
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.83B | node_id stringlengths 18 32 | number int64 1 6.09k | title stringlengths 1 290 | labels list | state stringclasses 2
values | locked bool 1
class | milestone dict | comments int64 0 54 | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | closed_at stringlengths 20 20 ⌀ | active_lock_reason null | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 3
values | draft bool 2
classes | pull_request dict | is_pull_request bool 2
classes | comments_text list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2111 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2111/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2111/comments | https://api.github.com/repos/huggingface/datasets/issues/2111/events | https://github.com/huggingface/datasets/pull/2111 | 841,082,087 | MDExOlB1bGxSZXF1ZXN0NjAwODY4OTg5 | 2,111 | Compute WER metric iteratively | [] | closed | false | null | 7 | 2021-03-25T16:06:48Z | 2021-04-06T07:20:43Z | 2021-04-06T07:20:43Z | null | Compute WER metric iteratively to avoid MemoryError.
Fix #2078. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2111/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2111/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2111.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2111",
"merged_at": "2021-04-06T07:20:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2111.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"I discussed with Patrick and I think we could have a nice addition: have a parameter `concatenate_texts` that, if `True`, uses the old implementation.\r\n\r\nBy default `concatenate_texts` would be `False`, so that sentences are evaluated independently, and to save resources (the WER computation has a quadratic co... |
https://api.github.com/repos/huggingface/datasets/issues/1125 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1125/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1125/comments | https://api.github.com/repos/huggingface/datasets/issues/1125/events | https://github.com/huggingface/datasets/pull/1125 | 757,194,531 | MDExOlB1bGxSZXF1ZXN0NTMyNjExMDU5 | 1,125 | Add Urdu fake news dataset. | [] | closed | false | null | 3 | 2020-12-04T15:38:17Z | 2020-12-07T03:21:05Z | 2020-12-07T03:21:05Z | null | Added Urdu fake news dataset. More information about the dataset can be found <a href="https://github.com/MaazAmjad/Datasets-for-Urdu-news">here</a>. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1125/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1125/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1125.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1125",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1125.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1125"
} | true | [
"@lhoestq looks like a lot of files were updated... shall I create a new PR?",
"Hi @chaitnayabasava ! you can try rebasing and see if that fixes the number of files changed, otherwise please do open a new PR with only the relevant files and close this one :) ",
"Created a new PR #1230.\r\nclosing this one :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/3315 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3315/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3315/comments | https://api.github.com/repos/huggingface/datasets/issues/3315/events | https://github.com/huggingface/datasets/pull/3315 | 1,061,678,452 | PR_kwDODunzps4u7WpU | 3,315 | Removing query params for dynamic URL caching | [] | closed | false | null | 5 | 2021-11-23T20:24:12Z | 2021-11-25T14:44:32Z | 2021-11-25T14:44:31Z | null | The main use case for this is to make dynamically generated private URLs (like the ones returned by CommonVoice API) compatible with the datasets' caching logic.
Usage example:
```python
import datasets
class CommonVoice(datasets.GeneratorBasedBuilder):
def _info(self):
return datasets.DatasetInfo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3315/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3315/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3315.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3315",
"merged_at": "2021-11-25T14:44:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3315.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"IMO it makes more sense to have `ignore_url_params` as an attribute of `DownloadConfig` to avoid defining a new argument in `DownloadManger`'s methods.",
"@mariosasko that would make sense to me too, but it seems like `DownloadConfig` wasn't intended to be modified from a dataset loading script. @lhoestq wdyt?",... |
https://api.github.com/repos/huggingface/datasets/issues/6075 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6075/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6075/comments | https://api.github.com/repos/huggingface/datasets/issues/6075/events | https://github.com/huggingface/datasets/issues/6075 | 1,822,341,398 | I_kwDODunzps5snrkW | 6,075 | Error loading music files using `load_dataset` | [] | closed | false | null | 2 | 2023-07-26T12:44:05Z | 2023-07-26T13:08:08Z | 2023-07-26T13:08:08Z | null | ### Describe the bug
I tried to load a music file using `datasets.load_dataset()` from the repository - https://huggingface.co/datasets/susnato/pop2piano_real_music_test
I got the following error -
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/susnato/anaconda3/en... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6075/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6075/timeline | null | completed | null | null | false | [
"This code behaves as expected on my local machine or in Colab. Which version of `soundfile` do you have installed? MP3 requires `soundfile>=0.12.1`.",
"I upgraded the `soundfile` and it's working now! \r\nThanks @mariosasko for the help!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2628/comments | https://api.github.com/repos/huggingface/datasets/issues/2628/events | https://github.com/huggingface/datasets/pull/2628 | 941,676,404 | MDExOlB1bGxSZXF1ZXN0Njg3NTE0NzQz | 2,628 | Use ETag of remote data files | [] | closed | false | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/... | 0 | 2021-07-12T05:10:10Z | 2021-07-12T14:08:34Z | 2021-07-12T08:40:07Z | null | Use ETag of remote data files to create config ID.
Related to #2616. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2628/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2628/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2628.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2628",
"merged_at": "2021-07-12T08:40:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2628.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1334 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1334/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1334/comments | https://api.github.com/repos/huggingface/datasets/issues/1334/events | https://github.com/huggingface/datasets/pull/1334 | 759,699,993 | MDExOlB1bGxSZXF1ZXN0NTM0NjU5MDg2 | 1,334 | Add QED Amara Dataset | [] | closed | false | null | 0 | 2020-12-08T19:01:13Z | 2020-12-10T11:17:25Z | 2020-12-10T11:15:57Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1334/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1334/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1334.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1334",
"merged_at": "2020-12-10T11:15:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1334.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] | |
https://api.github.com/repos/huggingface/datasets/issues/31 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/31/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/31/comments | https://api.github.com/repos/huggingface/datasets/issues/31/events | https://github.com/huggingface/datasets/pull/31 | 610,677,641 | MDExOlB1bGxSZXF1ZXN0NDEyMDczNDE4 | 31 | [Circle ci] Install a virtual env before running tests | [] | closed | false | null | 0 | 2020-05-01T10:11:17Z | 2020-05-01T22:06:16Z | 2020-05-01T22:06:15Z | null | Install a virtual env before running tests to not running into sudo issues when dynamically downloading files.
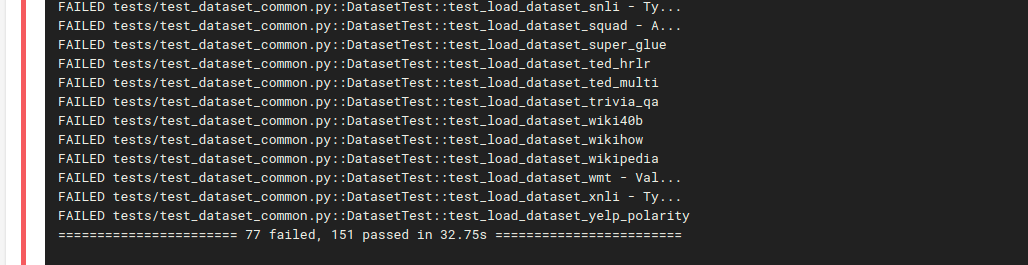
Same number of tests now pass / fail as on my local computer:
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/31/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/31/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/31.diff",
"html_url": "https://github.com/huggingface/datasets/pull/31",
"merged_at": "2020-05-01T22:06:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/31.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/31"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/594/comments | https://api.github.com/repos/huggingface/datasets/issues/594/events | https://github.com/huggingface/datasets/pull/594 | 696,816,893 | MDExOlB1bGxSZXF1ZXN0NDgyODQ1OTc5 | 594 | Fix germeval url | [] | closed | false | null | 0 | 2020-09-09T13:29:35Z | 2020-09-09T13:34:35Z | 2020-09-09T13:34:34Z | null | Continuation of #593 but without the dummy data hack | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/594/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/594.diff",
"html_url": "https://github.com/huggingface/datasets/pull/594",
"merged_at": "2020-09-09T13:34:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/594.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/594... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5088 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5088/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5088/comments | https://api.github.com/repos/huggingface/datasets/issues/5088/events | https://github.com/huggingface/datasets/issues/5088 | 1,400,530,412 | I_kwDODunzps5TemXs | 5,088 | load_datasets("json", ...) don't read local .json.gz properly | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 2 | 2022-10-07T02:16:58Z | 2022-10-07T14:43:16Z | null | null | ## Describe the bug
I have a local file `*.json.gz` and it can be read by `pandas.read_json(lines=True)`, but cannot be read by `load_datasets("json")` (resulting in 0 lines)
## Steps to reproduce the bug
```python
fpath = '/data/junwang/.cache/general/57b6f2314cbe0bc45dda5b78f0871df2/test.json.gz'
ds_panda = Da... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5088/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5088/timeline | null | null | null | null | false | [
"Hi @junwang-wish, thanks for reporting.\r\n\r\nUnfortunately, I'm not able to reproduce the bug. Which version of `datasets` are you using? Does the problem persist if you update `datasets`?\r\n```shell\r\npip install -U datasets\r\n``` ",
"Thanks @albertvillanova I updated `datasets` from `2.5.1` to `2.5.2` and... |
https://api.github.com/repos/huggingface/datasets/issues/3841 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3841/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3841/comments | https://api.github.com/repos/huggingface/datasets/issues/3841/events | https://github.com/huggingface/datasets/issues/3841 | 1,161,203,842 | I_kwDODunzps5FNpCC | 3,841 | Pyright reportPrivateImportUsage when `from datasets import load_dataset` | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 6 | 2022-03-07T10:24:04Z | 2023-02-18T19:14:03Z | 2023-02-13T13:48:41Z | null | ## Describe the bug
Pyright complains about module not exported.
## Steps to reproduce the bug
Use an editor/IDE with Pyright Language server with default configuration:
```python
from datasets import load_dataset
```
## Expected results
No complain from Pyright
## Actual results
Pyright complain below... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3841/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3841/timeline | null | completed | null | null | false | [
"Hi! \r\n\r\nThis issue stems from `datasets` having `py.typed` defined (see https://github.com/microsoft/pyright/discussions/3764#discussioncomment-3282142) - to avoid it, we would either have to remove `py.typed` (added to be compliant with PEP-561) or export the names with `__all__`/`from .submodule import name ... |
https://api.github.com/repos/huggingface/datasets/issues/223 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/223/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/223/comments | https://api.github.com/repos/huggingface/datasets/issues/223/events | https://github.com/huggingface/datasets/issues/223 | 627,683,386 | MDU6SXNzdWU2Mjc2ODMzODY= | 223 | [Feature request] Add FLUE dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 3 | 2020-05-30T08:52:15Z | 2020-12-03T13:39:33Z | 2020-12-03T13:39:33Z | null | Hi,
I think it would be interesting to add the FLUE dataset for francophones or anyone wishing to work on French.
In other requests, I read that you are already working on some datasets, and I was wondering if FLUE was planned.
If it is not the case, I can provide each of the cleaned FLUE datasets (in the form... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/223/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/223/timeline | null | completed | null | null | false | [
"Hi @lbourdois, yes please share it with us",
"@mariamabarham \r\nI put all the datasets on this drive: https://1drv.ms/u/s!Ao2Rcpiny7RFinDypq7w-LbXcsx9?e=iVsEDh\r\n\r\n\r\nSome information : \r\n• For FLUE, the quote used is\r\n\r\n> @misc{le2019flaubert,\r\n> title={FlauBERT: Unsupervised Language Model Pre... |
https://api.github.com/repos/huggingface/datasets/issues/1518 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1518/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1518/comments | https://api.github.com/repos/huggingface/datasets/issues/1518/events | https://github.com/huggingface/datasets/pull/1518 | 764,045,722 | MDExOlB1bGxSZXF1ZXN0NTM4MzAyNzYy | 1,518 | Add twi text | [] | closed | false | null | 2 | 2020-12-12T16:52:02Z | 2020-12-13T18:53:37Z | 2020-12-13T18:53:37Z | null | Add Twi texts | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1518/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1518/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1518.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1518",
"merged_at": "2020-12-13T18:53:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1518.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Hii please follow me",
"thank you"
] |
https://api.github.com/repos/huggingface/datasets/issues/4267 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4267/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4267/comments | https://api.github.com/repos/huggingface/datasets/issues/4267/events | https://github.com/huggingface/datasets/pull/4267 | 1,223,214,275 | PR_kwDODunzps43LzOR | 4,267 | Replace data URL in SAMSum dataset within the same repository | [] | closed | false | null | 1 | 2022-05-02T18:38:08Z | 2022-05-06T08:38:13Z | 2022-05-02T19:03:49Z | null | Replace data URL with one in the same repository. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4267/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4267/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4267.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4267",
"merged_at": "2022-05-02T19:03:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4267.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1418/comments | https://api.github.com/repos/huggingface/datasets/issues/1418/events | https://github.com/huggingface/datasets/pull/1418 | 760,672,320 | MDExOlB1bGxSZXF1ZXN0NTM1NDY0NzQ4 | 1,418 | Add arabic dialects | [] | closed | false | null | 1 | 2020-12-09T21:06:07Z | 2020-12-17T09:40:56Z | 2020-12-17T09:40:56Z | null | Data loading script and dataset card for Dialectal Arabic Resources dataset.
Fixed git issues from PR #976 | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1418/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1418/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1418.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1418",
"merged_at": "2020-12-17T09:40:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1418.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/136 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/136/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/136/comments | https://api.github.com/repos/huggingface/datasets/issues/136/events | https://github.com/huggingface/datasets/pull/136 | 619,211,018 | MDExOlB1bGxSZXF1ZXN0NDE4NzgxNzI4 | 136 | Update README.md | [] | closed | false | null | 1 | 2020-05-15T20:01:07Z | 2020-05-17T12:17:28Z | 2020-05-17T12:17:28Z | null | small typo | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/136/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/136/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/136.diff",
"html_url": "https://github.com/huggingface/datasets/pull/136",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/136.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/136"
} | true | [
"Thanks, this was fixed with #135 :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/2916 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2916/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2916/comments | https://api.github.com/repos/huggingface/datasets/issues/2916/events | https://github.com/huggingface/datasets/pull/2916 | 997,003,661 | PR_kwDODunzps4rx5ua | 2,916 | Add OpenAI's pass@k code evaluation metric | [] | closed | false | null | 4 | 2021-09-15T12:05:43Z | 2021-11-12T14:19:51Z | 2021-11-12T14:19:50Z | null | This PR introduces the `code_eval` metric which implements [OpenAI's code evaluation harness](https://github.com/openai/human-eval) introduced in the [Codex paper](https://arxiv.org/abs/2107.03374). It is heavily based on the original implementation and just adapts the interface to follow the `predictions`/`references`... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2916/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2916/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2916.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2916",
"merged_at": "2021-11-12T14:19:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2916.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"> The implementation makes heavy use of multiprocessing which this PR does not touch. Is this conflicting with multiprocessing natively integrated in datasets?\r\n\r\nIt should work normally, but feel free to test it.\r\nThere is some documentation about using metrics in a distributed setup that uses multiprocessi... |
https://api.github.com/repos/huggingface/datasets/issues/1078 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1078/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1078/comments | https://api.github.com/repos/huggingface/datasets/issues/1078/events | https://github.com/huggingface/datasets/pull/1078 | 756,633,215 | MDExOlB1bGxSZXF1ZXN0NTMyMTUyMzgx | 1,078 | add AJGT dataset | [] | closed | false | null | 0 | 2020-12-03T22:16:31Z | 2020-12-04T09:55:15Z | 2020-12-04T09:55:15Z | null | Arabic Jordanian General Tweets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1078/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1078/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1078.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1078",
"merged_at": "2020-12-04T09:55:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1078.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5145 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5145/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5145/comments | https://api.github.com/repos/huggingface/datasets/issues/5145/events | https://github.com/huggingface/datasets/issues/5145 | 1,418,005,452 | I_kwDODunzps5UhQvM | 5,145 | Dataset order is not deterministic with ZIP archives and `iter_files` | [] | closed | false | null | 8 | 2022-10-21T09:00:03Z | 2022-10-27T09:51:49Z | 2022-10-27T09:51:10Z | null | ### Describe the bug
For the `beans` dataset (did not try on other), the order of samples is not the same on different machines. Tested on my local laptop, github actions machine, and ec2 instance. The three yield a different order.
### Steps to reproduce the bug
In a clean docker container or conda environmen... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5145/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5145/timeline | null | completed | null | null | false | [
"Thanks for reporting ! The issue doesn't come from shuffling, but from `beans` row order not being deterministic:\r\n\r\nhttps://huggingface.co/datasets/beans/blob/main/beans.py uses `dl_manager.iter_files` on ZIP archives and the file order doesn't seen to be deterministic and changes across machines",
"Thank y... |
https://api.github.com/repos/huggingface/datasets/issues/2187 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2187/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2187/comments | https://api.github.com/repos/huggingface/datasets/issues/2187/events | https://github.com/huggingface/datasets/issues/2187 | 852,939,736 | MDU6SXNzdWU4NTI5Mzk3MzY= | 2,187 | Question (potential issue?) related to datasets caching | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | open | false | null | 15 | 2021-04-08T00:16:28Z | 2023-01-03T18:30:38Z | null | null | I thought I had disabled datasets caching in my code, as follows:
```
from datasets import set_caching_enabled
...
def main():
# disable caching in datasets
set_caching_enabled(False)
```
However, in my log files I see messages like the following:
```
04/07/2021 18:34:42 - WARNING - datasets.build... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2187/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2187/timeline | null | null | null | null | false | [
"An educated guess: does this refer to the fact that depending on the custom column names in the dataset files (csv in this case), there is a dataset loader being created? and this dataset loader - using the \"custom data configuration\" is used among all jobs running using this particular csv files? (thinking out ... |
https://api.github.com/repos/huggingface/datasets/issues/6003 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6003/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6003/comments | https://api.github.com/repos/huggingface/datasets/issues/6003/events | https://github.com/huggingface/datasets/issues/6003 | 1,786,554,110 | I_kwDODunzps5qfKb- | 6,003 | interleave_datasets & DataCollatorForLanguageModeling having a conflict ? | [] | open | false | null | 0 | 2023-07-03T17:15:31Z | 2023-07-03T17:15:31Z | null | null | ### Describe the bug
Hi everyone :)
I have two local & custom datasets (1 "sentence" per line) which I split along the 95/5 lines for pre-training a Bert model. I use a modified version of `run_mlm.py` in order to be able to make use of `interleave_dataset`:
- `tokenize()` runs fine
- `group_text()` runs fine
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6003/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6003/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/217 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/217/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/217/comments | https://api.github.com/repos/huggingface/datasets/issues/217/events | https://github.com/huggingface/datasets/issues/217 | 627,128,403 | MDU6SXNzdWU2MjcxMjg0MDM= | 217 | Multi-task dataset mixing | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | open | false | null | 26 | 2020-05-29T09:22:26Z | 2022-10-22T00:45:50Z | null | null | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | {
"+1": 12,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 12,
"url": "https://api.github.com/repos/huggingface/datasets/issues/217/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/217/timeline | null | null | null | null | false | [
"I like this feature! I think the first question we should decide on is how to convert all datasets into the same format. In T5, the authors decided to format every dataset into a text-to-text format. If the dataset had \"multiple\" inputs like MNLI, the inputs were concatenated. So in MNLI the input:\r\n\r\n> - **... |
https://api.github.com/repos/huggingface/datasets/issues/1579 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1579/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1579/comments | https://api.github.com/repos/huggingface/datasets/issues/1579/events | https://github.com/huggingface/datasets/pull/1579 | 767,808,465 | MDExOlB1bGxSZXF1ZXN0NTQwMzk5OTY5 | 1,579 | Adding CLIMATE-FEVER dataset | [] | closed | false | null | 5 | 2020-12-15T16:49:22Z | 2020-12-22T13:43:16Z | 2020-12-22T13:43:15Z | null | This PR request the addition of the CLIMATE-FEVER dataset:
A dataset adopting the FEVER methodology that consists of 1,535 real-world claims regarding climate-change collected on the internet. Each claim is accompanied by five manually annotated evidence sentences retrieved from the English Wikipedia that support, ref... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1579/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1579/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1579.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1579",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1579.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1579"
} | true | [
"I `git rebase`ed my branch to `upstream/master` as suggested in point 7 of <https://huggingface.co/docs/datasets/share_dataset.html> and subsequently used `git pull` to be able to push to my remote branch. However, I think this messed up the history.\r\n\r\nPlease let me know if I should create a clean new PR with... |
https://api.github.com/repos/huggingface/datasets/issues/2543 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2543/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2543/comments | https://api.github.com/repos/huggingface/datasets/issues/2543/events | https://github.com/huggingface/datasets/issues/2543 | 928,571,915 | MDU6SXNzdWU5Mjg1NzE5MTU= | 2,543 | switching some low-level log.info's to log.debug? | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2021-06-23T19:26:55Z | 2021-06-25T13:40:19Z | 2021-06-25T13:40:19Z | null | In https://github.com/huggingface/transformers/pull/12276 we are now changing the examples to have `datasets` on the same log level as `transformers`, so that one setting can do a consistent logging across all involved components.
The trouble is that now we get a ton of these:
```
06/23/2021 12:15:31 - INFO - da... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2543/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2543/timeline | null | completed | null | null | false | [
"Hi @stas00, thanks for pointing out this issue with logging.\r\n\r\nI agree that `datasets` can sometimes be too verbose... I can create a PR and we could discuss there the choice of the log levels for different parts of the code."
] |
https://api.github.com/repos/huggingface/datasets/issues/3306 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3306/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3306/comments | https://api.github.com/repos/huggingface/datasets/issues/3306/events | https://github.com/huggingface/datasets/issues/3306 | 1,059,185,860 | I_kwDODunzps4_IeTE | 3,306 | nested sequence feature won't encode example if the first item of the outside sequence is an empty list | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 3 | 2021-11-20T16:57:54Z | 2021-12-08T13:02:15Z | 2021-12-08T13:02:15Z | null | ## Describe the bug
As the title, nested sequence feature won't encode example if the first item of the outside sequence is an empty list.
## Steps to reproduce the bug
```python
from datasets import Features, Sequence, ClassLabel
features = Features({
'x': Sequence(Sequence(ClassLabel(names=['a', 'b']))),
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3306/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3306/timeline | null | completed | null | null | false | [
"knock knock",
"Hi, thanks for reporting! I've linked a PR that should fix the issue.",
"I've checked the PR and it looks great, thanks a lot!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2146 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2146/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2146/comments | https://api.github.com/repos/huggingface/datasets/issues/2146/events | https://github.com/huggingface/datasets/issues/2146 | 844,673,244 | MDU6SXNzdWU4NDQ2NzMyNDQ= | 2,146 | Dataset file size on disk is very large with 3D Array | [] | open | false | null | 6 | 2021-03-30T14:46:09Z | 2021-04-16T13:07:02Z | null | null | Hi,
I have created my own dataset using the provided dataset loading script. It is an image dataset where images are stored as 3D Array with dtype=uint8.
The actual size on disk is surprisingly large. It takes 520 MB. Here is some info from `dataset_info.json`.
`{
"description": "",
"citation": ""... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2146/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2146/timeline | null | null | null | null | false | [
"Hi ! In the arrow file we store all the integers as uint8.\r\nSo your arrow file should weigh around `height x width x n_channels x n_images` bytes.\r\n\r\nWhat feature type do your TFDS dataset have ?\r\n\r\nIf it uses a `tfds.features.Image` type, then what is stored is the encoded data (as png or jpg for exampl... |
https://api.github.com/repos/huggingface/datasets/issues/674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/674/comments | https://api.github.com/repos/huggingface/datasets/issues/674/events | https://github.com/huggingface/datasets/issues/674 | 709,661,006 | MDU6SXNzdWU3MDk2NjEwMDY= | 674 | load_dataset() won't download in Windows | [] | closed | false | null | 3 | 2020-09-27T03:56:25Z | 2020-10-05T08:28:18Z | 2020-10-05T08:28:18Z | null | I don't know if this is just me or Windows. Maybe other Windows users can chime in if they don't have this problem. I've been trying to get some of the tutorials working on Windows, but when I use the load_dataset() function, it just stalls and the script keeps running indefinitely without downloading anything. I've wa... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/674/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/674/timeline | null | completed | null | null | false | [
"I have the same issue. Tried to download a few of them and not a single one is downloaded successfully.\r\n\r\nThis is the output:\r\n```\r\n>>> dataset = load_dataset('blended_skill_talk', split='train')\r\nUsing custom data configuration default <-- This step never ends\r\n```",
"This was fixed i... |
https://api.github.com/repos/huggingface/datasets/issues/3965 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3965/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3965/comments | https://api.github.com/repos/huggingface/datasets/issues/3965/events | https://github.com/huggingface/datasets/issues/3965 | 1,173,708,739 | I_kwDODunzps5F9V_D | 3,965 | TypeError: Couldn't cast array of type for JSONLines dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-03-18T15:17:53Z | 2022-05-06T16:13:51Z | 2022-05-06T16:13:51Z | null | ## Describe the bug
One of the [course participants](https://discuss.huggingface.co/t/chapter-5-questions/11744/20?u=lewtun) is having trouble loading a JSONLines dataset that's composed of the GitHub issues from `spacy` (see stack trace below).
This reminds me a bit of #2799 where one can load the dataset in `pan... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3965/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3965/timeline | null | completed | null | null | false | [
"Hi @lewtun, thanks for reporting.\r\n\r\nIt seems that our library fails at inferring the dtype of the columns:\r\n- `milestone`\r\n- `performed_via_github_app` \r\n\r\n(and assigns them `null` dtype)."
] |
https://api.github.com/repos/huggingface/datasets/issues/2858 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2858/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2858/comments | https://api.github.com/repos/huggingface/datasets/issues/2858/events | https://github.com/huggingface/datasets/pull/2858 | 984,145,568 | MDExOlB1bGxSZXF1ZXN0NzIzNjEzNzQ0 | 2,858 | Fix s3fs version in CI | [] | closed | false | null | 0 | 2021-08-31T18:05:43Z | 2021-09-06T13:33:35Z | 2021-08-31T21:29:51Z | null | The latest s3fs version has new constrains on aiobotocore, and therefore on boto3 and botocore
This PR changes the constrains to avoid the new conflicts
In particular it pins the version of s3fs. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2858/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2858/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2858.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2858",
"merged_at": "2021-08-31T21:29:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2858.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5569/comments | https://api.github.com/repos/huggingface/datasets/issues/5569/events | https://github.com/huggingface/datasets/pull/5569 | 1,597,132,383 | PR_kwDODunzps5KnwHD | 5,569 | pass the dataset features to the IterableDataset.from_generator function | [] | closed | false | null | 3 | 2023-02-23T16:06:04Z | 2023-02-24T14:06:37Z | 2023-02-23T18:15:16Z | null | [5558](https://github.com/huggingface/datasets/issues/5568) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5569/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5569/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5569.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5569",
"merged_at": "2023-02-23T18:15:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5569.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/2992 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2992/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2992/comments | https://api.github.com/repos/huggingface/datasets/issues/2992/events | https://github.com/huggingface/datasets/pull/2992 | 1,012,325,594 | PR_kwDODunzps4sg4ZP | 2,992 | Fix f1 metric with None average | [] | closed | false | null | 0 | 2021-09-30T15:31:57Z | 2021-10-01T14:17:39Z | 2021-10-01T14:17:38Z | null | Fix #2979. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2992/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2992/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2992.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2992",
"merged_at": "2021-10-01T14:17:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2992.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5520 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5520/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5520/comments | https://api.github.com/repos/huggingface/datasets/issues/5520/events | https://github.com/huggingface/datasets/issues/5520 | 1,578,417,074 | I_kwDODunzps5eFLuy | 5,520 | ClassLabel.cast_storage raises TypeError when called on an empty IntegerArray | [] | closed | false | null | 0 | 2023-02-09T18:46:52Z | 2023-02-12T11:17:18Z | 2023-02-12T11:17:18Z | null | ### Describe the bug
`ClassLabel.cast_storage` raises `TypeError` when called on an empty `IntegerArray`.
### Steps to reproduce the bug
Minimal steps:
```python
import pyarrow as pa
from datasets import ClassLabel
ClassLabel(names=['foo', 'bar']).cast_storage(pa.array([], pa.int64()))
```
In practice, thi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5520/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5520/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/195 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/195/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/195/comments | https://api.github.com/repos/huggingface/datasets/issues/195/events | https://github.com/huggingface/datasets/pull/195 | 624,858,686 | MDExOlB1bGxSZXF1ZXN0NDIzMTg1NTAy | 195 | [Dummy data command] add new case to command | [] | closed | false | null | 1 | 2020-05-26T12:50:47Z | 2020-05-26T14:38:28Z | 2020-05-26T14:38:27Z | null | Qanta: #194 introduces a case that was not noticed before. This change in code helps community users to have an easier time creating the dummy data. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/195/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/195/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/195.diff",
"html_url": "https://github.com/huggingface/datasets/pull/195",
"merged_at": "2020-05-26T14:38:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/195.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/195... | true | [
"@lhoestq - tiny change in the dummy data command, should be good to merge."
] |
https://api.github.com/repos/huggingface/datasets/issues/3297 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3297/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3297/comments | https://api.github.com/repos/huggingface/datasets/issues/3297/events | https://github.com/huggingface/datasets/issues/3297 | 1,058,263,859 | I_kwDODunzps4_E9Mz | 3,297 | .map() cache is wrongfully reused - only happens when the mapping function is imported | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 3 | 2021-11-19T08:18:36Z | 2023-01-30T12:40:17Z | null | null | ## Describe the bug
When `.map` is used with a mapping function that is imported, the cache is reused even if the mapping function has been modified.
The reason for this is that `dill` that is used for creating the fingerprint [pickles imported functions by reference](https://stackoverflow.com/a/67851411).
I guess... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3297/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3297/timeline | null | null | null | null | false | [
"Hi ! Thanks for reporting. Indeed this is a current limitation of the usage we have of `dill` in `datasets`. I'd suggest you use your workaround for now until we find a way to fix this. Maybe functions that are not coming from a module not installed with pip should be dumped completely, rather than only taking the... |
https://api.github.com/repos/huggingface/datasets/issues/3391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3391/comments | https://api.github.com/repos/huggingface/datasets/issues/3391/events | https://github.com/huggingface/datasets/issues/3391 | 1,072,849,055 | I_kwDODunzps4_8mCf | 3,391 | method to select columns | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2021-12-07T02:44:19Z | 2021-12-07T02:45:27Z | 2021-12-07T02:45:27Z | null | **Is your feature request related to a problem? Please describe.**
* There is currently no way to select some columns of a dataset. In pandas, one can use `df[['col1', 'col2']]` to select columns, but in `datasets`, it results in error.
**Describe the solution you'd like**
* A new method that can be used to cr... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3391/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3391/timeline | null | completed | null | null | false | [
"duplicate of #2655"
] |
https://api.github.com/repos/huggingface/datasets/issues/5087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5087/comments | https://api.github.com/repos/huggingface/datasets/issues/5087/events | https://github.com/huggingface/datasets/pull/5087 | 1,400,487,967 | PR_kwDODunzps5AW-N9 | 5,087 | Fix filter with empty indices | [] | closed | false | null | 1 | 2022-10-07T01:07:00Z | 2022-10-07T18:43:03Z | 2022-10-07T18:40:26Z | null | Fix #5085 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5087/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5087.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5087",
"merged_at": "2022-10-07T18:40:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5087.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2906 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2906/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2906/comments | https://api.github.com/repos/huggingface/datasets/issues/2906/events | https://github.com/huggingface/datasets/pull/2906 | 995,962,905 | PR_kwDODunzps4rulH- | 2,906 | feat: 🎸 add a function to get a dataset config's split names | [] | closed | false | null | 1 | 2021-09-14T12:31:22Z | 2021-10-04T09:55:38Z | 2021-10-04T09:55:37Z | null | Also: pass additional arguments (use_auth_token) to get private configs + info of private datasets on the hub
Questions:
- [x] I'm not sure how the versions work: I changed 1.12.1.dev0 to 1.12.1.dev1, was it correct?
-> no: reverted
- [x] Should I add a section in https://github.com/huggingface/datasets/blo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2906/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2906/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2906.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2906",
"merged_at": "2021-10-04T09:55:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2906.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"> Should I add a section in https://github.com/huggingface/datasets/blob/master/docs/source/load_hub.rst? (there is no section for get_dataset_infos)\r\n\r\nYes totally :) This tutorial should indeed mention this, given how fundamental it is"
] |
https://api.github.com/repos/huggingface/datasets/issues/5363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5363/comments | https://api.github.com/repos/huggingface/datasets/issues/5363/events | https://github.com/huggingface/datasets/issues/5363 | 1,498,171,317 | I_kwDODunzps5ZTEe1 | 5,363 | Dataset.from_generator() crashes on simple example | [] | closed | false | null | 0 | 2022-12-15T10:21:28Z | 2022-12-15T11:51:33Z | 2022-12-15T11:51:33Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5363/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2618/comments | https://api.github.com/repos/huggingface/datasets/issues/2618/events | https://github.com/huggingface/datasets/issues/2618 | 940,852,640 | MDU6SXNzdWU5NDA4NTI2NDA= | 2,618 | `filelock.py` Error | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 1 | 2021-07-09T15:12:49Z | 2021-07-12T06:20:30Z | null | null | ## Describe the bug
It seems that the `filelock.py` went error.
```
>>> ds=load_dataset('xsum')
^CTraceback (most recent call last):
File "/user/HS502/yl02706/.conda/envs/lyc/lib/python3.6/site-packages/datasets/utils/filelock.py", line 402, in _acquire
fcntl.flock(fd, fcntl.LOCK_EX | fcntl.LOCK_NB)
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2618/timeline | null | null | null | null | false | [
"Hi @liyucheng09, thanks for reporting.\r\n\r\nApparently this issue has to do with your environment setup. One question: is your data in an NFS share? Some people have reported this error when using `fcntl` to write to an NFS share... If this is the case, then it might be that your NFS just may not be set up to pr... |
https://api.github.com/repos/huggingface/datasets/issues/1288 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1288/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1288/comments | https://api.github.com/repos/huggingface/datasets/issues/1288/events | https://github.com/huggingface/datasets/pull/1288 | 759,309,457 | MDExOlB1bGxSZXF1ZXN0NTM0MzM2Mzgz | 1,288 | Add CodeSearchNet corpus dataset | [] | closed | false | null | 1 | 2020-12-08T10:07:50Z | 2020-12-09T17:05:28Z | 2020-12-09T17:05:28Z | null | This PR adds the CodeSearchNet corpus proxy dataset for semantic code search: https://github.com/github/CodeSearchNet
I have had a few issues, mentioned below. Would appreciate some help on how to solve them.
## Issues generating dataset card
Is there something wrong with my declaration of the dataset features ?
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1288/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1288/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1288.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1288",
"merged_at": "2020-12-09T17:05:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1288.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"@lhoestq ready for a second review"
] |
https://api.github.com/repos/huggingface/datasets/issues/3056 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3056/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3056/comments | https://api.github.com/repos/huggingface/datasets/issues/3056/events | https://github.com/huggingface/datasets/pull/3056 | 1,022,345,564 | PR_kwDODunzps4tAB9h | 3,056 | Fix meteor metric for version >= 3.6.4 | [] | closed | false | null | 0 | 2021-10-11T07:11:44Z | 2021-10-11T07:29:20Z | 2021-10-11T07:29:19Z | null | After `nltk` update, the meteor metric expects pre-tokenized inputs (breaking change).
This PR fixes this issue, while maintaining compatibility with older versions. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3056/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3056/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3056.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3056",
"merged_at": "2021-10-11T07:29:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3056.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2150 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2150/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2150/comments | https://api.github.com/repos/huggingface/datasets/issues/2150/events | https://github.com/huggingface/datasets/pull/2150 | 844,776,448 | MDExOlB1bGxSZXF1ZXN0NjAzOTg3OTcx | 2,150 | Allow pickling of big in-memory tables | [] | closed | false | null | 0 | 2021-03-30T15:51:56Z | 2021-03-31T10:37:15Z | 2021-03-31T10:37:14Z | null | This should fix issue #2134
Pickling is limited to <4GiB objects, it's not possible to pickle a big arrow table (for multiprocessing for example).
For big tables, we have to write them on disk and only pickle the path to the table. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2150/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2150/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2150.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2150",
"merged_at": "2021-03-31T10:37:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2150.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2943 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2943/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2943/comments | https://api.github.com/repos/huggingface/datasets/issues/2943/events | https://github.com/huggingface/datasets/issues/2943 | 1,000,355,115 | I_kwDODunzps47oDUr | 2,943 | Backwards compatibility broken for cached datasets that use `.filter()` | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 6 | 2021-09-19T16:16:37Z | 2021-09-20T16:25:43Z | 2021-09-20T16:25:42Z | null | ## Describe the bug
After upgrading to datasets `1.12.0`, some cached `.filter()` steps from `1.11.0` started failing with
`ValueError: Keys mismatch: between {'indices': Value(dtype='uint64', id=None)} and {'file': Value(dtype='string', id=None), 'text': Value(dtype='string', id=None), 'speaker_id': Value(dtype='in... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2943/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2943/timeline | null | completed | null | null | false | [
"Hi ! I guess the caching mechanism should have considered the new `filter` to be different from the old one, and don't use cached results from the old `filter`.\r\nTo avoid other users from having this issue we could make the caching differentiate the two, what do you think ?",
"If it's easy enough to implement,... |
https://api.github.com/repos/huggingface/datasets/issues/2145 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2145/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2145/comments | https://api.github.com/repos/huggingface/datasets/issues/2145/events | https://github.com/huggingface/datasets/pull/2145 | 844,603,518 | MDExOlB1bGxSZXF1ZXN0NjAzODMxOTE2 | 2,145 | Implement Dataset add_column | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"closed_at": "2021-05-31T16:20:53Z",
"closed_issues": 3,
"created_at": "2021-04-09T13:16:31Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/u... | 1 | 2021-03-30T14:02:14Z | 2021-04-29T14:50:44Z | 2021-04-29T14:50:43Z | null | Implement `Dataset.add_column`.
Close #1954. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2145/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2145/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2145.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2145",
"merged_at": "2021-04-29T14:50:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2145.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"#2274 has been merged. You can now merge master into this branch and use `assert_arrow_metadata_are_synced_with_dataset_features(dset)` to make sure that the metadata are good :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/1645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1645/comments | https://api.github.com/repos/huggingface/datasets/issues/1645/events | https://github.com/huggingface/datasets/pull/1645 | 775,473,106 | MDExOlB1bGxSZXF1ZXN0NTQ2MTQ4OTUx | 1,645 | Rename "part-of-speech-tagging" tag in some dataset cards | [] | closed | false | null | 0 | 2020-12-28T16:09:09Z | 2021-01-07T10:08:14Z | 2021-01-07T10:08:13Z | null | `part-of-speech-tagging` was not part of the tagging taxonomy under `structure-prediction` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1645/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1645.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1645",
"merged_at": "2021-01-07T10:08:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1645.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/879 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/879/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/879/comments | https://api.github.com/repos/huggingface/datasets/issues/879/events | https://github.com/huggingface/datasets/issues/879 | 748,848,847 | MDU6SXNzdWU3NDg4NDg4NDc= | 879 | boolq does not load | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 3 | 2020-11-23T14:28:28Z | 2022-10-05T12:23:32Z | 2022-10-05T12:23:32Z | null | Hi
I am getting these errors trying to load boolq thanks
Traceback (most recent call last):
File "test.py", line 5, in <module>
data = AutoTask().get("boolq").get_dataset("train", n_obs=10)
File "/remote/idiap.svm/user.active/rkarimi/dev/internship/seq2seq/tasks/tasks.py", line 42, in get_dataset
d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/879/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/879/timeline | null | completed | null | null | false | [
"Hi ! It runs on my side without issues. I tried\r\n```python\r\nfrom datasets import load_dataset\r\nload_dataset(\"boolq\")\r\n```\r\n\r\nWhat version of datasets and tensorflow are your runnning ?\r\nAlso if you manage to get a minimal reproducible script (on google colab for example) that would be useful.",
"... |
https://api.github.com/repos/huggingface/datasets/issues/5299 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5299/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5299/comments | https://api.github.com/repos/huggingface/datasets/issues/5299/events | https://github.com/huggingface/datasets/pull/5299 | 1,464,695,091 | PR_kwDODunzps5Dt3Sk | 5,299 | Fix xopen for Windows pathnames | [] | closed | false | null | 1 | 2022-11-25T15:35:28Z | 2022-11-29T08:23:58Z | 2022-11-29T08:21:24Z | null | This PR fixes a bug in `xopen` function for Windows pathnames.
Fix #5298. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5299/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5299/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5299.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5299",
"merged_at": "2022-11-29T08:21:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5299.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3989 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3989/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3989/comments | https://api.github.com/repos/huggingface/datasets/issues/3989/events | https://github.com/huggingface/datasets/pull/3989 | 1,176,955,078 | PR_kwDODunzps400l1S | 3,989 | Remove old wikipedia leftovers | [] | closed | false | null | 3 | 2022-03-22T15:25:46Z | 2022-03-31T15:35:26Z | 2022-03-31T15:30:16Z | null | After updating Wikipedia dataset, remove old wikipedia leftovers from doc.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3989/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3989/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3989.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3989",
"merged_at": "2022-03-31T15:30:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3989.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> This makes me think we shouldn't advise the use of load_dataset in dataset scripts, since it doesn't guarantee that the cache will work as expected (the cache directory is not set correctly, and the required disk space for download... |
https://api.github.com/repos/huggingface/datasets/issues/3488 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3488/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3488/comments | https://api.github.com/repos/huggingface/datasets/issues/3488/events | https://github.com/huggingface/datasets/issues/3488 | 1,089,345,653 | I_kwDODunzps5A7hh1 | 3,488 | URL query parameters are set as path in the compression hop for fsspec | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 1 | 2021-12-27T16:29:00Z | 2022-01-05T15:15:25Z | null | null | ## Describe the bug
There is an ssue with `StreamingDownloadManager._extract`.
I don't know how the test `test_streaming_gg_drive_gzipped` passes:
For
```python
TEST_GG_DRIVE_GZIPPED_URL = "https://drive.google.com/uc?export=download&id=1Bt4Garpf0QLiwkJhHJzXaVa0I0H5Qhwz"
urlpath = StreamingDownloadManager().... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3488/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3488/timeline | null | null | null | null | false | [
"I think the test passes because it simply ignore what's after `gzip://`.\r\n\r\nThe returned urlpath is expected to look like `gzip://filename::url`, and the filename is currently considered to be what's after the final `/`, hence the result.\r\n\r\nWe can decide to change this and simply have `gzip://::url`, this... |
https://api.github.com/repos/huggingface/datasets/issues/5459 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5459/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5459/comments | https://api.github.com/repos/huggingface/datasets/issues/5459/events | https://github.com/huggingface/datasets/pull/5459 | 1,555,367,504 | PR_kwDODunzps5Icjwe | 5,459 | Disable aiohttp requoting of redirection URL | [] | closed | false | null | 7 | 2023-01-24T17:18:59Z | 2023-02-01T08:45:33Z | 2023-01-31T08:37:54Z | null | The library `aiohttp` performs a requoting of redirection URLs that unquotes the single quotation mark character: `%27` => `'`
This is a problem for our Hugging Face Hub, which requires exact URL from location header.
Specifically, in the query component of the URL (`https://netloc/path?query`), the value for `re... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5459/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5459/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5459.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5459",
"merged_at": "2023-01-31T08:37:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5459.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Comment by @lhoestq:\r\n> Do you think we need this in `datasets` if it's fixed on the moon landing side ? In the aiohttp doc they consider those symbols as \"non-safe\" ",
"The lib `requests` does not perform that requote on redir... |
https://api.github.com/repos/huggingface/datasets/issues/1011 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1011/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1011/comments | https://api.github.com/repos/huggingface/datasets/issues/1011/events | https://github.com/huggingface/datasets/pull/1011 | 755,463,726 | MDExOlB1bGxSZXF1ZXN0NTMxMTY5MjA3 | 1,011 | Add Bilingual Corpus of Arabic-English Parallel Tweets | [] | closed | false | null | 6 | 2020-12-02T17:20:02Z | 2020-12-04T14:45:10Z | 2020-12-04T14:44:33Z | null | Added Bilingual Corpus of Arabic-English Parallel Tweets. The link to the dataset can be found [here](https://alt.qcri.org/wp-content/uploads/2020/08/Bilingual-Corpus-of-Arabic-English-Parallel-Tweets.zip) and the paper can be found [here](https://www.aclweb.org/anthology/2020.bucc-1.3.pdf)
- [x] Followed the instru... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1011/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1011/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1011.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1011",
"merged_at": "2020-12-04T14:44:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1011.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"IMO, the problem with this dataset is that it is not really a text/nlp dataset. These are just collections of tweet ids. So, ultimately, one needs to crawl twitter to get the actual text.",
"That's true.\r\n\r\n",
"at least it's clear in the description that one needs to collect the tweets : \r\n```\r\nThis re... |
https://api.github.com/repos/huggingface/datasets/issues/5115 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5115/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5115/comments | https://api.github.com/repos/huggingface/datasets/issues/5115/events | https://github.com/huggingface/datasets/pull/5115 | 1,409,250,020 | PR_kwDODunzps5Az9Pm | 5,115 | Fix iter_batches | [] | closed | false | null | 3 | 2022-10-14T12:06:14Z | 2022-10-14T15:02:15Z | 2022-10-14T14:59:58Z | null | The `pa.Table.to_reader()` method available in `pyarrow>=8.0.0` may return chunks of size < `max_chunksize`, therefore `iter_batches` can return batches smaller than the `batch_size` specified by the user
Therefore batched `map` couldn't always use batches of the right size, e.g. this fails because it runs only on o... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5115/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5115/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5115.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5115",
"merged_at": "2022-10-14T14:59:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5115.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I also ran the code in https://github.com/huggingface/datasets/issues/5111 and it works fine now :)",
"This is ready for review :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/551/comments | https://api.github.com/repos/huggingface/datasets/issues/551/events | https://github.com/huggingface/datasets/pull/551 | 690,034,762 | MDExOlB1bGxSZXF1ZXN0NDc2OTkwNjAw | 551 | added HANS dataset | [] | closed | false | null | 0 | 2020-09-01T10:42:02Z | 2020-09-01T12:17:10Z | 2020-09-01T12:17:10Z | null | Adds the [HANS](https://github.com/tommccoy1/hans) dataset to evaluate NLI systems. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/551/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/551/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/551.diff",
"html_url": "https://github.com/huggingface/datasets/pull/551",
"merged_at": "2020-09-01T12:17:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/551.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/551... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4840 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4840/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4840/comments | https://api.github.com/repos/huggingface/datasets/issues/4840/events | https://github.com/huggingface/datasets/issues/4840 | 1,337,342,672 | I_kwDODunzps5PtjrQ | 4,840 | Dataset Viewer issue for darragh/demo_data_raw3 | [] | open | false | null | 5 | 2022-08-12T15:22:58Z | 2022-09-08T07:55:44Z | null | null | ### Link
https://huggingface.co/datasets/darragh/demo_data_raw3
### Description
```
Exception: ValueError
Message: Arrow type extension<arrow.py_extension_type<pyarrow.lib.UnknownExtensionType>> does not have a datasets dtype equivalent.
```
reported by @NielsRogge
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4840/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4840/timeline | null | null | null | null | false | [
"do you have an idea of why it can occur @huggingface/datasets? The dataset consists of a single parquet file.",
"Thanks for reporting @severo.\r\n\r\nI'm not able to reproduce that error. I get instead:\r\n```\r\nFileNotFoundError: [Errno 2] No such file or directory: 'orix/data/ChiSig/唐合乐-9-3.jpg'\r\n```\r\n\r\... |
https://api.github.com/repos/huggingface/datasets/issues/5395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5395/comments | https://api.github.com/repos/huggingface/datasets/issues/5395/events | https://github.com/huggingface/datasets/pull/5395 | 1,513,997,335 | PR_kwDODunzps5GXLUl | 5,395 | Temporarily pin pydantic test dependency | [] | closed | false | null | 3 | 2022-12-29T19:34:19Z | 2022-12-30T06:36:57Z | 2022-12-29T21:00:26Z | null | Temporarily pin `pydantic` until a permanent solution is found.
Fix #5394. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5395/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5395/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5395.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5395",
"merged_at": "2022-12-29T21:00:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5395.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/1494 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1494/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1494/comments | https://api.github.com/repos/huggingface/datasets/issues/1494/events | https://github.com/huggingface/datasets/pull/1494 | 762,992,601 | MDExOlB1bGxSZXF1ZXN0NTM3NDg2MzU4 | 1,494 | Added Opus Wikipedia | [] | closed | false | null | 1 | 2020-12-11T22:28:03Z | 2020-12-17T14:38:28Z | 2020-12-17T14:38:28Z | null | Dataset : http://opus.nlpl.eu/Wikipedia.php | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1494/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1494/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1494.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1494",
"merged_at": "2020-12-17T14:38:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1494.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/4986 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4986/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4986/comments | https://api.github.com/repos/huggingface/datasets/issues/4986/events | https://github.com/huggingface/datasets/pull/4986 | 1,375,895,035 | PR_kwDODunzps4_GNSd | 4,986 | [doc] Fix broken snippet that had too many quotes | [] | closed | false | null | 2 | 2022-09-16T12:41:07Z | 2022-09-16T22:12:21Z | 2022-09-16T17:32:14Z | null | Hello!
### Pull request overview
* Fix broken snippet in https://huggingface.co/docs/datasets/main/en/process that has too many quotes
### Details
The snippet in question can be found here: https://huggingface.co/docs/datasets/main/en/process#map
This screenshot shows the issue, there is a quote too many, caus... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4986/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4986/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4986.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4986",
"merged_at": "2022-09-16T17:32:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4986.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Spent the day familiarising myself with the huggingface line of products, and happened to run into some small issues here and there. Magically, I've found exactly one small issue in `transformers`, one in `accelerate` and now one in ... |
https://api.github.com/repos/huggingface/datasets/issues/5561 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5561/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5561/comments | https://api.github.com/repos/huggingface/datasets/issues/5561/events | https://github.com/huggingface/datasets/pull/5561 | 1,593,862,388 | PR_kwDODunzps5Kcxw_ | 5,561 | Add pre-commit config yaml file to enable automatic code formatting | [] | closed | false | null | 6 | 2023-02-21T17:35:07Z | 2023-02-28T15:37:22Z | 2023-02-23T18:23:29Z | null | @huggingface/datasets do you think it would be useful? Motivation - sometimes PRs are like 30% "fix: style" commits :)
If so - I need to double check the config but for me locally it works as expected. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5561/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5561/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5561.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5561",
"merged_at": "2023-02-23T18:23:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5561.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Better yet have someone enable pre-commit CI https://pre-commit.ci/ and it will apply the pre-commit fixes to the PR automatically as an additional commit.",
"@Skylion007 hi! I agree with @nateraw here, I'd better not force to use ... |
https://api.github.com/repos/huggingface/datasets/issues/673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/673/comments | https://api.github.com/repos/huggingface/datasets/issues/673/events | https://github.com/huggingface/datasets/issues/673 | 709,603,989 | MDU6SXNzdWU3MDk2MDM5ODk= | 673 | blog_authorship_corpus crashed | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | 1 | 2020-09-26T20:15:28Z | 2022-02-15T10:47:58Z | 2022-02-15T10:47:58Z | null | This is just to report that When I pick blog_authorship_corpus in
https://huggingface.co/nlp/viewer/?dataset=blog_authorship_corpus
I get this:

| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/673/timeline | null | completed | null | null | false | [
"Thanks for reporting !\r\nWe'll free some memory"
] |
https://api.github.com/repos/huggingface/datasets/issues/3771 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3771/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3771/comments | https://api.github.com/repos/huggingface/datasets/issues/3771/events | https://github.com/huggingface/datasets/pull/3771 | 1,146,561,140 | PR_kwDODunzps4zRHsd | 3,771 | Fix DuplicatedKeysError on msr_sqa dataset | [] | closed | false | null | 0 | 2022-02-22T07:44:24Z | 2022-02-22T08:12:40Z | 2022-02-22T08:12:39Z | null | Fix #3770. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3771/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3771/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3771.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3771",
"merged_at": "2022-02-22T08:12:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3771.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5656/comments | https://api.github.com/repos/huggingface/datasets/issues/5656/events | https://github.com/huggingface/datasets/pull/5656 | 1,634,156,563 | PR_kwDODunzps5Mjxoo | 5,656 | Fix `fsspec.open` when using an HTTP proxy | [] | closed | false | null | 2 | 2023-03-21T15:23:29Z | 2023-03-23T14:14:50Z | 2023-03-23T13:15:46Z | null | Most HTTP(S) downloads from this library support proxy automatically by reading the `HTTP_PROXY` environment variable (et al.) because `requests` is widely used. However, in some parts of the code, `fsspec` is used, which in turn uses `aiohttp` for HTTP(S) requests (as opposed to `requests`), which in turn doesn't supp... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5656/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5656/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5656.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5656",
"merged_at": "2023-03-23T13:15:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5656.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/4346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4346/comments | https://api.github.com/repos/huggingface/datasets/issues/4346/events | https://github.com/huggingface/datasets/issues/4346 | 1,235,067,062 | I_kwDODunzps5JnaC2 | 4,346 | GH Action to build documentation never ends | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-05-13T10:44:44Z | 2022-05-13T11:22:00Z | 2022-05-13T11:22:00Z | null | ## Describe the bug
See: https://github.com/huggingface/datasets/runs/6418035586?check_suite_focus=true
I finally forced the cancel of the workflow. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4346/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4346/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5950 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5950/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5950/comments | https://api.github.com/repos/huggingface/datasets/issues/5950/events | https://github.com/huggingface/datasets/issues/5950 | 1,755,197,946 | I_kwDODunzps5onjH6 | 5,950 | Support for data with instance-wise dictionary as features | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2023-06-13T15:49:00Z | 2023-06-14T12:13:38Z | null | null | ### Feature request
I notice that when loading data instances with feature type of python dictionary, the dictionary keys would be broadcast so that every instance has the same set of keys. Please see an example in the Motivation section.
It is possible to avoid this behavior, i.e., load dictionary features as it i... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5950/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5950/timeline | null | null | null | null | false | [
"Hi ! We use the Arrow columnar format under the hood, which doesn't support such dictionaries: each field must have a fixed type and exist in each sample.\r\n\r\nInstead you can restructure your data like\r\n```\r\n{\r\n \"index\": 0,\r\n \"keys\": [\"2 * x + y >= 3\"],\r\n \"values\": [[\"2 * x + y >= 3\... |
https://api.github.com/repos/huggingface/datasets/issues/1116 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1116/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1116/comments | https://api.github.com/repos/huggingface/datasets/issues/1116/events | https://github.com/huggingface/datasets/pull/1116 | 757,133,502 | MDExOlB1bGxSZXF1ZXN0NTMyNTYwNDk4 | 1,116 | add dbpedia_14 dataset | [] | closed | false | null | 5 | 2020-12-04T14:13:59Z | 2020-12-07T10:06:54Z | 2020-12-05T15:36:23Z | null | This dataset corresponds to the DBpedia dataset requested in https://github.com/huggingface/datasets/issues/353. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1116/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1116/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1116.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1116",
"merged_at": "2020-12-05T15:36:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1116.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Thanks for the review. \r\nCheers!",
"Hi @hfawaz, this week we are doing the 🤗 `datasets` sprint (see some details [here](https://discuss.huggingface.co/t/open-to-the-community-one-week-team-effort-to-reach-v2-0-of-hf-datasets-library/2176)).\r\n\r\nNothing more to do on your side but it means that if you regis... |
https://api.github.com/repos/huggingface/datasets/issues/1560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1560/comments | https://api.github.com/repos/huggingface/datasets/issues/1560/events | https://github.com/huggingface/datasets/pull/1560 | 765,814,964 | MDExOlB1bGxSZXF1ZXN0NTM5MDkzMzky | 1,560 | Adding the BrWaC dataset | [] | closed | false | null | 0 | 2020-12-14T03:03:56Z | 2020-12-18T15:56:56Z | 2020-12-18T15:56:55Z | null | Adding the BrWaC dataset, a large corpus of Portuguese language texts | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1560/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1560/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1560.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1560",
"merged_at": "2020-12-18T15:56:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1560.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5213 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5213/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5213/comments | https://api.github.com/repos/huggingface/datasets/issues/5213/events | https://github.com/huggingface/datasets/pull/5213 | 1,440,037,534 | PR_kwDODunzps5CalQ_ | 5,213 | Add support for different configs with `push_to_hub` | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 8 | 2022-11-08T11:45:47Z | 2022-12-02T16:48:23Z | 2022-12-02T16:44:07Z | null | will solve #5151
@lhoestq @albertvillanova @mariosasko
This is still a super draft so please ignore code issues but I want to discuss some conceptually important things.
I suggest a way to do `.push_to_hub("repo_id", "config_name")` with pushing parquet files to directories named as `config_name` (inside `data... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5213/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5213/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/5213.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5213",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5213.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5213"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5213). All of your documentation changes will be reflected on that endpoint.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface... |
https://api.github.com/repos/huggingface/datasets/issues/2242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2242/comments | https://api.github.com/repos/huggingface/datasets/issues/2242/events | https://github.com/huggingface/datasets/issues/2242 | 862,870,205 | MDU6SXNzdWU4NjI4NzAyMDU= | 2,242 | Link to datasets viwer on Quick Tour page returns "502 Bad Gateway" | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-04-20T14:19:51Z | 2021-04-20T15:02:45Z | 2021-04-20T15:02:45Z | null | Link to datasets viwer (https://huggingface.co/datasets/viewer/) on Quick Tour page (https://huggingface.co/docs/datasets/quicktour.html) returns "502 Bad Gateway"
The same error with https://huggingface.co/datasets/viewer/?dataset=glue&config=mrpc | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2242/timeline | null | completed | null | null | false | [
"This should be fixed now!\r\n\r\ncc @srush "
] |
https://api.github.com/repos/huggingface/datasets/issues/5997 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5997/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5997/comments | https://api.github.com/repos/huggingface/datasets/issues/5997/events | https://github.com/huggingface/datasets/issues/5997 | 1,781,582,818 | I_kwDODunzps5qMMvi | 5,997 | extend the map function so it can wrap around long text that does not fit in the context window | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 2 | 2023-06-29T22:15:21Z | 2023-07-03T17:58:52Z | null | null | ### Feature request
I understand `dataset` provides a [`map`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L2849) function. This function in turn takes in a callable that is used to tokenize the text on which a model is trained. Frequently this text will not fit within a models's con... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5997/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5997/timeline | null | null | null | null | false | [
"I just noticed the [docs](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L2881C11-L2881C200) say:\r\n\r\n>If batched is `True` and `batch_size` is `n > 1`, then the function takes a batch of `n` examples as input and can return a batch with `n` examples, or with an arbitrary number... |
https://api.github.com/repos/huggingface/datasets/issues/3217 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3217/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3217/comments | https://api.github.com/repos/huggingface/datasets/issues/3217/events | https://github.com/huggingface/datasets/issues/3217 | 1,045,029,710 | I_kwDODunzps4-SeNO | 3,217 | Fix code quality bug in riddle_sense dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-11-04T17:40:32Z | 2021-11-04T17:50:02Z | 2021-11-04T17:50:02Z | null | ## Describe the bug
```
datasets/riddle_sense/riddle_sense.py:36:21: W291 trailing whitespace
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3217/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3217/timeline | null | completed | null | null | false | [
"To give more context: https://github.com/psf/black/issues/318. `black` doesn't treat this as a bug, but `flake8` does. \r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2802 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2802/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2802/comments | https://api.github.com/repos/huggingface/datasets/issues/2802/events | https://github.com/huggingface/datasets/pull/2802 | 970,848,302 | MDExOlB1bGxSZXF1ZXN0NzEyNzM0MTc3 | 2,802 | add openwebtext2 | [] | closed | false | null | 3 | 2021-08-14T07:09:03Z | 2021-08-23T14:06:14Z | 2021-08-23T14:06:14Z | null | openwebtext2 is part of EleutherAI/The Pile, but AFAIK, The Pile dataset blend all sub datasets together thus we are not able to use just one of its sub dataset from The Pile data. So I create an independent dataset using The Pile preliminary components.
When I was creating dataset card. I found there is room for cr... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2802/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2802/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2802.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2802",
"merged_at": "2021-08-23T14:06:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2802.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"It seems we need to `pip install jsonlines` to pass the checks ?",
"Hi ! Do you really need `jsonlines` ? I think it simply uses `json.loads` under the hood.\r\n\r\nCurrently the test are failing because `jsonlines` is not part of the extra requirements `TESTS_REQUIRE` in setup.py\r\n\r\nSo either you can replac... |
https://api.github.com/repos/huggingface/datasets/issues/3949 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3949/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3949/comments | https://api.github.com/repos/huggingface/datasets/issues/3949/events | https://github.com/huggingface/datasets/pull/3949 | 1,171,467,981 | PR_kwDODunzps40jia- | 3,949 | Remove GLEU metric | [] | closed | false | null | 1 | 2022-03-16T19:35:31Z | 2022-04-12T20:43:26Z | 2022-04-12T20:37:09Z | null | Remove the GLEU metric as it is not actually implemented. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 1,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3949/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3949/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3949.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3949",
"merged_at": "2022-04-12T20:37:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3949.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3406/comments | https://api.github.com/repos/huggingface/datasets/issues/3406/events | https://github.com/huggingface/datasets/pull/3406 | 1,074,366,050 | PR_kwDODunzps4vjV21 | 3,406 | Fix module inference for archive with a directory | [] | closed | false | null | 0 | 2021-12-08T12:39:12Z | 2021-12-08T13:03:30Z | 2021-12-08T13:03:29Z | null | Fix module inference for an archive file that contains files within a directory.
Fix #3405. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3406/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3406/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3406.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3406",
"merged_at": "2021-12-08T13:03:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3406.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4730/comments | https://api.github.com/repos/huggingface/datasets/issues/4730/events | https://github.com/huggingface/datasets/issues/4730 | 1,313,421,263 | I_kwDODunzps5OSTfP | 4,730 | Loading imagenet-1k validation split takes much more RAM than expected | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2022-07-21T15:14:06Z | 2022-07-21T16:41:04Z | 2022-07-21T16:41:04Z | null | ## Describe the bug
Loading into memory the validation split of imagenet-1k takes much more RAM than expected. Assuming ImageNet-1k is 150 GB, split is 50000 validation images and 1,281,167 train images, I would expect only about 6 GB loaded in RAM.
## Steps to reproduce the bug
```python
from datasets import... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4730/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4730/timeline | null | completed | null | null | false | [
"My bad, `482 * 418 * 50000 * 3 / 1000000 = 30221 MB` ( https://stackoverflow.com/a/42979315 ).\r\n\r\nMeanwhile `256 * 256 * 50000 * 3 / 1000000 = 9830 MB`. We are loading the non-cropped images and that is why we take so much RAM."
] |
https://api.github.com/repos/huggingface/datasets/issues/5227 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5227/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5227/comments | https://api.github.com/repos/huggingface/datasets/issues/5227/events | https://github.com/huggingface/datasets/issues/5227 | 1,444,620,094 | I_kwDODunzps5WGyc- | 5,227 | datasets.data_files.EmptyDatasetError: The directory at wikisql doesn't contain any data files | [] | closed | false | null | 1 | 2022-11-10T21:57:06Z | 2022-11-10T22:05:43Z | 2022-11-10T22:05:43Z | null | ### Describe the bug
From these lines:
from datasets import list_datasets, load_dataset
dataset = load_dataset("wikisql","binary")
I get error message:
datasets.data_files.EmptyDatasetError: The directory at wikisql doesn't contain any data files
And yet the 'wikisql' is reported to exist via the list_datas... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5227/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5227/timeline | null | completed | null | null | false | [
"Fixed. Please close."
] |
https://api.github.com/repos/huggingface/datasets/issues/3871 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3871/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3871/comments | https://api.github.com/repos/huggingface/datasets/issues/3871/events | https://github.com/huggingface/datasets/pull/3871 | 1,163,714,113 | PR_kwDODunzps40KRcM | 3,871 | add pandas to env command | [] | closed | false | null | 2 | 2022-03-09T09:48:51Z | 2022-03-09T11:21:38Z | 2022-03-09T11:21:37Z | null | Pandas is a required packages and used quite a bit. I don't see any downside with adding its version to the `datasets-cli env` command. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3871/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3871/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3871.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3871",
"merged_at": "2022-03-09T11:21:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3871.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_3871). All of your documentation changes will be reflected on that endpoint.",
"Think failures are unrelated - feel free to merge whenever you want :-)"
] |
https://api.github.com/repos/huggingface/datasets/issues/92 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/92/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/92/comments | https://api.github.com/repos/huggingface/datasets/issues/92/events | https://github.com/huggingface/datasets/pull/92 | 617,341,505 | MDExOlB1bGxSZXF1ZXN0NDE3Mjc1ODky | 92 | [WIP] add wmt14 | [] | closed | false | null | 0 | 2020-05-13T10:42:03Z | 2020-05-16T11:17:38Z | 2020-05-16T11:17:37Z | null | WMT14 takes forever to download :-/
- WMT is the first dataset that uses an abstract class IMO, so I had to modify the `load_dataset_module` a bit. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/92/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/92/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/92.diff",
"html_url": "https://github.com/huggingface/datasets/pull/92",
"merged_at": "2020-05-16T11:17:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/92.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/92"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4197 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4197/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4197/comments | https://api.github.com/repos/huggingface/datasets/issues/4197/events | https://github.com/huggingface/datasets/pull/4197 | 1,211,342,558 | PR_kwDODunzps42kyXD | 4,197 | Add remove_columns=True | [] | closed | false | null | 4 | 2022-04-21T17:28:13Z | 2022-04-22T14:51:41Z | 2022-04-22T14:45:30Z | null | This should fix all the issue we have with in place operations in mapping functions. This is crucial as where we do some weird things like:
```
def apply(batch):
batch_size = len(batch["id"])
batch["text"] = ["potato" for _ range(batch_size)]
return {}
# Columns are: {"id": int}
dset.map(apply, bat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4197/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4197/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4197.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4197",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4197.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4197"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Any reason why we can't just do `[inputs.copy()]` in this line for in-place operations to not have effects anymore:\r\nhttps://github.com/huggingface/datasets/blob/bf432011ff9155a5bc16c03956bc63e514baf80d/src/datasets/arrow_dataset.p... |
https://api.github.com/repos/huggingface/datasets/issues/3235 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3235/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3235/comments | https://api.github.com/repos/huggingface/datasets/issues/3235/events | https://github.com/huggingface/datasets/pull/3235 | 1,047,808,263 | PR_kwDODunzps4uPr9Z | 3,235 | Addd options to use updated bleurt checkpoints | [] | closed | false | null | 0 | 2021-11-08T18:53:54Z | 2021-11-12T14:05:28Z | 2021-11-12T14:05:28Z | null | Adds options to use newer recommended checkpoint (as of 2021/10/8) bleurt-20 and its distilled versions.
Updated checkpoints are described in https://github.com/google-research/bleurt/blob/master/checkpoints.md#the-recommended-checkpoint-bleurt-20
This change won't affect the default behavior of metrics/bleurt. ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3235/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3235/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3235.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3235",
"merged_at": "2021-11-12T14:05:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3235.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1376/comments | https://api.github.com/repos/huggingface/datasets/issues/1376/events | https://github.com/huggingface/datasets/pull/1376 | 760,309,300 | MDExOlB1bGxSZXF1ZXN0NTM1MTYyODU4 | 1,376 | Add SETimes Dataset | [] | closed | false | null | 1 | 2020-12-09T13:01:08Z | 2020-12-10T16:11:57Z | 2020-12-10T16:11:56Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1376/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1376.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1376",
"merged_at": "2020-12-10T16:11:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1376.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"merging since the CI is fixed on master"
] | |
https://api.github.com/repos/huggingface/datasets/issues/4927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4927/comments | https://api.github.com/repos/huggingface/datasets/issues/4927/events | https://github.com/huggingface/datasets/pull/4927 | 1,360,428,139 | PR_kwDODunzps4-S0we | 4,927 | fix BLEU metric card | [] | closed | false | null | 0 | 2022-09-02T17:00:56Z | 2022-09-09T16:28:15Z | 2022-09-09T16:28:15Z | null | I've fixed some typos in BLEU metric card. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4927/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4927/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4927.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4927",
"merged_at": "2022-09-09T16:28:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4927.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4002 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4002/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4002/comments | https://api.github.com/repos/huggingface/datasets/issues/4002/events | https://github.com/huggingface/datasets/pull/4002 | 1,179,263,787 | PR_kwDODunzps408Cfp | 4,002 | Support streaming conll2012_ontonotesv5 dataset | [] | closed | false | null | 1 | 2022-03-24T09:49:56Z | 2022-03-24T10:53:41Z | 2022-03-24T10:48:47Z | null | Use another URL whit a single ZIP file (instead of previous one with a ZIP file inside another ZIP file). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4002/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4002/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4002.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4002",
"merged_at": "2022-03-24T10:48:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4002.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4950 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4950/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4950/comments | https://api.github.com/repos/huggingface/datasets/issues/4950/events | https://github.com/huggingface/datasets/pull/4950 | 1,365,458,633 | PR_kwDODunzps4-jWZ1 | 4,950 | Update Enwik8 broken link and information | [] | closed | false | null | 1 | 2022-09-08T03:15:00Z | 2022-09-24T22:14:35Z | 2022-09-08T14:51:00Z | null | The current enwik8 dataset link give a 502 bad gateway error which can be view on https://huggingface.co/datasets/enwik8 (click the dropdown to see the dataset preview, it will show the error). This corrects the links, and json metadata as well as adds a little bit more information about enwik8. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4950/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4950/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4950.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4950",
"merged_at": "2022-09-08T14:51:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4950.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1046 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1046/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1046/comments | https://api.github.com/repos/huggingface/datasets/issues/1046/events | https://github.com/huggingface/datasets/issues/1046 | 756,122,709 | MDU6SXNzdWU3NTYxMjI3MDk= | 1,046 | Dataset.map() turns tensors into lists? | [] | closed | false | null | 2 | 2020-12-03T11:43:46Z | 2022-10-05T12:12:41Z | 2022-10-05T12:12:41Z | null | I apply `Dataset.map()` to a function that returns a dict of torch tensors (like a tokenizer from the repo transformers). However, in the mapped dataset, these tensors have turned to lists!
```import datasets
import torch
from datasets import load_dataset ... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1046/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1046/timeline | null | completed | null | null | false | [
"A solution is to have the tokenizer return a list instead of a tensor, and then use `dataset_tok.set_format(type = 'torch')` to convert that list into a tensor. Still not sure if bug.",
"It is expected behavior, you should set the format to `\"torch\"` as you mentioned to get pytorch tensors back.\r\nBy default ... |
https://api.github.com/repos/huggingface/datasets/issues/1246 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1246/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1246/comments | https://api.github.com/repos/huggingface/datasets/issues/1246/events | https://github.com/huggingface/datasets/pull/1246 | 758,418,652 | MDExOlB1bGxSZXF1ZXN0NTMzNTk0NjIz | 1,246 | arXiv dataset added | [] | closed | false | null | 0 | 2020-12-07T11:20:23Z | 2020-12-07T14:22:58Z | 2020-12-07T14:22:58Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1246/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1246/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1246.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1246",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1246.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1246"
} | true | [] | |
https://api.github.com/repos/huggingface/datasets/issues/5140 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5140/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5140/comments | https://api.github.com/repos/huggingface/datasets/issues/5140/events | https://github.com/huggingface/datasets/pull/5140 | 1,415,075,530 | PR_kwDODunzps5BHTNq | 5,140 | Make the KeyHasher FIPS compliant | [] | closed | false | null | 0 | 2022-10-19T14:25:52Z | 2022-11-07T16:20:43Z | 2022-11-07T16:20:43Z | null | MD5 is not FIPS compliant thus I am proposing this minimal change to make datasets package FIPS compliant | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5140/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5140/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5140.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5140",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5140.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5140"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2586/comments | https://api.github.com/repos/huggingface/datasets/issues/2586/events | https://github.com/huggingface/datasets/pull/2586 | 936,747,588 | MDExOlB1bGxSZXF1ZXN0NjgzNDEwMDU3 | 2,586 | Fix misalignment in SQuAD | [] | closed | false | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/... | 0 | 2021-07-05T06:42:20Z | 2021-07-12T14:11:10Z | 2021-07-07T13:18:51Z | null | Fix misalignment between:
- the answer text and
- the answer_start within the context
by keeping original leading blank spaces in the context.
Fix #2585. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2586/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2586.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2586",
"merged_at": "2021-07-07T13:18:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2586.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4906 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4906/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4906/comments | https://api.github.com/repos/huggingface/datasets/issues/4906/events | https://github.com/huggingface/datasets/issues/4906 | 1,353,223,925 | I_kwDODunzps5QqI71 | 4,906 | Can't import datasets AttributeError: partially initialized module 'datasets' has no attribute 'utils' (most likely due to a circular import) | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2022-08-28T02:23:24Z | 2023-05-13T13:53:30Z | 2022-10-03T12:22:50Z | null | ## Describe the bug
A clear and concise description of what the bug is.
Not able to import datasets
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import os
os.environ["WANDB_API_KEY"] = "0" ## to silence warning
import numpy as np
import random
import sklearn
import matplotlib.p... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4906/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4906/timeline | null | completed | null | null | false | [
"Thanks for reporting, @OPterminator.\r\n\r\nHowever, we are not able to reproduce this issue.\r\n\r\nThere might be 2 reasons why you get this exception:\r\n- Either the name of your local Python file: if it is called `datasets.py` this could generate a circular import when trying to import the Hugging Face `data... |
https://api.github.com/repos/huggingface/datasets/issues/5521 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5521/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5521/comments | https://api.github.com/repos/huggingface/datasets/issues/5521/events | https://github.com/huggingface/datasets/pull/5521 | 1,578,418,289 | PR_kwDODunzps5JpWnp | 5,521 | Fix bug when casting empty array to class labels | [] | closed | false | null | 1 | 2023-02-09T18:47:59Z | 2023-02-13T20:40:48Z | 2023-02-12T11:17:17Z | null | Fix https://github.com/huggingface/datasets/issues/5520. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5521/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5521/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5521.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5521",
"merged_at": "2023-02-12T11:17:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5521.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4861 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4861/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4861/comments | https://api.github.com/repos/huggingface/datasets/issues/4861/events | https://github.com/huggingface/datasets/issues/4861 | 1,343,260,220 | I_kwDODunzps5QEIY8 | 4,861 | Using disk for memory with the method `from_dict` | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 1 | 2022-08-18T15:18:18Z | 2023-01-26T18:36:28Z | null | null | **Is your feature request related to a problem? Please describe.**
I start with an empty dataset. In a loop, at each iteration, I create a new dataset with the method `from_dict` (based on some data I load) and I concatenate this new dataset with the one at the previous iteration. After some iterations, I have an OOM ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4861/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4861/timeline | null | null | null | null | false | [
"This issue was also causing an OOM in @nateraw 's workflow and shows again that behavior is confusing - we should definitely switch to using the disk IMO"
] |
https://api.github.com/repos/huggingface/datasets/issues/4103 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4103/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4103/comments | https://api.github.com/repos/huggingface/datasets/issues/4103/events | https://github.com/huggingface/datasets/pull/4103 | 1,193,987,104 | PR_kwDODunzps41s3T4 | 4,103 | Add the `GSM8K` dataset | [] | closed | false | null | 2 | 2022-04-06T04:07:52Z | 2022-04-12T15:38:28Z | 2022-04-12T10:21:16Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4103/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4103/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4103.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4103",
"merged_at": "2022-04-12T10:21:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4103.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The CI is failing because it's outdated, but the task tags are updated on `master`, merging :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4877 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4877/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4877/comments | https://api.github.com/repos/huggingface/datasets/issues/4877/events | https://github.com/huggingface/datasets/pull/4877 | 1,348,246,755 | PR_kwDODunzps49qF-w | 4,877 | Fix documentation card of covid_qa_castorini dataset | [] | closed | false | null | 1 | 2022-08-23T16:52:33Z | 2022-08-23T18:05:01Z | 2022-08-23T18:05:00Z | null | Fix documentation card of covid_qa_castorini dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4877/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4877/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4877.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4877",
"merged_at": "2022-08-23T18:05:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4877.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4877). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/5878 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5878/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5878/comments | https://api.github.com/repos/huggingface/datasets/issues/5878/events | https://github.com/huggingface/datasets/issues/5878 | 1,718,203,843 | I_kwDODunzps5mabXD | 5,878 | Prefetching for IterableDataset | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 5 | 2023-05-20T15:25:40Z | 2023-06-01T17:40:00Z | null | null | ### Feature request
Add support for prefetching the next n batches through iterabledataset to reduce batch loading bottleneck in training loop.
### Motivation
The primary motivation behind this is to use hardware accelerators alongside a streaming dataset. This is required when you are in a low ram or low disk... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5878/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5878/timeline | null | null | null | null | false | [
"Very cool! Do you have a link to the code that you're using to eagerly fetch the data? Would also be interested in hacking around something here for pre-fetching iterable datasets",
"I ended up just switching back to the pytorch dataloader and using it's multiprocessing functionality to handle this :(. I'm just ... |
https://api.github.com/repos/huggingface/datasets/issues/5268 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5268/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5268/comments | https://api.github.com/repos/huggingface/datasets/issues/5268/events | https://github.com/huggingface/datasets/pull/5268 | 1,455,633,978 | PR_kwDODunzps5DPIsp | 5,268 | Sharded save_to_disk + multiprocessing | [] | closed | false | null | 4 | 2022-11-18T18:50:01Z | 2022-12-14T18:25:52Z | 2022-12-14T18:22:58Z | null | Added `num_shards=` and `num_proc=` to `save_to_disk()`
EDIT: also added `max_shard_size=` to `save_to_disk()`, and also `num_shards=` to `push_to_hub`
I also:
- deprecated the fs parameter in favor of storage_options (for consistency with the rest of the lib) in save_to_disk and load_from_disk
- always embed t... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5268/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5268/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5268.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5268",
"merged_at": "2022-12-14T18:22:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5268.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Added both num_shards and max_shard_size in push_to_hub/save_to_disk. Will take care of updating the tests later",
"It's ready for a final review @mariosasko and @albertvillanova, let me know what you think :)",
"Took your commen... |
https://api.github.com/repos/huggingface/datasets/issues/5257 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5257/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5257/comments | https://api.github.com/repos/huggingface/datasets/issues/5257/events | https://github.com/huggingface/datasets/pull/5257 | 1,452,656,891 | PR_kwDODunzps5DFENm | 5,257 | remove an unused statement | [] | closed | false | null | 0 | 2022-11-17T04:00:50Z | 2022-11-18T11:04:08Z | 2022-11-18T11:04:08Z | null | remove the unused statement: `input_pairs = list(zip())` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5257/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5257/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5257.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5257",
"merged_at": "2022-11-18T11:04:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5257.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4886 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4886/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4886/comments | https://api.github.com/repos/huggingface/datasets/issues/4886/events | https://github.com/huggingface/datasets/issues/4886 | 1,349,285,569 | I_kwDODunzps5QbHbB | 4,886 | Loading huggan/CelebA-HQ throws pyarrow.lib.ArrowInvalid | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 9 | 2022-08-24T11:24:21Z | 2023-02-02T02:40:53Z | null | null | ## Describe the bug
Loading huggan/CelebA-HQ throws pyarrow.lib.ArrowInvalid
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset('huggan/CelebA-HQ')
```
## Expected results
See https://colab.research.google.com/drive/141LJCcM2XyqprPY83nIQ-Zk3BbxWeahq?usp=sharing#... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4886/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4886/timeline | null | null | null | null | false | [
"Hi! IIRC one of the files in this dataset is corrupted due to https://github.com/huggingface/datasets/pull/4081 (fixed now).\r\n\r\n@NielsRogge Could you please re-generate and re-push this dataset (or I can do it if you share the generation script)?",
"Could you put something in place to catch these problems? ... |
https://api.github.com/repos/huggingface/datasets/issues/2568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2568/comments | https://api.github.com/repos/huggingface/datasets/issues/2568/events | https://github.com/huggingface/datasets/pull/2568 | 932,934,795 | MDExOlB1bGxSZXF1ZXN0NjgwMjE5MDU2 | 2,568 | Add interleave_datasets for map-style datasets | [] | closed | false | null | 0 | 2021-06-29T17:19:24Z | 2021-07-01T09:33:34Z | 2021-07-01T09:33:33Z | null | ### Add interleave_datasets for map-style datasets
Add support for map-style datasets (i.e. `Dataset` objects) in `interleave_datasets`.
It was only supporting iterable datasets (i.e. `IterableDataset` objects).
### Implementation details
It works by concatenating the datasets and then re-order the indices to... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2568/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2568/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2568.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2568",
"merged_at": "2021-07-01T09:33:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2568.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5079 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5079/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5079/comments | https://api.github.com/repos/huggingface/datasets/issues/5079/events | https://github.com/huggingface/datasets/pull/5079 | 1,398,609,305 | PR_kwDODunzps5AQemi | 5,079 | refactor: replace AssertionError with more meaningful exceptions (#5074) | [] | closed | false | null | 1 | 2022-10-06T01:39:35Z | 2022-10-07T14:35:43Z | 2022-10-07T14:33:10Z | null | Closes #5074
Replaces `AssertionError` in the following files with more descriptive exceptions:
- `src/datasets/arrow_reader.py`
- `src/datasets/builder.py`
- `src/datasets/utils/version.py`
The issue listed more files that needed to be fixed, but the rest of them were contained in the top-level `datasets` d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5079/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5079/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5079.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5079",
"merged_at": "2022-10-07T14:33:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5079.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3/comments | https://api.github.com/repos/huggingface/datasets/issues/3/events | https://github.com/huggingface/datasets/issues/3 | 600,180,050 | MDU6SXNzdWU2MDAxODAwNTA= | 3 | [Feature] More dataset outputs | [] | closed | false | null | 3 | 2020-04-15T10:08:14Z | 2020-05-04T06:12:27Z | 2020-05-04T06:12:27Z | null | Add the following dataset outputs:
- Spark
- Pandas | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3/timeline | null | completed | null | null | false | [
"Yes!\r\n- pandas will be a one-liner in `arrow_dataset`: https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_pandas\r\n- for Spark I have no idea. let's investigate that at some point",
"For Spark it looks to be pretty straightforward as well https://spark.apache.org/docs/latest/sq... |
https://api.github.com/repos/huggingface/datasets/issues/17 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/17/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/17/comments | https://api.github.com/repos/huggingface/datasets/issues/17/events | https://github.com/huggingface/datasets/pull/17 | 605,753,027 | MDExOlB1bGxSZXF1ZXN0NDA4MDk3NjM0 | 17 | Add Pandas as format type | [] | closed | false | null | 0 | 2020-04-23T18:20:14Z | 2020-04-27T18:07:50Z | 2020-04-27T18:07:48Z | null | As detailed in the title ^^ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/17/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/17/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/17.diff",
"html_url": "https://github.com/huggingface/datasets/pull/17",
"merged_at": "2020-04-27T18:07:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/17.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/17"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5574/comments | https://api.github.com/repos/huggingface/datasets/issues/5574/events | https://github.com/huggingface/datasets/issues/5574 | 1,598,104,691 | I_kwDODunzps5fQSRz | 5,574 | c4 dataset streaming fails with `FileNotFoundError` | [] | closed | false | null | 9 | 2023-02-24T07:57:32Z | 2023-03-06T13:14:11Z | 2023-02-27T04:03:38Z | null | ### Describe the bug
Loading the `c4` dataset in streaming mode with `load_dataset("c4", "en", split="validation", streaming=True)` and then using it fails with a `FileNotFoundException`.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("c4", "en", split="train", ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5574/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5574/timeline | null | completed | null | null | false | [
"Also encountering this issue for every dataset I try to stream! Installed datasets from main:\r\n```\r\n- `datasets` version: 2.10.1.dev0\r\n- Platform: macOS-13.1-arm64-arm-64bit\r\n- Python version: 3.9.13\r\n- PyArrow version: 10.0.1\r\n- Pandas version: 1.5.2\r\n```\r\n\r\nRepro:\r\n```python\r\nfrom datasets ... |
https://api.github.com/repos/huggingface/datasets/issues/1177 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1177/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1177/comments | https://api.github.com/repos/huggingface/datasets/issues/1177/events | https://github.com/huggingface/datasets/pull/1177 | 757,778,684 | MDExOlB1bGxSZXF1ZXN0NTMzMDkxMTQ3 | 1,177 | Add Korean NER dataset | [] | closed | false | null | 1 | 2020-12-05T20:56:00Z | 2020-12-06T20:19:48Z | 2020-12-06T20:19:48Z | null | This PR adds the [Korean named entity recognition dataset](https://github.com/kmounlp/NER). This dataset has been used in many downstream tasks, such as training [KoBERT](https://github.com/SKTBrain/KoBERT) for NER, as seen in this [KoBERT-CRF implementation](https://github.com/eagle705/pytorch-bert-crf-ner). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1177/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1177/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1177.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1177",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1177.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1177"
} | true | [
"Closed via #1219 "
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.