

task_categories:
- image-text-to-text
- text-to-image
license: other
language:
- en
tags:
- multimodal
- benchmark
- unified-models
RealUnify: Do Unified Models Truly Benefit from Unification? A Comprehensive Benchmark
Paper: https://huggingface.co/papers/2509.24897 | Code: https://github.com/FrankYang-17/RealUnify
📢 News
- [2025/09/29] We are proud to introduce RealUnify, a comprehensive benchmark designed to evaluate bidirectional capability synergy. 🎉
- We aim to raise a key question through RealUnify: **Do Unified Models Truly Benefit from Unification?**💥
Abstract
The integration of visual understanding and generation into unified multimodal models represents a significant stride toward general-purpose AI. However, a fundamental question remains unanswered by existing benchmarks: does this architectural unification actually enable synergetic interaction between the constituent capabilities? Existing evaluation paradigms, which primarily assess understanding and generation in isolation, are insufficient for determining whether a unified model can leverage its understanding to enhance its generation, or use generative simulation to facilitate deeper comprehension. To address this critical gap, we introduce RealUnify, a benchmark specifically designed to evaluate bidirectional capability synergy. RealUnify comprises 1,000 meticulously human-annotated instances spanning 10 categories and 32 subtasks. It is structured around two core axes: 1) Understanding Enhances Generation, which requires reasoning (e.g., commonsense, logic) to guide image generation, and 2) Generation Enhances Understanding, which necessitates mental simulation or reconstruction (e.g., of transformed or disordered visual inputs) to solve reasoning tasks. A key contribution is our dual-evaluation protocol, which combines direct end-to-end assessment with a diagnostic stepwise evaluation that decomposes tasks into distinct understanding and generation phases. This protocol allows us to precisely discern whether performance bottlenecks stem from deficiencies in core abilities or from a failure to integrate them. Through large-scale evaluations of 12 leading unified models and 6 specialized baselines, we find that current unified models still struggle to achieve effective synergy, indicating that architectural unification alone is insufficient. These results highlight the need for new training strategies and inductive biases to fully unlock the potential of unified modeling.
📌 Introduction
- The integration of visual understanding and generation into unified multimodal models represents a significant stride toward general-purpose AI. However, a fundamental question remains unanswered by existing benchmarks: does this architectural unification actually enable synergetic interaction between the constituent capabilities?
- Existing evaluation paradigms, which primarily assess understanding and generation in isolation, are insufficient for determining whether a unified model can leverage its understanding to enhance its generation, or use generative simulation to facilitate deeper comprehension.
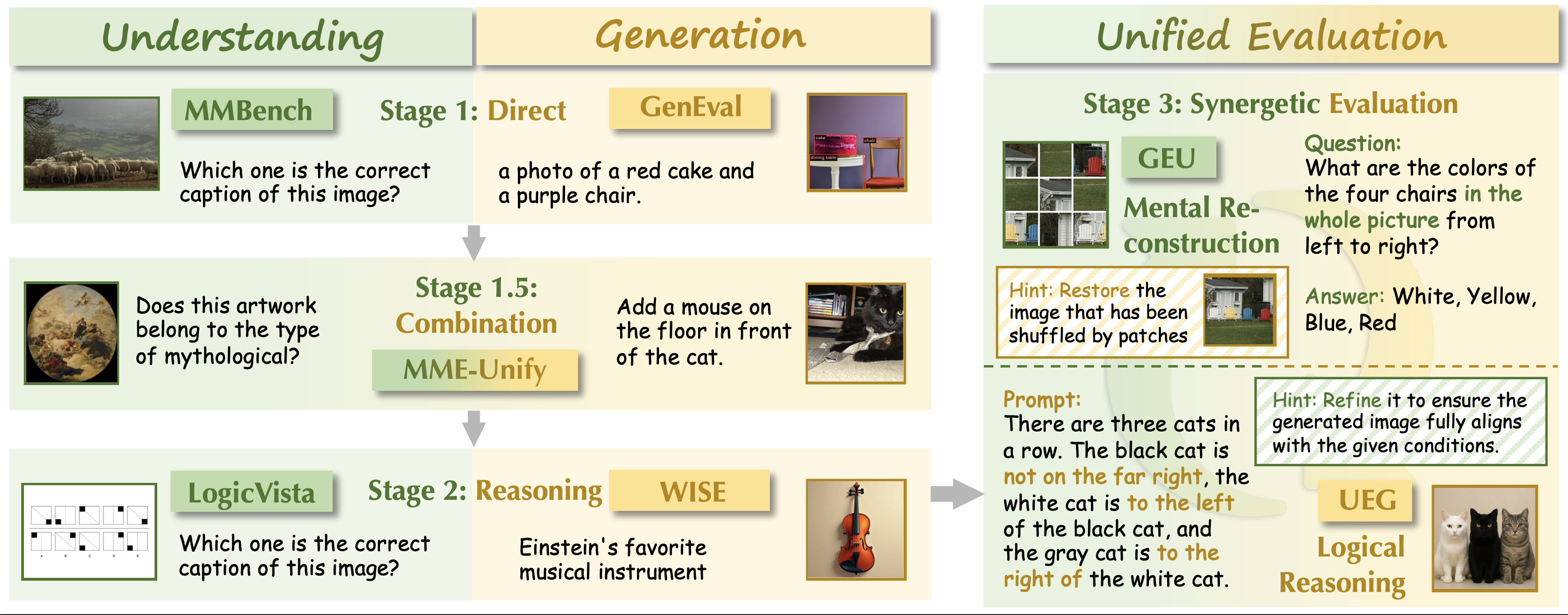
- To address this critical gap, we introduce RealUnify, a benchmark specifically designed to evaluate bidirectional capability synergy. RealUnify comprises 1,000 meticulously human-annotated instances spanning 10 categories and 32 subtasks.
- It is structured around two core axes: 1) Understanding Enhances Generation (UEG), which requires reasoning (e.g., commonsense, logic) to guide image generation, and 2) Generation Enhances Understanding (GEU), which necessitates mental simulation or reconstruction (e.g., of transformed or disordered visual inputs) to solve reasoning tasks.
- A key contribution is our dual-evaluation protocol, which combines direct end-to-end assessment with a diagnostic stepwise evaluation that decomposes tasks into distinct understanding and generation phases. This protocol allows us to precisely discern whether performance bottlenecks stem from deficiencies in core abilities or from a failure to integrate them.
🔍 Benchmark Overview

✨ Sample Usage (Evaluation Pipeline)
We support two evaluation methods: direct evaluation and stepwise evaluation.
Before evaluation, please download the dataset files from our Hugging Face repository to your local path.
📍 Direct Evaluation
Understanding Ehances Generation (UEG) Tasks
- For the UEG task, please use
UEG_direct.jsonas the dataset for evaluation.- The prompts for image generation are stored in the
promptfield. Please save the path to the generated image in thegenerated_imagefield.
- The prompts for image generation are stored in the
- After obtaining all the generated images and saving the JSON file, please use
eval/eval_generation.pyfor evaluation.- Please add the model names and their corresponding result JSON files to
task_json_listineval/eval_generation.py, and set the directory for saving the evaluation results asRES_JSON_DIR.
- Please add the model names and their corresponding result JSON files to
- For the UEG task, please use
Generation Enhances Understanding (GEU) Tasks
- For the GEU task, please use
GEU_direct.jsonas the dataset for evaluation.- The prompts for visual understanding are stored in the
evaluation_promptfield. Please save the response of model in theresponsefield.
- The prompts for visual understanding are stored in the
- After obtaining all the responses and saving the JSON file, please use
eval/eval_understanding.pyfor evaluation.- Please add the model names and their corresponding result JSON files to
task_json_listineval/eval_understanding.py.
- Please add the model names and their corresponding result JSON files to
- For the GEU task, please use
📍 Stepwise Evaluation
- Understanding Ehances Generation (UEG) Tasks
- For the UEG task, please use
UEG_step.jsonas the dataset for evaluation.- The prompts for prompt refine (understanding) are stored in the
new_promptfield. Please save the response of model in theresponsefield.
- The prompts for prompt refine (understanding) are stored in the
- After obtaining all the responses and saving the JSON file, please use
responseas the prompt for image generation. Please save the path to the generated image in thegenerated_imagefield. - Please add the model names and their corresponding result JSON files to
task_json_listineval/eval_generation.py, and set the directory for saving the evaluation results asRES_JSON_DIR.
- For the UEG task, please use
- Generation Enhances Understanding (GEU) Tasks
- For the GEU task, please use
GEU_step.jsonas the dataset for evaluation.- The prompts for image manipulation (editing) are stored in the
edit_promptfield. Please save the path to the generated image in theedit_imagefield.
- The prompts for image manipulation (editing) are stored in the
- After obtaining all the edited images and saving the JSON file, please use
edit_imageas the input image for visual understanding. Please save the response of model in theresponsefield. - Please add the model names and their corresponding result JSON files to
task_json_listineval/eval_understanding.py.
- For the GEU task, please use
💡 Representive Examples of Each Task
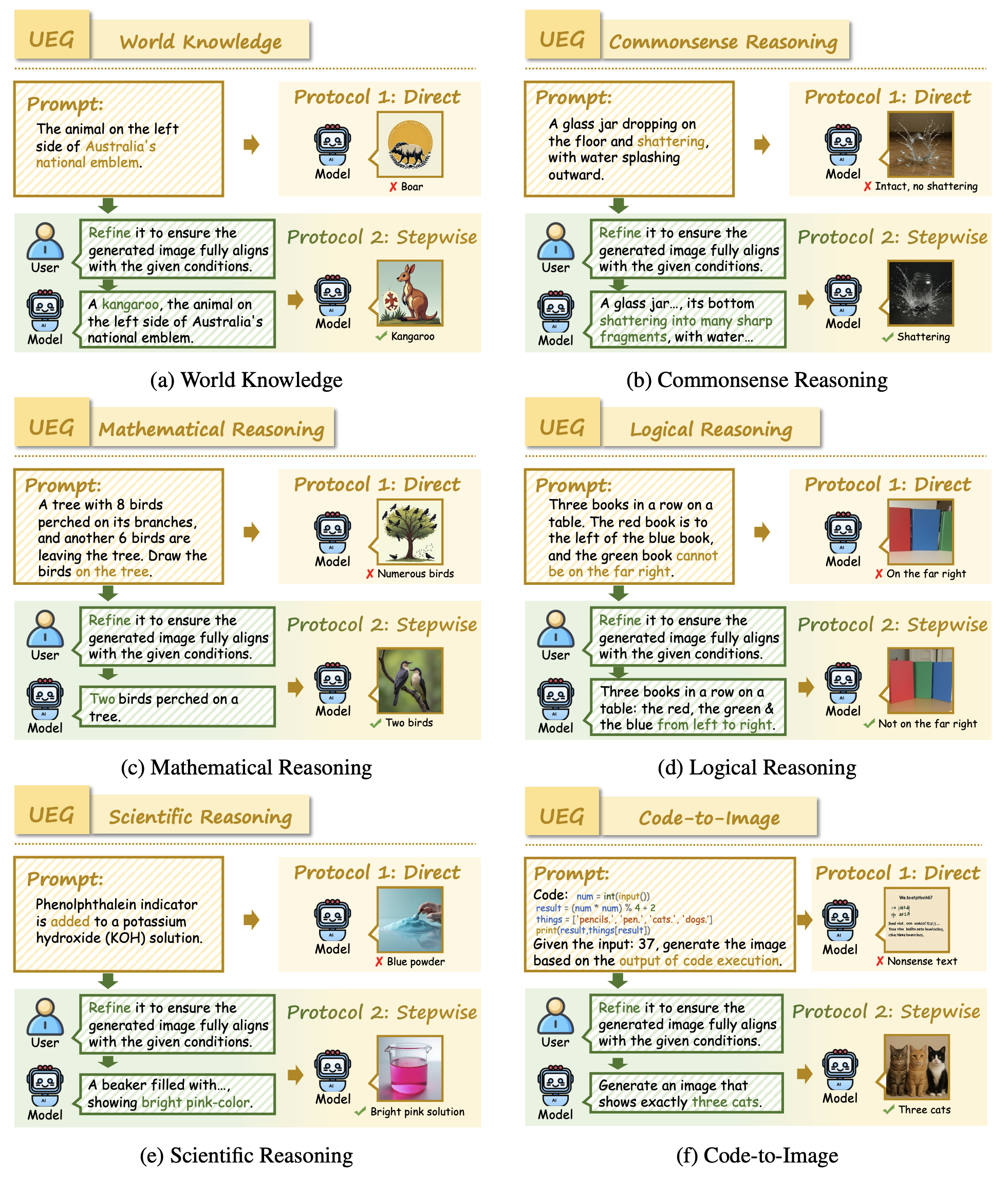
🔍 Examples of Understanding Enhances Generation (UEG) tasks in RealUnify.
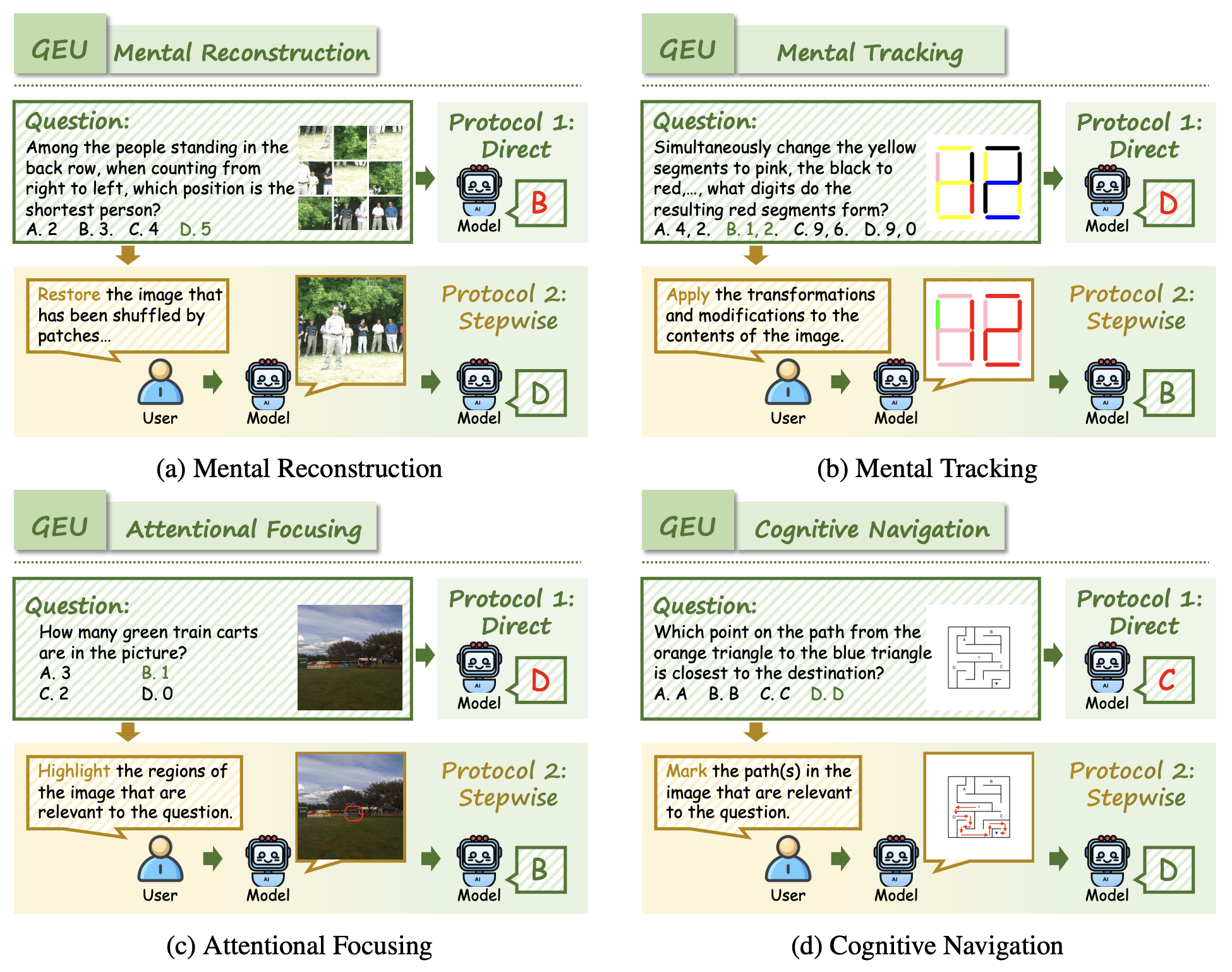
🔍 Examples of Generation Enhances Understanding (GEU) tasks in RealUnify.
🔖 Dataset License
License:
RealUnify is only used for academic research. Commercial use in any form is prohibited.
The copyright of all (generated) images belongs to the image/model owners.
If there is any infringement in RealUnify, please email frankyang1517@gmail.com and we will remove it immediately.
Without prior approval, you cannot distribute, publish, copy, disseminate, or modify RealUnify in whole or in part.
You must strictly comply with the above restrictions.
Please send an email to frankyang1517@gmail.com. 🌟
📚 Citation
@misc{shi2025realunifyunifiedmodelstruly,
title={RealUnify: Do Unified Models Truly Benefit from Unification? A Comprehensive Benchmark},
author={Yang Shi and Yuhao Dong and Yue Ding and Yuran Wang and Xuanyu Zhu and Sheng Zhou and Wenting Liu and Haochen Tian and Rundong Wang and Huanqian Wang and Zuyan Liu and Bohan Zeng and Ruizhe Chen and Qixun Wang and Zhuoran Zhang and Xinlong Chen and Chengzhuo Tong and Bozhou Li and Chaoyou Fu and Qiang Liu and Haotian Wang and Wenjing Yang and Yuanxing Zhang and Pengfei Wan and Yi-Fan Zhang and Ziwei Liu},
year={2025},
eprint={2509.24897},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2509.24897},
}