Datasets:


metadata
language:
- en
- ar
- fr
- jp
- ru
license: apache-2.0
size_categories:
- n<1K
task_categories:
- feature-extraction
pretty_name: MOLE
tags:
- metadata
- extraction
- validation
dataset_info:
features:
- name: category
dtype: string
- name: split
dtype: string
- name: Name
dtype: string
- name: Subsets
dtype: string
- name: HF Link
dtype: 'null'
- name: Link
dtype: string
- name: License
dtype: string
- name: Year
dtype: int64
- name: Language
dtype: string
- name: Dialect
dtype: string
- name: Domain
dtype: string
- name: Form
dtype: string
- name: Collection Style
dtype: 'null'
- name: Description
dtype: string
- name: Volume
dtype: float64
- name: Unit
dtype: string
- name: Ethical Risks
dtype: 'null'
- name: Provider
dtype: string
- name: Derived From
dtype: 'null'
- name: Paper Title
dtype: 'null'
- name: Paper Link
dtype: 'null'
- name: Script
dtype: string
- name: Tokenized
dtype: bool
- name: Host
dtype: string
- name: Access
dtype: string
- name: Cost
dtype: string
- name: Test Split
dtype: 'null'
- name: Tasks
dtype: string
- name: Venue Title
dtype: 'null'
- name: Venue Type
dtype: 'null'
- name: Venue Name
dtype: 'null'
- name: Authors
dtype: string
- name: Affiliations
dtype: string
- name: Abstract
dtype: string
- name: Name_exist
dtype: int64
- name: Subsets_exist
dtype: int64
- name: HF Link_exist
dtype: 'null'
- name: Link_exist
dtype: int64
- name: License_exist
dtype: int64
- name: Year_exist
dtype: int64
- name: Language_exist
dtype: int64
- name: Dialect_exist
dtype: int64
- name: Domain_exist
dtype: int64
- name: Form_exist
dtype: int64
- name: Collection Style_exist
dtype: 'null'
- name: Description_exist
dtype: int64
- name: Volume_exist
dtype: int64
- name: Unit_exist
dtype: int64
- name: Ethical Risks_exist
dtype: 'null'
- name: Provider_exist
dtype: int64
- name: Derived From_exist
dtype: 'null'
- name: Paper Title_exist
dtype: 'null'
- name: Paper Link_exist
dtype: 'null'
- name: Script_exist
dtype: int64
- name: Tokenized_exist
dtype: int64
- name: Host_exist
dtype: int64
- name: Access_exist
dtype: int64
- name: Cost_exist
dtype: int64
- name: Test Split_exist
dtype: 'null'
- name: Tasks_exist
dtype: int64
- name: Venue Title_exist
dtype: 'null'
- name: Venue Type_exist
dtype: 'null'
- name: Venue Name_exist
dtype: 'null'
- name: Authors_exist
dtype: int64
- name: Affiliations_exist
dtype: int64
- name: Abstract_exist
dtype: int64
splits:
- name: train
num_bytes: 264736
num_examples: 132
download_size: 154734
dataset_size: 264736
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
MOLE: Metadata Extraction and Validation in Scientific Papers
MOLE is a dataset for evaluating and validating metadata extracted from scientific papers. The paper can be found here.
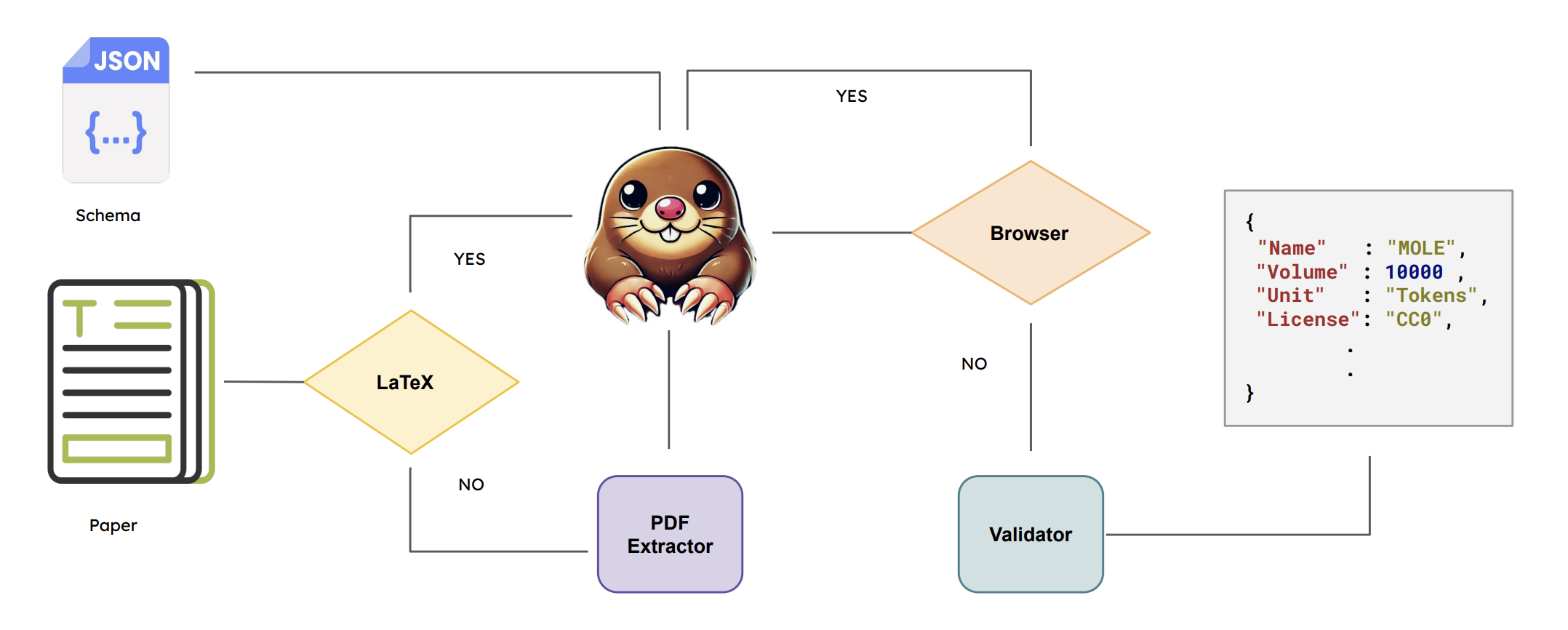
📋 Dataset Structure
The main datasets attributes are shown below. Also for earch feature there is binary value attribute_exist. The value is 1 if the attribute is retrievable form the paper, otherwise it is 0.
Name (str): What is the name of the dataset?Subsets (List[Dict[Name, Volume, Unit, Dialect]]): What are the dialect subsets of this dataset?Link (url): What is the link to access the dataset?HF Link (url): What is the Huggingface link of the dataset?License (str): What is the license of the dataset?Year (date[year]): What year was the dataset published?Language (str): What languages are in the dataset?Dialect (str): What is the dialect of the dataset?Domain (List[str]): What is the source of the dataset?Form (str): What is the form of the data?Collection Style (List[str]): How was this dataset collected?Description (str): Write a brief description about the dataset.Volume (float): What is the size of the dataset?Unit (str): What kind of examples does the dataset include?Ethical Risks (str): What is the level of the ethical risks of the dataset?Provider (List[str]): What entity is the provider of the dataset?Derived From (List[str]): What datasets were used to create the dataset?Paper Title (str): What is the title of the paper?Paper Link (url): What is the link to the paper?Script (str): What is the script of this dataset?Tokenized (bool): Is the dataset tokenized?Host (str): What is name of the repository that hosts the dataset?Access (str): What is the accessibility of the dataset?Cost (str): If the dataset is not free, what is the cost?Test Split (bool): Does the dataset contain a train/valid and test split?Tasks (List[str]): What NLP tasks is this dataset intended for?Venue Title (str): What is the venue title of the published paper?Venue Type (str): What is the venue type?Venue Name (str): What is the full name of the venue that published the paper?Authors (List[str]): Who are the authors of the paper?Affiliations (List[str]): What are the affiliations of the authors?Abstract (str): What is the abstract of the paper?
📁 Loading The Dataset
How to load the dataset
from datasets import load_dataset
dataset = load_dataset('IVUL-KAUST/mole')
📄 Sample From The Dataset:
A sample for an annotated paper
{
"metadata": {
"Name": "TUNIZI",
"Subsets": [],
"Link": "https://github.com/chaymafourati/TUNIZI-Sentiment-Analysis-Tunisian-Arabizi-Dataset",
"HF Link": "",
"License": "unknown",
"Year": 2020,
"Language": "ar",
"Dialect": "Tunisia",
"Domain": [
"social media"
],
"Form": "text",
"Collection Style": [
"crawling",
"manual curation",
"human annotation"
],
"Description": "TUNIZI is a sentiment analysis dataset of over 9,000 Tunisian Arabizi sentences collected from YouTube comments, preprocessed, and manually annotated by native Tunisian speakers.",
"Volume": 9210.0,
"Unit": "sentences",
"Ethical Risks": "Medium",
"Provider": [
"iCompass"
],
"Derived From": [],
"Paper Title": "TUNIZI: A TUNISIAN ARABIZI SENTIMENT ANALYSIS DATASET",
"Paper Link": "https://arxiv.org/abs/2004.14303",
"Script": "Latin",
"Tokenized": false,
"Host": "GitHub",
"Access": "Free",
"Cost": "",
"Test Split": false,
"Tasks": [
"sentiment analysis"
],
"Venue Title": "International Conference on Learning Representations",
"Venue Type": "conference",
"Venue Name": "International Conference on Learning Representations 2020",
"Authors": [
"Chayma Fourati",
"Abir Messaoudi",
"Hatem Haddad"
],
"Affiliations": [
"iCompass"
],
"Abstract": "On social media, Arabic people tend to express themselves in their own local dialects. More particularly, Tunisians use the informal way called 'Tunisian Arabizi'. Analytical studies seek to explore and recognize online opinions aiming to exploit them for planning and prediction purposes such as measuring the customer satisfaction and establishing sales and marketing strategies. However, analytical studies based on Deep Learning are data hungry. On the other hand, African languages and dialects are considered low resource languages. For instance, to the best of our knowledge, no annotated Tunisian Arabizi dataset exists. In this paper, we introduce TUNIZI as a sentiment analysis Tunisian Arabizi Dataset, collected from social networks, preprocessed for analytical studies and annotated manually by Tunisian native speakers."
},
}
⛔️ Limitations
The dataset contains 52 annotated papers, it might be limited to truely evaluate LLMs. We are working on increasing the size of the dataset.
🔑 License
Citation
@misc{mole,
title={MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs},
author={Zaid Alyafeai and Maged S. Al-Shaibani and Bernard Ghanem},
year={2025},
eprint={2505.19800},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.19800},
}