
text stringlengths 5 631k | id stringlengths 14 178 | metadata dict | __index_level_0__ int64 0 647 |
|---|---|---|---|
import inspect
from typing import Any, Dict, List, Optional, Union
import torch
import torch.nn as nn
from transformers import AutoModel, AutoTokenizer, CLIPImageProcessor
from diffusers import DiffusionPipeline
from diffusers.image_processor import VaeImageProcessor
from diffusers.loaders import StableDiffusionLoraL... | diffusers/examples/community/gluegen.py/0 | {
"file_path": "diffusers/examples/community/gluegen.py",
"repo_id": "diffusers",
"token_count": 16737
} | 137 |
from typing import Union
import torch
from PIL import Image
from torchvision import transforms as tfms
from tqdm.auto import tqdm
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DiffusionPipeline,
LMSDiscreteScheduler,
PNDMScheduler,
... | diffusers/examples/community/magic_mix.py/0 | {
"file_path": "diffusers/examples/community/magic_mix.py",
"repo_id": "diffusers",
"token_count": 2445
} | 138 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/examples/community/pipeline_controlnet_xl_kolors_inpaint.py/0 | {
"file_path": "diffusers/examples/community/pipeline_controlnet_xl_kolors_inpaint.py",
"repo_id": "diffusers",
"token_count": 43810
} | 139 |
# Inspired by: https://github.com/Mikubill/sd-webui-controlnet/discussions/1236 and https://github.com/Mikubill/sd-webui-controlnet/discussions/1280
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from diffusers import StableDiffusionControlNetPipe... | diffusers/examples/community/stable_diffusion_controlnet_reference.py/0 | {
"file_path": "diffusers/examples/community/stable_diffusion_controlnet_reference.py",
"repo_id": "diffusers",
"token_count": 21059
} | 140 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/examples/dreambooth/test_dreambooth_lora.py/0 | {
"file_path": "diffusers/examples/dreambooth/test_dreambooth_lora.py",
"repo_id": "diffusers",
"token_count": 8107
} | 141 |
# Research projects
This folder contains various research projects using 🧨 Diffusers.
They are not really maintained by the core maintainers of this library and often require a specific version of Diffusers that is indicated in the requirements file of each folder.
Updating them to the most recent version of the libr... | diffusers/examples/research_projects/README.md/0 | {
"file_path": "diffusers/examples/research_projects/README.md",
"repo_id": "diffusers",
"token_count": 144
} | 142 |
import argparse
import itertools
import math
import os
import random
from pathlib import Path
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set... | diffusers/examples/research_projects/dreambooth_inpaint/train_dreambooth_inpaint.py/0 | {
"file_path": "diffusers/examples/research_projects/dreambooth_inpaint/train_dreambooth_inpaint.py",
"repo_id": "diffusers",
"token_count": 14371
} | 143 |
# InstructPix2Pix text-to-edit-image fine-tuning
This extended LoRA training script was authored by [Aiden-Frost](https://github.com/Aiden-Frost).
This is an experimental LoRA extension of [this example](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py). This script... | diffusers/examples/research_projects/instructpix2pix_lora/README.md/0 | {
"file_path": "diffusers/examples/research_projects/instructpix2pix_lora/README.md",
"repo_id": "diffusers",
"token_count": 1406
} | 144 |
## Diffusers examples with ONNXRuntime optimizations
**This research project is not actively maintained by the diffusers team. For any questions or comments, please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions.**
This aims to ... | diffusers/examples/research_projects/onnxruntime/README.md/0 | {
"file_path": "diffusers/examples/research_projects/onnxruntime/README.md",
"repo_id": "diffusers",
"token_count": 134
} | 145 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless r... | diffusers/examples/research_projects/pixart/train_pixart_controlnet_hf.py/0 | {
"file_path": "diffusers/examples/research_projects/pixart/train_pixart_controlnet_hf.py",
"repo_id": "diffusers",
"token_count": 21144
} | 146 |
import argparse
import copy
import itertools
import logging
import math
import os
import random
import shutil
from pathlib import Path
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import torchvision.transforms.v2 as transforms_v2
import transformers
from accelerate impo... | diffusers/examples/research_projects/realfill/train_realfill.py/0 | {
"file_path": "diffusers/examples/research_projects/realfill/train_realfill.py",
"repo_id": "diffusers",
"token_count": 16391
} | 147 |
# Stable Diffusion XL for JAX + TPUv5e
[TPU v5e](https://cloud.google.com/blog/products/compute/how-cloud-tpu-v5e-accelerates-large-scale-ai-inference) is a new generation of TPUs from Google Cloud. It is the most cost-effective, versatile, and scalable Cloud TPU to date. This makes them ideal for serving and scaling ... | diffusers/examples/research_projects/sdxl_flax/README.md/0 | {
"file_path": "diffusers/examples/research_projects/sdxl_flax/README.md",
"repo_id": "diffusers",
"token_count": 3344
} | 148 |
import argparse
import torch
from diffusers import HunyuanDiT2DControlNetModel
def main(args):
state_dict = torch.load(args.pt_checkpoint_path, map_location="cpu")
if args.load_key != "none":
try:
state_dict = state_dict[args.load_key]
except KeyError:
raise KeyError... | diffusers/scripts/convert_hunyuandit_controlnet_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_hunyuandit_controlnet_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 5703
} | 149 |
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 3608
} | 150 |
# Run this script to convert the Stable Audio model weights to a diffusers pipeline.
import argparse
import json
import os
from contextlib import nullcontext
import torch
from safetensors.torch import load_file
from transformers import (
AutoTokenizer,
T5EncoderModel,
)
from diffusers import (
Autoencoder... | diffusers/scripts/convert_stable_audio.py/0 | {
"file_path": "diffusers/scripts/convert_stable_audio.py",
"repo_id": "diffusers",
"token_count": 4812
} | 151 |
"""
This script modified from
https://github.com/huggingface/diffusers/blob/bc691231360a4cbc7d19a58742ebb8ed0f05e027/scripts/convert_original_stable_diffusion_to_diffusers.py
Convert original Zero1to3 checkpoint to diffusers checkpoint.
# run the convert script
$ python convert_zero123_to_diffusers.py \
--checkpoi... | diffusers/scripts/convert_zero123_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_zero123_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 15250
} | 152 |
from .value_guided_sampling import ValueGuidedRLPipeline
| diffusers/src/diffusers/experimental/rl/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/experimental/rl/__init__.py",
"repo_id": "diffusers",
"token_count": 17
} | 153 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/hooks/faster_cache.py/0 | {
"file_path": "diffusers/src/diffusers/hooks/faster_cache.py",
"repo_id": "diffusers",
"token_count": 13569
} | 154 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/loaders/single_file.py/0 | {
"file_path": "diffusers/src/diffusers/loaders/single_file.py",
"repo_id": "diffusers",
"token_count": 11135
} | 155 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/attention_processor.py/0 | {
"file_path": "diffusers/src/diffusers/models/attention_processor.py",
"repo_id": "diffusers",
"token_count": 110474
} | 156 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/autoencoders/autoencoder_oobleck.py/0 | {
"file_path": "diffusers/src/diffusers/models/autoencoders/autoencoder_oobleck.py",
"repo_id": "diffusers",
"token_count": 7331
} | 157 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/controlnets/controlnet_sana.py/0 | {
"file_path": "diffusers/src/diffusers/models/controlnets/controlnet_sana.py",
"repo_id": "diffusers",
"token_count": 5455
} | 158 |
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team.
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.a... | diffusers/src/diffusers/models/modeling_utils.py/0 | {
"file_path": "diffusers/src/diffusers/models/modeling_utils.py",
"repo_id": "diffusers",
"token_count": 38990
} | 159 |
# Copyright 2025 Stability AI and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless requ... | diffusers/src/diffusers/models/transformers/stable_audio_transformer.py/0 | {
"file_path": "diffusers/src/diffusers/models/transformers/stable_audio_transformer.py",
"repo_id": "diffusers",
"token_count": 8041
} | 160 |
# Copyright 2025 The Genmo team and The HuggingFace Team.
# All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless ... | diffusers/src/diffusers/models/transformers/transformer_mochi.py/0 | {
"file_path": "diffusers/src/diffusers/models/transformers/transformer_mochi.py",
"repo_id": "diffusers",
"token_count": 8519
} | 161 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/models/unets/unet_3d_blocks.py/0 | {
"file_path": "diffusers/src/diffusers/models/unets/unet_3d_blocks.py",
"repo_id": "diffusers",
"token_count": 27076
} | 162 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/modular_pipelines/flux/denoise.py/0 | {
"file_path": "diffusers/src/diffusers/modular_pipelines/flux/denoise.py",
"repo_id": "diffusers",
"token_count": 3663
} | 163 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/modular_pipelines/wan/decoders.py/0 | {
"file_path": "diffusers/src/diffusers/modular_pipelines/wan/decoders.py",
"repo_id": "diffusers",
"token_count": 1540
} | 164 |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_flax_available,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transfor... | diffusers/src/diffusers/pipelines/controlnet_xs/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/controlnet_xs/__init__.py",
"repo_id": "diffusers",
"token_count": 894
} | 165 |
from dataclasses import dataclass
from typing import List, Optional, Union
import numpy as np
import PIL.Image
from ....utils import (
BaseOutput,
)
@dataclass
# Copied from diffusers.pipelines.stable_diffusion.pipeline_output.StableDiffusionPipelineOutput with Stable->Alt
class AltDiffusionPipelineOutput(BaseO... | diffusers/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_output.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/alt_diffusion/pipeline_output.py",
"repo_id": "diffusers",
"token_count": 344
} | 166 |
# Copyright 2022 The Music Spectrogram Diffusion Authors.
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache... | diffusers/src/diffusers/pipelines/deprecated/spectrogram_diffusion/pipeline_spectrogram_diffusion.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/spectrogram_diffusion/pipeline_spectrogram_diffusion.py",
"repo_id": "diffusers",
"token_count": 4994
} | 167 |
from typing import TYPE_CHECKING
from ....utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is_torch_available()):
... | diffusers/src/diffusers/pipelines/deprecated/vq_diffusion/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/vq_diffusion/__init__.py",
"repo_id": "diffusers",
"token_count": 682
} | 168 |
# Copyright 2025 The HunyuanVideo Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Un... | diffusers/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video.py",
"repo_id": "diffusers",
"token_count": 15724
} | 169 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky2_2/pipeline_kandinsky2_2.py",
"repo_id": "diffusers",
"token_count": 6374
} | 170 |
# Copyright 2025 ChatGLM3-6B Model Team, Kwai-Kolors Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses... | diffusers/src/diffusers/pipelines/kolors/text_encoder.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kolors/text_encoder.py",
"repo_id": "diffusers",
"token_count": 15955
} | 171 |
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/src/diffusers/pipelines/pipeline_loading_utils.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/pipeline_loading_utils.py",
"repo_id": "diffusers",
"token_count": 19640
} | 172 |
# Copyright 2025 PixArt-Sigma Authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unl... | diffusers/src/diffusers/pipelines/sana/pipeline_sana_sprint.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/sana/pipeline_sana_sprint.py",
"repo_id": "diffusers",
"token_count": 18344
} | 173 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py",
"repo_id": "diffusers",
"token_count": 12276
} | 174 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/pipelines/stable_diffusion/stable_unclip_image_normalizer.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/stable_unclip_image_normalizer.py",
"repo_id": "diffusers",
"token_count": 674
} | 175 |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is... | diffusers/src/diffusers/pipelines/wuerstchen/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/wuerstchen/__init__.py",
"repo_id": "diffusers",
"token_count": 849
} | 176 |
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Union
from ..base import DiffusersQuantizer
if TYPE_CHECKING:
from ...models.modeling_utils import ModelMixin
from ...utils import (
get_module_from_name,
is_accelerate_available,
is_accelerate_version,
is_gguf_available,
is_gguf_... | diffusers/src/diffusers/quantizers/gguf/gguf_quantizer.py/0 | {
"file_path": "diffusers/src/diffusers/quantizers/gguf/gguf_quantizer.py",
"repo_id": "diffusers",
"token_count": 2627
} | 177 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | diffusers/src/diffusers/schedulers/scheduling_consistency_models.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_consistency_models.py",
"repo_id": "diffusers",
"token_count": 8105
} | 178 |
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by appl... | diffusers/src/diffusers/utils/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/utils/__init__.py",
"repo_id": "diffusers",
"token_count": 2027
} | 179 |
# This file is autogenerated by the command `make fix-copies`, do not edit.
from ..utils import DummyObject, requires_backends
class StableDiffusionKDiffusionPipeline(metaclass=DummyObject):
_backends = ["torch", "transformers", "k_diffusion"]
def __init__(self, *args, **kwargs):
requires_backends(se... | diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_k_diffusion_objects.py/0 | {
"file_path": "diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_k_diffusion_objects.py",
"repo_id": "diffusers",
"token_count": 451
} | 180 |
from typing import List
import PIL.Image
import PIL.ImageOps
from packaging import version
from PIL import Image
if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
PIL_INTERPOLATION = {
"linear": PIL.Image.Resampling.BILINEAR,
"bilinear": PIL.Image.Resampling... | diffusers/src/diffusers/utils/pil_utils.py/0 | {
"file_path": "diffusers/src/diffusers/utils/pil_utils.py",
"repo_id": "diffusers",
"token_count": 849
} | 181 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/lora/test_lora_layers_auraflow.py/0 | {
"file_path": "diffusers/tests/lora/test_lora_layers_auraflow.py",
"repo_id": "diffusers",
"token_count": 1812
} | 182 |
import unittest
from diffusers import FlaxAutoencoderKL
from diffusers.utils import is_flax_available
from diffusers.utils.testing_utils import require_flax
from ..test_modeling_common_flax import FlaxModelTesterMixin
if is_flax_available():
import jax
@require_flax
class FlaxAutoencoderKLTests(FlaxModelTeste... | diffusers/tests/models/autoencoders/test_models_vae_flax.py/0 | {
"file_path": "diffusers/tests/models/autoencoders/test_models_vae_flax.py",
"repo_id": "diffusers",
"token_count": 513
} | 183 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/models/transformers/test_models_transformer_mochi.py/0 | {
"file_path": "diffusers/tests/models/transformers/test_models_transformer_mochi.py",
"repo_id": "diffusers",
"token_count": 1188
} | 184 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/models/unets/test_models_unet_spatiotemporal.py/0 | {
"file_path": "diffusers/tests/models/unets/test_models_unet_spatiotemporal.py",
"repo_id": "diffusers",
"token_count": 3217
} | 185 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/others/test_training.py/0 | {
"file_path": "diffusers/tests/others/test_training.py",
"repo_id": "diffusers",
"token_count": 1481
} | 186 |
import unittest
import numpy as np
import torch
from transformers import AutoTokenizer, UMT5EncoderModel
from diffusers import AuraFlowPipeline, AuraFlowTransformer2DModel, AutoencoderKL, FlowMatchEulerDiscreteScheduler
from ..test_pipelines_common import (
PipelineTesterMixin,
check_qkv_fusion_matches_attn_... | diffusers/tests/pipelines/aura_flow/test_pipeline_aura_flow.py/0 | {
"file_path": "diffusers/tests/pipelines/aura_flow/test_pipeline_aura_flow.py",
"repo_id": "diffusers",
"token_count": 2305
} | 187 |
# Copyright 2025 The HuggingFace Team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in... | diffusers/tests/pipelines/consisid/test_consisid.py/0 | {
"file_path": "diffusers/tests/pipelines/consisid/test_consisid.py",
"repo_id": "diffusers",
"token_count": 6148
} | 188 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc and Tencent Hunyuan Team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless require... | diffusers/tests/pipelines/controlnet_hunyuandit/test_controlnet_hunyuandit.py/0 | {
"file_path": "diffusers/tests/pipelines/controlnet_hunyuandit/test_controlnet_hunyuandit.py",
"repo_id": "diffusers",
"token_count": 6280
} | 189 |
import inspect
import unittest
import numpy as np
import torch
from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
from diffusers import (
AnimateDiffPAGPipeline,
AnimateDiffPipeline,
AutoencoderKL,
DDIMScheduler,
DPMSolverMultistepScheduler,
LCMScheduler,
MotionAdapter,
... | diffusers/tests/pipelines/pag/test_pag_animatediff.py/0 | {
"file_path": "diffusers/tests/pipelines/pag/test_pag_animatediff.py",
"repo_id": "diffusers",
"token_count": 11061
} | 190 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/pag/test_pag_sdxl_inpaint.py/0 | {
"file_path": "diffusers/tests/pipelines/pag/test_pag_sdxl_inpaint.py",
"repo_id": "diffusers",
"token_count": 6012
} | 191 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/stable_cascade/test_stable_cascade_prior.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_cascade/test_stable_cascade_prior.py",
"repo_id": "diffusers",
"token_count": 4050
} | 192 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_latent_upscale.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_latent_upscale.py",
"repo_id": "diffusers",
"token_count": 5957
} | 193 |
# coding=utf-8
# Copyright 2025 Harutatsu Akiyama and HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required b... | diffusers/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_instruction_pix2pix.py/0 | {
"file_path": "diffusers/tests/pipelines/stable_diffusion_xl/test_stable_diffusion_xl_instruction_pix2pix.py",
"repo_id": "diffusers",
"token_count": 3108
} | 194 |
# coding=utf-8
# Copyright 2025 The HuggingFace Team Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a clone of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/tests/quantization/test_pipeline_level_quantization.py/0 | {
"file_path": "diffusers/tests/quantization/test_pipeline_level_quantization.py",
"repo_id": "diffusers",
"token_count": 5520
} | 195 |
import tempfile
import unittest
import torch
from diffusers import PNDMScheduler
from .test_schedulers import SchedulerCommonTest
class PNDMSchedulerTest(SchedulerCommonTest):
scheduler_classes = (PNDMScheduler,)
forward_default_kwargs = (("num_inference_steps", 50),)
def get_scheduler_config(self, **... | diffusers/tests/schedulers/test_scheduler_pndm.py/0 | {
"file_path": "diffusers/tests/schedulers/test_scheduler_pndm.py",
"repo_id": "diffusers",
"token_count": 4674
} | 196 |
# coding=utf-8
# Copyright 2025 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ag... | diffusers/tests/single_file/test_model_vae_single_file.py/0 | {
"file_path": "diffusers/tests/single_file/test_model_vae_single_file.py",
"repo_id": "diffusers",
"token_count": 1718
} | 197 |
# coding=utf-8
# Copyright 2025 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable... | diffusers/utils/check_config_docstrings.py/0 | {
"file_path": "diffusers/utils/check_config_docstrings.py",
"repo_id": "diffusers",
"token_count": 1113
} | 198 |
# coding=utf-8
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless requir... | diffusers/utils/notify_community_pipelines_mirror.py/0 | {
"file_path": "diffusers/utils/notify_community_pipelines_mirror.py",
"repo_id": "diffusers",
"token_count": 679
} | 199 |
# Cameras
LeRobot offers multiple options for video capture, including phone cameras, built-in laptop cameras, external webcams, and Intel RealSense cameras. To efficiently record frames from most cameras, you can use either the `OpenCVCamera` or `RealSenseCamera` class. For additional compatibility details on the `Op... | lerobot/docs/source/cameras.mdx/0 | {
"file_path": "lerobot/docs/source/cameras.mdx",
"repo_id": "lerobot",
"token_count": 2240
} | 200 |
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by appl... | lerobot/src/lerobot/constants.py/0 | {
"file_path": "lerobot/src/lerobot/constants.py",
"repo_id": "lerobot",
"token_count": 685
} | 201 |
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by appl... | lerobot/src/lerobot/datasets/v21/convert_dataset_v20_to_v21.py/0 | {
"file_path": "lerobot/src/lerobot/datasets/v21/convert_dataset_v20_to_v21.py",
"repo_id": "lerobot",
"token_count": 1441
} | 202 |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/src/lerobot/policies/normalize.py/0 | {
"file_path": "lerobot/src/lerobot/policies/normalize.py",
"repo_id": "lerobot",
"token_count": 8709
} | 203 |
#!/usr/bin/env python
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/src/lerobot/processor/pipeline.py/0 | {
"file_path": "lerobot/src/lerobot/processor/pipeline.py",
"repo_id": "lerobot",
"token_count": 19984
} | 204 |
# !/usr/bin/env python
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#... | lerobot/src/lerobot/scripts/rl/eval_policy.py/0 | {
"file_path": "lerobot/src/lerobot/scripts/rl/eval_policy.py",
"repo_id": "lerobot",
"token_count": 910
} | 205 |
#!/usr/bin/env python
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/src/lerobot/teleoperators/widowx/widowx.py/0 | {
"file_path": "lerobot/src/lerobot/teleoperators/widowx/widowx.py",
"repo_id": "lerobot",
"token_count": 2507
} | 206 |
#!/usr/bin/env python
# Copyright 2025 The HuggingFace Inc. team.
# All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
... | lerobot/src/lerobot/utils/process.py/0 | {
"file_path": "lerobot/src/lerobot/utils/process.py",
"repo_id": "lerobot",
"token_count": 1216
} | 207 |
#!/usr/bin/env python
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# ... | lerobot/tests/configs/test_plugin_loading.py/0 | {
"file_path": "lerobot/tests/configs/test_plugin_loading.py",
"repo_id": "lerobot",
"token_count": 1154
} | 208 |
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by appl... | lerobot/tests/fixtures/hub.py/0 | {
"file_path": "lerobot/tests/fixtures/hub.py",
"repo_id": "lerobot",
"token_count": 2299
} | 209 |
# !/usr/bin/env python
# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#... | lerobot/tests/policies/test_sac_policy.py/0 | {
"file_path": "lerobot/tests/policies/test_sac_policy.py",
"repo_id": "lerobot",
"token_count": 7256
} | 210 |
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by appl... | lerobot/tests/utils/test_logging_utils.py/0 | {
"file_path": "lerobot/tests/utils/test_logging_utils.py",
"repo_id": "lerobot",
"token_count": 1482
} | 211 |
# Pass rate filtering
We provide support to filter datasets by generating and computing pass rate on veriable tasks
See `scripts/pass_rate_filtering/compute_pass_rate.py` and `scripts/pass_rate_filtering/launch_filtering.sh` (hardcoded for DAPO at the moment)
By default the script chunks the dataset, merge can be ru... | open-r1/scripts/pass_rate_filtering/README.md/0 | {
"file_path": "open-r1/scripts/pass_rate_filtering/README.md",
"repo_id": "open-r1",
"token_count": 531
} | 212 |
#!/bin/bash
#SBATCH --job-name=piston_worker
#SBATCH --output=/fsx/open-r1/logs/piston/worker-logs/%x-%j.out
#SBATCH --error=/fsx/open-r1/logs/piston/worker-logs/%x-%j.out # Redirect error logs to .out
#SBATCH --cpus-per-task=2
#SBATCH --mem-per-cpu=1950M
#SBATCH --partition=hopper-cpu
#SBATCH --time=48:00:00
# somet... | open-r1/slurm/piston/launch_single_piston.sh/0 | {
"file_path": "open-r1/slurm/piston/launch_single_piston.sh",
"repo_id": "open-r1",
"token_count": 636
} | 213 |
import asyncio
from dataclasses import asdict, dataclass, field
from typing import Union
from .ioi_utils import load_ioi_tests
from .piston_client import PistonClient, PistonError
from .utils import batched
@dataclass
class TestResult:
"""
Represents the result of a single test case execution.
Attribute... | open-r1/src/open_r1/utils/competitive_programming/ioi_scoring.py/0 | {
"file_path": "open-r1/src/open_r1/utils/competitive_programming/ioi_scoring.py",
"repo_id": "open-r1",
"token_count": 4604
} | 214 |
# Copyright 2025 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicabl... | open-r1/tests/utils/test_data.py/0 | {
"file_path": "open-r1/tests/utils/test_data.py",
"repo_id": "open-r1",
"token_count": 2442
} | 215 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | peft/docs/source/conceptual_guides/ia3.md/0 | {
"file_path": "peft/docs/source/conceptual_guides/ia3.md",
"repo_id": "peft",
"token_count": 1031
} | 216 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed... | peft/docs/source/package_reference/lora.md/0 | {
"file_path": "peft/docs/source/package_reference/lora.md",
"repo_id": "peft",
"token_count": 627
} | 217 |
#!/usr/bin/env python
# Copyright 2023-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless require... | peft/examples/boft_controlnet/train_controlnet.py/0 | {
"file_path": "peft/examples/boft_controlnet/train_controlnet.py",
"repo_id": "peft",
"token_count": 10191
} | 218 |
# DoRA: Weight-Decomposed Low-Rank Adaptation
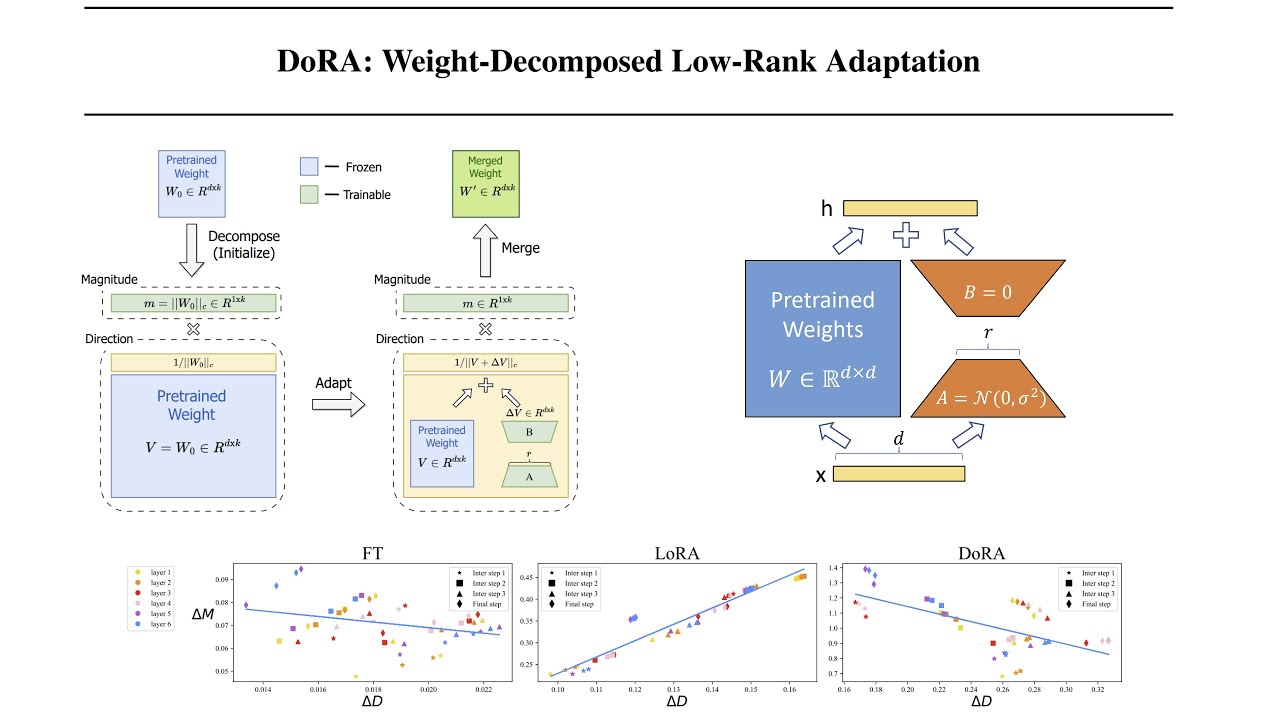
## Introduction
[DoRA](https://huggingface.co/papers/2402.09353) is a novel approach that leverages low rank adaptation through weight decomposition analysis to investigate the inherent differences between ful... | peft/examples/dora_finetuning/README.md/0 | {
"file_path": "peft/examples/dora_finetuning/README.md",
"repo_id": "peft",
"token_count": 1501
} | 219 |
accelerate launch --config_file config.yaml peft_adalora_whisper_large_training.py \
--model_name_or_path "openai/whisper-large-v2" \
--language "Marathi" \
--language_abbr "mr" \
--task "transcribe" \
--dataset_name "mozilla-foundation/common_voice_11_0" \
--push_to_hub \
--preprocessing_nu... | peft/examples/int8_training/run_adalora_whisper_int8.sh/0 | {
"file_path": "peft/examples/int8_training/run_adalora_whisper_int8.sh",
"repo_id": "peft",
"token_count": 509
} | 220 |
<jupyter_start><jupyter_code>!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q git+https://github.com/huggingface/peft.git
!pip install -q git+https://github.com/huggingface/accelerate.git@main
!pip install huggingface_hub
!pip install bitsandbytes
!pip install SentencePiece
import os
... | peft/examples/multi_adapter_examples/PEFT_Multi_LoRA_Inference.ipynb/0 | {
"file_path": "peft/examples/multi_adapter_examples/PEFT_Multi_LoRA_Inference.ipynb",
"repo_id": "peft",
"token_count": 1267
} | 221 |
# This script is based on examples/dora_finetuning/dora_finetuning.py
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
DataCollatorForLanguageModeling,
Trainer,
TrainingArguments,
)
from peft import Lor... | peft/examples/randlora_finetuning/randlora_finetuning.py/0 | {
"file_path": "peft/examples/randlora_finetuning/randlora_finetuning.py",
"repo_id": "peft",
"token_count": 3678
} | 222 |
{
"auto_mapping": null,
"base_model_name_or_path": null,
"encoder_dropout": 0.0,
"encoder_hidden_size": 3072,
"encoder_num_layers": 2,
"encoder_reparameterization_type": "MLP",
"inference_mode": false,
"num_attention_heads": 24,
"num_layers": 28,
"num_transformer_submodules": 1,
"num_virtual_token... | peft/method_comparison/MetaMathQA/experiments/ptuning/llama-3.2-3B-default/adapter_config.json/0 | {
"file_path": "peft/method_comparison/MetaMathQA/experiments/ptuning/llama-3.2-3B-default/adapter_config.json",
"repo_id": "peft",
"token_count": 188
} | 223 |
# Copyright 2025-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or... | peft/method_comparison/processing.py/0 | {
"file_path": "peft/method_comparison/processing.py",
"repo_id": "peft",
"token_count": 2374
} | 224 |
# Copyright 2023-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or... | peft/src/peft/tuners/adaption_prompt/model.py/0 | {
"file_path": "peft/src/peft/tuners/adaption_prompt/model.py",
"repo_id": "peft",
"token_count": 3046
} | 225 |
# Copyright 2023-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or... | peft/src/peft/tuners/ia3/layer.py/0 | {
"file_path": "peft/src/peft/tuners/ia3/layer.py",
"repo_id": "peft",
"token_count": 6988
} | 226 |
# Copyright 2024-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or... | peft/src/peft/tuners/lora/awq.py/0 | {
"file_path": "peft/src/peft/tuners/lora/awq.py",
"repo_id": "peft",
"token_count": 1820
} | 227 |
# Copyright 2024-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or... | peft/src/peft/tuners/oft/hqq.py/0 | {
"file_path": "peft/src/peft/tuners/oft/hqq.py",
"repo_id": "peft",
"token_count": 3598
} | 228 |
# Copyright 2023-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or... | peft/src/peft/tuners/prompt_tuning/config.py/0 | {
"file_path": "peft/src/peft/tuners/prompt_tuning/config.py",
"repo_id": "peft",
"token_count": 1410
} | 229 |
# Copyright 2025-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or... | peft/src/peft/tuners/shira/model.py/0 | {
"file_path": "peft/src/peft/tuners/shira/model.py",
"repo_id": "peft",
"token_count": 5527
} | 230 |
# Copyright 2023-present the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or... | peft/src/peft/tuners/xlora/classifier.py/0 | {
"file_path": "peft/src/peft/tuners/xlora/classifier.py",
"repo_id": "peft",
"token_count": 3252
} | 231 |
# Copyright 2023-present the HuggingFace Inc. team.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or a... | peft/tests/test_gpu_examples.py/0 | {
"file_path": "peft/tests/test_gpu_examples.py",
"repo_id": "peft",
"token_count": 101037
} | 232 |
import argparse
import hashlib
import os
import mxnet as mx
import gluoncv
import torch
from timm import create_model
parser = argparse.ArgumentParser(description='Convert from MXNet')
parser.add_argument('--model', default='all', type=str, metavar='MODEL',
help='Name of model to train (default: "... | pytorch-image-models/convert/convert_from_mxnet.py/0 | {
"file_path": "pytorch-image-models/convert/convert_from_mxnet.py",
"repo_id": "pytorch-image-models",
"token_count": 1786
} | 233 |
# HRNet
**HRNet**, or **High-Resolution Net**, is a general purpose convolutional neural network for tasks like semantic segmentation, object detection and image classification. It is able to maintain high resolution representations through the whole process. We start from a high-resolution convolution stream, gradual... | pytorch-image-models/hfdocs/source/models/hrnet.mdx/0 | {
"file_path": "pytorch-image-models/hfdocs/source/models/hrnet.mdx",
"repo_id": "pytorch-image-models",
"token_count": 5059
} | 234 |
# RegNetY
**RegNetY** is a convolutional network design space with simple, regular models with parameters: depth \\( d \\), initial width \\( w_{0} > 0 \\), and slope \\( w_{a} > 0 \\), and generates a different block width \\( u_{j} \\) for each block \\( j < d \\). The key restriction for the RegNet types of model i... | pytorch-image-models/hfdocs/source/models/regnety.mdx/0 | {
"file_path": "pytorch-image-models/hfdocs/source/models/regnety.mdx",
"repo_id": "pytorch-image-models",
"token_count": 6762
} | 235 |
# Scripts
A train, validation, inference, and checkpoint cleaning script included in the github root folder. Scripts are not currently packaged in the pip release.
The training and validation scripts evolved from early versions of the [PyTorch Imagenet Examples](https://github.com/pytorch/examples). I have added sign... | pytorch-image-models/hfdocs/source/training_script.mdx/0 | {
"file_path": "pytorch-image-models/hfdocs/source/training_script.mdx",
"repo_id": "pytorch-image-models",
"token_count": 2364
} | 236 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.