
url stringlengths 58 61 | number int64 1 8.23k | title stringlengths 1 290 | body stringlengths 0 228k ⌀ | state stringclasses 2
values | created_at timestamp[s]date 2020-04-14 10:18:02 2026-05-30 09:38:59 | comments_url stringlengths 67 70 | pull_request dict | is_pull_request bool 2
classes | text stringlengths 2 228k | comments listlengths 0 30 |
|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5410 | 5,410 | Map-style Dataset to IterableDataset | Added `ds.to_iterable()` to get an iterable dataset from a map-style arrow dataset.
It also has a `num_shards` argument to split the dataset before converting to an iterable dataset. Sharding is important to enable efficient shuffling and parallel loading of iterable datasets.
TODO:
- [x] tests
- [x] docs
Fi... | closed | 2023-01-05T18:12:17 | https://api.github.com/repos/huggingface/datasets/issues/5410/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5410",
"html_url": "https://github.com/huggingface/datasets/pull/5410",
"diff_url": "https://github.com/huggingface/datasets/pull/5410.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5410.patch",
"merged_at": "2023-02-01T16:36... | true | Map-style Dataset to IterableDataset
Added `ds.to_iterable()` to get an iterable dataset from a map-style arrow dataset.
It also has a `num_shards` argument to split the dataset before converting to an iterable dataset. Sharding is important to enable efficient shuffling and parallel loading of iterable datasets.
... | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... |
https://api.github.com/repos/huggingface/datasets/issues/5409 | 5,409 | Fix deprecation warning when use_auth_token passed to download_and_prepare | The `DatasetBuilder.download_and_prepare` argument `use_auth_token` was deprecated in:
- #5302
However, `use_auth_token` is still passed to `download_and_prepare` in our built-in `io` readers (csv, json, parquet,...).
This PR fixes it, so that no deprecation warning is raised.
Fix #5407. | closed | 2023-01-05T09:10:58 | https://api.github.com/repos/huggingface/datasets/issues/5409/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5409",
"html_url": "https://github.com/huggingface/datasets/pull/5409",
"diff_url": "https://github.com/huggingface/datasets/pull/5409.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5409.patch",
"merged_at": "2023-01-06T10:59... | true | Fix deprecation warning when use_auth_token passed to download_and_prepare
The `DatasetBuilder.download_and_prepare` argument `use_auth_token` was deprecated in:
- #5302
However, `use_auth_token` is still passed to `download_and_prepare` in our built-in `io` readers (csv, json, parquet,...).
This PR fixes it, s... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5408 | 5,408 | dataset map function could not be hash properly | ### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_... | closed | 2023-01-05T01:59:59 | https://api.github.com/repos/huggingface/datasets/issues/5408/comments | null | false | dataset map function could not be hash properly
### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_da... | [
"Hi ! On macos I tried with\r\n- py 3.9.11\r\n- datasets 2.8.0\r\n- transformers 4.25.1\r\n- dill 0.3.4\r\n\r\nand I was able to hash `prepare_dataset` correctly:\r\n```python\r\nfrom datasets.fingerprint import Hasher\r\nHasher.hash(prepare_dataset)\r\n```\r\n\r\nWhat version of transformers do you have ? Can you ... |
https://api.github.com/repos/huggingface/datasets/issues/5407 | 5,407 | Datasets.from_sql() generates deprecation warning | ### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the ... | closed | 2023-01-05T00:43:17 | https://api.github.com/repos/huggingface/datasets/issues/5407/comments | null | false | Datasets.from_sql() generates deprecation warning
### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset... | [
"Thanks for reporting @msummerfield. We are fixing it."
] |
https://api.github.com/repos/huggingface/datasets/issues/5406 | 5,406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | open | 2023-01-04T15:10:04 | https://api.github.com/repos/huggingface/datasets/issues/5406/comments | null | false | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str`
`datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: ca... | [
"I still get this error on 2.9.0\r\n<img width=\"1925\" alt=\"image\" src=\"https://user-images.githubusercontent.com/7208470/215597359-2f253c76-c472-4612-8099-d3a74d16eb29.png\">\r\n",
"Hi ! I just tested locally and or colab and it works fine for 2.9 on `sst2`.\r\n\r\nAlso the code that is shown in your stack t... |
https://api.github.com/repos/huggingface/datasets/issues/5405 | 5,405 | size_in_bytes the same for all splits | ### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
```
>>> from datasets import load_da... | open | 2023-01-03T20:25:48 | https://api.github.com/repos/huggingface/datasets/issues/5405/comments | null | false | size_in_bytes the same for all splits
### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
... | [
"Hi @Breakend,\r\n\r\nIndeed, the attribute `size_in_bytes` refers to the size of the entire dataset configuration, for all splits (size of downloaded files + Arrow files), not the specific split.\r\nThis is also the case for `download_size` (downloaded files) and `dataset_size` (Arrow files).\r\n\r\nThe size of th... |
https://api.github.com/repos/huggingface/datasets/issues/5404 | 5,404 | Better integration of BIG-bench | ### Feature request
Ideally, it would be nice to have a maintained PyPI package for `bigbench`.
### Motivation
We'd like to allow anyone to access, explore and use any task.
### Your contribution
@lhoestq has opened an issue in their repo:
- https://github.com/google/BIG-bench/issues/906 | open | 2023-01-03T15:37:57 | https://api.github.com/repos/huggingface/datasets/issues/5404/comments | null | false | Better integration of BIG-bench
### Feature request
Ideally, it would be nice to have a maintained PyPI package for `bigbench`.
### Motivation
We'd like to allow anyone to access, explore and use any task.
### Your contribution
@lhoestq has opened an issue in their repo:
- https://github.com/google/BIG-bench/issu... | [
"Hi, I made my version : https://huggingface.co/datasets/tasksource/bigbench"
] |
https://api.github.com/repos/huggingface/datasets/issues/5403 | 5,403 | Replace one letter import in docs | This PR updates a code example for consistency across the docs based on [feedback from this comment](https://github.com/huggingface/transformers/pull/20925/files/9fda31634d203a47d3212e4e8d43d3267faf9808#r1058769500):
"In terms of style we usually stay away from one-letter imports like this (even if the community use... | closed | 2023-01-03T14:26:32 | https://api.github.com/repos/huggingface/datasets/issues/5403/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5403",
"html_url": "https://github.com/huggingface/datasets/pull/5403",
"diff_url": "https://github.com/huggingface/datasets/pull/5403.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5403.patch",
"merged_at": "2023-01-03T14:59... | true | Replace one letter import in docs
This PR updates a code example for consistency across the docs based on [feedback from this comment](https://github.com/huggingface/transformers/pull/20925/files/9fda31634d203a47d3212e4e8d43d3267faf9808#r1058769500):
"In terms of style we usually stay away from one-letter imports li... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks for the docs fix for consistency.\r\n> \r\n> Again for consistency, it would be nice to make the same fix across all the docs, e.g.\r\n> \r\n> https://github.com/huggingface/datasets/blob/310cdddd1c43f9658de172b85b6509d07d5e... |
https://api.github.com/repos/huggingface/datasets/issues/5402 | 5,402 | Missing state.json when creating a cloud dataset using a dataset_builder | ### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_da... | open | 2023-01-03T13:39:59 | https://api.github.com/repos/huggingface/datasets/issues/5402/comments | null | false | Missing state.json when creating a cloud dataset using a dataset_builder
### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session i... | [
"`load_from_disk` must be used on datasets saved using `save_to_disk`: they correspond to fully serialized datasets including their state.\r\n\r\nOn the other hand, `download_and_prepare` just downloads the raw data and convert them to arrow (or parquet if you want). We are working on allowing you to reload a datas... |
https://api.github.com/repos/huggingface/datasets/issues/5401 | 5,401 | Support Dataset conversion from/to Spark | This PR implements Spark integration by supporting `Dataset` conversion from/to Spark `DataFrame`. | open | 2023-01-03T09:57:40 | https://api.github.com/repos/huggingface/datasets/issues/5401/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5401",
"html_url": "https://github.com/huggingface/datasets/pull/5401",
"diff_url": "https://github.com/huggingface/datasets/pull/5401.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5401.patch",
"merged_at": null
} | true | Support Dataset conversion from/to Spark
This PR implements Spark integration by supporting `Dataset` conversion from/to Spark `DataFrame`. | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5401). All of your documentation changes will be reflected on that endpoint.",
"Cool thanks !\r\n\r\nSpark DataFrame are usually quite big, and I believe here `from_spark` would load everything in the driver node's RAM, which i... |
https://api.github.com/repos/huggingface/datasets/issues/5400 | 5,400 | Support streaming datasets with os.path.exists and Path.exists | Support streaming datasets with `os.path.exists` and `pathlib.Path.exists`. | closed | 2023-01-03T07:42:37 | https://api.github.com/repos/huggingface/datasets/issues/5400/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5400",
"html_url": "https://github.com/huggingface/datasets/pull/5400",
"diff_url": "https://github.com/huggingface/datasets/pull/5400.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5400.patch",
"merged_at": "2023-01-06T10:35... | true | Support streaming datasets with os.path.exists and Path.exists
Support streaming datasets with `os.path.exists` and `pathlib.Path.exists`. | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5399 | 5,399 | Got disconnected from remote data host. Retrying in 5sec [2/20] | ### Describe the bug
While trying to upload my image dataset of a CSV file type to huggingface by running the below code. The dataset consists of a little over 100k of image-caption pairs
### Steps to reproduce the bug
```
df = pd.read_csv('x.csv', encoding='utf-8-sig')
features = Features({
'link': Ima... | closed | 2023-01-01T13:00:11 | https://api.github.com/repos/huggingface/datasets/issues/5399/comments | null | false | Got disconnected from remote data host. Retrying in 5sec [2/20]
### Describe the bug
While trying to upload my image dataset of a CSV file type to huggingface by running the below code. The dataset consists of a little over 100k of image-caption pairs
### Steps to reproduce the bug
```
df = pd.read_csv('x.csv',... | [] |
https://api.github.com/repos/huggingface/datasets/issues/5398 | 5,398 | Unpin pydantic | Once `pydantic` fixes their issue in their 1.10.3 version, unpin it.
See issue:
- #5394
See temporary fix:
- #5395 | closed | 2022-12-30T10:37:31 | https://api.github.com/repos/huggingface/datasets/issues/5398/comments | null | false | Unpin pydantic
Once `pydantic` fixes their issue in their 1.10.3 version, unpin it.
See issue:
- #5394
See temporary fix:
- #5395 | [] |
https://api.github.com/repos/huggingface/datasets/issues/5397 | 5,397 | Unpin pydantic test dependency | Once pydantic-1.10.3 has been yanked, we can unpin it: https://pypi.org/project/pydantic/1.10.3/
See reply by pydantic team https://github.com/pydantic/pydantic/issues/4885#issuecomment-1367819807
```
v1.10.3 has been yanked.
```
in response to spacy request: https://github.com/pydantic/pydantic/issues/4885#issu... | closed | 2022-12-30T10:22:09 | https://api.github.com/repos/huggingface/datasets/issues/5397/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5397",
"html_url": "https://github.com/huggingface/datasets/pull/5397",
"diff_url": "https://github.com/huggingface/datasets/pull/5397.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5397.patch",
"merged_at": "2022-12-30T10:43... | true | Unpin pydantic test dependency
Once pydantic-1.10.3 has been yanked, we can unpin it: https://pypi.org/project/pydantic/1.10.3/
See reply by pydantic team https://github.com/pydantic/pydantic/issues/4885#issuecomment-1367819807
```
v1.10.3 has been yanked.
```
in response to spacy request: https://github.com/pyd... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5396 | 5,396 | Fix checksum verification | Expected checksum was verified against checksum dict (not checksum). | closed | 2022-12-29T19:45:17 | https://api.github.com/repos/huggingface/datasets/issues/5396/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5396",
"html_url": "https://github.com/huggingface/datasets/pull/5396",
"diff_url": "https://github.com/huggingface/datasets/pull/5396.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5396.patch",
"merged_at": null
} | true | Fix checksum verification
Expected checksum was verified against checksum dict (not checksum). | [
"Hi ! If I'm not mistaken both `expected_checksums[url]` and `recorded_checksums[url]` are dictionaries with keys \"checksum\" and \"num_bytes\". So we need to check whether `expected_checksums[url] != recorded_checksums[url]` (or simply `expected_checksums[url][\"checksum\"] != recorded_checksums[url][\"checksum\"... |
https://api.github.com/repos/huggingface/datasets/issues/5395 | 5,395 | Temporarily pin pydantic test dependency | Temporarily pin `pydantic` until a permanent solution is found.
Fix #5394. | closed | 2022-12-29T19:34:19 | https://api.github.com/repos/huggingface/datasets/issues/5395/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5395",
"html_url": "https://github.com/huggingface/datasets/pull/5395",
"diff_url": "https://github.com/huggingface/datasets/pull/5395.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5395.patch",
"merged_at": "2022-12-29T21:00... | true | Temporarily pin pydantic test dependency
Temporarily pin `pydantic` until a permanent solution is found.
Fix #5394. | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5394 | 5,394 | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers' | ### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/hoste... | closed | 2022-12-29T18:58:44 | https://api.github.com/repos/huggingface/datasets/issues/5394/comments | null | false | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers'
### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_... | [
"I still getting the same error :\r\n\r\n`python -m spacy download fr_core_news_lg\r\n`.\r\n`import spacy`",
"@MFatnassi, this issue and the corresponding fix only affect our Continuous Integration testing environment.\r\n\r\nNote that `datasets` does not depend on `spacy`."
] |
https://api.github.com/repos/huggingface/datasets/issues/5393 | 5,393 | Finish deprecating the fs argument | See #5385 for some discussion on this
The `fs=` arg was depcrecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in `2.8.0` (to be removed in `3.0.0`). There are a few other places where the `fs=` arg was still used (functions/methods in `datasets.info` and `datasets.load`). This PR adds a similar beha... | closed | 2022-12-28T15:33:17 | https://api.github.com/repos/huggingface/datasets/issues/5393/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5393",
"html_url": "https://github.com/huggingface/datasets/pull/5393",
"diff_url": "https://github.com/huggingface/datasets/pull/5393.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5393.patch",
"merged_at": "2023-01-18T12:35... | true | Finish deprecating the fs argument
See #5385 for some discussion on this
The `fs=` arg was depcrecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in `2.8.0` (to be removed in `3.0.0`). There are a few other places where the `fs=` arg was still used (functions/methods in `datasets.info` and `datasets.l... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Thanks for the deprecation. Some minor suggested fixes below...\r\n> \r\n> Also note that the corresponding tests should be updated as well.\r\n\r\nThanks for the suggestions/typo fixes. I updated the failing test - passing locall... |
https://api.github.com/repos/huggingface/datasets/issues/5392 | 5,392 | Fix Colab notebook link | Fix notebook link to open in Colab. | closed | 2022-12-28T11:44:53 | https://api.github.com/repos/huggingface/datasets/issues/5392/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5392",
"html_url": "https://github.com/huggingface/datasets/pull/5392",
"diff_url": "https://github.com/huggingface/datasets/pull/5392.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5392.patch",
"merged_at": "2023-01-03T15:27... | true | Fix Colab notebook link
Fix notebook link to open in Colab. | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5391 | 5,391 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it] | Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1... | closed | 2022-12-25T15:17:14 | https://api.github.com/repos/huggingface/datasets/issues/5391/comments | null | false | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it]
Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-even... | [
"Hey @catswithbats! Super sorry for the late reply! This is happening because there is data with label length (504) that exceeds the model's max length (448). \r\n\r\nThere are two options here:\r\n1. Increase the model's `max_length` parameter: \r\n```python\r\nmodel.config.max_length = 512\r\n```\r\n2. Filter dat... |
https://api.github.com/repos/huggingface/datasets/issues/5390 | 5,390 | Error when pushing to the CI hub | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████... | closed | 2022-12-23T13:36:37 | https://api.github.com/repos/huggingface/datasets/issues/5390/comments | null | false | Error when pushing to the CI hub
### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|█... | [
"Hmmm, git bisect tells me that the behavior is the same since https://github.com/huggingface/datasets/commit/67e65c90e9490810b89ee140da11fdd13c356c9c (3 Oct), i.e. https://github.com/huggingface/datasets/pull/4926",
"Maybe related to the discussions in https://github.com/huggingface/datasets/pull/5196",
"Maybe... |
https://api.github.com/repos/huggingface/datasets/issues/5389 | 5,389 | Fix link in `load_dataset` docstring | Fix https://github.com/huggingface/datasets/issues/5387, fix https://github.com/huggingface/datasets/issues/4566 | closed | 2022-12-23T13:26:31 | https://api.github.com/repos/huggingface/datasets/issues/5389/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5389",
"html_url": "https://github.com/huggingface/datasets/pull/5389",
"diff_url": "https://github.com/huggingface/datasets/pull/5389.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5389.patch",
"merged_at": "2023-01-24T16:33... | true | Fix link in `load_dataset` docstring
Fix https://github.com/huggingface/datasets/issues/5387, fix https://github.com/huggingface/datasets/issues/4566 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5388 | 5,388 | Getting Value Error while loading a dataset.. | ### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---... | closed | 2022-12-23T08:16:43 | https://api.github.com/repos/huggingface/datasets/issues/5388/comments | null | false | Getting Value Error while loading a dataset..
### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom da... | [
"Hi! I can't reproduce this error locally (Mac) or in Colab. What version of `datasets` are you using?",
"Hi [mariosasko](https://github.com/mariosasko), the datasets version is '2.8.0'.",
"@valmetisrinivas you get that error because you imported `datasets` (and thus `fsspec`) before installing `zstandard`.\r\n... |
https://api.github.com/repos/huggingface/datasets/issues/5387 | 5,387 | Missing documentation page : improve-performance | ### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.load_dataset.keep_in_memory
### Steps to reproduce t... | closed | 2022-12-23T01:12:57 | https://api.github.com/repos/huggingface/datasets/issues/5387/comments | null | false | Missing documentation page : improve-performance
### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.load... | [
"Hi! Our documentation builder does not support links to sections, hence the bug. This is the link it should point to https://huggingface.co/docs/datasets/v2.8.0/en/cache#improve-performance."
] |
https://api.github.com/repos/huggingface/datasets/issues/5386 | 5,386 | `max_shard_size` in `datasets.push_to_hub()` breaks with large files | ### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (up to `~100MB` per file), I've encountered cases where `max_shard_siz... | closed | 2022-12-22T21:50:58 | https://api.github.com/repos/huggingface/datasets/issues/5386/comments | null | false | `max_shard_size` in `datasets.push_to_hub()` breaks with large files
### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (... | [
"Hi! \r\n\r\nThis behavior stems from the fact that we don't always embed image bytes in the underlying arrow table, which can lead to bad size estimation (we use the first 1000 table rows to [estimate](https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.... |
https://api.github.com/repos/huggingface/datasets/issues/5385 | 5,385 | Is `fs=` deprecated in `load_from_disk()` as well? | ### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the... | closed | 2022-12-22T21:00:45 | https://api.github.com/repos/huggingface/datasets/issues/5385/comments | null | false | Is `fs=` deprecated in `load_from_disk()` as well?
### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/ar... | [
"Hi! Yes, we should deprecate the `fs` param here. Would you be interested in submitting a PR? ",
"> Hi! Yes, we should deprecate the `fs` param here. Would you be interested in submitting a PR?\r\n\r\nYeah I can do that sometime next week. Should the storage_options be a new arg here? I’ll look around for anywh... |
https://api.github.com/repos/huggingface/datasets/issues/5384 | 5,384 | Handle 0-dim tensors in `cast_to_python_objects` | Fix #5229 | closed | 2022-12-22T16:15:30 | https://api.github.com/repos/huggingface/datasets/issues/5384/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5384",
"html_url": "https://github.com/huggingface/datasets/pull/5384",
"diff_url": "https://github.com/huggingface/datasets/pull/5384.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5384.patch",
"merged_at": "2023-01-13T16:00... | true | Handle 0-dim tensors in `cast_to_python_objects`
Fix #5229 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5383 | 5,383 | IterableDataset missing column_names, differs from Dataset interface | ### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.colu... | closed | 2022-12-22T05:27:02 | https://api.github.com/repos/huggingface/datasets/issues/5383/comments | null | false | IterableDataset missing column_names, differs from Dataset interface
### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_... | [
"Another example is that `IterableDataset.map` does not have `fn_kwargs`, among other arguments. It makes it harder to convert code from Dataset to IterableDataset.",
"Hi! `fn_kwargs` was added to `IterableDataset.map` in `datasets 2.5.0`, so please update your installation (`pip install -U datasets`) to use it.\... |
https://api.github.com/repos/huggingface/datasets/issues/5382 | 5,382 | Raise from disconnect error in xopen | this way we can know the cause of the disconnect
related to https://github.com/huggingface/datasets/issues/5374 | closed | 2022-12-20T15:52:44 | https://api.github.com/repos/huggingface/datasets/issues/5382/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5382",
"html_url": "https://github.com/huggingface/datasets/pull/5382",
"diff_url": "https://github.com/huggingface/datasets/pull/5382.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5382.patch",
"merged_at": "2023-01-26T09:42... | true | Raise from disconnect error in xopen
this way we can know the cause of the disconnect
related to https://github.com/huggingface/datasets/issues/5374 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Could you review this small PR @albertvillanova ? :)",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric... |
https://api.github.com/repos/huggingface/datasets/issues/5381 | 5,381 | Wrong URL for the_pile dataset | ### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name": "FileNotFoundError",
"message... | closed | 2022-12-20T12:40:14 | https://api.github.com/repos/huggingface/datasets/issues/5381/comments | null | false | Wrong URL for the_pile dataset
### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name": ... | [
"Hi! This error can happen if there is a local file/folder with the same name as the requested dataset. And to avoid it, rename the local file/folder.\r\n\r\nSoon, it will be possible to explicitly request a Hub dataset as follows:https://github.com/huggingface/datasets/issues/5228#issuecomment-1313494020"
] |
https://api.github.com/repos/huggingface/datasets/issues/5380 | 5,380 | Improve dataset `.skip()` speed in streaming mode | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | open | 2022-12-20T11:25:23 | https://api.github.com/repos/huggingface/datasets/issues/5380/comments | null | false | Improve dataset `.skip()` speed in streaming mode
### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the downlo... | [
"Hi! I agree `skip` can be inefficient to use in the current state.\r\n\r\nTo make it fast, we could use \"statistics\" stored in Parquet metadata and read only the chunks needed to form a dataset. \r\n\r\nAnd thanks to the \"datasets-server\" project, which aims to store the Parquet versions of the Hub datasets (o... |
https://api.github.com/repos/huggingface/datasets/issues/5379 | 5,379 | feat: depth estimation dataset guide. | This PR adds a guide for prepping datasets for depth estimation.
PR to add documentation images is up here: https://huggingface.co/datasets/huggingface/documentation-images/discussions/22 | closed | 2022-12-20T05:32:11 | https://api.github.com/repos/huggingface/datasets/issues/5379/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5379",
"html_url": "https://github.com/huggingface/datasets/pull/5379",
"diff_url": "https://github.com/huggingface/datasets/pull/5379.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5379.patch",
"merged_at": "2023-01-13T12:23... | true | feat: depth estimation dataset guide.
This PR adds a guide for prepping datasets for depth estimation.
PR to add documentation images is up here: https://huggingface.co/datasets/huggingface/documentation-images/discussions/22 | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the changes, looks good to me!",
"@stevhliu I have pushed some quality improvements both in terms of code and content. Would you be able to re-review? ",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0... |
https://api.github.com/repos/huggingface/datasets/issues/5378 | 5,378 | The dataset "the_pile", subset "enron_emails" , load_dataset() failure | ### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run below code in python cli:
>>> import datasets
>>> datasets.load_dataset(... | closed | 2022-12-20T02:19:13 | https://api.github.com/repos/huggingface/datasets/issues/5378/comments | null | false | The dataset "the_pile", subset "enron_emails" , load_dataset() failure
### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run below... | [
"Thanks for reporting @shaoyuta. We are investigating it.\r\n\r\nWe are transferring the issue to \"the_pile\" Community tab on the Hub: https://huggingface.co/datasets/the_pile/discussions/4"
] |
https://api.github.com/repos/huggingface/datasets/issues/5377 | 5,377 | Add a parallel implementation of to_tf_dataset() | Hey all! Here's a first draft of the PR to add a multiprocessing implementation for `to_tf_dataset()`. It worked in some quick testing for me, but obviously I need to do some much more rigorous testing/benchmarking, and add some proper library tests.
The core idea is that we do everything using `multiprocessing` and... | closed | 2022-12-19T19:40:27 | https://api.github.com/repos/huggingface/datasets/issues/5377/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5377",
"html_url": "https://github.com/huggingface/datasets/pull/5377",
"diff_url": "https://github.com/huggingface/datasets/pull/5377.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5377.patch",
"merged_at": "2023-01-25T16:21... | true | Add a parallel implementation of to_tf_dataset()
Hey all! Here's a first draft of the PR to add a multiprocessing implementation for `to_tf_dataset()`. It worked in some quick testing for me, but obviously I need to do some much more rigorous testing/benchmarking, and add some proper library tests.
The core idea is ... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Failing because the test server uses Py3.7 but the `SharedMemory` features require Py3.8! I forgot we still support 3.7 for another couple of months. I'm not sure exactly how to proceed, whether I should leave this PR until then, or ... |
https://api.github.com/repos/huggingface/datasets/issues/5376 | 5,376 | set dev version | null | closed | 2022-12-19T10:56:56 | https://api.github.com/repos/huggingface/datasets/issues/5376/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5376",
"html_url": "https://github.com/huggingface/datasets/pull/5376",
"diff_url": "https://github.com/huggingface/datasets/pull/5376.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5376.patch",
"merged_at": "2022-12-19T10:57... | true | set dev version
| [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5376). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/5375 | 5,375 | Release: 2.8.0 | null | closed | 2022-12-19T10:48:26 | https://api.github.com/repos/huggingface/datasets/issues/5375/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5375",
"html_url": "https://github.com/huggingface/datasets/pull/5375",
"diff_url": "https://github.com/huggingface/datasets/pull/5375.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5375.patch",
"merged_at": "2022-12-19T10:53... | true | Release: 2.8.0
| [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5374 | 5,374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | closed | 2022-12-18T11:38:58 | https://api.github.com/repos/huggingface/datasets/issues/5374/comments | null | false | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec
### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
P... | [
"The data files are hosted on HF at https://huggingface.co/datasets/allenai/c4/tree/main\r\n\r\nYou have 200 runs streaming the same files in parallel. So this is probably a Hub limitation. Maybe rate limiting ? cc @julien-c \r\n\r\nMaybe you can also try to reduce the number of HTTP requests by increasing the bloc... |
https://api.github.com/repos/huggingface/datasets/issues/5373 | 5,373 | Simplify skipping | Was hoping to find a way to speed up the skipping as I'm running into bottlenecks skipping 100M examples on C4 (it takes 12 hours to skip), but didn't find anything better than this small change :(
Maybe there's a way to directly skip whole shards to speed it up? 🧐 | closed | 2022-12-17T17:23:52 | https://api.github.com/repos/huggingface/datasets/issues/5373/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5373",
"html_url": "https://github.com/huggingface/datasets/pull/5373",
"diff_url": "https://github.com/huggingface/datasets/pull/5373.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5373.patch",
"merged_at": "2022-12-18T21:40... | true | Simplify skipping
Was hoping to find a way to speed up the skipping as I'm running into bottlenecks skipping 100M examples on C4 (it takes 12 hours to skip), but didn't find anything better than this small change :(
Maybe there's a way to directly skip whole shards to speed it up? 🧐 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5372 | 5,372 | Fix streaming pandas.read_excel | This PR fixes `xpandas_read_excel`:
- Support passing a path string, besides a file-like object
- Support passing `use_auth_token`
- First assumes the host server supports HTTP range requests; only if a ValueError is thrown (Cannot seek streaming HTTP file), then it preserves previous behavior (see [#3355](https://g... | closed | 2022-12-17T12:58:52 | https://api.github.com/repos/huggingface/datasets/issues/5372/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5372",
"html_url": "https://github.com/huggingface/datasets/pull/5372",
"diff_url": "https://github.com/huggingface/datasets/pull/5372.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5372.patch",
"merged_at": "2023-01-06T11:43... | true | Fix streaming pandas.read_excel
This PR fixes `xpandas_read_excel`:
- Support passing a path string, besides a file-like object
- Support passing `use_auth_token`
- First assumes the host server supports HTTP range requests; only if a ValueError is thrown (Cannot seek streaming HTTP file), then it preserves previous... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... |
https://api.github.com/repos/huggingface/datasets/issues/5371 | 5,371 | Add a robustness benchmark dataset for vision | ### Name
ImageNet-C
### Paper
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
### Data
https://github.com/hendrycks/robustness
### Motivation
It's a known fact that vision models are brittle when they meet with slightly corrupted and perturbed data. This is also corre... | open | 2022-12-17T12:35:13 | https://api.github.com/repos/huggingface/datasets/issues/5371/comments | null | false | Add a robustness benchmark dataset for vision
### Name
ImageNet-C
### Paper
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
### Data
https://github.com/hendrycks/robustness
### Motivation
It's a known fact that vision models are brittle when they meet with slightly co... | [
"Ccing @nazneenrajani @lvwerra @osanseviero "
] |
https://api.github.com/repos/huggingface/datasets/issues/5369 | 5,369 | Distributed support | To split your dataset across your training nodes, you can use the new [`datasets.distributed.split_dataset_by_node`]:
```python
import os
from datasets.distributed import split_dataset_by_node
ds = split_dataset_by_node(ds, rank=int(os.environ["RANK"]), world_size=int(os.environ["WORLD_SIZE"]))
```
This wor... | closed | 2022-12-16T17:43:47 | https://api.github.com/repos/huggingface/datasets/issues/5369/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5369",
"html_url": "https://github.com/huggingface/datasets/pull/5369",
"diff_url": "https://github.com/huggingface/datasets/pull/5369.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5369.patch",
"merged_at": "2023-01-16T13:33... | true | Distributed support
To split your dataset across your training nodes, you can use the new [`datasets.distributed.split_dataset_by_node`]:
```python
import os
from datasets.distributed import split_dataset_by_node
ds = split_dataset_by_node(ds, rank=int(os.environ["RANK"]), world_size=int(os.environ["WORLD_SIZE"... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Alright all the tests are passing - this is ready for review",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n... |
https://api.github.com/repos/huggingface/datasets/issues/5368 | 5,368 | Align remove columns behavior and input dict mutation in `map` with previous behavior | Align the `remove_columns` behavior and input dict mutation in `map` with the behavior before https://github.com/huggingface/datasets/pull/5252. | closed | 2022-12-16T14:28:47 | https://api.github.com/repos/huggingface/datasets/issues/5368/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5368",
"html_url": "https://github.com/huggingface/datasets/pull/5368",
"diff_url": "https://github.com/huggingface/datasets/pull/5368.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5368.patch",
"merged_at": "2022-12-16T16:25... | true | Align remove columns behavior and input dict mutation in `map` with previous behavior
Align the `remove_columns` behavior and input dict mutation in `map` with the behavior before https://github.com/huggingface/datasets/pull/5252. | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5367 | 5,367 | Fix remove columns from lazy dict | This was introduced in https://github.com/huggingface/datasets/pull/5252 and causing the transformers CI to break: https://app.circleci.com/pipelines/github/huggingface/transformers/53886/workflows/522faf2e-a053-454c-94f8-a617fde33393/jobs/648597
Basically this code should return a dataset with only one column:
`... | closed | 2022-12-15T22:04:12 | https://api.github.com/repos/huggingface/datasets/issues/5367/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5367",
"html_url": "https://github.com/huggingface/datasets/pull/5367",
"diff_url": "https://github.com/huggingface/datasets/pull/5367.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5367.patch",
"merged_at": "2022-12-15T22:24... | true | Fix remove columns from lazy dict
This was introduced in https://github.com/huggingface/datasets/pull/5252 and causing the transformers CI to break: https://app.circleci.com/pipelines/github/huggingface/transformers/53886/workflows/522faf2e-a053-454c-94f8-a617fde33393/jobs/648597
Basically this code should return a ... | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5366 | 5,366 | ExamplesIterable fixes | fix typing and ExamplesIterable.shard_data_sources | closed | 2022-12-15T14:23:05 | https://api.github.com/repos/huggingface/datasets/issues/5366/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5366",
"html_url": "https://github.com/huggingface/datasets/pull/5366",
"diff_url": "https://github.com/huggingface/datasets/pull/5366.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5366.patch",
"merged_at": "2022-12-15T14:41... | true | ExamplesIterable fixes
fix typing and ExamplesIterable.shard_data_sources | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5365 | 5,365 | fix: image array should support other formats than uint8 | Currently images that are provided as ndarrays, but not in `uint8` format are going to loose data. Namely, for example in a depth image where the data is in float32 format, the type-casting to uint8 will basically make the whole image blank.
`PIL.Image.fromarray` [does support mode `F`](https://pillow.readthedocs.io/e... | closed | 2022-12-15T13:17:50 | https://api.github.com/repos/huggingface/datasets/issues/5365/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5365",
"html_url": "https://github.com/huggingface/datasets/pull/5365",
"diff_url": "https://github.com/huggingface/datasets/pull/5365.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5365.patch",
"merged_at": "2023-01-26T18:39... | true | fix: image array should support other formats than uint8
Currently images that are provided as ndarrays, but not in `uint8` format are going to loose data. Namely, for example in a depth image where the data is in float32 format, the type-casting to uint8 will basically make the whole image blank.
`PIL.Image.fromarray... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi, thanks for working on this! \r\n\r\nI agree that the current type-casting (always cast to `np.uint8` as Tensorflow Datasets does) is a bit too harsh. However, not all dtypes are supported in `Image.fromarray` (e.g. np.int64), so ... |
https://api.github.com/repos/huggingface/datasets/issues/5364 | 5,364 | Support for writing arrow files directly with BeamWriter | Make it possible to write Arrow files directly with `BeamWriter` rather than converting from Parquet to Arrow, which is sub-optimal, especially for big datasets for which Beam is primarily used. | closed | 2022-12-15T12:38:05 | https://api.github.com/repos/huggingface/datasets/issues/5364/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5364",
"html_url": "https://github.com/huggingface/datasets/pull/5364",
"diff_url": "https://github.com/huggingface/datasets/pull/5364.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5364.patch",
"merged_at": null
} | true | Support for writing arrow files directly with BeamWriter
Make it possible to write Arrow files directly with `BeamWriter` rather than converting from Parquet to Arrow, which is sub-optimal, especially for big datasets for which Beam is primarily used. | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5364). All of your documentation changes will be reflected on that endpoint.",
"Deleting `BeamPipeline` and `upload_local_to_remote` would break the existing Beam scripts, so I reverted this change.\r\n\r\nFrom what I understan... |
https://api.github.com/repos/huggingface/datasets/issues/5363 | 5,363 | Dataset.from_generator() crashes on simple example | null | closed | 2022-12-15T10:21:28 | https://api.github.com/repos/huggingface/datasets/issues/5363/comments | null | false | Dataset.from_generator() crashes on simple example
| [] |
https://api.github.com/repos/huggingface/datasets/issues/5362 | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
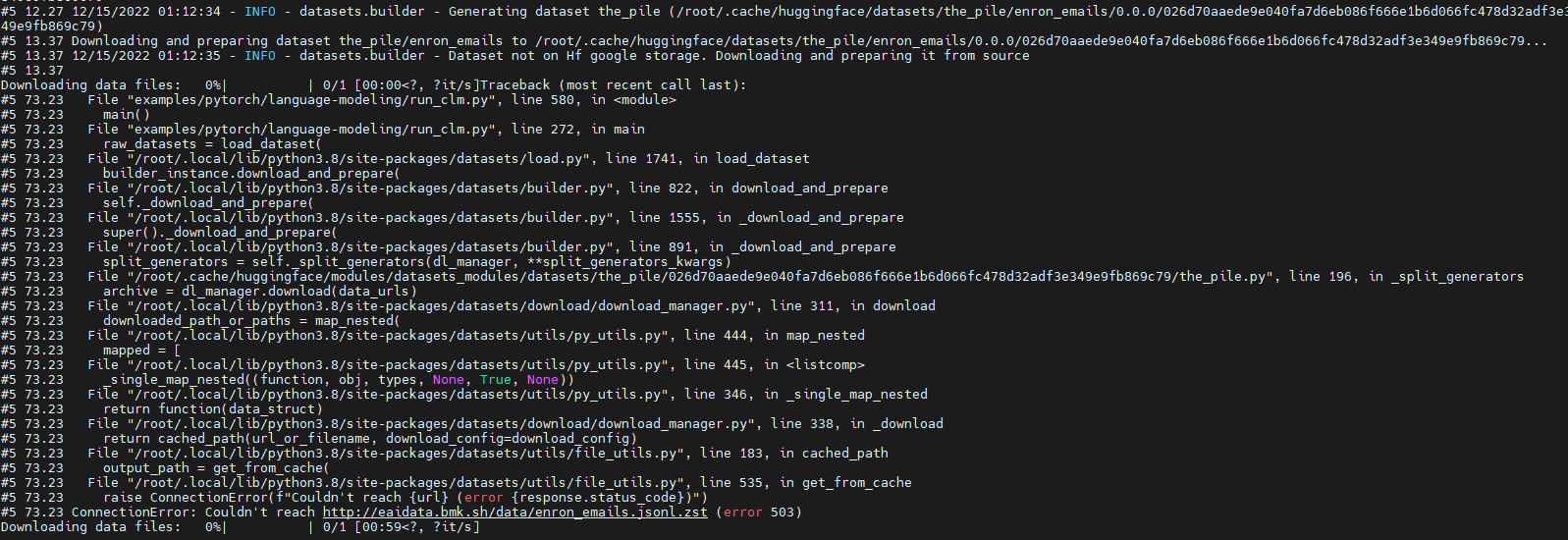
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | closed | 2022-12-15T01:23:03 | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | null | false | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' )
### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:

# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batc... | closed | 2022-12-14T18:13:55 | https://api.github.com/repos/huggingface/datasets/issues/5361/comments | null | false | How concatenate `Audio` elements using batch mapping
### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.... | [
"You can try something like this ?\r\n```python\r\ndef mapper_function(batch):\r\n return {\"concatenated_audio\": [np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]])]}\r\n\r\ndataset = dataset.map(\r\n mapper_function,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.... |
https://api.github.com/repos/huggingface/datasets/issues/5360 | 5,360 | IterableDataset returns duplicated data using PyTorch DDP | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | closed | 2022-12-14T16:06:19 | https://api.github.com/repos/huggingface/datasets/issues/5360/comments | null | false | IterableDataset returns duplicated data using PyTorch DDP
As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()... | [
"If you use huggingface trainer, you will find the trainer has wrapped a `IterableDatasetShard` to avoid duplication.\r\nSee:\r\nhttps://github.com/huggingface/transformers/blob/dfd818420dcbad68e05a502495cf666d338b2bfb/src/transformers/trainer.py#L835\r\n",
"If you want to support it by datasets natively, maybe w... |
https://api.github.com/repos/huggingface/datasets/issues/5359 | 5,359 | Raise error if ClassLabel names is not python list | Checks type of names provided to ClassLabel to avoid easy and hard to debug errors (closes #5332 - see for discussion) | closed | 2022-12-13T23:04:06 | https://api.github.com/repos/huggingface/datasets/issues/5359/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5359",
"html_url": "https://github.com/huggingface/datasets/pull/5359",
"diff_url": "https://github.com/huggingface/datasets/pull/5359.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5359.patch",
"merged_at": "2022-12-22T16:32... | true | Raise error if ClassLabel names is not python list
Checks type of names provided to ClassLabel to avoid easy and hard to debug errors (closes #5332 - see for discussion) | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for your proposed fix, @freddyheppell.\r\n\r\nCurrently the CI fails because in a test we pass a `tuple` instead of a `list`. I would say we should accept `tuple` as a valid input type as well...\r\n\r\nWhat about checking for... |
https://api.github.com/repos/huggingface/datasets/issues/5358 | 5,358 | Fix `fs.open` resource leaks | Invoking `{load,save}_from_dict` results in resource leak warnings, this should fix.
Introduces no significant logic changes. | closed | 2022-12-13T22:35:51 | https://api.github.com/repos/huggingface/datasets/issues/5358/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5358",
"html_url": "https://github.com/huggingface/datasets/pull/5358",
"diff_url": "https://github.com/huggingface/datasets/pull/5358.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5358.patch",
"merged_at": "2023-01-05T15:59... | true | Fix `fs.open` resource leaks
Invoking `{load,save}_from_dict` results in resource leak warnings, this should fix.
Introduces no significant logic changes. | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@mariosasko Sorry, I didn't check tests/style after doing a merge from the Git UI last week. Thx for fixing. \r\n\r\nFYI I'm getting \"Only those with [write access](https://docs.github.com/articles/what-are-the-different-access-perm... |
https://api.github.com/repos/huggingface/datasets/issues/5357 | 5,357 | Support torch dataloader without torch formatting | In https://github.com/huggingface/datasets/pull/5084 we make the torch formatting consistent with the map-style datasets formatting: a torch formatted iterable dataset will yield torch tensors.
The previous behavior of the torch formatting for iterable dataset was simply to make the iterable dataset inherit from `to... | closed | 2022-12-13T19:39:24 | https://api.github.com/repos/huggingface/datasets/issues/5357/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5357",
"html_url": "https://github.com/huggingface/datasets/pull/5357",
"diff_url": "https://github.com/huggingface/datasets/pull/5357.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5357.patch",
"merged_at": "2022-12-15T19:15... | true | Support torch dataloader without torch formatting
In https://github.com/huggingface/datasets/pull/5084 we make the torch formatting consistent with the map-style datasets formatting: a torch formatted iterable dataset will yield torch tensors.
The previous behavior of the torch formatting for iterable dataset was si... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Need some more time to fix the tests, especially with pickle",
"> And I actually don't quite understand the idea - what's the motivation behind making only IterableDataset compatible with torch DataLoader without setting the format... |
https://api.github.com/repos/huggingface/datasets/issues/5356 | 5,356 | Clean filesystem and logging docstrings | This PR cleans the `Filesystems` and `Logging` docstrings. | closed | 2022-12-13T18:54:09 | https://api.github.com/repos/huggingface/datasets/issues/5356/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5356",
"html_url": "https://github.com/huggingface/datasets/pull/5356",
"diff_url": "https://github.com/huggingface/datasets/pull/5356.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5356.patch",
"merged_at": "2022-12-14T17:22... | true | Clean filesystem and logging docstrings
This PR cleans the `Filesystems` and `Logging` docstrings. | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5355 | 5,355 | Clean up Table class docstrings | This PR cleans up the `Table` class docstrings :) | closed | 2022-12-13T00:29:47 | https://api.github.com/repos/huggingface/datasets/issues/5355/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5355",
"html_url": "https://github.com/huggingface/datasets/pull/5355",
"diff_url": "https://github.com/huggingface/datasets/pull/5355.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5355.patch",
"merged_at": "2022-12-13T18:14... | true | Clean up Table class docstrings
This PR cleans up the `Table` class docstrings :) | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5354 | 5,354 | Consider using "Sequence" instead of "List" | ### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, see below.
**How to reproduce**
```py
... | open | 2022-12-12T15:39:45 | https://api.github.com/repos/huggingface/datasets/issues/5354/comments | null | false | Consider using "Sequence" instead of "List"
### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, ... | [
"Hi! Linking a comment to provide more info on the issue: https://stackoverflow.com/a/39458225. This means we should replace all (most of) the occurrences of `List` with `Sequence` in function signatures.\r\n\r\n@tranhd95 Would you be interested in submitting a PR?",
"Hi all! I tried to reproduce this issue and d... |
https://api.github.com/repos/huggingface/datasets/issues/5353 | 5,353 | Support remote file systems for `Audio` | ### Feature request
Hi there!
It would be super cool if `Audio()`, and potentially other features, could read files from a remote file system.
### Motivation
Large amounts of data is often stored in buckets. `load_from_disk` is able to retrieve data from cloud storage but to my knowledge actually copies the datas... | closed | 2022-12-12T13:22:13 | https://api.github.com/repos/huggingface/datasets/issues/5353/comments | null | false | Support remote file systems for `Audio`
### Feature request
Hi there!
It would be super cool if `Audio()`, and potentially other features, could read files from a remote file system.
### Motivation
Large amounts of data is often stored in buckets. `load_from_disk` is able to retrieve data from cloud storage but t... | [
"Just seen https://github.com/huggingface/datasets/issues/5281"
] |
https://api.github.com/repos/huggingface/datasets/issues/5352 | 5,352 | __init__() got an unexpected keyword argument 'input_size' | ### Describe the bug
I try to define a custom configuration with a input_size attribute following the instructions by "Specifying several dataset configurations" in https://huggingface.co/docs/datasets/v1.2.1/add_dataset.html
But when I load the dataset, I got an error "__init__() got an unexpected keyword argument... | open | 2022-12-12T02:52:03 | https://api.github.com/repos/huggingface/datasets/issues/5352/comments | null | false | __init__() got an unexpected keyword argument 'input_size'
### Describe the bug
I try to define a custom configuration with a input_size attribute following the instructions by "Specifying several dataset configurations" in https://huggingface.co/docs/datasets/v1.2.1/add_dataset.html
But when I load the dataset, I ... | [
"Hi @J-shel, thanks for reporting.\r\n\r\nI think the issue comes from your call to `load_dataset`. As first argument, you should pass:\r\n- either the name of your dataset (\"mrf\") if this is already published on the Hub\r\n- or the path to the loading script of your dataset (\"path/to/your/local/mrf.py\").",
"... |
https://api.github.com/repos/huggingface/datasets/issues/5351 | 5,351 | Do we need to implement `_prepare_split`? | ### Describe the bug
I'm not sure this is a bug or if it's just missing in the documentation, or i'm not doing something correctly, but I'm subclassing `DatasetBuilder` and getting the following error because on the `DatasetBuilder` class the `_prepare_split` method is abstract (as are the others we are required to im... | closed | 2022-12-12T01:38:54 | https://api.github.com/repos/huggingface/datasets/issues/5351/comments | null | false | Do we need to implement `_prepare_split`?
### Describe the bug
I'm not sure this is a bug or if it's just missing in the documentation, or i'm not doing something correctly, but I'm subclassing `DatasetBuilder` and getting the following error because on the `DatasetBuilder` class the `_prepare_split` method is abstrac... | [
"Hi! `DatasetBuilder` is a parent class for concrete builders: `GeneratorBasedBuilder`, `ArrowBasedBuilder` and `BeamBasedBuilder`. When writing a builder script, these classes are the ones you should inherit from. And since all of them implement `_prepare_split`, you only have to implement the three methods mentio... |
https://api.github.com/repos/huggingface/datasets/issues/5350 | 5,350 | Clean up Loading methods docstrings | Clean up for the docstrings in Loading methods! | closed | 2022-12-09T22:25:30 | https://api.github.com/repos/huggingface/datasets/issues/5350/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5350",
"html_url": "https://github.com/huggingface/datasets/pull/5350",
"diff_url": "https://github.com/huggingface/datasets/pull/5350.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5350.patch",
"merged_at": "2022-12-12T17:24... | true | Clean up Loading methods docstrings
Clean up for the docstrings in Loading methods! | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5349 | 5,349 | Clean up remaining Main Classes docstrings | This PR cleans up the remaining docstrings in Main Classes (`IterableDataset`, `IterableDatasetDict`, and `Features`). | closed | 2022-12-09T20:17:15 | https://api.github.com/repos/huggingface/datasets/issues/5349/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5349",
"html_url": "https://github.com/huggingface/datasets/pull/5349",
"diff_url": "https://github.com/huggingface/datasets/pull/5349.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5349.patch",
"merged_at": "2022-12-12T17:24... | true | Clean up remaining Main Classes docstrings
This PR cleans up the remaining docstrings in Main Classes (`IterableDataset`, `IterableDatasetDict`, and `Features`). | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5348 | 5,348 | The data downloaded in the download folder of the cache does not respect `umask` | ### Describe the bug
For a project on a cluster we are several users to share the same cache for the datasets library. And we have a problem with the permissions on the data downloaded in the cache.
Indeed, it seems that the data is downloaded by giving read and write permissions only to the user launching the com... | open | 2022-12-09T15:46:27 | https://api.github.com/repos/huggingface/datasets/issues/5348/comments | null | false | The data downloaded in the download folder of the cache does not respect `umask`
### Describe the bug
For a project on a cluster we are several users to share the same cache for the datasets library. And we have a problem with the permissions on the data downloaded in the cache.
Indeed, it seems that the data is d... | [
"note, that `datasets` already did some of that umask fixing in the past and also at the hub - the recent work on the hub about the same: https://github.com/huggingface/huggingface_hub/pull/1220\r\n\r\nAlso I noticed that each file has a .json counterpart and the latter always has the correct perms:\r\n\r\n```\r\n-... |
https://api.github.com/repos/huggingface/datasets/issues/5347 | 5,347 | Force soundfile to return float32 instead of the default float64 | (Fixes issue #5345) | open | 2022-12-09T15:10:24 | https://api.github.com/repos/huggingface/datasets/issues/5347/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5347",
"html_url": "https://github.com/huggingface/datasets/pull/5347",
"diff_url": "https://github.com/huggingface/datasets/pull/5347.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5347.patch",
"merged_at": null
} | true | Force soundfile to return float32 instead of the default float64
(Fixes issue #5345) | [
"cc @polinaeterna",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5347). All of your documentation changes will be reflected on that endpoint.",
"Cool ! Feel free to add a comment in the code to explain that and we can merge :)",
"I'm not sure if this is a good change ... |
https://api.github.com/repos/huggingface/datasets/issues/5346 | 5,346 | [Quick poll] Give your opinion on the future of the Hugging Face Open Source ecosystem! | Thanks to all of you, Datasets is just about to pass 15k stars!
Since the last survey, a lot has happened: the [diffusers](https://github.com/huggingface/diffusers), [evaluate](https://github.com/huggingface/evaluate) and [skops](https://github.com/skops-dev/skops) libraries were born. `timm` joined the Hugging Face... | closed | 2022-12-09T14:48:02 | https://api.github.com/repos/huggingface/datasets/issues/5346/comments | null | false | [Quick poll] Give your opinion on the future of the Hugging Face Open Source ecosystem!
Thanks to all of you, Datasets is just about to pass 15k stars!
Since the last survey, a lot has happened: the [diffusers](https://github.com/huggingface/diffusers), [evaluate](https://github.com/huggingface/evaluate) and [skops]... | [
"As the survey is finished, can we close this issue, @LysandreJik ?",
"Yes! I'll post a public summary on the forums shortly.",
"Is the summary available? I would be interested in reading your findings."
] |
https://api.github.com/repos/huggingface/datasets/issues/5345 | 5,345 | Wrong dtype for array in audio features | ### Describe the bug
When concatenating/interleaving different datasets, I stumble into an error because the features can't be aligned. After some investigation, I understood that the audio arrays had different dtypes, namely `float32` and `float64`. Consequently, the datasets cannot be merged.
### Steps to repro... | open | 2022-12-09T11:05:11 | https://api.github.com/repos/huggingface/datasets/issues/5345/comments | null | false | Wrong dtype for array in audio features
### Describe the bug
When concatenating/interleaving different datasets, I stumble into an error because the features can't be aligned. After some investigation, I understood that the audio arrays had different dtypes, namely `float32` and `float64`. Consequently, the datasets... | [
"After some more investigation, this is due to [this line of code](https://github.com/huggingface/datasets/blob/main/src/datasets/features/audio.py#L279). The function `sf.read(file)` should be updated to `sf.read(file, dtype=\"float32\")`\r\n\r\nIndeed, the default value in soundfile is `float64` ([see here](https... |
https://api.github.com/repos/huggingface/datasets/issues/5344 | 5,344 | Clean up Dataset and DatasetDict | This PR cleans up the docstrings for the other half of the methods in `Dataset` and finishes `DatasetDict`. | closed | 2022-12-09T00:02:08 | https://api.github.com/repos/huggingface/datasets/issues/5344/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5344",
"html_url": "https://github.com/huggingface/datasets/pull/5344",
"diff_url": "https://github.com/huggingface/datasets/pull/5344.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5344.patch",
"merged_at": "2022-12-13T00:53... | true | Clean up Dataset and DatasetDict
This PR cleans up the docstrings for the other half of the methods in `Dataset` and finishes `DatasetDict`. | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5343 | 5,343 | T5 for Q&A produces truncated sentence | Dear all, I am fine-tuning T5 for Q&A task using the MedQuAD ([GitHub - abachaa/MedQuAD: Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites](https://github.com/abachaa/MedQuAD)) dataset. In the dataset, there are many long answers with thousands of words. I have used pytorch_lightning to... | closed | 2022-12-08T19:48:46 | https://api.github.com/repos/huggingface/datasets/issues/5343/comments | null | false | T5 for Q&A produces truncated sentence
Dear all, I am fine-tuning T5 for Q&A task using the MedQuAD ([GitHub - abachaa/MedQuAD: Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites](https://github.com/abachaa/MedQuAD)) dataset. In the dataset, there are many long answers with thousands of ... | [] |
https://api.github.com/repos/huggingface/datasets/issues/5342 | 5,342 | Emotion dataset cannot be downloaded | ### Describe the bug
The emotion dataset gives a FileNotFoundError. The full error is: `FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1`.
It was working yesterday (December 7, 2022), but stopped working today (December 8, 2022).
### Steps to reproduce the bug
... | closed | 2022-12-08T19:07:09 | https://api.github.com/repos/huggingface/datasets/issues/5342/comments | null | false | Emotion dataset cannot be downloaded
### Describe the bug
The emotion dataset gives a FileNotFoundError. The full error is: `FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1`.
It was working yesterday (December 7, 2022), but stopped working today (December 8, 2022)... | [
"Hi @cbarond there's already an open issue at https://github.com/dair-ai/emotion_dataset/issues/5, as the data seems to be missing now, so check that issue instead 👍🏻 ",
"Thanks @cbarond for reporting and @alvarobartt for pointing to the issue we opened in the author's repo.\r\n\r\nIndeed, this issue was first ... |
https://api.github.com/repos/huggingface/datasets/issues/5341 | 5,341 | Remove tasks.json | After discussions in https://github.com/huggingface/datasets/pull/5335 we should remove this file that is not used anymore. We should update https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts instead. | closed | 2022-12-08T11:04:35 | https://api.github.com/repos/huggingface/datasets/issues/5341/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5341",
"html_url": "https://github.com/huggingface/datasets/pull/5341",
"diff_url": "https://github.com/huggingface/datasets/pull/5341.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5341.patch",
"merged_at": "2022-12-09T12:23... | true | Remove tasks.json
After discussions in https://github.com/huggingface/datasets/pull/5335 we should remove this file that is not used anymore. We should update https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts instead. | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5340 | 5,340 | Clean up DatasetInfo and Dataset docstrings | This PR cleans up the docstrings for `DatasetInfo` and about half of the methods in `Dataset`. | closed | 2022-12-08T00:17:53 | https://api.github.com/repos/huggingface/datasets/issues/5340/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5340",
"html_url": "https://github.com/huggingface/datasets/pull/5340",
"diff_url": "https://github.com/huggingface/datasets/pull/5340.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5340.patch",
"merged_at": "2022-12-08T19:30... | true | Clean up DatasetInfo and Dataset docstrings
This PR cleans up the docstrings for `DatasetInfo` and about half of the methods in `Dataset`. | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5339 | 5,339 | Add Video feature, videofolder, and video-classification task | This PR does the following:
- Adds `Video` feature (Resolves #5225 )
- Adds `video-classification` task
- Adds `videofolder` packaged module for easy loading of local video classification datasets
TODO:
- [ ] add tests
- [ ] add docs | closed | 2022-12-07T20:48:34 | https://api.github.com/repos/huggingface/datasets/issues/5339/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5339",
"html_url": "https://github.com/huggingface/datasets/pull/5339",
"diff_url": "https://github.com/huggingface/datasets/pull/5339.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5339.patch",
"merged_at": null
} | true | Add Video feature, videofolder, and video-classification task
This PR does the following:
- Adds `Video` feature (Resolves #5225 )
- Adds `video-classification` task
- Adds `videofolder` packaged module for easy loading of local video classification datasets
TODO:
- [ ] add tests
- [ ] add docs | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5339). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq I think I need some serious help with the tests 😅...I started this locally but it got too time consuming.\n\nOne issue I remember running... |
https://api.github.com/repos/huggingface/datasets/issues/5338 | 5,338 | `map()` stops every 1000 steps | ### Describe the bug
I am passing the following `prepare_dataset` function to `Dataset.map` (code is inspired from [here](https://github.com/huggingface/community-events/blob/main/whisper-fine-tuning-event/run_speech_recognition_seq2seq_streaming.py#L454))
```python3
def prepare_dataset(batch):
# load and res... | closed | 2022-12-07T19:09:40 | https://api.github.com/repos/huggingface/datasets/issues/5338/comments | null | false | `map()` stops every 1000 steps
### Describe the bug
I am passing the following `prepare_dataset` function to `Dataset.map` (code is inspired from [here](https://github.com/huggingface/community-events/blob/main/whisper-fine-tuning-event/run_speech_recognition_seq2seq_streaming.py#L454))
```python3
def prepare_data... | [
"Hi !\r\n\r\n> It starts using all the cores (I am not sure why because I did not pass num_proc)\r\n\r\nThe tokenizer uses Rust code that is multithreaded. And maybe the `feature_extractor` might run some things in parallel as well - but I'm not super familiar with its internals.\r\n\r\n> then progress bar stops at... |
https://api.github.com/repos/huggingface/datasets/issues/5337 | 5,337 | Support webdataset format | Webdataset is an efficient format for iterable datasets. It would be nice to support it in `datasets`, as discussed in https://github.com/rom1504/img2dataset/issues/234.
In particular it would be awesome to be able to load one using `load_dataset` in streaming mode (either from a local directory, or from a dataset o... | closed | 2022-12-07T11:32:25 | https://api.github.com/repos/huggingface/datasets/issues/5337/comments | null | false | Support webdataset format
Webdataset is an efficient format for iterable datasets. It would be nice to support it in `datasets`, as discussed in https://github.com/rom1504/img2dataset/issues/234.
In particular it would be awesome to be able to load one using `load_dataset` in streaming mode (either from a local dire... | [
"I like the idea of having `webdataset` as an optional dependency to ensure our loader generates web datasets the same way as the main project.",
"Webdataset is the one of the most popular dataset formats for large scale computer vision tasks. Upvote for this issue. ",
"Any updates on this?",
"We haven't had ... |
https://api.github.com/repos/huggingface/datasets/issues/5336 | 5,336 | Set `IterableDataset.map` param `batch_size` typing as optional | This PR solves #5325
~Indeed we're using the typing for optional values as `Union[type, None]` as it's similar to how Python 3.10 handles optional values as `type | None`, instead of using `Optional[type]`.~
~Do we want to start using `Union[type, None]` for type-hinting optional values or just keep on using `Op... | closed | 2022-12-06T17:08:10 | https://api.github.com/repos/huggingface/datasets/issues/5336/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5336",
"html_url": "https://github.com/huggingface/datasets/pull/5336",
"diff_url": "https://github.com/huggingface/datasets/pull/5336.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5336.patch",
"merged_at": "2022-12-07T14:06... | true | Set `IterableDataset.map` param `batch_size` typing as optional
This PR solves #5325
~Indeed we're using the typing for optional values as `Union[type, None]` as it's similar to how Python 3.10 handles optional values as `type | None`, instead of using `Optional[type]`.~
~Do we want to start using `Union[type, N... | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5336). All of your documentation changes will be reflected on that endpoint.",
"Hi @mariosasko, @lhoestq I was wondering whether we should include `batched` as a `pytest.mark` param for the functions testing `IterableDataset.ma... |
https://api.github.com/repos/huggingface/datasets/issues/5335 | 5,335 | Update tasks.json | Context:
* https://github.com/huggingface/datasets/issues/5255#issuecomment-1339107195
Cc: @osanseviero | closed | 2022-12-06T11:37:57 | https://api.github.com/repos/huggingface/datasets/issues/5335/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5335",
"html_url": "https://github.com/huggingface/datasets/pull/5335",
"diff_url": "https://github.com/huggingface/datasets/pull/5335.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5335.patch",
"merged_at": null
} | true | Update tasks.json
Context:
* https://github.com/huggingface/datasets/issues/5255#issuecomment-1339107195
Cc: @osanseviero | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think the only place where we need to add it is here https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts\r\n\r\nAnd I think we can remove tasks.json completely from this repo",
"Isn't tasks.json used ... |
https://api.github.com/repos/huggingface/datasets/issues/5334 | 5,334 | Clean up docstrings | As raised by @polinaeterna in #5324, some of the docstrings are a bit of a mess because it has both Markdown and Sphinx syntax. This PR fixes the docstring for `DatasetBuilder`.
I'll start working on cleaning up the rest of the docstrings and removing the old Sphinx syntax (let me know if you prefer one big PR with... | closed | 2022-12-05T20:56:08 | https://api.github.com/repos/huggingface/datasets/issues/5334/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5334",
"html_url": "https://github.com/huggingface/datasets/pull/5334",
"diff_url": "https://github.com/huggingface/datasets/pull/5334.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5334.patch",
"merged_at": "2022-12-09T01:41... | true | Clean up docstrings
As raised by @polinaeterna in #5324, some of the docstrings are a bit of a mess because it has both Markdown and Sphinx syntax. This PR fixes the docstring for `DatasetBuilder`.
I'll start working on cleaning up the rest of the docstrings and removing the old Sphinx syntax (let me know if you pr... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks ! Let us know if we can help :)\r\n\r\nSmall pref for having multiple PRs",
"Awesome, thanks! Sorry this one is a little big, I'll open some smaller ones next :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5333 | 5,333 | fix: 🐛 pass the token to get the list of config names | Otherwise, get_dataset_infos doesn't work on gated or private datasets, even with the correct token. | closed | 2022-12-05T16:06:09 | https://api.github.com/repos/huggingface/datasets/issues/5333/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5333",
"html_url": "https://github.com/huggingface/datasets/pull/5333",
"diff_url": "https://github.com/huggingface/datasets/pull/5333.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5333.patch",
"merged_at": "2022-12-06T08:22... | true | fix: 🐛 pass the token to get the list of config names
Otherwise, get_dataset_infos doesn't work on gated or private datasets, even with the correct token. | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5332 | 5,332 | Passing numpy array to ClassLabel names causes ValueError | ### Describe the bug
If a numpy array is passed to the names argument of ClassLabel, creating a dataset with those features causes an error.
### Steps to reproduce the bug
https://colab.research.google.com/drive/1cV_es1PWZiEuus17n-2C-w0KEoEZ68IX
TLDR:
If I define my classes as:
```
my_classes = np.array(['on... | closed | 2022-12-05T12:59:03 | https://api.github.com/repos/huggingface/datasets/issues/5332/comments | null | false | Passing numpy array to ClassLabel names causes ValueError
### Describe the bug
If a numpy array is passed to the names argument of ClassLabel, creating a dataset with those features causes an error.
### Steps to reproduce the bug
https://colab.research.google.com/drive/1cV_es1PWZiEuus17n-2C-w0KEoEZ68IX
TLDR:
I... | [
"Should `datasets` allow `ClassLabel` input parameter to be an `np.array` even though internally we need to cast it to a Python list? @lhoestq @mariosasko ",
"Hi! No, I don't think so. The `names` parameter is [annotated](https://github.com/huggingface/datasets/blob/582236640b9109988e5f7a16a8353696ffa09a16/src/d... |
https://api.github.com/repos/huggingface/datasets/issues/5331 | 5,331 | Support for multiple configs in packaged modules via metadata yaml info | will solve https://github.com/huggingface/datasets/issues/5209 and https://github.com/huggingface/datasets/issues/5151 and many other...
Config parameters for packaged builders are parsed from `“builder_config”` field in README.md file (separate firs-level field, not part of “dataset_info”), example:
```yaml
---
... | closed | 2022-12-02T16:43:44 | https://api.github.com/repos/huggingface/datasets/issues/5331/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5331",
"html_url": "https://github.com/huggingface/datasets/pull/5331",
"diff_url": "https://github.com/huggingface/datasets/pull/5331.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5331.patch",
"merged_at": "2023-07-13T13:27... | true | Support for multiple configs in packaged modules via metadata yaml info
will solve https://github.com/huggingface/datasets/issues/5209 and https://github.com/huggingface/datasets/issues/5151 and many other...
Config parameters for packaged builders are parsed from `“builder_config”` field in README.md file (separate... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"feel free to merge `main` into your PR to fix the CI :)",
"Let me see if I can fix the pattern thing ^^'",
"Hmm I think it would be easier to specify the `data_files` in the end, because having a split pattern like `{split}-...` ... |
https://api.github.com/repos/huggingface/datasets/issues/5329 | 5,329 | Clarify imagefolder is for small datasets | Based on feedback from [here](https://github.com/huggingface/datasets/issues/5317#issuecomment-1334108824), this PR adds a note to the `imagefolder` loading and creating docs that `imagefolder` is designed for small scale image datasets. | closed | 2022-12-01T21:47:29 | https://api.github.com/repos/huggingface/datasets/issues/5329/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5329",
"html_url": "https://github.com/huggingface/datasets/pull/5329",
"diff_url": "https://github.com/huggingface/datasets/pull/5329.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5329.patch",
"merged_at": "2022-12-06T17:16... | true | Clarify imagefolder is for small datasets
Based on feedback from [here](https://github.com/huggingface/datasets/issues/5317#issuecomment-1334108824), this PR adds a note to the `imagefolder` loading and creating docs that `imagefolder` is designed for small scale image datasets. | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think it's also reasonable to add the same note to the AudioFolder decription",
"Thank you ! I think \"regular\" is more appropriate than \"small\". It can easily scale to a few thousands of images - just not millions x)",
"Rep... |
https://api.github.com/repos/huggingface/datasets/issues/5328 | 5,328 | Fix docs building for main | This PR reverts the triggering event for building documentation introduced by:
- #5250
Fix #5326. | closed | 2022-12-01T17:07:45 | https://api.github.com/repos/huggingface/datasets/issues/5328/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5328",
"html_url": "https://github.com/huggingface/datasets/pull/5328",
"diff_url": "https://github.com/huggingface/datasets/pull/5328.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5328.patch",
"merged_at": "2022-12-02T16:26... | true | Fix docs building for main
This PR reverts the triggering event for building documentation introduced by:
- #5250
Fix #5326. | [
"_The documentation is not available anymore as the PR was closed or merged._",
"EDIT\r\nAt least the docs for ~~main~~ PR branch are now built:\r\n- https://github.com/huggingface/datasets/actions/runs/3594847760/jobs/6053620813",
"Build documentation for main branch was triggered after this PR being merged: h... |
https://api.github.com/repos/huggingface/datasets/issues/5327 | 5,327 | Avoid unwanted behaviour when splits from script and metadata are not matching because of outdated metadata | will fix #5315 | open | 2022-12-01T17:05:23 | https://api.github.com/repos/huggingface/datasets/issues/5327/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5327",
"html_url": "https://github.com/huggingface/datasets/pull/5327",
"diff_url": "https://github.com/huggingface/datasets/pull/5327.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5327.patch",
"merged_at": null
} | true | Avoid unwanted behaviour when splits from script and metadata are not matching because of outdated metadata
will fix #5315 | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5327). All of your documentation changes will be reflected on that endpoint."
] |
https://api.github.com/repos/huggingface/datasets/issues/5326 | 5,326 | No documentation for main branch is built | Since:
- #5250
- Commit: 703b84311f4ead83c7f79639f2dfa739295f0be6
the docs for main branch are no longer built.
The change introduced only triggers the docs building for releases. | closed | 2022-12-01T16:50:58 | https://api.github.com/repos/huggingface/datasets/issues/5326/comments | null | false | No documentation for main branch is built
Since:
- #5250
- Commit: 703b84311f4ead83c7f79639f2dfa739295f0be6
the docs for main branch are no longer built.
The change introduced only triggers the docs building for releases. | [] |
https://api.github.com/repos/huggingface/datasets/issues/5325 | 5,325 | map(...batch_size=None) for IterableDataset | ### Feature request
Dataset.map(...) allows batch_size to be None. It would be nice if IterableDataset did too.
### Motivation
Although it may seem a bit of a spurious request given that `IterableDataset` is meant for larger than memory datasets, but there are a couple of reasons why this might be nice.
One is th... | closed | 2022-12-01T15:43:42 | https://api.github.com/repos/huggingface/datasets/issues/5325/comments | null | false | map(...batch_size=None) for IterableDataset
### Feature request
Dataset.map(...) allows batch_size to be None. It would be nice if IterableDataset did too.
### Motivation
Although it may seem a bit of a spurious request given that `IterableDataset` is meant for larger than memory datasets, but there are a couple of ... | [
"Hi! I agree it makes sense for `IterableDataset.map` to support the `batch_size=None` case. This should be super easy to fix.",
"@mariosasko as this is something simple maybe I can include it as part of https://github.com/huggingface/datasets/pull/5311? Let me know :+1:",
"#self-assign",
"Feel free to close ... |
https://api.github.com/repos/huggingface/datasets/issues/5324 | 5,324 | Fix docstrings and types in documentation that appears on the website | While I was working on https://github.com/huggingface/datasets/pull/5313 I've noticed that we have a mess in how we annotate types and format args and return values in the code. And some of it is displayed in the [Reference section](https://huggingface.co/docs/datasets/package_reference/builder_classes) of the document... | open | 2022-12-01T15:34:53 | https://api.github.com/repos/huggingface/datasets/issues/5324/comments | null | false | Fix docstrings and types in documentation that appears on the website
While I was working on https://github.com/huggingface/datasets/pull/5313 I've noticed that we have a mess in how we annotate types and format args and return values in the code. And some of it is displayed in the [Reference section](https://huggingfa... | [
"I agree we have a mess with docstrings...",
"Ok, I believe we've cleaned up most of the old syntax we were using for the user-facing docs! There are still a couple of `:obj:`'s and `:class:` floating around in the docstrings we don't expose that I'll track down :)",
"Hi @polinaeterna @albertvillanova @stevhliu... |
https://api.github.com/repos/huggingface/datasets/issues/5323 | 5,323 | Duplicated Keys in Taskmaster-2 Dataset | ### Describe the bug
Loading certain splits () of the taskmaster-2 dataset fails because of a DuplicatedKeysError. This occurs for the following domains: `'hotels', 'movies', 'music', 'sports'`. The domains `'flights', 'food-ordering', 'restaurant-search'` load fine.
Output:
### Steps to reproduce the bug
```
... | closed | 2022-12-01T15:31:06 | https://api.github.com/repos/huggingface/datasets/issues/5323/comments | null | false | Duplicated Keys in Taskmaster-2 Dataset
### Describe the bug
Loading certain splits () of the taskmaster-2 dataset fails because of a DuplicatedKeysError. This occurs for the following domains: `'hotels', 'movies', 'music', 'sports'`. The domains `'flights', 'food-ordering', 'restaurant-search'` load fine.
Output: ... | [
"Thanks for reporting, @liaeh.\r\n\r\nWe are having a look at it. ",
"I have transferred the discussion to the Community tab of the dataset: https://huggingface.co/datasets/taskmaster2/discussions/1"
] |
https://api.github.com/repos/huggingface/datasets/issues/5322 | 5,322 | Raise error for `.tar` archives in the same way as for `.tar.gz` and `.tgz` in `_get_extraction_protocol` | Currently `download_and_extract` doesn't throw an error when it is used with files with `.tar` extension in streaming mode because `_get_extraction_protocol` doesn't do it (like it does for `tar.gz` and `tgz`). `_get_extraction_protocol` returns formatted url as if we support tar protocol but we don't.
That means tha... | closed | 2022-12-01T15:19:28 | https://api.github.com/repos/huggingface/datasets/issues/5322/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5322",
"html_url": "https://github.com/huggingface/datasets/pull/5322",
"diff_url": "https://github.com/huggingface/datasets/pull/5322.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5322.patch",
"merged_at": "2022-12-14T16:33... | true | Raise error for `.tar` archives in the same way as for `.tar.gz` and `.tgz` in `_get_extraction_protocol`
Currently `download_and_extract` doesn't throw an error when it is used with files with `.tar` extension in streaming mode because `_get_extraction_protocol` doesn't do it (like it does for `tar.gz` and `tgz`). `_... | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5321 | 5,321 | Fix loading from HF GCP cache | As reported in https://discuss.huggingface.co/t/error-loading-wikipedia-dataset/26599/4 it's not possible to download a cached version of Wikipedia from the HF GCP cache
I fixed it and added an integration test (runs in 10sec) | closed | 2022-12-01T14:39:06 | https://api.github.com/repos/huggingface/datasets/issues/5321/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5321",
"html_url": "https://github.com/huggingface/datasets/pull/5321",
"diff_url": "https://github.com/huggingface/datasets/pull/5321.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5321.patch",
"merged_at": "2022-12-01T16:07... | true | Fix loading from HF GCP cache
As reported in https://discuss.huggingface.co/t/error-loading-wikipedia-dataset/26599/4 it's not possible to download a cached version of Wikipedia from the HF GCP cache
I fixed it and added an integration test (runs in 10sec) | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> Do you know why this stopped working?\r\n\r\nIt comes from the changes in https://github.com/huggingface/datasets/pull/5107/files#diff-355ae5c229f95f86895404b72378ecd6e966c41cbeebb674af6fe6e9611bc126"
] |
https://api.github.com/repos/huggingface/datasets/issues/5320 | 5,320 | [Extract] Place the lock file next to the destination directory | Previously it was placed next to the archive to extract, but the archive can be in a read-only directory as noticed in https://github.com/huggingface/datasets/issues/5295
Therefore I moved the lock location to be next to the destination directory, which is required to have write permissions | closed | 2022-12-01T13:55:49 | https://api.github.com/repos/huggingface/datasets/issues/5320/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5320",
"html_url": "https://github.com/huggingface/datasets/pull/5320",
"diff_url": "https://github.com/huggingface/datasets/pull/5320.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5320.patch",
"merged_at": "2022-12-01T15:33... | true | [Extract] Place the lock file next to the destination directory
Previously it was placed next to the archive to extract, but the archive can be in a read-only directory as noticed in https://github.com/huggingface/datasets/issues/5295
Therefore I moved the lock location to be next to the destination directory, which... | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5319 | 5,319 | Fix Text sample_by paragraph | Fix #5316. | closed | 2022-12-01T09:08:09 | https://api.github.com/repos/huggingface/datasets/issues/5319/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5319",
"html_url": "https://github.com/huggingface/datasets/pull/5319",
"diff_url": "https://github.com/huggingface/datasets/pull/5319.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5319.patch",
"merged_at": "2022-12-01T15:19... | true | Fix Text sample_by paragraph
Fix #5316. | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5318 | 5,318 | Origin/fix missing features error | This fixes the problem of when the dataset_load function reads a function with "features" provided but some read batches don't have columns that later show up. For instance, the provided "features" requires columns A,B,C but only columns B,C show. This fixes this by adding the column A with nulls. | closed | 2022-12-01T06:18:39 | https://api.github.com/repos/huggingface/datasets/issues/5318/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5318",
"html_url": "https://github.com/huggingface/datasets/pull/5318",
"diff_url": "https://github.com/huggingface/datasets/pull/5318.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5318.patch",
"merged_at": "2022-12-04T05:49... | true | Origin/fix missing features error
This fixes the problem of when the dataset_load function reads a function with "features" provided but some read batches don't have columns that later show up. For instance, the provided "features" requires columns A,B,C but only columns B,C show. This fixes this by adding the column A... | [
"_The documentation is not available anymore as the PR was closed or merged._",
"please review :) @lhoestq @ola13 thankoo",
"Thanks :) I just updated the test to make sure it works even when there's a column missing, and did a minor change to json.py to add the missing columns for the other kinds of JSON files ... |
https://api.github.com/repos/huggingface/datasets/issues/5317 | 5,317 | `ImageFolder` performs poorly with large datasets | ### Describe the bug
While testing image dataset creation, I'm seeing significant performance bottlenecks with imagefolders when scanning a directory structure with large number of images.
## Setup
* Nested directories (5 levels deep)
* 3M+ images
* 1 `metadata.jsonl` file
## Performance Degradation Point... | open | 2022-12-01T00:04:21 | https://api.github.com/repos/huggingface/datasets/issues/5317/comments | null | false | `ImageFolder` performs poorly with large datasets
### Describe the bug
While testing image dataset creation, I'm seeing significant performance bottlenecks with imagefolders when scanning a directory structure with large number of images.
## Setup
* Nested directories (5 levels deep)
* 3M+ images
* 1 `metadata... | [
"Hi ! ImageFolder is made for small scale datasets indeed. For large scale image datasets you better group your images in TAR archives or Arrow/Parquet files. This is true not just for ImageFolder loading performance, but also because having millions of files is not ideal for your filesystem or when moving the data... |
https://api.github.com/repos/huggingface/datasets/issues/5316 | 5,316 | Bug in sample_by="paragraph" | ### Describe the bug
I think [this line](https://github.com/huggingface/datasets/blob/main/src/datasets/packaged_modules/text/text.py#L96) is wrong and should be `batch = f.read(self.config.chunksize)`. Otherwise it will never terminate because even when `f` is finished reading, `batch` will still be truthy from the l... | closed | 2022-11-30T19:24:13 | https://api.github.com/repos/huggingface/datasets/issues/5316/comments | null | false | Bug in sample_by="paragraph"
### Describe the bug
I think [this line](https://github.com/huggingface/datasets/blob/main/src/datasets/packaged_modules/text/text.py#L96) is wrong and should be `batch = f.read(self.config.chunksize)`. Otherwise it will never terminate because even when `f` is finished reading, `batch` wi... | [
"Thanks for reporting, @adampauls.\r\n\r\nWe are having a look at it. "
] |
https://api.github.com/repos/huggingface/datasets/issues/5315 | 5,315 | Adding new splits to a dataset script with existing old splits info in metadata's `dataset_info` fails | ### Describe the bug
If you first create a custom dataset with a specific set of splits, generate metadata with `datasets-cli test ... --save_info`, then change your script to include more splits, it fails.
That's what happened in https://huggingface.co/datasets/mrdbourke/food_vision_199_classes/discussions/2#6385f... | open | 2022-11-30T18:02:15 | https://api.github.com/repos/huggingface/datasets/issues/5315/comments | null | false | Adding new splits to a dataset script with existing old splits info in metadata's `dataset_info` fails
### Describe the bug
If you first create a custom dataset with a specific set of splits, generate metadata with `datasets-cli test ... --save_info`, then change your script to include more splits, it fails.
That's... | [
"EDIT:\r\nI think in this case, the metadata files (either README or JSON) should not be read (i.e. `self.info.splits` should be None).\r\n\r\nOne idea: \r\n- I think ideally we should set this behavior when we pass `--save_info` to the CLI `test`\r\n- However, currently, the builder is unaware of this: `save_info`... |
https://api.github.com/repos/huggingface/datasets/issues/5314 | 5,314 | Datasets: classification_report() got an unexpected keyword argument 'suffix' | https://github.com/huggingface/datasets/blob/main/metrics/seqeval/seqeval.py
> import datasets
predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
seqeval = datasets.load_metri... | closed | 2022-11-30T14:01:03 | https://api.github.com/repos/huggingface/datasets/issues/5314/comments | null | false | Datasets: classification_report() got an unexpected keyword argument 'suffix'
https://github.com/huggingface/datasets/blob/main/metrics/seqeval/seqeval.py
> import datasets
predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
references = [['O', 'O', 'O', 'B-MISC', 'I-... | [
"This seems similar to https://github.com/huggingface/datasets/issues/2512 Can you try to update seqeval ? ",
"@JonathanAlis also note that the metrics are deprecated in our `datasets` library.\r\n\r\nPlease, use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate"
] |
https://api.github.com/repos/huggingface/datasets/issues/5313 | 5,313 | Fix description of streaming in the docs | We say that "the data is being downloaded progressively" which is not true, it's just streamed, so I fixed it. Probably I missed some other places where it is written?
Also changed docstrings for `StreamingDownloadManager`'s `download` and `extract` to reflect the same, as these docstrings are displayed in the docu... | closed | 2022-11-29T18:00:28 | https://api.github.com/repos/huggingface/datasets/issues/5313/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5313",
"html_url": "https://github.com/huggingface/datasets/pull/5313",
"diff_url": "https://github.com/huggingface/datasets/pull/5313.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5313.patch",
"merged_at": "2022-12-01T14:00... | true | Fix description of streaming in the docs
We say that "the data is being downloaded progressively" which is not true, it's just streamed, so I fixed it. Probably I missed some other places where it is written?
Also changed docstrings for `StreamingDownloadManager`'s `download` and `extract` to reflect the same, as t... | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5312 | 5,312 | Add DatasetDict.to_pandas | From discussions in https://github.com/huggingface/datasets/issues/5189, for tabular data it doesn't really make sense to have to do
```python
df = load_dataset(...)["train"].to_pandas()
```
because many datasets are not split.
In this PR I added `to_pandas` to `DatasetDict` which returns the DataFrame:
If th... | closed | 2022-11-29T16:30:02 | https://api.github.com/repos/huggingface/datasets/issues/5312/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5312",
"html_url": "https://github.com/huggingface/datasets/pull/5312",
"diff_url": "https://github.com/huggingface/datasets/pull/5312.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5312.patch",
"merged_at": null
} | true | Add DatasetDict.to_pandas
From discussions in https://github.com/huggingface/datasets/issues/5189, for tabular data it doesn't really make sense to have to do
```python
df = load_dataset(...)["train"].to_pandas()
```
because many datasets are not split.
In this PR I added `to_pandas` to `DatasetDict` which retur... | [
"The current implementation is what I had in mind, i.e. concatenate all splits by default.\r\n\r\nHowever, I think most tabular datasets would come as a single split. So for that usecase, it wouldn't change UX if we raise when there are more than one splits.\r\n\r\nAnd for multiple splits, the user either passes a ... |
https://api.github.com/repos/huggingface/datasets/issues/5311 | 5,311 | Add `features` param to `IterableDataset.map` | ## Description
As suggested by @lhoestq in #3888, we should be adding the param `features` to `IterableDataset.map` so that the features can be preserved (not turned into `None` as that's the default behavior) whenever the user passes those as param, so as to be consistent with `Dataset.map`, as it provides the `fea... | closed | 2022-11-29T11:08:34 | https://api.github.com/repos/huggingface/datasets/issues/5311/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5311",
"html_url": "https://github.com/huggingface/datasets/pull/5311",
"diff_url": "https://github.com/huggingface/datasets/pull/5311.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5311.patch",
"merged_at": "2022-12-06T15:42... | true | Add `features` param to `IterableDataset.map`
## Description
As suggested by @lhoestq in #3888, we should be adding the param `features` to `IterableDataset.map` so that the features can be preserved (not turned into `None` as that's the default behavior) whenever the user passes those as param, so as to be consiste... | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5310 | 5,310 | Support xPath for Windows pathnames | This PR implements a string representation of `xPath`, which is valid for local paths (also windows) and remote URLs.
Additionally, some `os.path` methods are fixed for remote URLs on Windows machines.
Now, on Windows machines:
```python
In [2]: str(xPath("C:\\dir\\file.txt"))
Out[2]: 'C:\\dir\\file.txt'
In [... | closed | 2022-11-29T09:20:47 | https://api.github.com/repos/huggingface/datasets/issues/5310/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5310",
"html_url": "https://github.com/huggingface/datasets/pull/5310",
"diff_url": "https://github.com/huggingface/datasets/pull/5310.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5310.patch",
"merged_at": "2022-11-30T11:57... | true | Support xPath for Windows pathnames
This PR implements a string representation of `xPath`, which is valid for local paths (also windows) and remote URLs.
Additionally, some `os.path` methods are fixed for remote URLs on Windows machines.
Now, on Windows machines:
```python
In [2]: str(xPath("C:\\dir\\file.txt")... | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5309 | 5,309 | Close stream in `ArrowWriter.finalize` before inference error | Ensure the file stream is closed in `ArrowWriter.finalize` before raising the `SchemaInferenceError` to avoid the `PermissionError` on Windows in `incomplete_dir`'s `shutil.rmtree`. | closed | 2022-11-28T16:59:39 | https://api.github.com/repos/huggingface/datasets/issues/5309/comments | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5309",
"html_url": "https://github.com/huggingface/datasets/pull/5309",
"diff_url": "https://github.com/huggingface/datasets/pull/5309.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5309.patch",
"merged_at": "2022-12-07T12:52... | true | Close stream in `ArrowWriter.finalize` before inference error
Ensure the file stream is closed in `ArrowWriter.finalize` before raising the `SchemaInferenceError` to avoid the `PermissionError` on Windows in `incomplete_dir`'s `shutil.rmtree`. | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.