
code stringlengths 1 25.8M | language stringclasses 18 values | source stringclasses 4 values | repo stringclasses 78 values | path stringlengths 0 268 |
|---|---|---|---|---|
#include "internal.h"
#include "internal/string.h"
#include "ruby/encoding.h"
static VALUE
bug_str_cstr_term(VALUE str)
{
long len;
char *s;
int c;
rb_encoding *enc;
len = RSTRING_LEN(str);
s = StringValueCStr(str);
rb_gc();
enc = rb_enc_get(str);
c = rb_enc_codepoint(&s[len], &s[len+rb_enc_mbminlen(enc)], enc);
return INT2NUM(c);
}
static VALUE
bug_str_cstr_unterm(VALUE str, VALUE c)
{
long len;
rb_str_modify(str);
len = RSTRING_LEN(str);
RSTRING_PTR(str)[len] = NUM2CHR(c);
return str;
}
static VALUE
bug_str_cstr_term_char(VALUE str)
{
long len;
char *s;
int c;
rb_encoding *enc = rb_enc_get(str);
RSTRING_GETMEM(str, s, len);
s += len;
len = rb_enc_mbminlen(enc);
c = rb_enc_precise_mbclen(s, s + len, enc);
if (!MBCLEN_CHARFOUND_P(c)) {
c = (unsigned char)*s;
}
else {
c = rb_enc_mbc_to_codepoint(s, s + len, enc);
if (!c) return Qnil;
}
return rb_enc_uint_chr((unsigned int)c, enc);
}
static VALUE
bug_str_unterminated_substring(VALUE str, VALUE vbeg, VALUE vlen)
{
long beg = NUM2LONG(vbeg);
long len = NUM2LONG(vlen);
rb_str_modify(str);
if (len < 0) rb_raise(rb_eArgError, "negative length: %ld", len);
if (RSTRING_LEN(str) < beg) rb_raise(rb_eIndexError, "beg: %ld", beg);
if (RSTRING_LEN(str) < beg + len) rb_raise(rb_eIndexError, "end: %ld", beg + len);
str = rb_str_new_shared(str);
RSTRING(str)->len = len;
if (STR_EMBED_P(str)) {
memmove(RSTRING(str)->as.embed.ary, RSTRING(str)->as.embed.ary + beg, len);
}
else {
RSTRING(str)->as.heap.ptr += beg;
}
return str;
}
static VALUE
bug_str_s_cstr_term(VALUE self, VALUE str)
{
Check_Type(str, T_STRING);
return bug_str_cstr_term(str);
}
static VALUE
bug_str_s_cstr_unterm(VALUE self, VALUE str, VALUE c)
{
Check_Type(str, T_STRING);
return bug_str_cstr_unterm(str, c);
}
static VALUE
bug_str_s_cstr_term_char(VALUE self, VALUE str)
{
Check_Type(str, T_STRING);
return bug_str_cstr_term_char(str);
}
#define TERM_LEN(str) rb_enc_mbminlen(rb_enc_get(str))
#define TERM_FILL(ptr, termlen) do {\
char *const term_fill_ptr = (ptr);\
const int term_fill_len = (termlen);\
*term_fill_ptr = '\0';\
if (UNLIKELY(term_fill_len > 1))\
memset(term_fill_ptr, 0, term_fill_len);\
} while (0)
static VALUE
bug_str_s_cstr_noembed(VALUE self, VALUE str)
{
VALUE str2 = rb_str_new(NULL, 0);
long capacity = RSTRING_LEN(str) + TERM_LEN(str);
char *buf = ALLOC_N(char, capacity);
Check_Type(str, T_STRING);
FL_SET((str2), STR_NOEMBED);
memcpy(buf, RSTRING_PTR(str), capacity);
RBASIC(str2)->flags &= ~(STR_SHARED | FL_USER5 | FL_USER6);
RSTRING(str2)->as.heap.aux.capa = RSTRING_LEN(str);
RSTRING(str2)->as.heap.ptr = buf;
RSTRING(str2)->len = RSTRING_LEN(str);
TERM_FILL(RSTRING_END(str2), TERM_LEN(str));
return str2;
}
static VALUE
bug_str_s_cstr_embedded_p(VALUE self, VALUE str)
{
return STR_EMBED_P(str) ? Qtrue : Qfalse;
}
static VALUE
bug_str_s_rb_str_new_frozen(VALUE self, VALUE str)
{
return rb_str_new_frozen(str);
}
void
Init_string_cstr(VALUE klass)
{
rb_define_method(klass, "cstr_term", bug_str_cstr_term, 0);
rb_define_method(klass, "cstr_unterm", bug_str_cstr_unterm, 1);
rb_define_method(klass, "cstr_term_char", bug_str_cstr_term_char, 0);
rb_define_method(klass, "unterminated_substring", bug_str_unterminated_substring, 2);
rb_define_singleton_method(klass, "cstr_term", bug_str_s_cstr_term, 1);
rb_define_singleton_method(klass, "cstr_unterm", bug_str_s_cstr_unterm, 2);
rb_define_singleton_method(klass, "cstr_term_char", bug_str_s_cstr_term_char, 1);
rb_define_singleton_method(klass, "cstr_noembed", bug_str_s_cstr_noembed, 1);
rb_define_singleton_method(klass, "cstr_embedded?", bug_str_s_cstr_embedded_p, 1);
rb_define_singleton_method(klass, "rb_str_new_frozen", bug_str_s_rb_str_new_frozen, 1);
} | c | github | https://github.com/ruby/ruby | ext/-test-/string/cstr.c |
# Copyright 2010 Hakan Kjellerstrand hakank@bonetmail.com
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Eq 20 in Google CP Solver.
Standard benchmark problem.
Compare with the following models:
* Gecode/R: http://hakank.org/gecode_r/eq20.rb
* ECLiPSe: http://hakank.org/eclipse/eq20.ecl
* SICStus: http://hakank.org/sicstus/eq20.pl
This model was created by Hakan Kjellerstrand (hakank@bonetmail.com)
Also see my other Google CP Solver models:
http://www.hakank.org/google_or_tools/
"""
from ortools.constraint_solver import pywrapcp
def main():
# Create the solver.
solver = pywrapcp.Solver("Eq 20")
#
# data
#
n = 7
#
# variables
#
X = [solver.IntVar(0, 10, "X(%i)" % i) for i in range(n)]
X0, X1, X2, X3, X4, X5, X6 = X
#
# constraints
#
solver.Add(-76706 * X0 + 98205 * X1 + 23445 * X2 + 67921 * X3 + 24111 * X4 +
-48614 * X5 + -41906 * X6 == 821228)
solver.Add(87059 * X0 + -29101 * X1 + -5513 * X2 + -21219 * X3 + 22128 * X4 +
7276 * X5 + 57308 * X6 == 22167)
solver.Add(-60113 * X0 + 29475 * X1 + 34421 * X2 + -76870 * X3 + 62646 * X4 +
29278 * X5 + -15212 * X6 == 251591)
solver.Add(49149 * X0 + 52871 * X1 + -7132 * X2 + 56728 * X3 + -33576 * X4 +
-49530 * X5 + -62089 * X6 == 146074)
solver.Add(-10343 * X0 + 87758 * X1 + -11782 * X2 + 19346 * X3 + 70072 * X4 +
-36991 * X5 + 44529 * X6 == 740061)
solver.Add(85176 * X0 + -95332 * X1 + -1268 * X2 + 57898 * X3 + 15883 * X4 +
50547 * X5 + 83287 * X6 == 373854)
solver.Add(-85698 * X0 + 29958 * X1 + 57308 * X2 + 48789 * X3 + -78219 * X4 +
4657 * X5 + 34539 * X6 == 249912)
solver.Add(-67456 * X0 + 84750 * X1 + -51553 * X2 + 21239 * X3 + 81675 * X4 +
-99395 * X5 + -4254 * X6 == 277271)
solver.Add(94016 * X0 + -82071 * X1 + 35961 * X2 + 66597 * X3 + -30705 * X4 +
-44404 * X5 + -38304 * X6 == 25334)
solver.Add(-60301 * X0 + 31227 * X1 + 93951 * X2 + 73889 * X3 + 81526 * X4 +
-72702 * X5 + 68026 * X6 == 1410723)
solver.Add(-16835 * X0 + 47385 * X1 + 97715 * X2 + -12640 * X3 + 69028 * X4 +
76212 * X5 + -81102 * X6 == 1244857)
solver.Add(-43277 * X0 + 43525 * X1 + 92298 * X2 + 58630 * X3 + 92590 * X4 +
-9372 * X5 + -60227 * X6 == 1503588)
solver.Add(-64919 * X0 + 80460 * X1 + 90840 * X2 + -59624 * X3 + -75542 * X4 +
25145 * X5 + -47935 * X6 == 18465)
solver.Add(-45086 * X0 + 51830 * X1 + -4578 * X2 + 96120 * X3 + 21231 * X4 +
97919 * X5 + 65651 * X6 == 1198280)
solver.Add(85268 * X0 + 54180 * X1 + -18810 * X2 + -48219 * X3 + 6013 * X4 +
78169 * X5 + -79785 * X6 == 90614)
solver.Add(8874 * X0 + -58412 * X1 + 73947 * X2 + 17147 * X3 + 62335 * X4 +
16005 * X5 + 8632 * X6 == 752447)
solver.Add(71202 * X0 + -11119 * X1 + 73017 * X2 + -38875 * X3 + -14413 * X4 +
-29234 * X5 + 72370 * X6 == 129768)
solver.Add(1671 * X0 + -34121 * X1 + 10763 * X2 + 80609 * X3 + 42532 * X4 +
93520 * X5 + -33488 * X6 == 915683)
solver.Add(51637 * X0 + 67761 * X1 + 95951 * X2 + 3834 * X3 + -96722 * X4 +
59190 * X5 + 15280 * X6 == 533909)
solver.Add(-16105 * X0 + 62397 * X1 + -6704 * X2 + 43340 * X3 + 95100 * X4 +
-68610 * X5 + 58301 * X6 == 876370)
#
# search and result
#
db = solver.Phase(X,
solver.CHOOSE_FIRST_UNBOUND,
solver.ASSIGN_MIN_VALUE)
solver.NewSearch(db)
num_solutions = 0
while solver.NextSolution():
num_solutions += 1
print "X:", [X[i].Value() for i in range(n)]
print
solver.EndSearch()
print
print "num_solutions:", num_solutions
print "failures:", solver.Failures()
print "branches:", solver.Branches()
print "WallTime:", solver.WallTime()
if __name__ == "__main__":
main() | unknown | codeparrot/codeparrot-clean | ||
from uwsgidecorators import spool
import Queue
from threading import Thread
queues = {}
class queueconsumer(object):
def __init__(self, name, num=1, **kwargs):
self.name = name
self.num = num
self.queue = Queue.Queue()
self.threads = []
self.func = None
queues[self.name] = self
@staticmethod
def consumer(self):
while True:
req = self.queue.get()
print req
self.func(req)
self.queue.task_done()
def __call__(self, f):
self.func = f
for i in range(self.num):
t = Thread(target=self.consumer, args=(self,))
self.threads.append(t)
t.daemon = True
t.start()
@spool
def spooler_enqueuer(arguments):
if 'queue' in arguments:
queue = arguments['queue']
queues[queue].queue.put(arguments)
else:
raise Exception("You have to specify a queue name")
def enqueue(*args, **kwargs):
return spooler_enqueuer.spool(*args, **kwargs) | unknown | codeparrot/codeparrot-clean | ||
#---------------------------------------------------------------------------
# This Python script will traverse through a workspace/folder of shapefiles
# and inspect them in regards to attributes/fields. The list of fields will
# are written to a spreadsheet with names and properties.
#
# This script has not been tested with other kinds of workspaces, e.g.
# Geodatabases etc...
#---------------------------------------------------------------------------
# Name: FcFieldInfo
# Version: 1.0
# Authored By: Hugo Ahlenius, Nordpil - http://nordpil.com
# Copyright: Creative Commons.
#---------------------------------------------------------------------------
#Import modules
import arcpy,sys,os,datetime
# {{{ HANDLE PARAMETERS
paramWorkspace = arcpy.GetParameterAsText(0)
paramOutFile = arcpy.GetParameterAsText(1)
paramWildcard = arcpy.GetParameterAsText(2)
if len(paramWorkspace) == 0:
paramWorkspace = arcpy.env.workspace
if not os.path.isdir(paramWorkspace):
arcpy.AddError("Input parameters are incorrect\rfieldinfo.py {optional workspace path} {optional output xls/htm file} {optional wildcard}")
raise StandardError
arcpy.env.workspace = paramWorkspace
if len(paramOutFile) == 0:
paramOutFile = arcpy.env.workspace + '/fieldinfo_%s.xls' % datetime.datetime.now().strftime("%Y%m%d-%H%M")
if paramOutFile.find('xls') <1 and paramOutFile.find('htm') <1:
paramOutFile = paramOutFile + '.xls'
# }}}
# {{{ INSPECT THE WORKSPACE
dataList = arcpy.ListFeatureClasses()
dataList.sort()
if len(dataList) == 0:
arcpy.AddWarning('No featureclasses found')
sys.exit()
arcpy.SetProgressor('step','Analyzing %s featureclasses...' % len(dataList), 0, len(dataList))
arcpy.AddMessage ('Examining %s featureclasses in workspace %s\nResults will be written to %s' % (len(dataList),paramWorkspace,paramOutFile))
# }}}
# {{{ SPREADSHEET HEADERS
# We are doing this as an html file, for simplicity - it opens well in OpenOffice.org, LibreOffice as well as Microsoft Excel or Microsoft Access
fieldSheet = open(paramOutFile,'wb')
fieldSheet.write('<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE html PUBLIC "-//Extender//DTD XHTML-Extended 1.1//EN" "http://maps.grida.no/include2/xhtml11s_extend.dtd"><html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" ><head>\n')
fieldSheet.write('<style type="text/css">html,body: font-family{Helvetica,Arial,Sans-Serif} td,tr,table,th,thead{Border: 1px solid #999} thead,th{font-weight:bold;background:#060075;color:white;}</style>')
fieldSheet.write('<title>%s</title><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><meta http-equiv="content-language" content="us-en" /><meta name="content-language" content="us-en" />\n' % paramOutFile)
fieldSheet.write('</head><body><table>\n<thead><tr>')
for field in ('File', 'Field', 'Alias', 'Domain', 'Type', 'Length', 'Precision', 'Scale', 'Editable', 'hasIndex', 'isNullable', 'isUnique'):
fieldSheet.write('<th>%s</th>' % field)
fieldSheet.write('</tr></thead><tbody>\n')
# }}}
# {{{ Main loop - loop over all fc's in the workspace, and then over all their fields...
iteration = 0
for dataset in dataList:
iteration = iteration + 1
arcpy.SetProgressorLabel('Examining %s' % dataset)
arcpy.SetProgressorPosition(iteration)
allFields = arcpy.ListFields(dataset)
for field in allFields:
fieldSheet.write('<tr><td>%s</td>' % dataset)
for property in ('name', 'aliasName', 'domain', 'type', 'length', 'precision', 'scale', 'editable', 'hasIndex', 'isNullable', 'isUnique'):
try:
fieldSheet.write('<td>%s</td>' % eval('field.%s' % property))
except:
fieldSheet.write('<td></td>')
fieldSheet.write('</tr>\n')
# }}}
# Closing tags at end of file, and then close() the file...
fieldSheet.write('</tbody></table></body></html>')
fieldSheet.close() | unknown | codeparrot/codeparrot-clean | ||
#!/usr/bin/env python
#
# Generated Thu May 16 21:05:38 2013 by parse_xsd.py version 0.5.
#
import saml2
from saml2 import SamlBase
NAMESPACE = 'urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken'
class PhysicalVerification(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:
PhysicalVerification element """
c_tag = 'PhysicalVerification'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['credentialLevel'] = ('credential_level', 'None', False)
def __init__(self,
credential_level=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.credential_level = credential_level
def physical_verification_from_string(xml_string):
return saml2.create_class_from_xml_string(PhysicalVerification, xml_string)
class Generation(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Generation
element """
c_tag = 'Generation'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['mechanism'] = ('mechanism', 'None', True)
def __init__(self,
mechanism=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.mechanism = mechanism
def generation_from_string(xml_string):
return saml2.create_class_from_xml_string(Generation, xml_string)
class NymType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:nymType
element """
c_tag = 'nymType'
c_namespace = NAMESPACE
c_value_type = {'base': 'xs:NMTOKEN',
'enumeration': ['anonymity', 'verinymity', 'pseudonymity']}
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
def nym_type__from_string(xml_string):
return saml2.create_class_from_xml_string(NymType_, xml_string)
class GoverningAgreementRefType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:
GoverningAgreementRefType element """
c_tag = 'GoverningAgreementRefType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['governingAgreementRef'] = (
'governing_agreement_ref', 'anyURI', True)
def __init__(self,
governing_agreement_ref=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.governing_agreement_ref = governing_agreement_ref
def governing_agreement_ref_type__from_string(xml_string):
return saml2.create_class_from_xml_string(GoverningAgreementRefType_,
xml_string)
class KeySharingType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:KeySharingType
element """
c_tag = 'KeySharingType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['sharing'] = ('sharing', 'boolean', True)
def __init__(self,
sharing=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.sharing = sharing
def key_sharing_type__from_string(xml_string):
return saml2.create_class_from_xml_string(KeySharingType_, xml_string)
class RestrictedLengthType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:
RestrictedLengthType element """
c_tag = 'RestrictedLengthType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['min'] = ('min', 'None', True)
c_attributes['max'] = ('max', 'integer', False)
def __init__(self,
min=None,
max=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.min = min
self.max = max
def restricted_length_type__from_string(xml_string):
return saml2.create_class_from_xml_string(RestrictedLengthType_, xml_string)
class AlphabetType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AlphabetType
element """
c_tag = 'AlphabetType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['requiredChars'] = ('required_chars', 'string', True)
c_attributes['excludedChars'] = ('excluded_chars', 'string', False)
c_attributes['case'] = ('case', 'string', False)
def __init__(self,
required_chars=None,
excluded_chars=None,
case=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.required_chars = required_chars
self.excluded_chars = excluded_chars
self.case = case
def alphabet_type__from_string(xml_string):
return saml2.create_class_from_xml_string(AlphabetType_, xml_string)
class DeviceTypeType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:DeviceTypeType
element """
c_tag = 'DeviceTypeType'
c_namespace = NAMESPACE
c_value_type = {'base': 'xs:NMTOKEN',
'enumeration': ['hardware', 'software']}
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
def device_type_type__from_string(xml_string):
return saml2.create_class_from_xml_string(DeviceTypeType_, xml_string)
class BooleanType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:booleanType
element """
c_tag = 'booleanType'
c_namespace = NAMESPACE
c_value_type = {'base': 'xs:NMTOKEN', 'enumeration': ['true', 'false']}
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
def boolean_type__from_string(xml_string):
return saml2.create_class_from_xml_string(BooleanType_, xml_string)
class ActivationLimitDurationType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:
ActivationLimitDurationType element """
c_tag = 'ActivationLimitDurationType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['duration'] = ('duration', 'duration', True)
def __init__(self,
duration=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.duration = duration
def activation_limit_duration_type__from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationLimitDurationType_,
xml_string)
class ActivationLimitUsagesType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:
ActivationLimitUsagesType element """
c_tag = 'ActivationLimitUsagesType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['number'] = ('number', 'integer', True)
def __init__(self,
number=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.number = number
def activation_limit_usages_type__from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationLimitUsagesType_,
xml_string)
class ActivationLimitSessionType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:
ActivationLimitSessionType element """
c_tag = 'ActivationLimitSessionType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
def activation_limit_session_type__from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationLimitSessionType_,
xml_string)
class LengthType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:LengthType
element """
c_tag = 'LengthType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['min'] = ('min', 'integer', True)
c_attributes['max'] = ('max', 'integer', False)
def __init__(self,
min=None,
max=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.min = min
self.max = max
def length_type__from_string(xml_string):
return saml2.create_class_from_xml_string(LengthType_, xml_string)
class MediumType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:mediumType
element """
c_tag = 'mediumType'
c_namespace = NAMESPACE
c_value_type = {'base': 'xs:NMTOKEN',
'enumeration': ['memory', 'smartcard', 'token',
'MobileDevice', 'MobileAuthCard']}
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
def medium_type__from_string(xml_string):
return saml2.create_class_from_xml_string(MediumType_, xml_string)
class KeyStorageType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:KeyStorageType
element """
c_tag = 'KeyStorageType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['medium'] = ('medium', MediumType_, True)
def __init__(self,
medium=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.medium = medium
def key_storage_type__from_string(xml_string):
return saml2.create_class_from_xml_string(KeyStorageType_, xml_string)
class ExtensionType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ExtensionType
element """
c_tag = 'ExtensionType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
def extension_type__from_string(xml_string):
return saml2.create_class_from_xml_string(ExtensionType_, xml_string)
class TimeSyncTokenType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:
TimeSyncTokenType element """
c_tag = 'TimeSyncTokenType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_attributes['DeviceType'] = ('device_type', 'None', True)
c_attributes['SeedLength'] = ('seed_length', 'None', True)
c_attributes['DeviceInHand'] = ('device_in_hand', 'None', True)
def __init__(self,
device_type=None,
seed_length=None,
device_in_hand=None,
text=None,
extension_elements=None,
extension_attributes=None):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes)
self.device_type = device_type
self.seed_length = seed_length
self.device_in_hand = device_in_hand
def time_sync_token_type__from_string(xml_string):
return saml2.create_class_from_xml_string(TimeSyncTokenType_, xml_string)
class KeySharing(KeySharingType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:KeySharing
element """
c_tag = 'KeySharing'
c_namespace = NAMESPACE
c_children = KeySharingType_.c_children.copy()
c_attributes = KeySharingType_.c_attributes.copy()
c_child_order = KeySharingType_.c_child_order[:]
c_cardinality = KeySharingType_.c_cardinality.copy()
def key_sharing_from_string(xml_string):
return saml2.create_class_from_xml_string(KeySharing, xml_string)
class KeyStorage(KeyStorageType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:KeyStorage
element """
c_tag = 'KeyStorage'
c_namespace = NAMESPACE
c_children = KeyStorageType_.c_children.copy()
c_attributes = KeyStorageType_.c_attributes.copy()
c_child_order = KeyStorageType_.c_child_order[:]
c_cardinality = KeyStorageType_.c_cardinality.copy()
def key_storage_from_string(xml_string):
return saml2.create_class_from_xml_string(KeyStorage, xml_string)
class TimeSyncToken(TimeSyncTokenType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:TimeSyncToken
element """
c_tag = 'TimeSyncToken'
c_namespace = NAMESPACE
c_children = TimeSyncTokenType_.c_children.copy()
c_attributes = TimeSyncTokenType_.c_attributes.copy()
c_child_order = TimeSyncTokenType_.c_child_order[:]
c_cardinality = TimeSyncTokenType_.c_cardinality.copy()
def time_sync_token_from_string(xml_string):
return saml2.create_class_from_xml_string(TimeSyncToken, xml_string)
class Length(LengthType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Length element """
c_tag = 'Length'
c_namespace = NAMESPACE
c_children = LengthType_.c_children.copy()
c_attributes = LengthType_.c_attributes.copy()
c_child_order = LengthType_.c_child_order[:]
c_cardinality = LengthType_.c_cardinality.copy()
def length_from_string(xml_string):
return saml2.create_class_from_xml_string(Length, xml_string)
class GoverningAgreementRef(GoverningAgreementRefType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:GoverningAgreementRef element """
c_tag = 'GoverningAgreementRef'
c_namespace = NAMESPACE
c_children = GoverningAgreementRefType_.c_children.copy()
c_attributes = GoverningAgreementRefType_.c_attributes.copy()
c_child_order = GoverningAgreementRefType_.c_child_order[:]
c_cardinality = GoverningAgreementRefType_.c_cardinality.copy()
def governing_agreement_ref_from_string(xml_string):
return saml2.create_class_from_xml_string(GoverningAgreementRef, xml_string)
class GoverningAgreementsType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:
GoverningAgreementsType element """
c_tag = 'GoverningAgreementsType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}GoverningAgreementRef'] = (
'governing_agreement_ref', [GoverningAgreementRef])
c_cardinality['governing_agreement_ref'] = {"min": 1}
c_child_order.extend(['governing_agreement_ref'])
def __init__(self,
governing_agreement_ref=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.governing_agreement_ref = governing_agreement_ref or []
def governing_agreements_type__from_string(xml_string):
return saml2.create_class_from_xml_string(GoverningAgreementsType_,
xml_string)
class RestrictedPasswordType_Length(RestrictedLengthType_):
c_tag = 'Length'
c_namespace = NAMESPACE
c_children = RestrictedLengthType_.c_children.copy()
c_attributes = RestrictedLengthType_.c_attributes.copy()
c_child_order = RestrictedLengthType_.c_child_order[:]
c_cardinality = RestrictedLengthType_.c_cardinality.copy()
def restricted_password_type__length_from_string(xml_string):
return saml2.create_class_from_xml_string(RestrictedPasswordType_Length,
xml_string)
class Alphabet(AlphabetType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Alphabet element """
c_tag = 'Alphabet'
c_namespace = NAMESPACE
c_children = AlphabetType_.c_children.copy()
c_attributes = AlphabetType_.c_attributes.copy()
c_child_order = AlphabetType_.c_child_order[:]
c_cardinality = AlphabetType_.c_cardinality.copy()
def alphabet_from_string(xml_string):
return saml2.create_class_from_xml_string(Alphabet, xml_string)
class ActivationLimitDuration(ActivationLimitDurationType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ActivationLimitDuration element """
c_tag = 'ActivationLimitDuration'
c_namespace = NAMESPACE
c_children = ActivationLimitDurationType_.c_children.copy()
c_attributes = ActivationLimitDurationType_.c_attributes.copy()
c_child_order = ActivationLimitDurationType_.c_child_order[:]
c_cardinality = ActivationLimitDurationType_.c_cardinality.copy()
def activation_limit_duration_from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationLimitDuration,
xml_string)
class ActivationLimitUsages(ActivationLimitUsagesType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ActivationLimitUsages element """
c_tag = 'ActivationLimitUsages'
c_namespace = NAMESPACE
c_children = ActivationLimitUsagesType_.c_children.copy()
c_attributes = ActivationLimitUsagesType_.c_attributes.copy()
c_child_order = ActivationLimitUsagesType_.c_child_order[:]
c_cardinality = ActivationLimitUsagesType_.c_cardinality.copy()
def activation_limit_usages_from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationLimitUsages, xml_string)
class ActivationLimitSession(ActivationLimitSessionType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ActivationLimitSession element """
c_tag = 'ActivationLimitSession'
c_namespace = NAMESPACE
c_children = ActivationLimitSessionType_.c_children.copy()
c_attributes = ActivationLimitSessionType_.c_attributes.copy()
c_child_order = ActivationLimitSessionType_.c_child_order[:]
c_cardinality = ActivationLimitSessionType_.c_cardinality.copy()
def activation_limit_session_from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationLimitSession,
xml_string)
class Extension(ExtensionType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Extension element """
c_tag = 'Extension'
c_namespace = NAMESPACE
c_children = ExtensionType_.c_children.copy()
c_attributes = ExtensionType_.c_attributes.copy()
c_child_order = ExtensionType_.c_child_order[:]
c_cardinality = ExtensionType_.c_cardinality.copy()
def extension_from_string(xml_string):
return saml2.create_class_from_xml_string(Extension, xml_string)
class TokenType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:TokenType element """
c_tag = 'TokenType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}TimeSyncToken'] = (
'time_sync_token', TimeSyncToken)
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(['time_sync_token', 'extension'])
def __init__(self,
time_sync_token=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.time_sync_token = time_sync_token
self.extension = extension or []
def token_type__from_string(xml_string):
return saml2.create_class_from_xml_string(TokenType_, xml_string)
class Token(TokenType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Token element """
c_tag = 'Token'
c_namespace = NAMESPACE
c_children = TokenType_.c_children.copy()
c_attributes = TokenType_.c_attributes.copy()
c_child_order = TokenType_.c_child_order[:]
c_cardinality = TokenType_.c_cardinality.copy()
def token_from_string(xml_string):
return saml2.create_class_from_xml_string(Token, xml_string)
class SharedSecretChallengeResponseType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SharedSecretChallengeResponseType element """
c_tag = 'SharedSecretChallengeResponseType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_attributes['method'] = ('method', 'anyURI', False)
c_child_order.extend(['extension'])
def __init__(self,
extension=None,
method=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.extension = extension or []
self.method = method
def shared_secret_challenge_response_type__from_string(xml_string):
return saml2.create_class_from_xml_string(
SharedSecretChallengeResponseType_, xml_string)
class PublicKeyType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:PublicKeyType element """
c_tag = 'PublicKeyType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_attributes['keyValidation'] = ('key_validation', 'None', False)
c_child_order.extend(['extension'])
def __init__(self,
extension=None,
key_validation=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.extension = extension or []
self.key_validation = key_validation
def public_key_type__from_string(xml_string):
return saml2.create_class_from_xml_string(PublicKeyType_, xml_string)
class GoverningAgreements(GoverningAgreementsType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:GoverningAgreements element """
c_tag = 'GoverningAgreements'
c_namespace = NAMESPACE
c_children = GoverningAgreementsType_.c_children.copy()
c_attributes = GoverningAgreementsType_.c_attributes.copy()
c_child_order = GoverningAgreementsType_.c_child_order[:]
c_cardinality = GoverningAgreementsType_.c_cardinality.copy()
def governing_agreements_from_string(xml_string):
return saml2.create_class_from_xml_string(GoverningAgreements, xml_string)
class PasswordType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:PasswordType element """
c_tag = 'PasswordType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Length'] = (
'length', Length)
c_cardinality['length'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Alphabet'] = (
'alphabet', Alphabet)
c_cardinality['alphabet'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Generation'] = (
'generation', Generation)
c_cardinality['generation'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_attributes['ExternalVerification'] = (
'external_verification', 'anyURI', False)
c_child_order.extend(['length', 'alphabet', 'generation', 'extension'])
def __init__(self,
length=None,
alphabet=None,
generation=None,
extension=None,
external_verification=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.length = length
self.alphabet = alphabet
self.generation = generation
self.extension = extension or []
self.external_verification = external_verification
def password_type__from_string(xml_string):
return saml2.create_class_from_xml_string(PasswordType_, xml_string)
class RestrictedPasswordType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:RestrictedPasswordType element """
c_tag = 'RestrictedPasswordType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Length'] = (
'length', RestrictedPasswordType_Length)
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Generation'] = (
'generation', Generation)
c_cardinality['generation'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_attributes['ExternalVerification'] = (
'external_verification', 'anyURI', False)
c_child_order.extend(['length', 'generation', 'extension'])
def __init__(self,
length=None,
generation=None,
extension=None,
external_verification=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.length = length
self.generation = generation
self.extension = extension or []
self.external_verification = external_verification
def restricted_password_type__from_string(xml_string):
return saml2.create_class_from_xml_string(RestrictedPasswordType_,
xml_string)
class ActivationLimitType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ActivationLimitType element """
c_tag = 'ActivationLimitType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ActivationLimitDuration'] = (
'activation_limit_duration', ActivationLimitDuration)
c_cardinality['activation_limit_duration'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ActivationLimitUsages'] = (
'activation_limit_usages', ActivationLimitUsages)
c_cardinality['activation_limit_usages'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ActivationLimitSession'] = (
'activation_limit_session', ActivationLimitSession)
c_cardinality['activation_limit_session'] = {"min": 0, "max": 1}
c_child_order.extend(
['activation_limit_duration', 'activation_limit_usages',
'activation_limit_session'])
def __init__(self,
activation_limit_duration=None,
activation_limit_usages=None,
activation_limit_session=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.activation_limit_duration = activation_limit_duration
self.activation_limit_usages = activation_limit_usages
self.activation_limit_session = activation_limit_session
def activation_limit_type__from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationLimitType_, xml_string)
class ExtensionOnlyType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ExtensionOnlyType element """
c_tag = 'ExtensionOnlyType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(['extension'])
def __init__(self,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.extension = extension or []
def extension_only_type__from_string(xml_string):
return saml2.create_class_from_xml_string(ExtensionOnlyType_, xml_string)
class PrincipalAuthenticationMechanismType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:PrincipalAuthenticationMechanismType element """
c_tag = 'PrincipalAuthenticationMechanismType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Token'] = (
'token', Token)
c_child_order.extend(['token'])
def __init__(self,
token=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.token = token
def principal_authentication_mechanism_type__from_string(xml_string):
return saml2.create_class_from_xml_string(
PrincipalAuthenticationMechanismType_, xml_string)
class WrittenConsent(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:WrittenConsent element """
c_tag = 'WrittenConsent'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def written_consent_from_string(xml_string):
return saml2.create_class_from_xml_string(WrittenConsent, xml_string)
class SubscriberLineNumber(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SubscriberLineNumber element """
c_tag = 'SubscriberLineNumber'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def subscriber_line_number_from_string(xml_string):
return saml2.create_class_from_xml_string(SubscriberLineNumber, xml_string)
class UserSuffix(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:UserSuffix element """
c_tag = 'UserSuffix'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def user_suffix_from_string(xml_string):
return saml2.create_class_from_xml_string(UserSuffix, xml_string)
class Password(PasswordType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Password element """
c_tag = 'Password'
c_namespace = NAMESPACE
c_children = PasswordType_.c_children.copy()
c_attributes = PasswordType_.c_attributes.copy()
c_child_order = PasswordType_.c_child_order[:]
c_cardinality = PasswordType_.c_cardinality.copy()
def password_from_string(xml_string):
return saml2.create_class_from_xml_string(Password, xml_string)
class Smartcard(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Smartcard element """
c_tag = 'Smartcard'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def smartcard_from_string(xml_string):
return saml2.create_class_from_xml_string(Smartcard, xml_string)
class ActivationLimit(ActivationLimitType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ActivationLimit element """
c_tag = 'ActivationLimit'
c_namespace = NAMESPACE
c_children = ActivationLimitType_.c_children.copy()
c_attributes = ActivationLimitType_.c_attributes.copy()
c_child_order = ActivationLimitType_.c_child_order[:]
c_cardinality = ActivationLimitType_.c_cardinality.copy()
def activation_limit_from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationLimit, xml_string)
class PrincipalAuthenticationMechanism(PrincipalAuthenticationMechanismType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:PrincipalAuthenticationMechanism element """
c_tag = 'PrincipalAuthenticationMechanism'
c_namespace = NAMESPACE
c_children = PrincipalAuthenticationMechanismType_.c_children.copy()
c_attributes = PrincipalAuthenticationMechanismType_.c_attributes.copy()
c_child_order = PrincipalAuthenticationMechanismType_.c_child_order[:]
c_cardinality = PrincipalAuthenticationMechanismType_.c_cardinality.copy()
def principal_authentication_mechanism_from_string(xml_string):
return saml2.create_class_from_xml_string(PrincipalAuthenticationMechanism,
xml_string)
class PreviousSession(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:PreviousSession element """
c_tag = 'PreviousSession'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def previous_session_from_string(xml_string):
return saml2.create_class_from_xml_string(PreviousSession, xml_string)
class ResumeSession(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ResumeSession element """
c_tag = 'ResumeSession'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def resume_session_from_string(xml_string):
return saml2.create_class_from_xml_string(ResumeSession, xml_string)
class ZeroKnowledge(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ZeroKnowledge element """
c_tag = 'ZeroKnowledge'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def zero_knowledge_from_string(xml_string):
return saml2.create_class_from_xml_string(ZeroKnowledge, xml_string)
class SharedSecretChallengeResponse(SharedSecretChallengeResponseType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SharedSecretChallengeResponse element """
c_tag = 'SharedSecretChallengeResponse'
c_namespace = NAMESPACE
c_children = SharedSecretChallengeResponseType_.c_children.copy()
c_attributes = SharedSecretChallengeResponseType_.c_attributes.copy()
c_child_order = SharedSecretChallengeResponseType_.c_child_order[:]
c_cardinality = SharedSecretChallengeResponseType_.c_cardinality.copy()
def shared_secret_challenge_response_from_string(xml_string):
return saml2.create_class_from_xml_string(SharedSecretChallengeResponse,
xml_string)
class DigSig(PublicKeyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:DigSig element """
c_tag = 'DigSig'
c_namespace = NAMESPACE
c_children = PublicKeyType_.c_children.copy()
c_attributes = PublicKeyType_.c_attributes.copy()
c_child_order = PublicKeyType_.c_child_order[:]
c_cardinality = PublicKeyType_.c_cardinality.copy()
def dig_sig_from_string(xml_string):
return saml2.create_class_from_xml_string(DigSig, xml_string)
class AsymmetricDecryption(PublicKeyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AsymmetricDecryption element """
c_tag = 'AsymmetricDecryption'
c_namespace = NAMESPACE
c_children = PublicKeyType_.c_children.copy()
c_attributes = PublicKeyType_.c_attributes.copy()
c_child_order = PublicKeyType_.c_child_order[:]
c_cardinality = PublicKeyType_.c_cardinality.copy()
def asymmetric_decryption_from_string(xml_string):
return saml2.create_class_from_xml_string(AsymmetricDecryption, xml_string)
class AsymmetricKeyAgreement(PublicKeyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AsymmetricKeyAgreement element """
c_tag = 'AsymmetricKeyAgreement'
c_namespace = NAMESPACE
c_children = PublicKeyType_.c_children.copy()
c_attributes = PublicKeyType_.c_attributes.copy()
c_child_order = PublicKeyType_.c_child_order[:]
c_cardinality = PublicKeyType_.c_cardinality.copy()
def asymmetric_key_agreement_from_string(xml_string):
return saml2.create_class_from_xml_string(AsymmetricKeyAgreement,
xml_string)
class IPAddress(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:IPAddress element """
c_tag = 'IPAddress'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def ip_address_from_string(xml_string):
return saml2.create_class_from_xml_string(IPAddress, xml_string)
class SharedSecretDynamicPlaintext(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SharedSecretDynamicPlaintext element """
c_tag = 'SharedSecretDynamicPlaintext'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def shared_secret_dynamic_plaintext_from_string(xml_string):
return saml2.create_class_from_xml_string(SharedSecretDynamicPlaintext,
xml_string)
class HTTP(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:HTTP element """
c_tag = 'HTTP'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def http_from_string(xml_string):
return saml2.create_class_from_xml_string(HTTP, xml_string)
class IPSec(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:IPSec element """
c_tag = 'IPSec'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def ip_sec_from_string(xml_string):
return saml2.create_class_from_xml_string(IPSec, xml_string)
class WTLS(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:WTLS element """
c_tag = 'WTLS'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def wtls_from_string(xml_string):
return saml2.create_class_from_xml_string(WTLS, xml_string)
class MobileNetworkNoEncryption(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:MobileNetworkNoEncryption element """
c_tag = 'MobileNetworkNoEncryption'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def mobile_network_no_encryption_from_string(xml_string):
return saml2.create_class_from_xml_string(MobileNetworkNoEncryption,
xml_string)
class MobileNetworkRadioEncryption(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:MobileNetworkRadioEncryption element """
c_tag = 'MobileNetworkRadioEncryption'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def mobile_network_radio_encryption_from_string(xml_string):
return saml2.create_class_from_xml_string(MobileNetworkRadioEncryption,
xml_string)
class MobileNetworkEndToEndEncryption(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:MobileNetworkEndToEndEncryption element """
c_tag = 'MobileNetworkEndToEndEncryption'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def mobile_network_end_to_end_encryption_from_string(xml_string):
return saml2.create_class_from_xml_string(MobileNetworkEndToEndEncryption,
xml_string)
class SSL(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SSL element """
c_tag = 'SSL'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def ssl_from_string(xml_string):
return saml2.create_class_from_xml_string(SSL, xml_string)
class PSTN(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:PSTN element """
c_tag = 'PSTN'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def pstn_from_string(xml_string):
return saml2.create_class_from_xml_string(PSTN, xml_string)
class ISDN(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ISDN element """
c_tag = 'ISDN'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def isdn_from_string(xml_string):
return saml2.create_class_from_xml_string(ISDN, xml_string)
class ADSL(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ADSL element """
c_tag = 'ADSL'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def adsl_from_string(xml_string):
return saml2.create_class_from_xml_string(ADSL, xml_string)
class SwitchAudit(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SwitchAudit element """
c_tag = 'SwitchAudit'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def switch_audit_from_string(xml_string):
return saml2.create_class_from_xml_string(SwitchAudit, xml_string)
class DeactivationCallCenter(ExtensionOnlyType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:DeactivationCallCenter element """
c_tag = 'DeactivationCallCenter'
c_namespace = NAMESPACE
c_children = ExtensionOnlyType_.c_children.copy()
c_attributes = ExtensionOnlyType_.c_attributes.copy()
c_child_order = ExtensionOnlyType_.c_child_order[:]
c_cardinality = ExtensionOnlyType_.c_cardinality.copy()
def deactivation_call_center_from_string(xml_string):
return saml2.create_class_from_xml_string(DeactivationCallCenter,
xml_string)
class IdentificationType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:IdentificationType element """
c_tag = 'IdentificationType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}PhysicalVerification'] = (
'physical_verification', PhysicalVerification)
c_cardinality['physical_verification'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}WrittenConsent'] = (
'written_consent', WrittenConsent)
c_cardinality['written_consent'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}GoverningAgreements'] = (
'governing_agreements', GoverningAgreements)
c_cardinality['governing_agreements'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_attributes['nym'] = ('nym', NymType_, False)
c_child_order.extend(
['physical_verification', 'written_consent', 'governing_agreements',
'extension'])
def __init__(self,
physical_verification=None,
written_consent=None,
governing_agreements=None,
extension=None,
nym=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.physical_verification = physical_verification
self.written_consent = written_consent
self.governing_agreements = governing_agreements
self.extension = extension or []
self.nym = nym
def identification_type__from_string(xml_string):
return saml2.create_class_from_xml_string(IdentificationType_, xml_string)
class AuthenticatorTransportProtocolType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AuthenticatorTransportProtocolType element """
c_tag = 'AuthenticatorTransportProtocolType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children['{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}HTTP'] = (
'http', HTTP)
c_cardinality['http'] = {"min": 0, "max": 1}
c_children['{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SSL'] = (
'ssl', SSL)
c_cardinality['ssl'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}MobileNetworkNoEncryption'] = (
'mobile_network_no_encryption', MobileNetworkNoEncryption)
c_cardinality['mobile_network_no_encryption'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}MobileNetworkRadioEncryption'] = (
'mobile_network_radio_encryption', MobileNetworkRadioEncryption)
c_cardinality['mobile_network_radio_encryption'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}MobileNetworkEndToEndEncryption'] = (
'mobile_network_end_to_end_encryption', MobileNetworkEndToEndEncryption)
c_cardinality['mobile_network_end_to_end_encryption'] = {"min": 0, "max": 1}
c_children['{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}WTLS'] = (
'wtls', WTLS)
c_cardinality['wtls'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}IPSec'] = (
'ip_sec', IPSec)
c_cardinality['ip_sec'] = {"min": 0, "max": 1}
c_children['{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}PSTN'] = (
'pstn', PSTN)
c_cardinality['pstn'] = {"min": 0, "max": 1}
c_children['{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ISDN'] = (
'isdn', ISDN)
c_cardinality['isdn'] = {"min": 0, "max": 1}
c_children['{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ADSL'] = (
'adsl', ADSL)
c_cardinality['adsl'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(['http', 'ssl', 'mobile_network_no_encryption',
'mobile_network_radio_encryption',
'mobile_network_end_to_end_encryption', 'wtls',
'ip_sec', 'pstn', 'isdn', 'adsl', 'extension'])
def __init__(self,
http=None,
ssl=None,
mobile_network_no_encryption=None,
mobile_network_radio_encryption=None,
mobile_network_end_to_end_encryption=None,
wtls=None,
ip_sec=None,
pstn=None,
isdn=None,
adsl=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.http = http
self.ssl = ssl
self.mobile_network_no_encryption = mobile_network_no_encryption
self.mobile_network_radio_encryption = mobile_network_radio_encryption
self.mobile_network_end_to_end_encryption = mobile_network_end_to_end_encryption
self.wtls = wtls
self.ip_sec = ip_sec
self.pstn = pstn
self.isdn = isdn
self.adsl = adsl
self.extension = extension or []
def authenticator_transport_protocol_type__from_string(xml_string):
return saml2.create_class_from_xml_string(
AuthenticatorTransportProtocolType_, xml_string)
class RestrictedPassword(RestrictedPasswordType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:RestrictedPassword element """
c_tag = 'RestrictedPassword'
c_namespace = NAMESPACE
c_children = RestrictedPasswordType_.c_children.copy()
c_attributes = RestrictedPasswordType_.c_attributes.copy()
c_child_order = RestrictedPasswordType_.c_child_order[:]
c_cardinality = RestrictedPasswordType_.c_cardinality.copy()
def restricted_password_from_string(xml_string):
return saml2.create_class_from_xml_string(RestrictedPassword, xml_string)
class ActivationPinType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ActivationPinType element """
c_tag = 'ActivationPinType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Length'] = (
'length', Length)
c_cardinality['length'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Alphabet'] = (
'alphabet', Alphabet)
c_cardinality['alphabet'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Generation'] = (
'generation', Generation)
c_cardinality['generation'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ActivationLimit'] = (
'activation_limit', ActivationLimit)
c_cardinality['activation_limit'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(
['length', 'alphabet', 'generation', 'activation_limit', 'extension'])
def __init__(self,
length=None,
alphabet=None,
generation=None,
activation_limit=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.length = length
self.alphabet = alphabet
self.generation = generation
self.activation_limit = activation_limit
self.extension = extension or []
def activation_pin_type__from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationPinType_, xml_string)
class SecurityAuditType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SecurityAuditType element """
c_tag = 'SecurityAuditType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SwitchAudit'] = (
'switch_audit', SwitchAudit)
c_cardinality['switch_audit'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(['switch_audit', 'extension'])
def __init__(self,
switch_audit=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.switch_audit = switch_audit
self.extension = extension or []
def security_audit_type__from_string(xml_string):
return saml2.create_class_from_xml_string(SecurityAuditType_, xml_string)
class Identification(IdentificationType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Identification element """
c_tag = 'Identification'
c_namespace = NAMESPACE
c_children = IdentificationType_.c_children.copy()
c_attributes = IdentificationType_.c_attributes.copy()
c_child_order = IdentificationType_.c_child_order[:]
c_cardinality = IdentificationType_.c_cardinality.copy()
def identification_from_string(xml_string):
return saml2.create_class_from_xml_string(Identification, xml_string)
class ActivationPin(ActivationPinType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ActivationPin element """
c_tag = 'ActivationPin'
c_namespace = NAMESPACE
c_children = ActivationPinType_.c_children.copy()
c_attributes = ActivationPinType_.c_attributes.copy()
c_child_order = ActivationPinType_.c_child_order[:]
c_cardinality = ActivationPinType_.c_cardinality.copy()
def activation_pin_from_string(xml_string):
return saml2.create_class_from_xml_string(ActivationPin, xml_string)
class AuthenticatorTransportProtocol(AuthenticatorTransportProtocolType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AuthenticatorTransportProtocol element """
c_tag = 'AuthenticatorTransportProtocol'
c_namespace = NAMESPACE
c_children = AuthenticatorTransportProtocolType_.c_children.copy()
c_attributes = AuthenticatorTransportProtocolType_.c_attributes.copy()
c_child_order = AuthenticatorTransportProtocolType_.c_child_order[:]
c_cardinality = AuthenticatorTransportProtocolType_.c_cardinality.copy()
def authenticator_transport_protocol_from_string(xml_string):
return saml2.create_class_from_xml_string(AuthenticatorTransportProtocol,
xml_string)
class SecurityAudit(SecurityAuditType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SecurityAudit element """
c_tag = 'SecurityAudit'
c_namespace = NAMESPACE
c_children = SecurityAuditType_.c_children.copy()
c_attributes = SecurityAuditType_.c_attributes.copy()
c_child_order = SecurityAuditType_.c_child_order[:]
c_cardinality = SecurityAuditType_.c_cardinality.copy()
def security_audit_from_string(xml_string):
return saml2.create_class_from_xml_string(SecurityAudit, xml_string)
class OperationalProtectionType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:OperationalProtectionType element """
c_tag = 'OperationalProtectionType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SecurityAudit'] = (
'security_audit', SecurityAudit)
c_cardinality['security_audit'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}DeactivationCallCenter'] = (
'deactivation_call_center', DeactivationCallCenter)
c_cardinality['deactivation_call_center'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(
['security_audit', 'deactivation_call_center', 'extension'])
def __init__(self,
security_audit=None,
deactivation_call_center=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.security_audit = security_audit
self.deactivation_call_center = deactivation_call_center
self.extension = extension or []
def operational_protection_type__from_string(xml_string):
return saml2.create_class_from_xml_string(OperationalProtectionType_,
xml_string)
class KeyActivationType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:KeyActivationType element """
c_tag = 'KeyActivationType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ActivationPin'] = (
'activation_pin', ActivationPin)
c_cardinality['activation_pin'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(['activation_pin', 'extension'])
def __init__(self,
activation_pin=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.activation_pin = activation_pin
self.extension = extension or []
def key_activation_type__from_string(xml_string):
return saml2.create_class_from_xml_string(KeyActivationType_, xml_string)
class KeyActivation(KeyActivationType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:KeyActivation element """
c_tag = 'KeyActivation'
c_namespace = NAMESPACE
c_children = KeyActivationType_.c_children.copy()
c_attributes = KeyActivationType_.c_attributes.copy()
c_child_order = KeyActivationType_.c_child_order[:]
c_cardinality = KeyActivationType_.c_cardinality.copy()
def key_activation_from_string(xml_string):
return saml2.create_class_from_xml_string(KeyActivation, xml_string)
class OperationalProtection(OperationalProtectionType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:OperationalProtection element """
c_tag = 'OperationalProtection'
c_namespace = NAMESPACE
c_children = OperationalProtectionType_.c_children.copy()
c_attributes = OperationalProtectionType_.c_attributes.copy()
c_child_order = OperationalProtectionType_.c_child_order[:]
c_cardinality = OperationalProtectionType_.c_cardinality.copy()
def operational_protection_from_string(xml_string):
return saml2.create_class_from_xml_string(OperationalProtection, xml_string)
class PrivateKeyProtectionType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:PrivateKeyProtectionType element """
c_tag = 'PrivateKeyProtectionType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}KeyActivation'] = (
'key_activation', KeyActivation)
c_cardinality['key_activation'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}KeyStorage'] = (
'key_storage', KeyStorage)
c_cardinality['key_storage'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}KeySharing'] = (
'key_sharing', KeySharing)
c_cardinality['key_sharing'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(
['key_activation', 'key_storage', 'key_sharing', 'extension'])
def __init__(self,
key_activation=None,
key_storage=None,
key_sharing=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.key_activation = key_activation
self.key_storage = key_storage
self.key_sharing = key_sharing
self.extension = extension or []
def private_key_protection_type__from_string(xml_string):
return saml2.create_class_from_xml_string(PrivateKeyProtectionType_,
xml_string)
class SecretKeyProtectionType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SecretKeyProtectionType element """
c_tag = 'SecretKeyProtectionType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}KeyActivation'] = (
'key_activation', KeyActivation)
c_cardinality['key_activation'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}KeyStorage'] = (
'key_storage', KeyStorage)
c_cardinality['key_storage'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(['key_activation', 'key_storage', 'extension'])
def __init__(self,
key_activation=None,
key_storage=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.key_activation = key_activation
self.key_storage = key_storage
self.extension = extension or []
def secret_key_protection_type__from_string(xml_string):
return saml2.create_class_from_xml_string(SecretKeyProtectionType_,
xml_string)
class SecretKeyProtection(SecretKeyProtectionType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:SecretKeyProtection element """
c_tag = 'SecretKeyProtection'
c_namespace = NAMESPACE
c_children = SecretKeyProtectionType_.c_children.copy()
c_attributes = SecretKeyProtectionType_.c_attributes.copy()
c_child_order = SecretKeyProtectionType_.c_child_order[:]
c_cardinality = SecretKeyProtectionType_.c_cardinality.copy()
def secret_key_protection_from_string(xml_string):
return saml2.create_class_from_xml_string(SecretKeyProtection, xml_string)
class PrivateKeyProtection(PrivateKeyProtectionType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:PrivateKeyProtection element """
c_tag = 'PrivateKeyProtection'
c_namespace = NAMESPACE
c_children = PrivateKeyProtectionType_.c_children.copy()
c_attributes = PrivateKeyProtectionType_.c_attributes.copy()
c_child_order = PrivateKeyProtectionType_.c_child_order[:]
c_cardinality = PrivateKeyProtectionType_.c_cardinality.copy()
def private_key_protection_from_string(xml_string):
return saml2.create_class_from_xml_string(PrivateKeyProtection, xml_string)
class TechnicalProtectionBaseType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:TechnicalProtectionBaseType element """
c_tag = 'TechnicalProtectionBaseType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}PrivateKeyProtection'] = (
'private_key_protection', PrivateKeyProtection)
c_cardinality['private_key_protection'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SecretKeyProtection'] = (
'secret_key_protection', SecretKeyProtection)
c_cardinality['secret_key_protection'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(
['private_key_protection', 'secret_key_protection', 'extension'])
def __init__(self,
private_key_protection=None,
secret_key_protection=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.private_key_protection = private_key_protection
self.secret_key_protection = secret_key_protection
self.extension = extension or []
def technical_protection_base_type__from_string(xml_string):
return saml2.create_class_from_xml_string(TechnicalProtectionBaseType_,
xml_string)
class TechnicalProtection(TechnicalProtectionBaseType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:TechnicalProtection element """
c_tag = 'TechnicalProtection'
c_namespace = NAMESPACE
c_children = TechnicalProtectionBaseType_.c_children.copy()
c_attributes = TechnicalProtectionBaseType_.c_attributes.copy()
c_child_order = TechnicalProtectionBaseType_.c_child_order[:]
c_cardinality = TechnicalProtectionBaseType_.c_cardinality.copy()
def technical_protection_from_string(xml_string):
return saml2.create_class_from_xml_string(TechnicalProtection, xml_string)
#..................
# ['ComplexAuthenticator', 'Authenticator', 'AuthnMethod', 'ComplexAuthenticatorType', 'AuthenticatorBaseType', 'AuthnContextDeclarationBaseType', 'AuthnMethodBaseType', 'AuthenticationContextDeclaration']
class ComplexAuthenticatorType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ComplexAuthenticatorType element """
c_tag = 'ComplexAuthenticatorType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}PreviousSession'] = (
'previous_session', PreviousSession)
c_cardinality['previous_session'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ResumeSession'] = (
'resume_session', ResumeSession)
c_cardinality['resume_session'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}DigSig'] = (
'dig_sig', DigSig)
c_cardinality['dig_sig'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Password'] = (
'password', Password)
c_cardinality['password'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}RestrictedPassword'] = (
'restricted_password', RestrictedPassword)
c_cardinality['restricted_password'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ZeroKnowledge'] = (
'zero_knowledge', ZeroKnowledge)
c_cardinality['zero_knowledge'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SharedSecretChallengeResponse'] = (
'shared_secret_challenge_response', SharedSecretChallengeResponse)
c_cardinality['shared_secret_challenge_response'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SharedSecretDynamicPlaintext'] = (
'shared_secret_dynamic_plaintext', SharedSecretDynamicPlaintext)
c_cardinality['shared_secret_dynamic_plaintext'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}IPAddress'] = (
'ip_address', IPAddress)
c_cardinality['ip_address'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}AsymmetricDecryption'] = (
'asymmetric_decryption', AsymmetricDecryption)
c_cardinality['asymmetric_decryption'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}AsymmetricKeyAgreement'] = (
'asymmetric_key_agreement', AsymmetricKeyAgreement)
c_cardinality['asymmetric_key_agreement'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SubscriberLineNumber'] = (
'subscriber_line_number', SubscriberLineNumber)
c_cardinality['subscriber_line_number'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}UserSuffix'] = (
'user_suffix', UserSuffix)
c_cardinality['user_suffix'] = {"min": 0, "max": 1}
c_cardinality['complex_authenticator'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(
['previous_session', 'resume_session', 'dig_sig', 'password',
'restricted_password', 'zero_knowledge',
'shared_secret_challenge_response', 'shared_secret_dynamic_plaintext',
'ip_address', 'asymmetric_decryption', 'asymmetric_key_agreement',
'subscriber_line_number', 'user_suffix', 'complex_authenticator',
'extension'])
def __init__(self,
previous_session=None,
resume_session=None,
dig_sig=None,
password=None,
restricted_password=None,
zero_knowledge=None,
shared_secret_challenge_response=None,
shared_secret_dynamic_plaintext=None,
ip_address=None,
asymmetric_decryption=None,
asymmetric_key_agreement=None,
subscriber_line_number=None,
user_suffix=None,
complex_authenticator=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.previous_session = previous_session
self.resume_session = resume_session
self.dig_sig = dig_sig
self.password = password
self.restricted_password = restricted_password
self.zero_knowledge = zero_knowledge
self.shared_secret_challenge_response = shared_secret_challenge_response
self.shared_secret_dynamic_plaintext = shared_secret_dynamic_plaintext
self.ip_address = ip_address
self.asymmetric_decryption = asymmetric_decryption
self.asymmetric_key_agreement = asymmetric_key_agreement
self.subscriber_line_number = subscriber_line_number
self.user_suffix = user_suffix
self.complex_authenticator = complex_authenticator
self.extension = extension or []
def complex_authenticator_type__from_string(xml_string):
return saml2.create_class_from_xml_string(ComplexAuthenticatorType_,
xml_string)
class ComplexAuthenticator(ComplexAuthenticatorType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:ComplexAuthenticator element """
c_tag = 'ComplexAuthenticator'
c_namespace = NAMESPACE
c_children = ComplexAuthenticatorType_.c_children.copy()
c_attributes = ComplexAuthenticatorType_.c_attributes.copy()
c_child_order = ComplexAuthenticatorType_.c_child_order[:]
c_cardinality = ComplexAuthenticatorType_.c_cardinality.copy()
def complex_authenticator_from_string(xml_string):
return saml2.create_class_from_xml_string(ComplexAuthenticator, xml_string)
class AuthenticatorBaseType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AuthenticatorBaseType element """
c_tag = 'AuthenticatorBaseType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}PreviousSession'] = (
'previous_session', PreviousSession)
c_cardinality['previous_session'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ResumeSession'] = (
'resume_session', ResumeSession)
c_cardinality['resume_session'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}DigSig'] = (
'dig_sig', DigSig)
c_cardinality['dig_sig'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Password'] = (
'password', Password)
c_cardinality['password'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}RestrictedPassword'] = (
'restricted_password', RestrictedPassword)
c_cardinality['restricted_password'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ZeroKnowledge'] = (
'zero_knowledge', ZeroKnowledge)
c_cardinality['zero_knowledge'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SharedSecretChallengeResponse'] = (
'shared_secret_challenge_response', SharedSecretChallengeResponse)
c_cardinality['shared_secret_challenge_response'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SharedSecretDynamicPlaintext'] = (
'shared_secret_dynamic_plaintext', SharedSecretDynamicPlaintext)
c_cardinality['shared_secret_dynamic_plaintext'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}IPAddress'] = (
'ip_address', IPAddress)
c_cardinality['ip_address'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}AsymmetricDecryption'] = (
'asymmetric_decryption', AsymmetricDecryption)
c_cardinality['asymmetric_decryption'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}AsymmetricKeyAgreement'] = (
'asymmetric_key_agreement', AsymmetricKeyAgreement)
c_cardinality['asymmetric_key_agreement'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}SubscriberLineNumber'] = (
'subscriber_line_number', SubscriberLineNumber)
c_cardinality['subscriber_line_number'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}UserSuffix'] = (
'user_suffix', UserSuffix)
c_cardinality['user_suffix'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ComplexAuthenticator'] = (
'complex_authenticator', ComplexAuthenticator)
c_cardinality['complex_authenticator'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(
['previous_session', 'resume_session', 'dig_sig', 'password',
'restricted_password', 'zero_knowledge',
'shared_secret_challenge_response', 'shared_secret_dynamic_plaintext',
'ip_address', 'asymmetric_decryption', 'asymmetric_key_agreement',
'subscriber_line_number', 'user_suffix', 'complex_authenticator',
'extension'])
def __init__(self,
previous_session=None,
resume_session=None,
dig_sig=None,
password=None,
restricted_password=None,
zero_knowledge=None,
shared_secret_challenge_response=None,
shared_secret_dynamic_plaintext=None,
ip_address=None,
asymmetric_decryption=None,
asymmetric_key_agreement=None,
subscriber_line_number=None,
user_suffix=None,
complex_authenticator=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.previous_session = previous_session
self.resume_session = resume_session
self.dig_sig = dig_sig
self.password = password
self.restricted_password = restricted_password
self.zero_knowledge = zero_knowledge
self.shared_secret_challenge_response = shared_secret_challenge_response
self.shared_secret_dynamic_plaintext = shared_secret_dynamic_plaintext
self.ip_address = ip_address
self.asymmetric_decryption = asymmetric_decryption
self.asymmetric_key_agreement = asymmetric_key_agreement
self.subscriber_line_number = subscriber_line_number
self.user_suffix = user_suffix
self.complex_authenticator = complex_authenticator
self.extension = extension or []
def authenticator_base_type__from_string(xml_string):
return saml2.create_class_from_xml_string(AuthenticatorBaseType_,
xml_string)
class Authenticator(AuthenticatorBaseType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:Authenticator element """
c_tag = 'Authenticator'
c_namespace = NAMESPACE
c_children = AuthenticatorBaseType_.c_children.copy()
c_attributes = AuthenticatorBaseType_.c_attributes.copy()
c_child_order = AuthenticatorBaseType_.c_child_order[:]
c_cardinality = AuthenticatorBaseType_.c_cardinality.copy()
def authenticator_from_string(xml_string):
return saml2.create_class_from_xml_string(Authenticator, xml_string)
class AuthnMethodBaseType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AuthnMethodBaseType element """
c_tag = 'AuthnMethodBaseType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}PrincipalAuthenticationMechanism'] = (
'principal_authentication_mechanism', PrincipalAuthenticationMechanism)
c_cardinality['principal_authentication_mechanism'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Authenticator'] = (
'authenticator', Authenticator)
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}AuthenticatorTransportProtocol'] = (
'authenticator_transport_protocol', AuthenticatorTransportProtocol)
c_cardinality['authenticator_transport_protocol'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_child_order.extend(['principal_authentication_mechanism', 'authenticator',
'authenticator_transport_protocol', 'extension'])
def __init__(self,
principal_authentication_mechanism=None,
authenticator=None,
authenticator_transport_protocol=None,
extension=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.principal_authentication_mechanism = principal_authentication_mechanism
self.authenticator = authenticator
self.authenticator_transport_protocol = authenticator_transport_protocol
self.extension = extension or []
def authn_method_base_type__from_string(xml_string):
return saml2.create_class_from_xml_string(AuthnMethodBaseType_, xml_string)
class AuthnMethod(AuthnMethodBaseType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AuthnMethod element """
c_tag = 'AuthnMethod'
c_namespace = NAMESPACE
c_children = AuthnMethodBaseType_.c_children.copy()
c_attributes = AuthnMethodBaseType_.c_attributes.copy()
c_child_order = AuthnMethodBaseType_.c_child_order[:]
c_cardinality = AuthnMethodBaseType_.c_cardinality.copy()
def authn_method_from_string(xml_string):
return saml2.create_class_from_xml_string(AuthnMethod, xml_string)
class AuthnContextDeclarationBaseType_(SamlBase):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AuthnContextDeclarationBaseType element """
c_tag = 'AuthnContextDeclarationBaseType'
c_namespace = NAMESPACE
c_children = SamlBase.c_children.copy()
c_attributes = SamlBase.c_attributes.copy()
c_child_order = SamlBase.c_child_order[:]
c_cardinality = SamlBase.c_cardinality.copy()
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Identification'] = (
'identification', Identification)
c_cardinality['identification'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}TechnicalProtection'] = (
'technical_protection', TechnicalProtection)
c_cardinality['technical_protection'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}OperationalProtection'] = (
'operational_protection', OperationalProtection)
c_cardinality['operational_protection'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}AuthnMethod'] = (
'authn_method', AuthnMethod)
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}GoverningAgreements'] = (
'governing_agreements', GoverningAgreements)
c_cardinality['governing_agreements'] = {"min": 0, "max": 1}
c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}Extension'] = (
'extension', [Extension])
c_cardinality['extension'] = {"min": 0}
c_attributes['ID'] = ('id', 'ID', False)
c_child_order.extend(
['identification', 'technical_protection', 'operational_protection',
'authn_method', 'governing_agreements', 'extension'])
def __init__(self,
identification=None,
technical_protection=None,
operational_protection=None,
authn_method=None,
governing_agreements=None,
extension=None,
id=None,
text=None,
extension_elements=None,
extension_attributes=None,
):
SamlBase.__init__(self,
text=text,
extension_elements=extension_elements,
extension_attributes=extension_attributes,
)
self.identification = identification
self.technical_protection = technical_protection
self.operational_protection = operational_protection
self.authn_method = authn_method
self.governing_agreements = governing_agreements
self.extension = extension or []
self.id = id
def authn_context_declaration_base_type__from_string(xml_string):
return saml2.create_class_from_xml_string(AuthnContextDeclarationBaseType_,
xml_string)
class AuthenticationContextDeclaration(AuthnContextDeclarationBaseType_):
"""The urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken:AuthenticationContextDeclaration element """
c_tag = 'AuthenticationContextDeclaration'
c_namespace = NAMESPACE
c_children = AuthnContextDeclarationBaseType_.c_children.copy()
c_attributes = AuthnContextDeclarationBaseType_.c_attributes.copy()
c_child_order = AuthnContextDeclarationBaseType_.c_child_order[:]
c_cardinality = AuthnContextDeclarationBaseType_.c_cardinality.copy()
def authentication_context_declaration_from_string(xml_string):
return saml2.create_class_from_xml_string(AuthenticationContextDeclaration,
xml_string)
# ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
ComplexAuthenticatorType_.c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ComplexAuthenticator'] = (
'complex_authenticator', ComplexAuthenticator)
ComplexAuthenticator.c_children[
'{urn:oasis:names:tc:SAML:2.0:ac:classes:TimeSyncToken}ComplexAuthenticator'] = (
'complex_authenticator', ComplexAuthenticator)
# ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
ELEMENT_FROM_STRING = {
AuthenticationContextDeclaration.c_tag: authentication_context_declaration_from_string,
Identification.c_tag: identification_from_string,
PhysicalVerification.c_tag: physical_verification_from_string,
WrittenConsent.c_tag: written_consent_from_string,
TechnicalProtection.c_tag: technical_protection_from_string,
SecretKeyProtection.c_tag: secret_key_protection_from_string,
PrivateKeyProtection.c_tag: private_key_protection_from_string,
KeyActivation.c_tag: key_activation_from_string,
KeySharing.c_tag: key_sharing_from_string,
KeyStorage.c_tag: key_storage_from_string,
SubscriberLineNumber.c_tag: subscriber_line_number_from_string,
UserSuffix.c_tag: user_suffix_from_string,
Password.c_tag: password_from_string,
ActivationPin.c_tag: activation_pin_from_string,
Token.c_tag: token_from_string,
TimeSyncToken.c_tag: time_sync_token_from_string,
Smartcard.c_tag: smartcard_from_string,
Length.c_tag: length_from_string,
ActivationLimit.c_tag: activation_limit_from_string,
Generation.c_tag: generation_from_string,
AuthnMethod.c_tag: authn_method_from_string,
PrincipalAuthenticationMechanism.c_tag: principal_authentication_mechanism_from_string,
Authenticator.c_tag: authenticator_from_string,
ComplexAuthenticator.c_tag: complex_authenticator_from_string,
PreviousSession.c_tag: previous_session_from_string,
ResumeSession.c_tag: resume_session_from_string,
ZeroKnowledge.c_tag: zero_knowledge_from_string,
SharedSecretChallengeResponse.c_tag: shared_secret_challenge_response_from_string,
SharedSecretChallengeResponseType_.c_tag: shared_secret_challenge_response_type__from_string,
DigSig.c_tag: dig_sig_from_string,
AsymmetricDecryption.c_tag: asymmetric_decryption_from_string,
AsymmetricKeyAgreement.c_tag: asymmetric_key_agreement_from_string,
PublicKeyType_.c_tag: public_key_type__from_string,
IPAddress.c_tag: ip_address_from_string,
SharedSecretDynamicPlaintext.c_tag: shared_secret_dynamic_plaintext_from_string,
AuthenticatorTransportProtocol.c_tag: authenticator_transport_protocol_from_string,
HTTP.c_tag: http_from_string,
IPSec.c_tag: ip_sec_from_string,
WTLS.c_tag: wtls_from_string,
MobileNetworkNoEncryption.c_tag: mobile_network_no_encryption_from_string,
MobileNetworkRadioEncryption.c_tag: mobile_network_radio_encryption_from_string,
MobileNetworkEndToEndEncryption.c_tag: mobile_network_end_to_end_encryption_from_string,
SSL.c_tag: ssl_from_string,
PSTN.c_tag: pstn_from_string,
ISDN.c_tag: isdn_from_string,
ADSL.c_tag: adsl_from_string,
OperationalProtection.c_tag: operational_protection_from_string,
SecurityAudit.c_tag: security_audit_from_string,
SwitchAudit.c_tag: switch_audit_from_string,
DeactivationCallCenter.c_tag: deactivation_call_center_from_string,
GoverningAgreements.c_tag: governing_agreements_from_string,
GoverningAgreementRef.c_tag: governing_agreement_ref_from_string,
NymType_.c_tag: nym_type__from_string,
IdentificationType_.c_tag: identification_type__from_string,
TechnicalProtectionBaseType_.c_tag: technical_protection_base_type__from_string,
OperationalProtectionType_.c_tag: operational_protection_type__from_string,
GoverningAgreementsType_.c_tag: governing_agreements_type__from_string,
GoverningAgreementRefType_.c_tag: governing_agreement_ref_type__from_string,
AuthenticatorBaseType_.c_tag: authenticator_base_type__from_string,
ComplexAuthenticatorType_.c_tag: complex_authenticator_type__from_string,
AuthenticatorTransportProtocolType_.c_tag: authenticator_transport_protocol_type__from_string,
KeyActivationType_.c_tag: key_activation_type__from_string,
KeySharingType_.c_tag: key_sharing_type__from_string,
PrivateKeyProtectionType_.c_tag: private_key_protection_type__from_string,
PasswordType_.c_tag: password_type__from_string,
RestrictedPassword.c_tag: restricted_password_from_string,
RestrictedPasswordType_.c_tag: restricted_password_type__from_string,
RestrictedLengthType_.c_tag: restricted_length_type__from_string,
ActivationPinType_.c_tag: activation_pin_type__from_string,
Alphabet.c_tag: alphabet_from_string,
AlphabetType_.c_tag: alphabet_type__from_string,
DeviceTypeType_.c_tag: device_type_type__from_string,
BooleanType_.c_tag: boolean_type__from_string,
ActivationLimitType_.c_tag: activation_limit_type__from_string,
ActivationLimitDuration.c_tag: activation_limit_duration_from_string,
ActivationLimitUsages.c_tag: activation_limit_usages_from_string,
ActivationLimitSession.c_tag: activation_limit_session_from_string,
ActivationLimitDurationType_.c_tag: activation_limit_duration_type__from_string,
ActivationLimitUsagesType_.c_tag: activation_limit_usages_type__from_string,
ActivationLimitSessionType_.c_tag: activation_limit_session_type__from_string,
LengthType_.c_tag: length_type__from_string,
MediumType_.c_tag: medium_type__from_string,
KeyStorageType_.c_tag: key_storage_type__from_string,
SecretKeyProtectionType_.c_tag: secret_key_protection_type__from_string,
SecurityAuditType_.c_tag: security_audit_type__from_string,
ExtensionOnlyType_.c_tag: extension_only_type__from_string,
Extension.c_tag: extension_from_string,
ExtensionType_.c_tag: extension_type__from_string,
AuthnContextDeclarationBaseType_.c_tag: authn_context_declaration_base_type__from_string,
AuthnMethodBaseType_.c_tag: authn_method_base_type__from_string,
PrincipalAuthenticationMechanismType_.c_tag: principal_authentication_mechanism_type__from_string,
TokenType_.c_tag: token_type__from_string,
TimeSyncTokenType_.c_tag: time_sync_token_type__from_string,
}
ELEMENT_BY_TAG = {
'AuthenticationContextDeclaration': AuthenticationContextDeclaration,
'Identification': Identification,
'PhysicalVerification': PhysicalVerification,
'WrittenConsent': WrittenConsent,
'TechnicalProtection': TechnicalProtection,
'SecretKeyProtection': SecretKeyProtection,
'PrivateKeyProtection': PrivateKeyProtection,
'KeyActivation': KeyActivation,
'KeySharing': KeySharing,
'KeyStorage': KeyStorage,
'SubscriberLineNumber': SubscriberLineNumber,
'UserSuffix': UserSuffix,
'Password': Password,
'ActivationPin': ActivationPin,
'Token': Token,
'TimeSyncToken': TimeSyncToken,
'Smartcard': Smartcard,
'Length': Length,
'ActivationLimit': ActivationLimit,
'Generation': Generation,
'AuthnMethod': AuthnMethod,
'PrincipalAuthenticationMechanism': PrincipalAuthenticationMechanism,
'Authenticator': Authenticator,
'ComplexAuthenticator': ComplexAuthenticator,
'PreviousSession': PreviousSession,
'ResumeSession': ResumeSession,
'ZeroKnowledge': ZeroKnowledge,
'SharedSecretChallengeResponse': SharedSecretChallengeResponse,
'SharedSecretChallengeResponseType': SharedSecretChallengeResponseType_,
'DigSig': DigSig,
'AsymmetricDecryption': AsymmetricDecryption,
'AsymmetricKeyAgreement': AsymmetricKeyAgreement,
'PublicKeyType': PublicKeyType_,
'IPAddress': IPAddress,
'SharedSecretDynamicPlaintext': SharedSecretDynamicPlaintext,
'AuthenticatorTransportProtocol': AuthenticatorTransportProtocol,
'HTTP': HTTP,
'IPSec': IPSec,
'WTLS': WTLS,
'MobileNetworkNoEncryption': MobileNetworkNoEncryption,
'MobileNetworkRadioEncryption': MobileNetworkRadioEncryption,
'MobileNetworkEndToEndEncryption': MobileNetworkEndToEndEncryption,
'SSL': SSL,
'PSTN': PSTN,
'ISDN': ISDN,
'ADSL': ADSL,
'OperationalProtection': OperationalProtection,
'SecurityAudit': SecurityAudit,
'SwitchAudit': SwitchAudit,
'DeactivationCallCenter': DeactivationCallCenter,
'GoverningAgreements': GoverningAgreements,
'GoverningAgreementRef': GoverningAgreementRef,
'nymType': NymType_,
'IdentificationType': IdentificationType_,
'TechnicalProtectionBaseType': TechnicalProtectionBaseType_,
'OperationalProtectionType': OperationalProtectionType_,
'GoverningAgreementsType': GoverningAgreementsType_,
'GoverningAgreementRefType': GoverningAgreementRefType_,
'AuthenticatorBaseType': AuthenticatorBaseType_,
'ComplexAuthenticatorType': ComplexAuthenticatorType_,
'AuthenticatorTransportProtocolType': AuthenticatorTransportProtocolType_,
'KeyActivationType': KeyActivationType_,
'KeySharingType': KeySharingType_,
'PrivateKeyProtectionType': PrivateKeyProtectionType_,
'PasswordType': PasswordType_,
'RestrictedPassword': RestrictedPassword,
'RestrictedPasswordType': RestrictedPasswordType_,
'RestrictedLengthType': RestrictedLengthType_,
'ActivationPinType': ActivationPinType_,
'Alphabet': Alphabet,
'AlphabetType': AlphabetType_,
'DeviceTypeType': DeviceTypeType_,
'booleanType': BooleanType_,
'ActivationLimitType': ActivationLimitType_,
'ActivationLimitDuration': ActivationLimitDuration,
'ActivationLimitUsages': ActivationLimitUsages,
'ActivationLimitSession': ActivationLimitSession,
'ActivationLimitDurationType': ActivationLimitDurationType_,
'ActivationLimitUsagesType': ActivationLimitUsagesType_,
'ActivationLimitSessionType': ActivationLimitSessionType_,
'LengthType': LengthType_,
'mediumType': MediumType_,
'KeyStorageType': KeyStorageType_,
'SecretKeyProtectionType': SecretKeyProtectionType_,
'SecurityAuditType': SecurityAuditType_,
'ExtensionOnlyType': ExtensionOnlyType_,
'Extension': Extension,
'ExtensionType': ExtensionType_,
'AuthnContextDeclarationBaseType': AuthnContextDeclarationBaseType_,
'AuthnMethodBaseType': AuthnMethodBaseType_,
'PrincipalAuthenticationMechanismType': PrincipalAuthenticationMechanismType_,
'TokenType': TokenType_,
'TimeSyncTokenType': TimeSyncTokenType_,
}
def factory(tag, **kwargs):
return ELEMENT_BY_TAG[tag](**kwargs) | unknown | codeparrot/codeparrot-clean | ||
/* Copyright 2016 The TensorFlow Authors All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
// Build a graph structure based on op inputs/outputs. The graph is a directed
// acyclic graph pointing *from outputs to inputs*.
#ifndef TENSORFLOW_CORE_PROFILER_INTERNAL_TFPROF_GRAPH_H_
#define TENSORFLOW_CORE_PROFILER_INTERNAL_TFPROF_GRAPH_H_
#include <deque>
#include <map>
#include <memory>
#include <set>
#include <string>
#include <vector>
#include "tensorflow/core/lib/core/errors.h"
#include "tensorflow/core/profiler/internal/tfprof_node.h"
#include "tensorflow/core/profiler/internal/tfprof_show.h"
#include "tensorflow/core/profiler/internal/tfprof_utils.h"
#include "tensorflow/core/profiler/tfprof_options.h"
#include "tensorflow/core/profiler/tfprof_output.pb.h"
namespace tensorflow {
namespace tfprof {
// Organize tensorflow ops in a graph structure, pointing from output ops
// to input ops.
class TFGraph : public TFShow {
public:
explicit TFGraph(checkpoint::CheckpointReader* ckpt_reader)
: TFShow(ckpt_reader), root_(nullptr) {}
~TFGraph() override = default;
void AddNode(TFGraphNode* node) override;
void Build() override;
private:
const ShowNode* ShowInternal(const Options& opts,
Timeline* timeline) override;
bool ShouldShowIfExtra(const ShowNode* node, const Options& opts,
int depth) const override {
return true;
}
GraphNode* CreateParentNode(const std::string& name);
std::vector<GraphNode*> SearchRoot(const std::vector<GraphNode*>& roots,
const std::vector<std::string>& regexes,
std::set<std::string>* visited);
std::vector<GraphNode*> PrintGraph(std::vector<GraphNode*> roots,
const Options& opts, int depth,
int last_ident,
std::set<std::string>* visits);
std::vector<GraphNode*> Account(const std::vector<GraphNode*>& roots,
const Options& opts,
std::set<std::string>* visits);
void Format(std::vector<GraphNode*> roots, std::string* display_str,
GraphNodeProto* proto);
MemoryTracker memory_tracker_;
GraphNode* root_;
std::vector<std::unique_ptr<NodeDef>> node_defs_;
std::map<std::string, std::unique_ptr<TFGraphNode>> parent_nodes_;
std::map<std::string, std::unique_ptr<GraphNode>> nodes_map_;
};
} // namespace tfprof
} // namespace tensorflow
#endif // TENSORFLOW_CORE_PROFILER_INTERNAL_TFPROF_GRAPH_H_ | c | github | https://github.com/tensorflow/tensorflow | tensorflow/core/profiler/internal/tfprof_graph.h |
#!/usr/bin/env python2
# vim:fileencoding=utf-8
# License: GPLv3 Copyright: 2016, Kovid Goyal <kovid at kovidgoyal.net>
from __future__ import (unicode_literals, division, absolute_import,
print_function)
import os, string, _winreg as winreg, re, sys
from collections import namedtuple, defaultdict
from operator import itemgetter
from ctypes import (
Structure, POINTER, c_ubyte, windll, byref, c_void_p, WINFUNCTYPE, c_uint,
WinError, get_last_error, sizeof, c_wchar, create_string_buffer, cast,
memset, wstring_at, addressof, create_unicode_buffer, string_at, c_uint64 as QWORD
)
from ctypes.wintypes import DWORD, WORD, ULONG, LPCWSTR, HWND, BOOL, LPWSTR, UINT, BYTE, HANDLE, USHORT
from pprint import pprint, pformat
from future_builtins import map
from calibre import prints, as_unicode
is64bit = sys.maxsize > (1 << 32)
# Data and function type definitions {{{
class GUID(Structure):
_fields_ = [
("data1", DWORD),
("data2", WORD),
("data3", WORD),
("data4", c_ubyte * 8)]
def __init__(self, l, w1, w2, b1, b2, b3, b4, b5, b6, b7, b8):
self.data1 = l
self.data2 = w1
self.data3 = w2
self.data4[0] = b1
self.data4[1] = b2
self.data4[2] = b3
self.data4[3] = b4
self.data4[4] = b5
self.data4[5] = b6
self.data4[6] = b7
self.data4[7] = b8
def __str__(self):
return "{%08x-%04x-%04x-%s-%s}" % (
self.data1,
self.data2,
self.data3,
''.join(["%02x" % d for d in self.data4[:2]]),
''.join(["%02x" % d for d in self.data4[2:]]),
)
CONFIGRET = DWORD
DEVINST = DWORD
LPDWORD = POINTER(DWORD)
LPVOID = c_void_p
REG_QWORD = 11
IOCTL_STORAGE_MEDIA_REMOVAL = 0x2D4804
IOCTL_STORAGE_EJECT_MEDIA = 0x2D4808
IOCTL_STORAGE_GET_DEVICE_NUMBER = 0x2D1080
def CTL_CODE(DeviceType, Function, Method, Access):
return (DeviceType << 16) | (Access << 14) | (Function << 2) | Method
def USB_CTL(id):
# CTL_CODE(FILE_DEVICE_USB, (id), METHOD_BUFFERED, FILE_ANY_ACCESS)
return CTL_CODE(0x22, id, 0, 0)
IOCTL_USB_GET_ROOT_HUB_NAME = USB_CTL(258)
IOCTL_USB_GET_NODE_INFORMATION = USB_CTL(258)
IOCTL_USB_GET_NODE_CONNECTION_INFORMATION = USB_CTL(259)
IOCTL_USB_GET_NODE_CONNECTION_INFORMATION_EX = USB_CTL(274)
IOCTL_USB_GET_NODE_CONNECTION_DRIVERKEY_NAME = USB_CTL(264)
IOCTL_USB_GET_NODE_CONNECTION_NAME = USB_CTL(261)
IOCTL_USB_GET_DESCRIPTOR_FROM_NODE_CONNECTION = USB_CTL(260)
USB_CONFIGURATION_DESCRIPTOR_TYPE = 2
USB_STRING_DESCRIPTOR_TYPE = 3
USB_INTERFACE_DESCRIPTOR_TYPE = 4
USB_REQUEST_GET_DESCRIPTOR = 0x06
MAXIMUM_USB_STRING_LENGTH = 255
StorageDeviceNumber = namedtuple('StorageDeviceNumber', 'type number partition_number')
class STORAGE_DEVICE_NUMBER(Structure):
_fields_ = [
('DeviceType', DWORD),
('DeviceNumber', ULONG),
('PartitionNumber', ULONG)
]
def as_tuple(self):
return StorageDeviceNumber(self.DeviceType, self.DeviceNumber, self.PartitionNumber)
class SP_DEVINFO_DATA(Structure):
_fields_ = [
('cbSize', DWORD),
('ClassGuid', GUID),
('DevInst', DEVINST),
('Reserved', POINTER(ULONG)),
]
def __str__(self):
return "ClassGuid:%s DevInst:%s" % (self.ClassGuid, self.DevInst)
PSP_DEVINFO_DATA = POINTER(SP_DEVINFO_DATA)
class SP_DEVICE_INTERFACE_DATA(Structure):
_fields_ = [
('cbSize', DWORD),
('InterfaceClassGuid', GUID),
('Flags', DWORD),
('Reserved', POINTER(ULONG)),
]
def __str__(self):
return "InterfaceClassGuid:%s Flags:%s" % (self.InterfaceClassGuid, self.Flags)
ANYSIZE_ARRAY = 1
class SP_DEVICE_INTERFACE_DETAIL_DATA(Structure):
_fields_ = [
("cbSize", DWORD),
("DevicePath", c_wchar*ANYSIZE_ARRAY)
]
UCHAR = c_ubyte
class USB_DEVICE_DESCRIPTOR(Structure):
_fields_ = (
('bLength', UCHAR),
('bDescriptorType', UCHAR),
('bcdUSB', USHORT),
('bDeviceClass', UCHAR),
('bDeviceSubClass', UCHAR),
('bDeviceProtocol', UCHAR),
('bMaxPacketSize0', UCHAR),
('idVendor', USHORT),
('idProduct', USHORT),
('bcdDevice', USHORT),
('iManufacturer', UCHAR),
('iProduct', UCHAR),
('iSerialNumber', UCHAR),
('bNumConfigurations', UCHAR),
)
def __repr__(self):
return 'USBDevice(class=0x%x sub_class=0x%x protocol=0x%x vendor_id=0x%x product_id=0x%x bcd=0x%x manufacturer=%d product=%d serial_number=%d)' % (
self.bDeviceClass, self.bDeviceSubClass, self.bDeviceProtocol,
self.idVendor, self.idProduct, self.bcdDevice, self.iManufacturer,
self.iProduct, self.iSerialNumber)
class USB_ENDPOINT_DESCRIPTOR(Structure):
_fields_ = (
('bLength', UCHAR),
('bDescriptorType', UCHAR),
('bEndpointAddress', UCHAR),
('bmAttributes', UCHAR),
('wMaxPacketSize', USHORT),
('bInterval', UCHAR)
)
class USB_PIPE_INFO(Structure):
_fields_ = (
('EndpointDescriptor', USB_ENDPOINT_DESCRIPTOR),
('ScheduleOffset', ULONG),
)
class USB_NODE_CONNECTION_INFORMATION_EX(Structure):
_fields_ = (
('ConnectionIndex', ULONG),
('DeviceDescriptor', USB_DEVICE_DESCRIPTOR),
('CurrentConfigurationValue', UCHAR),
('Speed', UCHAR),
('DeviceIsHub', BOOL),
('DeviceAddress', USHORT),
('NumberOfOpenPipes', ULONG),
('ConnectionStatus', c_uint),
('PipeList', USB_PIPE_INFO*ANYSIZE_ARRAY),
)
class USB_STRING_DESCRIPTOR(Structure):
_fields_ = (
('bLength', UCHAR),
('bType', UCHAR),
('String', UCHAR * ANYSIZE_ARRAY),
)
class USB_DESCRIPTOR_REQUEST(Structure):
class SetupPacket(Structure):
_fields_ = (
('bmRequest', UCHAR),
('bRequest', UCHAR),
('wValue', UCHAR*2),
('wIndex', USHORT),
('wLength', USHORT),
)
_fields_ = (
('ConnectionIndex', ULONG),
('SetupPacket', SetupPacket),
('Data', USB_STRING_DESCRIPTOR),
)
PUSB_DESCRIPTOR_REQUEST = POINTER(USB_DESCRIPTOR_REQUEST)
PSP_DEVICE_INTERFACE_DETAIL_DATA = POINTER(SP_DEVICE_INTERFACE_DETAIL_DATA)
PSP_DEVICE_INTERFACE_DATA = POINTER(SP_DEVICE_INTERFACE_DATA)
INVALID_HANDLE_VALUE = c_void_p(-1).value
GENERIC_READ = 0x80000000L
GENERIC_WRITE = 0x40000000L
FILE_SHARE_READ = 0x1
FILE_SHARE_WRITE = 0x2
OPEN_EXISTING = 0x3
GUID_DEVINTERFACE_VOLUME = GUID(0x53F5630D, 0xB6BF, 0x11D0, 0x94, 0xF2, 0x00, 0xA0, 0xC9, 0x1E, 0xFB, 0x8B)
GUID_DEVINTERFACE_DISK = GUID(0x53F56307, 0xB6BF, 0x11D0, 0x94, 0xF2, 0x00, 0xA0, 0xC9, 0x1E, 0xFB, 0x8B)
GUID_DEVINTERFACE_CDROM = GUID(0x53f56308, 0xb6bf, 0x11d0, 0x94, 0xf2, 0x00, 0xa0, 0xc9, 0x1e, 0xfb, 0x8b)
GUID_DEVINTERFACE_FLOPPY = GUID(0x53f56311, 0xb6bf, 0x11d0, 0x94, 0xf2, 0x00, 0xa0, 0xc9, 0x1e, 0xfb, 0x8b)
GUID_DEVINTERFACE_USB_DEVICE = GUID(0xA5DCBF10, 0x6530, 0x11D2, 0x90, 0x1F, 0x00, 0xC0, 0x4F, 0xB9, 0x51, 0xED)
GUID_DEVINTERFACE_USB_HUB = GUID(0xf18a0e88, 0xc30c, 0x11d0, 0x88, 0x15, 0x00, 0xa0, 0xc9, 0x06, 0xbe, 0xd8)
DRIVE_UNKNOWN, DRIVE_NO_ROOT_DIR, DRIVE_REMOVABLE, DRIVE_FIXED, DRIVE_REMOTE, DRIVE_CDROM, DRIVE_RAMDISK = 0, 1, 2, 3, 4, 5, 6
DIGCF_PRESENT = 0x00000002
DIGCF_ALLCLASSES = 0x00000004
DIGCF_DEVICEINTERFACE = 0x00000010
ERROR_INSUFFICIENT_BUFFER = 0x7a
ERROR_MORE_DATA = 234
ERROR_INVALID_DATA = 0xd
ERROR_GEN_FAILURE = 31
HDEVINFO = HANDLE
SPDRP_DEVICEDESC = DWORD(0x00000000)
SPDRP_HARDWAREID = DWORD(0x00000001)
SPDRP_COMPATIBLEIDS = DWORD(0x00000002)
SPDRP_UNUSED0 = DWORD(0x00000003)
SPDRP_SERVICE = DWORD(0x00000004)
SPDRP_UNUSED1 = DWORD(0x00000005)
SPDRP_UNUSED2 = DWORD(0x00000006)
SPDRP_CLASS = DWORD(0x00000007)
SPDRP_CLASSGUID = DWORD(0x00000008)
SPDRP_DRIVER = DWORD(0x00000009)
SPDRP_CONFIGFLAGS = DWORD(0x0000000A)
SPDRP_MFG = DWORD(0x0000000B)
SPDRP_FRIENDLYNAME = DWORD(0x0000000C)
SPDRP_LOCATION_INFORMATION = DWORD(0x0000000D)
SPDRP_PHYSICAL_DEVICE_OBJECT_NAME = DWORD(0x0000000E)
SPDRP_CAPABILITIES = DWORD(0x0000000F)
SPDRP_UI_NUMBER = DWORD(0x00000010)
SPDRP_UPPERFILTERS = DWORD(0x00000011)
SPDRP_LOWERFILTERS = DWORD(0x00000012)
SPDRP_BUSTYPEGUID = DWORD(0x00000013)
SPDRP_LEGACYBUSTYPE = DWORD(0x00000014)
SPDRP_BUSNUMBER = DWORD(0x00000015)
SPDRP_ENUMERATOR_NAME = DWORD(0x00000016)
SPDRP_SECURITY = DWORD(0x00000017)
SPDRP_SECURITY_SDS = DWORD(0x00000018)
SPDRP_DEVTYPE = DWORD(0x00000019)
SPDRP_EXCLUSIVE = DWORD(0x0000001A)
SPDRP_CHARACTERISTICS = DWORD(0x0000001B)
SPDRP_ADDRESS = DWORD(0x0000001C)
SPDRP_UI_NUMBER_DESC_FORMAT = DWORD(0x0000001D)
SPDRP_DEVICE_POWER_DATA = DWORD(0x0000001E)
SPDRP_REMOVAL_POLICY = DWORD(0x0000001F)
SPDRP_REMOVAL_POLICY_HW_DEFAULT = DWORD(0x00000020)
SPDRP_REMOVAL_POLICY_OVERRIDE = DWORD(0x00000021)
SPDRP_INSTALL_STATE = DWORD(0x00000022)
SPDRP_LOCATION_PATHS = DWORD(0x00000023)
CR_CODES, CR_CODE_NAMES = {}, {}
for line in '''\
#define CR_SUCCESS 0x00000000
#define CR_DEFAULT 0x00000001
#define CR_OUT_OF_MEMORY 0x00000002
#define CR_INVALID_POINTER 0x00000003
#define CR_INVALID_FLAG 0x00000004
#define CR_INVALID_DEVNODE 0x00000005
#define CR_INVALID_DEVINST CR_INVALID_DEVNODE
#define CR_INVALID_RES_DES 0x00000006
#define CR_INVALID_LOG_CONF 0x00000007
#define CR_INVALID_ARBITRATOR 0x00000008
#define CR_INVALID_NODELIST 0x00000009
#define CR_DEVNODE_HAS_REQS 0x0000000A
#define CR_DEVINST_HAS_REQS CR_DEVNODE_HAS_REQS
#define CR_INVALID_RESOURCEID 0x0000000B
#define CR_DLVXD_NOT_FOUND 0x0000000C
#define CR_NO_SUCH_DEVNODE 0x0000000D
#define CR_NO_SUCH_DEVINST CR_NO_SUCH_DEVNODE
#define CR_NO_MORE_LOG_CONF 0x0000000E
#define CR_NO_MORE_RES_DES 0x0000000F
#define CR_ALREADY_SUCH_DEVNODE 0x00000010
#define CR_ALREADY_SUCH_DEVINST CR_ALREADY_SUCH_DEVNODE
#define CR_INVALID_RANGE_LIST 0x00000011
#define CR_INVALID_RANGE 0x00000012
#define CR_FAILURE 0x00000013
#define CR_NO_SUCH_LOGICAL_DEV 0x00000014
#define CR_CREATE_BLOCKED 0x00000015
#define CR_NOT_SYSTEM_VM 0x00000016
#define CR_REMOVE_VETOED 0x00000017
#define CR_APM_VETOED 0x00000018
#define CR_INVALID_LOAD_TYPE 0x00000019
#define CR_BUFFER_SMALL 0x0000001A
#define CR_NO_ARBITRATOR 0x0000001B
#define CR_NO_REGISTRY_HANDLE 0x0000001C
#define CR_REGISTRY_ERROR 0x0000001D
#define CR_INVALID_DEVICE_ID 0x0000001E
#define CR_INVALID_DATA 0x0000001F
#define CR_INVALID_API 0x00000020
#define CR_DEVLOADER_NOT_READY 0x00000021
#define CR_NEED_RESTART 0x00000022
#define CR_NO_MORE_HW_PROFILES 0x00000023
#define CR_DEVICE_NOT_THERE 0x00000024
#define CR_NO_SUCH_VALUE 0x00000025
#define CR_WRONG_TYPE 0x00000026
#define CR_INVALID_PRIORITY 0x00000027
#define CR_NOT_DISABLEABLE 0x00000028
#define CR_FREE_RESOURCES 0x00000029
#define CR_QUERY_VETOED 0x0000002A
#define CR_CANT_SHARE_IRQ 0x0000002B
#define CR_NO_DEPENDENT 0x0000002C
#define CR_SAME_RESOURCES 0x0000002D
#define CR_NO_SUCH_REGISTRY_KEY 0x0000002E
#define CR_INVALID_MACHINENAME 0x0000002F
#define CR_REMOTE_COMM_FAILURE 0x00000030
#define CR_MACHINE_UNAVAILABLE 0x00000031
#define CR_NO_CM_SERVICES 0x00000032
#define CR_ACCESS_DENIED 0x00000033
#define CR_CALL_NOT_IMPLEMENTED 0x00000034
#define CR_INVALID_PROPERTY 0x00000035
#define CR_DEVICE_INTERFACE_ACTIVE 0x00000036
#define CR_NO_SUCH_DEVICE_INTERFACE 0x00000037
#define CR_INVALID_REFERENCE_STRING 0x00000038
#define CR_INVALID_CONFLICT_LIST 0x00000039
#define CR_INVALID_INDEX 0x0000003A
#define CR_INVALID_STRUCTURE_SIZE 0x0000003B'''.splitlines():
line = line.strip()
if line:
name, code = line.split()[1:]
if code.startswith('0x'):
code = int(code, 16)
else:
code = CR_CODES[code]
CR_CODES[name] = code
CR_CODE_NAMES[code] = name
CM_GET_DEVICE_INTERFACE_LIST_PRESENT = 0
CM_GET_DEVICE_INTERFACE_LIST_ALL_DEVICES = 1
CM_GET_DEVICE_INTERFACE_LIST_BITS = 1
setupapi = windll.setupapi
cfgmgr = windll.CfgMgr32
kernel32 = windll.Kernel32
def cwrap(name, restype, *argtypes, **kw):
errcheck = kw.pop('errcheck', None)
use_last_error = bool(kw.pop('use_last_error', True))
prototype = WINFUNCTYPE(restype, *argtypes, use_last_error=use_last_error)
lib = cfgmgr if name.startswith('CM') else setupapi
func = prototype((name, kw.pop('lib', lib)))
if kw:
raise TypeError('Unknown keyword arguments: %r' % kw)
if errcheck is not None:
func.errcheck = errcheck
return func
def handle_err_check(result, func, args):
if result == INVALID_HANDLE_VALUE:
raise WinError(get_last_error())
return result
def bool_err_check(result, func, args):
if not result:
raise WinError(get_last_error())
return result
def config_err_check(result, func, args):
if result != CR_CODES['CR_SUCCESS']:
raise WindowsError(result, 'The cfgmgr32 function failed with err: %s' % CR_CODE_NAMES.get(result, result))
return args
GetLogicalDrives = cwrap('GetLogicalDrives', DWORD, errcheck=bool_err_check, lib=kernel32)
GetDriveType = cwrap('GetDriveTypeW', UINT, LPCWSTR, lib=kernel32)
GetVolumeNameForVolumeMountPoint = cwrap('GetVolumeNameForVolumeMountPointW', BOOL, LPCWSTR, LPWSTR, DWORD, errcheck=bool_err_check, lib=kernel32)
GetVolumePathNamesForVolumeName = cwrap('GetVolumePathNamesForVolumeNameW', BOOL, LPCWSTR, LPWSTR, DWORD, LPDWORD, errcheck=bool_err_check, lib=kernel32)
GetVolumeInformation = cwrap(
'GetVolumeInformationW', BOOL, LPCWSTR, LPWSTR, DWORD, POINTER(DWORD), POINTER(DWORD), POINTER(DWORD), LPWSTR, DWORD, errcheck=bool_err_check, lib=kernel32)
ExpandEnvironmentStrings = cwrap('ExpandEnvironmentStringsW', DWORD, LPCWSTR, LPWSTR, DWORD, errcheck=bool_err_check, lib=kernel32)
CreateFile = cwrap('CreateFileW', HANDLE, LPCWSTR, DWORD, DWORD, c_void_p, DWORD, DWORD, HANDLE, errcheck=handle_err_check, lib=kernel32)
DeviceIoControl = cwrap('DeviceIoControl', BOOL, HANDLE, DWORD, LPVOID, DWORD, LPVOID, DWORD, POINTER(DWORD), LPVOID, errcheck=bool_err_check, lib=kernel32)
CloseHandle = cwrap('CloseHandle', BOOL, HANDLE, errcheck=bool_err_check, lib=kernel32)
QueryDosDevice = cwrap('QueryDosDeviceW', DWORD, LPCWSTR, LPWSTR, DWORD, errcheck=bool_err_check, lib=kernel32)
SetupDiGetClassDevs = cwrap('SetupDiGetClassDevsW', HDEVINFO, POINTER(GUID), LPCWSTR, HWND, DWORD, errcheck=handle_err_check)
SetupDiEnumDeviceInterfaces = cwrap('SetupDiEnumDeviceInterfaces', BOOL, HDEVINFO, PSP_DEVINFO_DATA, POINTER(GUID), DWORD, PSP_DEVICE_INTERFACE_DATA)
SetupDiDestroyDeviceInfoList = cwrap('SetupDiDestroyDeviceInfoList', BOOL, HDEVINFO, errcheck=bool_err_check)
SetupDiGetDeviceInterfaceDetail = cwrap(
'SetupDiGetDeviceInterfaceDetailW', BOOL, HDEVINFO, PSP_DEVICE_INTERFACE_DATA, PSP_DEVICE_INTERFACE_DETAIL_DATA, DWORD, POINTER(DWORD), PSP_DEVINFO_DATA)
SetupDiEnumDeviceInfo = cwrap('SetupDiEnumDeviceInfo', BOOL, HDEVINFO, DWORD, PSP_DEVINFO_DATA)
SetupDiGetDeviceRegistryProperty = cwrap(
'SetupDiGetDeviceRegistryPropertyW', BOOL, HDEVINFO, PSP_DEVINFO_DATA, DWORD, POINTER(DWORD), POINTER(BYTE), DWORD, POINTER(DWORD))
CM_Get_Parent = cwrap('CM_Get_Parent', CONFIGRET, POINTER(DEVINST), DEVINST, ULONG, errcheck=config_err_check)
CM_Get_Child = cwrap('CM_Get_Child', CONFIGRET, POINTER(DEVINST), DEVINST, ULONG, errcheck=config_err_check)
CM_Get_Sibling = cwrap('CM_Get_Sibling', CONFIGRET, POINTER(DEVINST), DEVINST, ULONG, errcheck=config_err_check)
CM_Get_Device_ID_Size = cwrap('CM_Get_Device_ID_Size', CONFIGRET, POINTER(ULONG), DEVINST, ULONG)
CM_Get_Device_ID = cwrap('CM_Get_Device_IDW', CONFIGRET, DEVINST, LPWSTR, ULONG, ULONG)
# }}}
# Utility functions {{{
_devid_pat = None
def devid_pat():
global _devid_pat
if _devid_pat is None:
_devid_pat = re.compile(r'VID_([a-f0-9]{4})&PID_([a-f0-9]{4})&REV_([a-f0-9:]{4})', re.I)
return _devid_pat
class DeviceSet(object):
def __init__(self, guid=GUID_DEVINTERFACE_VOLUME, enumerator=None, flags=DIGCF_PRESENT | DIGCF_DEVICEINTERFACE):
self.guid_ref, self.enumerator, self.flags = (None if guid is None else byref(guid)), enumerator, flags
self.dev_list = SetupDiGetClassDevs(self.guid_ref, self.enumerator, None, self.flags)
def __del__(self):
SetupDiDestroyDeviceInfoList(self.dev_list)
del self.dev_list
def interfaces(self, ignore_errors=False, yield_devlist=False):
interface_data = SP_DEVICE_INTERFACE_DATA()
interface_data.cbSize = sizeof(SP_DEVICE_INTERFACE_DATA)
buf = None
i = -1
while True:
i += 1
if not SetupDiEnumDeviceInterfaces(self.dev_list, None, self.guid_ref, i, byref(interface_data)):
break
try:
buf, devinfo, devpath = get_device_interface_detail_data(self.dev_list, byref(interface_data), buf)
except WindowsError:
if ignore_errors:
continue
raise
if yield_devlist:
yield self.dev_list, devinfo, devpath
else:
yield devinfo, devpath
def devices(self):
devinfo = SP_DEVINFO_DATA()
devinfo.cbSize = sizeof(SP_DEVINFO_DATA)
i = -1
while True:
i += 1
if not SetupDiEnumDeviceInfo(self.dev_list, i, byref(devinfo)):
break
yield self.dev_list, devinfo
def iterchildren(parent_devinst):
child = DEVINST(0)
NO_MORE = CR_CODES['CR_NO_SUCH_DEVINST']
try:
CM_Get_Child(byref(child), parent_devinst, 0)
except WindowsError as err:
if err.winerror == NO_MORE:
return
raise
yield child.value
while True:
try:
CM_Get_Sibling(byref(child), child, 0)
except WindowsError as err:
if err.winerror == NO_MORE:
break
raise
yield child.value
def iterdescendants(parent_devinst):
for child in iterchildren(parent_devinst):
yield child
for gc in iterdescendants(child):
yield gc
def iterancestors(devinst):
NO_MORE = CR_CODES['CR_NO_SUCH_DEVINST']
parent = DEVINST(devinst)
while True:
try:
CM_Get_Parent(byref(parent), parent, 0)
except WindowsError as err:
if err.winerror == NO_MORE:
break
raise
yield parent.value
def device_io_control(handle, which, inbuf, outbuf, initbuf):
bytes_returned = DWORD(0)
while True:
initbuf(inbuf)
try:
DeviceIoControl(handle, which, inbuf, len(inbuf), outbuf, len(outbuf), byref(bytes_returned), None)
except WindowsError as err:
if err.winerror not in (ERROR_INSUFFICIENT_BUFFER, ERROR_MORE_DATA):
raise
outbuf = create_string_buffer(2*len(outbuf))
else:
return outbuf, bytes_returned
def get_storage_number(devpath):
sdn = STORAGE_DEVICE_NUMBER()
handle = CreateFile(devpath, 0, FILE_SHARE_READ | FILE_SHARE_WRITE, None, OPEN_EXISTING, 0, None)
bytes_returned = DWORD(0)
try:
DeviceIoControl(handle, IOCTL_STORAGE_GET_DEVICE_NUMBER, None, 0, byref(sdn), sizeof(STORAGE_DEVICE_NUMBER), byref(bytes_returned), None)
finally:
CloseHandle(handle)
return sdn.as_tuple()
def get_device_id(devinst, buf=None):
if buf is None:
buf = create_unicode_buffer(512)
while True:
ret = CM_Get_Device_ID(devinst, buf, len(buf), 0)
if ret == CR_CODES['CR_BUFFER_SMALL']:
devid_size = ULONG(0)
CM_Get_Device_ID_Size(byref(devid_size), devinst, 0)
buf = create_unicode_buffer(devid_size.value)
continue
if ret != CR_CODES['CR_SUCCESS']:
raise WindowsError((ret, 'The cfgmgr32 function failed with err: %s' % CR_CODE_NAMES.get(ret, ret)))
break
return wstring_at(buf), buf
def expand_environment_strings(src):
sz = ExpandEnvironmentStrings(src, None, 0)
while True:
buf = create_unicode_buffer(sz)
nsz = ExpandEnvironmentStrings(src, buf, len(buf))
if nsz <= sz:
return buf.value
sz = nsz
def convert_registry_data(raw, size, dtype):
if dtype == winreg.REG_NONE:
return None
if dtype == winreg.REG_BINARY:
return string_at(raw, size)
if dtype in (winreg.REG_SZ, winreg.REG_EXPAND_SZ, winreg.REG_MULTI_SZ):
ans = wstring_at(raw, size // 2).rstrip('\0')
if dtype == winreg.REG_MULTI_SZ:
ans = tuple(ans.split('\0'))
elif dtype == winreg.REG_EXPAND_SZ:
ans = expand_environment_strings(ans)
return ans
if dtype == winreg.REG_DWORD:
if size == 0:
return 0
return cast(raw, LPDWORD).contents.value
if dtype == REG_QWORD:
if size == 0:
return 0
return cast(raw, POINTER(QWORD)).contents.value
raise ValueError('Unsupported data type: %r' % dtype)
def get_device_registry_property(dev_list, p_devinfo, property_type=SPDRP_HARDWAREID, buf=None):
if buf is None:
buf = create_string_buffer(1024)
data_type = DWORD(0)
required_size = DWORD(0)
ans = None
while True:
if not SetupDiGetDeviceRegistryProperty(dev_list, p_devinfo, property_type, byref(data_type), cast(buf, POINTER(BYTE)), len(buf), byref(required_size)):
err = get_last_error()
if err == ERROR_INSUFFICIENT_BUFFER:
buf = create_string_buffer(required_size.value)
continue
if err == ERROR_INVALID_DATA:
break
raise WinError(err)
ans = convert_registry_data(buf, required_size.value, data_type.value)
break
return buf, ans
def get_device_interface_detail_data(dev_list, p_interface_data, buf=None):
if buf is None:
buf = create_string_buffer(512)
detail = cast(buf, PSP_DEVICE_INTERFACE_DETAIL_DATA)
# See http://stackoverflow.com/questions/10728644/properly-declare-sp-device-interface-detail-data-for-pinvoke
# for why cbSize needs to be hardcoded below
detail.contents.cbSize = 8 if is64bit else 6
required_size = DWORD(0)
devinfo = SP_DEVINFO_DATA()
devinfo.cbSize = sizeof(devinfo)
while True:
if not SetupDiGetDeviceInterfaceDetail(dev_list, p_interface_data, detail, len(buf), byref(required_size), byref(devinfo)):
err = get_last_error()
if err == ERROR_INSUFFICIENT_BUFFER:
buf = create_string_buffer(required_size.value + 50)
detail = cast(buf, PSP_DEVICE_INTERFACE_DETAIL_DATA)
detail.contents.cbSize = 8 if is64bit else 6
continue
raise WinError(err)
break
return buf, devinfo, wstring_at(addressof(buf) + sizeof(SP_DEVICE_INTERFACE_DETAIL_DATA._fields_[0][1]))
def get_volume_information(drive_letter):
if not drive_letter.endswith('\\'):
drive_letter += ':\\'
fsname = create_unicode_buffer(255)
vname = create_unicode_buffer(500)
flags, serial_number, max_component_length = DWORD(0), DWORD(0), DWORD(0)
GetVolumeInformation(drive_letter, vname, len(vname), byref(serial_number), byref(max_component_length), byref(flags), fsname, len(fsname))
flags = flags.value
ans = {
'name': vname.value,
'filesystem': fsname.value,
'serial_number': serial_number.value,
'max_component_length': max_component_length.value,
}
for name, num in {'FILE_CASE_PRESERVED_NAMES':0x00000002, 'FILE_CASE_SENSITIVE_SEARCH':0x00000001, 'FILE_FILE_COMPRESSION':0x00000010,
'FILE_NAMED_STREAMS':0x00040000, 'FILE_PERSISTENT_ACLS':0x00000008, 'FILE_READ_ONLY_VOLUME':0x00080000,
'FILE_SEQUENTIAL_WRITE_ONCE':0x00100000, 'FILE_SUPPORTS_ENCRYPTION':0x00020000, 'FILE_SUPPORTS_EXTENDED_ATTRIBUTES':0x00800000,
'FILE_SUPPORTS_HARD_LINKS':0x00400000, 'FILE_SUPPORTS_OBJECT_IDS':0x00010000, 'FILE_SUPPORTS_OPEN_BY_FILE_ID':0x01000000,
'FILE_SUPPORTS_REPARSE_POINTS':0x00000080, 'FILE_SUPPORTS_SPARSE_FILES':0x00000040, 'FILE_SUPPORTS_TRANSACTIONS':0x00200000,
'FILE_SUPPORTS_USN_JOURNAL':0x02000000, 'FILE_UNICODE_ON_DISK':0x00000004, 'FILE_VOLUME_IS_COMPRESSED':0x00008000,
'FILE_VOLUME_QUOTAS':0x00000020}.iteritems():
ans[name] = bool(num & flags)
return ans
def get_volume_pathnames(volume_id, buf=None):
if buf is None:
buf = create_unicode_buffer(512)
bufsize = DWORD(0)
while True:
try:
GetVolumePathNamesForVolumeName(volume_id, buf, len(buf), byref(bufsize))
break
except WindowsError as err:
if err.winerror == ERROR_MORE_DATA:
buf = create_unicode_buffer(bufsize.value + 10)
continue
raise
ans = wstring_at(buf, bufsize.value)
return buf, filter(None, ans.split('\0'))
# }}}
# def scan_usb_devices(): {{{
_USBDevice = namedtuple('USBDevice', 'vendor_id product_id bcd devid devinst')
class USBDevice(_USBDevice):
def __repr__(self):
def r(x):
if x is None:
return 'None'
return '0x%x' % x
return 'USBDevice(vendor_id=%s product_id=%s bcd=%s devid=%s devinst=%s)' % (
r(self.vendor_id), r(self.product_id), r(self.bcd), self.devid, self.devinst)
def parse_hex(x):
return int(x.replace(':', 'a'), 16)
def iterusbdevices():
buf = None
pat = devid_pat()
for dev_list, devinfo in DeviceSet(guid=None, enumerator='USB', flags=DIGCF_PRESENT | DIGCF_ALLCLASSES).devices():
buf, devid = get_device_registry_property(dev_list, byref(devinfo), buf=buf)
if devid:
devid = devid[0].lower()
m = pat.search(devid)
if m is None:
yield USBDevice(None, None, None, devid, devinfo.DevInst)
else:
try:
vid, pid, bcd = map(parse_hex, m.group(1, 2, 3))
except Exception:
yield USBDevice(None, None, None, devid, devinfo.DevInst)
else:
yield USBDevice(vid, pid, bcd, devid, devinfo.DevInst)
def scan_usb_devices():
return tuple(iterusbdevices())
# }}}
def get_drive_letters_for_device(usbdev, storage_number_map=None, debug=False): # {{{
'''
Get the drive letters for a connected device. The drive letters are sorted
by storage number, which (I think) corresponds to the order they are
exported by the firmware.
:param usbdevice: As returned by :function:`scan_usb_devices`
'''
ans = {'pnp_id_map': {}, 'drive_letters':[], 'readonly_drives':set(), 'sort_map':{}}
sn_map = get_storage_number_map(debug=debug) if storage_number_map is None else storage_number_map
if debug:
prints('Storage number map:')
prints(pformat(sn_map))
if not sn_map:
return ans
devid, mi = (usbdev.devid or '').rpartition('&')[::2]
if mi.startswith('mi_'):
if debug:
prints('Iterating over all devices of composite device:', devid)
dl = ans['drive_letters']
for c in iterusbdevices():
if c.devid and c.devid.startswith(devid):
a = get_drive_letters_for_device_single(c, sn_map, debug=debug)
if debug:
prints('Drive letters for:', c.devid, ':', a['drive_letters'])
for m in ('pnp_id_map', 'sort_map'):
ans[m].update(a[m])
ans['readonly_drives'] |= a['readonly_drives']
for x in a['drive_letters']:
if x not in dl:
dl.append(x)
ans['drive_letters'].sort(key=ans['sort_map'].get)
return ans
else:
return get_drive_letters_for_device_single(usbdev, sn_map, debug=debug)
def get_drive_letters_for_device_single(usbdev, storage_number_map, debug=False):
ans = {'pnp_id_map': {}, 'drive_letters':[], 'readonly_drives':set(), 'sort_map':{}}
descendants = frozenset(iterdescendants(usbdev.devinst))
for devinfo, devpath in DeviceSet(GUID_DEVINTERFACE_DISK).interfaces():
if devinfo.DevInst in descendants:
if debug:
try:
devid = get_device_id(devinfo.DevInst)[0]
except Exception as err:
devid = 'Unknown'
try:
storage_number = get_storage_number(devpath)
except WindowsError as err:
if debug:
prints('Failed to get storage number for: %s with error: %s' % (devid, as_unicode(err)))
continue
if debug:
prints('Storage number for %s: %s' % (devid, storage_number))
if storage_number:
partitions = storage_number_map.get(storage_number[:2])
drive_letters = []
for partition_number, dl in partitions or ():
drive_letters.append(dl)
ans['sort_map'][dl] = storage_number.number, partition_number
if drive_letters:
for dl in drive_letters:
ans['pnp_id_map'][dl] = devpath
ans['drive_letters'].append(dl)
ans['drive_letters'].sort(key=ans['sort_map'].get)
for dl in ans['drive_letters']:
try:
if is_readonly(dl):
ans['readonly_drives'].add(dl)
except WindowsError as err:
if debug:
prints('Failed to get readonly status for drive: %s with error: %s' % (dl, as_unicode(err)))
return ans
def get_storage_number_map(drive_types=(DRIVE_REMOVABLE, DRIVE_FIXED), debug=False):
' Get a mapping of drive letters to storage numbers for all drives on system (of the specified types) '
mask = GetLogicalDrives()
type_map = {letter:GetDriveType(letter + ':' + os.sep) for i, letter in enumerate(string.ascii_uppercase) if mask & (1 << i)}
drives = (letter for letter, dt in type_map.iteritems() if dt in drive_types)
ans = defaultdict(list)
for letter in drives:
try:
sn = get_storage_number('\\\\.\\' + letter + ':')
ans[sn[:2]].append((sn[2], letter))
except WindowsError as err:
if debug:
prints('Failed to get storage number for drive: %s with error: %s' % (letter, as_unicode(err)))
continue
for val in ans.itervalues():
val.sort(key=itemgetter(0))
return dict(ans)
def get_storage_number_map_alt(debug=False):
' Alternate implementation that works without needing to call GetDriveType() (which causes floppy drives to seek) '
wbuf = create_unicode_buffer(512)
ans = defaultdict(list)
for devinfo, devpath in DeviceSet().interfaces():
if not devpath.endswith(os.sep):
devpath += os.sep
try:
GetVolumeNameForVolumeMountPoint(devpath, wbuf, len(wbuf))
except WindowsError as err:
if debug:
prints('Failed to get volume id for drive: %s with error: %s' % (devpath, as_unicode(err)))
continue
vname = wbuf.value
try:
wbuf, names = get_volume_pathnames(vname, buf=wbuf)
except WindowsError as err:
if debug:
prints('Failed to get mountpoints for volume %s with error: %s' % (devpath, as_unicode(err)))
continue
for name in names:
name = name.upper()
if len(name) == 3 and name.endswith(':\\') and name[0] in string.ascii_uppercase:
break
else:
if debug:
prints('Ignoring volume %s as it has no assigned drive letter. Mountpoints: %s' % (devpath, names))
continue
try:
sn = get_storage_number('\\\\.\\' + name[0] + ':')
ans[sn[:2]].append((sn[2], name[0]))
except WindowsError as err:
if debug:
prints('Failed to get storage number for drive: %s with error: %s' % (name[0], as_unicode(err)))
continue
for val in ans.itervalues():
val.sort(key=itemgetter(0))
return dict(ans)
# }}}
def is_usb_device_connected(vendor_id, product_id): # {{{
for usbdev in iterusbdevices():
if usbdev.vendor_id == vendor_id and usbdev.product_id == product_id:
return True
return False
# }}}
def get_usb_info(usbdev, debug=False): # {{{
'''
The USB info (manufacturer/product names and serial number) Requires communication with the hub the device is connected to.
:param usbdev: A usb device as returned by :function:`scan_usb_devices`
'''
ans = {}
hub_map = {devinfo.DevInst:path for devinfo, path in DeviceSet(guid=GUID_DEVINTERFACE_USB_HUB).interfaces()}
for parent in iterancestors(usbdev.devinst):
parent_path = hub_map.get(parent)
if parent_path is not None:
break
else:
if debug:
prints('Cannot get USB info as parent of device is not a HUB or device has no parent (was probably disconnected)')
return ans
for devlist, devinfo in DeviceSet(guid=GUID_DEVINTERFACE_USB_DEVICE).devices():
if devinfo.DevInst == usbdev.devinst:
device_port = get_device_registry_property(devlist, byref(devinfo), SPDRP_ADDRESS)[1]
break
else:
return ans
if not device_port:
if debug:
prints('Cannot get usb info as the SPDRP_ADDRESS property is not present in the registry (can happen with broken USB hub drivers)')
return ans
handle = CreateFile(parent_path, GENERIC_READ | GENERIC_WRITE, FILE_SHARE_READ | FILE_SHARE_WRITE, None, OPEN_EXISTING, 0, None)
try:
buf, dd = get_device_descriptor(handle, device_port)
if dd.idVendor == usbdev.vendor_id and dd.idProduct == usbdev.product_id and dd.bcdDevice == usbdev.bcd:
# Dont need to read language since we only care about english names
# buf, langs = get_device_languages(handle, device_port)
# print(111, langs)
for index, name in ((dd.iManufacturer, 'manufacturer'), (dd.iProduct, 'product'), (dd.iSerialNumber, 'serial_number')):
if index:
try:
buf, ans[name] = get_device_string(handle, device_port, index, buf=buf)
except WindowsError as err:
if debug:
# Note that I have observed that this fails
# randomly after some time of my Kindle being
# connected. Disconnecting and reconnecting causes
# it to start working again.
prints('Failed to read %s from device, with error: [%d] %s' % (name, err.winerror, as_unicode(err)))
finally:
CloseHandle(handle)
return ans
def alloc_descriptor_buf(buf):
if buf is None:
buf = create_string_buffer(sizeof(USB_DESCRIPTOR_REQUEST) + 700)
else:
memset(buf, 0, len(buf))
return buf
def get_device_descriptor(hub_handle, device_port, buf=None):
buf = alloc_descriptor_buf(buf)
def initbuf(b):
cast(b, POINTER(USB_NODE_CONNECTION_INFORMATION_EX)).contents.ConnectionIndex = device_port
buf, bytes_returned = device_io_control(hub_handle, IOCTL_USB_GET_NODE_CONNECTION_INFORMATION_EX, buf, buf, initbuf)
return buf, USB_DEVICE_DESCRIPTOR.from_buffer_copy(cast(buf, POINTER(USB_NODE_CONNECTION_INFORMATION_EX)).contents.DeviceDescriptor)
def get_device_string(hub_handle, device_port, index, buf=None, lang=0x409):
buf = alloc_descriptor_buf(buf)
def initbuf(b):
p = cast(b, PUSB_DESCRIPTOR_REQUEST).contents
p.ConnectionIndex = device_port
sp = p.SetupPacket
sp.bmRequest, sp.bRequest = 0x80, USB_REQUEST_GET_DESCRIPTOR
sp.wValue[0], sp.wValue[1] = index, USB_STRING_DESCRIPTOR_TYPE
sp.wIndex = lang
sp.wLength = MAXIMUM_USB_STRING_LENGTH + 2
buf, bytes_returned = device_io_control(hub_handle, IOCTL_USB_GET_DESCRIPTOR_FROM_NODE_CONNECTION, buf, buf, initbuf)
data = cast(buf, PUSB_DESCRIPTOR_REQUEST).contents.Data
sz, dtype = data.bLength, data.bType
if dtype != 0x03:
raise WindowsError('Invalid datatype for string descriptor: 0x%x' % dtype)
return buf, wstring_at(addressof(data.String), sz // 2).rstrip('\0')
def get_device_languages(hub_handle, device_port, buf=None):
' Get the languages supported by the device for strings '
buf = alloc_descriptor_buf(buf)
def initbuf(b):
p = cast(b, PUSB_DESCRIPTOR_REQUEST).contents
p.ConnectionIndex = device_port
sp = p.SetupPacket
sp.bmRequest, sp.bRequest = 0x80, USB_REQUEST_GET_DESCRIPTOR
sp.wValue[1] = USB_STRING_DESCRIPTOR_TYPE
sp.wLength = MAXIMUM_USB_STRING_LENGTH + 2
buf, bytes_returned = device_io_control(hub_handle, IOCTL_USB_GET_DESCRIPTOR_FROM_NODE_CONNECTION, buf, buf, initbuf)
data = cast(buf, PUSB_DESCRIPTOR_REQUEST).contents.Data
sz, dtype = data.bLength, data.bType
if dtype != 0x03:
raise WindowsError('Invalid datatype for string descriptor: 0x%x' % dtype)
data = cast(data.String, POINTER(USHORT*(sz//2)))
return buf, filter(None, data.contents)
# }}}
def is_readonly(drive_letter): # {{{
return get_volume_information(drive_letter)['FILE_READ_ONLY_VOLUME']
# }}}
def develop(): # {{{
from calibre.customize.ui import device_plugins
usb_devices = scan_usb_devices()
drive_letters = set()
pprint(usb_devices)
print()
devplugins = list(sorted(device_plugins(), cmp=lambda
x,y:cmp(x.__class__.__name__, y.__class__.__name__)))
for dev in devplugins:
dev.startup()
for dev in devplugins:
if dev.MANAGES_DEVICE_PRESENCE:
continue
connected, usbdev = dev.is_usb_connected(usb_devices, debug=True)
if connected:
print('\n')
print('Potentially connected device: %s at %s' % (dev.get_gui_name(), usbdev))
print()
print('Drives for this device:')
data = get_drive_letters_for_device(usbdev, debug=True)
pprint(data)
drive_letters |= set(data['drive_letters'])
print()
print('Is device connected:', is_usb_device_connected(*usbdev[:2]))
print()
print('Device USB data:', get_usb_info(usbdev, debug=True))
def drives_for(vendor_id, product_id=None):
usb_devices = scan_usb_devices()
pprint(usb_devices)
for usbdev in usb_devices:
if usbdev.vendor_id == vendor_id and (product_id is None or usbdev.product_id == product_id):
print('Drives for: {}'.format(usbdev))
pprint(get_drive_letters_for_device(usbdev, debug=True))
print('USB info:', get_usb_info(usbdev, debug=True))
if __name__ == '__main__':
develop()
# }}} | unknown | codeparrot/codeparrot-clean | ||
# Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
# License for the specific language governing permissions and limitations
# under the License.
from keystoneclient import base
from keystoneclient import utils
class ServiceProvider(base.Resource):
"""Object representing Service Provider container
Attributes:
* id: user-defined unique string identifying Service Provider.
* sp_url: the shibboleth endpoint of a Service Provider.
* auth_url: the authentication url of Service Provider.
"""
pass
class ServiceProviderManager(base.CrudManager):
"""Manager class for manipulating Service Providers."""
resource_class = ServiceProvider
collection_key = 'service_providers'
key = 'service_provider'
base_url = 'OS-FEDERATION'
def _build_url_and_put(self, **kwargs):
url = self.build_url(dict_args_in_out=kwargs)
body = {self.key: kwargs}
return self._update(url, body=body, response_key=self.key,
method='PUT')
@utils.positional.method(0)
def create(self, id, **kwargs):
"""Create Service Provider object.
Utilize Keystone URI:
``PUT /OS-FEDERATION/service_providers/{id}``
:param id: unique id of the service provider.
"""
return self._build_url_and_put(service_provider_id=id,
**kwargs)
def get(self, service_provider):
"""Fetch Service Provider object
Utilize Keystone URI:
``GET /OS-FEDERATION/service_providers/{id}``
:param service_provider: an object with service_provider_id
stored inside.
"""
return super(ServiceProviderManager, self).get(
service_provider_id=base.getid(service_provider))
def list(self, **kwargs):
"""List all Service Providers.
Utilize Keystone URI:
``GET /OS-FEDERATION/service_providers``
"""
return super(ServiceProviderManager, self).list(**kwargs)
def update(self, service_provider, **kwargs):
"""Update the existing Service Provider object on the server.
Only properties provided to the function are being updated.
Utilize Keystone URI:
``PATCH /OS-FEDERATION/service_providers/{id}``
:param service_provider: an object with service_provider_id
stored inside.
"""
return super(ServiceProviderManager, self).update(
service_provider_id=base.getid(service_provider), **kwargs)
def delete(self, service_provider):
"""Delete Service Provider object.
Utilize Keystone URI:
``DELETE /OS-FEDERATION/service_providers/{id}``
:param service_provider: an object with service_provider_id
stored inside.
"""
return super(ServiceProviderManager, self).delete(
service_provider_id=base.getid(service_provider)) | unknown | codeparrot/codeparrot-clean | ||
# Copyright 2015, Google Inc.
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are
# met:
#
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above
# copyright notice, this list of conditions and the following disclaimer
# in the documentation and/or other materials provided with the
# distribution.
# * Neither the name of Google Inc. nor the names of its
# contributors may be used to endorse or promote products derived from
# this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
# A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
# OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
# DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""Constants shared among tests throughout RPC Framework."""
# Value for maximum duration in seconds that a test is allowed for its actual
# behavioral logic, excluding all time spent deliberately waiting in the test.
TIME_ALLOWANCE = 10
# Value for maximum duration in seconds of RPCs that may time out as part of a
# test.
SHORT_TIMEOUT = 4
# Absurdly large value for maximum duration in seconds for should-not-time-out
# RPCs made during tests.
LONG_TIMEOUT = 3000
# Values to supply on construction of an object that will service RPCs; these
# should not be used as the actual timeout values of any RPCs made during tests.
DEFAULT_TIMEOUT = 300
MAXIMUM_TIMEOUT = 3600
# The number of payloads to transmit in streaming tests.
STREAM_LENGTH = 200
# The size of payloads to transmit in tests.
PAYLOAD_SIZE = 256 * 1024 + 17
# The size of thread pools to use in tests.
POOL_SIZE = 10 | unknown | codeparrot/codeparrot-clean | ||
"""Logic for converting human-readable benchmarks into executable form.
This is mostly string manipulation, with just a bit of importlib magic.
"""
# mypy: ignore-errors
import importlib.abc
import importlib.util
import itertools as it
import os
import re
import textwrap
import uuid
from typing import Optional, TYPE_CHECKING
import torch
if TYPE_CHECKING:
# See the note in api.py for why this is necessary.
from torch.utils.benchmark.utils.timer import Language
else:
from torch.utils.benchmark import Language
from core.api import AutogradMode, AutoLabels, GroupedBenchmark, RuntimeMode, TimerArgs
from core.types import FlatDefinition, FlatIntermediateDefinition, Label
from core.utils import get_temp_dir
_ALL_MODES = tuple(
it.product(
RuntimeMode,
AutogradMode,
Language,
)
)
def _generate_torchscript_file(model_src: str, name: str) -> Optional[str]:
"""Returns the path a saved model if one can be constructed from `spec`.
Because TorchScript requires actual source code in order to script a
model, we can't simply `eval` an appropriate model string. Instead, we
must write the correct source to a temporary Python file and then import
the TorchScript model from that temporary file.
`model_src` must contain `jit_model = ...`, which `materialize` will supply.
"""
# Double check.
if "jit_model = " not in model_src:
raise AssertionError(f"Missing jit_model definition:\n{model_src}")
# `torch.utils.benchmark.Timer` will automatically import torch, so we
# need to match that convention.
model_src = f"import torch\n{model_src}"
model_root = os.path.join(get_temp_dir(), "TorchScript_models")
os.makedirs(model_root, exist_ok=True)
module_path = os.path.join(model_root, f"torchscript_{name}.py")
artifact_path = os.path.join(model_root, f"torchscript_{name}.pt")
if os.path.exists(module_path):
# The uuid in `name` should protect against this, but it doesn't hurt
# to confirm.
raise ValueError(f"File {module_path} already exists.")
with open(module_path, "w") as f:
f.write(model_src)
# Import magic to actually load our function.
module_spec = importlib.util.spec_from_file_location(
f"torchscript__{name}", module_path
)
if module_spec is None:
raise AssertionError(f"Failed to create module spec for {module_path}")
module = importlib.util.module_from_spec(module_spec)
loader = module_spec.loader
if loader is None:
raise AssertionError(f"Module spec has no loader for {module_path}")
loader.exec_module(module)
# And again, the type checker has no way of knowing that this line is valid.
jit_model = module.jit_model # type: ignore[attr-defined]
if not isinstance(jit_model, (torch.jit.ScriptFunction, torch.jit.ScriptModule)):
raise AssertionError(
f"Expected ScriptFunction or ScriptModule, got: {type(jit_model)}"
)
jit_model.save(artifact_path) # type: ignore[call-arg]
# Cleanup now that we have the actual serialized model.
os.remove(module_path)
return artifact_path
def _get_stmt(
benchmark: GroupedBenchmark,
runtime: RuntimeMode,
autograd: AutogradMode,
language: Language,
) -> Optional[str]:
"""Specialize a GroupedBenchmark for a particular configuration."""
is_python = language == Language.PYTHON
# During GroupedBenchmark construction, py_fwd_stmt and cpp_fwd_stmt are
# set to the eager invocation. So in the RuntimeMode.EAGER case we can
# simply reuse them. For the RuntimeMode.JIT case, we need to generate
# an appropriate `jit_model(...)` invocation.
if runtime == RuntimeMode.EAGER:
stmts = (benchmark.py_fwd_stmt, benchmark.cpp_fwd_stmt)
else:
if runtime != RuntimeMode.JIT:
raise AssertionError(f"Expected RuntimeMode.JIT, but got {runtime}")
if benchmark.signature_args is None:
raise AssertionError(
"benchmark.signature_args must not be None for JIT mode"
)
stmts = GroupedBenchmark._make_model_invocation(
benchmark.signature_args, benchmark.signature_output, RuntimeMode.JIT
)
stmt = stmts[0 if is_python else 1]
if autograd == AutogradMode.FORWARD_BACKWARD and stmt is not None:
if benchmark.signature_output is None:
raise AssertionError(
"benchmark.signature_output must not be None for FORWARD_BACKWARD mode"
)
backward = (
f"{benchmark.signature_output}"
# In C++ we have to get the Tensor out of the IValue to call `.backward()`
f"{'.toTensor()' if runtime == RuntimeMode.JIT and language == Language.CPP else ''}"
f".backward(){';' if language == Language.CPP else ''}"
)
stmt = f"{stmt}\n{backward}"
return stmt
def _get_setup(
benchmark: GroupedBenchmark,
runtime: RuntimeMode,
language: Language,
stmt: str,
model_path: Optional[str],
) -> str:
"""Specialize a GroupedBenchmark for a particular configuration.
Setup requires two extra pieces of information:
1) The benchmark stmt. This is needed to warm up the model and avoid
measuring lazy initialization.
2) The model path so we can load it during the benchmark.
These are only used when `runtime == RuntimeMode.JIT`.
"""
# By the time we get here, details about how to set up a model have already
# been determined by GroupedBenchmark. (Or set to None if appropriate.) We
# simply need to collect and package the code blocks.
if language == Language.PYTHON:
setup = benchmark.setup.py_setup
model_setup = benchmark.py_model_setup
else:
if language != Language.CPP:
raise AssertionError(f"Expected Language.CPP, but got {language}")
setup = benchmark.setup.cpp_setup
model_setup = benchmark.cpp_model_setup
if runtime == RuntimeMode.EAGER:
return "\n".join([setup, model_setup or ""])
if runtime != RuntimeMode.JIT:
raise AssertionError(f"Expected RuntimeMode.JIT, but got {runtime}")
if model_path is None:
raise AssertionError("model_path must not be None for JIT mode")
# We template `"{model_path}"`, so quotes would break model loading. The
# model path is generated within the benchmark, so this is just an
# abundance of caution rather than something that is expected in practice.
if '"' in model_path:
raise AssertionError(f"model_path contains quotes: {model_path}")
# `stmt` may contain newlines, so we can't use f-strings. Instead we need
# to generate templates so that dedent works properly.
if language == Language.PYTHON:
setup_template: str = textwrap.dedent(
f"""
jit_model = torch.jit.load("{model_path}")
# Warmup `jit_model`
for _ in range(3):
{{stmt}}
"""
)
else:
if language != Language.CPP:
raise AssertionError(f"Expected Language.CPP, but got {language}")
setup_template = textwrap.dedent(
f"""
const std::string fpath = "{model_path}";
auto jit_model = torch::jit::load(fpath);
// Warmup `jit_model`
for (int i = 0; i < 3; i++) {{{{
{{stmt}}
}}}}
"""
)
model_load = setup_template.format(stmt=textwrap.indent(stmt, " " * 4))
return "\n".join([setup, model_load])
def materialize(benchmarks: FlatIntermediateDefinition) -> FlatDefinition:
"""Convert a heterogeneous benchmark into an executable state.
This entails generation of TorchScript model artifacts, splitting
GroupedBenchmarks into multiple TimerArgs, and tagging the results with
AutoLabels.
"""
results: list[tuple[Label, AutoLabels, TimerArgs]] = []
for label, args in benchmarks.items():
if isinstance(args, TimerArgs):
# User provided an explicit TimerArgs, so no processing is necessary.
auto_labels = AutoLabels(
RuntimeMode.EXPLICIT, AutogradMode.EXPLICIT, args.language
)
results.append((label, auto_labels, args))
else:
if not isinstance(args, GroupedBenchmark):
raise AssertionError(f"Expected GroupedBenchmark, but got {type(args)}")
model_path: Optional[str] = None
if args.py_model_setup and args.torchscript:
model_setup = (
f"{args.py_model_setup}\njit_model = torch.jit.script(model)"
)
# This is just for debugging. We just need a unique name for the
# model, but embedding the label makes debugging easier.
name: str = re.sub(r"[^a-z0-9_]", "_", "_".join(label).lower())
name = f"{name}_{uuid.uuid4()}"
model_path = _generate_torchscript_file(model_setup, name=name)
for (runtime, autograd, language), num_threads in it.product(
_ALL_MODES, args.num_threads
):
if runtime == RuntimeMode.EXPLICIT or autograd == AutogradMode.EXPLICIT:
continue
if runtime == RuntimeMode.JIT and not args.torchscript:
continue
if autograd == AutogradMode.FORWARD_BACKWARD and not args.autograd:
continue
stmt = _get_stmt(args, runtime, autograd, language)
if stmt is None:
continue
setup = _get_setup(args, runtime, language, stmt, model_path)
global_setup: str = ""
if language == Language.CPP and runtime == RuntimeMode.JIT:
global_setup = textwrap.dedent(
"""
#include <string>
#include <vector>
#include <torch/script.h>
"""
)
autolabels = AutoLabels(runtime, autograd, language)
timer_args = TimerArgs(
stmt=stmt,
setup=setup,
global_setup=global_setup,
num_threads=num_threads,
language=language,
)
results.append((label, autolabels, timer_args))
return tuple(results) | python | github | https://github.com/pytorch/pytorch | benchmarks/instruction_counts/core/expand.py |
"""
Helper functions that convert strftime formats into more readable representations.
"""
from rest_framework import ISO_8601
def datetime_formats(formats):
format = ', '.join(formats).replace(
ISO_8601,
'YYYY-MM-DDThh:mm[:ss[.uuuuuu]][+HH:MM|-HH:MM|Z]'
)
return humanize_strptime(format)
def date_formats(formats):
format = ', '.join(formats).replace(ISO_8601, 'YYYY[-MM[-DD]]')
return humanize_strptime(format)
def time_formats(formats):
format = ', '.join(formats).replace(ISO_8601, 'hh:mm[:ss[.uuuuuu]]')
return humanize_strptime(format)
def humanize_strptime(format_string):
# Note that we're missing some of the locale specific mappings that
# don't really make sense.
mapping = {
"%Y": "YYYY",
"%y": "YY",
"%m": "MM",
"%b": "[Jan-Dec]",
"%B": "[January-December]",
"%d": "DD",
"%H": "hh",
"%I": "hh", # Requires '%p' to differentiate from '%H'.
"%M": "mm",
"%S": "ss",
"%f": "uuuuuu",
"%a": "[Mon-Sun]",
"%A": "[Monday-Sunday]",
"%p": "[AM|PM]",
"%z": "[+HHMM|-HHMM]"
}
for key, val in mapping.items():
format_string = format_string.replace(key, val)
return format_string | unknown | codeparrot/codeparrot-clean | ||
#
# Copyright 2009-2017 Red Hat, Inc.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
#
# Refer to the README and COPYING files for full details of the license
#
import os
import threading
import logging
import signal
import errno
import re
from StringIO import StringIO
import time
import functools
import sys
from collections import namedtuple
from contextlib import contextmanager
from operator import itemgetter
import six
from vdsm import concurrent
from vdsm.common import exception
from vdsm.common import proc
from vdsm.common.threadlocal import vars
from vdsm.config import config
from vdsm import constants
from vdsm import utils
from vdsm.storage import blockdev
from vdsm.storage import clusterlock
from vdsm.storage import constants as sc
from vdsm.storage import directio
from vdsm.storage import exception as se
from vdsm.storage import fileUtils
from vdsm.storage import fsutils
from vdsm.storage import iscsi
from vdsm.storage import lvm
from vdsm.storage import misc
from vdsm.storage import mount
from vdsm.storage import multipath
from vdsm.storage import resourceManager as rm
from vdsm.storage.mailbox import MAILBOX_SIZE
from vdsm.storage.persistent import PersistentDict, DictValidator
import vdsm.supervdsm as svdsm
import sd
from sdm import volume_artifacts
import blockVolume
import resourceFactories
STORAGE_DOMAIN_TAG = "RHAT_storage_domain"
STORAGE_UNREADY_DOMAIN_TAG = STORAGE_DOMAIN_TAG + "_UNREADY"
MASTERLV = "master"
# Special lvs available since storage domain version 0
SPECIAL_LVS_V0 = sd.SPECIAL_VOLUMES_V0 + (MASTERLV,)
# Special lvs avilable since storage domain version 4.
SPECIAL_LVS_V4 = sd.SPECIAL_VOLUMES_V4 + (MASTERLV,)
MASTERLV_SIZE = "1024" # In MiB = 2 ** 20 = 1024 ** 2 => 1GiB
BlockSDVol = namedtuple("BlockSDVol", "name, image, parent")
log = logging.getLogger("storage.BlockSD")
# FIXME: Make this calculated from something logical
RESERVED_METADATA_SIZE = 40 * (2 ** 20)
RESERVED_MAILBOX_SIZE = MAILBOX_SIZE * clusterlock.MAX_HOST_ID
METADATA_BASE_SIZE = 378
# VG's min metadata threshold is 20%
VG_MDA_MIN_THRESHOLD = 0.2
# VG's metadata size in MiB
VG_METADATASIZE = 128
MAX_PVS_LIMIT = 10 # BZ#648051
MAX_PVS = config.getint('irs', 'maximum_allowed_pvs')
if MAX_PVS > MAX_PVS_LIMIT:
log.warning("maximum_allowed_pvs = %d ignored. MAX_PVS = %d", MAX_PVS,
MAX_PVS_LIMIT)
MAX_PVS = MAX_PVS_LIMIT
PVS_METADATA_SIZE = MAX_PVS * 142
SD_METADATA_SIZE = 2048
DEFAULT_BLOCKSIZE = 512
DMDK_VGUUID = "VGUUID"
DMDK_PV_REGEX = re.compile(r"^PV\d+$")
DMDK_LOGBLKSIZE = "LOGBLKSIZE"
DMDK_PHYBLKSIZE = "PHYBLKSIZE"
VERS_METADATA_LV = (0,)
VERS_METADATA_TAG = (2, 3, 4)
def encodePVInfo(pvInfo):
return (
"pv:%s," % pvInfo["guid"] +
"uuid:%s," % pvInfo["uuid"] +
"pestart:%s," % pvInfo["pestart"] +
"pecount:%s," % pvInfo["pecount"] +
"mapoffset:%s" % pvInfo["mapoffset"])
def decodePVInfo(value):
# TODO: need to support cases where a comma is part of the value
pvInfo = dict([item.split(":", 1) for item in value.split(",")])
pvInfo["guid"] = pvInfo["pv"]
del pvInfo["pv"]
return pvInfo
BLOCK_SD_MD_FIELDS = sd.SD_MD_FIELDS.copy()
# TBD: Do we really need this key?
BLOCK_SD_MD_FIELDS.update({
# Key dec, enc
DMDK_PV_REGEX: (decodePVInfo, encodePVInfo),
DMDK_VGUUID: (str, str),
DMDK_LOGBLKSIZE: (functools.partial(sd.intOrDefault, DEFAULT_BLOCKSIZE),
str),
DMDK_PHYBLKSIZE: (functools.partial(sd.intOrDefault, DEFAULT_BLOCKSIZE),
str),
})
INVALID_CHARS = re.compile(r"[^a-zA-Z0-9_+.\-/=!:#]")
LVM_ENC_ESCAPE = re.compile("&(\d+)&")
# Move to lvm
def lvmTagEncode(s):
return INVALID_CHARS.sub(lambda c: "&%s&" % ord(c.group()), s)
def lvmTagDecode(s):
return LVM_ENC_ESCAPE.sub(lambda c: unichr(int(c.groups()[0])), s)
def _getVolsTree(sdUUID):
lvs = lvm.getLV(sdUUID)
vols = {}
for lv in lvs:
if sc.TEMP_VOL_LVTAG in lv.tags:
continue
image = ""
parent = ""
for tag in lv.tags:
if tag.startswith(sc.TAG_PREFIX_IMAGE):
image = tag[len(sc.TAG_PREFIX_IMAGE):]
elif tag.startswith(sc.TAG_PREFIX_PARENT):
parent = tag[len(sc.TAG_PREFIX_PARENT):]
if parent and image:
vols[lv.name] = BlockSDVol(lv.name, image, parent)
break
else:
if lv.name not in SPECIAL_LVS_V4:
log.warning("Ignoring Volume %s that lacks minimal tag set"
"tags %s" % (lv.name, lv.tags))
return vols
def getAllVolumes(sdUUID):
"""
Return dict {volUUID: ((imgUUIDs,), parentUUID)} of the domain.
imgUUIDs is a list of all images dependant on volUUID.
For template based volumes, the first image is the template's image.
For other volumes, there is just a single imageUUID.
Template self image is the 1st term in template volume entry images.
"""
vols = _getVolsTree(sdUUID)
res = {}
for volName in vols.iterkeys():
res[volName] = {'imgs': [], 'parent': None}
for volName, vImg, parentVol in vols.itervalues():
res[volName]['parent'] = parentVol
if vImg not in res[volName]['imgs']:
res[volName]['imgs'].insert(0, vImg)
if parentVol != sd.BLANK_UUID:
try:
imgIsUnknown = vImg not in res[parentVol]['imgs']
except KeyError:
log.warning("Found broken image %s, orphan volume %s/%s, "
"parent %s", vImg, sdUUID, volName, parentVol)
else:
if imgIsUnknown:
res[parentVol]['imgs'].append(vImg)
return dict((k, sd.ImgsPar(tuple(v['imgs']), v['parent']))
for k, v in res.iteritems())
def deleteVolumes(sdUUID, vols):
lvm.removeLVs(sdUUID, vols)
def zeroImgVolumes(sdUUID, imgUUID, volUUIDs, discard):
taskid = vars.task.id
task = vars.task
try:
lvm.changelv(sdUUID, volUUIDs, ("--permission", "rw"))
except se.StorageException as e:
# We ignore the failure hoping that the volumes were
# already writable.
log.debug('Ignoring failed permission change: %s', e)
def zeroVolume(volUUID):
log.debug('Zero volume thread started for '
'volume %s task %s', volUUID, taskid)
path = lvm.lvPath(sdUUID, volUUID)
blockdev.zero(path, task=task)
if discard or blockdev.discard_enabled():
blockdev.discard(path)
try:
log.debug('Removing volume %s task %s', volUUID, taskid)
deleteVolumes(sdUUID, volUUID)
except se.CannotRemoveLogicalVolume:
log.exception("Removing volume %s task %s failed", volUUID, taskid)
log.debug('Zero volume thread finished for '
'volume %s task %s', volUUID, taskid)
log.debug('Starting to zero image %s', imgUUID)
results = concurrent.tmap(zeroVolume, volUUIDs)
errors = [str(res.value) for res in results if not res.succeeded]
if errors:
raise se.VolumesZeroingError(errors)
class VGTagMetadataRW(object):
log = logging.getLogger("storage.Metadata.VGTagMetadataRW")
METADATA_TAG_PREFIX = "MDT_"
METADATA_TAG_PREFIX_LEN = len(METADATA_TAG_PREFIX)
def __init__(self, vgName):
self._vgName = vgName
def readlines(self):
lvm.invalidateVG(self._vgName)
vg = lvm.getVG(self._vgName)
metadata = []
for tag in vg.tags:
if not tag.startswith(self.METADATA_TAG_PREFIX):
continue
metadata.append(lvmTagDecode(tag[self.METADATA_TAG_PREFIX_LEN:]))
return metadata
def writelines(self, lines):
currentMetadata = set(self.readlines())
newMetadata = set(lines)
# Remove all items that do not exist in the new metadata
toRemove = [self.METADATA_TAG_PREFIX + lvmTagEncode(item) for item in
currentMetadata.difference(newMetadata)]
# Add all missing items that do no exist in the old metadata
toAdd = [self.METADATA_TAG_PREFIX + lvmTagEncode(item) for item in
newMetadata.difference(currentMetadata)]
if len(toAdd) == 0 and len(toRemove) == 0:
return
self.log.debug("Updating metadata adding=%s removing=%s",
", ".join(toAdd), ", ".join(toRemove))
lvm.changeVGTags(self._vgName, delTags=toRemove, addTags=toAdd)
class LvMetadataRW(object):
"""
Block Storage Domain metadata implementation
"""
log = logging.getLogger("storage.Metadata.LvMetadataRW")
def __init__(self, vgName, lvName, offset, size):
self._size = size
self._lvName = lvName
self._vgName = vgName
self._offset = offset
self.metavol = lvm.lvPath(vgName, lvName)
def readlines(self):
# Fetch the metadata from metadata volume
lvm.activateLVs(self._vgName, [self._lvName])
m = misc.readblock(self.metavol, self._offset, self._size)
# Read from metadata volume will bring a load of zeroes trailing
# actual metadata. Strip it out.
metadata = [i for i in m if len(i) > 0 and i[0] != '\x00' and "=" in i]
return metadata
def writelines(self, lines):
lvm.activateLVs(self._vgName, [self._lvName])
# Write `metadata' to metadata volume
metaStr = StringIO()
for line in lines:
metaStr.write(line)
metaStr.write("\n")
if metaStr.pos > self._size:
raise se.MetadataOverflowError(metaStr.getvalue())
# Clear out previous data - it is a volume, not a file
metaStr.write('\0' * (self._size - metaStr.pos))
data = metaStr.getvalue()
with directio.DirectFile(self.metavol, "r+") as f:
f.seek(self._offset)
f.write(data)
LvBasedSDMetadata = lambda vg, lv: DictValidator(
PersistentDict(LvMetadataRW(vg, lv, 0, SD_METADATA_SIZE)),
BLOCK_SD_MD_FIELDS)
TagBasedSDMetadata = lambda vg: DictValidator(
PersistentDict(VGTagMetadataRW(vg)),
BLOCK_SD_MD_FIELDS)
def selectMetadata(sdUUID):
mdProvider = LvBasedSDMetadata(sdUUID, sd.METADATA)
if len(mdProvider) > 0:
metadata = mdProvider
else:
metadata = TagBasedSDMetadata(sdUUID)
return metadata
def metadataValidity(vg):
"""
Return the metadata validity:
mdathreshold - False if the VG's metadata exceeded its threshold,
else True
mdavalid - False if the VG's metadata size too small, else True
"""
mda_size = int(vg.vg_mda_size)
mda_free = int(vg.vg_mda_free)
mda_size_ok = mda_size >= VG_METADATASIZE * constants.MEGAB / 2
mda_free_ok = mda_free >= mda_size * VG_MDA_MIN_THRESHOLD
return {'mdathreshold': mda_free_ok, 'mdavalid': mda_size_ok}
class BlockStorageDomainManifest(sd.StorageDomainManifest):
mountpoint = os.path.join(sd.StorageDomain.storage_repository,
sd.DOMAIN_MNT_POINT, sd.BLOCKSD_DIR)
def __init__(self, sdUUID, metadata=None):
domaindir = os.path.join(self.mountpoint, sdUUID)
if metadata is None:
metadata = selectMetadata(sdUUID)
sd.StorageDomainManifest.__init__(self, sdUUID, domaindir, metadata)
# _extendlock is used to prevent race between
# VG extend and LV extend.
self._extendlock = threading.Lock()
try:
self.logBlkSize = self.getMetaParam(DMDK_LOGBLKSIZE)
self.phyBlkSize = self.getMetaParam(DMDK_PHYBLKSIZE)
except KeyError:
# 512 by Saggi "Trust me (Smoch Alai (sic))"
# *blkSize keys may be missing from metadata only for domains that
# existed before the introduction of the keys.
# Such domains supported only 512 sizes
self.logBlkSize = 512
self.phyBlkSize = 512
@classmethod
def special_volumes(cls, version):
if cls.supports_external_leases(version):
return SPECIAL_LVS_V4
else:
return SPECIAL_LVS_V0
def readMetadataMapping(self):
meta = self.getMetadata()
for key in meta.keys():
if not DMDK_PV_REGEX.match(key):
del meta[key]
self.log.info("META MAPPING: %s" % meta)
return meta
def supports_device_reduce(self):
return self.getVersion() not in VERS_METADATA_LV
def getMonitoringPath(self):
return lvm.lvPath(self.sdUUID, sd.METADATA)
def getVSize(self, imgUUUID, volUUID):
""" Return the block volume size in bytes. """
try:
size = fsutils.size(lvm.lvPath(self.sdUUID, volUUID))
except IOError as e:
if e.errno == os.errno.ENOENT:
# Inactive volume has no /dev entry. Fallback to lvm way.
size = lvm.getLV(self.sdUUID, volUUID).size
else:
self.log.warn("Could not get size for vol %s/%s",
self.sdUUID, volUUID, exc_info=True)
raise
return int(size)
getVAllocSize = getVSize
def getLeasesFilePath(self):
# TODO: Determine the path without activating the LV
lvm.activateLVs(self.sdUUID, [sd.LEASES])
return lvm.lvPath(self.sdUUID, sd.LEASES)
def getIdsFilePath(self):
# TODO: Determine the path without activating the LV
lvm.activateLVs(self.sdUUID, [sd.IDS])
return lvm.lvPath(self.sdUUID, sd.IDS)
def extendVolume(self, volumeUUID, size, isShuttingDown=None):
with self._extendlock:
self.log.debug("Extending thinly-provisioned LV for volume %s to "
"%d MB", volumeUUID, size)
# FIXME: following line.
lvm.extendLV(self.sdUUID, volumeUUID, size) # , isShuttingDown)
def getMetadataLVDevice(self):
"""
Returns the first device of the domain metadata lv.
NOTE: This device may not be the same device as the vg
metadata device.
"""
dev, _ = lvm.getFirstExt(self.sdUUID, sd.METADATA)
return os.path.basename(dev)
def getVgMetadataDevice(self):
"""
Returns the device containing the domain vg metadata.
NOTE: This device may not be the same device as the lv
metadata first device.
"""
return os.path.basename(lvm.getVgMetadataPv(self.sdUUID))
def _validateNotFirstMetadataLVDevice(self, guid):
if self.getMetadataLVDevice() == guid:
raise se.ForbiddenPhysicalVolumeOperation(
"This PV is the first metadata LV device")
def _validateNotVgMetadataDevice(self, guid):
if self.getVgMetadataDevice() == guid:
raise se.ForbiddenPhysicalVolumeOperation(
"This PV is used by LVM to store the VG metadata")
def _validatePVsPartOfVG(self, pv, dstPVs=None):
vgPvs = {os.path.basename(pv) for pv in lvm.listPVNames(self.sdUUID)}
if pv not in vgPvs:
raise se.NoSuchPhysicalVolume(pv, self.sdUUID)
if dstPVs:
unrelated_pvs = set(dstPVs) - vgPvs
if unrelated_pvs:
raise se.NoSuchDestinationPhysicalVolumes(
', '.join(unrelated_pvs), self.sdUUID)
@classmethod
def getMetaDataMapping(cls, vgName, oldMapping={}):
firstDev, firstExtent = lvm.getFirstExt(vgName, sd.METADATA)
firstExtent = int(firstExtent)
if firstExtent != 0:
cls.log.error("INTERNAL: metadata ext is not 0")
raise se.MetaDataMappingError("vg %s: metadata extent is not the "
"first extent" % vgName)
pvlist = list(lvm.listPVNames(vgName))
pvlist.remove(firstDev)
pvlist.insert(0, firstDev)
cls.log.info("Create: SORT MAPPING: %s" % pvlist)
mapping = {}
devNum = len(oldMapping)
for dev in pvlist:
knownDev = False
for pvID, oldInfo in oldMapping.iteritems():
if os.path.basename(dev) == oldInfo["guid"]:
mapping[pvID] = oldInfo
knownDev = True
break
if knownDev:
continue
pv = lvm.getPV(dev)
pvInfo = {}
pvInfo["guid"] = os.path.basename(pv.name)
pvInfo["uuid"] = pv.uuid
# this is another trick, it's not the
# the pestart value you expect, it's just
# 0, always
pvInfo["pestart"] = 0
pvInfo["pecount"] = pv.pe_count
if devNum == 0:
mapOffset = 0
else:
prevDevNum = devNum - 1
try:
prevInfo = mapping["PV%d" % (prevDevNum,)]
except KeyError:
prevInfo = oldMapping["PV%d" % (prevDevNum,)]
mapOffset = int(prevInfo["mapoffset"]) + \
int(prevInfo["pecount"])
pvInfo["mapoffset"] = mapOffset
mapping["PV%d" % devNum] = pvInfo
devNum += 1
return mapping
def updateMapping(self):
# First read existing mapping from metadata
with self._metadata.transaction():
mapping = self.getMetaDataMapping(self.sdUUID,
self.readMetadataMapping())
for key in set(self._metadata.keys() + mapping.keys()):
if DMDK_PV_REGEX.match(key):
if key in mapping:
self._metadata[key] = mapping[key]
else:
del self._metadata[key]
@classmethod
def metaSize(cls, vgroup):
''' Calc the minimal meta volume size in MB'''
# In any case the metadata volume cannot be less than 512MB for the
# case of 512 bytes per volume metadata, 2K for domain metadata and
# extent size of 128MB. In any case we compute the right size on line.
vg = lvm.getVG(vgroup)
minmetasize = (SD_METADATA_SIZE / sd.METASIZE * int(vg.extent_size) +
(1024 * 1024 - 1)) / (1024 * 1024)
metaratio = int(vg.extent_size) / sd.METASIZE
metasize = (int(vg.extent_count) * sd.METASIZE +
(1024 * 1024 - 1)) / (1024 * 1024)
metasize = max(minmetasize, metasize)
if metasize > int(vg.free) / (1024 * 1024):
raise se.VolumeGroupSizeError(
"volume group has not enough extents %s (Minimum %s), VG may "
"be too small" % (vg.extent_count,
(1024 * 1024) / sd.METASIZE))
cls.log.info("size %s MB (metaratio %s)" % (metasize, metaratio))
return metasize
def extend(self, devlist, force):
with self._extendlock:
if self.getVersion() in VERS_METADATA_LV:
mapping = self.readMetadataMapping().values()
if len(mapping) + len(devlist) > MAX_PVS:
raise se.StorageDomainIsMadeFromTooManyPVs()
knowndevs = set(multipath.getMPDevNamesIter())
unknowndevs = set(devlist) - knowndevs
if unknowndevs:
raise se.InaccessiblePhysDev(unknowndevs)
lvm.extendVG(self.sdUUID, devlist, force)
self.updateMapping()
newsize = self.metaSize(self.sdUUID)
lvm.extendLV(self.sdUUID, sd.METADATA, newsize)
def resizePV(self, guid):
with self._extendlock:
lvm.resizePV(self.sdUUID, guid)
self.updateMapping()
newsize = self.metaSize(self.sdUUID)
lvm.extendLV(self.sdUUID, sd.METADATA, newsize)
def movePV(self, src_device, dst_devices):
self._validatePVsPartOfVG(src_device, dst_devices)
self._validateNotFirstMetadataLVDevice(src_device)
self._validateNotVgMetadataDevice(src_device)
# TODO: check if we can avoid using _extendlock here
with self._extendlock:
lvm.movePV(self.sdUUID, src_device, dst_devices)
def reduceVG(self, guid):
self._validatePVsPartOfVG(guid)
self._validateNotFirstMetadataLVDevice(guid)
self._validateNotVgMetadataDevice(guid)
with self._extendlock:
try:
lvm.reduceVG(self.sdUUID, guid)
except Exception:
exc = sys.exc_info()
else:
exc = None
# We update the mapping even in case of failure to reduce,
# this operation isn't be executed often so we prefer to be on
# the safe side on case something has changed.
try:
self.updateMapping()
except Exception:
if exc is None:
raise
log.exception("Failed to update the domain metadata mapping")
if exc:
try:
six.reraise(*exc)
finally:
del exc
def getVolumeClass(self):
"""
Return a type specific volume generator object
"""
return blockVolume.BlockVolumeManifest
def get_volume_artifacts(self, img_id, vol_id):
return volume_artifacts.BlockVolumeArtifacts(self, img_id, vol_id)
def _getImgExclusiveVols(self, imgUUID, volsImgs):
"""Filter vols belonging to imgUUID only."""
exclusives = dict((vName, v) for vName, v in volsImgs.iteritems()
if v.imgs[0] == imgUUID)
return exclusives
def _markForDelVols(self, sdUUID, imgUUID, volUUIDs, opTag):
"""
Mark volumes that will be zeroed or removed.
Mark for delete just in case that lvremove [lvs] success partialy.
Mark for zero just in case that zero process is interrupted.
Tagging is preferable to rename since it can be done in a single lvm
operation and is resilient to open LVs, etc.
"""
try:
lvm.changelv(sdUUID, volUUIDs,
(("-a", "y"),
("--deltag", sc.TAG_PREFIX_IMAGE + imgUUID),
("--addtag", sc.TAG_PREFIX_IMAGE +
opTag + imgUUID)))
except se.StorageException as e:
log.error("Can't activate or change LV tags in SD %s. "
"failing Image %s %s operation for vols: %s. %s",
sdUUID, imgUUID, opTag, volUUIDs, e)
raise
def _rmDCVolLinks(self, imgPath, volsImgs):
for vol in volsImgs:
lPath = os.path.join(imgPath, vol)
removedPaths = []
try:
os.unlink(lPath)
except OSError as e:
self.log.warning("Can't unlink %s. %s", lPath, e)
else:
removedPaths.append(lPath)
self.log.debug("removed: %s", removedPaths)
return tuple(removedPaths)
def rmDCImgDir(self, imgUUID, volsImgs):
imgPath = os.path.join(self.domaindir, sd.DOMAIN_IMAGES, imgUUID)
self._rmDCVolLinks(imgPath, volsImgs)
try:
os.rmdir(imgPath)
except OSError:
self.log.warning("Can't rmdir %s", imgPath, exc_info=True)
else:
self.log.debug("removed image dir: %s", imgPath)
return imgPath
def deleteImage(self, sdUUID, imgUUID, volsImgs):
toDel = self._getImgExclusiveVols(imgUUID, volsImgs)
self._markForDelVols(sdUUID, imgUUID, toDel, sd.REMOVED_IMAGE_PREFIX)
def purgeImage(self, sdUUID, imgUUID, volsImgs, discard):
taskid = vars.task.id
def purge_volume(volUUID):
self.log.debug('Purge volume thread started for volume %s task %s',
volUUID, taskid)
path = lvm.lvPath(sdUUID, volUUID)
if discard or blockdev.discard_enabled():
blockdev.discard(path)
self.log.debug('Removing volume %s task %s', volUUID, taskid)
deleteVolumes(sdUUID, volUUID)
self.log.debug('Purge volume thread finished for '
'volume %s task %s', volUUID, taskid)
self.log.debug("Purging image %s", imgUUID)
toDel = self._getImgExclusiveVols(imgUUID, volsImgs)
results = concurrent.tmap(purge_volume, toDel)
errors = [str(res.value) for res in results if not res.succeeded]
if errors:
raise se.CannotRemoveLogicalVolume(errors)
self.rmDCImgDir(imgUUID, volsImgs)
def getAllVolumesImages(self):
"""
Return all the images that depend on a volume.
Return dicts:
vols = {volUUID: ([imgUUID1, imgUUID2], parentUUID)]}
for complete images.
remnants (same) for broken imgs, orphan volumes, etc.
"""
vols = {} # The "legal" volumes: not half deleted/removed volumes.
remnants = {} # Volumes which are part of failed image deletes.
allVols = getAllVolumes(self.sdUUID)
for volName, ip in allVols.iteritems():
if (volName.startswith(sd.REMOVED_IMAGE_PREFIX) or
ip.imgs[0].startswith(sd.REMOVED_IMAGE_PREFIX)):
remnants[volName] = ip
else:
# Deleted images are not dependencies of valid volumes.
images = [img for img in ip.imgs
if not img.startswith(sd.REMOVED_IMAGE_PREFIX)]
vols[volName] = sd.ImgsPar(images, ip.parent)
return vols, remnants
def getAllVolumes(self):
vols, rems = self.getAllVolumesImages()
return vols
def getAllImages(self):
"""
Get the set of all images uuids in the SD.
"""
vols = self.getAllVolumes() # {volName: ([imgs], parent)}
images = set()
for imgs, parent in vols.itervalues():
images.update(imgs)
return images
def refreshDirTree(self):
# create domain images folder
imagesPath = os.path.join(self.domaindir, sd.DOMAIN_IMAGES)
fileUtils.createdir(imagesPath)
# create domain special volumes folder
domMD = os.path.join(self.domaindir, sd.DOMAIN_META_DATA)
fileUtils.createdir(domMD)
special_lvs = self.special_volumes(self.getVersion())
lvm.activateLVs(self.sdUUID, special_lvs)
for lvName in special_lvs:
dst = os.path.join(domMD, lvName)
if not os.path.lexists(dst):
src = lvm.lvPath(self.sdUUID, lvName)
self.log.debug("Creating symlink from %s to %s", src, dst)
os.symlink(src, dst)
def refresh(self):
self.refreshDirTree()
lvm.invalidateVG(self.sdUUID)
self.replaceMetadata(selectMetadata(self.sdUUID))
_lvTagMetaSlotLock = threading.Lock()
@contextmanager
def acquireVolumeMetadataSlot(self, vol_name, slotSize):
# TODO: Check if the lock is needed when using
# getVolumeMetadataOffsetFromPvMapping()
with self._lvTagMetaSlotLock:
if self.getVersion() in VERS_METADATA_LV:
yield self._getVolumeMetadataOffsetFromPvMapping(vol_name)
else:
yield self._getFreeMetadataSlot(slotSize)
def _getVolumeMetadataOffsetFromPvMapping(self, vol_name):
dev, ext = lvm.getFirstExt(self.sdUUID, vol_name)
self.log.debug("vol %s dev %s ext %s" % (vol_name, dev, ext))
for pv in self.readMetadataMapping().values():
self.log.debug("MAPOFFSET: pv %s -- dev %s ext %s" %
(pv, dev, ext))
pestart = int(pv["pestart"])
pecount = int(pv["pecount"])
if (os.path.basename(dev) == pv["guid"] and
int(ext) in range(pestart, pestart + pecount)):
offs = int(ext) + int(pv["mapoffset"])
if offs < SD_METADATA_SIZE / sd.METASIZE:
raise se.MetaDataMappingError(
"domain %s: vol %s MD offset %s is bad - will "
"overwrite SD's MD" % (self.sdUUID, vol_name, offs))
return offs
raise se.MetaDataMappingError("domain %s: can't map PV %s ext %s" %
(self.sdUUID, dev, ext))
def _getFreeMetadataSlot(self, slotSize):
occupiedSlots = self._getOccupiedMetadataSlots()
# It might look weird skipping the sd metadata when it has been moved
# to tags. But this is here because domain metadata and volume metadata
# look the same. The domain might get confused and think it has lv
# metadata if it finds something is written in that area.
freeSlot = (SD_METADATA_SIZE + self.logBlkSize - 1) / self.logBlkSize
for offset, size in occupiedSlots:
if offset >= freeSlot + slotSize:
break
freeSlot = offset + size
self.log.debug("Found freeSlot %s in VG %s", freeSlot, self.sdUUID)
return freeSlot
def _getOccupiedMetadataSlots(self):
stripPrefix = lambda s, pfx: s[len(pfx):]
occupiedSlots = []
special_lvs = self.special_volumes(self.getVersion())
for lv in lvm.getLV(self.sdUUID):
if lv.name in special_lvs:
# Special LVs have no mapping
continue
offset = None
size = sc.VOLUME_MDNUMBLKS
for tag in lv.tags:
if tag.startswith(sc.TAG_PREFIX_MD):
offset = int(stripPrefix(tag, sc.TAG_PREFIX_MD))
if tag.startswith(sc.TAG_PREFIX_MDNUMBLKS):
size = int(stripPrefix(tag,
sc.TAG_PREFIX_MDNUMBLKS))
if offset is not None and size != sc.VOLUME_MDNUMBLKS:
# I've found everything I need
break
if offset is None:
self.log.warn("Could not find mapping for lv %s/%s",
self.sdUUID, lv.name)
continue
occupiedSlots.append((offset, size))
occupiedSlots.sort(key=itemgetter(0))
return occupiedSlots
def validateCreateVolumeParams(self, volFormat, srcVolUUID,
preallocate=None):
super(BlockStorageDomainManifest, self).validateCreateVolumeParams(
volFormat, srcVolUUID, preallocate=preallocate)
# Sparse-Raw not supported for block volumes
if preallocate == sc.SPARSE_VOL and volFormat == sc.RAW_FORMAT:
raise se.IncorrectFormat(sc.type2name(volFormat))
def getVolumeLease(self, imgUUID, volUUID):
"""
Return the volume lease (leasePath, leaseOffset)
"""
if not self.hasVolumeLeases():
return clusterlock.Lease(None, None, None)
# TODO: use the sanlock specific offset when present
slot = self.produceVolume(imgUUID, volUUID).getMetaOffset()
offset = ((slot + blockVolume.RESERVED_LEASES) * self.logBlkSize *
sd.LEASE_BLOCKS)
return clusterlock.Lease(volUUID, self.getLeasesFilePath(), offset)
def teardownVolume(self, imgUUID, volUUID):
lvm.deactivateLVs(self.sdUUID, [volUUID])
self.removeVolumeRunLink(imgUUID, volUUID)
def removeVolumeRunLink(self, imgUUID, volUUID):
"""
Remove /run/vdsm/storage/sdUUID/imgUUID/volUUID
"""
vol_run_link = os.path.join(constants.P_VDSM_STORAGE,
self.sdUUID, imgUUID, volUUID)
self.log.info("Unlinking volme runtime link: %r", vol_run_link)
try:
os.unlink(vol_run_link)
except OSError as e:
if e.errno != errno.ENOENT:
raise
self.log.debug("Volume run link %r does not exist", vol_run_link)
# External leases support
def external_leases_path(self):
"""
Return the path to the external leases volume.
"""
return _external_leases_path(self.sdUUID)
class BlockStorageDomain(sd.StorageDomain):
manifestClass = BlockStorageDomainManifest
def __init__(self, sdUUID):
manifest = self.manifestClass(sdUUID)
sd.StorageDomain.__init__(self, manifest)
# TODO: Move this to manifest.activate_special_lvs
special_lvs = manifest.special_volumes(manifest.getVersion())
lvm.activateLVs(self.sdUUID, special_lvs)
self.metavol = lvm.lvPath(self.sdUUID, sd.METADATA)
# Check that all devices in the VG have the same logical and physical
# block sizes.
lvm.checkVGBlockSizes(sdUUID, (self.logBlkSize, self.phyBlkSize))
self.imageGarbageCollector()
self._registerResourceNamespaces()
self._lastUncachedSelftest = 0
@property
def logBlkSize(self):
return self._manifest.logBlkSize
@property
def phyBlkSize(self):
return self._manifest.phyBlkSize
def _registerResourceNamespaces(self):
"""
Register resources namespaces and create
factories for it.
"""
sd.StorageDomain._registerResourceNamespaces(self)
# Register lvm activation resource namespace for the underlying VG
lvmActivationFactory = resourceFactories.LvmActivationFactory(
self.sdUUID)
lvmActivationNamespace = sd.getNamespace(sc.LVM_ACTIVATION_NAMESPACE,
self.sdUUID)
try:
rm.registerNamespace(lvmActivationNamespace, lvmActivationFactory)
except rm.NamespaceRegistered:
self.log.debug("Resource namespace %s already registered",
lvmActivationNamespace)
@classmethod
def metaSize(cls, vgroup):
return cls.manifestClass.metaSize(vgroup)
@classmethod
def create(cls, sdUUID, domainName, domClass, vgUUID, storageType,
version):
""" Create new storage domain
'sdUUID' - Storage Domain UUID
'domainName' - storage domain name
'domClass' - Data/Iso
'vgUUID' - volume group UUID
'storageType' - NFS_DOMAIN, LOCALFS_DOMAIN, &etc.
'version' - DOMAIN_VERSIONS
"""
cls.log.info("sdUUID=%s domainName=%s domClass=%s vgUUID=%s "
"storageType=%s version=%s", sdUUID, domainName, domClass,
vgUUID, storageType, version)
if not misc.isAscii(domainName) and not sd.supportsUnicode(version):
raise se.UnicodeArgumentException()
if len(domainName) > sd.MAX_DOMAIN_DESCRIPTION_SIZE:
raise se.StorageDomainDescriptionTooLongError()
sd.validateDomainVersion(version)
vg = lvm.getVGbyUUID(vgUUID)
vgName = vg.name
if set((STORAGE_UNREADY_DOMAIN_TAG,)) != set(vg.tags):
raise se.VolumeGroupHasDomainTag(vgUUID)
try:
lvm.getLV(vgName)
raise se.StorageDomainNotEmpty(vgUUID)
except se.LogicalVolumeDoesNotExistError:
pass
numOfPVs = len(lvm.listPVNames(vgName))
if version in VERS_METADATA_LV and numOfPVs > MAX_PVS:
cls.log.debug("%d > %d", numOfPVs, MAX_PVS)
raise se.StorageDomainIsMadeFromTooManyPVs()
# Create metadata service volume
metasize = cls.metaSize(vgName)
lvm.createLV(vgName, sd.METADATA, "%s" % (metasize))
# Create the mapping right now so the index 0 is guaranteed
# to belong to the metadata volume. Since the metadata is at
# least SDMETADATA/METASIZE units, we know we can use the first
# SDMETADATA bytes of the metadata volume for the SD metadata.
# pass metadata's dev to ensure it is the first mapping
mapping = cls.getMetaDataMapping(vgName)
# Create the rest of the BlockSD internal volumes
special_lvs = cls.manifestClass.special_volumes(version)
for name, size_mb in sd.SPECIAL_VOLUME_SIZES_MIB.iteritems():
if name in special_lvs:
lvm.createLV(vgName, name, size_mb)
lvm.createLV(vgName, MASTERLV, MASTERLV_SIZE)
if cls.supports_external_leases(version):
xleases_path = _external_leases_path(vgName)
cls.format_external_leases(vgName, xleases_path)
# Create VMS file system
_createVMSfs(os.path.join("/dev", vgName, MASTERLV))
lvm.deactivateLVs(vgName, [MASTERLV])
path = lvm.lvPath(vgName, sd.METADATA)
# Zero out the metadata and special volumes before use
try:
blockdev.zero(path, size=RESERVED_METADATA_SIZE)
path = lvm.lvPath(vgName, sd.INBOX)
blockdev.zero(path, size=RESERVED_MAILBOX_SIZE)
path = lvm.lvPath(vgName, sd.OUTBOX)
blockdev.zero(path, size=RESERVED_MAILBOX_SIZE)
except exception.ActionStopped:
raise
except se.StorageException:
raise se.VolumesZeroingError(path)
if version in VERS_METADATA_LV:
md = LvBasedSDMetadata(vgName, sd.METADATA)
elif version in VERS_METADATA_TAG:
md = TagBasedSDMetadata(vgName)
logBlkSize, phyBlkSize = lvm.getVGBlockSizes(vgName)
# create domain metadata
# FIXME : This is 99% like the metadata in file SD
# Do we really need to keep the VGUUID?
# no one reads it from here anyway
initialMetadata = {
sd.DMDK_VERSION: version,
sd.DMDK_SDUUID: sdUUID,
sd.DMDK_TYPE: storageType,
sd.DMDK_CLASS: domClass,
sd.DMDK_DESCRIPTION: domainName,
sd.DMDK_ROLE: sd.REGULAR_DOMAIN,
sd.DMDK_POOLS: [],
sd.DMDK_LOCK_POLICY: '',
sd.DMDK_LOCK_RENEWAL_INTERVAL_SEC: sd.DEFAULT_LEASE_PARAMS[
sd.DMDK_LOCK_RENEWAL_INTERVAL_SEC],
sd.DMDK_LEASE_TIME_SEC: sd.DEFAULT_LEASE_PARAMS[
sd.DMDK_LEASE_TIME_SEC],
sd.DMDK_IO_OP_TIMEOUT_SEC: sd.DEFAULT_LEASE_PARAMS[
sd.DMDK_IO_OP_TIMEOUT_SEC],
sd.DMDK_LEASE_RETRIES: sd.DEFAULT_LEASE_PARAMS[
sd.DMDK_LEASE_RETRIES],
DMDK_VGUUID: vgUUID,
DMDK_LOGBLKSIZE: logBlkSize,
DMDK_PHYBLKSIZE: phyBlkSize,
}
initialMetadata.update(mapping)
md.update(initialMetadata)
# Mark VG with Storage Domain Tag
try:
lvm.replaceVGTag(vgName, STORAGE_UNREADY_DOMAIN_TAG,
STORAGE_DOMAIN_TAG)
except se.StorageException:
raise se.VolumeGroupUninitialized(vgName)
bsd = BlockStorageDomain(sdUUID)
bsd.initSPMlease()
return bsd
@classmethod
def getMetaDataMapping(cls, vgName, oldMapping={}):
return cls.manifestClass.getMetaDataMapping(vgName, oldMapping)
def extend(self, devlist, force):
self._manifest.extend(devlist, force)
def resizePV(self, guid):
self._manifest.resizePV(guid)
_lvTagMetaSlotLock = threading.Lock()
@contextmanager
def acquireVolumeMetadataSlot(self, vol_name, slotSize):
with self._manifest.acquireVolumeMetadataSlot(vol_name, slotSize) \
as slot:
yield slot
def readMetadataMapping(self):
return self._manifest.readMetadataMapping()
def getLeasesFileSize(self):
lv = lvm.getLV(self.sdUUID, sd.LEASES)
return int(lv.size)
def selftest(self):
"""
Run the underlying VG validation routine
"""
timeout = config.getint("irs", "repo_stats_cache_refresh_timeout")
now = time.time()
if now - self._lastUncachedSelftest > timeout:
self._lastUncachedSelftest = now
lvm.chkVG(self.sdUUID)
elif lvm.getVG(self.sdUUID).partial != lvm.VG_OK:
raise se.StorageDomainAccessError(self.sdUUID)
def validate(self):
"""
Validate that the storage domain metadata
"""
self.log.info("sdUUID=%s", self.sdUUID)
lvm.chkVG(self.sdUUID)
self.invalidateMetadata()
if not len(self.getMetadata()):
raise se.StorageDomainAccessError(self.sdUUID)
def invalidate(self):
"""
Make sure that storage domain is inaccessible.
1. Make sure master LV is not mounted
2. Deactivate all the volumes from the underlying VG
3. Destroy any possible dangling maps left in device mapper
"""
try:
self.unmountMaster()
except se.StorageDomainMasterUnmountError:
self.log.warning("Unable to unmount master LV during invalidateSD")
except se.CannotDeactivateLogicalVolume:
# It could be that at this point there is no LV, so just ignore it
pass
except Exception:
# log any other exception, but keep going
self.log.error("Unexpected error", exc_info=True)
# FIXME: remove this and make sure nothing breaks
try:
lvm.deactivateVG(self.sdUUID)
except Exception:
# log any other exception, but keep going
self.log.error("Unexpected error", exc_info=True)
fileUtils.cleanupdir(os.path.join("/dev", self.sdUUID))
@classmethod
def format(cls, sdUUID):
"""Format detached storage domain.
This removes all data from the storage domain.
"""
# Remove the directory tree
try:
domaindir = cls.findDomainPath(sdUUID)
except (se.StorageDomainDoesNotExist):
pass
else:
fileUtils.cleanupdir(domaindir, ignoreErrors=True)
# Remove special metadata and service volumes
# Remove all volumes LV if exists
_removeVMSfs(lvm.lvPath(sdUUID, MASTERLV))
try:
lvs = lvm.getLV(sdUUID)
except se.LogicalVolumeDoesNotExistError:
lvs = () # No LVs in this VG (domain)
for lv in lvs:
# Fix me: Should raise and get resource lock.
try:
lvm.removeLVs(sdUUID, lv.name)
except se.CannotRemoveLogicalVolume as e:
cls.log.warning("Remove logical volume failed %s/%s %s",
sdUUID, lv.name, str(e))
lvm.removeVG(sdUUID)
return True
def getInfo(self):
"""
Get storage domain info
"""
# self.log.info("sdUUID=%s", self.sdUUID)
# First call parent getInfo() - it fills in all the common details
info = sd.StorageDomain.getInfo(self)
# Now add blockSD specific data
vg = lvm.getVG(self.sdUUID) # vg.name = self.sdUUID
info['vguuid'] = vg.uuid
info['state'] = vg.partial
info['metadataDevice'] = self._manifest.getMetadataLVDevice()
# Some users may have storage domains with incorrect lvm metadata
# configuration, caused by faulty restore from lvm backup. Such storage
# domain is not supported, but this issue may be too common and we
# cannot fail here. See https://bugzilla.redhat.com/1446492.
try:
info['vgMetadataDevice'] = self._manifest.getVgMetadataDevice()
except se.UnexpectedVolumeGroupMetadata as e:
self.log.warning("Cannot get VG metadata device, this storage "
"domain is unsupported: %s", e)
return info
def getStats(self):
"""
"""
vg = lvm.getVG(self.sdUUID)
vgMetadataStatus = metadataValidity(vg)
return dict(disktotal=vg.size, diskfree=vg.free,
mdasize=vg.vg_mda_size, mdafree=vg.vg_mda_free,
mdavalid=vgMetadataStatus['mdavalid'],
mdathreshold=vgMetadataStatus['mdathreshold'])
def rmDCImgDir(self, imgUUID, volsImgs):
return self._manifest.rmDCImgDir(imgUUID, volsImgs)
def zeroImage(self, sdUUID, imgUUID, volsImgs, discard):
toZero = self._manifest._getImgExclusiveVols(imgUUID, volsImgs)
self._manifest._markForDelVols(sdUUID, imgUUID, toZero,
sd.ZEROED_IMAGE_PREFIX)
zeroImgVolumes(sdUUID, imgUUID, toZero, discard)
self.rmDCImgDir(imgUUID, volsImgs)
def deactivateImage(self, imgUUID):
"""
Deactivate all the volumes belonging to the image.
imgUUID: the image to be deactivated.
If the image is based on a template image it should be expressly
deactivated.
"""
self.removeImageLinks(imgUUID)
allVols = self.getAllVolumes()
volUUIDs = self._manifest._getImgExclusiveVols(imgUUID, allVols)
lvm.deactivateLVs(self.sdUUID, volUUIDs)
def linkBCImage(self, imgPath, imgUUID):
dst = self.getLinkBCImagePath(imgUUID)
self.log.debug("Creating symlink from %s to %s", imgPath, dst)
try:
os.symlink(imgPath, dst)
except OSError as e:
if e.errno == errno.EEXIST:
self.log.debug("path to image directory already exists: %s",
dst)
else:
raise
return dst
def unlinkBCImage(self, imgUUID):
img_path = self.getLinkBCImagePath(imgUUID)
if os.path.islink(img_path):
self.log.debug("Removing image directory link %r", img_path)
os.unlink(img_path)
def createImageLinks(self, srcImgPath, imgUUID, volUUIDs):
"""
qcow chain is built by reading each qcow header and reading the path
to the parent. When creating the qcow layer, we pass a relative path
which allows us to build a directory with links to all volumes in the
chain anywhere we want. This method creates a directory with the image
uuid under /var/run/vdsm and creates sym links to all the volumes in
the chain.
srcImgPath: Dir where the image volumes are.
"""
sdRunDir = os.path.join(constants.P_VDSM_STORAGE, self.sdUUID)
imgRunDir = os.path.join(sdRunDir, imgUUID)
fileUtils.createdir(imgRunDir)
for volUUID in volUUIDs:
srcVol = os.path.join(srcImgPath, volUUID)
dstVol = os.path.join(imgRunDir, volUUID)
self.log.debug("Creating symlink from %s to %s", srcVol, dstVol)
try:
os.symlink(srcVol, dstVol)
except OSError as e:
if e.errno == errno.EEXIST:
self.log.debug("img run vol already exists: %s", dstVol)
else:
raise
return imgRunDir
def removeImageLinks(self, imgUUID):
"""
Remove /run/vdsm/storage/sd_uuid/img_uuid directory, created in
createImageLinks.
Should be called when tearing down an image.
"""
fileUtils.cleanupdir(self.getImageRundir(imgUUID))
def activateVolumes(self, imgUUID, volUUIDs):
"""
Activate all the volumes belonging to the image.
imgUUID: the image to be deactivated.
allVols: getAllVolumes result.
If the image is based on a template image it will be activated.
"""
lvm.activateLVs(self.sdUUID, volUUIDs)
vgDir = os.path.join("/dev", self.sdUUID)
return self.createImageLinks(vgDir, imgUUID, volUUIDs)
def validateMasterMount(self):
return mount.isMounted(self.getMasterDir())
def mountMaster(self):
"""
Mount the master metadata file system. Should be called only by SPM.
"""
lvm.activateLVs(self.sdUUID, [MASTERLV])
masterDir = os.path.join(self.domaindir, sd.MASTER_FS_DIR)
fileUtils.createdir(masterDir)
masterfsdev = lvm.lvPath(self.sdUUID, MASTERLV)
cmd = [constants.EXT_FSCK, "-p", masterfsdev]
(rc, out, err) = misc.execCmd(cmd, sudo=True)
# fsck exit codes
# 0 - No errors
# 1 - File system errors corrected
# 2 - File system errors corrected, system should
# be rebooted
# 4 - File system errors left uncorrected
# 8 - Operational error
# 16 - Usage or syntax error
# 32 - E2fsck canceled by user request
# 128 - Shared library error
if rc == 1 or rc == 2:
# rc is a number
self.log.info("fsck corrected fs errors (%s)", rc)
if rc >= 4:
raise se.BlockStorageDomainMasterFSCKError(masterfsdev, rc)
# TODO: Remove when upgrade is only from a version which creates ext3
# Try to add a journal - due to unfortunate circumstances we exposed
# to the public the code that created ext2 file system instead of ext3.
# In order to make up for it we are trying to add journal here, just
# to be sure (and we have fixed the file system creation).
# If there is a journal already tune2fs will do nothing, indicating
# this condition only with exit code. However, we do not really care.
cmd = [constants.EXT_TUNE2FS, "-j", masterfsdev]
misc.execCmd(cmd, sudo=True)
masterMount = mount.Mount(masterfsdev, masterDir)
try:
masterMount.mount(vfstype=mount.VFS_EXT3)
except mount.MountError as ex:
rc, out = ex
raise se.BlockStorageDomainMasterMountError(masterfsdev, rc, out)
cmd = [constants.EXT_CHOWN, "%s:%s" %
(constants.METADATA_USER, constants.METADATA_GROUP), masterDir]
(rc, out, err) = misc.execCmd(cmd, sudo=True)
if rc != 0:
self.log.error("failed to chown %s", masterDir)
@classmethod
def __handleStuckUmount(cls, masterDir):
umountPids = proc.pgrep("umount")
try:
masterMount = mount.getMountFromTarget(masterDir)
except OSError as ex:
if ex.errno == errno.ENOENT:
return
raise
for umountPid in umountPids:
try:
state = proc.pidstat(umountPid).state
mountPoint = utils.getCmdArgs(umountPid)[-1]
except:
# Process probably exited
continue
if mountPoint != masterDir:
continue
if state != "D":
# If the umount is not in d state there
# is a possibility that the world might
# be in flux and umount will get stuck
# in an unkillable state that is not D
# which I don't know about, perhaps a
# bug in umount will cause umount to
# wait for something unrelated that is
# not the syscall. Waiting on a process
# which is not your child is race prone
# I will just call for another umount
# and wait for it to finish. That way I
# know that a umount ended.
try:
masterMount.umount()
except mount.MountError:
# timeout! we are stuck again.
# if you are here spmprotect forgot to
# reboot the machine but in any case
# continue with the disconnection.
pass
try:
vgName = masterDir.rsplit("/", 2)[1]
masterDev = os.path.join(
"/dev/mapper", vgName.replace("-", "--") + "-" + MASTERLV)
except KeyError:
# Umount succeeded after all
return
cls.log.warn("master mount resource is `%s`, trying to disconnect "
"underlying storage", masterDev)
iscsi.disconnectFromUndelyingStorage(masterDev)
@classmethod
def doUnmountMaster(cls, masterdir):
"""
Unmount the master metadata file system. Should be called only by SPM.
"""
# fuser processes holding mount point and validate that the umount
# succeeded
cls.__handleStuckUmount(masterdir)
try:
masterMount = mount.getMountFromTarget(masterdir)
except OSError as ex:
if ex.errno == errno.ENOENT:
return
raise
if masterMount.isMounted():
# Try umount, take 1
try:
masterMount.umount()
except mount.MountError:
# umount failed, try to kill that processes holding mount point
svdsmp = svdsm.getProxy()
pids = svdsmp.fuser(masterMount.fs_file, mountPoint=True)
# It was unmounted while I was checking no need to do anything
if not masterMount.isMounted():
return
if len(pids) == 0:
cls.log.warn("Unmount failed because of errors that fuser "
"can't solve")
else:
for pid in pids:
try:
cls.log.debug("Trying to kill pid %d", pid)
os.kill(pid, signal.SIGKILL)
except OSError as e:
if e.errno == errno.ESRCH: # No such process
pass
elif e.errno == errno.EPERM: # Op. not permitted
cls.log.warn("Could not kill pid %d because "
"operation was not permitted",
pid)
else:
cls.log.warn("Could not kill pid %d because an"
" unexpected error",
exc_info=True)
except:
cls.log.warn("Could not kill pid %d because an "
"unexpected error", exc_info=True)
# Try umount, take 2
try:
masterMount.umount()
except mount.MountError:
pass
if masterMount.isMounted():
# We failed to umount masterFS
# Forcibly rebooting the SPM host would be safer. ???
raise se.StorageDomainMasterUnmountError(masterdir, 1)
def unmountMaster(self):
"""
Unmount the master metadata file system. Should be called only by SPM.
"""
masterdir = os.path.join(self.domaindir, sd.MASTER_FS_DIR)
self.doUnmountMaster(masterdir)
# It is time to deactivate the master LV now
lvm.deactivateLVs(self.sdUUID, [MASTERLV])
def extendVolume(self, volumeUUID, size, isShuttingDown=None):
return self._manifest.extendVolume(volumeUUID, size, isShuttingDown)
@staticmethod
def findDomainPath(sdUUID):
try:
vg = lvm.getVG(sdUUID)
except se.VolumeGroupDoesNotExist:
raise se.StorageDomainDoesNotExist(sdUUID)
if _isSD(vg):
return vg.name
raise se.StorageDomainDoesNotExist(sdUUID)
def getVolumeClass(self):
"""
Return a type specific volume generator object
"""
return blockVolume.BlockVolume
# External leases support
def create_external_leases(self):
"""
Create the external leases special volume.
Called during upgrade from version 3 to version 4.
"""
path = self.external_leases_path()
try:
lvm.getLV(self.sdUUID, sd.XLEASES)
except se.LogicalVolumeDoesNotExistError:
self.log.info("Creating external leases volume %s", path)
size = sd.SPECIAL_VOLUME_SIZES_MIB[sd.XLEASES]
lvm.createLV(self.sdUUID, sd.XLEASES, size)
else:
self.log.info("Reusing external leases volume %s", path)
lvm.activateLVs(self.sdUUID, [sd.XLEASES])
def _external_leases_path(sdUUID):
return lvm.lvPath(sdUUID, sd.XLEASES)
def _createVMSfs(dev):
"""
Create a special file system to store VM data
"""
cmd = [constants.EXT_MKFS, "-q", "-j", "-E", "nodiscard", dev]
rc = misc.execCmd(cmd, sudo=True)[0]
if rc != 0:
raise se.MkfsError(dev)
def _removeVMSfs(dev):
"""
Destroy special VM data file system
"""
# XXX Add at least minimal sanity check:. i.e. fs not mounted
pass
def _isSD(vg):
return STORAGE_DOMAIN_TAG in vg.tags
def findDomain(sdUUID):
return BlockStorageDomain(BlockStorageDomain.findDomainPath(sdUUID))
def getStorageDomainsList():
return [vg.name for vg in lvm.getAllVGs() if _isSD(vg)] | unknown | codeparrot/codeparrot-clean | ||
"""Model retry middleware for agents."""
from __future__ import annotations
import asyncio
import time
from typing import TYPE_CHECKING
from langchain_core.messages import AIMessage
from langchain.agents.middleware._retry import (
OnFailure,
RetryOn,
calculate_delay,
should_retry_exception,
validate_retry_params,
)
from langchain.agents.middleware.types import (
AgentMiddleware,
AgentState,
ContextT,
ModelRequest,
ModelResponse,
ResponseT,
)
if TYPE_CHECKING:
from collections.abc import Awaitable, Callable
class ModelRetryMiddleware(AgentMiddleware[AgentState[ResponseT], ContextT, ResponseT]):
"""Middleware that automatically retries failed model calls with configurable backoff.
Supports retrying on specific exceptions and exponential backoff.
Examples:
!!! example "Basic usage with default settings (2 retries, exponential backoff)"
```python
from langchain.agents import create_agent
from langchain.agents.middleware import ModelRetryMiddleware
agent = create_agent(model, tools=[search_tool], middleware=[ModelRetryMiddleware()])
```
!!! example "Retry specific exceptions only"
```python
from anthropic import RateLimitError
from openai import APITimeoutError
retry = ModelRetryMiddleware(
max_retries=4,
retry_on=(APITimeoutError, RateLimitError),
backoff_factor=1.5,
)
```
!!! example "Custom exception filtering"
```python
from anthropic import APIStatusError
def should_retry(exc: Exception) -> bool:
# Only retry on 5xx errors
if isinstance(exc, APIStatusError):
return 500 <= exc.status_code < 600
return False
retry = ModelRetryMiddleware(
max_retries=3,
retry_on=should_retry,
)
```
!!! example "Custom error handling"
```python
def format_error(exc: Exception) -> str:
return "Model temporarily unavailable. Please try again later."
retry = ModelRetryMiddleware(
max_retries=4,
on_failure=format_error,
)
```
!!! example "Constant backoff (no exponential growth)"
```python
retry = ModelRetryMiddleware(
max_retries=5,
backoff_factor=0.0, # No exponential growth
initial_delay=2.0, # Always wait 2 seconds
)
```
!!! example "Raise exception on failure"
```python
retry = ModelRetryMiddleware(
max_retries=2,
on_failure="error", # Re-raise exception instead of returning message
)
```
"""
def __init__(
self,
*,
max_retries: int = 2,
retry_on: RetryOn = (Exception,),
on_failure: OnFailure = "continue",
backoff_factor: float = 2.0,
initial_delay: float = 1.0,
max_delay: float = 60.0,
jitter: bool = True,
) -> None:
"""Initialize `ModelRetryMiddleware`.
Args:
max_retries: Maximum number of retry attempts after the initial call.
Must be `>= 0`.
retry_on: Either a tuple of exception types to retry on, or a callable
that takes an exception and returns `True` if it should be retried.
Default is to retry on all exceptions.
on_failure: Behavior when all retries are exhausted.
Options:
- `'continue'`: Return an `AIMessage` with error details,
allowing the agent to continue with an error response.
- `'error'`: Re-raise the exception, stopping agent execution.
- **Custom callable:** Function that takes the exception and returns a
string for the `AIMessage` content, allowing custom error
formatting.
backoff_factor: Multiplier for exponential backoff.
Each retry waits `initial_delay * (backoff_factor ** retry_number)`
seconds.
Set to `0.0` for constant delay.
initial_delay: Initial delay in seconds before first retry.
max_delay: Maximum delay in seconds between retries.
Caps exponential backoff growth.
jitter: Whether to add random jitter (`±25%`) to delay to avoid thundering herd.
Raises:
ValueError: If `max_retries < 0` or delays are negative.
"""
super().__init__()
# Validate parameters
validate_retry_params(max_retries, initial_delay, max_delay, backoff_factor)
self.max_retries = max_retries
self.tools = [] # No additional tools registered by this middleware
self.retry_on = retry_on
self.on_failure = on_failure
self.backoff_factor = backoff_factor
self.initial_delay = initial_delay
self.max_delay = max_delay
self.jitter = jitter
@staticmethod
def _format_failure_message(exc: Exception, attempts_made: int) -> AIMessage:
"""Format the failure message when retries are exhausted.
Args:
exc: The exception that caused the failure.
attempts_made: Number of attempts actually made.
Returns:
`AIMessage` with formatted error message.
"""
exc_type = type(exc).__name__
exc_msg = str(exc)
attempt_word = "attempt" if attempts_made == 1 else "attempts"
content = (
f"Model call failed after {attempts_made} {attempt_word} with {exc_type}: {exc_msg}"
)
return AIMessage(content=content)
def _handle_failure(self, exc: Exception, attempts_made: int) -> ModelResponse[ResponseT]:
"""Handle failure when all retries are exhausted.
Args:
exc: The exception that caused the failure.
attempts_made: Number of attempts actually made.
Returns:
`ModelResponse` with error details.
Raises:
Exception: If `on_failure` is `'error'`, re-raises the exception.
"""
if self.on_failure == "error":
raise exc
if callable(self.on_failure):
content = self.on_failure(exc)
ai_msg = AIMessage(content=content)
else:
ai_msg = self._format_failure_message(exc, attempts_made)
return ModelResponse(result=[ai_msg])
def wrap_model_call(
self,
request: ModelRequest[ContextT],
handler: Callable[[ModelRequest[ContextT]], ModelResponse[ResponseT]],
) -> ModelResponse[ResponseT] | AIMessage:
"""Intercept model execution and retry on failure.
Args:
request: Model request with model, messages, state, and runtime.
handler: Callable to execute the model (can be called multiple times).
Returns:
`ModelResponse` or `AIMessage` (the final result).
Raises:
RuntimeError: If the retry loop completes without returning. (This should not happen.)
"""
# Initial attempt + retries
for attempt in range(self.max_retries + 1):
try:
return handler(request)
except Exception as exc:
attempts_made = attempt + 1 # attempt is 0-indexed
# Check if we should retry this exception
if not should_retry_exception(exc, self.retry_on):
# Exception is not retryable, handle failure immediately
return self._handle_failure(exc, attempts_made)
# Check if we have more retries left
if attempt < self.max_retries:
# Calculate and apply backoff delay
delay = calculate_delay(
attempt,
backoff_factor=self.backoff_factor,
initial_delay=self.initial_delay,
max_delay=self.max_delay,
jitter=self.jitter,
)
if delay > 0:
time.sleep(delay)
# Continue to next retry
else:
# No more retries, handle failure
return self._handle_failure(exc, attempts_made)
# Unreachable: loop always returns via handler success or _handle_failure
msg = "Unexpected: retry loop completed without returning"
raise RuntimeError(msg)
async def awrap_model_call(
self,
request: ModelRequest[ContextT],
handler: Callable[[ModelRequest[ContextT]], Awaitable[ModelResponse[ResponseT]]],
) -> ModelResponse[ResponseT] | AIMessage:
"""Intercept and control async model execution with retry logic.
Args:
request: Model request with model, messages, state, and runtime.
handler: Async callable to execute the model and returns `ModelResponse`.
Returns:
`ModelResponse` or `AIMessage` (the final result).
Raises:
RuntimeError: If the retry loop completes without returning. (This should not happen.)
"""
# Initial attempt + retries
for attempt in range(self.max_retries + 1):
try:
return await handler(request)
except Exception as exc:
attempts_made = attempt + 1 # attempt is 0-indexed
# Check if we should retry this exception
if not should_retry_exception(exc, self.retry_on):
# Exception is not retryable, handle failure immediately
return self._handle_failure(exc, attempts_made)
# Check if we have more retries left
if attempt < self.max_retries:
# Calculate and apply backoff delay
delay = calculate_delay(
attempt,
backoff_factor=self.backoff_factor,
initial_delay=self.initial_delay,
max_delay=self.max_delay,
jitter=self.jitter,
)
if delay > 0:
await asyncio.sleep(delay)
# Continue to next retry
else:
# No more retries, handle failure
return self._handle_failure(exc, attempts_made)
# Unreachable: loop always returns via handler success or _handle_failure
msg = "Unexpected: retry loop completed without returning"
raise RuntimeError(msg) | python | github | https://github.com/langchain-ai/langchain | libs/langchain_v1/langchain/agents/middleware/model_retry.py |
# Copyright (c) 2013-2018 Quarkslab.
# This file is part of IRMA project.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License in the top-level directory
# of this distribution and at:
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# No part of the project, including this file, may be copied,
# modified, propagated, or distributed except according to the
# terms contained in the LICENSE file.
import logging
import hug
import json
from hug.types import one_of, uuid
from falcon.errors import HTTPInvalidParam
from irma.common.utils.utils import decode_utf8
from api.common.middlewares import db
from .helpers import get_file_ext_schemas, new_file_ext
from .models import FileExt, File
log = logging.getLogger("hug")
@hug.get("/{external_id}")
def get(hug_api_version,
external_id: uuid,
formatted: one_of(("yes", "no")) = "yes"):
""" Retrieve a single file_ext result, with details.
"""
session = db.session
formatted = False if formatted == 'no' else True
log.debug("resultid %s formatted %s", external_id, formatted)
file_ext = FileExt.load_from_ext_id(external_id, session)
schema = get_file_ext_schemas(file_ext.submitter)
schema.context = {'formatted': formatted,
'api_version': hug_api_version}
data = schema.dump(file_ext).data
return data
@hug.post("/", versions=2,
input_format=hug.input_format.multipart)
def create(request):
""" Create a file_ext (could be later attached to a scan
The request should be performed using a POST request method.
Input format is multipart-form-data with file and a json containing
at least the submitter type
"""
log.debug("create file")
session = db.session
# request._params is init by Falcon
# Multipart Middleware giving a dict of part in the form
form_dict = request._params
if 'files' not in form_dict:
raise HTTPInvalidParam("Empty list", "files")
form_file = form_dict.pop('files')
if type(form_file) is list:
raise HTTPInvalidParam("Only one file at a time", "files")
if 'json' not in form_dict:
raise HTTPInvalidParam("Missing json parameter", "json")
payload = json.loads(form_dict['json'])
submitter = payload.pop('submitter', None)
# ByteIO object is in file
data = form_file.file
filename = decode_utf8(form_file.filename)
file = File.get_or_create(data, session)
file_ext = new_file_ext(submitter, file, filename, payload)
session.add(file_ext)
session.commit()
log.debug("filename: %s file_ext: %s created", filename,
file_ext.external_id)
schema = get_file_ext_schemas(file_ext.submitter)
schema.exclude += ("probe_results",)
return schema.dump(file_ext).data | unknown | codeparrot/codeparrot-clean | ||
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
sys.path.append('.')
import omero.gateway
import omero.model
import os
import subprocess
import urllib2
from types import StringTypes
from path import path
BASEPATH = os.path.dirname(os.path.abspath(__file__))
TESTIMG_URL = 'http://downloads.openmicroscopy.org/images/gateway_tests/'
DEFAULT_GROUP_PERMS = 'rwr---'
if not omero.gateway.BlitzGateway.ICE_CONFIG:
try:
import settings
iceconfig = os.environ.get('ICE_CONFIG', None)
if iceconfig is None:
iceconfig = os.path.join(settings.OMERO_HOME, 'etc', 'ice.config')
omero.gateway.BlitzGateway.ICE_CONFIG = iceconfig
except ImportError:
pass
except AttributeError:
pass
# Gateway = omero.gateway.BlitzGateway
def refreshConfig():
bg = omero.gateway.BlitzGateway()
try:
ru = bg.c.ic.getProperties().getProperty('omero.rootuser')
rp = bg.c.ic.getProperties().getProperty('omero.rootpass')
finally:
bg.close()
if ru:
ROOT.name = ru
if rp:
ROOT.passwd = rp
def loginAsRoot():
refreshConfig()
return login(ROOT)
def loginAsPublic():
return login(settings.PUBLIC_USER, settings.PUBLIC_PASSWORD)
def login(alias, pw=None, groupname=None):
if isinstance(alias, UserEntry):
return alias.login(groupname=groupname)
elif pw is None:
return USERS[alias].login(groupname=groupname)
else:
return UserEntry(alias, pw).login(groupname=groupname)
class BadGroupPermissionsException(Exception):
pass
class UserEntry (object):
def __init__(self, name, passwd, firstname='', middlename='', lastname='',
email='', ldap=False, groupname=None, groupperms=None,
groupowner=False, admin=False):
"""
If no groupperms are passed, then check_group_perms will do nothing.
The default perms for newly created groups is defined
in _getOrCreateGroup
"""
self.name = name
self.passwd = passwd
self.firstname = firstname
self.middlename = middlename
self.lastname = lastname
self.ldap = ldap
self.email = email
self.admin = admin
self.groupname = groupname
self.groupperms = groupperms
self.groupowner = groupowner
def fullname(self):
return '%s %s' % (self.firstname, self.lastname)
def login(self, groupname=None):
if groupname is None:
groupname = self.groupname
client = omero.gateway.BlitzGateway(
self.name, self.passwd, group=groupname, try_super=self.admin)
if not client.connect():
print "Can not connect"
return None
a = client.getAdminService()
if groupname is not None:
if client.getEventContext().groupName != groupname:
try:
g = a.lookupGroup(groupname)
client.setGroupForSession(g.getId().val)
except:
pass
# Reset group name and evaluate
self.groupname = a.getEventContext().groupName
if self.groupname != "system":
UserEntry.check_group_perms(
client, self.groupname, self.groupperms)
return client
@staticmethod
def check_group_perms(client, group, groupperms):
"""
If expected permissions have been set, then this will
enforce equality. If groupperms are None, then
nothing will be checked.
"""
if groupperms is not None:
if isinstance(group, StringTypes):
a = client.getAdminService()
g = a.lookupGroup(group)
else:
g = group
p = g.getDetails().getPermissions()
if str(p) != groupperms:
raise BadGroupPermissionsException(
"%s group has wrong permissions! Expected: %s Found: %s" %
(g.getName(), groupperms, p))
@staticmethod
def assert_group_perms(client, group, groupperms):
"""
If expected permissions have been set, then this will
change group permissions to those requested if not
already equal. If groupperms are None, then
nothing will be checked.
"""
a = client.getAdminService()
try:
if isinstance(group, StringTypes):
g = a.lookupGroup(group)
else:
g = group
UserEntry.check_group_perms(client, g, groupperms)
except BadGroupPermissionsException:
client._waitOnCmd(client.chmodGroup(g.id.val, groupperms))
@staticmethod
def _getOrCreateGroup(client, groupname, ldap=False, groupperms=None):
# Default on class is None
if groupperms is None:
groupperms = DEFAULT_GROUP_PERMS
a = client.getAdminService()
try:
g = a.lookupGroup(groupname)
except:
g = omero.model.ExperimenterGroupI()
g.setName(omero.gateway.omero_type(groupname))
g.setLdap(omero.gateway.omero_type(ldap))
p = omero.model.PermissionsI(groupperms)
g.details.setPermissions(p)
a.createGroup(g)
g = a.lookupGroup(groupname)
UserEntry.check_group_perms(client, groupname, groupperms)
return g
def create(self, client, password):
a = client.getAdminService()
try:
a.lookupExperimenter(self.name)
# print "Already exists: %s" % self.name
return False
except:
# print "Creating: %s" % self.name
pass
if self.groupname is None:
self.groupname = self.name + '_group'
g = UserEntry._getOrCreateGroup(
client, self.groupname, groupperms=self.groupperms)
u = omero.model.ExperimenterI()
u.setOmeName(omero.gateway.omero_type(self.name))
u.setFirstName(omero.gateway.omero_type(self.firstname))
u.setMiddleName(omero.gateway.omero_type(self.middlename))
u.setLastName(omero.gateway.omero_type(self.lastname))
u.setLdap(omero.gateway.omero_type(self.ldap))
u.setEmail(omero.gateway.omero_type(self.email))
a.createUser(u, g.getName().val)
u = a.lookupExperimenter(self.name)
if self.admin:
a.addGroups(u, (a.lookupGroup("system"),))
client.c.sf.setSecurityPassword(password) # See #3202
a.changeUserPassword(
u.getOmeName().val, omero.gateway.omero_type(self.passwd))
if self.groupowner:
a.setGroupOwner(g, u)
return True
def changePassword(self, client, password, rootpass):
a = client.getAdminService()
client.c.sf.setSecurityPassword(rootpass) # See #3202
a.changeUserPassword(self.name, omero.gateway.omero_type(password))
@staticmethod
def addGroupToUser(client, groupname, groupperms=None):
if groupperms is None:
groupperms = DEFAULT_GROUP_PERMS
a = client.getAdminService()
admin_gateway = None
try:
if 'system' not in [x.name.val for x in a.containedGroups(
client.getUserId())]:
admin_gateway = loginAsRoot()
a = admin_gateway.getAdminService()
g = UserEntry._getOrCreateGroup(
client, groupname, groupperms=groupperms)
a.addGroups(a.getExperimenter(client.getUserId()), (g,))
finally:
# Always clean up the results of login
if admin_gateway:
admin_gateway.close()
@staticmethod
def setGroupForSession(client, groupname, groupperms=None):
if groupperms is None:
groupperms = DEFAULT_GROUP_PERMS
a = client.getAdminService()
if groupname not in [x.name.val for x in a.containedGroups(
client.getUserId())]:
UserEntry.addGroupToUser(client, groupname, groupperms)
# Must reconnect to read new groupexperimentermap
t = client.clone()
client.c.closeSession()
client._proxies = omero.gateway.NoProxies()
client._ctx = None
client.c = t.c
client.connect()
a = client.getAdminService()
g = a.lookupGroup(groupname)
client.setGroupForSession(g.getId().val)
return client
class ObjectEntry (object):
pass
class ProjectEntry (ObjectEntry):
def __init__(self, name, owner, create_group=False, group_perms=None):
self.name = name
self.owner = owner
self.create_group = create_group
self.group_perms = group_perms
def get(self, client=None, fromCreate=False):
if client is None:
client = USERS[self.owner].login()
for p in client.listProjects():
if p.getName() == self.name:
p.__loadedHotSwap__()
return p
return None
def create(self, client=None):
if client is None:
client = USERS[self.owner].login()
p = self.get(client)
if p is not None:
return p
p = omero.model.ProjectI(loaded=True)
p.setName(omero.gateway.omero_type(self.name))
p.setDescription(omero.gateway.omero_type(self.name))
if self.create_group:
if isinstance(self.create_group, StringTypes):
groupname = self.create_group
else:
raise ValueError('group must be string')
groupname = 'project_test'
s = loginAsRoot()
UserEntry._getOrCreateGroup(
s, groupname, groupperms=self.group_perms)
try:
UserEntry.addGroupToUser(s, groupname, self.group_perms)
finally:
s.close()
UserEntry.setGroupForSession(client, groupname, self.group_perms)
p = omero.gateway.ProjectWrapper(
client, client.getUpdateService().saveAndReturnObject(p))
return self.get(client, True)
class DatasetEntry (ObjectEntry):
def __init__(self, name, project, description=None, callback=None):
self.name = name
self.project = project
self.description = description
self.callback = callback
def get(self, client, forceproj=None):
if forceproj is None:
if isinstance(self.project, StringTypes):
project = PROJECTS[self.project].get(client)
elif isinstance(self.project, ProjectEntry):
project = self.project.get(client)
else:
project = self.project
else:
project = forceproj
for d in project.listChildren():
if d.getName() == self.name and self.description_check(d):
d.__loadedHotSwap__()
return d
return None
def create(self):
if isinstance(self.project, StringTypes):
project = PROJECTS[self.project]
user = USERS[project.owner]
client = user.login()
project = project.get(client)
else:
project = self.project
client = project._conn
d = self.get(client, project)
if d is not None and self.description_check(d):
return d
d = omero.model.DatasetI(loaded=True)
d.setName(omero.gateway.omero_type(self.name))
if self.description is not None:
d.setDescription(omero.gateway.omero_type(self.description))
project.linkDataset(d)
project.save()
rv = self.get(client, project)
if self.callback:
self.callback(rv)
return rv
def description_check(self, d):
desc_match = (
omero.gateway.omero_type(d.getDescription()) ==
omero.gateway.omero_type(self.description))
desc_check = (
(self.description is None and d.getDescription() == '')
or (self.description is not None and desc_match))
return desc_check
class ImageEntry (ObjectEntry):
def __init__(self, name, filename, dataset, callback=None):
self.name = name
self.filename = filename # If False will create image without pixels
if self.name is None and filename:
self.name = os.path.basename(filename)
self.dataset = dataset
self.callback = callback
def get(self, client, forceds=None):
if forceds is None:
dataset = DATASETS[self.dataset].get(client)
else:
dataset = forceds
for i in dataset.listChildren():
if i.getName() == self.name:
return i
return None
def create(self):
if isinstance(self.dataset, StringTypes):
dataset = DATASETS[self.dataset]
project = PROJECTS[dataset.project]
client = USERS[project.owner].login()
dataset = dataset.get(client)
else:
dataset = self.dataset
client = dataset._conn
i = self.get(client, dataset)
if i is not None:
# print ".. -> image already exists: %s" % self.name
return i
# print ".. -> create new image: %s" % self.name
sys.stderr.write('I')
if self.filename is False:
UserEntry.setGroupForSession(
client, dataset.getDetails().getGroup().getName())
self._createWithoutPixels(client, dataset)
return self.get(client, dataset)
fpath = os.path.join(BASEPATH, self.filename)
if not os.path.exists(fpath):
if not os.path.exists(os.path.dirname(fpath)):
os.makedirs(os.path.dirname(fpath))
# First try to download the image
try:
# print "Trying to get test image from " + TESTIMG_URL +
# self.filename
sys.stderr.write('<')
f = urllib2.urlopen(TESTIMG_URL + self.filename)
open(fpath, 'wb').write(f.read())
except urllib2.HTTPError:
raise IOError('No such file %s' % fpath)
host = dataset._conn.c.ic.getProperties().getProperty(
'omero.host') or 'localhost'
port = dataset._conn.c.ic.getProperties().getProperty(
'omero.port') or '4063'
possiblepaths = (
# Running from dist
path(".") / ".." / "bin" / "omero",
# Running from OmeroPy
path(".") / ".." / ".." / ".." / "dist" / "bin" / "omero",
# Running from OmeroWeb
path(".") / ".." / ".." / ".." / "bin" / "omero",
# not found
"omero",
)
for exe in possiblepaths:
if exe.exists():
break
if exe == 'omero':
print "\n\nNo omero found!" \
"Add OMERO_HOME/bin to your PATH variable (See #5176)\n\n"
newconn = dataset._conn.clone()
newconn.connect()
try:
UserEntry.setGroupForSession(
newconn, dataset.getDetails().getGroup().getName())
session = newconn._sessionUuid
# print session
exe += ' -s %s -k %s -p %s import -d %i --output legacy -n' % (
host, session, port, dataset.getId())
exe = exe.split() + [self.name, fpath]
print ' '.join(exe)
try:
p = subprocess.Popen(
exe, shell=False, stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
except OSError:
print "!!Please make sure the 'omero' executable is in PATH"
return None
# print ' '.join(exe)
# [0].strip() #re.search(
# 'Saving pixels id: (\d*)', p.communicate()[0]).group(1)
pid = p.communicate()
# print pid
try:
img = omero.gateway.ImageWrapper(
dataset._conn,
dataset._conn.getQueryService().find(
'Pixels', long(pid[0].split('\n')[0].strip())).image)
except ValueError:
print pid
raise
# print "imgid = %i" % img.getId()
img.setName(self.name)
# img._obj.objectiveSettings = None
img.save()
if self.callback:
self.callback(img)
return img
finally:
# Always cleanup the return from clone/connect
newconn.close()
def _createWithoutPixels(self, client, dataset):
img = omero.model.ImageI()
img.setName(omero.gateway.omero_type(self.name))
if not dataset.imageLinksLoaded:
print ".!."
dataset._obj._imageLinksSeq = []
dataset._obj._imageLinksLoaded = True
dataset.linkImage(img)
dataset.save()
def getProject(client, alias):
return PROJECTS[alias].get(client)
def assertCommentAnnotation(object, ns, value):
ann = object.getAnnotation(ns)
if ann is None or ann.getValue() != value:
ann = omero.gateway.CommentAnnotationWrapper()
ann.setNs(ns)
ann.setValue(value)
object.linkAnnotation(ann)
return ann
def getDataset(client, alias, forceproj=None):
return DATASETS[alias].get(client, forceproj)
def getImage(client, alias, forceds=None, autocreate=False):
rv = IMAGES[alias].get(client, forceds)
if rv is None and autocreate:
i = IMAGES[alias].create()
i._conn.close()
rv = IMAGES[alias].get(client, forceds)
return rv
def bootstrap(onlyUsers=False, skipImages=True):
# Create users
client = loginAsRoot()
try:
for k, u in USERS.items():
if not u.create(client, ROOT.passwd):
u.changePassword(client, u.passwd, ROOT.passwd)
u.assert_group_perms(client, u.groupname, u.groupperms)
if onlyUsers:
return
for k, p in PROJECTS.items():
p = p.create()
p._conn.close()
# print p.get(client).getDetails().getPermissions().isUserWrite()
for k, d in DATASETS.items():
d = d.create()
d._conn.close()
if not skipImages:
for k, i in IMAGES.items():
i = i.create()
i._conn.close()
finally:
client.close()
def cleanup():
for k, p in PROJECTS.items():
sys.stderr.write('*')
p = p.get()
if p is not None:
client = p._conn
handle = client.deleteObjects(
'Project', [p.getId()], deleteAnns=True, deleteChildren=True)
try:
client._waitOnCmd(handle)
finally:
handle.close()
client.close()
client = loginAsRoot()
for k, u in USERS.items():
u.changePassword(client, None, ROOT.passwd)
client.close()
ROOT = UserEntry('root', 'ome', admin=True)
USERS = {
# 'alias': UserEntry entry,
}
PROJECTS = {
# 'alias': ProjectEntry entry,
}
DATASETS = {
# 'alias': DatasetEntry entry,
}
IMAGES = {
# 'alias': ImageEntry entry,
} | unknown | codeparrot/codeparrot-clean | ||
"""
genetrack.py
Input: either scidx or gff format of reads
Output: Called peaks in gff format
"""
import csv
import optparse
import os
import genetrack_util
CHUNK_SIZE = 10000000
if __name__ == '__main__':
parser = optparse.OptionParser()
parser.add_option('-t', '--input_format', dest='input_format', type='string', help='Input format')
parser.add_option('-i', '--input', dest='inputs', type='string', action='append', nargs=2, help='Input datasets')
parser.add_option('-s', '--sigma', dest='sigma', type='int', default=5, help='Sigma.')
parser.add_option('-e', '--exclusion', dest='exclusion', type='int', default=20, help='Exclusion zone.')
parser.add_option('-u', '--up_width', dest='up_width', type='int', default=10, help='Upstream width of called peaks.')
parser.add_option('-d', '--down_width', dest='down_width', type='int', default=10, help='Downstream width of called peaks.')
parser.add_option('-f', '--filter', dest='filter', type='int', default=1, help='Absolute read filter.')
options, args = parser.parse_args()
os.mkdir('output')
for (dataset_path, hid) in options.inputs:
if options.input_format == 'gff':
# Make sure the reads for each chromosome are sorted by index.
input_path = genetrack_util.sort_chromosome_reads_by_index(dataset_path)
else:
# We're processing scidx data.
input_path = dataset_path
output_name = 's%se%su%sd%sF%s_on_data_%s' % (options.sigma,
options.exclusion,
options.up_width,
options.down_width,
options.filter,
hid)
output_path = os.path.join('output', output_name)
reader = csv.reader(open(input_path, 'rU'), delimiter='\t')
writer = csv.writer(open(output_path, 'wt'), delimiter='\t')
width = options.sigma * 5
manager = genetrack_util.ChromosomeManager(reader)
while not manager.done:
cname = manager.chromosome_name()
# Should we process this chromosome?
data = manager.load_chromosome()
if not data:
continue
keys = genetrack_util.make_keys(data)
lo, hi = genetrack_util.get_range(data)
for chunk in genetrack_util.get_chunks(lo, hi, size=CHUNK_SIZE, overlap=width):
(slice_start, slice_end), process_bounds = chunk
window = genetrack_util.get_window(data, slice_start, slice_end, keys)
genetrack_util.process_chromosome(cname,
window,
writer,
process_bounds,
width,
options.sigma,
options.up_width,
options.down_width,
options.exclusion,
options.filter) | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
#
# This file is part of the bliss project
#
# Copyright (c) 2016 Beamline Control Unit, ESRF
# Distributed under the GNU LGPLv3. See LICENSE for more info.
import pytest
import time
import numpy
from bliss import setup_globals
from bliss.common import scans
from bliss.scanning import scan
from bliss.common import event
def test_ascan(beacon):
session = beacon.get("test_session")
session.setup()
counter_class = getattr(setup_globals, 'TestScanGaussianCounter')
m1 = getattr(setup_globals, 'm1')
counter = counter_class("gaussian", 10, cnt_time=0)
s = scans.ascan(m1, 0, 10, 10, 0, counter, return_scan=True, save=False)
assert m1.position() == 10
scan_data = scans.get_data(s)
assert numpy.array_equal(scan_data['gaussian'], counter.data)
def test_dscan(beacon):
session = beacon.get("test_session")
session.setup()
counter_class = getattr(setup_globals, 'TestScanGaussianCounter')
counter = counter_class("gaussian", 10, cnt_time=0)
m1 = getattr(setup_globals, 'm1')
# contrary to ascan, dscan returns to start pos
start_pos = m1.position()
s = scans.dscan(m1, -2, 2, 10, 0, counter, return_scan=True, save=False)
assert m1.position() == start_pos
scan_data = scans.get_data(s)
assert numpy.allclose(scan_data['m1'], numpy.linspace(start_pos-2, start_pos+2, 10), atol=5e-4)
assert numpy.array_equal(scan_data['gaussian'], counter.data)
def test_timescan(beacon):
session = beacon.get("test_session")
session.setup()
counter_class = getattr(setup_globals, 'TestScanGaussianCounter')
counter = counter_class("gaussian", 10, cnt_time=0.1)
s = scans.timescan(0.1, counter, npoints=10, return_scan=True, save=False)
scan_data = scans.get_data(s)
assert numpy.array_equal(scan_data['gaussian'], counter.data)
def test_pointscan(beacon):
session = beacon.get("test_session")
session.setup()
m0 = getattr(setup_globals, 'm0')
counter_class = getattr(setup_globals, 'TestScanGaussianCounter')
counter = counter_class("gaussian", 10, cnt_time=0)
print counter.data
points = [0.0, 1.0, 3.0, 7.0, 8.0, 10.0, 12.0, 15.0, 20.0, 50.0]
s = scans.pointscan(m0, points, 0, counter, return_scan=True, save=False)
assert m0.position() == 50.0
scan_data = scans.get_data(s)
assert numpy.array_equal(scan_data['m0'], points)
assert numpy.array_equal(scan_data['gaussian'], counter.data)
def test_scan_callbacks(beacon):
session = beacon.get("test_session")
session.setup()
res = {"new": False, "end": False, "values": []}
def on_scan_new(scan_info):
res["new"] = True
def on_scan_data(scan_info, values):
res["values"].append(values[counter.name])
def on_scan_end(scan_info):
res["end"] = True
event.connect(scan, 'scan_new', on_scan_new)
event.connect(scan, 'scan_data', on_scan_data)
event.connect(scan, 'scan_end', on_scan_end)
counter_class = getattr(setup_globals, 'TestScanGaussianCounter')
counter = counter_class("gaussian", 10, cnt_time=0.1)
s = scans.timescan(0.1, counter, npoints=10, return_scan=True, save=False)
assert res["new"]
assert res["end"]
assert numpy.array_equal(numpy.array(res["values"]), counter.data) | unknown | codeparrot/codeparrot-clean | ||
# -*- test-case-name: twisted.python.test.test_urlpath -*-
# Copyright (c) Twisted Matrix Laboratories.
# See LICENSE for details.
"""
L{URLPath}, a representation of a URL.
"""
from __future__ import division, absolute_import
from twisted.python.compat import (
nativeString, unicode, urllib_parse as urlparse, urlunquote, urlquote
)
from hyperlink import URL as _URL
_allascii = b"".join([chr(x).encode('ascii') for x in range(1, 128)])
def _rereconstituter(name):
"""
Attriute declaration to preserve mutability on L{URLPath}.
@param name: a public attribute name
@type name: native L{str}
@return: a descriptor which retrieves the private version of the attribute
on get and calls rerealize on set.
"""
privateName = nativeString("_") + name
return property(
lambda self: getattr(self, privateName),
lambda self, value: (setattr(self, privateName,
value if isinstance(value, bytes)
else value.encode("charmap")) or
self._reconstitute())
)
class URLPath(object):
"""
A representation of a URL.
@ivar scheme: The scheme of the URL (e.g. 'http').
@type scheme: L{bytes}
@ivar netloc: The network location ("host").
@type netloc: L{bytes}
@ivar path: The path on the network location.
@type path: L{bytes}
@ivar query: The query argument (the portion after ? in the URL).
@type query: L{bytes}
@ivar fragment: The page fragment (the portion after # in the URL).
@type fragment: L{bytes}
"""
def __init__(self, scheme=b'', netloc=b'localhost', path=b'',
query=b'', fragment=b''):
self._scheme = scheme or b'http'
self._netloc = netloc
self._path = path or b'/'
self._query = query
self._fragment = fragment
self._reconstitute()
def _reconstitute(self):
"""
Reconstitute this L{URLPath} from all its given attributes.
"""
urltext = urlquote(
urlparse.urlunsplit((self._scheme, self._netloc,
self._path, self._query, self._fragment)),
safe=_allascii
)
self._url = _URL.fromText(urltext.encode("ascii").decode("ascii"))
scheme = _rereconstituter("scheme")
netloc = _rereconstituter("netloc")
path = _rereconstituter("path")
query = _rereconstituter("query")
fragment = _rereconstituter("fragment")
@classmethod
def _fromURL(cls, urlInstance):
"""
Reconstruct all the public instance variables of this L{URLPath} from
its underlying L{_URL}.
@param urlInstance: the object to base this L{URLPath} on.
@type urlInstance: L{_URL}
@return: a new L{URLPath}
"""
self = cls.__new__(cls)
self._url = urlInstance.replace(path=urlInstance.path or [u""])
self._scheme = self._url.scheme.encode("ascii")
self._netloc = self._url.authority().encode("ascii")
self._path = (_URL(path=self._url.path,
rooted=True).asURI().asText()
.encode("ascii"))
self._query = (_URL(query=self._url.query).asURI().asText()
.encode("ascii"))[1:]
self._fragment = self._url.fragment.encode("ascii")
return self
def pathList(self, unquote=False, copy=True):
"""
Split this URL's path into its components.
@param unquote: whether to remove %-encoding from the returned strings.
@param copy: (ignored, do not use)
@return: The components of C{self.path}
@rtype: L{list} of L{bytes}
"""
segments = self._url.path
mapper = lambda x: x.encode("ascii")
if unquote:
mapper = (lambda x, m=mapper: m(urlunquote(x)))
return [b''] + [mapper(segment) for segment in segments]
@classmethod
def fromString(klass, url):
"""
Make a L{URLPath} from a L{str} or L{unicode}.
@param url: A L{str} representation of a URL.
@type url: L{str} or L{unicode}.
@return: a new L{URLPath} derived from the given string.
@rtype: L{URLPath}
"""
if not isinstance(url, (str, unicode)):
raise ValueError("'url' must be a str or unicode")
if isinstance(url, bytes):
# On Python 2, accepting 'str' (for compatibility) means we might
# get 'bytes'. On py3, this will not work with bytes due to the
# check above.
return klass.fromBytes(url)
return klass._fromURL(_URL.fromText(url))
@classmethod
def fromBytes(klass, url):
"""
Make a L{URLPath} from a L{bytes}.
@param url: A L{bytes} representation of a URL.
@type url: L{bytes}
@return: a new L{URLPath} derived from the given L{bytes}.
@rtype: L{URLPath}
@since: 15.4
"""
if not isinstance(url, bytes):
raise ValueError("'url' must be bytes")
quoted = urlquote(url, safe=_allascii)
if isinstance(quoted, bytes):
# This will only be bytes on python 2, where we can transform it
# into unicode. On python 3, urlquote always returns str.
quoted = quoted.decode("ascii")
return klass.fromString(quoted)
@classmethod
def fromRequest(klass, request):
"""
Make a L{URLPath} from a L{twisted.web.http.Request}.
@param request: A L{twisted.web.http.Request} to make the L{URLPath}
from.
@return: a new L{URLPath} derived from the given request.
@rtype: L{URLPath}
"""
return klass.fromBytes(request.prePathURL())
def _mod(self, newURL, keepQuery):
"""
Return a modified copy of C{self} using C{newURL}, keeping the query
string if C{keepQuery} is C{True}.
@param newURL: a L{URL} to derive a new L{URLPath} from
@type newURL: L{URL}
@param keepQuery: if C{True}, preserve the query parameters from
C{self} on the new L{URLPath}; if C{False}, give the new L{URLPath}
no query parameters.
@type keepQuery: L{bool}
@return: a new L{URLPath}
"""
return self._fromURL(newURL.replace(
fragment=u'', query=self._url.query if keepQuery else ()
))
def sibling(self, path, keepQuery=False):
"""
Get the sibling of the current L{URLPath}. A sibling is a file which
is in the same directory as the current file.
@param path: The path of the sibling.
@type path: L{bytes}
@param keepQuery: Whether to keep the query parameters on the returned
L{URLPath}.
@type: keepQuery: L{bool}
@return: a new L{URLPath}
"""
return self._mod(self._url.sibling(path.decode("ascii")), keepQuery)
def child(self, path, keepQuery=False):
"""
Get the child of this L{URLPath}.
@param path: The path of the child.
@type path: L{bytes}
@param keepQuery: Whether to keep the query parameters on the returned
L{URLPath}.
@type: keepQuery: L{bool}
@return: a new L{URLPath}
"""
return self._mod(self._url.child(path.decode("ascii")), keepQuery)
def parent(self, keepQuery=False):
"""
Get the parent directory of this L{URLPath}.
@param keepQuery: Whether to keep the query parameters on the returned
L{URLPath}.
@type: keepQuery: L{bool}
@return: a new L{URLPath}
"""
return self._mod(self._url.click(u".."), keepQuery)
def here(self, keepQuery=False):
"""
Get the current directory of this L{URLPath}.
@param keepQuery: Whether to keep the query parameters on the returned
L{URLPath}.
@type: keepQuery: L{bool}
@return: a new L{URLPath}
"""
return self._mod(self._url.click(u"."), keepQuery)
def click(self, st):
"""
Return a path which is the URL where a browser would presumably take
you if you clicked on a link with an HREF as given.
@param st: A relative URL, to be interpreted relative to C{self} as the
base URL.
@type st: L{bytes}
@return: a new L{URLPath}
"""
return self._fromURL(self._url.click(st.decode("ascii")))
def __str__(self):
"""
The L{str} of a L{URLPath} is its URL text.
"""
return nativeString(self._url.asURI().asText())
def __repr__(self):
"""
The L{repr} of a L{URLPath} is an eval-able expression which will
construct a similar L{URLPath}.
"""
return ('URLPath(scheme=%r, netloc=%r, path=%r, query=%r, fragment=%r)'
% (self.scheme, self.netloc, self.path, self.query,
self.fragment)) | unknown | codeparrot/codeparrot-clean | ||
# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors
# License: GNU General Public License v3. See license.txt
from __future__ import unicode_literals
import frappe
from frappe import _
from frappe.desk.reportview import execute as runreport
def execute(filters=None):
if not filters: filters = {}
employee_filters = filters.get("company") and \
[["Employee", "company", "=", filters.get("company")]] or None
employees = runreport(doctype="Employee", fields=["name", "employee_name", "department"],
filters=employee_filters, limit_page_length=None)
if not employees:
frappe.throw(_("No employee found!"))
leave_types = frappe.db.sql_list("select name from `tabLeave Type`")
if filters.get("fiscal_year"):
fiscal_years = [filters["fiscal_year"]]
else:
fiscal_years = frappe.db.sql_list("select name from `tabFiscal Year` order by name desc")
employee_names = [d.name for d in employees]
allocations = frappe.db.sql("""select employee, fiscal_year, leave_type, total_leaves_allocated
from `tabLeave Allocation`
where docstatus=1 and employee in (%s)""" %
','.join(['%s']*len(employee_names)), employee_names, as_dict=True)
applications = frappe.db.sql("""select employee, fiscal_year, leave_type,
SUM(total_leave_days) as leaves
from `tabLeave Application`
where status="Approved" and docstatus = 1 and employee in (%s)
group by employee, fiscal_year, leave_type""" %
','.join(['%s']*len(employee_names)), employee_names, as_dict=True)
columns = [
_("Fiscal Year"), _("Employee") + ":Link/Employee:150", _("Employee Name") + "::200", _("Department") +"::150"
]
for leave_type in leave_types:
columns.append(_(leave_type) + " " + _("Allocated") + ":Float")
columns.append(_(leave_type) + " " + _("Taken") + ":Float")
columns.append(_(leave_type) + " " + _("Balance") + ":Float")
data = {}
for d in allocations:
data.setdefault((d.fiscal_year, d.employee,
d.leave_type), frappe._dict()).allocation = d.total_leaves_allocated
for d in applications:
data.setdefault((d.fiscal_year, d.employee,
d.leave_type), frappe._dict()).leaves = d.leaves
result = []
for fiscal_year in fiscal_years:
for employee in employees:
row = [fiscal_year, employee.name, employee.employee_name, employee.department]
result.append(row)
for leave_type in leave_types:
tmp = data.get((fiscal_year, employee.name, leave_type), frappe._dict())
row.append(tmp.allocation or 0)
row.append(tmp.leaves or 0)
row.append((tmp.allocation or 0) - (tmp.leaves or 0))
return columns, result | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
import unittest
from wechatpy.enterprise import parse_message
class ParseMessageTestCase(unittest.TestCase):
def test_parse_text_message(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[this is a test]]></Content>
<MsgId>1234567890123456</MsgId>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('text', msg.type)
self.assertEqual(1, msg.agent)
def test_parse_image_message(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<PicUrl><![CDATA[this is a url]]></PicUrl>
<MediaId><![CDATA[media_id]]></MediaId>
<MsgId>1234567890123456</MsgId>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('image', msg.type)
def test_parse_voice_message(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1357290913</CreateTime>
<MsgType><![CDATA[voice]]></MsgType>
<MediaId><![CDATA[media_id]]></MediaId>
<Format><![CDATA[Format]]></Format>
<MsgId>1234567890123456</MsgId>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('voice', msg.type)
def test_parse_video_message(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1357290913</CreateTime>
<MsgType><![CDATA[video]]></MsgType>
<MediaId><![CDATA[media_id]]></MediaId>
<ThumbMediaId><![CDATA[thumb_media_id]]></ThumbMediaId>
<MsgId>1234567890123456</MsgId>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('video', msg.type)
def test_parse_location_message(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1351776360</CreateTime>
<MsgType><![CDATA[location]]></MsgType>
<Location_X>23.134521</Location_X>
<Location_Y>113.358803</Location_Y>
<Scale>20</Scale>
<Label><![CDATA[位置信息]]></Label>
<MsgId>1234567890123456</MsgId>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('location', msg.type)
def test_parse_subscribe_event(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[subscribe]]></Event>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('event', msg.type)
self.assertEqual('subscribe', msg.event)
def test_parse_location_event(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[LOCATION]]></Event>
<Latitude>23.137466</Latitude>
<Longitude>113.352425</Longitude>
<Precision>119.385040</Precision>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('event', msg.type)
self.assertEqual('location', msg.event)
self.assertEqual(23.137466, msg.latitude)
self.assertEqual(113.352425, msg.longitude)
self.assertEqual(119.385040, msg.precision)
def test_parse_click_event(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[CLICK]]></Event>
<EventKey><![CDATA[EVENTKEY]]></EventKey>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('event', msg.type)
self.assertEqual('click', msg.event)
self.assertEqual('EVENTKEY', msg.key)
def test_parse_view_event(self):
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[FromUser]]></FromUserName>
<CreateTime>123456789</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[VIEW]]></Event>
<EventKey><![CDATA[www.qq.com]]></EventKey>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertEqual('event', msg.type)
self.assertEqual('view', msg.event)
self.assertEqual('www.qq.com', msg.url)
def test_parse_unknown_message(self):
from wechatpy.messages import UnknownMessage
xml = """<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[notsure]]></MsgType>
<MsgId>1234567890123456</MsgId>
<AgentID>1</AgentID>
</xml>"""
msg = parse_message(xml)
self.assertTrue(isinstance(msg, UnknownMessage)) | unknown | codeparrot/codeparrot-clean | ||
# SPDX-License-Identifier: (GPL-2.0 OR BSD-2-Clause)
%YAML 1.2
---
$id: http://devicetree.org/schemas/interconnect/qcom,rpm.yaml#
$schema: http://devicetree.org/meta-schemas/core.yaml#
title: Qualcomm RPM Network-On-Chip Interconnect
maintainers:
- Georgi Djakov <djakov@kernel.org>
description: |
RPM interconnect providers support system bandwidth requirements through
RPM processor. The provider is able to communicate with the RPM through
the RPM shared memory device.
allOf:
- $ref: qcom,rpm-common.yaml#
properties:
reg:
maxItems: 1
compatible:
enum:
- qcom,msm8909-bimc
- qcom,msm8909-pcnoc
- qcom,msm8909-snoc
- qcom,msm8916-bimc
- qcom,msm8916-pcnoc
- qcom,msm8916-snoc
- qcom,qcs404-bimc
- qcom,qcs404-pcnoc
- qcom,qcs404-snoc
required:
- compatible
- reg
unevaluatedProperties: false
examples:
- |
#include <dt-bindings/clock/qcom,rpmcc.h>
interconnect@400000 {
compatible = "qcom,msm8916-bimc";
reg = <0x00400000 0x62000>;
#interconnect-cells = <1>;
}; | unknown | github | https://github.com/torvalds/linux | Documentation/devicetree/bindings/interconnect/qcom,rpm.yaml |
from __future__ import division, print_function, absolute_import
import numpy as np
from numpy.testing import TestCase, run_module_suite, assert_raises, \
assert_almost_equal, assert_array_almost_equal, assert_equal, \
assert_, assert_allclose
from scipy.special import sinc
from scipy.signal import kaiser_beta, kaiser_atten, kaiserord, \
firwin, firwin2, freqz, remez, firls
def test_kaiser_beta():
b = kaiser_beta(58.7)
assert_almost_equal(b, 0.1102 * 50.0)
b = kaiser_beta(22.0)
assert_almost_equal(b, 0.5842 + 0.07886)
b = kaiser_beta(21.0)
assert_equal(b, 0.0)
b = kaiser_beta(10.0)
assert_equal(b, 0.0)
def test_kaiser_atten():
a = kaiser_atten(1, 1.0)
assert_equal(a, 7.95)
a = kaiser_atten(2, 1/np.pi)
assert_equal(a, 2.285 + 7.95)
def test_kaiserord():
assert_raises(ValueError, kaiserord, 1.0, 1.0)
numtaps, beta = kaiserord(2.285 + 7.95 - 0.001, 1/np.pi)
assert_equal((numtaps, beta), (2, 0.0))
class TestFirwin(TestCase):
def check_response(self, h, expected_response, tol=.05):
N = len(h)
alpha = 0.5 * (N-1)
m = np.arange(0,N) - alpha # time indices of taps
for freq, expected in expected_response:
actual = abs(np.sum(h*np.exp(-1.j*np.pi*m*freq)))
mse = abs(actual-expected)**2
self.assertTrue(mse < tol, 'response not as expected, mse=%g > %g'
% (mse, tol))
def test_response(self):
N = 51
f = .5
# increase length just to try even/odd
h = firwin(N, f) # low-pass from 0 to f
self.check_response(h, [(.25,1), (.75,0)])
h = firwin(N+1, f, window='nuttall') # specific window
self.check_response(h, [(.25,1), (.75,0)])
h = firwin(N+2, f, pass_zero=False) # stop from 0 to f --> high-pass
self.check_response(h, [(.25,0), (.75,1)])
f1, f2, f3, f4 = .2, .4, .6, .8
h = firwin(N+3, [f1, f2], pass_zero=False) # band-pass filter
self.check_response(h, [(.1,0), (.3,1), (.5,0)])
h = firwin(N+4, [f1, f2]) # band-stop filter
self.check_response(h, [(.1,1), (.3,0), (.5,1)])
h = firwin(N+5, [f1, f2, f3, f4], pass_zero=False, scale=False)
self.check_response(h, [(.1,0), (.3,1), (.5,0), (.7,1), (.9,0)])
h = firwin(N+6, [f1, f2, f3, f4]) # multiband filter
self.check_response(h, [(.1,1), (.3,0), (.5,1), (.7,0), (.9,1)])
h = firwin(N+7, 0.1, width=.03) # low-pass
self.check_response(h, [(.05,1), (.75,0)])
h = firwin(N+8, 0.1, pass_zero=False) # high-pass
self.check_response(h, [(.05,0), (.75,1)])
def mse(self, h, bands):
"""Compute mean squared error versus ideal response across frequency
band.
h -- coefficients
bands -- list of (left, right) tuples relative to 1==Nyquist of
passbands
"""
w, H = freqz(h, worN=1024)
f = w/np.pi
passIndicator = np.zeros(len(w), bool)
for left, right in bands:
passIndicator |= (f >= left) & (f < right)
Hideal = np.where(passIndicator, 1, 0)
mse = np.mean(abs(abs(H)-Hideal)**2)
return mse
def test_scaling(self):
"""
For one lowpass, bandpass, and highpass example filter, this test
checks two things:
- the mean squared error over the frequency domain of the unscaled
filter is smaller than the scaled filter (true for rectangular
window)
- the response of the scaled filter is exactly unity at the center
of the first passband
"""
N = 11
cases = [
([.5], True, (0, 1)),
([0.2, .6], False, (.4, 1)),
([.5], False, (1, 1)),
]
for cutoff, pass_zero, expected_response in cases:
h = firwin(N, cutoff, scale=False, pass_zero=pass_zero, window='ones')
hs = firwin(N, cutoff, scale=True, pass_zero=pass_zero, window='ones')
if len(cutoff) == 1:
if pass_zero:
cutoff = [0] + cutoff
else:
cutoff = cutoff + [1]
self.assertTrue(self.mse(h, [cutoff]) < self.mse(hs, [cutoff]),
'least squares violation')
self.check_response(hs, [expected_response], 1e-12)
class TestFirWinMore(TestCase):
"""Different author, different style, different tests..."""
def test_lowpass(self):
width = 0.04
ntaps, beta = kaiserord(120, width)
taps = firwin(ntaps, cutoff=0.5, window=('kaiser', beta), scale=False)
# Check the symmetry of taps.
assert_array_almost_equal(taps[:ntaps//2], taps[ntaps:ntaps-ntaps//2-1:-1])
# Check the gain at a few samples where we know it should be approximately 0 or 1.
freq_samples = np.array([0.0, 0.25, 0.5-width/2, 0.5+width/2, 0.75, 1.0])
freqs, response = freqz(taps, worN=np.pi*freq_samples)
assert_array_almost_equal(np.abs(response),
[1.0, 1.0, 1.0, 0.0, 0.0, 0.0], decimal=5)
def test_highpass(self):
width = 0.04
ntaps, beta = kaiserord(120, width)
# Ensure that ntaps is odd.
ntaps |= 1
taps = firwin(ntaps, cutoff=0.5, window=('kaiser', beta),
pass_zero=False, scale=False)
# Check the symmetry of taps.
assert_array_almost_equal(taps[:ntaps//2], taps[ntaps:ntaps-ntaps//2-1:-1])
# Check the gain at a few samples where we know it should be approximately 0 or 1.
freq_samples = np.array([0.0, 0.25, 0.5-width/2, 0.5+width/2, 0.75, 1.0])
freqs, response = freqz(taps, worN=np.pi*freq_samples)
assert_array_almost_equal(np.abs(response),
[0.0, 0.0, 0.0, 1.0, 1.0, 1.0], decimal=5)
def test_bandpass(self):
width = 0.04
ntaps, beta = kaiserord(120, width)
taps = firwin(ntaps, cutoff=[0.3, 0.7], window=('kaiser', beta),
pass_zero=False, scale=False)
# Check the symmetry of taps.
assert_array_almost_equal(taps[:ntaps//2], taps[ntaps:ntaps-ntaps//2-1:-1])
# Check the gain at a few samples where we know it should be approximately 0 or 1.
freq_samples = np.array([0.0, 0.2, 0.3-width/2, 0.3+width/2, 0.5,
0.7-width/2, 0.7+width/2, 0.8, 1.0])
freqs, response = freqz(taps, worN=np.pi*freq_samples)
assert_array_almost_equal(np.abs(response),
[0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0], decimal=5)
def test_multi(self):
width = 0.04
ntaps, beta = kaiserord(120, width)
taps = firwin(ntaps, cutoff=[0.2, 0.5, 0.8], window=('kaiser', beta),
pass_zero=True, scale=False)
# Check the symmetry of taps.
assert_array_almost_equal(taps[:ntaps//2], taps[ntaps:ntaps-ntaps//2-1:-1])
# Check the gain at a few samples where we know it should be approximately 0 or 1.
freq_samples = np.array([0.0, 0.1, 0.2-width/2, 0.2+width/2, 0.35,
0.5-width/2, 0.5+width/2, 0.65,
0.8-width/2, 0.8+width/2, 0.9, 1.0])
freqs, response = freqz(taps, worN=np.pi*freq_samples)
assert_array_almost_equal(np.abs(response),
[1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0],
decimal=5)
def test_nyq(self):
"""Test the nyq keyword."""
nyquist = 1000
width = 40.0
relative_width = width/nyquist
ntaps, beta = kaiserord(120, relative_width)
taps = firwin(ntaps, cutoff=[300, 700], window=('kaiser', beta),
pass_zero=False, scale=False, nyq=nyquist)
# Check the symmetry of taps.
assert_array_almost_equal(taps[:ntaps//2], taps[ntaps:ntaps-ntaps//2-1:-1])
# Check the gain at a few samples where we know it should be approximately 0 or 1.
freq_samples = np.array([0.0, 200, 300-width/2, 300+width/2, 500,
700-width/2, 700+width/2, 800, 1000])
freqs, response = freqz(taps, worN=np.pi*freq_samples/nyquist)
assert_array_almost_equal(np.abs(response),
[0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0], decimal=5)
def test_bad_cutoff(self):
"""Test that invalid cutoff argument raises ValueError."""
# cutoff values must be greater than 0 and less than 1.
assert_raises(ValueError, firwin, 99, -0.5)
assert_raises(ValueError, firwin, 99, 1.5)
# Don't allow 0 or 1 in cutoff.
assert_raises(ValueError, firwin, 99, [0, 0.5])
assert_raises(ValueError, firwin, 99, [0.5, 1])
# cutoff values must be strictly increasing.
assert_raises(ValueError, firwin, 99, [0.1, 0.5, 0.2])
assert_raises(ValueError, firwin, 99, [0.1, 0.5, 0.5])
# Must have at least one cutoff value.
assert_raises(ValueError, firwin, 99, [])
# 2D array not allowed.
assert_raises(ValueError, firwin, 99, [[0.1, 0.2],[0.3, 0.4]])
# cutoff values must be less than nyq.
assert_raises(ValueError, firwin, 99, 50.0, nyq=40)
assert_raises(ValueError, firwin, 99, [10, 20, 30], nyq=25)
def test_even_highpass_raises_value_error(self):
"""Test that attempt to create a highpass filter with an even number
of taps raises a ValueError exception."""
assert_raises(ValueError, firwin, 40, 0.5, pass_zero=False)
assert_raises(ValueError, firwin, 40, [.25, 0.5])
class TestFirwin2(TestCase):
def test_invalid_args(self):
# `freq` and `gain` have different lengths.
assert_raises(ValueError, firwin2, 50, [0, 0.5, 1], [0.0, 1.0])
# `nfreqs` is less than `ntaps`.
assert_raises(ValueError, firwin2, 50, [0, 0.5, 1], [0.0, 1.0, 1.0], nfreqs=33)
# Decreasing value in `freq`
assert_raises(ValueError, firwin2, 50, [0, 0.5, 0.4, 1.0], [0, .25, .5, 1.0])
# Value in `freq` repeated more than once.
assert_raises(ValueError, firwin2, 50, [0, .1, .1, .1, 1.0],
[0.0, 0.5, 0.75, 1.0, 1.0])
# `freq` does not start at 0.0.
assert_raises(ValueError, firwin2, 50, [0.5, 1.0], [0.0, 1.0])
# Type II filter, but the gain at nyquist rate is not zero.
assert_raises(ValueError, firwin2, 16, [0.0, 0.5, 1.0], [0.0, 1.0, 1.0])
# Type III filter, but the gains at nyquist and zero rate are not zero.
assert_raises(ValueError, firwin2, 17, [0.0, 0.5, 1.0], [0.0, 1.0, 1.0],
antisymmetric=True)
assert_raises(ValueError, firwin2, 17, [0.0, 0.5, 1.0], [1.0, 1.0, 0.0],
antisymmetric=True)
assert_raises(ValueError, firwin2, 17, [0.0, 0.5, 1.0], [1.0, 1.0, 1.0],
antisymmetric=True)
# Type VI filter, but the gain at zero rate is not zero.
assert_raises(ValueError, firwin2, 16, [0.0, 0.5, 1.0], [1.0, 1.0, 0.0],
antisymmetric=True)
def test01(self):
width = 0.04
beta = 12.0
ntaps = 400
# Filter is 1 from w=0 to w=0.5, then decreases linearly from 1 to 0 as w
# increases from w=0.5 to w=1 (w=1 is the Nyquist frequency).
freq = [0.0, 0.5, 1.0]
gain = [1.0, 1.0, 0.0]
taps = firwin2(ntaps, freq, gain, window=('kaiser', beta))
freq_samples = np.array([0.0, 0.25, 0.5-width/2, 0.5+width/2,
0.75, 1.0-width/2])
freqs, response = freqz(taps, worN=np.pi*freq_samples)
assert_array_almost_equal(np.abs(response),
[1.0, 1.0, 1.0, 1.0-width, 0.5, width], decimal=5)
def test02(self):
width = 0.04
beta = 12.0
# ntaps must be odd for positive gain at Nyquist.
ntaps = 401
# An ideal highpass filter.
freq = [0.0, 0.5, 0.5, 1.0]
gain = [0.0, 0.0, 1.0, 1.0]
taps = firwin2(ntaps, freq, gain, window=('kaiser', beta))
freq_samples = np.array([0.0, 0.25, 0.5-width, 0.5+width, 0.75, 1.0])
freqs, response = freqz(taps, worN=np.pi*freq_samples)
assert_array_almost_equal(np.abs(response),
[0.0, 0.0, 0.0, 1.0, 1.0, 1.0], decimal=5)
def test03(self):
width = 0.02
ntaps, beta = kaiserord(120, width)
# ntaps must be odd for positive gain at Nyquist.
ntaps = int(ntaps) | 1
freq = [0.0, 0.4, 0.4, 0.5, 0.5, 1.0]
gain = [1.0, 1.0, 0.0, 0.0, 1.0, 1.0]
taps = firwin2(ntaps, freq, gain, window=('kaiser', beta))
freq_samples = np.array([0.0, 0.4-width, 0.4+width, 0.45,
0.5-width, 0.5+width, 0.75, 1.0])
freqs, response = freqz(taps, worN=np.pi*freq_samples)
assert_array_almost_equal(np.abs(response),
[1.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0], decimal=5)
def test04(self):
"""Test firwin2 when window=None."""
ntaps = 5
# Ideal lowpass: gain is 1 on [0,0.5], and 0 on [0.5, 1.0]
freq = [0.0, 0.5, 0.5, 1.0]
gain = [1.0, 1.0, 0.0, 0.0]
taps = firwin2(ntaps, freq, gain, window=None, nfreqs=8193)
alpha = 0.5 * (ntaps - 1)
m = np.arange(0, ntaps) - alpha
h = 0.5 * sinc(0.5 * m)
assert_array_almost_equal(h, taps)
def test05(self):
"""Test firwin2 for calculating Type IV filters"""
ntaps = 1500
freq = [0.0, 1.0]
gain = [0.0, 1.0]
taps = firwin2(ntaps, freq, gain, window=None, antisymmetric=True)
assert_array_almost_equal(taps[: ntaps // 2], -taps[ntaps // 2:][::-1])
freqs, response = freqz(taps, worN=2048)
assert_array_almost_equal(abs(response), freqs / np.pi, decimal=4)
def test06(self):
"""Test firwin2 for calculating Type III filters"""
ntaps = 1501
freq = [0.0, 0.5, 0.55, 1.0]
gain = [0.0, 0.5, 0.0, 0.0]
taps = firwin2(ntaps, freq, gain, window=None, antisymmetric=True)
assert_equal(taps[ntaps // 2], 0.0)
assert_array_almost_equal(taps[: ntaps // 2], -taps[ntaps // 2 + 1:][::-1])
freqs, response1 = freqz(taps, worN=2048)
response2 = np.interp(freqs / np.pi, freq, gain)
assert_array_almost_equal(abs(response1), response2, decimal=3)
def test_nyq(self):
taps1 = firwin2(80, [0.0, 0.5, 1.0], [1.0, 1.0, 0.0])
taps2 = firwin2(80, [0.0, 30.0, 60.0], [1.0, 1.0, 0.0], nyq=60.0)
assert_array_almost_equal(taps1, taps2)
class TestRemez(TestCase):
def test_bad_args(self):
assert_raises(ValueError, remez, 11, [0.1, 0.4], [1], type='pooka')
def test_hilbert(self):
N = 11 # number of taps in the filter
a = 0.1 # width of the transition band
# design an unity gain hilbert bandpass filter from w to 0.5-w
h = remez(11, [a, 0.5-a], [1], type='hilbert')
# make sure the filter has correct # of taps
assert_(len(h) == N, "Number of Taps")
# make sure it is type III (anti-symmetric tap coefficients)
assert_array_almost_equal(h[:(N-1)//2], -h[:-(N-1)//2-1:-1])
# Since the requested response is symmetric, all even coeffcients
# should be zero (or in this case really small)
assert_((abs(h[1::2]) < 1e-15).all(), "Even Coefficients Equal Zero")
# now check the frequency response
w, H = freqz(h, 1)
f = w/2/np.pi
Hmag = abs(H)
# should have a zero at 0 and pi (in this case close to zero)
assert_((Hmag[[0, -1]] < 0.02).all(), "Zero at zero and pi")
# check that the pass band is close to unity
idx = np.logical_and(f > a, f < 0.5-a)
assert_((abs(Hmag[idx] - 1) < 0.015).all(), "Pass Band Close To Unity")
class TestFirls(TestCase):
def test_bad_args(self):
# even numtaps
assert_raises(ValueError, firls, 10, [0.1, 0.2], [0, 0])
# odd bands
assert_raises(ValueError, firls, 11, [0.1, 0.2, 0.4], [0, 0, 0])
# len(bands) != len(desired)
assert_raises(ValueError, firls, 11, [0.1, 0.2, 0.3, 0.4], [0, 0, 0])
# non-monotonic bands
assert_raises(ValueError, firls, 11, [0.2, 0.1], [0, 0])
assert_raises(ValueError, firls, 11, [0.1, 0.2, 0.3, 0.3], [0] * 4)
assert_raises(ValueError, firls, 11, [0.3, 0.4, 0.1, 0.2], [0] * 4)
assert_raises(ValueError, firls, 11, [0.1, 0.3, 0.2, 0.4], [0] * 4)
# negative desired
assert_raises(ValueError, firls, 11, [0.1, 0.2], [-1, 1])
# len(weight) != len(pairs)
assert_raises(ValueError, firls, 11, [0.1, 0.2], [0, 0], [1, 2])
# negative weight
assert_raises(ValueError, firls, 11, [0.1, 0.2], [0, 0], [-1])
def test_firls(self):
N = 11 # number of taps in the filter
a = 0.1 # width of the transition band
# design a halfband symmetric low-pass filter
h = firls(11, [0, a, 0.5-a, 0.5], [1, 1, 0, 0], nyq=0.5)
# make sure the filter has correct # of taps
assert_equal(len(h), N)
# make sure it is symmetric
midx = (N-1) // 2
assert_array_almost_equal(h[:midx], h[:-midx-1:-1])
# make sure the center tap is 0.5
assert_almost_equal(h[midx], 0.5)
# For halfband symmetric, odd coefficients (except the center)
# should be zero (really small)
hodd = np.hstack((h[1:midx:2], h[-midx+1::2]))
assert_array_almost_equal(hodd, 0)
# now check the frequency response
w, H = freqz(h, 1)
f = w/2/np.pi
Hmag = np.abs(H)
# check that the pass band is close to unity
idx = np.logical_and(f > 0, f < a)
assert_array_almost_equal(Hmag[idx], 1, decimal=3)
# check that the stop band is close to zero
idx = np.logical_and(f > 0.5-a, f < 0.5)
assert_array_almost_equal(Hmag[idx], 0, decimal=3)
def test_compare(self):
# compare to OCTAVE output
taps = firls(9, [0, 0.5, 0.55, 1], [1, 1, 0, 0], [1, 2])
# >> taps = firls(8, [0 0.5 0.55 1], [1 1 0 0], [1, 2]);
known_taps = [-6.26930101730182e-04, -1.03354450635036e-01,
-9.81576747564301e-03, 3.17271686090449e-01,
5.11409425599933e-01, 3.17271686090449e-01,
-9.81576747564301e-03, -1.03354450635036e-01,
-6.26930101730182e-04]
assert_allclose(taps, known_taps)
# compare to MATLAB output
taps = firls(11, [0, 0.5, 0.5, 1], [1, 1, 0, 0], [1, 2])
# >> taps = firls(10, [0 0.5 0.5 1], [1 1 0 0], [1, 2]);
known_taps = [
0.058545300496815, -0.014233383714318, -0.104688258464392,
0.012403323025279, 0.317930861136062, 0.488047220029700,
0.317930861136062, 0.012403323025279, -0.104688258464392,
-0.014233383714318, 0.058545300496815]
assert_allclose(taps, known_taps)
# With linear changes:
taps = firls(7, (0, 1, 2, 3, 4, 5), [1, 0, 0, 1, 1, 0], nyq=10)
# >> taps = firls(6, [0, 0.1, 0.2, 0.3, 0.4, 0.5], [1, 0, 0, 1, 1, 0])
known_taps = [
1.156090832768218, -4.1385894727395849, 7.5288619164321826,
-8.5530572592947856, 7.5288619164321826, -4.1385894727395849,
1.156090832768218]
assert_allclose(taps, known_taps)
if __name__ == "__main__":
run_module_suite() | unknown | codeparrot/codeparrot-clean | ||
/*
* Licensed to Elasticsearch B.V. under one or more contributor
* license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright
* ownership. Elasticsearch B.V. licenses this file to you under
* the Apache License, Version 2.0 (the "License"); you may
* not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
package org.elasticsearch.client;
import com.sun.net.httpserver.HttpExchange;
import com.sun.net.httpserver.HttpHandler;
import com.sun.net.httpserver.HttpServer;
import org.apache.http.HttpHost;
import org.elasticsearch.mocksocket.MockHttpServer;
import org.junit.AfterClass;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Ignore;
import java.io.IOException;
import java.io.OutputStream;
import java.net.ConnectException;
import java.net.InetAddress;
import java.net.InetSocketAddress;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.CancellationException;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import static org.elasticsearch.client.RestClientTestUtil.getAllStatusCodes;
import static org.elasticsearch.client.RestClientTestUtil.randomErrorNoRetryStatusCode;
import static org.elasticsearch.client.RestClientTestUtil.randomOkStatusCode;
import static org.hamcrest.CoreMatchers.instanceOf;
import static org.hamcrest.Matchers.startsWith;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertThat;
import static org.junit.Assert.assertTrue;
import static org.junit.Assert.fail;
/**
* Integration test to check interaction between {@link RestClient} and {@link org.apache.http.client.HttpClient}.
* Works against real http servers, multiple hosts. Also tests failover by randomly shutting down hosts.
*/
public class RestClientMultipleHostsIntegTests extends RestClientTestCase {
private static WaitForCancelHandler waitForCancelHandler;
private static HttpServer[] httpServers;
private static HttpHost[] httpHosts;
private static boolean stoppedFirstHost = false;
private static String pathPrefixWithoutLeadingSlash;
private static String pathPrefix;
private static RestClient restClient;
@BeforeClass
public static void startHttpServer() throws Exception {
if (randomBoolean()) {
pathPrefixWithoutLeadingSlash = "testPathPrefix/" + randomAsciiLettersOfLengthBetween(1, 5);
pathPrefix = "/" + pathPrefixWithoutLeadingSlash;
} else {
pathPrefix = pathPrefixWithoutLeadingSlash = "";
}
int numHttpServers = randomIntBetween(2, 4);
httpServers = new HttpServer[numHttpServers];
httpHosts = new HttpHost[numHttpServers];
waitForCancelHandler = new WaitForCancelHandler();
for (int i = 0; i < numHttpServers; i++) {
HttpServer httpServer = createHttpServer();
httpServers[i] = httpServer;
httpHosts[i] = new HttpHost(httpServer.getAddress().getHostString(), httpServer.getAddress().getPort());
}
restClient = buildRestClient(NodeSelector.ANY);
}
private static RestClient buildRestClient(NodeSelector nodeSelector) {
return buildRestClient(nodeSelector, null);
}
private static RestClient buildRestClient(NodeSelector nodeSelector, RestClient.FailureListener failureListener) {
RestClientBuilder restClientBuilder = RestClient.builder(httpHosts);
if (pathPrefix.length() > 0) {
restClientBuilder.setPathPrefix((randomBoolean() ? "/" : "") + pathPrefixWithoutLeadingSlash);
}
if (failureListener != null) {
restClientBuilder.setFailureListener(failureListener);
}
restClientBuilder.setNodeSelector(nodeSelector);
return restClientBuilder.build();
}
private static HttpServer createHttpServer() throws Exception {
HttpServer httpServer = MockHttpServer.createHttp(new InetSocketAddress(InetAddress.getLoopbackAddress(), 0), 0);
httpServer.start();
// returns a different status code depending on the path
for (int statusCode : getAllStatusCodes()) {
httpServer.createContext(pathPrefix + "/" + statusCode, new ResponseHandler(statusCode));
}
httpServer.createContext(pathPrefix + "/20bytes", new ResponseHandlerWithContent());
httpServer.createContext(pathPrefix + "/wait", waitForCancelHandler);
return httpServer;
}
private static WaitForCancelHandler resetWaitHandlers() {
WaitForCancelHandler handler = new WaitForCancelHandler();
for (HttpServer httpServer : httpServers) {
httpServer.removeContext(pathPrefix + "/wait");
httpServer.createContext(pathPrefix + "/wait", handler);
}
return handler;
}
private static class WaitForCancelHandler implements HttpHandler {
private final CountDownLatch requestCameInLatch = new CountDownLatch(1);
private final CountDownLatch cancelHandlerLatch = new CountDownLatch(1);
void cancelDone() {
cancelHandlerLatch.countDown();
}
void awaitRequest() throws InterruptedException {
requestCameInLatch.await();
}
@Override
public void handle(HttpExchange exchange) throws IOException {
requestCameInLatch.countDown();
try {
cancelHandlerLatch.await();
} catch (InterruptedException ignore) {} finally {
exchange.sendResponseHeaders(200, 0);
exchange.close();
}
}
}
private static class ResponseHandler implements HttpHandler {
private final int statusCode;
ResponseHandler(int statusCode) {
this.statusCode = statusCode;
}
@Override
public void handle(HttpExchange httpExchange) throws IOException {
httpExchange.getRequestBody().close();
httpExchange.sendResponseHeaders(statusCode, -1);
httpExchange.close();
}
}
private static class ResponseHandlerWithContent implements HttpHandler {
@Override
public void handle(HttpExchange httpExchange) throws IOException {
byte[] body = "01234567890123456789".getBytes(StandardCharsets.UTF_8);
httpExchange.sendResponseHeaders(200, body.length);
try (OutputStream out = httpExchange.getResponseBody()) {
out.write(body);
}
httpExchange.close();
}
}
@AfterClass
public static void stopHttpServers() throws IOException {
restClient.close();
restClient = null;
for (HttpServer httpServer : httpServers) {
httpServer.stop(0);
}
httpServers = null;
}
@Before
public void stopRandomHost() {
// verify that shutting down some hosts doesn't matter as long as one working host is left behind
if (httpServers.length > 1 && randomBoolean()) {
List<HttpServer> updatedHttpServers = new ArrayList<>(httpServers.length - 1);
int nodeIndex = randomIntBetween(0, httpServers.length - 1);
if (0 == nodeIndex) {
stoppedFirstHost = true;
}
for (int i = 0; i < httpServers.length; i++) {
HttpServer httpServer = httpServers[i];
if (i == nodeIndex) {
httpServer.stop(0);
} else {
updatedHttpServers.add(httpServer);
}
}
httpServers = updatedHttpServers.toArray(new HttpServer[0]);
}
}
public void testSyncRequests() throws IOException {
int numRequests = randomIntBetween(5, 20);
for (int i = 0; i < numRequests; i++) {
final String method = RestClientTestUtil.randomHttpMethod(getRandom());
// we don't test status codes that are subject to retries as they interfere with hosts being stopped
final int statusCode = randomBoolean() ? randomOkStatusCode(getRandom()) : randomErrorNoRetryStatusCode(getRandom());
Response response;
try {
response = restClient.performRequest(new Request(method, "/" + statusCode));
} catch (ResponseException responseException) {
response = responseException.getResponse();
}
assertEquals(method, response.getRequestLine().getMethod());
assertEquals(statusCode, response.getStatusLine().getStatusCode());
assertEquals((pathPrefix.length() > 0 ? pathPrefix : "") + "/" + statusCode, response.getRequestLine().getUri());
}
}
public void testAsyncRequests() throws Exception {
int numRequests = randomIntBetween(5, 20);
final CountDownLatch latch = new CountDownLatch(numRequests);
final List<TestResponse> responses = new CopyOnWriteArrayList<>();
for (int i = 0; i < numRequests; i++) {
final String method = RestClientTestUtil.randomHttpMethod(getRandom());
// we don't test status codes that are subject to retries as they interfere with hosts being stopped
final int statusCode = randomBoolean() ? randomOkStatusCode(getRandom()) : randomErrorNoRetryStatusCode(getRandom());
restClient.performRequestAsync(new Request(method, "/" + statusCode), new ResponseListener() {
@Override
public void onSuccess(Response response) {
responses.add(new TestResponse(method, statusCode, response));
latch.countDown();
}
@Override
public void onFailure(Exception exception) {
responses.add(new TestResponse(method, statusCode, exception));
latch.countDown();
}
});
}
assertTrue(latch.await(5, TimeUnit.SECONDS));
assertEquals(numRequests, responses.size());
for (TestResponse testResponse : responses) {
Response response = testResponse.getResponse();
assertEquals(testResponse.method, response.getRequestLine().getMethod());
assertEquals(testResponse.statusCode, response.getStatusLine().getStatusCode());
assertEquals((pathPrefix.length() > 0 ? pathPrefix : "") + "/" + testResponse.statusCode, response.getRequestLine().getUri());
}
}
public void testCancelAsyncRequests() throws Exception {
int numRequests = randomIntBetween(5, 20);
final List<Response> responses = new CopyOnWriteArrayList<>();
final List<Exception> exceptions = new CopyOnWriteArrayList<>();
for (int i = 0; i < numRequests; i++) {
CountDownLatch latch = new CountDownLatch(1);
waitForCancelHandler = resetWaitHandlers();
Cancellable cancellable = restClient.performRequestAsync(new Request("GET", "/wait"), new ResponseListener() {
@Override
public void onSuccess(Response response) {
responses.add(response);
latch.countDown();
}
@Override
public void onFailure(Exception exception) {
exceptions.add(exception);
latch.countDown();
}
});
if (randomBoolean()) {
// we wait for the request to get to the server-side otherwise we almost always cancel
// the request artificially on the client-side before even sending it
waitForCancelHandler.awaitRequest();
}
cancellable.cancel();
waitForCancelHandler.cancelDone();
assertTrue(latch.await(5, TimeUnit.SECONDS));
}
assertEquals(0, responses.size());
assertEquals(numRequests, exceptions.size());
for (Exception exception : exceptions) {
assertThat(exception, instanceOf(CancellationException.class));
}
}
/**
* Test host selector against a real server <strong>and</strong>
* test what happens after calling
*/
public void testNodeSelector() throws Exception {
try (RestClient restClient = buildRestClient(firstPositionNodeSelector())) {
Request request = new Request("GET", "/200");
int rounds = between(1, 10);
for (int i = 0; i < rounds; i++) {
/*
* Run the request more than once to verify that the
* NodeSelector overrides the round robin behavior.
*/
if (stoppedFirstHost) {
try {
RestClientSingleHostTests.performRequestSyncOrAsync(restClient, request);
fail("expected to fail to connect");
} catch (ConnectException e) {
// Windows isn't consistent here. Sometimes the message is even null!
if (false == System.getProperty("os.name").startsWith("Windows")) {
assertThat(e.getMessage(), startsWith("Connection refused"));
}
}
} else {
Response response = RestClientSingleHostTests.performRequestSyncOrAsync(restClient, request);
assertEquals(httpHosts[0], response.getHost());
}
}
}
}
@Ignore("https://github.com/elastic/elasticsearch/issues/87314")
public void testNonRetryableException() throws Exception {
RequestOptions.Builder options = RequestOptions.DEFAULT.toBuilder();
options.setHttpAsyncResponseConsumerFactory(
// Limit to very short responses to trigger a ContentTooLongException
() -> new HeapBufferedAsyncResponseConsumer(10)
);
AtomicInteger failureCount = new AtomicInteger();
RestClient client = buildRestClient(NodeSelector.ANY, new RestClient.FailureListener() {
@Override
public void onFailure(Node node) {
failureCount.incrementAndGet();
}
});
failureCount.set(0);
Request request = new Request("POST", "/20bytes");
request.setOptions(options);
try {
RestClientSingleHostTests.performRequestSyncOrAsync(client, request);
fail("Request should not succeed");
} catch (IOException e) {
assertEquals(stoppedFirstHost ? 2 : 1, failureCount.intValue());
}
client.close();
}
private static class TestResponse {
private final String method;
private final int statusCode;
private final Object response;
TestResponse(String method, int statusCode, Object response) {
this.method = method;
this.statusCode = statusCode;
this.response = response;
}
Response getResponse() {
if (response instanceof Response) {
return (Response) response;
}
if (response instanceof ResponseException) {
return ((ResponseException) response).getResponse();
}
throw new AssertionError("unexpected response " + response.getClass());
}
}
private NodeSelector firstPositionNodeSelector() {
return nodes -> {
for (Iterator<Node> itr = nodes.iterator(); itr.hasNext();) {
if (httpHosts[0] != itr.next().getHost()) {
itr.remove();
}
}
};
}
} | java | github | https://github.com/elastic/elasticsearch | client/rest/src/test/java/org/elasticsearch/client/RestClientMultipleHostsIntegTests.java |
# Copyright 2014 eBay Inc.
#
# Author: Ron Rickard <rrickard@ebay.com>
#
# Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
# License for the specific language governing permissions and limitations
# under the License.
import random
import six
from oslo_log import log as logging
from designate import exceptions
from designate import utils
from designate.backend import base
LOG = logging.getLogger(__name__)
DEFAULT_MASTER_PORT = 5354
class Bind9Backend(base.Backend):
__plugin_name__ = 'bind9'
__backend_status__ = 'integrated'
def __init__(self, target):
super(Bind9Backend, self).__init__(target)
self.host = self.options.get('host', '127.0.0.1')
self.port = int(self.options.get('port', 53))
self.rndc_host = self.options.get('rndc_host', '127.0.0.1')
self.rndc_port = int(self.options.get('rndc_port', 953))
self.rndc_config_file = self.options.get('rndc_config_file')
self.rndc_key_file = self.options.get('rndc_key_file')
def create_domain(self, context, domain):
LOG.debug('Create Domain')
masters = []
for master in self.masters:
host = master['host']
port = master['port']
masters.append('%s port %s' % (host, port))
# Ensure different MiniDNS instances are targeted for AXFRs
random.shuffle(masters)
rndc_op = [
'addzone',
'%s { type slave; masters { %s;}; file "slave.%s%s"; };' %
(domain['name'].rstrip('.'), '; '.join(masters), domain['name'],
domain['id']),
]
try:
self._execute_rndc(rndc_op)
except exceptions.Backend as e:
# If create fails because the domain exists, don't reraise
if "already exists" not in six.text_type(e):
raise
self.mdns_api.notify_zone_changed(
context, domain, self.host, self.port, self.timeout,
self.retry_interval, self.max_retries, self.delay)
def delete_domain(self, context, domain):
LOG.debug('Delete Domain')
rndc_op = [
'delzone',
'%s' % domain['name'].rstrip('.'),
]
try:
self._execute_rndc(rndc_op)
except exceptions.Backend as e:
# If domain is already deleted, don't reraise
if "not found" not in six.text_type(e):
raise
def _rndc_base(self):
rndc_call = [
'rndc',
'-s', self.rndc_host,
'-p', str(self.rndc_port),
]
if self.rndc_config_file:
rndc_call.extend(
['-c', self.rndc_config_file])
if self.rndc_key_file:
rndc_call.extend(
['-k', self.rndc_key_file])
return rndc_call
def _execute_rndc(self, rndc_op):
try:
rndc_call = self._rndc_base()
rndc_call.extend(rndc_op)
LOG.debug('Executing RNDC call: %s' % " ".join(rndc_call))
utils.execute(*rndc_call)
except utils.processutils.ProcessExecutionError as e:
LOG.debug('RNDC call failure: %s' % e)
raise exceptions.Backend(e) | unknown | codeparrot/codeparrot-clean | ||
"""
The contents of this file are taken from
[Django-admin](https://github.com/niwinz/django-jinja/blob/master/django_jinja/management/commands/makemessages.py)
Jinja2's i18n functionality is not exactly the same as Django's.
In particular, the tags names and their syntax are different:
1. The Django ``trans`` tag is replaced by a _() global.
2. The Django ``blocktrans`` tag is called ``trans``.
(1) isn't an issue, since the whole ``makemessages`` process is based on
converting the template tags to ``_()`` calls. However, (2) means that
those Jinja2 ``trans`` tags will not be picked up by Django's
``makemessages`` command.
There aren't any nice solutions here. While Jinja2's i18n extension does
come with extraction capabilities built in, the code behind ``makemessages``
unfortunately isn't extensible, so we can:
* Duplicate the command + code behind it.
* Offer a separate command for Jinja2 extraction.
* Try to get Django to offer hooks into makemessages().
* Monkey-patch.
We are currently doing that last thing. It turns out there we are lucky
for once: It's simply a matter of extending two regular expressions.
Credit for the approach goes to:
http://stackoverflow.com/questions/2090717/getting-translation-strings-for-jinja2-templates-integrated-with-django-1-x
"""
from __future__ import absolute_import
from typing import Any, Dict, Iterable, Optional, Mapping, Set, Tuple, Text
from argparse import ArgumentParser
import os
import re
import glob
import json
from six.moves import filter
from six.moves import map
from six.moves import zip
from django.core.management.commands import makemessages
from django.utils.translation import trans_real
from django.template.base import BLOCK_TAG_START, BLOCK_TAG_END
from django.conf import settings
from zerver.lib.str_utils import force_text
strip_whitespace_right = re.compile(u"(%s-?\\s*(trans|pluralize).*?-%s)\\s+" % (BLOCK_TAG_START, BLOCK_TAG_END), re.U)
strip_whitespace_left = re.compile(u"\\s+(%s-\\s*(endtrans|pluralize).*?-?%s)" % (
BLOCK_TAG_START, BLOCK_TAG_END), re.U)
regexes = ['{{#tr .*?}}([\s\S]*?){{/tr}}', # '.' doesn't match '\n' by default
'{{t "(.*?)"\W*}}',
"{{t '(.*?)'\W*}}",
"i18n\.t\('([^\']*?)'\)",
"i18n\.t\('(.*?)',.*?[^,]\)",
'i18n\.t\("([^\"]*?)"\)',
'i18n\.t\("(.*?)",.*?[^,]\)',
]
frontend_compiled_regexes = [re.compile(regex) for regex in regexes]
multiline_js_comment = re.compile("/\*.*?\*/", re.DOTALL)
singleline_js_comment = re.compile("//.*?\n")
def strip_whitespaces(src):
# type: (Text) -> Text
src = strip_whitespace_left.sub(u'\\1', src)
src = strip_whitespace_right.sub(u'\\1', src)
return src
class Command(makemessages.Command):
def add_arguments(self, parser):
# type: (ArgumentParser) -> None
super(Command, self).add_arguments(parser)
parser.add_argument('--frontend-source', type=str,
default='static/templates',
help='Name of the Handlebars template directory')
parser.add_argument('--frontend-output', type=str,
default='static/locale',
help='Name of the frontend messages output directory')
parser.add_argument('--frontend-namespace', type=str,
default='translations.json',
help='Namespace of the frontend locale file')
def handle(self, *args, **options):
# type: (*Any, **Any) -> None
self.handle_django_locales(*args, **options)
self.handle_frontend_locales(*args, **options)
def handle_frontend_locales(self, *args, **options):
# type: (*Any, **Any) -> None
self.frontend_source = options.get('frontend_source')
self.frontend_output = options.get('frontend_output')
self.frontend_namespace = options.get('frontend_namespace')
self.frontend_locale = options.get('locale')
self.frontend_exclude = options.get('exclude')
self.frontend_all = options.get('all')
translation_strings = self.get_translation_strings()
self.write_translation_strings(translation_strings)
def handle_django_locales(self, *args, **options):
# type: (*Any, **Any) -> None
old_endblock_re = trans_real.endblock_re
old_block_re = trans_real.block_re
old_constant_re = trans_real.constant_re
old_templatize = trans_real.templatize
# Extend the regular expressions that are used to detect
# translation blocks with an "OR jinja-syntax" clause.
trans_real.endblock_re = re.compile(
trans_real.endblock_re.pattern + '|' + r"""^-?\s*endtrans\s*-?$""")
trans_real.block_re = re.compile(
trans_real.block_re.pattern + '|' + r"""^-?\s*trans(?:\s+(?!'|")(?=.*?=.*?)|\s*-?$)""")
trans_real.plural_re = re.compile(
trans_real.plural_re.pattern + '|' + r"""^-?\s*pluralize(?:\s+.+|-?$)""")
trans_real.constant_re = re.compile(r"""_\(((?:".*?")|(?:'.*?')).*\)""")
def my_templatize(src, origin=None):
# type: (Text, Optional[Text]) -> Text
new_src = strip_whitespaces(src)
return old_templatize(new_src, origin)
trans_real.templatize = my_templatize
try:
ignore_patterns = options.get('ignore_patterns', [])
ignore_patterns.append('docs/*')
options['ignore_patterns'] = ignore_patterns
super(Command, self).handle(*args, **options)
finally:
trans_real.endblock_re = old_endblock_re
trans_real.block_re = old_block_re
trans_real.templatize = old_templatize
trans_real.constant_re = old_constant_re
def extract_strings(self, data):
# type: (str) -> Dict[str, str]
data = self.ignore_javascript_comments(data)
translation_strings = {} # type: Dict[str, str]
for regex in frontend_compiled_regexes:
for match in regex.findall(data):
match = match.strip()
match = ' '.join(line.strip() for line in match.splitlines())
match = match.replace('\n', '\\n')
translation_strings[match] = ""
return translation_strings
def ignore_javascript_comments(self, data):
# type: (str) -> str
# Removes multi line comments.
data = multiline_js_comment.sub('', data)
# Removes single line (//) comments.
data = singleline_js_comment.sub('', data)
return data
def get_translation_strings(self):
# type: () -> Dict[str, str]
translation_strings = {} # type: Dict[str, str]
dirname = self.get_template_dir()
for dirpath, dirnames, filenames in os.walk(dirname):
for filename in [f for f in filenames if f.endswith(".handlebars")]:
if filename.startswith('.'):
continue
with open(os.path.join(dirpath, filename), 'r') as reader:
data = reader.read()
translation_strings.update(self.extract_strings(data))
dirname = os.path.join(settings.DEPLOY_ROOT, 'static/js')
for filename in os.listdir(dirname):
if filename.endswith('.js') and not filename.startswith('.'):
with open(os.path.join(dirname, filename)) as reader:
data = reader.read()
translation_strings.update(self.extract_strings(data))
return translation_strings
def get_template_dir(self):
# type: () -> str
return self.frontend_source
def get_namespace(self):
# type: () -> str
return self.frontend_namespace
def get_locales(self):
# type: () -> Iterable[str]
locale = self.frontend_locale
exclude = self.frontend_exclude
process_all = self.frontend_all
paths = glob.glob('%s/*' % self.default_locale_path,)
all_locales = [os.path.basename(path) for path in paths if os.path.isdir(path)]
# Account for excluded locales
if process_all:
return all_locales
else:
locales = locale or all_locales
return set(locales) - set(exclude)
def get_base_path(self):
# type: () -> str
return self.frontend_output
def get_output_paths(self):
# type: () -> Iterable[str]
base_path = self.get_base_path()
locales = self.get_locales()
for path in [os.path.join(base_path, locale) for locale in locales]:
if not os.path.exists(path):
os.makedirs(path)
yield os.path.join(path, self.get_namespace())
def get_new_strings(self, old_strings, translation_strings):
# type: (Mapping[str, str], Iterable[str]) -> Dict[str, str]
"""
Missing strings are removed, new strings are added and already
translated strings are not touched.
"""
new_strings = {} # Dict[str, str]
for k in translation_strings:
k = k.replace('\\n', '\n')
new_strings[k] = old_strings.get(k, k)
plurals = {k: v for k, v in old_strings.items() if k.endswith('_plural')}
for plural_key, value in plurals.items():
components = plural_key.split('_')
singular_key = '_'.join(components[:-1])
if singular_key in new_strings:
new_strings[plural_key] = value
return new_strings
def write_translation_strings(self, translation_strings):
# type: (Iterable[str]) -> None
for locale, output_path in zip(self.get_locales(), self.get_output_paths()):
self.stdout.write("[frontend] processing locale {}".format(locale))
try:
with open(output_path, 'r') as reader:
old_strings = json.load(reader)
except (IOError, ValueError):
old_strings = {}
new_strings = {
force_text(k): v
for k, v in self.get_new_strings(old_strings,
translation_strings).items()
}
with open(output_path, 'w') as writer:
json.dump(new_strings, writer, indent=2, sort_keys=True) | unknown | codeparrot/codeparrot-clean | ||
"""HTML form handling for web clients.
ClientForm is a Python module for handling HTML forms on the client
side, useful for parsing HTML forms, filling them in and returning the
completed forms to the server. It has developed from a port of Gisle
Aas' Perl module HTML::Form, from the libwww-perl library, but the
interface is not the same.
The most useful docstring is the one for HTMLForm.
RFC 1866: HTML 2.0
RFC 1867: Form-based File Upload in HTML
RFC 2388: Returning Values from Forms: multipart/form-data
HTML 3.2 Specification, W3C Recommendation 14 January 1997 (for ISINDEX)
HTML 4.01 Specification, W3C Recommendation 24 December 1999
Copyright 2002-2007 John J. Lee <jjl@pobox.com>
Copyright 2005 Gary Poster
Copyright 2005 Zope Corporation
Copyright 1998-2000 Gisle Aas.
This code is free software; you can redistribute it and/or modify it
under the terms of the BSD or ZPL 2.1 licenses (see the file
COPYING.txt included with the distribution).
"""
# XXX
# Remove parser testing hack
# safeUrl()-ize action
# Switch to unicode throughout (would be 0.3.x)
# See Wichert Akkerman's 2004-01-22 message to c.l.py.
# Add charset parameter to Content-type headers? How to find value??
# Add some more functional tests
# Especially single and multiple file upload on the internet.
# Does file upload work when name is missing? Sourceforge tracker form
# doesn't like it. Check standards, and test with Apache. Test
# binary upload with Apache.
# mailto submission & enctype text/plain
# I'm not going to fix this unless somebody tells me what real servers
# that want this encoding actually expect: If enctype is
# application/x-www-form-urlencoded and there's a FILE control present.
# Strictly, it should be 'name=data' (see HTML 4.01 spec., section
# 17.13.2), but I send "name=" ATM. What about multiple file upload??
# Would be nice, but I'm not going to do it myself:
# -------------------------------------------------
# Maybe a 0.4.x?
# Replace by_label etc. with moniker / selector concept. Allows, eg.,
# a choice between selection by value / id / label / element
# contents. Or choice between matching labels exactly or by
# substring. Etc.
# Remove deprecated methods.
# ...what else?
# Work on DOMForm.
# XForms? Don't know if there's a need here.
__all__ = ['AmbiguityError', 'CheckboxControl', 'Control',
'ControlNotFoundError', 'FileControl', 'FormParser', 'HTMLForm',
'HiddenControl', 'IgnoreControl', 'ImageControl', 'IsindexControl',
'Item', 'ItemCountError', 'ItemNotFoundError', 'Label',
'ListControl', 'LocateError', 'Missing', 'ParseError', 'ParseFile',
'ParseFileEx', 'ParseResponse', 'ParseResponseEx','PasswordControl',
'RadioControl', 'ScalarControl', 'SelectControl',
'SubmitButtonControl', 'SubmitControl', 'TextControl',
'TextareaControl', 'XHTMLCompatibleFormParser']
try: True
except NameError:
True = 1
False = 0
try: bool
except NameError:
def bool(expr):
if expr: return True
else: return False
try:
import logging
import inspect
except ImportError:
def debug(msg, *args, **kwds):
pass
else:
_logger = logging.getLogger("ClientForm")
OPTIMIZATION_HACK = True
def debug(msg, *args, **kwds):
if OPTIMIZATION_HACK:
return
caller_name = inspect.stack()[1][3]
extended_msg = '%%s %s' % msg
extended_args = (caller_name,)+args
debug = _logger.debug(extended_msg, *extended_args, **kwds)
def _show_debug_messages():
global OPTIMIZATION_HACK
OPTIMIZATION_HACK = False
_logger.setLevel(logging.DEBUG)
handler = logging.StreamHandler(sys.stdout)
handler.setLevel(logging.DEBUG)
_logger.addHandler(handler)
import sys, urllib, urllib2, types, mimetools, copy, urlparse, \
htmlentitydefs, re, random
from cStringIO import StringIO
import sgmllib
# monkeypatch to fix http://www.python.org/sf/803422 :-(
sgmllib.charref = re.compile("&#(x?[0-9a-fA-F]+)[^0-9a-fA-F]")
# HTMLParser.HTMLParser is recent, so live without it if it's not available
# (also, sgmllib.SGMLParser is much more tolerant of bad HTML)
try:
import HTMLParser
except ImportError:
HAVE_MODULE_HTMLPARSER = False
else:
HAVE_MODULE_HTMLPARSER = True
try:
import warnings
except ImportError:
def deprecation(message, stack_offset=0):
pass
else:
def deprecation(message, stack_offset=0):
warnings.warn(message, DeprecationWarning, stacklevel=3+stack_offset)
VERSION = "0.2.9"
CHUNK = 1024 # size of chunks fed to parser, in bytes
DEFAULT_ENCODING = "latin-1"
class Missing: pass
_compress_re = re.compile(r"\s+")
def compress_text(text): return _compress_re.sub(" ", text.strip())
def normalize_line_endings(text):
return re.sub(r"(?:(?<!\r)\n)|(?:\r(?!\n))", "\r\n", text)
# This version of urlencode is from my Python 1.5.2 back-port of the
# Python 2.1 CVS maintenance branch of urllib. It will accept a sequence
# of pairs instead of a mapping -- the 2.0 version only accepts a mapping.
def urlencode(query,doseq=False,):
"""Encode a sequence of two-element tuples or dictionary into a URL query \
string.
If any values in the query arg are sequences and doseq is true, each
sequence element is converted to a separate parameter.
If the query arg is a sequence of two-element tuples, the order of the
parameters in the output will match the order of parameters in the
input.
"""
if hasattr(query,"items"):
# mapping objects
query = query.items()
else:
# it's a bother at times that strings and string-like objects are
# sequences...
try:
# non-sequence items should not work with len()
x = len(query)
# non-empty strings will fail this
if len(query) and type(query[0]) != types.TupleType:
raise TypeError()
# zero-length sequences of all types will get here and succeed,
# but that's a minor nit - since the original implementation
# allowed empty dicts that type of behavior probably should be
# preserved for consistency
except TypeError:
ty,va,tb = sys.exc_info()
raise TypeError("not a valid non-string sequence or mapping "
"object", tb)
l = []
if not doseq:
# preserve old behavior
for k, v in query:
k = urllib.quote_plus(str(k))
v = urllib.quote_plus(str(v))
l.append(k + '=' + v)
else:
for k, v in query:
k = urllib.quote_plus(str(k))
if type(v) == types.StringType:
v = urllib.quote_plus(v)
l.append(k + '=' + v)
elif type(v) == types.UnicodeType:
# is there a reasonable way to convert to ASCII?
# encode generates a string, but "replace" or "ignore"
# lose information and "strict" can raise UnicodeError
v = urllib.quote_plus(v.encode("ASCII","replace"))
l.append(k + '=' + v)
else:
try:
# is this a sufficient test for sequence-ness?
x = len(v)
except TypeError:
# not a sequence
v = urllib.quote_plus(str(v))
l.append(k + '=' + v)
else:
# loop over the sequence
for elt in v:
l.append(k + '=' + urllib.quote_plus(str(elt)))
return '&'.join(l)
def unescape(data, entities, encoding=DEFAULT_ENCODING):
if data is None or "&" not in data:
return data
def replace_entities(match, entities=entities, encoding=encoding):
ent = match.group()
if ent[1] == "#":
return unescape_charref(ent[2:-1], encoding)
repl = entities.get(ent)
if repl is not None:
if type(repl) != type(""):
try:
repl = repl.encode(encoding)
except UnicodeError:
repl = ent
else:
repl = ent
return repl
return re.sub(r"&#?[A-Za-z0-9]+?;", replace_entities, data)
def unescape_charref(data, encoding):
name, base = data, 10
if name.startswith("x"):
name, base= name[1:], 16
uc = unichr(int(name, base))
if encoding is None:
return uc
else:
try:
repl = uc.encode(encoding)
except UnicodeError:
repl = "&#%s;" % data
return repl
def get_entitydefs():
import htmlentitydefs
from codecs import latin_1_decode
entitydefs = {}
try:
htmlentitydefs.name2codepoint
except AttributeError:
entitydefs = {}
for name, char in htmlentitydefs.entitydefs.items():
uc = latin_1_decode(char)[0]
if uc.startswith("&#") and uc.endswith(";"):
uc = unescape_charref(uc[2:-1], None)
entitydefs["&%s;" % name] = uc
else:
for name, codepoint in htmlentitydefs.name2codepoint.items():
entitydefs["&%s;" % name] = unichr(codepoint)
return entitydefs
def issequence(x):
try:
x[0]
except (TypeError, KeyError):
return False
except IndexError:
pass
return True
def isstringlike(x):
try: x+""
except: return False
else: return True
def choose_boundary():
"""Return a string usable as a multipart boundary."""
# follow IE and firefox
nonce = "".join([str(random.randint(0, sys.maxint-1)) for i in 0,1,2])
return "-"*27 + nonce
# This cut-n-pasted MimeWriter from standard library is here so can add
# to HTTP headers rather than message body when appropriate. It also uses
# \r\n in place of \n. This is a bit nasty.
class MimeWriter:
"""Generic MIME writer.
Methods:
__init__()
addheader()
flushheaders()
startbody()
startmultipartbody()
nextpart()
lastpart()
A MIME writer is much more primitive than a MIME parser. It
doesn't seek around on the output file, and it doesn't use large
amounts of buffer space, so you have to write the parts in the
order they should occur on the output file. It does buffer the
headers you add, allowing you to rearrange their order.
General usage is:
f = <open the output file>
w = MimeWriter(f)
...call w.addheader(key, value) 0 or more times...
followed by either:
f = w.startbody(content_type)
...call f.write(data) for body data...
or:
w.startmultipartbody(subtype)
for each part:
subwriter = w.nextpart()
...use the subwriter's methods to create the subpart...
w.lastpart()
The subwriter is another MimeWriter instance, and should be
treated in the same way as the toplevel MimeWriter. This way,
writing recursive body parts is easy.
Warning: don't forget to call lastpart()!
XXX There should be more state so calls made in the wrong order
are detected.
Some special cases:
- startbody() just returns the file passed to the constructor;
but don't use this knowledge, as it may be changed.
- startmultipartbody() actually returns a file as well;
this can be used to write the initial 'if you can read this your
mailer is not MIME-aware' message.
- If you call flushheaders(), the headers accumulated so far are
written out (and forgotten); this is useful if you don't need a
body part at all, e.g. for a subpart of type message/rfc822
that's (mis)used to store some header-like information.
- Passing a keyword argument 'prefix=<flag>' to addheader(),
start*body() affects where the header is inserted; 0 means
append at the end, 1 means insert at the start; default is
append for addheader(), but insert for start*body(), which use
it to determine where the Content-type header goes.
"""
def __init__(self, fp, http_hdrs=None):
self._http_hdrs = http_hdrs
self._fp = fp
self._headers = []
self._boundary = []
self._first_part = True
def addheader(self, key, value, prefix=0,
add_to_http_hdrs=0):
"""
prefix is ignored if add_to_http_hdrs is true.
"""
lines = value.split("\r\n")
while lines and not lines[-1]: del lines[-1]
while lines and not lines[0]: del lines[0]
if add_to_http_hdrs:
value = "".join(lines)
self._http_hdrs.append((key, value))
else:
for i in range(1, len(lines)):
lines[i] = " " + lines[i].strip()
value = "\r\n".join(lines) + "\r\n"
line = key + ": " + value
if prefix:
self._headers.insert(0, line)
else:
self._headers.append(line)
def flushheaders(self):
self._fp.writelines(self._headers)
self._headers = []
def startbody(self, ctype=None, plist=[], prefix=1,
add_to_http_hdrs=0, content_type=1):
"""
prefix is ignored if add_to_http_hdrs is true.
"""
if content_type and ctype:
for name, value in plist:
ctype = ctype + ';\r\n %s=%s' % (name, value)
self.addheader("Content-type", ctype, prefix=prefix,
add_to_http_hdrs=add_to_http_hdrs)
self.flushheaders()
if not add_to_http_hdrs: self._fp.write("\r\n")
self._first_part = True
return self._fp
def startmultipartbody(self, subtype, boundary=None, plist=[], prefix=1,
add_to_http_hdrs=0, content_type=1):
boundary = boundary or choose_boundary()
self._boundary.append(boundary)
return self.startbody("multipart/" + subtype,
[("boundary", boundary)] + plist,
prefix=prefix,
add_to_http_hdrs=add_to_http_hdrs,
content_type=content_type)
def nextpart(self):
boundary = self._boundary[-1]
if self._first_part:
self._first_part = False
else:
self._fp.write("\r\n")
self._fp.write("--" + boundary + "\r\n")
return self.__class__(self._fp)
def lastpart(self):
if self._first_part:
self.nextpart()
boundary = self._boundary.pop()
self._fp.write("\r\n--" + boundary + "--\r\n")
class LocateError(ValueError): pass
class AmbiguityError(LocateError): pass
class ControlNotFoundError(LocateError): pass
class ItemNotFoundError(LocateError): pass
class ItemCountError(ValueError): pass
# for backwards compatibility, ParseError derives from exceptions that were
# raised by versions of ClientForm <= 0.2.5
if HAVE_MODULE_HTMLPARSER:
SGMLLIB_PARSEERROR = sgmllib.SGMLParseError
class ParseError(sgmllib.SGMLParseError,
HTMLParser.HTMLParseError,
):
pass
else:
if hasattr(sgmllib, "SGMLParseError"):
SGMLLIB_PARSEERROR = sgmllib.SGMLParseError
class ParseError(sgmllib.SGMLParseError):
pass
else:
SGMLLIB_PARSEERROR = RuntimeError
class ParseError(RuntimeError):
pass
class _AbstractFormParser:
"""forms attribute contains HTMLForm instances on completion."""
# thanks to Moshe Zadka for an example of sgmllib/htmllib usage
def __init__(self, entitydefs=None, encoding=DEFAULT_ENCODING):
if entitydefs is None:
entitydefs = get_entitydefs()
self._entitydefs = entitydefs
self._encoding = encoding
self.base = None
self.forms = []
self.labels = []
self._current_label = None
self._current_form = None
self._select = None
self._optgroup = None
self._option = None
self._textarea = None
# forms[0] will contain all controls that are outside of any form
# self._global_form is an alias for self.forms[0]
self._global_form = None
self.start_form([])
self.end_form()
self._current_form = self._global_form = self.forms[0]
def do_base(self, attrs):
debug("%s", attrs)
for key, value in attrs:
if key == "href":
self.base = self.unescape_attr_if_required(value)
def end_body(self):
debug("")
if self._current_label is not None:
self.end_label()
if self._current_form is not self._global_form:
self.end_form()
def start_form(self, attrs):
debug("%s", attrs)
if self._current_form is not self._global_form:
raise ParseError("nested FORMs")
name = None
action = None
enctype = "application/x-www-form-urlencoded"
method = "GET"
d = {}
for key, value in attrs:
if key == "name":
name = self.unescape_attr_if_required(value)
elif key == "action":
action = self.unescape_attr_if_required(value)
elif key == "method":
method = self.unescape_attr_if_required(value.upper())
elif key == "enctype":
enctype = self.unescape_attr_if_required(value.lower())
d[key] = self.unescape_attr_if_required(value)
controls = []
self._current_form = (name, action, method, enctype), d, controls
def end_form(self):
debug("")
if self._current_label is not None:
self.end_label()
if self._current_form is self._global_form:
raise ParseError("end of FORM before start")
self.forms.append(self._current_form)
self._current_form = self._global_form
def start_select(self, attrs):
debug("%s", attrs)
if self._select is not None:
raise ParseError("nested SELECTs")
if self._textarea is not None:
raise ParseError("SELECT inside TEXTAREA")
d = {}
for key, val in attrs:
d[key] = self.unescape_attr_if_required(val)
self._select = d
self._add_label(d)
self._append_select_control({"__select": d})
def end_select(self):
debug("")
if self._select is None:
raise ParseError("end of SELECT before start")
if self._option is not None:
self._end_option()
self._select = None
def start_optgroup(self, attrs):
debug("%s", attrs)
if self._select is None:
raise ParseError("OPTGROUP outside of SELECT")
d = {}
for key, val in attrs:
d[key] = self.unescape_attr_if_required(val)
self._optgroup = d
def end_optgroup(self):
debug("")
if self._optgroup is None:
raise ParseError("end of OPTGROUP before start")
self._optgroup = None
def _start_option(self, attrs):
debug("%s", attrs)
if self._select is None:
raise ParseError("OPTION outside of SELECT")
if self._option is not None:
self._end_option()
d = {}
for key, val in attrs:
d[key] = self.unescape_attr_if_required(val)
self._option = {}
self._option.update(d)
if (self._optgroup and self._optgroup.has_key("disabled") and
not self._option.has_key("disabled")):
self._option["disabled"] = None
def _end_option(self):
debug("")
if self._option is None:
raise ParseError("end of OPTION before start")
contents = self._option.get("contents", "").strip()
self._option["contents"] = contents
if not self._option.has_key("value"):
self._option["value"] = contents
if not self._option.has_key("label"):
self._option["label"] = contents
# stuff dict of SELECT HTML attrs into a special private key
# (gets deleted again later)
self._option["__select"] = self._select
self._append_select_control(self._option)
self._option = None
def _append_select_control(self, attrs):
debug("%s", attrs)
controls = self._current_form[2]
name = self._select.get("name")
controls.append(("select", name, attrs))
def start_textarea(self, attrs):
debug("%s", attrs)
if self._textarea is not None:
raise ParseError("nested TEXTAREAs")
if self._select is not None:
raise ParseError("TEXTAREA inside SELECT")
d = {}
for key, val in attrs:
d[key] = self.unescape_attr_if_required(val)
self._add_label(d)
self._textarea = d
def end_textarea(self):
debug("")
if self._textarea is None:
raise ParseError("end of TEXTAREA before start")
controls = self._current_form[2]
name = self._textarea.get("name")
controls.append(("textarea", name, self._textarea))
self._textarea = None
def start_label(self, attrs):
debug("%s", attrs)
if self._current_label:
self.end_label()
d = {}
for key, val in attrs:
d[key] = self.unescape_attr_if_required(val)
taken = bool(d.get("for")) # empty id is invalid
d["__text"] = ""
d["__taken"] = taken
if taken:
self.labels.append(d)
self._current_label = d
def end_label(self):
debug("")
label = self._current_label
if label is None:
# something is ugly in the HTML, but we're ignoring it
return
self._current_label = None
# if it is staying around, it is True in all cases
del label["__taken"]
def _add_label(self, d):
#debug("%s", d)
if self._current_label is not None:
if not self._current_label["__taken"]:
self._current_label["__taken"] = True
d["__label"] = self._current_label
def handle_data(self, data):
debug("%s", data)
# according to http://www.w3.org/TR/html4/appendix/notes.html#h-B.3.1
# line break immediately after start tags or immediately before end
# tags must be ignored, but real browsers only ignore a line break
# after a start tag, so we'll do that.
if data[0:2] == "\r\n":
data = data[2:]
if data[0:1] in ["\n", "\r"]:
data = data[1:]
if self._option is not None:
# self._option is a dictionary of the OPTION element's HTML
# attributes, but it has two special keys, one of which is the
# special "contents" key contains text between OPTION tags (the
# other is the "__select" key: see the end_option method)
map = self._option
key = "contents"
elif self._textarea is not None:
map = self._textarea
key = "value"
data = normalize_line_endings(data)
# not if within option or textarea
elif self._current_label is not None:
map = self._current_label
key = "__text"
else:
return
if not map.has_key(key):
map[key] = data
else:
map[key] = map[key] + data
def do_button(self, attrs):
debug("%s", attrs)
d = {}
d["type"] = "submit" # default
for key, val in attrs:
d[key] = self.unescape_attr_if_required(val)
controls = self._current_form[2]
type = d["type"]
name = d.get("name")
# we don't want to lose information, so use a type string that
# doesn't clash with INPUT TYPE={SUBMIT,RESET,BUTTON}
# e.g. type for BUTTON/RESET is "resetbutton"
# (type for INPUT/RESET is "reset")
type = type+"button"
self._add_label(d)
controls.append((type, name, d))
def do_input(self, attrs):
debug("%s", attrs)
d = {}
d["type"] = "text" # default
for key, val in attrs:
d[key] = self.unescape_attr_if_required(val)
controls = self._current_form[2]
type = d["type"]
name = d.get("name")
self._add_label(d)
controls.append((type, name, d))
def do_isindex(self, attrs):
debug("%s", attrs)
d = {}
for key, val in attrs:
d[key] = self.unescape_attr_if_required(val)
controls = self._current_form[2]
self._add_label(d)
# isindex doesn't have type or name HTML attributes
controls.append(("isindex", None, d))
def handle_entityref(self, name):
#debug("%s", name)
self.handle_data(unescape(
'&%s;' % name, self._entitydefs, self._encoding))
def handle_charref(self, name):
#debug("%s", name)
self.handle_data(unescape_charref(name, self._encoding))
def unescape_attr(self, name):
#debug("%s", name)
return unescape(name, self._entitydefs, self._encoding)
def unescape_attrs(self, attrs):
#debug("%s", attrs)
escaped_attrs = {}
for key, val in attrs.items():
try:
val.items
except AttributeError:
escaped_attrs[key] = self.unescape_attr(val)
else:
# e.g. "__select" -- yuck!
escaped_attrs[key] = self.unescape_attrs(val)
return escaped_attrs
def unknown_entityref(self, ref): self.handle_data("&%s;" % ref)
def unknown_charref(self, ref): self.handle_data("&#%s;" % ref)
if not HAVE_MODULE_HTMLPARSER:
class XHTMLCompatibleFormParser:
def __init__(self, entitydefs=None, encoding=DEFAULT_ENCODING):
raise ValueError("HTMLParser could not be imported")
else:
class XHTMLCompatibleFormParser(_AbstractFormParser, HTMLParser.HTMLParser):
"""Good for XHTML, bad for tolerance of incorrect HTML."""
# thanks to Michael Howitz for this!
def __init__(self, entitydefs=None, encoding=DEFAULT_ENCODING):
HTMLParser.HTMLParser.__init__(self)
_AbstractFormParser.__init__(self, entitydefs, encoding)
def feed(self, data):
try:
HTMLParser.HTMLParser.feed(self, data)
except HTMLParser.HTMLParseError, exc:
raise ParseError(exc)
def start_option(self, attrs):
_AbstractFormParser._start_option(self, attrs)
def end_option(self):
_AbstractFormParser._end_option(self)
def handle_starttag(self, tag, attrs):
try:
method = getattr(self, "start_" + tag)
except AttributeError:
try:
method = getattr(self, "do_" + tag)
except AttributeError:
pass # unknown tag
else:
method(attrs)
else:
method(attrs)
def handle_endtag(self, tag):
try:
method = getattr(self, "end_" + tag)
except AttributeError:
pass # unknown tag
else:
method()
def unescape(self, name):
# Use the entitydefs passed into constructor, not
# HTMLParser.HTMLParser's entitydefs.
return self.unescape_attr(name)
def unescape_attr_if_required(self, name):
return name # HTMLParser.HTMLParser already did it
def unescape_attrs_if_required(self, attrs):
return attrs # ditto
class _AbstractSgmllibParser(_AbstractFormParser):
def do_option(self, attrs):
_AbstractFormParser._start_option(self, attrs)
if sys.version_info[:2] >= (2,5):
# we override this attr to decode hex charrefs
entity_or_charref = re.compile(
'&(?:([a-zA-Z][-.a-zA-Z0-9]*)|#(x?[0-9a-fA-F]+))(;?)')
def convert_entityref(self, name):
return unescape("&%s;" % name, self._entitydefs, self._encoding)
def convert_charref(self, name):
return unescape_charref("%s" % name, self._encoding)
def unescape_attr_if_required(self, name):
return name # sgmllib already did it
def unescape_attrs_if_required(self, attrs):
return attrs # ditto
else:
def unescape_attr_if_required(self, name):
return self.unescape_attr(name)
def unescape_attrs_if_required(self, attrs):
return self.unescape_attrs(attrs)
class FormParser(_AbstractSgmllibParser, sgmllib.SGMLParser):
"""Good for tolerance of incorrect HTML, bad for XHTML."""
def __init__(self, entitydefs=None, encoding=DEFAULT_ENCODING):
sgmllib.SGMLParser.__init__(self)
_AbstractFormParser.__init__(self, entitydefs, encoding)
def feed(self, data):
try:
sgmllib.SGMLParser.feed(self, data)
except SGMLLIB_PARSEERROR, exc:
raise ParseError(exc)
# sigh, must support mechanize by allowing dynamic creation of classes based on
# its bundled copy of BeautifulSoup (which was necessary because of dependency
# problems)
def _create_bs_classes(bs,
icbinbs,
):
class _AbstractBSFormParser(_AbstractSgmllibParser):
bs_base_class = None
def __init__(self, entitydefs=None, encoding=DEFAULT_ENCODING):
_AbstractFormParser.__init__(self, entitydefs, encoding)
self.bs_base_class.__init__(self)
def handle_data(self, data):
_AbstractFormParser.handle_data(self, data)
self.bs_base_class.handle_data(self, data)
def feed(self, data):
try:
self.bs_base_class.feed(self, data)
except SGMLLIB_PARSEERROR, exc:
raise ParseError(exc)
class RobustFormParser(_AbstractBSFormParser, bs):
"""Tries to be highly tolerant of incorrect HTML."""
pass
RobustFormParser.bs_base_class = bs
class NestingRobustFormParser(_AbstractBSFormParser, icbinbs):
"""Tries to be highly tolerant of incorrect HTML.
Different from RobustFormParser in that it more often guesses nesting
above missing end tags (see BeautifulSoup docs).
"""
pass
NestingRobustFormParser.bs_base_class = icbinbs
return RobustFormParser, NestingRobustFormParser
try:
if sys.version_info[:2] < (2, 2):
raise ImportError # BeautifulSoup uses generators
import BeautifulSoup
except ImportError:
pass
else:
RobustFormParser, NestingRobustFormParser = _create_bs_classes(
BeautifulSoup.BeautifulSoup, BeautifulSoup.ICantBelieveItsBeautifulSoup
)
__all__ += ['RobustFormParser', 'NestingRobustFormParser']
#FormParser = XHTMLCompatibleFormParser # testing hack
#FormParser = RobustFormParser # testing hack
def ParseResponseEx(response,
select_default=False,
form_parser_class=FormParser,
request_class=urllib2.Request,
entitydefs=None,
encoding=DEFAULT_ENCODING,
# private
_urljoin=urlparse.urljoin,
_urlparse=urlparse.urlparse,
_urlunparse=urlparse.urlunparse,
):
"""Identical to ParseResponse, except that:
1. The returned list contains an extra item. The first form in the list
contains all controls not contained in any FORM element.
2. The arguments ignore_errors and backwards_compat have been removed.
3. Backwards-compatibility mode (backwards_compat=True) is not available.
"""
return _ParseFileEx(response, response.geturl(),
select_default,
False,
form_parser_class,
request_class,
entitydefs,
False,
encoding,
_urljoin=_urljoin,
_urlparse=_urlparse,
_urlunparse=_urlunparse,
)
def ParseFileEx(file, base_uri,
select_default=False,
form_parser_class=FormParser,
request_class=urllib2.Request,
entitydefs=None,
encoding=DEFAULT_ENCODING,
# private
_urljoin=urlparse.urljoin,
_urlparse=urlparse.urlparse,
_urlunparse=urlparse.urlunparse,
):
"""Identical to ParseFile, except that:
1. The returned list contains an extra item. The first form in the list
contains all controls not contained in any FORM element.
2. The arguments ignore_errors and backwards_compat have been removed.
3. Backwards-compatibility mode (backwards_compat=True) is not available.
"""
return _ParseFileEx(file, base_uri,
select_default,
False,
form_parser_class,
request_class,
entitydefs,
False,
encoding,
_urljoin=_urljoin,
_urlparse=_urlparse,
_urlunparse=_urlunparse,
)
def ParseResponse(response, *args, **kwds):
"""Parse HTTP response and return a list of HTMLForm instances.
The return value of urllib2.urlopen can be conveniently passed to this
function as the response parameter.
ClientForm.ParseError is raised on parse errors.
response: file-like object (supporting read() method) with a method
geturl(), returning the URI of the HTTP response
select_default: for multiple-selection SELECT controls and RADIO controls,
pick the first item as the default if none are selected in the HTML
form_parser_class: class to instantiate and use to pass
request_class: class to return from .click() method (default is
urllib2.Request)
entitydefs: mapping like {"&": "&", ...} containing HTML entity
definitions (a sensible default is used)
encoding: character encoding used for encoding numeric character references
when matching link text. ClientForm does not attempt to find the encoding
in a META HTTP-EQUIV attribute in the document itself (mechanize, for
example, does do that and will pass the correct value to ClientForm using
this parameter).
backwards_compat: boolean that determines whether the returned HTMLForm
objects are backwards-compatible with old code. If backwards_compat is
true:
- ClientForm 0.1 code will continue to work as before.
- Label searches that do not specify a nr (number or count) will always
get the first match, even if other controls match. If
backwards_compat is False, label searches that have ambiguous results
will raise an AmbiguityError.
- Item label matching is done by strict string comparison rather than
substring matching.
- De-selecting individual list items is allowed even if the Item is
disabled.
The backwards_compat argument will be deprecated in a future release.
Pass a true value for select_default if you want the behaviour specified by
RFC 1866 (the HTML 2.0 standard), which is to select the first item in a
RADIO or multiple-selection SELECT control if none were selected in the
HTML. Most browsers (including Microsoft Internet Explorer (IE) and
Netscape Navigator) instead leave all items unselected in these cases. The
W3C HTML 4.0 standard leaves this behaviour undefined in the case of
multiple-selection SELECT controls, but insists that at least one RADIO
button should be checked at all times, in contradiction to browser
behaviour.
There is a choice of parsers. ClientForm.XHTMLCompatibleFormParser (uses
HTMLParser.HTMLParser) works best for XHTML, ClientForm.FormParser (uses
sgmllib.SGMLParser) (the default) works better for ordinary grubby HTML.
Note that HTMLParser is only available in Python 2.2 and later. You can
pass your own class in here as a hack to work around bad HTML, but at your
own risk: there is no well-defined interface.
"""
return _ParseFileEx(response, response.geturl(), *args, **kwds)[1:]
def ParseFile(file, base_uri, *args, **kwds):
"""Parse HTML and return a list of HTMLForm instances.
ClientForm.ParseError is raised on parse errors.
file: file-like object (supporting read() method) containing HTML with zero
or more forms to be parsed
base_uri: the URI of the document (note that the base URI used to submit
the form will be that given in the BASE element if present, not that of
the document)
For the other arguments and further details, see ParseResponse.__doc__.
"""
return _ParseFileEx(file, base_uri, *args, **kwds)[1:]
def _ParseFileEx(file, base_uri,
select_default=False,
ignore_errors=False,
form_parser_class=FormParser,
request_class=urllib2.Request,
entitydefs=None,
backwards_compat=True,
encoding=DEFAULT_ENCODING,
_urljoin=urlparse.urljoin,
_urlparse=urlparse.urlparse,
_urlunparse=urlparse.urlunparse,
):
if backwards_compat:
deprecation("operating in backwards-compatibility mode", 1)
fp = form_parser_class(entitydefs, encoding)
while 1:
data = file.read(CHUNK)
try:
fp.feed(data)
except ParseError, e:
e.base_uri = base_uri
raise
if len(data) != CHUNK: break
if fp.base is not None:
# HTML BASE element takes precedence over document URI
base_uri = fp.base
labels = [] # Label(label) for label in fp.labels]
id_to_labels = {}
for l in fp.labels:
label = Label(l)
labels.append(label)
for_id = l["for"]
coll = id_to_labels.get(for_id)
if coll is None:
id_to_labels[for_id] = [label]
else:
coll.append(label)
forms = []
for (name, action, method, enctype), attrs, controls in fp.forms:
if action is None:
action = base_uri
else:
action = _urljoin(base_uri, action)
# would be nice to make HTMLForm class (form builder) pluggable
form = HTMLForm(
action, method, enctype, name, attrs, request_class,
forms, labels, id_to_labels, backwards_compat)
form._urlparse = _urlparse
form._urlunparse = _urlunparse
for ii in range(len(controls)):
type, name, attrs = controls[ii]
# index=ii*10 allows ImageControl to return multiple ordered pairs
form.new_control(
type, name, attrs, select_default=select_default, index=ii*10)
forms.append(form)
for form in forms:
form.fixup()
return forms
class Label:
def __init__(self, attrs):
self.id = attrs.get("for")
self._text = attrs.get("__text").strip()
self._ctext = compress_text(self._text)
self.attrs = attrs
self._backwards_compat = False # maintained by HTMLForm
def __getattr__(self, name):
if name == "text":
if self._backwards_compat:
return self._text
else:
return self._ctext
return getattr(Label, name)
def __setattr__(self, name, value):
if name == "text":
# don't see any need for this, so make it read-only
raise AttributeError("text attribute is read-only")
self.__dict__[name] = value
def __str__(self):
return "<Label(id=%r, text=%r)>" % (self.id, self.text)
def _get_label(attrs):
text = attrs.get("__label")
if text is not None:
return Label(text)
else:
return None
class Control:
"""An HTML form control.
An HTMLForm contains a sequence of Controls. The Controls in an HTMLForm
are accessed using the HTMLForm.find_control method or the
HTMLForm.controls attribute.
Control instances are usually constructed using the ParseFile /
ParseResponse functions. If you use those functions, you can ignore the
rest of this paragraph. A Control is only properly initialised after the
fixup method has been called. In fact, this is only strictly necessary for
ListControl instances. This is necessary because ListControls are built up
from ListControls each containing only a single item, and their initial
value(s) can only be known after the sequence is complete.
The types and values that are acceptable for assignment to the value
attribute are defined by subclasses.
If the disabled attribute is true, this represents the state typically
represented by browsers by 'greying out' a control. If the disabled
attribute is true, the Control will raise AttributeError if an attempt is
made to change its value. In addition, the control will not be considered
'successful' as defined by the W3C HTML 4 standard -- ie. it will
contribute no data to the return value of the HTMLForm.click* methods. To
enable a control, set the disabled attribute to a false value.
If the readonly attribute is true, the Control will raise AttributeError if
an attempt is made to change its value. To make a control writable, set
the readonly attribute to a false value.
All controls have the disabled and readonly attributes, not only those that
may have the HTML attributes of the same names.
On assignment to the value attribute, the following exceptions are raised:
TypeError, AttributeError (if the value attribute should not be assigned
to, because the control is disabled, for example) and ValueError.
If the name or value attributes are None, or the value is an empty list, or
if the control is disabled, the control is not successful.
Public attributes:
type: string describing type of control (see the keys of the
HTMLForm.type2class dictionary for the allowable values) (readonly)
name: name of control (readonly)
value: current value of control (subclasses may allow a single value, a
sequence of values, or either)
disabled: disabled state
readonly: readonly state
id: value of id HTML attribute
"""
def __init__(self, type, name, attrs, index=None):
"""
type: string describing type of control (see the keys of the
HTMLForm.type2class dictionary for the allowable values)
name: control name
attrs: HTML attributes of control's HTML element
"""
raise NotImplementedError()
def add_to_form(self, form):
self._form = form
form.controls.append(self)
def fixup(self):
pass
def is_of_kind(self, kind):
raise NotImplementedError()
def clear(self):
raise NotImplementedError()
def __getattr__(self, name): raise NotImplementedError()
def __setattr__(self, name, value): raise NotImplementedError()
def pairs(self):
"""Return list of (key, value) pairs suitable for passing to urlencode.
"""
return [(k, v) for (i, k, v) in self._totally_ordered_pairs()]
def _totally_ordered_pairs(self):
"""Return list of (key, value, index) tuples.
Like pairs, but allows preserving correct ordering even where several
controls are involved.
"""
raise NotImplementedError()
def _write_mime_data(self, mw, name, value):
"""Write data for a subitem of this control to a MimeWriter."""
# called by HTMLForm
mw2 = mw.nextpart()
mw2.addheader("Content-disposition",
'form-data; name="%s"' % name, 1)
f = mw2.startbody(prefix=0)
f.write(value)
def __str__(self):
raise NotImplementedError()
def get_labels(self):
"""Return all labels (Label instances) for this control.
If the control was surrounded by a <label> tag, that will be the first
label; all other labels, connected by 'for' and 'id', are in the order
that appear in the HTML.
"""
res = []
if self._label:
res.append(self._label)
if self.id:
res.extend(self._form._id_to_labels.get(self.id, ()))
return res
#---------------------------------------------------
class ScalarControl(Control):
"""Control whose value is not restricted to one of a prescribed set.
Some ScalarControls don't accept any value attribute. Otherwise, takes a
single value, which must be string-like.
Additional read-only public attribute:
attrs: dictionary mapping the names of original HTML attributes of the
control to their values
"""
def __init__(self, type, name, attrs, index=None):
self._index = index
self._label = _get_label(attrs)
self.__dict__["type"] = type.lower()
self.__dict__["name"] = name
self._value = attrs.get("value")
self.disabled = attrs.has_key("disabled")
self.readonly = attrs.has_key("readonly")
self.id = attrs.get("id")
self.attrs = attrs.copy()
self._clicked = False
self._urlparse = urlparse.urlparse
self._urlunparse = urlparse.urlunparse
def __getattr__(self, name):
if name == "value":
return self.__dict__["_value"]
else:
raise AttributeError("%s instance has no attribute '%s'" %
(self.__class__.__name__, name))
def __setattr__(self, name, value):
if name == "value":
if not isstringlike(value):
raise TypeError("must assign a string")
elif self.readonly:
raise AttributeError("control '%s' is readonly" % self.name)
elif self.disabled:
raise AttributeError("control '%s' is disabled" % self.name)
self.__dict__["_value"] = value
elif name in ("name", "type"):
raise AttributeError("%s attribute is readonly" % name)
else:
self.__dict__[name] = value
def _totally_ordered_pairs(self):
name = self.name
value = self.value
if name is None or value is None or self.disabled:
return []
return [(self._index, name, value)]
def clear(self):
if self.readonly:
raise AttributeError("control '%s' is readonly" % self.name)
self.__dict__["_value"] = None
def __str__(self):
name = self.name
value = self.value
if name is None: name = "<None>"
if value is None: value = "<None>"
infos = []
if self.disabled: infos.append("disabled")
if self.readonly: infos.append("readonly")
info = ", ".join(infos)
if info: info = " (%s)" % info
return "<%s(%s=%s)%s>" % (self.__class__.__name__, name, value, info)
#---------------------------------------------------
class TextControl(ScalarControl):
"""Textual input control.
Covers:
INPUT/TEXT
INPUT/PASSWORD
INPUT/HIDDEN
TEXTAREA
"""
def __init__(self, type, name, attrs, index=None):
ScalarControl.__init__(self, type, name, attrs, index)
if self.type == "hidden": self.readonly = True
if self._value is None:
self._value = ""
def is_of_kind(self, kind): return kind == "text"
#---------------------------------------------------
class FileControl(ScalarControl):
"""File upload with INPUT TYPE=FILE.
The value attribute of a FileControl is always None. Use add_file instead.
Additional public method: add_file
"""
def __init__(self, type, name, attrs, index=None):
ScalarControl.__init__(self, type, name, attrs, index)
self._value = None
self._upload_data = []
def is_of_kind(self, kind): return kind == "file"
def clear(self):
if self.readonly:
raise AttributeError("control '%s' is readonly" % self.name)
self._upload_data = []
def __setattr__(self, name, value):
if name in ("value", "name", "type"):
raise AttributeError("%s attribute is readonly" % name)
else:
self.__dict__[name] = value
def add_file(self, file_object, content_type=None, filename=None):
if not hasattr(file_object, "read"):
raise TypeError("file-like object must have read method")
if content_type is not None and not isstringlike(content_type):
raise TypeError("content type must be None or string-like")
if filename is not None and not isstringlike(filename):
raise TypeError("filename must be None or string-like")
if content_type is None:
content_type = "application/octet-stream"
self._upload_data.append((file_object, content_type, filename))
def _totally_ordered_pairs(self):
# XXX should it be successful even if unnamed?
if self.name is None or self.disabled:
return []
return [(self._index, self.name, "")]
def _write_mime_data(self, mw, _name, _value):
# called by HTMLForm
# assert _name == self.name and _value == ''
if len(self._upload_data) == 1:
# single file
file_object, content_type, filename = self._upload_data[0]
mw2 = mw.nextpart()
fn_part = filename and ('; filename="%s"' % filename) or ""
disp = 'form-data; name="%s"%s' % (self.name, fn_part)
mw2.addheader("Content-disposition", disp, prefix=1)
fh = mw2.startbody(content_type, prefix=0)
fh.write(file_object.read())
elif len(self._upload_data) != 0:
# multiple files
mw2 = mw.nextpart()
disp = 'form-data; name="%s"' % self.name
mw2.addheader("Content-disposition", disp, prefix=1)
fh = mw2.startmultipartbody("mixed", prefix=0)
for file_object, content_type, filename in self._upload_data:
mw3 = mw2.nextpart()
fn_part = filename and ('; filename="%s"' % filename) or ""
disp = "file%s" % fn_part
mw3.addheader("Content-disposition", disp, prefix=1)
fh2 = mw3.startbody(content_type, prefix=0)
fh2.write(file_object.read())
mw2.lastpart()
def __str__(self):
name = self.name
if name is None: name = "<None>"
if not self._upload_data:
value = "<No files added>"
else:
value = []
for file, ctype, filename in self._upload_data:
if filename is None:
value.append("<Unnamed file>")
else:
value.append(filename)
value = ", ".join(value)
info = []
if self.disabled: info.append("disabled")
if self.readonly: info.append("readonly")
info = ", ".join(info)
if info: info = " (%s)" % info
return "<%s(%s=%s)%s>" % (self.__class__.__name__, name, value, info)
#---------------------------------------------------
class IsindexControl(ScalarControl):
"""ISINDEX control.
ISINDEX is the odd-one-out of HTML form controls. In fact, it isn't really
part of regular HTML forms at all, and predates it. You're only allowed
one ISINDEX per HTML document. ISINDEX and regular form submission are
mutually exclusive -- either submit a form, or the ISINDEX.
Having said this, since ISINDEX controls may appear in forms (which is
probably bad HTML), ParseFile / ParseResponse will include them in the
HTMLForm instances it returns. You can set the ISINDEX's value, as with
any other control (but note that ISINDEX controls have no name, so you'll
need to use the type argument of set_value!). When you submit the form,
the ISINDEX will not be successful (ie., no data will get returned to the
server as a result of its presence), unless you click on the ISINDEX
control, in which case the ISINDEX gets submitted instead of the form:
form.set_value("my isindex value", type="isindex")
urllib2.urlopen(form.click(type="isindex"))
ISINDEX elements outside of FORMs are ignored. If you want to submit one
by hand, do it like so:
url = urlparse.urljoin(page_uri, "?"+urllib.quote_plus("my isindex value"))
result = urllib2.urlopen(url)
"""
def __init__(self, type, name, attrs, index=None):
ScalarControl.__init__(self, type, name, attrs, index)
if self._value is None:
self._value = ""
def is_of_kind(self, kind): return kind in ["text", "clickable"]
def _totally_ordered_pairs(self):
return []
def _click(self, form, coord, return_type, request_class=urllib2.Request):
# Relative URL for ISINDEX submission: instead of "foo=bar+baz",
# want "bar+baz".
# This doesn't seem to be specified in HTML 4.01 spec. (ISINDEX is
# deprecated in 4.01, but it should still say how to submit it).
# Submission of ISINDEX is explained in the HTML 3.2 spec, though.
parts = self._urlparse(form.action)
rest, (query, frag) = parts[:-2], parts[-2:]
parts = rest + (urllib.quote_plus(self.value), None)
url = self._urlunparse(parts)
req_data = url, None, []
if return_type == "pairs":
return []
elif return_type == "request_data":
return req_data
else:
return request_class(url)
def __str__(self):
value = self.value
if value is None: value = "<None>"
infos = []
if self.disabled: infos.append("disabled")
if self.readonly: infos.append("readonly")
info = ", ".join(infos)
if info: info = " (%s)" % info
return "<%s(%s)%s>" % (self.__class__.__name__, value, info)
#---------------------------------------------------
class IgnoreControl(ScalarControl):
"""Control that we're not interested in.
Covers:
INPUT/RESET
BUTTON/RESET
INPUT/BUTTON
BUTTON/BUTTON
These controls are always unsuccessful, in the terminology of HTML 4 (ie.
they never require any information to be returned to the server).
BUTTON/BUTTON is used to generate events for script embedded in HTML.
The value attribute of IgnoreControl is always None.
"""
def __init__(self, type, name, attrs, index=None):
ScalarControl.__init__(self, type, name, attrs, index)
self._value = None
def is_of_kind(self, kind): return False
def __setattr__(self, name, value):
if name == "value":
raise AttributeError(
"control '%s' is ignored, hence read-only" % self.name)
elif name in ("name", "type"):
raise AttributeError("%s attribute is readonly" % name)
else:
self.__dict__[name] = value
#---------------------------------------------------
# ListControls
# helpers and subsidiary classes
class Item:
def __init__(self, control, attrs, index=None):
label = _get_label(attrs)
self.__dict__.update({
"name": attrs["value"],
"_labels": label and [label] or [],
"attrs": attrs,
"_control": control,
"disabled": attrs.has_key("disabled"),
"_selected": False,
"id": attrs.get("id"),
"_index": index,
})
control.items.append(self)
def get_labels(self):
"""Return all labels (Label instances) for this item.
For items that represent radio buttons or checkboxes, if the item was
surrounded by a <label> tag, that will be the first label; all other
labels, connected by 'for' and 'id', are in the order that appear in
the HTML.
For items that represent select options, if the option had a label
attribute, that will be the first label. If the option has contents
(text within the option tags) and it is not the same as the label
attribute (if any), that will be a label. There is nothing in the
spec to my knowledge that makes an option with an id unable to be the
target of a label's for attribute, so those are included, if any, for
the sake of consistency and completeness.
"""
res = []
res.extend(self._labels)
if self.id:
res.extend(self._control._form._id_to_labels.get(self.id, ()))
return res
def __getattr__(self, name):
if name=="selected":
return self._selected
raise AttributeError(name)
def __setattr__(self, name, value):
if name == "selected":
self._control._set_selected_state(self, value)
elif name == "disabled":
self.__dict__["disabled"] = bool(value)
else:
raise AttributeError(name)
def __str__(self):
res = self.name
if self.selected:
res = "*" + res
if self.disabled:
res = "(%s)" % res
return res
def __repr__(self):
# XXX appending the attrs without distinguishing them from name and id
# is silly
attrs = [("name", self.name), ("id", self.id)]+self.attrs.items()
return "<%s %s>" % (
self.__class__.__name__,
" ".join(["%s=%r" % (k, v) for k, v in attrs])
)
def disambiguate(items, nr, **kwds):
msgs = []
for key, value in kwds.items():
msgs.append("%s=%r" % (key, value))
msg = " ".join(msgs)
if not items:
raise ItemNotFoundError(msg)
if nr is None:
if len(items) > 1:
raise AmbiguityError(msg)
nr = 0
if len(items) <= nr:
raise ItemNotFoundError(msg)
return items[nr]
class ListControl(Control):
"""Control representing a sequence of items.
The value attribute of a ListControl represents the successful list items
in the control. The successful list items are those that are selected and
not disabled.
ListControl implements both list controls that take a length-1 value
(single-selection) and those that take length >1 values
(multiple-selection).
ListControls accept sequence values only. Some controls only accept
sequences of length 0 or 1 (RADIO, and single-selection SELECT).
In those cases, ItemCountError is raised if len(sequence) > 1. CHECKBOXes
and multiple-selection SELECTs (those having the "multiple" HTML attribute)
accept sequences of any length.
Note the following mistake:
control.value = some_value
assert control.value == some_value # not necessarily true
The reason for this is that the value attribute always gives the list items
in the order they were listed in the HTML.
ListControl items can also be referred to by their labels instead of names.
Use the label argument to .get(), and the .set_value_by_label(),
.get_value_by_label() methods.
Note that, rather confusingly, though SELECT controls are represented in
HTML by SELECT elements (which contain OPTION elements, representing
individual list items), CHECKBOXes and RADIOs are not represented by *any*
element. Instead, those controls are represented by a collection of INPUT
elements. For example, this is a SELECT control, named "control1":
<select name="control1">
<option>foo</option>
<option value="1">bar</option>
</select>
and this is a CHECKBOX control, named "control2":
<input type="checkbox" name="control2" value="foo" id="cbe1">
<input type="checkbox" name="control2" value="bar" id="cbe2">
The id attribute of a CHECKBOX or RADIO ListControl is always that of its
first element (for example, "cbe1" above).
Additional read-only public attribute: multiple.
"""
# ListControls are built up by the parser from their component items by
# creating one ListControl per item, consolidating them into a single
# master ListControl held by the HTMLForm:
# -User calls form.new_control(...)
# -Form creates Control, and calls control.add_to_form(self).
# -Control looks for a Control with the same name and type in the form,
# and if it finds one, merges itself with that control by calling
# control.merge_control(self). The first Control added to the form, of
# a particular name and type, is the only one that survives in the
# form.
# -Form calls control.fixup for all its controls. ListControls in the
# form know they can now safely pick their default values.
# To create a ListControl without an HTMLForm, use:
# control.merge_control(new_control)
# (actually, it's much easier just to use ParseFile)
_label = None
def __init__(self, type, name, attrs={}, select_default=False,
called_as_base_class=False, index=None):
"""
select_default: for RADIO and multiple-selection SELECT controls, pick
the first item as the default if no 'selected' HTML attribute is
present
"""
if not called_as_base_class:
raise NotImplementedError()
self.__dict__["type"] = type.lower()
self.__dict__["name"] = name
self._value = attrs.get("value")
self.disabled = False
self.readonly = False
self.id = attrs.get("id")
self._closed = False
# As Controls are merged in with .merge_control(), self.attrs will
# refer to each Control in turn -- always the most recently merged
# control. Each merged-in Control instance corresponds to a single
# list item: see ListControl.__doc__.
self.items = []
self._form = None
self._select_default = select_default
self._clicked = False
def clear(self):
self.value = []
def is_of_kind(self, kind):
if kind == "list":
return True
elif kind == "multilist":
return bool(self.multiple)
elif kind == "singlelist":
return not self.multiple
else:
return False
def get_items(self, name=None, label=None, id=None,
exclude_disabled=False):
"""Return matching items by name or label.
For argument docs, see the docstring for .get()
"""
if name is not None and not isstringlike(name):
raise TypeError("item name must be string-like")
if label is not None and not isstringlike(label):
raise TypeError("item label must be string-like")
if id is not None and not isstringlike(id):
raise TypeError("item id must be string-like")
items = [] # order is important
compat = self._form.backwards_compat
for o in self.items:
if exclude_disabled and o.disabled:
continue
if name is not None and o.name != name:
continue
if label is not None:
for l in o.get_labels():
if ((compat and l.text == label) or
(not compat and l.text.find(label) > -1)):
break
else:
continue
if id is not None and o.id != id:
continue
items.append(o)
return items
def get(self, name=None, label=None, id=None, nr=None,
exclude_disabled=False):
"""Return item by name or label, disambiguating if necessary with nr.
All arguments must be passed by name, with the exception of 'name',
which may be used as a positional argument.
If name is specified, then the item must have the indicated name.
If label is specified, then the item must have a label whose
whitespace-compressed, stripped, text substring-matches the indicated
label string (eg. label="please choose" will match
" Do please choose an item ").
If id is specified, then the item must have the indicated id.
nr is an optional 0-based index of the items matching the query.
If nr is the default None value and more than item is found, raises
AmbiguityError (unless the HTMLForm instance's backwards_compat
attribute is true).
If no item is found, or if items are found but nr is specified and not
found, raises ItemNotFoundError.
Optionally excludes disabled items.
"""
if nr is None and self._form.backwards_compat:
nr = 0 # :-/
items = self.get_items(name, label, id, exclude_disabled)
return disambiguate(items, nr, name=name, label=label, id=id)
def _get(self, name, by_label=False, nr=None, exclude_disabled=False):
# strictly for use by deprecated methods
if by_label:
name, label = None, name
else:
name, label = name, None
return self.get(name, label, nr, exclude_disabled)
def toggle(self, name, by_label=False, nr=None):
"""Deprecated: given a name or label and optional disambiguating index
nr, toggle the matching item's selection.
Selecting items follows the behavior described in the docstring of the
'get' method.
if the item is disabled, or this control is disabled or readonly,
raise AttributeError.
"""
deprecation(
"item = control.get(...); item.selected = not item.selected")
o = self._get(name, by_label, nr)
self._set_selected_state(o, not o.selected)
def set(self, selected, name, by_label=False, nr=None):
"""Deprecated: given a name or label and optional disambiguating index
nr, set the matching item's selection to the bool value of selected.
Selecting items follows the behavior described in the docstring of the
'get' method.
if the item is disabled, or this control is disabled or readonly,
raise AttributeError.
"""
deprecation(
"control.get(...).selected = <boolean>")
self._set_selected_state(self._get(name, by_label, nr), selected)
def _set_selected_state(self, item, action):
# action:
# bool False: off
# bool True: on
if self.disabled:
raise AttributeError("control '%s' is disabled" % self.name)
if self.readonly:
raise AttributeError("control '%s' is readonly" % self.name)
action == bool(action)
compat = self._form.backwards_compat
if not compat and item.disabled:
raise AttributeError("item is disabled")
else:
if compat and item.disabled and action:
raise AttributeError("item is disabled")
if self.multiple:
item.__dict__["_selected"] = action
else:
if not action:
item.__dict__["_selected"] = False
else:
for o in self.items:
o.__dict__["_selected"] = False
item.__dict__["_selected"] = True
def toggle_single(self, by_label=None):
"""Deprecated: toggle the selection of the single item in this control.
Raises ItemCountError if the control does not contain only one item.
by_label argument is ignored, and included only for backwards
compatibility.
"""
deprecation(
"control.items[0].selected = not control.items[0].selected")
if len(self.items) != 1:
raise ItemCountError(
"'%s' is not a single-item control" % self.name)
item = self.items[0]
self._set_selected_state(item, not item.selected)
def set_single(self, selected, by_label=None):
"""Deprecated: set the selection of the single item in this control.
Raises ItemCountError if the control does not contain only one item.
by_label argument is ignored, and included only for backwards
compatibility.
"""
deprecation(
"control.items[0].selected = <boolean>")
if len(self.items) != 1:
raise ItemCountError(
"'%s' is not a single-item control" % self.name)
self._set_selected_state(self.items[0], selected)
def get_item_disabled(self, name, by_label=False, nr=None):
"""Get disabled state of named list item in a ListControl."""
deprecation(
"control.get(...).disabled")
return self._get(name, by_label, nr).disabled
def set_item_disabled(self, disabled, name, by_label=False, nr=None):
"""Set disabled state of named list item in a ListControl.
disabled: boolean disabled state
"""
deprecation(
"control.get(...).disabled = <boolean>")
self._get(name, by_label, nr).disabled = disabled
def set_all_items_disabled(self, disabled):
"""Set disabled state of all list items in a ListControl.
disabled: boolean disabled state
"""
for o in self.items:
o.disabled = disabled
def get_item_attrs(self, name, by_label=False, nr=None):
"""Return dictionary of HTML attributes for a single ListControl item.
The HTML element types that describe list items are: OPTION for SELECT
controls, INPUT for the rest. These elements have HTML attributes that
you may occasionally want to know about -- for example, the "alt" HTML
attribute gives a text string describing the item (graphical browsers
usually display this as a tooltip).
The returned dictionary maps HTML attribute names to values. The names
and values are taken from the original HTML.
"""
deprecation(
"control.get(...).attrs")
return self._get(name, by_label, nr).attrs
def close_control(self):
self._closed = True
def add_to_form(self, form):
assert self._form is None or form == self._form, (
"can't add control to more than one form")
self._form = form
if self.name is None:
# always count nameless elements as separate controls
Control.add_to_form(self, form)
else:
for ii in range(len(form.controls)-1, -1, -1):
control = form.controls[ii]
if control.name == self.name and control.type == self.type:
if control._closed:
Control.add_to_form(self, form)
else:
control.merge_control(self)
break
else:
Control.add_to_form(self, form)
def merge_control(self, control):
assert bool(control.multiple) == bool(self.multiple)
# usually, isinstance(control, self.__class__)
self.items.extend(control.items)
def fixup(self):
"""
ListControls are built up from component list items (which are also
ListControls) during parsing. This method should be called after all
items have been added. See ListControl.__doc__ for the reason this is
required.
"""
# Need to set default selection where no item was indicated as being
# selected by the HTML:
# CHECKBOX:
# Nothing should be selected.
# SELECT/single, SELECT/multiple and RADIO:
# RFC 1866 (HTML 2.0): says first item should be selected.
# W3C HTML 4.01 Specification: says that client behaviour is
# undefined in this case. For RADIO, exactly one must be selected,
# though which one is undefined.
# Both Netscape and Microsoft Internet Explorer (IE) choose first
# item for SELECT/single. However, both IE5 and Mozilla (both 1.0
# and Firebird 0.6) leave all items unselected for RADIO and
# SELECT/multiple.
# Since both Netscape and IE all choose the first item for
# SELECT/single, we do the same. OTOH, both Netscape and IE
# leave SELECT/multiple with nothing selected, in violation of RFC 1866
# (but not in violation of the W3C HTML 4 standard); the same is true
# of RADIO (which *is* in violation of the HTML 4 standard). We follow
# RFC 1866 if the _select_default attribute is set, and Netscape and IE
# otherwise. RFC 1866 and HTML 4 are always violated insofar as you
# can deselect all items in a RadioControl.
for o in self.items:
# set items' controls to self, now that we've merged
o.__dict__["_control"] = self
def __getattr__(self, name):
if name == "value":
compat = self._form.backwards_compat
if self.name is None:
return []
return [o.name for o in self.items if o.selected and
(not o.disabled or compat)]
else:
raise AttributeError("%s instance has no attribute '%s'" %
(self.__class__.__name__, name))
def __setattr__(self, name, value):
if name == "value":
if self.disabled:
raise AttributeError("control '%s' is disabled" % self.name)
if self.readonly:
raise AttributeError("control '%s' is readonly" % self.name)
self._set_value(value)
elif name in ("name", "type", "multiple"):
raise AttributeError("%s attribute is readonly" % name)
else:
self.__dict__[name] = value
def _set_value(self, value):
if value is None or isstringlike(value):
raise TypeError("ListControl, must set a sequence")
if not value:
compat = self._form.backwards_compat
for o in self.items:
if not o.disabled or compat:
o.selected = False
elif self.multiple:
self._multiple_set_value(value)
elif len(value) > 1:
raise ItemCountError(
"single selection list, must set sequence of "
"length 0 or 1")
else:
self._single_set_value(value)
def _get_items(self, name, target=1):
all_items = self.get_items(name)
items = [o for o in all_items if not o.disabled]
if len(items) < target:
if len(all_items) < target:
raise ItemNotFoundError(
"insufficient items with name %r" % name)
else:
raise AttributeError(
"insufficient non-disabled items with name %s" % name)
on = []
off = []
for o in items:
if o.selected:
on.append(o)
else:
off.append(o)
return on, off
def _single_set_value(self, value):
assert len(value) == 1
on, off = self._get_items(value[0])
assert len(on) <= 1
if not on:
off[0].selected = True
def _multiple_set_value(self, value):
compat = self._form.backwards_compat
turn_on = [] # transactional-ish
turn_off = [item for item in self.items if
item.selected and (not item.disabled or compat)]
names = {}
for nn in value:
if nn in names.keys():
names[nn] += 1
else:
names[nn] = 1
for name, count in names.items():
on, off = self._get_items(name, count)
for i in range(count):
if on:
item = on[0]
del on[0]
del turn_off[turn_off.index(item)]
else:
item = off[0]
del off[0]
turn_on.append(item)
for item in turn_off:
item.selected = False
for item in turn_on:
item.selected = True
def set_value_by_label(self, value):
"""Set the value of control by item labels.
value is expected to be an iterable of strings that are substrings of
the item labels that should be selected. Before substring matching is
performed, the original label text is whitespace-compressed
(consecutive whitespace characters are converted to a single space
character) and leading and trailing whitespace is stripped. Ambiguous
labels are accepted without complaint if the form's backwards_compat is
True; otherwise, it will not complain as long as all ambiguous labels
share the same item name (e.g. OPTION value).
"""
if isstringlike(value):
raise TypeError(value)
if not self.multiple and len(value) > 1:
raise ItemCountError(
"single selection list, must set sequence of "
"length 0 or 1")
items = []
for nn in value:
found = self.get_items(label=nn)
if len(found) > 1:
if not self._form.backwards_compat:
# ambiguous labels are fine as long as item names (e.g.
# OPTION values) are same
opt_name = found[0].name
if [o for o in found[1:] if o.name != opt_name]:
raise AmbiguityError(nn)
else:
# OK, we'll guess :-( Assume first available item.
found = found[:1]
for o in found:
# For the multiple-item case, we could try to be smarter,
# saving them up and trying to resolve, but that's too much.
if self._form.backwards_compat or o not in items:
items.append(o)
break
else: # all of them are used
raise ItemNotFoundError(nn)
# now we have all the items that should be on
# let's just turn everything off and then back on.
self.value = []
for o in items:
o.selected = True
def get_value_by_label(self):
"""Return the value of the control as given by normalized labels."""
res = []
compat = self._form.backwards_compat
for o in self.items:
if (not o.disabled or compat) and o.selected:
for l in o.get_labels():
if l.text:
res.append(l.text)
break
else:
res.append(None)
return res
def possible_items(self, by_label=False):
"""Deprecated: return the names or labels of all possible items.
Includes disabled items, which may be misleading for some use cases.
"""
deprecation(
"[item.name for item in self.items]")
if by_label:
res = []
for o in self.items:
for l in o.get_labels():
if l.text:
res.append(l.text)
break
else:
res.append(None)
return res
return [o.name for o in self.items]
def _totally_ordered_pairs(self):
if self.disabled or self.name is None:
return []
else:
return [(o._index, self.name, o.name) for o in self.items
if o.selected and not o.disabled]
def __str__(self):
name = self.name
if name is None: name = "<None>"
display = [str(o) for o in self.items]
infos = []
if self.disabled: infos.append("disabled")
if self.readonly: infos.append("readonly")
info = ", ".join(infos)
if info: info = " (%s)" % info
return "<%s(%s=[%s])%s>" % (self.__class__.__name__,
name, ", ".join(display), info)
class RadioControl(ListControl):
"""
Covers:
INPUT/RADIO
"""
def __init__(self, type, name, attrs, select_default=False, index=None):
attrs.setdefault("value", "on")
ListControl.__init__(self, type, name, attrs, select_default,
called_as_base_class=True, index=index)
self.__dict__["multiple"] = False
o = Item(self, attrs, index)
o.__dict__["_selected"] = attrs.has_key("checked")
def fixup(self):
ListControl.fixup(self)
found = [o for o in self.items if o.selected and not o.disabled]
if not found:
if self._select_default:
for o in self.items:
if not o.disabled:
o.selected = True
break
else:
# Ensure only one item selected. Choose the last one,
# following IE and Firefox.
for o in found[:-1]:
o.selected = False
def get_labels(self):
return []
class CheckboxControl(ListControl):
"""
Covers:
INPUT/CHECKBOX
"""
def __init__(self, type, name, attrs, select_default=False, index=None):
attrs.setdefault("value", "on")
ListControl.__init__(self, type, name, attrs, select_default,
called_as_base_class=True, index=index)
self.__dict__["multiple"] = True
o = Item(self, attrs, index)
o.__dict__["_selected"] = attrs.has_key("checked")
def get_labels(self):
return []
class SelectControl(ListControl):
"""
Covers:
SELECT (and OPTION)
OPTION 'values', in HTML parlance, are Item 'names' in ClientForm parlance.
SELECT control values and labels are subject to some messy defaulting
rules. For example, if the HTML representation of the control is:
<SELECT name=year>
<OPTION value=0 label="2002">current year</OPTION>
<OPTION value=1>2001</OPTION>
<OPTION>2000</OPTION>
</SELECT>
The items, in order, have labels "2002", "2001" and "2000", whereas their
names (the OPTION values) are "0", "1" and "2000" respectively. Note that
the value of the last OPTION in this example defaults to its contents, as
specified by RFC 1866, as do the labels of the second and third OPTIONs.
The OPTION labels are sometimes more meaningful than the OPTION values,
which can make for more maintainable code.
Additional read-only public attribute: attrs
The attrs attribute is a dictionary of the original HTML attributes of the
SELECT element. Other ListControls do not have this attribute, because in
other cases the control as a whole does not correspond to any single HTML
element. control.get(...).attrs may be used as usual to get at the HTML
attributes of the HTML elements corresponding to individual list items (for
SELECT controls, these are OPTION elements).
Another special case is that the Item.attrs dictionaries have a special key
"contents" which does not correspond to any real HTML attribute, but rather
contains the contents of the OPTION element:
<OPTION>this bit</OPTION>
"""
# HTML attributes here are treated slightly differently from other list
# controls:
# -The SELECT HTML attributes dictionary is stuffed into the OPTION
# HTML attributes dictionary under the "__select" key.
# -The content of each OPTION element is stored under the special
# "contents" key of the dictionary.
# After all this, the dictionary is passed to the SelectControl constructor
# as the attrs argument, as usual. However:
# -The first SelectControl constructed when building up a SELECT control
# has a constructor attrs argument containing only the __select key -- so
# this SelectControl represents an empty SELECT control.
# -Subsequent SelectControls have both OPTION HTML-attribute in attrs and
# the __select dictionary containing the SELECT HTML-attributes.
def __init__(self, type, name, attrs, select_default=False, index=None):
# fish out the SELECT HTML attributes from the OPTION HTML attributes
# dictionary
self.attrs = attrs["__select"].copy()
self.__dict__["_label"] = _get_label(self.attrs)
self.__dict__["id"] = self.attrs.get("id")
self.__dict__["multiple"] = self.attrs.has_key("multiple")
# the majority of the contents, label, and value dance already happened
contents = attrs.get("contents")
attrs = attrs.copy()
del attrs["__select"]
ListControl.__init__(self, type, name, self.attrs, select_default,
called_as_base_class=True, index=index)
self.disabled = self.attrs.has_key("disabled")
self.readonly = self.attrs.has_key("readonly")
if attrs.has_key("value"):
# otherwise it is a marker 'select started' token
o = Item(self, attrs, index)
o.__dict__["_selected"] = attrs.has_key("selected")
# add 'label' label and contents label, if different. If both are
# provided, the 'label' label is used for display in HTML
# 4.0-compliant browsers (and any lower spec? not sure) while the
# contents are used for display in older or less-compliant
# browsers. We make label objects for both, if the values are
# different.
label = attrs.get("label")
if label:
o._labels.append(Label({"__text": label}))
if contents and contents != label:
o._labels.append(Label({"__text": contents}))
elif contents:
o._labels.append(Label({"__text": contents}))
def fixup(self):
ListControl.fixup(self)
# Firefox doesn't exclude disabled items from those considered here
# (i.e. from 'found', for both branches of the if below). Note that
# IE6 doesn't support the disabled attribute on OPTIONs at all.
found = [o for o in self.items if o.selected]
if not found:
if not self.multiple or self._select_default:
for o in self.items:
if not o.disabled:
was_disabled = self.disabled
self.disabled = False
try:
o.selected = True
finally:
o.disabled = was_disabled
break
elif not self.multiple:
# Ensure only one item selected. Choose the last one,
# following IE and Firefox.
for o in found[:-1]:
o.selected = False
#---------------------------------------------------
class SubmitControl(ScalarControl):
"""
Covers:
INPUT/SUBMIT
BUTTON/SUBMIT
"""
def __init__(self, type, name, attrs, index=None):
ScalarControl.__init__(self, type, name, attrs, index)
# IE5 defaults SUBMIT value to "Submit Query"; Firebird 0.6 leaves it
# blank, Konqueror 3.1 defaults to "Submit". HTML spec. doesn't seem
# to define this.
if self.value is None: self.value = ""
self.readonly = True
def get_labels(self):
res = []
if self.value:
res.append(Label({"__text": self.value}))
res.extend(ScalarControl.get_labels(self))
return res
def is_of_kind(self, kind): return kind == "clickable"
def _click(self, form, coord, return_type, request_class=urllib2.Request):
self._clicked = coord
r = form._switch_click(return_type, request_class)
self._clicked = False
return r
def _totally_ordered_pairs(self):
if not self._clicked:
return []
return ScalarControl._totally_ordered_pairs(self)
#---------------------------------------------------
class ImageControl(SubmitControl):
"""
Covers:
INPUT/IMAGE
Coordinates are specified using one of the HTMLForm.click* methods.
"""
def __init__(self, type, name, attrs, index=None):
SubmitControl.__init__(self, type, name, attrs, index)
self.readonly = False
def _totally_ordered_pairs(self):
clicked = self._clicked
if self.disabled or not clicked:
return []
name = self.name
if name is None: return []
pairs = [
(self._index, "%s.x" % name, str(clicked[0])),
(self._index+1, "%s.y" % name, str(clicked[1])),
]
value = self._value
if value:
pairs.append((self._index+2, name, value))
return pairs
get_labels = ScalarControl.get_labels
# aliases, just to make str(control) and str(form) clearer
class PasswordControl(TextControl): pass
class HiddenControl(TextControl): pass
class TextareaControl(TextControl): pass
class SubmitButtonControl(SubmitControl): pass
def is_listcontrol(control): return control.is_of_kind("list")
class HTMLForm:
"""Represents a single HTML <form> ... </form> element.
A form consists of a sequence of controls that usually have names, and
which can take on various values. The values of the various types of
controls represent variously: text, zero-or-one-of-many or many-of-many
choices, and files to be uploaded. Some controls can be clicked on to
submit the form, and clickable controls' values sometimes include the
coordinates of the click.
Forms can be filled in with data to be returned to the server, and then
submitted, using the click method to generate a request object suitable for
passing to urllib2.urlopen (or the click_request_data or click_pairs
methods if you're not using urllib2).
import ClientForm
forms = ClientForm.ParseFile(html, base_uri)
form = forms[0]
form["query"] = "Python"
form.find_control("nr_results").get("lots").selected = True
response = urllib2.urlopen(form.click())
Usually, HTMLForm instances are not created directly. Instead, the
ParseFile or ParseResponse factory functions are used. If you do construct
HTMLForm objects yourself, however, note that an HTMLForm instance is only
properly initialised after the fixup method has been called (ParseFile and
ParseResponse do this for you). See ListControl.__doc__ for the reason
this is required.
Indexing a form (form["control_name"]) returns the named Control's value
attribute. Assignment to a form index (form["control_name"] = something)
is equivalent to assignment to the named Control's value attribute. If you
need to be more specific than just supplying the control's name, use the
set_value and get_value methods.
ListControl values are lists of item names (specifically, the names of the
items that are selected and not disabled, and hence are "successful" -- ie.
cause data to be returned to the server). The list item's name is the
value of the corresponding HTML element's"value" attribute.
Example:
<INPUT type="CHECKBOX" name="cheeses" value="leicester"></INPUT>
<INPUT type="CHECKBOX" name="cheeses" value="cheddar"></INPUT>
defines a CHECKBOX control with name "cheeses" which has two items, named
"leicester" and "cheddar".
Another example:
<SELECT name="more_cheeses">
<OPTION>1</OPTION>
<OPTION value="2" label="CHEDDAR">cheddar</OPTION>
</SELECT>
defines a SELECT control with name "more_cheeses" which has two items,
named "1" and "2" (because the OPTION element's value HTML attribute
defaults to the element contents -- see SelectControl.__doc__ for more on
these defaulting rules).
To select, deselect or otherwise manipulate individual list items, use the
HTMLForm.find_control() and ListControl.get() methods. To set the whole
value, do as for any other control: use indexing or the set_/get_value
methods.
Example:
# select *only* the item named "cheddar"
form["cheeses"] = ["cheddar"]
# select "cheddar", leave other items unaffected
form.find_control("cheeses").get("cheddar").selected = True
Some controls (RADIO and SELECT without the multiple attribute) can only
have zero or one items selected at a time. Some controls (CHECKBOX and
SELECT with the multiple attribute) can have multiple items selected at a
time. To set the whole value of a ListControl, assign a sequence to a form
index:
form["cheeses"] = ["cheddar", "leicester"]
If the ListControl is not multiple-selection, the assigned list must be of
length one.
To check if a control has an item, if an item is selected, or if an item is
successful (selected and not disabled), respectively:
"cheddar" in [item.name for item in form.find_control("cheeses").items]
"cheddar" in [item.name for item in form.find_control("cheeses").items and
item.selected]
"cheddar" in form["cheeses"] # (or "cheddar" in form.get_value("cheeses"))
Note that some list items may be disabled (see below).
Note the following mistake:
form[control_name] = control_value
assert form[control_name] == control_value # not necessarily true
The reason for this is that form[control_name] always gives the list items
in the order they were listed in the HTML.
List items (hence list values, too) can be referred to in terms of list
item labels rather than list item names using the appropriate label
arguments. Note that each item may have several labels.
The question of default values of OPTION contents, labels and values is
somewhat complicated: see SelectControl.__doc__ and
ListControl.get_item_attrs.__doc__ if you think you need to know.
Controls can be disabled or readonly. In either case, the control's value
cannot be changed until you clear those flags (see example below).
Disabled is the state typically represented by browsers by 'greying out' a
control. Disabled controls are not 'successful' -- they don't cause data
to get returned to the server. Readonly controls usually appear in
browsers as read-only text boxes. Readonly controls are successful. List
items can also be disabled. Attempts to select or deselect disabled items
fail with AttributeError.
If a lot of controls are readonly, it can be useful to do this:
form.set_all_readonly(False)
To clear a control's value attribute, so that it is not successful (until a
value is subsequently set):
form.clear("cheeses")
More examples:
control = form.find_control("cheeses")
control.disabled = False
control.readonly = False
control.get("gruyere").disabled = True
control.items[0].selected = True
See the various Control classes for further documentation. Many methods
take name, type, kind, id, label and nr arguments to specify the control to
be operated on: see HTMLForm.find_control.__doc__.
ControlNotFoundError (subclass of ValueError) is raised if the specified
control can't be found. This includes occasions where a non-ListControl
is found, but the method (set, for example) requires a ListControl.
ItemNotFoundError (subclass of ValueError) is raised if a list item can't
be found. ItemCountError (subclass of ValueError) is raised if an attempt
is made to select more than one item and the control doesn't allow that, or
set/get_single are called and the control contains more than one item.
AttributeError is raised if a control or item is readonly or disabled and
an attempt is made to alter its value.
Security note: Remember that any passwords you store in HTMLForm instances
will be saved to disk in the clear if you pickle them (directly or
indirectly). The simplest solution to this is to avoid pickling HTMLForm
objects. You could also pickle before filling in any password, or just set
the password to "" before pickling.
Public attributes:
action: full (absolute URI) form action
method: "GET" or "POST"
enctype: form transfer encoding MIME type
name: name of form (None if no name was specified)
attrs: dictionary mapping original HTML form attributes to their values
controls: list of Control instances; do not alter this list
(instead, call form.new_control to make a Control and add it to the
form, or control.add_to_form if you already have a Control instance)
Methods for form filling:
-------------------------
Most of the these methods have very similar arguments. See
HTMLForm.find_control.__doc__ for details of the name, type, kind, label
and nr arguments.
def find_control(self,
name=None, type=None, kind=None, id=None, predicate=None,
nr=None, label=None)
get_value(name=None, type=None, kind=None, id=None, nr=None,
by_label=False, # by_label is deprecated
label=None)
set_value(value,
name=None, type=None, kind=None, id=None, nr=None,
by_label=False, # by_label is deprecated
label=None)
clear_all()
clear(name=None, type=None, kind=None, id=None, nr=None, label=None)
set_all_readonly(readonly)
Method applying only to FileControls:
add_file(file_object,
content_type="application/octet-stream", filename=None,
name=None, id=None, nr=None, label=None)
Methods applying only to clickable controls:
click(name=None, type=None, id=None, nr=0, coord=(1,1), label=None)
click_request_data(name=None, type=None, id=None, nr=0, coord=(1,1),
label=None)
click_pairs(name=None, type=None, id=None, nr=0, coord=(1,1), label=None)
"""
type2class = {
"text": TextControl,
"password": PasswordControl,
"hidden": HiddenControl,
"textarea": TextareaControl,
"isindex": IsindexControl,
"file": FileControl,
"button": IgnoreControl,
"buttonbutton": IgnoreControl,
"reset": IgnoreControl,
"resetbutton": IgnoreControl,
"submit": SubmitControl,
"submitbutton": SubmitButtonControl,
"image": ImageControl,
"radio": RadioControl,
"checkbox": CheckboxControl,
"select": SelectControl,
}
#---------------------------------------------------
# Initialisation. Use ParseResponse / ParseFile instead.
def __init__(self, action, method="GET",
enctype="application/x-www-form-urlencoded",
name=None, attrs=None,
request_class=urllib2.Request,
forms=None, labels=None, id_to_labels=None,
backwards_compat=True):
"""
In the usual case, use ParseResponse (or ParseFile) to create new
HTMLForm objects.
action: full (absolute URI) form action
method: "GET" or "POST"
enctype: form transfer encoding MIME type
name: name of form
attrs: dictionary mapping original HTML form attributes to their values
"""
self.action = action
self.method = method
self.enctype = enctype
self.name = name
if attrs is not None:
self.attrs = attrs.copy()
else:
self.attrs = {}
self.controls = []
self._request_class = request_class
# these attributes are used by zope.testbrowser
self._forms = forms # this is a semi-public API!
self._labels = labels # this is a semi-public API!
self._id_to_labels = id_to_labels # this is a semi-public API!
self.backwards_compat = backwards_compat # note __setattr__
self._urlunparse = urlparse.urlunparse
self._urlparse = urlparse.urlparse
def __getattr__(self, name):
if name == "backwards_compat":
return self._backwards_compat
return getattr(HTMLForm, name)
def __setattr__(self, name, value):
# yuck
if name == "backwards_compat":
name = "_backwards_compat"
value = bool(value)
for cc in self.controls:
try:
items = cc.items
except AttributeError:
continue
else:
for ii in items:
for ll in ii.get_labels():
ll._backwards_compat = value
self.__dict__[name] = value
def new_control(self, type, name, attrs,
ignore_unknown=False, select_default=False, index=None):
"""Adds a new control to the form.
This is usually called by ParseFile and ParseResponse. Don't call it
youself unless you're building your own Control instances.
Note that controls representing lists of items are built up from
controls holding only a single list item. See ListControl.__doc__ for
further information.
type: type of control (see Control.__doc__ for a list)
attrs: HTML attributes of control
ignore_unknown: if true, use a dummy Control instance for controls of
unknown type; otherwise, use a TextControl
select_default: for RADIO and multiple-selection SELECT controls, pick
the first item as the default if no 'selected' HTML attribute is
present (this defaulting happens when the HTMLForm.fixup method is
called)
index: index of corresponding element in HTML (see
MoreFormTests.test_interspersed_controls for motivation)
"""
type = type.lower()
klass = self.type2class.get(type)
if klass is None:
if ignore_unknown:
klass = IgnoreControl
else:
klass = TextControl
a = attrs.copy()
if issubclass(klass, ListControl):
control = klass(type, name, a, select_default, index)
else:
control = klass(type, name, a, index)
if type == "select" and len(attrs) == 1:
for ii in range(len(self.controls)-1, -1, -1):
ctl = self.controls[ii]
if ctl.type == "select":
ctl.close_control()
break
control.add_to_form(self)
control._urlparse = self._urlparse
control._urlunparse = self._urlunparse
def fixup(self):
"""Normalise form after all controls have been added.
This is usually called by ParseFile and ParseResponse. Don't call it
youself unless you're building your own Control instances.
This method should only be called once, after all controls have been
added to the form.
"""
for control in self.controls:
control.fixup()
self.backwards_compat = self._backwards_compat
#---------------------------------------------------
def __str__(self):
header = "%s%s %s %s" % (
(self.name and self.name+" " or ""),
self.method, self.action, self.enctype)
rep = [header]
for control in self.controls:
rep.append(" %s" % str(control))
return "<%s>" % "\n".join(rep)
#---------------------------------------------------
# Form-filling methods.
def __getitem__(self, name):
return self.find_control(name).value
def __contains__(self, name):
return bool(self.find_control(name))
def __setitem__(self, name, value):
control = self.find_control(name)
try:
control.value = value
except AttributeError, e:
raise ValueError(str(e))
def get_value(self,
name=None, type=None, kind=None, id=None, nr=None,
by_label=False, # by_label is deprecated
label=None):
"""Return value of control.
If only name and value arguments are supplied, equivalent to
form[name]
"""
if by_label:
deprecation("form.get_value_by_label(...)")
c = self.find_control(name, type, kind, id, label=label, nr=nr)
if by_label:
try:
meth = c.get_value_by_label
except AttributeError:
raise NotImplementedError(
"control '%s' does not yet support by_label" % c.name)
else:
return meth()
else:
return c.value
def set_value(self, value,
name=None, type=None, kind=None, id=None, nr=None,
by_label=False, # by_label is deprecated
label=None):
"""Set value of control.
If only name and value arguments are supplied, equivalent to
form[name] = value
"""
if by_label:
deprecation("form.get_value_by_label(...)")
c = self.find_control(name, type, kind, id, label=label, nr=nr)
if by_label:
try:
meth = c.set_value_by_label
except AttributeError:
raise NotImplementedError(
"control '%s' does not yet support by_label" % c.name)
else:
meth(value)
else:
c.value = value
def get_value_by_label(
self, name=None, type=None, kind=None, id=None, label=None, nr=None):
"""
All arguments should be passed by name.
"""
c = self.find_control(name, type, kind, id, label=label, nr=nr)
return c.get_value_by_label()
def set_value_by_label(
self, value,
name=None, type=None, kind=None, id=None, label=None, nr=None):
"""
All arguments should be passed by name.
"""
c = self.find_control(name, type, kind, id, label=label, nr=nr)
c.set_value_by_label(value)
def set_all_readonly(self, readonly):
for control in self.controls:
control.readonly = bool(readonly)
def clear_all(self):
"""Clear the value attributes of all controls in the form.
See HTMLForm.clear.__doc__.
"""
for control in self.controls:
control.clear()
def clear(self,
name=None, type=None, kind=None, id=None, nr=None, label=None):
"""Clear the value attribute of a control.
As a result, the affected control will not be successful until a value
is subsequently set. AttributeError is raised on readonly controls.
"""
c = self.find_control(name, type, kind, id, label=label, nr=nr)
c.clear()
#---------------------------------------------------
# Form-filling methods applying only to ListControls.
def possible_items(self, # deprecated
name=None, type=None, kind=None, id=None,
nr=None, by_label=False, label=None):
"""Return a list of all values that the specified control can take."""
c = self._find_list_control(name, type, kind, id, label, nr)
return c.possible_items(by_label)
def set(self, selected, item_name, # deprecated
name=None, type=None, kind=None, id=None, nr=None,
by_label=False, label=None):
"""Select / deselect named list item.
selected: boolean selected state
"""
self._find_list_control(name, type, kind, id, label, nr).set(
selected, item_name, by_label)
def toggle(self, item_name, # deprecated
name=None, type=None, kind=None, id=None, nr=None,
by_label=False, label=None):
"""Toggle selected state of named list item."""
self._find_list_control(name, type, kind, id, label, nr).toggle(
item_name, by_label)
def set_single(self, selected, # deprecated
name=None, type=None, kind=None, id=None,
nr=None, by_label=None, label=None):
"""Select / deselect list item in a control having only one item.
If the control has multiple list items, ItemCountError is raised.
This is just a convenience method, so you don't need to know the item's
name -- the item name in these single-item controls is usually
something meaningless like "1" or "on".
For example, if a checkbox has a single item named "on", the following
two calls are equivalent:
control.toggle("on")
control.toggle_single()
""" # by_label ignored and deprecated
self._find_list_control(
name, type, kind, id, label, nr).set_single(selected)
def toggle_single(self, name=None, type=None, kind=None, id=None,
nr=None, by_label=None, label=None): # deprecated
"""Toggle selected state of list item in control having only one item.
The rest is as for HTMLForm.set_single.__doc__.
""" # by_label ignored and deprecated
self._find_list_control(name, type, kind, id, label, nr).toggle_single()
#---------------------------------------------------
# Form-filling method applying only to FileControls.
def add_file(self, file_object, content_type=None, filename=None,
name=None, id=None, nr=None, label=None):
"""Add a file to be uploaded.
file_object: file-like object (with read method) from which to read
data to upload
content_type: MIME content type of data to upload
filename: filename to pass to server
If filename is None, no filename is sent to the server.
If content_type is None, the content type is guessed based on the
filename and the data from read from the file object.
XXX
At the moment, guessed content type is always application/octet-stream.
Use sndhdr, imghdr modules. Should also try to guess HTML, XML, and
plain text.
Note the following useful HTML attributes of file upload controls (see
HTML 4.01 spec, section 17):
accept: comma-separated list of content types that the server will
handle correctly; you can use this to filter out non-conforming files
size: XXX IIRC, this is indicative of whether form wants multiple or
single files
maxlength: XXX hint of max content length in bytes?
"""
self.find_control(name, "file", id=id, label=label, nr=nr).add_file(
file_object, content_type, filename)
#---------------------------------------------------
# Form submission methods, applying only to clickable controls.
def click(self, name=None, type=None, id=None, nr=0, coord=(1,1),
request_class=urllib2.Request,
label=None):
"""Return request that would result from clicking on a control.
The request object is a urllib2.Request instance, which you can pass to
urllib2.urlopen (or ClientCookie.urlopen).
Only some control types (INPUT/SUBMIT & BUTTON/SUBMIT buttons and
IMAGEs) can be clicked.
Will click on the first clickable control, subject to the name, type
and nr arguments (as for find_control). If no name, type, id or number
is specified and there are no clickable controls, a request will be
returned for the form in its current, un-clicked, state.
IndexError is raised if any of name, type, id or nr is specified but no
matching control is found. ValueError is raised if the HTMLForm has an
enctype attribute that is not recognised.
You can optionally specify a coordinate to click at, which only makes a
difference if you clicked on an image.
"""
return self._click(name, type, id, label, nr, coord, "request",
self._request_class)
def click_request_data(self,
name=None, type=None, id=None,
nr=0, coord=(1,1),
request_class=urllib2.Request,
label=None):
"""As for click method, but return a tuple (url, data, headers).
You can use this data to send a request to the server. This is useful
if you're using httplib or urllib rather than urllib2. Otherwise, use
the click method.
# Untested. Have to subclass to add headers, I think -- so use urllib2
# instead!
import urllib
url, data, hdrs = form.click_request_data()
r = urllib.urlopen(url, data)
# Untested. I don't know of any reason to use httplib -- you can get
# just as much control with urllib2.
import httplib, urlparse
url, data, hdrs = form.click_request_data()
tup = urlparse(url)
host, path = tup[1], urlparse.urlunparse((None, None)+tup[2:])
conn = httplib.HTTPConnection(host)
if data:
httplib.request("POST", path, data, hdrs)
else:
httplib.request("GET", path, headers=hdrs)
r = conn.getresponse()
"""
return self._click(name, type, id, label, nr, coord, "request_data",
self._request_class)
def click_pairs(self, name=None, type=None, id=None,
nr=0, coord=(1,1),
label=None):
"""As for click_request_data, but returns a list of (key, value) pairs.
You can use this list as an argument to ClientForm.urlencode. This is
usually only useful if you're using httplib or urllib rather than
urllib2 or ClientCookie. It may also be useful if you want to manually
tweak the keys and/or values, but this should not be necessary.
Otherwise, use the click method.
Note that this method is only useful for forms of MIME type
x-www-form-urlencoded. In particular, it does not return the
information required for file upload. If you need file upload and are
not using urllib2, use click_request_data.
Also note that Python 2.0's urllib.urlencode is slightly broken: it
only accepts a mapping, not a sequence of pairs, as an argument. This
messes up any ordering in the argument. Use ClientForm.urlencode
instead.
"""
return self._click(name, type, id, label, nr, coord, "pairs",
self._request_class)
#---------------------------------------------------
def find_control(self,
name=None, type=None, kind=None, id=None,
predicate=None, nr=None,
label=None):
"""Locate and return some specific control within the form.
At least one of the name, type, kind, predicate and nr arguments must
be supplied. If no matching control is found, ControlNotFoundError is
raised.
If name is specified, then the control must have the indicated name.
If type is specified then the control must have the specified type (in
addition to the types possible for <input> HTML tags: "text",
"password", "hidden", "submit", "image", "button", "radio", "checkbox",
"file" we also have "reset", "buttonbutton", "submitbutton",
"resetbutton", "textarea", "select" and "isindex").
If kind is specified, then the control must fall into the specified
group, each of which satisfies a particular interface. The types are
"text", "list", "multilist", "singlelist", "clickable" and "file".
If id is specified, then the control must have the indicated id.
If predicate is specified, then the control must match that function.
The predicate function is passed the control as its single argument,
and should return a boolean value indicating whether the control
matched.
nr, if supplied, is the sequence number of the control (where 0 is the
first). Note that control 0 is the first control matching all the
other arguments (if supplied); it is not necessarily the first control
in the form. If no nr is supplied, AmbiguityError is raised if
multiple controls match the other arguments (unless the
.backwards-compat attribute is true).
If label is specified, then the control must have this label. Note
that radio controls and checkboxes never have labels: their items do.
"""
if ((name is None) and (type is None) and (kind is None) and
(id is None) and (label is None) and (predicate is None) and
(nr is None)):
raise ValueError(
"at least one argument must be supplied to specify control")
return self._find_control(name, type, kind, id, label, predicate, nr)
#---------------------------------------------------
# Private methods.
def _find_list_control(self,
name=None, type=None, kind=None, id=None,
label=None, nr=None):
if ((name is None) and (type is None) and (kind is None) and
(id is None) and (label is None) and (nr is None)):
raise ValueError(
"at least one argument must be supplied to specify control")
return self._find_control(name, type, kind, id, label,
is_listcontrol, nr)
def _find_control(self, name, type, kind, id, label, predicate, nr):
if ((name is not None) and (name is not Missing) and
not isstringlike(name)):
raise TypeError("control name must be string-like")
if (type is not None) and not isstringlike(type):
raise TypeError("control type must be string-like")
if (kind is not None) and not isstringlike(kind):
raise TypeError("control kind must be string-like")
if (id is not None) and not isstringlike(id):
raise TypeError("control id must be string-like")
if (label is not None) and not isstringlike(label):
raise TypeError("control label must be string-like")
if (predicate is not None) and not callable(predicate):
raise TypeError("control predicate must be callable")
if (nr is not None) and nr < 0:
raise ValueError("control number must be a positive integer")
orig_nr = nr
found = None
ambiguous = False
if nr is None and self.backwards_compat:
nr = 0
for control in self.controls:
if ((name is not None and name != control.name) and
(name is not Missing or control.name is not None)):
continue
if type is not None and type != control.type:
continue
if kind is not None and not control.is_of_kind(kind):
continue
if id is not None and id != control.id:
continue
if predicate and not predicate(control):
continue
if label:
for l in control.get_labels():
if l.text.find(label) > -1:
break
else:
continue
if nr is not None:
if nr == 0:
return control # early exit: unambiguous due to nr
nr -= 1
continue
if found:
ambiguous = True
break
found = control
if found and not ambiguous:
return found
description = []
if name is not None: description.append("name %s" % repr(name))
if type is not None: description.append("type '%s'" % type)
if kind is not None: description.append("kind '%s'" % kind)
if id is not None: description.append("id '%s'" % id)
if label is not None: description.append("label '%s'" % label)
if predicate is not None:
description.append("predicate %s" % predicate)
if orig_nr: description.append("nr %d" % orig_nr)
description = ", ".join(description)
if ambiguous:
raise AmbiguityError("more than one control matching "+description)
elif not found:
raise ControlNotFoundError("no control matching "+description)
assert False
def _click(self, name, type, id, label, nr, coord, return_type,
request_class=urllib2.Request):
try:
control = self._find_control(
name, type, "clickable", id, label, None, nr)
except ControlNotFoundError:
if ((name is not None) or (type is not None) or (id is not None) or
(nr != 0)):
raise
# no clickable controls, but no control was explicitly requested,
# so return state without clicking any control
return self._switch_click(return_type, request_class)
else:
return control._click(self, coord, return_type, request_class)
def _pairs(self):
"""Return sequence of (key, value) pairs suitable for urlencoding."""
return [(k, v) for (i, k, v, c_i) in self._pairs_and_controls()]
def _pairs_and_controls(self):
"""Return sequence of (index, key, value, control_index)
of totally ordered pairs suitable for urlencoding.
control_index is the index of the control in self.controls
"""
pairs = []
for control_index in range(len(self.controls)):
control = self.controls[control_index]
for ii, key, val in control._totally_ordered_pairs():
pairs.append((ii, key, val, control_index))
# stable sort by ONLY first item in tuple
pairs.sort()
return pairs
def _request_data(self):
"""Return a tuple (url, data, headers)."""
method = self.method.upper()
#scheme, netloc, path, parameters, query, frag = urlparse.urlparse(self.action)
parts = self._urlparse(self.action)
rest, (query, frag) = parts[:-2], parts[-2:]
if method == "GET":
if self.enctype != "application/x-www-form-urlencoded":
raise ValueError(
"unknown GET form encoding type '%s'" % self.enctype)
parts = rest + (urlencode(self._pairs()), None)
uri = self._urlunparse(parts)
return uri, None, []
elif method == "POST":
parts = rest + (query, None)
uri = self._urlunparse(parts)
if self.enctype == "application/x-www-form-urlencoded":
return (uri, urlencode(self._pairs()),
[("Content-type", self.enctype)])
elif self.enctype == "multipart/form-data":
data = StringIO()
http_hdrs = []
mw = MimeWriter(data, http_hdrs)
f = mw.startmultipartbody("form-data", add_to_http_hdrs=True,
prefix=0)
for ii, k, v, control_index in self._pairs_and_controls():
self.controls[control_index]._write_mime_data(mw, k, v)
mw.lastpart()
return uri, data.getvalue(), http_hdrs
else:
raise ValueError(
"unknown POST form encoding type '%s'" % self.enctype)
else:
raise ValueError("Unknown method '%s'" % method)
def _switch_click(self, return_type, request_class=urllib2.Request):
# This is called by HTMLForm and clickable Controls to hide switching
# on return_type.
if return_type == "pairs":
return self._pairs()
elif return_type == "request_data":
return self._request_data()
else:
req_data = self._request_data()
req = request_class(req_data[0], req_data[1])
for key, val in req_data[2]:
add_hdr = req.add_header
if key.lower() == "content-type":
try:
add_hdr = req.add_unredirected_header
except AttributeError:
# pre-2.4 and not using ClientCookie
pass
add_hdr(key, val)
return req | unknown | codeparrot/codeparrot-clean | ||
import json
import os
from ctypes import addressof, byref, c_double, c_void_p
from django.contrib.gis.gdal.base import GDALBase
from django.contrib.gis.gdal.driver import Driver
from django.contrib.gis.gdal.error import GDALException
from django.contrib.gis.gdal.prototypes import raster as capi
from django.contrib.gis.gdal.raster.band import BandList
from django.contrib.gis.gdal.raster.const import GDAL_RESAMPLE_ALGORITHMS
from django.contrib.gis.gdal.srs import SpatialReference, SRSException
from django.contrib.gis.geometry.regex import json_regex
from django.utils import six
from django.utils.encoding import (
force_bytes, force_text, python_2_unicode_compatible,
)
from django.utils.functional import cached_property
class TransformPoint(list):
indices = {
'origin': (0, 3),
'scale': (1, 5),
'skew': (2, 4),
}
def __init__(self, raster, prop):
x = raster.geotransform[self.indices[prop][0]]
y = raster.geotransform[self.indices[prop][1]]
list.__init__(self, [x, y])
self._raster = raster
self._prop = prop
@property
def x(self):
return self[0]
@x.setter
def x(self, value):
gtf = self._raster.geotransform
gtf[self.indices[self._prop][0]] = value
self._raster.geotransform = gtf
@property
def y(self):
return self[1]
@y.setter
def y(self, value):
gtf = self._raster.geotransform
gtf[self.indices[self._prop][1]] = value
self._raster.geotransform = gtf
@python_2_unicode_compatible
class GDALRaster(GDALBase):
"""
Wraps a raster GDAL Data Source object.
"""
destructor = capi.close_ds
def __init__(self, ds_input, write=False):
self._write = 1 if write else 0
Driver.ensure_registered()
# Preprocess json inputs. This converts json strings to dictionaries,
# which are parsed below the same way as direct dictionary inputs.
if isinstance(ds_input, six.string_types) and json_regex.match(ds_input):
ds_input = json.loads(ds_input)
# If input is a valid file path, try setting file as source.
if isinstance(ds_input, six.string_types):
if not os.path.exists(ds_input):
raise GDALException('Unable to read raster source input "{}"'.format(ds_input))
try:
# GDALOpen will auto-detect the data source type.
self._ptr = capi.open_ds(force_bytes(ds_input), self._write)
except GDALException as err:
raise GDALException('Could not open the datasource at "{}" ({}).'.format(ds_input, err))
elif isinstance(ds_input, dict):
# A new raster needs to be created in write mode
self._write = 1
# Create driver (in memory by default)
driver = Driver(ds_input.get('driver', 'MEM'))
# For out of memory drivers, check filename argument
if driver.name != 'MEM' and 'name' not in ds_input:
raise GDALException('Specify name for creation of raster with driver "{}".'.format(driver.name))
# Check if width and height where specified
if 'width' not in ds_input or 'height' not in ds_input:
raise GDALException('Specify width and height attributes for JSON or dict input.')
# Check if srid was specified
if 'srid' not in ds_input:
raise GDALException('Specify srid for JSON or dict input.')
# Create GDAL Raster
self._ptr = capi.create_ds(
driver._ptr,
force_bytes(ds_input.get('name', '')),
ds_input['width'],
ds_input['height'],
ds_input.get('nr_of_bands', len(ds_input.get('bands', []))),
ds_input.get('datatype', 6),
None
)
# Set band data if provided
for i, band_input in enumerate(ds_input.get('bands', [])):
band = self.bands[i]
if 'nodata_value' in band_input:
band.nodata_value = band_input['nodata_value']
# Instantiate band filled with nodata values if only
# partial input data has been provided.
if band.nodata_value is not None and (
'data' not in band_input or
'size' in band_input or
'shape' in band_input):
band.data(data=(band.nodata_value,), shape=(1, 1))
# Set band data values from input.
band.data(
data=band_input.get('data'),
size=band_input.get('size'),
shape=band_input.get('shape'),
offset=band_input.get('offset'),
)
# Set SRID
self.srs = ds_input.get('srid')
# Set additional properties if provided
if 'origin' in ds_input:
self.origin.x, self.origin.y = ds_input['origin']
if 'scale' in ds_input:
self.scale.x, self.scale.y = ds_input['scale']
if 'skew' in ds_input:
self.skew.x, self.skew.y = ds_input['skew']
elif isinstance(ds_input, c_void_p):
# Instantiate the object using an existing pointer to a gdal raster.
self._ptr = ds_input
else:
raise GDALException('Invalid data source input type: "{}".'.format(type(ds_input)))
def __str__(self):
return self.name
def __repr__(self):
"""
Short-hand representation because WKB may be very large.
"""
return '<Raster object at %s>' % hex(addressof(self._ptr))
def _flush(self):
"""
Flush all data from memory into the source file if it exists.
The data that needs flushing are geotransforms, coordinate systems,
nodata_values and pixel values. This function will be called
automatically wherever it is needed.
"""
# Raise an Exception if the value is being changed in read mode.
if not self._write:
raise GDALException('Raster needs to be opened in write mode to change values.')
capi.flush_ds(self._ptr)
@property
def name(self):
"""
Returns the name of this raster. Corresponds to filename
for file-based rasters.
"""
return force_text(capi.get_ds_description(self._ptr))
@cached_property
def driver(self):
"""
Returns the GDAL Driver used for this raster.
"""
ds_driver = capi.get_ds_driver(self._ptr)
return Driver(ds_driver)
@property
def width(self):
"""
Width (X axis) in pixels.
"""
return capi.get_ds_xsize(self._ptr)
@property
def height(self):
"""
Height (Y axis) in pixels.
"""
return capi.get_ds_ysize(self._ptr)
@property
def srs(self):
"""
Returns the SpatialReference used in this GDALRaster.
"""
try:
wkt = capi.get_ds_projection_ref(self._ptr)
if not wkt:
return None
return SpatialReference(wkt, srs_type='wkt')
except SRSException:
return None
@srs.setter
def srs(self, value):
"""
Sets the spatial reference used in this GDALRaster. The input can be
a SpatialReference or any parameter accepted by the SpatialReference
constructor.
"""
if isinstance(value, SpatialReference):
srs = value
elif isinstance(value, six.integer_types + six.string_types):
srs = SpatialReference(value)
else:
raise ValueError('Could not create a SpatialReference from input.')
capi.set_ds_projection_ref(self._ptr, srs.wkt.encode())
self._flush()
@property
def srid(self):
"""
Shortcut to access the srid of this GDALRaster.
"""
return self.srs.srid
@srid.setter
def srid(self, value):
"""
Shortcut to set this GDALRaster's srs from an srid.
"""
self.srs = value
@property
def geotransform(self):
"""
Returns the geotransform of the data source.
Returns the default geotransform if it does not exist or has not been
set previously. The default is [0.0, 1.0, 0.0, 0.0, 0.0, -1.0].
"""
# Create empty ctypes double array for data
gtf = (c_double * 6)()
capi.get_ds_geotransform(self._ptr, byref(gtf))
return list(gtf)
@geotransform.setter
def geotransform(self, values):
"Sets the geotransform for the data source."
if sum([isinstance(x, (int, float)) for x in values]) != 6:
raise ValueError('Geotransform must consist of 6 numeric values.')
# Create ctypes double array with input and write data
values = (c_double * 6)(*values)
capi.set_ds_geotransform(self._ptr, byref(values))
self._flush()
@property
def origin(self):
"""
Coordinates of the raster origin.
"""
return TransformPoint(self, 'origin')
@property
def scale(self):
"""
Pixel scale in units of the raster projection.
"""
return TransformPoint(self, 'scale')
@property
def skew(self):
"""
Skew of pixels (rotation parameters).
"""
return TransformPoint(self, 'skew')
@property
def extent(self):
"""
Returns the extent as a 4-tuple (xmin, ymin, xmax, ymax).
"""
# Calculate boundary values based on scale and size
xval = self.origin.x + self.scale.x * self.width
yval = self.origin.y + self.scale.y * self.height
# Calculate min and max values
xmin = min(xval, self.origin.x)
xmax = max(xval, self.origin.x)
ymin = min(yval, self.origin.y)
ymax = max(yval, self.origin.y)
return xmin, ymin, xmax, ymax
@property
def bands(self):
return BandList(self)
def warp(self, ds_input, resampling='NearestNeighbour', max_error=0.0):
"""
Returns a warped GDALRaster with the given input characteristics.
The input is expected to be a dictionary containing the parameters
of the target raster. Allowed values are width, height, SRID, origin,
scale, skew, datatype, driver, and name (filename).
By default, the warp functions keeps all parameters equal to the values
of the original source raster. For the name of the target raster, the
name of the source raster will be used and appended with
_copy. + source_driver_name.
In addition, the resampling algorithm can be specified with the "resampling"
input parameter. The default is NearestNeighbor. For a list of all options
consult the GDAL_RESAMPLE_ALGORITHMS constant.
"""
# Get the parameters defining the geotransform, srid, and size of the raster
if 'width' not in ds_input:
ds_input['width'] = self.width
if 'height' not in ds_input:
ds_input['height'] = self.height
if 'srid' not in ds_input:
ds_input['srid'] = self.srs.srid
if 'origin' not in ds_input:
ds_input['origin'] = self.origin
if 'scale' not in ds_input:
ds_input['scale'] = self.scale
if 'skew' not in ds_input:
ds_input['skew'] = self.skew
# Get the driver, name, and datatype of the target raster
if 'driver' not in ds_input:
ds_input['driver'] = self.driver.name
if 'name' not in ds_input:
ds_input['name'] = self.name + '_copy.' + self.driver.name
if 'datatype' not in ds_input:
ds_input['datatype'] = self.bands[0].datatype()
# Instantiate raster bands filled with nodata values.
ds_input['bands'] = [{'nodata_value': bnd.nodata_value} for bnd in self.bands]
# Create target raster
target = GDALRaster(ds_input, write=True)
# Select resampling algorithm
algorithm = GDAL_RESAMPLE_ALGORITHMS[resampling]
# Reproject image
capi.reproject_image(
self._ptr, self.srs.wkt.encode(),
target._ptr, target.srs.wkt.encode(),
algorithm, 0.0, max_error,
c_void_p(), c_void_p(), c_void_p()
)
# Make sure all data is written to file
target._flush()
return target
def transform(self, srid, driver=None, name=None, resampling='NearestNeighbour',
max_error=0.0):
"""
Returns a copy of this raster reprojected into the given SRID.
"""
# Convert the resampling algorithm name into an algorithm id
algorithm = GDAL_RESAMPLE_ALGORITHMS[resampling]
# Instantiate target spatial reference system
target_srs = SpatialReference(srid)
# Create warped virtual dataset in the target reference system
target = capi.auto_create_warped_vrt(
self._ptr, self.srs.wkt.encode(), target_srs.wkt.encode(),
algorithm, max_error, c_void_p()
)
target = GDALRaster(target)
# Construct the target warp dictionary from the virtual raster
data = {
'srid': srid,
'width': target.width,
'height': target.height,
'origin': [target.origin.x, target.origin.y],
'scale': [target.scale.x, target.scale.y],
'skew': [target.skew.x, target.skew.y],
}
# Set the driver and filepath if provided
if driver:
data['driver'] = driver
if name:
data['name'] = name
# Warp the raster into new srid
return self.warp(data, resampling=resampling, max_error=max_error) | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
import datetime
import logging
import re
import time
import flask
import gevent
from docker_registry.core import compat
from docker_registry.core import exceptions
json = compat.json
from . import storage
from . import toolkit
from .app import app
from .lib import mirroring
from .lib import signals
store = storage.load()
logger = logging.getLogger(__name__)
RE_USER_AGENT = re.compile('([^\s/]+)/([^\s/]+)')
RE_VALID_TAG = re.compile('^[\w][\w.-]{0,127}$')
@app.route('/v1/repositories/<path:repository>/properties', methods=['PUT'])
@toolkit.parse_repository_name
@toolkit.requires_auth
def set_properties(namespace, repository):
logger.debug("[set_access] namespace={0}; repository={1}".format(namespace,
repository))
data = None
try:
# Note(dmp): unicode patch
data = json.loads(flask.request.data.decode('utf8'))
except ValueError:
pass
if not data or not isinstance(data, dict):
return toolkit.api_error('Invalid data')
private_flag_path = store.private_flag_path(namespace, repository)
if (data['access'] == 'private'
and not store.is_private(namespace, repository)):
store.put_content(private_flag_path, '')
elif (data['access'] == 'public'
and store.is_private(namespace, repository)):
# XXX is this necessary? Or do we know for sure the file exists?
try:
store.remove(private_flag_path)
except Exception:
pass
return toolkit.response()
@app.route('/v1/repositories/<path:repository>/properties', methods=['GET'])
@toolkit.parse_repository_name
@toolkit.requires_auth
def get_properties(namespace, repository):
logger.debug("[get_access] namespace={0}; repository={1}".format(namespace,
repository))
is_private = store.is_private(namespace, repository)
return toolkit.response({
'access': 'private' if is_private else 'public'
})
def get_tags(namespace, repository):
tag_path = store.tag_path(namespace, repository)
greenlets = {}
for fname in store.list_directory(tag_path):
full_tag_name = fname.split('/').pop()
if not full_tag_name.startswith('tag_'):
continue
tag_name = full_tag_name[4:]
greenlets[tag_name] = gevent.spawn(
store.get_content,
store.tag_path(namespace, repository, tag_name),
)
gevent.joinall(greenlets.values())
return dict((k, g.value) for (k, g) in greenlets.items())
@app.route('/v1/repositories/<path:repository>/tags', methods=['GET'])
@toolkit.parse_repository_name
@toolkit.requires_auth
@mirroring.source_lookup_tag
def _get_tags(namespace, repository):
logger.debug("[get_tags] namespace={0}; repository={1}".format(namespace,
repository))
try:
data = get_tags(namespace=namespace, repository=repository)
except exceptions.FileNotFoundError:
return toolkit.api_error('Repository not found', 404)
return toolkit.response(data)
@app.route('/v1/repositories/<path:repository>/tags/<tag>', methods=['GET'])
@toolkit.parse_repository_name
@toolkit.requires_auth
@mirroring.source_lookup_tag
def get_tag(namespace, repository, tag):
logger.debug("[get_tag] namespace={0}; repository={1}; tag={2}".format(
namespace, repository, tag))
data = None
tag_path = store.tag_path(namespace, repository, tag)
try:
data = store.get_content(tag_path)
except exceptions.FileNotFoundError:
return toolkit.api_error('Tag not found', 404)
return toolkit.response(data)
# warning: this endpoint is deprecated in favor of tag-specific json
# implemented by get_repository_tag_json
@app.route('/v1/repositories/<path:repository>/json', methods=['GET'])
@toolkit.parse_repository_name
@toolkit.requires_auth
@mirroring.source_lookup(stream=False, cache=True)
def get_repository_json(namespace, repository):
json_path = store.repository_json_path(namespace, repository)
headers = {}
data = {'last_update': None,
'docker_version': None,
'docker_go_version': None,
'arch': 'amd64',
'os': 'linux',
'kernel': None}
try:
# Note(dmp): unicode patch
data = store.get_json(json_path)
except exceptions.FileNotFoundError:
if mirroring.is_mirror():
# use code 404 to trigger the source_lookup decorator.
# TODO(joffrey): make sure this doesn't break anything or have the
# decorator rewrite the status code before sending
return toolkit.response(data, code=404, headers=headers)
# else we ignore the error, we'll serve the default json declared above
return toolkit.response(data, headers=headers)
@app.route(
'/v1/repositories/<path:repository>/tags/<tag>/json',
methods=['GET'])
@toolkit.parse_repository_name
@toolkit.requires_auth
def get_repository_tag_json(namespace, repository, tag):
json_path = store.repository_tag_json_path(namespace, repository, tag)
data = {'last_update': None,
'docker_version': None,
'docker_go_version': None,
'arch': 'amd64',
'os': 'linux',
'kernel': None}
try:
# Note(dmp): unicode patch
data = store.get_json(json_path)
except exceptions.FileNotFoundError:
# We ignore the error, we'll serve the default json declared above
pass
return toolkit.response(data)
def create_tag_json(user_agent):
props = {
'last_update': int(time.mktime(datetime.datetime.utcnow().timetuple()))
}
ua = dict(RE_USER_AGENT.findall(user_agent))
if 'docker' in ua:
props['docker_version'] = ua['docker']
if 'go' in ua:
props['docker_go_version'] = ua['go']
for k in ['arch', 'kernel', 'os']:
if k in ua:
props[k] = ua[k].lower()
return json.dumps(props)
@app.route('/v1/repositories/<path:repository>/tags/<tag>',
methods=['PUT'])
@toolkit.parse_repository_name
@toolkit.requires_auth
def put_tag(namespace, repository, tag):
logger.debug("[put_tag] namespace={0}; repository={1}; tag={2}".format(
namespace, repository, tag))
if not RE_VALID_TAG.match(tag):
return toolkit.api_error('Invalid tag name (must match {0})'.format(
RE_VALID_TAG.pattern
))
data = None
try:
# Note(dmp): unicode patch
data = json.loads(flask.request.data.decode('utf8'))
except ValueError:
pass
if not data or not isinstance(data, basestring):
return toolkit.api_error('Invalid data')
if not store.exists(store.image_json_path(data)):
return toolkit.api_error('Image not found', 404)
store.put_content(store.tag_path(namespace, repository, tag), data)
sender = flask.current_app._get_current_object()
signals.tag_created.send(sender, namespace=namespace,
repository=repository, tag=tag, value=data)
# Write some meta-data about the repos
ua = flask.request.headers.get('user-agent', '')
data = create_tag_json(user_agent=ua)
json_path = store.repository_tag_json_path(namespace, repository, tag)
store.put_content(json_path, data)
if tag == "latest": # TODO(dustinlacewell) : deprecate this for v2
json_path = store.repository_json_path(namespace, repository)
store.put_content(json_path, data)
return toolkit.response()
def delete_tag(namespace, repository, tag):
logger.debug("[delete_tag] namespace={0}; repository={1}; tag={2}".format(
namespace, repository, tag))
tag_path = store.tag_path(namespace, repository, tag)
image = store.get_content(path=tag_path)
store.remove(tag_path)
store.remove(store.repository_tag_json_path(namespace, repository,
tag))
sender = flask.current_app._get_current_object()
if tag == "latest": # TODO(wking) : deprecate this for v2
store.remove(store.repository_json_path(namespace, repository))
signals.tag_deleted.send(
sender, namespace=namespace, repository=repository, tag=tag,
image=image)
@app.route('/v1/repositories/<path:repository>/tags/<tag>',
methods=['DELETE'])
@toolkit.parse_repository_name
@toolkit.requires_auth
def _delete_tag(namespace, repository, tag):
# XXX backends are inconsistent on this - some will throw, but not all
try:
delete_tag(namespace=namespace, repository=repository, tag=tag)
except exceptions.FileNotFoundError:
return toolkit.api_error('Tag not found: %s' % tag, 404)
return toolkit.response()
@app.route('/v1/repositories/<path:repository>/', methods=['DELETE'])
@app.route('/v1/repositories/<path:repository>/tags', methods=['DELETE'])
@toolkit.parse_repository_name
@toolkit.requires_auth
def delete_repository(namespace, repository):
"""Remove a repository from storage
This endpoint exists in both the registry API [1] and the indexer
API [2], but has the same semantics in each instance. It's in the
tags module (instead of the index module which handles most
repository tasks) because it should be available regardless of
whether the rest of the index-module endpoints are enabled via the
'standalone' config setting.
[1]: http://docs.docker.io/en/latest/reference/api/registry_api/#delete--v1-repositories-%28namespace%29-%28repository%29- # nopep8
[2]: http://docs.docker.io/en/latest/reference/api/index_api/#delete--v1-repositories-%28namespace%29-%28repo_name%29- # nopep8
"""
logger.debug("[delete_repository] namespace={0}; repository={1}".format(
namespace, repository))
try:
for tag_name, tag_content in get_tags(
namespace=namespace, repository=repository).items():
delete_tag(
namespace=namespace, repository=repository, tag=tag_name)
# TODO(wking): remove images, but may need refcounting
store.remove(store.repository_path(
namespace=namespace, repository=repository))
except exceptions.FileNotFoundError:
return toolkit.api_error('Repository not found', 404)
else:
sender = flask.current_app._get_current_object()
signals.repository_deleted.send(
sender, namespace=namespace, repository=repository)
return toolkit.response() | unknown | codeparrot/codeparrot-clean | ||
# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: t -*-
# vi: set ft=python sts=4 ts=4 sw=4 noet :
# This file is part of Fail2Ban.
#
# Fail2Ban is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# Fail2Ban is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with Fail2Ban; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
__author__ = "Yaroslav Halchenko"
__copyright__ = "Copyright (c) 2013 Yaroslav Halchenko"
__license__ = "GPL"
import logging
import os
import re
import time
import unittest
from StringIO import StringIO
from ..server.mytime import MyTime
from ..helpers import getLogger
logSys = getLogger(__name__)
CONFIG_DIR = os.environ.get('FAIL2BAN_CONFIG_DIR', None)
if not CONFIG_DIR:
# Use heuristic to figure out where configuration files are
if os.path.exists(os.path.join('config', 'fail2ban.conf')):
CONFIG_DIR = 'config'
else:
CONFIG_DIR = '/etc/fail2ban'
def mtimesleep():
# no sleep now should be necessary since polling tracks now not only
# mtime but also ino and size
pass
old_TZ = os.environ.get('TZ', None)
def setUpMyTime():
# Set the time to a fixed, known value
# Sun Aug 14 12:00:00 CEST 2005
# yoh: we need to adjust TZ to match the one used by Cyril so all the timestamps match
os.environ['TZ'] = 'Europe/Zurich'
time.tzset()
MyTime.setTime(1124013600)
def tearDownMyTime():
os.environ.pop('TZ')
if old_TZ:
os.environ['TZ'] = old_TZ
time.tzset()
MyTime.myTime = None
def gatherTests(regexps=None, no_network=False):
# Import all the test cases here instead of a module level to
# avoid circular imports
from . import banmanagertestcase
from . import clientreadertestcase
from . import failmanagertestcase
from . import filtertestcase
from . import servertestcase
from . import datedetectortestcase
from . import actiontestcase
from . import actionstestcase
from . import sockettestcase
from . import misctestcase
from . import databasetestcase
from . import samplestestcase
if not regexps: # pragma: no cover
tests = unittest.TestSuite()
else: # pragma: no cover
class FilteredTestSuite(unittest.TestSuite):
_regexps = [re.compile(r) for r in regexps]
def addTest(self, suite):
suite_str = str(suite)
for r in self._regexps:
if r.search(suite_str):
super(FilteredTestSuite, self).addTest(suite)
return
tests = FilteredTestSuite()
# Server
#tests.addTest(unittest.makeSuite(servertestcase.StartStop))
tests.addTest(unittest.makeSuite(servertestcase.Transmitter))
tests.addTest(unittest.makeSuite(servertestcase.JailTests))
tests.addTest(unittest.makeSuite(servertestcase.RegexTests))
tests.addTest(unittest.makeSuite(servertestcase.LoggingTests))
tests.addTest(unittest.makeSuite(actiontestcase.CommandActionTest))
tests.addTest(unittest.makeSuite(actionstestcase.ExecuteActions))
# FailManager
tests.addTest(unittest.makeSuite(failmanagertestcase.AddFailure))
# BanManager
tests.addTest(unittest.makeSuite(banmanagertestcase.AddFailure))
try:
import dns
tests.addTest(unittest.makeSuite(banmanagertestcase.StatusExtendedCymruInfo))
except ImportError:
pass
# ClientReaders
tests.addTest(unittest.makeSuite(clientreadertestcase.ConfigReaderTest))
tests.addTest(unittest.makeSuite(clientreadertestcase.JailReaderTest))
tests.addTest(unittest.makeSuite(clientreadertestcase.FilterReaderTest))
tests.addTest(unittest.makeSuite(clientreadertestcase.JailsReaderTest))
tests.addTest(unittest.makeSuite(clientreadertestcase.JailsReaderTestCache))
# CSocket and AsyncServer
tests.addTest(unittest.makeSuite(sockettestcase.Socket))
tests.addTest(unittest.makeSuite(sockettestcase.ClientMisc))
# Misc helpers
tests.addTest(unittest.makeSuite(misctestcase.HelpersTest))
tests.addTest(unittest.makeSuite(misctestcase.SetupTest))
tests.addTest(unittest.makeSuite(misctestcase.TestsUtilsTest))
tests.addTest(unittest.makeSuite(misctestcase.CustomDateFormatsTest))
# Database
tests.addTest(unittest.makeSuite(databasetestcase.DatabaseTest))
# Filter
tests.addTest(unittest.makeSuite(filtertestcase.IgnoreIP))
tests.addTest(unittest.makeSuite(filtertestcase.BasicFilter))
tests.addTest(unittest.makeSuite(filtertestcase.LogFile))
tests.addTest(unittest.makeSuite(filtertestcase.LogFileMonitor))
tests.addTest(unittest.makeSuite(filtertestcase.LogFileFilterPoll))
if not no_network:
tests.addTest(unittest.makeSuite(filtertestcase.IgnoreIPDNS))
tests.addTest(unittest.makeSuite(filtertestcase.GetFailures))
tests.addTest(unittest.makeSuite(filtertestcase.DNSUtilsTests))
tests.addTest(unittest.makeSuite(filtertestcase.JailTests))
# DateDetector
tests.addTest(unittest.makeSuite(datedetectortestcase.DateDetectorTest))
# Filter Regex tests with sample logs
tests.addTest(unittest.makeSuite(samplestestcase.FilterSamplesRegex))
#
# Python action testcases
#
testloader = unittest.TestLoader()
from . import action_d
for file_ in os.listdir(
os.path.abspath(os.path.dirname(action_d.__file__))):
if file_.startswith("test_") and file_.endswith(".py"):
if no_network and file_ in ['test_badips.py', 'test_smtp.py']: #pragma: no cover
# Test required network
continue
tests.addTest(testloader.loadTestsFromName(
"%s.%s" % (action_d.__name__, os.path.splitext(file_)[0])))
#
# Extensive use-tests of different available filters backends
#
from ..server.filterpoll import FilterPoll
filters = [FilterPoll] # always available
# Additional filters available only if external modules are available
# yoh: Since I do not know better way for parametric tests
# with good old unittest
try:
from ..server.filtergamin import FilterGamin
filters.append(FilterGamin)
except Exception, e: # pragma: no cover
logSys.warning("Skipping gamin backend testing. Got exception '%s'" % e)
try:
from ..server.filterpyinotify import FilterPyinotify
filters.append(FilterPyinotify)
except Exception, e: # pragma: no cover
logSys.warning("I: Skipping pyinotify backend testing. Got exception '%s'" % e)
for Filter_ in filters:
tests.addTest(unittest.makeSuite(
filtertestcase.get_monitor_failures_testcase(Filter_)))
try: # pragma: systemd no cover
from ..server.filtersystemd import FilterSystemd
tests.addTest(unittest.makeSuite(filtertestcase.get_monitor_failures_journal_testcase(FilterSystemd)))
except Exception, e: # pragma: no cover
logSys.warning("I: Skipping systemd backend testing. Got exception '%s'" % e)
# Server test for logging elements which break logging used to support
# testcases analysis
tests.addTest(unittest.makeSuite(servertestcase.TransmitterLogging))
return tests
class LogCaptureTestCase(unittest.TestCase):
def setUp(self):
# For extended testing of what gets output into logging
# system, we will redirect it to a string
logSys = getLogger("fail2ban")
# Keep old settings
self._old_level = logSys.level
self._old_handlers = logSys.handlers
# Let's log everything into a string
self._log = StringIO()
logSys.handlers = [logging.StreamHandler(self._log)]
if self._old_level < logging.DEBUG: # so if HEAVYDEBUG etc -- show them!
logSys.handlers += self._old_handlers
logSys.setLevel(getattr(logging, 'DEBUG'))
def tearDown(self):
"""Call after every test case."""
# print "O: >>%s<<" % self._log.getvalue()
logSys = getLogger("fail2ban")
logSys.handlers = self._old_handlers
logSys.level = self._old_level
def _is_logged(self, s):
return s in self._log.getvalue()
def getLog(self):
return self._log.getvalue()
def printLog(self):
print(self._log.getvalue())
# Solution from http://stackoverflow.com/questions/568271/how-to-check-if-there-exists-a-process-with-a-given-pid
# under cc by-sa 3.0
if os.name == 'posix':
def pid_exists(pid):
"""Check whether pid exists in the current process table."""
import errno
if pid < 0:
return False
try:
os.kill(pid, 0)
except OSError as e:
return e.errno == errno.EPERM
else:
return True
else:
def pid_exists(pid):
import ctypes
kernel32 = ctypes.windll.kernel32
SYNCHRONIZE = 0x100000
process = kernel32.OpenProcess(SYNCHRONIZE, 0, pid)
if process != 0:
kernel32.CloseHandle(process)
return True
else:
return False | unknown | codeparrot/codeparrot-clean | ||
// errorcheck -0 -m -l
// Copyright 2019 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// Test escape analysis for internal/runtime/atomic.
package escape
import (
"internal/runtime/atomic"
"unsafe"
)
// BAD: should always be "leaking param: addr to result ~r0 level=1$".
func Loadp(addr unsafe.Pointer) unsafe.Pointer { // ERROR "leaking param: addr( to result ~r0 level=1)?$"
return atomic.Loadp(addr)
}
var ptr unsafe.Pointer
func Storep() {
var x int // ERROR "moved to heap: x"
atomic.StorepNoWB(unsafe.Pointer(&ptr), unsafe.Pointer(&x))
}
func Casp1() {
// BAD: should always be "does not escape"
x := new(int) // ERROR "escapes to heap|does not escape"
var y int // ERROR "moved to heap: y"
atomic.Casp1(&ptr, unsafe.Pointer(x), unsafe.Pointer(&y))
} | go | github | https://github.com/golang/go | test/escape_runtime_atomic.go |
#!/usr/bin/env python
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
# Use of this source code is governed by a BSD-style license that can be
# found in the LICENSE file.
"""Embeds standalone JavaScript snippets in C++ code.
Each argument to the script must be a file containing an associated JavaScript
function (e.g., evaluate_script.js should contain an evaluateScript function).
This is called the exported function of the script. The entire script will be
put into a C-style string in the form of an anonymous function which invokes
the exported function when called.
"""
import optparse
import os
import sys
import cpp_source
def main():
parser = optparse.OptionParser()
parser.add_option(
'', '--directory', type='string', default='.',
help='Path to directory where the cc/h js file should be created')
options, args = parser.parse_args()
global_string_map = {}
for js_file in args:
base_name = os.path.basename(js_file)[:-3].title().replace('_', '')
func_name = base_name[0].lower() + base_name[1:]
script_name = 'k%sScript' % base_name
with open(js_file, 'r') as f:
contents = f.read()
script = 'function() { %s; return %s.apply(null, arguments) }' % (
contents, func_name)
global_string_map[script_name] = script
cpp_source.WriteSource('js', 'chrome/test/chromedriver/chrome',
options.directory, global_string_map)
if __name__ == '__main__':
sys.exit(main()) | unknown | codeparrot/codeparrot-clean | ||
# mssql/__init__.py
# Copyright (C) 2005-2014 the SQLAlchemy authors and contributors <see AUTHORS file>
#
# This module is part of SQLAlchemy and is released under
# the MIT License: http://www.opensource.org/licenses/mit-license.php
from sqlalchemy.dialects.mssql import base, pyodbc, adodbapi, \
pymssql, zxjdbc, mxodbc
base.dialect = pyodbc.dialect
from sqlalchemy.dialects.mssql.base import \
INTEGER, BIGINT, SMALLINT, TINYINT, VARCHAR, NVARCHAR, CHAR, \
NCHAR, TEXT, NTEXT, DECIMAL, NUMERIC, FLOAT, DATETIME,\
DATETIME2, DATETIMEOFFSET, DATE, TIME, SMALLDATETIME, \
BINARY, VARBINARY, BIT, REAL, IMAGE, TIMESTAMP,\
MONEY, SMALLMONEY, UNIQUEIDENTIFIER, SQL_VARIANT, dialect
__all__ = (
'INTEGER', 'BIGINT', 'SMALLINT', 'TINYINT', 'VARCHAR', 'NVARCHAR', 'CHAR',
'NCHAR', 'TEXT', 'NTEXT', 'DECIMAL', 'NUMERIC', 'FLOAT', 'DATETIME',
'DATETIME2', 'DATETIMEOFFSET', 'DATE', 'TIME', 'SMALLDATETIME',
'BINARY', 'VARBINARY', 'BIT', 'REAL', 'IMAGE', 'TIMESTAMP',
'MONEY', 'SMALLMONEY', 'UNIQUEIDENTIFIER', 'SQL_VARIANT', 'dialect'
) | unknown | codeparrot/codeparrot-clean | ||
import matplotlib
from matplotlib.patches import Circle, Wedge, Polygon
from matplotlib.collections import PatchCollection
import pylab
fig=pylab.figure()
ax=fig.add_subplot(111)
resolution = 50 # the number of vertices
N = 3
x = pylab.rand(N)
y = pylab.rand(N)
radii = 0.1*pylab.rand(N)
patches = []
for x1,y1,r in zip(x, y, radii):
circle = Circle((x1,y1), r)
patches.append(circle)
x = pylab.rand(N)
y = pylab.rand(N)
radii = 0.1*pylab.rand(N)
theta1 = 360.0*pylab.rand(N)
theta2 = 360.0*pylab.rand(N)
for x1,y1,r,t1,t2 in zip(x, y, radii, theta1, theta2):
wedge = Wedge((x1,y1), r, t1, t2)
patches.append(wedge)
# Some limiting conditions on Wedge
patches += [
Wedge((.3,.7), .1, 0, 360), # Full circle
Wedge((.7,.8), .2, 0, 360, width=0.05), # Full ring
Wedge((.8,.3), .2, 0, 45), # Full sector
Wedge((.8,.3), .2, 45, 90, width=0.10), # Ring sector
]
for i in range(N):
polygon = Polygon(pylab.rand(N,2), True)
patches.append(polygon)
colors = 100*pylab.rand(len(patches))
p = PatchCollection(patches, cmap=matplotlib.cm.jet, alpha=0.4)
p.set_array(pylab.array(colors))
ax.add_collection(p)
pylab.colorbar(p)
pylab.show() | unknown | codeparrot/codeparrot-clean | ||
"""
This disables builtin functions (and one exception class) which are
removed from Python 3.3.
This module is designed to be used like this::
from future.builtins.disabled import *
This disables the following obsolete Py2 builtin functions::
apply, cmp, coerce, execfile, file, input, long,
raw_input, reduce, reload, unicode, xrange
We don't hack __builtin__, which is very fragile because it contaminates
imported modules too. Instead, we just create new functions with
the same names as the obsolete builtins from Python 2 which raise
NameError exceptions when called.
Note that both ``input()`` and ``raw_input()`` are among the disabled
functions (in this module). Although ``input()`` exists as a builtin in
Python 3, the Python 2 ``input()`` builtin is unsafe to use because it
can lead to shell injection. Therefore we shadow it by default upon ``from
future.builtins.disabled import *``, in case someone forgets to import our
replacement ``input()`` somehow and expects Python 3 semantics.
See the ``future.builtins.misc`` module for a working version of
``input`` with Python 3 semantics.
(Note that callable() is not among the functions disabled; this was
reintroduced into Python 3.2.)
This exception class is also disabled:
StandardError
"""
from __future__ import division, absolute_import, print_function
from future import utils
OBSOLETE_BUILTINS = ['apply', 'chr', 'cmp', 'coerce', 'execfile', 'file',
'input', 'long', 'raw_input', 'reduce', 'reload',
'unicode', 'xrange', 'StandardError']
def disabled_function(name):
'''
Returns a function that cannot be called
'''
def disabled(*args, **kwargs):
'''
A function disabled by the ``future`` module. This function is
no longer a builtin in Python 3.
'''
raise NameError('obsolete Python 2 builtin {0} is disabled'.format(name))
return disabled
if not utils.PY3:
for fname in OBSOLETE_BUILTINS:
locals()[fname] = disabled_function(fname)
__all__ = OBSOLETE_BUILTINS
else:
__all__ = [] | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
##############################################################################
#
# OpenERP, Open Source Business Applications
# Copyright (c) 2013-TODAY OpenERP S.A. <http://www.openerp.com>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
#
# You should have received a copy of the GNU Affero General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
##############################################################################
from openerp.addons.project.tests.test_project_base import TestProjectBase
from openerp.exceptions import AccessError
from openerp.tools import mute_logger
EMAIL_TPL = """Return-Path: <whatever-2a840@postmaster.twitter.com>
X-Original-To: {email_to}
Delivered-To: {email_to}
To: {email_to}
cc: {cc}
Received: by mail1.openerp.com (Postfix, from userid 10002)
id 5DF9ABFB2A; Fri, 10 Aug 2012 16:16:39 +0200 (CEST)
Message-ID: {msg_id}
Date: Tue, 29 Nov 2011 12:43:21 +0530
From: {email_from}
MIME-Version: 1.0
Subject: {subject}
Content-Type: text/plain; charset=ISO-8859-1; format=flowed
Hello,
This email should create a new entry in your module. Please check that it
effectively works.
Thanks,
--
Raoul Boitempoils
Integrator at Agrolait"""
class TestProjectFlow(TestProjectBase):
@mute_logger('openerp.addons.base.ir.ir_model', 'openerp.models')
def test_00_project_process(self):
""" Testing project management """
cr, uid, user_projectuser_id, user_projectmanager_id, project_pigs_id = self.cr, self.uid, self.user_projectuser_id, self.user_projectmanager_id, self.project_pigs_id
# ProjectUser: set project as template -> raise
self.assertRaises(AccessError, self.project_project.set_template, cr, user_projectuser_id, [project_pigs_id])
# Other tests are done using a ProjectManager
project = self.project_project.browse(cr, user_projectmanager_id, project_pigs_id)
self.assertNotEqual(project.state, 'template', 'project: incorrect state, should not be a template')
# Set test project as template
self.project_project.set_template(cr, user_projectmanager_id, [project_pigs_id])
project.refresh()
self.assertEqual(project.state, 'template', 'project: set_template: project state should be template')
self.assertEqual(len(project.tasks), 0, 'project: set_template: project tasks should have been set inactive')
# Duplicate template
new_template_act = self.project_project.duplicate_template(cr, user_projectmanager_id, [project_pigs_id])
new_project = self.project_project.browse(cr, user_projectmanager_id, new_template_act['res_id'])
self.assertEqual(new_project.state, 'open', 'project: incorrect duplicate_template')
self.assertEqual(len(new_project.tasks), 2, 'project: duplicating a project template should duplicate its tasks')
# Convert into real project
self.project_project.reset_project(cr, user_projectmanager_id, [project_pigs_id])
project.refresh()
self.assertEqual(project.state, 'open', 'project: resetted project should be in open state')
self.assertEqual(len(project.tasks), 2, 'project: reset_project: project tasks should have been set active')
# Put as pending
self.project_project.set_pending(cr, user_projectmanager_id, [project_pigs_id])
project.refresh()
self.assertEqual(project.state, 'pending', 'project: should be in pending state')
# Re-open
self.project_project.set_open(cr, user_projectmanager_id, [project_pigs_id])
project.refresh()
self.assertEqual(project.state, 'open', 'project: reopened project should be in open state')
# Close project
self.project_project.set_done(cr, user_projectmanager_id, [project_pigs_id])
project.refresh()
self.assertEqual(project.state, 'close', 'project: closed project should be in close state')
# Re-open
self.project_project.set_open(cr, user_projectmanager_id, [project_pigs_id])
project.refresh()
# Re-convert into a template and schedule tasks
self.project_project.set_template(cr, user_projectmanager_id, [project_pigs_id])
self.project_project.schedule_tasks(cr, user_projectmanager_id, [project_pigs_id])
# Copy the project
new_project_id = self.project_project.copy(cr, user_projectmanager_id, project_pigs_id)
new_project = self.project_project.browse(cr, user_projectmanager_id, new_project_id)
self.assertEqual(len(new_project.tasks), 2, 'project: copied project should have copied task')
# Cancel the project
self.project_project.set_cancel(cr, user_projectmanager_id, [project_pigs_id])
self.assertEqual(project.state, 'cancelled', 'project: cancelled project should be in cancel state')
def test_10_task_process(self):
""" Testing task creation and management """
cr, uid, user_projectuser_id, user_projectmanager_id, project_pigs_id = self.cr, self.uid, self.user_projectuser_id, self.user_projectmanager_id, self.project_pigs_id
# create new partner
self.partner_id = self.registry('res.partner').create(cr, uid, {
'name': 'Pigs',
'email': 'otherid@gmail.com',
}, {'mail_create_nolog': True})
def format_and_process(template, email_to='project+pigs@mydomain.com, other@gmail.com', cc='otherid@gmail.com', subject='Frogs',
email_from='Patrick Ratatouille <patrick.ratatouille@agrolait.com>',
msg_id='<1198923581.41972151344608186760.JavaMail@agrolait.com>'):
self.assertEqual(self.project_task.search(cr, uid, [('name', '=', subject)]), [])
mail = template.format(email_to=email_to, cc=cc, subject=subject, email_from=email_from, msg_id=msg_id)
self.mail_thread.message_process(cr, uid, None, mail)
return self.project_task.search(cr, uid, [('name', '=', subject)])
# Do: incoming mail from an unknown partner on an alias creates a new task 'Frogs'
frogs = format_and_process(EMAIL_TPL)
# Test: one task created by mailgateway administrator
self.assertEqual(len(frogs), 1, 'project: message_process: a new project.task should have been created')
task = self.project_task.browse(cr, user_projectuser_id, frogs[0])
# Test: check partner in message followers
self.assertTrue((self.partner_id in [follower.id for follower in task.message_follower_ids]),"Partner in message cc is not added as a task followers.")
res = self.project_task.get_metadata(cr, uid, [task.id])[0].get('create_uid') or [None]
self.assertEqual(res[0], uid,
'project: message_process: task should have been created by uid as alias_user_id is False on the alias')
# Test: messages
self.assertEqual(len(task.message_ids), 3,
'project: message_process: newly created task should have 2 messages: creation and email')
self.assertEqual(task.message_ids[2].subtype_id.name, 'Task Created',
'project: message_process: first message of new task should have Task Created subtype')
self.assertEqual(task.message_ids[1].subtype_id.name, 'Task Assigned',
'project: message_process: first message of new task should have Task Created subtype')
self.assertEqual(task.message_ids[0].author_id.id, self.email_partner_id,
'project: message_process: second message should be the one from Agrolait (partner failed)')
self.assertEqual(task.message_ids[0].subject, 'Frogs',
'project: message_process: second message should be the one from Agrolait (subject failed)')
# Test: task content
self.assertEqual(task.name, 'Frogs', 'project_task: name should be the email subject')
self.assertEqual(task.project_id.id, self.project_pigs_id, 'project_task: incorrect project')
self.assertEqual(task.stage_id.sequence, 1, 'project_task: should have a stage with sequence=1')
# Open the delegation wizard
delegate_id = self.project_task_delegate.create(cr, user_projectuser_id, {
'user_id': user_projectuser_id,
'planned_hours': 12.0,
'planned_hours_me': 2.0,
}, {'active_id': task.id})
self.project_task_delegate.delegate(cr, user_projectuser_id, [delegate_id], {'active_id': task.id})
# Check delegation details
task.refresh()
self.assertEqual(task.planned_hours, 2, 'project_task_delegate: planned hours is not correct after delegation') | unknown | codeparrot/codeparrot-clean | ||
/* Copyright 2018 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#ifndef TENSORFLOW_CORE_GRAPPLER_MUTABLE_GRAPH_VIEW_H_
#define TENSORFLOW_CORE_GRAPPLER_MUTABLE_GRAPH_VIEW_H_
#include <set>
#include <string>
#include "absl/container/flat_hash_set.h"
#include "absl/strings/string_view.h"
#include "absl/types/span.h"
#include "tensorflow/core/framework/graph.pb.h"
#include "tensorflow/core/framework/node_def.pb.h"
#include "tensorflow/core/graph/graph.h"
#include "tensorflow/core/graph/tensor_id.h"
#include "tensorflow/core/grappler/graph_view.h"
#include "tensorflow/core/grappler/op_types.h"
#include "tensorflow/core/lib/core/status.h"
#include "tensorflow/core/platform/types.h"
namespace tensorflow {
namespace grappler {
const char kMutableGraphViewCtrl[] = "ConstantFoldingCtrl";
// A utility class to simplify the traversal of a GraphDef that, unlike
// GraphView, supports updating the graph. Note that you should not modify the
// graph separately, because the view will get out of sync.
class MutableGraphView : public internal::GraphViewInternal<GraphDef, NodeDef> {
public:
explicit MutableGraphView(GraphDef* graph) : GraphViewInternal(graph) {
for (NodeDef& node : *graph->mutable_node()) AddUniqueNodeOrDie(&node);
for (NodeDef& node : *graph->mutable_node()) AddAndDedupFanouts(&node);
}
// Lookup fanouts/fanins using immutable ports.
using GraphViewInternal::GetFanout;
const absl::flat_hash_set<InputPort>& GetFanout(
const GraphView::OutputPort& port) const;
using GraphViewInternal::GetFanin;
absl::flat_hash_set<OutputPort> GetFanin(
const GraphView::InputPort& port) const;
using GraphViewInternal::GetRegularFanin;
const OutputPort GetRegularFanin(const GraphView::InputPort& port) const;
// Adds a new node to graph and updates the view. Returns a pointer to the
// node in graph.
NodeDef* AddNode(NodeDef&& node);
// Adds all nodes from the `subgraph` to the underlying graph and updates the
// view. `subgraph` doesn't have to be a valid graph definition on it's own,
// it can have edges to the nodes that are not in it, however after adding
// it to the underlying graph, final graph must be valid.
//
// If subgraph function library is not empty, all new functions will be added
// to the graph. Functions that appear with the same name in both subgraph and
// the graph represented by *this, must have identical function definitions.
//
// IMPORTANT: All nodes and functions of the given subgraph moved into the
// underlying graph, which leaves subgraph in valid but undefined state.
absl::Status AddSubgraph(GraphDef&& subgraph);
// Updates node `node_name` op, device, and attributes. This will clear any
// existing attributes. If it is not possible to update the node or if the
// node does not exist, an error will be returned and nothing will be modified
// in the graph.
absl::Status UpdateNode(
absl::string_view node_name, absl::string_view op,
absl::string_view device,
absl::Span<const std::pair<std::string, AttrValue>> attrs);
// Updates node `from_node_name` name to `to_node_name`. If `to_node_name` is
// in use, node `from_node_name` does not exist, or node `from_node_name` has
// fanouts and `update_fanouts` is set to false, an error will be returned and
// nothing will be modified in the graph.
absl::Status UpdateNodeName(absl::string_view from_node_name,
absl::string_view to_node_name,
bool update_fanouts);
// Swap node names `from_node_name` and `to_node_name`. Self loops of one node
// are removed by updating the inputs introducing self loops to use the other
// node's name. Setting `update_fanouts` to false will exclude other fanouts
// from having their inputs updated, but inputs introducing self loops will
// always be updated regardless of `update_fanouts.
//
// Example:
// 1. foo(other:3, bar:2, ^bar)
// 2. bar(foo:3, other:1, foo:1, ^foo)
// 3. other(foo:5, bar:6)
//
// After calling SwapNodeNames("foo", "bar", false):
// 1. bar(other:3, foo:2, ^foo)
// 2. foo(bar:3, other:1, bar:1, ^bar)
// 3. other(foo:5, bar:6)
//
// After calling SwapNodeNames("foo", "bar", true):
// 1. bar(other:3, foo:2, ^foo)
// 2. foo(bar:3, other:1, bar:1, ^bar)
// 3. other(bar:5, foo:6)
//
// If it is not possible to swap node names (i.e. nodes do not exist or Switch
// control dependency may be introduced), an error will be returned and
// nothing will be modified in the graph.
absl::Status SwapNodeNames(absl::string_view from_node_name,
absl::string_view to_node_name,
bool update_fanouts);
// Updates all fanouts (input ports fetching output tensors) from
// `from_node_name` to the `to_node_name`, including control dependencies.
//
// Example: We have 3 nodes that use `bar` node output tensors as inputs:
// 1. foo1(bar:0, bar:1, other:0)
// 2. foo2(bar:1, other:1)
// 3. foo3(other:2, ^bar)
//
// After calling UpdateFanouts(bar, new_bar):
// 1. foo1(new_bar:0, new_bar:1, other:0)
// 2. foo2(new_bar:1, other:1)
// 3. foo3(other:2, ^new_bar)
absl::Status UpdateFanouts(absl::string_view from_node_name,
absl::string_view to_node_name);
// Adds regular fanin `fanin` to node `node_name`. If the node or fanin do not
// exist in the graph, nothing will be modified in the graph. Otherwise fanin
// will be added after existing non control dependency fanins. Control
// dependencies will be deduped. To add control dependencies, use
// AddControllingFanin.
absl::Status AddRegularFanin(absl::string_view node_name,
const TensorId& fanin);
// Adds regular fanin `fanin` to node `node_name` at port `port`. If the node
// or fanin do not exist in the graph, nothing will be modified in the graph.
// Otherwise fanin will be inserted at port `port`. Control dependencies will
// be deduped. To add control dependencies, use AddControllingFanin.
//
// If the port is not a valid port (less than 0 or greater than the number of
// regular fanins), this will result in an error and the node will not be
// modified.
absl::Status AddRegularFaninByPort(absl::string_view node_name, int port,
const TensorId& fanin);
// Adds control dependency `fanin` to the target node named `node_name`. To
// add regular fanins, use AddRegularFanin.
//
// Case 1: If the fanin is not a Switch node, the control dependency is simply
// added to the target node:
//
// fanin -^> target node.
//
// Case 2: If the fanin is a Switch node, we cannot anchor a control
// dependency on it, because unlike other nodes, only one of its outputs will
// be generated when the node is activated. In this case, we try to find an
// Identity/IdentityN node in the fanout of the relevant port of the Switch
// and add it as a fanin to the target node. If no such Identity/IdentityN
// node can be found, a new Identity node will be created. In both cases, we
// end up with:
//
// fanin -> Identity{N} -^> target node.
//
// If the control dependency being added is redundant (control dependency
// already exists or control dependency can be deduped from regular fanins),
// this will not result in an error and the node will not be modified.
absl::Status AddControllingFanin(absl::string_view node_name,
const TensorId& fanin);
// Removes regular fanin `fanin` from node `node_name`. If the node or fanin
// do not exist in the graph, nothing will be modified in the graph. If there
// are multiple inputs that match the fanin, all of them will be removed. To
// remove controlling fanins, use RemoveControllingFanin.
//
// If the fanin being removed doesn't exist in the node's inputs, this will
// not result in an error and the node will not be modified.
absl::Status RemoveRegularFanin(absl::string_view node_name,
const TensorId& fanin);
// Removes regular fanin at port `port` from node `node_name`. If the node
// does not exist in the graph, nothing will be modified in the graph.
// To remove controlling fanins, use RemoveControllingFanin.
//
// If the port is not a valid port (less than 0 or greater than the last index
// of the regular fanins), this will result in an error and the node will not
// be modified.
absl::Status RemoveRegularFaninByPort(absl::string_view node_name, int port);
// Removes control dependency `fanin_node_name` from the target node named
// `node_name`. If the node or fanin do not exist in the graph, nothing will
// be modified in the graph. To remove regular fanins, use RemoveRegularFanin.
//
// If the fanin being removed doesn't exist in the node's inputs, this will
// not result in an error and the node will not be modified.
absl::Status RemoveControllingFanin(absl::string_view node_name,
absl::string_view fanin_node_name);
// Removes all fanins from node `node_name`. Control dependencies will be
// retained if keep_controlling_fanins is true.
//
// If no fanins are removed, this will not result in an error and the node
// will not be modified.
absl::Status RemoveAllFanins(absl::string_view node_name,
bool keep_controlling_fanins);
// Replaces all fanins `from_fanin` with `to_fanin` in node `node_name`. If
// the fanins or node do not exist, nothing will be modified in the graph.
// Control dependencies will be deduped.
//
// If the fanin being updated doesn't exist in the node's inputs, this will
// not result in an error and the node will not be modified.
absl::Status UpdateFanin(absl::string_view node_name,
const TensorId& from_fanin,
const TensorId& to_fanin);
// Replaces fanin at port `port` in node `node_name` with fanin `fanin`. If
// the fanins or node do not exist, nothing will be modified in the graph.
// Control dependencies will be deduped.
//
// If the port is not a valid port (less than 0 or greater than the last index
// of the regular fanins), this will result in an error and the node will not
// be modified.
absl::Status UpdateRegularFaninByPort(absl::string_view node_name, int port,
const TensorId& fanin);
// Swaps fanins at ports `from_port` and `to_port` in node `node_name`. If the
// node does not exist, nothing will be modified in the graph.
//
// If the ports are not a valid port (less than 0 or greater than the last
// index of the regular fanins), this will result in an error and the node
// will not be modified.
absl::Status SwapRegularFaninsByPorts(absl::string_view node_name,
int from_port, int to_port);
// Updates all regular fanins to equivalent controlling fanins. If it is not
// possible, an error will be returned and nothing will be modified in the
// graph.
absl::Status UpdateAllRegularFaninsToControlling(absl::string_view node_name);
// Deletes nodes from the graph. If a node can't be safely removed,
// specifically if a node still has fanouts, an error will be returned. Nodes
// that can't be found are ignored.
absl::Status DeleteNodes(
const absl::flat_hash_set<std::string>& nodes_to_delete);
private:
// Adds fanouts for fanins of node to graph, while deduping control
// dependencies from existing control dependencies and regular fanins. Note,
// node inputs will be mutated if control dependencies can be deduped.
void AddAndDedupFanouts(NodeDef* node);
// Finds next output port smaller than fanin.port_id and update. The
// max_regular_output_port is only updated if fanin.port_id is the same as the
// current max_regular_output_port and if the fanouts set is empty. If there
// are no regular outputs, max_regular_output_port will be erased.
void UpdateMaxRegularOutputPortForRemovedFanin(
const OutputPort& fanin,
const absl::flat_hash_set<InputPort>& fanin_fanouts);
// Updates max regular output port for newly added fanin by checking the
// current max and updating if the newly added fanin is of a larger port.
void UpdateMaxRegularOutputPortForAddedFanin(const OutputPort& fanin);
// Updates all fanouts (input ports fetching output tensors) from `from_node`
// to the `to_node`, including control dependencies.
//
// Example: We have 3 nodes that use `bar` node output tensors as inputs:
// 1. foo1(bar:0, bar:1, other:0)
// 2. foo2(bar:1, other:1)
// 3. foo3(other:2, ^bar)
//
// After calling UpdateFanouts(bar, new_bar):
// 1. foo1(new_bar:0, new_bar:1, other:0)
// 2. foo2(new_bar:1, other:1)
// 3. foo3(other:2, ^new_bar)
//
// IMPORTANT: If `from_node` or `to_node` is not in the underlying graph, the
// behavior is undefined.
absl::Status UpdateFanoutsInternal(NodeDef* from_node, NodeDef* to_node);
// Adds fanin to node. If fanin is a control dependency, existing control
// dependencies will be checked first before adding. Otherwise fanin will be
// added after existing non control dependency inputs.
bool AddFaninInternal(NodeDef* node, const OutputPort& fanin);
// Finds control dependency node to be used based on fanin. If fanin is not a
// Switch node, fanin.node is simply returned. Otherwise this will try to find
// a candidate Identity node consuming fanin, as the control dependency. If it
// is not possible or will introduce a self loop, an error message will be
// set. If nullptr is returned with no error
// GetOrCreateIdentityConsumingSwitch should be called to generate the new
// Identity node.
NodeDef* GetControllingFaninToAdd(absl::string_view node_name,
const OutputPort& fanin,
std::string* error_msg);
// Finds a generated Identity node consuming Switch node `fanin.node` at port
// `fanin.port_id`. If such a node does not exist, a new Identity node will be
// created.
NodeDef* GetOrCreateIdentityConsumingSwitch(const OutputPort& fanin);
// Removes all instances of regular fanin `fanin` from node `node`.
bool RemoveRegularFaninInternal(NodeDef* node, const OutputPort& fanin);
// Removes controlling fanin `fanin_node` from node if such controlling fanin
// exists.
bool RemoveControllingFaninInternal(NodeDef* node, NodeDef* fanin_node);
// Checks if nodes to be deleted are missing or have any fanouts that will
// remain in the graph. If node is removed in either case, the graph will
// enter an invalid state.
absl::Status CheckNodesCanBeDeleted(
const absl::flat_hash_set<std::string>& nodes_to_delete);
// Removes fanins of the deleted node from internal state. Control
// dependencies are retained iff keep_controlling_fanins is true.
void RemoveFaninsInternal(NodeDef* deleted_node,
bool keep_controlling_fanins);
// Removes fanouts of the deleted node from internal state.
void RemoveFanoutsInternal(NodeDef* deleted_node);
};
} // end namespace grappler
} // end namespace tensorflow
#endif // TENSORFLOW_CORE_GRAPPLER_MUTABLE_GRAPH_VIEW_H_ | c | github | https://github.com/tensorflow/tensorflow | tensorflow/core/grappler/mutable_graph_view.h |
"""
Call Stack Manager deals with tracking call stacks of functions/methods/classes(Django Model Classes)
Call Stack Manager logs unique call stacks. The call stacks then can be retrieved via Splunk, or log reads.
classes:
CallStackManager - stores all stacks in global dictionary and logs
CallStackMixin - used for Model save(), and delete() method
Decorators:
@donottrack - Decorator that will halt tracking for parameterized entities,
(or halt tracking anything in case of non-parametrized decorator).
@trackit - Decorator that will start tracking decorated entity.
@track_till_now - Will log every unique call stack of parametrized entity/ entities.
TRACKING DJANGO MODEL CLASSES -
Call stacks of Model Class
in three cases-
1. QuerySet API
2. save()
3. delete()
How to use:
1. Import following in the file where class to be tracked resides
from openedx.core.djangoapps.call_stack_manager import CallStackManager, CallStackMixin
2. Override objects of default manager by writing following in any model class which you want to track-
objects = CallStackManager()
3. For tracking Save and Delete events-
Use mixin called "CallStackMixin"
For ex.
class StudentModule(models.Model, CallStackMixin):
TRACKING FUNCTIONS, and METHODS-
1. Import following-
from openedx.core.djangoapps.call_stack_manager import trackit
NOTE - @trackit is non-parameterized decorator.
FOR DISABLING TRACKING-
1. Import following at appropriate location-
from openedx.core.djangoapps.call_stack_manager import donottrack
NOTE - You need to import function/class you do not want to track.
"""
import logging
import traceback
import re
import collections
import wrapt
import types
import inspect
from django.db.models import Manager
log = logging.getLogger(__name__)
# List of regular expressions acting as filters
REGULAR_EXPS = [re.compile(x) for x in ['^.*python2.7.*$', '^.*<exec_function>.*$', '^.*exec_code_object.*$',
'^.*edxapp/src.*$', '^.*call_stack_manager.*$']]
# List keeping track of entities not to be tracked
HALT_TRACKING = []
STACK_BOOK = collections.defaultdict(list)
# Dictionary which stores call logs
# {'EntityName' : ListOf<CallStacks>}
# CallStacks is ListOf<Frame>
# Frame is a tuple ('FilePath','LineNumber','Function Name', 'Context')
# {"<class 'courseware.models.StudentModule'>" : [[(file, line number, function name, context),(---,---,---)],
# [(file, line number, function name, context),(---,---,---)]]}
def capture_call_stack(entity_name):
""" Logs customised call stacks in global dictionary STACK_BOOK and logs it.
Arguments:
entity_name - entity
"""
# Holds temporary callstack
# List with each element 4-tuple(filename, line number, function name, text)
# and filtered with respect to regular expressions
temp_call_stack = [frame for frame in traceback.extract_stack()
if not any(reg.match(frame[0]) for reg in REGULAR_EXPS)]
final_call_stack = "".join(traceback.format_list(temp_call_stack))
def _should_get_logged(entity_name): # pylint: disable=
""" Checks if current call stack of current entity should be logged or not.
Arguments:
entity_name - Name of the current entity
Returns:
True if the current call stack is to logged, False otherwise
"""
is_class_in_halt_tracking = bool(HALT_TRACKING and inspect.isclass(entity_name) and
issubclass(entity_name, tuple(HALT_TRACKING[-1])))
is_function_in_halt_tracking = bool(HALT_TRACKING and not inspect.isclass(entity_name) and
any((entity_name.__name__ == x.__name__ and
entity_name.__module__ == x.__module__)
for x in tuple(HALT_TRACKING[-1])))
is_top_none = HALT_TRACKING and HALT_TRACKING[-1] is None
# if top of STACK_BOOK is None
if is_top_none:
return False
# if call stack is empty
if not temp_call_stack:
return False
if HALT_TRACKING:
if is_class_in_halt_tracking or is_function_in_halt_tracking:
return False
else:
return temp_call_stack not in STACK_BOOK[entity_name]
else:
return temp_call_stack not in STACK_BOOK[entity_name]
if _should_get_logged(entity_name):
STACK_BOOK[entity_name].append(temp_call_stack)
if inspect.isclass(entity_name):
log.info("Logging new call stack number %s for %s:\n %s", len(STACK_BOOK[entity_name]),
entity_name, final_call_stack)
else:
log.info("Logging new call stack number %s for %s.%s:\n %s", len(STACK_BOOK[entity_name]),
entity_name.__module__, entity_name.__name__, final_call_stack)
class CallStackMixin(object):
""" Mixin class for getting call stacks when save() and delete() methods are called """
def save(self, *args, **kwargs):
""" Logs before save() and overrides respective model API save() """
capture_call_stack(type(self))
return super(CallStackMixin, self).save(*args, **kwargs)
def delete(self, *args, **kwargs):
""" Logs before delete() and overrides respective model API delete() """
capture_call_stack(type(self))
return super(CallStackMixin, self).delete(*args, **kwargs)
class CallStackManager(Manager):
""" Manager class which overrides the default Manager class for getting call stacks """
def get_query_set(self):
""" Override the default queryset API method """
capture_call_stack(self.model)
return super(CallStackManager, self).get_query_set()
def donottrack(*entities_not_to_be_tracked):
""" Decorator which halts tracking for some entities for specific functions
Arguments:
entities_not_to_be_tracked: entities which are not to be tracked
Returns:
wrapped function
"""
if not entities_not_to_be_tracked:
entities_not_to_be_tracked = None
@wrapt.decorator
def real_donottrack(wrapped, instance, args, kwargs): # pylint: disable=unused-argument
""" Takes function to be decorated and returns wrapped function
Arguments:
wrapped - The wrapped function which in turns needs to be called by wrapper function
instance - The object to which the wrapped function was bound when it was called.
args - The list of positional arguments supplied when the decorated function was called.
kwargs - The dictionary of keyword arguments supplied when the decorated function was called.
Returns:
return of wrapped function
"""
global HALT_TRACKING # pylint: disable=global-variable-not-assigned
if entities_not_to_be_tracked is None:
HALT_TRACKING.append(None)
else:
if HALT_TRACKING:
if HALT_TRACKING[-1] is None: # if @donottrack() calls @donottrack('xyz')
pass
else:
HALT_TRACKING.append(set(HALT_TRACKING[-1].union(set(entities_not_to_be_tracked))))
else:
HALT_TRACKING.append(set(entities_not_to_be_tracked))
return_value = wrapped(*args, **kwargs)
# check if the returning class is a generator
if isinstance(return_value, types.GeneratorType):
def generator_wrapper(wrapped_generator):
""" Function handling wrapped yielding values.
Argument:
wrapped_generator - wrapped function returning generator function
Returns:
Generator Wrapper
"""
try:
while True:
return_value = next(wrapped_generator)
yield return_value
finally:
HALT_TRACKING.pop()
return generator_wrapper(return_value)
else:
HALT_TRACKING.pop()
return return_value
return real_donottrack
@wrapt.decorator
def trackit(wrapped, instance, args, kwargs): # pylint: disable=unused-argument
""" Decorator which tracks logs call stacks
Arguments:
wrapped - The wrapped function which in turns needs to be called by wrapper function.
instance - The object to which the wrapped function was bound when it was called.
args - The list of positional arguments supplied when the decorated function was called.
kwargs - The dictionary of keyword arguments supplied when the decorated function was called.
Returns:
wrapped function
"""
capture_call_stack(wrapped)
return wrapped(*args, **kwargs) | unknown | codeparrot/codeparrot-clean | ||
############################################################################
# GE class representing SGE batch system
# 10.11.2014
# Author: A.T.
############################################################################
""" Torque.py is a DIRAC independent class representing Torque batch system.
Torque objects are used as backend batch system representation for
LocalComputingElement and SSHComputingElement classes
The GE relies on the SubmitOptions parameter to choose the right queue.
This should be specified in the Queue description in the CS. e.g.
SubmitOption = -l ct=6000
"""
from __future__ import print_function
import re
import commands
import os
__RCSID__ = "$Id$"
class GE(object):
def submitJob(self, **kwargs):
""" Submit nJobs to the condor batch system
"""
resultDict = {}
MANDATORY_PARAMETERS = ['Executable', 'OutputDir', 'ErrorDir', 'SubmitOptions']
for argument in MANDATORY_PARAMETERS:
if argument not in kwargs:
resultDict['Status'] = -1
resultDict['Message'] = 'No %s' % argument
return resultDict
nJobs = kwargs.get('NJobs', 1)
preamble = kwargs.get('Preamble')
outputs = []
output = ''
for _i in xrange(int(nJobs)):
cmd = '%s; ' % preamble if preamble else ''
cmd += "qsub -o %(OutputDir)s -e %(ErrorDir)s -N DIRACPilot %(SubmitOptions)s %(Executable)s" % kwargs
status, output = commands.getstatusoutput(cmd)
if status == 0:
outputs.append(output)
else:
break
if outputs:
resultDict['Status'] = 0
resultDict['Jobs'] = []
for output in outputs:
match = re.match('Your job (\d*) ', output)
if match:
resultDict['Jobs'].append(match.groups()[0])
else:
resultDict['Status'] = status
resultDict['Message'] = output
return resultDict
def killJob(self, **kwargs):
""" Kill jobs in the given list
"""
resultDict = {}
MANDATORY_PARAMETERS = ['JobIDList']
for argument in MANDATORY_PARAMETERS:
if argument not in kwargs:
resultDict['Status'] = -1
resultDict['Message'] = 'No %s' % argument
return resultDict
jobIDList = kwargs.get('JobIDList')
if not jobIDList:
resultDict['Status'] = -1
resultDict['Message'] = 'Empty job list'
return resultDict
successful = []
failed = []
for job in jobIDList:
status, output = commands.getstatusoutput('qdel %s' % job)
if status != 0:
failed.append(job)
else:
successful.append(job)
resultDict['Status'] = 0
if failed:
resultDict['Status'] = 1
resultDict['Message'] = output
resultDict['Successful'] = successful
resultDict['Failed'] = failed
return resultDict
def getJobStatus(self, **kwargs):
""" Get status of the jobs in the given list
"""
resultDict = {}
MANDATORY_PARAMETERS = ['JobIDList']
for argument in MANDATORY_PARAMETERS:
if argument not in kwargs:
resultDict['Status'] = -1
resultDict['Message'] = 'No %s' % argument
return resultDict
user = kwargs.get('User')
if not user:
user = os.environ.get('USER')
if not user:
resultDict['Status'] = -1
resultDict['Message'] = 'No user name'
return resultDict
jobIDList = kwargs.get('JobIDList')
if not jobIDList:
resultDict['Status'] = -1
resultDict['Message'] = 'Empty job list'
return resultDict
status, output = commands.getstatusoutput('qstat -u %s' % user)
if status != 0:
resultDict['Status'] = status
resultDict['Message'] = output
return resultDict
jobDict = {}
if output:
lines = output.split('\n')
for line in lines:
l = line.strip()
for job in jobIDList:
if l.startswith(job):
jobStatus = l.split()[4]
if jobStatus in ['Tt', 'Tr']:
jobDict[job] = 'Done'
elif jobStatus in ['Rr', 'r']:
jobDict[job] = 'Running'
elif jobStatus in ['qw', 'h']:
jobDict[job] = 'Waiting'
status, output = commands.getstatusoutput('qstat -u %s -s z' % user)
if status == 0:
if output:
lines = output.split('\n')
for line in lines:
l = line.strip()
for job in jobIDList:
if l.startswith(job):
jobDict[job] = 'Done'
if len(resultDict) != len(jobIDList):
for job in jobIDList:
if job not in jobDict:
jobDict[job] = 'Unknown'
# Final output
status = 0
resultDict['Status'] = 0
resultDict['Jobs'] = jobDict
return resultDict
def getCEStatus(self, **kwargs):
""" Get the overall CE status
"""
resultDict = {}
user = kwargs.get('User')
if not user:
user = os.environ.get('USER')
if not user:
resultDict['Status'] = -1
resultDict['Message'] = 'No user name'
return resultDict
cmd = 'qstat -u %s' % user
status, output = commands.getstatusoutput(cmd)
if status != 0:
resultDict['Status'] = status
resultDict['Message'] = output
return resultDict
waitingJobs = 0
runningJobs = 0
doneJobs = 0
if output:
lines = output.split('\n')
for line in lines:
if not line.strip():
continue
if 'DIRACPilot %s' % user in line:
jobStatus = line.split()[4]
if jobStatus in ['Tt', 'Tr']:
doneJobs += 1
elif jobStatus in ['Rr', 'r']:
runningJobs += 1
elif jobStatus in ['qw', 'h']:
waitingJobs = waitingJobs + 1
# Final output
resultDict['Status'] = 0
resultDict["Waiting"] = waitingJobs
resultDict["Running"] = runningJobs
resultDict["Done"] = doneJobs
return resultDict
def getJobOutputFiles(self, **kwargs):
""" Get output file names and templates for the specific CE
"""
resultDict = {}
MANDATORY_PARAMETERS = ['JobIDList', 'OutputDir', 'ErrorDir']
for argument in MANDATORY_PARAMETERS:
if argument not in kwargs:
resultDict['Status'] = -1
resultDict['Message'] = 'No %s' % argument
return resultDict
outputDir = kwargs['OutputDir']
errorDir = kwargs['ErrorDir']
outputTemplate = '%s/DIRACPilot.o%%s' % outputDir
errorTemplate = '%s/DIRACPilot.e%%s' % errorDir
outputTemplate = os.path.expandvars(outputTemplate)
errorTemplate = os.path.expandvars(errorTemplate)
jobIDList = kwargs['JobIDList']
jobDict = {}
for job in jobIDList:
jobDict[job] = {}
jobDict[job]['Output'] = outputTemplate % job
jobDict[job]['Error'] = errorTemplate % job
resultDict['Status'] = 0
resultDict['Jobs'] = jobDict
resultDict['OutputTemplate'] = outputTemplate
resultDict['ErrorTemplate'] = errorTemplate
return resultDict | unknown | codeparrot/codeparrot-clean | ||
# Copyright (c) 2007 The Hewlett-Packard Development Company
# All rights reserved.
#
# The license below extends only to copyright in the software and shall
# not be construed as granting a license to any other intellectual
# property including but not limited to intellectual property relating
# to a hardware implementation of the functionality of the software
# licensed hereunder. You may use the software subject to the license
# terms below provided that you ensure that this notice is replicated
# unmodified and in its entirety in all distributions of the software,
# modified or unmodified, in source code or in binary form.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are
# met: redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer;
# redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution;
# neither the name of the copyright holders nor the names of its
# contributors may be used to endorse or promote products derived from
# this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
# A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
# OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
# DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
#
# Authors: Gabe Black
microcode = ""
#let {{
# class LDS(Inst):
# "GenFault ${new UnimpInstFault}"
# class LES(Inst):
# "GenFault ${new UnimpInstFault}"
# class LFS(Inst):
# "GenFault ${new UnimpInstFault}"
# class LGS(Inst):
# "GenFault ${new UnimpInstFault}"
# class LSS(Inst):
# "GenFault ${new UnimpInstFault}"
# class MOV_SEG(Inst):
# "GenFault ${new UnimpInstFault}"
# class POP(Inst):
# "GenFault ${new UnimpInstFault}"
#}}; | unknown | codeparrot/codeparrot-clean | ||
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# pylint: disable=no-self-use,pointless-statement,missing-docstring,invalid-name,line-too-long
import time
import pytest
from ..api import guessit
def case1():
return guessit('Fear.and.Loathing.in.Las.Vegas.FRENCH.ENGLISH.720p.HDDVD.DTS.x264-ESiR.mkv')
def case2():
return guessit('Movies/Fantastic Mr Fox/Fantastic.Mr.Fox.2009.DVDRip.{x264+LC-AAC.5.1}{Fr-Eng}{Sub.Fr-Eng}-™.[sharethefiles.com].mkv')
def case3():
return guessit('Series/dexter/Dexter.5x02.Hello,.Bandit.ENG.-.sub.FR.HDTV.XviD-AlFleNi-TeaM.[tvu.org.ru].avi')
def case4():
return guessit('Movies/The Doors (1991)/09.03.08.The.Doors.(1991).BDRip.720p.AC3.X264-HiS@SiLUHD-English.[sharethefiles.com].mkv')
@pytest.mark.benchmark(
group="Performance Tests",
min_time=1,
max_time=2,
min_rounds=5,
timer=time.time,
disable_gc=True,
warmup=False
)
@pytest.mark.skipif(True, reason="Disabled")
class TestBenchmark(object):
def test_case1(self, benchmark):
ret = benchmark(case1)
assert ret
def test_case2(self, benchmark):
ret = benchmark(case2)
assert ret
def test_case3(self, benchmark):
ret = benchmark(case3)
assert ret
def test_case4(self, benchmark):
ret = benchmark(case4)
assert ret | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
##############################################################################
#
# OpenERP, Open Source Management Solution
# Copyright (C) 2004-2010 Tiny SPRL (<http://tiny.be>).
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
#
# You should have received a copy of the GNU Affero General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
##############################################################################
import logging
import time
from datetime import datetime
from openerp import tools
from openerp.osv import fields, osv
from openerp.tools import float_is_zero
from openerp.tools.translate import _
import openerp.addons.decimal_precision as dp
import openerp.addons.product.product
_logger = logging.getLogger(__name__)
class pos_config(osv.osv):
_name = 'pos.config'
POS_CONFIG_STATE = [
('active', 'Active'),
('inactive', 'Inactive'),
('deprecated', 'Deprecated')
]
def _get_currency(self, cr, uid, ids, fieldnames, args, context=None):
result = dict.fromkeys(ids, False)
for pos_config in self.browse(cr, uid, ids, context=context):
if pos_config.journal_id:
currency_id = pos_config.journal_id.currency.id or pos_config.journal_id.company_id.currency_id.id
else:
currency_id = self.pool['res.users'].browse(cr, uid, uid, context=context).company_id.currency_id.id
result[pos_config.id] = currency_id
return result
_columns = {
'name' : fields.char('Point of Sale Name', select=1,
required=True, help="An internal identification of the point of sale"),
'journal_ids' : fields.many2many('account.journal', 'pos_config_journal_rel',
'pos_config_id', 'journal_id', 'Available Payment Methods',
domain="[('journal_user', '=', True ), ('type', 'in', ['bank', 'cash'])]",),
'picking_type_id': fields.many2one('stock.picking.type', 'Picking Type'),
'stock_location_id': fields.many2one('stock.location', 'Stock Location', domain=[('usage', '=', 'internal')], required=True),
'journal_id' : fields.many2one('account.journal', 'Sale Journal',
domain=[('type', '=', 'sale')],
help="Accounting journal used to post sales entries."),
'currency_id' : fields.function(_get_currency, type="many2one", string="Currency", relation="res.currency"),
'iface_self_checkout' : fields.boolean('Self Checkout Mode', # FIXME : this field is obsolete
help="Check this if this point of sale should open by default in a self checkout mode. If unchecked, Odoo uses the normal cashier mode by default."),
'iface_cashdrawer' : fields.boolean('Cashdrawer', help="Automatically open the cashdrawer"),
'iface_payment_terminal' : fields.boolean('Payment Terminal', help="Enables Payment Terminal integration"),
'iface_electronic_scale' : fields.boolean('Electronic Scale', help="Enables Electronic Scale integration"),
'iface_vkeyboard' : fields.boolean('Virtual KeyBoard', help="Enables an integrated Virtual Keyboard"),
'iface_print_via_proxy' : fields.boolean('Print via Proxy', help="Bypass browser printing and prints via the hardware proxy"),
'iface_scan_via_proxy' : fields.boolean('Scan via Proxy', help="Enable barcode scanning with a remotely connected barcode scanner"),
'iface_invoicing': fields.boolean('Invoicing',help='Enables invoice generation from the Point of Sale'),
'iface_big_scrollbars': fields.boolean('Large Scrollbars',help='For imprecise industrial touchscreens'),
'receipt_header': fields.text('Receipt Header',help="A short text that will be inserted as a header in the printed receipt"),
'receipt_footer': fields.text('Receipt Footer',help="A short text that will be inserted as a footer in the printed receipt"),
'proxy_ip': fields.char('IP Address', help='The hostname or ip address of the hardware proxy, Will be autodetected if left empty', size=45),
'state' : fields.selection(POS_CONFIG_STATE, 'Status', required=True, readonly=True, copy=False),
'sequence_id' : fields.many2one('ir.sequence', 'Order IDs Sequence', readonly=True,
help="This sequence is automatically created by Odoo but you can change it "\
"to customize the reference numbers of your orders.", copy=False),
'session_ids': fields.one2many('pos.session', 'config_id', 'Sessions'),
'group_by' : fields.boolean('Group Journal Items', help="Check this if you want to group the Journal Items by Product while closing a Session"),
'pricelist_id': fields.many2one('product.pricelist','Pricelist', required=True),
'company_id': fields.many2one('res.company', 'Company', required=True),
'barcode_product': fields.char('Product Barcodes', size=64, help='The pattern that identifies product barcodes'),
'barcode_cashier': fields.char('Cashier Barcodes', size=64, help='The pattern that identifies cashier login barcodes'),
'barcode_customer': fields.char('Customer Barcodes',size=64, help='The pattern that identifies customer\'s client card barcodes'),
'barcode_price': fields.char('Price Barcodes', size=64, help='The pattern that identifies a product with a barcode encoded price'),
'barcode_weight': fields.char('Weight Barcodes', size=64, help='The pattern that identifies a product with a barcode encoded weight'),
'barcode_discount': fields.char('Discount Barcodes', size=64, help='The pattern that identifies a product with a barcode encoded discount'),
}
def _check_cash_control(self, cr, uid, ids, context=None):
return all(
(sum(int(journal.cash_control) for journal in record.journal_ids) <= 1)
for record in self.browse(cr, uid, ids, context=context)
)
def _check_company_location(self, cr, uid, ids, context=None):
for config in self.browse(cr, uid, ids, context=context):
if config.stock_location_id.company_id and config.stock_location_id.company_id.id != config.company_id.id:
return False
return True
def _check_company_journal(self, cr, uid, ids, context=None):
for config in self.browse(cr, uid, ids, context=context):
if config.journal_id and config.journal_id.company_id.id != config.company_id.id:
return False
return True
def _check_company_payment(self, cr, uid, ids, context=None):
for config in self.browse(cr, uid, ids, context=context):
journal_ids = [j.id for j in config.journal_ids]
if self.pool['account.journal'].search(cr, uid, [
('id', 'in', journal_ids),
('company_id', '!=', config.company_id.id)
], count=True, context=context):
return False
return True
_constraints = [
(_check_cash_control, "You cannot have two cash controls in one Point Of Sale !", ['journal_ids']),
(_check_company_location, "The company of the stock location is different than the one of point of sale", ['company_id', 'stock_location_id']),
(_check_company_journal, "The company of the sale journal is different than the one of point of sale", ['company_id', 'journal_id']),
(_check_company_payment, "The company of a payment method is different than the one of point of sale", ['company_id', 'journal_ids']),
]
def name_get(self, cr, uid, ids, context=None):
result = []
states = {
'opening_control': _('Opening Control'),
'opened': _('In Progress'),
'closing_control': _('Closing Control'),
'closed': _('Closed & Posted'),
}
for record in self.browse(cr, uid, ids, context=context):
if (not record.session_ids) or (record.session_ids[0].state=='closed'):
result.append((record.id, record.name+' ('+_('not used')+')'))
continue
session = record.session_ids[0]
result.append((record.id, record.name + ' ('+session.user_id.name+')')) #, '+states[session.state]+')'))
return result
def _default_sale_journal(self, cr, uid, context=None):
company_id = self.pool.get('res.users').browse(cr, uid, uid, context=context).company_id.id
res = self.pool.get('account.journal').search(cr, uid, [('type', '=', 'sale'), ('company_id', '=', company_id)], limit=1, context=context)
return res and res[0] or False
def _default_pricelist(self, cr, uid, context=None):
res = self.pool.get('product.pricelist').search(cr, uid, [('type', '=', 'sale')], limit=1, context=context)
return res and res[0] or False
def _get_default_location(self, cr, uid, context=None):
wh_obj = self.pool.get('stock.warehouse')
user = self.pool.get('res.users').browse(cr, uid, uid, context)
res = wh_obj.search(cr, uid, [('company_id', '=', user.company_id.id)], limit=1, context=context)
if res and res[0]:
return wh_obj.browse(cr, uid, res[0], context=context).lot_stock_id.id
return False
def _get_default_company(self, cr, uid, context=None):
company_id = self.pool.get('res.users')._get_company(cr, uid, context=context)
return company_id
_defaults = {
'state' : POS_CONFIG_STATE[0][0],
'journal_id': _default_sale_journal,
'group_by' : True,
'pricelist_id': _default_pricelist,
'iface_invoicing': True,
'stock_location_id': _get_default_location,
'company_id': _get_default_company,
'barcode_product': '*',
'barcode_cashier': '041*',
'barcode_customer':'042*',
'barcode_weight': '21xxxxxNNDDD',
'barcode_discount':'22xxxxxxxxNN',
'barcode_price': '23xxxxxNNNDD',
}
def onchange_picking_type_id(self, cr, uid, ids, picking_type_id, context=None):
p_type_obj = self.pool.get("stock.picking.type")
p_type = p_type_obj.browse(cr, uid, picking_type_id, context=context)
if p_type.default_location_src_id and p_type.default_location_src_id.usage == 'internal' and p_type.default_location_dest_id and p_type.default_location_dest_id.usage == 'customer':
return {'value': {'stock_location_id': p_type.default_location_src_id.id}}
return False
def set_active(self, cr, uid, ids, context=None):
return self.write(cr, uid, ids, {'state' : 'active'}, context=context)
def set_inactive(self, cr, uid, ids, context=None):
return self.write(cr, uid, ids, {'state' : 'inactive'}, context=context)
def set_deprecate(self, cr, uid, ids, context=None):
return self.write(cr, uid, ids, {'state' : 'deprecated'}, context=context)
def create(self, cr, uid, values, context=None):
ir_sequence = self.pool.get('ir.sequence')
# force sequence_id field to new pos.order sequence
values['sequence_id'] = ir_sequence.create(cr, uid, {
'name': 'POS Order %s' % values['name'],
'padding': 4,
'prefix': "%s/" % values['name'],
'code': "pos.order",
'company_id': values.get('company_id', False),
}, context=context)
# TODO master: add field sequence_line_id on model
# this make sure we always have one available per company
ir_sequence.create(cr, uid, {
'name': 'POS order line %s' % values['name'],
'padding': 4,
'prefix': "%s/" % values['name'],
'code': "pos.order.line",
'company_id': values.get('company_id', False),
}, context=context)
return super(pos_config, self).create(cr, uid, values, context=context)
def unlink(self, cr, uid, ids, context=None):
for obj in self.browse(cr, uid, ids, context=context):
if obj.sequence_id:
obj.sequence_id.unlink()
return super(pos_config, self).unlink(cr, uid, ids, context=context)
class pos_session(osv.osv):
_name = 'pos.session'
_order = 'id desc'
POS_SESSION_STATE = [
('opening_control', 'Opening Control'), # Signal open
('opened', 'In Progress'), # Signal closing
('closing_control', 'Closing Control'), # Signal close
('closed', 'Closed & Posted'),
]
def _compute_cash_all(self, cr, uid, ids, fieldnames, args, context=None):
result = dict()
for record in self.browse(cr, uid, ids, context=context):
result[record.id] = {
'cash_journal_id' : False,
'cash_register_id' : False,
'cash_control' : False,
}
for st in record.statement_ids:
if st.journal_id.cash_control == True:
result[record.id]['cash_control'] = True
result[record.id]['cash_journal_id'] = st.journal_id.id
result[record.id]['cash_register_id'] = st.id
return result
_columns = {
'config_id' : fields.many2one('pos.config', 'Point of Sale',
help="The physical point of sale you will use.",
required=True,
select=1,
domain="[('state', '=', 'active')]",
),
'name' : fields.char('Session ID', required=True, readonly=True),
'user_id' : fields.many2one('res.users', 'Responsible',
required=True,
select=1,
readonly=True,
states={'opening_control' : [('readonly', False)]}
),
'currency_id' : fields.related('config_id', 'currency_id', type="many2one", relation='res.currency', string="Currnecy"),
'start_at' : fields.datetime('Opening Date', readonly=True),
'stop_at' : fields.datetime('Closing Date', readonly=True),
'state' : fields.selection(POS_SESSION_STATE, 'Status',
required=True, readonly=True,
select=1, copy=False),
'sequence_number': fields.integer('Order Sequence Number', help='A sequence number that is incremented with each order'),
'login_number': fields.integer('Login Sequence Number', help='A sequence number that is incremented each time a user resumes the pos session'),
'cash_control' : fields.function(_compute_cash_all,
multi='cash',
type='boolean', string='Has Cash Control'),
'cash_journal_id' : fields.function(_compute_cash_all,
multi='cash',
type='many2one', relation='account.journal',
string='Cash Journal', store=True),
'cash_register_id' : fields.function(_compute_cash_all,
multi='cash',
type='many2one', relation='account.bank.statement',
string='Cash Register', store=True),
'opening_details_ids' : fields.related('cash_register_id', 'opening_details_ids',
type='one2many', relation='account.cashbox.line',
string='Opening Cash Control'),
'details_ids' : fields.related('cash_register_id', 'details_ids',
type='one2many', relation='account.cashbox.line',
string='Cash Control'),
'cash_register_balance_end_real' : fields.related('cash_register_id', 'balance_end_real',
type='float',
digits_compute=dp.get_precision('Account'),
string="Ending Balance",
help="Total of closing cash control lines.",
readonly=True),
'cash_register_balance_start' : fields.related('cash_register_id', 'balance_start',
type='float',
digits_compute=dp.get_precision('Account'),
string="Starting Balance",
help="Total of opening cash control lines.",
readonly=True),
'cash_register_total_entry_encoding' : fields.related('cash_register_id', 'total_entry_encoding',
string='Total Cash Transaction',
readonly=True,
help="Total of all paid sale orders"),
'cash_register_balance_end' : fields.related('cash_register_id', 'balance_end',
type='float',
digits_compute=dp.get_precision('Account'),
string="Theoretical Closing Balance",
help="Sum of opening balance and transactions.",
readonly=True),
'cash_register_difference' : fields.related('cash_register_id', 'difference',
type='float',
string='Difference',
help="Difference between the theoretical closing balance and the real closing balance.",
readonly=True),
'journal_ids' : fields.related('config_id', 'journal_ids',
type='many2many',
readonly=True,
relation='account.journal',
string='Available Payment Methods'),
'order_ids' : fields.one2many('pos.order', 'session_id', 'Orders'),
'statement_ids' : fields.one2many('account.bank.statement', 'pos_session_id', 'Bank Statement', readonly=True),
}
_defaults = {
'name' : '/',
'user_id' : lambda obj, cr, uid, context: uid,
'state' : 'opening_control',
'sequence_number': 1,
'login_number': 0,
}
_sql_constraints = [
('uniq_name', 'unique(name)', "The name of this POS Session must be unique !"),
]
def _check_unicity(self, cr, uid, ids, context=None):
for session in self.browse(cr, uid, ids, context=None):
# open if there is no session in 'opening_control', 'opened', 'closing_control' for one user
domain = [
('state', 'not in', ('closed','closing_control')),
('user_id', '=', session.user_id.id)
]
count = self.search_count(cr, uid, domain, context=context)
if count>1:
return False
return True
def _check_pos_config(self, cr, uid, ids, context=None):
for session in self.browse(cr, uid, ids, context=None):
domain = [
('state', '!=', 'closed'),
('config_id', '=', session.config_id.id)
]
count = self.search_count(cr, uid, domain, context=context)
if count>1:
return False
return True
_constraints = [
(_check_unicity, "You cannot create two active sessions with the same responsible!", ['user_id', 'state']),
(_check_pos_config, "You cannot create two active sessions related to the same point of sale!", ['config_id']),
]
def create(self, cr, uid, values, context=None):
context = dict(context or {})
config_id = values.get('config_id', False) or context.get('default_config_id', False)
if not config_id:
raise osv.except_osv( _('Error!'),
_("You should assign a Point of Sale to your session."))
# journal_id is not required on the pos_config because it does not
# exists at the installation. If nothing is configured at the
# installation we do the minimal configuration. Impossible to do in
# the .xml files as the CoA is not yet installed.
jobj = self.pool.get('pos.config')
pos_config = jobj.browse(cr, uid, config_id, context=context)
context.update({'company_id': pos_config.company_id.id})
if not pos_config.journal_id:
jid = jobj.default_get(cr, uid, ['journal_id'], context=context)['journal_id']
if jid:
jobj.write(cr, openerp.SUPERUSER_ID, [pos_config.id], {'journal_id': jid}, context=context)
else:
raise osv.except_osv( _('error!'),
_("Unable to open the session. You have to assign a sale journal to your point of sale."))
# define some cash journal if no payment method exists
if not pos_config.journal_ids:
journal_proxy = self.pool.get('account.journal')
cashids = journal_proxy.search(cr, uid, [('journal_user', '=', True), ('type','=','cash')], context=context)
if not cashids:
cashids = journal_proxy.search(cr, uid, [('type', '=', 'cash')], context=context)
if not cashids:
cashids = journal_proxy.search(cr, uid, [('journal_user','=',True)], context=context)
journal_proxy.write(cr, openerp.SUPERUSER_ID, cashids, {'journal_user': True})
jobj.write(cr, openerp.SUPERUSER_ID, [pos_config.id], {'journal_ids': [(6,0, cashids)]})
pos_config = jobj.browse(cr, uid, config_id, context=context)
bank_statement_ids = []
for journal in pos_config.journal_ids:
bank_values = {
'journal_id' : journal.id,
'user_id' : uid,
'company_id' : pos_config.company_id.id
}
statement_id = self.pool.get('account.bank.statement').create(cr, uid, bank_values, context=context)
bank_statement_ids.append(statement_id)
values.update({
'name': self.pool['ir.sequence'].get(cr, uid, 'pos.session', context=context),
'statement_ids' : [(6, 0, bank_statement_ids)],
'config_id': config_id
})
return super(pos_session, self).create(cr, uid, values, context=context)
def unlink(self, cr, uid, ids, context=None):
for obj in self.browse(cr, uid, ids, context=context):
for statement in obj.statement_ids:
statement.unlink(context=context)
return super(pos_session, self).unlink(cr, uid, ids, context=context)
def open_cb(self, cr, uid, ids, context=None):
"""
call the Point Of Sale interface and set the pos.session to 'opened' (in progress)
"""
if context is None:
context = dict()
if isinstance(ids, (int, long)):
ids = [ids]
this_record = self.browse(cr, uid, ids[0], context=context)
this_record.signal_workflow('open')
context.update(active_id=this_record.id)
return {
'type' : 'ir.actions.act_url',
'url' : '/pos/web/',
'target': 'self',
}
def login(self, cr, uid, ids, context=None):
this_record = self.browse(cr, uid, ids[0], context=context)
this_record.write({
'login_number': this_record.login_number+1,
})
def wkf_action_open(self, cr, uid, ids, context=None):
# second browse because we need to refetch the data from the DB for cash_register_id
for record in self.browse(cr, uid, ids, context=context):
values = {}
if not record.start_at:
values['start_at'] = time.strftime('%Y-%m-%d %H:%M:%S')
values['state'] = 'opened'
record.write(values)
for st in record.statement_ids:
st.button_open()
return self.open_frontend_cb(cr, uid, ids, context=context)
def wkf_action_opening_control(self, cr, uid, ids, context=None):
return self.write(cr, uid, ids, {'state' : 'opening_control'}, context=context)
def wkf_action_closing_control(self, cr, uid, ids, context=None):
for session in self.browse(cr, uid, ids, context=context):
for statement in session.statement_ids:
if (statement != session.cash_register_id) and (statement.balance_end != statement.balance_end_real):
self.pool.get('account.bank.statement').write(cr, uid, [statement.id], {'balance_end_real': statement.balance_end})
return self.write(cr, uid, ids, {'state' : 'closing_control', 'stop_at' : time.strftime('%Y-%m-%d %H:%M:%S')}, context=context)
def wkf_action_close(self, cr, uid, ids, context=None):
# Close CashBox
for record in self.browse(cr, uid, ids, context=context):
for st in record.statement_ids:
if abs(st.difference) > st.journal_id.amount_authorized_diff:
# The pos manager can close statements with maximums.
if not self.pool.get('ir.model.access').check_groups(cr, uid, "point_of_sale.group_pos_manager"):
raise osv.except_osv( _('Error!'),
_("Your ending balance is too different from the theoretical cash closing (%.2f), the maximum allowed is: %.2f. You can contact your manager to force it.") % (st.difference, st.journal_id.amount_authorized_diff))
if (st.journal_id.type not in ['bank', 'cash']):
raise osv.except_osv(_('Error!'),
_("The type of the journal for your payment method should be bank or cash "))
getattr(st, 'button_confirm_%s' % st.journal_id.type)(context=context)
self._confirm_orders(cr, uid, ids, context=context)
self.write(cr, uid, ids, {'state' : 'closed'}, context=context)
obj = self.pool.get('ir.model.data').get_object_reference(cr, uid, 'point_of_sale', 'menu_point_root')[1]
return {
'type' : 'ir.actions.client',
'name' : 'Point of Sale Menu',
'tag' : 'reload',
'params' : {'menu_id': obj},
}
def _confirm_orders(self, cr, uid, ids, context=None):
pos_order_obj = self.pool.get('pos.order')
for session in self.browse(cr, uid, ids, context=context):
company_id = session.config_id.journal_id.company_id.id
local_context = dict(context or {}, force_company=company_id)
order_ids = [order.id for order in session.order_ids if order.state == 'paid']
move_id = pos_order_obj._create_account_move(cr, uid, session.start_at, session.name, session.config_id.journal_id.id, company_id, context=context)
pos_order_obj._create_account_move_line(cr, uid, order_ids, session, move_id, context=local_context)
for order in session.order_ids:
if order.state == 'done':
continue
if order.state not in ('paid', 'invoiced'):
raise osv.except_osv(
_('Error!'),
_("You cannot confirm all orders of this session, because they have not the 'paid' status"))
else:
pos_order_obj.signal_workflow(cr, uid, [order.id], 'done')
return True
def open_frontend_cb(self, cr, uid, ids, context=None):
if not context:
context = {}
if not ids:
return {}
for session in self.browse(cr, uid, ids, context=context):
if session.user_id.id != uid:
raise osv.except_osv(
_('Error!'),
_("You cannot use the session of another users. This session is owned by %s. Please first close this one to use this point of sale." % session.user_id.name))
context.update({'active_id': ids[0]})
return {
'type' : 'ir.actions.act_url',
'target': 'self',
'url': '/pos/web/',
}
class pos_order(osv.osv):
_name = "pos.order"
_description = "Point of Sale"
_order = "id desc"
def _amount_line_tax(self, cr, uid, line, context=None):
account_tax_obj = self.pool['account.tax']
taxes_ids = [tax for tax in line.product_id.taxes_id if tax.company_id.id == line.order_id.company_id.id]
price = line.price_unit * (1 - (line.discount or 0.0) / 100.0)
taxes = account_tax_obj.compute_all(cr, uid, taxes_ids, price, line.qty, product=line.product_id, partner=line.order_id.partner_id or False)['taxes']
val = 0.0
for c in taxes:
val += c.get('amount', 0.0)
return val
def _order_fields(self, cr, uid, ui_order, context=None):
return {
'name': ui_order['name'],
'user_id': ui_order['user_id'] or False,
'session_id': ui_order['pos_session_id'],
'lines': ui_order['lines'],
'pos_reference':ui_order['name'],
'partner_id': ui_order['partner_id'] or False,
}
def _payment_fields(self, cr, uid, ui_paymentline, context=None):
return {
'amount': ui_paymentline['amount'] or 0.0,
'payment_date': ui_paymentline['name'],
'statement_id': ui_paymentline['statement_id'],
'payment_name': ui_paymentline.get('note',False),
'journal': ui_paymentline['journal_id'],
}
def _process_order(self, cr, uid, order, context=None):
order_id = self.create(cr, uid, self._order_fields(cr, uid, order, context=context),context)
journal_ids = set()
for payments in order['statement_ids']:
self.add_payment(cr, uid, order_id, self._payment_fields(cr, uid, payments[2], context=context), context=context)
journal_ids.add(payments[2]['journal_id'])
session = self.pool.get('pos.session').browse(cr, uid, order['pos_session_id'], context=context)
if session.sequence_number <= order['sequence_number']:
session.write({'sequence_number': order['sequence_number'] + 1})
session.refresh()
if not float_is_zero(order['amount_return'], self.pool.get('decimal.precision').precision_get(cr, uid, 'Account')):
cash_journal = session.cash_journal_id.id
if not cash_journal:
# Select for change one of the cash journals used in this payment
cash_journal_ids = self.pool['account.journal'].search(cr, uid, [
('type', '=', 'cash'),
('id', 'in', list(journal_ids)),
], limit=1, context=context)
if not cash_journal_ids:
# If none, select for change one of the cash journals of the POS
# This is used for example when a customer pays by credit card
# an amount higher than total amount of the order and gets cash back
cash_journal_ids = [statement.journal_id.id for statement in session.statement_ids
if statement.journal_id.type == 'cash']
if not cash_journal_ids:
raise osv.except_osv( _('error!'),
_("No cash statement found for this session. Unable to record returned cash."))
cash_journal = cash_journal_ids[0]
self.add_payment(cr, uid, order_id, {
'amount': -order['amount_return'],
'payment_date': time.strftime('%Y-%m-%d %H:%M:%S'),
'payment_name': _('return'),
'journal': cash_journal,
}, context=context)
return order_id
def create_from_ui(self, cr, uid, orders, context=None):
# Keep only new orders
submitted_references = [o['data']['name'] for o in orders]
existing_order_ids = self.search(cr, uid, [('pos_reference', 'in', submitted_references)], context=context)
existing_orders = self.read(cr, uid, existing_order_ids, ['pos_reference'], context=context)
existing_references = set([o['pos_reference'] for o in existing_orders])
orders_to_save = [o for o in orders if o['data']['name'] not in existing_references]
order_ids = []
for tmp_order in orders_to_save:
to_invoice = tmp_order['to_invoice']
order = tmp_order['data']
order_id = self._process_order(cr, uid, order, context=context)
order_ids.append(order_id)
try:
self.signal_workflow(cr, uid, [order_id], 'paid')
except Exception as e:
_logger.error('Could not fully process the POS Order: %s', tools.ustr(e))
if to_invoice:
self.action_invoice(cr, uid, [order_id], context)
order_obj = self.browse(cr, uid, order_id, context)
self.pool['account.invoice'].signal_workflow(cr, uid, [order_obj.invoice_id.id], 'invoice_open')
return order_ids
def write(self, cr, uid, ids, vals, context=None):
res = super(pos_order, self).write(cr, uid, ids, vals, context=context)
#If you change the partner of the PoS order, change also the partner of the associated bank statement lines
partner_obj = self.pool.get('res.partner')
bsl_obj = self.pool.get("account.bank.statement.line")
if 'partner_id' in vals:
for posorder in self.browse(cr, uid, ids, context=context):
if posorder.invoice_id:
raise osv.except_osv( _('Error!'), _("You cannot change the partner of a POS order for which an invoice has already been issued."))
if vals['partner_id']:
p_id = partner_obj.browse(cr, uid, vals['partner_id'], context=context)
part_id = partner_obj._find_accounting_partner(p_id).id
else:
part_id = False
bsl_ids = [x.id for x in posorder.statement_ids]
bsl_obj.write(cr, uid, bsl_ids, {'partner_id': part_id}, context=context)
return res
def unlink(self, cr, uid, ids, context=None):
for rec in self.browse(cr, uid, ids, context=context):
if rec.state not in ('draft','cancel'):
raise osv.except_osv(_('Unable to Delete!'), _('In order to delete a sale, it must be new or cancelled.'))
return super(pos_order, self).unlink(cr, uid, ids, context=context)
def onchange_partner_id(self, cr, uid, ids, part=False, context=None):
if not part:
return {'value': {}}
pricelist = self.pool.get('res.partner').browse(cr, uid, part, context=context).property_product_pricelist.id
return {'value': {'pricelist_id': pricelist}}
def _amount_all(self, cr, uid, ids, name, args, context=None):
cur_obj = self.pool.get('res.currency')
res = {}
for order in self.browse(cr, uid, ids, context=context):
res[order.id] = {
'amount_paid': 0.0,
'amount_return':0.0,
'amount_tax':0.0,
}
val1 = val2 = 0.0
cur = order.pricelist_id.currency_id
for payment in order.statement_ids:
res[order.id]['amount_paid'] += payment.amount
res[order.id]['amount_return'] += (payment.amount < 0 and payment.amount or 0)
for line in order.lines:
val1 += self._amount_line_tax(cr, uid, line, context=context)
val2 += line.price_subtotal
res[order.id]['amount_tax'] = cur_obj.round(cr, uid, cur, val1)
amount_untaxed = cur_obj.round(cr, uid, cur, val2)
res[order.id]['amount_total'] = res[order.id]['amount_tax'] + amount_untaxed
return res
_columns = {
'name': fields.char('Order Ref', required=True, readonly=True, copy=False),
'company_id':fields.many2one('res.company', 'Company', required=True, readonly=True),
'date_order': fields.datetime('Order Date', readonly=True, select=True),
'user_id': fields.many2one('res.users', 'Salesman', help="Person who uses the the cash register. It can be a reliever, a student or an interim employee."),
'amount_tax': fields.function(_amount_all, string='Taxes', digits_compute=dp.get_precision('Account'), multi='all'),
'amount_total': fields.function(_amount_all, string='Total', digits_compute=dp.get_precision('Account'), multi='all'),
'amount_paid': fields.function(_amount_all, string='Paid', states={'draft': [('readonly', False)]}, readonly=True, digits_compute=dp.get_precision('Account'), multi='all'),
'amount_return': fields.function(_amount_all, 'Returned', digits_compute=dp.get_precision('Account'), multi='all'),
'lines': fields.one2many('pos.order.line', 'order_id', 'Order Lines', states={'draft': [('readonly', False)]}, readonly=True, copy=True),
'statement_ids': fields.one2many('account.bank.statement.line', 'pos_statement_id', 'Payments', states={'draft': [('readonly', False)]}, readonly=True),
'pricelist_id': fields.many2one('product.pricelist', 'Pricelist', required=True, states={'draft': [('readonly', False)]}, readonly=True),
'partner_id': fields.many2one('res.partner', 'Customer', change_default=True, select=1, states={'draft': [('readonly', False)], 'paid': [('readonly', False)]}),
'sequence_number': fields.integer('Sequence Number', help='A session-unique sequence number for the order'),
'session_id' : fields.many2one('pos.session', 'Session',
#required=True,
select=1,
domain="[('state', '=', 'opened')]",
states={'draft' : [('readonly', False)]},
readonly=True),
'state': fields.selection([('draft', 'New'),
('cancel', 'Cancelled'),
('paid', 'Paid'),
('done', 'Posted'),
('invoiced', 'Invoiced')],
'Status', readonly=True, copy=False),
'invoice_id': fields.many2one('account.invoice', 'Invoice', copy=False),
'account_move': fields.many2one('account.move', 'Journal Entry', readonly=True, copy=False),
'picking_id': fields.many2one('stock.picking', 'Picking', readonly=True, copy=False),
'picking_type_id': fields.related('session_id', 'config_id', 'picking_type_id', string="Picking Type", type='many2one', relation='stock.picking.type'),
'location_id': fields.related('session_id', 'config_id', 'stock_location_id', string="Location", type='many2one', store=True, relation='stock.location'),
'note': fields.text('Internal Notes'),
'nb_print': fields.integer('Number of Print', readonly=True, copy=False),
'pos_reference': fields.char('Receipt Ref', readonly=True, copy=False),
'sale_journal': fields.related('session_id', 'config_id', 'journal_id', relation='account.journal', type='many2one', string='Sale Journal', store=True, readonly=True),
}
def _default_session(self, cr, uid, context=None):
so = self.pool.get('pos.session')
session_ids = so.search(cr, uid, [('state','=', 'opened'), ('user_id','=',uid)], context=context)
return session_ids and session_ids[0] or False
def _default_pricelist(self, cr, uid, context=None):
session_ids = self._default_session(cr, uid, context)
if session_ids:
session_record = self.pool.get('pos.session').browse(cr, uid, session_ids, context=context)
return session_record.config_id.pricelist_id and session_record.config_id.pricelist_id.id or False
return False
def _get_out_picking_type(self, cr, uid, context=None):
return self.pool.get('ir.model.data').xmlid_to_res_id(
cr, uid, 'point_of_sale.picking_type_posout', context=context)
_defaults = {
'user_id': lambda self, cr, uid, context: uid,
'state': 'draft',
'name': '/',
'date_order': lambda *a: time.strftime('%Y-%m-%d %H:%M:%S'),
'nb_print': 0,
'sequence_number': 1,
'session_id': _default_session,
'company_id': lambda self,cr,uid,c: self.pool.get('res.users').browse(cr, uid, uid, c).company_id.id,
'pricelist_id': _default_pricelist,
}
def create(self, cr, uid, values, context=None):
if values.get('session_id'):
# set name based on the sequence specified on the config
session = self.pool['pos.session'].browse(cr, uid, values['session_id'], context=context)
values['name'] = session.config_id.sequence_id._next()
else:
# fallback on any pos.order sequence
values['name'] = self.pool.get('ir.sequence').get_id(cr, uid, 'pos.order', 'code', context=context)
return super(pos_order, self).create(cr, uid, values, context=context)
def test_paid(self, cr, uid, ids, context=None):
"""A Point of Sale is paid when the sum
@return: True
"""
for order in self.browse(cr, uid, ids, context=context):
if order.lines and not order.amount_total:
return True
if (not order.lines) or (not order.statement_ids) or \
(abs(order.amount_total-order.amount_paid) > 0.00001):
return False
return True
def create_picking(self, cr, uid, ids, context=None):
"""Create a picking for each order and validate it."""
picking_obj = self.pool.get('stock.picking')
partner_obj = self.pool.get('res.partner')
move_obj = self.pool.get('stock.move')
for order in self.browse(cr, uid, ids, context=context):
if all(t == 'service' for t in order.lines.mapped('product_id.type')):
continue
addr = order.partner_id and partner_obj.address_get(cr, uid, [order.partner_id.id], ['delivery']) or {}
picking_type = order.picking_type_id
picking_id = False
if picking_type:
picking_id = picking_obj.create(cr, uid, {
'origin': order.name,
'partner_id': addr.get('delivery',False),
'date_done' : order.date_order,
'picking_type_id': picking_type.id,
'company_id': order.company_id.id,
'move_type': 'direct',
'note': order.note or "",
'invoice_state': 'none',
}, context=context)
self.write(cr, uid, [order.id], {'picking_id': picking_id}, context=context)
location_id = order.location_id.id
if order.partner_id:
destination_id = order.partner_id.property_stock_customer.id
elif picking_type:
if not picking_type.default_location_dest_id:
raise osv.except_osv(_('Error!'), _('Missing source or destination location for picking type %s. Please configure those fields and try again.' % (picking_type.name,)))
destination_id = picking_type.default_location_dest_id.id
else:
destination_id = partner_obj.default_get(cr, uid, ['property_stock_customer'], context=context)['property_stock_customer']
move_list = []
for line in order.lines:
if line.product_id and line.product_id.type == 'service':
continue
move_list.append(move_obj.create(cr, uid, {
'name': line.name,
'product_uom': line.product_id.uom_id.id,
'product_uos': line.product_id.uom_id.id,
'picking_id': picking_id,
'picking_type_id': picking_type.id,
'product_id': line.product_id.id,
'product_uos_qty': abs(line.qty),
'product_uom_qty': abs(line.qty),
'state': 'draft',
'location_id': location_id if line.qty >= 0 else destination_id,
'location_dest_id': destination_id if line.qty >= 0 else location_id,
}, context=context))
if picking_id:
picking_obj.action_confirm(cr, uid, [picking_id], context=context)
picking_obj.force_assign(cr, uid, [picking_id], context=context)
picking_obj.action_done(cr, uid, [picking_id], context=context)
elif move_list:
move_obj.action_confirm(cr, uid, move_list, context=context)
move_obj.force_assign(cr, uid, move_list, context=context)
move_obj.action_done(cr, uid, move_list, context=context)
return True
def cancel_order(self, cr, uid, ids, context=None):
""" Changes order state to cancel
@return: True
"""
stock_picking_obj = self.pool.get('stock.picking')
for order in self.browse(cr, uid, ids, context=context):
stock_picking_obj.action_cancel(cr, uid, [order.picking_id.id])
if stock_picking_obj.browse(cr, uid, order.picking_id.id, context=context).state <> 'cancel':
raise osv.except_osv(_('Error!'), _('Unable to cancel the picking.'))
self.write(cr, uid, ids, {'state': 'cancel'}, context=context)
return True
def add_payment(self, cr, uid, order_id, data, context=None):
"""Create a new payment for the order"""
context = dict(context or {})
statement_line_obj = self.pool.get('account.bank.statement.line')
property_obj = self.pool.get('ir.property')
order = self.browse(cr, uid, order_id, context=context)
date = data.get('payment_date', time.strftime('%Y-%m-%d'))
if len(date) > 10:
timestamp = datetime.strptime(date, tools.DEFAULT_SERVER_DATETIME_FORMAT)
ts = fields.datetime.context_timestamp(cr, uid, timestamp, context)
date = ts.strftime(tools.DEFAULT_SERVER_DATE_FORMAT)
args = {
'amount': data['amount'],
'date': date,
'name': order.name + ': ' + (data.get('payment_name', '') or ''),
'partner_id': order.partner_id and self.pool.get("res.partner")._find_accounting_partner(order.partner_id).id or False,
}
journal_id = data.get('journal', False)
statement_id = data.get('statement_id', False)
assert journal_id or statement_id, "No statement_id or journal_id passed to the method!"
journal = self.pool['account.journal'].browse(cr, uid, journal_id, context=context)
# use the company of the journal and not of the current user
company_cxt = dict(context, force_company=journal.company_id.id)
account_def = property_obj.get(cr, uid, 'property_account_receivable', 'res.partner', context=company_cxt)
args['account_id'] = (order.partner_id and order.partner_id.property_account_receivable \
and order.partner_id.property_account_receivable.id) or (account_def and account_def.id) or False
if not args['account_id']:
if not args['partner_id']:
msg = _('There is no receivable account defined to make payment.')
else:
msg = _('There is no receivable account defined to make payment for the partner: "%s" (id:%d).') % (order.partner_id.name, order.partner_id.id,)
raise osv.except_osv(_('Configuration Error!'), msg)
context.pop('pos_session_id', False)
for statement in order.session_id.statement_ids:
if statement.id == statement_id:
journal_id = statement.journal_id.id
break
elif statement.journal_id.id == journal_id:
statement_id = statement.id
break
if not statement_id:
raise osv.except_osv(_('Error!'), _('You have to open at least one cashbox.'))
args.update({
'statement_id': statement_id,
'pos_statement_id': order_id,
'journal_id': journal_id,
'ref': order.session_id.name,
})
statement_line_obj.create(cr, uid, args, context=context)
return statement_id
def refund(self, cr, uid, ids, context=None):
"""Create a copy of order for refund order"""
clone_list = []
line_obj = self.pool.get('pos.order.line')
for order in self.browse(cr, uid, ids, context=context):
current_session_ids = self.pool.get('pos.session').search(cr, uid, [
('state', '!=', 'closed'),
('user_id', '=', uid)], context=context)
if not current_session_ids:
raise osv.except_osv(_('Error!'), _('To return product(s), you need to open a session that will be used to register the refund.'))
clone_id = self.copy(cr, uid, order.id, {
'name': order.name + ' REFUND', # not used, name forced by create
'session_id': current_session_ids[0],
'date_order': time.strftime('%Y-%m-%d %H:%M:%S'),
}, context=context)
clone_list.append(clone_id)
for clone in self.browse(cr, uid, clone_list, context=context):
for order_line in clone.lines:
line_obj.write(cr, uid, [order_line.id], {
'qty': -order_line.qty
}, context=context)
abs = {
'name': _('Return Products'),
'view_type': 'form',
'view_mode': 'form',
'res_model': 'pos.order',
'res_id':clone_list[0],
'view_id': False,
'context':context,
'type': 'ir.actions.act_window',
'nodestroy': True,
'target': 'current',
}
return abs
def action_invoice_state(self, cr, uid, ids, context=None):
return self.write(cr, uid, ids, {'state':'invoiced'}, context=context)
def action_invoice(self, cr, uid, ids, context=None):
inv_ref = self.pool.get('account.invoice')
inv_line_ref = self.pool.get('account.invoice.line')
product_obj = self.pool.get('product.product')
inv_ids = []
for order in self.pool.get('pos.order').browse(cr, uid, ids, context=context):
if order.invoice_id:
inv_ids.append(order.invoice_id.id)
continue
if not order.partner_id:
raise osv.except_osv(_('Error!'), _('Please provide a partner for the sale.'))
acc = order.partner_id.property_account_receivable.id
inv = {
'name': order.name,
'origin': order.name,
'account_id': acc,
'journal_id': order.sale_journal.id or None,
'type': 'out_invoice',
'reference': order.name,
'partner_id': order.partner_id.id,
'comment': order.note or '',
'currency_id': order.pricelist_id.currency_id.id, # considering partner's sale pricelist's currency
}
inv.update(inv_ref.onchange_partner_id(cr, uid, [], 'out_invoice', order.partner_id.id)['value'])
if not inv.get('account_id', None):
inv['account_id'] = acc
inv_id = inv_ref.create(cr, uid, inv, context=context)
self.write(cr, uid, [order.id], {'invoice_id': inv_id, 'state': 'invoiced'}, context=context)
inv_ids.append(inv_id)
for line in order.lines:
inv_line = {
'invoice_id': inv_id,
'product_id': line.product_id.id,
'quantity': line.qty,
}
inv_name = product_obj.name_get(cr, uid, [line.product_id.id], context=context)[0][1]
inv_line.update(inv_line_ref.product_id_change(cr, uid, [],
line.product_id.id,
line.product_id.uom_id.id,
line.qty, partner_id = order.partner_id.id,
fposition_id=order.partner_id.property_account_position.id)['value'])
if not inv_line.get('account_analytic_id', False):
inv_line['account_analytic_id'] = \
self._prepare_analytic_account(cr, uid, line,
context=context)
inv_line['price_unit'] = line.price_unit
inv_line['discount'] = line.discount
inv_line['name'] = inv_name
inv_line['invoice_line_tax_id'] = [(6, 0, inv_line['invoice_line_tax_id'])]
inv_line_ref.create(cr, uid, inv_line, context=context)
inv_ref.button_reset_taxes(cr, uid, [inv_id], context=context)
self.signal_workflow(cr, uid, [order.id], 'invoice')
inv_ref.signal_workflow(cr, uid, [inv_id], 'validate')
if not inv_ids: return {}
mod_obj = self.pool.get('ir.model.data')
res = mod_obj.get_object_reference(cr, uid, 'account', 'invoice_form')
res_id = res and res[1] or False
return {
'name': _('Customer Invoice'),
'view_type': 'form',
'view_mode': 'form',
'view_id': [res_id],
'res_model': 'account.invoice',
'context': "{'type':'out_invoice'}",
'type': 'ir.actions.act_window',
'nodestroy': True,
'target': 'current',
'res_id': inv_ids and inv_ids[0] or False,
}
def create_account_move(self, cr, uid, ids, context=None):
return self._create_account_move_line(cr, uid, ids, None, None, context=context)
def _prepare_analytic_account(self, cr, uid, line, context=None):
'''This method is designed to be inherited in a custom module'''
return False
def _create_account_move(self, cr, uid, dt, ref, journal_id, company_id, context=None):
local_context = dict(context or {}, company_id=company_id)
start_at_datetime = datetime.strptime(dt, tools.DEFAULT_SERVER_DATETIME_FORMAT)
date_tz_user = fields.datetime.context_timestamp(cr, uid, start_at_datetime, context=context)
date_tz_user = date_tz_user.strftime(tools.DEFAULT_SERVER_DATE_FORMAT)
period_id = self.pool['account.period'].find(cr, uid, dt=date_tz_user, context=local_context)
return self.pool['account.move'].create(cr, uid, {'ref': ref, 'journal_id': journal_id, 'period_id': period_id[0]}, context=context)
def _create_account_move_line(self, cr, uid, ids, session=None, move_id=None, context=None):
# Tricky, via the workflow, we only have one id in the ids variable
"""Create a account move line of order grouped by products or not."""
account_move_obj = self.pool.get('account.move')
account_period_obj = self.pool.get('account.period')
account_tax_obj = self.pool.get('account.tax')
property_obj = self.pool.get('ir.property')
cur_obj = self.pool.get('res.currency')
#session_ids = set(order.session_id for order in self.browse(cr, uid, ids, context=context))
if session and not all(session.id == order.session_id.id for order in self.browse(cr, uid, ids, context=context)):
raise osv.except_osv(_('Error!'), _('Selected orders do not have the same session!'))
grouped_data = {}
have_to_group_by = session and session.config_id.group_by or False
def compute_tax(amount, tax, line):
if amount > 0:
tax_code_id = tax['base_code_id']
tax_amount = line.price_subtotal * tax['base_sign']
else:
tax_code_id = tax['ref_base_code_id']
tax_amount = -line.price_subtotal * tax['ref_base_sign']
return (tax_code_id, tax_amount,)
for order in self.browse(cr, uid, ids, context=context):
if order.account_move:
continue
if order.state != 'paid':
continue
current_company = order.sale_journal.company_id
group_tax = {}
account_def = property_obj.get(cr, uid, 'property_account_receivable', 'res.partner', context=context)
order_account = order.partner_id and \
order.partner_id.property_account_receivable and \
order.partner_id.property_account_receivable.id or \
account_def and account_def.id
if move_id is None:
# Create an entry for the sale
move_id = self._create_account_move(cr, uid, order.session_id.start_at, order.name, order.sale_journal.id, order.company_id.id, context=context)
move = account_move_obj.browse(cr, uid, move_id, context=context)
def insert_data(data_type, values):
# if have_to_group_by:
sale_journal_id = order.sale_journal.id
# 'quantity': line.qty,
# 'product_id': line.product_id.id,
values.update({
'date': order.date_order[:10],
'ref': order.name,
'partner_id': order.partner_id and self.pool.get("res.partner")._find_accounting_partner(order.partner_id).id or False,
'journal_id' : sale_journal_id,
'period_id': move.period_id.id,
'move_id' : move_id,
'company_id': current_company.id,
})
if data_type == 'product':
key = ('product', values['partner_id'], values['product_id'], values['analytic_account_id'], values['debit'] > 0)
elif data_type == 'tax':
key = ('tax', values['partner_id'], values['tax_code_id'], values['debit'] > 0)
elif data_type == 'counter_part':
key = ('counter_part', values['partner_id'], values['account_id'], values['debit'] > 0)
else:
return
grouped_data.setdefault(key, [])
# if not have_to_group_by or (not grouped_data[key]):
# grouped_data[key].append(values)
# else:
# pass
if have_to_group_by:
if not grouped_data[key]:
grouped_data[key].append(values)
else:
for line in grouped_data[key]:
if line.get('tax_code_id') == values.get('tax_code_id'):
current_value = line
current_value['quantity'] = current_value.get('quantity', 0.0) + values.get('quantity', 0.0)
current_value['credit'] = current_value.get('credit', 0.0) + values.get('credit', 0.0)
current_value['debit'] = current_value.get('debit', 0.0) + values.get('debit', 0.0)
current_value['tax_amount'] = current_value.get('tax_amount', 0.0) + values.get('tax_amount', 0.0)
break
else:
grouped_data[key].append(values)
else:
grouped_data[key].append(values)
#because of the weird way the pos order is written, we need to make sure there is at least one line,
#because just after the 'for' loop there are references to 'line' and 'income_account' variables (that
#are set inside the for loop)
#TOFIX: a deep refactoring of this method (and class!) is needed in order to get rid of this stupid hack
assert order.lines, _('The POS order must have lines when calling this method')
# Create an move for each order line
cur = order.pricelist_id.currency_id
round_per_line = True
if order.company_id.tax_calculation_rounding_method == 'round_globally':
round_per_line = False
for line in order.lines:
tax_amount = 0
taxes = []
for t in line.product_id.taxes_id:
if t.company_id.id == current_company.id:
taxes.append(t)
computed_taxes = account_tax_obj.compute_all(cr, uid, taxes, line.price_unit * (100.0-line.discount) / 100.0, line.qty)['taxes']
for tax in computed_taxes:
tax_amount += cur_obj.round(cr, uid, cur, tax['amount']) if round_per_line else tax['amount']
if tax_amount < 0:
group_key = (tax['ref_tax_code_id'], tax['base_code_id'], tax['account_collected_id'], tax['id'])
else:
group_key = (tax['tax_code_id'], tax['base_code_id'], tax['account_collected_id'], tax['id'])
group_tax.setdefault(group_key, 0)
group_tax[group_key] += cur_obj.round(cr, uid, cur, tax['amount']) if round_per_line else tax['amount']
amount = line.price_subtotal
# Search for the income account
if line.product_id.property_account_income.id:
income_account = line.product_id.property_account_income.id
elif line.product_id.categ_id.property_account_income_categ.id:
income_account = line.product_id.categ_id.property_account_income_categ.id
else:
raise osv.except_osv(_('Error!'), _('Please define income '\
'account for this product: "%s" (id:%d).') \
% (line.product_id.name, line.product_id.id, ))
# Empty the tax list as long as there is no tax code:
tax_code_id = False
tax_amount = 0
while computed_taxes:
tax = computed_taxes.pop(0)
tax_code_id, tax_amount = compute_tax(amount, tax, line)
# If there is one we stop
if tax_code_id:
break
# Create a move for the line
insert_data('product', {
'name': line.product_id.name,
'quantity': line.qty,
'product_id': line.product_id.id,
'account_id': income_account,
'analytic_account_id': self._prepare_analytic_account(cr, uid, line, context=context),
'credit': ((amount>0) and amount) or 0.0,
'debit': ((amount<0) and -amount) or 0.0,
'tax_code_id': tax_code_id,
'tax_amount': tax_amount,
'partner_id': order.partner_id and self.pool.get("res.partner")._find_accounting_partner(order.partner_id).id or False
})
# For each remaining tax with a code, whe create a move line
for tax in computed_taxes:
tax_code_id, tax_amount = compute_tax(amount, tax, line)
if not tax_code_id:
continue
insert_data('tax', {
'name': _('Tax'),
'product_id':line.product_id.id,
'quantity': line.qty,
'account_id': income_account,
'credit': 0.0,
'debit': 0.0,
'tax_code_id': tax_code_id,
'tax_amount': tax_amount,
'partner_id': order.partner_id and self.pool.get("res.partner")._find_accounting_partner(order.partner_id).id or False
})
# Create a move for each tax group
(tax_code_pos, base_code_pos, account_pos, tax_id)= (0, 1, 2, 3)
for key, tax_amount in group_tax.items():
tax = self.pool.get('account.tax').browse(cr, uid, key[tax_id], context=context)
insert_data('tax', {
'name': _('Tax') + ' ' + tax.name,
'quantity': line.qty,
'product_id': line.product_id.id,
'account_id': key[account_pos] or income_account,
'credit': ((tax_amount>0) and tax_amount) or 0.0,
'debit': ((tax_amount<0) and -tax_amount) or 0.0,
'tax_code_id': key[tax_code_pos],
'tax_amount': abs(tax_amount),
'partner_id': order.partner_id and self.pool.get("res.partner")._find_accounting_partner(order.partner_id).id or False
})
# counterpart
insert_data('counter_part', {
'name': _("Trade Receivables"), #order.name,
'account_id': order_account,
'credit': ((order.amount_total < 0) and -order.amount_total) or 0.0,
'debit': ((order.amount_total > 0) and order.amount_total) or 0.0,
'partner_id': order.partner_id and self.pool.get("res.partner")._find_accounting_partner(order.partner_id).id or False
})
order.write({'state':'done', 'account_move': move_id})
all_lines = []
for group_key, group_data in grouped_data.iteritems():
for value in group_data:
all_lines.append((0, 0, value),)
if move_id: #In case no order was changed
self.pool.get("account.move").write(cr, uid, [move_id], {'line_id':all_lines}, context=context)
return True
def action_payment(self, cr, uid, ids, context=None):
return self.write(cr, uid, ids, {'state': 'payment'}, context=context)
def action_paid(self, cr, uid, ids, context=None):
self.write(cr, uid, ids, {'state': 'paid'}, context=context)
self.create_picking(cr, uid, ids, context=context)
return True
def action_cancel(self, cr, uid, ids, context=None):
self.write(cr, uid, ids, {'state': 'cancel'}, context=context)
return True
def action_done(self, cr, uid, ids, context=None):
self.create_account_move(cr, uid, ids, context=context)
return True
class account_bank_statement(osv.osv):
_inherit = 'account.bank.statement'
_columns= {
'user_id': fields.many2one('res.users', 'User', readonly=True),
}
_defaults = {
'user_id': lambda self,cr,uid,c={}: uid
}
class account_bank_statement_line(osv.osv):
_inherit = 'account.bank.statement.line'
_columns= {
'pos_statement_id': fields.many2one('pos.order', ondelete='cascade'),
}
class pos_order_line(osv.osv):
_name = "pos.order.line"
_description = "Lines of Point of Sale"
_rec_name = "product_id"
def _amount_line_all(self, cr, uid, ids, field_names, arg, context=None):
res = dict([(i, {}) for i in ids])
account_tax_obj = self.pool.get('account.tax')
cur_obj = self.pool.get('res.currency')
for line in self.browse(cr, uid, ids, context=context):
taxes_ids = [ tax for tax in line.product_id.taxes_id if tax.company_id.id == line.order_id.company_id.id ]
price = line.price_unit * (1 - (line.discount or 0.0) / 100.0)
taxes = account_tax_obj.compute_all(cr, uid, taxes_ids, price, line.qty, product=line.product_id, partner=line.order_id.partner_id or False)
cur = line.order_id.pricelist_id.currency_id
res[line.id]['price_subtotal'] = taxes['total']
res[line.id]['price_subtotal_incl'] = taxes['total_included']
return res
def onchange_product_id(self, cr, uid, ids, pricelist, product_id, qty=0, partner_id=False, context=None):
context = context or {}
if not product_id:
return {}
if not pricelist:
raise osv.except_osv(_('No Pricelist!'),
_('You have to select a pricelist in the sale form !\n' \
'Please set one before choosing a product.'))
price = self.pool.get('product.pricelist').price_get(cr, uid, [pricelist],
product_id, qty or 1.0, partner_id)[pricelist]
result = self.onchange_qty(cr, uid, ids, product_id, 0.0, qty, price, context=context)
result['value']['price_unit'] = price
return result
def onchange_qty(self, cr, uid, ids, product, discount, qty, price_unit, context=None):
result = {}
if not product:
return result
account_tax_obj = self.pool.get('account.tax')
cur_obj = self.pool.get('res.currency')
prod = self.pool.get('product.product').browse(cr, uid, product, context=context)
price = price_unit * (1 - (discount or 0.0) / 100.0)
taxes = account_tax_obj.compute_all(cr, uid, prod.taxes_id, price, qty, product=prod, partner=False)
result['price_subtotal'] = taxes['total']
result['price_subtotal_incl'] = taxes['total_included']
return {'value': result}
_columns = {
'company_id': fields.many2one('res.company', 'Company', required=True),
'name': fields.char('Line No', required=True, copy=False),
'notice': fields.char('Discount Notice'),
'product_id': fields.many2one('product.product', 'Product', domain=[('sale_ok', '=', True)], required=True, change_default=True),
'price_unit': fields.float(string='Unit Price', digits_compute=dp.get_precision('Product Price')),
'qty': fields.float('Quantity', digits_compute=dp.get_precision('Product UoS')),
'price_subtotal': fields.function(_amount_line_all, multi='pos_order_line_amount', digits_compute=dp.get_precision('Product Price'), string='Subtotal w/o Tax', store=True),
'price_subtotal_incl': fields.function(_amount_line_all, multi='pos_order_line_amount', digits_compute=dp.get_precision('Account'), string='Subtotal', store=True),
'discount': fields.float('Discount (%)', digits_compute=dp.get_precision('Account')),
'order_id': fields.many2one('pos.order', 'Order Ref', ondelete='cascade'),
'create_date': fields.datetime('Creation Date', readonly=True),
}
_defaults = {
'name': lambda obj, cr, uid, context: obj.pool.get('ir.sequence').get(cr, uid, 'pos.order.line'),
'qty': lambda *a: 1,
'discount': lambda *a: 0.0,
'company_id': lambda self,cr,uid,c: self.pool.get('res.users').browse(cr, uid, uid, c).company_id.id,
}
class ean_wizard(osv.osv_memory):
_name = 'pos.ean_wizard'
_columns = {
'ean13_pattern': fields.char('Reference', size=13, required=True, translate=True),
}
def sanitize_ean13(self, cr, uid, ids, context):
for r in self.browse(cr,uid,ids):
ean13 = openerp.addons.product.product.sanitize_ean13(r.ean13_pattern)
m = context.get('active_model')
m_id = context.get('active_id')
self.pool[m].write(cr,uid,[m_id],{'ean13':ean13})
return { 'type' : 'ir.actions.act_window_close' }
class pos_category(osv.osv):
_name = "pos.category"
_description = "Public Category"
_order = "sequence, name"
_constraints = [
(osv.osv._check_recursion, 'Error ! You cannot create recursive categories.', ['parent_id'])
]
def name_get(self, cr, uid, ids, context=None):
res = []
for cat in self.browse(cr, uid, ids, context=context):
names = [cat.name]
pcat = cat.parent_id
while pcat:
names.append(pcat.name)
pcat = pcat.parent_id
res.append((cat.id, ' / '.join(reversed(names))))
return res
def _name_get_fnc(self, cr, uid, ids, prop, unknow_none, context=None):
res = self.name_get(cr, uid, ids, context=context)
return dict(res)
def _get_image(self, cr, uid, ids, name, args, context=None):
result = dict.fromkeys(ids, False)
for obj in self.browse(cr, uid, ids, context=context):
result[obj.id] = tools.image_get_resized_images(obj.image)
return result
def _set_image(self, cr, uid, id, name, value, args, context=None):
return self.write(cr, uid, [id], {'image': tools.image_resize_image_big(value)}, context=context)
_columns = {
'name': fields.char('Name', required=True, translate=True),
'complete_name': fields.function(_name_get_fnc, type="char", string='Name'),
'parent_id': fields.many2one('pos.category','Parent Category', select=True),
'child_id': fields.one2many('pos.category', 'parent_id', string='Children Categories'),
'sequence': fields.integer('Sequence', help="Gives the sequence order when displaying a list of product categories."),
# NOTE: there is no 'default image', because by default we don't show thumbnails for categories. However if we have a thumbnail
# for at least one category, then we display a default image on the other, so that the buttons have consistent styling.
# In this case, the default image is set by the js code.
# NOTE2: image: all image fields are base64 encoded and PIL-supported
'image': fields.binary("Image",
help="This field holds the image used as image for the cateogry, limited to 1024x1024px."),
'image_medium': fields.function(_get_image, fnct_inv=_set_image,
string="Medium-sized image", type="binary", multi="_get_image",
store={
'pos.category': (lambda self, cr, uid, ids, c={}: ids, ['image'], 10),
},
help="Medium-sized image of the category. It is automatically "\
"resized as a 128x128px image, with aspect ratio preserved. "\
"Use this field in form views or some kanban views."),
'image_small': fields.function(_get_image, fnct_inv=_set_image,
string="Smal-sized image", type="binary", multi="_get_image",
store={
'pos.category': (lambda self, cr, uid, ids, c={}: ids, ['image'], 10),
},
help="Small-sized image of the category. It is automatically "\
"resized as a 64x64px image, with aspect ratio preserved. "\
"Use this field anywhere a small image is required."),
}
class product_template(osv.osv):
_inherit = 'product.template'
_columns = {
'income_pdt': fields.boolean('Point of Sale Cash In', help="Check if, this is a product you can use to put cash into a statement for the point of sale backend."),
'expense_pdt': fields.boolean('Point of Sale Cash Out', help="Check if, this is a product you can use to take cash from a statement for the point of sale backend, example: money lost, transfer to bank, etc."),
'available_in_pos': fields.boolean('Available in the Point of Sale', help='Check if you want this product to appear in the Point of Sale'),
'to_weight' : fields.boolean('To Weigh With Scale', help="Check if the product should be weighted using the hardware scale integration"),
'pos_categ_id': fields.many2one('pos.category','Point of Sale Category', help="Those categories are used to group similar products for point of sale."),
}
_defaults = {
'to_weight' : False,
'available_in_pos': True,
}
def unlink(self, cr, uid, ids, context=None):
product_ctx = dict(context or {}, active_test=False)
if self.search_count(cr, uid, [('id', 'in', ids), ('available_in_pos', '=', True)], context=product_ctx):
if self.pool['pos.session'].search_count(cr, uid, [('state', '!=', 'closed')], context=context):
raise osv.except_osv(_('Error!'),
_('You cannot delete a product saleable in point of sale while a session is still opened.'))
return super(product_template, self).unlink(cr, uid, ids, context=context)
class res_partner(osv.osv):
_inherit = 'res.partner'
def create_from_ui(self, cr, uid, partner, context=None):
""" create or modify a partner from the point of sale ui.
partner contains the partner's fields. """
#image is a dataurl, get the data after the comma
if partner.get('image',False):
img = partner['image'].split(',')[1]
partner['image'] = img
if partner.get('id',False): # Modifying existing partner
partner_id = partner['id']
del partner['id']
self.write(cr, uid, [partner_id], partner, context=context)
else:
partner_id = self.create(cr, uid, partner, context=context)
return partner_id
# vim:expandtab:smartindent:tabstop=4:softtabstop=4:shiftwidth=4: | unknown | codeparrot/codeparrot-clean | ||
// Copyright IBM Corp. 2016, 2025
// SPDX-License-Identifier: BUSL-1.1
package gcs
import (
"context"
"crypto/md5"
"errors"
"fmt"
"io"
"os"
"sort"
"strconv"
"strings"
"time"
"cloud.google.com/go/storage"
metrics "github.com/armon/go-metrics"
log "github.com/hashicorp/go-hclog"
multierror "github.com/hashicorp/go-multierror"
"github.com/hashicorp/go-secure-stdlib/permitpool"
"github.com/hashicorp/vault/helper/useragent"
"github.com/hashicorp/vault/sdk/physical"
"google.golang.org/api/iterator"
"google.golang.org/api/option"
)
// Verify Backend satisfies the correct interfaces
var _ physical.Backend = (*Backend)(nil)
const (
// envBucket is the name of the environment variable to search for the
// storage bucket name.
envBucket = "GOOGLE_STORAGE_BUCKET"
// envChunkSize is the environment variable to serach for the chunk size for
// requests.
envChunkSize = "GOOGLE_STORAGE_CHUNK_SIZE"
// envHAEnabled is the name of the environment variable to search for the
// boolean indicating if HA is enabled.
envHAEnabled = "GOOGLE_STORAGE_HA_ENABLED"
// defaultChunkSize is the number of bytes the writer will attempt to write in
// a single request.
defaultChunkSize = "8192"
// objectDelimiter is the string to use to delimit objects.
objectDelimiter = "/"
)
var (
// metricDelete is the key for the metric for measuring a Delete call.
metricDelete = []string{"gcs", "delete"}
// metricGet is the key for the metric for measuring a Get call.
metricGet = []string{"gcs", "get"}
// metricList is the key for the metric for measuring a List call.
metricList = []string{"gcs", "list"}
// metricPut is the key for the metric for measuring a Put call.
metricPut = []string{"gcs", "put"}
)
// Backend implements physical.Backend and describes the steps necessary to
// persist data in Google Cloud Storage.
type Backend struct {
// bucket is the name of the bucket to use for data storage and retrieval.
bucket string
// chunkSize is the chunk size to use for requests.
chunkSize int
// client is the API client and permitPool is the allowed concurrent uses of
// the client.
client *storage.Client
permitPool *permitpool.Pool
// haEnabled indicates if HA is enabled.
haEnabled bool
// haClient is the API client. This is managed separately from the main client
// because a flood of requests should not block refreshing the TTLs on the
// lock.
//
// This value will be nil if haEnabled is false.
haClient *storage.Client
// logger is an internal logger.
logger log.Logger
}
// NewBackend constructs a Google Cloud Storage backend with the given
// configuration. This uses the official Golang Cloud SDK and therefore supports
// specifying credentials via envvars, credential files, etc. from environment
// variables or a service account file
func NewBackend(c map[string]string, logger log.Logger) (physical.Backend, error) {
logger.Debug("configuring backend")
// Bucket name
bucket := os.Getenv(envBucket)
if bucket == "" {
bucket = c["bucket"]
}
if bucket == "" {
return nil, errors.New("missing bucket name")
}
// Chunk size
chunkSizeStr := os.Getenv(envChunkSize)
if chunkSizeStr == "" {
chunkSizeStr = c["chunk_size"]
}
if chunkSizeStr == "" {
chunkSizeStr = defaultChunkSize
}
chunkSize, err := strconv.Atoi(chunkSizeStr)
if err != nil {
return nil, fmt.Errorf("failed to parse chunk_size: %w", err)
}
// Values are specified as kb, but the API expects them as bytes.
chunkSize = chunkSize * 1024
// HA configuration
haClient := (*storage.Client)(nil)
haEnabled := false
haEnabledStr := os.Getenv(envHAEnabled)
if haEnabledStr == "" {
haEnabledStr = c["ha_enabled"]
}
if haEnabledStr != "" {
var err error
haEnabled, err = strconv.ParseBool(haEnabledStr)
if err != nil {
return nil, fmt.Errorf("failed to parse HA enabled: %w", err)
}
}
if haEnabled {
logger.Debug("creating client")
var err error
ctx := context.Background()
haClient, err = storage.NewClient(ctx, option.WithUserAgent(useragent.String()))
if err != nil {
return nil, fmt.Errorf("failed to create HA storage client: %w", err)
}
}
// Max parallel
maxParallel, err := extractInt(c["max_parallel"])
if err != nil {
return nil, fmt.Errorf("failed to parse max_parallel: %w", err)
}
logger.Debug("configuration",
"bucket", bucket,
"chunk_size", chunkSize,
"ha_enabled", haEnabled,
"max_parallel", maxParallel,
)
logger.Debug("creating client")
ctx := context.Background()
client, err := storage.NewClient(ctx, option.WithUserAgent(useragent.String()))
if err != nil {
return nil, fmt.Errorf("failed to create storage client: %w", err)
}
return &Backend{
bucket: bucket,
chunkSize: chunkSize,
client: client,
permitPool: permitpool.New(maxParallel),
haEnabled: haEnabled,
haClient: haClient,
logger: logger,
}, nil
}
// Put is used to insert or update an entry
func (b *Backend) Put(ctx context.Context, entry *physical.Entry) (retErr error) {
defer metrics.MeasureSince(metricPut, time.Now())
// Pooling
if err := b.permitPool.Acquire(ctx); err != nil {
return err
}
defer b.permitPool.Release()
// Insert
w := b.client.Bucket(b.bucket).Object(entry.Key).NewWriter(ctx)
w.ChunkSize = b.chunkSize
md5Array := md5.Sum(entry.Value)
w.MD5 = md5Array[:]
defer func() {
closeErr := w.Close()
if closeErr != nil {
retErr = multierror.Append(retErr, fmt.Errorf("error closing connection: %w", closeErr))
}
}()
if _, err := w.Write(entry.Value); err != nil {
return fmt.Errorf("failed to put data: %w", err)
}
return nil
}
// Get fetches an entry. If no entry exists, this function returns nil.
func (b *Backend) Get(ctx context.Context, key string) (retEntry *physical.Entry, retErr error) {
defer metrics.MeasureSince(metricGet, time.Now())
// Pooling
if err := b.permitPool.Acquire(ctx); err != nil {
return nil, err
}
defer b.permitPool.Release()
// Read
r, err := b.client.Bucket(b.bucket).Object(key).NewReader(ctx)
if errors.Is(err, storage.ErrObjectNotExist) {
return nil, nil
}
if err != nil {
return nil, fmt.Errorf("failed to read value for %q: %w", key, err)
}
defer func() {
closeErr := r.Close()
if closeErr != nil {
retErr = multierror.Append(retErr, fmt.Errorf("error closing connection: %w", closeErr))
}
}()
value, err := io.ReadAll(r)
if err != nil {
return nil, fmt.Errorf("failed to read value into a string: %w", err)
}
return &physical.Entry{
Key: key,
Value: value,
}, nil
}
// Delete deletes an entry with the given key
func (b *Backend) Delete(ctx context.Context, key string) error {
defer metrics.MeasureSince(metricDelete, time.Now())
// Pooling
if err := b.permitPool.Acquire(ctx); err != nil {
return err
}
defer b.permitPool.Release()
// Delete
err := b.client.Bucket(b.bucket).Object(key).Delete(ctx)
if err != nil && !errors.Is(err, storage.ErrObjectNotExist) {
return fmt.Errorf("failed to delete key %q: %w", key, err)
}
return nil
}
// List is used to list all the keys under a given
// prefix, up to the next prefix.
func (b *Backend) List(ctx context.Context, prefix string) ([]string, error) {
defer metrics.MeasureSince(metricList, time.Now())
// Pooling
if err := b.permitPool.Acquire(ctx); err != nil {
return nil, err
}
defer b.permitPool.Release()
iter := b.client.Bucket(b.bucket).Objects(ctx, &storage.Query{
Prefix: prefix,
Delimiter: objectDelimiter,
Versions: false,
})
keys := []string{}
for {
objAttrs, err := iter.Next()
if err == iterator.Done {
break
}
if err != nil {
return nil, fmt.Errorf("failed to read object: %w", err)
}
var path string
if objAttrs.Prefix != "" {
// "subdirectory"
path = objAttrs.Prefix
} else {
// file
path = objAttrs.Name
}
// get relative file/dir just like "basename"
key := strings.TrimPrefix(path, prefix)
keys = append(keys, key)
}
sort.Strings(keys)
return keys, nil
}
// extractInt is a helper function that takes a string and converts that string
// to an int, but accounts for the empty string.
func extractInt(s string) (int, error) {
if s == "" {
return 0, nil
}
return strconv.Atoi(s)
} | go | github | https://github.com/hashicorp/vault | physical/gcs/gcs.go |
# -*- coding: utf-8 -*-
##############################################################################
#
# OpenERP, Open Source Management Solution
# Copyright (C) 2004-2009 Tiny SPRL (<http://tiny.be>).
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
#
# You should have received a copy of the GNU Affero General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
##############################################################################
## this functions are taken from the setuptools package (version 0.6c8)
## http://peak.telecommunity.com/DevCenter/PkgResources#parsing-utilities
import re
component_re = re.compile(r'(\d+ | [a-z]+ | \.| -)', re.VERBOSE)
replace = {'pre':'c', 'preview':'c','-':'final-','_':'final-','rc':'c','dev':'@','saas':'','~':''}.get
def _parse_version_parts(s):
for part in component_re.split(s):
part = replace(part,part)
if not part or part=='.':
continue
if part[:1] in '0123456789':
yield part.zfill(8) # pad for numeric comparison
else:
yield '*'+part
yield '*final' # ensure that alpha/beta/candidate are before final
def parse_version(s):
"""Convert a version string to a chronologically-sortable key
This is a rough cross between distutils' StrictVersion and LooseVersion;
if you give it versions that would work with StrictVersion, then it behaves
the same; otherwise it acts like a slightly-smarter LooseVersion. It is
*possible* to create pathological version coding schemes that will fool
this parser, but they should be very rare in practice.
The returned value will be a tuple of strings. Numeric portions of the
version are padded to 8 digits so they will compare numerically, but
without relying on how numbers compare relative to strings. Dots are
dropped, but dashes are retained. Trailing zeros between alpha segments
or dashes are suppressed, so that e.g. "2.4.0" is considered the same as
"2.4". Alphanumeric parts are lower-cased.
The algorithm assumes that strings like "-" and any alpha string that
alphabetically follows "final" represents a "patch level". So, "2.4-1"
is assumed to be a branch or patch of "2.4", and therefore "2.4.1" is
considered newer than "2.4-1", whic in turn is newer than "2.4".
Strings like "a", "b", "c", "alpha", "beta", "candidate" and so on (that
come before "final" alphabetically) are assumed to be pre-release versions,
so that the version "2.4" is considered newer than "2.4a1".
Finally, to handle miscellaneous cases, the strings "pre", "preview", and
"rc" are treated as if they were "c", i.e. as though they were release
candidates, and therefore are not as new as a version string that does not
contain them.
"""
parts = []
for part in _parse_version_parts((s or '0.1').lower()):
if part.startswith('*'):
if part<'*final': # remove '-' before a prerelease tag
while parts and parts[-1]=='*final-': parts.pop()
# remove trailing zeros from each series of numeric parts
while parts and parts[-1]=='00000000':
parts.pop()
parts.append(part)
return tuple(parts)
if __name__ == '__main__':
def cmp(a, b):
msg = '%s < %s == %s' % (a, b, a < b)
assert a < b, msg
return b
def chk(lst, verbose=False):
pvs = []
for v in lst:
pv = parse_version(v)
pvs.append(pv)
if verbose:
print v, pv
reduce(cmp, pvs)
chk(('0', '4.2', '4.2.3.4', '5.0.0-alpha', '5.0.0-rc1', '5.0.0-rc1.1', '5.0.0_rc2', '5.0.0_rc3', '5.0.0'), False)
chk(('5.0.0-0_rc3', '5.0.0-1dev', '5.0.0-1'), False)
# vim:expandtab:smartindent:tabstop=4:softtabstop=4:shiftwidth=4: | unknown | codeparrot/codeparrot-clean | ||
# ext/hybrid.py
# Copyright (C) 2005-2014 the SQLAlchemy authors and contributors
# <see AUTHORS file>
#
# This module is part of SQLAlchemy and is released under
# the MIT License: http://www.opensource.org/licenses/mit-license.php
"""Define attributes on ORM-mapped classes that have "hybrid" behavior.
"hybrid" means the attribute has distinct behaviors defined at the
class level and at the instance level.
The :mod:`~sqlalchemy.ext.hybrid` extension provides a special form of
method decorator, is around 50 lines of code and has almost no
dependencies on the rest of SQLAlchemy. It can, in theory, work with
any descriptor-based expression system.
Consider a mapping ``Interval``, representing integer ``start`` and ``end``
values. We can define higher level functions on mapped classes that produce
SQL expressions at the class level, and Python expression evaluation at the
instance level. Below, each function decorated with :class:`.hybrid_method` or
:class:`.hybrid_property` may receive ``self`` as an instance of the class, or
as the class itself::
from sqlalchemy import Column, Integer
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import Session, aliased
from sqlalchemy.ext.hybrid import hybrid_property, hybrid_method
Base = declarative_base()
class Interval(Base):
__tablename__ = 'interval'
id = Column(Integer, primary_key=True)
start = Column(Integer, nullable=False)
end = Column(Integer, nullable=False)
def __init__(self, start, end):
self.start = start
self.end = end
@hybrid_property
def length(self):
return self.end - self.start
@hybrid_method
def contains(self,point):
return (self.start <= point) & (point < self.end)
@hybrid_method
def intersects(self, other):
return self.contains(other.start) | self.contains(other.end)
Above, the ``length`` property returns the difference between the
``end`` and ``start`` attributes. With an instance of ``Interval``,
this subtraction occurs in Python, using normal Python descriptor
mechanics::
>>> i1 = Interval(5, 10)
>>> i1.length
5
When dealing with the ``Interval`` class itself, the :class:`.hybrid_property`
descriptor evaluates the function body given the ``Interval`` class as
the argument, which when evaluated with SQLAlchemy expression mechanics
returns a new SQL expression::
>>> print Interval.length
interval."end" - interval.start
>>> print Session().query(Interval).filter(Interval.length > 10)
SELECT interval.id AS interval_id, interval.start AS interval_start,
interval."end" AS interval_end
FROM interval
WHERE interval."end" - interval.start > :param_1
ORM methods such as :meth:`~.Query.filter_by` generally use ``getattr()`` to
locate attributes, so can also be used with hybrid attributes::
>>> print Session().query(Interval).filter_by(length=5)
SELECT interval.id AS interval_id, interval.start AS interval_start,
interval."end" AS interval_end
FROM interval
WHERE interval."end" - interval.start = :param_1
The ``Interval`` class example also illustrates two methods,
``contains()`` and ``intersects()``, decorated with
:class:`.hybrid_method`. This decorator applies the same idea to
methods that :class:`.hybrid_property` applies to attributes. The
methods return boolean values, and take advantage of the Python ``|``
and ``&`` bitwise operators to produce equivalent instance-level and
SQL expression-level boolean behavior::
>>> i1.contains(6)
True
>>> i1.contains(15)
False
>>> i1.intersects(Interval(7, 18))
True
>>> i1.intersects(Interval(25, 29))
False
>>> print Session().query(Interval).filter(Interval.contains(15))
SELECT interval.id AS interval_id, interval.start AS interval_start,
interval."end" AS interval_end
FROM interval
WHERE interval.start <= :start_1 AND interval."end" > :end_1
>>> ia = aliased(Interval)
>>> print Session().query(Interval, ia).filter(Interval.intersects(ia))
SELECT interval.id AS interval_id, interval.start AS interval_start,
interval."end" AS interval_end, interval_1.id AS interval_1_id,
interval_1.start AS interval_1_start, interval_1."end" AS interval_1_end
FROM interval, interval AS interval_1
WHERE interval.start <= interval_1.start
AND interval."end" > interval_1.start
OR interval.start <= interval_1."end"
AND interval."end" > interval_1."end"
Defining Expression Behavior Distinct from Attribute Behavior
--------------------------------------------------------------
Our usage of the ``&`` and ``|`` bitwise operators above was
fortunate, considering our functions operated on two boolean values to
return a new one. In many cases, the construction of an in-Python
function and a SQLAlchemy SQL expression have enough differences that
two separate Python expressions should be defined. The
:mod:`~sqlalchemy.ext.hybrid` decorators define the
:meth:`.hybrid_property.expression` modifier for this purpose. As an
example we'll define the radius of the interval, which requires the
usage of the absolute value function::
from sqlalchemy import func
class Interval(object):
# ...
@hybrid_property
def radius(self):
return abs(self.length) / 2
@radius.expression
def radius(cls):
return func.abs(cls.length) / 2
Above the Python function ``abs()`` is used for instance-level
operations, the SQL function ``ABS()`` is used via the :attr:`.func`
object for class-level expressions::
>>> i1.radius
2
>>> print Session().query(Interval).filter(Interval.radius > 5)
SELECT interval.id AS interval_id, interval.start AS interval_start,
interval."end" AS interval_end
FROM interval
WHERE abs(interval."end" - interval.start) / :abs_1 > :param_1
Defining Setters
----------------
Hybrid properties can also define setter methods. If we wanted
``length`` above, when set, to modify the endpoint value::
class Interval(object):
# ...
@hybrid_property
def length(self):
return self.end - self.start
@length.setter
def length(self, value):
self.end = self.start + value
The ``length(self, value)`` method is now called upon set::
>>> i1 = Interval(5, 10)
>>> i1.length
5
>>> i1.length = 12
>>> i1.end
17
Working with Relationships
--------------------------
There's no essential difference when creating hybrids that work with
related objects as opposed to column-based data. The need for distinct
expressions tends to be greater. Two variants of we'll illustrate
are the "join-dependent" hybrid, and the "correlated subquery" hybrid.
Join-Dependent Relationship Hybrid
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Consider the following declarative
mapping which relates a ``User`` to a ``SavingsAccount``::
from sqlalchemy import Column, Integer, ForeignKey, Numeric, String
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.ext.hybrid import hybrid_property
Base = declarative_base()
class SavingsAccount(Base):
__tablename__ = 'account'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('user.id'), nullable=False)
balance = Column(Numeric(15, 5))
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(100), nullable=False)
accounts = relationship("SavingsAccount", backref="owner")
@hybrid_property
def balance(self):
if self.accounts:
return self.accounts[0].balance
else:
return None
@balance.setter
def balance(self, value):
if not self.accounts:
account = Account(owner=self)
else:
account = self.accounts[0]
account.balance = value
@balance.expression
def balance(cls):
return SavingsAccount.balance
The above hybrid property ``balance`` works with the first
``SavingsAccount`` entry in the list of accounts for this user. The
in-Python getter/setter methods can treat ``accounts`` as a Python
list available on ``self``.
However, at the expression level, it's expected that the ``User`` class will
be used in an appropriate context such that an appropriate join to
``SavingsAccount`` will be present::
>>> print Session().query(User, User.balance).\\
... join(User.accounts).filter(User.balance > 5000)
SELECT "user".id AS user_id, "user".name AS user_name,
account.balance AS account_balance
FROM "user" JOIN account ON "user".id = account.user_id
WHERE account.balance > :balance_1
Note however, that while the instance level accessors need to worry
about whether ``self.accounts`` is even present, this issue expresses
itself differently at the SQL expression level, where we basically
would use an outer join::
>>> from sqlalchemy import or_
>>> print (Session().query(User, User.balance).outerjoin(User.accounts).
... filter(or_(User.balance < 5000, User.balance == None)))
SELECT "user".id AS user_id, "user".name AS user_name,
account.balance AS account_balance
FROM "user" LEFT OUTER JOIN account ON "user".id = account.user_id
WHERE account.balance < :balance_1 OR account.balance IS NULL
Correlated Subquery Relationship Hybrid
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
We can, of course, forego being dependent on the enclosing query's usage
of joins in favor of the correlated subquery, which can portably be packed
into a single column expression. A correlated subquery is more portable, but
often performs more poorly at the SQL level. Using the same technique
illustrated at :ref:`mapper_column_property_sql_expressions`,
we can adjust our ``SavingsAccount`` example to aggregate the balances for
*all* accounts, and use a correlated subquery for the column expression::
from sqlalchemy import Column, Integer, ForeignKey, Numeric, String
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.ext.hybrid import hybrid_property
from sqlalchemy import select, func
Base = declarative_base()
class SavingsAccount(Base):
__tablename__ = 'account'
id = Column(Integer, primary_key=True)
user_id = Column(Integer, ForeignKey('user.id'), nullable=False)
balance = Column(Numeric(15, 5))
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(100), nullable=False)
accounts = relationship("SavingsAccount", backref="owner")
@hybrid_property
def balance(self):
return sum(acc.balance for acc in self.accounts)
@balance.expression
def balance(cls):
return select([func.sum(SavingsAccount.balance)]).\\
where(SavingsAccount.user_id==cls.id).\\
label('total_balance')
The above recipe will give us the ``balance`` column which renders
a correlated SELECT::
>>> print s.query(User).filter(User.balance > 400)
SELECT "user".id AS user_id, "user".name AS user_name
FROM "user"
WHERE (SELECT sum(account.balance) AS sum_1
FROM account
WHERE account.user_id = "user".id) > :param_1
.. _hybrid_custom_comparators:
Building Custom Comparators
---------------------------
The hybrid property also includes a helper that allows construction of
custom comparators. A comparator object allows one to customize the
behavior of each SQLAlchemy expression operator individually. They
are useful when creating custom types that have some highly
idiosyncratic behavior on the SQL side.
The example class below allows case-insensitive comparisons on the attribute
named ``word_insensitive``::
from sqlalchemy.ext.hybrid import Comparator, hybrid_property
from sqlalchemy import func, Column, Integer, String
from sqlalchemy.orm import Session
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class CaseInsensitiveComparator(Comparator):
def __eq__(self, other):
return func.lower(self.__clause_element__()) == func.lower(other)
class SearchWord(Base):
__tablename__ = 'searchword'
id = Column(Integer, primary_key=True)
word = Column(String(255), nullable=False)
@hybrid_property
def word_insensitive(self):
return self.word.lower()
@word_insensitive.comparator
def word_insensitive(cls):
return CaseInsensitiveComparator(cls.word)
Above, SQL expressions against ``word_insensitive`` will apply the ``LOWER()``
SQL function to both sides::
>>> print Session().query(SearchWord).filter_by(word_insensitive="Trucks")
SELECT searchword.id AS searchword_id, searchword.word AS searchword_word
FROM searchword
WHERE lower(searchword.word) = lower(:lower_1)
The ``CaseInsensitiveComparator`` above implements part of the
:class:`.ColumnOperators` interface. A "coercion" operation like
lowercasing can be applied to all comparison operations (i.e. ``eq``,
``lt``, ``gt``, etc.) using :meth:`.Operators.operate`::
class CaseInsensitiveComparator(Comparator):
def operate(self, op, other):
return op(func.lower(self.__clause_element__()), func.lower(other))
Hybrid Value Objects
--------------------
Note in our previous example, if we were to compare the
``word_insensitive`` attribute of a ``SearchWord`` instance to a plain
Python string, the plain Python string would not be coerced to lower
case - the ``CaseInsensitiveComparator`` we built, being returned by
``@word_insensitive.comparator``, only applies to the SQL side.
A more comprehensive form of the custom comparator is to construct a
*Hybrid Value Object*. This technique applies the target value or
expression to a value object which is then returned by the accessor in
all cases. The value object allows control of all operations upon
the value as well as how compared values are treated, both on the SQL
expression side as well as the Python value side. Replacing the
previous ``CaseInsensitiveComparator`` class with a new
``CaseInsensitiveWord`` class::
class CaseInsensitiveWord(Comparator):
"Hybrid value representing a lower case representation of a word."
def __init__(self, word):
if isinstance(word, basestring):
self.word = word.lower()
elif isinstance(word, CaseInsensitiveWord):
self.word = word.word
else:
self.word = func.lower(word)
def operate(self, op, other):
if not isinstance(other, CaseInsensitiveWord):
other = CaseInsensitiveWord(other)
return op(self.word, other.word)
def __clause_element__(self):
return self.word
def __str__(self):
return self.word
key = 'word'
"Label to apply to Query tuple results"
Above, the ``CaseInsensitiveWord`` object represents ``self.word``,
which may be a SQL function, or may be a Python native. By
overriding ``operate()`` and ``__clause_element__()`` to work in terms
of ``self.word``, all comparison operations will work against the
"converted" form of ``word``, whether it be SQL side or Python side.
Our ``SearchWord`` class can now deliver the ``CaseInsensitiveWord``
object unconditionally from a single hybrid call::
class SearchWord(Base):
__tablename__ = 'searchword'
id = Column(Integer, primary_key=True)
word = Column(String(255), nullable=False)
@hybrid_property
def word_insensitive(self):
return CaseInsensitiveWord(self.word)
The ``word_insensitive`` attribute now has case-insensitive comparison
behavior universally, including SQL expression vs. Python expression
(note the Python value is converted to lower case on the Python side
here)::
>>> print Session().query(SearchWord).filter_by(word_insensitive="Trucks")
SELECT searchword.id AS searchword_id, searchword.word AS searchword_word
FROM searchword
WHERE lower(searchword.word) = :lower_1
SQL expression versus SQL expression::
>>> sw1 = aliased(SearchWord)
>>> sw2 = aliased(SearchWord)
>>> print Session().query(
... sw1.word_insensitive,
... sw2.word_insensitive).\\
... filter(
... sw1.word_insensitive > sw2.word_insensitive
... )
SELECT lower(searchword_1.word) AS lower_1,
lower(searchword_2.word) AS lower_2
FROM searchword AS searchword_1, searchword AS searchword_2
WHERE lower(searchword_1.word) > lower(searchword_2.word)
Python only expression::
>>> ws1 = SearchWord(word="SomeWord")
>>> ws1.word_insensitive == "sOmEwOrD"
True
>>> ws1.word_insensitive == "XOmEwOrX"
False
>>> print ws1.word_insensitive
someword
The Hybrid Value pattern is very useful for any kind of value that may
have multiple representations, such as timestamps, time deltas, units
of measurement, currencies and encrypted passwords.
.. seealso::
`Hybrids and Value Agnostic Types
<http://techspot.zzzeek.org/2011/10/21/hybrids-and-value-agnostic-types/>`_
- on the techspot.zzzeek.org blog
`Value Agnostic Types, Part II
<http://techspot.zzzeek.org/2011/10/29/value-agnostic-types-part-ii/>`_ -
on the techspot.zzzeek.org blog
.. _hybrid_transformers:
Building Transformers
----------------------
A *transformer* is an object which can receive a :class:`.Query`
object and return a new one. The :class:`.Query` object includes a
method :meth:`.with_transformation` that returns a new :class:`.Query`
transformed by the given function.
We can combine this with the :class:`.Comparator` class to produce one type
of recipe which can both set up the FROM clause of a query as well as assign
filtering criterion.
Consider a mapped class ``Node``, which assembles using adjacency list
into a hierarchical tree pattern::
from sqlalchemy import Column, Integer, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Node(Base):
__tablename__ = 'node'
id =Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('node.id'))
parent = relationship("Node", remote_side=id)
Suppose we wanted to add an accessor ``grandparent``. This would
return the ``parent`` of ``Node.parent``. When we have an instance of
``Node``, this is simple::
from sqlalchemy.ext.hybrid import hybrid_property
class Node(Base):
# ...
@hybrid_property
def grandparent(self):
return self.parent.parent
For the expression, things are not so clear. We'd need to construct
a :class:`.Query` where we :meth:`~.Query.join` twice along
``Node.parent`` to get to the ``grandparent``. We can instead return
a transforming callable that we'll combine with the
:class:`.Comparator` class to receive any :class:`.Query` object, and
return a new one that's joined to the ``Node.parent`` attribute and
filtered based on the given criterion::
from sqlalchemy.ext.hybrid import Comparator
class GrandparentTransformer(Comparator):
def operate(self, op, other):
def transform(q):
cls = self.__clause_element__()
parent_alias = aliased(cls)
return q.join(parent_alias, cls.parent).\\
filter(op(parent_alias.parent, other))
return transform
Base = declarative_base()
class Node(Base):
__tablename__ = 'node'
id =Column(Integer, primary_key=True)
parent_id = Column(Integer, ForeignKey('node.id'))
parent = relationship("Node", remote_side=id)
@hybrid_property
def grandparent(self):
return self.parent.parent
@grandparent.comparator
def grandparent(cls):
return GrandparentTransformer(cls)
The ``GrandparentTransformer`` overrides the core
:meth:`.Operators.operate` method at the base of the
:class:`.Comparator` hierarchy to return a query-transforming
callable, which then runs the given comparison operation in a
particular context. Such as, in the example above, the ``operate``
method is called, given the :attr:`.Operators.eq` callable as well as
the right side of the comparison ``Node(id=5)``. A function
``transform`` is then returned which will transform a :class:`.Query`
first to join to ``Node.parent``, then to compare ``parent_alias``
using :attr:`.Operators.eq` against the left and right sides, passing
into :class:`.Query.filter`:
.. sourcecode:: pycon+sql
>>> from sqlalchemy.orm import Session
>>> session = Session()
{sql}>>> session.query(Node).\\
... with_transformation(Node.grandparent==Node(id=5)).\\
... all()
SELECT node.id AS node_id, node.parent_id AS node_parent_id
FROM node JOIN node AS node_1 ON node_1.id = node.parent_id
WHERE :param_1 = node_1.parent_id
{stop}
We can modify the pattern to be more verbose but flexible by separating
the "join" step from the "filter" step. The tricky part here is ensuring
that successive instances of ``GrandparentTransformer`` use the same
:class:`.AliasedClass` object against ``Node``. Below we use a simple
memoizing approach that associates a ``GrandparentTransformer``
with each class::
class Node(Base):
# ...
@grandparent.comparator
def grandparent(cls):
# memoize a GrandparentTransformer
# per class
if '_gp' not in cls.__dict__:
cls._gp = GrandparentTransformer(cls)
return cls._gp
class GrandparentTransformer(Comparator):
def __init__(self, cls):
self.parent_alias = aliased(cls)
@property
def join(self):
def go(q):
return q.join(self.parent_alias, Node.parent)
return go
def operate(self, op, other):
return op(self.parent_alias.parent, other)
.. sourcecode:: pycon+sql
{sql}>>> session.query(Node).\\
... with_transformation(Node.grandparent.join).\\
... filter(Node.grandparent==Node(id=5))
SELECT node.id AS node_id, node.parent_id AS node_parent_id
FROM node JOIN node AS node_1 ON node_1.id = node.parent_id
WHERE :param_1 = node_1.parent_id
{stop}
The "transformer" pattern is an experimental pattern that starts
to make usage of some functional programming paradigms.
While it's only recommended for advanced and/or patient developers,
there's probably a whole lot of amazing things it can be used for.
"""
from .. import util
from ..orm import attributes, interfaces
HYBRID_METHOD = util.symbol('HYBRID_METHOD')
"""Symbol indicating an :class:`_InspectionAttr` that's
of type :class:`.hybrid_method`.
Is assigned to the :attr:`._InspectionAttr.extension_type`
attibute.
.. seealso::
:attr:`.Mapper.all_orm_attributes`
"""
HYBRID_PROPERTY = util.symbol('HYBRID_PROPERTY')
"""Symbol indicating an :class:`_InspectionAttr` that's
of type :class:`.hybrid_method`.
Is assigned to the :attr:`._InspectionAttr.extension_type`
attibute.
.. seealso::
:attr:`.Mapper.all_orm_attributes`
"""
class hybrid_method(interfaces._InspectionAttr):
"""A decorator which allows definition of a Python object method with both
instance-level and class-level behavior.
"""
is_attribute = True
extension_type = HYBRID_METHOD
def __init__(self, func, expr=None):
"""Create a new :class:`.hybrid_method`.
Usage is typically via decorator::
from sqlalchemy.ext.hybrid import hybrid_method
class SomeClass(object):
@hybrid_method
def value(self, x, y):
return self._value + x + y
@value.expression
def value(self, x, y):
return func.some_function(self._value, x, y)
"""
self.func = func
self.expr = expr or func
def __get__(self, instance, owner):
if instance is None:
return self.expr.__get__(owner, owner.__class__)
else:
return self.func.__get__(instance, owner)
def expression(self, expr):
"""Provide a modifying decorator that defines a
SQL-expression producing method."""
self.expr = expr
return self
class hybrid_property(interfaces._InspectionAttr):
"""A decorator which allows definition of a Python descriptor with both
instance-level and class-level behavior.
"""
is_attribute = True
extension_type = HYBRID_PROPERTY
def __init__(self, fget, fset=None, fdel=None, expr=None):
"""Create a new :class:`.hybrid_property`.
Usage is typically via decorator::
from sqlalchemy.ext.hybrid import hybrid_property
class SomeClass(object):
@hybrid_property
def value(self):
return self._value
@value.setter
def value(self, value):
self._value = value
"""
self.fget = fget
self.fset = fset
self.fdel = fdel
self.expr = expr or fget
util.update_wrapper(self, fget)
def __get__(self, instance, owner):
if instance is None:
return self.expr(owner)
else:
return self.fget(instance)
def __set__(self, instance, value):
if self.fset is None:
raise AttributeError("can't set attribute")
self.fset(instance, value)
def __delete__(self, instance):
if self.fdel is None:
raise AttributeError("can't delete attribute")
self.fdel(instance)
def setter(self, fset):
"""Provide a modifying decorator that defines a value-setter method."""
self.fset = fset
return self
def deleter(self, fdel):
"""Provide a modifying decorator that defines a
value-deletion method."""
self.fdel = fdel
return self
def expression(self, expr):
"""Provide a modifying decorator that defines a SQL-expression
producing method."""
self.expr = expr
return self
def comparator(self, comparator):
"""Provide a modifying decorator that defines a custom
comparator producing method.
The return value of the decorated method should be an instance of
:class:`~.hybrid.Comparator`.
"""
proxy_attr = attributes.\
create_proxied_attribute(self)
def expr(owner):
return proxy_attr(owner, self.__name__, self, comparator(owner))
self.expr = expr
return self
class Comparator(interfaces.PropComparator):
"""A helper class that allows easy construction of custom
:class:`~.orm.interfaces.PropComparator`
classes for usage with hybrids."""
property = None
def __init__(self, expression):
self.expression = expression
def __clause_element__(self):
expr = self.expression
while hasattr(expr, '__clause_element__'):
expr = expr.__clause_element__()
return expr
def adapt_to_entity(self, adapt_to_entity):
# interesting....
return self | unknown | codeparrot/codeparrot-clean | ||
# Copyright (C) 2009 Google Inc. All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are
# met:
#
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above
# copyright notice, this list of conditions and the following disclaimer
# in the documentation and/or other materials provided with the
# distribution.
# * Neither the name of Google Inc. nor the names of its
# contributors may be used to endorse or promote products derived from
# this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
# A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
# OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
# DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
import StringIO
import errno
import hashlib
import os
import re
from webkitpy.common.system import path
class MockFileSystem(object):
sep = '/'
pardir = '..'
def __init__(self, files=None, dirs=None, cwd='/'):
"""Initializes a "mock" filesystem that can be used to completely
stub out a filesystem.
Args:
files: a dict of filenames -> file contents. A file contents
value of None is used to indicate that the file should
not exist.
"""
self.files = files or {}
self.written_files = {}
self.last_tmpdir = None
self.current_tmpno = 0
self.cwd = cwd
self.dirs = set(dirs or [])
self.dirs.add(cwd)
for f in self.files:
d = self.dirname(f)
while not d in self.dirs:
self.dirs.add(d)
d = self.dirname(d)
def clear_written_files(self):
# This function can be used to track what is written between steps in a test.
self.written_files = {}
def _raise_not_found(self, path):
raise IOError(errno.ENOENT, path, os.strerror(errno.ENOENT))
def _split(self, path):
# This is not quite a full implementation of os.path.split
# http://docs.python.org/library/os.path.html#os.path.split
if self.sep in path:
return path.rsplit(self.sep, 1)
return ('', path)
def abspath(self, path):
if os.path.isabs(path):
return self.normpath(path)
return self.abspath(self.join(self.cwd, path))
def realpath(self, path):
return self.abspath(path)
def basename(self, path):
return self._split(path)[1]
def expanduser(self, path):
if path[0] != "~":
return path
parts = path.split(self.sep, 1)
home_directory = self.sep + "Users" + self.sep + "mock"
if len(parts) == 1:
return home_directory
return home_directory + self.sep + parts[1]
def path_to_module(self, module_name):
return "/mock-checkout/third_party/WebKit/tools/" + module_name.replace('.', '/') + ".py"
def chdir(self, path):
path = self.normpath(path)
if not self.isdir(path):
raise OSError(errno.ENOENT, path, os.strerror(errno.ENOENT))
self.cwd = path
def copyfile(self, source, destination):
if not self.exists(source):
self._raise_not_found(source)
if self.isdir(source):
raise IOError(errno.EISDIR, source, os.strerror(errno.EISDIR))
if self.isdir(destination):
raise IOError(errno.EISDIR, destination, os.strerror(errno.EISDIR))
if not self.exists(self.dirname(destination)):
raise IOError(errno.ENOENT, destination, os.strerror(errno.ENOENT))
self.files[destination] = self.files[source]
self.written_files[destination] = self.files[source]
def dirname(self, path):
return self._split(path)[0]
def exists(self, path):
return self.isfile(path) or self.isdir(path)
def files_under(self, path, dirs_to_skip=[], file_filter=None):
def filter_all(fs, dirpath, basename):
return True
file_filter = file_filter or filter_all
files = []
if self.isfile(path):
if file_filter(self, self.dirname(path), self.basename(path)) and self.files[path] is not None:
files.append(path)
return files
if self.basename(path) in dirs_to_skip:
return []
if not path.endswith(self.sep):
path += self.sep
dir_substrings = [self.sep + d + self.sep for d in dirs_to_skip]
for filename in self.files:
if not filename.startswith(path):
continue
suffix = filename[len(path) - 1:]
if any(dir_substring in suffix for dir_substring in dir_substrings):
continue
dirpath, basename = self._split(filename)
if file_filter(self, dirpath, basename) and self.files[filename] is not None:
files.append(filename)
return files
def getcwd(self):
return self.cwd
def glob(self, glob_string):
# FIXME: This handles '*', but not '?', '[', or ']'.
glob_string = re.escape(glob_string)
glob_string = glob_string.replace('\\*', '[^\\/]*') + '$'
glob_string = glob_string.replace('\\/', '/')
path_filter = lambda path: re.match(glob_string, path)
# We could use fnmatch.fnmatch, but that might not do the right thing on windows.
existing_files = [path for path, contents in self.files.items() if contents is not None]
return filter(path_filter, existing_files) + filter(path_filter, self.dirs)
def isabs(self, path):
return path.startswith(self.sep)
def isfile(self, path):
return path in self.files and self.files[path] is not None
def isdir(self, path):
return self.normpath(path) in self.dirs
def _slow_but_correct_join(self, *comps):
return re.sub(re.escape(os.path.sep), self.sep, os.path.join(*comps))
def join(self, *comps):
# This function is called a lot, so we optimize it; there are
# unittests to check that we match _slow_but_correct_join(), above.
path = ''
sep = self.sep
for comp in comps:
if not comp:
continue
if comp[0] == sep:
path = comp
continue
if path:
path += sep
path += comp
if comps[-1] == '' and path:
path += '/'
path = path.replace(sep + sep, sep)
return path
def listdir(self, path):
root, dirs, files = list(self.walk(path))[0]
return dirs + files
def walk(self, top):
sep = self.sep
if not self.isdir(top):
raise OSError("%s is not a directory" % top)
if not top.endswith(sep):
top += sep
dirs = []
files = []
for f in self.files:
if self.exists(f) and f.startswith(top):
remaining = f[len(top):]
if sep in remaining:
dir = remaining[:remaining.index(sep)]
if not dir in dirs:
dirs.append(dir)
else:
files.append(remaining)
return [(top[:-1], dirs, files)]
def mtime(self, path):
if self.exists(path):
return 0
self._raise_not_found(path)
def _mktemp(self, suffix='', prefix='tmp', dir=None, **kwargs):
if dir is None:
dir = self.sep + '__im_tmp'
curno = self.current_tmpno
self.current_tmpno += 1
self.last_tmpdir = self.join(dir, '%s_%u_%s' % (prefix, curno, suffix))
return self.last_tmpdir
def mkdtemp(self, **kwargs):
class TemporaryDirectory(object):
def __init__(self, fs, **kwargs):
self._kwargs = kwargs
self._filesystem = fs
self._directory_path = fs._mktemp(**kwargs)
fs.maybe_make_directory(self._directory_path)
def __str__(self):
return self._directory_path
def __enter__(self):
return self._directory_path
def __exit__(self, type, value, traceback):
# Only self-delete if necessary.
# FIXME: Should we delete non-empty directories?
if self._filesystem.exists(self._directory_path):
self._filesystem.rmtree(self._directory_path)
return TemporaryDirectory(fs=self, **kwargs)
def maybe_make_directory(self, *path):
norm_path = self.normpath(self.join(*path))
while norm_path and not self.isdir(norm_path):
self.dirs.add(norm_path)
norm_path = self.dirname(norm_path)
def move(self, source, destination):
if not self.exists(source):
self._raise_not_found(source)
if self.isfile(source):
self.files[destination] = self.files[source]
self.written_files[destination] = self.files[destination]
self.files[source] = None
self.written_files[source] = None
return
self.copytree(source, destination)
self.rmtree(source)
def _slow_but_correct_normpath(self, path):
return re.sub(re.escape(os.path.sep), self.sep, os.path.normpath(path))
def normpath(self, path):
# This function is called a lot, so we try to optimize the common cases
# instead of always calling _slow_but_correct_normpath(), above.
if '..' in path or '/./' in path:
# This doesn't happen very often; don't bother trying to optimize it.
return self._slow_but_correct_normpath(path)
if not path:
return '.'
if path == '/':
return path
if path == '/.':
return '/'
if path.endswith('/.'):
return path[:-2]
if path.endswith('/'):
return path[:-1]
return path
def open_binary_tempfile(self, suffix=''):
path = self._mktemp(suffix)
return (WritableBinaryFileObject(self, path), path)
def open_binary_file_for_reading(self, path):
if self.files[path] is None:
self._raise_not_found(path)
return ReadableBinaryFileObject(self, path, self.files[path])
def read_binary_file(self, path):
# Intentionally raises KeyError if we don't recognize the path.
if self.files[path] is None:
self._raise_not_found(path)
return self.files[path]
def write_binary_file(self, path, contents):
# FIXME: should this assert if dirname(path) doesn't exist?
self.maybe_make_directory(self.dirname(path))
self.files[path] = contents
self.written_files[path] = contents
def open_text_file_for_reading(self, path):
if self.files[path] is None:
self._raise_not_found(path)
return ReadableTextFileObject(self, path, self.files[path])
def open_text_file_for_writing(self, path):
return WritableTextFileObject(self, path)
def read_text_file(self, path):
return self.read_binary_file(path).decode('utf-8')
def write_text_file(self, path, contents):
return self.write_binary_file(path, contents.encode('utf-8'))
def sha1(self, path):
contents = self.read_binary_file(path)
return hashlib.sha1(contents).hexdigest()
def relpath(self, path, start='.'):
# Since os.path.relpath() calls os.path.normpath()
# (see http://docs.python.org/library/os.path.html#os.path.abspath )
# it also removes trailing slashes and converts forward and backward
# slashes to the preferred slash os.sep.
start = self.abspath(start)
path = self.abspath(path)
common_root = start
dot_dot = ''
while not common_root == '':
if path.startswith(common_root):
break
common_root = self.dirname(common_root)
dot_dot += '..' + self.sep
rel_path = path[len(common_root):]
if not rel_path:
return '.'
if rel_path[0] == self.sep:
# It is probably sufficient to remove just the first character
# since os.path.normpath() collapses separators, but we use
# lstrip() just to be sure.
rel_path = rel_path.lstrip(self.sep)
elif not common_root == '/':
# We are in the case typified by the following example:
# path = "/tmp/foobar", start = "/tmp/foo" -> rel_path = "bar"
common_root = self.dirname(common_root)
dot_dot += '..' + self.sep
rel_path = path[len(common_root) + 1:]
return dot_dot + rel_path
def remove(self, path):
if self.files[path] is None:
self._raise_not_found(path)
self.files[path] = None
self.written_files[path] = None
def rmtree(self, path):
path = self.normpath(path)
for f in self.files:
# We need to add a trailing separator to path to avoid matching
# cases like path='/foo/b' and f='/foo/bar/baz'.
if f == path or f.startswith(path + self.sep):
self.files[f] = None
self.dirs = set(filter(lambda d: not (d == path or d.startswith(path + self.sep)), self.dirs))
def copytree(self, source, destination):
source = self.normpath(source)
destination = self.normpath(destination)
for source_file in list(self.files):
if source_file.startswith(source):
destination_path = self.join(destination, self.relpath(source_file, source))
self.maybe_make_directory(self.dirname(destination_path))
self.files[destination_path] = self.files[source_file]
def split(self, path):
idx = path.rfind(self.sep)
if idx == -1:
return ('', path)
return (path[:idx], path[(idx + 1):])
def splitext(self, path):
idx = path.rfind('.')
if idx == -1:
idx = len(path)
return (path[0:idx], path[idx:])
class WritableBinaryFileObject(object):
def __init__(self, fs, path):
self.fs = fs
self.path = path
self.closed = False
self.fs.files[path] = ""
def __enter__(self):
return self
def __exit__(self, type, value, traceback):
self.close()
def close(self):
self.closed = True
def write(self, str):
self.fs.files[self.path] += str
self.fs.written_files[self.path] = self.fs.files[self.path]
class WritableTextFileObject(WritableBinaryFileObject):
def write(self, str):
WritableBinaryFileObject.write(self, str.encode('utf-8'))
class ReadableBinaryFileObject(object):
def __init__(self, fs, path, data):
self.fs = fs
self.path = path
self.closed = False
self.data = data
self.offset = 0
def __enter__(self):
return self
def __exit__(self, type, value, traceback):
self.close()
def close(self):
self.closed = True
def read(self, bytes=None):
if not bytes:
return self.data[self.offset:]
start = self.offset
self.offset += bytes
return self.data[start:self.offset]
class ReadableTextFileObject(ReadableBinaryFileObject):
def __init__(self, fs, path, data):
super(ReadableTextFileObject, self).__init__(fs, path, StringIO.StringIO(data.decode("utf-8")))
def close(self):
self.data.close()
super(ReadableTextFileObject, self).close()
def read(self, bytes=-1):
return self.data.read(bytes)
def readline(self, length=None):
return self.data.readline(length)
def __iter__(self):
return self.data.__iter__()
def next(self):
return self.data.next()
def seek(self, offset, whence=os.SEEK_SET):
self.data.seek(offset, whence) | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
#
# Copyright 2012-2015 Spotify AB
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
"""
Abstract class for task history.
Currently the only subclass is :py:class:`~luigi.db_task_history.DbTaskHistory`.
"""
import abc
import logging
from luigi import six
logger = logging.getLogger('luigi-interface')
class StoredTask(object):
"""
Interface for methods on TaskHistory
"""
# TODO : do we need this task as distinct from luigi.scheduler.Task?
# this only records host and record_id in addition to task parameters.
def __init__(self, task, status, host=None):
self._task = task
self.status = status
self.record_id = None
self.host = host
@property
def task_family(self):
return self._task.family
@property
def parameters(self):
return self._task.params
@six.add_metaclass(abc.ABCMeta)
class TaskHistory(object):
"""
Abstract Base Class for updating the run history of a task
"""
@abc.abstractmethod
def task_scheduled(self, task):
pass
@abc.abstractmethod
def task_finished(self, task, successful):
pass
@abc.abstractmethod
def task_started(self, task, worker_host):
pass
# TODO(erikbern): should web method (find_latest_runs etc) be abstract?
class NopHistory(TaskHistory):
def task_scheduled(self, task):
pass
def task_finished(self, task, successful):
pass
def task_started(self, task, worker_host):
pass | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
##############################################################################
#
# OpenERP, Open Source Management Solution
# Copyright (C) 2010 Akretion LDTA (<http://www.akretion.com>).
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU Affero General Public License as
# published by the Free Software Foundation, either version 3 of the
# License, or (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU Affero General Public License for more details.
#
# You should have received a copy of the GNU Affero General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
#
##############################################################################
{'name': 'Project requiring functional blocks',
'version': '1.2',
'author': 'Akretion',
'website': 'www.akretion.com',
'license': 'AGPL-3',
'category': 'Generic Modules',
'description': """
Adds functional blocks to organize the projects tasks.
""",
'depends': [
'project',
],
'data': [
'security/ir.model.access.csv',
'project_view.xml',
],
'demo': [
'project_demo.xml',
],
'installable': False,
'application': True,
} | unknown | codeparrot/codeparrot-clean | ||
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
package path_test
import (
"fmt"
. "path"
"testing"
)
type MatchTest struct {
pattern, s string
match bool
err error
}
var matchTests = []MatchTest{
{"abc", "abc", true, nil},
{"*", "abc", true, nil},
{"*c", "abc", true, nil},
{"a*", "a", true, nil},
{"a*", "abc", true, nil},
{"a*", "ab/c", false, nil},
{"a*/b", "abc/b", true, nil},
{"a*/b", "a/c/b", false, nil},
{"a*b*c*d*e*/f", "axbxcxdxe/f", true, nil},
{"a*b*c*d*e*/f", "axbxcxdxexxx/f", true, nil},
{"a*b*c*d*e*/f", "axbxcxdxe/xxx/f", false, nil},
{"a*b*c*d*e*/f", "axbxcxdxexxx/fff", false, nil},
{"a*b?c*x", "abxbbxdbxebxczzx", true, nil},
{"a*b?c*x", "abxbbxdbxebxczzy", false, nil},
{"ab[c]", "abc", true, nil},
{"ab[b-d]", "abc", true, nil},
{"ab[e-g]", "abc", false, nil},
{"ab[^c]", "abc", false, nil},
{"ab[^b-d]", "abc", false, nil},
{"ab[^e-g]", "abc", true, nil},
{"a\\*b", "a*b", true, nil},
{"a\\*b", "ab", false, nil},
{"a?b", "a☺b", true, nil},
{"a[^a]b", "a☺b", true, nil},
{"a???b", "a☺b", false, nil},
{"a[^a][^a][^a]b", "a☺b", false, nil},
{"[a-ζ]*", "α", true, nil},
{"*[a-ζ]", "A", false, nil},
{"a?b", "a/b", false, nil},
{"a*b", "a/b", false, nil},
{"[\\]a]", "]", true, nil},
{"[\\-]", "-", true, nil},
{"[x\\-]", "x", true, nil},
{"[x\\-]", "-", true, nil},
{"[x\\-]", "z", false, nil},
{"[\\-x]", "x", true, nil},
{"[\\-x]", "-", true, nil},
{"[\\-x]", "a", false, nil},
{"[]a]", "]", false, ErrBadPattern},
{"[-]", "-", false, ErrBadPattern},
{"[x-]", "x", false, ErrBadPattern},
{"[x-]", "-", false, ErrBadPattern},
{"[x-]", "z", false, ErrBadPattern},
{"[-x]", "x", false, ErrBadPattern},
{"[-x]", "-", false, ErrBadPattern},
{"[-x]", "a", false, ErrBadPattern},
{"\\", "a", false, ErrBadPattern},
{"[a-b-c]", "a", false, ErrBadPattern},
{"[", "a", false, ErrBadPattern},
{"[^", "a", false, ErrBadPattern},
{"[^bc", "a", false, ErrBadPattern},
{"a[", "a", false, ErrBadPattern},
{"a[", "ab", false, ErrBadPattern},
{"a[", "x", false, ErrBadPattern},
{"a/b[", "x", false, ErrBadPattern},
{"*x", "xxx", true, nil},
}
func TestMatch(t *testing.T) {
for _, tt := range matchTests {
ok, err := Match(tt.pattern, tt.s)
if ok != tt.match || err != tt.err {
t.Errorf("Match(%#q, %#q) = %v, %v want %v, %v", tt.pattern, tt.s, ok, err, tt.match, tt.err)
}
}
}
func BenchmarkMatch(b *testing.B) {
for _, tt := range matchTests {
name := fmt.Sprintf("%q %q", tt.pattern, tt.s)
b.Run(name, func(b *testing.B) {
b.ReportAllocs()
for range b.N {
bSink, errSink = Match(tt.pattern, tt.s)
}
})
}
}
var (
bSink bool
errSink error
) | go | github | https://github.com/golang/go | src/path/match_test.go |
/*
MIT License http://www.opensource.org/licenses/mit-license.php
Author Tobias Koppers @sokra
*/
"use strict";
const asyncLib = require("neo-async");
const EntryDependency = require("./dependencies/EntryDependency");
const { someInIterable } = require("./util/IterableHelpers");
const { compareModulesById } = require("./util/comparators");
const { dirname, mkdirp } = require("./util/fs");
/** @typedef {import("./ChunkGraph").ModuleId} ModuleId */
/** @typedef {import("./Compiler")} Compiler */
/** @typedef {import("./Compiler").IntermediateFileSystem} IntermediateFileSystem */
/** @typedef {import("./Module").BuildMeta} BuildMeta */
/** @typedef {import("./ExportsInfo").ExportInfoName} ExportInfoName */
/**
* @typedef {object} ManifestModuleData
* @property {ModuleId} id
* @property {BuildMeta=} buildMeta
* @property {ExportInfoName[]=} exports
*/
/**
* @typedef {object} LibManifestPluginOptions
* @property {string=} context Context of requests in the manifest file (defaults to the webpack context).
* @property {boolean=} entryOnly If true, only entry points will be exposed (default: true).
* @property {boolean=} format If true, manifest json file (output) will be formatted.
* @property {string=} name Name of the exposed dll function (external name, use value of 'output.library').
* @property {string} path Absolute path to the manifest json file (output).
* @property {string=} type Type of the dll bundle (external type, use value of 'output.libraryTarget').
*/
const PLUGIN_NAME = "LibManifestPlugin";
class LibManifestPlugin {
/**
* @param {LibManifestPluginOptions} options the options
*/
constructor(options) {
this.options = options;
}
/**
* Apply the plugin
* @param {Compiler} compiler the compiler instance
* @returns {void}
*/
apply(compiler) {
compiler.hooks.emit.tapAsync(
{ name: PLUGIN_NAME, stage: 110 },
(compilation, callback) => {
const moduleGraph = compilation.moduleGraph;
// store used paths to detect issue and output an error. #18200
/** @type {Set<string>} */
const usedPaths = new Set();
asyncLib.each(
[...compilation.chunks],
(chunk, callback) => {
if (!chunk.canBeInitial()) {
callback();
return;
}
const chunkGraph = compilation.chunkGraph;
const targetPath = compilation.getPath(this.options.path, {
chunk
});
if (usedPaths.has(targetPath)) {
callback(new Error("each chunk must have a unique path"));
return;
}
usedPaths.add(targetPath);
const name =
this.options.name &&
compilation.getPath(this.options.name, {
chunk,
contentHashType: "javascript"
});
const content = Object.create(null);
for (const module of chunkGraph.getOrderedChunkModulesIterable(
chunk,
compareModulesById(chunkGraph)
)) {
if (
this.options.entryOnly &&
!someInIterable(
moduleGraph.getIncomingConnections(module),
(c) => c.dependency instanceof EntryDependency
)
) {
continue;
}
const ident = module.libIdent({
context: this.options.context || compiler.context,
associatedObjectForCache: compiler.root
});
if (ident) {
const exportsInfo = moduleGraph.getExportsInfo(module);
const providedExports = exportsInfo.getProvidedExports();
/** @type {ManifestModuleData} */
const data = {
id: /** @type {ModuleId} */ (chunkGraph.getModuleId(module)),
buildMeta: /** @type {BuildMeta} */ (module.buildMeta),
exports: Array.isArray(providedExports)
? providedExports
: undefined
};
content[ident] = data;
}
}
const manifest = {
name,
type: this.options.type,
content
};
// Apply formatting to content if format flag is true;
const manifestContent = this.options.format
? JSON.stringify(manifest, null, 2)
: JSON.stringify(manifest);
const buffer = Buffer.from(manifestContent, "utf8");
const intermediateFileSystem =
/** @type {IntermediateFileSystem} */ (
compiler.intermediateFileSystem
);
mkdirp(
intermediateFileSystem,
dirname(intermediateFileSystem, targetPath),
(err) => {
if (err) return callback(err);
intermediateFileSystem.writeFile(targetPath, buffer, callback);
}
);
},
callback
);
}
);
}
}
module.exports = LibManifestPlugin; | javascript | github | https://github.com/webpack/webpack | lib/LibManifestPlugin.js |
# populator.py
# Backend code for populating a DeviceTree.
#
# Copyright (C) 2009-2015 Red Hat, Inc.
#
# This copyrighted material is made available to anyone wishing to use,
# modify, copy, or redistribute it subject to the terms and conditions of
# the GNU Lesser General Public License v.2, or (at your option) any later
# version. This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY expressed or implied, including the implied
# warranties of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See
# the GNU Lesser General Public License for more details. You should have
# received a copy of the GNU Lesser General Public License along with this
# program; if not, write to the Free Software Foundation, Inc., 51 Franklin
# Street, Fifth Floor, Boston, MA 02110-1301, USA. Any Red Hat trademarks
# that are incorporated in the source code or documentation are not subject
# to the GNU Lesser General Public License and may only be used or
# replicated with the express permission of Red Hat, Inc.
#
# Red Hat Author(s): David Lehman <dlehman@redhat.com>
#
import os
import re
import shutil
import pprint
import copy
import parted
import gi
gi.require_version("BlockDev", "1.0")
from gi.repository import BlockDev as blockdev
from .errors import CorruptGPTError, DeviceError, DeviceTreeError, DiskLabelScanError, DuplicateVGError, FSError, InvalidDiskLabelError, LUKSError
from .devices import BTRFSSubVolumeDevice, BTRFSVolumeDevice, BTRFSSnapShotDevice
from .devices import DASDDevice, DMDevice, DMLinearDevice, DMRaidArrayDevice, DiskDevice
from .devices import FcoeDiskDevice, FileDevice, LoopDevice, LUKSDevice
from .devices import LVMLogicalVolumeDevice, LVMVolumeGroupDevice
from .devices import LVMThinPoolDevice, LVMThinLogicalVolumeDevice
from .devices import LVMSnapShotDevice, LVMThinSnapShotDevice
from .devices import MDRaidArrayDevice, MDBiosRaidArrayDevice
from .devices import MDContainerDevice
from .devices import MultipathDevice, OpticalDevice
from .devices import PartitionDevice, ZFCPDiskDevice, iScsiDiskDevice
from .devices import devicePathToName
from .devices.lvm import get_internal_lv_class
from . import formats
from .devicelibs import lvm
from .devicelibs import raid
from . import udev
from . import util
from .util import open # pylint: disable=redefined-builtin
from .flags import flags
from .storage_log import log_exception_info, log_method_call
from .i18n import _
from .size import Size
import logging
log = logging.getLogger("blivet")
def parted_exn_handler(exn_type, exn_options, exn_msg):
""" Answer any of parted's yes/no questions in the affirmative.
This allows us to proceed with partially corrupt gpt disklabels.
"""
log.info("parted exception: %s", exn_msg)
ret = parted.EXCEPTION_RESOLVE_UNHANDLED
if exn_type == parted.EXCEPTION_TYPE_ERROR and \
exn_options == parted.EXCEPTION_OPT_YES_NO:
ret = parted.EXCEPTION_RESOLVE_YES
return ret
class Populator(object):
def __init__(self, devicetree=None, conf=None, passphrase=None,
luksDict=None, iscsi=None, dasd=None):
"""
:keyword conf: storage discovery configuration
:type conf: :class:`~.StorageDiscoveryConfig`
:keyword passphrase: default LUKS passphrase
:keyword luksDict: a dict with UUID keys and passphrase values
:type luksDict: dict
:keyword iscsi: ISCSI control object
:type iscsi: :class:`~.iscsi.iscsi`
:keyword dasd: DASD control object
:type dasd: :class:`~.dasd.DASD`
"""
self.devicetree = devicetree
# indicates whether or not the tree has been fully populated
self.populated = False
self.exclusiveDisks = getattr(conf, "exclusiveDisks", [])
self.ignoredDisks = getattr(conf, "ignoredDisks", [])
self.iscsi = iscsi
self.dasd = dasd
self.diskImages = {}
images = getattr(conf, "diskImages", {})
if images:
# this will overwrite self.exclusiveDisks
self.setDiskImages(images)
# protected device specs as provided by the user
self.protectedDevSpecs = getattr(conf, "protectedDevSpecs", [])
self.liveBackingDevice = None
# names of protected devices at the time of tree population
self.protectedDevNames = []
self.unusedRaidMembers = []
self.__passphrases = []
if passphrase:
self.__passphrases.append(passphrase)
self.__luksDevs = {}
if luksDict and isinstance(luksDict, dict):
self.__luksDevs = luksDict
self.__passphrases.extend([p for p in luksDict.values() if p])
self._cleanup = False
def setDiskImages(self, images):
""" Set the disk images and reflect them in exclusiveDisks.
:param images: dict with image name keys and filename values
:type images: dict
.. note::
Disk images are automatically exclusive. That means that, in the
presence of disk images, any local storage not associated with
the disk images is ignored.
"""
self.diskImages = images
# disk image files are automatically exclusive
self.exclusiveDisks = list(self.diskImages.keys())
def addIgnoredDisk(self, disk):
self.ignoredDisks.append(disk)
lvm.lvm_cc_addFilterRejectRegexp(disk)
def isIgnored(self, info):
""" Return True if info is a device we should ignore.
:param info: udevdb device entry
:type info: dict
:returns: whether the device will be ignored
:rtype: bool
"""
sysfs_path = udev.device_get_sysfs_path(info)
name = udev.device_get_name(info)
if not sysfs_path:
return None
# Special handling for mdraid external metadata sets (mdraid BIOSRAID):
# 1) The containers are intermediate devices which will never be
# in exclusiveDisks
# 2) Sets get added to exclusive disks with their dmraid set name by
# the filter ui. Note that making the ui use md names instead is not
# possible as the md names are simpy md# and we cannot predict the #
if udev.device_is_md(info) and \
udev.device_get_md_level(info) == "container":
return False
if udev.device_get_md_container(info) and \
udev.device_is_md(info) and \
udev.device_get_md_name(info):
md_name = udev.device_get_md_name(info)
# mdadm may have appended _<digit>+ if the current hostname
# does not match the one in the array metadata
alt_name = re.sub(r"_\d+$", "", md_name)
raw_pattern = "isw_[a-z]*_%s"
# XXX FIXME: This is completely insane.
for i in range(0, len(self.exclusiveDisks)):
if re.match(raw_pattern % md_name, self.exclusiveDisks[i]) or \
re.match(raw_pattern % alt_name, self.exclusiveDisks[i]):
self.exclusiveDisks[i] = name
return False
# never ignore mapped disk images. if you don't want to use them,
# don't specify them in the first place
if udev.device_is_dm_anaconda(info) or udev.device_is_dm_livecd(info):
return False
# Ignore loop and ram devices, we normally already skip these in
# udev.py: enumerate_block_devices(), but we can still end up trying
# to add them to the tree when they are slaves of other devices, this
# happens for example with the livecd
if name.startswith("ram"):
return True
if name.startswith("loop"):
# ignore loop devices unless they're backed by a file
return (not blockdev.loop.get_backing_file(name))
# FIXME: check for virtual devices whose slaves are on the ignore list
def _isIgnoredDisk(self, disk):
return self.devicetree._isIgnoredDisk(disk)
def udevDeviceIsDisk(self, info):
""" Return True if the udev device looks like a disk.
:param info: udevdb device entry
:type info: dict
:returns: whether the device is a disk
:rtype: bool
We want exclusiveDisks to operate on anything that could be
considered a directly usable disk, ie: fwraid array, mpath, or disk.
Unfortunately, since so many things are represented as disks by
udev/sysfs, we have to define what is a disk in terms of what is
not a disk.
"""
return (udev.device_is_disk(info) and
not (udev.device_is_cdrom(info) or
udev.device_is_partition(info) or
udev.device_is_dm_partition(info) or
udev.device_is_dm_lvm(info) or
udev.device_is_dm_crypt(info) or
(udev.device_is_md(info) and
not udev.device_get_md_container(info))))
def _addSlaveDevices(self, info):
""" Add all slaves of a device, raising DeviceTreeError on failure.
:param :class:`pyudev.Device` info: the device's udev info
:raises: :class:`~.errors.DeviceTreeError if no slaves are found or
if we fail to add any slave
:returns: a list of slave devices
:rtype: list of :class:`~.StorageDevice`
"""
name = udev.device_get_name(info)
sysfs_path = udev.device_get_sysfs_path(info)
slave_dir = os.path.normpath("%s/slaves" % sysfs_path)
slave_names = os.listdir(slave_dir)
slave_devices = []
if not slave_names:
log.error("no slaves found for %s", name)
raise DeviceTreeError("no slaves found for device %s" % name)
for slave_name in slave_names:
path = os.path.normpath("%s/%s" % (slave_dir, slave_name))
slave_info = udev.get_device(os.path.realpath(path))
# cciss in sysfs is "cciss!cXdYpZ" but we need "cciss/cXdYpZ"
slave_name = udev.device_get_name(slave_info).replace("!", "/")
if not slave_info:
log.warning("unable to get udev info for %s", slave_name)
slave_dev = self.getDeviceByName(slave_name)
if not slave_dev and slave_info:
# we haven't scanned the slave yet, so do it now
self.addUdevDevice(slave_info)
slave_dev = self.getDeviceByName(slave_name)
if slave_dev is None:
if udev.device_is_dm_lvm(info):
if slave_name not in self.devicetree.lvInfo:
# we do not expect hidden lvs to be in the tree
continue
# if the current slave is still not in
# the tree, something has gone wrong
log.error("failure scanning device %s: could not add slave %s", name, slave_name)
msg = "failed to add slave %s of device %s" % (slave_name,
name)
raise DeviceTreeError(msg)
slave_devices.append(slave_dev)
return slave_devices
def addUdevLVDevice(self, info):
name = udev.device_get_name(info)
log_method_call(self, name=name)
vg_name = udev.device_get_lv_vg_name(info)
device = self.getDeviceByName(vg_name, hidden=True)
if device and not isinstance(device, LVMVolumeGroupDevice):
log.warning("found non-vg device with name %s", vg_name)
device = None
self._addSlaveDevices(info)
# LVM provides no means to resolve conflicts caused by duplicated VG
# names, so we're just being optimistic here. Woo!
vg_name = udev.device_get_lv_vg_name(info)
vg_device = self.getDeviceByName(vg_name)
if not vg_device:
log.error("failed to find vg '%s' after scanning pvs", vg_name)
return self.getDeviceByName(name)
def addUdevDMDevice(self, info):
name = udev.device_get_name(info)
log_method_call(self, name=name)
sysfs_path = udev.device_get_sysfs_path(info)
slave_devices = self._addSlaveDevices(info)
device = self.getDeviceByName(name)
# if this is a luks device whose map name is not what we expect,
# fix up the map name and see if that sorts us out
handle_luks = (udev.device_is_dm_luks(info) and
(self._cleanup or not flags.installer_mode))
if device is None and handle_luks and slave_devices:
slave_dev = slave_devices[0]
slave_dev.format.mapName = name
slave_info = udev.get_device(slave_dev.sysfsPath)
self.handleUdevLUKSFormat(slave_info, slave_dev)
# try once more to get the device
device = self.getDeviceByName(name)
# create a device for the livecd OS image(s)
if device is None and udev.device_is_dm_livecd(info):
device = DMDevice(name, dmUuid=info.get('DM_UUID'),
sysfsPath=sysfs_path, exists=True,
parents=[slave_devices[0]])
device.protected = True
device.controllable = False
self.devicetree._addDevice(device)
# if we get here, we found all of the slave devices and
# something must be wrong -- if all of the slaves are in
# the tree, this device should be as well
if device is None:
lvm.lvm_cc_addFilterRejectRegexp(name)
log.warning("ignoring dm device %s", name)
return device
def addUdevMultiPathDevice(self, info):
name = udev.device_get_name(info)
log_method_call(self, name=name)
slave_devices = self._addSlaveDevices(info)
device = None
if slave_devices:
try:
serial = info["DM_UUID"].split("-", 1)[1]
except (IndexError, AttributeError):
log.error("multipath device %s has no DM_UUID", name)
raise DeviceTreeError("multipath %s has no DM_UUID" % name)
device = MultipathDevice(name, parents=slave_devices,
sysfsPath=udev.device_get_sysfs_path(info),
serial=serial)
self.devicetree._addDevice(device)
return device
def addUdevMDDevice(self, info):
name = udev.device_get_md_name(info)
log_method_call(self, name=name)
self._addSlaveDevices(info)
# try to get the device again now that we've got all the slaves
device = self.getDeviceByName(name, incomplete=flags.allow_imperfect_devices)
if device is None:
try:
uuid = udev.device_get_md_uuid(info)
except KeyError:
log.warning("failed to obtain uuid for mdraid device")
else:
device = self.getDeviceByUuid(uuid, incomplete=flags.allow_imperfect_devices)
if device:
# update the device instance with the real name in case we had to
# look it up by something other than name
device.name = name
else:
# if we get here, we found all of the slave devices and
# something must be wrong -- if all of the slaves are in
# the tree, this device should be as well
if name is None:
name = udev.device_get_name(info)
path = "/dev/" + name
else:
path = "/dev/md/" + name
log.error("failed to scan md array %s", name)
try:
blockdev.md.deactivate(path)
except blockdev.MDRaidError:
log.error("failed to stop broken md array %s", name)
return device
def addUdevPartitionDevice(self, info, disk=None):
name = udev.device_get_name(info)
log_method_call(self, name=name)
sysfs_path = udev.device_get_sysfs_path(info)
if name.startswith("md"):
name = blockdev.md.name_from_node(name)
device = self.getDeviceByName(name)
if device:
return device
if disk is None:
disk_name = os.path.basename(os.path.dirname(sysfs_path))
disk_name = disk_name.replace('!','/')
if disk_name.startswith("md"):
disk_name = blockdev.md.name_from_node(disk_name)
disk = self.getDeviceByName(disk_name)
if disk is None:
# create a device instance for the disk
new_info = udev.get_device(os.path.dirname(sysfs_path))
if new_info:
self.addUdevDevice(new_info)
disk = self.getDeviceByName(disk_name)
if disk is None:
# if the current device is still not in
# the tree, something has gone wrong
log.error("failure scanning device %s", disk_name)
lvm.lvm_cc_addFilterRejectRegexp(name)
return
if not disk.partitioned:
# Ignore partitions on:
# - devices we do not support partitioning of, like logical volumes
# - devices that do not have a usable disklabel
# - devices that contain disklabels made by isohybrid
#
if disk.partitionable and \
disk.format.type != "iso9660" and \
not disk.format.hidden and \
not self._isIgnoredDisk(disk):
if info.get("ID_PART_TABLE_TYPE") == "gpt":
msg = "corrupt gpt disklabel on disk %s" % disk.name
cls = CorruptGPTError
else:
msg = "failed to scan disk %s" % disk.name
cls = DiskLabelScanError
raise cls(msg)
# there's no need to filter partitions on members of multipaths or
# fwraid members from lvm since multipath and dmraid are already
# active and lvm should therefore know to ignore them
if not disk.format.hidden:
lvm.lvm_cc_addFilterRejectRegexp(name)
log.debug("ignoring partition %s on %s", name, disk.format.type)
return
device = None
try:
device = PartitionDevice(name, sysfsPath=sysfs_path,
major=udev.device_get_major(info),
minor=udev.device_get_minor(info),
exists=True, parents=[disk])
except DeviceError as e:
# corner case sometime the kernel accepts a partition table
# which gets rejected by parted, in this case we will
# prompt to re-initialize the disk, so simply skip the
# faulty partitions.
# XXX not sure about this
log.error("Failed to instantiate PartitionDevice: %s", e)
return
self.devicetree._addDevice(device)
return device
def addUdevDiskDevice(self, info):
name = udev.device_get_name(info)
log_method_call(self, name=name)
sysfs_path = udev.device_get_sysfs_path(info)
serial = udev.device_get_serial(info)
bus = udev.device_get_bus(info)
vendor = util.get_sysfs_attr(sysfs_path, "device/vendor")
model = util.get_sysfs_attr(sysfs_path, "device/model")
kwargs = { "serial": serial, "vendor": vendor, "model": model, "bus": bus }
if udev.device_is_iscsi(info) and not self._cleanup:
diskType = iScsiDiskDevice
initiator = udev.device_get_iscsi_initiator(info)
target = udev.device_get_iscsi_name(info)
address = udev.device_get_iscsi_address(info)
port = udev.device_get_iscsi_port(info)
nic = udev.device_get_iscsi_nic(info)
kwargs["initiator"] = initiator
if initiator == self.iscsi.initiator:
node = self.iscsi.getNode(target, address, port, nic)
kwargs["node"] = node
kwargs["ibft"] = node in self.iscsi.ibftNodes
kwargs["nic"] = self.iscsi.ifaces.get(node.iface, node.iface)
log.info("%s is an iscsi disk", name)
else:
# qla4xxx partial offload
kwargs["node"] = None
kwargs["ibft"] = False
kwargs["nic"] = "offload:not_accessible_via_iscsiadm"
kwargs["fw_address"] = address
kwargs["fw_port"] = port
kwargs["fw_name"] = name
elif udev.device_is_fcoe(info):
diskType = FcoeDiskDevice
kwargs["nic"] = udev.device_get_fcoe_nic(info)
kwargs["identifier"] = udev.device_get_fcoe_identifier(info)
log.info("%s is an fcoe disk", name)
elif udev.device_get_md_container(info):
name = udev.device_get_md_name(info)
diskType = MDBiosRaidArrayDevice
parentPath = udev.device_get_md_container(info)
parentName = devicePathToName(parentPath)
container = self.getDeviceByName(parentName)
if not container:
parentSysName = blockdev.md.node_from_name(parentName)
container_sysfs = "/sys/class/block/" + parentSysName
container_info = udev.get_device(container_sysfs)
if not container_info:
log.error("failed to find md container %s at %s",
parentName, container_sysfs)
return
self.addUdevDevice(container_info)
container = self.getDeviceByName(parentName)
if not container:
log.error("failed to scan md container %s", parentName)
return
kwargs["parents"] = [container]
kwargs["level"] = udev.device_get_md_level(info)
kwargs["memberDevices"] = udev.device_get_md_devices(info)
kwargs["uuid"] = udev.device_get_md_uuid(info)
kwargs["exists"] = True
del kwargs["model"]
del kwargs["serial"]
del kwargs["vendor"]
del kwargs["bus"]
elif udev.device_is_dasd(info) and not self._cleanup:
diskType = DASDDevice
kwargs["busid"] = udev.device_get_dasd_bus_id(info)
kwargs["opts"] = {}
for attr in ['readonly', 'use_diag', 'erplog', 'failfast']:
kwargs["opts"][attr] = udev.device_get_dasd_flag(info, attr)
log.info("%s is a dasd device", name)
elif udev.device_is_zfcp(info):
diskType = ZFCPDiskDevice
for attr in ['hba_id', 'wwpn', 'fcp_lun']:
kwargs[attr] = udev.device_get_zfcp_attribute(info, attr=attr)
log.info("%s is a zfcp device", name)
else:
diskType = DiskDevice
log.info("%s is a disk", name)
device = diskType(name,
major=udev.device_get_major(info),
minor=udev.device_get_minor(info),
sysfsPath=sysfs_path, **kwargs)
if diskType == DASDDevice:
self.dasd.append(device)
self.devicetree._addDevice(device)
return device
def addUdevOpticalDevice(self, info):
log_method_call(self)
# XXX should this be RemovableDevice instead?
#
# Looks like if it has ID_INSTANCE=0:1 we can ignore it.
device = OpticalDevice(udev.device_get_name(info),
major=udev.device_get_major(info),
minor=udev.device_get_minor(info),
sysfsPath=udev.device_get_sysfs_path(info),
vendor=udev.device_get_vendor(info),
model=udev.device_get_model(info))
self.devicetree._addDevice(device)
return device
def addUdevLoopDevice(self, info):
name = udev.device_get_name(info)
log_method_call(self, name=name)
sysfs_path = udev.device_get_sysfs_path(info)
sys_file = "%s/loop/backing_file" % sysfs_path
backing_file = open(sys_file).read().strip()
file_device = self.getDeviceByName(backing_file)
if not file_device:
file_device = FileDevice(backing_file, exists=True)
self.devicetree._addDevice(file_device)
device = LoopDevice(name,
parents=[file_device],
sysfsPath=sysfs_path,
exists=True)
if not self._cleanup or file_device not in self.diskImages.values():
# don't allow manipulation of loop devices other than those
# associated with disk images, and then only during cleanup
file_device.controllable = False
device.controllable = False
self.devicetree._addDevice(device)
return device
def addUdevDevice(self, info, updateOrigFmt=False):
"""
:param :class:`pyudev.Device` info: udev info for the device
:keyword bool updateOrigFmt: update original format unconditionally
If a device is added to the tree based on info its original format
will be saved after the format has been detected. If the device
that corresponds to info is already in the tree, its original format
will not be updated unless updateOrigFmt is True.
"""
name = udev.device_get_name(info)
log_method_call(self, name=name, info=pprint.pformat(dict(info)))
uuid = udev.device_get_uuid(info)
sysfs_path = udev.device_get_sysfs_path(info)
# make sure this device was not scheduled for removal and also has not
# been hidden
removed = [a.device for a in self.devicetree.actions.find(
action_type="destroy",
object_type="device")]
for ignored in removed + self.devicetree._hidden:
if (sysfs_path and ignored.sysfsPath == sysfs_path) or \
(uuid and uuid in (ignored.uuid, ignored.format.uuid)):
if ignored in removed:
reason = "removed"
else:
reason = "hidden"
log.debug("skipping %s device %s", reason, name)
return
# make sure we note the name of every device we see
if name not in self.names:
self.names.append(name)
if self.isIgnored(info):
log.info("ignoring %s (%s)", name, sysfs_path)
if name not in self.ignoredDisks:
self.addIgnoredDisk(name)
return
log.info("scanning %s (%s)...", name, sysfs_path)
device = self.getDeviceByName(name)
if device is None and udev.device_is_md(info):
# If the md name is None, then some udev info is missing. Likely,
# this is because the array is degraded, and mdadm has deactivated
# it. Try to activate it and re-get the udev info.
if flags.allow_imperfect_devices and udev.device_get_md_name(info) is None:
devname = udev.device_get_devname(info)
if devname:
try:
blockdev.md.run(devname)
except blockdev.MDRaidError as e:
log.warning("Failed to start possibly degraded md array: %s", e)
else:
udev.settle()
info = udev.get_device(sysfs_path)
else:
log.warning("Failed to get devname for possibly degraded md array.")
md_name = udev.device_get_md_name(info)
if md_name is None:
log.warning("No name for possibly degraded md array.")
else:
device = self.getDeviceByName(md_name, incomplete=flags.allow_imperfect_devices)
if device and not isinstance(device, MDRaidArrayDevice):
log.warning("Found device %s, but it turns out not be an md array device after all.", device.name)
device = None
if device and device.isDisk and \
blockdev.mpath.is_mpath_member(device.path):
# newly added device (eg iSCSI) could make this one a multipath member
if device.format and device.format.type != "multipath_member":
log.debug("%s newly detected as multipath member, dropping old format and removing kids", device.name)
# remove children from tree so that we don't stumble upon them later
for child in self.devicetree.getChildren(device):
self.devicetree.recursiveRemove(child, actions=False)
device.format = None
#
# The first step is to either look up or create the device
#
device_added = True
if device:
device_added = False
elif udev.device_is_loop(info):
log.info("%s is a loop device", name)
device = self.addUdevLoopDevice(info)
elif udev.device_is_dm_mpath(info) and \
not udev.device_is_dm_partition(info):
log.info("%s is a multipath device", name)
device = self.addUdevMultiPathDevice(info)
elif udev.device_is_dm_lvm(info):
log.info("%s is an lvm logical volume", name)
device = self.addUdevLVDevice(info)
elif udev.device_is_dm(info):
log.info("%s is a device-mapper device", name)
device = self.addUdevDMDevice(info)
elif udev.device_is_md(info) and not udev.device_get_md_container(info):
log.info("%s is an md device", name)
device = self.addUdevMDDevice(info)
elif udev.device_is_cdrom(info):
log.info("%s is a cdrom", name)
device = self.addUdevOpticalDevice(info)
elif udev.device_is_disk(info):
device = self.addUdevDiskDevice(info)
elif udev.device_is_partition(info):
log.info("%s is a partition", name)
device = self.addUdevPartitionDevice(info)
else:
log.error("Unknown block device type for: %s", name)
return
if not device:
log.debug("no device obtained for %s", name)
return
# If this device is read-only, mark it as such now.
if self.udevDeviceIsDisk(info) and \
util.get_sysfs_attr(udev.device_get_sysfs_path(info), 'ro') == '1':
device.readonly = True
# If this device is protected, mark it as such now. Once the tree
# has been populated, devices' protected attribute is how we will
# identify protected devices.
if device.name in self.protectedDevNames:
device.protected = True
# if this is the live backing device we want to mark its parents
# as protected also
if device.name == self.liveBackingDevice:
for parent in device.parents:
parent.protected = True
# If we just added a multipath or fwraid disk that is in exclusiveDisks
# we have to make sure all of its members are in the list too.
mdclasses = (DMRaidArrayDevice, MDRaidArrayDevice, MultipathDevice)
if device.isDisk and isinstance(device, mdclasses):
if device.name in self.exclusiveDisks:
for parent in device.parents:
if parent.name not in self.exclusiveDisks:
self.exclusiveDisks.append(parent.name)
log.info("got device: %r", device)
# now handle the device's formatting
self.handleUdevDeviceFormat(info, device)
if device_added or updateOrigFmt:
device.originalFormat = copy.deepcopy(device.format)
device.deviceLinks = udev.device_get_symlinks(info)
def handleUdevDiskLabelFormat(self, info, device):
disklabel_type = udev.device_get_disklabel_type(info)
log_method_call(self, device=device.name, label_type=disklabel_type)
# if there is no disklabel on the device
# blkid doesn't understand dasd disklabels, so bypass for dasd
if disklabel_type is None and not \
(device.isDisk and udev.device_is_dasd(info)):
log.debug("device %s does not contain a disklabel", device.name)
return
if device.partitioned:
# this device is already set up
log.debug("disklabel format on %s already set up", device.name)
return
try:
device.setup()
except Exception: # pylint: disable=broad-except
log_exception_info(log.warning, "setup of %s failed, aborting disklabel handler", [device.name])
return
# special handling for unsupported partitioned devices
if not device.partitionable:
try:
fmt = formats.getFormat("disklabel",
device=device.path,
labelType=disklabel_type,
exists=True)
except InvalidDiskLabelError:
log.warning("disklabel detected but not usable on %s",
device.name)
else:
device.format = fmt
return
try:
fmt = formats.getFormat("disklabel",
device=device.path,
exists=True)
except InvalidDiskLabelError as e:
log.info("no usable disklabel on %s", device.name)
if disklabel_type == "gpt":
log.debug(e)
device.format = formats.getFormat(_("Invalid Disk Label"))
else:
device.format = fmt
def handleUdevLUKSFormat(self, info, device):
# pylint: disable=unused-argument
log_method_call(self, name=device.name, type=device.format.type)
if not device.format.uuid:
log.info("luks device %s has no uuid", device.path)
return
# look up or create the mapped device
if not self.getDeviceByName(device.format.mapName):
passphrase = self.__luksDevs.get(device.format.uuid)
if device.format.configured:
pass
elif passphrase:
device.format.passphrase = passphrase
elif device.format.uuid in self.__luksDevs:
log.info("skipping previously-skipped luks device %s",
device.name)
elif self._cleanup or flags.testing:
# if we're only building the devicetree so that we can
# tear down all of the devices we don't need a passphrase
if device.format.status:
# this makes device.configured return True
device.format.passphrase = 'yabbadabbadoo'
else:
# Try each known passphrase. Include luksDevs values in case a
# passphrase has been set for a specific device without a full
# reset/populate, in which case the new passphrase would not be
# in self.__passphrases.
for passphrase in self.__passphrases + list(self.__luksDevs.values()):
device.format.passphrase = passphrase
try:
device.format.setup()
except blockdev.BlockDevError:
device.format.passphrase = None
else:
break
luks_device = LUKSDevice(device.format.mapName,
parents=[device],
exists=True)
try:
luks_device.setup()
except (LUKSError, blockdev.CryptoError, DeviceError) as e:
log.info("setup of %s failed: %s", device.format.mapName, e)
device.removeChild()
else:
luks_device.updateSysfsPath()
self.devicetree._addDevice(luks_device)
luks_info = udev.get_device(luks_device.sysfsPath)
if not luks_info:
log.error("failed to get udev data for %s", luks_device.name)
return
self.addUdevDevice(luks_info, updateOrigFmt=True)
else:
log.warning("luks device %s already in the tree",
device.format.mapName)
def handleVgLvs(self, vg_device):
""" Handle setup of the LV's in the vg_device. """
vg_name = vg_device.name
lv_info = dict((k, v) for (k, v) in iter(self.devicetree.lvInfo.items())
if v.vg_name == vg_name)
self.names.extend(n for n in lv_info.keys() if n not in self.names)
if not vg_device.complete:
log.warning("Skipping LVs for incomplete VG %s", vg_name)
return
if not lv_info:
log.debug("no LVs listed for VG %s", vg_name)
return
all_lvs = []
internal_lvs = []
def addRequiredLV(name, msg):
""" Add a prerequisite/parent LV.
The parent is strictly required in order to be able to add
some other LV that depends on it. For this reason, failure to
add the specified LV results in a DeviceTreeError with the
message string specified in the msg parameter.
:param str name: the full name of the LV (including vgname)
:param str msg: message to pass DeviceTreeError ctor on error
:returns: None
:raises: :class:`~.errors.DeviceTreeError` on failure
"""
vol = self.getDeviceByName(name)
if vol is None:
new_lv = addLV(lv_info[name])
if new_lv:
all_lvs.append(new_lv)
vol = self.getDeviceByName(name)
if vol is None:
log.error("%s: %s", msg, name)
raise DeviceTreeError(msg)
def addLV(lv):
""" Instantiate and add an LV based on data from the VG. """
lv_name = lv.lv_name
lv_uuid = lv.uuid
lv_attr = lv.attr
lv_size = Size(lv.size)
lv_type = lv.segtype
lv_class = LVMLogicalVolumeDevice
lv_parents = [vg_device]
lv_kwargs = {}
name = "%s-%s" % (vg_name, lv_name)
if self.getDeviceByName(name):
# some lvs may have been added on demand below
log.debug("already added %s", name)
return
if lv_attr[0] in 'Ss':
log.info("found lvm snapshot volume '%s'", name)
origin_name = blockdev.lvm.lvorigin(vg_name, lv_name)
if not origin_name:
log.error("lvm snapshot '%s-%s' has unknown origin",
vg_name, lv_name)
return
if origin_name.endswith("_vorigin]"):
lv_kwargs["vorigin"] = True
origin = None
else:
origin_device_name = "%s-%s" % (vg_name, origin_name)
addRequiredLV(origin_device_name,
"failed to locate origin lv")
origin = self.getDeviceByName(origin_device_name)
lv_kwargs["origin"] = origin
lv_class = LVMSnapShotDevice
elif lv_attr[0] == 'v':
# skip vorigins
return
elif lv_attr[0] in 'IielTCo' and lv_name.endswith(']'):
# an internal LV, add the an instance of the appropriate class
# to internal_lvs for later processing when non-internal LVs are
# processed
internal_lvs.append(lv_name)
return
elif lv_attr[0] == 't':
# thin pool
lv_class = LVMThinPoolDevice
elif lv_attr[0] == 'V':
# thin volume
pool_name = blockdev.lvm.thlvpoolname(vg_name, lv_name)
pool_device_name = "%s-%s" % (vg_name, pool_name)
addRequiredLV(pool_device_name, "failed to look up thin pool")
origin_name = blockdev.lvm.lvorigin(vg_name, lv_name)
if origin_name:
origin_device_name = "%s-%s" % (vg_name, origin_name)
addRequiredLV(origin_device_name, "failed to locate origin lv")
origin = self.getDeviceByName(origin_device_name)
lv_kwargs["origin"] = origin
lv_class = LVMThinSnapShotDevice
else:
lv_class = LVMThinLogicalVolumeDevice
lv_parents = [self.getDeviceByName(pool_device_name)]
elif lv_name.endswith(']'):
# unrecognized Internal LVM2 device
return
elif lv_attr[0] not in '-mMrRoOC':
# Ignore anything else except for the following:
# - normal lv
# m mirrored
# M mirrored without initial sync
# r raid
# R raid without initial sync
# o origin
# O origin with merging snapshot
# C cached LV
return
lv_dev = self.getDeviceByUuid(lv_uuid)
if lv_dev is None:
lv_device = lv_class(lv_name, parents=lv_parents,
uuid=lv_uuid, size=lv_size,segType=lv_type,
exists=True, **lv_kwargs)
self.devicetree._addDevice(lv_device)
if flags.installer_mode:
lv_device.setup()
if lv_device.status:
lv_device.updateSysfsPath()
lv_device.updateSize()
lv_info = udev.get_device(lv_device.sysfsPath)
if not lv_info:
log.error("failed to get udev data for lv %s", lv_device.name)
return lv_device
# do format handling now
self.addUdevDevice(lv_info, updateOrigFmt=True)
return lv_device
return None
def createInternalLV(lv):
lv_name = lv.lv_name
lv_uuid = lv.uuid
lv_attr = lv.attr
lv_size = Size(lv.size)
lv_type = lv.segtype
matching_cls = get_internal_lv_class(lv_attr)
if matching_cls is None:
raise DeviceTreeError("No internal LV class supported for type '%s'" % lv_attr[0])
# strip the "[]"s marking the LV as internal
lv_name = lv_name.strip("[]")
# don't know the parent LV yet, will be set later
new_lv = matching_cls(lv_name, vg_device, parent_lv=None, size=lv_size, uuid=lv_uuid, exists=True, segType=lv_type)
if new_lv.status:
new_lv.updateSysfsPath()
new_lv.updateSize()
lv_info = udev.get_device(new_lv.sysfsPath)
if not lv_info:
log.error("failed to get udev data for lv %s", new_lv.name)
return new_lv
return new_lv
# add LVs
for lv in lv_info.values():
# add the LV to the DeviceTree
new_lv = addLV(lv)
if new_lv:
# save the reference for later use
all_lvs.append(new_lv)
# Instead of doing a topological sort on internal LVs to make sure the
# parent LV is always created before its internal LVs (an internal LV
# can have internal LVs), we just create all the instances here and
# assign their parents later. Those who are not assinged a parent (which
# would hold a reference to them) will get eaten by the garbage
# collector.
# create device instances for the internal LVs
orphan_lvs = dict()
for lv_name in internal_lvs:
full_name = "%s-%s" % (vg_name, lv_name)
try:
new_lv = createInternalLV(lv_info[full_name])
except DeviceTreeError as e:
log.warning("Failed to process an internal LV '%s': %s", full_name, e)
else:
orphan_lvs[full_name] = new_lv
all_lvs.append(new_lv)
# assign parents to internal LVs (and vice versa, see
# :class:`~.devices.lvm.LVMInternalLogicalVolumeDevice`)
for lv in orphan_lvs.values():
parent_lv = lvm.determine_parent_lv(vg_name, lv, all_lvs)
if parent_lv:
lv.parent_lv = parent_lv
else:
log.warning("Failed to determine parent LV for an internal LV '%s'", lv.name)
def handleUdevLVMPVFormat(self, info, device):
# pylint: disable=unused-argument
log_method_call(self, name=device.name, type=device.format.type)
pv_info = self.devicetree.pvInfo.get(device.path, None)
if pv_info:
vg_name = pv_info.vg_name
vg_uuid = pv_info.vg_uuid
else:
# no info about the PV -> we're done
return
if not vg_name:
log.info("lvm pv %s has no vg", device.name)
return
vg_device = self.getDeviceByUuid(vg_uuid, incomplete=True)
if vg_device:
vg_device.parents.append(device)
else:
same_name = self.getDeviceByName(vg_name)
if isinstance(same_name, LVMVolumeGroupDevice) and \
not (all(self._isIgnoredDisk(d) for d in same_name.disks) or
all(self._isIgnoredDisk(d) for d in device.disks)):
raise DuplicateVGError("multiple LVM volume groups with the same name (%s)" % vg_name)
try:
vg_size = Size(pv_info.vg_size)
vg_free = Size(pv_info.vg_free)
pe_size = Size(pv_info.vg_extent_size)
pe_count = pv_info.vg_extent_count
pe_free = pv_info.vg_free_count
pv_count = pv_info.vg_pv_count
except (KeyError, ValueError) as e:
log.warning("invalid data for %s: %s", device.name, e)
return
vg_device = LVMVolumeGroupDevice(vg_name,
parents=[device],
uuid=vg_uuid,
size=vg_size,
free=vg_free,
peSize=pe_size,
peCount=pe_count,
peFree=pe_free,
pvCount=pv_count,
exists=True)
self.devicetree._addDevice(vg_device)
self.handleVgLvs(vg_device)
def handleUdevMDMemberFormat(self, info, device):
# pylint: disable=unused-argument
log_method_call(self, name=device.name, type=device.format.type)
md_info = blockdev.md.examine(device.path)
# Use mdadm info if udev info is missing
md_uuid = md_info.uuid
device.format.mdUuid = device.format.mdUuid or md_uuid
md_array = self.getDeviceByUuid(device.format.mdUuid, incomplete=True)
if md_array:
md_array.parents.append(device)
else:
# create the array with just this one member
# level is reported as, eg: "raid1"
md_level = md_info.level
md_devices = md_info.num_devices
if md_level is None:
log.warning("invalid data for %s: no RAID level", device.name)
return
# md_examine yields metadata (MD_METADATA) only for metadata version > 0.90
# if MD_METADATA is missing, assume metadata version is 0.90
md_metadata = md_info.metadata or "0.90"
md_name = None
md_path = md_info.device or ""
if md_path:
md_name = devicePathToName(md_path)
if re.match(r'md\d+$', md_name):
# md0 -> 0
md_name = md_name[2:]
if md_name:
array = self.getDeviceByName(md_name, incomplete=True)
if array and array.uuid != md_uuid:
log.error("found multiple devices with the name %s", md_name)
if md_name:
log.info("using name %s for md array containing member %s",
md_name, device.name)
else:
log.error("failed to determine name for the md array %s", (md_uuid or "unknown"))
return
array_type = MDRaidArrayDevice
try:
if raid.getRaidLevel(md_level) is raid.Container and \
getattr(device.format, "biosraid", False):
array_type = MDContainerDevice
except raid.RaidError as e:
log.error("failed to create md array: %s", e)
return
try:
md_array = array_type(
md_name,
level=md_level,
memberDevices=md_devices,
uuid=md_uuid,
metadataVersion=md_metadata,
exists=True
)
except (ValueError, DeviceError) as e:
log.error("failed to create md array: %s", e)
return
md_array.updateSysfsPath()
md_array.parents.append(device)
self.devicetree._addDevice(md_array)
if md_array.status:
array_info = udev.get_device(md_array.sysfsPath)
if not array_info:
log.error("failed to get udev data for %s", md_array.name)
return
self.addUdevDevice(array_info, updateOrigFmt=True)
def handleUdevDMRaidMemberFormat(self, info, device):
# if dmraid usage is disabled skip any dmraid set activation
if not flags.dmraid:
return
log_method_call(self, name=device.name, type=device.format.type)
name = udev.device_get_name(info)
uuid = udev.device_get_uuid(info)
major = udev.device_get_major(info)
minor = udev.device_get_minor(info)
# Have we already created the DMRaidArrayDevice?
rs_names = blockdev.dm.get_member_raid_sets(uuid, name, major, minor)
if len(rs_names) == 0:
log.warning("dmraid member %s does not appear to belong to any "
"array", device.name)
return
for rs_name in rs_names:
dm_array = self.getDeviceByName(rs_name, incomplete=True)
if dm_array is not None:
# We add the new device.
dm_array.parents.append(device)
else:
# Activate the Raid set.
blockdev.dm.activate_raid_set(rs_name)
dm_array = DMRaidArrayDevice(rs_name,
parents=[device])
self.devicetree._addDevice(dm_array)
# Wait for udev to scan the just created nodes, to avoid a race
# with the udev.get_device() call below.
udev.settle()
# Get the DMRaidArrayDevice a DiskLabel format *now*, in case
# its partitions get scanned before it does.
dm_array.updateSysfsPath()
dm_array_info = udev.get_device(dm_array.sysfsPath)
self.handleUdevDiskLabelFormat(dm_array_info, dm_array)
# Use the rs's object on the device.
# pyblock can return the memebers of a set and the
# device has the attribute to hold it. But ATM we
# are not really using it. Commenting this out until
# we really need it.
#device.format.raidmem = block.getMemFromRaidSet(dm_array,
# major=major, minor=minor, uuid=uuid, name=name)
def handleBTRFSFormat(self, info, device):
log_method_call(self, name=device.name)
uuid = udev.device_get_uuid(info)
btrfs_dev = None
for d in self.devicetree.devices:
if isinstance(d, BTRFSVolumeDevice) and d.uuid == uuid:
btrfs_dev = d
break
if btrfs_dev:
log.info("found btrfs volume %s", btrfs_dev.name)
btrfs_dev.parents.append(device)
else:
label = udev.device_get_label(info)
log.info("creating btrfs volume btrfs.%s", label)
btrfs_dev = BTRFSVolumeDevice(label, parents=[device], uuid=uuid,
exists=True)
self.devicetree._addDevice(btrfs_dev)
if not btrfs_dev.subvolumes:
snapshots = btrfs_dev.listSubVolumes(snapshotsOnly=True)
snapshot_ids = [s.id for s in snapshots]
for subvol_dict in btrfs_dev.listSubVolumes():
vol_id = subvol_dict.id
vol_path = subvol_dict.path
parent_id = subvol_dict.parent_id
if vol_path in [sv.name for sv in btrfs_dev.subvolumes]:
continue
# look up the parent subvol
parent = None
subvols = [btrfs_dev] + btrfs_dev.subvolumes
for sv in subvols:
if sv.vol_id == parent_id:
parent = sv
break
if parent is None:
log.error("failed to find parent (%d) for subvol %s",
parent_id, vol_path)
raise DeviceTreeError("could not find parent for subvol")
fmt = formats.getFormat("btrfs",
device=btrfs_dev.path,
exists=True,
volUUID=btrfs_dev.format.volUUID,
subvolspec=vol_path,
mountopts="subvol=%s" % vol_path)
if vol_id in snapshot_ids:
device_class = BTRFSSnapShotDevice
else:
device_class = BTRFSSubVolumeDevice
subvol = device_class(vol_path,
vol_id=vol_id,
fmt=fmt,
parents=[parent],
exists=True)
self.devicetree._addDevice(subvol)
def handleUdevDeviceFormat(self, info, device):
log_method_call(self, name=getattr(device, "name", None))
if not info:
log.debug("no information for device %s", device.name)
return
if not device.mediaPresent:
log.debug("no media present for device %s", device.name)
return
name = udev.device_get_name(info)
uuid = udev.device_get_uuid(info)
label = udev.device_get_label(info)
format_type = udev.device_get_format(info)
serial = udev.device_get_serial(info)
is_multipath_member = blockdev.mpath.is_mpath_member(device.path)
if is_multipath_member:
format_type = "multipath_member"
# Now, if the device is a disk, see if there is a usable disklabel.
# If not, see if the user would like to create one.
# XXX ignore disklabels on multipath or biosraid member disks
if not udev.device_is_biosraid_member(info) and \
not is_multipath_member and \
format_type != "iso9660":
self.handleUdevDiskLabelFormat(info, device)
if device.partitioned or self.isIgnored(info) or \
(not device.partitionable and
device.format.type == "disklabel"):
# If the device has a disklabel, or the user chose not to
# create one, we are finished with this device. Otherwise
# it must have some non-disklabel formatting, in which case
# we fall through to handle that.
return
if (not device) or (not format_type) or device.format.type:
# this device has no formatting or it has already been set up
# FIXME: this probably needs something special for disklabels
log.debug("no type or existing type for %s, bailing", name)
return
# set up the common arguments for the format constructor
format_designator = format_type
kwargs = {"uuid": uuid,
"label": label,
"device": device.path,
"serial": serial,
"exists": True}
# set up type-specific arguments for the format constructor
if format_type == "crypto_LUKS":
# luks/dmcrypt
kwargs["name"] = "luks-%s" % uuid
elif format_type in formats.mdraid.MDRaidMember._udevTypes:
# mdraid
try:
# ID_FS_UUID contains the array UUID
kwargs["mdUuid"] = udev.device_get_uuid(info)
except KeyError:
log.warning("mdraid member %s has no md uuid", name)
# reset the uuid to the member-specific value
# this will be None for members of v0 metadata arrays
kwargs["uuid"] = udev.device_get_md_device_uuid(info)
kwargs["biosraid"] = udev.device_is_biosraid_member(info)
elif format_type == "LVM2_member":
# lvm
pv_info = self.devicetree.pvInfo.get(device.path, None)
if pv_info:
if pv_info.vg_name:
kwargs["vgName"] = pv_info.vg_name
else:
log.warning("PV %s has no vg_name", name)
if pv_info.vg_uuid:
kwargs["vgUuid"] = pv_info.vg_uuid
else:
log.warning("PV %s has no vg_uuid", name)
if pv_info.pe_start:
kwargs["peStart"] = Size(pv_info.pe_start)
else:
log.warning("PV %s has no pe_start", name)
elif format_type == "vfat":
# efi magic
if isinstance(device, PartitionDevice) and device.bootable:
efi = formats.getFormat("efi")
if efi.minSize <= device.size <= efi.maxSize:
format_designator = "efi"
elif format_type == "hfsplus":
if isinstance(device, PartitionDevice):
macefi = formats.getFormat("macefi")
if macefi.minSize <= device.size <= macefi.maxSize and \
device.partedPartition.name == macefi.name:
format_designator = "macefi"
elif format_type == "hfs":
# apple bootstrap magic
if isinstance(device, PartitionDevice) and device.bootable:
apple = formats.getFormat("appleboot")
if apple.minSize <= device.size <= apple.maxSize:
format_designator = "appleboot"
elif format_type == "btrfs":
# the format's uuid attr will contain the UUID_SUB, while the
# overarching volume UUID will be stored as volUUID
kwargs["uuid"] = info["ID_FS_UUID_SUB"]
kwargs["volUUID"] = uuid
try:
log.info("type detected on '%s' is '%s'", name, format_designator)
device.format = formats.getFormat(format_designator, **kwargs)
if device.format.type:
log.info("got format: %s", device.format)
except FSError:
log.warning("type '%s' on '%s' invalid, assuming no format",
format_designator, name)
device.format = formats.DeviceFormat()
return
#
# now do any special handling required for the device's format
#
if device.format.type == "luks":
self.handleUdevLUKSFormat(info, device)
elif device.format.type == "mdmember":
self.handleUdevMDMemberFormat(info, device)
elif device.format.type == "dmraidmember":
self.handleUdevDMRaidMemberFormat(info, device)
elif device.format.type == "lvmpv":
self.handleUdevLVMPVFormat(info, device)
elif device.format.type == "btrfs":
self.handleBTRFSFormat(info, device)
def updateDeviceFormat(self, device):
log.info("updating format of device: %s", device)
try:
util.notify_kernel(device.sysfsPath)
except (ValueError, IOError) as e:
log.warning("failed to notify kernel of change: %s", e)
udev.settle()
info = udev.get_device(device.sysfsPath)
self.handleUdevDeviceFormat(info, device)
def _handleInconsistencies(self):
for vg in [d for d in self.devicetree.devices if d.type == "lvmvg"]:
if vg.complete:
continue
# Make sure lvm doesn't get confused by PVs that belong to
# incomplete VGs. We will remove the PVs from the blacklist when/if
# the time comes to remove the incomplete VG and its PVs.
for pv in vg.pvs:
lvm.lvm_cc_addFilterRejectRegexp(pv.name)
def setupDiskImages(self):
""" Set up devices to represent the disk image files. """
for (name, path) in self.diskImages.items():
log.info("setting up disk image file '%s' as '%s'", path, name)
dmdev = self.getDeviceByName(name)
if dmdev and isinstance(dmdev, DMLinearDevice) and \
path in (d.path for d in dmdev.ancestors):
log.debug("using %s", dmdev)
dmdev.setup()
continue
try:
filedev = FileDevice(path, exists=True)
filedev.setup()
log.debug("%s", filedev)
loop_name = blockdev.loop.get_loop_name(filedev.path)
loop_sysfs = None
if loop_name:
loop_sysfs = "/class/block/%s" % loop_name
loopdev = LoopDevice(name=loop_name,
parents=[filedev],
sysfsPath=loop_sysfs,
exists=True)
loopdev.setup()
log.debug("%s", loopdev)
dmdev = DMLinearDevice(name,
dmUuid="ANACONDA-%s" % name,
parents=[loopdev],
exists=True)
dmdev.setup()
dmdev.updateSysfsPath()
log.debug("%s", dmdev)
except (ValueError, DeviceError) as e:
log.error("failed to set up disk image: %s", e)
else:
self.devicetree._addDevice(filedev)
self.devicetree._addDevice(loopdev)
self.devicetree._addDevice(dmdev)
info = udev.get_device(dmdev.sysfsPath)
self.addUdevDevice(info, updateOrigFmt=True)
def teardownDiskImages(self):
""" Tear down any disk image stacks. """
for (name, _path) in self.diskImages.items():
dm_device = self.getDeviceByName(name)
if not dm_device:
continue
dm_device.deactivate()
loop_device = dm_device.parents[0]
loop_device.teardown()
def backupConfigs(self, restore=False):
""" Create a backup copies of some storage config files. """
configs = ["/etc/mdadm.conf"]
for cfg in configs:
if restore:
src = cfg + ".anacbak"
dst = cfg
func = os.rename
op = "restore from backup"
else:
src = cfg
dst = cfg + ".anacbak"
func = shutil.copy2
op = "create backup copy"
if os.access(dst, os.W_OK):
try:
os.unlink(dst)
except OSError as e:
msg = str(e)
log.info("failed to remove %s: %s", dst, msg)
if os.access(src, os.W_OK):
# copy the config to a backup with extension ".anacbak"
try:
func(src, dst)
except (IOError, OSError) as e:
msg = str(e)
log.error("failed to %s of %s: %s", op, cfg, msg)
elif restore and os.access(cfg, os.W_OK):
# remove the config since we created it
log.info("removing anaconda-created %s", cfg)
try:
os.unlink(cfg)
except OSError as e:
msg = str(e)
log.error("failed to remove %s: %s", cfg, msg)
else:
# don't try to backup non-existent configs
log.info("not going to %s of non-existent %s", op, cfg)
def restoreConfigs(self):
self.backupConfigs(restore=True)
def saveLUKSpassphrase(self, device):
""" Save a device's LUKS passphrase in case of reset. """
passphrase = device.format._LUKS__passphrase
self.__luksDevs[device.format.uuid] = passphrase
self.__passphrases.append(passphrase)
def populate(self, cleanupOnly=False):
""" Locate all storage devices.
Everything should already be active. We just go through and gather
details as needed and set up the relations between various devices.
Devices excluded via disk filtering (or because of disk images) are
scanned just the rest, but then they are hidden at the end of this
process.
"""
self.backupConfigs()
if cleanupOnly:
self._cleanup = True
parted.register_exn_handler(parted_exn_handler)
try:
self._populate()
except Exception:
raise
finally:
parted.clear_exn_handler()
self.restoreConfigs()
def _populate(self):
log.info("DeviceTree.populate: ignoredDisks is %s ; exclusiveDisks is %s",
self.ignoredDisks, self.exclusiveDisks)
self.devicetree.dropLVMCache()
if flags.installer_mode and not flags.image_install:
blockdev.mpath.set_friendly_names(flags.multipath_friendly_names)
self.setupDiskImages()
# mark the tree as unpopulated so exception handlers can tell the
# exception originated while finding storage devices
self.populated = False
# resolve the protected device specs to device names
for spec in self.protectedDevSpecs:
name = udev.resolve_devspec(spec)
log.debug("protected device spec %s resolved to %s", spec, name)
if name:
self.protectedDevNames.append(name)
# FIXME: the backing dev for the live image can't be used as an
# install target. note that this is a little bit of a hack
# since we're assuming that /run/initramfs/live will exist
for mnt in open("/proc/mounts").readlines():
if " /run/initramfs/live " not in mnt:
continue
live_device_name = mnt.split()[0].split("/")[-1]
log.info("%s looks to be the live device; marking as protected",
live_device_name)
self.protectedDevNames.append(live_device_name)
self.liveBackingDevice = live_device_name
break
old_devices = {}
# Now, loop and scan for devices that have appeared since the two above
# blocks or since previous iterations.
while True:
devices = []
new_devices = udev.get_devices()
for new_device in new_devices:
new_name = udev.device_get_name(new_device)
if new_name not in old_devices:
old_devices[new_name] = new_device
devices.append(new_device)
if len(devices) == 0:
# nothing is changing -- we are finished building devices
break
log.info("devices to scan: %s", [udev.device_get_name(d) for d in devices])
for dev in devices:
self.addUdevDevice(dev)
self.populated = True
# After having the complete tree we make sure that the system
# inconsistencies are ignored or resolved.
self._handleInconsistencies()
@property
def names(self):
return self.devicetree.names
def getDeviceByName(self, *args, **kwargs):
return self.devicetree.getDeviceByName(*args, **kwargs)
def getDeviceByUuid(self, *args, **kwargs):
return self.devicetree.getDeviceByUuid(*args, **kwargs) | unknown | codeparrot/codeparrot-clean | ||
# coding=utf-8
"""Dialog test.
.. note:: This program is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation; either version 2 of the License, or
(at your option) any later version.
"""
__author__ = 'arnaud.poncet-montanges@outlook.com'
__date__ = '2016-04-27'
__copyright__ = 'Copyright 2016, QWAT Users Lausanne'
import unittest
from PyQt4.QtGui import QDialogButtonBox, QDialog
from document_linker_dialog import DocumentLinkerDialog
from utilities import get_qgis_app
QGIS_APP = get_qgis_app()
class DocumentLinkerDialogTest(unittest.TestCase):
"""Test dialog works."""
def setUp(self):
"""Runs before each test."""
self.dialog = DocumentLinkerDialog(None)
def tearDown(self):
"""Runs after each test."""
self.dialog = None
def test_dialog_ok(self):
"""Test we can click OK."""
button = self.dialog.button_box.button(QDialogButtonBox.Ok)
button.click()
result = self.dialog.result()
self.assertEqual(result, QDialog.Accepted)
def test_dialog_cancel(self):
"""Test we can click cancel."""
button = self.dialog.button_box.button(QDialogButtonBox.Cancel)
button.click()
result = self.dialog.result()
self.assertEqual(result, QDialog.Rejected)
if __name__ == "__main__":
suite = unittest.makeSuite(DocumentLinkerDialogTest)
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suite) | unknown | codeparrot/codeparrot-clean | ||
# Copyright (c) Twisted Matrix Laboratories.
# See LICENSE for details.
"""
Tests for L{twisted.conch.ssh.forwarding}.
"""
from __future__ import division, absolute_import
from twisted.conch.ssh import forwarding
from twisted.internet.address import IPv6Address
from twisted.trial import unittest
from twisted.internet.test.test_endpoints import deterministicResolvingReactor
from twisted.test.proto_helpers import MemoryReactorClock, StringTransport
class TestSSHConnectForwardingChannel(unittest.TestCase):
"""
Unit and integration tests for L{SSHConnectForwardingChannel}.
"""
def makeTCPConnection(self, reactor):
"""
Fake that connection was established for first connectTCP request made
on C{reactor}.
@param reactor: Reactor on which to fake the connection.
@type reactor: A reactor.
"""
factory = reactor.tcpClients[0][2]
connector = reactor.connectors[0]
protocol = factory.buildProtocol(None)
transport = StringTransport(peerAddress=connector.getDestination())
protocol.makeConnection(transport)
def test_channelOpenHostnameRequests(self):
"""
When a hostname is sent as part of forwarding requests, it
is resolved using HostnameEndpoint's resolver.
"""
sut = forwarding.SSHConnectForwardingChannel(
hostport=('fwd.example.org', 1234))
# Patch channel and resolver to not touch the network.
memoryReactor = MemoryReactorClock()
sut._reactor = deterministicResolvingReactor(memoryReactor, ['::1'])
sut.channelOpen(None)
self.makeTCPConnection(memoryReactor)
self.successResultOf(sut._channelOpenDeferred)
# Channel is connected using a forwarding client to the resolved
# address of the requested host.
self.assertIsInstance(sut.client, forwarding.SSHForwardingClient)
self.assertEqual(
IPv6Address('TCP', '::1', 1234), sut.client.transport.getPeer()) | unknown | codeparrot/codeparrot-clean | ||
#
# Copyright 2015-2019, Institute for Systems Biology
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
from builtins import object
def enum(**enums):
return type('Enum', (), enums)
# TODO decouple from protorpc.messages
class ValueType(object):
STRING = 1
INTEGER = 2
FLOAT = 3
BOOLEAN = 4
UNKNOWN = 5 # We can get queries that return no data, which may be of an unknown type
def is_log_transformable(attr_type):
return isinstance(attr_type, ValueType) and (attr_type == ValueType.FLOAT or attr_type == ValueType.INTEGER)
IdentifierTypes = enum(PATIENT=1, SAMPLE=2, ALIQUOT=3)
DataTypes = enum(CLIN=1, GEXP=2, METH=3, CNVR=4, RPPA=5, MIRN=6, GNAB=7, USER=8)
IDENTIER_FIELDS_FOR_DATA_TYPES = {
#TODO: change clin to match new BQ clin table in tcga_data_open
DataTypes.CLIN: {
IdentifierTypes.PATIENT: 'ParticipantBarcode'
},
#TODO: change gexp to match new BQ gexp table in tcga_data_open; not yet uploaded yet
DataTypes.GEXP: {
IdentifierTypes.PATIENT: 'ParticipantBarcode',
IdentifierTypes.SAMPLE: 'SampleBarcode',
IdentifierTypes.ALIQUOT: 'AliquotBarcode'
},
DataTypes.METH: {
IdentifierTypes.PATIENT: 'ParticipantBarcode',
IdentifierTypes.SAMPLE: 'SampleBarcode',
IdentifierTypes.ALIQUOT: 'AliquotBarcode'
},
DataTypes.CNVR: {
IdentifierTypes.PATIENT: 'ParticipantBarcode',
IdentifierTypes.SAMPLE: 'SampleBarcode',
IdentifierTypes.ALIQUOT: 'AliquotBarcode'
},
DataTypes.RPPA: {
IdentifierTypes.PATIENT: 'ParticipantBarcode',
IdentifierTypes.SAMPLE: 'SampleBarcode',
IdentifierTypes.ALIQUOT: 'AliquotBarcode'
},
DataTypes.MIRN: {
IdentifierTypes.PATIENT: 'ParticipantBarcode',
IdentifierTypes.SAMPLE: 'SampleBarcode',
IdentifierTypes.ALIQUOT: 'AliquotBarcode'
},
DataTypes.GNAB: {
IdentifierTypes.PATIENT: 'ParticipantBarcode',
IdentifierTypes.SAMPLE: 'Tumor_SampleBarcode',
IdentifierTypes.ALIQUOT: 'Tumor_AliquotBarcode'
},
DataTypes.USER: {
IdentifierTypes.SAMPLE: 'sample_barcode'
}
}
class DataPointIdentifierTools(object):
@classmethod
def get_id_field_name_for_data_type(cls, data_type, identifier_type):
return IDENTIER_FIELDS_FOR_DATA_TYPES[data_type][identifier_type]
class BigQuerySchemaToValueTypeConverter(object):
field_to_value_types = {
'STRING': ValueType.STRING,
'INTEGER': ValueType.INTEGER,
'FLOAT': ValueType.FLOAT,
'BOOLEAN': ValueType.BOOLEAN
}
@classmethod
def get_value_type(cls, schema_field):
return cls.field_to_value_types[schema_field]
class StringToDataTypeConverter(object):
@classmethod
def get_datatype(cls, x):
pass | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
###############################################################################
#
# DescribeDBInstances
# Returns information about privisioned database instances.
#
# Python versions 2.6, 2.7, 3.x
#
# Copyright 2014, Temboo Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND,
# either express or implied. See the License for the specific
# language governing permissions and limitations under the License.
#
#
###############################################################################
from temboo.core.choreography import Choreography
from temboo.core.choreography import InputSet
from temboo.core.choreography import ResultSet
from temboo.core.choreography import ChoreographyExecution
import json
class DescribeDBInstances(Choreography):
def __init__(self, temboo_session):
"""
Create a new instance of the DescribeDBInstances Choreo. A TembooSession object, containing a valid
set of Temboo credentials, must be supplied.
"""
super(DescribeDBInstances, self).__init__(temboo_session, '/Library/Amazon/RDS/DescribeDBInstances')
def new_input_set(self):
return DescribeDBInstancesInputSet()
def _make_result_set(self, result, path):
return DescribeDBInstancesResultSet(result, path)
def _make_execution(self, session, exec_id, path):
return DescribeDBInstancesChoreographyExecution(session, exec_id, path)
class DescribeDBInstancesInputSet(InputSet):
"""
An InputSet with methods appropriate for specifying the inputs to the DescribeDBInstances
Choreo. The InputSet object is used to specify input parameters when executing this Choreo.
"""
def set_AWSAccessKeyId(self, value):
"""
Set the value of the AWSAccessKeyId input for this Choreo. ((required, string) The Access Key ID provided by Amazon Web Services.)
"""
super(DescribeDBInstancesInputSet, self)._set_input('AWSAccessKeyId', value)
def set_AWSSecretKeyId(self, value):
"""
Set the value of the AWSSecretKeyId input for this Choreo. ((required, string) The Secret Key ID provided by Amazon Web Services.)
"""
super(DescribeDBInstancesInputSet, self)._set_input('AWSSecretKeyId', value)
def set_DBInstanceIdentifier(self, value):
"""
Set the value of the DBInstanceIdentifier input for this Choreo. ((optional, string) The DB Instance identifier. Should be in all lowercase.)
"""
super(DescribeDBInstancesInputSet, self)._set_input('DBInstanceIdentifier', value)
def set_Marker(self, value):
"""
Set the value of the Marker input for this Choreo. ((optional, integer) If this parameter is specified, the response includes only records beyond the marker, up to the value specified by MaxRecords.)
"""
super(DescribeDBInstancesInputSet, self)._set_input('Marker', value)
def set_MaxRecords(self, value):
"""
Set the value of the MaxRecords input for this Choreo. ((optional, integer) The max number of results to return in the response. Defaults to 100. Minimum is 20.)
"""
super(DescribeDBInstancesInputSet, self)._set_input('MaxRecords', value)
def set_UserRegion(self, value):
"""
Set the value of the UserRegion input for this Choreo. ((optional, string) The AWS region that corresponds to the RDS endpoint you wish to access. The default region is "us-east-1". See description below for valid values.)
"""
super(DescribeDBInstancesInputSet, self)._set_input('UserRegion', value)
class DescribeDBInstancesResultSet(ResultSet):
"""
A ResultSet with methods tailored to the values returned by the DescribeDBInstances Choreo.
The ResultSet object is used to retrieve the results of a Choreo execution.
"""
def getJSONFromString(self, str):
return json.loads(str)
def get_Response(self):
"""
Retrieve the value for the "Response" output from this Choreo execution. ((xml) The response from Amazon.)
"""
return self._output.get('Response', None)
class DescribeDBInstancesChoreographyExecution(ChoreographyExecution):
def _make_result_set(self, response, path):
return DescribeDBInstancesResultSet(response, path) | unknown | codeparrot/codeparrot-clean | ||
# Copyright (c) 2012 Rackspace Hosting
# All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
# License for the specific language governing permissions and limitations
# under the License.
"""
CellState Manager
"""
import copy
import datetime
import functools
import time
from oslo.config import cfg
from oslo.db import exception as db_exc
from oslo.serialization import jsonutils
from oslo.utils import timeutils
from oslo.utils import units
from nova.cells import rpc_driver
from nova import context
from nova.db import base
from nova import exception
from nova.i18n import _, _LE
from nova.openstack.common import fileutils
from nova.openstack.common import log as logging
from nova import rpc
from nova import utils
cell_state_manager_opts = [
cfg.IntOpt('db_check_interval',
default=60,
help='Interval, in seconds, for getting fresh cell '
'information from the database.'),
cfg.StrOpt('cells_config',
help='Configuration file from which to read cells '
'configuration. If given, overrides reading cells '
'from the database.'),
]
LOG = logging.getLogger(__name__)
CONF = cfg.CONF
CONF.import_opt('name', 'nova.cells.opts', group='cells')
CONF.import_opt('reserve_percent', 'nova.cells.opts', group='cells')
CONF.import_opt('mute_child_interval', 'nova.cells.opts', group='cells')
CONF.register_opts(cell_state_manager_opts, group='cells')
class CellState(object):
"""Holds information for a particular cell."""
def __init__(self, cell_name, is_me=False):
self.name = cell_name
self.is_me = is_me
self.last_seen = datetime.datetime.min
self.capabilities = {}
self.capacities = {}
self.db_info = {}
# TODO(comstud): The DB will specify the driver to use to talk
# to this cell, but there's no column for this yet. The only
# available driver is the rpc driver.
self.driver = rpc_driver.CellsRPCDriver()
def update_db_info(self, cell_db_info):
"""Update cell credentials from db."""
self.db_info = dict(
[(k, v) for k, v in cell_db_info.iteritems()
if k != 'name'])
def update_capabilities(self, cell_metadata):
"""Update cell capabilities for a cell."""
self.last_seen = timeutils.utcnow()
self.capabilities = cell_metadata
def update_capacities(self, capacities):
"""Update capacity information for a cell."""
self.last_seen = timeutils.utcnow()
self.capacities = capacities
def get_cell_info(self):
"""Return subset of cell information for OS API use."""
db_fields_to_return = ['is_parent', 'weight_scale', 'weight_offset']
url_fields_to_return = {
'username': 'username',
'hostname': 'rpc_host',
'port': 'rpc_port',
}
cell_info = dict(name=self.name, capabilities=self.capabilities)
if self.db_info:
for field in db_fields_to_return:
cell_info[field] = self.db_info[field]
url = rpc.get_transport_url(self.db_info['transport_url'])
if url.hosts:
for field, canonical in url_fields_to_return.items():
cell_info[canonical] = getattr(url.hosts[0], field)
return cell_info
def send_message(self, message):
"""Send a message to a cell. Just forward this to the driver,
passing ourselves and the message as arguments.
"""
self.driver.send_message_to_cell(self, message)
def __repr__(self):
me = "me" if self.is_me else "not_me"
return "Cell '%s' (%s)" % (self.name, me)
def sync_before(f):
"""Use as a decorator to wrap methods that use cell information to
make sure they sync the latest information from the DB periodically.
"""
@functools.wraps(f)
def wrapper(self, *args, **kwargs):
self._cell_data_sync()
return f(self, *args, **kwargs)
return wrapper
def sync_after(f):
"""Use as a decorator to wrap methods that update cell information
in the database to make sure the data is synchronized immediately.
"""
@functools.wraps(f)
def wrapper(self, *args, **kwargs):
result = f(self, *args, **kwargs)
self._cell_data_sync(force=True)
return result
return wrapper
_unset = object()
class CellStateManager(base.Base):
def __new__(cls, cell_state_cls=None, cells_config=_unset):
if cls is not CellStateManager:
return super(CellStateManager, cls).__new__(cls)
if cells_config is _unset:
cells_config = CONF.cells.cells_config
if cells_config:
return CellStateManagerFile(cell_state_cls)
return CellStateManagerDB(cell_state_cls)
def __init__(self, cell_state_cls=None):
super(CellStateManager, self).__init__()
if not cell_state_cls:
cell_state_cls = CellState
self.cell_state_cls = cell_state_cls
self.my_cell_state = cell_state_cls(CONF.cells.name, is_me=True)
self.parent_cells = {}
self.child_cells = {}
self.last_cell_db_check = datetime.datetime.min
attempts = 0
while True:
try:
self._cell_data_sync(force=True)
break
except db_exc.DBError as e:
attempts += 1
if attempts > 120:
raise
LOG.exception(_('DB error: %s') % e)
time.sleep(30)
my_cell_capabs = {}
for cap in CONF.cells.capabilities:
name, value = cap.split('=', 1)
if ';' in value:
values = set(value.split(';'))
else:
values = set([value])
my_cell_capabs[name] = values
self.my_cell_state.update_capabilities(my_cell_capabs)
def _refresh_cells_from_dict(self, db_cells_dict):
"""Make our cell info map match the db."""
# Update current cells. Delete ones that disappeared
for cells_dict in (self.parent_cells, self.child_cells):
for cell_name, cell_info in cells_dict.items():
is_parent = cell_info.db_info['is_parent']
db_dict = db_cells_dict.get(cell_name)
if db_dict and is_parent == db_dict['is_parent']:
cell_info.update_db_info(db_dict)
else:
del cells_dict[cell_name]
# Add new cells
for cell_name, db_info in db_cells_dict.items():
if db_info['is_parent']:
cells_dict = self.parent_cells
else:
cells_dict = self.child_cells
if cell_name not in cells_dict:
cells_dict[cell_name] = self.cell_state_cls(cell_name)
cells_dict[cell_name].update_db_info(db_info)
def _time_to_sync(self):
"""Is it time to sync the DB against our memory cache?"""
diff = timeutils.utcnow() - self.last_cell_db_check
return diff.seconds >= CONF.cells.db_check_interval
def _update_our_capacity(self, ctxt=None):
"""Update our capacity in the self.my_cell_state CellState.
This will add/update 2 entries in our CellState.capacities,
'ram_free' and 'disk_free'.
The values of these are both dictionaries with the following
format:
{'total_mb': <total_memory_free_in_the_cell>,
'units_by_mb: <units_dictionary>}
<units_dictionary> contains the number of units that we can build for
every distinct memory or disk requirement that we have based on
instance types. This number is computed by looking at room available
on every compute_node.
Take the following instance_types as an example:
[{'memory_mb': 1024, 'root_gb': 10, 'ephemeral_gb': 100},
{'memory_mb': 2048, 'root_gb': 20, 'ephemeral_gb': 200}]
capacities['ram_free']['units_by_mb'] would contain the following:
{'1024': <number_of_instances_that_will_fit>,
'2048': <number_of_instances_that_will_fit>}
capacities['disk_free']['units_by_mb'] would contain the following:
{'122880': <number_of_instances_that_will_fit>,
'225280': <number_of_instances_that_will_fit>}
Units are in MB, so 122880 = (10 + 100) * 1024.
NOTE(comstud): Perhaps we should only report a single number
available per instance_type.
"""
if not ctxt:
ctxt = context.get_admin_context()
reserve_level = CONF.cells.reserve_percent / 100.0
compute_hosts = {}
def _get_compute_hosts():
compute_nodes = self.db.compute_node_get_all(ctxt)
for compute in compute_nodes:
service = compute['service']
if not service or service['disabled']:
continue
host = service['host']
compute_hosts[host] = {
'free_ram_mb': compute['free_ram_mb'],
'free_disk_mb': compute['free_disk_gb'] * 1024,
'total_ram_mb': compute['memory_mb'],
'total_disk_mb': compute['local_gb'] * 1024}
_get_compute_hosts()
if not compute_hosts:
self.my_cell_state.update_capacities({})
return
ram_mb_free_units = {}
disk_mb_free_units = {}
total_ram_mb_free = 0
total_disk_mb_free = 0
def _free_units(total, free, per_inst):
if per_inst:
min_free = total * reserve_level
free = max(0, free - min_free)
return int(free / per_inst)
else:
return 0
instance_types = self.db.flavor_get_all(ctxt)
memory_mb_slots = frozenset(
[inst_type['memory_mb'] for inst_type in instance_types])
disk_mb_slots = frozenset(
[(inst_type['root_gb'] + inst_type['ephemeral_gb']) * units.Ki
for inst_type in instance_types])
for compute_values in compute_hosts.values():
total_ram_mb_free += compute_values['free_ram_mb']
total_disk_mb_free += compute_values['free_disk_mb']
for memory_mb_slot in memory_mb_slots:
ram_mb_free_units.setdefault(str(memory_mb_slot), 0)
free_units = _free_units(compute_values['total_ram_mb'],
compute_values['free_ram_mb'], memory_mb_slot)
ram_mb_free_units[str(memory_mb_slot)] += free_units
for disk_mb_slot in disk_mb_slots:
disk_mb_free_units.setdefault(str(disk_mb_slot), 0)
free_units = _free_units(compute_values['total_disk_mb'],
compute_values['free_disk_mb'], disk_mb_slot)
disk_mb_free_units[str(disk_mb_slot)] += free_units
capacities = {'ram_free': {'total_mb': total_ram_mb_free,
'units_by_mb': ram_mb_free_units},
'disk_free': {'total_mb': total_disk_mb_free,
'units_by_mb': disk_mb_free_units}}
self.my_cell_state.update_capacities(capacities)
@sync_before
def get_cell_info_for_neighbors(self):
"""Return cell information for all neighbor cells."""
cell_list = [cell.get_cell_info()
for cell in self.child_cells.itervalues()]
cell_list.extend([cell.get_cell_info()
for cell in self.parent_cells.itervalues()])
return cell_list
@sync_before
def get_my_state(self):
"""Return information for my (this) cell."""
return self.my_cell_state
@sync_before
def get_child_cells(self):
"""Return list of child cell_infos."""
return self.child_cells.values()
@sync_before
def get_parent_cells(self):
"""Return list of parent cell_infos."""
return self.parent_cells.values()
@sync_before
def get_parent_cell(self, cell_name):
return self.parent_cells.get(cell_name)
@sync_before
def get_child_cell(self, cell_name):
return self.child_cells.get(cell_name)
@sync_before
def update_cell_capabilities(self, cell_name, capabilities):
"""Update capabilities for a cell."""
cell = (self.child_cells.get(cell_name) or
self.parent_cells.get(cell_name))
if not cell:
LOG.error(_LE("Unknown cell '%(cell_name)s' when trying to "
"update capabilities"),
{'cell_name': cell_name})
return
# Make sure capabilities are sets.
for capab_name, values in capabilities.items():
capabilities[capab_name] = set(values)
cell.update_capabilities(capabilities)
@sync_before
def update_cell_capacities(self, cell_name, capacities):
"""Update capacities for a cell."""
cell = (self.child_cells.get(cell_name) or
self.parent_cells.get(cell_name))
if not cell:
LOG.error(_LE("Unknown cell '%(cell_name)s' when trying to "
"update capacities"),
{'cell_name': cell_name})
return
cell.update_capacities(capacities)
@sync_before
def get_our_capabilities(self, include_children=True):
capabs = copy.deepcopy(self.my_cell_state.capabilities)
if include_children:
for cell in self.child_cells.values():
if timeutils.is_older_than(cell.last_seen,
CONF.cells.mute_child_interval):
continue
for capab_name, values in cell.capabilities.items():
if capab_name not in capabs:
capabs[capab_name] = set([])
capabs[capab_name] |= values
return capabs
def _add_to_dict(self, target, src):
for key, value in src.items():
if isinstance(value, dict):
target.setdefault(key, {})
self._add_to_dict(target[key], value)
continue
target.setdefault(key, 0)
target[key] += value
@sync_before
def get_our_capacities(self, include_children=True):
capacities = copy.deepcopy(self.my_cell_state.capacities)
if include_children:
for cell in self.child_cells.values():
self._add_to_dict(capacities, cell.capacities)
return capacities
@sync_before
def get_capacities(self, cell_name=None):
if not cell_name or cell_name == self.my_cell_state.name:
return self.get_our_capacities()
if cell_name in self.child_cells:
return self.child_cells[cell_name].capacities
raise exception.CellNotFound(cell_name=cell_name)
@sync_before
def cell_get(self, ctxt, cell_name):
for cells_dict in (self.parent_cells, self.child_cells):
if cell_name in cells_dict:
return cells_dict[cell_name]
raise exception.CellNotFound(cell_name=cell_name)
class CellStateManagerDB(CellStateManager):
@utils.synchronized('cell-db-sync')
def _cell_data_sync(self, force=False):
"""Update cell status for all cells from the backing data store
when necessary.
:param force: If True, cell status will be updated regardless
of whether it's time to do so.
"""
if force or self._time_to_sync():
LOG.debug("Updating cell cache from db.")
self.last_cell_db_check = timeutils.utcnow()
ctxt = context.get_admin_context()
db_cells = self.db.cell_get_all(ctxt)
db_cells_dict = dict((cell['name'], cell) for cell in db_cells)
self._refresh_cells_from_dict(db_cells_dict)
self._update_our_capacity(ctxt)
@sync_after
def cell_create(self, ctxt, values):
return self.db.cell_create(ctxt, values)
@sync_after
def cell_update(self, ctxt, cell_name, values):
return self.db.cell_update(ctxt, cell_name, values)
@sync_after
def cell_delete(self, ctxt, cell_name):
return self.db.cell_delete(ctxt, cell_name)
class CellStateManagerFile(CellStateManager):
def __init__(self, cell_state_cls=None):
cells_config = CONF.cells.cells_config
self.cells_config_path = CONF.find_file(cells_config)
if not self.cells_config_path:
raise cfg.ConfigFilesNotFoundError(config_files=[cells_config])
super(CellStateManagerFile, self).__init__(cell_state_cls)
def _cell_data_sync(self, force=False):
"""Update cell status for all cells from the backing data store
when necessary.
:param force: If True, cell status will be updated regardless
of whether it's time to do so.
"""
reloaded, data = fileutils.read_cached_file(self.cells_config_path,
force_reload=force)
if reloaded:
LOG.debug("Updating cell cache from config file.")
self.cells_config_data = jsonutils.loads(data)
self._refresh_cells_from_dict(self.cells_config_data)
if force or self._time_to_sync():
self.last_cell_db_check = timeutils.utcnow()
self._update_our_capacity()
def cell_create(self, ctxt, values):
raise exception.CellsUpdateUnsupported()
def cell_update(self, ctxt, cell_name, values):
raise exception.CellsUpdateUnsupported()
def cell_delete(self, ctxt, cell_name):
raise exception.CellsUpdateUnsupported() | unknown | codeparrot/codeparrot-clean | ||
# -*- coding: utf-8 -*-
"""
pythoncompat
"""
from .packages import chardet
import sys
# -------
# Pythons
# -------
# Syntax sugar.
_ver = sys.version_info
#: Python 2.x?
is_py2 = (_ver[0] == 2)
#: Python 3.x?
is_py3 = (_ver[0] == 3)
#: Python 3.0.x
is_py30 = (is_py3 and _ver[1] == 0)
#: Python 3.1.x
is_py31 = (is_py3 and _ver[1] == 1)
#: Python 3.2.x
is_py32 = (is_py3 and _ver[1] == 2)
#: Python 3.3.x
is_py33 = (is_py3 and _ver[1] == 3)
#: Python 3.4.x
is_py34 = (is_py3 and _ver[1] == 4)
#: Python 2.7.x
is_py27 = (is_py2 and _ver[1] == 7)
#: Python 2.6.x
is_py26 = (is_py2 and _ver[1] == 6)
#: Python 2.5.x
is_py25 = (is_py2 and _ver[1] == 5)
#: Python 2.4.x
is_py24 = (is_py2 and _ver[1] == 4) # I'm assuming this is not by choice.
# ---------
# Platforms
# ---------
# Syntax sugar.
_ver = sys.version.lower()
is_pypy = ('pypy' in _ver)
is_jython = ('jython' in _ver)
is_ironpython = ('iron' in _ver)
# Assume CPython, if nothing else.
is_cpython = not any((is_pypy, is_jython, is_ironpython))
# Windows-based system.
is_windows = 'win32' in str(sys.platform).lower()
# Standard Linux 2+ system.
is_linux = ('linux' in str(sys.platform).lower())
is_osx = ('darwin' in str(sys.platform).lower())
is_hpux = ('hpux' in str(sys.platform).lower()) # Complete guess.
is_solaris = ('solar==' in str(sys.platform).lower()) # Complete guess.
try:
import simplejson as json
except (ImportError, SyntaxError):
# simplejson does not support Python 3.2, it throws a SyntaxError
# because of u'...' Unicode literals.
import json
# ---------
# Specifics
# ---------
if is_py2:
from urllib import quote, unquote, quote_plus, unquote_plus, urlencode, getproxies, proxy_bypass
from urlparse import urlparse, urlunparse, urljoin, urlsplit, urldefrag
from urllib2 import parse_http_list
import cookielib
from Cookie import Morsel
from StringIO import StringIO
from .packages.urllib3.packages.ordered_dict import OrderedDict
builtin_str = str
bytes = str
str = unicode
basestring = basestring
numeric_types = (int, long, float)
elif is_py3:
from urllib.parse import urlparse, urlunparse, urljoin, urlsplit, urlencode, quote, unquote, quote_plus, unquote_plus, urldefrag
from urllib.request import parse_http_list, getproxies, proxy_bypass
from http import cookiejar as cookielib
from http.cookies import Morsel
from io import StringIO
from collections import OrderedDict
builtin_str = str
str = str
bytes = bytes
basestring = (str, bytes)
numeric_types = (int, float) | unknown | codeparrot/codeparrot-clean | ||
import logging
import time
from datetime import datetime
from boto.sdb.db.model import Model
from boto.sdb.db.property import StringProperty, IntegerProperty, BooleanProperty
from boto.sdb.db.property import DateTimeProperty, FloatProperty, ReferenceProperty
from boto.sdb.db.property import PasswordProperty, ListProperty, MapProperty
from boto.exception import SDBPersistenceError
logging.basicConfig()
log = logging.getLogger('test_db')
log.setLevel(logging.DEBUG)
_objects = {}
#
# This will eventually be moved to the boto.tests module and become a real unit test
# but for now it will live here. It shows examples of each of the Property types in
# use and tests the basic operations.
#
class TestBasic(Model):
name = StringProperty()
size = IntegerProperty()
foo = BooleanProperty()
date = DateTimeProperty()
class TestFloat(Model):
name = StringProperty()
value = FloatProperty()
class TestRequired(Model):
req = StringProperty(required=True, default='foo')
class TestReference(Model):
ref = ReferenceProperty(reference_class=TestBasic, collection_name='refs')
class TestSubClass(TestBasic):
answer = IntegerProperty()
class TestPassword(Model):
password = PasswordProperty()
class TestList(Model):
name = StringProperty()
nums = ListProperty(int)
class TestMap(Model):
name = StringProperty()
map = MapProperty()
class TestListReference(Model):
name = StringProperty()
basics = ListProperty(TestBasic)
class TestAutoNow(Model):
create_date = DateTimeProperty(auto_now_add=True)
modified_date = DateTimeProperty(auto_now=True)
class TestUnique(Model):
name = StringProperty(unique=True)
def test_basic():
global _objects
t = TestBasic()
t.name = 'simple'
t.size = -42
t.foo = True
t.date = datetime.now()
log.debug('saving object')
t.put()
_objects['test_basic_t'] = t
time.sleep(5)
log.debug('now try retrieving it')
tt = TestBasic.get_by_id(t.id)
_objects['test_basic_tt'] = tt
assert tt.id == t.id
l = TestBasic.get_by_id([t.id])
assert len(l) == 1
assert l[0].id == t.id
assert t.size == tt.size
assert t.foo == tt.foo
assert t.name == tt.name
#assert t.date == tt.date
return t
def test_float():
global _objects
t = TestFloat()
t.name = 'float object'
t.value = 98.6
log.debug('saving object')
t.save()
_objects['test_float_t'] = t
time.sleep(5)
log.debug('now try retrieving it')
tt = TestFloat.get_by_id(t.id)
_objects['test_float_tt'] = tt
assert tt.id == t.id
assert tt.name == t.name
assert tt.value == t.value
return t
def test_required():
global _objects
t = TestRequired()
_objects['test_required_t'] = t
t.put()
return t
def test_reference(t=None):
global _objects
if not t:
t = test_basic()
tt = TestReference()
tt.ref = t
tt.put()
time.sleep(10)
tt = TestReference.get_by_id(tt.id)
_objects['test_reference_tt'] = tt
assert tt.ref.id == t.id
for o in t.refs:
log.debug(o)
def test_subclass():
global _objects
t = TestSubClass()
_objects['test_subclass_t'] = t
t.name = 'a subclass'
t.size = -489
t.save()
def test_password():
global _objects
t = TestPassword()
_objects['test_password_t'] = t
t.password = "foo"
t.save()
time.sleep(5)
# Make sure it stored ok
tt = TestPassword.get_by_id(t.id)
_objects['test_password_tt'] = tt
#Testing password equality
assert tt.password == "foo"
#Testing password not stored as string
assert str(tt.password) != "foo"
def test_list():
global _objects
t = TestList()
_objects['test_list_t'] = t
t.name = 'a list of ints'
t.nums = [1, 2, 3, 4, 5]
t.put()
tt = TestList.get_by_id(t.id)
_objects['test_list_tt'] = tt
assert tt.name == t.name
for n in tt.nums:
assert isinstance(n, int)
def test_list_reference():
global _objects
t = TestBasic()
t.put()
_objects['test_list_ref_t'] = t
tt = TestListReference()
tt.name = "foo"
tt.basics = [t]
tt.put()
time.sleep(5)
_objects['test_list_ref_tt'] = tt
ttt = TestListReference.get_by_id(tt.id)
assert ttt.basics[0].id == t.id
def test_unique():
global _objects
t = TestUnique()
name = 'foo' + str(int(time.time()))
t.name = name
t.put()
_objects['test_unique_t'] = t
time.sleep(10)
tt = TestUnique()
_objects['test_unique_tt'] = tt
tt.name = name
try:
tt.put()
assert False
except(SDBPersistenceError):
pass
def test_datetime():
global _objects
t = TestAutoNow()
t.put()
_objects['test_datetime_t'] = t
time.sleep(5)
tt = TestAutoNow.get_by_id(t.id)
assert tt.create_date.timetuple() == t.create_date.timetuple()
def test():
log.info('test_basic')
t1 = test_basic()
log.info('test_required')
test_required()
log.info('test_reference')
test_reference(t1)
log.info('test_subclass')
test_subclass()
log.info('test_password')
test_password()
log.info('test_list')
test_list()
log.info('test_list_reference')
test_list_reference()
log.info("test_datetime")
test_datetime()
log.info('test_unique')
test_unique()
if __name__ == "__main__":
test() | unknown | codeparrot/codeparrot-clean | ||
import base64
import datetime
import json
import logging
from jumpgate.common import aes
from jumpgate.common import exceptions
from jumpgate.common import utils
from jumpgate.identity.drivers import core as identity
from oslo.config import cfg
import SoftLayer
LOG = logging.getLogger(__name__)
USER_MASK = 'id, username, accountId'
def parse_templates(template_lines):
o = {}
for line in template_lines:
if ' = ' not in line:
continue
k, v = line.strip().split(' = ')
if not k.startswith('catalog.'):
continue
parts = k.split('.')
region, service, key = parts[1:4]
region_ref = o.get(region, {})
service_ref = region_ref.get(service, {})
service_ref[key] = v
service_ref['region'] = region
region_ref[service] = service_ref
o[region] = region_ref
return o
def get_access(token_id, token_details):
tokens = identity.token_driver()
return {
'token': {
# replaced isoformat() with strftime to make tempest pass
'expires': datetime.datetime.fromtimestamp(
tokens.expires(token_details)).strftime('%Y-%m-%dT%H:%M:%SZ'),
'id': token_id,
'tenant': {
'id': tokens.tenant_id(token_details),
'name': tokens.tenant_name(token_details),
},
},
'user': {
'username': tokens.username(token_details),
'id': tokens.user_id(token_details),
'roles': [{'id': rid, 'name': name} for rid, name in
tokens.roles(token_details).items()],
'role_links': [],
'name': tokens.username(token_details),
},
}
class SLAuthDriver(identity.AuthDriver):
"""Jumpgate SoftLayer auth driver which authenticates using the SLAPI.
Suitable for most implementations who's authentication requests should
be validates against SoftLayer's credential system which uses either a
username/password scheme or a username/api-key scheme.
"""
def __init__(self):
super(SLAuthDriver, self).__init__()
def authenticate(self, creds):
username = utils.lookup(creds,
'auth',
'passwordCredentials',
'username')
credential = utils.lookup(creds,
'auth',
'passwordCredentials',
'password')
token_id = utils.lookup(creds, 'auth', 'token', 'id')
token_driver = identity.token_driver()
token_auth = None
if token_id:
token = identity.token_id_driver().token_from_id(token_id)
token_driver.validate_token(token)
username = token_driver.username(token)
credential = token_driver.credential(token)
token_auth = token['auth_type'] == 'token'
def assert_tenant(user):
tenant = (utils.lookup(creds, 'auth', 'tenantId')
or utils.lookup(creds, 'auth', 'tenantName'))
if tenant and str(user['accountId']) != tenant:
raise exceptions.Unauthorized(
'Invalid username, password or tenant id')
endpoint = cfg.CONF['softlayer']['endpoint']
proxy = cfg.CONF['softlayer']['proxy']
# If the 'password' is the right length, treat it as an API api_key
if len(credential) == 64:
client = SoftLayer.Client(username=username,
api_key=credential,
endpoint_url=endpoint,
proxy=proxy)
user = client['Account'].getCurrentUser(mask=USER_MASK)
assert_tenant(user)
return {'user': user, 'credential': credential,
'auth_type': 'api_key'}
else:
client = SoftLayer.Client(endpoint_url=endpoint,
proxy=proxy)
client.auth = None
try:
if token_auth:
client.auth = SoftLayer.TokenAuthentication(
token['user_id'], credential)
else:
userId, tokenHash = (
client.authenticate_with_password(username, credential)
)
user = client['Account'].getCurrentUser(mask=USER_MASK)
assert_tenant(user)
if token_auth:
tokenHash = credential
return {'user': user, 'credential': tokenHash,
'auth_type': 'token'}
except SoftLayer.SoftLayerAPIError as e:
if (e.faultCode == "SoftLayer_Exception_User_Customer"
"_LoginFailed"):
raise exceptions.Unauthorized(e.faultString)
raise
class NoAuthDriver(identity.AuthDriver):
"""Auto-approve an identity request to a single default SL credential.
Validates a consumer's identity in the jumpgate.conf and grants the
consumer eligibility for an authentication token.
"""
def __init__(self):
super(NoAuthDriver, self).__init__()
def authenticate(self, creds):
"""Performs faux authentication
:param creds: The credentials in dict form as passed to the API
in a request to authenticate and obtain a new token. Not used,
but present for parent-class compatibility.
"""
endpoint = cfg.CONF['softlayer']['endpoint']
proxy = cfg.CONF['softlayer']['proxy']
default_user = cfg.CONF['softlayer']['noauth_user']
default_api_key = cfg.CONF['softlayer']['noauth_api_key']
client = SoftLayer.Client(username=default_user,
api_key=default_api_key,
endpoint_url=endpoint,
proxy=proxy)
user = client['Account'].getCurrentUser(mask=USER_MASK)
return {'user': user, 'credential': default_api_key,
'auth_type': 'api_key'}
class TokensV2(object):
def __init__(self, template_file):
self._load_templates(template_file)
def _load_templates(self, template_file):
try:
self.templates = parse_templates(open(template_file))
except IOError:
LOG.critical('Unable to open template file %s', template_file)
raise
def _get_catalog(self, tenant_id, user_id):
d = {'tenant_id': tenant_id, 'user_id': user_id}
o = {}
for region, region_ref in self.templates.items():
o[region] = {}
for service, service_ref in region_ref.items():
o[region][service] = {}
for k, v in service_ref.items():
o[region][service][k] = v.replace('$(', '%(') % d
return o
def _add_catalog_to_access(self, access, token):
tokens = identity.token_driver()
raw_catalog = self._get_catalog(tokens.tenant_id(token),
tokens.user_id(token))
catalog = []
for services in raw_catalog.values():
for service_type, service in services.items():
d = {
'type': service_type,
'name': service.get('name', 'Unknown'),
'endpoints': [{
'region': service.get('region', 'RegionOne'),
'publicURL': service.get('publicURL'),
'internalURL': service.get('internalURL'),
'adminURL': service.get('adminURL'),
}],
'endpoint_links': [],
}
catalog.append(d)
access['serviceCatalog'] = catalog
def on_post(self, req, resp):
body = req.stream.read().decode()
credentials = json.loads(body)
tokens = identity.token_driver()
auth = identity.auth_driver().authenticate(credentials)
if auth is None:
raise exceptions.Unauthorized('Unauthorized credentials')
token = tokens.create_token(credentials, auth)
tok_id = identity.token_id_driver().create_token_id(token)
access = get_access(tok_id, token)
# Add catalog to the access data
self._add_catalog_to_access(access, token)
resp.status = 200
resp.body = {'access': access}
def on_get(self, req, resp, token_id):
tokens = identity.token_driver()
token = identity.token_id_driver().token_from_id(token_id)
identity.token_driver().validate_token(token)
raw_endpoints = self._get_catalog(tokens.tenant_id(token),
tokens.user_id(token))
endpoints = []
for services in raw_endpoints.values():
for service_type, service in services.items():
d = {
'adminURL': service.get('adminURL'),
'name': service.get('name', 'Unknown'),
'publicURL': service.get('publicURL'),
'internalURL': service.get('internalURL'),
'region': service.get('region', 'RegionOne'),
'tenantId': tokens.tenant_id(token),
'type': service_type,
}
endpoints.append(d)
resp.status = 200
resp.body = {'endpoints': endpoints, 'endpoints_links': []}
class TokenV2(TokensV2):
def __init__(self, template_file):
super(TokenV2, self).__init__(template_file)
def on_get(self, req, resp, token_id):
token = identity.token_id_driver().token_from_id(token_id)
identity.token_driver().validate_access(token, tenant_id=req.get_param(
'belongsTo'))
access = get_access(token_id, token)
# Add catalog to the access data
self._add_catalog_to_access(access, token)
resp.status = 200
resp.body = {'access': access}
def on_delete(self, req, resp, token_id):
# This method is called when OpenStack wants to remove a token's
# validity, such as when a cookie expires. Our login tokens can't
# be forced to expire yet, so this does nothing.
LOG.warning('User attempted to delete token: %s', token_id)
resp.status = 202
resp.body = ''
class FakeTokenIdDriver(identity.TokenIdDriver):
"""Fake 'accept-anything' Jumpgate token ID driver
All token ids map to a single Softlayer user/tenant.
This is meant for environments that use a separate 'real' keystone
and want to just have any token be accepted andmap to a single
SoftLayer user/tenant, defined in the jumpgate.conf.
"""
def __init__(self):
super(FakeTokenIdDriver, self).__init__()
def create_token_id(self, token):
# Doesn't matter how we encode, since decode will always give
# same result no matter what input, but for now do the same as our
# default driver
return base64.b64encode(aes.encode_aes(json.dumps(token)))
def token_from_id(self, token_id):
try:
tokens = identity.token_driver()
if (identity.auth_driver().__class__.__name__ != "NoAuthDriver"):
raise exceptions.InvalidTokenError(
'Auth-driver must be NoAuthDriver')
auth = identity.auth_driver().authenticate(None)
if auth is None:
raise exceptions.Unauthorized('Unauthorized credentials')
token = tokens.create_token(None, auth)
return token
except (TypeError, ValueError):
raise exceptions.InvalidTokenError('Malformed token') | unknown | codeparrot/codeparrot-clean | ||
import BaseHTTPServer
import errno
import os
import mimetypes
import socket
import sys
import threading
class MinimalistHTTPServer(BaseHTTPServer.HTTPServer):
'A HTTP server class to pass parameters to MinimalistHTTPRequestHandler'
def set_file(self, allowed_file):
'Prepare everything for serving our single available file.'
# Avoid any funny business regarding the path, just in case.
self.allowed_file = os.path.realpath(allowed_file)
class MinimalistHTTPRequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
'''A minimalist request handler, to handle only GET requests
for a single, specified file'''
def do_GET(self):
'Serve the specified file when requested, return errors otherwise'
# The only request path to accept is '/self.server.allowed_file'.
if self.path != '/' + os.path.basename(self.server.allowed_file):
self.send_error(403)
return
try:
fout = open(self.server.allowed_file)
except IOError:
self.send_error(404)
return
self.send_response(200)
mimetypes.init()
mime_guess = mimetypes.guess_type(self.server.allowed_file)
if mime_guess[0] is not None:
self.send_header('Content-Type', mime_guess[0])
if mime_guess[1] is not None:
self.send_header('Content-Encoding', mime_guess[1])
statinfo = os.stat(self.server.allowed_file)
self.send_header('Content-Length', statinfo.st_size)
self.end_headers()
try:
self.wfile.write(fout.read())
except socket.error, e:
# EPIPE likely means the client's closed the connection,
# it's nothing of concern so suppress the error message.
if errno.errorcode[e[0]] == 'EPIPE':
pass
fout.close()
return
class HTTPServerLauncher(object):
'A launcher class for MinimalistHTTPServer.'
def __init__(self, server_addr, file):
self.server = MinimalistHTTPServer(server_addr,
MinimalistHTTPRequestHandler)
self.server.set_file(file)
def request_shutdown(self):
if sys.version_info >= (2, 6):
self.server.shutdown()
else:
self.run_it = False
def run(self):
if sys.version_info >= (2, 6):
# Safe to use here because 2.6 provides server.shutdown().
self.server.serve_forever()
else:
self.run_it = True
while self.run_it == True:
# WARNING: if this blocks and no request arrives, the server
# may remain up indefinitely! FIXME?
self.server.handle_request() | unknown | codeparrot/codeparrot-clean | ||
"""Simple example to show how to use weave.inline on SWIG2 wrapped
objects. SWIG2 refers to SWIG versions >= 1.3.
To run this example you must build the trivial SWIG2 extension called
swig2_ext. To do this you need to do something like this::
$ swig -c++ -python -I. -o swig2_ext_wrap.cxx swig2_ext.i
$ g++ -Wall -O2 -I/usr/include/python2.3 -fPIC -I. -c \
-o swig2_ext_wrap.os swig2_ext_wrap.cxx
$ g++ -shared -o _swig2_ext.so swig2_ext_wrap.os \
-L/usr/lib/python2.3/config
The files swig2_ext.i and swig2_ext.h are included in the same
directory that contains this file.
Note that weave's SWIG2 support works fine whether SWIG_COBJECT_TYPES
are used or not.
Author: Prabhu Ramachandran
Copyright (c) 2004, Prabhu Ramachandran
License: BSD Style.
"""
from __future__ import absolute_import, print_function
# Import our SWIG2 wrapped library
import swig2_ext
import scipy.weave as weave
from scipy.weave import swig2_spec, converters
# SWIG2 support is not enabled by default. We do this by adding the
# swig2 converter to the default list of converters.
converters.default.insert(0, swig2_spec.swig2_converter())
def test():
"""Instantiate the SWIG wrapped object and then call its method
from C++ using weave.inline
"""
a = swig2_ext.A()
b = swig2_ext.foo() # This will be an APtr instance.
b.thisown = 1 # Prevent memory leaks.
code = """a->f();
b->f();
"""
weave.inline(code, ['a', 'b'], include_dirs=['.'],
headers=['"swig2_ext.h"'], verbose=1)
if __name__ == "__main__":
test() | unknown | codeparrot/codeparrot-clean | ||
"""
websocket - WebSocket client library for Python
Copyright (C) 2010 Hiroki Ohtani(liris)
This library is free software; you can redistribute it and/or
modify it under the terms of the GNU Lesser General Public
License as published by the Free Software Foundation; either
version 2.1 of the License, or (at your option) any later version.
This library is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with this library; if not, write to the Free Software
Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
"""
import socket
try:
import ssl
from ssl import SSLError
HAVE_SSL = True
except ImportError:
# dummy class of SSLError for ssl none-support environment.
class SSLError(Exception):
pass
HAVE_SSL = False
from urlparse import urlparse
import os
import array
import struct
import uuid
import hashlib
import base64
import threading
import time
import logging
import traceback
import sys
"""
websocket python client.
=========================
This version support only hybi-13.
Please see http://tools.ietf.org/html/rfc6455 for protocol.
"""
# websocket supported version.
VERSION = 13
# closing frame status codes.
STATUS_NORMAL = 1000
STATUS_GOING_AWAY = 1001
STATUS_PROTOCOL_ERROR = 1002
STATUS_UNSUPPORTED_DATA_TYPE = 1003
STATUS_STATUS_NOT_AVAILABLE = 1005
STATUS_ABNORMAL_CLOSED = 1006
STATUS_INVALID_PAYLOAD = 1007
STATUS_POLICY_VIOLATION = 1008
STATUS_MESSAGE_TOO_BIG = 1009
STATUS_INVALID_EXTENSION = 1010
STATUS_UNEXPECTED_CONDITION = 1011
STATUS_TLS_HANDSHAKE_ERROR = 1015
logger = logging.getLogger()
class WebSocketException(Exception):
"""
websocket exeception class.
"""
pass
class WebSocketConnectionClosedException(WebSocketException):
"""
If remote host closed the connection or some network error happened,
this exception will be raised.
"""
pass
class WebSocketTimeoutException(WebSocketException):
"""
WebSocketTimeoutException will be raised at socket timeout during read/write data.
"""
pass
default_timeout = None
traceEnabled = False
def enableTrace(tracable):
"""
turn on/off the tracability.
tracable: boolean value. if set True, tracability is enabled.
"""
global traceEnabled
traceEnabled = tracable
if tracable:
if not logger.handlers:
logger.addHandler(logging.StreamHandler())
logger.setLevel(logging.DEBUG)
def setdefaulttimeout(timeout):
"""
Set the global timeout setting to connect.
timeout: default socket timeout time. This value is second.
"""
global default_timeout
default_timeout = timeout
def getdefaulttimeout():
"""
Return the global timeout setting(second) to connect.
"""
return default_timeout
def _parse_url(url):
"""
parse url and the result is tuple of
(hostname, port, resource path and the flag of secure mode)
url: url string.
"""
if ":" not in url:
raise ValueError("url is invalid")
scheme, url = url.split(":", 1)
parsed = urlparse(url, scheme="http")
if parsed.hostname:
hostname = parsed.hostname
else:
raise ValueError("hostname is invalid")
port = 0
if parsed.port:
port = parsed.port
is_secure = False
if scheme == "ws":
if not port:
port = 80
elif scheme == "wss":
is_secure = True
if not port:
port = 443
else:
raise ValueError("scheme %s is invalid" % scheme)
if parsed.path:
resource = parsed.path
else:
resource = "/"
if parsed.query:
resource += "?" + parsed.query
return (hostname, port, resource, is_secure)
def create_connection(url, timeout=None, **options):
"""
connect to url and return websocket object.
Connect to url and return the WebSocket object.
Passing optional timeout parameter will set the timeout on the socket.
If no timeout is supplied, the global default timeout setting returned by getdefauttimeout() is used.
You can customize using 'options'.
If you set "header" list object, you can set your own custom header.
>>> conn = create_connection("ws://echo.websocket.org/",
... header=["User-Agent: MyProgram",
... "x-custom: header"])
timeout: socket timeout time. This value is integer.
if you set None for this value, it means "use default_timeout value"
options: current support option is only "header".
if you set header as dict value, the custom HTTP headers are added.
"""
sockopt = options.get("sockopt", [])
sslopt = options.get("sslopt", {})
websock = WebSocket(sockopt=sockopt, sslopt=sslopt)
websock.settimeout(timeout if timeout is not None else default_timeout)
websock.connect(url, **options)
return websock
_MAX_INTEGER = (1 << 32) -1
_AVAILABLE_KEY_CHARS = range(0x21, 0x2f + 1) + range(0x3a, 0x7e + 1)
_MAX_CHAR_BYTE = (1<<8) -1
# ref. Websocket gets an update, and it breaks stuff.
# http://axod.blogspot.com/2010/06/websocket-gets-update-and-it-breaks.html
def _create_sec_websocket_key():
uid = uuid.uuid4()
return base64.encodestring(uid.bytes).strip()
_HEADERS_TO_CHECK = {
"upgrade": "websocket",
"connection": "upgrade",
}
class ABNF(object):
"""
ABNF frame class.
see http://tools.ietf.org/html/rfc5234
and http://tools.ietf.org/html/rfc6455#section-5.2
"""
# operation code values.
OPCODE_CONT = 0x0
OPCODE_TEXT = 0x1
OPCODE_BINARY = 0x2
OPCODE_CLOSE = 0x8
OPCODE_PING = 0x9
OPCODE_PONG = 0xa
# available operation code value tuple
OPCODES = (OPCODE_CONT, OPCODE_TEXT, OPCODE_BINARY, OPCODE_CLOSE,
OPCODE_PING, OPCODE_PONG)
# opcode human readable string
OPCODE_MAP = {
OPCODE_CONT: "cont",
OPCODE_TEXT: "text",
OPCODE_BINARY: "binary",
OPCODE_CLOSE: "close",
OPCODE_PING: "ping",
OPCODE_PONG: "pong"
}
# data length threashold.
LENGTH_7 = 0x7d
LENGTH_16 = 1 << 16
LENGTH_63 = 1 << 63
def __init__(self, fin=0, rsv1=0, rsv2=0, rsv3=0,
opcode=OPCODE_TEXT, mask=1, data=""):
"""
Constructor for ABNF.
please check RFC for arguments.
"""
self.fin = fin
self.rsv1 = rsv1
self.rsv2 = rsv2
self.rsv3 = rsv3
self.opcode = opcode
self.mask = mask
self.data = data
self.get_mask_key = os.urandom
def __str__(self):
return "fin=" + str(self.fin) \
+ " opcode=" + str(self.opcode) \
+ " data=" + str(self.data)
@staticmethod
def create_frame(data, opcode):
"""
create frame to send text, binary and other data.
data: data to send. This is string value(byte array).
if opcode is OPCODE_TEXT and this value is uniocde,
data value is conveted into unicode string, automatically.
opcode: operation code. please see OPCODE_XXX.
"""
if opcode == ABNF.OPCODE_TEXT and isinstance(data, unicode):
data = data.encode("utf-8")
# mask must be set if send data from client
return ABNF(1, 0, 0, 0, opcode, 1, data)
def format(self):
"""
format this object to string(byte array) to send data to server.
"""
if any(x not in (0, 1) for x in [self.fin, self.rsv1, self.rsv2, self.rsv3]):
raise ValueError("not 0 or 1")
if self.opcode not in ABNF.OPCODES:
raise ValueError("Invalid OPCODE")
length = len(self.data)
if length >= ABNF.LENGTH_63:
raise ValueError("data is too long")
frame_header = chr(self.fin << 7
| self.rsv1 << 6 | self.rsv2 << 5 | self.rsv3 << 4
| self.opcode)
if length < ABNF.LENGTH_7:
frame_header += chr(self.mask << 7 | length)
elif length < ABNF.LENGTH_16:
frame_header += chr(self.mask << 7 | 0x7e)
frame_header += struct.pack("!H", length)
else:
frame_header += chr(self.mask << 7 | 0x7f)
frame_header += struct.pack("!Q", length)
if not self.mask:
return frame_header + self.data
else:
mask_key = self.get_mask_key(4)
return frame_header + self._get_masked(mask_key)
def _get_masked(self, mask_key):
s = ABNF.mask(mask_key, self.data)
return mask_key + "".join(s)
@staticmethod
def mask(mask_key, data):
"""
mask or unmask data. Just do xor for each byte
mask_key: 4 byte string(byte).
data: data to mask/unmask.
"""
_m = array.array("B", mask_key)
_d = array.array("B", data)
for i in xrange(len(_d)):
_d[i] ^= _m[i % 4]
return _d.tostring()
class WebSocket(object):
"""
Low level WebSocket interface.
This class is based on
The WebSocket protocol draft-hixie-thewebsocketprotocol-76
http://tools.ietf.org/html/draft-hixie-thewebsocketprotocol-76
We can connect to the websocket server and send/recieve data.
The following example is a echo client.
>>> import websocket
>>> ws = websocket.WebSocket()
>>> ws.connect("ws://echo.websocket.org")
>>> ws.send("Hello, Server")
>>> ws.recv()
'Hello, Server'
>>> ws.close()
get_mask_key: a callable to produce new mask keys, see the set_mask_key
function's docstring for more details
sockopt: values for socket.setsockopt.
sockopt must be tuple and each element is argument of sock.setscokopt.
sslopt: dict object for ssl socket option.
"""
def __init__(self, get_mask_key=None, sockopt=None, sslopt=None):
"""
Initalize WebSocket object.
"""
if sockopt is None:
sockopt = []
if sslopt is None:
sslopt = {}
self.connected = False
self.sock = socket.socket()
for opts in sockopt:
self.sock.setsockopt(*opts)
self.sslopt = sslopt
self.get_mask_key = get_mask_key
# Buffers over the packets from the layer beneath until desired amount
# bytes of bytes are received.
self._recv_buffer = []
# These buffer over the build-up of a single frame.
self._frame_header = None
self._frame_length = None
self._frame_mask = None
self._cont_data = None
def fileno(self):
return self.sock.fileno()
def set_mask_key(self, func):
"""
set function to create musk key. You can custumize mask key generator.
Mainly, this is for testing purpose.
func: callable object. the fuct must 1 argument as integer.
The argument means length of mask key.
This func must be return string(byte array),
which length is argument specified.
"""
self.get_mask_key = func
def gettimeout(self):
"""
Get the websocket timeout(second).
"""
return self.sock.gettimeout()
def settimeout(self, timeout):
"""
Set the timeout to the websocket.
timeout: timeout time(second).
"""
self.sock.settimeout(timeout)
timeout = property(gettimeout, settimeout)
def connect(self, url, **options):
"""
Connect to url. url is websocket url scheme. ie. ws://host:port/resource
You can customize using 'options'.
If you set "header" dict object, you can set your own custom header.
>>> ws = WebSocket()
>>> ws.connect("ws://echo.websocket.org/",
... header={"User-Agent: MyProgram",
... "x-custom: header"})
timeout: socket timeout time. This value is integer.
if you set None for this value,
it means "use default_timeout value"
options: current support option is only "header".
if you set header as dict value,
the custom HTTP headers are added.
"""
hostname, port, resource, is_secure = _parse_url(url)
# TODO: we need to support proxy
self.sock.connect((hostname, port))
if is_secure:
if HAVE_SSL:
if self.sslopt is None:
sslopt = {}
else:
sslopt = self.sslopt
self.sock = ssl.wrap_socket(self.sock, **sslopt)
else:
raise WebSocketException("SSL not available.")
self._handshake(hostname, port, resource, **options)
def _handshake(self, host, port, resource, **options):
sock = self.sock
headers = []
headers.append("GET %s HTTP/1.1" % resource)
headers.append("Upgrade: websocket")
headers.append("Connection: Upgrade")
if port == 80:
hostport = host
else:
hostport = "%s:%d" % (host, port)
headers.append("Host: %s" % hostport)
if "origin" in options:
headers.append("Origin: %s" % options["origin"])
else:
headers.append("Origin: http://%s" % hostport)
key = _create_sec_websocket_key()
headers.append("Sec-WebSocket-Key: %s" % key)
headers.append("Sec-WebSocket-Version: %s" % VERSION)
if "header" in options:
headers.extend(options["header"])
headers.append("")
headers.append("")
header_str = "\r\n".join(headers)
self._send(header_str)
if traceEnabled:
logger.debug("--- request header ---")
logger.debug(header_str)
logger.debug("-----------------------")
status, resp_headers = self._read_headers()
if status != 101:
self.close()
raise WebSocketException("Handshake Status %d" % status)
success = self._validate_header(resp_headers, key)
if not success:
self.close()
raise WebSocketException("Invalid WebSocket Header")
self.connected = True
def _validate_header(self, headers, key):
for k, v in _HEADERS_TO_CHECK.iteritems():
r = headers.get(k, None)
if not r:
return False
r = r.lower()
if v != r:
return False
result = headers.get("sec-websocket-accept", None)
if not result:
return False
result = result.lower()
value = key + "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"
hashed = base64.encodestring(hashlib.sha1(value).digest()).strip().lower()
return hashed == result
def _read_headers(self):
status = None
headers = {}
if traceEnabled:
logger.debug("--- response header ---")
while True:
line = self._recv_line()
if line == "\r\n":
break
line = line.strip()
if traceEnabled:
logger.debug(line)
if not status:
status_info = line.split(" ", 2)
status = int(status_info[1])
else:
kv = line.split(":", 1)
if len(kv) == 2:
key, value = kv
headers[key.lower()] = value.strip().lower()
else:
raise WebSocketException("Invalid header")
if traceEnabled:
logger.debug("-----------------------")
return status, headers
def send(self, payload, opcode=ABNF.OPCODE_TEXT):
"""
Send the data as string.
payload: Payload must be utf-8 string or unicoce,
if the opcode is OPCODE_TEXT.
Otherwise, it must be string(byte array)
opcode: operation code to send. Please see OPCODE_XXX.
"""
frame = ABNF.create_frame(payload, opcode)
if self.get_mask_key:
frame.get_mask_key = self.get_mask_key
data = frame.format()
length = len(data)
if traceEnabled:
logger.debug("send: " + repr(data))
while data:
l = self._send(data)
data = data[l:]
return length
def send_binary(self, payload):
return self.send(payload, ABNF.OPCODE_BINARY)
def ping(self, payload=""):
"""
send ping data.
payload: data payload to send server.
"""
self.send(payload, ABNF.OPCODE_PING)
def pong(self, payload):
"""
send pong data.
payload: data payload to send server.
"""
self.send(payload, ABNF.OPCODE_PONG)
def recv(self):
"""
Receive string data(byte array) from the server.
return value: string(byte array) value.
"""
opcode, data = self.recv_data()
return data
def recv_data(self):
"""
Recieve data with operation code.
return value: tuple of operation code and string(byte array) value.
"""
while True:
frame = self.recv_frame()
if not frame:
# handle error:
# 'NoneType' object has no attribute 'opcode'
raise WebSocketException("Not a valid frame %s" % frame)
elif frame.opcode in (ABNF.OPCODE_TEXT, ABNF.OPCODE_BINARY, ABNF.OPCODE_CONT):
if frame.opcode == ABNF.OPCODE_CONT and not self._cont_data:
raise WebSocketException("Illegal frame")
if self._cont_data:
self._cont_data[1] += frame.data
else:
self._cont_data = [frame.opcode, frame.data]
if frame.fin:
data = self._cont_data
self._cont_data = None
return data
elif frame.opcode == ABNF.OPCODE_CLOSE:
self.send_close()
return (frame.opcode, None)
elif frame.opcode == ABNF.OPCODE_PING:
self.pong(frame.data)
def recv_frame(self):
"""
recieve data as frame from server.
return value: ABNF frame object.
"""
# Header
if self._frame_header is None:
self._frame_header = self._recv_strict(2)
b1 = ord(self._frame_header[0])
fin = b1 >> 7 & 1
rsv1 = b1 >> 6 & 1
rsv2 = b1 >> 5 & 1
rsv3 = b1 >> 4 & 1
opcode = b1 & 0xf
b2 = ord(self._frame_header[1])
has_mask = b2 >> 7 & 1
# Frame length
if self._frame_length is None:
length_bits = b2 & 0x7f
if length_bits == 0x7e:
length_data = self._recv_strict(2)
self._frame_length = struct.unpack("!H", length_data)[0]
elif length_bits == 0x7f:
length_data = self._recv_strict(8)
self._frame_length = struct.unpack("!Q", length_data)[0]
else:
self._frame_length = length_bits
# Mask
if self._frame_mask is None:
self._frame_mask = self._recv_strict(4) if has_mask else ""
# Payload
payload = self._recv_strict(self._frame_length)
if has_mask:
payload = ABNF.mask(self._frame_mask, payload)
# Reset for next frame
self._frame_header = None
self._frame_length = None
self._frame_mask = None
return ABNF(fin, rsv1, rsv2, rsv3, opcode, has_mask, payload)
def send_close(self, status=STATUS_NORMAL, reason=""):
"""
send close data to the server.
status: status code to send. see STATUS_XXX.
reason: the reason to close. This must be string.
"""
if status < 0 or status >= ABNF.LENGTH_16:
raise ValueError("code is invalid range")
self.send(struct.pack('!H', status) + reason, ABNF.OPCODE_CLOSE)
def close(self, status=STATUS_NORMAL, reason=""):
"""
Close Websocket object
status: status code to send. see STATUS_XXX.
reason: the reason to close. This must be string.
"""
if self.connected:
if status < 0 or status >= ABNF.LENGTH_16:
raise ValueError("code is invalid range")
try:
self.send(struct.pack('!H', status) + reason, ABNF.OPCODE_CLOSE)
timeout = self.sock.gettimeout()
self.sock.settimeout(3)
try:
frame = self.recv_frame()
if logger.isEnabledFor(logging.ERROR):
recv_status = struct.unpack("!H", frame.data)[0]
if recv_status != STATUS_NORMAL:
logger.error("close status: " + repr(recv_status))
except:
pass
self.sock.settimeout(timeout)
self.sock.shutdown(socket.SHUT_RDWR)
except:
pass
self._closeInternal()
def _closeInternal(self):
self.connected = False
self.sock.close()
def _send(self, data):
try:
return self.sock.send(data)
except socket.timeout as e:
raise WebSocketTimeoutException(e.message)
except Exception as e:
if "timed out" in e.message:
raise WebSocketTimeoutException(e.message)
else:
raise e
def _recv(self, bufsize):
try:
bytes = self.sock.recv(bufsize)
except socket.timeout as e:
raise WebSocketTimeoutException(e.message)
except SSLError as e:
if e.message == "The read operation timed out":
raise WebSocketTimeoutException(e.message)
else:
raise
if not bytes:
raise WebSocketConnectionClosedException()
return bytes
def _recv_strict(self, bufsize):
shortage = bufsize - sum(len(x) for x in self._recv_buffer)
while shortage > 0:
bytes = self._recv(shortage)
self._recv_buffer.append(bytes)
shortage -= len(bytes)
unified = "".join(self._recv_buffer)
if shortage == 0:
self._recv_buffer = []
return unified
else:
self._recv_buffer = [unified[bufsize:]]
return unified[:bufsize]
def _recv_line(self):
line = []
while True:
c = self._recv(1)
line.append(c)
if c == "\n":
break
return "".join(line)
class WebSocketApp(object):
"""
Higher level of APIs are provided.
The interface is like JavaScript WebSocket object.
"""
def __init__(self, url, header=[],
on_open=None, on_message=None, on_error=None,
on_close=None, keep_running=True, get_mask_key=None):
"""
url: websocket url.
header: custom header for websocket handshake.
on_open: callable object which is called at opening websocket.
this function has one argument. The arugment is this class object.
on_message: callbale object which is called when recieved data.
on_message has 2 arguments.
The 1st arugment is this class object.
The passing 2nd arugment is utf-8 string which we get from the server.
on_error: callable object which is called when we get error.
on_error has 2 arguments.
The 1st arugment is this class object.
The passing 2nd arugment is exception object.
on_close: callable object which is called when closed the connection.
this function has one argument. The arugment is this class object.
keep_running: a boolean flag indicating whether the app's main loop should
keep running, defaults to True
get_mask_key: a callable to produce new mask keys, see the WebSocket.set_mask_key's
docstring for more information
"""
self.url = url
self.header = header
self.on_open = on_open
self.on_message = on_message
self.on_error = on_error
self.on_close = on_close
self.keep_running = keep_running
self.get_mask_key = get_mask_key
self.sock = None
def send(self, data, opcode=ABNF.OPCODE_TEXT):
"""
send message.
data: message to send. If you set opcode to OPCODE_TEXT, data must be utf-8 string or unicode.
opcode: operation code of data. default is OPCODE_TEXT.
"""
if self.sock.send(data, opcode) == 0:
raise WebSocketConnectionClosedException()
def close(self):
"""
close websocket connection.
"""
self.keep_running = False
self.sock.close()
def _send_ping(self, interval):
while True:
for i in range(interval):
time.sleep(1)
if not self.keep_running:
return
self.sock.ping()
def run_forever(self, sockopt=None, sslopt=None, ping_interval=0):
"""
run event loop for WebSocket framework.
This loop is infinite loop and is alive during websocket is available.
sockopt: values for socket.setsockopt.
sockopt must be tuple and each element is argument of sock.setscokopt.
sslopt: ssl socket optional dict.
ping_interval: automatically send "ping" command every specified period(second)
if set to 0, not send automatically.
"""
if sockopt is None:
sockopt = []
if sslopt is None:
sslopt = {}
if self.sock:
raise WebSocketException("socket is already opened")
thread = None
try:
self.sock = WebSocket(self.get_mask_key, sockopt=sockopt, sslopt=sslopt)
self.sock.settimeout(default_timeout)
self.sock.connect(self.url, header=self.header)
self._callback(self.on_open)
if ping_interval:
thread = threading.Thread(target=self._send_ping, args=(ping_interval,))
thread.setDaemon(True)
thread.start()
while self.keep_running:
data = self.sock.recv()
if data is None:
break
self._callback(self.on_message, data)
except Exception, e:
self._callback(self.on_error, e)
finally:
if thread:
self.keep_running = False
self.sock.close()
self._callback(self.on_close)
self.sock = None
def _callback(self, callback, *args):
if callback:
try:
callback(self, *args)
except Exception, e:
logger.error(e)
if logger.isEnabledFor(logging.DEBUG):
_, _, tb = sys.exc_info()
traceback.print_tb(tb)
if __name__ == "__main__":
enableTrace(True)
ws = create_connection("ws://echo.websocket.org/")
print("Sending 'Hello, World'...")
ws.send("Hello, World")
print("Sent")
print("Receiving...")
result = ws.recv()
print("Received '%s'" % result)
ws.close() | unknown | codeparrot/codeparrot-clean | ||
from __future__ import absolute_import, unicode_literals
import datetime
from operator import attrgetter
from django.core.exceptions import ValidationError
from django.test import TestCase, skipUnlessDBFeature
from django.utils import six
from django.utils import tzinfo
from .models import (Worker, Article, Party, Event, Department,
BrokenUnicodeMethod, NonAutoPK, Model1, Model2, Model3)
class ModelTests(TestCase):
# The bug is that the following queries would raise:
# "TypeError: Related Field has invalid lookup: gte"
def test_related_gte_lookup(self):
"""
Regression test for #10153: foreign key __gte lookups.
"""
Worker.objects.filter(department__gte=0)
def test_related_lte_lookup(self):
"""
Regression test for #10153: foreign key __lte lookups.
"""
Worker.objects.filter(department__lte=0)
def test_empty_choice(self):
# NOTE: Part of the regression test here is merely parsing the model
# declaration. The verbose_name, in particular, did not always work.
a = Article.objects.create(
headline="Look at me!", pub_date=datetime.datetime.now()
)
# An empty choice field should return None for the display name.
self.assertIs(a.get_status_display(), None)
# Empty strings should be returned as Unicode
a = Article.objects.get(pk=a.pk)
self.assertEqual(a.misc_data, '')
self.assertIs(type(a.misc_data), six.text_type)
def test_long_textfield(self):
# TextFields can hold more than 4000 characters (this was broken in
# Oracle).
a = Article.objects.create(
headline="Really, really big",
pub_date=datetime.datetime.now(),
article_text="ABCDE" * 1000
)
a = Article.objects.get(pk=a.pk)
self.assertEqual(len(a.article_text), 5000)
def test_date_lookup(self):
# Regression test for #659
Party.objects.create(when=datetime.datetime(1999, 12, 31))
Party.objects.create(when=datetime.datetime(1998, 12, 31))
Party.objects.create(when=datetime.datetime(1999, 1, 1))
self.assertQuerysetEqual(
Party.objects.filter(when__month=2), []
)
self.assertQuerysetEqual(
Party.objects.filter(when__month=1), [
datetime.date(1999, 1, 1)
],
attrgetter("when")
)
self.assertQuerysetEqual(
Party.objects.filter(when__month=12), [
datetime.date(1999, 12, 31),
datetime.date(1998, 12, 31),
],
attrgetter("when")
)
self.assertQuerysetEqual(
Party.objects.filter(when__year=1998), [
datetime.date(1998, 12, 31),
],
attrgetter("when")
)
# Regression test for #8510
self.assertQuerysetEqual(
Party.objects.filter(when__day="31"), [
datetime.date(1999, 12, 31),
datetime.date(1998, 12, 31),
],
attrgetter("when")
)
self.assertQuerysetEqual(
Party.objects.filter(when__month="12"), [
datetime.date(1999, 12, 31),
datetime.date(1998, 12, 31),
],
attrgetter("when")
)
self.assertQuerysetEqual(
Party.objects.filter(when__year="1998"), [
datetime.date(1998, 12, 31),
],
attrgetter("when")
)
def test_date_filter_null(self):
# Date filtering was failing with NULL date values in SQLite
# (regression test for #3501, amongst other things).
Party.objects.create(when=datetime.datetime(1999, 1, 1))
Party.objects.create()
p = Party.objects.filter(when__month=1)[0]
self.assertEqual(p.when, datetime.date(1999, 1, 1))
self.assertQuerysetEqual(
Party.objects.filter(pk=p.pk).dates("when", "month"), [
1
],
attrgetter("month")
)
def test_get_next_prev_by_field(self):
# Check that get_next_by_FIELD and get_previous_by_FIELD don't crash
# when we have usecs values stored on the database
#
# It crashed after the Field.get_db_prep_* refactor, because on most
# backends DateTimeFields supports usecs, but DateTimeField.to_python
# didn't recognize them. (Note that
# Model._get_next_or_previous_by_FIELD coerces values to strings)
Event.objects.create(when=datetime.datetime(2000, 1, 1, 16, 0, 0))
Event.objects.create(when=datetime.datetime(2000, 1, 1, 6, 1, 1))
Event.objects.create(when=datetime.datetime(2000, 1, 1, 13, 1, 1))
e = Event.objects.create(when=datetime.datetime(2000, 1, 1, 12, 0, 20, 24))
self.assertEqual(
e.get_next_by_when().when, datetime.datetime(2000, 1, 1, 13, 1, 1)
)
self.assertEqual(
e.get_previous_by_when().when, datetime.datetime(2000, 1, 1, 6, 1, 1)
)
def test_primary_key_foreign_key_types(self):
# Check Department and Worker (non-default PK type)
d = Department.objects.create(id=10, name="IT")
w = Worker.objects.create(department=d, name="Full-time")
self.assertEqual(six.text_type(w), "Full-time")
def test_broken_unicode(self):
# Models with broken unicode methods should still have a printable repr
b = BrokenUnicodeMethod.objects.create(name="Jerry")
self.assertEqual(repr(b), "<BrokenUnicodeMethod: [Bad Unicode data]>")
@skipUnlessDBFeature("supports_timezones")
def test_timezones(self):
# Saving an updating with timezone-aware datetime Python objects.
# Regression test for #10443.
# The idea is that all these creations and saving should work without
# crashing. It's not rocket science.
dt1 = datetime.datetime(2008, 8, 31, 16, 20, tzinfo=tzinfo.FixedOffset(600))
dt2 = datetime.datetime(2008, 8, 31, 17, 20, tzinfo=tzinfo.FixedOffset(600))
obj = Article.objects.create(
headline="A headline", pub_date=dt1, article_text="foo"
)
obj.pub_date = dt2
obj.save()
self.assertEqual(
Article.objects.filter(headline="A headline").update(pub_date=dt1),
1
)
def test_chained_fks(self):
"""
Regression for #18432: Chained foreign keys with to_field produce incorrect query
"""
m1 = Model1.objects.create(pkey=1000)
m2 = Model2.objects.create(model1=m1)
m3 = Model3.objects.create(model2=m2)
# this is the actual test for #18432
m3 = Model3.objects.get(model2=1000)
m3.model2
class ModelValidationTest(TestCase):
def test_pk_validation(self):
one = NonAutoPK.objects.create(name="one")
again = NonAutoPK(name="one")
self.assertRaises(ValidationError, again.validate_unique)
class EvaluateMethodTest(TestCase):
"""
Regression test for #13640: cannot filter by objects with 'evaluate' attr
"""
def test_model_with_evaluate_method(self):
"""
Ensures that you can filter by objects that have an 'evaluate' attr
"""
dept = Department.objects.create(pk=1, name='abc')
dept.evaluate = 'abc'
Worker.objects.filter(department=dept) | unknown | codeparrot/codeparrot-clean | ||
#!/usr/bin/env python
#
# Use the raw transactions API to spend quarks received on particular addresses,
# and send any change back to that same address.
#
# Example usage:
# spendfrom.py # Lists available funds
# spendfrom.py --from=ADDRESS --to=ADDRESS --amount=11.00
#
# Assumes it will talk to a quarkd or Quark-Qt running
# on localhost.
#
# Depends on jsonrpc
#
from decimal import *
import getpass
import math
import os
import os.path
import platform
import sys
import time
from jsonrpc import ServiceProxy, json
BASE_FEE=Decimal("0.001")
def check_json_precision():
"""Make sure json library being used does not lose precision converting BTC values"""
n = Decimal("20000000.00000003")
satoshis = int(json.loads(json.dumps(float(n)))*1.0e8)
if satoshis != 2000000000000003:
raise RuntimeError("JSON encode/decode loses precision")
def determine_db_dir():
"""Return the default location of the quark data directory"""
if platform.system() == "Darwin":
return os.path.expanduser("~/Library/Application Support/Quarkcoin/")
elif platform.system() == "Windows":
return os.path.join(os.environ['APPDATA'], "Quarkcoin")
return os.path.expanduser("~/.quarkcoin")
def read_bitcoin_config(dbdir):
"""Read the quarkcoin.conf file from dbdir, returns dictionary of settings"""
from ConfigParser import SafeConfigParser
class FakeSecHead(object):
def __init__(self, fp):
self.fp = fp
self.sechead = '[all]\n'
def readline(self):
if self.sechead:
try: return self.sechead
finally: self.sechead = None
else:
s = self.fp.readline()
if s.find('#') != -1:
s = s[0:s.find('#')].strip() +"\n"
return s
config_parser = SafeConfigParser()
config_parser.readfp(FakeSecHead(open(os.path.join(dbdir, "quarkcoin.conf"))))
return dict(config_parser.items("all"))
def connect_JSON(config):
"""Connect to a quark JSON-RPC server"""
testnet = config.get('testnet', '0')
testnet = (int(testnet) > 0) # 0/1 in config file, convert to True/False
if not 'rpcport' in config:
config['rpcport'] = 18332 if testnet else 8332
connect = "http://%s:%s@127.0.0.1:%s"%(config['rpcuser'], config['rpcpassword'], config['rpcport'])
try:
result = ServiceProxy(connect)
# ServiceProxy is lazy-connect, so send an RPC command mostly to catch connection errors,
# but also make sure the quarkd we're talking to is/isn't testnet:
if result.getmininginfo()['testnet'] != testnet:
sys.stderr.write("RPC server at "+connect+" testnet setting mismatch\n")
sys.exit(1)
return result
except:
sys.stderr.write("Error connecting to RPC server at "+connect+"\n")
sys.exit(1)
def unlock_wallet(bitcoind):
info = bitcoind.getinfo()
if 'unlocked_until' not in info:
return True # wallet is not encrypted
t = int(info['unlocked_until'])
if t <= time.time():
try:
passphrase = getpass.getpass("Wallet is locked; enter passphrase: ")
bitcoind.walletpassphrase(passphrase, 5)
except:
sys.stderr.write("Wrong passphrase\n")
info = bitcoind.getinfo()
return int(info['unlocked_until']) > time.time()
def list_available(bitcoind):
address_summary = dict()
address_to_account = dict()
for info in bitcoind.listreceivedbyaddress(0):
address_to_account[info["address"]] = info["account"]
unspent = bitcoind.listunspent(0)
for output in unspent:
# listunspent doesn't give addresses, so:
rawtx = bitcoind.getrawtransaction(output['txid'], 1)
vout = rawtx["vout"][output['vout']]
pk = vout["scriptPubKey"]
# This code only deals with ordinary pay-to-bitcoin-address
# or pay-to-script-hash outputs right now; anything exotic is ignored.
if pk["type"] != "pubkeyhash" and pk["type"] != "scripthash":
continue
address = pk["addresses"][0]
if address in address_summary:
address_summary[address]["total"] += vout["value"]
address_summary[address]["outputs"].append(output)
else:
address_summary[address] = {
"total" : vout["value"],
"outputs" : [output],
"account" : address_to_account.get(address, "")
}
return address_summary
def select_coins(needed, inputs):
# Feel free to improve this, this is good enough for my simple needs:
outputs = []
have = Decimal("0.0")
n = 0
while have < needed and n < len(inputs):
outputs.append({ "txid":inputs[n]["txid"], "vout":inputs[n]["vout"]})
have += inputs[n]["amount"]
n += 1
return (outputs, have-needed)
def create_tx(bitcoind, fromaddresses, toaddress, amount, fee):
all_coins = list_available(bitcoind)
total_available = Decimal("0.0")
needed = amount+fee
potential_inputs = []
for addr in fromaddresses:
if addr not in all_coins:
continue
potential_inputs.extend(all_coins[addr]["outputs"])
total_available += all_coins[addr]["total"]
if total_available < needed:
sys.stderr.write("Error, only %f BTC available, need %f\n"%(total_available, needed));
sys.exit(1)
#
# Note:
# Python's json/jsonrpc modules have inconsistent support for Decimal numbers.
# Instead of wrestling with getting json.dumps() (used by jsonrpc) to encode
# Decimals, I'm casting amounts to float before sending them to bitcoind.
#
outputs = { toaddress : float(amount) }
(inputs, change_amount) = select_coins(needed, potential_inputs)
if change_amount > BASE_FEE: # don't bother with zero or tiny change
change_address = fromaddresses[-1]
if change_address in outputs:
outputs[change_address] += float(change_amount)
else:
outputs[change_address] = float(change_amount)
rawtx = bitcoind.createrawtransaction(inputs, outputs)
signed_rawtx = bitcoind.signrawtransaction(rawtx)
if not signed_rawtx["complete"]:
sys.stderr.write("signrawtransaction failed\n")
sys.exit(1)
txdata = signed_rawtx["hex"]
return txdata
def compute_amount_in(bitcoind, txinfo):
result = Decimal("0.0")
for vin in txinfo['vin']:
in_info = bitcoind.getrawtransaction(vin['txid'], 1)
vout = in_info['vout'][vin['vout']]
result = result + vout['value']
return result
def compute_amount_out(txinfo):
result = Decimal("0.0")
for vout in txinfo['vout']:
result = result + vout['value']
return result
def sanity_test_fee(bitcoind, txdata_hex, max_fee):
class FeeError(RuntimeError):
pass
try:
txinfo = bitcoind.decoderawtransaction(txdata_hex)
total_in = compute_amount_in(bitcoind, txinfo)
total_out = compute_amount_out(txinfo)
if total_in-total_out > max_fee:
raise FeeError("Rejecting transaction, unreasonable fee of "+str(total_in-total_out))
tx_size = len(txdata_hex)/2
kb = tx_size/1000 # integer division rounds down
if kb > 1 and fee < BASE_FEE:
raise FeeError("Rejecting no-fee transaction, larger than 1000 bytes")
if total_in < 0.01 and fee < BASE_FEE:
raise FeeError("Rejecting no-fee, tiny-amount transaction")
# Exercise for the reader: compute transaction priority, and
# warn if this is a very-low-priority transaction
except FeeError as err:
sys.stderr.write((str(err)+"\n"))
sys.exit(1)
def main():
import optparse
parser = optparse.OptionParser(usage="%prog [options]")
parser.add_option("--from", dest="fromaddresses", default=None,
help="addresses to get quarks from")
parser.add_option("--to", dest="to", default=None,
help="address to get send quarks to")
parser.add_option("--amount", dest="amount", default=None,
help="amount to send")
parser.add_option("--fee", dest="fee", default="0.0",
help="fee to include")
parser.add_option("--datadir", dest="datadir", default=determine_db_dir(),
help="location of quarkcoin.conf file with RPC username/password (default: %default)")
parser.add_option("--testnet", dest="testnet", default=False, action="store_true",
help="Use the test network")
parser.add_option("--dry_run", dest="dry_run", default=False, action="store_true",
help="Don't broadcast the transaction, just create and print the transaction data")
(options, args) = parser.parse_args()
check_json_precision()
config = read_bitcoin_config(options.datadir)
if options.testnet: config['testnet'] = True
bitcoind = connect_JSON(config)
if options.amount is None:
address_summary = list_available(bitcoind)
for address,info in address_summary.iteritems():
n_transactions = len(info['outputs'])
if n_transactions > 1:
print("%s %.8f %s (%d transactions)"%(address, info['total'], info['account'], n_transactions))
else:
print("%s %.8f %s"%(address, info['total'], info['account']))
else:
fee = Decimal(options.fee)
amount = Decimal(options.amount)
while unlock_wallet(bitcoind) == False:
pass # Keep asking for passphrase until they get it right
txdata = create_tx(bitcoind, options.fromaddresses.split(","), options.to, amount, fee)
sanity_test_fee(bitcoind, txdata, amount*Decimal("0.01"))
if options.dry_run:
print(txdata)
else:
txid = bitcoind.sendrawtransaction(txdata)
print(txid)
if __name__ == '__main__':
main() | unknown | codeparrot/codeparrot-clean | ||
/*
* Copyright 2014-2021 JetBrains s.r.o and contributors. Use of this source code is governed by the Apache 2.0 license.
*/
package io.ktor.tests.server.jetty
import io.ktor.client.request.*
import io.ktor.client.statement.*
import io.ktor.http.*
import io.ktor.server.routing.*
import io.ktor.server.servlet.*
import io.ktor.server.testing.*
import org.eclipse.jetty.server.handler.*
import org.junit.jupiter.api.*
import org.junit.jupiter.api.io.*
import java.net.*
import java.nio.file.*
import kotlin.io.path.*
import kotlin.test.*
import kotlin.test.Test
private const val PlainTextContent = "plain text"
private const val HtmlContent = "<p>HTML</p>"
class WebResourcesTest {
@TempDir
lateinit var testDir: Path
lateinit var textFile: Path
lateinit var htmlFile: Path
@BeforeEach
fun createFiles() {
textFile = testDir.resolve("1.txt").apply {
writeText(PlainTextContent)
}
htmlFile = testDir.resolve("2.html").apply {
writeText(HtmlContent)
}
}
@OptIn(ExperimentalPathApi::class)
@AfterEach
fun cleanup() {
testDir.deleteRecursively()
}
@Test
fun testServeWebResources() = testApplication {
application {
attributes.put(ServletContextAttribute, TestContext())
routing {
route("webapp") {
webResources("pages") {
include { it.endsWith(".txt") }
include { it.endsWith(".html") }
exclude { it.endsWith("password.txt") }
}
}
}
}
val client = createClient { expectSuccess = false }
client.get("/webapp/index.txt").bodyAsText().let {
assertEquals(PlainTextContent, it)
}
client.get("/webapp/index.html").bodyAsText().let {
assertEquals(HtmlContent, it)
}
client.get("/webapp/password.txt").let {
assertFalse(it.status.isSuccess())
}
}
private inner class TestContext : ContextHandler.StaticContext() {
override fun getResource(path: String?): URL? {
return when (path) {
"/pages/index.txt" -> textFile
"/pages/password.txt" -> textFile
"/pages/index.html" -> htmlFile
else -> null
}?.toUri()?.toURL()
}
}
} | kotlin | github | https://github.com/ktorio/ktor | ktor-server/ktor-server-jetty/jvm/test/io/ktor/tests/server/jetty/WebResourcesTest.kt |
# Copyright (c) 2010-2012 OpenStack Foundation
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
# implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import os
import sys
import unittest
from contextlib import contextmanager, nested
from shutil import rmtree
from StringIO import StringIO
import gc
import time
from textwrap import dedent
from urllib import quote
from hashlib import md5
from tempfile import mkdtemp
import weakref
import operator
import functools
from swift.obj import diskfile
import re
import random
import mock
from eventlet import sleep, spawn, wsgi, listen, Timeout
from swift.common.utils import json
from test.unit import (
connect_tcp, readuntil2crlfs, FakeLogger, fake_http_connect, FakeRing,
FakeMemcache, debug_logger, patch_policies, write_fake_ring,
mocked_http_conn)
from swift.proxy import server as proxy_server
from swift.account import server as account_server
from swift.container import server as container_server
from swift.obj import server as object_server
from swift.common.middleware import proxy_logging
from swift.common.middleware.acl import parse_acl, format_acl
from swift.common.exceptions import ChunkReadTimeout, DiskFileNotExist
from swift.common import utils, constraints
from swift.common.utils import mkdirs, normalize_timestamp, NullLogger
from swift.common.wsgi import monkey_patch_mimetools, loadapp
from swift.proxy.controllers import base as proxy_base
from swift.proxy.controllers.base import get_container_memcache_key, \
get_account_memcache_key, cors_validation
import swift.proxy.controllers
from swift.common.swob import Request, Response, HTTPUnauthorized, \
HTTPException
from swift.common import storage_policy
from swift.common.storage_policy import StoragePolicy, \
StoragePolicyCollection, POLICIES
from swift.common.request_helpers import get_sys_meta_prefix
# mocks
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
STATIC_TIME = time.time()
_test_coros = _test_servers = _test_sockets = _orig_container_listing_limit = \
_testdir = _orig_SysLogHandler = _orig_POLICIES = _test_POLICIES = None
def do_setup(the_object_server):
utils.HASH_PATH_SUFFIX = 'endcap'
global _testdir, _test_servers, _test_sockets, \
_orig_container_listing_limit, _test_coros, _orig_SysLogHandler, \
_orig_POLICIES, _test_POLICIES
_orig_POLICIES = storage_policy._POLICIES
_orig_SysLogHandler = utils.SysLogHandler
utils.SysLogHandler = mock.MagicMock()
monkey_patch_mimetools()
# Since we're starting up a lot here, we're going to test more than
# just chunked puts; we're also going to test parts of
# proxy_server.Application we couldn't get to easily otherwise.
_testdir = \
os.path.join(mkdtemp(), 'tmp_test_proxy_server_chunked')
mkdirs(_testdir)
rmtree(_testdir)
mkdirs(os.path.join(_testdir, 'sda1'))
mkdirs(os.path.join(_testdir, 'sda1', 'tmp'))
mkdirs(os.path.join(_testdir, 'sdb1'))
mkdirs(os.path.join(_testdir, 'sdb1', 'tmp'))
conf = {'devices': _testdir, 'swift_dir': _testdir,
'mount_check': 'false', 'allowed_headers':
'content-encoding, x-object-manifest, content-disposition, foo',
'allow_versions': 'True'}
prolis = listen(('localhost', 0))
acc1lis = listen(('localhost', 0))
acc2lis = listen(('localhost', 0))
con1lis = listen(('localhost', 0))
con2lis = listen(('localhost', 0))
obj1lis = listen(('localhost', 0))
obj2lis = listen(('localhost', 0))
_test_sockets = \
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis, obj2lis)
account_ring_path = os.path.join(_testdir, 'account.ring.gz')
account_devs = [
{'port': acc1lis.getsockname()[1]},
{'port': acc2lis.getsockname()[1]},
]
write_fake_ring(account_ring_path, *account_devs)
container_ring_path = os.path.join(_testdir, 'container.ring.gz')
container_devs = [
{'port': con1lis.getsockname()[1]},
{'port': con2lis.getsockname()[1]},
]
write_fake_ring(container_ring_path, *container_devs)
storage_policy._POLICIES = StoragePolicyCollection([
StoragePolicy(0, 'zero', True),
StoragePolicy(1, 'one', False),
StoragePolicy(2, 'two', False)])
obj_rings = {
0: ('sda1', 'sdb1'),
1: ('sdc1', 'sdd1'),
2: ('sde1', 'sdf1'),
}
for policy_index, devices in obj_rings.items():
policy = POLICIES[policy_index]
dev1, dev2 = devices
obj_ring_path = os.path.join(_testdir, policy.ring_name + '.ring.gz')
obj_devs = [
{'port': obj1lis.getsockname()[1], 'device': dev1},
{'port': obj2lis.getsockname()[1], 'device': dev2},
]
write_fake_ring(obj_ring_path, *obj_devs)
prosrv = proxy_server.Application(conf, FakeMemcacheReturnsNone(),
logger=debug_logger('proxy'))
for policy in POLICIES:
# make sure all the rings are loaded
prosrv.get_object_ring(policy.idx)
# don't loose this one!
_test_POLICIES = storage_policy._POLICIES
acc1srv = account_server.AccountController(
conf, logger=debug_logger('acct1'))
acc2srv = account_server.AccountController(
conf, logger=debug_logger('acct2'))
con1srv = container_server.ContainerController(
conf, logger=debug_logger('cont1'))
con2srv = container_server.ContainerController(
conf, logger=debug_logger('cont2'))
obj1srv = the_object_server.ObjectController(
conf, logger=debug_logger('obj1'))
obj2srv = the_object_server.ObjectController(
conf, logger=debug_logger('obj2'))
_test_servers = \
(prosrv, acc1srv, acc2srv, con1srv, con2srv, obj1srv, obj2srv)
nl = NullLogger()
logging_prosv = proxy_logging.ProxyLoggingMiddleware(prosrv, conf,
logger=prosrv.logger)
prospa = spawn(wsgi.server, prolis, logging_prosv, nl)
acc1spa = spawn(wsgi.server, acc1lis, acc1srv, nl)
acc2spa = spawn(wsgi.server, acc2lis, acc2srv, nl)
con1spa = spawn(wsgi.server, con1lis, con1srv, nl)
con2spa = spawn(wsgi.server, con2lis, con2srv, nl)
obj1spa = spawn(wsgi.server, obj1lis, obj1srv, nl)
obj2spa = spawn(wsgi.server, obj2lis, obj2srv, nl)
_test_coros = \
(prospa, acc1spa, acc2spa, con1spa, con2spa, obj1spa, obj2spa)
# Create account
ts = normalize_timestamp(time.time())
partition, nodes = prosrv.account_ring.get_nodes('a')
for node in nodes:
conn = swift.proxy.controllers.obj.http_connect(node['ip'],
node['port'],
node['device'],
partition, 'PUT', '/a',
{'X-Timestamp': ts,
'x-trans-id': 'test'})
resp = conn.getresponse()
assert(resp.status == 201)
# Create another account
# used for account-to-account tests
ts = normalize_timestamp(time.time())
partition, nodes = prosrv.account_ring.get_nodes('a1')
for node in nodes:
conn = swift.proxy.controllers.obj.http_connect(node['ip'],
node['port'],
node['device'],
partition, 'PUT',
'/a1',
{'X-Timestamp': ts,
'x-trans-id': 'test'})
resp = conn.getresponse()
assert(resp.status == 201)
# Create containers, 1 per test policy
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/c HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
assert headers[:len(exp)] == exp, "Expected '%s', encountered '%s'" % (
exp, headers[:len(exp)])
# Create container in other account
# used for account-to-account tests
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a1/c1 HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
assert headers[:len(exp)] == exp, "Expected '%s', encountered '%s'" % (
exp, headers[:len(exp)])
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write(
'PUT /v1/a/c1 HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\nX-Storage-Policy: one\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
assert headers[:len(exp)] == exp, \
"Expected '%s', encountered '%s'" % (exp, headers[:len(exp)])
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write(
'PUT /v1/a/c2 HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\nX-Storage-Policy: two\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
assert headers[:len(exp)] == exp, \
"Expected '%s', encountered '%s'" % (exp, headers[:len(exp)])
def unpatch_policies(f):
"""
This will unset a TestCase level patch_policies to use the module level
policies setup for the _test_servers instead.
N.B. You should NEVER modify the _test_server policies or rings during a
test because they persist for the life of the entire module!
"""
@functools.wraps(f)
def wrapper(*args, **kwargs):
with patch_policies(_test_POLICIES):
return f(*args, **kwargs)
return wrapper
def setup():
do_setup(object_server)
def teardown():
for server in _test_coros:
server.kill()
rmtree(os.path.dirname(_testdir))
utils.SysLogHandler = _orig_SysLogHandler
storage_policy._POLICIES = _orig_POLICIES
def sortHeaderNames(headerNames):
"""
Return the given string of header names sorted.
headerName: a comma-delimited list of header names
"""
headers = [a.strip() for a in headerNames.split(',') if a.strip()]
headers.sort()
return ', '.join(headers)
def node_error_count(proxy_app, ring_node):
# Reach into the proxy's internals to get the error count for a
# particular node
node_key = proxy_app._error_limit_node_key(ring_node)
return proxy_app._error_limiting.get(node_key, {}).get('errors', 0)
def node_last_error(proxy_app, ring_node):
# Reach into the proxy's internals to get the last error for a
# particular node
node_key = proxy_app._error_limit_node_key(ring_node)
return proxy_app._error_limiting.get(node_key, {}).get('last_error')
def set_node_errors(proxy_app, ring_node, value, last_error):
# Set the node's error count to value
node_key = proxy_app._error_limit_node_key(ring_node)
stats = proxy_app._error_limiting.setdefault(node_key, {})
stats['errors'] = value
stats['last_error'] = last_error
class FakeMemcacheReturnsNone(FakeMemcache):
def get(self, key):
# Returns None as the timestamp of the container; assumes we're only
# using the FakeMemcache for container existence checks.
return None
@contextmanager
def save_globals():
orig_http_connect = getattr(swift.proxy.controllers.base, 'http_connect',
None)
orig_account_info = getattr(swift.proxy.controllers.Controller,
'account_info', None)
orig_container_info = getattr(swift.proxy.controllers.Controller,
'container_info', None)
try:
yield True
finally:
swift.proxy.controllers.Controller.account_info = orig_account_info
swift.proxy.controllers.base.http_connect = orig_http_connect
swift.proxy.controllers.obj.http_connect = orig_http_connect
swift.proxy.controllers.account.http_connect = orig_http_connect
swift.proxy.controllers.container.http_connect = orig_http_connect
swift.proxy.controllers.Controller.container_info = orig_container_info
def set_http_connect(*args, **kwargs):
new_connect = fake_http_connect(*args, **kwargs)
swift.proxy.controllers.base.http_connect = new_connect
swift.proxy.controllers.obj.http_connect = new_connect
swift.proxy.controllers.account.http_connect = new_connect
swift.proxy.controllers.container.http_connect = new_connect
return new_connect
def _make_callback_func(calls):
def callback(ipaddr, port, device, partition, method, path,
headers=None, query_string=None, ssl=False):
context = {}
context['method'] = method
context['path'] = path
context['headers'] = headers or {}
calls.append(context)
return callback
def _limit_max_file_size(f):
"""
This will limit constraints.MAX_FILE_SIZE for the duration of the
wrapped function, based on whether MAX_FILE_SIZE exceeds the
sys.maxsize limit on the system running the tests.
This allows successful testing on 32 bit systems.
"""
@functools.wraps(f)
def wrapper(*args, **kwargs):
test_max_file_size = constraints.MAX_FILE_SIZE
if constraints.MAX_FILE_SIZE >= sys.maxsize:
test_max_file_size = (2 ** 30 + 2)
with mock.patch.object(constraints, 'MAX_FILE_SIZE',
test_max_file_size):
return f(*args, **kwargs)
return wrapper
# tests
class TestController(unittest.TestCase):
def setUp(self):
self.account_ring = FakeRing()
self.container_ring = FakeRing()
self.memcache = FakeMemcache()
app = proxy_server.Application(None, self.memcache,
account_ring=self.account_ring,
container_ring=self.container_ring)
self.controller = swift.proxy.controllers.Controller(app)
class FakeReq(object):
def __init__(self):
self.url = "/foo/bar"
self.method = "METHOD"
def as_referer(self):
return self.method + ' ' + self.url
self.account = 'some_account'
self.container = 'some_container'
self.request = FakeReq()
self.read_acl = 'read_acl'
self.write_acl = 'write_acl'
def test_transfer_headers(self):
src_headers = {'x-remove-base-meta-owner': 'x',
'x-base-meta-size': '151M',
'new-owner': 'Kun'}
dst_headers = {'x-base-meta-owner': 'Gareth',
'x-base-meta-size': '150M'}
self.controller.transfer_headers(src_headers, dst_headers)
expected_headers = {'x-base-meta-owner': '',
'x-base-meta-size': '151M'}
self.assertEquals(dst_headers, expected_headers)
def check_account_info_return(self, partition, nodes, is_none=False):
if is_none:
p, n = None, None
else:
p, n = self.account_ring.get_nodes(self.account)
self.assertEqual(p, partition)
self.assertEqual(n, nodes)
def test_account_info_container_count(self):
with save_globals():
set_http_connect(200, count=123)
partition, nodes, count = \
self.controller.account_info(self.account)
self.assertEquals(count, 123)
with save_globals():
set_http_connect(200, count='123')
partition, nodes, count = \
self.controller.account_info(self.account)
self.assertEquals(count, 123)
with save_globals():
cache_key = get_account_memcache_key(self.account)
account_info = {'status': 200, 'container_count': 1234}
self.memcache.set(cache_key, account_info)
partition, nodes, count = \
self.controller.account_info(self.account)
self.assertEquals(count, 1234)
with save_globals():
cache_key = get_account_memcache_key(self.account)
account_info = {'status': 200, 'container_count': '1234'}
self.memcache.set(cache_key, account_info)
partition, nodes, count = \
self.controller.account_info(self.account)
self.assertEquals(count, 1234)
def test_make_requests(self):
with save_globals():
set_http_connect(200)
partition, nodes, count = \
self.controller.account_info(self.account, self.request)
set_http_connect(201, raise_timeout_exc=True)
self.controller._make_request(
nodes, partition, 'POST', '/', '', '',
self.controller.app.logger.thread_locals)
# tests if 200 is cached and used
def test_account_info_200(self):
with save_globals():
set_http_connect(200)
partition, nodes, count = \
self.controller.account_info(self.account, self.request)
self.check_account_info_return(partition, nodes)
self.assertEquals(count, 12345)
# Test the internal representation in memcache
# 'container_count' changed from int to str
cache_key = get_account_memcache_key(self.account)
container_info = {'status': 200,
'container_count': '12345',
'total_object_count': None,
'bytes': None,
'meta': {},
'sysmeta': {}}
self.assertEquals(container_info,
self.memcache.get(cache_key))
set_http_connect()
partition, nodes, count = \
self.controller.account_info(self.account, self.request)
self.check_account_info_return(partition, nodes)
self.assertEquals(count, 12345)
# tests if 404 is cached and used
def test_account_info_404(self):
with save_globals():
set_http_connect(404, 404, 404)
partition, nodes, count = \
self.controller.account_info(self.account, self.request)
self.check_account_info_return(partition, nodes, True)
self.assertEquals(count, None)
# Test the internal representation in memcache
# 'container_count' changed from 0 to None
cache_key = get_account_memcache_key(self.account)
account_info = {'status': 404,
'container_count': None, # internally keep None
'total_object_count': None,
'bytes': None,
'meta': {},
'sysmeta': {}}
self.assertEquals(account_info,
self.memcache.get(cache_key))
set_http_connect()
partition, nodes, count = \
self.controller.account_info(self.account, self.request)
self.check_account_info_return(partition, nodes, True)
self.assertEquals(count, None)
# tests if some http status codes are not cached
def test_account_info_no_cache(self):
def test(*status_list):
set_http_connect(*status_list)
partition, nodes, count = \
self.controller.account_info(self.account, self.request)
self.assertEqual(len(self.memcache.keys()), 0)
self.check_account_info_return(partition, nodes, True)
self.assertEquals(count, None)
with save_globals():
# We cache if we have two 404 responses - fail if only one
test(503, 503, 404)
test(504, 404, 503)
test(404, 507, 503)
test(503, 503, 503)
def test_account_info_no_account(self):
with save_globals():
self.memcache.store = {}
set_http_connect(404, 404, 404)
partition, nodes, count = \
self.controller.account_info(self.account, self.request)
self.check_account_info_return(partition, nodes, is_none=True)
self.assertEquals(count, None)
def check_container_info_return(self, ret, is_none=False):
if is_none:
partition, nodes, read_acl, write_acl = None, None, None, None
else:
partition, nodes = self.container_ring.get_nodes(self.account,
self.container)
read_acl, write_acl = self.read_acl, self.write_acl
self.assertEqual(partition, ret['partition'])
self.assertEqual(nodes, ret['nodes'])
self.assertEqual(read_acl, ret['read_acl'])
self.assertEqual(write_acl, ret['write_acl'])
def test_container_info_invalid_account(self):
def account_info(self, account, request, autocreate=False):
return None, None
with save_globals():
swift.proxy.controllers.Controller.account_info = account_info
ret = self.controller.container_info(self.account,
self.container,
self.request)
self.check_container_info_return(ret, True)
# tests if 200 is cached and used
def test_container_info_200(self):
with save_globals():
headers = {'x-container-read': self.read_acl,
'x-container-write': self.write_acl}
set_http_connect(200, # account_info is found
200, headers=headers) # container_info is found
ret = self.controller.container_info(
self.account, self.container, self.request)
self.check_container_info_return(ret)
cache_key = get_container_memcache_key(self.account,
self.container)
cache_value = self.memcache.get(cache_key)
self.assertTrue(isinstance(cache_value, dict))
self.assertEquals(200, cache_value.get('status'))
set_http_connect()
ret = self.controller.container_info(
self.account, self.container, self.request)
self.check_container_info_return(ret)
# tests if 404 is cached and used
def test_container_info_404(self):
def account_info(self, account, request):
return True, True, 0
with save_globals():
set_http_connect(503, 204, # account_info found
504, 404, 404) # container_info 'NotFound'
ret = self.controller.container_info(
self.account, self.container, self.request)
self.check_container_info_return(ret, True)
cache_key = get_container_memcache_key(self.account,
self.container)
cache_value = self.memcache.get(cache_key)
self.assertTrue(isinstance(cache_value, dict))
self.assertEquals(404, cache_value.get('status'))
set_http_connect()
ret = self.controller.container_info(
self.account, self.container, self.request)
self.check_container_info_return(ret, True)
set_http_connect(503, 404, 404) # account_info 'NotFound'
ret = self.controller.container_info(
self.account, self.container, self.request)
self.check_container_info_return(ret, True)
cache_key = get_container_memcache_key(self.account,
self.container)
cache_value = self.memcache.get(cache_key)
self.assertTrue(isinstance(cache_value, dict))
self.assertEquals(404, cache_value.get('status'))
set_http_connect()
ret = self.controller.container_info(
self.account, self.container, self.request)
self.check_container_info_return(ret, True)
# tests if some http status codes are not cached
def test_container_info_no_cache(self):
def test(*status_list):
set_http_connect(*status_list)
ret = self.controller.container_info(
self.account, self.container, self.request)
self.assertEqual(len(self.memcache.keys()), 0)
self.check_container_info_return(ret, True)
with save_globals():
# We cache if we have two 404 responses - fail if only one
test(503, 503, 404)
test(504, 404, 503)
test(404, 507, 503)
test(503, 503, 503)
@patch_policies([StoragePolicy(0, 'zero', True, object_ring=FakeRing())])
class TestProxyServer(unittest.TestCase):
def test_get_object_ring(self):
baseapp = proxy_server.Application({},
FakeMemcache(),
container_ring=FakeRing(),
account_ring=FakeRing())
with patch_policies([
StoragePolicy(0, 'a', False, object_ring=123),
StoragePolicy(1, 'b', True, object_ring=456),
StoragePolicy(2, 'd', False, object_ring=789)
]):
# None means legacy so always use policy 0
ring = baseapp.get_object_ring(None)
self.assertEqual(ring, 123)
ring = baseapp.get_object_ring('')
self.assertEqual(ring, 123)
ring = baseapp.get_object_ring('0')
self.assertEqual(ring, 123)
ring = baseapp.get_object_ring('1')
self.assertEqual(ring, 456)
ring = baseapp.get_object_ring('2')
self.assertEqual(ring, 789)
# illegal values
self.assertRaises(ValueError, baseapp.get_object_ring, '99')
self.assertRaises(ValueError, baseapp.get_object_ring, 'asdf')
def test_unhandled_exception(self):
class MyApp(proxy_server.Application):
def get_controller(self, path):
raise Exception('this shouldnt be caught')
app = MyApp(None, FakeMemcache(), account_ring=FakeRing(),
container_ring=FakeRing())
req = Request.blank('/v1/account', environ={'REQUEST_METHOD': 'HEAD'})
app.update_request(req)
resp = app.handle_request(req)
self.assertEquals(resp.status_int, 500)
def test_internal_method_request(self):
baseapp = proxy_server.Application({},
FakeMemcache(),
container_ring=FakeRing(),
account_ring=FakeRing())
resp = baseapp.handle_request(
Request.blank('/v1/a', environ={'REQUEST_METHOD': '__init__'}))
self.assertEquals(resp.status, '405 Method Not Allowed')
def test_inexistent_method_request(self):
baseapp = proxy_server.Application({},
FakeMemcache(),
container_ring=FakeRing(),
account_ring=FakeRing())
resp = baseapp.handle_request(
Request.blank('/v1/a', environ={'REQUEST_METHOD': '!invalid'}))
self.assertEquals(resp.status, '405 Method Not Allowed')
def test_calls_authorize_allow(self):
called = [False]
def authorize(req):
called[0] = True
with save_globals():
set_http_connect(200)
app = proxy_server.Application(None, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
req = Request.blank('/v1/a')
req.environ['swift.authorize'] = authorize
app.update_request(req)
app.handle_request(req)
self.assert_(called[0])
def test_calls_authorize_deny(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
app = proxy_server.Application(None, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
req = Request.blank('/v1/a')
req.environ['swift.authorize'] = authorize
app.update_request(req)
app.handle_request(req)
self.assert_(called[0])
def test_negative_content_length(self):
swift_dir = mkdtemp()
try:
baseapp = proxy_server.Application({'swift_dir': swift_dir},
FakeMemcache(), FakeLogger(),
FakeRing(), FakeRing())
resp = baseapp.handle_request(
Request.blank('/', environ={'CONTENT_LENGTH': '-1'}))
self.assertEquals(resp.status, '400 Bad Request')
self.assertEquals(resp.body, 'Invalid Content-Length')
resp = baseapp.handle_request(
Request.blank('/', environ={'CONTENT_LENGTH': '-123'}))
self.assertEquals(resp.status, '400 Bad Request')
self.assertEquals(resp.body, 'Invalid Content-Length')
finally:
rmtree(swift_dir, ignore_errors=True)
def test_adds_transaction_id(self):
swift_dir = mkdtemp()
try:
logger = FakeLogger()
baseapp = proxy_server.Application({'swift_dir': swift_dir},
FakeMemcache(), logger,
container_ring=FakeLogger(),
account_ring=FakeRing())
baseapp.handle_request(
Request.blank('/info',
environ={'HTTP_X_TRANS_ID_EXTRA': 'sardine',
'REQUEST_METHOD': 'GET'}))
# This is kind of a hokey way to get the transaction ID; it'd be
# better to examine response headers, but the catch_errors
# middleware is what sets the X-Trans-Id header, and we don't have
# that available here.
self.assertTrue(logger.txn_id.endswith('-sardine'))
finally:
rmtree(swift_dir, ignore_errors=True)
def test_adds_transaction_id_length_limit(self):
swift_dir = mkdtemp()
try:
logger = FakeLogger()
baseapp = proxy_server.Application({'swift_dir': swift_dir},
FakeMemcache(), logger,
container_ring=FakeLogger(),
account_ring=FakeRing())
baseapp.handle_request(
Request.blank('/info',
environ={'HTTP_X_TRANS_ID_EXTRA': 'a' * 1000,
'REQUEST_METHOD': 'GET'}))
self.assertTrue(logger.txn_id.endswith(
'-aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa'))
finally:
rmtree(swift_dir, ignore_errors=True)
def test_denied_host_header(self):
swift_dir = mkdtemp()
try:
baseapp = proxy_server.Application({'swift_dir': swift_dir,
'deny_host_headers':
'invalid_host.com'},
FakeMemcache(),
container_ring=FakeLogger(),
account_ring=FakeRing())
resp = baseapp.handle_request(
Request.blank('/v1/a/c/o',
environ={'HTTP_HOST': 'invalid_host.com'}))
self.assertEquals(resp.status, '403 Forbidden')
finally:
rmtree(swift_dir, ignore_errors=True)
def test_node_timing(self):
baseapp = proxy_server.Application({'sorting_method': 'timing'},
FakeMemcache(),
container_ring=FakeRing(),
account_ring=FakeRing())
self.assertEquals(baseapp.node_timings, {})
req = Request.blank('/v1/account', environ={'REQUEST_METHOD': 'HEAD'})
baseapp.update_request(req)
resp = baseapp.handle_request(req)
self.assertEquals(resp.status_int, 503) # couldn't connect to anything
exp_timings = {}
self.assertEquals(baseapp.node_timings, exp_timings)
times = [time.time()]
exp_timings = {'127.0.0.1': (0.1, times[0] + baseapp.timing_expiry)}
with mock.patch('swift.proxy.server.time', lambda: times.pop(0)):
baseapp.set_node_timing({'ip': '127.0.0.1'}, 0.1)
self.assertEquals(baseapp.node_timings, exp_timings)
nodes = [{'ip': '127.0.0.1'}, {'ip': '127.0.0.2'}, {'ip': '127.0.0.3'}]
with mock.patch('swift.proxy.server.shuffle', lambda l: l):
res = baseapp.sort_nodes(nodes)
exp_sorting = [{'ip': '127.0.0.2'}, {'ip': '127.0.0.3'},
{'ip': '127.0.0.1'}]
self.assertEquals(res, exp_sorting)
def test_node_affinity(self):
baseapp = proxy_server.Application({'sorting_method': 'affinity',
'read_affinity': 'r1=1'},
FakeMemcache(),
container_ring=FakeRing(),
account_ring=FakeRing())
nodes = [{'region': 2, 'zone': 1, 'ip': '127.0.0.1'},
{'region': 1, 'zone': 2, 'ip': '127.0.0.2'}]
with mock.patch('swift.proxy.server.shuffle', lambda x: x):
app_sorted = baseapp.sort_nodes(nodes)
exp_sorted = [{'region': 1, 'zone': 2, 'ip': '127.0.0.2'},
{'region': 2, 'zone': 1, 'ip': '127.0.0.1'}]
self.assertEquals(exp_sorted, app_sorted)
def test_info_defaults(self):
app = proxy_server.Application({}, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
self.assertTrue(app.expose_info)
self.assertTrue(isinstance(app.disallowed_sections, list))
self.assertEqual(0, len(app.disallowed_sections))
self.assertTrue(app.admin_key is None)
def test_get_info_controller(self):
path = '/info'
app = proxy_server.Application({}, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
controller, path_parts = app.get_controller(path)
self.assertTrue('version' in path_parts)
self.assertTrue(path_parts['version'] is None)
self.assertTrue('disallowed_sections' in path_parts)
self.assertTrue('expose_info' in path_parts)
self.assertTrue('admin_key' in path_parts)
self.assertEqual(controller.__name__, 'InfoController')
@patch_policies([
StoragePolicy(0, 'zero', is_default=True),
StoragePolicy(1, 'one'),
])
class TestProxyServerLoading(unittest.TestCase):
def setUp(self):
self._orig_hash_suffix = utils.HASH_PATH_SUFFIX
utils.HASH_PATH_SUFFIX = 'endcap'
self.tempdir = mkdtemp()
def tearDown(self):
rmtree(self.tempdir)
utils.HASH_PATH_SUFFIX = self._orig_hash_suffix
for policy in POLICIES:
policy.object_ring = None
def test_load_policy_rings(self):
for policy in POLICIES:
self.assertFalse(policy.object_ring)
conf_path = os.path.join(self.tempdir, 'proxy-server.conf')
conf_body = """
[DEFAULT]
swift_dir = %s
[pipeline:main]
pipeline = catch_errors cache proxy-server
[app:proxy-server]
use = egg:swift#proxy
[filter:cache]
use = egg:swift#memcache
[filter:catch_errors]
use = egg:swift#catch_errors
""" % self.tempdir
with open(conf_path, 'w') as f:
f.write(dedent(conf_body))
account_ring_path = os.path.join(self.tempdir, 'account.ring.gz')
write_fake_ring(account_ring_path)
container_ring_path = os.path.join(self.tempdir, 'container.ring.gz')
write_fake_ring(container_ring_path)
for policy in POLICIES:
object_ring_path = os.path.join(self.tempdir,
policy.ring_name + '.ring.gz')
write_fake_ring(object_ring_path)
app = loadapp(conf_path)
# find the end of the pipeline
while hasattr(app, 'app'):
app = app.app
# validate loaded rings
self.assertEqual(app.account_ring.serialized_path,
account_ring_path)
self.assertEqual(app.container_ring.serialized_path,
container_ring_path)
for policy in POLICIES:
self.assertEqual(policy.object_ring,
app.get_object_ring(int(policy)))
def test_missing_rings(self):
conf_path = os.path.join(self.tempdir, 'proxy-server.conf')
conf_body = """
[DEFAULT]
swift_dir = %s
[pipeline:main]
pipeline = catch_errors cache proxy-server
[app:proxy-server]
use = egg:swift#proxy
[filter:cache]
use = egg:swift#memcache
[filter:catch_errors]
use = egg:swift#catch_errors
""" % self.tempdir
with open(conf_path, 'w') as f:
f.write(dedent(conf_body))
ring_paths = [
os.path.join(self.tempdir, 'account.ring.gz'),
os.path.join(self.tempdir, 'container.ring.gz'),
]
for policy in POLICIES:
self.assertFalse(policy.object_ring)
object_ring_path = os.path.join(self.tempdir,
policy.ring_name + '.ring.gz')
ring_paths.append(object_ring_path)
for policy in POLICIES:
self.assertFalse(policy.object_ring)
for ring_path in ring_paths:
self.assertFalse(os.path.exists(ring_path))
self.assertRaises(IOError, loadapp, conf_path)
write_fake_ring(ring_path)
# all rings exist, app should load
loadapp(conf_path)
for policy in POLICIES:
self.assert_(policy.object_ring)
@patch_policies([StoragePolicy(0, 'zero', True,
object_ring=FakeRing(base_port=3000))])
class TestObjectController(unittest.TestCase):
def setUp(self):
self.app = proxy_server.Application(
None, FakeMemcache(),
logger=debug_logger('proxy-ut'),
account_ring=FakeRing(),
container_ring=FakeRing())
def tearDown(self):
self.app.account_ring.set_replicas(3)
self.app.container_ring.set_replicas(3)
for policy in POLICIES:
policy.object_ring = FakeRing(base_port=3000)
def assert_status_map(self, method, statuses, expected, raise_exc=False):
with save_globals():
kwargs = {}
if raise_exc:
kwargs['raise_exc'] = raise_exc
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o',
headers={'Content-Length': '0',
'Content-Type': 'text/plain'})
self.app.update_request(req)
res = method(req)
self.assertEquals(res.status_int, expected)
# repeat test
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o',
headers={'Content-Length': '0',
'Content-Type': 'text/plain'})
self.app.update_request(req)
res = method(req)
self.assertEquals(res.status_int, expected)
@unpatch_policies
def test_policy_IO(self):
if hasattr(_test_servers[-1], '_filesystem'):
# ironically, the _filesystem attribute on the object server means
# the in-memory diskfile is in use, so this test does not apply
return
def check_file(policy_idx, cont, devs, check_val):
partition, nodes = prosrv.get_object_ring(policy_idx).get_nodes(
'a', cont, 'o')
conf = {'devices': _testdir, 'mount_check': 'false'}
df_mgr = diskfile.DiskFileManager(conf, FakeLogger())
for dev in devs:
file = df_mgr.get_diskfile(dev, partition, 'a',
cont, 'o',
policy_idx=policy_idx)
if check_val is True:
file.open()
prolis = _test_sockets[0]
prosrv = _test_servers[0]
# check policy 0: put file on c, read it back, check loc on disk
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
obj = 'test_object0'
path = '/v1/a/c/o'
fd.write('PUT %s HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Length: %s\r\n'
'Content-Type: text/plain\r\n'
'\r\n%s' % (path, str(len(obj)), obj))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEqual(headers[:len(exp)], exp)
req = Request.blank(path,
environ={'REQUEST_METHOD': 'GET'},
headers={'Content-Type':
'text/plain'})
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 200)
self.assertEqual(res.body, obj)
check_file(0, 'c', ['sda1', 'sdb1'], True)
check_file(0, 'c', ['sdc1', 'sdd1', 'sde1', 'sdf1'], False)
# check policy 1: put file on c1, read it back, check loc on disk
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
path = '/v1/a/c1/o'
obj = 'test_object1'
fd.write('PUT %s HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Length: %s\r\n'
'Content-Type: text/plain\r\n'
'\r\n%s' % (path, str(len(obj)), obj))
fd.flush()
headers = readuntil2crlfs(fd)
self.assertEqual(headers[:len(exp)], exp)
req = Request.blank(path,
environ={'REQUEST_METHOD': 'GET'},
headers={'Content-Type':
'text/plain'})
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 200)
self.assertEqual(res.body, obj)
check_file(1, 'c1', ['sdc1', 'sdd1'], True)
check_file(1, 'c1', ['sda1', 'sdb1', 'sde1', 'sdf1'], False)
# check policy 2: put file on c2, read it back, check loc on disk
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
path = '/v1/a/c2/o'
obj = 'test_object2'
fd.write('PUT %s HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Length: %s\r\n'
'Content-Type: text/plain\r\n'
'\r\n%s' % (path, str(len(obj)), obj))
fd.flush()
headers = readuntil2crlfs(fd)
self.assertEqual(headers[:len(exp)], exp)
req = Request.blank(path,
environ={'REQUEST_METHOD': 'GET'},
headers={'Content-Type':
'text/plain'})
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 200)
self.assertEqual(res.body, obj)
check_file(2, 'c2', ['sde1', 'sdf1'], True)
check_file(2, 'c2', ['sda1', 'sdb1', 'sdc1', 'sdd1'], False)
@unpatch_policies
def test_policy_IO_override(self):
if hasattr(_test_servers[-1], '_filesystem'):
# ironically, the _filesystem attribute on the object server means
# the in-memory diskfile is in use, so this test does not apply
return
prosrv = _test_servers[0]
# validate container policy is 1
req = Request.blank('/v1/a/c1', method='HEAD')
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 204) # sanity check
self.assertEqual(POLICIES[1].name, res.headers['x-storage-policy'])
# check overrides: put it in policy 2 (not where the container says)
req = Request.blank(
'/v1/a/c1/wrong-o',
environ={'REQUEST_METHOD': 'PUT',
'wsgi.input': StringIO("hello")},
headers={'Content-Type': 'text/plain',
'Content-Length': '5',
'X-Backend-Storage-Policy-Index': '2'})
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 201) # sanity check
# go to disk to make sure it's there
partition, nodes = prosrv.get_object_ring(2).get_nodes(
'a', 'c1', 'wrong-o')
node = nodes[0]
conf = {'devices': _testdir, 'mount_check': 'false'}
df_mgr = diskfile.DiskFileManager(conf, FakeLogger())
df = df_mgr.get_diskfile(node['device'], partition, 'a',
'c1', 'wrong-o', policy_idx=2)
with df.open():
contents = ''.join(df.reader())
self.assertEqual(contents, "hello")
# can't get it from the normal place
req = Request.blank('/v1/a/c1/wrong-o',
environ={'REQUEST_METHOD': 'GET'},
headers={'Content-Type': 'text/plain'})
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 404) # sanity check
# but we can get it from policy 2
req = Request.blank('/v1/a/c1/wrong-o',
environ={'REQUEST_METHOD': 'GET'},
headers={'Content-Type': 'text/plain',
'X-Backend-Storage-Policy-Index': '2'})
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 200)
self.assertEqual(res.body, 'hello')
# and we can delete it the same way
req = Request.blank('/v1/a/c1/wrong-o',
environ={'REQUEST_METHOD': 'DELETE'},
headers={'Content-Type': 'text/plain',
'X-Backend-Storage-Policy-Index': '2'})
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 204)
df = df_mgr.get_diskfile(node['device'], partition, 'a',
'c1', 'wrong-o', policy_idx=2)
try:
df.open()
except DiskFileNotExist as e:
now = time.time()
self.assert_(now - 1 < float(e.timestamp) < now + 1)
else:
self.fail('did not raise DiskFileNotExist')
@unpatch_policies
def test_GET_newest_large_file(self):
prolis = _test_sockets[0]
prosrv = _test_servers[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
obj = 'a' * (1024 * 1024)
path = '/v1/a/c/o.large'
fd.write('PUT %s HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Length: %s\r\n'
'Content-Type: application/octet-stream\r\n'
'\r\n%s' % (path, str(len(obj)), obj))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEqual(headers[:len(exp)], exp)
req = Request.blank(path,
environ={'REQUEST_METHOD': 'GET'},
headers={'Content-Type':
'application/octet-stream',
'X-Newest': 'true'})
res = req.get_response(prosrv)
self.assertEqual(res.status_int, 200)
self.assertEqual(res.body, obj)
def test_PUT_expect_header_zero_content_length(self):
test_errors = []
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
if path == '/a/c/o.jpg':
if 'expect' in headers or 'Expect' in headers:
test_errors.append('Expect was in headers for object '
'server!')
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
# The (201, Exception('test')) tuples in there have the effect of
# changing the status of the initial expect response. The default
# expect response from FakeConn for 201 is 100.
# But the object server won't send a 100 continue line if the
# client doesn't send a expect 100 header (as is the case with
# zero byte PUTs as validated by this test), nevertheless the
# object controller calls getexpect without prejudice. In this
# case the status from the response shows up early in getexpect
# instead of having to wait until getresponse. The Exception is
# in there to ensure that the object controller also *uses* the
# result of getexpect instead of calling getresponse in which case
# our FakeConn will blow up.
success_codes = [(201, Exception('test'))] * 3
set_http_connect(200, 200, *success_codes,
give_connect=test_connect)
req = Request.blank('/v1/a/c/o.jpg', {})
req.content_length = 0
self.app.update_request(req)
self.app.memcache.store = {}
res = controller.PUT(req)
self.assertEqual(test_errors, [])
self.assertTrue(res.status.startswith('201 '), res.status)
def test_PUT_expect_header_nonzero_content_length(self):
test_errors = []
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
if path == '/a/c/o.jpg':
if 'Expect' not in headers:
test_errors.append('Expect was not in headers for '
'non-zero byte PUT!')
with save_globals():
controller = \
proxy_server.ObjectController(self.app, 'a', 'c', 'o.jpg')
# the (100, 201) tuples in there are just being extra explicit
# about the FakeConn returning the 100 Continue status when the
# object controller calls getexpect. Which is FakeConn's default
# for 201 if no expect_status is specified.
success_codes = [(100, 201)] * 3
set_http_connect(200, 200, *success_codes,
give_connect=test_connect)
req = Request.blank('/v1/a/c/o.jpg', {})
req.content_length = 1
req.body = 'a'
self.app.update_request(req)
self.app.memcache.store = {}
res = controller.PUT(req)
self.assertEqual(test_errors, [])
self.assertTrue(res.status.startswith('201 '))
def test_PUT_respects_write_affinity(self):
written_to = []
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
if path == '/a/c/o.jpg':
written_to.append((ipaddr, port, device))
with save_globals():
def is_r0(node):
return node['region'] == 0
object_ring = self.app.get_object_ring(None)
object_ring.max_more_nodes = 100
self.app.write_affinity_is_local_fn = is_r0
self.app.write_affinity_node_count = lambda r: 3
controller = \
proxy_server.ObjectController(self.app, 'a', 'c', 'o.jpg')
set_http_connect(200, 200, 201, 201, 201,
give_connect=test_connect)
req = Request.blank('/v1/a/c/o.jpg', {})
req.content_length = 1
req.body = 'a'
self.app.memcache.store = {}
res = controller.PUT(req)
self.assertTrue(res.status.startswith('201 '))
self.assertEqual(3, len(written_to))
for ip, port, device in written_to:
# this is kind of a hokey test, but in FakeRing, the port is even
# when the region is 0, and odd when the region is 1, so this test
# asserts that we only wrote to nodes in region 0.
self.assertEqual(0, port % 2)
def test_PUT_respects_write_affinity_with_507s(self):
written_to = []
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
if path == '/a/c/o.jpg':
written_to.append((ipaddr, port, device))
with save_globals():
def is_r0(node):
return node['region'] == 0
object_ring = self.app.get_object_ring(None)
object_ring.max_more_nodes = 100
self.app.write_affinity_is_local_fn = is_r0
self.app.write_affinity_node_count = lambda r: 3
controller = \
proxy_server.ObjectController(self.app, 'a', 'c', 'o.jpg')
self.app.error_limit(
object_ring.get_part_nodes(1)[0], 'test')
set_http_connect(200, 200, # account, container
201, 201, 201, # 3 working backends
give_connect=test_connect)
req = Request.blank('/v1/a/c/o.jpg', {})
req.content_length = 1
req.body = 'a'
self.app.memcache.store = {}
res = controller.PUT(req)
self.assertTrue(res.status.startswith('201 '))
self.assertEqual(3, len(written_to))
# this is kind of a hokey test, but in FakeRing, the port is even when
# the region is 0, and odd when the region is 1, so this test asserts
# that we wrote to 2 nodes in region 0, then went to 1 non-r0 node.
self.assertEqual(0, written_to[0][1] % 2) # it's (ip, port, device)
self.assertEqual(0, written_to[1][1] % 2)
self.assertNotEqual(0, written_to[2][1] % 2)
@unpatch_policies
def test_PUT_message_length_using_content_length(self):
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
obj = 'j' * 20
fd.write('PUT /v1/a/c/o.content-length HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Length: %s\r\n'
'Content-Type: application/octet-stream\r\n'
'\r\n%s' % (str(len(obj)), obj))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEqual(headers[:len(exp)], exp)
@unpatch_policies
def test_PUT_message_length_using_transfer_encoding(self):
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/c/o.chunked HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Type: application/octet-stream\r\n'
'Transfer-Encoding: chunked\r\n\r\n'
'2\r\n'
'oh\r\n'
'4\r\n'
' say\r\n'
'4\r\n'
' can\r\n'
'4\r\n'
' you\r\n'
'4\r\n'
' see\r\n'
'3\r\n'
' by\r\n'
'4\r\n'
' the\r\n'
'8\r\n'
' dawns\'\n\r\n'
'0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEqual(headers[:len(exp)], exp)
@unpatch_policies
def test_PUT_message_length_using_both(self):
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/c/o.chunked HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Type: application/octet-stream\r\n'
'Content-Length: 33\r\n'
'Transfer-Encoding: chunked\r\n\r\n'
'2\r\n'
'oh\r\n'
'4\r\n'
' say\r\n'
'4\r\n'
' can\r\n'
'4\r\n'
' you\r\n'
'4\r\n'
' see\r\n'
'3\r\n'
' by\r\n'
'4\r\n'
' the\r\n'
'8\r\n'
' dawns\'\n\r\n'
'0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEqual(headers[:len(exp)], exp)
@unpatch_policies
def test_PUT_bad_message_length(self):
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/c/o.chunked HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Type: application/octet-stream\r\n'
'Content-Length: 33\r\n'
'Transfer-Encoding: gzip\r\n\r\n'
'2\r\n'
'oh\r\n'
'4\r\n'
' say\r\n'
'4\r\n'
' can\r\n'
'4\r\n'
' you\r\n'
'4\r\n'
' see\r\n'
'3\r\n'
' by\r\n'
'4\r\n'
' the\r\n'
'8\r\n'
' dawns\'\n\r\n'
'0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 400'
self.assertEqual(headers[:len(exp)], exp)
@unpatch_policies
def test_PUT_message_length_unsup_xfr_encoding(self):
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/c/o.chunked HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Type: application/octet-stream\r\n'
'Content-Length: 33\r\n'
'Transfer-Encoding: gzip,chunked\r\n\r\n'
'2\r\n'
'oh\r\n'
'4\r\n'
' say\r\n'
'4\r\n'
' can\r\n'
'4\r\n'
' you\r\n'
'4\r\n'
' see\r\n'
'3\r\n'
' by\r\n'
'4\r\n'
' the\r\n'
'8\r\n'
' dawns\'\n\r\n'
'0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 501'
self.assertEqual(headers[:len(exp)], exp)
@unpatch_policies
def test_PUT_message_length_too_large(self):
with mock.patch('swift.common.constraints.MAX_FILE_SIZE', 10):
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/c/o.chunked HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Type: application/octet-stream\r\n'
'Content-Length: 33\r\n\r\n'
'oh say can you see by the dawns\'\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 413'
self.assertEqual(headers[:len(exp)], exp)
@unpatch_policies
def test_PUT_last_modified(self):
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/c/o.last_modified HTTP/1.1\r\n'
'Host: localhost\r\nConnection: close\r\n'
'X-Storage-Token: t\r\nContent-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
lm_hdr = 'Last-Modified: '
self.assertEqual(headers[:len(exp)], exp)
last_modified_put = [line for line in headers.split('\r\n')
if lm_hdr in line][0][len(lm_hdr):]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('HEAD /v1/a/c/o.last_modified HTTP/1.1\r\n'
'Host: localhost\r\nConnection: close\r\n'
'X-Storage-Token: t\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEqual(headers[:len(exp)], exp)
last_modified_head = [line for line in headers.split('\r\n')
if lm_hdr in line][0][len(lm_hdr):]
self.assertEqual(last_modified_put, last_modified_head)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/c/o.last_modified HTTP/1.1\r\n'
'Host: localhost\r\nConnection: close\r\n'
'If-Modified-Since: %s\r\n'
'X-Storage-Token: t\r\n\r\n' % last_modified_put)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 304'
self.assertEqual(headers[:len(exp)], exp)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/c/o.last_modified HTTP/1.1\r\n'
'Host: localhost\r\nConnection: close\r\n'
'If-Unmodified-Since: %s\r\n'
'X-Storage-Token: t\r\n\r\n' % last_modified_put)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEqual(headers[:len(exp)], exp)
def test_expirer_DELETE_on_versioned_object(self):
test_errors = []
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
if method == 'DELETE':
if 'x-if-delete-at' in headers or 'X-If-Delete-At' in headers:
test_errors.append('X-If-Delete-At in headers')
body = json.dumps(
[{"name": "001o/1",
"hash": "x",
"bytes": 0,
"content_type": "text/plain",
"last_modified": "1970-01-01T00:00:01.000000"}])
body_iter = ('', '', body, '', '', '', '', '', '', '', '', '', '', '')
with save_globals():
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
# HEAD HEAD GET GET HEAD GET GET GET PUT PUT
# PUT DEL DEL DEL
set_http_connect(200, 200, 200, 200, 200, 200, 200, 200, 201, 201,
201, 204, 204, 204,
give_connect=test_connect,
body_iter=body_iter,
headers={'x-versions-location': 'foo'})
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o',
headers={'X-If-Delete-At': 1},
environ={'REQUEST_METHOD': 'DELETE'})
self.app.update_request(req)
controller.DELETE(req)
self.assertEquals(test_errors, [])
@patch_policies([
StoragePolicy(0, 'zero', False, object_ring=FakeRing()),
StoragePolicy(1, 'one', True, object_ring=FakeRing())
])
def test_DELETE_on_expired_versioned_object(self):
methods = set()
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
methods.add((method, path))
def fake_container_info(account, container, req):
return {'status': 200, 'sync_key': None,
'meta': {}, 'cors': {'allow_origin': None,
'expose_headers': None,
'max_age': None},
'sysmeta': {}, 'read_acl': None, 'object_count': None,
'write_acl': None, 'versions': 'foo',
'partition': 1, 'bytes': None, 'storage_policy': '1',
'nodes': [{'zone': 0, 'ip': '10.0.0.0', 'region': 0,
'id': 0, 'device': 'sda', 'port': 1000},
{'zone': 1, 'ip': '10.0.0.1', 'region': 1,
'id': 1, 'device': 'sdb', 'port': 1001},
{'zone': 2, 'ip': '10.0.0.2', 'region': 0,
'id': 2, 'device': 'sdc', 'port': 1002}]}
def fake_list_iter(container, prefix, env):
object_list = [{'name': '1'}, {'name': '2'}, {'name': '3'}]
for obj in object_list:
yield obj
with save_globals():
controller = proxy_server.ObjectController(self.app,
'a', 'c', 'o')
controller.container_info = fake_container_info
controller._listing_iter = fake_list_iter
set_http_connect(404, 404, 404, # get for the previous version
200, 200, 200, # get for the pre-previous
201, 201, 201, # put move the pre-previous
204, 204, 204, # delete for the pre-previous
give_connect=test_connect)
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
self.app.memcache.store = {}
self.app.update_request(req)
controller.DELETE(req)
exp_methods = [('GET', '/a/foo/3'),
('GET', '/a/foo/2'),
('PUT', '/a/c/o'),
('DELETE', '/a/foo/2')]
self.assertEquals(set(exp_methods), (methods))
def test_PUT_auto_content_type(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
def test_content_type(filename, expected):
# The three responses here are for account_info() (HEAD to
# account server), container_info() (HEAD to container server)
# and three calls to _connect_put_node() (PUT to three object
# servers)
set_http_connect(201, 201, 201, 201, 201,
give_content_type=lambda content_type:
self.assertEquals(content_type,
expected.next()))
# We need into include a transfer-encoding to get past
# constraints.check_object_creation()
req = Request.blank('/v1/a/c/%s' % filename, {},
headers={'transfer-encoding': 'chunked'})
self.app.update_request(req)
self.app.memcache.store = {}
res = controller.PUT(req)
# If we don't check the response here we could miss problems
# in PUT()
self.assertEquals(res.status_int, 201)
test_content_type('test.jpg', iter(['', '', 'image/jpeg',
'image/jpeg', 'image/jpeg']))
test_content_type('test.html', iter(['', '', 'text/html',
'text/html', 'text/html']))
test_content_type('test.css', iter(['', '', 'text/css',
'text/css', 'text/css']))
def test_custom_mime_types_files(self):
swift_dir = mkdtemp()
try:
with open(os.path.join(swift_dir, 'mime.types'), 'w') as fp:
fp.write('foo/bar foo\n')
proxy_server.Application({'swift_dir': swift_dir},
FakeMemcache(), FakeLogger(),
FakeRing(), FakeRing())
self.assertEquals(proxy_server.mimetypes.guess_type('blah.foo')[0],
'foo/bar')
self.assertEquals(proxy_server.mimetypes.guess_type('blah.jpg')[0],
'image/jpeg')
finally:
rmtree(swift_dir, ignore_errors=True)
def test_PUT(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
def test_status_map(statuses, expected):
set_http_connect(*statuses)
req = Request.blank('/v1/a/c/o.jpg', {})
req.content_length = 0
self.app.update_request(req)
self.app.memcache.store = {}
res = controller.PUT(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((200, 200, 201, 201, 201), 201)
test_status_map((200, 200, 201, 201, 500), 201)
test_status_map((200, 200, 204, 404, 404), 404)
test_status_map((200, 200, 204, 500, 404), 503)
test_status_map((200, 200, 202, 202, 204), 204)
def test_PUT_connect_exceptions(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
def test_status_map(statuses, expected):
set_http_connect(*statuses)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o.jpg', {})
req.content_length = 0
self.app.update_request(req)
res = controller.PUT(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((200, 200, 201, 201, -1), 201) # connect exc
# connect errors
test_status_map((200, 200, Timeout(), 201, 201, ), 201)
test_status_map((200, 200, 201, 201, Exception()), 201)
# expect errors
test_status_map((200, 200, (Timeout(), None), 201, 201), 201)
test_status_map((200, 200, (Exception(), None), 201, 201), 201)
# response errors
test_status_map((200, 200, (100, Timeout()), 201, 201), 201)
test_status_map((200, 200, (100, Exception()), 201, 201), 201)
test_status_map((200, 200, 507, 201, 201), 201) # error limited
test_status_map((200, 200, -1, 201, -1), 503)
test_status_map((200, 200, 503, -1, 503), 503)
def test_PUT_send_exceptions(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
def test_status_map(statuses, expected):
self.app.memcache.store = {}
set_http_connect(*statuses)
req = Request.blank('/v1/a/c/o.jpg',
environ={'REQUEST_METHOD': 'PUT'},
body='some data')
self.app.update_request(req)
res = controller.PUT(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((200, 200, 201, -1, 201), 201)
test_status_map((200, 200, 201, -1, -1), 503)
test_status_map((200, 200, 503, 503, -1), 503)
def test_PUT_max_size(self):
with save_globals():
set_http_connect(201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o', {}, headers={
'Content-Length': str(constraints.MAX_FILE_SIZE + 1),
'Content-Type': 'foo/bar'})
self.app.update_request(req)
res = controller.PUT(req)
self.assertEquals(res.status_int, 413)
def test_PUT_bad_content_type(self):
with save_globals():
set_http_connect(201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o', {}, headers={
'Content-Length': 0, 'Content-Type': 'foo/bar;swift_hey=45'})
self.app.update_request(req)
res = controller.PUT(req)
self.assertEquals(res.status_int, 400)
def test_PUT_getresponse_exceptions(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
def test_status_map(statuses, expected):
self.app.memcache.store = {}
set_http_connect(*statuses)
req = Request.blank('/v1/a/c/o.jpg', {})
req.content_length = 0
self.app.update_request(req)
res = controller.PUT(req)
expected = str(expected)
self.assertEquals(res.status[:len(str(expected))],
str(expected))
test_status_map((200, 200, 201, 201, -1), 201)
test_status_map((200, 200, 201, -1, -1), 503)
test_status_map((200, 200, 503, 503, -1), 503)
def test_POST(self):
with save_globals():
self.app.object_post_as_copy = False
def test_status_map(statuses, expected):
set_http_connect(*statuses)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o', {}, method='POST',
headers={'Content-Type': 'foo/bar'})
self.app.update_request(req)
res = req.get_response(self.app)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((200, 200, 202, 202, 202), 202)
test_status_map((200, 200, 202, 202, 500), 202)
test_status_map((200, 200, 202, 500, 500), 503)
test_status_map((200, 200, 202, 404, 500), 503)
test_status_map((200, 200, 202, 404, 404), 404)
test_status_map((200, 200, 404, 500, 500), 503)
test_status_map((200, 200, 404, 404, 404), 404)
@patch_policies([
StoragePolicy(0, 'zero', is_default=True, object_ring=FakeRing()),
StoragePolicy(1, 'one', object_ring=FakeRing()),
])
def test_POST_backend_headers(self):
self.app.object_post_as_copy = False
self.app.sort_nodes = lambda nodes: nodes
backend_requests = []
def capture_requests(ip, port, method, path, headers, *args,
**kwargs):
backend_requests.append((method, path, headers))
req = Request.blank('/v1/a/c/o', {}, method='POST',
headers={'X-Object-Meta-Color': 'Blue'})
# we want the container_info response to says a policy index of 1
resp_headers = {'X-Backend-Storage-Policy-Index': 1}
with mocked_http_conn(
200, 200, 202, 202, 202,
headers=resp_headers, give_connect=capture_requests
) as fake_conn:
resp = req.get_response(self.app)
self.assertRaises(StopIteration, fake_conn.code_iter.next)
self.assertEqual(resp.status_int, 202)
self.assertEqual(len(backend_requests), 5)
def check_request(req, method, path, headers=None):
req_method, req_path, req_headers = req
self.assertEqual(method, req_method)
# caller can ignore leading path parts
self.assertTrue(req_path.endswith(path),
'expected path to end with %s, it was %s' % (
path, req_path))
headers = headers or {}
# caller can ignore some headers
for k, v in headers.items():
self.assertEqual(req_headers[k], v)
account_request = backend_requests.pop(0)
check_request(account_request, method='HEAD', path='/sda/0/a')
container_request = backend_requests.pop(0)
check_request(container_request, method='HEAD', path='/sda/0/a/c')
# make sure backend requests included expected container headers
container_headers = {}
for request in backend_requests:
req_headers = request[2]
device = req_headers['x-container-device']
host = req_headers['x-container-host']
container_headers[device] = host
expectations = {
'method': 'POST',
'path': '/0/a/c/o',
'headers': {
'X-Container-Partition': '0',
'Connection': 'close',
'User-Agent': 'proxy-server %s' % os.getpid(),
'Host': 'localhost:80',
'Referer': 'POST http://localhost/v1/a/c/o',
'X-Object-Meta-Color': 'Blue',
'X-Backend-Storage-Policy-Index': '1'
},
}
check_request(request, **expectations)
expected = {}
for i, device in enumerate(['sda', 'sdb', 'sdc']):
expected[device] = '10.0.0.%d:100%d' % (i, i)
self.assertEqual(container_headers, expected)
# and again with policy override
self.app.memcache.store = {}
backend_requests = []
req = Request.blank('/v1/a/c/o', {}, method='POST',
headers={'X-Object-Meta-Color': 'Blue',
'X-Backend-Storage-Policy-Index': 0})
with mocked_http_conn(
200, 200, 202, 202, 202,
headers=resp_headers, give_connect=capture_requests
) as fake_conn:
resp = req.get_response(self.app)
self.assertRaises(StopIteration, fake_conn.code_iter.next)
self.assertEqual(resp.status_int, 202)
self.assertEqual(len(backend_requests), 5)
for request in backend_requests[2:]:
expectations = {
'method': 'POST',
'path': '/0/a/c/o', # ignore device bit
'headers': {
'X-Object-Meta-Color': 'Blue',
'X-Backend-Storage-Policy-Index': '0',
}
}
check_request(request, **expectations)
# and this time with post as copy
self.app.object_post_as_copy = True
self.app.memcache.store = {}
backend_requests = []
req = Request.blank('/v1/a/c/o', {}, method='POST',
headers={'X-Object-Meta-Color': 'Blue',
'X-Backend-Storage-Policy-Index': 0})
with mocked_http_conn(
200, 200, 200, 200, 200, 201, 201, 201,
headers=resp_headers, give_connect=capture_requests
) as fake_conn:
resp = req.get_response(self.app)
self.assertRaises(StopIteration, fake_conn.code_iter.next)
self.assertEqual(resp.status_int, 202)
self.assertEqual(len(backend_requests), 8)
policy0 = {'X-Backend-Storage-Policy-Index': '0'}
policy1 = {'X-Backend-Storage-Policy-Index': '1'}
expected = [
# account info
{'method': 'HEAD', 'path': '/0/a'},
# container info
{'method': 'HEAD', 'path': '/0/a/c'},
# x-newests
{'method': 'GET', 'path': '/0/a/c/o', 'headers': policy1},
{'method': 'GET', 'path': '/0/a/c/o', 'headers': policy1},
{'method': 'GET', 'path': '/0/a/c/o', 'headers': policy1},
# new writes
{'method': 'PUT', 'path': '/0/a/c/o', 'headers': policy0},
{'method': 'PUT', 'path': '/0/a/c/o', 'headers': policy0},
{'method': 'PUT', 'path': '/0/a/c/o', 'headers': policy0},
]
for request, expectations in zip(backend_requests, expected):
check_request(request, **expectations)
def test_POST_as_copy(self):
with save_globals():
def test_status_map(statuses, expected):
set_http_connect(*statuses)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar'})
self.app.update_request(req)
res = req.get_response(self.app)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((200, 200, 200, 200, 200, 202, 202, 202), 202)
test_status_map((200, 200, 200, 200, 200, 202, 202, 500), 202)
test_status_map((200, 200, 200, 200, 200, 202, 500, 500), 503)
test_status_map((200, 200, 200, 200, 200, 202, 404, 500), 503)
test_status_map((200, 200, 200, 200, 200, 202, 404, 404), 404)
test_status_map((200, 200, 200, 200, 200, 404, 500, 500), 503)
test_status_map((200, 200, 200, 200, 200, 404, 404, 404), 404)
def test_DELETE(self):
with save_globals():
def test_status_map(statuses, expected):
set_http_connect(*statuses)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'DELETE'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status[:len(str(expected))],
str(expected))
test_status_map((200, 200, 204, 204, 204), 204)
test_status_map((200, 200, 204, 204, 500), 204)
test_status_map((200, 200, 204, 404, 404), 404)
test_status_map((200, 204, 500, 500, 404), 503)
test_status_map((200, 200, 404, 404, 404), 404)
test_status_map((200, 200, 400, 400, 400), 400)
def test_HEAD(self):
with save_globals():
def test_status_map(statuses, expected):
set_http_connect(*statuses)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'HEAD'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status[:len(str(expected))],
str(expected))
if expected < 400:
self.assert_('x-works' in res.headers)
self.assertEquals(res.headers['x-works'], 'yes')
self.assert_('accept-ranges' in res.headers)
self.assertEquals(res.headers['accept-ranges'], 'bytes')
test_status_map((200, 200, 200, 404, 404), 200)
test_status_map((200, 200, 200, 500, 404), 200)
test_status_map((200, 200, 304, 500, 404), 304)
test_status_map((200, 200, 404, 404, 404), 404)
test_status_map((200, 200, 404, 404, 500), 404)
test_status_map((200, 200, 500, 500, 500), 503)
def test_HEAD_newest(self):
with save_globals():
def test_status_map(statuses, expected, timestamps,
expected_timestamp):
set_http_connect(*statuses, timestamps=timestamps)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'HEAD'},
headers={'x-newest': 'true'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status[:len(str(expected))],
str(expected))
self.assertEquals(res.headers.get('last-modified'),
expected_timestamp)
# acct cont obj obj obj
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'2', '3'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'3', '2'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'3', '1'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '3',
'3', '1'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', None,
None, None), None)
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', None,
None, '1'), '1')
test_status_map((200, 200, 404, 404, 200), 200, ('0', '0', None,
None, '1'), '1')
def test_GET_newest(self):
with save_globals():
def test_status_map(statuses, expected, timestamps,
expected_timestamp):
set_http_connect(*statuses, timestamps=timestamps)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'GET'},
headers={'x-newest': 'true'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status[:len(str(expected))],
str(expected))
self.assertEquals(res.headers.get('last-modified'),
expected_timestamp)
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'2', '3'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'3', '2'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'3', '1'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '3',
'3', '1'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', None,
None, None), None)
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', None,
None, '1'), '1')
with save_globals():
def test_status_map(statuses, expected, timestamps,
expected_timestamp):
set_http_connect(*statuses, timestamps=timestamps)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'HEAD'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status[:len(str(expected))],
str(expected))
self.assertEquals(res.headers.get('last-modified'),
expected_timestamp)
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'2', '3'), '1')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'3', '2'), '1')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '1',
'3', '1'), '1')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', '3',
'3', '1'), '3')
test_status_map((200, 200, 200, 200, 200), 200, ('0', '0', None,
'1', '2'), None)
def test_POST_meta_val_len(self):
with save_globals():
limit = constraints.MAX_META_VALUE_LENGTH
self.app.object_post_as_copy = False
proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 200, 202, 202, 202)
# acct cont obj obj obj
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar',
'X-Object-Meta-Foo': 'x' * limit})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 202)
set_http_connect(202, 202, 202)
req = Request.blank(
'/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar',
'X-Object-Meta-Foo': 'x' * (limit + 1)})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 400)
def test_POST_as_copy_meta_val_len(self):
with save_globals():
limit = constraints.MAX_META_VALUE_LENGTH
set_http_connect(200, 200, 200, 200, 200, 202, 202, 202)
# acct cont objc objc objc obj obj obj
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar',
'X-Object-Meta-Foo': 'x' * limit})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 202)
set_http_connect(202, 202, 202)
req = Request.blank(
'/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar',
'X-Object-Meta-Foo': 'x' * (limit + 1)})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 400)
def test_POST_meta_key_len(self):
with save_globals():
limit = constraints.MAX_META_NAME_LENGTH
self.app.object_post_as_copy = False
set_http_connect(200, 200, 202, 202, 202)
# acct cont obj obj obj
req = Request.blank(
'/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar',
('X-Object-Meta-' + 'x' * limit): 'x'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 202)
set_http_connect(202, 202, 202)
req = Request.blank(
'/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar',
('X-Object-Meta-' + 'x' * (limit + 1)): 'x'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 400)
def test_POST_as_copy_meta_key_len(self):
with save_globals():
limit = constraints.MAX_META_NAME_LENGTH
set_http_connect(200, 200, 200, 200, 200, 202, 202, 202)
# acct cont objc objc objc obj obj obj
req = Request.blank(
'/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar',
('X-Object-Meta-' + 'x' * limit): 'x'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 202)
set_http_connect(202, 202, 202)
req = Request.blank(
'/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'foo/bar',
('X-Object-Meta-' + 'x' * (limit + 1)): 'x'})
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 400)
def test_POST_meta_count(self):
with save_globals():
limit = constraints.MAX_META_COUNT
headers = dict(
(('X-Object-Meta-' + str(i), 'a') for i in xrange(limit + 1)))
headers.update({'Content-Type': 'foo/bar'})
set_http_connect(202, 202, 202)
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers=headers)
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 400)
def test_POST_meta_size(self):
with save_globals():
limit = constraints.MAX_META_OVERALL_SIZE
count = limit / 256 # enough to cause the limit to be reached
headers = dict(
(('X-Object-Meta-' + str(i), 'a' * 256)
for i in xrange(count + 1)))
headers.update({'Content-Type': 'foo/bar'})
set_http_connect(202, 202, 202)
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'POST'},
headers=headers)
self.app.update_request(req)
res = req.get_response(self.app)
self.assertEquals(res.status_int, 400)
def test_PUT_not_autodetect_content_type(self):
with save_globals():
headers = {'Content-Type': 'something/right', 'Content-Length': 0}
it_worked = []
def verify_content_type(ipaddr, port, device, partition,
method, path, headers=None,
query_string=None):
if path == '/a/c/o.html':
it_worked.append(
headers['Content-Type'].startswith('something/right'))
set_http_connect(204, 204, 201, 201, 201,
give_connect=verify_content_type)
req = Request.blank('/v1/a/c/o.html', {'REQUEST_METHOD': 'PUT'},
headers=headers)
self.app.update_request(req)
req.get_response(self.app)
self.assertNotEquals(it_worked, [])
self.assertTrue(all(it_worked))
def test_PUT_autodetect_content_type(self):
with save_globals():
headers = {'Content-Type': 'something/wrong', 'Content-Length': 0,
'X-Detect-Content-Type': 'True'}
it_worked = []
def verify_content_type(ipaddr, port, device, partition,
method, path, headers=None,
query_string=None):
if path == '/a/c/o.html':
it_worked.append(
headers['Content-Type'].startswith('text/html'))
set_http_connect(204, 204, 201, 201, 201,
give_connect=verify_content_type)
req = Request.blank('/v1/a/c/o.html', {'REQUEST_METHOD': 'PUT'},
headers=headers)
self.app.update_request(req)
req.get_response(self.app)
self.assertNotEquals(it_worked, [])
self.assertTrue(all(it_worked))
def test_client_timeout(self):
with save_globals():
self.app.account_ring.get_nodes('account')
for dev in self.app.account_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
self.app.container_ring.get_nodes('account')
for dev in self.app.container_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
object_ring = self.app.get_object_ring(None)
object_ring.get_nodes('account')
for dev in object_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
class SlowBody(object):
def __init__(self):
self.sent = 0
def read(self, size=-1):
if self.sent < 4:
sleep(0.1)
self.sent += 1
return ' '
return ''
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'PUT',
'wsgi.input': SlowBody()},
headers={'Content-Length': '4',
'Content-Type': 'text/plain'})
self.app.update_request(req)
set_http_connect(200, 200, 201, 201, 201)
# acct cont obj obj obj
resp = req.get_response(self.app)
self.assertEquals(resp.status_int, 201)
self.app.client_timeout = 0.05
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'PUT',
'wsgi.input': SlowBody()},
headers={'Content-Length': '4',
'Content-Type': 'text/plain'})
self.app.update_request(req)
set_http_connect(201, 201, 201)
# obj obj obj
resp = req.get_response(self.app)
self.assertEquals(resp.status_int, 408)
def test_client_disconnect(self):
with save_globals():
self.app.account_ring.get_nodes('account')
for dev in self.app.account_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
self.app.container_ring.get_nodes('account')
for dev in self.app.container_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
object_ring = self.app.get_object_ring(None)
object_ring.get_nodes('account')
for dev in object_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
class SlowBody(object):
def __init__(self):
self.sent = 0
def read(self, size=-1):
raise Exception('Disconnected')
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'PUT',
'wsgi.input': SlowBody()},
headers={'Content-Length': '4',
'Content-Type': 'text/plain'})
self.app.update_request(req)
set_http_connect(200, 200, 201, 201, 201)
# acct cont obj obj obj
resp = req.get_response(self.app)
self.assertEquals(resp.status_int, 499)
def test_node_read_timeout(self):
with save_globals():
self.app.account_ring.get_nodes('account')
for dev in self.app.account_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
self.app.container_ring.get_nodes('account')
for dev in self.app.container_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
object_ring = self.app.get_object_ring(None)
object_ring.get_nodes('account')
for dev in object_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'GET'})
self.app.update_request(req)
set_http_connect(200, 200, 200, slow=0.1)
req.sent_size = 0
resp = req.get_response(self.app)
got_exc = False
try:
resp.body
except ChunkReadTimeout:
got_exc = True
self.assert_(not got_exc)
self.app.recoverable_node_timeout = 0.1
set_http_connect(200, 200, 200, slow=1.0)
resp = req.get_response(self.app)
got_exc = False
try:
resp.body
except ChunkReadTimeout:
got_exc = True
self.assert_(got_exc)
def test_node_read_timeout_retry(self):
with save_globals():
self.app.account_ring.get_nodes('account')
for dev in self.app.account_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
self.app.container_ring.get_nodes('account')
for dev in self.app.container_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
object_ring = self.app.get_object_ring(None)
object_ring.get_nodes('account')
for dev in object_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'GET'})
self.app.update_request(req)
self.app.recoverable_node_timeout = 0.1
set_http_connect(200, 200, 200, slow=[1.0, 1.0, 1.0])
resp = req.get_response(self.app)
got_exc = False
try:
self.assertEquals('', resp.body)
except ChunkReadTimeout:
got_exc = True
self.assert_(got_exc)
set_http_connect(200, 200, 200, body='lalala',
slow=[1.0, 1.0])
resp = req.get_response(self.app)
got_exc = False
try:
self.assertEquals(resp.body, 'lalala')
except ChunkReadTimeout:
got_exc = True
self.assert_(not got_exc)
set_http_connect(200, 200, 200, body='lalala',
slow=[1.0, 1.0], etags=['a', 'a', 'a'])
resp = req.get_response(self.app)
got_exc = False
try:
self.assertEquals(resp.body, 'lalala')
except ChunkReadTimeout:
got_exc = True
self.assert_(not got_exc)
set_http_connect(200, 200, 200, body='lalala',
slow=[1.0, 1.0], etags=['a', 'b', 'a'])
resp = req.get_response(self.app)
got_exc = False
try:
self.assertEquals(resp.body, 'lalala')
except ChunkReadTimeout:
got_exc = True
self.assert_(not got_exc)
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'GET'})
set_http_connect(200, 200, 200, body='lalala',
slow=[1.0, 1.0], etags=['a', 'b', 'b'])
resp = req.get_response(self.app)
got_exc = False
try:
resp.body
except ChunkReadTimeout:
got_exc = True
self.assert_(got_exc)
def test_node_write_timeout(self):
with save_globals():
self.app.account_ring.get_nodes('account')
for dev in self.app.account_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
self.app.container_ring.get_nodes('account')
for dev in self.app.container_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
object_ring = self.app.get_object_ring(None)
object_ring.get_nodes('account')
for dev in object_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '4',
'Content-Type': 'text/plain'},
body=' ')
self.app.update_request(req)
set_http_connect(200, 200, 201, 201, 201, slow=0.1)
resp = req.get_response(self.app)
self.assertEquals(resp.status_int, 201)
self.app.node_timeout = 0.1
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '4',
'Content-Type': 'text/plain'},
body=' ')
self.app.update_request(req)
set_http_connect(201, 201, 201, slow=1.0)
resp = req.get_response(self.app)
self.assertEquals(resp.status_int, 503)
def test_node_request_setting(self):
baseapp = proxy_server.Application({'request_node_count': '3'},
FakeMemcache(),
container_ring=FakeRing(),
account_ring=FakeRing())
self.assertEquals(baseapp.request_node_count(3), 3)
def test_iter_nodes(self):
with save_globals():
try:
object_ring = self.app.get_object_ring(None)
object_ring.max_more_nodes = 2
partition, nodes = object_ring.get_nodes('account',
'container',
'object')
collected_nodes = []
for node in self.app.iter_nodes(object_ring,
partition):
collected_nodes.append(node)
self.assertEquals(len(collected_nodes), 5)
object_ring.max_more_nodes = 20
self.app.request_node_count = lambda r: 20
partition, nodes = object_ring.get_nodes('account',
'container',
'object')
collected_nodes = []
for node in self.app.iter_nodes(object_ring,
partition):
collected_nodes.append(node)
self.assertEquals(len(collected_nodes), 9)
# zero error-limited primary nodes -> no handoff warnings
self.app.log_handoffs = True
self.app.logger = FakeLogger()
self.app.request_node_count = lambda r: 7
object_ring.max_more_nodes = 20
partition, nodes = object_ring.get_nodes('account',
'container',
'object')
collected_nodes = []
for node in self.app.iter_nodes(object_ring, partition):
collected_nodes.append(node)
self.assertEquals(len(collected_nodes), 7)
self.assertEquals(self.app.logger.log_dict['warning'], [])
self.assertEquals(self.app.logger.get_increments(), [])
# one error-limited primary node -> one handoff warning
self.app.log_handoffs = True
self.app.logger = FakeLogger()
self.app.request_node_count = lambda r: 7
self.app._error_limiting = {} # clear out errors
set_node_errors(self.app, object_ring._devs[0], 999,
last_error=(2 ** 63 - 1))
collected_nodes = []
for node in self.app.iter_nodes(object_ring, partition):
collected_nodes.append(node)
self.assertEquals(len(collected_nodes), 7)
self.assertEquals(self.app.logger.log_dict['warning'], [
(('Handoff requested (5)',), {})])
self.assertEquals(self.app.logger.get_increments(),
['handoff_count'])
# two error-limited primary nodes -> two handoff warnings
self.app.log_handoffs = True
self.app.logger = FakeLogger()
self.app.request_node_count = lambda r: 7
self.app._error_limiting = {} # clear out errors
for i in range(2):
set_node_errors(self.app, object_ring._devs[i], 999,
last_error=(2 ** 63 - 1))
collected_nodes = []
for node in self.app.iter_nodes(object_ring, partition):
collected_nodes.append(node)
self.assertEquals(len(collected_nodes), 7)
self.assertEquals(self.app.logger.log_dict['warning'], [
(('Handoff requested (5)',), {}),
(('Handoff requested (6)',), {})])
self.assertEquals(self.app.logger.get_increments(),
['handoff_count',
'handoff_count'])
# all error-limited primary nodes -> four handoff warnings,
# plus a handoff-all metric
self.app.log_handoffs = True
self.app.logger = FakeLogger()
self.app.request_node_count = lambda r: 10
object_ring.set_replicas(4) # otherwise we run out of handoffs
self.app._error_limiting = {} # clear out errors
for i in range(4):
set_node_errors(self.app, object_ring._devs[i], 999,
last_error=(2 ** 63 - 1))
collected_nodes = []
for node in self.app.iter_nodes(object_ring, partition):
collected_nodes.append(node)
self.assertEquals(len(collected_nodes), 10)
self.assertEquals(self.app.logger.log_dict['warning'], [
(('Handoff requested (7)',), {}),
(('Handoff requested (8)',), {}),
(('Handoff requested (9)',), {}),
(('Handoff requested (10)',), {})])
self.assertEquals(self.app.logger.get_increments(),
['handoff_count',
'handoff_count',
'handoff_count',
'handoff_count',
'handoff_all_count'])
finally:
object_ring.max_more_nodes = 0
def test_iter_nodes_calls_sort_nodes(self):
with mock.patch.object(self.app, 'sort_nodes') as sort_nodes:
object_ring = self.app.get_object_ring(None)
for node in self.app.iter_nodes(object_ring, 0):
pass
sort_nodes.assert_called_once_with(
object_ring.get_part_nodes(0))
def test_iter_nodes_skips_error_limited(self):
with mock.patch.object(self.app, 'sort_nodes', lambda n: n):
object_ring = self.app.get_object_ring(None)
first_nodes = list(self.app.iter_nodes(object_ring, 0))
second_nodes = list(self.app.iter_nodes(object_ring, 0))
self.assertTrue(first_nodes[0] in second_nodes)
self.app.error_limit(first_nodes[0], 'test')
second_nodes = list(self.app.iter_nodes(object_ring, 0))
self.assertTrue(first_nodes[0] not in second_nodes)
def test_iter_nodes_gives_extra_if_error_limited_inline(self):
object_ring = self.app.get_object_ring(None)
with nested(
mock.patch.object(self.app, 'sort_nodes', lambda n: n),
mock.patch.object(self.app, 'request_node_count',
lambda r: 6),
mock.patch.object(object_ring, 'max_more_nodes', 99)):
first_nodes = list(self.app.iter_nodes(object_ring, 0))
second_nodes = []
for node in self.app.iter_nodes(object_ring, 0):
if not second_nodes:
self.app.error_limit(node, 'test')
second_nodes.append(node)
self.assertEquals(len(first_nodes), 6)
self.assertEquals(len(second_nodes), 7)
def test_iter_nodes_with_custom_node_iter(self):
object_ring = self.app.get_object_ring(None)
node_list = [dict(id=n, ip='1.2.3.4', port=n, device='D')
for n in xrange(10)]
with nested(
mock.patch.object(self.app, 'sort_nodes', lambda n: n),
mock.patch.object(self.app, 'request_node_count',
lambda r: 3)):
got_nodes = list(self.app.iter_nodes(object_ring, 0,
node_iter=iter(node_list)))
self.assertEqual(node_list[:3], got_nodes)
with nested(
mock.patch.object(self.app, 'sort_nodes', lambda n: n),
mock.patch.object(self.app, 'request_node_count',
lambda r: 1000000)):
got_nodes = list(self.app.iter_nodes(object_ring, 0,
node_iter=iter(node_list)))
self.assertEqual(node_list, got_nodes)
def test_best_response_sets_headers(self):
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'GET'})
resp = controller.best_response(req, [200] * 3, ['OK'] * 3, [''] * 3,
'Object', headers=[{'X-Test': '1'},
{'X-Test': '2'},
{'X-Test': '3'}])
self.assertEquals(resp.headers['X-Test'], '1')
def test_best_response_sets_etag(self):
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'GET'})
resp = controller.best_response(req, [200] * 3, ['OK'] * 3, [''] * 3,
'Object')
self.assertEquals(resp.etag, None)
resp = controller.best_response(req, [200] * 3, ['OK'] * 3, [''] * 3,
'Object',
etag='68b329da9893e34099c7d8ad5cb9c940'
)
self.assertEquals(resp.etag, '68b329da9893e34099c7d8ad5cb9c940')
def test_proxy_passes_content_type(self):
with save_globals():
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'GET'})
self.app.update_request(req)
set_http_connect(200, 200, 200)
resp = req.get_response(self.app)
self.assertEquals(resp.status_int, 200)
self.assertEquals(resp.content_type, 'x-application/test')
set_http_connect(200, 200, 200)
resp = req.get_response(self.app)
self.assertEquals(resp.status_int, 200)
self.assertEquals(resp.content_length, 0)
set_http_connect(200, 200, 200, slow=True)
resp = req.get_response(self.app)
self.assertEquals(resp.status_int, 200)
self.assertEquals(resp.content_length, 4)
def test_proxy_passes_content_length_on_head(self):
with save_globals():
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'HEAD'})
self.app.update_request(req)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 200, 200)
resp = controller.HEAD(req)
self.assertEquals(resp.status_int, 200)
self.assertEquals(resp.content_length, 0)
set_http_connect(200, 200, 200, slow=True)
resp = controller.HEAD(req)
self.assertEquals(resp.status_int, 200)
self.assertEquals(resp.content_length, 4)
def test_error_limiting(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
controller.app.sort_nodes = lambda l: l
object_ring = controller.app.get_object_ring(None)
self.assert_status_map(controller.HEAD, (200, 200, 503, 200, 200),
200)
self.assertEquals(
node_error_count(controller.app, object_ring.devs[0]), 2)
self.assert_(node_last_error(controller.app, object_ring.devs[0])
is not None)
for _junk in xrange(self.app.error_suppression_limit):
self.assert_status_map(controller.HEAD, (200, 200, 503, 503,
503), 503)
self.assertEquals(
node_error_count(controller.app, object_ring.devs[0]),
self.app.error_suppression_limit + 1)
self.assert_status_map(controller.HEAD, (200, 200, 200, 200, 200),
503)
self.assert_(node_last_error(controller.app, object_ring.devs[0])
is not None)
self.assert_status_map(controller.PUT, (200, 200, 200, 201, 201,
201), 503)
self.assert_status_map(controller.POST,
(200, 200, 200, 200, 200, 200, 202, 202,
202), 503)
self.assert_status_map(controller.DELETE,
(200, 200, 200, 204, 204, 204), 503)
self.app.error_suppression_interval = -300
self.assert_status_map(controller.HEAD, (200, 200, 200, 200, 200),
200)
self.assertRaises(BaseException,
self.assert_status_map, controller.DELETE,
(200, 200, 200, 204, 204, 204), 503,
raise_exc=True)
def test_error_limiting_survives_ring_reload(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
controller.app.sort_nodes = lambda l: l
object_ring = controller.app.get_object_ring(None)
self.assert_status_map(controller.HEAD, (200, 200, 503, 200, 200),
200)
self.assertEquals(
node_error_count(controller.app, object_ring.devs[0]), 2)
self.assert_(node_last_error(controller.app, object_ring.devs[0])
is not None)
for _junk in xrange(self.app.error_suppression_limit):
self.assert_status_map(controller.HEAD, (200, 200, 503, 503,
503), 503)
self.assertEquals(
node_error_count(controller.app, object_ring.devs[0]),
self.app.error_suppression_limit + 1)
# wipe out any state in the ring
for policy in POLICIES:
policy.object_ring = FakeRing(base_port=3000)
# and we still get an error, which proves that the
# error-limiting info survived a ring reload
self.assert_status_map(controller.HEAD, (200, 200, 200, 200, 200),
503)
def test_PUT_error_limiting(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
controller.app.sort_nodes = lambda l: l
object_ring = controller.app.get_object_ring(None)
# acc con obj obj obj
self.assert_status_map(controller.PUT, (200, 200, 503, 200, 200),
200)
# 2, not 1, because assert_status_map() calls the method twice
odevs = object_ring.devs
self.assertEquals(node_error_count(controller.app, odevs[0]), 2)
self.assertEquals(node_error_count(controller.app, odevs[1]), 0)
self.assertEquals(node_error_count(controller.app, odevs[2]), 0)
self.assert_(node_last_error(controller.app, odevs[0]) is not None)
self.assert_(node_last_error(controller.app, odevs[1]) is None)
self.assert_(node_last_error(controller.app, odevs[2]) is None)
def test_PUT_error_limiting_last_node(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
controller.app.sort_nodes = lambda l: l
object_ring = controller.app.get_object_ring(None)
# acc con obj obj obj
self.assert_status_map(controller.PUT, (200, 200, 200, 200, 503),
200)
# 2, not 1, because assert_status_map() calls the method twice
odevs = object_ring.devs
self.assertEquals(node_error_count(controller.app, odevs[0]), 0)
self.assertEquals(node_error_count(controller.app, odevs[1]), 0)
self.assertEquals(node_error_count(controller.app, odevs[2]), 2)
self.assert_(node_last_error(controller.app, odevs[0]) is None)
self.assert_(node_last_error(controller.app, odevs[1]) is None)
self.assert_(node_last_error(controller.app, odevs[2]) is not None)
def test_acc_or_con_missing_returns_404(self):
with save_globals():
self.app.memcache = FakeMemcacheReturnsNone()
self.app._error_limiting = {}
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 200, 200, 200, 200, 200)
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
self.app.update_request(req)
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 200)
set_http_connect(404, 404, 404)
# acct acct acct
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(503, 404, 404)
# acct acct acct
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(503, 503, 404)
# acct acct acct
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(503, 503, 503)
# acct acct acct
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(200, 200, 204, 204, 204)
# acct cont obj obj obj
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 204)
set_http_connect(200, 404, 404, 404)
# acct cont cont cont
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(200, 503, 503, 503)
# acct cont cont cont
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 404)
for dev in self.app.account_ring.devs:
set_node_errors(
self.app, dev, self.app.error_suppression_limit + 1,
time.time())
set_http_connect(200)
# acct [isn't actually called since everything
# is error limited]
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 404)
for dev in self.app.account_ring.devs:
set_node_errors(self.app, dev, 0, last_error=None)
for dev in self.app.container_ring.devs:
set_node_errors(self.app, dev,
self.app.error_suppression_limit + 1,
time.time())
set_http_connect(200, 200)
# acct cont [isn't actually called since
# everything is error limited]
# make sure to use a fresh request without cached env
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'})
resp = getattr(controller, 'DELETE')(req)
self.assertEquals(resp.status_int, 404)
def test_PUT_POST_requires_container_exist(self):
with save_globals():
self.app.object_post_as_copy = False
self.app.memcache = FakeMemcacheReturnsNone()
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 404, 404, 404, 200, 200, 200)
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'PUT'})
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(200, 404, 404, 404, 200, 200)
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'text/plain'})
self.app.update_request(req)
resp = controller.POST(req)
self.assertEquals(resp.status_int, 404)
def test_PUT_POST_as_copy_requires_container_exist(self):
with save_globals():
self.app.memcache = FakeMemcacheReturnsNone()
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 404, 404, 404, 200, 200, 200)
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'})
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(200, 404, 404, 404, 200, 200, 200, 200, 200, 200)
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'text/plain'})
self.app.update_request(req)
resp = controller.POST(req)
self.assertEquals(resp.status_int, 404)
def test_bad_metadata(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 200, 201, 201, 201)
# acct cont obj obj obj
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0'})
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank(
'/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Object-Meta-' + (
'a' * constraints.MAX_META_NAME_LENGTH): 'v'})
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank(
'/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={
'Content-Length': '0',
'X-Object-Meta-' + (
'a' * (constraints.MAX_META_NAME_LENGTH + 1)): 'v'})
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Object-Meta-Too-Long': 'a' *
constraints.MAX_META_VALUE_LENGTH})
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank(
'/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Object-Meta-Too-Long': 'a' *
(constraints.MAX_META_VALUE_LENGTH + 1)})
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
headers = {'Content-Length': '0'}
for x in xrange(constraints.MAX_META_COUNT):
headers['X-Object-Meta-%d' % x] = 'v'
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers=headers)
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
headers = {'Content-Length': '0'}
for x in xrange(constraints.MAX_META_COUNT + 1):
headers['X-Object-Meta-%d' % x] = 'v'
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers=headers)
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
headers = {'Content-Length': '0'}
header_value = 'a' * constraints.MAX_META_VALUE_LENGTH
size = 0
x = 0
while size < constraints.MAX_META_OVERALL_SIZE - 4 - \
constraints.MAX_META_VALUE_LENGTH:
size += 4 + constraints.MAX_META_VALUE_LENGTH
headers['X-Object-Meta-%04d' % x] = header_value
x += 1
if constraints.MAX_META_OVERALL_SIZE - size > 1:
headers['X-Object-Meta-a'] = \
'a' * (constraints.MAX_META_OVERALL_SIZE - size - 1)
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers=headers)
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
headers['X-Object-Meta-a'] = \
'a' * (constraints.MAX_META_OVERALL_SIZE - size)
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers=headers)
self.app.update_request(req)
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 400)
@contextmanager
def controller_context(self, req, *args, **kwargs):
_v, account, container, obj = utils.split_path(req.path, 4, 4, True)
controller = proxy_server.ObjectController(self.app, account,
container, obj)
self.app.update_request(req)
self.app.memcache.store = {}
with save_globals():
new_connect = set_http_connect(*args, **kwargs)
yield controller
unused_status_list = []
while True:
try:
unused_status_list.append(new_connect.code_iter.next())
except StopIteration:
break
if unused_status_list:
raise self.fail('UN-USED STATUS CODES: %r' %
unused_status_list)
def test_basic_put_with_x_copy_from(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': 'c/o'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
def test_basic_put_with_x_copy_from_account(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': 'c/o',
'X-Copy-From-Account': 'a'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acc1 con1 objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_basic_put_with_x_copy_from_across_container(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': 'c2/o'})
status_list = (200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont conc objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c2/o')
def test_basic_put_with_x_copy_from_across_container_and_account(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': 'c2/o',
'X-Copy-From-Account': 'a'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acc1 con1 objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c2/o')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_copy_non_zero_content_length(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '5',
'X-Copy-From': 'c/o'})
status_list = (200, 200)
# acct cont
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 400)
def test_copy_non_zero_content_length_with_account(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '5',
'X-Copy-From': 'c/o',
'X-Copy-From-Account': 'a'})
status_list = (200, 200)
# acct cont
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 400)
def test_copy_with_slashes_in_x_copy_from(self):
# extra source path parsing
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': 'c/o/o2'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o/o2')
def test_copy_with_slashes_in_x_copy_from_and_account(self):
# extra source path parsing
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': 'c/o/o2',
'X-Copy-From-Account': 'a'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acc1 con1 objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o/o2')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_copy_with_spaces_in_x_copy_from(self):
# space in soure path
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': 'c/o%20o2'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o%20o2')
def test_copy_with_spaces_in_x_copy_from_and_account(self):
# space in soure path
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': 'c/o%20o2',
'X-Copy-From-Account': 'a'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acc1 con1 objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o%20o2')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_copy_with_leading_slash_in_x_copy_from(self):
# repeat tests with leading /
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
def test_copy_with_leading_slash_in_x_copy_from_and_account(self):
# repeat tests with leading /
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o',
'X-Copy-From-Account': 'a'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acc1 con1 objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_copy_with_leading_slash_and_slashes_in_x_copy_from(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o/o2'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o/o2')
def test_copy_with_leading_slash_and_slashes_in_x_copy_from_acct(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o/o2',
'X-Copy-From-Account': 'a'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acc1 con1 objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o/o2')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_copy_with_no_object_in_x_copy_from(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c'})
status_list = (200, 200)
# acct cont
with self.controller_context(req, *status_list) as controller:
try:
controller.PUT(req)
except HTTPException as resp:
self.assertEquals(resp.status_int // 100, 4) # client error
else:
raise self.fail('Invalid X-Copy-From did not raise '
'client error')
def test_copy_with_no_object_in_x_copy_from_and_account(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c',
'X-Copy-From-Account': 'a'})
status_list = (200, 200)
# acct cont
with self.controller_context(req, *status_list) as controller:
try:
controller.PUT(req)
except HTTPException as resp:
self.assertEquals(resp.status_int // 100, 4) # client error
else:
raise self.fail('Invalid X-Copy-From did not raise '
'client error')
def test_copy_server_error_reading_source(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o'})
status_list = (200, 200, 503, 503, 503)
# acct cont objc objc objc
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 503)
def test_copy_server_error_reading_source_and_account(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o',
'X-Copy-From-Account': 'a'})
status_list = (200, 200, 200, 200, 503, 503, 503)
# acct cont acct cont objc objc objc
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 503)
def test_copy_not_found_reading_source(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o'})
# not found
status_list = (200, 200, 404, 404, 404)
# acct cont objc objc objc
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 404)
def test_copy_not_found_reading_source_and_account(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o',
'X-Copy-From-Account': 'a'})
# not found
status_list = (200, 200, 200, 200, 404, 404, 404)
# acct cont acct cont objc objc objc
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 404)
def test_copy_with_some_missing_sources(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o'})
status_list = (200, 200, 404, 404, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
def test_copy_with_some_missing_sources_and_account(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o',
'X-Copy-From-Account': 'a'})
status_list = (200, 200, 200, 200, 404, 404, 200, 201, 201, 201)
# acct cont acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
def test_copy_with_object_metadata(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o',
'X-Object-Meta-Ours': 'okay'})
# test object metadata
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers.get('x-object-meta-test'), 'testing')
self.assertEquals(resp.headers.get('x-object-meta-ours'), 'okay')
self.assertEquals(resp.headers.get('x-delete-at'), '9876543210')
def test_copy_with_object_metadata_and_account(self):
req = Request.blank('/v1/a1/c1/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o',
'X-Object-Meta-Ours': 'okay',
'X-Copy-From-Account': 'a'})
# test object metadata
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers.get('x-object-meta-test'), 'testing')
self.assertEquals(resp.headers.get('x-object-meta-ours'), 'okay')
self.assertEquals(resp.headers.get('x-delete-at'), '9876543210')
@_limit_max_file_size
def test_copy_source_larger_than_max_file_size(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0',
'X-Copy-From': '/c/o'})
# copy-from object is too large to fit in target object
class LargeResponseBody(object):
def __len__(self):
return constraints.MAX_FILE_SIZE + 1
def __getitem__(self, key):
return ''
copy_from_obj_body = LargeResponseBody()
status_list = (200, 200, 200, 200, 200)
# acct cont objc objc objc
kwargs = dict(body=copy_from_obj_body)
with self.controller_context(req, *status_list,
**kwargs) as controller:
self.app.update_request(req)
self.app.memcache.store = {}
resp = controller.PUT(req)
self.assertEquals(resp.status_int, 413)
def test_basic_COPY(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': 'c/o2'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
def test_basic_COPY_account(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': 'c1/o2',
'Destination-Account': 'a1'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_COPY_across_containers(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': 'c2/o'})
status_list = (200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont c2 objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
def test_COPY_source_with_slashes_in_name(self):
req = Request.blank('/v1/a/c/o/o2',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': 'c/o'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o/o2')
def test_COPY_account_source_with_slashes_in_name(self):
req = Request.blank('/v1/a/c/o/o2',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': 'c1/o',
'Destination-Account': 'a1'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o/o2')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_COPY_destination_leading_slash(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
def test_COPY_account_destination_leading_slash(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'Destination-Account': 'a1'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_COPY_source_with_slashes_destination_leading_slash(self):
req = Request.blank('/v1/a/c/o/o2',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o/o2')
def test_COPY_account_source_with_slashes_destination_leading_slash(self):
req = Request.blank('/v1/a/c/o/o2',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'Destination-Account': 'a1'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from'], 'c/o/o2')
self.assertEquals(resp.headers['x-copied-from-account'], 'a')
def test_COPY_no_object_in_destination(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': 'c_o'})
status_list = [] # no requests needed
with self.controller_context(req, *status_list) as controller:
self.assertRaises(HTTPException, controller.COPY, req)
def test_COPY_account_no_object_in_destination(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': 'c_o',
'Destination-Account': 'a1'})
status_list = [] # no requests needed
with self.controller_context(req, *status_list) as controller:
self.assertRaises(HTTPException, controller.COPY, req)
def test_COPY_server_error_reading_source(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o'})
status_list = (200, 200, 503, 503, 503)
# acct cont objc objc objc
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 503)
def test_COPY_account_server_error_reading_source(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'Destination-Account': 'a1'})
status_list = (200, 200, 200, 200, 503, 503, 503)
# acct cont acct cont objc objc objc
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 503)
def test_COPY_not_found_reading_source(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o'})
status_list = (200, 200, 404, 404, 404)
# acct cont objc objc objc
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 404)
def test_COPY_account_not_found_reading_source(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'Destination-Account': 'a1'})
status_list = (200, 200, 200, 200, 404, 404, 404)
# acct cont acct cont objc objc objc
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 404)
def test_COPY_with_some_missing_sources(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o'})
status_list = (200, 200, 404, 404, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
def test_COPY_account_with_some_missing_sources(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'Destination-Account': 'a1'})
status_list = (200, 200, 200, 200, 404, 404, 200, 201, 201, 201)
# acct cont acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
def test_COPY_with_metadata(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o',
'X-Object-Meta-Ours': 'okay'})
status_list = (200, 200, 200, 200, 200, 201, 201, 201)
# acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers.get('x-object-meta-test'),
'testing')
self.assertEquals(resp.headers.get('x-object-meta-ours'), 'okay')
self.assertEquals(resp.headers.get('x-delete-at'), '9876543210')
def test_COPY_account_with_metadata(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'X-Object-Meta-Ours': 'okay',
'Destination-Account': 'a1'})
status_list = (200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
# acct cont acct cont objc objc objc obj obj obj
with self.controller_context(req, *status_list) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers.get('x-object-meta-test'),
'testing')
self.assertEquals(resp.headers.get('x-object-meta-ours'), 'okay')
self.assertEquals(resp.headers.get('x-delete-at'), '9876543210')
@_limit_max_file_size
def test_COPY_source_larger_than_max_file_size(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o'})
class LargeResponseBody(object):
def __len__(self):
return constraints.MAX_FILE_SIZE + 1
def __getitem__(self, key):
return ''
copy_from_obj_body = LargeResponseBody()
status_list = (200, 200, 200, 200, 200)
# acct cont objc objc objc
kwargs = dict(body=copy_from_obj_body)
with self.controller_context(req, *status_list,
**kwargs) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 413)
@_limit_max_file_size
def test_COPY_account_source_larger_than_max_file_size(self):
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'Destination-Account': 'a1'})
class LargeResponseBody(object):
def __len__(self):
return constraints.MAX_FILE_SIZE + 1
def __getitem__(self, key):
return ''
copy_from_obj_body = LargeResponseBody()
status_list = (200, 200, 200, 200, 200)
# acct cont objc objc objc
kwargs = dict(body=copy_from_obj_body)
with self.controller_context(req, *status_list,
**kwargs) as controller:
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 413)
def test_COPY_newest(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o'})
req.account = 'a'
controller.object_name = 'o'
set_http_connect(200, 200, 200, 200, 200, 201, 201, 201,
#act cont objc objc objc obj obj obj
timestamps=('1', '1', '1', '3', '2', '4', '4',
'4'))
self.app.memcache.store = {}
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from-last-modified'],
'3')
def test_COPY_account_newest(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'Destination-Account': 'a1'})
req.account = 'a'
controller.object_name = 'o'
set_http_connect(200, 200, 200, 200, 200, 200, 200, 201, 201, 201,
#act cont acct cont objc objc objc obj obj obj
timestamps=('1', '1', '1', '1', '3', '2', '1',
'4', '4', '4'))
self.app.memcache.store = {}
resp = controller.COPY(req)
self.assertEquals(resp.status_int, 201)
self.assertEquals(resp.headers['x-copied-from-last-modified'],
'3')
def test_COPY_delete_at(self):
with save_globals():
given_headers = {}
def fake_connect_put_node(nodes, part, path, headers,
logger_thread_locals):
given_headers.update(headers)
controller = proxy_server.ObjectController(self.app, 'a',
'c', 'o')
controller._connect_put_node = fake_connect_put_node
set_http_connect(200, 200, 200, 200, 200, 201, 201, 201)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c/o'})
self.app.update_request(req)
controller.COPY(req)
self.assertEquals(given_headers.get('X-Delete-At'), '9876543210')
self.assertTrue('X-Delete-At-Host' in given_headers)
self.assertTrue('X-Delete-At-Device' in given_headers)
self.assertTrue('X-Delete-At-Partition' in given_headers)
self.assertTrue('X-Delete-At-Container' in given_headers)
def test_COPY_account_delete_at(self):
with save_globals():
given_headers = {}
def fake_connect_put_node(nodes, part, path, headers,
logger_thread_locals):
given_headers.update(headers)
controller = proxy_server.ObjectController(self.app, 'a',
'c', 'o')
controller._connect_put_node = fake_connect_put_node
set_http_connect(200, 200, 200, 200, 200, 200, 200, 201, 201, 201)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': '/c1/o',
'Destination-Account': 'a1'})
self.app.update_request(req)
controller.COPY(req)
self.assertEquals(given_headers.get('X-Delete-At'), '9876543210')
self.assertTrue('X-Delete-At-Host' in given_headers)
self.assertTrue('X-Delete-At-Device' in given_headers)
self.assertTrue('X-Delete-At-Partition' in given_headers)
self.assertTrue('X-Delete-At-Container' in given_headers)
def test_chunked_put(self):
class ChunkedFile(object):
def __init__(self, bytes):
self.bytes = bytes
self.read_bytes = 0
@property
def bytes_left(self):
return self.bytes - self.read_bytes
def read(self, amt=None):
if self.read_bytes >= self.bytes:
raise StopIteration()
if not amt:
amt = self.bytes_left
data = 'a' * min(amt, self.bytes_left)
self.read_bytes += len(data)
return data
with save_globals():
set_http_connect(201, 201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Transfer-Encoding': 'chunked',
'Content-Type': 'foo/bar'})
req.body_file = ChunkedFile(10)
self.app.memcache.store = {}
self.app.update_request(req)
res = controller.PUT(req)
self.assertEquals(res.status_int // 100, 2) # success
# test 413 entity to large
set_http_connect(201, 201, 201, 201)
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Transfer-Encoding': 'chunked',
'Content-Type': 'foo/bar'})
req.body_file = ChunkedFile(11)
self.app.memcache.store = {}
self.app.update_request(req)
with mock.patch('swift.common.constraints.MAX_FILE_SIZE', 10):
res = controller.PUT(req)
self.assertEquals(res.status_int, 413)
@unpatch_policies
def test_chunked_put_bad_version(self):
# Check bad version
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v0 HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nContent-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 412'
self.assertEquals(headers[:len(exp)], exp)
@unpatch_policies
def test_chunked_put_bad_path(self):
# Check bad path
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET invalid HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nContent-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 404'
self.assertEquals(headers[:len(exp)], exp)
@unpatch_policies
def test_chunked_put_bad_utf8(self):
# Check invalid utf-8
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a%80 HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 412'
self.assertEquals(headers[:len(exp)], exp)
@unpatch_policies
def test_chunked_put_bad_path_no_controller(self):
# Check bad path, no controller
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1 HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 412'
self.assertEquals(headers[:len(exp)], exp)
@unpatch_policies
def test_chunked_put_bad_method(self):
# Check bad method
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('LICK /v1/a HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 405'
self.assertEquals(headers[:len(exp)], exp)
@unpatch_policies
def test_chunked_put_unhandled_exception(self):
# Check unhandled exception
(prosrv, acc1srv, acc2srv, con1srv, con2srv, obj1srv,
obj2srv) = _test_servers
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
orig_update_request = prosrv.update_request
def broken_update_request(*args, **kwargs):
raise Exception('fake: this should be printed')
prosrv.update_request = broken_update_request
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('HEAD /v1/a HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 500'
self.assertEquals(headers[:len(exp)], exp)
prosrv.update_request = orig_update_request
@unpatch_policies
def test_chunked_put_head_account(self):
# Head account, just a double check and really is here to test
# the part Application.log_request that 'enforces' a
# content_length on the response.
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('HEAD /v1/a HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 204'
self.assertEquals(headers[:len(exp)], exp)
self.assert_('\r\nContent-Length: 0\r\n' in headers)
@unpatch_policies
def test_chunked_put_utf8_all_the_way_down(self):
# Test UTF-8 Unicode all the way through the system
ustr = '\xe1\xbc\xb8\xce\xbf\xe1\xbd\xba \xe1\xbc\xb0\xce' \
'\xbf\xe1\xbd\xbb\xce\x87 \xcf\x84\xe1\xbd\xb0 \xcf' \
'\x80\xe1\xbd\xb1\xce\xbd\xcf\x84\xca\xbc \xe1\xbc' \
'\x82\xce\xbd \xe1\xbc\x90\xce\xbe\xe1\xbd\xb5\xce' \
'\xba\xce\xbf\xce\xb9 \xcf\x83\xce\xb1\xcf\x86\xe1' \
'\xbf\x86.Test'
ustr_short = '\xe1\xbc\xb8\xce\xbf\xe1\xbd\xbatest'
# Create ustr container
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Content-Length: 0\r\n\r\n' % quote(ustr))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# List account with ustr container (test plain)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
containers = fd.read().split('\n')
self.assert_(ustr in containers)
# List account with ustr container (test json)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a?format=json HTTP/1.1\r\n'
'Host: localhost\r\nConnection: close\r\n'
'X-Storage-Token: t\r\nContent-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
listing = json.loads(fd.read())
self.assert_(ustr.decode('utf8') in [l['name'] for l in listing])
# List account with ustr container (test xml)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a?format=xml HTTP/1.1\r\n'
'Host: localhost\r\nConnection: close\r\n'
'X-Storage-Token: t\r\nContent-Length: 0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
self.assert_('<name>%s</name>' % ustr in fd.read())
# Create ustr object with ustr metadata in ustr container
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'X-Object-Meta-%s: %s\r\nContent-Length: 0\r\n\r\n' %
(quote(ustr), quote(ustr), quote(ustr_short),
quote(ustr)))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# List ustr container with ustr object (test plain)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Content-Length: 0\r\n\r\n' % quote(ustr))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
objects = fd.read().split('\n')
self.assert_(ustr in objects)
# List ustr container with ustr object (test json)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s?format=json HTTP/1.1\r\n'
'Host: localhost\r\nConnection: close\r\n'
'X-Storage-Token: t\r\nContent-Length: 0\r\n\r\n' %
quote(ustr))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
listing = json.loads(fd.read())
self.assertEquals(listing[0]['name'], ustr.decode('utf8'))
# List ustr container with ustr object (test xml)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s?format=xml HTTP/1.1\r\n'
'Host: localhost\r\nConnection: close\r\n'
'X-Storage-Token: t\r\nContent-Length: 0\r\n\r\n' %
quote(ustr))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
self.assert_('<name>%s</name>' % ustr in fd.read())
# Retrieve ustr object with ustr metadata
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Content-Length: 0\r\n\r\n' %
(quote(ustr), quote(ustr)))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
self.assert_('\r\nX-Object-Meta-%s: %s\r\n' %
(quote(ustr_short).lower(), quote(ustr)) in headers)
@unpatch_policies
def test_chunked_put_chunked_put(self):
# Do chunked object put
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
# Also happens to assert that x-storage-token is taken as a
# replacement for x-auth-token.
fd.write('PUT /v1/a/c/o/chunky HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Transfer-Encoding: chunked\r\n\r\n'
'2\r\noh\r\n4\r\n hai\r\nf\r\n123456789abcdef\r\n'
'0\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# Ensure we get what we put
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/c/o/chunky HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
body = fd.read()
self.assertEquals(body, 'oh hai123456789abcdef')
@unpatch_policies
def test_version_manifest(self, oc='versions', vc='vers', o='name'):
versions_to_create = 3
# Create a container for our versioned object testing
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis,
obj2lis) = _test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
pre = quote('%03x' % len(o))
osub = '%s/sub' % o
presub = quote('%03x' % len(osub))
osub = quote(osub)
presub = quote(presub)
oc = quote(oc)
vc = quote(vc)
fd.write('PUT /v1/a/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Content-Length: 0\r\nX-Versions-Location: %s\r\n\r\n'
% (oc, vc))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# check that the header was set
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n\r\n\r\n' % oc)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx series response
self.assertEquals(headers[:len(exp)], exp)
self.assert_('X-Versions-Location: %s' % vc in headers)
# make the container for the object versions
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Content-Length: 0\r\n\r\n' % vc)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# Create the versioned file
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 5\r\nContent-Type: text/jibberish0\r\n'
'X-Object-Meta-Foo: barbaz\r\n\r\n00000\r\n' % (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# Create the object versions
for segment in xrange(1, versions_to_create):
sleep(.01) # guarantee that the timestamp changes
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 5\r\nContent-Type: text/jibberish%s'
'\r\n\r\n%05d\r\n' % (oc, o, segment, segment))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# Ensure retrieving the manifest file gets the latest version
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n'
'\r\n' % (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
self.assert_('Content-Type: text/jibberish%s' % segment in headers)
self.assert_('X-Object-Meta-Foo: barbaz' not in headers)
body = fd.read()
self.assertEquals(body, '%05d' % segment)
# Ensure we have the right number of versions saved
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s?prefix=%s%s/ HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n\r\n'
% (vc, pre, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
body = fd.read()
versions = [x for x in body.split('\n') if x]
self.assertEquals(len(versions), versions_to_create - 1)
# copy a version and make sure the version info is stripped
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('COPY /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: '
't\r\nDestination: %s/copied_name\r\n'
'Content-Length: 0\r\n\r\n' % (oc, o, oc))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx series response to the COPY
self.assertEquals(headers[:len(exp)], exp)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s/copied_name HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n\r\n'
% oc)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
body = fd.read()
self.assertEquals(body, '%05d' % segment)
# post and make sure it's updated
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('POST /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: '
't\r\nContent-Type: foo/bar\r\nContent-Length: 0\r\n'
'X-Object-Meta-Bar: foo\r\n\r\n' % (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx series response to the POST
self.assertEquals(headers[:len(exp)], exp)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n\r\n'
% (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
self.assert_('Content-Type: foo/bar' in headers)
self.assert_('X-Object-Meta-Bar: foo' in headers)
body = fd.read()
self.assertEquals(body, '%05d' % segment)
# Delete the object versions
for segment in xrange(versions_to_create - 1, 0, -1):
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('DELETE /v1/a/%s/%s HTTP/1.1\r\nHost: localhost\r'
'\nConnection: close\r\nX-Storage-Token: t\r\n\r\n'
% (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx series response
self.assertEquals(headers[:len(exp)], exp)
# Ensure retrieving the manifest file gets the latest version
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Auth-Token: t\r\n\r\n'
% (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEquals(headers[:len(exp)], exp)
self.assert_('Content-Type: text/jibberish%s' % (segment - 1)
in headers)
body = fd.read()
self.assertEquals(body, '%05d' % (segment - 1))
# Ensure we have the right number of versions saved
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s?prefix=%s%s/ HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n\r'
'\n' % (vc, pre, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx series response
self.assertEquals(headers[:len(exp)], exp)
body = fd.read()
versions = [x for x in body.split('\n') if x]
self.assertEquals(len(versions), segment - 1)
# there is now one segment left (in the manifest)
# Ensure we have no saved versions
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s?prefix=%s%s/ HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n\r\n'
% (vc, pre, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 204 No Content'
self.assertEquals(headers[:len(exp)], exp)
# delete the last verision
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('DELETE /v1/a/%s/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n\r\n' % (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx series response
self.assertEquals(headers[:len(exp)], exp)
# Ensure it's all gone
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n\r\n'
% (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 404'
self.assertEquals(headers[:len(exp)], exp)
# make sure dlo manifest files don't get versioned
for _junk in xrange(1, versions_to_create):
sleep(.01) # guarantee that the timestamp changes
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 0\r\n'
'Content-Type: text/jibberish0\r\n'
'Foo: barbaz\r\nX-Object-Manifest: %s/%s/\r\n\r\n'
% (oc, o, oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# Ensure we have no saved versions
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s?prefix=%s%s/ HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n\r\n'
% (vc, pre, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 204 No Content'
self.assertEquals(headers[:len(exp)], exp)
# DELETE v1/a/c/obj shouldn't delete v1/a/c/obj/sub versions
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 5\r\nContent-Type: text/jibberish0\r\n'
'Foo: barbaz\r\n\r\n00000\r\n' % (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 5\r\nContent-Type: text/jibberish0\r\n'
'Foo: barbaz\r\n\r\n00001\r\n' % (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 4\r\nContent-Type: text/jibberish0\r\n'
'Foo: barbaz\r\n\r\nsub1\r\n' % (oc, osub))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%s/%s HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 4\r\nContent-Type: text/jibberish0\r\n'
'Foo: barbaz\r\n\r\nsub2\r\n' % (oc, osub))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('DELETE /v1/a/%s/%s HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n\r\n' % (oc, o))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx series response
self.assertEquals(headers[:len(exp)], exp)
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/%s?prefix=%s%s/ HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Auth-Token: t\r\n\r\n'
% (vc, presub, osub))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx series response
self.assertEquals(headers[:len(exp)], exp)
body = fd.read()
versions = [x for x in body.split('\n') if x]
self.assertEquals(len(versions), 1)
# Check for when the versions target container doesn't exist
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%swhoops HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Content-Length: 0\r\nX-Versions-Location: none\r\n\r\n' % oc)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# Create the versioned file
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%swhoops/foo HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 5\r\n\r\n00000\r\n' % oc)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEquals(headers[:len(exp)], exp)
# Create another version
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/%swhoops/foo HTTP/1.1\r\nHost: '
'localhost\r\nConnection: close\r\nX-Storage-Token: '
't\r\nContent-Length: 5\r\n\r\n00001\r\n' % oc)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 412'
self.assertEquals(headers[:len(exp)], exp)
# Delete the object
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('DELETE /v1/a/%swhoops/foo HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n\r\n' % oc)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 2' # 2xx response
self.assertEquals(headers[:len(exp)], exp)
@unpatch_policies
def test_version_manifest_utf8(self):
oc = '0_oc_non_ascii\xc2\xa3'
vc = '0_vc_non_ascii\xc2\xa3'
o = '0_o_non_ascii\xc2\xa3'
self.test_version_manifest(oc, vc, o)
@unpatch_policies
def test_version_manifest_utf8_container(self):
oc = '1_oc_non_ascii\xc2\xa3'
vc = '1_vc_ascii'
o = '1_o_ascii'
self.test_version_manifest(oc, vc, o)
@unpatch_policies
def test_version_manifest_utf8_version_container(self):
oc = '2_oc_ascii'
vc = '2_vc_non_ascii\xc2\xa3'
o = '2_o_ascii'
self.test_version_manifest(oc, vc, o)
@unpatch_policies
def test_version_manifest_utf8_containers(self):
oc = '3_oc_non_ascii\xc2\xa3'
vc = '3_vc_non_ascii\xc2\xa3'
o = '3_o_ascii'
self.test_version_manifest(oc, vc, o)
@unpatch_policies
def test_version_manifest_utf8_object(self):
oc = '4_oc_ascii'
vc = '4_vc_ascii'
o = '4_o_non_ascii\xc2\xa3'
self.test_version_manifest(oc, vc, o)
@unpatch_policies
def test_version_manifest_utf8_version_container_utf_object(self):
oc = '5_oc_ascii'
vc = '5_vc_non_ascii\xc2\xa3'
o = '5_o_non_ascii\xc2\xa3'
self.test_version_manifest(oc, vc, o)
@unpatch_policies
def test_version_manifest_utf8_container_utf_object(self):
oc = '6_oc_non_ascii\xc2\xa3'
vc = '6_vc_ascii'
o = '6_o_non_ascii\xc2\xa3'
self.test_version_manifest(oc, vc, o)
@unpatch_policies
def test_conditional_range_get(self):
(prolis, acc1lis, acc2lis, con1lis, con2lis, obj1lis, obj2lis) = \
_test_sockets
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
# make a container
fd = sock.makefile()
fd.write('PUT /v1/a/con HTTP/1.1\r\nHost: localhost\r\n'
'Connection: close\r\nX-Storage-Token: t\r\n'
'Content-Length: 0\r\n\r\n')
fd.flush()
exp = 'HTTP/1.1 201'
headers = readuntil2crlfs(fd)
self.assertEquals(headers[:len(exp)], exp)
# put an object in it
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/con/o HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Length: 10\r\n'
'Content-Type: text/plain\r\n'
'\r\n'
'abcdefghij\r\n')
fd.flush()
exp = 'HTTP/1.1 201'
headers = readuntil2crlfs(fd)
self.assertEquals(headers[:len(exp)], exp)
# request with both If-None-Match and Range
etag = md5("abcdefghij").hexdigest()
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/con/o HTTP/1.1\r\n' +
'Host: localhost\r\n' +
'Connection: close\r\n' +
'X-Storage-Token: t\r\n' +
'If-None-Match: "' + etag + '"\r\n' +
'Range: bytes=3-8\r\n' +
'\r\n')
fd.flush()
exp = 'HTTP/1.1 304'
headers = readuntil2crlfs(fd)
self.assertEquals(headers[:len(exp)], exp)
def test_mismatched_etags(self):
with save_globals():
# no etag supplied, object servers return success w/ diff values
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0'})
self.app.update_request(req)
set_http_connect(200, 201, 201, 201,
etags=[None,
'68b329da9893e34099c7d8ad5cb9c940',
'68b329da9893e34099c7d8ad5cb9c940',
'68b329da9893e34099c7d8ad5cb9c941'])
resp = controller.PUT(req)
self.assertEquals(resp.status_int // 100, 5) # server error
# req supplies etag, object servers return 422 - mismatch
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={
'Content-Length': '0',
'ETag': '68b329da9893e34099c7d8ad5cb9c940',
})
self.app.update_request(req)
set_http_connect(200, 422, 422, 503,
etags=['68b329da9893e34099c7d8ad5cb9c940',
'68b329da9893e34099c7d8ad5cb9c941',
None,
None])
resp = controller.PUT(req)
self.assertEquals(resp.status_int // 100, 4) # client error
def test_response_get_accept_ranges_header(self):
with save_globals():
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'GET'})
self.app.update_request(req)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 200, 200)
resp = controller.GET(req)
self.assert_('accept-ranges' in resp.headers)
self.assertEquals(resp.headers['accept-ranges'], 'bytes')
def test_response_head_accept_ranges_header(self):
with save_globals():
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'HEAD'})
self.app.update_request(req)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 200, 200)
resp = controller.HEAD(req)
self.assert_('accept-ranges' in resp.headers)
self.assertEquals(resp.headers['accept-ranges'], 'bytes')
def test_GET_calls_authorize(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
with save_globals():
set_http_connect(200, 200, 201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o')
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
controller.GET(req)
self.assert_(called[0])
def test_HEAD_calls_authorize(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
with save_globals():
set_http_connect(200, 200, 201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o', {'REQUEST_METHOD': 'HEAD'})
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
controller.HEAD(req)
self.assert_(called[0])
def test_POST_calls_authorize(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
with save_globals():
self.app.object_post_as_copy = False
set_http_connect(200, 200, 201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'POST'},
headers={'Content-Length': '5'}, body='12345')
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
controller.POST(req)
self.assert_(called[0])
def test_POST_as_copy_calls_authorize(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
with save_globals():
set_http_connect(200, 200, 200, 200, 200, 201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'POST'},
headers={'Content-Length': '5'}, body='12345')
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
controller.POST(req)
self.assert_(called[0])
def test_PUT_calls_authorize(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
with save_globals():
set_http_connect(200, 200, 201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '5'}, body='12345')
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
controller.PUT(req)
self.assert_(called[0])
def test_COPY_calls_authorize(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
with save_globals():
set_http_connect(200, 200, 200, 200, 200, 201, 201, 201)
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'COPY'},
headers={'Destination': 'c/o'})
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
controller.COPY(req)
self.assert_(called[0])
def test_POST_converts_delete_after_to_delete_at(self):
with save_globals():
self.app.object_post_as_copy = False
controller = proxy_server.ObjectController(self.app, 'account',
'container', 'object')
set_http_connect(200, 200, 202, 202, 202)
self.app.memcache.store = {}
orig_time = time.time
try:
t = time.time()
time.time = lambda: t
req = Request.blank('/v1/a/c/o', {},
headers={'Content-Type': 'foo/bar',
'X-Delete-After': '60'})
self.app.update_request(req)
res = controller.POST(req)
self.assertEquals(res.status, '202 Fake')
self.assertEquals(req.headers.get('x-delete-at'),
str(int(t + 60)))
finally:
time.time = orig_time
@patch_policies([
StoragePolicy(0, 'zero', False, object_ring=FakeRing()),
StoragePolicy(1, 'one', True, object_ring=FakeRing())
])
def test_PUT_versioning_with_nonzero_default_policy(self):
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
if method == "HEAD":
self.assertEquals(path, '/a/c/o.jpg')
self.assertNotEquals(None,
headers['X-Backend-Storage-Policy-Index'])
self.assertEquals(1, int(headers
['X-Backend-Storage-Policy-Index']))
def fake_container_info(account, container, req):
return {'status': 200, 'sync_key': None, 'storage_policy': '1',
'meta': {}, 'cors': {'allow_origin': None,
'expose_headers': None,
'max_age': None},
'sysmeta': {}, 'read_acl': None, 'object_count': None,
'write_acl': None, 'versions': 'c-versions',
'partition': 1, 'bytes': None,
'nodes': [{'zone': 0, 'ip': '10.0.0.0', 'region': 0,
'id': 0, 'device': 'sda', 'port': 1000},
{'zone': 1, 'ip': '10.0.0.1', 'region': 1,
'id': 1, 'device': 'sdb', 'port': 1001},
{'zone': 2, 'ip': '10.0.0.2', 'region': 0,
'id': 2, 'device': 'sdc', 'port': 1002}]}
with save_globals():
controller = proxy_server.ObjectController(self.app, 'a',
'c', 'o.jpg')
controller.container_info = fake_container_info
set_http_connect(200, 200, 200, # head: for the last version
200, 200, 200, # get: for the last version
201, 201, 201, # put: move the current version
201, 201, 201, # put: save the new version
give_connect=test_connect)
req = Request.blank('/v1/a/c/o.jpg',
environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '0'})
self.app.update_request(req)
self.app.memcache.store = {}
res = controller.PUT(req)
self.assertEquals(201, res.status_int)
@patch_policies([
StoragePolicy(0, 'zero', False, object_ring=FakeRing()),
StoragePolicy(1, 'one', True, object_ring=FakeRing())
])
def test_cross_policy_DELETE_versioning(self):
requests = []
def capture_requests(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
requests.append((method, path, headers))
def fake_container_info(app, env, account, container, **kwargs):
info = {'status': 200, 'sync_key': None, 'storage_policy': None,
'meta': {}, 'cors': {'allow_origin': None,
'expose_headers': None,
'max_age': None},
'sysmeta': {}, 'read_acl': None, 'object_count': None,
'write_acl': None, 'versions': None,
'partition': 1, 'bytes': None,
'nodes': [{'zone': 0, 'ip': '10.0.0.0', 'region': 0,
'id': 0, 'device': 'sda', 'port': 1000},
{'zone': 1, 'ip': '10.0.0.1', 'region': 1,
'id': 1, 'device': 'sdb', 'port': 1001},
{'zone': 2, 'ip': '10.0.0.2', 'region': 0,
'id': 2, 'device': 'sdc', 'port': 1002}]}
if container == 'c':
info['storage_policy'] = '1'
info['versions'] = 'c-versions'
elif container == 'c-versions':
info['storage_policy'] = '0'
else:
self.fail('Unexpected call to get_info for %r' % container)
return info
container_listing = json.dumps([{'name': 'old_version'}])
with save_globals():
resp_status = (
200, 200, # listings for versions container
200, 200, 200, # get: for the last version
201, 201, 201, # put: move the last version
200, 200, 200, # delete: for the last version
)
body_iter = iter([container_listing] + [
'' for x in range(len(resp_status) - 1)])
set_http_connect(*resp_status, body_iter=body_iter,
give_connect=capture_requests)
req = Request.blank('/v1/a/c/current_version', method='DELETE')
self.app.update_request(req)
self.app.memcache.store = {}
with mock.patch('swift.proxy.controllers.base.get_info',
fake_container_info):
resp = self.app.handle_request(req)
self.assertEquals(200, resp.status_int)
expected = [('GET', '/a/c-versions')] * 2 + \
[('GET', '/a/c-versions/old_version')] * 3 + \
[('PUT', '/a/c/current_version')] * 3 + \
[('DELETE', '/a/c-versions/old_version')] * 3
self.assertEqual(expected, [(m, p) for m, p, h in requests])
for method, path, headers in requests:
if 'current_version' in path:
expected_storage_policy = 1
elif 'old_version' in path:
expected_storage_policy = 0
else:
continue
storage_policy_index = \
int(headers['X-Backend-Storage-Policy-Index'])
self.assertEqual(
expected_storage_policy, storage_policy_index,
'Unexpected %s request for %s '
'with storage policy index %s' % (
method, path, storage_policy_index))
@unpatch_policies
def test_leak_1(self):
_request_instances = weakref.WeakKeyDictionary()
_orig_init = Request.__init__
def request_init(self, *args, **kwargs):
_orig_init(self, *args, **kwargs)
_request_instances[self] = None
with mock.patch.object(Request, "__init__", request_init):
prolis = _test_sockets[0]
prosrv = _test_servers[0]
obj_len = prosrv.client_chunk_size * 2
# PUT test file
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('PUT /v1/a/c/test_leak_1 HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Auth-Token: t\r\n'
'Content-Length: %s\r\n'
'Content-Type: application/octet-stream\r\n'
'\r\n%s' % (obj_len, 'a' * obj_len))
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEqual(headers[:len(exp)], exp)
# Remember Request instance count, make sure the GC is run for
# pythons without reference counting.
for i in xrange(4):
sleep(0) # let eventlet do its thing
gc.collect()
else:
sleep(0)
before_request_instances = len(_request_instances)
# GET test file, but disconnect early
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
fd = sock.makefile()
fd.write('GET /v1/a/c/test_leak_1 HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Auth-Token: t\r\n'
'\r\n')
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEqual(headers[:len(exp)], exp)
fd.read(1)
fd.close()
sock.close()
# Make sure the GC is run again for pythons without reference
# counting
for i in xrange(4):
sleep(0) # let eventlet do its thing
gc.collect()
else:
sleep(0)
self.assertEquals(
before_request_instances, len(_request_instances))
def test_OPTIONS(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'a',
'c', 'o.jpg')
def my_empty_container_info(*args):
return {}
controller.container_info = my_empty_container_info
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.com',
'Access-Control-Request-Method': 'GET'})
resp = controller.OPTIONS(req)
self.assertEquals(401, resp.status_int)
def my_empty_origin_container_info(*args):
return {'cors': {'allow_origin': None}}
controller.container_info = my_empty_origin_container_info
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.com',
'Access-Control-Request-Method': 'GET'})
resp = controller.OPTIONS(req)
self.assertEquals(401, resp.status_int)
def my_container_info(*args):
return {
'cors': {
'allow_origin': 'http://foo.bar:8080 https://foo.bar',
'max_age': '999',
}
}
controller.container_info = my_container_info
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'https://foo.bar',
'Access-Control-Request-Method': 'GET'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
self.assertEquals(
'https://foo.bar',
resp.headers['access-control-allow-origin'])
for verb in 'OPTIONS COPY GET POST PUT DELETE HEAD'.split():
self.assertTrue(
verb in resp.headers['access-control-allow-methods'])
self.assertEquals(
len(resp.headers['access-control-allow-methods'].split(', ')),
7)
self.assertEquals('999', resp.headers['access-control-max-age'])
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'https://foo.bar'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(401, resp.status_int)
req = Request.blank('/v1/a/c/o.jpg', {'REQUEST_METHOD': 'OPTIONS'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
for verb in 'OPTIONS COPY GET POST PUT DELETE HEAD'.split():
self.assertTrue(
verb in resp.headers['Allow'])
self.assertEquals(len(resp.headers['Allow'].split(', ')), 7)
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.com'})
resp = controller.OPTIONS(req)
self.assertEquals(401, resp.status_int)
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.bar',
'Access-Control-Request-Method': 'GET'})
controller.app.cors_allow_origin = ['http://foo.bar', ]
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
def my_container_info_wildcard(*args):
return {
'cors': {
'allow_origin': '*',
'max_age': '999',
}
}
controller.container_info = my_container_info_wildcard
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'https://bar.baz',
'Access-Control-Request-Method': 'GET'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
self.assertEquals('*', resp.headers['access-control-allow-origin'])
for verb in 'OPTIONS COPY GET POST PUT DELETE HEAD'.split():
self.assertTrue(
verb in resp.headers['access-control-allow-methods'])
self.assertEquals(
len(resp.headers['access-control-allow-methods'].split(', ')),
7)
self.assertEquals('999', resp.headers['access-control-max-age'])
def test_CORS_valid(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
def stubContainerInfo(*args):
return {
'cors': {
'allow_origin': 'http://not.foo.bar'
}
}
controller.container_info = stubContainerInfo
controller.app.strict_cors_mode = False
def objectGET(controller, req):
return Response(headers={
'X-Object-Meta-Color': 'red',
'X-Super-Secret': 'hush',
})
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'GET'},
headers={'Origin': 'http://foo.bar'})
resp = cors_validation(objectGET)(controller, req)
self.assertEquals(200, resp.status_int)
self.assertEquals('http://foo.bar',
resp.headers['access-control-allow-origin'])
self.assertEquals('red', resp.headers['x-object-meta-color'])
# X-Super-Secret is in the response, but not "exposed"
self.assertEquals('hush', resp.headers['x-super-secret'])
self.assertTrue('access-control-expose-headers' in resp.headers)
exposed = set(
h.strip() for h in
resp.headers['access-control-expose-headers'].split(','))
expected_exposed = set(['cache-control', 'content-language',
'content-type', 'expires', 'last-modified',
'pragma', 'etag', 'x-timestamp',
'x-trans-id', 'x-object-meta-color'])
self.assertEquals(expected_exposed, exposed)
controller.app.strict_cors_mode = True
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'GET'},
headers={'Origin': 'http://foo.bar'})
resp = cors_validation(objectGET)(controller, req)
self.assertEquals(200, resp.status_int)
self.assertTrue('access-control-allow-origin' not in resp.headers)
def test_CORS_valid_with_obj_headers(self):
with save_globals():
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
def stubContainerInfo(*args):
return {
'cors': {
'allow_origin': 'http://foo.bar'
}
}
controller.container_info = stubContainerInfo
def objectGET(controller, req):
return Response(headers={
'X-Object-Meta-Color': 'red',
'X-Super-Secret': 'hush',
'Access-Control-Allow-Origin': 'http://obj.origin',
'Access-Control-Expose-Headers': 'x-trans-id'
})
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'GET'},
headers={'Origin': 'http://foo.bar'})
resp = cors_validation(objectGET)(controller, req)
self.assertEquals(200, resp.status_int)
self.assertEquals('http://obj.origin',
resp.headers['access-control-allow-origin'])
self.assertEquals('x-trans-id',
resp.headers['access-control-expose-headers'])
def _gather_x_container_headers(self, controller_call, req, *connect_args,
**kwargs):
header_list = kwargs.pop('header_list', ['X-Container-Device',
'X-Container-Host',
'X-Container-Partition'])
seen_headers = []
def capture_headers(ipaddr, port, device, partition, method,
path, headers=None, query_string=None):
captured = {}
for header in header_list:
captured[header] = headers.get(header)
seen_headers.append(captured)
with save_globals():
self.app.allow_account_management = True
set_http_connect(*connect_args, give_connect=capture_headers,
**kwargs)
resp = controller_call(req)
self.assertEqual(2, resp.status_int // 100) # sanity check
# don't care about the account/container HEADs, so chuck
# the first two requests
return sorted(seen_headers[2:],
key=lambda d: d.get(header_list[0]) or 'z')
def test_PUT_x_container_headers_with_equal_replicas(self):
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '5'}, body='12345')
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
seen_headers = self._gather_x_container_headers(
controller.PUT, req,
200, 200, 201, 201, 201) # HEAD HEAD PUT PUT PUT
self.assertEqual(
seen_headers, [
{'X-Container-Host': '10.0.0.0:1000',
'X-Container-Partition': '0',
'X-Container-Device': 'sda'},
{'X-Container-Host': '10.0.0.1:1001',
'X-Container-Partition': '0',
'X-Container-Device': 'sdb'},
{'X-Container-Host': '10.0.0.2:1002',
'X-Container-Partition': '0',
'X-Container-Device': 'sdc'}])
def test_PUT_x_container_headers_with_fewer_container_replicas(self):
self.app.container_ring.set_replicas(2)
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '5'}, body='12345')
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
seen_headers = self._gather_x_container_headers(
controller.PUT, req,
200, 200, 201, 201, 201) # HEAD HEAD PUT PUT PUT
self.assertEqual(
seen_headers, [
{'X-Container-Host': '10.0.0.0:1000',
'X-Container-Partition': '0',
'X-Container-Device': 'sda'},
{'X-Container-Host': '10.0.0.1:1001',
'X-Container-Partition': '0',
'X-Container-Device': 'sdb'},
{'X-Container-Host': None,
'X-Container-Partition': None,
'X-Container-Device': None}])
def test_PUT_x_container_headers_with_more_container_replicas(self):
self.app.container_ring.set_replicas(4)
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Length': '5'}, body='12345')
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
seen_headers = self._gather_x_container_headers(
controller.PUT, req,
200, 200, 201, 201, 201) # HEAD HEAD PUT PUT PUT
self.assertEqual(
seen_headers, [
{'X-Container-Host': '10.0.0.0:1000,10.0.0.3:1003',
'X-Container-Partition': '0',
'X-Container-Device': 'sda,sdd'},
{'X-Container-Host': '10.0.0.1:1001',
'X-Container-Partition': '0',
'X-Container-Device': 'sdb'},
{'X-Container-Host': '10.0.0.2:1002',
'X-Container-Partition': '0',
'X-Container-Device': 'sdc'}])
def test_POST_x_container_headers_with_more_container_replicas(self):
self.app.container_ring.set_replicas(4)
self.app.object_post_as_copy = False
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'POST'},
headers={'Content-Type': 'application/stuff'})
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
seen_headers = self._gather_x_container_headers(
controller.POST, req,
200, 200, 200, 200, 200) # HEAD HEAD POST POST POST
self.assertEqual(
seen_headers, [
{'X-Container-Host': '10.0.0.0:1000,10.0.0.3:1003',
'X-Container-Partition': '0',
'X-Container-Device': 'sda,sdd'},
{'X-Container-Host': '10.0.0.1:1001',
'X-Container-Partition': '0',
'X-Container-Device': 'sdb'},
{'X-Container-Host': '10.0.0.2:1002',
'X-Container-Partition': '0',
'X-Container-Device': 'sdc'}])
def test_DELETE_x_container_headers_with_more_container_replicas(self):
self.app.container_ring.set_replicas(4)
req = Request.blank('/v1/a/c/o',
environ={'REQUEST_METHOD': 'DELETE'},
headers={'Content-Type': 'application/stuff'})
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
seen_headers = self._gather_x_container_headers(
controller.DELETE, req,
200, 200, 200, 200, 200) # HEAD HEAD DELETE DELETE DELETE
self.assertEqual(seen_headers, [
{'X-Container-Host': '10.0.0.0:1000,10.0.0.3:1003',
'X-Container-Partition': '0',
'X-Container-Device': 'sda,sdd'},
{'X-Container-Host': '10.0.0.1:1001',
'X-Container-Partition': '0',
'X-Container-Device': 'sdb'},
{'X-Container-Host': '10.0.0.2:1002',
'X-Container-Partition': '0',
'X-Container-Device': 'sdc'}
])
@mock.patch('time.time', new=lambda: STATIC_TIME)
def test_PUT_x_delete_at_with_fewer_container_replicas(self):
self.app.container_ring.set_replicas(2)
delete_at_timestamp = int(time.time()) + 100000
delete_at_container = utils.get_expirer_container(
delete_at_timestamp, self.app.expiring_objects_container_divisor,
'a', 'c', 'o')
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Type': 'application/stuff',
'Content-Length': '0',
'X-Delete-At': str(delete_at_timestamp)})
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
seen_headers = self._gather_x_container_headers(
controller.PUT, req,
200, 200, 201, 201, 201, # HEAD HEAD PUT PUT PUT
header_list=('X-Delete-At-Host', 'X-Delete-At-Device',
'X-Delete-At-Partition', 'X-Delete-At-Container'))
self.assertEqual(seen_headers, [
{'X-Delete-At-Host': '10.0.0.0:1000',
'X-Delete-At-Container': delete_at_container,
'X-Delete-At-Partition': '0',
'X-Delete-At-Device': 'sda'},
{'X-Delete-At-Host': '10.0.0.1:1001',
'X-Delete-At-Container': delete_at_container,
'X-Delete-At-Partition': '0',
'X-Delete-At-Device': 'sdb'},
{'X-Delete-At-Host': None,
'X-Delete-At-Container': None,
'X-Delete-At-Partition': None,
'X-Delete-At-Device': None}
])
@mock.patch('time.time', new=lambda: STATIC_TIME)
def test_PUT_x_delete_at_with_more_container_replicas(self):
self.app.container_ring.set_replicas(4)
self.app.expiring_objects_account = 'expires'
self.app.expiring_objects_container_divisor = 60
delete_at_timestamp = int(time.time()) + 100000
delete_at_container = utils.get_expirer_container(
delete_at_timestamp, self.app.expiring_objects_container_divisor,
'a', 'c', 'o')
req = Request.blank('/v1/a/c/o', environ={'REQUEST_METHOD': 'PUT'},
headers={'Content-Type': 'application/stuff',
'Content-Length': 0,
'X-Delete-At': str(delete_at_timestamp)})
controller = proxy_server.ObjectController(self.app, 'a', 'c', 'o')
seen_headers = self._gather_x_container_headers(
controller.PUT, req,
200, 200, 201, 201, 201, # HEAD HEAD PUT PUT PUT
header_list=('X-Delete-At-Host', 'X-Delete-At-Device',
'X-Delete-At-Partition', 'X-Delete-At-Container'))
self.assertEqual(seen_headers, [
{'X-Delete-At-Host': '10.0.0.0:1000,10.0.0.3:1003',
'X-Delete-At-Container': delete_at_container,
'X-Delete-At-Partition': '0',
'X-Delete-At-Device': 'sda,sdd'},
{'X-Delete-At-Host': '10.0.0.1:1001',
'X-Delete-At-Container': delete_at_container,
'X-Delete-At-Partition': '0',
'X-Delete-At-Device': 'sdb'},
{'X-Delete-At-Host': '10.0.0.2:1002',
'X-Delete-At-Container': delete_at_container,
'X-Delete-At-Partition': '0',
'X-Delete-At-Device': 'sdc'}
])
@patch_policies([
StoragePolicy(0, 'zero', True, object_ring=FakeRing(base_port=3000)),
StoragePolicy(1, 'one', False, object_ring=FakeRing(base_port=3000)),
StoragePolicy(2, 'two', False, True, object_ring=FakeRing(base_port=3000))
])
class TestContainerController(unittest.TestCase):
"Test swift.proxy_server.ContainerController"
def setUp(self):
self.app = proxy_server.Application(
None, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing(base_port=2000),
logger=debug_logger())
def test_convert_policy_to_index(self):
controller = swift.proxy.controllers.ContainerController(self.app,
'a', 'c')
expected = {
'zero': 0,
'ZeRo': 0,
'one': 1,
'OnE': 1,
}
for name, index in expected.items():
req = Request.blank('/a/c', headers={'Content-Length': '0',
'Content-Type': 'text/plain',
'X-Storage-Policy': name})
self.assertEqual(controller._convert_policy_to_index(req), index)
# default test
req = Request.blank('/a/c', headers={'Content-Length': '0',
'Content-Type': 'text/plain'})
self.assertEqual(controller._convert_policy_to_index(req), None)
# negative test
req = Request.blank('/a/c', headers={'Content-Length': '0',
'Content-Type': 'text/plain',
'X-Storage-Policy': 'nada'})
self.assertRaises(HTTPException, controller._convert_policy_to_index,
req)
# storage policy two is deprecated
req = Request.blank('/a/c', headers={'Content-Length': '0',
'Content-Type': 'text/plain',
'X-Storage-Policy': 'two'})
self.assertRaises(HTTPException, controller._convert_policy_to_index,
req)
def test_convert_index_to_name(self):
policy = random.choice(list(POLICIES))
req = Request.blank('/v1/a/c')
with mocked_http_conn(
200, 200,
headers={'X-Backend-Storage-Policy-Index': int(policy)},
) as fake_conn:
resp = req.get_response(self.app)
self.assertRaises(StopIteration, fake_conn.code_iter.next)
self.assertEqual(resp.status_int, 200)
self.assertEqual(resp.headers['X-Storage-Policy'], policy.name)
def test_no_convert_index_to_name_when_container_not_found(self):
policy = random.choice(list(POLICIES))
req = Request.blank('/v1/a/c')
with mocked_http_conn(
200, 404, 404, 404,
headers={'X-Backend-Storage-Policy-Index':
int(policy)}) as fake_conn:
resp = req.get_response(self.app)
self.assertRaises(StopIteration, fake_conn.code_iter.next)
self.assertEqual(resp.status_int, 404)
self.assertEqual(resp.headers['X-Storage-Policy'], None)
def test_error_convert_index_to_name(self):
req = Request.blank('/v1/a/c')
with mocked_http_conn(
200, 200,
headers={'X-Backend-Storage-Policy-Index': '-1'}) as fake_conn:
resp = req.get_response(self.app)
self.assertRaises(StopIteration, fake_conn.code_iter.next)
self.assertEqual(resp.status_int, 200)
self.assertEqual(resp.headers['X-Storage-Policy'], None)
error_lines = self.app.logger.get_lines_for_level('error')
self.assertEqual(2, len(error_lines))
for msg in error_lines:
expected = "Could not translate " \
"X-Backend-Storage-Policy-Index ('-1')"
self.assertTrue(expected in msg)
def test_transfer_headers(self):
src_headers = {'x-remove-versions-location': 'x',
'x-container-read': '*:user',
'x-remove-container-sync-key': 'x'}
dst_headers = {'x-versions-location': 'backup'}
controller = swift.proxy.controllers.ContainerController(self.app,
'a', 'c')
controller.transfer_headers(src_headers, dst_headers)
expected_headers = {'x-versions-location': '',
'x-container-read': '*:user',
'x-container-sync-key': ''}
self.assertEqual(dst_headers, expected_headers)
def assert_status_map(self, method, statuses, expected,
raise_exc=False, missing_container=False):
with save_globals():
kwargs = {}
if raise_exc:
kwargs['raise_exc'] = raise_exc
kwargs['missing_container'] = missing_container
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c', headers={'Content-Length': '0',
'Content-Type': 'text/plain'})
self.app.update_request(req)
res = method(req)
self.assertEquals(res.status_int, expected)
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c/', headers={'Content-Length': '0',
'Content-Type': 'text/plain'})
self.app.update_request(req)
res = method(req)
self.assertEquals(res.status_int, expected)
def test_HEAD_GET(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'a', 'c')
def test_status_map(statuses, expected,
c_expected=None, a_expected=None, **kwargs):
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c', {})
self.app.update_request(req)
res = controller.HEAD(req)
self.assertEquals(res.status[:len(str(expected))],
str(expected))
if expected < 400:
self.assert_('x-works' in res.headers)
self.assertEquals(res.headers['x-works'], 'yes')
if c_expected:
self.assertTrue('swift.container/a/c' in res.environ)
self.assertEquals(
res.environ['swift.container/a/c']['status'],
c_expected)
else:
self.assertTrue('swift.container/a/c' not in res.environ)
if a_expected:
self.assertTrue('swift.account/a' in res.environ)
self.assertEquals(res.environ['swift.account/a']['status'],
a_expected)
else:
self.assertTrue('swift.account/a' not in res.environ)
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c', {})
self.app.update_request(req)
res = controller.GET(req)
self.assertEquals(res.status[:len(str(expected))],
str(expected))
if expected < 400:
self.assert_('x-works' in res.headers)
self.assertEquals(res.headers['x-works'], 'yes')
if c_expected:
self.assertTrue('swift.container/a/c' in res.environ)
self.assertEquals(
res.environ['swift.container/a/c']['status'],
c_expected)
else:
self.assertTrue('swift.container/a/c' not in res.environ)
if a_expected:
self.assertTrue('swift.account/a' in res.environ)
self.assertEquals(res.environ['swift.account/a']['status'],
a_expected)
else:
self.assertTrue('swift.account/a' not in res.environ)
# In all the following tests cache 200 for account
# return and ache vary for container
# return 200 and cache 200 for and container
test_status_map((200, 200, 404, 404), 200, 200, 200)
test_status_map((200, 200, 500, 404), 200, 200, 200)
# return 304 don't cache container
test_status_map((200, 304, 500, 404), 304, None, 200)
# return 404 and cache 404 for container
test_status_map((200, 404, 404, 404), 404, 404, 200)
test_status_map((200, 404, 404, 500), 404, 404, 200)
# return 503, don't cache container
test_status_map((200, 500, 500, 500), 503, None, 200)
self.assertFalse(self.app.account_autocreate)
# In all the following tests cache 404 for account
# return 404 (as account is not found) and don't cache container
test_status_map((404, 404, 404), 404, None, 404)
# This should make no difference
self.app.account_autocreate = True
test_status_map((404, 404, 404), 404, None, 404)
def test_PUT_policy_headers(self):
backend_requests = []
def capture_requests(ipaddr, port, device, partition, method,
path, headers=None, query_string=None):
if method == 'PUT':
backend_requests.append(headers)
def test_policy(requested_policy):
with save_globals():
mock_conn = set_http_connect(200, 201, 201, 201,
give_connect=capture_requests)
self.app.memcache.store = {}
req = Request.blank('/v1/a/test', method='PUT',
headers={'Content-Length': 0})
if requested_policy:
expected_policy = requested_policy
req.headers['X-Storage-Policy'] = policy.name
else:
expected_policy = POLICIES.default
res = req.get_response(self.app)
if expected_policy.is_deprecated:
self.assertEquals(res.status_int, 400)
self.assertEqual(0, len(backend_requests))
expected = 'is deprecated'
self.assertTrue(expected in res.body,
'%r did not include %r' % (
res.body, expected))
return
self.assertEquals(res.status_int, 201)
self.assertEqual(
expected_policy.object_ring.replicas,
len(backend_requests))
for headers in backend_requests:
if not requested_policy:
self.assertFalse('X-Backend-Storage-Policy-Index' in
headers)
self.assertTrue(
'X-Backend-Storage-Policy-Default' in headers)
self.assertEqual(
int(expected_policy),
int(headers['X-Backend-Storage-Policy-Default']))
else:
self.assertTrue('X-Backend-Storage-Policy-Index' in
headers)
self.assertEqual(int(headers
['X-Backend-Storage-Policy-Index']),
policy.idx)
# make sure all mocked responses are consumed
self.assertRaises(StopIteration, mock_conn.code_iter.next)
test_policy(None) # no policy header
for policy in POLICIES:
backend_requests = [] # reset backend requests
test_policy(policy)
def test_PUT(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'account',
'container')
def test_status_map(statuses, expected, **kwargs):
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c', {})
req.content_length = 0
self.app.update_request(req)
res = controller.PUT(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((200, 201, 201, 201), 201, missing_container=True)
test_status_map((200, 201, 201, 500), 201, missing_container=True)
test_status_map((200, 204, 404, 404), 404, missing_container=True)
test_status_map((200, 204, 500, 404), 503, missing_container=True)
self.assertFalse(self.app.account_autocreate)
test_status_map((404, 404, 404), 404, missing_container=True)
self.app.account_autocreate = True
# fail to retrieve account info
test_status_map(
(503, 503, 503), # account_info fails on 503
404, missing_container=True)
# account fail after creation
test_status_map(
(404, 404, 404, # account_info fails on 404
201, 201, 201, # PUT account
404, 404, 404), # account_info fail
404, missing_container=True)
test_status_map(
(503, 503, 404, # account_info fails on 404
503, 503, 503, # PUT account
503, 503, 404), # account_info fail
404, missing_container=True)
# put fails
test_status_map(
(404, 404, 404, # account_info fails on 404
201, 201, 201, # PUT account
200, # account_info success
503, 503, 201), # put container fail
503, missing_container=True)
# all goes according to plan
test_status_map(
(404, 404, 404, # account_info fails on 404
201, 201, 201, # PUT account
200, # account_info success
201, 201, 201), # put container success
201, missing_container=True)
test_status_map(
(503, 404, 404, # account_info fails on 404
503, 201, 201, # PUT account
503, 200, # account_info success
503, 201, 201), # put container success
201, missing_container=True)
def test_PUT_autocreate_account_with_sysmeta(self):
# x-account-sysmeta headers in a container PUT request should be
# transferred to the account autocreate PUT request
with save_globals():
controller = proxy_server.ContainerController(self.app, 'account',
'container')
def test_status_map(statuses, expected, headers=None, **kwargs):
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c', {}, headers=headers)
req.content_length = 0
self.app.update_request(req)
res = controller.PUT(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
self.app.account_autocreate = True
calls = []
callback = _make_callback_func(calls)
key, value = 'X-Account-Sysmeta-Blah', 'something'
headers = {key: value}
# all goes according to plan
test_status_map(
(404, 404, 404, # account_info fails on 404
201, 201, 201, # PUT account
200, # account_info success
201, 201, 201), # put container success
201, missing_container=True,
headers=headers,
give_connect=callback)
self.assertEqual(10, len(calls))
for call in calls[3:6]:
self.assertEqual('/account', call['path'])
self.assertTrue(key in call['headers'],
'%s call, key %s missing in headers %s' %
(call['method'], key, call['headers']))
self.assertEqual(value, call['headers'][key])
def test_POST(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'account',
'container')
def test_status_map(statuses, expected, **kwargs):
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c', {})
req.content_length = 0
self.app.update_request(req)
res = controller.POST(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((200, 201, 201, 201), 201, missing_container=True)
test_status_map((200, 201, 201, 500), 201, missing_container=True)
test_status_map((200, 204, 404, 404), 404, missing_container=True)
test_status_map((200, 204, 500, 404), 503, missing_container=True)
self.assertFalse(self.app.account_autocreate)
test_status_map((404, 404, 404), 404, missing_container=True)
self.app.account_autocreate = True
test_status_map((404, 404, 404), 404, missing_container=True)
def test_PUT_max_containers_per_account(self):
with save_globals():
self.app.max_containers_per_account = 12346
controller = proxy_server.ContainerController(self.app, 'account',
'container')
self.assert_status_map(controller.PUT,
(200, 201, 201, 201), 201,
missing_container=True)
self.app.max_containers_per_account = 12345
controller = proxy_server.ContainerController(self.app, 'account',
'container')
self.assert_status_map(controller.PUT,
(200, 200, 201, 201, 201), 201,
missing_container=True)
controller = proxy_server.ContainerController(self.app, 'account',
'container_new')
self.assert_status_map(controller.PUT, (200, 404, 404, 404), 403,
missing_container=True)
self.app.max_containers_per_account = 12345
self.app.max_containers_whitelist = ['account']
controller = proxy_server.ContainerController(self.app, 'account',
'container')
self.assert_status_map(controller.PUT,
(200, 201, 201, 201), 201,
missing_container=True)
def test_PUT_max_container_name_length(self):
with save_globals():
limit = constraints.MAX_CONTAINER_NAME_LENGTH
controller = proxy_server.ContainerController(self.app, 'account',
'1' * limit)
self.assert_status_map(controller.PUT,
(200, 201, 201, 201), 201,
missing_container=True)
controller = proxy_server.ContainerController(self.app, 'account',
'2' * (limit + 1))
self.assert_status_map(controller.PUT, (201, 201, 201), 400,
missing_container=True)
def test_PUT_connect_exceptions(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'account',
'container')
self.assert_status_map(controller.PUT, (200, 201, 201, -1), 201,
missing_container=True)
self.assert_status_map(controller.PUT, (200, 201, -1, -1), 503,
missing_container=True)
self.assert_status_map(controller.PUT, (200, 503, 503, -1), 503,
missing_container=True)
def test_acc_missing_returns_404(self):
for meth in ('DELETE', 'PUT'):
with save_globals():
self.app.memcache = FakeMemcacheReturnsNone()
self.app._error_limiting = {}
controller = proxy_server.ContainerController(self.app,
'account',
'container')
if meth == 'PUT':
set_http_connect(200, 200, 200, 200, 200, 200,
missing_container=True)
else:
set_http_connect(200, 200, 200, 200)
self.app.memcache.store = {}
req = Request.blank('/v1/a/c',
environ={'REQUEST_METHOD': meth})
self.app.update_request(req)
resp = getattr(controller, meth)(req)
self.assertEquals(resp.status_int, 200)
set_http_connect(404, 404, 404, 200, 200, 200)
# Make sure it is a blank request wthout env caching
req = Request.blank('/v1/a/c',
environ={'REQUEST_METHOD': meth})
resp = getattr(controller, meth)(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(503, 404, 404)
# Make sure it is a blank request wthout env caching
req = Request.blank('/v1/a/c',
environ={'REQUEST_METHOD': meth})
resp = getattr(controller, meth)(req)
self.assertEquals(resp.status_int, 404)
set_http_connect(503, 404, raise_exc=True)
# Make sure it is a blank request wthout env caching
req = Request.blank('/v1/a/c',
environ={'REQUEST_METHOD': meth})
resp = getattr(controller, meth)(req)
self.assertEquals(resp.status_int, 404)
for dev in self.app.account_ring.devs:
set_node_errors(self.app, dev,
self.app.error_suppression_limit + 1,
time.time())
set_http_connect(200, 200, 200, 200, 200, 200)
# Make sure it is a blank request wthout env caching
req = Request.blank('/v1/a/c',
environ={'REQUEST_METHOD': meth})
resp = getattr(controller, meth)(req)
self.assertEquals(resp.status_int, 404)
def test_put_locking(self):
class MockMemcache(FakeMemcache):
def __init__(self, allow_lock=None):
self.allow_lock = allow_lock
super(MockMemcache, self).__init__()
@contextmanager
def soft_lock(self, key, timeout=0, retries=5):
if self.allow_lock:
yield True
else:
raise NotImplementedError
with save_globals():
controller = proxy_server.ContainerController(self.app, 'account',
'container')
self.app.memcache = MockMemcache(allow_lock=True)
set_http_connect(200, 201, 201, 201,
missing_container=True)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': 'PUT'})
self.app.update_request(req)
res = controller.PUT(req)
self.assertEquals(res.status_int, 201)
def test_error_limiting(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'account',
'container')
container_ring = controller.app.container_ring
controller.app.sort_nodes = lambda l: l
self.assert_status_map(controller.HEAD, (200, 503, 200, 200), 200,
missing_container=False)
self.assertEquals(
node_error_count(controller.app, container_ring.devs[0]), 2)
self.assert_(
node_last_error(controller.app, container_ring.devs[0])
is not None)
for _junk in xrange(self.app.error_suppression_limit):
self.assert_status_map(controller.HEAD,
(200, 503, 503, 503), 503)
self.assertEquals(
node_error_count(controller.app, container_ring.devs[0]),
self.app.error_suppression_limit + 1)
self.assert_status_map(controller.HEAD, (200, 200, 200, 200), 503)
self.assert_(
node_last_error(controller.app, container_ring.devs[0])
is not None)
self.assert_status_map(controller.PUT, (200, 201, 201, 201), 503,
missing_container=True)
self.assert_status_map(controller.DELETE,
(200, 204, 204, 204), 503)
self.app.error_suppression_interval = -300
self.assert_status_map(controller.HEAD, (200, 200, 200, 200), 200)
self.assert_status_map(controller.DELETE, (200, 204, 204, 204),
404, raise_exc=True)
def test_DELETE(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'account',
'container')
self.assert_status_map(controller.DELETE,
(200, 204, 204, 204), 204)
self.assert_status_map(controller.DELETE,
(200, 204, 204, 503), 204)
self.assert_status_map(controller.DELETE,
(200, 204, 503, 503), 503)
self.assert_status_map(controller.DELETE,
(200, 204, 404, 404), 404)
self.assert_status_map(controller.DELETE,
(200, 404, 404, 404), 404)
self.assert_status_map(controller.DELETE,
(200, 204, 503, 404), 503)
self.app.memcache = FakeMemcacheReturnsNone()
# 200: Account check, 404x3: Container check
self.assert_status_map(controller.DELETE,
(200, 404, 404, 404), 404)
def test_response_get_accept_ranges_header(self):
with save_globals():
set_http_connect(200, 200, body='{}')
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c?format=json')
self.app.update_request(req)
res = controller.GET(req)
self.assert_('accept-ranges' in res.headers)
self.assertEqual(res.headers['accept-ranges'], 'bytes')
def test_response_head_accept_ranges_header(self):
with save_globals():
set_http_connect(200, 200, body='{}')
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c?format=json')
self.app.update_request(req)
res = controller.HEAD(req)
self.assert_('accept-ranges' in res.headers)
self.assertEqual(res.headers['accept-ranges'], 'bytes')
def test_PUT_metadata(self):
self.metadata_helper('PUT')
def test_POST_metadata(self):
self.metadata_helper('POST')
def metadata_helper(self, method):
for test_header, test_value in (
('X-Container-Meta-TestHeader', 'TestValue'),
('X-Container-Meta-TestHeader', ''),
('X-Remove-Container-Meta-TestHeader', 'anything'),
('X-Container-Read', '.r:*'),
('X-Remove-Container-Read', 'anything'),
('X-Container-Write', 'anyone'),
('X-Remove-Container-Write', 'anything')):
test_errors = []
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
if path == '/a/c':
find_header = test_header
find_value = test_value
if find_header.lower().startswith('x-remove-'):
find_header = \
find_header.lower().replace('-remove', '', 1)
find_value = ''
for k, v in headers.iteritems():
if k.lower() == find_header.lower() and \
v == find_value:
break
else:
test_errors.append('%s: %s not in %s' %
(find_header, find_value, headers))
with save_globals():
controller = \
proxy_server.ContainerController(self.app, 'a', 'c')
set_http_connect(200, 201, 201, 201, give_connect=test_connect)
req = Request.blank(
'/v1/a/c',
environ={'REQUEST_METHOD': method, 'swift_owner': True},
headers={test_header: test_value})
self.app.update_request(req)
getattr(controller, method)(req)
self.assertEquals(test_errors, [])
def test_PUT_bad_metadata(self):
self.bad_metadata_helper('PUT')
def test_POST_bad_metadata(self):
self.bad_metadata_helper('POST')
def bad_metadata_helper(self, method):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'a', 'c')
set_http_connect(200, 201, 201, 201)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers={'X-Container-Meta-' +
('a' * constraints.MAX_META_NAME_LENGTH): 'v'})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank(
'/v1/a/c', environ={'REQUEST_METHOD': method},
headers={'X-Container-Meta-' +
('a' * (constraints.MAX_META_NAME_LENGTH + 1)): 'v'})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers={'X-Container-Meta-Too-Long':
'a' * constraints.MAX_META_VALUE_LENGTH})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers={'X-Container-Meta-Too-Long':
'a' * (constraints.MAX_META_VALUE_LENGTH + 1)})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
headers = {}
for x in xrange(constraints.MAX_META_COUNT):
headers['X-Container-Meta-%d' % x] = 'v'
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers=headers)
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
headers = {}
for x in xrange(constraints.MAX_META_COUNT + 1):
headers['X-Container-Meta-%d' % x] = 'v'
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers=headers)
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
headers = {}
header_value = 'a' * constraints.MAX_META_VALUE_LENGTH
size = 0
x = 0
while size < (constraints.MAX_META_OVERALL_SIZE - 4
- constraints.MAX_META_VALUE_LENGTH):
size += 4 + constraints.MAX_META_VALUE_LENGTH
headers['X-Container-Meta-%04d' % x] = header_value
x += 1
if constraints.MAX_META_OVERALL_SIZE - size > 1:
headers['X-Container-Meta-a'] = \
'a' * (constraints.MAX_META_OVERALL_SIZE - size - 1)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers=headers)
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
headers['X-Container-Meta-a'] = \
'a' * (constraints.MAX_META_OVERALL_SIZE - size)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers=headers)
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 400)
def test_POST_calls_clean_acl(self):
called = [False]
def clean_acl(header, value):
called[0] = True
raise ValueError('fake error')
with save_globals():
set_http_connect(200, 201, 201, 201)
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': 'POST'},
headers={'X-Container-Read': '.r:*'})
req.environ['swift.clean_acl'] = clean_acl
self.app.update_request(req)
controller.POST(req)
self.assert_(called[0])
called[0] = False
with save_globals():
set_http_connect(200, 201, 201, 201)
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': 'POST'},
headers={'X-Container-Write': '.r:*'})
req.environ['swift.clean_acl'] = clean_acl
self.app.update_request(req)
controller.POST(req)
self.assert_(called[0])
def test_PUT_calls_clean_acl(self):
called = [False]
def clean_acl(header, value):
called[0] = True
raise ValueError('fake error')
with save_globals():
set_http_connect(200, 201, 201, 201)
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': 'PUT'},
headers={'X-Container-Read': '.r:*'})
req.environ['swift.clean_acl'] = clean_acl
self.app.update_request(req)
controller.PUT(req)
self.assert_(called[0])
called[0] = False
with save_globals():
set_http_connect(200, 201, 201, 201)
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': 'PUT'},
headers={'X-Container-Write': '.r:*'})
req.environ['swift.clean_acl'] = clean_acl
self.app.update_request(req)
controller.PUT(req)
self.assert_(called[0])
def test_GET_no_content(self):
with save_globals():
set_http_connect(200, 204, 204, 204)
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c')
self.app.update_request(req)
res = controller.GET(req)
self.assertEquals(res.status_int, 204)
self.assertEquals(
res.environ['swift.container/a/c']['status'], 204)
self.assertEquals(res.content_length, 0)
self.assertTrue('transfer-encoding' not in res.headers)
def test_GET_calls_authorize(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
with save_globals():
set_http_connect(200, 201, 201, 201)
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c')
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
res = controller.GET(req)
self.assertEquals(res.environ['swift.container/a/c']['status'], 201)
self.assert_(called[0])
def test_HEAD_calls_authorize(self):
called = [False]
def authorize(req):
called[0] = True
return HTTPUnauthorized(request=req)
with save_globals():
set_http_connect(200, 201, 201, 201)
controller = proxy_server.ContainerController(self.app, 'account',
'container')
req = Request.blank('/v1/a/c', {'REQUEST_METHOD': 'HEAD'})
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
controller.HEAD(req)
self.assert_(called[0])
def test_unauthorized_requests_when_account_not_found(self):
# verify unauthorized container requests always return response
# from swift.authorize
called = [0, 0]
def authorize(req):
called[0] += 1
return HTTPUnauthorized(request=req)
def account_info(*args):
called[1] += 1
return None, None, None
def _do_test(method):
with save_globals():
swift.proxy.controllers.Controller.account_info = account_info
app = proxy_server.Application(None, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c', {'REQUEST_METHOD': method})
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
res = app.handle_request(req)
return res
for method in ('PUT', 'POST', 'DELETE'):
# no delay_denial on method, expect one call to authorize
called = [0, 0]
res = _do_test(method)
self.assertEqual(401, res.status_int)
self.assertEqual([1, 0], called)
for method in ('HEAD', 'GET'):
# delay_denial on method, expect two calls to authorize
called = [0, 0]
res = _do_test(method)
self.assertEqual(401, res.status_int)
self.assertEqual([2, 1], called)
def test_authorized_requests_when_account_not_found(self):
# verify authorized container requests always return 404 when
# account not found
called = [0, 0]
def authorize(req):
called[0] += 1
def account_info(*args):
called[1] += 1
return None, None, None
def _do_test(method):
with save_globals():
swift.proxy.controllers.Controller.account_info = account_info
app = proxy_server.Application(None, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c', {'REQUEST_METHOD': method})
req.environ['swift.authorize'] = authorize
self.app.update_request(req)
res = app.handle_request(req)
return res
for method in ('PUT', 'POST', 'DELETE', 'HEAD', 'GET'):
# expect one call to authorize
called = [0, 0]
res = _do_test(method)
self.assertEqual(404, res.status_int)
self.assertEqual([1, 1], called)
def test_OPTIONS_get_info_drops_origin(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'a', 'c')
count = [0]
def my_get_info(app, env, account, container=None,
ret_not_found=False, swift_source=None):
if count[0] > 11:
return {}
count[0] += 1
if not container:
return {'some': 'stuff'}
return proxy_base.was_get_info(
app, env, account, container, ret_not_found, swift_source)
proxy_base.was_get_info = proxy_base.get_info
with mock.patch.object(proxy_base, 'get_info', my_get_info):
proxy_base.get_info = my_get_info
req = Request.blank(
'/v1/a/c',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.com',
'Access-Control-Request-Method': 'GET'})
controller.OPTIONS(req)
self.assertTrue(count[0] < 11)
def test_OPTIONS(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'a', 'c')
def my_empty_container_info(*args):
return {}
controller.container_info = my_empty_container_info
req = Request.blank(
'/v1/a/c',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.com',
'Access-Control-Request-Method': 'GET'})
resp = controller.OPTIONS(req)
self.assertEquals(401, resp.status_int)
def my_empty_origin_container_info(*args):
return {'cors': {'allow_origin': None}}
controller.container_info = my_empty_origin_container_info
req = Request.blank(
'/v1/a/c',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.com',
'Access-Control-Request-Method': 'GET'})
resp = controller.OPTIONS(req)
self.assertEquals(401, resp.status_int)
def my_container_info(*args):
return {
'cors': {
'allow_origin': 'http://foo.bar:8080 https://foo.bar',
'max_age': '999',
}
}
controller.container_info = my_container_info
req = Request.blank(
'/v1/a/c',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'https://foo.bar',
'Access-Control-Request-Method': 'GET'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
self.assertEquals(
'https://foo.bar',
resp.headers['access-control-allow-origin'])
for verb in 'OPTIONS GET POST PUT DELETE HEAD'.split():
self.assertTrue(
verb in resp.headers['access-control-allow-methods'])
self.assertEquals(
len(resp.headers['access-control-allow-methods'].split(', ')),
6)
self.assertEquals('999', resp.headers['access-control-max-age'])
req = Request.blank(
'/v1/a/c',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'https://foo.bar'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(401, resp.status_int)
req = Request.blank('/v1/a/c', {'REQUEST_METHOD': 'OPTIONS'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
for verb in 'OPTIONS GET POST PUT DELETE HEAD'.split():
self.assertTrue(
verb in resp.headers['Allow'])
self.assertEquals(len(resp.headers['Allow'].split(', ')), 6)
req = Request.blank(
'/v1/a/c',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.bar',
'Access-Control-Request-Method': 'GET'})
resp = controller.OPTIONS(req)
self.assertEquals(401, resp.status_int)
req = Request.blank(
'/v1/a/c',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.bar',
'Access-Control-Request-Method': 'GET'})
controller.app.cors_allow_origin = ['http://foo.bar', ]
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
def my_container_info_wildcard(*args):
return {
'cors': {
'allow_origin': '*',
'max_age': '999',
}
}
controller.container_info = my_container_info_wildcard
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'https://bar.baz',
'Access-Control-Request-Method': 'GET'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
self.assertEquals('*', resp.headers['access-control-allow-origin'])
for verb in 'OPTIONS GET POST PUT DELETE HEAD'.split():
self.assertTrue(
verb in resp.headers['access-control-allow-methods'])
self.assertEquals(
len(resp.headers['access-control-allow-methods'].split(', ')),
6)
self.assertEquals('999', resp.headers['access-control-max-age'])
req = Request.blank(
'/v1/a/c/o.jpg',
{'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'https://bar.baz',
'Access-Control-Request-Headers':
'x-foo, x-bar, x-auth-token',
'Access-Control-Request-Method': 'GET'}
)
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
self.assertEquals(
sortHeaderNames('x-foo, x-bar, x-auth-token'),
sortHeaderNames(resp.headers['access-control-allow-headers']))
def test_CORS_valid(self):
with save_globals():
controller = proxy_server.ContainerController(self.app, 'a', 'c')
def stubContainerInfo(*args):
return {
'cors': {
'allow_origin': 'http://foo.bar'
}
}
controller.container_info = stubContainerInfo
def containerGET(controller, req):
return Response(headers={
'X-Container-Meta-Color': 'red',
'X-Super-Secret': 'hush',
})
req = Request.blank(
'/v1/a/c',
{'REQUEST_METHOD': 'GET'},
headers={'Origin': 'http://foo.bar'})
resp = cors_validation(containerGET)(controller, req)
self.assertEquals(200, resp.status_int)
self.assertEquals('http://foo.bar',
resp.headers['access-control-allow-origin'])
self.assertEquals('red', resp.headers['x-container-meta-color'])
# X-Super-Secret is in the response, but not "exposed"
self.assertEquals('hush', resp.headers['x-super-secret'])
self.assertTrue('access-control-expose-headers' in resp.headers)
exposed = set(
h.strip() for h in
resp.headers['access-control-expose-headers'].split(','))
expected_exposed = set(['cache-control', 'content-language',
'content-type', 'expires', 'last-modified',
'pragma', 'etag', 'x-timestamp',
'x-trans-id', 'x-container-meta-color'])
self.assertEquals(expected_exposed, exposed)
def _gather_x_account_headers(self, controller_call, req, *connect_args,
**kwargs):
seen_headers = []
to_capture = ('X-Account-Partition', 'X-Account-Host',
'X-Account-Device')
def capture_headers(ipaddr, port, device, partition, method,
path, headers=None, query_string=None):
captured = {}
for header in to_capture:
captured[header] = headers.get(header)
seen_headers.append(captured)
with save_globals():
self.app.allow_account_management = True
set_http_connect(*connect_args, give_connect=capture_headers,
**kwargs)
resp = controller_call(req)
self.assertEqual(2, resp.status_int // 100) # sanity check
# don't care about the account HEAD, so throw away the
# first element
return sorted(seen_headers[1:],
key=lambda d: d['X-Account-Host'] or 'Z')
def test_PUT_x_account_headers_with_fewer_account_replicas(self):
self.app.account_ring.set_replicas(2)
req = Request.blank('/v1/a/c', headers={'': ''})
controller = proxy_server.ContainerController(self.app, 'a', 'c')
seen_headers = self._gather_x_account_headers(
controller.PUT, req,
200, 201, 201, 201) # HEAD PUT PUT PUT
self.assertEqual(seen_headers, [
{'X-Account-Host': '10.0.0.0:1000',
'X-Account-Partition': '0',
'X-Account-Device': 'sda'},
{'X-Account-Host': '10.0.0.1:1001',
'X-Account-Partition': '0',
'X-Account-Device': 'sdb'},
{'X-Account-Host': None,
'X-Account-Partition': None,
'X-Account-Device': None}
])
def test_PUT_x_account_headers_with_more_account_replicas(self):
self.app.account_ring.set_replicas(4)
req = Request.blank('/v1/a/c', headers={'': ''})
controller = proxy_server.ContainerController(self.app, 'a', 'c')
seen_headers = self._gather_x_account_headers(
controller.PUT, req,
200, 201, 201, 201) # HEAD PUT PUT PUT
self.assertEqual(seen_headers, [
{'X-Account-Host': '10.0.0.0:1000,10.0.0.3:1003',
'X-Account-Partition': '0',
'X-Account-Device': 'sda,sdd'},
{'X-Account-Host': '10.0.0.1:1001',
'X-Account-Partition': '0',
'X-Account-Device': 'sdb'},
{'X-Account-Host': '10.0.0.2:1002',
'X-Account-Partition': '0',
'X-Account-Device': 'sdc'}
])
def test_DELETE_x_account_headers_with_fewer_account_replicas(self):
self.app.account_ring.set_replicas(2)
req = Request.blank('/v1/a/c', headers={'': ''})
controller = proxy_server.ContainerController(self.app, 'a', 'c')
seen_headers = self._gather_x_account_headers(
controller.DELETE, req,
200, 204, 204, 204) # HEAD DELETE DELETE DELETE
self.assertEqual(seen_headers, [
{'X-Account-Host': '10.0.0.0:1000',
'X-Account-Partition': '0',
'X-Account-Device': 'sda'},
{'X-Account-Host': '10.0.0.1:1001',
'X-Account-Partition': '0',
'X-Account-Device': 'sdb'},
{'X-Account-Host': None,
'X-Account-Partition': None,
'X-Account-Device': None}
])
def test_DELETE_x_account_headers_with_more_account_replicas(self):
self.app.account_ring.set_replicas(4)
req = Request.blank('/v1/a/c', headers={'': ''})
controller = proxy_server.ContainerController(self.app, 'a', 'c')
seen_headers = self._gather_x_account_headers(
controller.DELETE, req,
200, 204, 204, 204) # HEAD DELETE DELETE DELETE
self.assertEqual(seen_headers, [
{'X-Account-Host': '10.0.0.0:1000,10.0.0.3:1003',
'X-Account-Partition': '0',
'X-Account-Device': 'sda,sdd'},
{'X-Account-Host': '10.0.0.1:1001',
'X-Account-Partition': '0',
'X-Account-Device': 'sdb'},
{'X-Account-Host': '10.0.0.2:1002',
'X-Account-Partition': '0',
'X-Account-Device': 'sdc'}
])
def test_PUT_backed_x_timestamp_header(self):
timestamps = []
def capture_timestamps(*args, **kwargs):
headers = kwargs['headers']
timestamps.append(headers.get('X-Timestamp'))
req = Request.blank('/v1/a/c', method='PUT', headers={'': ''})
with save_globals():
new_connect = set_http_connect(200, # account existence check
201, 201, 201,
give_connect=capture_timestamps)
resp = self.app.handle_request(req)
# sanity
self.assertRaises(StopIteration, new_connect.code_iter.next)
self.assertEqual(2, resp.status_int // 100)
timestamps.pop(0) # account existence check
self.assertEqual(3, len(timestamps))
for timestamp in timestamps:
self.assertEqual(timestamp, timestamps[0])
self.assert_(re.match('[0-9]{10}\.[0-9]{5}', timestamp))
def test_DELETE_backed_x_timestamp_header(self):
timestamps = []
def capture_timestamps(*args, **kwargs):
headers = kwargs['headers']
timestamps.append(headers.get('X-Timestamp'))
req = Request.blank('/v1/a/c', method='DELETE', headers={'': ''})
self.app.update_request(req)
with save_globals():
new_connect = set_http_connect(200, # account existence check
201, 201, 201,
give_connect=capture_timestamps)
resp = self.app.handle_request(req)
# sanity
self.assertRaises(StopIteration, new_connect.code_iter.next)
self.assertEqual(2, resp.status_int // 100)
timestamps.pop(0) # account existence check
self.assertEqual(3, len(timestamps))
for timestamp in timestamps:
self.assertEqual(timestamp, timestamps[0])
self.assert_(re.match('[0-9]{10}\.[0-9]{5}', timestamp))
def test_node_read_timeout_retry_to_container(self):
with save_globals():
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': 'GET'})
self.app.node_timeout = 0.1
set_http_connect(200, 200, 200, body='abcdef', slow=[1.0, 1.0])
resp = req.get_response(self.app)
got_exc = False
try:
resp.body
except ChunkReadTimeout:
got_exc = True
self.assert_(got_exc)
@patch_policies([StoragePolicy(0, 'zero', True, object_ring=FakeRing())])
class TestAccountController(unittest.TestCase):
def setUp(self):
self.app = proxy_server.Application(None, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
def assert_status_map(self, method, statuses, expected, env_expected=None,
headers=None, **kwargs):
headers = headers or {}
with save_globals():
set_http_connect(*statuses, **kwargs)
req = Request.blank('/v1/a', {}, headers=headers)
self.app.update_request(req)
res = method(req)
self.assertEquals(res.status_int, expected)
if env_expected:
self.assertEquals(res.environ['swift.account/a']['status'],
env_expected)
set_http_connect(*statuses)
req = Request.blank('/v1/a/', {})
self.app.update_request(req)
res = method(req)
self.assertEquals(res.status_int, expected)
if env_expected:
self.assertEquals(res.environ['swift.account/a']['status'],
env_expected)
def test_OPTIONS(self):
with save_globals():
self.app.allow_account_management = False
controller = proxy_server.AccountController(self.app, 'account')
req = Request.blank('/v1/account', {'REQUEST_METHOD': 'OPTIONS'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
for verb in 'OPTIONS GET POST HEAD'.split():
self.assertTrue(
verb in resp.headers['Allow'])
self.assertEquals(len(resp.headers['Allow'].split(', ')), 4)
# Test a CORS OPTIONS request (i.e. including Origin and
# Access-Control-Request-Method headers)
self.app.allow_account_management = False
controller = proxy_server.AccountController(self.app, 'account')
req = Request.blank(
'/v1/account', {'REQUEST_METHOD': 'OPTIONS'},
headers={'Origin': 'http://foo.com',
'Access-Control-Request-Method': 'GET'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
for verb in 'OPTIONS GET POST HEAD'.split():
self.assertTrue(
verb in resp.headers['Allow'])
self.assertEquals(len(resp.headers['Allow'].split(', ')), 4)
self.app.allow_account_management = True
controller = proxy_server.AccountController(self.app, 'account')
req = Request.blank('/v1/account', {'REQUEST_METHOD': 'OPTIONS'})
req.content_length = 0
resp = controller.OPTIONS(req)
self.assertEquals(200, resp.status_int)
for verb in 'OPTIONS GET POST PUT DELETE HEAD'.split():
self.assertTrue(
verb in resp.headers['Allow'])
self.assertEquals(len(resp.headers['Allow'].split(', ')), 6)
def test_GET(self):
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
# GET returns after the first successful call to an Account Server
self.assert_status_map(controller.GET, (200,), 200, 200)
self.assert_status_map(controller.GET, (503, 200), 200, 200)
self.assert_status_map(controller.GET, (503, 503, 200), 200, 200)
self.assert_status_map(controller.GET, (204,), 204, 204)
self.assert_status_map(controller.GET, (503, 204), 204, 204)
self.assert_status_map(controller.GET, (503, 503, 204), 204, 204)
self.assert_status_map(controller.GET, (404, 200), 200, 200)
self.assert_status_map(controller.GET, (404, 404, 200), 200, 200)
self.assert_status_map(controller.GET, (404, 503, 204), 204, 204)
# If Account servers fail, if autocreate = False, return majority
# response
self.assert_status_map(controller.GET, (404, 404, 404), 404, 404)
self.assert_status_map(controller.GET, (404, 404, 503), 404, 404)
self.assert_status_map(controller.GET, (404, 503, 503), 503)
self.app.memcache = FakeMemcacheReturnsNone()
self.assert_status_map(controller.GET, (404, 404, 404), 404, 404)
def test_GET_autocreate(self):
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
self.app.memcache = FakeMemcacheReturnsNone()
self.assertFalse(self.app.account_autocreate)
# Repeat the test for autocreate = False and 404 by all
self.assert_status_map(controller.GET,
(404, 404, 404), 404)
self.assert_status_map(controller.GET,
(404, 503, 404), 404)
# When autocreate is True, if none of the nodes respond 2xx
# And quorum of the nodes responded 404,
# ALL nodes are asked to create the account
# If successful, the GET request is repeated.
controller.app.account_autocreate = True
self.assert_status_map(controller.GET,
(404, 404, 404), 204)
self.assert_status_map(controller.GET,
(404, 503, 404), 204)
# We always return 503 if no majority between 4xx, 3xx or 2xx found
self.assert_status_map(controller.GET,
(500, 500, 400), 503)
def test_HEAD(self):
# Same behaviour as GET
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
self.assert_status_map(controller.HEAD, (200,), 200, 200)
self.assert_status_map(controller.HEAD, (503, 200), 200, 200)
self.assert_status_map(controller.HEAD, (503, 503, 200), 200, 200)
self.assert_status_map(controller.HEAD, (204,), 204, 204)
self.assert_status_map(controller.HEAD, (503, 204), 204, 204)
self.assert_status_map(controller.HEAD, (204, 503, 503), 204, 204)
self.assert_status_map(controller.HEAD, (204,), 204, 204)
self.assert_status_map(controller.HEAD, (404, 404, 404), 404, 404)
self.assert_status_map(controller.HEAD, (404, 404, 200), 200, 200)
self.assert_status_map(controller.HEAD, (404, 200), 200, 200)
self.assert_status_map(controller.HEAD, (404, 404, 503), 404, 404)
self.assert_status_map(controller.HEAD, (404, 503, 503), 503)
self.assert_status_map(controller.HEAD, (404, 503, 204), 204, 204)
def test_HEAD_autocreate(self):
# Same behaviour as GET
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
self.app.memcache = FakeMemcacheReturnsNone()
self.assertFalse(self.app.account_autocreate)
self.assert_status_map(controller.HEAD,
(404, 404, 404), 404)
controller.app.account_autocreate = True
self.assert_status_map(controller.HEAD,
(404, 404, 404), 204)
self.assert_status_map(controller.HEAD,
(500, 404, 404), 204)
# We always return 503 if no majority between 4xx, 3xx or 2xx found
self.assert_status_map(controller.HEAD,
(500, 500, 400), 503)
def test_POST_autocreate(self):
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
self.app.memcache = FakeMemcacheReturnsNone()
# first test with autocreate being False
self.assertFalse(self.app.account_autocreate)
self.assert_status_map(controller.POST,
(404, 404, 404), 404)
# next turn it on and test account being created than updated
controller.app.account_autocreate = True
self.assert_status_map(
controller.POST,
(404, 404, 404, 202, 202, 202, 201, 201, 201), 201)
# account_info PUT account POST account
self.assert_status_map(
controller.POST,
(404, 404, 503, 201, 201, 503, 204, 204, 504), 204)
# what if create fails
self.assert_status_map(
controller.POST,
(404, 404, 404, 403, 403, 403, 400, 400, 400), 400)
def test_POST_autocreate_with_sysmeta(self):
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
self.app.memcache = FakeMemcacheReturnsNone()
# first test with autocreate being False
self.assertFalse(self.app.account_autocreate)
self.assert_status_map(controller.POST,
(404, 404, 404), 404)
# next turn it on and test account being created than updated
controller.app.account_autocreate = True
calls = []
callback = _make_callback_func(calls)
key, value = 'X-Account-Sysmeta-Blah', 'something'
headers = {key: value}
self.assert_status_map(
controller.POST,
(404, 404, 404, 202, 202, 202, 201, 201, 201), 201,
# POST , autocreate PUT, POST again
headers=headers,
give_connect=callback)
self.assertEqual(9, len(calls))
for call in calls:
self.assertTrue(key in call['headers'],
'%s call, key %s missing in headers %s' %
(call['method'], key, call['headers']))
self.assertEqual(value, call['headers'][key])
def test_connection_refused(self):
self.app.account_ring.get_nodes('account')
for dev in self.app.account_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = 1 # can't connect on this port
controller = proxy_server.AccountController(self.app, 'account')
req = Request.blank('/v1/account', environ={'REQUEST_METHOD': 'HEAD'})
self.app.update_request(req)
resp = controller.HEAD(req)
self.assertEquals(resp.status_int, 503)
def test_other_socket_error(self):
self.app.account_ring.get_nodes('account')
for dev in self.app.account_ring.devs:
dev['ip'] = '127.0.0.1'
dev['port'] = -1 # invalid port number
controller = proxy_server.AccountController(self.app, 'account')
req = Request.blank('/v1/account', environ={'REQUEST_METHOD': 'HEAD'})
self.app.update_request(req)
resp = controller.HEAD(req)
self.assertEquals(resp.status_int, 503)
def test_response_get_accept_ranges_header(self):
with save_globals():
set_http_connect(200, 200, body='{}')
controller = proxy_server.AccountController(self.app, 'account')
req = Request.blank('/v1/a?format=json')
self.app.update_request(req)
res = controller.GET(req)
self.assert_('accept-ranges' in res.headers)
self.assertEqual(res.headers['accept-ranges'], 'bytes')
def test_response_head_accept_ranges_header(self):
with save_globals():
set_http_connect(200, 200, body='{}')
controller = proxy_server.AccountController(self.app, 'account')
req = Request.blank('/v1/a?format=json')
self.app.update_request(req)
res = controller.HEAD(req)
res.body
self.assert_('accept-ranges' in res.headers)
self.assertEqual(res.headers['accept-ranges'], 'bytes')
def test_PUT(self):
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
def test_status_map(statuses, expected, **kwargs):
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a', {})
req.content_length = 0
self.app.update_request(req)
res = controller.PUT(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((201, 201, 201), 405)
self.app.allow_account_management = True
test_status_map((201, 201, 201), 201)
test_status_map((201, 201, 500), 201)
test_status_map((201, 500, 500), 503)
test_status_map((204, 500, 404), 503)
def test_PUT_max_account_name_length(self):
with save_globals():
self.app.allow_account_management = True
limit = constraints.MAX_ACCOUNT_NAME_LENGTH
controller = proxy_server.AccountController(self.app, '1' * limit)
self.assert_status_map(controller.PUT, (201, 201, 201), 201)
controller = proxy_server.AccountController(
self.app, '2' * (limit + 1))
self.assert_status_map(controller.PUT, (201, 201, 201), 400)
def test_PUT_connect_exceptions(self):
with save_globals():
self.app.allow_account_management = True
controller = proxy_server.AccountController(self.app, 'account')
self.assert_status_map(controller.PUT, (201, 201, -1), 201)
self.assert_status_map(controller.PUT, (201, -1, -1), 503)
self.assert_status_map(controller.PUT, (503, 503, -1), 503)
def test_PUT_status(self):
with save_globals():
self.app.allow_account_management = True
controller = proxy_server.AccountController(self.app, 'account')
self.assert_status_map(controller.PUT, (201, 201, 202), 202)
def test_PUT_metadata(self):
self.metadata_helper('PUT')
def test_POST_metadata(self):
self.metadata_helper('POST')
def metadata_helper(self, method):
for test_header, test_value in (
('X-Account-Meta-TestHeader', 'TestValue'),
('X-Account-Meta-TestHeader', ''),
('X-Remove-Account-Meta-TestHeader', 'anything')):
test_errors = []
def test_connect(ipaddr, port, device, partition, method, path,
headers=None, query_string=None):
if path == '/a':
find_header = test_header
find_value = test_value
if find_header.lower().startswith('x-remove-'):
find_header = \
find_header.lower().replace('-remove', '', 1)
find_value = ''
for k, v in headers.iteritems():
if k.lower() == find_header.lower() and \
v == find_value:
break
else:
test_errors.append('%s: %s not in %s' %
(find_header, find_value, headers))
with save_globals():
self.app.allow_account_management = True
controller = \
proxy_server.AccountController(self.app, 'a')
set_http_connect(201, 201, 201, give_connect=test_connect)
req = Request.blank('/v1/a/c',
environ={'REQUEST_METHOD': method},
headers={test_header: test_value})
self.app.update_request(req)
getattr(controller, method)(req)
self.assertEquals(test_errors, [])
def test_PUT_bad_metadata(self):
self.bad_metadata_helper('PUT')
def test_POST_bad_metadata(self):
self.bad_metadata_helper('POST')
def bad_metadata_helper(self, method):
with save_globals():
self.app.allow_account_management = True
controller = proxy_server.AccountController(self.app, 'a')
set_http_connect(200, 201, 201, 201)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers={'X-Account-Meta-' +
('a' * constraints.MAX_META_NAME_LENGTH): 'v'})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank(
'/v1/a/c', environ={'REQUEST_METHOD': method},
headers={'X-Account-Meta-' +
('a' * (constraints.MAX_META_NAME_LENGTH + 1)): 'v'})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers={'X-Account-Meta-Too-Long':
'a' * constraints.MAX_META_VALUE_LENGTH})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers={'X-Account-Meta-Too-Long':
'a' * (constraints.MAX_META_VALUE_LENGTH + 1)})
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
headers = {}
for x in xrange(constraints.MAX_META_COUNT):
headers['X-Account-Meta-%d' % x] = 'v'
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers=headers)
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
headers = {}
for x in xrange(constraints.MAX_META_COUNT + 1):
headers['X-Account-Meta-%d' % x] = 'v'
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers=headers)
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 400)
set_http_connect(201, 201, 201)
headers = {}
header_value = 'a' * constraints.MAX_META_VALUE_LENGTH
size = 0
x = 0
while size < (constraints.MAX_META_OVERALL_SIZE - 4
- constraints.MAX_META_VALUE_LENGTH):
size += 4 + constraints.MAX_META_VALUE_LENGTH
headers['X-Account-Meta-%04d' % x] = header_value
x += 1
if constraints.MAX_META_OVERALL_SIZE - size > 1:
headers['X-Account-Meta-a'] = \
'a' * (constraints.MAX_META_OVERALL_SIZE - size - 1)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers=headers)
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 201)
set_http_connect(201, 201, 201)
headers['X-Account-Meta-a'] = \
'a' * (constraints.MAX_META_OVERALL_SIZE - size)
req = Request.blank('/v1/a/c', environ={'REQUEST_METHOD': method},
headers=headers)
self.app.update_request(req)
resp = getattr(controller, method)(req)
self.assertEquals(resp.status_int, 400)
def test_DELETE(self):
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
def test_status_map(statuses, expected, **kwargs):
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a', {'REQUEST_METHOD': 'DELETE'})
req.content_length = 0
self.app.update_request(req)
res = controller.DELETE(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((201, 201, 201), 405)
self.app.allow_account_management = True
test_status_map((201, 201, 201), 201)
test_status_map((201, 201, 500), 201)
test_status_map((201, 500, 500), 503)
test_status_map((204, 500, 404), 503)
def test_DELETE_with_query_string(self):
# Extra safety in case someone typos a query string for an
# account-level DELETE request that was really meant to be caught by
# some middleware.
with save_globals():
controller = proxy_server.AccountController(self.app, 'account')
def test_status_map(statuses, expected, **kwargs):
set_http_connect(*statuses, **kwargs)
self.app.memcache.store = {}
req = Request.blank('/v1/a?whoops',
environ={'REQUEST_METHOD': 'DELETE'})
req.content_length = 0
self.app.update_request(req)
res = controller.DELETE(req)
expected = str(expected)
self.assertEquals(res.status[:len(expected)], expected)
test_status_map((201, 201, 201), 400)
self.app.allow_account_management = True
test_status_map((201, 201, 201), 400)
test_status_map((201, 201, 500), 400)
test_status_map((201, 500, 500), 400)
test_status_map((204, 500, 404), 400)
@patch_policies([StoragePolicy(0, 'zero', True, object_ring=FakeRing())])
class TestAccountControllerFakeGetResponse(unittest.TestCase):
"""
Test all the faked-out GET responses for accounts that don't exist. They
have to match the responses for empty accounts that really exist.
"""
def setUp(self):
conf = {'account_autocreate': 'yes'}
self.app = proxy_server.Application(conf, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
self.app.memcache = FakeMemcacheReturnsNone()
def test_GET_autocreate_accept_json(self):
with save_globals():
set_http_connect(*([404] * 100)) # nonexistent: all backends 404
req = Request.blank(
'/v1/a', headers={'Accept': 'application/json'},
environ={'REQUEST_METHOD': 'GET',
'PATH_INFO': '/v1/a'})
resp = req.get_response(self.app)
self.assertEqual(200, resp.status_int)
self.assertEqual('application/json; charset=utf-8',
resp.headers['Content-Type'])
self.assertEqual("[]", resp.body)
def test_GET_autocreate_format_json(self):
with save_globals():
set_http_connect(*([404] * 100)) # nonexistent: all backends 404
req = Request.blank('/v1/a?format=json',
environ={'REQUEST_METHOD': 'GET',
'PATH_INFO': '/v1/a',
'QUERY_STRING': 'format=json'})
resp = req.get_response(self.app)
self.assertEqual(200, resp.status_int)
self.assertEqual('application/json; charset=utf-8',
resp.headers['Content-Type'])
self.assertEqual("[]", resp.body)
def test_GET_autocreate_accept_xml(self):
with save_globals():
set_http_connect(*([404] * 100)) # nonexistent: all backends 404
req = Request.blank('/v1/a', headers={"Accept": "text/xml"},
environ={'REQUEST_METHOD': 'GET',
'PATH_INFO': '/v1/a'})
resp = req.get_response(self.app)
self.assertEqual(200, resp.status_int)
self.assertEqual('text/xml; charset=utf-8',
resp.headers['Content-Type'])
empty_xml_listing = ('<?xml version="1.0" encoding="UTF-8"?>\n'
'<account name="a">\n</account>')
self.assertEqual(empty_xml_listing, resp.body)
def test_GET_autocreate_format_xml(self):
with save_globals():
set_http_connect(*([404] * 100)) # nonexistent: all backends 404
req = Request.blank('/v1/a?format=xml',
environ={'REQUEST_METHOD': 'GET',
'PATH_INFO': '/v1/a',
'QUERY_STRING': 'format=xml'})
resp = req.get_response(self.app)
self.assertEqual(200, resp.status_int)
self.assertEqual('application/xml; charset=utf-8',
resp.headers['Content-Type'])
empty_xml_listing = ('<?xml version="1.0" encoding="UTF-8"?>\n'
'<account name="a">\n</account>')
self.assertEqual(empty_xml_listing, resp.body)
def test_GET_autocreate_accept_unknown(self):
with save_globals():
set_http_connect(*([404] * 100)) # nonexistent: all backends 404
req = Request.blank('/v1/a', headers={"Accept": "mystery/meat"},
environ={'REQUEST_METHOD': 'GET',
'PATH_INFO': '/v1/a'})
resp = req.get_response(self.app)
self.assertEqual(406, resp.status_int)
def test_GET_autocreate_format_invalid_utf8(self):
with save_globals():
set_http_connect(*([404] * 100)) # nonexistent: all backends 404
req = Request.blank('/v1/a?format=\xff\xfe',
environ={'REQUEST_METHOD': 'GET',
'PATH_INFO': '/v1/a',
'QUERY_STRING': 'format=\xff\xfe'})
resp = req.get_response(self.app)
self.assertEqual(400, resp.status_int)
def test_account_acl_header_access(self):
acl = {
'admin': ['AUTH_alice'],
'read-write': ['AUTH_bob'],
'read-only': ['AUTH_carol'],
}
prefix = get_sys_meta_prefix('account')
privileged_headers = {(prefix + 'core-access-control'): format_acl(
version=2, acl_dict=acl)}
app = proxy_server.Application(
None, FakeMemcache(), account_ring=FakeRing(),
container_ring=FakeRing())
with save_globals():
# Mock account server will provide privileged information (ACLs)
set_http_connect(200, 200, 200, headers=privileged_headers)
req = Request.blank('/v1/a', environ={'REQUEST_METHOD': 'GET'})
resp = app.handle_request(req)
# Not a swift_owner -- ACLs should NOT be in response
header = 'X-Account-Access-Control'
self.assert_(header not in resp.headers, '%r was in %r' % (
header, resp.headers))
# Same setup -- mock acct server will provide ACLs
set_http_connect(200, 200, 200, headers=privileged_headers)
req = Request.blank('/v1/a', environ={'REQUEST_METHOD': 'GET',
'swift_owner': True})
resp = app.handle_request(req)
# For a swift_owner, the ACLs *should* be in response
self.assert_(header in resp.headers, '%r not in %r' % (
header, resp.headers))
def test_account_acls_through_delegation(self):
# Define a way to grab the requests sent out from the AccountController
# to the Account Server, and a way to inject responses we'd like the
# Account Server to return.
resps_to_send = []
@contextmanager
def patch_account_controller_method(verb):
old_method = getattr(proxy_server.AccountController, verb)
new_method = lambda self, req, *_, **__: resps_to_send.pop(0)
try:
setattr(proxy_server.AccountController, verb, new_method)
yield
finally:
setattr(proxy_server.AccountController, verb, old_method)
def make_test_request(http_method, swift_owner=True):
env = {
'REQUEST_METHOD': http_method,
'swift_owner': swift_owner,
}
acl = {
'admin': ['foo'],
'read-write': ['bar'],
'read-only': ['bas'],
}
headers = {} if http_method in ('GET', 'HEAD') else {
'x-account-access-control': format_acl(version=2, acl_dict=acl)
}
return Request.blank('/v1/a', environ=env, headers=headers)
# Our AccountController will invoke methods to communicate with the
# Account Server, and they will return responses like these:
def make_canned_response(http_method):
acl = {
'admin': ['foo'],
'read-write': ['bar'],
'read-only': ['bas'],
}
headers = {'x-account-sysmeta-core-access-control': format_acl(
version=2, acl_dict=acl)}
canned_resp = Response(headers=headers)
canned_resp.environ = {
'PATH_INFO': '/acct',
'REQUEST_METHOD': http_method,
}
resps_to_send.append(canned_resp)
app = proxy_server.Application(
None, FakeMemcache(), account_ring=FakeRing(),
container_ring=FakeRing())
app.allow_account_management = True
ext_header = 'x-account-access-control'
with patch_account_controller_method('GETorHEAD_base'):
# GET/HEAD requests should remap sysmeta headers from acct server
for verb in ('GET', 'HEAD'):
make_canned_response(verb)
req = make_test_request(verb)
resp = app.handle_request(req)
h = parse_acl(version=2, data=resp.headers.get(ext_header))
self.assertEqual(h['admin'], ['foo'])
self.assertEqual(h['read-write'], ['bar'])
self.assertEqual(h['read-only'], ['bas'])
# swift_owner = False: GET/HEAD shouldn't return sensitive info
make_canned_response(verb)
req = make_test_request(verb, swift_owner=False)
resp = app.handle_request(req)
h = resp.headers
self.assertEqual(None, h.get(ext_header))
# swift_owner unset: GET/HEAD shouldn't return sensitive info
make_canned_response(verb)
req = make_test_request(verb, swift_owner=False)
del req.environ['swift_owner']
resp = app.handle_request(req)
h = resp.headers
self.assertEqual(None, h.get(ext_header))
# Verify that PUT/POST requests remap sysmeta headers from acct server
with patch_account_controller_method('make_requests'):
make_canned_response('PUT')
req = make_test_request('PUT')
resp = app.handle_request(req)
h = parse_acl(version=2, data=resp.headers.get(ext_header))
self.assertEqual(h['admin'], ['foo'])
self.assertEqual(h['read-write'], ['bar'])
self.assertEqual(h['read-only'], ['bas'])
make_canned_response('POST')
req = make_test_request('POST')
resp = app.handle_request(req)
h = parse_acl(version=2, data=resp.headers.get(ext_header))
self.assertEqual(h['admin'], ['foo'])
self.assertEqual(h['read-write'], ['bar'])
self.assertEqual(h['read-only'], ['bas'])
class FakeObjectController(object):
def __init__(self):
self.app = self
self.logger = self
self.account_name = 'a'
self.container_name = 'c'
self.object_name = 'o'
self.trans_id = 'tx1'
self.object_ring = FakeRing()
self.node_timeout = 1
self.rate_limit_after_segment = 3
self.rate_limit_segments_per_sec = 2
self.GETorHEAD_base_args = []
def exception(self, *args):
self.exception_args = args
self.exception_info = sys.exc_info()
def GETorHEAD_base(self, *args):
self.GETorHEAD_base_args.append(args)
req = args[0]
path = args[4]
body = data = path[-1] * int(path[-1])
if req.range:
r = req.range.ranges_for_length(len(data))
if r:
(start, stop) = r[0]
body = data[start:stop]
resp = Response(app_iter=iter(body))
return resp
def iter_nodes(self, ring, partition):
for node in ring.get_part_nodes(partition):
yield node
for node in ring.get_more_nodes(partition):
yield node
def sort_nodes(self, nodes):
return nodes
def set_node_timing(self, node, timing):
return
class TestProxyObjectPerformance(unittest.TestCase):
def setUp(self):
# This is just a simple test that can be used to verify and debug the
# various data paths between the proxy server and the object
# server. Used as a play ground to debug buffer sizes for sockets.
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
# Client is transmitting in 2 MB chunks
fd = sock.makefile('wb', 2 * 1024 * 1024)
# Small, fast for testing
obj_len = 2 * 64 * 1024
# Use 1 GB or more for measurements
#obj_len = 2 * 512 * 1024 * 1024
self.path = '/v1/a/c/o.large'
fd.write('PUT %s HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'Content-Length: %s\r\n'
'Content-Type: application/octet-stream\r\n'
'\r\n' % (self.path, str(obj_len)))
fd.write('a' * obj_len)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 201'
self.assertEqual(headers[:len(exp)], exp)
self.obj_len = obj_len
def test_GET_debug_large_file(self):
for i in range(10):
start = time.time()
prolis = _test_sockets[0]
sock = connect_tcp(('localhost', prolis.getsockname()[1]))
# Client is reading in 2 MB chunks
fd = sock.makefile('wb', 2 * 1024 * 1024)
fd.write('GET %s HTTP/1.1\r\n'
'Host: localhost\r\n'
'Connection: close\r\n'
'X-Storage-Token: t\r\n'
'\r\n' % self.path)
fd.flush()
headers = readuntil2crlfs(fd)
exp = 'HTTP/1.1 200'
self.assertEqual(headers[:len(exp)], exp)
total = 0
while True:
buf = fd.read(100000)
if not buf:
break
total += len(buf)
self.assertEqual(total, self.obj_len)
end = time.time()
print "Run %02d took %07.03f" % (i, end - start)
@patch_policies([StoragePolicy(0, 'migrated', object_ring=FakeRing()),
StoragePolicy(1, 'ernie', True, object_ring=FakeRing()),
StoragePolicy(2, 'deprecated', is_deprecated=True,
object_ring=FakeRing()),
StoragePolicy(3, 'bert', object_ring=FakeRing())])
class TestSwiftInfo(unittest.TestCase):
def setUp(self):
utils._swift_info = {}
utils._swift_admin_info = {}
def test_registered_defaults(self):
proxy_server.Application({}, FakeMemcache(),
account_ring=FakeRing(),
container_ring=FakeRing())
si = utils.get_swift_info()['swift']
self.assertTrue('version' in si)
self.assertEqual(si['max_file_size'], constraints.MAX_FILE_SIZE)
self.assertEqual(si['max_meta_name_length'],
constraints.MAX_META_NAME_LENGTH)
self.assertEqual(si['max_meta_value_length'],
constraints.MAX_META_VALUE_LENGTH)
self.assertEqual(si['max_meta_count'], constraints.MAX_META_COUNT)
self.assertEqual(si['max_header_size'], constraints.MAX_HEADER_SIZE)
self.assertEqual(si['max_meta_overall_size'],
constraints.MAX_META_OVERALL_SIZE)
self.assertEqual(si['account_listing_limit'],
constraints.ACCOUNT_LISTING_LIMIT)
self.assertEqual(si['container_listing_limit'],
constraints.CONTAINER_LISTING_LIMIT)
self.assertEqual(si['max_account_name_length'],
constraints.MAX_ACCOUNT_NAME_LENGTH)
self.assertEqual(si['max_container_name_length'],
constraints.MAX_CONTAINER_NAME_LENGTH)
self.assertEqual(si['max_object_name_length'],
constraints.MAX_OBJECT_NAME_LENGTH)
self.assertTrue('strict_cors_mode' in si)
self.assertEqual(si['allow_account_management'], False)
self.assertEqual(si['account_autocreate'], False)
# this next test is deliberately brittle in order to alert if
# other items are added to swift info
self.assertEqual(len(si), 16)
self.assertTrue('policies' in si)
sorted_pols = sorted(si['policies'], key=operator.itemgetter('name'))
self.assertEqual(len(sorted_pols), 3)
for policy in sorted_pols:
self.assertNotEquals(policy['name'], 'deprecated')
self.assertEqual(sorted_pols[0]['name'], 'bert')
self.assertEqual(sorted_pols[1]['name'], 'ernie')
self.assertEqual(sorted_pols[2]['name'], 'migrated')
if __name__ == '__main__':
setup()
try:
unittest.main()
finally:
teardown() | unknown | codeparrot/codeparrot-clean | ||
A value with a custom `Drop` implementation may be dropped during const-eval.
Erroneous code example:
```compile_fail,E0493
enum DropType {
A,
}
impl Drop for DropType {
fn drop(&mut self) {}
}
struct Foo {
field1: DropType,
}
static FOO: Foo = Foo { field1: (DropType::A, DropType::A).1 }; // error!
```
The problem here is that if the given type or one of its fields implements the
`Drop` trait, this `Drop` implementation cannot be called within a const
context since it may run arbitrary, non-const-checked code. To prevent this
issue, ensure all values with a custom `Drop` implementation escape the
initializer.
```
enum DropType {
A,
}
impl Drop for DropType {
fn drop(&mut self) {}
}
struct Foo {
field1: DropType,
}
static FOO: Foo = Foo { field1: DropType::A }; // We initialize all fields
// by hand.
``` | unknown | github | https://github.com/rust-lang/rust | compiler/rustc_error_codes/src/error_codes/E0493.md |
#ifndef JEMALLOC_INTERNAL_INLINES_A_H
#define JEMALLOC_INTERNAL_INLINES_A_H
#include "jemalloc/internal/atomic.h"
#include "jemalloc/internal/bit_util.h"
#include "jemalloc/internal/jemalloc_internal_types.h"
#include "jemalloc/internal/sc.h"
#include "jemalloc/internal/ticker.h"
JEMALLOC_ALWAYS_INLINE malloc_cpuid_t
malloc_getcpu(void) {
assert(have_percpu_arena);
#if defined(_WIN32)
return GetCurrentProcessorNumber();
#elif defined(JEMALLOC_HAVE_SCHED_GETCPU)
return (malloc_cpuid_t)sched_getcpu();
#else
not_reached();
return -1;
#endif
}
/* Return the chosen arena index based on current cpu. */
JEMALLOC_ALWAYS_INLINE unsigned
percpu_arena_choose(void) {
assert(have_percpu_arena && PERCPU_ARENA_ENABLED(opt_percpu_arena));
malloc_cpuid_t cpuid = malloc_getcpu();
assert(cpuid >= 0);
unsigned arena_ind;
if ((opt_percpu_arena == percpu_arena) || ((unsigned)cpuid < ncpus /
2)) {
arena_ind = cpuid;
} else {
assert(opt_percpu_arena == per_phycpu_arena);
/* Hyper threads on the same physical CPU share arena. */
arena_ind = cpuid - ncpus / 2;
}
return arena_ind;
}
/* Return the limit of percpu auto arena range, i.e. arenas[0...ind_limit). */
JEMALLOC_ALWAYS_INLINE unsigned
percpu_arena_ind_limit(percpu_arena_mode_t mode) {
assert(have_percpu_arena && PERCPU_ARENA_ENABLED(mode));
if (mode == per_phycpu_arena && ncpus > 1) {
if (ncpus % 2) {
/* This likely means a misconfig. */
return ncpus / 2 + 1;
}
return ncpus / 2;
} else {
return ncpus;
}
}
static inline arena_t *
arena_get(tsdn_t *tsdn, unsigned ind, bool init_if_missing) {
arena_t *ret;
assert(ind < MALLOCX_ARENA_LIMIT);
ret = (arena_t *)atomic_load_p(&arenas[ind], ATOMIC_ACQUIRE);
if (unlikely(ret == NULL)) {
if (init_if_missing) {
ret = arena_init(tsdn, ind, &arena_config_default);
}
}
return ret;
}
JEMALLOC_ALWAYS_INLINE bool
tcache_available(tsd_t *tsd) {
/*
* Thread specific auto tcache might be unavailable if: 1) during tcache
* initialization, or 2) disabled through thread.tcache.enabled mallctl
* or config options. This check covers all cases.
*/
if (likely(tsd_tcache_enabled_get(tsd))) {
/* Associated arena == NULL implies tcache init in progress. */
if (config_debug && tsd_tcache_slowp_get(tsd)->arena != NULL) {
tcache_assert_initialized(tsd_tcachep_get(tsd));
}
return true;
}
return false;
}
JEMALLOC_ALWAYS_INLINE tcache_t *
tcache_get(tsd_t *tsd) {
if (!tcache_available(tsd)) {
return NULL;
}
return tsd_tcachep_get(tsd);
}
JEMALLOC_ALWAYS_INLINE tcache_slow_t *
tcache_slow_get(tsd_t *tsd) {
if (!tcache_available(tsd)) {
return NULL;
}
return tsd_tcache_slowp_get(tsd);
}
static inline void
pre_reentrancy(tsd_t *tsd, arena_t *arena) {
/* arena is the current context. Reentry from a0 is not allowed. */
assert(arena != arena_get(tsd_tsdn(tsd), 0, false));
tsd_pre_reentrancy_raw(tsd);
}
static inline void
post_reentrancy(tsd_t *tsd) {
tsd_post_reentrancy_raw(tsd);
}
#endif /* JEMALLOC_INTERNAL_INLINES_A_H */ | c | github | https://github.com/redis/redis | deps/jemalloc/include/jemalloc/internal/jemalloc_internal_inlines_a.h |
__kupfer_name__ = _("File Actions")
__kupfer_sources__ = ()
__kupfer_text_sources__ = ()
__kupfer_actions__ = (
"MoveTo",
"Rename",
"CopyTo",
)
__description__ = _("More file actions")
__version__ = ""
__author__ = "Ulrik"
import gio
import os
# since "path" is a very generic name, you often forget..
from os import path as os_path
from kupfer.objects import Action, FileLeaf, TextLeaf, TextSource
from kupfer.objects import OperationError
from kupfer import pretty
def _good_destination(dpath, spath):
"""If directory path @dpath is a valid destination for file @spath
to be copied or moved to.
"""
if not os_path.isdir(dpath):
return False
spath = os_path.normpath(spath)
dpath = os_path.normpath(dpath)
if not os.access(dpath, os.R_OK | os.W_OK | os.X_OK):
return False
cpfx = os_path.commonprefix((spath, dpath))
if os_path.samefile(dpath, spath) or cpfx == spath:
return False
return True
class MoveTo (Action, pretty.OutputMixin):
def __init__(self):
Action.__init__(self, _("Move To..."))
def has_result(self):
return True
def activate(self, leaf, obj):
sfile = gio.File(leaf.object)
bname = sfile.get_basename()
dfile = gio.File(os_path.join(obj.object, bname))
try:
ret = sfile.move(dfile, flags=gio.FILE_COPY_ALL_METADATA)
self.output_debug("Move %s to %s (ret: %s)" % (sfile, dfile, ret))
except gio.Error, exc:
raise OperationError(unicode(exc))
else:
return FileLeaf(dfile.get_path())
def valid_for_item(self, item):
return os.access(item.object, os.R_OK | os.W_OK)
def requires_object(self):
return True
def item_types(self):
yield FileLeaf
def object_types(self):
yield FileLeaf
def valid_object(self, obj, for_item):
return _good_destination(obj.object, for_item.object)
def get_description(self):
return _("Move file to new location")
def get_icon_name(self):
return "go-next"
class RenameSource (TextSource):
"""A source for new names for a file;
here we "autopropose" the source file's extension,
but allow overriding it as well as renaming to without
extension (either using a terminating space, or selecting the
normal TextSource-returned string).
"""
def __init__(self, sourcefile):
self.sourcefile = sourcefile
name = _("Rename To...").rstrip(".")
TextSource.__init__(self, name)
def get_rank(self):
# this should rank high
return 100
def get_items(self, text):
if not text:
return
basename = os_path.basename(self.sourcefile.object)
root, ext = os_path.splitext(basename)
t_root, t_ext = os_path.splitext(text)
if text.endswith(u" "):
yield TextLeaf(text.rstrip())
else:
yield TextLeaf(text) if t_ext else TextLeaf(t_root + ext)
def get_gicon(self):
return self.sourcefile.get_gicon()
class Rename (Action, pretty.OutputMixin):
def __init__(self):
Action.__init__(self, _("Rename To..."))
def has_result(self):
return True
def activate(self, leaf, obj):
sfile = gio.File(leaf.object)
dest = os_path.join(os_path.dirname(leaf.object), obj.object)
dfile = gio.File(dest)
try:
ret = sfile.move(dfile)
self.output_debug("Move %s to %s (ret: %s)" % (sfile, dfile, ret))
except gio.Error, exc:
raise OperationError(unicode(exc))
else:
return FileLeaf(dfile.get_path())
def activate_multiple(self, objs, iobjs):
raise NotImplementedError
def item_types(self):
yield FileLeaf
def valid_for_item(self, item):
return os.access(item.object, os.R_OK | os.W_OK)
def requires_object(self):
return True
def object_types(self):
yield TextLeaf
def valid_object(self, obj, for_item):
dest = os_path.join(os_path.dirname(for_item.object), obj.object)
return os_path.exists(os_path.dirname(dest)) and \
not os_path.exists(dest)
def object_source(self, for_item):
return RenameSource(for_item)
def get_description(self):
return None
class CopyTo (Action, pretty.OutputMixin):
def __init__(self):
Action.__init__(self, _("Copy To..."))
def has_result(self):
return True
def _finish_callback(self, gfile, result, data):
self.output_debug("Finished copying", gfile)
dfile, ctx = data
try:
gfile.copy_finish(result)
except gio.Error:
ctx.register_late_error()
else:
ctx.register_late_result(FileLeaf(dfile.get_path()))
def wants_context(self):
return True
def activate(self, leaf, iobj, ctx):
sfile = gio.File(leaf.object)
dpath = os_path.join(iobj.object, os_path.basename(leaf.object))
dfile = gio.File(dpath)
try:
ret = sfile.copy_async(dfile, self._finish_callback,
user_data=(dfile, ctx),
flags=gio.FILE_COPY_ALL_METADATA)
self.output_debug("Copy %s to %s (ret: %s)" % (sfile, dfile, ret))
except gio.Error, exc:
raise OperationError(unicode(exc))
def item_types(self):
yield FileLeaf
def valid_for_item(self, item):
return (not item.is_dir()) and os.access(item.object, os.R_OK)
def requires_object(self):
return True
def object_types(self):
yield FileLeaf
def valid_object(self, obj, for_item):
return _good_destination(obj.object, for_item.object)
def get_description(self):
return _("Copy file to a chosen location") | unknown | codeparrot/codeparrot-clean | ||
---
mapped_pages:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-minimum-should-match.html
---
# minimum_should_match parameter [query-dsl-minimum-should-match]
The `minimum_should_match` parameter’s possible values:
| Type | Example | Description |
| --- | --- | --- |
| Integer | `3` | Indicates a fixed value regardless of the number of optional clauses. |
| Negative integer | `-2` | Indicates that the total number of optional clauses, minus this number should be mandatory. |
| Percentage | `75%` | Indicates that this percent of the total number of optional clauses are necessary. The number computed from the percentage is rounded down and used as the minimum. |
| Negative percentage | `-25%` | Indicates that this percent of the total number of optional clauses can be missing. The number computed from the percentage is rounded down, before being subtracted from the total to determine the minimum. |
| Combination | `3<90%` | A positive integer, followed by the less-than symbol, followed by any of the previously mentioned specifiers is a conditional specification. It indicates that if the number of optional clauses is equal to (or less than) the integer, they are all required, but if it’s greater than the integer, the specification applies. In this example: if there are 1 to 3 clauses they are all required, but for 4 or more clauses only 90% are required. |
| Multiple combinations | `2<-25% 9<-3` | Multiple conditional specifications can be separated by spaces, each one only being valid for numbers greater than the one before it. In this example: if there are 1 or 2 clauses both are required, if there are 3-9 clauses all but 25% are required, and if there are more than 9 clauses, all but three are required. |
**NOTE:**
When dealing with percentages, negative values can be used to get different behavior in edge cases. 75% and -25% mean the same thing when dealing with 4 clauses, but when dealing with 5 clauses 75% means 3 are required, but -25% means 4 are required.
If the calculations based on the specification determine that no optional clauses are needed, the usual rules about BooleanQueries still apply at search time (a BooleanQuery containing no required clauses must still match at least one optional clause)
No matter what number the calculation arrives at, a value greater than the number of optional clauses, or a value less than 1 will never be used. (ie: no matter how low or how high the result of the calculation result is, the minimum number of required matches will never be lower than 1 or greater than the number of clauses. | unknown | github | https://github.com/elastic/elasticsearch | docs/reference/query-languages/query-dsl/query-dsl-minimum-should-match.md |
from urlparse import urlparse
import os.path
from multiprocessing import Process, Queue
import json
import sys
WORKERS = 16
INFILE = '../certs_using_crl.json'
CRL = 'megaCRL'
OUTFILE = 'revokedCRLCerts/certs'
def doWork(i, megaCRL_org, megaCRL_CN):
print('starting worker ' + str(i))
with open(OUTFILE + str(i), 'w') as out:
while True:
try:
cert = json.loads(q.get())
serial = int(cert['parsed']['serial_number'])
issuer = cert['parsed']['issuer']
except:
continue # skip to next certificate
try:
org = issuer['organization'][0].replace(" ", "_")
except:
org = 'unknown'
try:
CN = issuer['common_name'][0].replace(" ", "_")
except:
CN = 'unknown'
if(isRevoked(megaCRL_org, megaCRL_CN, org, CN, serial)):
out.write(json.dumps(cert) + '\n')
def isRevoked(megaCRL_org, megaCRL_CN, org, CN, serial):
if org in megaCRL_org:
if serial in megaCRL_org[org]:
return True
if CN in megaCRL_CN:
if serial in megaCRL_CN[CN]:
return True
return False
def buildDict():
megaCRL_CN = {}
megaCRL_org = {}
crlFile = open(CRL, 'r')
for line in crlFile:
parsed = json.loads(line)
issuer = parsed['crl_issuer']
for entry in issuer:
if entry[0] == "O":
org = entry[1].replace(" ", "_")
if not org in megaCRL_org:
megaCRL_org[org] = []
for serial in parsed['cert_serials']:
megaCRL_org[org].append(int(serial, 16))
if entry[0] == "CN":
CN = entry[1].replace(" ", "_")
if not CN in megaCRL_CN:
megaCRL_CN[CN] = []
for serial in parsed['cert_serials']:
megaCRL_CN[CN].append(int(serial, 16))
return megaCRL_CN, megaCRL_org
if __name__ == '__main__':
print('building megaCRL...')
megaCRL_CN, megaCRL_org = buildDict()
q = Queue(WORKERS * 16)
for i in range(WORKERS):
p = Process(target=doWork, args=(i, megaCRL_org, megaCRL_CN, ))
p.start()
try:
ctr = 0
for cert in open(INFILE, 'r'):
q.put(cert)
ctr += 1
if(ctr % 10000 == 0):
print(str(ctr) + " certificates processed")
except KeyboardInterrupt:
sys.exit(1) | unknown | codeparrot/codeparrot-clean | ||
<!DOCTYPE html>
<html lang="en">
<head>
<title>DataPreprocessor Protocol Reference</title>
<link rel="stylesheet" type="text/css" href="../css/jazzy.css" />
<link rel="stylesheet" type="text/css" href="../css/highlight.css" />
<meta charset="utf-8">
<script src="../js/jquery.min.js" defer></script>
<script src="../js/jazzy.js" defer></script>
<script src="../js/lunr.min.js" defer></script>
<script src="../js/typeahead.jquery.js" defer></script>
<script src="../js/jazzy.search.js" defer></script>
</head>
<body>
<a name="//apple_ref/swift/Protocol/DataPreprocessor" class="dashAnchor"></a>
<a title="DataPreprocessor Protocol Reference"></a>
<header class="header">
<p class="header-col header-col--primary">
<a class="header-link" href="../index.html">
Alamofire 5.11.0 Docs
</a>
(96% documented)
</p>
<div class="header-col--secondary">
<form role="search" action="../search.json">
<input type="text" placeholder="Search documentation" data-typeahead>
</form>
</div>
<p class="header-col header-col--secondary">
<a class="header-link" href="https://github.com/Alamofire/Alamofire">
<img class="header-icon" src="../img/gh.png" alt="GitHub"/>
View on GitHub
</a>
</p>
<p class="header-col header-col--secondary">
<a class="header-link" href="dash-feed://https%3A%2F%2Falamofire.github.io%2FAlamofire%2Fdocsets%2FAlamofire.xml">
<img class="header-icon" src="../img/dash.png" alt="Dash"/>
Install in Dash
</a>
</p>
</header>
<p class="breadcrumbs">
<a class="breadcrumb" href="../index.html">Alamofire</a>
<img class="carat" src="../img/carat.png" alt=""/>
<a class="breadcrumb" href="../Protocols.html">Protocols</a>
<img class="carat" src="../img/carat.png" alt=""/>
DataPreprocessor Protocol Reference
</p>
<div class="content-wrapper">
<nav class="navigation">
<ul class="nav-groups">
<li class="nav-group-name">
<a class="nav-group-name-link" href="../Classes.html">Classes</a>
<ul class="nav-group-tasks">
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/Adapter.html">Adapter</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/AlamofireNotifications.html">AlamofireNotifications</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/AuthenticationInterceptor.html">AuthenticationInterceptor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/AuthenticationInterceptor/RefreshWindow.html">– RefreshWindow</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/ClosureEventMonitor.html">ClosureEventMonitor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/CompositeEventMonitor.html">CompositeEventMonitor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/CompositeTrustEvaluator.html">CompositeTrustEvaluator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/ConnectionLostRetryPolicy.html">ConnectionLostRetryPolicy</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DataRequest.html">DataRequest</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DataResponseSerializer.html">DataResponseSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DataStreamRequest.html">DataStreamRequest</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DataStreamRequest/Stream.html">– Stream</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DataStreamRequest/Event.html">– Event</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DataStreamRequest/Completion.html">– Completion</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DataStreamRequest/CancellationToken.html">– CancellationToken</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DecodableResponseSerializer.html">DecodableResponseSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DefaultTrustEvaluator.html">DefaultTrustEvaluator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DisabledTrustEvaluator.html">DisabledTrustEvaluator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DownloadRequest.html">DownloadRequest</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DownloadRequest/Options.html">– Options</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/DownloadRequest/Downloadable.html">– Downloadable</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/Interceptor.html">Interceptor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/JSONParameterEncoder.html">JSONParameterEncoder</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/JSONResponseSerializer.html">JSONResponseSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/MultipartFormData.html">MultipartFormData</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/NetworkReachabilityManager.html">NetworkReachabilityManager</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/NetworkReachabilityManager/NetworkReachabilityStatus.html">– NetworkReachabilityStatus</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/OfflineRetrier.html">OfflineRetrier</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/PinnedCertificatesTrustEvaluator.html">PinnedCertificatesTrustEvaluator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/PublicKeysTrustEvaluator.html">PublicKeysTrustEvaluator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/Request.html">Request</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/Request/State.html">– State</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/Request/ResponseDisposition.html">– ResponseDisposition</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/Retrier.html">Retrier</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/RetryPolicy.html">RetryPolicy</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/RevocationTrustEvaluator.html">RevocationTrustEvaluator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/RevocationTrustEvaluator/Options.html">– Options</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/ServerTrustManager.html">ServerTrustManager</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/Session.html">Session</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/Session/RequestSetup.html">– RequestSetup</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/SessionDelegate.html">SessionDelegate</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/StringResponseSerializer.html">StringResponseSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder.html">URLEncodedFormEncoder</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/ArrayEncoding.html">– ArrayEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/BoolEncoding.html">– BoolEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/DataEncoding.html">– DataEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/DateEncoding.html">– DateEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/KeyEncoding.html">– KeyEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/KeyPathEncoding.html">– KeyPathEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/NilEncoding.html">– NilEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/SpaceEncoding.html">– SpaceEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormEncoder/Error.html">– Error</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormParameterEncoder.html">URLEncodedFormParameterEncoder</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/URLEncodedFormParameterEncoder/Destination.html">– Destination</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/UploadRequest.html">UploadRequest</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Classes/UploadRequest/Uploadable.html">– Uploadable</a>
</li>
</ul>
</li>
<li class="nav-group-name">
<a class="nav-group-name-link" href="../Global%20Variables.html">Global Variables</a>
<ul class="nav-group-tasks">
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Global%20Variables.html#/s:9Alamofire2AFAA7SessionCvp">AF</a>
</li>
</ul>
</li>
<li class="nav-group-name">
<a class="nav-group-name-link" href="../Enums.html">Enumerations</a>
<ul class="nav-group-tasks">
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError.html">AFError</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError/MultipartEncodingFailureReason.html">– MultipartEncodingFailureReason</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError/UnexpectedInputStreamLength.html">– UnexpectedInputStreamLength</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError/ParameterEncodingFailureReason.html">– ParameterEncodingFailureReason</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError/ParameterEncoderFailureReason.html">– ParameterEncoderFailureReason</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError/ResponseValidationFailureReason.html">– ResponseValidationFailureReason</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError/ResponseSerializationFailureReason.html">– ResponseSerializationFailureReason</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError/ServerTrustFailureReason.html">– ServerTrustFailureReason</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFError/URLRequestValidationFailureReason.html">– URLRequestValidationFailureReason</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AFInfo.html">AFInfo</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/AuthenticationError.html">AuthenticationError</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Enums/RetryResult.html">RetryResult</a>
</li>
</ul>
</li>
<li class="nav-group-name">
<a class="nav-group-name-link" href="../Extensions.html">Extensions</a>
<ul class="nav-group-tasks">
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/s:Sa">Array</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/c:objc(cs)NSBundle">Bundle</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/CharacterSet.html">CharacterSet</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/Error.html">Error</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/HTTPURLResponse.html">HTTPURLResponse</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/s:10Foundation11JSONDecoderC">JSONDecoder</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/Notification.html">Notification</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/c:@T@OSStatus">OSStatus</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/s:10Foundation19PropertyListDecoderC">PropertyListDecoder</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/c:@T@SecCertificateRef">SecCertificate</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/c:@T@SecPolicyRef">SecPolicy</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/c:@T@SecTrustRef">SecTrust</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions.html#/c:@E@SecTrustResultType">SecTrustResultType</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/String.html">String</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/URL.html">URL</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/URLComponents.html">URLComponents</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/URLRequest.html">URLRequest</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/URLSessionConfiguration.html">URLSessionConfiguration</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Extensions/%5BServerTrustEvaluating%5D.html">[ServerTrustEvaluating]</a>
</li>
</ul>
</li>
<li class="nav-group-name">
<a class="nav-group-name-link" href="../Protocols.html">Protocols</a>
<ul class="nav-group-tasks">
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/AlamofireExtended.html">AlamofireExtended</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/AuthenticationCredential.html">AuthenticationCredential</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/Authenticator.html">Authenticator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/CachedResponseHandler.html">CachedResponseHandler</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/DataDecoder.html">DataDecoder</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/DataPreprocessor.html">DataPreprocessor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/DataResponseSerializerProtocol.html">DataResponseSerializerProtocol</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/DataStreamSerializer.html">DataStreamSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/DownloadResponseSerializerProtocol.html">DownloadResponseSerializerProtocol</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/EmptyResponse.html">EmptyResponse</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/EventMonitor.html">EventMonitor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/ParameterEncoder.html">ParameterEncoder</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/ParameterEncoding.html">ParameterEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/RedirectHandler.html">RedirectHandler</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/RequestAdapter.html">RequestAdapter</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/RequestDelegate.html">RequestDelegate</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/RequestInterceptor.html">RequestInterceptor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/RequestRetrier.html">RequestRetrier</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/ResponseSerializer.html">ResponseSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/ServerTrustEvaluating.html">ServerTrustEvaluating</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/URLConvertible.html">URLConvertible</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/URLRequestConvertible.html">URLRequestConvertible</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols.html#/s:9Alamofire17UploadConvertibleP">UploadConvertible</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/UploadableConvertible.html">UploadableConvertible</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Protocols/WebSocketMessageSerializer.html">WebSocketMessageSerializer</a>
</li>
</ul>
</li>
<li class="nav-group-name">
<a class="nav-group-name-link" href="../Structs.html">Structures</a>
<ul class="nav-group-tasks">
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/AlamofireExtension.html">AlamofireExtension</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DataResponse.html">DataResponse</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DataResponsePublisher.html">DataResponsePublisher</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DataStreamPublisher.html">DataStreamPublisher</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DataStreamTask.html">DataStreamTask</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DataTask.html">DataTask</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DecodableStreamSerializer.html">DecodableStreamSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DecodableWebSocketMessageDecoder.html">DecodableWebSocketMessageDecoder</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DecodableWebSocketMessageDecoder/Error.html">– Error</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DeflateRequestCompressor.html">DeflateRequestCompressor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DeflateRequestCompressor/DuplicateHeaderBehavior.html">– DuplicateHeaderBehavior</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DeflateRequestCompressor.html#/s:9Alamofire24DeflateRequestCompressorV20DuplicateHeaderErrorV">– DuplicateHeaderError</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DownloadResponse.html">DownloadResponse</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DownloadResponsePublisher.html">DownloadResponsePublisher</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/DownloadTask.html">DownloadTask</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/Empty.html">Empty</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/GoogleXSSIPreprocessor.html">GoogleXSSIPreprocessor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/HTTPHeader.html">HTTPHeader</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/HTTPHeaders.html">HTTPHeaders</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/HTTPMethod.html">HTTPMethod</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/JSONEncoding.html">JSONEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/JSONEncoding/Error.html">– Error</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/PassthroughPreprocessor.html">PassthroughPreprocessor</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/PassthroughStreamSerializer.html">PassthroughStreamSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/Redirector.html">Redirector</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/Redirector/Behavior.html">– Behavior</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/RequestAdapterState.html">RequestAdapterState</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/ResponseCacher.html">ResponseCacher</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/ResponseCacher/Behavior.html">– Behavior</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/StreamOf.html">StreamOf</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/StreamOf/Iterator.html">– Iterator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/StringStreamSerializer.html">StringStreamSerializer</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/URLEncoding.html">URLEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/URLEncoding/Destination.html">– Destination</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/URLEncoding/ArrayEncoding.html">– ArrayEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/URLEncoding/BoolEncoding.html">– BoolEncoding</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Structs/URLResponseSerializer.html">URLResponseSerializer</a>
</li>
</ul>
</li>
<li class="nav-group-name">
<a class="nav-group-name-link" href="../Typealiases.html">Type Aliases</a>
<ul class="nav-group-tasks">
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Typealiases.html#/s:9Alamofire14AFDataResponsea">AFDataResponse</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Typealiases.html#/s:9Alamofire18AFDownloadResponsea">AFDownloadResponse</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Typealiases.html#/s:9Alamofire8AFResulta">AFResult</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Typealiases.html#/s:9Alamofire12AdaptHandlera">AdaptHandler</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Typealiases.html#/s:9Alamofire17DisabledEvaluatora">DisabledEvaluator</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Typealiases.html#/s:9Alamofire10Parametersa">Parameters</a>
</li>
<li class="nav-group-task">
<a class="nav-group-task-link" href="../Typealiases.html#/s:9Alamofire12RetryHandlera">RetryHandler</a>
</li>
</ul>
</li>
</ul>
</nav>
<article class="main-content">
<section class="section">
<div class="section-content top-matter">
<h1>DataPreprocessor</h1>
<div class="declaration">
<div class="language">
<pre class="highlight swift"><code><span class="kd">public</span> <span class="kd">protocol</span> <span class="kt">DataPreprocessor</span> <span class="p">:</span> <span class="kt">Sendable</span></code></pre>
</div>
</div>
<p>Type used to preprocess <code>Data</code> before it handled by a serializer.</p>
</div>
</section>
<section class="section">
<div class="section-content">
<div class="task-group">
<ul class="item-container">
<li class="item">
<div>
<code>
<a name="/s:9Alamofire16DataPreprocessorP10preprocessy10Foundation0B0VAGKF"></a>
<a name="//apple_ref/swift/Method/preprocess(_:)" class="dashAnchor"></a>
<a class="token" href="#/s:9Alamofire16DataPreprocessorP10preprocessy10Foundation0B0VAGKF">preprocess(_:<wbr>)</a>
</code>
</div>
<div class="height-container">
<div class="pointer-container"></div>
<section class="section">
<div class="pointer"></div>
<div class="abstract">
<p>Process <code>Data</code> before it’s handled by a serializer.</p>
</div>
<div class="declaration">
<h4>Declaration</h4>
<div class="language">
<p class="aside-title">Swift</p>
<pre class="highlight swift"><code><span class="kd">func</span> <span class="nf">preprocess</span><span class="p">(</span><span class="n">_</span> <span class="nv">data</span><span class="p">:</span> <span class="kt">Data</span><span class="p">)</span> <span class="k">throws</span> <span class="o">-></span> <span class="kt">Data</span></code></pre>
</div>
</div>
<div>
<h4>Parameters</h4>
<table class="graybox">
<tbody>
<tr>
<td>
<code>
<em>data</em>
</code>
</td>
<td>
<div>
<p>The raw <code>Data</code> to process.</p>
</div>
</td>
</tr>
</tbody>
</table>
</div>
</section>
</div>
</li>
</ul>
</div>
<div class="task-group">
<div class="task-name-container">
<a name="/Available%20where%20%60Self%60%20%3D%3D%20%60PassthroughPreprocessor%60"></a>
<a name="//apple_ref/swift/Section/Available where `Self` == `PassthroughPreprocessor`" class="dashAnchor"></a>
<div class="section-name-container">
<a class="section-name-link" href="#/Available%20where%20%60Self%60%20%3D%3D%20%60PassthroughPreprocessor%60"></a>
<h3 class="section-name"><span>Available where <code>Self</code> == <code><a href="../Structs/PassthroughPreprocessor.html">PassthroughPreprocessor</a></code></span>
</h3>
</div>
</div>
<ul class="item-container">
<li class="item">
<div>
<code>
<a name="/s:9Alamofire16DataPreprocessorPA2A011PassthroughC0VRszrlE11passthroughAEvpZ"></a>
<a name="//apple_ref/swift/Variable/passthrough" class="dashAnchor"></a>
<a class="token" href="#/s:9Alamofire16DataPreprocessorPA2A011PassthroughC0VRszrlE11passthroughAEvpZ">passthrough</a>
</code>
<span class="declaration-note">
Extension method
</span>
</div>
<div class="height-container">
<div class="pointer-container"></div>
<section class="section">
<div class="pointer"></div>
<div class="abstract">
<p>Provides a <code><a href="../Structs/PassthroughPreprocessor.html">PassthroughPreprocessor</a></code> instance.</p>
</div>
<div class="declaration">
<h4>Declaration</h4>
<div class="language">
<p class="aside-title">Swift</p>
<pre class="highlight swift"><code><span class="kd">public</span> <span class="kd">static</span> <span class="k">var</span> <span class="nv">passthrough</span><span class="p">:</span> <span class="kt"><a href="../Structs/PassthroughPreprocessor.html">PassthroughPreprocessor</a></span> <span class="p">{</span> <span class="k">get</span> <span class="p">}</span></code></pre>
</div>
</div>
</section>
</div>
</li>
</ul>
</div>
<div class="task-group">
<div class="task-name-container">
<a name="/Available%20where%20%60Self%60%20%3D%3D%20%60GoogleXSSIPreprocessor%60"></a>
<a name="//apple_ref/swift/Section/Available where `Self` == `GoogleXSSIPreprocessor`" class="dashAnchor"></a>
<div class="section-name-container">
<a class="section-name-link" href="#/Available%20where%20%60Self%60%20%3D%3D%20%60GoogleXSSIPreprocessor%60"></a>
<h3 class="section-name"><span>Available where <code>Self</code> == <code><a href="../Structs/GoogleXSSIPreprocessor.html">GoogleXSSIPreprocessor</a></code></span>
</h3>
</div>
</div>
<ul class="item-container">
<li class="item">
<div>
<code>
<a name="/s:9Alamofire16DataPreprocessorPA2A22GoogleXSSIPreprocessorVRszrlE10googleXSSIAEvpZ"></a>
<a name="//apple_ref/swift/Variable/googleXSSI" class="dashAnchor"></a>
<a class="token" href="#/s:9Alamofire16DataPreprocessorPA2A22GoogleXSSIPreprocessorVRszrlE10googleXSSIAEvpZ">googleXSSI</a>
</code>
<span class="declaration-note">
Extension method
</span>
</div>
<div class="height-container">
<div class="pointer-container"></div>
<section class="section">
<div class="pointer"></div>
<div class="abstract">
<p>Provides a <code><a href="../Structs/GoogleXSSIPreprocessor.html">GoogleXSSIPreprocessor</a></code> instance.</p>
</div>
<div class="declaration">
<h4>Declaration</h4>
<div class="language">
<p class="aside-title">Swift</p>
<pre class="highlight swift"><code><span class="kd">public</span> <span class="kd">static</span> <span class="k">var</span> <span class="nv">googleXSSI</span><span class="p">:</span> <span class="kt"><a href="../Structs/GoogleXSSIPreprocessor.html">GoogleXSSIPreprocessor</a></span> <span class="p">{</span> <span class="k">get</span> <span class="p">}</span></code></pre>
</div>
</div>
</section>
</div>
</li>
</ul>
</div>
</div>
</section>
</article>
</div>
<section class="footer">
<p>© 2026 <a class="link" href="http://alamofire.org/" target="_blank" rel="external noopener">Alamofire Software Foundation</a>. All rights reserved. (Last updated: 2026-01-31)</p>
<p>Generated by <a class="link" href="https://github.com/realm/jazzy" target="_blank" rel="external noopener">jazzy ♪♫ v0.15.4</a>, a <a class="link" href="https://realm.io" target="_blank" rel="external noopener">Realm</a> project.</p>
</section>
</body>
</html> | html | github | https://github.com/Alamofire/Alamofire | docs/Protocols/DataPreprocessor.html |
'''
Given a string that contains only digits 0-9 and a target value, return all possibilities to add binary operators (not unary) +, -, or * between the digits so they evaluate to the target value.
Examples:
"123", 6 -> ["1+2+3", "1*2*3"]
"232", 8 -> ["2*3+2", "2+3*2"]
"105", 5 -> ["1*0+5","10-5"]
"00", 0 -> ["0+0", "0-0", "0*0"]
"3456237490", 9191 -> []
'''
def getOp(ops, num):
ops2 = map(tuple, (ops,)) * num
res = [[]]
for op in ops2:
res = [x+[y] for x in res for y in op]
for op in res:
yield tuple(op)
class OpIterator():
'''
iterate all operator combinations
'''
def __init__(self, ops, num):
self.num = num
self.ops = []
self.idx = 0
ops2 = map(tuple, (ops,)) * self.num
res = [[]]
for op in ops2:
res = [x+[y] for x in res for y in op]
self.ops = res
def __iter__(self):
self.idx = 0
return self
def next(self):
if self.idx == len(self.ops):
raise StopIteration
res = tuple(self.ops[self.idx])
self.idx = self.idx + 1
return res
class Solution(object):
def __init__(self):
self.exprs = []
self.idx = 0
def __iter__(self):
self.idx = 0
return self
def next(self):
if self.idx == len(self.expr):
raise StopIteration
res = self.exprs[self.idx]
self.idx = self.idx + 1
return res
def addOperators(self, num, target):
"""
:type num: str
:type target: int
:rtype: List[str]
"""
assert (num)
if len(num) == 1:
return None if eval(num) != target else num
for ops in OpIterator('+-*', len(num)-1):
expr = num[0]
for i in xrange(len(num)-1):
expr = expr + ops[i] + num[i+1]
self.exprs.append(expr)
res = []
for expr in self.exprs:
if eval(expr) == target:
res.append(expr)
return res
def product(*args, **kwds):
# product('ABCD', 'xy') --> Ax Ay Bx By Cx Cy Dx Dy
# product(range(2), repeat=3) --> 000 001 010 011 100 101 110 111
pools = map(tuple, args) * kwds.get('repeat', 1)
result = [[]]
for pool in pools:
result = [x+[y] for x in result for y in pool]
for prod in result:
yield tuple(prod)
'''
for s in OpIterator('+-*', 2):
print s
for s in product('+-*', repeat=2):
print s
for s in getOp('+-*', 2):
print s
'''
if __name__ == "__main__":
s = Solution()
res = s.addOperators('123', 6)
assert (res == ['1+2+3', '1*2*3'])
s = Solution()
res = s.addOperators('232', 8)
assert (set(res) == set(['2*3+2', '2+3*2']))
s = Solution()
res = s.addOperators('105', 5)
assert (set(res) == set(['1*0+5' ]))
s = Solution()
res = s.addOperators('00', 0)
assert (set(res) == set(["0+0", "0-0", "0*0"])) | unknown | codeparrot/codeparrot-clean | ||
import numpy.testing as npt
import os
from pymc3.tests import backend_fixtures as bf
from pymc3.backends import ndarray, sqlite
import tempfile
DBNAME = os.path.join(tempfile.gettempdir(), 'test.db')
class TestSQlite0dSampling(bf.SamplingTestCase):
backend = sqlite.SQLite
name = DBNAME
shape = ()
class TestSQlite1dSampling(bf.SamplingTestCase):
backend = sqlite.SQLite
name = DBNAME
shape = 2
class TestSQlite2dSampling(bf.SamplingTestCase):
backend = sqlite.SQLite
name = DBNAME
shape = (2, 3)
class TestSQLite0dSelection(bf.SelectionTestCase):
backend = sqlite.SQLite
name = DBNAME
shape = ()
class TestSQLite1dSelection(bf.SelectionTestCase):
backend = sqlite.SQLite
name = DBNAME
shape = 2
class TestSQLite2dSelection(bf.SelectionTestCase):
backend = sqlite.SQLite
name = DBNAME
shape = (2, 3)
class TestSQLiteDumpLoad(bf.DumpLoadTestCase):
backend = sqlite.SQLite
load_func = staticmethod(sqlite.load)
name = DBNAME
shape = (2, 3)
class TestNDArraySqliteEquality(bf.BackendEqualityTestCase):
backend0 = ndarray.NDArray
name0 = None
backend1 = sqlite.SQLite
name1 = DBNAME
shape = (2, 3) | unknown | codeparrot/codeparrot-clean | ||
{
"kind": "Dashboard",
"apiVersion": "dashboard.grafana.app/v1beta1",
"metadata": {
"name": "v0alpha1.gauge-multi-series.v42"
},
"spec": {
"annotations": {
"list": [
{
"builtIn": 1,
"datasource": {
"uid": "-- Grafana --"
},
"enable": true,
"hide": true,
"iconColor": "rgba(0, 211, 255, 1)",
"name": "Annotations \u0026 Alerts",
"type": "dashboard"
}
]
},
"editable": true,
"fiscalYearStartMonth": 0,
"graphTooltip": 0,
"links": [],
"panels": [
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"gridPos": {
"h": 8,
"w": 20,
"x": 0,
"y": 0
},
"id": 6,
"options": {
"fieldOptions": {
"calcs": [
"mean"
],
"defaults": {
"decimals": 0,
"max": 100,
"min": 0,
"unit": "none"
},
"mappings": [],
"override": {},
"thresholds": [
{
"color": "#7EB26D",
"index": 0
},
{
"color": "#EAB839",
"index": 1,
"value": 50
},
{
"color": "#6ED0E0",
"index": 2,
"value": 75
},
{
"color": "#EF843C",
"index": 3,
"value": 87.5
},
{
"color": "#E24D42",
"index": 4,
"value": 93.75
},
{
"color": "#1F78C1",
"index": 5,
"value": 96.875
}
],
"values": false
},
"orientation": "auto",
"showThresholdLabels": false,
"showThresholdMarkers": true
},
"pluginVersion": "6.3.0-pre",
"targets": [
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "A",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "B",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "C",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "D",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "E",
"scenarioId": "random_walk"
}
],
"title": "Horizontal with range variable",
"type": "gauge"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"gridPos": {
"h": 28,
"w": 4,
"x": 20,
"y": 0
},
"id": 4,
"options": {
"fieldOptions": {
"calcs": [
"max"
],
"defaults": {
"decimals": 0,
"max": "200",
"min": 0,
"unit": "none"
},
"mappings": [],
"override": {},
"thresholds": [
{
"color": "#7EB26D",
"index": 0
},
{
"color": "#EAB839",
"index": 1,
"value": 50
},
{
"color": "#6ED0E0",
"index": 2,
"value": 75
}
],
"values": false
},
"orientation": "auto",
"showThresholdLabels": false,
"showThresholdMarkers": true
},
"pluginVersion": "6.3.0-pre",
"targets": [
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "A",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "B",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "C",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "D",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "E",
"scenarioId": "random_walk"
}
],
"title": "Vertical",
"type": "gauge"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"gridPos": {
"h": 20,
"w": 20,
"x": 0,
"y": 8
},
"id": 2,
"options": {
"fieldOptions": {
"calcs": [
"mean"
],
"defaults": {
"decimals": 0,
"max": 100,
"min": 0,
"unit": "none"
},
"mappings": [],
"override": {},
"thresholds": [
{
"color": "#7EB26D",
"index": 0
},
{
"color": "#EAB839",
"index": 1,
"value": 50
}
],
"values": false
},
"orientation": "auto",
"showThresholdLabels": false,
"showThresholdMarkers": true
},
"pluginVersion": "6.3.0-pre",
"targets": [
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "A",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "B",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "C",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "D",
"scenarioId": "random_walk"
},
{
"datasource": {
"type": "grafana-testdata-datasource"
},
"refId": "E",
"scenarioId": "random_walk"
}
],
"title": "Repeat horizontal",
"type": "gauge"
}
],
"refresh": "",
"schemaVersion": 42,
"tags": [
"panel-tests",
"gdev",
"gauge"
],
"templating": {
"list": []
},
"time": {
"from": "now-6h",
"to": "now"
},
"timepicker": {
"refresh_intervals": [
"5s",
"10s",
"30s",
"1m",
"5m",
"15m",
"30m",
"1h",
"2h",
"1d"
]
},
"timezone": "",
"title": "Panel Tests - Gauge Multi Series",
"uid": "szkuR1umk",
"weekStart": ""
},
"status": {
"conversion": {
"failed": false,
"storedVersion": "v0alpha1"
}
}
} | json | github | https://github.com/grafana/grafana | apps/dashboard/pkg/migration/conversion/testdata/output/migrated_dev_dashboards/panel-gauge/v0alpha1.gauge-multi-series.v42.v1beta1.json |
<?php
namespace Illuminate\Testing;
use Closure;
use Illuminate\Database\Eloquent\Collection as EloquentCollection;
use Illuminate\Database\Eloquent\Model;
use Illuminate\Support\Arr;
use Illuminate\Support\Traits\Macroable;
use Illuminate\Testing\Assert as PHPUnit;
use Illuminate\Testing\Constraints\SeeInOrder;
use Illuminate\View\View;
use Stringable;
class TestView implements Stringable
{
use Macroable;
/**
* The original view.
*
* @var \Illuminate\View\View
*/
protected $view;
/**
* The rendered view contents.
*
* @var string
*/
protected $rendered;
/**
* Create a new test view instance.
*
* @param \Illuminate\View\View $view
*/
public function __construct(View $view)
{
$this->view = $view;
$this->rendered = $view->render();
}
/**
* Assert that the response view has a given piece of bound data.
*
* @param string|array $key
* @param mixed $value
* @return $this
*/
public function assertViewHas($key, $value = null)
{
if (is_array($key)) {
return $this->assertViewHasAll($key);
}
if (is_null($value)) {
PHPUnit::assertTrue(Arr::has($this->view->gatherData(), $key));
} elseif ($value instanceof Closure) {
PHPUnit::assertTrue($value(Arr::get($this->view->gatherData(), $key)));
} elseif ($value instanceof Model) {
PHPUnit::assertTrue($value->is(Arr::get($this->view->gatherData(), $key)));
} elseif ($value instanceof EloquentCollection) {
$actual = Arr::get($this->view->gatherData(), $key);
PHPUnit::assertInstanceOf(EloquentCollection::class, $actual);
PHPUnit::assertSameSize($value, $actual);
$value->each(fn ($item, $index) => PHPUnit::assertTrue($actual->get($index)->is($item)));
} else {
PHPUnit::assertEquals($value, Arr::get($this->view->gatherData(), $key));
}
return $this;
}
/**
* Assert that the response view has a given list of bound data.
*
* @param array $bindings
* @return $this
*/
public function assertViewHasAll(array $bindings)
{
foreach ($bindings as $key => $value) {
if (is_int($key)) {
$this->assertViewHas($value);
} else {
$this->assertViewHas($key, $value);
}
}
return $this;
}
/**
* Assert that the response view is missing a piece of bound data.
*
* @param string $key
* @return $this
*/
public function assertViewMissing($key)
{
PHPUnit::assertFalse(Arr::has($this->view->gatherData(), $key));
return $this;
}
/**
* Assert that the view's rendered content is empty.
*
* @return $this
*/
public function assertViewEmpty()
{
PHPUnit::assertEmpty($this->rendered);
return $this;
}
/**
* Assert that the given string is contained within the view.
*
* @param string $value
* @param bool $escape
* @return $this
*/
public function assertSee($value, $escape = true)
{
$value = $escape ? e($value) : $value;
PHPUnit::assertStringContainsString((string) $value, $this->rendered);
return $this;
}
/**
* Assert that the given strings are contained in order within the view.
*
* @param array $values
* @param bool $escape
* @return $this
*/
public function assertSeeInOrder(array $values, $escape = true)
{
$values = $escape ? array_map(e(...), $values) : $values;
PHPUnit::assertThat($values, new SeeInOrder($this->rendered));
return $this;
}
/**
* Assert that the given string is contained within the view text.
*
* @param string $value
* @param bool $escape
* @return $this
*/
public function assertSeeText($value, $escape = true)
{
$value = $escape ? e($value) : $value;
PHPUnit::assertStringContainsString((string) $value, strip_tags($this->rendered));
return $this;
}
/**
* Assert that the given strings are contained in order within the view text.
*
* @param array $values
* @param bool $escape
* @return $this
*/
public function assertSeeTextInOrder(array $values, $escape = true)
{
$values = $escape ? array_map(e(...), $values) : $values;
PHPUnit::assertThat($values, new SeeInOrder(strip_tags($this->rendered)));
return $this;
}
/**
* Assert that the given string is not contained within the view.
*
* @param string $value
* @param bool $escape
* @return $this
*/
public function assertDontSee($value, $escape = true)
{
$value = $escape ? e($value) : $value;
PHPUnit::assertStringNotContainsString((string) $value, $this->rendered);
return $this;
}
/**
* Assert that the given string is not contained within the view text.
*
* @param string $value
* @param bool $escape
* @return $this
*/
public function assertDontSeeText($value, $escape = true)
{
$value = $escape ? e($value) : $value;
PHPUnit::assertStringNotContainsString((string) $value, strip_tags($this->rendered));
return $this;
}
/**
* Get the string contents of the rendered view.
*
* @return string
*/
public function __toString()
{
return $this->rendered;
}
} | php | github | https://github.com/laravel/framework | src/Illuminate/Testing/TestView.php |
#ifndef DATE_TIME_DATE_NAMES_PUT_HPP___
#define DATE_TIME_DATE_NAMES_PUT_HPP___
/* Copyright (c) 2002-2005 CrystalClear Software, Inc.
* Use, modification and distribution is subject to the
* Boost Software License, Version 1.0. (See accompanying
* file LICENSE_1_0.txt or http://www.boost.org/LICENSE_1_0.txt)
* Author: Jeff Garland, Bart Garst
* $Date$
*/
#include <boost/date_time/locale_config.hpp> // set BOOST_DATE_TIME_NO_LOCALE
#ifndef BOOST_DATE_TIME_NO_LOCALE
#include <boost/date_time/compiler_config.hpp>
#include <boost/date_time/special_defs.hpp>
#include <boost/date_time/date_defs.hpp>
#include <boost/date_time/parse_format_base.hpp>
#include <boost/lexical_cast.hpp>
#include <locale>
namespace boost {
namespace date_time {
//! Output facet base class for gregorian dates.
/*! This class is a base class for date facets used to localize the
* names of months and the names of days in the week.
*
* Requirements of Config
* - define an enumeration month_enum that enumerates the months.
* The enumeration should be '1' based eg: Jan==1
* - define as_short_string and as_long_string
*
* (see langer & kreft p334).
*
*/
template<class Config,
class charT = char,
class OutputIterator = std::ostreambuf_iterator<charT> >
class BOOST_SYMBOL_VISIBLE date_names_put : public std::locale::facet
{
public:
date_names_put() {}
typedef OutputIterator iter_type;
typedef typename Config::month_type month_type;
typedef typename Config::month_enum month_enum;
typedef typename Config::weekday_enum weekday_enum;
typedef typename Config::special_value_enum special_value_enum;
//typedef typename Config::format_type format_type;
typedef std::basic_string<charT> string_type;
typedef charT char_type;
static const char_type default_special_value_names[3][17];
static const char_type separator[2];
static std::locale::id id;
#if defined (__SUNPRO_CC) && defined (_RWSTD_VER)
std::locale::id& __get_id (void) const { return id; }
#endif
void put_special_value(iter_type& oitr, special_value_enum sv) const
{
do_put_special_value(oitr, sv);
}
void put_month_short(iter_type& oitr, month_enum moy) const
{
do_put_month_short(oitr, moy);
}
void put_month_long(iter_type& oitr, month_enum moy) const
{
do_put_month_long(oitr, moy);
}
void put_weekday_short(iter_type& oitr, weekday_enum wd) const
{
do_put_weekday_short(oitr, wd);
}
void put_weekday_long(iter_type& oitr, weekday_enum wd) const
{
do_put_weekday_long(oitr, wd);
}
bool has_date_sep_chars() const
{
return do_has_date_sep_chars();
}
void year_sep_char(iter_type& oitr) const
{
do_year_sep_char(oitr);
}
//! char between year-month
void month_sep_char(iter_type& oitr) const
{
do_month_sep_char(oitr);
}
//! Char to separate month-day
void day_sep_char(iter_type& oitr) const
{
do_day_sep_char(oitr);
}
//! Determines the order to put the date elements
ymd_order_spec date_order() const
{
return do_date_order();
}
//! Determines if month is displayed as integer, short or long string
month_format_spec month_format() const
{
return do_month_format();
}
protected:
//! Default facet implementation uses month_type defaults
virtual void do_put_month_short(iter_type& oitr, month_enum moy) const
{
month_type gm(moy);
charT c = '\0';
put_string(oitr, gm.as_short_string(c));
}
//! Default facet implementation uses month_type defaults
virtual void do_put_month_long(iter_type& oitr,
month_enum moy) const
{
month_type gm(moy);
charT c = '\0';
put_string(oitr, gm.as_long_string(c));
}
//! Default facet implementation for special value types
virtual void do_put_special_value(iter_type& oitr, special_value_enum sv) const
{
if(sv <= 2) { // only output not_a_date_time, neg_infin, or pos_infin
string_type s(default_special_value_names[sv]);
put_string(oitr, s);
}
}
virtual void do_put_weekday_short(iter_type&, weekday_enum) const
{
}
virtual void do_put_weekday_long(iter_type&, weekday_enum) const
{
}
virtual bool do_has_date_sep_chars() const
{
return true;
}
virtual void do_year_sep_char(iter_type& oitr) const
{
string_type s(separator);
put_string(oitr, s);
}
//! char between year-month
virtual void do_month_sep_char(iter_type& oitr) const
{
string_type s(separator);
put_string(oitr, s);
}
//! Char to separate month-day
virtual void do_day_sep_char(iter_type& oitr) const
{
string_type s(separator); //put in '-'
put_string(oitr, s);
}
//! Default for date order
virtual ymd_order_spec do_date_order() const
{
return ymd_order_iso;
}
//! Default month format
virtual month_format_spec do_month_format() const
{
return month_as_short_string;
}
void put_string(iter_type& oi, const charT* const s) const
{
string_type s1(boost::lexical_cast<string_type>(s));
typename string_type::iterator si,end;
for (si=s1.begin(), end=s1.end(); si!=end; si++, oi++) {
*oi = *si;
}
}
void put_string(iter_type& oi, const string_type& s1) const
{
typename string_type::const_iterator si,end;
for (si=s1.begin(), end=s1.end(); si!=end; si++, oi++) {
*oi = *si;
}
}
};
template<class Config, class charT, class OutputIterator>
const typename date_names_put<Config, charT, OutputIterator>::char_type
date_names_put<Config, charT, OutputIterator>::default_special_value_names[3][17] = {
{'n','o','t','-','a','-','d','a','t','e','-','t','i','m','e'},
{'-','i','n','f','i','n','i','t','y'},
{'+','i','n','f','i','n','i','t','y'} };
template<class Config, class charT, class OutputIterator>
const typename date_names_put<Config, charT, OutputIterator>::char_type
date_names_put<Config, charT, OutputIterator>::separator[2] =
{'-', '\0'} ;
//! Generate storage location for a std::locale::id
template<class Config, class charT, class OutputIterator>
std::locale::id date_names_put<Config, charT, OutputIterator>::id;
//! A date name output facet that takes an array of char* to define strings
template<class Config,
class charT = char,
class OutputIterator = std::ostreambuf_iterator<charT> >
class BOOST_SYMBOL_VISIBLE all_date_names_put : public date_names_put<Config, charT, OutputIterator>
{
public:
all_date_names_put(const charT* const month_short_names[],
const charT* const month_long_names[],
const charT* const special_value_names[],
const charT* const weekday_short_names[],
const charT* const weekday_long_names[],
charT separator_char = '-',
ymd_order_spec order_spec = ymd_order_iso,
month_format_spec month_format = month_as_short_string) :
month_short_names_(month_short_names),
month_long_names_(month_long_names),
special_value_names_(special_value_names),
weekday_short_names_(weekday_short_names),
weekday_long_names_(weekday_long_names),
order_spec_(order_spec),
month_format_spec_(month_format)
{
separator_char_[0] = separator_char;
separator_char_[1] = '\0';
}
typedef OutputIterator iter_type;
typedef typename Config::month_enum month_enum;
typedef typename Config::weekday_enum weekday_enum;
typedef typename Config::special_value_enum special_value_enum;
const charT* const* get_short_month_names() const
{
return month_short_names_;
}
const charT* const* get_long_month_names() const
{
return month_long_names_;
}
const charT* const* get_special_value_names() const
{
return special_value_names_;
}
const charT* const* get_short_weekday_names()const
{
return weekday_short_names_;
}
const charT* const* get_long_weekday_names()const
{
return weekday_long_names_;
}
protected:
//! Generic facet that takes array of chars
virtual void do_put_month_short(iter_type& oitr, month_enum moy) const
{
this->put_string(oitr, month_short_names_[moy-1]);
}
//! Long month names
virtual void do_put_month_long(iter_type& oitr, month_enum moy) const
{
this->put_string(oitr, month_long_names_[moy-1]);
}
//! Special values names
virtual void do_put_special_value(iter_type& oitr, special_value_enum sv) const
{
this->put_string(oitr, special_value_names_[sv]);
}
virtual void do_put_weekday_short(iter_type& oitr, weekday_enum wd) const
{
this->put_string(oitr, weekday_short_names_[wd]);
}
virtual void do_put_weekday_long(iter_type& oitr, weekday_enum wd) const
{
this->put_string(oitr, weekday_long_names_[wd]);
}
//! char between year-month
virtual void do_month_sep_char(iter_type& oitr) const
{
this->put_string(oitr, separator_char_);
}
//! Char to separate month-day
virtual void do_day_sep_char(iter_type& oitr) const
{
this->put_string(oitr, separator_char_);
}
//! Set the date ordering
virtual ymd_order_spec do_date_order() const
{
return order_spec_;
}
//! Set the date ordering
virtual month_format_spec do_month_format() const
{
return month_format_spec_;
}
private:
const charT* const* month_short_names_;
const charT* const* month_long_names_;
const charT* const* special_value_names_;
const charT* const* weekday_short_names_;
const charT* const* weekday_long_names_;
charT separator_char_[2];
ymd_order_spec order_spec_;
month_format_spec month_format_spec_;
};
} } //namespace boost::date_time
#endif //BOOST_NO_STD_LOCALE
#endif | unknown | github | https://github.com/mysql/mysql-server | extra/boost/boost_1_87_0/boost/date_time/date_names_put.hpp |
# -*- coding: utf-8 -*-
##
## This file is part of Invenio.
## Copyright (C) 2011 CERN.
##
## Invenio is free software; you can redistribute it and/or
## modify it under the terms of the GNU General Public License as
## published by the Free Software Foundation; either version 2 of the
## License, or (at your option) any later version.
##
## Invenio is distributed in the hope that it will be useful, but
## WITHOUT ANY WARRANTY; without even the implied warranty of
## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
## General Public License for more details.
##
## You should have received a copy of the GNU General Public License
## along with Invenio; if not, write to the Free Software Foundation, Inc.,
## 59 Temple Place, Suite 330, Boston, MA 02111-1307, USA.
"""
Bibauthorid Daemon
This module IS NOT standalone safe - it should never be run this way.
"""
import sys
from invenio import bibauthorid_config as bconfig
from invenio import bibtask
from invenio.bibauthorid_backinterface import get_modified_papers_since
from invenio.bibauthorid_backinterface import get_user_logs
from invenio.bibauthorid_backinterface import insert_user_log
from invenio.bibauthorid_backinterface import get_db_time
from invenio.bibauthorid_backinterface import get_authors_of_claimed_paper
from invenio.bibauthorid_backinterface import get_claimed_papers_from_papers
from invenio.bibauthorid_backinterface import get_all_valid_papers
#python 2.4 compatibility
from invenio.bibauthorid_general_utils import bai_any as any
def bibauthorid_daemon():
"""Constructs the Bibauthorid bibtask."""
bibtask.task_init(authorization_action='runbibclassify',
authorization_msg="Bibauthorid Task Submission",
description="""
Purpose:
Disambiguate Authors and find their identities.
Examples:
- Process all records that hold an author with last name 'Ellis':
$ bibauthorid -u admin --update-personid --all-records
- Disambiguate all records on a fresh installation
$ bibauthorid -u admin --disambiguate --from-scratch
""",
help_specific_usage="""
bibauthorid [COMMAND] [OPTIONS]
COMMAND
You can choose only one from the following:
--update-personid Updates personid adding not yet assigned papers
to the system, in a fast, best effort basis.
Cleans the table from stale records.
--disambiguate Disambiguates all signatures in the database
using the tortoise/wedge algorithm. This usually
takes a LOT of time so the results are stored in
a special table. Use --merge to use the results.
--merge Updates the personid tables with the results from
the --disambiguate algorithm.
--update-search-index Updates the search engine index.
OPTIONS
Options for update personid
(default) Will update only the modified records since last
run.
-i, --record-ids Force the procedure to work only on the specified
records. This option is exclusive with --all-records.
--all-records Force the procedure to work on all records. This
option is exclusive with --record-ids.
Options for disambiguate
(default) Performs full disambiguation of all records in the
current personid tables with respect to the user
decisions.
--from-scratch Ignores the current information in the personid
tables and disambiguates everything from scratch.
There are no options for the merger.
""",
version="Invenio Bibauthorid v%s" % bconfig.VERSION,
specific_params=("i:",
[
"record-ids=",
"disambiguate",
"merge",
"update-search-index",
"all-records",
"update-personid",
"from-scratch"
]),
task_submit_elaborate_specific_parameter_fnc=_task_submit_elaborate_specific_parameter,
task_submit_check_options_fnc=_task_submit_check_options,
task_run_fnc=_task_run_core)
def _task_submit_elaborate_specific_parameter(key, value, opts, args):
"""
Given the string key it checks it's meaning, eventually using the
value. Usually, it fills some key in the options dict.
It must return True if it has elaborated the key, False, if it doesn't
know that key.
"""
if key in ("--update-personid",):
bibtask.task_set_option("update_personid", True)
elif key in ("--record-ids", '-i'):
if value.count("="):
value = value[1:]
value = value.split(",")
bibtask.task_set_option("record_ids", value)
elif key in ("--all-records",):
bibtask.task_set_option("all_records", True)
elif key in ("--disambiguate",):
bibtask.task_set_option("disambiguate", True)
elif key in ("--merge",):
bibtask.task_set_option("merge", True)
elif key in ("--update-search-index",):
bibtask.task_set_option("update_search_index", True)
elif key in ("--from-scratch",):
bibtask.task_set_option("from_scratch", True)
else:
return False
return True
def _task_run_core():
"""
Runs the requested task in the bibsched environment.
"""
if bibtask.task_get_option('update_personid'):
record_ids = bibtask.task_get_option('record_ids')
if record_ids:
record_ids = map(int, record_ids)
all_records = bibtask.task_get_option('all_records')
bibtask.task_update_progress('Updating personid...')
run_rabbit(record_ids, all_records)
bibtask.task_update_progress('PersonID update finished!')
if bibtask.task_get_option("disambiguate"):
bibtask.task_update_progress('Performing full disambiguation...')
run_tortoise(bool(bibtask.task_get_option("from_scratch")))
bibtask.task_update_progress('Full disambiguation finished!')
if bibtask.task_get_option("merge"):
bibtask.task_update_progress('Merging results...')
run_merge()
bibtask.task_update_progress('Merging finished!')
if bibtask.task_get_option("update_search_index"):
bibtask.task_update_progress('Indexing...')
update_index()
bibtask.task_update_progress('Indexing finished!')
return 1
def _task_submit_check_options():
"""
Required by bibtask. Checks the options.
"""
update_personid = bibtask.task_get_option("update_personid")
disambiguate = bibtask.task_get_option("disambiguate")
merge = bibtask.task_get_option("merge")
update_search_index = bibtask.task_get_option("update_search_index")
record_ids = bibtask.task_get_option("record_ids")
all_records = bibtask.task_get_option("all_records")
from_scratch = bibtask.task_get_option("from_scratch")
commands =( bool(update_personid) + bool(disambiguate) +
bool(merge) + bool(update_search_index) )
if commands == 0:
bibtask.write_message("ERROR: At least one command should be specified!"
, stream=sys.stdout, verbose=0)
return False
if commands > 1:
bibtask.write_message("ERROR: The options --update-personid, --disambiguate "
"and --merge are mutually exclusive."
, stream=sys.stdout, verbose=0)
return False
assert commands == 1
if update_personid:
if any((from_scratch,)):
bibtask.write_message("ERROR: The only options which can be specified "
"with --update-personid are --record-ids and "
"--all-records"
, stream=sys.stdout, verbose=0)
return False
options = bool(record_ids) + bool(all_records)
if options > 1:
bibtask.write_message("ERROR: conflicting options: --record-ids and "
"--all-records are mutually exclusive."
, stream=sys.stdout, verbose=0)
return False
if record_ids:
for iden in record_ids:
if not iden.isdigit():
bibtask.write_message("ERROR: Record_ids expects numbers. "
"Provided: %s." % iden)
return False
if disambiguate:
if any((record_ids, all_records)):
bibtask.write_message("ERROR: The only option which can be specified "
"with --disambiguate is from-scratch"
, stream=sys.stdout, verbose=0)
return False
if merge:
if any((record_ids, all_records, from_scratch)):
bibtask.write_message("ERROR: There are no options which can be "
"specified along with --merge"
, stream=sys.stdout, verbose=0)
return False
return True
def _get_personids_to_update_extids(papers=None):
'''
It returns the set of personids of which we should recalculate
their external ids.
@param papers: papers
@type papers: set or None
@return: personids
@rtype: set
'''
last_log = get_user_logs(userinfo='daemon', action='PID_UPDATE', only_most_recent=True)
if last_log:
daemon_last_time_run = last_log[0][2]
modified_bibrecs = get_modified_papers_since(daemon_last_time_run)
else:
modified_bibrecs = get_all_valid_papers()
if papers:
modified_bibrecs &= set(papers)
if not modified_bibrecs:
return None
if bconfig.LIMIT_EXTERNAL_IDS_COLLECTION_TO_CLAIMED_PAPERS:
modified_bibrecs = [rec[0] for rec in get_claimed_papers_from_papers(modified_bibrecs)]
personids_to_update_extids = set()
for bibrec in modified_bibrecs:
personids_to_update_extids |= set(get_authors_of_claimed_paper(bibrec))
return personids_to_update_extids
def rabbit_with_log(papers, check_invalid_papers, log_comment, partial=False):
from invenio.bibauthorid_rabbit import rabbit
personids_to_update_extids = _get_personids_to_update_extids(papers)
starting_time = get_db_time()
rabbit(papers, check_invalid_papers, personids_to_update_extids)
if partial:
action = 'PID_UPDATE_PARTIAL'
else:
action = 'PID_UPDATE'
insert_user_log('daemon', '-1', action, 'bibsched', 'status', comment=log_comment, timestamp=starting_time)
def run_rabbit(paperslist, all_records=False):
if not paperslist and all_records:
rabbit_with_log(None, True, 'bibauthorid_daemon, update_personid on all papers')
elif not paperslist:
last_log = get_user_logs(userinfo='daemon', action='PID_UPDATE', only_most_recent=True)
if len(last_log) >= 1:
#select only the most recent papers
recently_modified = get_modified_papers_since(since=last_log[0][2])
if not recently_modified:
bibtask.write_message("update_personID_table_from_paper: "
"All person entities up to date.",
stream=sys.stdout, verbose=0)
else:
bibtask.write_message("update_personID_table_from_paper: Running on: " +
str(recently_modified), stream=sys.stdout, verbose=0)
rabbit_with_log(recently_modified, True, 'bibauthorid_daemon, run_personid_fast_assign_papers on '
+ str([paperslist, all_records, recently_modified]))
else:
rabbit_with_log(None, True, 'bibauthorid_daemon, update_personid on all papers')
else:
rabbit_with_log(paperslist, True, 'bibauthorid_daemon, personid_fast_assign_papers on ' + str(paperslist), partial=True)
def run_tortoise(from_scratch):
from invenio.bibauthorid_tortoise import tortoise, tortoise_from_scratch
if from_scratch:
tortoise_from_scratch()
else:
start_time = get_db_time()
tortoise_db_name = 'tortoise'
last_run = get_user_logs(userinfo=tortoise_db_name, only_most_recent=True)
if last_run:
modified = get_modified_papers_since(last_run[0][2])
else:
modified = []
tortoise(modified)
insert_user_log(tortoise_db_name, '-1', '', '', '', timestamp=start_time)
def run_merge():
from invenio.bibauthorid_merge import merge_dynamic
merge_dynamic()
def update_index():
from bibauthorid_search_engine import create_bibauthorid_indexer
create_bibauthorid_indexer() | unknown | codeparrot/codeparrot-clean | ||
"""
Third_party_auth integration tests using a mock version of the TestShib provider
"""
import unittest
import httpretty
from mock import patch
from third_party_auth.tasks import fetch_saml_metadata
from third_party_auth.tests import testutil
from .base import IntegrationTestMixin
TESTSHIB_ENTITY_ID = 'https://idp.testshib.org/idp/shibboleth'
TESTSHIB_METADATA_URL = 'https://mock.testshib.org/metadata/testshib-providers.xml'
TESTSHIB_SSO_URL = 'https://idp.testshib.org/idp/profile/SAML2/Redirect/SSO'
@unittest.skipUnless(testutil.AUTH_FEATURE_ENABLED, 'third_party_auth not enabled')
class TestShibIntegrationTest(IntegrationTestMixin, testutil.SAMLTestCase):
"""
TestShib provider Integration Test, to test SAML functionality
"""
PROVIDER_ID = "saml-testshib"
PROVIDER_NAME = "TestShib"
PROVIDER_BACKEND = "tpa-saml"
USER_EMAIL = "myself@testshib.org"
USER_NAME = "Me Myself And I"
USER_USERNAME = "myself"
def setUp(self):
super(TestShibIntegrationTest, self).setUp()
self.enable_saml(
private_key=self._get_private_key(),
public_key=self._get_public_key(),
entity_id="https://saml.example.none",
)
# Mock out HTTP requests that may be made to TestShib:
httpretty.enable()
def metadata_callback(_request, _uri, headers):
""" Return a cached copy of TestShib's metadata by reading it from disk """
return (200, headers, self.read_data_file('testshib_metadata.xml'))
httpretty.register_uri(httpretty.GET, TESTSHIB_METADATA_URL, content_type='text/xml', body=metadata_callback)
self.addCleanup(httpretty.disable)
self.addCleanup(httpretty.reset)
# Configure the SAML library to use the same request ID for every request.
# Doing this and freezing the time allows us to play back recorded request/response pairs
uid_patch = patch('onelogin.saml2.utils.OneLogin_Saml2_Utils.generate_unique_id', return_value='TESTID')
uid_patch.start()
self.addCleanup(uid_patch.stop)
self._freeze_time(timestamp=1434326820) # This is the time when the saved request/response was recorded.
def test_login_before_metadata_fetched(self):
self._configure_testshib_provider(fetch_metadata=False)
# The user goes to the login page, and sees a button to login with TestShib:
testshib_login_url = self._check_login_page()
# The user clicks on the TestShib button:
try_login_response = self.client.get(testshib_login_url)
# The user should be redirected to back to the login page:
self.assertEqual(try_login_response.status_code, 302)
self.assertEqual(try_login_response['Location'], self.url_prefix + self.login_page_url)
# When loading the login page, the user will see an error message:
response = self.client.get(self.login_page_url)
self.assertEqual(response.status_code, 200)
self.assertIn('Authentication with TestShib is currently unavailable.', response.content)
def test_login(self):
""" Configure TestShib before running the login test """
self._configure_testshib_provider()
super(TestShibIntegrationTest, self).test_login()
def test_register(self):
""" Configure TestShib before running the register test """
self._configure_testshib_provider()
super(TestShibIntegrationTest, self).test_register()
def _freeze_time(self, timestamp):
""" Mock the current time for SAML, so we can replay canned requests/responses """
now_patch = patch('onelogin.saml2.utils.OneLogin_Saml2_Utils.now', return_value=timestamp)
now_patch.start()
self.addCleanup(now_patch.stop)
def _configure_testshib_provider(self, **kwargs):
""" Enable and configure the TestShib SAML IdP as a third_party_auth provider """
fetch_metadata = kwargs.pop('fetch_metadata', True)
kwargs.setdefault('name', 'TestShib')
kwargs.setdefault('enabled', True)
kwargs.setdefault('idp_slug', 'testshib')
kwargs.setdefault('entity_id', TESTSHIB_ENTITY_ID)
kwargs.setdefault('metadata_source', TESTSHIB_METADATA_URL)
kwargs.setdefault('icon_class', 'fa-university')
kwargs.setdefault('attr_email', 'urn:oid:1.3.6.1.4.1.5923.1.1.1.6') # eduPersonPrincipalName
self.configure_saml_provider(**kwargs)
if fetch_metadata:
self.assertTrue(httpretty.is_enabled())
num_changed, num_failed, num_total = fetch_saml_metadata()
self.assertEqual(num_failed, 0)
self.assertEqual(num_changed, 1)
self.assertEqual(num_total, 1)
def do_provider_login(self, provider_redirect_url):
""" Mocked: the user logs in to TestShib and then gets redirected back """
# The SAML provider (TestShib) will authenticate the user, then get the browser to POST a response:
self.assertTrue(provider_redirect_url.startswith(TESTSHIB_SSO_URL))
return self.client.post(
self.complete_url,
content_type='application/x-www-form-urlencoded',
data=self.read_data_file('testshib_response.txt'),
) | unknown | codeparrot/codeparrot-clean | ||
# Copyright 2014 OpenStack Foundation
# All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
# License for the specific language governing permissions and limitations
# under the License.
from oslotest import base
from glance_store.common import utils
class TestUtils(base.BaseTestCase):
"""Test routines in glance_store.common.utils."""
def test_exception_to_str(self):
class FakeException(Exception):
def __str__(self):
raise UnicodeError()
ret = utils.exception_to_str(Exception('error message'))
self.assertEqual(ret, 'error message')
ret = utils.exception_to_str(Exception('\xa5 error message'))
self.assertEqual(ret, ' error message')
ret = utils.exception_to_str(FakeException('\xa5 error message'))
self.assertEqual(ret, "Caught '%(exception)s' exception." %
{'exception': 'FakeException'}) | unknown | codeparrot/codeparrot-clean | ||
# Licensed to the StackStorm, Inc ('StackStorm') under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import random
import datetime
import bson
import six
from six.moves import http_client
import st2tests.config as tests_config
tests_config.parse_args()
from tests import FunctionalTest
from st2tests.fixtures.packs import executions as fixture
from st2tests.fixtures import history_views
from st2common.util import isotime
from st2common.util import date as date_utils
from st2api.controllers.v1.actionexecutions import ActionExecutionsController
from st2api.controllers.v1.executionviews import FILTERS_WITH_VALID_NULL_VALUES
from st2common.persistence.execution import ActionExecution
from st2common.models.api.execution import ActionExecutionAPI
class TestActionExecutionFilters(FunctionalTest):
@classmethod
def testDownClass(cls):
pass
@classmethod
def setUpClass(cls):
super(TestActionExecutionFilters, cls).setUpClass()
cls.dt_base = date_utils.add_utc_tz(datetime.datetime(2014, 12, 25, 0, 0, 0))
cls.num_records = 100
cls.refs = {}
cls.start_timestamps = []
cls.fake_types = [
{
'trigger': copy.deepcopy(fixture.ARTIFACTS['trigger']),
'trigger_type': copy.deepcopy(fixture.ARTIFACTS['trigger_type']),
'trigger_instance': copy.deepcopy(fixture.ARTIFACTS['trigger_instance']),
'rule': copy.deepcopy(fixture.ARTIFACTS['rule']),
'action': copy.deepcopy(fixture.ARTIFACTS['actions']['chain']),
'runner': copy.deepcopy(fixture.ARTIFACTS['runners']['action-chain']),
'liveaction': copy.deepcopy(fixture.ARTIFACTS['liveactions']['workflow']),
'context': copy.deepcopy(fixture.ARTIFACTS['context']),
'children': []
},
{
'action': copy.deepcopy(fixture.ARTIFACTS['actions']['local']),
'runner': copy.deepcopy(fixture.ARTIFACTS['runners']['run-local']),
'liveaction': copy.deepcopy(fixture.ARTIFACTS['liveactions']['task1'])
}
]
def assign_parent(child):
candidates = [v for k, v in cls.refs.iteritems() if v.action['name'] == 'chain']
if candidates:
parent = random.choice(candidates)
child['parent'] = str(parent.id)
parent.children.append(child['id'])
cls.refs[str(parent.id)] = ActionExecution.add_or_update(parent)
for i in range(cls.num_records):
obj_id = str(bson.ObjectId())
timestamp = cls.dt_base + datetime.timedelta(seconds=i)
fake_type = random.choice(cls.fake_types)
data = copy.deepcopy(fake_type)
data['id'] = obj_id
data['start_timestamp'] = isotime.format(timestamp, offset=False)
data['end_timestamp'] = isotime.format(timestamp, offset=False)
data['status'] = data['liveaction']['status']
data['result'] = data['liveaction']['result']
if fake_type['action']['name'] == 'local' and random.choice([True, False]):
assign_parent(data)
wb_obj = ActionExecutionAPI(**data)
db_obj = ActionExecutionAPI.to_model(wb_obj)
cls.refs[obj_id] = ActionExecution.add_or_update(db_obj)
cls.start_timestamps.append(timestamp)
cls.start_timestamps = sorted(cls.start_timestamps)
def test_get_all(self):
response = self.app.get('/v1/executions')
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), self.num_records)
self.assertEqual(response.headers['X-Total-Count'], str(self.num_records))
ids = [item['id'] for item in response.json]
self.assertListEqual(sorted(ids), sorted(self.refs.keys()))
def test_get_all_exclude_attributes(self):
# No attributes excluded
response = self.app.get('/v1/executions?action=executions.local&limit=1')
self.assertEqual(response.status_int, 200)
self.assertTrue('result' in response.json[0])
# Exclude "result" attribute
path = '/v1/executions?action=executions.local&limit=1&exclude_attributes=result'
response = self.app.get(path)
self.assertEqual(response.status_int, 200)
self.assertFalse('result' in response.json[0])
def test_get_one(self):
obj_id = random.choice(self.refs.keys())
response = self.app.get('/v1/executions/%s' % obj_id)
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, dict)
record = response.json
fake_record = ActionExecutionAPI.from_model(self.refs[obj_id])
self.assertEqual(record['id'], obj_id)
self.assertDictEqual(record['action'], fake_record.action)
self.assertDictEqual(record['runner'], fake_record.runner)
self.assertDictEqual(record['liveaction'], fake_record.liveaction)
def test_get_one_failed(self):
response = self.app.get('/v1/executions/%s' % str(bson.ObjectId()),
expect_errors=True)
self.assertEqual(response.status_int, http_client.NOT_FOUND)
def test_limit(self):
limit = 10
refs = [k for k, v in six.iteritems(self.refs) if v.action['name'] == 'chain']
response = self.app.get('/v1/executions?action=executions.chain&limit=%s' %
limit)
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), limit)
self.assertEqual(response.headers['X-Limit'], str(limit))
self.assertEqual(response.headers['X-Total-Count'], str(len(refs)), response.json)
ids = [item['id'] for item in response.json]
self.assertListEqual(list(set(ids) - set(refs)), [])
def test_query(self):
refs = [k for k, v in six.iteritems(self.refs) if v.action['name'] == 'chain']
response = self.app.get('/v1/executions?action=executions.chain')
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), len(refs))
self.assertEqual(response.headers['X-Total-Count'], str(len(refs)))
ids = [item['id'] for item in response.json]
self.assertListEqual(sorted(ids), sorted(refs))
def test_filters(self):
excludes = ['parent', 'timestamp', 'action', 'liveaction', 'timestamp_gt',
'timestamp_lt', 'status']
for param, field in six.iteritems(ActionExecutionsController.supported_filters):
if param in excludes:
continue
value = self.fake_types[0]
for item in field.split('.'):
value = value[item]
response = self.app.get('/v1/executions?%s=%s' % (param, value))
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertGreater(len(response.json), 0)
self.assertGreater(int(response.headers['X-Total-Count']), 0)
def test_parent(self):
refs = [v for k, v in six.iteritems(self.refs)
if v.action['name'] == 'chain' and v.children]
self.assertTrue(refs)
ref = random.choice(refs)
response = self.app.get('/v1/executions?parent=%s' % str(ref.id))
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), len(ref.children))
self.assertEqual(response.headers['X-Total-Count'], str(len(ref.children)))
ids = [item['id'] for item in response.json]
self.assertListEqual(sorted(ids), sorted(ref.children))
def test_parentless(self):
refs = {k: v for k, v in six.iteritems(self.refs) if not getattr(v, 'parent', None)}
self.assertTrue(refs)
self.assertNotEqual(len(refs), self.num_records)
response = self.app.get('/v1/executions?parent=null')
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), len(refs))
self.assertEqual(response.headers['X-Total-Count'], str(len(refs)))
ids = [item['id'] for item in response.json]
self.assertListEqual(sorted(ids), sorted(refs.keys()))
def test_pagination(self):
retrieved = []
page_size = 10
page_count = self.num_records / page_size
for i in range(page_count):
offset = i * page_size
response = self.app.get('/v1/executions?offset=%s&limit=%s' % (
offset, page_size))
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), page_size)
self.assertEqual(response.headers['X-Limit'], str(page_size))
self.assertEqual(response.headers['X-Total-Count'], str(self.num_records))
ids = [item['id'] for item in response.json]
self.assertListEqual(list(set(ids) - set(self.refs.keys())), [])
self.assertListEqual(sorted(list(set(ids) - set(retrieved))), sorted(ids))
retrieved += ids
self.assertListEqual(sorted(retrieved), sorted(self.refs.keys()))
def test_ui_history_query(self):
# In this test we only care about making sure this exact query works. This query is used
# by the webui for the history page so it is special and breaking this is bad.
limit = 50
history_query = '/v1/executions?limit={}&parent=null&exclude_attributes=' \
'result%2Ctrigger_instance&status=&action=&trigger_type=&rule=&' \
'offset=0'.format(limit)
response = self.app.get(history_query)
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), limit)
self.assertTrue(response.headers['X-Total-Count'] > limit)
def test_datetime_range(self):
dt_range = '2014-12-25T00:00:10Z..2014-12-25T00:00:19Z'
response = self.app.get('/v1/executions?timestamp=%s' % dt_range)
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), 10)
self.assertEqual(response.headers['X-Total-Count'], '10')
dt1 = response.json[0]['start_timestamp']
dt2 = response.json[9]['start_timestamp']
self.assertLess(isotime.parse(dt1), isotime.parse(dt2))
dt_range = '2014-12-25T00:00:19Z..2014-12-25T00:00:10Z'
response = self.app.get('/v1/executions?timestamp=%s' % dt_range)
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
self.assertEqual(len(response.json), 10)
self.assertEqual(response.headers['X-Total-Count'], '10')
dt1 = response.json[0]['start_timestamp']
dt2 = response.json[9]['start_timestamp']
self.assertLess(isotime.parse(dt2), isotime.parse(dt1))
def test_default_sort(self):
response = self.app.get('/v1/executions')
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
dt1 = response.json[0]['start_timestamp']
dt2 = response.json[len(response.json) - 1]['start_timestamp']
self.assertLess(isotime.parse(dt2), isotime.parse(dt1))
def test_ascending_sort(self):
response = self.app.get('/v1/executions?sort_asc=True')
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
dt1 = response.json[0]['start_timestamp']
dt2 = response.json[len(response.json) - 1]['start_timestamp']
self.assertLess(isotime.parse(dt1), isotime.parse(dt2))
def test_descending_sort(self):
response = self.app.get('/v1/executions?sort_desc=True')
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, list)
dt1 = response.json[0]['start_timestamp']
dt2 = response.json[len(response.json) - 1]['start_timestamp']
self.assertLess(isotime.parse(dt2), isotime.parse(dt1))
def test_timestamp_lt_and_gt_filter(self):
def isoformat(timestamp):
return isotime.format(timestamp, offset=False)
index = len(self.start_timestamps) - 1
timestamp = self.start_timestamps[index]
# Last (largest) timestamp, there are no executions with a greater timestamp
timestamp = self.start_timestamps[-1]
response = self.app.get('/v1/executions?timestamp_gt=%s' % (isoformat(timestamp)))
self.assertEqual(len(response.json), 0)
# First (smallest) timestamp, there are no executions with a smaller timestamp
timestamp = self.start_timestamps[0]
response = self.app.get('/v1/executions?timestamp_lt=%s' % (isoformat(timestamp)))
self.assertEqual(len(response.json), 0)
# Second last, there should be one timestamp greater than it
timestamp = self.start_timestamps[-2]
response = self.app.get('/v1/executions?timestamp_gt=%s' % (isoformat(timestamp)))
self.assertEqual(len(response.json), 1)
self.assertTrue(isotime.parse(response.json[0]['start_timestamp']) > timestamp)
# Second one, there should be one timestamp smaller than it
timestamp = self.start_timestamps[1]
response = self.app.get('/v1/executions?timestamp_lt=%s' % (isoformat(timestamp)))
self.assertEqual(len(response.json), 1)
self.assertTrue(isotime.parse(response.json[0]['start_timestamp']) < timestamp)
# Half of the timestamps should be smaller
index = (len(self.start_timestamps) - 1) // 2
timestamp = self.start_timestamps[index]
response = self.app.get('/v1/executions?timestamp_lt=%s' % (isoformat(timestamp)))
self.assertEqual(len(response.json), index)
self.assertTrue(isotime.parse(response.json[0]['start_timestamp']) < timestamp)
# Half of the timestamps should be greater
index = (len(self.start_timestamps) - 1) // 2
timestamp = self.start_timestamps[-index]
response = self.app.get('/v1/executions?timestamp_gt=%s' % (isoformat(timestamp)))
self.assertEqual(len(response.json), (index - 1))
self.assertTrue(isotime.parse(response.json[0]['start_timestamp']) > timestamp)
# Both, lt and gt filters, should return exactly two results
timestamp_gt = self.start_timestamps[10]
timestamp_lt = self.start_timestamps[13]
response = self.app.get('/v1/executions?timestamp_gt=%s×tamp_lt=%s' %
(isoformat(timestamp_gt), isoformat(timestamp_lt)))
self.assertEqual(len(response.json), 2)
self.assertTrue(isotime.parse(response.json[0]['start_timestamp']) > timestamp_gt)
self.assertTrue(isotime.parse(response.json[1]['start_timestamp']) > timestamp_gt)
self.assertTrue(isotime.parse(response.json[0]['start_timestamp']) < timestamp_lt)
self.assertTrue(isotime.parse(response.json[1]['start_timestamp']) < timestamp_lt)
def test_filters_view(self):
response = self.app.get('/v1/executions/views/filters')
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, dict)
self.assertEqual(len(response.json), len(history_views.ARTIFACTS['filters']['default']))
for key, value in six.iteritems(history_views.ARTIFACTS['filters']['default']):
filter_values = response.json[key]
# Verify empty (None / null) filters are excluded
if key not in FILTERS_WITH_VALID_NULL_VALUES:
self.assertTrue(None not in filter_values)
if None in value or None in filter_values:
filter_values = [item for item in filter_values if item is not None]
value = [item for item in value if item is not None]
self.assertEqual(set(filter_values), set(value))
def test_filters_view_specific_types(self):
response = self.app.get('/v1/executions/views/filters?types=action,user,nonexistent')
self.assertEqual(response.status_int, 200)
self.assertIsInstance(response.json, dict)
self.assertEqual(len(response.json), len(history_views.ARTIFACTS['filters']['specific']))
for key, value in six.iteritems(history_views.ARTIFACTS['filters']['specific']):
self.assertEqual(set(response.json[key]), set(value)) | unknown | codeparrot/codeparrot-clean | ||
// Copyright (c) HashiCorp, Inc.
// SPDX-License-Identifier: BUSL-1.1
package command
import (
"strings"
"github.com/hashicorp/cli"
)
// MetadataCommand is a Command implementation that just shows help for
// the subcommands nested below it.
type MetadataCommand struct {
Meta
}
func (c *MetadataCommand) Run(args []string) int {
return cli.RunResultHelp
}
func (c *MetadataCommand) Help() string {
helpText := `
Usage: terraform [global options] metadata <subcommand> [options] [args]
This command has subcommands for metadata related purposes.
`
return strings.TrimSpace(helpText)
}
func (c *MetadataCommand) Synopsis() string {
return "Metadata related commands"
} | go | github | https://github.com/hashicorp/terraform | internal/command/metadata_command.go |
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functional tests for the ops to generate and execute vocab remapping."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import numpy as np
from tensorflow.python.framework import constant_op
from tensorflow.python.framework import dtypes
from tensorflow.python.framework import errors
from tensorflow.python.framework import ops
from tensorflow.python.framework import test_util
from tensorflow.python.ops import gen_checkpoint_ops
from tensorflow.python.ops import partitioned_variables
from tensorflow.python.ops import variable_scope
from tensorflow.python.ops import variables
from tensorflow.python.platform import flags
from tensorflow.python.platform import test
from tensorflow.python.training import saver
FLAGS = flags.FLAGS
class GenerateVocabRemappingTest(test.TestCase):
"""Tests for the generate_vocab_remapping() method."""
def setUp(self):
self.new_vocab_file = os.path.join(self.get_temp_dir(),
'keyword_shifted.txt')
with open(self.new_vocab_file, 'w') as f:
f.write('\n'.join(['MISSING', 'knitting', 'eminem']) + '\n')
self.old_vocab_file = os.path.join(self.get_temp_dir(),
'keyword.txt')
with open(self.old_vocab_file, 'w') as f:
f.write('\n'.join(['knitting', 'eminem', 'MISSING']) + '\n')
@test_util.run_deprecated_v1
def test_generate_remapping_with_no_vocab_changes(self):
"""Tests where vocab does not change at all."""
remapping, num_present = gen_checkpoint_ops.generate_vocab_remapping(
new_vocab_file=self.old_vocab_file,
old_vocab_file=self.old_vocab_file,
num_new_vocab=3,
new_vocab_offset=0)
expected_remapping = range(0, 3)
expected_num_present = 3
with self.cached_session():
self.assertAllEqual(expected_remapping, self.evaluate(remapping))
self.assertAllEqual(expected_num_present, self.evaluate(num_present))
def test_generate_remapping_with_shifted_vocab(self):
"""Tests where vocab is the same, but shifted / ordered differently."""
remapping, num_present = gen_checkpoint_ops.generate_vocab_remapping(
new_vocab_file=self.new_vocab_file,
old_vocab_file=self.old_vocab_file,
num_new_vocab=3,
new_vocab_offset=0)
expected_remapping = [2, 0, 1]
expected_num_present = 3
with self.cached_session():
self.assertAllEqual(expected_remapping, self.evaluate(remapping))
self.assertAllEqual(expected_num_present, self.evaluate(num_present))
def test_generate_remapping_with_offset(self):
"""Tests offset and num_new_vocab logic."""
remapping, num_present = gen_checkpoint_ops.generate_vocab_remapping(
new_vocab_file=self.new_vocab_file,
old_vocab_file=self.old_vocab_file,
num_new_vocab=1,
new_vocab_offset=1)
expected_remapping = [0]
expected_num_present = 1
with self.cached_session():
self.assertAllEqual(expected_remapping, self.evaluate(remapping))
self.assertAllEqual(expected_num_present, self.evaluate(num_present))
def test_generate_remapping_with_old_vocab_size(self):
"""Tests where old_vocab_size is specified."""
remapping, num_present = gen_checkpoint_ops.generate_vocab_remapping(
new_vocab_file=self.new_vocab_file,
old_vocab_file=self.old_vocab_file,
num_new_vocab=3,
new_vocab_offset=0,
# Old vocabulary becomes ['knitting', 'eminem'].
old_vocab_size=2)
expected_remapping = [-1, 0, 1]
expected_num_present = 2
with self.cached_session():
self.assertAllEqual(expected_remapping, self.evaluate(remapping))
self.assertAllEqual(expected_num_present, self.evaluate(num_present))
class LoadAndRemapMatrixTest(test.TestCase):
"""Tests for the load_and_remap_matrix() op."""
def setUp(self):
ops.reset_default_graph()
self.old_num_rows = 5
self.old_num_cols = 16
self.matrix_value = np.reshape(
range(0, self.old_num_rows * self.old_num_cols), (self.old_num_rows,
self.old_num_cols))
with variable_scope.variable_scope('some_scope'):
matrix = variable_scope.get_variable(
'matrix',
dtype=dtypes.float32,
initializer=constant_op.constant(
self.matrix_value, dtype=dtypes.float32))
self.old_tensor_name = 'some_scope/matrix'
save = saver.Saver([matrix])
with self.cached_session() as sess:
self.evaluate(variables.global_variables_initializer())
self.bundle_file = os.path.join(test.get_temp_dir(), 'bundle_checkpoint')
save.save(sess, self.bundle_file)
def test_load_and_remap_no_missing(self):
"""Tests the op's load and remap where there are no missing entries."""
# No column remapping, new weight matrix has second row, then first row.
row_remapping = [1, 0]
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=row_remapping,
col_remapping=[],
initializing_values=[],
num_rows=2,
num_cols=self.old_num_cols)
with self.cached_session():
self.assertAllClose(self.matrix_value[row_remapping],
self.evaluate(remapped_matrix))
# No row remapping, new weight matrix has third col, then first col.
row_remapping = list(range(self.old_num_rows))
col_remapping = [2, 0]
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=row_remapping,
col_remapping=col_remapping,
initializing_values=[],
num_rows=len(row_remapping),
num_cols=len(col_remapping))
with self.cached_session():
self.assertAllClose(self.matrix_value[row_remapping][:, col_remapping],
self.evaluate(remapped_matrix))
# Both row and column remappings.
row_remapping = [1, 0, 4]
col_remapping = [1, 15]
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=row_remapping,
col_remapping=col_remapping,
initializing_values=[],
num_rows=len(row_remapping),
num_cols=len(col_remapping))
with self.cached_session():
self.assertAllClose(self.matrix_value[row_remapping][:, col_remapping],
self.evaluate(remapped_matrix))
def test_load_and_remap_with_init(self):
"""Tests the op's load and remap where there are missing entries."""
init_val = 42
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=[2, -1, 0],
col_remapping=[1, -1],
initializing_values=[init_val] * 4,
num_rows=3,
num_cols=2)
expected_remapped_matrix = np.reshape(
[33, init_val, init_val, init_val, 1, init_val], [3, 2])
with self.cached_session():
self.assertAllClose(expected_remapped_matrix,
self.evaluate(remapped_matrix))
def test_load_and_remap_all_missing_rows(self):
"""Tests when all the rows are missing and need to be initialized."""
num_rows = 7
initializing_values = [42] * num_rows * self.old_num_cols
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=[-1] * num_rows,
col_remapping=[],
initializing_values=initializing_values,
num_rows=num_rows,
num_cols=self.old_num_cols)
with self.cached_session():
self.assertAllClose(
np.reshape(initializing_values, (num_rows, self.old_num_cols)),
self.evaluate(remapped_matrix))
def test_load_and_remap_all_missing_rows_and_cols(self):
"""Tests when all the rows & cols are missing and need to be initialized."""
num_rows = 7
num_cols = 4
initializing_values = [42] * num_rows * num_cols
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=[-1] * num_rows,
col_remapping=[-1] * num_cols,
initializing_values=initializing_values,
num_rows=num_rows,
num_cols=num_cols)
with self.cached_session():
self.assertAllClose(
np.reshape(initializing_values, (num_rows, num_cols)),
self.evaluate(remapped_matrix))
@test_util.run_deprecated_v1
def test_load_and_remap_invalid_remapping(self):
"""Tests that errors are raised when an ID maps to multiple new IDs.
(This should usually not happen when using public APIs).
"""
invalid_remapping = [1, 0, 0, 0, 1, 2]
# Invalid row remapping.
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=invalid_remapping,
col_remapping=[],
initializing_values=[],
num_rows=len(invalid_remapping),
num_cols=self.old_num_cols)
with self.cached_session(), self.assertRaises(errors.UnimplementedError):
self.evaluate(remapped_matrix)
# Invalid column remapping.
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=list(range(self.old_num_rows)),
col_remapping=invalid_remapping,
initializing_values=[],
num_rows=self.old_num_rows,
num_cols=len(invalid_remapping))
with self.cached_session(), self.assertRaises(errors.UnimplementedError):
self.evaluate(remapped_matrix)
@test_util.run_deprecated_v1
def test_load_and_remap_incorrect_initializing_values(self):
"""Tests that errors are raised with incorrect number of init values."""
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=[2, -1, 0],
col_remapping=[1, -1],
# Too few initializing values - there should be 4. For some reason,
# initializing_values must contain no element (instead of 3 or fewer) to
# ensure that a seg fault would reliably occur if the check raising the
# InvalidArgumentError were not present.
initializing_values=[],
num_rows=3,
num_cols=2)
with self.cached_session(), self.assertRaises(errors.InvalidArgumentError):
self.evaluate(remapped_matrix)
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=[self.bundle_file],
old_tensor_name=self.old_tensor_name,
row_remapping=[2, -1, 0],
col_remapping=[1, -1],
# Too many initializing values - there should be 4.
initializing_values=[0] * 5,
num_rows=3,
num_cols=2)
with self.cached_session(), self.assertRaises(errors.InvalidArgumentError):
self.evaluate(remapped_matrix)
class LoadAndRemapMatrixWithMaxRowsTest(test.TestCase):
"""Tests for the load_and_remap_matrix() op.
(Specifically focused on the max_rows_in_memory arg and its effects on
TensorBundle's BundleReader and TensorSlice logic).
"""
def _test_loading_variable_with_max_rows(self, np_value, partitioner,
max_rows_in_memory):
"""Helper function for various tests using max_rows_in_memory."""
ops.reset_default_graph()
old_tensor_name = 'matrix_to_load_and_remap'
matrix = variable_scope.get_variable(
old_tensor_name,
dtype=dtypes.float32,
initializer=constant_op.constant(np_value, dtype=dtypes.float32),
partitioner=partitioner)
with self.cached_session() as sess:
ckpt_path = os.path.join(test.get_temp_dir(), 'temp_ckpt')
save = saver.Saver([matrix])
self.evaluate(variables.global_variables_initializer())
save.save(sess, ckpt_path)
num_rows, num_cols = np_value.shape
# Tests loading the entire tensor (except reversed).
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=ckpt_path,
old_tensor_name=old_tensor_name,
# Simply reverses the rows of the matrix.
row_remapping=list(range(num_rows - 1, -1, -1)),
col_remapping=[],
initializing_values=[],
num_rows=num_rows,
num_cols=num_cols,
max_rows_in_memory=max_rows_in_memory)
self.assertAllClose(np_value[::-1], self.evaluate(remapped_matrix))
# Tests loading the tensor (except for the first and last rows), with
# uninitialized values. Requires num_rows to be at least 3 since we're
# skipping the first and last rows.
self.assertGreater(num_rows, 2)
prefix_rows = 2
suffix_rows = 3
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=ckpt_path,
old_tensor_name=old_tensor_name,
# Reverses the rows of the matrix, then prepends and appends
# uninitialized rows.
row_remapping=([-1] * prefix_rows + list(range(1, num_rows - 1)) +
[-1] * suffix_rows),
col_remapping=[],
initializing_values=[42] * (prefix_rows + suffix_rows) * num_cols,
num_rows=num_rows - 2 + prefix_rows + suffix_rows,
num_cols=num_cols,
max_rows_in_memory=max_rows_in_memory)
self.assertAllClose(
np.vstack([
np.tile(42, [prefix_rows, num_cols]), np_value[1:-1],
np.tile(42, [suffix_rows, num_cols])
]), self.evaluate(remapped_matrix))
# Tests when everything is taken from initializing_values.
new_rows = 7
initializing_values = [42] * new_rows * num_cols
remapped_matrix = gen_checkpoint_ops.load_and_remap_matrix(
ckpt_path=ckpt_path,
old_tensor_name=old_tensor_name,
# Nothing is loaded from the old tensor.
row_remapping=[-1] * new_rows,
col_remapping=[],
initializing_values=initializing_values,
num_rows=new_rows,
num_cols=num_cols,
max_rows_in_memory=max_rows_in_memory)
self.assertAllClose(
np.reshape(initializing_values, (new_rows, num_cols)),
self.evaluate(remapped_matrix))
@test_util.run_deprecated_v1
def test_loading_rows_divisible_by_max_rows(self):
"""Tests loading normal var when rows are evenly divisible by max_rows."""
self._test_loading_variable_with_max_rows(
np_value=np.reshape(list(range(0, 36)), (9, 4)),
partitioner=None,
# 9 is evenly divisible by 3.
max_rows_in_memory=3)
@test_util.run_deprecated_v1
def test_loading_rows_not_divisible_by_max_rows(self):
"""Tests loading normal var when rows aren't divisible by max_rows."""
self._test_loading_variable_with_max_rows(
np_value=np.reshape(list(range(0, 36)), (9, 4)),
partitioner=None,
# 9 is not evenly divisible by 4.
max_rows_in_memory=4)
@test_util.run_deprecated_v1
def test_loading_rows_less_than_max_rows(self):
"""Tests loading normal var as a single slice.
(When the specified max_rows_in_memory is larger than the number of rows)
"""
self._test_loading_variable_with_max_rows(
np_value=np.reshape(list(range(0, 36)), (9, 4)),
partitioner=None,
# 10 > 9.
max_rows_in_memory=10)
@test_util.run_deprecated_v1
def test_loading_no_max_rows(self):
"""Tests loading normal var as a single slice with no valid max_rows."""
self._test_loading_variable_with_max_rows(
np_value=np.reshape(list(range(0, 18)), (6, 3)),
partitioner=None,
max_rows_in_memory=-1)
@test_util.run_deprecated_v1
def test_loading_partitions_equals_max_rows(self):
"""Tests loading partitioned var sliced on partition boundary."""
self._test_loading_variable_with_max_rows(
np_value=np.reshape(list(range(0, 36)), (9, 4)),
partitioner=partitioned_variables.fixed_size_partitioner(3),
# With a tensor of shape [9, 3] and 3 partitions, each partition has
# exactly 3 rows.
max_rows_in_memory=3)
@test_util.run_deprecated_v1
def test_loading_partitions_greater_than_max_rows(self):
"""Tests loading partitioned var with more slices than partitions."""
self._test_loading_variable_with_max_rows(
np_value=np.reshape(list(range(0, 36)), (9, 4)),
partitioner=partitioned_variables.fixed_size_partitioner(3),
# Even though each partition has 3 rows, we'll only load the tensor one
# row at a time.
max_rows_in_memory=1)
@test_util.run_deprecated_v1
def test_loading_partitions_less_than_max_rows(self):
"""Tests loading partitioned var as a single slice.
(When the specified max_rows_in_memory is larger than the number of rows)
"""
self._test_loading_variable_with_max_rows(
np_value=np.reshape(list(range(0, 36)), (9, 4)),
partitioner=partitioned_variables.fixed_size_partitioner(3),
max_rows_in_memory=10)
@test_util.run_deprecated_v1
def test_loading_partitions_no_max_rows(self):
"""Tests loading partitioned var as single slice with no valid max_rows."""
self._test_loading_variable_with_max_rows(
np_value=np.reshape(list(range(0, 36)), (9, 4)),
partitioner=partitioned_variables.fixed_size_partitioner(3),
max_rows_in_memory=-1)
if __name__ == '__main__':
test.main() | unknown | codeparrot/codeparrot-clean | ||
// Copyright 2022 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
package sync
// OnceFunc returns a function that invokes f only once. The returned function
// may be called concurrently.
//
// If f panics, the returned function will panic with the same value on every call.
func OnceFunc(f func()) func() {
// Use a struct so that there's a single heap allocation.
d := struct {
f func()
once Once
valid bool
p any
}{
f: f,
}
return func() {
d.once.Do(func() {
defer func() {
d.f = nil // Do not keep f alive after invoking it.
d.p = recover()
if !d.valid {
// Re-panic immediately so on the first
// call the user gets a complete stack
// trace into f.
panic(d.p)
}
}()
d.f()
d.valid = true // Set only if f does not panic.
})
if !d.valid {
panic(d.p)
}
}
}
// OnceValue returns a function that invokes f only once and returns the value
// returned by f. The returned function may be called concurrently.
//
// If f panics, the returned function will panic with the same value on every call.
func OnceValue[T any](f func() T) func() T {
// Use a struct so that there's a single heap allocation.
d := struct {
f func() T
once Once
valid bool
p any
result T
}{
f: f,
}
return func() T {
d.once.Do(func() {
defer func() {
d.f = nil
d.p = recover()
if !d.valid {
panic(d.p)
}
}()
d.result = d.f()
d.valid = true
})
if !d.valid {
panic(d.p)
}
return d.result
}
}
// OnceValues returns a function that invokes f only once and returns the values
// returned by f. The returned function may be called concurrently.
//
// If f panics, the returned function will panic with the same value on every call.
func OnceValues[T1, T2 any](f func() (T1, T2)) func() (T1, T2) {
// Use a struct so that there's a single heap allocation.
d := struct {
f func() (T1, T2)
once Once
valid bool
p any
r1 T1
r2 T2
}{
f: f,
}
return func() (T1, T2) {
d.once.Do(func() {
defer func() {
d.f = nil
d.p = recover()
if !d.valid {
panic(d.p)
}
}()
d.r1, d.r2 = d.f()
d.valid = true
})
if !d.valid {
panic(d.p)
}
return d.r1, d.r2
}
} | go | github | https://github.com/golang/go | src/sync/oncefunc.go |
# Copyright 2013 Hewlett-Packard Development Company, L.P.
#
# Licensed under the Apache License, Version 2.0 (the "License"); you may
# not use this file except in compliance with the License. You may obtain
# a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
# License for the specific language governing permissions and limitations
# under the License.
import logging
from django.conf import settings
from django.core.urlresolvers import reverse
from django.utils.translation import ugettext_lazy as _
from horizon import exceptions
from horizon import forms
from horizon import messages
from horizon import workflows
from openstack_dashboard import api
from openstack_dashboard.dashboards.identity.domains import constants
LOG = logging.getLogger(__name__)
class CreateDomainInfoAction(workflows.Action):
name = forms.CharField(label=_("Name"))
description = forms.CharField(widget=forms.widgets.Textarea(
attrs={'rows': 4}),
label=_("Description"),
required=False)
enabled = forms.BooleanField(label=_("Enabled"),
required=False,
initial=True)
class Meta(object):
name = _("Domain Information")
slug = "create_domain"
help_text = _("Domains provide separation between users and "
"infrastructure used by different organizations.")
class CreateDomainInfo(workflows.Step):
action_class = CreateDomainInfoAction
contributes = ("domain_id",
"name",
"description",
"enabled")
class UpdateDomainUsersAction(workflows.MembershipAction):
def __init__(self, request, *args, **kwargs):
super(UpdateDomainUsersAction, self).__init__(request,
*args,
**kwargs)
domain_id = self.initial.get("domain_id", '')
# Get the default role
try:
default_role = api.keystone.get_default_role(self.request)
# Default role is necessary to add members to a domain
if default_role is None:
default = getattr(settings,
"OPENSTACK_KEYSTONE_DEFAULT_ROLE", None)
msg = (_('Could not find default role "%s" in Keystone') %
default)
raise exceptions.NotFound(msg)
except Exception:
exceptions.handle(self.request,
_('Unable to find default role.'),
redirect=reverse(constants.DOMAINS_INDEX_URL))
default_role_name = self.get_default_role_field_name()
self.fields[default_role_name] = forms.CharField(required=False)
self.fields[default_role_name].initial = default_role.id
# Get list of available users
all_users = []
try:
all_users = api.keystone.user_list(request,
domain=domain_id)
except Exception:
exceptions.handle(request, _('Unable to retrieve user list.'))
users_list = [(user.id, user.name) for user in all_users]
# Get list of roles
role_list = []
try:
role_list = api.keystone.role_list(request)
except Exception:
exceptions.handle(request,
_('Unable to retrieve role list.'),
redirect=reverse(constants.DOMAINS_INDEX_URL))
for role in role_list:
field_name = self.get_member_field_name(role.id)
label = role.name
self.fields[field_name] = forms.MultipleChoiceField(required=False,
label=label)
self.fields[field_name].choices = users_list
self.fields[field_name].initial = []
# Figure out users & roles
if domain_id:
try:
users_roles = api.keystone.get_domain_users_roles(request,
domain_id)
except Exception:
exceptions.handle(request,
_('Unable to retrieve user domain role '
'assignments.'),
redirect=reverse(
constants.DOMAINS_INDEX_URL))
for user_id in users_roles:
roles_ids = users_roles[user_id]
for role_id in roles_ids:
field_name = self.get_member_field_name(role_id)
self.fields[field_name].initial.append(user_id)
class Meta(object):
name = _("Domain Members")
slug = constants.DOMAIN_USER_MEMBER_SLUG
class UpdateDomainUsers(workflows.UpdateMembersStep):
action_class = UpdateDomainUsersAction
available_list_title = _("All Users")
members_list_title = _("Domain Members")
no_available_text = _("No users found.")
no_members_text = _("No users.")
def contribute(self, data, context):
context = super(UpdateDomainUsers, self).contribute(data, context)
if data:
try:
roles = api.keystone.role_list(self.workflow.request)
except Exception:
exceptions.handle(self.workflow.request,
_('Unable to retrieve role list.'),
redirect=reverse(
constants.DOMAINS_INDEX_URL))
post = self.workflow.request.POST
for role in roles:
field = self.get_member_field_name(role.id)
context[field] = post.getlist(field)
return context
class UpdateDomainGroupsAction(workflows.MembershipAction):
def __init__(self, request, *args, **kwargs):
super(UpdateDomainGroupsAction, self).__init__(request,
*args,
**kwargs)
err_msg = _('Unable to retrieve group list. Please try again later.')
domain_id = self.initial.get("domain_id", '')
# Get the default role
try:
default_role = api.keystone.get_default_role(self.request)
# Default role is necessary to add members to a domain
if default_role is None:
default = getattr(settings,
"OPENSTACK_KEYSTONE_DEFAULT_ROLE", None)
msg = (_('Could not find default role "%s" in Keystone') %
default)
raise exceptions.NotFound(msg)
except Exception:
exceptions.handle(self.request,
err_msg,
redirect=reverse(constants.DOMAINS_INDEX_URL))
default_role_name = self.get_default_role_field_name()
self.fields[default_role_name] = forms.CharField(required=False)
self.fields[default_role_name].initial = default_role.id
# Get list of available groups
all_groups = []
try:
all_groups = api.keystone.group_list(request,
domain=domain_id)
except Exception:
exceptions.handle(request, err_msg)
groups_list = [(group.id, group.name) for group in all_groups]
# Get list of roles
role_list = []
try:
role_list = api.keystone.role_list(request)
except Exception:
exceptions.handle(request,
err_msg,
redirect=reverse(constants.DOMAINS_INDEX_URL))
for role in role_list:
field_name = self.get_member_field_name(role.id)
label = role.name
self.fields[field_name] = forms.MultipleChoiceField(required=False,
label=label)
self.fields[field_name].choices = groups_list
self.fields[field_name].initial = []
# Figure out groups & roles
if domain_id:
for group in all_groups:
try:
roles = api.keystone.roles_for_group(self.request,
group=group.id,
domain=domain_id)
except Exception:
exceptions.handle(request,
err_msg,
redirect=reverse(
constants.DOMAINS_INDEX_URL))
for role in roles:
field_name = self.get_member_field_name(role.id)
self.fields[field_name].initial.append(group.id)
class Meta(object):
name = _("Domain Groups")
slug = constants.DOMAIN_GROUP_MEMBER_SLUG
class UpdateDomainGroups(workflows.UpdateMembersStep):
action_class = UpdateDomainGroupsAction
available_list_title = _("All Groups")
members_list_title = _("Domain Groups")
no_available_text = _("No groups found.")
no_members_text = _("No groups.")
def contribute(self, data, context):
context = super(UpdateDomainGroups, self).contribute(data, context)
if data:
try:
roles = api.keystone.role_list(self.workflow.request)
except Exception:
exceptions.handle(self.workflow.request,
_('Unable to retrieve role list.'))
post = self.workflow.request.POST
for role in roles:
field = self.get_member_field_name(role.id)
context[field] = post.getlist(field)
return context
class CreateDomain(workflows.Workflow):
slug = "create_domain"
name = _("Create Domain")
finalize_button_name = _("Create Domain")
success_message = _('Created new domain "%s".')
failure_message = _('Unable to create domain "%s".')
success_url = constants.DOMAINS_INDEX_URL
default_steps = (CreateDomainInfo, )
def format_status_message(self, message):
return message % self.context.get('name', 'unknown domain')
def handle(self, request, data):
# create the domain
try:
LOG.info('Creating domain with name "%s"' % data['name'])
desc = data['description']
api.keystone.domain_create(request,
name=data['name'],
description=desc,
enabled=data['enabled'])
except Exception:
exceptions.handle(request, ignore=True)
return False
return True
class UpdateDomainInfoAction(CreateDomainInfoAction):
class Meta(object):
name = _("Domain Information")
slug = 'update_domain'
help_text = _("Domains provide separation between users and "
"infrastructure used by different organizations. "
"Edit the domain details to add or remove "
"groups in the domain.")
class UpdateDomainInfo(workflows.Step):
action_class = UpdateDomainInfoAction
depends_on = ("domain_id",)
contributes = ("name",
"description",
"enabled")
class UpdateDomain(workflows.Workflow):
slug = "update_domain"
name = _("Edit Domain")
finalize_button_name = _("Save")
success_message = _('Modified domain "%s".')
failure_message = _('Unable to modify domain "%s".')
success_url = constants.DOMAINS_INDEX_URL
default_steps = (UpdateDomainInfo,
UpdateDomainUsers,
UpdateDomainGroups)
def format_status_message(self, message):
return message % self.context.get('name', 'unknown domain')
def _update_domain_members(self, request, domain_id, data):
# update domain members
users_to_modify = 0
# Project-user member step
member_step = self.get_step(constants.DOMAIN_USER_MEMBER_SLUG)
try:
# Get our role options
available_roles = api.keystone.role_list(request)
# Get the users currently associated with this project so we
# can diff against it.
domain_members = api.keystone.user_list(request,
domain=domain_id)
users_to_modify = len(domain_members)
for user in domain_members:
# Check if there have been any changes in the roles of
# Existing project members.
current_roles = api.keystone.roles_for_user(self.request,
user.id,
domain=domain_id)
current_role_ids = [role.id for role in current_roles]
for role in available_roles:
field_name = member_step.get_member_field_name(role.id)
# Check if the user is in the list of users with this role.
if user.id in data[field_name]:
# Add it if necessary
if role.id not in current_role_ids:
# user role has changed
api.keystone.add_domain_user_role(
request,
domain=domain_id,
user=user.id,
role=role.id)
else:
# User role is unchanged, so remove it from the
# remaining roles list to avoid removing it later.
index = current_role_ids.index(role.id)
current_role_ids.pop(index)
# Prevent admins from doing stupid things to themselves.
is_current_user = user.id == request.user.id
# TODO(lcheng) When Horizon moves to Domain scoped token for
# invoking identity operation, replace this with:
# domain_id == request.user.domain_id
is_current_domain = True
admin_roles = [role for role in current_roles
if role.name.lower() == 'admin']
if len(admin_roles):
removing_admin = any([role.id in current_role_ids
for role in admin_roles])
else:
removing_admin = False
if is_current_user and is_current_domain and removing_admin:
# Cannot remove "admin" role on current(admin) domain
msg = _('You cannot revoke your administrative privileges '
'from the domain you are currently logged into. '
'Please switch to another domain with '
'administrative privileges or remove the '
'administrative role manually via the CLI.')
messages.warning(request, msg)
# Otherwise go through and revoke any removed roles.
else:
for id_to_delete in current_role_ids:
api.keystone.remove_domain_user_role(
request,
domain=domain_id,
user=user.id,
role=id_to_delete)
users_to_modify -= 1
# Grant new roles on the project.
for role in available_roles:
field_name = member_step.get_member_field_name(role.id)
# Count how many users may be added for exception handling.
users_to_modify += len(data[field_name])
for role in available_roles:
users_added = 0
field_name = member_step.get_member_field_name(role.id)
for user_id in data[field_name]:
if not filter(lambda x: user_id == x.id, domain_members):
api.keystone.add_tenant_user_role(request,
project=domain_id,
user=user_id,
role=role.id)
users_added += 1
users_to_modify -= users_added
return True
except Exception:
exceptions.handle(request,
_('Failed to modify %s project '
'members and update domain groups.')
% users_to_modify)
return False
def _update_domain_groups(self, request, domain_id, data):
# update domain groups
groups_to_modify = 0
member_step = self.get_step(constants.DOMAIN_GROUP_MEMBER_SLUG)
try:
# Get our role options
available_roles = api.keystone.role_list(request)
# Get the groups currently associated with this domain so we
# can diff against it.
domain_groups = api.keystone.group_list(request,
domain=domain_id)
groups_to_modify = len(domain_groups)
for group in domain_groups:
# Check if there have been any changes in the roles of
# Existing domain members.
current_roles = api.keystone.roles_for_group(
self.request,
group=group.id,
domain=domain_id)
current_role_ids = [role.id for role in current_roles]
for role in available_roles:
# Check if the group is in the list of groups with
# this role.
field_name = member_step.get_member_field_name(role.id)
if group.id in data[field_name]:
# Add it if necessary
if role.id not in current_role_ids:
# group role has changed
api.keystone.add_group_role(
request,
role=role.id,
group=group.id,
domain=domain_id)
else:
# Group role is unchanged, so remove it from
# the remaining roles list to avoid removing it
# later
index = current_role_ids.index(role.id)
current_role_ids.pop(index)
# Revoke any removed roles.
for id_to_delete in current_role_ids:
api.keystone.remove_group_role(request,
role=id_to_delete,
group=group.id,
domain=domain_id)
groups_to_modify -= 1
# Grant new roles on the domain.
for role in available_roles:
field_name = member_step.get_member_field_name(role.id)
# Count how many groups may be added for error handling.
groups_to_modify += len(data[field_name])
for role in available_roles:
groups_added = 0
field_name = member_step.get_member_field_name(role.id)
for group_id in data[field_name]:
if not filter(lambda x: group_id == x.id, domain_groups):
api.keystone.add_group_role(request,
role=role.id,
group=group_id,
domain=domain_id)
groups_added += 1
groups_to_modify -= groups_added
return True
except Exception:
exceptions.handle(request,
_('Failed to modify %s domain groups.')
% groups_to_modify)
return False
def handle(self, request, data):
domain_id = data.pop('domain_id')
try:
LOG.info('Updating domain with name "%s"' % data['name'])
api.keystone.domain_update(request,
domain_id=domain_id,
name=data['name'],
description=data['description'],
enabled=data['enabled'])
except Exception:
exceptions.handle(request, ignore=True)
return False
if not self._update_domain_members(request, domain_id, data):
return False
if not self._update_domain_groups(request, domain_id, data):
return False
return True | unknown | codeparrot/codeparrot-clean | ||
## Copyright (c) 2001-2014, Scott D. Peckham
## January 2013 (Removed "get_port_data" calls, etc.)
## January 2009 (converted from IDL)
## May, August 2009
## May 2010 (changes to initialize() and read_cfg_file()
#-----------------------------------------------------------------------
# Notes: This file defines a "base class" for infiltration
# components as well as functions used by most or
# all infiltration methods. The methods of this class
# (especially "update_infil_rate") should be over-ridden as
# necessary for different methods of modeling infiltration.
# See infil_green_ampt.py, infil_smith_parlange.py and
# infil_richards_1D.py.
#-----------------------------------------------------------------------
#
# class infil_component
#
# set_constants()
# initialize()
# update()
# update_nondrivers() ####### (OBSOLETE ??)
# finalize()
# initialize_layer_vars() # (5/11/10)
# set_computed_input_vars()
# ---------------------------
# check_input_types()
# initialize_computed_vars() #####
# ---------------------------
# update_surface_influx() #####
# update_infil_rate()
# adjust_infil_rate() #####
# update_IN_integral()
# update_Rg()
# update_Rg_integral()
# update_I()
# update_q0()
# check_infiltration()
# -------------------------
# open_input_files() # (ALL BELOW THIS OBSOLETE SOON/NOW.)
# read_input_files()
# close_input_files()
# ------------------------
# update_outfile_names()
# open_output_files()
# write_output_files()
# close_output_files()
# save_grids()
# save_pixel_values()
# save_profiles()
# save_cubes()
# ------------------------
# save_profiles_old()
# save_cubes_old()
#-----------------------------------------------------------------------
import numpy as np
import os
from topoflow.utils import BMI_base
from topoflow.utils import model_input
from topoflow.utils import model_output
#-----------------------------------------------------
# Moved these imports to: "embed_child_components()"
# because first one tries to "import infil_base" and
# this leads to a problem.
#-----------------------------------------------------
## from topoflow.components import channels_kinematic_wave
## from topoflow.components import snow_degree_day
## from topoflow.components import evap_priestley_taylor
## from topoflow.components import satzone_darcy_layers
## from topoflow.components import met_base
#-----------------------------------------------------------------------
class infil_component( BMI_base.BMI_component):
#---------------------------------------------------------
# Notes: Default settings are average for 'Loam', as
# returned by the Get_Soil_Params routine.
# Vars in 2nd line are set fairly arbitrary.
# eta = (2 + (3*lambda)) and needs to be
# updated whenever lambda is updated, as in
# Update_Infil_Vars. We want to avoid
# recomputing it everywhere it is used in
# order to save time.
# The vars computed by Richards' method are
# set to scalar 0d below, but they are set to
# arrays by Route_Flow according to user choices.
#---------------------------------------------------------
# NB! soil types are only used to pass defaults to
# the droplists in the GUI. "soil_type" field
# is only used by the non-Richards routines.
# NB! dz is a pointer, but dz1, dz2 & dz3 are scalars.
# For multiple soil layers, we build a 1D array
# for dz from the others.
#---------------------------------------------------------
#-------------------------------------------------------------------
def set_constants(self):
#------------------------
# Define some constants
#--------------------------------------------
# See Figure 6-13, p. 237 in Dingman (2002)
#----------------------------------------------------
# Psi_field_capacity is often used for psi_init.
# See initialize_theta_i() in infil_richards_1D.py.
#----------------------------------------------------
self.psi_oven_dry = np.float64(-1e8) # [m], oven dry
self.psi_air_dry = np.float64(-1e4) # [m], air dry
self.psi_min = np.float64(-1e4) # [m], air dry
self.psi_hygro = np.float64(-310) # [m], hygroscopic
self.psi_wilt = np.float64(-150) # [m], wilting pt.
self.psi_field = np.float64(-3.4) # [m], field cap.
#---------------------------------------------------------------
self.psi_oven_dry_cm = np.float64(-1e10) # [cm], oven dry
self.psi_air_dry_cm = np.float64(-1e6) # [cm], air dry
self.psi_min_cm = np.float64(-1e6) # [cm], air dry
self.psi_hygro_cm = np.float64(-31000) # [cm], hygroscopic
self.psi_wilt_cm = np.float64(-15000) # [cm], wilting pt.
self.psi_field_cm = np.float64(-340) # [cm], field cap.
#-------------------------------------
# Why isn't this used anywhere yet ?
#-------------------------------------
self.g = np.float64(9.81) # (gravitation const.)
# set_constants()
#-------------------------------------------------------------------
def initialize(self, cfg_file=None, mode="nondriver",
SILENT=False):
#---------------------------------------------------------
# Notes: Need to make sure than h_swe matches h_snow ?
# User may have entered incompatible valueself.
#---------------------------------------------------------
# (3/14/07) If the Energy Balance method is used for ET,
# then we must initialize and track snow depth even if
# there is no snowmelt method because the snow depth
# affects the ET rate. Otherwise, return to caller.
#---------------------------------------------------------
if not(SILENT):
print ' '
print 'Infiltration component: Initializing...'
self.status = 'initializing' # (OpenMI 2.0 convention)
self.mode = mode
self.cfg_file = cfg_file
#-------------------------------------------------
# Richards' method is special, so check for it
# But also set now in set_computed_input_vars().
#-------------------------------------------------
cfg_extension = self.get_attribute( 'cfg_extension' )
self.RICHARDS = ('richards' in cfg_extension.lower())
#-----------------------------------------------
# Load component parameters from a config file
#-----------------------------------------------
self.set_constants()
self.initialize_layer_vars() # (5/11/10)
self.initialize_config_vars()
self.read_grid_info()
self.initialize_basin_vars() # (5/14/10)
self.initialize_time_vars()
#----------------------------------
# Has component been turned off ?
#----------------------------------
if (self.comp_status == 'Disabled'):
if not(SILENT):
print 'Infiltration component: Disabled.'
#-------------------------------------------------
# IN = infiltration rate at land surface
# Rg = vertical flow rate just above water table
#-------------------------------------------------
self.IN = self.initialize_scalar( 0, dtype='float64' )
self.Rg = self.initialize_scalar( 0, dtype='float64' )
self.vol_IN = self.initialize_scalar( 0, dtype='float64' )
self.vol_Rg = self.initialize_scalar( 0, dtype='float64' )
self.DONE = True
self.status = 'initialized' # (OpenMI 2.0 convention)
return
#---------------------------------------------
# Open input files needed to initialize vars
#---------------------------------------------
self.open_input_files()
self.read_input_files()
#----------------------------------------------
# Must come before initialize_computed_vars()
# because it uses ALL_SCALARS.
#----------------------------------------------
self.check_input_types()
self.initialize_computed_vars()
self.open_output_files()
self.status = 'initialized' # (OpenMI 2.0 convention)
# initialize()
#-------------------------------------------------------------------
## def update(self, dt=-1.0, time_seconds=None):
def update(self, dt=-1.0):
#-------------------------------------------------
# Note: self.IN already set to 0 by initialize()
#-------------------------------------------------
if (self.comp_status == 'Disabled'): return
self.status = 'updating' # (OpenMI 2.0 convention)
#-------------------------
# Update computed values
#-------------------------
# self.update_nondrivers() ####### (10/7/10)
self.update_surface_influx() # (P_total = P + SM)
self.update_infil_rate()
self.adjust_infil_rate()
self.update_IN_integral()
self.update_Rg()
self.update_Rg_integral()
self.update_I() # (total infiltrated depth)
self.update_q0() # (soil moisture at surface)
#---------------------------------
# Check for NaNs in infiltration
#---------------------------------
self.check_infiltration()
#------------------------------------------
# Read next infil vars from input files ?
#------------------------------------------
if (self.time_index > 0):
self.read_input_files()
#----------------------------------------------
# Write user-specified data to output files ?
#----------------------------------------------
# Components use own self.time_sec by default.
#-----------------------------------------------
self.write_output_files()
## self.write_output_files( time_seconds )
#-----------------------------
# Update internal clock
# after write_output_files()
#-----------------------------
self.update_time( dt )
self.status = 'updated' # (OpenMI 2.0 convention)
# update()
#-------------------------------------------------------------------
def finalize(self):
self.status = 'finalizing' # (OpenMI 2.0 convention)
## if (self.mode == 'driver'): # (10/7/10)
## self.mp.finalize()
## self.sp.finalize()
## self.ep.finalize()
## self.gp.finalize()
## self.cp.finalize()
self.close_input_files() ## TopoFlow input "data streams"
self.close_output_files()
self.status = 'finalized' # (OpenMI 2.0 convention)
self.print_final_report(comp_name='Infiltration component')
#---------------------------
# Release all of the ports
#----------------------------------------
# Make this call in "finalize()" method
# of the component's CCA Imple file
#----------------------------------------
# self.release_cca_ports( port_names, d_services )
# finalize()
#-------------------------------------------------------------------
def initialize_layer_vars(self):
#-------------------------------------------------------
# Notes: We need to call initialize_layer_vars()
# before initialize_config_vars(), which may
# call read_cfg_file(). However, this means
# we haven't read "n_layers" yet, so just
# hardwire it here for now. (5/11/10)
#-------------------------------------------------------
n_layers = 1
# n_layers = self.n_layers
#-------------------------------------------------
# Get arrays to store soil params for each layer
#-------------------------------------------------
self.soil_type = np.zeros([n_layers], dtype='|S100')
## self.dz_val = np.zeros([n_layers], dtype='Float64') #### + dz3
## self.nz_val = np.zeros([n_layers], dtype='Int16') #### + nz3
#----------------------------------------------------------
self.Ks_type = np.zeros(n_layers, dtype='|S100')
self.Ki_type = np.zeros(n_layers, dtype='|S100')
self.qs_type = np.zeros(n_layers, dtype='|S100')
self.qi_type = np.zeros(n_layers, dtype='|S100')
self.G_type = np.zeros(n_layers, dtype='|S100')
self.gam_type = np.zeros(n_layers, dtype='|S100')
#--------------------------------------------------------
self.Ks_file = np.zeros(n_layers, dtype='|S100')
self.Ki_file = np.zeros(n_layers, dtype='|S100')
self.qs_file = np.zeros(n_layers, dtype='|S100')
self.qi_file = np.zeros(n_layers, dtype='|S100')
self.G_file = np.zeros(n_layers, dtype='|S100')
self.gam_file = np.zeros(n_layers, dtype='|S100')
#---------------------------------------------------------
# Note: self.Ks is a Python list. Initially, each entry
# is a numpy scalar (type 'np.float64'). However, we
# can later change any list entry to a scalar or grid
# (type 'np.ndarray'), according to its "Ks_type".
#---------------------------------------------------------
self.Ks_val = list(np.zeros(n_layers, dtype='Float64'))
self.Ki = list(np.zeros(n_layers, dtype='Float64'))
self.qs = list(np.zeros(n_layers, dtype='Float64'))
self.qi = list(np.zeros(n_layers, dtype='Float64'))
self.G = list(np.zeros(n_layers, dtype='Float64'))
self.gam = list(np.zeros(n_layers, dtype='Float64'))
# initialize_layer_vars()
#-------------------------------------------------------------------
def set_computed_input_vars(self):
# self.nz = 1 # (needed by self.save_profiles() ??)
#--------------------------------------------------------
# Define these here, so all components can use the same
# output file functions, like "open_output_files()".
#--------------------------------------------------------
self.SAVE_Q0_GRIDS = False
self.SAVE_ZW_GRIDS = False
#-----------------------------
self.SAVE_Q0_PIXELS = False
self.SAVE_ZW_PIXELS = False
#-----------------------------
self.SAVE_Q_CUBES = False
self.SAVE_P_CUBES = False
self.SAVE_K_CUBES = False
self.SAVE_V_CUBES = False
#--------------------------------------------
# Can maybe remove this when GUI info file
# has the "save cubes" part put back in.
#--------------------------------------------
self.q_cs_file = ''
self.p_cs_file = ''
self.K_cs_file = ''
self.v_cs_file = ''
self.save_cube_dt = np.float64( 60 )
#---------------------------------------------------------
# Make sure that all "save_dts" are larger or equal to
# the specified process dt. There is no point in saving
# results more often than they change.
# Issue a message to this effect if any are smaller ??
#---------------------------------------------------------
self.save_grid_dt = np.maximum(self.save_grid_dt, self.dt)
self.save_pixels_dt = np.maximum(self.save_pixels_dt, self.dt)
self.save_profile_dt = np.maximum(self.save_profile_dt, self.dt)
self.save_cube_dt = np.maximum(self.save_cube_dt, self.dt)
# set_computed_input_vars()
#-------------------------------------------------------------------
def check_input_types(self):
#------------------------------------------------------
# Notes: Usually this will be overridden by a given
# method of computing ET. But this one should
# work for Green-Ampt and Smith-Parlange.
#------------------------------------------------------
are_scalars = np.array([
self.is_scalar('P_rain'),
self.is_scalar('SM'),
self.is_scalar('h_table'),
#----------------------------
self.is_scalar('Ks'),
self.is_scalar('Ki'),
self.is_scalar('qs'),
self.is_scalar('qi'),
self.is_scalar('G') ])
self.ALL_SCALARS = np.all(are_scalars)
# check_input_types()
#-------------------------------------------------------------------
def initialize_computed_vars(self):
#-----------------------------------------------
# Note: h = water table elevation [m]
# z = land surface elevation [m]
#
# Currently, h and z are always grids,
# so IN will be a grid.
# z, h and IN must be compatible.
#-----------------------------------------------
#---------------------------------------------
# Reset cumulative infiltrated depth to zero
# before each model run (not in __init__)
# This block must come before if (RICHARDS).
#---------------------------------------------
self.vol_IN = self.initialize_scalar( 0, dtype='float64')
self.vol_Rg = self.initialize_scalar( 0, dtype='float64')
if (self.RICHARDS):
self.initialize_richards_vars()
return
if (self.ALL_SCALARS):
#-----------------------------------------------------
# Note: "I" is initialized to 1e-6 to avoid a divide
# by zero when first computing fc, which does
# have a singularity at the origin.
#-----------------------------------------------------
self.IN = self.initialize_scalar( 0, dtype='float64')
self.Rg = self.initialize_scalar( 0, dtype='float64')
self.I = self.initialize_scalar( 1e-6, dtype='float64')
self.tp = self.initialize_scalar( -1, dtype='float64')
self.fp = self.initialize_scalar( 0, dtype='float64')
self.r_last = self.initialize_scalar( 0, dtype='float64') # (P+SM at prev step)
else:
self.IN = np.zeros([self.ny, self.nx], dtype='float64')
self.Rg = np.zeros([self.ny, self.nx], dtype='float64')
self.I = np.zeros([self.ny, self.nx], dtype='float64') + 1e-6
self.tp = np.zeros([self.ny, self.nx], dtype='float64') - 1
self.fp = np.zeros([self.ny, self.nx], dtype='float64')
self.r_last = np.zeros([self.ny, self.nx], dtype='float64')
# initialize_computed_vars()
#-------------------------------------------------------------------
def update_surface_influx(self):
if (self.DEBUG):
print 'Calling update_surface_influx()...'
P_rain = self.P_rain # (2/3/13, new framework)
SM = self.SM # (2/3/13, new framework)
## ET = self.ET # (2/3/13, new framework)
self.P_total = (P_rain + SM)
## self.P_total = (P_rain + SM) - ET
# update_surface_influx()
#-------------------------------------------------------------------
def update_infil_rate(self):
if (self.DEBUG):
print 'Calling update_infil_rate()...'
#---------------------------------------------------------
# Note: Do nothing now unless this method is overridden
# by a particular method of computing infil rate.
#---------------------------------------------------------
print "Warning: update_infil_rate() method is inactive."
#------------------------------------------------------------
# Note: P = precipitation rate [m/s]
# SM = snowmelt rate [m/s]
# r = (P + SM) [m/s]
# ET = evapotranspiration rate [m/s]
# IN = infiltration rate with units of [m/s]
# Rg = rate at which water reaches water table [m/s]
# (Rg default is 0, but changed by Richards)
# h = water table elevation [m]
# z = land surface elevation [m]
# I = total infiltrated depth [m]
# n = time step (for computing t_start & t_end)
#------------------------------------------------------------
## r = self.P_total # (P_total, not R=runoff)
##
## if (self.method == 0):
## self.IN = np.float64(0)
## ## self.r_last = ???
## return
## elif (self.method == 1):
## self.IN = r
## #--------------------------------------------------------
## # These next two are not totally correct but are stable
## # and give results similar to the correct method
## #--------------------------------------------------------
## elif (self.method == 2):
## self.IN = Green_Ampt_Infil_Rate_v1(self, r)
## elif (self.method == 3):
## self.IN = Smith_Parlange_Infil_Rate_v1(self, r)
## #-------------------------------------------------
## # These next two use the correct approach but so
## # far have convergence and "jump" issues
## #------------------------------------------------------------
## #** 2 : IN = Green_Ampt_Infil_Rate_v2(self, r, r_last, n)
## #** 3 : IN = Smith_Parlange_Infil_Rate_v2(self, r, r_last, n)
## #------------------------------------------------------------
## elif (self.method == 4):
## P = self.mp.P_rain
## SM = self.sp.SM
## ET = self.ep.ET
## self.IN = Richards_Infil_Rate(self, P, SM, ET, self.Rg)
## #########################################################
## ## Richards_Infil_Rate should also return and save Rg
## #########################################################
## #** 5 : IN = Beven_Exp_K_Infil_Rate_v1(self, r) ;(no GUI yet)
## else:
## self.IN = np.float64(0)
##
## #---------------------------
## # Print min and max values
## #---------------------------
## #nI = np.size(Iself.N)
## #if (nI == 1):
## # print 'IN =', self.IN
## #else:
## # imin = self.IN.min()
## # imax = self.IN.max()
## # print '(imin, imax) =', imin, imax
##
## #--------------------------
## # For debugging & testing
## #--------------------------
## #print 'min(IN), max(IN) = ', self.IN.min(), self.IN.max()
## #print 'self.dt =', self.dt
# update_infile_rate()
#-------------------------------------------------------------
def adjust_infil_rate(self):
if (self.DEBUG):
print 'Calling adjust_infil_rate()...'
#-------------------------------------
# Is P_total less than Ks anywhere ?
# If so, set IN = P_total there.
#-------------------------------------
CHECK_LOW_RAIN = not(self.RICHARDS)
if (CHECK_LOW_RAIN):
self.check_low_rainrate()
#####################################################
# (10/8/10) The rest of this routine doesn't work
# if IN is a scalar. Need to look at this more.
#####################################################
## if (self.SINGLE_PROFILE):
if (self.IN.size == 1):
return
#-------------------------------------------
# Get water table and land surface from gp
#-------------------------------------------
## H_IS_GRID = self.gp.is_grid('h_table')
## Z_IS_GRID = self.gp.is_grid('elev')
h = self.h_table # (2/3/13, new framework)
z = self.elev # (2/3/13, new framework)
##### if (h or z is undefined): return
#----------------------------------------
# Can't infiltrate where water table
# is above ground, i.e. where (h ge z)
# If z & h are given, IN is a grid too.
#--------------------------------------------------
# Note: h = water table elevation [m]
# z = land surface elevation [m]
#
# Currently, h and z are always grids,
# so (nh > 1) and (nz > 1)
#--------------------------------------------------
w = np.where( h >= z ) # (changed on 8/19/09)
### w = np.where( h == z )
nw = np.size(w[0])
if (nw != 0):
self.IN[w] = np.float64(0)
##########################################
# ADD SIMILAR THING FOR GC2D
##########################################
##########################################
# adjust_infil_rate()
#-------------------------------------------------------------------
def update_IN_integral(self):
if (self.DEBUG):
print 'Calling update_IN_integral()...'
#------------------------------------------------
# Update mass total for IN, sum over all pixels
#------------------------------------------------
volume = np.double(self.IN * self.da * self.dt) # [m^3]
if (np.size( volume ) == 1):
self.vol_IN += (volume * self.rti.n_pixels)
else:
self.vol_IN += np.sum(volume)
# update_IN_integral()
#-------------------------------------------------------------------
def update_Rg(self):
if (self.DEBUG):
print 'Calling update_Rg()...'
#------------------------------------------------
# This works for Green-Ampt and Smith_Parlange,
# but should be overridden for Richards 1D.
#------------------------------------------------
# Set groundwater recharge rate to IN ?
# Save last value of r for next time.
#----------------------------------------
self.Rg = self.IN
P_rain = self.P_rain # (2/3/13, new framework)
SM = self.SM # (2/3/13, new framework)
#---------------------
self.r_last = (P_rain + SM)
# update_Rg()
#-------------------------------------------------------------------
def update_Rg_integral(self):
if (self.DEBUG):
print 'Calling update_Rg_integral()...'
#------------------------------------------------
# Update mass total for Rg, sum over all pixels
#------------------------------------------------
volume = np.double(self.Rg * self.da * self.dt) # [m^3]
if (np.size( volume ) == 1):
self.vol_Rg += (volume * self.rti.n_pixels)
else:
self.vol_Rg += np.sum(volume)
# update_Rg_integral()
#-------------------------------------------------------------------
def update_I(self):
if (self.DEBUG):
print 'Calling update_I()...'
#---------------------------------------
# Update the total infiltrated depth
#---------------------------------------
# Do this for all methods ? I is not
# used for Richards 1D method.
#
# This becomes a grid if IN is a grid.
#---------------------------------------
self.I += (self.IN * self.dt) # [meters]
#--------------
# For testing
#--------------
#if (np.size(self.I) == 1):
# print ' Tot. infil. depth =' + str(self.I)
#------------------------------------------
# Reset the total infiltrated depth after
# each "event"; not sure how to do this.
#------------------------------------------
#if (????): self.I = np.minimum(self.I, 0.0)
# update_I()
#-------------------------------------------------------------------
def update_q0(self):
if (self.DEBUG):
print 'Calling update_q0()...'
#-----------------------------------------------
# Note: self.q0 = np.float64(0) in __init__().
# Most infil methods don't compute q0.
# This method is over-ridden for Richards 1D
#-----------------------------------------------
pass
# update_q0()
#-------------------------------------------------------------------
def check_infiltration(self):
if (self.DEBUG):
print 'Calling check_infiltration()...'
#--------------------------------------
# Check for NaNs in infiltration rate
#--------------------------------------
# NB! Don't set DONE = False, it may
# already have been set to True
#--------------------------------------
if (np.size( self.IN ) == 1):
OK = np.isfinite( self.IN )
nbad = 1
else:
wbad = np.where( np.logical_not(np.isfinite( self.IN )) )
nbad = np.size( wbad[0] )
### nbad = np.size(wbad, 0)
OK = (nbad == 0)
if (OK):
return
#------------------------------------------
# Issue warning message and abort the run
#------------------------------------------
msg = np.array(['ERROR: Aborting model run.', \
' NaNs found in infiltration rates.', \
' Number of NaN values = ' + str(nbad) ])
## GUI_Error_Message(msg) #########
print '##############################################'
for line in msg:
print line
print '##############################################'
print ' '
self.status = 'failed'
self.DONE = True
# check_infiltration
#-----------------------------------------------------------------------
def check_low_rainrate(self):
#------------------------------------------------------------
# Notes: If (P_total < Ks), then we need to set the infil
# rate to P_total. P_total = (P + SM).
#
# This needs to be called by Green-Ampt and Smith-
# Parlange methods for computing IN; perhaps by
# any method based on total infiltrated depth, I.
# This isn't needed for Richards' equation method.
#------------------------------------------------------------
#--------------------------------------
# Is P_total less than Ks anywhere ?
# If so, set IN = P_total there.
#--------------------------------------
nPt = np.size( self.P_total )
nK = np.size( self.Ks[0] )
if ((nPt == 1) and (nK == 1)):
#----------------------------------
# P_total and Ks are both scalars
#----------------------------------
if (self.P_total < self.Ks[0]):
self.IN = self.P_total
else:
#---------------------------------
# Either P_total or Ks is a grid
# so IN will have become a grid
#---------------------------------
w = np.where( self.P_total < self.Ks[0] )
nw = np.size( w[0] )
if (nw != 0):
if (nPt > 1):
self.IN[w] = self.P_total[w]
else:
self.IN[w] = self.P_total
# check_low_rainrate
#-------------------------------------------------------------------
def open_input_files(self):
#-------------------------------------------------------
# This method works for Green-Ampt and Smith-Parlange
# but must be overridden for Richards 1D.
#-------------------------------------------------------
# NB! Green-Ampt and Smith-Parlange currently only
# support ONE layer (n_layers == 1).
#-------------------------------------------------------
self.Ks_unit = [] # (empty lists to hold file objects)
self.Ki_unit = []
self.qs_unit = []
self.qi_unit = []
self.G_unit = []
self.gam_unit = []
for k in xrange(self.n_layers):
self.Ks_file[k] = self.in_directory + self.Ks_file[k]
self.Ki_file[k] = self.in_directory + self.Ki_file[k]
self.qs_file[k] = self.in_directory + self.qs_file[k]
self.qi_file[k] = self.in_directory + self.qi_file[k]
self.G_file[k] = self.in_directory + self.G_file[k]
self.gam_file[k] = self.in_directory + self.gam_file[k]
self.Ks_unit.append( model_input.open_file(self.Ks_type[k], self.Ks_file[k]) )
self.Ki_unit.append( model_input.open_file(self.Ki_type[k], self.Ki_file[k]) )
self.qs_unit.append( model_input.open_file(self.qs_type[k], self.qs_file[k]) )
self.qi_unit.append( model_input.open_file(self.qi_type[k], self.qi_file[k]) )
self.G_unit.append( model_input.open_file(self.G_type[k], self.G_file[k]) )
self.gam_unit.append( model_input.open_file(self.gam_type[k], self.gam_file[k]) )
# open_input_files()
#-------------------------------------------------------------------
def read_input_files(self):
if (self.DEBUG):
print 'Calling read_input_files()...'
rti = self.rti
#-------------------------------------------------------
# All grids are assumed to have data type of Float32.
#-------------------------------------------------------
# This method works for Green-Ampt and Smith-Parlange
# but must be overridden for Richards 1D.
#-------------------------------------------------------
# NB! Green-Ampt and Smith-Parlange currently only
# support ONE layer (n_layers == 1).
#-------------------------------------------------------
for k in xrange(self.n_layers):
Ks = model_input.read_next(self.Ks_unit[k], self.Ks_type[k], rti)
if (Ks is not None): self.Ks[k] = Ks
Ki = model_input.read_next(self.Ki_unit[k], self.Ki_type[k], rti)
if (Ki is not None): self.Ki[k] = Ki
qs = model_input.read_next(self.qs_unit[k], self.qs_type[k], rti)
if (qs is not None): self.qs[k] = qs
qi = model_input.read_next(self.qi_unit[k], self.qi_type[k], rti)
if (qi is not None): self.qi[k] = qi
G = model_input.read_next(self.G_unit[k], self.G_type[k], rti)
if (G is not None): self.G[k] = G
gam = model_input.read_next(self.gam_unit[k], self.gam_type[k], rti)
if (gam is not None): self.gam[k] = gam
# read_input_files()
#-------------------------------------------------------------------
def close_input_files(self):
#-------------------------------------------------------
# This method works for Green-Ampt and Smith-Parlange
# but must be overridden for Richards 1D.
#-------------------------------------------------------
# NB! Green-Ampt and Smith-Parlange currently only
# support ONE layer (n_layers == 1).
#-------------------------------------------------------
for k in xrange(self.n_layers):
if (self.Ks_type[k] != 'Scalar'): self.Ks_unit[k].close()
if (self.Ki_type[k] != 'Scalar'): self.Ki_unit[k].close()
if (self.qs_type[k] != 'Scalar'): self.qs_unit[k].close()
if (self.qi_type[k] != 'Scalar'): self.qi_unit[k].close()
if (self.G_type[k] != 'Scalar'): self.G_unit[k].close()
if (self.gam_type[k] != 'Scalar'): self.gam_unit[k].close()
#------------------------------------------------------------
## if (self.Ks_file[k] != ''): self.Ks_unit[k].close()
## if (self.Ki_file[k] != ''): self.Ki_unit[k].close()
## if (self.qs_file[k] != ''): self.qs_unit[k].close()
## if (self.qi_file[k] != ''): self.qi_unit[k].close()
## if (self.G_file[k] != ''): self.G_unit[k].close()
## if (self.gam_file[k] != ''): self.gam_unit[k].close()
# close_input_files()
#-------------------------------------------------------------------
def update_outfile_names(self):
#-------------------------------------------------
# Notes: Append out_directory to outfile names.
#-------------------------------------------------
self.v0_gs_file = (self.out_directory + self.v0_gs_file)
self.I_gs_file = (self.out_directory + self.I_gs_file)
self.q0_gs_file = (self.out_directory + self.q0_gs_file)
self.Zw_gs_file = (self.out_directory + self.Zw_gs_file)
#-------------------------------------------------------------
self.v0_ts_file = (self.out_directory + self.v0_ts_file)
self.I_ts_file = (self.out_directory + self.I_ts_file)
self.q0_ts_file = (self.out_directory + self.q0_ts_file)
self.Zw_ts_file = (self.out_directory + self.Zw_ts_file)
#-----------------------------------------------------------------
self.q_ps_file = (self.out_directory + self.q_ps_file)
self.p_ps_file = (self.out_directory + self.p_ps_file)
self.K_ps_file = (self.out_directory + self.K_ps_file)
self.v_ps_file = (self.out_directory + self.v_ps_file)
#-------------------------------------------------------------
self.q_cs_file = (self.out_directory + self.q_cs_file)
self.p_cs_file = (self.out_directory + self.p_cs_file)
self.K_cs_file = (self.out_directory + self.K_cs_file)
self.v_cs_file = (self.out_directory + self.v_cs_file)
## self.v0_gs_file = (self.case_prefix + '_2D-v0.rts')
## self.q0_gs_file = (self.case_prefix + '_2D-q0.rts')
## self.I_gs_file = (self.case_prefix + '_2D-I.rts')
## self.Zw_gs_file = (self.case_prefix + '_2D-Zw.rts')
## #---------------------------------------------------------
## self.v0_ts_file = (self.case_prefix + '_0D-v0.txt')
## self.q0_ts_file = (self.case_prefix + '_0D-q0.txt')
## self.I_ts_file = (self.case_prefix + '_0D-I.txt')
## self.Zw_ts_file = (self.case_prefix + '_0D-Zw.txt')
## #---------------------------------------------------------
## self.q_cs_file = (self.case_prefix + '_3D-q.rt3')
## self.p_cs_file = (self.case_prefix + '_3D-p.rt3')
## self.K_cs_file = (self.case_prefix + '_3D-K.rt3')
## self.v_cs_file = (self.case_prefix + '_3D-v.rt3')
## #---------------------------------------------------------
## self.q_ps_file = (self.case_prefix + '_1D-q.txt')
## self.p_ps_file = (self.case_prefix + '_1D_p.txt')
## self.K_ps_file = (self.case_prefix + '_1D_K.txt')
## self.v_ps_file = (self.case_prefix + '_1D_v.txt')
# update_outfile_names()
#-------------------------------------------------------------------
def open_output_files(self):
#-------------------------------------------------
# Notes: v0 = infiltration rate at surface
# q0 = soil moisture at surface
# I = total infiltrated depth
# Zw = wetting front
# q = soil moisture
# p = pressure head
# K = hydraulic conductivity
# v = vertical flow rate (see v0)
#-------------------------------------------------
model_output.check_netcdf()
self.update_outfile_names()
#--------------------------------------
# Open new files to write grid stacks
#--------------------------------------
if (self.SAVE_V0_GRIDS):
model_output.open_new_gs_file( self, self.v0_gs_file, self.rti,
var_name='v0',
long_name='infiltration_rate_at_surface',
units_name='m/s')
if (self.SAVE_I_GRIDS):
model_output.open_new_gs_file( self, self.I_gs_file, self.rti,
var_name='I',
long_name='total_infiltrated_depth',
units_name='m')
if (self.SAVE_Q0_GRIDS):
model_output.open_new_gs_file( self, self.q0_gs_file, self.rti,
var_name='q0',
long_name='soil_moisture_at_surface',
units_name='none')
if (self.SAVE_ZW_GRIDS):
model_output.open_new_gs_file( self, self.Zw_gs_file, self.rti,
var_name='Zw',
long_name='depth_to_wetting_front',
units_name='m')
#--------------------------------------
# Open new files to write time series
#--------------------------------------
IDs = self.outlet_IDs
if (self.SAVE_V0_PIXELS):
model_output.open_new_ts_file( self, self.v0_ts_file, IDs,
var_name='v0',
long_name='infiltration_rate_at_surface',
units_name='m/s')
if (self.SAVE_I_PIXELS):
model_output.open_new_ts_file( self, self.I_ts_file, IDs,
var_name='I',
long_name='total_infiltrated_depth',
units_name='m')
if (self.SAVE_Q0_PIXELS):
model_output.open_new_ts_file( self, self.q0_ts_file, IDs,
var_name='q0',
long_name='soil_moisture_at_surface',
units_name='none')
if (self.SAVE_ZW_PIXELS):
model_output.open_new_ts_file( self, self.Zw_ts_file, IDs,
var_name='Zw',
long_name='depth_to_wetting_front',
units_name='m')
#-----------------------------------------------------
# Remaining parts are only valid for Richards method
#-----------------------------------------------------
if not(self.RICHARDS):
return
#--------------------------------------------------
# Open "profile files" to write vertical profiles
#--------------------------------------------------
if (self.SAVE_Q_PROFILES):
model_output.open_new_ps_file( self, self.q_ps_file, IDs,
z_values=self.z, z_units='m',
var_name='q',
long_name='soil_water_content',
units_name='none')
if (self.SAVE_P_PROFILES):
model_output.open_new_ps_file( self, self.p_ps_file, IDs,
z_values=self.z, z_units='m',
var_name='p',
long_name='pressure_head',
units_name='m')
#################################################################
# NOTE: Should we convert these units from "m/s" to "mm/hr" ??
#################################################################
if (self.SAVE_K_PROFILES):
model_output.open_new_ps_file( self, self.K_ps_file, IDs,
z_values=self.z, z_units='m',
var_name='K',
long_name='hydraulic_conductivity',
units_name='m/s')
if (self.SAVE_V_PROFILES):
model_output.open_new_ps_file( self, self.v_ps_file, IDs,
z_values=self.z, z_units='m',
var_name='v',
long_name='vertical_flow_rate',
units_name='m/s')
#---------------------------------------------
# Open "cube files" to write 3D grid "cubes"
#---------------------------------------------
if (self.SAVE_Q_CUBES):
model_output.open_new_cs_file( self, self.q_cs_file, self.rti,
var_name='q',
long_name='soil_water_content',
units_name='none')
if (self.SAVE_P_CUBES):
model_output.open_new_cs_file( self, self.p_cs_file, self.rti,
var_name='p',
long_name='pressure_head',
units_name='m')
#################################################################
# NOTE: Should we convert these units from "m/s" to "mm/hr" ??
#################################################################
if (self.SAVE_K_CUBES):
model_output.open_new_cs_file( self, self.K_cs_file, self.rti,
var_name='K',
long_name='hydraulic_conductivity',
units_name='m/s')
if (self.SAVE_V_CUBES):
model_output.open_new_cs_file( self, self.v_cs_file, self.rti,
var_name='v',
long_name='vertical_flow_rate',
units_name='m/s')
#--------------------------------------------------
# Open "profile files" to write vertical profiles
#--------------------------------------------------
## if (self.SAVE_Q_PROFILES):
## self.q_profile_unit = open(self.q_ps_file, 'w')
## write_ps_file_header(self.q_profile_unit, IDs, var_name='q')
##
## if (self.SAVE_P_PROFILES):
## self.p_profile_unit = open(self.p_ps_file, 'w')
## write_ps_file_header(self.p_profile_unit, IDs, var_name='p')
##
## if (self.SAVE_K_PROFILES):
## self.K_profile_unit = open(self.K_ps_file, 'w')
## write_ps_file_header(self.K_profile_unit, IDs, var_name='K')
##
## if (self.SAVE_V_PROFILES):
## self.v_profile_unit = open(self.v_ps_file, 'w')
## write_ps_file_header(self.v_profile_unit, IDs, var_name='v')
#---------------------------------------
# Open RT3 files to write grid "cubes"
#---------------------------------------
## if (self.SAVE_Q_STACKS):
## self.q_stack_unit = open(self.q_cs_file, 'wb')
## if (self.SAVE_P_STACKS):
## self.p_stack_unit = open(self.p_cs_file, 'wb')
## if (self.SAVE_K_STACKS):
## self.K_stack_unit = open(self.K_cs_file, 'wb')
## if (self.SAVE_V_STACKS):
## self.v_stack_unit = open(self.v_cs_file, 'wb')
# open_output_files()
#-------------------------------------------------------------------
def write_output_files(self, time_seconds=None):
#---------------------------------------------------------
# Notes: This function was written to use only model
# time (maybe from a caller) in seconds, and
# the save_grid_dt and save_pixels_dt parameters
# read by read_cfg_file().
#
# read_cfg_file() makes sure that all of
# the "save_dts" are larger than or equal to the
# process dt.
#---------------------------------------------------------
if (self.DEBUG):
print 'Calling write_output_files()...'
#-----------------------------------------
# Allows time to be passed from a caller
#-----------------------------------------
if (time_seconds is None):
time_seconds = self.time_sec
model_time = int(time_seconds)
#----------------------------------------
# Save computed values at sampled times
#----------------------------------------
if (model_time % int(self.save_grid_dt) == 0):
self.save_grids()
if (model_time % int(self.save_pixels_dt) == 0):
self.save_pixel_values()
if not(self.RICHARDS):
return
if (model_time % int(self.save_profile_dt) == 0):
self.save_profiles()
if (model_time % int(self.save_cube_dt) == 0):
self.save_cubes()
# write_output_files()
#-------------------------------------------------------------------
def close_output_files(self):
if (self.SAVE_V0_GRIDS): model_output.close_gs_file( self, 'v0')
if (self.SAVE_I_GRIDS): model_output.close_gs_file( self, 'I')
if (self.SAVE_Q0_GRIDS): model_output.close_gs_file( self, 'q0')
if (self.SAVE_ZW_GRIDS): model_output.close_gs_file( self, 'Zw')
if (self.SAVE_V0_PIXELS): model_output.close_ts_file( self, 'v0')
if (self.SAVE_I_PIXELS): model_output.close_ts_file( self, 'I')
if (self.SAVE_Q0_PIXELS): model_output.close_ts_file( self, 'q0')
if (self.SAVE_ZW_PIXELS): model_output.close_ts_file( self, 'Zw')
if not(self.RICHARDS):
return
if (self.SAVE_Q_PROFILES): model_output.close_ps_file( self, 'q')
if (self.SAVE_P_PROFILES): model_output.close_ps_file( self, 'p')
if (self.SAVE_K_PROFILES): model_output.close_ps_file( self, 'K')
if (self.SAVE_V_PROFILES): model_output.close_ps_file( self, 'v')
if (self.SAVE_Q_CUBES): model_output.close_cs_file( self, 'q')
if (self.SAVE_P_CUBES): model_output.close_cs_file( self, 'p')
if (self.SAVE_K_CUBES): model_output.close_cs_file( self, 'K')
if (self.SAVE_V_CUBES): model_output.close_cs_file( self, 'v')
# close_output_files()
#-------------------------------------------------------------------
def save_grids(self):
#-----------------------------------
# Save grid stack to a netCDF file
#---------------------------------------------
# Note that add_grid() methods will convert
# var from scalar to grid now, if necessary.
#---------------------------------------------
if (self.DEBUG):
print 'Calling save_grids()...'
if (self.SAVE_V0_GRIDS):
model_output.add_grid( self, self.IN, 'v0', self.time_min )
if (self.SAVE_I_GRIDS):
model_output.add_grid( self, self.I, 'I', self.time_min )
if (self.SAVE_Q0_GRIDS):
model_output.add_grid( self, self.q0, 'q0', self.time_min )
if (self.SAVE_ZW_GRIDS):
model_output.add_grid( self, self.Zw, 'Zw', self.time_min )
# save_grids()
#-------------------------------------------------------------------
def save_pixel_values(self):
if (self.DEBUG):
print 'Calling save_pixel_values()...'
IDs = self.outlet_IDs
time = self.time_min ########
#--------------------------------------------
# Save a subsequence of IN var pixel values
#--------------------------------------------
if (self.SAVE_V0_PIXELS):
model_output.add_values_at_IDs( self, time, self.IN, 'v0', IDs )
if (self.SAVE_I_PIXELS):
model_output.add_values_at_IDs( self, time, self.I, 'I', IDs )
#----------------------------------------
# Richards' equation for infiltration ?
#----------------------------------------
if not(self.RICHARDS):
return
if (self.SAVE_Q0_PIXELS):
model_output.add_values_at_IDs( self, time, self.q0, 'q0', IDs )
if (self.SAVE_ZW_PIXELS):
model_output.add_values_at_IDs( self, time, self.Zw, 'Zw', IDs )
#-------------------------------------
# This should no longer be necessary
#--------------------------------------
## if (self.ALL_SCALARS):
## if (self.SAVE_Q0_PIXELS):
## write_ts_file_line(self.q0_ts_unit, time_min, self.q0, IDs)
## if (self.SAVE_ZW_PIXELS):
## write_ts_file_line(self.Zw_ts_unit, time_min, self.Zw, IDs)
## else:
## if (self.SAVE_Q0_PIXELS):
## write_ts_file_line(self.q0_ts_unit, time_min, self.q0, IDs)
## if (self.SAVE_ZW_PIXELS):
## write_ts_file_line(self.Zw_ts_unit, time_min, self.Zw, IDs)
# save_pixel_values()
#-------------------------------------------------------------------
def save_profiles(self):
#-----------------------------------------------------------
# Notes: A "profile" is a 1D array, in this case a set of
# values that vary with depth below the surface
# (z-axis) and that are obtained by "skewering" a
# "stack variable" (see above) at a prescribed set
# of pixel or grid cell IDs (outlet_IDs).
#-----------------------------------------------------------
if (self.DEBUG):
print 'Calling save_profiles()...'
IDs = self.outlet_IDs
time = self.time_min
#------------------------------------------
# Save a subsequence of vertical profiles
#------------------------------------------
if (self.SAVE_Q_PROFILES):
model_output.add_profiles_at_IDs( self, self.q, 'q', IDs, time )
if (self.SAVE_P_PROFILES):
model_output.add_profiles_at_IDs( self, self.p, 'p', IDs, time )
if (self.SAVE_K_PROFILES):
model_output.add_profiles_at_IDs( self, self.K, 'K', IDs, time )
if (self.SAVE_V_PROFILES):
model_output.add_profiles_at_IDs( self, self.v, 'v', IDs, time )
# save_profiles()
#-------------------------------------------------------------------
def save_cubes(self):
#---------------------------------------------------------
# Notes: A "cube" is a 3D array, in this case for a set
# of subsurface values such as K or v that vary
# in 3 space dimensions and with time. This
# function saves a "snapshot" of such a 3D array
# to a "cube file" whenever it is called.
#---------------------------------------------------------
if (self.DEBUG):
print 'Calling save_cubes()...'
time = self.time_min
#------------------------------------------
# Save a subsequence of vertical profiles
#------------------------------------------
if (self.SAVE_Q_CUBES):
model_output.add_cube( self, time, self.q, 'q' )
if (self.SAVE_P_CUBES):
model_output.add_cube( self, time, self.p, 'p' )
if (self.SAVE_K_CUBES):
model_output.add_cube( self, time, self.K, 'K' )
if (self.SAVE_V_CUBES):
model_output.add_cube( self, time, self.v, 'v' )
# save_cubes()
#-------------------------------------------------------------------
## def save_profiles_old(self):
##
## #-----------------------------------------------------------
## # Notes: A "profile" is a 1D array, in this case a set of
## # values that vary with depth below the surface
## # (z-axis) and that are obtained by "skewering" a
## # "stack variable" (see above) at a prescribed set
## # of pixel or grid cell IDs (outlet_IDs).
## #-----------------------------------------------------------
## nz = self.nz
## IDs = self.outlet_IDs
##
## #----------------------------------
## # Construct a "time stamp" string
## #----------------------------------
## tmstr = '*********** Time = '
## tmstr = tmstr + ('%f8.1' % self.time_min) ######
## tmstr = tmstr + ' [minutes]'
##
## #---------------------------------------
## # Save a subsequence of IN var profiles
## #---------------------------------------
## if (self.SAVE_Q_PROFILES):
## Write_Profile(self.q_profile_unit, self.q, IDs, nz, tmstr)
## if (self.SAVE_P_PROFILES):
## Write_Profile(self.p_profile_unit, self.p, IDs, nz, tmstr)
## if (self.SAVE_K_PROFILES):
## Write_Profile(self.K_profile_unit, self.K, IDs, nz, tmstr)
## if (self.SAVE_V_PROFILES):
## Write_Profile(self.v_profile_unit, self.v, IDs, nz, tmstr)
##
## # save_profiles_old()
#-------------------------------------------------------------------
## def save_cubes_old(self):
##
## #---------------------------------------------------------
## # Notes: A "stack" is a 3D array, in this case for a set
## # of subsurface values such as K or v that vary
## # in 3 space dimensions and with time. This
## # function saves a "snapshot" of such a 3D array
## # to a "stack file" whenever it is called.
## #
## # The Stack function will work whether argument
## # is a 1D profile or already a 3D array.
## # The Profile_Var function will work whether its
## # its argument is a 1D profile or a 3D array.
## # (It is called by Write_Profile.)
## #---------------------------------------------------------
## nx = self.nx
## ny = self.ny
## SWAP_ENDIAN = self.rti.SWAP_ENDIAN
##
## #--------------------------------------
## # Save a subsequence of IN var stacks
## #--------------------------------------
## if (self.SAVE_Q_STACKS):
## if (SWAP_ENDIAN): self.q.byteswap(True)
## Stack(self.q, nx, ny).tofile(self.q_stack_unit)
## if (self.SAVE_P_STACKS):
## if (SWAP_ENDIAN): self.p.byteswap(True)
## Stack(self.p, nx, ny).tofile(self.p_stack_unit)
## if (self.SAVE_K_STACKS):
## if (SWAP_ENDIAN): self.K.byteswap(True)
## Stack(self.K, nx, ny).tofile(self.K_stack_unit)
## if (self.SAVE_V_STACKS):
## if (SWAP_ENDIAN): self.v.byteswap(True)
## Stack(self.v, nx, ny).tofile(self.v_stack_unit)
##
## # save_cubes_old()
## #------------------------------------------------------------------- | unknown | codeparrot/codeparrot-clean | ||
from django.template import TemplateSyntaxError
from django.test import SimpleTestCase
from ..utils import setup
class FilterTagTests(SimpleTestCase):
@setup({'filter01': '{% filter upper %}{% endfilter %}'})
def test_filter01(self):
output = self.engine.render_to_string('filter01')
self.assertEqual(output, '')
@setup({'filter02': '{% filter upper %}django{% endfilter %}'})
def test_filter02(self):
output = self.engine.render_to_string('filter02')
self.assertEqual(output, 'DJANGO')
@setup({'filter03': '{% filter upper|lower %}django{% endfilter %}'})
def test_filter03(self):
output = self.engine.render_to_string('filter03')
self.assertEqual(output, 'django')
@setup({'filter04': '{% filter cut:remove %}djangospam{% endfilter %}'})
def test_filter04(self):
output = self.engine.render_to_string('filter04', {'remove': 'spam'})
self.assertEqual(output, 'django')
@setup({'filter05': '{% filter safe %}fail{% endfilter %}'})
def test_filter05(self):
with self.assertRaises(TemplateSyntaxError):
self.engine.get_template('filter05')
@setup({'filter05bis': '{% filter upper|safe %}fail{% endfilter %}'})
def test_filter05bis(self):
with self.assertRaises(TemplateSyntaxError):
self.engine.get_template('filter05bis')
@setup({'filter06': '{% filter escape %}fail{% endfilter %}'})
def test_filter06(self):
with self.assertRaises(TemplateSyntaxError):
self.engine.get_template('filter06')
@setup({'filter06bis': '{% filter upper|escape %}fail{% endfilter %}'})
def test_filter06bis(self):
with self.assertRaises(TemplateSyntaxError):
self.engine.get_template('filter06bis') | unknown | codeparrot/codeparrot-clean | ||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimize inference using torch.compile()
このガイドは、[`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) を使用した推論速度の向上に関するベンチマークを提供することを目的としています。これは、[🤗 Transformers のコンピュータビジョンモデル](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending)向けのものです。
## Benefits of torch.compile
`torch.compile()`の利点
モデルとGPUによっては、torch.compile()は推論時に最大30%の高速化を実現します。 `torch.compile()`を使用するには、バージョン2.0以上のtorchをインストールするだけです。
モデルのコンパイルには時間がかかるため、毎回推論するのではなく、モデルを1度だけコンパイルする場合に役立ちます。
任意のコンピュータビジョンモデルをコンパイルするには、以下のようにモデルに`torch.compile()`を呼び出します:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID, device_map="auto")
+ model = torch.compile(model)
```
`compile()` は、コンパイルに関する異なるモードを備えており、基本的にはコンパイル時間と推論のオーバーヘッドが異なります。`max-autotune` は `reduce-overhead` よりも時間がかかりますが、推論速度が速くなります。デフォルトモードはコンパイルにおいては最速ですが、推論時間においては `reduce-overhead` に比べて効率が良くありません。このガイドでは、デフォルトモードを使用しました。詳細については、[こちら](https://pytorch.org/get-started/pytorch-2.0/#user-experience) を参照してください。
`torch` バージョン 2.0.1 で異なるコンピュータビジョンモデル、タスク、ハードウェアの種類、およびバッチサイズを使用して `torch.compile` をベンチマークしました。
## Benchmarking code
以下に、各タスクのベンチマークコードを示します。推論前にGPUをウォームアップし、毎回同じ画像を使用して300回の推論の平均時間を取得します。
### Image Classification with ViT
```python
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224", device_map="auto")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(model.device)
with torch.no_grad():
_ = model(**processed_input)
```
#### Object Detection with DETR
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50", device_map="auto")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to(model.device)
with torch.no_grad():
_ = model(**inputs)
```
#### Image Segmentation with Segformer
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512", device_map="auto")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to(model.device)
with torch.no_grad():
_ = model(**seg_inputs)
```
以下は、私たちがベンチマークを行ったモデルのリストです。
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
以下は、`torch.compile()`を使用した場合と使用しない場合の推論時間の可視化と、異なるハードウェアとバッチサイズの各モデルに対するパフォーマンス向上の割合です。
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
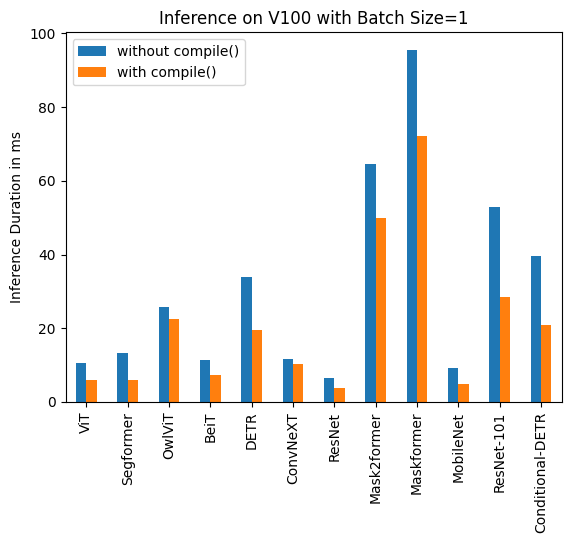
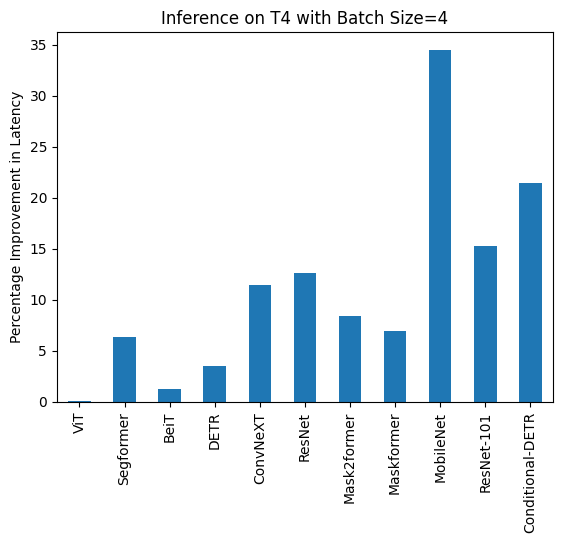
下記は、各モデルについて`compile()`を使用した場合と使用しなかった場合の推論時間(ミリ秒単位)です。なお、OwlViTは大きなバッチサイズでの使用時にメモリ不足(OOM)が発生することに注意してください。
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
また、PyTorchのナイトリーバージョン(2.1.0dev)でのベンチマークを行い、コンパイルされていないモデルとコンパイル済みモデルの両方でレイテンシーの向上を観察しました。ホイールは[こちら](https://download.pytorch.org/whl/nightly/cu118)から入手できます。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## Reduce Overhead
NightlyビルドでA100およびT4向けの `reduce-overhead` コンパイルモードをベンチマークしました。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 | | unknown | github | https://github.com/huggingface/transformers | docs/source/ja/perf_torch_compile.md |
from misc.colour_terminal import print_green
from server.http.http_server import HTTPd, HTTPSd
from test.base_test import BaseTest, HTTP, HTTPS
class HTTPTest(BaseTest):
""" Class for HTTP Tests. """
# Temp Notes: It is expected that when pre-hook functions are executed,
# only an empty test-dir exists. pre-hook functions are executed just prior
# to the call to Wget is made. post-hook functions will be executed
# immediately after the call to Wget returns.
def __init__(self,
name="Unnamed Test",
pre_hook=None,
test_params=None,
post_hook=None,
protocols=(HTTP,)):
super(HTTPTest, self).__init__(name,
pre_hook,
test_params,
post_hook,
protocols)
with self:
# if any exception occurs, self.__exit__ will be immediately called
self.server_setup()
self.do_test()
print_green('Test Passed.')
def instantiate_server_by(self, protocol):
server = {HTTP: HTTPd,
HTTPS: HTTPSd}[protocol]()
server.start()
return server
def request_remaining(self):
return [s.server_inst.get_req_headers()
for s in self.servers]
def stop_server(self):
for server in self.servers:
server.server_inst.shutdown()
# vim: set ts=4 sts=4 sw=4 tw=80 et : | unknown | codeparrot/codeparrot-clean | ||
/*
* Copyright 2014-2021 JetBrains s.r.o and contributors. Use of this source code is governed by the Apache 2.0 license.
*/
package io.ktor.network.sockets
import io.ktor.network.selector.*
import io.ktor.network.util.*
import io.ktor.utils.io.*
import io.ktor.utils.io.errors.*
import kotlinx.cinterop.*
import kotlinx.coroutines.*
import kotlinx.io.IOException
import kotlin.math.*
@OptIn(ExperimentalForeignApi::class)
internal fun CoroutineScope.attachForWritingImpl(
userChannel: ByteChannel,
descriptor: Int,
selectable: Selectable,
selector: SelectorManager
): ReaderJob = reader(Dispatchers.IO, userChannel) {
val source = channel
var sockedClosed = false
var needSelect = false
var total = 0
while (!sockedClosed && !source.isClosedForRead) {
val count = source.read { memory, start, stop ->
val written = memory.usePinned { pinned ->
val bufferStart = pinned.addressOf(start).reinterpret<ByteVar>()
val remaining = stop - start
val bytesWritten = if (remaining > 0) {
ktor_send(descriptor, bufferStart, remaining.convert(), 0).toInt()
} else {
0
}
when (bytesWritten) {
0 -> sockedClosed = true
-1 -> {
val error = getSocketError()
if (isWouldBlockError(error)) {
needSelect = true
} else {
throw PosixException.forSocketError(error)
}
}
}
bytesWritten
}
max(0, written)
}
total += count
if (!sockedClosed && needSelect) {
selector.select(selectable, SelectInterest.WRITE)
needSelect = false
}
}
if (!source.isClosedForRead) {
val availableForRead = source.availableForRead
val cause = IOException("Failed writing to closed socket. Some bytes remaining: $availableForRead")
source.cancel(cause)
} else {
source.closedCause?.let { throw it }
}
}.apply {
invokeOnCompletion {
ktor_shutdown(descriptor, ShutdownCommands.Send)
}
} | kotlin | github | https://github.com/ktorio/ktor | ktor-network/posix/src/io/ktor/network/sockets/CIOWriter.kt |
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Tests for tf.contrib.tensor_forest.client.eval_metrics."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from tensorflow.contrib.tensor_forest.client import eval_metrics
from tensorflow.python.framework import constant_op
from tensorflow.python.framework import test_util
from tensorflow.python.ops import variables
from tensorflow.python.platform import googletest
class EvalMetricsTest(test_util.TensorFlowTestCase):
def testTop2(self):
top_2_fn = eval_metrics._top_k_generator(2)
probabilities = constant_op.constant([[0.1, 0.2, 0.3], [0.4, 0.7, 0.5],
[0.9, 0.8, 0.2], [0.6, 0.4, 0.8]])
targets = constant_op.constant([[0], [2], [1], [1]])
in_top_2_op, update_op = top_2_fn(probabilities, targets)
with self.test_session():
# initializes internal accuracy vars
variables.local_variables_initializer().run()
# need to call in order to run the in_top_2_op internal operations because
# it is a streaming function
update_op.eval()
self.assertNear(0.5, in_top_2_op.eval(), 0.0001)
def testTop3(self):
top_3_fn = eval_metrics._top_k_generator(3)
probabilities = constant_op.constant([[0.1, 0.2, 0.6, 0.3, 0.5, 0.5],
[0.1, 0.4, 0.7, 0.3, 0.5, 0.2],
[0.1, 0.3, 0.8, 0.7, 0.4, 0.9],
[0.9, 0.8, 0.1, 0.8, 0.2, 0.7],
[0.3, 0.6, 0.9, 0.4, 0.8, 0.6]])
targets = constant_op.constant([3, 0, 2, 5, 1])
in_top_3_op, update_op = top_3_fn(probabilities, targets)
with self.test_session():
# initializes internal accuracy vars
variables.local_variables_initializer().run()
# need to call in order to run the in_top_3_op internal operations because
# it is a streaming function
update_op.eval()
self.assertNear(0.4, in_top_3_op.eval(), 0.0001)
def testAccuracy(self):
predictions = constant_op.constant([0, 1, 3, 6, 5, 2, 7, 6, 4, 9])
targets = constant_op.constant([0, 1, 4, 6, 5, 1, 7, 5, 4, 8])
accuracy_op, update_op = eval_metrics._accuracy(predictions, targets)
with self.test_session():
variables.local_variables_initializer().run()
# need to call in order to run the accuracy_op internal operations because
# it is a streaming function
update_op.eval()
self.assertNear(0.6, accuracy_op.eval(), 0.0001)
def testR2(self):
probabilities = constant_op.constant(
[1.2, 3.9, 2.1, 0.9, 2.2, 0.1, 6.0, 4.0, 0.9])
targets = constant_op.constant(
[1.0, 4.3, 2.6, 0.5, 1.1, 0.7, 5.1, 3.4, 1.8])
r2_op, update_op = eval_metrics._r2(probabilities, targets)
with self.test_session():
# initializes internal accuracy vars
variables.local_variables_initializer().run()
# need to call in order to run the r2_op internal operations because
# it is a streaming function
update_op.eval()
self.assertNear(-19.7729, r2_op.eval(), 0.0001)
if __name__ == '__main__':
googletest.main() | unknown | codeparrot/codeparrot-clean | ||
# Copyright 2009 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""A base user-interface workflow, to be inherited by UI modules."""
import tempfile
import benchmark
import better_webbrowser
import config
import data_sources
import geoip
import nameserver_list
import reporter
import site_connector
import util
__author__ = 'tstromberg@google.com (Thomas Stromberg)'
class BaseUI(object):
"""Common methods for all UI implementations."""
def __init__(self):
self.SetupDataStructures()
def SetupDataStructures(self):
"""Instead of requiring users to inherit __init__(), this sets up structures."""
self.reporter = None
self.nameservers = None
self.bmark = None
self.report_path = None
self.csv_path = None
self.geodata = None
self.country = None
self.sources = {}
self.url = None
self.share_state = None
self.test_records = []
def UpdateStatus(self, msg, **kwargs):
"""Update the little status message on the bottom of the window."""
if hasattr(self, 'status_callback') and self.status_callback:
self.status_callback(msg, **kwargs)
else:
print msg
def DebugMsg(self, message):
self.UpdateStatus(message, debug=True)
def LoadDataSources(self):
self.data_src = data_sources.DataSources(status_callback=self.UpdateStatus)
def PrepareTestRecords(self):
"""Figure out what data source a user wants, and create test_records."""
if self.options.input_source:
src_type = self.options.input_source
else:
src_type = self.data_src.GetBestSourceDetails()[0]
self.options.input_source = src_type
self.test_records = self.data_src.GetTestsFromSource(
src_type,
self.options.query_count,
select_mode=self.options.select_mode
)
def PrepareNameServers(self):
"""Setup self.nameservers to have a list of healthy fast servers."""
self.nameservers = nameserver_list.NameServers(
self.supplied_ns,
global_servers=self.global_ns,
regional_servers=self.regional_ns,
include_internal=self.include_internal,
num_servers=self.options.num_servers,
timeout=self.options.timeout,
ping_timeout=self.options.ping_timeout,
health_timeout=self.options.health_timeout,
ipv6_only=self.options.ipv6_only,
status_callback=self.UpdateStatus
)
if self.options.invalidate_cache:
self.nameservers.InvalidateSecondaryCache()
self.nameservers.cache_dir = tempfile.gettempdir()
# Don't waste time checking the health of the only nameserver in the list.
if len(self.nameservers) > 1:
self.nameservers.thread_count = int(self.options.health_thread_count)
self.nameservers.cache_dir = tempfile.gettempdir()
self.UpdateStatus('Checking latest sanity reference')
(primary_checks, secondary_checks, censor_tests) = config.GetLatestSanityChecks()
if not self.options.enable_censorship_checks:
censor_tests = []
else:
self.UpdateStatus('Censorship checks enabled: %s found.' % len(censor_tests))
self.nameservers.CheckHealth(primary_checks, secondary_checks, censor_tests=censor_tests)
def PrepareBenchmark(self):
"""Setup the benchmark object with the appropriate dataset."""
if len(self.nameservers) == 1:
thread_count = 1
else:
thread_count = self.options.benchmark_thread_count
self.bmark = benchmark.Benchmark(self.nameservers,
query_count=self.options.query_count,
run_count=self.options.run_count,
thread_count=thread_count,
status_callback=self.UpdateStatus)
def RunBenchmark(self):
"""Run the benchmark."""
results = self.bmark.Run(self.test_records)
index = []
if self.options.upload_results in (1, True):
connector = site_connector.SiteConnector(self.options, status_callback=self.UpdateStatus)
index_hosts = connector.GetIndexHosts()
if index_hosts:
index = self.bmark.RunIndex(index_hosts)
else:
index = []
self.DiscoverLocation()
if len(self.nameservers) > 1:
self.nameservers.RunPortBehaviorThreads()
self.reporter = reporter.ReportGenerator(self.options, self.nameservers,
results, index=index, geodata=self.geodata)
def DiscoverLocation(self):
if not getattr(self, 'geodata', None):
self.geodata = geoip.GetGeoData()
self.country = self.geodata.get('country_name', None)
return self.geodata
def RunAndOpenReports(self):
"""Run the benchmark and open up the report on completion."""
self.RunBenchmark()
best = self.reporter.BestOverallNameServer()
self.CreateReports()
if self.options.template == 'html':
self.DisplayHtmlReport()
if self.url:
self.UpdateStatus('Complete! Your results: %s' % self.url)
else:
self.UpdateStatus('Complete! %s [%s] is the best.' % (best.name, best.ip))
def CreateReports(self):
"""Create CSV & HTML reports for the latest run."""
if self.options.output_file:
self.report_path = self.options.output_file
else:
self.report_path = util.GenerateOutputFilename(self.options.template)
if self.options.csv_file:
self.csv_path = self.options_csv_file
else:
self.csv_path = util.GenerateOutputFilename('csv')
if self.options.upload_results in (1, True):
# This is for debugging and transparency only.
self.json_path = util.GenerateOutputFilename('js')
self.UpdateStatus('Saving anonymized JSON to %s' % self.json_path)
json_data = self.reporter.CreateJsonData()
f = open(self.json_path, 'w')
f.write(json_data)
f.close()
self.UpdateStatus('Uploading results to %s' % self.options.site_url)
connector = site_connector.SiteConnector(self.options, status_callback=self.UpdateStatus)
self.url, self.share_state = connector.UploadJsonResults(
json_data,
hide_results=self.options.hide_results
)
if self.url:
self.UpdateStatus('Your sharing URL: %s (%s)' % (self.url, self.share_state))
self.UpdateStatus('Saving report to %s' % self.report_path)
f = open(self.report_path, 'w')
self.reporter.CreateReport(format=self.options.template,
output_fp=f,
csv_path=self.csv_path,
sharing_url=self.url,
sharing_state=self.share_state)
f.close()
self.UpdateStatus('Saving detailed results to %s' % self.csv_path)
self.reporter.SaveResultsToCsv(self.csv_path)
def DisplayHtmlReport(self):
self.UpdateStatus('Opening %s' % self.report_path)
better_webbrowser.output = self.DebugMsg
better_webbrowser.open(self.report_path) | unknown | codeparrot/codeparrot-clean | ||
/* Copyright 2017 - 2025 R. Thomas
* Copyright 2017 - 2025 Quarkslab
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include <sstream>
#include "LIEF/utils.hpp"
#include "LIEF/Visitor.hpp"
#include "LIEF/PE/resources/ResourceVarFileInfo.hpp"
#include "LIEF/PE/resources/ResourceVar.hpp"
#include "LIEF/BinaryStream/BinaryStream.hpp"
#include "internal_utils.hpp"
#include "logging.hpp"
namespace LIEF {
namespace PE {
result<ResourceVarFileInfo> ResourceVarFileInfo::parse(BinaryStream& stream) {
ResourceVarFileInfo info;
auto wLength = stream.read<uint16_t>();
if (!wLength) { return make_error_code(wLength.error()); }
auto wValueLength = stream.read<uint16_t>();
if (!wValueLength) { return make_error_code(wValueLength.error()); }
auto wType = stream.read<uint16_t>();
if (!wType) { return make_error_code(wType.error()); }
if (*wType != 0 && wType != 1) {
return make_error_code(lief_errors::corrupted);
}
auto szKey = stream.read_u16string();
if (!szKey) { return make_error_code(wType.error()); }
if (u16tou8(*szKey) != "VarFileInfo") {
return make_error_code(lief_errors::corrupted);
}
info
.type(*wType)
.key(std::move(*szKey));
while (stream) {
stream.align(sizeof(uint32_t));
auto var = ResourceVar::parse(stream);
if (!var) {
LIEF_WARN("Can't parse resource var #{}", info.vars_.size());
return info;
}
info.add_var(std::move(*var));
}
return info;
}
void ResourceVarFileInfo::accept(Visitor& visitor) const {
visitor.visit(*this);
}
std::string ResourceVarFileInfo::key_u8() const {
return u16tou8(key());
}
std::ostream& operator<<(std::ostream& os, const ResourceVarFileInfo& info) {
os << fmt::format("BLOCK '{}' {{\n", info.key_u8());
for (const ResourceVar& var : info.vars()) {
std::ostringstream oss;
oss << var;
os << indent(oss.str(), 2);
}
os << '}';
return os;
}
}
} | cpp | github | https://github.com/nodejs/node | deps/LIEF/src/PE/resources/ResourceVarFileInfo.cpp |
#!/usr/bin/python
# Copyright: (c) 2017, Giovanni Sciortino (@giovannisciortino)
# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
from __future__ import absolute_import, division, print_function
__metaclass__ = type
ANSIBLE_METADATA = {'metadata_version': '1.1',
'status': ['preview'],
'supported_by': 'community'}
DOCUMENTATION = '''
---
module: rhsm_repository
short_description: Manage RHSM repositories using the subscription-manager command
description:
- Manage (Enable/Disable) RHSM repositories to the Red Hat Subscription
Management entitlement platform using the C(subscription-manager) command.
version_added: '2.5'
author: Giovanni Sciortino (@giovannisciortino)
notes:
- In order to manage RHSM repositories the system must be already registered
to RHSM manually or using the Ansible C(redhat_subscription) module.
requirements:
- subscription-manager
options:
state:
description:
- If state is equal to present or disabled, indicates the desired
repository state.
choices: [present, enabled, absent, disabled]
required: True
default: "present"
name:
description:
- The ID of repositories to enable.
- To operate on several repositories this can accept a comma separated
list or a YAML list.
required: True
purge:
description:
- Disable all currently enabled repositories that are not not specified in C(name).
Only set this to C(True) if passing in a list of repositories to the C(name) field.
Using this with C(loop) will most likely not have the desired result.
type: bool
default: False
version_added: "2.8"
'''
EXAMPLES = '''
- name: Enable a RHSM repository
rhsm_repository:
name: rhel-7-server-rpms
- name: Disable all RHSM repositories
rhsm_repository:
name: '*'
state: disabled
- name: Enable all repositories starting with rhel-6-server
rhsm_repository:
name: rhel-6-server*
state: enabled
- name: Disable all repositories except rhel-7-server-rpms
rhsm_repository:
name: rhel-7-server-rpms
purge: True
'''
RETURN = '''
repositories:
description:
- The list of RHSM repositories with their states.
- When this module is used to change the repository states, this list contains the updated states after the changes.
returned: success
type: list
'''
import re
import os
from fnmatch import fnmatch
from copy import deepcopy
from ansible.module_utils.basic import AnsibleModule
def run_subscription_manager(module, arguments):
# Execute subuscription-manager with arguments and manage common errors
rhsm_bin = module.get_bin_path('subscription-manager')
if not rhsm_bin:
module.fail_json(msg='The executable file subscription-manager was not found in PATH')
lang_env = dict(LANG='C', LC_ALL='C', LC_MESSAGES='C')
rc, out, err = module.run_command("%s %s" % (rhsm_bin, " ".join(arguments)), environ_update=lang_env)
if rc == 1 and (err == 'The password you typed is invalid.\nPlease try again.\n' or os.getuid() != 0):
module.fail_json(msg='The executable file subscription-manager must be run using root privileges')
elif rc == 0 and out == 'This system has no repositories available through subscriptions.\n':
module.fail_json(msg='This system has no repositories available through subscriptions')
elif rc == 1:
module.fail_json(msg='subscription-manager failed with the following error: %s' % err)
else:
return rc, out, err
def get_repository_list(module, list_parameter):
# Generate RHSM repository list and return a list of dict
if list_parameter == 'list_enabled':
rhsm_arguments = ['repos', '--list-enabled']
elif list_parameter == 'list_disabled':
rhsm_arguments = ['repos', '--list-disabled']
elif list_parameter == 'list':
rhsm_arguments = ['repos', '--list']
rc, out, err = run_subscription_manager(module, rhsm_arguments)
skip_lines = [
'+----------------------------------------------------------+',
' Available Repositories in /etc/yum.repos.d/redhat.repo'
]
repo_id_re = re.compile(r'Repo ID:\s+(.*)')
repo_name_re = re.compile(r'Repo Name:\s+(.*)')
repo_url_re = re.compile(r'Repo URL:\s+(.*)')
repo_enabled_re = re.compile(r'Enabled:\s+(.*)')
repo_id = ''
repo_name = ''
repo_url = ''
repo_enabled = ''
repo_result = []
for line in out.splitlines():
if line == '' or line in skip_lines:
continue
repo_id_match = repo_id_re.match(line)
if repo_id_match:
repo_id = repo_id_match.group(1)
continue
repo_name_match = repo_name_re.match(line)
if repo_name_match:
repo_name = repo_name_match.group(1)
continue
repo_url_match = repo_url_re.match(line)
if repo_url_match:
repo_url = repo_url_match.group(1)
continue
repo_enabled_match = repo_enabled_re.match(line)
if repo_enabled_match:
repo_enabled = repo_enabled_match.group(1)
repo = {
"id": repo_id,
"name": repo_name,
"url": repo_url,
"enabled": True if repo_enabled == '1' else False
}
repo_result.append(repo)
return repo_result
def repository_modify(module, state, name, purge=False):
name = set(name)
current_repo_list = get_repository_list(module, 'list')
updated_repo_list = deepcopy(current_repo_list)
matched_existing_repo = {}
for repoid in name:
matched_existing_repo[repoid] = []
for idx, repo in enumerate(current_repo_list):
if fnmatch(repo['id'], repoid):
matched_existing_repo[repoid].append(repo)
# Update current_repo_list to return it as result variable
updated_repo_list[idx]['enabled'] = True if state == 'enabled' else False
changed = False
results = []
diff_before = ""
diff_after = ""
rhsm_arguments = ['repos']
for repoid in matched_existing_repo:
if len(matched_existing_repo[repoid]) == 0:
results.append("%s is not a valid repository ID" % repoid)
module.fail_json(results=results, msg="%s is not a valid repository ID" % repoid)
for repo in matched_existing_repo[repoid]:
if state in ['disabled', 'absent']:
if repo['enabled']:
changed = True
diff_before += "Repository '%s' is enabled for this system\n" % repo['id']
diff_after += "Repository '%s' is disabled for this system\n" % repo['id']
results.append("Repository '%s' is disabled for this system" % repo['id'])
rhsm_arguments += ['--disable', repo['id']]
elif state in ['enabled', 'present']:
if not repo['enabled']:
changed = True
diff_before += "Repository '%s' is disabled for this system\n" % repo['id']
diff_after += "Repository '%s' is enabled for this system\n" % repo['id']
results.append("Repository '%s' is enabled for this system" % repo['id'])
rhsm_arguments += ['--enable', repo['id']]
# Disable all enabled repos on the system that are not in the task and not
# marked as disabled by the task
if purge:
enabled_repo_ids = set(repo['id'] for repo in updated_repo_list if repo['enabled'])
matched_repoids_set = set(matched_existing_repo.keys())
difference = enabled_repo_ids.difference(matched_repoids_set)
if len(difference) > 0:
for repoid in difference:
changed = True
diff_before.join("Repository '{repoid}'' is enabled for this system\n".format(repoid=repoid))
diff_after.join("Repository '{repoid}' is disabled for this system\n".format(repoid=repoid))
results.append("Repository '{repoid}' is disabled for this system".format(repoid=repoid))
rhsm_arguments.extend(['--disable', repoid])
diff = {'before': diff_before,
'after': diff_after,
'before_header': "RHSM repositories",
'after_header': "RHSM repositories"}
if not module.check_mode:
rc, out, err = run_subscription_manager(module, rhsm_arguments)
results = out.splitlines()
module.exit_json(results=results, changed=changed, repositories=updated_repo_list, diff=diff)
def main():
module = AnsibleModule(
argument_spec=dict(
name=dict(type='list', required=True),
state=dict(choices=['enabled', 'disabled', 'present', 'absent'], default='enabled'),
purge=dict(type='bool', default=False),
),
supports_check_mode=True,
)
name = module.params['name']
state = module.params['state']
purge = module.params['purge']
repository_modify(module, state, name, purge)
if __name__ == '__main__':
main() | unknown | codeparrot/codeparrot-clean | ||
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
from __future__ import annotations
import os
from typing import Annotated
from fastapi import Depends, HTTPException, Query, status
from fastapi.exceptions import RequestValidationError
from pydantic import ValidationError
from sqlalchemy import select
from airflow.api_fastapi.common.db.common import SessionDep, paginated_select
from airflow.api_fastapi.common.parameters import (
QueryConnectionIdPatternSearch,
QueryLimit,
QueryOffset,
SortParam,
)
from airflow.api_fastapi.common.router import AirflowRouter
from airflow.api_fastapi.core_api.datamodels.common import (
BulkBody,
BulkResponse,
)
from airflow.api_fastapi.core_api.datamodels.connections import (
ConnectionBody,
ConnectionCollectionResponse,
ConnectionResponse,
ConnectionTestResponse,
)
from airflow.api_fastapi.core_api.openapi.exceptions import create_openapi_http_exception_doc
from airflow.api_fastapi.core_api.security import (
ReadableConnectionsFilterDep,
requires_access_connection,
requires_access_connection_bulk,
)
from airflow.api_fastapi.core_api.services.public.connections import (
BulkConnectionService,
update_orm_from_pydantic,
)
from airflow.api_fastapi.logging.decorators import action_logging
from airflow.configuration import conf
from airflow.exceptions import AirflowNotFoundException
from airflow.models import Connection
from airflow.secrets.environment_variables import CONN_ENV_PREFIX
from airflow.utils.db import create_default_connections as db_create_default_connections
from airflow.utils.strings import get_random_string
connections_router = AirflowRouter(tags=["Connection"], prefix="/connections")
@connections_router.delete(
"/{connection_id}",
status_code=status.HTTP_204_NO_CONTENT,
responses=create_openapi_http_exception_doc([status.HTTP_404_NOT_FOUND]),
dependencies=[Depends(requires_access_connection(method="DELETE")), Depends(action_logging())],
)
def delete_connection(
connection_id: str,
session: SessionDep,
):
"""Delete a connection entry."""
connection = session.scalar(select(Connection).filter_by(conn_id=connection_id))
if connection is None:
raise HTTPException(
status.HTTP_404_NOT_FOUND, f"The Connection with connection_id: `{connection_id}` was not found"
)
session.delete(connection)
@connections_router.get(
"/{connection_id}",
responses=create_openapi_http_exception_doc([status.HTTP_404_NOT_FOUND]),
dependencies=[Depends(requires_access_connection(method="GET"))],
)
def get_connection(
connection_id: str,
session: SessionDep,
) -> ConnectionResponse:
"""Get a connection entry."""
connection = session.scalar(select(Connection).filter_by(conn_id=connection_id))
if connection is None:
raise HTTPException(
status.HTTP_404_NOT_FOUND, f"The Connection with connection_id: `{connection_id}` was not found"
)
return connection
@connections_router.get(
"",
responses=create_openapi_http_exception_doc([status.HTTP_404_NOT_FOUND]),
dependencies=[Depends(requires_access_connection(method="GET"))],
)
def get_connections(
limit: QueryLimit,
offset: QueryOffset,
order_by: Annotated[
SortParam,
Depends(
SortParam(
["conn_id", "conn_type", "description", "host", "port", "id", "team_name"],
Connection,
{"connection_id": "conn_id"},
).dynamic_depends()
),
],
readable_connections_filter: ReadableConnectionsFilterDep,
session: SessionDep,
connection_id_pattern: QueryConnectionIdPatternSearch,
) -> ConnectionCollectionResponse:
"""Get all connection entries."""
connection_select, total_entries = paginated_select(
statement=select(Connection),
filters=[connection_id_pattern, readable_connections_filter],
order_by=order_by,
offset=offset,
limit=limit,
session=session,
)
connections = session.scalars(connection_select)
return ConnectionCollectionResponse(
connections=connections,
total_entries=total_entries,
)
@connections_router.post(
"",
status_code=status.HTTP_201_CREATED,
responses=create_openapi_http_exception_doc(
[status.HTTP_409_CONFLICT]
), # handled by global exception handler
dependencies=[Depends(requires_access_connection(method="POST")), Depends(action_logging())],
)
def post_connection(
post_body: ConnectionBody,
session: SessionDep,
) -> ConnectionResponse:
"""Create connection entry."""
connection = Connection(**post_body.model_dump(by_alias=True))
session.add(connection)
return connection
@connections_router.patch(
"", dependencies=[Depends(requires_access_connection_bulk()), Depends(action_logging())]
)
def bulk_connections(
request: BulkBody[ConnectionBody],
session: SessionDep,
) -> BulkResponse:
"""Bulk create, update, and delete connections."""
return BulkConnectionService(session=session, request=request).handle_request()
@connections_router.patch(
"/{connection_id}",
responses=create_openapi_http_exception_doc(
[
status.HTTP_400_BAD_REQUEST,
status.HTTP_404_NOT_FOUND,
]
),
dependencies=[Depends(requires_access_connection(method="PUT")), Depends(action_logging())],
)
def patch_connection(
connection_id: str,
patch_body: ConnectionBody,
session: SessionDep,
update_mask: list[str] | None = Query(None),
) -> ConnectionResponse:
"""Update a connection entry."""
if patch_body.connection_id != connection_id:
raise HTTPException(
status.HTTP_400_BAD_REQUEST,
"The connection_id in the request body does not match the URL parameter",
)
connection = session.scalar(select(Connection).filter_by(conn_id=connection_id).limit(1))
if connection is None:
raise HTTPException(
status.HTTP_404_NOT_FOUND, f"The Connection with connection_id: `{connection_id}` was not found"
)
try:
ConnectionBody(**patch_body.model_dump())
except ValidationError as e:
raise RequestValidationError(errors=e.errors())
update_orm_from_pydantic(connection, patch_body, update_mask)
return connection
@connections_router.post("/test", dependencies=[Depends(requires_access_connection(method="POST"))])
def test_connection(test_body: ConnectionBody) -> ConnectionTestResponse:
"""
Test an API connection.
This method first creates an in-memory transient conn_id & exports that to an env var,
as some hook classes tries to find out the `conn` from their __init__ method & errors out if not found.
It also deletes the conn id env connection after the test.
"""
if conf.get("core", "test_connection", fallback="Disabled").lower().strip() != "enabled":
raise HTTPException(
status.HTTP_403_FORBIDDEN,
"Testing connections is disabled in Airflow configuration. "
"Contact your deployment admin to enable it.",
)
transient_conn_id = get_random_string()
conn_env_var = f"{CONN_ENV_PREFIX}{transient_conn_id.upper()}"
try:
# Try to get existing connection and merge with provided values
try:
existing_conn = Connection.get_connection_from_secrets(test_body.connection_id)
existing_conn.conn_id = transient_conn_id
update_orm_from_pydantic(existing_conn, test_body)
conn = existing_conn
except AirflowNotFoundException:
data = test_body.model_dump(by_alias=True)
data["conn_id"] = transient_conn_id
conn = Connection(**data)
os.environ[conn_env_var] = conn.get_uri()
test_status, test_message = conn.test_connection()
return ConnectionTestResponse.model_validate({"status": test_status, "message": test_message})
finally:
os.environ.pop(conn_env_var, None)
@connections_router.post(
"/defaults",
status_code=status.HTTP_204_NO_CONTENT,
dependencies=[Depends(requires_access_connection(method="POST")), Depends(action_logging())],
)
def create_default_connections(
session: SessionDep,
):
"""Create default connections."""
db_create_default_connections(session) | python | github | https://github.com/apache/airflow | airflow-core/src/airflow/api_fastapi/core_api/routes/public/connections.py |
# -*- coding: utf-8 -*-
from collections import OrderedDict
from collections.abc import Iterable, Mapping
from decimal import Decimal
from itertools import chain as iter_chain
import sys
from ..util import NamedDict
from .typing import DAttribute
class ReshapeDescriptor:
def __get__(self, instance, owner):
if instance is None:
def op_func(*args, **kwargs):
return _reshape_class(owner, *args, **kwargs)
return op_func
else:
def op_func(*args, **kwargs):
return _reshape_object(instance, *args, **kwargs)
return op_func
def _reshape_object(instance, *args, **kwargs):
""" """
if args:
raise ValueError("The positional argument is not allowable here")
dobj_cls = instance.__class__
return dobj_cls(**kwargs)
def _reshape_class(orig_cls, *args, **kwargs):
new_type_name = None # string of type name
selected = set() # names
ignored = set() # names
new_pkeys = [] # list of names
declared = OrderedDict() # {attr_name: attribute}
new_bases = [] # list of type
combined = [] # list of type
substituted = {} # {new_attr : old_attr}
arg_name = '_ignore'
if arg_name in kwargs:
arg_value = kwargs[arg_name]
if isinstance(arg_value, Iterable):
for i, elem in enumerate(arg_value):
if isinstance(elem, str):
ignored.add(elem)
elif isinstance(elem, DAttribute):
ignored.add(elem.name)
else:
errmsg = ("The %d-th element in 'ignore' argument "
"should be a str or DAttribute object: %r")
errmsg %= (elem, arg_value)
raise ValueError(errmsg)
elif isinstance(arg_value, DAttribute):
ignored.add(arg_value.name)
elif isinstance(arg_value, str):
ignored.add(arg_value)
del kwargs[arg_name]
arg_name = '_key'
if arg_name in kwargs:
arg_value = kwargs[arg_name]
if isinstance(arg_value, Iterable):
for i, elem in enumerate(arg_value):
if isinstance(elem, str):
new_pkeys.append(elem)
elif isinstance(elem, DAttribute):
new_pkeys.append(elem.name)
else:
errmsg = ("The %d-th element in '_pkeys' argument "
"should be a str or DAttribute object: %r")
errmsg %= (elem, arg_value)
raise ValueError(errmsg)
elif isinstance(arg_value, DAttribute):
new_pkeys.append(arg_value.name)
elif isinstance(arg_value, str):
new_pkeys.append(arg_value)
del kwargs[arg_name]
arg_name = '_base'
if arg_name in kwargs:
arg_value = kwargs[arg_name]
if isinstance(arg_value, type):
new_bases.append(arg_value)
elif isinstance(arg_value, Iterable):
for i, cls in enumerate(arg_value):
if isinstance(cls, type):
new_bases.append(cls)
else:
errmsg = ("The %d-th element of '_base' should be"
" a type object")
errmsg %= (i + 1)
raise ValueError(errmsg)
else:
errmsg = ("The value of '_base' should be"
" a iterable object of type or a type object")
raise ValueError(errmsg)
del kwargs[arg_name]
arg_name = '_combine'
if arg_name in kwargs:
arg_value = kwargs[arg_name]
if isinstance(arg_value, type):
combined.append(arg_value)
elif isinstance(arg_value, Iterable):
for i, cls in enumerate(arg_value):
if isinstance(cls, type):
combined.append(cls)
else:
errmsg = ("The %d-th element of '_combine' should be"
" a type object")
errmsg %= (i + 1)
raise ValueError(errmsg)
else:
errmsg = ("The value of '_combine' should be"
" a iterable object of type or a type object")
raise ValueError(errmsg)
del kwargs[arg_name]
arg_name = '_subst'
if arg_name in kwargs:
arg_value = kwargs[arg_name]
if isinstance(arg_value, Mapping):
for new_attr, old_attr in arg_value.items():
if isinstance(old_attr, str):
substituted[new_attr] = old_attr
else:
errmsg = ("The target or source attribue names should be "
" a str object in _subst")
raise ValueError(errmsg)
else:
raise ValueError("The _subst should be a dict or Mapping object")
del kwargs[arg_name]
arg_name = '_name'
if arg_name in kwargs:
arg_value = kwargs[arg_name]
if isinstance(arg_value, str):
new_type_name = arg_value
else:
raise ValueError("The _name should be a str object")
del kwargs[arg_name]
for i, arg in enumerate(args):
if isinstance(arg, str):
selected.add(arg)
elif isinstance(arg, DAttribute):
selected.add(arg.name)
else:
errmsg = ("The %d-th argument must be a str or attribute object"
", not : %r")
errmsg %= (i + 1, arg)
raise ValueError(errmsg)
for attr_name, arg_value in kwargs.items():
if attr_name.startswith('_'):
raise ValueError("Unknown operation '%s'" % attr_name)
elif isinstance(arg_value, bool):
if arg_value:
selected.add(arg)
else:
ignored.add(arg)
elif(arg_value, DAttribute):
declared[attr_name] = arg_value
else:
errmsg = "Unknown operand: %s=%r" % (attr_name, arg_value)
raise ValueError(errmsg)
# -------------------------------------------------------------------
attributes = OrderedDict()
for attr_name, attr in iter_chain(orig_cls.__dobject_key__.items(),
orig_cls.__dobject_att__.items()):
attr = attr.copy()
attr.owner_class = None
if attr_name in substituted:
attributes[substituted[attr_name]] = attr
else:
attributes[attr_name] = attr
# ONLY substitute the original object's attribute names
for old_attr_name, new_attr_name in substituted.items():
if (old_attr_name not in orig_cls.__dobject_att__ and
old_attr_name not in orig_cls.__dobject_key__):
errmsg = "No found the attribute '%s' substituted by '%s' in %s"
errmsg = (old_attr_name, new_attr_name, orig_cls.__name__)
raise ValueError(errmsg)
if old_attr_name in selected:
selected.add(new_attr_name)
selected.remove(old_attr_name)
if old_attr_name in ignored:
ignored.add(new_attr_name)
ignored.remove(old_attr_name)
for cls in combined:
for attr_name, attr in iter_chain(cls.__dobject_key__.items(),
cls.__dobject_att__.items()):
if attr_name not in attributes:
attributes[attr_name] = attr
for attr_name, attr in declared.items():
attributes[attr_name] = attr
if selected:
attributes = OrderedDict([(k, v) for k, v in attributes.items()
if k in selected and k not in ignored])
else:
attributes = OrderedDict([(k, v) for k, v in attributes.items()
if k not in ignored])
if new_pkeys:
pkeys = []
for attr_name in new_pkeys:
if attr_name in ignored:
errmsg = ("Conflict! The attribute '%s' has specified as "
"primary key, and also as ignored attribute")
errmsg %= attr_name
raise ValueError(errmsg)
if attr_name not in attributes:
errmsg = ("The attribute '%s' specified as primary key does not"
" be declared in origin or base classes")
errmsg %= attr_name
raise ValueError(errmsg)
if attr_name in attributes:
pkeys.append(attr_name)
new_pkeys = pkeys
else:
if orig_cls.__dobject_key__:
new_pkeys = []
for attr_name in orig_cls.__dobject_key__:
if attr_name in substituted:
attr_name = substituted[attr_name]
if attr_name not in attributes:
continue
new_pkeys.append(attr_name)
attributes['__dobject_key__'] = new_pkeys
attributes['__dobject_origin_class__'] = orig_cls
subst_map = OrderedDict()
for old_name, new_name in substituted.items():
subst_map[new_name] = old_name
attributes['__dobject_mapping__'] = subst_map
if not new_bases:
new_bases = orig_cls.__bases__
else:
new_bases = tuple(new_bases)
if not new_type_name :
new_type_name = orig_cls.__name__
new_cls = type(new_type_name, new_bases, attributes)
new_cls.__module__ = sys._getframe(2).f_globals.get('__name__', '__main__')
setattr(new_cls, '__dobject_origin_class__', tuple([orig_cls] + combined))
if substituted:
setattr(new_cls, '__dobject_mapping__', substituted)
return new_cls
class ReshapeOperator:
__slot__ = ('source', 'requred', 'ignored')
def __init__(self, source, operands, kwoperands):
self.source = source
self.required = OrderedDict()
self.ignored = OrderedDict()
self._base = []
self._primary_key = None
self._name = None
self.parse_operands(operands, kwoperands)
def reshape_class(self):
""" """
tmpl_pkey = None
tmpl_attrs = OrderedDict()
for cls in iter_chain([self.source], self._base):
if tmpl_pkey is None and cls.__dobject_key__:
# The nearest primary key definition is valid
tmpl_pkey = cls.__dobject_key__
for attr_name, attr in iter_chain(cls.__dobject_key__.items(),
cls.__dobject_att__.items()):
if attr_name not in tmpl_attrs:
tmpl_attrs[attr_name] = attr
prop_dict = OrderedDict()
if self.required:
for attr_name, attr in tmpl_attrs.items():
if attr_name not in self.required:
continue
if attr_name in self.ignored:
continue
prop_dict[attr_name] = attr
else:
for attr_name, attr in tmpl_attrs.items():
if attr_name in self.ignored:
continue
prop_dict[attr_name] = attr
pkey_attrs = []
for attr in (self._primary_key if self._primary_key else tmpl_pkey):
if isinstance(attr, str):
if attr not in prop_dict:
continue
attr = prop_dict[attr]
else:
if attr.name not in prop_dict:
continue
pkey_attrs.append(attr)
prop_dict['__dobject_key__'] = pkey_attrs
if not self._base:
# Oops, workaround, avoid cyclical importing!!!
from ..db.dtable import dtable
from ._dobject import dobject
if issubclass(self.source, dtable):
base_cls = tuple([dtable])
else:
base_cls = tuple([dobject])
# no inheritance, it's too complicated
else:
base_cls = tuple(self._base)
if not self._name:
self._name = self.source.__name__ # keey the name
reshaped_cls = type(self._name, base_cls, prop_dict)
return reshaped_cls | unknown | codeparrot/codeparrot-clean | ||
#!/bin/sh
# Copyright 2009 The Go Authors. All rights reserved.
# Use of this source code is governed by a BSD-style
# license that can be found in the LICENSE file.
COMMAND="mksysnum_plan9.sh $@"
cat <<EOF
// $COMMAND
// Code generated by the command above; DO NOT EDIT.
package syscall
const(
EOF
SP='[ ]' # space or tab
sed "s/^#define${SP}\\([A-Z0-9_][A-Z0-9_]*\\)${SP}${SP}*\\([0-9][0-9]*\\)/SYS_\\1=\\2/g" \
< $1 | grep -v SYS__
cat <<EOF
)
EOF | unknown | github | https://github.com/golang/go | src/syscall/mksysnum_plan9.sh |
from _pydev_runfiles import pydev_runfiles_xml_rpc
import pickle
import zlib
import base64
import os
import py
from pydevd_file_utils import _NormFile
import pytest
import sys
import time
#=========================================================================
# Load filters with tests we should skip
#=========================================================================
py_test_accept_filter = None
def _load_filters():
global py_test_accept_filter
if py_test_accept_filter is None:
py_test_accept_filter = os.environ.get('PYDEV_PYTEST_SKIP')
if py_test_accept_filter:
py_test_accept_filter = pickle.loads(
zlib.decompress(base64.b64decode(py_test_accept_filter)))
else:
py_test_accept_filter = {}
def is_in_xdist_node():
main_pid = os.environ.get('PYDEV_MAIN_PID')
if main_pid and main_pid != str(os.getpid()):
return True
return False
connected = False
def connect_to_server_for_communication_to_xml_rpc_on_xdist():
global connected
if connected:
return
connected = True
if is_in_xdist_node():
port = os.environ.get('PYDEV_PYTEST_SERVER')
if not port:
sys.stderr.write(
'Error: no PYDEV_PYTEST_SERVER environment variable defined.\n')
else:
pydev_runfiles_xml_rpc.initialize_server(int(port), daemon=True)
PY2 = sys.version_info[0] <= 2
PY3 = not PY2
#=========================================================================
# Mocking to get clickable file representations
#=========================================================================
_mock_code = []
try:
from py._code import code # @UnresolvedImport
_mock_code.append(code)
except ImportError:
pass
try:
from _pytest._code import code # @UnresolvedImport
_mock_code.append(code)
except ImportError:
pass
def _MockFileRepresentation():
for code in _mock_code:
code.ReprFileLocation._original_toterminal = code.ReprFileLocation.toterminal
def toterminal(self, tw):
# filename and lineno output for each entry,
# using an output format that most editors understand
msg = self.message
i = msg.find("\n")
if i != -1:
msg = msg[:i]
path = os.path.abspath(self.path)
if PY2:
# Note: it usually is NOT unicode...
if not isinstance(path, unicode):
path = path.decode(sys.getfilesystemencoding(), 'replace')
# Note: it usually is unicode...
if not isinstance(msg, unicode):
msg = msg.decode('utf-8', 'replace')
unicode_line = unicode('File "%s", line %s\n%s') % (
path, self.lineno, msg)
tw.line(unicode_line)
else:
tw.line('File "%s", line %s\n%s' % (path, self.lineno, msg))
code.ReprFileLocation.toterminal = toterminal
def _UninstallMockFileRepresentation():
for code in _mock_code:
# @UndefinedVariable
code.ReprFileLocation.toterminal = code.ReprFileLocation._original_toterminal
#=========================================================================
# End mocking to get clickable file representations
#=========================================================================
class State:
start_time = time.time()
buf_err = None
buf_out = None
def start_redirect():
if State.buf_out is not None:
return
from _pydevd_bundle import pydevd_io
State.buf_err = pydevd_io.start_redirect(keep_original_redirection=True, std='stderr')
State.buf_out = pydevd_io.start_redirect(keep_original_redirection=True, std='stdout')
def get_curr_output():
return State.buf_out.getvalue(), State.buf_err.getvalue()
def pytest_configure():
_MockFileRepresentation()
def pytest_unconfigure():
_UninstallMockFileRepresentation()
if is_in_xdist_node():
return
# Only report that it finished when on the main node (we don't want to report
# the finish on each separate node).
pydev_runfiles_xml_rpc.notifyTestRunFinished(
'Finished in: %.2f secs.' % (time.time() - State.start_time,))
def pytest_collection_modifyitems(session, config, items):
# A note: in xdist, this is not called on the main process, only in the
# secondary nodes, so, we'll actually make the filter and report it multiple
# times.
connect_to_server_for_communication_to_xml_rpc_on_xdist()
_load_filters()
if not py_test_accept_filter:
pydev_runfiles_xml_rpc.notifyTestsCollected(len(items))
return # Keep on going (nothing to filter)
new_items = []
for item in items:
f = _NormFile(str(item.parent.fspath))
name = item.name
if f not in py_test_accept_filter:
# print('Skip file: %s' % (f,))
continue # Skip the file
accept_tests = py_test_accept_filter[f]
if item.cls is not None:
class_name = item.cls.__name__
else:
class_name = None
for test in accept_tests:
# This happens when parameterizing pytest tests.
i = name.find('[')
if i > 0:
name = name[:i]
if test == name:
# Direct match of the test (just go on with the default
# loading)
new_items.append(item)
break
if class_name is not None:
if test == class_name + '.' + name:
new_items.append(item)
break
if class_name == test:
new_items.append(item)
break
else:
pass
# print('Skip test: %s.%s. Accept: %s' % (class_name, name, accept_tests))
# Modify the original list
items[:] = new_items
pydev_runfiles_xml_rpc.notifyTestsCollected(len(items))
from py.io import TerminalWriter
def _get_error_contents_from_report(report):
if report.longrepr is not None:
tw = TerminalWriter(stringio=True)
tw.hasmarkup = False
report.toterminal(tw)
exc = tw.stringio.getvalue()
s = exc.strip()
if s:
return s
return ''
def pytest_collectreport(report):
error_contents = _get_error_contents_from_report(report)
if error_contents:
report_test('fail', '<collect errors>', '<collect errors>', '', error_contents, 0.0)
def append_strings(s1, s2):
if s1.__class__ == s2.__class__:
return s1 + s2
if sys.version_info[0] == 2:
if not isinstance(s1, basestring):
s1 = str(s1)
if not isinstance(s2, basestring):
s2 = str(s2)
# Prefer bytes
if isinstance(s1, unicode):
s1 = s1.encode('utf-8')
if isinstance(s2, unicode):
s2 = s2.encode('utf-8')
return s1 + s2
else:
# Prefer str
if isinstance(s1, bytes):
s1 = s1.decode('utf-8', 'replace')
if isinstance(s2, bytes):
s2 = s2.decode('utf-8', 'replace')
return s1 + s2
def pytest_runtest_logreport(report):
if is_in_xdist_node():
# When running with xdist, we don't want the report to be called from the node, only
# from the main process.
return
report_duration = report.duration
report_when = report.when
report_outcome = report.outcome
if hasattr(report, 'wasxfail'):
if report_outcome != 'skipped':
report_outcome = 'passed'
if report_outcome == 'passed':
# passed on setup/teardown: no need to report if in setup or teardown
# (only on the actual test if it passed).
if report_when in ('setup', 'teardown'):
return
status = 'ok'
elif report_outcome == 'skipped':
status = 'skip'
else:
# It has only passed, skipped and failed (no error), so, let's consider
# error if not on call.
if report_when in ('setup', 'teardown'):
status = 'error'
else:
# any error in the call (not in setup or teardown) is considered a
# regular failure.
status = 'fail'
# This will work if pytest is not capturing it, if it is, nothing will
# come from here...
captured_output, error_contents = getattr(report, 'pydev_captured_output', ''), getattr(report, 'pydev_error_contents', '')
for type_section, value in report.sections:
if value:
if type_section in ('err', 'stderr', 'Captured stderr call'):
error_contents = append_strings(error_contents, value)
else:
captured_output = append_strings(error_contents, value)
filename = getattr(report, 'pydev_fspath_strpath', '<unable to get>')
test = report.location[2]
if report_outcome != 'skipped':
# On skipped, we'll have a traceback for the skip, which is not what we
# want.
exc = _get_error_contents_from_report(report)
if exc:
if error_contents:
error_contents = append_strings(error_contents, '----------------------------- Exceptions -----------------------------\n')
error_contents = append_strings(error_contents, exc)
report_test(status, filename, test, captured_output, error_contents, report_duration)
def report_test(status, filename, test, captured_output, error_contents, duration):
'''
@param filename: 'D:\\src\\mod1\\hello.py'
@param test: 'TestCase.testMet1'
@param status: fail, error, ok
'''
time_str = '%.2f' % (duration,)
pydev_runfiles_xml_rpc.notifyTest(
status, captured_output, error_contents, filename, test, time_str)
@pytest.hookimpl(hookwrapper=True)
def pytest_runtest_makereport(item, call):
outcome = yield
report = outcome.get_result()
report.pydev_fspath_strpath = item.fspath.strpath
report.pydev_captured_output, report.pydev_error_contents = get_curr_output()
@pytest.mark.tryfirst
def pytest_runtest_setup(item):
'''
Note: with xdist will be on a secondary process.
'''
# We have our own redirection: if xdist does its redirection, we'll have
# nothing in our contents (which is OK), but if it does, we'll get nothing
# from pytest but will get our own here.
start_redirect()
filename = item.fspath.strpath
test = item.location[2]
pydev_runfiles_xml_rpc.notifyStartTest(filename, test) | unknown | codeparrot/codeparrot-clean | ||
"""
SCAN: A Structural Clustering Algorithm for Networks
"""
from collections import deque
import numpy as np
from scipy.sparse import csr_matrix
def struct_similarity(vcols, wcols):
count = [index for index in wcols if (index in vcols)]
#need to account for vertex itself, add 2(1 for each vertex)
ans = (len(count) +2) / (((vcols.size+1)*(wcols.size+1)) ** .5)
return ans
def neighborhood(G, vertex_v, eps):
""" Returns the neighbors, as well as all the connected vertices """
N = deque()
vcols = vertex_v.tocoo().col
#check the similarity for each connected vertex
for index in vcols:
wcols = G[index,:].tocoo().col
if struct_similarity(vcols, wcols)> eps:
N.append(index)
return N, vcols
def scan(G, eps =0.7, mu=2):
"""
Vertex Structure = sum of row + itself(1)
Structural Similarity is the geometric mean of the 2Vertex size of structure
"""
c = 0
v = G.shape[0]
# All vertices are labeled as unclassified(-1)
vertex_labels = -np.ones(v)
# start with a neg core(every new core we incr by 1)
cluster_id = -1
for vertex in xrange(v):
N ,vcols = neighborhood(G, G[vertex,:],eps)
# must include vertex itself
N.appendleft(vertex)
if len(N) >= mu:
#print "we have a cluster at: %d ,with length %d " % (vertex, len(N))
# gen a new cluster id (0 indexed)
cluster_id +=1
while N:
y = N.pop()
R , ycols = neighborhood(G, G[y,:], eps)
# include itself
R.appendleft(y)
# (struct reachable) check core and if y is connected to vertex
if len(R) >= mu and y in vcols:
#print "we have a structure Reachable at: %d ,with length %d " % (y, len(R))
while R:
r = R.pop()
label = vertex_labels[r]
# if unclassified or non-member
if (label == -1) or (label==0):
vertex_labels[r] = cluster_id
# unclassified ??
if label == -1:
N.appendleft(r)
else:
vertex_labels[vertex] = 0
#classify non-members
for index in np.where(vertex_labels ==0)[0]:
ncols= G[index,:].tocoo().col
if len(ncols) >=2:
## mark as a hub
vertex_labels[index] = -2
continue
else:
## mark as outlier
vertex_labels[index] = -3
continue
return vertex_labels | unknown | codeparrot/codeparrot-clean | ||
# Copyright 2015-2016 ARM Limited
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
"""Process the output of the power allocator trace in the current
directory's trace.dat"""
from collections import OrderedDict
import pandas as pd
import re
from trappy.base import Base
from trappy.dynamic import register_ftrace_parser
class Thermal(Base):
"""Process the thermal framework data in a FTrace dump"""
unique_word = "thermal_temperature:"
"""The unique word that will be matched in a trace line"""
name = "thermal"
"""The name of the :mod:`pandas.DataFrame` member that will be created in a
:mod:`trappy.ftrace.FTrace` object"""
pivot = "id"
"""The Pivot along which the data is orthogonal"""
def plot_temperature(self, control_temperature=None, title="", width=None,
height=None, ylim="range", ax=None, legend_label=""):
"""Plot the temperature.
:param ax: Axis instance
:type ax: :mod:`matplotlib.Axis`
:param legend_label: Label for the legend
:type legend_label: str
:param title: The title of the plot
:type title: str
:param control_temperature: If control_temp is a
:mod:`pd.Series` representing the (possible)
variation of :code:`control_temp` during the
run, draw it using a dashed yellow line.
Otherwise, only the temperature is plotted.
:type control_temperature: :mod:`pandas.Series`
:param width: The width of the plot
:type width: int
:param height: The height of the plot
:type int: int
"""
from matplotlib import pyplot as plt
from trappy.plot_utils import normalize_title, pre_plot_setup, post_plot_setup
title = normalize_title("Temperature", title)
if len(self.data_frame) == 0:
raise ValueError("Empty DataFrame")
setup_plot = False
if not ax:
ax = pre_plot_setup(width, height)
setup_plot = True
temp_label = normalize_title("Temperature", legend_label)
(self.data_frame["temp"] / 1000).plot(ax=ax, label=temp_label)
if control_temperature is not None:
ct_label = normalize_title("Control", legend_label)
control_temperature.plot(ax=ax, color="y", linestyle="--",
label=ct_label)
if setup_plot:
post_plot_setup(ax, title=title, ylim=ylim)
plt.legend()
def plot_temperature_hist(self, ax, title):
"""Plot a temperature histogram
:param ax: Axis instance
:type ax: :mod:`matplotlib.Axis`
:param title: The title of the plot
:type title: str
"""
from trappy.plot_utils import normalize_title, plot_hist
temps = self.data_frame["temp"] / 1000
title = normalize_title("Temperature", title)
xlim = (0, temps.max())
plot_hist(temps, ax, title, "C", 30, "Temperature", xlim, "default")
register_ftrace_parser(Thermal, "thermal")
class ThermalGovernor(Base):
"""Process the power allocator data in a ftrace dump"""
unique_word = "thermal_power_allocator:"
"""The unique word that will be matched in a trace line"""
name = "thermal_governor"
"""The name of the :mod:`pandas.DataFrame` member that will be created in a
:mod:`trappy.ftrace.FTrace` object"""
pivot = "thermal_zone_id"
"""The Pivot along which the data is orthogonal"""
def plot_temperature(self, title="", width=None, height=None, ylim="range",
ax=None, legend_label=""):
"""Plot the temperature"""
from matplotlib import pyplot as plt
from trappy.plot_utils import normalize_title, pre_plot_setup, post_plot_setup
dfr = self.data_frame
curr_temp = dfr["current_temperature"]
control_temp_series = (curr_temp + dfr["delta_temperature"]) / 1000
title = normalize_title("Temperature", title)
setup_plot = False
if not ax:
ax = pre_plot_setup(width, height)
setup_plot = True
temp_label = normalize_title("Temperature", legend_label)
(curr_temp / 1000).plot(ax=ax, label=temp_label)
control_temp_series.plot(ax=ax, color="y", linestyle="--",
label="control temperature")
if setup_plot:
post_plot_setup(ax, title=title, ylim=ylim)
plt.legend()
def plot_input_power(self, actor_order, title="", width=None, height=None,
ax=None):
"""Plot input power
:param ax: Axis instance
:type ax: :mod:`matplotlib.Axis`
:param title: The title of the plot
:type title: str
:param width: The width of the plot
:type width: int
:param height: The height of the plot
:type int: int
:param actor_order: An array showing the order in which the actors
were registered. The array values are the labels that
will be used in the input and output power plots.
For Example:
::
["GPU", "A15", "A7"]
:type actor_order: list
"""
from trappy.plot_utils import normalize_title, pre_plot_setup, post_plot_setup
dfr = self.data_frame
in_cols = [s for s in dfr.columns if re.match("req_power[0-9]+", s)]
plot_dfr = dfr[in_cols]
# Rename the columns from "req_power0" to "A15" or whatever is
# in actor_order. Note that we can do it just with an
# assignment because the columns are already sorted (i.e.:
# req_power0, req_power1...)
plot_dfr.columns = actor_order
title = normalize_title("Input Power", title)
if not ax:
ax = pre_plot_setup(width, height)
plot_dfr.plot(ax=ax)
post_plot_setup(ax, title=title)
def plot_weighted_input_power(self, actor_weights, title="", width=None,
height=None, ax=None):
"""Plot weighted input power
:param actor_weights: An array of tuples. First element of the
tuple is the name of the actor, the second is the weight. The
array is in the same order as the :code:`req_power` appear in the
trace.
:type actor_weights: list
:param ax: Axis instance
:type ax: :mod:`matplotlib.Axis`
:param title: The title of the plot
:type title: str
:param width: The width of the plot
:type width: int
:param height: The height of the plot
:type int: int
"""
from trappy.plot_utils import normalize_title, pre_plot_setup, post_plot_setup
dfr = self.data_frame
in_cols = [s for s in dfr.columns if re.match(r"req_power\d+", s)]
plot_dfr_dict = OrderedDict()
for in_col, (name, weight) in zip(in_cols, actor_weights):
plot_dfr_dict[name] = dfr[in_col] * weight / 1024
plot_dfr = pd.DataFrame(plot_dfr_dict)
title = normalize_title("Weighted Input Power", title)
if not ax:
ax = pre_plot_setup(width, height)
plot_dfr.plot(ax=ax)
post_plot_setup(ax, title=title)
def plot_output_power(self, actor_order, title="", width=None, height=None,
ax=None):
"""Plot output power
:param ax: Axis instance
:type ax: :mod:`matplotlib.Axis`
:param title: The title of the plot
:type title: str
:param width: The width of the plot
:type width: int
:param height: The height of the plot
:type int: int
:param actor_order: An array showing the order in which the actors
were registered. The array values are the labels that
will be used in the input and output power plots.
For Example:
::
["GPU", "A15", "A7"]
:type actor_order: list
"""
from trappy.plot_utils import normalize_title, pre_plot_setup, post_plot_setup
out_cols = [s for s in self.data_frame.columns
if re.match("granted_power[0-9]+", s)]
# See the note in plot_input_power()
plot_dfr = self.data_frame[out_cols]
plot_dfr.columns = actor_order
title = normalize_title("Output Power", title)
if not ax:
ax = pre_plot_setup(width, height)
plot_dfr.plot(ax=ax)
post_plot_setup(ax, title=title)
def plot_inout_power(self, title=""):
"""Make multiple plots showing input and output power for each actor
:param title: The title of the plot
:type title: str
"""
from trappy.plot_utils import normalize_title
dfr = self.data_frame
actors = []
for col in dfr.columns:
match = re.match("P(.*)_in", col)
if match and col != "Ptot_in":
actors.append(match.group(1))
for actor in actors:
cols = ["P" + actor + "_in", "P" + actor + "_out"]
this_title = normalize_title(actor, title)
dfr[cols].plot(title=this_title)
register_ftrace_parser(ThermalGovernor, "thermal") | unknown | codeparrot/codeparrot-clean | ||
"""
Serializers for use in the support app.
"""
import json
from django.urls import reverse
from rest_framework import serializers
from common.djangoapps.student.models import CourseEnrollment, ManualEnrollmentAudit
from lms.djangoapps.program_enrollments.models import ProgramCourseEnrollment, ProgramEnrollment
from openedx.core.djangoapps.catalog.utils import get_programs_by_uuids
from openedx.features.course_experience import default_course_url_name
DATETIME_FORMAT = '%Y-%m-%dT%H:%M:%S'
# pylint: disable=abstract-method
class ManualEnrollmentSerializer(serializers.ModelSerializer):
"""Serializes a manual enrollment audit object."""
enrolled_by = serializers.SlugRelatedField(slug_field='email', read_only=True, default='')
class Meta:
model = ManualEnrollmentAudit
fields = ('enrolled_by', 'time_stamp', 'reason')
class CourseEnrollmentSerializer(serializers.Serializer):
""" Serializers a student_courseenrollment model object """
course_id = serializers.CharField()
is_active = serializers.BooleanField()
mode = serializers.CharField()
class Meta:
model = CourseEnrollment
class ProgramCourseEnrollmentSerializer(serializers.Serializer):
""" Serializes a Program Course Enrollment model object """
created = serializers.DateTimeField(format=DATETIME_FORMAT)
modified = serializers.DateTimeField(format=DATETIME_FORMAT)
status = serializers.CharField()
course_key = serializers.CharField()
course_enrollment = CourseEnrollmentSerializer()
course_url = serializers.SerializerMethodField()
class Meta:
model = ProgramCourseEnrollment
def get_course_url(self, obj):
course_url_name = default_course_url_name(obj.course_key)
return reverse(course_url_name, kwargs={'course_id': obj.course_key})
class ProgramEnrollmentSerializer(serializers.Serializer):
""" Serializes a Program Enrollment Model object """
created = serializers.DateTimeField(format=DATETIME_FORMAT)
modified = serializers.DateTimeField(format=DATETIME_FORMAT)
external_user_key = serializers.CharField()
status = serializers.CharField()
program_uuid = serializers.UUIDField()
program_course_enrollments = ProgramCourseEnrollmentSerializer(many=True)
program_name = serializers.SerializerMethodField()
class Meta:
model = ProgramEnrollment
def get_program_name(self, obj):
program_list = get_programs_by_uuids([obj.program_uuid])
return next(iter(program_list), {}).get('title', '')
def serialize_user_info(user, user_social_auths=None):
"""
Helper method to serialize resulting in user_info_object
based on passed in django models
"""
user_info = {
'username': user.username,
'email': user.email,
}
if user_social_auths:
for user_social_auth in user_social_auths:
user_info.setdefault('sso_list', []).append({
'uid': user_social_auth.uid,
})
return user_info
def serialize_sso_records(user_social_auths):
"""
Serialize user social auth model object
"""
sso_records = []
for user_social_auth in user_social_auths:
sso_records.append({
'provider': user_social_auth.provider,
'uid': user_social_auth.uid,
'created': user_social_auth.created,
'modified': user_social_auth.modified,
'extraData': json.dumps(user_social_auth.extra_data),
})
return sso_records | unknown | codeparrot/codeparrot-clean |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.