
Prompt stringlengths 10 31k | Chosen stringlengths 3 29.4k | Rejected stringlengths 3 51.1k | Title stringlengths 9 150 | Tags listlengths 3 7 |
|---|---|---|---|---|
I am writing a searching function, and have thought up of this query using parameters to prevent, or at least limit, SQL injection attacks. However, when I run it through my program it does not return anything:
`SELECT * FROM compliance_corner WHERE (body LIKE '%@query%') OR (title LIKE '%@query%')`
Can parameters be... | Your visual basic code would look something like this:
```
Dim cmd as New SqlCommand("SELECT * FROM compliance_corner WHERE (body LIKE '%' + @query + '%') OR (title LIKE '%' + @query + '%')")
cmd.Parameters.Add("@query", searchString)
``` | Well, I'd go with:
```
Dim cmd as New SqlCommand(
"SELECT * FROM compliance_corner"_
+ " WHERE (body LIKE @query )"_
+ " OR (title LIKE @query)")
cmd.Parameters.Add("@query", "%" +searchString +"%")
``` | Howto? Parameters and LIKE statement SQL | [
"",
"asp.net",
"sql",
"vb.net",
""
] |
Is there a simple way to sort an iterator in PHP (without just pulling it all into an array and sorting that).
The specific example I have is a [DirectoryIterator](http://www.php.net/directoryiterator) but it would be nice to have a solution general to any iterator.
```
$dir = new DirectoryIterator('.');
foreach ($di... | There is no way to do that. An iterator should "iterate" through the list. You have to sort the underlying list to achieve the needed behavior.
By the way, the more complete reference to the SPL is here:
<http://www.php.net/~helly/php/ext/spl/> | For the ones that end up here 5 years later:
If you make the Iterator an extension of ArrayIterator you can use
ArrayIterator::uasort (to sort by value) and ArrayIterator::uksort (to sort by key)
<http://php.net/manual/en/arrayiterator.uasort.php>
<http://php.net/manual/en/arrayiterator.uksort.php> | Sorting PHP Iterators | [
"",
"php",
"iterator",
""
] |
I have a PHP class that creates a PNG image on the fly and sends it to browser. PHP manual says that I need to make sure that *imagedestroy* function is called at end to release the memory. Now, if I weren't using a class, I would have some code like this:
```
function shutdown_func()
{
global $img;
if ($img)... | I just tested with Apache, PHP being used as Apache module. I created an endless loop like this:
```
<?php
class X
{
function __destruct()
{
$fp = fopen("/var/www/htdocs/dtor.txt", "w+");
fputs($fp, "Destroyed\n");
fclose($fp);
}
};
$obj = new X();
while (true) {
// do nothing
... | Based on the principle that you should [finish what you start](http://www.pragprog.com/the-pragmatic-programmer/extracts/tips), I'd say the destructor is the correct place for the free call.
The [destructor](http://www.php.net/manual/en/language.oop5.decon.php) will be called when the object is disposed of, whereas a ... | PHP: destructor vs register_shutdown_function | [
"",
"php",
"image-processing",
"memory-leaks",
"destructor",
""
] |
What are the best practices to do transactions in C# .Net 2.0. What are the classes that should be used? What are the pitfalls to look out for etc. All that commit and rollback stuff. I'm just starting a project where I might need to do some transactions while inserting data into the DB. Any responses or links for even... | There are 2 main kinds of transactions; connection transactions and ambient transactions. A connection transaction (such as SqlTransaction) is tied directly to the db connection (such as SqlConnection), which means that you have to keep passing the connection around - OK in some cases, but doesn't allow "create/use/rel... | ```
protected void Button1_Click(object sender, EventArgs e)
{
using (SqlConnection connection1 = new SqlConnection("Data Source=.\\SQLEXPRESS;AttachDbFilename=|DataDirectory|\\Database.mdf;Integrated Security=True;User Instance=True"))
{
connection1.Open();
// Start a local tr... | Transactions in .net | [
"",
"c#",
".net",
"transactions",
""
] |
I've created a PHP DOM xml piece and saved it to a string like this:
```
<?php
// create a new XML document
$doc = new DomDocument('1.0');
...
...
...
$xmldata = $doc->saveXML();
?>
```
Now I can't use the headers to send a file download prompt and I can't write the file to the server, or rather I don'... | I see from the comments that you're working from within a CMS framework and are unable to stop content from being output prior to where your code will be.
If the script in which you're working has already output content (beyond your control), then you can't do what you're trying to achieve in just one script.
Your sc... | You could enable output\_buffering in your php.ini, then you might have some options with sending headers.
<http://us.php.net/manual/en/function.headers-sent.php> | Create PHP DOM xml file and create a save file link/prompt without writing the file to the server when headers already sent | [
"",
"php",
"xml",
"dom",
"file",
""
] |
I want to be able to load a serialized xml class to a Soap Envelope. I am starting so I am not filling the innards so it appears like:
```
<Envelope
xmlns="http://schemas.xmlsoap.org/soap/envelope/" />
```
I want it to appear like:
```
<Envelope
xmlns="http://schemas.xmlsoap.org/soap/envelope/" ></Envelope>`... | The main issue here is that the `XmlSerializer` calls `WriteEndElement()` on the `XmlWriter` when it would write an end tag. This, however, generates the shorthand `<tag/>` form when there is no content. The `WriteFullEndElement()` writes the end tag separately.
You can inject your own `XmlTextWriter` into the middle ... | Note for the record: The OP was using the [\*\*\*Microsoft.\*\*\*Web.Services.SoapEnvelope](http://msdn.microsoft.com/en-us/library/ms977223.aspx#) class, which is part of the extremely obsolete WSE 1.0 product. This class derived from the XmlDocument class, so it's possible that the same issues would have been seen wi... | XmlSerializer Serialize empty variable to use both tags? | [
"",
"c#",
"xml",
"xml-serialization",
""
] |
Does anyone know of a set of bindings for C# to drive the FFMpeg library directly ? I could shell to ffmpeg.exe directly but I found it hard to sync/control as a separate process. any help would be appreciated. | Tao.ffmpeg: <http://www.taoframework.com/project/ffmpeg>
it compiles and has a binary dist which is more than can be said for ffmpeg-sharp at this point. It is, however, not particularly easy to use. | I've seen this library:
[**ffmpeg-sharp**](http://code.google.com/p/ffmpeg-sharp/) a wrapper library over the FFmpeg multimedia suite that provides easy to use wrappers for use in C#. | Anyone know of a set of C# bindings for FFMPEG? | [
"",
"c#",
".net",
"binding",
"ffmpeg",
""
] |
I would like to have some kind of catch-all exceptions mechanism in the root of my code, so when an app terminates unexpectedly I can still provide some useful logging.
Something along the lines of
```
static void Main () {
if (Debugger.IsAttached)
RunApp();
else {
try {
RunApp();
... | As Paul Betts already mentioned, you might be better off using the [AppDomain.UnhandledException](http://msdn.microsoft.com/en-us/library/system.appdomain.unhandledexception.aspx) event instead of a try/catch block.
In your UnhandledException event handler you can log/display the exception and then offer the option to... | Horribly hacky but without runtime hooks (I know of none) the only way to get to the stack frame where you are throwing from....
All exceptions which are known to be terminal thrown would have to have the following in their constructor:
```
#if DEBUG
System.Diagnostics.Debugger.Launch()
#endif
```
This would present... | Attaching the .net debugger while still providing useful logging on death | [
"",
"c#",
"debugging",
"stack-trace",
""
] |
What are some ways that I can query the local machine's specifications (a range of things from CPU specs, OS version, graphics card specs and drivers, etc.) through a programmatic interface? We're writing a simple app in C# to test compatibility of our main app and want to have it dump out some system metrics, but I ca... | For this type of information [WMI](http://msdn.microsoft.com/en-us/library/aa394582(VS.85).aspx) is your friend. Fortunately dealing with WMI in .NET is much easier than in the unmanaged world. There are quite a lot of articles out there to get started with, like [this one](http://www.csharphelp.com/archives2/archive33... | Maybe look into using [Windows Management Instrumentation](http://msdn.microsoft.com/en-us/library/aa394582(VS.85).aspx) (WMI), assuming it's a Windows machine your planning to query. Take a look at the [WMI Code Creator](http://www.microsoft.com/downloads/details.aspx?familyid=2cc30a64-ea15-4661-8da4-55bbc145c30e&disp... | Querying machine specs | [
"",
"c#",
"wmi",
""
] |
I'm trying to deserialize an xml structure that looks like this:
```
<somecontainer>
<key1>Value1</key1>
<key1>Value2</key1>
<key2>Value3</key2>
<key2>Value4</key2>
</somecontainer>
```
I can basically choose what kind if element to deserialize to, maybe something like a List of Pair or something. The... | I have found that a custom serializer is needed for this case, no way around it.
Similarly
```
<node attr1="xxx">value1</node>
```
also needs a custom serializer. | I have not used XStream in some time, but [implicit collections](http://x-stream.github.io/alias-tutorial.html#omit) probably does what you want. | Deserializing a legacy XML structure in xstream | [
"",
"java",
"xstream",
""
] |
Added: Working with SQL Server 2000 and 2005, so has to work on both. Also, value\_rk is not a number/integer (Error: Operand data type uniqueidentifier is invalid for min operator)
Is there a way to do a single column "DISTINCT" match when I don't care about the other columns returned? Example:
```
**Table**
Value A... | this might work:
```
SELECT DISTINCT a.value, a.attribute_definition_id,
(SELECT TOP 1 value_rk FROM attribute_values WHERE value = a.value) as value_rk
FROM attribute_values as a
ORDER BY attribute_definition_id
```
.. not tested. | ```
SELECT a1.value, a1.attribute_definition_id, a1.value_rk
FROM attribute_values AS a1
LEFT OUTER JOIN attribute_values AS a2
ON (a1.value = a2.value AND a1.value_rk < a2.value_rk)
WHERE a2.value IS NULL
ORDER BY a1.attribute_definition_id;
```
In other words, find the row `a1` for which no row `a2` exists wit... | Select one column DISTINCT SQL | [
"",
"sql",
"sql-server",
"coldfusion",
"cfml",
""
] |
I'm working on a web application that will return a variable set of modules depending on user input. Each module is a Python class with a constructor that accepts a single parameter and has an '.html' property that contains the output.
Pulling the class dynamically from the global namespace works:
```
result = global... | A flaw with this approach is that it may give the user the ability to to more than you want them to. They can call *any* single-parameter function in that namespace just by providing the name. You can help guard against this with a few checks (eg. isinstance(SomeBaseClass, theClass), but its probably better to avoid th... | First of all, it sounds like you may be reinventing the wheel a little bit... most Python web frameworks (CherryPy/TurboGears is what I know) already include a way to dispatch requests to specific classes based on the contents of the URL, or the user input.
There is nothing **wrong** with the way that you do it, reall... | Best approach with dynamic classes using Python globals() | [
"",
"python",
"coding-style",
"namespaces",
""
] |
Are there any tools to transform SVG (XML) data to Canvas friendly input? | No I don't think so. SVG is actually rather different to Canvas. SVG is a vector graphics description language, whereas Canvases are programmatically "drawn" by sets of instructions. Also, Canvas isn't actually vector based at all.
Take a look at the [Raphael Javascript Library](http://www.raphaeljs.com/). Its API wil... | Take a look at canvg. It is a JavaScript library that will parse SVG and render into a specified canvas element:
<http://code.google.com/p/canvg/>
There's also an Ajaxian article (but I can only post one link per post) It's titled "CanVG: Using Canvas to render SVG files" | Are there any tools to transform SVG data to Canvas friendly input? | [
"",
"javascript",
"xml",
"svg",
""
] |
I've been wondering about how hard it would be to write some Python code to search a string for the index of a substring of the form `${`*expr*`}`, for example, where *expr* is meant to be a Python expression or something resembling one. Given such a thing, one could easily imagine going on to check the expression's sy... | I think your best bet is to match for all curly braced entries, and then check against Python itself whether or not it's valid Python, for which [compiler](https://docs.python.org/2/library/compiler.html) would be helpful. | I think what you're asking about is being able to insert Python code into text files to be evaluated. There are several modules that already exist to provide this kind of functionality. You can check the Python.org [**Templating wiki page**](http://wiki.python.org/moin/Templating) for a comprehensive list.
Some google... | Extracting a parenthesized Python expression from a string | [
"",
"python",
"parsing",
""
] |
I have a checkbox list control on my asp.net web form that I am dynamically populating from an arraylist. In javascript I want to be able to iterate through the values in the list and if a particular value has been selected to display other controls on the page.
My issue is that all the values in the checkbox list are... | I realised after much playing about with prerender events that I didn't actually need to know the exact value of the checkbox as the arraylist values would be in the same order as the checkboxes. I searched through the arraylist to get the position of the value that I needed and then used that position on the list of c... | `options[i].checked` will return true or false.
`options[i].value` will give you the value attribute of the checkbox tag. | Webform checkbox value in javascript | [
"",
"asp.net",
"javascript",
""
] |
What is the difference in the accessibility of the following variables in Java?
```
public class Joe {
public int a;
protected int b;
private int b;
int c;
}
```
I'm most interested in what the last one is doing. | * `public`: read/writable for anyone
* `protected`: read/writable for
instances of subclasses **and from within the enclosing package**
* `private`: read/writable for **any** instance of the class
and inner or outer (enclosing) instance
* `int c`:
package-private, read/writable for
all classes inside same packa... | Sorry for answering corrections to one previous answer but I don't have enough reputation to modify directly...
* `public` - read/writable for anyone
* `protected` - read/writable for
instances subclasses and all classes
inside same package
* `int c` : package-private,
read/writable for all classes inside
same... | Java Instance Variable Accessibility | [
"",
"java",
"variables",
"inheritance",
""
] |
So I've been trying to learn the boost::asio stuff to communicate to a serial device using RS232. The documementation is sparse and the examples are non-existent. Can't figure out exactly how to communicate with the device. The device can't send data so all I need to do is write, but other projects require actual back ... | In addition to the baud rate, you may also need to set other options like: character\_size, flow\_control, parity and stop\_bits. To write your data to the serial port you can do the following:
```
boost::asio::write(port, boost::asio::buffer(commands, 4));
```
The libraries acceptance of buffer types is very flexibl... | Thanks to the help from here and other places I got it working. Wrote a small program that might help some people figure out the boost serial port stuff as well.
[boostserialportdemo.cpp](http://www.college-code.com/blog/wp-content/uploads/2008/11/boost_serial_port_demo.cpp) | Boost Asio serial_port - need help with io | [
"",
"c++",
"boost",
""
] |
My co-founder is currently asking on our blog for an embeddable code widget.
<http://devver.net/blog/2008/10/someone-please-build-an-awesome-embeddable-code-widget/>
Basically we want something like <http://pastie.org/> or <http://codepad.org/> but we really want to embed the code section in our blog. We know there a... | We had a user point out a WordPress plugin that uses Gist to do exactly what we were asking for...
<http://pomoti.com/gist-it-english>
Even if you don't use the plug in it looks like a feature of Gist lets you embed the code anywhere you want on the web. <http://gist.github.com>
Looks pretty sweet. Thanks goes to Di... | I think you want a javascript syntax highlighter
* <http://code.google.com/p/syntaxhighlighter/>
* <http://shjs.sourceforge.net/>
* <http://www.google.com/search?q=javascript+syntax+highlighter>
Sometimes you just keep thinking in the wrong keywords ;-) | Is there a good embeddable code widget for blogs | [
"",
"javascript",
"blogs",
"widget",
""
] |
I noticed the specificaition for Collections.sort:
```
public static <T> void sort(List<T> list, Comparator<? super T> c)
```
Why is the "`? super`" necessary here? If `ClassB` extends `ClassA`, then wouldn't we have a guarantee that a `Comparator<ClassA>` would be able to compare two `ClassB` objects anyway, without... | Josh Bloch had a talk at Google I/O this year, called [Effective Java Reloaded](http://sites.google.com/site/io/effective-java-reloaded), which you may find interesting. It talks about a mnemonic called "Pecs" (producer `extends`, consumer `super`), which explains why you use `? extends T` and `? super T` in your input... | There's a really nice (but twisty) explanation of this in [More Fun with Wildcards](http://java.sun.com/docs/books/tutorial/extra/generics/morefun.html). | Why is SomeClass<? super T> not equivalent to SomeClass<T> in Java generic types? | [
"",
"java",
"generics",
""
] |
I have a resource handler that is Response.WriteFile(fileName) based on a parameter passed through the querystring. I am handling the mimetype correctly, but the issue is in some browsers, the filename comes up as Res.ashx (The name of the handler) instead of MyPdf.pdf (the file I am outputting). Can someone inform me ... | Extending from Joel's comment, your actual code would look something like this:
```
context.Response.AddHeader("content-disposition", "attachment; filename=" + resource);
``` | This Scott Hanselman post should be helpful:
<http://www.hanselman.com/blog/CommentView.aspx?guid=360> | Changing the name in the header for a resource handler in C# | [
"",
"c#",
"asp.net",
"mime-types",
"handler",
""
] |
Suppose you want to make an async request in JavaScript, but you want to pass some state along to the callback method. Is the following an appropriate use of closures in JavaScript?
```
function getSomethingAsync(someState, callback) {
var req = abc.createRequestObject(someParams);
req.invoke(makeCallback(some... | I don't see any immediate problems with this - closures are powerful for numerous reasons, one of which is removing the need to use global variables for state maintenance.
That said, the only thing you need to be wary of with regards to closures is memory leaks that typically occur in IE, but those are usually, IIRC, ... | The more idiomatic way is to use [`Function.bind`](https://developer.mozilla.org/en/JavaScript/Reference/Global_Objects/Function/bind), then you don't need to duplicate the code to create the closure. I'll use a simple example (that doesn't have your custom code) to explain
```
/**
* Retrieves the content of a url as... | Passing state to a callback in JavaScript an appropriate use of closures? | [
"",
"javascript",
"closures",
""
] |
How would I specify a color in app.config and then convert that into an actual System.Drawing.Color object at runtime? | One way would be to specify one of the [KnownColor](http://msdn.microsoft.com/en-us/library/system.drawing.knowncolor.aspx) values as the config text and then use [Color.FromName](http://msdn.microsoft.com/en-us/library/system.drawing.color.fromname.aspx) to create the Color object. | Have a look at [ColorTranslator](http://msdn.microsoft.com/en-us/library/system.drawing.colortranslator.aspx). You'll be able to specify a color, say in appSettings and use ColorTranslator to convert it into a real color. In particular I've found the .FromHtml() method very useful. | How to specify a Colour in config | [
"",
"c#",
".net",
"winforms",
""
] |
I use an anonymous object to pass my Html Attributes to some helper methods.
If the consumer didn't add an ID attribute, I want to add it in my helper method.
How can I add an attribute to this anonymous object? | If you're trying to extend this method:
```
public static MvcHtmlString ActionLink(this HtmlHelper htmlHelper, string linkText, string actionName, object routeValues);
```
Although I'm sure Khaja's Object extensions would work, you might get better performance by creating a RouteValueDictionary and passing in the rou... | The following extension class would get you what you need.
```
public static class ObjectExtensions
{
public static IDictionary<string, object> AddProperty(this object obj, string name, object value)
{
var dictionary = obj.ToDictionary();
dictionary.Add(name, value);
return dictionary;
... | Add property to anonymous type after creation | [
"",
"c#",
"reflection",
"anonymous-objects",
""
] |
Does anyone know how to databind the .Source property of the WebBrowser in WPF ( 3.5SP1 )?
I have a listview that I want to have a small WebBrowser on the left, and content on the right, and to databind the source of each WebBrowser with the URI in each object bound to the list item.
This is what I have as a proof of ... | The problem is that [`WebBrowser.Source`](https://learn.microsoft.com/en-us/dotnet/api/system.windows.controls.webbrowser.source?view=netframework-4.8) is not a `DependencyProperty`. One workaround would be to use some `AttachedProperty` magic to enable this ability.
```
public static class WebBrowserUtility
{
pub... | I wrote a wrapper usercontrol, which makes use of the DependencyProperties:
XAML:
```
<UserControl x:Class="HtmlBox">
<WebBrowser x:Name="browser" />
</UserControl>
```
C#:
```
public static readonly DependencyProperty HtmlTextProperty = DependencyProperty.Register("HtmlText", typeof(string), typeof(HtmlBox));
... | databind the Source property of the WebBrowser in WPF | [
"",
"c#",
"wpf",
"xaml",
"data-binding",
"browser",
""
] |
I have a text file of URLs, about 14000. Below is a couple of examples:
<http://www.domainname.com/pagename?CONTENT_ITEM_ID=100¶m2=123>
<http://www.domainname.com/images?IMAGE_ID=10>
<http://www.domainname.com/pagename?CONTENT_ITEM_ID=101¶m2=123>
<http://www.domainname.com/images?IMAGE_ID=11>
<http://w... | Here's another alternative to Graeme's, using the newer list comprehension syntax:
```
list2= [line for line in file if 'CONTENT_ITEM_ID' in line]
```
Which you prefer is a matter of taste! | I liked @bobince's answer (+1), but will up the ante.
Since you have a rather large starting set, you may wish to avoid loading the entire list into memory. Unless you need the whole list for something else, you could use a [Python generator expression](http://www.python.org/doc/2.5.2/ref/genexpr.html) to perform the ... | Python filter/remove URLs from a list | [
"",
"python",
"url",
"list",
"filter",
""
] |
Where can I find a list of all the C# Color constants and the associated R,G,B (Red, Green, Blue) values?
e.g.
Color.White == (255,255,255)
Color.Black == (0,0,0)
etc... | Run this program:
```
using System;
using System.Drawing;
using System.Reflection;
public class Test
{
static void Main()
{
var props = typeof(Color).GetProperties(BindingFlags.Public | BindingFlags.Static);
foreach (PropertyInfo prop in props)
{
Color color = (Color) prop.... | It looks like this [page](http://www.flounder.com/csharp_color_table.htm) has all of them. | C# Color constant R,G,B values | [
"",
"c#",
"colors",
"rgb",
"system.drawing.color",
""
] |
I have a form which takes both the user details and an image uploaded by them. I want to write the data to a user table and an image table but i am pretty sure that it cannot be done with just two separate insert statements. Any help would be much appreciated. | You need to insert the user first, then do "SELECT LAST\_INSERT\_ID()" to retrieve the id of the user. Then you can insert the image in the image table with the newly created user id. In PHP you can actually use [mysql\_insert\_id()](http://no.php.net/mysql_insert_id) to retrieve the new id. If you use mysql with InnoD... | ```
$rec = mysql_query("insert into userdet values("$id","$username",....)");
if($rec)
mysql_query("insert into imag values("$id","$imgname",...)");
``` | How do insert data into two different tables? | [
"",
"php",
"mysql",
""
] |
In C#, is it possible to extend a class that has no constructors?
Maybe I'm thinking about this incorrectly and just need a kick in the crotch. I have a Silverlight class that extends System.Windows.Media.Transform, With the official release of Silverlight 2, Transform now has no constructor. So, when I compile my cla... | The sole constructor to Transform is internal, so you can't derive from it yourself. | Hiding all public constructors is a technique used to prevent subclassing and force developers to use the class as intended. It may be the implementor wants you to use an Adapter or Facade or even a Proxy at the time of extension.
There may be important lifecycle details in the constructor that require the use as the ... | Extend No-Constructor class | [
"",
"c#",
".net",
"silverlight",
"oop",
""
] |
I found a while ago (and I want to confirm again) that if you declare a class level variable, you should not call its constructor until the class constructor or load has been called. The reason was performance - but are there other reasons to do or not do this? Are there exceptions to this rule?
**ie: this is what I d... | If you set your variable outside of the constructor then there is no error handling (handeling) available. While in your example it makes no difference, but there are many cases that you may want to have some sort of error handling. In that case using your first option would be correct.
Nescio talked about what implic... | Honestly, if you look at the IL, all that happens in the second case is the compiler moves the initialization to the constructor for you.
Personally, I like to see all initialization done in the constructor. If I'm working on a throwaway prototype project, I don't mind having the initialization and declaration in the ... | Declaring variables - best practices | [
"",
"c#",
".net",
""
] |
Java is nearing version 7. It occurs to me that there must be plenty of textbooks and training manuals kicking around that teach methods based on older versions of Java, where the methods taught, would have far better solutions now.
What are some boilerplate code situations, especially ones that you see people impleme... | Enums. Replacing
```
public static final int CLUBS = 0;
public static final int DIAMONDS = 1;
public static final int HEARTS = 2;
public static final int SPADES = 3;
```
with
```
public enum Suit {
CLUBS,
DIAMONDS,
HEARTS,
SPADES
}
``` | Generics and no longer needing to create an iterator to go through all elements in a collection. The new version is much better, easier to use, and easier to understand.
EDIT:
Before:
```
List l = someList;
Iterator i = l.getIterator();
while (i.hasNext()) {
MyObject o = (MyObject)i.next();
}
```
After
```
Lis... | Java: Out with the Old, In with the New | [
"",
"java",
""
] |
I expected `A::~A()` to be called in this program, but it isn't:
```
#include <iostream>
struct A {
~A() { std::cout << "~A()" << std::endl; }
};
void f() {
A a;
throw "spam";
}
int main() { f(); }
```
However, if I change last line to
```
int main() try { f(); } catch (...) { throw; }
```
then `A::~A()` *... | The destructor is not being called because terminate() for the unhandled exception is called before the stack gets unwound.
The specific details of what the C++ spec says is outside of my knowledge, but a debug trace with gdb and g++ seems to bear this out.
According to the [draft standard](http://www.csci.csusb.edu/... | C++ language specification states:
*The process of calling destructors for automatic objects constructed on the path from a try block to a throw-expression is called “stack unwinding.”*
Your original code does not contain try block, that is why stack unwinding does not happen. | Why destructor is not called on exception? | [
"",
"c++",
"exception",
"visual-c++",
"destructor",
"stack-unwinding",
""
] |
In our desktop application, we have implemented a simple search engine using an [inverted index](http://en.wikipedia.org/wiki/Inverted_index).
Unfortunately, some of our users' datasets can get very large, e.g. taking up ~1GB of memory before the inverted index has been created. The inverted index itself takes up a lo... | If it's going to be 1GB... put it on disk. Use something like Berkeley DB. It will still be very fast.
Here is a project that provides a .net interface to it:
<http://sourceforge.net/projects/libdb-dotnet> | I see a few solutions:
1. If you have the ApplicationObjects in an array, store just the index - might be smaller.
2. You could use a bit of C++/CLI to store the dictionary, using UTF-8.
3. Don't bother storing all the different strings, use a [Trie](http://en.wikipedia.org/wiki/Trie) | In-memory search index for application takes up too much memory - any suggestions? | [
"",
"c#",
"optimization",
"search",
"memory",
"search-engine",
""
] |
What's the best way to determine if the version of the JRE installed on a machine is high enough for the application which the user wants to run? Is there a way of doing it using java-only stuff? I'd like the solution to work on Windows/Linux/MacOSX - if the JRE version is too low a message should be displayed. Current... | An application built for a higher-version JRE will not run on a lower-version JRE. So you wouldn't be able to just add code to your application to check the JRE version - if the JRE version was incompatible, your JRE-version-checking code would not run in the first place.
What you'd have to do is have some sort of lau... | You could do this using reflection and two compilers. Compile a main class with the oldest java version you want to be able to run at all with. It checks the version using `System.getProperty("java.version")`, or whatever, and then uses reflection to load your *real* main class if that check passes, possibly even loadi... | How to check JRE version prior to launch? | [
"",
"version",
"java",
"launch",
""
] |
As the title suggests, is it correct or valid to import/export static data from within a C++ class?
I found out my problem - the author of the class I was looking at was trying to export writable static data which isn't supported on this platform.
Many thanks for the responses however. | Is it correct inasmuch as it'll work and do what you expect it to? Assuming that you are talking about using \_declspec(dllexport/dllimport) on a class or class member, yes, you can do that and it should give you the expected result - the static data would be accessible outside your dll and other C++ code could access ... | An exported C++ class means that the DLL clients have to use the same compiler as the DLL because of name mangling and other issues. This is actually a pretty big problem, I once had to write C wrappers to a bunch of C++ classes because the client programs had switched to MSVC9, while the DLL itself was using MSVC71. [... | Is it correct to export data members? (C++) | [
"",
"c++",
"dll",
"import",
"export",
""
] |
I have this piece of code (summarized)...
```
AnsiString working(AnsiString format,...)
{
va_list argptr;
AnsiString buff;
va_start(argptr, format);
buff.vprintf(format.c_str(), argptr);
va_end(argptr);
return buff;
}
```
And, on the basis that pass by reference is preferred where possible, ... | If you look at what va\_start expands out to, you'll see what's happening:
```
va_start(argptr, format);
```
becomes (roughly)
```
argptr = (va_list) (&format+1);
```
If format is a value-type, it gets placed on the stack right before all the variadic arguments. If format is a reference type, only the address gets ... | Here's what the [C++ standard, [support.runtime]/[cstdarg.syn] p1.2](https://eel.is/c++draft/cstdarg.syn#1.2) says about `va_start()` (emphasis mine):
> The restrictions that ISO C places on
> the second parameter to the
> `va_start()` macro in header
> `<stdarg.h>` are different in this
> International Standard. The ... | Are there gotchas using varargs with reference parameters | [
"",
"c++",
"reference",
"variadic-functions",
""
] |
Slightly related to my [other question](https://stackoverflow.com/questions/267750/java-instance-variable-accessibility): What is the difference between the following:
```
private class Joe
protected class Joe
public class Joe
class Joe
```
Once again, the difference between the last 2 is what I'm most interested in. | A public class is accessible to a class in any package.
A class with default access (`class Joe`) is only visible to other classes in the same package.
The private and protected modifiers can only be applied to inner classes.
A private class is only visible to its enclosing class, and other inner classes in the same... | * private: visible for outer classes only
* protected: visible for outer classes only
* public: visible for all other classes
* class: package-private, so visible for classes within the same package
See [JLS](http://java.sun.com/docs/books/jls/third_edition/html/names.html#104285) for more info. | Java Class Accessibility | [
"",
"java",
"class",
"accessibility",
""
] |
Is there any performance difference between the for loops on a primitive array?
Assume:
```
double[] doubleArray = new double[300000];
for (double var: doubleArray)
someComplexCalculation(var);
```
or :
```
for ( int i = 0, y = doubleArray.length; i < y; i++)
someComplexCalculation(doubleArray[i]);
```
**... | Your hand-written, "old" form executes fewer instructions, and may be faster, although you'd have to profile it under a given JIT compiler to know for sure. The "new" form is definitely **not** faster.
If you look at the disassembled code (compiled by Sun's JDK 1.5), you'll see that the "new" form is equivalent to the... | My opinion is that you don't know and shouldn't guess. Trying to outsmart compilers these days is fruitless.
There have been times people learned "Patterns" that seemed to optimize some operation, but in the next version of Java those patterns were actually slower.
Always write it as clear as you possibly can and don... | modern for loop for primitive array | [
"",
"java",
"performance",
"arrays",
"iteration",
""
] |
Specifically, I'm looking for a client-side, JavaScript and / or Flash based multiple file uploader. The closest thing I've found is [FancyUpload](http://digitarald.de/project/fancyupload/). Anyone have experience with it? If not, what else is out there? | Yahoo's [YUI Uploader](http://yuilibrary.com/yui/docs/uploader/uploader-dd.html) is your friend. | [Uploadify](http://www.uploadify.com/) is a jQuery / Flash hybrid (if you don't feel like adding in YUI just to handle uploads).
[Demo](http://www.uploadify.com/demo/)
[How to implement](http://www.uploadify.com/documentation/) | What is the best multiple file JavaScript / Flash file uploader? | [
"",
"javascript",
"ajax",
"flash",
"file-upload",
"multifile-uploader",
""
] |
I just downloaded Eclipse several hours ago, and needed to add Java3D to the classpath. Installing it went without a hitch, but Eclipse can't seem to find the documentation folders so that it can give super-IDE functionality, such as autocomplete and method signatures.
While I know how I would add them individually, t... | when you add a .JAR(library) to your project in the LIBRARIES tab for your project, you have the option of attaching the javadoc directory for the jar.
So, go to the LIBRARIES tab of the "java build path" for your projects. select your jar. expand the (+) sign and you will see that you can set the javadoc. path.
good... | I think I've got it (had the same issue as you). Better late than never.
Go here - <http://java3d.java.net/binary-builds.html> and download the documentation zip (j3d-1\_5\_2-api-docs.zip).
Extract the directory anywhere on your HD (Right in the Java3d folder is fine).
Link the Jar's JavaDoc listing to that Folder (... | Install [java library] in Eclipse | [
"",
"java",
"eclipse",
"configuration",
""
] |
I have db table with parent child relationship as:
```
NodeId NodeName ParentId
------------------------------
1 Node1 0
2 Node2 0
3 Node3 1
4 Node4 1
5 Node5 3
6 Node6 5
7 Node7 2
```
Here parentId = 0 means that ... | ```
with [CTE] as (
select * from [TheTable] c where c.[ParentId] = 1
union all
select * from [CTE] p, [TheTable] c where c.[ParentId] = p.[NodeId]
)
select * from [CTE]
``` | You should look into using the Nested Set Model for parent-child relationships within an SQL database. It's much nicer than trying to store the parentID of records in the table like this, and makes queries like this much easier. | SQL Query for Parent Child Relationship | [
"",
"sql",
"sql-server-2005",
"hierarchical-data",
""
] |
I am wondering how to use NUnit correctly. First, I created a separate test project that uses my main project as reference. But in that case, I am not able to test private methods. My guess was that I need to include my test code into my main code?! - That doesn't seem to be the correct way to do it. (I dislike the ide... | Generally, unit testing addresses a class's public interface, on the theory that the implementation is immaterial, so long as the results are correct from the client's point of view.
So, NUnit does not provide any mechanism for testing non-public members. | While I agree that the focus of unit testing should be the public interface, you get a far more granular impression of your code if you test private methods as well. The MS testing framework allows for this through the use of PrivateObject and PrivateType, NUnit does not. What I do instead is:
```
private MethodInfo G... | How do you test private methods with NUnit? | [
"",
"c#",
"unit-testing",
"testing",
"nunit",
""
] |
So let's say I have two different functions. One is a part of the BST class, one is just a helper function that will call on that Class function. I will list them out here.
```
sieve(BST<T>* t, int n);
```
this function is called like this: sieve(t,n) the object is called BST t;
I'm going to be using the class remov... | ```
sieve(BST<int>& t, int n)
```
The `&` specifies passing by *reference* rather than value. :-) | If I understand correctly your issue, you should use
```
BST t;
sieve(BST<T> *t, int n);
```
and invoke it as:
```
sieve(&t,n)
```
passing the pointer to the `t` object
OR
```
BST t;
sieve(BST<T> &t, int n);
```
and invoke it as:
```
sieve(t,n)
```
passing the reference to the `t` object | Passing a Class Object to a function (probably by pointer not reference) C++ | [
"",
"c++",
"reference",
"arguments",
""
] |
As can be seen in the Mozilla changlog for JavaScript 1.7 they have added destructuring assignment. Sadly I'm not very fond of the syntax (why write a and b twice?):
```
var a, b;
[a, b] = f();
```
Something like this would have been a lot better:
```
var [a, b] = f();
```
That would still be backwards compatible... | First off, `var [a, b] = f()` works just fine in JavaScript 1.7 - try it!
Second, you can smooth out the usage syntax *slightly* using `with()`:
```
var array = [1,2];
with (assign(array, { var1: null, var2: null }))
{
var1; // == 1
var2; // == 2
}
```
Of course, this won't allow you to modify the values of ex... | You don't need the dummy "\_" variable. You can directly create "global" variables by using the window object scope:
```
window["foo"] = "bar";
alert(foo); // Gives "bar"
```
Here are few more points:
* I wouldn't name this function
"assign" because that's too generic
a term.
* To more closely resemble JS
1.7 ... | Destructuring assignment in JavaScript | [
"",
"javascript",
"variable-assignment",
"destructuring",
""
] |
I have some System.Diagnotics.Processes to run. I'd like to call the close method on them automatically. Apparently the "using" keyword does this for me.
Is this the way to use the using keyword?
```
foreach(string command in S) // command is something like "c:\a.exe"
{
try
{
using(p = Process.Start(c... | ```
using(p = Process.Start(command))
```
This will compile, as the `Process` class implements `IDisposable`, however you actually want to call the `Close` method.
Logic would have it that the `Dispose` method would call `Close` for you, and by digging into the CLR using reflector, we can see that it does in fact do... | For reference:
The *using* keyword for *IDisposable* objects:
```
using(Writer writer = new Writer())
{
writer.Write("Hello");
}
```
is just compiler syntax. What it compiles down to is:
```
Writer writer = null;
try
{
writer = new Writer();
writer.Write("Hello");
}
finally
{
if( writer != null)
... | How do I programmatically use the "using" keyword in C#? | [
"",
"c#",
"process",
""
] |
While working on a C# app I just noticed that in several places static initializers have dependencies on each other like this:
```
static private List<int> a = new List<int>() { 0 };
static private List<int> b = new List<int>() { a[0] };
```
Without doing anything special that worked. Is that just luck? Does C# have ... | It seems to depend on the sequence of lines. This code works:
```
static private List<int> a = new List<int>() { 1 };
static private List<int> b = new List<int>() { a[0] };
```
while this code does not work (it throws a `NullReferenceException`)
```
static private List<int> a = new List<int>() { b[0] };
static priva... | See [section 10.4 of the C# spec](http://msdn.microsoft.com/en-us/library/aa645757(VS.71).aspx) for the rules here:
> when a class is initialized, all static fields in that class are first initialized to their default values, and then the static field initializers are executed in textual order. Likewise, when an insta... | Order of static constructors/initializers in C# | [
"",
"c#",
"static",
"dependencies",
"internals",
""
] |
I would like to be able to drop to the python REPL from the debugger -- if this is not possible is there an easier way to evaluate python expressions in the context of the current breakpoint other than manually adding them all as watch expressions? | I don't use *pydev*, but to drop to python's interactive REPL from code:
```
import code
code.interact(local=locals())
```
To drop to python's debugger from code:
```
import pdb
pdb.set_trace()
```
Finally, to run a interactive REPL after running some code, you can use python's `-i` switch:
```
python -i script.py... | There is a dedicated Pydev Console available by clicking on the "New console" dropdown in the console view.
See <http://pydev.sourceforge.net/console.html> | Is there any way to get a REPL in pydev? | [
"",
"python",
"ide",
"pydev",
"read-eval-print-loop",
""
] |
I am desiging a new website for my company and I am trying to implement switch navigation which is what I have used on all my sites in the past.
```
<?php
switch($x) {
default:
include("inc/main.php");
break;
case "products":
include("inc/products.php");
break;
}
?>
```
For some reason when I go to index.php?x=pro... | Yes, your PHP configuration has **correctly** got `register_globals` turned off, because that's incredibly insecure.
Just put:
```
$x = $_REQUEST['x']
```
at the top of your script.
You can also use `$_GET` if you specifically only want this to work for the `GET` HTTP method. I've seen some people claim that `$_REQ... | It seems like your previous webhosts all used [register\_globals](http://php.net/register_globals) and your code relies on that. This is a **dangerous** setting and was rightfully removed in PHP 6.0! Use `switch($_GET['x']) {` instead. | PHP Automatically "GET" Variables | [
"",
"php",
"get",
"global-variables",
""
] |
(Note: This is for MySQL's SQL, not SQL Server.)
I have a database column with values like "abc def GHI JKL". I want to write a WHERE clause that includes a case-insensitive test for any word that begins with a specific letter. For example, that example would test true for the letters a,c,g,j because there's a 'word' ... | Using REGEXP opearator:
```
SELECT * FROM `articles` WHERE `body` REGEXP '[[:<:]][acgj]'
```
It returns records where column body contains words starting with a,c,g or i (case insensitive)
Be aware though: this is not a very good idea if you expect any heavy load (not using index - it scans every row!) | You can use a `LIKE` operation. If your words are space-separated, append a space to the start of the string to give the first word a chance to match:
```
SELECT
StringCol
FROM
MyTable
WHERE
' ' + StringCol LIKE '% ' + MyLetterParam + '%'
```
Where `MyLetterParam` could be something like this:
```
'[acgj]'
```... | SQL (MySQL): Match first letter of any word in a string? | [
"",
"sql",
"mysql",
""
] |
what's the quickest way to extract a 5 digit number from a string in c#.
I've got
```
string.Join(null, System.Text.RegularExpressions.Regex.Split(expression, "[^\\d]"));
```
Any others? | The regex approach is probably the quickest to implement but not the quickest to run. I compared a simple regex solution to the following manual search code and found that the manual search code is ~2x-2.5x faster for large input strings and up to 4x faster for small strings:
```
static string Search(string expression... | Use a regular expression (\d{5}) to find the occurrence(s) of the 5 digit number in the string and use int.Parse or decimal.Parse on the match(s).
In the case where there is only one number in `text`.
```
int? value = null;
string pat = @"\d{5}"
Regex r = new Regex(pat);
Match m = r.Match(text);
if (m.Success)
{
v... | what's the quickest way to extract a 5 digit number from a string in c# | [
"",
"c#",
"regex",
"string",
""
] |
I'm looking for a library to save an array of colour data to a PNG file. (That's all there is to it, right? I know very little about the internals of a PNG.)
This is for use in Nintendo DS development, so something lightweight is preferable. I don't need any other fancy features like rotation, etc. | To encode any kind of PNG file, libpng is the way of the walk.
However, on small devices like the DS you really want to store your image data in the format which the display hardware expects. It is technically possible to get libpng working on the platform, but it will add significant overhead, both in terms of loadti... | Have you looked at libpng? <http://www.libpng.org/pub/png/libpng.html>
I'm not sure whether the memory footprint will be acceptable, but you should probably be aware that PNG files are a lot more involved than just an array of colors. Performance is likely to be a concern on a DS.
If you go with libpng, you'll also n... | Saving an array of colour data as a PNG file on DS | [
"",
"c++",
"png",
"nintendo-ds",
""
] |
Apparently, they're "confusing". Is that seriously the reason? Can you think of any others? | Have you seen how many developers don't really understand ref/out?
I use them where they're really necessary, but not otherwise. They're usually only useful if you want to effectively return two or more values - in which case it's worth at least *thinking* about whether there's a way of making the method only do one t... | In my opinion, they are considered a code smell because in general there is a much better option: returning an object.
If you notice, in the .NET library they are only used in some special cases, namely *tryparse*-like scenarios where:
* returning a class would mean boxing a value type
* the contract of the method re... | Why does the .Net framework guidelines recommend that you don't use ref/out arguments? | [
"",
"c#",
".net",
"parameters",
"function",
""
] |
Title says most of it.
I have inherited a Joomla site and the client wants part of the main template (a feature-type box) to be editable via the Joomla backend.
I guess really it is a content item that never gets displayed as its own page, but as a part of all pages.
Is that possible?
Thanks.
EDIT: By editable, I ... | You want the content items module.
[Content Items Module](http://extensions.joomla.org/component/option,com_mtree/task,viewlink/link_id,498/Itemid,35/)
This way a user can add content as normal using the standard content pages, but you as the developer can set the module up to show that content as a module only. You ... | The Custom HTML Module allows you to create, edit, and display your own free-form HTML on a Joomla site using a WYSIWYG editor.
In your administration control panel you can find the "Module Manager" under "Extensions" in the drop down navigation menu. There you can create this module, choose a position in your templat... | How can I make part of a Joomla template editable via the CMS interface? | [
"",
"php",
"content-management-system",
"joomla",
""
] |
I'm writing a data structure in C# (a priority queue using a [fibonacci heap](http://en.wikipedia.org/wiki/Fibonacci_heap)) and I'm trying to use it as a learning experience for TDD which I'm quite new to.
I understand that each test should only test one piece of the class so that a failure in one unit doesn't confuse... | Add a private accessor for the class to your test project. Use the accessor to set up the private properties of the class in some known way instead of using the classes methods to do so.
You also need to use `SetUp` and `TearDown` methods on your test class to perform any initializations needed between tests. I would ... | Theoretically, you only want to test a single feature at a time. However, if your queue only has a couple methods (`Enqueue`, `Peek`, `Dequeue`, `Count`) then you're quite limited in the kinds of tests you can do while using one method only.
It's best you don't over-engineer the problem and simply create a few simple ... | How do I set up the internal state of a data structure during unit testing? | [
"",
"c#",
"tdd",
""
] |
When we perform a fork in Unix, open file handles are inherited, and if we don't need to use them we should close them. However, when we use libraries, file handles may be opened for which we do not have access to the handle. How do we check for these open file handles? | If the libraries are opening files you don't know about, how do you know they don't need them after a fork? Unexported handles are an internal library detail, if the library wants them closed it will register an atfork() handler to close them. Walking around behind some piece of code closing its file handles behind its... | In Linux you can check `/proc/<pid>/fd` directory - for every open fd there will be a file, named as handle. I'm almost sure this way is non-portable.
Alternatively you can use `lsof` - available for Linux, AIX, FreeBSD and NetBSD, according to `man lsof`. | How do I find the file handles that my process has opened in Linux? | [
"",
"c++",
"c",
"linux",
"file-io",
""
] |
I have a page which dynamically loads a section of content via AJAX. I'm concerned that this means the content will not be found by search engines.
To show you what I mean, the site is at <http://www.gold09.net> and the dynamic content is at [/speakers.php](http://www.gold09.net/speakers.php) - Normally no one would v... | **Update: What I've done is this:**
Created another page called [`viewSpeakers.php`](http://www.gold09.net/viewSpeakers.php) which just includes the `speakers.php` file with the standard header and footer around it. This means that if someone goes to that site, then they'll see a vaguely attractive page. The only link... | Make the links that point to the pages you want indexed to have a real HREF to the content - but use javascript to intercept the event and "return false;" at the end. | How to make search engines find my AJAX content | [
"",
"php",
"ajax",
"seo",
""
] |
I'm having problems structuring classes in the Model part of an MVC pattern in my Python app. No matter how I turn things, I keep running into circular imports. Here's what I have:
**Model/\_\_init\_\_p.y**
* should hold all Model class names so
I can do a "from Model import User"
e.g. from a Controller or a unit... | There is an inconsistency in your specification. You say Database.py needs to import all Model classes to do ORM but then you say the User class need access to the Database to do queries.
Think of these as layers of an API. The Database class provides an API (maybe object-oriented) to some physical persistence layer (... | Generally, we put it all in one file. This isn't Java or C++.
Start with a single file until you get some more experience with Python. Unless your files are gargantuan, it will work fine.
For example, Django encourages this style, so copy their formula for success. One module for the model. A module for each applicat... | MVC model structure in Python | [
"",
"python",
"model-view-controller",
"model",
"structure",
""
] |
After looking on MSDN, it's still unclear to me how I should form a proper predicate to use the Find() method in List using a member variable of T (where T is a class)
For example:
```
public class Car
{
public string Make;
public string Model;
public int Year;
}
{ // somewhere in my code
List<Car> carL... | Ok, in .NET 2.0 you can use delegates, like so:
```
static Predicate<Car> ByYear(int year)
{
return delegate(Car car)
{
return car.Year == year;
};
}
static void Main(string[] args)
{
// yeah, this bit is C# 3.0, but ignore it - it's just setting up the list.
List<Car> list = new List<Car>... | You can use a lambda expression as follows:
```
myCar = carList.Find(car => car.Year == 1999);
``` | How do I form a good predicate delegate to Find() something in my List<T>? | [
"",
"c#",
"list",
"delegates",
"find",
"predicate",
""
] |
I have written a Windows service that allows me to remotely run and stop applications. These applications are run using CreateProcess, and this works for me because most of them only perform backend processing. Recently, I need to run applications that present GUI to the current log in user. How do I code in C++ to all... | Roger Lipscombe's answer, to use [WTSEnumerateSessions](http://msdn.microsoft.com/en-us/library/aa383833.aspx) to find the right desktop, then [CreateProcessAsUser](http://msdn.microsoft.com/en-us/library/ms682429.aspx) to start the application on that desktop (you pass it the handle of the desktop as part of the [STAR... | The short answer is "You don't", as opening a GUI program running under another user context is a security vulnerability commonly known as a [Shatter Attack](http://en.wikipedia.org/wiki/Shatter_attack).
Take a look at this MSDN article: [Interactive Services](http://msdn.microsoft.com/en-us/library/ms683502(VS.85).as... | How can a Windows service execute a GUI application? | [
"",
"c++",
"winapi",
"windows-services",
""
] |
I was reading an article on MSDN Magazine about using the [Enumerable class in LINQ](http://msdn.microsoft.com/en-us/magazine/cc700332.aspx) to generate a random array. The article uses VB.NET and I'm not immediately sure what the equivalent is in C#:
```
Dim rnd As New System.Random()
Dim numbers = Enumerable.Range(1... | The [Developer Fusion VB.Net to C# converter](http://www.developerfusion.com/tools/convert/vb-to-csharp/) says that the equivalent C# code is:
```
System.Random rnd = new System.Random();
IEnumerable<int> numbers = Enumerable.Range(1, 100).OrderBy(r => rnd.Next());
```
For future reference, they also have a [C# to VB... | I initially thought this would be a bad idea since the sort algorithm will need to do multiple comparisons for the numbers, and it will get a different sorting key for the same number each time it calls the lambda for that number. However, it looks like it only calls it once for each element in the list, and stores tha... | Random array using LINQ and C# | [
"",
"c#",
"vb.net",
"linq",
"enumerable",
""
] |
I'm looking for the .NET-preferred way of performing the same type of thing that ShellExecute does in Win32 (opening, printing, etc. for arbitrary file types).
I've been programming Windows for over 20 years, but I'm a complete newbie at .NET, so maybe I'm just looking in the wrong places. I'm currently using .NET 2.0... | [Process.Start](http://msdn.microsoft.com/en-us/library/system.diagnostics.process.start.aspx).
Note that advanced uses (printing etc) require using a [ProcessStartInfo](http://msdn.microsoft.com/en-us/library/system.diagnostics.processstartinfo_properties.aspx) and setting the [Verb](http://msdn.microsoft.com/en-us/l... | ```
System.Diagnostics.Process.Start(command)
```
I bet you had trouble finding it because it is in the System.Diagnostics namespace. "Diagnostics"? Usually with 20 years experience one thing you get good at is guessing at what something will be called in a new API/language, but this one tricked me. | ShellExecute equivalent in .NET | [
"",
"c#",
".net",
"winapi",
"windows-shell",
"shellexecute",
""
] |
I was wondering if in Java I would get any odd behaviour if I synchronise twice on the same object?
The scenario is as follows
```
pulbic class SillyClassName {
object moo;
...
public void method1(){
synchronized(moo)
{
....
method2();
....
}
... | # Reentrant
Synchronized blocks use *reentrant* locks, which means if the thread already holds the lock, it can re-aquire it without problems. Therefore your code will work as you expect.
See the bottom of the [Java Tutorial](https://docs.oracle.com/javase/tutorial/index.html) page [Intrinsic Locks and Synchronizatio... | I think we have to use reentrant lock for what you are trying to do. Here's a snippet from <http://docs.oracle.com/javase/1.5.0/docs/api/java/util/concurrent/locks/ReentrantLock.html>.
> What do we mean by a reentrant lock? Simply that there is an acquisition count associated with the lock, and if a thread that holds ... | Synchronising twice on the same object? | [
"",
"java",
"multithreading",
"synchronization",
"mutex",
""
] |
I ran into a problem while cleaning up some old code. This is the function:
```
uint32_t ADT::get_connectivity_data( std::vector< std::vector<uint8_t> > &output )
{
output.resize(chunks.size());
for(chunk_vec_t::iterator it = chunks.begin(); it < chunks.end(); ++it)
{
uint32_t success = (*it)->get_... | After a bit of work I came up with this solution:
```
std::transform(chunks.begin(), chunks.end(), back_inserter(tmp), boost::bind(&ADTChunk::get_connectivity_data, _1) );
```
It required that I change get\_connectivity\_data to return std::vector instead of taking one by reference, and it also required that I change... | I think you were correct in thinking that the best thing to do is leave the code as-is. If you're having a hard time understanding it when (a) you're writing it and (b) you understand the exact problem you're trying to solve, imagine how difficult it will be when someone comes along in 3 years time and has to understan... | boost lambda or phoenix problem: using std::for_each to operate on each element of a container | [
"",
"c++",
"boost-lambda",
"boost-phoenix",
""
] |
I just read a post mentioning "full text search" in SQL.
I was just wondering what the difference between FTS and LIKE are. I did read a couple of articles but couldn't find anything that explained it well. | In general, there is a tradeoff between "precision" and "recall". High precision means that fewer irrelevant results are presented (no false positives), while high recall means that fewer relevant results are missing (no false negatives). Using the LIKE operator gives you 100% precision with no concessions for recall. ... | FTS involves indexing the individual words within a text field in order to make searching through many records quick. Using LIKE still requires you to do a string search (linear or the like) within the field. | What is Full Text Search vs LIKE | [
"",
"sql",
"full-text-search",
"sql-like",
""
] |
When I'm building a java object using JNI methods, in order to pass it in as a parameter to a java method I'm invoking using the JNI invocation API, how do I manage its memory?
Here's what I am working with:
I have a C object that has a destructor method that is more complex that `free()`. This C object is to be asso... | There are a couple of strategies for reclaiming native resources (objects, file descriptors, etc.)
1. Invoke a JNI method during finalize() which frees the resource. Some people [recommend against implementing finalize](https://stackoverflow.com/questions/158174/why-would-you-ever-implement-finalize), and basically yo... | The JNI spec covers the issue of who "owns" Java objects created in JNI methods [here](http://java.sun.com/j2se/1.5.0/docs/guide/jni/spec/design.html#wp16785). You need to distinguish between **local** and **global** references.
When the JVM makes a JNI call out to native code, it sets up a registry to keep track of a... | JNI memory management using the Invocation API | [
"",
"java",
"c",
"memory-management",
"java-native-interface",
""
] |
That's basically the question, is there a "right" way to implement `operator<<` ?
Reading [this](http://bytes.com/forum/thread170304.html) I can see that something like:
```
friend bool operator<<(obj const& lhs, obj const& rhs);
```
is preferred to something like
```
ostream& operator<<(obj const& rhs);
```
But I ... | The problem here is in your interpretation of the article you [link](http://bytes.com/forum/thread170304.html).
### Equality
This article is about somebody that is having problems correctly defining the bool relationship operators.
The operator:
* Equality == and !=
* Relationship < > <= >=
These operators should ... | You can not do it as a member function, because the implicit `this` parameter is the left hand side of the `<<`-operator. (Hence, you would need to add it as a member function to the `ostream`-class. Not good :)
Could you do it as a free function without `friend`ing it? That's what I prefer, because it makes it clear ... | Should operator<< be implemented as a friend or as a member function? | [
"",
"c++",
"operator-overloading",
""
] |
I am trying to call php-cgi.exe from a .NET program. I use RedirectStandardOutput to get the output back as a stream but the whole thing is very slow.
Do you have any idea on how I can make that faster? Any other technique?
```
Dim oCGI As ProcessStartInfo = New ProcessStartInfo()
oCGI.WorkingDirectory = "C:\... | You can use the [OutputDataReceived event](http://msdn.microsoft.com/en-us/library/system.diagnostics.process.outputdatareceived.aspx) to receive data as it's pumped to StdOut. | The best solution I have found is:
```
private void Redirect(StreamReader input, TextBox output)
{
new Thread(a =>
{
var buffer = new char[1];
while (input.Read(buffer, 0, 1) > 0)
{
output.Dispatcher.Invoke(new Action(delegate
{
output.Text += new... | Redirect Standard Output Efficiently in .NET | [
"",
"c#",
".net",
"process",
"cgi",
""
] |
How do I discover classes at runtime in the classpath which implements a defined interface?
ServiceLoader suits well (I think, I haven't used it), but I need do it in Java 1.5. | There's nothing built into Java 1.5 for this. I implemented it myself; it's not too complicated. However, when we upgrade to Java 6, I will have to replace calls to my implementation with calls to `ServiceLoader`. I could have defined a little bridge between the app and the loader, but I only use it in a few places, an... | `javax.imageio.spi.ServiceRegistry` is the equivalent with prior Java versions. It's available since Java 1.4.
It does not look like a general utility class, but it is. It's even a bit more powerful than `ServiceLoader`, as it allows some control over the order of the returned providers and direct access to the regist... | Is something similar to ServiceLoader in Java 1.5? | [
"",
"java",
"reflection",
"plugins",
"service",
""
] |
What arbitrary-precision integers (and or rationals) library are there for compilers running on Microsoft Windows, and which would you recommend?
Please state license type / cost, supported compilers (i.e. GCC and or VC++) for the library. | [GMP](http://gmplib.org/).
LGPL. Standard download from official website is designed for GCC. VC++ port is available from [here](http://gladman.plushost.co.uk/oldsite/computing/gmp4win.php). | I have not used it, so I'm pointing you here blind:
LibTomMath by Tom St Denis: <http://libtom.org/>
Public Domain license. Website mentions that the library builds out of the box with GCC 2.95 [and up] as well as Visual C++ v6.00 [with SP5] without configuration.
A companion book is available: [http://www.amazon.co... | C or C++ BigInt library on Microsoft Windows | [
"",
"c++",
"c",
"windows",
"biginteger",
""
] |
I've been tasked with the awesome job of generating a look-up table for our application culture information. The columns I need to generate data for are:
* Dot Net Code
* Version
* Culture Name
* Country Name
* Language Name
* Java Country Code
* Java Language Code
* Iso Country Code
* Iso Language Code
I have found ... | Java uses the 2-letter ISO country and language codes. I recommend getting rid of the "Java Country Code" and "Java Language Code" fields in your lookup table, since they would be redundant.
I assume that wherever you get your ISO [country](http://en.wikipedia.org/wiki/ISO_3166-1_alpha-2) and [language](http://www.loc... | That's strange, the last time I visited this page, someone had beaten me to posting the links to the Java references for Localization.
However, since their post is gone, here's what I was writing before they beat me to it.
Java uses two ISO standards for localization with [java,util.Locale](http://java.sun.com/javase... | Dot Net and Java Culture Codes | [
"",
"java",
".net",
"globalization",
"culture",
""
] |
I'm working the the image upload piece of the [FCKEditor](http://www.fckeditor.net/) and I've got the uploading working properly but am stuck with the server file browser.
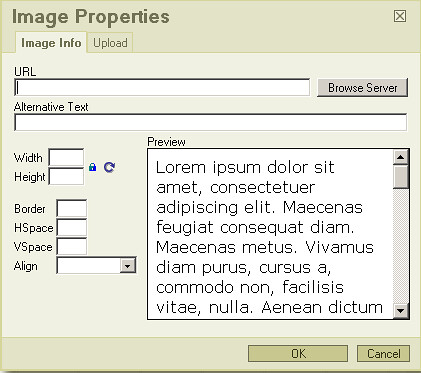
You can see in the dialog above has a **B... | Please read [this post of mine](http://www.fckeditor.net/forums/viewtopic.php?f=6&t=10432) on FCKeditor forums. Are you having the same problem I had? | Is it this?
ImageBrowserURL
(string) Sets the URL of the page called when the user clicks the "Browse Server" button in the "Image" dialog window.
In this way, you can create your custom Image Browser that is well integrated with your system.
See <http://www.clinicaestet.ro/FCKeditor/_docs/contents/012.html> | How to set the default location of the FCKEditor file browser? | [
"",
"php",
"fckeditor",
""
] |
In some of our projects, there's an class hierarchy that adds more parameters as it goes down the chain. At the bottom, some of the classes can have up to 30 parameters, 28 of which are just being passed into the super constructor.
I'll acknowledge that using automated DI through something like Guice would be nice, bu... | The Builder Design Pattern might help. Consider the following example
```
public class StudentBuilder
{
private String _name;
private int _age = 14; // this has a default
private String _motto = ""; // most students don't have one
public StudentBuilder() { }
public Student buildStudent()
... | Can you encapsulate related parameters inside an object?
e.g., if parameters are like
```
MyClass(String house, String street, String town, String postcode, String country, int foo, double bar) {
super(String house, String street, String town, String postcode, String country);
this.foo = foo;
this.bar = bar;
``... | Managing constructors with many parameters in Java | [
"",
"java",
""
] |
After using [`array_unique`](http://us.php.net/array_unique), an array without the duplicate values is removed. However, it appears that the keys are also removed, which leaves gaps in an array with numerical indexes (although is fine for an associative array). If I iterate using a for loop, I have to account for the m... | `$foo = array_values($foo);` will re-number an array for you | Instead of using for loops it sounds like you should use foreach loops. Apparently you don't care about indexes anyway since you are renumbering them.
This loop:
```
for ($i = 0; $i < $loopSize; $i++)
{
process($myArray[$i]);
}
```
turns into
```
foreach($myArray as $key=> $value)
{
process($value);
/** or ... | Loop an array which has gapped numeric keys | [
"",
"php",
"arrays",
"loops",
"key",
""
] |
I'm writing an app in C# (.net 3.5) and I have a question about class design:
I'd like to create a class which accesses a file (read, write) and provides its content to the users (instanciators) of the class. The most common operation on an instance will be to retrieve a certain value from the file. The actual read an... | Firstly, make your class implement an appropriate interface. That way, clients can test their behaviour without needing real files at all.
Testing the thread safety is hard - I've never seen anything which is really useful on that front, though that's not to say the tools aren't out there.
For unit testing your class... | Use [ReaderWriterLock](http://msdn.microsoft.com/en-us/library/system.threading.readerwriterlock.aspx), which I think fits the problem description.
Following is a quick and dirty implementation. Acquiring locks could be smarter, like trying multiple times before bailout etc. But you get the point:
```
public class My... | Class design: Wrapping up a datafile into a class with respect to thread-safety and testability | [
"",
"c#",
"class",
"thread-safety",
"design-patterns",
""
] |
I'm trying to read the contents of the clipboard using JavaScript. With Internet Explorer it's possible using the function
```
window.clipboardData.getData("Text")
```
Is there a similar way of reading the clipboard in Firefox, Safari and Chrome? | Safari supports reading the clipboard during `onpaste` events:
[Information](http://developer.apple.com/documentation/AppleApplications/Conceptual/SafariJSProgTopics/Tasks/CopyAndPaste.html#//apple_ref/doc/uid/30001234-176911)
You want to do something like:
```
someDomNode.onpaste = function(e) {
var paste = e.c... | Online Spreadsheets hook `Ctrl`+`C`, `Ctrl`+`V` events and transfer focus to a hidden TextArea control and either set it contents to desired new clipboard contents for copy or read its contents after the event had finished for paste. | Is it possible to read the clipboard in Firefox, Safari and Chrome using JavaScript? | [
"",
"javascript",
"cross-browser",
"clipboard",
""
] |
I'd like to have a page in php that normally displays information based on the GET request sent to it. However, I'd like for it to also be able to process certain POST requests. So, how can I tell if any data was sent by POST so I can act on it? | Use `$_SERVER['REQUEST_METHOD']` to determine whether your page was accessed via a GET or POST request.
If it was accessed via post then check for any variables in `$_POST` to process. | If you want to pass the same variables by both POST and GET then you can always use REQUEST which contains parameters from both POST and GET. However, this is generally seen as a security vulnerability as it means that variables can be more easily spoofed.
If you want to test on whether the request was sent POST or GE... | How do I tell for a php page if someone came by POST or GET? | [
"",
"php",
"http",
""
] |
I'm currently looking into options for creating a client API for a RESTfull application. Up until now we have had WCF services to allow all application to connect to the Business Layer and we're growing dissatisfied with it.
We already have most of the infrastructure in place for the web (html and json requests) but w... | A good rest client API is a set of wrappers around curl, wget, or your language specific HTTP libraries. You might need some extra methods or functions to deal with the specifics of your application as well (i.e. specialized XML/JSON parsing), but that should be about it. | In the REST architecture:
* The resources link to their description documents, if they have one, not the other way around.
* The resources are not complex (not RPC like), thus there is usually no need for a description document.
* Loose Coupling is king; contracts are both unnecessary and harmful.
* Resources link to ... | Creating a REST client API | [
"",
"c#",
"asp.net-mvc",
"rest",
"wadl",
""
] |
So I know it's considered somewhat good practice to always include curly braces for if, for, etc even though they're optional if there is only one following statement, for the reason that it's easier to accidentally do something like:
```
if(something == true)
DoSomething();
DoSomethingElse();
```
when quickl... | When I come across a one-line if statement, I usually skip the curlys and keep everything on the same line:
```
if (something == true) DoSomething();
```
It's quick, easy, and saves space. | Instead of:
```
if(something == true)
{ DoSomething(); }
```
Do this:
```
if(something == true) { DoSomething(); }
``` | Would it be bad form to put braces on the same line as the statement for single line "if" statements? | [
"",
"c#",
"language-agnostic",
"coding-style",
""
] |
I have a large project for which I am attempting to use TDD.
I am using [Tut](http://tut-framework.sourceforge.net/) as my test framework, which has its flaws but is sufficient for what I need.
I need to exploit link time test seams, **each test must be in its own executable**. The project for this executable then lau... | "Is it possible to hide projects from a build and yet still have them build?"
You can make separate solution for test cases.
Then you can set up post build step of your main projects. This post-build should build tests-projects via separate solution and run them. Building test-projects should be done via command line ... | You could try to group your tests into folders (are they called filters?) within your solution in Solution Explorer. This would separate tests from your other projects.
But, otherwise, could you avoid using link time test seams (Yes, I know, its probably too late to suggest this) and use polymorphism to provide your r... | Building and running C++ unit tests in Visual Studio (TDD) | [
"",
"c++",
"visual-studio",
"unit-testing",
"visual-studio-2005",
"tdd",
""
] |
I'm using a web service that returns a dataset. in this dataset there are 5 table, let's say table A, B, C, D, E. I use table A.
So
```
DataTable dt = new DataTable()
dt = dataset.Table["A"]
```
Now in this datatable there are columns a1,a2,a3,a4,a5,a6,a7.
Let's say I only want to get columns a3 and a4 then bind it... | Ignore the fact that you have more data than you need. Set `AutoGenerateColumns` to `false`. Create `BoundColumns` for `a3` and `a4`. | I'd recommend reading [this](https://web.archive.org/web/20210608183626/https://aspnet.4guysfromrolla.com/articles/040502-1.aspx) article from 4GuysFromRolla for anyone who needs a good understanding of the `DataGrid` Web Control.
Note: Since this question is already answered. I want to clarify what needs to be done, ... | How do I display only certain columns from a data table? | [
"",
"c#",
".net",
"datagrid",
"datatable",
"dataset",
""
] |
I have a form that kicks off a Response.Redirect to download a file once complete. I also want to hide the form and show a 'thank you' panel before the redirect takes place, however it seems the asp.net engine just does the redirect without doing the 2 tasks before in the following code:
```
if (success)
... | ```
if (success)
{
lblSuccessMessage.Text = _successMessage;
showMessage(true);
}
else
{
lblSuccessMessage.Text = _failureMessage;
showMessage(false);
... | You need some client side code to do the redirect.
My preference would be to embed some javascript to do the redirect.
So, hide the form, display the message, and (at the crudest level) use a literal control to add some text like this to the page.
```
<script>
location.href = "http://otherServerName/fileToDownlo... | How to Show/Hide Panels before executing Response.Redirect | [
"",
"c#",
"asp.net",
"redirect",
"response.redirect",
""
] |
I'm using SQLAlchemy 0.5rc, and I'd like to add an automatic filter to a relation, so that every time it tries to fetch records for that relation, it ignores the "remote" ones if they're flagged as "logically\_deleted" (a boolean field of the child table)
For example, if an object "parent" has a "children" relation th... | The and\_() function is the correct way to do logical conjunctions in SQLAlchemy, together with the & operator, but be careful with the latter as it has surprising precedence rules, i.e. higher precedence than comparison operators.
You could also use a string as a primary join with the text() constructor, but that wil... | > but is there a way to use a string as primaryjoin instead?
You can use the following:
```
children = relationship("Children", primaryjoin="and_(Parent.id==Children.parent_id, Children.logically_deleted==False)"
```
This worked for me! | How to add an automatic filter to a relation with SQLAlchemy? | [
"",
"python",
"sqlalchemy",
""
] |
What is the correct (most efficient) way to define the `main()` function in C and C++ — `int main()` or `void main()` — and why? And how about the arguments?
If `int main()` then `return 1` or `return 0`? | The return value for `main` indicates how the program exited. Normal exit is represented by a 0 return value from `main`. Abnormal exit is signaled by a non-zero return, but there is no standard for how non-zero codes are interpreted. As noted by others, `void main()` is prohibited by the C++ standard and should not be... | The accepted answer appears to be targetted for C++, so I thought I'd add an answer that pertains to C, and this differs in a few ways. There were also some changes made between ISO/IEC 9899:1989 (C90) and ISO/IEC 9899:1999 (C99).
`main()` should be declared as either:
```
int main(void)
int main(int argc, char **arg... | What should main() return in C and C++? | [
"",
"c++",
"c",
"return-value",
"program-entry-point",
"return-type",
""
] |
How can I check if a file uploaded by a user is a real jpg file in Python (Google App Engine)?
This is how far I got by now:
Script receives image via HTML Form Post and is processed by the following code
```
...
incomming_image = self.request.get("img")
image = db.Blob(incomming_image)
...
```
I found mimetypes.gu... | If you need more than looking at extension, one way would be to read the JPEG header, and check that it matches valid data. The format for this is:
```
Start Marker | JFIF Marker | Header Length | Identifier
0xff, 0xd8 | 0xff, 0xe0 | 2-bytes | "JFIF\0"
```
so a quick recogniser would be:
```
def is_jpg(fi... | No need to use and install the PIL lybrary for this, there is the imghdr standard module exactly fited for this sort of usage.
See <http://docs.python.org/library/imghdr.html>
```
import imghdr
image_type = imghdr.what(filename)
if not image_type:
print "error"
else:
print image_type
```
As you have an imag... | Python: Check if uploaded file is jpg | [
"",
"python",
"google-app-engine",
"image",
"image-processing",
"mime",
""
] |
I want to get the size of a drive (or UNC path pointing to a partition would be nice, but not required), as well as free space for said drive (or UNC path). This doesn't need to work cross platform; only in Windows.
I know it's easy to do in Java 6, but that's not an option; I'm stuck with Java 5.
I can get the free ... | One way to do it would be to use fsutil on the command line. It returns something like this:
```
D:\>fsutil fsinfo ntfsinfo c:
NTFS Volume Serial Number : 0xd49cf9cf9cf9ac5c
Version : 3.1
Number Sectors : 0x0000000004a813ff
Total Clusters : 0x000000000095... | You could do this pretty easily using a JNI call if you are comfortable with that...
If you want a pre-packaged library that you can use with JDK1.5, take a look at the [Apache FileSystemUtils](http://commons.apache.org/io/api-release/index.html?org/apache/commons/io/FileSystemUtils.html)
This just wraps the system c... | Get Drive Size in Java 5 | [
"",
"java",
"size",
"drive",
""
] |
I have two XML files with two different XSD schemas and different namespaces. They have both an identical substructure. And now i need to copy that node (and all childs) from one XML document to the other one.
Clone would do, if the namespaces were the same. Is there a nice way to do it?
(The substructure will change ... | Basically, you need an XSL transformation that creates new elements with equal names, but a different namespace.
Consider the following input XML:
```
<?xml version="1.0" encoding="UTF-8"?>
<test xmlns="http://tempuri.org/ns_old">
<child attrib="value">text</child>
</test>
```
Now you need a template that says "... | Not sure if this applies, but I've done something similar working with two xml docs in vb.net:
```
Private Shared Sub CopyElement(ByVal FromE As Xml.XmlElement, ByVal ToE As Xml.XmlElement)
CopyElement(FromE, ToE, Nothing)
End Sub
Private Shared Sub CopyElement(ByVal FromE As Xml.XmlElement, ByVal ToE As Xml.XmlEl... | How to copy a structure of nodes from one xml to an other with a different namespace? | [
"",
"c#",
"xml",
""
] |
What steps do I need to take to get HTML documentation automatically building via the build step in Visual Studio? I have all the comments in place and the comments.xml file being generated, and Sandcastle installed. I just need to know what to add to the post-build step in order to generate the docs. | Some changes have been made since this question was asked. Sandcastle no longer includes `SandcastleBuilderConsole.exe`. Instead it uses plain old `MSBuild.exe`.
To integrate this with visual studio here is what I did:
Place this in your Post-build event:
```
IF "$(ConfigurationName)"=="Release" Goto Exit
"$(System... | I recommend you install Sandcastle Help File Builder from [Codeplex](http://www.codeplex.com/SHFB).
You can run this from the command line, e.g. from a Post-Build event. The simplest command line is:
```
<install-path>\SandcastleBuilderConsole.exe ProjectName.shfb
```
Sandcastle is very slow, so I only run it for Re... | Generate html documentation automatically during a build with Sandcastle | [
"",
"c#",
"visual-studio-2008",
"documentation",
"sandcastle",
""
] |
I am writing controls that work nice with JavaScript, but they have to work even without it. Now testing with selenium works fine for me. But all test with disabled JavaScript (in my browser) won't run with selenium. Is there a way to do automated test for this purpose? | [WWW::Mechanize](http://search.cpan.org/perldoc?WWW::Mechanize) and [Test::WWW::Mechanize](http://search.cpan.org/perldoc?Test::WWW::Mechanize) are two Perl modules to do exactly that.
```
use Test::More tests => 5;
use Test::WWW::Mechanize;
my $mech = Test::WWW::Mechanize->new;
# Test you can get http://petdance.co... | I don't know Selenium, but with the NoScript Firefox extension, you can disable scripts on a per-domain basis. So could you use that to allow Selenium but disable your page's scripts? | How can I do automated tests on non JavaScript applications? | [
"",
"javascript",
"testing",
"selenium",
""
] |
I would like to create a trivial one-off Python object to hold some command-line options. I would like to do something like this:
```
options = ??????
options.VERBOSE = True
options.IGNORE_WARNINGS = False
# Then, elsewhere in the code...
if options.VERBOSE:
...
```
Of course I could use a dictionary, but `optio... | Given your requirements, I'd say the custom class is your best bet:
```
class options(object):
VERBOSE = True
IGNORE_WARNINGS = True
if options.VERBOSE:
# ...
```
To be complete, another approach would be using a separate module, i.e. `options.py` to encapsulate your option defaults.
`options.py`:
```
... | The [collections module](http://docs.python.org/library/collections.html) has grown a *namedtuple* function in 2.6:
```
import collections
opt=collections.namedtuple('options','VERBOSE IGNORE_WARNINGS')
myoptions=opt(True, False)
>>> myoptions
options(VERBOSE=True, IGNORE_WARNINGS=False)
>>> myoptions.VERBOSE
True
``... | What is an easy way to create a trivial one-off Python object? | [
"",
"python",
""
] |
Is this doable in either IE7 or Firefox? | You can do it in both - get the position relative to the document, then subtract the scroll position.
```
var e = document.getElementById('xxx');
var offset = {x:0,y:0};
while (e)
{
offset.x += e.offsetLeft;
offset.y += e.offsetTop;
e = e.offsetParent;
}
if (document.documentElement && (document.documentE... | [Pasting from the answer I gave [here](https://stackoverflow.com/questions/1350581/how-to-get-an-elements-top-position-relative-to-the-browsers-window/18794913#18794913)]
The native `getBoundingClientRect()` method has been around for quite a while now, and does exactly what the question asks for. Plus it is supported... | Is it possible to get the position of div within the browser viewport? Not within the document. Within the window | [
"",
"javascript",
"html",
"css",
""
] |
I'm learning C++ and writing little programs as I go along. The following is one such program:
```
// This program is intended to take any integer and convert to the
// corresponding signed char.
#include <iostream>
int main()
{
signed char sch = 0;
int n = 0;
while(true){
std::cin >> n;
sch = n;
s... | Basically your `cin` stream is in a fail state and thus returns immediately when you try to read it. Rewrite your example like this:
```
#include <iostream>
int main()
{
signed char sch = 0;
int n = 0;
while(std::cin >> n){
sch = n;
std::cout << n << " --> " << sch << std::endl;
}
}
```
`cin >> n` wi... | Yes, Evan Teran pointed out most things already. One thing i want to add (since i cannot comment his comment yet :)) is that you must put the call to istream::clear *before* the call to istream::ignore. The reason is that istream::ignore likewise will just refuse to do anything if the stream is still in the fail state. | infinite loop in c++ | [
"",
"c++",
"stream",
"infinite-loop",
"biginteger",
"largenumber",
""
] |
What would be the best hashing algorithm if we had the following priorities (in that order):
1. Minimal hash collisions
2. Performance
It doesn't have to be secure. Basically I'm trying to create an index based on a combination of properties of some objects. **All the properties are strings**.
Any references to c# i... | Forget about the term "best". No matter which hash algorithm anyone might come up with, unless you have a very limited set of data that needs to be hashed, every algorithm that performs very well on average can become completely useless if only being fed with the right (or from your perspective "wrong") data.
Instead ... | As [Nigel Campbell](https://stackoverflow.com/questions/251346/best-hashing-algorithm-in-terms-of-hash-collisions-and-performance#251361) indicated, there's no such thing as the 'best' hash function, as it depends on the data characteristics of what you're hashing as well as whether or not you need cryptographic qualit... | Best hashing algorithm in terms of hash collisions and performance for strings | [
"",
"c#",
"algorithm",
"hash",
""
] |
I use LINQ to Objects instructions on an ordered array.
Which operations shouldn't I do to be sure the order of the array is not changed? | I examined the methods of [System.Linq.Enumerable](http://msdn.microsoft.com/en-us/library/system.linq.enumerable_methods.aspx), discarding any that returned non-IEnumerable results. I checked the remarks of each to determine how the order of the result would differ from order of the source.
Preserves Order Absolutely... | Are you actually talking about SQL, or about arrays? To put it another way, are you using LINQ to SQL or LINQ to Objects?
The LINQ to Objects operators don't actually change their original data source - they build sequences which are effectively backed by the data source. The only operations which change the ordering ... | Preserving order with LINQ | [
"",
"c#",
"arrays",
"linq",
"sorting",
"data-structures",
""
] |
I just realized that in some place in my code I have the return statement inside the lock and sometime outside. Which one is the best?
1)
```
void example()
{
lock (mutex)
{
//...
}
return myData;
}
```
2)
```
void example()
{
lock (mutex)
{
//...
return myData;
}
}
```
Whi... | Essentially, which-ever makes the code simpler. Single point of exit is a nice ideal, but I wouldn't bend the code out of shape just to achieve it... And if the alternative is declaring a local variable (outside the lock), initializing it (inside the lock) and then returning it (outside the lock), then I'd say that a s... | It doesn't make any difference; they're both translated to the same thing by the compiler.
To clarify, either is effectively translated to something with the following semantics:
```
T myData;
Monitor.Enter(mutex)
try
{
myData= // something
}
finally
{
Monitor.Exit(mutex);
}
return myData;
``` | Should a return statement be inside or outside a lock? | [
"",
"c#",
".net",
"multithreading",
"mutex",
""
] |
I am using the ReportViewer control from Visual Studio 2008 in Local Mode with objects as the data source. My classes are mapped to data tables in my database. In the objects, it loads related objects as needed. So it leaves the reference null until you try to use the property, then it tries to load it from the databas... | I've found the solution. You specify System.Security.Policy.Evidence of you executing assembly (or one that has sufficient rights) to the LocalReport for use during execution.
```
reportViewer.LocalReport.ExecuteReportInCurrentAppDomain(System.Reflection.Assembly.GetExecutingAssembly().Evidence);
``` | In addition to the answer of CuppM.
The `ExecuteReportInCurrentAppDomain` method is deprecated since .NET4, and `LocalReport.SetBasePermissionsForSandboxAppDomain` should be used instead, as ReportViewer is now *always* executed in sandboxed domain:
```
PermissionSet permissions = new PermissionSet(PermissionState.Non... | Report Viewer - Request for the permission of type SqlClientPermission failed | [
"",
"c#",
"winforms",
"visual-studio-2008",
"reporting-services",
"sqlclient",
""
] |
Could someone please explain the best way to connect to an Interbase 7.1 database using .NET/C#?
The application will be installed on many end user computers so the less "add-ons" that I will have to package with my application the better. | CodeGear offers a free ADO.NET 2.0 driver for registered users of InterBase here:
<http://cc.embarcadero.com/item/25497>
Note that "registered users of InterBase" includes the free InterBase 2007 Developers Edition. The download says that it's for 2007, but it works fine with InterBase 7, and the InterBase team at Co... | Check this providers:
* [Interbase and Firebird Developer's for Visual Studio .Net](http://www.ibprovider.com/eng/documentation/firebird_adonet/firebird_adonet.html)
* [Firebird .NET Data Provider](http://www.firebirdsql.org/index.php?op=files&id=netprovider)
* [FireBird - InterBase .NET (Mono) Providers](http://www.m... | Best way to connect to Interbase 7.1 using .NET C# | [
"",
"c#",
".net",
"interbase",
""
] |
Ok, so I want to get a webapp running in tomcat (5.5) to run behind apache 2 (2.2.3 to be precise) serving from the root of the site (i.e. without the context), with static content being served via apache.
So if the app is running under "`/myapp`" on tomcat I want to use apache (plus `mod_rewrite`) to make it behave a... | Managed to get this working in the end. It appears that I need to set a JkOption to:
```
JkOptions +ForwardURICompat
```
And then `mod_jk` looks at the rewritten URL. Must admit not 100% sure quite why this works, but I believe it's reverting to an older form of behaviour. If anyone can tell me a better/more corr... | May be better use Apache for proxy instead of mod\_jk.
Something like this:
ProxyPass /static/ <http://localhost:8080/myapp/static/> | How do I get tomcat 5.5 to run behind apache 2 with mod_rewrite passing through requests to mod_jk and stripping app context? | [
"",
"java",
"apache",
"tomcat",
"mod-rewrite",
"mod-jk",
""
] |
I'm after some good tips for fluent interfaces in C#. I'm just learning about it myself but keen to hear what others think outside of the articles I am reading. In particular I'm after:
1. when is fluent too much?
2. are there any fluent patterns?
3. what is in C# that makes fluent interfaces more fluent (e.g. extensi... | On your 4th point;
Yes I think that a complex fluent interface can still be fluent.
I think fluent interfaces are somewhat of a compromise. (although a good one!) There has been much research into using natural language for programming and generally natural language isn't precise enough to express programs.
Fluent i... | The single biggest challenge I have experienced as a consumer of fluent interfaces is that most of them aren't really fluent intefaces -- instead they are really instances of what I tend to refer to as 'legible interfaces'.
A fluent interface implies that its primary goal is to make it easy to SPEAK it whereas a legib... | Tips for writing fluent interfaces in C# 3 | [
"",
"c#",
"design-patterns",
"fluent-interface",
""
] |
I'm using the contentEditable attribute on a DIV element in Firefox 3.03. Setting it to true allows me to edit the text content of the DIV, as expected.
Then, when I set contentEditable to "false", the div is no longer editable, also as expected.
However the flashing caret (text input cursor) remains visible even tho... | I've dealt with this and my workaround is clearing the selection when I disable contentEditable:
```
if ($.browser.mozilla) { // replace with browser detection of your choice
window.getSelection().removeAllRanges();
}
```
I am actually removing the "contenteditable" attribute for browsers other than IE, rather than... | The style attribute `-moz-user-input` can be used in Firefox to get the functionality `contenteditable=false` working.
The value assigned defines if user input is accepted. The possible values are
```
none : The element does not respond to user input.
enabled : The element can accepts user input. This is defau... | Firefox 3.03 and contentEditable | [
"",
"javascript",
"firefox",
""
] |
In Groovy, how do I grab a web page and remove HTML tags, etc., leaving only the document's text? I'd like the results dumped into a collection so I can build a word frequency counter.
Finally, let me mention again that I'd like to do this in Groovy. | Assuming you want to do this with Groovy (guessing based on the groovy tag), your approaches are likely to be either heavily shell-script oriented or using Java libraries. In the case of shell-scripting I would agree with moogs, using Lynx or Elinks is probably the easiest way to go about it. Otherwise have a look at [... | If you want a collection of tokenized words from HTML then can't you just parse it like XML (needs to be valid XML) and grab all of the text between tags? How about something like this:
```
def records = new XmlSlurper().parseText(YOURHTMLSTRING)
def allNodes = records.depthFirst().collect{ it }
def list = []
allNodes... | Strip HTML from a web page and calculate word frequency? | [
"",
"java",
"html",
"groovy",
"html-content-extraction",
"text-extraction",
""
] |
Any GOOD libraries available to access SVN from .net application (using C#). The only 3 I found so far that I will be trying out is:
* [SVN#](http://www.softec.st/en/OpenSource/ClrProjects/SubversionSharp/SubversionSharp.html)
* [SharpSVN](http://sharpsvn.open.collab.net/)
* [NSvn](http://www.hanselman.com/blog/PowerS... | SharpSvn was desiged for .Net 2.0 and Subversion 1.5 and later. It integrates all subversion dependencies in a single set of dll that is directly usable from .Net (XCopy deployable). One of the other strong points of SharpSvn is that it hides all memory management and transforms Subversion errors in exceptions, and mor... | I used SharpSvn. It was easy to integrate and works well for me. If you need some sample code have a look at this project <https://github.com/bhank/SVNCompleteSync>. | i have to access/commit/update SVN repository in WPF application using SVN API or libraries | [
"",
"c#",
".net",
"svn",
""
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.