
text stringlengths 7 328k | id stringlengths 14 166 | metadata dict | __index_level_0__ int64 0 459 |
|---|---|---|---|
[package]
name = "candle-wasm-example-whisper"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
candle-t... | candle/candle-wasm-examples/whisper/Cargo.toml/0 | {
"file_path": "candle/candle-wasm-examples/whisper/Cargo.toml",
"repo_id": "candle",
"token_count": 428
} | 46 |
## Running Yolo Examples
Here, we provide two examples of how to run YOLOv8 using a Candle-compiled WASM binary and runtimes.
### Pure Rust UI
To build and test the UI made in Rust you will need [Trunk](https://trunkrs.dev/#install)
From the `candle-wasm-examples/yolo` directory run:
Download assets:
```bash
wget ... | candle/candle-wasm-examples/yolo/README.md/0 | {
"file_path": "candle/candle-wasm-examples/yolo/README.md",
"repo_id": "candle",
"token_count": 412
} | 47 |
use candle::{
quantized::{self, k_quants, GgmlDType, GgmlType},
test_utils::to_vec2_round,
Device, Module, Result, Tensor,
};
use wasm_bindgen_test::*;
wasm_bindgen_test_configure!(run_in_browser);
#[wasm_bindgen_test]
fn quantized_matmul_neg() -> Result<()> {
let cpu = &Device::Cpu;
let (m, k, n)... | candle/candle-wasm-tests/tests/quantized_tests.rs/0 | {
"file_path": "candle/candle-wasm-tests/tests/quantized_tests.rs",
"repo_id": "candle",
"token_count": 3145
} | 48 |
# Prompt templates
These are the templates used to format the conversation history for different models used in HuggingChat. Set them in your `.env.local` [like so](https://github.com/huggingface/chat-ui#chatprompttemplate).
## Llama 2
```env
<s>[INST] <<SYS>>\n{{preprompt}}\n<</SYS>>\n\n{{#each messages}}{{#ifUser}... | chat-ui/PROMPTS.md/0 | {
"file_path": "chat-ui/PROMPTS.md",
"repo_id": "chat-ui",
"token_count": 1133
} | 49 |
<script lang="ts">
export let title = "";
export let classNames = "";
</script>
<div class="flex items-center rounded-xl bg-gray-100 p-1 text-sm dark:bg-gray-800 {classNames}">
<span
class="mr-2 inline-flex items-center rounded-lg bg-gradient-to-br from-primary-300 px-2 py-1 text-xxs font-medium uppercase leading... | chat-ui/src/lib/components/AnnouncementBanner.svelte/0 | {
"file_path": "chat-ui/src/lib/components/AnnouncementBanner.svelte",
"repo_id": "chat-ui",
"token_count": 184
} | 50 |
<script lang="ts">
import { onMount, onDestroy } from "svelte";
let el: HTMLElement;
onMount(() => {
el.ownerDocument.body.appendChild(el);
});
onDestroy(() => {
if (el?.parentNode) {
el.parentNode.removeChild(el);
}
});
</script>
<div bind:this={el} class="contents" hidden>
<slot />
</div>
| chat-ui/src/lib/components/Portal.svelte/0 | {
"file_path": "chat-ui/src/lib/components/Portal.svelte",
"repo_id": "chat-ui",
"token_count": 130
} | 51 |
<script lang="ts">
export let classNames = "";
</script>
<svg
width="1em"
height="1em"
viewBox="0 0 15 6"
class={classNames}
fill="none"
xmlns="http://www.w3.org/2000/svg"
>
<path
d="M1.67236 1L7.67236 7L13.6724 1"
stroke="currentColor"
stroke-width="2"
stroke-linecap="round"
stroke-linejoin="round"
... | chat-ui/src/lib/components/icons/IconChevron.svelte/0 | {
"file_path": "chat-ui/src/lib/components/icons/IconChevron.svelte",
"repo_id": "chat-ui",
"token_count": 156
} | 52 |
import { MONGODB_URL, MONGODB_DB_NAME, MONGODB_DIRECT_CONNECTION } from "$env/static/private";
import { GridFSBucket, MongoClient } from "mongodb";
import type { Conversation } from "$lib/types/Conversation";
import type { SharedConversation } from "$lib/types/SharedConversation";
import type { AbortedGeneration } from... | chat-ui/src/lib/server/database.ts/0 | {
"file_path": "chat-ui/src/lib/server/database.ts",
"repo_id": "chat-ui",
"token_count": 1994
} | 53 |
import type { Conversation } from "$lib/types/Conversation";
import { sha256 } from "$lib/utils/sha256";
import { collections } from "../database";
export async function uploadFile(file: Blob, conv: Conversation): Promise<string> {
const sha = await sha256(await file.text());
const upload = collections.bucket.openU... | chat-ui/src/lib/server/files/uploadFile.ts/0 | {
"file_path": "chat-ui/src/lib/server/files/uploadFile.ts",
"repo_id": "chat-ui",
"token_count": 244
} | 54 |
import type { Message } from "$lib/types/Message";
import { getContext, setContext } from "svelte";
import { writable, type Writable } from "svelte/store";
// used to store the id of the message that is the currently displayed leaf of the conversation tree
// (that is the last message in the current branch of the conv... | chat-ui/src/lib/stores/convTree.ts/0 | {
"file_path": "chat-ui/src/lib/stores/convTree.ts",
"repo_id": "chat-ui",
"token_count": 216
} | 55 |
import type { ObjectId } from "mongodb";
export interface MigrationResult {
_id: ObjectId;
name: string;
status: "success" | "failure" | "ongoing";
}
| chat-ui/src/lib/types/MigrationResult.ts/0 | {
"file_path": "chat-ui/src/lib/types/MigrationResult.ts",
"repo_id": "chat-ui",
"token_count": 53
} | 56 |
/**
* A debounce function that works in both browser and Nodejs.
* For pure Nodejs work, prefer the `Debouncer` class.
*/
export function debounce<T extends unknown[]>(
callback: (...rest: T) => unknown,
limit: number
): (...rest: T) => void {
let timer: ReturnType<typeof setTimeout>;
return function (...rest) ... | chat-ui/src/lib/utils/debounce.ts/0 | {
"file_path": "chat-ui/src/lib/utils/debounce.ts",
"repo_id": "chat-ui",
"token_count": 138
} | 57 |
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for-await...of#iterating_over_async_generators
export async function* streamToAsyncIterable(
stream: ReadableStream<Uint8Array>
): AsyncIterableIterator<Uint8Array> {
const reader = stream.getReader();
try {
while (true) {
const { d... | chat-ui/src/lib/utils/streamToAsyncIterable.ts/0 | {
"file_path": "chat-ui/src/lib/utils/streamToAsyncIterable.ts",
"repo_id": "chat-ui",
"token_count": 161
} | 58 |
import type { LayoutServerLoad } from "./$types";
import { collections } from "$lib/server/database";
import type { Conversation } from "$lib/types/Conversation";
import { UrlDependency } from "$lib/types/UrlDependency";
import { defaultModel, models, oldModels, validateModel } from "$lib/server/models";
import { authC... | chat-ui/src/routes/+layout.server.ts/0 | {
"file_path": "chat-ui/src/routes/+layout.server.ts",
"repo_id": "chat-ui",
"token_count": 2362
} | 59 |
import { collections } from "$lib/server/database";
import { ObjectId } from "mongodb";
import { error } from "@sveltejs/kit";
import { authCondition } from "$lib/server/auth";
import { UrlDependency } from "$lib/types/UrlDependency";
import { convertLegacyConversation } from "$lib/utils/tree/convertLegacyConversation.... | chat-ui/src/routes/conversation/[id]/+page.server.ts/0 | {
"file_path": "chat-ui/src/routes/conversation/[id]/+page.server.ts",
"repo_id": "chat-ui",
"token_count": 678
} | 60 |
<script lang="ts">
import { page } from "$app/stores";
import { base } from "$app/paths";
import { goto } from "$app/navigation";
import { onMount } from "svelte";
import { PUBLIC_APP_NAME, PUBLIC_ORIGIN } from "$env/static/public";
import ChatWindow from "$lib/components/chat/ChatWindow.svelte";
import { findCu... | chat-ui/src/routes/models/[...model]/+page.svelte/0 | {
"file_path": "chat-ui/src/routes/models/[...model]/+page.svelte",
"repo_id": "chat-ui",
"token_count": 1066
} | 61 |
<script lang="ts">
import type { PageData, ActionData } from "./$types";
import { page } from "$app/stores";
import AssistantSettings from "$lib/components/AssistantSettings.svelte";
export let data: PageData;
export let form: ActionData;
$: assistant = data.assistants.find((el) => el._id.toString() === $page.p... | chat-ui/src/routes/settings/(nav)/assistants/[assistantId]/edit/+page@settings.svelte/0 | {
"file_path": "chat-ui/src/routes/settings/(nav)/assistants/[assistantId]/edit/+page@settings.svelte",
"repo_id": "chat-ui",
"token_count": 130
} | 62 |
# Security Policy
## Supported Versions
<!--
Use this section to tell people about which versions of your project are
currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 5.1.x | :white_check_mark: |
| 5.0.x | :x: |
| 4.0.x | :white_... | datasets/SECURITY.md/0 | {
"file_path": "datasets/SECURITY.md",
"repo_id": "datasets",
"token_count": 306
} | 63 |
# docstyle-ignore
INSTALL_CONTENT = """
# Datasets installation
! pip install datasets transformers
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+https://github.com/huggingface/datasets.git
"""
notebook_first_cells = [{"type": "code... | datasets/docs/source/_config.py/0 | {
"file_path": "datasets/docs/source/_config.py",
"repo_id": "datasets",
"token_count": 118
} | 64 |
# Create a dataset
Sometimes, you may need to create a dataset if you're working with your own data. Creating a dataset with 🤗 Datasets confers all the advantages of the library to your dataset: fast loading and processing, [stream enormous datasets](stream), [memory-mapping](https://huggingface.co/course/chapter5/4?... | datasets/docs/source/create_dataset.mdx/0 | {
"file_path": "datasets/docs/source/create_dataset.mdx",
"repo_id": "datasets",
"token_count": 2167
} | 65 |
# Load a dataset from the Hub
Finding high-quality datasets that are reproducible and accessible can be difficult. One of 🤗 Datasets main goals is to provide a simple way to load a dataset of any format or type. The easiest way to get started is to discover an existing dataset on the [Hugging Face Hub](https://huggin... | datasets/docs/source/load_hub.mdx/0 | {
"file_path": "datasets/docs/source/load_hub.mdx",
"repo_id": "datasets",
"token_count": 1685
} | 66 |
# Share a dataset using the CLI
At Hugging Face, we are on a mission to democratize good Machine Learning and we believe in the value of open source. That's why we designed 🤗 Datasets so that anyone can share a dataset with the greater ML community. There are currently thousands of datasets in over 100 languages in t... | datasets/docs/source/share.mdx/0 | {
"file_path": "datasets/docs/source/share.mdx",
"repo_id": "datasets",
"token_count": 2930
} | 67 |
# Metric Card for BLEU
## Metric Description
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a ma... | datasets/metrics/bleu/README.md/0 | {
"file_path": "datasets/metrics/bleu/README.md",
"repo_id": "datasets",
"token_count": 1990
} | 68 |
# Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | datasets/metrics/coval/coval.py/0 | {
"file_path": "datasets/metrics/coval/coval.py",
"repo_id": "datasets",
"token_count": 5731
} | 69 |
# Metric Card for MAE
## Metric Description
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual numeric values:
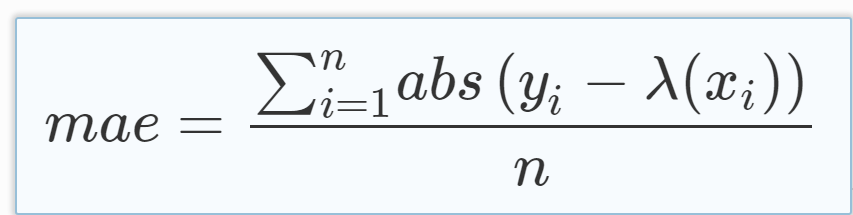
## How to Use
At minimum, this metric re... | datasets/metrics/mae/README.md/0 | {
"file_path": "datasets/metrics/mae/README.md",
"repo_id": "datasets",
"token_count": 1421
} | 70 |
# Metric Card for Perplexity
## Metric Description
Given a model and an input text sequence, perplexity measures how likely the model is to generate the input text sequence. This can be used in two main ways:
1. to evaluate how well the model has learned the distribution of the text it was trained on
- In this cas... | datasets/metrics/perplexity/README.md/0 | {
"file_path": "datasets/metrics/perplexity/README.md",
"repo_id": "datasets",
"token_count": 1345
} | 71 |
# Metric Card for Spearman Correlation Coefficient Metric (spearmanr)
## Metric Description
The Spearman rank-order correlation coefficient is a measure of the
relationship between two datasets. Like other correlation coefficients,
this one varies between -1 and +1 with 0 implying no correlation.
Positive correlation... | datasets/metrics/spearmanr/README.md/0 | {
"file_path": "datasets/metrics/spearmanr/README.md",
"repo_id": "datasets",
"token_count": 1585
} | 72 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | datasets/metrics/wiki_split/wiki_split.py/0 | {
"file_path": "datasets/metrics/wiki_split/wiki_split.py",
"repo_id": "datasets",
"token_count": 5827
} | 73 |
import os
import re
import shutil
from argparse import ArgumentParser, Namespace
from datasets.commands import BaseDatasetsCLICommand
from datasets.utils.logging import get_logger
HIGHLIGHT_MESSAGE_PRE = """<<<<<<< This should probably be modified because it mentions: """
HIGHLIGHT_MESSAGE_POST = """=======
>>>>>>>... | datasets/src/datasets/commands/convert.py/0 | {
"file_path": "datasets/src/datasets/commands/convert.py",
"repo_id": "datasets",
"token_count": 3822
} | 74 |
# ruff: noqa
__all__ = [
"Audio",
"Array2D",
"Array3D",
"Array4D",
"Array5D",
"ClassLabel",
"Features",
"Sequence",
"Value",
"Image",
"Translation",
"TranslationVariableLanguages",
]
from .audio import Audio
from .features import Array2D, Array3D, Array4D, Array5D, Class... | datasets/src/datasets/features/__init__.py/0 | {
"file_path": "datasets/src/datasets/features/__init__.py",
"repo_id": "datasets",
"token_count": 165
} | 75 |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# U... | datasets/src/datasets/info.py/0 | {
"file_path": "datasets/src/datasets/info.py",
"repo_id": "datasets",
"token_count": 11406
} | 76 |
import inspect
import re
from typing import Dict, List, Tuple
from huggingface_hub.utils import insecure_hashlib
from .arrow import arrow
from .audiofolder import audiofolder
from .cache import cache # noqa F401
from .csv import csv
from .imagefolder import imagefolder
from .json import json
from .pandas import pand... | datasets/src/datasets/packaged_modules/__init__.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/__init__.py",
"repo_id": "datasets",
"token_count": 1108
} | 77 |
import io
import itertools
import json
from dataclasses import dataclass
from typing import Optional
import pyarrow as pa
import pyarrow.json as paj
import datasets
from datasets.table import table_cast
from datasets.utils.file_utils import readline
logger = datasets.utils.logging.get_logger(__name__)
@dataclass
... | datasets/src/datasets/packaged_modules/json/json.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/json/json.py",
"repo_id": "datasets",
"token_count": 5320
} | 78 |
import importlib.util
import os
import tempfile
from pathlib import PurePath
from typing import TYPE_CHECKING, Dict, List, NamedTuple, Optional, Union
import fsspec
import numpy as np
from .utils import logging
from .utils import tqdm as hf_tqdm
if TYPE_CHECKING:
from .arrow_dataset import Dataset # noqa: F401... | datasets/src/datasets/search.py/0 | {
"file_path": "datasets/src/datasets/search.py",
"repo_id": "datasets",
"token_count": 15237
} | 79 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | datasets/src/datasets/utils/_filelock.py/0 | {
"file_path": "datasets/src/datasets/utils/_filelock.py",
"repo_id": "datasets",
"token_count": 903
} | 80 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | datasets/templates/new_dataset_script.py/0 | {
"file_path": "datasets/templates/new_dataset_script.py",
"repo_id": "datasets",
"token_count": 3156
} | 81 |
import contextlib
import os
import sqlite3
import pytest
from datasets import Dataset, Features, Value
from datasets.io.sql import SqlDatasetReader, SqlDatasetWriter
from ..utils import assert_arrow_memory_doesnt_increase, assert_arrow_memory_increases, require_sqlalchemy
def _check_sql_dataset(dataset, expected_f... | datasets/tests/io/test_sql.py/0 | {
"file_path": "datasets/tests/io/test_sql.py",
"repo_id": "datasets",
"token_count": 1628
} | 82 |
import importlib
import os
import tempfile
import types
from contextlib import nullcontext as does_not_raise
from multiprocessing import Process
from pathlib import Path
from unittest import TestCase
from unittest.mock import patch
import numpy as np
import pyarrow as pa
import pyarrow.parquet as pq
import pytest
from... | datasets/tests/test_builder.py/0 | {
"file_path": "datasets/tests/test_builder.py",
"repo_id": "datasets",
"token_count": 26111
} | 83 |
import pytest
import datasets.config
from datasets.utils.info_utils import is_small_dataset
@pytest.mark.parametrize("dataset_size", [None, 400 * 2**20, 600 * 2**20])
@pytest.mark.parametrize("input_in_memory_max_size", ["default", 0, 100 * 2**20, 900 * 2**20])
def test_is_small_dataset(dataset_size, input_in_memory... | datasets/tests/test_info_utils.py/0 | {
"file_path": "datasets/tests/test_info_utils.py",
"repo_id": "datasets",
"token_count": 366
} | 84 |
import copy
import pickle
from typing import List, Union
import numpy as np
import pyarrow as pa
import pytest
from datasets import Sequence, Value
from datasets.features.features import Array2D, Array2DExtensionType, ClassLabel, Features, Image, get_nested_type
from datasets.table import (
ConcatenationTable,
... | datasets/tests/test_table.py/0 | {
"file_path": "datasets/tests/test_table.py",
"repo_id": "datasets",
"token_count": 21863
} | 85 |
<jupyter_start><jupyter_text>Unit 3: Deep Q-Learning with Atari Games 👾 using RL Baselines3 ZooIn this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-basel... | deep-rl-class/notebooks/unit3/unit3.ipynb/0 | {
"file_path": "deep-rl-class/notebooks/unit3/unit3.ipynb",
"repo_id": "deep-rl-class",
"token_count": 3982
} | 86 |
# Conclusion [[conclusion]]
Congrats on finishing this unit! **That was the biggest one**, and there was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep RL agents and shared them with the community! 🥳
It's **normal if you still feel confused by some of these elements... | deep-rl-class/units/en/unit1/conclusion.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit1/conclusion.mdx",
"repo_id": "deep-rl-class",
"token_count": 349
} | 87 |
# Hands-on [[hands-on]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit2/unit2.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord"... | deep-rl-class/units/en/unit2/hands-on.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit2/hands-on.mdx",
"repo_id": "deep-rl-class",
"token_count": 13932
} | 88 |
# Glossary
This is a community-created glossary. Contributions are welcomed!
- **Tabular Method:** Type of problem in which the state and action spaces are small enough to approximate value functions to be represented as arrays and tables.
**Q-learning** is an example of tabular method since a table is used to repr... | deep-rl-class/units/en/unit3/glossary.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit3/glossary.mdx",
"repo_id": "deep-rl-class",
"token_count": 721
} | 89 |
# (Optional) What is Curiosity in Deep Reinforcement Learning?
This is an (optional) introduction to Curiosity. If you want to learn more, you can read two additional articles where we dive into the mathematical details:
- [Curiosity-Driven Learning through Next State Prediction](https://medium.com/data-from-the-tren... | deep-rl-class/units/en/unit5/curiosity.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit5/curiosity.mdx",
"repo_id": "deep-rl-class",
"token_count": 1153
} | 90 |
# Hands-on
Now that you learned the basics of multi-agents, you're ready to train your first agents in a multi-agent system: **a 2vs2 soccer team that needs to beat the opponent team**.
And you’re going to participate in AI vs. AI challenges where your trained agent will compete against other classmates’ **agents eve... | deep-rl-class/units/en/unit7/hands-on.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit7/hands-on.mdx",
"repo_id": "deep-rl-class",
"token_count": 5036
} | 91 |
# Conclusion [[conclusion]]
Congrats on finishing this bonus unit!
You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to spread the love by sharing Huggy with your friends 🤗**. And if you share about it on social media, **please tag us @huggingface and me @simoninithomas**
<img src="https://hu... | deep-rl-class/units/en/unitbonus1/conclusion.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus1/conclusion.mdx",
"repo_id": "deep-rl-class",
"token_count": 227
} | 92 |
# Model Based Reinforcement Learning (MBRL)
Model-based reinforcement learning only differs from its model-free counterpart in learning a *dynamics model*, but that has substantial downstream effects on how the decisions are made.
The dynamics model usually models the environment transition dynamics, \\( s_{t+1} = f_... | deep-rl-class/units/en/unitbonus3/model-based.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus3/model-based.mdx",
"repo_id": "deep-rl-class",
"token_count": 641
} | 93 |
.PHONY: deps_table_update modified_only_fixup extra_style_checks quality style fixup fix-copies test test-examples
# make sure to test the local checkout in scripts and not the pre-installed one (don't use quotes!)
export PYTHONPATH = src
check_dirs := examples scripts src tests utils benchmarks
modified_only_fixup:... | diffusers/Makefile/0 | {
"file_path": "diffusers/Makefile",
"repo_id": "diffusers",
"token_count": 889
} | 94 |
FROM ubuntu:20.04
LABEL maintainer="Hugging Face"
LABEL repository="diffusers"
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y bash \
build-essential \
git \
git-lfs \
curl \
ca-certificates \
... | diffusers/docker/diffusers-flax-tpu/Dockerfile/0 | {
"file_path": "diffusers/docker/diffusers-flax-tpu/Dockerfile",
"repo_id": "diffusers",
"token_count": 740
} | 95 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/loaders/ip_adapter.md/0 | {
"file_path": "diffusers/docs/source/en/api/loaders/ip_adapter.md",
"repo_id": "diffusers",
"token_count": 339
} | 96 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.md",
"repo_id": "diffusers",
"token_count": 680
} | 97 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/optimization/open_vino.md/0 | {
"file_path": "diffusers/docs/source/en/optimization/open_vino.md",
"repo_id": "diffusers",
"token_count": 1109
} | 98 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/training/lcm_distill.md/0 | {
"file_path": "diffusers/docs/source/en/training/lcm_distill.md",
"repo_id": "diffusers",
"token_count": 4582
} | 99 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/contribute_pipeline.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/contribute_pipeline.md",
"repo_id": "diffusers",
"token_count": 2939
} | 100 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/kandinsky.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/kandinsky.md",
"repo_id": "diffusers",
"token_count": 10810
} | 101 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/en/using-diffusers/svd.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/svd.md",
"repo_id": "diffusers",
"token_count": 1759
} | 102 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/training/controlnet.md/0 | {
"file_path": "diffusers/docs/source/ko/training/controlnet.md",
"repo_id": "diffusers",
"token_count": 7782
} | 103 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | diffusers/docs/source/ko/using-diffusers/controlling_generation.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/controlling_generation.md",
"repo_id": "diffusers",
"token_count": 14041
} | 104 |
# 세이프텐서 로드
[safetensors](https://github.com/huggingface/safetensors)는 텐서를 저장하고 로드하기 위한 안전하고 빠른 파일 형식입니다. 일반적으로 PyTorch 모델 가중치는 Python의 [`pickle`](https://docs.python.org/3/library/pickle.html) 유틸리티를 사용하여 `.bin` 파일에 저장되거나 `피클`됩니다. 그러나 `피클`은 안전하지 않으며 피클된 파일에는 실행될 수 있는 악성 코드가 포함될 수 있습니다. 세이프텐서는 `피클`의 안전한 대안으로 모델 가중치를 공유하... | diffusers/docs/source/ko/using-diffusers/using_safetensors.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/using_safetensors.md",
"repo_id": "diffusers",
"token_count": 4065
} | 105 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py/0 | {
"file_path": "diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py",
"repo_id": "diffusers",
"token_count": 47936
} | 106 |
import inspect
from typing import Callable, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.models import ... | diffusers/examples/community/img2img_inpainting.py/0 | {
"file_path": "diffusers/examples/community/img2img_inpainting.py",
"repo_id": "diffusers",
"token_count": 9677
} | 107 |
import inspect
from typing import Callable, List, Optional, Union
import torch
from transformers import (
CLIPImageProcessor,
CLIPTextModel,
CLIPTokenizer,
MBart50TokenizerFast,
MBartForConditionalGeneration,
pipeline,
)
from diffusers.configuration_utils import FrozenDict
from diffusers.model... | diffusers/examples/community/multilingual_stable_diffusion.py/0 | {
"file_path": "diffusers/examples/community/multilingual_stable_diffusion.py",
"repo_id": "diffusers",
"token_count": 9168
} | 108 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/examples/community/rerender_a_video.py/0 | {
"file_path": "diffusers/examples/community/rerender_a_video.py",
"repo_id": "diffusers",
"token_count": 27079
} | 109 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/examples/community/stable_diffusion_repaint.py/0 | {
"file_path": "diffusers/examples/community/stable_diffusion_repaint.py",
"repo_id": "diffusers",
"token_count": 19597
} | 110 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LI... | diffusers/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py/0 | {
"file_path": "diffusers/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py",
"repo_id": "diffusers",
"token_count": 26899
} | 111 |
# Copyright 2024 Custom Diffusion authors. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by appl... | diffusers/examples/custom_diffusion/retrieve.py/0 | {
"file_path": "diffusers/examples/custom_diffusion/retrieve.py",
"repo_id": "diffusers",
"token_count": 1429
} | 112 |
import warnings
from diffusers import StableDiffusionImg2ImgPipeline # noqa F401
warnings.warn(
"The `image_to_image.py` script is outdated. Please use directly `from diffusers import"
" StableDiffusionImg2ImgPipeline` instead."
)
| diffusers/examples/inference/image_to_image.py/0 | {
"file_path": "diffusers/examples/inference/image_to_image.py",
"repo_id": "diffusers",
"token_count": 84
} | 113 |
# Research projects
This folder contains various research projects using 🧨 Diffusers.
They are not really maintained by the core maintainers of this library and often require a specific version of Diffusers that is indicated in the requirements file of each folder.
Updating them to the most recent version of the libr... | diffusers/examples/research_projects/README.md/0 | {
"file_path": "diffusers/examples/research_projects/README.md",
"repo_id": "diffusers",
"token_count": 143
} | 114 |
# Diffusion Model Alignment Using Direct Preference Optimization
This directory provides LoRA implementations of Diffusion DPO proposed in [DiffusionModel Alignment Using Direct Preference Optimization](https://arxiv.org/abs/2311.12908) by Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Puru... | diffusers/examples/research_projects/diffusion_dpo/README.md/0 | {
"file_path": "diffusers/examples/research_projects/diffusion_dpo/README.md",
"repo_id": "diffusers",
"token_count": 1251
} | 115 |
## Diffusers examples with ONNXRuntime optimizations
**This research project is not actively maintained by the diffusers team. For any questions or comments, please contact Isamu Isozaki(isamu-isozaki) on github with any questions.**
The aim of this project is to provide retrieval augmented diffusion models to diffus... | diffusers/examples/research_projects/rdm/README.md/0 | {
"file_path": "diffusers/examples/research_projects/rdm/README.md",
"repo_id": "diffusers",
"token_count": 75
} | 116 |
# Stable Diffusion text-to-image fine-tuning
The `train_text_to_image.py` script shows how to fine-tune stable diffusion model on your own dataset.
___Note___:
___This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. I... | diffusers/examples/text_to_image/README.md/0 | {
"file_path": "diffusers/examples/text_to_image/README.md",
"repo_id": "diffusers",
"token_count": 4855
} | 117 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/examples/textual_inversion/test_textual_inversion.py/0 | {
"file_path": "diffusers/examples/textual_inversion/test_textual_inversion.py",
"repo_id": "diffusers",
"token_count": 2914
} | 118 |
import argparse
import re
import torch
import yaml
from transformers import (
CLIPProcessor,
CLIPTextModel,
CLIPTokenizer,
CLIPVisionModelWithProjection,
)
from diffusers import (
AutoencoderKL,
DDIMScheduler,
StableDiffusionGLIGENPipeline,
StableDiffusionGLIGENTextImagePipeline,
U... | diffusers/scripts/convert_gligen_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_gligen_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 11150
} | 119 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/scripts/convert_versatile_diffusion_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_versatile_diffusion_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 14926
} | 120 |
from .rl import ValueGuidedRLPipeline
| diffusers/src/diffusers/experimental/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/experimental/__init__.py",
"repo_id": "diffusers",
"token_count": 12
} | 121 |
# Models
For more detail on the models, please refer to the [docs](https://huggingface.co/docs/diffusers/api/models/overview). | diffusers/src/diffusers/models/README.md/0 | {
"file_path": "diffusers/src/diffusers/models/README.md",
"repo_id": "diffusers",
"token_count": 39
} | 122 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/downsampling.py/0 | {
"file_path": "diffusers/src/diffusers/models/downsampling.py",
"repo_id": "diffusers",
"token_count": 5528
} | 123 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/unets/unet_2d_blocks.py/0 | {
"file_path": "diffusers/src/diffusers/models/unets/unet_2d_blocks.py",
"repo_id": "diffusers",
"token_count": 77898
} | 124 |
from dataclasses import dataclass
from typing import List, Optional, Union
import numpy as np
import PIL
from PIL import Image
from ...utils import OptionalDependencyNotAvailable, is_torch_available, is_transformers_available
try:
if not (is_transformers_available() and is_torch_available()):
raise Opti... | diffusers/src/diffusers/pipelines/blip_diffusion/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/blip_diffusion/__init__.py",
"repo_id": "diffusers",
"token_count": 219
} | 125 |
fast27_timesteps = [
999,
800,
799,
600,
599,
500,
400,
399,
377,
355,
333,
311,
288,
266,
244,
222,
200,
199,
177,
155,
133,
111,
88,
66,
44,
22,
0,
]
smart27_timesteps = [
999,
976,
952,
928,
... | diffusers/src/diffusers/pipelines/deepfloyd_if/timesteps.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deepfloyd_if/timesteps.py",
"repo_id": "diffusers",
"token_count": 3772
} | 126 |
from typing import TYPE_CHECKING
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
_import_structure = {"pipeline_repaint": ["RePaintPipeline"]}
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .pipeline_repaint import RePaintPipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
... | diffusers/src/diffusers/pipelines/deprecated/repaint/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/repaint/__init__.py",
"repo_id": "diffusers",
"token_count": 183
} | 127 |
from typing import TYPE_CHECKING
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
_import_structure = {"pipeline_stochastic_karras_ve": ["KarrasVePipeline"]}
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .pipeline_stochastic_karras_ve import KarrasVePipeline
else:
import sys
sys.modules[__na... | diffusers/src/diffusers/pipelines/deprecated/stochastic_karras_ve/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/stochastic_karras_ve/__init__.py",
"repo_id": "diffusers",
"token_count": 199
} | 128 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py",
"repo_id": "diffusers",
"token_count": 7949
} | 129 |
#!/usr/bin/env python3
import argparse
import fnmatch
from safetensors.torch import load_file
from diffusers import Kandinsky3UNet
MAPPING = {
"to_time_embed.1": "time_embedding.linear_1",
"to_time_embed.3": "time_embedding.linear_2",
"in_layer": "conv_in",
"out_layer.0": "conv_norm_out",
"out_l... | diffusers/src/diffusers/pipelines/kandinsky3/convert_kandinsky3_unet.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky3/convert_kandinsky3_unet.py",
"repo_id": "diffusers",
"token_count": 1403
} | 130 |
from dataclasses import dataclass
from typing import TYPE_CHECKING, List, Optional, Union
import numpy as np
import PIL
from PIL import Image
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_... | diffusers/src/diffusers/pipelines/paint_by_example/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/paint_by_example/__init__.py",
"repo_id": "diffusers",
"token_count": 599
} | 131 |
# Copyright 2024 Open AI and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required ... | diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e_img2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e_img2img.py",
"repo_id": "diffusers",
"token_count": 5663
} | 132 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py",
"repo_id": "diffusers",
"token_count": 12562
} | 133 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py",
"repo_id": "diffusers",
"token_count": 22599
} | 134 |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is... | diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py",
"repo_id": "diffusers",
"token_count": 788
} | 135 |
import torch
import torch.nn as nn
from ...models.attention_processor import Attention
class WuerstchenLayerNorm(nn.LayerNorm):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
x = super().forward(x)
return... | diffusers/src/diffusers/pipelines/wuerstchen/modeling_wuerstchen_common.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/wuerstchen/modeling_wuerstchen_common.py",
"repo_id": "diffusers",
"token_count": 1389
} | 136 |
# Copyright 2024 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#... | diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py",
"repo_id": "diffusers",
"token_count": 5525
} | 137 |
# Copyright 2024 Katherine Crowson and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless... | diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py",
"repo_id": "diffusers",
"token_count": 10879
} | 138 |
# Copyright 2024 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#... | diffusers/src/diffusers/schedulers/scheduling_tcd.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_tcd.py",
"repo_id": "diffusers",
"token_count": 14800
} | 139 |
# This file is autogenerated by the command `make fix-copies`, do not edit.
from ..utils import DummyObject, requires_backends
class AsymmetricAutoencoderKL(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def ... | diffusers/src/diffusers/utils/dummy_pt_objects.py/0 | {
"file_path": "diffusers/src/diffusers/utils/dummy_pt_objects.py",
"repo_id": "diffusers",
"token_count": 12780
} | 140 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/utils/peft_utils.py/0 | {
"file_path": "diffusers/src/diffusers/utils/peft_utils.py",
"repo_id": "diffusers",
"token_count": 4356
} | 141 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/models/autoencoders/test_models_vae.py/0 | {
"file_path": "diffusers/tests/models/autoencoders/test_models_vae.py",
"repo_id": "diffusers",
"token_count": 19066
} | 142 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/models/unets/test_models_unet_motion.py/0 | {
"file_path": "diffusers/tests/models/unets/test_models_unet_motion.py",
"repo_id": "diffusers",
"token_count": 4946
} | 143 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/controlnet/test_controlnet.py/0 | {
"file_path": "diffusers/tests/pipelines/controlnet/test_controlnet.py",
"repo_id": "diffusers",
"token_count": 20126
} | 144 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/deepfloyd_if/test_if_img2img.py/0 | {
"file_path": "diffusers/tests/pipelines/deepfloyd_if/test_if_img2img.py",
"repo_id": "diffusers",
"token_count": 1947
} | 145 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.