
status stringclasses 1
value | repo_name stringclasses 31
values | repo_url stringclasses 31
values | issue_id int64 1 104k | title stringlengths 4 369 | body stringlengths 0 254k ⌀ | issue_url stringlengths 37 56 | pull_url stringlengths 37 54 | before_fix_sha stringlengths 40 40 | after_fix_sha stringlengths 40 40 | report_datetime timestamp[us, tz=UTC] | language stringclasses 5
values | commit_datetime timestamp[us, tz=UTC] | updated_file stringlengths 4 188 | file_content stringlengths 0 5.12M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54Z | python | 2023-01-22T00:08:14Z | langchain/vectorstores/faiss.py | """Wrapper around FAISS vector database."""
from __future__ import annotations
import uuid
from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
import numpy as np
from langchain.docstore.base import AddableMixin, Docstore
from langchain.docstore.document import Document
from langchain.docstore.in_... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 674 | test_faiss_with_metadatas: key mismatch in assert | https://github.com/hwchase17/langchain/blob/236ae93610a8538d3d0044fc29379c481acc6789/tests/integration_tests/vectorstores/test_faiss.py#L54
This test will fail because `FAISS.from_texts` will assign uuid4s as keys in its docstore, while `expected_docstore` has string numbers as keys. | https://github.com/langchain-ai/langchain/issues/674 | https://github.com/langchain-ai/langchain/pull/676 | e45f7e40e80d9b47fb51853f0c672e747735b951 | e04b063ff40d7f70eaa91f135729071de60b219d | 2023-01-21T16:02:54Z | python | 2023-01-22T00:08:14Z | tests/integration_tests/vectorstores/test_faiss.py | """Test FAISS functionality."""
from typing import List
import pytest
from langchain.docstore.document import Document
from langchain.docstore.in_memory import InMemoryDocstore
from langchain.docstore.wikipedia import Wikipedia
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.faiss import ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 897 | Pinecone in docs is outdated | Pinecone default environment was recently changed from `us-west1-gcp` to `us-east1-gcp` ([see here](https://docs.pinecone.io/docs/projects#project-environment)), so new users following the [docs here](https://langchain.readthedocs.io/en/latest/modules/utils/combine_docs_examples/vectorstores.html#pinecone) will hit an ... | https://github.com/langchain-ai/langchain/issues/897 | https://github.com/langchain-ai/langchain/pull/898 | 7658263bfbc9485ebbc85b7d4c2476ea68611e26 | 8217a2f26c94234a1ea99d1b9b815e4da577dcfe | 2023-02-05T18:33:50Z | python | 2023-02-05T23:21:56Z | docs/modules/utils/combine_docs_examples/vectorstores.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "7ef4d402-6662-4a26-b612-35b542066487",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"# VectorStores\n",
"\n",
"This notebook show cases how to use VectorStores. A key part of working with vectorstores is creatin... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 906 | Error in Pinecone batch selection logic | Current implementation of pinecone vec db finds the batches using:
```
# set end position of batch
i_end = min(i + batch_size, len(texts))
```
[link](https://github.com/hwchase17/langchain/blob/master/langchain/vectorstores/pinecone.py#L199)
But the following lines then go on to use a mix of `[i : i + batch_s... | https://github.com/langchain-ai/langchain/issues/906 | https://github.com/langchain-ai/langchain/pull/907 | 82c080c6e617d4959fb4ee808deeba075f361702 | 3aa53b44dd5f013e35c316d110d340a630b0abd1 | 2023-02-06T07:52:59Z | python | 2023-02-06T20:45:56Z | langchain/vectorstores/pinecone.py | """Wrapper around Pinecone vector database."""
from __future__ import annotations
import uuid
from typing import Any, Callable, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.base import VectorStore
class ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,087 | Qdrant Wrapper issue: _document_from_score_point exposes incorrect key for content | 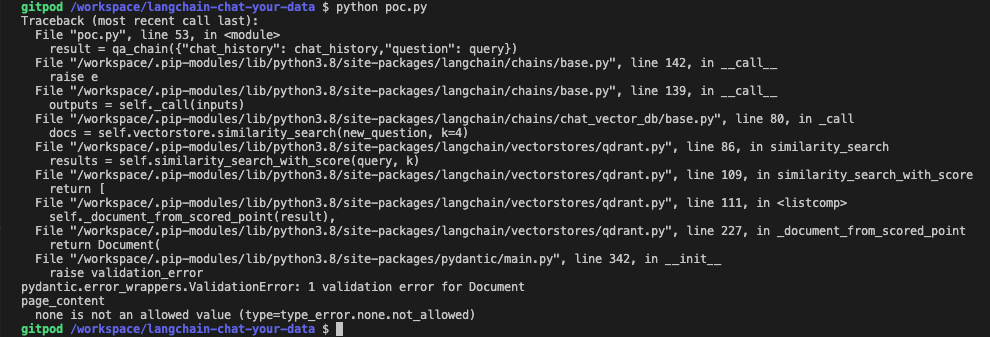
```
pydantic.error_wrappers.ValidationError: 1 validation error for Document
page_content
none is not an allowed value (type=type_error.none.not_allowed)
``` | https://github.com/langchain-ai/langchain/issues/1087 | https://github.com/langchain-ai/langchain/pull/1088 | 774550548242f44df9b219595cd46d9e238351e5 | 5d11e5da4077ad123bfff9f153f577fb5885af53 | 2023-02-16T13:18:41Z | python | 2023-02-16T15:06:02Z | langchain/vectorstores/qdrant.py | """Wrapper around Qdrant vector database."""
import uuid
from operator import itemgetter
from typing import Any, Callable, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import get_from_dict_or_env
from langchain.ve... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,103 | SQLDatabase chain having issue running queries on the database after connecting | Langchain SQLDatabase and using SQL chain is giving me issues in the recent versions. My goal has been this:
- Connect to a sql server (say, Azure SQL server) using mssql+pyodbc driver (also tried mssql+pymssql driver)
`connection_url = URL.create(
"mssql+pyodbc",
query={"odbc_connect": co... | https://github.com/langchain-ai/langchain/issues/1103 | https://github.com/langchain-ai/langchain/pull/1129 | 1ed708391e80a4de83e859b8364a32cc222df9ef | c39ef70aa457dcfcf8ddcf61f89dd69d55307744 | 2023-02-17T04:18:02Z | python | 2023-02-17T21:39:44Z | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import ast
from typing import Any, Iterable, List, Optional
from sqlalchemy import create_engine, inspect
from sqlalchemy.engine import Engine
_TEMPLATE_PREFIX = """Table data will be described in the following format:
Table 'table name'... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29Z | python | 2023-02-21T00:39:13Z | langchain/vectorstores/faiss.py | """Wrapper around FAISS vector database."""
from __future__ import annotations
import pickle
import uuid
from pathlib import Path
from typing import Any, Callable, Dict, Iterable, List, Optional, Tuple
import numpy as np
from langchain.docstore.base import AddableMixin, Docstore
from langchain.docstore.document impo... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,186 | max_marginal_relevance_search_by_vector with k > doc size | #1117 didn't seem to fix it? I still get an error `KeyError: -1`
Code to reproduce:
```py
output = docsearch.max_marginal_relevance_search_by_vector(query_vec, k=10)
```
where `k > len(docsearch)`. Pushing PR with unittest/fix shortly. | https://github.com/langchain-ai/langchain/issues/1186 | https://github.com/langchain-ai/langchain/pull/1187 | 159c560c95ed9e11cc740040cc6ee07abb871ded | c5015d77e23b24b3b65d803271f1fa9018d53a05 | 2023-02-20T19:19:29Z | python | 2023-02-21T00:39:13Z | tests/integration_tests/vectorstores/test_faiss.py | """Test FAISS functionality."""
import tempfile
import pytest
from langchain.docstore.document import Document
from langchain.docstore.in_memory import InMemoryDocstore
from langchain.docstore.wikipedia import Wikipedia
from langchain.vectorstores.faiss import FAISS
from tests.integration_tests.vectorstores.fake_embe... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 983 | SQLite Cache memory for async agent runs fails in concurrent calls | I have a slack bot using slack bolt for python to handle various request for certain topics.
Using the SQLite Cache as described in here
https://langchain.readthedocs.io/en/latest/modules/llms/examples/llm_caching.html
Fails when asking the same question mutiple times for the first time with error
> (sqlite3... | https://github.com/langchain-ai/langchain/issues/983 | https://github.com/langchain-ai/langchain/pull/1286 | 81abcae91a3bbd3c90ac9644d232509b3094b54d | 42b892c21be7278689cabdb83101631f286ffc34 | 2023-02-10T19:30:13Z | python | 2023-02-27T01:54:43Z | langchain/cache.py | """Beta Feature: base interface for cache."""
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple
from sqlalchemy import Column, Integer, String, create_engine, select
from sqlalchemy.engine.base import Engine
from sqlalchemy.orm import Session
try:
from sqlalchemy.orm import d... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,383 | ValueError: unsupported format character 'b' (0x62) at index 52 | python version 3.9.12, langchain version 0.0.98
Using this code
```
db = SQLDatabase.from_uri(DATABSE_URI, include_tables=['tbl_abc'])
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True
)
agent_executor.run("search for th... | https://github.com/langchain-ai/langchain/issues/1383 | https://github.com/langchain-ai/langchain/pull/1408 | 443992c4d58dcb168a21c0f45afb36b84fbdd46a | 882f7964fb0c5364bce0dcfb73abacd8ece525e4 | 2023-03-02T07:22:39Z | python | 2023-03-03T00:03:16Z | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
from typing import Any, Iterable, List, Optional
from sqlalchemy import MetaData, create_engine, inspect, select
from sqlalchemy.engine import Engine
from sqlalchemy.exc import ProgrammingError, SQLAlchemyError
from sqlalchemy.schema impor... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,489 | LLM making its own observation when a tool should be used | I'm playing with the [CSV agent example](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/csv.html) and notice something strange. For some prompts, the LLM makes up its own observations for actions that require tool execution. For example:
```
agent.run("Summarize the data in one sentence")
... | https://github.com/langchain-ai/langchain/issues/1489 | https://github.com/langchain-ai/langchain/pull/1566 | 30383abb127d7687a82df6593dd74329d00db730 | a9502872069409039c69b41d4857b2c7791c3752 | 2023-03-07T06:41:07Z | python | 2023-03-10T00:36:15Z | langchain/agents/agent.py | """Chain that takes in an input and produces an action and action input."""
from __future__ import annotations
import json
import logging
from abc import abstractmethod
from pathlib import Path
from typing import Any, Dict, List, Optional, Sequence, Tuple, Union
import yaml
from pydantic import BaseModel, root_valida... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,756 | namespace argument not taken into account when creating Pinecone index | # Quick summary
Using the `namespace` argument in the function `Pinecone.from_existing_index` has no effect. Indeed, it is passed to `pinecone.Index`, which has no `namespace` argument.
# Steps to reproduce a relevant bug
```
import pinecone
from langchain.docstore.document import Document
from langchain.vector... | https://github.com/langchain-ai/langchain/issues/1756 | https://github.com/langchain-ai/langchain/pull/1757 | 280cb4160d9bd6cdb80edb5f766a06216610002c | 3701b2901e76f2f97239c2152a6a7d01754fb666 | 2023-03-18T12:26:39Z | python | 2023-03-19T02:55:38Z | langchain/vectorstores/pinecone.py | """Wrapper around Pinecone vector database."""
from __future__ import annotations
import uuid
from typing import Any, Callable, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.base import VectorStore
class ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,756 | namespace argument not taken into account when creating Pinecone index | # Quick summary
Using the `namespace` argument in the function `Pinecone.from_existing_index` has no effect. Indeed, it is passed to `pinecone.Index`, which has no `namespace` argument.
# Steps to reproduce a relevant bug
```
import pinecone
from langchain.docstore.document import Document
from langchain.vector... | https://github.com/langchain-ai/langchain/issues/1756 | https://github.com/langchain-ai/langchain/pull/1757 | 280cb4160d9bd6cdb80edb5f766a06216610002c | 3701b2901e76f2f97239c2152a6a7d01754fb666 | 2023-03-18T12:26:39Z | python | 2023-03-19T02:55:38Z | tests/integration_tests/vectorstores/test_pinecone.py | """Test Pinecone functionality."""
import pinecone
from langchain.docstore.document import Document
from langchain.vectorstores.pinecone import Pinecone
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENV")
index = pinecone.Index... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,339 | UT test_bash.py broken on MacOS dev environment | I forked & cloned the project to my dev env on MacOS, then ran 'make test', the test case 'test_incorrect_command_return_err_output' from test_bash.py failed with the following output:
<img width="1139" alt="image" src="https://user-images.githubusercontent.com/64731944/221828313-4c3f6284-9fd4-4bb5-b489-8d7e911ada03... | https://github.com/langchain-ai/langchain/issues/1339 | https://github.com/langchain-ai/langchain/pull/1837 | b706966ebc7e17cef3ced81c8e59c8f2d648a8c8 | a92344f476fc3f18599442790a1423505eec9eb4 | 2023-02-28T10:51:39Z | python | 2023-03-21T16:06:52Z | tests/unit_tests/test_bash.py | """Test the bash utility."""
import subprocess
from pathlib import Path
from langchain.utilities.bash import BashProcess
def test_pwd_command() -> None:
"""Test correct functionality."""
session = BashProcess()
commands = ["pwd"]
output = session.run(commands)
assert output == subprocess.check_o... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | 2023-03-20T02:39:16Z | python | 2023-03-27T15:17:14Z | docs/modules/document_loaders/examples/azure_blob_storage_container.ipynb | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | 2023-03-20T02:39:16Z | python | 2023-03-27T15:17:14Z | docs/modules/document_loaders/examples/azure_blob_storage_file.ipynb | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | 2023-03-20T02:39:16Z | python | 2023-03-27T15:17:14Z | langchain/document_loaders/__init__.py | """All different types of document loaders."""
from langchain.document_loaders.airbyte_json import AirbyteJSONLoader
from langchain.document_loaders.azlyrics import AZLyricsLoader
from langchain.document_loaders.blackboard import BlackboardLoader
from langchain.document_loaders.college_confidential import CollegeConfi... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | 2023-03-20T02:39:16Z | python | 2023-03-27T15:17:14Z | langchain/document_loaders/azure_blob_storage_container.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,805 | Document loader for Azure Blob storage | Lots of customers is asking if langchain have a document loader like AWS S3 or GCS for Azure Blob Storage as well. As you know Microsoft is a big partner for OpenAI , so there is a real need to have native document loader for Azure Blob storage as well. We will be very happy to see this feature ASAP. | https://github.com/langchain-ai/langchain/issues/1805 | https://github.com/langchain-ai/langchain/pull/1890 | 42d725223ea3765a7699e19d46a6e0c70b4baa79 | c1a9d83b34441592d063c4d0753029c187b1c16a | 2023-03-20T02:39:16Z | python | 2023-03-27T15:17:14Z | langchain/document_loaders/azure_blob_storage_file.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,801 | Poetry 1.4.0 installation fails | `poetry install -E all` fails with Poetry >=1.4.0 due to upstream incompatibility between `poetry>=1.4.0` and `pydata_sphinx_theme`.
This is a tracking issue. I've already created an issue upstream here: https://github.com/pydata/pydata-sphinx-theme/issues/1253 | https://github.com/langchain-ai/langchain/issues/1801 | https://github.com/langchain-ai/langchain/pull/1935 | 3d3e52352005aef549f9e19ad6ab18428887865c | c50fafb35d22f0f2b4e39ebb24a5ee6177c8f44e | 2023-03-19T23:42:55Z | python | 2023-03-27T15:27:54Z | poetry.toml | [virtualenvs]
in-project = true
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,838 | How metadata is being used during similarity search and query? | I have 3 pdf files in my directory and I "documentized", added metadata, split, embed and store them in pinecone, like this:
```
loader = DirectoryLoader('data/dir', glob="**/*.pdf", loader_cls=UnstructuredPDFLoader)
data = loader.load()
#I added company names explicitly for now
data[0].metadata["company"]="Ap... | https://github.com/langchain-ai/langchain/issues/1838 | https://github.com/langchain-ai/langchain/pull/1964 | f257b08406563af9ffb044da45b829d0707d755b | 953e58d0040773c76f68e633c3db3cd371c9c350 | 2023-03-21T01:32:20Z | python | 2023-03-27T22:04:53Z | langchain/vectorstores/chroma.py | """Wrapper around ChromaDB embeddings platform."""
from __future__ import annotations
import logging
import uuid
from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Tuple
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.vectorstores.ba... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,712 | bug(QA with Sources): source parsing is not reliable | I was going through [Vectorstore Agent](https://langchain.readthedocs.io/en/latest/modules/agents/agent_toolkits/vectorstore.html?highlight=vectorstore%20agent#vectorstore-agent) tutorial and I am facing issues with the `VectorStoreQAWithSourcesTool`.
Looking closely at the code https://github.com/hwchase17/langchai... | https://github.com/langchain-ai/langchain/issues/1712 | https://github.com/langchain-ai/langchain/pull/2118 | c33e055f17d59e225cc009c49b28d4400d56e709 | 859502b16c132e6d2f02d5233233f20f78847bdb | 2023-03-16T15:47:53Z | python | 2023-03-28T22:28:20Z | langchain/chains/qa_with_sources/base.py | """Question answering with sources over documents."""
from __future__ import annotations
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional
from pydantic import BaseModel, Extra, root_validator
from langchain.chains.base import Chain
from langchain.chains.combine_documents.base import ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,834 | LLMMathChain to allow ChatOpenAI as an llm | 1. Cannot initialize match chain with ChatOpenAI LLM
llm_math = LLMMathChain(llm=ChatOpenAI(temperature=0))
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
Cell In[33], line 1
----> 1 llm_math = LLMMathChai... | https://github.com/langchain-ai/langchain/issues/1834 | https://github.com/langchain-ai/langchain/pull/2183 | 3207a7482915a658cf8f473ae0a81ba9998c8531 | fd1fcb5a7d48cbe18b480b1493b66540e4709745 | 2023-03-20T23:12:24Z | python | 2023-03-30T14:52:58Z | langchain/chains/llm_math/base.py | """Chain that interprets a prompt and executes python code to do math."""
from typing import Dict, List
from pydantic import BaseModel, Extra
from langchain.chains.base import Chain
from langchain.chains.llm import LLMChain
from langchain.chains.llm_math.prompt import PROMPT
from langchain.llms.base import BaseLLM
fr... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,245 | Wrong PromptLayer Dashboard hyperlink | In the docs, in https://python.langchain.com/en/latest/modules/models/llms/integrations/promptlayer_openai.html there is a hyperlink to the PromptLayer dashboard that links to "https://ww.promptlayer.com", which is incorrect. | https://github.com/langchain-ai/langchain/issues/2245 | https://github.com/langchain-ai/langchain/pull/2246 | e57b045402b52c2a602f4895c5b06fa2c22b745a | 632c2b49dabbccab92e37d01e4d1d86b6fa68457 | 2023-03-31T20:33:41Z | python | 2023-03-31T23:16:23Z | docs/modules/models/llms/integrations/promptlayer_openai.ipynb | {
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"id": "959300d4",
"metadata": {},
"source": [
"# PromptLayer OpenAI\n",
"\n",
"This example showcases how to connect to [PromptLayer](https://www.promptlayer.com) to start recording your OpenAI requests."
]
},
{
"attachme... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,174 | failed tests on Windows platform | NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_file... | https://github.com/langchain-ai/langchain/issues/2174 | https://github.com/langchain-ai/langchain/pull/2238 | 609b14a57004b4679341a05729577ec5dbcaff7d | 579ad85785a4011bdcb9fc316d2c1bcddfb9d427 | 2023-03-30T03:43:17Z | python | 2023-04-01T19:52:21Z | tests/unit_tests/chains/test_llm_bash.py | """Test LLM Bash functionality."""
import pytest
from langchain.chains.llm_bash.base import LLMBashChain
from langchain.chains.llm_bash.prompt import _PROMPT_TEMPLATE
from tests.unit_tests.llms.fake_llm import FakeLLM
@pytest.fixture
def fake_llm_bash_chain() -> LLMBashChain:
"""Fake LLM Bash chain for testing.... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,174 | failed tests on Windows platform | NOTE: fixed in #2238 PR.
I'm running `tests/unit_tests` on the Windows platform and several tests related to `bash` failed.
>test_llm_bash/
test_simple_question
and
>test_bash/
test_pwd_command
test_incorrect_command
test_incorrect_command_return_err_output
test_create_directory_and_file... | https://github.com/langchain-ai/langchain/issues/2174 | https://github.com/langchain-ai/langchain/pull/2238 | 609b14a57004b4679341a05729577ec5dbcaff7d | 579ad85785a4011bdcb9fc316d2c1bcddfb9d427 | 2023-03-30T03:43:17Z | python | 2023-04-01T19:52:21Z | tests/unit_tests/test_bash.py | """Test the bash utility."""
import re
import subprocess
from pathlib import Path
from langchain.utilities.bash import BashProcess
def test_pwd_command() -> None:
"""Test correct functionality."""
session = BashProcess()
commands = ["pwd"]
output = session.run(commands)
assert output == subproce... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're po... | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | 2023-04-06T15:46:29Z | python | 2023-04-06T19:45:56Z | docs/modules/indexes/vectorstores/examples/opensearch.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "683953b3",
"metadata": {},
"source": [
"# OpenSearch\n",
"\n",
"This notebook shows how to use functionality related to the OpenSearch database.\n",
"\n",
"To run, you should have the opensearch instance up and running: [here](https://ope... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,500 | OpenSearchVectorSearch doesn't permit the user to specify a field name | Currently the `OpenSearchVectorSearch` class [defaults to `vector_field`](https://github.com/hwchase17/langchain/blob/26314d7004f36ca01f2c843a3ac38b166c9d2c44/langchain/vectorstores/opensearch_vector_search.py#L189) as the field name of the vector field in all vector similarity searches.
This works fine if you're po... | https://github.com/langchain-ai/langchain/issues/2500 | https://github.com/langchain-ai/langchain/pull/2509 | ad87584c35f78551b3b02b2322c720b173584860 | 2ffb90b1613b01f238a084b5848bed80882f4720 | 2023-04-06T15:46:29Z | python | 2023-04-06T19:45:56Z | langchain/vectorstores/opensearch_vector_search.py | """Wrapper around OpenSearch vector database."""
from __future__ import annotations
import uuid
from typing import Any, Dict, Iterable, List, Optional
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import get_from_dict_or_env
from langchain.vecto... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,634 | GoogleDriveLoader not loading docs from Share Drives | https://github.com/hwchase17/langchain/blob/cb646082baa173fdee7f2b1e361be368acef4e7e/langchain/document_loaders/googledrive.py#L120
Suggestion: Include optional param `includeItemsFromAllDrives` when calling `service.files().list()`
Reference: https://stackoverflow.com/questions/65388539/using-python-i-cant-access-... | https://github.com/langchain-ai/langchain/issues/1634 | https://github.com/langchain-ai/langchain/pull/2562 | 7bf5b0ccd36a72395ac16ebafdfb3453d57c6e9d | 125afb51d791577ef078554f0ceec817a7ca4e22 | 2023-03-13T15:03:55Z | python | 2023-04-08T15:46:55Z | langchain/document_loaders/googledrive.py | """Loader that loads data from Google Drive."""
# Prerequisites:
# 1. Create a Google Cloud project
# 2. Enable the Google Drive API:
# https://console.cloud.google.com/flows/enableapi?apiid=drive.googleapis.com
# 3. Authorize credentials for desktop app:
# https://developers.google.com/drive/api/quickstart/python... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,624 | Missing import in AzureOpenAI embedding example | ## What's the issue?
Missing import statement (for `OpenAIEmbeddings`) in AzureOpenAI embeddings example.
<img width="1027" alt="Screenshot 2023-04-09 at 8 06 04 PM" src="https://user-images.githubusercontent.com/19938474/230779010-e7935543-6ae7-477c-872d-8a5220fc60c9.png">
https://github.com/hwchase17/langc... | https://github.com/langchain-ai/langchain/issues/2624 | https://github.com/langchain-ai/langchain/pull/2625 | 0f5d3b339009f0bc0d5a59356e82870d9f0f15d6 | 9aed565f130b44a6e6287ac572be6be26f064f71 | 2023-04-09T14:38:44Z | python | 2023-04-09T19:25:31Z | docs/modules/models/text_embedding/examples/azureopenai.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "c3852491",
"metadata": {},
"source": [
"# AzureOpenAI\n",
"\n",
"Let's load the OpenAI Embedding class with environment variables set to indicate to use Azure endpoints."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,677 | Langchain should use tiktoken tokenizer for python 3.8 | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However th... | https://github.com/langchain-ai/langchain/issues/2677 | https://github.com/langchain-ai/langchain/pull/2709 | 186ca9d3e485f3209aa6b465377a46c23fb98c87 | f435f2267c015ffd97ff5eea9ad8c8051ea0dc0f | 2023-04-10T18:40:46Z | python | 2023-04-11T18:02:28Z | langchain/chat_models/openai.py | """OpenAI chat wrapper."""
from __future__ import annotations
import logging
import sys
from typing import Any, Callable, Dict, List, Mapping, Optional, Tuple
from pydantic import Extra, Field, root_validator
from tenacity import (
before_sleep_log,
retry,
retry_if_exception_type,
stop_after_attempt,
... |
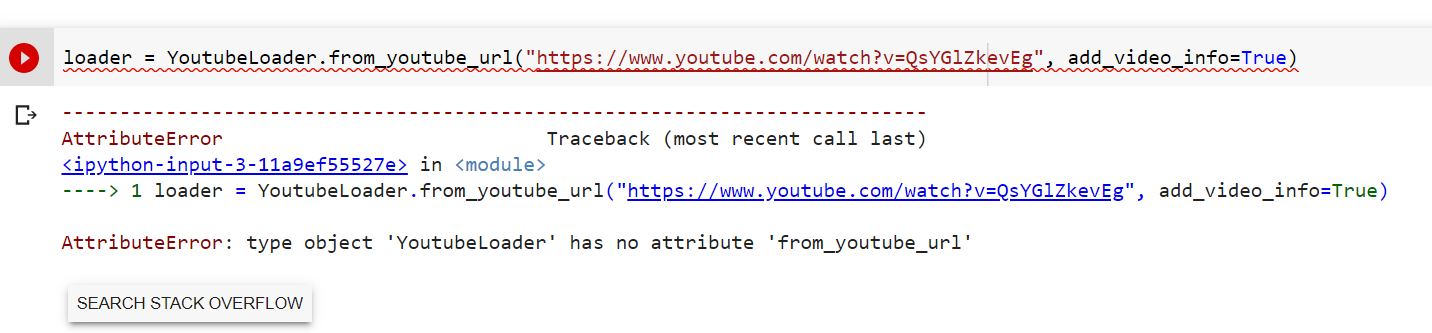
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,962 | AttributeError: type object 'YoutubeLoader' has no attribute 'from_youtube_url' | I am trying to load load video and came across below issue.
I am using langchain version 0.0.121
| https://github.com/langchain-ai/langchain/issues/1962 | https://github.com/langchain-ai/langchain/pull/2734 | 0ab364404ecfcda96a67c0fe81b24fc870617976 | 744c25cd0ac74c5608a564312c6e5b48c6276359 | 2023-03-24T10:08:17Z | python | 2023-04-12T04:12:58Z | langchain/document_loaders/youtube.py | """Loader that loads YouTube transcript."""
from __future__ import annotations
from pathlib import Path
from typing import Any, Dict, List, Optional
from pydantic import root_validator
from pydantic.dataclasses import dataclass
from langchain.docstore.document import Document
from langchain.document_loaders.base imp... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputPar... | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | 2023-04-11T14:20:29Z | python | 2023-04-12T16:12:20Z | langchain/output_parsers/fix.py | from __future__ import annotations
from typing import Any
from langchain.chains.llm import LLMChain
from langchain.output_parsers.prompts import NAIVE_FIX_PROMPT
from langchain.prompts.base import BasePromptTemplate
from langchain.schema import BaseLanguageModel, BaseOutputParser, OutputParserException
class Output... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputPar... | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | 2023-04-11T14:20:29Z | python | 2023-04-12T16:12:20Z | langchain/output_parsers/pydantic.py | import json
import re
from typing import Any
from pydantic import BaseModel, ValidationError
from langchain.output_parsers.format_instructions import PYDANTIC_FORMAT_INSTRUCTIONS
from langchain.schema import BaseOutputParser, OutputParserException
class PydanticOutputParser(BaseOutputParser):
pydantic_object: A... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputPar... | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | 2023-04-11T14:20:29Z | python | 2023-04-12T16:12:20Z | langchain/output_parsers/retry.py | from __future__ import annotations
from typing import Any
from langchain.chains.llm import LLMChain
from langchain.prompts.base import BasePromptTemplate
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import (
BaseLanguageModel,
BaseOutputParser,
OutputParserException,
Promp... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputPar... | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | 2023-04-11T14:20:29Z | python | 2023-04-12T16:12:20Z | langchain/output_parsers/structured.py | from __future__ import annotations
import json
from typing import List
from pydantic import BaseModel
from langchain.output_parsers.format_instructions import STRUCTURED_FORMAT_INSTRUCTIONS
from langchain.schema import BaseOutputParser, OutputParserException
line_template = '\t"{name}": {type} // {description}'
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputPar... | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | 2023-04-11T14:20:29Z | python | 2023-04-12T16:12:20Z | langchain/schema.py | """Common schema objects."""
from __future__ import annotations
from abc import ABC, abstractmethod
from typing import Any, Dict, List, NamedTuple, Optional
from pydantic import BaseModel, Extra, Field, root_validator
def get_buffer_string(
messages: List[BaseMessage], human_prefix: str = "Human", ai_prefix: st... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,715 | Better type hints for OutputParser | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputPar... | https://github.com/langchain-ai/langchain/issues/2715 | https://github.com/langchain-ai/langchain/pull/2769 | 789cc314c5987a4d3ba5a5e8819d889036974966 | 59d054308c850da1a61fc9621385182c7459120d | 2023-04-11T14:20:29Z | python | 2023-04-12T16:12:20Z | tests/unit_tests/output_parsers/test_pydantic_parser.py | """Test PydanticOutputParser"""
from enum import Enum
from typing import Optional
from pydantic import BaseModel, Field
from langchain.output_parsers.pydantic import PydanticOutputParser
from langchain.schema import OutputParserException
class Actions(Enum):
SEARCH = "Search"
CREATE = "Create"
UPDATE = ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,905 | Ignore files from `.gitignore` in Git loader | those files may be `node_modules` or `.pycache` files or sensitive env files, all of which should be ignored by default | https://github.com/langchain-ai/langchain/issues/2905 | https://github.com/langchain-ai/langchain/pull/2909 | 7ee87eb0c8df10315b45ebbddcad36a72b7fe7b9 | 66bef1d7ed17f00e7b554ca5413e336970489253 | 2023-04-14T17:08:38Z | python | 2023-04-14T22:02:21Z | langchain/document_loaders/git.py | import os
from typing import Callable, List, Optional
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
class GitLoader(BaseLoader):
"""Loads files from a Git repository into a list of documents.
Repository can be local on disk available at `repo_path`,
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | 2023-04-13T17:10:45Z | python | 2023-04-16T20:44:04Z | docs/modules/indexes/vectorstores/examples/annoy.ipynb | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | 2023-04-13T17:10:45Z | python | 2023-04-16T20:44:04Z | langchain/vectorstores/__init__.py | """Wrappers on top of vector stores."""
from langchain.vectorstores.atlas import AtlasDB
from langchain.vectorstores.base import VectorStore
from langchain.vectorstores.chroma import Chroma
from langchain.vectorstores.deeplake import DeepLake
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | 2023-04-13T17:10:45Z | python | 2023-04-16T20:44:04Z | langchain/vectorstores/annoy.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,842 | Add Annoy as VectorStore | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | https://github.com/langchain-ai/langchain/issues/2842 | https://github.com/langchain-ai/langchain/pull/2939 | e12e00df12c6830cd267df18e96fda1ef8df6c7a | a9310a3e8b6781bdc8f64a379eb844f8c8154584 | 2023-04-13T17:10:45Z | python | 2023-04-16T20:44:04Z | tests/integration_tests/vectorstores/test_annoy.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle... | https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | 2023-04-15T15:38:36Z | python | 2023-04-18T03:28:01Z | langchain/chains/combine_documents/base.py | """Base interface for chains combining documents."""
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple
from pydantic import Field
from langchain.chains.base import Chain
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSp... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle... | https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | 2023-04-15T15:38:36Z | python | 2023-04-18T03:28:01Z | langchain/chains/combine_documents/refine.py | """Combining documents by doing a first pass and then refining on more documents."""
from __future__ import annotations
from typing import Any, Dict, List, Tuple
from pydantic import Extra, Field, root_validator
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
from langchain.chains.llm ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle... | https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | 2023-04-15T15:38:36Z | python | 2023-04-18T03:28:01Z | langchain/chains/combine_documents/stuff.py | """Chain that combines documents by stuffing into context."""
from typing import Any, Dict, List, Optional, Tuple
from pydantic import Extra, Field, root_validator
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.docstore.document ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,944 | Question Answering over Docs giving cryptic error upon query | After ingesting some markdown files using a slightly modified version of the question-answering over docs example, I ran the qa.py script as it was in the example
```
# qa.py
import faiss
from langchain import OpenAI, HuggingFaceHub, LLMChain
from langchain.chains import VectorDBQAWithSourcesChain
import pickle... | https://github.com/langchain-ai/langchain/issues/2944 | https://github.com/langchain-ai/langchain/pull/3026 | 3453b7457ca60227430d85e6f6f58a2aafae559d | 19c85aa9907765c0a2dbe7c46e9d5dd2d6df0f30 | 2023-04-15T15:38:36Z | python | 2023-04-18T03:28:01Z | tests/unit_tests/chains/test_combine_documents.py | """Test functionality related to combining documents."""
from typing import Any, List
import pytest
from langchain.chains.combine_documents.map_reduce import (
_collapse_docs,
_split_list_of_docs,
)
from langchain.docstore.document import Document
def _fake_docs_len_func(docs: List[Document]) -> int:
r... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,874 | Redundunt piece of code | In Agents -> loading.py on line 40 there is a redundant piece of code.
```
if config_type not in AGENT_TO_CLASS:
raise ValueError(f"Loading {config_type} agent not supported")
``` | https://github.com/langchain-ai/langchain/issues/2874 | https://github.com/langchain-ai/langchain/pull/2934 | b40f90ea042b20440cb7c1a9e70a6e4cd4a0089c | ae7ed31386c10cee1683419a4ab45562830bf8eb | 2023-04-14T05:28:42Z | python | 2023-04-18T04:05:48Z | langchain/agents/loading.py | """Functionality for loading agents."""
import json
from pathlib import Path
from typing import Any, Dict, List, Optional, Type, Union
import yaml
from langchain.agents.agent import BaseSingleActionAgent
from langchain.agents.agent_types import AgentType
from langchain.agents.chat.base import ChatAgent
from langchain... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,057 | Error when parsing code from LLM response ValueError: Could not parse LLM output: | Sometimes the LLM response (generated code) tends to miss the ending ticks "```". Therefore causing the text parsing to fail due to `not enough values to unpack`.
Suggest to simply the `_, action, _' to just `action` then with index
Error message below
```
> Entering new AgentExecutor chain...
Traceback (mo... | https://github.com/langchain-ai/langchain/issues/3057 | https://github.com/langchain-ai/langchain/pull/3058 | db968284f8f3964630f119c95cca923f112ad47b | 2984ad39645c80411cee5e7f77a3c116b88d008e | 2023-04-18T04:13:20Z | python | 2023-04-18T04:42:13Z | langchain/agents/chat/output_parser.py | import json
from typing import Union
from langchain.agents.agent import AgentOutputParser
from langchain.schema import AgentAction, AgentFinish
FINAL_ANSWER_ACTION = "Final Answer:"
class ChatOutputParser(AgentOutputParser):
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
if FINAL_ANSWER_... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,157 | Missing Observation and Thought prefix in output | The console output when running a tool is missing the "Observation" and "Thought" prefixes.
I noticed this when using the SQL Toolkit, but other tools are likely affected.
Here is the current INCORRECT output format:
```
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input: ""invoice_... | https://github.com/langchain-ai/langchain/issues/3157 | https://github.com/langchain-ai/langchain/pull/3158 | 126d7f11dd17a8ea71a4427951f10cefc862ba3a | 0b542661b46d42ee501c6681a4519f2c4e76de23 | 2023-04-19T15:15:26Z | python | 2023-04-19T16:00:10Z | langchain/tools/base.py | """Base implementation for tools or skills."""
from abc import ABC, abstractmethod
from inspect import signature
from typing import Any, Dict, Optional, Sequence, Tuple, Type, Union
from pydantic import BaseModel, Extra, Field, validate_arguments, validator
from langchain.callbacks import get_callback_manager
from l... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,077 | Error `can only concatenate str (not "tuple") to str` when using `ConversationBufferWindowMemory` | I'm facing a weird issue with the `ConversationBufferWindowMemory`
Running `memory.load_memory_variables({})` prints:
```
{'chat_history': [HumanMessage(content='Hi my name is Ismail', additional_kwargs={}), AIMessage(content='Hello Ismail! How can I assist you today?', additional_kwargs={})]}
```
The error ... | https://github.com/langchain-ai/langchain/issues/3077 | https://github.com/langchain-ai/langchain/pull/3187 | 6adf2d1c39ca4e157377f20d3029d062342093e6 | c757c3cde45a24e0cd6a3ebe6bb0f8176cae4726 | 2023-04-18T08:38:57Z | python | 2023-04-20T00:08:10Z | docs/modules/models/llms/integrations/huggingface_hub.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "959300d4",
"metadata": {},
"source": [
"# Hugging Face Hub\n",
"\n",
"The [Hugging Face Hub](https://huggingface.co/docs/hub/index) is a platform with over 120k models, 20k datasets, and 50k demo apps (Spaces), all open source and publicly availa... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,077 | Error `can only concatenate str (not "tuple") to str` when using `ConversationBufferWindowMemory` | I'm facing a weird issue with the `ConversationBufferWindowMemory`
Running `memory.load_memory_variables({})` prints:
```
{'chat_history': [HumanMessage(content='Hi my name is Ismail', additional_kwargs={}), AIMessage(content='Hello Ismail! How can I assist you today?', additional_kwargs={})]}
```
The error ... | https://github.com/langchain-ai/langchain/issues/3077 | https://github.com/langchain-ai/langchain/pull/3187 | 6adf2d1c39ca4e157377f20d3029d062342093e6 | c757c3cde45a24e0cd6a3ebe6bb0f8176cae4726 | 2023-04-18T08:38:57Z | python | 2023-04-20T00:08:10Z | docs/modules/models/llms/integrations/huggingface_pipelines.ipynb | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,301 | Output using llamacpp is garbage | Hi there,
Trying to setup a langchain with llamacpp as a first step to use langchain offline:
`from langchain.llms import LlamaCpp
llm = LlamaCpp(model_path="../llama/models/ggml-vicuna-13b-4bit-rev1.bin")
text = "Question: What NFL team won the Super Bowl in the year Justin Bieber was born? Answer: Let's thi... | https://github.com/langchain-ai/langchain/issues/3301 | https://github.com/langchain-ai/langchain/pull/3320 | 3a1bdce3f51e302d468807e980455d676c0f5fd6 | 77bb6c99f7ee189ce3734c47b27e70dc237bbce7 | 2023-04-21T14:01:59Z | python | 2023-04-23T01:46:55Z | langchain/llms/llamacpp.py | """Wrapper around llama.cpp."""
import logging
from typing import Any, Dict, List, Optional
from pydantic import Field, root_validator
from langchain.llms.base import LLM
logger = logging.getLogger(__name__)
class LlamaCpp(LLM):
"""Wrapper around the llama.cpp model.
To use, you should have the llama-cpp-... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,241 | llama.cpp => model runs fine but bad output | Hi,
Windows 11 environement
Python: 3.10.11
I installed
- llama-cpp-python and it works fine and provides output
- transformers
- pytorch
Code run:
```
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think ste... | https://github.com/langchain-ai/langchain/issues/3241 | https://github.com/langchain-ai/langchain/pull/3320 | 3a1bdce3f51e302d468807e980455d676c0f5fd6 | 77bb6c99f7ee189ce3734c47b27e70dc237bbce7 | 2023-04-20T20:36:45Z | python | 2023-04-23T01:46:55Z | langchain/llms/llamacpp.py | """Wrapper around llama.cpp."""
import logging
from typing import Any, Dict, List, Optional
from pydantic import Field, root_validator
from langchain.llms.base import LLM
logger = logging.getLogger(__name__)
class LlamaCpp(LLM):
"""Wrapper around the llama.cpp model.
To use, you should have the llama-cpp-... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,404 | marathon_times.ipynb: mismatched text and code | Text mentions inflation and tuition:
Here is the prompt comparing inflation and college tuition.
Code is about marathon times:
agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."]) | https://github.com/langchain-ai/langchain/issues/3404 | https://github.com/langchain-ai/langchain/pull/3408 | b4de839ed8a1bea7425a6923b2cd635068b6015a | 73bc70b4fa7bb69647d9dbe81943b88ce6ccc180 | 2023-04-23T21:06:49Z | python | 2023-04-24T01:14:11Z | docs/use_cases/autonomous_agents/marathon_times.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "14f8b67b",
"metadata": {},
"source": [
"## AutoGPT example finding Winning Marathon Times\n",
"\n",
"* Implementation of https://github.com/Significant-Gravitas/Auto-GPT \n",
"* With LangChain primitives (LLMs, PromptTemplates, VectorStores, ... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,404 | marathon_times.ipynb: mismatched text and code | Text mentions inflation and tuition:
Here is the prompt comparing inflation and college tuition.
Code is about marathon times:
agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."]) | https://github.com/langchain-ai/langchain/issues/3404 | https://github.com/langchain-ai/langchain/pull/3408 | b4de839ed8a1bea7425a6923b2cd635068b6015a | 73bc70b4fa7bb69647d9dbe81943b88ce6ccc180 | 2023-04-23T21:06:49Z | python | 2023-04-24T01:14:11Z | langchain/tools/ddg_search/__init__.py | """DuckDuckGo Search API toolkit."""
|
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,384 | ValueError in cosine_similarity when using FAISS index as vector store | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py... | https://github.com/langchain-ai/langchain/issues/3384 | https://github.com/langchain-ai/langchain/pull/3475 | 53b14de636080e09e128d829aafa9ea34ac34a94 | b2564a63911f8a77272ac9e93e5558384f00155c | 2023-04-23T07:51:56Z | python | 2023-04-25T02:54:15Z | langchain/math_utils.py | """Math utils."""
from typing import List, Union
import numpy as np
Matrix = Union[List[List[float]], List[np.ndarray], np.ndarray]
def cosine_similarity(X: Matrix, Y: Matrix) -> np.ndarray:
"""Row-wise cosine similarity between two equal-width matrices."""
if len(X) == 0 or len(Y) == 0:
return np.a... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,384 | ValueError in cosine_similarity when using FAISS index as vector store | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py... | https://github.com/langchain-ai/langchain/issues/3384 | https://github.com/langchain-ai/langchain/pull/3475 | 53b14de636080e09e128d829aafa9ea34ac34a94 | b2564a63911f8a77272ac9e93e5558384f00155c | 2023-04-23T07:51:56Z | python | 2023-04-25T02:54:15Z | langchain/vectorstores/utils.py | """Utility functions for working with vectors and vectorstores."""
from typing import List
import numpy as np
from langchain.math_utils import cosine_similarity
def maximal_marginal_relevance(
query_embedding: np.ndarray,
embedding_list: list,
lambda_mult: float = 0.5,
k: int = 4,
) -> List[int]:
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,384 | ValueError in cosine_similarity when using FAISS index as vector store | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py... | https://github.com/langchain-ai/langchain/issues/3384 | https://github.com/langchain-ai/langchain/pull/3475 | 53b14de636080e09e128d829aafa9ea34ac34a94 | b2564a63911f8a77272ac9e93e5558384f00155c | 2023-04-23T07:51:56Z | python | 2023-04-25T02:54:15Z | tests/unit_tests/vectorstores/__init__.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,384 | ValueError in cosine_similarity when using FAISS index as vector store | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py... | https://github.com/langchain-ai/langchain/issues/3384 | https://github.com/langchain-ai/langchain/pull/3475 | 53b14de636080e09e128d829aafa9ea34ac34a94 | b2564a63911f8a77272ac9e93e5558384f00155c | 2023-04-23T07:51:56Z | python | 2023-04-25T02:54:15Z | tests/unit_tests/vectorstores/test_utils.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,766 | Update poetry lock to allow SQLAlchemy v2 | It seems that #1578 adds support for SQLAlchemy v2 but the [poetry lock file](https://github.com/hwchase17/langchain/blob/8685d53adcdd0310e76349ecb4e2b87f980c4673/poetry.lock#L6211) is still at 1.4.46. | https://github.com/langchain-ai/langchain/issues/1766 | https://github.com/langchain-ai/langchain/pull/3310 | 7c2c73af5f15799c9326e99ed15c4a30fd19ad11 | b7658059643cd2f8fa58a2132b7d723638445ebc | 2023-03-19T01:48:23Z | python | 2023-04-25T04:10:56Z | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import warnings
from typing import Any, Iterable, List, Optional
from sqlalchemy import MetaData, Table, create_engine, inspect, select, text
from sqlalchemy.engine import Engine
from sqlalchemy.exc import ProgrammingError, SQLAlchemyError... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,766 | Update poetry lock to allow SQLAlchemy v2 | It seems that #1578 adds support for SQLAlchemy v2 but the [poetry lock file](https://github.com/hwchase17/langchain/blob/8685d53adcdd0310e76349ecb4e2b87f980c4673/poetry.lock#L6211) is still at 1.4.46. | https://github.com/langchain-ai/langchain/issues/1766 | https://github.com/langchain-ai/langchain/pull/3310 | 7c2c73af5f15799c9326e99ed15c4a30fd19ad11 | b7658059643cd2f8fa58a2132b7d723638445ebc | 2023-03-19T01:48:23Z | python | 2023-04-25T04:10:56Z | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.148"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependenc... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown... | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | 2023-04-11T05:19:00Z | python | 2023-04-27T04:45:03Z | langchain/vectorstores/weaviate.py | """Wrapper around weaviate vector database."""
from __future__ import annotations
from typing import Any, Dict, Iterable, List, Optional, Type
from uuid import uuid4
import numpy as np
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from langchain.utils import get_fr... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown... | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | 2023-04-11T05:19:00Z | python | 2023-04-27T04:45:03Z | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_max_marginal_relevance_search.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Age... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown... | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | 2023-04-11T05:19:00Z | python | 2023-04-27T04:45:03Z | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_max_marginal_relevance_search_by_vector.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Age... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown... | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | 2023-04-11T05:19:00Z | python | 2023-04-27T04:45:03Z | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_max_marginal_relevance_search_with_filter.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Age... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown... | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | 2023-04-11T05:19:00Z | python | 2023-04-27T04:45:03Z | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_similarity_search_with_metadata.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Age... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown... | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | 2023-04-11T05:19:00Z | python | 2023-04-27T04:45:03Z | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_similarity_search_with_metadata_and_filter.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Age... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown... | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | 2023-04-11T05:19:00Z | python | 2023-04-27T04:45:03Z | tests/integration_tests/vectorstores/cassettes/test_weaviate/TestWeaviate.test_similarity_search_without_metadata.yaml | interactions:
- request:
body: '{"input": [[8134], [2308], [43673]], "encoding_format": "base64"}'
headers:
Accept:
- '*/*'
Accept-Encoding:
- gzip, deflate
Connection:
- keep-alive
Content-Length:
- '65'
Content-Type:
- application/json
User-Age... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 2,695 | Allow Weaviate initialization with alternative embedding implementation | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown... | https://github.com/langchain-ai/langchain/issues/2695 | https://github.com/langchain-ai/langchain/pull/3608 | 615812581ea3175b3ae9ec59036008d013052396 | 440c98e24bf3f18c132694309872592ef550e1bc | 2023-04-11T05:19:00Z | python | 2023-04-27T04:45:03Z | tests/integration_tests/vectorstores/test_weaviate.py | """Test Weaviate functionality."""
import logging
import os
from typing import Generator, Union
import pytest
from weaviate import Client
from langchain.docstore.document import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.weaviate import Weaviate
logging.basicConfig(... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,664 | import error when importing `from langchain import OpenAI` on 0.0.151 | got the following error when running today:
``` File "venv/lib/python3.11/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "venv/lib/python3.11/site-packages/langchain/agents/__init__.py", line 2, in <module>
from l... | https://github.com/langchain-ai/langchain/issues/3664 | https://github.com/langchain-ai/langchain/pull/3667 | 708787dddb2fa3cdb2d1dabefa00c01ffec572f6 | 1b5721c999c9fc310cefec383666f43c80ec9620 | 2023-04-27T16:24:30Z | python | 2023-04-27T18:39:01Z | langchain/utilities/bash.py | """Wrapper around subprocess to run commands."""
import re
import subprocess
from typing import List, Union
from uuid import uuid4
import pexpect
class BashProcess:
"""Executes bash commands and returns the output."""
def __init__(
self,
strip_newlines: bool = False,
return_err_outpu... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,664 | import error when importing `from langchain import OpenAI` on 0.0.151 | got the following error when running today:
``` File "venv/lib/python3.11/site-packages/langchain/__init__.py", line 6, in <module>
from langchain.agents import MRKLChain, ReActChain, SelfAskWithSearchChain
File "venv/lib/python3.11/site-packages/langchain/agents/__init__.py", line 2, in <module>
from l... | https://github.com/langchain-ai/langchain/issues/3664 | https://github.com/langchain-ai/langchain/pull/3667 | 708787dddb2fa3cdb2d1dabefa00c01ffec572f6 | 1b5721c999c9fc310cefec383666f43c80ec9620 | 2023-04-27T16:24:30Z | python | 2023-04-27T18:39:01Z | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.151"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependenc... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,628 | Chroma.py max_marginal_relevance_search_by_vector method currently broken | Using MMR with Chroma currently does not work because the max_marginal_relevance_search_by_vector method calls self.__query_collection with the parameter "include:", but "include" is not an accepted parameter for __query_collection. This appears to be a regression introduced with #3372
Excerpt from max_marginal_rel... | https://github.com/langchain-ai/langchain/issues/3628 | https://github.com/langchain-ai/langchain/pull/3897 | 3e1cb31f63b5c7147939feca7f8095377f64e145 | 245131097557b73774197b01e326206fa2a1b83a | 2023-04-27T00:21:42Z | python | 2023-05-01T17:47:15Z | langchain/vectorstores/chroma.py | """Wrapper around ChromaDB embeddings platform."""
from __future__ import annotations
import logging
import uuid
from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Tuple, Type
import numpy as np
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,628 | Chroma.py max_marginal_relevance_search_by_vector method currently broken | Using MMR with Chroma currently does not work because the max_marginal_relevance_search_by_vector method calls self.__query_collection with the parameter "include:", but "include" is not an accepted parameter for __query_collection. This appears to be a regression introduced with #3372
Excerpt from max_marginal_rel... | https://github.com/langchain-ai/langchain/issues/3628 | https://github.com/langchain-ai/langchain/pull/3897 | 3e1cb31f63b5c7147939feca7f8095377f64e145 | 245131097557b73774197b01e326206fa2a1b83a | 2023-04-27T00:21:42Z | python | 2023-05-01T17:47:15Z | tests/integration_tests/vectorstores/test_chroma.py | """Test Chroma functionality."""
import pytest
from langchain.docstore.document import Document
from langchain.vectorstores import Chroma
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
def test_chroma() -> None:
"""Test end to end construction and search."""
texts = ["foo", "... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,988 | LangChain openAI callback doesn't allow finetuned models | Hi all!
I have an [application](https://github.com/ur-whitelab/BO-LIFT) based on langchain.
A few months ago, I used it with fine-tuned (FT) models.
We added a token usage counter later, and I haven't tried fine-tuned models again since then.
Recently we have been interested in using (FT) models again, but the ... | https://github.com/langchain-ai/langchain/issues/3988 | https://github.com/langchain-ai/langchain/pull/4009 | aa383559999b3d6a781c62ed7f8589fef8892879 | f08a76250fe8995fb3f05bf785677070922d4b0d | 2023-05-02T18:00:22Z | python | 2023-05-02T23:19:57Z | langchain/callbacks/openai_info.py | """Callback Handler that prints to std out."""
from typing import Any, Dict, List, Optional, Union
from langchain.callbacks.base import BaseCallbackHandler
from langchain.schema import AgentAction, AgentFinish, LLMResult
def get_openai_model_cost_per_1k_tokens(
model_name: str, is_completion: bool = False
) -> f... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,988 | LangChain openAI callback doesn't allow finetuned models | Hi all!
I have an [application](https://github.com/ur-whitelab/BO-LIFT) based on langchain.
A few months ago, I used it with fine-tuned (FT) models.
We added a token usage counter later, and I haven't tried fine-tuned models again since then.
Recently we have been interested in using (FT) models again, but the ... | https://github.com/langchain-ai/langchain/issues/3988 | https://github.com/langchain-ai/langchain/pull/4009 | aa383559999b3d6a781c62ed7f8589fef8892879 | f08a76250fe8995fb3f05bf785677070922d4b0d | 2023-05-02T18:00:22Z | python | 2023-05-02T23:19:57Z | tests/unit_tests/callbacks/test_openai_info.py | |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,997 | Llama-cpp docs loading has CallbackManager error | As in title, I think it might be because of deprecation and renaming at some point? Updated to use BaseCallbackManager in PR #3996 , please merge, thanks! | https://github.com/langchain-ai/langchain/issues/3997 | https://github.com/langchain-ai/langchain/pull/4010 | f08a76250fe8995fb3f05bf785677070922d4b0d | df3bc707fc916811183d2487e2fac5dc69327177 | 2023-05-02T20:13:28Z | python | 2023-05-02T23:20:16Z | docs/modules/models/chat/integrations/anthropic.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "bf733a38-db84-4363-89e2-de6735c37230",
"metadata": {},
"source": [
"# Anthropic\n",
"\n",
"This notebook covers how to get started with Anthropic chat models."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "d4a7c55d-b235... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 3,997 | Llama-cpp docs loading has CallbackManager error | As in title, I think it might be because of deprecation and renaming at some point? Updated to use BaseCallbackManager in PR #3996 , please merge, thanks! | https://github.com/langchain-ai/langchain/issues/3997 | https://github.com/langchain-ai/langchain/pull/4010 | f08a76250fe8995fb3f05bf785677070922d4b0d | df3bc707fc916811183d2487e2fac5dc69327177 | 2023-05-02T20:13:28Z | python | 2023-05-02T23:20:16Z | docs/modules/models/llms/integrations/llamacpp.ipynb | {
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Llama-cpp\n",
"\n",
"[llama-cpp](https://github.com/abetlen/llama-cpp-python) is a Python binding for [llama.cpp](https://github.com/ggerganov/llama.cpp). \n",
"It supports [several LLMs](https://github.com/ggerganov/llam... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,053 | Tools with partials (Partial functions not yet supported in tools) | We commonly used this pattern to create tools:
```py
from langchain.tools import Tool
from functools import partial
def foo(x, y):
return y
Tool.from_function(
func=partial(foo, "bar"),
name = "foo",
description="foobar"
)
```
which as of 0.0.148 (I think) gives a pydantic error "Par... | https://github.com/langchain-ai/langchain/issues/4053 | https://github.com/langchain-ai/langchain/pull/4058 | 7e967aa4d581bec8b29e9ea44267505b0bad18b9 | afa9d1292b0a152e36d338dde7b02f0b93bd37d9 | 2023-05-03T17:28:46Z | python | 2023-05-03T20:16:41Z | langchain/tools/base.py | """Base implementation for tools or skills."""
from __future__ import annotations
import warnings
from abc import ABC, abstractmethod
from functools import partial
from inspect import signature
from typing import Any, Awaitable, Callable, Dict, Optional, Tuple, Type, Union
from pydantic import (
BaseModel,
Ex... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,053 | Tools with partials (Partial functions not yet supported in tools) | We commonly used this pattern to create tools:
```py
from langchain.tools import Tool
from functools import partial
def foo(x, y):
return y
Tool.from_function(
func=partial(foo, "bar"),
name = "foo",
description="foobar"
)
```
which as of 0.0.148 (I think) gives a pydantic error "Par... | https://github.com/langchain-ai/langchain/issues/4053 | https://github.com/langchain-ai/langchain/pull/4058 | 7e967aa4d581bec8b29e9ea44267505b0bad18b9 | afa9d1292b0a152e36d338dde7b02f0b93bd37d9 | 2023-05-03T17:28:46Z | python | 2023-05-03T20:16:41Z | tests/unit_tests/agents/test_tools.py | """Test tool utils."""
from datetime import datetime
from functools import partial
from typing import Any, Optional, Type, Union
from unittest.mock import MagicMock
import pydantic
import pytest
from pydantic import BaseModel
from langchain.agents.agent import Agent
from langchain.agents.chat.base import ChatAgent
fr... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,052 | Arxiv loader does not work | Hey,
I tried to use the Arxiv loader but it seems that this type of document does not exist anymore. The documentation is still there https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/arxiv.html
Do you have any details on that? | https://github.com/langchain-ai/langchain/issues/4052 | https://github.com/langchain-ai/langchain/pull/4068 | 374725a715d287fe2ddb9dfda36e0dc14efa254d | 9b830f437cdfd82d9b53bd38e58b27bb9ecf970c | 2023-05-03T16:23:51Z | python | 2023-05-04T00:54:30Z | docs/modules/indexes/document_loaders/examples/arxiv.ipynb | {
"cells": [
{
"cell_type": "markdown",
"id": "bda1f3f5",
"metadata": {},
"source": [
"# Arxiv\n",
"\n",
">[arXiv](https://arxiv.org/) is an open-access archive for 2 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,142 | ImportError: cannot import name 'CursorResult' from 'sqlalchemy' | ### System Info
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 1_gnu
aiohttp 3.8.3 py310h5eee18b_0
aiosignal 1.3.1 pyhd8ed... | https://github.com/langchain-ai/langchain/issues/4142 | https://github.com/langchain-ai/langchain/pull/4145 | 2f087d63af45a172fc363b3370e49141bd663ed2 | fea639c1fc1ac324f1300016a02b6d30a2f8d249 | 2023-05-05T00:47:24Z | python | 2023-05-05T03:46:38Z | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import warnings
from typing import Any, Iterable, List, Optional
import sqlalchemy
from sqlalchemy import (
CursorResult,
MetaData,
Table,
create_engine,
inspect,
select,
text,
)
from sqlalchemy.engine import En... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,142 | ImportError: cannot import name 'CursorResult' from 'sqlalchemy' | ### System Info
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 1_gnu
aiohttp 3.8.3 py310h5eee18b_0
aiosignal 1.3.1 pyhd8ed... | https://github.com/langchain-ai/langchain/issues/4142 | https://github.com/langchain-ai/langchain/pull/4145 | 2f087d63af45a172fc363b3370e49141bd663ed2 | fea639c1fc1ac324f1300016a02b6d30a2f8d249 | 2023-05-05T00:47:24Z | python | 2023-05-05T03:46:38Z | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.158"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependenc... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,129 | Bug introduced in 0.0.158 | Updates in version 0.0.158 have introduced a bug that prevents this import from being successful, while it works in 0.0.157
```
Traceback (most recent call last):
File "path", line 5, in <module>
from langchain.chains import OpenAIModerationChain, SequentialChain, ConversationChain
File "/Users/chasemcdo... | https://github.com/langchain-ai/langchain/issues/4129 | https://github.com/langchain-ai/langchain/pull/4145 | 2f087d63af45a172fc363b3370e49141bd663ed2 | fea639c1fc1ac324f1300016a02b6d30a2f8d249 | 2023-05-04T19:24:15Z | python | 2023-05-05T03:46:38Z | langchain/sql_database.py | """SQLAlchemy wrapper around a database."""
from __future__ import annotations
import warnings
from typing import Any, Iterable, List, Optional
import sqlalchemy
from sqlalchemy import (
CursorResult,
MetaData,
Table,
create_engine,
inspect,
select,
text,
)
from sqlalchemy.engine import En... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,129 | Bug introduced in 0.0.158 | Updates in version 0.0.158 have introduced a bug that prevents this import from being successful, while it works in 0.0.157
```
Traceback (most recent call last):
File "path", line 5, in <module>
from langchain.chains import OpenAIModerationChain, SequentialChain, ConversationChain
File "/Users/chasemcdo... | https://github.com/langchain-ai/langchain/issues/4129 | https://github.com/langchain-ai/langchain/pull/4145 | 2f087d63af45a172fc363b3370e49141bd663ed2 | fea639c1fc1ac324f1300016a02b6d30a2f8d249 | 2023-05-04T19:24:15Z | python | 2023-05-05T03:46:38Z | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.158"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependenc... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,120 | [Feature Request] Allow users to pass additional arguments to the WebDriver | Description:
Currently, when creating a Chrome or Firefox web driver using the `selenium.webdriver` module, users can only pass a limited set of arguments such as `headless` mode and hardcoded `no-sandbox`. However, there are many additional options available for these browsers that cannot be passed in using the exist... | https://github.com/langchain-ai/langchain/issues/4120 | https://github.com/langchain-ai/langchain/pull/4121 | 2a3c5f83537817d06ea8fad2836bbcd1cb33a551 | 19e28d8784adef90553da071ed891fc3252b2c63 | 2023-05-04T18:15:03Z | python | 2023-05-05T20:24:42Z | langchain/document_loaders/url_selenium.py | """Loader that uses Selenium to load a page, then uses unstructured to load the html.
"""
import logging
from typing import TYPE_CHECKING, List, Literal, Optional, Union
if TYPE_CHECKING:
from selenium.webdriver import Chrome, Firefox
from langchain.docstore.document import Document
from langchain.document_loader... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,304 | [Feature Request] Allow users to pass binary location to Selenium WebDriver | ### Feature request
Problem:
Unable to set binary_location for the Webdriver via SeleniumURLLoader
Proposal:
The proposal is to adding a new arguments parameter to the SeleniumURLLoader that allows users to pass binary_location
### Motivation
To deploy Selenium on Heroku ([tutorial](https://romik-kelesh.m... | https://github.com/langchain-ai/langchain/issues/4304 | https://github.com/langchain-ai/langchain/pull/4305 | 65c95f9fb2b86cf3281f2f3939b37e71f048f741 | 637c61cffbd279dc2431f9e224cfccec9c81f6cd | 2023-05-07T23:25:37Z | python | 2023-05-08T15:05:55Z | langchain/document_loaders/url_selenium.py | """Loader that uses Selenium to load a page, then uses unstructured to load the html.
"""
import logging
from typing import TYPE_CHECKING, List, Literal, Optional, Union
if TYPE_CHECKING:
from selenium.webdriver import Chrome, Firefox
from langchain.docstore.document import Document
from langchain.document_loader... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,096 | Callbacks are ignored when passed to load_tools | Hello,
I cannot figure out how to pass callback when using `load_tools`, I used to pass a callback_manager but I understand that it's now deprecated. I was able to reproduce with the following snippet:
```python
from langchain.agents import load_tools
from langchain.callbacks.base import BaseCallbackHandler
f... | https://github.com/langchain-ai/langchain/issues/4096 | https://github.com/langchain-ai/langchain/pull/4298 | 0870a45a697a75ac839b724311ce7a8b59a09058 | 35c9e6ab407003e0c1f16fcf6d4c73f6637db731 | 2023-05-04T09:05:12Z | python | 2023-05-08T15:44:26Z | langchain/agents/load_tools.py | # flake8: noqa
"""Load tools."""
import warnings
from typing import Any, Dict, List, Optional, Callable, Tuple
from mypy_extensions import Arg, KwArg
from langchain.agents.tools import Tool
from langchain.base_language import BaseLanguageModel
from langchain.callbacks.base import BaseCallbackManager
from langchain.cha... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,096 | Callbacks are ignored when passed to load_tools | Hello,
I cannot figure out how to pass callback when using `load_tools`, I used to pass a callback_manager but I understand that it's now deprecated. I was able to reproduce with the following snippet:
```python
from langchain.agents import load_tools
from langchain.callbacks.base import BaseCallbackHandler
f... | https://github.com/langchain-ai/langchain/issues/4096 | https://github.com/langchain-ai/langchain/pull/4298 | 0870a45a697a75ac839b724311ce7a8b59a09058 | 35c9e6ab407003e0c1f16fcf6d4c73f6637db731 | 2023-05-04T09:05:12Z | python | 2023-05-08T15:44:26Z | tests/unit_tests/agents/test_tools.py | """Test tool utils."""
from typing import Any, Type
from unittest.mock import MagicMock
import pytest
from langchain.agents.agent import Agent
from langchain.agents.chat.base import ChatAgent
from langchain.agents.conversational.base import ConversationalAgent
from langchain.agents.conversational_chat.base import Con... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,331 | Issue: Model and model_name inconsistency in OpenAI LLMs such as ChatOpenAI | ### Issue you'd like to raise.
Argument `model_name` is the standard way of defining a model in LangChain's [ChatOpenAI](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L115). However, OpenAI uses `model` in their own [API](https://platform.openai.co... | https://github.com/langchain-ai/langchain/issues/4331 | https://github.com/langchain-ai/langchain/pull/4366 | 02ebb15c4a92a23818c2c17486bdaf9f590dc6a5 | ba0057c07712e5e725c7c5e14c02d223783b183c | 2023-05-08T10:49:23Z | python | 2023-05-08T23:37:34Z | langchain/chat_models/openai.py | """OpenAI chat wrapper."""
from __future__ import annotations
import logging
import sys
from typing import Any, Callable, Dict, List, Mapping, Optional, Tuple, Union
from pydantic import Extra, Field, root_validator
from tenacity import (
before_sleep_log,
retry,
retry_if_exception_type,
stop_after_at... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,331 | Issue: Model and model_name inconsistency in OpenAI LLMs such as ChatOpenAI | ### Issue you'd like to raise.
Argument `model_name` is the standard way of defining a model in LangChain's [ChatOpenAI](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L115). However, OpenAI uses `model` in their own [API](https://platform.openai.co... | https://github.com/langchain-ai/langchain/issues/4331 | https://github.com/langchain-ai/langchain/pull/4366 | 02ebb15c4a92a23818c2c17486bdaf9f590dc6a5 | ba0057c07712e5e725c7c5e14c02d223783b183c | 2023-05-08T10:49:23Z | python | 2023-05-08T23:37:34Z | langchain/llms/openai.py | """Wrapper around OpenAI APIs."""
from __future__ import annotations
import logging
import sys
import warnings
from typing import (
AbstractSet,
Any,
Callable,
Collection,
Dict,
Generator,
List,
Literal,
Mapping,
Optional,
Set,
Tuple,
Union,
)
from pydantic import E... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,331 | Issue: Model and model_name inconsistency in OpenAI LLMs such as ChatOpenAI | ### Issue you'd like to raise.
Argument `model_name` is the standard way of defining a model in LangChain's [ChatOpenAI](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L115). However, OpenAI uses `model` in their own [API](https://platform.openai.co... | https://github.com/langchain-ai/langchain/issues/4331 | https://github.com/langchain-ai/langchain/pull/4366 | 02ebb15c4a92a23818c2c17486bdaf9f590dc6a5 | ba0057c07712e5e725c7c5e14c02d223783b183c | 2023-05-08T10:49:23Z | python | 2023-05-08T23:37:34Z | tests/integration_tests/chat_models/test_openai.py | """Test ChatOpenAI wrapper."""
import pytest
from langchain.callbacks.manager import CallbackManager
from langchain.chat_models.openai import ChatOpenAI
from langchain.schema import (
BaseMessage,
ChatGeneration,
ChatResult,
HumanMessage,
LLMResult,
SystemMessage,
)
from tests.unit_tests.call... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,331 | Issue: Model and model_name inconsistency in OpenAI LLMs such as ChatOpenAI | ### Issue you'd like to raise.
Argument `model_name` is the standard way of defining a model in LangChain's [ChatOpenAI](https://github.com/hwchase17/langchain/blob/65c95f9fb2b86cf3281f2f3939b37e71f048f741/langchain/chat_models/openai.py#L115). However, OpenAI uses `model` in their own [API](https://platform.openai.co... | https://github.com/langchain-ai/langchain/issues/4331 | https://github.com/langchain-ai/langchain/pull/4366 | 02ebb15c4a92a23818c2c17486bdaf9f590dc6a5 | ba0057c07712e5e725c7c5e14c02d223783b183c | 2023-05-08T10:49:23Z | python | 2023-05-08T23:37:34Z | tests/integration_tests/llms/test_openai.py | """Test OpenAI API wrapper."""
from pathlib import Path
from typing import Generator
import pytest
from langchain.callbacks.manager import CallbackManager
from langchain.llms.loading import load_llm
from langchain.llms.openai import OpenAI, OpenAIChat
from langchain.schema import LLMResult
from tests.unit_tests.call... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,153 | WhatsAppChatLoader doesn't work on chats exported from WhatsApp | ### System Info
langchain 0.0.158
Mac OS M1
Python 3.11
### Who can help?
@ey
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] O... | https://github.com/langchain-ai/langchain/issues/4153 | https://github.com/langchain-ai/langchain/pull/4420 | f2150285a495fc530a7707218ea4980c17a170e5 | 2b1403612614127da4e3bd3d22595ce7b3eb1540 | 2023-05-05T05:25:38Z | python | 2023-05-09T22:00:04Z | langchain/document_loaders/whatsapp_chat.py | import re
from pathlib import Path
from typing import List
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
def concatenate_rows(date: str, sender: str, text: str) -> str:
"""Combine message information in a readable format ready to be used."""
return f"... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,153 | WhatsAppChatLoader doesn't work on chats exported from WhatsApp | ### System Info
langchain 0.0.158
Mac OS M1
Python 3.11
### Who can help?
@ey
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] O... | https://github.com/langchain-ai/langchain/issues/4153 | https://github.com/langchain-ai/langchain/pull/4420 | f2150285a495fc530a7707218ea4980c17a170e5 | 2b1403612614127da4e3bd3d22595ce7b3eb1540 | 2023-05-05T05:25:38Z | python | 2023-05-09T22:00:04Z | tests/integration_tests/document_loaders/test_whatsapp_chat.py | from pathlib import Path
from langchain.document_loaders import WhatsAppChatLoader
def test_whatsapp_chat_loader() -> None:
"""Test WhatsAppChatLoader."""
file_path = Path(__file__).parent.parent / "examples" / "whatsapp_chat.txt"
loader = WhatsAppChatLoader(str(file_path))
docs = loader.load()
... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,153 | WhatsAppChatLoader doesn't work on chats exported from WhatsApp | ### System Info
langchain 0.0.158
Mac OS M1
Python 3.11
### Who can help?
@ey
### Information
- [X] The official example notebooks/scripts
- [ ] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] Prompts / Prompt Templates / Prompt Selectors
- [ ] O... | https://github.com/langchain-ai/langchain/issues/4153 | https://github.com/langchain-ai/langchain/pull/4420 | f2150285a495fc530a7707218ea4980c17a170e5 | 2b1403612614127da4e3bd3d22595ce7b3eb1540 | 2023-05-05T05:25:38Z | python | 2023-05-09T22:00:04Z | tests/integration_tests/examples/whatsapp_chat.txt | [05.05.23, 15:48:11] James: Hi here
[11/8/21, 9:41:32 AM] User name: Message 123
1/23/23, 3:19 AM - User 2: Bye!
1/23/23, 3:22_AM - User 1: And let me know if anything changes |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 1,619 | ChromaDB does not support filtering when using ```similarity_search``` or ```similarity_search_by_vector``` | Whereas it should be possible to filter by metadata :
- ```langchain.vectorstores.chroma.similarity_search``` takes a ```filter``` input parameter but do not forward it to ```langchain.vectorstores.chroma.similarity_search_with_score```
- ```langchain.vectorstores.chroma.similarity_search_by_vector``` don't take thi... | https://github.com/langchain-ai/langchain/issues/1619 | https://github.com/langchain-ai/langchain/pull/1621 | 28091c21018677355a124dd9c46213db3a229183 | d383c0cb435273de83595160c14a2cb45dcecf2a | 2023-03-12T23:58:13Z | python | 2023-05-09T23:43:00Z | langchain/vectorstores/chroma.py | """Wrapper around ChromaDB embeddings platform."""
from __future__ import annotations
import logging
import uuid
from typing import TYPE_CHECKING, Any, Dict, Iterable, List, Optional, Tuple, Type
import numpy as np
from langchain.docstore.document import Document
from langchain.embeddings.base import Embeddings
from... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,368 | Add distance metric param to to redis vectorstore index | ### Feature request
Redis vectorstore allows for three different distance metrics: `L2` (flat L2), `COSINE`, and `IP` (inner product). Currently, the `Redis._create_index` method hard codes the distance metric to COSINE.
```py
def _create_index(self, dim: int = 1536) -> None:
try:
from redis... | https://github.com/langchain-ai/langchain/issues/4368 | https://github.com/langchain-ai/langchain/pull/4375 | f46710d4087c3f27e95cfc4b2c96956d7c4560e8 | f668251948c715ef3102b2bf84ff31aed45867b5 | 2023-05-09T00:40:32Z | python | 2023-05-11T07:20:01Z | langchain/vectorstores/redis.py | """Wrapper around Redis vector database."""
from __future__ import annotations
import json
import logging
import uuid
from typing import (
TYPE_CHECKING,
Any,
Callable,
Dict,
Iterable,
List,
Mapping,
Optional,
Tuple,
Type,
)
import numpy as np
from pydantic import BaseModel, ro... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,368 | Add distance metric param to to redis vectorstore index | ### Feature request
Redis vectorstore allows for three different distance metrics: `L2` (flat L2), `COSINE`, and `IP` (inner product). Currently, the `Redis._create_index` method hard codes the distance metric to COSINE.
```py
def _create_index(self, dim: int = 1536) -> None:
try:
from redis... | https://github.com/langchain-ai/langchain/issues/4368 | https://github.com/langchain-ai/langchain/pull/4375 | f46710d4087c3f27e95cfc4b2c96956d7c4560e8 | f668251948c715ef3102b2bf84ff31aed45867b5 | 2023-05-09T00:40:32Z | python | 2023-05-11T07:20:01Z | tests/integration_tests/vectorstores/test_redis.py | """Test Redis functionality."""
from langchain.docstore.document import Document
from langchain.vectorstores.redis import Redis
from tests.integration_tests.vectorstores.fake_embeddings import FakeEmbeddings
TEST_INDEX_NAME = "test"
TEST_REDIS_URL = "redis://localhost:6379"
TEST_SINGLE_RESULT = [Document(page_content=... |
closed | langchain-ai/langchain | https://github.com/langchain-ai/langchain | 4,513 | [pyproject.toml] add `tiktoken` to `tool.poetry.extras.openai` | ### System Info
langchain[openai]==0.0.165
Ubuntu 22.04.2 LTS (Jammy Jellyfish)
python 3.10.6
### Who can help?
@vowelparrot
### Information
- [ ] The official example notebooks/scripts
- [X] My own modified scripts
### Related Components
- [ ] LLMs/Chat Models
- [ ] Embedding Models
- [ ] ... | https://github.com/langchain-ai/langchain/issues/4513 | https://github.com/langchain-ai/langchain/pull/4514 | 4ee47926cafba0eb00851972783c1d66236f6f00 | 1c0ec26e40f07cdf9eabae2f018dff05f97d8595 | 2023-05-11T07:54:40Z | python | 2023-05-11T19:21:06Z | pyproject.toml | [tool.poetry]
name = "langchain"
version = "0.0.166"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
readme = "README.md"
repository = "https://www.github.com/hwchase17/langchain"
[tool.poetry.scripts]
langchain-server = "langchain.server:main"
[tool.poetry.dependenc... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.