
license: cc-by-sa-4.0
task_categories:
- image-classification
- zero-shot-classification
language:
- en
tags:
- vision-language
- CLIP
- out-of-pre-training
- OOP
- benchmark
- multimodal
- few-shot
- zero-shot
pretty_name: LAION-Beyond
size_categories:
- 100K<n<1M
LAION-Beyond: Reproducible Vision-Language Models Meet Concepts Out of Pre-Training
📄 Paper (CVPR 2025) | 💻 Code | 🌐 Project Page
Dataset Summary
LAION-Beyond is the first multi-domain benchmark specifically designed to evaluate the Out-of-Pre-training (OOP) generalization of vision-language models (e.g., CLIP, OpenCLIP, EVA-CLIP).
We distinguish two types of visual concepts:
- IP (In-Pre-training): concepts that appear in the pre-training data (e.g., LAION-400M / 2B / 5B)
- OOP (Out-of-Pre-training): concepts entirely absent from the pre-training data
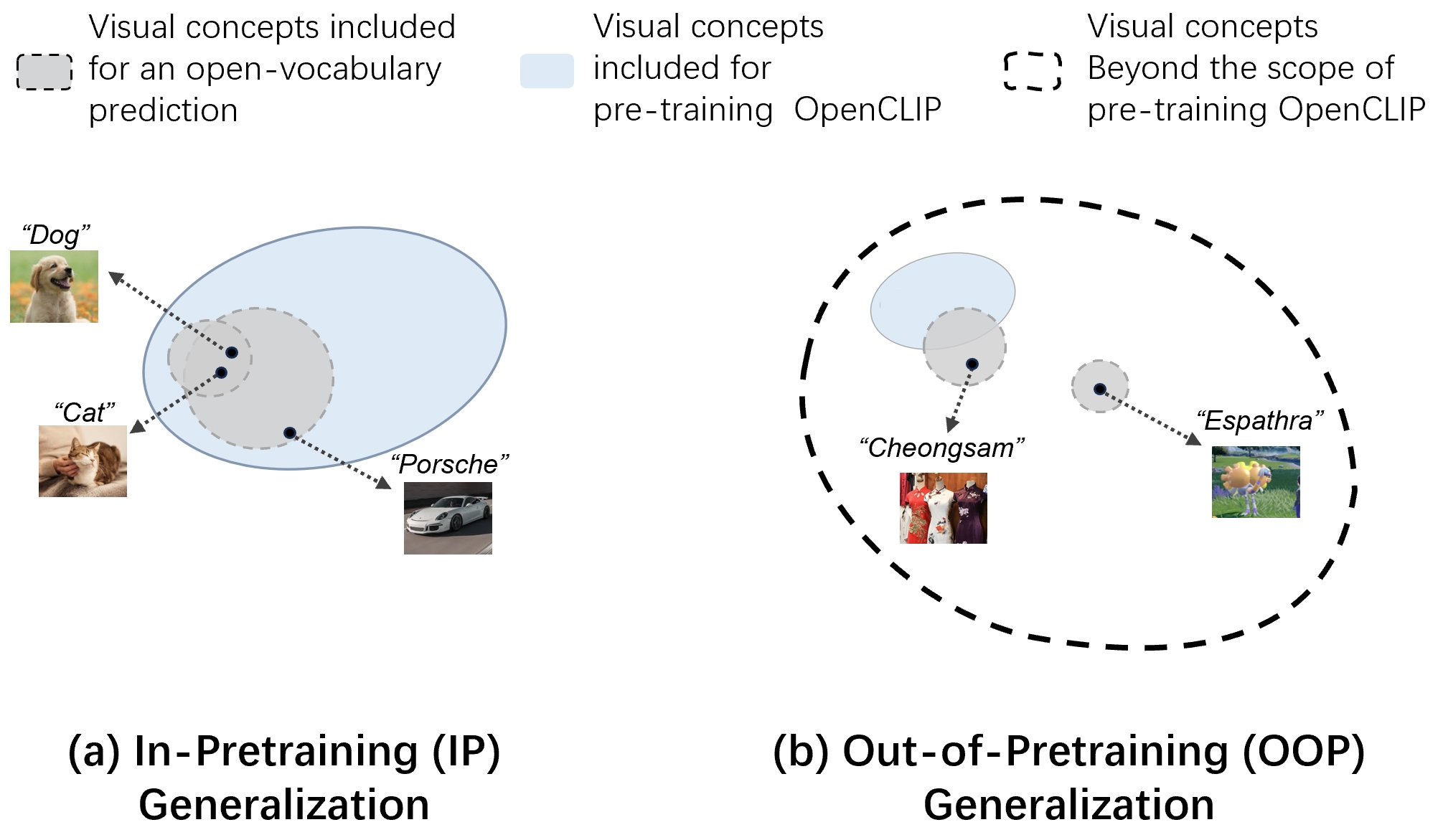
Figure 1: Comparison between IP and OOP generalization. The former evaluates generalization within seen visual concepts, while the latter tests concepts absent during pre-training.
The key finding of our paper is that despite OpenCLIP's image encoder forming well-separated clusters for OOP concepts, zero-shot transfer fails significantly due to poor image-text alignment — the token embeddings for OOP class names were never aligned with visual features during pre-training.
Dataset Statistics
| Split | Images | Concepts |
|---|---|---|
| OOP | 106,052 | 674 |
| IP | 51,330 | 324 |
| Total | 157,382 | 998 |
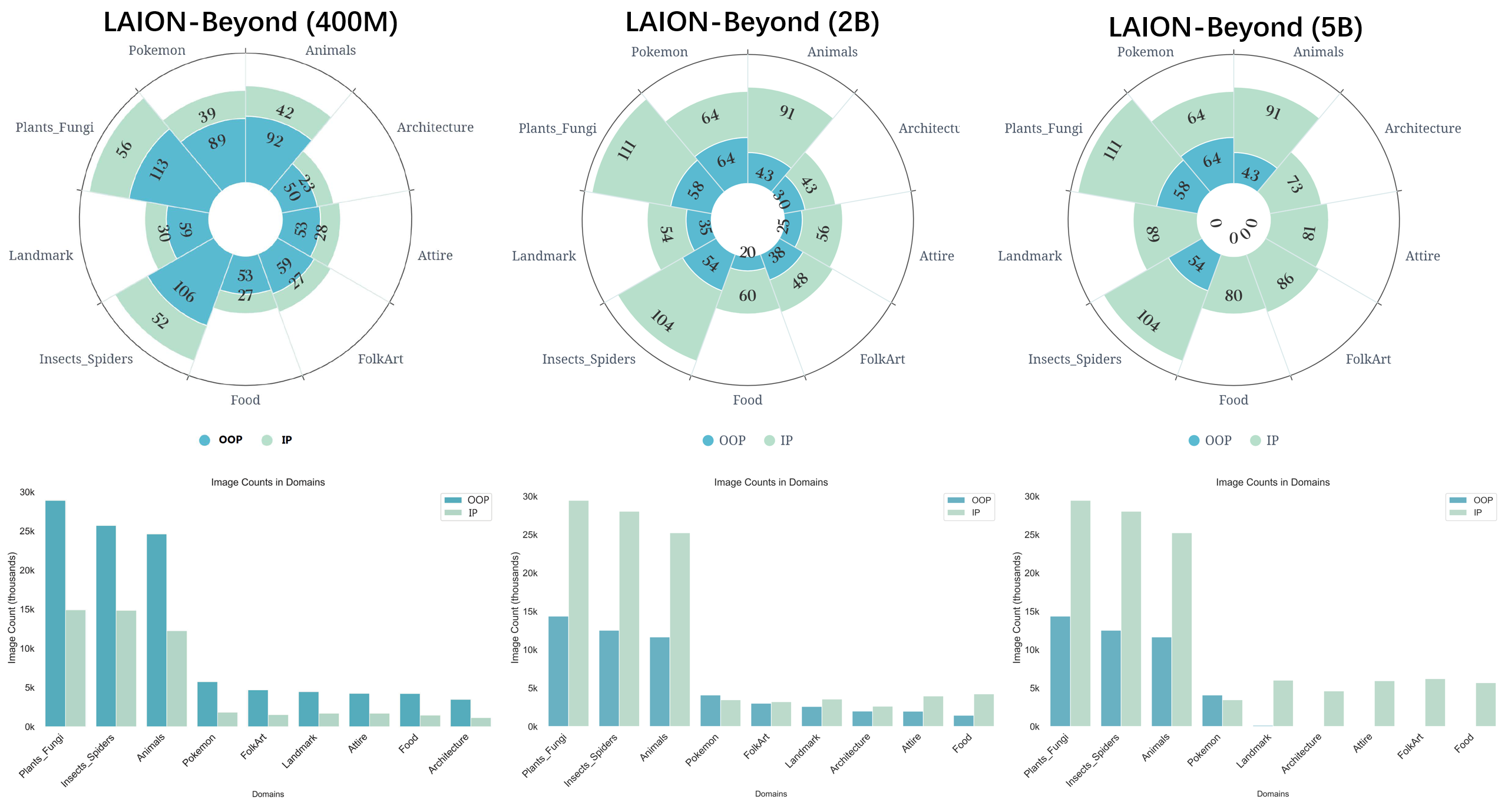
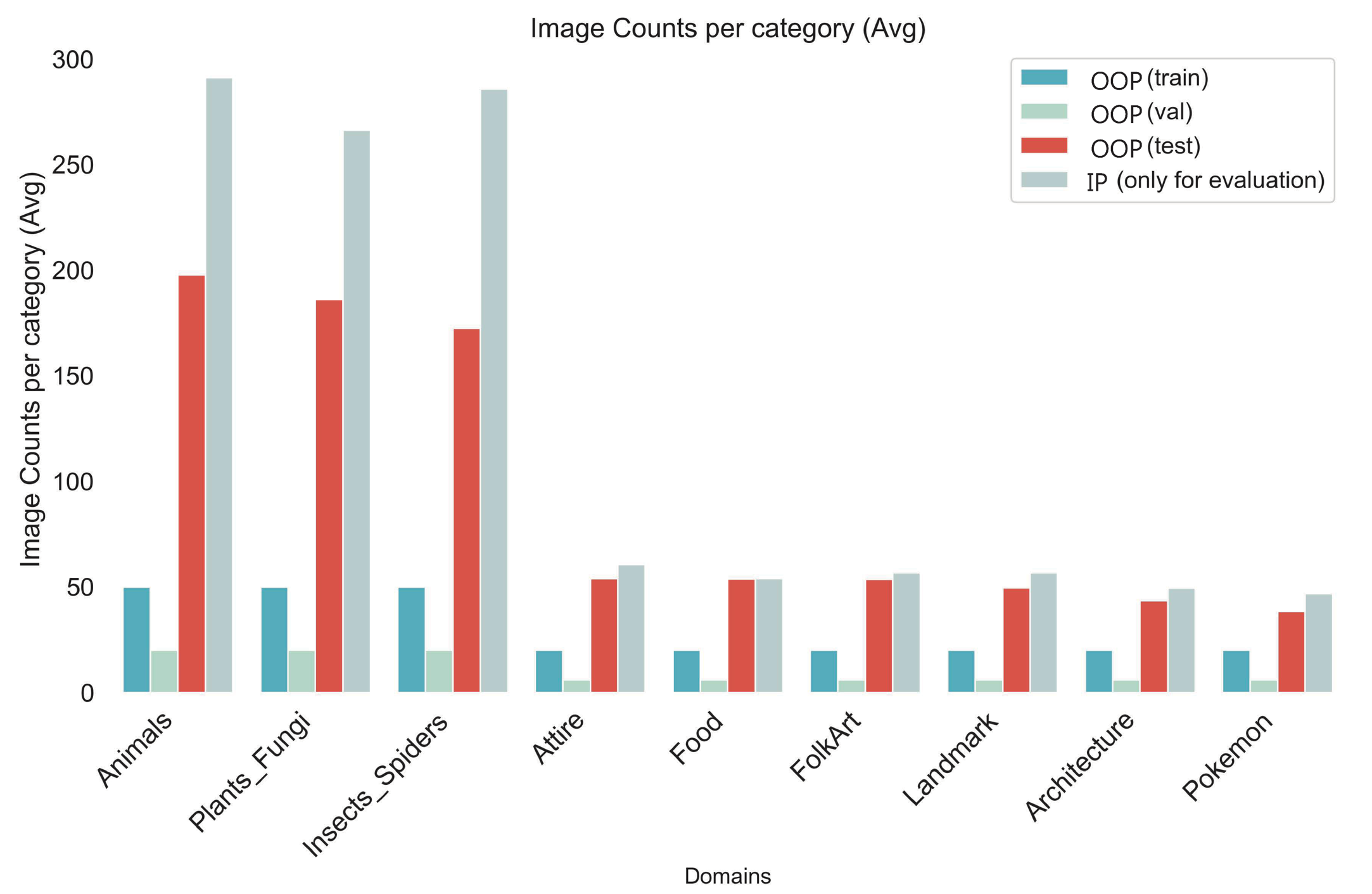
Figure 2: (Left) Statistics of OOP/IP concepts across different LAION scales; (Right) Detailed train/val/test split in LAION-Beyond (400M).
Domains Covered:
- 🐾 Animals | 🏛️ Architecture | 👘 Attire
- 🎨 FolkArt | 🍜 Food | 🦋 Insects & Spiders
- 🗺️ Landmark | 🌿 Plants & Fungi | 🎮 Pokemon
Each domain contains an IP subset and an OOP subset, covering LAION-400M, LAION-2B, and LAION-5B scales to support neural scaling law research.
Dataset Structure
Each domain folder is named {Domain}{NumClasses}_{IP/OOP}, e.g., Animals42_IP, Animals92_OOP.
LAION_Beyond/
├── Animals42_IP/
│ ├── images/ # jpg images organized by class
│ ├── label2name.json # label index → class name
│ ├── name2label.json # class name → label index
│ ├── merged_mapping.json # merged label mapping
│ └── split_Xin_Animals42_IP.json # train/val/test split info
├── Animals92_OOP/
│ └── ...
├── Architecture23_IP/
├── Architecture50_OOP/
├── Attire28_IP/
├── Attire54_OOP/
├── FolkArt27_IP/
├── FolkArt59_OOP/
├── Food27_IP/
├── Food53_OOP/
├── Insects_Spiders52_IP/
├── Insects_Spiders106_OOP/
├── Landmark30_IP/
├── Landmark59_OOP/
├── Plants_Fugi56_IP/
├── Plants_Fugi113_OOP/
├── Pokemon39_IP/
└── Pokemon89_OOP/
File Descriptions
| File | Description |
|---|---|
images/ |
Raw image files (JPG), organized by class subfolder |
label2name.json |
Mapping from integer label to class name string |
name2label.json |
Mapping from class name string to integer label |
merged_mapping.json |
Combined label mapping across splits |
split_Xin_*.json |
Train / val / test split assignments per image |
Loading the Dataset
Option 1: Download full dataset (recommended)
from huggingface_hub import snapshot_download
local_dir = snapshot_download(
repo_id="MHuangX/LAION-Beyond",
repo_type="dataset",
local_dir="./LAION_Beyond"
)
Option 2: Download a single domain only
from huggingface_hub import snapshot_download
local_dir = snapshot_download(
repo_id="MHuangX/LAION-Beyond",
repo_type="dataset",
local_dir="./LAION_Beyond",
allow_patterns="Animals42_IP/**"
)
Key Findings
Strong image features for OOP concepts: OpenCLIP's image encoder forms well-separated clusters for OOP concepts (clustering accuracy gap < 3% on most domains vs. IP concepts).
Image-text alignment failure: Zero-shot accuracy on OOP concepts is significantly lower than IP concepts, persisting even as pre-training data scales from 400M to 5B.
Name-tuning is the key: Our proposed FSNL and ZSNL algorithms, which fine-tune only the name (token) embeddings of OOP concepts, efficiently restore OOP generalization without degrading IP performance.
Algorithms
FSNL — Few-Shot Name Learning
Optimizes only OOP concept name embeddings using a few image-text pairs, with context augmentation via similar concept shuffling. Achieves state-of-the-art on 8/9 domains.
ZSNL — Zero-Shot Name Learning
Requires no image-text pairs. Uses Novel Class Discovery (NCD) and image-text bipartite graph matching to optimize OOP name embeddings from unlabeled images only.
Benchmark Results (400M split)
OOP Few-Shot Learning (4-shot, H-mean of OOP & IP accuracy)
| Method | Animals | Architecture | Attire | FolkArt | Food | Insects | Landmark | Plants | Pokemon | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenCLIP | 26.75 | 30.75 | 25.88 | 35.04 | 15.36 | 22.38 | 40.25 | 21.43 | 24.48 | 26.92 |
| CoOp | 31.37 | 57.8 | 50.39 | 52.06 | 42.55 | 25.73 | 85.89 | 24.78 | 35.52 | 45.12 |
| CLIP-Adapter | 38.98 | 59.27 | 64.56 | 56.32 | 64.32 | 32.51 | 90.82 | 31.97 | 54.99 | 54.86 |
| FSNL (ours) | 46.17 | 62.63 | 71.65 | 63.03 | 70.0 | 44.03 | 94.48 | 44.12 | 68.87 | 62.55 |
Citation
If you use LAION-Beyond in your research, please cite:
@inproceedings{chen2025reproducible,
title={Reproducible vision-language models meet concepts out of pre-training},
author={Chen, Ziliang and Huang, Xin and Fan, Xiaoxuan and Wang, Keze and Zhou, Yuyu and Guan, Quanlong and Lin, Liang},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={14701--14711},
year={2025}
}
License
This dataset is released under the Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0).
Authors
Xin Huang†, Ziliang Chen†, Xiaoxuan Fan, Keze Wang, Yuyu Zhou, Quanlong Guan, Liang Lin*
Affiliations: Peng Cheng Laboratory, Sun Yat-sen University, EPFL, Jinan University
†Equal Contribution · *Corresponding Author