
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.32B | node_id stringlengths 18 32 | number int64 1 4.77k | title stringlengths 1 276 | user dict | labels list | state stringclasses 2
values | locked bool 1
class | assignee null | assignees sequence | milestone null | comments sequence | created_at int64 1,587B 1,659B | updated_at int64 1,587B 1,659B | closed_at int64 1,587B 1,659B ⌀ | author_association stringclasses 3
values | active_lock_reason null | draft bool 2
classes | pull_request dict | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason nullclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4773/comments | https://api.github.com/repos/huggingface/datasets/issues/4773/events | https://github.com/huggingface/datasets/pull/4773 | 1,322,796,721 | PR_kwDODunzps48WNV3 | 4,773 | Document loading from relative path | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4773). All of your documentation changes will be reflected on that endpoint."
] | 1,659,137,541,000 | 1,659,137,987,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4773",
"html_url": "https://github.com/huggingface/datasets/pull/4773",
"diff_url": "https://github.com/huggingface/datasets/pull/4773.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4773.patch",
"merged_at": null
} | This PR describes loading a dataset from the Hub by specifying a relative path in `data_dir` or `data_files` in `load_dataset` (see #4757). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4773/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4773/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4772 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4772/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4772/comments | https://api.github.com/repos/huggingface/datasets/issues/4772/events | https://github.com/huggingface/datasets/issues/4772 | 1,322,693,123 | I_kwDODunzps5O1rID | 4,772 | AssertionError when using label_cols in to_tf_dataset | {
"login": "lehrig",
"id": 9555494,
"node_id": "MDQ6VXNlcjk1NTU0OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9555494?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lehrig",
"html_url": "https://github.com/lehrig",
"followers_url": "https://api.github.com/users/lehrig/foll... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,659,130,332,000 | 1,659,130,380,000 | null | NONE | null | null | null | ## Describe the bug
An incorrect `AssertionError` is raised when using `label_cols` in `to_tf_dataset` and the label's key name is `label`.
The assertion is in this line:
https://github.com/huggingface/datasets/blob/2.4.0/src/datasets/arrow_dataset.py#L475
## Steps to reproduce the bug
```python
from datasets... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4772/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4772/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4771 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4771/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4771/comments | https://api.github.com/repos/huggingface/datasets/issues/4771/events | https://github.com/huggingface/datasets/pull/4771 | 1,322,600,725 | PR_kwDODunzps48VjWx | 4,771 | Remove dummy data generation docs | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4771). All of your documentation changes will be reflected on that endpoint."
] | 1,659,122,446,000 | 1,659,132,435,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4771",
"html_url": "https://github.com/huggingface/datasets/pull/4771",
"diff_url": "https://github.com/huggingface/datasets/pull/4771.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4771.patch",
"merged_at": null
} | This PR removes instructions to generate dummy data since that is no longer necessary for datasets that are uploaded to the Hub instead of our GitHub repo (see #4744). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4771/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4771/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4770 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4770/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4770/comments | https://api.github.com/repos/huggingface/datasets/issues/4770/events | https://github.com/huggingface/datasets/pull/4770 | 1,322,147,855 | PR_kwDODunzps48UEBT | 4,770 | fix typo | {
"login": "xwwwwww",
"id": 48146603,
"node_id": "MDQ6VXNlcjQ4MTQ2NjAz",
"avatar_url": "https://avatars.githubusercontent.com/u/48146603?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xwwwwww",
"html_url": "https://github.com/xwwwwww",
"followers_url": "https://api.github.com/users/xwwwww... | [] | closed | false | null | [] | null | [
"good catch thanks ! Can you check if the same typo is also present in `add_elasticsearch_index` ? It has a very similar signature",
"> good catch thanks ! Can you check if the same typo is also present in `add_elasticsearch_index` ? It has a very similar signature\r\n\r\nfixed"
] | 1,659,095,172,000 | 1,659,110,527,000 | 1,659,110,527,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4770",
"html_url": "https://github.com/huggingface/datasets/pull/4770",
"diff_url": "https://github.com/huggingface/datasets/pull/4770.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4770.patch",
"merged_at": 1659110527000
} | By defaul -> By default | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4770/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4770/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4769 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4769/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4769/comments | https://api.github.com/repos/huggingface/datasets/issues/4769/events | https://github.com/huggingface/datasets/issues/4769 | 1,322,121,554 | I_kwDODunzps5OzflS | 4,769 | Fail to process SQuADv1.1 datasets with max_seq_length=128, doc_stride=96. | {
"login": "zhuango",
"id": 5491519,
"node_id": "MDQ6VXNlcjU0OTE1MTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/5491519?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhuango",
"html_url": "https://github.com/zhuango",
"followers_url": "https://api.github.com/users/zhuango/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,659,093,504,000 | 1,659,093,504,000 | null | NONE | null | null | null | ## Describe the bug
datasets fail to process SQuADv1.1 with max_seq_length=128, doc_stride=96 when calling datasets["train"].train_dataset.map().
## Steps to reproduce the bug
I used huggingface[ TF2 question-answering examples](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-a... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4769/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4769/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4768 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4768/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4768/comments | https://api.github.com/repos/huggingface/datasets/issues/4768/events | https://github.com/huggingface/datasets/pull/4768 | 1,321,913,645 | PR_kwDODunzps48TRUH | 4,768 | Unpin rouge_score test dependency | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,659,082,660,000 | 1,659,112,948,000 | 1,659,112,157,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4768",
"html_url": "https://github.com/huggingface/datasets/pull/4768",
"diff_url": "https://github.com/huggingface/datasets/pull/4768.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4768.patch",
"merged_at": 1659112157000
} | Once `rouge-score` has made the 0.1.2 release to fix their issue https://github.com/google-research/google-research/issues/1212, we can unpin it.
Related to:
- #4735 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4768/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4768/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4767 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4767/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4767/comments | https://api.github.com/repos/huggingface/datasets/issues/4767/events | https://github.com/huggingface/datasets/pull/4767 | 1,321,843,538 | PR_kwDODunzps48TCpI | 4,767 | Add 2.4.0 version added to docstrings | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,659,078,116,000 | 1,659,093,409,000 | 1,659,092,638,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4767",
"html_url": "https://github.com/huggingface/datasets/pull/4767",
"diff_url": "https://github.com/huggingface/datasets/pull/4767.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4767.patch",
"merged_at": 1659092638000
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4767/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4767/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4766 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4766/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4766/comments | https://api.github.com/repos/huggingface/datasets/issues/4766/events | https://github.com/huggingface/datasets/issues/4766 | 1,321,809,380 | I_kwDODunzps5OyTXk | 4,766 | Dataset Viewer issue for openclimatefix/goes-mrms | {
"login": "cheaterHy",
"id": 101324688,
"node_id": "U_kgDOBgoXkA",
"avatar_url": "https://avatars.githubusercontent.com/u/101324688?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cheaterHy",
"html_url": "https://github.com/cheaterHy",
"followers_url": "https://api.github.com/users/cheate... | [] | open | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thanks for reporting, @cheaterHy.\r\n\r\nThe cause of this issue is a misalignment between the names of the repo (`goes-mrms`, with hyphen) and its Python loading scrip file (`goes_mrms.py`, with underscore).\r\n\r\nI've opened an Issue discussion in their repo: https://huggingface.co/datasets/openclimatefix/goes-... | 1,659,075,434,000 | 1,659,084,238,000 | null | NONE | null | null | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4766/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4766/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4765/comments | https://api.github.com/repos/huggingface/datasets/issues/4765/events | https://github.com/huggingface/datasets/pull/4765 | 1,321,787,428 | PR_kwDODunzps48S2rM | 4,765 | Fix version in map_nested docstring | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,659,073,472,000 | 1,659,095,485,000 | 1,659,094,716,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4765",
"html_url": "https://github.com/huggingface/datasets/pull/4765",
"diff_url": "https://github.com/huggingface/datasets/pull/4765.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4765.patch",
"merged_at": 1659094716000
} | After latest release, `map_nested` docstring needs being updated with the right version for versionchanged and versionadded. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4765/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4765/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4764 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4764/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4764/comments | https://api.github.com/repos/huggingface/datasets/issues/4764/events | https://github.com/huggingface/datasets/pull/4764 | 1,321,295,961 | PR_kwDODunzps48RMLu | 4,764 | Update CI badge | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,659,031,460,000 | 1,659,094,597,000 | 1,659,093,831,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4764",
"html_url": "https://github.com/huggingface/datasets/pull/4764",
"diff_url": "https://github.com/huggingface/datasets/pull/4764.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4764.patch",
"merged_at": 1659093831000
} | Replace the old CircleCI badge with a new one for GH Actions. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4764/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4764/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4763 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4763/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4763/comments | https://api.github.com/repos/huggingface/datasets/issues/4763/events | https://github.com/huggingface/datasets/pull/4763 | 1,321,295,876 | PR_kwDODunzps48RMKi | 4,763 | More rigorous shape inference in to_tf_dataset | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.githu... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4763). All of your documentation changes will be reflected on that endpoint."
] | 1,659,031,455,000 | 1,659,100,551,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4763",
"html_url": "https://github.com/huggingface/datasets/pull/4763",
"diff_url": "https://github.com/huggingface/datasets/pull/4763.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4763.patch",
"merged_at": null
} | `tf.data` needs to know the shape of tensors emitted from a `tf.data.Dataset`. Although `None` dimensions are possible, overusing them can cause problems - Keras uses the dataset tensor spec at compile-time, and so saying that a dimension is `None` when it's actually constant can hurt performance, or even cause trainin... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4763/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4763/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4762 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4762/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4762/comments | https://api.github.com/repos/huggingface/datasets/issues/4762/events | https://github.com/huggingface/datasets/pull/4762 | 1,321,261,733 | PR_kwDODunzps48RE56 | 4,762 | Improve features resolution in streaming | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4762). All of your documentation changes will be reflected on that endpoint."
] | 1,659,029,291,000 | 1,659,029,694,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4762",
"html_url": "https://github.com/huggingface/datasets/pull/4762",
"diff_url": "https://github.com/huggingface/datasets/pull/4762.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4762.patch",
"merged_at": null
} | `IterableDataset._resolve_features` was returning the features sorted alphabetically by column name, which is not consistent with non-streaming. I changed this and used the order of columns from the data themselves. It was causing some inconsistencies in the dataset viewer as well.
I also fixed `interleave_datasets`... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4762/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4762/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4761 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4761/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4761/comments | https://api.github.com/repos/huggingface/datasets/issues/4761/events | https://github.com/huggingface/datasets/issues/4761 | 1,321,068,411 | I_kwDODunzps5Oved7 | 4,761 | parallel searching in multi-gpu setting using faiss | {
"login": "xwwwwww",
"id": 48146603,
"node_id": "MDQ6VXNlcjQ4MTQ2NjAz",
"avatar_url": "https://avatars.githubusercontent.com/u/48146603?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xwwwwww",
"html_url": "https://github.com/xwwwwww",
"followers_url": "https://api.github.com/users/xwwwww... | [] | open | false | null | [] | null | [
"And I don't see any speed up when increasing the number of GPUs while calling `get_nearest_examples_batch`.",
"Hi ! Yes search_batch uses FAISS search which happens in parallel across the GPUs\r\n\r\n> And I don't see any speed up when increasing the number of GPUs while calling get_nearest_examples_batch.\r\n\r... | 1,659,020,223,000 | 1,659,108,274,000 | null | CONTRIBUTOR | null | null | null | While I notice that `add_faiss_index` has supported assigning multiple GPUs, I am still confused about how it works.
Does the `search-batch` function automatically parallelizes the input queries to different gpus?https://github.com/huggingface/datasets/blob/d76599bdd4d186b2e7c4f468b05766016055a0a5/src/datasets/sea... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4761/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4761/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4760 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4760/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4760/comments | https://api.github.com/repos/huggingface/datasets/issues/4760/events | https://github.com/huggingface/datasets/issues/4760 | 1,320,878,223 | I_kwDODunzps5OuwCP | 4,760 | Issue with offline mode | {
"login": "SaulLu",
"id": 55560583,
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SaulLu",
"html_url": "https://github.com/SaulLu",
"followers_url": "https://api.github.com/users/SaulLu/fo... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @SaulLu, thanks for reporting.\r\n\r\nI think offline mode is not supported for datasets containing only data files (without any loading script). I'm having a look into this...",
"Thanks for your feedback! \r\n\r\nTo give you a little more info, if you don't set the offline mode flag, the script will load the... | 1,659,012,314,000 | 1,659,024,336,000 | null | NONE | null | null | null | ## Describe the bug
I can't retrieve a cached dataset with offline mode enabled
## Steps to reproduce the bug
To reproduce my issue, first, you'll need to run a script that will cache the dataset
```python
import os
os.environ["HF_DATASETS_OFFLINE"] = "0"
import datasets
datasets.logging.set_verbosity_i... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4760/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4760/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4759 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4759/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4759/comments | https://api.github.com/repos/huggingface/datasets/issues/4759/events | https://github.com/huggingface/datasets/issues/4759 | 1,320,783,300 | I_kwDODunzps5OuY3E | 4,759 | Dataset Viewer issue for Toygar/turkish-offensive-language-detection | {
"login": "Toygarr",
"id": 44132720,
"node_id": "MDQ6VXNlcjQ0MTMyNzIw",
"avatar_url": "https://avatars.githubusercontent.com/u/44132720?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Toygarr",
"html_url": "https://github.com/Toygarr",
"followers_url": "https://api.github.com/users/Toygar... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"I refreshed the dataset viewer manually, it's fixed now. Sorry for the inconvenience.\r\n<img width=\"1557\" alt=\"Capture d’écran 2022-07-28 à 09 17 39\" src=\"https://user-images.githubusercontent.com/1676121/181514666-92d7f8e1-ddc1-4769-84f3-f1edfdb902e8.png\">\r\n\r\n"
] | 1,659,007,303,000 | 1,659,014,276,000 | 1,659,014,268,000 | NONE | null | null | null | ### Link
https://huggingface.co/datasets/Toygar/turkish-offensive-language-detection
### Description
Status code: 400
Exception: Status400Error
Message: The dataset does not exist.
Hi, I provided train.csv, test.csv and valid.csv files. However, viewer says dataset does not exist.
Should I n... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4759/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4759/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4757 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4757/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4757/comments | https://api.github.com/repos/huggingface/datasets/issues/4757/events | https://github.com/huggingface/datasets/issues/4757 | 1,320,602,532 | I_kwDODunzps5Otsuk | 4,757 | Document better when relative paths are transformed to URLs | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [] | 1,658,997,987,000 | 1,658,997,987,000 | null | MEMBER | null | null | null | As discussed with @ydshieh, when passing a relative path as `data_dir` to `load_dataset` of a dataset hosted on the Hub, the relative path is transformed to the corresponding URL of the Hub dataset.
Currently, we mention this in our docs here: [Create a dataset loading script > Download data files and organize split... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4757/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4757/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4755 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4755/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4755/comments | https://api.github.com/repos/huggingface/datasets/issues/4755/events | https://github.com/huggingface/datasets/issues/4755 | 1,319,687,044 | I_kwDODunzps5OqNOE | 4,755 | Datasets.map causes incorrect overflow_to_sample_mapping when used with tokenizers and small batch size | {
"login": "srobertjames",
"id": 662612,
"node_id": "MDQ6VXNlcjY2MjYxMg==",
"avatar_url": "https://avatars.githubusercontent.com/u/662612?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/srobertjames",
"html_url": "https://github.com/srobertjames",
"followers_url": "https://api.github.com/u... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"I've built a minimal example that shows this bug without `n_proc`. It seems like it's a problem any way of using **tokenizers, `overflow_to_sample_mapping`, and Dataset.map, with a small batch size**:\r\n\r\n```\r\nimport datasets\r\nimport transformers\r\npretrained = 'deepset/tinyroberta-squad2'\r\ntokenizer = t... | 1,658,933,651,000 | 1,658,944,648,000 | null | NONE | null | null | null | ## Describe the bug
When using `tokenizer`, we can retrieve the field `overflow_to_sample_mapping`, since long samples will be overflown into multiple token sequences.
However, when tokenizing is done via `Dataset.map`, with `n_proc > 1`, the `overflow_to_sample_mapping` field is wrong. This seems to be because ea... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4755/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4755/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4754 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4754/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4754/comments | https://api.github.com/repos/huggingface/datasets/issues/4754/events | https://github.com/huggingface/datasets/pull/4754 | 1,319,681,541 | PR_kwDODunzps48L9p6 | 4,754 | Remove "unkown" language tags | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,933,412,000 | 1,658,934,180,000 | 1,658,933,466,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4754",
"html_url": "https://github.com/huggingface/datasets/pull/4754",
"diff_url": "https://github.com/huggingface/datasets/pull/4754.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4754.patch",
"merged_at": 1658933466000
} | Following https://github.com/huggingface/datasets/pull/4753 there was still a "unknown" langauge tag in `wikipedia` so the job at https://github.com/huggingface/datasets/runs/7542567336?check_suite_focus=true failed for wikipedia | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4754/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4754/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4753 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4753/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4753/comments | https://api.github.com/repos/huggingface/datasets/issues/4753/events | https://github.com/huggingface/datasets/pull/4753 | 1,319,571,745 | PR_kwDODunzps48Ll8G | 4,753 | Add `language_bcp47` tag | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,928,676,000 | 1,658,933,403,000 | 1,658,932,676,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4753",
"html_url": "https://github.com/huggingface/datasets/pull/4753",
"diff_url": "https://github.com/huggingface/datasets/pull/4753.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4753.patch",
"merged_at": 1658932676000
} | Following (internal) https://github.com/huggingface/moon-landing/pull/3509, we need to move the bcp47 tags to `language_bcp47` and keep the `language` tag for iso 639 1-2-3 codes. In particular I made sure that all the tags in `languages` are not longer than 3 characters. I moved the rest to `language_bcp47` and fixed ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4753/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4753/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4752 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4752/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4752/comments | https://api.github.com/repos/huggingface/datasets/issues/4752/events | https://github.com/huggingface/datasets/issues/4752 | 1,319,464,409 | I_kwDODunzps5OpW3Z | 4,752 | DatasetInfo issue when testing multiple configs: mixed task_templates | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"I've narrowed down the issue to the `dataset_module_factory` which already creates a `dataset_infos.json` file down in the `.cache/modules/dataset_modules/..` folder. That JSON file already contains the wrong task_templates for `unfiltered`.",
"Ugh. Found the issue: apparently `datasets` was reusing the already ... | 1,658,923,494,000 | 1,658,941,951,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
When running the `datasets-cli test` it would seem that some config properties in a DatasetInfo get mangled, leading to issues, e.g., about the ClassLabel.
## Steps to reproduce the bug
In summary, what I want to do is create three configs:
- unfiltered: no classlabel, no tasks. Gets data fr... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4752/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4752/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4751 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4751/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4751/comments | https://api.github.com/repos/huggingface/datasets/issues/4751/events | https://github.com/huggingface/datasets/pull/4751 | 1,319,440,903 | PR_kwDODunzps48LJ7U | 4,751 | Added dataset information in clinic oos dataset card | {
"login": "Arnav-Ladkat",
"id": 84362194,
"node_id": "MDQ6VXNlcjg0MzYyMTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/84362194?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Arnav-Ladkat",
"html_url": "https://github.com/Arnav-Ladkat",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,922,268,000 | 1,659,005,601,000 | 1,659,004,837,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4751",
"html_url": "https://github.com/huggingface/datasets/pull/4751",
"diff_url": "https://github.com/huggingface/datasets/pull/4751.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4751.patch",
"merged_at": 1659004837000
} | This PR aims to add relevant information like the Description, Language and citation information of the clinic oos dataset card. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4751/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4751/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4750 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4750/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4750/comments | https://api.github.com/repos/huggingface/datasets/issues/4750/events | https://github.com/huggingface/datasets/issues/4750 | 1,319,333,645 | I_kwDODunzps5Oo28N | 4,750 | Easily create loading script for benchmark comprising multiple huggingface datasets | {
"login": "JoelNiklaus",
"id": 3775944,
"node_id": "MDQ6VXNlcjM3NzU5NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3775944?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JoelNiklaus",
"html_url": "https://github.com/JoelNiklaus",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | null | [
"Hi ! I think the simplest is to copy paste the `_split_generators` code from the other datasets and do a bunch of if-else, as in the glue dataset: https://huggingface.co/datasets/glue/blob/main/glue.py#L467",
"Ok, I see. Thank you"
] | 1,658,916,818,000 | 1,658,930,287,000 | 1,658,930,287,000 | CONTRIBUTOR | null | null | null | Hi,
I would like to create a loading script for a benchmark comprising multiple huggingface datasets.
The function _split_generators needs to return the files for the respective dataset. However, the files are not always in the same location for each dataset. I want to just make a wrapper dataset that provides a si... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4750/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4750/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4748/comments | https://api.github.com/repos/huggingface/datasets/issues/4748/events | https://github.com/huggingface/datasets/pull/4748 | 1,318,874,913 | PR_kwDODunzps48JTEb | 4,748 | Add image classification processing guide | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,880,671,000 | 1,658,942,901,000 | 1,658,942,172,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4748",
"html_url": "https://github.com/huggingface/datasets/pull/4748",
"diff_url": "https://github.com/huggingface/datasets/pull/4748.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4748.patch",
"merged_at": 1658942172000
} | This PR follows up on #4710 to separate the object detection and image classification guides. It expands a little more on the original guide to include a more complete example of loading and transforming a whole dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4748/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4748/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4747/comments | https://api.github.com/repos/huggingface/datasets/issues/4747/events | https://github.com/huggingface/datasets/pull/4747 | 1,318,586,932 | PR_kwDODunzps48IWKj | 4,747 | Shard parquet in `download_and_prepare` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4747). All of your documentation changes will be reflected on that endpoint."
] | 1,658,858,701,000 | 1,659,104,371,000 | null | MEMBER | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4747",
"html_url": "https://github.com/huggingface/datasets/pull/4747",
"diff_url": "https://github.com/huggingface/datasets/pull/4747.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4747.patch",
"merged_at": null
} | Following https://github.com/huggingface/datasets/pull/4724 (needs to be merged first)
It's good practice to shard parquet files to enable parallelism with spark/dask/etc.
I added the `max_shard_size` parameter to `download_and_prepare` (default to 500MB for parquet, and None for arrow).
```python
from datase... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4747/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4747/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4746/comments | https://api.github.com/repos/huggingface/datasets/issues/4746/events | https://github.com/huggingface/datasets/issues/4746 | 1,318,486,599 | I_kwDODunzps5OloJH | 4,746 | Dataset Viewer issue for yanekyuk/wikikey | {
"login": "ai-ashok",
"id": 91247690,
"node_id": "MDQ6VXNlcjkxMjQ3Njkw",
"avatar_url": "https://avatars.githubusercontent.com/u/91247690?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ai-ashok",
"html_url": "https://github.com/ai-ashok",
"followers_url": "https://api.github.com/users/ai-... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | null | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"The dataset is empty, as far as I can tell: there are no files in the repository at https://huggingface.co/datasets/yanekyuk/wikikey/tree/main\r\n\r\nMaybe the viewer can display a better message for empty datasets"
] | 1,658,852,716,000 | 1,658,858,857,000 | null | NONE | null | null | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4746/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4746/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4745 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4745/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4745/comments | https://api.github.com/repos/huggingface/datasets/issues/4745/events | https://github.com/huggingface/datasets/issues/4745 | 1,318,016,655 | I_kwDODunzps5Oj1aP | 4,745 | Allow `list_datasets` to include private datasets | {
"login": "ola13",
"id": 1528523,
"node_id": "MDQ6VXNlcjE1Mjg1MjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1528523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ola13",
"html_url": "https://github.com/ola13",
"followers_url": "https://api.github.com/users/ola13/follower... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Thanks for opening this issue :)\r\n\r\nIf it can help, I think you can already use `huggingface_hub` to achieve this:\r\n```python\r\n>>> from huggingface_hub import HfApi\r\n>>> [ds_info.id for ds_info in HfApi().list_datasets(use_auth_token=token) if ds_info.private]\r\n['bigscience/xxxx', 'bigscience-catalogue... | 1,658,830,568,000 | 1,658,836,765,000 | null | NONE | null | null | null | I am working with a large collection of private datasets, it would be convenient for me to be able to list them.
I would envision extending the convention of using `use_auth_token` keyword argument to `list_datasets` function, then calling:
```
list_datasets(use_auth_token="my_token")
```
would return the li... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4745/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4745/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4744 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4744/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4744/comments | https://api.github.com/repos/huggingface/datasets/issues/4744/events | https://github.com/huggingface/datasets/issues/4744 | 1,317,822,345 | I_kwDODunzps5OjF-J | 4,744 | Remove instructions to generate dummy data from our docs | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"Note that for me personally, conceptually all the dummy data (even for \"canonical\" datasets) should be superseded by `datasets-server`, which performs some kind of CI/CD of datasets (including the canonical ones)",
"I totally agree: next step should be rethinking if dummy data makes sense for canonical dataset... | 1,658,820,778,000 | 1,658,823,453,000 | null | MEMBER | null | null | null | In our docs, we indicate to generate the dummy data: https://huggingface.co/docs/datasets/dataset_script#testing-data-and-checksum-metadata
However:
- dummy data makes sense only for datasets in our GitHub repo: so that we can test their loading with our CI
- for datasets on the Hub:
- they do not pass any CI t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4744/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4744/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4743/comments | https://api.github.com/repos/huggingface/datasets/issues/4743/events | https://github.com/huggingface/datasets/pull/4743 | 1,317,362,561 | PR_kwDODunzps48EUFs | 4,743 | Update map docs | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,782,775,000 | 1,658,938,924,000 | 1,658,938,204,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4743",
"html_url": "https://github.com/huggingface/datasets/pull/4743",
"diff_url": "https://github.com/huggingface/datasets/pull/4743.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4743.patch",
"merged_at": 1658938204000
} | This PR updates the `map` docs for processing text to include `return_tensors="np"` to make it run faster (see #4676). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4743/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4742 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4742/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4742/comments | https://api.github.com/repos/huggingface/datasets/issues/4742/events | https://github.com/huggingface/datasets/issues/4742 | 1,317,260,663 | I_kwDODunzps5Og813 | 4,742 | Dummy data nowhere to be found | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi @BramVanroy, thanks for reporting.\r\n\r\nFirst of all, please note that you do not need the dummy data: this was the case when we were adding datasets to the `datasets` library (on this GitHub repo), so that we could test the correct loading of all datasets with our CI. However, this is no longer the case for ... | 1,658,776,722,000 | 1,658,820,827,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
To finalize my dataset, I wanted to create dummy data as per the guide and I ran
```shell
datasets-cli dummy_data datasets/hebban-reviews --auto_generate
```
where hebban-reviews is [this repo](https://huggingface.co/datasets/BramVanroy/hebban-reviews). And even though the scripts runs an... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4742/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4742/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4741/comments | https://api.github.com/repos/huggingface/datasets/issues/4741/events | https://github.com/huggingface/datasets/pull/4741 | 1,316,621,272 | PR_kwDODunzps48B2fl | 4,741 | Fix to dict conversion of `DatasetInfo`/`Features` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,745,687,000 | 1,658,753,436,000 | 1,658,752,673,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4741",
"html_url": "https://github.com/huggingface/datasets/pull/4741",
"diff_url": "https://github.com/huggingface/datasets/pull/4741.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4741.patch",
"merged_at": 1658752673000
} | Fix #4681 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4741/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4741/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4740 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4740/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4740/comments | https://api.github.com/repos/huggingface/datasets/issues/4740/events | https://github.com/huggingface/datasets/pull/4740 | 1,316,478,007 | PR_kwDODunzps48BX5l | 4,740 | Fix multiprocessing in map_nested | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq as a workaround to preserve previous behavior, the parameter `multiprocessing_min_length=16` is passed from `download` to `map_nested`, so that multiprocessing is only used if at least 16 files to be downloaded.\r\n\r\nNote ... | 1,658,738,659,000 | 1,659,005,603,000 | 1,659,004,831,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4740",
"html_url": "https://github.com/huggingface/datasets/pull/4740",
"diff_url": "https://github.com/huggingface/datasets/pull/4740.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4740.patch",
"merged_at": 1659004831000
} | As previously discussed:
Before, multiprocessing was not used in `map_nested` if `num_proc` was greater than or equal to `len(iterable)`.
- Multiprocessing was not used e.g. when passing `num_proc=20` but having 19 files to download
- As by default, `DownloadManager` sets `num_proc=16`, before multiprocessing was ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4740/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4740/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4739 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4739/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4739/comments | https://api.github.com/repos/huggingface/datasets/issues/4739/events | https://github.com/huggingface/datasets/pull/4739 | 1,316,400,915 | PR_kwDODunzps48BHdE | 4,739 | Deprecate metrics | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I mark this as Draft because the deprecated version number needs being updated after the latest release.",
"Perhaps now is the time to also update the `inspect_metric` from `evaluate` with the changes introduced in https://github.c... | 1,658,734,555,000 | 1,659,008,667,000 | 1,659,007,936,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4739",
"html_url": "https://github.com/huggingface/datasets/pull/4739",
"diff_url": "https://github.com/huggingface/datasets/pull/4739.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4739.patch",
"merged_at": 1659007936000
} | Deprecate metrics:
- deprecate public functions: `load_metric`, `list_metrics` and `inspect_metric`: docstring and warning
- test deprecation warnings are issues
- deprecate metrics in all docs
- remove mentions to metrics in docs and README
- deprecate internal functions/classes
Maybe we should also stop testi... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4739/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4739/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4738/comments | https://api.github.com/repos/huggingface/datasets/issues/4738/events | https://github.com/huggingface/datasets/pull/4738 | 1,315,222,166 | PR_kwDODunzps479hq4 | 4,738 | Use CI unit/integration tests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think this PR can be merged. Willing to see it in action.\r\n\r\nCC: @lhoestq "
] | 1,658,508,480,000 | 1,658,866,762,000 | 1,658,866,025,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4738",
"html_url": "https://github.com/huggingface/datasets/pull/4738",
"diff_url": "https://github.com/huggingface/datasets/pull/4738.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4738.patch",
"merged_at": 1658866025000
} | This PR:
- Implements separate unit/integration tests
- A fail in integration tests does not cancel the rest of the jobs
- We should implement more robust integration tests: work in progress in a subsequent PR
- For the moment, test involving network requests are marked as integration: to be evolved | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4738/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4738/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4737/comments | https://api.github.com/repos/huggingface/datasets/issues/4737/events | https://github.com/huggingface/datasets/issues/4737 | 1,315,011,004 | I_kwDODunzps5OYXm8 | 4,737 | Download error on scene_parse_150 | {
"login": "juliensimon",
"id": 3436143,
"node_id": "MDQ6VXNlcjM0MzYxNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3436143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/juliensimon",
"html_url": "https://github.com/juliensimon",
"followers_url": "https://api.github.com/us... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi! The server with the data seems to be down. I've reported this issue (https://github.com/CSAILVision/sceneparsing/issues/34) in the dataset repo. "
] | 1,658,496,508,000 | 1,658,500,151,000 | null | NONE | null | null | null | ```
from datasets import load_dataset
dataset = load_dataset("scene_parse_150", "scene_parsing")
FileNotFoundError: Couldn't find file at http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4737/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4737/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4736/comments | https://api.github.com/repos/huggingface/datasets/issues/4736/events | https://github.com/huggingface/datasets/issues/4736 | 1,314,931,996 | I_kwDODunzps5OYEUc | 4,736 | Dataset Viewer issue for deepklarity/huggingface-spaces-dataset | {
"login": "dk-crazydiv",
"id": 47515542,
"node_id": "MDQ6VXNlcjQ3NTE1NTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47515542?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dk-crazydiv",
"html_url": "https://github.com/dk-crazydiv",
"followers_url": "https://api.github.com/... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"Thanks for reporting. You're right, workers were under-provisioned due to a manual error, and the job queue was full. It's fixed now."
] | 1,658,492,058,000 | 1,658,497,598,000 | 1,658,497,598,000 | NONE | null | null | null | ### Link
https://huggingface.co/datasets/deepklarity/huggingface-spaces-dataset/viewer/deepklarity--huggingface-spaces-dataset/train
### Description
Hi Team,
I'm getting the following error on a uploaded dataset. I'm getting the same status for a couple of hours now. The dataset size is `<1MB` and the format is cs... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4736/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4736/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4735/comments | https://api.github.com/repos/huggingface/datasets/issues/4735/events | https://github.com/huggingface/datasets/pull/4735 | 1,314,501,641 | PR_kwDODunzps477CuP | 4,735 | Pin rouge_score test dependency | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,474,301,000 | 1,658,476,694,000 | 1,658,475,918,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4735",
"html_url": "https://github.com/huggingface/datasets/pull/4735",
"diff_url": "https://github.com/huggingface/datasets/pull/4735.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4735.patch",
"merged_at": 1658475918000
} | Temporarily pin `rouge_score` (to avoid latest version 0.7.0) until the issue is fixed.
Fix #4734 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4735/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4735/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4734/comments | https://api.github.com/repos/huggingface/datasets/issues/4734/events | https://github.com/huggingface/datasets/issues/4734 | 1,314,495,382 | I_kwDODunzps5OWZuW | 4,734 | Package rouge-score cannot be imported | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"We have added a comment on an existing issue opened in their repo: https://github.com/google-research/google-research/issues/1212#issuecomment-1192267130\r\n- https://github.com/google-research/google-research/issues/1212"
] | 1,658,474,105,000 | 1,658,475,919,000 | 1,658,475,918,000 | MEMBER | null | null | null | ## Describe the bug
After the today release of `rouge_score-0.0.7` it seems no longer importable. Our CI fails: https://github.com/huggingface/datasets/runs/7463218591?check_suite_focus=true
```
FAILED tests/test_dataset_common.py::LocalDatasetTest::test_builder_class_bigbench
FAILED tests/test_dataset_common.py::L... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4734/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4734/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4733/comments | https://api.github.com/repos/huggingface/datasets/issues/4733/events | https://github.com/huggingface/datasets/issues/4733 | 1,314,479,616 | I_kwDODunzps5OWV4A | 4,733 | rouge metric | {
"login": "asking28",
"id": 29248466,
"node_id": "MDQ6VXNlcjI5MjQ4NDY2",
"avatar_url": "https://avatars.githubusercontent.com/u/29248466?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asking28",
"html_url": "https://github.com/asking28",
"followers_url": "https://api.github.com/users/ask... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Fixed by:\r\n- #4735"
] | 1,658,473,611,000 | 1,658,480,882,000 | 1,658,480,735,000 | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Loading Rouge metric gives error after latest rouge-score==0.0.7 release.
Downgrading rougemetric==0.0.4 works fine.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
## Expected results
A clear and concis... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4733/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4733/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4732/comments | https://api.github.com/repos/huggingface/datasets/issues/4732/events | https://github.com/huggingface/datasets/issues/4732 | 1,314,371,566 | I_kwDODunzps5OV7fu | 4,732 | Document better that loading a dataset passing its name does not use the local script | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"Thanks for the feedback!\r\n\r\nI think since this issue is closely related to loading, I can add a clearer explanation under [Load > local loading script](https://huggingface.co/docs/datasets/main/en/loading#local-loading-script).",
"That makes sense but I think having a line about it under https://huggingface.... | 1,658,470,051,000 | 1,658,777,132,000 | null | MEMBER | null | null | null | As reported by @TrentBrick here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191858596, it could be more clear that loading a dataset by passing its name does not use the (modified) local script of it.
What he did:
- he installed `datasets` from source
- he modified locally `datasets/the_pile/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4732/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4732/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4731/comments | https://api.github.com/repos/huggingface/datasets/issues/4731/events | https://github.com/huggingface/datasets/pull/4731 | 1,313,773,348 | PR_kwDODunzps474dlZ | 4,731 | docs: ✏️ fix TranslationVariableLanguages example | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,435,741,000 | 1,658,473,260,000 | 1,658,472,522,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4731",
"html_url": "https://github.com/huggingface/datasets/pull/4731",
"diff_url": "https://github.com/huggingface/datasets/pull/4731.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4731.patch",
"merged_at": 1658472522000
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4731/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4731/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4730/comments | https://api.github.com/repos/huggingface/datasets/issues/4730/events | https://github.com/huggingface/datasets/issues/4730 | 1,313,421,263 | I_kwDODunzps5OSTfP | 4,730 | Loading imagenet-1k validation split takes much more RAM than expected | {
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"My bad, `482 * 418 * 50000 * 3 / 1000000 = 30221 MB` ( https://stackoverflow.com/a/42979315 ).\r\n\r\nMeanwhile `256 * 256 * 50000 * 3 / 1000000 = 9830 MB`. We are loading the non-cropped images and that is why we take so much RAM."
] | 1,658,416,446,000 | 1,658,421,664,000 | 1,658,421,664,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
Loading into memory the validation split of imagenet-1k takes much more RAM than expected. Assuming ImageNet-1k is 150 GB, split is 50000 validation images and 1,281,167 train images, I would expect only about 6 GB loaded in RAM.
## Steps to reproduce the bug
```python
from datasets import... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4730/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4730/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4729 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4729/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4729/comments | https://api.github.com/repos/huggingface/datasets/issues/4729/events | https://github.com/huggingface/datasets/pull/4729 | 1,313,374,015 | PR_kwDODunzps473GmR | 4,729 | Refactor Hub tests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,414,593,000 | 1,658,502,589,000 | 1,658,501,789,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4729",
"html_url": "https://github.com/huggingface/datasets/pull/4729",
"diff_url": "https://github.com/huggingface/datasets/pull/4729.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4729.patch",
"merged_at": 1658501789000
} | This PR refactors `test_upstream_hub` by removing unittests and using the following pytest Hub fixtures:
- `ci_hub_config`
- `set_ci_hub_access_token`: to replace setUp/tearDown
- `temporary_repo` context manager: to replace `try... finally`
- `cleanup_repo`: to delete repo accidentally created if one of the tests ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4729/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4728/comments | https://api.github.com/repos/huggingface/datasets/issues/4728/events | https://github.com/huggingface/datasets/issues/4728 | 1,312,897,454 | I_kwDODunzps5OQTmu | 4,728 | load_dataset gives "403" error when using Financial Phrasebank | {
"login": "rohitvincent",
"id": 2209134,
"node_id": "MDQ6VXNlcjIyMDkxMzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2209134?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rohitvincent",
"html_url": "https://github.com/rohitvincent",
"followers_url": "https://api.github.com... | [] | open | false | null | [] | null | [
"Hi @rohitvincent, thanks for reporting.\r\n\r\nUnfortunately I'm not able to reproduce your issue:\r\n```python\r\nIn [2]: from datasets import load_dataset, DownloadMode\r\n ...: load_dataset(path='financial_phrasebank',name='sentences_allagree', download_mode=\"force_redownload\")\r\nDownloading builder script... | 1,658,393,012,000 | 1,658,478,333,000 | null | NONE | null | null | null | I tried both codes below to download the financial phrasebank dataset (https://huggingface.co/datasets/financial_phrasebank) with the sentences_allagree subset. However, the code gives a 403 error when executed from multiple machines locally or on the cloud.
```
from datasets import load_dataset, DownloadMode
load... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4728/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4728/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"login": "thenerd31",
"id": 53668030,
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thenerd31",
"html_url": "https://github.com/thenerd31",
"followers_url": "https://api.github.com/users/... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"The preview is working OK:\r\n\r\n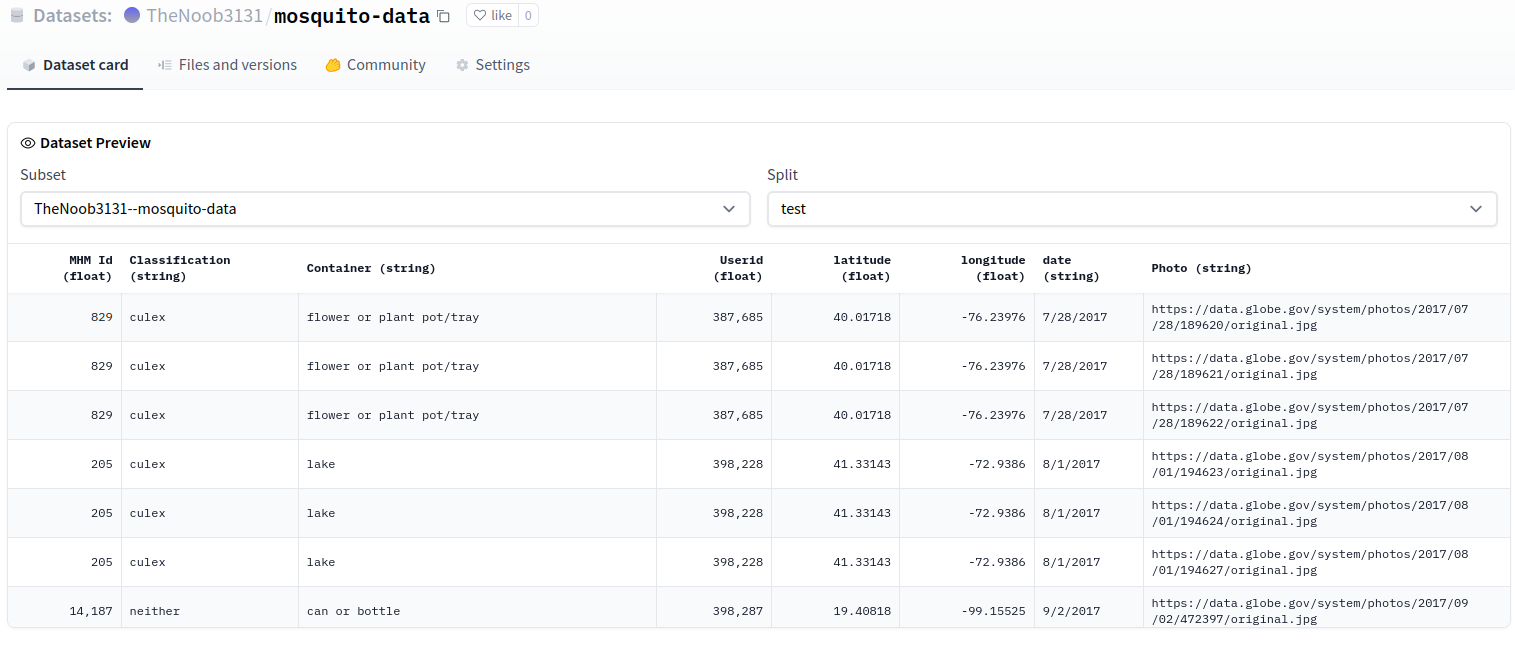\r\n\r\n"
] | 1,658,381,088,000 | 1,658,389,916,000 | 1,658,389,501,000 | NONE | null | null | null | ### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4726/comments | https://api.github.com/repos/huggingface/datasets/issues/4726/events | https://github.com/huggingface/datasets/pull/4726 | 1,312,082,175 | PR_kwDODunzps47ykPI | 4,726 | Fix broken link to the Hub | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,357,847,000 | 1,658,413,998,000 | 1,658,390,454,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4726",
"html_url": "https://github.com/huggingface/datasets/pull/4726",
"diff_url": "https://github.com/huggingface/datasets/pull/4726.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4726.patch",
"merged_at": 1658390454000
} | The Markdown link fails to render if it is in the same line as the `<span>`. This PR implements @mishig25's fix by using `<a href=" ">` instead.
 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4726/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4726/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4725/comments | https://api.github.com/repos/huggingface/datasets/issues/4725/events | https://github.com/huggingface/datasets/issues/4725 | 1,311,907,096 | I_kwDODunzps5OMh0Y | 4,725 | the_pile datasets URL broken. | {
"login": "TrentBrick",
"id": 12433427,
"node_id": "MDQ6VXNlcjEyNDMzNDI3",
"avatar_url": "https://avatars.githubusercontent.com/u/12433427?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TrentBrick",
"html_url": "https://github.com/TrentBrick",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thanks for reporting, @TrentBrick. We are addressing the change with their data host server.\r\n\r\nOn the meantime, if you would like to work with your fixed local copy of the_pile script, you should use:\r\n```python\r\nload_dataset(\"path/to/your/local/the_pile/the_pile.py\",...\r\n```\r\ninstead of just `load_... | 1,658,350,650,000 | 1,658,470,186,000 | 1,658,389,099,000 | NONE | null | null | null | https://github.com/huggingface/datasets/pull/3627 changed the Eleuther AI Pile dataset URL from https://the-eye.eu/ to https://mystic.the-eye.eu/ but the latter is now broken and the former works again.
Note that when I git clone the repo and use `pip install -e .` and then edit the URL back the codebase doesn't se... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4725/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4725/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4724/comments | https://api.github.com/repos/huggingface/datasets/issues/4724/events | https://github.com/huggingface/datasets/pull/4724 | 1,311,127,404 | PR_kwDODunzps47vLrP | 4,724 | Download and prepare as Parquet for cloud storage | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4724). All of your documentation changes will be reflected on that endpoint.",
"Added some docs for dask and took your comments into account\r\n\r\ncc @philschmid if you also want to take a look :)"
] | 1,658,324,342,000 | 1,659,105,431,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4724",
"html_url": "https://github.com/huggingface/datasets/pull/4724",
"diff_url": "https://github.com/huggingface/datasets/pull/4724.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4724.patch",
"merged_at": null
} | Download a dataset as Parquet in a cloud storage can be useful for streaming mode and to use with spark/dask/ray.
This PR adds support for `fsspec` URIs like `s3://...`, `gcs://...` etc. and ads the `file_format` to save as parquet instead of arrow:
```python
from datasets import *
cache_dir = "s3://..."
build... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4724/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4724/timeline | null | null | true |
End of preview. Expand in Data Studio
No dataset card yet
- Downloads last month
- 16