(pShortcutName);
FileInfo destination = new FileInfo(getStartupShortcutFilename());
if (destination.Exists)
{
// Don't do anything file already exists. -- Potentially overwrite?
}
else if (!shortcutFile.Exists)
{
MessageBox.Show("Unable to RunOnStartup because '" + pShortcutName + "' can't be found. Was this application installed properly?");
}
else
{
retVal = copyFile(shortcutFile, destination);
}
return retVal;
}
public static bool doesShortcutExistInAllUsersStartupFolder()
{
return File.Exists(getStartupShortcutFilename());
}
public static bool RemoveShortcutFromAllUsersStartupFolder() {
bool retVal = false;
string path = Path.Combine(getAllUsersStartupFolder(), Application.ProductName) + ".lnk";
if( File.Exists(path) ) {
try
{
File.Delete(path);
retVal = true;
}
catch (Exception ex)
{
MessageBox.Show(string.Format("Unable to remove this application from the Startup list. Administrative privledges are required to perform this operation.\n\nDetails: SecurityException: {0}", ex.Message), "Update Startup Mode", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
return retVal;
}
// TODO: Test this in vista to see if it prompts for credentials.
public static bool copyFile(FileInfo pSource, FileInfo pDestination)
{
bool retVal = false;
try
{
File.Copy(pSource.FullName, pDestination.FullName);
//MessageBox.Show("File has successfully been added.", "Copy File", MessageBoxButtons.OK, MessageBoxIcon.Information);
retVal = true;
}
catch (System.Security.SecurityException secEx)
{
MessageBox.Show(string.Format("SecurityException: {0}", secEx.Message), "Copy File", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
catch (UnauthorizedAccessException authEx)
{
MessageBox.Show(string.Format("UnauthorizedAccessException: {0}", authEx.Message), "Copy File", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
catch (Exception ex)
{
MessageBox.Show(ex.Message, "Copy File", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
return retVal;
}
#region Special Folder constants
const int CSIDL_DESKTOP = 0x0000; // <desktop>
const int CSIDL_INTERNET = 0x0001; // Internet Explorer (icon on desktop)
const int CSIDL_PROGRAMS = 0x0002; // Start Menu\Programs
const int CSIDL_CONTROLS = 0x0003; // My Computer\Control Panel
const int CSIDL_PRINTERS = 0x0004; // My Computer\Printers
const int CSIDL_PERSONAL = 0x0005; // My Documents
const int CSIDL_FAVORITES = 0x0006; // <user name>\Favorites
const int CSIDL_STARTUP = 0x0007; // Start Menu\Programs\Startup
const int CSIDL_RECENT = 0x0008; // <user name>\Recent
const int CSIDL_SENDTO = 0x0009; // <user name>\SendTo
const int CSIDL_BITBUCKET = 0x000a; // <desktop>\Recycle Bin
const int CSIDL_STARTMENU = 0x000b; // <user name>\Start Menu
const int CSIDL_MYDOCUMENTS = CSIDL_PERSONAL; // Personal was just a silly name for My Documents
const int CSIDL_MYMUSIC = 0x000d; // "My Music" folder
const int CSIDL_MYVIDEO = 0x000e; // "My Videos" folder
const int CSIDL_DESKTOPDIRECTORY = 0x0010; // <user name>\Desktop
const int CSIDL_DRIVES = 0x0011; // My Computer
const int CSIDL_NETWORK = 0x0012; // Network Neighborhood (My Network Places)
const int CSIDL_NETHOOD = 0x0013; // <user name>\nethood
const int CSIDL_FONTS = 0x0014; // windows\fonts
const int CSIDL_TEMPLATES = 0x0015;
const int CSIDL_COMMON_STARTMENU = 0x0016; // All Users\Start Menu
const int CSIDL_COMMON_PROGRAMS = 0x0017; // All Users\Start Menu\Programs
const int CSIDL_COMMON_STARTUP = 0x0018; // All Users\Startup
const int CSIDL_COMMON_DESKTOPDIRECTORY = 0x0019; // All Users\Desktop
const int CSIDL_APPDATA = 0x001a; // <user name>\Application Data
const int CSIDL_PRINTHOOD = 0x001b; // <user name>\PrintHood
const int CSIDL_LOCAL_APPDATA = 0x001c; // <user name>\Local Settings\Applicaiton Data (non roaming)
const int CSIDL_ALTSTARTUP = 0x001d; // non localized startup
const int CSIDL_COMMON_ALTSTARTUP = 0x001e; // non localized common startup
const int CSIDL_COMMON_FAVORITES = 0x001f;
const int CSIDL_INTERNET_CACHE = 0x0020;
const int CSIDL_COOKIES = 0x0021;
const int CSIDL_HISTORY = 0x0022;
const int CSIDL_COMMON_APPDATA = 0x0023; // All Users\Application Data
const int CSIDL_WINDOWS = 0x0024; // GetWindowsDirectory()
const int CSIDL_SYSTEM = 0x0025; // GetSystemDirectory()
const int CSIDL_PROGRAM_FILES = 0x0026; // C:\Program Files
const int CSIDL_MYPICTURES = 0x0027; // C:\Program Files\My Pictures
const int CSIDL_PROFILE = 0x0028; // USERPROFILE
const int CSIDL_SYSTEMX86 = 0x0029; // x86 system directory on RISC
const int CSIDL_PROGRAM_FILESX86 = 0x002a; // x86 C:\Program Files on RISC
const int CSIDL_PROGRAM_FILES_COMMON = 0x002b; // C:\Program Files\Common
const int CSIDL_PROGRAM_FILES_COMMONX86 = 0x002c; // x86 Program Files\Common on RISC
const int CSIDL_COMMON_TEMPLATES = 0x002d; // All Users\Templates
const int CSIDL_COMMON_DOCUMENTS = 0x002e; // All Users\Documents
const int CSIDL_COMMON_ADMINTOOLS = 0x002f; // All Users\Start Menu\Programs\Administrative Tools
const int CSIDL_ADMINTOOLS = 0x0030; // <user name>\Start Menu\Programs\Administrative Tools
const int CSIDL_CONNECTIONS = 0x0031; // Network and Dial-up Connections
const int CSIDL_COMMON_MUSIC = 0x0035; // All Users\My Music
const int CSIDL_COMMON_PICTURES = 0x0036; // All Users\My Pictures
const int CSIDL_COMMON_VIDEO = 0x0037; // All Users\My Video
const int CSIDL_RESOURCES = 0x0038; // Resource Direcotry
const int CSIDL_RESOURCES_LOCALIZED = 0x0039; // Localized Resource Direcotry
const int CSIDL_COMMON_OEM_LINKS = 0x003a; // Links to All Users OEM specific apps
const int CSIDL_CDBURN_AREA = 0x003b; // USERPROFILE\Local Settings\Application Data\Microsoft\CD Burning
const int CSIDL_COMPUTERSNEARME = 0x003d; // Computers Near Me (computered from Workgroup membership)
const int CSIDL_FLAG_CREATE = 0x8000; // combine with CSIDL_ value to force folder creation in SHGetFolderPath()
const int CSIDL_FLAG_DONT_VERIFY = 0x4000; // combine with CSIDL_ value to return an unverified folder path
const int CSIDL_FLAG_DONT_UNEXPAND = 0x2000; // combine with CSIDL_ value to avoid unexpanding environment variables
const int CSIDL_FLAG_NO_ALIAS = 0x1000; // combine with CSIDL_ value to insure non-alias versions of the pidl
const int CSIDL_FLAG_PER_USER_INIT = 0x0800; // combine with CSIDL_ value to indicate per-user init (eg. upgrade)
#endregion
}
```
While I was writing this solution, I thought of a better way of handling the problem which wouldn't require users to have escalated privledges in order to disable run on startup.
My solution was to check as soon as the program loaded if a user scoped setting called RunOnStartup. To detect if the application was being started when the system loads or logs in I added an argument to the shortcut which gets added to the All Users -> Startup folder called shortcut.
```
// Quit the application if the per user setting for RunOnStartup is false.
if (args != null && args.Length > 0 && args[0].Contains("startup"))
{
if (Settings1.Default.RunOnStartup == false)
{
Application.Exit();
}
}
``` | You can install a shortcut to your app in it's program files folder, and then just copy that .lnk file as needed. | How do I create add a shortcut (.lnk) for my application to the Startup folder programatically in .NET/C# | [
"",
"c#",
".net",
"windows-vista",
"installation",
"uac",
""
] |
The requirement I have is for every type T, I have a number of elements (between 1-30+) and at first I need random item, then I need the next, and when I reach the last item, it should return the first one and so on.
So say T is Icon, and the collection is Images (instance).
I want to have:
```
// program start:
Icon icon = RandomIcon(); // say 5th one for this case
// user clicks next icon:
icon = current++; (6, 7, 8, 1, 2, ...)
```
To me a circular linked list makes sense, except that I have to do O(n) where n is the random index.
I want to have the cleanest, best implemenation, hence the question. | I would consider using a custom class containing an array or a List<T> internally, and making a custom enumerator that starts at any index, and enumerates around the loop.
The main reason I think this would be better than a LinkedList has to do with this line:
```
Icon icon = RandomIcon(); // say 5th one for this case
```
It is much easier and more performant to get a random item from an indexible collection than a linked list.... And with 30 elements, enumerating will be quick in either case.
To handle the iteration in a circle, all you need is something like this:
```
class CircularlyEnumerableList<T>
{
private List<T> list;
// Implement whatever you need for list...
IEnumerable<T> EnumerateFromElement(int index)
{
for (int i=index; i<list.Count; ++i)
yield return list[i];
for (int i=0; i<index; ++i)
yield return list[i];
}
}
``` | Another possible solution is to create a linked list with the underlying data structure being an array. This way you can index in at O(1) while maintaining your "circularity"
```
public class myLL
{
private T[] items;
private int i;
private int max_size;
public T GetCurrent() {
return items[i];
}
public T GetNext() {
i = i++ % max_size;
return items[i];
}
}
``` | Choosing the right data structure for this problem: circular linked list, list, array or something else | [
"",
"c#",
".net",
"performance",
"data-structures",
""
] |
Does anyone know or know of somewhere I can learn how to create a custom authentication process using Python and Google App Engine?
I don't want to use Google accounts for authentication and want to be able to create my own users.
If not specifically for Google App Engine, any resource on how to implement authentication using Python and Django? | Well django 1.0 was updated today on Google AppEngine. But you can make user authentication like anything else you just can't really use sessions because it is so massive.
There is a session utility in <http://gaeutilities.appspot.com/>
<http://gaeutilities.appspot.com/session>
<http://code.google.com/p/gaeutilities/>
Or,
You have to create your own user tables and hash or encrypt passwords, then probably create a token system that mimics session with just a token hash or uuid cookie (sessions are just cookies anyways).
I have implemented a few with just basic google.webapp request and response headers. I typically use uuids for primary keys as the user id, then encrypt the user password and have their email for resets.
If you want to authorize users for external access to data you could look at OAuth for application access.
If you just want to store data by an id and it is more consumer facing, maybe just use openid like stackoverflow and then attach profile data to that identifier like django profiles (<http://code.google.com/p/openid-selector/>).
django 1.0 just came out today on GAE but I think the same problems exist, no sessions, you have to really create your own that store session data. | This is a pretty out-of-the-box solution, and works pretty well:
<http://code.scotchmedia.com/engineauth/docs/index.html>
It has built-in support for Facebook, Google+, Twitter, LinkedIn, GitHub and OpenId (via Google App Engine).
you just have to redirect the user to `/auth/facebook` or `/auth/google` and so on (this url is customizable).
It also implements two classes: `User` and `UserProfile`, every `User` is a unique account in your app and may relate to one or more `UserProfiles` -- which one is a login strategy that the unique `User` has to login into your app (if it's unclear, it's because my English is very bad, the [docs](http://code.scotchmedia.com/engineauth/docs/index.html) explain better).
P.S.: The documentation is not very complete, but the code is pretty simple, short and self-explanatory. Also, there is a discussion [here](https://groups.google.com/forum/#!topic/webapp2/Ui5FEFVnyIY) in which the author provides various answers to questions of confused and beggining users. | Custom authentication in Google App Engine | [
"",
"python",
"google-app-engine",
"authentication",
""
] |
I'm just beginning to learn the concept of threading, and I'm kind of stuck at this one problem, its driving me crazy....
What I actually need to accomplish -
I have some 300 text files in a local directory, that need to be parsed for specific values... After I find these "values" in each text file, I need to store them in a database..
So I followed the plain approach of accessing each text file in the directory - parsing and updating the resulting values as a row to a local DataTable, and when I'm done parsing all the files and storing 300 rows to the DataTable, I would do a SQLBulkCopy of DataTable to my database. This approach works fine except that it takes me about 10 minutes to run my code!
What I'm attempting to do now -
Create a new thread for each file and keep the thread count below 4 at any given time... then each thread would parse through the file and return a row to update the local DataTable
Where I'm stuck - I don't understand how to update this single Datatable that gets rows from multiple threads...
Quite an explanation isn't it.. hope some one here can suggest a good idea for this...
Thanks,
Nidhi | This will be much easier if you just let each of your four threads write to the database themselves. In this scenario you don't have to worry about threading (except for what files each thread works on) as each worker thread could maintain their own datatable and consume 25% of the files.
Alternatively, you can have a single datatable that all the threads use--just make sure to wrap accesses to it with a lock like so:
```
lock(YourTable.Rows.SyncRoot){
// add rows to table
}
```
---
Of course this is all moot if the bottleneck is the disk, as @David B notes. | As was somewhat pointed out, you need to examine exactly where your bottleneck is and why you're using threading.
By moving to multiple threads, you do have a potential for increased performance. However, if you're updating the same DataTable with each thread, you're limited by the DataTable. Only one thread can write to the DataTable at one time (which you control with a lock), so you're still fundamentally processing in sequence.
On the other hand, most databases are designed for multiple connections, running on multiple threads, and have been highly tuned for that purpose. If you want to still use multiple threads: let each thread have its own connection to the database, and do its own processing.
Now, depending on the kind of processing going on, your bottleneck may be in opening and processing the file, and not in the database update.
One way to split things up:
1. Put all the file names to be processed into a filename Queue.
2. Create a thread (or threads) to pull an item off the filename Queue, open and parse and process the file, and push the results into a result Queue.
3. Have another thread take the results from the result Queue, and insert them into the database.
These can run simultaneously... the database won't be updated until there's something to update, and will just wait in the meantime.
This approach lets you really know who is waiting on whom. If the read/process file part is slow, create more threads to do that. If the insert into database part is slow, create more threads to do that. The queues just need to be synchronized.
So, pseudocode:
```
Queue<string> _filesToProcess = new Queue<string>();
Queue<string> _results = new Queue<string>();
Thread _fileProcessingThread = new Thread( ProcessFiles );
Thread _databaseUpdatingThread = new Thread( UpdateDatabase );
bool _finished = false;
static void Main()
{
foreach( string fileName in GetFileNamesToProcess() )
{
_filesToProcess.Enqueue( fileName );
}
_fileProcessingThread.Start();
_databaseUpdatingThread.Start();
// if we want to wait until they're both finished
_fileProcessingThread.Join();
_databaseUpdatingThread.Join();
Console.WriteLine( "Done" );
}
void ProcessFiles()
{
bool filesLeft = true;
lock( _filesToProcess ){ filesLeft = _filesToProcess.Count() > 0; }
while( filesLeft )
{
string fileToProcess;
lock( _filesToProcess ){ fileToProcess = _filesToProcess.Dequeue(); }
string resultAsString = ProcessFileAndGetResult( fileToProcess );
lock( _results ){ _results.Enqueue( resultAsString ); }
Thread.Sleep(1); // prevent the CPU from being 100%
lock( _filesToProcess ){ filesLeft = _filesToProcess.Count() > 0; }
}
_finished = true;
}
void UpdateDatabase()
{
bool pendingResults = false;
lock( _results ){ pendingResults = _results.Count() > 0; }
while( !_finished || pendingResults )
{
if( pendingResults )
{
string resultsAsString;
lock( _results ){ resultsAsString = _results.Dequeue(); }
InsertIntoDatabase( resultsAsString ); // implement this however
}
Thread.Sleep( 1 ); // prevents the CPU usage from being 100%
lock( _results ){ pendingResults = _results.Count() > 0; }
}
}
```
I'm pretty sure there's ways to make that "better", but it should do the trick so you can read and process data while also adding completed data to the database, and take advantage of threading.
If you want another Thread to process files, or to update the database, just create a new Thread( MethodName ), and call Start().
It's not the simplest example, but I think it's thorough. You're synchronizing two queues, and you need to make sure each is locked before accessing. You're keeping track of when each thread should finish, and you have data being marshaled between threads, but never processed more than once, using Queues.
Hope that helps. | Multiple threads filling up their result in one DataTable C# | [
"",
"c#",
"multithreading",
"datatable",
""
] |
> **There are cases when an instance of a
> value type needs to be treated as an
> instance of a reference type.** For
> situations like this, a value type
> instance can be converted into a
> reference type instance through a
> process called boxing. When a value
> type instance is boxed, storage is
> allocated on the heap and the
> instance's value is copied into that
> space. A reference to this storage is
> placed on the stack. The boxed value
> is an object, a reference type that
> contains the contents of the value
> type instance.
>
> [Understanding .NET's Common Type System](http://www.informit.com/articles/article.aspx?p=24456)
In [Wikipedia](http://en.wikipedia.org/wiki/Boxing_(computer_science)#Boxing) there is an example for Java. But in C#, what are some cases where one would have to box a value type? Or would a better/similar question be, why would one want to store a value type on the heap (boxed) rather than on the stack? | In general, you typically will want to avoid boxing your value types.
However, there are rare occurances where this is useful. If you need to target the 1.1 framework, for example, you will not have access to the generic collections. Any use of the collections in .NET 1.1 would require treating your value type as a System.Object, which causes boxing/unboxing.
There are still cases for this to be useful in .NET 2.0+. Any time you want to take advantage of the fact that all types, including value types, can be treated as an object directly, you may need to use boxing/unboxing. This can be handy at times, since it allows you to save any type in a collection (by using object instead of T in a generic collection), but in general, it is better to avoid this, as you're losing type safety. The one case where boxing frequently occurs, though, is when you're using Reflection - many of the calls in reflection will require boxing/unboxing when working with value types, since the type is not known in advance. | There is almost never a good reason to deliberately box a value type. Almost always, the reason to box a value type is to store it in some collection that is not type aware. The old [ArrayList](http://msdn.microsoft.com/en-us/library/system.collections.arraylist.aspx), for example, is a collection of objects, which are reference types. The only way to collect, say, integers, is to box them as objects and pass them to ArrayList.
Nowadays, we have generic collections, so this is less of an issue. | Use cases for boxing a value type in C#? | [
"",
"c#",
"boxing",
"value-type",
"reference-type",
"cts",
""
] |
I am working on a .NET C# application that has a main Form which is MDI container. When the user maximizes a MDI child, Windows draws a control strip right under the title bar of the container Form which has the Icon of the child and the system buttons on the right. Basically, what I need is hide this strip and use a custom control to provide the same functionality.
Is there any way to prevent Windows from drawing this MDI strip? | Actually, I found an easy and interesting way to remove this thing from my form by assigning the MainMenuStrip property of the Form with a dummy MenuStrip control (without putting it in the Controls collection of the Form):
```
private void OnForm_Load(object sender, EventArgs e)
{
this.MainMenuStrip = new MenuStrip();
}
```
This prevents the default MDI caption from being painted since the Form delegates its functionality to its default menu strip if any. Since the MenuStrip control is not in the Controls collection of the Form, it is also not visible and thus it just serves as a dummy menu used for hiding the nasty MDI menu when a child is maximized. | This conversation from years ago suggests that there's no way to do it, and he ended up with User Controls on the main form, instead of actually using an MDI interface:
<http://answers.google.com/answers/threadview/id/135136.html>
Every other thread I can find online is either abandoned with no answers or a dead-end. I can't believe this functionality if so cumbersome and not something natively available. | Removing the default MDI menu of a MDI Container form when a MDI Child is maximized | [
"",
"c#",
".net",
"menu",
"mdi",
"childwindow",
""
] |
Are there any good way to use the Conditional-attribute in the context of testing?
My thoughts were that if you can do this:
```
[Conditional("Debug")]
public void DebugMethod()
{
//...
}
```
Maybe you could have some use for: (?)
```
[Conditional("Test")]
public void TestableMethod()
{
//...
}
``` | I don't see a use when there's a better alternative: Test Projects.
Use NUnit or MSTest to achieve this functionality in a more graceful way. | I'd accept Mehrdad's answer - I just wanted to give more context on when you *might* use these attributes:
Things like `[Conditional]` are more generally used to control things like logging/tracing, or interactions with an executing debugger; where it makes sense for the calls to be in the middle of your regular code, but which you might not want in certain builds (and #if... etc is just so ugly and easy to forget). | C#: Using Conditional-attribute for tests | [
"",
"c#",
"testing",
"attributes",
"conditional-statements",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.