
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.83B | node_id stringlengths 18 32 | number int64 1 6.09k | title stringlengths 1 290 | labels list | state stringclasses 2
values | locked bool 1
class | milestone dict | comments int64 0 54 | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | closed_at stringlengths 20 20 ⌀ | active_lock_reason null | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 3
values | draft bool 2
classes | pull_request dict | is_pull_request bool 2
classes | comments_text list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4180 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4180/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4180/comments | https://api.github.com/repos/huggingface/datasets/issues/4180/events | https://github.com/huggingface/datasets/issues/4180 | 1,208,042,320 | I_kwDODunzps5IAUNQ | 4,180 | Add some iteration method on a dataset column (specific for inference) | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 5 | 2022-04-19T09:15:45Z | 2022-04-21T10:30:58Z | null | null | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is.
Currently, `dataset["audio"]` will load EVERY element in the dataset in RAM, which can be quite big for an audio dataset.
Having an iterator (or sequence) type of object, would make inference ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4180/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4180/timeline | null | null | null | null | false | [
"Thanks for the suggestion ! I agree it would be nice to have something directly in `datasets` to do something as simple as that\r\n\r\ncc @albertvillanova @mariosasko @polinaeterna What do you think if we have something similar to pandas `Series` that wouldn't bring everything in memory when doing `dataset[\"audio... |
https://api.github.com/repos/huggingface/datasets/issues/2046 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2046/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2046/comments | https://api.github.com/repos/huggingface/datasets/issues/2046/events | https://github.com/huggingface/datasets/issues/2046 | 830,423,033 | MDU6SXNzdWU4MzA0MjMwMzM= | 2,046 | add_faisis_index gets very slow when doing it interatively | [] | closed | false | null | 11 | 2021-03-12T20:27:18Z | 2021-03-24T22:29:11Z | 2021-03-24T22:29:11Z | null | As the below code suggests, I want to run add_faisis_index in every nth interaction from the training loop. I have 7.2 million documents. Usually, it takes 2.5 hours (if I run an as a separate process similar to the script given in rag/use_own_knowleldge_dataset.py). Now, this takes usually 5hrs. Is this normal? Any ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2046/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2046/timeline | null | completed | null | null | false | [
"I think faiss automatically sets the number of threads to use to build the index.\r\nCan you check how many CPU cores are being used when you build the index in `use_own_knowleldge_dataset` as compared to this script ? Are there other programs running (maybe for rank>0) ?",
"Hi,\r\n I am running the add_faiss_in... |
https://api.github.com/repos/huggingface/datasets/issues/1550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1550/comments | https://api.github.com/repos/huggingface/datasets/issues/1550/events | https://github.com/huggingface/datasets/pull/1550 | 765,620,925 | MDExOlB1bGxSZXF1ZXN0NTM5MDEwMDY1 | 1,550 | Add offensive langauge dravidian dataset | [] | closed | false | null | 1 | 2020-12-13T19:54:19Z | 2020-12-18T15:52:49Z | 2020-12-18T14:25:30Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1550/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1550/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1550.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1550",
"merged_at": "2020-12-18T14:25:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1550.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Thanks much!"
] | |
https://api.github.com/repos/huggingface/datasets/issues/4636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4636/comments | https://api.github.com/repos/huggingface/datasets/issues/4636/events | https://github.com/huggingface/datasets/issues/4636 | 1,294,547,836 | I_kwDODunzps5NKTt8 | 4,636 | Add info in docs about behavior of download_config.num_proc | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 0 | 2022-07-05T17:01:00Z | 2022-07-28T10:40:32Z | 2022-07-28T10:40:32Z | null | **Is your feature request related to a problem? Please describe.**
I went to override `download_config.num_proc` and was confused about what was happening under the hood. It would be nice to have the behavior documented a bit better so folks know what's happening when they use it.
**Describe the solution you'd li... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4636/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4636/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2468 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2468/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2468/comments | https://api.github.com/repos/huggingface/datasets/issues/2468/events | https://github.com/huggingface/datasets/pull/2468 | 916,427,320 | MDExOlB1bGxSZXF1ZXN0NjY2MDk0ODI5 | 2,468 | Implement ClassLabel encoding in JSON loader | [] | closed | false | {
"closed_at": "2021-07-09T05:50:07Z",
"closed_issues": 12,
"created_at": "2021-05-31T16:13:06Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/... | 1 | 2021-06-09T17:08:54Z | 2021-06-28T15:39:54Z | 2021-06-28T15:05:35Z | null | Close #2365. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2468/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2468/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2468.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2468",
"merged_at": "2021-06-28T15:05:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2468.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"No, nevermind @lhoestq. Thanks to you for your reviews!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1210 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1210/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1210/comments | https://api.github.com/repos/huggingface/datasets/issues/1210/events | https://github.com/huggingface/datasets/pull/1210 | 757,966,959 | MDExOlB1bGxSZXF1ZXN0NTMzMjI2NDQ2 | 1,210 | Add XSUM Hallucination Annotations Dataset | [] | closed | false | null | 1 | 2020-12-06T16:40:19Z | 2020-12-20T13:34:56Z | 2020-12-16T16:57:11Z | null | Adding Google [XSum Hallucination Annotations](https://github.com/google-research-datasets/xsum_hallucination_annotations) dataset. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1210/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1210/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1210.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1210",
"merged_at": "2020-12-16T16:57:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1210.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"@lhoestq All necessary modifications have been done."
] |
https://api.github.com/repos/huggingface/datasets/issues/222 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/222/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/222/comments | https://api.github.com/repos/huggingface/datasets/issues/222/events | https://github.com/huggingface/datasets/issues/222 | 627,586,690 | MDU6SXNzdWU2Mjc1ODY2OTA= | 222 | Colab Notebook breaks when downloading the squad dataset | [] | closed | false | null | 6 | 2020-05-29T22:55:59Z | 2020-06-04T00:21:05Z | 2020-06-04T00:21:05Z | null | When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:
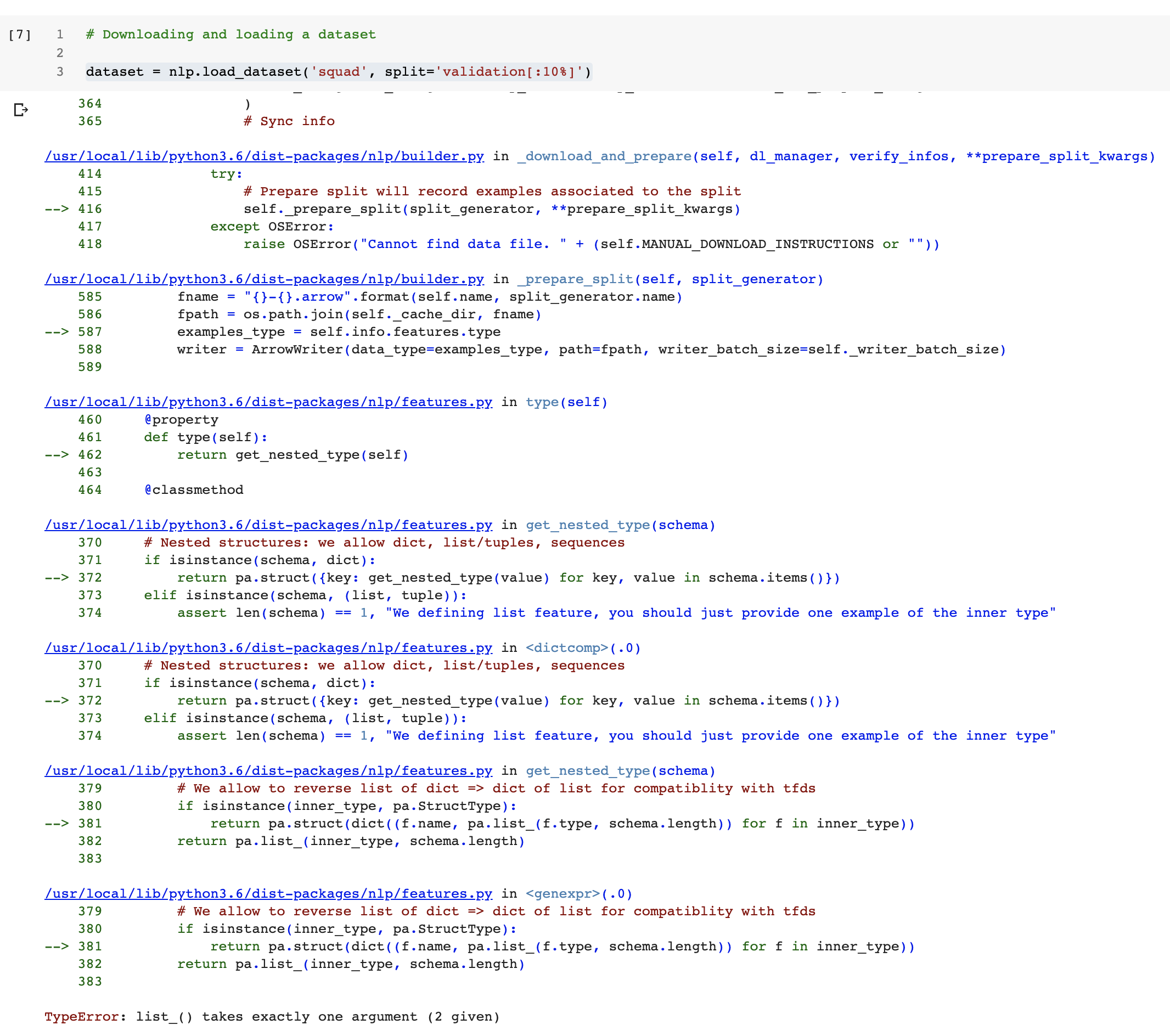
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/222/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/222/timeline | null | completed | null | null | false | [
"The notebook forces version 0.1.0. If I use the latest, things work, I'll run the whole notebook and create a PR.\r\n\r\nBut in the meantime, this issue gets fixed by changing:\r\n`!pip install nlp==0.1.0`\r\nto\r\n`!pip install nlp`",
"It still breaks very near the end\r\n\r\n says \r\n> Datasets is tested on Python 3.7+.\r\n\r\nb... |
https://api.github.com/repos/huggingface/datasets/issues/4413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4413/comments | https://api.github.com/repos/huggingface/datasets/issues/4413/events | https://github.com/huggingface/datasets/issues/4413 | 1,250,259,822 | I_kwDODunzps5KhXNu | 4,413 | Dataset Viewer issue for ett | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 3 | 2022-05-27T02:12:35Z | 2022-06-15T07:30:46Z | 2022-06-15T07:30:46Z | null | ### Link
https://huggingface.co/datasets/ett
### Description
Timestamp is not JSON serializable.
```
Status code: 500
Exception: Status500Error
Message: Type is not JSON serializable: Timestamp
```
### Owner
No | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4413/timeline | null | completed | null | null | false | [
"Thanks for reporting @dgcnz.\r\n\r\nI have checked that the dataset works fine in streaming mode.\r\n\r\nAdditionally, other datasets containing timestamps are properly rendered by the viewer: https://huggingface.co/datasets/blbooks\r\n\r\nI have tried to force the refresh of the preview, but the endpoint is not r... |
https://api.github.com/repos/huggingface/datasets/issues/3253 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3253/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3253/comments | https://api.github.com/repos/huggingface/datasets/issues/3253/events | https://github.com/huggingface/datasets/issues/3253 | 1,051,308,972 | I_kwDODunzps4-qbOs | 3,253 | `GeneratorBasedBuilder` does not support `None` values | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-11-11T19:51:21Z | 2021-12-09T14:26:58Z | 2021-12-09T14:26:58Z | null | ## Describe the bug
`GeneratorBasedBuilder` does not support `None` values.
## Steps to reproduce the bug
See [this repository](https://github.com/pavel-lexyr/huggingface-datasets-bug-reproduction) for minimal reproduction.
## Expected results
Dataset is initialized with a `None` value in the `value` column.
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3253/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3253/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\nthanks for reporting and providing a minimal reproducible example. \r\n\r\nThis line of the PR I've linked in our discussion on the Forum will add support for `None` values:\r\nhttps://github.com/huggingface/datasets/blob/a53de01842aac65c66a49b2439e18fa93ff73ceb/src/datasets/features/features.py#L835\r\... |
https://api.github.com/repos/huggingface/datasets/issues/1854 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1854/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1854/comments | https://api.github.com/repos/huggingface/datasets/issues/1854/events | https://github.com/huggingface/datasets/issues/1854 | 805,204,397 | MDU6SXNzdWU4MDUyMDQzOTc= | 1,854 | Feature Request: Dataset.add_item | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 3 | 2021-02-10T06:06:00Z | 2021-04-23T10:01:30Z | 2021-04-23T10:01:30Z | null | I'm trying to integrate `huggingface/datasets` functionality into `fairseq`, which requires (afaict) being able to build a dataset through an `add_item` method, such as https://github.com/pytorch/fairseq/blob/master/fairseq/data/indexed_dataset.py#L318, as opposed to loading all the text into arrow, and then `dataset.m... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1854/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1854/timeline | null | completed | null | null | false | [
"Hi @sshleifer.\r\n\r\nI am not sure of understanding the need of the `add_item` approach...\r\n\r\nBy just reading your \"Desired API\" section, I would say you could (nearly) get it with a 1-column Dataset:\r\n```python\r\ndata = {\"input_ids\": [np.array([4,4,2]), np.array([8,6,5,5,2]), np.array([3,3,31,5])]}\r\... |
https://api.github.com/repos/huggingface/datasets/issues/4583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4583/comments | https://api.github.com/repos/huggingface/datasets/issues/4583/events | https://github.com/huggingface/datasets/pull/4583 | 1,286,790,871 | PR_kwDODunzps46d7xo | 4,583 | <code> implementation of FLAC support using torchaudio | [] | closed | false | null | 0 | 2022-06-28T05:24:21Z | 2022-06-28T05:47:02Z | 2022-06-28T05:47:02Z | null | I had added Audio FLAC support with torchaudio given that Librosa and SoundFile can give problems. Also, FLAC is been used as audio from https://mlcommons.org/en/peoples-speech/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4583/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4583",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4583"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4037 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4037/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4037/comments | https://api.github.com/repos/huggingface/datasets/issues/4037/events | https://github.com/huggingface/datasets/issues/4037 | 1,183,144,486 | I_kwDODunzps5GhVom | 4,037 | Error while building documentation | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-03-28T09:22:44Z | 2022-03-28T10:01:52Z | 2022-03-28T10:00:48Z | null | ## Describe the bug
Documentation building is failing:
- https://github.com/huggingface/datasets/runs/5716300989?check_suite_focus=true
```
ValueError: There was an error when converting ../datasets/docs/source/package_reference/main_classes.mdx to the MDX format.
Unable to find datasets.filesystems.S3FileSystem... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4037/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4037/timeline | null | completed | null | null | false | [
"After some investigation, maybe the bug is in `doc-builder`.\r\n\r\nI've opened an issue there:\r\n- huggingface/doc-builder#160",
"Fixed by @lewtun (thank you):\r\n- huggingface/doc-builder@31fe6c8bc7225810e281c2f6c6cd32f38828c504"
] |
https://api.github.com/repos/huggingface/datasets/issues/1822 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1822/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1822/comments | https://api.github.com/repos/huggingface/datasets/issues/1822/events | https://github.com/huggingface/datasets/pull/1822 | 802,003,835 | MDExOlB1bGxSZXF1ZXN0NTY4MjIxMzIz | 1,822 | Add Hindi Discourse Analysis Natural Language Inference Dataset | [] | closed | false | null | 2 | 2021-02-05T09:30:54Z | 2021-02-15T09:57:39Z | 2021-02-15T09:57:39Z | null | # Dataset Card for Hindi Discourse Analysis Dataset
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1822/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1822/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1822.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1822",
"merged_at": "2021-02-15T09:57:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1822.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Could you also run `make style` to fix the CI check on code formatting ?",
"@lhoestq completed and resolved all comments."
] |
https://api.github.com/repos/huggingface/datasets/issues/265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/265/comments | https://api.github.com/repos/huggingface/datasets/issues/265/events | https://github.com/huggingface/datasets/pull/265 | 637,139,220 | MDExOlB1bGxSZXF1ZXN0NDMzMTgxNDMz | 265 | Add pyarrow warning colab | [] | closed | false | null | 0 | 2020-06-11T15:57:51Z | 2020-08-02T18:14:36Z | 2020-06-12T08:14:16Z | null | When a user installs `nlp` on google colab, then google colab doesn't update pyarrow, and the runtime needs to be restarted to use the updated version of pyarrow.
This is an issue because `nlp` requires the updated version to work correctly.
In this PR I added en error that is shown to the user in google colab if... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/265/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/265",
"merged_at": "2020-06-12T08:14:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/265... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/415/comments | https://api.github.com/repos/huggingface/datasets/issues/415/events | https://github.com/huggingface/datasets/issues/415 | 660,687,076 | MDU6SXNzdWU2NjA2ODcwNzY= | 415 | Something is wrong with WMT 19 kk-en dataset | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | open | false | null | 0 | 2020-07-19T08:18:51Z | 2020-07-20T09:54:26Z | null | null | The translation in the `train` set does not look right:
```
>>>import nlp
>>>from nlp import load_dataset
>>>dataset = load_dataset('wmt19', 'kk-en')
>>>dataset["train"]["translation"][0]
{'kk': 'Trumpian Uncertainty', 'en': 'Трамптық белгісіздік'}
>>>dataset["validation"]["translation"][0]
{'kk': 'Ақша-несие... | {
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/415/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4087/comments | https://api.github.com/repos/huggingface/datasets/issues/4087/events | https://github.com/huggingface/datasets/pull/4087 | 1,191,819,805 | PR_kwDODunzps41lnfO | 4,087 | Fix BeamWriter output Parquet file | [] | closed | false | null | 1 | 2022-04-04T13:46:50Z | 2022-04-05T15:00:40Z | 2022-04-05T14:54:48Z | null | Since now, the `BeamWriter` saved a Parquet file with a simplified schema, where each field value was serialized to JSON. That resulted in Parquet files larger than Arrow files.
This PR:
- writes Parquet file preserving original schema and without serialization, thus avoiding serialization overhead and resulting in... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4087/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4087/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4087.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4087",
"merged_at": "2022-04-05T14:54:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4087.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3270 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3270/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3270/comments | https://api.github.com/repos/huggingface/datasets/issues/3270/events | https://github.com/huggingface/datasets/pull/3270 | 1,053,465,662 | PR_kwDODunzps4uhcxm | 3,270 | Add os.listdir for streaming | [] | closed | false | null | 0 | 2021-11-15T10:14:04Z | 2021-11-15T10:27:03Z | 2021-11-15T10:27:03Z | null | Extend `os.listdir` to support streaming data from remote files. This is often used to navigate in remote ZIP files for example | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3270/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3270/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3270.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3270",
"merged_at": "2021-11-15T10:27:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3270.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5504 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5504/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5504/comments | https://api.github.com/repos/huggingface/datasets/issues/5504/events | https://github.com/huggingface/datasets/pull/5504 | 1,570,621,242 | PR_kwDODunzps5JPoWy | 5,504 | don't zero copy timestamps | [] | closed | false | null | 3 | 2023-02-03T23:39:04Z | 2023-02-08T17:28:50Z | 2023-02-08T14:33:17Z | null | Fixes https://github.com/huggingface/datasets/issues/5495
I'm not sure whether we prefer a test here or if timestamps are known to be unsupported (like booleans). The current test at least covers the bug | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5504/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5504/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5504.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5504",
"merged_at": "2023-02-08T14:33:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5504.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/225 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/225/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/225/comments | https://api.github.com/repos/huggingface/datasets/issues/225/events | https://github.com/huggingface/datasets/issues/225 | 628,083,366 | MDU6SXNzdWU2MjgwODMzNjY= | 225 | [ROUGE] Different scores with `files2rouge` | [
{
"color": "d722e8",
"default": false,
"description": "Discussions on the metrics",
"id": 2067400959,
"name": "Metric discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwOTU5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Metric%20discussion"
}
] | closed | false | null | 3 | 2020-06-01T00:50:36Z | 2020-06-03T15:27:18Z | 2020-06-03T15:27:18Z | null | It seems that the ROUGE score of `nlp` is lower than the one of `files2rouge`.
Here is a self-contained notebook to reproduce both scores : https://colab.research.google.com/drive/14EyAXValB6UzKY9x4rs_T3pyL7alpw_F?usp=sharing
---
`nlp` : (Only mid F-scores)
>rouge1 0.33508031962733364
rouge2 0.145743337761... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/225/timeline | null | completed | null | null | false | [
"@Colanim unfortunately there are different implementations of the ROUGE metric floating around online which yield different results, and we had to chose one for the package :) We ended up including the one from the google-research repository, which does minimal post-processing before computing the P/R/F scores. If... |
https://api.github.com/repos/huggingface/datasets/issues/5175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5175/comments | https://api.github.com/repos/huggingface/datasets/issues/5175/events | https://github.com/huggingface/datasets/issues/5175 | 1,428,696,231 | I_kwDODunzps5VKCyn | 5,175 | Loading an external NER dataset | [] | closed | false | null | 0 | 2022-10-30T09:31:55Z | 2022-11-01T13:15:49Z | 2022-11-01T13:15:49Z | null | I need to use huggingface datasets to load a custom dataset similar to conll2003 but with more entities and each the files contain only two columns: word and ner tag.
I tried this code snnipet that I found here as an answer to a similar issue:
from datasets import Dataset
INPUT_COLUMNS = "ID Text NER".split()
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5175/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5175/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5562/comments | https://api.github.com/repos/huggingface/datasets/issues/5562/events | https://github.com/huggingface/datasets/pull/5562 | 1,594,625,539 | PR_kwDODunzps5KfTUT | 5,562 | Update csv.py | [] | closed | false | null | 4 | 2023-02-22T07:56:10Z | 2023-02-23T11:07:49Z | 2023-02-23T11:00:58Z | null | Removed mangle_dup_cols=True from BuilderConfig.
It triggered following deprecation warning:
/usr/local/lib/python3.8/dist-packages/datasets/download/streaming_download_manager.py:776: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5562/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5562/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5562.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5562",
"merged_at": "2023-02-23T11:00:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5562.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Removed it :)",
"Changed it :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_format... |
https://api.github.com/repos/huggingface/datasets/issues/676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/676/comments | https://api.github.com/repos/huggingface/datasets/issues/676/events | https://github.com/huggingface/datasets/issues/676 | 710,014,319 | MDU6SXNzdWU3MTAwMTQzMTk= | 676 | train_test_split returns empty dataset item | [] | closed | false | null | 4 | 2020-09-28T07:19:33Z | 2020-10-07T13:46:33Z | 2020-10-07T13:38:06Z | null | I try to split my dataset by `train_test_split`, but after that the item in `train` and `test` `Dataset` is empty.
The codes:
```
yelp_data = datasets.load_from_disk('/home/ssd4/huanglianzhe/test_yelp')
print(yelp_data[0])
yelp_data = yelp_data.train_test_split(test_size=0.1)
print(yelp_data)
pri... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/676/timeline | null | completed | null | null | false | [
"The problem still exists after removing the cache files.",
"Can you reproduce this example in a Colab so we can investigate? (or give more information on your software/hardware config)",
"Thanks for reporting.\r\nI just found the issue, I'm creating a PR",
"We'll do a release pretty soon to include the fix :... |
https://api.github.com/repos/huggingface/datasets/issues/4081 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4081/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4081/comments | https://api.github.com/repos/huggingface/datasets/issues/4081/events | https://github.com/huggingface/datasets/pull/4081 | 1,189,916,472 | PR_kwDODunzps41fsxW | 4,081 | Close parquet writer properly in `push_to_hub` | [] | closed | false | null | 2 | 2022-04-01T14:58:50Z | 2022-07-14T19:22:06Z | 2022-04-01T16:16:19Z | null | We don’t call writer.close(), which causes https://github.com/huggingface/datasets/issues/4077. It can happen that we upload the file before the writer is garbage collected and writes the footer.
I fixed this by explicitly closing the parquet writer.
Close https://github.com/huggingface/datasets/issues/4077. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4081/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4081/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4081.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4081",
"merged_at": "2022-04-01T16:16:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4081.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq / @albertvillanova / @mariosasko \r\nI am facing the same scenario. Let me explain the situation point. I have a glue ETL job\r\n\r\n1--> My files are in parquet format and stored in AWS s3.\r\n2--> I am iterating a loop fo... |
https://api.github.com/repos/huggingface/datasets/issues/3333 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3333/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3333/comments | https://api.github.com/repos/huggingface/datasets/issues/3333/events | https://github.com/huggingface/datasets/issues/3333 | 1,065,346,919 | I_kwDODunzps4_f-dn | 3,333 | load JSON files, get the errors | [] | closed | false | null | 12 | 2021-11-28T14:29:58Z | 2021-12-01T09:34:31Z | 2021-12-01T03:57:48Z | null | Hi, does this bug be fixed? when I load JSON files, I get the same errors by the command
`!python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_dir ./re_trained_model/`
change the dateset to load json by refering to https://huggingface.co/docs/datasets/loading.html
`dataset = ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3333/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3333/timeline | null | completed | null | null | false | [
"Hi ! The message you're getting is not an error. It simply says that your JSON dataset is being prepared to a location in `/root/.cache/huggingface/datasets`",
"> \r\n\r\nbut I want to load local JSON file by command\r\n`python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_di... |
https://api.github.com/repos/huggingface/datasets/issues/550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/550/comments | https://api.github.com/repos/huggingface/datasets/issues/550/events | https://github.com/huggingface/datasets/pull/550 | 689,775,914 | MDExOlB1bGxSZXF1ZXN0NDc2NzgyNDY1 | 550 | [BUGFIX] Solving mismatched checksum issue for the LinCE dataset (#539) | [] | closed | false | null | 2 | 2020-09-01T03:27:03Z | 2020-09-03T09:06:01Z | 2020-09-03T09:06:01Z | null | Hi,
I have added the updated `dataset_infos.json` file for the LinCE benchmark. This update is to fix the mismatched checksum bug #539 for one of the datasets in the LinCE benchmark. To update the file, I run this command from the nlp root directory:
```
python nlp-cli test ./datasets/lince --save_infos --all_co... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/550/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/550/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/550.diff",
"html_url": "https://github.com/huggingface/datasets/pull/550",
"merged_at": "2020-09-03T09:06:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/550.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/550... | true | [
"Thanks a lot for that!\r\nThe line you are mentioning is a bug indeed, do you mind fixing it at the same time?",
"No worries! \r\n\r\nI pushed right away the fix, but then I realized that the master branch already had it, so I ended up merging the master branch with lince locally and then overwriting the previou... |
https://api.github.com/repos/huggingface/datasets/issues/4625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4625/comments | https://api.github.com/repos/huggingface/datasets/issues/4625/events | https://github.com/huggingface/datasets/pull/4625 | 1,293,163,744 | PR_kwDODunzps46zELz | 4,625 | Unpack `dl_manager.iter_files` to allow parallization | [] | closed | false | null | 2 | 2022-07-04T13:16:58Z | 2022-07-05T11:11:54Z | 2022-07-05T11:00:48Z | null | Iterate over data files outside `dl_manager.iter_files` to allow parallelization in streaming mode.
(The issue reported [here](https://discuss.huggingface.co/t/dataset-only-have-n-shard-1-when-has-multiple-shards-in-repo/19887))
PS: Another option would be to override `FilesIterable.__getitem__` to make it indexa... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4625/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4625.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4625",
"merged_at": "2022-07-05T11:00:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4625.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool thanks ! Yup it sounds like the right solution.\r\n\r\nIt looks like `_generate_tables` needs to be updated as well to fix the CI"
] |
https://api.github.com/repos/huggingface/datasets/issues/1991 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1991/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1991/comments | https://api.github.com/repos/huggingface/datasets/issues/1991/events | https://github.com/huggingface/datasets/pull/1991 | 822,554,473 | MDExOlB1bGxSZXF1ZXN0NTg1MTYwNDkx | 1,991 | Adding the conllpp dataset | [] | closed | false | null | 1 | 2021-03-04T22:19:43Z | 2021-03-17T10:37:39Z | 2021-03-17T10:37:39Z | null | Adding the conllpp dataset, is a revision from https://github.com/huggingface/datasets/pull/1910. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1991/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1991/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1991.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1991",
"merged_at": "2021-03-17T10:37:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1991.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"Thanks for the reviews! A note that I have addressed the comments, and waiting for a further review."
] |
https://api.github.com/repos/huggingface/datasets/issues/228 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/228/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/228/comments | https://api.github.com/repos/huggingface/datasets/issues/228/events | https://github.com/huggingface/datasets/issues/228 | 629,952,402 | MDU6SXNzdWU2Mjk5NTI0MDI= | 228 | Not able to access the XNLI dataset | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | 4 | 2020-06-03T12:25:14Z | 2020-07-17T17:44:22Z | 2020-07-17T17:44:22Z | null | When I try to access the XNLI dataset, I get the following error. The option of plain_text get selected automatically and then I get the following error.
```
FileNotFoundError: [Errno 2] No such file or directory: '/home/sasha/.cache/huggingface/datasets/xnli/plain_text/1.0.0/dataset_info.json'
Traceback:
File "/... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/228/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/228/timeline | null | completed | null | null | false | [
"Added pull request to change the name of the file from dataset_infos.json to dataset_info.json",
"Thanks for reporting this bug !\r\nAs it seems to be just a cache problem, I closed your PR.\r\nI think we might just need to clear and reload the `xnli` cache @srush ? ",
"Update: The dataset_info.json error is g... |
https://api.github.com/repos/huggingface/datasets/issues/3487 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3487/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3487/comments | https://api.github.com/repos/huggingface/datasets/issues/3487/events | https://github.com/huggingface/datasets/pull/3487 | 1,089,209,031 | PR_kwDODunzps4wTVeN | 3,487 | Update ADD_NEW_DATASET.md | [] | closed | false | null | 0 | 2021-12-27T12:24:51Z | 2021-12-27T15:00:45Z | 2021-12-27T15:00:45Z | null | fixed make style prompt for Windows Terminal | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3487/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3487/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3487.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3487",
"merged_at": "2021-12-27T15:00:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3487.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2610/comments | https://api.github.com/repos/huggingface/datasets/issues/2610/events | https://github.com/huggingface/datasets/pull/2610 | 939,899,829 | MDExOlB1bGxSZXF1ZXN0Njg2MDUwMzI5 | 2,610 | Add missing WikiANN language tags | [] | closed | false | {
"closed_at": "2021-07-21T15:36:49Z",
"closed_issues": 29,
"created_at": "2021-06-08T18:48:33Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/... | 0 | 2021-07-08T14:08:01Z | 2021-07-12T14:12:16Z | 2021-07-08T15:44:04Z | null | Add missing language tags for WikiANN datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2610/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2610.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2610",
"merged_at": "2021-07-08T15:44:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2610.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2940 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2940/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2940/comments | https://api.github.com/repos/huggingface/datasets/issues/2940/events | https://github.com/huggingface/datasets/pull/2940 | 999,680,796 | PR_kwDODunzps4r6EUF | 2,940 | add swedish_medical_ner dataset | [] | closed | false | null | 0 | 2021-09-17T20:03:05Z | 2021-10-05T12:13:34Z | 2021-10-05T12:13:33Z | null | Adding the Swedish Medical NER dataset, listed in "Biomedical Datasets - BigScience Workshop 2021" | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2940/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2940/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2940.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2940",
"merged_at": "2021-10-05T12:13:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2940.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1644/comments | https://api.github.com/repos/huggingface/datasets/issues/1644/events | https://github.com/huggingface/datasets/issues/1644 | 775,375,880 | MDU6SXNzdWU3NzUzNzU4ODA= | 1,644 | HoVeR dataset fails to load | [] | closed | false | null | 1 | 2020-12-28T12:27:07Z | 2022-10-05T12:40:34Z | 2022-10-05T12:40:34Z | null | Hi! I'm getting an error when trying to load **HoVeR** dataset. Another one (**SQuAD**) does work for me. I'm using the latest (1.1.3) version of the library.
Steps to reproduce the error:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("hover")
Traceback (most recent call last):
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1644/timeline | null | completed | null | null | false | [
"Hover was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `hover` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"hover\")\r\n```"
] |
https://api.github.com/repos/huggingface/datasets/issues/1009 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1009/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1009/comments | https://api.github.com/repos/huggingface/datasets/issues/1009/events | https://github.com/huggingface/datasets/pull/1009 | 755,384,433 | MDExOlB1bGxSZXF1ZXN0NTMxMTA0NDc5 | 1,009 | Adding C3 dataset: the first free-form multiple-Choice Chinese machine reading Comprehension dataset. | [] | closed | false | null | 0 | 2020-12-02T15:40:36Z | 2020-12-03T13:16:30Z | 2020-12-03T13:16:29Z | null | https://github.com/nlpdata/c3
https://arxiv.org/abs/1904.09679 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1009/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1009/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1009.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1009",
"merged_at": "2020-12-03T13:16:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1009.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2927/comments | https://api.github.com/repos/huggingface/datasets/issues/2927/events | https://github.com/huggingface/datasets/issues/2927 | 997,654,680 | I_kwDODunzps47dwCY | 2,927 | Datasets 1.12 dataset.filter TypeError: get_indices_from_mask_function() got an unexpected keyword argument | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-09-16T01:14:02Z | 2021-09-20T16:23:22Z | 2021-09-20T16:23:21Z | null | ## Describe the bug
Upgrading to 1.12 caused `dataset.filter` call to fail with
> get_indices_from_mask_function() got an unexpected keyword argument valid_rel_labels
## Steps to reproduce the bug
```pythondef
filter_good_rows(
ex: Dict,
valid_rel_labels: Set[str],
valid_ner_labels: Set[st... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2927/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2927/timeline | null | completed | null | null | false | [
"Thanks for reporting, I'm looking into it :)",
"Fixed by #2950."
] |
https://api.github.com/repos/huggingface/datasets/issues/5362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | https://api.github.com/repos/huggingface/datasets/issues/5362/events | https://github.com/huggingface/datasets/issues/5362 | 1,497,643,744 | I_kwDODunzps5ZRDrg | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | [] | closed | false | null | 2 | 2022-12-15T01:23:03Z | 2022-12-15T07:45:54Z | 2022-12-15T07:45:53Z | null | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
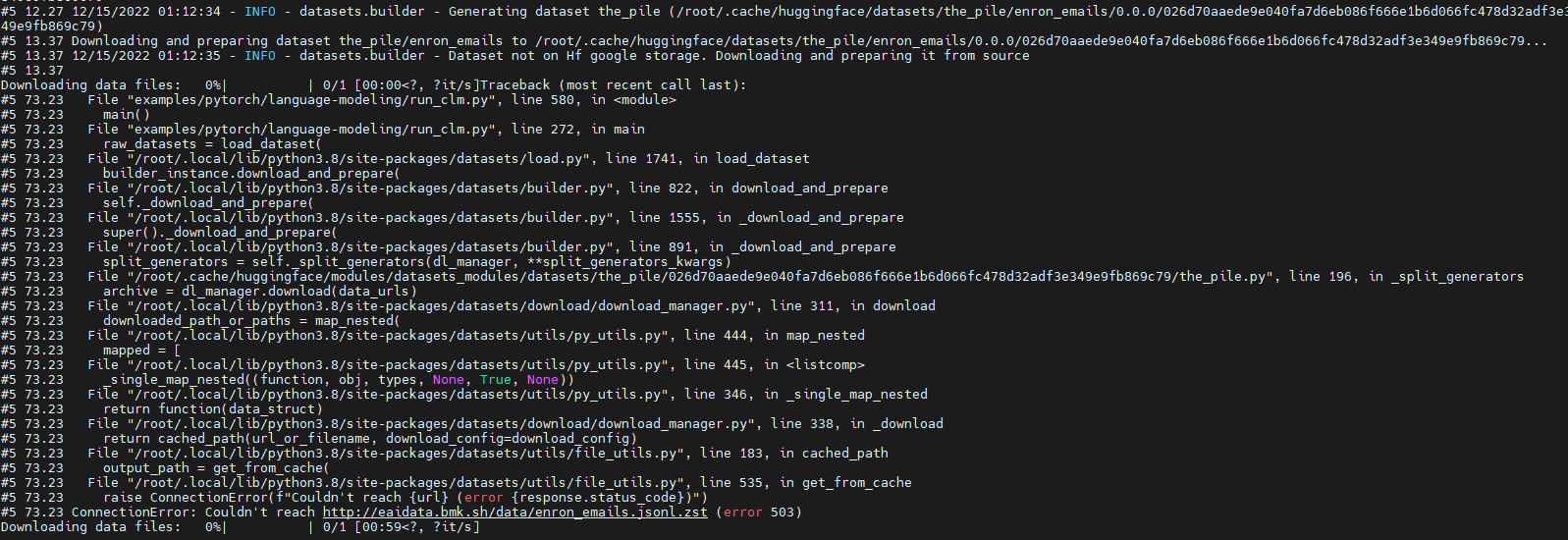
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5362/timeline | null | completed | null | null | false | [
"Thanks for reporting, @shaoyuta.\r\n\r\nWe have checked and yes, apparently there is an issue with the server hosting the data of the \"enron_emails\" subset of \"the_pile\" dataset: http://eaidata.bmk.sh/data/enron_emails.jsonl.zst\r\nIt seems to be down: The connection has timed out.\r\n\r\nPlease note that at t... |
https://api.github.com/repos/huggingface/datasets/issues/5131 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5131/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5131/comments | https://api.github.com/repos/huggingface/datasets/issues/5131/events | https://github.com/huggingface/datasets/issues/5131 | 1,413,534,863 | I_kwDODunzps5UQNSP | 5,131 | WikiText 103 tokenizer hangs | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2022-10-18T16:44:00Z | 2023-07-21T14:41:51Z | 2023-07-21T14:41:51Z | null | See issue here: https://github.com/huggingface/transformers/issues/19702 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5131/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5131/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4020 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4020/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4020/comments | https://api.github.com/repos/huggingface/datasets/issues/4020/events | https://github.com/huggingface/datasets/pull/4020 | 1,180,636,754 | PR_kwDODunzps41Am4R | 4,020 | Replace amazon_polarity data URL | [] | closed | false | null | 1 | 2022-03-25T10:50:57Z | 2022-03-25T15:02:36Z | 2022-03-25T14:57:41Z | null | I replaced the Google Drive URL of the dataset by the FastAI one, since we've had some issues with Google Drive. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4020/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4020/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4020.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4020",
"merged_at": "2022-03-25T14:57:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4020.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/709/comments | https://api.github.com/repos/huggingface/datasets/issues/709/events | https://github.com/huggingface/datasets/issues/709 | 714,067,902 | MDU6SXNzdWU3MTQwNjc5MDI= | 709 | How to use similarity settings other then "BM25" in Elasticsearch index ? | [] | closed | false | null | 1 | 2020-10-03T11:18:49Z | 2022-10-04T17:19:37Z | 2022-10-04T17:19:37Z | null | **QUESTION : How should we use other similarity algorithms supported by Elasticsearch other than "BM25" ?**
**ES Reference**
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
**HF doc reference:**
https://huggingface.co/docs/datasets/faiss_and_ea.html
**context :**
=... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/709/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/709/timeline | null | completed | null | null | false | [
"Datasets does not use elasticsearch API to define custom similarity. If you want to use a custom similarity, the best would be to run a curl request directly to your elasticsearch instance (see sample hereafter, directly from ES documentation), then you should be able to use `my_similarity` in your configuration p... |
https://api.github.com/repos/huggingface/datasets/issues/1353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1353/comments | https://api.github.com/repos/huggingface/datasets/issues/1353/events | https://github.com/huggingface/datasets/pull/1353 | 759,980,004 | MDExOlB1bGxSZXF1ZXN0NTM0ODg2MDk4 | 1,353 | New instruction for how to generate dataset_infos.json | [] | closed | false | null | 0 | 2020-12-09T04:24:40Z | 2020-12-10T13:45:15Z | 2020-12-10T13:45:15Z | null | Add additional instructions for how to generate dataset_infos.json for manual download datasets. Information courtesy of `Taimur Ibrahim` from the slack channel | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1353/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1353.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1353",
"merged_at": "2020-12-10T13:45:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1353.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2251 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2251/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2251/comments | https://api.github.com/repos/huggingface/datasets/issues/2251/events | https://github.com/huggingface/datasets/issues/2251 | 865,848,705 | MDU6SXNzdWU4NjU4NDg3MDU= | 2,251 | while running run_qa.py, ran into a value error | [] | open | false | null | 0 | 2021-04-23T07:51:03Z | 2021-04-23T07:51:03Z | null | null | command:
python3 run_qa.py --model_name_or_path hyunwoongko/kobart --dataset_name squad_kor_v2 --do_train --do_eval --per_device_train_batch_size 8 --learning_rate 3e-5 --num_train_epochs 3 --max_seq_length 512 --doc_stride 128 --output_dir /tmp/debug_squad/
error:
ValueError: External fe... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2251/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2251/timeline | null | null | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/4484 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4484/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4484/comments | https://api.github.com/repos/huggingface/datasets/issues/4484/events | https://github.com/huggingface/datasets/pull/4484 | 1,269,383,811 | PR_kwDODunzps45jywZ | 4,484 | Better ImportError message when a dataset script dependency is missing | [] | closed | false | null | 4 | 2022-06-13T12:44:37Z | 2022-07-08T14:30:44Z | 2022-06-13T13:50:47Z | null | When a depenency is missing for a dataset script, an ImportError message is shown, with a tip to install the missing dependencies. This message is not ideal at the moment: it may show duplicate dependencies, and is not very readable.
I improved it from
```
ImportError: To be able to use bigbench, you need to insta... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4484/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4484/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4484.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4484",
"merged_at": "2022-06-13T13:50:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4484.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Discussed offline with @mariosasko, merging :)",
"Fwiw, i think this same issue is occurring on the datasets website page, where preview isn't available due to the `bigbench` import error",
"For the preview of BigBench datasets, ... |
https://api.github.com/repos/huggingface/datasets/issues/3658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3658/comments | https://api.github.com/repos/huggingface/datasets/issues/3658/events | https://github.com/huggingface/datasets/issues/3658 | 1,120,880,395 | I_kwDODunzps5Cz0cL | 3,658 | Dataset viewer issue for *P3* | [] | open | false | null | 3 | 2022-02-01T15:57:56Z | 2022-09-08T08:18:28Z | null | null | ## Dataset viewer issue for '*P3*'
**Link: https://huggingface.co/datasets/bigscience/P3**
```
Status code: 400
Exception: SplitsNotFoundError
Message: The split names could not be parsed from the dataset config.
```
Am I the one who added this dataset ? No
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3658/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3658/timeline | null | null | null | null | false | [
"The error is now:\r\n\r\n```\r\nStatus code: 400\r\nException: Status400Error\r\nMessage: this dataset is not supported for now.\r\n```\r\n\r\nWe've disabled the dataset viewer for several big datasets like this one. We hope being able to reenable it soon.",
"The list of splits cannot be obtained. cc... |
https://api.github.com/repos/huggingface/datasets/issues/3703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3703/comments | https://api.github.com/repos/huggingface/datasets/issues/3703/events | https://github.com/huggingface/datasets/issues/3703 | 1,131,882,772 | I_kwDODunzps5DdykU | 3,703 | ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance' | [] | closed | false | null | 9 | 2022-02-11T06:38:42Z | 2023-07-11T09:31:59Z | 2023-07-11T09:31:59Z | null | hi :
I want to use the seqeval indicator because of direct load_ When metric ('seqeval '), it will prompt that the network connection fails. So I downloaded the seqeval Py to load locally. Loading code: metric = load_ metric(path='mymetric/seqeval/seqeval.py')
But tips:
Traceback (most recent call last):
File... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3703/timeline | null | completed | null | null | false | [
"\r\nMy datasets version",
"\r\n",
"Hi! Some of our metrics require additional dependencies to w... |
https://api.github.com/repos/huggingface/datasets/issues/3719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3719/comments | https://api.github.com/repos/huggingface/datasets/issues/3719/events | https://github.com/huggingface/datasets/pull/3719 | 1,137,237,622 | PR_kwDODunzps4yyFv7 | 3,719 | Check if indices values in `Dataset.select` are within bounds | [] | closed | false | null | 0 | 2022-02-14T12:31:41Z | 2022-02-14T19:19:22Z | 2022-02-14T19:19:22Z | null | Fix #3707
Instead of reusing `_check_valid_index_key` from `datasets.formatting`, I defined a new function to provide a more meaningful error message.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3719/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3719/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3719.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3719",
"merged_at": "2022-02-14T19:19:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3719.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1810 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1810/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1810/comments | https://api.github.com/repos/huggingface/datasets/issues/1810/events | https://github.com/huggingface/datasets/issues/1810 | 799,168,650 | MDU6SXNzdWU3OTkxNjg2NTA= | 1,810 | Add Hateful Memes Dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",... | open | false | null | 4 | 2021-02-02T10:53:59Z | 2021-12-08T12:03:59Z | null | null | ## Add Hateful Memes Dataset
- **Name:** Hateful Memes
- **Description:** [https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set]( https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set)
- **Paper:** [https://arxiv.org/pdf/2005.04790.pdf](https://arxiv.org/pdf/2005.04790.pdf)
- **Data:** [Thi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1810/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1810/timeline | null | null | null | null | false | [
"I am not sure, but would `datasets.Sequence(datasets.Sequence(datasets.Sequence(datasets.Value(\"int\")))` work?",
"Also, I found the information for loading only subsets of the data [here](https://github.com/huggingface/datasets/blob/master/docs/source/splits.rst).",
"Hi @lhoestq,\r\n\r\nRequest you to check ... |
https://api.github.com/repos/huggingface/datasets/issues/3216 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3216/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3216/comments | https://api.github.com/repos/huggingface/datasets/issues/3216/events | https://github.com/huggingface/datasets/pull/3216 | 1,045,027,733 | PR_kwDODunzps4uG1YS | 3,216 | Pin version exclusion for tensorflow incompatible with keras | [] | closed | false | null | 0 | 2021-11-04T17:38:06Z | 2021-11-05T10:57:38Z | 2021-11-05T10:57:37Z | null | Once `tensorflow` version 2.6.2 is released:
- https://github.com/tensorflow/tensorflow/commit/c1867f3bfdd1042f694df7a9870be51ba80543cb
- https://pypi.org/project/tensorflow/2.6.2/
with the patch:
- tensorflow/tensorflow#52927
we can remove the temporary fix we introduced in:
- #3208
Fix #3209. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3216/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3216/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3216.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3216",
"merged_at": "2021-11-05T10:57:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3216.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/899 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/899/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/899/comments | https://api.github.com/repos/huggingface/datasets/issues/899/events | https://github.com/huggingface/datasets/pull/899 | 752,191,227 | MDExOlB1bGxSZXF1ZXN0NTI4NTYzNzYz | 899 | Allow arrow based builder in auto dummy data generation | [] | closed | false | null | 0 | 2020-11-27T11:39:38Z | 2020-11-27T13:30:09Z | 2020-11-27T13:30:08Z | null | Following #898 I added support for arrow based builder for the auto dummy data generator | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/899/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/899/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/899.diff",
"html_url": "https://github.com/huggingface/datasets/pull/899",
"merged_at": "2020-11-27T13:30:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/899.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/899... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2274/comments | https://api.github.com/repos/huggingface/datasets/issues/2274/events | https://github.com/huggingface/datasets/pull/2274 | 869,186,276 | MDExOlB1bGxSZXF1ZXN0NjI0NTkyMjQx | 2,274 | Always update metadata in arrow schema | [] | closed | false | null | 0 | 2021-04-27T19:21:57Z | 2022-06-03T08:31:19Z | 2021-04-29T09:57:50Z | null | We store a redundant copy of the features in the metadata of the schema of the arrow table. This is used to recover the features when doing `Dataset.from_file`. These metadata are updated after each transfor, that changes the feature types.
For each function that transforms the feature types of the dataset, I added ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2274/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2274.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2274",
"merged_at": "2021-04-29T09:57:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2274.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3225 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3225/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3225/comments | https://api.github.com/repos/huggingface/datasets/issues/3225/events | https://github.com/huggingface/datasets/pull/3225 | 1,046,530,493 | PR_kwDODunzps4uLrB3 | 3,225 | Update tatoeba to v2021-07-22 | [] | closed | false | null | 4 | 2021-11-06T15:14:31Z | 2021-11-12T11:13:13Z | 2021-11-12T11:13:13Z | null | Tatoeba's latest version is v2021-07-22 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3225/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3225.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3225",
"merged_at": "2021-11-12T11:13:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3225.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"How about this? @lhoestq @abhishekkrthakur ",
"Hi ! I think it would be nice if people could still be able to load the old version.\r\nMaybe this can be a parameter ? For example to load the old version they could do\r\n```python\r\nload_dataset(\"tatoeba\", lang1=\"en\", lang2=\"mr\", date=\"v2020-11-09\")\r\n`... |
https://api.github.com/repos/huggingface/datasets/issues/4515 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4515/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4515/comments | https://api.github.com/repos/huggingface/datasets/issues/4515/events | https://github.com/huggingface/datasets/pull/4515 | 1,273,626,131 | PR_kwDODunzps45x5mB | 4,515 | Add uppercased versions of image file extensions for automatic module inference | [] | closed | false | null | 1 | 2022-06-16T14:14:49Z | 2022-06-16T17:21:53Z | 2022-06-16T17:11:41Z | null | Adds the uppercased versions of the image file extensions to the supported extensions.
Another approach would be to call `.lower()` on extensions while resolving data files, but uppercased extensions are not something we want to encourage out of the box IMO unless they are commonly used (as they are in the vision d... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4515/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4515/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4515.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4515",
"merged_at": "2022-06-16T17:11:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4515.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1682/comments | https://api.github.com/repos/huggingface/datasets/issues/1682/events | https://github.com/huggingface/datasets/pull/1682 | 778,268,156 | MDExOlB1bGxSZXF1ZXN0NTQ4Mzg1NTk1 | 1,682 | Don't use xlrd for xlsx files | [] | closed | false | null | 0 | 2021-01-04T18:11:50Z | 2021-01-04T18:13:14Z | 2021-01-04T18:13:13Z | null | Since the latest release of `xlrd` (2.0), the support for xlsx files stopped.
Therefore we needed to use something else.
A good alternative is `openpyxl` which has also an integration with pandas si we can still call `pd.read_excel`.
I left the unused import of `openpyxl` in the dataset scripts to show users that ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1682/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1682/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1682.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1682",
"merged_at": "2021-01-04T18:13:13Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1682.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3365/comments | https://api.github.com/repos/huggingface/datasets/issues/3365/events | https://github.com/huggingface/datasets/issues/3365 | 1,069,195,887 | I_kwDODunzps4_uqJv | 3,365 | Add task tags for multimodal datasets | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 1 | 2021-12-02T06:58:20Z | 2023-07-25T18:21:33Z | 2023-07-25T18:21:32Z | null | ## **Is your feature request related to a problem? Please describe.**
Currently, task tags are either exclusively related to text or speech processing:
- https://github.com/huggingface/datasets/blob/master/src/datasets/utils/resources/tasks.json
## **Describe the solution you'd like**
We should also add tasks... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3365/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3365/timeline | null | completed | null | null | false | [
"The Hub pulls these tags from [here](https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts) (allows multimodal tasks) now, so I'm closing this issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/5836 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5836/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5836/comments | https://api.github.com/repos/huggingface/datasets/issues/5836/events | https://github.com/huggingface/datasets/pull/5836 | 1,702,773,316 | PR_kwDODunzps5QIgzu | 5,836 | [docs] Custom decoding transforms | [] | closed | false | null | 4 | 2023-05-09T21:21:41Z | 2023-05-15T07:36:12Z | 2023-05-10T20:23:03Z | null | Adds custom decoding transform solution to the docs to fix #5782. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5836/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5836/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5836.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5836",
"merged_at": "2023-05-10T20:23:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5836.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5836). All of your documentation changes will be reflected on that endpoint.",
"The error seems unrelated to the changes, so feel free to merge.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\... |
https://api.github.com/repos/huggingface/datasets/issues/4964 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4964/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4964/comments | https://api.github.com/repos/huggingface/datasets/issues/4964/events | https://github.com/huggingface/datasets/issues/4964 | 1,368,617,322 | I_kwDODunzps5Rk3Fq | 4,964 | Column of arrays (2D+) are using unreasonably high memory | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 10 | 2022-09-10T13:07:22Z | 2022-09-22T18:29:22Z | null | null | ## Describe the bug
When trying to store `Array2D, Array3D, etc` as column values in a dataset, accessing that column (or creating depending on how you create it, see code below) will cause more than 10 fold of memory usage.
## Steps to reproduce the bug
```python
from datasets import Dataset, Features, Array2D, ... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4964/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4964/timeline | null | null | null | null | false | [
"note i have tried the same code with `datasets` version 2.4.0, the outcome is the very same as described above.",
"Seems related to issues #4623 and #4802 so it would appear this issue has been around for a few months.",
"Hi ! `Dataset.from_dict` keeps the data in memory. You can write on disk and reload them ... |
https://api.github.com/repos/huggingface/datasets/issues/1703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1703/comments | https://api.github.com/repos/huggingface/datasets/issues/1703/events | https://github.com/huggingface/datasets/pull/1703 | 781,395,146 | MDExOlB1bGxSZXF1ZXN0NTUxMTI2MjA5 | 1,703 | Improvements regarding caching and fingerprinting | [] | closed | false | null | 8 | 2021-01-07T15:26:29Z | 2021-01-19T17:32:11Z | 2021-01-19T17:32:10Z | null | This PR adds these features:
- Enable/disable caching
If disabled, the library will no longer reload cached datasets files when applying transforms to the datasets.
It is equivalent to setting `load_from_cache` to `False` in dataset transforms.
```python
from datasets import set_caching_enabled
set_cach... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1703/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1703.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1703",
"merged_at": "2021-01-19T17:32:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1703.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"I few comments here for discussion:\r\n- I'm not convinced yet the end user should really have to understand the difference between \"caching\" and 'fingerprinting\", what do you think? I think fingerprinting should probably stay as an internal thing. Is there a case where we want cahing without fingerprinting or ... |
https://api.github.com/repos/huggingface/datasets/issues/5317 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5317/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5317/comments | https://api.github.com/repos/huggingface/datasets/issues/5317/events | https://github.com/huggingface/datasets/issues/5317 | 1,470,390,164 | I_kwDODunzps5XpF-U | 5,317 | `ImageFolder` performs poorly with large datasets | [] | open | false | null | 3 | 2022-12-01T00:04:21Z | 2022-12-01T21:49:26Z | null | null | ### Describe the bug
While testing image dataset creation, I'm seeing significant performance bottlenecks with imagefolders when scanning a directory structure with large number of images.
## Setup
* Nested directories (5 levels deep)
* 3M+ images
* 1 `metadata.jsonl` file
## Performance Degradation Point... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5317/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5317/timeline | null | null | null | null | false | [
"Hi ! ImageFolder is made for small scale datasets indeed. For large scale image datasets you better group your images in TAR archives or Arrow/Parquet files. This is true not just for ImageFolder loading performance, but also because having millions of files is not ideal for your filesystem or when moving the data... |
https://api.github.com/repos/huggingface/datasets/issues/4089 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4089/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4089/comments | https://api.github.com/repos/huggingface/datasets/issues/4089/events | https://github.com/huggingface/datasets/pull/4089 | 1,191,915,196 | PR_kwDODunzps41l7yd | 4,089 | Create metric card for Frugal Score | [] | closed | false | null | 1 | 2022-04-04T14:53:49Z | 2022-04-05T14:14:46Z | 2022-04-05T14:06:50Z | null | Proposing metric card for Frugal Score.
@albertvillanova or @lhoestq -- there are certain aspects that I'm not 100% sure on (such as how exactly the distillation between BertScore and FrugalScore is done) -- so if you find that something isn't clear, please let me know! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4089/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4089/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4089.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4089",
"merged_at": "2022-04-05T14:06:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4089.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/1247 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1247/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1247/comments | https://api.github.com/repos/huggingface/datasets/issues/1247/events | https://github.com/huggingface/datasets/pull/1247 | 758,431,640 | MDExOlB1bGxSZXF1ZXN0NTMzNjA1NzE2 | 1,247 | Adding indonlu dataset | [] | closed | false | null | 2 | 2020-12-07T11:38:45Z | 2020-12-08T14:11:50Z | 2020-12-08T14:11:50Z | null | IndoNLU benchmark is a collection of resources for training, evaluating, and analyzing natural language understanding systems for Bahasa Indonesia. It contains 12 datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1247/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1247/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1247.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1247",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1247.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1247"
} | true | [
"looks like this PR includes changes about many files other than the ones for IndoNLU\r\nCould you create another branch and another PR please ?",
"> looks like this PR includes changes about many files other than the ones for IndoNLU\r\n> Could you create another branch and another PR please ?\r\n\r\nOkay I'll m... |
https://api.github.com/repos/huggingface/datasets/issues/695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/695/comments | https://api.github.com/repos/huggingface/datasets/issues/695/events | https://github.com/huggingface/datasets/pull/695 | 712,843,949 | MDExOlB1bGxSZXF1ZXN0NDk2MjU5NTM0 | 695 | Update XNLI download link | [] | closed | false | null | 0 | 2020-10-01T13:27:22Z | 2020-10-01T14:01:15Z | 2020-10-01T14:01:14Z | null | The old link isn't working anymore. I updated it with the new official link.
Fix #690 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/695/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/695/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/695.diff",
"html_url": "https://github.com/huggingface/datasets/pull/695",
"merged_at": "2020-10-01T14:01:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/695.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/695... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2953 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2953/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2953/comments | https://api.github.com/repos/huggingface/datasets/issues/2953/events | https://github.com/huggingface/datasets/issues/2953 | 1,002,766,517 | I_kwDODunzps47xQC1 | 2,953 | Trying to get in touch regarding a security issue | [] | closed | false | null | 1 | 2021-09-21T15:58:13Z | 2021-10-21T15:16:43Z | 2021-10-21T15:16:43Z | null | Hey there!
I'd like to report a security issue but cannot find contact instructions on your repository.
If not a hassle, might you kindly add a `SECURITY.md` file with an email, or another contact method? GitHub [recommends](https://docs.github.com/en/code-security/getting-started/adding-a-security-policy-to-your-rep... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2953/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2953/timeline | null | completed | null | null | false | [
"Hi @JamieSlome,\r\n\r\nThanks for reaching out. Yes, you are right: I'm opening a PR to add the `SECURITY.md` file and a contact method.\r\n\r\nIn the meantime, please feel free to report the security issue to: feedback@huggingface.co"
] |
https://api.github.com/repos/huggingface/datasets/issues/5756 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5756/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5756/comments | https://api.github.com/repos/huggingface/datasets/issues/5756/events | https://github.com/huggingface/datasets/issues/5756 | 1,669,678,080 | I_kwDODunzps5jhUQA | 5,756 | Calling shuffle on a IterableDataset with streaming=True, gives "ValueError: cannot reshape array" | [] | closed | false | null | 2 | 2023-04-16T04:59:47Z | 2023-04-18T03:40:56Z | 2023-04-18T03:40:56Z | null | ### Describe the bug
When calling shuffle on a IterableDataset with streaming=True, I get the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/administrator/Documents/Projects/huggingface/jax-diffusers-sprint-consistency-models/virtualenv/lib/python3.1... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5756/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5756/timeline | null | completed | null | null | false | [
"Hi! I've merged a PR on the Hub with a fix: https://huggingface.co/datasets/fashion_mnist/discussions/3",
"Thanks, this appears to have fixed the issue.\r\n\r\nI've created a PR for the same change in the mnist dataset: https://huggingface.co/datasets/mnist/discussions/3/files"
] |
https://api.github.com/repos/huggingface/datasets/issues/5660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5660/comments | https://api.github.com/repos/huggingface/datasets/issues/5660/events | https://github.com/huggingface/datasets/issues/5660 | 1,635,543,646 | I_kwDODunzps5hfGpe | 5,660 | integration with imbalanced-learn | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "ffffff",
"default": true... | closed | false | null | 1 | 2023-03-22T11:05:17Z | 2023-07-06T18:10:15Z | 2023-07-06T18:10:15Z | null | ### Feature request
Wouldn't it be great if the various class balancing operations from imbalanced-learn were available as part of datasets?
### Motivation
I'm trying to use imbalanced-learn to balance a dataset, but it's not clear how to get the two to interoperate - what would be great would be some examples. I'v... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5660/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5660/timeline | null | completed | null | null | false | [
"You can convert any dataset to pandas to be used with imbalanced-learn using `.to_pandas()`\r\n\r\nOtherwise if you want to keep a `Dataset` object and still use e.g. [make_imbalance](https://imbalanced-learn.org/stable/references/generated/imblearn.datasets.make_imbalance.html#imblearn.datasets.make_imbalance), y... |
https://api.github.com/repos/huggingface/datasets/issues/840 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/840/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/840/comments | https://api.github.com/repos/huggingface/datasets/issues/840/events | https://github.com/huggingface/datasets/pull/840 | 740,632,771 | MDExOlB1bGxSZXF1ZXN0NTE5MDg2NDUw | 840 | Update squad_v2.py | [] | closed | false | null | 2 | 2020-11-11T09:58:41Z | 2020-11-11T15:29:34Z | 2020-11-11T15:26:35Z | null | Change lines 100 and 102 to prevent overwriting ```predictions``` variable. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/840/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/840/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/840.diff",
"html_url": "https://github.com/huggingface/datasets/pull/840",
"merged_at": "2020-11-11T15:26:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/840.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/840... | true | [
"With this change all the checks are passed.",
"Good"
] |
https://api.github.com/repos/huggingface/datasets/issues/5682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5682/comments | https://api.github.com/repos/huggingface/datasets/issues/5682/events | https://github.com/huggingface/datasets/issues/5682 | 1,646,000,571 | I_kwDODunzps5iG_m7 | 5,682 | ValueError when passing ignore_verifications | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 0 | 2023-03-29T15:00:30Z | 2023-03-29T17:28:58Z | 2023-03-29T17:28:58Z | null | When passing `ignore_verifications=True` to `load_dataset`, we get a ValueError:
```
ValueError: 'none' is not a valid VerificationMode
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5682/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5682/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5229 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5229/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5229/comments | https://api.github.com/repos/huggingface/datasets/issues/5229/events | https://github.com/huggingface/datasets/issues/5229 | 1,445,121,028 | I_kwDODunzps5WIswE | 5,229 | Type error when calling `map` over dataset containing 0-d tensors | [] | closed | false | null | 2 | 2022-11-11T08:27:28Z | 2023-01-13T16:00:53Z | 2023-01-13T16:00:53Z | null | ### Describe the bug
0-dimensional tensors in a dataset lead to `TypeError: iteration over a 0-d array` when calling `map`. It is easy to generate such tensors by using `.with_format("...")` on the whole dataset.
### Steps to reproduce the bug
```
ds = datasets.Dataset.from_list([{"a": 1}, {"a": 1}]).with_fo... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5229/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5229/timeline | null | completed | null | null | false | [
"Hi! \r\n\r\nWe could address this by calling `.item()` on such tensors to extract the value, but this would lose us the type, which could lead to storing the generated dataset in a suboptimal format. Considering this, I think the only proper fix would be implementing support for 0-D tensors on Apache Arrow's side ... |
https://api.github.com/repos/huggingface/datasets/issues/3627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3627/comments | https://api.github.com/repos/huggingface/datasets/issues/3627/events | https://github.com/huggingface/datasets/pull/3627 | 1,113,556,837 | PR_kwDODunzps4xitGe | 3,627 | Fix host URL in The Pile datasets | [] | closed | false | null | 4 | 2022-01-25T08:11:28Z | 2022-07-20T20:54:42Z | 2022-02-14T08:40:58Z | null | This PR fixes the host URL in The Pile datasets, once they have mirrored their data in another server.
Fix #3626. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3627/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3627/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3627.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3627",
"merged_at": "2022-02-14T08:40:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3627.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"We should also update the `bookcorpusopen` download url (see #3561) , no? ",
"For `the_pile_openwebtext2` and `the_pile_stack_exchange` I did not regenerate the JSON files, but instead I just changed the download_checksums URL. ",
"Seems like the mystic URL is now broken and the original should be used. ",
"... |
https://api.github.com/repos/huggingface/datasets/issues/1440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1440/comments | https://api.github.com/repos/huggingface/datasets/issues/1440/events | https://github.com/huggingface/datasets/pull/1440 | 760,973,057 | MDExOlB1bGxSZXF1ZXN0NTM1NzEyNDY1 | 1,440 | Adding english plaintext jokes dataset | [] | closed | false | null | 2 | 2020-12-10T07:04:17Z | 2020-12-13T05:22:00Z | 2020-12-12T05:55:43Z | null | This PR adds a dataset of 200k English plaintext Jokes from three sources: Reddit, Stupidstuff, and Wocka.
Link: https://github.com/taivop/joke-dataset
This is my second PR.
First was: [#1269 ](https://github.com/huggingface/datasets/pull/1269) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1440/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1440.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1440",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1440.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1440"
} | true | [
"Hi @purvimisal, thanks for your contributions!\r\n\r\nThis jokes dataset has come up before, and after a conversation with the initial submitter, we decided not to add it then. Humor is important, but looking at the actual data points in this set raises several concerns :) \r\n\r\nThe main issue is the Reddit part... |
https://api.github.com/repos/huggingface/datasets/issues/345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/345/comments | https://api.github.com/repos/huggingface/datasets/issues/345/events | https://github.com/huggingface/datasets/issues/345 | 651,761,201 | MDU6SXNzdWU2NTE3NjEyMDE= | 345 | Supporting documents in ELI5 | [] | closed | false | null | 2 | 2020-07-06T19:14:13Z | 2020-10-27T15:38:45Z | 2020-10-27T15:38:45Z | null | I was attempting to use the ELI5 dataset, when I realized that huggingface does not provide the supporting documents (the source documents from the common crawl). Without the supporting documents, this makes the dataset about as useful for my project as a block of cheese, or some other more apt metaphor. According to ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/345/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/345/timeline | null | completed | null | null | false | [
"Hi @saverymax ! For licensing reasons, the original team was unable to release pre-processed CommonCrawl documents. Instead, they provided a script to re-create them from a CommonCrawl dump, but it unfortunately requires access to a medium-large size cluster:\r\nhttps://github.com/facebookresearch/ELI5#downloading... |
https://api.github.com/repos/huggingface/datasets/issues/2132 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2132/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2132/comments | https://api.github.com/repos/huggingface/datasets/issues/2132/events | https://github.com/huggingface/datasets/issues/2132 | 843,142,822 | MDU6SXNzdWU4NDMxNDI4MjI= | 2,132 | TydiQA dataset is mixed and is not split per language | [] | open | false | null | 3 | 2021-03-29T08:56:21Z | 2021-04-04T09:57:15Z | null | null | Hi @lhoestq
Currently TydiQA is mixed and user can only access the whole training set of all languages:
https://www.tensorflow.org/datasets/catalog/tydi_qa
for using this dataset, one need to train/evaluate in each separate language, and having them mixed, makes it hard to use this dataset. This is much convenien... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2132/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2132/timeline | null | null | null | null | false | [
"You can filter the languages this way:\r\n```python\r\ntydiqa_en = tydiqa_dataset.filter(lambda x: x[\"language\"] == \"english\")\r\n```\r\n\r\nOtherwise maybe we can have one configuration per language ?\r\nWhat do you think of this for example ?\r\n\r\n```python\r\nload_dataset(\"tydiqa\", \"primary_task.en\")\... |
https://api.github.com/repos/huggingface/datasets/issues/4052 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4052/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4052/comments | https://api.github.com/repos/huggingface/datasets/issues/4052/events | https://github.com/huggingface/datasets/issues/4052 | 1,184,447,977 | I_kwDODunzps5GmT3p | 4,052 | metric = metric_cls( TypeError: 'NoneType' object is not callable | [] | closed | false | null | 1 | 2022-03-29T07:43:08Z | 2022-03-29T14:06:01Z | 2022-03-29T14:06:01Z | null | Hi, friend. I meet a problem.
When I run the code:
`metric = load_metric('glue', 'rte')`
There is a problem raising:
`metric = metric_cls(
TypeError: 'NoneType' object is not callable `
I don't know why. Thanks for your help!
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4052/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4052/timeline | null | completed | null | null | false | [
"Hi @klyuhang9,\r\n\r\nI'm sorry but I can't reproduce your problem:\r\n```python\r\nIn [2]: metric = load_metric('glue', 'rte')\r\nDownloading builder script: 5.76kB [00:00, 2.40MB/s]\r\n```\r\n\r\nCould you please, retry to load the metric? Sometimes there are temporary connectivity issues.\r\n\r\nFeel free to re... |
https://api.github.com/repos/huggingface/datasets/issues/1128 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1128/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1128/comments | https://api.github.com/repos/huggingface/datasets/issues/1128/events | https://github.com/huggingface/datasets/pull/1128 | 757,245,404 | MDExOlB1bGxSZXF1ZXN0NTMyNjUzMzgy | 1,128 | Add xquad-r dataset | [] | closed | false | null | 0 | 2020-12-04T16:48:53Z | 2020-12-04T18:14:30Z | 2020-12-04T18:14:26Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1128/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1128/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1128.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1128",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1128.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1128"
} | true | [] | |
https://api.github.com/repos/huggingface/datasets/issues/5359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5359/comments | https://api.github.com/repos/huggingface/datasets/issues/5359/events | https://github.com/huggingface/datasets/pull/5359 | 1,495,297,857 | PR_kwDODunzps5FYHWm | 5,359 | Raise error if ClassLabel names is not python list | [] | closed | false | null | 3 | 2022-12-13T23:04:06Z | 2022-12-22T16:35:49Z | 2022-12-22T16:32:49Z | null | Checks type of names provided to ClassLabel to avoid easy and hard to debug errors (closes #5332 - see for discussion) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5359/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5359/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5359.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5359",
"merged_at": "2022-12-22T16:32:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5359.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for your proposed fix, @freddyheppell.\r\n\r\nCurrently the CI fails because in a test we pass a `tuple` instead of a `list`. I would say we should accept `tuple` as a valid input type as well...\r\n\r\nWhat about checking for... |
https://api.github.com/repos/huggingface/datasets/issues/4823 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4823/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4823/comments | https://api.github.com/repos/huggingface/datasets/issues/4823/events | https://github.com/huggingface/datasets/pull/4823 | 1,335,687,033 | PR_kwDODunzps49A0O_ | 4,823 | Update data URL in mkqa dataset | [] | closed | false | null | 1 | 2022-08-11T09:16:13Z | 2022-08-11T09:51:50Z | 2022-08-11T09:37:52Z | null | Update data URL in mkqa dataset.
Fix #4817. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4823/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4823/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4823.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4823",
"merged_at": "2022-08-11T09:37:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4823.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | 1 | 2023-03-07T01:52:00Z | 2023-03-09T15:24:05Z | 2023-03-09T15:23:54Z | null | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | null | null | false | [
"Hi! You can use `concatenate_datasets([ids1, ids2], axis=1)` to do this."
] |
https://api.github.com/repos/huggingface/datasets/issues/1352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1352/comments | https://api.github.com/repos/huggingface/datasets/issues/1352/events | https://github.com/huggingface/datasets/pull/1352 | 759,978,543 | MDExOlB1bGxSZXF1ZXN0NTM0ODg0ODg4 | 1,352 | change url for prachathai67k to internet archive | [] | closed | false | null | 0 | 2020-12-09T04:20:37Z | 2020-12-10T13:42:17Z | 2020-12-10T13:42:17Z | null | `prachathai67k` is currently downloaded from git-lfs of PyThaiNLP github. Since the size is quite large (~250MB), I moved the URL to archive.org in order to prevent rate limit issues. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1352/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1352/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1352.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1352",
"merged_at": "2020-12-10T13:42:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1352.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4635/comments | https://api.github.com/repos/huggingface/datasets/issues/4635/events | https://github.com/huggingface/datasets/issues/4635 | 1,294,475,931 | I_kwDODunzps5NKCKb | 4,635 | Dataset Viewer issue for vadis/sv-ident | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 6 | 2022-07-05T15:48:13Z | 2022-07-06T07:13:33Z | 2022-07-06T07:12:14Z | null | ### Link
https://huggingface.co/datasets/vadis/sv-ident/viewer/default/validation
### Description
Error message when loading validation split in the viewer:
```
Status code: 400
Exception: Status400Error
Message: The split cache is empty.
```
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4635/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4635/timeline | null | completed | null | null | false | [
"Thanks for reporting, @e-tornike \r\n\r\nSome context:\r\n- #4527 \r\n\r\nThe dataset loads locally in streaming mode:\r\n```python\r\nIn [2]: from datasets import load_dataset; ds = load_dataset(\"vadis/sv-ident\", split=\"validation\", streaming=True); item = next(iter(ds)); item\r\nUsing custom data configurati... |
https://api.github.com/repos/huggingface/datasets/issues/2316 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2316/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2316/comments | https://api.github.com/repos/huggingface/datasets/issues/2316/events | https://github.com/huggingface/datasets/issues/2316 | 875,756,353 | MDU6SXNzdWU4NzU3NTYzNTM= | 2,316 | Incorrect version specification for pyarrow | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-05-04T19:15:11Z | 2021-05-05T10:10:03Z | 2021-05-05T10:10:03Z | null | ## Describe the bug
The pyarrow dependency is incorrectly specified in setup.py file, in [this line](https://github.com/huggingface/datasets/blob/3a3e5a4da20bfcd75f8b6a6869b240af8feccc12/setup.py#L77).
Also as a snippet:
```python
"pyarrow>=1.0.0<4.0.0",
```
## Steps to reproduce the bug
```bash
pip install... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2316/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2316/timeline | null | completed | null | null | false | [
"Fixed by #2317."
] |
https://api.github.com/repos/huggingface/datasets/issues/4566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4566/comments | https://api.github.com/repos/huggingface/datasets/issues/4566/events | https://github.com/huggingface/datasets/issues/4566 | 1,284,397,594 | I_kwDODunzps5Mjloa | 4,566 | Document link #load_dataset_enhancing_performance points to nowhere | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-06-25T01:18:19Z | 2023-01-24T16:33:40Z | 2023-01-24T16:33:40Z | null | ## Describe the bug
A clear and concise description of what the bug is.

The [load_dataset_enhancing_performance](https://huggingface.co/docs/datasets/v2.3.2/en/package_reference/main_classes#load_dat... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4566/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4566/timeline | null | completed | null | null | false | [
"Hi! This is indeed the link the docstring should point to. Are you interested in submitting a PR to fix this?",
"https://github.com/huggingface/datasets/blame/master/docs/source/cache.mdx#L93\r\n\r\nThere seems already an anchor here. Somehow it doesn't work. I am not very familiar with how this online documenta... |
https://api.github.com/repos/huggingface/datasets/issues/2216 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2216/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2216/comments | https://api.github.com/repos/huggingface/datasets/issues/2216/events | https://github.com/huggingface/datasets/pull/2216 | 856,955,534 | MDExOlB1bGxSZXF1ZXN0NjE0NDU0MjE1 | 2,216 | added real label for glue/mrpc to test set | [] | closed | false | null | 0 | 2021-04-13T13:20:20Z | 2021-04-13T13:53:20Z | 2021-04-13T13:53:19Z | null | Added real label to `glue.py` `mrpc` task for test split. | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2216/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2216/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2216.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2216",
"merged_at": "2021-04-13T13:53:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2216.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3201 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3201/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3201/comments | https://api.github.com/repos/huggingface/datasets/issues/3201/events | https://github.com/huggingface/datasets/issues/3201 | 1,043,209,142 | I_kwDODunzps4-Lhu2 | 3,201 | Add GSM8K dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 1 | 2021-11-03T08:36:44Z | 2022-04-13T11:56:12Z | 2022-04-13T11:56:11Z | null | ## Adding a Dataset
- **Name:** GSM8K (short for Grade School Math 8k)
- **Description:** GSM8K is a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers.
- **Paper:** https://openai.com/blog/grade-school-math/
- **Data:** https://github.com/openai/gra... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3201/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3201/timeline | null | completed | null | null | false | [
"Closed via https://github.com/huggingface/datasets/pull/4103"
] |
https://api.github.com/repos/huggingface/datasets/issues/5267 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5267/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5267/comments | https://api.github.com/repos/huggingface/datasets/issues/5267/events | https://github.com/huggingface/datasets/pull/5267 | 1,455,466,464 | PR_kwDODunzps5DOlFR | 5,267 | Fix `max_shard_size` docs | [] | closed | false | null | 1 | 2022-11-18T16:55:22Z | 2022-11-18T17:28:58Z | 2022-11-18T17:25:27Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5267/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5267/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5267.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5267",
"merged_at": "2022-11-18T17:25:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5267.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/4900 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4900/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4900/comments | https://api.github.com/repos/huggingface/datasets/issues/4900/events | https://github.com/huggingface/datasets/issues/4900 | 1,352,405,855 | I_kwDODunzps5QnBNf | 4,900 | Dataset Viewer issue for asaxena1990/Dummy_dataset | [] | closed | false | null | 3 | 2022-08-26T15:15:44Z | 2023-07-24T15:42:09Z | 2023-07-24T15:42:09Z | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4900/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4900/timeline | null | completed | null | null | false | [
"Seems to be linked to the use of the undocumented `_resolve_features` method in the dataset viewer backend:\r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>> dataset = load_dataset(\"asaxena1990/Dummy_dataset\", name=\"asaxena1990--Dummy_dataset\", split=\"train\", streaming=True)\r\nUsing custom data con... |
https://api.github.com/repos/huggingface/datasets/issues/1197 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1197/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1197/comments | https://api.github.com/repos/huggingface/datasets/issues/1197/events | https://github.com/huggingface/datasets/pull/1197 | 757,900,160 | MDExOlB1bGxSZXF1ZXN0NTMzMTc4MTIz | 1,197 | add taskmaster-2 | [] | closed | false | null | 0 | 2020-12-06T11:05:18Z | 2020-12-07T15:22:43Z | 2020-12-07T15:22:43Z | null | Adding taskmaster-2 dataset.
https://github.com/google-research-datasets/Taskmaster/tree/master/TM-2-2020 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1197/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1197/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1197.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1197",
"merged_at": "2020-12-07T15:22:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1197.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/869 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/869/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/869/comments | https://api.github.com/repos/huggingface/datasets/issues/869/events | https://github.com/huggingface/datasets/pull/869 | 746,495,711 | MDExOlB1bGxSZXF1ZXN0NTIzODc3OTkw | 869 | Update ner datasets infos | [] | closed | false | null | 1 | 2020-11-19T11:28:03Z | 2020-11-19T14:14:18Z | 2020-11-19T14:14:17Z | null | Update the dataset_infos.json files for changes made in #850 regarding the ner datasets feature types (and the change to ClassLabel)
I also fixed the ner types of conll2003 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/869/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/869/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/869.diff",
"html_url": "https://github.com/huggingface/datasets/pull/869",
"merged_at": "2020-11-19T14:14:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/869.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/869... | true | [
":+1: Thanks for fixing it!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2829 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2829/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2829/comments | https://api.github.com/repos/huggingface/datasets/issues/2829/events | https://github.com/huggingface/datasets/issues/2829 | 977,233,360 | MDU6SXNzdWU5NzcyMzMzNjA= | 2,829 | Optimize streaming from TAR archives | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "fef2c0",
"default": fals... | closed | false | null | 1 | 2021-08-23T16:56:40Z | 2022-09-21T14:29:46Z | 2022-09-21T14:08:39Z | null | Hi ! As you know TAR has some constraints for data streaming. While it is optimized for buffering, the files in the TAR archive **need to be streamed in order**. It means that we can't choose which file to stream from, and this notation is to be avoided for TAR archives:
```
tar://books_large_p1.txt::https://storage.... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2829/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2829/timeline | null | completed | null | null | false | [
"Closed by: \r\n- #3066"
] |
https://api.github.com/repos/huggingface/datasets/issues/2031 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2031/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2031/comments | https://api.github.com/repos/huggingface/datasets/issues/2031/events | https://github.com/huggingface/datasets/issues/2031 | 829,122,778 | MDU6SXNzdWU4MjkxMjI3Nzg= | 2,031 | wikipedia.py generator that extracts XML doesn't release memory | [] | closed | false | null | 2 | 2021-03-11T12:51:24Z | 2021-03-22T08:33:52Z | 2021-03-22T08:33:52Z | null | I tried downloading Japanese wikipedia, but it always failed because of out of memory maybe.
I found that the generator function that extracts XML data in wikipedia.py doesn't release memory in the loop.
https://github.com/huggingface/datasets/blob/13a5b7db992ad5cf77895e4c0f76595314390418/datasets/wikipedia/wikip... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2031/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2031/timeline | null | completed | null | null | false | [
"Hi @miyamonz \r\nThanks for investigating this issue, good job !\r\nIt would be awesome to integrate your fix in the library, could you open a pull request ?",
"OK! I'll send it later."
] |
https://api.github.com/repos/huggingface/datasets/issues/1583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1583/comments | https://api.github.com/repos/huggingface/datasets/issues/1583/events | https://github.com/huggingface/datasets/pull/1583 | 768,795,986 | MDExOlB1bGxSZXF1ZXN0NTQxMTIyODEz | 1,583 | Update metrics docstrings. | [] | closed | false | null | 0 | 2020-12-16T12:14:18Z | 2020-12-18T18:39:06Z | 2020-12-18T18:39:06Z | null | #1478 Correcting the argument descriptions for metrics.
Let me know if there's any issues.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1583/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1583",
"merged_at": "2020-12-18T18:39:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/924 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/924/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/924/comments | https://api.github.com/repos/huggingface/datasets/issues/924/events | https://github.com/huggingface/datasets/pull/924 | 753,631,951 | MDExOlB1bGxSZXF1ZXN0NTI5NjcyMzgw | 924 | Add DART | [] | closed | false | null | 1 | 2020-11-30T16:42:37Z | 2020-12-02T03:13:42Z | 2020-12-02T03:13:41Z | null | - **Name:** *DART*
- **Description:** *DART is a large dataset for open-domain structured data record to text generation.*
- **Paper:** *https://arxiv.org/abs/2007.02871*
- **Data:** *https://github.com/Yale-LILY/dart#leaderboard*
### Checkbox
- [x] Create the dataset script `/datasets/my_dataset/my_dataset.py... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/924/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/924/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/924.diff",
"html_url": "https://github.com/huggingface/datasets/pull/924",
"merged_at": "2020-12-02T03:13:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/924.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/924... | true | [
"LGTM!"
] |
https://api.github.com/repos/huggingface/datasets/issues/5502 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5502/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5502/comments | https://api.github.com/repos/huggingface/datasets/issues/5502/events | https://github.com/huggingface/datasets/pull/5502 | 1,570,091,225 | PR_kwDODunzps5JN0aX | 5,502 | Added functionality: sort datasets by multiple keys | [] | closed | false | null | 5 | 2023-02-03T16:17:00Z | 2023-02-21T14:46:49Z | 2023-02-21T14:39:23Z | null | Added functionality implementation: sort datasets by multiple keys/columns as discussed in https://github.com/huggingface/datasets/issues/5425. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5502/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5502/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5502.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5502",
"merged_at": "2023-02-21T14:39:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5502.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks! I've left some comments.\r\n> \r\n> We should also add some tests, mainly to make sure `reverse` behaves as expected. Let me know if you need help with that.\r\n\r\nThanks for the offer! I couldn't find any guidelines on ho... |
https://api.github.com/repos/huggingface/datasets/issues/1141 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1141/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1141/comments | https://api.github.com/repos/huggingface/datasets/issues/1141/events | https://github.com/huggingface/datasets/pull/1141 | 757,411,057 | MDExOlB1bGxSZXF1ZXN0NTMyNzkyNzU3 | 1,141 | Add GitHub version of ETH Py150 Corpus | [] | closed | false | null | 2 | 2020-12-04T21:16:08Z | 2020-12-09T18:32:44Z | 2020-12-07T10:00:24Z | null | Add the redistributable version of **ETH Py150 Corpus** | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1141/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1141/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1141.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1141",
"merged_at": "2020-12-07T10:00:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1141.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"The `RemoteDatasetTest` is fixed on master so it's fine",
"thanks for rebasing :)\r\n\r\nCI is green now, merging"
] |
https://api.github.com/repos/huggingface/datasets/issues/662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/662/comments | https://api.github.com/repos/huggingface/datasets/issues/662/events | https://github.com/huggingface/datasets/pull/662 | 706,689,866 | MDExOlB1bGxSZXF1ZXN0NDkxMTkyNTM3 | 662 | Created dataset card snli.md | [
{
"color": "72f99f",
"default": false,
"description": "Discussions on the datasets",
"id": 2067401494,
"name": "Dataset discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAxNDk0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Dataset%20discussion"
}
] | closed | false | null | 1 | 2020-09-22T21:00:17Z | 2020-09-22T21:26:21Z | 2020-09-22T21:26:21Z | null | First draft of a dataset card using the SNLI corpus as an example | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/662/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/662/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/662.diff",
"html_url": "https://github.com/huggingface/datasets/pull/662",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/662.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/662"
} | true | [
"Resubmitting on a new fork"
] |
https://api.github.com/repos/huggingface/datasets/issues/2338 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2338/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2338/comments | https://api.github.com/repos/huggingface/datasets/issues/2338/events | https://github.com/huggingface/datasets/pull/2338 | 882,046,077 | MDExOlB1bGxSZXF1ZXN0NjM1NjA3NzQx | 2,338 | fixed download link for web_science | [] | closed | false | null | 0 | 2021-05-09T09:12:20Z | 2021-05-10T13:35:53Z | 2021-05-10T13:35:53Z | null | Fixes #2337. Should work with:
`dataset = load_dataset("web_of_science", "WOS11967", ignore_verifications=True)` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2338/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2338/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2338.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2338",
"merged_at": "2021-05-10T13:35:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2338.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3600/comments | https://api.github.com/repos/huggingface/datasets/issues/3600/events | https://github.com/huggingface/datasets/pull/3600 | 1,108,131,878 | PR_kwDODunzps4xQ-vt | 3,600 | Use old url for conll2003 | [] | closed | false | null | 0 | 2022-01-19T13:56:49Z | 2022-01-19T14:16:28Z | 2022-01-19T14:16:28Z | null | As reported in https://github.com/huggingface/datasets/issues/3582 the CoNLL2003 data files are not available in the master branch of the repo that used to host them.
For now we can use the URL from an older commit to access the data files | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3600/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/3600.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3600",
"merged_at": "2022-01-19T14:16:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/3600.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5748/comments | https://api.github.com/repos/huggingface/datasets/issues/5748/events | https://github.com/huggingface/datasets/pull/5748 | 1,667,517,024 | PR_kwDODunzps5OSgNH | 5,748 | [BUG FIX] Issue 5739 | [] | open | false | null | 0 | 2023-04-14T05:07:31Z | 2023-04-14T05:07:31Z | null | null | A fix for https://github.com/huggingface/datasets/issues/5739 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5748/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5748/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5748.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5748",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5748.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5748"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4424/comments | https://api.github.com/repos/huggingface/datasets/issues/4424/events | https://github.com/huggingface/datasets/pull/4424 | 1,253,542,488 | PR_kwDODunzps44uZBD | 4,424 | Fix DuplicatedKeysError in timit_asr dataset | [] | closed | false | null | 1 | 2022-05-31T08:47:45Z | 2022-05-31T13:50:50Z | 2022-05-31T13:42:31Z | null | Fix #4422. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4424/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4424/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4424.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4424",
"merged_at": "2022-05-31T13:42:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4424.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2035 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2035/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2035/comments | https://api.github.com/repos/huggingface/datasets/issues/2035/events | https://github.com/huggingface/datasets/issues/2035 | 829,475,544 | MDU6SXNzdWU4Mjk0NzU1NDQ= | 2,035 | wiki40b/wikipedia for almost all languages cannot be downloaded | [] | open | false | null | 10 | 2021-03-11T19:54:54Z | 2021-03-16T14:53:37Z | null | null | Hi
I am trying to download the data as below:
```
from datasets import load_dataset
dataset = load_dataset("wiki40b", "cs")
print(dataset)
```
I am getting this error. @lhoestq I will be grateful if you could assist me with this error. For almost all languages except english I am getting this error.
I rea... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2035/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2035/timeline | null | null | null | null | false | [
"Dear @lhoestq for wikipedia dataset I also get the same error, I greatly appreciate if you could have a look into this dataset as well. Below please find the command to reproduce the error:\r\n\r\n```\r\ndataset = load_dataset(\"wikipedia\", \"20200501.bg\")\r\nprint(dataset)\r\n```\r\n\r\nYour library is my only ... |
https://api.github.com/repos/huggingface/datasets/issues/4695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4695/comments | https://api.github.com/repos/huggingface/datasets/issues/4695/events | https://github.com/huggingface/datasets/pull/4695 | 1,307,134,701 | PR_kwDODunzps47hobQ | 4,695 | Add MANtIS dataset | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 2 | 2022-07-17T15:53:05Z | 2022-09-30T14:39:30Z | 2022-09-30T14:37:16Z | null | This PR adds MANtIS dataset.
Arxiv: [https://arxiv.org/abs/1912.04639](https://arxiv.org/abs/1912.04639)
Github: [https://github.com/Guzpenha/MANtIS](https://github.com/Guzpenha/MANtIS)
README and dataset tags are WIP. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4695/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4695/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/4695.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4695",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4695.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4695"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for your contribution, @bhavitvyamalik. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets... |
https://api.github.com/repos/huggingface/datasets/issues/5300 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5300/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5300/comments | https://api.github.com/repos/huggingface/datasets/issues/5300/events | https://github.com/huggingface/datasets/pull/5300 | 1,464,697,136 | PR_kwDODunzps5Dt3uK | 5,300 | Use same `num_proc` for dataset download and generation | [] | closed | false | null | 2 | 2022-11-25T15:37:42Z | 2022-12-07T12:55:39Z | 2022-12-07T12:52:51Z | null | Use the same `num_proc` value for data download and generation. Additionally, do not set `num_proc` to 16 in `DownloadManager` by default (`num_proc` now has to be specified explicitly). | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5300/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5300/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5300.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5300",
"merged_at": "2022-12-07T12:52:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5300.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I noticed this bug the other day and was going to look into it! \"Where are these processes coming from?\" ;-)"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.