
id int64 599M 3.26B | number int64 1 7.7k | title stringlengths 1 290 | body stringlengths 0 228k ⌀ | state stringclasses 2
values | html_url stringlengths 46 51 | created_at timestamp[s]date 2020-04-14 10:18:02 2025-07-23 08:04:53 | updated_at timestamp[s]date 2020-04-27 16:04:17 2025-07-23 18:53:44 | closed_at timestamp[s]date 2020-04-14 12:01:40 2025-07-23 16:44:42 ⌀ | user dict | labels listlengths 0 4 | is_pull_request bool 2
classes | comments listlengths 0 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
618,864,284 | 124 | Xsum, require manual download of some files | closed | https://github.com/huggingface/datasets/pull/124 | 2020-05-15T10:26:13 | 2020-05-15T11:04:48 | 2020-05-15T11:04:46 | {
"login": "mariamabarham",
"id": 38249783,
"type": "User"
} | [] | true | [] | |
618,820,140 | 123 | [Tests] Local => aws | ## Change default Test from local => aws
As a default we set` aws=True`, `Local=False`, `slow=False`
### 1. RUN_AWS=1 (default)
This runs 4 tests per dataset script.
a) Does the dataset script have a valid etag / Can it be reached on AWS?
b) Can we load its `builder_class`?
c) Can we load **all** dataset c... | closed | https://github.com/huggingface/datasets/pull/123 | 2020-05-15T09:12:25 | 2020-05-15T10:06:12 | 2020-05-15T10:03:26 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
618,813,182 | 122 | Final cleanup of readme and metrics | closed | https://github.com/huggingface/datasets/pull/122 | 2020-05-15T09:00:52 | 2021-09-03T19:40:09 | 2020-05-15T09:02:22 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] | |
618,790,040 | 121 | make style | closed | https://github.com/huggingface/datasets/pull/121 | 2020-05-15T08:23:36 | 2020-05-15T08:25:39 | 2020-05-15T08:25:38 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] | |
618,737,783 | 120 | 🐛 `map` not working | I'm trying to run a basic example (mapping function to add a prefix).
[Here is the colab notebook I'm using.](https://colab.research.google.com/drive/1YH4JCAy0R1MMSc-k_Vlik_s1LEzP_t1h?usp=sharing)
```python
import nlp
dataset = nlp.load_dataset('squad', split='validation[:10%]')
def test(sample):
samp... | closed | https://github.com/huggingface/datasets/issues/120 | 2020-05-15T06:43:08 | 2020-05-15T07:02:38 | 2020-05-15T07:02:38 | {
"login": "astariul",
"id": 43774355,
"type": "User"
} | [] | false | [] |
618,652,145 | 119 | 🐛 Colab : type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array' | I'm trying to load CNN/DM dataset on Colab.
[Colab notebook](https://colab.research.google.com/drive/11Mf7iNhIyt6GpgA1dBEtg3cyMHmMhtZS?usp=sharing)
But I meet this error :
> AttributeError: type object 'pyarrow.lib.RecordBatch' has no attribute 'from_struct_array'
| closed | https://github.com/huggingface/datasets/issues/119 | 2020-05-15T02:27:26 | 2020-05-15T05:11:22 | 2020-05-15T02:45:28 | {
"login": "astariul",
"id": 43774355,
"type": "User"
} | [] | false | [] |
618,643,088 | 118 | ❓ How to apply a map to all subsets ? | I'm working with CNN/DM dataset, where I have 3 subsets : `train`, `test`, `validation`.
Should I apply my map function on the subsets one by one ?
```python
import nlp
cnn_dm = nlp.load_dataset('cnn_dailymail')
for corpus in ['train', 'test', 'validation']:
cnn_dm[corpus] = cnn_dm[corpus].map(my_f... | closed | https://github.com/huggingface/datasets/issues/118 | 2020-05-15T01:58:52 | 2020-05-15T07:05:49 | 2020-05-15T07:04:25 | {
"login": "astariul",
"id": 43774355,
"type": "User"
} | [] | false | [] |
618,632,573 | 117 | ❓ How to remove specific rows of a dataset ? | I saw on the [example notebook](https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb#scrollTo=efFhDWhlvSVC) how to remove a specific column :
```python
dataset.drop('id')
```
But I didn't find how to remove a specific row.
**For example, how can I remove all sample w... | closed | https://github.com/huggingface/datasets/issues/117 | 2020-05-15T01:25:06 | 2022-07-15T08:36:44 | 2020-05-15T07:04:32 | {
"login": "astariul",
"id": 43774355,
"type": "User"
} | [] | false | [] |
618,628,264 | 116 | 🐛 Trying to use ROUGE metric : pyarrow.lib.ArrowInvalid: Column 1 named references expected length 534 but got length 323 | I'm trying to use rouge metric.
I have to files : `test.pred.tokenized` and `test.gold.tokenized` with each line containing a sentence.
I tried :
```python
import nlp
rouge = nlp.load_metric('rouge')
with open("test.pred.tokenized") as p, open("test.gold.tokenized") as g:
for lp, lg in zip(p, g):
... | closed | https://github.com/huggingface/datasets/issues/116 | 2020-05-15T01:12:06 | 2020-05-28T23:43:07 | 2020-05-28T23:43:07 | {
"login": "astariul",
"id": 43774355,
"type": "User"
} | [
{
"name": "metric bug",
"color": "25b21e"
}
] | false | [] |
618,615,855 | 115 | AttributeError: 'dict' object has no attribute 'info' | I'm trying to access the information of CNN/DM dataset :
```python
cnn_dm = nlp.load_dataset('cnn_dailymail')
print(cnn_dm.info)
```
returns :
> AttributeError: 'dict' object has no attribute 'info' | closed | https://github.com/huggingface/datasets/issues/115 | 2020-05-15T00:29:47 | 2020-05-17T13:11:00 | 2020-05-17T13:11:00 | {
"login": "astariul",
"id": 43774355,
"type": "User"
} | [] | false | [] |
618,611,310 | 114 | Couldn't reach CNN/DM dataset | I can't get CNN / DailyMail dataset.
```python
import nlp
assert "cnn_dailymail" in [dataset.id for dataset in nlp.list_datasets()]
cnn_dm = nlp.load_dataset('cnn_dailymail')
```
[Colab notebook](https://colab.research.google.com/drive/1zQ3bYAVzm1h0mw0yWPqKAg_4EUlSx5Ex?usp=sharing)
gives following error ... | closed | https://github.com/huggingface/datasets/issues/114 | 2020-05-15T00:16:17 | 2020-05-15T00:19:52 | 2020-05-15T00:19:51 | {
"login": "astariul",
"id": 43774355,
"type": "User"
} | [] | false | [] |
618,590,562 | 113 | Adding docstrings and some doc | Some doc | closed | https://github.com/huggingface/datasets/pull/113 | 2020-05-14T23:14:41 | 2020-05-14T23:22:45 | 2020-05-14T23:22:44 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
618,569,195 | 112 | Qa4mre - add dataset | Added dummy data test only for the first config. Will do the rest later.
I had to do add some minor hacks to an important function to make it work.
There might be a cleaner way to handle it - can you take a look @thomwolf ? | closed | https://github.com/huggingface/datasets/pull/112 | 2020-05-14T22:17:51 | 2020-05-15T09:16:43 | 2020-05-15T09:16:42 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
618,528,060 | 111 | [Clean-up] remove under construction datastes | closed | https://github.com/huggingface/datasets/pull/111 | 2020-05-14T20:52:13 | 2020-05-14T20:52:23 | 2020-05-14T20:52:22 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] | |
618,520,325 | 110 | fix reddit tifu dummy data | closed | https://github.com/huggingface/datasets/pull/110 | 2020-05-14T20:37:37 | 2020-05-14T20:40:14 | 2020-05-14T20:40:13 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] | |
618,508,359 | 109 | [Reclor] fix reclor | - That's probably one me. Could have made the manual data test more flexible. @mariamabarham | closed | https://github.com/huggingface/datasets/pull/109 | 2020-05-14T20:16:26 | 2020-05-14T20:19:09 | 2020-05-14T20:19:08 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
618,386,394 | 108 | convert can use manual dir as second argument | @mariamabarham | closed | https://github.com/huggingface/datasets/pull/108 | 2020-05-14T16:52:32 | 2020-05-14T16:52:43 | 2020-05-14T16:52:42 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
618,373,045 | 107 | add writer_batch_size to GeneratorBasedBuilder | You can now specify `writer_batch_size` in the builder arguments or directly in `load_dataset` | closed | https://github.com/huggingface/datasets/pull/107 | 2020-05-14T16:35:39 | 2020-05-14T16:50:30 | 2020-05-14T16:50:29 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
618,361,418 | 106 | Add data dir test command | closed | https://github.com/huggingface/datasets/pull/106 | 2020-05-14T16:18:39 | 2020-05-14T16:49:11 | 2020-05-14T16:49:10 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] | |
618,345,191 | 105 | [New structure on AWS] Adapt paths | Some small changes so that we have the correct paths. @julien-c | closed | https://github.com/huggingface/datasets/pull/105 | 2020-05-14T15:55:57 | 2020-05-14T15:56:28 | 2020-05-14T15:56:27 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
618,277,081 | 104 | Add trivia_q | Currently tested only for one config to pass tests. Needs to add more dummy data later. | closed | https://github.com/huggingface/datasets/pull/104 | 2020-05-14T14:27:19 | 2020-07-12T05:34:20 | 2020-05-14T20:23:32 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
618,233,637 | 103 | [Manual downloads] add logic proposal for manual downloads and add wikihow | Wikihow is an example that needs to manually download two files as stated in: https://github.com/mahnazkoupaee/WikiHow-Dataset.
The user can then store these files under a hard-coded name: `wikihowAll.csv` and `wikihowSep.csv` in this case in a directory of his choice, e.g. `~/wikihow/manual_dir`.
The dataset ca... | closed | https://github.com/huggingface/datasets/pull/103 | 2020-05-14T13:30:36 | 2020-05-14T14:27:41 | 2020-05-14T14:27:40 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
618,231,216 | 102 | Run save infos | I replaced the old checksum file with the new `dataset_infos.json` by running the script on almost all the datasets we have. The only one that is still running on my side is the cornell dialog | closed | https://github.com/huggingface/datasets/pull/102 | 2020-05-14T13:27:26 | 2020-05-14T15:43:04 | 2020-05-14T15:43:03 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
618,111,651 | 101 | [Reddit] add reddit | - Everything worked fine @mariamabarham. Made my computer nearly crash, but all seems to be working :-) | closed | https://github.com/huggingface/datasets/pull/101 | 2020-05-14T10:25:02 | 2020-05-14T10:27:25 | 2020-05-14T10:27:24 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
618,081,602 | 100 | Add per type scores in seqeval metric | This PR add a bit more detail in the seqeval metric. Now the usage and output are:
```python
import nlp
met = nlp.load_metric('metrics/seqeval')
references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-... | closed | https://github.com/huggingface/datasets/pull/100 | 2020-05-14T09:37:52 | 2020-05-14T23:21:35 | 2020-05-14T23:21:34 | {
"login": "jplu",
"id": 959590,
"type": "User"
} | [] | true | [] |
618,026,700 | 99 | [Cmrc 2018] fix cmrc2018 | closed | https://github.com/huggingface/datasets/pull/99 | 2020-05-14T08:22:03 | 2020-05-14T08:49:42 | 2020-05-14T08:49:41 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] | |
617,957,739 | 98 | Webis tl-dr | Add the Webid TL:DR dataset. | closed | https://github.com/huggingface/datasets/pull/98 | 2020-05-14T06:22:18 | 2020-09-03T10:00:21 | 2020-05-14T20:54:16 | {
"login": "jplu",
"id": 959590,
"type": "User"
} | [] | true | [] |
617,809,431 | 97 | [Csv] add tests for csv dataset script | Adds dummy data tests for csv. | closed | https://github.com/huggingface/datasets/pull/97 | 2020-05-13T23:06:11 | 2020-05-13T23:23:16 | 2020-05-13T23:23:15 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
617,739,521 | 96 | lm1b | Add lm1b dataset. | closed | https://github.com/huggingface/datasets/pull/96 | 2020-05-13T20:38:44 | 2020-05-14T14:13:30 | 2020-05-14T14:13:29 | {
"login": "jplu",
"id": 959590,
"type": "User"
} | [] | true | [] |
617,703,037 | 95 | Replace checksums files by Dataset infos json | ### Better verifications when loading a dataset
I replaced the `urls_checksums` directory that used to contain `checksums.txt` and `cached_sizes.txt`, by a single file `dataset_infos.json`. It's just a dict `config_name` -> `DatasetInfo`.
It simplifies and improves how verifications of checksums and splits sizes ... | closed | https://github.com/huggingface/datasets/pull/95 | 2020-05-13T19:36:16 | 2020-05-14T08:58:43 | 2020-05-14T08:58:42 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
617,571,340 | 94 | Librispeech | Add librispeech dataset and remove some useless content. | closed | https://github.com/huggingface/datasets/pull/94 | 2020-05-13T16:04:14 | 2020-05-13T21:29:03 | 2020-05-13T21:29:02 | {
"login": "jplu",
"id": 959590,
"type": "User"
} | [] | true | [] |
617,522,029 | 93 | Cleanup notebooks and various fixes | Fixes on dataset (more flexible) metrics (fix) and general clean ups | closed | https://github.com/huggingface/datasets/pull/93 | 2020-05-13T14:58:58 | 2020-05-13T15:01:48 | 2020-05-13T15:01:47 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
617,341,505 | 92 | [WIP] add wmt14 | WMT14 takes forever to download :-/
- WMT is the first dataset that uses an abstract class IMO, so I had to modify the `load_dataset_module` a bit. | closed | https://github.com/huggingface/datasets/pull/92 | 2020-05-13T10:42:03 | 2020-05-16T11:17:38 | 2020-05-16T11:17:37 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
617,339,484 | 91 | [Paracrawl] add paracrawl | - Huge dataset - took ~1h to download
- Also this PR reformats all dataset scripts and adds `datasets` to `make style` | closed | https://github.com/huggingface/datasets/pull/91 | 2020-05-13T10:39:00 | 2020-05-13T10:40:15 | 2020-05-13T10:40:14 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
617,311,877 | 90 | Add download gg drive | We can now add datasets that download from google drive | closed | https://github.com/huggingface/datasets/pull/90 | 2020-05-13T09:56:02 | 2020-05-13T12:46:28 | 2020-05-13T10:05:31 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
617,295,069 | 89 | Add list and inspect methods - cleanup hf_api | Add a bunch of methods to easily list and inspect the processing scripts up-loaded on S3:
```python
nlp.list_datasets()
nlp.list_metrics()
# Copy and prepare the scripts at `local_path` for easy inspection/modification.
nlp.inspect_dataset(path, local_path)
# Copy and prepare the scripts at `local_path` for easy... | closed | https://github.com/huggingface/datasets/pull/89 | 2020-05-13T09:30:15 | 2020-05-13T14:05:00 | 2020-05-13T09:33:10 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
617,284,664 | 88 | Add wiki40b | This one is a beam dataset that downloads files using tensorflow.
I tested it on a small config and it works fine | closed | https://github.com/huggingface/datasets/pull/88 | 2020-05-13T09:16:01 | 2020-05-13T12:31:55 | 2020-05-13T12:31:54 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
617,267,118 | 87 | Add Flores | Beautiful language for sure! | closed | https://github.com/huggingface/datasets/pull/87 | 2020-05-13T08:51:29 | 2020-05-13T09:23:34 | 2020-05-13T09:23:33 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
617,260,972 | 86 | [Load => load_dataset] change naming | Rename leftovers @thomwolf | closed | https://github.com/huggingface/datasets/pull/86 | 2020-05-13T08:43:00 | 2020-05-13T08:50:58 | 2020-05-13T08:50:57 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
617,253,428 | 85 | Add boolq | I just added the dummy data for this dataset.
This one was uses `tf.io.gfile.copy` to download the data but I added the support for custom download in the mock_download_manager. I also had to add a `tensorflow` dependency for tests. | closed | https://github.com/huggingface/datasets/pull/85 | 2020-05-13T08:32:27 | 2020-05-13T09:09:39 | 2020-05-13T09:09:38 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
617,249,815 | 84 | [TedHrLr] add left dummy data | closed | https://github.com/huggingface/datasets/pull/84 | 2020-05-13T08:27:20 | 2020-05-13T08:29:22 | 2020-05-13T08:29:21 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] | |
616,863,601 | 83 | New datasets | closed | https://github.com/huggingface/datasets/pull/83 | 2020-05-12T18:22:27 | 2020-05-12T18:22:47 | 2020-05-12T18:22:45 | {
"login": "mariamabarham",
"id": 38249783,
"type": "User"
} | [] | true | [] | |
616,805,194 | 82 | [Datasets] add ted_hrlr | @thomwolf - After looking at `xnli` I think it's better to leave the translation features and add a `translation` key to make them work in our framework.
The result looks like this:

2. GLEU: Google-BLEU: https://github.com/cnap/gec-... | closed | https://github.com/huggingface/datasets/pull/75 | 2020-05-12T09:52:00 | 2020-05-13T07:44:12 | 2020-05-13T07:44:10 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
616,511,101 | 74 | fix overflow check | I did some tests and unfortunately the test
```
pa_array.nbytes > MAX_BATCH_BYTES
```
doesn't work. Indeed for a StructArray, `nbytes` can be less 2GB even if there is an overflow (it loops...).
I don't think we can do a proper overflow test for the limit of 2GB...
For now I replaced it with a sanity check on... | closed | https://github.com/huggingface/datasets/pull/74 | 2020-05-12T09:38:01 | 2020-05-12T10:04:39 | 2020-05-12T10:04:38 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
616,417,845 | 73 | JSON script | Add a JSONS script to read JSON datasets from files. | closed | https://github.com/huggingface/datasets/pull/73 | 2020-05-12T07:11:22 | 2020-05-18T06:50:37 | 2020-05-18T06:50:36 | {
"login": "jplu",
"id": 959590,
"type": "User"
} | [] | true | [] |
616,225,010 | 72 | [README dummy data tests] README to better understand how the dummy data structure works | In this PR a README.md is added to tests to shine more light on how the dummy data structure works. I try to explain the different possible cases. IMO the best way to understand the logic is to checkout the dummy data structure of the different datasets I mention in the README.md since those are the "edge cases".
@... | closed | https://github.com/huggingface/datasets/pull/72 | 2020-05-11T22:19:03 | 2020-05-11T22:26:03 | 2020-05-11T22:26:01 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
615,942,180 | 71 | Fix arrow writer for big datasets using writer_batch_size | This PR fixes Yacine's bug.
According to [this](https://github.com/apache/arrow/blob/master/docs/source/cpp/arrays.rst#size-limitations-and-recommendations), it is not recommended to have pyarrow arrays bigger than 2Go.
Therefore I set a default batch size of 100 000 examples per batch. In general it shouldn't exce... | closed | https://github.com/huggingface/datasets/pull/71 | 2020-05-11T14:45:36 | 2020-05-11T20:09:47 | 2020-05-11T20:00:38 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
615,679,102 | 70 | adding RACE, QASC, Super_glue and Tiny_shakespear datasets | closed | https://github.com/huggingface/datasets/pull/70 | 2020-05-11T08:07:49 | 2020-05-12T13:21:52 | 2020-05-12T13:21:51 | {
"login": "mariamabarham",
"id": 38249783,
"type": "User"
} | [] | true | [] | |
615,450,534 | 69 | fix cache dir in builder tests | minor fix | closed | https://github.com/huggingface/datasets/pull/69 | 2020-05-10T18:39:21 | 2020-05-11T07:19:30 | 2020-05-11T07:19:28 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
614,882,655 | 68 | [CSV] re-add csv | Re-adding csv under the datasets under construction to keep circle ci happy - will have to see how to include it in the tests.
@lhoestq noticed that I accidently deleted it in https://github.com/huggingface/nlp/pull/63#discussion_r422263729. | closed | https://github.com/huggingface/datasets/pull/68 | 2020-05-08T17:38:29 | 2020-05-08T17:40:48 | 2020-05-08T17:40:46 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
614,798,483 | 67 | [Tests] Test files locally | This PR adds a `aws` and a `local` decorator to the tests so that tests now run on the local datasets.
By default, the `aws` is deactivated and `local` is activated and `slow` is deactivated, so that only 1 test per dataset runs on circle ci.
**When local is activated all folders in `./datasets` are tested.**
... | closed | https://github.com/huggingface/datasets/pull/67 | 2020-05-08T15:02:43 | 2020-05-08T19:50:47 | 2020-05-08T15:17:00 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
614,748,552 | 66 | [Datasets] ReadME | closed | https://github.com/huggingface/datasets/pull/66 | 2020-05-08T13:37:43 | 2020-05-08T13:39:23 | 2020-05-08T13:39:22 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] | |
614,746,516 | 65 | fix math dataset and xcopa | - fixes math dataset and xcopa, uploaded both of the to S3 | closed | https://github.com/huggingface/datasets/pull/65 | 2020-05-08T13:33:55 | 2020-05-08T13:35:41 | 2020-05-08T13:35:40 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
614,737,057 | 64 | [Datasets] Make master ready for datasets adding | Add all relevant files so that datasets can now be added on master | closed | https://github.com/huggingface/datasets/pull/64 | 2020-05-08T13:17:00 | 2020-05-08T13:17:31 | 2020-05-08T13:17:30 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
614,666,365 | 63 | [Dataset scripts] add all datasets scripts | As mentioned, we can have the canonical datasets in the master. For now I also want to include all the data as present on S3 to make the synchronization easier when uploading new datastes.
@mariamabarham @lhoestq @thomwolf - what do you think?
If this is ok for you, I can sync up the master with the `add_datase... | closed | https://github.com/huggingface/datasets/pull/63 | 2020-05-08T10:50:15 | 2020-05-08T17:39:22 | 2020-05-08T11:34:00 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
614,630,830 | 62 | [Cached Path] Better error message | IMO returning `None` in this function only leads to confusion and is never helpful. | closed | https://github.com/huggingface/datasets/pull/62 | 2020-05-08T09:39:47 | 2020-05-08T09:45:47 | 2020-05-08T09:45:47 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
614,607,474 | 61 | [Load] rename setup_module to prepare_module | rename setup_module to prepare_module due to issues with pytests `setup_module` function.
See: PR #59. | closed | https://github.com/huggingface/datasets/pull/61 | 2020-05-08T08:54:22 | 2020-05-08T08:56:32 | 2020-05-08T08:56:16 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
614,372,553 | 60 | Update to simplify some datasets conversion | This PR updates the encoding of `Values` like `integers`, `boolean` and `float` to use python casting and avoid having to cast in the dataset scripts, as mentioned here: https://github.com/huggingface/nlp/pull/37#discussion_r420176626
We could also change (not included in this PR yet):
- `supervized_keys` to make t... | closed | https://github.com/huggingface/datasets/pull/60 | 2020-05-07T22:02:24 | 2020-05-08T10:38:32 | 2020-05-08T10:18:24 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
614,366,045 | 59 | Fix tests | @patrickvonplaten I've broken a bit the tests with #25 while simplifying and re-organizing the `load.py` and `download_manager.py` scripts.
I'm trying to fix them here but I have a weird error, do you think you can have a look?
```bash
(datasets) MacBook-Pro-de-Thomas:datasets thomwolf$ python -m pytest -sv ./test... | closed | https://github.com/huggingface/datasets/pull/59 | 2020-05-07T21:48:09 | 2020-05-08T10:57:57 | 2020-05-08T10:46:51 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
614,362,308 | 58 | Aborted PR - Fix tests | @patrickvonplaten I've broken a bit the tests with #25 while simplifying and re-organizing the `load.py` and `download_manager.py` scripts.
I'm trying to fix them here but I have a weird error, do you think you can have a look?
```bash
(datasets) MacBook-Pro-de-Thomas:datasets thomwolf$ python -m pytest -sv ./test... | closed | https://github.com/huggingface/datasets/pull/58 | 2020-05-07T21:40:19 | 2020-05-07T21:48:01 | 2020-05-07T21:41:27 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
614,261,638 | 57 | Better cached path | ### Changes:
- The `cached_path` no longer returns None if the file is missing/the url doesn't work. Instead, it can raise `FileNotFoundError` (missing file), `ConnectionError` (no cache and unreachable url) or `ValueError` (parsing error)
- Fix requests to firebase API that doesn't handle HEAD requests...
- Allow c... | closed | https://github.com/huggingface/datasets/pull/57 | 2020-05-07T18:36:00 | 2020-05-08T13:20:30 | 2020-05-08T13:20:28 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
614,236,869 | 56 | [Dataset] Tester add mock function | need to add an empty `extract()` function to make `hansard` dataset test work. | closed | https://github.com/huggingface/datasets/pull/56 | 2020-05-07T17:51:37 | 2020-05-07T17:52:51 | 2020-05-07T17:52:50 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
613,968,072 | 55 | Beam datasets | # Beam datasets
## Intro
Beam Datasets are using beam pipelines for preprocessing (basically lots of `.map` over objects called PCollections).
The advantage of apache beam is that you can choose which type of runner you want to use to preprocess your data. The main runners are:
- the `DirectRunner` to run the p... | closed | https://github.com/huggingface/datasets/pull/55 | 2020-05-07T11:04:32 | 2020-05-11T07:20:02 | 2020-05-11T07:20:00 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
613,513,348 | 54 | [Tests] Improved Error message for dummy folder structure | Improved Error message | closed | https://github.com/huggingface/datasets/pull/54 | 2020-05-06T18:11:48 | 2020-05-06T18:13:00 | 2020-05-06T18:12:59 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
613,436,158 | 53 | [Features] Typo in generate_from_dict | Change `isinstance` test in features when generating features from dict. | closed | https://github.com/huggingface/datasets/pull/53 | 2020-05-06T16:05:23 | 2020-05-07T15:28:46 | 2020-05-07T15:28:45 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
613,339,071 | 52 | allow dummy folder structure to handle dict of lists | `esnli.py` needs that extension of the dummy data testing. | closed | https://github.com/huggingface/datasets/pull/52 | 2020-05-06T13:54:35 | 2020-05-06T13:55:19 | 2020-05-06T13:55:18 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
613,266,668 | 51 | [Testing] Improved testing structure | This PR refactors the test design a bit and puts the mock download manager in the `utils` files as it is just a test helper class.
as @mariamabarham pointed out, creating a dummy folder structure can be quite hard to grasp.
This PR tries to change that to some extent.
It follows the following logic for the `dumm... | closed | https://github.com/huggingface/datasets/pull/51 | 2020-05-06T12:03:07 | 2020-05-07T22:07:19 | 2020-05-06T13:20:18 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
612,583,126 | 50 | [Tests] test only for fast test as a default | Test only for one config on circle ci to speed up testing. Add all config test as a slow test.
@mariamabarham @thomwolf | closed | https://github.com/huggingface/datasets/pull/50 | 2020-05-05T12:59:22 | 2020-05-05T13:02:18 | 2020-05-05T13:02:16 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
612,545,483 | 49 | fix flatten nested | closed | https://github.com/huggingface/datasets/pull/49 | 2020-05-05T11:55:13 | 2020-05-05T13:59:26 | 2020-05-05T13:59:25 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] | |
612,504,687 | 48 | [Command Convert] remove tensorflow import | Remove all tensorflow import statements. | closed | https://github.com/huggingface/datasets/pull/48 | 2020-05-05T10:41:00 | 2020-05-05T11:13:58 | 2020-05-05T11:13:56 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
612,446,493 | 47 | [PyArrow Feature] fix py arrow bool | To me it seems that `bool` can only be accessed with `bool_` when looking at the pyarrow types: https://arrow.apache.org/docs/python/api/datatypes.html. | closed | https://github.com/huggingface/datasets/pull/47 | 2020-05-05T08:56:28 | 2020-05-05T10:40:28 | 2020-05-05T10:40:27 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
612,398,190 | 46 | [Features] Strip str key before dict look-up | The dataset `anli.py` currently fails because it tries to look up a key `1\n` in a dict that only has the key `1`. Added an if statement to strip key if it cannot be found in dict. | closed | https://github.com/huggingface/datasets/pull/46 | 2020-05-05T07:31:45 | 2020-05-05T08:37:45 | 2020-05-05T08:37:44 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
612,386,583 | 45 | [Load] Separate Module kwargs and builder kwargs. | Kwargs for the `load_module` fn should be passed with `module_xxxx` to `builder_kwargs` of `load` fn.
This is a follow-up PR of: https://github.com/huggingface/nlp/pull/41 | closed | https://github.com/huggingface/datasets/pull/45 | 2020-05-05T07:09:54 | 2022-10-04T09:32:11 | 2020-05-08T09:51:22 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
611,873,486 | 44 | [Tests] Fix tests for datasets with no config | Forgot to fix `None` problem for datasets that have no config this in PR: https://github.com/huggingface/nlp/pull/42 | closed | https://github.com/huggingface/datasets/pull/44 | 2020-05-04T13:25:38 | 2020-05-04T13:28:04 | 2020-05-04T13:28:03 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
611,773,279 | 43 | [Checksums] If no configs exist prevent to run over empty list | `movie_rationales` e.g. has no configs. | closed | https://github.com/huggingface/datasets/pull/43 | 2020-05-04T10:39:42 | 2022-10-04T09:32:02 | 2020-05-04T13:18:03 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
611,754,343 | 42 | [Tests] allow tests for builders without config | Some dataset scripts have no configs - the tests have to be adapted for this case.
In this case the dummy data will be saved as:
- natural_questions
-> dummy
-> -> 1.0.0 (version num)
-> -> -> dummy_data.zip
| closed | https://github.com/huggingface/datasets/pull/42 | 2020-05-04T10:06:22 | 2020-05-04T13:10:50 | 2020-05-04T13:10:48 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
611,739,219 | 41 | [Load module] allow kwargs into load module | Currenly it is not possible to force a re-download of the dataset script.
This simple change allows to pass ``force_reload=True`` as ``builder_kwargs`` in the ``load.py`` function. | closed | https://github.com/huggingface/datasets/pull/41 | 2020-05-04T09:42:11 | 2020-05-04T19:39:07 | 2020-05-04T19:39:06 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
611,721,308 | 40 | Update remote checksums instead of overwrite | When the user uploads a dataset on S3, checksums are also uploaded with the `--upload_checksums` parameter.
If the user uploads the dataset in several steps, then the remote checksums file was previously overwritten. Now it's going to be updated with the new checksums. | closed | https://github.com/huggingface/datasets/pull/40 | 2020-05-04T09:13:14 | 2020-05-04T11:51:51 | 2020-05-04T11:51:49 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
611,712,135 | 39 | [Test] improve slow testing | closed | https://github.com/huggingface/datasets/pull/39 | 2020-05-04T08:58:33 | 2020-05-04T08:59:50 | 2020-05-04T08:59:49 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] | |
611,677,656 | 38 | [Checksums] Error for some datasets | The checksums command works very nicely for `squad`. But for `crime_and_punish` and `xnli`,
the same bug happens:
When running:
```
python nlp-cli nlp-cli test xnli --save_checksums
```
leads to:
```
File "nlp-cli", line 33, in <module>
service.run()
File "/home/patrick/python_bin/nlp/commands... | closed | https://github.com/huggingface/datasets/issues/38 | 2020-05-04T08:00:16 | 2020-05-04T09:48:20 | 2020-05-04T09:48:20 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | false | [] |
611,670,295 | 37 | [Datasets ToDo-List] add datasets | ## Description
This PR acts as a dashboard to see which datasets are added to the library and work.
Cicle-ci should always be green so that we can be sure that newly added datasets are functional.
This PR should not be merged.
## Progress
**For the following datasets the test commands**:
```
RUN_SLOW... | closed | https://github.com/huggingface/datasets/pull/37 | 2020-05-04T07:47:39 | 2022-10-04T09:32:17 | 2020-05-08T13:48:23 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
611,528,349 | 36 | Metrics - refactoring, adding support for download and distributed metrics | Refactoring metrics to have a similar loading API than the datasets and improving the import system.
# Import system
The import system has ben upgraded. There are now three types of imports allowed:
1. `library` imports (identified as "absolute imports")
```python
import seqeval
```
=> we'll test all the impor... | closed | https://github.com/huggingface/datasets/pull/36 | 2020-05-03T23:00:17 | 2020-05-11T08:16:02 | 2020-05-11T08:16:00 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
611,413,731 | 35 | [Tests] fix typo | @lhoestq - currently the slow test fail with:
```
_____________________________________________________________________________________ DatasetTest.test_load_real_dataset_xnli _____________________________________________________________________________________
... | closed | https://github.com/huggingface/datasets/pull/35 | 2020-05-03T13:23:49 | 2020-05-03T13:24:21 | 2020-05-03T13:24:20 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
611,385,516 | 34 | [Tests] add slow tests | This PR adds a slow test that downloads the "real" dataset. The test is decorated as "slow" so that it will not automatically run on circle ci.
Before uploading a dataset, one should test that this test passes, manually by running
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_d... | closed | https://github.com/huggingface/datasets/pull/34 | 2020-05-03T11:01:22 | 2020-05-03T12:18:30 | 2020-05-03T12:18:29 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
611,052,081 | 33 | Big cleanup/refactoring for clean serialization | This PR cleans many base classes to re-build them as `dataclasses`. We can thus use a simple serialization workflow for `DatasetInfo`, including it's `Features` and `SplitDict` based on `dataclasses` `asdict()`.
The resulting code is a lot shorter, can be easily serialized/deserialized, dataset info are human-readab... | closed | https://github.com/huggingface/datasets/pull/33 | 2020-05-01T23:45:57 | 2020-05-03T12:17:34 | 2020-05-03T12:17:33 | {
"login": "thomwolf",
"id": 7353373,
"type": "User"
} | [] | true | [] |
610,715,580 | 32 | Fix map caching notebooks | Previously, caching results with `.map()` didn't work in notebooks.
To reuse a result, `.map()` serializes the functions with `dill.dumps` and then it hashes it.
The problem is that when using `dill.dumps` to serialize a function, it also saves its origin (filename + line no.) and the origin of all the `globals` th... | closed | https://github.com/huggingface/datasets/pull/32 | 2020-05-01T11:55:26 | 2020-05-03T12:15:58 | 2020-05-03T12:15:57 | {
"login": "lhoestq",
"id": 42851186,
"type": "User"
} | [] | true | [] |
610,677,641 | 31 | [Circle ci] Install a virtual env before running tests | Install a virtual env before running tests to not running into sudo issues when dynamically downloading files.
Same number of tests now pass / fail as on my local computer:
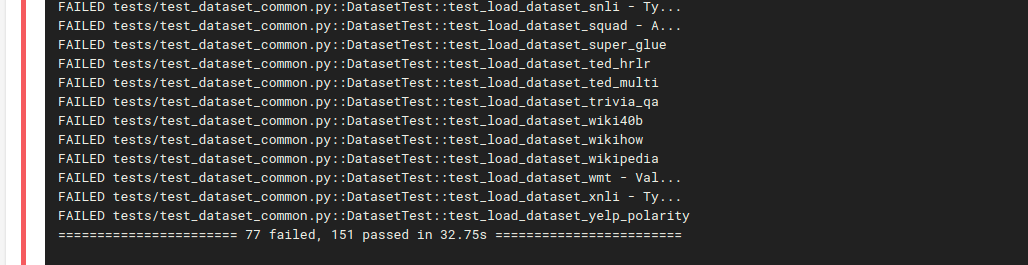
... | closed | https://github.com/huggingface/datasets/pull/31 | 2020-05-01T10:11:17 | 2020-05-01T22:06:16 | 2020-05-01T22:06:15 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
610,549,072 | 30 | add metrics which require download files from github | To download files from github, I copied the `load_dataset_module` and its dependencies (without the builder) in `load.py` to `metrics/metric_utils.py`. I made the following changes:
- copy the needed files in a folder`metric_name`
- delete all other files that are not needed
For metrics that require an external... | closed | https://github.com/huggingface/datasets/pull/30 | 2020-05-01T04:13:22 | 2022-10-04T09:31:58 | 2020-05-11T08:19:54 | {
"login": "mariamabarham",
"id": 38249783,
"type": "User"
} | [] | true | [] |
610,243,997 | 29 | Hf_api small changes | From Patrick:
```python
from nlp import hf_api
api = hf_api.HfApi()
api.dataset_list()
```
works :-) | closed | https://github.com/huggingface/datasets/pull/29 | 2020-04-30T17:06:43 | 2020-04-30T19:51:45 | 2020-04-30T19:51:44 | {
"login": "julien-c",
"id": 326577,
"type": "User"
} | [] | true | [] |
610,241,907 | 28 | [Circle ci] Adds circle ci config | @thomwolf can you take a look and set up circle ci on:
https://app.circleci.com/projects/project-dashboard/github/huggingface
I think for `nlp` only admins can set it up, which I guess is you :-) | closed | https://github.com/huggingface/datasets/pull/28 | 2020-04-30T17:03:35 | 2020-04-30T19:51:09 | 2020-04-30T19:51:08 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
610,230,476 | 27 | [Cleanup] Removes all files in testing except test_dataset_common | As far as I know, all files in `tests` were old `tfds test files` so I removed them. We can still look them up on the other library. | closed | https://github.com/huggingface/datasets/pull/27 | 2020-04-30T16:45:21 | 2020-04-30T17:39:25 | 2020-04-30T17:39:23 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
610,226,047 | 26 | [Tests] Clean tests | the abseil testing library (https://abseil.io/docs/python/quickstart.html) is better than the one I had before, so I decided to switch to that and changed the `setup.py` config file.
Abseil has more support and a cleaner API for parametrized testing I think.
I added a list of all dataset scripts that are currentl... | closed | https://github.com/huggingface/datasets/pull/26 | 2020-04-30T16:38:29 | 2020-04-30T20:12:04 | 2020-04-30T20:12:03 | {
"login": "patrickvonplaten",
"id": 23423619,
"type": "User"
} | [] | true | [] |
609,708,863 | 25 | Add script csv datasets | This is a PR allowing to create datasets from local CSV files. A usage might be:
```python
import nlp
ds = nlp.load(
path="csv",
name="bbc",
dataset_files={
nlp.Split.TRAIN: ["datasets/dummy_data/csv/train.csv"],
nlp.Split.TEST: [""datasets/dummy_data/csv/test.csv""]
},
c... | closed | https://github.com/huggingface/datasets/pull/25 | 2020-04-30T08:28:08 | 2022-10-04T09:32:13 | 2020-05-07T21:14:49 | {
"login": "jplu",
"id": 959590,
"type": "User"
} | [] | true | [] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.