
url string | repository_url string | labels_url string | comments_url string | events_url string | html_url string | id int64 | node_id string | number int64 | title string | user dict | labels list | state string | locked bool | assignee dict | assignees list | milestone dict | comments list | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association string | type float64 | active_lock_reason float64 | sub_issues_summary dict | body string | closed_by dict | reactions dict | timeline_url string | performed_via_github_app float64 | state_reason string | draft float64 | pull_request dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5429/comments | https://api.github.com/repos/huggingface/datasets/issues/5429/events | https://github.com/huggingface/datasets/pull/5429 | 1,535,192,687 | PR_kwDODunzps5HeuyT | 5,429 | Fix CI by temporarily pinning apache-beam < 2.44.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2023-01-16T16:20:09Z | 2023-01-16T16:51:42Z | 2023-01-16T16:49:03Z | MEMBER | null | null | null | Temporarily pin apache-beam < 2.44.0
Fix #5426. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5429/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5429/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5429.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5429",
"merged_at": "2023-01-16T16:49:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5429.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6288 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6288/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6288/comments | https://api.github.com/repos/huggingface/datasets/issues/6288/events | https://github.com/huggingface/datasets/issues/6288 | 1,935,005,457 | I_kwDODunzps5zVdcR | 6,288 | Dataset.from_pandas with a DataFrame of PIL.Images | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"A duplicate of https://github.com/huggingface/datasets/issues/4796.\r\n\r\nWe could get this for free by implementing the `Image` feature as an extension type, as shown in [this](https://colab.research.google.com/drive/1Uzm_tXVpGTwbzleDConWcNjacwO1yxE4?usp=sharing) Colab (example with UUIDs).\r\n",
"+1 to this\r... | 2023-10-10T10:29:16Z | 2024-11-29T16:35:30Z | null | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Currently type inference doesn't know what to do with a Pandas Series of PIL.Image objects, though it would be nice to get a Dataset with the Image type this way | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6288/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6288/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6200 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6200/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6200/comments | https://api.github.com/repos/huggingface/datasets/issues/6200/events | https://github.com/huggingface/datasets/pull/6200 | 1,875,169,551 | PR_kwDODunzps5ZOCee | 6,200 | Temporarily pin pandas < 2.1.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-08-31T09:45:17Z | 2023-08-31T10:33:24Z | 2023-08-31T10:24:38Z | MEMBER | null | null | null | Temporarily pin `pandas` < 2.1.0 until permanent solution is found.
Hot fix #6197. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6200/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6200/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6200.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6200",
"merged_at": "2023-08-31T10:24:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6200.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5972 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5972/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5972/comments | https://api.github.com/repos/huggingface/datasets/issues/5972/events | https://github.com/huggingface/datasets/pull/5972 | 1,767,897,485 | PR_kwDODunzps5TkE7K | 5,972 | Filter unsupported extensions | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-06-21T15:43:01Z | 2023-06-22T14:23:29Z | 2023-06-22T14:16:26Z | MEMBER | null | null | null | I used a regex to filter the data files based on their extension for packaged builders.
I tried and a regex is 10x faster that using `in` to check if the extension is in the list of supported extensions.
Supersedes https://github.com/huggingface/datasets/pull/5850
Close https://github.com/huggingface/datasets/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5972/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5972/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5972.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5972",
"merged_at": "2023-06-22T14:16:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5972.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6485 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6485/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6485/comments | https://api.github.com/repos/huggingface/datasets/issues/6485/events | https://github.com/huggingface/datasets/issues/6485 | 2,035,141,884 | I_kwDODunzps55Tcz8 | 6,485 | FileNotFoundError: [Errno 2] No such file or directory: 'nul' | {
"avatar_url": "https://avatars.githubusercontent.com/u/73683903?v=4",
"events_url": "https://api.github.com/users/amanyara/events{/privacy}",
"followers_url": "https://api.github.com/users/amanyara/followers",
"following_url": "https://api.github.com/users/amanyara/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi! It seems like the problem is your environment. Maybe this issue can help: https://github.com/pytest-dev/pytest/issues/9519. "
] | 2023-12-11T08:52:13Z | 2023-12-14T08:09:08Z | 2023-12-14T08:09:08Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
it seems that sth wrong with my terrible "bug body" life, When i run this code, "import datasets"
i meet this error FileNotFoundError: [Errno 2] No such file or directory: 'nul'

\r\n\r\nI guess we'll also have to create the NYU CS Department on the Hub ?",
"> I guess we'll also have to create the NYU CS Department on the Hub ?\r\n\r\nYes, you're right! Let me add it to my profile first, a... | 2022-11-17T03:22:22Z | 2022-12-17T12:20:38Z | 2022-12-17T12:20:37Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Name
NYUDepth
### Paper
http://cs.nyu.edu/~silberman/papers/indoor_seg_support.pdf
### Data
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
### Motivation
Depth estimation is an important problem in computer vision. We have a couple of Depth Estimation models on Hub as well:
* [GLPN... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5255/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5255/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6584/comments | https://api.github.com/repos/huggingface/datasets/issues/6584/events | https://github.com/huggingface/datasets/issues/6584 | 2,078,454,878 | I_kwDODunzps574rRe | 6,584 | np.fromfile not supported | {
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [
"@lhoestq\r\nCan you provide me with some ideas?",
"Hi ! What's the error ?",
"@lhoestq \r\n```\r\nTraceback (most recent call last):\r\n File \"/home/dongzf/miniconda3/envs/dataset_ai/lib/python3.11/runpy.py\", line 198, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n ^^... | 2024-01-12T09:46:17Z | 2024-01-15T05:20:50Z | null | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | How to do np.fromfile to use it like np.load
```python
def xnumpy_fromfile(filepath_or_buffer, *args, download_config: Optional[DownloadConfig] = None, **kwargs):
import numpy as np
if hasattr(filepath_or_buffer, "read"):
return np.fromfile(filepath_or_buffer, *args, **kwargs)
else:
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6584/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6584/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6100 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6100/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6100/comments | https://api.github.com/repos/huggingface/datasets/issues/6100/events | https://github.com/huggingface/datasets/issues/6100 | 1,828,118,930 | I_kwDODunzps5s9uGS | 6,100 | TypeError when loading from GCP bucket | {
"avatar_url": "https://avatars.githubusercontent.com/u/16692099?v=4",
"events_url": "https://api.github.com/users/bilelomrani1/events{/privacy}",
"followers_url": "https://api.github.com/users/bilelomrani1/followers",
"following_url": "https://api.github.com/users/bilelomrani1/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @bilelomrani1.\r\n\r\nWe are fixing it. ",
"We have fixed it. We are planning to do a patch release today."
] | 2023-07-30T23:03:00Z | 2023-08-03T10:00:48Z | 2023-08-01T10:38:55Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Loading a dataset from a GCP bucket raises a type error. This bug was introduced recently (either in 2.14 or 2.14.1), and appeared during a migration from 2.13.1.
### Steps to reproduce the bug
Load any file from a GCP bucket:
```python
import datasets
datasets.load_dataset("json", data_f... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6100/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6100/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5920 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5920/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5920/comments | https://api.github.com/repos/huggingface/datasets/issues/5920/events | https://github.com/huggingface/datasets/pull/5920 | 1,736,196,991 | PR_kwDODunzps5R5TRB | 5,920 | Optimize IterableDataset.from_file using ArrowExamplesIterable | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-06-01T12:14:36Z | 2023-06-01T12:42:10Z | 2023-06-01T12:35:14Z | MEMBER | null | null | null | following https://github.com/huggingface/datasets/pull/5893 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5920/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5920/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5920.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5920",
"merged_at": "2023-06-01T12:35:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5920.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7226 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7226/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7226/comments | https://api.github.com/repos/huggingface/datasets/issues/7226/events | https://github.com/huggingface/datasets/issues/7226 | 2,586,920,351 | I_kwDODunzps6aMUWf | 7,226 | Add R as a How to use from the Polars (R) Library as an option | {
"avatar_url": "https://avatars.githubusercontent.com/u/45013044?v=4",
"events_url": "https://api.github.com/users/ran-codes/events{/privacy}",
"followers_url": "https://api.github.com/users/ran-codes/followers",
"following_url": "https://api.github.com/users/ran-codes/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2024-10-14T19:56:07Z | 2024-10-14T19:57:13Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
The boiler plate code to access a dataset via the hugging face file system is very useful. Please addd
## Add Polars (R) option
The equivailent code works, because the [Polars-R](https://github.com/pola-rs/r-polars) wrapper has hugging faces funcitonaliy as well.
```r
library(polars)
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7226/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7226/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5684 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5684/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5684/comments | https://api.github.com/repos/huggingface/datasets/issues/5684/events | https://github.com/huggingface/datasets/pull/5684 | 1,646,013,226 | PR_kwDODunzps5NLXWm | 5,684 | Release: 2.11.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-29T15:06:07Z | 2023-03-29T18:30:34Z | 2023-03-29T18:15:54Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5684/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5684/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5684.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5684",
"merged_at": "2023-03-29T18:15:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5684.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4720 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4720/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4720/comments | https://api.github.com/repos/huggingface/datasets/issues/4720/events | https://github.com/huggingface/datasets/issues/4720 | 1,309,980,195 | I_kwDODunzps5OFLYj | 4,720 | Dataset Viewer issue for shamikbose89/lancaster_newsbooks | {
"avatar_url": "https://avatars.githubusercontent.com/u/50837285?v=4",
"events_url": "https://api.github.com/users/shamikbose/events{/privacy}",
"followers_url": "https://api.github.com/users/shamikbose/followers",
"following_url": "https://api.github.com/users/shamikbose/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"It seems like the list of splits could not be obtained:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"shamikbose89/lancaster_newsbooks\", \"default\")\r\nUsing custom data configuration default\r\nTraceback (most recent call last):\r\n File \"/home/slesage/h... | 2022-07-19T20:00:07Z | 2022-09-08T16:47:21Z | 2022-09-08T16:47:21Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Link
https://huggingface.co/datasets/shamikbose89/lancaster_newsbooks
### Description
Status code: 400
Exception: ValueError
Message: Cannot seek streaming HTTP file
I am able to use the dataset loading script locally and it also runs when I'm using the one from the hub, but the viewer sti... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4720/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4720/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5408/comments | https://api.github.com/repos/huggingface/datasets/issues/5408/events | https://github.com/huggingface/datasets/issues/5408 | 1,519,890,752 | I_kwDODunzps5al7FA | 5,408 | dataset map function could not be hash properly | {
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"events_url": "https://api.github.com/users/Tungway1990/events{/privacy}",
"followers_url": "https://api.github.com/users/Tungway1990/followers",
"following_url": "https://api.github.com/users/Tungway1990/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Hi ! On macos I tried with\r\n- py 3.9.11\r\n- datasets 2.8.0\r\n- transformers 4.25.1\r\n- dill 0.3.4\r\n\r\nand I was able to hash `prepare_dataset` correctly:\r\n```python\r\nfrom datasets.fingerprint import Hasher\r\nHasher.hash(prepare_dataset)\r\n```\r\n\r\nWhat version of transformers do you have ? Can you ... | 2023-01-05T01:59:59Z | 2023-01-06T13:22:19Z | 2023-01-06T13:22:18Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"events_url": "https://api.github.com/users/Tungway1990/events{/privacy}",
"followers_url": "https://api.github.com/users/Tungway1990/followers",
"following_url": "https://api.github.com/users/Tungway1990/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5408/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5408/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5530 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5530/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5530/comments | https://api.github.com/repos/huggingface/datasets/issues/5530/events | https://github.com/huggingface/datasets/pull/5530 | 1,582,938,241 | PR_kwDODunzps5J4W_4 | 5,530 | Add missing license in `NumpyFormatter` | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-02-13T19:33:23Z | 2023-02-14T14:40:41Z | 2023-02-14T12:23:58Z | MEMBER | null | null | null | ## What's in this PR?
As discussed with @lhoestq in https://github.com/huggingface/datasets/pull/5522, the license for `NumpyFormatter` at `datasets/formatting/np_formatter.py` was missing, but present on the rest of the `formatting/*.py` files. So this PR is basically to include it there. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5530/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5530/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5530.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5530",
"merged_at": "2023-02-14T12:23:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5530.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6486 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6486/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6486/comments | https://api.github.com/repos/huggingface/datasets/issues/6486/events | https://github.com/huggingface/datasets/pull/6486 | 2,035,206,206 | PR_kwDODunzps5hqCSc | 6,486 | Fix docs phrasing about supported formats when sharing a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6486). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2023-12-11T09:21:22Z | 2023-12-13T14:21:29Z | 2023-12-13T14:15:21Z | MEMBER | null | null | null | Fix docs phrasing. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6486/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6486/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6486.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6486",
"merged_at": "2023-12-13T14:15:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6486.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6626/comments | https://api.github.com/repos/huggingface/datasets/issues/6626/events | https://github.com/huggingface/datasets/pull/6626 | 2,105,482,522 | PR_kwDODunzps5lU0I2 | 6,626 | Raise error on bad split name | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6626). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-01-29T13:17:41Z | 2024-01-29T15:18:25Z | 2024-01-29T15:12:18Z | MEMBER | null | null | null | e.g. dashes '-' are not allowed in split names
This should add an error message on datasets with unsupported split names like https://huggingface.co/datasets/open-source-metrics/test
cc @AndreaFrancis | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6626/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6626/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6626.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6626",
"merged_at": "2024-01-29T15:12:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6626.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4997 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4997/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4997/comments | https://api.github.com/repos/huggingface/datasets/issues/4997/events | https://github.com/huggingface/datasets/pull/4997 | 1,379,430,711 | PR_kwDODunzps4_RrBU | 4,997 | Add support for parsing JSON files in array form | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-20T13:31:26Z | 2022-09-20T15:42:40Z | 2022-09-20T15:40:06Z | COLLABORATOR | null | null | null | Support parsing JSON files in the array form (top-level object is an array). For simplicity, `json.load` is used for decoding. This means the entire file is loaded into memory. If requested, we can optimize this by introducing a param similar to `lines` in [`pandas.read_json`](https://pandas.pydata.org/docs/reference/a... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4997/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4997/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4997.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4997",
"merged_at": "2022-09-20T15:40:05Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4997.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6604/comments | https://api.github.com/repos/huggingface/datasets/issues/6604/events | https://github.com/huggingface/datasets/issues/6604 | 2,089,713,945 | I_kwDODunzps58joEZ | 6,604 | Transform fingerprint collisions due to setting fixed random seed | {
"avatar_url": "https://avatars.githubusercontent.com/u/6687910?v=4",
"events_url": "https://api.github.com/users/normster/events{/privacy}",
"followers_url": "https://api.github.com/users/normster/followers",
"following_url": "https://api.github.com/users/normster/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"I've opened a PR with a fix.",
"I don't think the PR fixes the root cause, since it still relies on the `random` library which will often have its seed fixed. I think the builtin `uuid.uuid4()` is a better choice: https://docs.python.org/3/library/uuid.html"
] | 2024-01-19T06:32:25Z | 2024-01-26T15:05:35Z | 2024-01-26T15:05:35Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
The transform fingerprinting logic relies on the `random` library for random bits when the function is not hashable (e.g. bound methods as used in `trl`: https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py#L356). This causes collisions when the training code sets a fixed random... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6604/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6604/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6031 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6031/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6031/comments | https://api.github.com/repos/huggingface/datasets/issues/6031/events | https://github.com/huggingface/datasets/issues/6031 | 1,804,183,858 | I_kwDODunzps5riaky | 6,031 | Argument type for map function changes when using `input_columns` for `IterableDataset` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8953934?v=4",
"events_url": "https://api.github.com/users/kwonmha/events{/privacy}",
"followers_url": "https://api.github.com/users/kwonmha/followers",
"following_url": "https://api.github.com/users/kwonmha/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Yes, this is intended."
] | 2023-07-14T05:11:14Z | 2023-07-14T14:44:15Z | 2023-07-14T14:44:15Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I wrote `tokenize(examples)` function as an argument for `map` function for `IterableDataset`.
It process dictionary type `examples` as a parameter.
It is used in `train_dataset = train_dataset.map(tokenize, batched=True)`
No error is raised.
And then, I found some unnecessary keys and val... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6031/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6031/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6892 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6892/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6892/comments | https://api.github.com/repos/huggingface/datasets/issues/6892/events | https://github.com/huggingface/datasets/pull/6892 | 2,291,201,347 | PR_kwDODunzps5vLIlp | 6,892 | Add support for categorical/dictionary types | {
"avatar_url": "https://avatars.githubusercontent.com/u/342233?v=4",
"events_url": "https://api.github.com/users/EthanSteinberg/events{/privacy}",
"followers_url": "https://api.github.com/users/EthanSteinberg/followers",
"following_url": "https://api.github.com/users/EthanSteinberg/following{/other_user}",
"... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6892). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-05-12T07:15:08Z | 2024-06-07T15:01:39Z | 2024-06-07T12:20:42Z | CONTRIBUTOR | null | null | null | Arrow has a very useful dictionary/categorical type (https://arrow.apache.org/docs/python/generated/pyarrow.dictionary.html). This data type has significant speed, memory and disk benefits over pa.string() when there are only a few unique text strings in a column.
Unfortunately, huggingface datasets currently does n... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6892/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6892/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6892.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6892",
"merged_at": "2024-06-07T12:20:42Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6892.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5444/comments | https://api.github.com/repos/huggingface/datasets/issues/5444/events | https://github.com/huggingface/datasets/issues/5444 | 1,550,185,071 | I_kwDODunzps5cZfJv | 5,444 | info messages logged as warnings | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | closed | false | null | [] | null | [
"Looks like a duplicate of https://github.com/huggingface/datasets/issues/1948. \r\n\r\nI also think these should be logged as INFO messages, but let's see what @lhoestq thinks.",
"It can be considered unexpected to see a `map` function return instantaneously. The warning is here to explain this case by mentionin... | 2023-01-20T01:19:18Z | 2023-07-12T17:19:31Z | 2023-07-12T17:19:31Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Code in `datasets` is using `logger.warning` when it should be using `logger.info`.
Some of these are probably a matter of opinion, but I think anything starting with `logger.warning(f"Loading chached` clearly falls into the info category.
Definitions from the Python docs for reference:
* I... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5444/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5444/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4820 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4820/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4820/comments | https://api.github.com/repos/huggingface/datasets/issues/4820/events | https://github.com/huggingface/datasets/issues/4820 | 1,335,117,132 | I_kwDODunzps5PlEVM | 4,820 | Terminating: fork() called from a process already using GNU OpenMP, this is unsafe. | {
"avatar_url": "https://avatars.githubusercontent.com/u/37379131?v=4",
"events_url": "https://api.github.com/users/talhaanwarch/events{/privacy}",
"followers_url": "https://api.github.com/users/talhaanwarch/followers",
"following_url": "https://api.github.com/users/talhaanwarch/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Fixed by installing either resampy<3 or resampy>=4"
] | 2022-08-10T19:42:33Z | 2022-08-10T19:53:10Z | 2022-08-10T19:53:10Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hi, when i try to run prepare_dataset function in [fine tuning ASR tutorial 4](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tuning_Wav2Vec2_for_English_ASR.ipynb) , i got this error.
I got this error
Terminating: fork() called from a process already using GNU OpenMP, this is un... | {
"avatar_url": "https://avatars.githubusercontent.com/u/37379131?v=4",
"events_url": "https://api.github.com/users/talhaanwarch/events{/privacy}",
"followers_url": "https://api.github.com/users/talhaanwarch/followers",
"following_url": "https://api.github.com/users/talhaanwarch/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4820/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4820/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6515 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6515/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6515/comments | https://api.github.com/repos/huggingface/datasets/issues/6515/events | https://github.com/huggingface/datasets/issues/6515 | 2,049,724,251 | I_kwDODunzps56LE9b | 6,515 | Why call http_head() when fsspec_head() succeeds | {
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2023-12-20T02:25:51Z | 2023-12-26T05:35:46Z | 2023-12-26T05:35:46Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | https://github.com/huggingface/datasets/blob/a91582de288d98e94bcb5ab634ca1cfeeff544c5/src/datasets/utils/file_utils.py#L510C1-L523C14 | {
"avatar_url": "https://avatars.githubusercontent.com/u/12895488?v=4",
"events_url": "https://api.github.com/users/d710055071/events{/privacy}",
"followers_url": "https://api.github.com/users/d710055071/followers",
"following_url": "https://api.github.com/users/d710055071/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6515/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6515/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5422 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5422/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5422/comments | https://api.github.com/repos/huggingface/datasets/issues/5422/events | https://github.com/huggingface/datasets/issues/5422 | 1,533,385,239 | I_kwDODunzps5bZZoX | 5,422 | Datasets load error for saved github issues | {
"avatar_url": "https://avatars.githubusercontent.com/u/7360564?v=4",
"events_url": "https://api.github.com/users/folterj/events{/privacy}",
"followers_url": "https://api.github.com/users/folterj/followers",
"following_url": "https://api.github.com/users/folterj/following{/other_user}",
"gists_url": "https:/... | [] | open | false | null | [] | null | [
"I can confirm that the error exists!\r\nI'm trying to read 3 parquet files locally:\r\n```python\r\nfrom datasets import load_dataset, Features, Value, ClassLabel\r\n\r\nreview_dataset = load_dataset(\r\n \"parquet\",\r\n data_files={\r\n \"train\": os.path.join(sentiment_analysis_data_path, \"train.p... | 2023-01-14T17:29:38Z | 2023-09-14T11:39:57Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5422/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5422/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5171 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5171/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5171/comments | https://api.github.com/repos/huggingface/datasets/issues/5171/events | https://github.com/huggingface/datasets/pull/5171 | 1,425,355,111 | PR_kwDODunzps5BpsXf | 5,171 | Add PB and TB in convert_file_size_to_int | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-27T09:50:31Z | 2022-10-27T12:14:27Z | 2022-10-27T12:12:30Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5171/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5171/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5171.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5171",
"merged_at": "2022-10-27T12:12:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5171.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5320 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5320/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5320/comments | https://api.github.com/repos/huggingface/datasets/issues/5320/events | https://github.com/huggingface/datasets/pull/5320 | 1,471,360,910 | PR_kwDODunzps5ED_UQ | 5,320 | [Extract] Place the lock file next to the destination directory | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-01T13:55:49Z | 2022-12-01T15:36:44Z | 2022-12-01T15:33:58Z | MEMBER | null | null | null | Previously it was placed next to the archive to extract, but the archive can be in a read-only directory as noticed in https://github.com/huggingface/datasets/issues/5295
Therefore I moved the lock location to be next to the destination directory, which is required to have write permissions | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5320/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5320/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5320.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5320",
"merged_at": "2022-12-01T15:33:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5320.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6074 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6074/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6074/comments | https://api.github.com/repos/huggingface/datasets/issues/6074/events | https://github.com/huggingface/datasets/pull/6074 | 1,822,299,128 | PR_kwDODunzps5Wb8O_ | 6,074 | Misc doc improvements | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-07-26T12:20:54Z | 2023-07-27T16:16:28Z | 2023-07-27T16:16:02Z | COLLABORATOR | null | null | null | Removes the warning about requiring to write a dataset loading script to define multiple configurations, as the README YAML can be used instead (for simple cases). Also, deletes the section about using the `BatchSampler` in `torch<=1.12.1` to speed up loading, as `torch 1.12.1` is over a year old (and `torch 2.0` has b... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6074/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6074/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6074.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6074",
"merged_at": "2023-07-27T16:16:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6074.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5618/comments | https://api.github.com/repos/huggingface/datasets/issues/5618/events | https://github.com/huggingface/datasets/issues/5618 | 1,612,977,934 | I_kwDODunzps5gJBcO | 5,618 | Unpin fsspec < 2023.3.0 once issue fixed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2023-03-07T08:41:51Z | 2023-03-07T13:39:03Z | 2023-03-07T13:39:03Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5618/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5701 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5701/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5701/comments | https://api.github.com/repos/huggingface/datasets/issues/5701/events | https://github.com/huggingface/datasets/pull/5701 | 1,652,931,399 | PR_kwDODunzps5NiSCy | 5,701 | Add Dataset.from_spark | {
"avatar_url": "https://avatars.githubusercontent.com/u/106995444?v=4",
"events_url": "https://api.github.com/users/maddiedawson/events{/privacy}",
"followers_url": "https://api.github.com/users/maddiedawson/followers",
"following_url": "https://api.github.com/users/maddiedawson/following{/other_user}",
"gis... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@mariosasko Would you or another HF datasets maintainer be able to review this, please?",
"Amazing ! Great job @maddiedawson \r\n\r\nDo you know if it's possible to also support writing to Parquet using the HF ParquetWriter if `fil... | 2023-04-03T23:51:29Z | 2023-06-16T16:39:32Z | 2023-04-26T15:43:39Z | CONTRIBUTOR | null | null | null | Adds static method Dataset.from_spark to create datasets from Spark DataFrames.
This approach alleviates users of the need to materialize their dataframe---a common use case is that the user loads their dataset into a dataframe, uses Spark to apply some transformation to some of the columns, and then wants to train ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 4,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5701/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5701/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5701.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5701",
"merged_at": "2023-04-26T15:43:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5701.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7536 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7536/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7536/comments | https://api.github.com/repos/huggingface/datasets/issues/7536/events | https://github.com/huggingface/datasets/issues/7536 | 3,018,425,549 | I_kwDODunzps6z6YTN | 7,536 | [Errno 13] Permission denied: on `.incomplete` file | {
"avatar_url": "https://avatars.githubusercontent.com/u/1282383?v=4",
"events_url": "https://api.github.com/users/ryan-clancy/events{/privacy}",
"followers_url": "https://api.github.com/users/ryan-clancy/followers",
"following_url": "https://api.github.com/users/ryan-clancy/following{/other_user}",
"gists_ur... | [] | open | false | null | [] | null | [
"It must be an issue with umask being used by multiple threads indeed. Maybe we can try to make a thread safe function to apply the umask (using filelock for example)"
] | 2025-04-24T20:52:45Z | 2025-04-26T12:40:25Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When downloading a dataset, we frequently hit the below Permission Denied error. This looks to happen (at least) across datasets in from HF, S3, and GCS.
It looks like the `temp_file` being passed [here](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/file_utils.py#L412) can ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7536/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7536/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4874 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4874/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4874/comments | https://api.github.com/repos/huggingface/datasets/issues/4874/events | https://github.com/huggingface/datasets/pull/4874 | 1,347,618,197 | PR_kwDODunzps49n_nI | 4,874 | [docs] Some tiny doc tweaks | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4874). All of your documentation changes will be reflected on that endpoint."
] | 2022-08-23T09:19:40Z | 2022-08-24T17:27:57Z | 2022-08-24T17:27:56Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4874/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4874/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4874.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4874",
"merged_at": "2022-08-24T17:27:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4874.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5566/comments | https://api.github.com/repos/huggingface/datasets/issues/5566/events | https://github.com/huggingface/datasets/issues/5566 | 1,595,916,674 | I_kwDODunzps5fH8GC | 5,566 | Directly reading parquet files in a s3 bucket from the load_dataset method | {
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "htt... | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
},
{
"color": "a2eeef",
... | open | false | null | [] | null | [
"Hi ! I think is in the scope of this other issue: to https://github.com/huggingface/datasets/issues/5281 "
] | 2023-02-22T22:13:40Z | 2023-02-23T11:03:29Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Right now, we have to read the get the parquet file to the local storage. So having ability to read given the bucket directly address would be benificial
### Motivation
In a production set up, this feature can help us a lot. So we do not need move training datafiles in between storage.
### Yo... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5566/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5566/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4816 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4816/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4816/comments | https://api.github.com/repos/huggingface/datasets/issues/4816/events | https://github.com/huggingface/datasets/pull/4816 | 1,334,099,454 | PR_kwDODunzps487kpq | 4,816 | Update version of opus_paracrawl dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-10T05:39:44Z | 2022-08-12T14:32:29Z | 2022-08-12T14:17:56Z | MEMBER | null | null | null | This PR updates OPUS ParaCrawl from 7.1 to 9 version.
Fix #4815. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4816/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4816/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4816.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4816",
"merged_at": "2022-08-12T14:17:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4816.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6229 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6229/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6229/comments | https://api.github.com/repos/huggingface/datasets/issues/6229/events | https://github.com/huggingface/datasets/issues/6229 | 1,889,050,954 | I_kwDODunzps5wmKFK | 6,229 | Apply inference on all images in the dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"From what I see, `MMSegInferencer` supports NumPy arrays, so replace the line `image_path = example['image']` with `image_path = np.array(example['image'])` to fix the issue (`example[\"image\"]` is a `PIL.Image` object). ",
"> From what I see, `MMSegInferencer` supports NumPy arrays, so replace the line `image_... | 2023-09-10T08:36:12Z | 2023-09-20T16:11:53Z | 2023-09-20T16:11:52Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
```
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
Cell In[14], line 11
9 for idx, example in enumerate(dataset['train']):
10 image_path = example['image']
---> 11 mask... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6229/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6229/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6556/comments | https://api.github.com/repos/huggingface/datasets/issues/6556/events | https://github.com/huggingface/datasets/pull/6556 | 2,064,018,208 | PR_kwDODunzps5jI0nN | 6,556 | Fix imagefolder with one image | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6556). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Fixed in dataset viewer: https://huggingface.co/datasets/multimodalart/repro_1_image\r\... | 2024-01-03T13:13:02Z | 2024-02-12T21:57:34Z | 2024-01-09T13:06:30Z | MEMBER | null | null | null | A dataset repository with one image and one metadata file was considered a JSON dataset instead of an ImageFolder dataset. This is because we pick the dataset type with the most compatible data file extensions present in the repository and it results in a tie in this case.
e.g. for https://huggingface.co/datasets/mu... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6556/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6556/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6556.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6556",
"merged_at": "2024-01-09T13:06:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6556.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5955 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5955/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5955/comments | https://api.github.com/repos/huggingface/datasets/issues/5955/events | https://github.com/huggingface/datasets/issues/5955 | 1,756,827,133 | I_kwDODunzps5otw39 | 5,955 | Strange bug in loading local JSON files, using load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/73934131?v=4",
"events_url": "https://api.github.com/users/Night-Quiet/events{/privacy}",
"followers_url": "https://api.github.com/users/Night-Quiet/followers",
"following_url": "https://api.github.com/users/Night-Quiet/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"This is the actual error:\r\n```\r\nFailed to read file '/home/lakala/hjc/code/pycode/glm/temp.json' with error <class 'pyarrow.lib.ArrowInvalid'>: cannot mix list and non-list, non-null values\r\n```\r\nWhich means some samples are incorrectly formatted.\r\n\r\nPyArrow, a storage backend that we use under the hoo... | 2023-06-14T12:46:00Z | 2023-06-21T14:42:15Z | 2023-06-21T14:42:15Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I am using 'load_dataset 'loads a JSON file, but I found a strange bug: an error will be reported when the length of the JSON file exceeds 160000 (uncertain exact number). I have checked the data through the following code and there are no issues. So I cannot determine the true reason for this err... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5955/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5955/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5827 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5827/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5827/comments | https://api.github.com/repos/huggingface/datasets/issues/5827/events | https://github.com/huggingface/datasets/issues/5827 | 1,698,891,246 | I_kwDODunzps5lQwXu | 5,827 | load json dataset interrupt when dtype cast problem occured | {
"avatar_url": "https://avatars.githubusercontent.com/u/46060451?v=4",
"events_url": "https://api.github.com/users/1014661165/events{/privacy}",
"followers_url": "https://api.github.com/users/1014661165/followers",
"following_url": "https://api.github.com/users/1014661165/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [
"Indeed the JSON dataset builder raises an error when it encounters an unexpected type.\r\n\r\nThere's an old PR open to add away to ignore such elements though, if it can help: https://github.com/huggingface/datasets/pull/2838"
] | 2023-05-07T04:52:09Z | 2023-05-10T12:32:28Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
i have a json like this:
[
{"id": 1, "name": 1},
{"id": 2, "name": "Nan"},
{"id": 3, "name": 3},
....
]
,which have several problematic rows data like row 2, then i load it with datasets.load_dataset('json', data_files=['xx.json'], split='train'), it will report like this:
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5827/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5827/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5968 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5968/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5968/comments | https://api.github.com/repos/huggingface/datasets/issues/5968/events | https://github.com/huggingface/datasets/issues/5968 | 1,765,252,561 | I_kwDODunzps5pN53R | 5,968 | Common Voice datasets still need `use_auth_token=True` | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [
"cc @pcuenca as well. \r\n\r\nNot super urgent btw",
"The issue commes from the dataset itself and is not related to the `datasets` lib\r\n\r\nsee https://huggingface.co/datasets/mozilla-foundation/common_voice_6_1/blob/2c475b3b88e0f2e5828f830a4b91618a25ff20b7/common_voice_6_1.py#L148-L152",
"Let's remove these... | 2023-06-20T11:58:37Z | 2023-07-29T16:08:59Z | 2023-07-29T16:08:58Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
We don't need to pass `use_auth_token=True` anymore to download gated datasets or models, so the following should work if correctly logged in.
```py
from datasets import load_dataset
load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="train+validation")
```
However it throw... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5968/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5968/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5736/comments | https://api.github.com/repos/huggingface/datasets/issues/5736/events | https://github.com/huggingface/datasets/issues/5736 | 1,662,286,061 | I_kwDODunzps5jFHjt | 5,736 | FORCE_REDOWNLOAD raises "Directory not empty" exception on second run | {
"avatar_url": "https://avatars.githubusercontent.com/u/1219084?v=4",
"events_url": "https://api.github.com/users/rcasero/events{/privacy}",
"followers_url": "https://api.github.com/users/rcasero/followers",
"following_url": "https://api.github.com/users/rcasero/following{/other_user}",
"gists_url": "https:/... | [] | open | false | null | [] | null | [
"Hi ! I couldn't reproduce your issue :/\r\n\r\nIt seems that `shutil.rmtree` failed. It is supposed to work even if the directory is not empty, but you still end up with `OSError: [Errno 39] Directory not empty:`. Can you make sure another process is not using this directory at the same time ?",
"I have the same... | 2023-04-11T11:29:15Z | 2023-11-30T07:16:58Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Running `load_dataset(..., download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD)` twice raises a `Directory not empty` exception on the second run.
### Steps to reproduce the bug
I cannot test this on datasets v2.11.0 due to #5711, but this happens in v2.10.1.
1. Set up a script `my_dataset.p... | null | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5736/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5736/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5375/comments | https://api.github.com/repos/huggingface/datasets/issues/5375/events | https://github.com/huggingface/datasets/pull/5375 | 1,502,720,404 | PR_kwDODunzps5FxUbG | 5,375 | Release: 2.8.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-12-19T10:48:26Z | 2022-12-19T10:55:43Z | 2022-12-19T10:53:15Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5375/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5375/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5375.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5375",
"merged_at": "2022-12-19T10:53:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5375.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4847 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4847/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4847/comments | https://api.github.com/repos/huggingface/datasets/issues/4847/events | https://github.com/huggingface/datasets/pull/4847 | 1,338,270,636 | PR_kwDODunzps49JNWX | 4,847 | Test win ci | {
"avatar_url": "https://avatars.githubusercontent.com/u/49282718?v=4",
"events_url": "https://api.github.com/users/Mr-Robot-001/events{/privacy}",
"followers_url": "https://api.github.com/users/Mr-Robot-001/followers",
"following_url": "https://api.github.com/users/Mr-Robot-001/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2022-08-14T14:57:00Z | 2023-09-24T10:04:13Z | 2022-08-14T14:57:45Z | NONE | null | null | null | aa | {
"avatar_url": "https://avatars.githubusercontent.com/u/49282718?v=4",
"events_url": "https://api.github.com/users/Mr-Robot-001/events{/privacy}",
"followers_url": "https://api.github.com/users/Mr-Robot-001/followers",
"following_url": "https://api.github.com/users/Mr-Robot-001/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4847/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4847/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4847.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4847",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4847.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4847"
} |
https://api.github.com/repos/huggingface/datasets/issues/7483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7483/comments | https://api.github.com/repos/huggingface/datasets/issues/7483/events | https://github.com/huggingface/datasets/pull/7483 | 2,951,856,468 | PR_kwDODunzps6QVInB | 7,483 | Support skip_trying_type | {
"avatar_url": "https://avatars.githubusercontent.com/u/11156001?v=4",
"events_url": "https://api.github.com/users/yoshitomo-matsubara/events{/privacy}",
"followers_url": "https://api.github.com/users/yoshitomo-matsubara/followers",
"following_url": "https://api.github.com/users/yoshitomo-matsubara/following{/... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7483). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Cool ! Can you run `make style` to fix code formatting ?\r\n\r\nI was also thinking of ... | 2025-03-27T07:07:20Z | 2025-04-09T19:46:46Z | 2025-04-09T09:53:10Z | CONTRIBUTOR | null | null | null | This PR addresses Issue #7472
cc: @lhoestq | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7483/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7483/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7483.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7483",
"merged_at": "2025-04-09T09:53:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7483.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5925 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5925/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5925/comments | https://api.github.com/repos/huggingface/datasets/issues/5925/events | https://github.com/huggingface/datasets/issues/5925 | 1,741,941,436 | I_kwDODunzps5n0-q8 | 5,925 | Breaking API change in datasets.list_datasets caused by change in HfApi.list_datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/78868366?v=4",
"events_url": "https://api.github.com/users/mtkinit/events{/privacy}",
"followers_url": "https://api.github.com/users/mtkinit/followers",
"following_url": "https://api.github.com/users/mtkinit/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2023-06-05T14:46:04Z | 2023-06-19T17:22:43Z | 2023-06-19T17:22:43Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi all,
after an update of the `datasets` library, we observer crashes in our code. We relied on `datasets.list_datasets` returning a `list`. Now, after the API of the HfApi.list_datasets was changed and it returns a `list` instead of an `Iterable`, the `datasets.list_datasets` now sometimes re... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5925/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5925/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7004 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7004/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7004/comments | https://api.github.com/repos/huggingface/datasets/issues/7004/events | https://github.com/huggingface/datasets/pull/7004 | 2,376,064,264 | PR_kwDODunzps5zrIYR | 7,004 | Fix WebDatasets KeyError for user-defined Features when a field is missing in an example | {
"avatar_url": "https://avatars.githubusercontent.com/u/10626398?v=4",
"events_url": "https://api.github.com/users/ProGamerGov/events{/privacy}",
"followers_url": "https://api.github.com/users/ProGamerGov/followers",
"following_url": "https://api.github.com/users/ProGamerGov/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7004). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-06-26T18:58:05Z | 2024-06-29T00:15:49Z | 2024-06-28T09:30:12Z | CONTRIBUTOR | null | null | null | Fixes: https://github.com/huggingface/datasets/issues/6900
Not sure if this needs any addition stuff before merging | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7004/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7004/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7004.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7004",
"merged_at": "2024-06-28T09:30:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7004.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6583/comments | https://api.github.com/repos/huggingface/datasets/issues/6583/events | https://github.com/huggingface/datasets/pull/6583 | 2,077,049,491 | PR_kwDODunzps5j1DzY | 6,583 | remove eli5 test | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6583). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-01-11T16:05:20Z | 2024-01-11T16:15:34Z | 2024-01-11T16:09:24Z | MEMBER | null | null | null | since the dataset is defunct | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6583/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6583/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6583.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6583",
"merged_at": "2024-01-11T16:09:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6583.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5964 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5964/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5964/comments | https://api.github.com/repos/huggingface/datasets/issues/5964/events | https://github.com/huggingface/datasets/pull/5964 | 1,763,513,574 | PR_kwDODunzps5TVweZ | 5,964 | Always return list in `list_datasets` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-06-19T13:07:08Z | 2023-06-19T17:29:37Z | 2023-06-19T17:22:41Z | COLLABORATOR | null | null | null | Fix #5925
Plus, deprecate `list_datasets`/`inspect_dataset` in favor of `huggingface_hub.list_datasets`/"git clone workflow" (downloads data files) | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5964/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5964/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5964.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5964",
"merged_at": "2023-06-19T17:22:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5964.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4788 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4788/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4788/comments | https://api.github.com/repos/huggingface/datasets/issues/4788/events | https://github.com/huggingface/datasets/pull/4788 | 1,328,246,021 | PR_kwDODunzps48oUNx | 4,788 | Fix NonMatchingChecksumError in mbpp dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Thank you for the quick response! Before noticing that you already had implemented the fix, I already had implemened my own version. I'd also suggest bumping the major version because the contents of the dataset changed, even if only... | 2022-08-04T08:17:40Z | 2022-08-04T17:34:00Z | 2022-08-04T17:21:01Z | MEMBER | null | null | null | Fix issue reported on the Hub: https://huggingface.co/datasets/mbpp/discussions/1
Fix #4787. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4788/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4788/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4788.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4788",
"merged_at": "2022-08-04T17:21:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4788.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7488 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7488/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7488/comments | https://api.github.com/repos/huggingface/datasets/issues/7488/events | https://github.com/huggingface/datasets/pull/7488 | 2,956,559,358 | PR_kwDODunzps6QlLmn | 7,488 | Support underscore int read instruction | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7488). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"you rock, Quentin - thank you!"
] | 2025-03-28T16:01:15Z | 2025-03-28T16:20:44Z | 2025-03-28T16:20:43Z | MEMBER | null | null | null | close https://github.com/huggingface/datasets/issues/7481 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7488/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7488/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7488.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7488",
"merged_at": "2025-03-28T16:20:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7488.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7304/comments | https://api.github.com/repos/huggingface/datasets/issues/7304/events | https://github.com/huggingface/datasets/pull/7304 | 2,715,179,811 | PR_kwDODunzps6D5saw | 7,304 | Update iterable_dataset.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7304). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2024-12-03T14:25:42Z | 2024-12-03T14:28:10Z | 2024-12-03T14:27:02Z | MEMBER | null | null | null | close https://github.com/huggingface/datasets/issues/7297 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7304/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7304/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7304.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7304",
"merged_at": "2024-12-03T14:27:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7304.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6577/comments | https://api.github.com/repos/huggingface/datasets/issues/6577/events | https://github.com/huggingface/datasets/issues/6577 | 2,074,790,848 | I_kwDODunzps57qsvA | 6,577 | 502 Server Errors when streaming large dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | null | [] | null | [
"cc @mariosasko @lhoestq ",
"Hi! We should be able to avoid this error by retrying to read the data when it happens. I'll open a PR in `huggingface_hub` to address this.",
"Thanks for the fix @mariosasko! Just wondering whether \"500 error\" should also be excluded? I got these errors overnight:\r\n\r\n```\r\nh... | 2024-01-10T16:59:36Z | 2024-02-12T11:46:03Z | 2024-01-15T16:05:44Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When streaming a [large ASR dataset](https://huggingface.co/datasets/sanchit-gandhi/concatenated-train-set) from the Hug (~3TB) I often encounter 502 Server Errors seemingly randomly during streaming:
```
huggingface_hub.utils._errors.HfHubHTTPError: 502 Server Error: Bad Gateway for url: http... | {
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"events_url": "https://api.github.com/users/Wauplin/events{/privacy}",
"followers_url": "https://api.github.com/users/Wauplin/followers",
"following_url": "https://api.github.com/users/Wauplin/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6577/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6577/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4845 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4845/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4845/comments | https://api.github.com/repos/huggingface/datasets/issues/4845/events | https://github.com/huggingface/datasets/pull/4845 | 1,337,928,283 | PR_kwDODunzps49IOjf | 4,845 | Mark CI tests as xfail if Hub HTTP error | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-13T10:45:11Z | 2022-08-23T04:57:12Z | 2022-08-23T04:42:26Z | MEMBER | null | null | null | In order to make testing more robust (and avoid merges to master with red tests), we could mark tests as xfailed (instead of failed) when the Hub raises some temporary HTTP errors.
This PR:
- marks tests as xfailed only if the Hub raises a 500 error for:
- test_upstream_hub
- makes pytest report the xfailed/xpa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4845/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4845/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4845.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4845",
"merged_at": "2022-08-23T04:42:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4845.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6862 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6862/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6862/comments | https://api.github.com/repos/huggingface/datasets/issues/6862/events | https://github.com/huggingface/datasets/pull/6862 | 2,276,763,745 | PR_kwDODunzps5ubOoL | 6,862 | Fix load_dataset for data_files with protocols other than HF | {
"avatar_url": "https://avatars.githubusercontent.com/u/544843?v=4",
"events_url": "https://api.github.com/users/matstrand/events{/privacy}",
"followers_url": "https://api.github.com/users/matstrand/followers",
"following_url": "https://api.github.com/users/matstrand/following{/other_user}",
"gists_url": "ht... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6862). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-05-03T01:43:47Z | 2024-07-23T14:37:08Z | 2024-07-23T14:30:09Z | CONTRIBUTOR | null | null | null | Fixes huggingface/datasets/issues/6598
I've added a new test case and a solution. Before applying the solution the test case was failing with the same error described in the linked issue.
MRE:
```
pip install "datasets[s3]"
python -c "from datasets import load_dataset; load_dataset('csv', data_files={'train': ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6862/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6862/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6862.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6862",
"merged_at": "2024-07-23T14:30:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6862.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6727/comments | https://api.github.com/repos/huggingface/datasets/issues/6727/events | https://github.com/huggingface/datasets/pull/6727 | 2,177,826,110 | PR_kwDODunzps5pLJyE | 6,727 | Using a registry instead of calling globals for fetching feature types | {
"avatar_url": "https://avatars.githubusercontent.com/u/11325244?v=4",
"events_url": "https://api.github.com/users/psmyth94/events{/privacy}",
"followers_url": "https://api.github.com/users/psmyth94/followers",
"following_url": "https://api.github.com/users/psmyth94/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6727). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"looks like some files are missing in your google storage",
"cc @mariosasko is it rela... | 2024-03-10T17:47:51Z | 2024-03-13T12:08:49Z | 2024-03-13T10:46:02Z | CONTRIBUTOR | null | null | null | Hello,
When working with bio-data, each feature often has metadata associated with it (e.g. species, lineage, snp position, etc). To store this, I like to use the feature classes with the added `metadata` attribute. However, when saving or loading with custom features, you get an error since that class doesn't exist... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6727/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6727.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6727",
"merged_at": "2024-03-13T10:46:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6727.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | {
"avatar_url": "https://avatars.githubusercontent.com/u/6466389?v=4",
"events_url": "https://api.github.com/users/zsaladin/events{/privacy}",
"followers_url": "https://api.github.com/users/zsaladin/followers",
"following_url": "https://api.github.com/users/zsaladin/following{/other_user}",
"gists_url": "http... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"Hi! You can use `concatenate_datasets([ids1, ids2], axis=1)` to do this."
] | 2023-03-07T01:52:00Z | 2023-03-09T15:24:05Z | 2023-03-09T15:23:54Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6072 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6072/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6072/comments | https://api.github.com/repos/huggingface/datasets/issues/6072/events | https://github.com/huggingface/datasets/pull/6072 | 1,822,123,560 | PR_kwDODunzps5WbWFN | 6,072 | Fix fsspec storage_options from load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-07-26T10:44:23Z | 2023-07-27T12:51:51Z | 2023-07-27T12:42:57Z | MEMBER | null | null | null | close https://github.com/huggingface/datasets/issues/6071 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6072/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6072/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6072.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6072",
"merged_at": "2023-07-27T12:42:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6072.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5986 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5986/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5986/comments | https://api.github.com/repos/huggingface/datasets/issues/5986/events | https://github.com/huggingface/datasets/pull/5986 | 1,772,233,111 | PR_kwDODunzps5TygOZ | 5,986 | Make IterableDataset.from_spark more efficient | {
"avatar_url": "https://avatars.githubusercontent.com/u/134338709?v=4",
"events_url": "https://api.github.com/users/mathewjacob1002/events{/privacy}",
"followers_url": "https://api.github.com/users/mathewjacob1002/followers",
"following_url": "https://api.github.com/users/mathewjacob1002/following{/other_user}... | [] | closed | false | null | [] | null | [
"@lhoestq would you be able to review this please and also approve the workflow?",
"Sounds good to me :) feel free to run `make style` to apply code formatting",
"_The documentation is not available anymore as the PR was closed or merged._",
"cool ! I think we can merge once all comments have been addressed",... | 2023-06-23T22:18:20Z | 2023-07-07T10:05:58Z | 2023-07-07T09:56:09Z | CONTRIBUTOR | null | null | null | Moved the code from using collect() to using toLocalIterator, which allows for prefetching partitions that will be selected next, thus allowing for better performance when iterating. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5986/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5986/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5986.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5986",
"merged_at": "2023-07-07T09:56:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5986.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5633/comments | https://api.github.com/repos/huggingface/datasets/issues/5633/events | https://github.com/huggingface/datasets/issues/5633 | 1,621,469,970 | I_kwDODunzps5gpasS | 5,633 | Cannot import datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/11250555?v=4",
"events_url": "https://api.github.com/users/eerio/events{/privacy}",
"followers_url": "https://api.github.com/users/eerio/followers",
"following_url": "https://api.github.com/users/eerio/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"Okay, the issue was likely caused by mixing `conda` and `pip` usage - I forgot that I have already used `pip` in this environment previously and that it was 'spoiled' because of it. Creating another environment and installing `datasets` by pip with other packages from the `requirements.txt` file solved the problem... | 2023-03-13T13:14:44Z | 2023-03-13T17:54:19Z | 2023-03-13T17:54:19Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi,
I cannot even import the library :( I installed it by running:
```
$ conda install datasets
```
Then I realized I should maybe use the huggingface channel, because I encountered the error below, so I ran:
```
$ conda remove datasets
$ conda install -c huggingface datasets
```
Pl... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5633/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5633/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5898 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5898/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5898/comments | https://api.github.com/repos/huggingface/datasets/issues/5898/events | https://github.com/huggingface/datasets/issues/5898 | 1,726,190,481 | I_kwDODunzps5m45OR | 5,898 | Loading The flores data set for specific language | {
"avatar_url": "https://avatars.githubusercontent.com/u/36159918?v=4",
"events_url": "https://api.github.com/users/106AbdulBasit/events{/privacy}",
"followers_url": "https://api.github.com/users/106AbdulBasit/followers",
"following_url": "https://api.github.com/users/106AbdulBasit/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"got that the syntax is like this\r\n\r\ndataset = load_dataset(\"facebook/flores\", \"ace_Arab\")"
] | 2023-05-25T17:08:55Z | 2023-05-25T17:21:38Z | 2023-05-25T17:21:37Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I am trying to load the Flores data set
the code which is given is
```
from datasets import load_dataset
dataset = load_dataset("facebook/flores")
```
This gives the error of config name
""ValueError: Config name is missing"
Now if I add some config it gives me the some error
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/36159918?v=4",
"events_url": "https://api.github.com/users/106AbdulBasit/events{/privacy}",
"followers_url": "https://api.github.com/users/106AbdulBasit/followers",
"following_url": "https://api.github.com/users/106AbdulBasit/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5898/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5898/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5296 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5296/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5296/comments | https://api.github.com/repos/huggingface/datasets/issues/5296/events | https://github.com/huggingface/datasets/issues/5296 | 1,464,553,580 | I_kwDODunzps5XS1Bs | 5,296 | Bug in xjoin with Windows pathnames | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-11-25T13:29:33Z | 2022-11-29T08:05:13Z | 2022-11-29T08:05:13Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Currently, `xjoin` function has a bug with local Windows pathnames: instead of returning the OS-dependent join pathname, it always returns it in POSIX format.
```python
from datasets.download.streaming_download_manager import xjoin
path = xjoin("C:\\Users\\USERNAME", "filename.txt")
```
Join path should be:
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5296/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5296/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5735/comments | https://api.github.com/repos/huggingface/datasets/issues/5735/events | https://github.com/huggingface/datasets/pull/5735 | 1,662,150,903 | PR_kwDODunzps5OAY3A | 5,735 | Implement sharding on merged iterable datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi ! What if one of the sub-iterables only has one shard ? In that case I don't think we'd end up with a correctly interleaved dataset, since only rank 0 would yield examples from this sub-iterable",
"Hi ! \r\nI just tested this ou... | 2023-04-11T10:02:25Z | 2023-04-27T16:39:04Z | 2023-04-27T16:32:09Z | CONTRIBUTOR | null | null | null | This PR allows sharding of merged iterable datasets.
Merged iterable datasets with for instance the `interleave_datasets` command are comprised of multiple sub-iterable, one for each dataset that has been merged.
With this PR, sharding a merged iterable will result in multiple merged datasets each comprised of sh... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5735/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5735/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5735.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5735",
"merged_at": "2023-04-27T16:32:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5735.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6292 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6292/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6292/comments | https://api.github.com/repos/huggingface/datasets/issues/6292/events | https://github.com/huggingface/datasets/issues/6292 | 1,937,050,470 | I_kwDODunzps5zdQtm | 6,292 | how to load the image of dtype float32 or float64 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26437644?v=4",
"events_url": "https://api.github.com/users/wanglaofei/events{/privacy}",
"followers_url": "https://api.github.com/users/wanglaofei/followers",
"following_url": "https://api.github.com/users/wanglaofei/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [
"Hi! Can you provide a code that reproduces the issue?\r\n\r\nAlso, which version of `datasets` are you using? You can check this by running `python -c \"import datasets; print(datasets.__version__)\"` inside the env. We added support for \"float images\" in `datasets 2.9`."
] | 2023-10-11T07:27:16Z | 2023-10-11T13:19:11Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | _FEATURES = datasets.Features(
{
"image": datasets.Image(),
"text": datasets.Value("string"),
},
)
The datasets builder seems only support the unit8 data. How to load the float dtype data? | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6292/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6292/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7496 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7496/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7496/comments | https://api.github.com/repos/huggingface/datasets/issues/7496/events | https://github.com/huggingface/datasets/issues/7496 | 2,967,345,522 | I_kwDODunzps6w3hly | 7,496 | Json builder: Allow features to override problematic Arrow types | {
"avatar_url": "https://avatars.githubusercontent.com/u/1017189?v=4",
"events_url": "https://api.github.com/users/edmcman/events{/privacy}",
"followers_url": "https://api.github.com/users/edmcman/followers",
"following_url": "https://api.github.com/users/edmcman/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! It would be cool indeed, currently the JSON data are generally loaded here: \n\nhttps://github.com/huggingface/datasets/blob/90e5bf8a8599b625d6103ee5ac83b98269991141/src/datasets/packaged_modules/json/json.py#L137-L140\n\nMaybe we can pass a Arrow `schema` to avoid errors ?"
] | 2025-04-02T19:27:16Z | 2025-04-15T13:06:09Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
In the JSON builder, use explicitly requested feature types before or while converting to Arrow.
### Motivation
Working with JSON datasets is really hard because of Arrow. At the very least, it seems like it should be possible to work-around these problems by explicitly setting problematic colum... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7496/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7496/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6909 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6909/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6909/comments | https://api.github.com/repos/huggingface/datasets/issues/6909/events | https://github.com/huggingface/datasets/pull/6909 | 2,307,508,120 | PR_kwDODunzps5wCoiE | 6,909 | Update requests >=2.32.1 to fix vulnerability | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6909). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-05-21T07:11:20Z | 2024-05-21T07:45:58Z | 2024-05-21T07:38:25Z | MEMBER | null | null | null | Update requests >=2.32.1 to fix vulnerability. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6909/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6909/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6909.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6909",
"merged_at": "2024-05-21T07:38:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6909.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6119 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6119/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6119/comments | https://api.github.com/repos/huggingface/datasets/issues/6119/events | https://github.com/huggingface/datasets/pull/6119 | 1,835,996,350 | PR_kwDODunzps5XKI19 | 6,119 | [Docs] Add description of `select_columns` to guide | {
"avatar_url": "https://avatars.githubusercontent.com/u/18213435?v=4",
"events_url": "https://api.github.com/users/unifyh/events{/privacy}",
"followers_url": "https://api.github.com/users/unifyh/followers",
"following_url": "https://api.github.com/users/unifyh/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-08-04T03:13:30Z | 2023-08-16T10:13:02Z | 2023-08-16T10:02:52Z | CONTRIBUTOR | null | null | null | Closes #6116 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6119/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6119/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6119.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6119",
"merged_at": "2023-08-16T10:02:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6119.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6264/comments | https://api.github.com/repos/huggingface/datasets/issues/6264/events | https://github.com/huggingface/datasets/pull/6264 | 1,914,958,781 | PR_kwDODunzps5bTvzh | 6,264 | Temporarily pin tensorflow < 2.14.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-09-27T08:16:06Z | 2023-09-27T08:45:24Z | 2023-09-27T08:36:39Z | MEMBER | null | null | null | Temporarily pin tensorflow < 2.14.0 until permanent solution is found.
Hot fix #6263. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6264/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6264/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6264.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6264",
"merged_at": "2023-09-27T08:36:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6264.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4569/comments | https://api.github.com/repos/huggingface/datasets/issues/4569/events | https://github.com/huggingface/datasets/issues/4569 | 1,284,833,694 | I_kwDODunzps5MlQGe | 4,569 | Dataset Viewer issue for sst2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @lewtun, thanks for reporting.\r\n\r\nI have checked locally and refreshed the preview and it seems working smooth now:\r\n```python\r\nIn [8]: ds\r\nOut[8]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['idx', 'sentence', 'label'],\r\n num_rows: 67349\r\n })\r\n validation: Datas... | 2022-06-26T07:32:54Z | 2022-06-27T06:37:48Z | 2022-06-27T06:37:48Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Link
https://huggingface.co/datasets/sst2
### Description
Not sure what is causing this, however it seems that `load_dataset("sst2")` also hangs (even though it downloads the files without problem):
```
Status code: 400
Exception: Exception
Message: Give up after 5 attempts with Connectio... | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4569/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4569/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5483 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5483/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5483/comments | https://api.github.com/repos/huggingface/datasets/issues/5483/events | https://github.com/huggingface/datasets/issues/5483 | 1,560,894,690 | I_kwDODunzps5dCVzi | 5,483 | Unable to upload dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Seems to work now, perhaps it was something internal with our university's network."
] | 2023-01-28T15:18:26Z | 2023-01-29T08:09:49Z | 2023-01-29T08:09:49Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Uploading a simple dataset ends with an exception
### Steps to reproduce the bug
I created a new conda env with python 3.10, pip installed datasets and:
```python
>>> from datasets import load_dataset, load_from_disk, Dataset
>>> d = Dataset.from_dict({"text": ["hello"] * 2})
>>> d.pus... | {
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5483/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5483/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6941/comments | https://api.github.com/repos/huggingface/datasets/issues/6941/events | https://github.com/huggingface/datasets/issues/6941 | 2,328,930,165 | I_kwDODunzps6K0Kd1 | 6,941 | Supporting FFCV: Fast Forward Computer Vision | {
"avatar_url": "https://avatars.githubusercontent.com/u/20135317?v=4",
"events_url": "https://api.github.com/users/Luciennnnnnn/events{/privacy}",
"followers_url": "https://api.github.com/users/Luciennnnnnn/followers",
"following_url": "https://api.github.com/users/Luciennnnnnn/following{/other_user}",
"gist... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2024-06-01T05:34:52Z | 2024-06-01T05:34:52Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Supporting FFCV, https://github.com/libffcv/ffcv
### Motivation
According to the benchmark, FFCV seems to be fastest image loading method.
### Your contribution
no | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6941/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5630/comments | https://api.github.com/repos/huggingface/datasets/issues/5630/events | https://github.com/huggingface/datasets/pull/5630 | 1,620,327,510 | PR_kwDODunzps5L1ahF | 5,630 | adds early exit if url is `PathLike` | {
"avatar_url": "https://avatars.githubusercontent.com/u/44398246?v=4",
"events_url": "https://api.github.com/users/vvvm23/events{/privacy}",
"followers_url": "https://api.github.com/users/vvvm23/followers",
"following_url": "https://api.github.com/users/vvvm23/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5630). All of your documentation changes will be reflected on that endpoint."
] | 2023-03-12T11:23:28Z | 2023-03-15T11:58:38Z | null | NONE | null | null | null | Closes #4864
Should fix errors thrown when attempting to load `json` dataset using `pathlib.Path` in `data_files` argument. | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5630/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5630/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5630.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5630",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5630.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5630"
} |
https://api.github.com/repos/huggingface/datasets/issues/5782 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5782/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5782/comments | https://api.github.com/repos/huggingface/datasets/issues/5782/events | https://github.com/huggingface/datasets/issues/5782 | 1,679,622,367 | I_kwDODunzps5kHQDf | 5,782 | Support for various audio-loading backends instead of always relying on SoundFile | {
"avatar_url": "https://avatars.githubusercontent.com/u/129098876?v=4",
"events_url": "https://api.github.com/users/BoringDonut/events{/privacy}",
"followers_url": "https://api.github.com/users/BoringDonut/followers",
"following_url": "https://api.github.com/users/BoringDonut/following{/other_user}",
"gists_... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou can use `set_transform`/`with_transform` to define a custom decoding for audio formats not supported by `soundfile`:\r\n```python\r\naudio_dataset_amr = Dataset.from_dict({\"audio\": [\"audio_samples/audio.amr\"]})\r\n\r\ndef decode_audio(batch):\r\n batch[\"audio\"] = [read_ffmpeg(audio_path) f... | 2023-04-22T17:09:25Z | 2023-05-10T20:23:04Z | 2023-05-10T20:23:04Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Introduce an option to select from a variety of audio-loading backends rather than solely relying on the SoundFile library. For instance, if the ffmpeg library is installed, it can serve as a fallback loading option.
### Motivation
- The SoundFile library, used in [features/audio.py](https://gith... | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5782/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5782/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6058 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6058/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6058/comments | https://api.github.com/repos/huggingface/datasets/issues/6058/events | https://github.com/huggingface/datasets/issues/6058 | 1,815,131,397 | I_kwDODunzps5sMLUF | 6,058 | laion-coco download error | {
"avatar_url": "https://avatars.githubusercontent.com/u/54424110?v=4",
"events_url": "https://api.github.com/users/yangyijune/events{/privacy}",
"followers_url": "https://api.github.com/users/yangyijune/followers",
"following_url": "https://api.github.com/users/yangyijune/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"This can also mean one of the files was not downloaded correctly.\r\n\r\nWe log an erroneous file's name before raising the reader's error, so this is how you can find the problematic file. Then, you should delete it and call `load_dataset` again.\r\n\r\n(I checked all the uploaded files, and they seem to be valid... | 2023-07-21T04:24:15Z | 2023-07-22T01:42:06Z | 2023-07-22T01:42:06Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
The full trace:
```
/home/bian/anaconda3/envs/sd/lib/python3.10/site-packages/datasets/load.py:1744: FutureWarning: 'ignore_verifications' was de
precated in favor of 'verification_mode' in version 2.9.1 and will be removed in 3.0.0.
You can remove this warning by passing 'verification_mode=no... | {
"avatar_url": "https://avatars.githubusercontent.com/u/54424110?v=4",
"events_url": "https://api.github.com/users/yangyijune/events{/privacy}",
"followers_url": "https://api.github.com/users/yangyijune/followers",
"following_url": "https://api.github.com/users/yangyijune/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6058/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6058/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6324 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6324/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6324/comments | https://api.github.com/repos/huggingface/datasets/issues/6324/events | https://github.com/huggingface/datasets/issues/6324 | 1,955,126,687 | I_kwDODunzps50iN2f | 6,324 | Conversion to Arrow fails due to wrong type heuristic | {
"avatar_url": "https://avatars.githubusercontent.com/u/2862336?v=4",
"events_url": "https://api.github.com/users/jphme/events{/privacy}",
"followers_url": "https://api.github.com/users/jphme/followers",
"following_url": "https://api.github.com/users/jphme/following{/other_user}",
"gists_url": "https://api.g... | [] | closed | false | null | [] | null | [
"Unlike Pandas, Arrow is strict with types, so converting the problematic strings to ints (or ints to strings) to ensure all the values have the same type is the only fix. \r\n\r\nJSON support has been requested in Arrow [here](https://github.com/apache/arrow/issues/32538), but I don't expect this to be implemented... | 2023-10-20T23:20:58Z | 2023-10-23T20:52:57Z | 2023-10-23T20:52:57Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I have a list of dictionaries with valid/JSON-serializable values.
One key is the denominator for a paragraph. In 99.9% of cases its a number, but there are some occurences of '1a', '2b' and so on.
If trying to convert this list to a dataset with `Dataset.from_list()`, I always get
`ArrowI... | {
"avatar_url": "https://avatars.githubusercontent.com/u/2862336?v=4",
"events_url": "https://api.github.com/users/jphme/events{/privacy}",
"followers_url": "https://api.github.com/users/jphme/followers",
"following_url": "https://api.github.com/users/jphme/following{/other_user}",
"gists_url": "https://api.g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6324/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6324/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6658/comments | https://api.github.com/repos/huggingface/datasets/issues/6658/events | https://github.com/huggingface/datasets/pull/6658 | 2,129,158,371 | PR_kwDODunzps5mlZyb | 6,658 | [Resumable IterableDataset] Add IterableDataset state_dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6658). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"would be nice to have this feature in the new dataset release!",
"Before finalising t... | 2024-02-11T20:35:52Z | 2024-10-01T10:19:38Z | 2024-06-03T19:15:39Z | MEMBER | null | null | null | A simple implementation of a mechanism to resume an IterableDataset.
It works by restarting at the latest shard and skip samples. It provides fast resuming (though not instantaneous).
Example:
```python
from datasets import Dataset, concatenate_datasets
ds = Dataset.from_dict({"a": range(5)}).to_iterable_d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6658/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6658/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6658.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6658",
"merged_at": "2024-06-03T19:15:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6658.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6282 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6282/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6282/comments | https://api.github.com/repos/huggingface/datasets/issues/6282/events | https://github.com/huggingface/datasets/pull/6282 | 1,928,473,630 | PR_kwDODunzps5cBT5p | 6,282 | Drop data_files duplicates | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-10-05T14:43:08Z | 2024-09-02T14:08:35Z | 2024-09-02T14:08:35Z | MEMBER | null | null | null | I just added drop_duplicates=True to `.from_patterns`. I used a dict to deduplicate and preserve the order
close https://github.com/huggingface/datasets/issues/6259
close https://github.com/huggingface/datasets/issues/6272
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6282/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6282/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6282.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6282",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6282.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6282"
} |
https://api.github.com/repos/huggingface/datasets/issues/5412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5412/comments | https://api.github.com/repos/huggingface/datasets/issues/5412/events | https://github.com/huggingface/datasets/issues/5412 | 1,524,250,269 | I_kwDODunzps5a2jad | 5,412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | {
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"events_url": "https://api.github.com/users/mtoles/events{/privacy}",
"followers_url": "https://api.github.com/users/mtoles/followers",
"following_url": "https://api.github.com/users/mtoles/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [
"Hi ! It fails because the dataset is already being prepared by your first run. I'd encourage you to prepare your dataset before using it for multiple trainings.\r\n\r\nYou can also specify another cache directory by passing `cache_dir=` to `load_dataset()`.",
"Thank you! What do you mean by prepare it beforehand... | 2023-01-08T00:44:32Z | 2023-01-19T20:28:43Z | 2023-01-19T20:28:43Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"events_url": "https://api.github.com/users/mtoles/events{/privacy}",
"followers_url": "https://api.github.com/users/mtoles/followers",
"following_url": "https://api.github.com/users/mtoles/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5412/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5412/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6844 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6844/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6844/comments | https://api.github.com/repos/huggingface/datasets/issues/6844/events | https://github.com/huggingface/datasets/pull/6844 | 2,265,870,546 | PR_kwDODunzps5t2PRA | 6,844 | Retry on HF Hub error when streaming | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6844). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@Wauplin This PR is indeed not needed as explained in https://github.com/huggingface/da... | 2024-04-26T14:09:04Z | 2024-04-26T15:37:42Z | 2024-04-26T15:37:42Z | COLLABORATOR | null | null | null | Retry on the `huggingface_hub`'s `HfHubHTTPError` in the streaming mode.
Fix #6843 | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6844/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6844/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6844.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6844",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6844.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6844"
} |
https://api.github.com/repos/huggingface/datasets/issues/6054 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6054/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6054/comments | https://api.github.com/repos/huggingface/datasets/issues/6054/events | https://github.com/huggingface/datasets/issues/6054 | 1,813,271,304 | I_kwDODunzps5sFFMI | 6,054 | Multi-processed `Dataset.map` slows down a lot when `import torch` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47121592?v=4",
"events_url": "https://api.github.com/users/ShinoharaHare/events{/privacy}",
"followers_url": "https://api.github.com/users/ShinoharaHare/followers",
"following_url": "https://api.github.com/users/ShinoharaHare/following{/other_user}",
"g... | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | null | [] | null | [
"A duplicate of https://github.com/huggingface/datasets/issues/5929"
] | 2023-07-20T06:36:14Z | 2023-07-21T15:19:37Z | 2023-07-21T15:19:37Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When using `Dataset.map` with `num_proc > 1`, the speed slows down much if I add `import torch` to the start of the script even though I don't use it.
I'm not sure if it's `torch` only or if any other package that is "large" will also cause the same result.
BTW, `import lightning` also slows i... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47121592?v=4",
"events_url": "https://api.github.com/users/ShinoharaHare/events{/privacy}",
"followers_url": "https://api.github.com/users/ShinoharaHare/followers",
"following_url": "https://api.github.com/users/ShinoharaHare/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6054/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6054/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4558 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4558/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4558/comments | https://api.github.com/repos/huggingface/datasets/issues/4558/events | https://github.com/huggingface/datasets/pull/4558 | 1,283,479,650 | PR_kwDODunzps46THl_ | 4,558 | Add evaluation metadata to wmt14 | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4558). All of your documentation changes will be reflected on that endpoint.",
"As discussed with @lewtun, we are closing this PR, because it requires first the task names to be aligned between AutoTrain and datasets."
] | 2022-06-24T09:08:54Z | 2023-09-24T09:35:39Z | 2022-09-23T09:36:50Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4558/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4558/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4558.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4558",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4558.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4558"
} |
https://api.github.com/repos/huggingface/datasets/issues/5150 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5150/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5150/comments | https://api.github.com/repos/huggingface/datasets/issues/5150/events | https://github.com/huggingface/datasets/issues/5150 | 1,420,684,999 | I_kwDODunzps5Ure7H | 5,150 | Problems after upgrading to 2.6.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_u... | [] | open | false | null | [] | null | [
"Hi! I can't reproduce the error following these steps. Can you please provide a reproducible example?",
"I faced the same issue:\r\n\r\n### Repro\r\n```\r\n!pip install datasets==2.6.1\r\nimport datasets as Dataset\r\ndataset = Dataset.from_pandas(dataframe)\r\ndataset.save_to_disk(local)\r\n\r\n!pip install dat... | 2022-10-24T11:32:36Z | 2024-05-12T07:40:03Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Loading a dataset_dict from disk with `load_from_disk` is now creating a `KeyError "length"` that was not occurring in v2.5.2.
Context:
- Each individual dataset in the dict is created with `Dataset.from_pandas`
- The dataset_dict is create from a dict of `Dataset`s, e.g., `DatasetDict({"tr... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5150/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5150/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5418/comments | https://api.github.com/repos/huggingface/datasets/issues/5418/events | https://github.com/huggingface/datasets/issues/5418 | 1,530,111,184 | I_kwDODunzps5bM6TQ | 5,418 | Add ProgressBar for `to_parquet` | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
... | null | [
"Thanks for your proposal, @zanussbaum. Yes, I agree that would definitely be a nice feature to have!",
"@albertvillanova I’m happy to make a quick PR for the feature! let me know ",
"That would be awesome ! You can comment `#self-assign` to assign you to this issue and open a PR :) Will be happy to review",
... | 2023-01-12T05:06:20Z | 2023-01-24T18:18:24Z | 2023-01-24T18:18:24Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed | {
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5418/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5418/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"events_url": "https://api.github.com/users/sentialx/events{/privacy}",
"followers_url": "https://api.github.com/users/sentialx/followers",
"following_url": "https://api.github.com/users/sentialx/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n\r\nYou can specify `download_config=DownloadConfig(resume_download=True))` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\da... | 2023-03-03T09:52:08Z | 2023-10-14T02:15:52Z | 2023-03-24T12:44:25Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
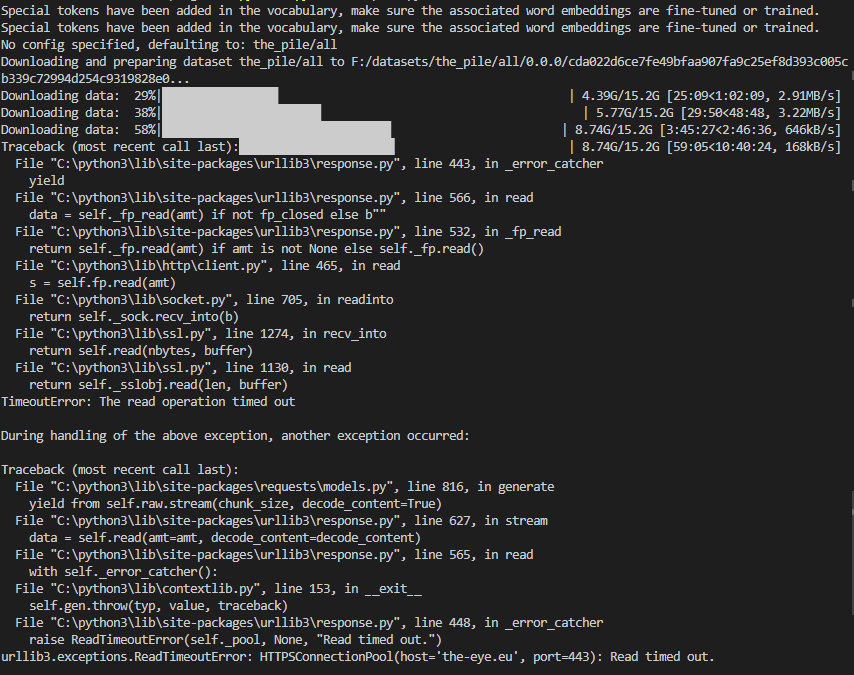
Here are the downloaded files:
:
File "/usr/share/miniconda/envs/build-datasets/conda-bld/datasets_1700036460222/t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6423/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6423/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6423.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6423",
"merged_at": "2023-11-15T17:09:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6423.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6322 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6322/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6322/comments | https://api.github.com/repos/huggingface/datasets/issues/6322/events | https://github.com/huggingface/datasets/pull/6322 | 1,952,947,461 | PR_kwDODunzps5dT5vG | 6,322 | Fix regex `get_data_files` formatting for base paths | {
"avatar_url": "https://avatars.githubusercontent.com/u/1981179?v=4",
"events_url": "https://api.github.com/users/ZachNagengast/events{/privacy}",
"followers_url": "https://api.github.com/users/ZachNagengast/followers",
"following_url": "https://api.github.com/users/ZachNagengast/following{/other_user}",
"gi... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"> The reason why I used the the glob_pattern_to_regex in the entire pattern is because otherwise I got an error for Windows local paths: a base_path like 'C:\\\\Users\\\\runneradmin... made the function string_to_dict raise re.error:... | 2023-10-19T19:45:10Z | 2023-10-23T14:40:45Z | 2023-10-23T14:31:21Z | CONTRIBUTOR | null | null | null | With this pr https://github.com/huggingface/datasets/pull/6309, it is formatting the entire base path into regex, which results in the undesired formatting error `doesn't match the pattern` because of the line in `glob_pattern_to_regex`: `.replace("//", "/")`:
- Input: `hf://datasets/...`
- Output: `hf:/datasets/...`... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6322/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6322/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6322.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6322",
"merged_at": "2023-10-23T14:31:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6322.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7207 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7207/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7207/comments | https://api.github.com/repos/huggingface/datasets/issues/7207/events | https://github.com/huggingface/datasets/pull/7207 | 2,573,582,335 | PR_kwDODunzps59-Dms | 7,207 | apply formatting after iter_arrow to speed up format -> map, filter for iterable datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/5719745?v=4",
"events_url": "https://api.github.com/users/alex-hh/events{/privacy}",
"followers_url": "https://api.github.com/users/alex-hh/followers",
"following_url": "https://api.github.com/users/alex-hh/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"I think the problem is that the underlying ex_iterable will not use iter_arrow unless the formatting type is arrow, which leads to conversion from arrow -> python -> numpy in this case rather than arrow -> numpy.\r\n\r\nIdea of updated fix is to use the ex_iterable's iter_arrow in any case where it's available and... | 2024-10-08T15:44:53Z | 2025-01-14T18:36:03Z | 2025-01-14T16:59:30Z | CONTRIBUTOR | null | null | null | I got to this by hacking around a bit but it seems to solve #7206
I have no idea if this approach makes sense or would break something else?
Could maybe work on a full pr if this looks reasonable @lhoestq ? I imagine the same issue might affect other iterable dataset methods? | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7207/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7207/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7207.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7207",
"merged_at": "2025-01-14T16:59:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7207.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6838 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6838/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6838/comments | https://api.github.com/repos/huggingface/datasets/issues/6838/events | https://github.com/huggingface/datasets/issues/6838 | 2,263,674,843 | I_kwDODunzps6G7O_b | 6,838 | Remove token arg from CLI examples | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2024-04-25T14:00:38Z | 2024-04-26T16:57:41Z | 2024-04-26T16:57:41Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | As suggested by @Wauplin, see: https://github.com/huggingface/datasets/pull/6831#discussion_r1579492603
> I would not advertise the --token arg in the example as this shouldn't be the recommended way (best to login with env variable or huggingface-cli login) | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6838/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6838/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6706/comments | https://api.github.com/repos/huggingface/datasets/issues/6706/events | https://github.com/huggingface/datasets/pull/6706 | 2,163,783,123 | PR_kwDODunzps5obgt- | 6,706 | Update ruff | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6706). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-03-01T16:44:58Z | 2024-03-01T17:02:13Z | 2024-03-01T16:52:17Z | MEMBER | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6706/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6706/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6706.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6706",
"merged_at": "2024-03-01T16:52:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6706.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6630/comments | https://api.github.com/repos/huggingface/datasets/issues/6630/events | https://github.com/huggingface/datasets/pull/6630 | 2,106,478,275 | PR_kwDODunzps5lYPi3 | 6,630 | Bump max range of dill to 0.3.8 | {
"avatar_url": "https://avatars.githubusercontent.com/u/27844407?v=4",
"events_url": "https://api.github.com/users/ringohoffman/events{/privacy}",
"followers_url": "https://api.github.com/users/ringohoffman/followers",
"following_url": "https://api.github.com/users/ringohoffman/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6630). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"Hmm these errors look pretty weird... can they be retried?",
"Hi, thanks for working ... | 2024-01-29T21:35:55Z | 2024-01-30T16:19:45Z | 2024-01-30T15:12:25Z | CONTRIBUTOR | null | null | null | Release on Jan 27, 2024: https://pypi.org/project/dill/0.3.8/#history
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6630/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6630/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6630.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6630",
"merged_at": "2024-01-30T15:12:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6630.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5748/comments | https://api.github.com/repos/huggingface/datasets/issues/5748/events | https://github.com/huggingface/datasets/pull/5748 | 1,667,517,024 | PR_kwDODunzps5OSgNH | 5,748 | [BUG FIX] Issue 5739 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1772912?v=4",
"events_url": "https://api.github.com/users/airlsyn/events{/privacy}",
"followers_url": "https://api.github.com/users/airlsyn/followers",
"following_url": "https://api.github.com/users/airlsyn/following{/other_user}",
"gists_url": "https:/... | [] | open | false | null | [] | null | [] | 2023-04-14T05:07:31Z | 2023-04-14T05:07:31Z | null | NONE | null | null | null | A fix for https://github.com/huggingface/datasets/issues/5739 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5748/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5748/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5748.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5748",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5748.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5748"
} |
https://api.github.com/repos/huggingface/datasets/issues/5017 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5017/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5017/comments | https://api.github.com/repos/huggingface/datasets/issues/5017/events | https://github.com/huggingface/datasets/issues/5017 | 1,384,022,463 | I_kwDODunzps5SfoG_ | 5,017 | xcsr: X-CSQA simply uses english for all alleged non-english data | {
"avatar_url": "https://avatars.githubusercontent.com/u/26286291?v=4",
"events_url": "https://api.github.com/users/thesofakillers/events{/privacy}",
"followers_url": "https://api.github.com/users/thesofakillers/followers",
"following_url": "https://api.github.com/users/thesofakillers/following{/other_user}",
... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @thesofakillers. Good catch. We are fixing this. "
] | 2022-09-23T16:11:54Z | 2022-09-26T10:57:31Z | 2022-09-26T10:57:31Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
All the alleged non-english subcollections for the X-CSQA task in the [xcsr benchmark dataset ](https://huggingface.co/datasets/xcsr) seem to be copies of the english subcollection, rather than translations. This is in contrast to the data description:
> we automatically translate the original C... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5017/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5017/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7346/comments | https://api.github.com/repos/huggingface/datasets/issues/7346/events | https://github.com/huggingface/datasets/issues/7346 | 2,758,752,118 | I_kwDODunzps6kbzd2 | 7,346 | OSError: Invalid flatbuffers message. | {
"avatar_url": "https://avatars.githubusercontent.com/u/46232487?v=4",
"events_url": "https://api.github.com/users/antecede/events{/privacy}",
"followers_url": "https://api.github.com/users/antecede/followers",
"following_url": "https://api.github.com/users/antecede/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Thanks for reporting, it looks like an issue with `pyarrow.ipc.open_stream`\r\n\r\nCan you try installing `datasets` from this pull request and see if it helps ? https://github.com/huggingface/datasets/pull/7348",
"> Thanks for reporting, it looks like an issue with `pyarrow.ipc.open_stream`\r\n> \r\n> Can you t... | 2024-12-25T11:38:52Z | 2025-01-09T14:25:29Z | 2025-01-09T14:25:05Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When loading a large 2D data (1000 × 1152) with a large number of (2,000 data in this case) in `load_dataset`, the error message `OSError: Invalid flatbuffers message` is reported.
When only 300 pieces of data of this size (1000 × 1152) are stored, they can be loaded correctly.
When 2,00... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7346/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7346/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7161 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7161/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7161/comments | https://api.github.com/repos/huggingface/datasets/issues/7161/events | https://github.com/huggingface/datasets/issues/7161 | 2,541,971,931 | I_kwDODunzps6Xg2nb | 7,161 | JSON lines with empty struct raise ArrowTypeError | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2024-09-23T08:48:56Z | 2024-09-25T04:43:44Z | 2024-09-23T11:30:07Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | JSON lines with empty struct raise ArrowTypeError: struct fields don't match or are in the wrong order
See example: https://huggingface.co/datasets/wikimedia/structured-wikipedia/discussions/5
> ArrowTypeError: struct fields don't match or are in the wrong order: Input fields: struct<> output fields: struct<pov_c... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7161/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7161/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5680/comments | https://api.github.com/repos/huggingface/datasets/issues/5680/events | https://github.com/huggingface/datasets/pull/5680 | 1,645,430,103 | PR_kwDODunzps5NJYNz | 5,680 | Fix a description error for interleave_datasets. | {
"avatar_url": "https://avatars.githubusercontent.com/u/55624066?v=4",
"events_url": "https://api.github.com/users/QizhiPei/events{/privacy}",
"followers_url": "https://api.github.com/users/QizhiPei/followers",
"following_url": "https://api.github.com/users/QizhiPei/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_a... | 2023-03-29T09:50:23Z | 2023-03-30T13:14:19Z | 2023-03-30T13:07:18Z | CONTRIBUTOR | null | null | null | There is a description mistake in the annotation of interleave_dataset with "all_exhausted" stopping_strategy.
``` python
d1 = Dataset.from_dict({"a": [0, 1, 2]})
d2 = Dataset.from_dict({"a": [10, 11, 12, 13]})
d3 = Dataset.from_dict({"a": [20, 21, 22, 23, 24]})
dataset = interleave_datasets([d1, d2, d3], stopping... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5680/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5680/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5680.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5680",
"merged_at": "2023-03-30T13:07:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5680.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7015 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7015/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7015/comments | https://api.github.com/repos/huggingface/datasets/issues/7015/events | https://github.com/huggingface/datasets/pull/7015 | 2,383,151,220 | PR_kwDODunzps50CJuE | 7,015 | add split argument to Generator | {
"avatar_url": "https://avatars.githubusercontent.com/u/156736?v=4",
"events_url": "https://api.github.com/users/piercus/events{/privacy}",
"followers_url": "https://api.github.com/users/piercus/followers",
"following_url": "https://api.github.com/users/piercus/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7015). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@albertvillanova thanks for the review, please take a look",
"@albertvillanova please... | 2024-07-01T08:09:25Z | 2024-07-26T09:37:51Z | 2024-07-26T09:31:56Z | CONTRIBUTOR | null | null | null | ## Actual
When creating a multi-split dataset using generators like
```python
datasets.DatasetDict({
"val": datasets.Dataset.from_generator(
generator=generator_val,
features=features
),
"test": datasets.Dataset.from_generator(
generator=generator_test,
features=features,
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7015/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7015/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7015.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7015",
"merged_at": "2024-07-26T09:31:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7015.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5713/comments | https://api.github.com/repos/huggingface/datasets/issues/5713/events | https://github.com/huggingface/datasets/issues/5713 | 1,657,141,251 | I_kwDODunzps5ixfgD | 5,713 | ArrowNotImplementedError when loading dataset from the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | [] | closed | false | null | [] | null | [
"Hi Julien ! This sounds related to https://github.com/huggingface/datasets/issues/5695 - TL;DR: you need to have shards smaller than 2GB to avoid this issue\r\n\r\nThe number of rows per shard is computed using an estimated size of the full dataset, which can sometimes lead to shards bigger than `max_shard_size`. ... | 2023-04-06T10:27:22Z | 2023-04-06T13:06:22Z | 2023-04-06T13:06:21Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hello,
I have created a dataset by using the image loader. Once the dataset is created I try to download it and I get the error:
```
Traceback (most recent call last):
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1860, in _prepare_split_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5713/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5713/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6132 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6132/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6132/comments | https://api.github.com/repos/huggingface/datasets/issues/6132/events | https://github.com/huggingface/datasets/issues/6132 | 1,843,491,020 | I_kwDODunzps5t4XDM | 6,132 | to_iterable_dataset is missing in document | {
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Fixed with PR"
] | 2023-08-09T15:15:03Z | 2023-08-16T04:43:36Z | 2023-08-16T04:43:29Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
to_iterable_dataset is missing in document
### Steps to reproduce the bug
to_iterable_dataset is missing in document
### Expected behavior
document enhancement
### Environment info
unrelated | {
"avatar_url": "https://avatars.githubusercontent.com/u/11533479?v=4",
"events_url": "https://api.github.com/users/npuichigo/events{/privacy}",
"followers_url": "https://api.github.com/users/npuichigo/followers",
"following_url": "https://api.github.com/users/npuichigo/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6132/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6132/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6077 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6077/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6077/comments | https://api.github.com/repos/huggingface/datasets/issues/6077/events | https://github.com/huggingface/datasets/issues/6077 | 1,822,486,810 | I_kwDODunzps5soPEa | 6,077 | Mapping gets stuck at 99% | {
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"events_url": "https://api.github.com/users/Laurent2916/events{/privacy}",
"followers_url": "https://api.github.com/users/Laurent2916/followers",
"following_url": "https://api.github.com/users/Laurent2916/following{/other_user}",
"gists_u... | [] | open | false | null | [] | null | [
"The `MAX_MAP_BATCH_SIZE = 1_000_000_000` hack is bad as it loads the entire dataset into RAM when performing `.map`. Instead, it's best to use `.iter(batch_size)` to iterate over the data batches and compute `mean` for each column. (`stddev` can be computed in another pass).\r\n\r\nAlso, these arrays are big, so i... | 2023-07-26T14:00:40Z | 2024-07-22T12:28:06Z | null | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi !
I'm currently working with a large (~150GB) unnormalized dataset at work.
The dataset is available on a read-only filesystem internally, and I use a [loading script](https://huggingface.co/docs/datasets/dataset_script) to retreive it.
I want to normalize the features of the dataset, ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6077/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6077/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5778 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5778/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5778/comments | https://api.github.com/repos/huggingface/datasets/issues/5778/events | https://github.com/huggingface/datasets/issues/5778 | 1,678,125,951 | I_kwDODunzps5kBit_ | 5,778 | Schrödinger's dataset_dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/902005?v=4",
"events_url": "https://api.github.com/users/liujuncn/events{/privacy}",
"followers_url": "https://api.github.com/users/liujuncn/followers",
"following_url": "https://api.github.com/users/liujuncn/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"Hi ! Passing `data_files=\"path/test.json\"` is equivalent to `data_files={\"train\": [\"path/test.json\"]}`, that's why you end up with a train split. If you don't pass `data_files=`, then split names are inferred from the data files names"
] | 2023-04-21T08:38:12Z | 2023-07-24T15:15:14Z | 2023-07-24T15:15:14Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
If you use load_dataset('json', data_files="path/test.json"), it will return DatasetDict({train:...}).
And if you use load_dataset("path"), it will return DatasetDict({test:...}).
Why can't the output behavior be unified?
### Steps to reproduce the bug
as description above.
### Expected b... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5778/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5778/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6440/comments | https://api.github.com/repos/huggingface/datasets/issues/6440/events | https://github.com/huggingface/datasets/issues/6440 | 2,004,509,301 | I_kwDODunzps53emJ1 | 6,440 | `.map` not hashing under python 3.9 | {
"avatar_url": "https://avatars.githubusercontent.com/u/9058204?v=4",
"events_url": "https://api.github.com/users/changyeli/events{/privacy}",
"followers_url": "https://api.github.com/users/changyeli/followers",
"following_url": "https://api.github.com/users/changyeli/following{/other_user}",
"gists_url": "h... | [] | closed | false | null | [] | null | [
"Tried to upgrade Python to 3.11 - still get this message. A partial solution is to NOT use `num_proc` at all. It will be considerably longer to finish the job.",
"Hi! The `model = torch.compile(model)` line is problematic for our hashing logic. We would have to merge https://github.com/huggingface/datasets/pull/... | 2023-11-21T15:14:54Z | 2023-11-28T16:29:33Z | 2023-11-28T16:29:33Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
The `.map` function cannot hash under python 3.9. Tried to use [the solution here](https://github.com/huggingface/datasets/issues/4521#issuecomment-1205166653), but still get the same message:
`Parameter 'function'=<function map_to_pred at 0x7fa0b49ead30> of the transform datasets.arrow_data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6440/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4541/comments | https://api.github.com/repos/huggingface/datasets/issues/4541/events | https://github.com/huggingface/datasets/pull/4541 | 1,280,161,436 | PR_kwDODunzps46HyPK | 4,541 | Fix timestamp conversion from Pandas to Python datetime in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI failures are unrelated to this PR, merging"
] | 2022-06-22T13:40:01Z | 2022-06-22T16:39:27Z | 2022-06-22T16:29:09Z | MEMBER | null | null | null | Arrow accepts both pd.Timestamp and datetime.datetime objects to create timestamp arrays.
However a timestamp array is always converted to datetime.datetime objects.
This created an inconsistency between streaming in non-streaming. e.g. the `ett` dataset outputs datetime.datetime objects in non-streaming but pd.tim... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4541/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4541/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4541.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4541",
"merged_at": "2022-06-22T16:29:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4541.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5242/comments | https://api.github.com/repos/huggingface/datasets/issues/5242/events | https://github.com/huggingface/datasets/issues/5242 | 1,449,069,382 | I_kwDODunzps5WXwtG | 5,242 | Failed Data Processing upon upload with zip file full of images | {
"avatar_url": "https://avatars.githubusercontent.com/u/82735473?v=4",
"events_url": "https://api.github.com/users/scrambled2/events{/privacy}",
"followers_url": "https://api.github.com/users/scrambled2/followers",
"following_url": "https://api.github.com/users/scrambled2/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [
"cc @abhishekkrthakur @SBrandeis "
] | 2022-11-15T02:47:52Z | 2022-11-15T17:59:23Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I went to autotrain and under image classification arrived where it was time to prepare my dataset. Screenshot below

I chose the method 2 option. I have a csv file with two columns. ~23,000 files.
I... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5242/timeline | null | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.