
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I need to conduct a survey of 3 questions:
* The first question will be Yes/No.
* The second will have multiple answers, in which you can select multiple answers for just that question, as well as an "other" box that you can use to fill in an answer.
* The last question will be a textarea in which the user can enter g... | <http://docs.google.com> Create a form and collect results of the survey in spreadsheet | I looked into this a few years ago. Surveymonkey is a web service that appears to be widely used, especially by non-computer literate. If you want to modify, serve and count yourself (possible for free), see [this comparison chart](http://websurveytoolbox.org/FeatureTable.html "this comparison chart"). | What is a good free online poll/survey app? | [
"",
"php",
"mysql",
"survey",
""
] |
**Update:** Thanks for the suggestions guys. After further research, I’ve reformulated the question here: [Python/editline on OS X: £ sign seems to be bound to ed-prev-word](https://stackoverflow.com/questions/217020/pythoneditline-on-os-x-163-sign-seems-to-be-bound-to-ed-prev-word)
On Mac OS X I can’t enter a pound s... | I'd imagine that the terminal emulator is eating the keystroke as a control code. Maybe see if it has a config file you can mess around with? | Not the best solution, but you could type:
```
pound = u'\u00A3'
```
Then you have it in a variable you can use in the rest of your session. | How do I enter a pound sterling character (£) into the Python interactive shell on Mac OS X? | [
"",
"python",
"bash",
"macos",
"shell",
"terminal",
""
] |
We are building a framework that will be used by other developers and for now we have been using a lot of TDD practices. We have interfaces everywhere and have well-written unit tests that mock the interfaces.
However, we are now reaching the point where some of the properties/methods of the input classes need to be i... | You need to be able to replicate those internal methods in your mock up objects. And call them in the same way the real object would call them. Then you focus your unit test on the public method that relies on that private method you need to test. If these internal methods are calling other objects or doing a lot of wo... | First, there is no general TDD rule that says everything should be an interface. This is coming from a specific style that is not practiced by every TDDer. See <http://martinfowler.com/articles/mocksArentStubs.html>
Second, you are experiencing the dichotomy of [public vs. published](http://martinfowler.com/ieeeSoftwa... | How do you balance Framework/API Design and TDD | [
"",
"c#",
"design-patterns",
"oop",
"interface",
"tdd",
""
] |
I have a Winforms application created in Visual Studio 2005 Pro, it connects to an SQL Server 2005 database using the SqlConnection / SqlCommand / SqlDataAdapter classes to extract data. I have stored procedures in my database to return the data to me.
What is the best way to handle queries that take a "long time" to ... | Making sure that the queries are optimized is the first step, but afterwards, you have to use threading, and .NET has the [BackgroundWorker component](http://msdn.microsoft.com/en-us/library/8xs8549b.aspx) for these cases.
Here's a [complete example](http://msdn.microsoft.com/en-us/library/waw3xexc.aspx) | Simple C# 2.0 example:
```
private void Form_Load(object sender, EventArgs e)
{
BackgroundWorker bw = new BackgroundWorker();
bw.DoWork += new DoWorkEventHandler(bw_DoWork);
bw.RunWorkerCompleted += new RunWorkerCompletedEventHandler(bw_RunWorkerCompleted);
//change UI to reflec... | What is the correct way to deal with procedures that take a "long time" to complete? | [
"",
"c#",
"database",
"sql-server-2005",
"multithreading",
"visual-studio-2005",
""
] |
While working on a project, I came across a JS-script created by a former employee that basically creates a report in the form of
```
Name : Value
Name2 : Value2
```
etc.
The peoblem is that the values can sometimes be floats (with different precision), integers, or even in the form `2.20011E+17`. What I want to out... | You hav to convert your input into a number and then round them:
```
function toInteger(number){
return Math.round( // round to nearest integer
Number(number) // type cast your input
);
};
```
Or as a one liner:
```
function toInt(n){ return Math.round(Number(n)); };
```
Testing with different values:... | If you need to round to a certain number of digits use the following function
```
function roundNumber(number, digits) {
var multiple = Math.pow(10, digits);
var rndedNum = Math.round(number * multiple) / multiple;
return rndedNum;
}
``` | How do I round a number in JavaScript? | [
"",
"javascript",
"floating-point",
"numbers",
"rounding",
""
] |
Does anyone know of a really simple way of publishing Java methods as web services? I don't really want the overhead of using Tomcat or Jetty or any of the other container frameworks.
Scenario: I've got a set of Java methods in a service type application that I want to access from other machines on the local LAN. | Well, Tomcat or Jetty may be overkill for publishing just some methods as a web service. But on the other hand its not too complicated and they do the job, so why not?
I had a similar problem not too long ago and used a Tomcat together with Axis2. Just download Tomcat, unpack it, deploy the Axis2 WAR. To publish a web... | Erhm. Why not just use [RMI](http://java.sun.com/javase/technologies/core/basic/rmi/index.jsp)? | Simple Java web services | [
"",
"java",
"web-services",
"remoting",
""
] |
How can I document a member inline in .Net? Let me explain. Most tools that extract documentation from comments support some kind of inline documentation where you can add a brief after the member declaration. Something like:
```
public static string MyField; /// <summary>Information about MyField.</summary>
```
Is t... | No, you can't. XML comments are only supported as a block level comment, meaning it must be placed before the code element you are documenting. The common tools for extracting XML comments from .NET code do not understand how to parse inline comments like that. If you need this ability you will need to write your own p... | There is not a built-in way to do this. The XML documentation system is hierarchical; it defines a relationship between the tag `<summary />` and the data that immediately follows it. | How to use inline comments to document members in .NET? | [
"",
"c#",
".net",
"documentation",
"documentation-generation",
"xml-documentation",
""
] |
I would like to load a BMP file, do some operations on it in memory, and output a new BMP file using C++ on Windows (Win32 native). I am aware of [ImageMagick](http://www.imagemagick.org/) and it's C++ binding [Magick++](http://www.imagemagick.org/Magick%2B%2B/), but I think it's an overkill for this project since I am... | When developing just for Windows I usually just use the ATL [CImage](http://msdn.microsoft.com/en-us/library/bwea7by5(VS.80).aspx) class | [EasyBMP](http://easybmp.sourceforge.net/) if you want just bmp support. I'ts simple enough to start using within minutes, and it's multiplatform if you would need that. | C++: What's the simplest way to read and write BMP files using C++ on Windows? | [
"",
"c++",
"windows",
"winapi",
"image-manipulation",
"bmp",
""
] |
I have SQL data that looks like this:
```
events
id name capacity
1 Cooking 10
2 Swimming 20
3 Archery 15
registrants
id name
1 Jimmy
2 Billy
3 Sally
registrant_event
registrant_id event_id
1 3
2 3
3 2
```
I would like to sele... | ```
SELECT e.*, ISNULL(ec.TotalRegistrants, 0) FROM events e LEFT OUTER JOIN
(
SELECT event_id, Count(registrant_id) AS TotalRegistrants
FROM registrant_event
GROUP BY event_id
) ec ON e.id = ec.event_id
``` | ```
SELECT Events.ID, Events.Name, Events.Capacity,
ISNULL(COUNT(Registrant_Event.Registrant_ID), 0)
FROM Events
LEFT OUTER JOIN Registrant_Event ON Events.ID = Registrant_Event.Event_ID
GROUP BY Events.ID, Events.Name, Events.Capacity
``` | SQL LEFT OUTER JOIN subquery | [
"",
"sql",
"database",
"count",
"subquery",
""
] |
I am an advocate of ORM-solutions and from time to time I am giving a workshop about Hibernate.
When talking about framework-generated SQL, people usually start talking about how they need to be able to use "hints", and this is supposedly not possible with ORM frameworks.
Usually something like: "We tried Hibernate. ... | A SQL statement, especially a complex one, can actually be executed by the DB engine in any number of different ways (which table in the join to read first, which index to use based on many different parameters, etc).
An experienced dba can use hints to *encourage* the DB engine to choose a particular method when it g... | Query hints are used to guide the query optimiser when it doesn't produce sensible query plans by default. First, a small background in query optimisers:
Database programming is different from pretty much all other software development because it has a mechanical component. Disk seeks and rotational latency (waiting f... | What are "SQL-Hints"? | [
"",
"sql",
"hibernate",
"orm",
""
] |
What is the default capacity of a `StringBuilder`?
And when should (or shouldn't) the default be used? | The Venerable J. Skeet has provided a good analysis of precisely this problem:
<https://jonskeet.uk/csharp/stringbuilder.html> | The default capacity of StringBuilder is 16 characters (I used .NET Reflector to find out). | Default capacity of StringBuilder | [
"",
"c#",
".net",
"stringbuilder",
"capacity",
""
] |
I'm writing code like this, doing a little quick and dirty timing:
```
var sw = new Stopwatch();
sw.Start();
for (int i = 0; i < 1000; i++)
{
b = DoStuff(s);
}
sw.Stop();
Console.WriteLine(sw.ElapsedMilliseconds);
```
Surely there's a way to call this bit of timing code as a fancy-schmancy .NET 3.0 lambda rather ... | How about extending the Stopwatch class?
```
public static class StopwatchExtensions
{
public static long Time(this Stopwatch sw, Action action, int iterations)
{
sw.Reset();
sw.Start();
for (int i = 0; i < iterations; i++)
{
action();
}
sw.Stop();
... | Here's what I've been using:
```
public class DisposableStopwatch: IDisposable {
private readonly Stopwatch sw;
private readonly Action<TimeSpan> f;
public DisposableStopwatch(Action<TimeSpan> f) {
this.f = f;
sw = Stopwatch.StartNew();
}
public void Dispose() {
sw.Stop();... | Wrapping StopWatch timing with a delegate or lambda? | [
"",
"c#",
".net",
"delegates",
"lambda",
""
] |
I have some complex stored procedures that may return many thousands of rows, and take a long time to complete.
Is there any way to find out how many rows are going to be returned before the query executes and fetches the data?
This is with Visual Studio 2005, a Winforms application and SQL Server 2005. | A solution to your problem might be to re-write the stored procedure so that it limits the result set to some number, like:
```
SELECT TOP 1000 * FROM tblWHATEVER
```
in SQL Server, or
```
SELECT * FROM tblWHATEVER WHERE ROWNUM <= 1000
```
in Oracle. Or implement a paging solution so that the result set of each cal... | You mentioned your stored procedures take a long time to complete. Is the majority of the time taken up during the process of selecting the rows from the database or returning the rows to the caller?
If it is the latter, maybe you can create a mirror version of your SP that just gets the count instead of the actual ro... | Can I get the rowcount before executing a stored procedure? | [
"",
"c#",
"sql-server-2005",
"stored-procedures",
"visual-studio-2005",
"count",
""
] |
I need to create a midnight DateTime
I've just done this:
```
DateTime endTime = DateTime.Now;
endTime.Subtract(endTime.TimeOfDay);
```
Haven't test it yet, I'm assuming it works but is there a better/cleaner way? | Just use `foo.Date`, or [`DateTime.Today`](https://learn.microsoft.com/en-us/dotnet/api/system.datetime.today) for today's date | ```
DateTime endTime = DateTime.Now.Date;
```
Now `endTime.TimeOfDay.ToString()` returns `"00:00:00"` | Best way to create a Midnight DateTime in C# | [
"",
"c#",
"datetime",
""
] |
I have this code:
```
CCalcArchive::CCalcArchive() : m_calcMap()
{
}
```
`m_calcMap` is defined as this:
```
typedef CTypedPtrMap<CMapStringToPtr, CString, CCalculation*> CCalcMap;
CCalcMap& m_calcMap;
```
When I compile in Visual Studio 2008, I get this error:
```
error C2440: 'initializing' : cannot convert from... | The `int` is coming from the fact that `CTypedPtrMap` has a constructor that takes an `int` argument that is defaulted to 10.
The real problem that you're running into is that the `m_calcMap` reference initalization you have there is trying to default construct a temporary `CTypedPtrMap` object to bind the reference t... | I'm not sure where it's getting the `int` from, but you **must** initialize all references in the initializer list. `m_calcMap` is declared as a reference, and so it must be initialized to refer to some instance of a `CCalcMap` object - you can't leave it uninitialized. If there's no way for you to pass the referred-to... | Can't initialize an object in a member initialization list | [
"",
"c++",
"mfc",
""
] |
**Background:** I have an HTML page which lets you expand certain content. As only small portions of the page need to be loaded for such an expansion, it's done via JavaScript, and not by directing to a new URL/ HTML page. However, as a bonus the user is able to permalink to such expanded sections, i.e. send someone el... | As others have mentioned, [replaceState](https://developer.mozilla.org/en-US/docs/DOM/Manipulating_the_browser_history#The_replaceState%28%29.C2.A0method) in HTML5 can be used to remove the URL fragment.
Here is an example:
```
// remove fragment as much as it can go without adding an entry in browser history:
window... | Since you are controlling the action on the hash value, why not just use a token that means "nothing", like "#\_" or "#default". | Remove fragment in URL with JavaScript w/out causing page reload | [
"",
"javascript",
"html",
"url",
"fragment-identifier",
""
] |
I'm writing code on the master page, and I need to know which child (content) page is being displayed. How can I do this programmatically? | This sounds like a bad idea to start with. The idea of the master is that it shouldn't care what page is there as this is all common code for each page. | I use this:
```
string pageName = this.ContentPlaceHolder1.Page.GetType().FullName;
```
It retuns the class name in this format "ASP.default\_aspx", but I find that easy to parse for most purposes.
Hope that helps! | How to determine which Child Page is being displayed from Master Page? | [
"",
"c#",
"asp.net",
"master-pages",
""
] |
If I make a JFrame like this
```
public static void main(String[] args) {
new JFrame().setVisible(true);
}
```
then after closing the window the appication doesn't stop (I need to kill it).
What is the proper way of showing application's main windows ?
I'd also like to know a reason of a proposed solution.
T... | You should call the `setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);` in your JFrame.
Example code:
```
public static void main(String[] args) {
Runnable guiCreator = new Runnable() {
public void run() {
JFrame fenster = new JFrame("Hallo Welt mit Swing");
fenster.setDefaultCloseOp... | There's a difference between the application window and the application itself... The window runs in its own thread, and finishing `main()` will not end the application if other threads are still active. When closing the window you should also make sure to close the application, possibly by calling `System.exit(0);`
Y... | Why does my application still run after closing main window? | [
"",
"java",
"swing",
""
] |
I'm trying to print to Dot Matrix printers (various models) out of C#, currently I'm using Win32 API (you can find alot of examples online) calls to send escape codes directly to the printer out of my C# application. This works great, but...
My problem is because I'm generating the escape codes and not relying on the ... | You should probably use a reporting tool to make templates that allow you or users to correctly position the fields with regards to the pre-printed stationery.
Using dot-matrix printers, you basically have to work in either of 2 modes:
* simple type-writer mode of line/column text where you send escape sequences to m... | From my experience, it is easier to use two kinds of reports for the same data:
* one report for dot matrix printers using escape codes and anything else is required, which is saved in a text file and then printed using various methods (`type file.txt > lpt1` or selecting in code the default printer and using `NOTEPAD... | Dot Matrix printing in C#? | [
"",
"c#",
"printing",
"xps",
""
] |
For instance, winsock libs works great across all versions of the visual studio. But I am having real trouble to provide a consistent binary across all the versions. The dll compiled with VS 2005 won't work when linked to an application written in 2008. I upgraded both 2k5 and 2k8 to SP1, but the results haven't change... | First, dont pass anything other than plain old data accross DLL boundries. i.e. structs are fine. classes are not.
Second, make sure that ownership is not transferred - i.e. any structs passed accross the dll boundry are never deallocated outside the dll. So, if you dll exports a X\* GetX() function, there is a corresp... | I disagree with Chris Becke's viewpoint, while seeing the advantages of his approach.
The disadvantage is that you are unable to create libraries of utility objects, because you are forbidden to share them across libraries.
## Expanding Chris' solution
[How to make consistent dll binaries across VS versions?](https:... | How to make consistent dll binaries across VS versions? | [
"",
".net",
"c++",
"dll",
""
] |
How do I multiply the values of a multi-dimensional array with weights and sum up the results into a new array in PHP or in general?
The boring way looks like this:
```
$weights = array(0.25, 0.4, 0.2, 0.15);
$values = array
(
array(5,10,15),
array(20,25,30),
arra... | Depends on what you mean by elegant, of course.
```
function weigh(&$vals, $key, $weights) {
$sum = 0;
foreach($vals as $v)
$sum += $v*$weights[$key];
$vals = $sum;
}
$result = $values;
array_walk($result, "weigh", $weights);
```
EDIT: Sorry for not reading your example better.
I make result a co... | Hm...
```
foreach($values as $index => $ary )
$result[$index] = array_sum($ary) * $weights[$index];
``` | How do I sum up weighted arrays in PHP? | [
"",
"php",
"arrays",
"interpolation",
""
] |
I want to find an SQL query to find rows where field1 does not contain $x. How can I do this? | What kind of field is this? The IN operator cannot be used with a single field, but is meant to be used in subqueries or with predefined lists:
```
-- subquery
SELECT a FROM x WHERE x.b NOT IN (SELECT b FROM y);
-- predefined list
SELECT a FROM x WHERE x.b NOT IN (1, 2, 3, 6);
```
If you are searching a string, go fo... | `SELECT * FROM table WHERE field1 NOT LIKE '%$x%';` (Make sure you escape $x properly beforehand to avoid SQL injection)
Edit: `NOT IN` does something a bit different - your question isn't totally clear so pick which one to use. `LIKE 'xxx%'` can use an index. `LIKE '%xxx'` or `LIKE '%xxx%'` can't. | SQL Query Where Field DOES NOT Contain $x | [
"",
"sql",
"mysql",
""
] |
How can I use/display characters like ♥, ♦, ♣, or ♠ in Java/Eclipse?
When I try to use them directly, e.g. in the source code, Eclipse cannot save the file.
What can I do?
Edit: How can I find the unicode escape sequence? | The problem is that the characters you are using cannot be represented in the encoding you have the file set to (Cp1252). The way I see it, you essentially have two options:
Option 1. **Change the encoding.** [According to IBM](http://publib.boulder.ibm.com/infocenter/eruinf/v2r1m1/index.jsp?topic=/com.ibm.iru.doc/con... | In Eclipse:
1. Go to Window -> Preferences -> General -> Workspace -> TextFileEncoding
2. Set it to UTF-8 | How to use Special Chars in Java/Eclipse | [
"",
"java",
"eclipse",
"unicode",
"encoding",
"cp1252",
""
] |
Hey right now I'm using jQuery and I have some global variables to hold a bit of preloaded ajax stuff (preloaded to make pages come up nice and fast):
```
$.get("content.py?pageName=viewer", function(data)
{viewer = data;});
$.get("content.py?pageName=artists", function(data)
{artists = data;});
$.get("content... | You don't need `eval()` or `Function()` for this. An array, as you suspected, will do the job nicely:
```
(function() // keep outer scope clean
{
// pages to load. Each name is used both for the request and the name
// of the property to store the result in (so keep them valid identifiers
// unless you want t... | Using the jQuery each method to iterate through an array of page names and then setting a global (in window scope) variable:
```
jQuery.each(
["viewer", "artists", "instores", "specs", "about"],
function (page) {
$.get("content.py?pageName=" + page,
new Function("window[" + page + "] = argu... | Assigning values to a list of global variables in JavaScript | [
"",
"javascript",
"jquery",
"dry",
""
] |
I have an MFC legacy app that I help to maintain. I'm not quite sure how to identify the version of MFC and I don't think it would make a difference anyway.
The app can take some parameters on the command line; I would like to be able to set an errorlevel on exiting the app to allow a bat/cmd file to check for failure... | I can't take credit for this so please don't up this reply.
CWinApp::ExitInstance();
return myExitCode;
This will return the errorlevel to the calling batch file for you to then evaluate and act upon. | If your application refuses to update ERRORLEVEL in the DOS shell you run it from no matter what you do in the code of your program, it might help to run your app with "start /wait" so that the shell is locked until your program ends. | How To Set Errorlevel On Exit of MFC App | [
"",
"c++",
"windows",
"mfc",
"batch-file",
"cmd",
""
] |
Lets say I have an array like this:
```
string [] Filelist = ...
```
I want to create an Linq result where each entry has it's position in the array like this:
```
var list = from f in Filelist
select new { Index = (something), Filename = f};
```
Index to be 0 for the 1st item, 1 for the 2nd, etc.
What should ... | Don't use a query expression. Use [the overload of `Select` which passes you an index](http://msdn.microsoft.com/en-us/library/bb534869.aspx):
```
var list = FileList.Select((file, index) => new { Index=index, Filename=file });
``` | ```
string[] values = { "a", "b", "c" };
int i = 0;
var t = (from v in values
select new { Index = i++, Value = v}).ToList();
``` | How do you add an index field to Linq results | [
"",
"c#",
"linq",
""
] |
I'm writing some mail-processing software in Python that is encountering strange bytes in header fields. I suspect this is just malformed mail; the message itself claims to be us-ascii, so I don't think there is a true encoding, but I'd like to get out a unicode string approximating the original one without throwing a ... | As far as I can tell, the standard library doesn't have a function, though it's not too difficult to write one as suggested above. I think the real thing I was looking for was a way to decode a string and guarantee that it wouldn't throw an exception. The errors parameter to string.decode does that.
```
def decode(s, ... | +1 for the [chardet](https://chardet.readthedocs.io/en/latest/usage.html) module.
It is not in the standard library, but you can easily install it with the following command:
```
$ pip install chardet
```
[Example](https://chardet.readthedocs.io/en/latest/usage.html#example-using-the-detect-function):
```
>>> impor... | Is there a Python library function which attempts to guess the character-encoding of some bytes? | [
"",
"python",
"email",
"character-encoding",
"invalid-characters",
""
] |
I have a requirement to hide a process in Task Manager. It is for Intranet scenario. So, everything is legitimate. :)
Please feel free to share any code you have (preferably in C#) or any other techniques or any issues in going with this route.
**Update1**: Most of the users have admin privileges in order to run some... | There is no supported way to accomplish this. The process list can be read at any privilege level. If you were hoping to hide a process from even Administrators, then this is doubly unsupported.
To get this to work, you would need to write a kernel mode rootkit to intercept calls to [NtQuerySystemInformation](http://m... | Don't try to stop it from being killed - you're not going to manage it. Instead, make it regularly call home to a webservice. When the webservice notices a client "going silent" it can ping the machine to see if it's just a reboot issue, and send an email to a manager (or whoever) to discipline whoever has killed the p... | How do I hide a process in Task Manager in C#? | [
"",
"c#",
".net",
"taskmanager",
""
] |
How do I learn where the source file for a given Python module is installed? Is the method different on Windows than on Linux?
I'm trying to look for the source of the `datetime` module in particular, but I'm interested in a more general answer as well. | For a pure python module you can find the source by looking at `themodule.__file__`.
The datetime module, however, is written in C, and therefore `datetime.__file__` points to a .so file (there is no `datetime.__file__` on Windows), and therefore, you can't see the source.
If you download a python source tarball and e... | Running `python -v` from the command line should tell you what is being imported and from where. This works for me on Windows and Mac OS X.
```
C:\>python -v
# installing zipimport hook
import zipimport # builtin
# installed zipimport hook
# C:\Python24\lib\site.pyc has bad mtime
import site # from C:\Python24\lib\sit... | How do I find the location of Python module sources? | [
"",
"python",
"module",
""
] |
I'm looking to get data such as Size/Capacity, Serial No, Model No, Heads Sectors, Manufacturer and possibly SMART data. | You can use WMI Calls to access info about the hard disks.
//Requires using System.Management; & System.Management.dll Reference
```
ManagementObject disk = new ManagementObject("win32_logicaldisk.deviceid=\"c:\"");
disk.Get();
Console.WriteLine("Logical Disk Size = " + disk["Size"] + " bytes");
Console.WriteLine(... | You should use the [System.Management](http://msdn.microsoft.com/en-us/library/system.management.aspx) namespace:
```
System.Management.ManagementObjectSearcher ms =
new System.Management.ManagementObjectSearcher("SELECT * FROM Win32_DiskDrive");
foreach (ManagementObject mo in ms.Get())
{
System.Console.Write... | using c# how can I extract information about the hard drives present on the local machine | [
"",
"c#",
"hard-drive",
""
] |
I have been trying to parse Java exceptions that appear in a log for some code I'm working with. My question is, do you parse the exception trace from the top down, or the bottom up? It looks something like this:
```
ERROR [main]</b> Nov/04 11:03:19,440 [localhost].[/BookmarksPortlet].[] - Exception sending context...... | In your particular example, there's a class missing. As soon as you see an error like that, you know what needs fixing (either correcting the class name, or updating the classpath so that the class can be found).
In general, though, I look from my code toward the generated code until I find the error. If I get a NullP... | This stuff is a little hard to explain, but my first step is nearly always starting from the top and skimming down until I see the familiar `com.mycompany.myproject`.
Given the line number attached to that you have a place to work from in your own code, which is often a good start.
**Edit:** But, re-reading your ques... | How do I approach debugging starting from a Java exception log entry? | [
"",
"java",
"debugging",
"exception",
""
] |
I have a C++ library that provides various classes for managing data. I have the source code for the library.
I want to extend the C++ API to support C function calls so that the library can be used with C code and C++ code at the same time.
I'm using GNU tool chain (gcc, glibc, etc), so language and architecture sup... | Yes, this is certainly possible. You will need to write an interface layer in C++ that declares functions with `extern "C"`:
```
extern "C" int foo(char *bar)
{
return realFoo(std::string(bar));
}
```
Then, you will call `foo()` from your C module, which will pass the call on to the `realFoo()` function which is ... | C++ FAQ Lite: ["How to mix C and C++ code"](https://isocpp.org/wiki/faq/mixing-c-and-cpp).
Some gotchas are described in answers to these questions:
* [32.8] How can I pass an object of a C++ class to/from a C function?
* [32.9] Can my C function directly access data in an object of a C++ class? | Using C++ library in C code | [
"",
"c++",
"c",
"gcc",
"glibc",
""
] |
I have what is essentially a jagged array of name value pairs - i need to generate a set of unique name values from this. the jagged array is approx 86,000 x 11 values.
It does not matter to me what way I have to store a name value pair (a single string "name=value" or a specialised class for example KeyValuePair).
*... | **I have it running in 0.34 seconds** down from 9+ minutes
The problem is when comparing the KeyValuePair structs.
I worked around it by writing a comparer object, and passing an instance of it to the Dictionary.
From what I can determine, the KeyValuePair.GetHashCode() returns the hashcode of it's `Key` object (in t... | if you don't need any specific correlation between each key/value pair and the unique values you're generating, you could just use a GUID? I'm assuming the problem is that your current 'Key' isn't unique in this jagged array.
```
Dictionary<System.Guid, KeyValuePair<string, string>> myDict
= new Dictionary<Guid, K... | what is the fastest way to generate a unique set in .net 2 | [
"",
"c#",
".net",
"performance",
"collections",
""
] |
Is there a collection (BCL or other) that has the following characteristics:
Sends event if collection is changed AND sends event if any of the elements in the collection sends a `PropertyChanged` event. Sort of an `ObservableCollection<T>` where `T: INotifyPropertyChanged` and the collection is also monitoring the el... | Made a quick implementation myself:
```
public class ObservableCollectionEx<T> : ObservableCollection<T> where T : INotifyPropertyChanged
{
protected override void OnCollectionChanged(NotifyCollectionChangedEventArgs e)
{
Unsubscribe(e.OldItems);
Subscribe(e.NewItems);
base.OnCollection... | @soren.enemaerke:
I would have made this comment on your answer post, but I can't (I don't know why, maybe because I don't have many rep points). Anyway, I just thought that I'd mention that in your code you posted I don't think that the Unsubscribe would work correctly because it is creating a new lambda inline and th... | ObservableCollection that also monitors changes on the elements in collection | [
"",
"c#",
"collections",
""
] |
I have an `ArrayList<String>`, and I want to remove repeated strings from it. How can I do this? | If you don't want duplicates in a `Collection`, you should consider why you're using a `Collection` that allows duplicates. The easiest way to remove repeated elements is to add the contents to a `Set` (which will not allow duplicates) and then add the `Set` back to the `ArrayList`:
```
Set<String> set = new HashSet<>... | Although converting the `ArrayList` to a `HashSet` effectively removes duplicates, if you need to preserve insertion order, I'd rather suggest you to use this variant
```
// list is some List of Strings
Set<String> s = new LinkedHashSet<>(list);
```
Then, if you need to get back a `List` reference, you can use again ... | How do I remove repeated elements from ArrayList? | [
"",
"java",
"list",
"collections",
"arraylist",
"duplicates",
""
] |
Here's what [MSDN has to say under *When to Use Static Classes*](https://learn.microsoft.com/en-us/dotnet/csharp/programming-guide/classes-and-structs/static-classes-and-static-class-members):
> ```
> static class CompanyInfo
> {
> public static string GetCompanyName() { return "CompanyName"; }
> public static... | I wrote my thoughts of static classes in an earlier Stack Overflow answer:
*[Class with single method -- best approach?](https://stackoverflow.com/questions/205689/class-with-single-method-best-approach#206481)*
I used to love utility classes filled up with static methods. They made a great consolidation of helper met... | When deciding whether to make a class static or non-static you need to look at what information you are trying to represent. This entails a more '**bottom-up**' style of programming where you focus on the data you are representing first. Is the class you are writing a real-world object like a rock, or a chair? These th... | When to use static classes in C# | [
"",
"c#",
"class",
"static",
""
] |
```
template <class M, class A> class C { std::list<M> m_List; ... }
```
Is the above code possible? I would like to be able to do something similar.
Why I ask is that i get the following error:
```
Error 1 error C2079: 'std::_List_nod<_Ty,_Alloc>::_Node::_Myval' uses undefined class 'M' C:\Program Files\Microsoft... | My guess: you forward declared class M somewhere, and only declared it fully after the template instantiation.
My hint: give your formal template arguments a different name than the actual ones. (i.e. class M)
```
// template definition file
#include <list>
template< class aM, class aT >
class C {
std::list<M> m... | Yes. This is very common.
As xtofl mentioned, a forward declaration of your parameter would cause a problem at the time of template instantiation, which looks like what the error message is hinting at. | is it possible to have templated classes within a template class? | [
"",
"c++",
"oop",
"visual-c++",
"templates",
""
] |
I am new to Java and am trying to run a program using Eclipse. But I have no idea how to get the command prompt running in with Eclipse...
I did some online research and couldn't get anything consolidated!
### Update:
I'm not using an applet. It's a normal Java program trying to read a line from command prompt. I'm ... | Check out this lesson plan on how to get started with Eclipse programs:
[Lesson](http://www.ics.uci.edu/~thornton/ics22/LabManual/Lab0/)
Specifically, see this image:
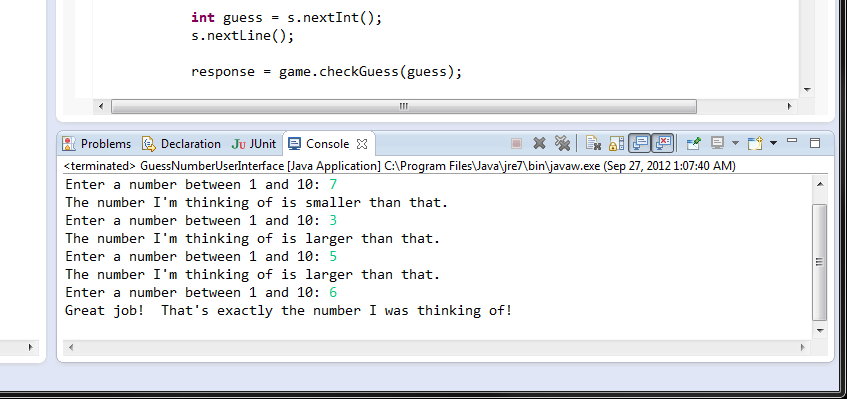
If the Conso... | If you downloaded the Eclipse/Java package, and you wrote a Java program in Eclipse in a project, just click compile and run, it will run in the output window in Eclipse. | Open command prompt using Eclipse | [
"",
"java",
"eclipse",
""
] |
I have a database with a table which is full of conditions and error messages for checking another database.
I want to run a loop such that each of these conditions is checked against all the tables in the second database and generae a report which gives the errors.
Is this possible in ms access.
For example,
query... | Here is some more sample code. It illustrates the use of two different types of recordsets. You may wish to read [VBA Traps: Working with Recordsets](http://allenbrowne.com/ser-29.html) by Allen Browne and [List of reserved words in Access 2002 and in later versions of Access](http://support.microsoft.com/kb/286335).
... | When you say "report", do you mean an Access Report, or would writing to a file or Access Form work?
You can create a function or sub in a Module to do this. Open a recordset on your querycrit table and spin through the records dynamically building and running the SQL for the records table. You can write the results o... | How to run a loop of queries in access? | [
"",
"sql",
"ms-access",
"loops",
""
] |
`select max(DELIVERY_TIMESTAMP) from DOCUMENTS;` will return the time that the latest document was delivered. How do I return **the other columns** for the latest document? For example I want `DOC_NAME` for the document that was most recently delivered?
I'm not sure how to form the `WHERE` clause. | You have a few options
```
SELECT DOC_NAME
FROM DOCUMENTS
WHERE DELIVERY_TIMESTAMP IN (
SELECT MAX(DELIVERY_TIMESTAMP)
FROM DOCUMENTS
)
```
Or with joins
```
SELECT DOC_NAME
FROM DOCUMENTS
INNER JOIN (
SELECT MAX(DELIVERY_TIMESTAMP) AS MAX_DELIVERY_TIMESTAMP
FROM DOCUMENTS
) AS M
ON M.MAX_DELIVER... | ```
SELECT
DELIVERY_TIMESTAMP,
OTHER_COLUMN
FROM
DOCUMENTS
WHERE
DELIVERY_TIMESTAMP = (SELECT MAX(DELIVERY_TIMESTAMP) FROM DOCUMENTS)
``` | SQL Searching by MAX() | [
"",
"sql",
""
] |
I have a C++ app in VS2005 and import a VB DLL. IntelliSense shows me all the symbols in the DLL as expected but it also shows all (or nearly all) of them again with an underscore prefix (no @s in them though). Why is this? What are the differences between the underscored items and the normal items? | Assuming you're talking VB6, the leading underscore version \_Klass is the Vb-generated default interface for the class Klass. This site has a nice explanation:
<http://www.15seconds.com/issue/040721.htm> | In (some) c# coding standards the underscore prefix denotes a private variable, that might explain it... is it VB or VB.Net? | What are underscored symbols in a VB DLL? | [
"",
"c++",
"dll",
"com",
"vb6",
""
] |
I've a terrible memory. Whenever I do a CONNECT BY query in Oracle - and I do mean *every* time - I have to think hard and usually through trial and error work out on which argument the PRIOR should go.
I don't know why I don't remember - but I don't.
Does anyone have a handy memory mnemonic so I always remember ?
F... | Think about the order in which the records are going to be selected: the link-back column on each record must match the link-forward column on the PRIOR record selected. | I always try to put the expressions in `JOIN`'s in the following order:
```
joined.column = leading.column
```
This query:
```
SELECT t.value, d.name
FROM transactions t
JOIN
dimensions d
ON d.id = t.dimension
```
can be treated either like "for each transaction, find the corresponding dimension na... | How do I remember which way round PRIOR should go in CONNECT BY queries | [
"",
"sql",
"oracle",
""
] |
I've got a junk directory where I toss downloads, one-off projects, email drafts, and other various things that might be useful for a few days but don't need to be saved forever. To stop this directory from taking over my machine, I wrote a program that will delete all files older than a specified number of days and lo... | According to [File.Delete's documentation,](http://msdn.microsoft.com/en-us/library/system.io.file.delete.aspx), you'll have to strip the read-only attribute. You can set the file's attributes using [File.SetAttributes()](http://msdn.microsoft.com/en-us/library/system.io.file.setattributes.aspx).
```
using System.IO;
... | According to [File.Delete's documentation,](http://msdn.microsoft.com/en-us/library/system.io.file.delete.aspx), you'll have to strip the read-only attribute. You can set the file's attributes using [File.SetAttributes()](http://msdn.microsoft.com/en-us/library/system.io.file.setattributes.aspx). | How do I delete a read-only file? | [
"",
"c#",
".net",
"file",
""
] |
Is there a way in C# to:
1. Get all the properties of a class that have attributes on them (versus having to loop through all properties and then check if attribute exists.
2. If i want all Public, Internal, and Protected properties but NOT private properties, i can't find a way of doing that. I can only do this:
... | I don't believe there's a way to do either of these.
Just how many types do you have to reflect over, though? Is it really a bottleneck? Are you able to cache the results to avoid having to do it more than once per type? | There isn't really a way to do it any *quicker* - but what you can do is do it less often by caching the data. A generic utility class can be a handy way of doing this, for example:
```
static class PropertyCache<T>
{
private static SomeCacheType cache;
public static SomeCacheType Cache
{
get
... | Reflection optimizations with attributes . | [
"",
"c#",
"reflection",
"attributes",
""
] |
I was wondering if I could pop up `JOptionPane`s or other Swing components from within a browser using JSP. | If you embed an applet. But I don't think that's what you want. Swing is for desktop apps. JSP web pages. If you want components, try looking into JSF or some of the many AJAX Javascript frameworks like prototype. | You may also want to consider GWT, which enables you to develop a web interface in Java code (the Java code is converted to HTML & JavaScript by the GWT compiler). Although you don't program to the Swing API *directly* when writing GWT applications, the GWT API is very similar in style to Swing programming. | Is it possible to display Swing components in a JSP? | [
"",
"java",
"swing",
"jsp",
""
] |
I have a class derived from `CTreeCtrl`. In `OnCreate()` I replace the default `CToolTipCtrl` object with a custom one:
```
int CMyTreeCtrl::OnCreate(LPCREATESTRUCT lpCreateStruct)
{
if (CTreeCtrl::OnCreate(lpCreateStruct) == -1)
return -1;
// Replace tool tip with our own which will
// ask us for... | Finally! I (partially) solved it:
It looks like the CDockablePane parent window indeed caused this problem...
First I removed all the tooltip-specific code from the CTreeCtrl-derived class. Everything is done in the parent pane window.
Then I edited the parent window's `OnCreate()` method:
```
int CMyPane::OnCreate... | I believe you still have to enable the tooltip, even though you are replacing the builtin.
```
EnableToolTips(TRUE);
```
Well, since that did not work for you and since no-one more expert has offered any help, here a few more suggestions from me. Although they are lame, they might get you moving again:
* Make sure y... | How do I display custom tooltips in a CTreeCtrl? | [
"",
"c++",
"mfc",
"tooltip",
"mfc-feature-pack",
""
] |
This probably has a simple answer, but I must not have had enough coffee to figure it out on my own:
If I had a comma delimited string such as:
```
string list = "Fred,Sam,Mike,Sarah";
```
How would get each element and add quotes around it and stick it back in a string like this:
```
string newList = "'Fred','Sam'... | ```
string s = "A,B,C";
string replaced = "'"+s.Replace(",", "','")+"'";
```
Thanks for the comments, I had missed the external quotes.
Of course.. if the source was an empty string, would you want the extra quotes around it or not ? And what if the input was a bunch of whitespaces... ? I mean, to give a 100% complet... | Following Jon Skeet's example above, this is what worked for me. I already had a `List<String>` variable called \_\_messages so this is what I did:
```
string sep = String.Join(", ", __messages.Select(x => "'" + x + "'"));
``` | In C#: Add Quotes around string in a comma delimited list of strings | [
"",
"c#",
"string",
""
] |
I have an application which has to live as a service, I create an object which then spawns off a buch of threads.
If I set the only reference to that object to null will all the child threads get cleaned up? or will I suffer from a memory leak.
Do I have to explicitly terminate all the child threads? | Yes, you need to make sure your other threads stop. The garbage collector is irrelevant to this. You should also do so in an orderly fashion though - don't just abort them.
[Here's a pattern in C# for terminating threads co-operatively](http://pobox.com/~skeet/csharp/threads/shutdown.shtml) - it's easy to translate to... | Threads and static references are 'root objects'. They are immune from GCing and anything that can be traced back to them directly or indirectly cannot be collected. Threads will therefore not be collected as long as they are running. Once the run method exits though, the GC can eat up any unreferenced thread objects. | Will setting the only reference to null mean it and its child threads are garbage collected? | [
"",
"java",
"multithreading",
""
] |
My studio has a large codebase that has been developed over 10+ years. The coding standards that we started with were developed with few developers in house and long before we had to worry about any kind of standards related to C++.
Recently, we started a small R&D project in house and we updated our coding convention... | My process would be to rename each time someone touches a given module. Eventually, all modules would be refactored, but the incremental approach would result in less code breakage(assuming you have a complete set of tests. ;) ) | I've made changes like this using custom scripts. If I can, I use sed. Otherwise I'll use a scripting language with good support for regular expressions. It is a crude hack which is sure to introduce bugs but unless you find a better solution, it is a path forward. | Code standard refactoring on large codebase | [
"",
"c++",
"refactoring",
""
] |
I've been looking for a simple regex for URLs, does anybody have one handy that works well? I didn't find one with the zend framework validation classes and have seen several implementations. | I used this on a few projects, I don't believe I've run into issues, but I'm sure it's not exhaustive:
```
$text = preg_replace(
'#((https?|ftp)://(\S*?\.\S*?))([\s)\[\]{},;"\':<]|\.\s|$)#i',
"'<a href=\"$1\" target=\"_blank\">$3</a>$4'",
$text
);
```
Most of the random junk at the end is to deal with situation... | Use the `filter_var()` function to validate whether a string is URL or not:
```
var_dump(filter_var('example.com', FILTER_VALIDATE_URL));
```
It is bad practice to use regular expressions when not necessary.
**EDIT**: Be careful, this solution is not unicode-safe and not XSS-safe. If you need a complex validation, m... | PHP validation/regex for URL | [
"",
"php",
"regex",
"url",
"validation",
""
] |
This has happened to me 3 times now, and I am wondering if anyone is having the same problem. I am running Visual Studio 2008 SP1, and hitting SQL Server 2005 developer edition.
For testing, I use the Server Explorer to browse a database I have already created. For testing I will insert data by hand (right click table... | Just so you know, when your computer just snaps right back to the BIOS boot screen with no blue screen or other crash data, this is called a "[triple fault](http://en.wikipedia.org/wiki/Triple_fault)" Basically, there was an exception (on a hardware level) whose exception handler triggered an exception whose exception ... | [Test your memory](http://www.memtest.org/), it's the most likely cause of your reboots. | Visual Studio 2008 crashes horribly | [
"",
"c#",
"sql-server",
"visual-studio",
"visual-studio-2008",
"ide",
""
] |
Generally, when using the conditional operator, here's the syntax:
```
int x = 6;
int y = x == 6 ? 5 : 9;
```
Nothing fancy, pretty straight forward.
Now, let's try to use this when assigning a Lambda to a Func type. Let me explain:
```
Func<Order, bool> predicate = id == null
? p => p.EmployeeID == null
: ... | You can convert a lambda expression to a particular target delegate type, but in order to determine the type of the conditional expression, the compiler needs to know the type of each of the second and third operands. While they're both just "lambda expression" there's no conversion from one to the other, so the compil... | The C# compiler cannot infer the type of the created lambda expression because it processes the ternary first and then the assignment. you could also do:
```
Func<Order, bool> predicate =
id == null ?
new Func<Order,bool>(p => p.EmployeeID == null) :
new Func<Order,bool>(p => p.EmployeeID == id);... | How can I assign a Func<> conditionally between lambdas using the conditional ternary operator? | [
"",
"c#",
"lambda",
"conditional-operator",
""
] |
Is there any good practice related to dynamic\_cast error handling (except not using it when you don't have to)? I'm wondering how should I go about NULL and bad\_cast it can throw.
Should I check for both? And if I catch bad\_cast or detect NULL I probably can't recover anyway...
For now, I'm using assert to check if ... | If the `dynamic_cast` *should* succeed, it would be good practice to use `boost::polymorphic_downcast` instead, which goes a little something like this:
```
assert(dynamic_cast<T*>(o) == static_cast<T*>(o));
return static_cast<T*>(o);
```
This way, you will detect errors in the debug build while at the same time avoi... | bad\_cast is only thrown when casting references
```
dynamic_cast< Derived & >(baseclass)
```
NULL is returned when casting pointers
```
dynamic_cast< Derived * >(&baseclass)
```
So there's never a need to check both.
Assert can be acceptable, but that greatly depends on the context, then again, that's true for pr... | c++ dynamic_cast error handling | [
"",
"c++",
"dynamic-cast",
""
] |
What possible reasons could exist for MySQL giving the error `“Access denied for user 'xxx'@'yyy'”` when trying to access a database using PHP-mysqli and working fine when using the command-line mysql tool with exactly the same username, password, socket, database and host?
**Update:**
There were indeed three users... | In case anyone’s still interested: I never did solve this particular problem. It really seems like the problem was with the hardware I was running MySQL on. I’ve never seen anything remotely like it since. | Sometimes in php/mysql there is a difference between localhost and 127.0.0.1
In mysql you grant access based on the host name, for localusers this would be localhost.
I have seen php trying to connect with 'myservername' instead of localhost allthough in the config 'localhost' was defined.
Try to grant access in mysq... | Reasons for MySQL authentication error: "Access denied for user 'xxx'@'yyy'"? | [
"",
"php",
"mysql",
"mysql-error-1045",
""
] |
I'm trying to compile such code:
```
#include <iostream>
using namespace std;
class CPosition
{
private:
int itsX,itsY;
public:
void Show();
void Set(int,int);
};
void CPosition::Set(int a, int b)
{
itsX=a;
itsY=b;
}
void CPosition::Show()
{
cout << "x:" << itsX << " y:" << itsY << endl;
}
... | In addition to the normal getter you should also have a const getter.
Please note the return by reference. This allows you any call to SetXX() to affect the copy of Position inside CCube and not the copy that you have been updating.
```
class CCube
{
private:
CPosition Position;
public:
CPosi... | The statement `friend class CPosition;` means that CPosition can now access the private members of the CCube class. To every other class the members are still as private as you declared them. To make the sample work you'd:
```
class CCube
{
public:
CPosition Position;
};
``` | c++ class friend | [
"",
"c++",
"class",
"inheritance",
"friend",
""
] |
Here's a very simple question. I have an SP that inserts a row into a table and at the end there's the statement RETURN @@IDENTITY. What I can't seem to find is a way to retrieve this value in C#. I'm using the Enterprise library and using the method:
```
db.ExecuteNonQuery(cmd);
```
I've tried **cmd.Parameters[0].Va... | ```
Dim c as new sqlcommand("...")
Dim d As New SqlParameter()
d.Direction = ParameterDirection.ReturnValue
c.parameters.add(d)
c.executeNonQuery
(@@IDENTITY) = d.value
```
It is more or less like this...either this or just return the value from a stored procedure as an output parameter. | BTW, in most circumstances, you should use SCOPE\_IDENTITY() rather than @@IDENTITY. [Ref](http://msdn.microsoft.com/en-us/library/aa259185.aspx). | Retrieving the value of RETURN @@IDENTITY in C# | [
"",
"c#",
".net",
"ado.net",
""
] |
I am reading a binary log file produced by a piece of equipment.
I have the data in a byte[].
If I need to read two bytes to create a short I can do something like this:
```
short value = (short)(byte[1] << 8);
value += byte[2];
```
Now I know the value is the correct for valid data.
How would I know if the file w... | `0xffff` (all bits equal to 1) is -1 for signed shorts, yes. Read up on [Two's complement](http://en.wikipedia.org/wiki/Two's_complement) to learn more about the details. You can switch to a larger datatype, or (as suggested by Grzenio) just use an unsigned type. | Well, you seemed to have found `BitConverter` for singles. Now let's see if we can get to to use it for everything else as well...
```
MemoryStream mem = new MemoryStream(_array);
float ReadFloat(Stream str)
{
byte[] bytes = str.Read(out bytes, 0, 4);
return BitConverter.ToSingle(bytes, 0)
}
public int ReadIn... | Is the binary data I convert to a Short valid? | [
"",
"c#",
"binary",
"bit-shift",
""
] |
How do I get the type of a generic typed class within the class?
An example:
I build a generic typed collection implementing *ICollection< T>*. Within I have methods like
```
public void Add(T item){
...
}
public void Add(IEnumerable<T> enumItems){
...
}
```
How can I ask within the... | Personally, I would side step the issue by renaming the `IEnumerable<T>` method to `AddRange`. This avoids such issues, and is consistent with existing APIs such as [`List<T>.AddRange`](http://msdn.microsoft.com/en-us/library/z883w3dc.aspx).
It also keeps things clean when the `T` you want to add implements `IEnumerab... | You can use: `typeof(T)`
```
if (typeof(T) == typeof(object) ) {
// Check for IEnumerable
}
``` | .NET: How to check the type within a generic typed class? | [
"",
"c#",
".net",
"generics",
"types",
""
] |
We have a function which a single thread calls into (we name this the main thread). Within the body of the function we spawn multiple worker threads to do CPU intensive work, wait for all threads to finish, then return the result on the main thread.
The result is that the caller can use the function naively, and inter... | C++11 introduced the `exception_ptr` type that allows to transport exceptions between threads:
```
#include<iostream>
#include<thread>
#include<exception>
#include<stdexcept>
static std::exception_ptr teptr = nullptr;
void f()
{
try
{
std::this_thread::sleep_for(std::chrono::seconds(1));
thro... | Currently, the only **portable** way is to write catch clauses for all the types of exceptions that you might like to transfer between threads, store the information somewhere from that catch clause and then use it later to rethrow an exception. This is the approach taken by [Boost.Exception](http://www.boost.org/doc/l... | How can I propagate exceptions between threads? | [
"",
"c++",
"multithreading",
"exception",
""
] |
I am using the WMD markdown editor in a project for a large number of fields that correspond to a large number of properties in a large number of Entity classes. Some classes may have multiple properties that require the markdown.
I am storing the markdown itself since this makes it easier to edit the fields later. Ho... | > The classes that require this are not part of a single inheritance hierarchy.
They should at least implement a common interface, otherwise coming up with a clean generic solution is going to be cumbersome.
> The other option I am considering is doing this in the controller rather than the model. What are your thoug... | You do have one option for doing this if you can't use inheritance or an interface. I know, I know refactor but this is reality and \*hit happens.
You can use reflection to iterate over your properties and apply the formatting to them. You could either tag them with an attribute or you could adopt a naming scheme (bri... | Design Pattern to apply conversion to multiple properties in multiple classes | [
"",
"java",
"design-patterns",
"markdown",
""
] |
I tried to use `OPTION (MAXRECURSION 0)` in a view to generate a list of dates.
This seems to be unsupported. Is there a workaround for this issue?
EDIT to Explain what I actually want to do:
I have 2 tables.
table1: int weekday, bool available
table2: datetime date, bool available
I want the result:
view1: date (... | [No](http://connect.microsoft.com/SQLServer/feedback/ViewFeedback.aspx?FeedbackID=124653) - if you can find a way to do it within 100 levels of recusion (have a table of numbers), which will get you to within 100 recursion levels, you'll be able to do it. But if you have a numbers or pivot table, you won't need the rec... | You can use a [CTE](http://blog.crowe.co.nz/archive/2007/09/06/Microsoft-SQL-Server-2005---CTE-Example-of-a-simple.aspx) for hierarchical queries. | Can I use recursion in a Sql Server 2005 View? | [
"",
"sql",
"sql-server",
"recursion",
""
] |
In MySQL 5.0 why does the following error occur when trying to create a view with a subquery in the FROM clause?
> ERROR 1349 (HY000): View's SELECT contains a subquery in the FROM clause
If this is a limitation of the MySQL engine, then why haven't they implemented this feature yet?
Also, what are some good workaro... | Couldn't your query just be written as:
```
SELECT u1.name as UserName from Message m1, User u1
WHERE u1.uid = m1.UserFromID GROUP BY u1.name HAVING count(m1.UserFromId)>3
```
That should also help with the known speed issues with subqueries in MySQL | I had the same problem. I wanted to create a view to show information of the most recent year, from a table with records from 2009 to 2011. Here's the original query:
```
SELECT a.*
FROM a
JOIN (
SELECT a.alias, MAX(a.year) as max_year
FROM a
GROUP BY a.alias
) b
ON a.alias=b.alias and a.year=b.max_year
``... | MySQL: View with Subquery in the FROM Clause Limitation | [
"",
"mysql",
"sql",
"view",
"mysql-error-1349",
""
] |
[1] In JDBC, why should we first load drivers using Class.forName("some driver name").
Why SUN didnt take care of loading driver within the getConnection() method itself.If I pass driver name as a parameter to the getConnection() method.
[2] I want to understand JBDC internals.Any pointers towards it are appreciated. | With JDBC 4, you no longer need to use Class.forName(...) see [here](http://www.artima.com/lejava/articles/jdbc_four.html) for one article explaining this:
> Connection to a database requires that a suitable JDBC database driver be loaded in the client's VM. In the early days of JDBC, it was common to load a suitable ... | There is no way for java.sql to know which class to load if you only give it the JDBC protocol name. Arguably JDBC driver jar files should be able to specify protocol name and driver class within their manifest or elsewhere under META-INF/. In my opinion, you might as well construct the driver instance yourself rather ... | Understanding JDBC internals | [
"",
"java",
"jdbc",
""
] |
i have the following script
```
import getopt, sys
opts, args = getopt.getopt(sys.argv[1:], "h:s")
for key,value in opts:
print key, "=>", value
```
if i name this getopt.py and run it doesn't work as it tries to import itself
is there a way around this, so i can keep this filename but specify on import that i w... | You shouldn't name your scripts like existing modules. Especially if standard.
That said, you can touch sys.path to modify the library loading order
```
~# cat getopt.py
print "HI"
~# python
Python 2.5.2 (r252:60911, Jul 31 2008, 17:28:52)
[GCC 4.2.3 (Ubuntu 4.2.3-2ubuntu7)] on linux2
Type "help", "copyright", "credi... | You should avoid naming your python files with standard library module names. | python name a file same as a lib | [
"",
"python",
""
] |
I recently switched my hosting provider and due to the time zone that the server is now in, my code has stopped working.
The hosting server reports in Pacific time, However, my code needs to work with GMT as my site is for the UK market. So, all my displays and searches need to be in the format dd/MM/yyyy
How can I a... | In your web.config file add `<globalization>` element under `<system.web>` node:
```
<system.web>
<globalization culture="en-gb"/>
<!-- ... -->
</system.web>
``` | Try
```
DateTime.Parse("28/11/2008", new CultureInfo("en-GB"))
```
Have a look at [the overload for DateTime.Parse on MSDN](http://msdn.microsoft.com/en-us/library/kc8s65zs.aspx).
Also, be careful not to confuse time zones (pacific, GMT) with cultures.
Cultures are your actual problem here. | DateTime format on hosting server | [
"",
"c#",
"asp.net",
"datetime",
""
] |
I have barcode images in jpg format and want to extract barcode # from those. Please help! | See the CodeProject article: [Reading Barcodes from an Image - II](http://www.codeproject.com/KB/graphics/barcodeimaging2.aspx).
The author ([James](http://www.codeproject.com/script/Membership/Profiles.aspx?mid=1770204)) improves (and credits) a [previously written](http://www.codeproject.com/KB/dotnet/barcodeImaging... | we've developed a c# component that reads values from barcodes of all dimension, rotation, quality etc. it's not yet release but we will release detailed information about it at <http://blog.lemqi.com> . it will be probably free (maybe open source). but maybe it's still 1-2 weeks till release as we have to refactor the... | barcode image to Code39 conversion in C#? | [
"",
"c#",
"image-processing",
"barcode",
"code39",
""
] |
I have a Python script that needs to execute an external program, but for some reason fails.
If I have the following script:
```
import os;
os.system("C:\\Temp\\a b c\\Notepad.exe");
raw_input();
```
Then it fails with the following error:
> 'C:\Temp\a' is not recognized as an internal or external command, operable... | [`subprocess.call`](http://docs.python.org/2/library/subprocess.html#using-the-subprocess-module) will avoid problems with having to deal with quoting conventions of various shells. It accepts a list, rather than a string, so arguments are more easily delimited. i.e.
```
import subprocess
subprocess.call(['C:\\Temp\\a... | Here's a different way of doing it.
If you're using Windows the following acts like double-clicking the file in Explorer, or giving the file name as an argument to the DOS "start" command: the file is opened with whatever application (if any) its extension is associated with.
```
filepath = 'textfile.txt'
import os
o... | How do I execute a program from Python? os.system fails due to spaces in path | [
"",
"python",
"shellexecute",
""
] |
Is there any way in SQL Server to get the results starting at a given offset? For example, in another type of SQL database, it's possible to do:
```
SELECT * FROM MyTable OFFSET 50 LIMIT 25
```
to get results 51-75. This construct does not appear to exist in SQL Server.
How can I accomplish this without loading all ... | I would avoid using `SELECT *`. Specify columns you actually want even though it may be all of them.
**SQL Server 2005+**
```
SELECT col1, col2
FROM (
SELECT col1, col2, ROW_NUMBER() OVER (ORDER BY ID) AS RowNum
FROM MyTable
) AS MyDerivedTable
WHERE MyDerivedTable.RowNum BETWEEN @startRow AND @endRow
```
*... | If you will be processing all pages in order then simply remembering the last key value seen on the previous page and using `TOP (25) ... WHERE Key > @last_key ORDER BY Key` can be the best performing method if suitable indexes exist to allow this to be seeked efficiently - or [an API cursor](https://dba.stackexchange.... | Row Offset in SQL Server | [
"",
"sql",
"sql-server",
""
] |
It appear that SQL Server like most other products Random Function really is not that random. So we have this nice little function to generate a 10 char value. Is there a better way to accomplish what the following does. I am betting there is.
```
DECLARE @SaltCount INT;
SELECT @SaltCount = COUNT(*) FROM tmp_NewLogin;... | Most programmers make a mistake of reinventing the randomization functionality and end up with something that is not random at all. I'd recommend you to stick with built-in RAND() function. Seed it once then fetch as many values as you need. | Reinventing RAND is a recipe for disaster. Where have you ever noticed it behaving incorrectly? I don't think you even need to seed it. SQL Server should seed it on its own just fine. Seeding should just be necessary when you need to produce the same "random" sequence several times when testing algorithms or some such. | Generate Random values from SQL | [
"",
"sql",
"sql-server",
"t-sql",
""
] |
I would like to be able to emulate the functionality of the "Presenter Tools" in MS Office. This requires the program to be able to detect and use an external/secondary monitor/projector.
Could somebody please point me in the right direction for achieving this.
I would like to use Java 1.5
Thankyou. | Through the [GraphicsEnvironment](http://java.sun.com/javase/6/docs/api/java/awt/GraphicsEnvironment.html) class you can get information about the available screens on the computer. In the docs for [GraphicsDevice](http://java.sun.com/javase/6/docs/api/java/awt/GraphicsDevice.html) there is a basic example showing how ... | It really depends on the GUI API you are planning.
For AWT, see John Meagher's post.
For SWT, you can look at Display.getMonitors() for a starting point. | How can I send output to an external/second display in Java? | [
"",
"java",
"ms-office",
""
] |
I would like to either prevent or handle a `StackOverflowException` that I am getting from a call to the `XslCompiledTransform.Transform` method within an `Xsl Editor` I am writing. The problem seems to be that the user can write an `Xsl script` that is infinitely recursive, and it just blows up on the call to the `Tra... | From Microsoft:
> Starting with the .NET Framework
> version 2.0, a StackOverflowException
> object cannot be caught by a try-catch
> block and the corresponding process is
> terminated by default. Consequently,
> users are advised to write their code
> to detect and prevent a stack
> overflow. For example, if your
> ... | > **NOTE** The question in the bounty by @WilliamJockusch and the original question are different.
>
> This answer is about StackOverflow's in the general case of third-party libraries and what you can/can't do with them. If you're looking about the special case with XslTransform, see the accepted answer.
---
Stack o... | How do I prevent and/or handle a StackOverflowException? | [
"",
"c#",
".net",
"stack-overflow",
"xslcompiledtransform",
""
] |
I am interested in getting some Python code talking to some Ruby code on Windows, Linux and possibly other platforms. Specificlly I would like to access classes in Ruby from Python and call their methods, access their data, create new instances and so on.
An obvious way to do this is via something like XML-RPC or mayb... | Well, you could try [named pipes](http://en.wikipedia.org/wiki/Named_pipe) or something similar but I really think that XML-RPC would be the most headache-free way. | Please be advised that I don't speak from personal experience here, but I imagine JRuby and Jython (The ruby and python implementations in the JVM) would be able to to easily talk to each other, as well as Java code. You may want to look into that. | Ruby to Python bridge | [
"",
"python",
"ruby",
"interop",
""
] |
If I do this:
```
// In header
class Foo {
void foo(bar*);
};
// In cpp
void Foo::foo(bar* const pBar) {
//Stuff
}
```
The compiler does not complain that the signatures for Foo::foo do not match. However if I had:
```
void foo(const bar*); //In header
void Foo::foo(bar*) {} //In cpp
```
The code will fail to com... | The *const* keyword in the first example is meaningless. You are saying that you don't plan on changing the pointer. However, the pointer was passed by value and so it dos not matter if you change it or not; it will not effect the caller. Similarly, you could also do this:
```
// In header
class Foo {
void foo( int b... | In the first, you've promised the compiler, but not other users of the class that you will not edit the variable.
In your second example, you've promised other users of the class that you will not edit their variable, but failed to uphold that promise.
I should also note that there is a distinct difference between
`... | C++ const question | [
"",
"c++",
"gcc",
"constants",
""
] |
A couple of recent questions discuss strategies for naming columns, and I was rather surprised to discover the concept of embedding the notion of foreign and primary keys in column names. That is
```
select t1.col_a, t1.col_b, t2.col_z
from t1 inner join t2 on t1.id_foo_pk = t2.id_foo_fk
```
I have to confess I have ... | I agree with you that the foreign key column in a child table should have the same name as the primary key column in the parent table. Note that this permits syntax like the following:
```
SELECT * FROM foo JOIN bar USING (foo_id);
```
The USING keyword assumes that a column exists by the same name in both tables, an... | I agree with you. Putting this information in the column name smacks of the crappy Hungarian Notation idiocy of the early Windows days. | Why specify primary/foreign key attributes in column names | [
"",
"sql",
"naming-conventions",
"foreign-keys",
""
] |
I'm trying to write some LINQ To SQL code that would generate SQL like
```
SELECT t.Name, g.Name
FROM Theme t
INNER JOIN (
SELECT TOP 5 * FROM [Group] ORDER BY TotalMembers
) as g ON t.K = g.ThemeK
```
So far I have
```
var q = from t in dc.Themes
join g in dc.Groups on t.K equals g.ThemeK into groups
select n... | Here's a faithful translation of the original query. This should not generate repeated roundtrips.
```
var subquery =
dc.Groups
.OrderBy(g => g.TotalMembers)
.Take(5);
var query =
dc.Themes
.Join(subquery, t => t.K, g => g.ThemeK, (t, g) => new
{
ThemeName = t.Name, GroupName = g.Name
}
);
```
Th... | Second answer, now I've reread the original question.
Are you sure the SQL you've shown is actually correct? It won't give the top 5 groups within each theme - it'll match each theme just against the top 5 groups *overall*.
In short, I suspect you'll get your original SQL if you use:
```
var q = from t in dc.Themes ... | Can take be used in a query expression in c# linq instead of using .Take(x)? | [
"",
"c#",
"linq",
"linq-to-sql",
""
] |
I'm working on a program that processes many requests, none of them reaching more than 50% of CPU (**currently I'm working on a dual core**). So I created a thread for each request, the whole process is faster. Processing 9 requests, a single thread lasts 02min08s, while with 3 threads working simultaneously the time d... | Do you have significant locking within your application? If the threads are waiting for each other a lot, that could easily explain it.
Other than that (and the other answers given), it's very hard to guess, really. A profiler is your friend...
EDIT: Okay, given the comments below, I think we're onto something:
> Th... | The problem is the COM object.
Most COM objects run in the context of a 'single-threaded apartment'. (You may have seen a [STAThread] annotation on the main method of a .NET application from time to time?)
Effectively this means that all dispatches to that object are handled by a single thread. Throwing more cores at... | Why doesn't multithreading in C# reach 100% CPU? | [
"",
"c#",
".net",
"multithreading",
"multicore",
""
] |
We use Tomcat to host our WAR based applications. We are servlet container compliant J2EE applications with the exception of org.apache.catalina.authenticator.SingleSignOn.
We are being asked to move to a commercial Java EE application server.
1. The first downside to changing that
I see is the cost. No matter wha... | Unless you want EJB proper, you don't need a full stack J2EE server (commercial or not).
You can have most J2EE features (such as JTA, JPA, JMS, JSF) with no full stack J2EE server. The only benefit of a full stack j2ee is that the container will manage all these on your behalf declaratively. With the advent of EJB3, ... | When we set out with the goal to Java EE 6 certify Apache Tomcat as [Apache TomEE](http://tomee.apache.org/comparison.html), here are some of the gaps we had to fill in order to finally pass the Java EE 6 TCK.
Not a complete list, but some highlights that might not be obvious even with the existing answers.
## No Tra... | Besides EAR and EJB, what do I get from a Java EE app server that I don't get in a servlet container like Tomcat? | [
"",
"java",
"tomcat",
"jakarta-ee",
"application-server",
""
] |
Is there an official C# guideline for the order of items in terms of class structure?
Does it go:
* Public Fields
* Private Fields
* Properties
* Constructors
* Methods
?
I'm curious if there is a hard and fast rule about the order of items? I'm kind of all over the place. I want to stick with a particular stand... | According to the [StyleCop Rules Documentation](https://github.com/DotNetAnalyzers/StyleCopAnalyzers/blob/master/documentation/SA1201.md) the ordering is as follows.
Within a class, struct or interface: (SA1201 and SA1203)
* Constant Fields
* Fields
* Constructors
* Finalizers (Destructors)
* Delegates
* Events
* Enu... | Rather than grouping by visibility or by type of item (field, property, method, etc.), how about grouping by functionality? | Order of items in classes: Fields, Properties, Constructors, Methods | [
"",
"c#",
".net",
"code-cleanup",
"code-structure",
""
] |
I've got two ListBox'es that are databound to the same BindingList.
The issue is that when changing the selected item from the GUI it's changing the position in the BindingList and then the BindingList signals the other ListBox to change its selected item.
So I've got the two ListBoxes Selected Item also synchronized... | Add this line to `Form_Load`:
```
this.listBox1.BindingContext = new BindingContext();
``` | Declaring listBox1 and listBox2 to be of the following type seems to result in the desired behaviour.
```
class MyListBox: ListBox {
protected override void OnSelectedIndexChanged (EventArgs a) {
if (DataManager != null) {
DataManager.SuspendBinding();
}
}
}
```
Regards,
tamberg | C# Binding: How can I disable the CurrencyManager in BindingList so Current Item position is not maintained and not signaled? | [
"",
"c#",
"data-binding",
"binding",
"currencymanager",
""
] |
I was taking a look through some open-source C++ code and I noticed a lot of double underscores used within in the code, mainly at the start of variable names.
```
return __CYGWIN__;
```
Just wondering: Is there a reason for this, or is it just some people's code styles? I would think that it makes it hard to read. | From [Programming in C++, Rules and Recommendations](http://www.doc.ic.ac.uk/lab/cplus/c++.rules/chap5.html) :
> The use of two underscores (`\_\_') in identifiers is reserved for the compiler's internal use according to the ANSI-C standard.
>
> Underscores (`\_') are often used in names of library functions (such as ... | Unless they feel that they are "part of the implementation", i.e. the standard libraries, then they shouldn't.
The rules are fairly specific, and are slightly more detailed than some others have suggested.
All identifiers that contain a double underscore or start with an underscore followed by an uppercase letter are... | Why do people use __ (double underscore) so much in C++ | [
"",
"c++",
"syntax",
""
] |
Is there a better/simpler way to find the number of images in a directory and output them to a variable?
```
function dirCount($dir) {
$x = 0;
while (($file = readdir($dir)) !== false) {
if (isImage($file)) {$x = $x + 1}
}
return $x;
}
```
This seems like such a long way of doing this, is there no simpler... | Check out the Standard PHP Library (aka SPL) for DirectoryIterator:
```
$dir = new DirectoryIterator('/path/to/dir');
foreach($dir as $file ){
$x += (isImage($file)) ? 1 : 0;
}
```
(FYI there is an undocumented function called iterator\_count() but probably best not to rely on it for now I would imagine. And you'd ... | This will give you the count of what is in your dir. I'll leave the part about counting only images to you as I am about to fallll aaasssllleeelppppppzzzzzzzzzzzzz.
```
iterator_count(new DirectoryIterator('path/to/dir/'));
``` | Return total number of files within a folder using PHP | [
"",
"php",
"file",
"count",
"directory",
""
] |
I need to store log files and configuration files for my application. Where is the best place to store them?
Right now, I'm just using the current directory, which ends up putting them in the Program Files directory where my program lives.
The log files will probably be accessed by the user somewhat regularly, so `%A... | If you're not using `ConfigurationManager` to manage your application and user settings, you should be. The configuration toolkit in the .NET Framework is remarkably well thought out, and the Visual Studio tools that interoperate with it are too.
The default behavior of `ConfigurationManager` puts both invariant (appl... | Note: You can get the path to the LocalApplicationData folder in .NET by using the following function:
```
string strPath=System.Environment.GetFolderPath(System.Environment.SpecialFolder.LocalApplicationData);
``` | Best place to store configuration files and log files on Windows for my program? | [
"",
"c#",
"windows",
""
] |
I have implemented a SAX parser in Java by extending the default handler. The XML has a ñ in its content. When it hits this character it breaks. I print out the char array in the character method and it simply ends with the character before the ñ. The parser seems to stop after this as no other methods are called even ... | What's the encoding on the file? Make sure the file's encoding decloration matches it. Your parser may be defaulting to ascii or ISO-8859-1. You can set the encoding like so
```
<?xml version="1.0" encoding="UTF-8"?>
```
UTF-8 will cover that character, just make sure that's what the file actually is in. | If you are saving your XMLs in ASCII, you can only use the lower half (first 128 characters) of the 8-bit character table. To include accented, or other non-english characters in your XML, you will either have to save your XML in UTF-8 or escape your charaters like ñ for ñ. | SAX parser breaking on ñ | [
"",
"java",
"xml",
"encoding",
"sax",
""
] |
* What is the main difference between `int.Parse()` and `Convert.ToInt32()`?
* Which one is to be preferred | * If you've got a string, and you expect it to always be an integer (say, if some web service is handing you an integer in string format), you'd use [**`Int32.Parse()`**](http://msdn.microsoft.com/en-us/library/system.int32.parse.aspx).
* If you're collecting input from a user, you'd generally use [**`Int32.TryParse()`... | Have a look in reflector:
**int.Parse("32"):**
```
public static int Parse(string s)
{
return System.Number.ParseInt32(s, NumberStyles.Integer, NumberFormatInfo.CurrentInfo);
}
```
which is a call to:
```
internal static unsafe int ParseInt32(string s, NumberStyles style, NumberFormatInfo info)
{
byte* stac... | What's the main difference between int.Parse() and Convert.ToInt32 | [
"",
"c#",
""
] |
We have an Java application running on Weblogic server that picks up XML messages from a JMS or MQ queue and writes it into another JMS queue. The application doesn't modify the XML content in any way. We use BEA's XMLObject to read and write the messages into queues.
The XML messages contain the encoding type declara... | > once we write it to the destination queue, the £ symbol is lost and is replaced with £ instead
That tells me the character is being *written* as UTF-8, but it's being *read* as if it were in a single-byte encoding like ISO-8859-1. (For any character in the range U+00A0..U+00BF, if you encode it as UTF-8 and decode ... | You should use `InputStream`, `OutputStream`, and `byte[]` to handle XML documents, not `Reader`, `Writer`, and `String`. In the world of JMS, `BytesMessage` is a better fit for XML payloads than `TextMessage`.
Every XML document specifies its character encoding internally, and all XML processing APIs are oriented to ... | Handling UTF-8 encoding | [
"",
"java",
"xml",
"unicode",
"encoding",
"utf-8",
""
] |
I just learned about [ngrep](http://ngrep.sourceforge.net/), a cool program that lets you easily sniff packets that match a particular string.
The only problem is that it can be hard to see the match in the big blob of output. I'd like to write a wrapper script to highlight these matches -- it could use ANSI escape se... | Ah, forget it. This is too much of a pain. It was a lot easier to get the source to ngrep and make it print the hash marks to stderr:
```
--- ngrep.c 2006-11-28 05:38:43.000000000 -0800
+++ ngrep.c.new 2008-10-17 16:28:29.000000000 -0700
@@ -687,8 +687,7 @@
}
if (quiet < 1) {
- printf("#");
- ... | This seems to do the trick, at least comparing two windows, one running a straight ngrep (e.g. ngrep whatever) and one being piped into the following program (with ngrep whatever | ngrephl target-string).
```
#! /usr/bin/perl
use strict;
use warnings;
$| = 1; # autoflush on
my $keyword = shift or die "No pattern sp... | How can I write a wrapper around ngrep that highlights matches? | [
"",
"python",
"perl",
"unix",
"networking",
""
] |
We're building some software for an in-house Kiosk. The software is a basic .net windows form with an embedded browser. The Kiosk is outfitted with a mat that the user steps on. When the user steps on the mat, it sends a key comination through the keyboard. When the user steps off the mat it sends a different key combi... | If your window is the active window, then you can simply override the forms ProcessCmdKey as such below.
```
protected override bool ProcessCmdKey(ref Message msg, Keys keyData)
{
const int WM_KEYDOWN = 0x100;
const int WM_SYSKEYDOWN = 0x104;
if ((msg.Msg == WM_KEYDOWN) || (msg.Msg == WM_SYSKEYDOWN))
... | I was doing a somewhat similar search just a short while ago regarding USB card readers.
I came across [this article on CodeProject](http://www.codeproject.com/KB/system/rawinput.aspx) for handling raw input of devices.
My main goal was differentiating multiple devices that act as keyboards. Your device may have a di... | Capturing key press messages | [
"",
"c#",
".net",
"winforms",
"winapi",
""
] |
As I understand, the pimpl idiom is exists only because C++ forces you to place all the private class members in the header. If the header were to contain only the public interface, theoretically, any change in class implementation would not have necessitated a recompile for the rest of the program.
What I want to kno... | This has to do with the size of the object. The h file is used, among other things, to determine the size of the object. If the private members are not given in it, then you would not know how large an object to new.
You can simulate, however, your desired behavior by the following:
```
class MyClass
{
public:
// ... | I think there is a confusion here. The problem is not about headers. Headers don't do anything (they are just ways to include common bits of source text among several source-code files).
The problem, as much as there is one, is that class declarations in C++ have to define everything, public and private, that an insta... | Could C++ have not obviated the pimpl idiom? | [
"",
"c++",
"language-design",
"compiler-theory",
"pimpl-idiom",
""
] |
The problem is quite basic. I have a JTable showing cached data from a database. If a user clicks in a cell for editing, I want to attempt a lock on that row in the database. If the lock does not succeed, I want to prevent editing.
But I can't seem to find any clean way to accomplish this. Am I missing something? | Because you have to test on the click you can't use the model's way of doing this so you should try overriding the JTable's [public void changeSelection(int rowIndex, int columnIndex, boolean toggle, oolean extend)](http://java.sun.com/javase/6/docs/api/javax/swing/JTable.html) method. If the row is locked then don't c... | Before editing/setting value the table model is asked via TableModel.isCellEditable(row,col) whether this cell is editable. Here you can implement your lock. and after TableModel.setValue(row,col,val) you should unlock this. BUT. The lock operation should take a lot of time and makes your UI un-responsible. And it si B... | How to do a check before allowing editing of a given row in a JTable | [
"",
"java",
"swing",
"jtable",
""
] |
What is the best way of working with calculated fields of Propel objects?
Say I have an object "Customer" that has a corresponding table "customers" and each column corresponds to an attribute of my object. What I would like to do is: add a calculated attribute "Number of completed orders" to my object when using it o... | There are several choices. First, is to create a view in your DB that will do the counts for you, similar to my answer [here](https://stackoverflow.com/questions/234785/#235267). I do this for a current Symfony project I work on where the read-only attributes for a given table are actually much, much wider than the tab... | I am doing this in a project now by overriding hydrate() and Peer::addSelectColumns() for accessing postgis fields:
```
// in peer
public static function locationAsEWKTColumnIndex()
{
return GeographyPeer::NUM_COLUMNS - GeographyPeer::NUM_LAZY_LOAD_COLUMNS;
}
public static function polygonAsEWKTColumnIndex()
{
... | Symfony app - how to add calculated fields to Propel objects? | [
"",
"php",
"orm",
"symfony1",
"propel",
""
] |
In C# there is the static property [Environment.Newline](http://msdn.microsoft.com/en-us/library/system.environment.newline.aspx) that changed depending on the running platform.
Is there anything similar in Java? | **As of Java 7 (and Android API level 19):**
```
System.lineSeparator()
```
Documentation: [Java Platform SE 7](https://docs.oracle.com/javase/7/docs/api/java/lang/System.html#lineSeparator%28%29)
---
**For older versions of Java, use:**
```
System.getProperty("line.separator");
```
See <https://java.sun.com/docs... | As of Java 7:
```
System.lineSeparator()
```
> [**Java API : System.lineSeparator**](http://docs.oracle.com/javase/7/docs/api/java/lang/System.html#lineSeparator%28%29)
>
> Returns the system-dependent line separator string. It always returns
> the same value - the initial value of the system property
> line.separato... | Is there a Newline constant defined in Java like Environment.Newline in C#? | [
"",
"java",
""
] |
I've recently been lifted out of the .Net world into the Java world and I miss my unit tests.
Using Visual Studio I used NUnit and TestDriven.net to run my unit tests.
What is a comparable system for Java Using Eclipse?
I'm looking specifically for the plugins that will get me going, or a guide on how to do it.
I'm... | Using JUnit with eclipse is actually very easy. Just go to File->New... and select JUnit Test Case. Eclipse will handle adding the JUnit library and all of the imports. | Which version of Eclipse are you using?
For as long as I remember (I've been using Eclipse since early 3.xs), Eclipse supports JUnit out of the box. You just:
Right-click on a project -> Run As -> JUnit Test
Does this not work for you? | What do you need to do Unit testing in Java with Eclipse? | [
"",
"java",
"eclipse",
"unit-testing",
"junit",
""
] |
Does anyone know how could I programatically disable/enable sleep mode on Windows Mobile?
Thanks! | If you want your program to not be put to sleep while it's running, the best way is to create a KeepAlive type function that calls SystemIdleTimerReset, SHIdleTimerReset and simulates a key touch. Then you need to call it a lot, basically everywhere.
```
#include <windows.h>
#include <commctrl.h>
extern "C"
{
voi... | Modify [the Power Manager registry setting](http://msdn.microsoft.com/en-us/library/aa932196.aspx) that affects the specific sleep condition you want (timeout, batter, AC power, etc) and the SetEvent on a named system event called "PowerManager/ReloadActivityTimeouts" to tell the OS to reload the settings. | Disable sleep mode in Windows Mobile 6 | [
"",
"c++",
"windows-mobile",
"pocketpc",
""
] |
```
function Submit_click()
{
if (!bValidateFields())
return;
}
function bValidateFields() {
/// <summary>Validation rules</summary>
/// <returns>Boolean</returns>
...
}
```
So, when I type the call to my bValidateFields() function intellisence in Visual Studio doesn't show my comments. But according to [this](... | I recall an issue where having turned off the Navigation Bar in VS stopped a lot of the JS intellisense from working properly. If you have it turned off, try turning the Navigation Bar on again and see if it helps.
Edit: You may also have to do Ctrl+Shift+J to force the IDE to update the intellisense.
Edit2: As @blub... | The XML comments have to be inside the function, not above it.
In Visual Studio 2008, the XML comment information is only display for files referenced with a /// <reference... item.
Visual Studio 2010 will display XML comment information for functions in the file your are editing and for files you are referencing. | Visual Studio 2008 doesn't show my XML comments in JS files | [
"",
"javascript",
"visual-studio-2008",
"comments",
"intellisense",
""
] |
What is the best way to do GUIs in [Clojure](http://en.wikipedia.org/wiki/Clojure)?
Is there an example of some functional [Swing](http://en.wikipedia.org/wiki/Swing_%28Java%29) or [SWT](http://en.wikipedia.org/wiki/Standard_Widget_Toolkit) wrapper?
Or some integration with [JavaFX](http://en.wikipedia.org/wiki/JavaFX... | I will humbly suggest [Seesaw](https://github.com/daveray/seesaw).
[Here's a REPL-based tutorial](https://gist.github.com/1441520) that assumes no Java or Swing knowledge.
---
Seesaw's a lot like what @tomjen suggests. Here's "Hello, World":
```
(use 'seesaw.core)
(-> (frame :title "Hello"
:content "Hello, ... | Stuart Sierra recently published a series of blog posts on GUI-development with clojure (and swing). Start off here: <http://stuartsierra.com/2010/01/02/first-steps-with-clojure-swing> | What is the best way to do GUIs in Clojure? | [
"",
"java",
"user-interface",
"lisp",
"clojure",
""
] |
I have a not-so-small class under development (that it changes often) and I need not to provide a public copy constructor and copy assignment.
The class has objects with value semantics, so default copy and assignment work.
the class is in a hierarchy, with virtual methods, so I provide a virtual Clone() to avoid slic... | An object from a polymorphic hierarchy, and with value semantics ? Something is wrong here.
If you really do need your class to have a value semantics, have a look at J.Coplien's Envelop-Letter Idiom, or at this article about Regular Objects [1].
[1] Sean Parent. “Beyond Objects”. Understanding The Software We Write.... | I don't think there is anything in the C++ language that allows you to do this. Although I'd love to be wrong on this point.
I've run into this in the past and come up with the following solution. Asumme the class is C1.
1. Define a private inner class called Data
2. Put all of my members I would delare in C1 on Data... | There's a way to declare Copy Constructor non-public AND using default copy Constructor? | [
"",
"c++",
"constructor",
"copy",
""
] |
What do I have to consider **in database design** for a new application which should be able to support the most common relational database systems (SQL Server, MySQL, Oracle, PostgreSQL ...)?
Is it even worth the effort? What are the pitfalls? | The short answer is to stick to features that are standardly, or close to standardly implemented. What this means in more detail is:
* Avoid anything that uses the database's procedural language (stored procedures or triggers) since this is where the huge differences between the systems come in. You may need to use th... | If I were you, I'd **think hard about the return on your investment here**.
It always *sounds* like a great idea to be able to hook up to any back end or to change back ends whenever you like, but this very rarely happens in The Real World in my experience.
It might turn out that you may cover 95% of your potential c... | Database design for database-agnostic applications | [
"",
"sql",
"database",
"database-design",
""
] |
Using the PHP [pack()](http://www.php.net/pack) function, I have converted a string into a binary hex representation:
```
$string = md5(time); // 32 character length
$packed = pack('H*', $string);
```
The H\* formatting means "Hex string, high nibble first".
To unpack this in PHP, I would simply use the [unpack()](h... | There's an easy way to do this with the `binascii` module:
```
>>> import binascii
>>> print binascii.hexlify("ABCZ")
'4142435a'
>>> print binascii.unhexlify("4142435a")
'ABCZ'
```
Unless I'm misunderstanding something about the nibble ordering (high-nibble first is the default… anything different is insane), that sh... | There's no corresponding "hex nibble" code for struct.pack, so you'll either need to manually pack into bytes first, like:
```
hex_string = 'abcdef12'
hexdigits = [int(x, 16) for x in hex_string]
data = ''.join(struct.pack('B', (high <<4) + low)
for high, low in zip(hexdigits[::2], hexdigits[1::2]))
`... | How can I unpack binary hex formatted data in Python? | [
"",
"python",
"binary",
"hex",
""
] |
How do I split strings in J2ME in an effective way?
There is a [`StringTokenizer`](http://download.oracle.com/javase/1.4.2/docs/api/java/util/StringTokenizer.html) or [`String.split(String regex)`](http://download.oracle.com/javase/1.5.0/docs/api/java/lang/String.html#split%28java.lang.String%29) in the standard editi... | There are a few implementations of a StringTokenizer class for J2ME. This one by [Ostermiller](http://ostermiller.org/utils/StringTokenizer.html) will most likely include the functionality you need
See also [this page on Mobile Programming Pit Stop](https://web.archive.org/web/20120206073031/http://mobilepit.com:80/09... | There is no built in method to split strings. You have to write it on your own using
`String.indexOf()` and `String.substring()`. Not hard. | How do I split strings in J2ME? | [
"",
"java",
"algorithm",
"string",
"java-me",
""
] |
I wrote a managed C++ class that has the following function:
```
void EndPointsMappingWrapper::GetLastError(char* strErrorMessage)
{
strErrorMessage = (char*) Marshal::StringToHGlobalAnsi(_managedObject->GetLastError()).ToPointer();
}
```
As you can see, this is a simple method to copy the managed string of the l... | You are assigning the value of the passed parameter (strErrorMessage) instead of copying to that address the content of the buffer returned by Marshal::StringToHGlobalAnsi.
A correct implementation should be:
```
void EndPointsMappingWrapper::GetLastError(char* strErrorMessage, int len)
{ char *str = (char*) Marshal... | We use the following C++ Class to do the conversions for us and it works fine. You should be able to modify your method to use it.
**H File**
```
public ref class ManagedStringConverter
{
public:
ManagedStringConverter( System::String^ pString );
~ManagedStringConverter();
property char* PrimitiveString
{
... | string to char* marshaling | [
"",
".net",
"c++",
"managed-c++",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.