

Upload README.md with huggingface_hub
Browse files
README.md
CHANGED
|
@@ -1,22 +1,10 @@
|
|
| 1 |
-
|
| 2 |
-
license: mit
|
| 3 |
-
language:
|
| 4 |
-
- en
|
| 5 |
-
pretty_name: SLM-Lab Benchmark Results
|
| 6 |
-
tags:
|
| 7 |
-
- reinforcement-learning
|
| 8 |
-
- deep-learning
|
| 9 |
-
- pytorch
|
| 10 |
-
task_categories:
|
| 11 |
-
- reinforcement-learning
|
| 12 |
-
---
|
| 13 |
-
|
| 14 |
-
# SLM Lab <br>  
|
| 15 |
-
|
| 16 |
|
| 17 |
<p align="center">
|
| 18 |
<i>Modular Deep Reinforcement Learning framework in PyTorch.</i>
|
| 19 |
<br>
|
|
|
|
|
|
|
| 20 |
<a href="https://slm-lab.gitbook.io/slm-lab/">Documentation</a> · <a href="https://github.com/kengz/SLM-Lab/blob/master/docs/BENCHMARKS.md">Benchmark Results</a>
|
| 21 |
</p>
|
| 22 |
|
|
@@ -35,6 +23,44 @@ task_categories:
|
|
| 35 |
| 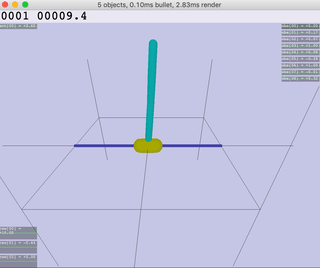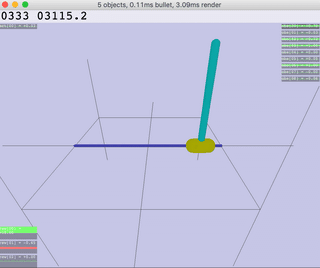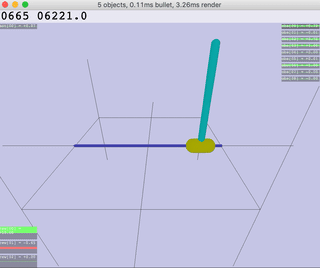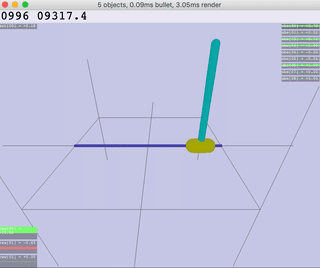 |  |  |  |
|
| 36 |
| Inv.DoublePendulum | InvertedPendulum | Reacher | Walker |
|
| 37 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
## Quick Start
|
| 39 |
|
| 40 |
```bash
|
|
@@ -58,14 +84,6 @@ slm-lab run --help # options for run command
|
|
| 58 |
uv run slm-lab run
|
| 59 |
```
|
| 60 |
|
| 61 |
-
## Features
|
| 62 |
-
|
| 63 |
-
- **Algorithms**: DQN, DDQN+PER, A2C, PPO, SAC and variants
|
| 64 |
-
- **Environments**: Gymnasium (Atari, MuJoCo, Box2D)
|
| 65 |
-
- **Networks**: MLP, ConvNet, RNN with flexible architectures
|
| 66 |
-
- **Hyperparameter Search**: ASHA scheduler with Ray Tune
|
| 67 |
-
- **Cloud Training**: dstack integration with auto HuggingFace sync
|
| 68 |
-
|
| 69 |
## Cloud Training (dstack)
|
| 70 |
|
| 71 |
Run experiments on cloud GPUs with automatic result sync to HuggingFace.
|
|
@@ -99,3 +117,21 @@ uv run --no-default-groups slm-lab pull spec_name
|
|
| 99 |
uv run --no-default-groups slm-lab plot -f folder1,folder2
|
| 100 |
```
|
| 101 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# [SLM Lab](https://www.amazon.com/dp/0135172381) <br>  
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
<p align="center">
|
| 4 |
<i>Modular Deep Reinforcement Learning framework in PyTorch.</i>
|
| 5 |
<br>
|
| 6 |
+
<i>Companion library of the book <a href="https://www.amazon.com/dp/0135172381">Foundations of Deep Reinforcement Learning</a>.</i>
|
| 7 |
+
<br>
|
| 8 |
<a href="https://slm-lab.gitbook.io/slm-lab/">Documentation</a> · <a href="https://github.com/kengz/SLM-Lab/blob/master/docs/BENCHMARKS.md">Benchmark Results</a>
|
| 9 |
</p>
|
| 10 |
|
|
|
|
| 23 |
|  |  |  |  |
|
| 24 |
| Inv.DoublePendulum | InvertedPendulum | Reacher | Walker |
|
| 25 |
|
| 26 |
+
SLM Lab is a software framework for **reinforcement learning** (RL) research and application in PyTorch. RL trains agents to make decisions by learning from trial and error—like teaching a robot to walk or an AI to play games.
|
| 27 |
+
|
| 28 |
+
## What SLM Lab Offers
|
| 29 |
+
|
| 30 |
+
| Feature | Description |
|
| 31 |
+
|---------|-------------|
|
| 32 |
+
| **Ready-to-use algorithms** | PPO, SAC, DQN, A2C, REINFORCE—validated on 70+ environments |
|
| 33 |
+
| **Easy configuration** | JSON spec files fully define experiments—no code changes needed |
|
| 34 |
+
| **Reproducibility** | Every run saves its spec + git SHA for exact reproduction |
|
| 35 |
+
| **Automatic analysis** | Training curves, metrics, and TensorBoard logging out of the box |
|
| 36 |
+
| **Cloud integration** | dstack for GPU training, HuggingFace for sharing results |
|
| 37 |
+
|
| 38 |
+
## Algorithms
|
| 39 |
+
|
| 40 |
+
| Algorithm | Type | Best For | Validated Environments |
|
| 41 |
+
|-----------|------|----------|------------------------|
|
| 42 |
+
| **REINFORCE** | On-policy | Learning/teaching | Classic |
|
| 43 |
+
| **SARSA** | On-policy | Tabular-like | Classic |
|
| 44 |
+
| **DQN/DDQN+PER** | Off-policy | Discrete actions | Classic, Box2D, Atari |
|
| 45 |
+
| **A2C** | On-policy | Fast iteration | Classic, Box2D, Atari |
|
| 46 |
+
| **PPO** | On-policy | General purpose | Classic, Box2D, MuJoCo (11), Atari (54) |
|
| 47 |
+
| **SAC** | Off-policy | Continuous control | Classic, Box2D, MuJoCo |
|
| 48 |
+
|
| 49 |
+
See [Benchmark Results](docs/BENCHMARKS.md) for detailed performance data.
|
| 50 |
+
|
| 51 |
+
## Environments
|
| 52 |
+
|
| 53 |
+
SLM Lab uses [Gymnasium](https://gymnasium.farama.org/) (the maintained fork of OpenAI Gym):
|
| 54 |
+
|
| 55 |
+
| Category | Examples | Difficulty | Docs |
|
| 56 |
+
|----------|----------|------------|------|
|
| 57 |
+
| **Classic Control** | CartPole, Pendulum, Acrobot | Easy | [Gymnasium Classic](https://gymnasium.farama.org/environments/classic_control/) |
|
| 58 |
+
| **Box2D** | LunarLander, BipedalWalker | Medium | [Gymnasium Box2D](https://gymnasium.farama.org/environments/box2d/) |
|
| 59 |
+
| **MuJoCo** | Hopper, HalfCheetah, Humanoid | Hard | [Gymnasium MuJoCo](https://gymnasium.farama.org/environments/mujoco/) |
|
| 60 |
+
| **Atari** | Breakout, MsPacman, and 54 more | Varied | [ALE](https://ale.farama.org/environments/) |
|
| 61 |
+
|
| 62 |
+
Any gymnasium-compatible environment works—just specify its name in the spec.
|
| 63 |
+
|
| 64 |
## Quick Start
|
| 65 |
|
| 66 |
```bash
|
|
|
|
| 84 |
uv run slm-lab run
|
| 85 |
```
|
| 86 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 87 |
## Cloud Training (dstack)
|
| 88 |
|
| 89 |
Run experiments on cloud GPUs with automatic result sync to HuggingFace.
|
|
|
|
| 117 |
uv run --no-default-groups slm-lab plot -f folder1,folder2
|
| 118 |
```
|
| 119 |
|
| 120 |
+
## Citation
|
| 121 |
+
|
| 122 |
+
If you use SLM Lab in your research, please cite:
|
| 123 |
+
|
| 124 |
+
```bibtex
|
| 125 |
+
@misc{kenggraesser2017slmlab,
|
| 126 |
+
author = {Keng, Wah Loon and Graesser, Laura},
|
| 127 |
+
title = {SLM Lab},
|
| 128 |
+
year = {2017},
|
| 129 |
+
publisher = {GitHub},
|
| 130 |
+
journal = {GitHub repository},
|
| 131 |
+
howpublished = {\url{https://github.com/kengz/SLM-Lab}},
|
| 132 |
+
}
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
## License
|
| 136 |
+
|
| 137 |
+
MIT
|