
url string | repository_url string | labels_url string | comments_url string | events_url string | html_url string | id int64 | node_id string | number int64 | title string | user dict | labels list | state string | locked bool | assignee dict | assignees list | milestone dict | comments list | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[ns, tz=UTC] | author_association string | type float64 | active_lock_reason float64 | sub_issues_summary dict | body string | closed_by dict | reactions dict | timeline_url string | performed_via_github_app float64 | state_reason string | draft float64 | pull_request dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5061 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5061/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5061/comments | https://api.github.com/repos/huggingface/datasets/issues/5061/events | https://github.com/huggingface/datasets/issues/5061 | 1,395,476,770 | I_kwDODunzps5TLUki | 5,061 | `_pickle.PicklingError: logger cannot be pickled` in multiprocessing `map` | {
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"This is maybe related to python 3.10, do you think you could try on 3.8 ?\r\n\r\nIn the meantime we'll keep improving the support for 3.10. Let me add a dedicated CI",
"I did some binary search and seems like the root cause is either `multiprocess` or `dill`. python 3.10 is fine. Specifically:\r\n- `multiprocess... | 2022-10-03T23:51:38Z | 2023-07-21T14:43:35Z | 2023-07-21T14:43:34Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
When I `map` with multiple processes, this error occurs. The `.name` of the `logger` that fails to pickle in the final line is `datasets.fingerprint`.
```
File "~/project/dataset.py", line 204, in <dictcomp>
split: dataset.map(
File ".../site-packages/datasets/arrow_dataset.py", line 24... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5061/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5061/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6327 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6327/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6327/comments | https://api.github.com/repos/huggingface/datasets/issues/6327/events | https://github.com/huggingface/datasets/issues/6327 | 1,955,470,755 | I_kwDODunzps50jh2j | 6,327 | FileNotFoundError when trying to load the downloaded dataset with `load_dataset(..., streaming=True)` | {
"avatar_url": "https://avatars.githubusercontent.com/u/18402347?v=4",
"events_url": "https://api.github.com/users/yzhangcs/events{/privacy}",
"followers_url": "https://api.github.com/users/yzhangcs/followers",
"following_url": "https://api.github.com/users/yzhangcs/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"You can clone the `togethercomputer/RedPajama-Data-1T-Sample` repo and load the dataset with `load_dataset(\"path/to/cloned_repo\")` to use it offline.",
"@mariosasko Thank you for your kind reply! I'll try it as a workaround.\r\nDoes that mean that currently it's not supported to simply load with a short name?"... | 2023-10-21T12:27:03Z | 2023-10-23T18:50:07Z | 2023-10-23T18:50:07Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Hi, I'm trying to load the dataset `togethercomputer/RedPajama-Data-1T-Sample` with `load_dataset` in streaming mode, i.e., `streaming=True`, but `FileNotFoundError` occurs.
### Steps to reproduce the bug
I've downloaded the dataset and save it to the cache dir in advance. My hope is loadi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/18402347?v=4",
"events_url": "https://api.github.com/users/yzhangcs/events{/privacy}",
"followers_url": "https://api.github.com/users/yzhangcs/followers",
"following_url": "https://api.github.com/users/yzhangcs/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6327/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6327/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5277 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5277/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5277/comments | https://api.github.com/repos/huggingface/datasets/issues/5277/events | https://github.com/huggingface/datasets/pull/5277 | 1,459,388,551 | PR_kwDODunzps5Dbybu | 5,277 | Remove YAML integer keys from class_label metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Also note that this approach is valid when metadata keys are str, but also if they are int.\r\n- This will be helpful for any community dataset using old integer keys in their metadata",
"perfect !"
] | 2022-11-22T08:34:07Z | 2022-11-22T13:58:26Z | 2022-11-22T13:55:49Z | MEMBER | null | null | null | Fix partially #5275. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5277/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5277/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5277.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5277",
"merged_at": "2022-11-22T13:55:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5277.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5488 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5488/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5488/comments | https://api.github.com/repos/huggingface/datasets/issues/5488/events | https://github.com/huggingface/datasets/issues/5488 | 1,565,025,262 | I_kwDODunzps5dSGPu | 5,488 | Error loading MP3 files from CommonVoice | {
"avatar_url": "https://avatars.githubusercontent.com/u/110259722?v=4",
"events_url": "https://api.github.com/users/kradonneoh/events{/privacy}",
"followers_url": "https://api.github.com/users/kradonneoh/followers",
"following_url": "https://api.github.com/users/kradonneoh/following{/other_user}",
"gists_url... | [] | closed | false | null | [] | null | [
"Hi @kradonneoh, thanks for reporting.\r\n\r\nPlease note that to work with audio datasets (and specifically with MP3 files) we have detailed installation instructions in our docs: https://huggingface.co/docs/datasets/installation#audio\r\n- one of the requirements is torchaudio<0.12.0\r\n\r\nLet us know if the pro... | 2023-01-31T21:25:33Z | 2023-03-02T16:25:14Z | 2023-03-02T16:25:13Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When loading a CommonVoice dataset with `datasets==2.9.0` and `torchaudio>=0.12.0`, I get an error reading the audio arrays:
```python
---------------------------------------------------------------------------
LibsndfileError Traceback (most recent call last)
~/.l... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5488/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5488/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6935 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6935/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6935/comments | https://api.github.com/repos/huggingface/datasets/issues/6935/events | https://github.com/huggingface/datasets/issues/6935 | 2,325,612,022 | I_kwDODunzps6KngX2 | 6,935 | Support for pathlib.Path in datasets 2.19.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/12202811?v=4",
"events_url": "https://api.github.com/users/lamyiowce/events{/privacy}",
"followers_url": "https://api.github.com/users/lamyiowce/followers",
"following_url": "https://api.github.com/users/lamyiowce/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | [
"+1 I just noticed this when I tried to update `datasets` today.",
"The same issue, I also get error."
] | 2024-05-30T12:53:36Z | 2025-01-14T11:50:22Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
After the recent update of `datasets`, Dataset.save_to_disk does not accept a pathlib.Path anymore. It was supported in 2.18.0 and previous versions. Is this intentional? Was it supported before only because of a Python dusk-typing miracle?
### Steps to reproduce the bug
```
from datasets impor... | null | {
"+1": 6,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6935/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6935/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5501 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5501/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5501/comments | https://api.github.com/repos/huggingface/datasets/issues/5501/events | https://github.com/huggingface/datasets/pull/5501 | 1,569,644,159 | PR_kwDODunzps5JMTn8 | 5,501 | Increase chunk size for speeding up file downloads | {
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5501). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchma... | 2023-02-03T10:50:10Z | 2023-02-09T11:04:11Z | null | CONTRIBUTOR | null | null | null | Original fix: https://github.com/huggingface/huggingface_hub/pull/1267
Not sure this function is actually still called though.
I haven't done benches on this. Is there a dataset where files are hosted on the hub through cloudfront so we can have the same setup as in `hf_hub` ? | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5501/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5501/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5501.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5501",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5501.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5501"
} |
https://api.github.com/repos/huggingface/datasets/issues/7199 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7199/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7199/comments | https://api.github.com/repos/huggingface/datasets/issues/7199/events | https://github.com/huggingface/datasets/pull/7199 | 2,566,788,225 | PR_kwDODunzps59pN_M | 7,199 | Add with_rank to Dataset.from_generator | {
"avatar_url": "https://avatars.githubusercontent.com/u/17828087?v=4",
"events_url": "https://api.github.com/users/muthissar/events{/privacy}",
"followers_url": "https://api.github.com/users/muthissar/followers",
"following_url": "https://api.github.com/users/muthissar/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | [] | 2024-10-04T16:51:53Z | 2024-10-04T16:51:53Z | null | NONE | null | null | null | Adds `with_rank` to `Dataset.from_generator`. As for `Dataset.map` and `Dataset.filter`, this is useful when creating cache files using multi-GPU. | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7199/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7199/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7199.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7199",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7199.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7199"
} |
https://api.github.com/repos/huggingface/datasets/issues/5643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5643/comments | https://api.github.com/repos/huggingface/datasets/issues/5643/events | https://github.com/huggingface/datasets/pull/5643 | 1,626,160,220 | PR_kwDODunzps5MI9zO | 5,643 | Support PyArrow arrays as column values in `from_dict` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-15T19:32:40Z | 2023-03-16T17:23:06Z | 2023-03-16T17:15:40Z | COLLABORATOR | null | null | null | For consistency with `pa.Table.from_pydict`, which supports both Python lists and PyArrow arrays as column values.
"Fixes" https://discuss.huggingface.co/t/pyarrow-lib-floatarray-did-not-recognize-python-value-type-when-inferring-an-arrow-data-type/33417 | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5643/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5643/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5643.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5643",
"merged_at": "2023-03-16T17:15:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5643.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7280 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7280/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7280/comments | https://api.github.com/repos/huggingface/datasets/issues/7280/events | https://github.com/huggingface/datasets/issues/7280 | 2,639,977,077 | I_kwDODunzps6dWtp1 | 7,280 | Add filename in error message when ReadError or similar occur | {
"avatar_url": "https://avatars.githubusercontent.com/u/37046039?v=4",
"events_url": "https://api.github.com/users/elisa-aleman/events{/privacy}",
"followers_url": "https://api.github.com/users/elisa-aleman/followers",
"following_url": "https://api.github.com/users/elisa-aleman/following{/other_user}",
"gist... | [] | open | false | null | [] | null | [
"Hi Elisa, please share the error traceback here, and if you manage to find the location in the `datasets` code where the error occurs, feel free to open a PR to add the necessary logging / improve the error message.",
"> please share the error traceback\n\nI don't have access to it but it should be during [this ... | 2024-11-07T06:00:53Z | 2024-11-20T13:23:12Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Please update error messages to include relevant information for debugging when loading datasets with `load_dataset()` that may have a few corrupted files.
Whenever downloading a full dataset, some files might be corrupted (either at the source or from downloading corruption).
However the errors often only let me k... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7280/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7280/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4649/comments | https://api.github.com/repos/huggingface/datasets/issues/4649/events | https://github.com/huggingface/datasets/issues/4649 | 1,296,673,712 | I_kwDODunzps5NSauw | 4,649 | Add PAQ dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"uploaded dataset [here](https://huggingface.co/datasets/embedding-data/PAQ_pairs)"
] | 2022-07-07T01:29:42Z | 2022-07-14T02:06:27Z | 2022-07-14T02:06:27Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Adding a Dataset
- **Name:** *PAQ*
- **Description:** *This repository contains code and models to support the research paper PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them*
- **Paper:** *https://arxiv.org/abs/2102.07033*
- **Data:** *https://huggingface.co/datasets/sentence-transformers/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"events_url": "https://api.github.com/users/omarespejel/events{/privacy}",
"followers_url": "https://api.github.com/users/omarespejel/followers",
"following_url": "https://api.github.com/users/omarespejel/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4649/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4649/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6402/comments | https://api.github.com/repos/huggingface/datasets/issues/6402/events | https://github.com/huggingface/datasets/pull/6402 | 1,989,094,542 | PR_kwDODunzps5fOBdK | 6,402 | Update torch_formatter.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/32204417?v=4",
"events_url": "https://api.github.com/users/varunneal/events{/privacy}",
"followers_url": "https://api.github.com/users/varunneal/followers",
"following_url": "https://api.github.com/users/varunneal/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6402). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2023-11-11T19:40:41Z | 2024-03-15T11:31:53Z | 2024-03-15T11:25:37Z | CONTRIBUTOR | null | null | null | Ensure PyTorch images are converted to (C, H, W) instead of (H, W, C). See #6394 for motivation. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6402/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6402/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6402.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6402",
"merged_at": "2024-03-15T11:25:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6402.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7534 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7534/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7534/comments | https://api.github.com/repos/huggingface/datasets/issues/7534/events | https://github.com/huggingface/datasets/issues/7534 | 3,017,259,407 | I_kwDODunzps6z17mP | 7,534 | TensorFlow RaggedTensor Support (batch-level) | {
"avatar_url": "https://avatars.githubusercontent.com/u/7490199?v=4",
"events_url": "https://api.github.com/users/Lundez/events{/privacy}",
"followers_url": "https://api.github.com/users/Lundez/followers",
"following_url": "https://api.github.com/users/Lundez/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2025-04-24T13:14:52Z | 2025-04-24T13:17:20Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Hi,
Currently datasets does not support RaggedTensor output on batch-level.
When building a Object Detection Dataset (with TensorFlow) I need to enable RaggedTensors as that's how BBoxes & classes are expected from the Keras Model POV.
Currently there's a error thrown saying that "Nested Data is ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7534/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7534/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5012 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5012/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5012/comments | https://api.github.com/repos/huggingface/datasets/issues/5012/events | https://github.com/huggingface/datasets/issues/5012 | 1,382,851,096 | I_kwDODunzps5SbKIY | 5,012 | Force JSON format regardless of file naming on S3 | {
"avatar_url": "https://avatars.githubusercontent.com/u/112650299?v=4",
"events_url": "https://api.github.com/users/junwang-wish/events{/privacy}",
"followers_url": "https://api.github.com/users/junwang-wish/followers",
"following_url": "https://api.github.com/users/junwang-wish/following{/other_user}",
"gis... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi ! Support for URIs like `s3://...` is not implemented yet in `data_files=`. You can use the HTTP URL instead if your data is public in the meantime",
"Hi,\r\nI want to make sure I understand this response. I have a set of files on S3 that are private for security reasons. Because they are not public files I ... | 2022-09-22T18:28:15Z | 2023-08-16T09:58:36Z | 2023-08-16T09:58:36Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I have a file on S3 created by Data Version Control, it looks like `s3://dvc/ac/badff5b134382a0f25248f1b45d7b2` but contains a json file. If I run
```python
dataset = load_dataset(
"json",
data_files='s3://dvc/ac/badff5b134382a0f25248f1b45d7b2'
)
```
It gives me
```
InvalidSchema: No connection adap... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5012/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5012/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4887 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4887/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4887/comments | https://api.github.com/repos/huggingface/datasets/issues/4887/events | https://github.com/huggingface/datasets/pull/4887 | 1,349,426,693 | PR_kwDODunzps49t_PM | 4,887 | Add "cc-by-nc-sa-2.0" to list of licenses | {
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Sorry for the issue @albertvillanova! I think it's now fixed! :heart: "
] | 2022-08-24T13:11:49Z | 2022-08-26T10:31:32Z | 2022-08-26T10:29:20Z | CONTRIBUTOR | null | null | null | Datasets side of https://github.com/huggingface/hub-docs/pull/285 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4887/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4887/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4887.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4887",
"merged_at": "2022-08-26T10:29:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4887.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6902 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6902/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6902/comments | https://api.github.com/repos/huggingface/datasets/issues/6902/events | https://github.com/huggingface/datasets/pull/6902 | 2,300,256,241 | PR_kwDODunzps5vqLIv | 6,902 | Make CLI convert_to_parquet not raise error if no rights to create script branch | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6902). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-05-16T12:21:27Z | 2024-06-03T04:43:17Z | 2024-05-16T12:51:05Z | MEMBER | null | null | null | Make CLI convert_to_parquet not raise error if no rights to create "script" branch.
Not that before this PR, the error was not critical because it was raised at the end of the script, once all the rest of the steps were already performed.
Fix #6901.
Bug introduced in datasets-2.19.0 by:
- #6809 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6902/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6902/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6902.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6902",
"merged_at": "2024-05-16T12:51:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6902.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7143 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7143/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7143/comments | https://api.github.com/repos/huggingface/datasets/issues/7143/events | https://github.com/huggingface/datasets/pull/7143 | 2,512,327,211 | PR_kwDODunzps56xCm6 | 7,143 | Modify add_column() to optionally accept a FeatureType as param | {
"avatar_url": "https://avatars.githubusercontent.com/u/20443618?v=4",
"events_url": "https://api.github.com/users/varadhbhatnagar/events{/privacy}",
"followers_url": "https://api.github.com/users/varadhbhatnagar/followers",
"following_url": "https://api.github.com/users/varadhbhatnagar/following{/other_user}"... | [] | closed | false | null | [] | null | [
"Requesting review @lhoestq \r\nI will also update the docs if this looks good.",
"Cool ! maybe you can rename the argument `feature` and with type `FeatureType` ? This way it would work the same way as `.cast_column()` ?",
"@lhoestq Since there is no way to get a `pyarrow.Schema` from a `FeatureType`, I had to... | 2024-09-08T10:56:57Z | 2024-09-17T06:01:23Z | 2024-09-16T15:11:01Z | CONTRIBUTOR | null | null | null | Fix #7142.
**Before (Add + Cast)**:
```
from datasets import load_dataset, Value
ds = load_dataset("rotten_tomatoes", split="test")
lst = [i for i in range(len(ds))]
ds = ds.add_column("new_col", lst)
# Assigns int64 to new_col by default
print(ds.features)
ds = ds.cast_column("new_col", Value(dtype="u... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7143/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7143/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7143.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7143",
"merged_at": "2024-09-16T15:11:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7143.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5169 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5169/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5169/comments | https://api.github.com/repos/huggingface/datasets/issues/5169/events | https://github.com/huggingface/datasets/pull/5169 | 1,425,075,254 | PR_kwDODunzps5Bow1Q | 5,169 | Add "ipykernel" to list of `co_filename`s to remove | {
"avatar_url": "https://avatars.githubusercontent.com/u/32967787?v=4",
"events_url": "https://api.github.com/users/gpucce/events{/privacy}",
"followers_url": "https://api.github.com/users/gpucce/followers",
"following_url": "https://api.github.com/users/gpucce/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"I don't know how I could add some tests for this, although jupyter is not among the dependencies so at least that would need to be added. If someone can tell a recommended way I will try to do it!",
"So testing by myself and looking around the jupyter codebase it looks like the `co_filename` of objects created w... | 2022-10-27T05:56:17Z | 2022-11-02T15:46:00Z | 2022-11-02T15:43:20Z | CONTRIBUTOR | null | null | null | Should resolve #5157 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5169/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5169/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5169.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5169",
"merged_at": "2022-11-02T15:43:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5169.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7170 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7170/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7170/comments | https://api.github.com/repos/huggingface/datasets/issues/7170/events | https://github.com/huggingface/datasets/pull/7170 | 2,546,944,016 | PR_kwDODunzps58mfF5 | 7,170 | Support JSON lines with missing columns | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7170). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update."
] | 2024-09-25T05:08:15Z | 2024-09-26T06:42:09Z | 2024-09-26T06:42:07Z | MEMBER | null | null | null | Support JSON lines with missing columns.
Fix #7169.
The implemented test raised:
```
datasets.table.CastError: Couldn't cast
age: int64
to
{'age': Value(dtype='int32', id=None), 'name': Value(dtype='string', id=None)}
because column names don't match
```
Related to:
- #7160
- #7162 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7170/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7170/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7170.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7170",
"merged_at": "2024-09-26T06:42:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7170.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6928/comments | https://api.github.com/repos/huggingface/datasets/issues/6928/events | https://github.com/huggingface/datasets/pull/6928 | 2,322,267,727 | PR_kwDODunzps5w1ECb | 6,928 | Update process.mdx: Code Listings Fixes | {
"avatar_url": "https://avatars.githubusercontent.com/u/16918280?v=4",
"events_url": "https://api.github.com/users/FadyMorris/events{/privacy}",
"followers_url": "https://api.github.com/users/FadyMorris/followers",
"following_url": "https://api.github.com/users/FadyMorris/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2024-05-29T03:17:07Z | 2024-06-04T13:08:19Z | 2024-06-04T12:55:00Z | CONTRIBUTOR | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6928/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6928.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6928",
"merged_at": "2024-06-04T12:55:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6928.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7397/comments | https://api.github.com/repos/huggingface/datasets/issues/7397/events | https://github.com/huggingface/datasets/pull/7397 | 2,852,829,763 | PR_kwDODunzps6LMuQD | 7,397 | Kannada dataset(Conversations, Wikipedia etc) | {
"avatar_url": "https://avatars.githubusercontent.com/u/146451281?v=4",
"events_url": "https://api.github.com/users/Likhith2612/events{/privacy}",
"followers_url": "https://api.github.com/users/Likhith2612/followers",
"following_url": "https://api.github.com/users/Likhith2612/following{/other_user}",
"gists_... | [] | closed | false | null | [] | null | [
"Hi ! feel free to uplad the CSV on https://huggingface.co/datasets :)\r\n\r\nwe don't store the datasets' data in this github repository"
] | 2025-02-14T06:53:03Z | 2025-02-20T17:28:54Z | 2025-02-20T17:28:53Z | NONE | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7397/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7397/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7397.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7397",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7397.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7397"
} |
https://api.github.com/repos/huggingface/datasets/issues/4836 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4836/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4836/comments | https://api.github.com/repos/huggingface/datasets/issues/4836/events | https://github.com/huggingface/datasets/issues/4836 | 1,337,067,632 | I_kwDODunzps5Psghw | 4,836 | Is it possible to pass multiple links to a split in load script? | {
"avatar_url": "https://avatars.githubusercontent.com/u/43045767?v=4",
"events_url": "https://api.github.com/users/sadrasabouri/events{/privacy}",
"followers_url": "https://api.github.com/users/sadrasabouri/followers",
"following_url": "https://api.github.com/users/sadrasabouri/following{/other_user}",
"gist... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2022-08-12T11:06:11Z | 2022-08-12T11:06:11Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | **Is your feature request related to a problem? Please describe.**
I wanted to use a python loading script in hugging face datasets that use different sources of text (it's somehow a compilation of multiple datasets + my own dataset) based on how `load_dataset` [works](https://huggingface.co/docs/datasets/loading) I a... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4836/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4836/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5231/comments | https://api.github.com/repos/huggingface/datasets/issues/5231/events | https://github.com/huggingface/datasets/issues/5231 | 1,445,883,267 | I_kwDODunzps5WLm2D | 5,231 | Using `set_format(type='torch', columns=columns)` makes Array2D/3D columns stop formatting correctly | {
"avatar_url": "https://avatars.githubusercontent.com/u/99206017?v=4",
"events_url": "https://api.github.com/users/plamb-viso/events{/privacy}",
"followers_url": "https://api.github.com/users/plamb-viso/followers",
"following_url": "https://api.github.com/users/plamb-viso/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"In case others find this, the problem was not with set_format, but my usages of `to_pandas()` and `from_pandas()` which I was using during dataset splitting; somewhere in the chain of converting to and from pandas the `Array2D/Array3D` types get converted to series of `Sequence()` types"
] | 2022-11-11T18:54:36Z | 2022-11-11T20:42:29Z | 2022-11-11T18:59:50Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I have a Dataset with two Features defined as follows:
```
'image': Array3D(dtype="int64", shape=(3, 224, 224)),
'bbox': Array2D(dtype="int64", shape=(512, 4)),
```
On said dataset, if I `dataset.set_format(type='torch')` and then use the dataset in a dataloader, these columns are correctly cast to Tensors of ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/99206017?v=4",
"events_url": "https://api.github.com/users/plamb-viso/events{/privacy}",
"followers_url": "https://api.github.com/users/plamb-viso/followers",
"following_url": "https://api.github.com/users/plamb-viso/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5231/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5137 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5137/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5137/comments | https://api.github.com/repos/huggingface/datasets/issues/5137/events | https://github.com/huggingface/datasets/issues/5137 | 1,414,642,723 | I_kwDODunzps5UUbwj | 5,137 | Align task tags in dataset metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I removed all the invalid task_ids in datasts without namespace, based on the <s>(internal)</s> types.ts",
"(Types.ts is not internal it's public)",
"I have opened PRs to fix the task_ids in all datasets within a namespace as well.\r\n\r\nWorking on task_categories...",
"For future reference: this fix had so... | 2022-10-19T09:41:42Z | 2022-11-10T05:25:58Z | 2022-10-25T06:17:00Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe
Once we have agreed on a common naming for task tags for all open source projects, we should align on them.
## Steps
- [x] Align task tags in canonical datasets
- [x] task_categories: 4 datasets
- [x] task_ids (by @lhoestq)
- [x] Open PRs in community datasets
- [x] task_categories: 451 datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5137/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5137/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6456 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6456/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6456/comments | https://api.github.com/repos/huggingface/datasets/issues/6456/events | https://github.com/huggingface/datasets/pull/6456 | 2,015,186,090 | PR_kwDODunzps5gmDJY | 6,456 | Don't require trust_remote_code in inspect_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-11-28T19:47:07Z | 2023-11-30T10:40:23Z | 2023-11-30T10:34:12Z | MEMBER | null | null | null | don't require `trust_remote_code` in (deprecated) `inspect_dataset` (it defeats its purpose)
(not super important but we might as well keep it until the next major release)
this is needed to fix the tests in https://github.com/huggingface/datasets/pull/6448 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6456/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6456/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6456.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6456",
"merged_at": "2023-11-30T10:34:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6456.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5415/comments | https://api.github.com/repos/huggingface/datasets/issues/5415/events | https://github.com/huggingface/datasets/issues/5415 | 1,526,904,861 | I_kwDODunzps5bArgd | 5,415 | RuntimeError: Sharding is ambiguous for this dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-01-10T07:36:11Z | 2023-01-18T14:09:04Z | 2023-01-18T14:09:03Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When loading some datasets, a RuntimeError is raised.
For example, for "ami" dataset: https://huggingface.co/datasets/ami/discussions/3
```
.../huggingface/datasets/src/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5415/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5415/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6958/comments | https://api.github.com/repos/huggingface/datasets/issues/6958/events | https://github.com/huggingface/datasets/issues/6958 | 2,337,476,383 | I_kwDODunzps6LUw8f | 6,958 | My Private Dataset doesn't exist on the Hub or cannot be accessed | {
"avatar_url": "https://avatars.githubusercontent.com/u/39621324?v=4",
"events_url": "https://api.github.com/users/wangguan1995/events{/privacy}",
"followers_url": "https://api.github.com/users/wangguan1995/followers",
"following_url": "https://api.github.com/users/wangguan1995/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"I can load public dataset, but for my private dataset it fails",
"https://huggingface.co/docs/datasets/upload_dataset",
"I have checked the API HTTP link. Repository Not Found for url: https://huggingface.co/api/datasets/xxx/xxx.\r\n\r\n
datasets.exceptions.DatasetNotFoundError: Dataset 'xxx' doesn't exist on t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6958/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5318 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5318/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5318/comments | https://api.github.com/repos/huggingface/datasets/issues/5318/events | https://github.com/huggingface/datasets/pull/5318 | 1,470,749,750 | PR_kwDODunzps5EB6RM | 5,318 | Origin/fix missing features error | {
"avatar_url": "https://avatars.githubusercontent.com/u/12104720?v=4",
"events_url": "https://api.github.com/users/eunseojo/events{/privacy}",
"followers_url": "https://api.github.com/users/eunseojo/followers",
"following_url": "https://api.github.com/users/eunseojo/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"please review :) @lhoestq @ola13 thankoo",
"Thanks :) I just updated the test to make sure it works even when there's a column missing, and did a minor change to json.py to add the missing columns for the other kinds of JSON files ... | 2022-12-01T06:18:39Z | 2022-12-12T19:06:42Z | 2022-12-04T05:49:39Z | CONTRIBUTOR | null | null | null | This fixes the problem of when the dataset_load function reads a function with "features" provided but some read batches don't have columns that later show up. For instance, the provided "features" requires columns A,B,C but only columns B,C show. This fixes this by adding the column A with nulls. | {
"avatar_url": "https://avatars.githubusercontent.com/u/12104720?v=4",
"events_url": "https://api.github.com/users/eunseojo/events{/privacy}",
"followers_url": "https://api.github.com/users/eunseojo/followers",
"following_url": "https://api.github.com/users/eunseojo/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5318/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5318/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5318.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5318",
"merged_at": "2022-12-04T05:49:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5318.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6580/comments | https://api.github.com/repos/huggingface/datasets/issues/6580/events | https://github.com/huggingface/datasets/issues/6580 | 2,075,645,042 | I_kwDODunzps57t9Ry | 6,580 | dataset cache only stores one config of the dataset in parquet dir, and uses that for all other configs resulting in showing same data in all configs. | {
"avatar_url": "https://avatars.githubusercontent.com/u/78641018?v=4",
"events_url": "https://api.github.com/users/kartikgupta321/events{/privacy}",
"followers_url": "https://api.github.com/users/kartikgupta321/followers",
"following_url": "https://api.github.com/users/kartikgupta321/following{/other_user}",
... | [] | closed | false | null | [] | null | [] | 2024-01-11T03:14:18Z | 2024-01-20T12:46:16Z | 2024-01-20T12:46:16Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
ds = load_dataset("ai2_arc", "ARC-Easy"), i have tried to force redownload, delete cache and changing the cache dir.
### Steps to reproduce the bug
dataset = []
dataset_name = "ai2_arc"
possible_configs = [
'ARC-Challenge',
'ARC-Easy'
]
for config in possible_configs:
data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/78641018?v=4",
"events_url": "https://api.github.com/users/kartikgupta321/events{/privacy}",
"followers_url": "https://api.github.com/users/kartikgupta321/followers",
"following_url": "https://api.github.com/users/kartikgupta321/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6580/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6580/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6905 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6905/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6905/comments | https://api.github.com/repos/huggingface/datasets/issues/6905/events | https://github.com/huggingface/datasets/issues/6905 | 2,303,098,587 | I_kwDODunzps6JRn7b | 6,905 | Extraction protocol for arrow files is not defined | {
"avatar_url": "https://avatars.githubusercontent.com/u/26553095?v=4",
"events_url": "https://api.github.com/users/radulescupetru/events{/privacy}",
"followers_url": "https://api.github.com/users/radulescupetru/followers",
"following_url": "https://api.github.com/users/radulescupetru/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Fixed in https://github.com/huggingface/datasets/pull/7083"
] | 2024-05-17T16:01:41Z | 2025-02-06T19:50:22Z | 2025-02-06T19:50:20Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Passing files with `.arrow` extension into data_files argument, at least when `streaming=True` is very slow.
### Steps to reproduce the bug
Basically it goes through the `_get_extraction_protocol` method located [here](https://github.com/huggingface/datasets/blob/main/src/datasets/utils/file_ut... | {
"avatar_url": "https://avatars.githubusercontent.com/u/26553095?v=4",
"events_url": "https://api.github.com/users/radulescupetru/events{/privacy}",
"followers_url": "https://api.github.com/users/radulescupetru/followers",
"following_url": "https://api.github.com/users/radulescupetru/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6905/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6905/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7505 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7505/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7505/comments | https://api.github.com/repos/huggingface/datasets/issues/7505/events | https://github.com/huggingface/datasets/issues/7505 | 2,979,926,156 | I_kwDODunzps6xnhCM | 7,505 | HfHubHTTPError: 403 Forbidden: None. Cannot access content at: https://hf.co/api/s3proxy | {
"avatar_url": "https://avatars.githubusercontent.com/u/1412262?v=4",
"events_url": "https://api.github.com/users/hissain/events{/privacy}",
"followers_url": "https://api.github.com/users/hissain/followers",
"following_url": "https://api.github.com/users/hissain/following{/other_user}",
"gists_url": "https:/... | [] | open | false | null | [] | null | [] | 2025-04-08T14:08:40Z | 2025-04-08T14:08:40Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I have already logged in Huggingface using CLI with my valid token. Now trying to download the datasets using following code:
from transformers import WhisperProcessor, WhisperForConditionalGeneration, WhisperTokenizer, Trainer, TrainingArguments, DataCollatorForSeq2Seq
from datasets import load_dataset, Data... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7505/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7505/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5647/comments | https://api.github.com/repos/huggingface/datasets/issues/5647/events | https://github.com/huggingface/datasets/issues/5647 | 1,628,225,544 | I_kwDODunzps5hDMAI | 5,647 | Make all print statements optional | {
"avatar_url": "https://avatars.githubusercontent.com/u/49101362?v=4",
"events_url": "https://api.github.com/users/gagan3012/events{/privacy}",
"followers_url": "https://api.github.com/users/gagan3012/followers",
"following_url": "https://api.github.com/users/gagan3012/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"related to #5444 ",
"We now log these messages instead of printing them (addressed in #6019), so I'm closing this issue."
] | 2023-03-16T20:30:07Z | 2023-07-21T14:20:25Z | 2023-07-21T14:20:24Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Make all print statements optional to speed up the development
### Motivation
Im loading multiple tiny datasets and all the print statements make the loading slower
### Your contribution
I can help contribute | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5647/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7475 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7475/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7475/comments | https://api.github.com/repos/huggingface/datasets/issues/7475/events | https://github.com/huggingface/datasets/issues/7475 | 2,946,640,570 | I_kwDODunzps6voiq6 | 7,475 | IterableDataset's state_dict shard_example_idx is always equal to the number of samples in a shard | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url"... | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/ot... | null | [
"Hey, I’d love to work on this issue but I am a beginner, can I work it with you?",
"Hello. I'm sorry but I don't have much time to get in the details for now.\nHave you managed to reproduce the issue with the code provided ?\nIf you want to work on it, you can self-assign and ask @lhoestq for directions",
"Hi ... | 2025-03-25T13:58:07Z | 2025-04-18T00:49:37Z | null | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
I've noticed a strange behaviour with Iterable state_dict: the value of shard_example_idx is always equal to the amount of samples in a shard.
### Steps to reproduce the bug
I am reusing the example from the doc
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(6)}).to_... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7475/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7475/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6629/comments | https://api.github.com/repos/huggingface/datasets/issues/6629/events | https://github.com/huggingface/datasets/pull/6629 | 2,105,774,482 | PR_kwDODunzps5lV0aF | 6,629 | Support push_to_hub without org/user to default to logged-in user | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6629). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"@huggingface/datasets, feel free to review this PR so that it can be included in the ne... | 2024-01-29T15:36:52Z | 2024-02-05T12:35:43Z | 2024-02-05T12:29:36Z | MEMBER | null | null | null | This behavior is aligned with:
- the behavior of `datasets` before merging #6519
- the behavior described in the corresponding docstring
- the behavior of `huggingface_hub.create_repo`
Revert "Support push_to_hub canonical datasets (#6519)"
- This reverts commit a887ee78835573f5d80f9e414e8443b4caff3541.
Fix... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6629/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6629/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6629.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6629",
"merged_at": "2024-02-05T12:29:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6629.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7168 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7168/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7168/comments | https://api.github.com/repos/huggingface/datasets/issues/7168/events | https://github.com/huggingface/datasets/issues/7168 | 2,546,710,631 | I_kwDODunzps6Xy7hn | 7,168 | sd1.5 diffusers controlnet training script gives new error | {
"avatar_url": "https://avatars.githubusercontent.com/u/90132896?v=4",
"events_url": "https://api.github.com/users/Night1099/events{/privacy}",
"followers_url": "https://api.github.com/users/Night1099/followers",
"following_url": "https://api.github.com/users/Night1099/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"not sure why the issue is formatting oddly",
"I guess this is a dupe of\r\n\r\nhttps://github.com/huggingface/datasets/issues/7071",
"this turned out to be because of a bad image in dataset"
] | 2024-09-25T01:42:49Z | 2024-09-30T05:24:03Z | 2024-09-30T05:24:02Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
This will randomly pop up during training now
```
Traceback (most recent call last):
File "/workspace/diffusers/examples/controlnet/train_controlnet.py", line 1192, in <module>
main(args)
File "/workspace/diffusers/examples/controlnet/train_controlnet.py", line 1041, in main
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/90132896?v=4",
"events_url": "https://api.github.com/users/Night1099/events{/privacy}",
"followers_url": "https://api.github.com/users/Night1099/followers",
"following_url": "https://api.github.com/users/Night1099/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7168/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7168/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5699 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5699/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5699/comments | https://api.github.com/repos/huggingface/datasets/issues/5699/events | https://github.com/huggingface/datasets/issues/5699 | 1,652,437,419 | I_kwDODunzps5ifjGr | 5,699 | Issue when wanting to split in memory a cached dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47528215?v=4",
"events_url": "https://api.github.com/users/FrancoisNoyez/events{/privacy}",
"followers_url": "https://api.github.com/users/FrancoisNoyez/followers",
"following_url": "https://api.github.com/users/FrancoisNoyez/following{/other_user}",
"g... | [] | open | false | null | [] | null | [
"Hi ! Good catch, this is wrong indeed and thanks for opening a PR :)",
"Facing the same issue. Kindly fix this bug."
] | 2023-04-03T17:00:07Z | 2024-05-15T13:12:18Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
**In the 'train_test_split' method of the Dataset class** (defined datasets/arrow_dataset.py), **if 'self.cache_files' is not empty**, then, **regarding the input parameters 'train_indices_cache_file_name' and 'test_indices_cache_file_name', if they are None**, we modify them to make them not No... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5699/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5699/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5131 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5131/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5131/comments | https://api.github.com/repos/huggingface/datasets/issues/5131/events | https://github.com/huggingface/datasets/issues/5131 | 1,413,534,863 | I_kwDODunzps5UQNSP | 5,131 | WikiText 103 tokenizer hangs | {
"avatar_url": "https://avatars.githubusercontent.com/u/12433427?v=4",
"events_url": "https://api.github.com/users/TrentBrick/events{/privacy}",
"followers_url": "https://api.github.com/users/TrentBrick/followers",
"following_url": "https://api.github.com/users/TrentBrick/following{/other_user}",
"gists_url"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"any updates on this? It happens to me on [OpenWikiText-20%](https://huggingface.co/datasets/Bingsu/openwebtext_20p) dataset, but not on [OpenWebText-10k](https://huggingface.co/datasets/stas/openwebtext-10k). This is really strange because I don't change anything else in my running script.\r\n\r\ntransformers vers... | 2022-10-18T16:44:00Z | 2023-08-08T08:42:40Z | 2023-07-21T14:41:51Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | See issue here: https://github.com/huggingface/transformers/issues/19702 | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5131/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5131/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4869 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4869/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4869/comments | https://api.github.com/repos/huggingface/datasets/issues/4869/events | https://github.com/huggingface/datasets/pull/4869 | 1,345,513,758 | PR_kwDODunzps49hBGY | 4,869 | Fix typos in documentation | {
"avatar_url": "https://avatars.githubusercontent.com/u/85993954?v=4",
"events_url": "https://api.github.com/users/fl-lo/events{/privacy}",
"followers_url": "https://api.github.com/users/fl-lo/followers",
"following_url": "https://api.github.com/users/fl-lo/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-08-21T15:10:03Z | 2022-08-22T09:25:39Z | 2022-08-22T09:09:58Z | CONTRIBUTOR | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4869/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4869/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4869.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4869",
"merged_at": "2022-08-22T09:09:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4869.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4697 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4697/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4697/comments | https://api.github.com/repos/huggingface/datasets/issues/4697/events | https://github.com/huggingface/datasets/issues/4697 | 1,307,332,253 | I_kwDODunzps5N7E6d | 4,697 | Trouble with streaming frgfm/imagenette vision dataset with TAR archive | {
"avatar_url": "https://avatars.githubusercontent.com/u/26927750?v=4",
"events_url": "https://api.github.com/users/frgfm/events{/privacy}",
"followers_url": "https://api.github.com/users/frgfm/followers",
"following_url": "https://api.github.com/users/frgfm/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "fef2c0",
"default": false,
"description": "",
"id": 3287858981,
"name": "streaming",
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @frgfm, thanks for reporting.\r\n\r\nAs the error message says, streaming mode is not supported out of the box when the dataset contains TAR archive files.\r\n\r\nTo make the dataset streamable, you have to use `dl_manager.iter_archive`.\r\n\r\nThere are several examples in other datasets, e.g. food101: https:/... | 2022-07-18T02:51:09Z | 2022-08-01T15:10:57Z | 2022-08-01T15:10:57Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Link
https://huggingface.co/datasets/frgfm/imagenette
### Description
Hello there :wave:
Thanks for the amazing work you've done with HF Datasets! I've just started playing with it, and managed to upload my first dataset. But for the second one, I'm having trouble with the preview since there is some archive... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4697/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4697/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5574/comments | https://api.github.com/repos/huggingface/datasets/issues/5574/events | https://github.com/huggingface/datasets/issues/5574 | 1,598,104,691 | I_kwDODunzps5fQSRz | 5,574 | c4 dataset streaming fails with `FileNotFoundError` | {
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"events_url": "https://api.github.com/users/krasserm/events{/privacy}",
"followers_url": "https://api.github.com/users/krasserm/followers",
"following_url": "https://api.github.com/users/krasserm/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"Also encountering this issue for every dataset I try to stream! Installed datasets from main:\r\n```\r\n- `datasets` version: 2.10.1.dev0\r\n- Platform: macOS-13.1-arm64-arm-64bit\r\n- Python version: 3.9.13\r\n- PyArrow version: 10.0.1\r\n- Pandas version: 1.5.2\r\n```\r\n\r\nRepro:\r\n```python\r\nfrom datasets ... | 2023-02-24T07:57:32Z | 2023-12-18T07:32:32Z | 2023-02-27T04:03:38Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Loading the `c4` dataset in streaming mode with `load_dataset("c4", "en", split="validation", streaming=True)` and then using it fails with a `FileNotFoundException`.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("c4", "en", split="train", ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"events_url": "https://api.github.com/users/krasserm/events{/privacy}",
"followers_url": "https://api.github.com/users/krasserm/followers",
"following_url": "https://api.github.com/users/krasserm/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5574/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5574/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7440/comments | https://api.github.com/repos/huggingface/datasets/issues/7440/events | https://github.com/huggingface/datasets/issues/7440 | 2,903,740,662 | I_kwDODunzps6tE5D2 | 7,440 | IterableDataset raises FileNotFoundError instead of retrying | {
"avatar_url": "https://avatars.githubusercontent.com/u/145220868?v=4",
"events_url": "https://api.github.com/users/bauwenst/events{/privacy}",
"followers_url": "https://api.github.com/users/bauwenst/followers",
"following_url": "https://api.github.com/users/bauwenst/following{/other_user}",
"gists_url": "ht... | [] | open | false | null | [] | null | [
"I have since been training more models with identical architectures over the same dataset, and it is completely unstable. One has now failed at chunk9/1215, whilst others have gotten past that.\n```python\nFileNotFoundError: zstd://example_train_1215.jsonl::hf://datasets/cerebras/SlimPajama-627B@2d0accdd58c5d55119... | 2025-03-07T19:14:18Z | 2025-04-17T23:40:35Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
In https://github.com/huggingface/datasets/issues/6843 it was noted that the streaming feature of `datasets` is highly susceptible to outages and doesn't back off for long (or even *at all*).
I was training a model while streaming SlimPajama and training crashed with a `FileNotFoundError`. I can ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7440/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7440/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5031 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5031/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5031/comments | https://api.github.com/repos/huggingface/datasets/issues/5031/events | https://github.com/huggingface/datasets/pull/5031 | 1,388,201,146 | PR_kwDODunzps4_t82_ | 5,031 | Support hfh 0.10 implicit auth | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq it is now released so you can move forward with it :) ",
"I took your comments into account @Wauplin :)\r\nI also bumped the requirement to 0.2.0 because we're using `set_access_token`\r\n\r\ncc @albertvillanova WDYT ? I e... | 2022-09-27T18:37:49Z | 2022-09-30T09:18:24Z | 2022-09-30T09:15:59Z | MEMBER | null | null | null | In huggingface-hub 0.10 the `token` parameter is deprecated for dataset_info and list_repo_files in favor of use_auth_token.
Moreover if use_auth_token=None then the user's token is used implicitly.
I took those two changes into account
Close https://github.com/huggingface/datasets/issues/4990
TODO:
- [x] fi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5031/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5031/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5031.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5031",
"merged_at": "2022-09-30T09:15:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5031.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4826 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4826/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4826/comments | https://api.github.com/repos/huggingface/datasets/issues/4826/events | https://github.com/huggingface/datasets/pull/4826 | 1,335,987,583 | PR_kwDODunzps49B0V3 | 4,826 | Fix language tags in dataset cards | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The non-passing tests are caused by other missing information in the dataset cards."
] | 2022-08-11T13:47:14Z | 2022-08-11T14:17:48Z | 2022-08-11T14:03:12Z | MEMBER | null | null | null | Fix language tags in all dataset cards, so that they are validated (aligned with our `languages.json` resource). | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4826/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4826/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4826.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4826",
"merged_at": "2022-08-11T14:03:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4826.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5824 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5824/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5824/comments | https://api.github.com/repos/huggingface/datasets/issues/5824/events | https://github.com/huggingface/datasets/pull/5824 | 1,697,152,148 | PR_kwDODunzps5P1rIZ | 5,824 | Fix incomplete docstring for `BuilderConfig` | {
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"events_url": "https://api.github.com/users/Laurent2916/events{/privacy}",
"followers_url": "https://api.github.com/users/Laurent2916/followers",
"following_url": "https://api.github.com/users/Laurent2916/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-05-05T07:34:28Z | 2023-05-05T12:39:14Z | 2023-05-05T12:31:54Z | CONTRIBUTOR | null | null | null | Fixes #5820
Also fixed a couple of typos I spotted | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5824/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5824/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5824.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5824",
"merged_at": "2023-05-05T12:31:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5824.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7439/comments | https://api.github.com/repos/huggingface/datasets/issues/7439/events | https://github.com/huggingface/datasets/pull/7439 | 2,900,143,289 | PR_kwDODunzps6NoCdD | 7,439 | Fix multi gpu process example | {
"avatar_url": "https://avatars.githubusercontent.com/u/46050679?v=4",
"events_url": "https://api.github.com/users/SwayStar123/events{/privacy}",
"followers_url": "https://api.github.com/users/SwayStar123/followers",
"following_url": "https://api.github.com/users/SwayStar123/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Okay nevermind looks like to works both ways for models. but my doubt still remains, isnt this changing the device of the model every batch?"
] | 2025-03-06T11:29:19Z | 2025-03-06T17:07:28Z | 2025-03-06T17:06:38Z | NONE | null | null | null | to is not an inplace function.
But i am not sure about this code anyway, i think this is modifying the global variable `model` everytime the function is called? Which is on every batch? So it is juggling the same model on every gpu right? Isnt that very inefficient? | {
"avatar_url": "https://avatars.githubusercontent.com/u/46050679?v=4",
"events_url": "https://api.github.com/users/SwayStar123/events{/privacy}",
"followers_url": "https://api.github.com/users/SwayStar123/followers",
"following_url": "https://api.github.com/users/SwayStar123/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7439/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7439/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7439.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7439",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7439.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7439"
} |
https://api.github.com/repos/huggingface/datasets/issues/5234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5234/comments | https://api.github.com/repos/huggingface/datasets/issues/5234/events | https://github.com/huggingface/datasets/pull/5234 | 1,447,999,062 | PR_kwDODunzps5C1diq | 5,234 | fix: dataset path should be absolute | {
"avatar_url": "https://avatars.githubusercontent.com/u/30353?v=4",
"events_url": "https://api.github.com/users/vigsterkr/events{/privacy}",
"followers_url": "https://api.github.com/users/vigsterkr/followers",
"following_url": "https://api.github.com/users/vigsterkr/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Good catch thanks ! Have you tried to use the absolue path in `MemoryMappedTable.__init__` in `table.py`?\r\n\r\nI think it can fix issues with relative paths at more levels than just fixing it `load_from_disk`. If it works I think it would be a more robust fix to this issue",
"@lhoestq right, that actually fixe... | 2022-11-14T12:47:40Z | 2022-12-07T23:49:22Z | 2022-12-07T23:46:34Z | CONTRIBUTOR | null | null | null | cache_file_name depends on dataset's path.
A simple way where this could cause a problem:
```
import os
import datasets
def add_prefix(example):
example["text"] = "Review: " + example["text"]
return example
ds = datasets.load_from_disk("a/relative/path")
os.chdir("/tmp")
ds_1 = ds.map(add_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5234/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5234.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5234",
"merged_at": "2022-12-07T23:46:34Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5234.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4876 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4876/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4876/comments | https://api.github.com/repos/huggingface/datasets/issues/4876/events | https://github.com/huggingface/datasets/issues/4876 | 1,348,202,678 | I_kwDODunzps5QW_C2 | 4,876 | Move DatasetInfo from `datasets_infos.json` to the YAML tags in `README.md` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"also @osanseviero @Pierrci @SBrandeis potentially",
"Love this in principle 🚀 \r\n\r\nLet's keep in mind users might rely on `dataset_infos.json` already.\r\n\r\nI'm not convinced by the two-syntax solution, wouldn't it be simpler to have only one syntax with a `default` config for datasets with only one config... | 2022-08-23T16:16:41Z | 2022-10-03T09:11:13Z | 2022-10-03T09:11:13Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Currently there are two places to find metadata for datasets:
- datasets_infos.json, which contains **per dataset config**
- description
- citation
- license
- splits and sizes
- checksums of the data files
- feature types
- and more
- YAML tags, which contain
- license
- language
- trai... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 3,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4876/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4876/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6590/comments | https://api.github.com/repos/huggingface/datasets/issues/6590/events | https://github.com/huggingface/datasets/issues/6590 | 2,082,000,084 | I_kwDODunzps58GMzU | 6,590 | Feature request: Multi-GPU dataset mapping for SDXL training | {
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2024-01-15T13:06:06Z | 2024-01-15T13:07:07Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
We need to speed up SDXL dataset pre-process. Please make it possible to use multiple GPUs for the [official SDXL trainer](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_sdxl.py) :)
### Motivation
Pre-computing 3 million of images takes around ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6590/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6590/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6457/comments | https://api.github.com/repos/huggingface/datasets/issues/6457/events | https://github.com/huggingface/datasets/issues/6457 | 2,015,650,563 | I_kwDODunzps54JGMD | 6,457 | `TypeError`: huggingface_hub.hf_file_system.HfFileSystem.find() got multiple values for keyword argument 'maxdepth' | {
"avatar_url": "https://avatars.githubusercontent.com/u/79070834?v=4",
"events_url": "https://api.github.com/users/wasertech/events{/privacy}",
"followers_url": "https://api.github.com/users/wasertech/followers",
"following_url": "https://api.github.com/users/wasertech/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Updating `fsspec>=2023.10.0` did solve the issue.",
"May be it should be pinned somewhere?",
"> Maybe this should go in datasets directly... anyways you can easily fix this error by updating datasets>=2.15.1.dev0.\r\n\r\n@lhoestq @mariosasko for what I understand this is a bug fixed in `datasets` already, righ... | 2023-11-29T01:57:36Z | 2023-11-29T15:39:03Z | 2023-11-29T02:02:38Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Steps to reproduce the bug
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Expected behavior
Please see https://github.com/huggingface/huggingface_hub/issues/1872
### Environment info
Please s... | {
"avatar_url": "https://avatars.githubusercontent.com/u/79070834?v=4",
"events_url": "https://api.github.com/users/wasertech/events{/privacy}",
"followers_url": "https://api.github.com/users/wasertech/followers",
"following_url": "https://api.github.com/users/wasertech/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6457/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5090/comments | https://api.github.com/repos/huggingface/datasets/issues/5090/events | https://github.com/huggingface/datasets/issues/5090 | 1,401,102,407 | I_kwDODunzps5TgyBH | 5,090 | Review sync issues from GitHub to Hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Nice!!"
] | 2022-10-07T12:31:56Z | 2022-10-08T07:07:36Z | 2022-10-08T07:07:36Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
We have discovered that sometimes there were sync issues between GitHub and Hub datasets, after a merge commit to main branch.
For example:
- this merge commit: https://github.com/huggingface/datasets/commit/d74a9e8e4bfff1fed03a4cab99180a841d7caf4b
- was not properly synced with the Hub: https... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5090/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5090/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | [] | null | [
"The preview is working OK:\r\n\r\n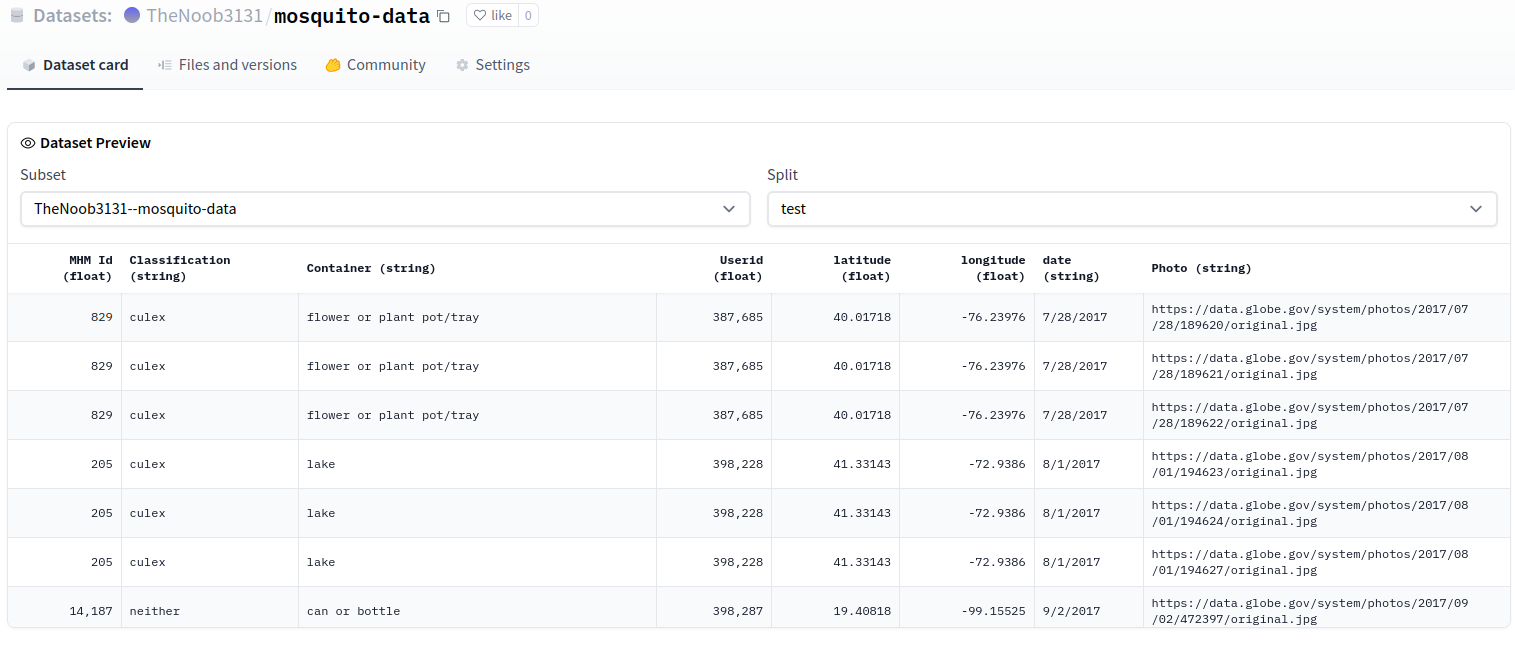\r\n\r\n"
] | 2022-07-21T05:24:48Z | 2022-07-21T07:51:56Z | 2022-07-21T07:45:01Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7457/comments | https://api.github.com/repos/huggingface/datasets/issues/7457/events | https://github.com/huggingface/datasets/issues/7457 | 2,924,886,467 | I_kwDODunzps6uVjnD | 7,457 | Document the HF_DATASETS_CACHE env variable | {
"avatar_url": "https://avatars.githubusercontent.com/u/92166725?v=4",
"events_url": "https://api.github.com/users/LSerranoPEReN/events{/privacy}",
"followers_url": "https://api.github.com/users/LSerranoPEReN/followers",
"following_url": "https://api.github.com/users/LSerranoPEReN/following{/other_user}",
"g... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/ot... | null | [
"Strongly agree to this, in addition, I am also suffering to change the cache location similar to other issues (since I changed the environmental variables).\nhttps://github.com/huggingface/datasets/issues/6886",
"`HF_DATASETS_CACHE` should be documented there indeed, feel free to open a PR :) ",
"Hey, I’d love... | 2025-03-17T12:24:50Z | 2025-03-20T10:36:46Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Hello,
I have a use case where my team is sharing models and dataset in shared directory to avoid duplication.
I noticed that the [cache documentation for datasets](https://huggingface.co/docs/datasets/main/en/cache) only mention the `HF_HOME` environment variable but never the `HF_DATASETS_CACHE`... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7457/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5047 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5047/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5047/comments | https://api.github.com/repos/huggingface/datasets/issues/5047/events | https://github.com/huggingface/datasets/pull/5047 | 1,392,088,398 | PR_kwDODunzps4_64bS | 5,047 | Fix cats_vs_dogs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-30T08:47:29Z | 2022-09-30T10:23:22Z | 2022-09-30T09:34:28Z | MEMBER | null | null | null | Reported in https://github.com/huggingface/datasets/pull/3878
I updated the number of examples | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5047/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5047/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5047.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5047",
"merged_at": "2022-09-30T09:34:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5047.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4753 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4753/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4753/comments | https://api.github.com/repos/huggingface/datasets/issues/4753/events | https://github.com/huggingface/datasets/pull/4753 | 1,319,571,745 | PR_kwDODunzps48Ll8G | 4,753 | Add `language_bcp47` tag | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-07-27T13:31:16Z | 2022-07-27T14:50:03Z | 2022-07-27T14:37:56Z | MEMBER | null | null | null | Following (internal) https://github.com/huggingface/moon-landing/pull/3509, we need to move the bcp47 tags to `language_bcp47` and keep the `language` tag for iso 639 1-2-3 codes. In particular I made sure that all the tags in `languages` are not longer than 3 characters. I moved the rest to `language_bcp47` and fixed ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4753/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4753/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4753.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4753",
"merged_at": "2022-07-27T14:37:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4753.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5443 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5443/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5443/comments | https://api.github.com/repos/huggingface/datasets/issues/5443/events | https://github.com/huggingface/datasets/pull/5443 | 1,550,178,914 | PR_kwDODunzps5ILbk8 | 5,443 | Update share tutorial | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-01-20T01:09:14Z | 2023-01-20T15:44:45Z | 2023-01-20T15:37:30Z | MEMBER | null | null | null | Based on feedback from discussion #5423, this PR updates the sharing tutorial with a mention of writing your own dataset loading script to support more advanced dataset creation options like multiple configs.
I'll open a separate PR to update the *Create a Dataset card* with the new Hub metadata UI update 😄 | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5443/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5443/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5443.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5443",
"merged_at": "2023-01-20T15:37:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5443.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6121 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6121/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6121/comments | https://api.github.com/repos/huggingface/datasets/issues/6121/events | https://github.com/huggingface/datasets/pull/6121 | 1,836,761,712 | PR_kwDODunzps5XMsWd | 6,121 | Small typo in the code example of create imagefolder dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/19688994?v=4",
"events_url": "https://api.github.com/users/WangXin93/events{/privacy}",
"followers_url": "https://api.github.com/users/WangXin93/followers",
"following_url": "https://api.github.com/users/WangXin93/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hi,\r\n\r\nI found a small typo in the code example of create imagefolder dataset. It confused me a little when I first saw it.\r\n\r\nBest Regards.\r\n\r\nXin"
] | 2023-08-04T13:36:59Z | 2023-08-04T13:45:32Z | 2023-08-04T13:41:43Z | NONE | null | null | null | Fix type of code example of load imagefolder dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/19688994?v=4",
"events_url": "https://api.github.com/users/WangXin93/events{/privacy}",
"followers_url": "https://api.github.com/users/WangXin93/followers",
"following_url": "https://api.github.com/users/WangXin93/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6121/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6121/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6121.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6121",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6121.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6121"
} |
https://api.github.com/repos/huggingface/datasets/issues/4949 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4949/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4949/comments | https://api.github.com/repos/huggingface/datasets/issues/4949/events | https://github.com/huggingface/datasets/pull/4949 | 1,365,251,916 | PR_kwDODunzps4-iqzI | 4,949 | Update enwik8 fixing the broken link | {
"avatar_url": "https://avatars.githubusercontent.com/u/54819091?v=4",
"events_url": "https://api.github.com/users/mtanghu/events{/privacy}",
"followers_url": "https://api.github.com/users/mtanghu/followers",
"following_url": "https://api.github.com/users/mtanghu/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Closing pull request to following contributing guidelines of making a new branch and will make a new pull request"
] | 2022-09-07T22:17:14Z | 2022-09-08T03:14:04Z | 2022-09-08T03:14:04Z | CONTRIBUTOR | null | null | null | The current enwik8 dataset link give a 502 bad gateway error which can be view on https://huggingface.co/datasets/enwik8 (click the dropdown to see the dataset preview, it will show the error). This corrects the links, and json metadata as well as adds a little bit more information about enwik8. | {
"avatar_url": "https://avatars.githubusercontent.com/u/54819091?v=4",
"events_url": "https://api.github.com/users/mtanghu/events{/privacy}",
"followers_url": "https://api.github.com/users/mtanghu/followers",
"following_url": "https://api.github.com/users/mtanghu/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4949/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4949/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4949.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4949",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4949.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4949"
} |
https://api.github.com/repos/huggingface/datasets/issues/4759 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4759/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4759/comments | https://api.github.com/repos/huggingface/datasets/issues/4759/events | https://github.com/huggingface/datasets/issues/4759 | 1,320,783,300 | I_kwDODunzps5OuY3E | 4,759 | Dataset Viewer issue for Toygar/turkish-offensive-language-detection | {
"avatar_url": "https://avatars.githubusercontent.com/u/44132720?v=4",
"events_url": "https://api.github.com/users/tanyelai/events{/privacy}",
"followers_url": "https://api.github.com/users/tanyelai/followers",
"following_url": "https://api.github.com/users/tanyelai/following{/other_user}",
"gists_url": "htt... | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url... | null | [
"I refreshed the dataset viewer manually, it's fixed now. Sorry for the inconvenience.\r\n<img width=\"1557\" alt=\"Capture d’écran 2022-07-28 à 09 17 39\" src=\"https://user-images.githubusercontent.com/1676121/181514666-92d7f8e1-ddc1-4769-84f3-f1edfdb902e8.png\">\r\n\r\n"
] | 2022-07-28T11:21:43Z | 2022-07-28T13:17:56Z | 2022-07-28T13:17:48Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Link
https://huggingface.co/datasets/Toygar/turkish-offensive-language-detection
### Description
Status code: 400
Exception: Status400Error
Message: The dataset does not exist.
Hi, I provided train.csv, test.csv and valid.csv files. However, viewer says dataset does not exist.
Should I n... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4759/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4759/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7286 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7286/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7286/comments | https://api.github.com/repos/huggingface/datasets/issues/7286/events | https://github.com/huggingface/datasets/issues/7286 | 2,645,350,151 | I_kwDODunzps6drNcH | 7,286 | Concurrent loading in `load_from_disk` - `num_proc` as a param | {
"avatar_url": "https://avatars.githubusercontent.com/u/5240449?v=4",
"events_url": "https://api.github.com/users/unography/events{/privacy}",
"followers_url": "https://api.github.com/users/unography/followers",
"following_url": "https://api.github.com/users/unography/following{/other_user}",
"gists_url": "h... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | 2024-11-08T23:21:40Z | 2024-11-09T16:14:37Z | 2024-11-09T16:14:37Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
https://github.com/huggingface/datasets/pull/6464 mentions a `num_proc` param while loading dataset from disk, but can't find that in the documentation and code anywhere
### Motivation
Make loading large datasets from disk faster
### Your contribution
Happy to contribute if given pointers | {
"avatar_url": "https://avatars.githubusercontent.com/u/5240449?v=4",
"events_url": "https://api.github.com/users/unography/events{/privacy}",
"followers_url": "https://api.github.com/users/unography/followers",
"following_url": "https://api.github.com/users/unography/following{/other_user}",
"gists_url": "h... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7286/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7286/timeline | null | not_planned | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6948 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6948/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6948/comments | https://api.github.com/repos/huggingface/datasets/issues/6948/events | https://github.com/huggingface/datasets/issues/6948 | 2,331,758,300 | I_kwDODunzps6K-87c | 6,948 | to_tf_dataset: Visible devices cannot be modified after being initialized | {
"avatar_url": "https://avatars.githubusercontent.com/u/7151661?v=4",
"events_url": "https://api.github.com/users/logasja/events{/privacy}",
"followers_url": "https://api.github.com/users/logasja/followers",
"following_url": "https://api.github.com/users/logasja/following{/other_user}",
"gists_url": "https:/... | [] | open | false | null | [] | null | [] | 2024-06-03T18:10:57Z | 2024-06-03T18:10:57Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When trying to use to_tf_dataset with a custom data_loader collate_fn when I use parallelism I am met with the following error as many times as number of workers there were in ``num_workers``.
File "/opt/miniconda/envs/env/lib/python3.11/site-packages/multiprocess/process.py", line 314, in _b... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6948/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6948/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4673/comments | https://api.github.com/repos/huggingface/datasets/issues/4673/events | https://github.com/huggingface/datasets/issues/4673 | 1,301,010,331 | I_kwDODunzps5Ni9eb | 4,673 | load_datasets on csv returns everything as a string | {
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @courtneysprouse, thanks for reporting.\r\n\r\nYes, you are right: by default the \"csv\" loader loads all columns as strings. \r\n\r\nYou could tweak this behavior by passing the `feature` argument to `load_dataset`, but it is also true that currently it is not possible to perform some kind of casts, due to la... | 2022-07-11T17:30:24Z | 2024-11-05T03:55:10Z | 2022-07-12T13:33:08Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
If you use:
`conll_dataset.to_csv("ner_conll.csv")`
It will create a csv file with all of your data as expected, however when you load it with:
`conll_dataset = load_dataset("csv", data_files="ner_conll.csv")`
everything is read in as a string. For example if I look at everything in 'n... | {
"avatar_url": "https://avatars.githubusercontent.com/u/25102613?v=4",
"events_url": "https://api.github.com/users/courtneysprouse/events{/privacy}",
"followers_url": "https://api.github.com/users/courtneysprouse/followers",
"following_url": "https://api.github.com/users/courtneysprouse/following{/other_user}"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4673/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4673/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5401/comments | https://api.github.com/repos/huggingface/datasets/issues/5401/events | https://github.com/huggingface/datasets/pull/5401 | 1,517,160,935 | PR_kwDODunzps5Gh1XQ | 5,401 | Support Dataset conversion from/to Spark | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5401). All of your documentation changes will be reflected on that endpoint.",
"Cool thanks !\r\n\r\nSpark DataFrame are usually quite big, and I believe here `from_spark` would load everything in the driver node's RAM, which i... | 2023-01-03T09:57:40Z | 2023-01-05T14:21:33Z | null | MEMBER | null | null | null | This PR implements Spark integration by supporting `Dataset` conversion from/to Spark `DataFrame`. | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5401/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5401/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5401.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5401",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/5401.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5401"
} |
https://api.github.com/repos/huggingface/datasets/issues/5667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5667/comments | https://api.github.com/repos/huggingface/datasets/issues/5667/events | https://github.com/huggingface/datasets/pull/5667 | 1,637,789,361 | PR_kwDODunzps5Mv8Im | 5,667 | Jax requires jaxlib | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-03-23T15:41:09Z | 2023-03-23T16:23:11Z | 2023-03-23T16:14:52Z | MEMBER | null | null | null | close https://github.com/huggingface/datasets/issues/5666 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5667/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5667/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5667.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5667",
"merged_at": "2023-03-23T16:14:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5667.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7208 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7208/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7208/comments | https://api.github.com/repos/huggingface/datasets/issues/7208/events | https://github.com/huggingface/datasets/issues/7208 | 2,575,484,256 | I_kwDODunzps6ZgsVg | 7,208 | Iterable dataset.filter should not override features | {
"avatar_url": "https://avatars.githubusercontent.com/u/5719745?v=4",
"events_url": "https://api.github.com/users/alex-hh/events{/privacy}",
"followers_url": "https://api.github.com/users/alex-hh/followers",
"following_url": "https://api.github.com/users/alex-hh/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"closed by https://github.com/huggingface/datasets/pull/7209, thanks @alex-hh !"
] | 2024-10-09T10:23:45Z | 2024-10-09T16:08:46Z | 2024-10-09T16:08:45Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When calling filter on an iterable dataset, the features get set to None
### Steps to reproduce the bug
import numpy as np
import time
from datasets import Dataset, Features, Array3D
```python
features=Features(**{"array0": Array3D((None, 10, 10), dtype="float32"), "array1": Array3D((None,... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7208/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7208/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7503 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7503/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7503/comments | https://api.github.com/repos/huggingface/datasets/issues/7503/events | https://github.com/huggingface/datasets/issues/7503 | 2,978,512,625 | I_kwDODunzps6xiH7x | 7,503 | Inconsistency between load_dataset and load_from_disk functionality | {
"avatar_url": "https://avatars.githubusercontent.com/u/60975422?v=4",
"events_url": "https://api.github.com/users/zzzzzec/events{/privacy}",
"followers_url": "https://api.github.com/users/zzzzzec/followers",
"following_url": "https://api.github.com/users/zzzzzec/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"Hi ! you can find more info here: https://github.com/huggingface/datasets/issues/5044#issuecomment-1263714347\n\n> What's the recommended approach for this use case? Should I manually process my gsm8k-new dataset to make it compatible with load_dataset? Is there a standard way to convert between these formats?\n\n... | 2025-04-08T03:46:22Z | 2025-04-15T12:39:53Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Issue Description
I've encountered confusion when using `load_dataset` and `load_from_disk` in the datasets library. Specifically, when working offline with the gsm8k dataset, I can load it using a local path:
```python
import datasets
ds = datasets.load_dataset('/root/xxx/datasets/gsm8k', 'main')
```
output:
```t... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7503/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7503/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6858 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6858/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6858/comments | https://api.github.com/repos/huggingface/datasets/issues/6858/events | https://github.com/huggingface/datasets/issues/6858 | 2,274,917,185 | I_kwDODunzps6HmHtB | 6,858 | Segmentation fault | {
"avatar_url": "https://avatars.githubusercontent.com/u/554155?v=4",
"events_url": "https://api.github.com/users/scampion/events{/privacy}",
"followers_url": "https://api.github.com/users/scampion/followers",
"following_url": "https://api.github.com/users/scampion/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [
"I downloaded the jsonl file and extract it manually. \r\nThe issue seems to be related to pyarrow.json \r\n\r\n\r\n\r\npython3 -q -X faulthandler -c \"from datasets import load_dataset; load_dataset('json', data_files='/Users/scampion/Downloads/1998-09.jsonl')\"\r\nGenerating train split: 0 examples [00:00, ? exa... | 2024-05-02T08:28:49Z | 2024-05-03T08:43:21Z | 2024-05-03T08:42:36Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Using various version for datasets, I'm no more longer able to load that dataset without a segmentation fault.
Several others files are also concerned.
### Steps to reproduce the bug
# Create a new venv
python3 -m venv venv_test
source venv_test/bin/activate
# Install the latest versio... | {
"avatar_url": "https://avatars.githubusercontent.com/u/554155?v=4",
"events_url": "https://api.github.com/users/scampion/events{/privacy}",
"followers_url": "https://api.github.com/users/scampion/followers",
"following_url": "https://api.github.com/users/scampion/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6858/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6858/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5592/comments | https://api.github.com/repos/huggingface/datasets/issues/5592/events | https://github.com/huggingface/datasets/pull/5592 | 1,603,619,124 | PR_kwDODunzps5K9dWr | 5,592 | Fix docstring example | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-02-28T18:42:37Z | 2023-02-28T19:26:33Z | 2023-02-28T19:19:15Z | MEMBER | null | null | null | Fixes #5581 to use the correct output for the `set_format` method. | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5592/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5592/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/5592.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5592",
"merged_at": "2023-02-28T19:19:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5592.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7473 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7473/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7473/comments | https://api.github.com/repos/huggingface/datasets/issues/7473/events | https://github.com/huggingface/datasets/issues/7473 | 2,939,034,643 | I_kwDODunzps6vLhwT | 7,473 | Webdataset data format problem | {
"avatar_url": "https://avatars.githubusercontent.com/u/1017189?v=4",
"events_url": "https://api.github.com/users/edmcman/events{/privacy}",
"followers_url": "https://api.github.com/users/edmcman/followers",
"following_url": "https://api.github.com/users/edmcman/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"I was able to work around it"
] | 2025-03-21T17:23:52Z | 2025-03-21T19:19:58Z | 2025-03-21T19:19:58Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Please see https://huggingface.co/datasets/ejschwartz/idioms/discussions/1
Error code: FileFormatMismatchBetweenSplitsError
All three splits, train, test, and validation, use webdataset. But only the train split has more than one file. How can I force the other two splits to also be interpreted ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1017189?v=4",
"events_url": "https://api.github.com/users/edmcman/events{/privacy}",
"followers_url": "https://api.github.com/users/edmcman/followers",
"following_url": "https://api.github.com/users/edmcman/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7473/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7473/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6671/comments | https://api.github.com/repos/huggingface/datasets/issues/6671/events | https://github.com/huggingface/datasets/issues/6671 | 2,138,727,870 | I_kwDODunzps5_emW- | 6,671 | CSV builder raises deprecation warning on verbose parameter | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2024-02-16T14:23:46Z | 2024-02-19T09:20:23Z | 2024-02-19T09:20:23Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | CSV builder raises a deprecation warning on `verbose` parameter:
```
FutureWarning: The 'verbose' keyword in pd.read_csv is deprecated and will be removed in a future version.
```
See:
- https://github.com/pandas-dev/pandas/pull/56556
- https://github.com/pandas-dev/pandas/pull/57450 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6671/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6671/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7127 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7127/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7127/comments | https://api.github.com/repos/huggingface/datasets/issues/7127/events | https://github.com/huggingface/datasets/issues/7127 | 2,486,524,966 | I_kwDODunzps6UNVwm | 7,127 | Caching shuffles by np.random.Generator results in unintiutive behavior | {
"avatar_url": "https://avatars.githubusercontent.com/u/11832922?v=4",
"events_url": "https://api.github.com/users/el-hult/events{/privacy}",
"followers_url": "https://api.github.com/users/el-hult/followers",
"following_url": "https://api.github.com/users/el-hult/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"I first thought this was a mistake of mine, and also posted on stack overflow. https://stackoverflow.com/questions/78913797/iterating-a-huggingface-dataset-from-disk-using-generator-seems-broken-how-to-d \r\n\r\nIt seems to me the issue is the caching step in \r\n\r\nhttps://github.com/huggingface/datasets/blob/be... | 2024-08-26T10:29:48Z | 2025-03-10T17:12:57Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Create a dataset. Save it to disk. Load from disk. Shuffle, usning a `np.random.Generator`. Iterate. Shuffle again. Iterate. The iterates are different since the supplied np.random.Generator has progressed between the shuffles.
Load dataset from disk again. Shuffle and Iterate. See same result ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7127/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7127/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7373/comments | https://api.github.com/repos/huggingface/datasets/issues/7373/events | https://github.com/huggingface/datasets/issues/7373 | 2,793,237,139 | I_kwDODunzps6mfWqT | 7,373 | Excessive RAM Usage After Dataset Concatenation concatenate_datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/40773225?v=4",
"events_url": "https://api.github.com/users/sam-hey/events{/privacy}",
"followers_url": "https://api.github.com/users/sam-hey/followers",
"following_url": "https://api.github.com/users/sam-hey/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"\n\n\n\nAdding a img from memray\nhttps://gist.github.com/sam-hey/00c958f13fb0f7b54d17197fe353002f",
"I'm having the same issue where c... | 2025-01-16T16:33:10Z | 2025-03-27T17:40:59Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
When loading a dataset from disk, concatenating it, and starting the training process, the RAM usage progressively increases until the kernel terminates the process due to excessive memory consumption.
https://github.com/huggingface/datasets/issues/2276
### Steps to reproduce the bug
```python
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7373/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7373/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6056 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6056/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6056/comments | https://api.github.com/repos/huggingface/datasets/issues/6056/events | https://github.com/huggingface/datasets/pull/6056 | 1,815,086,963 | PR_kwDODunzps5WD4RY | 6,056 | Implement proper checkpointing for dataset uploading with resume function that does not require remapping shards that have already been uploaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/10792502?v=4",
"events_url": "https://api.github.com/users/AntreasAntoniou/events{/privacy}",
"followers_url": "https://api.github.com/users/AntreasAntoniou/followers",
"following_url": "https://api.github.com/users/AntreasAntoniou/following{/other_user}"... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6056). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq Reading the filenames is something I tried earlier, but I decided to use the yaml direction because:\r\n\r\n1. The yaml file name is const... | 2023-07-21T03:13:21Z | 2023-08-17T08:26:53Z | null | NONE | null | null | null | Context: issue #5990
In order to implement the checkpointing, I introduce a metadata folder that keeps one yaml file for each set that one is uploading. This yaml keeps track of what shards have already been uploaded, and which one the idx of the latest one was. Using this information I am then able to easily get th... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6056/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6056/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6056.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6056",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/6056.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/6056"
} |
https://api.github.com/repos/huggingface/datasets/issues/6153 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6153/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6153/comments | https://api.github.com/repos/huggingface/datasets/issues/6153/events | https://github.com/huggingface/datasets/issues/6153 | 1,852,630,074 | I_kwDODunzps5ubOQ6 | 6,153 | custom load dataset to hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"This is an issue for the [Datasets repo](https://github.com/huggingface/datasets).",
"> This is an issue for the [Datasets repo](https://github.com/huggingface/datasets).\r\n\r\nThanks @sgugger , I guess I will wait for them to address the issue . Looking forward to hearing from them ",
"You can use `.push_to_... | 2023-08-13T04:42:22Z | 2023-11-21T11:50:28Z | 2023-10-08T17:04:16Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### System Info
kaggle notebook
i transformed dataset:
```
dataset = load_dataset("Dahoas/first-instruct-human-assistant-prompt")
```
to
formatted_dataset:
```
Dataset({
features: ['message_tree_id', 'message_tree_text'],
num_rows: 33143
})
```
but would like to know how to upload to hub
### ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6153/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6153/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6705/comments | https://api.github.com/repos/huggingface/datasets/issues/6705/events | https://github.com/huggingface/datasets/pull/6705 | 2,163,768,640 | PR_kwDODunzps5obdbY | 6,705 | Fix data_files when passing data_dir | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6705). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-03-01T16:38:53Z | 2024-03-01T18:59:06Z | 2024-03-01T18:52:49Z | MEMBER | null | null | null | This code should not return empty data files
```python
from datasets import load_dataset_builder
revision = "3d406e70bc21c3ca92a9a229b4c6fc3ed88279fd"
b = load_dataset_builder("bigcode/the-stack-v2-dedup", data_dir="data/Dockerfile", revision=revision)
print(b.config.data_files)
```
Previously it would ret... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6705/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6705/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6705.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6705",
"merged_at": "2024-03-01T18:52:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6705.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/4939 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4939/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4939/comments | https://api.github.com/repos/huggingface/datasets/issues/4939/events | https://github.com/huggingface/datasets/pull/4939 | 1,363,468,679 | PR_kwDODunzps4-cw4A | 4,939 | Fix NonMatchingChecksumError in adv_glue dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-06T15:31:16Z | 2022-09-06T17:42:10Z | 2022-09-06T17:39:16Z | MEMBER | null | null | null | Fix issue reported on the Hub: https://huggingface.co/datasets/adv_glue/discussions/1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4939/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4939/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4939.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4939",
"merged_at": "2022-09-06T17:39:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4939.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6802 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6802/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6802/comments | https://api.github.com/repos/huggingface/datasets/issues/6802/events | https://github.com/huggingface/datasets/pull/6802 | 2,237,365,489 | PR_kwDODunzps5sV0m8 | 6,802 | Fix typo in docs (upload CLI) | {
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"events_url": "https://api.github.com/users/Wauplin/events{/privacy}",
"followers_url": "https://api.github.com/users/Wauplin/followers",
"following_url": "https://api.github.com/users/Wauplin/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6802). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-04-11T10:05:05Z | 2024-04-11T16:19:00Z | 2024-04-11T13:19:43Z | CONTRIBUTOR | null | null | null | Related to https://huggingface.slack.com/archives/C04RG8YRVB8/p1712643948574129 (interal)
Positional args must be placed before optional args.
Feel free to merge whenever it's ready. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6802/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6802/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6802.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6802",
"merged_at": "2024-04-11T13:19:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6802.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5794 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5794/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5794/comments | https://api.github.com/repos/huggingface/datasets/issues/5794/events | https://github.com/huggingface/datasets/issues/5794 | 1,685,196,061 | I_kwDODunzps5kcg0d | 5,794 | CI ZeroDivisionError | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hello!\r\nThis issue seems to have been fixed in https://github.com/huggingface/transformers/pull/24049 \r\nI was looking for my first issue to work on when I noticed this; not sure if there is a specific protocol for suggesting to close an issue.",
"Thanks for informing, @zeppdev. I am closing this issue.\r\n\r... | 2023-04-26T14:55:23Z | 2024-05-17T09:12:11Z | 2024-05-17T09:12:11Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Sometimes when running our CI on Windows, we get a ZeroDivisionError:
```
FAILED tests/test_metric_common.py::LocalMetricTest::test_load_metric_frugalscore - ZeroDivisionError: float division by zero
```
See for example:
- https://github.com/huggingface/datasets/actions/runs/4809358266/jobs/8560513110
- https:/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5794/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5794/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/5839 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5839/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5839/comments | https://api.github.com/repos/huggingface/datasets/issues/5839/events | https://github.com/huggingface/datasets/issues/5839 | 1,704,554,718 | I_kwDODunzps5lmXDe | 5,839 | Make models/functions optimized with `torch.compile` hashable | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [] | 2023-05-10T20:02:08Z | 2023-11-28T16:29:33Z | 2023-11-28T16:29:33Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | As reported in https://github.com/huggingface/datasets/issues/5819, hashing functions/transforms that reference a model, or a function, optimized with `torch.compile` currently fails due to them not being picklable (the concrete error can be found in the linked issue).
The solutions to consider:
1. hashing/pickling... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5839/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5839/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4625/comments | https://api.github.com/repos/huggingface/datasets/issues/4625/events | https://github.com/huggingface/datasets/pull/4625 | 1,293,163,744 | PR_kwDODunzps46zELz | 4,625 | Unpack `dl_manager.iter_files` to allow parallization | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Cool thanks ! Yup it sounds like the right solution.\r\n\r\nIt looks like `_generate_tables` needs to be updated as well to fix the CI"
] | 2022-07-04T13:16:58Z | 2022-07-05T11:11:54Z | 2022-07-05T11:00:48Z | COLLABORATOR | null | null | null | Iterate over data files outside `dl_manager.iter_files` to allow parallelization in streaming mode.
(The issue reported [here](https://discuss.huggingface.co/t/dataset-only-have-n-shard-1-when-has-multiple-shards-in-repo/19887))
PS: Another option would be to override `FilesIterable.__getitem__` to make it indexa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4625/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4625.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4625",
"merged_at": "2022-07-05T11:00:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4625.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5182 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5182/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5182/comments | https://api.github.com/repos/huggingface/datasets/issues/5182/events | https://github.com/huggingface/datasets/issues/5182 | 1,431,029,547 | I_kwDODunzps5VS8cr | 5,182 | Add notebook / other resource links to the task-specific data loading guides | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
... | null | [
"Yea this would be great! We would need an object detection tutorial notebook too if it doesn't already exist there. ",
"There is one: https://huggingface.co/docs/datasets/object_detection.\r\n\r\nI will start the work. "
] | 2022-11-01T07:57:26Z | 2022-11-03T01:49:57Z | 2022-11-03T01:49:57Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Does it make sense to include links to notebooks / scripts that show how to use a dataset for training / fine-tuning a model?
For example, here in [https://huggingface.co/docs/datasets/image_classification] we could include a mention of https://github.com/huggingface/notebooks/blob/main/examples/image_classificatio... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5182/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5182/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6676/comments | https://api.github.com/repos/huggingface/datasets/issues/6676/events | https://github.com/huggingface/datasets/issues/6676 | 2,140,648,619 | I_kwDODunzps5_l7Sr | 6,676 | Can't Read List of JSON Files Properly | {
"avatar_url": "https://avatars.githubusercontent.com/u/20232088?v=4",
"events_url": "https://api.github.com/users/lordsoffallen/events{/privacy}",
"followers_url": "https://api.github.com/users/lordsoffallen/followers",
"following_url": "https://api.github.com/users/lordsoffallen/following{/other_user}",
"g... | [] | open | false | null | [] | null | [
"Found the issue, if there are other files in the directory, it gets caught into this `*` so essentially it should be `*.json`. Could we possibly to check for list of files to make sure the pattern matches json files and raise error if not?",
"I don't think we should filter for `*.json` as this might silently rem... | 2024-02-17T22:58:15Z | 2024-03-02T20:47:22Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Trying to read a bunch of JSON files into Dataset class but default approach doesn't work. I don't get why it works when I read it one by one but not when I pass as a list :man_shrugging:
The code fails with
```
ArrowInvalid: JSON parse error: Invalid value. in row 0
UnicodeDecodeError... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6676/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6676/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6421/comments | https://api.github.com/repos/huggingface/datasets/issues/6421/events | https://github.com/huggingface/datasets/pull/6421 | 1,994,451,553 | PR_kwDODunzps5fgG1h | 6,421 | Add pyarrow-hotfix to release docs | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | null | [] | null | [
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_a... | 2023-11-15T10:06:44Z | 2023-11-15T13:49:55Z | 2023-11-15T13:38:22Z | MEMBER | null | null | null | Add `pyarrow-hotfix` to release docs. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6421/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6421/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6421.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6421",
"merged_at": "2023-11-15T13:38:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6421.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6224/comments | https://api.github.com/repos/huggingface/datasets/issues/6224/events | https://github.com/huggingface/datasets/pull/6224 | 1,886,043,692 | PR_kwDODunzps5Zym3j | 6,224 | Ignore `dataset_info.json` in data files resolution | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-09-07T14:43:51Z | 2023-09-07T15:46:10Z | 2023-09-07T15:37:20Z | COLLABORATOR | null | null | null | `save_to_disk` creates this file, but also [`HugginFaceDatasetSever`](https://github.com/gradio-app/gradio/blob/26fef8c7f85a006c7e25cdbed1792df19c512d02/gradio/flagging.py#L214), so this is needed to avoid issues such as [this one](https://discord.com/channels/879548962464493619/1149295819938349107/1149295819938349107)... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6224/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6224.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6224",
"merged_at": "2023-09-07T15:37:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6224.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7457 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7457/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7457/comments | https://api.github.com/repos/huggingface/datasets/issues/7457/events | https://github.com/huggingface/datasets/issues/7457 | 2,924,886,467 | I_kwDODunzps6uVjnD | 7,457 | Document the HF_DATASETS_CACHE env variable | {
"avatar_url": "https://avatars.githubusercontent.com/u/92166725?v=4",
"events_url": "https://api.github.com/users/LSerranoPEReN/events{/privacy}",
"followers_url": "https://api.github.com/users/LSerranoPEReN/followers",
"following_url": "https://api.github.com/users/LSerranoPEReN/following{/other_user}",
"g... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/other_user}",
... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/129883215?v=4",
"events_url": "https://api.github.com/users/Harry-Yang0518/events{/privacy}",
"followers_url": "https://api.github.com/users/Harry-Yang0518/followers",
"following_url": "https://api.github.com/users/Harry-Yang0518/following{/ot... | null | [
"Strongly agree to this, in addition, I am also suffering to change the cache location similar to other issues (since I changed the environmental variables).\nhttps://github.com/huggingface/datasets/issues/6886",
"`HF_DATASETS_CACHE` should be documented there indeed, feel free to open a PR :) ",
"Hey, I’d love... | 2025-03-17T12:24:50Z | 2025-03-20T10:36:46Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Feature request
Hello,
I have a use case where my team is sharing models and dataset in shared directory to avoid duplication.
I noticed that the [cache documentation for datasets](https://huggingface.co/docs/datasets/main/en/cache) only mention the `HF_HOME` environment variable but never the `HF_DATASETS_CACHE`... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7457/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7457/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6698 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6698/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6698/comments | https://api.github.com/repos/huggingface/datasets/issues/6698/events | https://github.com/huggingface/datasets/pull/6698 | 2,157,752,392 | PR_kwDODunzps5oG6Xt | 6,698 | Faster `xlistdir` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6698). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"CI failure is unrelated to the changes.",
"<details>\n<summary>Show benchmarks</summa... | 2024-02-27T22:55:08Z | 2024-02-27T23:44:49Z | 2024-02-27T23:38:14Z | COLLABORATOR | null | null | null | Pass `detail=False` to the `fsspec` `listdir` to avoid unnecessarily fetching expensive metadata about the paths. | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6698/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6698/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6698.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6698",
"merged_at": "2024-02-27T23:38:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6698.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7118 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7118/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7118/comments | https://api.github.com/repos/huggingface/datasets/issues/7118/events | https://github.com/huggingface/datasets/pull/7118 | 2,477,676,893 | PR_kwDODunzps549yu4 | 7,118 | Allow numpy-2.1 and test it without audio extra | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_7118). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-08-21T10:29:35Z | 2024-08-21T11:05:03Z | 2024-08-21T10:58:15Z | MEMBER | null | null | null | Allow numpy-2.1 and test it without audio extra.
This PR reverts:
- #7114
Note that audio extra tests can be included again with numpy-2.1 once next numba-0.61.0 version is released. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7118/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7118/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7118.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7118",
"merged_at": "2024-08-21T10:58:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7118.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7529 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7529/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7529/comments | https://api.github.com/repos/huggingface/datasets/issues/7529/events | https://github.com/huggingface/datasets/issues/7529 | 3,007,118,969 | I_kwDODunzps6zPP55 | 7,529 | audio folder builder cannot detect custom split name | {
"avatar_url": "https://avatars.githubusercontent.com/u/37548991?v=4",
"events_url": "https://api.github.com/users/phineas-pta/events{/privacy}",
"followers_url": "https://api.github.com/users/phineas-pta/followers",
"following_url": "https://api.github.com/users/phineas-pta/following{/other_user}",
"gists_u... | [] | open | false | null | [] | null | [] | 2025-04-20T16:53:21Z | 2025-04-20T16:53:21Z | null | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
when using audio folder builder (`load_dataset("audiofolder", data_dir="/path/to/folder")`), it cannot detect custom split name other than train/validation/test
### Steps to reproduce the bug
i have the following folder structure
```
my_dataset/
├── train/
│ ├── lorem.wav
│ ├── …
│ └── met... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7529/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7529/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4806 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4806/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4806/comments | https://api.github.com/repos/huggingface/datasets/issues/4806/events | https://github.com/huggingface/datasets/pull/4806 | 1,332,664,038 | PR_kwDODunzps482yiS | 4,806 | Fix opus_gnome dataset card | {
"avatar_url": "https://avatars.githubusercontent.com/u/38291975?v=4",
"events_url": "https://api.github.com/users/gojiteji/events{/privacy}",
"followers_url": "https://api.github.com/users/gojiteji/followers",
"following_url": "https://api.github.com/users/gojiteji/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"@gojiteji why have you closed this PR and created an identical one?\r\n- #4807 ",
"@albertvillanova \r\nI forgot to follow \"How to create a Pull\" in CONTRIBUTING.md in this branch.",
"Both are identical. And you can push additi... | 2022-08-09T03:40:15Z | 2022-08-09T12:06:46Z | 2022-08-09T11:52:04Z | CONTRIBUTOR | null | null | null | I fixed a issue #4805.
I changed `"gnome"` to `"opus_gnome"` in[ README.md](https://github.com/huggingface/datasets/tree/main/datasets/opus_gnome#dataset-summary).
Fix #4805 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 2,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4806/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4806/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4806.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4806",
"merged_at": "2022-08-09T11:52:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4806.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/5098 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5098/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5098/comments | https://api.github.com/repos/huggingface/datasets/issues/5098/events | https://github.com/huggingface/datasets/issues/5098 | 1,404,058,518 | I_kwDODunzps5TsDuW | 5,098 | Classes label error when loading symbolic links using imagefolder | {
"avatar_url": "https://avatars.githubusercontent.com/u/49552732?v=4",
"events_url": "https://api.github.com/users/horizon86/events{/privacy}",
"followers_url": "https://api.github.com/users/horizon86/followers",
"following_url": "https://api.github.com/users/horizon86/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gi... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_u... | null | [
"It can be solved temporarily by remove `resolve` in \r\nhttps://github.com/huggingface/datasets/blob/bef23be3d9543b1ca2da87ab2f05070201044ddc/src/datasets/data_files.py#L278",
"Hi, thanks for reporting and suggesting a fix! We still need to account for `.`/`..` in the file path, so a more robust fix would be `P... | 2022-10-11T06:10:58Z | 2022-11-14T14:40:20Z | 2022-11-14T14:40:20Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | **Is your feature request related to a problem? Please describe.**
Like this: #4015
When there are **symbolic links** to pictures in the data folder, the parent folder name of the **real file** will be used as the class name instead of the parent folder of the symbolic link itself. Can you give an option to decide wh... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5098/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5098/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6046 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6046/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6046/comments | https://api.github.com/repos/huggingface/datasets/issues/6046/events | https://github.com/huggingface/datasets/issues/6046 | 1,808,154,414 | I_kwDODunzps5rxj8u | 6,046 | Support proxy and user-agent in fsspec calls | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": fals... | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/95092167?v=4",
"events_url": "https://api.github.com/users/zutarich/events{/privacy}",
"followers_url": "https://api.github.com/users/zutarich/followers",
"following_url": "https://api.github.com/users/zutarich/following{/other_user}",
"gists_url": "htt... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/95092167?v=4",
"events_url": "https://api.github.com/users/zutarich/events{/privacy}",
"followers_url": "https://api.github.com/users/zutarich/followers",
"following_url": "https://api.github.com/users/zutarich/following{/other_user}",
"gi... | null | [
"hii @lhoestq can you assign this issue to me?\r\n",
"You can reply \"#self-assign\" to this issue to automatically get assigned to it :)\r\nLet me know if you have any questions or if I can help",
"#2289 ",
"Actually i am quite new to figure it out how everything goes and done \r\n\r\n> You can reply \"#self... | 2023-07-17T16:39:26Z | 2023-10-09T13:49:14Z | null | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Since we switched to the new HfFileSystem we no longer apply user's proxy and user-agent.
Using the HTTP_PROXY and HTTPS_PROXY environment variables works though since we use aiohttp to call the HF Hub.
This can be implemented in `_prepare_single_hop_path_and_storage_options`.
Though ideally the `HfFileSystem`... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6046/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6046/timeline | null | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4926 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4926/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4926/comments | https://api.github.com/repos/huggingface/datasets/issues/4926/events | https://github.com/huggingface/datasets/pull/4926 | 1,360,384,484 | PR_kwDODunzps4-Srm1 | 4,926 | Dataset infos in yaml | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Alright this is ready for review :)\r\nI mostly would like your opinion on the YAML structure and what we can do in the docs (IMO we can add the docs about those fields in the Hub docs). Other than that let me know if the changes in ... | 2022-09-02T16:10:05Z | 2024-05-04T14:52:50Z | 2022-10-03T09:11:12Z | MEMBER | null | null | null | To simplify the addition of new datasets, we'd like to have the dataset infos in the YAML and deprecate the dataset_infos.json file. YAML is readable and easy to edit, and the YAML metadata of the readme already contain dataset metadata so we would have everything in one place.
To be more specific, I moved these fie... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4926/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4926/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4926.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4926",
"merged_at": "2022-10-03T09:11:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4926.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6479 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6479/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6479/comments | https://api.github.com/repos/huggingface/datasets/issues/6479/events | https://github.com/huggingface/datasets/pull/6479 | 2,029,040,121 | PR_kwDODunzps5hVLom | 6,479 | More robust preupload retry mechanism | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6479). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2023-12-06T17:19:38Z | 2023-12-06T19:47:29Z | 2023-12-06T19:41:06Z | COLLABORATOR | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6479/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6479/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6479.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6479",
"merged_at": "2023-12-06T19:41:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6479.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6225 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6225/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6225/comments | https://api.github.com/repos/huggingface/datasets/issues/6225/events | https://github.com/huggingface/datasets/issues/6225 | 1,887,054,320 | I_kwDODunzps5weinw | 6,225 | Conversion from RGB to BGR in Object Detection tutorial | {
"avatar_url": "https://avatars.githubusercontent.com/u/33297401?v=4",
"events_url": "https://api.github.com/users/samokhinv/events{/privacy}",
"followers_url": "https://api.github.com/users/samokhinv/followers",
"following_url": "https://api.github.com/users/samokhinv/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Good catch!"
] | 2023-09-08T06:49:19Z | 2023-09-08T17:52:18Z | 2023-09-08T17:52:17Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | The [tutorial](https://huggingface.co/docs/datasets/main/en/object_detection) mentions the necessity of conversion the input image from BGR to RGB
> albumentations expects the image to be in BGR format, not RGB, so you’ll have to convert the image before applying the transform.
[Link to tutorial](https://github.c... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6225/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6792 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6792/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6792/comments | https://api.github.com/repos/huggingface/datasets/issues/6792/events | https://github.com/huggingface/datasets/pull/6792 | 2,231,318,682 | PR_kwDODunzps5sBEyn | 6,792 | Fix cache conflict in `_check_legacy_cache2` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6792). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2024-04-08T14:05:42Z | 2024-04-09T11:34:08Z | 2024-04-09T11:27:58Z | MEMBER | null | null | null | It was reloading from the wrong cache dir because of a bug in `_check_legacy_cache2`. This function should not trigger if there are config_kwars like `sample_by=`
fix https://github.com/huggingface/datasets/issues/6758 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6792/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6792/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6792.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6792",
"merged_at": "2024-04-09T11:27:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6792.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7470 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7470/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7470/comments | https://api.github.com/repos/huggingface/datasets/issues/7470/events | https://github.com/huggingface/datasets/issues/7470 | 2,937,236,323 | I_kwDODunzps6vEqtj | 7,470 | Is it possible to shard a single-sharded IterableDataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_... | [] | closed | false | null | [] | null | [
"Hi ! Maybe you can look for an option in your dataset to partition your data based on a deterministic filter ? For example each worker could stream the data based on `row.id % num_shards` or something like that ?",
"So the recommendation is to start out with multiple shards initially and re-sharding after is not... | 2025-03-21T04:33:37Z | 2025-03-26T09:34:46Z | 2025-03-26T06:49:28Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I thought https://github.com/huggingface/datasets/pull/7252 might be applicable but looking at it maybe not.
Say we have a process, eg. a database query, that can return data in slightly different order each time. So, the initial query needs to be run by a single thread (not to mention running multiple times incurs mo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7470/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7470/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6533 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6533/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6533/comments | https://api.github.com/repos/huggingface/datasets/issues/6533/events | https://github.com/huggingface/datasets/issues/6533 | 2,055,929,101 | I_kwDODunzps56iv0N | 6,533 | ted_talks_iwslt | Error: Config name is missing | {
"avatar_url": "https://avatars.githubusercontent.com/u/35850903?v=4",
"events_url": "https://api.github.com/users/rayliuca/events{/privacy}",
"followers_url": "https://api.github.com/users/rayliuca/followers",
"following_url": "https://api.github.com/users/rayliuca/following{/other_user}",
"gists_url": "htt... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi ! Thanks for reporting. I opened https://github.com/huggingface/datasets/pull/6544 to fix this",
"We just released 2.16.1 with a fix:\r\n\r\n```\r\npip install -U datasets\r\n```"
] | 2023-12-26T00:38:18Z | 2023-12-30T18:58:21Z | 2023-12-30T16:09:50Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ### Describe the bug
Running load_dataset using the newest `datasets` library like below on the ted_talks_iwslt using year pair data will throw an error "Config name is missing"
see also:
https://huggingface.co/datasets/ted_talks_iwslt/discussions/3
likely caused by #6493, where the `and not config_kwargs` part... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6533/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6533/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/4941 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4941/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4941/comments | https://api.github.com/repos/huggingface/datasets/issues/4941/events | https://github.com/huggingface/datasets/pull/4941 | 1,363,622,861 | PR_kwDODunzps4-dQ9F | 4,941 | Add Papers with Code ID to scifact dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-06T17:46:37Z | 2022-09-06T18:28:17Z | 2022-09-06T18:26:01Z | MEMBER | null | null | null | This PR:
- adds Papers with Code ID
- forces sync between GitHub and Hub, which previously failed due to Hub validation error of the license tag: https://github.com/huggingface/datasets/runs/8200223631?check_suite_focus=true | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4941/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4941/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/4941.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4941",
"merged_at": "2022-09-06T18:26:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4941.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/7502 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7502/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7502/comments | https://api.github.com/repos/huggingface/datasets/issues/7502/events | https://github.com/huggingface/datasets/issues/7502 | 2,977,453,814 | I_kwDODunzps6xeFb2 | 7,502 | `load_dataset` of size 40GB creates a cache of >720GB | {
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Hi ! Parquet is a compressed format. When you load a dataset, it uncompresses the Parquet data into Arrow data on your disk. That's why you can indeed end up with 720GB of uncompressed data on disk. The uncompression is needed to enable performant dataset objects (especially for random access).\n\nTo save some sto... | 2025-04-07T16:52:34Z | 2025-04-15T15:22:12Z | 2025-04-15T15:22:11Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hi there,
I am trying to load a dataset from the Hugging Face Hub and split it into train and validation splits. Somehow, when I try to do it with `load_dataset`, it exhausts my disk quota. So, I tried manually downloading the parquet files from the hub and loading them as follows:
```python
ds = DatasetDict(
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7502/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7502/timeline | null | completed | null | null |
https://api.github.com/repos/huggingface/datasets/issues/6233 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6233/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6233/comments | https://api.github.com/repos/huggingface/datasets/issues/6233/events | https://github.com/huggingface/datasets/pull/6233 | 1,891,804,286 | PR_kwDODunzps5aF3kd | 6,233 | Update README.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-09-12T06:53:06Z | 2023-09-13T18:20:50Z | 2023-09-13T18:10:04Z | CONTRIBUTOR | null | null | null | fixed a typo | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6233/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6233/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6233.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6233",
"merged_at": "2023-09-13T18:10:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6233.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6164 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6164/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6164/comments | https://api.github.com/repos/huggingface/datasets/issues/6164/events | https://github.com/huggingface/datasets/pull/6164 | 1,859,560,007 | PR_kwDODunzps5YZZAJ | 6,164 | Fix: Missing a MetadataConfigs init when the repo has a `datasets_info.json` but no README | {
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | rea... | 2023-08-21T14:57:54Z | 2023-08-21T16:27:05Z | 2023-08-21T16:18:26Z | MEMBER | null | null | null | When I try to push to an arrow repo (can provide the link on Slack), it uploads the files but fails to update the metadata, with
```
File "app.py", line 123, in add_new_eval
eval_results[level].push_to_hub(my_repo, token=TOKEN, split=SPLIT)
File "blabla_my_env_path/lib/python3.10/site-packages/datasets/arro... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6164/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6164/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6164.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6164",
"merged_at": "2023-08-21T16:18:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6164.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
https://api.github.com/repos/huggingface/datasets/issues/6526 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6526/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6526/comments | https://api.github.com/repos/huggingface/datasets/issues/6526/events | https://github.com/huggingface/datasets/pull/6526 | 2,053,726,451 | PR_kwDODunzps5ipB5v | 6,526 | Preserve order of configs and splits when using Parquet exports | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_6526). All of your documentation changes will be reflected on that endpoint. The docs are available until 30 days after the last update.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>... | 2023-12-22T10:35:56Z | 2023-12-22T11:42:22Z | 2023-12-22T11:36:14Z | MEMBER | null | null | null | Preserve order of configs and splits, as defined in dataset infos.
Fix #6521. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6526/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6526/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/6526.diff",
"html_url": "https://github.com/huggingface/datasets/pull/6526",
"merged_at": "2023-12-22T11:36:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/6526.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.