
Islamic Knowledge in LLMs
Collection
This collection focuses on Islamic religious resources, Islamic media ethics and other relevant content. • 5 items • Updated • 1
title stringlengths 14 175 | abstract stringlengths 1 4.02k | url stringlengths 33 78 | stream stringclasses 6
values | domain stringclasses 10
values | topic stringclasses 17
values | leaf stringlengths 10 47 |
|---|---|---|---|---|---|---|
Applying Ontological Modeling on Quranic Nature Domain | The holy Quran is the holy book of the Muslims. It contains information about many domains. Often people search for particular concepts of holy Quran based on the relations among concepts. An ontological modeling of holy Quran can be useful in such a scenario. In this paper, we have modeled nature related concepts of h... | http://arxiv.org/abs/1604.03318v1 | Scriptural Sources | Quran & Tafsir | Retrieval & QA | Search & Datasets |
Towards A Time Based Video Search Engine for Al Quran Interpretation | The number of Internet Muslim-users is remarkably increasing from all over the world countries. There are a lot of structured, and well-documented text resources for the Quran interpretation, Tafsir, over the Internet with several languages. Nevertheless, when searching for the meaning of specific words, many users pre... | http://arxiv.org/abs/1701.09138v1 | Scriptural Sources | Quran & Tafsir | Retrieval & QA | Search & Datasets |
Activity Monitoring of Islamic Prayer (Salat) Postures using Deep Learning | In the Muslim community, the prayer (i.e. Salat) is the second pillar of Islam, and it is the most essential and fundamental worshiping activity that believers have to perform five times a day. From a gestures' perspective, there are predefined human postures that must be performed in a precise manner. However, for sev... | http://arxiv.org/abs/1911.04102v1 | Law & Practice | Ibadat (Rituals) | Tutoring & QA | Salah / Zakah / Sawm; Hajj/Umrah Guidance |
SemEval-2015 Task 3: Answer Selection in Community Question Answering | Community Question Answering (cQA) provides new interesting research directions to the traditional Question Answering (QA) field, e.g., the exploitation of the interaction between users and the structure of related posts. In this context, we organized SemEval-2015 Task 3 on "Answer Selection in cQA", which included two... | http://arxiv.org/abs/1911.11403v1 | Shared Resources | Datasets & Benchmarks | Creation | Shared Tasks |
Answering Islamic Questions with a Chatbot using Fuzzy String-Matching Algorithm | The guidance of Muslims in worship refers to the holy Quran and the hadith. Not all people understand the law related to a case in accordance with Islamic teachings. Questions relating to a matter based on Islamic law are widely circulated on the Internet with long and detailed answers. This is good but for some people... | https://www.semanticscholar.org/paper/fde52da0329158adca0c401e007ca881169c16b2 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Development Grouping of Synonym Set Thesaurus Vocabulary The Qur’an in English Using Hierarchical Clustering Algorithm | Research in the field of text mining to process entries or words from the Qur'an is very beneficial for Muslims. This study aims to establish a set of synonyms for the thesaurus in the words of the Qur'an. This research is used because the source of knowledge about the science of the Qur'an is still lacking. The datase... | https://www.semanticscholar.org/paper/c3cb2fa360625f678b01ab911d718a84058fa116 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Smartajweed Automatic Recognition of Arabic Quranic Recitation Rules | Tajweed is a set of rules to read the Quran in a correct Pronunciation of the letters with all its Qualities, while Reciting the Quran. which means you have to give every letter in the Quran its due of characteristics and apply it to this particular letter in this specific situation while reading, which may differ in o... | http://arxiv.org/abs/2101.04200v1 | Scriptural Sources | Quran & Tafsir | Audio/Multimodal | ASR/Recitation Support |
Quran content representation in NLP | Word representation is a starting point for Natural Language Processing (NLP). These representations transform words into symbolic vectors of a given length that reveal the hidden linguistic and semantic similarities. This paper presents a study of the various word representation tools used for the content of the texts... | https://www.semanticscholar.org/paper/6c2fadbf5068efa12785ffafb02708a2449f84fc | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Hadith Authenticity Prediction using Sentiment Analysis and Machine Learning | Starting around 815AD/200AH scholars have put immense effort towards gathering and sifting authentic hadiths, which are prophetic traditions of the Muslim community. The authenticity of a hadith solely depends on the reliability of its reporters and narrators. Till now scholars have had to do this task manually by prec... | https://www.semanticscholar.org/paper/4e2a505ef27bfe707333b7be96f25f914e2fe18b | Scriptural Sources | Hadith Sciences | Authenticity & Isnad | Chain/Matn Features |
A Survey of the Meaning of Amnesty in the Qur'an Based on Relationships and Succession with Emphasis on Answering a Question about the Prophet's Islamic Infallibility | The word amnesty and its derivatives have been used in several verses of the Qur'an. The main question of this article is what exactly does Amnesty mean in all the verses of the Qur'an in the same sense? What is the meaning of pardon based on the relations of companionship and succession? Why, God willing, has the Prop... | https://www.semanticscholar.org/paper/6e72ce7435f800894b0c3ea6ef615b6d4b396e53 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Automatic Text Summarization for Hadith with Indonesian Text using Bellman-Ford Algorithm | Automatic text summarization is one of Natural Language Processing technology to create a summary automatically by not changing the core or main idea of a summarized document. According to the agreement of the majority of Muslim scholars, Hadith is a second source of Muslim's life guideline. This study aims to extract ... | https://www.semanticscholar.org/paper/eeed3718dfeb8ccf50ce9e769c981de292b0f673 | Scriptural Sources | Hadith Sciences | Structuring | NER & Ontologies |
Arabic Text Processing Model: Verbs Roots and Conjugation Automation | The Natural Language Processing (NLP) is a process to automate the text or speech of Natural Languages. This automation is mainly conducted for Western languages. The Arabic Language got less focus in this area. This paper presents a Model to recognize an Arabic sentence. A new morphological model based on regular expr... | https://www.semanticscholar.org/paper/ea17a3edbf5b13d26d517f50d6e8f4447ab901a2 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Developing FB Chatbot Based on Deep Learning Using RASA Framework for University Enquiries | Smart systems for Universities powered by Artificial Intelligence have been massively developed to help humans in various tasks. The chatbot concept is not something new in today society which is developing with recent technology. College students or candidates of college students often need actual information like ask... | http://arxiv.org/abs/2009.12341v1 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Chatbot as Islamic Finance Expert (CaIFE): When Finance Meets Artificial Intelligence | Artificial intelligence (AI) is the key technology in the new disruptive technological innovation and industrial transformation. AI has very wide application in finance and banking. The financial institutions not only answer the queries of the customers, but they should also clarify the complaints the customer face and... | https://www.semanticscholar.org/paper/1e45b14fe3c1f72467b99b75b109b37ec710f369 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Quran Intelligent Ontology Construction Approach Using Association Rules Mining | Ontology can be seen as a formal representation of knowledge. They have been investigated in many artificial intelligence studies including semantic web, software engineering, and information retrieval. The aim of ontology is to develop knowledge representations that can be shared and reused. This research project is c... | http://arxiv.org/abs/2008.03232v2 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Social Network Analysis of Hadith Narrators from Sahih Bukhari | The ahadith, prophetic traditions for the Muslims around the world, are narrations originating from the sayings and the deeds of Prophet Muhammad (pbuh). They are considered one of the fundamental sources of Islamic legislation along with the Quran. The list of persons involved in the narration of each hadith is carefu... | http://arxiv.org/abs/2102.02009v1 | Scriptural Sources | Hadith Sciences | Authenticity & Isnad | Graph/Network Analysis |
Ethico-religious green supply chain management (GSCM): embedding Islamic ethics’ codes for improving environmental concerns |
Purpose
This study aims to propose an Ethico-Religious green supply chain management (GSCM) view grounded in Islamic teachings design to govern human beings working in the industries.
Design/methodology/approach
This study adopts a qualitative approach that used the semi-structured-interview method as a research ins... | https://www.semanticscholar.org/paper/73773f733659331afabc450ad46d43e591cb3f9d | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
Towards an Automated Islamic Fatwa System: Survey, Dataset and Benchmarks | — Islam is the second largest and the fastest growing religion. The Islamic Law, Sharia, represents a profound component of the day-to-day lives of Muslims. This creates a lot of queries, about specific problems, that requires answers, or Fatwas. While sources of Sharia are available for anyone, it often requires a hig... | https://www.semanticscholar.org/paper/1dc60fc5d0caf1c6e09bab0ed3d95b5e14c25225 | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation; Shared Tasks |
Enhancing the Takhrij Al-Hadith based on Contextual Similarity using BERT Embeddings | Muslims are required to conduct Takhrij to validate the truth of Hadith text, especially when it is obtained from online media. Typically, the traditional Takhrij processes are conducted by experts and apply to Arabic Hadith text. This study introduces a contextual similarity model based on BERT Embedding to handle Tak... | https://www.semanticscholar.org/paper/86907686d66e0c5ed2a9282f99e00cadd833c296 | Scriptural Sources | Hadith Sciences | Authenticity & Isnad | Chain/Matn Features |
Arabic Part Of Speech (POS) Tagging Analysis using HMM Trigram method on Al-Qur’an Ayah Sentences | Part Of Speech (POS) tagging is part of Natural Language Processing to determine correctly the label in a sentence from the given input. Different POS tagging techniques in some literatures have been developed for English text, and few for Arabic texts. This problem uses a method based on the second hidden Markov model... | https://www.semanticscholar.org/paper/6e00592eb07128eef4304bcd0407f9d1b463db64 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Proposing machine learning of Tafsir al-Quran: In search of objectivity with semantic analysis and Natural Language Processing | Computer technology is neutral information technology without any subjectivities and biases. The advantages of computer technology can help to minimize intervention and subjectivity in the interpretation of the Quran. The problem of subjectivity in interpretation of the Quran is a long discussion. However, Interpretati... | https://www.semanticscholar.org/paper/2f67571a66e6a634a633f7d8fe4f7ee17688e366 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Arabic Part Of Speech (POS) Tagging Analysis using Bee Colony Optimization (BCO) Algorithm on Quran Corpus | Part Of Speech (POS) tagging is an automated process for determining the appropriate grammatical label or syntactic category of a word depending on the context. POS tagging is one of the important processes in Natural Language Processing (NLP) applications such as summarization text, Speech Recognition (SR), Question A... | https://www.semanticscholar.org/paper/63aa61a5147cc4b0ed89b47b8cdada0b942d3272 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Automatic Speech Recognition (ASR) Systems for Learning Arabic Language and Al-Quran Recitation: A Review | This paper provides a literature survey about Automatic Speech Recognition (ASR) systems for learning Arabic language and Al-Quran Recitation. The growth in communication technologies and AI (specially Machine learning and Deep learning) led researchers in ASR field to thinking of and developing ASR systems which mimic... | https://www.semanticscholar.org/paper/14c916e5000f9c0b2107afdd65016ca5058335f9 | Scriptural Sources | Quran & Tafsir | Audio/Multimodal | ASR/Recitation Support |
Artificial Intelligence and NLP -Based Chatbot for Islamic Banking and Finance | The role of artificial intelligence (AI) is becoming increasingly important in the field of banking and finance. It has come a long way, and the trend is likely to continue for some time in the future as well. This research study reviews the role of artificial intelligence and use of technology in the finance and banki... | https://www.semanticscholar.org/paper/816676f81a97c4cf05c511955fe4766c83fb1a5e | Law & Practice | Fiqh & Fatwa | Fatwa QA & Support | RAG + Citations; Uncertainty/Deferral |
A Text Mining Discovery of Similarities and Dissimilarities Among Sacred Scriptures | The careful examination of sacred texts gives valuable insights into human psychology, different ideas regarding the organization of societies as well as into terms like truth and God. To improve and deepen our understanding of sacred texts, their comparison, and their separation is crucial. For this purpose, we use ou... | https://www.semanticscholar.org/paper/f8f1a49a709fac1d82af680fe970d10a71cd2ecf | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
THQuAD: Turkish Historic Question Answering Dataset for Reading Comprehension | Question answering(QA) is a field in natural language processing and information retrieval, it aims to give answers to the questions using natural language. In this paper, we present the Turkish question answering dataset, which is THQuAD and baseline results with contextualized word embeddings. THQuAD consists of two ... | https://www.semanticscholar.org/paper/f5a50d8639889641c03f7707389be36d1f41b229 | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation |
Islamic and Late Modern Comparative Worldviews on Language: Towards Model for Translating Alien Key Concepts | Within the area of cultural discourse studies (CDSs), this article is presented to compare the late modern and Islamic worldviews on language. In so doing, the researcher uses a comparative qualitative method to explore the worldviews on language, word meaning, text, and context with specific attention to the writings ... | https://www.semanticscholar.org/paper/77e838f8de36c394e2be1017de7241d34652ae31 | Education & Community | Contemporary Discourse | Analysis | Sermons/Media; Stance/Theme Analysis |
Quran Ontology: Review on Recent Research Issues | : In recent years, there are growing interests of Islamic Knowledge by both Muslims and non Muslims especially in Holy Quran. The researchers of religious Studies started to use the ontology to improve the knowledge construction and extraction from religious texts such as the Qur’an and Hadith. Ontology provide a share... | https://www.semanticscholar.org/paper/f350e84f88319b231ffcefa6ffa304ae41176088 | Scriptural Sources | Hadith Sciences | Structuring | NER & Ontologies; KG Construction |
Automated Islamic Jurisprudential Legal Opinions Generation Using Artificial Intelligence | Islam is the second-largest and fastest-growing religion. The Islamic Law, Sharia, represents a profound component of the day-to-day lives of Muslims. While sources of Sharia are available for anyone, it often requires a highly qualified person, the Mufti, to provide Fatwa. With Islam followers representing almost 25% ... | https://www.semanticscholar.org/paper/ce7eca727a28f0c230ed65bcd5da3be54db52c6f | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation; Shared Tasks |
DTW at Qur’an QA 2022: Utilising Transfer Learning with Transformers for Question Answering in a Low-resource Domain | The task of machine reading comprehension (MRC) is a useful benchmark to evaluate the natural language understanding of machines. It has gained popularity in the natural language processing (NLP) field mainly due to the large number of datasets released for many languages. However, the research in MRC has been understu... | https://www.semanticscholar.org/paper/a56c8e6b2db32abe2c38bbc4a78a4a895137d15d | Scriptural Sources | Quran & Tafsir | Retrieval & QA | Search & Datasets |
Arabic Quran Verses Authentication Using Deep Learning and Word Embeddings | Nowadays, with the developments witnessed by the Internet, algorithms have come to control all aspects of digital content. Due to its Arabic roots, it is ironic to find that Arabic Quranic content is still thirsty to benefit from computer linguistics, especially with the advent of artificial intelligence algorithms. Th... | https://www.semanticscholar.org/paper/533c68890751a45303b6d1a71724d02f9ea12347 | Objectives & Governance | Doctrinal Integrity | Authenticity | Attribution Checks; Fabrication Signals |
BERT based Named Entity Recognition for Automated Hadith Narrator Identification | Hadith serves as a second source of Islamic law for Muslims worldwide, especially in Indonesia, which has the world's most significant Muslim population of 228.68 million people. However, not all Hadith texts have been certified and approved for use, and several falsified Hadiths make it challenging to distinguish betw... | https://www.semanticscholar.org/paper/05ff3506924b93819c92f8333fc0ed340c661e3e | Scriptural Sources | Hadith Sciences | Structuring | NER & Ontologies |
An English Islamic Articles Dataset (EIAD) for developing an IslamBot Question Answering Chatbot | A chatbot is one of the most vastly recommended technologies to be used during these decades, especially through the digitization era. It could save much consumed time for both the users and the customer service employees. Chatbots could provide an answer to the asked questions instantly. IslamBot is an Islamic religio... | https://www.semanticscholar.org/paper/870e51833d71bcee713a69236065c20105d690aa | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation |
Islamic virtue-based ethics for artificial intelligence | The twenty-first century technological advances driven by exponential rise of artificial intelligence (AI) technology have ushered in a new era that offers many of us hitherto unimagined luxuries and facilities. However, under the guise of this progressive discourse, particularly in the backdrop of current neo-liberal ... | https://www.semanticscholar.org/paper/50e96cb48d5e455bd39839ec69e712ea6b7ad1a5 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
The Fellowship of the Authors: Disambiguating Names from Social Network Context | Most NLP approaches to entity linking and coreference resolution focus on retrieving similar mentions using sparse or dense text representations. The common"Wikification"task, for instance, retrieves candidate Wikipedia articles for each entity mention. For many domains, such as bibliographic citations, authority lists... | https://www.semanticscholar.org/paper/8322e837c31501eaa06ed2e80e3e746b42e15f13 | Scriptural Sources | Hadith Sciences | Authenticity & Isnad | Graph/Network Analysis |
Quranic Conversations: Developing a Semantic Search tool for the Quran using Arabic NLP Techniques | The Holy Book of Quran is believed to be the literal word of God (Allah) as revealed to the Prophet Muhammad (PBUH) over a period of approximately 23 years. It is the book where God provides guidance on how to live a righteous and just life, emphasizing principles like honesty, compassion, charity and justice, as well ... | http://arxiv.org/abs/2311.05120v1 | Scriptural Sources | Quran & Tafsir | Retrieval & QA | Search & Datasets |
AraQA: An Arabic Generative Question-Answering Model for Authentic Religious Text | Recently, the internet has become a vast repository of religious texts and sources. The quest for valid and dependable Islamic Q/A that provides accurate substantiation from the Holy Quran (Muslim holy book) and Hadith (Prophet Muhammed teachings) has become challenging, given the abundance of misleading answers lackin... | https://www.semanticscholar.org/paper/1adfc2185a0ce393f0ca15ebdbd3f0d991b53fe8 | Scriptural Sources | Quran & Tafsir | Retrieval & QA | RAG & Evidence Linking; Search & Datasets |
A Data-Driven Exploration of a New Islamic Fatwas Dataset for Arabic NLP Tasks | Islamic content is a broad and diverse domain that encompasses various sources, topics, and perspectives. However, there is a lack of comprehensive and reliable datasets that can facilitate conducting studies on Islamic content. In this paper, we present fatwaset, the first public Arabic dataset of Islamic fatwas. It c... | https://www.semanticscholar.org/paper/2cf09b9348eacfeaea43ba03a8e1a846adb1012c | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation; Shared Tasks |
ARABIC-FUNDAMENTALS OF FINANCIAL INTEGRITY AND THEIR APPLICATIONS IN ISLAMIC LAW | The study of the foundations of integrity and its applications in Islamic law stems from the priorities of reality, the requirements of safety of life, the development of society, and the success of economic and social life. This study came to show the foundations of integrity based on the legal evidence from the Holy ... | https://www.semanticscholar.org/paper/2beb254017fd7eecb7a8479b7f3da3b4d6a67a05 | Law & Practice | Fiqh & Fatwa | Reasoning & Evaluation | Benchmarks |
HAQA and QUQA: Constructing Two Arabic Question-Answering Corpora for the Quran and Hadith | It is neither possible nor fair to compare the performance of question-answering systems for the Holy Quran and Hadith Sharif in Arabic due to both the absence of a golden test dataset on the Hadith Sharif and the small size and easy questions of the newly created golden test dataset on the Holy Quran. This article pre... | https://www.semanticscholar.org/paper/2aa382e75e8bc9dbb7e4d5e895152208b76b668a | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation; Shared Tasks |
Building Domain-Specific LLMs Faithful To The Islamic Worldview: Mirage or Technical Possibility? | Large Language Models (LLMs) have demonstrated remarkable performance across numerous natural language understanding use cases. However, this impressive performance comes with inherent limitations, such as the tendency to perpetuate stereotypical biases or fabricate non-existent facts. In the context of Islam and its r... | http://arxiv.org/abs/2312.06652v1 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
Optimalisasi Menghafal Al-Qur'an: Penerapan Metode Neuro Linguistic Programming (NLP) di Pesantren Islamic Centre Sumut | This research aims to analyze the application of NLP/Neuro Linguistic Programming methods in improving the quality of memorizing the Quran at the Islamic Center. Sumut is well organized from the formation of the tasmi class, creating a conversational atmosphere to memorize, reminding that everything is aimed at and mea... | https://www.semanticscholar.org/paper/6d4c1c727ad4d7869b04be2a5e1bd371786b6074 | Education & Community | Islamic Education | Pedagogy | Qualitative Studies |
Hadiths Classification Using a Novel Author-Based Hadith Classification Dataset (ABCD) | Religious studies are a rich land for Natural Language Processing (NLP). The reason is that all religions have their instructions as written texts. In this paper, we apply NLP to Islamic Hadiths, which are the written traditions, sayings, actions, approvals, and discussions of the Prophet Muhammad, his companions, or h... | https://www.semanticscholar.org/paper/695bc796f9452a56624c0977248bc3e652823468 | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation; Shared Tasks |
What Makes Work “Good” in the Age of Artificial Intelligence (AI)? Islamic Perspectives on AI-Mediated Work Ethics | Artificial intelligence (AI) technologies are increasingly creeping into the work sphere, thereby gradually questioning and/or disturbing the long-established moral concepts and norms communities have been using to define what makes work good. Each community, and Muslims make no exception in this regard, has to revisit... | https://www.semanticscholar.org/paper/bdcdb9c4e8bcdae8f130711abb88dd430ded380c | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
Usability Measurement of Aswaja Chatbot with System Usability Scale (SUS) | Chatbots are becoming increasingly popular as human-computer interfaces or robots. Virtual assistants, such as chatbots, have exploded in popularity in recent years thanks to breakthroughs in areas like machine learning, artificial intelligence, and even more fundamental technologies like neural networks and natural la... | https://www.semanticscholar.org/paper/60bc9d03dccbb0da8034c69b8fcd02fb0ac120a7 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Model Pembelajaran Amtsal Dan Implikasinya Dalam Pembelajaran Pendidikan Agama Islam | Quranic verses contain amtsal (examples and figurative language) which can be used in teaching. As a learning model, amtsal can become a necessary alternative to achieve efficient and effective teaching and learning. Yet, this model in teaching is not sufficiently explored. A review of Quranic verses identifies three t... | https://www.semanticscholar.org/paper/19238e8fd2136ddd8ab0831d3a8cb082b03e2d03 | Education & Community | Islamic Education | Pedagogy | Qualitative Studies |
DIACRITIC-AWARE ALIGNMENT AND CLASSIFICATION IN ARABIC SPEECH: A FUSION OF FUZTPI AND ML MODELS | This paper presents the Quran Speech Recognition (QRSR) system, achieving alignment and classification accuracies up to 96%. The system is designed to advance Arabic Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) by focusing on the Arabic diacritic-annotated text. We address the limitations of existing Ara... | https://www.semanticscholar.org/paper/83d64f0185cdba3ce28cda4b465029bfc60337c3 | Scriptural Sources | Quran & Tafsir | Audio/Multimodal | ASR/Recitation Support |
(An Analysis of the Content of the Holy Qur’an and Islamic Education For The Second intermediate According to the Skills of Imaginative Thinking |
This current paper analyzes the book of the Holy Quran and Islamic Education for the second intermediate, according to their performance of the imaginative thinking skills (2021-2022) by answering the following question:
What are the imaginative thinking skills included in the content of the Holy Qur’an and Is... | https://www.semanticscholar.org/paper/f9cac4cb563cfa835deb6a7ad1cfba4cb49dbee4 | Education & Community | Islamic Education | Pedagogy | Curriculum Design |
Revolutionizing Arabic Language Reading Skills Among Junior Islamic School Students via Innovative Digital Comic Learning Media | This research aims to investigate the efficacy of utilizing digital comic media to enhance Qira'ah proficiency among seventh-grade students at MTs AL-Hikmah Bandar Lampung. The study addresses the following research questions: 1) How does the development of digital comic media contribute to improving Qira'ah proficienc... | https://www.semanticscholar.org/paper/45ec34b9469dcd204b2b8ffdd4ce75119a3964f3 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Quran Recitation Recognition using End-to-End Deep Learning | The Quran is the holy scripture of Islam, and its recitation is an important aspect of the religion. Recognizing the recitation of the Holy Quran automatically is a challenging task due to its unique rules that are not applied in normal speaking speeches. A lot of research has been done in this domain, but previous wor... | http://arxiv.org/abs/2305.07034v1 | Scriptural Sources | Quran & Tafsir | Audio/Multimodal | ASR/Recitation Support |
Universal Language Modelling agent | Large Language Models are designed to understand complex Human Language. Yet, Understanding of animal language has long intrigued researchers striving to bridge the communication gap between humans and other species. This research paper introduces a novel approach that draws inspiration from the linguistic concepts fou... | https://www.semanticscholar.org/paper/a89398dbe455796abf9398241e397d3753544ef2 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Natural Language Processing for Interactive and Personalized Qur’anic Education | The development of artificial intelligence technology, particularly Natural Language Processing (NLP), has opened significant opportunities for transforming Qur’anic learning methods. NLP, as a branch of AI focused on the interaction between computers and human languages, offers new approaches to understanding, analyzi... | https://www.semanticscholar.org/paper/f9a18cd858354c20d5753b5cf17f5667c4933fe2 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Teaching Arabic Reading Skills For Bahtsul Masail Purpose In Islamic Boarding School/ تعليم مهارة القراءة لأغراض بحث المسائل في المعهد | In teaching Arabic as a foreign language, several problems were found, including linguistic and non-linguistic issues. Salafiyah Shirothul Fuqoha Islamic Boarding School has a system to solve this problem so that students have high reading competence, namely a Teaching System of Reading Skills for Bahtsul Masail purpos... | https://www.semanticscholar.org/paper/1a87a3af1ec209d62a2b252f82d32966aeed549d | Education & Community | Islamic Education | Pedagogy | Qualitative Studies |
AceGPT, Localizing Large Language Models in Arabic | This paper is devoted to the development of a localized Large Language Model (LLM) specifically for Arabic, a language imbued with unique cultural characteristics inadequately addressed by current mainstream models. Significant concerns emerge when addressing cultural sensitivity and local values. To address this, the ... | https://www.semanticscholar.org/paper/859d9e9c77ef556fc6257c2a395e9edfcac3b775 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
Artificial Intelligence (AI) in Islamic Ethics: Towards Pluralist Ethical Benchmarking for AI | This paper explores artificial intelligence (AI) ethics from an Islamic perspective at a critical time for AI ethical norm-setting. It advocates for a pluralist approach to ethical AI benchmarking. As rapid advancements in AI technologies pose challenges surrounding autonomy, privacy, fairness, and transparency, the pr... | https://www.semanticscholar.org/paper/e700e8b1620a31af8f866a623e1e35caa05882a0 | Objectives & Governance | Maqasid Lens | Pluralism | Handling Disagreement |
QASiNa: Religious Domain Question Answering Using Sirah Nabawiyah | Nowadays, Question Answering (QA) tasks receive significant research focus, particularly with the development of Large Language Model (LLM) such as Chat GPT [1]. LLM can be applied to various domains, but it contradicts the principles of information transmission when applied to the Islamic domain. In Islam we strictly ... | https://www.semanticscholar.org/paper/25a948ef2f05450ef229e532b2c5144d07bef2e3 | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation; Shared Tasks |
DEVELOPMENT OF MODERN INDONESIAN NOVEL TEACHING BOOKS IN THE 2000 RELIGIOUS EDUCATION BASED | Literary criticism course is a compulsory subject that must be taken and taken by Indonesian Language Education students. This course has achievements, namely that students are able to distinguish types of literary criticism, methods of literary criticism, and schools of literary criticism. however, this material is of... | https://www.semanticscholar.org/paper/0143dd66497e98035f332c0e6e45ae0fe8486813 | Education & Community | Islamic Education | Pedagogy | Curriculum Design |
Implementation of Finite State Automata on e-Knows Telegram Chatbot | The State Islamic University of Sunan Gunung Djati Bandung has a bold learning system called e-Knows. So far, if the user has a school, he must contact the admin manually. The problems are diverse, and several issues can bring personal impact. Automata language theory is the basic logic for mapping the telegram e-Knows... | https://www.semanticscholar.org/paper/014bbee71e5aa703e25dfd65a346e30e4b8a33e9 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Tagging Algorithm and POS Tags for Narrator's Name in Hadith Document | Named Entity Recognition (NER) is important in many domains, such as information retrieval and text classification. Typically, NER uses machine learning (ML) or rule-based methods to recognize NER. ML works well with annotated corpora. The most commonly used annotated corpora are in English but not in Malay. Non-annota... | https://www.semanticscholar.org/paper/d62cdb99599d8a9f99a1b8442404e37abe4c3712 | Scriptural Sources | Hadith Sciences | Structuring | NER & Ontologies; KG Construction |
Answering Divine Love: Human Distinctiveness in the Light of Islam and Artificial Superintelligence | In the Qur’an, human distinctiveness was first questioned by angels. These established denizens of the cosmos could not understand why God would create a seemingly pernicious human when immaculate devotees of God such as themselves existed. In other words, the angels asked the age-old question: what makes humans so spe... | https://www.semanticscholar.org/paper/b8d8148573385068c3f7282e653d191a15cb128a | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
IslamicPCQA: A Dataset for Persian Multi-hop Complex Question Answering in Islamic Text Resources | Nowadays, one of the main challenges for Question Answering Systems is to answer complex questions using various sources of information. Multi-hop questions are a type of complex questions that require multi-step reasoning to answer. In this article, the IslamicPCQA dataset is introduced. This is the first Persian data... | http://arxiv.org/abs/2304.11664v1 | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation; Shared Tasks |
Explainable Identification of Hate Speech towards Islam using Graph Neural Networks | Islamophobic language on online platforms fosters intolerance, making detection and elimination crucial for promoting harmony. Traditional hate speech detection models rely on NLP techniques like tokenization, part-of-speech tagging, and encoder-decoder models. However, Graph Neural Networks (GNNs), with their ability ... | http://arxiv.org/abs/2311.04916v4 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
Bowed Generation and Digital Ethics Challenges in Islamic Education | Generation Bowing Down and the Challenges of Digital Ethics in Islamic Education" is a study that explores the impact of the evolution of digital technology on Islamic values among the younger generation. In an era where technologies like smartphones, the internet, and social media have become inseparable from daily li... | https://www.semanticscholar.org/paper/47fc922d8df163dfcfcb6483b20bb81f8224ed91 | Education & Community | Islamic Education | Pedagogy | Qualitative Studies |
The Ethics of Artificial Intelligence (AI) Utilization in Qur'anic Studies: An Islamic Philosophical Perspective | Artificial Intelligence (AI) has presented a major breakthrough in Qur'anic studies, enabling text analysis, thematic classification, and the development of digital commentaries. These innovations provide opportunities to expand accessibility and improve the accuracy of Qur'anic analysis. However, AI also poses ethical... | https://www.semanticscholar.org/paper/bcca6b45168a76faf82e1b13d69844a91ab8f8e1 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
Arabic Ontology for Hadith texts - A survey | : Hadith texts play a significant role in Islamic scholarship, providing guidance for Muslims in understanding and practicing Islam. This paper explores the importance of Hadith texts, their categorization based on reliability, and the structure of a typical Hadith. It discusses the use of software tools and ontologies... | https://www.semanticscholar.org/paper/97cc639c27771111c4a41b7c8658515fa634b26d | Scriptural Sources | Hadith Sciences | Structuring | NER & Ontologies |
AI model for Parsing the Text of Holy Quran Sentences | The Holy Quran is of immense importance to many societies due to the position that this book holds for Muslims around the world and the religious teachings it contains. The Holy Quran employs a high-standard Arabic language, which requires analysis and simplification of expressions to enhance comprehension and applicat... | https://www.semanticscholar.org/paper/b2bad1b1231ed4d1a2f07a08c21c91fc6c194e74 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Critical Discourse Analysis of Islamic Ideological Expressions in Acknowledgement Sections of Theses Written by Scholars in English Language Teaching (ELT) | The objective of current research is to analyze the expressions of Islamic ideology in the acknowledgement sections of theses written by researchers in the field of English Language Teaching (ELT) from Pakistan. These acknowledgements, a specific concept in academic writing, offers a particular frame to capture the rel... | https://www.semanticscholar.org/paper/d2d4cf8c40d8c13c4bc52701a08f7ea27bd0e218 | Education & Community | Contemporary Discourse | Analysis | Sermons/Media; Stance/Theme Analysis |
A Benchmark Dataset with Larger Context for Non-Factoid Question Answering over Islamic Text | Accessing and comprehending religious texts, particularly the Quran (the sacred scripture of Islam) and Ahadith (the corpus of the sayings or traditions of the Prophet Muhammad), in today's digital era necessitates efficient and accurate Question-Answering (QA) systems. Yet, the scarcity of QA systems tailored specific... | https://www.semanticscholar.org/paper/d177e20a752677cb3b4c0dadb7d51f368ca0c267 | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation |
Evaluating Artificial Intelligence Bias In Answering Religious Questions | Question Answering (QA) is a specialized field in the field of NLP and most studies in this field focus on the English language, while other languages, such as Arabic, are still in their early stages. Recently, research has turned to developing answering systems for Questions for Arabic-Islamic texts, which may impose ... | https://www.semanticscholar.org/paper/29fdbdd270d619c2c913a1bf7ec6412d4ccd3419 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
Fikr: AI Chatbot Powered with Vector Search | Fikr is a cutting-edge chatbot designed to enhance access to Islamic knowledge by leveraging advanced AI technologies such as vector search and Large Language Models (LLMs), including GPT-3.5. Developed using a combination of Streamlit for the frontend, Flask for the backend, and Firebase for data storage and authentic... | https://www.semanticscholar.org/paper/aa7fcc24526097d3078668ca7695c67c5d287b43 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
SoulScripture: Chatbot using Bidirectional Encoder Representations from Transformers as a Medium of Spiritual Guidance | Mental health is an important aspect of human life. Many people face stress, anxiety, and distress daily without adequate support to manage these conditions. Islamic teachings from the Quran and Hadith provide wisdom as a source of inspiration and inner peace. However, accessing and understanding these teachings requir... | https://www.semanticscholar.org/paper/70e0542b5573626e20bd0d72db0ba2a10273264e | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Penerapan Chatbot pada Aplikasi Web Tanya Jawab Tentang Fiqih Jual Beli Islam Menggunakan LangChain | Fiqh is the field that studies Islamic rules on how humans behave, both in speech and action. Islamic Fiqh of buying and selling is a branch of fiqh that concentrates on the laws and rules relating to transactions and social interactions that occur in the daily lives of Muslims. There are many sources of learning about... | https://www.semanticscholar.org/paper/20243457b54c5644659d30c2ed44fea8d0370cbd | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Optimized Quran Passage Retrieval Using an Expanded QA Dataset and Fine-Tuned Language Models | Understanding the deep meanings of the Qur'an and bridging the language gap between modern standard Arabic and classical Arabic is essential to improve the question-and-answer system for the Holy Qur'an. The Qur'an QA 2023 shared task dataset had a limited number of questions with weak model retrieval. To address this ... | https://www.semanticscholar.org/paper/efe3628d43a3d4efbc954d6e3b974113cf1c68f4 | Scriptural Sources | Quran & Tafsir | Retrieval & QA | Search & Datasets |
The Holy Quran | This paper provides an editorial reflection on the enduring relevance of the Holy Quran as a foundational text in Islam. The Quran, which is believed to be the word of God as revealed to the Prophet Muhammad, serves as a comprehensive guide for Muslims in both spiritual and worldly matters. It addresses ethical dilemma... | https://www.semanticscholar.org/paper/d15deb526ca59e3d8891e32bf18b6bad9f994e14 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Relevance of the Retrieval of Hadith Information (RoHI) using Bidirectional Encoder Representations from Transformers (BERT) in religious education media | This research explores the impact of integrating Bidirectional Encoder Representations from Transformers (BERT) into the Retrieval of Hadith Information (RoHI) application within the realm of religious education media. Hadith, the sayings and actions of Prophet Muhammad, play a pivotal role in Islamic teachings, requir... | https://www.semanticscholar.org/paper/225256c3e0192e39538194db108d9568b46bac97 | Scriptural Sources | Hadith Sciences | Retrieval & QA | IR & Citations |
A Comparative Study of Religious Scriptures Using Natural Language Processing | Over the past few years, Natural Language Processing (“NLP”) has emerged as a powerful tool and has enabled computational analysis of texts by offering insights into the subtleties of language, emotion, and thematic frameworks. This research paper employs NLP strategies such as topic modelling and sentiment analysis to... | https://www.semanticscholar.org/paper/ae2b197afc03970b2705444ea09b0cf8bb4438a1 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Islamic Lifestyle Applications: Meeting the Spiritual Needs of Modern Muslims | We evaluated contemporary Islamic lifestyle applications supporting religious practices and motivation among Muslims. We reviewed 11 popular applications using self-determination theory and the technology-as-experience framework to assess their support for motivation and affective needs. Most applications lack features... | http://arxiv.org/abs/2402.02061v1 | Education & Community | Islamic Education | Learning Systems | User Studies |
Using the Book "Al-Miftah lil-‘Ulum" in Teaching Arabic Grammar at the Islamic Boarding School in Indonesia: Benefits and Obstacles | This research aims to comprehend the utilization of the book "Al-Miftah lil-‘Ulum" in teaching Nahwu science at Darul Falah International School, Bagon Mataram, and to identify obstacles arising in teaching Nahwu science using the book. The research methodology employed is qualitative descriptive, utilizing observation... | https://www.semanticscholar.org/paper/c4136fe16ac471e685fa729b308e592ff4a22a1a | Education & Community | Islamic Education | Pedagogy | Qualitative Studies |
Evaluating the Regular Sharaf Learning Program at the Foundation of Islamic and Arabic Language Learning In Indonesia | This research aims to scrutinize and assess the learning dynamics within the regular Sharaf learning program conducted by the Islamic and Arabic Learning Foundation. Employing a descriptive qualitative approach, data for this study were obtained through interviews with the program director, supervisors, and administrat... | https://www.semanticscholar.org/paper/572ab070c61a34bdab4b87e49ee6edc583e2a77a | Education & Community | Islamic Education | Pedagogy | Qualitative Studies |
Penerapan Langchain Retriever dengan Model Chat Openai dalam Pengembangan Sistem Chatbot Hadis Berbasis Telegram | In Islamic studies, the Hadiths of Prophet Muhammad (SAW) hold significant value as guides for behavior and faith. However, access to understanding Hadiths often presents challenges, espe-cially for those who are not Hadith experts. The digitalization of Hadiths is still limited, making it time-consuming to find answer... | https://www.semanticscholar.org/paper/7f38a6e5cdfb36e8fc61b5318c98cc8ed56f3596 | Scriptural Sources | Hadith Sciences | Retrieval & QA | Grounded QA |
Predicting Revelation Periods of Verses of the Quran via Deep Learning | The revelation period of a verse of the Quran provides invaluable insights into the historical context of that verse, helps us understand the prophet's biography, and empowers Islamic scholars to decide about the applicability of certain laws and/or to interpret that verse. They mostly relied on traditional methods (su... | https://www.semanticscholar.org/paper/4ce8831ba0b6517cc0e1f2842a925e737d81f6c9 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Integration Portal of Arabic Language and Islamic Education in the Digital Era | The digital era has brought significant changes to the learning of the Arabic language and Islamic education. This study explores the potential and challenges of using an integration portal as an innovative solution in this context. Through a descriptive qualitative approach, involving literature review, content analys... | https://www.semanticscholar.org/paper/0e7b668ecd4526c0f41047ecf8aa85c9e7dcaf80 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
Do Islamic epistemology and ethics advance the understanding and promotion of sustainable development? A systematic review using PRISMA | Purpose
This study addresses the question of whether Islamic epistemology and ethics advance the understanding and promotion of sustainable development (SD) in the field of Islamic management, economics and finance (IMEF). This study also aims to understand how contemporary ethical theories explain and harmonise Islami... | https://www.semanticscholar.org/paper/65d1365d976cbece39d2efbfd3655125d298c2f4 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
The Impact of Generative AI on Islamic Studies: Case Analysis of "Digital Muhammad ibn Ismail Al-Bukhari" | The emergence of large language models (LLMs) such as ChatGPT, LLaMA, Gemini, and Claude has transformed natural language processing (NLP) tasks by demonstrating remarkable capabilities in generating fluent and contextually appropriate responses. This paper examines the current state of LLMs, their applications, inhere... | https://www.semanticscholar.org/paper/e343640203b1ec3085d2ff36fcccf20325c4e994 | Scriptural Sources | Hadith Sciences | Retrieval & QA | Grounded QA |
Quranic Audio Dataset: Crowdsourced and Labeled Recitation from Non-Arabic Speakers | This paper addresses the challenge of learning to recite the Quran for non-Arabic speakers. We explore the possibility of crowdsourcing a carefully annotated Quranic dataset, on top of which AI models can be built to simplify the learning process. In particular, we use the volunteer-based crowdsourcing genre and implem... | http://arxiv.org/abs/2405.02675v1 | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation |
The Contribution of al-'Ilm Sharaf To the Development of Understanding Classical Arabic Grammar at Islamic Educational Institutions | This study examines the contribution of al-'Ilm Sharaf to the development of understanding classical Arabic grammar in Islamic educational institutions. Al-'Ilm Sharaf is a key branch of Arabic grammar that focuses on word formation and meaning through the manipulation of root letters. Although this subject has been in... | https://www.semanticscholar.org/paper/4ecc74aecb74f1ed7ac3a1cb925b0e547ada8dee | Education & Community | Islamic Education | Pedagogy | Qualitative Studies |
AraTrust: An Evaluation of Trustworthiness for LLMs in Arabic | The swift progress and widespread acceptance of artificial intelligence (AI) systems highlight a pressing requirement to comprehend both the capabilities and potential risks associated with AI. Given the linguistic complexity, cultural richness, and underrepresented status of Arabic in AI research, there is a pressing ... | https://www.semanticscholar.org/paper/504f07874899ad12db96abb0121d9a86b00cbb63 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
CamelEval: Advancing Culturally Aligned Arabic Language Models and Benchmarks | Large Language Models (LLMs) are the cornerstones of modern artificial intelligence systems. This paper introduces Juhaina, a Arabic-English bilingual LLM specifically designed to align with the values and preferences of Arabic speakers. Juhaina inherently supports advanced functionalities such as instruction following... | https://www.semanticscholar.org/paper/adb9dc13a0ffdda8aa5cb472b10c41fbbfcaf10f | Shared Resources | Datasets & Benchmarks | Evaluation | Cross-domain Benchmarks; Reproducible Protocols |
Investigating Cultural Alignment of Large Language Models | The intricate relationship between language and culture has long been a subject of exploration within the realm of linguistic anthropology. Large Language Models (LLMs), promoted as repositories of collective human knowledge, raise a pivotal question: do these models genuinely encapsulate the diverse knowledge adopted ... | https://www.semanticscholar.org/paper/b1890367317f0657c08ed96be4c474035b34b485 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation; Benchmark Creation |
Exploring Bengali Religious Dialect Biases in Large Language Models with Evaluation Perspectives | While Large Language Models (LLM) have created a massive technological impact in the past decade, allowing for human-enabled applications, they can produce output that contains stereotypes and biases, especially when using low-resource languages. This can be of great ethical concern when dealing with sensitive topics s... | http://arxiv.org/abs/2407.18376v1 | Objectives & Governance | Maqasid Lens | Alignment | Bias/Safety Evaluation |
Integration of AI Chatbots in Islamic Religious Education: Potential and Challenges from a Doctoral Student Perspective | This article examines the application of artificial intelligence (AI), particularly chatbot technology such as ChatGPT, in higher education, with a specific focus on Islamic religious learning. The study involved 27 doctoral students from Sunan Ampel State Islamic University, Surabaya, using a survey method to explore... | https://www.semanticscholar.org/paper/245d8489af00fe5e06cb7a51c34719ad0a69c5ad | Education & Community | Islamic Education | Learning Systems | User Studies |
Model of Text-to-Text Transfer Transformer for Hadith Question Answering System | The advancement of Artificial Intelligence (AI), notably in Natural Language Processing (NLP), has been remarkable. Among its applications, Question-Answering (QA) systems stand out, assisting users in accessing pertinent information across various topics, including religious contexts. Religion plays a significant role... | https://www.semanticscholar.org/paper/f09b3178a74d653cfdcf18231cccd8c9f03aa969 | Scriptural Sources | Hadith Sciences | Retrieval & QA | Grounded QA; IR & Citations |
ArabLegalEval: A Multitask Benchmark for Assessing Arabic Legal Knowledge in Large Language Models | The rapid advancements in Large Language Models (LLMs) have led to significant improvements in various natural language processing tasks. However, the evaluation of LLMs’ legal knowledge, particularly in non English languages such as Arabic, remains under-explored. To address this gap, we introduce ArabLegalEval, a mul... | https://www.semanticscholar.org/paper/d614fbd773678d2844a829b0c91716f3ddb3e28a | Shared Resources | Datasets & Benchmarks | Creation | Corpora/Annotation; Shared Tasks |
Opportunities, Challenges and Ethics of Artificial Intelligence Implementation in Teaching Islamic Religious Education in Public Universities: A Case Study in South Kalimantan |
This research presents a comprehensive overview of the opportunities and challenges in the utilization of Artificial Intelligence (AI) to improve the quality of Islamic Religious Education teaching in universities in South Kalimantan. Furthermore, the researcher explores how the ethics of using AI in Islamic Educati... | https://www.semanticscholar.org/paper/7411c19c67986e45b50722f82da12a7a3f132ce6 | Education & Community | Islamic Education | Pedagogy | Qualitative Studies |
Adjusting the Ideal Islamic Religious Education Curriculum to the Development of AI-Based Technology | The development of technology is currently experiencing a very rapid development, one of which is the emergence of an innovation called AI (artificial intelligence). Islamic religious education indirectly gets an impact on the emergence of AI (artificial intelligence) so that it requires adjustments in the Islamic reli... | https://www.semanticscholar.org/paper/12a8db799175465dbad38af6d52bce7fb2235d96 | Education & Community | Islamic Education | Pedagogy | Curriculum Design |
Topic Modeling of Quranic Verses using Latent Dirichlet Allocation with English Language | This study aims to assess the effectiveness of topic modeling in the English translation of the Holy Quran. Topic modeling is a popular text mining technique for uncovering latent semantic patterns in the collection of textual documents and helps to annotate the documents based on these topics. This study identifies th... | https://www.semanticscholar.org/paper/c76ff407a2ca0ff35f5a69e5fc5f64c2d263e179 | Scriptural Sources | Quran & Tafsir | Processing & Analysis | Morphology/Syntax; Semantics/Topics |
Integrating English Language Materials and Islamic Values: Research and Development in Islamic Higher Education | Developing English material is an effort to develop and validate English material based on students' characteristics and students’ needs. Students of Islamic universities have different characters and needs from general universities. Therefore, this study aims at describing the process of developing English language ma... | https://www.semanticscholar.org/paper/d3a44473592281d5de128764234bab776d8aa6cb | Education & Community | Islamic Education | Pedagogy | Curriculum Design; Qualitative Studies |
UTILIZING RETRIEVAL-AUGMENTED GENERATION IN LARGE LANGUAGE MODELS TO ENHANCE INDONESIAN LANGUAGE NLP | The improvement of Large Language Models (LLM) such as ChatGPT through Retrieval-Augmented Generation (RAG) techniques has urgency in the development of natural language translation technology and dialogue systems. LLMs often experience obstacles in addressing special requests that require information outside the train... | https://www.semanticscholar.org/paper/1ffbf3ddf77375fccb5bc9e1552df7509d0cb2f8 | Scriptural Sources | Quran & Tafsir | Retrieval & QA | RAG & Evidence Linking; Search & Datasets |
A Proposed Model for Organizing The Regulation and Supervision of The Saudi Central Bank on Islamic Banks | The study aimed to design a proposed model for a system of regulation and supervision of Islamic banks that is consistent with the characteristics and nature of its work, by answering the main question: What is the proposed vision for the Saudi Central Bank to create an appropriate regulatory and supervisory regime for... | https://www.semanticscholar.org/paper/7114721011ced29c150bd5ff837f630207891780 | Objectives & Governance | Doctrinal Integrity | Authenticity | Attribution Checks; Fabrication Signals |
Islamic QA with Chatbot System Using Convolutional Neural Network | Many questions and answers about Islamic law are scattered on the internet and have been explained repeatedly by various sites. One solution is presented by the website www.piss-ktb.com, which creates a web-based source of information in the form of Frequently Asked Questions (FAQ). However, web-based FAQs have a ... | https://www.semanticscholar.org/paper/18a830f1ea73e2295d8ab247613de7fc11e7a4a8 | Education & Community | Islamic Education | Learning Systems | Chatbots/Apps/Portals; User Studies |
![]()
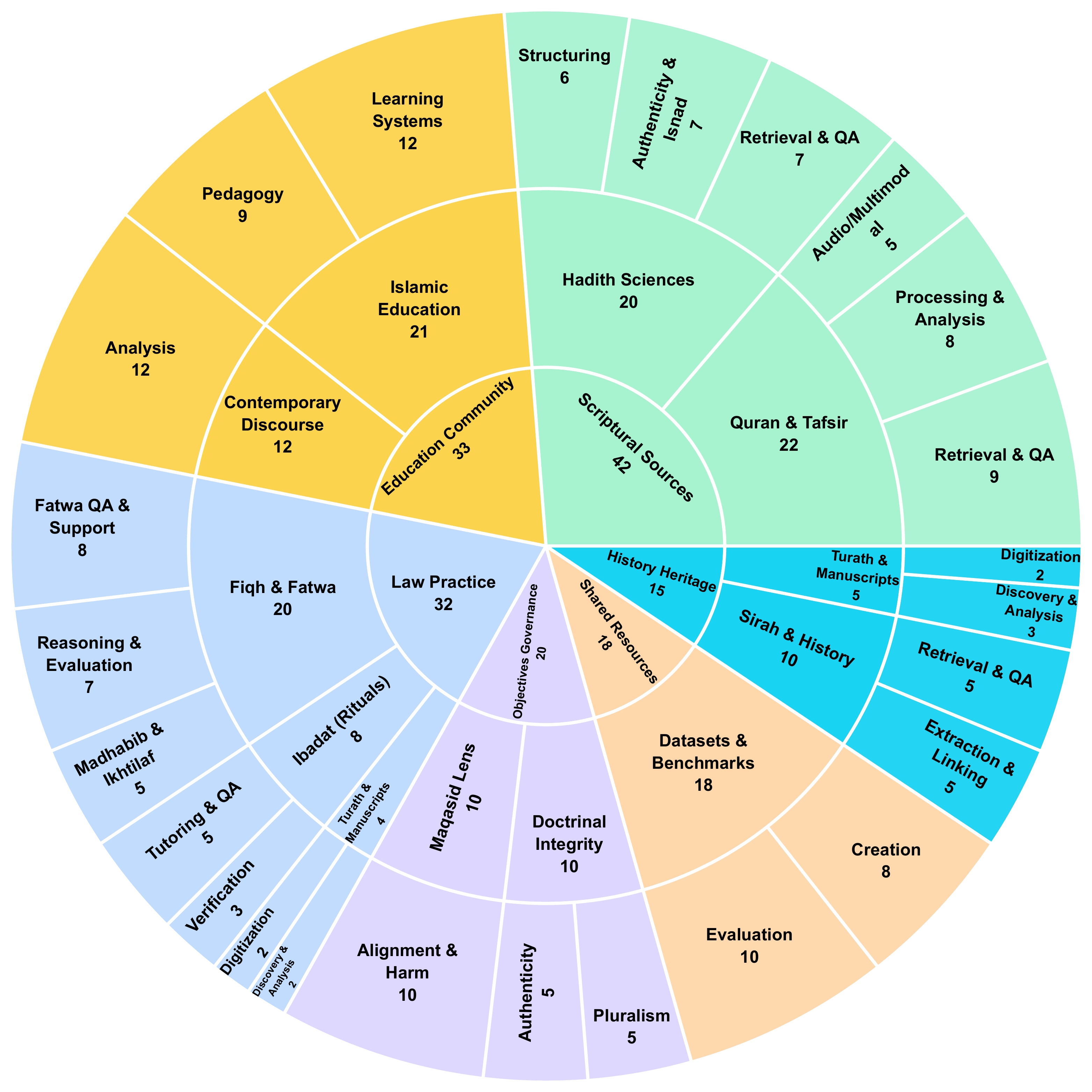
A comprehensive systematic survey of 160+ papers (2016–2026) examining how AI systems operationalize Islamic knowledge, spanning NLP, information retrieval, speech processing, multimodal learning, educational technology, and LLM alignment.
-1.png)
AI systems are increasingly mediating how Islamic communities access, study, and apply Islamic sources; still, research on Islamic-knowledge capabilities remains fragmented across NLP, information retrieval, speech, multimodal learning, educational technology, and recent LLM alignment work.
This survey presents a critical systematic review of 160+ papers from the past decade that incorporate Islamic knowledge in Machine Learning/AI. We propose a layered taxonomy that separates an epistemic view of Islamic knowledge (authority-bearing foundations and established disciplines) from an instrumental AI task layer (data and corpora, retrieval and grounding, understanding, reasoning support, evaluation and governance, and multimodal methods), while treating normative concerns as cross-cutting constraints.
Using this framework, we synthesize trends in datasets, benchmarks, and system architectures, highlighting the shift toward retrieval-grounded LLM pipelines, verification and deferral mechanisms, and emerging multimodal recitation and manuscript-processing systems. We also consolidate evaluation practices for trustworthiness, including provenance and faithfulness, disagreement-aware and school-of-thought-sensitive framing, calibrated abstention under underspecified queries, and safety and bias assessment for Islamic contexts.
| Category | Domains |
|---|---|
| Foundations | Qur'an, Hadith |
| Disciplines | Qur'anic Sciences, Hadith Sciences, Usul al-Fiqh, Fiqh, Theology (Kalam), Sufism (Tasawwuf), History & Sirah |
| Task Family | Description |
|---|---|
| Data & Corpora | Digitized texts, annotated datasets, knowledge graphs |
| Retrieval & Grounding | Source-grounded search, RAG pipelines, citation verification |
| Understanding | Classification, NER, topic modeling, sentiment analysis |
| Reasoning Support | QA, fatwa generation, legal reasoning, school-aware inference |
| Evaluation & Governance | Trustworthiness metrics, bias assessment, abstention protocols |
| Multimodal Methods | Recitation analysis, manuscript OCR, speech processing |
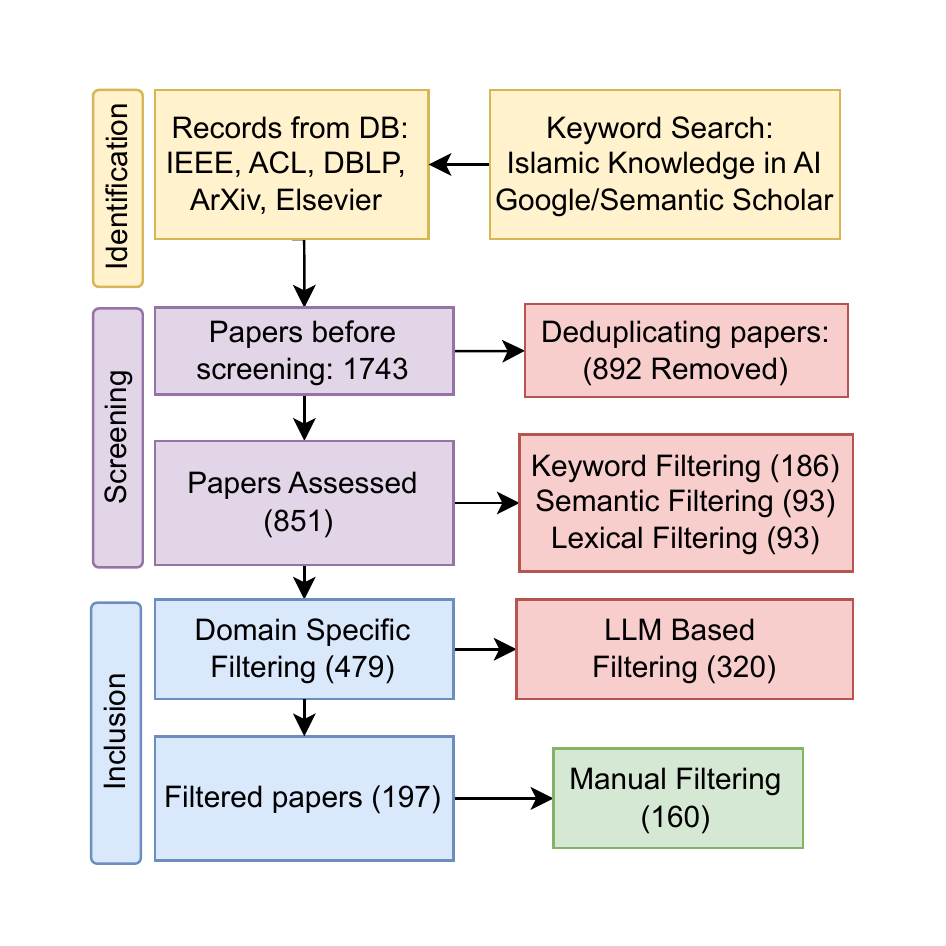
We followed the PRISMA-ScR (Preferred Reporting Items for Systematic reviews and Meta-Analyses extension for Scoping Reviews) framework:
| Challenge | Description |
|---|---|
| Data Scarcity | Most Islamic NLP datasets are small-scale and single-domain; cross-domain benchmarks are rare |
| Pluralism Gaps | Systems tend to collapse diverse scholarly opinions into single answers rather than presenting school-of-thought-aware alternatives |
| Hallucination Risks | LLMs fabricate Qur'anic verses and Hadith with confident presentation; fabricated citations are uniquely harmful in religious contexts |
| Safety & Governance | High-stakes religious guidance requires conservative abstention strategies, scholar-in-the-loop validation, and Islamic-specific red-teaming protocols |
If you use this survey in your research, please cite:
@article{Bhatia_2026,
title = {Advances in AI Systems on Islamic Knowledge Capabilities: A Critical Survey},
url = {http://dx.doi.org/10.36227/techrxiv.177155997.77147487/v1},
DOI = {10.36227/techrxiv.177155997.77147487/v1},
author = {Bhatia, Gagan and Mubarak, Hamdy and Hawasly, Majd and Jarrar, Mustafa and
Mikros, George and Zaraket, Fadi and Alhirthani, Mahmoud and Al-Khatib, Mutaz and
Cochrane, Logan and Darwish, Kareem and Yahiaoui, Rashid and Alam, Firoj},
year = {2026},
month = feb
}