
Aesthetics is Cheap, Show me the Text: An Empirical Evaluation of State-of-the-Art Generative Models for OCR
Paper • 2507.15085 • Published • 7
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
⚠️ Clicking "Agree" alone is not sufficient. / 仅点击「Agree」不足以获得访问权限
⚠️ Clicking "Agree" alone is not sufficient. / 仅点击「Agree」不足以获得访问权限
⚠️ Clicking "Agree" alone is not sufficient. / 仅点击「Agree」不足以获得访问权限
You must also submit an application form on our website. Access will be granted automatically. / 请在我们的网站提交申请表,提交后将自动授权
Log in or Sign Up to review the conditions and access this dataset content.
![]()
This dataset is gated. To download OCRGenBench, please submit an access request:
👉 Apply for Access — click the Access button on the dataset page
Applications are automatically approved. You will receive an email confirmation once access is granted.
OCRGenBench is the most comprehensive benchmark to date for evaluating the OCR generative capabilities of generative models. It pioneers in the unification of:
The benchmark covers 5 common text categories and 33 OCR generative tasks, including 1,060 challenging, human-annotated samples with dense text, varied layouts, multiple aspect ratios, and bilingual (English/Chinese) content.
We also design a unified metric OCRGenScore, assessing text accuracy, instruction following, visual quality, and structural consistency in visual text synthesis.
OCRGenBench encompasses five major text scenarios and 33 OCR generative tasks:
OCRGenBench includes 1,060 high-quality, manually annotated samples:
Performance across tasks (main leaderboard)
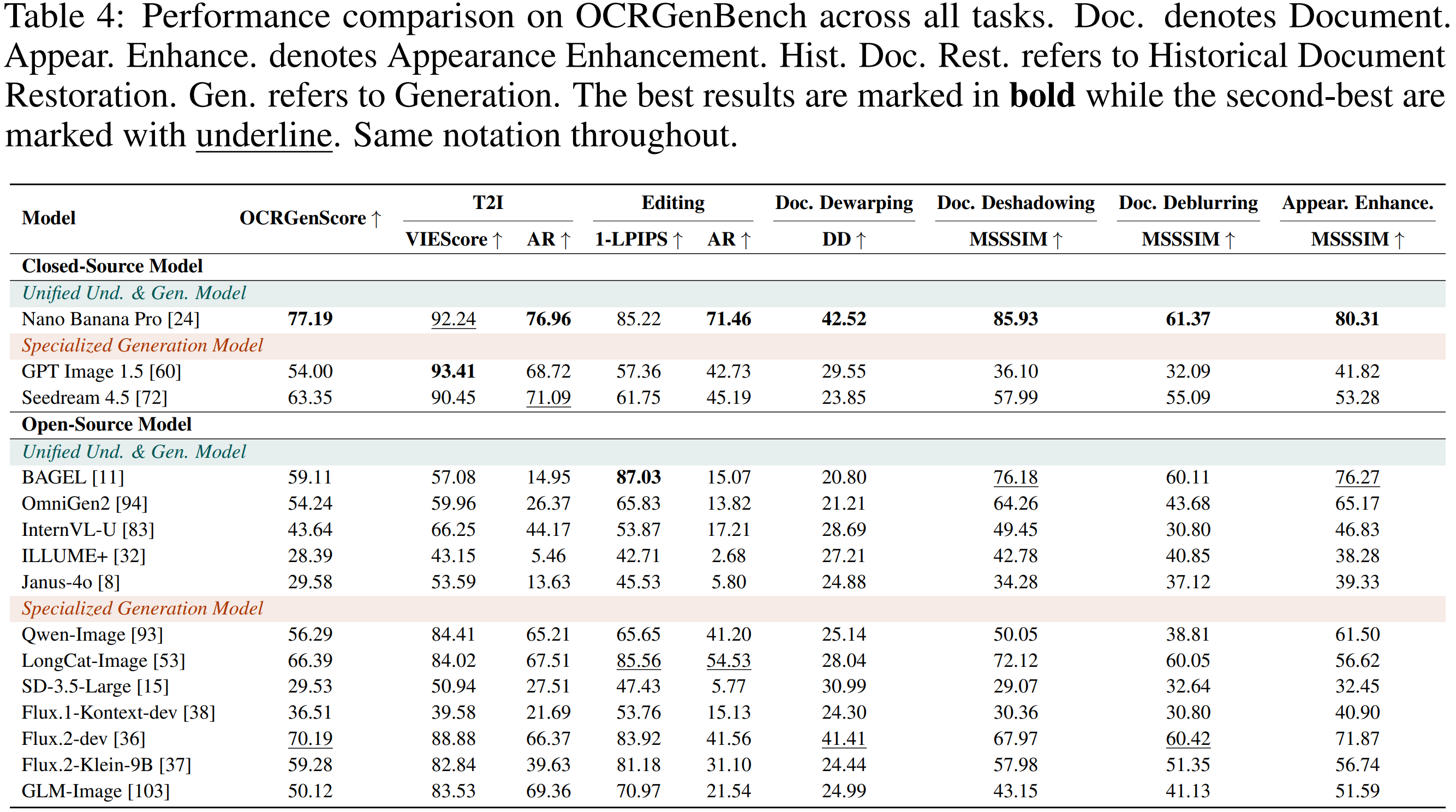
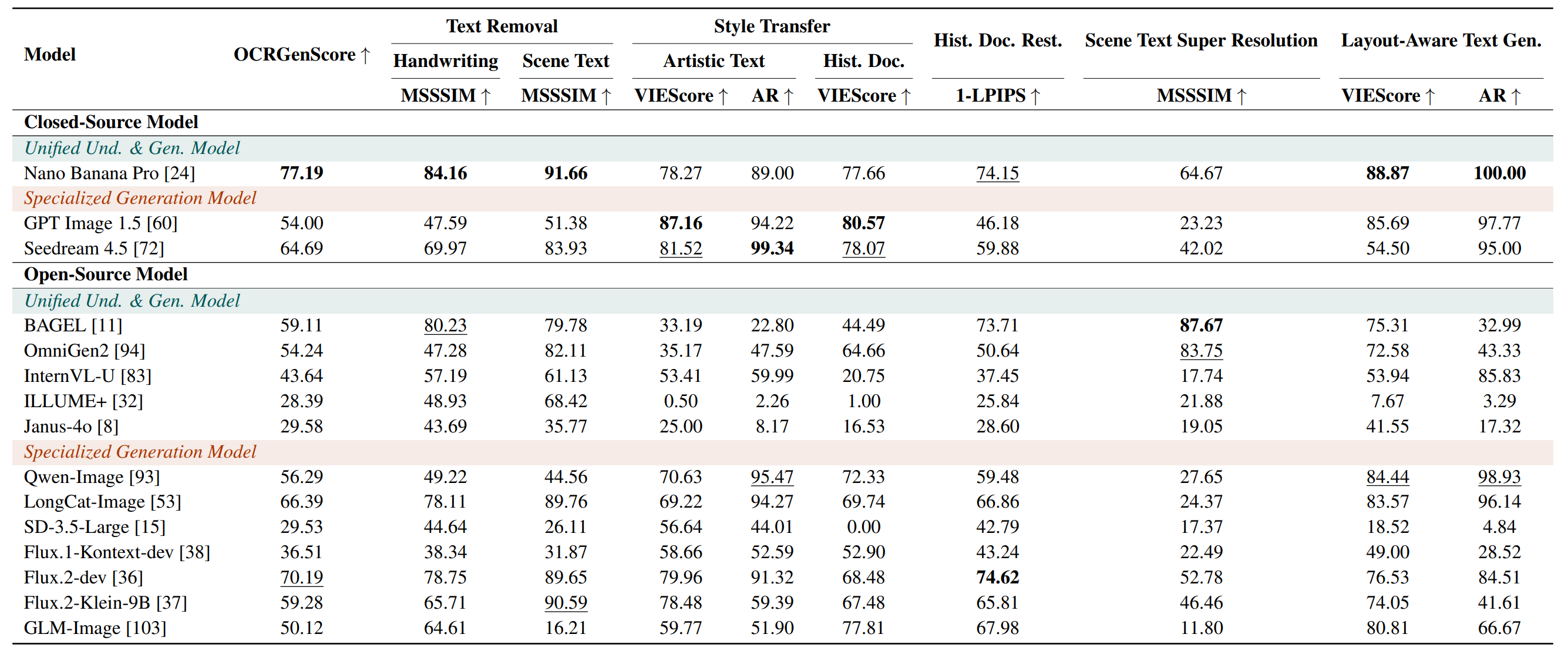
View the full interactive leaderboard: OCRGenBench Leaderboard
If you find our work helpful, please cite our paper:
@article{zhang2025ocrgenbench,
title={{OCRGenBench: A Comprehensive Benchmark for Evaluating OCR Generative Capabilities}},
author={Zhang, Peirong and Xu, Haowei and Zhang, Jiaxin and Zheng, Xuhan and Xu, Guitao and Zhang, Yuyi and Liu, Junle and Yang, Zhenhua and Zhou, Wei and Jin, Lianwen},
journal={arXiv preprint arXiv:2507.15085},
year={2025}
}
For questions about the dataset: eeprzhang@mail.scut.edu.cn
Copyright 2025–2026, Deep Learning and Vision Computing (DLVC) Lab, South China University of Technology.