Datasets:

Update dataset card: task category, paper link, and usage instructions
#2
by nielsr HF Staff - opened
README.md
CHANGED
|
@@ -1,24 +1,25 @@
|
|
| 1 |
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
task_categories:
|
| 4 |
-
- visual-question-answering
|
| 5 |
language:
|
| 6 |
- en
|
| 7 |
- zh
|
| 8 |
- ko
|
| 9 |
- ja
|
| 10 |
- fr
|
|
|
|
|
|
|
|
|
|
| 11 |
configs:
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
---
|
|
|
|
| 17 |
# MMTR-Bench: Multimodal Masked Text Reconstruction Benchmark
|
| 18 |
-
<div align="center">
|
| 19 |
<a href="https://mmtr-bench-dataset.github.io/MMTR-Bench/">🏠 HomePage</a> |
|
| 20 |
-
<a href="
|
| 21 |
-
<a href="
|
| 22 |
<a href="https://github.com/MMTR-Bench-Dataset/MMTR-Bench-eval">💻 Code</a>
|
| 23 |
</div>
|
| 24 |
|
|
@@ -35,12 +36,12 @@ To solve the task, models must recover the hidden text by relying on the remaini
|
|
| 35 |
|
| 36 |
MMTR-Bench evaluates a model's ability to maintain a continuous, structured reading flow across complex multimodal layouts. The dataset is rigorously balanced across various dimensions to ensure a comprehensive evaluation of current Multimodal Large Language Models (MLLMs).
|
| 37 |
|
| 38 |
-
 models reveals a significant paradigm shift in how MLLMs approach visual text reconstruction.
|
| 50 |
|
| 51 |
-
 to L4 (paragraph-level). Even the leading model, Gemini-3.1-Pro, struggles at L4 (31.86%), proving that MMTR-Bench leaves ample headroom for future research in multimodal document understanding.
|
| 76 |
-
|
| 77 |
---
|
| 78 |
|
| 79 |
## 🚀 How to Use
|
| 80 |
|
| 81 |
MMTR-Bench is an evaluation-only benchmark designed to test Multimodal LLMs. There is no training set.
|
| 82 |
|
| 83 |
-
The dataset annotations (including mask bounding boxes, ground truth answers, and image paths) are stored in the metadata file, and the images are located in the `images/` directory.
|
| 84 |
-
|
| 85 |
### 1. Installation
|
| 86 |
Ensure you have the required libraries installed:
|
| 87 |
```bash
|
|
@@ -94,12 +88,11 @@ pip install datasets
|
|
| 94 |
from datasets import load_dataset
|
| 95 |
|
| 96 |
# Load the benchmark dataset
|
| 97 |
-
# Note: Hugging Face maps single data files to the 'train' split by default.
|
| 98 |
dataset = load_dataset(
|
| 99 |
-
"MMTR-Bench/
|
| 100 |
-
data_files="
|
| 101 |
)
|
| 102 |
-
benchmark_data = dataset["
|
| 103 |
|
| 104 |
# Inspect the first evaluation sample
|
| 105 |
sample = benchmark_data[0]
|
|
@@ -107,8 +100,7 @@ sample = benchmark_data[0]
|
|
| 107 |
print(f"Sample ID: {sample['sample_id']}")
|
| 108 |
print(f"Difficulty Level: L{sample['level']}")
|
| 109 |
print(f"Ground Truth Answer: {sample['answer']}")
|
| 110 |
-
print(f"
|
| 111 |
-
print(f"Target Image: {sample['image_path']}")
|
| 112 |
```
|
| 113 |
|
| 114 |
---
|
|
@@ -119,9 +111,9 @@ If you find our benchmark, models, or data useful in your research, please consi
|
|
| 119 |
|
| 120 |
```bibtex
|
| 121 |
@article{mmtrbench2026,
|
| 122 |
-
title={
|
| 123 |
author={Anonymous Authors},
|
| 124 |
-
journal={
|
| 125 |
year={2026}
|
| 126 |
}
|
| 127 |
```
|
|
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
| 2 |
language:
|
| 3 |
- en
|
| 4 |
- zh
|
| 5 |
- ko
|
| 6 |
- ja
|
| 7 |
- fr
|
| 8 |
+
license: apache-2.0
|
| 9 |
+
task_categories:
|
| 10 |
+
- image-text-to-text
|
| 11 |
configs:
|
| 12 |
+
- config_name: default
|
| 13 |
+
data_files:
|
| 14 |
+
- split: test
|
| 15 |
+
path: MMTR.jsonl
|
| 16 |
---
|
| 17 |
+
|
| 18 |
# MMTR-Bench: Multimodal Masked Text Reconstruction Benchmark
|
| 19 |
+
<div align="center Krank">
|
| 20 |
<a href="https://mmtr-bench-dataset.github.io/MMTR-Bench/">🏠 HomePage</a> |
|
| 21 |
+
<a href="https://huggingface.co/datasets/MMTR-Bench/MMTR-Bench-Dataset">📊 Dataset</a> |
|
| 22 |
+
<a href="https://huggingface.co/papers/2604.21277">📄 Paper</a> |
|
| 23 |
<a href="https://github.com/MMTR-Bench-Dataset/MMTR-Bench-eval">💻 Code</a>
|
| 24 |
</div>
|
| 25 |
|
|
|
|
| 36 |
|
| 37 |
MMTR-Bench evaluates a model's ability to maintain a continuous, structured reading flow across complex multimodal layouts. The dataset is rigorously balanced across various dimensions to ensure a comprehensive evaluation of current Multimodal Large Language Models (MLLMs).
|
| 38 |
|
| 39 |
+
|
| 40 |
|
| 41 |
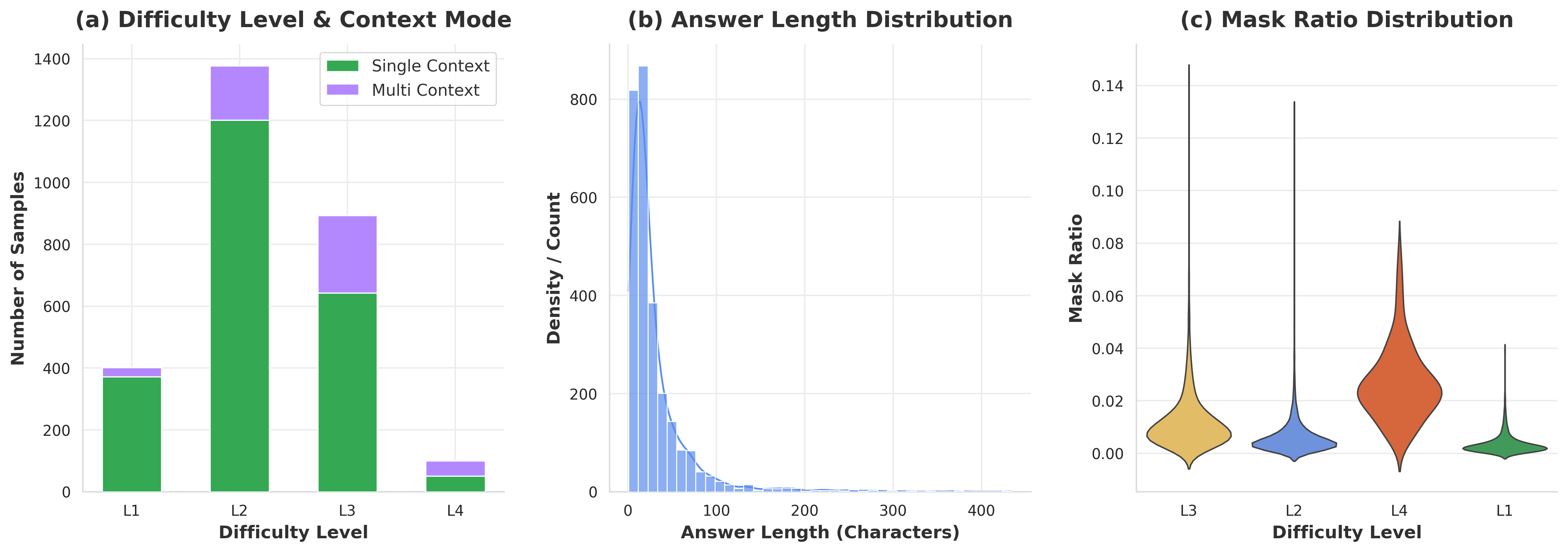
The distributions in the dataset highlight our multi-faceted evaluation strategy:
|
| 42 |
+
* **Difficulty Level & Context Mode:** The dataset is categorized into four distinct difficulty levels (L1 to L4), scaling from word-level completion to complex paragraph-level reconstruction. It incorporates both Single Context (single-page) and Multi Context (multi-page) scenarios, demanding robust cross-page reasoning.
|
| 43 |
+
* **Answer Length Distribution:** Target texts span a wide spectrum of character lengths, ensuring models are tested on both concise factual recall and extended, coherent text generation based on visual context.
|
| 44 |
+
* **Mask Ratio Distribution:** The proportion of masked content varies dynamically across difficulty levels, pushing the boundaries of how much missing information a model can infer purely from surrounding document structures and visual semantics.
|
| 45 |
|
| 46 |
---
|
| 47 |
|
|
|
|
| 49 |
|
| 50 |
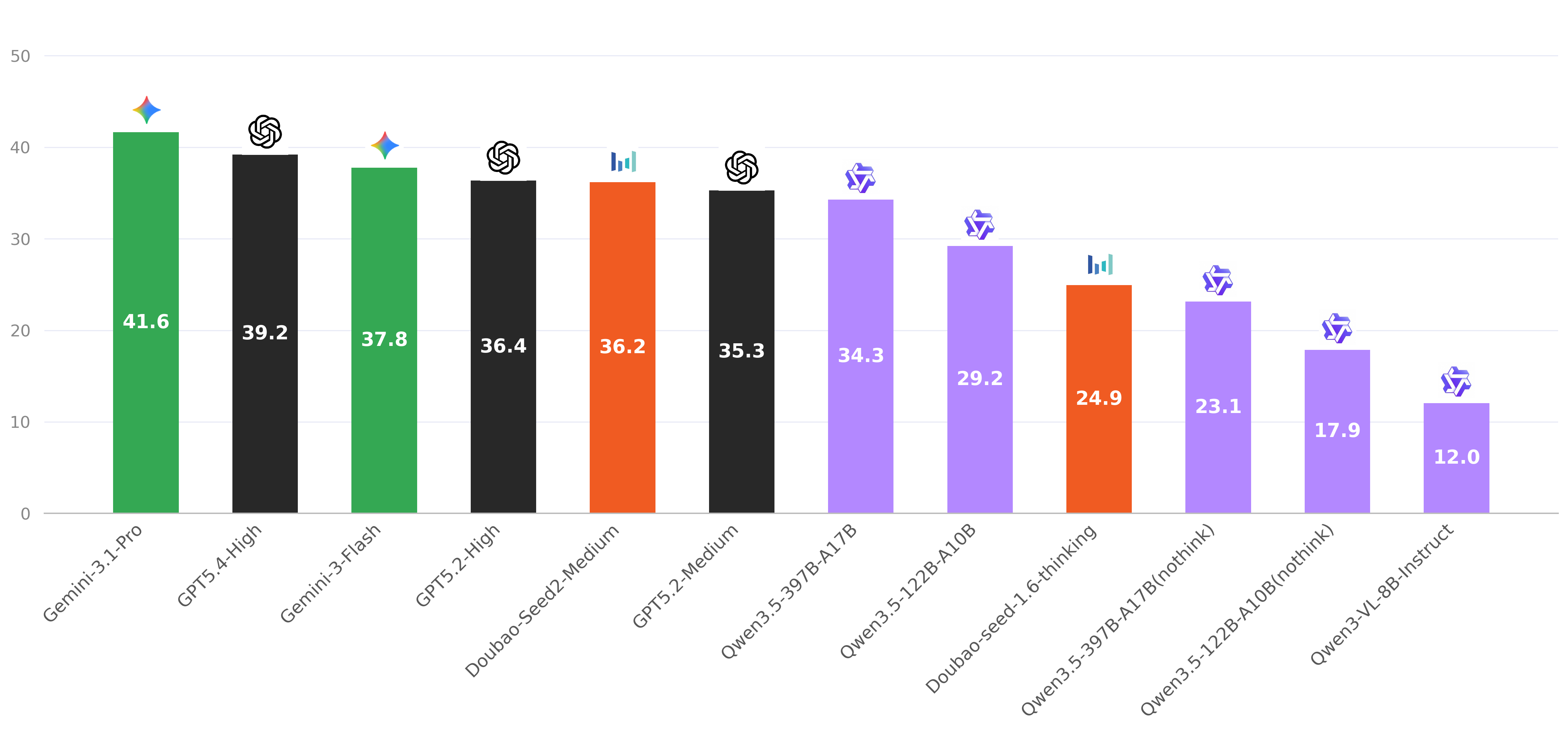
The benchmark assesses models using a specialized level-aware scoring mechanism to account for the varying complexities of L1 through L4 tasks. The inclusion of explicit reasoning ("Thinking") models reveals a significant paradigm shift in how MLLMs approach visual text reconstruction.
|
| 51 |
|
| 52 |
+
|
| 53 |
|
| 54 |
### Main Results
|
| 55 |
|
|
|
|
| 70 |
| Qwen3.5-112B-A10B | | 18.56 | 15.47 | 18.79 | 13.62 | 19.31 | 23.40 | 18.00 |
|
| 71 |
| Qwen3-VL-8B-Instruct | | 12.16 | 11.38 | 7.94 | 7.12 | 14.19 | 20.11 | 12.02 |
|
| 72 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
---
|
| 74 |
|
| 75 |
## 🚀 How to Use
|
| 76 |
|
| 77 |
MMTR-Bench is an evaluation-only benchmark designed to test Multimodal LLMs. There is no training set.
|
| 78 |
|
|
|
|
|
|
|
| 79 |
### 1. Installation
|
| 80 |
Ensure you have the required libraries installed:
|
| 81 |
```bash
|
|
|
|
| 88 |
from datasets import load_dataset
|
| 89 |
|
| 90 |
# Load the benchmark dataset
|
|
|
|
| 91 |
dataset = load_dataset(
|
| 92 |
+
"MMTR-Bench/MMTR-Bench-Dataset",
|
| 93 |
+
data_files="MMTR.jsonl"
|
| 94 |
)
|
| 95 |
+
benchmark_data = dataset["test"]
|
| 96 |
|
| 97 |
# Inspect the first evaluation sample
|
| 98 |
sample = benchmark_data[0]
|
|
|
|
| 100 |
print(f"Sample ID: {sample['sample_id']}")
|
| 101 |
print(f"Difficulty Level: L{sample['level']}")
|
| 102 |
print(f"Ground Truth Answer: {sample['answer']}")
|
| 103 |
+
print(f"Context Image Paths: {sample['context_img_paths']}")
|
|
|
|
| 104 |
```
|
| 105 |
|
| 106 |
---
|
|
|
|
| 111 |
|
| 112 |
```bibtex
|
| 113 |
@article{mmtrbench2026,
|
| 114 |
+
title={Can MLLMs "Read" What is Missing?},
|
| 115 |
author={Anonymous Authors},
|
| 116 |
+
journal={arXiv preprint arXiv:2604.21277},
|
| 117 |
year={2026}
|
| 118 |
}
|
| 119 |
```
|