
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
What if I increment an iterator by 2 when it points onto the last element of a vector? In [this question](https://stackoverflow.com/questions/1057529/how-to-increment-an-iterator-by-2) asking how to adjust the iterator to an STL container by 2 elements two different approaches are offered:
* either use a form of arithmetic operator - +=2 or ++ twice
* or use std::advance()
I've tested both of them with VC++ 7 for the edge case when the iterator points onto the last element of the STL container or beyond:
```
vector<int> vec;
vec.push_back( 1 );
vec.push_back( 2 );
vector<int>::iterator it = vec.begin();
advance( it, 2 );
bool isAtEnd = it == vec.end(); // true
it++; // or advance( it, 1 ); - doesn't matter
isAtEnd = it == vec.end(); //false
it = vec.begin();
advance( it, 3 );
isAtEnd = it == vec.end(); // false
```
I've seen may times an advise to compare against vector::end() when traversing the vector and other containers:
```
for( vector<int>::iterator it = vec.begin(); it != vec.end(); it++ ) {
//manipulate the element through the iterator here
}
```
Obviously if the iterator is advanced past the last element inside the loop the comparison in the for-loop statement will evaluate to false and the loop will happily continue into undefined behaviour.
Do I get it right that if I ever use advance() or any kind of increment operation on an iterator and make it point past the container's end I will be unable to detect this situation? If so, what is the best practice - not to use such advancements? | Following is the quote from Nicolai Josuttis book:
> Note that advance() does not check
> whether it crosses the end() of a
> sequence (it can't check because
> iterators in general do not know the
> containers on which they operate).
> Thus, calling this function might
> result in undefined behavior because
> calling operator ++ for the end of a
> sequence is not defined
In other words, the responsibility of maintaining the iterator within the range lies totally with the caller. | Perhaps you should have something like this:
```
template <typename Itr>
Itr safe_advance(Itr i, Itr end, size_t delta)
{
while(i != end && delta--)
i++;
return i;
}
```
You can overload this for when `iterator_category<Itr>` is `random_access_iterator` to do something like the following:
```
return (delta > end - i)? end : i + delta;
``` | What happens if you increment an iterator that is equal to the end iterator of an STL container | [
"",
"c++",
"stl",
"vector",
"iterator",
""
] |
I have a method that tries to create a Uri and then clean it up (removes fragments, excludes some domains and query string patterns, etc.). The method looks like this:
```
static public bool TryCreateCleanUri(Uri baseUri, string relstr, out Uri result)
{
if (!Uri.TryCreate(baseUri, relstr, out result))
{
return false;
}
return CleanupUri(result, out result);
}
```
This method has been working fine for months. But last night it failed. Uri.TryCreate() threw an exception! Here's the stack trace:
```
ERROR: Unhandled exception caught. Program terminating.
System.UriFormatException: Invalid URI: The hostname could not be parsed.
at System.Uri.CreateHostStringHelper(String str, UInt16 idx, UInt16 end, Flags& flags, String& scopeId)
at System.Uri.CreateHostString()
at System.Uri.GetComponentsHelper(UriComponents uriComponents, UriFormat uriFormat)
at System.Uri.CombineUri(Uri basePart, String relativePart, UriFormat uriFormat)
at System.Uri.GetCombinedString(Uri baseUri, String relativeStr, Boolean dontEscape, String& result)
at System.Uri.ResolveHelper(Uri baseUri, Uri relativeUri, String& newUriString, Boolean& userEscaped, UriFormatException& e)
at System.Uri.TryCreate(Uri baseUri, Uri relativeUri, Uri& result)
at System.Uri.TryCreate(Uri baseUri, String relativeUri, Uri& result)
```
Documentation for `Uri.TryCreate(Uri, String, out Uri)` says that the return value is `True` if successful, `False` otherwise, but it's silent about exceptions. However, documentation for `Uri.TryCreate(Uri, Uri, out Uri)` says:
> This method constructs the URI, puts
> it in canonical form, and validates
> it. If an unhandled exception occurs,
> this method catches it. If you want to
> create a Uri and get exceptions use
> one of the Uri constructors.
The stack trace shows that the exception was thrown in `Uri.TryCreate(Uri, Uri, out Uri)`, which, according to the documentation, shouldn't happen.
This is a very rare occurrence. I've been using that code for months, running literally billions of urls through it, and haven't encountered a problem until now. Unfortunately I don't know what combination of things caused the problem. I'm hoping to construct a test case that shows the error.
Is this a known bug in `Uri.TryCreate`, or am I missing something? | Unwilling to wait potentially several months for my code to encounter this situation again, I spent some time with ILDASM to figure out what `TryCreate` is doing, and then a little more time coming up with a way to reproduce the error.
The reason for the crash in `Uri.TryCreate(Uri baseUri, Uri relativeUri, out Uri result)` appears to be a badly formatted `baseUri`. For example, the `Uri` constructor allows the following:
```
Uri badUri = new Uri("mailto:test1@mischel.comtest2@mischel.com");
```
According to the RFC for mailto: URIs, that shouldn't be allowed. And although the constructor creates and returns a `Uri` object, trying to access (some of) its properties throws `UriFormatException`. For example, given the above code, this line will throw an exception:
```
string badUriString = badUri.AbsoluteUri;
```
I find it rather interesting that the `Uri` class appears to use two different parsing algorithms: one used during construction, and one used internally for getting the individual components.
Passing this invalid `Uri` to `TryCreate` will result in the exception that I described in the original question. The `TryCreate` method checks the `baseUri` parameter for `null`, but doesn't (can't, I would imagine) validate it otherwise. It has to assume that, if the parameter is non-null, the passed object is a fully initialized and valid `Uri` instance. But at some point in constructing the result, `TryCreate` attempts to obtain the components of `baseUri` and an exception is thrown.
I can't say that my program actually encountered a mailto: URL that was formatted this way. I can say with some degree of certainty, though, that an invalid `Uri` object was the cause of the crash in my program, simply because the exception stack trace from my program matches the stack trace from the test program. Simply put, the bug is in the `Uri` constructor (and also in the `TryCreate` methods) which allow the invalid `Uri` to be created.
You can follow the [bug report](http://connect.microsoft.com/VisualStudio/feedback/ViewFeedback.aspx?FeedbackID=475897) on Microsoft Connect. | Now that you know it can fail, let's get more information:
```
static public bool TryCreateCleanUri(Uri baseUri, string relstr, out Uri result)
{
try {
if (!Uri.TryCreate(baseUri, relstr, out result))
{
return false;
}
}
catch (UriFormatException ex) {
throw new InvalidOperationException(
String.Format("Can create URI for base={0}, rel={1}", baseUri.ToString(), relstr),
ex);
}
return CleanupUri(result, out result);
}
``` | Uri.TryCreate throws UriFormatException? | [
"",
"c#",
".net",
""
] |
In my program, I draw some quads. I want to add the functionality for them to scale up, then down, then go back to being static (to draw attention). In the quads I have:
```
self.scale = 10
```
Making scale change according to sin would be nice. But adding frequency, amplitude and logic to my already bloated quad class is something I take as a challenge to avoid.
Something like this:
```
class mysin:
def __init__(self):
self.tick = 0.0
self.freq = 1.0
self.ampl = 1.0
def update(self, amount):
self.tick += amount
def value(self):
return math.sin(self.tick)
```
That class would also add itself to the logic system (getting update calls every frame). I would then do:
```
quad.scale = 10 # for static quad
quad.scale = mysin() # for cool scaling quad
```
The problem is that some calculations expect scale to hold a value. I could of course add another class where value() returns a (previously saved) constant value and adapt all the calculations.
What I want to know now is... does this have a name, is it a valid technique? I read the wiki article on functional programming and this idea sprung to mind as a wacky implementation (although Im not sure it qualifies as FP). I could very well have been driven mad by that article. Put me back in line fellow coders. | The distinction between
```
quad.scale= 10
```
and
```
quad.scale= MySin()
```
Is minor. Within the `Quad` class definition the "scale" attribute can be a property with proper getter and setter functions.
```
class Quad( object ):
@property
def scale( self ):
return self._scale
@scale.setter
def set_scale( self, value ):
# handle numeric and MySin() values appropriately.
```
Alternate version with the explicit `property` function (which I prefer).
```
class Quad( object ):
def get_scale( self ):
return self._scale
def set_scale( self, value )
# Handle numeric and MySin() values
scale = property( get_scale, set_scale )
```
Any other class should NOT know or care what type of value `scale` has. If some client does this
```
quad.scale * 2
```
Then you have design issues. You haven't properly encapsulated your design and Quad's client classes are too friendly with Quad.
If you absolutely must do this -- because you can't write a method function of Quad to encapsulate this -- then you have to make `MySin` a proper numeric class so it can respond to `quad.scale * 2` requests properly. | It sounds like you want your quads to be dumb, and to have an animator class which is smart. So,here are some suggestions:
1. Give the quads an attribute which indicates how to animate them (in addition to the `scale` and whatever else).
2. In an `Animator` class, on a frame update, iterate over your quads and decide how to treat each one, based on that attribute.
3. In the treatment of a quad, update the scale property of each dynamically changing quad to the appropriate float value. For static quads it never changes, for dynamic ones it changes based on any algorithm you like.
One advantage this approach is that it allows you to vary different attributes (scale, opacity, fill colour ... you name it) while keeping the logic in the animator. | Replacing variable with function/class indicating dynamic value | [
"",
"python",
""
] |
I am currently using $.blur(fn();) for form validation, but this only takes effect when the form field loses focus. Is there a way of doing it on keypress to get realtime validation? I suppose I could do the 'poll all fields every second' approach, but I am sure there must be a more elegant way? | You can use $.keyup | There are lots of other events you could use. See here: <http://docs.jquery.com/Events>
I would recommend change or keypress or keydown. | jQuery realtime form validation | [
"",
"javascript",
"jquery",
"html",
""
] |
Over the last few weeks I have been studying the MVC design pattern for web applications using PHP. Taking a broad view I understand how the pattern works and why it is a very good way of implementing any sort of web application from small or large.
As I understand it we have 3 distinct layers that talk to each other via the Controller like so:
User Input ---> View ---> Controller ---> Model
Site Output <--- View <--- Controller <--- Model
With my planned implementation I hope to have a model for each table in my database, and each model will have all the functions/logic necessary to manage this table. In turn each of these models will have an associated view. The Model and View will of course have a Controller which allows them to be used.
Now this is easy to get my head around as each single, logical action requiring the database has been covered. However, what happens when a particular action requires the use of more than one table/model?
The Admin side of the application isn’t likely to need more than one model at a time to maintain the database. The front-end or user side of the application is a different matter! Say I have a webpage that shows a list of articles for a particular section, a list of currently logged-in users and – borrowing an example from SO – site statistics such as a tag cloud.
This one page would require at least 3 models in my planned design – Article, Users and Tags.
Obviously my single controllers aren’t going to cut it. So what do I do?
1. Create new monolithic controllers for my web pages?
* allow me to get the results I want
* would require a lot of duplicate coding
* really hard to maintain if changes required
2. Create a “super” controller that manipulates smaller specific controllers
* allows me to get the results I want
* would be modular so changes to one script *shouldn’t* affect the others
* minimal code duplication
3. Create [insert brilliant solution here]
I am currently erring towards Option 2. Simply because it should in theory cut down on coding as all the necessary behaviour will exist in the smaller controllers - and everything will be easy to maintain.
Perhaps it could look like this:
**articlecontroller.php**
```
<?php
//Article Controller Script
if($_GET['article'] = 'foo')
{
//magic necessary for displaying article "foo".
}
?>
```
**usercontroller.php**
```
<?php
//User Controller Script
if($_GET['user'] = 'display')
{
//magic necessary for displaying users
}
?>
```
**supercontroller.php**
```
<?php
//"Super" Controller
//magic for setting up page
if(isset($_GET['article']))
{
include('articlecontroller.php');
}
if(isset($_GET['user']))
{
include('usercontroller.php');
}
?>
```
As you can see, my super controller looks at what that particular page requires and includes the necessary controllers which do the grunt work. **NB:** The code is just a quick and dirty example :)
However, I am by no means a pro so that is why I am asking you, SO. Which option is preferred? If neither what Option 3 would you suggest? Any code snippets/examples would be lovely but not required.
If you made it this far, thank you for your time.
---
I thought I would update this question [and accept an answer - forgot to do that :P]. I took a look at the concept of Fat Models/Skinny Controllers and I like how it is done, so I will definitely be taking that directions.
I have also taken the advice to look at some of the other frameworks and how they achieve their MVC patterns. There is rather a lot to take in! Still, I have learned quite a few new things along the way, so it was of great benefit. I may have more questions in the future, but for now I have more than enough to make a start.
Thank you all for your input. | I disagree with the direction you want to take in your model. The 1 model = 1 table design is going to hurt you in the long run.
First of all, I think you need to drop the strict notion that model == database. While that is very often true, really the model is just data - it could come from XML files, a cache, or even a web service.
Check out [this excellent answer](https://stackoverflow.com/questions/373244/how-to-design-domain-layer-objects-to-represent-multiple-objects-single-object#373401) by [Bill Karwin](https://stackoverflow.com/users/20860/bill-karwin) - it addresses these concerns very well.
Secondly, do some reading on the topic of [fat models, skinny controllers](http://www.google.com/search?q=fat+models+skinny+controllers) (or [thin controllers](http://www.google.com/search?q=fat+models+thin+controllers))
Lastly, just as more of an FYI, your idea of a "supercontroller" is what's more commonly known as a "front controller" | You should really take a look at the PHP MVC frameworks out there. They have figured all this stuff out already. They will have URL routing (/article/edit/1), good MVC seperation, and great docs to help you through it. So instead of worring about how to call the view from the controller, you can think about your application. I've personally saved **tons** of time when i finally took the dive.
* [Zend MVC framework](http://framework.zend.com/) (my personal favorite, use as much or as little as you need)
* [Symfony](http://www.symfony-project.org/)
* [Codeigniter](http://codeigniter.com/)
* [CakePHP](http://cakephp.org/) (I hate its rigid structure, but some people adore it)
There are many others out there.
Creating a PHP MVC framework from scratch just probably isn't worth the effort. If you are dead set on reinventing the wheel, you should at least take a look at the design considerations that went into these frameworks for inspiration. | Creating and combining controllers in an MVC PHP web application | [
"",
"php",
"model-view-controller",
""
] |
When I execute this query:
```
Dim Var
Var = ("select max(Autonumber) from tblAutonumber")
DoCmd.RunSQL (Var)
```
I am getting the value of var as `"select max(Autonumber) from tblAutonumber"` instead of the maximum value I am looking for.
### Code:
```
Private Sub btnSubmit_Enter()
DoCmd.RunSQL ("insert into tblAutonumber (Dummy)values ('DummyValue')")
Dim db As DAO.Database
Dim rst As DAO.Recordset
Dim strMaxNum As String
Dim strSQL As String
strSQL = "select max(Autonumber) as maxNum from tblAutonumber"
Set db = CurrentDb
Set rst = db.OpenRecordset(strSQL)
rst.MoveFirst
strMaxNum = rst!maxNum
'Dim Var As Variant
'Var = "select max(Autonumber) from tblAutonumber"
'DoCmd.RunSQL (Var)
txtAutoNumber.Value = strSQL
DoCmd.RunSQL ("insert into tbltesting (Empid,TestScenario,owner,event,version,expresult,variation,status,homestore)values ('" & Me.txtEmpNo.Value & "','" & Me.txtTestScenario.Value & "','" & Me.txtOwner.Value & "','" & Me.txtEvent.Value & "', '" & Me.txtVersion.Value & "','" & Me.txtExpectedResult.Value & "', '" & Me.txtVariation.Value & "', '" & Me.txtStatus.Value & "','" & Me.txtHomeStore.Value & "')")
'DoCmd.RunSQL ("INSERT INTO tblContract(testid)select max(testid) FROM tbltesting")
DoCmd.RunSQL ("insert into tblContract (Empid,testid,Start1,Finish1,Store1,Start2,Finish2,Store2 )values ('" & Me.txtEmpNo.Value & "','" & Me.txtAutoNumber.Value & "','" & Me.txtContSunStart1.Value & "', '" & Me.txtContSunFinish1.Value & "','" & Me.txtContSunStore1.Value & "','" & Me.txtContSunStart2.Value & "', '" & Me.txtContSunFinish2.Value & "','" & Me.txtContSunStore2.Value & "')")
'DoCmd.RunSQL = "INSERT INTO tblContract (Empid,testid, Start1, Finish1, Store1, Start2, Finish2, Store2) SELECT " & Me.txtEmpNo.Value & "', MAX(testid), '" & Me.txtContSunStart1.Value & "', '" & Me.txtContSunFinish1.Value & "','" & Me.txtContSunStore1.Value & "','" & Me.txtContSunStart2.Value & "', '" & Me.txtContSunFinish2.Value & "','" & Me.txtContSunStore2.Value & "' " & "FROM tbltesting'"
'DoCmd.RunSQL = "INSERT INTO tblContract (Empid,testid, Start1, Finish1, Store1, Start2, Finish2, Store2) SELECT " & Me.txtEmpNo.Value & "', MAX(testid), '" & Me.txtContSunStart1.Value & "', '" & Me.txtContSunFinish1.Value & "','" & Me.txtContSunStore1.Value & "','" & Me.txtContSunStart2.Value & "', '" & Me.txtContSunFinish2.Value & "','" & Me.txtContSunStore2.Value & "' " & "FROM tbltesting'"
End Sub
``` | For what you are trying to accomplish you might want to just use the DMAX Domain Aggregate Function which will return the max expression (i.e. column) for a given domain (i.e. table). Here is an example:
```
Dim lastAutonumber As Long
lastAutonumber = DMax("Autonumber", "tblAutonumber")
``` | As Rich commented:
```
Dim Var
Var = "select max(Autonumber) from tblAutonumber"
DoCmd.RunSQL (Var)
``` | Query problem | [
"",
"sql",
"ms-access",
"vba",
""
] |
I think that this problem can be sorted using reflection (a technology which I'm not too sure about).
My code is receiving some code objects that have been serialised to XML at runtime. When I receive it and deserialise it one field is causing me some hassle.
There is a field that can contain a combination of the following data classes (simplified for clarity):
```
class KeyValuePairType
{
public string Key;
public string Value;
}
class KeyValueListPair
{
public string Key;
public string[] Value;
}
```
I receive these into my code as an object[] and I need to determine at runtime what exactly this contains so that I can call an interface on a local object that requires
KeyValuePairType[] and KeyValueListPair[] as parameters e.g.
```
public DoSomeWork(KeyValuePairType[] data1, KeyValueListPair[] data2)
```
I have the following cases to cope with:
object[] contains:
1. nothing in which case I call
DoSomeWork(null,null);
2. an array of KeyValuePairType only,
in which case I call
DoSomeWork(KeyValuePairType[],
null);
3. an array of KeyValueListPair only,
in which case I call
DoSomework(null,
KeyValueListPair[]);
4. or an array of each, in which case I
call DoSomework(KeyValuePairType[],
KeyValueListPair[]);
Any ideas are welcome.
**Thank you**
It turns out that the object array contains a random sequence of discrete objects. Initially I was led to belive that it may be a sequence of discretes and arrays of those objects.
As it is the LINQ statements will cover all eventualities.
Can I say a big thank you to those that that answered. I have posted a +1 for those answering with the LINQ statements. | Assuming you've got LINQ available to you...
```
public void Foo(object[] values)
{
var pairs = values.OfType<KeyValuePairType>().ToArray();
var lists = values.OfType<KeyValueListPair>().ToArray();
pairs = pairs.Length == 0 ? null : pairs;
lists = lists.Length == 0 ? null : lists;
DoSomeWork(pairs, lists);
}
``` | You can do this using LINQ in C# 3, like this:
```
void HandleThings(params object[] values) {
var pairTypes = values.OfType<KeyValuePairType>().ToArray();
var listPairs = values.OfType<KeyValueListPair>().ToArray();
DoSomeWork(pairTypes.Any() ? pairTypes : null, listPairs.Any() ? listPairs : null);
}
```
You can make it a tiny bit faster by replacing `.Any()` with `.Length > 0`, at the cost of brevity. | How to determine what object[] passed as parameter contains? | [
"",
"c#",
"reflection",
""
] |
What's the Fastest way to get a large number of files (relatively small 10-50kB) from Amazon S3 from Python? (In the order of 200,000 - million files).
At the moment I am using boto to generate Signed URLs, and using PyCURL to get the files one by one.
Would some type of concurrency help? PyCurl.CurlMulti object?
I am open to all suggestions. Thanks! | In the case of python, as this is IO bound, multiple threads will use of the CPU, but it will probably use up only one core. If you have multiple cores, you might want to consider the new [multiprocessor](http://docs.python.org/dev/library/multiprocessing.html) module. Even then you may want to have each process use multiple threads. You would have to do some tweaking of number of processors and threads.
If you do use multiple threads, this is a good candidate for the [Queue](http://docs.python.org/dev/library/queue.html) class. | I don't know anything about python, but in general you would want to break the task down into smaller chunks so that they can be run concurrently. You could break it down by file type, or alphabetical or something, and then run a separate script for each portion of the break down. | Downloading a Large Number of Files from S3 | [
"",
"python",
"curl",
"amazon-s3",
"amazon-web-services",
"boto",
""
] |
What is the fastest way to compare a string with an array of strings in C#2.0 | You mean to see if the string is in the array? I can't remember if arrays support the .Contains() method, so if not, create a List< string >, add your array to the list via AddRange(), then call list.Contains({string to compare}). Will return a boolean value indicating whether or not the string is in the array. | What kind of comparison do you want? Do you want to know if the given string is in the array?
```
bool targetStringInArray = array.Contains(targetString);
```
do you want an array of comparison values (positive, negative, zero)?
```
var comparisons = array.Select(x => targetString.CompareTo(x));
```
If you're checking for containment (i.e. the first option) and you're going to do this with multiple strings, it would probably be better to build a `HashSet<string>` from the array:
```
var stringSet = new HashSet<string>(array);
if (stringSet.Contains(firstString)) ...
if (stringSet.Contains(secondString)) ...
if (stringSet.Contains(thirdString)) ...
if (stringSet.Contains(fourthString)) ...
``` | Fastest way to compare a string with an array of strings in C#2.0 | [
"",
"c#",
".net",
"arrays",
"string",
"comparison",
""
] |
As a beginner in programming it always bugs me when I run into a walls.
Currently one of the wall are co-depending objects.
As you can see in my question history I'm currently working on a blackberry application, in which I implemented something I call the MVC Pattern, but it isn't exactly what I think it's meant to be.
You see, a novice programmer you look on abstracts like this graphic and you get the idea behind it. But implementing it is another thing.
[alt text http://www.ibm.com/developerworks/wireless/library/wi-arch6/theoretical.gif](http://www.ibm.com/developerworks/wireless/library/wi-arch6/theoretical.gif)
Please, don't stop reading :) I'm showing you some of me code, which contains some blackberry specific stuff, but you should see what I'm doing.
**Main Entry Point for my Application**
```
public class ContactManager extends UiApplication
{
private static ContactManagerMainScreenModel MainScreenModel = new ContactManagerMainScreenModel();
private static ContactManagerMainScreen MainScreenView = null;
public static void main(String[] args)
{
new ContactManager().enterEventDispatcher();
}
public ContactManager()
{
MainScreenView = new ContactManagerMainScreen(MainScreenModel);
// Displays the Splashscreen then opens the Mainscreen
new SplashScreen(UiApplication.getUiApplication(), MainScreenView);
}
}
```
**The Mainscreen Model**
```
public class ContactManagerMainScreenModel
{
ContactManagerMainScreen v;
// Loading Local Storage
LocalContactStorage LocalContactStorage = new LocalContactStorage();
// Define Data List
private Vector vContacts_Favorites;
public void register(ContactManagerMainScreen v)
{
this.v = v;
}
// Retrieve Favorite Contacts from Persistant Storage
public Vector getFavoriteContactsFromLocalStorage()
{
vContacts_Favorites = LocalContactStorage.getFavoriteContactsFromLocalStorage();
return vContacts_Favorites;
}
// Put Retrieve Favorite Contacts from Persistant Storage
public void saveFavoriteContactsToLocalStorage()
{
LocalContactStorage.saveFavoriteContactsToLocalStorage(vContacts_Favorites);
}
}
```
**The MainScreenController**
```
public class ContactManagerMainScreenController
{
private ContactManagerMainScreenModel _model = null;
private ContactManagerMainScreen _view = null;
public ContactManagerMainScreenController(ContactManagerMainScreen view, ContactManagerMainScreenModel model)
{
this._model = model;
this._view = view;
}
public void HideFavoriteList()
{
if( this._view._ContactList.getManager() != null)
{
this._view._ContactList.getManager().delete(this._view._ContactList);
} else
{
this._view._bottom_box.add(this._view._ContactList);
}
}
}
```
Still there? Okay ...
My Problem here is, that I want to use the controller to change UI Elements, like Displaying a PopUp Box, hide someting or other things.
But all these UI Elements are defined in the View (here ContactManagerMainScreen) so have to give to the Controller a reference to the View. Which leads to my co-depending objects misery.
I cannot create the controller before the view is declared. Without the requirement to allow the controller to change UIElements, it would be no problem (as shown in the Graphics).
What I'm doing now is that the View creates the Controller
```
controller = new ContactManagerMainScreenController(this , model);
```
Does that makes sense? I want to understand the pattern, so call my code trash or anything you like :) I just want to learn something.
P.S. I beg your pardon for my bad english :) | MVC is an interesting abstraction, but has some problems.
In reality, the controller and view are often paired--even though in theory you should be able to replace either one without the other, in reality the interface mechanisms to different views are so different that the controller & view are combined.
The best description I've seen relating to Java is that the view is your swing components so your portion of the view code is nothing but placing those components on the screen.
Your controller is the rest of that class, the listeners and the rest of your code that interacts with the view.
My suggestion would be to not worry too much about isolating the view and controller, but that said, I am totally behind keeping a very strong separation between the model and the view/controller.
EDIT/Advanced:
I have used a pattern where controller and view are isolated and it is more flexible, but it tends to be a lot more work. I think Struts uses the binding model--if you want to see some abstraction techniques you might look there or search for stuff about "binding" swing controls. | I don't think that diagram is very good, and probably makes things a lot more confusing.
The controller should be responsible for giving the Model to the View. The Model should contain nothing more than simple accessors for your data. Any need to interact with the Model - or change any of it's values - should take place thru the Controller.
This way, the View only needs to know how to render/present the Model to the user. So any operations on the Model - things like `saveFavoriteContactsToLocalStorage()` - should be methods of the Controller, not the View class. Also, the Controller should not need a reference to the View to be constructed - I think that ends up reversing the intended order of the entire MVC pattern. | Java MVC - Doesn't feel like I get it | [
"",
"java",
"model-view-controller",
"design-patterns",
"java-me",
""
] |
In my application, \_collection is a List from which I need to **remove all User objects** which do not match the **criteria**.
However, the following code gets an **invalid operation** error in its second iteration since the \_collection itself has been changed:
```
foreach (User user in _collection)
{
if (!user.IsApproved())
{
_collection.Remove(user);
}
}
```
I could create another List collection and copy them back and forth but then I have the issue of non-cloned reference types, etc.
**Is there a way to do the above more elegantly than copying \_collection to another another List variable?** | ```
_collection.RemoveAll(user => !user.IsApproved());
```
If you're *still* on 2.0:
```
_collection.RemoveAll(delegate(User u) { return !u.IsApproved(); });
```
By the way, if you don't want to touch the original list, you can get *another* list of approved users with:
```
_collection.FindAll(user => user.IsApproved());
``` | You can always start at the top index and iterate downward towards 0:
```
for (int i = _collection.Count - 1; i >= 0; i--)
{
User user = _collection[i];
if (!user.IsApproved())
{
_collection.RemoveAt(i);
}
}
```
Mehrdad's answer looks pretty darn elegant, though. | What is the easiest way to foreach through a List<T> removing unwanted objects? | [
"",
"c#",
".net",
"generics",
"list",
"collections",
""
] |
I have a table with the following
```
Table1
col1 col2
------------
1 A
2 B
3 C
0 D
```
Result
```
col1 col2 col3
------------------
0 D ABC
```
I am not sure how to go about writing the query , col1 and col2 can be selected by this
```
select col1, col2 from Table1 where col1 = 0;
```
How should I go about adding a col3 with value ABC. | Try this:
```
select col1, col2, 'ABC' as col3 from Table1 where col1 = 0;
``` | If you meant just ABC as simple value, answer above is the one that works fine.
If you meant concatenation of values of rows that are not selected by your main query, you will need to use a subquery.
Something like this may work:
```
SELECT t1.col1,
t1.col2,
(SELECT GROUP_CONCAT(col2 SEPARATOR '') FROM Table1 t2 WHERE t2.col1 != 0) as col3
FROM Table1 t1
WHERE t1.col1 = 0;
```
Actual syntax maybe a bit off though | Select a dummy column with a dummy value in SQL? | [
"",
"sql",
""
] |
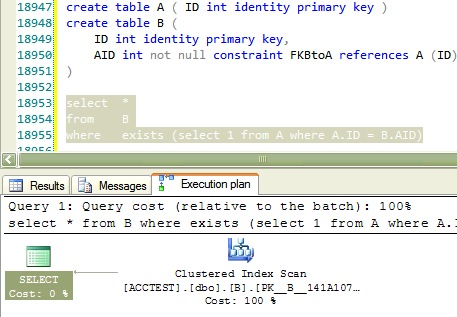
I have a weird problem where after setting `nocheck` on a foreign constraint and re-enabling it,
I am getting a same out-dated execution plan that was used with `nocheck` on.
Why would SQL server generate an execution plan as if foreign constraint `FKBtoA` is disabled even after adding the check again with following statement?
```
alter table B check constraint FKBtoA
```
---
**[UPDATE1]**
So far dropping foreign constraint and readding it worked.
```
alter table B drop constraint FKBtoA
alter table B add constraint FKBtoA foreign key (AID) references A(ID)
```
But for really big tables, this seems like an overkill - Is there a better way?
**[ANSWER]**
I had to add `WITH CHECK` in alter statement like following to get the old execution plan
```
alter table B WITH CHECK add constraint FKBtoA foreign key (AID) references A(ID)
```
---
Here is a full SQL statement
```
create table A ( ID int identity primary key )
create table B (
ID int identity primary key,
AID int not null constraint FKBtoA references A (ID)
)
select *
from B
where exists (select 1 from A where A.ID = B.AID)
alter table B nocheck constraint FKBtoA
GO
select *
from B
where exists (select 1 from A where A.ID = B.AID)
alter table B check constraint FKBtoA
GO
select *
from B
where exists (select 1 from A where A.ID = B.AID)
```
---
Here is the screenshot of execution plans per each `SELECT` statement
Before disabling foreign key constraint
After disabling foreign key constraint
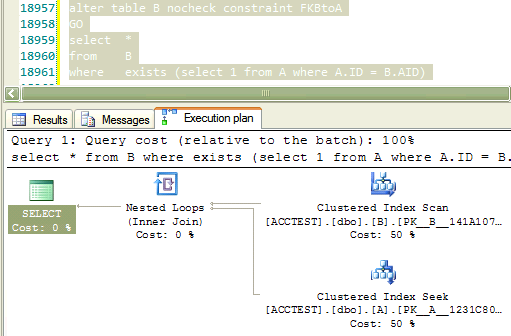
After re-enabling foreign key constraint
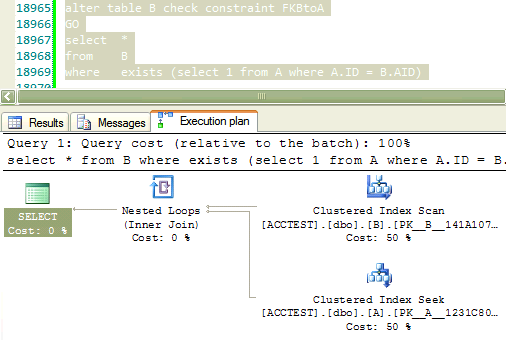 | Most likely your constraint is enabled but not trusted, so there can be orphan rows in your child table. Read this great post by Hugo Kornelis:[Can you trust your constraints?](https://sqlserverfast.com/blog/hugo/2007/03/can-you-trust-your-constraints/) | There doesn't seem to be any data in those tables, judging from both the scripts you posted and from the width of the connectors in the plan. Analyzing query plans on empty tables is largely irrelevant: at one single page read, the optimizer will almost certainly choose a full scan.
I assume you're doing this as some sort of experiment, in real world you should join those tables not use inner EXIST. | Execution plan oddity after re-enabling foreign key constraint | [
"",
"sql",
"sql-server",
"t-sql",
"sql-execution-plan",
""
] |
I inherited a system that stores default values for some fields in some tables in the database. These default values are used in the application to prepopulate control values. So, essentially, every field in every table in the database can potentially have a default value. The previous developer decided to store these values in a single table that had a key/value pair combo. The key represented by the source table + field name (as a varchar) and the default value as a varchar field as well. The Business layer would then cast the varchar field to the appropriate data type.
Somehow, I feel this is brittle. Though the application works as expected, there appears to be a flaw in the design.
Any suggestions on how this requirement could have been handled earlier? Is there anything that can be done now to make it more robust?
**EDIT: I should have defined what the term "default" meant. This is NOT related to the default value of a field in the table. Instead, it's a default value that will be used by the application in the front end.** | That schema design is fine. I've seen it used in commercial apps and I've also used it in a few apps of my own where the users needed to be able to change the defaults or other parameters around fields in the application (limits, allowable characters etc.) or the application allowed the users to add new fields for use in the app.
Having it in a single table (not separate default tables for each table) protects it from schema changes in the tables it supports. Those schema changes become simple configuration changes in this model.
The single table makes it easy to encapsulate in a Class to serve as the "defaults" configuration object.
Some general advice:
When you inherit a working system and don't understand why something was designed the way it is - **the problem is most likely your understanding, not the system**. If it isn't broken, **do not fix it**.
Specific advice on the only improvements I would recommend (if they become necessary):
You can use the new SQLVARIANT field for the value rather than a varchar - it can hold any of the regular data types - you will need to add support for casting them to the correct data type when using the value though. | A better way to go would be using SQL Server's built-in [DEFAULT](http://www.odetocode.com/Articles/79.aspx) constraint.
e.g.
```
CREATE TABLE Orders
(
OrderID int IDENTITY NOT NULL,
OrderDate datetime NULL CONSTRAINT DF_Orders_OrderDate DEFAULT(GETDATE()),
Freight money NULL CONSTRAINT DF_Orders_Freight DEFAULT (0) CHECK(Freight >= 0),
ShipAddress nvarchar (60) NULL DF_Orders_ShipAddress DEFAULT('NO SHIPPING ADDRESS'),
EnteredBy nvarchar (60) NOT NULL DF_Orders_EnteredBy DEFAULT(SUSER_SNAME())
)
``` | Is this schema design good? | [
"",
"sql",
"sql-server",
"sql-server-2005",
""
] |
I was sure that it hasn't, but looking for a definite answer on the Interwebs left me in doubt. For example, I got a [2008 post](http://journal.thobe.org/2008/03/next-step-to-increase-python.html) which sort of looked like a joke at first glance but seemed to be serious at looking closer.
*Edit:*
**... and turned out to *be* a joke after looking even closer**. Sorry for the confusion. Actually the comments on that post answer my question, as Nikhil has pointed out correctly.
> We realized that CPython is far ahead of us in this area, and that we are lacking in compatibility. After serious brainstorming (and a few glasses of wine), we decided that introducing a Global Interpreter Lock in Jython would solve the entire issue!
Now, what's the status here? The ["differences" page on sourceforge](http://jython.sourceforge.net/docs/differences.html) doesn't mention the GIL at all. Is there any official source I have overlooked?
Note also that I'm aware of the ongoing discussion whether the GIL matters at all, but I don't care about that for the moment. | No, it does not. It's a part of the VM implementation, not the language.
See also:
```
from __future__ import braces
``` | The quote you found was indeed a joke, here is a demo of Jython's implementation of the GIL:
```
Jython 2.5.0 (trunk:6550M, Jul 20 2009, 08:40:15)
[Java HotSpot(TM) Client VM (Apple Inc.)] on java1.5.0_19
Type "help", "copyright", "credits" or "license" for more information.
>>> from __future__ import GIL
File "<stdin>", line 1
SyntaxError: Never going to happen!
>>>
``` | Does Jython have the GIL? | [
"",
"python",
"multithreading",
"jython",
""
] |
Does it make sense that if the Text on a TextBox is databound to a property using the twoway mode and I set the Text to something, it should update the property? My property gets updated when I type inside the control, but not when I set the value in code. | I would say it makes no sense to modify a bound Text property directly. Your code should be setting the other end of the binding and allowing the binding to update the control.
If the bound object is updated when the Text property is set then special case code would be needed to detect when such an assignent is the result of the bound object changing for other reasons. Otherwise you would end up with an infinite loop. | This is because it only commits the data when the textbox loses focus. [Here](https://stackoverflow.com/questions/563195/wpf-textbox-databind-on-enterkey-press) is a question that is somewhat related that eludes to this. | Setting textBox.Text doesn't update bound twoway property? | [
"",
"c#",
"wpf",
"data-binding",
"properties",
""
] |
I'd like to use git to manage my various Visual Studio projects. Unfortunately they seem to consist of a multitude of files beyond the one or two .cs files my code is contained in.
Which of these files is actually required to build the project? | .csproj, assemblyinfo.cs, plus your code and solution (.sln) file.
Also, you might take a look at [cleansoureplus](http://www.codinghorror.com/blog/archives/000368.html) from Jeff. This program will clean out all unnecessary files and folders. | I think it's easier to look at a Visual Studio project and know what to exclude from a project. There are too many different flavors of visual studio projects to possibly list all of the file types which are important. However the unimportant files usually follow a specific pattern.
In general I exclude the following directories and files
Directories:
* bin
* obj
Files Extensions:
* \*.suo
* \*.sdf
* \*.user
* \*.obj
* \*.dll
* \*.exe | Which files are required for a Visual Studio project? | [
"",
"c#",
"visual-studio",
""
] |
I am trying to store IPv6 addresses in MySQL 5.0 in an efficient way. I have read the other questions related to this, [such as this one](https://stackoverflow.com/questions/420680/how-to-store-ipv6-compatible-address-in-a-relational-database). The author of that question eventually chose for two BIGINT fields. My searches have also turned up another often used mechanism: Using a DECIMAL(39,0) to store the IPv6 address. I have two questions about that.
1. What are the advantages and disadvantages of using DECIMAL(39,0) over the other methods such as 2\*BIGINT?
2. How do I convert (in PHP) from the binary format as returned by [inet\_pton()](http://www.php.net/inet_pton) to a decimal string format usable by MySQL, and how do I convert back so I can pretty-print with inet\_ntop()? | Here are the functions I now use to convert IP addresses from and to DECIMAL(39,0) format. They are named inet\_ptod and inet\_dtop for "presentation-to-decimal" and "decimal-to-presentation". It needs IPv6 and bcmath support in PHP.
```
/**
* Convert an IP address from presentation to decimal(39,0) format suitable for storage in MySQL
*
* @param string $ip_address An IP address in IPv4, IPv6 or decimal notation
* @return string The IP address in decimal notation
*/
function inet_ptod($ip_address)
{
// IPv4 address
if (strpos($ip_address, ':') === false && strpos($ip_address, '.') !== false) {
$ip_address = '::' . $ip_address;
}
// IPv6 address
if (strpos($ip_address, ':') !== false) {
$network = inet_pton($ip_address);
$parts = unpack('N*', $network);
foreach ($parts as &$part) {
if ($part < 0) {
$part = bcadd((string) $part, '4294967296');
}
if (!is_string($part)) {
$part = (string) $part;
}
}
$decimal = $parts[4];
$decimal = bcadd($decimal, bcmul($parts[3], '4294967296'));
$decimal = bcadd($decimal, bcmul($parts[2], '18446744073709551616'));
$decimal = bcadd($decimal, bcmul($parts[1], '79228162514264337593543950336'));
return $decimal;
}
// Decimal address
return $ip_address;
}
/**
* Convert an IP address from decimal format to presentation format
*
* @param string $decimal An IP address in IPv4, IPv6 or decimal notation
* @return string The IP address in presentation format
*/
function inet_dtop($decimal)
{
// IPv4 or IPv6 format
if (strpos($decimal, ':') !== false || strpos($decimal, '.') !== false) {
return $decimal;
}
// Decimal format
$parts = array();
$parts[1] = bcdiv($decimal, '79228162514264337593543950336', 0);
$decimal = bcsub($decimal, bcmul($parts[1], '79228162514264337593543950336'));
$parts[2] = bcdiv($decimal, '18446744073709551616', 0);
$decimal = bcsub($decimal, bcmul($parts[2], '18446744073709551616'));
$parts[3] = bcdiv($decimal, '4294967296', 0);
$decimal = bcsub($decimal, bcmul($parts[3], '4294967296'));
$parts[4] = $decimal;
foreach ($parts as &$part) {
if (bccomp($part, '2147483647') == 1) {
$part = bcsub($part, '4294967296');
}
$part = (int) $part;
}
$network = pack('N4', $parts[1], $parts[2], $parts[3], $parts[4]);
$ip_address = inet_ntop($network);
// Turn IPv6 to IPv4 if it's IPv4
if (preg_match('/^::\d+.\d+.\d+.\d+$/', $ip_address)) {
return substr($ip_address, 2);
}
return $ip_address;
}
``` | We went for a `VARBINARY(16)` column instead and use [`inet_pton()`](http://man7.org/linux/man-pages/man3/inet_pton.3.html) and [`inet_ntop()`](http://man7.org/linux/man-pages/man3/inet_ntop.3.html) to do the conversions:
<https://github.com/skion/mysql-udf-ipv6>
The functions can be loaded into a running MySQL server and will give you `INET6_NTOP` and `INET6_PTON` in SQL, just as the familiar `INET_NTOA` and `INET_ATON` functions for IPv4.
Edit: There are compatible functions in MySQL now, just with [different](http://dev.mysql.com/doc/refman/5.7/en/miscellaneous-functions.html#function_inet6-aton) [names](http://dev.mysql.com/doc/refman/5.7/en/miscellaneous-functions.html#function_inet6-ntoa). Only use the above if you are on pre-5.6 MySQL and are looking for a convenient future upgrade path. | How to convert IPv6 from binary for storage in MySQL | [
"",
"php",
"mysql",
"ipv6",
""
] |
Doesn't the space occupied by a variable get deallocated as soon as the control is returned from the function??
I thought it got deallocated.
Here I have written a function which is working fine even after returning a local reference of an array from function CoinDenom,Using it to print the result of minimum number of coins required to denominate a sum.
How is it able to print the right answer if the space got deallocated??
```
int* CoinDenom(int CoinVal[],int NumCoins,int Sum) {
int min[Sum+1];
int i,j;
min[0]=0;
for(i=1;i<=Sum;i++) {
min[i]=INT_MAX;
}
for(i=1;i<=Sum;i++) {
for(j=0;j< NumCoins;j++) {
if(CoinVal[j]<=i && min[i-CoinVal[j]]+1<min[i]) {
min[i]=min[i-CoinVal[j]]+1;
}
}
}
return min; //returning address of a local array
}
int main() {
int Coins[50],Num,Sum,*min;
cout<<"Enter Sum:";
cin>>Sum;
cout<<"Enter Number of coins :";
cin>>Num;
cout<<"Enter Values";
for(int i=0;i<Num;i++) {
cin>>Coins[i];
}
min=CoinDenom(Coins,Num,Sum);
cout<<"Min Coins required are:"<< min[Sum];
return 0;
}
``` | The contents of the memory taken by local variables is undefined after the function returns, but in practice it'll stay unchanged until something actively changes it.
If you change your code to do some significant work between populating that memory and then using it, you'll see it fail. | What you have posted is not C++ code - the following is illegal in C++:
```
int min[Sum+1];
```
But in general, your program exhibits undefined behaviour. That means anything could happen - it could even appear to work. | When does the space occupied by a variable get deallocated in c++? | [
"",
"c++",
"scope",
""
] |
is there any way to reference a class name from within the class declaration? an example follows:
```
class Plan(SiloBase):
cost = DataField(int)
start = DataField(System.DateTime)
name = DataField(str)
items = DataCollection(int)
subPlan = ReferenceField(Plan)
```
i've got a metaclass that reads this information and does some setup, and the base class implements some common saving stuff. i would love to be able to create recursive definitions like this, but so far in my experimentation i have been unable to get the effect i desire, usually running into a "Plan is not defined" error. I understand what is happening, the name of the class isn't in scope inside the class. | > i've got a metaclass that reads this information and does some setup
Most frameworks that use metaclasses provide a way to resolve this. For instance, [Django](http://docs.djangoproject.com/en/1.0/ref/models/fields/#foreignkey):
```
subplan = ForeignKey('self')
```
[Google App Engine](http://code.google.com/appengine/docs/python/datastore/typesandpropertyclasses.html#SelfReferenceProperty):
```
subplan = SelfReferenceProperty()
```
The problem with solutions like tacking an additional property on later or using `__new__` is that most ORM metaclasses expect the class properties to exist at the time when the class is created. | **Try this:**
```
class Plan(SiloBase):
cost = DataField(int)
start = DataField(System.DateTime)
name = DataField(str)
items = DataCollection(int)
Plan.subPlan = ReferenceField(Plan)
```
**OR use `__new__` like this:**
```
class Plan(SiloBase):
def __new__(cls, *args, **kwargs):
cls.cost = DataField(int)
cls.start = DataField(System.DateTime)
cls.name = DataField(str)
cls.items = DataCollection(int)
cls.subPlan = ReferenceField(cls)
return object.__new__(cls, *args, **kwargs)
``` | Self Referencing Class Definition in python | [
"",
"python",
""
] |
I've run into this problems several times before when trying to do some html scraping with php and the preg\* functions.
Most of the time I've to capture structures like that:
```
<!-- comment -->
<tag1>lorem ipsum</tag>
<p>just more text with several html tags in it, sometimes CDATA encapsulated…</p>
<!-- /comment -->
```
In particular I want something like this:
```
/<tag1>(.*?)<\/tag1>\n\n<p>(.*?)<\/p>/mi
```
but the **\n\n** doesn't look like it would work.
Is there a general line-break switch? | I think you could replace the `\n\n` with `(\r?\n){2}` this way you capture the `CRLF` pair instead of just the `LF` char. | Are you sure you want to parse HTML using regexps ? HTML isn't regular and there are too many corner cases.
I would investigate some form of HTML parser (perhaps [this one](https://sourceforge.net/projects/simplehtmldom/) ?), and then identify the pattern you're interested in via the returned HTML data structure. | Is there a token for capture line breaks in multiline regex? | [
"",
"php",
"regex",
"multiline",
"pcre",
""
] |
Is there a way to tell the php complier that I want a specific implicit conversion from one type to another?
A simple example:
```
class Integer
{
public $val;
}
function ExampleFunc(Interger $i){...}
ExamFunc(333); // 333 -> Integer object with $val == 333.
```
[edit]... someone asked for an example. Here's an example from c#. This is a boolean type that changes value after it has been accessed once.
```
/// <summary>
/// A Heisenberg style boolean that changes after it has been read. Defaults to false.
/// </summary>
public class hbool
{
private bool value;
private bool changed = false;
public hbool()
{
value = false;
}
public hbool(bool value)
{
this.value = value;
}
public static implicit operator bool(hbool item)
{
return item.Value;
}
public static implicit operator hbool(bool item)
{
return new hbool(item);
}
public bool Value
{
get
{
if (!changed)
{
value = !value;
changed = true;
return !value;
}
return value;
}
}
public void TouchValue()
{
bool value1 = Value;
}
public static hbool False
{
get { return new hbool(); }
}
public static hbool True
{
get { return new hbool(true); }
}
}
[Test]
public void hboolShouldChangeAfterRead()
{
hbool b = false;
Assert.IsFalse(b);
Assert.IsTrue(b);
Assert.IsTrue(b);
hbool b1 = false;
Assert.IsFalse(b1);
Assert.IsTrue(b1);
Assert.IsTrue(b1);
hbool b2 = true;
Assert.IsTrue(b2);
Assert.IsFalse(b2);
Assert.IsFalse(b2);
bool b3 = new hbool();
Assert.IsFalse(b3);
Assert.IsFalse(b3);
Assert.IsFalse(b3);
}
``` | **Long answer:**
I think it is very difficult (read *impossible*) for PHP to do an *implicit* conversion in this case.
Remember: the fact that you call your class Integer is a hint to the human reader of the code, PHP does not understand that it actually is used to hold an integer. Also, the fact that it has an attribute called $val is a hint to a human reader that it should probably contain the value of your integer. Again PHP does not understand your code, it only executes it.
At some point in your code you should do an *explicit* conversion. It might be possible that PHP has some nice syntactig sugar for that, but a first attempt would be something like:
```
class Integer
{
public $val;
function __construct($val) { $this->val = $val; }
}
function ExampleFunc($i){
if (is_numeric($i)) { $iObj = new Integer($i); }
...
}
ExamFunc(333); // 333 -> Integer object with $val === 333.
```
This is not as cool as you would like it, but again, it is possible that PHP has some syntactic sugar that will hide the explicit conversion more or less.
**Short version:**
In one way or another, you will need an *explicit* conversion | PHP5 has type hinting, with limitations:
<https://www.php.net/manual/en/language.oop5.typehinting.php>
Specified types must be objects or *array*, so built in types such as *string* and *int* are not allowed.
This is not a conversion, but will throw an error if an object of the specified type is not passed to the method or function, as in your example. | Implicit Type Conversion for PHP Classes? | [
"",
"php",
"types",
""
] |
I've written a fairly simple little C# web service, hosted from a standalone EXE via WCF. The code - somewhat simplified - looks like this:
```
namespace VMProvisionEXE
{
class EXEWrapper
{
static void Main(string[] args)
{
WSHttpBinding myBinding = new WSHttpBinding();
myBinding.Security.Mode = SecurityMode.None;
Uri baseAddress = new Uri("http://bernard3:8000/VMWareProvisioning/Service");
ServiceHost selfHost = new ServiceHost(typeof(VMPService), baseAddress);
try
{
selfHost.AddServiceEndpoint(typeof(IVMProvisionCore), myBinding, "CoreServices");
ServiceMetadataBehavior smb = new ServiceMetadataBehavior();
smb.HttpGetEnabled = true;
smb.MetadataExporter.PolicyVersion = PolicyVersion.Policy12;
selfHost.Description.Behaviors.Add(smb);
// Add MEX endpoint
selfHost.AddServiceEndpoint(ServiceMetadataBehavior.MexContractName, MetadataExchangeBindings.CreateMexHttpBinding(), "mex");
selfHost.Open();
Console.WriteLine("The service is ready.");
Console.ReadLine();
```
The rest of the C# code; the class VMPService above implements VMProvisionCore.IVMProvisionCore.
```
namespace VMProvisionCore
{
[ServiceContract(Namespace = "http://Cisco.VMProvision.Core", ProtectionLevel = System.Net.Security.ProtectionLevel.None)]
public interface IVMProvisionCore
{
[OperationContract]
bool AuthenticateUser(string username, string password);
}
```
I can easily create a Visual Studio 2008 client application that consumes this service. No problems. But using Delphi 2007 is a different issue. I can use the WSDL importer in Delphi to retrieve the WSDL from (in this case) <http://bernard3:8000/VMWareProvisioning/Service?wsdl> The import unit compiles just fine. I have to initialize the proxy by hand since the WSDL doesn't contain a URL (notice the extra "/CoreServices" as shown in the C# code):
```
var
Auth: AuthenticateUser;
AuthResponse: AuthenticateUserResponse;
CoreI: IVMProvisionCore;
begin
CoreI:= GetIVMProvisionCore(False, 'http://bernard3:8000/VMWareProvisioning/Service/CoreServices');
Auth:= AuthenticateUser.Create;
try
Auth.username:= 'test';
Auth.password:= 'test';
AuthResponse:= CoreI.AuthenticateUser(Auth);
finally
FreeAndNIL(Auth);
end;
```
The above code will generate an error when it hits the "CoreI.AuthenticateUser(Auth);". The error is "**Cannot process the message because the content type 'text/xml; charset="utf-8" was not the expected type 'application/soap+xml; charset=utf-8.**"
I suspect that I've got a stupid little error somewhere, perhaps during the import of the WSDL or in the connection options or something. Can anyone help? | Found the solution. It's multiple parts and requires a few changes to the C# side, more to the Delphi side. Note that this was tested with Delphi 2007 and Visual Studio 2008.
C# side:
Use BasicHttpBinding rather than WSHttpBinding.
**Fix Step 1**
```
BasicHttpBinding myBinding = new BasicHttpBinding();
myBinding.Security.Mode = BasicHttpSecurityMode.None;
```
This change will resolve the application/soap+xml errors on the Delphi side.
Delphi 2007 side:
Running against the modified C# web service will now generate errors like this:
> Exception class ERemotableException
> with message 'The message with Action
> '' cannot be processed at the
> receiver, due to a ContractFilter
> mismatch at the EndpointDispatcher.
> This may be because of either a
> contract mismatch (mismatched Actions
> between sender and receiver) or a
> binding/security mismatch between the
> sender and the receiver. Check that
> sender and receiver have the same
> contract and the same binding
> (including security requirements, e.g.
> Message, Transport, None).'
To resolve this problem, add SOAPActions to all your supported interfaces. Here's the example from my code; this must be done AFTER all of the InvRegistry changes made by the import-from-WSDL-PAS-file's initialization section:
**Fix Step 2**
```
InvRegistry.RegisterDefaultSOAPAction(TypeInfo(IVMProvisionCore), 'http://Cisco.VMProvision.Core/CoreServices/%operationName%');
```
The type name and URL should be obtainable from the Delphi generated import file from the WSDL and/or an inspection of the actual WSDL. The above example was for my own project. After these code changes, then you'll the error:
> Exception class ERemotableException
> with message 'The formatter threw an
> exception while trying to deserialize
> the message: Error in deserializing
> body of request message for
> operation....
This error is resolved by adding the following code (credits to <http://www.bobswart.nl/weblog/Blog.aspx?RootId=5:798>). Again, this new code must be after all the InvRegistry stuff in the initialization of the WSDL-to-PAS file.
**Fix Step 3**
```
InvRegistry.RegisterInvokeOptions(TypeInfo(IVMProvisionCore), ioDocument);
```
At this point, packets will go back and forth between Delphi and C# - but parameters won't work properly. The C# will receive all parameters as nulls and Delphi doesn't seem to be receiving response parameters properly. The final code step is to use a slightly customized THTTPRIO object that will allow for literal parameters. The trick to this part is to make sure that the option is applied AFTER the interface has been obtained; doing it before won't work. Here's the code from my example (just snippets).
**Fix Step 4**
```
var
R: THTTPRIO;
C: IVMProvisionCore;
begin
R:= THTTPRIO.Create(NIL);
C:= GetIVMProvisionCore(False, TheURL, R);
R.Converter.Options:= R.Converter.Options + [soLiteralParams];
```
And now - my Delphi 2007 app can talk to the C#, stand-alone, non-IIS, WCF web service! | This is caused by a SOAP version mismatch. The C# service is expecting a SOAP12 message and receiving a SOAP11 message from your Delphi app. Depending on your situation you need to change either of the two sides. I can't really comment on the Delphi side. On the WCF side you can use the BasicHttpBinding which defaults to SOAP11 or, if you need more control, use a CustomBinding specifying a message type of SOAP11. | How to consume non-IIS hosted, WCF, C# web service from Delphi 2007? | [
"",
"c#",
"wcf",
"web-services",
"delphi",
""
] |
I need to keep a field in a data-base and update it with a time somehow, then later I need to check that time to see if it was over 30 minutes ago or not, and if not, how minutes left until 30?
I am going to be doing this with PHP+MySql can anyone tell me the simplest way to do this?
Thanks!! | Let's assume you want to know how long ago the last update/insert in the table occurred.
You can set up a table with a timestamp field with an on update clause
```
CREATE TABLE foo (
id int auto_increment,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
primary key(id),
key(ts)
)
```
and then query the record with the largest value in ts
```
SELECT
TIMEDIFF(Now()-Interval 30 Minute, ts)
FROM
foo
ORDER BY
ts DESC
LIMIT
1
```
edit: This also works if you want to get all records that have been inserted/modified within e.g. the last 12 hours.
```
SELECT
TIMEDIFF(Now()-Interval 30 Minute, ts)
FROM
foo
WHERE
ts > Now()-Interval 12 hour
ORDER BY
ts DESC
```
edit2: there's also an off chance you might be interested in <http://dev.mysql.com/doc/refman/5.1/en/show-table-status.html>:
> SHOW TABLE STATUS returns the following fields:
> ...
> Update\_time
> When the data file was last updated. For some storage engines, this value is NULL. For example, InnoDB stores multiple tables in its tablespace and the data file timestamp does not apply. For MyISAM, the data file timestamp is used; however, on Windows the timestamp is not updated by updates so the value is inaccurate. | I could wrap all you insert and update MySql calls in a function something like the following:
```
function MySqlQuery($query, $res){
$result = mysql_query($qs, $res);
if($result === false){
mysql_query("QUERY STRING TO UPDATE FIELD IN DATABASE WITH NEW TIME", $res);
}
return $result;
}
```
Replace the "QUERY STRING TO UPDATE FIELD IN DATABASE WITH NEW TIME" with an actual update query and you should be good to go. | MySQL: How many minutes ago was DB updated? | [
"",
"php",
"mysql",
"php4",
""
] |
I have a php page. This has multiple images which looks like tabs. With in this php page i have a div which will load different PHP pages on click of different images i mentioned before. This is done using Ajax. This much of it works fine with no page reload. This is done to simulate the tab operation without page reload. This much of it is working fine.
But now i need to have a search operation into one of the inner php file. When i use this using Ajax on kepup to do a search operation and display the result in another div with in the inner php, it becomes a php, within php and another php into it. Totally 3 layers php with all loaded using ajax.
I am facing a problem at this stage. The first layer that is the tab operation works fine with AJAX. the next layer of search using ajax also works but reloads the outer php aswell. So it looks as if the tab is clicked instead of the search operation. So now i run into a confusion as if the concept of loading a form by ajax and then having a ajax search within itself to display the result with keyup, would it be right? will this be possible?
So is is that i have done it wrong or it is not possible to have this option? Because when i load the inner php directly with url without ajax, the search works perfectly fine. Is this possible in a simpler way using code igniter. Please let me know your comments on this and also u'r suggessions. I am sure you would have many questions on what i have asked. Please let me know your questions i will try to reply to them. All suggessions appreciated. Thanks in advance. | I think you're confusing AJAX with frame here.
When using frames, you are loading pages inside parent page, and normal operations in child pages does not affect parent.
When using AJAX, think it as inserting content into current page, and whatever content inserted becomes part of the page and whatever action performed there will affect the page, there is no concept as child page in ajax.
For your problem, as many have mentioned, you must have initiated a post-back (like form submit) when clicking Search, which causes the page to reload. | Theoretically, the idea should work. If possible, can you provide me more information?
Questions:
Is your setup similar to this?
Parent HTML (parent) > (innverdiv1) DIV where tabs load pages by ajax appear > (innerdiv2) DIV inside the loaded pages
Cause, by theory, you can make an Ajax-loaded page (innverdiv1) do ajax as well, but the new page's (innerdiv2) domain should only be limited to the DIVS inside the first ajax-loaded page. | Ajax with in Ajax. Is this possible | [
"",
"php",
"ajax",
"ajaxcontroltoolkit",
""
] |
I'm getting a "Object doesn't support this property or method error", does anyone know why?
I do have values plugged into userId, fname, lname, oname, sam, hasAccess
```
function Employee(id, fname, lname, oname, sam, access) {
this.id = id;
this.fname = fname;
this.lname = lname;
this.oname = oname
this.sam = sam;
this.access = access;
}
var emp = new Employee(userId, fname, lname, oname, sam, hasAccess);
var jsonstuff = emp.toSource(); //Breaking here
```
Although this link says its possible <http://www.w3schools.com/jsref/jsref_toSource_date.asp> | `toSource()` does not work in Internet Explorer or Safari. It is Gecko-only. See [Implementing Mozilla's toSource() method in Internet Explorer](https://stackoverflow.com/questions/171407/implementing-mozillas-tosource-method-in-internet-explorer) for alternatives. | Try using a [JSON serializer](http://www.json.org/js.html) instead. `toSource` is Mozilla specific and not supported by IE.
If you are just debugging then your best bet is going to be to [install Firebug](http://getfirebug.com/) and use console.dir(emp); to print the contents of an object to the console window.
Update: Just notice that on the [link you posted](http://www.w3schools.com/jsref/jsref_toSource_date.asp) it says, "Note: This method does not work in Internet Explorer!" And on the [MDC page](https://developer.mozilla.org/en/Core_JavaScript_1.5_Reference/Global_Objects/Object/toSource) it says "Non-Standard". | Javascript toSource() method not working | [
"",
"javascript",
""
] |
I am currently trying to cleanup a bit of a corporate website that I inherited here. I managed to clean up most of the errors in the website but something is still up here.
I have one masterpage that have this code :
```
using System;
using System.Data;
using System.Configuration;
using System.Collections;
using System.ComponentModel;
using System.Web;
using System.Web.Security;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using System.Web.UI.HtmlControls;
public partial class MasterPage : System.Web.UI.MasterPage {
public lists m_listsClass = new lists();
```
(no it's not a typo the S in lists).
Now in App\_code I have one class lists.cs
```
using System;
using System.Data;
using System.Configuration;
using System.Linq;
using System.Web;
using System.Web.Security;
using System.Web.UI;
using System.Web.UI.HtmlControls;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using System.Xml.Linq;
/// <summary>
/// Summary description for lists
/// </summary>
public class lists
{
public lists()
{
```
When I try to build the website in visual studio 2008 I have this error :
```
Error 3 The type or namespace name 'lists' could not be found (are you missing a using directive or an assembly reference?) C:\Users\egirard\Documents\Visual Studio 2008\Projects\iFuzioncorp\iFuzioncorp\Masters\MasterPage.master.cs 23 12 iFuzioncorp
```
Am I missing something ?
Also I saw some strange behaviour on the server. Apparently according to IIS7 it is compiling using .net 2.0 (the pool is configured with .net 2) but there are some `"using`" statements that include Linq ... how is it possible to compile the page if Linq is not part of the .net 2 itself ?
Just edited with news details on the code itself. No namespace at all everywhere. | Finally I understood quite lately that it was a *website* and not a *web application* I had to question the guys here to get it... So it's quite normal all the error I had. I haven't had the occasion to convert it first. | Hi There – i had a similar problem; all my namespaces and inheritance was in place. Then i then noticed that the class file’s build action was set to “Content” not “Compile” (in the properties window. | namespace or class could not be found (ASP.NET WebSite "project") | [
"",
"c#",
"asp.net",
"c#-3.0",
""
] |
I am trying to list last a website's statistics.
I listed Last 30 days with;
```
CONVERT(VARCHAR(10), S.DATEENTERED, 101)
BETWEEN
CONVERT(VARCHAR(10), GETDATE()-30, 101)
AND
CONVERT(VARCHAR(10), GETDATE(), 101)
```
and this month with;
```
RIGHT(CONVERT(VARCHAR(10), S.DATEENTERED, 103), 7) =
RIGHT(CONVERT(VARCHAR(10), GETDATE(), 103), 7)
```
but I have no idea what query to use for last month. I tried with;
```
RIGHT(CONVERT(VARCHAR(10), S.DATEENTERED, 103), 7) =
RIGHT(CONVERT(VARCHAR(10), GETDATE()-1, 103), 7)
```
Did not work. | The following will find you the start of the last month:
```
-- Start of last month
SELECT CAST('01 '+ RIGHT(CONVERT(CHAR(11),DATEADD(MONTH,-1,GETDATE()),113),8) AS datetime)
```
You would then find the start of this month, using the following, minus one.
```
-- Start of the month
SELECT CAST('01 '+ RIGHT(CONVERT(CHAR(11),GETDATE(),113),8) AS datetime)
```
When I have to work with dates in SQL Server I often reference [Robyn Page's SQL Server DATE/TIME Workbench](http://www.simple-talk.com/sql/learn-sql-server/robyn-pages-sql-server-datetime-workbench/). The workbench (tutorial) is well laid out and contains just about everything I have ever needed when working with dates on SQL Server. | Dates are always a joy to work with in any programming language, SQL not excluded.
To answer your question to find all records that occurred last month
```
select S.DATEENTERED
,*
from sometable S
where S.DATEENTERED
between dateadd(mm, datediff(mm, 0, dateadd(MM, -1, getdate())), 0)
and dateadd(ms, -3, dateadd(mm, datediff(mm, 0, dateadd(MM, -1, getdate())) + 1, 0))
order by 1
```
To expand the best means for getting records within a certain time-frame is by utilizing the datediff function, dateadd function, and the between condition in the where clause.
```
select 'howdy'
,getdate()
where getdate()
between dateadd(mm, 0, 0)
and dateadd(ms, -3, dateadd(mm, datediff(mm, 0, dateadd(mm,-1,getutcdate())) + 1, 0))
```
The above code will result in no records returned because it is checking to see if today's date is between 1900-01-01 00:00:00.000 and the last possible recorded date of last month (the last day and 23:59:59.997 - SQL Server DATETIME columns have at most a 3 millisecond resolution).
The following code will return a record as the date we are searching for is one month ago.
```
select 'howdy'
,dateadd(mm, -1, getdate())
where dateadd(mm, -1, getdate())
between dateadd(mm, 0, 0)
and dateadd(ms, -3, dateadd(mm, datediff(mm, 0, dateadd(mm,-1,getutcdate())) + 1, 0))
```
A break down of the where clause:
```
WHERE getdate() -- date to check
between dateadd(mm, 0, 0) -- begin date
and dateadd(ms, -3, dateadd(mm, datediff(mm, 0, dateadd(mm,-1,getutcdate())) + 1, 0)) -- end date
```
Finally, a variety of dates can be ascertained in this manner here is a pretty complete list:
```
select dateadd(mm, 0, 0) as BeginningOfTime
,dateadd(dd, datediff(dd, 0, getdate()), 0) as Today
,dateadd(wk, datediff(wk, 0, getdate()), 0) as ThisWeekStart
,dateadd(mm, datediff(mm, 0, getdate()), 0) as ThisMonthStart
,dateadd(qq, datediff(qq, 0, getdate()), 0) as ThisQuarterStart
,dateadd(yy, datediff(yy, 0, getdate()), 0) as ThisYearStart
,dateadd(dd, datediff(dd, 0, getdate()) + 1, 0) as Tomorrow
,dateadd(wk, datediff(wk, 0, getdate()) + 1, 0) as NextWeekStart
,dateadd(mm, datediff(mm, 0, getdate()) + 1, 0) as NextMonthStart
,dateadd(qq, datediff(qq, 0, getdate()) + 1, 0) as NextQuarterStart
,dateadd(yy, datediff(yy, 0, getdate()) + 1, 0) as NextYearStart
,dateadd(ms, -3, dateadd(dd, datediff(dd, 0, getdate()) + 1, 0)) as TodayEnd
,dateadd(ms, -3, dateadd(wk, datediff(wk, 0, getdate()) + 1, 0)) as ThisWeekEnd
,dateadd(ms, -3, dateadd(mm, datediff(mm, 0, getdate()) + 1, 0)) as ThisMonthEnd
,dateadd(ms, -3, dateadd(qq, datediff(qq, 0, getdate()) + 1, 0)) as ThisQuarterEnd
,dateadd(ms, -3, dateadd(yy, datediff(yy, 0, getdate()) + 1, 0)) as ThisYearEnd
```
Using the above list a range of any type can be determined. | GETDATE last month | [
"",
"sql",
"sql-server",
"sql-server-2005",
""
] |
If I have an array as `$keys => $values`, how can I get two arrays of `$keys` and `$values`? | Using [`array_keys()`](http://www.php.net/array_keys) and [`array_values()`](http://www.php.net/array_values).
```
$keys = array_keys($array);
$values = array_values($array);
``` | [`array_keys`](http://docs.php.net/array_keys) and [`array_values`](http://docs.php.net/array_values) will return a numerical array of the keys/values of a given array:
```
$keys = array_keys($array);
$values = array_values($array);
```
Or if you want a `foreach` solution:
```
$keys = array();
$values = array();
foreach ($array as $key => $value) {
$keys[] = $key;
$values[] = $value;
}
``` | How do I turn a PHP array into $keys and $values? | [
"",
"php",
"arrays",
"associative-array",
""
] |
I'm looking for a Java UI designer allowing me to drag and drop controls directly to the design surface in a floating mode (without the hassle of north, south etc that comes with SWT). Is there any such tool?
Also, I'm only interested in tools offering a trial version.
**EDIT**: I'm only interested in solutions allowing me to drag/drop items regardless of panels margin, LayoutManager stuff etc. The position should preferably be just relative to the window margin.
Thanks in advance | You can use NetBeans to design your GUI. Instead of messing with Layout Managers, just use the "Absolute" layout. It will put the UI Components exactly where you drop them, pixel for pixel. | Eclipse has a free visual editor called VEP. See <http://www.eclipse.org/vep/>
Instantiations has a very nice set of tools with a trial version:
<http://instantiations.com>
Note that for any visual designer, you should know how layout managers work to use them properly (and make sure your UI expands/contracts/adapts to font/locale properly). If you just use absolute placement, things can get cropped, for example.
See <http://developer.java.sun.com/developer/onlineTraining/GUI/AWTLayoutMgr/> for my article on layout management to get a feel for how to use things like North, South. It only covers the original five Java layout managers, but describes why you need them and how you can nest them. | Java UI designer + framework similar to visual studio (drag and drop, floating controls) | [
"",
"java",
"user-interface",
"gui-designer",
""
] |
I've created an ISearchable interface that I've Typed so that I can retrieve an IEnumerable of T for the results.
I have a number of services that implement ISearchable for different domain objects ...
```
Container.RegisterType<ISearchable<Animal>, AnimalService>();
Container.RegisterType<ISearchable<Fish>, FishService>();
```
I want to resolve (through Unity) an ISearchable based on the type, but am struggling to get it to work ...
The following dosn't compile but will hopefully give an idea of what I'm trying to achieve.
```
Type t = typeof(Animal);
var searchProvider = _container.Resolve<ISearchable<t>>();
```
Any helped gratefully received!
Thanks,
Andy | Finally sorted it, hopefully it'll be of help to someone else!
```
var type = filter.GetType();
var genericType = typeof(ISearchable<>).MakeGenericType(type);
var searchProvider = _unityContainer.Resolve(genericType);
``` | Why not register your types by name and resolve that way?
```
Container.RegisterType<ITelescopeView, TelescopeView>("type1");
Container.RegisterType<ITelescopeView, TelescopeView2>("type2");
Container.Resolve(ITelescopeView, "type1");
```
If you want your names can simply be the type's full name or you could use something else. Dmitri's approach will work too. But this might result in clearer code. | Unity Container - Passing in T dynamically to the Resolve method | [
"",
"c#",
"inversion-of-control",
"unity-container",
"ioc-container",
""
] |
I have two classes that refer to each other, but obviously the compiler complains. Is there any way around this?
**EDIT**
Actually my code is slightly different than what Hank Gay uses. So python can definitely deal with some kinds of circular references, but it tosses an error in the following situation. Below is what I've got and I get an 'name Y not defined error'
```
class X(models.Model):
creator = Registry()
creator.register(Y)
class Y(models.Model):
a = models.ForeignKey(X)
b = models.CharField(max_length=200)
```
Hope this helps clarify. Any suggestions. | In python, the code in a class is run when the class is loaded.
Now, what the hell does that mean? ;-)
Consider the following code:
```
class x:
print "hello"
def __init__(self): print "hello again"
```
When you load the module that contains the code, python will print `hello`. Whenever you create an `x`, python will print `hello again`.
You can think of `def __init__(self): ...` as equivalent with `__init__ = lambda self: ...`, except none of the python lambda restrictions apply. That is, `def` is an assignment, which might explain why code outside methods but not inside methods is run.
When your code says
```
class X(models.Model):
creator = Registry()
creator.register(Y)
```
You refer to `Y` when the module is loaded, before `Y` has a value. You can think of `class X` as an assignment (but I can't remember the syntax for creating anonymous classes off-hand; maybe it's an invocation of `type`?)
What you may want to do is this:
```
class X(models.Model):
pass
class Y(models.Model):
foo = something_that_uses_(X)
X.bar = something_which_uses(Y)
```
That is, create the class attributes of `X` which reference `Y` after `Y` is created. Or vice versa: create `Y` first, then `X`, then the attributes of `Y` which depend on `X`, if that's easier.
Hope this helps :) | This is a great question. Although others have already answered it, I will feel free to provide another example.
Consider this program.
```
@dataclass
class A:
b: B
class B:
def __init__(self):
pass
```
`b` is now a **class**-level variable and this program does not work. The name `B` is not defined at the moment when the Python interpreter loads (executes) the code of class `A`. Unlike compiled languages (such as C/C++), interpreters execute the code from the beginning to the end of the file command by command, in one pass. Since Python needs to know what `B` is when it defines the class `A`, it fails. `B` is only defined later.
Now, consider a slightly different program.
```
class A:
def __init__(self):
self.b = B()
class B:
def __init__(self):
pass
```
`b` is now an **object**-level variable and this program works. Python still executes the code from the beginning to the end of the file in the single pass, however, now it does not need to know what `B` is at the moment it reads the `self.b = B()` line. This is because the `__init__` method is executed only when someone wants to construct an object of class `A`. Since the construction of an object will happen somewhere later in the program (when `B` is already defined), `__init__` will work fine when it is needed. | python classes that refer to each other | [
"",
"python",
"django",
"oop",
""
] |
I'm currently toying with python at home and I'm planning to switch to python 3.1. The fact is that I have some scripts that use python 2.6 and I can't convert them since they use some modules that aren't available for python 3.1 atm. So I'm considering installing python 3.1 along with my python 2.6. I only found people on the internet that achieve that by compiling python from the source and use `make altinstall` instead of the classic `make install`. Anyway, I think compiling from the source is a bit complicated. I thought running two different versions of a program is easy on Linux (I run fedora 11 for the record). Any hint?
Thanks for reading. | On my Linux system (Ubuntu Jaunty), I have Python 2.5, 2.6 and 3.0 installed, just by installing the binary (deb) packages **'python2.5'**, **'python2.6'** and **'python3.0'** using apt-get. Perhaps Fedora packages them and names them as RPMs in a similar way.
I can run the one I need from the command line just by typing e.g. **`python2.6`**. So I can also specify the one I want at the top of my script by putting e.g.:
```
#!/usr/bin/python2.6
``` | Download the python version you want to have as an alternative, untar it, and when you configure it, use --prefix=/my/alt/dir
Cheers
```
Nik
``` | Running both python 2.6 and 3.1 on the same machine | [
"",
"python",
"linux",
"python-3.x",
""
] |
I noticed that most scripts for e-mail validation do not use DNS information to ensure the given domain actually exists.
What are the reasons why one might not use DNS checks?
Does it actually reduce the number of fake e-mails or make a form more usable?
Example snippet:
```
$host = explode('@', $email);
if(checkdnsrr($host[1].'.', 'MX') ) return true;
if(checkdnsrr($host[1].'.', 'A') ) return true;
if(checkdnsrr($host[1].'.', 'CNAME') ) return true;
``` | Most sites, especially ones that retain login information, send confirmation emails after you sign up. This not only confirms the email address is valid but also confirms that the email address belongs to the submitter. Having a DNS lookup would be redundant unless you wanted to tip off the user that they misspelled their email address.
And if I wanted to put in a fake email address, aaa@aaa.com (AAA, the auto club) and somebody@example.com (from RFC 2606) would both pass. I don't think a DNS lookup would catch as many fake addresses as you think. | It might be slow to do so. If you do DNS validation in a form, it would be wise to use AJAX in some way to start validating before the form is submitted.
Other than that, your check would fail on addresses with literal IP addresses, but personally I wouldn't want to accept those on my web form anyway. I don't care if they're RFC822 compliant ;) | Should e-mail validation using DNS/MX record be used? | [
"",
"php",
"email",
"forms",
"validation",
""
] |
I have a website that tells the output is UTF-8, but I never make sure that it is. Should I use a regular expression or Iconv library to convert UTF-8 to UTF-8 (leaving invalid sequences)? Is this a security issue if I do not do it? | First of all I would never just blindly encode it as UTF-8 (possibly) a second time because this would lead to invalid chars as you say. I would certainly try to detect if the charset of the content is *not* UTF-8 before attempting such a thing.
Secondly if the content in question comes from a source wich you have control over and control the charset for such as a file with UTF-8 or a database with UTF-8 in use in the tables and on the connection, I would trust that source unless something gives me hints that I can't and there is something funky going on. If the content is coming from more or less random places outside your control, well all the more reason to inspect it and possibly try to re-encode og transform from other charsets if you can detect it. So the bottom line is: It depends.
As to wether this is a security issue or not I wouldn't think so (at least I can't think of any scenarios where this could be exploitable) but I'll leave to others to be definitive about that. | Not a security issue, but your users (especially non-english speaking) will be very annoyed, if you send invalid UTF-8 byte streams.
In the best case (what most browsers do) all invalid strings just disappear or show up as gibberish. The worst case is that the browser quits interpreting your page and says something like "invalid encoding". That is what, e.g., some text editors (namely gedit) on Linux do.
OK, to keep it realistic: If you have an english-centered website without heavily relying on some maths characters or Unicode arrows, it will almost make no difference. But if you serve, e.g., a Chinese site, you can totally screw it up.
Cheers, | Do I need to make sure output data is valid UTF-8? | [
"",
"php",
"utf-8",
""
] |
I am trying to find out the difficulty of implementing a queue system. I know how to implement a basic queue, so i'll explain a little about what i'm after with some background:
I will be implementing a queue where messages will be placed, this will come from several users, the messages will be scheduled to be posted at user defined times (multiple occurrences are allowed with the precision of Minutes, from a UI perspective i will be restricting: "every minute or every hour" occurrences but id like the system to still be able to handle this).
Here is where my question comes in:
Eventually I may be in a situation (and maybe not) where MANY messages need to be posted at the current time, I'd like to have several processes (multiple instances of a script) running to fetch [x,10,25] number of messages from the queue at a time and process them. The problem is: how to do this so that each instance processes unique messages (without processing something that is already being processed by another instance)? I'm worried about current connections, how to lock records, and anything else i may not be thinking about.
Technologies I will be using are PHP and MySQL. I am looking for some solutions to the above, terms I should be using in my searches, real world examples, thoughts, comments and ideas?
Thanks you all!
One solution i came across was using Amazon Simple Queue Service ... it promises unique message processing/locking <http://aws.amazon.com/sqs/> | Well, I'd do it like this:
Make your table for messages and add two more fields - "PROCESS\_ID" and "PROCESS\_TIME". These will be explained later.
Give each process a unique ID. They can generate it at the startup (like a GUID), or you can assign them yourself (then you can tell them apart more easily).
When a process wants to fetch a bunch of messages, it then does something like this:
1. `UPDATE messages SET process_id=$id, process_time=now() where process_id is null LIMIT 20`
2. SELECT \* FROM messages WHERE process\_id=$id
This will find 20 "free" messages and "lock" them. Then it will find the messages that it locked and process them. After each message is processed, `DELETE` it.
The UPDATE statement should be pretty atomic, especially if you use InnoDB, which wraps each such statement in a transaction automatically. MySQL should take care of all the concurrency there.
The PROCESS\_TIME field is optional, but you can use that to see when a process has hanged. If a message is locked for too long, you can conclude that something went wrong and investigate. | Have a look at the [Beanstalkd](http://xph.us/software/beanstalkd/) message queue. There are PHP clients for it. One of the nice features of Beanstalkd (as opposed to e.g. dropr) is that you can delay messages. That is, you can post a message to the queue and it will not be delivered to a client until X seconds have passed.
Beanstalkd does have one big downside though: It's an in-memory queue. That means if it (or your machine) crashes then the queue is empty and the contents lost. Persistence is a feature planned for the next version of beanstalkd. | what are queue access concurrency solutions? | [
"",
"php",
"mysql",
"transactions",
"process",
"innodb",
""
] |
I have a php script that is run once a minute. The script runs a second script, then sleeps for a given amount of time.
Right now the time is static. 20 seconds each time.
What I need is to randomize the amount of time it sleeps. It can be more than a total of 60 seconds, but not less.
So here is what i have now.
```
$sleep1 = rand(2,18);
$sleep2 = rand(2,18);
$sleep3 = rand(2,18);
$sleep4 = rand(2,18);
if $sleep1 + $sleep2 + $sleep3 + $sleep4 <= 60 ?
```
I need to add up all the `$sleep` variables, and then determine if the total is less than 60. If it is, I need to increase the value of one or more of the variables to make up the difference. | If you can have more than, or do not need exactly 4 $sleep\_ variables:
```
<?php
$time = 0;
$i = 1;
$array = array();
do {
$sleep{$i} = rand(2,18);
$array[] = $sleep{$i};
$time += $sleep{$i};
$i++;
} while ($time <= 60);
print_r($array);
echo $time;
?>
```
Gives you something like:
```
Array
(
[0] => 5
[1] => 2
[2] => 18
[3] => 9
[4] => 11
[5] => 10
[6] => 3
[7] => 13
)
71
``` | Why not pass that value to [`rand()`](http://php.net/rand)?
```
sleep(rand(60, 120));
```
If you really need your method, just use [`max()`](http://php.net/max):
```
sleep(max(60, $sleep1 + $sleep2 + $sleep3 + $sleep4));
``` | Check if a series of numbers adds up to a set value, and increase if necessary | [
"",
"php",
"random",
""
] |
One of the most difficult things about understand Spring is that Spring supports multiple approaches to the same problem.
So in my application I using injected EntityManager using the @PersistanceContext annotation, for example:
```
@Repository
public class JpaDao extends JpaDaoSupport implements Dao {
@PersistenceContext(unitName = "PersistanceUnit", type = PersistenceContextType.EXTENDED)
private EntityManager em;
```
**Is this approach compatible with extending JpaDaoSupport** (which requires injecting in an EntityManager)? To me it looks like two incompatible approaches to the solving the same problem, but I would like some advice from someone who has more experience with Spring.
If I shouldn't be extending JpaDaoSupport, how should I build my DAO using the @PersistenceContext approach? | You're correct that they are two different approaches to the same problem. Which one is "better" is a matter of taste, I think. Using annotations has the benefit of avoiding Spring import dependencies in your code, and even the Spring JavaDoc for **JpaDaoSupport** suggests using them for new JPA projects. **JpaDaoSupport** is there to make Spring's support for JPA equivalent to its support for other ORM strategies (**HibernateDaoSupport**, **JdbcDaoSupport**, **TopLinkDaoSupport**, etc.). In those cases, annotation-based injection isn't an option. | For injecting the EntityManager you just need to add the next definition
```
<bean class="org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor" />
```
you can get more information about this topic in [this post](http://blog.springsource.com/2006/08/07/using-jpa-in-spring-without-referencing-spring/) from the oficial blog | Spring DaoSupport and @PersistanceContext EntityManager? | [
"",
"java",
"spring",
"jpa",
"persistence",
"dao",
""
] |
Alex explained what I'm looking for much better than I have:
> You want an existing program that
> allows you to draw a picture, captures
> what you do as you draw, and writes
> each action as a Java command. When
> you click the "Drawl Oval" tool and
> click at 0,0 and then at 50,50, it
> would generate the line
> g.drawOval(0,0,50,50).
If anybody knows of a program such as this, let me know. Thanks.
---
*Original question:*
I've been working with Java and custom drawing using the java.awt.Graphics library lately, but find it is taking too much time to write manually. Is there any simple graphics editor (like mspaint) which generates source code?
Example:
Drawing this:

Would generate:
```
public void update(Graphics g) {
g.translate(0, 0);
g.drawOval(0, 0, 50, 50);
}
```
Thanks. | If they are vectors, you could use an SVG Editor (eg, Inkscape) along with [Kirill's SVG to Java2D](http://weblogs.java.net/blog/kirillcool/archive/2006/10/svg_and_java_ui_3.html) Transcoder to simplify this. It isn't perfect, but Kirill is very responsive in responding to requests for enhancement. | It's unclear what you are asking. Two guesses:
1. You want an existing program that allows you to draw a picture, captures what you do as you draw, and writes each action as a Java command. When you click the "Drawl Oval" tool and click at 0,0 and then at 50,50, it would generate the line `g.drawOval(0,0,50,50)`.
I do not know of any such tool. But the above might help you reword your question so that others can share their knowledge.
2. You want a program that takes an existing bitmap and converts it into a series of commands that will replicate the bitmap. Other than simply outputting pixels, such a tool is nearly impossible to write; attempting to decompose an arbitrary picture into simple drawing commands is very hard.
In this case, I would recommend simply importing the bitmap as a JPG, PNG, whatever, and using drawImage() instead of using Graphics calls. | Java Image Editor which renders output as source code? | [
"",
"java",
"graphics",
"code-generation",
"image-editor",
""
] |
I'm finding it difficult to find a decent example on how to implement a parent-child hierarchy class.
I have a treeView control that I want to convert into a class hierarchy, adding extra data to each node and be able to easely iterate over each parent's nodes using IEnumerable.
```
public IEnumerable<Node> GetAllChildsFromParent(Node parent)
{
foreach (Node node in parent.NodeChildsCollection)
{
yield return node;
}
}
```
I already have implemented the following piece of code but got stuck and don't really
have a clue whether I am on the right track or not? How should I proceed to complete this ?
```
public class NodeChildsCollection : IEnumerable<Node>
{
IList<Node> nodeCollection = new List<Node>();
Node parent;
public Node Parent
{
get { return parent; }
set { parent = value; }
}
public NodeChildsCollection()
{
}
public void AddNode(Node parent, Node child)
{
this.parent = parent;
nodeCollection.Add(child);
}
#region IEnumerable<Node> Members
public IEnumerator<Node> GetEnumerator()
{
foreach (Node node in nodeCollection)
{
yield return node;
}
}
#endregion
#region IEnumerable Members
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
#endregion
}
public class Node
{
NodeChildsCollection nodeChildsCollection = new NodeChildsCollection();
public Node Parent
{
get { return nodeChildsCollection.Parent; }
set { nodeChildsCollection.Parent = value; }
}
public void AddChild(Node child)
{
nodeChildsCollection.AddNode(this, child);
}
}
``` | You're mixing the responsibilities of the Node with the responsibilities of the collection. See how you're setting the parent in the collection? It's not the collection that has a parent; its the node.
I'd structure my nodes like thus:
```
public class Node
{
public Node Parent {get;set;} // null for roots
public NodeCollection Children {get; private set;}
public Node()
{
Children = new NodeCollection();
Children.ChildAdded += ChildAdded;
Children.ChildRemoved += ChildRemoved;
};
private void ChildAdded(object sender, NodeEvent args)
{
if(args.Child.Parent != null)
throw new ParentNotDeadYetAdoptionException("Child already has parent");
args.Child.Parent = this;
}
private void ChildRemoved(object sender, NodeEvent args)
{
args.Child.Parent = null;
}
}
```
And the NodeCollection would look like
```
public class NodeCollection : INodeCollection {/*...*/}
```
and INodeCollection would be:
```
public interface INodeColleciton : IList<Node>
{
event EventHandler<NodeEvent> ChildAdded;
event EventHandler<NodeEvent> ChildRemoved;
}
```
The collection responsibilities are on the Child collection property of the Node. You can, of course, have node implement INodeCollection, but that's a matter of programming tastes. I prefer to have the Children public property (its how the framework is designed).
With this implementation you don't need to implement a "GetChildren" method; the public Children property provides them for all. | I found the [this blog article](http://dvanderboom.wordpress.com/2008/03/15/treet-implementing-a-non-binary-tree-in-c/) quite useful when attempting to solve the same problem. | Implement a parent-child class hierarchy | [
"",
"c#",
"collections",
".net-2.0",
"parent-child",
""
] |
I'm rusty with delegates and closures in JavaScript, and think I came across a situation where I'd like to try to use one or both.
I have a web app that behaves a lot like a forms app, with fields hitting a server to change data on every onBlur or onChange (depending on the form element). I use ASP.NET 3.5's Web Services and jQuery to do most of the work.
What you need to know for the example:
* `isBlocking()` is a simple mechanism to form some functions to be synchronous (like a mutex)
* `isDirty(el)` checks to make sure the value of the element actually changed before wasting a call to the server
* `Agent()` returns a singleton instance of the WebService proxy class
* `getApplicationState()` passes a base-64 encoded string to the web service. This string represents the state of the application -- the value of the element and the state are passed to a service that does some calculations. The onSuccess function of the web service call returns the new state, which the client processes and updates the entire screen.
* `waitForCallback()` sets a flag that `isBlocking()` checks for the mutex
Here's an example of one of about 50 very similar functions:
```
function Field1_Changed(el) {
if (isBlocking()) return false;
if (isDirty(el)) {
Agent().Field1_Changed($j(el).val(), getApplicationState());
waitForCallback();
}
}
```
The big problem is that the `Agent().Field_X_Changed` methods can accept a different number of parameters, but it's usually just the value and the state. So, writing these functions gets repetitive. I have done this so far to try out using delegates:
```
function Field_Changed(el, updateFunction, checkForDirty) {
if (isBlocking()) return false;
var isDirty = true; // assume true
if (checkForDirty === true) {
isDirty = IsDirty(el);
}
if (isDirty) {
updateFunction(el);
waitForCallback();
}
}
function Field1_Changed(el) {
Field_Changed(el, function(el) {
Agent().Field1_Changed($j(el).val(), getTransactionState());
}, true);
}
```
This is ok, but sometimes I could have many parameters:
```
...
Agent().Field2_Changed($j(el).val(), index, count, getApplicationState());
....
```
What I'd ultimately like to do is make one-linen calls, something like this (notice no `getTransactionState()` calls -- I would like that automated somehow):
```
// Typical case: 1 value parameter
function Field1_Changed(el) {
Field_Changed(el, delegate(Agent().Field1_Changed, $j(el).val()), true);
}
// Rare case: multiple value parameters
function Field2_Changed(el, index, count) {
Field_Changed(el, delegate(Agent().Field1_Changed, $j(el).val(), index, count), true);
}
function Field_Changed(el, theDelegate, checkIsDirty) {
???
}
function delegate(method) {
/* create the change delegate */
???
}
```
Ok, my first question is: Is this all worth it? Is this harder to read but easier to maintain or the other way around? This is a pretty good undertaking, so I may end up putting a bounty on this one, but I'd appreciate any help you could offer. Thanks!
**UPDATE**
So, I've accepted an answer based on the fact that it pointed me in the right direction. I thought I'd come back and post my solution so that others who may just be starting out with delegates have something to model from. I'm also posting it to see if anybody wants to try an optimize it or make suggestions. Here's the common `Field_Changed()` method I came up with, with `checkForDirty` and `omitState` being optional parameters:
```
function Field_Changed(el, args, delegate, checkForDirty, omitState) {
if (isBlocking()) return false;
if (!$j.isArray(args) || args.length == 0) {
alert('The "args" parameter in Field_Changed() must be an array.');
return false;
}
checkForDirty = checkForDirty || true; // assume true if not passed
var isDirty = true; // assume true for updates that don't require this check
if (checkForDirty === true) {
isDirty = fieldIsDirty(el);
}
if (isDirty) {
omitState = omitState || false; // assume false if not passed
if (!omitState) {
var state = getTransactionState();
args.push(state);
}
delegate.apply(this, args);
waitForCallback();
}
}
```
It handles everything I need it to (check for dirty, applying the application state when I need it to, and forcing synchronous webservice calls. I use it like this:
```
function TransactionAmount_Changed(el) {
Field_Changed(el, [cleanDigits($j(el).val())], Agent().TransactionAmount_Changed, true);
}
```
`cleanDigits` strips out junk characters the user may have tried to type in. So, thanks to everyone, and happy coding! | OK, few things:
1. Delegates are extremely simple in javascript since functions are first class members.- `Function.apply` lets you call a function with an array of arguments.
So you can write it this way
```
function Field_Changed(delegate, args)
{
if (isBlocking()) return false;
if (isDirty(args[0])) { //args[0] is el
delegate.apply(this, args);
waitForCallback();
}
}
```
And call it as:
```
Field_Changed(Agent().Field2_Changed, [el, getApplicationState(), whatever...]);
``` | I have been using the following utility function that I wrote a long time ago:
```
/**
* @classDescription This class contains different utility functions
*/
function Utils()
{}
/**
* This method returns a delegate function closure that will call
* targetMethod on targetObject with specified arguments and with
* arguments specified by the caller of this delegate
*
* @param {Object} targetObj - the object to call the method on
* @param {Object} targetMethod - the method to call on the object
* @param {Object} [arg1] - optional argument 1
* @param {Object} [arg2] - optional argument 2
* @param {Object} [arg3] - optional argument 3
*/
Utils.createDelegate = function( targetObj, targetMethod, arg1, arg2, arg3 )
{
// Create an array containing the arguments
var initArgs = new Array();
// Skip the first two arguments as they are the target object and method
for( var i = 2; i < arguments.length; ++i )
{
initArgs.push( arguments[i] );
}
// Return the closure
return function()
{
// Add the initial arguments of the delegate
var args = initArgs.slice(0);
// Add the actual arguments specified by the call to this list
for( var i = 0; i < arguments.length; ++i )
{
args.push( arguments[i] );
}
return targetMethod.apply( targetObj, args );
};
}
```
So, in your example, I would replace
```
function Field1_Changed(el) {
Field_Changed(el, delegate(Agent().Field1_Changed, $j(el).val()), true);
}
```
With something along the lines
```
function Field1_Changed(el) {
Field_Changed(el, Utils.createDelegate(Agent(), Agent().Field1_Changed, $j(el).val()), true);
}
```
Then, inside of `Agent().FieldX_Changed` I would manually call `getApplicationState()` (and encapsulate that logic into a generic method to process field changes that all of the `Agent().FieldX_Changed` methods would internally call). | Can I get some advice on JavaScript delegates? | [
"",
"asp.net",
"javascript",
"jquery",
"delegates",
"closures",
""
] |
I am working on a social network, and I am doing it with php and mysql, I need to know how to make users have customizable profiles...
Like editing status, ect...
Also making it so only friends can veiw their profile..
Also how do I add a user's page/directory to the website directory(example: domainname.com/someonesprofile)
Thank You
-Techy | That's a pretty generic question, but I'll give it a whirl.
First of all, you need to determine what a profile should contain and so forth, such as status, relationships, name, addresses, .... The list goes on. You then need to write an interface to a service that provides this information; this can be a PHP function, a class, whatever, really.
Second, you need to access this interface from within your web application. A suitable course of action is probably to have a function that assures that whoever is trying to access the information is logged in, is in the relevant authorization group (friends list), and so on.
The editing part is done quite simply through an HTML form or similar; there's no magick[sic] involved. The function to parse this form would again assure that the logged in user has the appropriate rights to edit the profile (e.g. is the same user or a trustee of some kind, parent, lover, who knows...)
As for the last bit; here mod\_rewrite is your friend. You probably would want to have URLs along the line of <http://example.org/profile/username> , which the server would translate to /?action=profile&user=username, or something to that effect.
The file /profile/username would as such not exist on the server file system in any real sense, but seem to be a completely normal HTML file when viewed from the outside. | You must start with the database. You will need a table for Person, obviously. You will need a table that joins Person to Person many-to-many, for viewing privileges. You will need a table for levels of authorization. And you will need other tables that serve up what privileges go where.
The interface is secondary. Some developers would use something simpler than PHP to develop the UI functions that rely on these database resources. | Making A Website With Profiles | [
"",
"php",
"profile",
"social-networking",
""
] |
The following piece of code is used to print the time in the logs:
```
#define PRINTTIME() struct tm * tmptime;
time_t tmpGetTime;
time(&tmpGetTime);
tmptime = localtime(&tmpGetTime);
cout << tmptime->tm_mday << "/" <<tmptime->tm_mon+1 << "/" << 1900+tmptime->tm_year << " " << tmptime->tm_hour << ":" << tmptime->tm_min << ":" << tmptime->tm_sec<<">>";
```
Is there any way to add milliseconds to this? | To have millisecond precision you have to use system calls specific to your OS.
In Linux you can use
```
#include <sys/time.h>
timeval tv;
gettimeofday(&tv, 0);
// then convert struct tv to your needed ms precision
```
`timeval` has microsecond precision.
In Windows you can use:
```
#include <Windows.h>
SYSTEMTIME st;
GetSystemTime(&st);
// then convert st to your precision needs
```
Of course you can use [Boost](http://en.wikipedia.org/wiki/Boost_C%2B%2B_Libraries) to do that for you :) | //***C++11 Style:***
```
cout << "Time in Milliseconds =" <<
chrono::duration_cast<chrono::milliseconds>(chrono::steady_clock::now().time_since_epoch()).count()
<< std::endl;
cout << "Time in MicroSeconds=" <<
chrono::duration_cast<chrono::microseconds>(chrono::steady_clock::now().time_since_epoch()).count()
<< std::endl;
``` | Capturing a time in milliseconds | [
"",
"c++",
"stl",
"timer",
"resolution",
""
] |
Someone else's process is creating a CSV file by appending a line at a time to it, as events occur. I have no control over the file format or the other process, but I know it will only append.
In a Java program, I would like to monitor this file, and when a line is appended read the new line and react according to the contents. Ignore the CSV parsing issue for now. What is the best way to monitor the file for changes and read a line at a time?
Ideally this will use the standard library classes. The file may well be on a network drive, so I'd like something robust to failure. I'd rather not use polling if possible - I'd prefer some sort of blocking solution instead.
Edit -- given that a blocking solution is not possible with standard classes (thanks for that answer), what is the most robust polling solution? I'd rather not re-read the whole file each time as it could grow quite large. | Since Java 7 there has been the [newWatchService()](http://docs.oracle.com/javase/7/docs/api/java/nio/file/FileSystem.html#newWatchService%28%29) method on the [FileSystem class](http://docs.oracle.com/javase/7/docs/api/java/nio/file/FileSystems.html).
However, there are some caveats:
* It is only Java 7
* It is an optional method
* it only watches directories, so you have to do the file handling yourself, and worry about the file moving etc
Before Java 7 it is not possible with standard APIs.
I tried the following (polling on a 1 sec interval) and it works (just prints in processing):
```
private static void monitorFile(File file) throws IOException {
final int POLL_INTERVAL = 1000;
FileReader reader = new FileReader(file);
BufferedReader buffered = new BufferedReader(reader);
try {
while(true) {
String line = buffered.readLine();
if(line == null) {
// end of file, start polling
Thread.sleep(POLL_INTERVAL);
} else {
System.out.println(line);
}
}
} catch(InterruptedException ex) {
ex.printStackTrace();
}
}
```
As no-one else has suggested a solution which uses a current production Java I thought I'd add it. If there are flaws please add in comments. | You can register to get notified by the file system if any change happens to the file using WatchService class. This requires Java7, here the link for the documentation <http://docs.oracle.com/javase/tutorial/essential/io/notification.html>
here the snippet code to do that:
```
public FileWatcher(Path dir) {
this.watcher = FileSystems.getDefault().newWatchService();
WatchKey key = dir.register(watcher, ENTRY_MODIFY);
}
void processEvents() {
for (;;) {
// wait for key to be signalled
WatchKey key;
try {
key = watcher.take();
} catch (InterruptedException x) {
return;
}
for (WatchEvent<?> event : key.pollEvents()) {
WatchEvent.Kind<?> kind = event.kind();
if (kind == OVERFLOW) {
continue;
}
// Context for directory entry event is the file name of entry
WatchEvent<Path> ev = cast(event);
Path name = ev.context();
Path child = dir.resolve(name);
// print out event
System.out.format("%s: %s file \n", event.kind().name(), child);
}
// reset key and remove from set if directory no longer accessible
boolean valid = key.reset();
}
}
``` | In Java, what is the best/safest pattern for monitoring a file being appended to? | [
"",
"java",
"file",
"nio",
""
] |
I want to save a PdfSharp.Pdf.PdfDocument by its Save method to a Stream, but it doesn't attach the PDF header settings to it. So when I read back the Stream and return it to the user, he see that the PDF file is invalid. Is there a solution to attach the PDF header settings when PDFsharp saves to memory? | So the solution:
```
MigraDoc.DocumentObjectModel.Document doc = new MigraDoc.DocumentObjectModel.Document();
MigraDoc.Rendering.DocumentRenderer renderer = new DocumentRenderer(doc);
MigraDoc.Rendering.PdfDocumentRenderer pdfRenderer = new MigraDoc.Rendering.PdfDocumentRenderer();
pdfRenderer.PdfDocument = pDoc;
pdfRenderer.DocumentRenderer = renderer;
using (MemoryStream ms = new MemoryStream())
{
pdfRenderer.Save(ms, false);
byte[] buffer = new byte[ms.Length];
ms.Seek(0, SeekOrigin.Begin);
ms.Flush();
ms.Read(buffer, 0, (int)ms.Length);
}
```
There is this MigraDoc stuff which comes with PdfSharp, but i hardly found any proper doc/faq for it. After hours of googling i've found a snippet which was something like this. Now it works. | If you think there is an issue with PdfDocument.Save, then please report this on the PDFsharp forum (but please be more specific with your error description).
Your "solution" looks like a hack to me.
"pdfRenderer.Save" calls "PdfDocument.Save" internally.
Whatever the problem is - your "solution" still calls the same Save routine.
Edit:
To get a byte[] containing a PDF file, you only have to call:
```
MemoryStream stream = new MemoryStream();
document.Save(stream, false);
byte[] bytes = stream.ToArray();
```
Early versions of PDFsharp do not reset the stream position.
So you have to call
```
ms.Seek(0, SeekOrigin.Begin);
```
to reset the stream position before reading from the stream; this is no longer required for current versions.
Using ToArray can often be used instead of reading from the stream.
Edit 2: instead of `stream.ToArray()` it may be more efficient to use `stream.GetBuffer()`, but this buffer is usually larger than the PDF file and you only have to use `stream.Length` bytes from that buffer. Very useful for method that take a `byte[]` along with a length parameter. | PDFsharp save to MemoryStream | [
"",
"c#",
".net",
"pdf",
"stream",
"pdfsharp",
""
] |
Is there a SQL equivalent to `#define`?
I am using `NUMBER(7)` for ID's in my DB and I'd like to do something like:
```
#define ID NUMBER(7)
```
Then I could use ID in the creation of my tables:
```
CREATE table Person (
PersonID ID,
Name VARCHAR2(31)
)
```
This will allow me to easily change the type of all of my IDs if I realize I need more/less space later. | In SQL Plus scripts you can use a substitution variable like this:
```
DEFINE ID = "NUMBER(7)"
CREATE table Person (
PersonID &ID.,
Name VARCHAR2(31)
);
``` | Basic definitions (similar to the C #define) are called inquiry directives. the inquiry directive cannot be used to define macros.
You can read about inquiry directives [here](http://www.mcs.csueastbay.edu/support/oracle/doc/10.2/appdev.102/b14261/fundamentals.htm) but I think that what you need it's a simple constant.
```
constant_name CONSTANT datatype := VALUE;
``` | #define Equivalent for Oracle SQL? | [
"",
"sql",
"oracle",
""
] |
Is there a built-in data structure in Java to represent a Crit-bit tree? Or any libraries available that might provide this functionality? I would also accept brief code as an answer, if one can be implemented in a simplistic brief way. | Did you try the [**radixtree**](http://code.google.com/p/radixtree/) java project?
You might find in it the structure you are looking for, like the:
* **RadixTree** class
(extract):
```
/**
* This interface represent the operation of a radix tree. A radix tree,
* Patricia trie/tree, or crit bit tree is a specialized set data structure
* based on the trie that is used to store a set of strings. In contrast with a
* regular trie, the edges of a Patricia trie are labelled with sequences of
* characters rather than with single characters. These can be strings of
* characters, bit strings such as integers or IP addresses, or generally
* arbitrary sequences of objects in lexicographical order. Sometimes the names
* radix tree and crit bit tree are only applied to trees storing integers and
* Patricia trie is retained for more general inputs, but the structure works
* the same way in all cases.
*
* @author Tahseen Ur Rehman
* email: tahseen.ur.rehman {at.spam.me.not} gmail.com
*/
public interface RadixTree<T> {
/**
* Insert a new string key and its value to the tree.
*
* @param key
* The string key of the object
* @param value
* The value that need to be stored corresponding to the given
* key.
* @throws DuplicateKeyException
*/
public void insert(String key, T value) throws DuplicateKeyException;
```
* **RadixTreeNode** class
(extract):
```
/**
* Represents a node of a Radix tree {@link RadixTreeImpl}
*
* @author Tahseen Ur Rehman
* @email tahseen.ur.rehman {at.spam.me.not} gmail.com
* @param <T>
*/
class RadixTreeNode<T> {
private String key;
private List<RadixTreeNode<T>> childern;
private boolean real;
private T value;
/**
* intailize the fields with default values to avoid null reference checks
* all over the places
*/
public RadixTreeNode() {
key = "";
childern = new ArrayList<RadixTreeNode<T>>();
real = false;
}
``` | Another option is rkapsi's [patricia-trie](https://github.com/rkapsi/patricia-trie), or if you're looking for something a little less complicated that you can hack on yourself, you can try his [simple-patricia-trie](https://github.com/rkapsi/simple-patricia-trie).
I've also got a [functional-critbit](https://github.com/jfager/functional-critbit) implementation available that's focused on space-efficiency (though its performance is fine, as well). It comes in both mutable and immutable flavors. | Java Crit-bit Trees | [
"",
"java",
"collections",
"tree",
""
] |
I wonder what is the most useful class in the [Google collections framework](http://code.google.com/p/google-collections/)? | In my experience, `Iterables` and `Lists`.
I use `Lists.newArrayList` frequently (usually as a static import) and `Iterables` is the closest that Java gets to LINQ...
Oh, and not particularly collection-y, but `Preconditions.checkNotNull` is very handy too, again with a static import:
```
public MyClass (String name, ...)
{
this.name = checkNotNull(name);
// etc
}
```
Then there's all the immutability stuff, multi-maps, `MapMaker` etc... It's just a great library. KevinB et al rock :) | Inside Google, the answer is com.google.common.collect.Lists. | What is the most used class in Google collections framework? | [
"",
"java",
"entity-framework",
"collections",
"frameworks",
""
] |
I'm sorry for flaming std::string and std::wstring. They are quite limited and far from being thread safe. Performance wise, they are not that good too. I miss simple features:
1. Splitting a string into array/vector/list
2. Simple & intuitive case-insensitive find & replace
3. Support for i18n without worrying about string or wstring
4. Conversion to and from int, float, double
5. Conversion to and from UTF-8, UTF-16 & other encodings
6. Thread-safe/reentrant
7. Small footprint & no dependencies
8. Highly portable & cross-platform
I've found Qt QString to be useful and also found CBString <http://bstring.sourceforge.net/bstrFAQ.shtml>
Any other suggestions & comparisons? Thank you. | The [C++ String Algorithms Library](http://www.boost.org/doc/libs/1_39_0/doc/html/string_algo.html) from [Boost](http://boost.org) has pretty much all of the features you need. | The C++ String Toolkit (StrTk) Library is a free library that consists of robust, optimized and portable generic string processing algorithms and procedures for the C++ language. The library is designed to be easy to use and integrate within existing code.
The library has the following capabilities:
* Generic string tokenizer and token iterators
* Split routines
* User specified delimiter and splitter policies (simple and regex based etc.)
* Conversions between data and hex and base-64
* In-place removal and replace routines
* Wild-card matching and globing
* Fast 2D token grid processing
* Extensible string processing templates
and plenty more...
Compatible C++ Compilers:
* GCC 4.0+
* Intel C++ Compiler 9.0+
* Microsoft Visual C++ 8.0+
* Comeau C/C++ 4.1+
Source:
* Download: <http://www.partow.net/programming/strtk/index.html>
* SVN: <http://code.google.com/p/strtk/> | Good C++ string manipulation library | [
"",
"c++",
"string",
""
] |
I have this c# web app that relies heavily on two dll files that i can't see nor edit. The rest of the app is visible and editable.
The app generates SQL exceptions, and i would like to see the queries sent from the DLLs. Is there a way to do that? | You can use [SQL Profiler](http://msdn.microsoft.com/en-us/library/ms187929.aspx) to see the queries that goes to your database. | For SQL Server 2005/2008 Express you can try [AnjLab's SQL Profiler](http://sqlprofiler.googlepages.com/). | How can i see the SQL Server queries coming from my program? | [
"",
"sql",
"sql-server",
""
] |
Is it possible, in Javascript, to prompt user for downloading a file that isn't actually on the server, but has contents of a script variable, instead?
Something in spirit with:
```
var contents = "Foo bar";
invoke_download_dialog(contents, "text/plain");
```
Cheers,
MH | javascript: URIs should work for this - indeed, this is exactly what they're meant for. However, IE doesn't honour the type attribute, and in Safari this technique has no effect at all.
data: URIs work in Firefox (3.0.11) and Safari (4.0) (and probably other compliant browsers), but I can't get this approach to work in IE (8.0). (All tested in Windows)
`<a href="data:text/plain,The%20quick%20brown%20fox%20jumps%20over%20the%20lazy%20dog.">Data URI</a>`
This isn't a JS solution in itself, but JS can be used to set the href dynamically. Use the escape function to turn raw text/data into URI-encoded form.
Combining this with detecting IE and using the IE-specific solution already linked to might do what you want....
I shall add that you can't force it to trigger a download dialog (that's beyond the scope of both HTML and JS), but you can persuade it to do so by setting application/octet-stream as the type. Trouble is that the user'll then have to add the right filename extension manually. | See the accepted answer to my question [here](https://stackoverflow.com/questions/1067162/download-javascript-generated-xml-in-ie6). This is only possible in IE browsers.
```
document.execCommand('SaveAs',true,'file.xml')
``` | Downloading a variable | [
"",
"javascript",
""
] |
How to find how much disk space is left using Java? | Have a look at the File class [documentation](http://java.sun.com/javase/6/docs/api/java/io/File.html#getTotalSpace()). This is one of the new features in 1.6.
These new methods also include:
* `public long getTotalSpace()`
* `public long getFreeSpace()`
* `public long getUsableSpace()`
---
If you're still using 1.5 then you can use the [Apache Commons IO](http://commons.apache.org/io/description.html) library and its [FileSystem class](http://commons.apache.org/proper/commons-configuration/apidocs/org/apache/commons/configuration/FileSystem.html) | Java 1.7 has a slightly different API, free space can be queried through the [FileStore](http://download.oracle.com/javase/7/docs/api/java/nio/file/FileStore.html) class through the [getTotalSpace()](http://download.oracle.com/javase/7/docs/api/java/nio/file/FileStore.html#getTotalSpace%28%29), [getUnallocatedSpace()](http://download.oracle.com/javase/7/docs/api/java/nio/file/FileStore.html#getUnallocatedSpace%28%29) and [getUsableSpace()](http://download.oracle.com/javase/7/docs/api/java/nio/file/FileStore.html#getUsableSpace%28%29) methods.
```
NumberFormat nf = NumberFormat.getNumberInstance();
for (Path root : FileSystems.getDefault().getRootDirectories()) {
System.out.print(root + ": ");
try {
FileStore store = Files.getFileStore(root);
System.out.println("available=" + nf.format(store.getUsableSpace())
+ ", total=" + nf.format(store.getTotalSpace()));
} catch (IOException e) {
System.out.println("error querying space: " + e.toString());
}
}
```
The advantage of this API is that you get meaningful exceptions back when querying disk space fails. | How to find how much disk space is left using Java? | [
"",
"java",
"diskspace",
""
] |
I want to start a background process in a Java EE (OC4J 10) environment. It seems wrong to just start a Thread with "new Thread" But I can't find a good way for this.
Using a JMS queue is difficult in my special case, since my parameters for this method call are not serializable.
I also thought about using an `onTimeout` Timer Method on a session bean but this does not allow me to pass parameters (as far as I know).
Is there any "canon" way to handle such a task, or do I just have to revert to "new Thread" or a `java.concurrent.ThreadPool`. | Java EE usually attempts to removing threading from the developers concerns. (It's success at this is a completely different topic).
JMS is clearly the preferred approach to handle this.
With most parameters, you have the option of forcing or faking serialization, even if they aren't serializable by default. Depending on the data, consider wrapping it in a serializable object that can reload the data. This will clearly depend on the parameter and application. | JMS is the Java EE way of doing this. You can start your own threads if the container lets you, but that does violate the Java EE spec (you may or may not care about this).
If you don't care about Java EE generic compliance (if you would in fact resort to threads rather than deal with JMS), the Oracle container will for sure have proprietary ways of doing this (such as the [OracleAS Job Scheduler](http://www.oracle.com/technology/tech/java/oc4j/1003/how_to/jobscheduler/index.html)). | How to start a background process in Java EE | [
"",
"java",
"jakarta-ee",
"ejb",
""
] |
I need a function to get the height of the highest element inside a div.
I have an element with many others inside (dynamically generated), and when I ask for the height of the container element using $(elem).height(), I get a smaller height than some of the contents inside it.
Some of the elements inside are images that are bigger than the size this element says to have.
I need to know the highest element so I can get it's height. | You could always do:
```
var t=0; // the height of the highest element (after the function runs)
var t_elem; // the highest element (after the function runs)
$("*",elem).each(function () {
$this = $(this);
if ( $this.outerHeight() > t ) {
t_elem=this;
t=$this.outerHeight();
}
});
```
Edited to make it work again. | I found this snippet which seems more straight forward and shorter at <http://css-tricks.com/snippets/jquery/equalize-heights-of-divs>
```
var maxHeight = 0;
$(yourelemselector).each(function(){
var thisH = $(this).height();
if (thisH > maxHeight) { maxHeight = thisH; }
});
$(yourelemselector).height(maxHeight);
``` | How to get height of the highest children element in javascript/jQuery? | [
"",
"javascript",
"jquery",
"dom",
"height",
""
] |
Hmmm. Consider this program, whose goal is to figure out the best way to get the bottom 16 bits of an integer, as a signed integer.
```
public class SignExtend16 {
public static int get16Bits(int x)
{
return (x & 0xffff) - ((x & 0x8000) << 1);
}
public static int get16Bits0(int x)
{
return (int)(short)(x);
}
public static void main(String[] args)
{
for (String s : args)
{
int x = Integer.parseInt(s);
System.out.printf("%08x => %08x, %08x\n",
x, get16Bits0(x), get16Bits(x));
}
}
}
```
I was going to use the code in get16Bits0, but I got the warning "Unnecessary cast from short to int" with Eclipse's compiler and it makes me suspicious, thinking the compiler could optimize out my "unnecessary cast". When I run it on my machine using Eclipse's compiler, I get identical results from both functions that behave the way I intended (test arguments: 1 1111 11111 33333 66666 99999 ). Does this mean I can use get16Bits0? (with suitable warnings to future code maintainers) I've always assumed that JRE and compiler behavior are both machine-independent for arithmetic, but this case is testing my faith somewhat. | Since numeric casts are implicit-friendly, I think the only reason you're getting the warning is that the compiler will always make the cast to int upon return, making your explicit cast redundant. | Well, first of all the warning is correct as you can always move "up" with arithmetic conversions. Only the other way needs a cast because you might lose data (or precision for floats).
When you reduce from int to short you have to indicate that it's intentional by using a cast. But when you convert the short value back to int there's no danger and it happens automatically.
So, all you need is
```
return (short) x;
``` | getting the bottom 16 bits of a Java int as a signed 16-bit value | [
"",
"java",
"bit-manipulation",
"math",
""
] |
I have created some python code which creates an object in a loop, and in every iteration overwrites this object with a new one of the same type. This is done 10.000 times, and Python takes up 7mb of memory every second until my 3gb RAM is used. Does anyone know of a way to remove the objects from memory? | You haven't provided enough information - this depends on the specifics of the object you are creating and what else you're doing with it in the loop. If the object does not create circular references, it should be deallocated on the next iteration. For example, the code
```
for x in range(100000):
obj = " " * 10000000
```
will not result in ever-increasing memory allocation. | I think this is circular reference (though the question isn't explicit about this information.)
One way to solve this problem is to manually invoke garbage collection. When you manually run garbage collector, it will sweep circular referenced objects too.
```
import gc
for i in xrange(10000):
j = myObj()
processObj(j)
#assuming count reference is not zero but still
#object won't remain usable after the iteration
if !(i%100):
gc.collect()
```
Here don't run garbage collector too often because it has its own overhead, e.g. if you run garbage collector in every loop, interpretation will become extremely slow. | Python garbage collection | [
"",
"python",
"optimization",
"memory-management",
"garbage-collection",
""
] |
What should I use to get semantics equivalent to [AutoResetEvent](http://msdn.microsoft.com/en-us/library/system.threading.autoresetevent.aspx) in Java?
(See [this question](https://stackoverflow.com/questions/1064596/what-is-javas-equivalent-of-manualresetevent) for ManualResetEvent). | @user249654's answer looked promising. I added some unit tests to verify it, and indeed it works as expected.
I also added an overload of `waitOne` that takes a timeout.
The code is here in case anyone else finds it useful:
### Unit Test
```
import org.junit.Assert;
import org.junit.Test;
import static java.lang.System.currentTimeMillis;
/**
* @author Drew Noakes http://drewnoakes.com
*/
public class AutoResetEventTest
{
@Test
public void synchronisesProperly() throws InterruptedException
{
final AutoResetEvent event1 = new AutoResetEvent(false);
final AutoResetEvent event2 = new AutoResetEvent(false);
final int loopCount = 10;
final int sleepMillis = 50;
Thread thread1 = new Thread(new Runnable()
{
@Override
public void run()
{
try {
for (int i = 0; i < loopCount; i++)
{
long t = currentTimeMillis();
event1.waitOne();
Assert.assertTrue("Time to wait should be within 5ms of sleep time",
Math.abs(currentTimeMillis() - t - sleepMillis) < 5);
Thread.sleep(sleepMillis);
t = currentTimeMillis();
event2.set();
Assert.assertTrue("Time to set should be within 1ms", currentTimeMillis() - t <= 1);
}
} catch (InterruptedException e) {
Assert.fail();
}
}
});
Thread thread2 = new Thread(new Runnable()
{
@Override
public void run()
{
try {
for (int i = 0; i < loopCount; i++)
{
Thread.sleep(sleepMillis);
long t = currentTimeMillis();
event1.set();
Assert.assertTrue("Time to set should be within 1ms", currentTimeMillis() - t <= 1);
t = currentTimeMillis();
event2.waitOne();
Assert.assertTrue("Time to wait should be within 5ms of sleep time",
Math.abs(currentTimeMillis() - t - sleepMillis) < 5);
}
} catch (InterruptedException e) {
Assert.fail();
}
}
});
long t = currentTimeMillis();
thread1.start();
thread2.start();
int maxTimeMillis = loopCount * sleepMillis * 2 * 2;
thread1.join(maxTimeMillis);
thread2.join(maxTimeMillis);
Assert.assertTrue("Thread should not be blocked.", currentTimeMillis() - t < maxTimeMillis);
}
@Test
public void timeout() throws InterruptedException
{
AutoResetEvent event = new AutoResetEvent(false);
int timeoutMillis = 100;
long t = currentTimeMillis();
event.waitOne(timeoutMillis);
long took = currentTimeMillis() - t;
Assert.assertTrue("Timeout should have occurred, taking within 5ms of the timeout period, but took " + took,
Math.abs(took - timeoutMillis) < 5);
}
@Test
public void noBlockIfInitiallyOpen() throws InterruptedException
{
AutoResetEvent event = new AutoResetEvent(true);
long t = currentTimeMillis();
event.waitOne(200);
Assert.assertTrue("Should not have taken very long to wait when already open",
Math.abs(currentTimeMillis() - t) < 5);
}
}
```
### AutoResetEvent with overload that accepts a timeout
```
public class AutoResetEvent
{
private final Object _monitor = new Object();
private volatile boolean _isOpen = false;
public AutoResetEvent(boolean open)
{
_isOpen = open;
}
public void waitOne() throws InterruptedException
{
synchronized (_monitor) {
while (!_isOpen) {
_monitor.wait();
}
_isOpen = false;
}
}
public void waitOne(long timeout) throws InterruptedException
{
synchronized (_monitor) {
long t = System.currentTimeMillis();
while (!_isOpen) {
_monitor.wait(timeout);
// Check for timeout
if (System.currentTimeMillis() - t >= timeout)
break;
}
_isOpen = false;
}
}
public void set()
{
synchronized (_monitor) {
_isOpen = true;
_monitor.notify();
}
}
public void reset()
{
_isOpen = false;
}
}
``` | ```
class AutoResetEvent {
private final Object monitor = new Object();
private volatile boolean open = false;
public AutoResetEvent(boolean open) {
this.open = open;
}
public void waitOne() throws InterruptedException {
synchronized (monitor) {
while (open == false) {
monitor.wait();
}
open = false; // close for other
}
}
public void set() {
synchronized (monitor) {
open = true;
monitor.notify(); // open one
}
}
public void reset() {//close stop
open = false;
}
}
``` | Java's equivalent to .Net's AutoResetEvent? | [
"",
"java",
"events",
"concurrency",
"synchronization",
"autoresetevent",
""
] |
I've a chunk of code that works fine in isolation, but used a dependency in a clients project fails. A call to
Document doc = impl.createDocument(null,null,null);
fails (looks like the problem at <https://bugs.java.com/bugdatabase/view_bug?bug_id=4913257>). The instance of 'impl' in my unit tests is an instance of com.sun.org.apache.xerces.internal.dom.DOMImplementationImpl. In my clients code, its an instance of org.apache.xerces.dom.DOMImplementationImpl.
How do I trace back this dependency? I've tried manually going through all classes and jar files in the classpath, but cannot find the provider of org.apache.xerces.dom.DOMImplementation. Is is possible to observe when classes are loaded (and why)? How is the particular DOM implementation selected? Can I for now force the jvm to use a particular implementation? | The implementation in the "com.sun.org.apache..." package is the Xerces that's packaged as part of the JRE. The one starting "org.apache..." is the standalone distribution from Apache. They can be run together in the same application, but it can get quite confusing.
Your client's project would appear to contain a copy of the standalone apache distribution (probably xercesImpl.jar). Ask them to rem,ove it and see if it starts using the built-in JRE code. | Most likely you do not have xercesImpl.jar in the client project's classpath | How to debug java depenendency failure on version of DOMImplementation | [
"",
"java",
"xml",
"dom",
"dependencies",
""
] |
can nvl() function be cascaded,...it was asked me in IBM interview .....and why???? | Better yet, use `COALESCE` | My answer:
> Yes, NVL can be cascaded. It's something I'd expect to see on code ported from Oracle versions up to and including 8i, because COALESCE wasn't supported until Oracle 9i.
>
> COALESCE is an ANSI SQL 99 standard, and works like a CASE/SWITCH statement in how it evaluates each expression in order and does not continue evaluating expressions once it hits a non-null expression. This is called short-circuiting. Another benefit of using COALESCE is that the data types do not need to match, which is required when using NVL.
This:
```
SELECT COALESCE( 1.5 / NULL,
SUM(NULL),
TO_CHAR(SYSDATE, 'YYYY') ) abc
FROM DUAL
```
...will return: `2009` (for the next ~32 days, anyways) | Can NVL Function be Cascaded? | [
"",
"sql",
"database",
"oracle",
"plsql",
""
] |
When I look at Java frameworks like Hibernate, JPA, or Spring, I usually have the possibility to make my configuration via an xml-file or put annotations directly in my classes.
I am cosistently asking myself what way should I go.
When I use annotations, I have the class and its configuration together but with an xml I get a bigger picture of my system because I can see all class-configurations.
Annotations also get compiled in some way I guess and it should be quicker than parsing the xml, but on the other hand, if I want to change my configuration I have to recompile it instead of just changing the xml file (which might become even more handy for production environments on customer side).
So, when looking at my points, I tend to go the xml-way. But when looking at forums or tutorials usually annotations are used.
What are your pros and cons? | A good rule of thumb: anything you can see yourself wanting to change without a full redeploy (e.g. tweaking performance parameters) should really go in something "soft-configurable" such as an XML file. Anything which is never realistically going to change - or only in the sort of situation where you'll be having to change the code anyway - can reasonably be in an annotation.
Ignore any ideas of performance differences between annotations and XML - unless your configuration is absolutely *massive* the difference will be insignificant.
Concentrate on flexibility and readability. | If you're writing an API, then a word of warning: Annotations can leak out into your public interface which can be unbelievably infuriating.
I'm currently working with APIs where the API vendor has peppered his implementation with Spring `MBean` annotations, which suddenly means I have a dependency upon the Spring libraries, despite the possibility I might not need to use Spring at all :(
(Of course, if your API was an extension to Spring itself, this might be a valid assumption.) | What are the Pros/Cons of Annotations (non-compiler) compared to xml config files | [
"",
"java",
"annotations",
""
] |
I am trying to write a python script
that takes record data like this
```
6xxxxxxxx
7xxxxxxxx
6xxxxxxxx
7xxxxxxxx
7xxxxxxxx
6xxxxxxxx
6xxxxxxxx
6xxxxxxxx
7xxxxxxxx
7xxxxxxxx
7xxxxxxxx
```
and performs the following logic
```
newline = ""
read in a record
if the record starts with a 6 and newline = ''
newline = record
if the records starts with a 7
newline = newline + record
if the record starts with a 6 and newline != ''
print newline
newline = record
```
So it should print out like this:
```
6xxxxxx 7xxxxxxxx
6xxxxxx 7xxxxxxxx 7xxxxxxx 7xxxxxxx
6xxxxxx
6xxxxxx
etc..
```
Here is my code:
```
han1 = open("file","r")
newline = ""
for i in han1:
if i[0] == "6" and newline == "":
newline = i
elif i[0] == "7":
newline = newline + i
elif i[0] == "6" and newline != "":
print newline
newline = ""
newline = i
han1.close()
```
When I run my script the output looks untouched. Where do you think I'm going wrong. Is it because the newline variable won't store values between iterations of the loop? Any guidance would be appreciated. | You can simplify this by simply appending a newline for a record that starts with 6, and not appending one if it doens't.
```
for line in open('infile'):
if line[0] == '6':
print ''
print line.strip() ,
```
OK, this creates one empty line first in the file, and may not end the file with an newline. Still, that's easy to fix.
Or a solution that doens't have that problem and is closer to yours:
```
newline = ''
for line in open('infile'):
if line[0] == '6':
if newline:
print newline
newline = ''
newline += ' ' + line.strip()
if newline:
print newline
```
Also works, but is slightly longer.
That said I think your main problem is that you don't strip the records, so you preserve the line feed. | None of the branches in your if statement finish with `newline` set to "". Therefore, the first branch will never evaluate because `newline` is never "" except for the very first case. | Join Records on Multiple Line File based on Criteria | [
"",
"python",
"file-io",
""
] |
I am pulling `varchar` values out of a DB and want to set the `string` I am assigning them to as "" if they are `null`. I'm currently doing it like this:
```
if (string.IsNullOrEmpty(planRec.approved_by) == true)
this.approved_by = "";
else
this.approved_by = planRec.approved_by.toString();
```
There seems like there should be a way to do this in a single line something like:
```
this.approved_by = "" || planRec.approved_by.toString();
```
However I can't find an optimal way to do this. Is there a better way or is what I have the best way to do it? | Try this:
```
this.approved_by = IsNullOrEmpty(planRec.approved_by) ? string.Empty : planRec.approved_by.toString();
```
You can also use the null-coalescing operator as other have said - since no one has given an example that works with your code here is one:
```
this.approved_by = planRec.approved_by ?? planRec.approved_by.toString();
```
But this example only works since a possible value for `this.approved_by` is the same as one of the potential values that you wish to set it to. For all other cases you will need to use the conditional operator as I showed in my first example. | Starting with C# 8.0, you can use the `??=` operator to replace the code of the form
```
if (variable is null)
{
variable = expression;
}
```
with the following code:
```
variable ??= expression;
```
More information is [here](https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/operators/null-coalescing-operator) | Shortest way to check for null and assign another value if not | [
"",
"c#",
".net",
"null",
"variable-assignment",
""
] |
I've got a situation like this:
**Table: FunTable**
```
ItemKey ItemName ItemPriceEffectiveDate ItemPrice
11 ItemA 6/6/2009 $500
12 ItemA 6/15/2009 $550
13 ItemA 9/9/2009 $450
14 ItemB 3/9/2009 $150
15 ItemB 9/9/2009 $350
```
**I need to do the following:**
```
Select
ItemName as ItemDescription,
(SELECT THE PRICE WITH THE LATEST EFFECTIVE DATE FROM TODAY THROUGH THE PAST)
FROM
FunTable
GROUP BY
ItemName
```
**The output should be this:**
```
ItemA $550
ItemB $150
```
So, effective dates for prices can range from 5 years ago through 5 years from now. I want to select the price that is effective either today or in the past (not in the future! it's not effective yet). It's got to be the "most recent" effective price.
Any thoughts? | Something like this (don't have your names, but you get the idea) ...
```
WITH A (Row, Price) AS
(
SELECT Row_Number() OVER (PARTITION BY Item ORDER BY Effective DESC) AS [RN],
Price FROM Table2
WHERE Effective <= GETDATE()
)
SELECT * FROM A WHERE A.Row = 1
``` | ```
select ft.ItemName,
price
from (select ItemName,
Max(ItemPriceEffectiveDate) as MaxEff
from FunTable
where ItemPriceEffectiveDate <= GETDATE()
group by ItemName) as d,
FunTable as ft
where d.MaxEff = ft.ItemPriceEffectiveDate;
```
Edit: Changed the query to actually work, assuming the price does not change more than once a day. | SQL Syntax -- Group By ... Custom Aggregate Functionality? | [
"",
"sql",
"sql-server",
"sql-server-2005",
"group-by",
""
] |
I've got a class something like this:
```
public class Account
{
public virtual int Id { get; private set; }
public virtual string Username { get; set; }
[EditorBrowsable( EditorBrowsableState.Never )]
public virtual string Password { get; private set; }
public void SetPassword( string password ){ ... }
public bool CheckPassword( string password ) { ... }
}
```
I've set it up this way since I don't ever want the `Password` property used directly in code that uses the `Account` type. The Account map looks something like this:
```
public class AccountMap : ClassMap<Account>
{
public AccountMap()
{
Id( x => x.Id );
Map( x => x.Username );
Map( x => x.Password );
}
}
```
When I actually use this with NHibernate I get an `InvalidProxyTypeException`
```
NHibernate.InvalidProxyTypeException: The following types may not be used as proxies:
Fringine.Users.Account: method SetPassword should be virtual
Fringine.Users.Account: method CheckPassword should be virtual
```
I understand that NHibernate is trying to create a proxy class to support lazy loading and that I can either mark the methods as virtual add a Not.LazyLoad() to the map to resolve the exception. But - I don't want to do either of those. I want to support lazy loading but I don't see why those methods need to be virtual.
Does NHibernate (or Castle internally) evaluate the contents of the method to determine which fields are used and optimize the lazy loading for those properties? If not, why does the method need to be virtual if all the properties are and they'll be lazy-loaded when they're referenced by the method.
Is there a way to exclude certain methods from the virtual requirement? | The reason is that you could access fields in your methods, which will not be initialized. So the easiest way is to load the contents of the entity on any call to the object (the only exception is the access to the id, which is already available in the proxy).
So you can safely implement your methods as if there weren't proxies - with the trade-off that the method needs to be virtual (which - I agree - is not perfect).
If you think that this is a problem for your class design, try to move the functionality to another class (eg. PasswordManager, PasswordValidator etc). This class will aggregate the Account or take it it as argument, so the Account will only be loaded when this class actually calls one of its properties. | I've noticed that NHibernate heavily relies on POCOs for all of its entities. For better or worse, I haven't run across any scenario where someone has broken that convention. Davy Brion [explains it in great detail here.](http://davybrion.com/blog/2009/03/must-everything-be-virtual-with-nhibernate/) *(He references your point that, yes, you can mark classes as not lazy load. But, since nHibernate then won't create any of your proxies, you're stuck.)*
I don't know if this is helpful, but that's how Castle does it. Now that (if you're using 2.1) [you're able to choose which proxy generator to use](http://nhforge.org/blogs/nhibernate/archive/2008/10/11/nh2-1-0-reference-to-castle-removed.aspx), moving to [one of the other choices](http://nhforge.org/blogs/nhibernate/archive/2009/03/03/nhibernate-with-spring-net.aspx) might allow you to generate proxies in a way that suits your needs. | Ignoring methods on entity types with nHibernate | [
"",
"c#",
"fluent-nhibernate",
""
] |
I'm trying to remove some items of a dict based on their key, here is my code:
```
d1 = {'a': 1, 'b': 2}
d2 = {'a': 1}
l = [d1, d2, d1, d2, d1, d2]
for i in range(len(l)):
if l[i].has_key('b'):
del l[i]['b']
print l
```
The output will be:
```
[{'a': 1}, {'a': 1}, {'a': 1}, {'a': 1}, {'a': 1}, {'a': 1}]
```
Is there a better way to do it? | ```
d1 = {'a': 1, 'b': 2}
d2 = {'a': 1}
l = [d1, d2, d1, d2, d1, d2]
for d in l:
d.pop('b',None)
print l
``` | A slight simplification:
```
for d in l:
if d.has_key('b'):
del d['b']
```
Some people might also do
```
for d in l:
try:
del d['b']
except KeyError:
pass
```
Catching exceptions like this is not considered as expensive in Python as in other languages. | How to delete all the items of a specific key in a list of dicts? | [
"",
"python",
""
] |
This is a challenge question / problem. Hope you find it interesing.
Scenario: You have a very long list (unreasonably long) in a single column. It would be much better displayed in multiple shorter columns. Using jQuery or another tool, what do you do?
The format of the list is as follows:
```
<div class="toc">
<dl>
<dt>item 1</dt>
<dd>related to 1</dd>
<dt>item 2</dt>
<dd>related to 2</dd>
<dt>item 3</dt>
<dd>related to 3</dd>
<dt>item 4</dt>
<dd>related to 4</dd>
<dt>item 5</dt>
<dd>related to 5</dd>
<dt>item 6</dt>
<dd>related to 6</dd>
<dt>item 7</dt>
<dd>related to 7</dd>
<dt>item 8</dt>
<dd>related to 8</dd>
<dt>item 9</dt>
<dd>related to 9</dd>
<dt>item 10</dt>
<dd>related to 10</dd>
</dl>
</div>
```
Caveat: The dd's may contain nested dl's, dt's, & dd's.
Also be sure to keep related items in the same column (ie. if dt 7 is col x, so should dd 7).
This problem inspired by the somewhat ridiculously laid out [Zend Framework manual](http://framework.zend.com/manual/en/).
**Edit:** See below for answer. | **Answer** So this problem is more difficult than it first appears.
My initial thought was that I would wrap the column in `<table><tr><td></td></tr></table>` and then after every nth *parent* dd output a `</td><td>`. Simple, right? Except you can't really output a closing tag like that. Ultimately when you write `$('</td><td>').after('.toc > dl > dd')`, you'll be creating **nodes** - that's nodes with opening and closing **tags**. Since you must create nodes, the browser will ignore the first closing tag.
Well, let's say that you solve that problem somehow. What are you're iteration conditions? My first attempt was to construct a for loop. It seems reasonable. For every nth parent dd, do whatever you need to do. However, how do you construct those conditions in jQuery? You have less than, greater than, and equal. But you **don't have** greater than or equal to (>=) or less than or equal to (<=), and this is a critical distinction.
You might try something like this:
```
for (i = 0; i < len; i+=40) { // where 40 determines the # per col
get elements i thru i+40;
wrap this set and float left
}
```
So how would you do this in jQuery?
```
// note that you must use > to prevent nested descendants from being selected
var len = jQuery('.toc > dl > dd').size()
for (i = 0; i < len; i+=40) {
// this selector says give me the first 40 child elements
// whatever type of element they may be
$('.toc > dl > *:gt('+i+'):lt('+(i+40)').wrapAll('<div style="float:left">');
// however because we don't have >= and :gt won't accept negatives as an input
// we must either do a special case for the first iteration
// or construct a different selector
$('.toc > dl > *:eq('+i+')', ' +
'.toc > dl > *:gt('+i+'):lt('+(i+40)')
.wrapAll('<div style="float:left">');
}
```
You could also do something with jQuery's add() method to add the first element of each iteration to your set, but you must maintain document order in your selection or jQuery will rearrange the set, so you have to do that first.
Ultimately, the for loop made sense initially, but it ran into problems with challenging selectors. Of course, we're not using the `$('selector').each(function () { });` construct because that would only be useful if we could output independent closing tags.
So what did I end up with? **Final Answer:**
```
$('.toc').after('<div id="new"></div>');
do {
var curSet = $('.toc > dl > *:lt(40)')
.appendTo('#new').wrapAll('<div style="float:left"></div>');
} while (curSet.size());
```
This approach appends a new div after the old one. Then iteratively grabs the first 40 elements from the old and appends them to the new div after wrapping them in a div that will float left, looping as long as there are elements left to grab, and it maintains order.
Not terribly complicated after you figure it out, but there were a few gotcha's throughout the problem that I hope you find interesting. I did.
**To finish up the ultimate goal of making the documentation significantly more useful:**
I added some style and used the dt's as togglers to show the dd's. I also used a simple php proxy wrapper (5-10 LOC) so I could bring in any given, desired doc page thru an ajax call without remote ajax warnings.
I ended up with a nice little document in **a single, navigable page** that loads in < 2 secs (and uses ajax to load all subsequent pages in < 1 sec) rather than a monstrous page that takes 15-20 sec to load **per page**!
Problem solved. Something much more **enjoyable** and useful in 10-15 lines of javascript (total with the reorganizing, toggling, and ajax code), < 10 lines of PHP, and a few style rules.
*No more slow Zend docs and endless scrolling.* | i would do a count of the array of $("dt") then if it's over a certain size inject a closing and opening then using styling to float them into columns.
Josh | How to turn a very long column into multiple shorter ones? | [
"",
"javascript",
"jquery",
"dom",
""
] |
I am using DefaultTable Model for showing my records in Jtable.But there is a problem like in the picture.When i load jtable its showing like LJava.lang.Object type. NOT in string..How can i solve this.
Here is my codes ;
```
EntityManagerFactory emf = Persistence.createEntityManagerFactory("SwingDenemePU");
EntityManager em = emf.createEntityManager();
Query sorgu = em.createQuery("select p from Personel p where p.personelAdSoyad like :ad");
Object[] kolonAdi = {"AD SOYAD","ÜNVAN ADI"};
sorgu.setParameter("ad", jTextField1.getText()+"%");
personelList = sorgu.getResultList();
Object[][] data = new Object[personelList.size()][kolonAdi.length];
for(int m=0; m<personelList.size(); m++)
for(int n=0; n<kolonAdi.length; n++)
for(Personel o : personelList) {
Personel personel = (Personel)o;
data[m][n] = new Object[][]{
{
personel.getPersonelAdSoyad(),
personel.getUnvanID().getUnvanAdi()
}
};
}
DefaultTableModel def = new DefaultTableModel();
def.setDataVector(data, kolonAdi);
jTable1.setModel(def);
```
[Jtable Screen http://img244.yukle.tc/images/6092jtable\_scr.jpg](http://img244.yukle.tc/images/6092jtable_scr.jpg) | The reason it outputs [[Ljava/lang/Object@.... is simply because the values you assign to the fields seems to be of type "Object[][]"
Are you sure this is what you want?
```
data[m][n] = new Object[][] {}?
```
I have not put too much effort in it but my gut feeling tells me what you really want to do is something like:
```
for(int m=0; m<personelList.size(); m++) {
Personel personel = personelList.get(m);
data[m] = new Object[]{
personel.getPersonelAdSoyad(),
personel.getUnvanID().getUnvanAdi()
};
}
```
(I have of course not compiled or tested the above code) | I'm not 100% sure on what your data layout is from the code posted. However, I can tell you where your problem is.
```
data[m][n] = new Object[][]{{personel.getPersonelAdSoyad(),personel.getUnvanID().getUnvanAdi()}}
```
This is creating a 2-dimensional array of Object[][] objects. Or rather, a m**x**n**x**1**x**2 array.
If you're looking for an mx2 array you'd do (notthat this is what you're going for, just by way of example [plus personel isn't in scope, etc. etc.]):
```
data[m] = new Object[]{personel.getPersonelAdSoyad(),personel.getUnvanID().getUnvanAdi()};
```
The *[[Ljava.lang.Object...* text is the result of toString() on an Object[]. Which is what tells me your matrix dimensions are wrong. | Problem with Showing Records in Jtable | [
"",
"java",
"swing",
"jtable",
""
] |
```
var allProductIDs = [5410, 8362, 6638, 6758, 7795, 5775, 1004, 1008, 1013, 1014, 1015, 1072, 1076, 1086, 1111, 1112, 1140];
lastProductID = 6758;
```
for some reason I get a -1 or I guess which is equivalent to not found for this:
```
alert(allProductIDs[allProductIDs.indexOf(lastProductID));
```
I can't figure out for the life of my why because it should find 6758 and that would be index 3. If it's index 3 then I should get back 6758 I would think. | `.indexOf()` is used for strings, not arrays.
Using regular Javascript you'll have to loop through the array until you find a match, or use the `inArray()` function of jQuery.
[jQuery inArray()](http://docs.jquery.com/Utilities/jQuery.inArray#valuearray) | ```
var allProductIDs = [5410, 8362, 6638, 6758, 7795, 5775, 1004, 1008, 1013, 1014, 1015, 1072, 1076, 1086, 1111, 1112, 1140];
lastProductID = 6758;
for (i in allProductIDs)
{
if (allProductIDs[i] == lastProductID) {
alert(allProductIDs[i] + " is at index " + i);
break;
}
}
```
or
```
i = $.inArray(lastProductID, allProductIDs)
alert(allProductIDs[i] + " is at index " + i);
``` | Problem with indexOf on JavaScript array | [
"",
"javascript",
""
] |
I have a situation where i want to add LinePragmas to CodeDom objects. But some code dom objects have the LinePragma property and some don't.
So I'm wondering if it's possible to use the dynamic keyword to detect if the property exists on the object (without throwing an exception) and if it does then add the pragma. Here is my current method:
```
public static T SetSource<T>(this T codeObject, INode sourceNode)
where T : CodeObject
{
codeObject.UserData["Node"] = sourceNode.Source;
dynamic dynamicCodeObject = codeObject;
// How can I not throw an exception here?
if (dynamicCodeObject.LinePragma != null)
{
dynamicCodeObject.LinePragma = new CodeLinePragma(
sourceNode.Source.Path.AbsoluteUri,
sourceNode.Source.StartLine);
}
return codeObject;
}
```
**UPDATE:**
The solution I went with was to add an extension method called Exists(). I wrote a blog post about it here:
[Member Exists Dynamic C# 4.0](http://justinmchase.com/2009/07/02/member-exists-e28093-dynamic-c-40/)
The jist was to create an extension method that returns an object that implements DynamicObject's TryGetMember. It uses reflection to then return true or false. Which allows you to write code like this:
```
object instance = new { Foo = "Hello World!" };
if (instance.Reflection().Exists().Foo)
{
string value = instance.Reflection().Call().Foo;
Console.WriteLine(value);
}
``` | You can detect if an object has a property without having to use the dynamic features of C# 4.0 - instead using the reflection features that have been around for a while (I know at least .NET 2.0, not sure about < 2.0)
```
PropertyInfo info = codeObject.getType().GetProperty(
"LinePragma",
BindingFlags.Public | BindingFlags.Instance
)
```
If it the object does not have the property, then GetProperty() will return null. You can do similar for fields ( GetField() ) and methods ( GetMethod() ).
Not only that, but once you have the PropertyInfo, you can use it directly to do your set:
```
info.SetValue(codeObject, new CodeLinePragma(), null);
```
If you're not sure whether the property has a set method, you could take the even safer route:
```
MethodInfo method = info.GetSetMethod();
if(method != null)
method.Invoke(codeObject, new object[]{ new CodeLinePragma() });
```
This also gives you the added benefit of being a little more performant over the lookup overhead of the dynamic call (can't find a reference for that statement, so I'll just float it out there).
I suppose that doesn't answer your question directly, but rather is an alternative solution to accomplish the same goal. I haven't actually used #4.0 features yet (even though I'm a huge fan of the dynamic typing available in Ruby). It certainly not as clean/readable as the dynamic solution, but if you don't want to throw an exception it may be the way to go.
EDIT: as @arbiter points out, "This is valid only for native .net dynamic objects. This will not work for example for IDispatch." | I just spent almost an hour searching for ways to get some kind of ruby-esque "RespondTo" Method on dynamic. There certainly isn't an easy answer, but I haven't given up yet.
The point made on reflection should be the thing to try.
With dynamic, the only thing I get so far is an extension method that treats your object as dynamic. If it works, it works, if not it silently fails...
```
public static void Dynamight<T>(this T target, Action<dynamic> action)
{
dynamic d = target;
try
{
action(d);
}
catch (RuntimeBinderException)
{
//That was that, didn't work out
}
}
```
Then you can do...
```
string h = "Hello";
h.Dynamight(d => Console.WriteLine(d.Length)); //Prints out 5
h.Dynamight(d => d.Foo()); //Nothing happens
```
**Update:**
Since I am getting downvotes and what-have-you let me be more concise than the subtle naming of the extension method: It is **dynamite** (Geddit?)! Gobbling exceptions and doing nothing is **bad**. This is no production code, but a version 1 of a spike of a proof of concept. I keep forgetting that you can't be subtle on a multi-thousands forum like stackoverflow. Mea culpa. | C# 4.0, detect if a method is missing | [
"",
"c#",
"dynamic",
"codedom",
""
] |
Is there a way to watch an object graph for changes on any object, and do something based on that change?
Lets say I have the following:
```
public class Main:INotifyPropertyChanged
{
public ObservableCollection<Foo> FooItems { get; }
public ObservableCollection<Bar> BarItems { get; }
}
public class Foo:INotifyPropertyChanged
public class Bar:INotifyPropertyChanged
{
public ObservableCollection<Other> OtherItems { get; }
}
public class Other:INotifyPropertyChanged
```
What would be the best way to implement some sort of change notification system across all objects? For example an autosave, where any change would trigger the system to serialize the `Main` class.
Should I have glue code in the `Main` class watching the `BarItems` for changes, hooking up to their `PropertyChanged`? This seems a bit messy, and error prone to me. Is there a better way? | Rather than objects raising their own property changed events, perhaps they could raise a shared event instead. For example:
```
public class SharedChangeNotifier
{
public static event EventHandler<DataChangedEventArgs> SharedChangeEvent;
protected void RaiseChangeEvent()
{
if (SharedChangeNotifier.SharedChangeEvent != null)
{
SharedChangeNotifier.SharedChangeEvent(
this, new DataChangedEventArgs());
}
}
}
public class Foo : SharedChangeNotifier
{
public int MyProperty
{
get { ... }
set
{
...
RaiseChangeEvent();
}
}
}
```
You could then attach an event handler to the static SharedChangeNotifier's SharedChangeEvent to be notified whenever any object deriving from SharedChangeNotifier is changed, like this:
```
SharedChangeNotifier.SharedChangeEvent += (sender, args) => {
DoWhatever();
};
``` | The way I have done it in the past was to create a separate ChangeTracker class with a method to Register objects into it. Inside that method, use reflection to explore the registered object, and hook into events on each of its properties that implements INotifyPropertyChanged.
You can then add methods to the ChangeTracker to interrogate the state, e.g. IsDirty(), or even implement INotifyPropertyChanged on the ChangeTracker.
(Be sure to implement and use IDisposable on the ChangeTracker, and drop all the event handlers at that time). | Watch an object graph for changes | [
"",
"c#",
".net",
"design-patterns",
"inotifypropertychanged",
""
] |
What is the logic behind disk defragmentation and Disk Check in Windows? Can I do it using C# coding? | For completeness sake, here's a C# API wrapper for defragmentation:
<http://blogs.msdn.com/jeffrey_wall/archive/2004/09/13/229137.aspx>
Defragmentation with these APIs is (supposed to be) very safe nowadays. You shouldn't be able to corrupt the file system even if you wanted to.
Commercial defragmentation programs use the same APIs. | Look at [Defragmenting Files](http://msdn.microsoft.com/en-us/library/aa363911%28VS.85%29.aspx) at msdn for possible API helpers.
You should carefully think about using C# for this task, as it may introduce some undesired overhead for marshaling into native Win32. | Logic in Disk Defragmantation & Disk Check | [
"",
"c#",
"windows",
"disk",
"defragmentation",
""
] |
I have a CSV file which has the following format:
```
id,case1,case2,case3
```
Here is a sample:
```
123,null,X,Y
342,X,X,Y
456,null,null,null
789,null,null,X
```
For each line I need to know which of the cases is not null. Is there an easy way to find out which case(s) are not null without splitting the string and going through each element?
This is what the result should look like:
```
123,case2:case3
342,case1:case2:case3
456:None
789:case3
``` | You probably want to take a look at the [CSV module](http://docs.python.org/library/csv.html#module-csv), which has readers and writers that will enable you to create transforms.
```
>>> from StringIO import StringIO
>>> from csv import DictReader
>>> fh = StringIO("""
... id,case1,case2,case3
...
... 123,null,X,Y
...
... 342,X,X,Y
...
... 456,null,null,null
...
... 789,null,null,X
... """.strip())
>>> dr = DictReader(fh)
>>> dr.next()
{'case1': 'null', 'case3': 'Y', 'case2': 'X', 'id': '123'}
```
At which point you can do something like:
```
>>> from csv import DictWriter
>>> out_fh = StringIO()
>>> writer = DictWriter(fh, fieldnames=dr.fieldnames)
>>> for mapping in dr:
... writer.write(dict((k, v) for k, v in mapping.items() if v != 'null'))
...
```
The last bit is just pseudocode -- not sure `dr.fieldnames` is actually a property. Replace `out_fh` with the filehandle that you'd like to output to. | Anyway you slice it, you are still going to have to go through the list. There are more and less elegant ways to do it. Depending on the python version you are using, you can use list comprehensions.
```
ids=line.split(",")
print "%s:%s" % (ids[0], ":".join(["case%d" % x for x in range(1, len(ids)) if ids[x] != "null"])
``` | Python strings / match case | [
"",
"python",
"csv",
""
] |
I'm writing a Firefox extension and I need to find the ip address of the currently loaded page. I can get the hostname of the page with window.location.host, but is there any way to find the ip for that hostname?
I tried looking for the answer at the Mozilla Developer Center but was unable to find anything.
EDIT: I would use something like PHP to do this, but cannot, because it's a firefox extension, running on the client side only. I have no web server to do back end PHP. | You could look at how the [ShowIP Firefox extension](https://addons.mozilla.org/en-US/firefox/addon/590) does it. | ```
var cls = Cc['@mozilla.org/network/dns-service;1'];
var iface = Ci.nsIDNSService;
var dns = cls.getService(iface); //dns object
var nsrecord = dns.resolve(HOSTNAME_HERE, true); //resolve hostname
while (nsrecord && nsrecord.hasMore()){
alert(nsrecord.getNextAddrAsString()); //here you are
}
``` | IP Address Lookup in a Firefox Extension | [
"",
"javascript",
"firefox",
"firefox-addon",
"ip-address",
""
] |
What is considered better style for an event definition:
```
public event Action<object, double> OnNumberChanged;
```
or
```
public delegate void DNumberChanged(object sender, double number);
public event DNumberChanged OnNumberChanged;
```
The first takes less typing, but the delegate one gives names to the parameters. As I type this, I think number 2 is the winner, but I could be wrong.
Edit: A different (third) approach is the winner. Read below. | Neither 1 or 2. A third option is the winner
```
public event EventHandler<NumberChangedEventArgs> NumberChanged;
```
You're breaking a number of style guidelines for developing in C#, such as using a type for event args that doesn't extend EventArgs.
Yes, you can do it this way, as the compiler doesn't care. However, people reading your code will do a WTF. | Don't create a new type if you don't have to. I think this is better:
```
public event Action<object, double> OnNumberChanged;
```
The reason that the `Action` and `Func` delegate families exist is to serve this very purpose and reduce the need for new delegate type creation by developers. | C# Action/Delegate Style Question | [
"",
"c#",
".net",
"coding-style",
""
] |
I am copying an VBA code snippet from MSDN that shows me how to grab results from a SQL query into excel sheet (Excel 2007):
```
Sub GetDataFromADO()
'Declare variables'
Set objMyConn = New ADODB.Connection
Set objMyCmd = New ADODB.Command
Set objMyRecordset = New ADODB.Recordset
'Open Connection'
objMyConn.ConnectionString = "Provider=SQLOLEDB;Data Source=localhost;User ID=abc;Password=abc;"
objMyConn.Open
'Set and Excecute SQL Command'
Set objMyCmd.ActiveConnection = objMyConn
objMyCmd.CommandText = "select * from myTable"
objMyCmd.CommandType = adCmdText
objMyCmd.Execute
'Open Recordset'
Set objMyRecordset.ActiveConnection = objMyConn
objMyRecordset.Open objMyCmd
'Copy Data to Excel'
ActiveSheet.Range("A1").CopyFromRecordset (objMyRecordset)
End Sub
```
I have already added Microsoft ActiveX Data Objects 2.1 Library under as a reference. And this database is accessible.
Now, when I run this subroutine, it has an error:
Run-time error 3704: Operation is not allowed when object is closed.
On the statement:
```
ActiveSheet.Range("A1").CopyFromRecordset (objMyRecordset)
```
Any idea why?
Thanks. | I've added the Initial Catalog to your connection string. I've also abandonded the ADODB.Command syntax in favor of simply creating my own SQL statement and open the recordset on that variable.
Hope this helps.
```
Sub GetDataFromADO()
'Declare variables'
Set objMyConn = New ADODB.Connection
Set objMyRecordset = New ADODB.Recordset
Dim strSQL As String
'Open Connection'
objMyConn.ConnectionString = "Provider=SQLOLEDB;Data Source=localhost;Initial Catalog=MyDatabase;User ID=abc;Password=abc;"
objMyConn.Open
'Set and Excecute SQL Command'
strSQL = "select * from myTable"
'Open Recordset'
Set objMyRecordset.ActiveConnection = objMyConn
objMyRecordset.Open strSQL
'Copy Data to Excel'
ActiveSheet.Range("A1").CopyFromRecordset (objMyRecordset)
End Sub
``` | Suggested changes:
* Do not invoke the Command object's Execute method;
* Set the Recordset object's Source property to be your Command object;
* Invoke the Recordset object's Open method with no parameters;
* Remove the parentheses from around the Recordset object in the call to `CopyFromRecordset`;
* Actually declare your variables :)
Revised code:
```
Sub GetDataFromADO()
'Declare variables'
Dim objMyConn As ADODB.Connection
Dim objMyCmd As ADODB.Command
Dim objMyRecordset As ADODB.Recordset
Set objMyConn = New ADODB.Connection
Set objMyCmd = New ADODB.Command
Set objMyRecordset = New ADODB.Recordset
'Open Connection'
objMyConn.ConnectionString = "Provider=SQLOLEDB;Data Source=localhost;User ID=abc;Password=abc;"
objMyConn.Open
'Set and Excecute SQL Command'
Set objMyCmd.ActiveConnection = objMyConn
objMyCmd.CommandText = "select * from mytable"
objMyCmd.CommandType = adCmdText
'Open Recordset'
Set objMyRecordset.Source = objMyCmd
objMyRecordset.Open
'Copy Data to Excel'
ActiveSheet.Range("A1").CopyFromRecordset objMyRecordset
End Sub
``` | Accessing SQL Database in Excel-VBA | [
"",
"sql",
"vba",
"excel",
"adodb",
""
] |
I've been writing little Python programs at home to learn more about the language. The most recent feature I've tried to understand are List Comprehensions. I created a little script that estimates when my car needs its next oil change based on how frequently I've gotten the oil changed in the past. In the code snippet below, `oil_changes` is a list of the mileages at which I got the oil changed.
```
# Compute a list of the mileage differences between each oil change.
diffs = [j - i for i, j in zip(oil_changes[:-1], oil_changes[1:])]
# Use the average difference between oil changes to estimate the next change.
next_oil = oil_changes[-1] + sum(diffs) / len(diffs)
```
The code produces the right answer (did the math by hand to check) but it doesn't feel quite Pythonic yet. Am I doing a lot of needless copying of the original list in the first line? I feel like there's a much better way to do this but I don't know what it is. | As other answers pointed out, you don't really need to worry unless your `oil_changes` list is extremely long. However, as a fan of "stream-based" computing, I think it's interesting to point out that `itertools` offers all the tools you need to compute your `next_oil` value in O(1) space (and O(N) time of course!-) no matter how big N, that is, `len(next_oil)`, gets.
`izip` per se is insufficient, because it only reduces a bit the multiplicative constant but leaves your space demands as O(N). The key idea to bring those demands down to O(1) is to pair `izip` with `tee` -- and avoiding the list comprehension, which would be O(N) in space anyway, in favor of a good simple old-fashioned loop!-). Here comes:
```
it = iter(oil_changes)
a, b = itertools.tee(it)
b.next()
thesum = 0
for thelen, (i, j) in enumerate(itertools.izip(a, b)):
thesum += j - i
last_one = j
next_oil = last_one + thesum / (thelen + 1)
```
Instead of taking slices from the list, we take an iterator on it, tee it (making two independently advanceable clones thereof), and advance, once, one of the clones, `b`. `tee` takes space O(x) where x is the maximum absolute difference between the advancement of the various clones; here, the two clones' advancement only differs by 1 at most, so the space requirement is clearly O(1).
`izip` makes a one-at-a-time "zipping" of the two slightly-askew clone iterators, and we dress it up in `enumerate` so we can track how many times we go through the loop, i.e. the length of the iterable we're iterating on (we need the +1 in the final expression, because `enumerate` starts from 0!-). We compute the sum with a simple `+=`, which is fine for numbers (`sum` is even better, but it wouldn't track the length!-).
It's tempting after the loop to use `last_one = a.next()`, but that would not work because `a` is actually exhausted -- `izip` advances its argument iterables left to right, so it has advanced `a` one last time before it realizes `b` is over!-). That's OK, because Python loop variables are NOT limited in scope to the loop itself -- after the loop, `j` still has the value that was last extracted by advancing `b` before `izip` gave up (just like `thelen` still has the last count value returned by `enumerate`). I'm still naming the value `last_one` rather than using `j` directly in the final expression, because I think it's clearer and more readable.
So there it is -- I hope it was instructive!-) -- although for the solution of the specific problem that you posed this time, it's almost certain to be overkill. We Italians have an ancient proverb -- "Impara l'Arte, e mettila da parte!"... "Learn the Art, and then set it aside" -- which I think is quite applicable here: it's a good thing to learn advanced and sophisticated ways to solve very hard problems, in case you ever meet them, but for all that you need to go for simplicity and directness in the vastly more common case of simple, ordinary problems -- not apply advanced solutions that most likely won't be needed!-) | Try this:
```
assert len(oil_changes) >= 2
sum_of_diffs = oil_changes[-1] - oil_changes[0]
number_of_diffs = len(oil_changes) - 1
average_diff = sum_of_diffs / float(number_of_diffs)
``` | Help needed improving Python code using List Comprehensions | [
"",
"python",
"list-comprehension",
""
] |
This should be an easy problem but...
I need to format a currency for display (string) in C#
The currency in question will have its own rules such as the symbol to use and if that symbol should come before the value (e.g. $ 10) or after (e.g. 10 ₫ which is Vietnamese Dong).
But how the numbers are formatted depends upon the users local, not the currency.
E.g.
```
1.234,56 ₫ should be displayed to a user in Vietnam but
1,234.56 ₫ should be displayed to a user in the US
```
*(formatted as code so easy to see difference between , and.)*
So code like
```
Double vietnamTotal = 1234.56;
return vietnamTotal.ToString("c");
```
Won't work as it will use the users (or more accuratly CultureInfo.CurrentCulture) locale for format and currency so you would get things like $1,123.56 - right use of , and . but wrong symbol.
```
Double vietnamTotal = 1234.56;
CultureInfo ci = new CultureInfo(1066); // Vietnam
return vietnameTotal.ToString("c",ci));
```
Would give 1.234,56 ₫ - Right symbol, wrong use of , and . for current user.
This post [gives more detail](https://stackoverflow.com/questions/850673/proper-currency-format-when-not-displaying-the-native-currency-of-a-culture) on the right thing to do, but not how to do it.
What obvious method hidden in the framework am I missing? | * Take the `NumberFormatInfo` from the user's currency, and clone it
* Set the `CurrencySymbol` in the cloned format to the `CurrencySymbol` of the currency in question
* If you want the currency position (and some other aspects of the format) to be copied,
set `CurrencyPositivePattern` and `CurrencyNegativePattern` in the same way.
* Use the result to format.
For example:
```
using System;
using System.Globalization;
class Test
{
static void Main()
{
decimal total = 1234.56m;
CultureInfo vietnam = new CultureInfo(1066);
CultureInfo usa = new CultureInfo("en-US");
NumberFormatInfo nfi = usa.NumberFormat;
nfi = (NumberFormatInfo) nfi.Clone();
NumberFormatInfo vnfi = vietnam.NumberFormat;
nfi.CurrencySymbol = vnfi.CurrencySymbol;
nfi.CurrencyNegativePattern = vnfi.CurrencyNegativePattern;
nfi.CurrencyPositivePattern = vnfi.CurrencyPositivePattern;
Console.WriteLine(total.ToString("c", nfi));
}
}
```
Admittedly my console doesn't manage to display the right symbol, but I'm sure that's just due to font issues :) | Sorry, I may be being a little slow here, but I still don't see your point. It seems to me that the original question is *"I have a dong value which, in Vietnam, I want displayed as per Vietnamese currency format, with a "₫" symbol, and in the US, I want displayed as per US currency format, but still with a "₫"."*.
I guess I'm getting confused by the two contradictory statements... *"The currency in question will have its own rules"* and *"how the numbers are formatted depends upon the users local [sic], not the currency."*
If all you wanted to change was the currency symbol, and leave the formatting as per the current culture, wouldn't cloning the nfi and setting the symbol be enough ?
```
NumberFormatInfo nfi;
// pretend we're in Vietnam
Thread.CurrentThread.CurrentCulture = CultureInfo.GetCultureInfo("vi-VN");
nfi = CultureInfo.CurrentCulture.NumberFormat.Clone() as NumberFormatInfo;
nfi.CurrencySymbol = "₫";
String s1 = (1234.5678).ToString("c", nfi);
// pretend we're in America
Thread.CurrentThread.CurrentCulture = CultureInfo.GetCultureInfo("en-US");
nfi = CultureInfo.CurrentCulture.NumberFormat.Clone() as NumberFormatInfo;
nfi.CurrencySymbol = "₫";
String s2 = (1234.5678).ToString("c", nfi);
``` | Currency formatting | [
"",
"c#",
".net",
"currency",
""
] |
This is one of those "I probably should know this, but I don't" questions. How do I make a copy of a table in Enterprise Manager? Not export the data into a different database, just make a copy of the table within the *same database*. At this point, I don't care whether the data comes with or not, but the table definition should definitely be duplicated.
If I do Ctrl+C on a selected table and paste the results into a text editor, it gives me a Create Table statement that looks promising, but I can't for the life of me find any place to run that statement.
Edit: note that I'm asking about **SQL Server Enterprise Manager.** This is NOT the same thing as "SQL Server Management Studio". There's no "New Query" button, neither in the top left corner nor anywhere else. In fact, the word 'query' does not occur anywhere in EM except on the Tools menu, and there it's a link to Query Analyzer. | If you're talking 2000 enterprise manager:
Tools -> Query analyzer
Will give you a place to execute the query. | Copy a table with all content (without keys and constraints)
```
select * into tablecopy from table
```
Copy a table without content (without keys and constraints)
```
select top 0 * into tablecopy from table
```
There's a way to copy it with all constraints, in the right click menu (of the table) then all tasks then script as then create to then new query editor window (or a file). You will have to modify the generated script so the constraints and keys are named differently though, and then do an
```
insert into tablecopy select * from table
```
to populate it.
EDIT: If what you are actually asking is a place to run SQL in the Enterprise Manager, try either the Query Analyzer or the Management Studio. | How do I make a copy of a table within SQL Server Enterprise Manager? | [
"",
"sql",
"sql-server",
""
] |
An idle question on language design, see ["Does C# have a right hand if like Perl"](https://stackoverflow.com/questions/1080111/does-c-have-a-right-hand-if-like-perl).
For example, in recent C family languages
```
z = foo ( a, b, c );
```
`a` is evaluated, then `b`, then `c`, so left-to-right.
```
z = a ? b : c;
```
`a` is evaluated, then either `b` or `c`, so left-to-right order.
In Python, you write a conditional expression as
```
z = b if a else c
```
so the order is the same - `a`,then `b` or `c`, but it's not left-to-right.
Strict left-to-right ordering was put into Java to simplify the language; ordering is implementation dependent in C or C++. | Assignment is (sort of) right to left:
```
int a = b + c;
```
b+c gets evaluated, then assigned to a.
---
In general, though, the C# designers have purposely tried to keep most things left->right. A great example is LINQ. Here, instead of going with the traditional SQL ordering (SELECT XXX FROM XXX), they purposely reordered the query to be more left->right.
```
// Note the left->right ordering:
var results = from member in collection where member.element == condition select member;
// Which is equivelent to:
var resultsNonLinq = collection.Where().Select();
```
This is part of why I like C# - the consistency in the language is very refreshing, especially when compared to some languages like perl where there is purposely many ways of doing simple things. | No it doesn't check the MS C# lang spec or the [ECMA334](http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-334.pdf) spec (chapter 14) | Does c# have any statements which don't follow left to right evaluation order? | [
"",
"c#",
"language-design",
""
] |
I have a business object that compiles into a DLL that handles all calculations for my system for concepts such as eligibility, etc. The object also handles the connectivity to the DB via some wrappers around it.
Is there anyway to take this .NET DLL and use it as a datasource for a reporting services report (SSRS)? We don't want to have the logic in multiple places.
**EDIT**
What about exposing the functionality in a webservice in the web app itself and having the report connect to the web service? Anyone done this before? We are using asp.net MVC for our web app if that helps. | Your probably going to have to do this with the Report Viewer Control, as I have not ever seen an example using the reporting web service.
<http://www.gotreportviewer.com/>
Here is the section on using Object data sources:
<http://www.gotreportviewer.com/objectdatasources/index.html>
These can be conceptually similar to ViewModels in MVC, so you would have to build ReportViewModels™ to handle reporting requirements. | Not overly familiar with SSRS but I would imagine it would be able to consume XML web services.
If this is the case you could use the underlying data and logic and expose it as HTML for the web site and XML for SSRS. | Re-use business logic from MVC Application (DLL) in Reporting Services | [
"",
"c#",
"asp.net-mvc",
"reporting-services",
"business-logic",
"code-reuse",
""
] |
Our .NET app copies large files, and needs to give the user feedback; so rather than use `File.Copy` we read a chunk of one file and write it to the other, and display the progress after each chunk. Nothing out of the ordinary. But what's the right size of chunk to use, to give the fastest file copy, assuming the time to display the progress is negligible? | You should consider using win32 function [CopyFileTransacted](http://msdn.microsoft.com/en-us/library/aa363853%28VS.85%29.aspx) (Vista Only) or [CopyFileEx](http://msdn.microsoft.com/en-us/library/aa363852%28VS.85%29.aspx) (Windows 2000 and higher). These are provided by Windows and are optimized for speed.
I would recommend you to test your custom C# implementation performance and compare it to native File.Copy performance. If the performance is comparable (i.e. same order of magnitude) than go with your custom C# implementation. Otherwise it's better to use CopyFileTransacted or CopyFileEx function.
P.s. from [here](http://msdn.microsoft.com/en-us/library/aa363853%28VS.85%29.aspx):
```
[return: MarshalAs(UnmanagedType.Bool)]
[DllImport("kernel32.dll", CharSet=CharSet.Unicode, SetLastError=true)]
internal static extern bool CopyFileTransacted([In] string lpExistingFileName, [In] string lpNewFileName, [In] IntPtr lpProgressRoutine, [In] IntPtr lpData, [In, MarshalAs(UnmanagedType.Bool)] ref bool pbCancel, [In] CopyFileFlags dwCopyFlags, [In] KtmTransactionHandle hTransaction);
``` | A very large buffer will give you the best transfer speed but a coarse feedback. So it's a trade-off and it also depends very much on the hardware.
I did something like this a while back and settled on a 64k buffer, but you might want to experiment a little.
And whatever you pick, make sure it's a multiple of 512 (1 sector) | What size chunks should I copy files in? | [
"",
"c#",
".net",
"file-io",
""
] |
I work with Visual Studio in my day to day job and I love the productivity features that it has. The Visual designers it provides are wonderful, such as for **Winforms, WPF, DataSets, LINQ to SQL, Entity Framework, Class diagrams**, etc...
I am after a similar development experience for developing in Java. It has been many years since I last did any professional Java development (2003 ish). I would hope that the tools have matured greatly since then.
I am looking for an IDE with a good GUI editor, and a good Data object editor. Other stuff would be a bonus (I've been intentionally vague with the Data point because it greatly depends upon the provider).
It would be lovely to have Visual Studio for Java, is there anything as good as Visual Studio **(or better?)**.
Here is a short list of my requirements:
* The IDE does not have to be free
* The IDE does not need to have all features "out of the box" **(plugins are ok)**
* The IDE has to run under Windows
* The IDE must have a good GUI designer
* The IDE must have a good Data object designer (ORM, etc)
Thanks for any feedback you can provide. | [IntelliJ](http://www.jetbrains.com) is not free, but I think it's superior to anything out there, including Eclipse and Netbeans. Well worth the money.
UPDATE: There's a free community edition of IntelliJ now, so the price tag need not be a deterrent anymore. | As a long time Java developer (12 years) who has suffered a number of IDEs over the years I have to say that Intellij is my IDE of choice. Last year I used both Netbeans and Eclipse on one of my personal projects but in the end I bought a personal copy of Intellij due to the extra productivity I get out of this powerfull IDE. | Java IDE recommendations (GUI designer, ORM designer, etc...) for a VS user | [
"",
"java",
"visual-studio",
"user-interface",
"ide",
""
] |
How would I go about setting a link to perform certain functions like hide div then go to destined url
something like this
$(document).ready(function(){
$("a").click(function(){
$("#div1").slideUp("slow");
$("#div2").slideUp("slow");
// then go to index.html
});
});
This is my setup.
```
<script type="text/javascript"> $(document).ready(function(){
$("a").click(function(){
$("#one").hide("slow");
$("#two").hide("slow" , function(){
window.location (index.html);
});
}); }); </script>
<div id="one"> some content </div>
<div id="two"> some content </div>
<a href="#">BUTTON HERE</a>
```
It only performs the hide function, if I replace the url in the html it perform the url only. I must be doing something Wrong | "Location" is actually a property of the window object, *not* a method. This means you need to assign it with =, instead of passing it as a parameter with (). Try this code out:
```
$("a").click(function(event){
event.preventDefault();
var url = $(this).attr("href");
$("#div1").slideUp("slow");
$("#div2").slideUp("slow", function(){
window.location=url;
});
});
```
Also, the default behavior of a link is to go to a URL, and it's going to run that behavior unless you stop it with something like "return false;". While setting the href to "#" won't take a user anywhere, it WILL scroll them to the top of the page, which could be annoying. Better to just return false it. | try to put the redirect as callback to be executed after the last slideup:
```
$(document).ready(function(){
$("a").click(function(){
$("#div1").slideUp("slow");
$("#div2").slideUp("slow", function(){
window.location(url); // or window.location.replace(url);
});
});
});
``` | How to Hide Div then visit Url on One Click | [
"",
"javascript",
"jquery",
""
] |
How can I persistently modify the Windows environment variables from a Python script? (it's the setup.py script)
I'm looking for a standard function or module to use for this. I'm already familiar with the [registry way of doing it](http://code.activestate.com/recipes/416087/), but any comments regarding that are also welcome. | Using setx has few drawbacks, especially if you're trying to append to environment variables (eg. setx PATH %Path%;C:\mypath) This will repeatedly append to the path every time you run it, which can be a problem. Worse, it doesn't distinguish between the machine path (stored in HKEY\_LOCAL\_MACHINE), and the user path, (stored in HKEY\_CURRENT\_USER). The environment variable you see at a command prompt is made up of a concatenation of these two values. Hence, before calling setx:
```
user PATH == u
machine PATH == m
%PATH% == m;u
> setx PATH %PATH%;new
Calling setx sets the USER path by default, hence now:
user PATH == m;u;new
machine PATH == m
%PATH% == m;m;u;new
```
The system path is unavoidably duplicated in the %PATH% environment variable every time you call setx to append to PATH. These changes are permanent, never reset by reboots, and so accumulate through the life of the machine.
Trying to compensate for this in DOS is beyond my ability. So I turned to Python. The solution I have come up with today, to set environment variables by tweaking the registry, including appending to PATH without introducing duplicates, is as follows:
```
from os import system, environ
import win32con
from win32gui import SendMessage
from _winreg import (
CloseKey, OpenKey, QueryValueEx, SetValueEx,
HKEY_CURRENT_USER, HKEY_LOCAL_MACHINE,
KEY_ALL_ACCESS, KEY_READ, REG_EXPAND_SZ, REG_SZ
)
def env_keys(user=True):
if user:
root = HKEY_CURRENT_USER
subkey = 'Environment'
else:
root = HKEY_LOCAL_MACHINE
subkey = r'SYSTEM\CurrentControlSet\Control\Session Manager\Environment'
return root, subkey
def get_env(name, user=True):
root, subkey = env_keys(user)
key = OpenKey(root, subkey, 0, KEY_READ)
try:
value, _ = QueryValueEx(key, name)
except WindowsError:
return ''
return value
def set_env(name, value):
key = OpenKey(HKEY_CURRENT_USER, 'Environment', 0, KEY_ALL_ACCESS)
SetValueEx(key, name, 0, REG_EXPAND_SZ, value)
CloseKey(key)
SendMessage(
win32con.HWND_BROADCAST, win32con.WM_SETTINGCHANGE, 0, 'Environment')
def remove(paths, value):
while value in paths:
paths.remove(value)
def unique(paths):
unique = []
for value in paths:
if value not in unique:
unique.append(value)
return unique
def prepend_env(name, values):
for value in values:
paths = get_env(name).split(';')
remove(paths, '')
paths = unique(paths)
remove(paths, value)
paths.insert(0, value)
set_env(name, ';'.join(paths))
def prepend_env_pathext(values):
prepend_env('PathExt_User', values)
pathext = ';'.join([
get_env('PathExt_User'),
get_env('PathExt', user=False)
])
set_env('PathExt', pathext)
set_env('Home', '%HomeDrive%%HomePath%')
set_env('Docs', '%HomeDrive%%HomePath%\docs')
set_env('Prompt', '$P$_$G$S')
prepend_env('Path', [
r'%SystemDrive%\cygwin\bin', # Add cygwin binaries to path
r'%HomeDrive%%HomePath%\bin', # shortcuts and 'pass-through' bat files
r'%HomeDrive%%HomePath%\docs\bin\mswin', # copies of standalone executables
])
# allow running of these filetypes without having to type the extension
prepend_env_pathext(['.lnk', '.exe.lnk', '.py'])
```
It does not affect the current process or the parent shell, but it will affect all cmd windows opened after it is run, without needing a reboot, and can safely be edited and re-run many times without introducing any duplicates. | It may be just as easy to use the external Windows `setx` command:
```
C:\>set NEWVAR
Environment variable NEWVAR not defined
C:\>python
Python 2.5.4 (r254:67916, Dec 23 2008, 15:10:54) [MSC v.1310 32 bit (Intel)] on
win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import os
>>> os.system('setx NEWVAR newvalue')
0
>>> os.getenv('NEWVAR')
>>> ^Z
C:\>set NEWVAR
Environment variable NEWVAR not defined
```
Now open a new Command Prompt:
```
C:\>set NEWVAR
NEWVAR=newvalue
```
As you can see, `setx` neither sets the variable for the current session, nor for the parent process (the first Command Prompt). But it does set the variable persistently in the registry for future processes.
I don't think there is a way of changing the parent process's environment at all (and if there is, I'd love to hear it!). | Interface for modifying Windows environment variables from Python | [
"",
"python",
"windows",
"environment-variables",
""
] |
Using C#, is there a direct way to export a List of Lists (i.e., `List<List<T>>`) to Excel 2003?
I am parsing out large text files and exporting to Excel. Writing one cell at a time creates way too much overhead. I chose to use `List<T>` so that I would not have to worry about specifying the number of rows or columns.
Currently, I wait until end of file, then put the contents of my `List<List<object>>` into a 2-dimensional array. Then the array can be set as the value of an Excel.Range object. It works, but it seems like I should be able to take my List of Lists, without worrying about the number of rows or columns, and just dump it into a worksheet from A1 to wherever.
Here's a snippet of the code I'd like to replace or improve on:
```
object oOpt = System.Reflection.Missing.Value; //for optional arguments
Excel.Application oXL = new Excel.Application();
Excel.Workbooks oWBs = oXL.Workbooks;
Excel._Workbook oWB = oWBs.Add(Excel.XlWBATemplate.xlWBATWorksheet);
Excel._Worksheet oSheet = (Excel._Worksheet)oWB.ActiveSheet;
int numberOfRows = outputRows.Count;
int numberOfColumns = int.MinValue;
//outputRows is a List<List<object>>
foreach (List<object> outputColumns in outputRows)
{
if (numberOfColumns < outputColumns.Count)
{ numberOfColumns = outputColumns.Count; }
}
Excel.Range oRng = oSheet.get_Range("A1", oSheet.Cells[numberOfRows,numberOfColumns]);
object[,] outputArray = new object[numberOfRows,numberOfColumns];
for (int row = 0; row < numberOfRows; row++)
{
for (int col = 0; col < outputRows[row].Count; col++)
{
outputArray[row, col] = outputRows[row][col];
}
}
oRng.set_Value(oOpt, outputArray);
oXL.Visible = true;
oXL.UserControl = true;
```
This works, but I'd rather use the List directly to Excel than having the intermediary step of creating an array just for the sake of Excel. Any ideas? | Strategically, you are doing it correctly. As Joe says, it is massively faster to execute cell value assignments by passing an entire array of values in one shot rather than by looping through the cells one by one.
Excel is COM based and so operates with Excel via the .NET interop. The interop is ignorant of generics, unfortunately, so you cannot pass it a List<T> or the like. A two dimensional array really is the only way to go.
That said, there are a few ways to clean up your code to make it a bit more manageable. Here are some thoughts:
(1) If you are using .NET 3.0, you can use LINQ to shorten your code from:
```
int numberOfColumns = int.MinValue;
foreach (List<object> outputColumns in outputRows)
{
if (numberOfColumns < outputColumns.Count)
{ numberOfColumns = outputColumns.Count; }
}
```
to a single line:
```
int numberOfColumns = outputRows.Max(list => list.Count);
```
(2) Don't use the `_Worksheet` or `_Workbook` interfaces. Make use of `Worksheet` or `Workbook` instead. See here for a discussion: [Excel interop: \_Worksheet or Worksheet?](https://stackoverflow.com/questions/1051464/excel-interop-worksheet-or-worksheet).
(3) Consider making use of the `Range.Resize` method, which comes through as `Range.get_Resize` in C#. This is a toss-up though -- I actually like the way you are setting your range size. But it's something that I thought that you might want to know about. For example, your line here:
```
Excel.Range oRng = oSheet.get_Range("A1", oSheet.Cells[numberOfRows,numberOfColumns]);
```
Could be changed to:
```
Excel.Range oRng =
oSheet.get_Range("A1", Type.Missing)
.get_Resize(numberOfRows, numberOfColumns);
```
(4) You do not have to set the `Application.UserControl` to `true`. Making Excel visible to the user is enough. The `UserControl` property is not doing what you think it does. (See the help files [here](http://msdn.microsoft.com/en-us/library/bb221971.aspx)) If you want to control whether the user can control Excel or not, you should utilze Worksheet protection, or you *could* set `Application.Interactive = false` if you want to lock out your users. (Rarely a good idea.) But if you want to allow the user to use Excel, then simply making it visible is enough.
Overall, with these in mind, I think that your code could look something like this:
```
object oOpt = System.Reflection.Missing.Value; //for optional arguments
Excel.Application oXL = new Excel.Application();
Excel.Workbooks oWBs = oXL.Workbooks;
Excel.Workbook oWB = oWBs.Add(Excel.XlWBATemplate.xlWBATWorksheet);
Excel.Worksheet oSheet = (Excel.Worksheet)oWB.ActiveSheet;
//outputRows is a List<List<object>>
int numberOfRows = outputRows.Count;
int numberOfColumns = outputRows.Max(list => list.Count);
Excel.Range oRng =
oSheet.get_Range("A1", oOpt)
.get_Resize(numberOfRows, numberOfColumns);
object[,] outputArray = new object[numberOfRows, numberOfColumns];
for (int row = 0; row < numberOfRows; row++)
{
for (int col = 0; col < outputRows[row].Count; col++)
{
outputArray[row, col] = outputRows[row][col];
}
}
oRng.set_Value(oOpt, outputArray);
oXL.Visible = true;
```
Hope this helps...
Mike | It's *much* faster to pass a two-dimensional array to Excel than to update cells one at a time.
Create a 2-dimensional array of objects with values from your list of lists, redimension the Excel range to the dimensions of your array, and then call range.set\_Value, passing your two-dimensional array. | Export a C# List of Lists to Excel | [
"",
"c#",
".net",
"excel",
"list",
"generic-list",
""
] |
Story:
One of the app that i have works on python 2.4 and other on 2.6. I tried to do a sym link of python2.4 to python and things started to break loose on ubuntu jaunty.
Now i am downloading every dependency of 2.4 and installing it using python2.4 setup.py install. The dependencies seem to be endless.
Question1: How will i tell any framework that go and use version so and so pf python like day django to use 2.6 and say mjango to use 2.4? Something like we say use database databasename kinda syntax.
Question2: Is there more elegant way to switch between version as my hack of symlinking was a virtual disaster?
Question3: Can I download a deb for say hardy and make jaunty believe its for her? | Use [Virtualenv](http://pypi.python.org/pypi/virtualenv).
There is more information here: [Working with virtualenv](http://web.archive.org/web/20120303203403/http://www.arthurkoziel.com/2008/10/22/working-virtualenv/).
Using virtualenv you can create a new virtual python environment with whatever version of Python you want for each project or application. You can then activate the appropriate environment when you need it.
**To expand on my answer:**
You can install multiple versions of Python on your computer (I have 2.4, 2.5, 2.6 and 3.1 on my machine - I install each from source). I use a Mac, and keep my system Python as whatever OS X sets as the default.
I use *easy\_install* to install packages. On ubuntu you can get easy\_install like this:
```
sudo apt-get install python-setuptools
```
To install virtualenv then do:
```
easy_install virtualenv
```
I tend to create a new virtualenv for each project I'm working on and don't give it access to the global site-packages. This keeps all the packages tight together and allows me to have the specific versions of everything I need.
```
virtualenv -p python2.6 --no-site-packages ~/env/NEW_DJANGO_PROJECT
```
And then whenever I am doing anything related to this project I activate it:
```
source ~/env/NEW_DJANGO_PROJECT/bin/activate
```
If I run python now it uses this new python. If I use easy\_install it installs things into my new virtual environment.
So, virtualenv should be able to solve all of your problems. | Pythonbrew is a magical tool. Which can also be called as Python version manager similar to that of RVM-Ruby version manager but Pythonbrew is inspired by Perlbrew.
Pythonbrew is a program to automate the building and installation of Python in the users $HOME.
```
Dependencies – curl
```
Before Installing the Pythonbrew, Install “curl” in the machine, to install curl use the below command in the terminal, give the the password for the user when prompted.
```
$sudo apt-get install curl
```
After Installing the curl, Now Install Pythonbrew, copy and paste the following commands in the terminal and type the password for the user when prompted.
Recomended method of installation - Easy Install
```
$ sudo easy_install pythonbrew
```
To complete the installation, type the following command
```
$pythonbrew_install
```
Alternate method of installation:
Use curl command to download the latest version of pythonbrew from github.
```
curl -kLO http://github.com/utahta/pythonbrew/raw/master/pythonbrew-install
```
After downloading, change “pythonbrew-install” to “executable”
```
chmod +x pythonbrew-install
```
Then, run the pythonbrew-install in the terminal
```
./pythonbrew-install
```
Now the Pythonbrew has been installed in the `“Home Directory”` i.e., `/home/user/.pythonbrew`
Next, copy and paste the following line to the end of ~/.bashrc
\*NOTE: change `“user”` to your user name in the system
```
source /home/user/.pythonbrew/etc/bashrc
```
Thats it! Close the terminal.
Steps to Install different versions of Python:
Open a new terminal, type the following command or copy and paste it.
```
$pythonbrew install 2.6.6
```
This will install Python 2.6.6 and to install Python 2.7 or Python 3.2, change the version number in the previous command.
```
$pythonbrew install 2.7
```
or
```
$pythonbrew install 3.2
```
Update: If you get error while Installing then Install using the below command.
```
$pythonbrew install --force 2.7
```
or
```
$pythonbrew install --force 3.2
```
How to manage different versions of Python installed in system
For instance, if Python `2.6.6`, `Python 2.7` and `Python 3.2` is installed in your system, switching between the versions can be done as follows:
By default, `Python 2.6.6` will be active and in order to switch to Python 2.7 use the below command
```
$pythonbrew switch 2.7
```
The default Python is changed to Python 2.7.
Now, to switch to Python 3.2 change the version number in the previous command.
```
$pythonbrew switch 3.2
```
Use the below command to check or list the installed Python versions
```
$pythonbrew list
```
Use the below command to check or list the available Python Versions to install
```
$pythonbrew list -k
```
To uninstall any of the installed Python version (for example to uninstall Python 2.7), use the below command.
```
$pythonbrew uninstall 2.7
```
Use the below command to update the `Pythonbrew`
```
$pythonbrew update
```
Use the below command to disable the `Pythonbrew` and to activate the default version
```
$pythonbrew off
```
Enjoy the experience of installing multiple versions of Python in single Linux / ubuntu machine! | switch versions of python | [
"",
"python",
"development-environment",
"ubuntu-9.04",
""
] |
I'm trying to create a Python script that would :
1. Look into the folder "/input"
2. For each video in that folder, run a mencoder command (to transcode them to something playable on my phone)
3. Once mencoder has finished his run, delete the original video.
That doesn't seem too hard, but I suck at python :)
Any ideas on what the script should look like ?
Bonus question : Should I use
> os.system
or
> subprocess.call
?
Subprocess.call seems to allow for a more readable script, since I can write the command like this :
> cmdLine = ['mencoder',
> sourceVideo,
> '-ovc',
> 'copy',
> '-oac',
> 'copy',
> '-ss',
> '00:02:54',
> '-endpos',
> '00:00:54',
> '-o',
> destinationVideo]
EDIT : Ok, that works :
```
import os, subprocess
bitrate = '100'
mencoder = 'C:\\Program Files\\_utilitaires\\MPlayer-1.0rc2\\mencoder.exe'
inputdir = 'C:\\Documents and Settings\\Administrator\\Desktop\\input'
outputdir = 'C:\\Documents and Settings\\Administrator\\Desktop\\output'
for fichier in os.listdir(inputdir):
print 'fichier :' + fichier
sourceVideo = inputdir + '\\' + fichier
destinationVideo = outputdir + '\\' + fichier[:-4] + ".mp4"
commande = [mencoder,
'-of',
'lavf',
[...]
'-mc',
'0',
sourceVideo,
'-o',
destinationVideo]
subprocess.call(commande)
os.remove(sourceVideo)
raw_input('Press Enter to exit')
```
I've removed the mencoder command, for clarity and because I'm still working on it.
Thanks to everyone for your input. | To find all the filenames use `os.listdir()`.
Then you loop over the filenames. Like so:
```
import os
for filename in os.listdir('dirname'):
callthecommandhere(blablahbla, filename, foo)
```
If you prefer subprocess, use subprocess. :-) | Use [os.walk](http://docs.python.org/library/os.html#os.walk) to iterate recursively over directory content:
```
import os
root_dir = '.'
for directory, subdirectories, files in os.walk(root_dir):
for file in files:
print os.path.join(directory, file)
```
No real difference between os.system and subprocess.call here - unless you have to deal with strangely named files (filenames including spaces, quotation marks and so on). If this is the case, subprocess.call is definitely better, because you don't need to do any shell-quoting on file names. os.system is better when you need to accept any valid shell command, e.g. received from user in the configuration file. | Using Python to execute a command on every file in a folder | [
"",
"python",
"foreach",
"mencoder",
""
] |
My data looks like the following:
```
id|category|insertdate|title....
--------------------------------
1|1|123|test 1
2|1|124|test 2
3|1|125|test 3
4|2|102|test 4
5|2|103|test 5
6|2|104|test 6
```
What I try to accomplish is get the latest 2 entries per category (as in order by insertdate DESC), so the result should be:
```
id|....
----
3|....
2|....
6|....
5|....
```
Getting the latest by using `group by` is easy, but how do I get the latest 2 without launching multiple queries?
Thanks for any help ;-)
S. | Here you go buddy!
```
SET @counter = 0;
SET @category = '';
SELECT
*
FROM
(
SELECT
@counter := IF(data.category = @category, @counter+1, 0) AS counter,
@category := data.category,
data.*
FROM
(
SELECT
*
FROM test
ORDER BY category, date DESC
) data
) data
HAVING counter < 2
``` | This is a tricky problem in SQL which is best answered by directing you to an excellent in-depth article covering the issue: [How to select the first/least/max row per group in SQL](http://www.xaprb.com/blog/2006/12/07/how-to-select-the-firstleastmax-row-per-group-in-sql/). It covers MySQL-specific means of doing this, as well as generic methods. | How to get the latest 2 items per category in one select (with mysql) | [
"",
"sql",
"mysql",
""
] |
I'd like to start coding for NVIDIA 3D Vision and wonder where can I find the documentation for it? | The docs should be on the [nVidia developer site](http://developer.nvidia.com/page/home.html), though I think that it may be called 3D sterio there. As there isn't a visible heading for either, the info you're looking for may be included in the OpenGL or DirectX docs. | I know this question is very very old but I was looking for the same information and have found these links to be useful.
The GDC 2009 PowerPoint that David mentioned:
<http://developer.download.nvidia.com/presentations/2009/GDC/GDC09-3DVision-The_In_and_Out.pdf>
A PDF put out by Nvidia:
<http://developer.download.nvidia.com/whitepapers/2010/NVIDIA%203D%20Vision%20Automatic.pdf>
These stackoverflow questions are handy:
[NV\_STEREO\_IMAGE\_SIGNATURE and DirectX 10/11 (nVidia 3D Vision)](https://stackoverflow.com/questions/7377861/nv-stereo-image-signature-and-directx-10-11-nvidia-3d-vision)
[Nvidia 3d Video using DirectX11 and SlimDX in C#](https://stackoverflow.com/questions/11277069/nvidia-3d-video-using-directx11-and-slimdx-in-c-sharp)
Also there were a number of good topics in the nvidia developers forum, but the forum remains down due to last July's hacker attack. Nvidia promised to restore the old content once they eventually get a new forum up and running. | Where to find API documentation for NVIDIA 3D Vision? | [
"",
"c++",
"winapi",
"api",
"3d",
"nvidia",
""
] |
One of the columns in my table is a varchar that is supposed to contain only numeric values (I can't change the definition to a number column). Thus my SQL query:
```
select to_number(col1) from tbl1 where ...
```
fails because for some row the contents of the column are not numeric.
What's a `select` query I can use to find these rows ?
I'm using an Oracle database
I'm looking for something like a `is_number` function. | There is no native "isnumeric" function in oracle, but this link shows you how to make one:
<http://www.oracle.com/technetwork/issue-archive/o44asktom-089519.html>
```
CREATE OR REPLACE FUNCTION isnumeric(p_string in varchar2)
RETURN BOOLEAN
AS
l_number number;
BEGIN
l_number := p_string;
RETURN TRUE;
EXCEPTION
WHEN OTHERS THEN
RETURN FALSE;
END;
/
``` | I don't disagree that the best solution is to follow Tom Kyte's examples others have linked to already. However, if you just need something that is SQL only because you unfortunately do not have the relationship with your DBA to add pl/sql functions to your schema you could possibly leverage regular expressions to meet a basic need. Example:
```
select '234', REGEXP_SUBSTR('234','^\d*\.{0,1}\d+$') from dual
union all
select 'abc', REGEXP_SUBSTR('abc','^\d*\.{0,1}\d+$') from dual
union all
select '234234abc', REGEXP_SUBSTR('234234abc','^\d*\.{0,1}\d+$') from dual
union all
select '100.4', REGEXP_SUBSTR('100.4','^\d*\.{0,1}\d+$') from dual
union all
select '-100.4', REGEXP_SUBSTR('-100.4','^\d*\.{0,1}\d+$') from dual
union all
select '', REGEXP_SUBSTR('','^\d*\.{0,1}\d+$') from dual
```
Below is the output of the above:
```
INPUT RESULT
234 234
abc -
234234abc -
100.4 100.4
-100.4 -
``` | SQL: how do I find if the contents of a varchar column are numeric? | [
"",
"sql",
"oracle",
""
] |
With the String class, you can do:
```
string text = new string('x', 5);
//text is "xxxxx"
```
What's the shortest way to create a List< T > that is full of `n` elements which are all the same reference? | Try the following
```
var l = Enumerable.Repeat('x',5).ToList();
``` | Fastest way I know is:
```
int i = 0;
MyObject obj = new MyObject();
List<MyObject> list = new List<MyObject>();
for(i = 0; i < 5; i++)
{
list.Add(obj);
}
```
which you can make an extension method if you want to use it multiple times:
```
public void AddMultiple(this List<T> list, T obj, int n)
{
int i;
for(i = 0; i < n; i++)
{
list.Add(obj);
}
}
```
Then you can just do:
```
List<MyObject> list = new List<MyObject>();
MyObject obj = new MyObject();
list.AddMultiple(obj, 5);
``` | Shortest way to create a List<T> of a repeated element | [
"",
"c#",
".net",
".net-3.5",
"list",
""
] |
I have passed the last couple of hours trying to downgrade Java to 1.6.0\_13 in my attempt to get Google Web Toolkit's hosted mode to work on Eclipse.
And it has proven to be a nightmare-ish task!
In retrospect:
- All references to Java in the Control Panel -> Uninstall a Program tool have been removed
- Those that didn't want to be removed, have been forced to by Microsoft's "Windows Installer Cleanup Utility" - <http://support.microsoft.com/default.aspx?scid=kb;en-us;290301>
- An annoying folder called "JRE" was still sitting around, so I deleted it
Now, if I open a command prompt and type java, I still get:
> Error: could not open `C:\Program Files\Java\jre6\lib\i386\jvm.cfg'
Which means that it's still hidden somewhere...
What else do I have to do to remove it completely? | I find it surprising that it's so hard to remove. Anyway, to answer your question, I'd look for and delete:
* c:\windows\system32\java.exe
* c:\windows\system32\javaw.exe
Once those are deleted, you should be fine.
That said, I seem to be able to run GWT in hosted mode with Java 1.6.0\_14 just fine. | If you want to downgrade Java you just need to set the JVM that Eclipse uses for compilation:
> Window > Preferences > Java >
> Installed JREs
and then add a new JDK/JRE that you want, in your case Java 5 then check the box next to the JVM/JRE. | How to completely remove Java? (Error: could not open `C:\Program Files\Java\jre6\lib\i386\jvm.cfg') | [
"",
"java",
"eclipse",
""
] |
In Java classes is it considered good or bad practice to access member fields with their getters and setters?
e.g which is better:
```
public Order {
private Agreement agreement;
public Agreement getAgreement() {
return agreement;
}
public void process() {
//should I use:
getAgreement().doSomething();
//Or:
agreement.doSomething();
}
}
```
In general I think accessing the field directly is best due to the KISS principle and also someone may override the get method later with unpredictable results.
However my colleagues argue that it is better to keep a layer of abstraction. Is there any consensus on this? | The core issue here is that direct field access is ineligible for interception by subclass overridden methods, AOP, dynamic proxies and the like. This can be a good or bad thing depending on the case. I would say that using getters and setters internally is not an anti-pattern or a pattern. It is a good or bad thing depending on the situation, and the design of your class. | Honestly, in my opinion, it depends on what you're using it for. Personally, when in doubt, I always leave that extra level of abstraction in there just in case I need to override it later in a subclass. Many times have I been saved from the pain of rewriting a class just because I left a getter or a setter open to overriding.
Another thing is that other clients/programmers might need to use your class in a way that you haven't yet thought of, for example, pulling the Agreement class out of a database. In that case, when they override your class, you have made it painless for them (or potentially a future you) to modify how that data is retrieved.
So unless you're absolutely certain that there is only one way to access that field, and that it's 100% direct, it's probably best to decouple the retrieval and modification of values so that at some future point you can save yourself from rewrite hardship. | Is it in an anti-pattern to always use get and set methods to access a class's own member fields? | [
"",
"java",
"anti-patterns",
""
] |
For example, I have two elements in an enum. I would like the first to be represented by the integer value 0 and the string A, but the second to be represented by the integer value of 2 and the string "B" (as opposed to 1). Is this possible?
Currently, my enum is declared as this:
```
public enum Constants {
ZERO("Zero");
TWO("Two");
}
```
If I were to get the integer values of ZERO and TWO, I would currently get 0 and 1, respectively. However, I would like to get 0 and 2. | I assume you are referring to a way to make the ordinal of the Enum return a user-defined value. If this is the case, no.
If you want to return a specific value, implement (e.g. getValue()) and pass it in the Enum constructor.
For example:
```
public enum Constants {
ZERO("Zero",0),
TWO("Two",2);
final private String label;
final private int value;
Constants(String label, int value) {
this.label = label;
this.value= value;
}
public int getValue() {
return value;
}
public String getLabel() {
return label;
}
}
``` | Define an appropriately named integer field for your enum and initialize it to whatever value suits you best. The internal ordinal of enums is not meant to carry an meaning. | Is there a way for a Java enum to have "missing" integer values for its elements? | [
"",
"java",
"enums",
""
] |
Reading the javadoc on FileDesciptor's .sync() method, it is apparent that sync() is primarily concerned with committing any modified buffers back to the underlying storage. I.e., making sure that anything that your program has *output* will actually make it to the disk (or socket or what-have-you, but my question pertains mainly to disks).
But what about the other direction, what about INPUT? Suppose my program has some parts of a java.io.RandomAccessFile buffered in memory, and I want to READ those parts of the file, but perhaps some other process has modified those parts of the file since the last time my program read those blocks?
This is akin to marking a variable as 'volatile' in a C program; something else may have changed the 'real version' of something you merely have a convenient copy of.
I.e., how can you be certain that what your java program reads is at least reasonably up-to-date?
(Clearly the definition of 'up to date' matters. Purely as an example, suppose that the other process, the one that writes to the file, does so on the order of maybe once per second, and suppose that the reading process reads maybe once per minute. In a situation like this, performance isn't a big deal, it's just a matter of making sure that what the reader reads is consistent with what the write writes, to within say, a second.) | Before re-reading your file, it is usually a good idea to check the last modified timestamp of the file with File.lastModified(). If this timestamp is not newer than the last time you read the file, you don't need to bother with more disk I/O to re-read the blocks you are interested in. One thing to keep in mind though, is that the last modifed timestamp may not always be updated immediately when the contents are updated if you are using a network filesystem. If you are dealing with a local process updating the file and another local process running your code reading the file, you most likely won't run into this issue.
One method I've had success with in the past was to have a separate thread poll the file for the last modified timestamp on certain intervals, say 5 seconds. If the file changed, re-process the file and send an event to registered listeners. In my case, 5 seconds was more than soon enough to get updates. | At the moment where the file is read into the internal buffer, the contents are up-to-date to the contents on the disk.
If you want to be sure to have the latest contents on your next access, you also have to go to the disk again, skipping all internal buffers and caches. If you really want to be sure, that all such layers are skipped, you'll have to reopen the file from scratch and seek to the according position you want to access.
Of course, your performance will go down the tubes if you access the disk on every possible access of the data. Don't think of 3-5 fold or so but orders of magnitudes. | Converse of java FileDescriptor .sync() for *reading* files | [
"",
"java",
"multithreading",
"file-io",
"concurrency",
""
] |
Here's a common, simple task: Read configuration settings from a configuration file, save the settings (e.g. as a hash) in an object, access this object from various objects that need to access the configuration parameters.
I found [this implementation](http://www-personal.umich.edu/~wagnerr/ConfigFile.html) for the ConfigFile class implementation and it works. My question is: what is the best way to make an instance of this class available from my other classes and be thread safe, avoid static initialization order fiasco, etc.
My current approach is to construct it in main() using
```
// Read face detection related parameter values from the configuration file.
string configFileName = "detection_parameters.txt";
try {
parameters = ConfigFile( configFileName );
}
catch(ConfigFile::file_not_found) {
cerr << "configuration file not found: " << configFileName << endl;
exit(-1);
}
```
and then make **parameters** a global variable. But I also read that singletons should be used instead of global variables. How can the singleton be instantiated with the file name?
This must be such a common task that I think there must be a generally accepted good way of doing it? I would appreciate if someone can point me to it.
Thanks,
C | If you're going to roll-your-own, I would recommend using the Singleton design pattern for your configuration class.
Have the class itself store a static pointer of its own type, and the constructor be private so one would be forced to use the static getter to get the one instance of the class.
so a mock-up (that may not compile, an is missing the fun Config functionality, but should illustrate the point)
```
class Config
{
public:
static Config * getConfig();
static void setConfigFileName(string filename);
private:
Config();
static string m_filename;
static Config * m_configInstance;
};
```
In case I'm not being clear, the getConfig() would look at m\_configInstance. If it isn't a valid one, then it would create one (has access to the private constructor) and store it in m\_configInstance so every subsequent call would access the same one.
So your main() would use setConfigFileName(), then any class would just have to call Config::getConfig() and then call the operations on it. A lot cleaner than a standard global variable.
Blast - in the time I spent writing this, other people have suggested the singleton design pattern too. Ah well - hope the additional explanation helps. | Have you looked at [Boost's Program Options](http://www.boost.org/doc/libs/1_37_0/doc/html/program_options/tutorial.html) library? | How to create a global parameters object | [
"",
"c++",
"configuration",
"global-variables",
""
] |
sending mail along with embedded image using asp.net
I have already used following but it can't work
```
Dim EM As System.Net.Mail.MailMessage = New System.Net.Mail.MailMessage(txtFrom.Text, txtTo.Text)
Dim A As System.Net.Mail.Attachment = New System.Net.Mail.Attachment(txtImagePath.Text)
Dim RGen As Random = New Random()
A.ContentId = RGen.Next(100000, 9999999).ToString()
EM.Attachments.Add(A)
EM.Subject = txtSubject.Text
EM.Body = "<body>" + txtBody.Text + "<br><img src='cid:" + A.ContentId +"'></body>"
EM.IsBodyHtml = True
Dim SC As System.Net.Mail.SmtpClient = New System.Net.Mail.SmtpClient(txtSMTPServer.Text)
SC.Send(EM)
``` | If you are using .NET 2 or above you can use the AlternateView and LinkedResource classes like this:
```
string html = @"<html><body><img src=""cid:YourPictureId""></body></html>";
AlternateView altView = AlternateView.CreateAlternateViewFromString(html, null, MediaTypeNames.Text.Html);
LinkedResource yourPictureRes = new LinkedResource("yourPicture.jpg", MediaTypeNames.Image.Jpeg);
yourPictureRes.ContentId = "YourPictureId";
altView.LinkedResources.Add(yourPictureRes);
MailMessage mail = new MailMessage();
mail.AlternateViews.Add(altView);
```
Hopefully you can deduce the VB equivalent. | After searching and trying must be four or five 'answers' I felt I had to share what I finally found to actually work as so many people seem to not know how to do this or some give elaborate answers that so many others have issues with, plus a few do and only give a snippet answer which then has to be interpreted. As I don't have a blog but I'd like to help others here is some full code to do it all. Big thanks to Alex Peck, as it's his answer expanded on.
inMy.aspx asp.net file
```
<div>
<asp:LinkButton ID="emailTestLnkBtn" runat="server" OnClick="sendHTMLEmail">testemail</asp:LinkButton>
</div>
```
inMy.aspx.cs code behind c# file
```
protected void sendHTMLEmail(object s, EventArgs e)
{
/* adapted from http://stackoverflow.com/questions/1113345/sending-mail-along-with-embedded-image-using-asp-net
and http://stackoverflow.com/questions/886728/generating-html-email-body-in-c-sharp */
string myTestReceivingEmail = "yourEmail@address.com"; // your Email address for testing or the person who you are sending the text to.
string subject = "This is the subject line";
string firstName = "John";
string mobileNo = "07711 111111";
// Create the message.
var from = new MailAddress("emailFrom@address.co.uk", "displayed from Name");
var to = new MailAddress(myTestReceivingEmail, "person emailing to's displayed Name");
var mail = new MailMessage(from, to);
mail.Subject = subject;
// Perform replacements on the HTML file (which you're using as a template).
var reader = new StreamReader(@"c:\Temp\HTMLfile.htm");
string body = reader.ReadToEnd().Replace("%TEMPLATE_TOKEN1%", firstName).Replace("%TEMPLATE_TOKEN2%", mobileNo); // and so on as needed...
// replaced this line with imported reader so can use a templete ....
//string html = body; //"<html><body>Text here <br/>- picture here <br /><br /><img src=""cid:SACP_logo_sml.jpg""></body></html>";
// Create an alternate view and add it to the email. Can implement an if statement to decide which view to add //
AlternateView altView = AlternateView.CreateAlternateViewFromString(body, null, MediaTypeNames.Text.Html);
// Logo 1 //
string imageSource = (Server.MapPath("") + "\\logo_sml.jpg");
LinkedResource PictureRes = new LinkedResource(imageSource, MediaTypeNames.Image.Jpeg);
PictureRes.ContentId = "logo_sml.jpg";
altView.LinkedResources.Add(PictureRes);
// Logo 2 //
string imageSource2 = (Server.MapPath("") + "\\booking_btn.jpg");
LinkedResource PictureRes2 = new LinkedResource(imageSource2, MediaTypeNames.Image.Jpeg);
PictureRes2.ContentId = "booking_btn.jpg";
altView.LinkedResources.Add(PictureRes2);
mail.AlternateViews.Add(altView);
// Send the email (using Web.Config file to store email Network link, etc.)
SmtpClient mySmtpClient = new SmtpClient();
mySmtpClient.Send(mail);
}
```
HTMLfile.htm
```
<html>
<body>
<img src="cid:logo_sml.jpg">
<br />
Hi %TEMPLATE_TOKEN1% .
<br />
<br/>
Your mobile no is %TEMPLATE_TOKEN2%
<br />
<br />
<img src="cid:booking_btn.jpg">
</body>
</html>
```
in your Web.Config file, inside your < configuration > block you need the following to allow testing in a TempMail folder on your c:\drive
```
<system.net>
<mailSettings>
<smtp deliveryMethod="SpecifiedPickupDirectory" from="madeupEmail@address.com">
<specifiedPickupDirectory pickupDirectoryLocation="C:\TempMail"/>
</smtp>
</mailSettings>
</system.net>
```
the only other things you will need at the top of your aspx.cs code behind file are the Using System includes (if I've missed one out you just right click on the unknown class and choose the 'Resolve' option)
```
using System.Net.Mail;
using System.Text;
using System.Reflection;
using System.Net.Mime; // need for mail message and text encoding
using System.IO;
```
Hope this helps someone and big thanks to the above poster for giving the answer needed to get the job done (as well as the other link in my code).
It works but im open to improvements.
cheers. | sending mail along with embedded image using asp.net | [
"",
"c#",
"asp.net",
""
] |
I have a (big) problem that all of you that work with Webforms might have.
The problem is the **time to load a page**.
Using localhost (witch should be the fastest mode) in Vista (IIS 7) I get this graph
[alt text http://www.balexandre.com/temp/2009-06-29\_1302\_soquestion.png](http://www.balexandre.com/temp/2009-06-29_1302_soquestion.png)
[original file link](http://www.balexandre.com/temp/2009-06-29_1302_soquestion.png)
as you can see, it takes **more than 17 seconds** to show the page!!! and only 2 seconds to load the page it self...
I'm using the ASP.NET AJAX framework to work with Web Parts.
How can I reduce this 17 seconds?
Any idea on where to go is greatly appreciated :)
---
**Added: Test for correct answer from [Jan Zich](https://stackoverflow.com/users/15716/jan-zich)**
I tested changing
```
<asp:ScriptManager ID="sm" runat="server" />
```
into
```
<ajax:ToolkitScriptManager ID="sm" runat="server" CombineScripts="true" />
```
and the result using FireBug is **impressive** (half of the time, and not using the cache!) as you can see in the image below
[alt text http://www.balexandre.com/temp/2009-06-29\_1543\_soquestion.png](http://www.balexandre.com/temp/2009-06-29_1543_soquestion.png)
[original file link](http://www.balexandre.com/temp/2009-06-29_1543_soquestion.png)
and with CSS and jQuery **files cached**, drops to half of it!
[alt text http://www.balexandre.com/temp/2009-06-29\_1550\_soquestion.png](http://www.balexandre.com/temp/2009-06-29_1550_soquestion.png)
[original file link](http://www.balexandre.com/temp/2009-06-29_1550_soquestion.png) | This won’t count as a valid answer because I don’t know how to actually fix that, but the problem is that most browsers (besides Safari and Chrome perhaps) load JavaScript sequentially because it’s necessary to wait for the previous script to finish executing (as it may change the document). This is typically fixed by combining all JavaScript files into one.
**Edit:** Related question: [How do I combine WebResource.axd and ScriptResource.axd files so as to result in less requests to my ASP.NET server?](https://stackoverflow.com/questions/505416/how-do-i-combine-webresource-axd-and-scriptresource-axd-files-so-as-to-result-in). Also, I cannot see what scripts you are actually including from the screenshot, but most likely it's your custom scripts. Is there a way in your application to combine them in some way? | Keep in mind, that when debug mode is enabled (in web.config: `<compilation debug="true"`>), resources such as javascript files, images and CSS files are not cached by the browser.
Therefore, in a production-environment (with debug disabled), these numbers might look different, since the browser will cache most of the resources and not request them again for each page/request. | How to manage that aspx pages load faster? | [
"",
"c#",
"iis-7",
"webforms",
"pageload",
""
] |
To check for odd and even integer, is the lowest bit checking more efficient than using the modulo?
```
>>> def isodd(num):
return num & 1 and True or False
>>> isodd(10)
False
>>> isodd(9)
True
``` | Yep. The `timeit` module in the standard library is how you check on those things. E.g:
```
$ python -m timeit -s 'def isodd(x): x & 1' 'isodd(9)'
1000000 loops, best of 3: 0.446 usec per loop
$ python -m timeit -s 'def isodd(x): x & 1' 'isodd(10)'
1000000 loops, best of 3: 0.443 usec per loop
$ python -m timeit -s 'def isodd(x): x % 2' 'isodd(9)'
1000000 loops, best of 3: 0.461 usec per loop
$ python -m timeit -s 'def isodd(x): x % 2' 'isodd(10)'
1000000 loops, best of 3: 0.453 usec per loop
```
As you see, on my (first-day==old==slow;-) Macbook Air, the `&` solution is repeatably between 7 and 18 nanoseconds faster than the `%` solution.
`timeit` not only tells you what's faster, but by how much (just run the tests a few times), which usually shows how supremely UNimportant it is (do you *really* care about 10 nanoseconds' difference, when the overhead of calling the function is around 400?!-)...
Convincing programmers that micro-optimizations are essentially irrelevant has proven to be an impossible task -- even though it's been 35 years (over which computers have gotten orders of magnitude faster!) since Knuth [wrote](http://pplab.snu.ac.kr/courses/adv_pl05/papers/p261-knuth.pdf)
> We should forget about small
> efficiencies, say about 97% of the
> time: premature optimization is the
> root of all evil.
which as he explained is a quote from an even older statement from Hoare. I guess everybody's totally convinced that THEIR case falls in the remaining 3%!
So instead of endlessly repeating "it doesn't matter", we (Tim Peters in particular deserves the honors there) put in the standard Python library module `timeit`, that makes it trivially easy to measure such micro-benchmarks and thereby lets at least *some* programmers convince themselves that, hmmm, this case DOES fall in the 97% group!-) | To be totally honest, **I don't think it matters.**
The first issue is readability. What makes more sense to other developers? I, personally, would expect a modulo when checking the evenness/oddness of a number. I would expect that most other developers would expect the same thing. By introducing a different, and unexpected, method, you might make code reading, and therefore maintenance, more difficult.
The second is just a fact that you probably won't ever have a bottleneck when doing either operation. I'm for optimization, but early optimization is the worst thing you can do in any language or environment. If, for some reason, determining if a number is even or odd is a bottleneck, then find the fastest way of solving the problem. However, this brings me back to my first point - the first time you write a routine, it should be written in the most readable way possible. | Is & faster than % when checking for odd numbers? | [
"",
"python",
"performance",
"bit-manipulation",
"modulo",
""
] |
I want to change the logging level depending if I'm debbugging or not, but I can't find a code snippet to check if the application is running in debug mode.
I'm using eclipse to debug the application, so if the solution only works within Eclipse it will be fine. | You could modify the Debug Configuration. For example add a special VM argument only in the Debug Configuration. You can use `System.getProperties()` to read the supplied arguments.
Even better, modify the configurations (Run and Debug) to load a different logging configuration file. It isn't good if you need to write code to determine the logging level. This should only be a matter of configuration. | Found the answer on [how-to-find-out-if-debug-mode-is-enabled](https://stackoverflow.com/questions/3776204/how-to-find-out-if-debug-mode-is-enabled)
```
boolean isDebug = java.lang.management.ManagementFactory.getRuntimeMXBean().
getInputArguments().toString().contains("-agentlib:jdwp");
```
This will check if the [Java Debug Wire Protocol](http://download.oracle.com/javase/1.5.0/docs/guide/jpda/jdwp-spec.html) agent is used. | Determine if a java application is in debug mode in Eclipse | [
"",
"java",
"eclipse",
"debugging",
"logging",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.